This PR:
- renames `torch.set_deterministic` to `torch._set_deterministic`
- renames `torch.is_deterministic` to `torch._is_deterministic`
- Modifies the docstrings for both to indicate that the feature is not
yet complete.
We would like to do this because this feature is experimental and the
docstrings before this PR are misleading.
This PR does not have an accompanying change in master. That is because
there still is discussion over what the eventual state of the feature
should be: https://github.com/pytorch/pytorch/issues/15359. I expect
that there will be a better plan for this once 1.7 rolls around.
Test Plan:
- wait for CI
* Add optimizer_for_mobile doc into python api root doc
* Apply suggestions from code review
Remove all references to `optimization_blacklist` as it's missing in 1.6
Co-authored-by: Nikita Shulga <nshulga@fb.com>
This reverts commit fe66bdb498efe912d8b9c437a14efa4295c04fdd.
This also makes a sense to THTensorEvenMoreMath because sumall was removed, see THTensor_wrap.
Summary:
In short, we messed up. The SHM and CMA backends of TensorPipe are Linux-specific and thus they are guarded by a #ifdef in the agent's code. Due to a mishap with CMake (due the fact that TensorPipe has two CMake files, one for PyTorch and a "standalone" one) we were not correctly propagating some flags and these #ifdefs were always false. This means that these two backends have always been disabled and have thus never been covered by our OSS CI. It would be irresponsible to enable them now in v1.6, so instead we remove any mention of them from the docs.
Note that this is perhaps not as bad as it sounds. These two backends were providing higher performance (latency) when the two endpoints were on the same machine. However, I suspect that most RPC users will only do transfers across machines, for which SHM and CMA wouldn't have played any role.
Original PR against master: #41200 (merged as dde3d5f4a8f713ecc4649d776565b68ca75ae5c8)
Test Plan: Docs only
Summary:
Add `torch._C._cuda_getArchFlags()` that returns list of architecture `torch_cuda` were compiled with
Add `torch.cuda.get_arch_list()` and `torch.cuda.get_gencode_flags()` methods that returns architecture list and gencode flags PyTorch were compiled with
Print warning if some of GPUs is not compatible with any of the CUBINs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41173
Differential Revision: D22459998
Pulled By: malfet
fbshipit-source-id: 65d40ae29e54a0ba0f3f2da11b821fdb4d452d95
Summary:
Fixes https://github.com/pytorch/pytorch/issues/41047.
Some CPU kernel implementations don't call `cast_outputs()`, so when CPU temporaries were created to hold their outputs they weren't copied back to the out parameters correctly. Instead of fixing that issue, for simplicity this PR disables the behavior. The corresponding test in test_type_promotion.py is expanded with more operations to verify that unary ops can no longer have out arguments with different dtypes than their inputs (except in special cases like torch.abs which maps complex inputs to float outputs and torch.deg2rad which is secretly torch.mul).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41097
Differential Revision: D22422352
Pulled By: mruberry
fbshipit-source-id: 8e61d34ef1c9608790b35cf035302fd226fd9421
Co-authored-by: Mike Ruberry <mruberry@devfair044.maas>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40115
Closes https://github.com/pytorch/pytorch/issues/37790
Closes https://github.com/pytorch/pytorch/issues/37944
A user may wish to run DDP's forward + backwards step under a non-default CUDA stream such as those created by `with torch.cuda.Stream(stream)`. In this case, the user should be responsible for synchronizing events on this stream with other streams used in the program (per the documentation at https://pytorch.org/docs/stable/notes/cuda.html#cuda-semantics), but currently DDP has a bug which causes DDP under non-default streams to fail.
If a user does the following:
```
model = DDP(...)
loss = model(inptut).sum()
loss.backward()
grad = model.module.weight.grad()
average = dist.all_reduce(grad)
```
There is a chance that `average` and `grad` will not be equal. This is because the CUDA kernels corresponding to the `all_reduce` call may run before `loss.backward()`'s kernels are finished. Specifically, in DDP we copy the allreduced gradients back to the model parameter gradients in an autograd engine callback, but this callback runs on the default stream. Note that this can also be fixed by the application synchronizing on the current stream, although this should not be expected, since the application is not using the current stream at all.
This PR fixes the issue by passing the current stream into DDP's callback.
Tested by adding a UT `test_DistributedDataParallel_non_default_stream` that fails without this PR
ghstack-source-id: 106481208
Differential Revision: D22073353
fbshipit-source-id: 70da9b44e5f546ff8b6d8c42022ecc846dff033e
* Move OperatorSchema default inference function implementations to .cc… (#40845)
Summary:
… file
This prevents implementation of those functions(as lambdas) to be embedded as weak symbol into every shared library that includes this header.
Combination of this and https://github.com/pytorch/pytorch/pull/40844 reduces size of `libcaffe2_module_test_dynamic.so` from 500kb to 50Kb.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40845
Differential Revision: D22334779
Pulled By: malfet
fbshipit-source-id: 64706918fc2947350a58c0877f294b1b8b085455
* Move `OperatorBase::AddRelatedBlobInfo` implementation to .cc file (#40844)
Summary:
If virtual function is implemented in header file, it's implementation will be included as a weak symbol to every shared library that includes this header along with all of it's dependencies.
This was one of the reasons why size of libcaffe2_module_test_dynamic.so was 500Kb (AddRelatedBlobInfo implementation pulled a quarter of libprotobuf.a with it)
Combination of this and https://github.com/pytorch/pytorch/issues/40845 reduces size of `libcaffe2_module_test_dynamic.so` from 500kb to 50Kb.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40844
Differential Revision: D22334725
Pulled By: malfet
fbshipit-source-id: 836a4cbb9f344355ddd2512667e77472546616c0
Summary:
Right now it is used to check whether `math.remainder` exists, which is the case for both Python-3.7 and 3.8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40868
Differential Revision: D22343454
Pulled By: malfet
fbshipit-source-id: 6b6d4869705b64c4b952309120f92c04ac7e39fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40624
Previously we didn't clone schema, so the default schema is used, this is
causing issue for some models
Test Plan: Imported from OSS
Differential Revision: D22259519
fbshipit-source-id: e2a393a54cb18f55da0c7152a74ddc22079ac350
* [quant] aten::repeat work for quantized tensor (#40644)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/40644
Test Plan: Imported from OSS
Differential Revision: D22268558
fbshipit-source-id: 3bc9a129bece1b547c519772ecc6b980780fb904
* [quant][graphmode][fix] remove unsupported ops in the list (#40653)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40653
(Note: this ignores all push blocking failures!)
Test Plan: Imported from OSS
Differential Revision: D22271413
fbshipit-source-id: a01611b5d90849ac673fa5a310f910c858e907a3
* [quant][graphmode][fix] dequantize propagation for {add/mul}_scalar (#40596)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40596
Previously the fusion patterns for {add/mul}_scalar is inconsistent since the op pattern
produces a non-quantized tensor and the op replacement graph produces a quantized tensor
Test Plan: Imported from OSS
Differential Revision: D22251072
fbshipit-source-id: e16eb92cf6611578cca1ed8ebde961f8d0610137
* [quant][graphmode] Support quantization for `aten::apend` (#40743)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40743
`aten::append` modifies input inplace and the output is ignored, these ops are not
supported right now, so we'll need to first make `aten::append` non-inplace
by change
```
ignored = aten::append(list, x)
```
to
```
x_list = aten::ListConstruct(x)
result = aten::add(list, x_list)
```
and then quantize the aten::add instead.
Test Plan:
TestQuantizeJitOps.test_general_shape_ops
Imported from OSS
Differential Revision: D22302151
fbshipit-source-id: 931000388e7501e9dd17bec2fad8a96b71a5efc5
We need an easy to way to quickly visually grep binary sizes from builds
and then have a way to test out those binaries quickly.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
(cherry picked from commit 66813515d4dec66f319442ba967c64b87c0286cd)
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40931
Fix docstrings for dynamic quantized Linear/LSTM and associated classes
ghstack-source-id: 107064446
Test Plan: Docs show up in correctly
Differential Revision: D22360787
fbshipit-source-id: 8e357e081dc59ee42fd7f12ea5079ce5d0cc9df2
* properly skip legacy tests regardless of the default executor (#40381)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/40381
Differential Revision: D22173938
Pulled By: Krovatkin
fbshipit-source-id: 305fc4484977e828cc4cee6e053a1e1ab9f0d6c7
* [JIT] Switch executor from Simple to Legacy.
This is done for 1.6 only in order to recover performance regressions
caused by the Legacy->Simple switch that was done in 1.5. On master we
still plan to use Simple executor and fix the performance issues in 1.7
without falling back to the Legacy executor.
Co-authored-by: Nikolay Korovaiko <korovaikon@gmail.com>
* Re-apply PyTorch pthreadpool changes
Summary:
This re-applies D21232894 (b9d3869df3) and D22162524, plus updates jni_deps in a few places
to avoid breaking host JNI tests.
Test Plan: `buck test @//fbandroid/mode/server //fbandroid/instrumentation_tests/com/facebook/caffe2:host-test`
Reviewed By: xcheng16
Differential Revision: D22199952
fbshipit-source-id: df13eef39c01738637ae8cf7f581d6ccc88d37d5
* Enable XNNPACK ops on iOS and macOS.
Test Plan: buck run aibench:run_bench -- -b aibench/specifications/models/pytorch/pytext/pytext_mobile_inference.json --platform ios --framework pytorch --remote --devices D221 (9788a74da8)AP-12.0.1
Reviewed By: xta0
Differential Revision: D21886736
fbshipit-source-id: ac482619dc1b41a110a3c4c79cc0339e5555edeb
* Respect user set thread count. (#40707)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/40707
Test Plan: Imported from OSS
Differential Revision: D22318197
Pulled By: AshkanAliabadi
fbshipit-source-id: f11b7302a6e91d11d750df100d2a3d8d96b5d1db
* Fix and reenable threaded QNNPACK linear (#40587)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40587
Previously, this was causing divide-by-zero only in the multithreaded
empty-batch case, while calculating tiling parameters for the threads.
In my opinion, the bug here is using a value that is allowed to be zero
(batch size) for an argument that should not be zero (tile size), so I
fixed the bug by bailing out right before the call to
pthreadpool_compute_4d_tiled.
Test Plan: TestQuantizedOps.test_empty_batch
Differential Revision: D22264414
Pulled By: dreiss
fbshipit-source-id: 9446d5231ff65ef19003686f3989e62f04cf18c9
* Fix batch size zero for QNNPACK linear_dynamic (#40588)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40588
Two bugs were preventing this from working. One was a divide by zero
when multithreading was enabled, fixed similarly to the fix for static
quantized linear in the previous commit. The other was computation of
min and max to determine qparams. FBGEMM uses [0,0] for [min,max] of
empty input, do the same.
Test Plan: Added a unit test.
Differential Revision: D22264415
Pulled By: dreiss
fbshipit-source-id: 6ca9cf48107dd998ef4834e5540279a8826bc754
Co-authored-by: David Reiss <dreiss@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40549
Currently we didn't check if %weight_t is produced by `aten::t`, this will fuse some `matmul`/`addmm` that is
not 2d to `aten::linear`, which is incorrect
Test Plan: Imported from OSS
Differential Revision: D22225921
fbshipit-source-id: 9723e82fdbac6d8e1a7ade22f3a9791321ab12b6
* [WIP][JIT] Add ScriptModule._reconstruct (#39979)
Summary:
**Summary**
This commit adds an instance method `_reconstruct` that permits users
to reconstruct a `ScriptModule` from a given C++ `Module` instance.
**Testing**
This commit adds a unit test for `_reconstruct`.
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33912.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39979
Differential Revision: D22172323
Pulled By: SplitInfinity
fbshipit-source-id: 9aa6551c422a5a324b822a09cd8d7c660f99ca5c
* [quant][graphmode] Enable inplace option for top level API (#40414)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40414
after `_reconstruct` is supported in RecursiveScriptModule: https://github.com/pytorch/pytorch/pull/39979
we can support inplace option in quantization API
Test Plan: Imported from OSS
Differential Revision: D22178326
fbshipit-source-id: c78bc2bcf2c42b06280c12262bb31aebcadc6c32
Co-authored-by: Meghan Lele <meghanl@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40513
This PR makes the following changes:
1. Complex Printing now uses print formatting for it's real and imaginary values and they are joined at the end.
2. Adding 1. naturally fixes the printing of complex tensors in sci_mode=True
```
>>> torch.tensor(float('inf')+float('inf')*1j)
tensor(nan+infj)
>>> torch.randn(2000, dtype=torch.cfloat)
tensor([ 0.3015-0.2502j, -1.1102+1.2218j, -0.6324+0.0640j, ...,
-1.0200-0.2302j, 0.6511-0.1889j, -0.1069+0.1702j])
>>> torch.tensor([1e-3, 3+4j, 1e-5j, 1e-2+3j, 5+1e-6j])
tensor([1.0000e-03+0.0000e+00j, 3.0000e+00+4.0000e+00j, 0.0000e+00+1.0000e-05j,
1.0000e-02+3.0000e+00j, 5.0000e+00+1.0000e-06j])
>>> torch.randn(3, dtype=torch.cfloat)
tensor([ 1.0992-0.4459j, 1.1073+0.1202j, -0.2177-0.6342j])
>>> x = torch.tensor([1e2, 1e-2])
>>> torch.set_printoptions(sci_mode=False)
>>> x
tensor([ 100.0000, 0.0100])
>>> x = torch.tensor([1e2, 1e-2j])
>>> x
tensor([100.+0.0000j, 0.+0.0100j])
```
Test Plan: Imported from OSS
Differential Revision: D22309294
Pulled By: anjali411
fbshipit-source-id: 20edf9e28063725aeff39f3a246a2d7f348ff1e8
Co-authored-by: anjali411 <chourdiaanjali123@gmail.com>
As ninja has accurate dependency tracking, if there is nothing to do,
then we will very quickly noop. But this is important for correctness:
if a change was made to a header that is not listed explicitly in
the distutils Extension, then distutils will come to the wrong
conclusion about whether or not recompilation is needed (but Ninja
will work it out.)
This caused https://github.com/pytorch/vision/issues/2367
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
ghstack-source-id: 6409595c8ac091f3863f305c123266b9d3a167ad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40837
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40495
As part of debugging flaky ddp_under_dist_autograd tests, I realized
we were running into the following deadlock.
1) Rank 0 would go into DDP construction, hold GIL and wait for broadcast in
DDP construction.
2) Rank 3 is a little slower and performs an RRef fetch call before the DDP
construction.
3) The RRef fetch call is done on Rank 0 and tries to acquire GIL.
4) We now have a deadlock since Rank 0 is waiting for Rank 3 to enter the
collective and Rank 3 is waiting for Rank 0 to release GIL.
ghstack-source-id: 106534442
Test Plan:
1) Ran ddp_under_dist_autograd 500 times.
2) waitforbuildbot
Differential Revision: D22205180
fbshipit-source-id: 6afd55342e801b9edb9591ff25158a244a8ea66a
Co-authored-by: Pritam Damania <pritam.damania@fb.com>
* [JIT] Update type of the unsqueeze's output in shape analysis.
* [JIT] Fix shape analysis for aten::masked_select.
The reference says that this op always returns a 1-D tensor, even if
the input and the mask are 0-D.
Upstream PR: #40614
Summary:
This update pulls in a oneliner fix, which sets the TCP_NODELAY option on the TCP sockets of the UV transport. This leads to exceptional performance gains in terms of latency, with about a 25x improvement in one simple benchmark. This thus resolves a regression that TensorPipe had compared to the ProcessGroup agent and, in fact, ends up beating it by 2x.
The benchmark I ran is this, with the two endpoints pinned to different cores of the same machine:
```
torch.jit.script
def remote_fn(t: int):
return t
torch.jit.script
def local_fn():
for _ in range(1_000_000):
fut = rpc.rpc_async("rhs", remote_fn, (42,))
fut.wait()
```
And the average round-trip time (one iteration) is:
- TensorPipe with SHM: 97.2 us
- TensorPipe with UV _after the fix_: 205us
- Gloo: 440us
- TensorPipe with UV _before the fix_: 5ms
Test Plan: Ran PyTorch RPC test suite
Summary:
Currently, torchvision annotates `batched_nms` with `torch.jit.script` so the function gets compiled when it is traced and ONNX will work. Unfortunately, this means we are eagerly compiling batched_nms, which fails if torchvision isn't built with `torchvision.ops.nms`. As a result, torchvision doesn't work on torch hub right now.
`_script_if_tracing` could solve our problem here, but right now it does not correctly interact with recursive compilation. This PR fixes that bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40468
Reviewed By: jamesr66a
Differential Revision: D22195771
Pulled By: eellison
fbshipit-source-id: 83022ca0bab6d389a48a478aec03052c9282d2b7
Co-authored-by: Elias Ellison <eellison@fb.com>
- fixes#38034
- works around missing slice functionality in Sequential
by casting to tuple and slicing that instead
- supports iterating on the resulting slice but not call()
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40461
It turned out `:inheried-members:` (see [doc](https://www.sphinx-doc.org/en/master/usage/extensions/autodoc.html#directive-autoclass)) is not really usable.
Because pybind11 generates a docstring that writes `self` as parent class, `rpc.PyRRef`, type.
As a workaround, I am pulling docstrings on parent-class, `PyRRef` class, into subclass, `RRef`. And do surgery on the docstring generated by pybind11.
{F241283111}
ghstack-source-id: 106472496
P134031188
Differential Revision: D7933834
fbshipit-source-id: c03a8a4c9d98888b64492a8caba1591595bfe247
Co-authored-by: Shihao Xu <shihaoxu@fb.com>
awscli was not loaded on conda builds and the backup upload did not work
since it was a recursive copy instead of just specifically copying what
we want.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Summary:
Updates concat kernel for contiguous input to support channels_last contig tensors.
This was tried on squeezenet model on pixel-2 device. It improves model perf by about 25%.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39448
Test Plan: test_cat_in_channels_last
Differential Revision: D22160526
Pulled By: kimishpatel
fbshipit-source-id: 6eee6e74b8a5c66167828283d16a52022a16997f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40422
fix the remaining differences to the emulation of fp16 layernorm
Test Plan: unit test of layernorm
Reviewed By: venkatacrc
Differential Revision: D22182849
fbshipit-source-id: 8a45c21418517d65d7a41663d5ad2110d6b4677a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40440
Shapes sometimes need more than 35 symbols
(Note: this ignores all push blocking failures!)
Test Plan:
found during testing the recipe
https://github.com/pytorch/tutorials/pull/1019
Differential Revision: D22188679
Pulled By: ilia-cher
fbshipit-source-id: efcf5d10882af7d9225897ec87debcf4abdc523f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39962
Adding a simple wrapper with ref count for cuda event and
destroying cuda event after the last copy is destroyed
Test Plan: CI cuda profiler tests
Differential Revision: D22027092
Pulled By: ilia-cher
fbshipit-source-id: e0810388aa60b2291eb010896e13af1fad92e472
Summary:
Currently, a custom autograd function written with
```
torch.cuda.amp.custom_fwd(cast_inputs=dtype)
def forward(ctx, *args):
...
```
casts incoming floating-point CUDA tensors to `dtype` unconditionally, regardless of whether the function executes in an autocast-enabled region. I think I had the wrong idea there. Autocast-disabled regions should give the user control of input types. Also, `custom_fwd(cast_inputs=dtype)`-decorated functions' behavior should align with native fp32list/fp16list functions. C++-side casting wrappers have no effect when autocast is disabled, and `custom_fwd`'s casting should behave the same way.
The present PR changes `custom_fwd` so it only casts in autocast-enabled regions (also updates custom_fwd to ignore fp64 inputs, like the C++ wrappers).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36171
Differential Revision: D22179511
Pulled By: ngimel
fbshipit-source-id: 5a93d070179a43206066bce19da0a5a19ecaabbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40377
Cleans up the docstring for quantized ELU and adds it to the quantization docs.
Test Plan: * build on Mac OS and inspect
Differential Revision: D22162834
Pulled By: vkuzo
fbshipit-source-id: e548fd4dc8d67db27ed19cac4dbdf2a942586759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40346
Cleans up docstrings for quantized BatchNorm and adds to quantization docs
Test Plan: * build on Mac OS and inspect
Differential Revision: D22152633
Pulled By: vkuzo
fbshipit-source-id: e0bf02194158231e0205b5b2df7f6f1ffc3c4d65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40345
Fixes docstrings and adds to quantization docs for quantized InstanceNorm.
Test Plan: * build on Mac OS and inspect
Differential Revision: D22152637
Pulled By: vkuzo
fbshipit-source-id: 7a485311ead20796b7a0944827d1d04e14ec8dcd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40343
Cleans up the quantized GroupNorm docstring and adds it to quantization docs.
Test Plan: * build on Mac OS and inspect
Differential Revision: D22152635
Pulled By: vkuzo
fbshipit-source-id: 5553b841c7a5d77f1467f0c40657db9e5d730a12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40342
Cleans up the docstrings for quantized LayerNorm, and adds it to the docs.
Test Plan: * build on Mac OS and inspect
Differential Revision: D22152639
Pulled By: vkuzo
fbshipit-source-id: 38adf14b34675d1983ac4ed751938aa396e5400b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40341
Cleans up the hardtanh docstring and adds it to quantization docs.
Test Plan: * build and inspect on Mac OS
Differential Revision: D22152636
Pulled By: vkuzo
fbshipit-source-id: c98e635199c8be332aa6958664ff23faad834908
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40340
Adds and simplifies quantization docs for hardsigmoid
Test Plan:
* build docs on Mac OS
* inspect
Differential Revision: D22152634
Pulled By: vkuzo
fbshipit-source-id: 18da273023fb00e5f0bc1e881b00536492c606d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40323
Cleans up the naming and the function param docs for quantized hardswish.
Remove redundant docstrings and link to floating point modules instead.
Test Plan:
* build the docs on Mac OS
* verify that every link works as expected
Differential Revision: D22152638
Pulled By: vkuzo
fbshipit-source-id: fef04874ae460b449c677424a6a1c6dd47054795
Summary:
Previous:
deco dont_wipe_extensions_build_folder control clean build path or not.
Now:
If cpp files or args changed, rebuild extension. clean build path only before and after test suite.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40169
Differential Revision: D22161450
Pulled By: ezyang
fbshipit-source-id: 9167c8265e13922f68cd886be900f84ffc6afb84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40312
As part of https://github.com/pytorch/pytorch/issues/40255, we
realized that GPU support for distributed autograd was broken as part of our
multithreaded autograd change.
To fix this in the short term for 1.6, this PR includes the following changes:
1) Long lived CPU thread in DistEngine to execute GPU->CPU continuations in the
autograd graph.
2) The long lived CPU thread has its own ready_queue and this queue is used for
all GraphTasks created by DistEngine.
3) In thread_main(), the CPU thread cannot exit once the GraphTask is done
processing because of the new CPU thread added in 1).
4) To resolve this, thread_main() now has a parameter `device_thread` instead
of `reentrant_thread`. When device_thread is True, we expect this to be a long
lived device thread that does not exit.
5) When device_thread is False, thread_main is expected to run a GraphTask and
return once done.
ghstack-source-id: 106391329
Test Plan: waitforbuildbot
Differential Revision: D22146183
fbshipit-source-id: dd146b7a95f55db75f6767889b7255e9d62d5825
Summary:
Also mark warning modifiers as private options (i.e. libraries depending on `torch_cpu` do not have to be compiled with `-Wall`)
Closes https://github.com/pytorch/pytorch/issues/31283
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40399
Differential Revision: D22186206
Pulled By: malfet
fbshipit-source-id: 1ad4277b5acc5c39849a3e4efe4b93a189d26e59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40390
Change the Int8FC/Int8Quantize op interface to use Int8QuantParamsBlob as the qparam input blob format when needed.
Test Plan:
```
buck test caffe2/caffe2/quantization/server:
```
Reviewed By: hx89
Differential Revision: D22124313
fbshipit-source-id: 6b5c1974c0fc5928f72773495f0da8d0eb9b98c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40389
The `mpt_uv` channel MultiPlexes over a Transport, namely the UV one. What this means is that it takes a tensor, chunks it into equal parts and sends each of them on a separate UV connection, each running in a separate UV loop. Thus they each have their own socket and thread. This allows them to reach bandwidths that go beyond what a simple single-threaded approach can do, which is necessary to reach the high bandwidths of some modern NICs.
ghstack-source-id: 106375511
Test Plan: Ran a few manual tests myself, for the rest relied on the PyTorch RPC tests.
Differential Revision: D22144380
fbshipit-source-id: ef555fa04c6f13a4acf3bd5f7b03d04d02460d38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40243
rocm bench has a large backlog right now. Let's skip some tests.
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D22125197
fbshipit-source-id: 330b52ce7f97af4e45c58f25bc7d57351d7c4efb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40383
debug option is not supported for these cases, so we print a warning if it occurs
Test Plan: Imported from OSS
Differential Revision: D22164071
fbshipit-source-id: 90459530f4efdd6d255df4f015606cb0e9070cd3
Summary:
I.e. do not accept `bytes` as possible type of `device` argument in
`torch.cuda._get_device_index`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40322
Differential Revision: D22176885
Pulled By: malfet
fbshipit-source-id: 2f3a46174161f1cdcf6a6ad94a31e54b18ad6186
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40396
Removes activation and normalization modules from eager mode QAT.
These were incorrectly added, but we don't actually need them.
Test Plan:
```
python test/test_quantization.py TestQuantizationAwareTraining
```
Imported from OSS
Differential Revision: D22169768
fbshipit-source-id: b5bd753dafe92e90e226fb773eb18c6aae179703
Summary:
https://github.com/pytorch/pytorch/pull/40129 fixed the error responsible for the first revert, but exposed another error in the same test.
This PR is intended as the "master copy" for merge, and it runs on full CI.
Two other PRs (restricted to run on a small subset of CI) supporting debugging DDP failures/hangs with multiple devices per process (`test_c10d.py:DistributedDataParallelTest.test_grad_layout_1devicemodule_2replicaperprocess`).
- https://github.com/pytorch/pytorch/pull/40290 tries the test with purely rowmajor contiguous params on an untouched master. In other words https://github.com/pytorch/pytorch/pull/40290 contains none of this PR's diffs aside from the test itself.
- https://github.com/pytorch/pytorch/pull/40178, for comparison, tries the test with this PR's diffs.
Both fail the same way, indicating failure is unrelated to this PR's other diffs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40358
Differential Revision: D22165785
Pulled By: albanD
fbshipit-source-id: ac7cdd79af5c080ab74341671392dca8e717554e
Summary:
Removes line mentioning `ProcessGroupRoundRobin` since we don't intend it to be used as a public API just yet. We can add this back when we officially support the API
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40380
Differential Revision: D22165556
Pulled By: rohan-varma
fbshipit-source-id: 24d0477d881dc74f2ff579de61dfd1ced2b09e75
Summary:
Not sure why there are so many issues for std & var, but this PR should close them all:
std: Fix https://github.com/pytorch/pytorch/issues/24771, Fix https://github.com/pytorch/pytorch/issues/24676, Fix https://github.com/pytorch/pytorch/issues/24639, Fix https://github.com/pytorch/pytorch/issues/24529
var: Fix https://github.com/pytorch/pytorch/issues/24782, Fix https://github.com/pytorch/pytorch/issues/24677, Fix https://github.com/pytorch/pytorch/issues/24652, Fix https://github.com/pytorch/pytorch/issues/24530
```py
import time
import torch
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
for device in (torch.device("cpu"), torch.device("cuda")):
for size in (
[100000000],
[10000, 10000],
[1000, 1000, 100],
[100, 100, 100, 100],
):
t = torch.randn(*size, device=device)
total_time = 0
for i in range(10):
t1 = _time()
t.std()
t2 = _time()
total_time += t2 - t1
print(f"Tensor of size {size} on {device}: {total_time / 10}")
```
Before:
```
Tensor of size [100000000] on cpu: 0.36041643619537356
Tensor of size [10000, 10000] on cpu: 0.37235140800476074
Tensor of size [1000, 1000, 100] on cpu: 0.386572527885437
Tensor of size [100, 100, 100, 100] on cpu: 0.37404844760894773
Tensor of size [100000000] on cuda: 0.0021645784378051757
Tensor of size [10000, 10000] on cuda: 0.002090191841125488
Tensor of size [1000, 1000, 100] on cuda: 0.00208127498626709
Tensor of size [100, 100, 100, 100] on cuda: 0.0020844221115112306
```
After:
```
Tensor of size [100000000] on cpu: 0.1339871883392334
Tensor of size [10000, 10000] on cpu: 0.1343991994857788
Tensor of size [1000, 1000, 100] on cpu: 0.1346735954284668
Tensor of size [100, 100, 100, 100] on cpu: 0.11906447410583496
Tensor of size [100000000] on cuda: 0.0013531208038330077
Tensor of size [10000, 10000] on cuda: 0.0012922048568725585
Tensor of size [1000, 1000, 100] on cuda: 0.001285886764526367
Tensor of size [100, 100, 100, 100] on cuda: 0.0012899160385131836
```
cc: VitalyFedyunin
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39967
Differential Revision: D22162469
Pulled By: VitalyFedyunin
fbshipit-source-id: 8d901c779767b00f81cd6231bc665e04f297b4c3
Summary:
Added a link to `CONTRIBUTION.md` in `README.md` for easy reference.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40353
Differential Revision: D22167138
Pulled By: ezyang
fbshipit-source-id: fe7b7f190c8135fdd2e71696c1cf8d84bcd40fc6
Summary:
Utilise the existing methods of `Vec256` class.
Not sure if there should be tests and if yes where.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36396
Differential Revision: D22155803
Pulled By: VitalyFedyunin
fbshipit-source-id: 500dcb5c79650bc5daa0c9683d65eeab6f9dd1d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40066
Builds on top of the previous PR to ensure that all remotely profiled events are prefixed with the key for the RPC that generated them.
The key is generated by the result of `_build_rpc_profiling_key` in `rpc/internal.py` and prefixed onto the event name. In order to do this, we set the current-key when creating the RPC in Python, retrieve the currently-set key in C++ and save a GloballyUniqueId -> key mapping to an in-memory map. When we receive an RPC with profiling information, we expect to receive this ID back, and look up the corresponding profiling key in the map.
The key is then added to all the remote events.
Tested by adding tests to ensure the key is added to all the remote events. Also added a UT which tests in under the multi-threading scenario, to ensure that the mapping's correctness is maintained when several RPCs are in the process of being created at once.
ghstack-source-id: 106316106
Test Plan: Unit test
Differential Revision: D22040035
fbshipit-source-id: 9215feb06084b294edbfa6e03385e13c1d730c43
Summary:
Many of them have already been migrated to ATen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39102
Differential Revision: D22162193
Pulled By: VitalyFedyunin
fbshipit-source-id: 80db9914fbd792cd610c4e8ab643ab97845fac9f
Summary:
Previously large tensor data in attributes and subgraphs are not stored externally. ONNX won't be able to serialize the model for cases where the total size sums up to >= 2GB. This PR enables that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38793
Reviewed By: hl475
Differential Revision: D22111092
Pulled By: houseroad
fbshipit-source-id: 355234e50825d576754de33c86a9690161caaeaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40150
added a skeleton for a Swish implementation using fakelowp
this implementation is as precise as it gets since it uses computation in fp32 as a reference
-simplified the test since this is a linear sweep, no need to randomize it
-modified the domain to ensure that 0 is always covered
Test Plan: ran this test against the lowered swish implementation and found that the interpolation domain should be [-21,12] to cover even the smallest value in the Y domain
Reviewed By: venkatacrc
Differential Revision: D22025105
fbshipit-source-id: dd8561243182c359003b4370ce2312f607d964c9
Summary:
The "cast" operator is currently added after the cumsum operator, but it should be added before, since torch.cumsum supports more types than ONNX (specifically, bool).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40044
Reviewed By: hl475
Differential Revision: D22158013
Pulled By: houseroad
fbshipit-source-id: e6c706572b9b8de880d4d71eaa132744ef01ad4d
Summary:
When an op involves creating a tensor of a certain type (such as torch.ones(...)), the tracer creates a `prim::Constant` node with an integer value representing the type. The mapping from the torch type to integers maps:
```
torch.complex32 -> 8
torch.complex64 -> 9
torch.complex128 -> 10
torch.bool -> 11
```
However, when the ONNX exporter maps back the integer to torch type, 10 is mapped to bool, 9 is mapped to complex128 and 8 is mapped to complex64.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40006
Reviewed By: hl475
Differential Revision: D22158019
Pulled By: houseroad
fbshipit-source-id: 42fbd6b56566017ff03382c4faf10d30ffde3802
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40374
To pick up two fixes to MPT:
4b1b855f21462200aad3
MPT isn't yet used by PyTorch so this should have no effect
Test Plan: Export to CircleCI and test
Reviewed By: patricklabatut
Differential Revision: D22160029
fbshipit-source-id: 202ea7487fcde015e5856f71ad6aebdfa6564ee1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38490
A meta tensor is a tensor that is a lot like a normal tensor,
except it doesn't actually have any data associated with it.
You can use them to carry out shape/dtype computations without
actually having to run the actual code; for example, this could
be used to do shape inference in a JIT analysis pass.
Check out the description in DispatchKey.h for more information.
Meta tensors are part of a larger project to rationalize how we
write kernels so that we don't have to duplicate shape logic
in CPU kernel, CUDA kernel and meta kernel (this PR makes the
duplication problem worse!) However, that infrastructure can
be built on top of this proof of concept, which just shows how
you can start writing meta kernels today even without this
infrastructure.
There are a lot of things that don't work:
- I special cased printing for dense tensors only; if you try to
allocate a meta sparse / quantized tensor things aren't going
to work.
- The printing formula implies that torch.tensor() can take an
ellipsis, but I didn't add this.
- I wrote an example formula for binary operators, but it isn't
even right! (It doesn't do type promotion of memory layout
correctly). The most future proof way to do it right is to
factor out the relevant computation out of TensorIterator,
as it is quite involved.
- Nothing besides torch.add works right now
- Meta functions are ALWAYS included in mobile builds (selective
build doesn't work on them). This isn't a big deal for now
but will become more pressing as more meta functions are added.
One reason I'm putting up this PR now is to check with Yinghai Lu
if we can unblock shape inference for accelerators, while we are
still working on a long term plan for how to unify all shape
computation across our kernels.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21935609
Pulled By: ezyang
fbshipit-source-id: f7d8636eeb8516b6bc296db99a16e56029972eee
Summary:
Before this PR, DLPack export was tricked by the CUDA masquerading of the HIP backend into thinking that it was exporting a CUDA tensor. We change that to use the ROCM device type instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40124
Differential Revision: D22145215
Pulled By: ezyang
fbshipit-source-id: 276f709861c55f499ae753d0bba48ddcc8b85926
Summary:
Enable ops used in BERT which were missed in one of my earlier PRs.
ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40236
Differential Revision: D22143965
Pulled By: ezyang
fbshipit-source-id: 5464ed021687fec1485e1c061e5a7aba71687fc4
Summary:
This PR aims at tackling https://github.com/pytorch/pytorch/issues/37823 by:
- ensuring that buffers will be used for normalization computation but won't be updated, when buffers are not None, and `track_running_stats=False`
- adding a corresponding unittest to ensure expected behaviour
Any feedback is welcome!
_Note: we might want to update the docstrings of `BatchNorm*d`, feel free to share any suggestion!_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38084
Differential Revision: D22047871
Pulled By: ezyang
fbshipit-source-id: 5acbcad9773e7901f26d625db71d43d7dc236d3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40100
ELU has a range of [-1, inf]. In the original PR which added
the quantized operator we decided to pass the quantization params
from the input. However, it makes more sense to require observation
for this op.
This PR changes the API to require observation. Next PRs in this stack
will add the eager and graph mode handling.
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_qelu
```
Imported from OSS
Differential Revision: D22075083
fbshipit-source-id: 0ea0fd05a00cc7a5f122a2b1de09144bbd586f32
Summary:
https://github.com/pytorch/pytorch/issues/39963 erroneously removed template specialization to compute offsets, causing cases relying on this specialization (topk for 4d+ tensors with topk dimension >= 1024/2048 depending on the type) to produce bogus results.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40349
Differential Revision: D22153756
Pulled By: ngimel
fbshipit-source-id: cac04969acb6d7733a7da2c1784df7d30fda1606
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40139
This unit test runs the same set of operations locally and then with
DDP + RPC to verify correctness.
ghstack-source-id: 106287490
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed/:ddp_under_dist_autograd
I ran these to make sure I am workin on a clean git repo.
git submodule update --init --recursive
to get latest tensor pipe code, otherwise build will have error.
to record installed binaries and torch package wheels to system paths
with-proxy env BUILD_CAFFE2_OPS=0 USE_CUDA=0 USE_MKLDNN=0 USE_DISTRIBUTED=1 python setup.py install --record files.txt
remove binaries and torch package wheels from system paths.
xargs rm -rf < files.txt
build in develop mode
with-proxy env BUILD_CAFFE2_OPS=0 USE_CUDA=0 USE_MKLDNN=0 USE_DISTRIBUTED=1 python setup.py develop
pytest test/distributed/test_ddp_under_dist_autograd.py::TestDdpUnderDistAutograd -v
Differential Revision: D22084385
fbshipit-source-id: e1f57e86ceddd4c96920ed904898e1763b47e8f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37968
Modify memory format promotion rules to avoid promoting when one of the input is ambiguous. New rules are:
Ambiguous + Contiguous = Contiguous
Ambiguous + Channels Last = Channels Last
Contiguous + Ambiguous ( NC11 ) = Contiguous
Contiguous + Channels Last = Contiguous ( + Warning ) Before this PR: Channels Last
Channels Last + Contiguous = Channels Last ( + Warning )
Channels Last + Ambiguous = Channels Last
Bias + Channels Last = Channels Last
Channels Last + Bias = Channels Last
Test Plan: Imported from OSS
Differential Revision: D21819573
Pulled By: VitalyFedyunin
fbshipit-source-id: 7381aad11720b2419fb37a6da6ff4f54009c6532
Summary:
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/387
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39985
avx2 optimized 2/4-bit row-wise quantization/dequantization in perfkernels.
This diff slightly change the numerics of quantization by multiplying with the inverse of scale instead of dividing with scale.
Test Plan:
In my devserver
for i in 2 4 8; do echo $i; buck run mode/opt :fused_rowwise_nbit_conversion_bench -- --bit-rate=$i; done
Before this diff
2-bit
3.35394 ms. 100%. FloatToFused2BitRowwiseQuantized
4-bit
3.60351 ms. 100%. FloatToFused4BitRowwiseQuantized
8-bit
0.434467 ms. 100%. FloatToFused8BitRowwiseQuantized
After this diff
2-bit
0.606386 ms. 100%. FloatToFused2BitRowwiseQuantized
4-bit
0.446683 ms. 100%. FloatToFused4BitRowwiseQuantized
8-bit
0.4349 ms. 100%. FloatToFused8BitRowwiseQuantized
Reviewed By: choudharydhruv, jianyuh
Differential Revision: D22033195
fbshipit-source-id: d3a219e47b8345268d90a160c9314ed0d5b71467
Summary: NVIDIA's Apex is updating to no longer rely on this behavior, but we're reverting this Python2->Python3 update to unblock internal apex users.
Test Plan: Sandcaslte + OSS CI.
Reviewed By: ngimel
Differential Revision: D22146782
fbshipit-source-id: f9483d2cbf9dc3a469ad48a6c863edea3ae51070
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40318
rename layernom fakefp16 to the right naming convention
add it to the map of replacement ops
this can be done even if the operator is not complete because we are blacklisting anyways
Test Plan: net_runner and inspected the log that replacement happened
Reviewed By: venkatacrc
Differential Revision: D22145900
fbshipit-source-id: f19794ec05234b877f7697ed8b05dd8f46606c47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40249
Blocking wait didn't work for dist.barrier() since we performed a
cudaDeviceSynchronize() before we performed any of the timeout checks. As a
result, in case of failures/desync the barrier() call would get stuck on
cudaDeviceSynchrnonize() and would never return a timeout error to the user.
To fix this, I've moved the device synchronization after the timeout checks.
ghstack-source-id: 106250153
ghstack-source-id: 106250153
Test Plan: waitforbuildbot
Differential Revision: D22126152
fbshipit-source-id: d919a7a6507cca7111d8ad72e916777b986d0d67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40296
1. Added a link to parameter server tutorial
2. Explained current states for TorchScript support
Test Plan: Imported from OSS
Differential Revision: D22142647
Pulled By: mrshenli
fbshipit-source-id: ffd697dd64a3aa874cf3f3488122ed805903370d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40276
- add a couple new namespaces;
- handle the case where both contextual namespace and opreator namespace
are set (BackendSelectRegister.cpp and #39401);
- improve error message;
Test Plan: Imported from OSS
Differential Revision: D22135686
Pulled By: ljk53
fbshipit-source-id: 14d359c93573349b8fe1e05d7e44d875295a5f6d
Summary:
Make `common_utils.TestCase.precision` a property, because it is overriden as such in `common_device_type`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40057
Differential Revision: D22138385
Pulled By: malfet
fbshipit-source-id: 0e7c14654bf60f18f585efc61f96fdd0af23346f
Summary:
Update pytorch/onnx docs for new export API args:
Use external data format and Training args.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39802
Reviewed By: hl475
Differential Revision: D22139664
Pulled By: houseroad
fbshipit-source-id: 7d6dcf75129cb88987f8c37b7d9d48ca594c0f38
Summary:
Remove black_listed_operators for opset 12 as we now support these ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39414
Reviewed By: hl475
Differential Revision: D21915584
Pulled By: houseroad
fbshipit-source-id: 37ec7bdd2b5a845484535054026d6613d0921b7a
Summary: enhance the sls test to reflect the shapes and values
Test Plan: ran sls tests on device and emulator
Reviewed By: amylittleyang
Differential Revision: D22094433
fbshipit-source-id: 610a79433ae6c58f626b5984a3d89d9e1bbf4668
Summary:
This is to import a few features:
- a fix to a race condition happening in SHM's use of epoll
- a new XTH channel, that uses a memcpy to transfer between threads of the same process
- a new MPT channel, that chunks and multiplexes tensors over multiple transport event loops
Test Plan: Run in CircleCI
Reviewed By: patricklabatut
Differential Revision: D22140736
fbshipit-source-id: a3cee8a3839d98a42b8438844a9fd24fd85b2744
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39126
futureResponseMessage is shadowed in the pipeWrite lambda which
creates some confusion, since it is used in the initial error handling but then
a future of the same name is created when marking the future as completed. This
change removes this by getting rid of the futureResponseMessage capture,
instead capturing the message id. This change also makes it so that we don't
need to copy it into the lambda.
ghstack-source-id: 106211353
Test Plan: CI
Differential Revision: D22127398
fbshipit-source-id: c98a53b5630ce487461e4ca9cd72fbd34788298d
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/39677
Test Plan:
Moved a test class suite between files, wanted to have same functionality (simple code refactor) so tested to make sure the test output was the same before/after the refactor.
Image below shows the output of TestGraphModePostTrainingStatic before refactor
{F239676498}
This image shows the output of TestQuantizeScript (renamed version that is in test_quantize_script.py instead of test_quantize.py)
{F239676509}
Differential Revision: D21940638
Pulled By: edmundw314
fbshipit-source-id: 54160a5151aadf3a34bdac2bcaeb52904e6653ed
Summary:
There has a missing '=' in rpc_sync call in RPC example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40280
Differential Revision: D22137619
Pulled By: mrshenli
fbshipit-source-id: f4e4b85f68fd68d29834e199416176454b6bbcc2
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/4618
`onnxInputNames_` originated from positional name binding. This is inherited from C2, where in C2 inputs are bound by position. So it's useless to check the name here as like as `onnxInputNames_` is filled. If should save cycles on string comparison.
Test Plan: run it.
Reviewed By: jackm321
Differential Revision: D22104338
fbshipit-source-id: 250463744aa37ed291aebd337e26d573048583ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40187
There were two issues:
1) The hand-written definition included an ambiguous default, which made the deprecated signature not selected. This didn't match the handwritten torch.nonzero, now they do.
2) A parsing bug for empty argument lists meant the signature wasn't being marked as deprecated.
Test Plan: Imported from OSS
Differential Revision: D22118236
Pulled By: gchanan
fbshipit-source-id: a433ce9069fef28aea97cbd76f2adf5a285abd73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38840
JIT graph executor runs some canonical optimizations such as cse, dead code
elimination etc before constructing code that interpreter executes.
Since we do not have full JIT in lite interpreter any such graph optimizations
must happen AOT.
This diff applies such canonical optimizations on graph.
Test Plan: CI's test_mobile_optimizer.
Reviewed By: dreiss
Differential Revision: D21675855
fbshipit-source-id: 5dd898088ef8250103ccbbb6aa2bbce156a8d61d
Summary:
Previously the module would log some data using `print()`. This can be
a problem when used in contexts where the process expects to write data to
stdout itself. This diff changes the log statements to use `logger` instead.
This makes it similar to other log statements in the same module.
Test Plan:
Confirmed no weird test showed up when running:
buck test caffe2/test/distributed/nn/api:remote_module_fork
Differential Revision: D22136172
fbshipit-source-id: a3d144eba6c75925ed684981793c84b36eb45a5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40222
Mention the TensorPipe agent in the RPC docs and give users the information they need to choose which agent to use.
ghstack-source-id: 106225711
Test Plan: Export to GitHub, build locally and try out the docs.
Differential Revision: D22116494
fbshipit-source-id: 30703ba8410c40f64e785f60d71dfd9faa8de4a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40270
Original commit changeset: 1227e243ab94
D22082806 (1e03d603c6) broke the model generation of pyper models. We trace the namedtuple as input. To unblock the development of PyPer project, let's revert the diff first.
Sorry about the inconvenience, SplitInfinity
ghstack-source-id: 106217609
Test Plan: buck run dper3/dper3_models/experimental/pytorch/feed:feed_generation_script -- --model_files_dir=/tmp/
Reviewed By: alyssawangqq
Differential Revision: D22132960
fbshipit-source-id: ce9278c8462602a341e231ea890e46f74e743ddf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40251
Rather than segfaulting, we should show a good error message when in op.call<Return, Args...>(...) the Return type or Args types mismatch the kernel.
This adds an assertion comparing two std::type_index to the call path, but that should be fast. Hashing the function signature is also in the call path and not strictly constexpr, but I checked on godbolt that GCC >=5 and Clang >=3.8 optimize it away and make it constexpr, i.e. it's not part of the assembly.
ghstack-source-id: 106194240
Test Plan: waitforsandcastle
Differential Revision: D22126701
fbshipit-source-id: 6c908a822e295757bcc0014f78f51e6a560f221f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40130
The sparse gradients for the model and the tensor that is used to
perform allreduce in DDP are essentially the same and have the same storage. As
a result, once allreduce is done, the sparse gradients are automatically
updated and unlike dense gradients we don't need to assign the bucket's
contents back to the grad.
In addition to this, I've also added a test for distributed autograd to ensure
it works correctly for sparse gradients. I discovered `finalize_bucket_sparse`
was redundant as part of this test since it passed without any changes needed
to `finalize_bucket_sparse` which only looked at the `.grad` field.
ghstack-source-id: 106090063
Test Plan: waitforbuildbot
Differential Revision: D22080004
fbshipit-source-id: 493ce48b673f26b55dffd6894a3915dc769839f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38748
This diff contains the message scaffolding and profiler changes in order to be able to remotely run the profiler across different nodes and aggregate the results on a single node.
As discussed, we have implemented this by creating new message types, that similar to autograd messages, wrap the profiling information with the original message, and send this new message over the wire. On the receiving end, this wrapped message is detected, we fetch the original message from it, and process the original message with the profiler enabled. When sending a response with profiling information, we serialize the profiled `Events` and send them back over RPC. When such a message is received, the events profiled on the remote node are stored (added back to the local profiler).
Changes in this PR:
- New message types (run_with_profiling_req, run_with_profiling_resp) to send profiling info over the wire. Message parsing logic is added to handle these wrapped types.
- Handling of sending profiler data over the wire, in particular, the attributes of the `ProfilerConfig` and the serialized profiled `Event`s
- The logic for wrapping RPC messages is deduped with that in `rpc_with_autograd`, and the common payload wrapping/unwrapping logic is moved to helper functions in `rpc/utils.cpp`
- Changes in `autograd/utils.cpp` to detect if we have enabled the profiler and are sending an RPC, if so, uses the above new message types
- Changes in request_callback to parse and turn on the profiler in a thread-local fashion
- Serialization and deserialization of profiling `Events`, and support to add the remote events to the thread-local profiler
- Introduction of the concept of `node_id`, which as discussed with ilia-cher , will be used along with the `Event`s handle attribute to distinguish between events. When there are events from different nodes, this node information is rendered in the profile output (e.g. when printing tables), otherwise, it is not, since it is irrelevant.
- Some changes to profiler.cpp to add useful helper methods/guards
- toHere() is now profiled for RRefs
- Unittests
ghstack-source-id: 106134626
Test Plan: Added unittests, existing profiler unittests.
Differential Revision: D19510010
fbshipit-source-id: 044347af992f19a9e3b357c9567f6fc73e988157
Summary:
**Summary**
This commit adds support for with statements to PyTorch JIT. Each
of the with items in a with statement is represented in the JIT IR
as a pair of `prim::Enter` and `prim::Exit` nodes that call the
`__enter__` and `__exit__` methods defined on the context manager objects
returned by the expressions in the with item.
**Testing**
This commit adds unit tests for with statements with named with items,
nameless with items, and with statements that encounter exceptions.
```
$ python test/test_jit.py TestWith.test_with_as
Fail to import hypothesis in common_utils, tests are not derandomized
.
----------------------------------------------------------------------
Ran 1 test in 0.430s
OK
```
```
$ python test/test_jit.py TestWith.test_with_no_as
Fail to import hypothesis in common_utils, tests are not derandomized
.
----------------------------------------------------------------------
Ran 1 test in 0.264s
OK
```
```
$ python test/test_jit.py TestWith.test_with_exceptions
Fail to import hypothesis in common_utils, tests are not derandomized
Couldn't download test skip set, leaving all tests enabled...
.
----------------------------------------------------------------------
Ran 1 test in 1.053s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34705
Differential Revision: D22095945
Pulled By: SplitInfinity
fbshipit-source-id: f661565a834786725259b8ea014b4d7532f9419d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40191
When the first couple of inputs passed to histogram observer are all 0's subsequent non-zero inputs cause a div by 0 error
Test Plan:
python test/test_quantization.py TestHistogramObserver.test_histogram_observer_zero_inputs
Imported from OSS
Differential Revision: D22119422
fbshipit-source-id: 8bbbba914ba7f343121830c768ca0444439f8e03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39587
Example of using direct linking to pytorch_jni library from aar and updating android/README.md with the tutorial how to do it.
Adding `nativeBuild` dimension to `test_app`, using direct aar dependencies, as headers packaging is not landed yet, excluding `nativeBuild` from building by default for CI.
Additional change to `scripts/build_pytorch_android.sh`:
Skipping clean task here as android gradle plugin 3.3.2 exteralNativeBuild has problems with it when abiFilters are specified.
Will be returned back in the following diffs with upgrading of gradle and android gradle plugin versions.
Test Plan: Imported from OSS
Differential Revision: D22118945
Pulled By: IvanKobzarev
fbshipit-source-id: 31c54b49b1f262cbe5f540461d3406f74851db6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40233
There was a question earlier whether torch.futures.wait_all() would
raised if the underlying futures raise (it was supposed to, but no test
coverage). This change adds a couple very basic torch.futures.collect_all/
wait_all tests.
ghstack-source-id: 106168134
Test Plan: buck test mode/dev-nosan caffe2/test:futures
Differential Revision: D22120284
fbshipit-source-id: 3a8edae5dbf8c58c8361eff156c386a684ec5e86
Summary:
Slightly modified Adam, following the python implementation, and the `ProducesPyTorchValues` tests pass. I had a problem with another test though (see commit c1a6241676ab84fc531c1c3a10f964aa5704092e), it seems that optimizing for two steps with the same optimizer vs optimizing for two steps using freshly initialized objects will produce the same output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40009
Differential Revision: D22096053
Pulled By: glaringlee
fbshipit-source-id: a31a8f5488cb37c53752ddf15436efabdba67dc4
Summary:
This test is flaky for rocm platform. Add to blacklist until it can be further reviewed.
CC ezyang xw285cornell sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40204
Differential Revision: D22108295
Pulled By: xw285cornell
fbshipit-source-id: 802444a7b41260edcb6ce393237784f3e6c52a74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40232
if an operator failed to onnxifi due to lack of support (not because of missing shapes), print out the position of such op, which can be used to feed net runner
Test Plan: I0618 09:25:06.299002 1570804 onnxifi_transformer.cc:1232] Don't support c2 op SparseLengthsSumFused4BitRowwise at pos 246 (1030)
Reviewed By: hl475
Differential Revision: D22120055
fbshipit-source-id: a3c68b93b7e38dfda5d70168e7541021a8e16dcb
Summary:
Quick fix due to code merging. With this feature working, the total size reduction in Android is 664 KB (Pytorch -26 KB and papaya - 639 KB)
https://fburl.com/unigraph/c726gvb1
Test Plan: CI
Reviewed By: kwanmacher
Differential Revision: D22053779
fbshipit-source-id: 8da4a651432b453c25e543bc64dbed02946de63d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38361
Rather than segfaulting, we should show a good error message when in op.call<Return, Args...>(...) the Return type or Args types mismatch the kernel.
This adds an assertion comparing two std::type_index to the call path, but that should be fast. Hashing the function signature is also in the call path and not strictly constexpr, but I checked on godbolt that GCC >=5 and Clang >=3.8 optimize it away and make it constexpr, i.e. it's not part of the assembly.
supersedes D17485438
ghstack-source-id: 106178820
Test Plan: waitforsandcastle
Differential Revision: D21534052
fbshipit-source-id: 6be436a3f20586277a051d764af29e21d5567da0
Summary:
Use switch instead of look ups in global std::unordered_maps<> to do enum-to-name conversions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40183
Reviewed By: malfet
Differential Revision: D22117731
Pulled By: ionsphere
fbshipit-source-id: d150114cfae5b1222bb9142d815f2379072506c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39588
Before this diff we used c++_static linking.
Users will dynamically link to libpytorch_jni.so and have at least one more their own shared library that probably uses stl library.
We must have not more than one stl per app. ( https://developer.android.com/ndk/guides/cpp-support#one_stl_per_app )
To have only one stl per app changing ANDROID_STL way to c++_shared, that will add libc++_shared.so to packaging.
Test Plan: Imported from OSS
Differential Revision: D22118031
Pulled By: IvanKobzarev
fbshipit-source-id: ea1e5085ae207a2f42d1fa9f6ab8ed0a21768e96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39507
Adding gradle task that will be run after `assemble` to add `headers` folder to the aar.
Headers are choosed for the first specified abi, they should be the same for all abis.
Adding headers works through temporary unpacking into gradle `$buildDir`, copying headers to it, zipping aar with headers.
Test Plan: Imported from OSS
Differential Revision: D22118009
Pulled By: IvanKobzarev
fbshipit-source-id: 52e5b1e779eb42d977c67dba79e278f1922b8483
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40194
Adds the scaffolding for doing docker builds based off git rev-parse
tags to detect changes.
Basically allows us to do our previous builds while also prepping for
the new builds by just retagging our current builds as the new ones and
telling the garbage collector not to reap them.
Should also skip out on redundant builds if the image already exists
thus saving us some compute time on docker builds.
Also adds the commands to load the calculated DOCKER_TAG from a shared
workspace file.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22120651
Pulled By: seemethere
fbshipit-source-id: c74f10816d63f440a9e0cdd00d6fa1a25eb7a2c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40144
as title, split remaining quantization tests out of test_jit to reduce
the size of test_jit
Test Plan: Imported from OSS
Differential Revision: D22085034
Pulled By: wanchaol
fbshipit-source-id: 0c8639da01ffc3e6a72e6f470837786c73a6b3f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39584
Removing `-DNO_EXPORT` for not-custom-build to be able to link to C10/A10 api.
Custom build stays the same as its main goal is to have minimum binary size, while export api functions will increase it.
Additional changes:
1. aten/src/ATen/DynamicLibrary.cpp uses libdl, if we need this functionality we will need to link result with libdl, but currently disabling this functionality for mobile.
Test Plan: Imported from OSS
Differential Revision: D22111600
Pulled By: IvanKobzarev
fbshipit-source-id: d730201c55f543c959a596b34be532aecee6b9ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40189
This is to allow for easier modification later on down the road.
Makes no actual modification to the `.circleci/config.yml`
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22119414
Pulled By: seemethere
fbshipit-source-id: c6cb105d983e43ae1bf289b2d9f734b34a7febe2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40055
Noticed this while reading the `helper.cpp` file, seems like this op
should be in the `single_input_general_value` bucket.
Test Plan:
CI
Imported from OSS
Differential Revision: D22054257
fbshipit-source-id: 2ca16ff863d644cbd03c3938eeca0fb87e3e4638
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39413
Implementing the request from
https://github.com/pytorch/pytorch/pull/39095
WIP so we can align on the API, once it looks good
will amend the PR to apply to all relevant functions.
Test Plan:
```
python test/test_quantization.py TestQuantizeScriptPTSQOps.test_hardswish
```
Imported from OSS
Differential Revision: D21885263
fbshipit-source-id: 029339a99f8c50e45dd1dfb7fd89c20e3188720d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39203
Adds logic and test coverage for optional weights and biases for
the quantized normalization operators. This was broken before this
PR because the `TORCH_LIBRARY` registration had these as required parameters
- removed it, and cleaned up the callsites.
Note: consolidating the registrations in `native_functions.yaml` as opposed to `library.cpp`
after a discussion with ezyang .
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_qlayer_norm
python test/test_quantization.py TestQuantizedOps.test_group_norm
python test/test_quantization.py TestQuantizedOps.test_instance_norm
python test/test_quantization.py TestStaticQuantizedModule.test_layer_norm
python test/test_quantization.py TestStaticQuantizedModule.test_group_norm
python test/test_quantization.py TestStaticQuantizedModule.test_instance_norm
python test/test_quantization.py TestQuantizeScriptPTSQOps.test_layer_norm
python test/test_quantization.py TestQuantizeScriptPTSQOps.test_group_norm
python test/test_quantization.py TestQuantizeScriptPTSQOps.test_instance_norm
```
Imported from OSS
Differential Revision: D21885259
fbshipit-source-id: 978c7b8bd6c11a03e9e5fdb68f154cb80cc43599
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40200
Since original weights are removed by default in mobile build, the check must
be moved to a place where orig_weight is still valid.
Test Plan:
CI
Plus observed a model run crash which was resolved after this change.
Reviewed By: supriyar
Differential Revision: D22101562
fbshipit-source-id: 9543e69a415beaef2a9fb92dc9cd87d636174d51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40162
The only public option is `num_worker_threads`. The other ones are private (as indicated by the leading underscore, is that enough?) and allow to specify a different set and order of transports/channels. These can thus be used to disable a backend (by not specifying it) or by forcing one (by raising its priority). They can therefore be used to work around defective backends, in case we'll find any post-release.
ghstack-source-id: 106103238
Test Plan: Built //caffe2:ifbpy and, using TensorPipe's verbose logging, verified that the transports/channels I specified were indeed the ones that were being registered.
Differential Revision: D22090661
fbshipit-source-id: 789bbe3bde4444cfa20c40276246e4ab67c50cd0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40207
Blocking wait didn't work for dist.barrier() since we performed a
cudaDeviceSynchronize() before we performed any of the timeout checks. As a
result, in case of failures/desync the barrier() call would get stuck on
cudaDeviceSynchrnonize() and would never return a timeout error to the user.
To fix this, I've moved the device synchronization after the timeout checks.
ghstack-source-id: 106123004
Test Plan: waitforbuildbot
Differential Revision: D22108899
fbshipit-source-id: 6b109ef9357e9464e7d66b540caabf5801e6a44a
Summary:
After this diff, on PR following compilation configuration would be running:
- VS2017 14.11, CUDA10.1
- VS2017 no CUDA, CUDA10.1
- VS2019, CUDA10.1
And tested:
- VS2017 14.11, CUDA10.1
- VS2017 14.11 no CUDA (only 1st half of tests)
- VS2017 14.11 force on CPU (only 1st half of test)
And on master, we would be building both VS2017 14.11 and 14.16, but testing only VS2017 14.11 and VS2019 builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38482
Differential Revision: D22111743
Pulled By: malfet
fbshipit-source-id: d660e4bc8f4f17a93f1cc18402cd5f2091b7789d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40196
- separate passes in insert observers to make it more robust
- added print for quantization type
- added more logging for insert observers
Test Plan: Imported from OSS
Differential Revision: D22106545
fbshipit-source-id: 6d8d722e33c1259b1a6a501853c801c275dbfcff
Summary:
Use it from both __init__ and streams to define dummy types when CUDA is missing
Fix accidental reference of global `storage_name` from `_dummy_type`
Add type annotations
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40177
Differential Revision: D22106922
Pulled By: malfet
fbshipit-source-id: 52fbfd91d70a78eb14d7ffda109c02ad1231497e
Summary: Export box_cox operator in caffe2
Test Plan: Pass all unit tests
Reviewed By: mingzhe09088
Differential Revision: D21515797
fbshipit-source-id: 777ee5e273caeab671ee2c22d133d3f628fb4a6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37462
Instead of running all the optimization pass in optimizeForMobile method,
introducing a whitelist optimizer dictionary as second param in the method,
when it is not passed during calling, the method will run all the optimization
passes, otherwise the method will read the dict and only run the pass with
value of True.
ghstack-source-id: 106104503
Test Plan:
python test/test_mobile_optimizer.py
Imported from OSS
Differential Revision: D22096029
fbshipit-source-id: daa9370c0510930f4c032328b225df0bcf97880f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40142
test_jit is becoming huge again, which makes editor hard to load and
write new tests, this split out the tracer related tests.
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D22085035
Pulled By: wanchaol
fbshipit-source-id: 696bee84985ecfbfeac8e2ee5c27f1bdda8de394
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40151
For debug android build it throws the following error:
```
In file included from src/pytorch/android/pytorch_android/src/main/cpp/pytorch_jni_common.cpp:9:
In file included from src/pytorch/android/pytorch_android/src/main/cpp/pytorch_jni_common.h:2:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/torch/csrc/api/include/torch/types.h:3:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/ATen.h:5:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/Context.h:4:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/Tensor.h:3:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/ATen/core/TensorBody.h:7:
In file included from ../../../../src/main/cpp/libtorch_include/armeabi-v7a/c10/core/Scalar.h:13:
../../../../src/main/cpp/libtorch_include/armeabi-v7a/c10/util/TypeCast.h:157:22: error: use of undeclared identifier '__assert_fail'
AT_FORALL_QINT_TYPES(DEFINE_UNCASTABLE)
^
```
Seems __assert_fail() isn't available on Android by default - in NDEBUG mode it forward declares the function and CI passes.
But CUDA_KERNEL_ASSERT() shouldn't be relevant for mobile build at all and we already bypass `__APPLE__` so the easiest fix is to add `__ANDROID__`.
Test Plan: Imported from OSS
Differential Revision: D22095562
Pulled By: ljk53
fbshipit-source-id: 793108a7bc64db161a0747761c0fbd70262e7d5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40081
Adding the functionality to enable timeout of OnnxifiOp run. In the case of backend hanging, it can error out quickly.
Test Plan:
```
buck test glow/fb/test:test_onnxifinnpi -- test_timeout
```
Reviewed By: jackm321
Differential Revision: D22064533
fbshipit-source-id: 25487287c10ab217eb95692f09d48e13e19436ab
Summary:
ROCm CI hosts will have their kernels upgraded first to ROCm 3.5.1. CI images will follow soon after. Due to the thunk/kernel mismatch during the interim, this PR will detect the mismatch and upgrade the thunk during the build. This PR will be reverted once migration to ROCm 3.5.1 images is complete.
CC ezyang xw285cornell
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40181
Differential Revision: D22104488
Pulled By: xw285cornell
fbshipit-source-id: 7192e1d0bb25bfb814e9a85efb4aa29d0e52b460
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40141
This rref timeout test could be flaky because we could end up processing `RRefUserDelete` messages on the owner node before processing the to_here message. This would result in a hang in `ProcessGroupAgent::sync()` that eventually results in a timeout.
The rough sequence of what happens is:
0) Node 0 creates RRef on node 1 with rpc.remote() call
1) rref.to_here() is called with a timeout. Because of delay injection, the processing of this message can be delayed (this is also technically possible in applications without delay injection)
2) At some point, callbacks corresponding to rpc.remote() runs and confirms the rref, adding it as a confirmed user
3) RPC shutdown starts, as part of which we send out RRef user deletes. In this case, 0 sends an RRef user delete to 1, and node 1 removes the owner from the `owners_` field.
4) The `to_here()` message is finally processed by node 1. But since we have deleted the `owner_`, while processing this message we create a future that will be complete when the owner exists (this is to account for the case of to_here() arriving here rpc.remote). But this future will never complete, since the owner is already deleted, so we hang indefnitely
As a workaround for now, we can force `to_here()` to run before RPC shutdown by adding a blocking `to_here()` call with no timeout.
A more robust, longer-term fix would be to detect if an owner has been previously deleted (such as by an RRefUserDelete). Then, we know that the future corresponding to owner creation on the remote end will never completee, and then we error out when processing a `to_here()`.
ghstack-source-id: 106036796
Differential Revision: D22084735
fbshipit-source-id: fe7265a4fe201c4d6d2f480f64fe085cd59dbfb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40175
Check that there is an increasing memory usage in the test
Test Plan: CI
Differential Revision: D22098192
Pulled By: ilia-cher
fbshipit-source-id: bbdbc71f66baf18514332a98d8927441c61ebc16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40173
- Avoid path sharing across runs and workers, so even the test methods/workers run in parallel on the same host, they don't interfere with each other.
- On some environment (e.g. fb internal CI platform), the torch package file tree is not writable. But the temporary folder chosen by Python `tempfile` module is always writable, on linux it's "/tmp".
close https://github.com/pytorch/pytorch/issues/40120
ghstack-source-id: 106086340
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/nn/jit:test_instantiator
buck build mode/dev-nosan //caffe2/test/distributed/nn/jit:test_instantiator && \
buck-out/gen/caffe2/test/distributed/nn/jit/test_instantiator\#binary.par -r test_instantiate_scripted_remote_module_template
buck build mode/dev-nosan //caffe2/test/distributed/nn/jit:test_instantiator && \
buck-out/gen/caffe2/test/distributed/nn/jit/test_instantiator\#binary.par -r test_instantiate_non_scripted_remote_module_template
```
```
buck test mode/dev-nosan //caffe2/test/distributed/nn/api:remote_module_fork
```
Differential Revision: D5708493
fbshipit-source-id: dd92695682433aaf79d1912c7956cef40a450eaf
Summary:
So it can still be a useful way to get all the build configs that target specifier can't handle yet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40186
Differential Revision: D22100671
Pulled By: ezyang
fbshipit-source-id: df291705e717c0c7e7cf4d675b9d49a1eba54a1d
Summary:
**Summary**
This commit modifies type inference for `nn.Module` instance attributes
such that the type of a `NamedTuple` attribute is inferred correctly and
such that the field names of this `NamedTuple` instance can be used in
scripted methods. At present, the type of this attribute is inferred to be
`Tuple[T, U, ..., V]`, so the field must be referred to by index and
cannot be referred to by name.
**Test Plan**
This commit adds a unit test to test that a field of a `NamedTuple`
attribute can be referred to by name in a scripted method.
**Fixes**
This commit fixes https://github.com/pytorch/pytorch/issues/37668.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39116
Differential Revision: D22082806
Pulled By: SplitInfinity
fbshipit-source-id: 1227e243ab941376cd5e382fb093751e88dc8846
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40127
Reland PR.
Similar to static quant, break it up into op level tests and tests for jit passes
Test Plan:
python test/test_quantization.py TestQuantizeScriptPTDQOps
python test/test_quantization.py TestDynamicQuantizeScriptJitPasses
Imported from OSS
Differential Revision: D22081259
fbshipit-source-id: cef8f78f89ef8789683b52508379ae1b9ad00700
Summary:
Resolve https://github.com/pytorch/pytorch/issues/38207
Below is the description of split function according to [Python doc](https://docs.python.org/3.8/library/stdtypes.html?highlight=split#str.split).
```
If sep is not specified or is None, a different splitting algorithm is applied:
runs of consecutive whitespace are regarded as a single separator,
and the result will contain no empty strings at the start or end
if the string has leading or trailing whitespace.
```
The logic to handle both none and empty separators is added in register_string_ops.cpp as fix.
Signed-off-by: Xiong Wei <xiongw.fnst@cn.fujitsu.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38772
Differential Revision: D21789612
Pulled By: suo
fbshipit-source-id: 4dfd74eda71e0bfd757378daedc927a4a63ec0e4
Summary:
This allows registering hooks that will be executed for every module.
This idea arose in a discussion with tkerola and niboshi kindly proposed this approach.
The use case for this is to avoid boilerplate code when registering the same hook for all the modules in a complex model, the internal use-case was to allow every model to accept a NumPy array in the forward pass in a simpler way. Other use cases involve general mechanisms for plotting or tracing & debugging.
Currently, this is shared for all the modules but this can be worked out to have the hooks shared only per type of module.
If this functionality is not needed feel free to close the PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38972
Differential Revision: D22091364
Pulled By: albanD
fbshipit-source-id: 204ff5f9e119eff5bdd9140c64cb5dc467bb23a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40167
In v1.6 TensorPipe will not support transferring GPU tensors so, just like other agents, it should raise the appropriate errors when the user attempts to do so. One such error is when sending the arguments, another is when sending the result.
ghstack-source-id: 106059723
Test Plan: Re-enabled the test for this
Differential Revision: D22091737
fbshipit-source-id: 23dda98bc006333c6179361e8cfaf00ecda06408
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40112
The changed code should be run for arm build even if qnnpack engine is not
enabled.
Furthermore the way AT_DISPATCH* stubs are defined, it just forms a lambda out
of the __VA__ARGS and executes the lambda. Thus return inside such lambda just
return to the original function and we end up executing the fallback path as
well.
Thus also changed #endif to #else...#endif.
This was causing per regression on mobile in one of the models.
ghstack-source-id: 105990691
Test Plan: CI
Reviewed By: supriyar
Differential Revision: D22072780
fbshipit-source-id: b12ca66aa19834b97b3eb0067af4e656cb8b3241
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40097
This is (probably) necessary for the vmap frontend API (coming up after
this PR should be the vmap frontend API).
There is some manual handling of sizes in the `expand_batching_rule`.
In particular, when performing expand(Tensor[B0, 3], [2, 3]), where B0
is a batch dimension and Tensor[B0, 3] is a batched tensor with batch
dimension B0, we can't call expand directly on the physical view and
instead first need to perform a view.
It's possible to add said view as a helper function on `VmapPhysicalView` but
after reading through the operator spreadsheet the conclusion was that
no other operator needs the same manual handling.
Test Plan: - `./build/bin/vmap_test`
Differential Revision: D22070657
Pulled By: zou3519
fbshipit-source-id: 911854b078a1a5c7d5934ef2e17b16673ed9d103
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40042
See title. Dynamic allocations are generally bad for performance. This
change was not benchmarked because we have not gotten to the stage where
we want to benchmark performance.
Test Plan: - `./build/bin/vmap_test`
Differential Revision: D22070656
Pulled By: zou3519
fbshipit-source-id: f6cf74a357bb52b75c0a02f1f82495c0a5329a28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40028
We have this call native::size directly. Some alternatives I considered
were:
- Call VariableType::size directly. That seems isomorphic to what we're
doing now.
- when creating a BatchedTensor from a regular tensor, put all of the
keys on that tensor into the BatchedTensor's dispatch key set and use
the dispatcher fallthrough mechanism. That seems weird because
BatchedTensor is a tensor wrapper and also error prone because if
BatchedTensor gets the VariableType key, there's a chance that if
something goes wrong, an autogradmeta gets created on it...
Test Plan: - `./build/bin/vmap_test`
Differential Revision: D22070655
Pulled By: zou3519
fbshipit-source-id: 18530579ad41f3c4f96589da41eb24a46caf7af9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40094
In #39182 we already silenced a few warnings when they were caused by expected errors, but left one case out, namely errors on an incoming pipe. The idea was to introduce a "proper" way of detecting these, for example by having the remote end send an empty message to indicate an intentional shutdown. I don't know if we'll have time to do that in time for v1.6, so as a temporary solution I'm implementing some approximation which, although imperfect, should cover most errors. I also made the warning message less scary by adding a clarification.
ghstack-source-id: 105969540
Test Plan: Unit tests
Differential Revision: D22067818
fbshipit-source-id: b2e2a37d633f21bca4a2873a05ad92b853dde079
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40149
Many math ops are moved to lite interpreter in D21992552, but some ops (like log) also have tensor version and we didn't check duplicated names in this case. This breaks some existing models.
Move back most ops for now until we have a cleaner solution
Test Plan: build
Reviewed By: pengtxiafb
Differential Revision: D22085208
fbshipit-source-id: 951805f43f84bd614cf914c17e00444a122158e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39868
### Summary
why disable NNPACK on iOS
- To stay consistency with our internal version
- It's currently blocking some external users due to its lack support of x86 architecture
- https://github.com/pytorch/pytorch/issues/32040
- https://discuss.pytorch.org/t/undefined-symbols-for-architecture-x86-64-for-libtorch-in-swift-unit-test/84552/6
- NNPACK uses fast convolution algorithms (FFT, winograd) to reduce the computational complexity of convolutions with large kernel size. The algorithmic speedup is limited to specific conv params which are unlikely to appear in mobile networks.
- Since XNNPACK has been enabled, it performs much better than NNPACK on depthwise-separable convolutions which is the algorithm being used by most of mobile computer vision networks.
### Test Plan
- CI Checks
Test Plan: Imported from OSS
Differential Revision: D22087365
Pulled By: xta0
fbshipit-source-id: 89a959b0736c1f8703eff10723a8fbd02357fd4a
Summary:
BC-breaking note:
If a user is using one of these dunders directly they will not longer be available. Users should update to Python3 compatible dunders.
Original PR note:
`__div__` (and `__idiv__` and `__rdiv__`) are no longer special dunders in Python3. This PR replaces them with the `__truediv__` (`__itrudediv__`, `__rtruediv__`) dunders, since we no longer support Python2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39151
Differential Revision: D22075713
Pulled By: mruberry
fbshipit-source-id: d318b47b51f7cc4c3728b1606a34d81e49ba0fa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40078
att. It's good to have net_pos for all the ops so that we can distinguish each op in minimizer in net_runner.
Test Plan: unittest
Reviewed By: ipiszy, ChunliF
Differential Revision: D22062748
fbshipit-source-id: 5266abdb6dde63055fdffdba6e8d65bd0f221d7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39602
This was added as a part of
https://github.com/pytorch/pytorch/pull/38590 but we can use default arguments
here. We use fmt:;format to bind the default value to the rpc timeout at
runtime.
ghstack-source-id: 105983645
Test Plan: Ci
Differential Revision: D21912719
fbshipit-source-id: 7525c1322a95126f529301be142248af48565b82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40101
Create three tests for LSTMs:
1. test_qlstm: Test to check numerics of quantized LSTM operator.
2. test_lstm_api: To check the LSTM module and compare
it with the quantized LSTM op
3. test_quantized_rnn: Check the dynamic quantization workflow, scriptability and serialization of quantized
LSTM
ghstack-source-id: 105997268
(Note: this ignores all push blocking failures!)
Test Plan:
buck test caffe2/test:quantization -- 'test_lstm_api \(quantization\.test_quantized_module\.TestDynamicQuantizedModule\)' --print-passing-details
buck test caffe2/test:quantization -- 'test_quantized_rnn \(quantization\.test_quantize\.TestPostTrainingDynamic\)'
buck test caffe2/test:quantization -- 'test_qlstm \(quantization\.test_quantized_op\.TestDynamicQuantizedRNNOp\)' --print-passing-details
Differential Revision: D22070826
fbshipit-source-id: 46c333e19b9eab8fa5cab6f132e89b80a635791a
Summary:
Reserves file format version 5 for marking when torch.full(int)->FloatTensor will be deprecated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40089
Differential Revision: D22066359
Pulled By: mruberry
fbshipit-source-id: 6158e03ca75e3795a2641123ff23d67975170f44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40096
Declaring `tensor_proto` to be of type `auto` means that it will copy the entire `TensorProto` instead of just keeping a reference. This changes it to just use a const reference instead.
Test Plan:
Using the model loader benchmark to measure model loading performance:
### `tensor_proto` is of type `const auto&`
```
============================================================================
caffe2/caffe2/fb/predictor/ModelLoaderBenchmark.cpprelative time/iter iters/s
============================================================================
BlobProtoInt32DeserializationFloat16 11.08ms 90.27
BlobProtoByteDeserializationFloat16 1509.73% 733.73us 1.36K
----------------------------------------------------------------------------
BlobProtoInt32DeserializationUInt8 10.48ms 95.45
BlobProtoByteDeserializationUInt8 2974.57% 352.22us 2.84K
============================================================================
```
### `tensor_proto` is of type `auto`
```
============================================================================
caffe2/caffe2/fb/predictor/ModelLoaderBenchmark.cpprelative time/iter iters/s
============================================================================
BlobProtoInt32DeserializationFloat16 13.84ms 72.26
BlobProtoByteDeserializationFloat16 658.85% 2.10ms 476.08
----------------------------------------------------------------------------
BlobProtoInt32DeserializationUInt8 17.09ms 58.51
BlobProtoByteDeserializationUInt8 3365.98% 507.80us 1.97K
============================================================================
```
Reviewed By: marksantaniello
Differential Revision: D21959644
fbshipit-source-id: 6bc2dfbde306f88bf7cd4f9b14b95ac69c2e1b4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39803
The basic concept is to make it more clear what the construction
side API is, as opposed to the "I want to actually do kernel stuff
with TensorIterator" API (which has been kept on TensorIterator.)
In fact, most of the stuff in TensorIteratorConfig isn't used by
TensorIterator later, so it can be dropped entirely after construction.
Before:
```
TensorIterator iter;
iter.config1();
iter.config2();
iter.config3();
iter.build();
// use iter
```
Now:
```
TensorIterator iter = TensorIteratorConfig()
.config1()
.config2()
.config3()
.build();
// use iter
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22018845
Pulled By: ezyang
fbshipit-source-id: 5baca9a4dc87149d71a44489da56d299f9b12b34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40012
Use Fused Multiply and Add
Test Plan: Tested using the test_layernorm_nnpi_fp16.py test case.
Reviewed By: hyuen
Differential Revision: D22039340
fbshipit-source-id: d979daac152f885318ddcbbb9d7108219d4743e9
Summary:
Since Argmax is updated in ONNX Runtime we can enable testing for all output, including keypoints_scores.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39589
Reviewed By: hl475
Differential Revision: D21992264
Pulled By: houseroad
fbshipit-source-id: a390b4628d2ac290902b9e651c69d47db9be540f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39919
e.g. torch.nn.ReLU6(inplace=True)
looks like this is already supported, but somehow it is not working in tutorial
Test Plan: Imported from OSS
Differential Revision: D22055695
fbshipit-source-id: 78a55b963cd3fac06f952f83c7c61c717cc839cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40039
Similar to static quant, break it up into op level tests and tests for jit passes
Test Plan:
python test/test_quantization.py TestQuantizeScriptPTDQOps
python test/test_quantization.py TestDynamicQuantizeScriptJitPasses
Imported from OSS
Differential Revision: D22071278
fbshipit-source-id: 54292addcfbc00f7af960fb333921db2ff9fda04
Summary:
Possible fix for gh-38385. Unfortunately, I haven't been able to reproduce the issue reliably, so can't say for certain.
Since this appears to be a destruction ordering issue, I've focused on making the destructor calls well-ordered:
- Each pool is now a function-local `static` instead of a global variable. This ensures the destructor happens before any relevant pytorch global state is destroyed.
- Each pool window now only stores a `std::weak_ptr` to the global pool. This means it can't extend the lifetime of the pool outside of the normal destructor ordering. That does also mean that if the `weak_ptr` is invalid, the handles will get leaked. However, that shouldn't happen under normal use.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39345
Differential Revision: D22044376
Pulled By: ezyang
fbshipit-source-id: da1713b42c143ed1452a6edf1ecb05cd45743c7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39909
As described in https://github.com/pytorch/pytorch/issues/33583,
ProcessGroupAgent initializes the default process group and this causes issues
if the user initializes the default process group themsleves. Either the RPC
initialization would fail or the user's process group initialization would
fail.
To avoid this, I've changed ProcessGroupAgent init to create its own
ProcessGroupGloo and not use the default one at all.
Closes: https://github.com/pytorch/pytorch/issues/33583
ghstack-source-id: 105953303
Test Plan: waitforbuildbot
Differential Revision: D22011868
fbshipit-source-id: 7346a3fcb2821a0bc08e0bdc0625947abb5ae16f
Summary:
Closes gh-35418,
PR gh-16414 added [the `CMAKE_INSTALL_RPATH_USE_LINK_PATH`directive](https://github.com/pytorch/pytorch/pull/16414/files#diff-dcf5891602b4162c36c2125c806639c5R16) which is non-standard and will cause CMake to write an `RPATH` entry for libraries outside the current build. Removing it leaves an RPATH entry for `$ORIGIN` but removes the entries for things like `/usr/local/cuda-10.2/lib64/stubs:/usr/local/cuda-10.2/lib64` for `libcaffe2_nvrtc.so` on linux.
The added test fails before this PR, passes after. It is equivalent to checking `objdump -p torch/lib/libcaffe2_nvrtc.so | grep RPATH` for an external path to the directory where cuda "lives"
I am not sure if it solve the `rpath/libc++.1.dylib` problem for `_C.cpython-37m-darwin.so` on macOS in issue gh-36941
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37737
Differential Revision: D22068657
Pulled By: ezyang
fbshipit-source-id: b04c529572a94363855f1e4dd3e93c9db3c85657
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40092
Move <windows.h> include in THAllocator after header that might include glog is included
Test Plan: buck build xplat/mode/arstudio/windows //xplat/caffe2:aten_cpuWindows
Reviewed By: nlutsenko
Differential Revision: D22061135
fbshipit-source-id: 10f51955c0092761a96bc6169236c6e07b412313
Summary:
Fix for https://github.com/pytorch/vision/issues/2320 - still need to fix whatever reverting this change breaks
EDIT: reverting this change doesnt seem to break anything, and fixes the torchvision issue
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40041
Reviewed By: eellison
Differential Revision: D22067586
Pulled By: fmassa
fbshipit-source-id: 4b235fd3a69665dcc5689f12310097be31b40a28
Summary:
This pr aims at improving `nn.UpSample()` performance on CPU with mode `linear`, `bilinear`, `trilinear`.
For single socket inference, up to **31x** performance improvement.
For single core inference, up to **1.8x** performance improvement.
For dual socket training, up to **28x** performance improvement.
`channel last` format kernel also provided.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34864
Differential Revision: D20772990
Pulled By: ngimel
fbshipit-source-id: a48307f2072227f20e742ebbd4a093bb29537d19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40090
I messed up in #39957: TensorPipe used to have a bug where it inverted priorities and preferred lower ones over higher ones. I had fixed that bug at the same time as I was writing that PR but then forgot to update the priority values once that PR landed. So this meant that TensorPipe was trying to bootstrap using SHM and then upgrade to UV. That worked in our tests because they are all run on the same machine, but that broke using TensorPipe across different machines. I'll take suggestions on how to have tests in place to prevent this type of breakages from happening.
The silver lining is that for some time our tests were testing the UV transport, instead of the SHM one, and it seems to be working alright. ;)
ghstack-source-id: 105967203
Differential Revision: D22067264
fbshipit-source-id: c6e3ae7a86038714cfba754b0811ca8a9a6f1347
Summary:
Fixes gh-40046
PR gh-37419 refactored the content of `docs/source/rpc/index.rst` into `docs/source/rpc.rst` but did not link to the latter from `doc/source/index.rst` so the top-level RPC documentation is missing from https://pytorch.org/docs/master/.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40077
Differential Revision: D22068128
Pulled By: mrshenli
fbshipit-source-id: 394433f98f86509e0c9cb6d910a86fb8a2932683
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39859
This PR implements the batching rule for `torch.mul` for the (Tensor,
Tensor) overload.
NB: ~250 lines of this PR are tests, so please don't be scared away by
the line count.
It introduces the BroadcastingVmapTransform, which is the VmapTransform
one should use for operations that broadcast their inputs. This
transform:
- permutes all batch dimensions to the front of the tensors
- aligns the batch dimensions of the tensors, adding extra 1's where
necessary
- aligns the non-batch dims of the tensors, adding extra 1's where
necessary.
Test Plan:
- Test BroadcastingVmapTransform in `./build/bin/vmap_test`.
- Test mul_batching_rule in `./build/bin/vmap_test`.
Differential Revision: D22067337
Pulled By: zou3519
fbshipit-source-id: 5862da8c2b28699b08c7884342a1621581cb2e7f
Summary:
**Summary**
This commit adds a registry for storing lowering functions for backends.
Instead of backends registering these lowering functions in separate C
extension modules, these will be registered in the Torch extension.
Backends are registered statically, so a registry is needed to hold
these lowering functions until Python bindings are created.
**Test Plan**
`python test/test_jit.py TestBackends`
```
Couldn't download test skip set, leaving all tests enabled...
..
----------------------------------------------------------------------
Ran 2 tests in 0.104s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39552
Reviewed By: mortzur
Differential Revision: D22033855
Pulled By: SplitInfinity
fbshipit-source-id: 05abf152274e5e51c37b6004886ea25bd4d33b80
Summary:
Closes gh-39060
The `TensorIterator` splitting is based on `can_use_32bit_indexing` which assumes 32-bit signed ints, so we can get away with just 2**31 as the axis length. Also tested on an old commit that I can reproduce the test failure on just a 1d tensor, overall quartering the memory requirement for the test.
4c7d81f847/aten/src/ATen/native/TensorIterator.cpp (L879)
For reference, the test was first added in gh-33310.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40036
Differential Revision: D22068690
Pulled By: ezyang
fbshipit-source-id: 83199fd31647d1ef106b08f471c0e9517d3516e3
Summary:
Currently, whether `AccumulateGrad` [steals](67cb018462/torch/csrc/autograd/functions/accumulate_grad.h (L42)) or [clones](67cb018462/torch/csrc/autograd/functions/accumulate_grad.h (L80)) an incoming gradient, the gradient ends up rowmajor contiguous, regardless of its param's layout. If the param's layout is channels last, or otherwise not rowmajor contigous, later kernels that apply gradients to params are forced into an uncoalesced memory access pattern for either the param or the gradient. This may not sound like a big deal but for any binary op on large tensors it's a >3X increase in gmem traffic => 3X slowdown.
The present PR changes `AccumulateGrad` to prefer, where possible, stashing gradients that match their params' layouts (["Gradient Layout Contract"](https://github.com/pytorch/pytorch/pull/34904/files#diff-ef1a56d24f66b280dcdb401502d6a796R29-R38)).
Allowing `AccumulateGrad` to stash non-rowmajor-contiguous grads means DDP allreduces and DP reduces must allow non-rowmajor-contiguous grads. This PR extends DDP and DP to allow gradients with non-rowmajor-contiguous strides as long as their layout is nonoverlapping and dense.
For good measure, I include changes that allow all five nccl primitives (allreduce, reduce, broadcast, allgather, reducescatter) to act on non-rowmajor-contiguous tensors (again as long as each input's layout is nonoverlapping and dense, and as long as all tensors participating in a given collective have the same layout). The primitive comm changes aren't necessary to enable the DDP changes, but I wasn't sure this would end up true until I had written both sets of changes. I think primitive comm enablement is reasonable to keep in the PR, especially since the code for it is simple.
Channels last params will be a major beneficiary of this PR, but I don't see it as channels-last-specific fix. The spirit is layout matching in general:
- Grads should be stashed with memory layouts matching their params.
- Src and dst tensors on opposite ends of collectives should have matching dense layouts.
This PR also updates autograd docs to describe potential BC-breaking changes below.
## BC notes
ngimel albanD gchanan
#### BC-breaking
In the common case where the user lets AccumulateGrad decide grad layouts, strides for grads of dense but non-rowmajor-contiguous params will change. Any user code that was accustomed to `view(-1)`ing these grads will break.
Also, the circumstances under which a grad can be stolen directly from the backward function that created it, as opposed to deep-copied by AccumulateGrad, have changed. In most cases we expect silent performance improvement, because we expect channels-last-aware backward kernels will create channels last gradients for channels last params. Now those can be stolen, whereas before this PR they were cloned and made rowmajor contiguous. IMO this is a mild BC breakage. Param backward hooks still see grads come in with whatever format the backward kernel gave them. The only BC breakage potential I see is if user code relies somehow on a grad in a hook having or not having the same deep memory as the eventual `param.grad`. Any such users hopefully know they're off the edge of the map and understand how to update their expectations.
#### BC escape hatches
At alband's recommendation, this PR's changes to AccumulateGrad do not alter the pre-PR code's decisions about whether grad is accumulated in or out of place. Accumulations of new grads onto an existing `.grad` attribute were (usually) in-place before this PR and remain in-place after this PR, keeping the existing `.grad`'s layout. After this PR, if the user wants to force accumulation into a grad with a particular layout, they can preset `param.grad` to a zeroed tensor with the desired strides or call `grad.contiguous(desired format)`. This likely won't be as performant as letting AccumulateGrad establish grad layouts by cloning or stealing grads with contract-compliant strides, but at least users have a control point.
One limitation (present before this PR and unchanged by this PR): Presetting `param.grad` does not ensure in-place accumulation all the time. For example, if `create_graph=True`, or if incoming `new_grad` is dense and existing `variable_grad` is sparse, accumulation occurs out of place, and the out-of-place result may not match the existing grad's strides.
----------------------------
I also noticed some potential DDP improvements that I considered out of scope but want to mention for visibility:
1. make sure Reducer's ops sync with AccumulateGrad streams
2. ~to reduce CPU overhead and incur fewer kernel launches, lazily create flat `contents` tensors by a single `cat` kernel only when a bucket is full, instead of `copy_`ing grads into `contents` individually as soon as they are received.~ PR includes a [minor change](https://github.com/pytorch/pytorch/pull/34904/files#diff-c269190a925a4b0df49eda8a8f6c5bd3R312-R315) to divide grads while copying them into flat buffers, instead of copying them in, then dividing separately. Without cat+div fusion, div-while-copying is the best we can do.
3. https://github.com/pytorch/pytorch/issues/38942
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34904
Differential Revision: D20496044
Pulled By: albanD
fbshipit-source-id: 248d680f4b1bf77b0a986451844ec6e254469217
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39800
I'm working on a refactor where I want to represent the inputs
and outputs to TensorIterator as just plain Tensors, which means
I need to kill this add_output with explicit dtype. This exists
solely to set what the output dtype should be. We have a pretty
similar API for doing this for shapes (declare_static_shape) so
I just copied this API for dtypes instead.
Although the new version is more code, I think the intent is more
explicit.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21981740
Pulled By: ezyang
fbshipit-source-id: cf45a6dbab6fb979ca3b412c31eca3dd4f4067de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39915
Some of the usage, e.g. add_scalar will not be supporting the debug option,
that is, we will not have a numerically exact representation of the final quantized model
before finalize if people use add scalar.
warning will be added in a later PR.
Test Plan: Imported from OSS
Differential Revision: D22013026
fbshipit-source-id: 714b938f25c10fad3dfc79f095356b9803ef4b47
Summary:
Currently compare_with_numpy requires a device and dtype, but these arguments are ignored if a tensor is provided. This PR updates the function to only take device and dtype if a tensor-like object is given. This should prevent confusion that you could, for example, pass a CPU float tensor but provided a CUDA device and integer dtype.
Several tests are updated to reflect this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40064
Differential Revision: D22058072
Pulled By: mruberry
fbshipit-source-id: b494bb759855977ce45b79ed3ffb0319a21c324c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39823
Add a compile time function pointer that can be used to pass function pointers in template args.
This is very useful for metaprogramming function wrappers.
ghstack-source-id: 105944072
Test Plan: waitforsandcastle
Differential Revision: D21986243
fbshipit-source-id: a123571c18aa0e65908cbb131f28922ceb59061c
Summary:
Create three tests for LSTMs:
1. test_qlstm: Test to check numerics of quantized LSTM operator.
2. test_lstm_api: To check the LSTM module and compare
it with the quantized LSTM op
3. test_quantized_rnn: Check the dynamic quantization workflow, scriptability and serialization of quantized
LSTM
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38851
ghstack-source-id: 105945574
(Note: this ignores all push blocking failures!)
Test Plan:
buck test caffe2/test:quantization -- 'test_lstm_api \(quantization\.test_quantized_module\.TestDynamicQuantizedModule\)' --print-passing-details
buck test caffe2/test:quantization -- 'test_quantized_rnn \(quantization\.test_quantize\.TestPostTrainingDynamic\)'
buck test caffe2/test:quantization -- 'test_qlstm \(quantization\.test_quantized_op\.TestDynamicQuantizedRNNOp\)' --print-passing-details
Differential Revision: D21628596
fbshipit-source-id: 4aeda899f2e5f14bfbe3d82096cb4ce89c725fa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39999
Cleaned up the android build scripts. Consolidated common functions into
common.sh. Also made a few minor fixes:
- We should trust build_android.sh doing right about reusing existing
`build_android_$abi` directory;
- We should clean up `pytorch_android/src/main/jniLibs/` to remove
broken symbolic links in case custom abi list changes since last build;
Test Plan: Imported from OSS
Differential Revision: D22036926
Pulled By: ljk53
fbshipit-source-id: e93915ee4f195111b6171cdabc667fa0135d5195
Summary: Original commit changeset: bfeeaebe93d9
Test Plan: CI runs
Differential Revision: D22062523
fbshipit-source-id: 6d827fd682a9e64c49876cd1c7269d145e93dc2c
Summary:
Android jobs don't seem to fit to `pytorch_build_data.py` data model
very well. Other mobile jobs all have their own data model files - even
for Android nightly jobs. As we are adding more variants like vulkan,
it's going to be hard to maintain.
So renamed `android_gradle.py` to `android_definitions.py` and moved
android jobs into it, following the conventions of `nightly_android.py`
and `ios_definitions.py`.
Differential Revision: D22036915
Test Plan: Imported from OSS
Reviewed By: IvanKobzarev
Pulled By: ljk53
fbshipit-source-id: 42ad5cbe451edecef17f6d3cbf85076cc3acf615
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39910
We need this for graph mode quantization, since we only have `aten::batch_norm` the dimension
is only known at runtime, we'll need to quantize it to `quantized::batch_norm`
Test Plan: Imported from OSS
Differential Revision: D22012281
fbshipit-source-id: 2973d86a17a02b7bdc36bd1e703e91584d9139d0
Summary:
For F.max_pool2d and F.avg_pool2d, there has **RuntimeErro**r when stride is **None**, this PR sovle it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39221
Differential Revision: D22059565
Pulled By: ngimel
fbshipit-source-id: 2080e1e010815aedd904c58552e92be9f7443d38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40060
As part of debugging https://github.com/pytorch/pytorch/issues/39855,
I noticed that TensorPipeAgent's ThreadPool was still executing tasks when the
python interpreter was shutting down. This caused issues with
pybind::gil_scoped_acquire() since it can't be called when the interpreter is
shutting down resulting in a crash.
The reason for this was that TensorPipeAgent was calling waitWorkComplete and
then shutting down the listeners. This meant that after waitWorkComplete
returned, there could still be a race where an RPC call gets enqueued before we
shutdown listeners.
To avoid this situation, I've moved the call to waitWorkComplete at the end of
shutdown (similar to ProcessGroupAgent).
Closes: https://github.com/pytorch/pytorch/issues/39855
ghstack-source-id: 105926653
Test Plan:
1) Ran test_backward_node_failure
(__main__.TensorPipeAgentDistAutogradTestWithSpawn) 100 times to verify the
fix.
2) waitforbuildbot
Differential Revision: D22055708
fbshipit-source-id: 2cbe388e654b511d85ad416e696f3671bd369372
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39816
This change replaces [`#if !defined(__CUDACC__) && !defined(__HIPCC__)`](856215509d/aten/src/ATen/core/DistributionsHelper.h (L147)) with SFINAE expression that checks if RNG typename has next_double_normal_sample, set_next_double_normal_sample, next_float_normal_sample, set_next_float_normal_sample methods
It is required by (and manually tested with) https://github.com/pytorch/csprng/pull/28Fixes#39618
Test Plan: Imported from OSS
Differential Revision: D22002599
Pulled By: pbelevich
fbshipit-source-id: e33d42a7e88c5729b077b9cdbf1437158dab48bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39691
After switching on using fbjni-java-only dependency, we do not need to have gradle subproject fbjni.
Test Plan: Imported from OSS
Differential Revision: D22054575
Pulled By: IvanKobzarev
fbshipit-source-id: 331478a57dd0d0aa06a5ce96278b6c897cb0ac78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39957
In order to provide a pluggable and extendable way to add new transports and channels to the TensorPipe agent, we use two registries. This allows us to separate the specific details of each backend (e.g., how it determines what address to use) from the generic logic of setting up TensorPipe.
Test Plan: Built `//caffe2:ifbpy` on two devservers, one in CLN and the other in PRN, and ran RPC across them.
Differential Revision: D22017614
fbshipit-source-id: 4ea7e6ed004a69187666f41bf59858e8174fde0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39964
The "[fut.wait() for fut in futs]" idiom can introduce up to
O(len(futs)) thread switches, which may be excessive for large N.
This plumbs through the new c++ c10::collectAll() to Python space
so that we only employ a single jit-side wait.
Test Plan: buck test mode/dev-nosan caffe2/test/distributed/rpc:rpc_spawn
Differential Revision: D22027412
fbshipit-source-id: 4e344a19a09638ee46e7fc478df80a41941b84ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39407
- support passing a single element tensor as k for topk module
- support passing a single element tensor to constant fill output
Test Plan:
buck test dper3/dper3/modules/tests:core_modules_test -- test_topk_gating_without_split_examples_tensor_k
buck test caffe2/caffe2/python:hypothesis_test -- test_constant_fill_from_tensor
Reviewed By: huayuli00
Differential Revision: D21843739
fbshipit-source-id: 0c5f5c03e9f57eeba40c0068784625164c2527ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39950
Per the comment in the code, constValue() should only be used in
the case where the future was complete and value was not an error.
Add an assert to enforce this.
Also, add hasValue() accessor for completeness.
ghstack-source-id: 105815597
Test Plan: buck test mode/dev-nosan caffe2/test/cpp/jit:
Differential Revision: D22021776
fbshipit-source-id: b59b6c775eab344068a76f4cd8c3a9dc1f2a174e
Summary:
There still are occasional reports of DataLoader workers not exiting (e.g., https://github.com/pytorch/pytorch/issues/39570). Before we figure out why, we should just kill them if the join timesout to prevent hanging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39869
Differential Revision: D22018501
Pulled By: ezyang
fbshipit-source-id: 66a00d0f5b3e303b6106b336949176b3ff8ac8ae
Summary:
Remove PY3 and PY34 checks from `torch/testing/_internal/common_utils.py`
Remove PY35 global var from `torch.jit.annotations`
Always call `try_get_real_signature` in `torch/jit/annotations.py`
Use `map` instead of `imap`, since Python-2 is no longer support, so map is always lazy.
Remove all pre Python-3.6 checks from `torch/_six.py` and `torch/_appdirs.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39879
Differential Revision: D22037811
Pulled By: malfet
fbshipit-source-id: af0c79f976569c2059d39ecb49c6b8285161734f
Summary:
This code was probably left behind after an ATen port.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39963
Differential Revision: D22039370
Pulled By: ezyang
fbshipit-source-id: 4ef75bac9b69f4b508a0b09c5c1f2ebc21bd9546
Summary:
- Fixed the bug discussed in https://github.com/pytorch/pytorch/issues/38558
- This PR is aim to make the processing of bernoulli on amd can move to the default version, even though `AT_MKL_ENABLED` is setting to `TRUE`.
- This logic used to be in the old code, but was broken by the latest update, this pr will be the fix for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40001
Differential Revision: D22037646
Pulled By: pbelevich
fbshipit-source-id: c0aa4ba37416d2568daf3463cfede6838ffaeac1
Summary:
While working on https://github.com/pytorch/pytorch/issues/38911, I realized that `nccl.reduce` only needs a single output tensor, while our current implementation requires a list of output tensors. This, along with a TODO I fixed in reduce_add, should have some speed up for data parallel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39688
Differential Revision: D22034547
Pulled By: mrshenli
fbshipit-source-id: e74d54d673ebbb062474b1bb5cc93a095a3a5f6c
Summary:
Batch permutation op does not support zero input now, it can output a tensor the same as the input if the first dimension is zero.
This can be solved: facebookresearch/detectron2#1580
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39851
Reviewed By: houseroad
Differential Revision: D22033207
Pulled By: ppwwyyxx
fbshipit-source-id: 73b540d2182fe85ed9a47220237a8f213d68ae16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39986
Mean and Variance computation to match with Intel NNPI implementation.
Test Plan: Manual Testing
Reviewed By: hyuen
Differential Revision: D22008566
fbshipit-source-id: 6ac4563859b84121a2482f8e2f738be5c6111f57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39974
# Problem
When this assertion happens, I don't know
- which worker_id it is on, even with the worker_name "trainer:0".
- which rref is throwing this exception.
```shell
File "/mnt/xarfuse/uid-213229/96b122e4-seed-df64b884-e2b4-4520-b7a8-777e79c829ac-ns-4026532900/caffe2/torch/fb/training_toolkit/backend/training_strategies/parameter_server_strategy.py", line 246, in _initialize_trainers
trainer_name: fut.wait() for trainer_name, fut in model_rref_futs.items()
File "/mnt/xarfuse/uid-213229/96b122e4-seed-df64b884-e2b4-4520-b7a8-777e79c829ac-ns-4026532900/caffe2/torch/fb/training_toolkit/backend/training_strategies/parameter_server_strategy.py", line 246, in <dictcomp>
trainer_name: fut.wait() for trainer_name, fut in model_rref_futs.items()
File "/mnt/xarfuse/uid-213229/96b122e4-seed-df64b884-e2b4-4520-b7a8-777e79c829ac-ns-4026532900/torch/distributed/rpc/internal.py", line 158, in _handle_exception
raise result.exception_type(result.msg)
RuntimeError: RuntimeError('Cannot call localValue() on a non-local reference. Call it on trainer:0')
Traceback (most recent call last):
File "/mnt/xarfuse/uid-213229/96b122e4-seed-21bc7792-3714-4e62-a1c1-32a7c38ed984-ns-4026533058/torch/distributed/rpc/internal.py", line 148, in _run_function
result = python_udf.func(*python_udf.args, **python_udf.kwargs)
File "/mnt/xarfuse/uid-213229/96b122e4-seed-21bc7792-3714-4e62-a1c1-32a7c38ed984-ns-4026533058/torch/distributed/rpc/rref_proxy.py", line 5, in _local_invoke
return getattr(rref.local_value(), func_name)(*args, **kwargs)
RuntimeError: Cannot call localValue() on a non-local reference. Call it on trainer:0
```
Changes,
- Add stringify WorkerInfo
- Make localValue() assertion message clearer about the case.
ghstack-source-id: 105840918
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork -- test_local_value_not_on_owner
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit/:rpc_fork
Reviewed By: mrshenli
Differential Revision: D5690653
fbshipit-source-id: ca6a8b1ff6e09f8644303a0f82f9b1a546a11170
Summary:
Mar 11 version of TorchVision still have some Python 2 anachronisms.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39970
Differential Revision: D22034738
Pulled By: malfet
fbshipit-source-id: aa281d50072e2448a6b202061f3ae8e8b65346ad
Summary: Add 'find_method' into 'LiteScriptModule' python binding method, so that we use it to find existence of methods, e.g. "get_all_bundled_inputs".
Reviewed By: linbinyu, houseroad
Differential Revision: D22029002
fbshipit-source-id: 9acf76880fc989e825dc3a9186dab6928caee75e
Summary: Extend int8 FC op to take scale and zero point from input to support int8 PTQ productization of online training models.
Test Plan: buck test caffe2/caffe2/quantization/server:fully_connected_dnnlowp_op_test
Reviewed By: csummersea
Differential Revision: D21944884
fbshipit-source-id: 2094827da903f3993afe4f8cf6e70286b195321d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39933
Fix rref related alias annotation to ensure it's not getting ebased by
the jit dce.
Test Plan: Imported from OSS
Differential Revision: D22015426
Pulled By: wanchaol
fbshipit-source-id: 3e74d49fa9f88abaf662bde7be5284f01f621b98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39932
This PR make RRef fork to use the jit type annotation_str recently introduce in
https://github.com/pytorch/pytorch/pull/39544 to allow consistent
serialization type str format, and fix the case when dict->str() format
not match the type resolver.
Test Plan: Imported from OSS
Differential Revision: D22015427
Pulled By: wanchaol
fbshipit-source-id: f64d7e3acde5312813816c8f3c7d8fa9379704e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39874
When fbgemm backend is set we make sure reduce_range is set to true to avoid overflow in the operator
Also adds test for per-channel quant with graph mode and compare numerics with eager mode
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D22011205
fbshipit-source-id: 1c7c9b7ab0d84200e3d8d85c34978554c30c0169
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39945
In order to pick up 8fb1fe66f8.
Test Plan: Export to CircleCI and make sure tests pass.
Reviewed By: patricklabatut
Differential Revision: D22019033
fbshipit-source-id: eb192ea3950e4f27ed222f84e2d9de8bf6eb927c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39790
The "[fut.wait() for fut in futs]" idiom can introduce up to
O(len(futs)) thread switches, which may be excessive for large N.
This plumbs through the new c++ c10::collectAll() to Python space
so that we only employ a single jit-side wait.
ghstack-source-id: 105779443
Test Plan: buck test mode/dev-nosan caffe2/test/distributed/rpc:rpc_spawn
Reviewed By: kiukchung
Differential Revision: D21976891
fbshipit-source-id: 253c61f503f4ffb9be784e6c49a0656cede139fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39934
Shouldn't write .cpp file when it's called to produce header file.
Test Plan: Imported from OSS
Differential Revision: D22016596
Pulled By: ljk53
fbshipit-source-id: 30a1b4a527bc1ffd8ee748c70494fe712be60c4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39818
Add histogram collection and qparam update support for Int8 PTQ during online training
Add caffe2 wrappers for generating int8 quant params based on output activation samples from the LastNWindowCollector op.
Test Plan:
```
buck test mode/opt caffe2/caffe2/quantization/server:int8_gen_quant_params_test
```
Reviewed By: hx89
Differential Revision: D21984455
fbshipit-source-id: 9479c87a5b1867aec662ecd21fe7ad2bc7e8652c
Summary:
Changes in PR https://github.com/pytorch/pytorch/issues/39759 broke HIP caffe2.
hipify for caffe2 renames CUDA to HIP; torch does not.
If caffe2 calls into torch, it needs to use CUDA-named functions.
CC ezyang xw285cornell sunway513 houseroad dzhulgakov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39801
Differential Revision: D21982493
Pulled By: xw285cornell
fbshipit-source-id: 8e88e0fb80c71f0342e23ef0214a42d5542bdc70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39912
Reland of https://github.com/pytorch/pytorch/pull/39767
What was wrong:
android_x86_32_vulkan job used the same docker image as android_x86_32
As a result vulkan job did commit and following android_gradle used libpytorch.so with USE_VULKAN, while vulkan wrapper was not added to the linking of libpytorch_jni
Fix: To commit to different docker images
```
elif [[ ${BUILD_ENVIRONMENT} == *"android-ndk-r19c-vulkan-x86_32"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-vulkan-x86_32
```
Test Plan: Imported from OSS
Differential Revision: D22012951
Pulled By: IvanKobzarev
fbshipit-source-id: 27908f630e6ce3613679a50b4c10f8b246718894
Summary: Extend int8 quantize op to take scale and zero point from input to support int8 PTQ productization of online training models.
Test Plan: buck test caffe2/caffe2/quantization/server:quantize_dnnlowp_op_test
Reviewed By: csummersea
Differential Revision: D21939660
fbshipit-source-id: 7ce2fbf9cd8a990c270f2187a49b1578ce76bc37
Summary:
Adds `torch.experimental.deterministic` flag to enforce deterministic algorithms across all of pytorch.
Adds `torch.experimental.deterministic_error_level` to allow users to choose between error/warning/silent if determinism for an operation is not available.
Adds `torch.experimental.alert_not_deterministic()` which should be called within operations that are not deterministic.
Offers both Python and ATen interfaces
Issue https://github.com/pytorch/pytorch/issues/15359
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38683
Differential Revision: D21998093
Pulled By: ezyang
fbshipit-source-id: 23aabbddd20f6199d846f97764ff24d728163737
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39867
Support list of filters in subgraph rewriter, the rewrite will execute only
when the match passes all filter check. this is useful for different matches
to share the same filter.
Test Plan: Imported from OSS
Differential Revision: D22009855
fbshipit-source-id: 67aab8d6326b2011a9061397699dc62ee9ad4e2d
Summary:
All std::complex has been migrated to c10::complex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39834
Differential Revision: D22001969
Pulled By: ezyang
fbshipit-source-id: 665a9198afde45a95309053b2f2381e123bf869a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39781
Use a new feature of TensorPipe where a pipe can tell you the name of the remote endpoint, in order to make the logging messages more informative: whenever there is a failure on a pipe, say which worker this was to/from, and the ID of the message involved.
Also, add plenty of verbose logging, to help with debugging. This is off by default, but can be enabled by setting the `GLOG_v` env var to a value of 1 or higher.
ghstack-source-id: 105777704
Test Plan: Builds.
Differential Revision: D21973150
fbshipit-source-id: 9e3ce1b9977e1e9ecd91ff4a6fe82786dc79a702
Summary:
Enhance FileCheck util to check for highlighted source ranges. This is useful when writing tests regarding generated error messages that require source code highlighting.
Here is how the error looks like in different cases:
- In case of needed source code token not found at all in input string:
```
RuntimeError: Expected to find "invalid_token" but did not find it
Searched string:
... <--- HERE
def to_list_missing_type_annotation(x):
# type: (torch.Tensor) -> List[float]
From CHECK-SOURCE-HIGHLIGHTED: invalid_token
```
- In case of source code token not highlighted:
```
Traceback (most recent call last):
File "test_range.py", line 11, in <module>
FileCheck().check_source_highlighted("x.tolist()").run(s)
RuntimeError: Expected to find "~~~~~~~~~~" but did not find it
Searched string:
# type: (torch.Tensor) -> List[float]
li = x.tolist()
~~~~~~~~~ <--- HERE
~~~~~~~~~~~~~~~~~~~... <--- HERE
return li
```
It is a bit confusing since both input text (usually an error message) and generated error messages have their highlighted portions, but this is consistent of previous behavior. Another option is to generate plain error messages without additional range highlighting on input text.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39692
Test Plan:
Added unit test.
Closes https://github.com/pytorch/pytorch/issues/38698
Differential Revision: D22001765
Pulled By: gmagogsfm
fbshipit-source-id: 6681441eee5853ab061d198ccfe55ebffddca202
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39078
Adding support of non-vulkan inputs for addmm operator:
if it is not on vulkan - converting to it inside operator,
if we run torchscript pretrained model - weights of linear op will be on CPU, we need this to run mobilenetV2 on Vulkan backend
Test Plan: Imported from OSS
Differential Revision: D21962425
Pulled By: IvanKobzarev
fbshipit-source-id: 8222edd31dfb14b326d15e6fec5c8778783479df
Summary:
We've got quite a few things going on, preparing a push back to upstream so we don't get too desynced.
- Major refactor of transform replay. It is now far more robust and fixes bugs discovered in reductions. Preparing for extension to explicit broadcast ops which will be the last major memory pattern for op coverage. Broadcast ops will allow us to express up to and potentially beyond norms and gemms.
- Initial runtime expression evaluator. This allows us to evaluate expressions at runtime. Will be useful for determining our grid/block layout at runtime, so we don't have to manually compute them according to the code we're trying to generate.
- Moving to int64 and double for scalar representations to match PyTorch JIT.
- Improvements in codegen interface where we return Tensor like object instead of parent class Val.
- Add `addcmul` and `lerp` ops
- General updates, fixes, test additions, test inprovements.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39579
Differential Revision: D21974001
Pulled By: soumith
fbshipit-source-id: 7f7ccc91593466e948f3ce90f8f9b7fbc5c28de2
Summary:
**Summary**
This commit adds support for annotations in method signatures of a
TorchScript class types that refer to the class being defined itself.
**Test Plan**
This commit adds a unit test to check that a method that uses
self-referential type annotations can be defined and produces the same
results in Python and TorchScript.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39821
Differential Revision: D22003624
Pulled By: SplitInfinity
fbshipit-source-id: dce921c2e0ca0c8aecb52d5b0646b419eb207146
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39825
Removing the pass for now since it is causing error for some models
Test Plan: Imported from OSS
Differential Revision: D21987878
fbshipit-source-id: 129aefb34754d5390a4c9d3108fa1b6c2eae5a74
Summary:
std::complex is gone, now we are using c10::complex on all dispatch macros.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39882
Differential Revision: D22009933
Pulled By: pbelevich
fbshipit-source-id: 613ac06d0024f149184d0b2e08ed06d7d6066017
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39861
move some basic math ops to lite interpreter
size change should be small
Test Plan: build
Reviewed By: iseeyuan
Differential Revision: D21992552
fbshipit-source-id: 7f5a7380ffc1519001a98169e6c5381e45e8e0ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39798
add_input's device/dtype are 100% redundant, as compute_types will
always (internal) assert that this dtype matches the expected dtype.
add_output's device/dtype is redundant UNLESS you have an undefined
tensor (in which case it seems to be an indication what the output type
should be). The one add_output case I killed can never be exercised, see:
```
import torch
x = torch.randn(3, 4)
mask = x.ge(0.5)
torch.masked_select(x.cuda(), mask.cuda(), out=torch.zeros((0), dtype=torch.int64, device='cuda'))
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21981742
Pulled By: ezyang
fbshipit-source-id: a042d1b9fce0ad58b833856ffe32001787551e59
Summary:
This is needed, because pip might want to build ninja from source
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39898
Differential Revision: D22010548
Pulled By: malfet
fbshipit-source-id: 55423324c381aaec8a3c81f95f9405dd618b4e49
Summary:
Fix another simplification edge case, a Cond statement when one branch is nullptr and the other is a zero stmt block. This happens mostly with an if with no else branch where all statements inside the if are removed (eg via inlining or simplification). Common case is SplitWithMask -> ComputeInline.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39754
Differential Revision: D21962987
Pulled By: nickgg
fbshipit-source-id: 2461415466fbbab88d2329061f90fcfdfa85e243
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39077
We plan to support strides for Vulkan, but that is not implemented yet.
The main intention of this faking of strides and is_contiguous - to be able to run torchscript mobilenetV2 on Vulkan backend for development and profiling.
This change adds strides to Vulkan interface and overrides strides(), stride(), is_contiguous() of OpaqueTensorImpl for that purpose.
Test Plan: Imported from OSS
Differential Revision: D21962426
Pulled By: IvanKobzarev
fbshipit-source-id: cfef4903ad7062170926264f45cff1293ade78f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38211
Just because the annotations are inline doesn't mean the files type
check; most of the newly annotated files have type errors and I
added exclusions for them in mypy.ini. The payoff of moving
all of these modules inline is I can delete the relevant code
generation logic for the pyi files (which was added ignore
annotations that weren't actually relevant anymore.)
For the most part the translation was completely mechanical, but there
were two hairy issues. First, I needed to work around a Python 3.6 and
earlier bug where Generic has a nontrivial metaclass. This fix is in
torch/jit/__init__.py. Second, module.py, we need to apply the same
fix for avoiding contravariance checks that the pyi file used to have;
this is done by declaring forward as a variable (rather than a
function), which appears to be sufficient enough to get mypy to not
contravariantly check input arguments.
Because we aren't actually typechecking these modules in most
cases, it is inevitable that some of these type annotations are wrong.
I slavishly copied the old annotations from the pyi files unless there
was an obvious correction I could make. These annotations will probably
need fixing up later.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21497397
Pulled By: ezyang
fbshipit-source-id: 2b08bacc152c48f074e7edc4ee5dce1b77d83702
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39875
Numba released a new version (0.50) that is causing problems with
librosa (we use this as a test dependency). Try pinning the version of
numba to temporarily fix. I am not actually sure if this is going to
work because it is unclear when we actually install numba.
Test Plan: - wait for CI.
Reviewed By: mruberry
Differential Revision: D22005838
Pulled By: zou3519
fbshipit-source-id: 4bccfa622c82533d85631052e4ad273617ea31d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39786
This wasn't really used since we already have an internal SCUBA table to
handle this use case and it doesn't rely on a singular script to run
after all binaries have been uploaded.
Also the web page took an enormously long time to actually load
decreasing its usefulness, let's just get rid of the job altogether
instead of trying to fix something no one really looked at
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D22007197
Pulled By: seemethere
fbshipit-source-id: d824b576e07c9cf1603db5ac14940b06ecdd2a0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39493
Make sure we wait for all types, incl. async cpu ops
Test Plan: CI
Reviewed By: kennyhorror
Differential Revision: D21873540
fbshipit-source-id: 37875cade68e1b3323086833f8d4db79362a68e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39792
I also deleted the dead TensorIterator::remove_dimension,
and reordered some properties so they were more logically
grouped.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21981739
Pulled By: ezyang
fbshipit-source-id: e7c9ad0233284f7c47322e62035edb704640aafd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39789
Some properties on TensorIterator are only set prior to build() by the
user and then immutable during the build process. I've renamed all such
properties so that they have a config_ prefix, gave them an explicit
accessor and audited every site to ensure they are only written once.
I also renamed check_mem_overlaps to compute_mem_overlaps to avoid
confusion with the accessor check_mem_overlap.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21981741
Pulled By: ezyang
fbshipit-source-id: b64e33a5d0bc01834ead6d7082605c20a5ed1a08
Summary:
THCAllocator functionality is pretty obscure and it's hard to get it working with HIP because of how Caffe2/PyTorch rules are set up (see https://github.com/pytorch/pytorch/issues/39801). Let's just disable the test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39843
Reviewed By: zou3519
Differential Revision: D21998687
Pulled By: dzhulgakov
fbshipit-source-id: cd12ba30cdfee658b98393ed3a72e83f4ecf1c9c
Summary:
# Motivations
As explained in the [link](https://stats.stackexchange.com/questions/86991/reason-for-not-shrinking-the-bias-intercept-term-in-regression/161689#161689), regularizing biases will cause mis-calibration of predicted probabilities.
In SparseNN, the unary processor may use 1d embedding tables for the sparse features to serve as biases.
In this diff, the regularization term is automatically skipped for the 1d sparse parameters to avoid regularizing biases.
# Experiments
Experiments were conducted to verify that it has no significant impact on the NE to skip the regularization on 1d sparse parameters.
Baseline.1 (no L2 regularization): f193105372
Baseline.2 (L2 regularization in prod): f193105522
Treatment (skipping L2 regularization on 1d sparse params): f193105708
{F239859690}
Test Plan:
Experiments were conducted to verify that it has no significant impact on the NE to skip the regularization on 1d sparse parameters using a canary package: `aml.dper2.canary:9efc576b35b24361bb600dcbf94d31ea`.
Baseline.1 (no L2 regularization): f193105372
Baseline.2 (L2 regularization in prod): f193105522
Treatment (skipping L2 regularization on 1d sparse params): f193105708
Reviewed By: zhongyx12
Differential Revision: D21757902
fbshipit-source-id: ced126e1eab270669b9981c9ecc287dfc9dee995
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39581
Context: Batching rules
------------------------------------
Batching rules take BatchedTensors and regular Tensors as arguments. A
batching rule generally does the following:
1. Converts (logical) BatchedTensors to views on physical tensors.
2. Converts logical arguments (e.g. dimension indexes, shapes) to
physical arguments that correspond to the physical tensors.
3. Calls at:: operations on the physical tensors and arguments.
4. Converts physical results back to BatchedTensors.
Steps 1 and 2 differ for operators with different batching behaviors.
(see next section)
VmapTransform abstraction
------------------------------------
(Previously known as a "Converter". Bikeshedding welcome on the naming).
An ArgTransform converts logical views of tensors to physical views.
When
writing a batching rule, users should select the ArgTransform that
matches
the batching behavior of their operator. If the batching behavior of the
op is complicated, then they’ll have to write some custom logic (either
by writing a new ArgTransform, or writing the logical->physical
transform
themselves).
*56% (~474) of (vmap-supported) operators can and will use these
VmapTransform. 20% (~168) of operators need custom handling*.
See `VmapTransforms.h` for more context.
PhysicalView
------------------------------------
VmapTransforms return physical views on tensors, represented by the
PhysicalView struct. It is effectively a Tensor and contains
enough metadata to enable mapping logical non-tensor arguments to
physical non-tensor arguments, and the other way around.
There are two methods on PhysicalView right now:
- `PhysicalView::getPhysicalDim(logical_dim)` and
`PhysicalView::getPhysicalDims(logical_dims)`.
are used to map logical dims to physical dims.
- `PhysicalView::newLogicalFromPhysical(Tensor)` is used to map a result
physical tensor from a batching rule to a logical tensor
(BatchedTensor).
Test Plan:
------------------------------------
- `./build/bin/vmap_test`
Differential Revision: D21983789
Pulled By: zou3519
fbshipit-source-id: dc558e05b596fd29f9643e933e4ece4b7866b6db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39580
We support 64 total levels. This is done so that we can represent lists
of levels as a bitset that fits into a single `int64_t` and is a
reasonable upper bound because we only support (physical) tensors of up
to 64 dimensions with vmap (see kVmapMaxTensorDims).
Test Plan:
`./build/bin/vmap_test`. One day we'll test this with the vmap Python
API.
Differential Revision: D21929249
Pulled By: zou3519
fbshipit-source-id: 2e99c0c519d6ab0c063fda20f4a0b1f53da6d450
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39645
This PR added quantization support for handling BatchNorm2d and ReLU(or F.relu) in both
scripting and tracing
Test Plan:
python test/test_quantization.py TestQuantizeScriptPTSQOps.test_qbatchnorm_relu
Imported from OSS
Differential Revision: D21942111
fbshipit-source-id: 680e16076a37b96d2485d5cbc39ce9a045c319c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39604
This change preserves BC for older models that are saved with reduce_range set to false.
Newer models will use the version information in RNN module to toggle reduce_range parameter
Internally this is implemented using a new CellParams type that calls the linear functions with reduce_range option set to true.
New models serialized will use the CellParams struct for the `__getstate__` and `__setstate__` calls. Older models using QuantizedCellParamsDynamic will continue to use their original serialization/de-serialization methods
tested using LSTM BC test and test_quantized_rnn
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D21977600
fbshipit-source-id: 0cb0e098b87207b537574d3beeab1f341c41c0d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39076
`--vulkan` argument to use torch benchmark on Vulkan Backend
if it is True - inputs will be converted to Vulkan backend before module.forward
Usage for mobilenetv2 fp32:
```
/build/bin/speed_benchmark_torch --model=mn-fp32.pt --input_type=float --input_dims=1,3,224,224 --warmup=1 --iter=5 --vulkan=true
```
Test Plan: Imported from OSS
Differential Revision: D21962428
Pulled By: IvanKobzarev
fbshipit-source-id: 3136af5386b6bce9ea53ba4a9019af2d312544b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39795
Replaces the `is_dynamic` bool by enums in Python and c++
graph quantization code. This makes the code more readable
and will make it easier to modify for adding QAT logic in the future.
Test Plan:
CI, as well as
```
python test/test_quantization.py TestQuantizeDynamicScript
python test/test_quantization.py TestQuantizeScriptJitPasses
```
Imported from OSS
Differential Revision: D21981643
fbshipit-source-id: d475760407bcc794aeae92a2c696bac4acda843d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39750
Add a test to make the default QAT qconfig scriptable, and fix
all the errors.
Test Plan:
```
python test/test_quantization.py TestQATScript.fake_quant_scriptable
```
Imported from OSS
Differential Revision: D21975879
fbshipit-source-id: 8c48ad9f24b2c941d2267cb53eb70ebecd103744
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39739
Adding more docs and examples to make code reasing easier for newcomers.
Test Plan:
CI, no logic changes
Imported from OSS
Differential Revision: D21975878
fbshipit-source-id: 464858c0490cfbdec165a5ddf3817ca4878abb09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39683
Adding a couple of docstrings to `_jit_pass_dedup_module_uses` and
`_jit_pass_insert_observers`.
Test Plan:
CI, no logic change
Imported from OSS
Differential Revision: D21975880
fbshipit-source-id: 8876e0e981d6675bce08fa8e08ac7a3d38c3c622
Summary:
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import time
import torch
import numpy as np
for n, t in [(500_000, 10),
(1_000_000, 10)]:
for dtype in (torch.half, torch.float, torch.double):
# Input Setup
p = torch.from_numpy(np.random.rand(n)).to(dtype)
want = 1000
print(f'torch.multinomial(a) a.numel() == {n} for {t} times {dtype}')
start = time.time()
# Iterate
for _ in range(t):
torch.multinomial(p, want, replacement=False)
print(f'Took:', time.time() - start)
print('****' * 10)
for n, t in [(50_000, 100),
(100_000, 100)]:
for dtype in (torch.half, torch.float, torch.double):
# Input Setup
p = torch.rand(n, device='cuda', dtype=dtype)
want = 1000
print(f'torch.multinomial(a) a.numel() == {n} for {t} times {dtype}')
start = time.time()
# torch.cuda.synchronize()
# Iterate
for _ in range(t):
torch.multinomial(p, want, replacement=False)
# torch.cuda.synchronize()
print(f'CUDA Took:', time.time() - start)
```
Before:
```
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float16
Took: 80.64455389976501
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float32
Took: 3.7778031826019287
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float64
Took: 5.045570611953735
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float16
Took: 161.53191947937012
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float32
Took: 7.640851736068726
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float64
Took: 10.399673461914062
****************************************
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float16
CUDA Took: 4.873984098434448
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float32
CUDA Took: 4.713594436645508
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float64
CUDA Took: 11.167185068130493
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float16
CUDA Took: 7.195427417755127
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float32
CUDA Took: 7.669712066650391
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float64
CUDA Took: 20.20938801765442
```
After:
```
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float16
Took: 81.09321522712708
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float32
Took: 0.06062650680541992
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float64
Took: 0.0862889289855957
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float16
Took: 161.85304307937622
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float32
Took: 0.13271093368530273
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float64
Took: 0.17215657234191895
****************************************
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float16
CUDA Took: 0.035035133361816406
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float32
CUDA Took: 0.03631949424743652
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float64
CUDA Took: 0.05507040023803711
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float16
CUDA Took: 0.05105161666870117
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float32
CUDA Took: 0.05449223518371582
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float64
CUDA Took: 0.09161853790283203
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39742
Differential Revision: D21976915
Pulled By: ngimel
fbshipit-source-id: 34431f814f31b6dfd6179a89f8e4fa574da7a306
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39373
Line 114 is the only actual change. Other changes are just formatting.
Test Plan: CI
Reviewed By: zrphercule
Differential Revision: D21830893
fbshipit-source-id: 83e49b1b3c48f6bc6de3c48ccce60c84aa49339b
Summary:
**1.6 Deprecation Note**
In PyTorch 1.6 attempting to divide two integer tensors or an integer tensor and an integer scalar will throw a runtime error. This behavior was deprecated with a warning in PyTorch 1.5. In PyTorch 1.7 torch.div and the division operator will always perform true division like Python3 and NumPy.
To divide integer values use either torch.true_divide, for true division, or torch.floor_divide (the // operator) for floor division.
**PR Summary**
This PR updates the warning message when performing integer division to be a runtime error. Because some serialized Torchscript programs may rely on torch.div's historic behavior it also implements a "versioned symbol" for div that lets those models retain their current behavior. Extensive tests of this behavior are the majority of this PR.
Note this change bumps the produced file format version to delineate which programs should have their historic div behavior preserved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38620
Differential Revision: D21612598
Pulled By: mruberry
fbshipit-source-id: c9c33591abce2f7e97f67f0f859901f5b03ed47d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39767
Adding android build for every PR with `-DUSE_VULKAN=ON` It will use vulkan from ANDROID_NDK, so no changes for docker images.
Test Plan: Imported from OSS
Differential Revision: D21976091
Pulled By: IvanKobzarev
fbshipit-source-id: cb9fa5612cfebc02dfd4946e50faa121311780f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39771
Vulkan build was not integrated with CI, it fails without this change.
There were 2 separate problems
1. Recently added aten/src/ATen/templates/Functions.cpp missed VulkanType in header
2. Applying the new registration api, similar to xnnpack change
https://github.com/pytorch/pytorch/pull/36800
Test Plan:
`ANDROID_ABI=x86 ./scripts/build_android.sh -DUSE_VULKAN=ON` builds ok
CI integration for it is in the next PR in this stack ( https://github.com/pytorch/pytorch/pull/39767 )
job `ci/circleci: pytorch_linux_xenial_py3_clang5_android_ndk_r19c_x86_32_vulkan_build`
Differential Revision: D21975992
Pulled By: IvanKobzarev
fbshipit-source-id: b0400a9cb0ae90d7763ebeb5b8f7ee932a2148e1
Summary:
- add call out to python resolver in parseArgsFromDecl, parserReturnFromDecl
- add support in python resolver for nested subexpressions
- wrap python resolver call in exception handling to fall back to c++ path
- add tests for newly resolvable types
- closes https://github.com/pytorch/pytorch/issues/38728
Fixes bug where SourceRange objects did not include the final closing ']' for a subscript expression. E.g. range for 'List[int]' previously included only 'List[int'.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39269
Differential Revision: D21956402
Pulled By: wconstab
fbshipit-source-id: 5d783260322eb1e04e20bc931a8e9d9179765f13
Summary:
The weights of the `MultiheadAttention` were incorrectly listed as constants, which produced warnings when converting to a TorchScript module.
```py
import torch
import torch.nn as nn
multihead_attn = nn.MultiheadAttention(256, 4)
torch.jit.script(multihead_attn)
```
Warnings:
```
/home/michael/.local/lib/python3.8/site-packages/torch/jit/_recursive.py:151: UserWarning: 'q_proj_weight' was found in ScriptModule constants, but it is a non-constant parameter. Consider removing it.
warnings.warn("'{}' was found in ScriptModule constants, "
/home/michael/.local/lib/python3.8/site-packages/torch/jit/_recursive.py:151: UserWarning: 'k_proj_weight' was found in ScriptModule constants, but it is a non-constant parameter. Consider removing it.
warnings.warn("'{}' was found in ScriptModule constants, "
/home/michael/.local/lib/python3.8/site-packages/torch/jit/_recursive.py:151: UserWarning: 'v_proj_weight' was found in ScriptModule constants, but it is a non-constant parameter. Consider removing it.
warnings.warn("'{}' was found in ScriptModule constants, "
/home/michael/.local/lib/python3.8/site-packages/torch/jit/_recursive.py:151: UserWarning: 'in_proj_weight' was found in ScriptModule constants, but it is a non-constant parameter. Consider removing it.
warnings.warn("'{}' was found in ScriptModule constants, "
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39768
Reviewed By: zhangguanheng66
Differential Revision: D21977032
Pulled By: ngimel
fbshipit-source-id: c2c3d0605a51324a9541f5a2caca7ab7a518dc00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39770
Remove duplicated piece of code in test (just a nit).
Test Plan: buck test test:quantization
Reviewed By: supriyar
Differential Revision: D21967877
fbshipit-source-id: 48a2d60e108fb9ddfa98e30888cf45744905277d
Summary:
Clearly expressing a type is inferred by PyTorch instead of explicitly annotated by user makes many error messages more user-friendly
Currently Type has two string conversion methods. str() for IR printing and python_str() for serialization and error message generation. If we want to include more information in type printing while maintaining serialization/deserialization correctness, we need to split python_str() into annotation_str() and repr_str().
annotation_str is solely responsible for serialization, it strictly matches format of python type annotation. repr_str() is responsible for generating a human-readable error message that includes information like "this type is inferred, not explicitly annotated"
Closes https://github.com/pytorch/pytorch/issues/39449
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39544
Differential Revision: D21978759
Pulled By: gmagogsfm
fbshipit-source-id: 733566f5a62e748b5ca4bb3c5943ebb6d5b664d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39747
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21961336
Pulled By: ezyang
fbshipit-source-id: 6c7b3ccebd8f95a04994d53e5b5e9471bfefb26b
Summary:
This commit also removes the clang7 install for ROCm images, and properly cleans up the apt cache after ROCm installation to reduce image sizes.
Embedding the ROCm version within the image name follows the precedent set by CUDA images and decouples image creation from ROCm implicitly installing the latest version when images are prepared.
CC sunway513 ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39735
Differential Revision: D21976162
Pulled By: ezyang
fbshipit-source-id: 9801106e8cb118a812113ec077154e72a9c2eb2d
Summary:
**BC breaking note:**
In PyTorch 1.5 passing the out= kwarg to some functions, like torch.add, could affect the computation. That is,
```
out = torch.add(a, b)
```
could produce a different tensor than
```
torch.add(a, b, out=out)
```
This is because previously the out argument participated in the type promotion rules. For greater consistency with NumPy, Python, and C++, in PyTorch 1.6 the out argument no longer participates in type promotion, and has no effect on the computation performed.
**ORIGINAL PR NOTE**
This PR effectively rewrites Tensor Iterator's "compute_types" function to both clarify its behavior and change how our type promotion works to never consider the out argument when determining the iterator's "common dtype," AKA its "computation type." That is,
```
a = op(b, c)
```
should always produce the same result as
```
op(b, c, out=a)
```
This is consistent with NumPy and programming languages like Python and C++.
The conceptual model for this change is that a TensorIterator may have a "common computation type" that all inputs are cast to and its computation performed in. This common computation type, if it exists, is determined by applying our type promotion rules to the inputs.
A common computation type is natural for some classes of functions, like many binary elementwise functions (e.g. add, sub, mul, div...). (NumPy describes these as "universal functions.") Many functions, however, like indexing operations, don't have a natural common computation type. In the future we'll likely want to support setting the TensorIterator's common computation type explicitly to enable "floating ufuncs" like the sin function that promote integer types to the default scalar type. Logic like that is beyond the type promotion system, which can only review inputs.
Implementing this change in a readable and maintainable manner was challenging because compute_types() has had many small modifications from many authors over ~2 year period, and the existing logic was in some places outdated and in other places unnecessarily complicated. The existing "strategies" approach also painted with a broad brush, and two of them no longer made conceptual sense after this change. As a result, the new version of this function has a small set of flags to control its behavior. This has the positive effect of disentangling checks like all operands having the same device and their having the same dtype.
Additional changes in this PR:
- Unary operations now support out arguments with different dtypes. Like binary ops they check canCast(computation type, out dtype).
- The dtype checking for lerp was outdated and its error message included the wrong variable. It has been fixed.
- The check for whether all tensors are on the same device has been separated from other checks. TensorIterators used by copy disable this check.
- As a result of this change, the output dtype can be computed if only the input types are available.
- The "fast path" for checking if a common dtype computation is necessary has been updated and simplified to also handle zero-dim tensors.
- A couple helper functions for compute_types() have been inlined to improve readability.
- The confusingly named and no longer used promote_gpu_output_dtypes_ has been removed. This variable was intended to support casting fp16 reductions on GPU, but it has become a nullop. That logic is now implemented here: 856215509d/aten/src/ATen/native/ReduceOpsUtils.h (L207).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39655
Differential Revision: D21970878
Pulled By: mruberry
fbshipit-source-id: 5e6354c78240877ab5d6b1f7cfb351bd89049012
Summary:
## Why doesn’t DDP work under dist_autograd?
DDP follows the steps below
1. [DDP Python constructor](8d6a8d2b3f/torch/nn/parallel/distributed.py (L389-L393)) (on a module) creates a [C++ Reducer](https://github.com/pytorch/pytorch/blob/master/torch/csrc/distributed/c10d/reducer.cpp), which holds references to all parameters (or variables in C++ code).
2. The reducer installs a post hook on each model parameter.
3. The backward run starts and triggers the post hooks installed above.
4. The post hook of a parameter simply marks the parameter ready for all-reduce.
5. Once all parameters in a bucket are ready, an all-reduce process starts by reading variable `.grad` and writes to variable `.grad`.
But under dist_autograd, `.grad` of a variable is not populated at all. Instead, grads are in a global map in distributed context from variables to their grads.
## Solution of this PR
The distributed engine to set a thread_local variable in a backward run indicating we're running in distributed mode. DDP reducer can then appropriately use `.grad` or the distributed context based on the thread local. More precisely, the thread local is set before calling the post hooks installed by the DDP reducer so that DDP post hooks can retrieve this thread local.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37998
Test Plan:
```
python test/distributed/test_ddp_under_dist_autograd.py
```
FB repo
```
buck test caffe2/test/distributed/...
```
DDP accuracy benchmark workflow run
```
flow-cli canary pytorch.benchmark.accuracy_comparison.workflow --parameters-json '{"node_world_size": 4, "dist_backend": "nccl"}' --run-as-secure-group fblearner_flow --entitlement gpu_prod
```
f196173157
Reviewed By: pritamdamania87
Differential Revision: D21513795
Pulled By: hczhu
fbshipit-source-id: fe21e68ecdc9274182db4d4bb5a1e2d68ef927a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38830
This patch enables to preserve user specified attributes or non forward
methods. The API:
_freeze_module(Module, ["a", "version"])
Test Plan: Imported from OSS
Differential Revision: D21957316
Pulled By: bzinodev
fbshipit-source-id: 5c9146ae679791070a9de868c45785725b48a9e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39743
### Summary
Still need this RAII guard for full JIT
### Test Plan
- CI checks
Test Plan: Imported from OSS
Differential Revision: D21968256
Pulled By: xta0
fbshipit-source-id: 8ea63c699fed4e2a01390232a58f039110391844
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39497
Previously, we didn't consider side effects at all when moving nodes in alias analysis. It is never valid to reorder a node with a side effect. This has led to bugs when used with Bailouts.
Unfortunately this will might cause regressions but it wasn't correct prior :/
Test Plan: Imported from OSS
Differential Revision: D21963774
Pulled By: eellison
fbshipit-source-id: 656995d1b82534eca65437ed4e397b2bf08a4dec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39700
Refactored files
1. Moved mm_cpu from BlasWrappersCPU.cpp to LinearAlgebra.cpp
2. Deleted BlasWrappersCPU.cpp
These functions are closely related to those in LinearAlgebra.cpp, we don't need a seperate file.
ghstack-source-id: 105503249
Test Plan:
`buck build //caffe2/aten/...`
`buck build //xplat/caffe2:ptmobile_benchmarkAndroid#android-armv7`
CI
Reviewed By: dreiss
Differential Revision: D21692154
fbshipit-source-id: 4edb7cee53c9e29700372f16ca1e6f85539dac24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39687
Run the observer on the weight values and compare it with the calculated attributes in the graph
Test Plan:
python test/test_quantization.py test_dynamic_weight_observer
Imported from OSS
Differential Revision: D21961907
fbshipit-source-id: dde3e629b8514e6c82346915ac35e35cf9c05f6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39759
Caffe2 has a mode where it uses PT's caching allocator. Somehow we were not calling the initialization explicitly.
Now, I have no idea why it worked before. Probably worth to run a bisect separately.
Reviewed By: houseroad
Differential Revision: D21962331
fbshipit-source-id: f16ad6b27a67dbe0bda93939cca8c94620d22a09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39736
in some rare cases we can end up generating a random number = 0
Test Plan: test_div
Reviewed By: yinghai
Differential Revision: D21953973
fbshipit-source-id: a834f624d72f1084c300163344662df121aae21b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39597
To complement collectAll(), this change adds collectAny(), and writes
up relevant unittest coverage.
We also remove the vector-based helper version of collectAll(), which
was debatable usefulness in a previous change.
ghstack-source-id: 105527180
Test Plan: buck test mode/dev-nosan caffe2/test/cpp/jit/...
Differential Revision: D21910311
fbshipit-source-id: dbb3ca404672a3d751b1b3cf016e6084a9ff8040
Summary:
When debugging it is sometimes useful to call test code manually. This change makes that easier.
Before this change, one would get the following error:
```
$ python -c "from torch.testing._internal.jit_utils import JitTestCase; JitTestCase()"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/jansel/pytorch/torch/testing/_internal/common_utils.py", line 740, in __init__
test_method = getattr(self, method_name)
AttributeError: 'JitTestCase' object has no attribute 'runTest'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39695
Test Plan: `python -c "from torch.testing._internal.jit_utils import JitTestCase; JitTestCase()"`
Differential Revision: D21959249
Pulled By: jansel
fbshipit-source-id: 8435249f102338c957c3a7a7aad48d21d372a8cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39550
This is to prepare for next PR that fixes propagate dequantize for ops with multiple outputs
Test Plan: Imported from OSS
Differential Revision: D21942063
fbshipit-source-id: 518b3e437140bec9620988d2eb59b6aae069245e
Summary:
'Program Files' does not have to be on disk C (nor necesserily should
be called `Program Files`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39707
Differential Revision: D21954235
Pulled By: malfet
fbshipit-source-id: 91a9b765cd1bc7e6201dd4b800d45257207010d9
Summary:
Switch off `/Z7` so that we don't generate debug info in Release and MinSizeRel builds, so that we will probably get smaller static libraries and object files and faster build time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39703
Differential Revision: D21960684
Pulled By: ezyang
fbshipit-source-id: 909a237a138183591d667885b13fc311470eed65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38582
Adding LpNorm regularization for sparse features in DPER3. This is done using a sparse regularization op with run_after_optimizer (see D21003029).
* Added code calling new caffe2 operator from D21003029 to caffe2/python/regularizer.py
* Added l1norm and l2norm to sparse regularizer thrift definition.
* Added the new regularization references to test utils.
* Added a new file for unit tests "sparse_nn_sparse_reg_test.py"
Test Plan:
buck test mode/dev //caffe2/caffe2/fb/dper/layer_models/tests:sparse_nn_sparse_reg_test
buck test mode/dev //caffe2/caffe2/fb/dper/layer_models/tests:sparse_nn_reg_test
DPER canary: https://fburl.com/fblearner/rcp5yzeh
New DPER canary: https://fburl.com/fblearner/0krgd74x
Differential Revision: D20704248
fbshipit-source-id: 7e3d5013b3ff3da95ea027f0f2dd855f3ae8e41d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39663
I was investigating a memory corruption issue and thought it may be due to a race condition in (un)setting the current RPC agent. It turns out it wasn't (still investigating...). I had already written this fix, and it is a real fix (there could really be a race condition), so I'm sending it out to see whether there's interest in merging it. I believe its practical usefulness is however very limited, since typically the current RPC agent is only changed twice (at start and at shutdown) and thus there's limited risk for races.
As there may be some confusion on atomicity of shared_ptrs, let me clarify a few things from the get go. Operations on the control blocks of shared_ptrs (i.e., increasing and decreasing the refcounts) are atomic, which means that it is safe to manipulate *two different* shared_ptrs that point to the *same* object from *different* threads. However, the shared_ptr object itself is not atomic, which means that it is *not* safe to manipulate the *same* shared_ptr from two *different* threads. For that reason, the STL provides atomic functions explicitly specialized for shared_ptrs: https://en.cppreference.com/w/cpp/memory/shared_ptr/atomic (in C++ 20, they are being replaced by a specialization of std::atomic<std::shared_ptr<T>>). Note that this has been called "the worst question of all of C++" by Louis Brandy at his CppCon talk: https://youtu.be/lkgszkPnV8g?t=1210
ghstack-source-id: 105475005
Test Plan: Unit tests
Differential Revision: D21932817
fbshipit-source-id: da33fedd98efb820f284583ce7ff1c1c531dea9c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/39624#11931
Based on the example by RobertoLat
https://github.com/pytorch/pytorch/issues/11931#issuecomment-625882503
**Fast-path is not taken on CPU for `Half` as `log` doesn't support it.**
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import time
import torch
import numpy as np
for n, t in [(500_000, 10),
(1_000_000, 10)]:
for dtype in (torch.half, torch.float, torch.double):
# Input Setup
p = torch.from_numpy(np.random.rand(n)).to(dtype)
want = 1000
print(f'torch.multinomial(a) a.numel() == {n} for {t} times {dtype}')
start = time.time()
# Iterate
for _ in range(t):
torch.multinomial(p, want, replacement=False)
print(f'Took:', time.time() - start)
print('****' * 10)
for n, t in [(50_000, 100),
(100_000, 100)]:
for dtype in (torch.half, torch.float, torch.double):
# Input Setup
p = torch.rand(n, device='cuda', dtype=dtype)
want = 1000
print(f'torch.multinomial(a) a.numel() == {n} for {t} times {dtype}')
start = time.time()
# torch.cuda.synchronize()
# Iterate
for _ in range(t):
torch.multinomial(p, want, replacement=False)
# torch.cuda.synchronize()
print(f'CUDA Took:', time.time() - start)
```
Before:
```
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float16
Took: 80.64455389976501
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float32
Took: 3.7778031826019287
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float64
Took: 5.045570611953735
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float16
Took: 161.53191947937012
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float32
Took: 7.640851736068726
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float64
Took: 10.399673461914062
****************************************
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float16
CUDA Took: 4.873984098434448
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float32
CUDA Took: 4.713594436645508
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float64
CUDA Took: 11.167185068130493
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float16
CUDA Took: 7.195427417755127
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float32
CUDA Took: 7.669712066650391
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float64
CUDA Took: 20.20938801765442
```
After:
```
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float16
Took: 80.6487455368042
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float32
Took: 0.0663309097290039
torch.multinomial(a) a.numel() == 500000 for 10 times torch.float64
Took: 0.09588909149169922
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float16
Took: 161.60748076438904
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float32
Took: 0.13187885284423828
torch.multinomial(a) a.numel() == 1000000 for 10 times torch.float64
Took: 0.17609834671020508
****************************************
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float16
CUDA Took: 0.007131099700927734
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float32
CUDA Took: 0.022255420684814453
torch.multinomial(a) a.numel() == 50000 for 100 times torch.float64
CUDA Took: 0.0323028564453125
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float16
CUDA Took: 0.04995012283325195
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float32
CUDA Took: 0.04948878288269043
torch.multinomial(a) a.numel() == 100000 for 100 times torch.float64
CUDA Took: 0.05495333671569824
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39636
Differential Revision: D21925406
Pulled By: ngimel
fbshipit-source-id: f2ee5148fa7dd88e018c461ced0e2361c3a43796
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39605
1. `RRef.to_here()` could serialize a Python object into a message.
However, we did not catch the Python pickle error, which would
result in crash. This was exposed when calling `rpc.remote` with
a user function that returns `torch.futures.Future`.
2. `rpc.function.async_execution` could throw error on the server.
This commit sets the error on the OwnerRRef properly.
Test Plan: Imported from OSS
Differential Revision: D21913820
Pulled By: mrshenli
fbshipit-source-id: 50b620641a3b89d310b3b907570561decd83ee34
Summary:
It's better to have skipping logic explicitly defined in test decorators rather than in some hard-to-find blacklists
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39693
Differential Revision: D21947893
Pulled By: malfet
fbshipit-source-id: 3d0855eda7e10746ead80fccf84a8db8bf5a3ef1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39531
Enables RRef timeout support in TP agent by having TP agent mark
timeout errors with `makeRPCError` API. Also does some refactoring so TP agent
can print out the timeout for each future that has timed out.
ghstack-source-id: 105461555
Test Plan: CI
Differential Revision: D21881475
fbshipit-source-id: f63300e1f0a80ac7eebc983752070c0ec6ac17a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39219
We didn't model clamp ops correctly right now, this PR fixes that.
Reason is quantized clamp op quantizes the scalar arguments in the op implementation: https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp#L614-L617
So we'll need to model this explicitly in the IR.
When we see a `aten::dequantize - aten::clamp(%x, %min, %max)`
we first make a scalar tensor with `aten::scalar_tensor(%scalar, ...)`, then we quantize the tensor with the same quantization parameters from the input tensor of the `aten::clamp`, dequantize the tensor, then convert the dequantized tensor to scalar using `aten::item`.
Test Plan: Imported from OSS
Differential Revision: D21831350
fbshipit-source-id: d60731459a0465d64946aabc62065d25d92faefc
Summary:
Reported by dlibenzi (thanks!) that these arguments are not used in the implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39664
Differential Revision: D21934989
Pulled By: ailzhang
fbshipit-source-id: 35e79ce7f49626c8ad79362f972e442c06022dcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39669
Folds the postnightly workflow, including html updating jobs and binary
size jobs, into the regular nightly workflow that should only run after
all upload jobs have completed.
This also moves the smoke testing jobs into the binary_builds workflow.
Do note that the devtoolset7 html update job has been removed since we
do not upload binaries specifically to that location anymore.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21936811
Pulled By: seemethere
fbshipit-source-id: a062413b69bafe0a85173020e8b218b375124106
Summary:
Adds the ability for all backward functions to accept undefined output gradient arguments. An undefined gradient is a Tensor that was created by the argumentless constructor `at::Tensor()`, where `tensor.defined() == false`.
Also adds new autograd nodes, UndefinedGrad and UndefinedGradBackward, that can be used from within Python code to inject undefined gradients into a backward function. A new test case is added to the backward function unit tests to use the UndefinedGrad node to ensure that undefined gradients do not break any backward functions.
Closes https://github.com/pytorch/pytorch/issues/33138
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39400
Differential Revision: D21936588
Pulled By: albanD
fbshipit-source-id: eccc5f55c77babe6dadcea4249d0c68a3c64e85d
Summary:
It didn't really make sense for it to be where it was and seeing how the
build only actually takes about 5 minutes to do it'd be best to just
move it into the garbage collection workflow.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38523
Reviewed By: malfet
Differential Revision: D21937332
Pulled By: seemethere
fbshipit-source-id: 6b797a6af88549dbd5ccce88814a1428354ce7f2
Summary:
Add a compilation error if they are individually included. Devs should
instead include c10/util/complex_type.h (which includes these two files).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39276
Differential Revision: D21924922
Pulled By: ezyang
fbshipit-source-id: ad1034be5d9d694b18cc5f03a44f540f10de568c
Summary: This is to test predictor on platform009
Test Plan:
```
fbpkg build -E fblearner/predictor
fbpkg build -E fblearner/predictor_proxy
```
# Performance test
## ServiceLab experiments
https://fburl.com/servicelab/p2xo4c85
## Perf A/B test
perf_b is platform-009
https://fburl.com/ods/59kdhdf9
perf_a is platform-09
https://fburl.com/ods/gjctzpe3
Differential Revision: D20552379
fbshipit-source-id: d6d9094aedfb2c1db623d44108627e8e00dde47e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39540
This gets picked up by mypy as an error in 1.5.1, not sure if it's a different version or setting, but might as well fix.
Test Plan: Imported from OSS
Differential Revision: D21891772
Pulled By: gchanan
fbshipit-source-id: 6f95bcd0652007323cd0c79070425b64e0b71c55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39614
add overload name to differentiate
prim::min.int(int a, int b) -> (int)
prim::min.int(int[] l, int[] r) -> (int[])
Test Plan:
verified op names for aten::min and aten::max are different
before
```
prim::min.int(int a, int b) -> (int)
prim::min.float(float a, float b) -> (float)
prim::min.int_float(int a, float b) -> (float)
prim::min.float_int(float a, int b) -> (float)
prim::min(Scalar a, Scalar b) -> (Scalar)
prim::max.int(int a, int b) -> (int)
prim::max.float(float a, float b) -> (float)
prim::max.int_float(int a, float b) -> (float)
prim::max.float_int(float a, int b) -> (float)
prim::max(Scalar a, Scalar b) -> (Scalar)
prim::min.int(int[] l, int[] r) -> (int[])
prim::max.int(int[] l, int[] r) -> (int[])
prim::min.self_int(int[] self) -> (int)
prim::max.self_int(int[] self) -> (int)
prim::min.float(float[] l, float[] r) -> (float[])
prim::max.float(float[] l, float[] r) -> (float[])
prim::min.self_float(float[] self) -> (float)
prim::max.self_float(float[] self) -> (float)
prim::min.bool(bool[] l, bool[] r) -> (bool[])
prim::max.bool(bool[] l, bool[] r) -> (bool[])
prim::min.self_bool(bool[] self) -> (bool)
prim::max.self_bool(bool[] self) -> (bool)
```
after
```
prim::min.int(int a, int b) -> (int)
prim::min.float(float a, float b) -> (float)
prim::min.int_float(int a, float b) -> (float)
prim::min.float_int(float a, int b) -> (float)
prim::min(Scalar a, Scalar b) -> (Scalar)
prim::max.int(int a, int b) -> (int)
prim::max.float(float a, float b) -> (float)
prim::max.int_float(int a, float b) -> (float)
prim::max.float_int(float a, int b) -> (float)
prim::max(Scalar a, Scalar b) -> (Scalar)
prim::min.int_list(int[] l, int[] r) -> (int[])
prim::max.int_list(int[] l, int[] r) -> (int[])
prim::min.self_int(int[] self) -> (int)
prim::max.self_int(int[] self) -> (int)
prim::min.float_list(float[] l, float[] r) -> (float[])
prim::max.float_list(float[] l, float[] r) -> (float[])
prim::min.self_float(float[] self) -> (float)
prim::max.self_float(float[] self) -> (float)
prim::min.bool_list(bool[] l, bool[] r) -> (bool[])
prim::max.bool_list(bool[] l, bool[] r) -> (bool[])
prim::min.self_bool(bool[] self) -> (bool)
prim::max.self_bool(bool[] self) -> (bool)
```
Reviewed By: iseeyuan
Differential Revision: D21914844
fbshipit-source-id: f1792a8c3b3ed6d1a4ba9705c4504f15e3665126
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39119
Add some base c++ unittest coverage for ivalue::Future, and in
the process, add a basic collectAll() primitive, per 38937.
In the process, I realized that List<Future> is effectively
impossible to construct (since the Future's type is not templated,
but rather passed in, the getTypePtr_<T>::call() isn't defined),
so added a workaround in List to make it possible.
ghstack-source-id: 105309650
Test Plan: buck test mode/dev-nosan caffe2/test/cpp/jit/...
Differential Revision: D21756884
fbshipit-source-id: 5d40c8d1c55098de5497655c7b887f4f56508a37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38898
Pickling will pickle the tensor meta info, and its up to the jit
exporter or other upstream who use the pickler to decide how to write
the actual tensor data.
This PR make we call getWritableTensorData in upper level so that rpc
and TensorPipe can leverge it with only pickling tensor meta data without
converting the tensor from GPU to CPU.
Test Plan: Imported from OSS
Differential Revision: D21879866
Pulled By: wanchaol
fbshipit-source-id: 75f7ff4073e4ad15b6588973dcbdc48f97a8329f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39606
Removed duplicated schema for aten::pow
Test Plan:
Previously there are many duplicated aten::pow
```
aten::pow.int(int a, int b) -> (float)
aten::pow.float(float a, float b) -> (float)
aten::pow.int_float(int a, float b) -> (float)
aten::pow.float_int(float a, int b) -> (float)
aten::pow(Scalar a, Scalar b) -> (float)
aten::pow.int(int a, int b) -> (int) // duplicated name!
aten::pow.float(float a, float b) -> (float) // duplicated schema!
aten::pow.int_float(int a, float b) -> (float) // duplicated schema!
aten::pow.float_int(float a, int b) -> (float) // duplicated schema!
aten::pow(Scalar a, Scalar b) -> (Scalar) // duplicated name!
```
After this diff, there are only 7 ops with different overload name:
```
aten::pow.int(int a, int b) -> (float)
aten::pow.float(float a, float b) -> (float)
aten::pow.int_float(int a, float b) -> (float)
aten::pow.float_int(float a, int b) -> (float)
aten::pow(Scalar a, Scalar b) -> (float)
aten::pow.Scalar(Scalar a, Scalar b) -> (Scalar)
aten::pow.int_to_int(int a, int b) -> (int)
```
Reviewed By: iseeyuan
Differential Revision: D21914441
fbshipit-source-id: 1e82c83c77d22206046276bbb52a65088c58ed33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39090
Makes quantized GroupNorm work in eager mode post training static quant.
Test Plan:
```
python test/test_quantization.py TestPostTrainingStatic.test_normalization
python test/test_quantization.py TestStaticQuantizedModule.test_group_norm
```
Imported from OSS
Differential Revision: D21885262
fbshipit-source-id: 58b0ffb59c601fcb4c79f711c7c98a667ffc6170
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39458
Previously if we had a CallMethod followed by a CallFunction, we didn't check for observers at output of CallMethod since it was handled separately.
This change makes it default to check the outputs of all nodes to identify values that need observers
Test Plan:
python test/test_quantization.py test_dynamic_shared_weights
Imported from OSS
Differential Revision: D21872939
fbshipit-source-id: 08dd8b7ddf73ef2cc26ebcf4ceb2f222c4559ab3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39412
This PR introduces changes to enable running the weight observer standalone in the graph
It extracts the nodes from the graph that correspond to the observed weight value and adds all the related nodes to a new subgraph
The subgraph is then executed using GraphFunction
Test Plan:
python test/test_quantization.py TestGraphMostPostTrainingStatic
python test/test_quantization.py TestQuantizeDynamicScript
Imported from OSS
Differential Revision: D21872940
fbshipit-source-id: 55f1dcc2caef193531e2b807c8e56288b9794520
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39608
As title. When adding a new build mode TypeDerived failed to compile due to macro redefinition. Conditional define fixes this issue.
Test Plan: Tests pass.
Reviewed By: iseeyuan
Differential Revision: D21914975
fbshipit-source-id: 12e04af29b7510106e8e47fa48e30b829aeff467
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39607
add overload name for strcmp macro to prevent duplicated op names in lite interpreter
also reformatted some other files
Test Plan:
verified these op schema are changed
```
-aten::eq(str a, str b) -> (bool)
+aten::eq.str(str a, str b) -> (bool)
-aten::ne(str a, str b) -> (bool)
+aten::ne.str(str a, str b) -> (bool)
-aten::lt(str a, str b) -> (bool)
+aten::lt.str(str a, str b) -> (bool)
-aten::gt(str a, str b) -> (bool)
+aten::gt.str(str a, str b) -> (bool)
-aten::le(str a, str b) -> (bool)
+aten::le.str(str a, str b) -> (bool)
-aten::ge(str a, str b) -> (bool)
+aten::ge.str(str a, str b) -> (bool)
```
Reviewed By: iseeyuan
Differential Revision: D21913049
fbshipit-source-id: 518db068c8c5b0efd19223f0bd94fc3351335dc4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39598
In order to include af5f68b241
Test Plan: CircleCI
Reviewed By: mrshenli
Differential Revision: D21910997
fbshipit-source-id: 98ac0a9431576e2984c0cac99cc83f7ba967ccde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39352
In this task, the quantized backend of the kernel is implemented for the threshold function, which clamps the entries in a tensor less than or equal to a given threshold to be a specified value.
The corresponding Python implementation and unit test are also added.
Test Plan:
1. On a devserver, build PyTorch from source by running the command `buck build mode/dev //caffe2:torch`
2. Run the unit test throught the command
`buck test mode/dev //caffe2/test:quantization -- test_qthreshold`
Reviewed By: z-a-f
Differential Revision: D21822446
fbshipit-source-id: e8c869664e6d4c664f0e7fa3957762992118c082
Summary:
Minor speed up when printing.
Also allows you to print Tensors that you cannot perform autograd ops on.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39420
Differential Revision: D21889390
Pulled By: albanD
fbshipit-source-id: 4e229994eb89484795282e6eac37359ce46b5ebc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39360
Makes the observer microbenchmarks also run on CUDA. This is useful
now that QAT is supported in DDP and is more likely to be run
on GPUs.
Test Plan:
```
python -m pt.qobserver_test
```
Imported from OSS
Differential Revision: D21828985
fbshipit-source-id: 6da4d61f744f7a2ee5e87963b3ec84579128d435
Summary:
All individual test_nccl unit tests have been disabled for ROCm in bf9395438f
test_nccl was also added to the ROCM_BLACKLIST in 87b198d309
However, the issue only arises when running the test_nccl suite as a whole (as opposed to any one test individually). More details in comments here: https://github.com/pytorch/pytorch/pull/38689
This PR enables test_nccl suite with only two tests so as to workaround the as-yet unresolved issue above, while allowing at least one test_nccl collective test to run on ROCm. This is also needed as a precursor for: https://github.com/pytorch/pytorch/pull/38515
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39354
Differential Revision: D21843194
Pulled By: mrshenli
fbshipit-source-id: b28d1e073d8d0fdc1b59928fc3b00187cfd02a35
Summary:
I added the following to the docs:
1. `torch.save`.
1. Added doc for `_use_new_zipfile_serialization` argument.
2. Added a note telling that extension does not matter while saving.
3. Added an example showing the use of above argument along with `pickle_protocol=5`.
2. `torch.split`
1. Added an example showing the use of the function.
3. `torch.squeeze`
1. Added a warning for batch_size=1 case.
4. `torch.set_printoptions`
1. Changed the docs of `sci_mode` argument from
```
sci_mode: Enable (True) or disable (False) scientific notation. If
None (default) is specified, the value is defined by `_Formatter`
```
to
```
sci_mode: Enable (True) or disable (False) scientific notation. If
None (default=False) is specified, the value is defined by
`torch._tensor_str._Formatter`.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39303
Differential Revision: D21904504
Pulled By: zou3519
fbshipit-source-id: 92a324257d09d6bcfa0b410d4578859782b94488
Summary:
Currently torch.Tensor subclasses (like torch.nn.Parameter) isn't a supported type annotation to torch script inputs. This PR allows it to be treated like torch.Tensor for compilation.
Closes https://github.com/pytorch/pytorch/issues/38235
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39487
Differential Revision: D21885827
Pulled By: gmagogsfm
fbshipit-source-id: 1ec51829b132b7b0293a6c526d73497b23dae113
Summary:
we were restricting it to 3, but in training we set up to 5, even that
in practice we just need 3 since we don't recompute mean/var
Test Plan: contrib tests for fakelowp
Reviewed By: hl475
Differential Revision: D21905490
fbshipit-source-id: 48f61c7ba7d95f19d55d2f65514a517c1514ae88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39446
In my unscientific testing, this reduces startup time by 50% on gcc 8.3.
That's a big fucking deal.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21862037
Pulled By: ezyang
fbshipit-source-id: 69fb401956304a97f8f80c48cecdb1cb199ff434
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39555
This function does not require GIL, as all OwnerRRef-related
py::object deletion is now guarded by ConcretePyObjectHolder. If
we hold lock here, we could potentially run into deadlock, if there
are other threads in the RPC thread pool trying to acquire GIL to
destruct Python UDFs or OwnerRRefs.
Test Plan: Imported from OSS
Differential Revision: D21897125
Pulled By: mrshenli
fbshipit-source-id: 96157689df38bc409af57b83248ae73823d1f959
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39535
This is my understanding of what could happen: on workerN (N != 0), `_wait_all_workers_sequence_id_to_states`, which is a `defaultdict`, is accessed twice: once in the body of `_wait_all_workers` (by the "main thread" of workerN) and once in `_set_proceed_shutdown_signal`, called by worker0 through a RPC call. I think the two could race and access the `_wait_all_workers_sequence_id_to_states` at the same time, and thus create two separate copies of `WaitAllWorkersStates`. One of those threads would wait on the event of one copy, but the other thread would set the event of the other copy. This lead to a deadlock, as the main thread would end up waiting forever.
ghstack-source-id: 105283327
Test Plan: I added additional logging in those functions, ran a stress test of the RPC test suite, based on the logs I suspected that this could be the issue, fixed it and re-run the stress test and didn't see the bug anymore. This is admittedly not very convincing evidence, as I may just have been lucky that second time...
Differential Revision: D21889752
fbshipit-source-id: 05ec710bd2930313e1480ae896b4b2f5f503aa17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39190
The tests covered previously by test_qrelu, test_qrelu6, test_qsigmoid, and test_qhardsigmoid are now merged into one test to ensure conciseness and reduce redundancy.
The refactoring aims to provide the basis for a more generalizable framework to test quantized activation functions and more in the future.
Test Plan:
1. On a devserver, build PyTorch from source by running the command "buck build mode/dev //caffe2:torch"
2. Run the merged unit test throught the command
"buck test mode/dev //caffe2/test:quantization -- test_qrelu"
"buck test mode/dev //caffe2/test:quantization -- test_qrelu6"
"buck test mode/dev //caffe2/test:quantization -- test_qsigmoid"
"buck test mode/dev //caffe2/test:quantization -- test_qhardsigmoid"
Reviewed By: z-a-f
Differential Revision: D21755690
fbshipit-source-id: ef62b2a50ee1c3b8607746f47fb587561e75ff25
Summary:
See https://github.com/pytorch/pytorch/pull/38620 for additional context.
When PyTorch begins producing file format 4 with the updated div behavior it's safe for older PyTorch versions to consume it, since file format 4 only prohibits functionality. Bumping the supported file format version now gives PyTorch users on Master some leeway on updating their services that consume vs. produce PyTorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39529
Differential Revision: D21886790
Pulled By: mruberry
fbshipit-source-id: d6098eff06c26f18c3fac5cc85e5db298ba86e27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39380
Test for inserting observers for if statement for ops that propagate quantization parameters
Test Plan: Imported from OSS
Differential Revision: D21832477
fbshipit-source-id: 6e0b4ce4a89f847af161bb22338525802adb8b41
Summary:
Instead of copying to a buffer, then setting a tensor's storage with that buffer, create a storage directly from the file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36362
Pulled By: driazati
Differential Revision: D21889537
fbshipit-source-id: edbd430073c2bbf52332fe7b3b2590e7d936dedf
Summary:
Misc updates to the fake FP16 tests.
1. seeding numpy with a random seed
2. test base class changed from unittest.TestCase=>serial.SerializedTestCase
3. Removed the hypothesis_test_util import
Reviewer: Hector Yuen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39405
Test Plan: Fake FP16 test
Differential Revision: D21890212
Pulled By: hyuen
fbshipit-source-id: 25e7e17f118655f32cdd06ea9db3cdac5277e649
Summary:
s/raise unittest.skip/raise unittest.SkipTest/
As `unittest.skip` is a decorator while `unittest.SkipTest` is an exception
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39532
Differential Revision: D21889152
Pulled By: malfet
fbshipit-source-id: 27a03dbf065a1e2712a63c6c27e156bd13edbbdf
Summary:
Fix type casting for reduce ops in ONNX exporter. PyTorch promotes dtypes bool and all integer types to long for these ops.
This fix only covers traced modules where dtype is present
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38829
Reviewed By: hl475
Differential Revision: D21833533
Pulled By: houseroad
fbshipit-source-id: 00d9ff692cc0b09d6ca169f6c63913f04b56f182
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39483
I fixed all of the new errors that occurred because of the upgrade.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21884575
Pulled By: ezyang
fbshipit-source-id: 45c8e1f1ecb410c8d7c46dd3922ad70e982a0685
Summary:
Previously, on conversion from python -> c++ it was casted to double list through bad copy pasta. It's pretty unusual for someone to script a broadcasting list function directly since it's an internal api, so it was unlikely to affect anyone.
Fix for https://github.com/pytorch/pytorch/issues/39450
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39481
Reviewed By: jamesr66a
Differential Revision: D21870557
Pulled By: eellison
fbshipit-source-id: e704e5e87d2702a270b7d65c4df444246a134480
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39379
Moves binary builds into their own workflow and adds the ability to
target specification on them. This allows you to run the binary build
workflow on a pull request without the need to modify any configuration
at all.
Some notes about this implementation:
* Upload jobs are still restricted to only the nightly branches and RC tags
* Parameters for circleci are currently defined in
.circleci/verbatim-sources/header-section.yml
* Target specification configuration is currently located at
.github/pytorch-circleci-labels.yml
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21886341
Pulled By: seemethere
fbshipit-source-id: 146ef5df2fea208d33e97862d52c170bf001bc98
Summary:
max_pool2d with ceil_mode calculates output size a little differently
than what we get with xnnpack max_pool2d. Thus when ceil_mode=True, we
disable this path. However if we get the same output size with ceil_mode
and without ceil_mode, we should use xnnpack based max_pool2d.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39447
Test Plan: CI
Differential Revision: D21873334
Pulled By: kimishpatel
fbshipit-source-id: b84abed1505e36e492cc87e7d40664ac63964909
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37531
All of these definitions are no longer "legacy" as their CPU
implementations have been ported to ATen. There are probably some
layers of indirection that could be reduced here, but for now just do a
minor but unlikely to break things cleanup.
The last thing in LegacyNNDefinitions truly is still in THCUNN and can't
be removed.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21310913
Pulled By: ezyang
fbshipit-source-id: 1ff4ff16abddf13f8d583df990242ac4b0461915
Summary:
This PR aims to add `arcosh`, `arcsinh` and `arctanh` support. Please see issue https://github.com/pytorch/pytorch/issues/38349 for more details.
**TODOs:**
* [x] Add test cases for `arcosh`, `arcsinh` and `arctanh`. (need help)
* [x] Overload ops if `std::op` does not work with `thrust::complex` types (like for `sinh`, `cosh`).
Note: `std::acosh, std::asinh, std::atanh` do not support `thrust::complex` types. Added support for complex types for these 3 ops (`arccosh, arcsinh, arctanh`)
cc: mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38388
Differential Revision: D21882055
Pulled By: mruberry
fbshipit-source-id: d334590b47c5a89e491a002c3e41e6ffa89000e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39331
Fixes gh-37590
Adds an extra `make coverage` to document building, which uses the built-in facility in sphinx to check docstring coverage. Also fixes a failure to import `torch/jit/supported_ops.py` which broke the [Torchscript Builtins](https://pytorch.org/docs/stable/jit_builtin_functions.html) page.
This also adds the required `SPHINXOPTS` to turn warnings into error, but this is commented out. Note that since documentation of `torchvision` is merged in here, failures there would cause failures here if this is made active. Some thought might be needed about pinning the torchvision version merged into documentation.
The first commit should fail, since the "ScriptModule" class is commented out. I did that in order to check that a CI failure is properly reported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38244
Differential Revision: D21640589
Pulled By: ezyang
fbshipit-source-id: 1e240d81669b5f21404d596de4a27d192dc9fd8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39527
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21884798
Pulled By: ezyang
fbshipit-source-id: a130bfd4cc122ea1d45e7db7303bf44e04f08703
Summary:
This corrects the build info for ppc64le in the main README.
I am opening this PR before renaming the build job. (So, the "live" master README has the correct "live" link and the PR does not.)
Immediately after submitting the PR, I will correct the name of the build job. This will make the new PR link correct, and the current "master" link will briefly appear broken until this PR gets merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39475
Differential Revision: D21883184
Pulled By: malfet
fbshipit-source-id: 148353b632448c98e5aff560d31642328afe7963
Summary:
Adding a SymbolicShape class to represent a generic tensor shape with ShapeSymbols.
Its core data structure is c10::optional<std::vector<ShapeSymbol>>. If has_value() == false, it represents an unranked tensor shape. At any dimension ShapeSymbol can contain dynamic size, checkable with ShapeSymbol::IsStatic method.
SymbolicShape now replaces all uses of VaryingShape<ShapeSymbol>, ie c10::optional<std::vector<c10::optional<ShapeSymbol>>>. The inner c10::optional wrapper around ShapeSymbol used to indicate dynamic shape, which overlaps with part of ShapeSymbol's representation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38544
Reviewed By: ZolotukhinM
Differential Revision: D21693984
Pulled By: gmagogsfm
fbshipit-source-id: 6e633e4f36cf570d6fb34ac15d00ec1fb2054a09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38590
This PR implements timeout semantics for RRef for parity with rpc_sync and rpc_async. How it works:
- Timeout parameter is added to rpc.remote. If the rpc.remote call times out, note that the error won't be raised to the user in that call, as it is not blocking (similar to rpc_async). Instead, the timeout error will be raised the next time the RRef is used (either by pickling or to_here call).
- Error handling semantics are added to RRef to deal with the timeout errors. Previously, if there was an error creating the OwnerRRef, the callback on the local user would throw an error in a callback, resulting in an `std::terminate`. Instead of this, the error is now caught and surfaced to the user the next time the RRef is used. As part of this, we have added an `RPCErrorType` enum and defined RRef error handlers to handle the `RPCErrorrTypes` (currently just timeout and unknown)
- A timeout parameter is added to `to_here()` which gives the user control over the max amount of time it can block for.
- `ctx.prepareChildForFork()` which is called when the RRef is pickled (i.e. used as an arg over RPC) checks if the `rpc.remote()` call had timed out, and if so, raises that error to the user.
- Tests are added, primarily via delay injection.
ghstack-source-id: 105232837
Test Plan: CI
Differential Revision: D21588165
fbshipit-source-id: c9f9e8aa3521012ea1de3e0f152a41afdf8b23f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39267
When combined with `torch.jit.script`, the order of decorators matter.
`rpc.functions.async_execution` must be the outmost one. The
`async_execution` decorator will store the TorchScript function in
attribute `_wrapped_async_rpc_function` on the wrapper function, and
pass this wrapped TorchScript function (i.e., an instance of
`torch.jit.ScriptFunction`) to RPC. The caller will mark the ScriptCall
with `isAsyncExecution=true`, and the callee will extract the returned
`Future` in C++ and install subsequent processing as a callback to
that `Future`.
Test Plan: Imported from OSS
Differential Revision: D21792688
fbshipit-source-id: de095eb148d21e9114a478e9e6047c707d34fd07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39501
fix internal targets, and disable the test until it is fixed
Test Plan:
built and ran the test, but venkat has to get access to nnpi before
fine tuning the last few pieces. Currently getting around 1e-5 relative error
Reviewed By: yinghai
Differential Revision: D21875657
fbshipit-source-id: 3ae762093084fa65b9aeedaef1b2ca1b1e13b587
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39456
Move aten::to.prim_dtype from full jit to lite interpreter
Test Plan: verify TTS model can be used
Reviewed By: iseeyuan
Differential Revision: D21856104
fbshipit-source-id: 774981a5c04798e3a87cf7d6e6682f35e604944e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38173
- Introduce torch.types.Device representing all "device-like" types
- Stubbed torch.device.__reduce__
- Stubbed all torch._C functions comprehensively
- Deleted _safe_call which is unused throughout the codebase
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21497399
Pulled By: ezyang
fbshipit-source-id: 1f534442b0ec9a70d556545d072f2c06a08b9d15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39393
Computing r_correction should be done only for radam . Otherwise can generate floating-point exceptions.
Test Plan:
buck test caffe2/caffe2/python/operator_test:adam_test -- test_sparse_adam
with --caffe2_operator_throw_if_fp_exceptions=1 gflags option
Differential Revision: D21834296
fbshipit-source-id: a9e6a93451423e76a99f6591d21cb65d4374b008
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39181
Create a python binding classes torch._C. LiteScriptModule for mobile::module, a python class called LiteScriptModule is created which wrap torch._C. LiteScriptModule.
Python class LiteScriptModule contains preliminary functions including forward, run_method and __call__.
Create a python api "load_for_lite_interpreter" under torch.jit.mobile where takes pre-saved mobile module in a file-like object as input and returns python class LiteScriptModule.
Add a python binding method "_save_to_buffer_for_mobile" under ScriptModule, and python method "_save_to_buffer_for_lite_interpreter" under RecursiveScriptModule which saves mobile module into buffer instead of file.
ghstack-source-id: 105215736
Test Plan: buck test caffe2/test:mobile
Differential Revision: D21757474
fbshipit-source-id: 758b87497d65c4686459a567d41887c7a577aa4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39452
Selective build works on training.
* VariableType_?.cpp are now selectively generated based on the operator list.
* Add a flag in pt_operator_library, "train". If it's True, an extra flag of "pt_train_operator_library" will be added to the labels. A query for "pt_train_operator_library" will be done to aggregate the training operators. With this flag we limit the generated VariableType to used training operators only, to conserve the code size. The models for inference only have train = False by default.
* For testing purpose, caffe2/fb/pytorch_trainer is created. It's based on full jit but the operators are selectively built.
* smartkeyboard_debug_model is used for test. Since the static code analysis is not applied for VariableType yet, the operators are manually added based on debugging error messages.
* At build stage, make selective build optional for training code-gen library.
The reason is that to make fb4a built, the generated VariableType.cpp needs to depend on torch_mobile_train. Torch_mobile_train is not needed for apps with inference only. In those cases training can be turned off to remove the dependency on torch_mobile_train to save size. It can also be used as a switch to check size regression introduced by training.
ghstack-source-id: 105190037
(Note: this ignores all push blocking failures!)
Test Plan:
Training:
```
buck run -c pt.build_from_deps_query=1 -c pt.selective_build=0 -c pt.static_dispatch=0 xplat/caffe2/fb/pytorch_trainer:trainer ~/models/papaya/keyboard/smartkeyboard_debug_model.pt
```
Inference, with and without the new query-based feature:
```
buck run -c pt.build_from_deps_query=1 -c pt.selective_build=0 -c pt.static_dispatch=0 xplat/caffe2/fb/lite_predictor:lite_predictor_bi -- --model=/home/myuan/models/pytext/BI/bi_pytext_0512.bc --input_dims "1,4" --input_type int64 --pytext_len=4
```
```
buck run xplat/caffe2/fb/lite_predictor:lite_predictor_bi -- --model=/home/myuan/models/pytext/BI/bi_pytext_0512.bc --input_dims "1,4" --input_type int64 --pytext_len=4
```
Reviewed By: ljk53
Differential Revision: D21459302
fbshipit-source-id: df71a46d74f8c7448cbf51990804104f1384594f
Summary:
`HTTPError` are raised when server is overloaded, while `URLError` is
raised when network is not available
And since `HTTPError` is an extension of `URLError`, `URLError` should catch both exceptions
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39477
Differential Revision: D21873560
Pulled By: malfet
fbshipit-source-id: 11806671b768705465f562087521ad4887fd20f7
Summary:
Re-enable some test cases in `test_memory_format_operators` since their corresponding issue has been fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38648
Differential Revision: D21689085
Pulled By: VitalyFedyunin
fbshipit-source-id: 0aa09e0bf31ba98c8ad0191ac3afd31dda0f1d42
Summary:
Cut from https://github.com/pytorch/pytorch/pull/38994.
This is a helper function for comparing torch and NumPy behavior. It updates the existing and increasingly popular _np_compare function and moves it to be a method on TestCase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39179
Differential Revision: D21855082
Pulled By: mruberry
fbshipit-source-id: edca3b78ae392d32243b02bf61960898b6ba590f
Summary:
Mainly, fix a bug in the HashProvider where it would not include LoopOptions in the hash, meaning two loops would be seen as identical even if they were bound to different thread/block axes. Also added symbolic names for the different axis options.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39408
Differential Revision: D21864494
Pulled By: nickgg
fbshipit-source-id: 9c28729984e7a3375e026c78294c9f75b9015123
Summary:
The two bugs were:
* Non-reduction axes were not added when inserting the new ReduceOp, meaning if a reduction with non-reduce axes was rfactored we'd produce bad outputs. There were no tests of Rfactor with non-reduce axis so I modified a test to do this.
* The new statements were always prepended to the block, meaning writes to a buffer could be reordered after the usage of that buffer. This mostly happened in the case where we rfactor a previously rfactored reduction. There was a test of this, but since it only tested rfactoring the outer reduction axis there was never any other statements at the insertion point (the tests of the insertion point argument also do this). I added a new test which covers various rfactor-axis cases.
Also cleaned up tests, removed some helper code we don't need etc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39268
Differential Revision: D21864489
Pulled By: nickgg
fbshipit-source-id: d314d20997a8472ec96b72f7a9068d6da6d2399c
Summary:
This patch removes call to run optimizations within freezing API.
Only dead code elimination is invoked to clean up the frozen module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38499
Reviewed By: eellison
Differential Revision: D21579607
Pulled By: bzinodev
fbshipit-source-id: a6231754fea89296a3dcf07b5e37a1c43cb8d5dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39378
Will initially only contain a label to trigger builds for binary tests
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21864091
Pulled By: seemethere
fbshipit-source-id: f69467ccc797b6b320dc8b7f2d50a8601c172a1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39337
In #39031 we made fake quantize respect device affinity of the
original module. However, that PR only handled modules with parameters
or buffers, and did not work properly for `ReLU`.
Fixing the logic to also work for `ReLU` by passing the parent's
device when adding observers.
Test Plan:
```
python test/test_quantization.py TestDistributed.test_device_affinity
```
Imported from OSS
Differential Revision: D21821243
fbshipit-source-id: cc6abda3694b80ce8ba0440dc6c1b5b58f3c0066
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39441
This is the last test suite to be enabled for TensorPipe.
ghstack-source-id: 105166757
Test Plan: Ran the tests, hundreds of times each, in different build modes.
Differential Revision: D21858975
fbshipit-source-id: ee0a7e64b77b4b1974f031207031cc14afb3a8c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39440
After the RPC tests, re-enable the second test suite: dist autograd.
ghstack-source-id: 105165393
Test Plan: Ran the tests, several times each, in different build configs.
Differential Revision: D21858974
fbshipit-source-id: 409377d564c36fecae51b9e4c776d94187b434a2
Summary:
Fixes gh-38966
If `THCTensor_(resizeAs)` fails to allocate, then these `free`s will never be reached. So, instead I use a wrapped tensor to do cleanup automatically.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39347
Differential Revision: D21838933
Pulled By: ezyang
fbshipit-source-id: 8c74ecdd720d6712a33ddef6126ea545761a269b
Summary:
ezyang,
I have added the changes to DispatchKey, DeviceType, Backend to support the out-of-tree FPGA.
cc. tataetae
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38938
Differential Revision: D21748955
Pulled By: ezyang
fbshipit-source-id: fe76d9730818205961430d2a0e00727b5c547b32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39406
For now, just the RPC test (no dist autograd or dist optimizer).
I removed the skipping decorator from all the tests except those that explicitly use the ProcessGroup options.
Includes #39027.
ghstack-source-id: 105159974
Test Plan: Ran the tests several hundred times, in various build modes. Saw some flakes, but at a rate of about 0.1%
Differential Revision: D21716069
fbshipit-source-id: 9d2a99e112049a63745772c18e7a58266ed8e74e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32866, resubmit of https://github.com/pytorch/pytorch/issues/38970
The memory error in the issue is caused by int overflowing in col2vol. This version using mixed 32-bit and 64-bit indexing calculation lifts the maximum indexing possible without compromising the performance of ConvTranspose3d. vs 20-30% regression with pure 64-bit indexing.
This requires that input.numel() <= UINT_MAX, and channels * kernel.numel() <= UINT_MAX otherwise it raises an error. Previously, the code would crash or give incorrect results unless input.numel() * kernel.numel() <= INT_MAX.
Note that the test is a minimised reproducer for the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39198
Differential Revision: D21817836
Pulled By: ezyang
fbshipit-source-id: b9adfe9f9dd00f04435be132966b33ac6b9efbef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39216
The `rpc.functions.async_execution` decorator specifies that the
wrapped function is guaranteed to return a `torch.futures.Future`.
The decorator adds a `_wrapped_async_rpc_function` attribute to
the wrapper function. The caller retrieves this information and
then sets `isAsyncFunction` argument accordingly which is later
added to PythonCall RPC message as a field. On the callee side,
if the PythonCall carries an asynchronous function, it will cast
the function's return value to a jit::PythonFutureWrapper object,
and then install response creation and communication as a callback
on the that jit::PythonFutureWrapper.
For applications, this feature is useful when a function needs to
wait for IO or additional singaling. In those cases, marking the
user function as `rpc.functions.async_execution` will prevent it
from blocking one thread on callee for too long.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D21779962
fbshipit-source-id: 6b6aa698bf6f91dad6ed2a7ee433df429b59e941
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39372
we only bump the submodule in oss to unblock some works
Test Plan: ci
Reviewed By: hl475
Differential Revision: D21830800
fbshipit-source-id: fb4a716992efcd71926f7bba24a7c24422c17e38
Summary:
fixes gh-32284
Move the non-parallel stanza out of the parallel context, and use `num_threads` to limit nesting `parallel for`s. The nesting caused a memory leak in the test script in the issue.
This should probably have a test somewhere: are there tests for ParallelOpenMP?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36479
Differential Revision: D21652452
Pulled By: ilia-cher
fbshipit-source-id: 2cda7777c0eafbe268550a82fed306e52fb6eb25
Summary:
If the size of a temporary buffer is reduced to zero via binding of a dynamic variable we still run the alloc, even though it is a no op. It's easy to strip these out during simplification, so the expr:
```
{
Allocate(x, int, {0});
// Stuff...
Free(x);
}
```
becomes
```
{
// Stuff...
}
```
I am assuming here that if the allocation size is zero then any usage of the buffer is also eliminated since theres no safe way to refer to a zero size buffer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38794
Differential Revision: D21723656
Pulled By: nickgg
fbshipit-source-id: 3eaa8bd8974a13b0a351be04abe2348498b31b02
Summary:
According to
<https://gitlab.kitware.com/cmake/cmake/-/blob/master/Modules/Compiler/MSVC-C.cmake>,
the option simply has no effect for MSVC as of today. It is better to not impose
such an if condition as it is a bit misleading (the current code makes it look like we have compatibility issues with MSVC C11 support), and also it's better to
leave the judgment of MSVC C support to CMake devs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39304
Differential Revision: D21846032
Pulled By: malfet
fbshipit-source-id: 962e5721da3d7b9be4117b42bdc35df426b7da7b
Summary:
## Description
* Updated assert statement to remove check on 3rd dimension (features) for keys and values in MultiheadAttention / Transform
* The feature dimension for keys and values can now be of different sizes
* Refer to https://github.com/pytorch/pytorch/issues/27623
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39402
Reviewed By: zhangguanheng66
Differential Revision: D21841678
Pulled By: Nayef211
fbshipit-source-id: f0c9e5e0f33259ae2abb6bf9e7fb14e3aa9008eb
Summary:
It just depends on a single `torch_python` library.
C library does not depend on standard C++ library and as result it closes https://github.com/pytorch/pytorch/issues/36941
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39375
Reviewed By: orionr
Differential Revision: D21840645
Pulled By: malfet
fbshipit-source-id: 777c189feee9d6fc686816d92cb9f109b8aac7ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38433
Wherever applicable it would be better to call contiguous with appropriate
memory format.
Plus output should be allocated with the same memory format as input when
applicable. Otherwise convert to that format upon returning.
This helps with some perf where otherwise calls to contiguous may involve
allocation and memcpy.
Test Plan: quantization tests
Reviewed By: vkuzo
Differential Revision: D21559301
fbshipit-source-id: 2ed5de05fb627eef1bf5d76fba0387ba67370007
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39353
This test failed with TSAN since the shortened timeout prevented all
messages from being processed within the timeout during Phase 1 of
wait_all_workers during RPC shutdown. Phase 2 already had a longer timeout, so
we extend this to Phase 1 as well.
ghstack-source-id: 105045926
Test Plan: Ran the test_get_and_set_timeout with TSAN
Differential Revision: D21826783
fbshipit-source-id: 7edfdeb50169b31e997dd36a3fd8eea0e9ae7189
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39230
Pull Request resolved: https://github.com/pytorch/glow/pull/4555
With this we now support cutting in the middle of the quantized domain for Onnxifi. This will allow us to observe intermediate quantized value during Onnxifi. Input still has to be non-quantized tensor though. This will be a follow-up.
Test Plan:
```
buck test glow/fb/test/numerics:test_fc_nnpi_int8nnpi -- test_quantize
```
Reviewed By: hyuen
Differential Revision: D21783368
fbshipit-source-id: 51001246e9e0357d7ba90bf12279b644f5f30221
Summary:
Partial fix of: https://github.com/pytorch/pytorch/issues/39060
There are actually two bugs:
1. `TensorIterator::get_dim_to_split` is asserting on what it shouldn't be.
2. `min_kernel_impl` and `max_kernel_impl` are setting `out_scalar_t` wrongly. `out_scalar_t` is used to compute indices for accumulation buffer, which is only used when the tensor is large enough.
Both are tested in `test_argminmax_large_axis_cuda`, but unfortunately, this test does not run on CI.
This PR makes `test_argminmax_large_axis_cuda` green, but this test is still not run on CI. I suggest keeping https://github.com/pytorch/pytorch/issues/39060 open until we figure out a way to run it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39212
Differential Revision: D21834723
Pulled By: ngimel
fbshipit-source-id: e8272ac8552c3954ac486ba6e4129fedb545031e
Summary:
# What's this
Just a small bug fix related to typing stubs.
I haven't open an issue. I will do so if I must open it, but this PR is very small (only 6 lines diff).
## What I encountered
pytorch 1.5.0 with mypy 0.770 behaves odd. The code is following:
```python
import torch
def f() -> int: # Mypy says: `error: Missing return statement`
with torch.no_grad():
return 1
```
No mypy error is expected, but actually mypy 0.770 warns about `Missing return statement`.
## This is because
`mypy >= 0.730` with `--warn-unreachable` says it's unreachable because `torch.no_grad()` may "swallows" the error in the return statement.
http://mypy-lang.blogspot.com/2019/09/mypy-730-released.html
Here is a small "swallowing" example:
```python
from typing import Generator
from contextlib import contextmanager
contextmanager
def swallow_zerodiv() -> Generator[None, None, None]:
try:
yield None
except ZeroDivisionError:
pass
finally:
pass
def div(a: int, b: int) -> float: # This function seems `(int, int) -> float` but actually `(int, int) -> Optional[float]` because ` return a / b` may be swallowed
with swallow_zerodiv():
return a / b
if __name__ == '__main__':
result = div(1, 0)
print(result, type(result)) # None <class 'NoneType'>
```
To supress this behavior, one can tell mypy not to swallow any exceptions, with returning `Literal[False]` or `None` in `__exit__` method of the context manager.
# What I did
Return `None` instead of `bool` to tell mypy that "I never swallow your exception".
I chose `None` because I cannot interpret `Literal[False]` without typing_extensions in `python <=3.7`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39324
Differential Revision: D21833651
Pulled By: albanD
fbshipit-source-id: d5cad2e5e19068bd68dc773e997bf13f7e60f4de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39008
This commit adds a `torch.futures.Future` type and exposes its ctor,
`wait`, `then`, and `set_result` APIs. This type is currently a
wrapper of `c10::ivalue::Future` and mainly used by RPC for now. Later,
we could revamp c10d APIs to return this `Future` type as well. More
utils will be added into `torch.futures` package in followup PRs.
Test Plan: Imported from OSS
Differential Revision: D21723022
Pulled By: mrshenli
fbshipit-source-id: 92e56160544e9bf00d11db3e8347a1b9707882c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39277
This PR contains initial changes that makes PyTorch build with Ampere GPU, CUDA 11, and cuDNN 8.
TF32 related features will not be included in this PR.
Test Plan: Imported from OSS
Differential Revision: D21832814
Pulled By: malfet
fbshipit-source-id: 37f9c6827e0c26ae3e303580f666584230832d06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39398
The `timeoutMapMutex_` was only used to guard accesses in the timeout thread, but it should have been used also to guard accesses in the `send` method.
The way I found this bug is rather odd. A test was failing because a timeout of 0.5 seconds was firing when it wasn't supposed to. The test was built with TSAN enabled and the point where we were wasting those 500ms was precisely when accessing the `timeoutMap_` in the `send` method. There is of course no reason it would take so long, so I suspect that either such an access triggered a whole lot of lengthy checks in TSAN or, perhaps, that TSAN was delaying it on purpose because it thought it was smelly and wanted to see whether it could cause a race.
ghstack-source-id: 105088618
Test Plan: The test started passing.
Differential Revision: D21838465
fbshipit-source-id: 02cf2bf1fef2e97da99b9c4e77070fe35d2bcbb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39397
I said I'd do it in a previous diff, but then I forgot, so here it is.
ghstack-source-id: 105088619
Test Plan: No functional changes
Differential Revision: D21838464
fbshipit-source-id: 74fbe76c7ce879b28c50fd29feecd9f4d71fc44c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39156
TensorList is now supported for boxing, so we can remove
unboxed only from it. I didn't check if there were other
operators that were incorrectly classified.
Fixes https://github.com/pytorch/pytorch/issues/38958
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21819821
Pulled By: ezyang
fbshipit-source-id: 6dcf91bc196554e1721d2c704f3bf524f069534b
Summary:
I'm using CUDA 10.1 on Debian buster but I can still experience
compilation issues:
```
/usr/include/thrust/detail/complex/complex.inl(64): error: no suitable conversion function from "const c10::complex<float>" to "float" exists
detected during:
instantiation of "thrust::complex<T>::complex(const R &) [with T=float, R=c10::complex<float>]"
/home/hong/xusrc/pytorch/c10/util/complex_type.h(503): here
instantiation of "T std::abs(const c10::complex<T> &) [with T=float]"
/home/hong/xusrc/pytorch/aten/src/ATen/native/cuda/AbsKernel.cu(17): here
instantiation of "c10::complex<T> at::native::abs_wrapper(c10::complex<T>) [with T=float]"
/home/hong/xusrc/pytorch/aten/src/ATen/native/cuda/AbsKernel.cu(29): here
/usr/include/thrust/detail/complex/complex.inl(64): error: no suitable conversion function from "const c10::complex<double>" to "double" exists
detected during:
instantiation of "thrust::complex<T>::complex(const R &) [with T=double, R=c10::complex<double>]"
/home/hong/xusrc/pytorch/c10/util/complex_type.h(503): here
instantiation of "T std::abs(const c10::complex<T> &) [with T=double]"
/home/hong/xusrc/pytorch/aten/src/ATen/native/cuda/AbsKernel.cu(17): here
instantiation of "c10::complex<T> at::native::abs_wrapper(c10::complex<T>) [with T=double]"
/home/hong/xusrc/pytorch/aten/src/ATen/native/cuda/AbsKernel.cu(29): here
2 errors detected in the compilation of "/tmp/hong/tmpxft_00005893_00000000-6_AbsKernel.cpp1.ii".
CMake Error at torch_cuda_generated_AbsKernel.cu.o.Debug.cmake:281 (message):
Error generating file
/home/hong/xusrc/pytorch/build/caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/./torch_cuda_generated_AbsKernel.cu.o
```
`nvcc --version`:
```
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Wed_Apr_24_19:10:27_PDT_2019
Cuda compilation tools, release 10.1, V10.1.168
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38941
Differential Revision: D21818790
Pulled By: ezyang
fbshipit-source-id: a4bfcd8ae701f7c214bea0731c13a5f3587b7a98
Summary:
**Summary**
This commit adds support for seralization and deserialization of
`ScriptModules` that have been lowered to a specific backend. Nothing
special was required to accomplish this, other than removing some code
in `unpickler.cpp` that guarded against the deserialization of `Any`
type objects. Now that lists and dicts are tagged with their types
during serialization, this check is no longer necessary.
**Test Plan**
This commit adds a unit test for testing that a lowered module still
produces the same results as Python and regular JIT after saving and
loading.
**Fixes**
This pull request fixes part of https://github.com/pytorch/pytorch/issues/37841.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38893
Differential Revision: D21825813
Pulled By: SplitInfinity
fbshipit-source-id: 77a7b84504e0dddf14c89b3ed5dd6b438c086f66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39377
Previous diff D21781515 had en compliation error on OSS CI and got reverted.
Test Plan: net runner
Reviewed By: jfix71
Differential Revision: D21832199
fbshipit-source-id: 07c6b6fe3bb18dc4f4ecec82ba9b99028086f55c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39367
We shouldn't match `%alpha` argument since it could be used by multiple functions
Test Plan: Imported from OSS
Differential Revision: D21829295
fbshipit-source-id: 6daa320a4b56df4e142b8e02e04a3ecb36284d1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39113
`setError` is overloaded - it can either take `FutureError` or an error message string as an argument. This PR replicates the same behavior for `setErrorIfNeeded`.
ghstack-source-id: 105038824
Test Plan: Sandcastle/CI
Differential Revision: D21753988
fbshipit-source-id: 0f413afd667f0416400aa95f0b2271b286326ac5
Summary:
Restores thrust path for computing prefix sums for tensors with a single non-degenerate dimension. Benchmark on P100 before:
```
import time
import torch
l = 4000
t=1000
for _ in range(6):
for dtype in (torch.half, torch.float, torch.double):
a = torch.randn(l, device="cuda", dtype=dtype)
print(f'torch.cumsum(a) a.numel() == {l} for {t} times {dtype}')
# dry run
torch.cumsum(a, 0)
torch.cuda.synchronize()
# Iterate
start = time.time()
for _ in range(t):
torch.cumsum(a, 0)
# Final Synchronize Before Teardown
torch.cuda.synchronize()
end = time.time()
elapsed = end - start
bw = t * l * 2 * a.element_size() * 1e-9/elapsed
print(f'Time {elapsed} bandwidth {bw}')
l *= 2
```
```
torch.cumsum(a) a.numel() == 4000 for 1000 times torch.float16
Time 0.29149866104125977 bandwidth 0.05488875984145705
torch.cumsum(a) a.numel() == 4000 for 1000 times torch.float32
Time 0.24511313438415527 bandwidth 0.130551959528402
torch.cumsum(a) a.numel() == 4000 for 1000 times torch.float64
Time 0.25238871574401855 bandwidth 0.25357710550304885
torch.cumsum(a) a.numel() == 8000 for 1000 times torch.float16
Time 0.5812790393829346 bandwidth 0.05505101307965633
torch.cumsum(a) a.numel() == 8000 for 1000 times torch.float32
Time 0.4885847568511963 bandwidth 0.13099057861007293
torch.cumsum(a) a.numel() == 8000 for 1000 times torch.float64
Time 0.5031211376190186 bandwidth 0.2544118909528429
torch.cumsum(a) a.numel() == 16000 for 1000 times torch.float16
Time 1.1607651710510254 bandwidth 0.05513604439220951
torch.cumsum(a) a.numel() == 16000 for 1000 times torch.float32
Time 0.9755356311798096 bandwidth 0.13120996907637011
torch.cumsum(a) a.numel() == 16000 for 1000 times torch.float64
Time 1.0045702457427979 bandwidth 0.25483533987283175
torch.cumsum(a) a.numel() == 32000 for 1000 times torch.float16
Time 2.3198938369750977 bandwidth 0.055174938594129294
torch.cumsum(a) a.numel() == 32000 for 1000 times torch.float32
Time 1.949366569519043 bandwidth 0.13132471029456586
torch.cumsum(a) a.numel() == 32000 for 1000 times torch.float64
Time 2.00749135017395 bandwidth 0.2550446854755488
torch.cumsum(a) a.numel() == 64000 for 1000 times torch.float16
Time 4.63812518119812 bandwidth 0.055194715536735495
torch.cumsum(a) a.numel() == 64000 for 1000 times torch.float32
Time 3.897014856338501 bandwidth 0.13138261435345344
torch.cumsum(a) a.numel() == 64000 for 1000 times torch.float64
Time 4.013219356536865 bandwidth 0.2551567479938705
torch.cumsum(a) a.numel() == 128000 for 1000 times torch.float16
Time 9.274584770202637 bandwidth 0.05520462777427539
torch.cumsum(a) a.numel() == 128000 for 1000 times torch.float32
Time 7.792156934738159 bandwidth 0.1314141910354645
torch.cumsum(a) a.numel() == 128000 for 1000 times torch.float64
Time 8.02474856376648 bandwidth 0.2552104883693396
```
after:
```
torch.cumsum(a) a.numel() == 4000 for 1000 times torch.float16
Time 0.033731937408447266 bandwidth 0.47432792864109924
torch.cumsum(a) a.numel() == 4000 for 1000 times torch.float32
Time 0.031197071075439453 bandwidth 1.025737317539167
torch.cumsum(a) a.numel() == 4000 for 1000 times torch.float64
Time 0.03245425224304199 bandwidth 1.972006611667389
torch.cumsum(a) a.numel() == 8000 for 1000 times torch.float16
Time 0.034340858459472656 bandwidth 0.931834596906329
torch.cumsum(a) a.numel() == 8000 for 1000 times torch.float32
Time 0.031183481216430664 bandwidth 2.0523686741645197
torch.cumsum(a) a.numel() == 8000 for 1000 times torch.float64
Time 0.031975507736206055 bandwidth 4.003063878015136
torch.cumsum(a) a.numel() == 16000 for 1000 times torch.float16
Time 0.032624006271362305 bandwidth 1.9617455767895642
torch.cumsum(a) a.numel() == 16000 for 1000 times torch.float32
Time 0.03129267692565918 bandwidth 4.0904138787514
torch.cumsum(a) a.numel() == 16000 for 1000 times torch.float64
Time 0.03260397911071777 bandwidth 7.851802356107085
torch.cumsum(a) a.numel() == 32000 for 1000 times torch.float16
Time 0.032918691635131836 bandwidth 3.888368390176069
torch.cumsum(a) a.numel() == 32000 for 1000 times torch.float32
Time 0.030851364135742188 bandwidth 8.29785026275116
torch.cumsum(a) a.numel() == 32000 for 1000 times torch.float64
Time 0.037447452545166016 bandwidth 13.6724921243299
torch.cumsum(a) a.numel() == 64000 for 1000 times torch.float16
Time 0.03391098976135254 bandwidth 7.549175114073387
torch.cumsum(a) a.numel() == 64000 for 1000 times torch.float32
Time 0.03214144706726074 bandwidth 15.929587704267457
torch.cumsum(a) a.numel() == 64000 for 1000 times torch.float64
Time 0.034329891204833984 bandwidth 29.828233182859922
torch.cumsum(a) a.numel() == 128000 for 1000 times torch.float16
Time 0.03589606285095215 bandwidth 14.263402705915954
torch.cumsum(a) a.numel() == 128000 for 1000 times torch.float32
Time 0.033178091049194336 bandwidth 30.863740728231736
torch.cumsum(a) a.numel() == 128000 for 1000 times torch.float64
Time 0.03487515449523926 bandwidth 58.72375419238841
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39180
Differential Revision: D21824498
Pulled By: ngimel
fbshipit-source-id: b50fadde598e9ce2871201cd6bb22fa6ac0d482e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39229
Previously we have a ad-hoc way of passing output shape/type hints which is very limited and doesn't support quantized output. We actually have all the shape_info/qshape_info so we pass them as TensorProto and QTensorProto directly. This will pave the way for us to set output to quantized type in OnnxifiOp.
Test Plan:
```
buck test glow/fb/test:net_runner
```
Reviewed By: hyuen
Differential Revision: D21781515
fbshipit-source-id: dfae3276e8f158eed830f1244bea6420a9135aab
Summary:
Should be a no-op, just makes the intent a bit cleaner
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39068
Differential Revision: D21829464
Pulled By: malfet
fbshipit-source-id: dc174a3d7da3701bd9d31c366dfa9d24044ef27a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39080
This PR adds a function similar to setErrorIfNeeded for marking
futures complete. It only completes futures if they haven't been completed
already.
ghstack-source-id: 105038825
Test Plan: Sandcastle/CI
Differential Revision: D21746065
fbshipit-source-id: a7791a070f19e1f56aa5c2822edc4b60d8227c2c
Summary:
The test is currently only enabled for CPU, and it will be enabled for CUDA after the migration of `min` and `max` from THC to ATen is done.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38850
Differential Revision: D21819388
Pulled By: ngimel
fbshipit-source-id: 406343e96bccbf9139eb1f8f2d49ed530dd83d62
Summary:
Fixes https://github.com/pytorch/pytorch/issues/36831.
Instead of using `id()`, an arbitrary yet consistent order-based index is used instead. This results in a deterministic output between runs.
I am not the biggest fan of using `nonlocal` (it appears to be used sparingly in the codebase) to get `start_index` between calls to `pack_group()`, but the alternatives had larger issues:
- Using the last value added to `param_mappings` would be ideal, but that only works if `dict` iteration order is consistent, and PyTorch currently supports Python <3.7.
- Using the maximum value added to `param_mappings` wouldn't have that issue but would not be constant time.
For testing, I confirmed that `test_optim.py` works before and after these changes. Randomizing the indices in `param_mappings` causes the tests to fail, which is further evidence these changes work. I'm not 100% if these tests are sufficient, but they're a start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37347
Differential Revision: D21353820
Pulled By: vincentqb
fbshipit-source-id: e549f1f154833a461b1f4df6d07ad509aab34ea1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38574
Adding sparse L1 and L2 regularization operator to Caffe2. This doesn't work using run_on_loss, only run_after_optimize. Applying it to run_after_optimize rather than run_on_loss was easier to implement, particularly for the L1 norm which is preferable in some cases and is non-differentiable at zero.
Test Plan: Wrote and ran unit tests in operator_test:sparse_lp_regularizer_test.
Differential Revision: D21003029
fbshipit-source-id: 81070a621752560ce03e320d065ce27807a5d278
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 7d673046a6
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39322
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jianyuh
Differential Revision: D21814389
fbshipit-source-id: cec819a28f08915e2443f405d42efaa41a523bc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38806
I'm trying to delete the Type wrapper code entirely, but I'm
trying to figure out exactly how many device guards I need to
preserve. For now, delete the guards that are known to be
useless.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21764403
Pulled By: ezyang
fbshipit-source-id: 9c3d18f209339dfe2adbe5866b31b03b55990b74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38739
Instead of codegenning the named tensor support checks into
CPUType/CUDAType, we instead add a new dispatch key that is put
into tensor whenever it has names. By default, the fallback
implementation says that named tensors are not supported, but
if they are supported, we register a fallthrough which lets
us through to the true backend implementation.
There are a bunch of small pieces which are necessary to make this
happen:
- NameMode now also excludes DispatchKey::Named from the dispatch set
- To avoid bad error messages, we add a teensy special case to
the dispatcher for named_not_supported_kernel: if we see that
the boxed kernel we need to invoke from unboxed is this kernel,
but we don't support boxing, but it's a kernel which is known
to not need boxing, we just pass in nullptr for the stack.
The special case here is very nice: it doesn't affect the fast
path and only gets exercised when things are not supported.
- I need to add support for per operator fallthrough registration.
This is done similarly to how we support fallthrough fallback,
by just keeping track if the registered kernel for an operator
is a fallthrough.
It is possible we could go even further down this path, and move
the named tensor logic itself into this key. I leave this
up to future work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21662643
Pulled By: ezyang
fbshipit-source-id: 5bc6ae14a1f600189bd8bf865f74dd1700d932f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38847
See motivation and design in https://github.com/pytorch/pytorch/issues/38845.
Close https://github.com/pytorch/pytorch/issues/38845.
Changes,
- Add pre-request and post-response hooks to RPC "request_callback_impl.cpp". For a thread that executes RPC handler, check if the server-side global profiling is on. If it's on, enable profiling on this thread and after response, merge the thread-local profiling result into the global profiling state.
- Add context-style Python API to parse the profiling Events into ranges represented by FunctionEvent.
- Add data-structures to work as global profiling state that support nesting and container for consolidating results from multiple threads.
Test,
- Add a test that uses nested profiling range and inspect the profiling events.
ghstack-source-id: 104991517
Test Plan:
buck test mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_server_process_global_profiler
Differential Revision: D5665992
fbshipit-source-id: 07f3bef5efd33d1214ef3404284c3803f5deca26
Summary:
Enable new test config in .circleci/config.yml
Skip scanning several 3rd-party packages to work around https://bugs.python.org/issue40350
Remove pre python-3.5 checks from `test.sh` and update `scikit-learn` to python-3.8 compatible version
This is a reland of https://github.com/pytorch/pytorch/pull/39030
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39121
Differential Revision: D21820375
Pulled By: malfet
fbshipit-source-id: d0be79b7d204cf692e055d42b9be42402dc4c1c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39263
CPPTypeToScalarType is confusing because it doesn't handle the different complex types and it maps everything that it doesn't know about to Undefined, which is error prone.
Test Plan: Imported from OSS
Differential Revision: D21790515
Pulled By: gchanan
fbshipit-source-id: ec897fd50bd8f7548a34573e59eb57bf3c6383c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39031
Makes the eager mode QAT prepare logic respect device affinity.
This fixes the issue where a module is on `cuda:0`, and running
the QAT prepare script would add observers on `cpu`. Now it
will add them on the original device.
Test Plan:
```
python test/test_quantization.py TestDistributed.test_device_affinity
```
Imported from OSS
Differential Revision: D21729272
fbshipit-source-id: 5537bf3977ddc23412184941978bf0d1cc6fb479
Summary:
Continuation of issue gh-36064 and PR gh-38042 which removed the unmaintained javaspinx extension. The unknown sphinx directives cause warnings when building documentation.
Edit: link to PR as well as issue
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38920
Differential Revision: D21818297
Pulled By: ezyang
fbshipit-source-id: 2c1d007a7689b26653d7dee081b0b969b8a731a2
Summary:
All the uses of `AT_DISPATCH_FLOATING_AND_COMPLEX_TYPES_AND2` are for CUDA.
Dispatch macro comes first, cleanup of remaining `c10::complex --> thrust::complex` will be done later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39285
Differential Revision: D21803978
Pulled By: anjali411
fbshipit-source-id: ec9837f121e3020dfa2d12c8bc9aede9fb01c375
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39258
On CUDA, we currently support casting loops dynamically (i.e. when the argument or return types of the lamba don't match the dtypes of the TensorIterator).
On CPU, before this change we would essentially reinterpret_cast, now we internal assert. We could add dynamic_casting support in the future on CPU.
Test Plan: Imported from OSS
Differential Revision: D21790020
Pulled By: gchanan
fbshipit-source-id: b52f4340a0553f0c1bd8fafaa58309bc110adecf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39255
We don't actually cast between these complex representations, but the prior implementation would indicate that we needed to dynamic_cast,
because we didn't have mappings for std::complex or thrust::complex.
This PR makes it so they all map to the same dtype.
Note that this has no functional change as all the use sites have already been changed to take this into account.
Test Plan: Imported from OSS
Differential Revision: D21789694
Pulled By: gchanan
fbshipit-source-id: 6127aab32c40e62bf1b60fe5ccaeffacc60e3b52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39254
dynamic_casting is meant to handle CUDA kernels when the operand dtypes don't match the C++ kernel function types.
This is made more complicated by the current state of complex, which uses thrust::complex, std::complex, c10::complex.
Currently, thrust::complex and std::complex map to need dynamic casting even though we don't actually cast them.
But, making them not need dynamic_cast doesn't work either because certain dynamic_casting optimizations don't work with thrust::complex and (maybe) std::complex.
So, we separate out these concerns so we can iterate on dynamic_casting checks, in particular by applying them to CPU.
This PR should have no functional change.
Test Plan: Imported from OSS
Differential Revision: D21788870
Pulled By: gchanan
fbshipit-source-id: 5d69c9851423dee2fbe789674f4306710378f4ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39315
As title
Test Plan: Just comment change
Reviewed By: jianyuh
Differential Revision: D21813196
fbshipit-source-id: 3ff6bcd3cc31a4820bf7c7a948123c9e968f5de2
Summary:
Fixes a bug in reorder axis where we append the new reordered loops to the enclosing block, even if there were statements after it. e.g. with 3 Computes:
```
for (int m1 ...
for (int n1 ...
for (int k1 ...
Body 1
for (int m2 ...
for (int n2 ...
for (int k2 ...
Body 2
for (int m3 ...
for (int n3 ...
for (int k3 ...
Body 3
```
If we reorder loops m2 and k2, we were also reordering the body statements like this:
```
for (int m1 ...
for (int n1 ...
for (int k1 ...
Body 1
for (int m3 ...
for (int n3 ...
for (int k3 ...
Body 3
for (int k2 ...
for (int n2 ...
for (int m2 ...
Body 2
```
This is because we always append the new loops to their parent. This PR fixes the logic to replace the old loop root with the new loop, which keeps things consistent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38841
Differential Revision: D21723670
Pulled By: nickgg
fbshipit-source-id: 1dee8bb153182fcaa2cabd948197577e8e80acd7
Summary:
Fix https://github.com/pytorch/pytorch/issues/38336
Add %= support in TorchScript. It's now possible to do something like:
```py
torch.jit.script
def mm(a,b):
a %= b
return a
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38983
Differential Revision: D21803523
Pulled By: SplitInfinity
fbshipit-source-id: 3437860d06d32e26ca9a5497099148c1f1616c5b
Summary:
**Main:**
- `c10::complex` is refactored: it no longer uses inheritance to specialize constructors, but using SFINAE instead. This implementation is cleaner and avoids some compiler bugs.
- `c10::Scalar` is cleaned up: it no longer needs to store complex as `double z[2]`, `c10::complex<double>` will work.
**Other cleanups:**
- `numeric_limits` of `c10::complex` is moved to `complex_utils.h`
- the variable in `c10::complex` storing real and imag is changed from `storage[2]` to `real_` and `imag_`
- remove the `c10::` before `complex` when in `c10` namespace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38593
Differential Revision: D21769463
Pulled By: anjali411
fbshipit-source-id: 3cb5bcbb0ff304d137221e00fe481a08dba7bc12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39297
histogram op doesn't have GPU implementation. It's breaking the CI GPU test. Make the test run cpu only.
Test Plan: CI
Reviewed By: hwangjeff
Differential Revision: D21800824
fbshipit-source-id: 9c835786f22bac7d420ce610397a6ee69084c19a
Summary:
This PR adds a new operator export type to exporter: ONNX_FALLTHROUGH
This new type allows ops that are not supported to pass through.
This PR also removes all aten ops in ONNX operator export type mode.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37239
Reviewed By: hl475
Differential Revision: D21440509
Pulled By: houseroad
fbshipit-source-id: 38b826677cf3431ea44868efebefe1ff51c9aa75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39271
Caused 10% NE loss. Bug in emulation itself and NNPI is fine.
Test Plan: mobile_cvr has no NE loss after this fix: https://fburl.com/mlhub/z6hd8rhn
Reviewed By: hyuen
Differential Revision: D21793205
fbshipit-source-id: a908e95c26c2353f982d05e0a20f02f3c724715d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39125
switch to setting reduce_range to true for version > 3.
Models serialized with older state_dict will have version <=3 so will be run with reduce_range=false
Verified with backward compatibility tests (works with no changes to these tests)
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D21769689
fbshipit-source-id: 131f2ae736e31705222e82bdc77480f2f1826fe8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39041
reduce_range option restricts the activation tensor to 7 bits instead of 8.
This is necessary to enable per channel quant for RNNs and LSTMs
Test Plan:
python test/test_quantization.py TestDynamicQuantizedLinear
Imported from OSS
Reviewed By: akinh
Differential Revision: D21769691
fbshipit-source-id: ef0e9873367f3c1b34091b0b3af788233ef60c6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39246
This was found by adding some error checking in https://github.com/pytorch/pytorch/pull/38817, but that needs more work to be able to merge, so we just do a one-off fix here.
Test Plan: Imported from OSS
Differential Revision: D21786761
Pulled By: gchanan
fbshipit-source-id: e4ecf6506c8649214d0fddfcca2ada6afa339d3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39265
In this PR we set id of RecordFunction only when callbacks need them and when
there's at least one active callback
Test Plan:
testRecordFunction unit test in test_misc.cpp
buck test mode/dev caffe2/test/cpp/jit:jit
https://our.intern.facebook.com/intern/testinfra/testrun/8725724291116413
Reviewed By: dzhulgakov
Differential Revision: D21790421
fbshipit-source-id: 016623d7f1a2a271921a71c0483061e232b40321
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39033
Added `real` and `imag` views as tensor attributes. Right now, tensor.imag is disabled for real tensors. This is because if we return a new tensor of zeros, the user would be able to update the tensor returned by tensor.imag which should not be allowed as numpy returns a read-only array, and pytorch doesn't support read-only tensors yet.
TODO in follow-up PRs:
1. add a setter for `real` and `imag`
2. add special case in codegen for `real` and `imag` backward functions.
3. remove `copy_real` and `copy_imag` methods.
Test Plan: Imported from OSS
Differential Revision: D21767542
Pulled By: anjali411
fbshipit-source-id: 539febf01f01ff055e3fbc7e9ff01fd3fe729056
Summary:
If Engine is created shortly before application exits, then non-reentrant thread might not have a chance to spawn which would result in an infinite wait in `Engine::~Engine()`
Prevent this by actually waiting for threads to spawn before returning from `Engine::start_device_threads()`
Make sure that thread count is incremented before GIL is acquired in PythonThread
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39194
Differential Revision: D21789219
Pulled By: malfet
fbshipit-source-id: d9b5e74d5ddeb2474b575af2e4f33d022efcfe53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39112
Allow int8 packed weights in int8 model to deserialize to original format. Set default deserialization behavior in eval workflows to original format.
Test Plan: Tested with workflow: f192797187
Reviewed By: yinghai
Differential Revision: D21737940
fbshipit-source-id: 7afaf307b16cb4e85e61f019356f83fdab772c57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38527
This PR solves issue (#37200).
Error is encountered during IR generation while trying to resolve the call to sum.
Should let user know it inferred the value for argument 'dim' to be of type 'Tensor'
because it was not annotated with an explicit type.
Test Plan:
Add code to reprodue the issue (#37200)
`python test/test_jit.py TestJit.test_inferred_as_tensor`
Differential Revision: D21743876
Pulled By: superwizard2019
fbshipit-source-id: 370ca32afea4d53b44d454f650f7d3006f86bcc6
Summary:
`msg` argument must be passed to `assertRaises`, because its exception is passed upstream (with custom error message) if `assertEquals` succeedes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39217
Differential Revision: D21786141
Pulled By: malfet
fbshipit-source-id: f8c3d4f30f474fe269e50252a06eade76d575a68
Summary:
Adds complex support to `cumsum`, `cumprod` and relevant test update in `test_torch::tensor_op_tests`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39063
Differential Revision: D21771186
Pulled By: anjali411
fbshipit-source-id: 632916d4bdbd1c0941001898ab8146be2b7884fc
Summary:
These warning's goal is to show the user where to be careful in their code. So make them point to the user's code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39143
Differential Revision: D21764201
Pulled By: albanD
fbshipit-source-id: f1369d1b0e71d93af892ad3b7b1b3030e6699c59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39185
The TP agent used the store for two things: mapping ranks to names, and mapping names to addresses. The former was prefixed, the latter wasn't. So, if a worker had a name which was `names/0` this would lead to a conflict. We should prefix both usages, and we can do so easily with the `PrefixStore`.
ghstack-source-id: 104837023
Test Plan: Unit tests
Differential Revision: D21767862
fbshipit-source-id: a256c0b9be349c7ffc11ac2790a2a682e3af84d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39184
TensorPipe has implemented some helpers to resolve the IP address of the hostname and to retrieve the IP address of a given interface using libuv, which means they are supposed to be portable across Linux, Mac, Windows... We can thus replace the version we had implemented inside the agent itself (which only resolved the hostname) with those helpers.
ghstack-source-id: 104837026
Test Plan: Unit tests
Differential Revision: D21494693
fbshipit-source-id: 4652dde6f7af3a90e15918506a103408f81ced0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39183
I didn't see any reason behind it, and it seems to work even after removing the unique_ptrs. (Well, it compiles...)
ghstack-source-id: 104837027
Test Plan: None...
Differential Revision: D21767863
fbshipit-source-id: daebfae69d5b63f1d10345abd625b7e0ddce7e6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39182
When the TensorPipe context is closed and joined, all pending callbacks are invoked with an error of type PipeClosedError. This is normal and expected, and should not be logged.
There is still one log that should be addressed, namely when an incoming pipe from a remote worker dies after we have joined, which I still need to address. That will require some type of "signal" from the remote worker that the shutdown is intentional, for example sending an empty packet?
ghstack-source-id: 104837024
Test Plan: Logs become less spammy.
Differential Revision: D21703036
fbshipit-source-id: 0a2f9985032b9f1aaf7d2b129ce6d577f13062a4
Summary:
Pick up a fix to SHM, which was crashing when writing to a full reactor ringbuffer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39189
Test Plan: Testing by CI.
Reviewed By: mrshenli
Differential Revision: D21769275
fbshipit-source-id: 1499f028d85de3a2facc79277ac5bdea73fd15cc
Summary: Fix operator perf observer index issue.
Test Plan:
make sure that the operator index is populated correctly, ran benchmarking for pytext_mobile_inference, see result:
https://www.internalfb.com/intern/aibench/details/598900068317693
Reviewed By: linbinyu
Differential Revision: D21779222
fbshipit-source-id: 0fc3561d83d10cfabd73e1e6b6ee240ce0bafd80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39213
This PR fixes the problem that [__expf/__logf/__tanf](https://docs.nvidia.com/cuda/cuda-math-api/group__CUDA__MATH__INTRINSIC__SINGLE.html) are "intrinsic functions that are only supported in device code", so nvcc doesn't recognize them if it compiles host code. So `__CUDACC__ ` should be replaced with `__CUDA_ARCH__ `
Test Plan: Imported from OSS
Differential Revision: D21779132
Pulled By: pbelevich
fbshipit-source-id: b326e2135525b6a1f2392f8d1c17b735d8ef431a
Summary:
DCHECK is never triggered and the user error could lead to crash.
I could make the error message be even nicer by checking shape in contructor, but even this would do.
Reviewed By: m3rlin45
Differential Revision: D21778992
fbshipit-source-id: a8ec2faaf734746f6dc42879705245851dc99bed
Summary:
No special changes are needed for CPU kernels, some CUDA kernels are still doing `c10::complex -> thrust::complex` casting, this will be cleaned up later. But for now, it will be good to just keep it as is, and change the dispatch macro first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39045
Differential Revision: D21741151
Pulled By: anjali411
fbshipit-source-id: 748f057f9f33338b8c9293aeaa228ad861172e71
Summary:
Invoke `Popen.communicate` with `timeout` argument and kill the process in `TimeoutExpired` handler
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39191
Differential Revision: D21773510
Pulled By: malfet
fbshipit-source-id: 52b94315f8aa4d6c330dd5c9a8936100e49aef2d
Summary:
Gets rid of some in-kernel asserts where they can be replaced with static_asserts
Replaces bare in-kernel `assert` in one case with `CUDA_KERNEL_ASSERT` where necessary
replaces host code `assert`s with `TORCH_INTERNAL_ASSERT`
Another group of asserts is in fractional max pooling kernels which should be fixed regardless https://github.com/pytorch/pytorch/issues/39044, the problems there are not just asserts.
I've audited remaining cases of in-kernel asserts, and they are more like `TORCH_INTERNAL_ASSERT`, so they should not happen with invalid user data. I think it's ok to leave them as is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39047
Differential Revision: D21750392
Pulled By: ngimel
fbshipit-source-id: e9417523a2c672284de3515933cb7ed166e56719
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38514
this diff introduces the `Histogram` caffe2 op, which computes a histogram tensor for a list of input tensors. the bin edges of the histogram are defined by arg `bin_edges`.
Test Plan: tests
Reviewed By: chocjy
Differential Revision: D21553956
fbshipit-source-id: fc98c8db691d66d2dad57b6ad14867109913cb6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39188
Extracting Vulkan_LIBS and Vulkan_INCLUDES setup from `cmake/Dependencies.cmake` to `cmake/VulkanDependencies.cmake` and reuse it in android/pytorch_android/CMakeLists.txt
Adding control to build with Vulkan setting env variable `USE_VULKAN` for `scripts/build_android.sh` `scripts/build_pytorch_android.sh`
We do not use Vulkan backend in pytorch_android, but with this build option we can track android aar change with `USE_VULKAN` added.
Currently it is 88Kb.
Test Plan: Imported from OSS
Differential Revision: D21770892
Pulled By: IvanKobzarev
fbshipit-source-id: a39433505fdcf43d3b524e0fe08062d5ebe0d872
Summary:
The setup job isn't really what we need anymore so let's get rid of it
and remove the single point of failure from our build pipeline.
Should also resolve issues with CircleCI where re-run workflow from failed would trigger an entire re-run instead of only jobs that we actually want to re-run.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39081
Differential Revision: D21770380
Pulled By: seemethere
fbshipit-source-id: 92a239deb6f2908eb46d519c332dc34c6023da6d
Summary:
**BC-breaking note:**
In previous versions of PyTorch zero dimensional CUDA tensors could be moved across devices implicitly. For example,
```
torch.tensor(5, device='cuda:0') + torch.tensor((1, 1), device='cuda:1')
```
would work, even though the tensors are on different CUDA devices. This is a frequent source of user confusion, however, and PyTorch generally does not move data across devices without it being explicit. This functionality is removed in PyTorch 1.6.
**PR Summary:**
Today in PyTorch we allow implicit data movement of zero dimensional CUDA tensors. For example, we allow:
```
torch.tensor(5, device='cuda:0') + torch.tensor((1, 1), device='cuda:1')
```
and
```
torch.tensor(2, device='cuda') + torch.tensor((3, 5))
```
In both of these cases TensorIterator would move the zero dim CUDA tensor to the device of the non-scalar tensor (cuda:1 in the first snippet, the CPU in the second snippet).
One of PyTorch's fundamental rules, however, is that it does not perform implicit data movement like this, and this change will causes these cases to throw an error. New tests for this behavior are added to test_torch.py, and tests of the old behavior are removed in test_torch.py and test_autograd.py. A cpp test in tensor_iterator_test.cpp is modified to account for the new behavior.
This addresses https://github.com/pytorch/pytorch/issues/36722.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38998
Differential Revision: D21757617
Pulled By: mruberry
fbshipit-source-id: 2498f07f4938d6de691fdbd5155ad2e881ff7fdb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38798
This makes it more in-line with the other keys in the file
(DispatchKey.h).
Test Plan: Imported from OSS
Differential Revision: D21691789
Pulled By: zou3519
fbshipit-source-id: 8d8b902360c0238f67bd0e58f9d969cec4b63320
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35137
bucket order is rebuilt dynamically in the first reduction backward pass when find_unused_parameters = false
ghstack-source-id: 104794018
Test Plan: unit test
Differential Revision: D20128537
fbshipit-source-id: fad73de965cdcb59a51c0a12b248271344584b9f
Summary:
See D21681838
There are two "aten::eq" in lite interpreter. Add overload name for op eq.str.
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D21729544
fbshipit-source-id: cf86f5eb101bb0530a3dca4051f8fe14ee184f9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39012
The `test_rref_context_debug_info` test was flaky with the TensorPipe agent, and I think the issue is the test itself.
What was happening is that on line 1826 the test was clearing a global variable on the remote side which was holding a rref. Even though the RPC call that unset the global variable was synchronous, the messages that the rref context needs to send around to delete that rref are asynchronous. Therefore, sometimes, when we reached line 1845 we saw the following check fail:
```
self.assertEqual(2, int(info["num_owner_rrefs"]))
```
because `num_owner_rrefs` was still 3, as the deletion hadn't yet been processed.
The only way I found to fix it is to add a synchronization step where we wait for all the futures from the rref context to complete. Since we must wait for this to happen on all workers, we synchronize with a barrier.
ghstack-source-id: 104810738
Test Plan: The test isn't flaky anymore.
Differential Revision: D21716070
fbshipit-source-id: e5a97e520c5b10b67c335abf2dc7187ee6227643
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39011
There's a test for this, so let's implement it. It's very easy.
ghstack-source-id: 104810739
Test Plan: The test now passes.
Differential Revision: D21716068
fbshipit-source-id: 1080040b12913ea0dcc4982182d6b3f6d9ac763c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39010
The initial version of the serialization for the TensorPipe RPC agent (i.e., the conversion from rpc::Message to tensorpipe::Message) worker around a limitation of TensorPipe of only allowing one payload per message by pickling each tensor separately and storing the pickles as metadata (which is a less efficient way of sending data over, as it goes through more copies). Having now lifter that limitation we can now improve the way we serialize. We now put the type and the id as their own payloads, we do a single pickling pass for all the tensors of the message (which allows us to deduplicate them) and store the pickle as a payload. My impression is that pickling is a somewhat costly operation, so reducing the number of times we do it should be beneficial for performance. For this same reason, another change I've done here is separate the allocation of the buffers from the deserialization. This will allow us (in the future) to perform the allocation on the I/O event loop but perform the unpickling in the worker thread, thus keeping the event loop more responsive.
ghstack-source-id: 104810740
Test Plan: RPC tests
Differential Revision: D21716067
fbshipit-source-id: c1475cc78afdcf0820a485ffd98c91abb35796c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38934
The TensorPipe context contains all the threads and global state. It needs to be closed and joined upon shutdown (joining implicitly closes it). Destructing the context implicitly joins it, which is what was happening so far: we were waiting for the RPC agent to be destroyed for the TP context to be closed. However, I was seeing some TSAN errors that seemed to be happening during the process termination, where the SHM reactor thread was trying to log something on GoogleLog while a static member of GoogleLog was being destructed. I suspect this means that this means that the TP agent was being "leaked" (probably because the `RpcAgent::currentRpcAgent_` static field was still storing it) and thus was destroyed too late. The obvious solution seems to be to destroy it earlier, when GoogleLog is still active.
Test Plan:
I guess land this and see if the TSAN flakes keep happening?
testinprod
Differential Revision: D21703016
fbshipit-source-id: d117e619bb835192b1f3c8e2eb3cee94dbdb050f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38933
Based on what I could understand from how the RPC shutdown operates and from what the ProcessGroup agent does, the join method is supposed to act as a barrier among all workers that waits until they all have finished all their pending work, including work that may be triggered by nested calls or by callbacks.
ghstack-source-id: 104760684
Test Plan: Before this diff, the `test_user_rrefs_confirmed` test of the RPC suite was flakily deadlocking. After this, I haven't been able to repro that.
Differential Revision: D21703020
fbshipit-source-id: 3d36c6544f1ba8e17ce27ef520ecfd30552045dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38930
Any time we mark a future as complete or set an error on it we call its callbacks, which could be arbitrary user functions and could thus be slow or blocking. The safest behavior is to always defer to the loop.
ghstack-source-id: 104760682
Test Plan: None... :(
Differential Revision: D21703017
fbshipit-source-id: ad2bdc6be25844628ae6f318ef98b496f3d93ffd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38931
When requests time out they are not aborted, so they could in fact still complete successfully but, when they do so, they try to mark an errored future as complete, which causes an error. I don't see any atomic way of doing future->markCompleteIfNeeded, so we implement it on top of it on our side.
ghstack-source-id: 104760689
Test Plan: Hit this error in the RPC test suite, and it disappeared after this fix.
Differential Revision: D21703015
fbshipit-source-id: af92f7819ed907efb9b068a4ca65420739fac8cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38929
Fixes a TSAN error that was reported by the internal tests.
Test Plan: None... :(
Differential Revision: D21703022
fbshipit-source-id: 54480d32d8c19db01d9608a52b7b906a622ca8b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38928
The original code was
```
steady_clock_time_point earliestTimeout = std::chrono::steady_clock::now() + kLargeTimeDuration;
if (std::chrono::steady_clock::now() >= earliestTimeout) {
break;
}
if (!timeoutMap_.empty()) {
earliestTimeout = timeoutMap_.begin()->first;
}
timeoutThreadCV_.wait_until(lock, earliestTimeout);
```
which meant we'd never break the loop, as that required `std::chrono::steady_clock::now()` to be *smaller* than `std::chrono::steady_clock::now() + kLargeTimeDuration`.
The fixed code looks like:
```
steady_clock_time_point earliestTimeout = std::chrono::steady_clock::now() + kLargeTimeDuration;
if (!timeoutMap_.empty()) {
earliestTimeout = timeoutMap_.begin()->first;
}
if (std::chrono::steady_clock::now() >= earliestTimeout) {
break;
}
timeoutThreadCV_.wait_until(lock, earliestTimeout);
```
but by staring at it for a second it becomes clear that the code behaves very differently based on whether `timeoutMap_.empty()`, so I think that for better readability we should reflect that in the code, making that `if` the main one. This then allows us to do a timeout-less wait if there are no messages, which avoids the hacky `kLargeTimeDuration`.
ghstack-source-id: 104760685
Test Plan: eyes
Differential Revision: D21703021
fbshipit-source-id: 0c5062b714c92b956376ae2a8372223fd0d9f871
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38927
Since the regexs weren't matching the RPC tests would never confirm that the remote end had correctly shut down and were thus retrying in a loop forever.
ghstack-source-id: 104760686
Test Plan: Ran the RPC test suite after re-enabling some of the TensorPipe tests
Differential Revision: D21703018
fbshipit-source-id: 3e4b8d22810e58c9d72c4317dcf5ba68d6e0b258
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38926
TensorPipe supports for the user to provide a meaningful name for each context and to specify what it thinks the name of the endpoint it's connecting to is, so that these names can be logged and matched to the otherwise not-very-informative ID of a pipe (given by the PID and some counters) for easier debugging.
ghstack-source-id: 104760688
Test Plan: Ran RPC tests with `TP_VERBOSE_LOGGING=1`.
Differential Revision: D21479799
fbshipit-source-id: 856d2ffac239a3f9b11318a92ba4534133865dc8
Summary:
Previously dynamic LSTM modules weren't able to save/load from state_dict since PackedParameter used in RNNs isn't serializable from python
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39105
Test Plan: python test/test_quantization.py TestSerialization
Reviewed By: jerryzh168
Differential Revision: D21752256
Pulled By: supriyar
fbshipit-source-id: ef82cf21ce21a3a1304d147ed0da538c639f952d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32866
The memory error in the issue is caused by `int` overflowing in `col2vol`. This version using mixed 32-bit and 64-bit indexing calculation lifts the maximum indexing possible without compromising the performance of `ConvTranspose3d`. vs 20-30% regression with pure 64-bit indexing.
This requires that `input.numel() <= UINT_MAX`, and `channels * kernel.numel() <= UINT_MAX` otherwise it raises an error. Previously, the code would crash or give incorrect results unless `input.numel() * kernel.numel() <= INT_MAX`.
Note that the test is a minimised reproducer for the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38970
Differential Revision: D21748644
Pulled By: ezyang
fbshipit-source-id: 95060423219dc647595e1a24b3dcac520d3aecba
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/39020 by requiring users to type-hint default arguments to a TorchScript when using the C++ frontend (the Python frontend will insert those automatically).
Since this is a bit of a niche use case, I opted for the simpler solution of making type-hints mandatory for default arguments, as opposed to trying to type-infer them. I left a comment in the code justifying this choice.
Test is included.
/cc t-vi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39021
Differential Revision: D21755317
Pulled By: suo
fbshipit-source-id: e007650d3bfb3a4c58c25ad2c3a17759898f303b
Summary:
`_TestTorchMixin` is base class which is instantiated across multiple types.
It was inherited from `object` in order to hide it from unittest test discovery mechanism.
But this approach makes it almost impossible to use static code analyzer on the class.
This PR implements alternative approach by hiding base class into inner class, per https://stackoverflow.com/a/25695512
Change imported class access path in `test_cuda.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39110
Test Plan:
run `test_torch.py --discover-tests` and `test_cuda.py --discover-tests` before and after change:
```
$ python test_torch.py --discover-tests|md5sum
2ca437bb5d65700763ce04cdacf6de3e -
$ python test_cuda.py --discover-tests|md5sum
b17df916fb0eeb6f0dd7222d7dae392c -
```
Differential Revision: D21759265
Pulled By: malfet
fbshipit-source-id: b01b06111469e551f7b78387449975e5248f6b9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38577
We don't want to limit a timeout to 30 min since there could be no
operations within that time frame. Bump to 2^31 - 1 (int32 max)
ghstack-source-id: 104743727
Test Plan: CI
Differential Revision: D21602425
fbshipit-source-id: ab002262f01664b538761202b3bd7584fcee3c6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39100
The old shape_hints format has a few cons:
- ',' is used to separate <model_id>:<shape_hints> pairs, as well as delimiter for dims in the <shape_hints>, which is an obvious bug
- it cannot handle the case of having ':' in tensor names
The new shape_hints format uses '::' to delimit <model_id> and <shape_hints>, ';' to delimit <model_id>::<shape_hints> pairs. Inside <shape_hints>, '|' is used to separate <tensor>,<shape> pairs, and ',' is used to delimit <tensor> and <shape>, as well as the dimensions inside <shape>.
Test Plan:
```
buck test //caffe2/caffe2/fb/opt:shape_info_utils_test
```
AI/AF canary:
https://www.internalfb.com/intern/ads/canary/426980448937212687https://www.internalfb.com/intern/ads/canary/426980529105312403
Reviewed By: yinghai
Differential Revision: D21656832
fbshipit-source-id: 9dec4b5586d093ddb814c3f15041a57d45a3de76
Summary:
In `LoopNest::rfactor` we assume that there is only a single reduction below the insertion point, and when replacing the reduction we recursively replace all reductions below that point. This is not a safe assumption, as a number of transformations can introduce additional ReduceOps - most directly a `splitWithTail` on the innermost reduce axis.
This PR fixes that bug, and adds some unit tests covering the case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38733
Differential Revision: D21723634
Pulled By: nickgg
fbshipit-source-id: 3ed6ffcdc2c15aef7504f9b2b91e8d827e0b5d88
Summary:
**Summary**
This commit gets rid of the separate compilation unit that is currently
being created for every backend-specific module generated by
`jit::backend::generateToBackendFn` and mangles the name properly to
allow multiple backend-specific modules to coexist in the same
compilation unit.
**Test Plan**
`python test/test_jit.py TestBackends`
**Fixes**
This pull request fixes part of https://github.com/pytorch/pytorch/issues/37841.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38679
Differential Revision: D21744620
Pulled By: SplitInfinity
fbshipit-source-id: ac85b8ce0d179c057991e9299fd53a4e13ba02a9
Summary:
1.6 Deprecation Note:
In 1.6 attempting to perform integer division using addcdiv will throw a RuntimeError, and in 1.7 the behavior will change so that addcdiv always performs a true division of its tensor1 and tensor2 inputs. See the warning in torch.addcdiv's documentation for more information.
PR Summary:
This PR updates the warning that appears when addcdiv performs integer division to throw a RuntimeError. This is intended to prevent silent errors when torch.addcdiv's behavior is changed to always perform true division in 1.7. The documentation is updated (slightly) to reflect this, as our the addcdiv tests in test_torch and test_type_promotion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38762
Differential Revision: D21657585
Pulled By: mruberry
fbshipit-source-id: c514b44409706f2bcfeca4473424b30cc48aafbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38896
Current way of exposing qnnpack's maxpool2d only works if max_pool2d op is
quantized::max_pool2d. This diff moves the function about to expose it via
aten::max_pool2d when dispatch key is QuantizedCPU.
Test Plan: Quantized tests.
Reviewed By: supriyar
Differential Revision: D21690913
fbshipit-source-id: 75fb77329b915e3a3c3aac4d76359482976ca783
Summary:
Since the indexed dimension in `scatter/gather` is traversed inside the kernel, all the memory conflicts of writing to the same memory between the threads are actually mutually disjoint.
See [this comment](https://github.com/pytorch/pytorch/issues/33389#issuecomment-590017938) for a graphical explanation. More formal description:
Suppose we deal with 3D tensors and `dim=0`, hence the `scatter_add` operations are
```
self[index[i][j][k]][j][k] += src[i][j][k],
...
self[index[i'][j'][k']][j'][k'] += src[i'][j'][k'],
...
```
Clearly, write/read to the same memory happens if and and only if:
```
index[i][j][k] = index[i'][j'][k'],
j = j',
k = k'.
```
Since the reduction over `dim=0` happens inside the kernel, threads `i` and `i'` partition `dim=1,2`. It means that threads `i` and `i'` receive indices
```
I = {(*, i, k) sent to the thread i},
I' = {(*, i', k') sent to the thread i'},
I intersection with I' = the empty set.
```
This happens:
```
index[i][j][k] = index[i'][j'][k'],
j = j',
k = k',
```
if and only if there exists some thread k which receives indices K and
`(*,j,k),(*,j',k') in K`.
Therefore it is possible to make `scatter_add` parallel and remove `serial_exec` from the `scatter_gather_base_kernel`.
CC v0dro
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36181
Differential Revision: D21716167
Pulled By: ngimel
fbshipit-source-id: 49aee2de43779a1f0b359c22c8589c0702ee68a2
Summary: change the test default to test the version we care about
Test Plan: ran the test
Reviewed By: amylittleyang
Differential Revision: D21725194
fbshipit-source-id: 243fcdf1dd5784768f6ceb2b46f9f1c9e64341eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37181
Now that assertEquals considers dtypes in determining tolerance, most
tests don't need explicitly set precision.
Those that do are a few half precision tests on cuda. In this PR, those
are broken out to be handled explicitly, though we may also want to
consider further loosening the tolerance on half-precision.
Test Plan: Imported from OSS
Differential Revision: D21728402
Pulled By: nairbv
fbshipit-source-id: 85f3daf63f1bdbb5101e8dea8c125f13448ca228
Summary:
When building, my log was being spammed with:
```
warning: attribute "__visibility__" does not apply here
```
Which, at least on gcc 7.4 isn't covered by silencing `-Wattribute`. The warning suggests `enum`s don't need to be exported on linux, so I just `ifdef` it out instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38988
Differential Revision: D21722032
Pulled By: ezyang
fbshipit-source-id: ed4cfebc187dceaa9e748d85f756611fd7eda4b4
Summary:
This PR adds the following changes:
1. It sets the default extension build to use ninja
2. Adds HIPCC flags to the host code compile string for ninja builds. This is needed when host code makes HIP API calls
cc: ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38939
Differential Revision: D21721905
Pulled By: ezyang
fbshipit-source-id: 75206838315a79850ecf86a78391a31ba5ee97cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38819
Logs a message when the agent is shutting down like the other RPC
Agents.
ghstack-source-id: 104673386
Test Plan: Sandcastle
Differential Revision: D21671061
fbshipit-source-id: a44f0e4976e3acc898645a2baf6f41f45a697166
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38818
Standardizes the error message when a response is attempted after the
agent has shut down.
ghstack-source-id: 104673115
Test Plan: Sandcastle - no functionality change, just error message
Differential Revision: D21670706
fbshipit-source-id: d26fcd7c76758c62d432d9c4e6ef2e3af7cbedff
Summary:
CC ezyang xw285cornell
HIP from ROCm 3.5 renames `hipOccupancyMaxActiveBlocksPerMultiprocessor` to `hipModuleOccupancyMaxActiveBlocksPerMultiprocessor`. In addition, the API parameter types now match CUDA. Add these changes in a backwards-compatible manner.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38551
Differential Revision: D21721832
Pulled By: ezyang
fbshipit-source-id: 6fc971845e363d7495d8be9550e76d0f082c3062
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38815
Some CPU kernels have void return types and the currently implementation segfaults on these cases.
Test Plan: Imported from OSS
Differential Revision: D21670717
Pulled By: gchanan
fbshipit-source-id: bc17b8330195601ca231a985ee44319447ba6cf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38813
We are going to apply this check to CPU (with some changes), so just moving this in preparation.
The code is just cut-pasted here, no behavioral change.
Test Plan: Imported from OSS
Differential Revision: D21670554
Pulled By: gchanan
fbshipit-source-id: c7e07f67bb4c6524fde12237e35892e42557103e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38810
Same change as was applied to CPU loops -- separate out checking of the inputs and outputs.
Test Plan: Imported from OSS
Differential Revision: D21670339
Pulled By: gchanan
fbshipit-source-id: 42f208538dce1a5598d14948d8d02a1c91ba152a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38809
This splits the asserts into separate input/output asserts and makes the numbers precise, instead of ranges.
This is an ongoing effort to improve the Loops assertion and to integrate dynamic cast checking into CPU loops.
Test Plan: Imported from OSS
Differential Revision: D21670263
Pulled By: gchanan
fbshipit-source-id: b1868db5255a69158045b759dc9171690a2dcd01
Summary:
This updates assertEqual and assertEqual-like functions to either require both or neither of atol and rtol be specified. This should improve clarity around handling precision in the test suite, and it allows us to remove the legacy positional atol argument from assertEqual. In addition, the "message" kwarg is replace with a kwarg-only "msg" argument whose name is consistent with unittest's assertEqual argument.
In the future we could make "msg" an optional third positional argument to be more consistent with unittest's assertEqual, but requiring it be specified should be clear, and we can easily update the signature to make "msg" an optional positional argument in the future, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38872
Differential Revision: D21740237
Pulled By: mruberry
fbshipit-source-id: acbc027aa1d7877a49664d94db9a5fff91a07042
Summary:
**Summary**
This commit enables the use of `torch.jit.unused` on methods of TorchScript classes.
This attribute is honoured by replacing the body of any method
marked as unused in the parsed AST for the class with `raise Exception(...)`.
**Test Plan**
This commit adds a unit test `TestClassType.test_unused_method` that
tests this feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38522
Differential Revision: D21733818
Pulled By: SplitInfinity
fbshipit-source-id: 771872359dad70fac4aae83b6b5f17abb6329890
Summary:
Fixes https://github.com/pytorch/pytorch/issues/38401
* `torch.hub.load_state_dict_from_url()` now also downloads to `$TORCH_HOME/hub/checkpoints` instead of `$TORCH_HOME/checkpoints` like `torch.hub.load()` and others.
* Make `hub_dir` private, add and use `get_dir()` instead.
Also updated docs. Did not see a need for additional unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38969
Differential Revision: D21725880
Pulled By: ailzhang
fbshipit-source-id: 58cc6b32ddbda91e58c1c1433cc3916223556ea1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38736
qconv2d and qlinear APIs were changed recently so updating the scale code accordingly
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py
Imported from OSS
Differential Revision: D21647724
fbshipit-source-id: 45d4b358ffb84f1e73da8ba3f702d5043bdb16d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38804
This is only needed in the process group agent implementation, and
removing it from the header file prevents other translation units that include
it from having this constant.
ghstack-source-id: 104666599
Test Plan: CI
Differential Revision: D21668514
fbshipit-source-id: 1c39cc98dea99518134c66dca3ca5b124a43de1b
Summary:
We do try to eliminate empty For loops, but missed a case where the body Block exists but is empty. In that case we can eliminate the loop as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38883
Differential Revision: D21723680
Pulled By: nickgg
fbshipit-source-id: 49610b0524af5b9ec30ef3b4cc0c8461838259c3
Summary:
* Disable the mode where PE can still run the old fuser.
* Clean up
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38591
Differential Revision: D21643664
Pulled By: Krovatkin
fbshipit-source-id: 6753ed6bdc544698a1340e59a624608ff3abf7f9
Summary:
Per title. https://github.com/pytorch/pytorch/issues/32719 essentially disabled asserts in cuda kernels in release build. Asserts in cuda kernels are typically used to prevent invalid reads/writes, so without asserts invalid read/writes are silent errors in most cases (sometimes they would still cause "illegal memory access" errors, but because of caching allocator this usually won't happen).
We don't need 2 macros, CUDA_ALWAYS_ASSERT and CUDA_KERNEL_ASSERT because all current asserts in cuda kernels are important to prevent illegal memory accesses, and they should never be disabled.
This PR removes macro CUDA_ALWAYS_ASSERT and instead makes CUDA_KERNEL_ASSERT (that is commonly used in the kernels) an asserttion both in release and debug builds.
Fixes https://github.com/pytorch/pytorch/issues/38771
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38943
Differential Revision: D21723767
Pulled By: ngimel
fbshipit-source-id: d88d8aa1b047b476d5340e69311e65aff4da5074
Summary:
As a follow up for https://github.com/pytorch/pytorch/pull/36491 and last comments on it.
Vulkan uses Strided Layout (at the moment strides are not supported, but in plan)
empty_strided just forwards to empty_vulkan, ignoring strides params.
Removing explicit ifs in TensorConversions that were added before decision to use Strided layout and have not been cleaned after that :(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39019
Differential Revision: D21726480
Pulled By: IvanKobzarev
fbshipit-source-id: d465456df248a118bfef441c85280aa0025860cd
Summary:
closes gh-32561 closes gh-38545. As part of the fallout from gh-36797, this PR
- replaces the producer_version: "1.6" in onnx expect tests with `producer_version: "XXX"
- adapts `testing/_internal/common_utils.py` with a regex to change the onnx producer_version so tests still pass
The consistency of the torch version and the onnx `producer_version` is tested in gh-36797, so there is no reason to test it again in the expect tests.
xref gh-38629 which documented how to run the onnx tests and at the same time refactored the Community documentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39002
Differential Revision: D21723062
Pulled By: ezyang
fbshipit-source-id: 1bd6a8ed37d5383e69d017226dc09c0645a69aff
Summary:
- Resolving the feature introduced in https://github.com/pytorch/pytorch/issues/38652
- Since the iteration will be terminated once the error occurred, perhaps we can only give the current index which caused the error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38978
Differential Revision: D21722426
Pulled By: ezyang
fbshipit-source-id: edfc3f7a320584ba22d790f2b79c3726e99aae2a
Summary:
Fixes errors when importing the module. The import is used by sphinx in documentation builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38921
Differential Revision: D21722144
Pulled By: ezyang
fbshipit-source-id: 5f31d4750325f1753de93754a009006cbc13655e
Summary:
In PyTorch 1.6 integer division using torch.div will throw a runtime error. When PyTorch Master adopts this behavior some of our ONNX tests would break if we continued to import torchvision v0.5, since v0.5 uses torch.div to perform integer division. fmassa and I recently updated Torchvision to use torch.floor_divide for integer division (at least on paths covered by the PyTorch OSS CI tests), and this PR updates our torchvision test version to include those changes. This will prevent the PyTorch OSS CI from breaking when PyTorch Master adopts the 1.6 integer division behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38848
Differential Revision: D21679988
Pulled By: mruberry
fbshipit-source-id: 1333f6254c295909cf05b6f3e352e4a0c336e5af
Summary:
Fix https://github.com/pytorch/pytorch/issues/38764
The current problem is that, `top_diff` and `top_mask` pointers are shifted "accumulatively" with for-n and for-c loops. This may cause overflow and illegal memory access when the loop counts are greater than one, that is n > 65535 or c > 65535 (the case in https://github.com/pytorch/pytorch/issues/38764). Since neither of n > 65535 or c > 65535 is common, it has not been seen before. The simple fix would be using new pointer variables for the n & c offset instead of directly modifying `top_diff` or `top_mask`.
However, I think the current nchw max_pool2d GPU impl still has plenty of room for performance improvement. We can check that in a later PR if needed.
Slightly clean up the indentation. Also add tests to use CPU impl as a reference check.
cc skrah
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38953
Differential Revision: D21721930
Pulled By: ezyang
fbshipit-source-id: fef7d911d814f8ed9fd67c60cabe5d52f8fd3d57
Summary:
Fixes https://github.com/pytorch/pytorch/issues/37558
Use a temporary file instead of `/dev/null` in `ReducerTest`, to prevent the chance of unintended deletion when running as root. It seemed that there were no strong side-effects (running time?) by fixing it at the test level, compared to other solutions that involved modifying the behaviour of `FileStore` (for example, adding an optional flag to avoid auto-deleting the file upon destruction).
Please note this is my first contribution - I have done my best to read the contributing guide and checked for duplicate PRs with no luck, but apologies in advance for any oversights and lack of familiarity with the procedures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39004
Differential Revision: D21721966
Pulled By: mrshenli
fbshipit-source-id: 76fb81600fa08a91c35d0eb9a5aab179f5371422
Summary:
This updates assertEqual and assertEqual-like functions to either require both or neither of atol and rtol be specified. This should improve clarity around handling precision in the test suite, and it allows us to remove the legacy positional atol argument from assertEqual. In addition, the "message" kwarg is replace with a kwarg-only "msg" argument whose name is consistent with unittest's assertEqual argument.
In the future we could make "msg" an optional third positional argument to be more consistent with unittest's assertEqual, but requiring it be specified should be clear, and we can easily update the signature to make "msg" an optional positional argument in the future, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38872
Differential Revision: D21717199
Pulled By: mruberry
fbshipit-source-id: 9feb856f94eee911b44f6c7140a1d07c1b026d3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38859
This error message indicates aten::eq expects different types
```
RUNNING 379 OP 76, aten::eq
terminate called after throwing an instance of 'c10::Error'
what(): isInt() INTERNAL ASSERT FAILED at "buck-out/gen/68e83026/xplat/caffe2/aten_header#header-mode-symlink-tree-with-header-map,headers/ATen/core/ivalue.h":331, please report a bug to PyTorch.
```
It turns out that there are two aten::eq in lite interpreter (https://www.internalfb.com/intern/diffusion/FBS/browse/master/xplat/caffe2/torch/csrc/jit/runtime/register_prim_ops.cpp?lines=417)
aten::eq(int, int)
aten::eq(str, str)
This diff add overload name for str and it fixed the problem.
Test Plan: local test
Reviewed By: pengtxiafb
Differential Revision: D21681838
fbshipit-source-id: 1f17ecdadb9bc1c16915a24c60fa57a6fc273865
Summary:
This PR contains the initial version of Vulkan (GPU) Backend integration.
The primary target environment is Android, but the desktop build is also supported.
## CMake
Introducing three cmake options:
USE_VULKAN:
The main switch, if it is off, all other options do not affect.
USE_VULKAN_WRAPPER:
ON - Vulkan will be used loading it at runtime as "libvulkan.so" using libdl, every function call is wrapped in vulkan_wrapper.h.
OFF - linking with libvulkan.so directly
USE_VULKAN_SHADERC_RUNTIME:
ON - Shader compilation library will be linked, and shaders will be compiled runtime.
OFF - Shaders will be precompiled and shader compilation library is not included.
## Codegen
if `USE_VULKAN_SHADERC_RUNTIME` is ON:
Shaders precompilation () starts in cmake/VulkanCodegen.cmake, which calls `aten/src/ATen/native/vulkan/gen_glsl.py` or `aten/src/ATen/native/vulkan/gen_spv.py` to include shaders source or SPIR-V bytecode inside binary as uint32_t array in spv.h,spv.cpp.
if `USE_VULKAN_SHADERC_RUNTIME` is OFF:
The source of shaders is included as `glsl.h`,`glsl.cpp`.
All codegen results happen in the build directory.
## Build dependencies
cmake/Dependencies.cmake
If the target platform is Android - vulkan library, headers, Vulkan wrapper will be used from ANDROID_NDK.
Desktop build requires the VULKAN_SDK environment variable, and all vulkan dependencies will be used from it.
(Desktop build was tested only on Linux).
## Pytorch integration:
Adding 'Vulkan" as new Backend, DispatchKey, DeviceType.
We are using Strided layout without supporting strides at the moment, but we plan to support them in the future.
Using OpaqueTensorImpl where OpaqueHandle is copyable VulkanTensor,
more details in comments in `aten/src/ATen/native/vulkan/Vulkan.h`
Main code location: `aten/src/ATen/native/vulkan`
`aten/src/ATen/native/vulkan/VulkanAten.cpp` - connection link between ATen and Vulkan api (Vulkan.h) that converts at::Tensor to VulkanTensor.
`aten/src/ATen/native/Vulkan/Vulkan.h` - Vulkan API that contains VulkanTensor representation and functions to work with it. Plan to expose it for clients to be able to write their own Vulkan Ops.
`aten/src/ATen/native/vulkan/VulkanOps.cpp` - Vulkan Operations Implementations that uses Vulkan.h API
## GLSL shaders
Located in `aten/src/ATen/native/vulkan/glsl` as *.glsl files.
All shaders use Vulkan specialized constants for workgroup sizes with ids 1, 2, 3
## Supported operations
Code point:
conv2d no-groups
conv2d depthwise
addmm
upsample nearest 2d
clamp
hardtanh
## Testing
`aten/src/ATen/test/vulkan_test.cpp` - contains tests for
copy from CPU to Vulkan and back
all supported operations
Desktop builds supported, and testing can be done on a desktop that has Vulkan supported GPU or with installed software implementation of Vulkan, like https://github.com/google/swiftshader
## Vulkan execution
The initial implementation is trivial and waits every operator's execution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36491
Differential Revision: D21696709
Pulled By: IvanKobzarev
fbshipit-source-id: da3e5a770b1a1995e9465d7e81963e7de56217fa
Summary:
Inspired by malfet
> By the way, once we have build_artifacts property, can someone try if its faster to use it as mean of transferring images between build and test instead of using AWS (i.e. use artifacts instead of jenkins/pytorch/win-test-helpers/upload_image.py /download_image.py pair)
Use CircleCI to store intermediate binaries and make them available to be downloaded as artifacts instead of uploading to S3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38971
Differential Revision: D21717080
Pulled By: seemethere
fbshipit-source-id: e3498b058778d02ae2f38daefbc7118a1a2cbe76
Summary:
Fixes https://github.com/pytorch/pytorch/issues/38839. Previously, if magnitude of input values was large, when computing `max+log(sum)` the `log(sum)` value was essentially ignored, now the result is computed as
`x-max-log(sum)` which has a better chance of preserving accuracy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38945
Differential Revision: D21712483
Pulled By: ngimel
fbshipit-source-id: c1a3599ed981ba7a7fd130cbd7040a706b7eace0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37098
### **Cherry-picked from another stack:**
Some code review already occurred here: https://github.com/pytorch/pytorch/pull/32582
### Summary:
Fixes: https://github.com/pytorch/pytorch/issues/32436
The issue caused incorrect handling of dtypes for scalar ** tensor.
e.g. before this change:
```
>>> 5.5 ** torch.ones(5, dtype=torch.int32)
tensor([5, 5, 5, 5, 5], dtype=torch.int32)
```
should return a float tensor.
Also fixes a number of incorrect cases:
* tensors to negative powers were giving incorrect results (1 instead
of 0 or error)
* Behavior wasn't consistent between cuda/cpu
* large_value ** 1 in some cases gave a result not equal
to large_value because of truncation in conversion to double and back.
BC-breaking:
Previously incorrect behavior (in 1.4):
```
>>> a
tensor([1, 1, 1, 1, 1], dtype=torch.int32)
>>> a.pow_(.5)
tensor([1, 1, 1, 1, 1], dtype=torch.int32)
```
After this change:
`RuntimeError: result type Float can't be cast to the desired output type Int`
Test Plan: Imported from OSS
Differential Revision: D21686207
Pulled By: nairbv
fbshipit-source-id: e797e7b195d224fa46404f668bb714e312ea78ac
Summary:
Related issue: https://github.com/pytorch/pytorch/issues/36900
Since I feel this PR is already large enough, I didn't migrate max in this PR. Legacy code is not cleaned up either. All these remaining work will be done in later PRs after this is merged.
Benchmark on an extreme case
```python
import torch
print(torch.__version__)
t = torch.randn(100000, 2, device='cuda')
warmup = torch.arange(100000000)
torch.cuda.synchronize()
%timeit t.min(dim=0); torch.cuda.synchronize()
```
Before: 4ms; After: 24.5us.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38440
Differential Revision: D21560691
Pulled By: ngimel
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38151
We need to expose this method to Clang unconditionally when building CUDA, otherwise it would error on device code calling `__ldg` with `Half*`.
Test Plan:
```
buck build -c fbcode.caffe2_use_mpi=1 -c fbcode.cuda_use_clang=true mode/opt //experimental/training_supercomputer/trainer/hpc_pt:trainer
```
Reviewed By: ngimel
Differential Revision: D21481297
fbshipit-source-id: aacfe7de2cdc8542908249081ddb58170b1e35ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38746
Factors out testing of op alias normalization so that there is a registry used for tests.
Test Plan: Imported from OSS
Differential Revision: D21673107
Pulled By: eellison
fbshipit-source-id: e06653cdf24f14a4253dd054e4d402d171d16a11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38735
Follow up to my comment https://github.com/pytorch/pytorch/pull/36597/#issuecomment-613674329
This adds a pass to convert op aliases into a normalized form. Having two ops generated in our IR that do the same thing makes the IR harder for downstream consumers of the IR, such as TorchScript passes but also ONNX, glow, etc.
Another solution would have been to fix our code generation to only emit `aten::abs` from the start. This seems trickier, and doesn't really buy us much if we still have to expose `aten::absolute` in C++, as glaringlee of the C++ API thinks we should.
Bike shedding: maybe this should be `CanonicalizeOps` instead
Test Plan: Imported from OSS
Differential Revision: D21673108
Pulled By: eellison
fbshipit-source-id: c328618907de1af22e07f57fd27fa619978c2817
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38734
As far as I can tell, this pass only exists to canonicalize ops that are generating in the graph fuser, so it's kind of a misnomer.
Test Plan: Imported from OSS
Differential Revision: D21673109
Pulled By: eellison
fbshipit-source-id: b7bedf34ccaf1fcd442bfb2bbb990e64915f51d4
Summary:
Add `store_artifacts` attribtue to Windows build jobs
In `vs_install.ps1` add logic to download vscollect tool and upload collected results as build artifacts
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38902
Differential Revision: D21700598
Pulled By: malfet
fbshipit-source-id: b51c47ff44ac522ad5581624f5b9a9a86cf1e595
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38878
We need to Packing op and shape extraction functions to make some of the FakeLowP tests run in OSS.
Test Plan: unittests
Reviewed By: hyuen
Differential Revision: D21682704
fbshipit-source-id: f36321b91acfd738e90543309b82ad87b9e5c156
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38587
Before this diff, scale+zp were initialized to tensors
with a single dimension and 1 element, and then switched
to scalar tensors after the first forward.
This diff makes the shape stay consistent. This should fix
an issue reported when saving/loading models, which crashes
on this inconsistent shape.
Test Plan:
```
python test/test_quantization.py TestFakeQuantizePerTensor.test_fake_quant_preserves_qparam_shapes_for_activations
```
Imported from OSS
Differential Revision: D21605532
fbshipit-source-id: e00cd268d6d3ded1006d18d6c6759c911b3a74ea
Summary:
Adds reduction support for the code generator. Reductions are fully supported with split/merge/reorder/rfactor/computeAt/unroll operators. There is also cross thread (intra-block) reduction support.
The two remaining pieces missing for reduction support is:
- Safety: If cross thread reduction was used, child operators shouldn't be able to bind that thread dim anymore
- Cross block reduction: we will want inter-block reduction support to match parity with tensor iterator
PR also provides FP16 support for fusions now. We insert casts on FP16 inputs to FP32, and we insert casts to FP16 on FP16 outputs.
Also working towards reductions and shape inference for reductions in the fusion pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38627
Reviewed By: albanD
Differential Revision: D21663196
Pulled By: soumith
fbshipit-source-id: 3ff2df563f86c39cd5821ab9c1148149e5172a9e
Summary:
These two macros only appear in `Dispatch.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37697
Differential Revision: D21666340
Pulled By: anjali411
fbshipit-source-id: 1f31ab46c08b77f1011367e471874d390ffa70fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38844
Enhances error message in ProcessGroupGloo to log the unsupported
device. Been seeing a few issues with this and this will provide more debug
information.
Test Plan: CI
Differential Revision: D21676881
fbshipit-source-id: 1fd727162682e1a55003adff67c4358dab488455
Summary:
* Does a basic upload of release candidates to an extra folder within our
S3 bucket.
* Refactors AWS promotion to allow for easier development of restoration
of backups
Backup restoration usage:
```
RESTORE_FROM=v1.6.0-rc3 restore-backup.sh
```
Requires:
* AWS credentials to upload / download stuff
* Anaconda credentials to upload
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38690
Differential Revision: D21691033
Pulled By: seemethere
fbshipit-source-id: 31118814db1ca701c55a3cb0bc32caa1e77a833d
Summary:
See https://www.sphinx-doc.org/en/master/man/sphinx-build.html#cmdoption-sphinx-build-j
> Distribute the build over N processes in parallel, to make building on multiprocessor machines more effective. Note that not all parts and not all builders of Sphinx can be parallelized. If auto argument is given, Sphinx uses the number of CPUs as N.
- Timing results
- Python doc build on a 40-core machine: 9:34 down to 1:29
- pytorch_cpp_doc_push: ~1h 10m down to 47m
- pytorch_python_doc_push: 34m down to 32m
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38785
Differential Revision: D21691991
Pulled By: zou3519
fbshipit-source-id: cfc5e8cd13414640f82edfd2ad1ce4d9c7afce12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38801
NCCL specific tests that shouldn't be run on ROCm
ghstack-source-id: 104481245
Test Plan: waitforbuildbot
Differential Revision: D21667348
fbshipit-source-id: a3e558185d9b74e1eac5fae27d97d5d026baa0a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38725
Today, there are two equivalent representations: named_tensor_meta_ is
null, or named_tensor_meta_ is non-null but all of the dimension names
are wildcard. Let's reduce the opportunity for behavior divergence by
making the second representation illegal.
This will make it easier for me to add a dispatch key for named
tensor as I can rely on setters to always go through TensorImpl to
maintain invariants on DispatchKey.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21662641
Pulled By: ezyang
fbshipit-source-id: ccc6566d23ad2ba850f653364a86cc8db0428223
Summary:
This PR fixes the tolerance values for some of the bfloat16 div tests that were enabled on ROCm with incorrect tolerance values in the PR https://github.com/pytorch/pytorch/pull/38621
Also disabled(to unblock CI) `test_addcdiv*` for which the error is large when absolute values in the tensor are higher. This will have to be investigated further.
ezyang jeffdaily sunway513
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38823
Differential Revision: D21686290
Pulled By: ezyang
fbshipit-source-id: 85472680e1886bdc7c227ed2656e0b4fd5328e46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38846
We begin to have fp16 inputs/outputs. Adding this will help with the debugging.
Test Plan: run.
Reviewed By: jfix71
Differential Revision: D21676805
fbshipit-source-id: 47788e631164d24aef0f659b281c59822b009e18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37626
Did some rescheduling of the instructions to hide latency of the loads.
Particularly at the start of the kernel we have latency bound chains.
It seems to improve perf form aarch32.
Also did some inst rescheduling for aarch64 gemm kernel. Not clear if
this actually helps with perf espcially in OOO CPUs, but worth a try.
Test Plan:
qnnpack tests
q8gemm-test
Imported from OSS
Differential Revision: D21339037
fbshipit-source-id: 0469581a0e3bd3fd04f15200c2171fc8c264722b
Summary:
This fixes `can not cast between incompatible function types` error if code is compiled by gcc-9.3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38842
Differential Revision: D21676360
Pulled By: malfet
fbshipit-source-id: d8b05d8381bfc961e06981731ebca87a516c2811
Summary:
The failure was caused by cross merge conflicts. A new use of `AT_DISPATCH_ALL_TYPES_AND_C10_COMPLEX_AND2` at `ATen/native/cuda/TensorTransformations.cu` was added before the reverted PR merged. See c73523a4c3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38814
Differential Revision: D21670650
Pulled By: malfet
fbshipit-source-id: 867636cdb0106cb1275617ad2e355736d5d77210
Summary:
Otherwise, I don't understand how those could have been invoked
Also, what is the benefit of importing the same module twice?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38832
Differential Revision: D21675081
Pulled By: malfet
fbshipit-source-id: fee5604c4c433161b6b1a999d505b5acbbc3b421
Summary:
I was so excited to take advantage of https://github.com/pytorch/pytorch/issues/36858 getting merged that I installed the nightly build, and I'm glad I did!
It turns out that there's a _very small_ chance that the current algorithm will return a negative value (I imagine only -1 is possible but not sure about that).
Basically the logic [here](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/Distributions.h#L198-L213), which returns a value that passes certain checks before checking if its negative. I can't figure out the particular range that causes this but could reproduce it by taking a billion samples with `count` 1 and `prob` 0.9:
```python
(
torch.distributions.Binomial(
total_count=torch.tensor(1.0).cuda(), probs=torch.tensor(0.9).cuda()
).sample(torch.Size((1000000000,))) >= 0
).all()
```
Reliably evaluates to `tensor(False, device='cuda:0')` on my machine. 100M samples usually does it but not always, so that's around the rate at which this crops up (it took me most of a whole day to run into it!). Seems to be CUDA specific, I imagine due to some esoteric reason I cannot begin to guess.
This PR tries to solve it in the most obvious way: reject negative values _before_ testing the bounding box, not after. But a better solution is probably to figure out why this occurs at all, and stop it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38456
Differential Revision: D21664886
Pulled By: jerryzh168
fbshipit-source-id: 99b0eed980e214bede484c100388a74d8c40ca55
Summary:
A local run shows it improves running 2000 guards time from 0.00282s to 0.00187s (~30%). This is for the case when tensor is contiguous, we don't have to recompute whether it's contiguous from stride for each dimension.
We can further optimize other cases if there's a repro script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38732
Differential Revision: D21664191
Pulled By: ailzhang
fbshipit-source-id: 125950f20c8676afc447f1d27ce4d14bbd445918
Summary:
`pytorch-linux-bionic-py3.8-gcc9` is based on Ubuntu 18.04 using gcc-9 and python-3.8
`pytorch-linux-bionic-cuda10.2-cudnn7-py3.8-gcc9` adds CUDA-10.2 to the same configuration
Also this in this PR:
- Updates valgrind to 3.15.0
- Fixes bug when gcc-5.5 were used in gcc-5.4 configurations
- Do not install `typing` when installing Python-3.8 from Conda
- Install `llvmdev-8` to for `numba/llvmlite` package compilation to succeed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38747
Differential Revision: D21670093
Pulled By: malfet
fbshipit-source-id: 995dfc20118a6945b55a81ef665a0b80dab97535
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37623
Follows the same strategy as static linear.
Same kernel now supports both per-channel and per-tensor linear.
Fixed fully connected test.
Test Plan:
qnnpack tests
q8gemm
fully-connected-test
Imported from OSS
Differential Revision: D21339040
fbshipit-source-id: 479d847c16b42c926acb67357dc3bdd2d0bd6ca4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37622
Enable channelwise quantized test on qlinear and qconv.
Dynmaic linear to follow.
Test Plan:
pytest test/quantization/test_quantized.py
pytest test/quantization/test_quantized_module.py
Imported from OSS
Differential Revision: D21339046
fbshipit-source-id: 32377680d3a6424ca1e98d3707b82839eeb349a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37621
Due to potential perf issues with using same depthwise conv kernels for
perf channel depthwise conv, we opt for replicating the kernels and
adding per channel support to them.
Note that the large kernels files are largely duplication of original
kernels. Assembly kernels have little more modifications than intrinsics
ones.
Test Plan:
qnnpack tests.
q8dwconv-test
convolution-test
Differential Revision: D21339042
Pulled By: kimishpatel
fbshipit-source-id: f2c3413e1e1af0b1f89770b5e0f66f402d38aee8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37620
Now channel wise quantization is supported for linear/conv.
Depthwise conv are still pending.
Tests are altered to generate per channel zero points and requant
scales.
All the kernels are fixed appropritately.
Added per_channel member to conv_param structure.
And replicated conv tests to exercise per_channel conv.
This was not strictly needed since conv kernels were changed
such that they did per channel anyway. When per channels is not needed
zp and scale were same across channels. This was to minimize code
duplicaiton as the perf impact is estimated (to be measured though) to
be low.
However this is not likely the case for depthwise convs. Thus they will
have separate kernels, which required us to introduce per_channel member
to conv_param structure, to know which kernels to apply for depthwise.
Ensuing modifications were to keep everything in
sync for both regular conv and depthwise so that we dont have caveat
when reading the code, that why does depthwise have separate test for
per channel and non-depthwise conv does not.
Test Plan:
Via tests inside qnnpack, i.e., q8gemm-test, q8conv/dwconv test.
fully-conntected-test, convolution-test.
Imported from OSS
Differential Revision: D21339041
fbshipit-source-id: 1b8fbd7fbd0fe0582a43996147171567b126d948
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37619
This PR introduces changes to add per channel zero point.
Modifies kernels appripriately.
Some bug fixes in enabling per channel zero point.
Test Plan:
Via tests inside qnnpack, i.e., q8gemm-test, q8conv/dwconv test.
fully-conntected-test, convolution-test.
Imported from OSS
Differential Revision: D21339044
fbshipit-source-id: fb69488b2b04da109c69f3dd1e8a285babf2863d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37618
This does not do any actual changes. Just introduces API changes and
some data struct changes to hold vector of data for zero point and
scale.
Test Plan:
Via unittests inside qnnpack, i.e., q8gemm-test, q8conv/dwconv test.
fully-conntected-test, convolution-test.
PT's quantization tests.
Imported from OSS
Differential Revision: D21339039
fbshipit-source-id: 4a20cff9795a105ddd31482d1f1fe2b1dbe18997
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38766
We will most likely hit int32, float16 and float inputs are Onnxifi inputs.
Test Plan: runs
Reviewed By: ipiszy
Differential Revision: D21658148
fbshipit-source-id: c51917c29e223051c5dfa1c21788c6d620539562
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38308
This PR doesn't add any new functionality. The purpose of this PR
is to validate reordering tracing code in variable kernel doesn't break
anything (which is a prerequisite of stacked change of moving tracing
logic into a new dispatch backend).
And it will be easier to bisect in case it breaks something which is not
covered by tests.
Test Plan: Imported from OSS
Differential Revision: D21570685
Pulled By: ljk53
fbshipit-source-id: 616b6434326df8381fb6f07c7b9aadac86dd02b4
Summary:
CC ezyang xw285cornell sunway513
Skip new test until triage of ROCm CI can be completed.
Test added by a94fb71b126001630d3d1e350347c20977f14ec0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38790
Differential Revision: D21665404
Pulled By: xw285cornell
fbshipit-source-id: c03227a91c9d06f8c0ff50f4593baa9ecb507743
Summary:
This PR ports `masked_select` from TH to ATen and optimize the performance on CPU with TensorIterator.
https://github.com/pytorch/pytorch/issues/33053
1. single socket run: up to **5.4x** speedup;
2. single core run: up to **1.16x** speedup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33269
Differential Revision: D20922288
Pulled By: ngimel
fbshipit-source-id: 38e183a4e3599bba29bbbebe36264026abe1c50e
Summary:
ghstack PRs has target branch changed to `gh/xxx/1234/base` so the merge didn't work. Change it to `master` by default.
IIRC we don't use ghstack with release branches so this should be good? cc: ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38745
Differential Revision: D21663796
Pulled By: ailzhang
fbshipit-source-id: 3d2c7b91b0e355dc8261d8f1e7da76af8d3bcee4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38424
On the way to adding initial vmap support, this is the implementation
for BatchedTensorImpl. Vmap (in future PRs) leverages Tensors backed by
BatchedTensorImpl to do its work.
For more context, here is an overview of the plan to add initial vmap support.
- [this PR] Add BatchedTensorImpl
- Add one or two batching rules
- Add vmap Python API
- Add "slow" for-loop fallbacks for out-of-place functions via
dispatcher fallback mechanism.
- Add batching rules for "view" functions
- Add "slow" for-loop fallbacks for in-place functions
- Miscellaneous handling for failure cases
- And more
Test Plan: - `./build/bin/vmap_test`
Differential Revision: D21640917
Pulled By: zou3519
fbshipit-source-id: 969490a838cf2099ed80104e7d51ee8ff069e168
Summary:
Updates our tests in preparation of integer division using torch.div and torch.addcdiv throwing a runtime error by avoiding integer division using torch.div. This creates a brief period where integer division using torch.div is untested, but that should be OK (since it will soon throw a runtime error).
These callsites were identified using https://github.com/pytorch/pytorch/issues/36897.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38621
Differential Revision: D21612823
Pulled By: mruberry
fbshipit-source-id: 749c03a69feae02590b4395335163d9bf047e162
Summary:
Update Argmin/Argmax ONNX export in opset 12 to export with "select_last_index", and export correctly cases where the same value appears multiple time in the input tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38329
Reviewed By: hl475
Differential Revision: D21613799
Pulled By: houseroad
fbshipit-source-id: 4597e23561f444c4e56d30c735dae7e9a8a41c5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38453
Two fixes:
- RecordFunction in JIT interpreter should exist during the execution
of the frame, and not just when we enter the frame
- When creating a JIT continuation in wait instruction, we'd want to
preserve the original thread local context, right now when we resume
execution in continuation we preserve the thread local state of the
thread that set future value (i.e. executed a forked task)
Test Plan: unittest, CI
Reviewed By: ngimel
Differential Revision: D21565959
Pulled By: ilia-cher
fbshipit-source-id: 206b98e3bfb0052fc8e4031da778e372cc71afc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38447
This PR modifies `run_tests.py` to enable running Tensorpipe Agent tests with the OSS CI.
ghstack-source-id: 104321881
Test Plan: CI
Differential Revision: D21560096
fbshipit-source-id: 7d61cc1c354e9353c4a586dd2b56690c28d51d10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38446
This PR enables the Distributed Optimizer tests for the Tensorpipe Agent - all of them are currently passing so there is no need to skip any tests.
ghstack-source-id: 104321883
Differential Revision: D21560097
fbshipit-source-id: 316971b96b632f12326872a51fd9124c9eae4720
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38445
This PR enables the Distributed Autograd tests for the Tensorpipe Agent. A decorator is used to skip all tests that are currently failing due to functionality lacking in the Tensorpipe RPC Agent (primarily timeouts and error handling).
ghstack-source-id: 104321884
Differential Revision: D21560098
fbshipit-source-id: 2564bfc96d196f35ef0dfb9de59791fcd29093cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38444
This enables the RPC/RRef test suites to run with the Tensorpipe RPC Agent. This creates a new fixture to ensure the backend/options used are Tensorpipe, as well as a decorator to skip tests that Tensorpipe currently cannot support due to missing functionality.
One small note: the decorator function is a class method of the test class so we can check whether `self.rpc_backend` is tensorpipe. In the class-scope, the `TEST_CONFIG.rpc_backend_name` string is set to Tensorpipe, but outside the class scope, it is PGA, possibly due to importing dist_utils which sets this config to PGA by default. The cleanest solution would be to refactor the backend selection to be more uniform (since currently every backend is set slightly differently), but that would be a longer-term fix.
ghstack-source-id: 104321885
Test Plan:
Note: A couple of these tests will fail right now due to missing features. I've skipped the ones that regularly fail, but there will be some flaky tests that still fail occasionally.
The decorator `@_skip_if_tensorpipe_agent` skips the tests that fail with the Tensorpipe Agent. Remove this decorator from above the tests once they are fixed.
Differential Revision: D21412016
fbshipit-source-id: 1e801ac5ccaf87974dd4df92d556895b01468bf3
Summary:
CC ezyang xw285cornell sunway513
Commit 59d92e442b88eae51b84adc4e902e36e8f12a4db (https://github.com/pytorch/pytorch/issues/38557) has caused this test to regularly fail on ROCm CI gfx900 hosts. Skipping test until root cause analysis can complete.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38724
Differential Revision: D21645815
Pulled By: xw285cornell
fbshipit-source-id: 4087e9565710c271ca5c026a5ae0c5132e56f44d
Summary:
current `to_mkldnn` model conversion logic under `torch.utils.mkldnn` does not cover `nn.Conv1d`. This patch fills the gap, using similar logic to `nn.Conv2d`. The model conversion will remove unnecessary memory format reorders of input/output tensors and thus speedup the model.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38528
Differential Revision: D21640325
Pulled By: albanD
fbshipit-source-id: c3340153b5c524e020c097eb4b9e2ffcbde8896d
Summary:
floordiv was missing a couple dunder registrations, which was causing __ifloordiv__ to not be called when it should. This adds the appropriate registrations and adds a test verifying that the inplace dunders are actually occuring inplace.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38695
Differential Revision: D21633980
Pulled By: mruberry
fbshipit-source-id: a423f5ec327cdc062fd6d9d56abd36fe44ac8198
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38570
We changed the rule of quantizing `aten::cat`, previously `aten::cat` is considered to be
an op that should always be quantized, like `aten::conv2d`, but this is not ideal, a better
way is to quantize the output of `aten::cat` depending on whether the input is quantized, if it is
then we'll quantize the output, if not, then we will not quantize the output, since `aten::cat` works both on
quantized and non-quantized tensor.
Test Plan: Imported from OSS
Differential Revision: D21600160
fbshipit-source-id: efa957e0eaa608fffefcdfefa7f442fab45605eb
Summary:
Previously we got a CI issue in original submission (D21562485), so we backout the original diff (D21588831). Resubmitting here to reprod the CI issue and ask caffe2 dev to take a look.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38566
Original commit changeset: 6dda4b71904d
Test Plan: buck test
Reviewed By: houseroad
Differential Revision: D21589352
fbshipit-source-id: de40ff2884019e14476e31c4c952f24d6e438f5f
Summary:
Per title.
We move all the individual gradient norms to a single device before stacking (no-op if all the gradients are already on a single device), `clip_coef` is copied to the device of gradient, which may be suboptimal as there could be multiple copies, but no worse than when we were synchronizing for each parameter. In a simple case of all gradients on a single device, there should be no synchronization.
Also, we no longer error out if parameter list is empty or none of the parameters have gradients, and return 0 total_norm instead.
Fixes https://github.com/pytorch/pytorch/issues/38605
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38615
Reviewed By: ailzhang
Differential Revision: D21634588
Pulled By: ngimel
fbshipit-source-id: ea4d08d4f3445438260052820c7ca285231a156b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37984
- `NumericUtils.h`
CUDA distribution kernels had two variants of transformation labdas(`uniform`/`normal` -> `lognormal`/`exponential`/`cauchy`/`geometric`...): for double-precision and optimized for CUDA single precision. It was done by using `::log`/`__logf`, `::exp`/`__expf` and `::tan/__tanf`. I moved them to `NumericUtils.h` and called them `at::exp`, `at::log` and `at::tan`. It allowed to unify CPU/CUDA transformation templates in `TransformationHelper.h`.
- `DistributionsHelper.h`
Made `normal_distribution`, `geometric_distribution`, `exponential_distribution`, `cauchy_distribution`, `lognormal_distribution` C10_HOST_DEVICE compatible to reuse them in CPU/CUDA distribution kernels.
Replaced explicit math with transformations from `TransformationHelper.h`
- `TransformationHelper.h`
Renamed `*_transformation` to `transformation::*`
Added clear unified host/device transformations templates `normal`, `cauchy`, `exponential`, `geometric`, `log_normal` which are used by both CPU and CUDA distribution kernels and custom PRNG distribution kernels.
- `cpu/DistributionTemplates.h`
Unified `normal_kernel`, `cauchy_kernel`, `log_normal_kernel`, `geometric_kernel`, `exponential_kernel`.
- `cuda/DistributionTemplates.h`
Extracted `UNIFORM_AND_TRANSFORM` and `NORMAL_AND_TRANSFORM` macros to reuse code between distribution kernel templates.
Unified transformation labdas(`uniform`/`normal` -> `lognormal`/`exponential`/`cauchy`/`geometric`...)
- `test_torch.py`
Added `scipy.stats.kstest` [Kolmogorov–Smirnov](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test) tests for `uniform`/`normal`/`lognormal`/`exponential`/`cauchy` distributions and [Chi-squared](https://en.wikipedia.org/wiki/Chi-squared_test) test for `geometric` one. To make sure that our distributions are correct.
- `cpu_rng_test.cpp`, `rng_test.h`
Fixed random_()'s from and to bounds issue for floating-point types, fixed cast/overflow warnings
- `THTensorRandom.h`, `THVector.h`
Moved unnecessary includes to `THTensorRandom.cpp`
Test Plan: Imported from OSS
Differential Revision: D21477955
Pulled By: pbelevich
fbshipit-source-id: 7b793d1761a7a921c4b4a4a7d21d5d6c48f03e72
Summary:
We have a bug where Function names are not uniqued which produces bad printed output, e.g:
```
{
for (int i0 = 0; i0 < 1024; i0++) {
input[i0] = t0[0 + i0 * 1];
}
for (int i0_1 = 0; i0_1 < 1024; i0_1++) {
input_1[i0_1] = t1[0 + i0_1 * 1];
}
for (int v = 0; v < 1024; v++) {
aten_add[v] = (input(v)) + float(1) * (input(v));
}
for (int v_1 = 0; v_1 < 1024; v_1++) {
aten_sub[v_1] = (aten_add(v_1)) - float(1) * (input(v_1));
}
}
```
Notice the names of the vars in the `aten_add` line which make it appear as though input_1 isn't used. This is because the Buf names are uniqued by the unique_name_manager but the FunctionCall names are not.
Not fixing this right now, but working around it by reducing the number of Tensors that are created with the same name ("input") in kernel.cpp. That example now looks like:
```
{
for (int i0 = 0; i0 < 1024; i0++) {
input1[i0] = t0[0 + i0 * 1];
}
for (int i0_1 = 0; i0_1 < 1024; i0_1++) {
input2[i0_1] = t1[0 + i0_1 * 1];
}
for (int v = 0; v < 1024; v++) {
aten_add[v] = (input1(v)) + float(1) * (input2(v));
}
for (int v_1 = 0; v_1 < 1024; v_1++) {
aten_sub[v_1] = (aten_add(v_1)) - float(1) * (input1(v_1));
}
}
```
To be clear, the bug still exists but it's not blocking what I'm trying to do right now 😄
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38678
Differential Revision: D21630276
Pulled By: nickgg
fbshipit-source-id: 39dec2178cf492302bc5a61e1e688ae81513858a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38478
Before this PR, the QAT ConvBN module inlined the batch normalization code
in order to reproduce Conv+BN folding.
This PR updates the module to use BN directly. This is mathematically
equivalent to previous behavior as long as we properly scale
and fake quant the conv weights, but allows us to reuse the BN code
instead of reimplementing it.
In particular, this should help with speed since we can use dedicated
BN kernels, and also with DDP since we can hook up SyncBatchNorm.
Test Plan:
```
python test/test_quantization.py TestQATModule
```
Imported from OSS
Differential Revision: D21603230
fbshipit-source-id: ecf8afdd833b67c2fbd21a8fd14366079fa55e64
Summary:
It seems like all this time this was accidentally doing a 3-way merge-base, oops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38661
Test Plan:
```
$ git checkout gh/mohammadmahdijavanmard/1/head
$ git merge-base origin master HEAD --all
8292742ba020fcff90f14418c18741ebf606103b
$ git merge-base origin/master HEAD --all
324dc1623e2f91892038fb1b151450a7c6529dd9
```
Differential Revision: D21640939
Pulled By: yns88
fbshipit-source-id: 0f59922e7c0fd046f48fec30e8aa25c244f6dd62
Summary:
Use recursive glob to make `aten_headers` and `torch_headers` declaration more compact
Use list generator to define torch_cpp_api tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38699
Differential Revision: D21635357
Pulled By: malfet
fbshipit-source-id: ecab437d471b6be0c3caf669d4f59fcda9409249
Summary:
`buffer` is also used to refer to `nn.Module`'s buffer. Wording is changed to reduce confusion between the two.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38625
Differential Revision: D21629396
Pulled By: albanD
fbshipit-source-id: acb5ef598739efabae7b388e1a4806c9caf0f589
Summary:
Fix https://github.com/pytorch/pytorch/issues/37500
I messed up with the old PR https://github.com/pytorch/pytorch/pull/37755 during rebasing and thus opened this one.
- Add call to `populate_cpu_children` for `__str__` to make sure that the printed result is correctly populated.
- Add test `test_profiler_aggregation_table`
- Fix a minor typo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37816
Reviewed By: ilia-cher
Differential Revision: D21627502
Pulled By: ngimel
fbshipit-source-id: 9c908986b6a979ff08c2ad7e6f4afac1f5fbeebb
Summary:
This PR removes the deferred initializer field from ReduceOp in favour of eagerly initializing buffers when they are created (either in the constructor of `LoopNest`, or in `rfactor()`). This allows a pretty good simplification of reduction logic, removing almost all of the reduction expander and the ReduceInitCleaner & unpopular NoOp node added in the last fix.
Eager initialization is better for us anyway because it allows more opportunities to transform the initialization loop.
Added a few more tests, testReduceOverSplitWithTail failed before this change due to a bug in splitWithTail which now can't happen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38585
Differential Revision: D21621551
Pulled By: nickgg
fbshipit-source-id: 378137e5723b4a6d6e390239efb12adce22a8215
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38584
All observers will support tensor lists in future PR
Test Plan: Imported from OSS
Differential Revision: D21623464
fbshipit-source-id: c5c57ecfe14f7c3aa92b7c99d724e846132ae03b
Summary:
Fix issue https://github.com/pytorch/pytorch/issues/23141#
In the below example ```default_collate``` collates each element of the list. Since the second element isn't present in all samples, it is discarded:
```
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
class CustomDataset(Dataset):
def __len__(self):
return 2
def __getitem__(self, idx):
tmp = {
"foo": np.array([1, 2, 3]),
"bar": ["X"] * (idx+1),
}
return tmp
training = CustomDataset()
for batch in DataLoader(training, batch_size=2):
print(batch)
```
Yields
```
{
'foo': tensor(
[
[1, 2, 3],
[1, 2, 3]
]
),
'bar': [
('X', 'X'),
]
}
```
Based on discussion in the issue, it seems the best course of action is to error out in this case. This seems consistent with what is done for tensor elements, as seen in [TensorShape.cpp line 1066](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorShape.cpp#L1060) which is called when ```torch.stack``` is called. In this PR, I introduce a similar message to error out for lists.
SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38492
Differential Revision: D21620396
Pulled By: ezyang
fbshipit-source-id: 17f59fbb1ed1f0d9b2185c95b9ebe55ece701b0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38416
This diff primarily changes the `debugInfoMap` to map from strings to ints, instead of strings to strings. We were basically just converting these back to ints in Python so this avoid the extra conversions.
`arc lint` also exposed tons of linting issues so fixing those here as well.
Test Plan: Build Bot - the tests already check whether the debugInfoMap is correct.
Differential Revision: D21266522
fbshipit-source-id: e742dec272bb1bab1bee01542610802922abab6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38592
I'm not sure that using couldMoveAfter was incorrect, but using
couldMoveBefore is more consistent with other subgraph-extraction
passes (old fuser, create autodiff graphs, etc.), so it would make it
easier to unify their implementations after this change.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D21607856
Pulled By: ZolotukhinM
fbshipit-source-id: 970583af7859889d48aacf620ae028258e37a75f
Summary:
This replaces all "verbatim-sources" files comprising the workflow named 'build' in the CircleCI config with code generation. This shall facilitate an automated conversion to workflow-per-job.
Note that the '.circleci/config.yml' file has some strictly cosmetic changes in this PR: some keys are sorted and inline comments are removed (moved to the Python modules that generate the config).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38631
Differential Revision: D21623528
Pulled By: kostmo
fbshipit-source-id: d86bd7aea979f443db14b4a3898220faad6bd0da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38489
Remove module and operator observer macros.
ghstack-source-id: 104290763
Test Plan:
a. Verify that QPL is being sent while testing FB4A BI Cloaking:
{F236982877}
b. Verify that AI Benchmark is working on both module and operator level:
https://our.intern.facebook.com/intern/aibench/details/808056762618979
c. Verify that macosx segmentation effect by running buck run xplat/arfx/tracking/segmentation/tools:person_segmentation_demoAppleMac#macosx-x86_64:
{F236982853}
Reviewed By: ljk53
Differential Revision: D21540838
fbshipit-source-id: 516f84ef5673d4ceed38ae152440a5cbacc6ddaa
Summary:
**Summary**
This commit modifies `BUILD.bazel` to include all headers in
`jit/backends` in `torch_headers` so that they can be accessed
by external backend code that lives in a different repository.
**Test Plan**
Continuous integration.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38668
Differential Revision: D21623755
Pulled By: SplitInfinity
fbshipit-source-id: 7f77b70e056205444e5ae63b47d87d8791131c3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38589
This PR creates a unified way of decrementing the active call count on the client side by attaching a callback to the future returned by `TensorPipeAgent::send`.
ghstack-source-id: 104227074
Test Plan: CI/Sandcastle once tests PR's are merged.
Differential Revision: D21605779
fbshipit-source-id: c82396de6984876b09ee032ab1aa0f68a87005be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38448
This PR implements timeout support for RPCs, and respects the new per-RPC timeout functionality.
A map containing RPC futures, keyed by an expiration time, is populated by the send function for each RPC.
A separate watchdog thread polls this map and sets all incomplete futures with errors.
Note: we cannot set errors to a future with the lock held (this will trigger callbacks immediately and, if one of the callback functions tries to acquire the lock that we held when setting the error, we have a lock order cycle). Thus we add all incomplete futures to a list, and then iterate through the list outside the lock to set errors on those futures if necessary.
ghstack-source-id: 104227075
Test Plan: Will patch the testing diff on top of this to run tests.
Differential Revision: D21468526
fbshipit-source-id: 4514484ece6fb6be673427d44c7f3164ab3d9d7c
Summary:
GreaterOrEqual and LessOrEqual were added in opset 12, this PR adds support to export these operators to ONNX instead of using "not" and "less than" or "greater than".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38311
Reviewed By: hl475
Differential Revision: D21613795
Pulled By: houseroad
fbshipit-source-id: 121d936d9787876ecb19cf24d661261e4abc82ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38594
By default, we don't have parition name, so previous impl will fail to rewire the input into the split-convert output. It's usually a hidden perf issue instead of a correctness issue.
Test Plan:
Enhanced
```
buck test glow/fb/test:test_merge_inputs_nnpi_fp16nnpi
```
Reviewed By: tracelogfb
Differential Revision: D21608439
fbshipit-source-id: d72b06500a3b84f6747aa77cf9fd8754a4ff1195
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38507
With `--merge_fp32_inputs_into_fp16` we added some ops to the net with out net_pos, this makes the cardinality of blacklist pos smaller than number of op in the net. Previously, the updateInternalState() function of minimizer will just enter infinite loop. This diff fixed it by changing the loop condition.
Reviewed By: tracelogfb
Differential Revision: D21578777
fbshipit-source-id: 0d5373fa0a417ded1c80a2dc03248c07b1e0a320
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38521
In the RPC Retry Thread, we add retriable futures to a list under the lock, release the lock, add callbacks/set errors to those futures, then re-acquire the lock to clean up the retry map. We can simply clean up the retry map before releasing the lock and not acquire it again - this would be cleaner and may results in better perf if this reduces context switching between threads looking to acquire the retryMapLock.
ghstack-source-id: 104062147
Test Plan: CI, there are thorough tests in the RPC framework to test errors with retries.
Differential Revision: D21563085
fbshipit-source-id: 35e620892da630d082c032f5f9ce16e8a9ffdfaa
Summary:
Enable tests in tests/onnx/test_pytorch_onnx_onnxruntime.py for:
- Einsum
- SoftmaxCrossEntropy
- NLLLoss
- normalize
- pixel_shuffle
- test_interpolate_no_shape
- test_arange_dynamic
- test_slice_neg_large_negone
since there is a support in ORT for these operators.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37868
Reviewed By: hl475
Differential Revision: D21440528
Pulled By: houseroad
fbshipit-source-id: 4e590c554d000981bb12d4ce3ff4c175ed73a274
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38368
There is a need for some customers to enable/disable these flags
in the middle of QAT. To make it work properly with DDP,
we need to implement them using buffers so that they are replicated
properly to all the nodes.
This should solve issue https://github.com/pytorch/pytorch/issues/38081
Test Plan:
CI
Imported from OSS
Differential Revision: D21537607
fbshipit-source-id: 8c9da022beb7aaa44c658268f02f99dd5aee93fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38565
Also note this turns on "-Wno-unused-local-typedefs" because we are using dispatch macros for error checking.
Test Plan: Imported from OSS
Differential Revision: D21598478
Pulled By: gchanan
fbshipit-source-id: 28f9ad01bd678df0601a10d0daf3ed31c47c4ab2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38369
Seems we have a lot of variables in codegen that carry duplicate information.
This PR is removing them. It unifies all use sites to use the same instance
ghstack-source-id: 104067031
Test Plan: waitforsandcastle
Differential Revision: D21537983
fbshipit-source-id: 8d3ce3d3f712f7ba355e8c192798dfefaf847dac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38512
As we gradually making the RPC non-blocking on server side, the
processing of the same request can yield-run on different threads.
Hence, we need to populate thread_local states (e.g., ctx id) in
the continuation thread.
Fixes#38439
Test Plan: Imported from OSS
Differential Revision: D21583642
Pulled By: mrshenli
fbshipit-source-id: a79bce1cb207fd11f1fa02b08465e49badda65fc
Summary:
Edit: this has been updated to reflect the PR's current status, which has changed after review.
This PR updates the behavior of the assertEqual, assertNotEqual, and assert_allclose to be consistent with each other and torch.isclose. It corrects several additional bugs in the current implementations and adds extensive testing and comments, too.
These updates follow from changes to assertEqual like https://github.com/pytorch/pytorch/pull/34258 and https://github.com/pytorch/pytorch/pull/37069, and from our discussion of torch.isclose for complex tensors (see https://github.com/pytorch/pytorch/issues/36462), where we decided to implement a NumPy-compatible mathematical notion of "closeness" for complex tensors that is not a great fit for our testing framework.
The detailed changelist is:
- New test framework functions for comparing tensors and scalars
- Tensors are compared using isclose; the real and imaginary parts of complex tensors are compared independently
- Scalars are compared using the same algorithm
- assertEqual and assert_allclose now use this common comparison function, instead of each implementing their own with divergent behavior
- assertEqual-like debug messages are now available for all tensor and scalar comparisons, with additional context when comparing the components of sparse, quantized, and complex tensors
- Extensive testing of the comparison behavior and debug messages
- Small Updates
- assertEqual now takes an "exact_device" argument, analogous to "exact_dtype", which should be useful in multidevice tests
- assertEqual now takes an "equal_nan" argument for argument consistency with torch.isclose
- assertEqual no longer takes the "allow_inf" keyword, which misleadingly only applied to scalar comparisons, was only ever set (rarely) to true, and is not supported by torch.isclose
- Bug fixes:
- the exact_dtype attribute has been removed (no longer needed after https://github.com/pytorch/pytorch/pull/38103)
- message arguments passed to assertEqual are now handled correctly
- bool x other dtype comparisons are now supported
- uint8 and int8 tensor comparisons now function properly
- rtol for integer comparisons is now supported (default is zero)
- rtol and atol for scalar comparisons are now supported
- complex scalar comparisons are now supported, analogous to complex tensor comparisons
- assertNotEqual is now equivalent to the logical negation of assertEqual
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37294
Differential Revision: D21596830
Pulled By: mruberry
fbshipit-source-id: f2576669f7113a06f82581fc71883e6b772de19b
Summary:
**Summary**
This commit adjusts the `pybind` includes in `backend.h` so
that we can avoid exporting some unrelated headers during install (which
probably shouldn't be exposed anyway). In addition, the headers that this commit
removes are not used.
**Test Plan**
Continuous integration (includes tests for JIT backends).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38562
Differential Revision: D21601694
Pulled By: SplitInfinity
fbshipit-source-id: c8f8103d24cb4f10d9eb6b3657eed75878078945
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38477
A few specific uses (e.g. Thrift rpc parsing) don't need source thread
state to be copied over. In microbenchmarks, this seems to add ~500ns,
so split code across functions, so some code can use directly.
ghstack-source-id: 104190095
Test Plan:
- Existing code using at::launch exercises this codepath, so buck test mode/dev-nosan caffe2/test/...
- For the split version, primarily the Thrift-based change layered on top of this.
Differential Revision: D21573168
fbshipit-source-id: 2ef1f196b5177634d4ee7fdca7371d36906a69d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38434
We insert dequantize for each use in order to produce quantization patterns that will
later be fused, after that we should also remove extra dequantize node produced by this operation.
Test Plan: Imported from OSS
Differential Revision: D21597834
fbshipit-source-id: 18dfb2760bbb08932aa4e1d06f96cfc5fb37ed88
Summary:
**Summary**
This commit adds the headers required to define and use JIT backends to
`package_data` in `setup.py` so that they are exported and copied to the
same place as the rest of the headers when PyTorch is installed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38525
Differential Revision: D21601806
Pulled By: SplitInfinity
fbshipit-source-id: 1615dd4047777926e013d7dd14fe427d5ffb8b70
Summary:
Right now it is an unused alias to `torch_library` interface library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38408
Differential Revision: D21598250
Pulled By: malfet
fbshipit-source-id: ec9a2446b94e7ea68298831212005c2c80bbc95c
Summary:
After an early return, we conditionalize all further execution. This means that currently the pattern of
`if return elif return elif return` generates better code than `if return if return if return`. It's obviously not good to have semantically equivalent code generate worse IR, so we should rewrite the graph to handle this case. This came up in https://github.com/pytorch/pytorch/pull/37171
```
torch.jit.script
def test_foo(x: bool, y: bool):
if x:
return 1
return 2
print(test_foo.code)
```
generates:
```
def test_foo(x: bool,
y: bool) -> int:
_0 = uninitialized(int)
if x:
_1, _2 = True, 1
else:
_1, _2 = False, _0
if _1:
_3 = _2
else:
_3 = 2
return _3
```
while
```
torch.jit.script
def test_foo(x: bool, y: bool):
if x:
return 1
else:
return 2
print(test_foo.code)
```
generates:
```
def test_foo(x: bool,
y: bool) -> int:
if x:
_0 = 1
else:
_0 = 2
return _0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38282
Differential Revision: D21576733
Pulled By: eellison
fbshipit-source-id: 80cf1ad7fbda6d8d58557abbfb21c90eafae7488
Summary:
**Summary**
This commit removes a print statement added in https://github.com/pytorch/pytorch/issues/37994 that appears to
be for debugging and was most likely not intended to be commited.
**Test Plan**
Continuous integration.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38524
Differential Revision: D21587268
Pulled By: SplitInfinity
fbshipit-source-id: 6bdcdce647c45f5c0a2ba179a3545a1c0cae1492
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38505
This takes the testing of https://github.com/pytorch/pytorch/pull/38275, but doesn't include the kernel changes which are still being worked out.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D21580574
Pulled By: gchanan
fbshipit-source-id: f12317259cb7373989f6c9ad345b19aaac524851
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38149
This is for (#21290) (#31894)
Instead of putting "Pytorch master documentation" in header's html title, now we use "Pytorch 1.x.x documentation", this is similar to tensorFlow and numpy doc page.
In google search, we will get
Pytorch Documentation - Pytorch 1.x.x Documentation instead.
Test Plan: Imported from OSS
Differential Revision: D21586559
Pulled By: glaringlee
fbshipit-source-id: 2995709ac3c22dbb0183b5b4abfde7d795f1f8eb
Summary:
Replace hardcoded filelist in aten/src/ATen/CMakeLists.txt with one from `jit_source_sources`
Fix `append_filelist` to work independently from the location it was invoked
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38526
Differential Revision: D21594582
Pulled By: malfet
fbshipit-source-id: c7f216a460edd474a6258ba5ddafd4c4f59b02be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38400
* #38399 Added autograd tests, disabled jit autograd tests for complex and added a separate list for tests for complex dtype only
Test Plan: Imported from OSS
Differential Revision: D21572209
Pulled By: anjali411
fbshipit-source-id: 7036029e9f8336139f5d54e0dfff9759f3bf8376
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37727
Check if the file exists locally only for `log_file_db` db_type. Reader files in other `db_type` like `manifold_log_file_db` are excluded from this check.
Test Plan: Verified that files stored in manifold can be loaded using `DBFileReader`.
Reviewed By: hbjerry
Differential Revision: D21329671
fbshipit-source-id: bbc0e88851783ca3f78f7c61bfe84b480c09b5ac
Summary:
Fixes a bug in the following code:
```
Tensor* c = Reduce("sum", {{10, "m"}}, Sum(), b, {{10, "n"}, {10, "k"}});
// split N loop with tail:
loop.splitWithTail(loop.getLoopStmtsFor(c)[1], 8, &outer, &inner, &tail);
```
When this is expanded there are two ReduceOps:
```
for (int m = 0; m < 10; m++) {
for (int n_outer = 0; n_outer < (10 - 0) / 8; n_outer++) {
for (int n_inner = 0; n_inner < 8; n_inner++) {
for (int k = 0; k < 10; k++) {
sum[m] = ReduceOp(sum, float(0), (sum[m]) + (b[m, n_outer * 8 + n_inner, k]), out_args={m}, reduce_args={n_inner, n_outer, k});
}
}
}
for (int n_tail = 0; n_tail < (10 - 0) % 8; n_tail++) {
for (int k = 0; k < 10; k++) {
sum[m] = ReduceOp(sum, float(0), (sum[m]) + (b[m, n_tail + ((10 - 0) / 8) * 8, k]), out_args={m}, reduce_args={n_tail, k});
}
}
}
```
But each ReduceOp will expand it's initializer, which in this case will overwrite the sum of the split loop:
```
for (int m = 0; m < 10; m++) {
sum[m] = 0.f;
for (int n_inner = 0; n_inner < 8; n_inner++) {
for (int k = 0; k < 10; k++) {
sum[m] = (sum[m]) + (b[(100 * m + k) + 10 * n_inner]);
}
}
sum[m] = 0.f; <------- *HERE*
for (int n_tail = 0; n_tail < 2; n_tail++) {
for (int k = 0; k < 10; k++) {
sum[m] = (sum[m]) + (b[((100 * m + k) + 10 * n_tail) + 80]);
}
}
}
```
The simplest fix is to remove the initializer from the tail loop, which requires adding support for Reductions without an initializer (I did via adding a NoOp Expr rather than handling nullptr). Also moved the ReductionExpander from loopnest.cpp to reduction.h as loopnest is getting a bit heavy.
Added tests for all kinds of splits on a simple 3D reduction to verify no more problems of this type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38420
Differential Revision: D21587583
Pulled By: nickgg
fbshipit-source-id: e0766934481917007119612eb60cc76c3242e44a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38422
This partially reverts #38021, due to the availability of #38418
Test Plan: Imported from OSS
Differential Revision: D21587201
Pulled By: malfet
fbshipit-source-id: c0717303c842ceb3a202986ec0e808ed45f682f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38418
This is useful in reducing verbosity in c10::complex's general usage, and potentially also offers
performance benefits.
This brings back #34506 (which was made for std::complex).
Differential Revision: D21587012
Test Plan: Imported from OSS
Pulled By: malfet
fbshipit-source-id: 6dd10c2f417d6f6d0935c9e1d8b457fd29c163af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38518
as title
Test Plan: buck test
Reviewed By: olittle
Differential Revision: D21562570
fbshipit-source-id: 3a2e8dea3d821a2bdb9f30db25816a2bfa6c5dcf
Summary:
closes https://github.com/pytorch/pytorch/issues/37855
Relies on https://github.com/pytorch/pytorch/pull/38483
Previous attempts to get this right:
* https://github.com/pytorch/pytorch/pull/38335
* https://github.com/pytorch/pytorch/pull/38279
* https://github.com/pytorch/pytorch/pull/37976
This reverts commit 80639604a82422e314890f154242202a43d264f9.
Improves the docker image build workflow from many steps to basically
transparent from a user's perspective.
To update docker images now all one has to do is edit the
.circleci/docker folder and it will update automatically and also
dynamically add the tags to the list of tags to keep from the garbage
collector.
Adding a new image will currently stay the same but we can explore doing
that dynamically as well.
How the build workflow works:
- Docker tags are determined by the hash defined from git for the
.circleci/docker sub-directory (extracted using git rev-parse)
- Images are only built if the computed hash is not found in ecr and
the hash is different than the previously computed hash. The
previously computed hash is found using the same process as before
but subbing out HEAD for the merge base between HEAD and the base
git revision
- That tag is then passed through the jobs using a shared workspace
which is added to downstream jobs using the circleci ${BASH_ENV}
How the new garbage collection works:
- Tags to keep are generated by stepping through all of the commits in
in the .circleci/docker subdirectory
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38484
Differential Revision: D21585458
Pulled By: seemethere
fbshipit-source-id: 37792a1e0f5e5531438c4ae61507639c133aa76d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38517
as title
Test Plan: buck test
Reviewed By: olittle
Differential Revision: D21562485
fbshipit-source-id: 573419e5a8dae4121d99d5b72ed3960a92db7a54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38449
Also update docs to reflect conv1d op support
Test Plan:
python test/test_quantization.py TestQuantizedFunctional.test_conv1d_api
Imported from OSS
Differential Revision: D21575921
fbshipit-source-id: 21c9f6b49ad456cd9d93e97f17cf5b8d87f0da6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38485
Python 2 has reached end-of-life and is no longer supported by PyTorch.
This class does nothing in Python 3.
Test Plan: CI
Reviewed By: ailzhang
Differential Revision: D21575260
Pulled By: dreiss
fbshipit-source-id: 184696c9fa501e8d2517950b47cdbc90b2ae8053
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35625
Python 2 has reached end-of-life and is no longer supported by PyTorch.
This function was already ifdef'ed out in Python 2.
Added a comment about when we might be able to remove this entire file.
Test Plan: CI
Differential Revision: D20842885
Pulled By: dreiss
fbshipit-source-id: 1fd3b1b2ff5a82caaf3bc11344dde2941427cfc0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35614
Python 2 has reached end-of-life and is no longer supported by PyTorch.
Now we can clean up a lot of cruft that we put in place to support it.
These changes were all done manually, and I skipped anything that seemed
like it would take more than a few seconds, so I think it makes sense to
review it manually as well.
Test Plan: CI
Differential Revision: D20842876
Pulled By: dreiss
fbshipit-source-id: 18abf0d324ed2185ec6d27c864e935d856dcc6ad
Summary:
This will support another round of migration from hand-written configs to code generation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38496
Differential Revision: D21581624
Pulled By: kostmo
fbshipit-source-id: aed814ef6d4fc6af9ce092727b2dacc99de14ae0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38352
Fixes the RPC profiling by using the `then()` API added in https://github.com/pytorch/pytorch/pull/37311. Instead of adding a regular callback, we return a new future that completes when the profiling callback is finished. This is transparent to the user as the future still completes with the value of the original future (i.e. the RPC's return value)
To make this work for RRef, we add a `_set_profiling_future` to set the profiling future, and `_get_profiling_future` to retrieve this future and wait on it in the tests.
Re-enabled profiling tests and stress tested them 1000 times to verify the fix
ghstack-source-id: 104086114
Test Plan: Re-enabled profiling tests
Differential Revision: D21506940
fbshipit-source-id: 35cde22f0551c825c9bc98ddc24cca412878a63a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37884
Adds support to use rpc_timeout param in rpc_async call from jit for
parity with eager mode. Done by:
1) Add timeout as an input in ir_emitter.cpp if it is specified
2) Parse float IValue from inputs in `prim::rpc_async` operator. Give the default if needed.
Added UTs in jit/rpc_test.
ghstack-source-id: 104083031
Test Plan: Added UTs in jit/rpc_test.
Differential Revision: D21268895
fbshipit-source-id: 34bb10a2ac08b67dd6b789121ab43e2c0e696229
Summary:
TorchScript currently doesn’t support `*args, **kwargs` in method signature, which is extensively used in DPER3 low-level modules’ forward method. In order to make DPER3 low-level modules scriptable, I was thinking about a solution of having a forward method *only* for TorchScript, and replace the forward method when we are not in scripting mode.
This solution works today, and I would like to add a test to make sure it will always work in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38158
Differential Revision: D21485657
Pulled By: yf225
fbshipit-source-id: df7368e8a5265418be7c305e6666ffd76e595466
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38267
Assert that the rpcTimeout is positive in RpcBackendOptions
constructor
ghstack-source-id: 104029918
Test Plan: CI
Differential Revision: D21509850
fbshipit-source-id: c925490e3d8fa2ffa42b0ae1170ca2f740af11f7
Summary:
These commits fixes a bug which was exposed when we took away the fallback path. The fix is to set the appropriate device before setting CUDA stream.
The improvement is when compiling, setting the device to new device only if it's different from prior device, and removing redundant call to cudaFree
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38365
Reviewed By: zheng-xq
Differential Revision: D21537469
Pulled By: protonu
fbshipit-source-id: b9662dd623b5c7cfd23eb6894e992a43665641e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38414
`std::to_string` call is unnecessary when using glog.
ghstack-source-id: 104030161
Test Plan: Ran the retry tests and checked logs to ensure correct message was printed upon message failure,
Differential Revision: D21266330
fbshipit-source-id: 53519287778d47d99b94ea34b7c551f910affda2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35624
Python 2 has reached end-of-life and is no longer supported by PyTorch.
This test case is valid syntax in Python 3.
Test Plan: CI
Differential Revision: D20842877
Pulled By: dreiss
fbshipit-source-id: 856e72171496aa1d517f2f27a8a5066462cf4f76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35623
Python 2 has reached end-of-life and is no longer supported by PyTorch.
This test case is valid syntax in Python 3.
Test Plan: CI
Differential Revision: D20842874
Pulled By: dreiss
fbshipit-source-id: 9f12e046f827d4f9d5eca99b0b0b46f73e06ff51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35621
Python 2 has reached end-of-life and is no longer supported by PyTorch.
`func.__wrapped__` can be used directly in Python 3.
Test Plan: CI
Differential Revision: D20842875
Pulled By: dreiss
fbshipit-source-id: 26f71df12db6d5118c8f278b27d747d647d07900
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35620
Python 2 has reached end-of-life and is no longer supported by PyTorch.
`self.subTest` can be used directly in Python 3.
Test Plan: CI
Differential Revision: D20842872
Pulled By: dreiss
fbshipit-source-id: 6ad42550c01e6959821ff07df767fc14b58c5a9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35618
Python 2 has reached end-of-life and is no longer supported by PyTorch.
Python 3 always uses true division.
Test Plan: CI
Differential Revision: D20842884
Pulled By: dreiss
fbshipit-source-id: 522e34bb584d4bdb01c9c40eb267955062a57774
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35617
Python 2 has reached end-of-life and is no longer supported by PyTorch.
Now we can clean up some cruft that we put in place to support it.
Test Plan: CI
Differential Revision: D20842883
Pulled By: dreiss
fbshipit-source-id: 18dc5219ba99658c0ca7e2f26863df008c420e6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38407
We can still run some quantized tests even when fbgemm/qnnpack isn't enabled
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D21554257
fbshipit-source-id: e4fa8f61f6a6717881c00620ed7938c01ffbf958
Summary:
Together with https://github.com/pytorch/pytorch/issues/37758, this fixes https://github.com/pytorch/pytorch/issues/37743 and fixes https://github.com/pytorch/pytorch/issues/24861.
This follows the CUDA fix in https://github.com/pytorch/pytorch/issues/37758, vectorised using a `blendv` to replace the if conditionals.
Most of the complication is from `remainder` supporting `at::Half` where `fmod` doesn't. I've now got `fmod` working on `Vec256<at::Half>` as well as enabling half dispatch for `fmod` so it matches `remainder`.
I also added `fmod` support to `Vec256<at::BFloat16>` before realising that `remainder` doesn't support `BFloat16` anyway. I could also enable `BFloat16` if that's desirable. If not, I don't think `Vec256<BFloat16>` should be missing `fmod` anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38293
Differential Revision: D21539801
Pulled By: ezyang
fbshipit-source-id: abac6a3ed2076932adc459174cd3d8d510f3e1d5
Summary:
Return unmodified type from decorator if fbgemm is present.
Fix `Tried to trace <__torch__.torch.classes.rnn.CellParamsBase object at 0x55f504c56b40> but it is not part of the active trace. Modules that are called during a trace must be registered as submodules of the thing being traced` thrown from `TestPostTrainingDynamic.test_quantized_rnn` by preserving modules in returned qRNNBase (i.e. by partially reverting https://github.com/pytorch/pytorch/pull/38134 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38432
Differential Revision: D21567333
Pulled By: malfet
fbshipit-source-id: 364fa2c8fc6e400b4f2e425b922a977756aec1d8
Summary:
Hi, I found the validation that is unreachable in `gradcheck` function :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37915
Differential Revision: D21551661
Pulled By: albanD
fbshipit-source-id: 8acadcc09cd2afb539061eda0ca5e98860e321eb
Summary:
This PR implements softmax support for sparse tensors.
The sparse softmax is related to dense softmax when the values of unspecified sparse tensor entries are taken to be `-inf` that will have the effect of "zero entries ignored". This relation is used for testing the correctness of results here.
Resolves https://github.com/pytorch/pytorch/issues/23651 for CPU.
- [x] sparse softmax
- [x] CPU C++ implementation
- [x] unittests
- [x] update softmax documentation
- [x] autograd support
- [x] sparse log_softmax
- [x] CPU C++ implementation
- [x] unittests
- [x] update log_softmax documentation
- [x] autograd support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36305
Differential Revision: D21566540
Pulled By: ezyang
fbshipit-source-id: a632ea69c38622f960721482e442efeb8d0a54fc
Summary:
Since the check was added in https://github.com/pytorch/pytorch/pull/6249, one can not pass an iterable as a sampler to the data loader anymore, which was a very handy feature (e.g., https://github.com/pytorch/pytorch/issues/1337). I think the check should be removed for two-fold reasons:
1. It is too strict. There is no reason that it should not be a general iterable.
2. It is inconsistent. In `DataLoader` (the main place where people use samplers), you can pass a general iterable as `batch_sampler` but not `sampler` due to this check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38403
Differential Revision: D21555958
Pulled By: soumith
fbshipit-source-id: c7267bb99a31edd8f2750689205d6edc5dab5cff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38430
Add `jit_core_[sources|headers]` to `build_variables.bzl`, use them from BUILD.bazel as wel as from internal build systems
Test Plan: CI
Reviewed By: suo
Differential Revision: D21555649
fbshipit-source-id: e78572465f36560806d646f147b2ef5a53ba1efe
Summary:
This file were separated from main CMakeLists.txt to enable mobile builds, but at the moment it is only referenced from CMakeLists.txt in parents folder
This is a preparatory step to move `jit_core_sources`,`jit_core_headers` to build_variables.bzl
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38426
Test Plan: CI
Differential Revision: D21567389
Pulled By: malfet
fbshipit-source-id: e6340fad1da75aa3e24d6c340df0c3e1e1957595
Summary:
CC ezyang xw285cornell sunway513
Forcing MAX_JOBS=4 was done 2 years ago. We have tested up to MAX_JOBS=256. OOM issues are no longer observed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38425
Differential Revision: D21566747
Pulled By: ezyang
fbshipit-source-id: f7f50e44a287268f1b06bcea3cb4e11c80260cc3
Summary:
Previously, we weren't adding the location to implicit conversions, so the error message wouldn't show location when these ops failed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38442
Differential Revision: D21563500
Pulled By: eellison
fbshipit-source-id: 19dd786ab8580f11ed919aac669efeed0ef52dcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37474
Previously we would segfault
Test Plan: Imported from OSS
Differential Revision: D21297542
Pulled By: suo
fbshipit-source-id: c7e2f828a250c490ec23fb51c6a4a642d3370e52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38283
Adds support for the modules and tests
Test Plan:
python test/test_quantization.py TestStaticQuantizedModule.test_conv1d_api
Imported from OSS
Differential Revision: D21553665
fbshipit-source-id: 7ea28da024bdf59f87f300d616c266f2b41f0bcd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38428
use and log a randomly generated seed with each test
Test Plan: locally tested
Reviewed By: amylittleyang
Differential Revision: D21554466
fbshipit-source-id: 008185d13116ec8553b082150a355ba87682bf6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38274
UnarySignKernels is one of the longest files to compile and Abs is not a sign function.
Test Plan: Imported from OSS
Differential Revision: D21511831
Pulled By: gchanan
fbshipit-source-id: f8572ab21321a241c984c64f7df83e2cb5e757d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38256
Removes hypothesis to speed these tests up, as these tests were flagged as top slow
tests in CI. At the same time, combines the fbgemm and qnnpack test
cases together for better reuse.
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_hardswish
python test/test_quantization.py TestQuantizedOps.test_qhardsigmoid
```
Imported from OSS
Differential Revision: D21506831
fbshipit-source-id: 9ff70e4ec7ae30b6948fe808878f0187e631f4d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38355
The torch::utils::Future api which this api was copied from last week
intentionally does not throw. Harmonize the semantics and comment
appropriately.
ghstack-source-id: 104014210
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D21533016
fbshipit-source-id: db26af32656d7b9dacf4fad4e77c944a0087c9b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37948
The input JIT graph has all the information we need to perform the
entire compilation at the construction time. We don't need to postpone
any steps until the execution time. Also, from the graph we always know
what device we will be executing on and thus we don't need to have a
CodeGen cache in TensorExprKernel - we always have one and only one
CodeGen.
Test Plan: Imported from OSS
Reviewed By: protonu
Differential Revision: D21432145
Pulled By: ZolotukhinM
fbshipit-source-id: 8dc86b891713056b2c62f30170cd4a168912f027
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38247
Per-channel quantized tensor axis value is shifted based on the unsqueeze/squeeze dim
Test Plan:
python test/test_quantization.py TestQuantizedTensor.test_qtensor_unsqueze
Imported from OSS
Differential Revision: D21550293
fbshipit-source-id: 90ea4a1bd637588360b3228cb5af9176176eb033
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38263
On my machine, compilation went from 4m8sec to the maximum of the files being compiled in 2m22sec.
Test Plan: Imported from OSS
Differential Revision: D21508985
Pulled By: gchanan
fbshipit-source-id: 2917cd5f30c6b31229053cada93c95e3a27ab29a
Summary:
Closes https://github.com/pytorch/pytorch/issues/24561
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.exp(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.exp(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.exp(a) a.numel() == 10000 for 20000 times torch.half
0.3001665159999902
torch.exp(a) a.numel() == 10000 for 20000 times torch.float
0.28265794499998265
torch.exp(a) a.numel() == 10000 for 20000 times torch.double
0.3432170909998149
torch.exp(a) a.numel() == 100000 for 20000 times torch.half
0.32273333800003456
torch.exp(a) a.numel() == 100000 for 20000 times torch.float
0.31498759600003723
torch.exp(a) a.numel() == 100000 for 20000 times torch.double
1.079708754999956
```
After:
```
torch.exp(a) a.numel() == 10000 for 20000 times torch.half
0.27996097300092515
torch.exp(a) a.numel() == 10000 for 20000 times torch.float
0.2774473429999489
torch.exp(a) a.numel() == 10000 for 20000 times torch.double
0.33066844799941464
torch.exp(a) a.numel() == 100000 for 20000 times torch.half
0.27641824200145493
torch.exp(a) a.numel() == 100000 for 20000 times torch.float
0.27805968599932385
torch.exp(a) a.numel() == 100000 for 20000 times torch.double
1.0644143180015817
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36652
Differential Revision: D21164653
Pulled By: VitalyFedyunin
fbshipit-source-id: 42c7b24b0d85ff1d390231f1457968a8869b8db3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38093
Benchmark (gcc 8.3, Debian Buster, turbo off, Release build, Intel(R) Xeon(R) E-2136, Parallelization using OpenMP):
```
import timeit
for dtype in ('torch.double', 'torch.float', 'torch.uint8', 'torch.int8', 'torch.int16', 'torch.int32', 'torch.int64'):
for n, t in [(40_000, 50000),
(400_000, 5000)]:
print(f'torch.linspace(0, 10, {n}, dtype={dtype}) for {t} times')
print(timeit.timeit(f'torch.linspace(0, 10, {n}, dtype={dtype})', setup=f'import torch', number=t))
```
With AVX
========
Before:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
1.0942596640015836
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
0.9209065200011537
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
1.0520610109997506
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
0.9031864690005023
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
1.949299545998656
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
1.82629113800067
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
1.9547776939980395
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
1.8259895039991534
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
2.759497356000793
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
2.6285490109985403
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
2.3456633150017296
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
2.2031515989983745
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
2.559069258000818
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
2.378239962999942
```
After:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
0.8100852870011295
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
0.18943897200006177
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
0.6679975400002149
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
0.17846923400065862
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
1.1431112539976311
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
0.3336703610002587
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
1.157699686998967
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
0.32964968899977976
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
1.5379577429994242
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
0.4638638729993545
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
1.360489848000725
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
0.4033017760011717
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
1.4591587399991113
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
0.44132660000104806
```
Without AVX
===========
Before:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
3.4967273879992717
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
3.330881046000286
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
2.176502857997548
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
2.023505228000431
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
2.117801246000454
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
1.9885458380013006
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
2.1057261179994384
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
1.9809251260012388
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
3.187070896001387
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
3.049615387000813
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
3.4874590049985272
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
3.33596555099939
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
4.256659758000751
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
4.100936053000623
```
After:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
1.9155298300029244
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
0.598213522000151
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
1.3183841649988608
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
0.40136947100108955
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
1.2191377319977619
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
0.35984685299990815
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
1.2153874989999167
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
0.35752785600197967
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
1.750796647000243
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
0.5376063230032742
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
1.9153429929974664
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
0.5952553579991218
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
2.281823589000851
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
0.7391443560009066
```
Differential Revision: D21528099
Test Plan: Imported from OSS
Pulled By: malfet
fbshipit-source-id: a6b3904e7860bb6d652a48b2056154509e73157d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37994
Before, reassigning a method in a module (like `forward = _forward`)
didn't work, because we look at the function object's name for our def
name when building AST. Mkae that overrideable to handle cases like
reassignment
Test Plan: Imported from OSS
Differential Revision: D21444535
Pulled By: suo
fbshipit-source-id: 4f045f18b5a146edc8005689af525d7d7ed8dd5f
Summary:
Before, multinomial kernels did not advance random states enough, which lead to the same sequence being generated over and over with a shift of 4. This PR fixes that.
Fixes https://github.com/pytorch/pytorch/issues/37403
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38046
Differential Revision: D21516542
Pulled By: ngimel
fbshipit-source-id: 23248a8c3a5c44316c4c35cd71a8c3b5f76c90f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37910
To resolve the issue: https://github.com/pytorch/pytorch/issues/36715
In tensorpipe rpc agent, we currently hardcoded localhost as pipes handshake IP address. This prevents us from setting up cross-host connections. As the first step, we start binding IP address for a given network device. For now it's defaulted to eth0. Will provide options to let user configure
Test Plan: CI
Reviewed By: lw
Differential Revision: D21421094
fbshipit-source-id: 60f612cbaeddcef7bd285136ad75af20709a7d56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38298
Moved unnecessary includes to `THTensorRandom.cpp`
Test Plan: Imported from OSS
Differential Revision: D21534864
Pulled By: pbelevich
fbshipit-source-id: bfec9cf5ce7587b1bd1674bc47850c16446621e9
Summary:
Fix for https://github.com/pytorch/pytorch/issues/37986
Follows the stack in https://github.com/pytorch/pytorch/pull/33783 stack to make functions in `torch/functional.py` resolve to their python implementations. Because the return type of `torch.unique` depends on `return_inverse` and `return_counts` I had to refactor the implementation to use our boolean_dispatch mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38156
Differential Revision: D21504449
Pulled By: eellison
fbshipit-source-id: 7efb1dff3b5c00655da10168403ac4817286ff59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37981
This additional parameter may be helpful in parallelize range factories
Differential Revision: D21506744
Test Plan: Imported from OSS
Pulled By: malfet
fbshipit-source-id: be9418216510ae600c555188971663fafb413fa0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/38018
when calling `eq_with_nan(v, kValue)` having `v` and `kValue` both `nan` is returning `false` when it should be `true`.
https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/SortingKthValue.cu#L76
The implementation is using intrinsics such as `__double_as_longlong` and comparing their bit representations. But the values of the bits obtained for both nans are different.
`9221120237041090560` for `v`
`9223372036854775807` for `kValue`
two different nans have different bit representations, so we have to do additional comparisons to fix this.
I changed this comparison and it seems to be working now.
However, when compared to a CPU implementation, the returned indices for the values seems to be random but valid.
Probably this is an effect of the comparison order in the Cuda version.
I am not sure if this is ok since all the indices point to valid elements.
For the snippet in the issue I get the following:
```
# CUDA Values
tensor([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan],
device='cuda:0', dtype=torch.float64)
# CUDA indices
tensor([304, 400, 400, 528, 304, 304, 528, 336, 304, 432, 400, 280, 280, 336,
304, 336, 400, 304, 336, 560], device='cuda:0')
```
```
# CPU values
tensor([nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan],
dtype=torch.float64)
# CPU indices
tensor([515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515, 515,
515, 515, 515, 515, 515, 515])
```
Also, maybe its better to change the `eq_with_nan` implementations to address this instead?
I am not sure if this will cause code to break in other places though ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38216
Differential Revision: D21517617
Pulled By: ngimel
fbshipit-source-id: deeb7bb0ac519a03aa0c5f365005a9150e6404e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38346
Given qtensor stores scale as double, this mismatch can cause use to
repack weights everytime in QNNPACK. Worse given that we release
original weights runtime can crash.
Test Plan:
pytest test/quantization/test_quantized_module.py::TestStaticQuantizedModule::test_conv2d_api
Imported from OSS
Differential Revision: D21529384
fbshipit-source-id: 859b763dee5476e1554ebc278c5b95199a298eab
Summary:
Make it so that non-nn Module classes do not need to be annotated with `torch.jit.script`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38050
Differential Revision: D21482654
Pulled By: eellison
fbshipit-source-id: 22689e4d7a33f6e1574b9495cff29a1fe6abb910
Summary:
This reverts commit 6e66e8562f276e2015af8ff76437a3f0277c4bcc.
Two things learned from the previous reland:
* `cirlceci-agent step halt` doesn't actually halt the step in place, you must explicitly exit the step after the `step halt` is called
* Even though `circleci` uses `git` to checkout repositories inside of docker images, that does not mean `git` is available after the fact.
<details>
<summary> Changes from previous reland </summary>
```patch
commit cc99a12c9029472bd73325876bc0e9dbb1746b05
Author: Eli Uriegas <eliuriegas@fb.com>
Date: Tue May 12 10:58:18 2020 -0700
.cirlceci: Install git for gc, exit step explicitly
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
diff --git a/.circleci/config.yml b/.circleci/config.yml
index 481d7889da..856a0fb10a 100644
--- a/.circleci/config.yml
+++ b/.circleci/config.yml
@@ -2018,13 +2018,15 @@ jobs:
export AWS_SECRET_ACCESS_KEY=${CIRCLECI_AWS_SECRET_KEY_FOR_DOCKER_BUILDER_V1}
eval $(aws ecr get-login --no-include-email --region us-east-1)
set -x
+ PREVIOUS_DOCKER_TAG=$(git rev-parse "$(git merge-base HEAD << pipeline.git.base_revision >>):.circleci/docker")
# Check if image already exists, if it does then skip building it
if docker manifest inspect "308535385114.dkr.ecr.us-east-1.amazonaws.com/pytorch/${IMAGE_NAME}:${DOCKER_TAG}"; then
circleci-agent step halt
+ # circleci-agent step halt doesn't actually halt the step so we need to
+ # explicitly exit the step here ourselves before it causes too much trouble
+ exit 0
fi
- PREVIOUS_DOCKER_TAG=$(git rev-parse "$(git merge-base HEAD << pipeline.git.base_revision >>):.circleci/docker")
# If no image exists but the hash is the same as the previous hash then we should error out here
- # no stampeding herd effect plz.
if [[ ${PREVIOUS_DOCKER_TAG} = ${DOCKER_TAG} ]]; then
echo "ERROR: Something has gone wrong and the previous image isn't available for the merge-base of your branch"
echo " contact the PyTorch team to restore the original images"
diff --git a/.circleci/ecr_gc_docker/Dockerfile b/.circleci/ecr_gc_docker/Dockerfile
index d0198acb86..36347d5e6d 100644
--- a/.circleci/ecr_gc_docker/Dockerfile
+++ b/.circleci/ecr_gc_docker/Dockerfile
@@ -1,6 +1,6 @@
FROM ubuntu:16.04
-RUN apt-get update && apt-get install -y python-pip && rm -rf /var/lib/apt/lists/* /var/log/dpkg.log
+RUN apt-get update && apt-get install -y git python-pip && rm -rf /var/lib/apt/lists/* /var/log/dpkg.log
ADD requirements.txt /requirements.txt
diff --git a/.circleci/verbatim-sources/docker_jobs.yml b/.circleci/verbatim-sources/docker_jobs.yml
index e04d11c5cd..3918cc04ae 100644
--- a/.circleci/verbatim-sources/docker_jobs.yml
+++ b/.circleci/verbatim-sources/docker_jobs.yml
@@ -35,13 +35,15 @@
export AWS_SECRET_ACCESS_KEY=${CIRCLECI_AWS_SECRET_KEY_FOR_DOCKER_BUILDER_V1}
eval $(aws ecr get-login --no-include-email --region us-east-1)
set -x
+ PREVIOUS_DOCKER_TAG=$(git rev-parse "$(git merge-base HEAD << pipeline.git.base_revision >>):.circleci/docker")
# Check if image already exists, if it does then skip building it
if docker manifest inspect "308535385114.dkr.ecr.us-east-1.amazonaws.com/pytorch/${IMAGE_NAME}:${DOCKER_TAG}"; then
circleci-agent step halt
+ # circleci-agent step halt doesn't actually halt the step so we need to
+ # explicitly exit the step here ourselves before it causes too much trouble
+ exit 0
fi
- PREVIOUS_DOCKER_TAG=$(git rev-parse "$(git merge-base HEAD << pipeline.git.base_revision >>):.circleci/docker")
# If no image exists but the hash is the same as the previous hash then we should error out here
- # no stampeding herd effect plz.
if [[ ${PREVIOUS_DOCKER_TAG} = ${DOCKER_TAG} ]]; then
echo "ERROR: Something has gone wrong and the previous image isn't available for the merge-base of your branch"
echo " contact the PyTorch team to restore the original images"
```
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38335
Differential Revision: D21536269
Pulled By: seemethere
fbshipit-source-id: 5577f84fa49dd6e1e88fce461646fd68be3d417d
Summary:
**Summary**
This commit modifies the JIT frontend to handle `del` statements with
variables as targets by dropping the mapping corresponding to that
variable from the environment stack maintained by the IR emitter code.
**Test Plan**
This commit adds test cases for deleting a variable, deleting a variable
and then using it, and deleting a variable in a if-statement, and then
using it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37608
Differential Revision: D21507239
Pulled By: SplitInfinity
fbshipit-source-id: ac7e353817dc76990ece294c95965cf585d6bdfb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38266
Add the client/server active and async call counters to the
Tensorpipe Agent metrics.
ghstack-source-id: 103949985
Test Plan: CI
Reviewed By: lw
Differential Revision: D21509236
fbshipit-source-id: 66277f44d974c929a65e87bd270222d0ae27395e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38265
Tracking the active calls counts in the TensorPipe Agent:
* clientActiveCalls: running count of un-responded/un-errored RPC's sent
* serverActiveCalls: running count of un-responded RPC's received
* serverAsyncCallCount: running count of received RPC's set to be completed asynchronously
ghstack-source-id: 103949984
Test Plan: CI
Reviewed By: lw
Differential Revision: D21508957
fbshipit-source-id: 8be9dbf77ec06c138c8dd70443976d7bccee0f1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38253
This pass removes dropout and dropout_ nodes when training is false. It
requires to have run freeze_module pass which does both inlining and constant
propagation, without which training variable remains as attribute instead of
constant.
ghstack-source-id: 103939141
Test Plan: python test/test_jit.py TestScript.test_remove_dropout
Reviewed By: dreiss
Differential Revision: D21505863
fbshipit-source-id: 42ea45804e4653b625b6a254c8d8480757264aa8
Summary:
Reland of https://github.com/pytorch/pytorch/issues/38140. It got reverted since it broke slow tests which were only run on master branch(thanks mruberry !). Enabling all CI tests in this PR to make sure they pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38288
Reviewed By: mruberry
Differential Revision: D21524923
Pulled By: ailzhang
fbshipit-source-id: 3a9ecc7461781066499c677249112434b08d2783
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37990
The code in `ddp.{h, cpp}` and the corresponding pybind implementations are no longer used. The pybinded calls were all private APIs and only ran in unittests, so we should remove these unused APIs.
https://github.com/pytorch/pytorch/pull/20234 from a year ago also mentioned that we should delete `_dist_broadcast_coalesced`
Verified that all tests pass with cuda by running `test_c10d` on a gpu-enabled machine.
ghstack-source-id: 103885383
Test Plan: CI
Differential Revision: D21443879
fbshipit-source-id: 764d8681ca629056bfe2c260ffab47fa5bdf07ff
Summary: Python 2 has reached end-of-life and is no longer supported by PyTorch. To avoid confusing behavior when trying to use PyTorch with Python 2, detect this case early and fail with a clear message in C++.
Test Plan: waitforsandcastle
Reviewed By: orionr
Differential Revision: D21043062
fbshipit-source-id: ab448d2888f5048a0180598b882adfc67e31d851
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38255
Now that the futures are consolidated after
https://github.com/pytorch/pytorch/pull/35154, there is no
`torch.distributed.rpc.Future` and we do not need a special path. All futures
can now be profiled through the use of the jit operator defined in
record_function_ops.cpp
As a result, we also get rid of the record_function_ops.h file.
RPC profiling tests are currently disabled, although I re-enabled them locally
to ensure that they still work with this change.
ghstack-source-id: 103869855
Test Plan: CI
Differential Revision: D21506091
fbshipit-source-id: ad68341c9f2eab2dadc72fe6a6c59b05693434f2
Summary: removing hard coded dimensions
Test Plan: ran the test itself
Reviewed By: jspark1105, amylittleyang
Differential Revision: D21520255
fbshipit-source-id: a75043103c61b91b8f10f405abff4790292e92c4
Summary:
Add `max_numel` option to `hypothesys_utils.array_shapes`
Use it to limit tensor element count to 100K for tensors whose maximum number of elements can exceed 250K
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38304
Differential Revision: D21525483
Pulled By: malfet
fbshipit-source-id: fac132dc7274b9417141b708cc9535561a95fcb3
Summary:
Otherwise, zero-point can be out of range, if selected type is torch.qint8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38327
Differential Revision: D21525214
Pulled By: malfet
fbshipit-source-id: 989f58f79830ec7f616a68f0ab00661b15030062
Summary:
This reverts commit 1ab4f35499aa933677152aca6a1ba2cbe86639f8.
Without this PR, the OS try to find the DLL in the following directories.
- The directory from which the application loaded.
- The system directory. Use the GetSystemDirectory function to get the path of this directory.
- The 16-bit system directory. There is no function that obtains the path of this directory, but it is searched.
- The Windows directory. Use the GetWindowsDirectory function to get the path of this directory.
- The current directory.
- The directories that are listed in the PATH environment variable. Note that this does not include the per-application path specified by the App Paths registry key. The App Paths key is not used when computing the DLL search path.
If we use LoadLibraryEx with LOAD_LIBRARY_SEARCH_* flags, the directories are searched in the following order.
- The directory that contains the DLL (LOAD_LIBRARY_SEARCH_DLL_LOAD_DIR). This directory is searched only for dependencies of the DLL to be loaded.
- The application directory (LOAD_LIBRARY_SEARCH_APPLICATION_DIR).
- Paths explicitly added to the application search path with the AddDllDirectory function (LOAD_LIBRARY_SEARCH_USER_DIRS) or the SetDllDirectory function. If more than one path has been added, the order in which the paths are searched is unspecified.
- The System32 directory (LOAD_LIBRARY_SEARCH_SYSTEM32).
Advantages:
1. The directory that contains the DLL comes first and it's desirable for us, because the dependencies in `lib` should always be preferred.
2. The system directory is considered in the last place. According to some of the bug reports, the DLL load failure are caused by loading the conflicting ones in systemroot.
Neural:
1. The directories in `PATH` are not considered. Similar things happen as described in the previous point. So it may be beneficial for normal users. However, it may cause failures if there are some new dependencies if built from source. (Resolved by making the fallback to `LoadLibraryW` if error code is `126`)
Disadvantages:
1. LoadLibraryEx with LOAD_LIBRARY_SEARCH_* flags is only available for Win7/2008 R2 + KB2533623 and up. (Resolved by making the fallback to `LoadLibraryW` if it is not supported)
2. Failure during the call of `LoadLibraryEx` will lead to the OS to pop up a modal dialog, which can block the process if user is using a CLI-only interface. This can be switched off by calling `SetErrorMode`. (Resolved by calling `SetErrorMode`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38302
Test Plan:
Test some common cases (in a new repo maybe) including
1. Python 3.6/3.7/3.8, conda python, conda install
2. Python 3.6/3.7/3.8, conda python, pip install
3. Python 3.6/3.7/3.8, official python, pip install
Plus some corner cases like
1. Conflicting DLLs in systemroot or `PATH`
2. Remove some local dependencies and use global ones
References:
1. https://docs.microsoft.com/en-us/windows/win32/api/errhandlingapi/nf-errhandlingapi-seterrormode
2. https://docs.microsoft.com/en-us/windows/win32/api/libloaderapi/nf-libloaderapi-loadlibraryexa
3. https://docs.microsoft.com/en-us/windows/win32/dlls/dynamic-link-library-search-order#standard-search-order-for-desktop-applications
Differential Revision: D21524090
Pulled By: malfet
fbshipit-source-id: 0cf5e260c91759b0af8c7aa0950a488e3b653ef5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38073
Most of the generated return statements don't depend on the scalar type and it saves ~900 lines of generated code.
Test Plan: Imported from OSS
Differential Revision: D21476010
Pulled By: gchanan
fbshipit-source-id: 3fcc4db466d697c90abafb9da6c3f3644621810b
Summary:
This is a step toward re-automating most of the CircleCI `config.yml` generation so that it can be safely refactored into multiple `workflow`s.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38292
Differential Revision: D21519337
Pulled By: kostmo
fbshipit-source-id: 09cc4f97ac52f37ef6d8a6fb8f49eeead052b446
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38294
Optimize the reference int8 gemm using avx2 intrinsics
Test Plan:
Before this diff
7.72164 GF/s
After this diff
27.7731 GF/s
Reviewed By: amylittleyang
Differential Revision: D21516439
fbshipit-source-id: 2b596605eec6a338a295701a01cf2c8639204274
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30922
New c++14 feature we can use now
ghstack-source-id: 103767403
Test Plan: waitforsandcastle
Differential Revision: D18869644
fbshipit-source-id: 54541c8004b2116386668a31eb9b0410a603b7dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38284
Bias is used to calculate out channels
Test Plan: Imported from OSS
Differential Revision: D21515997
fbshipit-source-id: 5fe5ddd4c7ce5cc49d15c477b744994a3db5fc89
Summary:
Most test files have a ton of errors; there's not much point adding ignores for them though. The way of working is simply to run `mypy test/test_somefile.py`, fix up the errors, then add that file to the `files =` list in `mypy.ini`.
Can't add all of `test/*` by default, because the JIT test files have (on purpose) syntax errors that are meant to exercise the robustness of the JIT to bad annotations. Leave those alone for now.
_Depends on the ghstacked PRs in gh-38173, only the last 2 commits are new._
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38220
Differential Revision: D21503481
Pulled By: ezyang
fbshipit-source-id: 63026e73201c549d64647a03a20a4c6687720244
Summary:
There is now a `zmath.h` and `zmath_std.h`, where the latter is the copy-paste of the original `zmath.h` and supporting `std::complex`, and `zmath.h` is for supporting `c10::complex`. `zmath_std.h` will be removed eventually.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38037
Differential Revision: D21518177
Pulled By: anjali411
fbshipit-source-id: 18552e955dc31f95870f34962d709de0444804f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37797
This is slow (see comment in code).
Not fixing this yet, but at least adding a warning so people are aware and don't add new call sites.
ghstack-source-id: 103887226
Test Plan: waitforsandcastle
Differential Revision: D21390364
fbshipit-source-id: 7bff1c3b9756a16c9d9110f209c23bf557266dda
Summary:
Fixes https://github.com/pytorch/pytorch/issues/36594
In some cases, when using memory that was allocated in another process before doing any memory-related operation in PyTorch, there are errors because the GPU CUDA context is not completely initialized.
I guess there is an explicit reason to leave the context not initialized at first, and don't do it in `THCudaInit` where other CUDA calls are going on.
I'd like to discuss it in this PR.
Possible better solutions are
Initialize the device context in `fromDLPack` or `from_blob`, probably by creating some dummy array with one element. But this feels like a hack.
Another possibility is to catch the exception in `getDeviceFromPtr`, check if the context was initialized, and if not repeat this operation. but we will need to check for every device.
This PR bypasses the `getDeviceFromPtr` call which is the one causing the problem if we already know the device. This allows us to create the Tensor from the shared memory storage but the context will not be initialized. However, it will be when the tensor is accessed later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36714
Differential Revision: D21504557
Pulled By: ngimel
fbshipit-source-id: 173ccdeb7c2a2b0ece53dd50be97f2df577a5634
Summary:
Make Linear layer working correct when bias is False
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38002
Differential Revision: D21509679
Pulled By: malfet
fbshipit-source-id: c7077992cf414ecc557b39e5ed1e39ef01c8b347
Summary:
closes https://github.com/pytorch/pytorch/issues/37855
## .circleci: Improve docker image build workflow
Improves the docker image build workflow from many steps to basically
transparent from a user's perspective.
To update docker images now all one has to do is edit the
.circleci/docker folder and it will update automatically and also
dynamically add the tags to the list of tags to keep from the garbage
collector.
Adding a new image will currently stay the same but we can explore doing
that dynamically as well.
### How the build workflow works:
- Docker tags are determined by the hash defined from git for the
.circleci/docker sub-directory (extracted using git rev-parse)
- Images are only built if the computed hash is not found in ecr and
the hash is different than the previously computed hash. The
previously computed hash is found using the same process as before
but subbing out HEAD for the merge base between HEAD and the base
git revision
- That tag is then passed through the jobs using a shared workspace
which is added to downstream jobs using the circleci ${BASH_ENV}
### How the new garbage collection works:
- Tags to keep are generated by stepping through all of the commits in
in the .circleci/docker subdirectory
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37976
Differential Revision: D21511048
Pulled By: seemethere
fbshipit-source-id: e4b153a6078e3875f6cfa03a903b2e951d803cce
Summary:
**Summary**
This commit detects and prohibits the case in which `typing.List` is
used as an annotation without a type argument (i.e. `typing.List[T]`).
At present, `typing.List` is always assumed to have one argument, and
when it is used without one, `typing.List.__args__[0]` is nonempty and
set to some `typing.TypeVar` instance, which has no JIT type equivalent.
Consequently, trying to convert `typing.List` to a JIT type results in
a `c10::ListType` with `nullptr` for its element type, which can cause
a segmentation fault.
This is fixed by returning a `ListType` from
`jit.annotations.try_ann_to_type` only if the element type is converted
successfully to a JIT type and returning `None` otherwise.
**Test Plan**
I ran the code from the issue (https://github.com/pytorch/pytorch/issues/37530) that reported this problem and also ran some unit tests.
*Before*
```
$ python3 segfault.py
Segmentation fault (core dumped)
```
*After*
```
$ python3 segfault.py
Traceback (most recent call last):
...
RuntimeError:
Unknown type name 'List':
File "segfault.py", line 9
classmethod
def cat(cls, box_lists: List):
~~~~ <--- HERE
return cls(torch.cat([x for x in box_lists]))
'Boxes.cat' is being compiled since it was called from 'Boxes'
File "segfault.py", line 13
def f(t: torch.Tensor):
b = Boxes(t)
~~~~~ <--- HERE
c = Boxes(torch.tensor([3, 4]))
return Boxes.cat([b, c])
'Boxes' is being compiled since it was called from 'f'
File "segfault.py", line 13
def f(t: torch.Tensor):
b = Boxes(t)
~~~~~~~~~~~ <--- HERE
c = Boxes(torch.tensor([3, 4]))
return Boxes.cat([b, c])
```
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/37530.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38130
Differential Revision: D21485284
Pulled By: SplitInfinity
fbshipit-source-id: 9b51ef6340485a24c8b7cfb85832d4668b8ac51a
Summary:
…n Windows
Without this PR, the OS try to find the DLL in the following directories.
- The directory from which the application loaded.
- The system directory. Use the GetSystemDirectory function to get the path of this directory.
- The 16-bit system directory. There is no function that obtains the path of this directory, but it is searched.
- The Windows directory. Use the GetWindowsDirectory function to get the path of this directory.
- The current directory.
- The directories that are listed in the PATH environment variable. Note that this does not include the per-application path specified by the App Paths registry key. The App Paths key is not used when computing the DLL search path.
If we use LoadLibraryEx with LOAD_LIBRARY_SEARCH_* flags, the directories are searched in the following order.
- The directory that contains the DLL (LOAD_LIBRARY_SEARCH_DLL_LOAD_DIR). This directory is searched only for dependencies of the DLL to be loaded.
- The application directory (LOAD_LIBRARY_SEARCH_APPLICATION_DIR).
- Paths explicitly added to the application search path with the AddDllDirectory function (LOAD_LIBRARY_SEARCH_USER_DIRS) or the SetDllDirectory function. If more than one path has been added, the order in which the paths are searched is unspecified.
- The System32 directory (LOAD_LIBRARY_SEARCH_SYSTEM32).
Advantages:
1. The directory that contains the DLL comes first and it's desirable for us, because the dependencies in `lib` should always be preferred.
2. The system directory is considered in the last place. According to some of the bug reports, the DLL load failure are caused by loading the conflicting ones in systemroot.
Neural:
1. The directories in `PATH` are not considered. Similar things happen as described in the previous point. So it may be beneficial for normal users. However, it may cause failures if there are some new dependencies if built from source. (Resolved by making the fallback to `LoadLibraryW` if error code is `126`)
Disadvantages:
1. LoadLibraryEx with LOAD_LIBRARY_SEARCH_* flags is only available for Win7/2008 R2 + KB2533623 and up. (Resolved by making the fallback to `LoadLibraryW` if it is not supported)
2. Failure during the call of `LoadLibraryEx` will lead to the OS to pop up a modal dialog, which can block the process if user is using a CLI-only interface. This can be switched off by calling `SetErrorMode`. (Resolved by calling `SetErrorMode`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37763
Test Plan:
Test some common cases (in a new repo maybe) including
1. Python 3.6/3.7/3.8, conda python, conda install
2. Python 3.6/3.7/3.8, conda python, pip install
3. Python 3.6/3.7/3.8, official python, pip install
Plus some corner cases like
1. Conflicting DLLs in systemroot or `PATH`
2. Remove some local dependencies and use global ones
References:
1. https://docs.microsoft.com/en-us/windows/win32/api/errhandlingapi/nf-errhandlingapi-seterrormode
2. https://docs.microsoft.com/en-us/windows/win32/api/libloaderapi/nf-libloaderapi-loadlibraryexa
3. https://docs.microsoft.com/en-us/windows/win32/dlls/dynamic-link-library-search-order#standard-search-order-for-desktop-applications
What do you think, malfet ezyang ?
Differential Revision: D21496081
Pulled By: malfet
fbshipit-source-id: aa5e528e5134326b00ac98982f4db4b4bbb47a44
Summary:
Fixes https://github.com/pytorch/pytorch/issues/37259, fixes https://github.com/pytorch/pytorch/issues/20156
This lazily calls `at::init_num_threads` once for each thread by adding a call to `lazy_init_num_threads` in `at::parallel_for` and `at::parallel_reduce`.
If this solution is okay, then we should add the same to guard other places that might use MKL or OpenMP.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37461
Reviewed By: ezyang
Differential Revision: D21472763
Pulled By: ilia-cher
fbshipit-source-id: 889d6664f5bd4080037ade02ee324b1233992915
Summary:
Related to gh-36318
Mention `bfloat16` dtype and `BFloat16Tensor` in documentation. The real fix would be to implement cpu operations on 16-bit float `half`, and I couldn't help but notice that `torch.finfo(torch.bfloat16).xxx` crashes for `xxx in ['max', 'min', 'eps']`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37051
Differential Revision: D21476851
Pulled By: ngimel
fbshipit-source-id: fef601d3116d130d67cd3a5654077f31b699409b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38154
This should give better error messages and shorter stack traces on C++17 builds (e.g. fbcode)
ghstack-source-id: 103775564
Test Plan: waitforsandcastle
Differential Revision: D21483327
fbshipit-source-id: 184d1f9c0543bf43dc9713fa97fcc5955e7be319
Summary:
jit.ScriptModule deletes all the actual attributes but still uses the nn.Module implementation.
Since I don't know how to add this new set() to the ScriptModule, it is simpler to just raise a nice error for now.
I also reverted the logic so that an empty set() (which is always the case in a ScriptModule) means that everything is persistent.
cc zdevito should we open an issue to add this to the ScriptModule?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38131
Differential Revision: D21502183
Pulled By: albanD
fbshipit-source-id: 96f83098d9a2a9156e8af5bf5bd3526dd0fefc98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37958
All codegen invocations have been removed at this point, so this has no effect.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D21433215
Pulled By: gchanan
fbshipit-source-id: 1f58f3022fab6443e34f0201ae4b32b2a99725cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38157
This removes the error prone process of assembling `torch/__init__.pyi`
(and frequently forgetting to expose things), since now we can simply
rely on the true source file to get things done. Most of the old
codegen in gen_pyi.py is now rerouted to various files:
- `torch/_C/__init__.pyi` (the dumping pile of all misc bindings)
- `torch/_C/_nn.pyi` (NN function bindings)
- `torch/_C/_VariableFunctions.pyi` (torch function bindings)
`torch.types` grew a bunch more definitions that previously where
defined in `torch/__init__.pyi`
Some miscellaneous changes
- Fixed a bug where we treat single TensorList argument as implying
varargs are accepted. This is actually only supported on IntList.
This means we can correctly generate a stub for dequantize.
- Add missing manual stub for nonzero
- Switched torch/onnx/operators.py to directly refer to _C module,
since apparently mypy doesn't think that methods prefixed with
underscores get reexported. This may be a recurring theme; maybe
we need to find a better way to solve it.
Because I was really lazy, I dumped namedtuple definitions in both
`torch._C` and `torch._C._VariableFunctions`. This is definitely wrong.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21497400
Pulled By: ezyang
fbshipit-source-id: 07b126141c82efaca37be27c07255cb2b9b3f064
Summary:
Reduces lock contention and BlockPool management costs by tracking applicable state in per-device structures.
`THCCachingAllocator` now maintains a set of `DeviceCachingAllocator` objects (one per device) each of which maintains its own allocator state and operations.
Only global state remains in the top-level THCCachingAllocator object -- namely, `allocated_blocks`, the mapping between the raw storage pointers and the allocator's underlying Block structure. Global operations deal mostly with this translation and then pass the bulk of the work on to the device-specific allocator.
Conversely, device-specific state and operations are comprised mostly of managing the device's underlying blocks.
This has the following benefits:
- Performance: Access to the global pointer map is serialized independently of the per-device state -- reducing lock contention between operations on different devices.
- Simplicity: Managing the block pools in separate device-specific objects is conceptually more intuitive, simplifies the code and makes certain operations more efficient -- even in the absence of contention (e.g. free_cached_blocks, synchronize_and_free_events, emptyCache, get_all_blocks, etc.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37567
Differential Revision: D21458556
Pulled By: colesbury
fbshipit-source-id: ef56cb373797b180df72f0998ebc35972c892288
Summary:
Add a comment because at first glance there doesn't seem to be any need to specify branch and tag filters, just to make them glob to everything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38169
Differential Revision: D21496261
Pulled By: kostmo
fbshipit-source-id: 7f75bb466ceffd6b17d4c97d711a8eb6e8b3143a
Summary:
Implementation of the less popular proposal for eliminating overlap between LetStmt and Let: removing both and storing a mapping between Var and value Expr in the Block.
This complicates some tests but simplifies the IR by restricting where variable binding can occur.
I used the unit tests & python integration tests to verify this is correct but I'm unsure of coverage, particularly around the dependency checker in loopnest - ZolotukhinM your review would be useful there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37606
Differential Revision: D21467483
Pulled By: nickgg
fbshipit-source-id: b402d3fce4cacf35d75f300f0a7dca32a43b6688
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38078
`common_distributed` and `test_distributed` have some error codes that overlap but are for different reasons, for example, code 75 in `test_distributed` is "no cuda available" but in common_distributed it is "need at least 2 CUDA devices".
This is an issue because the tests in `test_distributed` now use the utils in `common_distributed`, so we could get the wrong reason for skipping tests.
It is also the source of test failures in https://github.com/pytorch/pytorch/pull/37990.
This diff makes it so that the test skipping logic is deduped and put into `common_distributed.py`, where it can be reused and then imported into `test_distributed`
ghstack-source-id: 103782583
Test Plan: CI
Differential Revision: D21466768
fbshipit-source-id: 53b5af36672ebd8b51ba8b42709d87e96cadef20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38147
We're seeing many warnings of the form:
```
/home/rvarm1/pytorch/torch/distributed/rpc/__init__.py:14: FutureWarning:
pybind11-bound class 'torch.distributed.rpc.R
Ref' is using an old-style placement-new '__setstate__' which has been
deprecated. See the upgrade guide in pybind11's
docs. This message is only visible when compiled in debug mode.
```
in test logs, it turns out this is because pybind recommends using `py::pickle`
instead of manually defining getstate and setstate (see https://github.com/pybind/pybind11/blob/master/docs/upgrade.rst#id5). Changing to use pybind's
recommendation will silence these warnings.
Note that return types need to be added to the function to satisfy the contract
pybind expects, but they don't return anything since we TORCH_CHECK(false) in
all cases.
ghstack-source-id: 103769585
Test Plan: CI
Differential Revision: D21446260
fbshipit-source-id: a477e4937b1d6134992c57467cdbe10f54567b8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38136
This was a bit trickier than I expected, because modules have
to be importable to be pickleable, but adding a module to another
module in the C API isn't really the right way to make it importable.
We hack around it by manually adding the module to sys.modules.
Thanks Richard Zou for an extremely useful prior attempt which helped
me make this work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21487840
Pulled By: ezyang
fbshipit-source-id: 368da9b9c50e5de4d7dd265e6f9f189a882d75c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38080
Originally, my plan was to just delete the torch.autograd stub, but
this triggered a bunch of downstream errors relating to non-existent
to _C modules, and so instead of ignoring those files, I decided to
add a minimal _C type stubs, where it was easy (cases which were
codegened I ignored).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21487841
Pulled By: ezyang
fbshipit-source-id: cfcc467ff1c146d242cb9ff33a46ba26b33b8213
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38175
Also, make Tensor derived from KernelScopedObject - we must have missed
that originally.
Test Plan: Imported from OSS
Reviewed By: resistor
Differential Revision: D21489136
Pulled By: ZolotukhinM
fbshipit-source-id: fe003f44ef1265629fd84befc2e9ec8f48d2fc4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35154
This is for issue https://github.com/pytorch/pytorch/issues/34999.
close https://github.com/pytorch/pytorch/issues/34999.
https://github.com/pytorch/pytorch/issues/34997 need more work.
This will make a few work items easier, like 1) Dist autograd profiler, 2) JIT annotation for Future.
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_rref_forward_chain --stress-runs 100
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par \
-r test_call_method_on_rref
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- 'test_rref_proxy_class \(fb\.test_rpc_fork\.RpcTestWithFork\)' --stress-runs 100
test_rref_proxy_reuse
test_handle_send_exceptions
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par \
-r test_script_call_python_return_future
```
Differential Revision: D7722184
fbshipit-source-id: bd92b855bfea4913d6672700590c57622fa86e0e
Summary:
I'm mostly done with cleaning up test/ folder. There're a bunch of remaining callsites but they're "valid" in testing `type()` functionalities. We cannot remove them until it's fully deprecated.
Next PR would mainly focus on move some callsites to an internal API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38140
Differential Revision: D21483808
Pulled By: ailzhang
fbshipit-source-id: 12f5de6151bae59374cfa0372e827651de7e1c0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38145
Now that if_constexpr is landed, we can make this more readable
ghstack-source-id: 103765920
Test Plan: waitforsandcastle
Differential Revision: D21480798
fbshipit-source-id: 8181d4731036373cc3a1868fd6f4baeebb426081
Summary:
del in python supports multiple operands, but PyTorch c++ frontend doesn't support that. To be consistent across different frontends, we decided to throw an exception when finding del with multiple operands inside torchscript.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38089
Test Plan: Unit tests in test/jit/test_builtins.py
Differential Revision: D21478900
Pulled By: SplitInfinity
fbshipit-source-id: 1cbd61301680c5d6652ef104996178cefcdd3716
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37999
Next step: make explicit type arguments less intrusive, or fine
a way to eliminate them entirely.
Test Plan: Imported from OSS
Differential Revision: D21445646
Pulled By: bhosmer
fbshipit-source-id: 106b3381acea473ca686ab42b5ca610c89f5c531
Summary:
Followup of https://github.com/pytorch/pytorch/issues/37848 I realized that it's better to condition on `Value` type instead of token type. So now it also support indexing through list variables (used to be list literal only).
Also apparently our eager frontend accept indexing with float list as well, so matched this edge case behavior as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37966
Reviewed By: suo
Differential Revision: D21439642
Pulled By: ailzhang
fbshipit-source-id: cedb8431ef38747d4aa9909a6bbf8e954dbe0e25
Summary:
Add read/write vectorization to non-persistent softmax kernels only. At this point launch logic has minimal changes, and `ILP=vectorization=2` is always used (the code can handle other values, but `ILP=2` has been the most consistent performer).
Dispatch to persistent / non-persistent kernels is unchanged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36485
Differential Revision: D21477775
Pulled By: ngimel
fbshipit-source-id: 9ff7fd243695d7bbf4121390085b64db0bbdef35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38143
It's a followup of https://github.com/pytorch/pytorch/pull/32556, where an error handling boilerplate code path was added to the FutureMessage callback.
However, I noticed that the FutureMessage could never be set with an error, because the FutureMessage is a member in OwnerRRef,
- OwnerRRef does not have a setError method yet.
- The FutureMessage is only used for signaling
- The value of the RRef is contained in the `value_` field.
With the Future being generalized, it could contain more value types, not limited to Message.
This PR migrates the OwnerRRef value from the `value_` field to the generic Future.
In a later PR, it will be super easy to add a `setError` method for OwnerRRef, which calls `future_.setError(..)`. (I decide to do it later. I think it's better to migrate the call sites together with adding the new `setError` method.)
Also, this fixes the issue pointed out by https://github.com/pytorch/pytorch/pull/31086/files#r422256916.
This PR was submitted as https://github.com/pytorch/pytorch/pull/32608.
ghstack-source-id: 103757743
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par \
-r test_call_method_on_rref
```
Differential Revision: D5707692
fbshipit-source-id: 83ce0e5e5e97acb9ce8230fce5e4a3d806478b02
Summary:
In the IR Simplifier when doing partial factorization of Round+Mod patterns we divide by the lower number, which could be zero. Add in a quick check against zero avoid the crash.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38055
Differential Revision: D21478486
Pulled By: nickgg
fbshipit-source-id: c5083f672e91662b7d1271d817cade7fa6c39967
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38017
added a more comprehensive set of tests for int8fc
there are some failures but this emulation gets us much closer than the
existing one
there is still more work coming in
Test Plan: the test itself
Reviewed By: amylittleyang
Differential Revision: D21368530
fbshipit-source-id: 318722c030b2a1f8de37adb7c8633f75057edfab
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/38120
Test Plan: build docs locally and attach a screenshot to this PR.
Differential Revision: D21477815
Pulled By: zou3519
fbshipit-source-id: 420bbcfcbd191d1a8e33cdf4a90c95bf00a5d226
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38052
The initial version of the TensorPipe agent required the user to specify the full map between workers' names and their ids, on each worker. However it's enough for each worker to just specify their name and id, as these can then be exchanged using the store.
Addresses #37784, although I think we can go further and use the store to also automatically assign ranks to workers, so that the user only needs to specify a name.
ghstack-source-id: 103741595
(Note: this ignores all push blocking failures!)
Test Plan:
On worker 0:
```
In [1]: import os
...: import torch
...: import torch.distributed.rpc as rpc
...: os.environ["MASTER_ADDR"] = "127.0.0.1"
...: os.environ["MASTER_PORT"] = "8765"
In [2]: rpc.init_rpc(name="foo", rank=0, backend=rpc.backend_registry.BackendType.TENSORPIPE, world_size=2)
In [3]: rpc.rpc_sync("bar", torch.add, args=(torch.full((2,2), 1), torch.full((2,2), 2)))
Out[3]:
tensor([[3., 3.],
[3., 3.]])
In [4]: rpc.rpc_sync("bar", torch.add, args=(1, 2))
Out[4]: 3
```
On worker 1:
```
In [1]: import os
...: import torch
...: import torch.distributed.rpc as rpc
...: os.environ["MASTER_ADDR"] = "127.0.0.1"
...: os.environ["MASTER_PORT"] = "8765"
In [2]: rpc.init_rpc(name="bar", rank=1, backend=rpc.backend_registry.BackendType.TENSORPIPE, world_size=2)
```
Then also tested by adding `rpc_backend_options=rpc.TensorPipeRpcBackendOptions(init_method="file:///tmp/init/foo")` to `rpc_init`.
Differential Revision: D21463833
fbshipit-source-id: b53d7af6fc060789358ac845aa1898ddea6e8f31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37962
Temporarily re-enable RecordFunction in lite interpreter when profiler key is not set,
this allows the profiler to work without profiled wrappers in the build
Test Plan: CI
Reviewed By: smessmer, linbinyu
Differential Revision: D21409120
fbshipit-source-id: 6f0311c8eb55537a03b8bdac69def18a496ec672
Summary:
`is_tensor` doesn't really have a reason to exist anymore (other than
backwards compatibility) and is worse for typechecking with mypy (see
gh-32824). Given that it may not be obvious what the fix is once mypy
gives an error, make the change in a number of places at once, and add
a note on this to the `is_tensor` docstring.
Recommending an isinstance check instead has been done for quite a
while, e.g. https://github.com/pytorch/pytorch/pull/7769#discussion_r190458971
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38062
Differential Revision: D21470963
Pulled By: ezyang
fbshipit-source-id: 98dd60d32ca0650abd2de21910b541d32b0eea41
Summary:
The root cause of incorrect rendering is that numbers are treated as a string if the data type is not specified. Therefore the data is sort based on the first digit.
closes https://github.com/pytorch/pytorch/issues/29906
cc orionr sanekmelnikov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31544
Differential Revision: D21105403
Pulled By: natalialunova
fbshipit-source-id: a676ff5ab94c5bdb653615d43219604e54747e56
Summary:
`qemu-x86_64 -cpu Haswell` jit compiels x86_64 code to the host OS but lacks support for AVX/AVX2 instruction set emulation, which makes it ideal target for testing instruction set violation (especially via static initializes) even if it runs on CPU physically capable of executing AVX2 instructions.
It's quite easy to validate, that it is the case, by invoking ATen's `basic` cpp test with dispatch set to AVX: `qemu-x86_64 -cpu Broadwell -E ATEN_CPU_CAPABILITY=avx ./bin/basic --gtest_filter=BasicTest.BasicTestCPU`
This PR adds extra step to CircleCI tessuite that executes `basic` test with default CPU capability for `pytorch-linux-[xenial|bionic]-py3.6-...-test` configurations using qemu and validates that it completes successfully. (And fails before https://github.com/pytorch/pytorch/pull/38088 is merged)
Closes https://github.com/pytorch/pytorch/issues/37786
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38094
Differential Revision: D21472278
Pulled By: malfet
fbshipit-source-id: 722d4eceac8ce6fbc336ab883819cf7fccea3a66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38066
Increasing priority for PinnedCPUAllocator to make sure it is set when CUDA is enabled.
Test Plan: buck test mode/dev-nosan //vision/fair/detectron2/tests:test_export_caffe2 -- 'testMaskRCNNGPU \(test_export_caffe2\.TestCaffe2Export\)'
Reviewed By: ppwwyyxx
Differential Revision: D21465835
fbshipit-source-id: 643cff30d35c174085e5fde5197ddb05885b2e99
Summary:
This pull request adds a check for ROCm environment and skips adding CUDA specific flags for the scenario when a pytorch extension is built on ROCm.
ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38047
Differential Revision: D21470507
Pulled By: ezyang
fbshipit-source-id: 5af2d7235e306c7aa9a5f7fc8760025417383069
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38033
Pickles require class names to be actually accessible from the module
in question. _VariableFunction was not! This fixes it.
Fixes https://github.com/pytorch/pytorch/issues/37703
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21458068
Pulled By: ezyang
fbshipit-source-id: 2a5ac41f9d1972e300724981b9b4b84364ddc18c
Summary:
I think it would be nice to have these extra README links here so they're easier to find. There are even more READMEs throughout the source tree that I didn't include, but most of them seem to have pretty minimal information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38049
Differential Revision: D21470749
Pulled By: ezyang
fbshipit-source-id: aa164a3776ab90f2453634082eeae20c0dd002ce
Summary: Issue was introduced in D21258652. We need to make sure it compiles with opt mode. We may still have some left over py2 packages. Let's just use some format work with both.
Test Plan: ci
Reviewed By: xush6528
Differential Revision: D21457394
fbshipit-source-id: cde79a0fc6b4feba307bd9d45e1a1d4a42de9263
Summary:
It is currently broken due to a ninja bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37917
Differential Revision: D21470357
Pulled By: ezyang
fbshipit-source-id: c0ed858c63a7504bf2c4961dd7ed906fc3f4502a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38045
We are working on fixing these (e.g.
https://github.com/pytorch/pytorch/pull/37311) but a few PRs still need to land
before these tests are fixed. Disable them for now to avoid noise
ghstack-source-id: 103701518
Test Plan: CI
Differential Revision: D21461340
fbshipit-source-id: fbb029a19a93d439c9fce8424be0fb6409b52ff3
Summary:
**Summary**
This commit adds `torch::jit::RegisterBackend`, an API that allows
external backends to be registered for the execution of JIT subgraphs
outside the JIT interpreter. In order to register an external backend,
one must extend the provided abstract class `PyTorchBackendInterface` and provide
two additional functions: one that creates an instance of the aforementioned subclass
of `PyTorchBackendInterface`, and another that preprocesses a `ScriptModule` so that
it can run on the backend. Then, a `ScriptModule` that can compile and execute a given
JIT subgraph using the functions provided at registration time is generated
for each registered backend.
**Testing**
This commit adds a unit test that uses a minimal test backend
to make sure that the registration endpoint and generated
`ScriptModule` work.
```
$ python test/test_jit.py TestBackends
Fail to import hypothesis in common_utils, tests are not derandomized
.
----------------------------------------------------------------------
Ran 1 test in 0.183s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35833
Differential Revision: D21231955
Pulled By: SplitInfinity
fbshipit-source-id: 452db1123d0e5d83f97fe5da8a00fdfdb50dbef9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37937
Sometime traces models dont preseve aten::linear ops and they are decomposed
into addmm or mul + add. Adding thie preprocessing step helps us catch more
lowerable linear nodes.
Please see the test for example.
Test Plan: python test/test_xnnpack_integration.py
Reviewed By: xcheng16
Differential Revision: D21428069
fbshipit-source-id: 6c4ea3335eaf5722852c639fb4ee593746bb408f
Summary:
I've picked wrong revision when landed the diff, it should have had an actual check rather than `if True`:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38058
Differential Revision: D21466152
Pulled By: malfet
fbshipit-source-id: 03fdc510562fab44b7d64a42284d4c3c1f8e940a
Summary:
The IR Simplifier early exits when working with dtypes that are not safe to reorder. There are some cases where we still want to simplify ops in these dtypes: x + 0, x - 0, x * 0 and x * 1. It's safe to eliminate the op here and it reduces clutter in the expr.
Also added a quick simplification of casts which do nothing (their type is the same as the underlying).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37960
Differential Revision: D21457736
Pulled By: nickgg
fbshipit-source-id: 40e20a3b55fc1afb2ec50071812238a08bded2ac
Summary:
Fix https://github.com/pytorch/pytorch/issues/37680
Makes two changes:
- Add `argmin`, `argmax` and `argsort` to the list of non-differentiable functions to prevent them from generating outputs that requires_grad.
- Add a check to make sure we don't add such functions to the codegen by mistake.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37789
Differential Revision: D21389201
Pulled By: albanD
fbshipit-source-id: 6a7617e389e893f6f813d50f02700d32300b1386
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36291
Move profiler state to be a thread local property,
reuse existing thread local propagation mechanism to ensure
correct profiling of async tasks. This also makes
push/pop callback thread safe and easier to use in e.g.
distributed profilier
Test Plan:
USE_BLAS=MKL USE_MKLDNN=0 USE_CUDA=0 python setup.py develop install
./build/bin/test_jit
./build/bin/test_jit
python test/test_autograd.py
python test/test_jit.py
Differential Revision: D20938501
Pulled By: ilia-cher
fbshipit-source-id: c0c6c3eddcfea8fc7c14229534b7246a0ad25845
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37745
This PR makes it possible to set TLS callbacks and use
them transparently not only in the main thread but also
in any async tasks
Test Plan: Imported from OSS
Differential Revision: D21374873
Pulled By: ilia-cher
fbshipit-source-id: 3be2e121673b32d7694e17e794f3b474826dffe9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37548
Moving RecordFunction from torch::autograd::profiler into at namespace
Test Plan:
CI
Imported from OSS
Differential Revision: D21315852
fbshipit-source-id: 4a4dbabf116c162f9aef0da8606590ec3f3847aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37491
This PR modernizes RecordFunction API and adds thread local callbacks
in addition to the global ones
Changes:
- support for TLS callbacks, this is going to be the foundation of profiler and other tools
- modernize interface around simple set of functions (add|remove|has|clear)(Global|ThreadLocal)(Callback) and adding RecordFunctionCallback to easily construct callbacks to be passed
- we also add `.setShouldRun` into the callback interface to support cases when simple uniform sampling is not enough
- to properly support add/remove introduce the idea of callback handle returned by add
- internal implementation still uses SmallVector to store intermediate state (as before) - in this case these are vector of handles of callbacks that were picked to run
- to speed up runtime we keep these vectors sorted, this way we can quickly enumerate callbacks that need to be run
- added tests for new functionality
Test Plan:
BUILD_BINARY=1 USE_BLAS=MKL USE_MKLDNN=0 USE_CUDA=0 python setup.py
develop install
./build/bin/test_jit
CI
record_function_benchmark: https://gist.github.com/ilia-cher/f1e094dae47fe23e55e7672ac4dcda2f
Imported from OSS
Differential Revision: D21300448
fbshipit-source-id: 6d55c26dbf20b33d35c3f1604dcc07bb063c8c43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37956
This is basically just doing what the CPU code already does, but with keeping the kernel in THC, unlike in CPU where that has already moved to native.
Test Plan: Imported from OSS
Differential Revision: D21433211
Pulled By: gchanan
fbshipit-source-id: b7440aa50905b8c94b087eaa95f5b20a27b19d3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37973
Fix the unexpected memory usage issue in model QRT for the OC model.
Test Plan:
```
buck test mode/opt caffe2/caffe2/quantization/server:fully_connected_dnnlowp_op_test
```
```
buck test mode/opt caffe2/caffe2/fb/fbgemm:int8_serializer_test
```
Reviewed By: hx89
Differential Revision: D21422257
fbshipit-source-id: cc586123b8bfe41c85c6f2f7e493954845ad18a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37980
This implements `TensorPipeAgent::getMetrics` with the metrics currently available. Will add other metrics such as Client/Server Active Calls once time outs are implemented.
ghstack-source-id: 103624005
Test Plan: CI
Differential Revision: D21439184
fbshipit-source-id: 8a15df58cc23cdf954e604c0f806877ba111e0a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37852
This tracks network-related metrics in the Tensorpipe RPC Agent including number of bytes sent and recieved on each node, number of errors, number of successful calls, etc.
ghstack-source-id: 103681018
Test Plan: CI
Differential Revision: D21340499
fbshipit-source-id: 5682a3351a6394de92a7430869b24fc56c08d793
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37850
Adding the base structs for tracking time-series metrics in the Tensorpipe RPC Agent
ghstack-source-id: 103528373
Test Plan: CI
Differential Revision: D21339520
fbshipit-source-id: 8334044cdded44a940800c1d1f14d07ffab1a7e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37970
This change makes the pass friendlier for users who try to invoke it
directly.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D21444832
Pulled By: ZolotukhinM
fbshipit-source-id: 8be4b5028b3bd84082874e16f38a70b245af5d19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37595
QNNPACK currently does not support an unpack function. So we store the original weights in the packed structure which is directly returned to the user when unpack is called.
However for memory constrained environments (like mobile), storing these extra weights in memory is expensive. We need to release these weights after packing on mobile to free up the memory. As a side-effect user cannot call unpack on mobile once the model is run.
The change is gated by C10_MOBILE which is enabled for mobile builds.
The change saves 36MB on device for Speech Model.
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D21365495
fbshipit-source-id: 66465ea0b4a10d44187d150edfb90d989e872b65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37978
Faulty PGA tests now have message delayed by default. Tests that were written prior to this addition should explicitly turn this off since they are not designed to work reliably with message delays.
ghstack-source-id: 103622888
Test Plan: Stress-running this test with TSAN. Also added a sanity check in the verify_backend_options test that verifies the default value of `messages_to_delay`.
Differential Revision: D21440043
fbshipit-source-id: 78151f07a3294c3dfcfaeacd6a5e5b77a0f34da1
Summary:
Miniconda repo has moved from continuum.io to anaconda.com
Also we should be specific about cudatoolkit version so that it installs
the right CUDA version.
Resolves https://github.com/pytorch/pytorch/issues/37047
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37186
Differential Revision: D21443147
Pulled By: seemethere
fbshipit-source-id: 856718822bdd3ce51bbc6e59b0609fe6af77bd79
Summary:
This PR added more supported operations in CUDA fuser. We are covering major point-wise operations supported in legacy fuser.
In an attempt to adapt to legacy executor:
1. added an naive shape propagation pass on pytorch JIT IR;
2. small refactor on graph partitioning;
3. fallback interpreter execution of fusion group;
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37849
Reviewed By: yf225
Differential Revision: D21444320
Pulled By: soumith
fbshipit-source-id: 712e18ab8497f8d58a07e6f8d200cdab52cf0d74
Summary:
Also move the ignores for imports to the bottom in `mypy.ini`, those are much less interesting - start with the stuff people want to work on.
Second commit tests the instructions: remove an ignore, fix the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37594
Differential Revision: D21434858
Pulled By: ezyang
fbshipit-source-id: 4f1a6868cdb4cb59d072bcf105f48c3a5ba3ff98
Summary:
clamp_min is used in `torch.nn.functional.normalize`. Update symbolic_opset11 to support with updated clip in onnx opset 11.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37872
Reviewed By: hl475
Differential Revision: D21440450
Pulled By: houseroad
fbshipit-source-id: a59cbec3f4d00c3f6654da6a747fbfca59d618f1
Summary:
In D21209901 TensorPipe added support for a vector of payloads inside each message, instead of a single one, so that users with multiple payloads can send them separately as they are instead of having to copy them into a new block of contiguous memory. The PyTorch agent is using the old API, which is preventing us from deleting it. This change has no effects on over-the-wire format and thus on performance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37919
ghstack-source-id: 103572164
Test Plan:
On both workers
```
import os
import torch
import torch.distributed.rpc as rpc
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "8765"
```
On worker 0
```
rpc.init_rpc(name="foo", rank=0, backend=rpc.backend_registry.BackendType.TENSORPIPE, world_size=2, rpc_backend_options=rpc.TensorPipeRpcBackendOptions(worker_name_to_id={"foo": 0, "bar": 0}))
```
On worker 1
```
rpc.init_rpc(name="bar", rank=1, backend=rpc.backend_registry.BackendType.TENSORPIPE, world_size=2, rpc_backend_options=rpc.TensorPipeRpcBackendOptions(worker_name_to_id={"foo": 0, "bar": 0}))
```
On worker 0
```
In [15]: rpc.rpc_sync("bar", torch.add, args=(torch.full((2,2), 1), torch.full((2,2), 2)))
Out[15]:
tensor([[3., 3.],
[3., 3.]])
In [16]: rpc.rpc_sync("bar", torch.add, args=(1, 2))
Out[16]: 3
```
Differential Revision: D21425536
fbshipit-source-id: a0ec2be825556b39aff018a2834baf815a6d8fa5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37963
This function is still widely used in the codebase, so we don't want
to add noise to builds with a bunch of warnings. Seems like the
comment + macro are already pretty good indications that this
functionality is considered legacy
Test Plan: Imported from OSS
Differential Revision: D21434447
Pulled By: suo
fbshipit-source-id: 08162ed6502894ea5d3ccb92dfa0183232cc2ab5
Summary:
* Add error message when onnx model file path is not a string.
* Add error message when model size exceed 2GB when large model export is not turned on.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37798
Reviewed By: hl475
Differential Revision: D21440571
Pulled By: houseroad
fbshipit-source-id: 054aaa25ab0cffc229f9b487a2c160623c89b741
Summary:
Skip the tests if network is unaccessible and model can not be downloaded
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37972
Differential Revision: D21441996
Pulled By: malfet
fbshipit-source-id: 5ce59764584974aee9195572338ada1fa0351a75
Summary:
So far results looks quite promising: test_nn is purely sequential tests and can be accelerated 3x
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37180
Differential Revision: D21437871
Pulled By: malfet
fbshipit-source-id: 8679a8af355f839f2c9dae3bf36d2e102af05425
Summary:
There is no reason to put complex utilities to half header.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37676
Differential Revision: D21440270
Pulled By: anjali411
fbshipit-source-id: bbed5fcb5be33f6a4aedcc9932595d43d97672f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36847
Adds a quantized instancenorm operator, which can reuse most of
groupnorm's logic.
Benchmarking shows that the quantized version is about 10x faster than
floating point for equivalent input sizes
(https://gist.github.com/vkuzo/2f230e84d26f26cc6030afdbfbc8e7f0)
Test Plan:
```
python test/quantization/test_quantized.py TestQuantizedOps.test_instance_norm
```
Imported from OSS
Differential Revision: D21107925
fbshipit-source-id: 6bacda402f0eb9857bc8f9a5cf8ef306150613d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36835
Adds a quantized groupnorm operator. We reuse most of the layernorm
kernel, modifying it to be able to perform channel-wise scaling.
Benchmark results: the quantized layer is between 6x to 15x faster
from fp to q, depending on input shapes
(full results:
https://gist.github.com/vkuzo/db67623232415382dabff6c8923124e9)
Test Plan:
```
python test/quantization/test_quantized.py TestQuantizedOps.test_group_norm
python test/quantization/test_quantized.py TestQuantizedOps.test_qlayer_norm
```
Numerics are nearly equivalent, with the only difference documented
in the test case. The difference is the same type as with quantized
layernorm. Making numerics equivalent is possible but will sacrifice
speed.
Imported from OSS
Differential Revision: D21107926
fbshipit-source-id: 80e87e9e2c71310bc28c3d114c88de428819cb45
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37947
The current test is flaky, removing two potential causes of flakiness.
Test Plan:
CI
Imported from OSS
Differential Revision: D21434861
fbshipit-source-id: 82ea5762f3bb07a12052cde29729d73e95da8ddd
Summary:
Fixes https://github.com/pytorch/pytorch/issues/37157 on my machine.
This was annoying to track down. The essence is that cublas expects column major inputs and Pytorch tensors are usually row major. Cublas lets you request that it act on transposed data, and the erroring `gemv` calls in https://github.com/pytorch/pytorch/issues/37157 make that request. The problem is, [cublasSgemv and cublasDgemv](https://docs.nvidia.com/cuda/cublas/index.html#cublas-lt-t-gt-gemv) (called by [`gemv<float>`](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L318)) and `gemv<double>`) regard their `m, n` arguments values as _pre_-transpose sizes, while [cublasGemmEx](https://docs.nvidia.com/cuda/cublas/index.html#cublas-GemmEx) (called by `gemv<at::Half>`, see [here](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L342)) and [here](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L229))) regards its `m, k` argument values as _post_-transpose sizes. This is inconsistent. It turns out the `gemv<float>/<double>` calls are configured correctly and the `gemv<at::Half>` calls aren't.
Strikethrough text below is no longer accurate, ngimel suggested a better way to handle gemv->gemm forwarding. [Comments in code](https://github.com/pytorch/pytorch/pull/37569/files#diff-686aa86335f96b4ecb9b37f562feed12R323-R348) provide an up-to-date explanation.
Keeping out-of-date strikethrough text because I don't have the heart to delete it all and because it captures an intermediate state of my brain that will help orient me if i ever have to fix this again.
~~To convince myself this PR keeps `at::cuda::blas::gemv`'s external API consistent across dtypes, I need to think through what happens when a pytorch tensor input of size `(a,b)` multiples a vector of size `(b,)` for 4 cases:~~
### ~~1. input is row-major (needs cublas internal transpose)~~
#### ~~1a. input is float or double~~
~~`gemv<float>/<double>` call `cublasS/Dgemv`, forwarding `trans`,** `m`, and `n` directly.~~
~~`cublasS/Ggemv` expects "a m × n matrix stored in column-major format" (so m is the input's fast dim). Input has size `(a, b)` in row-major format. We can reinterpret it as a column-major matrix with size `(b, a)` without any memory movement. So the gemv call should supply `m=b`, `n=a`. However, we're not trying to multiply a matrix `(b, a)` x a vector `(b,)`, we're trying to sum across `b` for matrix and vector. So we also request that cublas transpose the matrix internally by supplying `trans='t'` to `blas::gemv`, which becomes `trans=CUBLAS_OP_T` to the `cublasS/Ggemv`.~~
~~As long as the code calling `blas::gemv` thinks carefully and passes `trans='t'`, `m=b`, `n=a`, cublas carries out `(a, b) x (b,)` and all is well.~~
#### ~~1b. input is half or bfloat16~~
~~`blas::gemv<at::Half>` takes a different code path, calling `gemm<at::Half>` which calls `cublasGemmEx`. The job of this PR is to make sure the exterior `blas::gemv` caller's carefully thought-out argument choices (`trans='t'`, `m=b`, `n=a`) remain correct.~~
~~`cublasGemmEx` takes args `transa, transb, m, n, k, ....others we don't care about` and carries out~~
```
C = α op ( A ) op ( B ) + β C
where α and β are scalars, and A , B and C are matrices stored in column-major format with
dimensions op ( A ) m × k , op ( B ) k × n and C m × n Also, for matrix A
A if transa == CUBLAS_OP_N
op ( A ) = A^T if transa == CUBLAS_OP_T ...
```
~~`gemv<at::Half>` hacks a gemv by calling gemm such that the raw gemm's `m` is the output dim, `k` is the summed dim, and `n=1`, . Reasonable, as long as we get the values right, given that we also need to transpose the input.~~
~~To conform with cublas docs we interpret input as column-major with size `(b, a)`. As for the `<float>/<double>` gemv we want cublas to carry out input (interpreted as column major), internally transposed, times vector of size `(b,)`. In other words we want cublas to apply `op(A) x B`, where op is transpose and `A` is input interpreted as column major. Docs define `m` and `k` by saying `op(A)` has dims `m x k` **(`m` and `k` are _post_-`op` sizes)**. `A` was `(b, a)`, `op(A)` is `(a, b)`, so the correct thing is to supply `m=a`, `k=b` to the underlying gemm. **For the `<float>/<double>` gemv, we passed `m=b`, not `m=a`, to the raw `cublasS/Dgemv`.**~~
~~The exterior `blas::gemv` must have been called with `trans='t'`, `m=b`, `n=a` (as required by the `<float>/<double>` versions). So when gemv is about to call gemm, **we [swap](https://github.com/pytorch/pytorch/pull/37569/files#diff-686aa86335f96b4ecb9b37f562feed12R330) the local values of `m` and `n` so that `m=a`, `n=b`,** then put `m (=a)` in the gemm's `m` spot, 1 in the gemm's `n` spot, and `n (=b)` in the gemm's `k` spot. All is well (we made the right gemm call after ingesting the same arg values as `blas::gemv<float>/<double>`).~~
### ~~2. input is column-major (doesn't need cublas transpose)~~
#### ~~2a. input is float or double~~
~~input is `(a,b)`, already column-major with strides `(1,a)`. Code calling `blas::gemv` supplies `trans='n'` (which becomes `CUBLAS_OP_N`, no internal transpose), `m=a`, `n=b`.~~
#### ~~2b. input is half or bfloat16~~
~~`blas::gemv` should pass `transa='n'`, `m=a`, `n=1`, `k=b` to the underlying gemm. The exterior `blas::gemv` must have been called with `trans='t'`, `m=a`, `n=b` (as required by the `<float>/<double>` versions). So **in this case we _don't_ swap `blas::gemv`'s local values of `m` and `n`.** We directly put `m (=a)` in the gemm's `m` spot, 1 in the gemm's `n` spot, and `n (=b)` in the gemm's `k` spot. All is well (we made the right gemm call after ingesting the same arg values as `blas::gemv<float>/<double>`).~~
~~** `trans` is a string `t` or `n` in the `at::cuda::blas::gemv` API, which gets [converted](091a1192d7/aten/src/ATen/cuda/CUDABlas.cpp (L314)) to a corresponding cublas enum value `CUBLAS_OP_T` (do transpose internally) or `CUBLAS_OP_N` (don't transpose internally) just before the raw cublas call.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37569
Differential Revision: D21405955
Pulled By: ngimel
fbshipit-source-id: e831414bbf54860fb7a4dd8d5666ef8081acd3ee
Summary:
We can implement this as a builtin instead of as a registered op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37886
Differential Revision: D21414329
Pulled By: eellison
fbshipit-source-id: 6e130fa83fbf7ba4d4601f509cb169a2fa804108
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37640
Enable oversize arena to reduce memory fragmentation. Memory request with large size (configurable with FLAGS_caffe2_oversize_threshold) are fulfilled from dedicated arena separate from the existing huge page arena.
Two additional parameters are introduced to configure the 2-phase decay of the memory arena:
- caffe2_dirty_decay_ms
- caffe2_muzzy_decay_ms
In current JEMalloc implementation, oversized allocations will be immediately purged regardless of putting it in arena or not. Therefore we need to extend the decay time to indefinite. Currently we set the default for caffe2_muzzy_decay_ms to -1.
We now enable the arena allocator statically. To ensure it is correctly installed regardless of static initialization order, we add a priority flag in c10::SetAllocator, and only higher priority allocators can overwrite existing ones.
ghstack-source-id: 103276877
Test Plan:
buck test mode/dev //caffe2/caffe2/fb/init:huge_pages_allocator_test
Benchmarking known CV model that benefits from page arena:
```
PyTorchModelBench.cpp:183] test / base : 86.9532%
```
By adjusting ```dirty_decay_ms``` and ```muzzy_decay_ms```, we have the following plots:
https://pxl.cl/15SWWhttps://pxl.cl/15TnL
From the figures above we can see performance does not change much until dirty decay time is indefinite (set to -1). Either setting muzzy decay or dirty decay time to -1 will reach best performance, regardless of which one it is. Even setting the decay time to very long (100s, which is longer than the run), does not change the performance by much.
## Observe performance difference in production with a variety of models (WIP)
Reviewed By: dzhulgakov
Differential Revision: D21258581
fbshipit-source-id: c006f8b94f28aef0666e52f48d4e82cf0d3a48af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37964
I thought it was because of flakiness that we didn't pass the conv2d_relu test, but turns out to
be a typo in the implementation
Also re-enabled the `use_fused` option in `test_conv2d_api`
Test Plan:
.
Imported from OSS
Differential Revision: D21434776
fbshipit-source-id: 7c24c13cde0a96807e8dfbd1deabf47e8280fdb7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37615
We probably missed a lot of these when we ported things from TH, but it's also probably not a huge deal. There is only one left with fmod.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D21338030
Pulled By: gchanan
fbshipit-source-id: c133b4e37df87a53797939e9f757cea9446834e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37936
Previously we classify ops like average pool to the category that doesn't require observation and
the quantization of these ops are done by swapping with dequantize ops: https://github.com/pytorch/pytorch/pull/33481
However, this operation is done in finalize, which means finalize is a numerics changing pass when we swap dequantize with
ops like average pool, this is not ideal since we want to restrict the scope of numerics changing passes.
Because although average pool doesn't require observation, quantized average pool = dequant + float32 average pool + quant
and swapping average pool with dequantize is a numerics changing operation.
This PR implements the support for that. We'll classify ops like average pool to a new category and we'll get average pool through fusion, like we did for other quantized ops. And the numerics changing pass will only happen in insert quant dequant pass, so the model will have the same numerics before and after finalize. With the new category, the debug only option(the model before finalize) for quantize_script will actually produce a model that's numerically consistent with the finalized model.
Test Plan: python test/test_quantization.py TestQuantizeScriptJitPasses
Differential Revision: D21432871
Pulled By: jerryzh168
fbshipit-source-id: 4926890441e39af4e459376038563c3882cc4c46
Summary:
In a case like below, if x0 and x1 are both unaliased an only have a single use, than we can rewite the mutation to x2 without breaking observable semantics. This PR makes torchvision.models.alexnet functionalizable.
```
if cond:
x0 = op()
else:
x1 = op()
x2.add_(1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37694
Differential Revision: D21428275
Pulled By: eellison
fbshipit-source-id: 1e2a39a8fb3819f1f225b7c345e986b3a3db253f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37472
Our convention is for `findX` to return an optional version and `getX`
to assert that the X is there. Fix up `getMethod` to be consistent with
this convention.
Test Plan: Imported from OSS
Differential Revision: D21297543
Pulled By: suo
fbshipit-source-id: b40f56231cc8183e61bbb01fe5c0c113bcb6464d
Summary:
this is failing in the profiling_executor job
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37961
Differential Revision: D21434341
Pulled By: eellison
fbshipit-source-id: b34f94b1595ef6f6edee76cd200f951a2ef21f22
Summary:
Fixes https://github.com/pytorch/pytorch/issues/26304
Test procedure:
With ninja:
[x] Build a clean checkout
[x] Build again. Result: Only 10 libraries are (needlessly) linked again, the extra delay on a 24-core machine is <10s.
[x] Build for the third time. Result: Virtually instantaneous, with no extra rebuilding.
[x] Modify DispatchTable.h. Build again. Result: `.cu` files are rebuilt, as well as many `.cpp` files
[x] Build for the fifth time. Result: Virtually instantaneous, with no extra rebuilding.
[x] Touch one of the `.depend` files. Build again. Result: Only 10 libraries are (needlessly) linked again, the extra delay on a 24-core machine is <10s.
Without ninja:
[x] Build a clean checkout
[x] Build again. Result: There is some unnecessary rebuilding. But it was also happening before this change.
[x] Build for the third time. Result: Virtually instantaneous, with no extra rebuilding.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37661
Differential Revision: D21434624
Pulled By: ezyang
fbshipit-source-id: 379d2315486b8bb5972c184f9b8da8e00d38c338
Summary:
This makes it a proper python package, therefore `ModuleFinder` will parse dependencies from this module. (see https://docs.python.org/3/tutorial/modules.html )
As result, changes to `torch/testing/_internal/common_quantization` or `test/quantization/*.py` would be considered affecting `test_quantization.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37934
Test Plan: CI
Differential Revision: D21432413
Pulled By: malfet
fbshipit-source-id: acff6cee69a1dfd5535e33978f826ed1f6a70821
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37169
This allows some cleanup of the code below by making lines shorter.
ghstack-source-id: 102773593
Test Plan: Existing tests for interpolate.
Reviewed By: kimishpatel
Differential Revision: D21209988
fbshipit-source-id: cffcdf9a580b15c4f1fa83e3f27b5a69f66bf6f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37168
It looks like this was made a separate function because of the `dim` argument,
but that argument is always equal to `input.dim() - 2`. Remove the argument
and consolidate all call sites into one. This also means that this will be
called on paths that previously didn't call it, but all those cases throw
exceptions anyway.
ghstack-source-id: 102773596
Test Plan: Existing tests for interpolate.
Reviewed By: kimishpatel
Differential Revision: D21209993
fbshipit-source-id: 2c274a3a6900ebfdb8d60b311a4c3bd956fa7c37
Summary:
Remove the requirement for the axes provided to reorderAxis to come from a Tensor. We were using that to determine the relevant loops, but we can alternatively determine it by traversing the parents of each provided For.
resistor does this work for you?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37873
Differential Revision: D21428016
Pulled By: nickgg
fbshipit-source-id: b16b2f41cb443dfc2c6548b7980731d1e7d89a35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37834
Ported all use sites of the old registration API to use new Integer operator registration API.
Test Plan: Imported from OSS
Differential Revision: D21415700
Pulled By: MohammadMahdiJavanmard
fbshipit-source-id: 34f18757bad1642e1c485bb30c9771f7b7102230
Summary:
The existing contextmanager only conditionally enabled_profiling_mode, which was counter intuitive. When we changed the default executor it broke internal benchmarking as a result.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37825
Differential Revision: D21404611
Pulled By: eellison
fbshipit-source-id: 306b3c333ef4eb44ab6a6e5ab4e0682e5ce312ce
Summary:
We used to only support indexing through
- numbers like `x[0, 1]`
- tuple like `x[(0, 1)]`
- tensor like `x[torch.tensor([0, 1])]`
This PR adds support for indexing through list which is equivalent to tensor.
- `x[[0, 1, 5]]`
- `x[[0, 1], [0, 1]]`
- `x[[[0, 1], [0, 1]], [[0, 1], [0, 1]]]`
Note for `x[[0, 1, 5]]` we had a bug in AST conversion code so we used to treat it like `x[0, 1, 5]` which means it might accidentally run and produce wrong result(fixes https://github.com/pytorch/pytorch/issues/37286 fixes https://github.com/pytorch/pytorch/issues/18616), now that it's fixed we probably want to mark it as BC breaking.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37848
Reviewed By: suo
Differential Revision: D21409840
Pulled By: ailzhang
fbshipit-source-id: 6f2d962885c6dc009cb384d98be1822f5ca7a189
Summary:
Now that we landed float requantization for conv/linear, we do not need
the constraint for requant_scale < 1.
Removing that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37683
Test Plan: Quantization tests
Differential Revision: D21412536
Pulled By: kimishpatel
fbshipit-source-id: c932b5ab3aa40407e9d7f0c877e2fe7fd544f8a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37922
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21426425
Pulled By: ezyang
fbshipit-source-id: 9d0d997f608a742668f64e7529c41feb39bec24e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37700
Certain autograd functions can have optional Tensor arguments. For
this purpose it would be nice to support c10::optional<Tensor> as an argument
for C++ autograd functions.
I've added the appropriate overload to ExtractVariables to ensure this works.
For an example, you can look at D21272807 in terms of how this is used.
ghstack-source-id: 103541789
Test Plan: waitforbuildbot
Differential Revision: D21363491
fbshipit-source-id: 0c8665e9bfe279e6b9ab84a889524fea11fa971c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37882
Previously we checked if a node's inputs and outputs have shape
info only when we tried to merge this node into an existing fusion
group, but we didn't check it for the first node in the group. This PR
fixes that. It was causing a failure on test_milstm_cuda, which is now
fixed.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D21412756
Pulled By: ZolotukhinM
fbshipit-source-id: 3ca30637ab8fe68443adb5fc03f1b8a11085a6a8
Summary:
This pull request enables ahead of time compilation of HIPExtensions with ninja by setting appropriate compilation flags for ROCm environment. Also, this enables the unit test for testing cuda_extensions on ROCm as well as removing test for ahead of time compilation of extensions with ninja from ROCM_BLACKLIST
ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37800
Differential Revision: D21408148
Pulled By: soumith
fbshipit-source-id: 146f4ffb3418f3534e6ce86805d3fe9c3eae84e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37815
Generated device-specific wrappers for Tensor factory ops now call
methods on `globalContext()` directly, rather than indirecting
through `globalLegacyTypeDispatch()`, which we can now delete.
Test Plan: Imported from OSS
Differential Revision: D21398294
Pulled By: bhosmer
fbshipit-source-id: b37bc67aa33bfda6f156d441df55ada40e9b814d
Summary:
Helps prevent following accidental failures:
```
..\caffe2\core\parallel_net_test.cc:303
The difference between ms and 350 is 41, which exceeds kTimeThreshold, where
ms evaluates to 391,
350 evaluates to 350, and
kTimeThreshold evaluates to 40.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37892
Differential Revision: D21417251
Pulled By: malfet
fbshipit-source-id: 300cff7042e466f014850cc7cc406c725d5d0c04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37515
Previously we classify ops like average pool to the category that doesn't require observation and
the quantization of these ops are done by swapping with dequantize ops: https://github.com/pytorch/pytorch/pull/33481
However, this operation is done in finalize, which means finalize is a numerics changing pass when we swap dequantize with
ops like average pool, this is not ideal since we want to restrict the scope of numerics changing passes.
Because although average pool doesn't require observation, quantized average pool = dequant + float32 average pool + quant
and swapping average pool with dequantize is a numerics changing operation.
This PR implements the support for that. We'll classify ops like average pool to a new category and we'll get average pool through fusion, like we did for other quantized ops. And the numerics changing pass will only happen in insert quant dequant pass, so the model will have the same numerics before and after finalize. With the new category, the debug only option(the model before finalize) for quantize_script will actually produce a model that's numerically consistent with the finalized model.
Test Plan:
python test/test_quantization.py TestQuantizeScriptJitPasses
Imported from OSS
Differential Revision: D21393512
fbshipit-source-id: 5632935fe1a7d76382fda22903d77586a08f0898
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37767Fixes#37577
Needs tests, and maybe a lint.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21386704
Pulled By: ezyang
fbshipit-source-id: 082c69f9e1f40dc5ed7d371902a4c498f105d99f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37853
```
Uninitialized value was created by an allocation of 'acc_arr_next' in the stack frame of function '_ZN2at6vec25614vec_reduce_allIfZZNS_6native12_GLOBAL__N_124_vec_log_softmax_lastdimIfEEvPT_S6_llENKUlllE_clEllEUlRNS0_12_GLOBAL__N_16Vec256IfEESB_E_EES5_RKT0_NS9_IS5_EEl'
#0 0xa961530 in float at::vec256::vec_reduce_all<float, void at::native::(anonymous namespace)::_vec_log_softmax_lastdim<float>(float*, float*, long, long)::'lambda'(long, long)::operator()(long, long) const::'lambda'(at::vec256::(anonymous namespace)::Vec256<float>&, at::vec256::(anonymous namespace)::Vec256<float>&)>(void at::native::(anonymous namespace)::_vec_log_softmax_lastdim<float>(float*, float*, long, long)::'lambda'(long, long)::operator()(long, long) const::'lambda'(at::vec256::(anonymous namespace)::Vec256<float>&, at::vec256::(anonymous namespace)::Vec256<float>&) const&, at::vec256::(anonymous namespace)::Vec256<float>, long) xplat/caffe2/aten/src/ATen/cpu/vec256/functional.h:12
```
Test Plan:
passed sanitizer locally after change,
CI green
Differential Revision: D21408120
fbshipit-source-id: b9d058cedf42b3d1d34ce05a42049d402906cd13
Summary:
so we can import torch compiled with cuda on a CPU-only machine.
need tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37811
Differential Revision: D21417082
Pulled By: ezyang
fbshipit-source-id: 7a521b651bca7cbe38269915bd1d1b1bb756b45b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35961
Weight quantization was done incorrectly for LSTMs, the statistics for all weights (across layers) were combined in the observer. This meant that weights for later layers in a LSTM would use sub-optimal scales impacting accuracy. The problem gets worse as the number of layers increases.
ghstack-source-id: 103511725
Test Plan: Will be updated
Differential Revision: D20842145
fbshipit-source-id: a622b012d393e0755970531583950b44f1964413
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37866
make sure not to check `CUDA_VERSION` if it is not defined
Test Plan: CI gree
Reviewed By: anjali411
Differential Revision: D21408844
fbshipit-source-id: 5a9afe372b3f1fbaf08a7c43fa3e0e654a569d5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37423
For now, see what breaks on CI
ghstack-source-id: 103508233
Test Plan:
CI
Imported from OSS
Differential Revision: D21310335
fbshipit-source-id: 99d22e61168fcb318b18a16522aabdc0115c1f39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37422
The test was failing because in fbcode the version of hypothesis was too old to know
about the width parameter, and it was trying to generate values larger than float32. The fix
is to explicitly set the defaults of the floats range for old versions of hypothesis.
For now, reenable the test and see what breaks in CI
ghstack-source-id: 103500358
Test Plan:
CI
```
buck test mode/dev-nosan //caffe2/test:quantization -- 'test_compare_tensor_scalar \(quantization\.test_quantized_op\.TestComparatorOps\)'
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D21310336
fbshipit-source-id: 1a59ab722daa28aab3d6d2d09bc527874942dc36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37867
this is to work around internal issue we are hitting with nvcc in ovrsource.
It does not seem to overload to the correct device version of `isinf` and `isnan` without this fudging of the code.
Test Plan:
CI green,
internal builds pass
Reviewed By: malfet
Differential Revision: D21408263
fbshipit-source-id: 1ff44e088b5c885d729cc95f00cf8fa07e525f6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37839
Calling `RpcAgent::shutdown` from the TensorpipeAgent will ensure that parent class threads are joined and the atomic is set to False.
ghstack-source-id: 103496383
Test Plan: CI Build - no Tensorpipe Agent tests yet
Differential Revision: D21291974
fbshipit-source-id: 50cab929b021faf7f80e0e8139d0c7d1788a3a6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36611
Currently Buf represents underlying storage but it didn't have dtype.
That resulted in specifying dtypes in different places and there was no
mechanism to enforce its consistency: e.g. one could've created a kFloat
expression and use a kInt buffer to store its result. Now we're
centralizing where the logic regarding the storage is located and we can
start enforcing semantics rules.
Follow-ups: we can merge Buffer and BufHandle classes as the former is
now a mere wrapper over the latter.
Test Plan: Imported from OSS
Differential Revision: D21027356
Pulled By: ZolotukhinM
fbshipit-source-id: c06aa2c4077fdcde3bb4ca622d324aece79b5a9c
Summary:
Passing `--save-xml` option to common test runner would have the same effect as setting up `IN_CIRCLECI` environment variable, but also would allow one to specify folder to save results
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37840
Differential Revision: D21410250
Pulled By: malfet
fbshipit-source-id: ae5855fafdc8c66b550d42b683d547c88b4e55d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37854
Adding Tensorpipe contributors to the Codeowners file for Tensorpipe-related functionality in PyTorch.
ghstack-source-id: 103507371
Test Plan: CI
Differential Revision: D21408676
fbshipit-source-id: ea7cc1fd7ec069c83e67812e704d31492ef2a3cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37776
* Remove type-specific size tracking in favor of byte size tracking in Storage and StorageImpl
* Changed numel() and set_numel() to nbytes() and set_nbytes()
* Added enum argument to Storage/StorageImpl constructor to indicate new meaning of the size parameter
* Update all callers of the changed API
Part of issue https://github.com/pytorch/pytorch/issues/33950
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37028
Differential Revision: D21171334
Pulled By: ezyang
fbshipit-source-id: 37329a379de9a3a83cc5e9007e455a3e1c2d10b8
Summary:
Closes https://github.com/pytorch/pytorch/issues/37154
Fixes a bug in `cdist` backward with `p=2`.
Under some circumstances, if the output has 0s, the gradient calculation of `sqrt` will be undefined. Leading to NaNs in the input gradients.
This PR defines a subgradient for this case.
A test is also added to verify this behavior, I was only able to reproduce it under certain shapes, so the shape is explicitly taken from https://github.com/pytorch/pytorch/issues/37154 example
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37337
Differential Revision: D21403178
Pulled By: albanD
fbshipit-source-id: deef9678c1958524b552504920f19617f9ad1da6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37842
Fixes https://github.com/pytorch/pytorch/issues/23993.
Previously our name lookup function for the tracer was looking in
f.globals for names. For example:
```
sample1 = torch.ones(1)
sample2 = torch.ones(1)
traced = torch.jit.trace(my_mod, ((sample1, sample2,),))
> produces a graph with something like:
> %sample1, %sample2 = prim::TupleUnpack(%input)
```
This is not great if you are, e.g. trace checking, because a non-local
bit of interpreter state is affected the graph produced:
```
traced = torch.jit.trace(my_mod, _clone_inputs((sample, sample,),))
> produces a graph with something like
> %0, %1 = prim::TupleUnpack(%input)
```
I have removed this functionality, as I don't think it provides huge
value. Things that look locally for names will still work, so e.g.
inputs, intermediate variables, and the like will be named correctly.
Test Plan: Imported from OSS
Differential Revision: D21406478
Pulled By: suo
fbshipit-source-id: 3c7066b95d4a6e9b528888309954b02dadbc1a07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37032
DataParallel requires all params and buffers of child modules to be updated
in place because of how it implements model replication during the
forward pass (see https://github.com/pytorch/pytorch/pull/12671 for
context). Any params or buffers not updated in place are lost and not
propagated back to the master.
This diff updates (some quantized modules) (TBD: all quantized modules? determine a good cut
point) to do their parameter update in-place. This will enable static
quant and QAT to work correctly with DataParallel.
TODO: https://github.com/pytorch/pytorch/pull/32684 needs to land before we can fix the graph mode test failures on this PR.
Test Plan:
script failed before and passes after the diff:
https://gist.github.com/vkuzo/78b06c01f23f98ee2aaaeb37e55f8d40
TODO before land: add integration testing
Imported from OSS
Differential Revision: D21206454
fbshipit-source-id: df6b4b04d0ae0f7ef582c82d81418163019e96f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37832
These tests were flaky and qint32 support is not a priority at
the moment, turning it off to improve test quality.
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_batch_norm2d
python test/test_quantization.py TestQuantizedOps.test_batch_norm2d_relu
python test/test_quantization.py TestQuantizedOps.test_batch_norm3d
```
Imported from OSS
Differential Revision: D21404980
fbshipit-source-id: 04f4308bc5d6e1a278c60985971d03c10a851915
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37813
This condition should never fire.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D21398021
Pulled By: suo
fbshipit-source-id: 7f2213a020071b8eab80ef40ac6a9de669722548
Summary:
I think, it's help faster compile pytorch from source without errors about incompatible compiler(such as: unsupported GNU version! gcc versions later than 8 are not supported!)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37301
Differential Revision: D21396682
Pulled By: ngimel
fbshipit-source-id: 5e21c36ee550424e820f3aa6e6131ca858994ae4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37771
Adds in place handling for other activations in graph mode
Test Plan:
```
python test/test_quantization.py TestQuantizeScriptPTSQOps.test_swap_dequantize
```
Imported from OSS
Differential Revision: D21382825
fbshipit-source-id: 6a4e64bae08fcbfb9bdab92aaac43da98207a1c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37592
Makes sure that all the standalone relu flavors are tested in
graph mode.
Test Plan:
```
python test/test_quantization.py TestQuantizeScriptPTSQOps.test_swap_dequantize
```
Imported from OSS
Differential Revision: D21366597
fbshipit-source-id: 103848b76a0c65b9adac5bae98b545aa1d30a9e2
Summary:
Closes https://github.com/pytorch/pytorch/issues/24558
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.erf(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.erf(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.erf(a) a.numel() == 10000 for 20000 times torch.half
0.29057903600187274
torch.erf(a) a.numel() == 10000 for 20000 times torch.float
0.2836507789979805
torch.erf(a) a.numel() == 10000 for 20000 times torch.double
0.44974555500084534
torch.erf(a) a.numel() == 100000 for 20000 times torch.half
0.31807255600142526
torch.erf(a) a.numel() == 100000 for 20000 times torch.float
0.3216503109979385
torch.erf(a) a.numel() == 100000 for 20000 times torch.double
2.0413486910001666
```
After:
```
torch.erf(a) a.numel() == 10000 for 20000 times torch.half
0.2867302739996376
torch.erf(a) a.numel() == 10000 for 20000 times torch.float
0.28851128199858067
torch.erf(a) a.numel() == 10000 for 20000 times torch.double
0.4592030350013374
torch.erf(a) a.numel() == 100000 for 20000 times torch.half
0.28704102400115517
torch.erf(a) a.numel() == 100000 for 20000 times torch.float
0.29036039400125446
torch.erf(a) a.numel() == 100000 for 20000 times torch.double
2.04035638699861
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36724
Differential Revision: D21164626
Pulled By: VitalyFedyunin
fbshipit-source-id: e6f3390b2bbb6e8d21e18ffe15f5d49a170fae83
Summary:
We were previously only looking at class attributes, so that didn't include methods etc, and would silently give wrong semantics. This makes hasAttr go through the same resolution as our other attribute lookups.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37424
Differential Revision: D21282633
Pulled By: eellison
fbshipit-source-id: 8e970f365c2740d137a02331739c2ed93747b918
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37681
By passing by value, we can std::move, and avoid unnecessarily copying
args that are part of any std::function/lambda state (e.g. in the jit
interpreter, there is a std::vector<> stack passed in the
InterpreterContinuation)
This makes the api also consistent with e.g. folly and best practices.
Added a minor at::launch() benchmark to test/cpp/, the difference is
mostly noticeable when copying the std::function<> internal args is
non-trivial.
Benchmarks pre/post (min over ~5 runs)
NoData: 5.81 us -> 5.63 us (-3.2%)
WithData(0): 6.67 us -> 5.88 us (-11.8%)
WithData(4): 6.98 us -> 6.51 us (-6.7%)
WithData(256): 9.44 us -> 7.89 (-16.5%)
ghstack-source-id: 103322321
Test Plan:
- perf: buck run mode/opt caffe2/test/cpp/api:parallel_benchmark pre/post
- correctness buck test mode/dev-nosan caffe2/test/...
Reviewed By: dzhulgakov
Differential Revision: D21355148
fbshipit-source-id: 3567e730845106f1991091e4a892d093e00571c3
Summary:
Fix https://github.com/pytorch/pytorch/issues/37672
Make sure we only access fields that exist and handle python errors correctly.
Before the fix, the given test would throw:
```
AttributeError: 'MyHookClass' object has no attribute '__name__'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "test_autograd.py", line 432, in test_hook_with_no_name
x.sum().backward()
File "/Users/albandes/workspace/pytorch_dev/torch/tensor.py", line 184, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/Users/albandes/workspace/pytorch_dev/torch/autograd/__init__.py", line 115, in backward
allow_unreachable=True) # allow_unreachable flag
SystemError: <built-in method run_backward of torch._C._EngineBase object at 0x112fd8100> returned a result with an error set
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37785
Differential Revision: D21387946
Pulled By: albanD
fbshipit-source-id: dcb9afa37b3e10620dc9182d8aa410e7130ffb64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35483
Implement the initial version of TensorPipe RPC agent, and register to RPC registry to expose to Python interface. As a starter, it utilizes all available TensorPipe transports (shm, uv) and channels (basic, cma).
Test Plan:
https://our.intern.facebook.com/intern/diffusion/FBS/browse/master/fbcode/experimental/jiayisuse/tensorpipe_rpc
export MASTER_ADDR=127.0.0.1
export MASTER_PORT=28500
buck build mode/dev-nosan mode/no-gpu //experimental/jiayisuse/tensorpipe_rpc:main
./buck-out/gen/experimental/jiayisuse/tensorpipe_rpc/main.par
buck build mode/dev-nosan mode/no-gpu //experimental/jiayisuse/tensorpipe_rpc:benchmark
./buck-out/gen/experimental/jiayisuse/tensorpipe_rpc/benchmark.par
Multiple connections with async echo
./buck-out/gen/experimental/jiayisuse/tensorpipe_rpc/async_echo.par
Reviewed By: lw
Differential Revision: D20088366
fbshipit-source-id: 980f641af3321ca93583c62753e1c9174b7d4afc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36197
Create APIs to convert between rpc::message and tensorpipe::message
1. tensorpipeSerialize() - converts rpc::message to tensorpipe::message without memory copy (tensors).
2. tensorpipeAllocateMessage - allocates rpc::message based on received tensorpipe descriptor to prepare memory-copy-free receiving.
Test Plan: buck test caffe2/test/cpp/rpc:test_tensorpipe_serialization
Reviewed By: lw
Differential Revision: D20084125
fbshipit-source-id: ffbc310f93443e50261aed752be0fe176610dd2a
Summary:
First one is to download build artifacts
Second is to run tests
Third is to upload test metadata (runs always, even if `Run` step has failed)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37808
Differential Revision: D21398398
Pulled By: malfet
fbshipit-source-id: da23c499a84136e12e88adcc60206ea26bc843c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37801
D21215050 was reverted. Re do it.
Test Plan: build, CI
Reviewed By: iseeyuan
Differential Revision: D21393474
fbshipit-source-id: 2e86d5d1980a122a847e146dc6357627ec31d80d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37721
Even though we disabled caffe2 test configs in Python, the BUILD_TEST
option was still building caffe2 test cpp binaries and various CI
configurations were running them (since they just run every binary in
`torch/test`).
This PR adds a caffe2-specific BUILD_TEST option (BUILD_CAFFE2_TEST),
which defaults to OFF, and gates the compilation of caffe2 test cpp
binaries under it.
Test Plan: Imported from OSS
Differential Revision: D21369541
Pulled By: suo
fbshipit-source-id: 669cff70c5b53f016e8e016bcb3a99bf3617e1f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35779
Adds a QNNPack path for the clamp kernel, which is useful for
hardtanh.
Test Plan:
python test/test_quantized.py TestQNNPackOps.test_hardtanh
Imported from OSS
Differential Revision: D20778588
fbshipit-source-id: 537de42e795a9c67924e1acb1d33b370beb9dbf5
Summary:
This is no longer needed because cuda copy kernel now uses `c10::complex`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37574
Differential Revision: D21328501
Pulled By: ngimel
fbshipit-source-id: dd5226e8b6c54915fb6ee52240a446f0ca30a800
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37796
Shape inference is costly. In bad cases, if we have a lot of uneven tails, we are going to do quite amount of shape inference. This diff will enable each Onnxifi operator to cache the shape inference result for given batch size. In the worst case, we will occupy `num_inference_threads * max_batch_size` OutputReshapeInfo objects per model, where `num_inference_threads` and `max_batch_size` are smaller than 64.
Reviewed By: benjibc
Differential Revision: D21389946
fbshipit-source-id: 23473e64c338d64d15c70292cca0056205d980eb
Summary:
The purpose of this PR is to enable HgemmBatched for ROCm. Since the inconsistency between CUDA_VERSION and HIP_VERSION, resulting in THCudaBlas_HgemmStridedBatched() not to be called.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37483
Differential Revision: D21395699
Pulled By: ngimel
fbshipit-source-id: c5c22d5f2041d4c9911558b2568fc9ce33ddeb5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37689
It has to be this way, otherwise, we will not be able to use it in vec256 because the function pointers declared there are using const reference.
Test Plan: Imported from OSS
Differential Revision: D21394603
Pulled By: anjali411
fbshipit-source-id: daa075b86daaa694489c883d79950a41d6e996ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37799
Failure to do so will results on some workspace contention.
Test Plan: unittest
Reviewed By: amylittleyang
Differential Revision: D21390900
fbshipit-source-id: 9e837f0f7aae32230740604069308f35b73612b9
Summary:
Hello there,
I was going through the default initialization of some layers, and ended up on the `torch.nn.init` documentation. As shown below, there was a slight issue with the docstrings of both `kaiming_normal_` and `kaiming_uniform_` that yielded a wrong list of function parameters:

This PR fixes the indentation in the corresponding docstrings.
Any feedback is welcome!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37739
Differential Revision: D21393728
Pulled By: ngimel
fbshipit-source-id: 64523cb328e72d2e51c2c42b20a4545c1ec5f478
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37402
Previously, BackendSelect kernels did just-in-time device type
initialization by calling `LegacyTypeDispatch.initForDispatchKey()`
with a computed dispatch key. Here we move the initialization to
the backend kernels themselves, where we can call the device-
specific initializer directly.
Putting this up to run tests on it, but a couple questions remain:
* why were only BackendSelect kernels doing this initialization?
Not all factory ops appear there, nor are all the ops that do
appear there factory ops. Currently we generate init code for
exactly the BackendSelect ops, but the choice should be better
motivated.
* the previous scheme maps HIP to its own legacy type dispatch
entry, but the logic assumes it's exclusive with CUDA, and no
ops appear to mention HIP explicitly, so the new logic doesn't
expose a static entry point for it. Needs to be verified.
Test Plan: Imported from OSS
Differential Revision: D21282974
Pulled By: bhosmer
fbshipit-source-id: cd46eb788596948e0572a15fac0f8b43feca5d75
Summary:
Fixes https://github.com/pytorch/pytorch/issues/34585.
This PR improves the workaround for the problem of different semantics between ONNX softmax and Pytorch softmax.
In Pytorch the `dim` parameter specifies over which dimension normalize the values. ONNX on the other hand always coerces the input into a 2D tensor and the `axis` parameter specifies which dimensions represent rows and columns of the resulting tensor. As a result, only when we are normalizing the last dimension (`dim == ndim - 1`) semantics are the same.
Previously this was handled by recognizing the `dim == ndim - 1` case and using `softmax` for that. All other cases used a fallback path of explicit invocations of exp, reducesum and div operators to compute the result. Unfortunately, this results in numeric errors when input values are large: the result of exp will produce infinity on both numerator and denumerator and the division of that will result in NaN.
This can be improved by transposing the input tensor so that we can reuse ONNX softmax.
Similar approach has been applied to `logsoftmax` function in https://github.com/pytorch/pytorch/issues/30433.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37326
Reviewed By: hl475
Differential Revision: D21389712
Pulled By: houseroad
fbshipit-source-id: 554fd1b98231a28984c30c7e7abd3c0643386ff7
Summary:
When a subprocess terminates with an exception in a distributed test, log the process number as well
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37627
Differential Revision: D21366149
Pulled By: rohan-varma
fbshipit-source-id: 132c4b4c1eb336761c2be26d034d8b739ae19691
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37779
We should just return empty output
Test Plan: Imported from OSS
Differential Revision: D21385789
fbshipit-source-id: 4b42f5aaebabfa3f329ed74356bddb33daad98d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37547
This shouldn't be used anymore.
Test Plan: Imported from OSS
Differential Revision: D21315037
Pulled By: gchanan
fbshipit-source-id: 12728f1d0e1856bf3e8fe1bfcf36cddd305a4a76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37637
Insert dequant op at specific offset, rather than for all inputs of user
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D21354931
fbshipit-source-id: 79a1dc63b0ed96c3d51d569116ed963106085d3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37635
replaceConvolutionWithConv2d incorrectly assumes that the size of padding is 2. For Conv1d it is 1, in which case we cannot replace with aten::conv2d
Test Plan: Imported from OSS
Differential Revision: D21354930
fbshipit-source-id: a2dbad856666b4bbb2d9015ade8e1704774f20dd
Summary:
If linking the same file multiple times, the trigger check becomes severe and crashes execution at startup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37772
Differential Revision: D21384072
Pulled By: bwasti
fbshipit-source-id: 3396e69cd361f65e50517970d23497804c76023e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37101Fixes#36954.
The basic concept is to streamline the process of rethrowing
c10::Error with extra error information. This is in a few
steps:
- I completely remodeled the Error data type and the internal
invariants. Instead of manually adding in newlines, the
message stack formatting process is responsible for inserting
newlines and spacing as necessary. Call sites are then
modified to respect the new API model.
- TORCH_RETHROW macro is added, which adds context to an error
message and then rethrows it.
New internal assert failure looks like:
```
0 INTERNAL ASSERT FAILED at ../c10/test/util/exception_test.cpp:64, please report a bug to PyTorch.
Exception raised from TestBody at ../c10/test/util/exception_test.cpp:64 (most recent call first):
frame #0: <unknown function> + 0x6aab9 (0x7ff611d3aab9 in /data/users/ezyang/pytorch-tmp/build/lib/libc10.so)
frame #1: ...
```
Error message with context looks like:
```
This is an error
This is context 1
This is context 2
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21202891
Pulled By: ezyang
fbshipit-source-id: 361cadd16bc52e5886dba08e79277771ada76169
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37094
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21202892
Pulled By: ezyang
fbshipit-source-id: d59e6bffabd90cc734056bdce2cd1fe63262fab8
Summary:
To fix caffe2 model with Copy OP cannot export to onnx model
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37144
Reviewed By: houseroad
Differential Revision: D21252421
Pulled By: yinghai
fbshipit-source-id: 4f1077188f36b0691d199e418880bbb27f11032d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37704
If input tensor can not be chunked, run `parallel_apply` on fewer devices
Modfy input tensor dimention in `DataParallelUsesAllAvailableCUDADevices_CUDA` to be chunkable by any number of available CUDA devices
Test Plan: Run `test/cpp/api/parallel` on machine with 6 GPUs
Differential Revision: D21365416
fbshipit-source-id: 60fdfed4a0e6256b2c966c2ea3e8d0bfb298d9a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37537
The documentation states that `random_()` samples "from the discrete uniform distribution". Floating-point types can support _discrete_ _uniform_ distribution only within range [-(2^digits), 2^digits], where `digits = std::numeric_limits<fp_type>::digits`, or
- [-(2^53), 2^53] for double
- [-(2^24), 2^24] for double
- [-(2^11), 2^11] for half
- [-(2^8), 2^8] for bfloat16
The worst scenario is when the floating-point type can not represent numbers between `from` and `to`. E.g.
```
torch.empty(10, dtype=torch.float).random_(16777217, 16777218)
tensor([16777216., 16777216., 16777216., 16777216., 16777216., 16777216.,
16777216., 16777216., 16777216., 16777216.])
```
Because 16777217 can not be represented in float
Test Plan: Imported from OSS
Differential Revision: D21380387
Pulled By: pbelevich
fbshipit-source-id: 80d77a5b592fff9ab35155a63045b71dcc8db2fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37719
As title
Test Plan: Just updating doc
Reviewed By: hyuen
Differential Revision: D21369227
fbshipit-source-id: a45e5d0fa34aea8046eb4bb83e6c4df4d2654252
Summary:
Small change to allow MSVC build pass.
The error is
```
D:\pytorch-scripts\caffe2_builders\v141\pytorch\torch/csrc/jit/tensorexpr/stmt.h(370): error C4805: '!=': unsafe mix
of type 'bool' and type 'int' in operation (compiling source file D:\pytorch-scripts\caffe2_builders\v141\pytorch\torch
\csrc\jit\passes\tensorexpr_fuser.cpp) [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\RelWithDebInfo\caffe2\tor
ch_cpu.vcxproj]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37578
Differential Revision: D21348964
Pulled By: ezyang
fbshipit-source-id: 2c5f995e0adbeb681c18625b59250d7ee3e958ef
Summary:
xref gh-32838, gh-34032
This is a major refactor of parts of the documentation to split it up using sphinx's `autosummary` feature which will build out `autofuction` and `autoclass` stub files and link to them. The end result is that the top module pages like torch.nn.rst and torch.rst are now more like table-of-contents to the actual single-class or single-function documentations pages.
Along the way, I modified many of the docstrings to eliminate sphinx warnings when building. I think the only thing I changed from a non-documentation perspective is to add names to `__all__` when adding them to `globals()` in `torch.__init__.py`
I do not know the CI system: are the documentation build artifacts available after the build, so reviewers can preview before merging?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37419
Differential Revision: D21337640
Pulled By: ezyang
fbshipit-source-id: d4ad198780c3ae7a96a9f22651e00ff2d31a0c0f
Summary:
This pull request fixes and re-enables two of the tests disabled in https://github.com/pytorch/pytorch/issues/37427
1. `test_sparse_add_out_bfloat16` in test_sparse.py fixed to use updated `atol` argument instead of `prec` for `assertEqual`
2. The conversion of `flt_min` to `int64` is divergent on HIP compared to numpy. The change removes that conversion from the `test_float_to_int_conversion_finite` test case in test_torch.py
cc: ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37616
Differential Revision: D21379876
Pulled By: ezyang
fbshipit-source-id: 2bfb41d67874383a01330c5d540ee516b3b07dcc
Summary:
Since UnPackRecords is part of the graph, we need to add shape inference for it to make it work e2e with tvm_jit_op. Because the input is packed, shape inference is impossible without shape info of the packed tensors. Some context, the shape of the packed tensor is 1 X num_embeddings X embedding_size, with 1 being the batch_size. The shape of the corresponding output tensor is thus batch_size X num_embeddings X embedding_size after concatenating the packed tensors on the batch axis. Therefore two more gflags need to be added
- caffe2_predictor_num_embeddings
- caffe2_predictor_embedding_size
These gflags are then added to the UnPackRecordsOp in the predict_net as args to pass the info to c2_frontend so TVM can do its own shape inference.
Reviewed By: yinghai
Differential Revision: D21286983
fbshipit-source-id: e9a19cb6b564905282a771df2b9d211d5d37dd71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37192
Add ops used by portal NLU model to lite interpreter
Test Plan: local test
Reviewed By: iseeyuan
Differential Revision: D21215050
fbshipit-source-id: 874023c449e4c04b9f3f871450a7cf02e8f5f5c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37653
Following up D21320243 adding weight_decay to rowwise fused sparse adagrad. This is more involved because we can't reuse g_sq_avg multiple times.
Test Plan: CI
Reviewed By: jspark1105
Differential Revision: D21335643
fbshipit-source-id: 491b385c5eb9c0d1e3d31a1cf50d7eb450c2d39d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37652
Add weight_decay to fused adagrad operators. This should be landed with the next diff together. Just separating out to make review easier.
Test Plan: CI
Reviewed By: jspark1105
Differential Revision: D21320243
fbshipit-source-id: 1157471988dedd60ba9b62949055f651b1fa028f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37705
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37372
Posted note: [Regularizing SparseNN Against Over-fitting](https://fb.workplace.com/notes/taiqing-wang/regularizing-sparsenn-against-over-fitting/220306075902708/)
**Problem formulation**
L(w) = J(w) + lambda/2 * ||w||^2
J(w) is the empirical loss, and ||w||^2 is the squared L2 norm of the parameters, a.k.a. L2 regularizer.
dL(w)/ dw_i = dJ(w)/dw_i + lambda w_i
dL(w)/ dw_i is the gradient of L(w) w.r.t. w_i.
To implement the L2 regularizer, the gradient of J(w) w.r.t. w_i is added with w_i. lambda is called as weight decay in this implementation.
**Code changes**
* In the initialization method of AdagradOptimizer, a new input argument, weight_decay, is added.
* In the _run function of AdagradOptimizer, the weight decay will be skipped for 1d bias vectors.
* In the parameter update functions of Adagrad, the gradient is updated by weight_decay * w_i. The default value for weight_decay is zero.
Test Plan:
`
buck build caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_weight_decay
`
`
./buck-out/gen/caffe2/caffe2/fb/dper/layer_models/tests/split_1/sparse_nn_test_weight_decay#binary.par
`
Reviewed By: jspark1105
Differential Revision: D21258652
fbshipit-source-id: d2366ddcd736a03205a2d16f914703b16d9fce8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37485
Adds arbitrary timeout injection to faulty RPC agent. This is to better test scenarios that need information about how long-running RPCs, such as properly testing RPC timeouts and the profiler in all scenarios.
This is done by overriding ProcessGroupAgent's `enqueueSend()` function to inject the timeout. Determining which messages to timeout is done similar to the existing `faulty_messages` by having the user specify a mapping of message to timeout.
Added unit tests that verify RPC timeouts work with builtin + TorchScript functions, which was not tested before.
ghstack-source-id: 103341662
Test Plan: Added unit tests in `FaultyRpcAgentTest`.
Differential Revision: D21296537
fbshipit-source-id: 1dbc21aee14e49780272634e9cbb2b5a448f2896
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37514
This is to constrain all numerics changing operations in insert quant dequant pass
Test Plan:
python test/test_quantization.py TestQuantizeScriptJitPasses
Imported from OSS
Differential Revision: D21364008
fbshipit-source-id: eb8774e9e4b1db8bf09560e7e4d69d28f9d954a5
Summary:
Update the requirements on input dimensions for torch.nn.SyncBatchNorm:
1. Checks the aggregated batch size `count_all` instead of batch size in every DDP process https://github.com/pytorch/pytorch/issues/36865
2. Added test function for SyncBatchNorm where every process only has 1 input
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37133
Differential Revision: D21331120
Pulled By: zhaojuanmao
fbshipit-source-id: ef3d1937990006609cfe4a68a64d90276c5085f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37655
Add override name for aten::tensor and aten::as_tensor.
These two ops are used in NLU model, and they will included them in lite interpreter
Test Plan: verified model can be loaded correctly
Reviewed By: iseeyuan
Differential Revision: D21346142
fbshipit-source-id: 05ff4d9e0bcf7f4f9a30d95ca81aef9c3f6b0990
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37507
Replace `TORCH_WARN` with `TORCH_CHECK` if `Tensor.random_()`'s `from` or `to-1` is out of bounds for tensor's dtype. Previously warning said "This warning will become an error in version 1.6 release, please fix the code in advance", so the time has come.
Related to #33106
Test Plan: Imported from OSS
Differential Revision: D21349413
Pulled By: pbelevich
fbshipit-source-id: ac7c196a48fc58634611e427e65429a948119e40
Summary:
as a part of moving to the dynamic shapes we are now passing `frame_id` to each profiling callback. The implementation of that requires copying profiling callbacks into Interpreter, so `first`s are actually different for every run. The dynamic shapes merging algorithm won't be using `first`, but in the meantime, while we get there, this should be a good enough fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36806
Differential Revision: D21307173
Pulled By: Krovatkin
fbshipit-source-id: 7dade56ebcc72ebd40bb7f3d636c7b83c99b628f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37675
Original commit changeset: 2c2481e3d497
(Note: this ignores all push blocking failures!)
Test Plan: Back out D21262085 due to ASAN crash P130123493
Differential Revision: D21353550
fbshipit-source-id: c43c8764322f7e58aca0c1360b1d03966b1d9798
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37666
Add `:orphan:` to avoid "WARNING: document isn't included in any toctree".
Test Plan: Imported from OSS
Differential Revision: D21351053
Pulled By: mrshenli
fbshipit-source-id: 6ff67c418fc1de410c7dc39ad9a0be5c30d07122
Summary:
Fixes https://github.com/pytorch/pytorch/issues/34964
Sparse cuda add was implemented by just concatenating the indices and values for the tensor. If called repeatedly in a tight loop this will let `nnz` grow unbounded. In the worst case of `x.add_(x)` it grows exponentially.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36030
Differential Revision: D20873504
Pulled By: zou3519
fbshipit-source-id: d90ed8dda0c89571fb89e358757b5dde299513df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37450
It doesn't seem like we could customize the retryable message types by
passing faulty_messages into dist_utils, as the `FaultyRpcAgentTestFixture`
overrode the `rpc_backend_options` function and provided the default list of
retryable message types. Needed to fix this as part of adding timeout injection
support as mentioned in https://github.com/pytorch/pytorch/issues/36272
ghstack-source-id: 103287164
Test Plan: `buck test mode/dev-nosan //caffe2/test/distributed/rpc/faulty_agent:rpc_spawn_faulty -- --print-passing-details`
Differential Revision: D21270127
fbshipit-source-id: e5dd847dcf92f14b490f84e9ee79291698b85ffa
Summary:
Following up on this: https://github.com/pytorch/pytorch/pull/35851 cross dtype storage copy is not being used internally, so I have not included cross dtype copy for complex.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35771
Differential Revision: D21319650
Pulled By: anjali411
fbshipit-source-id: 07c72996ee598eba0cf401ad61534494d6f5b5b3
Summary:
We don't need to create `torch.Generator()` and seed it if we are not shuffling.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37604
Differential Revision: D21346167
Pulled By: rohan-varma
fbshipit-source-id: 6ed560d236bc5c026a7d321755ddc02a29db1604
Summary:
This PR basically makes `c10::ComplexHalf` a template specialization of `c10::complex`. Since `c10::ComplexHalf` is not used much, this does not include much change.
Due to the fact that `c10::Half` does not have much `constexpr` methods, it is impossible to keep the same API. Currently, we are just completely reusing the old implementation. It is just the name getting changed from `c10::ComplexHalf` to `c10::complex<c10::Half>`. We can always change the implementation in the future when needed. But for now, I think this is OK.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37426
Differential Revision: D21300754
Pulled By: anjali411
fbshipit-source-id: fc0f65adccf97025a727735096780ce8078675a1
Summary:
Closes https://github.com/pytorch/pytorch/issues/24641
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.tan(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.tan(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.tan(a) a.numel() == 10000 for 20000 times torch.half
0.28325206200003095
torch.tan(a) a.numel() == 10000 for 20000 times torch.float
0.28363607099998944
torch.tan(a) a.numel() == 10000 for 20000 times torch.double
0.43924326799998425
torch.tan(a) a.numel() == 100000 for 20000 times torch.half
0.3754699589999859
torch.tan(a) a.numel() == 100000 for 20000 times torch.float
0.38143782899999223
torch.tan(a) a.numel() == 100000 for 20000 times torch.double
1.7672172019999834
```
After:
```
torch.tan(a) a.numel() == 10000 for 20000 times torch.half
0.28982524599996395
torch.tan(a) a.numel() == 10000 for 20000 times torch.float
0.29121579000002384
torch.tan(a) a.numel() == 10000 for 20000 times torch.double
0.4599610559998837
torch.tan(a) a.numel() == 100000 for 20000 times torch.half
0.3557764019997194
torch.tan(a) a.numel() == 100000 for 20000 times torch.float
0.34793807599999127
torch.tan(a) a.numel() == 100000 for 20000 times torch.double
1.7564662459999454
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36906
Differential Revision: D21335320
Pulled By: VitalyFedyunin
fbshipit-source-id: efab9c175c60fb09223105380d48b93a81994fb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36815
Pytorch does not have native channel shuffle op.
This diff adds that for both fp and quantized tensors.
For FP implementation is inefficient one. For quantized there is a native
QNNPACK op for this.
ghstack-source-id: 103267234
Test Plan:
buck run caffe2/test:quantization --
quantization.test_quantized.TestQuantizedOps.test_channel_shuffle
X86 implementation for QNNPACK is sse2 so this may not be the most efficient
for x86.
Reviewed By: dreiss
Differential Revision: D21093841
fbshipit-source-id: 5282945f352df43fdffaa8544fe34dba99a5b97e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36814
ghstack-source-id: 103218412
From the flamegraph it seems 40% the time we are spending going through the dispatch stack. I think in quantized model where compute can take less time, such overheads become noticeable
{F234432545}
Test Plan: Quantized op tests.
Reviewed By: jerryzh168
Differential Revision: D21093840
fbshipit-source-id: 1b98b57eae403353596fc31171069d2f43b13385
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36813
- Changes to q_avgpool to map special cases of adaptive avgpool to avgpool.
- Map special cases of adaptive avg pool to avgpool.
ghstack-source-id: 103218410
Test Plan: QuantizedOps.test_adaptive_avgpool2d
Reviewed By: z-a-f
Differential Revision: D21093837
fbshipit-source-id: c45a03b597eaa59e1057561ee4e8e116ac138f8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37106
Recomputing the aliasdb on every fusion iteration + in every subblock
is hugely expensive. Instead, update it in-place when doing fusion.
The graph fuser pass operates by pushing nodes into a fusion group. So
we start with
```
x, y = f(a, b, c)
```
and end with:
```
x_out, y_out = prim::fusionGroup(a, b, c)
x_in, y_in = f(a_in, b_in, c_in)
-> x_in, y_in
```
We destroy the `x` and `y` `Value*`s in the process. This operation is
easy to express as an update to the aliasDb--`x_out` just takes on all
the aliasing information `x` used to have. In particular, since we know
`f` and `prim::fusionGroup` are purely functional, we don't have to mess
with any write information.
This PR is the bare minimum to get this working, in the interest of
unscrewing the compilation times ASAP.
Followups I want to do:
- We don't have a way of expressing deletion of values in AliasDb. In
`graph_fuser.cpp` we sometimes construct nodes that we end up throwing
away, and we are littering `MemoryDAG` with references to dangling
pointers. Because of the way the pass works, it's fine, but this is
fragile so I want to fix it.
- We should decouple alias analysis from write tracking, to simplify the
job of keeping the write caches consistent as we mutate the aliasing
information.
- the tensorexpr fuser doesn't do this and thus is incorrect today, we
need to update it to work.
Test Plan: Imported from OSS
Differential Revision: D21219179
Pulled By: suo
fbshipit-source-id: 8ae5397b3a0ad90edec2fbc555647091f1ad5284
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36345
During compilation, we spend a huge amount of time in alias analyis.
This PR does a few things to speed it up.
1. Separate the analysis into two phases: one where we build up the
necessary data structures, and the other where we service aliasing
queries. This allows us to defer building indices/maintaining index
consistency until after the "buildup" phase is done.
2. Properly memoize/dynamic program the memory locations lookups.
3. Done naively, setting wildcards invalidates the above memoization,
trigger costly recomputation. So I added a cache-aware `setWildcards`.
Sadly that means you need alias analysis to reach into the guts of
memorydag, but the speedup is worth it.
Sadly, these changes are kind of coupled for correctness reasons, so
they're all here at once.
I used this model (thanks IlyaOvodov) as a provisional benchmark. You
can get it here:
https://www.dropbox.com/s/jlyygn6yygj1jkx/yolov3.zip. Unzip at run
`python test_timing.py`.
Baseline: (752.076s) right before 6bc8ffe82462c77ac4f9b27452046cb1f8f07d92
After optimizing before inlining: (699.593s)
After deferring cache construction: (426.180s)
After cache-aware `setWildcards`: (193.678s)
So a nice 75% speedup to overall compilation. There's a lot more to do
in other places of the compilation pipeline though.
Followup to this PR specifically: Everything that fans out from the
`analyze` call is the "buildup" phase of AliasDB construction. This
should be factored into a separate analysis pass to statically
distinguish the two phases (right now we just null out stuff to
accomplish the same thing dynamically).
Test Plan: Imported from OSS
Differential Revision: D20952727
Pulled By: suo
fbshipit-source-id: 099f797222d7e71e5c04991584adc2c7eab5a70f
Summary:
Changelog:
- The magma implementation of small singular square batch matrices had a bug that resulted in nan values in the LU factorization result. This has been fixed in MAGMA 2.5.2. This PR removes the existing patch that was a temporary workaround for this bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35973
Test Plan:
- Existing tests for det and lu should pass
This is a re-submit of https://github.com/pytorch/pytorch/issues/34357
Differential Revision: D21336552
Pulled By: seemethere
fbshipit-source-id: 9c3b350966913147f1d5811927f3cae10fe620f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37591
skip the tests since gluster is gone.
Test Plan: ci
Reviewed By: ezyang
Differential Revision: D21330359
fbshipit-source-id: a4e158fb72eddb08ba49fcfa9541569a150f8481
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27957
Benchmark (gcc 8.3, Debian Buster, turbo off, Release build, Intel(R) Xeon(R) E-2136):
```python
import timeit
for dtype in ('torch.double', 'torch.float', 'torch.uint8', 'torch.int8', 'torch.int16', 'torch.int32', 'torch.int64'):
for n, t in [(40_000, 50000),
(400_000, 5000)]:
print(f'torch.linspace(0, 10, {n}, dtype={dtype}) for {t} times')
print(timeit.timeit(f'torch.linspace(0, 10, {n}, dtype={dtype})', setup=f'import torch', number=t))
```
Before:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
1.3964195849839598
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
1.2374563289922662
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
1.8631796519621275
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
1.6991038109990768
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
1.8358083459897898
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
1.7214750979910605
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
1.8356257299892604
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
1.706238206999842
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
1.7463878280250356
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
1.6172360889613628
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
1.8656846070080064
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
1.714238062966615
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
1.8272205490502529
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
1.6409171230043285
```
After:
```
torch.linspace(0, 10, 40000, dtype=torch.double) for 50000 times
1.0077099470072426
torch.linspace(0, 10, 400000, dtype=torch.double) for 5000 times
0.8227124120458029
torch.linspace(0, 10, 40000, dtype=torch.float) for 50000 times
1.0058343949494883
torch.linspace(0, 10, 400000, dtype=torch.float) for 5000 times
0.8376779520185664
torch.linspace(0, 10, 40000, dtype=torch.uint8) for 50000 times
1.903041019977536
torch.linspace(0, 10, 400000, dtype=torch.uint8) for 5000 times
1.7576498500420712
torch.linspace(0, 10, 40000, dtype=torch.int8) for 50000 times
1.7628699769848026
torch.linspace(0, 10, 400000, dtype=torch.int8) for 5000 times
1.6204477970022708
torch.linspace(0, 10, 40000, dtype=torch.int16) for 50000 times
2.0970272019621916
torch.linspace(0, 10, 400000, dtype=torch.int16) for 5000 times
1.9493417189805768
torch.linspace(0, 10, 40000, dtype=torch.int32) for 50000 times
2.29020385700278
torch.linspace(0, 10, 400000, dtype=torch.int32) for 5000 times
2.1212510910118
torch.linspace(0, 10, 40000, dtype=torch.int64) for 50000 times
2.3479344319785014
torch.linspace(0, 10, 400000, dtype=torch.int64) for 5000 times
2.156775983981788
```
Test Plan: Imported from OSS
Differential Revision: D20773454
Pulled By: VitalyFedyunin
fbshipit-source-id: ebeef59a90edde581669cc2afcc3d65929c8ac79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37527
This is yet another place that needs to be updated for adding a new "Backend" and is unnecessary. Instead, just use layout_from_backend and have a map from Layout -> THPLayout.
Other changes:
- rename torch::getDtype and torch::getLayout to torch::getTHPDtype and torch::getTHPLayout since e.g. for layout you are both passing in and returning a "layout" type.
- add NumOptions to Layout to match the dtype/ScalarType formulation.
Test Plan: Imported from OSS
Differential Revision: D21309836
Pulled By: gchanan
fbshipit-source-id: ede0e4f3bf7ff2cd04a9b17df020f0d4fd654ba3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37535
Fuse ClipRanges + GatherRanges + SigridHash -> ClipRangesGatherSigridHash
dpa_product_ctr model's dper2 to dper3 migration is blocked by 3.6% higher prospector cpu usage. Root cause is traced down to sigrid transforms, where ClipRanges, GatherRanges, SigridHash are separately called, instead of fused, as is the case in dper2.
Further context:
https://fb.quip.com/GijaAZtX5mavhttps://fb.quip.com/pIDdAjJP2uiG
Test Plan:
Local benchmarking with small model 181513584_0
(Dper3 full model is 178772812, dper2 refresh is 178770392)
Transform turned on: P129799373
Iters per second: 609.291
Transform turned off: P129799397
Iters per second: 519.088
We also want to confirm this performance on the full model in canary and in qrt.
`buck build mode/opt-clang mode/no-gpu caffe2/caffe2/fb/predictor:ptvsc2_predictor_bench`
`MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 ./buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench --pred_net=/data/users/ansha/tmp/dpa/small_pred_net.pb --c2_model=/data/users/ansha/tmp/dpa/181513584_0.predictor --c2_inputs=/data/users/ansha/tmp/dpa/c2_inputs_small.pb --iters=3000 --warmup_iters=100 --num_threads=32 --c2_apply_nomnigraph_passes=1 --caffe2_predictor_enable_preproc_fusion=1`
Prospector canary:
https://our.intern.facebook.com/intern/ads/canary/426280288521552095/
Check that ClipRangesGatherSigridHash is used: https://fburl.com/scuba/caffe2_operator_stats_canary/e6qfdsat
Reviewed By: yinghai
Differential Revision: D21262085
fbshipit-source-id: 2c2481e3d4977abb8abe6e9ef0c9999382320ab2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37420
The quantized BN unit tests were disabled because they took too long.
This diff removes hypothesis from these test cases and instead generates
the cases manually. The run time is ~7 seconds per test on my devgpu.
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_batch_norm2d_relu
python test/test_quantization.py TestQuantizedOps.test_batch_norm3d
```
Imported from OSS
Differential Revision: D21310333
fbshipit-source-id: 2499f7a3d6a87c0278d012ae65132f148cee6d2e
Summary:
This is useful for linux distributions when the ABI/API of libtorch has
been changed. The default SOVERSION is set to
"${TORCH_VERSION_MAJOR}.${TORCH_VERSION_MINOR}".
ezyang
But if the release strategy of pytorch/caffe2 involves avoiding breaking API/ABI changes to libtorch for minor/patch releases, then we can set `TORCH_SOVERSION` to simply `TORCH_VERSION_MAJOR`. Please confirm that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37502
Differential Revision: D21303565
Pulled By: ezyang
fbshipit-source-id: 798f5ec7fc5f0431ff1a7f9e8e5d3a0d3b25bb22
Summary:
- Add debug mode to include debug information.
- Move codegen comment to FB shell script (as it's only checked-in FB repo).
- Analyze lite-predictor instead of full-JIT as full-JIT BUCK target contains variable kernels thus pull in a lot more dependencies.
- Use pre-opt bitcode instead of pre-codegen bitcode - there is one special `callOp()` case in RNN.cpp where optimized bitcode has opname string and API body inlined together: https://fburl.com/diffusion/8rz6u4rg; pre-optimization bitcode should give more stable result.
Test Plan: - Tested the bash script with stacked diff.
Reviewed By: iseeyuan
Differential Revision: D21298837
fbshipit-source-id: be33e2db5d8cb0f804460c503e52beb0dcb4857f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37562
The model has a LinearLayer which needs fbgemm. Fixes failing windows test.
Test Plan:
python test/test_quantization.py TestPostTrainingStatic
Imported from OSS
Differential Revision: D21321032
fbshipit-source-id: 1671fdef5d0a1b43e2a4e703a8852d522af32288
Summary:
**Summary**
Converting a float `Tensor` to a Python list is not supported because
Python's float is actually a double. This commit modifies the
implementation of `prim::tolist` so that it converts an input argument
that is a float Tensor into a double Tensor and emits a warning.
**Test Plan**
Modified and ran the corresponding unit test.
*Before*
```
======================================================================
ERROR: test_to_list (jit.test_list_dict.TestList)
Unit tests for Tensor.tolist() function.
----------------------------------------------------------------------
...
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: Output annotation element type and runtime tensor element type must match for tolist()
----------------------------------------------------------------------
Ran 1 test in 0.151s
FAILED (errors=1)
```
*After*
```
UserWarning: Converting float Tensor to double because tolist is only supported for double type Tensors (Triggered internally at ../torch/csrc/jit/runtime/register_prim_ops_fulljit.cpp:626.)
return callable(*args, **kwargs)
.
----------------------------------------------------------------------
Ran 1 test in 0.210s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37465
Differential Revision: D21311829
Pulled By: SplitInfinity
fbshipit-source-id: a0c1796013e35baf8d7641af271424a10e26f161
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37185
Previously observer instances are sharing the same Tensor attributes, it is
OK if we don't do inplace operations on these attributes, but will become a problem
when people do inplace changes.
This PR uses deepcopy instead of clone_instance which will copy the tensor for each instance.
Test Plan:
.
Imported from OSS
Differential Revision: D21309084
fbshipit-source-id: afd974b0c97886fbab815e9c711c126379fe3e17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37523
Makes the quantized hardswish function API more suited to graph mode
handling, which will come in the next PR.
Test Plan:
CI
Imported from OSS
Differential Revision: D21310364
fbshipit-source-id: 0d438dce5b87481d558c07bcccd9fe717200b4dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37522
Adds hardsigmoid op to graph mode handling.
Test Plan:
CI
Imported from OSS
Differential Revision: D21310363
fbshipit-source-id: 4d9f3bb032fb5a4d8f0cf84bff230fc1ce222c3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37521
Adds ELU to graph mode handling.
Test Plan:
CI
Imported from OSS
Differential Revision: D21310361
fbshipit-source-id: 045fc3af796dea67e0153255648fe5911e70bbed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37519closes#37446
Currently FutureMessage is used in several places:
1. `rpc_async` returns a `FutureMessage` object and we expose it
as `torch.distributed.rpc.Future`. From applications perspective,
they are expecting a `py::object` instead of a `Message`, and we
do the conversion in the `Future.wait()` pybind method.
2. RPC autograd profiler takes `FutureMessage` and installs
callbacks to it. The profiler actually only need a `Future<T>`
and does not care what `T` is.
3. `OwnerRRef` exposes a `getFuture()` API which returns a
`FutureMessage`. This `FutureMessage` will be marked completed
when the value referenced by the `OwnerRRef` is ready.
`OwnerRRef` does not need it to be a Message type either, it
actually creates an empty `Message` to mark the `Future`.
The above places are using `FutureMessage`, but they don't really
need a `Message`, and `Message` is a communication layer type that
applications or profiler or the RRef shouldn't be aware of.
Another motivation for making this change is that for async RPC
UDF #36071, we are going to allow application to call
`markCompleted` in Python. If we still use `FutureMessage`, then
in the `markCompleted` pybind function, it needs to convert the
provided `py::object` into a specific message type, which is
leaking communication layer code to pybind functions. Even if
this is doable, we will have two entities (RPC agent and pybind
Python frontend) accessing the same request callback logic. This is too messy.
This commit replaces all surface `FutureMessage` with `FutureIValue`,
so that `FutureMessage` is no longer visible from Python land. Note
that this does not cause BC issues, as the Python Future type name
and its API stay intact. Internally, we still have `FutureMessage`
in the communication layer.
Test Plan: Imported from OSS
Reviewed By: xush6528
Differential Revision: D21308887
Pulled By: mrshenli
fbshipit-source-id: 4f574f38e83125081f142813cfdde56119522089
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37037
For avgpool and gavgpool change requantization scheme:
Similar to conv and linear now convert the accumulated int32
values to float, apply requantization scale which includes the averaging
multiplier.
Conver the resulting float value to int32.
Add output_zero_point.
Benchmark numbers compared to baseline:
% speedup on pixel XL.
------------------------------
| | aarch32 | aarch64|
|avgpool | .4 | 13.6 |
|gavgpool | -2.6% | 3.5% |
-------------------------------
Test Plan:
Tested via q8avgpool-test, q8gavgpool-test, average-pooling-test and
global-average-pooling-test in PT QNNPACK.
Also via integated test_quantized.py.
python test/quantization/test_quantized.py
Imported from OSS
Differential Revision: D21168981
fbshipit-source-id: 9060324304603ca7fd380c788a87b01a6d586c5c
Summary:
Set opset version before model select call - which is used to trigger warnings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37466
Reviewed By: hl475
Differential Revision: D21308796
Pulled By: houseroad
fbshipit-source-id: 0974b9d5b6562d4451f54053138174f663a17aa3
Summary:
# Overview
This PR changes the backing type of complex tensors in `ScalarType` from `std::complex` to `c10::complex`.
Since `c10::complex` and `std::complex` are reinterpret-castable, we can freely use `std::complex *` to access `c10::complex` data and vice versa. The implementation of `c10::complex` is not complete yet, so we are reinterpret casting all complex data to `std::complex` during dispatch, and do all operations in `std::complex`.
# `std::complex` and `c10::complex` interoperatability
To use `std::complex *` to access `c10::complex` data, the following specializations are added:
```C++
template <> inline std::complex<float>* Tensor::data_ptr();
template <> inline std::complex<double>* Tensor::data_ptr();
template <> inline std::complex<float> Tensor::item();
template <> inline std::complex<double> Tensor::item();
```
See [`aten/src/ATen/templates/TensorMethods.h`](https://github.com/pytorch/pytorch/pull/37274/files#diff-0e8bf6f5024b32c240a4c1f0b4d8fd71)
And
```C++
template <> inline std::complex<float> Scalar::to();
template <> inline std::complex<double> Scalar::to();
```
is added in [`c10/core/Scalar.h`](https://github.com/pytorch/pytorch/pull/37274/files#diff-aabe1c134055c8dcefad830c1c7ae957)
# Dispatch
Macros in [`Dispatch.h`](https://github.com/pytorch/pytorch/pull/37274/files#diff-737cfdab7707be924da409a98d46cb98) still using `std::complex` as its type. We will add macros such as `AT_DISPATCH_ALL_TYPES_AND_C10_COMPLEX_AND3` as needed during the migration and not in this PR.
Note that `AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND3` is only used in copy kernel of CUDA, and this PR is already changing it to use `c10::complex` because CUDA copy kernel has to use its original dtype otherwise there will be funny casting of dtypes causing cuda unspecified launch error.
When all the migration is done, the c10 version of macros will be removed, and the default version will have `std::complex` replaced by `c10::complex` by default. This design allows us to incrementally migrate from `std::complex` to `c10::complex`.
# Note
Note that the `std::complex` is not completely replaced by `c10::complex` in c10 yet, for example `c10::Scalar` is still using `std::complex`. This will be fixed in later PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37421
Differential Revision: D21282161
Pulled By: anjali411
fbshipit-source-id: 635e309e8c8a807c2217723ad250b5ab5a20ce45
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37539
Bug fix
Test Plan:
This passed fbtranslate local integration test when I toggle fp16 to true on GPU.
Also it passed in with D21312488
Reviewed By: zhangguanheng66
Differential Revision: D21311505
fbshipit-source-id: 7ebd7375ef2c1b2ba4ac6fe7be5e7be1a490a319
Summary:
Benchmark with same build settings on same system.
Closes https://github.com/pytorch/pytorch/issues/24545
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.cos(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.cos(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.cos(a) a.numel() == 10000 for 20000 times torch.half
0.2797315450006863
torch.cos(a) a.numel() == 10000 for 20000 times torch.float
0.283109110998339
torch.cos(a) a.numel() == 10000 for 20000 times torch.double
0.3648525129974587
torch.cos(a) a.numel() == 100000 for 20000 times torch.half
0.34239949499897193
torch.cos(a) a.numel() == 100000 for 20000 times torch.float
0.33680364199972246
torch.cos(a) a.numel() == 100000 for 20000 times torch.double
1.0512770260102116
```
After:
```
torch.cos(a) a.numel() == 10000 for 20000 times torch.half
0.285825898999974
torch.cos(a) a.numel() == 10000 for 20000 times torch.float
0.2781305120001889
torch.cos(a) a.numel() == 10000 for 20000 times torch.double
0.34188826099989456
torch.cos(a) a.numel() == 100000 for 20000 times torch.half
0.29040409300023384
torch.cos(a) a.numel() == 100000 for 20000 times torch.float
0.28678944200009937
torch.cos(a) a.numel() == 100000 for 20000 times torch.double
1.065477349000048
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36653
Differential Revision: D21164675
Pulled By: VitalyFedyunin
fbshipit-source-id: 5dd5d3af47c2a5527e1f4ab7669c2ed9a2293cee
Summary:
- It's valid to call `sched_setaffinity` with nullptr
- The call is coming from libomp which should be valgrind safe
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37532
Test Plan: CI
Differential Revision: D21311252
Pulled By: malfet
fbshipit-source-id: a325f97741b997738c35759d02fcc34c1cb44d95
Summary:
Adds support for generating Vandermonde matrices based off of the Numpy implementation found [here](https://github.com/numpy/numpy/blob/v1.17.0/numpy/lib/twodim_base.py#L475-L563).
Adds test to ensure generated matrix matches expected Numpy implementation. Note test are only limited to torch.long and torch.double due to differences in now PyTorch and Numpy deal with type promotion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36725
Differential Revision: D21075138
Pulled By: jessebrizzi
fbshipit-source-id: 6bb1559e8247945714469b0e2b07c6f4d5fd1fd0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37425
The mobile type resolver that we inject into the unpickler currently
creates a dummy type for everything, even built-in types like
List[int]. This PR restricts that behavior to types that start with
`__torch__`, and uses the mobile type parser for everything else.
I don't like this solution because it relies on a fragile invariant that
all "class-like" types have qualified names that start with `__torch__`.
I think the long term solution is to just re-use the script type parser
here.
Test Plan: Imported from OSS
Differential Revision: D21291331
Pulled By: suo
fbshipit-source-id: c94709bcbd1bac75336e033fd9d3afa6656b0a77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36800
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21089650
Pulled By: ezyang
fbshipit-source-id: 1babdb5524038e3951d3c4303e4ba87e68b4f138
Summary:
- added tests that showcase the problems
- fixed the problems
These changes would allow me to remove many "# type: ignore" comments in my codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36358
Differential Revision: D21230704
Pulled By: ezyang
fbshipit-source-id: e6d475a0aa1fb40258fa0231ade28c38108355fb
Summary:
Added enough operators to make sure that all unit tests from ATen/basic are passing, except for MM and IntArrayRefExpansion
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37121
Test Plan: `./bin/basic --gtest_filter=--gtest_filter=BasicTest.BasicTestHalfCPU` + `python -c "import torch; x = torch.tensor([2], dtype=torch.half); print(torch.isfinite(x+x))"`
Differential Revision: D21296863
Pulled By: malfet
fbshipit-source-id: e03d7a6939df11f611a9b317543bac52403cd009
Summary:
This pull request disables the unit tests that were observed to be failing once `test2` was enabled. These tests will be one by one looked at and fixed at the earliest, but until then disabling them to unblock `test2`
The pull request also disables fftPlanDestroy for rocFFT to avoid double-freeing FFT handles
cc: ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37427
Differential Revision: D21302909
Pulled By: ezyang
fbshipit-source-id: ecadda3778e65b7f4f97e24b932b96b9ce928616
Summary:
`THCudaMemGetInfo` has only been used in `aten/src/ATen/native/cudnn/Conv.cpp`. We can extract `c10::cuda::CUDACachingAllocator::cacheInfo` out from it and use it in `aten/src/ATen/native/cudnn/Conv.cpp` directly and drop lines that are not used in `THCudaMemGetInfo`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37447
Differential Revision: D21302770
Pulled By: ezyang
fbshipit-source-id: 41ad68b8fd5ecc7bc666a6861789c6c1f743f420
Summary:
fmt is a formatting library for C++. It has several properties that make it nice
for inclusion in PyTorch:
- Widely used
- Basically copies how Python does it
- Support for all the compilers and platforms we care about
- Standards track (C++20)
- Small code size
- Header only
This PR includes it as a submodule and sets up the build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37356
Differential Revision: D21262619
Pulled By: suo
fbshipit-source-id: 1d9a1a5ed08a634213748e7b02fc718ef8dac4c9
Summary:
To address one of the problems with RNNs that emerged in https://github.com/pytorch/pytorch/issues/33618, I modified the `remove` methods in `torch.nn.utils.prune` and `torch.nn.utils.weight_norm` to make an explicit call to `setattr`, which, in `rnn.py` directly modifies `_flat_weights` (https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/rnn.py#L96) to include the new element.
This is important so that `_flat_weights` can reflect the presence of the `Parameter` after the (pruning or weight norm) reparametrization is removed. Without this, the weight in `_flat_weights` would remain a tensor, as originally set by the reparametrization.
Simple testing is added, which depends on the current naming scheme for the LSTM module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34170
Differential Revision: D21265965
Pulled By: mickypaganini
fbshipit-source-id: 29de4a6b17052d42ccfe67c8560b7f83c20fd09d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37460
It seems that stateless xnnpack integration for Convolution is breaking iOS
runs.
Issue seems to be stemming from passing some invalid pointer or pointer that is
not longer valid. But beyond this the issue has not been root caused.
The issues seems to appear only for iOS so far but blanket disabling it for
both ios and android since this improvement had only been recent so no
production models are running with this perf improvement yet. Hence no perf
regression expected.
Test Plan: buck run aibench:run_bench -- -b aibench/specifications/models/pytorch/pytext/pytext_mobile_inference.json --platform ios --framework pytorch --remote --devices D221AP-12.0.1
Reviewed By: xta0
Differential Revision: D21284385
fbshipit-source-id: 1fe01e3a476b340697972743dadf64333cc86b3f
Summary:
complex is not supported, so no need to use thrust
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37470
Differential Revision: D21296501
Pulled By: anjali411
fbshipit-source-id: bf2075ac933a793b9cdddcda0918604e7574ee2d
Summary:
It will be convenient to print ops names when converting the model in xplat.
This diff moves export_opnames to export_module.cpp so it can be used in xplat (caffe2:optimize_for_mobile and caffe2:torch_train). This function was in caffe2/torch/csrc/jit/serialization/export.cpp. I tried to create a target to include this file but it involves too many ONNX deps and I cannot get it to work.
Test Plan: local test, verified op names are printed
Reviewed By: iseeyuan
Differential Revision: D20961557
fbshipit-source-id: 293569081b29c263c1c441df7a63838a81560ce9
Summary:
On Windows, when you call those unsupported functions like `std::pow`, `std::isnan` or `std::isinf` in the device function and compile, a warning is thrown:
```
kernel.cu
kernel.cu(39): warning: calling a __host__ function from a __host__ __device__ function is not allowed
kernel.cu(42): warning: calling a __host__ function from a __host__ __device__ function is not allowed
kernel.cu(39): warning: calling a __host__ function("isnan<double> ") from a __host__ __device__ function("test_") is not allowed
kernel.cu(42): warning: calling a __host__ function("isinf<double> ") from a __host__ __device__ function("test_") is not allowed
```
However, those calls will lead to runtime errors, see https://github.com/pytorch/pytorch/pull/36749#issuecomment-619239788 and https://github.com/pytorch/pytorch/issues/31108. So we should treat them as errors.
Previously, the situation is worse because the warnings are turned off by passing in `-w`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37302
Differential Revision: D21297207
Pulled By: ngimel
fbshipit-source-id: 822b8a98c10e54c38319674763b6681db21c1021
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37464
Fixes https://github.com/pytorch/pytorch/issues/23993.
There are two fixes here:
1. Previously our name lookup function for the tracer was looking in
f.globals for names. For example:
```
sample = torch.ones(1)
traced = torch.jit.trace(my_mod, ((sample, sample,),))
# produces a graph with something like
# %sample, %sample = prim::TupleUnpack(%input)
```
This is not great if you are, e.g. trace checking, because a non-local
bit of interpreter state is affected the graph produced:
```
traced = torch.jit.trace(my_mod, _clone_inputs((sample, sample,),))
# produces a graph with something like
# %0, %1 = prim::TupleUnpack(%input)
```
I have removed this functionality, as I don't think it provides huge
value. Things that look locally for names will still work, so e.g.
inputs, intermediate variables, and the like will be named correctly.
2. Previously, our input cloning for trace checking didn't do a memoized
deep copy. So:
```
_clone_inputs((sample, sample, sample))
```
produces a tuple with three non-aliased tensors. That's wrong! Use
copy.deepcopy with a memoization argument to fix this.
Test Plan: Imported from OSS
Differential Revision: D21297549
Pulled By: suo
fbshipit-source-id: 981d5879a4a244520dd68489767129ff357f1497
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37012
Removes an if statement in `torch.nn.functional.affine_grid`
Test Plan: Imported from OSS
Differential Revision: D21160755
Pulled By: eellison
fbshipit-source-id: 8b030936c9fbdb05b44abc9f254805d102f2acc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36953
Add support for generic lists as a constant. generic dicts & tuples are already implemented. This is a pretty common pattern and cuts down on the number of non-tensor nodes executed in interpolate tests.
Test Plan: Imported from OSS
Differential Revision: D21160761
Pulled By: eellison
fbshipit-source-id: 1e6b7b25b7580f09067794772d44e615601c60c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36757
replacing x + 0 with x isn't that much of a speedup, and is an optimization also duplicated at the Tensor Expr level. Constructing an alias db is costly and it's not worth rebuilding an alias db each time we optimize out x + 0.
Test Plan: Imported from OSS
Differential Revision: D21160757
Pulled By: eellison
fbshipit-source-id: 9b3d4fa430b838898fe6c78660ec3c608547bb31
Summary:
dylanbespalko anjali411
Not sure if the test should be added to `test_torch` or `test_complex`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36749
Differential Revision: D21290529
Pulled By: anjali411
fbshipit-source-id: 07bc282e4c9480cd015ec5db104e79728437cd90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37207
The main idea here is to try and give build system more flexibility on when various AVX instruction are defined, previously it was based solely on compiler defined preprocessor flags.
Here we re-use `CPU_CAPABILITY` which already needs to be defined for each pass in `["DEFAULT", "AVX", "AVX2"]` over the source files.
To give a slightly more concrete reason this is needed, is that we have not found a way to override `/arch` flags previously specified on the command line from visual studio (causing us to duplicate symbols in some cases).
Test Plan: CI green
Differential Revision: D21218512
fbshipit-source-id: f628153f5f3d83cd6bd4a5283fb0dc751a58ebf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37366
- we can put both fake quant module and observer module tests in the test_workflow_module.py
- added test_quantized_functional.py
- moved tests in test_numerics.py to test_quantize.py and removed test_numerics.py
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D21282198
fbshipit-source-id: 60107cee7d1ed2cd14a45650e91ec28b8a262c52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37125
For dynamic quant we need to replicate the choose_qparams and quantize function in addition to replicating dequant.
RemoveRedundantQuantizeOps pass checks for the choose_qparams - quant - dequant pattern in the graph and removes it if the node following it cannot be quantized using dynamic quantization.
Test Plan:
python test_quantize_script.py test_dynamic_quant_multi_uses
Imported from OSS
Differential Revision: D21283697
fbshipit-source-id: 70fa0abdaeb2cc2935149a941d93a7e8b28d61d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37093
Specify which ops should/can be dynamically quantized. Similar to static quantization
Test Plan:
python test_quantize_script.py test_dynamic_multi_op
Imported from OSS
Differential Revision: D21283695
fbshipit-source-id: 7ee238940c5c239f6ef8af994655e0b13db64161
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37045
Fixes to get the correct path for child modules
Test Plan: Imported from OSS
Differential Revision: D21283698
fbshipit-source-id: 48a7f7762df86a5177ea117ab0cd7cb1d6e6209d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37014
User should only pass name as key in dict.
Test Plan: Imported from OSS
Differential Revision: D21283696
fbshipit-source-id: e6babbe9302c812d6ae03ed7f843d2816b752e78
Summary:
All templates which are included from `ATen/native/cpu` must be in anonymous namespace, especially if they are using instruction set extensions but do not support dynamic dispatching.
Otherwise, linker is free to pick AVX2, AVX or DEFAULT version of instantiated templates during final linking stage
Test Plan; Apply on top of https://github.com/pytorch/pytorch/pull/37121 and make sure that `basic` test successfully finishes on CircleCI MacPro (that does not support AVX2), but `ATEN_CPU_CAPABILITY=avx2 ./basic --gtest_filter=*HalfCPU` crashes with illegal instruction
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37429
Differential Revision: D21294818
Pulled By: malfet
fbshipit-source-id: ab32b8553de225d2f672fac2f48591682bd7dec4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32684
Previously we have `clone` and `clone_instance`, where `clone` will clone both type
and value, and `clone_instance` only clone the value, both of them are shallow copies.
We need to re-evaluate whether we should expose them as a user facing API.
I think we should hide `clone`, but `clone_instance` might be useful as well, especially
when we are copying a model with very large weights, people might just want to do shallow copy.
This PR adds a `deepcopy` that might be useful as a user API, which deep copies the values, including
Tensor, but we didn't deepcopy `Blob`, `Capsule`, `Future` or `PyObject`.
For more discussions please see the following issue.
fixes: https://github.com/pytorch/pytorch/issues/32519
Test Plan: Imported from OSS
Differential Revision: D21220756
fbshipit-source-id: 476bf11fe82c08fac36e7457879a09f545ffdc5e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/37084
There are 3 alternatives for this design.
This PR and the first one.
When a tensor is a scalar `ndim==0`, accessing view_offsets_[0] when doing reductions, yields an invalid offset for the index which is the output of `argmax` and `argmin`.
fba9b9a023/aten/src/ATen/native/cpu/Reduce.h (L217)
This also happens in cuda code:
fba9b9a023/aten/src/ATen/native/cuda/Reduce.cuh (L797)
The second alternative is to check the size of `view_offsets` before accessing it. But this introduces some burden.
The third alternative is related to the way that inputs are treated in `argmax` and `argmin`
depending on the `dim` argument value.
fba9b9a023/aten/src/ATen/native/ReduceOps.cpp (L775-L780)
If `dim` is not specified, then the scalar gets reshaped into a 1-dim tensor and everything works properly, since now `view_offsets` has an actual entry.
If dim is specified, then the input remains as a scalar causing the issue we see here.
This PR tries to solve it in a generic way for every case so I went with option 1. I am willing to discuss it and change if you think that the other alternatives are better.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37214
Differential Revision: D21258320
Pulled By: ngimel
fbshipit-source-id: 46223412187bbba4bfa7337e3f1d2518db72dea2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37404
Many aten operators are really like util functions, e.g.:
aten::is_nonzero, aten::is_floating_point, etc. These ops can be called
via overloaded c++ operator, so seemingly trivial and innocent code changes can
affect how these ops are used by other ops (thus changes the output of
static analyzer).
Most of these util ops are rather small in terms of build size cost, so
for the purpose of optimizing binary size with custom build, whether to
include these ops or not does not make significant difference. In fact
for non-trivial models a set of these ops are almost always used.
This PR introduced the (optional) '__BASE__' ops section to the dependency graph.
We can maintain the list of frequently used small util ops for internal BUCK
build. This way, the output dependency graph will only contain meaningful
edges with significant binary size impact, and it will be more stable from
trivial code changes (which is checked in FB codebase).
Having a stable and sparse deps graph by factoring out frequently used based ops
is also a nice property to allow us to explore alternative custom build
solutions in case we find it hard to maintain the static code analyzer.
Test Plan: Imported from OSS
Differential Revision: D21280835
Pulled By: ljk53
fbshipit-source-id: c4d0d1f07ca868c60f23118d877fc1eeead4c875
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37393
Simplify the code analyzer by removing some unused flags and moving the
different format printer logic to python script. It's easier to add other
post processing logic to adapt to different BUCK build configs.
Test Plan: Imported from OSS
Differential Revision: D21280836
Pulled By: ljk53
fbshipit-source-id: 0d66d5891d850f012c4ab4f39eabbd9aecc1caa9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37454
Fix a bug introduced in D21224497.
In the case of having a single unpacked tensor as input, we still need to copy the underline memory because only inputs are guaranteed to be read-only. The output could be overwritten later during inference. If we share the tensor, we could potentially overwrite the input, which in principle should be read only.
Test Plan:
```
buck test caffe2/caffe2/python/operator_test:dataset_ops_test
```
AdIndexer canary:
https://our.intern.facebook.com/intern/ads/canary/426290361213982683
Reviewed By: yinghai
Differential Revision: D21274309
fbshipit-source-id: 71931d4b1afbdc700ba070ea618d1679f1bbe5a7
Summary:
These two ops are needed for torchvision model export. Since we're scripting a part of the code for dynamic export of models (in https://github.com/pytorch/vision/pull/2052), these two changes are requited.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36501
Reviewed By: hl475
Differential Revision: D21260721
Pulled By: houseroad
fbshipit-source-id: 86d9d38665a4a36d22cec741012d976e5bd8d36b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/21821
This follows ngimel's [suggestion](https://github.com/pytorch/pytorch/issues/21821#issuecomment-502968982) to manually synchronize MAGMA calls with the current stream. This is handled automatically with `MagmaStreamSyncGuard`.
I think for the functions with `_batched` variants we could possibly avoid synchronisation by using a batch of size 1 since these have a `magma_queue_t` argument. However, I presume there's a reason it wasn't written like that in the first place.
I also figured out why porting to aten ["magically fixed"](https://github.com/pytorch/pytorch/issues/21821#issuecomment-527647971) `torch.svd`. The magma functions for svd all take host arrays as input and output. The ATen port uses blocking `copy_`s which fully synchronize the operation. On the other hand, the THC functions use `cudaMemcpy` which doesn't synchronize with streams created with `cudaStreamNonBlocking` (which `aten` does). The fix is to use `cudaMemcpyAsync` and `cudaStreamSynchronize`, the same as `copy_` does internally:
835ee34e38/aten/src/ATen/native/cuda/Copy.cu (L192-L193)
I'm not sure how to test these changes as I wasn't able to reproduce any of the stream sync issues. Possibly a mixture of non-determinism and because some of these functions are implicitly synchronous anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36605
Differential Revision: D21258265
Pulled By: ngimel
fbshipit-source-id: 76d8f687c605e5e9cd68b97dc1d70a39a13376ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37382
After adding c10::DispatchKey::Profiler the behavior of RecordFunction
observers is also controlled by the dispatch key,
this PR moves the logic outside of the profiler into the record function
Reviewed By: jamesr66a
Differential Revision: D21268320
fbshipit-source-id: 93207e3b55325d20dcc5b1e8f448ab86933321da
Summary:
We should not rely on the async exceptions. Catching C++ only exception is more sensible and may get a boost in both space (1163 MB -> 1073 MB, 0.92x) and performance(51m -> 49m, 0.96x).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37235
Differential Revision: D21256918
Pulled By: ezyang
fbshipit-source-id: 572ee96f2e4c48ad13f83409e4e113483b3a457a
Summary:
This enables type checking for named tensors, and fixes the underlying problems.
The bulk of the fix is modifying `gen_pyi.py` to generate reasonable types in `torch/__init__.pyi`. I took two approaches: First, I tried to take a generic approach and added `DimnameList` to the magic list of variable argument lists. Unfortunately that was insufficient for many of the method signatures, so I also added manual definitions for `rename`, `refine_names`, and `unflatten` in `__init__.pyi.in`.
Finally there were a few problems in the doctests that had to be cleaned up so that `test/test_type_hints.py` will run successfully.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36890
Differential Revision: D21259192
Pulled By: zou3519
fbshipit-source-id: 2a9e7d7bec9be5ae3ae2995078c6abfa3eca103c
Summary:
Make sleef dependency public so that `ATen_CPU_{capability}` libs can depend on it
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37381
Test Plan: CI
Differential Revision: D21273443
Pulled By: malfet
fbshipit-source-id: 7f756c7f3c605e51cf0c27ea37f687913cd48708
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37052
These only need to be in the cpp as they are not referenced anywhere
else. These functions should only be used from the python operators
torch.opts.profiler.record_function_{enter, exit}.
ghstack-source-id: 102979051
Test Plan: CI
Differential Revision: D21171987
fbshipit-source-id: dfe8130d2b64de6179222327069ce1ab877829e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37361
Add a fast path for the case of batch_size = 1 and single ad embedding in UnPackRecordsOp. In this case, there is no need to pack the single tensor into a shared_ptr<vector<vector<Tensor>>> and then unpack it in UnPackRecordsOp. Instead, we can just pass the tensor as it is into UnPackRecordsOp and share the data with the output tensor.
Reviewed By: yinghai
Differential Revision: D21224497
fbshipit-source-id: 70685e5cc20ffdc5e0044a4b97a7fc5133786db4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37027
The RPC timeout passed into rpc_sync and rpc_async after the below
change is now float, so we should make these APIs consistent.
ghstack-source-id: 102971906
Test Plan:
Existing unittests, also added unittest testing specific timeout set
in ProcessGroupRpcBackendOptions and the dispatch rpc backend options handling.
Differential Revision: D21125171
fbshipit-source-id: a5894b8ce31d2926f2c3d323d1cda4d54b30cef1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37367
Before this change we printed all the args in the same list, for example:
```
BEFORE RFACTOR:
{
for (int m = 0; m < m_1; m++) {
for (int n = 0; n < n_1; n++) {
sum[0] = ReduceOp(sum, float(0), (sum[0]) + (b[m, n]), {m, n});
}
}
}
AFTER RFACTOR:
{
for (int m = 0; m < m_1; m++) {
for (int n = 0; n < n_1; n++) {
tmp_buf[n] = ReduceOp(tmp_buf, float(0), (tmp_buf[n]) + (b[m, n]), {nm}); # <<< n is out, m is reduce here
}
}
for (int n = 0; n < n_1; n++) {
sum[0] = ReduceOp(sum, float(0), (sum[0]) + (tmp_buf[n]), {n});
}
}
```
With this change we explicitly show which args are reduce args:
```
BEFORE RFACTOR:
{
for (int m = 0; m < m_1; m++) {
for (int n = 0; n < n_1; n++) {
sum[0] = ReduceOp(sum, float(0), (sum[0]) + (b[m, n]), out_args={}, reduce_args={m, n});
}
}
}
AFTER RFACTOR:
{
for (int m = 0; m < m_1; m++) {
for (int n = 0; n < n_1; n++) {
tmp_buf[n] = ReduceOp(tmp_buf, float(0), (tmp_buf[n]) + (b[m, n]), out_args={n}, reduce_args={m});
}
}
for (int n = 0; n < n_1; n++) {
sum[0] = ReduceOp(sum, float(0), (sum[0]) + (tmp_buf[n]), out_args={}, reduce_args={n});
}
}
```
Test Plan: Imported from OSS
Differential Revision: D21265807
Pulled By: ZolotukhinM
fbshipit-source-id: 384396cd55562570f8e33657b856a4404d451080
Summary:
In build-variables.bzl split filelist into `libtorch_python_core_sources` and `libtorch_python_distributed_sources`
Move jit passes from `glob_libtorch_python_sources()` to `libtorch_core_jit_sources` filelist
Validated that original `TORCH_PYTHON_SRCS` filelist matches one in `build_varaiables.bzl` by running the following script:
```
import os
def read_file(path):
with open(path) as f:
return f.read()
def get_cmake_torch_python_srcs():
caffe2_cmake = read_file("torch/CMakeLists.txt")
start = caffe2_cmake.find("set(TORCH_PYTHON_SRCS")
end = caffe2_cmake.find(")", start)
return caffe2_cmake[start:end+1]
def get_cmake_torch_python_srcs_list():
_srcs = get_cmake_torch_python_srcs()
unfiltered_list = [x.strip() for x in _srcs.split("\n") if len(x.strip())>0]
return [x.replace("${TORCH_SRC_DIR}/","torch/") for x in unfiltered_list if 'TORCH_SRC_DIR' in x]
import imp
build_variables = imp.load_source('build_variables', 'tools/build_variables.bzl')
libtorch_python_sources = set(build_variables.libtorch_python_core_sources)
torch_python_srcs = set(get_cmake_torch_python_srcs_list())
print(set.difference(libtorch_python_sources, torch_python_srcs))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37267
Test Plan: CI
Differential Revision: D21258292
Pulled By: malfet
fbshipit-source-id: bb6d7ee73c97cbe149a9021756b9a4c9fb3ce50e
Summary:
See https://discuss.pytorch.org/t/training-with-gradient-checkpoints-torch-utils-checkpoint-appears-to-reduce-performance-of-model/78102/3?u=jwl for details.
Updated the docs to warn users about issues with checkpointing models that use `detach()` or `torch.no_grad()` to freeze their model layers/weights during training. When they do this, training with `checkpoint` will fail as it forces the outputs to require gradients when the model itself does not. Hence, during the backward pass it will output the error:
```
[4]<stderr>:RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
```
Maybe it is possible to fix this directly in the code, but I am not sure how in the current codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37266
Differential Revision: D21262558
Pulled By: mrshenli
fbshipit-source-id: 529cf370534504baf8937ef17dac5d6916fbf5ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37292
After adding c10::DispatchKey::Profiler the behavior of RecordFunction
observers is also controlled by the dispatch key,
this PR moves the logic outside of the profiler into the record function
Reviewed By: jamesr66a
Differential Revision: D21245094
fbshipit-source-id: 595e41b18206d2ba4cf639cb320f630907868b3f
Summary:
Fix https://github.com/pytorch/pytorch/issues/33928. Basically just move the dependency into a new imported target.
I'm not sure whether this modification will affect other parts, please test it throughly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37310
Differential Revision: D21263066
Pulled By: ezyang
fbshipit-source-id: 7dc38f578d7e9bcb491ef5e122106fb66a33156f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37273
The issues why those couldn't be `use_c10_dispatcher: full` have either been fixed or those ops have been newly introduced without the tag but could have used it.
Let's enable the tag for them.
ghstack-source-id: 102896116
Test Plan: waitforsandcastle
Differential Revision: D21242516
fbshipit-source-id: 5158ecc1ff6b34896f36904ea7bd7fcb4811a0bf
Summary:
As described in the issue (https://github.com/pytorch/pytorch/issues/33701) the compiler check
for building cpp extensions does not work with ccache.
In this case we check compiler -v to determine which
compiler is actually used and check it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37293
Differential Revision: D21256913
Pulled By: ezyang
fbshipit-source-id: 5483a10cc2dbcff98a7f069ea9dbc0c12b6502dc
Summary:
Issue: https://github.com/pytorch/pytorch/issues/35284
~This depends on and contains https://github.com/pytorch/pytorch/pull/35524. Please review after the dependency gets merged and I will rebase to get a clean diff.~
The implementation of most functions follow the pattern
```C++
template<typename T>
C10_HOST_DEVICE c10::complex<T> some_function(c10::complex<T> x) {
#if defined(__CUDACC__) || defined(__HIPCC__)
return static_cast<c10::complex<T>>(thrust::some_function(static_cast<thrust::complex<T>>(x)));
#else
return static_cast<c10::complex<T>>(std::some_function(static_cast<std::complex<T>>(x)));
#endif
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35725
Differential Revision: D21256854
Pulled By: ezyang
fbshipit-source-id: 2112ba6b79923450feafd7ebdc7184a3eaecadb6
Summary:
Hi everyone,
This is a supper small PR to enable `unit8` support for `nearest` up-sampling in `cpu` and `cuda`.
This works enables us to move forward with the support of 'uint8' images in 'torchvision`.
See impacted issues :
https://github.com/pytorch/vision/issues/1375https://github.com/pytorch/vision/issues/1179#issuecomment-558197607
Note: I wanted to add a unit test to ensure we have the expected behavior. I could not locate the `upsampling` unit tests for `nearest`. I can add the test if you point me to the right location.
Thanks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35029
Reviewed By: cpuhrsch
Differential Revision: D21227144
Pulled By: fmassa
fbshipit-source-id: 33c4b5188dedd8f7f872e9d797e2a9b58ee7315c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37046
ghstack-source-id: 102669259
Creating a python api entry to generate mobile model lints which takes a scripted module as argument and returns a map of module lints.
The initial version is to create placeholder which included module bundled input as the first lint instance. More lints will be added in the future.
Test Plan: python test/test_optimizer.py
Reviewed By: dreiss
Differential Revision: D21164648
fbshipit-source-id: 9e8f4e19d74b5464a55cc73b9dc18f358c5947d6
Summary:
These options are disabled by default, and are supposed to be used by
linux distro developers. With the existing shortcut option
USE_SYSTEM_LIBS toggled, these new options will be enabled as well.
Additionally, when USE_SYSTEM_LIBS is toggled, setup.py should
no longer check the existence of git submodules.
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37277
Differential Revision: D21256999
Pulled By: ezyang
fbshipit-source-id: 84f97d008db5a5e41a289cb7bce94906de3c52cf
Summary:
The "Generic" BLAS refers to the Netlib BLAS. This option is meaningful
to the Debian family due to the "update-alternatives" mechanism, which
enables the user to switch the libblas.so providers between different
implementations at runtime, such as ATLAS, OpenBLAS, and Intel MKL.
Such, building against generic BLAS provides much flexibility.
This new option is not documented in setup.py because it's only supposed
to be used by linux distro (especially Debian family) developersonly.
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37276
Differential Revision: D21256877
Pulled By: ezyang
fbshipit-source-id: 55a5356653a1cfc763a5699b04afe5938f2007ec
Summary:
This PR is based on the issue https://github.com/pytorch/pytorch/issues/29994#issue-524418771 and the discussion in the previous version of the PR https://github.com/pytorch/pytorch/pull/30559. Specifically, I followed the interface outlined in this [comment](https://github.com/pytorch/pytorch/pull/30559#issuecomment-574864768).
## Structure
- `torch/optim/swa_utils.py` contains the implementation of `AveragedModel` class, `SWALR` learning rate scheduler and `update_bn` utility
- `test/test_optim.py` contains unit tests for the three components of SWA
- `torch/optim/swa_utils.pyi` describes the interface of `torch/optim/swa_utils.py`
The new implementation consists of
- `AveragedModel` class; this class creates a copy of a given model and allows to compute running averages of the parameters.
- `SWALR` learning rate scheduler; after a certain number of epochs switches to a constant learning rate; this scheduler is supposed to be chained with other schedulers.
- `update_bn` utility; updates the Batch Normalization activation statistics for a given model and dataloader; this utility is meant to be applied to `AveragedModel` instances.
For `update_bn` I simplified the implementation compared to the [original PR](https://github.com/pytorch/pytorch/pull/30559) according to the sugestions by vadimkantorov.
## Example
```python
loader, optimizer, model = ...
swa_model = torch.optim.swa_utils.AveragedModel(model)
# You can use custom averaging functions with `avg_fun` parameter
ema_avg = lambda p_avg, p, n_avg: 0.1 * p_avg + 0.9 * p
ema_model = torch.optim.swa_utils.AveragedModel(model,
avg_function=ema_avg)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,
T_max=300)
swa_start = 160
swa_scheduler = SWALR(optimizer, start_epoch=swa_start, swa_lr=0.05)
for i in range(300):
for input, target in loader:
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
scheduler.step()
swa_scheduler.step()
if i > swa_start:
swa_model.update_parameters(model)
# Update bn statistics for the swa_model at the end
torch.optim.swa_utils.update_bn(loader, swa_model)
```
UPDATED:
```python3
loader, optimizer, model, loss_fn = ...
swa_model = torch.optim.swa_utils.AveragedModel(model)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=300)
swa_start = 160
swa_scheduler = SWALR(optimizer, swa_lr=0.05)
for i in range(300):
for input, target in loader:
optimizer.zero_grad()
loss_fn(model(input), target).backward()
optimizer.step()
if i > swa_start:
swa_model.update_parameters(model)
swa_scheduler.step()
else:
scheduler.step()
# Update bn statistics for the swa_model at the end
torch.optim.swa_utils.update_bn(loader, swa_model)
```
Fixes https://github.com/pytorch/pytorch/issues/29994
cc soumith vincentqb andrewgordonwilson vadimkantorov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35032
Differential Revision: D21079606
Pulled By: vincentqb
fbshipit-source-id: e07f5e821f72ada63789814c2dcbdc31f0160c37
Summary:
CC ezyang .
ROCm 3.3 packages went live on 2020-04-01. Tag 376 was pushed on 2020-04-15, so it should be based on ROCm 3.3.
The upgrade to ROCm 3.3 is required as part of the effort to stabilize ROCm CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37247
Differential Revision: D21256198
Pulled By: ezyang
fbshipit-source-id: 92ac21c0122eda360ec279d2c3d462c3e6bf4646
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36606
This PR refactor the continuation logic of the async mode on autograd
engine, to avoid launch spinning works. To achieve that:
1. remove the continuation logic in
execute_graph_task_with_continuiation
2. separate the usage of execute_graph_task between dist_engine and
local engine, now dist_engine universally use
`execute_graph_task_until_ready_queue_empty` (a better name appreciated
here).
3. remove enqueue_blocked_task_on_cpu
4. remove the async mode in `execute_with_graph_task` as we don't need
to use it in dist_engine
Test Plan: Imported from OSS
Differential Revision: D21032731
Pulled By: wanchaol
fbshipit-source-id: 708ea3bc14815bdc151b56afa15eb85b4ac0f4b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37061
This PR refactors:
1. `set_device` to make it out of Engine
2. put `graph_task_completed` into GraphTask
3. put `mark_graph_task_completed` into GraphTask
This also make the distributed engine easy to call those functions.
Test Plan: Imported from OSS
Differential Revision: D21188688
Pulled By: wanchaol
fbshipit-source-id: f56106e6ed7d966cfa4d962781c7865cc3c5321d
Summary:
Today in PyTorch, warnings triggered in C++ are printed to Python users like this:
`../aten/src/ATen/native/BinaryOps.cpp:81: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead.`
This may be unhelpful to Python users, who have complained it's difficult to relate these messages back to their programs. After this PR, warnings that go through the PyWarningHandler and allow it to add context print like this:
```
test/test_torch.py:16463: UserWarning: Integer division of tensors using div or / is deprecated, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead. (Triggered internally at ../aten/src/ATen/native/BinaryOps.cpp:81.)
cpu_result = getattr(cpu_tensor, op_str)(*cpu_args)
```
This relates the warning back to the user's program. The information about the cpp file and line number is preserved in the body of the warning message.
Some warnings, like those generated in the JIT, already account for a user's Python context, and so they specify that they should be printed verbatim and are unaffected by this change. Warnings originating in Python and warnings that go through c10's warning handler, which prints to cerr, are also unaffected.
A test is added to test_torch.py for this behavior. The test relies on uint8 indexing being deprecated and its warning originating from its current header file, which is an unfortunate dependency. We could implement a `torch.warn` function, instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36052
Differential Revision: D20887740
Pulled By: mruberry
fbshipit-source-id: d3515c6658a387acb7fccaf83f23dbb452f02847
Summary:
Fixes https://github.com/pytorch/pytorch/issues/37182
The `zero_grad` wrapper from `_replicate_for_data_parallel` can't be pickled. So instead, I set an attribute `_is_replica = True` and check for this in `Module.zero_grad`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37307
Differential Revision: D21246119
Pulled By: mrshenli
fbshipit-source-id: 4755786d48a20bc247570ba672de9dd526914ce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37265
In PGA, `listenLoopInternal` should not be virtual - PGA doesn't have any child classes that override this. Re-arranged some comments for `listenLoop` as well.
ghstack-source-id: 102880792
Test Plan: Sandcastle/CI
Differential Revision: D21238761
fbshipit-source-id: 5ec5058bc462182cf970faca9a734c11c7be2a32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37255
Improved error message logged when Distributed Autograd Context cleanup fails - added node information and underlying error. The previous error message also assumed that the cause of the error was due to too many RPC's failing, but this is not necessarily the case.
ghstack-source-id: 102867620
Test Plan: Ensuring Sandcastle/CI tests pass. Verified the correct message is logged when this code path is executed in `test_backward_node_failure` and `test_backward_node_failure_python_udf` .
Differential Revision: D20950664
fbshipit-source-id: 267318187b7ef386930753c9679a5dfab6d87018
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37262
It's convenient to have weights info in the debug_ssa_net so that we can tell what is weight and what is primary inputs. We can get their shape and size info with some post-processing script easily.
Reviewed By: ChunliF
Differential Revision: D21237537
fbshipit-source-id: 1fadc605283ef2eed78c44494e062a16ccf135ab
Summary:
Add ONNX export support for torch.nn.CrossEntropyLoss.
This PR makes following changes:
1. Updates nll_loss export
2. Makes a post pass for SoftmaxCrossEntropy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34830
Reviewed By: hl475
Differential Revision: D21230712
Pulled By: houseroad
fbshipit-source-id: c81911a41968e23813ba10274340ce4d8ba1ed78
Summary:
According to Darwin man-page:
`CLOCK_REALTIME` the system's real time (i.e. wall time) clock, expressed as the amount of time since the Epoch. This is the same as the value returned by `gettimeofday`(2).
I.e. its returns timestamp with microsecond resolution, as can be obvserved by running following small program:
```
#include <sys/time.h>
#include <stdint.h>
#include <stdbool.h>
#include <stdio.h>
bool conseq_time(clockid_t c) {
struct timespec t1, t2;
clock_gettime(c, &t1);
clock_gettime(c, &t2);
printf("t1={.tv_sec=%ld, .tv_nsec=%ld}\n", t1.tv_sec, t1.tv_nsec);
printf("t2={.tv_sec=%ld, .tv_nsec=%ld}\n", t2.tv_sec, t2.tv_nsec);
bool rc = t1.tv_sec == t2.tv_sec && t1.tv_nsec == t2.tv_nsec;
printf("Two timestamps are %sequal\n", rc ? "" : "not ");
return rc;
}
int main(void) {
printf("using CLOCK_REALTIME\n");
conseq_time(CLOCK_REALTIME);
printf("using CLOCK_MONOTONIC_RAW\n");
conseq_time(CLOCK_MONOTONIC_RAW);
return 0;
}
```
which if compiled outputs something like:
```
using CLOCK_REALTIME
t1={.tv_sec=107519, .tv_nsec=860315000}
t2={.tv_sec=107519, .tv_nsec=860315000}
Two timestamps are equal
using CLOCK_MONOTONIC_RAW
t1={.tv_sec=107520, .tv_nsec=954297363}
t2={.tv_sec=107520, .tv_nsec=954297426}
Two timestamps are not equal
```
But why do it, if all this platform specific logic is already nicely abstracted in `std::chrono::`:
https://github.com/llvm/llvm-project/blob/master/libcxx/src/chrono.cpp#L117
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37280
Differential Revision: D21246608
Pulled By: malfet
fbshipit-source-id: 6beada30657a2720000e34214b1348112e55be50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36009
When scale is very small (less than float eps, but greater than minimum double precision value), computation of reciprocal of scale in floating point precision within FBGEMM returns inf, while QuantUtils does not. Changed computation in QuantUtils to occur with floating point precision to re-enable tests.
ghstack-source-id: 102896302
Test Plan:
buck test caffe2/test:quantization -- 'test_quantized_rnn \(quantization\.test_quantization\.PostTrainingDynamicQuantTest\)' --print-passing-details --run-disabled
Summary (total time 59.91s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D20853000
fbshipit-source-id: 948a888f5516b3ba9c6efb7de31ef2cc9d431991
Summary:
This would run same testsuite (or individual test) multiple time
Useful for detecting flaky tests
Example usage: `python test_autograd.py TestAutograd.test_profiler -v --repeat=100`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37281
Differential Revision: D21244442
Pulled By: malfet
fbshipit-source-id: 3ecafec7ae87bc1e418aa28151bbc472ef37a713
Summary:
Because MacOS is not iOS
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37283
Test Plan: CI
Differential Revision: D21244398
Pulled By: malfet
fbshipit-source-id: b822e216e83887e2f2961b5c5384eaf749629f61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31091
This implements a C++17 "if constexpr" like feature for C++14.
This can be used, for example, to replace SFINAE or to force the compiler to remove some parts of a function in the assembly based on a condition.
PRs stacked on top will use this to simplify some of our template metaprogramming.
ghstack-source-id: 102867141
Test Plan: unit tests
Differential Revision: D18927220
fbshipit-source-id: 19a135e00af6ebb0139ce3730353762d4512158f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36785
Currently, RRef unpickle (both Python and TorchScript) will block
until the OwnerRRef has been created by the original `rpc.remote`
call, if it is an OwnerRRef. This is not ideal as the correctness
would then depends on the number of threads configuration. This
commit changed that behavior. Both `rpc.remote` and the unpickle
can create OwnerRRefs. More specifically, whichever one arrives
first will create the OwnerRRef and the subsequent ones will
retrieve the same OwnerRRef, so that no one is blocking.
Test Plan: Imported from OSS
Differential Revision: D21083089
Pulled By: mrshenli
fbshipit-source-id: 34ef063d50549b01c968b47815c4fe9fac179d3d
Summary:
Valgrind detects some unitialized variables if torch_cpu is compiled with clang, which are not reproducible if the same code is compiled with gcc nor using address sanitizer tool
See https://github.com/pytorch/pytorch/issues/37117
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37152
Differential Revision: D21241577
Pulled By: malfet
fbshipit-source-id: 4a5dddf2a4fc4238dc9117cb92ee4e34af9e6064
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37195
After adding c10::DispatchKey::Profiler the behavior of RecordFunction
observers is also controlled by the dispatch key,
this PR moves the logic outside of the profiler into the record function
Reviewed By: ngimel
Differential Revision: D21213786
fbshipit-source-id: e618254da74a4f1ce16c51a3869bbd75a4f561ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36850
Since now all unboxing happens after dispatch, which means that all c10 ops support unboxing, we can now use op.callBoxed() for all ops and don't need callBoxedWorkaround (which was going through the JIT registry) anymore.
ghstack-source-id: 102879558
Test Plan: waitforsandcastle
Differential Revision: D21102375
fbshipit-source-id: d1e041116563a9650d5a86b07eb96d217d8756f3
Summary:
This is generating a considerable amount of warning messages since TensorIterator.h is included from a lot of files:
/home/hong/xusrc/pytorch/aten/src/ATen/native/TensorIterator.h:372:47:
warning: comparison of integers of different signs: 'const int64_t' (aka 'const long') and 'c10::SmallVectorTemplateCommon::size_type' (aka 'unsigned long') [-Wsign-compare]
TORCH_CHECK(squash_dim >= 0 && squash_dim < shape_.size(),
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37109
Differential Revision: D21242163
Pulled By: ngimel
fbshipit-source-id: aec2978ee76750676a449eb6671142a782658de3
Summary:
Per https://cmake.org/cmake/help/latest/command/list.html list insert arguments order is
`list(INSERT <list> <index> [<element>...])`
That is first argument is list name not the index it gets inserted into
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37275
Differential Revision: D21243539
Pulled By: malfet
fbshipit-source-id: b947ad64f1a3549df68083383537899b19abd9ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37107
Currently histogram observers relax both the min and max values of the activations for performance speedup reasons. This causes an issue for glow where there is a slow down if the zero-point is not zero for post ReLU activations.
ghstack-source-id: 102768017
Test Plan: buck test caffe2/test:quantization -- 'test_histogram_observer_one_sided \(quantization\.test_quantization\.RecordHistogramObserverTest\)' --print-passing-details
Differential Revision: D21187636
fbshipit-source-id: 8d616b9e9caf2979a26a215e99434f71025e3d8b
Summary:
Reland of https://github.com/pytorch/pytorch/issues/36845 due to Windows CI failure.
binary_windows_wheel_3_7_cu102_build is passed, so the windows guard should be fine this time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37202
Differential Revision: D21233358
Pulled By: xw285cornell
fbshipit-source-id: 707de0ff21d178686354ffaea7625f1d68b3e8d3
Summary:
Add windows build and test for cpu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37135
Differential Revision: D21243189
Pulled By: ezyang
fbshipit-source-id: dd804ac258940e608facaf375d80ff5a0c59a7ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37254
This code is leftover from the KernelFactory deletion.
ghstack-source-id: 102866045
Test Plan: waitforsandcastle
Differential Revision: D21235480
fbshipit-source-id: 739ba677d2139ba9934d103f75a609638f1a3856
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37251
This was broken by recent changes to how we serialize with type tags. We
save a name (like `Dict[str, MyNamedTuple]`) and then relied on the
mobile type parser to resolve that name back into a set of types.
This doesn't work for any NamedTypes as the mobile type parser doesn't
know how to resolve those. The unpickler allows the caller to inject a
type resolver in for this purpose, use that so that when importing in a
non-mobile environment you get the right results.
A second problem also had to be fixed: the SourceImporter type loader
would only load named types directly (e.g. `MyNamedTuple`) and choked if
it was a general type that contained a named tupe (e.g.
`List[MyNamedTuple]`). Fixed that and renamed `loadNamedType` to
`loadType` for clarity.
Test Plan: Imported from OSS
Differential Revision: D21235213
Pulled By: suo
fbshipit-source-id: 16db0f4c5e91a890d67a8687cc8ababa6b94b0f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37257
Previously, we were relying on fragile invariants to avoid collecting
and feeding high precedence, non-backend dispatch keys to backend
initialization machinery, which would assert on them. (These same
keys are then used for redispatch, so a second latent problem lurks
behind the first.) Here we mask off the BackendDispatch key and all
keys to its left.
Followup: move backend init code to backend-specific wrappers
(`CPUType` etc.). This will let us remove the backend init code from
both BackendSelect and STATIC_DISPATCH wrappers. (Though BackendSelect
will still need to compute a dispatch key, so the logic introduced
here will still be necessary.)
Test Plan: Imported from OSS
Differential Revision: D21235856
Pulled By: bhosmer
fbshipit-source-id: 1b8bd7897ed4b41a95718f3cfceddf4ee094744a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37088
For an inlined expression tree like `(e_0, (e_1, e_long))` the previous
algoritm only scanned the same statement as `e_long`, splitting the
inlined expressions across lines. Because it did not scan `e_0`, `e_0`
would still get emitted inline, causing it to reverse order with `e_1` and
`e_long`. The new algorithm scans starting at `e_long` and going all
the way back up the expression until it reaches the end of the inlined
statement. Caching of what has already been scanned has been added so that
if there was a second long long `e_long2` after `e_long`, it would not
rescan and re-inline the statements that were already split.
Test Plan: Imported from OSS
Differential Revision: D21180394
Pulled By: zdevito
fbshipit-source-id: 4d142c83a04c89a47d04282f67a513f82cf153c0
Summary:
typing is available since Python 3.5, no need to try-import.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37245
Differential Revision: D21236650
Pulled By: albanD
fbshipit-source-id: daf150103835d0c6cd3c39300044e548bb6d311d
Summary:
Resolves https://github.com/pytorch/pytorch/issues/36730https://github.com/pytorch/pytorch/issues/36057
Partially resolves: https://github.com/pytorch/pytorch/issues/36671
```
>>> 2j / torch.tensor([4], dtype = torch.complex64)
tensor([(0.0000+0.5000j)], dtype=torch.complex64)
>>> 1 / torch.tensor(3+4j)
tensor((0.1200-0.1600j), dtype=torch.complex64)
```
rdiv is more generally broken for all dtypes because it doesn't promote the types properly
eg.
```
>>> 1 / torch.tensor(2)
tensor(0)
>>> 2j / torch.tensor(4)
tensor(0)
```
so that issue should be fixed in a separate PR
Adding CPU acc types for complex
Added cumsum, cumprod for complex dtypes
Added complex dtypes to get_all_math_dtypes to expand testing for complex dtypes
Old PR - https://github.com/pytorch/pytorch/pull/36747
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37193
Differential Revision: D21229373
Pulled By: anjali411
fbshipit-source-id: 8a086136d8c10dabe62358d276331e3f22bb2342
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37190
if module call return different types, we need to record them correctly
Test Plan: Imported from OSS
Differential Revision: D21214871
Pulled By: wanchaol
fbshipit-source-id: 46ba98f08ed4ade22f9740cb3fca84b29557e125
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37189
This fix bug in tracing module calls to correct lift values with its
correponding value type, rather than the default tensor type.
Test Plan: Imported from OSS
Differential Revision: D21214872
Pulled By: wanchaol
fbshipit-source-id: f635154851365e2d7b88186d6e47634123eac42f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37128
In certain build modes (in fbcode, building a .par) the mechanism to get test output "expect" files doesn't work.
All other tests in test_torch.py already had assertExpectedInline instead of assertExpected, with the expected result inline in the file.
There was no equivalent for assertExpectedRaises, so I added one, and changed the tests for test_is_nonzero (the only test using this)
Test Plan: CI, specifically the test test_is_nonzero should pass
Reviewed By: malfet
Differential Revision: D21197651
fbshipit-source-id: 2a07079efdcf1f0b0abe60e92cadcf55d81d4b13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34399
Custom ops can now take std::array as arguments and return it.
This PR also moves the ops in native_functions.yaml that were blocked by this to now `use_c10_dispatcher: full`.
ghstack-source-id: 102643208
Test Plan: unit tests
Differential Revision: D20315072
fbshipit-source-id: 93232448663df962f65e0f25bfb35826dd3374f8
Summary:
- add a couple of checks for USE_XNNPACK to disable additional
code paths if XNNPACK is not supported
When passing through the code paths where the platform checks
are made (cmake/Dependencies.cmake:89), if XNNPACK is not
supported, then the var FXDIV_SOURCE_DIR will not be
set. CMake emits the errors when add_directory is called and
FXDIV_SOURCE_DIR is empty.
see: https://github.com/pytorch/pytorch/issues/34606
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35607
Differential Revision: D20895645
Pulled By: seemethere
fbshipit-source-id: 3bd10cf89f0fb6825fdd6e1d52c71ee37c67b953
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36631
Summary of changes
1. Moved random transformation functions to DistributionHelper.h (`uniform_int_from_to_distribution`, `uniform_int_full_range_distribution`, `uniform_int_distribution`) to avoid code duplication between default CPU, CUDA rngs and custom rng extensions
2. Made GeneratorImpl fields protected instead of private
3. Introduced `TORCH_CHECK_IF_NOT_ON_CUDA` that does the same as `TORCH_CHECK` if it is not CUDA/ROCm device
4. To test multiple rng extensions I had to move ops registration to the method `registerOps()`, expose it to python and call it `def setUp(self)`
Test Plan: Imported from OSS
Differential Revision: D21229202
Pulled By: pbelevich
fbshipit-source-id: 6aa3280f2fc3324cf3e748388b5087e3a1e49f23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37127
Wrap what we're running in CI in a small script so we can exactly reproduce it locally if ncessary.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D21196804
Pulled By: suo
fbshipit-source-id: 45497daae4bafd236a0d1bb1480841f0d9f39262
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36767
Add a simpler implementation of the MulGradient cuda kernel for when inner_size==1, inner loop is eliminated.
Reviewed By: xw285cornell
Differential Revision: D21013269
fbshipit-source-id: bb62470d91a7fef6eecc3d4766a2c994ca6bb2c8
Summary:
Some links in the TOC of CONTRIBUTING.md is broken since GitHub removes the invalid characters (e.g., `+` in C++) in the anchor link, while the existing TOC uses `-` for replacement.
This PR uses `-` instead of `*` and `+` for the bullet lists to make it consistent with README.md.
b889e0da8a/README.md (L11-L18)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37131
Differential Revision: D21231299
Pulled By: zou3519
fbshipit-source-id: 8e7bb61550827ce97378d3428542e43612bac8e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37081
Closes https://github.com/pytorch/pytorch/issues/30813
Relanding of https://github.com/pytorch/pytorch/pull/35463
1. Tensor quantization logic(quantize_*) is moved to the aten/native/quantized. Previously all logic for tensor quantization lived in the aten/quantized/Quantizer.cpp file, and started to become complicated and hard to read. This problem should be addressed in refactoring PR. Still, I reworked this partially because I had to add tensor quantization logic for CUDA, and it was native to move everything to the aten/native/quantized.
2. Requirements to run CUDA_tensor_apply* was eased to process any tenser that lives on the CUDA device(QuantizedCUDA included).
3. All quantized data types now have a default constructor. NVCC refuses to compile any gpu_kernel or CUDA_tensor_apply* without them.
4. Minor changes in many files to register QuantizedCUDA backend.
5. test_quantized_tensor is extended to process QuantizedCUDA backend where possible.
Test Plan: Imported from OSS
Differential Revision: D21206694
Pulled By: jerryzh168
fbshipit-source-id: c7433aad9c095a34c57e6dddd128b5c5d9292373
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30485
Use vectorization to speed up calculate Qparams for per-channel observers. New implementation is about 1000 times faster.
Task:
https://github.com/pytorch/pytorch/issues/30348#event-2824868602
ghstack-source-id: 102808561
Test Plan:
```
import torch
import time
import numpy as np
from torch.quantization.observer import PerChannelMinMaxObserver
obs = PerChannelMinMaxObserver()
acc_time = 0
X = torch.randn(1000, 10)
obs(X)
for i in range(100):
start = time.time()
obs.calculate_qparams()
acc_time = acc_time + time.time()-start
print(acc_time)
```
Before change:
20.3
After change:
0.017
Differential Revision: D18711905
fbshipit-source-id: 3ed20a6734c9950773350957aaf0fc5d14827640
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32731
As we now support send to self, we no longer require world_size > 1.
Removing the assert from ProcessGroupAgent.
Test Plan: Imported from OSS
Differential Revision: D19609558
Pulled By: mrshenli
fbshipit-source-id: ecec18d756f97d8d78d4526a63b7cb8ab6f858a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37025
This allows us to reuse this framework in other places.
Test Plan:
buck test mode/dev-nosan
caffe2/torch/fb/distributed/model_parallel/tests:test_dist_optim --
test_optimizer_hook
Differential Revision: D20958327
fbshipit-source-id: 2a37dae3687fea8820427e174900111b58673194
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35791
The optimal solution to use XNNPACK is to separate operator creation
from execution - also called prepacking the weights. If we have done
our job properly, JIT must have caught and replaced nn.Linear on mobile
with the prepacked versions. Still, if we somehow end up in
at::native::linear for whatever reason, it is still more efficient to go
through XNNPACK than the alternatives of at::addmm or at::matmul.
Differential Revision: D20821863
Test Plan: Imported from OSS
Pulled By: AshkanAliabadi
fbshipit-source-id: 5a75bfd900435c89c1b8536dc09248e788292e0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35790
The optimal solution to use XNNPACK is to separate operator creation
from execution - also called prepacking the weights. If we have done
our job properly, JIT must have caught and replaced nn.Conv2ds on mobile
with the prepacked versions. Still, if we somehow end up in
_convolution for whatever reason, it is still more efficient to go
through XNNPACK for NHWC tensors, compared to the alternative of
converting NHWC to NCHW and going through NNPACK.
Differential Revision: D20821864
Test Plan: Imported from OSS
Pulled By: AshkanAliabadi
fbshipit-source-id: 2732280c2fd31edcb39658f6530d03331a1a4a75
Summary:
Closes https://github.com/pytorch/pytorch/issues/24642
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.tanh(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.tanh(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.tanh(a) a.numel() == 10000 for 20000 times torch.half
0.2816318240002147
torch.tanh(a) a.numel() == 10000 for 20000 times torch.float
0.2728829070001666
torch.tanh(a) a.numel() == 10000 for 20000 times torch.double
0.39797203200214426
torch.tanh(a) a.numel() == 100000 for 20000 times torch.half
0.3228214350019698
torch.tanh(a) a.numel() == 100000 for 20000 times torch.float
0.31780802399953245
torch.tanh(a) a.numel() == 100000 for 20000 times torch.double
1.3745740449994628
```
After:
```
torch.tanh(a) a.numel() == 10000 for 20000 times torch.half
0.27825374500025646
torch.tanh(a) a.numel() == 10000 for 20000 times torch.float
0.27764024499992956
torch.tanh(a) a.numel() == 10000 for 20000 times torch.double
0.3771585260001302
torch.tanh(a) a.numel() == 100000 for 20000 times torch.half
0.2995866400015075
torch.tanh(a) a.numel() == 100000 for 20000 times torch.float
0.28355561699936516
torch.tanh(a) a.numel() == 100000 for 20000 times torch.double
1.393811182002537
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36995
Differential Revision: D21163353
Pulled By: ngimel
fbshipit-source-id: e2216ff62cdfdd13b6a56daa63d4ef1440d991d4
Summary:
Fixes a safety issue (Nonsense values and segfaults) introduced by https://github.com/pytorch/pytorch/pull/36875 when in-place gather tries to use incorrect shapes.
Consider the following block of code:
```
k0 = 8
k1 = 8
m = 100
x = torch.rand((k0, k1))
ind = torch.randint(0, k0, (m, k1))
output = torch.empty((m, k1))
print(torch.gather(x, 0, ind, out=output))
print(torch.gather(x, 1, ind, out=output))
```
The first gather is legal, the second is not. (`ind` and `output` need to be transposed) Previously this was caught when the kernel tried to restride inputs for TensorIterator, but we can no longer rely on those checks and must test explicitly. If `m` is small the second gather returns gibberish; if it is large enough to push the read out of memory block the program segfaults.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37102
Differential Revision: D21190580
Pulled By: robieta
fbshipit-source-id: 80175620d24ad3380d78995f7ec7dbf2627d2998
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36032
QNNPACK AND XNNPACK may out-of-bound access the input and / or output tensors.
This is by-design, and chosen to make the implementation of micro-kernels
both simpler and faster as a result of not having to individually handle the
corner cases where the number of processed elements is not a multiple of SIMD
register width. This behavior will trigger ASAN though, and may result in a
segfault if the accessed memory location just so happens to fall on a page
the current process has no read access to. Here we define a custom allocator
that allocates the extra storage required to keep this behavior safe. This
allocator could have been restricted to QNNPACK and XNNPACK only, but that
would have negative performance ramifications, as input tensors must now be
reallocated, and copied over, if the tensor is not allocated with this
allocator to begin with. Making this allocator the default on mobile builds
minimizes the probability of unnecessary reallocations and copies, and
also enables acceleration of operations where the output tensor is allocated
outside of the function doing the implementation, wherein the implementation
cannot simply re-allocate the output with the guarding allocator.
Test Plan: Imported from OSS
Differential Revision: D20970217
Pulled By: AshkanAliabadi
fbshipit-source-id: 65cca2d38d7c0cef63c732f393016f50f1fa5199
Summary:
We should have
```C++
for (auto& sub_iter : iter.with_32bit_indexing()) {
launch_prelu_cuda_backward_share_weights_kernel(sub_iter, weight_data);
}
```
But I mistakenly wrote it as
```C++
for (auto& sub_iter : iter.with_32bit_indexing()) {
launch_prelu_cuda_backward_share_weights_kernel(iter, weight_data);
}
```
in my previous PR. Which leads to infinite recursion on it.
I found this bug when working on https://github.com/pytorch/pytorch/pull/34004
I also add a `TORCH_INTERNAL_ASSERT_DEBUG_ONLY` to test for this.
Besides, the caller is already guaranteed contiguous, so we don't need to handle no-contiguous tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36134
Differential Revision: D21187542
Pulled By: VitalyFedyunin
fbshipit-source-id: 0fafdd7b672bf89fcaa2b42e08b7d41ade7e6bcb
Summary:
As shown in https://github.com/pytorch/pytorch/issues/36452 , SyncBatchNorm can block host thread due the ``MemcpyDtoH`` and ``MemcpyHtoD`` when dealing with argument ``counts`` for native function ``batch_norm_gather_stats_with_counts``.
- This fix change signiture of ``batch_norm_gather_stats_with_counts`` to
```c++
std::tuple<Tensor, Tensor> batch_norm_gather_stats_with_counts_cuda(const Tensor& self, const Tensor& mean, const Tensor& invstd, const Tensor& running_mean, const Tensor& running_var, double momentum, double epsilon, const Tensor& counts)
```
so it can directly receive "counts" in a ``CUDATensor`` rather than ``IntArrayRef`` whose data is in host memory.
- This fix also improve implementation of ``SyncBatchNorm`` function so the construction of ``counts`` tensor will not cause additional ``MemcpyHtoD``, which will block host thread, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36659
Differential Revision: D21196991
Pulled By: ngimel
fbshipit-source-id: 84a529e6cf22e03618fecbb8f070ec452f81229e
Summary:
The original implementation of maxpool and im2col kernels will fail if `gridSize` * `blockSize` is smaller than the `nthreads` in maxpool kernel or `n` in im2col kernel. Input parameters `bottom_data`, `data_col`, `data_im`, and loop index `index` are modified inside the loop body and the corrupted data will be carried to the second iteration.
This patch uses temporary variables to replace the input parameters and loop indices.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36288
Differential Revision: D21189020
Pulled By: VitalyFedyunin
fbshipit-source-id: a8075a35e707e6cc99cffd0b2177369e8caea37c
Summary:
This makes its wrappers stackable with `common_utils.TestCase` ones
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36826
Test Plan: CI
Differential Revision: D21178217
Pulled By: mrshenli
fbshipit-source-id: f80dd4aa175e20bd338b38b2c42c3118258f45dc
Summary:
The new function signature https://docs.nvidia.com/cuda/cusparse/index.html#cusparse-generic-function-spmm.
Please also check https://docs.nvidia.com/cuda/cusparse/index.html#cusparse-generic-api-reference for the limitations. I have added windows guard in this PR.
> LIMITATION: The generic APIs are currently available for all platforms except Windows. Using these APIs in any other systems will result in compile-time or run-time failures. Their support will be extended in the next releases.
Edit: also add a cuda guard to let ROCm use old version API (avoid build failures)
Since the new cusparse signatures sometimes give inaccurate results in CUDA 10.1, and this was fixed in CUDA 10.2, the new signatures should only be used with CUDA >= 10.2
cc csarofeen ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36845
Differential Revision: D21196366
Pulled By: ezyang
fbshipit-source-id: 592d6bd6379f7db52cbad827d43864ea65ff18ea
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/24605https://github.com/pytorch/pytorch/issues/24535https://github.com/pytorch/pytorch/issues/24739https://github.com/pytorch/pytorch/issues/24680https://github.com/pytorch/pytorch/issues/30986
This does not fix https://github.com/pytorch/pytorch/issues/29984, it will be fixed in later PR.
Most of this PR is just following the same logic inside TH and THC except the handle of n-dimensional zero-sized tensor, in specific the case:
```
(m,).addmv((m, 0), (0,), beta, alpha)
```
# Legacy code bugs and how this PR deal with it
The above case is a case where BLAS often have a mismatch of semantics with PyTorch: For BLAS and cuBLAS, the above is a noop, but for PyTorch, it is a scalar-vector multiplication `output = beta * input`. The handle of this case is already very poor in legacy code and it is poorly tested:
For the CPU implementation, there are two code paths:
- Path 1: when dtype is float or double and `USE_BLAS`, then use BLAS
- Path 2: when other dtypes or not `USE_BLAS`, use a fallback kernel in PyTorch
For the CUDA implementation, there are also two code paths:
- Path 1: when float or double, then use `cublasSgemv` or `cublasDgemv` in cuBlas
- Path 2: when half, dispatch to `addmm`
`test_blas_alpha_beta_empty` is supposed to cover all cases, but unfortunately, it only tests the Path 1 of CUDA and Path 1 of CPU, and both uncovered paths (path 2 for CPU and path 2 for CUDA) are buggy in legacy code. In this PR, I expanded the coverage of `test_blas_alpha_beta_empty`, but unfortunately, I have to skip the `half` dtype on CUDA 9. See the description below for detail:
## Bug on CPU implementation
For the CPU implementation, the fallback kernel in path 2 already has the same semantics as PyTorch, not BLAS. But the code that tries to correct BLAS semantics to match PyTorch also runs on this case, leading to double correction, that is, `output = beta * input` now becomes `output = beta * beta * input`.
This leads to the issue https://github.com/pytorch/pytorch/issues/30986 I just opened, and it is fixed in this PR.
## Bug on CUDA implementation
For the CUDA implementation, path 2 dispatches to
```
(m, 1).addmm((m, 0), (0, 1), beta, alpha)
```
But unfortunately, for some old CUDA version when on old GPU on half dtype, the above is also noop, which is definitely not correct.
But from what I see, on newer CUDA version or newer GPU, this is not a problem. This is a bug of PyTorch in `addmm`, so I opened a new issue https://github.com/pytorch/pytorch/issues/31006 to track this problem. But this is highly likely a dependency bug for PyTorch originating from cuBLAS, and it is only on a rarely used edge case on old hardware and software, so this issue would be a `won't_fix` unless some real requirements strongly indicate that this should be fixed.
This issue is already with legacy code, and this PR does not make it worse. To prevent this issue from bothering us, I disable the test of `half` dtype for CUDA 9 when expanding the coverage of `test_blas_alpha_beta_empty`.
I promote a CircleCI CUDA 10.1 test to `XImportant` so that it runs on PRs, because the path 2 of CUDA implementation is only covered by this configuration. Let me know if I should revert this change.
## An additional problem
In legacy code for `addmv`, dtype `bfloat16` is enabled and dispatch to `addmm`, but `addmm` does not support `bfloat16` from what I test. I do the same thing in the new code. Let me know if I should do it differently.
# Benchmark
Code:
```python
import torch
print(torch.__version__)
for i in range(1000):
torch.arange(i, device='cuda')
print('cpu')
for i in 10, 100, 1000, 10000:
a = torch.randn((i,))
b = torch.randn((i, i))
c = torch.randn((i,))
%timeit a.addmv(b, c, alpha=1, beta=2)
print('cuda')
for i in 10, 100, 1000, 10000:
a = torch.randn((i,)).cuda()
b = torch.randn((i, i)).cuda()
c = torch.randn((i,)).cuda()
torch.cuda.synchronize()
%timeit a.addmv(b, c, alpha=1, beta=2); torch.cuda.synchronize()
```
Before:
```
1.5.0a0+2b45368
cpu
2.74 µs ± 30.8 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
8.5 µs ± 85.5 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
686 µs ± 2.95 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
74 ms ± 410 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
cuda
The slowest run took 4.81 times longer than the fastest. This could mean that an intermediate result is being cached.
27.6 µs ± 23 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)
17.3 µs ± 151 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
20.5 µs ± 369 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
756 µs ± 6.81 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After:
```
1.5.0a0+66b4034
cpu
3.29 µs ± 20 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
9.09 µs ± 7.41 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
687 µs ± 7.01 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
73.8 ms ± 453 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
cuda
18.2 µs ± 478 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
17.7 µs ± 299 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
21.5 µs ± 2.38 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
751 µs ± 35.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30898
Differential Revision: D20660338
Pulled By: anjali411
fbshipit-source-id: db1f521f124198f63545064026f93fcb16b68f18
Summary:
Lets dtypes take tuples of dtypes instead of just single dtypes. This pattern comes up when tests have distinct in and out types. A test in test_type_promotion is updated to use the new behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36908
Differential Revision: D21161523
Pulled By: mruberry
fbshipit-source-id: ebac81c1b6c494a2146d595fcdb3e35c22cf859c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36984
Follow LOG(WARNING) format for c++ side warnings in order to play well with larger services, especially when using glog. I need to hook up into GLOG internals a bit in order to override FILE/LINE without having to change the whole thing to be macros, but it seems to be stable between glog versions.
Note, this also changes caffe2_log_level to warning by default - I think it's a much better default when compiling without glog (or maybe even have info).
With glog output, stderr capture doesn't work any more in tests. That's why we instead use c10-level warnings capture.
Test Plan:
Run unittest in both glog and non-glog build mode:
glog:
```
W0416 12:06:49.778215 3311666 exception_test.cpp:23] Warning: I'm a warning (function TestBody)
```
no-glog:
```
[W exception_test.cpp:23] Warning: I'm a warning (function TestBody)
```
Reviewed By: ilia-cher
Differential Revision: D21151351
fbshipit-source-id: fa926d9e480db5ff696990dad3d80f79ef79f24a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36680
If torch compiled without MKL, this test fails with torch.fft requiring MKL support
Test Plan: CI
Reviewed By: malfet
Differential Revision: D21051362
fbshipit-source-id: dd2e2c7d323622c1c25fc4c817b85d83d2241b3a
Summary:
This pull request extends the fallback implemented in https://github.com/pytorch/pytorch/issues/31383 to not use MIOpen for tensors where number of elements in a tensor exceeds INT_MAX. The PR also enables the corresponding test in TestNN
cc: ezyang jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37110
Differential Revision: D21196336
Pulled By: ezyang
fbshipit-source-id: 25fd80308a0e2f7941c249735674ebc85d3fd39e
Summary:
Updates angle to return a float tensor, by default, when given complex inputs. This behavior is compatible with Python, NumPy, and C++. The implementation follows the former implementation for complex abs, extracting the logic into a common function for both abs and angle.
The test for complex abs's behavior in test_type_promotion.py is updated to also test the behavior of complex angle by comparing its results to NumPy's.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36896
Differential Revision: D21170589
Pulled By: mruberry
fbshipit-source-id: f5a634aea351dd58a8376f1474fc5a6422038cbf
Summary:
This test is never built in OSS CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37080
Differential Revision: D21179296
Pulled By: anjali411
fbshipit-source-id: 22a5b82f17676213c8ec51642bef35dc61f9cace
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36682
For fb internal builds we need to separate whether to use global deps library from loading with RTLD_GLOBAL.
Test Plan: CI -- this should be a no-op for existing builds
Reviewed By: ezyang
Differential Revision: D21051427
fbshipit-source-id: 83bb703d6ceb0265a4c58166749312a44172e78c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37023
Optimize binary size of assert macros, through two ideas:
Concatenate string literals with __FILE__ and __LINE__ at compile time into one literal instead of keeping them in separate literals and combining them with c10::str
Optimize binary size of c10::str for some scenarios, especially for the scenario where it is called with an empty parameter list, this is actually a common call scenario in assert macros.
In server oss builds, this PR reduces binary size from 118.05 MB to 117.05 MB
ghstack-source-id: 102607237
Test Plan: Run oss server build (python setup.py install) and check size of libtorch_cpu.so reducing from 118.05MB to 117.05MB
Differential Revision: D20719400
fbshipit-source-id: 5c61f4195b947f06aafb8f0c8e255de3366e1ff2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36981
Replaces unneeded quantize calls for remaining quantized
activations with empty tensor creation.
Should be a perf win for anyone who uses these.
Test Plan:
python test/quantization/test_quantized.py TestQuantizedOps
Imported from OSS
Differential Revision: D21185969
fbshipit-source-id: 473b2b8aa40046ea3f0665bd45b03f09e8a7d572
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36980
Missed this on the original diff, fixing. Create the output tensor directly instead of quantizing it.
Test Plan:
tests still pass
microbenchmarks show a 2x performance improvment for int8:
https://gist.github.com/vkuzo/3b321b428e4c38e805000961c263286b (this
will depend on input size)
Imported from OSS
Differential Revision: D21185970
fbshipit-source-id: 5b9e93d9f9ac05a8120532bd03ad347541a132c2
Summary:
This PR fixes a couple of syntax errors in `torch/` that prevent MyPy from running, fixes simple type annotation errors (e.g. missing `from typing import List, Tuple, Optional`), and adds granular ignores for errors in particular modules as well as for missing typing in third party packages.
As a result, running `mypy` in the root dir of the repo now runs on:
- `torch/`
- `aten/src/ATen/function_wrapper.py` (the only file already covered in CI)
In CI this runs on GitHub Actions, job Lint, sub-job "quick-checks", task "MyPy typecheck". It should give (right now): `Success: no issues found in 329 source files`.
Here are the details of the original 855 errors when running `mypy torch` on current master (after fixing the couple of syntax errors that prevent `mypy` from running through):
<details>
```
torch/utils/tensorboard/_proto_graph.py:1: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.node_def_pb2'
torch/utils/tensorboard/_proto_graph.py:2: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.attr_value_pb2'
torch/utils/tensorboard/_proto_graph.py:3: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.tensor_shape_pb2'
torch/utils/backcompat/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/for_onnx/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch.for_onnx.onnx'
torch/cuda/nvtx.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/utils/show_pickle.py:59: error: Name 'pickle._Unpickler' is not defined
torch/utils/show_pickle.py:113: error: "Type[PrettyPrinter]" has no attribute "_dispatch"
torch/utils/tensorboard/_onnx_graph.py:1: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.graph_pb2'
torch/utils/tensorboard/_onnx_graph.py:2: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.node_def_pb2'
torch/utils/tensorboard/_onnx_graph.py:3: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.versions_pb2'
torch/utils/tensorboard/_onnx_graph.py:4: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.attr_value_pb2'
torch/utils/tensorboard/_onnx_graph.py:5: error: Cannot find implementation or library stub for module named 'tensorboard.compat.proto.tensor_shape_pb2'
torch/utils/tensorboard/_onnx_graph.py:9: error: Cannot find implementation or library stub for module named 'onnx'
torch/contrib/_tensorboard_vis.py:10: error: Cannot find implementation or library stub for module named 'tensorflow.core.util'
torch/contrib/_tensorboard_vis.py:11: error: Cannot find implementation or library stub for module named 'tensorflow.core.framework'
torch/contrib/_tensorboard_vis.py:12: error: Cannot find implementation or library stub for module named 'tensorflow.python.summary.writer.writer'
torch/utils/hipify/hipify_python.py:43: error: Need type annotation for 'CAFFE2_TEMPLATE_MAP' (hint: "CAFFE2_TEMPLATE_MAP: Dict[<type>, <type>] = ...")
torch/utils/hipify/hipify_python.py:636: error: "object" has no attribute "items"
torch/nn/_reduction.py:27: error: Name 'Optional' is not defined
torch/nn/_reduction.py:27: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/_reduction.py:47: error: Name 'Optional' is not defined
torch/nn/_reduction.py:47: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/utils/tensorboard/_utils.py:17: error: Skipping analyzing 'matplotlib.pyplot': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:17: error: Skipping analyzing 'matplotlib': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:18: error: Skipping analyzing 'matplotlib.backends.backend_agg': found module but no type hints or library stubs
torch/utils/tensorboard/_utils.py:18: error: Skipping analyzing 'matplotlib.backends': found module but no type hints or library stubs
torch/nn/modules/utils.py:27: error: Name 'List' is not defined
torch/nn/modules/utils.py:27: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
caffe2/proto/caffe2_pb2.py:17: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/caffe2_pb2.py:25: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:31: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:35: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:39: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:43: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:47: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:51: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:55: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:59: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:63: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:67: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:71: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:75: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:108: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:112: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:124: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:130: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:134: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:138: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:142: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:146: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:150: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:154: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:158: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:162: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:166: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:170: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:174: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:178: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:182: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:194: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:200: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:204: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:208: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:212: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:224: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/caffe2_pb2.py:230: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:234: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:238: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:242: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:246: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:250: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:254: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/caffe2_pb2.py:267: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:274: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:281: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:288: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:295: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:302: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:327: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:334: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:341: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:364: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:371: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:378: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:385: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:392: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:399: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:406: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:413: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:420: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:427: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:434: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:441: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:448: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:455: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:462: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:488: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:495: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:502: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:509: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:516: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:523: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:530: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:537: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:544: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:551: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:558: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:565: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:572: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:596: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:603: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:627: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:634: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:641: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:648: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:655: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:662: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:686: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:693: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:717: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:724: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:731: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:738: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:763: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:770: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:777: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:784: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:808: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:815: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:822: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:829: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:836: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:843: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:850: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:857: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:864: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:871: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:878: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:885: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:892: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:916: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:923: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:930: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:937: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:944: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:951: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:958: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:982: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:989: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:996: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1003: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1010: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1017: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1024: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1031: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1038: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1045: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1052: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1059: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1066: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1090: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1097: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1104: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1128: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1135: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1142: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1166: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1173: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1180: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1187: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1194: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1218: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1225: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1232: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1239: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1246: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1253: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1260: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1267: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1274: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1281: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1305: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1312: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1319: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1326: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1333: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1340: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1347: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1354: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1361: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1368: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1375: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1382: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1389: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1396: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1420: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1427: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1434: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1441: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1465: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1472: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1479: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1486: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1493: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1500: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1507: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1514: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1538: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/caffe2_pb2.py:1545: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1552: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1559: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1566: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/caffe2_pb2.py:1667: error: "GeneratedProtocolMessageType" has no attribute "Segment"
torch/multiprocessing/queue.py:4: error: No library stub file for standard library module 'multiprocessing.reduction'
caffe2/proto/torch_pb2.py:18: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/torch_pb2.py:27: error: Unexpected keyword argument "serialized_options" for "EnumDescriptor"
caffe2/proto/torch_pb2.py:33: error: Unexpected keyword argument "serialized_options" for "EnumValueDescriptor"
caffe2/proto/torch_pb2.py:50: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:57: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:81: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:88: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:95: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:109: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:116: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:123: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:130: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:137: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:144: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:151: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:175: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:182: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:189: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:196: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:220: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:227: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:234: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:241: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:265: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:272: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:279: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:286: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:293: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:300: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:307: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:314: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:321: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:328: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:335: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:342: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:366: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:373: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:397: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/torch_pb2.py:404: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:411: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:418: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:425: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/torch_pb2.py:432: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:17: error: Unexpected keyword argument "serialized_options" for "FileDescriptor"; did you mean "serialized_pb"?
caffe2/proto/metanet_pb2.py:29: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:36: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:43: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:50: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:57: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:64: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:88: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:95: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:102: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:126: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:133: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:140: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:164: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:171: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:178: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:202: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:209: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:216: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:240: error: Unexpected keyword argument "serialized_options" for "Descriptor"
caffe2/proto/metanet_pb2.py:247: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:254: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:261: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:268: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:275: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:282: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:289: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/metanet_pb2.py:296: error: Unexpected keyword argument "serialized_options" for "FieldDescriptor"
caffe2/proto/__init__.py:13: error: Skipping analyzing 'caffe2.caffe2.fb.session.proto': found module but no type hints or library stubs
torch/multiprocessing/pool.py:3: error: No library stub file for standard library module 'multiprocessing.util'
torch/multiprocessing/pool.py:3: note: (Stub files are from https://github.com/python/typeshed)
caffe2/python/scope.py:10: error: Skipping analyzing 'past.builtins': found module but no type hints or library stubs
caffe2/python/__init__.py:7: error: Module has no attribute "CPU"
caffe2/python/__init__.py:8: error: Module has no attribute "CUDA"
caffe2/python/__init__.py:9: error: Module has no attribute "MKLDNN"
caffe2/python/__init__.py:10: error: Module has no attribute "OPENGL"
caffe2/python/__init__.py:11: error: Module has no attribute "OPENCL"
caffe2/python/__init__.py:12: error: Module has no attribute "IDEEP"
caffe2/python/__init__.py:13: error: Module has no attribute "HIP"
caffe2/python/__init__.py:14: error: Module has no attribute "COMPILE_TIME_MAX_DEVICE_TYPES"; maybe "PROTO_COMPILE_TIME_MAX_DEVICE_TYPES"?
caffe2/python/__init__.py:15: error: Module has no attribute "ONLY_FOR_TEST"; maybe "PROTO_ONLY_FOR_TEST"?
caffe2/python/__init__.py:34: error: Item "_Loader" of "Optional[_Loader]" has no attribute "exec_module"
caffe2/python/__init__.py:34: error: Item "None" of "Optional[_Loader]" has no attribute "exec_module"
caffe2/python/__init__.py:35: error: Module has no attribute "cuda"
caffe2/python/__init__.py:37: error: Module has no attribute "cuda"
caffe2/python/__init__.py:49: error: Module has no attribute "add_dll_directory"
torch/random.py:4: error: Cannot find implementation or library stub for module named 'torch._C'
torch/_classes.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/onnx/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/hub.py:21: error: Skipping analyzing 'tqdm.auto': found module but no type hints or library stubs
torch/hub.py:24: error: Skipping analyzing 'tqdm': found module but no type hints or library stubs
torch/hub.py:27: error: Name 'tqdm' already defined (possibly by an import)
torch/_tensor_str.py:164: error: Not all arguments converted during string formatting
torch/_ops.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/_linalg_utils.py:26: error: Name 'Optional' is not defined
torch/_linalg_utils.py:26: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:26: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:63: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:63: error: Name 'Optional' is not defined
torch/_linalg_utils.py:63: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:70: error: Name 'Optional' is not defined
torch/_linalg_utils.py:70: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:70: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:88: error: Name 'Tensor' is not defined
torch/_linalg_utils.py:88: error: Name 'Optional' is not defined
torch/_linalg_utils.py:88: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_linalg_utils.py:88: error: Name 'Tuple' is not defined
torch/_linalg_utils.py:88: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_jit_internal.py:17: error: Need type annotation for 'boolean_dispatched'
torch/_jit_internal.py:474: error: Need type annotation for '_overloaded_fns' (hint: "_overloaded_fns: Dict[<type>, <type>] = ...")
torch/_jit_internal.py:512: error: Need type annotation for '_overloaded_methods' (hint: "_overloaded_methods: Dict[<type>, <type>] = ...")
torch/_jit_internal.py:648: error: Incompatible types in assignment (expression has type "FinalCls", variable has type "_SpecialForm")
torch/sparse/__init__.py:11: error: Name 'Tensor' is not defined
torch/sparse/__init__.py:71: error: Name 'Tensor' is not defined
torch/sparse/__init__.py:71: error: Name 'Optional' is not defined
torch/sparse/__init__.py:71: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/sparse/__init__.py:71: error: Name 'Tuple' is not defined
torch/sparse/__init__.py:71: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/nn/init.py:109: error: Name 'Tensor' is not defined
torch/nn/init.py:126: error: Name 'Tensor' is not defined
torch/nn/init.py:142: error: Name 'Tensor' is not defined
torch/nn/init.py:165: error: Name 'Tensor' is not defined
torch/nn/init.py:180: error: Name 'Tensor' is not defined
torch/nn/init.py:194: error: Name 'Tensor' is not defined
torch/nn/init.py:287: error: Name 'Tensor' is not defined
torch/nn/init.py:315: error: Name 'Tensor' is not defined
torch/multiprocessing/reductions.py:8: error: No library stub file for standard library module 'multiprocessing.util'
torch/multiprocessing/reductions.py:9: error: No library stub file for standard library module 'multiprocessing.reduction'
torch/multiprocessing/reductions.py:17: error: No library stub file for standard library module 'multiprocessing.resource_sharer'
torch/jit/_builtins.py:72: error: Module has no attribute "_no_grad_embedding_renorm_"
torch/jit/_builtins.py:80: error: Module has no attribute "stft"
torch/jit/_builtins.py:81: error: Module has no attribute "cdist"
torch/jit/_builtins.py:82: error: Module has no attribute "norm"
torch/jit/_builtins.py:83: error: Module has no attribute "nuclear_norm"
torch/jit/_builtins.py:84: error: Module has no attribute "frobenius_norm"
torch/backends/cudnn/__init__.py:8: error: Cannot find implementation or library stub for module named 'torch._C'
torch/backends/cudnn/__init__.py:86: error: Need type annotation for '_handles' (hint: "_handles: Dict[<type>, <type>] = ...")
torch/autograd/profiler.py:13: error: Name 'ContextDecorator' already defined (possibly by an import)
torch/autograd/function.py:2: error: Cannot find implementation or library stub for module named 'torch._C'
torch/autograd/function.py:2: note: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports
torch/autograd/function.py:109: error: Unsupported dynamic base class "with_metaclass"
torch/serialization.py:609: error: "Callable[[Any], Any]" has no attribute "cache"
torch/_lowrank.py:11: error: Name 'Tensor' is not defined
torch/_lowrank.py:13: error: Name 'Optional' is not defined
torch/_lowrank.py:13: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:14: error: Name 'Optional' is not defined
torch/_lowrank.py:14: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:14: error: Name 'Tensor' is not defined
torch/_lowrank.py:82: error: Name 'Tensor' is not defined
torch/_lowrank.py:82: error: Name 'Optional' is not defined
torch/_lowrank.py:82: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:82: error: Name 'Tuple' is not defined
torch/_lowrank.py:82: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_lowrank.py:130: error: Name 'Tensor' is not defined
torch/_lowrank.py:130: error: Name 'Optional' is not defined
torch/_lowrank.py:130: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:130: error: Name 'Tuple' is not defined
torch/_lowrank.py:130: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/_lowrank.py:167: error: Name 'Tensor' is not defined
torch/_lowrank.py:167: error: Name 'Optional' is not defined
torch/_lowrank.py:167: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/_lowrank.py:167: error: Name 'Tuple' is not defined
torch/_lowrank.py:167: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:45: error: Variable "torch.quantization.observer.ABC" is not valid as a type
torch/quantization/observer.py:45: note: See https://mypy.readthedocs.io/en/latest/common_issues.html#variables-vs-type-aliases
torch/quantization/observer.py:45: error: Invalid base class "ABC"
torch/quantization/observer.py:127: error: Name 'Tensor' is not defined
torch/quantization/observer.py:127: error: Name 'Tuple' is not defined
torch/quantization/observer.py:127: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:172: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:172: error: Module has no attribute "per_channel_symmetric"
torch/quantization/observer.py:192: error: Name 'Tensor' is not defined
torch/quantization/observer.py:192: error: Name 'Tuple' is not defined
torch/quantization/observer.py:192: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:233: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:233: error: Module has no attribute "per_channel_symmetric"
torch/quantization/observer.py:534: error: Name 'Tensor' is not defined
torch/quantization/observer.py:885: error: Name 'Tensor' is not defined
torch/quantization/observer.py:885: error: Name 'Tuple' is not defined
torch/quantization/observer.py:885: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/quantization/observer.py:894: error: Cannot determine type of 'max_val'
torch/quantization/observer.py:894: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:899: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:902: error: Name 'Tensor' is not defined
torch/quantization/observer.py:925: error: Name 'Tensor' is not defined
torch/quantization/observer.py:928: error: Cannot determine type of 'min_val'
torch/quantization/observer.py:929: error: Cannot determine type of 'max_val'
torch/quantization/observer.py:946: error: Argument "min" to "histc" has incompatible type "Tuple[Tensor, Tensor]"; expected "Union[int, float, bool]"
torch/quantization/observer.py:946: error: Argument "max" to "histc" has incompatible type "Tuple[Tensor, Tensor]"; expected "Union[int, float, bool]"
torch/quantization/observer.py:1056: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/observer.py:1058: error: Module has no attribute "per_channel_symmetric"
torch/nn/quantized/functional.py:76: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:76: error: Name 'BroadcastingList2' is not defined
torch/nn/quantized/functional.py:259: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:259: error: Name 'Optional' is not defined
torch/nn/quantized/functional.py:259: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/functional.py:289: error: Module has no attribute "ops"
torch/nn/quantized/functional.py:290: error: Module has no attribute "ops"
torch/nn/quantized/functional.py:308: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:326: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:356: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:371: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:400: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:400: error: Name 'Optional' is not defined
torch/nn/quantized/functional.py:400: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/functional.py:430: error: Name 'Tensor' is not defined
torch/nn/quantized/functional.py:448: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/linear.py:26: error: Module has no attribute "ops"
torch/nn/quantized/modules/linear.py:28: error: Module has no attribute "ops"
torch/nn/quantized/modules/functional_modules.py:40: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:47: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:54: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:61: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:68: error: Name 'List' is not defined
torch/nn/quantized/modules/functional_modules.py:68: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/functional_modules.py:68: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:75: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:140: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:146: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:151: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:157: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:162: error: Name 'List' is not defined
torch/nn/quantized/modules/functional_modules.py:162: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/functional_modules.py:162: error: Name 'Tensor' is not defined
torch/nn/quantized/modules/functional_modules.py:168: error: Name 'Tensor' is not defined
torch/multiprocessing/spawn.py:9: error: Module 'torch.multiprocessing' has no attribute '_prctl_pr_set_pdeathsig'
torch/multiprocessing/__init__.py:28: error: Module has no attribute "__all__"
torch/jit/frontend.py:9: error: Cannot find implementation or library stub for module named 'torch._C._jit_tree_views'
torch/jit/annotations.py:6: error: Module 'torch._jit_internal' has no attribute 'BroadcastingList2'; maybe "BroadcastingList1" or "BroadcastingListCls"?
torch/jit/annotations.py:6: error: Module 'torch._jit_internal' has no attribute 'BroadcastingList3'; maybe "BroadcastingList1" or "BroadcastingListCls"?
torch/jit/annotations.py:9: error: Cannot find implementation or library stub for module named 'torch._C'
torch/distributions/distribution.py:16: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/distribution.py:74: error: Name 'arg_constraints' already defined on line 16
torch/distributions/distribution.py:84: error: Name 'support' already defined on line 15
torch/functional.py:114: error: Name 'Tuple' is not defined
torch/functional.py:114: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:114: error: Name 'Optional' is not defined
torch/functional.py:114: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:189: error: Incompatible types in assignment (expression has type "None", variable has type "Tensor")
torch/functional.py:200: error: Argument 1 to "_indices_product" has incompatible type "Tuple[int, ...]"; expected "List[int]"
torch/functional.py:204: error: No overload variant of "__setitem__" of "list" matches argument types "Tensor", "int"
torch/functional.py:204: note: Possible overload variants:
torch/functional.py:204: note: def __setitem__(self, int, int) -> None
torch/functional.py:204: note: def __setitem__(self, slice, Iterable[int]) -> None
torch/functional.py:204: error: No overload variant of "__getitem__" of "list" matches argument type "Tensor"
torch/functional.py:204: note: def __getitem__(self, int) -> int
torch/functional.py:204: note: def __getitem__(self, slice) -> List[int]
torch/functional.py:207: error: "Tensor" has no attribute "copy_"
torch/functional.py:212: error: No overload variant of "__setitem__" of "list" matches argument types "Tensor", "int"
torch/functional.py:212: note: Possible overload variants:
torch/functional.py:212: note: def __setitem__(self, int, int) -> None
torch/functional.py:212: note: def __setitem__(self, slice, Iterable[int]) -> None
torch/functional.py:212: error: No overload variant of "__getitem__" of "list" matches argument type "Tensor"
torch/functional.py:212: note: def __getitem__(self, int) -> int
torch/functional.py:212: note: def __getitem__(self, slice) -> List[int]
torch/functional.py:215: error: Incompatible types in assignment (expression has type "None", variable has type "Tensor")
torch/functional.py:334: error: Name 'Optional' is not defined
torch/functional.py:334: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:429: error: Argument 2 to "pad" has incompatible type "Tuple[int, int]"; expected "List[int]"
torch/functional.py:431: error: Module has no attribute "stft"
torch/functional.py:766: error: Module has no attribute "cdist"
torch/functional.py:768: error: Module has no attribute "cdist"
torch/functional.py:770: error: Module has no attribute "cdist"
torch/functional.py:775: error: Name 'Optional' is not defined
torch/functional.py:775: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:780: error: Name 'Optional' is not defined
torch/functional.py:780: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:780: error: Name 'number' is not defined
torch/functional.py:780: error: Name 'norm' already defined on line 775
torch/functional.py:785: error: Name 'Optional' is not defined
torch/functional.py:785: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:785: error: Name 'number' is not defined
torch/functional.py:785: error: Name 'norm' already defined on line 775
torch/functional.py:790: error: Name 'Optional' is not defined
torch/functional.py:790: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:790: error: Name 'norm' already defined on line 775
torch/functional.py:795: error: Name 'norm' already defined on line 775
torch/functional.py:960: error: Name 'Any' is not defined
torch/functional.py:960: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Any")
torch/functional.py:960: error: Name 'Tuple' is not defined
torch/functional.py:960: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:1036: error: Argument 1 to "len" has incompatible type "int"; expected "Sized"
torch/functional.py:1041: error: Name 'Optional' is not defined
torch/functional.py:1041: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:1041: error: Name 'Tuple' is not defined
torch/functional.py:1041: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/functional.py:1056: error: Name 'Optional' is not defined
torch/functional.py:1056: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/functional.py:1056: error: Name 'Tuple' is not defined
torch/functional.py:1056: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Tuple")
torch/distributions/von_mises.py:87: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/negative_binomial.py:25: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/multivariate_normal.py:116: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/laplace.py:23: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/independent.py:34: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/cauchy.py:28: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/poisson.py:28: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/one_hot_categorical.py:32: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/normal.py:27: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/lowrank_multivariate_normal.py:79: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/gamma.py:30: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/exponential.py:23: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/fishersnedecor.py:25: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/dirichlet.py:44: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/nn/quantized/dynamic/modules/rnn.py:230: error: Incompatible types in assignment (expression has type "int", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:232: error: Incompatible types in assignment (expression has type "int", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:236: error: Incompatible return value type (got "Tuple[Any, Tensor, Any]", expected "Tuple[int, int, int]")
torch/nn/quantized/dynamic/modules/rnn.py:351: error: Incompatible types in assignment (expression has type "Type[LSTM]", base class "RNNBase" defined the type as "Type[RNNBase]")
torch/nn/quantized/dynamic/modules/rnn.py:381: error: Module has no attribute "quantized_lstm"
torch/nn/quantized/dynamic/modules/rnn.py:385: error: Module has no attribute "quantized_lstm"
torch/nn/quantized/dynamic/modules/rnn.py:414: error: Argument 1 to "forward_impl" of "LSTM" has incompatible type "PackedSequence"; expected "Tensor"
torch/nn/quantized/dynamic/modules/rnn.py:416: error: Incompatible types in assignment (expression has type "PackedSequence", variable has type "Tensor")
torch/nn/quantized/dynamic/modules/rnn.py:418: error: Incompatible return value type (got "Tuple[Tensor, Tuple[Tensor, Tensor]]", expected "Tuple[PackedSequence, Tuple[Tensor, Tensor]]")
torch/nn/quantized/dynamic/modules/rnn.py:420: error: Argument 1 of "permute_hidden" is incompatible with supertype "RNNBase"; supertype defines the argument type as "Tensor"
torch/nn/quantized/dynamic/modules/rnn.py:420: error: Return type "Tuple[Tensor, Tensor]" of "permute_hidden" incompatible with return type "Tensor" in supertype "RNNBase"
torch/nn/quantized/dynamic/modules/rnn.py:426: error: Argument 2 of "check_forward_args" is incompatible with supertype "RNNBase"; supertype defines the argument type as "Tensor"
torch/nn/intrinsic/qat/modules/conv_fused.py:232: error: Incompatible types in assignment (expression has type "Type[ConvBnReLU2d]", base class "ConvBn2d" defined the type as "Type[ConvBn2d]")
torch/distributions/beta.py:27: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/geometric.py:31: error: Incompatible types in assignment (expression has type "_IntegerGreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/continuous_bernoulli.py:38: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/bernoulli.py:30: error: Incompatible types in assignment (expression has type "_Boolean", base class "Distribution" defined the type as "None")
torch/quantization/fake_quantize.py:126: error: Module has no attribute "per_tensor_symmetric"
torch/quantization/fake_quantize.py:132: error: Module has no attribute "per_channel_symmetric"
torch/distributions/transformed_distribution.py:41: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/jit/__init__.py:1: error: Cannot find implementation or library stub for module named 'torch._C'
torch/jit/__init__.py:15: error: Module 'torch.utils' has no attribute 'set_module'
torch/jit/__init__.py:70: error: Name 'Attribute' already defined on line 68
torch/jit/__init__.py:213: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/jit/__init__.py:215: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/jit/__init__.py:1524: error: Unsupported dynamic base class "with_metaclass"
torch/jit/__init__.py:1869: error: Name 'ScriptModule' already defined on line 1524
torch/jit/__init__.py:1998: error: Need type annotation for '_jit_caching_layer'
torch/jit/__init__.py:1999: error: Need type annotation for '_jit_function_overload_caching'
torch/distributions/relaxed_categorical.py:34: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_categorical.py:108: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_bernoulli.py:31: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/relaxed_bernoulli.py:114: error: Incompatible types in assignment (expression has type "_Interval", base class "Distribution" defined the type as "None")
torch/distributions/logistic_normal.py:31: error: Incompatible types in assignment (expression has type "_Simplex", base class "Distribution" defined the type as "None")
torch/distributions/log_normal.py:26: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/half_normal.py:27: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/half_cauchy.py:28: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/gumbel.py:28: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/nn/quantized/modules/conv.py:18: error: Module 'torch.nn.utils' has no attribute 'fuse_conv_bn_weights'
torch/nn/quantized/modules/conv.py:209: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:209: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:214: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:321: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:321: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:323: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:447: error: Name 'Optional' is not defined
torch/nn/quantized/modules/conv.py:447: note: Did you forget to import it from "typing"? (Suggestion: "from typing import Optional")
torch/nn/quantized/modules/conv.py:449: error: Module has no attribute "ops"
torch/nn/quantized/modules/conv.py:513: error: Name 'nn.modules.conv._ConvTransposeNd' is not defined
torch/nn/quantized/modules/conv.py:525: error: Name 'List' is not defined
torch/nn/quantized/modules/conv.py:525: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/quantized/modules/conv.py:527: error: Name 'List' is not defined
torch/nn/quantized/modules/conv.py:527: note: Did you forget to import it from "typing"? (Suggestion: "from typing import List")
torch/nn/intrinsic/quantized/modules/conv_relu.py:8: error: Module 'torch.nn.utils' has no attribute 'fuse_conv_bn_weights'
torch/nn/intrinsic/quantized/modules/conv_relu.py:21: error: Incompatible types in assignment (expression has type "Type[ConvReLU2d]", base class "Conv2d" defined the type as "Type[Conv2d]")
torch/nn/intrinsic/quantized/modules/conv_relu.py:62: error: Incompatible types in assignment (expression has type "Type[ConvReLU3d]", base class "Conv3d" defined the type as "Type[Conv3d]")
torch/distributions/weibull.py:25: error: Incompatible types in assignment (expression has type "_GreaterThan", base class "Distribution" defined the type as "None")
torch/distributions/kl.py:35: error: Need type annotation for '_KL_MEMOIZE' (hint: "_KL_MEMOIZE: Dict[<type>, <type>] = ...")
torch/distributions/studentT.py:27: error: Incompatible types in assignment (expression has type "_Real", base class "Distribution" defined the type as "None")
torch/distributions/mixture_same_family.py:48: error: Need type annotation for 'arg_constraints' (hint: "arg_constraints: Dict[<type>, <type>] = ...")
torch/distributions/__init__.py:158: error: Name 'transforms' is not defined
torch/onnx/utils.py:21: error: Cannot find implementation or library stub for module named 'torch._C'
torch/distributed/rendezvous.py:4: error: Cannot find implementation or library stub for module named 'urlparse'
torch/distributed/rendezvous.py:4: error: Name 'urlparse' already defined (possibly by an import)
torch/distributed/rendezvous.py:4: error: Name 'urlunparse' already defined (possibly by an import)
torch/distributed/rendezvous.py:9: error: Module 'torch.distributed' has no attribute 'FileStore'
torch/distributed/rendezvous.py:9: error: Module 'torch.distributed' has no attribute 'TCPStore'
torch/distributed/rendezvous.py:65: error: On Python 3 '{}'.format(b'abc') produces "b'abc'"; use !r if this is a desired behavior
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllreduceOptions'; maybe "ReduceOptions" or "AllreduceCoalescedOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllreduceCoalescedOptions'; maybe "AllreduceOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'AllToAllOptions'
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'BroadcastOptions'
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'GatherOptions'; maybe "ScatterOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ReduceOptions'; maybe "AllreduceOptions", "ReduceScatterOptions", or "ReduceOp"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ReduceScatterOptions'; maybe "ScatterOptions" or "ReduceOptions"?
torch/distributed/distributed_c10d.py:11: error: Module 'torch.distributed' has no attribute 'ScatterOptions'; maybe "ReduceScatterOptions" or
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36584
Reviewed By: seemethere, ailzhang
Differential Revision: D21155985
Pulled By: ezyang
fbshipit-source-id: f628d4293992576207167e7c417998fad15898d1
Summary:
Files that were named the same within the anaconda repository, i.e.
pytorch_1.5.0-cpu.bz2, were found to be clobbering each other,
especially amongst different platforms.
This lead to similarly named packages for different platforms to not get
promoted.
This also adds "--skip" to our anaconda upload so that we don't end up
overwriting our releases just in case this script gets run twice.
Also, conda search ends up erroring out if it doesn't find anything for
the current platform being searched for so we should just continue
forward if we don't find anything since we want to be able to use this
script for all of the packages we support which also do not release
packages for all of the same platforms. (torchtext for example only has
"noarch")
This should also probably be back-ported to the `release/1.5` branch since this changeset was used to release `v1.5.0`
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37089
Differential Revision: D21184768
Pulled By: seemethere
fbshipit-source-id: dbe12d74df593b57405b178ddb2375691e128a49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34650
Resubmit of https://github.com/pytorch/pytorch/pull/33840, which was overly eager in the sense that it deleted a lot of code that we didn't want to get rid of yet (default timeout handling).
This PR adds an optional argument into `rpc_sync` and `rpc_async` as well as `RpcAgent::send()` that allows the user to specify a timeout for an RPC to override the default set timeout. If the user does not specify this argument, then the currently set default RPC timeout given in the RPC constructor or by `rpc.set_rpc_timeout()` is used. Otherwise, we use the passed in timeout.
This diff does not address:
1) timeout support when called rpc.rpc_async is called as a JIT operator. For this to work, we would need to change the logic in `register_distributed_ops` to pass in this timeout to `rpcTorchscript`. One more issue is that torchscript doesn't support the timedelta object. This will be done in a follow up PR as it requires a fair amount of changes to the argument parsing logic.
2) Per-RPC timeouts for internal messages or `rpc.remote()`. A follow-up diff will address the latter with the approach of raising the timeout error at the earliest next possible time to the user, such as when the next time the RRef is forked or `to_here` is called
Added unit tests to confirm the current behavior
ghstack-source-id: 102622601
Test Plan: Added unit tests in rpc_test
Differential Revision: D20376953
fbshipit-source-id: 9fb3f147520588308ab50dd33286255658d76d47
Summary:
Changes the file_diff_from_base function to get the base reference
directly from CircleCI's pipeline variables instead of being hardcoded
to master.
cc gchanan
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36260
Differential Revision: D21144940
Pulled By: seemethere
fbshipit-source-id: ec6d1c2adcf703119bdab2a43f26a39a5fbaf71b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37058
We shouldn't add advisory checks to master, because PRs will get
reverted if they fail. This PR makes the following changes:
1. Factor out the binary fetch logic into `clang_format_utils.py`
2. Copypasta the canonical git integration from llvm and modify it to
use our binary fetcher. No more bikeshedding about how to integrate,
we just use the standard integration.
3. Change the CI job to run on pull-requests only and use
`git-clang-format`.
4. The original `clang_format.py` is now renamed `clang_format_all.py`
to reflect its purpose.
5. The pre-commit hook has been changed to use `git-clang-format`.
For pre-commit hook users: no changes required.
For others: add `tools/git-clang-format` to your PATH and you can do `git clang-format` to format your working tree.
Test Plan: Imported from OSS
Differential Revision: D21180893
Pulled By: suo
fbshipit-source-id: f8358fb7ce26f11585226aaac5ed89d379257bfb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36978
We're seeing quite a bit of these running unittests, might be a
bit verbose at LOG(INFO)
ghstack-source-id: 102557335
Test Plan: regular unittest coverage, this is logging-only
Differential Revision: D21149262
fbshipit-source-id: 4992342883920f58484afd8b1e432c1455035835
Summary:
Closes https://github.com/pytorch/pytorch/issues/24546
Benchmark with same build settings on same system.
gcc : version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)
CUDA : 10.1
GPU : 1050ti
```python
import timeit
for n, t in [(10_000, 20000),
(100_000, 20000)]:
for dtype in ('torch.half', 'torch.float', 'torch.double'):
print(f'torch.cosh(a) a.numel() == {n} for {t} times {dtype}')
print(timeit.timeit(f'torch.cosh(a); torch.cuda.synchronize()',
setup=f'import torch; a=torch.arange({n}, dtype={dtype}, device="cuda")',
number=t))
```
Before:
```
torch.cosh(a) a.numel() == 10000 for 20000 times torch.half
0.2813017509997735
torch.cosh(a) a.numel() == 10000 for 20000 times torch.float
0.28355878599904827
torch.cosh(a) a.numel() == 10000 for 20000 times torch.double
0.27810572300040803
torch.cosh(a) a.numel() == 100000 for 20000 times torch.half
0.3239932899996347
torch.cosh(a) a.numel() == 100000 for 20000 times torch.float
0.321233343998756
torch.cosh(a) a.numel() == 100000 for 20000 times torch.double
0.5546665399997437
```
After:
```
torch.cosh(a) a.numel() == 10000 for 20000 times torch.half
0.2905335750001541
torch.cosh(a) a.numel() == 10000 for 20000 times torch.float
0.27596429500044906
torch.cosh(a) a.numel() == 10000 for 20000 times torch.double
0.30358699899989006
torch.cosh(a) a.numel() == 100000 for 20000 times torch.half
0.30139567500009434
torch.cosh(a) a.numel() == 100000 for 20000 times torch.float
0.30246640400036995
torch.cosh(a) a.numel() == 100000 for 20000 times torch.double
0.5403946970000106
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36654
Differential Revision: D21164606
Pulled By: VitalyFedyunin
fbshipit-source-id: 55e88f94044957f81599ae3c12cda38a3e2c985c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35615
Python 2 has reached end-of-life and is no longer supported by PyTorch.
Now we can clean up a lot of cruft that we put in place to support it.
These changes were all done manually, and I skipped anything that seemed
like it would take more than a few seconds, so I think it makes sense to
review it manually as well (though using side-by-side view and ignoring
whitespace change might be helpful).
Test Plan: CI
Differential Revision: D20842886
Pulled By: dreiss
fbshipit-source-id: 8cad4e87c45895e7ce3938a88e61157a79504aed
Summary:
Resolves https://github.com/pytorch/pytorch/issues/36730https://github.com/pytorch/pytorch/issues/36057
Partially resolves: https://github.com/pytorch/pytorch/issues/36671
```
>>> 2j / torch.tensor([4], dtype = torch.complex64)
tensor([(0.0000+0.5000j)], dtype=torch.complex64)
>>> 1 / torch.tensor(3+4j)
tensor((0.1200-0.1600j), dtype=torch.complex64)
```
rdiv is more generally broken for all dtypes because it doesn't promote the types properly
eg.
```
>>> 1 / torch.tensor(2)
tensor(0)
>>> 2j / torch.tensor(4)
tensor(0)
```
so that issue should be fixed in a separate PR
Adding CPU acc types for complex
Added cumsum, cumprod for complex dtypes
Added complex dtypes to get_all_math_dtypes to expand testing for complex dtypes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36747
Differential Revision: D21138687
Pulled By: anjali411
fbshipit-source-id: ad3602ccf86c70294a6e71e564cb0d46c393dfab
Summary:
This PR tries to rebase on top of origin/master before building xla job.
I also saw a TODO in existing code which does a very similar thing (rebase on master for gcc5 jobs), so I just fixed the TODO by moving the logic into a separate step.
Currently the logic is:
For these gcc5 and xla jobs, we rebase on top of "target" branch before building.
- This only happens on PRs.
- "Target" branch is "origin/master" by default, but if it's trying to merge into a release branch, target branch will be the release branch.
- I made the "target" branch a param mainly it's allow us to rebase on `viable/strict` if we want. But after a second thought, how quickly `viable/strict` moves forward is not controlled only by xla job, and it's hard to predict how long the breakage will last if it's not moving. But we do have control over how long a xla breakage lasts on `origin/master` (which should be short since we monitor it closely). So I currently want to keep `origin/master` and move to `viable/strict` when it's super stable.
- There're jobs like `pytorch_paralleltbb_linux_xenial_py3_6_gcc5_4_build` which would fall into the rebase logic as well, but since those jobs doesn't run on PRs(so the old logic was essentially no-op), I didn't enabled the new logic on those jobs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36852
Differential Revision: D21171747
Pulled By: ailzhang
fbshipit-source-id: 433ea0e14d030e2e0fa74d2ff4244327e9db7044
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37050
With this change curly braces are printed as a part of Block rather than
a part of the enclosing statement. It allows us, for instance, to more
easily see nested blocks: now they will be printed each in its own
curly-braced scope.
As a side effect, I had to change how we print loop options. Previously
we did it like this:
```
for (...) { // <loop options>
<loop body (Block)>
}
```
Now, since everything in between { and } is a part of the block, we have
to do it the following way:
```
for (...) /* <loop options> */ {
<loop body (Block)>
}
```
Note the change from '//' to '/* .. */' for the loop option comments.
Test Plan: Imported from OSS
Differential Revision: D21171851
Pulled By: ZolotukhinM
fbshipit-source-id: 39f51a9e15aec03b6527b0634fd4b9e01a912cda
Summary:
Line 33+ contains instructions on how to disable use, 108+ on how to enable it.
The default in CMakeLists.txt is enabled, so drop the latter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36993
Differential Revision: D21161793
Pulled By: ngimel
fbshipit-source-id: 08c5eecaf8768491f90d4a52c338ecea32a0c35e
Summary:
Previously torch.isclose would RuntimeError when called on complex tensors. This update updates torch.isclose to run on complex tensors and be consistent with [NumPy](https://numpy.org/doc/1.18/reference/generated/numpy.isclose.html). However, NumPy's handling of NaN, -inf, and inf values is odd, so I adopted Python's [cmath.isclose](https://docs.python.org/3/library/cmath.html) behavior when dealing with them. See https://github.com/numpy/numpy/issues/15959 for more on NumPy's behavior.
While implementing complex isclose I also simplified the isclose algorithm to:
- A is close to B if A and B are equal, if equal_nan is true then NaN is equal to NaN
- If A and B are finite, then A is close to B if `abs(a - b) <= (atol + abs(rtol * b))`
This PR also documents torch.isclose, since it was undocumented, and adds multiple tests for its behavior to test_torch.py since it had no dedicated tests.
The PR leaves equal_nan=True with complex inputs an error for now, pending the outcome of https://github.com/numpy/numpy/issues/15959.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36456
Differential Revision: D21159853
Pulled By: mruberry
fbshipit-source-id: fb18fa7048e6104cc24f5ce308fdfb0ba5e4bb30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36619
With this PR, applications no longer need to create dedicated helpers
to run functions on the object referenced by an RRef. Instead,
`rref.rpc_sync().some_func()` will use `rpc_sync` to run `some_func`
on the owner of the RRef using the object referenced by the RRef.
Similar helpers for `rref.rpc_async().some_func()` and
`rref.remote().some_func()` are also added.
An alternative design is to expose PyRRef as RRefBase and then
implement everything in a new Python RRef class. However, the RRef
class cannot directly inherit from PyRRef/RRefBase, otherwise we
will need to let pyRemote* C++ functions to load RRef from Python
and return an RRef instance. It is possible to let RRef hold a
instance of PyRRef instead of inherit from it, but this does not
look like a elegant design, as we will have RRef holding PyRRef and
PyRRef holding the C++ RRef. Another alternative is to use dynamic
method loading, by installing member methods to PyRRef instances.
However, this would require different solutions to handle
RRef(data) and rpc.remote(...). Base on the above thinking, we
decided to go with the current implementation for simplicity and we
can also keep all RRef-related APIs in one place.
Test Plan: Imported from OSS
Differential Revision: D21028333
Pulled By: mrshenli
fbshipit-source-id: fe90f56ef7183d18874e357900093755e1601eb4
Summary:
Some IR optimizations were leaving superfluous Blocks in the IR, this PR adds simplification and merging of enclosing Block statements to the IR Simplifier, e.g.
```
Block {
Stmt 1
Block {
Stmt 2
}
Block {}
}
```
becomes
```
Block {
Stmt 1
Stmt 2
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37013
Differential Revision: D21166208
Pulled By: nickgg
fbshipit-source-id: 6dcdf863980d94731a8ddf184882c4a5b7259381
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36976
The bounds check and the read were swapped in two places - I noticed
ASAN complaining in an unrelated change on an erroneous buffer.
Adding a couple simple test cases.
ghstack-source-id: 102606986
Test Plan: buck test mode/dev caffe2/test/cpp/rpc:
Differential Revision: D21148936
fbshipit-source-id: 7ec5007535f7310437ac1b9a72852a223b9dd29a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36987
the discrepancy comes from using eigen's sqrt.
Replaced it with std::sqrt and worked, so using MKLs version
Removed momentum, made epsilon float, enhanced the test with hypothesis
Test Plan: testing the mkl dependencies in prod, if things work, will remove the intrinsics implementation, if no, will use intrinsics
Reviewed By: yinghai
Differential Revision: D21151661
fbshipit-source-id: 56e617b13bc32b0020691f7201d16dee00f651b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36969
`test_backward_node_failure_python_udf` was flaky since it used the
RPC framework to indicate rank 0 was done with processing. Since we kill nodes
in this unit test, it is very likely that listenLoop() has exited on some nodes
and hence using an RPC to inform all nodes about rank 0's completion
might not work, since the RPC might not be processed on certain nodes.
To fix this, we use the c10d store instead for this notification.
ghstack-source-id: 102549873
Test Plan: waitforbuildbot
Differential Revision: D21147099
fbshipit-source-id: 745273a6cae0debbae131bb4cc7debe9c201bf98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36628
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D21029702
Pulled By: ezyang
fbshipit-source-id: 2322094338ad896653b2db43ff74a8ab1593b3e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36188
* Need to remove n^2 behavior for scanning whether to split or not
otherwise long inline chains will take a long time re-scanning.
Test Plan: Imported from OSS
Differential Revision: D20907254
Pulled By: zdevito
fbshipit-source-id: ebfc1a4eefc26d5806381e7afd75b7a9cd4cde97
Summary:
This PR is motivated by two issues it tries to address:
1) relax the constraint on requantization scale (<1).
2) Unify requantization methodology across pytorch integration of QNNPACK and FBGEMM.
Here we are trying to address the first part for Conv and Linear.
Existing requantization scheme performs scale multiplication entirely in integer arithmetic by extracting mantissa and exponent part of FP scale and processing them. This including appropriate rounding required. The set of instruction, corresponding to this, are specifically tailored for the condition when scale < 1.
Relaxing this constraint requires us to fix that sequence of instruction. In this PR we take a simpler approach of essentially converting Int32 to FP32, apply scale, convert FP32 to Int32 with appropriate rounding, to-nearest-ties-to-even. This is followed by zero point add and clipping. Since in 32-bit ARM nearest-ties-to-even rounding instruction is not available, the sequence is little different. Sequence for both 32-bit and 64-bit are taken from https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/quantized/cpu/qnnpack/src/requantization/fp32-neon.c.
Furthermore relaxing the scale constraint and moving towards FP requantization also helps us move towards unifying requantization producer across QNNPACK and FBGEMM.
Summary of the PR:
- requantization params are modified to lift some computation that would have to be in the kernel otherwise for aarch32 kernels, particularly:
- Computing vfmin, vfmax, vfmagic and vimagic.
- Fixed q8gemm, q8conv and q8dwconv kernels.
- Fixed the corresponding tests.
What is not done:
- XZP kernels are not changed as part of this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35856
Differential Revision: D20996325
Pulled By: kimishpatel
fbshipit-source-id: 7a7a18b09dd2564768142371db06d98bf7479f49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37007
D20961463 was reverted due to clang-format. Redo it.
Test Plan: verified TTS model can be loaded without problem
Reviewed By: iseeyuan
Differential Revision: D21157626
fbshipit-source-id: 372bf6196da20b3ebafa283c5c3f7c924a37ed60
Summary:
Add the support to accept both float, byte, and bool tensors for `attn_mask`. No breakage is expected.
- If a bool tensor is provided, positions with `True` are not allowed to attend while `False` values will be unchanged.
- if a byte tensor is provided, it will be converted to bool tensor. Positions with non-zero are not allowed to attend while zero values will be unchanged.
- If a float tensor is provided, it will be added to the attention weight.
Note: the behavior of the float mask tensor is slightly different from the first two options because it is added to the attention weight, rather than calling `masked_fill_` function. Also, converting a byte tensor to bool tensor within `multi_head_attention_forward` causes extra overhead. Therefore, a bool mask is recommended here.
For `key_padding_mask`:
- if a bool tensor is provided, it will be converted to bool tensor. The positions with the value of `True` will be ignored while the position with the value of `False` will be unchanged.
- If a byte tensor is provided, the positions with the value of non-zero will be ignored while the position with the value of zero will be unchanged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33763
Differential Revision: D20925358
Pulled By: zhangguanheng66
fbshipit-source-id: de174056be183cdad0f3de8024ee0a3c5eb364c9
Summary:
When doing elimination of For loops which execute once, e.g. `for i = 0; i < 1; ++i { thing; } => thing;` we do var substitution while the temporary simplifier ExprNodes still exist, which could put them in an invalid state and leave unsimplified terms in the expression. The fix is to apply substitution before simplifying the body of the for loop.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36965
Differential Revision: D21145248
Pulled By: nickgg
fbshipit-source-id: d874600c7a098fc05b8ef3109e516e2eaa2c24e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36838
All ops now do unboxing after dispatch, i.e. c10 handles unboxing and c10 registers a wrapper for the op to JIT
The last op that manually registered its own wrapper to JIT in register_aten_ops.cpp was migrated.
Since there are no ops using use_c10_dispatcher: unboxed_only anymore, we can delete the feature.
Also:
- Rename some files to more accurately describe what they're doing now:
- OpsAlreadyMovedToC10.h/cpp -> ATenOpList.h/cpp
- register_aten_ops.cpp -> generated_unboxing_wrappers.cpp
- gen_jit_dispatch.py -> gen_unboxing_wrappers.cpp
ghstack-source-id: 102532915
Test Plan: waitforsandcastle
Differential Revision: D21100081
fbshipit-source-id: be824958eef33f6cd42a6a652175bd0b1df4ebf9
Summary:
# Goals
Do the following things during a distributed backward pass.
1. Accumulate the gradient of a variable to RPC context once the gradient is ready instead of at the very end of the backward pass.
2. Run post/pre hooks installed in`AccumulateGrad` nodes once the gradient is ready for the variable. Currently, the hooks in `AccumulateGrad` are not executed just because the function `AccumulateGrad` itself is not even evaluated by the local engine.
3. Make it extensible to support post hooks installed by DDP's reducer.
# Introduce GradCapturePreHook
## Why do we need this?
### Root issue:
* dist engine uses the autograd.grad-like API on the vanilla engine and then in the Future callback populates the context with the gradients. This is a bad emulation of the .backward() call on the vanilla engine.
### Practical issue:
* The leaf’s hook are not called (because associated with the AccumulateGrad that is not call in the autograd.grad-like API). Modules like DDP rely on these hooks.
* The Future is marked as completed before the context is actually populated with the grads leading to unexpected behavior on the user side.
* The Future callback is only called at the complete end of the backward and so too late for DDP if they want to overlap compute/transfert.
### Proposed solution:
* Provide hooks in the autograd.grad-like API that will allow the distributed engine to populate the context and call the hooks to better emulate the .backward call.
## Who can install a grad capture pre-hook?
This will be an internal hook at C++ level and it won’t be exposed to PyThon code. Only call-sites directly interacting with the local engine can install such hooks.
## Signature
The returned `grad` will be captured.
```
virtual const torch::Tensor& grad operator()(const torch::Tensor& grads) = 0;
```
## Where are hooks installed?
Grad capture pre-hooks are install in GraphTask::ExecInfo::Capture. ExecInfo is per node. Every backward run will have its own GraphTask instance.
## When/How will hooks be called?
When the local engine captures the grads for a node, all grad capture pre hooks are called one by one in the order they are added. The output grads of the hooks will replace the original grads.
The output of the last hook will be used for grad capturing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34501
Test Plan:
All existing tests should pass.
```
python setup.py develop
python test/distributed/rpc/test_dist_autograd_spawn.py DistAutogradTestWithSpawn.test_post_hooks
```
Differential Revision: D20953673
Pulled By: hczhu
fbshipit-source-id: 543b3844823330ea9f9856bab7c5cb2679290a53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36936
Closes https://github.com/pytorch/pytorch/issues/30813
Relanding of https://github.com/pytorch/pytorch/pull/35463
1. Tensor quantization logic(quantize_*) is moved to the aten/native/quantized. Previously all logic for tensor quantization lived in the aten/quantized/Quantizer.cpp file, and started to become complicated and hard to read. This problem should be addressed in refactoring PR. Still, I reworked this partially because I had to add tensor quantization logic for CUDA, and it was native to move everything to the aten/native/quantized.
2. Requirements to run CUDA_tensor_apply* was eased to process any tenser that lives on the CUDA device(QuantizedCUDA included).
3. All quantized data types now have a default constructor. NVCC refuses to compile any gpu_kernel or CUDA_tensor_apply* without them.
4. Minor changes in many files to register QuantizedCUDA backend.
5. test_quantized_tensor is extended to process QuantizedCUDA backend where possible.
Test Plan: Imported from OSS
Differential Revision: D21143025
Pulled By: jerryzh168
fbshipit-source-id: 11405e2e8f87e48fadc0a084c51db15f85ccb500
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36970
We would like to move all distributed testing to use the existing
multiprocessing tooling defined in common_distributed.py. With this change, we
make `TestDistBackend` inherit from `MultiProcessTestCase` and enable fork mode
multiprocessing. In the next step, we can enable spawn mode for these tests
which will give us TSAN coverage.
ghstack-source-id: 102553801
Test Plan: Unittests
Differential Revision: D21146947
fbshipit-source-id: 608fa2cb93e88f8de6a5ac87c523e2c4e4fede1b
Summary:
**Summary**
This commit disables the progress bar for the `clang-format` binary
download if stdout is not attached to a terminal. The cursor
repositioning tricks used to print out the progress bar don't work if
stdout is redirected something that is not a terminal, and so the file
ends up containing each progress bar update on a separate line. This
happens in the GitHub workflow for checking formatting and is annoying
to scroll through.
**Test Plan**
1. Manual invocation of the script still produces progress bar.
```
(pytorch) me@devgpuXXX:pytorch (disable-cf-progress-bar)$ with-proxy tools/clang_format.py
Downloading clang-format to /home/me/local/repos/pytorch/.clang-format-bin
0% |################################################################| 100%
Using clang-format located at /home/me/local/repos/pytorch/.clang-format-bin/clang-format
```
2. GitHub `clang-format` workflow output no longer contains progress bar.
```
Run set -eux
+ echo '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~'
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ echo '| Run tools/clang_format.py to fix formatting errors |'
| Run tools/clang_format.py to fix formatting errors |
+ echo '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~'
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ tools/clang_format.py --verbose --diff
Created directory /home/runner/work/pytorch/pytorch/.clang-format-bin for clang-format binary
Downloading clang-format to /home/runner/work/pytorch/pytorch/.clang-format-bin
Reference Hash: d1365110da598d148d8143a7f2ccfd8bac7df499
Actual Hash: d1365110da598d148d8143a7f2ccfd8bac7df499
Using clang-format located at /home/runner/work/pytorch/pytorch/.clang-format-bin/clang-format
All files formatted correctly
```
**Fixes**
This PR fixes https://github.com/pytorch/pytorch/issues/36949.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36955
Differential Revision: D21157861
Pulled By: SplitInfinity
fbshipit-source-id: 16c6d4395cee09f3bd2abac13e9be4acdde73406
Summary:
Our test suite used to set double as its default scalar type, and when it was switched to not do so (to be more consistent with how users experience PyTorch), a few tests had to still set the default scalar type to double to function properly. Now that the jit no longer creates double tensors so frequently, it appears that test_jit no longer needs to set double as its default scalar type, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36982
Differential Revision: D21152120
Pulled By: mruberry
fbshipit-source-id: ea6d3c1ad55552dc5affa1fe1bd0e5189849e6d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36355
Resolving issue in https://github.com/pytorch/pytorch/issues/36155, by:
- supporting grouped conv3d in ```slow_conv3d```
- adding a fast path in ```__convolution``` to call ```slow_conv3d``` when
running grouped conv3d on CPU
- bypassing unfolding when kernel_size = 1
Test Plan:
Added the following test cases in test_nn.py, testing both forward and
backward:
- test_Conv3d_groups_nobias
- test_Conv3d_groups_wbias
- test_Conv_1x1
Imported from OSS
Differential Revision: D20957073
fbshipit-source-id: 29afd1e6be8c484859eaedd51463954e2fdccc38
Summary:
This resolves an issue observed by stefanwebb where the composition of multiple transforms is cached only if all components are cached.
This PR adds a new method `.with_cache()` so that e.g. you can compose a normalizing flow (that needs to be cached) with a `SigmoidTransform` (that wasn't already cached) by calling `.with_cache()` on the latter. This issue also comes up when composing non-cached constraint transforms as returned by `transform_to()` and `biject_to()`: after this PR you can call `transform_to(constraints.positive).with_cache()` to get a cached `ExpTransform`.
## Tested
- [x] added a unit test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36882
Differential Revision: D21155914
Pulled By: ezyang
fbshipit-source-id: 3c06e63785ca2503e08a5cd7532aff81882835e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36742
Now, you can define a custom class inside a TORCH_LIBRARY block.
It looks very similar to what you did before. Instead of
```
static auto m = torch::class_<Class>("Namespace", "Class").def("foo", foo);
```
you write
```
TORCH_LIBRARY(Namespace, m) {
m.class_<Class>("Class")
.def("foo", foo);
}
```
All the old usages still work, but at some point we should start
updating the tutorials when we're ready to go 100% live with the
new pybind11 style API.
custom class API previously lived in torch/ folder and in torch
namespace, so for consistency, the new TORCH_LIBRARY also got
moved to torch/library.h The definition of Library::class_ is in the
bottom of that header because I need all of the class_ constructors
available, but there is a circular dependency between the two headers.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D21089648
Test Plan: Imported from OSS
Pulled By: ezyang
fbshipit-source-id: 8d54329c125242605336c22fa1642aae6940b507
Summary:
Fixes https://github.com/pytorch/pytorch/issues/26304
After this patch `build.ninja` entries for `.cu` files will contain a `depfile` variable pointing to a `.NVCC-depend` file containing dependencies (i.e., header files included directly or indirectly) of the `.cu` source file. Until now, those `.NVCC-depend` files were being transposed into `.cu.o.depend` files in CMake format. That did not work as intended because the `.cu.o` target file was declared to be dependent on the `.cu.o.depend` file itself, rather than its contents. In fact, Ninja lacks the functionality to process dependencies in the CMake format of those `.cu.o.depend` files.
This was tested on Linux as described in https://github.com/pytorch/pytorch/issues/26304#issuecomment-614667170
I have also verified that the original problem does not reproduce with Makefiles (i.e., when `ninja` is not present in the system) and that PyTorch still build successfully with Makefiles after this patch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36938
Differential Revision: D21156042
Pulled By: ezyang
fbshipit-source-id: fda3aaa57207f4d6bf74d2f254fe45fb7fd90eec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36973
handle the case where inputs are used in multiple partitions
Test Plan: unit tests
Reviewed By: yinghai
Differential Revision: D21107672
fbshipit-source-id: 9eca20220b80f27400aefcdaeff5d5503e32654c
Summary:
Use `std::decay_t<decltype(foo)>::size()` instead of `foo.size()` to help compiler with static array allocations.
Even if `Vec256::size()` is `constexpr`, `foo.size()` (where `foo` is of type `Vec256`) is not an integral constant expression, therefore compiler have to use VLAs, which are not part of C++ standard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36855
Test Plan: CI
Differential Revision: D21151194
Pulled By: malfet
fbshipit-source-id: eaf3e467c7f7ee6798ca82fe9f8fae725011ead0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36971
Add lite interpreter ops for portal TTS model.
Test Plan:
Convert to lite interpreter model:
buck run //xplat/caffe2/fb/pytorch_predictor:converter <FULL_JIT_MODEL> <LITE_MODEL>
Load model using benchmark program (on devserver)
buck run //xplat/caffe2/fb/lite_predictor:lite_predictor_tts -- --model <MODEL>
(Expect benchmark to fail because inputs are invalid)
Reviewed By: iseeyuan
Differential Revision: D20961463
fbshipit-source-id: 5022077caccd8c07666789bbbca68c643129ee0a
Summary:
Compute number of element as `constexpr` and use it as both `buffer` element size as well as for upper boundary
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36966
Differential Revision: D21150602
Pulled By: malfet
fbshipit-source-id: 581634565c54c7295f3b77c8dc86659d5cc4ce19
Summary:
This should have been intended to be the general version of fmadd in
vec256_double and vec256_float.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36751
Differential Revision: D21148849
Pulled By: pbelevich
fbshipit-source-id: 0805075d81c61d22383a3055aebcb91d09e545de
Summary:
hardsigmoid_backward is implemented in xla side so the test will not error out but is really slow due to a lot of recompile. Enable the test on the pytorch side but skip it in xla side so xla can control when to enable the test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36967
Differential Revision: D21149113
Pulled By: ailzhang
fbshipit-source-id: fc337622fafa7be9cff2631de131980ea53adb8d
Summary:
`skipIfRocm` skips the test on ROCm regardless of device type [CPU or GPU]. `skipCUDAIfRocm` skips only on GPU on ROCm and runs the test on CPU.
ezyang iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36968
Differential Revision: D21149721
Pulled By: ezyang
fbshipit-source-id: 361811b0b307f17193ad72ee8bcc7f2c65ce6203
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36959
This is a more straightforward solution to the problem than https://github.com/pytorch/pytorch/pull/36957; I don't know about the relative performance.
Fixes: #36956
Test Plan: Imported from OSS
Differential Revision: D21144146
Pulled By: gchanan
fbshipit-source-id: a10ab905219a73157d5d7183492b52d7c8dd6072
Summary:
JIT pointwise kernel currently does not do vectorized load/store, which may lead to not optimal performance in shorter data types, like half and int8.
In this PR, a fixed length of 4 elements per load/store is added for supported tensor shape, implemented as a runtime check inside kernel.
Supported tensor shape:
- all input/output data point are aligned to 4*sizeof(dtype)
- last dimension contiguous(stride 1) and size is multiple of 4
- all other dimension have stride that is multiple of 4
All test_jit* passed, and here is performance result on a simple `ax+by+c` fusion
result before PR:
```
torch.float32 kernel time: 0.748 ms.
torch.float16 kernel time: 0.423 ms.
torch.int8 kernel time: 0.268 ms.
```
result after PR:
```
torch.float32 kernel time: 0.733 ms.
torch.float16 kernel time: 0.363 ms.
torch.int8 kernel time: 0.191 ms.
```
test code:
```
import torch
import time
# disable profiling to test all data types
torch._C._jit_set_profiling_mode(False)
torch._C._jit_set_profiling_executor(False)
torch.jit.script
def axpby(x, y):
return x * 2 - y * 3 + 1
for test_dtype in [torch.float32, torch.float16, torch.int8]:
a = torch.randn(12345,4096, device="cuda").to(test_dtype)
b = torch.randn(12345,4096, device="cuda").to(test_dtype)
# warm up
for _ in range(100):
c = axpby(a,b)
torch.cuda.synchronize()
start = time.time()
for _ in range(1000):
c = axpby(a,b)
torch.cuda.synchronize()
end = time.time()
print("{} kernel time: {:.3f} ms.".format(test_dtype, end-start))
```
Generated code:
[log_with_generated_code.txt](https://github.com/pytorch/pytorch/files/4472813/log_with_generated_code.txt)
Additional note:
double type is disabled from vectorized code path.
We can later improve it with dynamic vectorization length support and less in-kernel check when we can use tensor shape information in codegen. For now, this implementation is following cache through TensorDesc mechanism, which does not have enough compile time information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36555
Differential Revision: D21142762
Pulled By: ngimel
fbshipit-source-id: 1cfdc5807a944c4670b040dc2d2dfa480377e7d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36215
Make it possible to disable observers, e.g. to avoid
infinite recursion if an observer uses an operator
Test Plan:
USE_BLAS=MKL USE_MKLDNN=0 USE_CUDA=0 python setup.py develop install
./build/bin/test_jit
Differential Revision: D20912676
Pulled By: ilia-cher
fbshipit-source-id: 29760cdfe488a02f943f755967b78779d6dbcef3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36948
Compiling with USE_DISTRIBUTED=0 fails as it would still try to
compile python_nccl.cpp which requires NCCL but the NCCL lib is not
linked.
Test Plan: Imported from OSS
Differential Revision: D21142012
Pulled By: mrshenli
fbshipit-source-id: 6ca94056ca859da7f833a31edcb4c5260d8625e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36963
A couple of reasons why these tests were flaky:
1) Sometimes the error message for timeout would include lowercase 'timeout'
which was not included in the regex.
2) The timeout was 0.2 seconds, which was probably too small for ASAN/TSAN.
ghstack-source-id: 102541231
Test Plan: waitforbuildbot
Differential Revision: D21144954
fbshipit-source-id: 57945f53e1627028835cbfd2adb72f21d87f593f
Summary:
Seems like no one is using this image. We could delete it from our docker hub.
I think we don't need to regenerate a new set of images, since we are only deleting. But please correct me if I'm wrong.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36930
Reviewed By: malfet
Differential Revision: D21138079
Pulled By: ailzhang
fbshipit-source-id: 4a563e6310b193cb885411bcd925296b01223368
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36765
We recently added support for bundling inputs with models. Now add
support to the benchmarker to use those inputs. This frees users from
having to look up the proper input format for each model.
Test Plan:
- Ran on a model without bundled inputs. Saw a clear error.
- Ran on a model with too few bundled inputs. Saw a clear error.
- Ran on a proper bundled input. Model executed.
Differential Revision: D21142659
Pulled By: dreiss
fbshipit-source-id: d23c1eb9d1de882345b007bf2bfbbbd6f964f6fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36699
Hooks up the QNNPACK op from the previous PR to work in the
PyTorch layers.
Test Plan:
```
python test/quantization/test_quantized.py TestQuantizedOps.test_qhardsigmoid
python test/quantization/test_quantized.py TestQNNPackOps.test_qhardsigmoid
```
Imported from OSS
Differential Revision: D21057152
fbshipit-source-id: 5f2094d1db80575f7f65497f553ca329f7518175
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36698
Adds the hardsigmoid op to QNNPACK using the LUT kernel
Test Plan:
```
cd aten/src/ATen/native/quantized/cpu/qnnpack
with-proxy ./scripts/build-local.sh
./build/local/hardsigmoid-test
```
Imported from OSS
Differential Revision: D21057153
fbshipit-source-id: 31ce09643959b159a82e7083fc11e1e5e98c49ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36817
For dynamic quant we need to run the observers on the weights to calculate the qparams before calling convert on the model.
The API requires the user to provide dummy inputs that will be fed to the model after the prepare step to run the observers
Test Plan:
test_quanitze_script.py
test_quantization.py
Imported from OSS
Differential Revision: D21134439
fbshipit-source-id: 8acaab4eb57aadb68a2a02cc470bb042c07e1f6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36666
We need to introduce hacked twin overloads for ops taking lists of optional tensors.
I'm not really sure why actually, but them being a special case in codegen blocks removal of `use_c10_dispatcher: unboxed_only`.
This PR does not remove the "hacked twin" hack, but it removes it from codegen, instead manually specifying them in register_prim_ops.cpp and unblocking removal of `use_c10_dispatcher: unboxed_only`.
Original commit changeset: c5e2386ad06a
ghstack-source-id: 102507901
Test Plan: waitforsandcastle
Differential Revision: D21044962
fbshipit-source-id: 9d423aac08a1dd2bab54940ccb6219ebdcb7d230
Summary:
gcc 5.3.0 has an issue which can't define default function as constexpr, see https://gcc.gnu.org/bugzilla/show_bug.cgi?id=68754. for works for gcc 5.3.0, not define default function as constexpr function now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36561
Differential Revision: D21024109
Pulled By: ezyang
fbshipit-source-id: 58fce704625b7d0926e40b6b12841ebbe392c59c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35055
This is the first step to improving the way RPCs are profiled as suggested by Ilia. For now, since RPC can return two different types of futures, we have to implement two different code paths, one for the python eager mode future and one for the jit future.
This diff implements the python eager part. We have defined a method `_call_end_callbacks_on_future` that takes in a future and schedules a `RecordFunction` to be completed as a callback on the future.
Once https://github.com/pytorch/pytorch/pull/35039 lands, we can implement the JIT codepath by registering an operator that takes a `Future(t)` as well.
These code paths will be merged once the futures are merged.
ghstack-source-id: 102478180
Test Plan: Added unit tests
Differential Revision: D20452003
fbshipit-source-id: 1acdcb073bd1f63d6fb2e78277ac0be00fd6671d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36857
This was a redundant call as we immediately took the msg and conerted
it back to a string
ghstack-source-id: 102424018
Test Plan: CI
Differential Revision: D21104235
fbshipit-source-id: 4124007d800dbe2718ddebb40281d0a86484685e
Summary:
This will allow xla to use this stmbol when lowering the hardsigmoid
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36851
Differential Revision: D21102827
Pulled By: ailzhang
fbshipit-source-id: 99429a40a61ba84eb38b872cb3656aa5a172b03b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36674
Slight changes to qlinear benchmark to have it be in the same format
as linear, for fairer comparisons between FP and Q.
Test Plan:
```
cd benchmarks/operator_benchmark
python -m pt.linear_test
python -m pt.qlinear_test
```
Imported from OSS
Differential Revision: D21102562
fbshipit-source-id: 4f5c693b5de7e26c4326a9ec276560714290f6c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36673
Slight changes to the qconv benchmark to make it match the floating
point benchmark, so we can compare across the two better.
Test Plan:
```
cd benchmarks/operator_benchmark
python -m pt.qconv_test --tag_filter all
python -m pt.conv_test --tag_filter all
```
Imported from OSS
Differential Revision: D21102563
fbshipit-source-id: d11c1e4c13d4c5fa1f2332c687aee6889c81b659
Summary:
Addresses https://github.com/pytorch/pytorch/issues/36807. Also updates the cast testing to catch issues like this better.
In the future a more constexpr based approach to casting would be nice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36832
Differential Revision: D21120822
Pulled By: mruberry
fbshipit-source-id: 9504ddd36cfe6d9f9f545fc277fef36855c1b221
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36768
Follow LOG(WARNING) format for c++ side warnings in order to play well with larger services, especially when using glog. I need to hook up into GLOG internals a bit in order to override FILE/LINE without having to change the whole thing to be macros, but it seems to be stable between glog versions.
Note, this also changes caffe2_log_level to warning by default - I think it's a much better default when compiling without glog (or maybe even have info)
Test Plan:
Run unittest in both glog and non-glog build mode:
glog:
```
W0416 12:06:49.778215 3311666 exception_test.cpp:23] Warning: I'm a warning (function TestBody)
```
no-glog:
```
[W exception_test.cpp:23] Warning: I'm a warning (function TestBody)
```
Reviewed By: ilia-cher
Differential Revision: D21078446
fbshipit-source-id: b5d36aac54d6b6295a72de6754696ccafbcb84ca
Summary: ATenOp should go away, but before it does it's important to understand what's going inside of it. We already log `arguments`, but it's rather hard to parse in scuba as its a list, not a dictionary. Let's extract operator name explicitly so that grouping works well
Test Plan: unittest
Reviewed By: ngimel
Differential Revision: D21057966
fbshipit-source-id: 86be7cca39055620477a28bd5d8ab29e8edd2ff9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36667
Hacky workaround that would allow us to reland https://github.com/pytorch/pytorch/pull/34418
Basically moves the type conversion into ATenOp wrapper that is still used in some models.
Test Plan: Added unittest. Before it was producing warnings about wrong dtype, with this fix it doesn't
Reviewed By: ngimel
Differential Revision: D21037368
fbshipit-source-id: 06b435525d8d182c7607e33fd745060d3d6869e9
Summary:
In the CUDA version of max_pool3d backward, function `max_pool3d_with_indices_backward_out_frame` is defined with args as `..., oheight, owidth, ...` but called with `..., owidth, oheight, ...`. As a result gradients are not fully calculated along the longer dimension due to insufficient grid size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36820
Differential Revision: D21120078
Pulled By: ngimel
fbshipit-source-id: d061726647a4a45d45d5c1a00f2f1cf2745726a8
Summary:
On some machine I found error like cannot find `cpuinfo.h` when building FakeLowp ops. Fixing it. Also updated the README.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36861
Reviewed By: amylittleyang
Differential Revision: D21105755
Pulled By: yinghai
fbshipit-source-id: 4f17bd969d38e1b2945b8753ffe4bdc703de36bf
Summary:
Closes https://github.com/pytorch/pytorch/issues/30813
1. Tensor quantization logic(quantize_*) is moved to the aten/native/quantized. Previously all logic for tensor quantization lived in the aten/quantized/Quantizer.cpp file, and started to become complicated and hard to read. This problem should be addressed in refactoring PR. Still, I reworked this partially because I had to add tensor quantization logic for CUDA, and it was native to move everything to the aten/native/quantized.
2. Requirements to run CUDA_tensor_apply* was eased to process any tenser that lives on the CUDA device(QuantizedCUDA included).
3. All quantized data types now have a default constructor. NVCC refuses to compile any gpu_kernel or CUDA_tensor_apply* without them.
4. Minor changes in many files to register QuantizedCUDA backend.
5. test_quantized_tensor is extended to process QuantizedCUDA backend where possible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35463
Differential Revision: D20896697
Pulled By: jerryzh168
fbshipit-source-id: 163554efa23d11a2b10bbc2492439db4798eb26b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34258
This PR allows both atol and rtol to be specified, uses defaults based on the prior analysis (spreadsheet attached to https://github.com/pytorch/pytorch/pull/32538), but retains the absolute tolerance behavior in cases where precision was previously specified explicitly.
Test Plan: Imported from OSS
Differential Revision: D21110255
Pulled By: nairbv
fbshipit-source-id: 57b3a004c7d5ac1be80ee765f03668b1b13f4a7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36756
1. Add missing ops for pytorch models used in AIDemos. This is because we're migrating towards the lite-interpreter on mobile, the full JIT version will be deprecated
2. Replace the old mobilenet model with a newer one in bytecode format
3. Regenerate the reddit model to include bytecode
ghstack-source-id: 102422498
Test Plan: `buck build AIDemos:AIDemos`
Reviewed By: iseeyuan, linbinyu
Differential Revision: D21013409
fbshipit-source-id: 7704d32fccfe61a2c9db38846ce3153bb93eee7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36833
Add hypothesis testing sweep for one test in each SLS test suite for different precisions.
Sweep random seed, embedding shape, batch_size, weight with hypothesis testing.
Refactor sls tests into proper file with precision labeled in filename.
Test Plan:
FB intern: buck test mode/dev //caffe2/caffe2/contrib/fakelowp/test:test_sls_8bit_nnpi_fp32nnpi
Will test OSS after exporting PR.
Reviewed By: yinghai
Differential Revision: D21098346
fbshipit-source-id: af167118e5289bb7178ffc27aaec3af101dcd828
Summary:
Allows creation of _NamedAnyModule_ directly from _AnyModule_, e.g.
```
auto a=torch::nn::AnyModule(torch::nn::Linear(1,2));
auto m=torch::nn::NamedAnyModule("fc", a);
```
Without the public constructor, it would be necessary to recast the AnyModule to underlying type,
then have the constructor cast it back to AnyModule.
With the public AnyModule constructor,
possible to do
```
auto q=Sequential({m});
```
or
```
q->push_back(m.name, m.module());
```
(works in conjunction with PR https://github.com/pytorch/pytorch/issues/36720 which allowed adding _AnyModule_ directly)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36869
Differential Revision: D21110074
Pulled By: yf225
fbshipit-source-id: aaea02282b9024824785e54d8732c0a12c850977
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36841
right now, all c2 ops's output will be unwrapped blindly. This is not correct, if we have a single tensor list returned.
Test Plan: buck test mode/dev-nosan mode/no-gpu //caffe2/caffe2/fb/python/operator_test:torch_integration_test
Reviewed By: alyssawangqq
Differential Revision: D21100463
fbshipit-source-id: 9f22f3ddf029e7da9d98008d68820bf7f8239d4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36856
Previously, we could early-exit mark_graph_task_completed() without the future
actually being fully complete - we were only guaranteeing that it was at least
in the process of being marked complete.
This seems to be triggering an assert graph_task->future_result_->completed()
This change simply adds a 1-line waitNoThrow() call to ensure that the future
has been marked complete before exiting the mark_graph_task_completed() function.
The cost is relatively reasonable, since this isn't the common path.
ghstack-source-id: 102423589
Test Plan: buck test mode/dev-nosan caffe2/test/,,,
Differential Revision: D21104121
fbshipit-source-id: 51c1554618880fe80d52d5eb96716abc15f6be8a
Summary:
Fix formatting: change "Frequently Asked Questions" into an RST header, which is clickable and one get a URL of the FAQ section
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36438
Differential Revision: D21106180
Pulled By: mruberry
fbshipit-source-id: 370dafd1883bd57285b478cf2faa14ae2f86e3ba
Summary:
re-created the same PR: https://github.com/pytorch/pytorch/pull/36639
because ghimport does not support importing binary files right now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36842
Test Plan: python test/quantization/test_backward_compatibility.py
Differential Revision: D21100689
Pulled By: jerryzh168
fbshipit-source-id: 625a0f9da98138c9c2891b9d99fc45d85fa27cca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36791
This should enable `test_fc_nnpi_fp16.py` test in fakelowp test.
Test Plan:
```
buck test caffe2/caffe2/fb/fbgemm:
```
Reviewed By: hyuen
Differential Revision: D21085221
fbshipit-source-id: 512bca2eea1a4cc5d11129cfe9e65e7a4a0ba1e0
Summary:
Older versions of MIOpen (<=2.2) don't have the `miopenGetVersion` api, but MIOpen is always a part of the ROCm builds, so do NOT set `lib` to None for ROCm builds. `__cudnn_version` will be `None` for older versions of MIOpen.
Setting `lib` to `None` ends up printing the following erroneous warning when running unit tests:
```
/root/.local/lib/python3.6/site-packages/torch/backends/cudnn/__init__.py:120: UserWarning: cuDNN/MIOpen library not found. Check your LD_LIBRARY_PATH
}.get(sys.platform, 'LD_LIBRARY_PATH')))
```
Eg.: https://ci.pytorch.org/jenkins/job/pytorch-builds/job/py3.6-clang7-rocmdeb-ubuntu16.04-test2/18387/consoleFull
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33837
Differential Revision: D20369285
Pulled By: xw285cornell
fbshipit-source-id: e82e6f8f5bccb486213cf868f40aece41ce11f98
Summary:
`configure_file` command adds its input as a top-level dependency triggering make file regeneration if file timestamp have changed
Also abort CMAKE if `exec` of build_variables.bzl failed for some reason
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36809
Test Plan: Add invalid statement to build_variables.bzl and check that build process fails
Differential Revision: D21100721
Pulled By: malfet
fbshipit-source-id: 79a54aa367fb8dedb269c78b9538b4da203d856b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36357
ghstack-source-id: 101907180
Creating a python api entry to optimize mobile model which takes a scripted module as argument and returns an optimized scripted module. The initial optimization features includes inserting and folding prepack ops.
Test Plan: python test/test_optimizer.py
Differential Revision: D20946076
fbshipit-source-id: 93cb4a5bb2371128f802d738eb26d0a4f3b2fe10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36808
Trying to run a model on mobile and prim::TupleIndex is reported as missing. Moving it out from fulljit.
Reviewed By: linbinyu
Differential Revision: D21065879
fbshipit-source-id: d7a6dc9e5ad306d76825eaef815ab5582d4bf9a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36799
This is a roll up of a bunch of small PRs for ease of landing.
- Update reference to RegisterOperators in error message in Convolution.
- Add explicit schema for quantized conv/conv_prepack (fixes#36511)
- Add a centralized TORCH_LIBRARY declaration for quantized and xnnpack ops (fixes#36510)
- Port to new registration API:
- Resize
- detach/detach_
- All quantization operators
- Update quantized README for registering operators with new API
Test Plan: Imported from OSS
Differential Revision: D21089649
Pulled By: ezyang
fbshipit-source-id: 3dd205c2c075f6a3d67aadb2b96af25512e7acd0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35187
When I touch these files, lint will always introduce some unintended change, to prevent it from happening, we need to format the code first.
change is generated by:
arc f
Test Plan: integration test.
Differential Revision: D20587596
fbshipit-source-id: 512cf6b86bd6632a61c80ed53e3a9e229feecc2a
Summary:
Several people have asked me about proper Amp usage with gradient accumulation. In particular, it's [unclear to people](https://github.com/NVIDIA/apex/issues/439#issuecomment-610351482) that you should only call `scaler.unscale_()` (if desired) and `scaler.update()` in iterations where you actually plan to step. This PR adds a minimal accumulation example.
I built the docs locally and it looks free from sphinx errors, at least.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36601
Differential Revision: D21082295
Pulled By: ngimel
fbshipit-source-id: b2faa6c02b9f7e1972618a0f1d5360a03f0450ac
Summary:
This pull request changes the datatype for `test_RNN_cpu_vs_cudnn_no_dropout` on ROCm testing to float.
Currently MIOpen RNN does not support double datatype, so using only double would not run this test using MIOpen. To correctly test PyTorch RNN operator using MIOpen, we would need to test it using float tensors and module.
The changes in this PR addresses the comments in https://github.com/pytorch/pytorch/issues/34615
ezyang iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36772
Differential Revision: D21089533
Pulled By: ezyang
fbshipit-source-id: b5781e4ca270d64c6b949b3f0436e7b4eb870e27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36736
Fixes: https://github.com/pytorch/pytorch/issues/36499
Changes:
1) Moves some bindings from LegacyNNDefinitions to Activation so all of log_sigmoid lives together
2) Properly handle non-contiguous / incorrectly sized out parameters to log_sigmoid. This is done by copying from a buffer if necessary.
3) Require that the internal buffer (different from 2)) is contiguous. This should always be the case because it's always created internally.
4) Adds a test
Test Plan: Imported from OSS
Differential Revision: D21070934
Pulled By: gchanan
fbshipit-source-id: 94577313c32d1ef04d65c1d6657598304a39fe6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36760
If you look at https://github.com/pytorch/pytorch/pull/34136/, you will notice a commit (80c15c087c) that didn't get merged.
This is to address that, to avoid crashing on remainder when the rhs is 0.
Test Plan: Imported from OSS
Differential Revision: D21078776
Pulled By: gchanan
fbshipit-source-id: 0ac138cbafac28cf8d696a2a413d3c542138cff9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36750
- It seems the JIT schema for aten::backward and the schema in native_functions.yaml diverged on whether the retain_graph/keep_graph parameter takes a `bool` or a `bool?`. Make them identical again.
- Also remove the mutability annotation for the self parameter. This does not make sense together with AliasAnalysisKind::CONSERVATIVE and it triggered an assertion
- After fixing the mutability annotation, we can fix that assertion so that it doesn't exclude aten::backward from its check anymore
- Last but not least, remove the unboxed_only marker from aten::backward. This requires us to add a special case in register_c10_ops.cpp for it, because JIT still has its own implementation.
ghstack-source-id: 102351871
Test Plan: waitforsandcastle
Differential Revision: D21004102
fbshipit-source-id: 19bd1adbd8103c214d32e5126671a809adec581e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36621
Instead of doing in-place transformation inside optimizeForMobile method,
we would like to maintain the original structure for passed scriptedModule,
so before optmization starts, we use the cloned module to do subsequent optimization
process and return the optimized cloned module.
Test Plan:
unit test
python test/test_mobile_optimizer.py
Imported from OSS
Differential Revision: D21028406
fbshipit-source-id: 756172ef99b1c1df6bb7d00e5deca85a4c239a87
Summary:
This should fix https://github.com/pytorch/pytorch/issues/36434
We create new nodes to insert explicit uses of loop counters while doing liveness analysis. This was totally fine when we had a two-pass liveness (since we don't really care about liveness sets for those nodes), but with the fixed-point algorithm we can *never* achieve the fixed point because the initial liveness sets for these new nodes start empty and we always add some live values to those sets thus `changed_` is always set `true`.
Now it's amazing that this didn't get exposed and worked for such a long time! Apparently, when we destroyed and recreated those new nodes they were allocated at the exact same addresses in the memory!!!!!! And we use those addresses as keys to get liveness sets, so these new nodes **inherited** the liveness sets �
I was still a bit sceptical of this explanation, so I added more tracing to liveness analysis and AFAICT this is exactly how we were able to get away with this bug for such a long time!!!
Here's a few excerpts from the trace.
Before we enter a loop we create a node to use loop's upper bound.
```
[DEBUG liveness.cpp:121] @#$Creating a store for mtc : 0x555777c19eb0
```
When processing the loop, we also process this node. Its liveness sets are empty!
```
[DEBUG liveness.cpp:099] Processing node = prim::Store(%3) addr = 0x555777c19eb0
[DEBUG liveness.cpp:148] @#$liveness_sets_[it] : {}
```
We are done with this loop. We remove the node we added
```
[DEBUG liveness.cpp:127] @#$Destroying a store for ctc : 0x555777c19eb0
```
We are about to process the loop for the second time, so we create the use node again.
Note, it's allocated at the exact same address!!!
```
[DEBUG liveness.cpp:118] @#$Creating a store for ctc : 0x555777c19eb0
```
Now we process it again. But now it has non-empty sets even though it's a brand new node!!!!
```
[DEBUG liveness.cpp:099] Processing node = prim::Store(%i) addr = 0x555777c19eb0
[DEBUG liveness.cpp:148] @#$liveness_sets_[it] : {2, 3, 10}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36697
Differential Revision: D21059313
Pulled By: Krovatkin
fbshipit-source-id: b0fdeb4418e0e73f34187826877179260f21cf7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36745
As we hold a mutex for our custom C++ Node, when calling reentrant
backward from custom C++ function, we will cocurrently holding many
mutexes up to MAX_DEPTH. TSAN only allow 65 mutexes at once, otherwise
it will complain. This PR lower the limit according to TSAN.
TSAN Reference: https://github.com/google/sanitizers/issues/950
Test Plan: Imported from OSS
Differential Revision: D21072604
Pulled By: wanchaol
fbshipit-source-id: 99cd1acab41a203d834fa4947f4e6f0ffd2e70f2
Summary:
Mimic `.bzl` parsing logic from https://github.com/pytorch/FBGEMM/pull/344
Generate `libtorch_cmake_sources` by running following script:
```
def read_file(path):
with open(path) as f:
return f.read()
def get_cmake_torch_srcs():
caffe2_cmake = read_file("caffe2/CMakeLists.txt")
start = caffe2_cmake.find("set(TORCH_SRCS")
end = caffe2_cmake.find(")", start)
return caffe2_cmake[start:end+1]
def get_cmake_torch_srcs_list():
caffe2_torch_srcs = get_cmake_torch_srcs()
unfiltered_list = [x.strip() for x in get_cmake_torch_srcs().split("\n") if len(x.strip())>0]
return [x.replace("${TORCH_SRC_DIR}/","torch/") for x in unfiltered_list if 'TORCH_SRC_DIR' in x]
import imp
build_variables = imp.load_source('build_variables', 'tools/build_variables.bzl')
libtorch_core_sources = set(build_variables.libtorch_core_sources)
caffe2_torch_srcs = set(get_cmake_torch_srcs_list())
if not libtorch_core_sources.issubset(caffe2_torch_srcs):
print("libtorch_core_sources must be a subset of caffe2_torch_srcs")
print(sorted(caffe2_torch_srcs.difference(libtorch_core_sources)))
```
Move common files between `libtorch_cmake_sources` and `libtorch_extra_sources` to `libtorch_jit_core_sources`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36737
Test Plan: CI
Differential Revision: D21078753
Pulled By: malfet
fbshipit-source-id: f46ca48d48aa122188f028136c14687ff52629ed
Summary:
re-created the same PR: https://github.com/pytorch/pytorch/pull/36639
because ghimport does not support importing binary files right now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36771
Test Plan: python test/quantization/test_backward_compatibility.py
Differential Revision: D21080503
Pulled By: jerryzh168
fbshipit-source-id: 1dca08208bccead60bba03e5fb5d39e1a1d7c20d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36696
This PR add dictionary as a supported output of tracer under the strict
flag.
Test Plan: Imported from OSS
Reviewed By: houseroad
Differential Revision: D21056962
Pulled By: wanchaol
fbshipit-source-id: ace498182d636de853cf8a1efb3dc77f5d53db29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36609
This PR remove iterationOrder that backed by CompareKeys, we universally
use Dict inseration order default backed by c10::Dict to match the
python behaviors
Test Plan: Imported from OSS
Reviewed By: houseroad
Differential Revision: D21056963
Pulled By: wanchaol
fbshipit-source-id: 487961c2db2cdc27461b2fbd6df91faafc6920b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36727
Looks like this was renamed by accident in 0cbd7fa46f2
Test Plan:
Unit test.
Lint.
Differential Revision: D21076697
Pulled By: dreiss
fbshipit-source-id: dbd18cb41c7b26479984a7a7b12ad41a4c5b7658
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36552
Do the fusion for inplace and non-inplace relu
Tested for functional relu as well.
Functional batch_norm is not a usual use-case (since it expects the weight, bias, mean, var) so that is not tested.
Test Plan:
test_quantize_script.py test_batch_norm2d_relu
Imported from OSS
Differential Revision: D21075253
fbshipit-source-id: 0a07ea477cab19abf1d1b0856e623b1436240da1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36389
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20964193
Pulled By: ezyang
fbshipit-source-id: 27aeea01ccf5dfcebb8f043cde009a14dde3958e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36741
Create child workspace that shares parent workspace's blobs. Register child workspace in registrar to enable switching into child workspace and feeding to child workspace alone.
Test Plan: numeric suite unit tests in stacked diff
Reviewed By: hx89
Differential Revision: D21055567
fbshipit-source-id: 374b12aef75a4c58452c271f8961ee156ce6c559
Summary:
Adds a capability for reordering axes in the LoopNest. This was fairly straightforward except when handling Reduction initializers which required more changes, UPDATE: actually the complicated bit was preserving the ordering of statements in the loopnest which should not be reordered.
Usage looks something like this:
```
Tensor* tensor = Compute(
"f", {{2, "x"}, {3, "y"}}, [](const VarHandle& x, const VarHandle& y) {
return ExprHandle(1.0f) + cast<float>(x) * x + cast<float>(y) * y;
});
LoopNest l({tensor});
/* LoopNest looks like:
for x in ...
for y in ...
f[x,y] = 1 + x * x + y * y;
*/
auto loops = l.getLoopStmtsFor(tensor);
l.reorderAxis(tensor, loops[0], loops[1])
/* LoopNest looks like:
for y in ...
for x in ...
f[x,y] = 1 + x * x + y * y;
*/
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36540
Differential Revision: D21068143
Pulled By: nickgg
fbshipit-source-id: f02c29004376df4f5a9bedff366c075772726618
Summary:
This test was failing because caching resulted into a function with multiple execution plans rather than multiple functions with a single execution plan each as a test writer intended.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35847
Differential Revision: D20839674
Pulled By: Krovatkin
fbshipit-source-id: 68f41610a823d94c1e744c85ac72652c741d73ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36729
setenv not available on windows
Test Plan: CI green in ovrsource
Reviewed By: stepancheg
Differential Revision: D21067835
fbshipit-source-id: ddbc3285ef88f123dc6a200b661c48cfafc6bf00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36691
Enables to selectively insert observers at the inputs of aten/call functionc
Test Plan:
test_quantize_script.py
Imported from OSS
Differential Revision: D21055597
fbshipit-source-id: b47733b94b127d7a47b3224da7af98f0da38d30d
Summary:
Previously we were always creating a double tensor from `torch.tensor(1.)`, whereas python eager uses the current default dtype. Fix for https://github.com/pytorch/pytorch/issues/36369
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36587
Differential Revision: D21043617
Pulled By: eellison
fbshipit-source-id: 38da303594f52e06941d86b6e57c4a06e7d36938
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36258
Previous we had a && chaining style API. There are some downsides to
this API:
- It's easy to forget the 'static' qualifier in front, leading to
subtle ODR bugs.
- It is not compatible with torchbind class_ definitions, as these
need multiple levels of chaining. So in practice people end
up having to define multiple static initializers, one per class.
- It's not like pybind11.
- There's no way to conveniently get the file and line number of
the registration, as there is no macro point in the API.
- The old API doesn't really encourage people to put all of their
definitions for a library in one place, and to give a custom
namespace for it. Similarly, the old API wasn't very DRY, because
you had to keep repeating the namespace/dispatch key you
were writing implementations for.
The new API is modeled exactly off of the PYBIND11_MODULE macro:
you write:
```
TORCH_LIBRARY(aten, m) {
m.def("aten::add(Tensor self, Tensor other) -> Tensor");
...
}
```
in a non-chaining fashion, and under the hood the macro expands to
define a function, and define a static initializer that allocates
c10::Library (previously called c10::Module, but we renamed it
to avoid confusion with the existing NN module concept), passes
it to your function, and then retains it for the rest of the lifetime
of the program. Specification of the namespace is mandatory,
and in later commit I plan to make it a hard error to TORCH_LIBRARY
the same library name twice.
If you are specifying an implementation for an existing operator
(e.g., you're the XLA backend, or even if you're just putting
registrations for implementations at the implementation site),
you should use TORCH_LIBRARY_IMPL, which instead takes a backend
argument (instead of namespace) and can be used to specify an
implementation for a backend. Unlike TORCH_LIBRARY, you can do
as many of these as you want for a backend.
This needs updates to the mobile code analyzer.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20929257
Pulled By: ezyang
fbshipit-source-id: ba04d78492e8c93ae7190165fb936f6872896ada
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35613
Python 2 has reached end-of-life and is no longer supported by PyTorch.
To spare users from a long, doomed setup when trying to use PyTorch with
Python 2, detect this case early and fail with a clear message. This
commit covers setup.py.
Test Plan: Attempted to build PyTorch with Python 2 and saw a clear error *quickly*.
Differential Revision: D20842881
Pulled By: dreiss
fbshipit-source-id: caaaa0dbff83145ff668bd25df6d7d4b3ce12e47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35612
Python 2 has reached end-of-life and is no longer supported by PyTorch.
To spare users from a long, doomed build when trying to use PyTorch with
Python 2, detect this case early and fail with a clear message. This
commit covers CMake setup.
Test Plan: Attempted to build PyTorch with Python 2 and saw a clear error *quickly*.
Differential Revision: D20842873
Pulled By: dreiss
fbshipit-source-id: b35e38c12f9381ff4ca10cf801b7a03da87b1d19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36677
Move the `futures` vector to be a local function var like `errorFutures`. Holding the lock to clear the vector is now unnecessary.
ghstack-source-id: 102265569
Differential Revision: D20884589
fbshipit-source-id: c9a13258bee737d86f9b0d11cdd28263bb923697
Summary:
Unrolling support has been added in a way that we get good performing code on GPUs. Not sure how long this link will last but an example of a generated unrolled kernel is:
https://godbolt.org/z/i0uAv3
What can be seen from there is multiple calls of "ld.global.f32" without "ld.store.f32" in between them (and vice versa). This means that we are launching multiple loads that can be run in parallel, as well as multiple stores that can be run in parallel. This can be a crucial optimization for memory bound kernels. This was generally a point of concern in TVM as an attempt of a similar kernel from TVM produces: https://godbolt.org/z/Vu97vG which surrounds load - store pairs in conditional branches preventing the benefits of unrolling.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36435
Reviewed By: ZolotukhinM
Differential Revision: D21024011
Pulled By: soumith
fbshipit-source-id: e852e282fa7a304aba962e1926f756098c011fe0
Summary:
Implements complex isfinite and isinf, consistent with NumPy.
A complex value is finite if and only if both its real and imaginary part are finite.
A complex value is infinite if and only if its real or imaginary part are infinite.
Old isfinite, isinf, and isnan tests are modernized and instead of fixtures the torch results are compared with NumPy. A new test is added for complex isfinite, isinf, and isnan. The docs for each function are updated to clarify what finite, infinite, and NaN values are.
The new tests rely on a new helper, _np_compare, that we'll likely want to generalize in the near future and use in more tests.
Addresses part of the complex support tasks. See https://github.com/pytorch/pytorch/issues/33152.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36648
Differential Revision: D21054766
Pulled By: mruberry
fbshipit-source-id: d947707c5437385775c82f4e6c722349ca5a2174
Summary:
Per title. A test is added to test_type_promotion for the behavior. This behavior is consistent with NumPy's.
For complex inputs to `abs` the result is cast to float after the computation since the computation of abs must be performed on the original complex tensor. While `std::abs` returns a float value when called on complex inputs, returning a FloatTensor directly would require additional loop instantiations in TensorIterator. This may be worthwhile to pursue in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35871
Differential Revision: D20984456
Pulled By: mruberry
fbshipit-source-id: 226445178f92f2b0292e92578656d98674a6aa20
Summary:
This code looks like a mistake
```C++
AT_ASSERT(size_t(kind) < sizeof(names) / sizeof(AttributeKind));
```
It does not check if `kind` variable fits in array of pointer called `names`
Even if we write something like this: that assert won't fail
```C++
AttributeKind kind = AttributeKind::ival;
*((unsigned int*)&kind2) += 1;
```
So I fixed it
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36476
Differential Revision: D21018748
Pulled By: colesbury
fbshipit-source-id: f4d3b8faf64cf07232d595075f831805084f5d00
Summary:
PyTorch users write programs and save them as serialized Torchscript. When this Torchscript is loaded it contains symbols like "aten::div" describing some of the program's behavior. If the behavior of these symbols has changed since the program was serialized, however, then the original program's semantics may not be preserved.
For example, when we make aten::div always perform "true" division, like NumPy, Python3, and JAX, then serialized Torchscript programs relying on aten::div performing floor division on integral inputs will break.
This PR demonstrates the "Versioned Symbol" pattern that lets symbols be remapped into Torchscript builtins that preserve their historic behavior. Using this pattern, after we update aten::div to always perform true division, we could remap it in older Torchscript programs to a builtin that implements its historic behavior.
The pattern is described in the [Versioned Symbols] note in the code and is implemented like this:
- If BuiltinModule is given a version, before it returns a symbol it queries to see if another symbol should be substituted for it.
- versioned_symbol.cpp has a map for symbols and the version range for which another symbol should be substituted for them.
- The substitutions are implemented as builtin functions.
An example using the new, test-only _subcmul function is implemented to test this behavior. A test in jit/test_save_load.py follows the pattern described in the [Versioned Symbols] note and uses a fixture serialized with file version 2 to verify that the historic behavior is preserved.
In the future we will likely need a slightly more complex mechanism with multiple substitutions with distinct version ranges, and this just requires changing the map to be Symbol->Iterable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36300
Differential Revision: D21058990
Pulled By: mruberry
fbshipit-source-id: 2b7c732878c0ecfcd9f0a6205fb6d6421feeaf61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36562
The BackendSelect dispatch key gives us a way to extract backend-
specific dispatch keys from non-Tensor arguments without teaching
the DispatchKeyExtractor about them. Here we finish switching over
to the BackendSelect approach for factory functions and remove
TensorOptions from the set of types DispatchKeyExtractor needs to
consider.
Test Plan: Imported from OSS
Differential Revision: D21013652
Pulled By: bhosmer
fbshipit-source-id: e30512d1c3202149e72b7d7ce15084bbfed63ac7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36708
WEIGHTS is the second input operand of SparseLengthsWeightedSum operators but in the documentation the order was wrong.
Test Plan: CI
Reviewed By: yinghai
Differential Revision: D21058240
fbshipit-source-id: e160e983603e606e63fbbfdee34d98d3587870d8
Summary:
Simplifies loops which can be collapsed down into a single block or removed entirely. E.g.
```
For 0..1 {
Statements...
}
```
Is now just `Block({Statements...})`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36348
Differential Revision: D21057959
Pulled By: nickgg
fbshipit-source-id: 2f95a19a965c4a6e023680e2cea9ea846e82d62e
Summary:
`std::mismatch( InputIt1 first1, InputIt1 last1, InputIt2 first2 )` assumes that container for `first2` iterator contains at least `last1 - first` elements, which is not the case if `prefix` is longer than `str`
Found while running unit tests on Windows
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36672
Differential Revision: D21049407
Pulled By: malfet
fbshipit-source-id: ad45779d47a0c6898900e0247c920829a2179f62
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36640
We had the following race when two threads entered
'mark_graph_task_completed'.
1) Thread 1 grabs the graph_task mutex first and moves captured_vars_ to its
local 'vars'.
2) Thread 1 releases the lock.
3) Thread 2 grabs the mutex and moves an empty captured_vars_ to its local
'vars'.
4) Thread 2 now proceeds to call 'markCompleted' with empty grads.
5) Thread 1 which actually has the right grads never gets to set the grads on
the future since future_completed_ is set to True by Thread 2.
Discovered this while running our RNN example:
https://github.com/pytorch/examples/tree/master/distributed/rpc/rnn and
verified this PR fixes the race.
ghstack-source-id: 102237850
Test Plan: waitforbuildbot
Differential Revision: D21035196
fbshipit-source-id: 1963826194d466b93f19e8016b38e4f9cad47720
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36604
Adds the logic to wrap the HardSwish module in FakeQuant
to support QAT.
Test Plan:
Added test to cover that this happens properly.
Imported from OSS
Differential Revision: D21045322
fbshipit-source-id: 8c46559ade58a5d5c56442285842627a3143eb0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36545
* adds a quantized nn.module for Hardswish so we can observe activation values
* modifies the hardswish op to allow specifying scale + zero_point
* makes hardswish model be properly swapped in static quantization
Test Plan:
added tests and they pass for:
* the new _out flavor of hardswish
* QNNPACK changes
* static quant e2e
Imported from OSS
Differential Revision: D21045320
fbshipit-source-id: ab7e52f0f54a7d5923ab6f58197022cc28c12354
Summary:
With https://github.com/pytorch/pytorch/pull/35562, we are running peephole optimization on inlining to reduce the number of nodes that are copied.
The tracer encodes the sizes in the graph like:
```
graph(%0 : Double(7)):
%1 : Function = prim::Constant[name="tensor_size"]()
%2 : Tensor = prim::CallFunction(%1, %0)
return (%2)
```
however people would like to reuse the graph with different shapes so running size invalidations would invalidate that. long term it might be better for the tracer to not include shape information but there are downstream users of that.
Separates out FuseAddMM from peephole so that now there is a single `disable_size_optimizations` parameter, and onnx explicitly invokes fuseaddmm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36404
Differential Revision: D20968974
Pulled By: eellison
fbshipit-source-id: 56f8f1699e3b0adeeccdfd5a67bb975fd41a2913
Summary:
LLVM Codegen assumes that the kernel contains real statements, but that is not guaranteed, especially after IR Simplification. This PR adds a catch for the case where no value is generated after recursing the LLVMCodegen visitor through the kernel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36660
Differential Revision: D21044066
Pulled By: nickgg
fbshipit-source-id: e521c766286b1ff4e26befcec7ff4959db8181a4
Summary:
Previously we were copying the bound method of the original class to the
new script module class, which causes `self` to be wrong. This PR
changes it so we fetch the unbound function, then bind it to the new
script module, then attach it to the module.
Fixes#28280
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36546
Pulled By: driazati
Differential Revision: D21023329
fbshipit-source-id: 6b3f8404700860151792f669a9c02fbd13365272
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36678
Updated the docs to explicitly indicate that RRef control messages are
idempotent and retried upon failure.
ghstack-source-id: 102225791
Test Plan: build bot
Differential Revision: D20828041
fbshipit-source-id: ca4d71c65a453664c16c32134c47637a966b1a19
Summary:
The test case exercised in `test_upsamplingNearest2d_launch_fail` will fail on ROCm. The max. grid size per dimension for ROCm are 4294967295(0xffffffff), which is why the tensor dims in `test_upsamplingNearest2d_launch_fail` must give correct results.
This PR adds that test case `test_upsamplingNearest2d_launch_rocm` for ONLY ROCm scenario which is essentially the same as `test_upsamplingNearest2d_launch_fail` without an expected failure decorator
ezyang iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36624
Differential Revision: D21050330
Pulled By: ezyang
fbshipit-source-id: d7370c97eaab98f382f97052ed39cc168a3bfa71
Summary:
XLA need to switch to clang9 to build with latest TF dependency.
We keep pytorch/pytorch build remain using gcc for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36618
Differential Revision: D21045723
Pulled By: ailzhang
fbshipit-source-id: 015b65dad2aeef31fd66b753d519b2c9b9ed8b7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36635
Those ops were manually written in register_aten_ops.cpp, which had a few issues, for example caused them to be duplicated across all register_aten_ops_X.cpp and exist multiple times.
Instead, these should just be regular prim ops.
ghstack-source-id: 102204991
Test Plan: waitforsandcastle
Differential Revision: D21032778
fbshipit-source-id: 18f5eef1cad842d89c97610fc77b957608d2b15e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36662
This was a mistake from an earlier change, though the expected impact is
relatively minimal - mostly keeping callback around longer than necessary
in the case of callbacks already-completed futures.
ghstack-source-id: 102203224
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D21044145
fbshipit-source-id: f3bd58bd6bde83caaa7b9bd0385d0ce3647dbc05
Summary:
Also print docker container stats at the end of the run
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36643
Differential Revision: D21044161
Pulled By: malfet
fbshipit-source-id: 6877d8ce4789116ef270124307844f6cef7dcef5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36607
PR #36258 and subsequent PRs in the stack switch c10 registrations to
the new pybind11 style registration API. One notable difference from old
c10 registration API is that, operator's namespace is no longer in op
schema string, e.g. "aten::" will be factored out from "aten::conv",
"aten::emtpy" and etc. The namespace string will be declared at the
beginning of registrations with TORCH_LIBRARY / TORCH_LIBRARY_IMPL
macro.
A rather simple fix is to extract namespace string from the name of
enclosing function of registrations, as the TORCH_LIBRARY macro will
always create an init function (per namespace) by appending namespace
string to a common prefix.
Another side effect of the API change is that it adds some debug string
constants to the registration API, and because of factoring out the
namespace part from op name, there is no longer an effect way to
differentiate between real op name and debug strings. A simple
workaround is that we only keep the first string constant it encounters
while BFSing the LLVM IR - the real op name is directly passed into the
registration call while the debug string is indirectly passed via
CppFunction.
These new assumptions might be broken by future changes but it's so simple
to implement to unblock the API work.
Test Plan: Imported from OSS
Differential Revision: D21026008
Pulled By: ljk53
fbshipit-source-id: c8c171d23aaba6d6b7985d342e8797525126a713
Summary: It was always skipped for last 1.5 years (since D10372230 was landed)
Test Plan: CI
Reviewed By: ailzhang
Differential Revision: D21036194
fbshipit-source-id: 9ace60b45a123a9372a88310b91f33a69ae8880c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36620
Sending to a node that has been shutdown in ProcessGroupAgent could throw several possible exceptions. This PR updates the tests to check for the right exceptions while waiting for other nodes in the gang to fail in `test_backward_node_failure` and `test_backward_node_failure_python_udf`.
ghstack-source-id: 102153944
Test Plan: Stress-tested `test_backward_node_failure` and `test_backward_node_failure_python_udf`. They were previously completely broken, but this change makes `test_backward_node_failure` functional and `test_backward_node_failure_python_udf` is flaky but fails infrequently. A change to make the last test work reliably is planned.
Differential Revision: D21027280
fbshipit-source-id: e85c2d219ee408483442bd9925fff7206c8efe4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35263
Process Group Agent throws an exception if a send attempt is made after the agent is shutdown. With retries, we should catch this exception and mark the original future with an error.
ghstack-source-id: 102153897
Test Plan: Running all rpc/dist_autograd tests.
Differential Revision: D20611412
fbshipit-source-id: a6009f0b0aa8be662364158962a054c5c29090bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36420
Adds a unit test for hardswish backward pass
Test Plan:
Unit test passes on cpu and cuda
Imported from OSS
Differential Revision: D20994100
fbshipit-source-id: 579df709cc2d92fce3b9a0eeb6faeb9fe8d2f641
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36351
Adds CUDA kernels for hardsigmoid, to enable its use in training.
Note: the update to the cpu backward pass is to keep the cpu vs cuda
logic consistent, no change in functionality.
Test Plan:
add CI for the forward pass
run this for the backward pass:
https://gist.github.com/vkuzo/95957d365600f9ad10d25bd20f58cc1a
Imported from OSS
Differential Revision: D20955589
fbshipit-source-id: dc198aa6a58e1a7996e1831f1e479c398ffcbc90
Summary:
soumith ezyang albanD After lots of experiments, I didn't manage to directly print the gradients of Fold/Unfold_backward (let me know if I am wrong).
Thus, in my testing codes, I compare the gradients of Fold/Unfold_backward implicitly by comparing the gradients of its following operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36379
Differential Revision: D21040646
Pulled By: ezyang
fbshipit-source-id: dafdbfe2c7b20efa535402c7f81fce5c681fce2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35941
The key step of mobile custom build is to find out ops used by specific
model, with which it can produce a tailored build of optimal size.
However, ops can not only be called from TorchScript model but can also
be called from C++ code directly, e.g.: via torch::jit:: APIs. With
static dispatch, ops called this way will be statically linked into client
code. With dynamic dispatch, we need obtain & keep these ops explicitly.
This PR improves static code analyzer to dump ops that are called from
visible c++ symbols matching specific regex. This provides a mechanism
to solve the custom build problem with dynamic dispatch.
It starts with dumping ops that are callable from functions in torch::jit
namespace and include them in custom build with dynamic dispatch. We can
extend it to analyze custom code / to refine the set of JIT APIs that
are relevant, and etc. This is just a preliminary version. We need
improve its usability for more general purpose.
Test Plan: Imported from OSS
Differential Revision: D20835166
Pulled By: ljk53
fbshipit-source-id: a87cfb22b34f89545edd0674a5dfca6b7cff2b0c
Summary:
Since aten;:__interpolate is removed in https://github.com/pytorch/pytorch/pull/34514, we need a pass replace interpolate function with aten::__interpolate for ONNX export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35744
Reviewed By: hl475
Differential Revision: D20907041
Pulled By: houseroad
fbshipit-source-id: f2d2cdfec47389245c50f538267124eedf682adf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36399
Added caffe2 python wrapper and unit test for the STORM C++ operator.
Test Plan:
All newly added unit tests passed using "buck test //caffe2/caffe2/python:optimizer_test -- TestStorm"
{F233644598}
Reviewed By: chocjy
Differential Revision: D18841013
fbshipit-source-id: f692bc18412839db140202ec9a971e556db0e54f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36225
Implemented the [STORM](https://arxiv.org/abs/1905.10018) optimizer operator for dense and sparse cases.
Test Plan:
All newly added unit tests passed using "buck test //caffe2/caffe2/python/operator_test:storm_test".
{F233643713}
Reviewed By: chocjy
Differential Revision: D18702897
fbshipit-source-id: d25eeb492aa2a03c69754d3f076a8239230b3bf4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36583
To make them more reusable across different build systems
Move `load()` directive at the head of `build_variables.bzl` inside function that uses them to make `build_variables.bzl` valid standalone python source file
Test Plan: CI + `python -c 'exec(open("tools/build_variables.bzl").read());print(libtorch_sources)'`
Reviewed By: EscapeZero
Differential Revision: D21018974
fbshipit-source-id: 3dbf2551620f164b8910270ad2c5c91125a9f5f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36602
`build_variables.bzl` should contain only filelists to make it interpretable between BUCK, Cmake and Bazel build systems.
Test Plan: CI
Reviewed By: dzhulgakov
Differential Revision: D21022886
fbshipit-source-id: 9dd1e289ac502bc325e1223197b6156a316498ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36502
We're sometimes deleting futures without completing them (discovered by logging),
and we've recently noticed a slow memory leak.
This change migrates the future lambda cases where there was self-capture.
- In some cases, we use weak_ptr<>, plus .lock()/assert in the lambda callback.
This avoids the reference cycle. We use this primarily in the case where the
value ends up being moved in the callback (something we want to be careful about)
- We also add a convenience api to Future where the completed Future is returned as an arg.
This allows us to avoid self-capture, though it assumes that the markCompleted()
caller is persisting the future for the markCompleted() duration (this has been the case)
ghstack-source-id: 102130672
Test Plan: ctr_mobile_feed, buck test mode/dev-nosan caffe2/test/...
Differential Revision: D20998905
fbshipit-source-id: 7dd52fe4e567a5dea20e8d43862fc2335fd3ce16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36250
The general concept is that I want a centralized location where you
can find all of the registrations for a library. I cannot do this
if I don't codegen all of the schemas in one spot--right now,
most schemas get generated, but not manually registered ones. Let us
assume that manual registration has to do with the actual
implementations; nothing strange is going on with the schema
definition itself. Make it so.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20929258
Pulled By: ezyang
fbshipit-source-id: 0a9fdc8eccd7b688b3e7bd8ed64b6e2af21978f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34787
This is a follow up patch of freezing of TorchScript modules. This patch
enables removal of constant attributes and unused method in submodules.
The clean up logic is generalized to handle attributes that share their class
type.
Test Plan: Imported from OSS
Differential Revision: D21004990
Pulled By: bzinodev
fbshipit-source-id: 84778aa9ae1a96d23db29c051031f9995ed3ac90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36542
Python 3.8 set the default multiprocessing start mode to spawn, but we
need fork in these tests, otherwise there are some pickling issues.
Test: Ensure that these tests succeed when run with python 3.8
ghstack-source-id: 102093824
Test Plan: Ensure success with python 3.8
Differential Revision: D21007753
fbshipit-source-id: 4b39844c6ba76a53293c0dfde7c98ec5a78fe113
Summary:
Step 0 of https://github.com/pytorch/pytorch/issues/35284
Reference: https://en.cppreference.com/w/cpp/numeric/complex
We are targeting C++20. The difference across C++ versions are mostly `constexpr` qualifiers, newer version has more function declared as `constexpr`
This PR adds the core of `c10::complex`, it includes
- standard constructors as in `std::complex`
- explicit conversion constructors converting from `std/thrust::complex` to `c10::complex`
- standard assignment operators as in `std::complex`
- conversion assignment operators converting from `std/thrust::complex` to `c10::complex`
- other standard operators as in `std::complex`
- standard methods as in `std::complex`
- explicit casting operators to std/thrust
- basic non-member functions as in `std::complex`:
- arithmetic operators
- `==`, `!=`
- `<<`, `>>`
- `std::real`, `std::imag`, `std::abs`, `std::arg`, `std::norm`, `std::conj`, `std::proj`, `std::polar`
- Some of them are intentionally not completely implemented, these are marked as `TODO` and will be implemented in the future.
This PR does not include:
- overload of math functions
which will come in the next PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35524
Differential Revision: D21021677
Pulled By: anjali411
fbshipit-source-id: 9e144e581fa4b2bee62d33adaf756ce5aadc0c71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36494
Make name consistent with op. Since we have batch_norm2d and batch_norm3d ops
Test Plan:
python test/quantization/test_quantized.py test_batch_norm2d
Imported from OSS
Differential Revision: D21008831
fbshipit-source-id: f81ca71a331d5620fd6a3f6175020a30f2e2566b
Summary:
Per title. test_abs used to be marked as slow_test and run on cpu only. Conceptually similar tests are done in TestTorchMathOps, so it's a matter of adding `abs` test there. 2 remaining checks (correct abs for large-valued long tensors, and correct abs for signed zeros) are factored into separate tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36465
Differential Revision: D21000248
Pulled By: ngimel
fbshipit-source-id: 8bc8b0da936b1c10fe016ff2f0dbb5ea428e7e61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36558
In the log, frequently see a large trunk of Using engine xx for rowWise Adagrad, but without information on which parameter is applied.
Test Plan: Should be covered by existing testing that use optimizer
Reviewed By: chocjy
Differential Revision: D20985176
fbshipit-source-id: 6eb4e19e5307db53fc89b38594a3f303f1492a1c
Summary:
An update on the note that the subgradients for min/max are not deterministic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36481
Differential Revision: D20993887
Pulled By: albanD
fbshipit-source-id: 4e1a7519d94a9dcf9d359ad679360874d32c1fe2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/973
Common failure scenario:
* DataLoader creates workers and communicates with them through SHMs
* Workers send back through an AF_UNIX socket file descriptors to SHMs containing data
* The limit of open files gets fully used
* A FD gets stripped from a socket message coming back from a worker, without the worker knowing this.
* This causes a `RuntimeError: received 0 items of ancdata` in the standard `multiprocessing` package
* The exception is not handled by PyTorch and so is presented to the users.
After this change the user will see
```
Traceback (most recent call last):
File "/home/wbaranowski/git/Quansight/pytorch/torch/utils/data/dataloader.py", line 761, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/home/wbaranowski/miniconda3/envs/pytorch-cuda-dev/lib/python3.6/multiprocessing/queues.py", line 113, in get
return _ForkingPickler.loads(res)
File "/home/wbaranowski/git/Quansight/pytorch/torch/multiprocessing/reductions.py", line 294, in rebuild_storage_fd
fd = df.detach()
File "/home/wbaranowski/miniconda3/envs/pytorch-cuda-dev/lib/python3.6/multiprocessing/resource_sharer.py", line 58, in detach
return reduction.recv_handle(conn)
File "/home/wbaranowski/miniconda3/envs/pytorch-cuda-dev/lib/python3.6/multiprocessing/reduction.py", line 184, in recv_handle
return recvfds(s, 1)[0]
File "/home/wbaranowski/miniconda3/envs/pytorch-cuda-dev/lib/python3.6/multiprocessing/reduction.py", line 162, in recvfds
len(ancdata))
RuntimeError: received 0 items of ancdata
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/wbaranowski/git/Quansight/pytorch/torch/utils/data/dataloader.py", line 787, in _try_get_data
fs = [tempfile.NamedTemporaryFile() for i in range(10)]
File "/home/wbaranowski/git/Quansight/pytorch/torch/utils/data/dataloader.py", line 787, in <listcomp>
fs = [tempfile.NamedTemporaryFile() for i in range(10)]
File "/home/wbaranowski/miniconda3/envs/pytorch-cuda-dev/lib/python3.6/tempfile.py", line 551, in NamedTemporaryFile
(fd, name) = _mkstemp_inner(dir, prefix, suffix, flags, output_type)
File "/home/wbaranowski/miniconda3/envs/pytorch-cuda-dev/lib/python3.6/tempfile.py", line 262, in _mkstemp_inner
fd = _os.open(file, flags, 0o600)
OSError: [Errno 24] Too many open files: '/tmp/tmpnx_f6v_f'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "test_shm_leak.py", line 56, in <module>
worker_init_fn=worker_init_fn
File "/home/wbaranowski/git/Quansight/pytorch/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/wbaranowski/git/Quansight/pytorch/torch/utils/data/dataloader.py", line 861, in _next_data
idx, data = self._get_data()
File "/home/wbaranowski/git/Quansight/pytorch/torch/utils/data/dataloader.py", line 828, in _get_data
success, data = self._try_get_data()
File "/home/wbaranowski/git/Quansight/pytorch/torch/utils/data/dataloader.py", line 791, in _try_get_data
"Too many open files. Communication with the"
RuntimeError: Too many open files. Communication with the workers is no longer possible. Please increase the limit using `ulimit -n` in the shell or change the sharing strategy by calling `torch.multiprocessing.set_sharing_strategy('file_system')` at the beginning of your code
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34768
Differential Revision: D20538053
Pulled By: ezyang
fbshipit-source-id: be4425cf2fa02aff61619b2b829c153cb1a867cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36551
Before, those ops were special cased in the jit codegen but that blocks our unboxing refactoring.
Instead, make those regular prim ops.
ghstack-source-id: 102081858
Test Plan: waitforsandcastle
Differential Revision: D21009196
fbshipit-source-id: b90320fce589fc0553f17582b66a5a05d0fd32d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36388
(This wants to make me barf).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20964195
Pulled By: ezyang
fbshipit-source-id: 3699a02b16060d79dae9890bafeaafad9ad9ae60
Summary:
This kernel debug flag should help locate the issues we are observing on
some of the CI nodes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36521
Differential Revision: D21010612
Pulled By: ezyang
fbshipit-source-id: d746e4eb0af832e770d2231bfee4154b6e703c19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36529
DistAutogradContainer is a singleton for the entire process and has a
single lock that protects access to map keyed by context_id. Performance
profiling showed that this lock is a potential bottleneck for training. As a
result, in this PR, we have the following optimizations:
1) Shard the map into 256 buckets with each bucket having its own lock. This
would ensure we hold much finer grained locks.
2) sendReleaseContextRpc was being called under a lock, moved this to be
outside the lock.
ghstack-source-id: 102085139
Test Plan: waitforbuildbot
Differential Revision: D21003934
fbshipit-source-id: 55f80dd317311bce0efd3ca8ca617d071297b5dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36277
This PR introduce a flag to the tracer that guard the risky behaviors
like adding list/dict as output of the tracer. Currently to ensure not
BC breaking user, we throw warning if the tracer output is list, and
will throw error when the tracer output is dict to enforce using this
flag (next PR)
Test Plan: Imported from OSS
Differential Revision: D20998157
Pulled By: wanchaol
fbshipit-source-id: 0d2c55f1a263a48b1b92dd6ad54407815e0a6f72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36290
The BackendSelect dispatch key gives us a way to extract backend-
specific dispatch keys from non-Tensor arguments without teaching
the DispatchKeyExtractor about them. Here we finish switching over
to the BackendSelect approach for factory functions and remove
TensorOptions from the set of types DispatchKeyExtractor needs to
consider.
Test Plan: Imported from OSS
Differential Revision: D20936595
Pulled By: bhosmer
fbshipit-source-id: c2f3cc56776197a792cae2a83aeaca995effaad2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33905
jit::Operator is semantically either a c10 op or a jit-only op but that is represented in a set of member variables with intricate invariants about their values.
Making this explicitly represented in a c10::either reduces the number of possible states, removing many of the invalid ones.
Similarly, if it is a jit-only op, there were schema_string_ and schema_ of which only one could be set at any time. Using a c10::either there too.
ghstack-source-id: 102084054
Test Plan: unit tests
Differential Revision: D20147487
fbshipit-source-id: 50ce10b56f2b1f51c8279cef03077c861db3eaac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33904
This was misnamed and should actually be either::fold.
ghstack-source-id: 102050883
Test Plan: it's just a rename
Differential Revision: D20148263
fbshipit-source-id: 5d2ed92230e20e8bb7dec26ac3f26de7f03a6e39
Summary:
Make the e2e FakeLowP python tests work with Glow lowering in OSS environment. Added a README.md as a guideline.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36525
Reviewed By: hyuen
Differential Revision: D21004706
Pulled By: yinghai
fbshipit-source-id: d182152e4a1a3368640bd7872cb9ea4d4bff4b02
Summary:
This PR fixes a bug related to object destruction order across threads. The bug can cause segfaults during shutdown of processes that use libtorch.
See https://github.com/pytorch/pytorch/issues/36408 for more detail
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36416
Differential Revision: D21006321
Pulled By: ezyang
fbshipit-source-id: da97936d9f2ed3f3e3aba8a3a29b38314f04b57f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36320
Hooks up the aten quantized hardswish op to the QNNPACK
path added in the previous PR.
Test Plan:
tests pass
will run benchmarking on mobile to confirm
Imported from OSS
Differential Revision: D20965043
fbshipit-source-id: e3f147268142103b5ea3f48610aa3b9837b7b61a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36252
Adds a baseline hardswish kernel using LUTs in QNNPACK.
Performance is 1.9 GB/s on a Nexus 6 and 2.2 GB/s on Pixel 3 - same as other LUT based ops.
Enforcing scale and zp to be equal to the input, to match the server implementation.
There are some potential improvements in rewriting this as NEON
kernels for a further speedup - saving that until later, if we need it.
Test Plan:
```
with-proxy ./scripts/build-local.sh
./build/local/hardswish-test
with-proxy scripts/build-android-armv7.sh
adb push ./build/android/armeabi-v7a/hardswish-* /data/qnnpack
adb shell
/data/qnnpack/hardswish-test
/data/qnnpack/hardswish-bench
with-proxy scripts/build-android-arm64.sh
adb push ./build/android/arm64-v8a/hardswish-* /data/qnnpack
/data/qnnpack/hardswish-test
/data/qnnpack/hardswish-bench
```
Imported from OSS
Differential Revision: D20965044
fbshipit-source-id: 982938361971513cb15873438e12c23a38e819e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36186
Start PyTorch Numeric Suite under PyTorch quantization and add weight compare API to it.
ghstack-source-id: 102062165
Test Plan: buck test mode/dev caffe2/test:quantization -- 'test_compare_weights'
Differential Revision: D20903395
fbshipit-source-id: 125d84569837142626a0e2119b3b7657a32dbf4e
Summary:
To make them compatible with python3.7 and python3.8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36422
Test Plan: CI
Differential Revision: D21006399
Pulled By: malfet
fbshipit-source-id: 725df277ff3e4479fc2c39d16a30fbf301fde9e5
Summary:
cc orionr sanekmelnikov
Confirm that the function was removed already.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36495
Differential Revision: D21003122
Pulled By: natalialunova
fbshipit-source-id: 364b0790953980e02eb7ff8fa0b6218d7e34a0c3
Summary:
Finding out how to ssh into a CircleCI job to debug a failure is a challenge because, as far as I know, there isn't any concise documentation about it. I figured it might be nice to include this in CONTRIBUTING.md.
Maybe there are some other tips about non-CircleCI jobs that could be added in the future as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36507
Differential Revision: D21006526
Pulled By: ezyang
fbshipit-source-id: 0a544ecf37bf9550e9b2f07595332dc5f394bb9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36232
The purpose of this PR is to replace `at::Generator generator = nullptr` with `c10::optional<at::Generator> = c10::nullopt` all over the code
* #36230 Replace std::shared_ptr with c10::intrusive_ptr in at::Generator
Test Plan: Imported from OSS
Differential Revision: D20943603
Pulled By: pbelevich
fbshipit-source-id: 65d335990f01fcc706867d5344e73793fad68ae6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36411
This PR remove pytorch specific defined assertwarns and use the unit
test one, also format some tests
Test Plan: Imported from OSS
Differential Revision: D20998159
Pulled By: wanchaol
fbshipit-source-id: 1280ecff2dd293b95a639d13cc7417fc819c2201
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36418
Those tests were only run in oss before but should also run in fbcode.
ghstack-source-id: 101973722
Test Plan: waitforsandcastle
Reviewed By: ezyang
Differential Revision: D20976954
fbshipit-source-id: 7ced56dcbdbfe0e07993871a7811a086894b6b32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35101
TSAN is noting lock-order-inversion in context of dist autograd because
we're holding lock when GraphTask calls markCompleted() on the relevant futureResult_.
Add an atomic bool to make it possible to protect this without holding the mutex,
and also fix alignment of a few struct vars.
ghstack-source-id: 101805283
Test Plan: buck test mode/opt-tsan //caffe2/test/distributed/rpc:dist_autograd_spawn_thrift
Differential Revision: D20553517
fbshipit-source-id: 446e3718dd68876bd312166ecceed1d92868ce4e
Summary:
This PR made the expected torch device string error message to include `xla` as the acceptable torch device prefix string.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36446
Test Plan:
No Logic changed, and made sure `xla` is acceptable in `torch.device`.
```
import torch
device = torch.device("xla")
```
```
device = torch.device("unrecognized")
RuntimeError: Expected one of cpu, cuda, mkldnn, opengl, opencl, ideep, hip, msnpu, xla device type at start of device string: unrecognized
```
Differential Revision: D20993449
Pulled By: dahsh
fbshipit-source-id: 83afe4f913a650a655bfda9c2a64bf9e5aa27e16
Summary:
This enables cpp_extensions.load/load_inline. This works by hipify-ing cuda sources.
Also enable tests.
CuDNN/MIOpen extensions aren't yet supported, I propose to not do this in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35897
Differential Revision: D20983279
Pulled By: ezyang
fbshipit-source-id: a5d0f5ac592d04488a6a46522c58e2ee0a6fd57c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36172
Original commit changeset: 3d7801613f86
D20449887 broke some OSS tests as the OSS export sync wasn't working correctly.
Test Plan:
Manually export latest version to OSS to trigger the tests
+ test plan in D20449887
verified onnx tests are passing in https://github.com/pytorch/pytorch/pull/36172
Reviewed By: andrewwdye
Differential Revision: D20902279
fbshipit-source-id: bc30fcc9f5cc8076f69a5d92675fd27455948372
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36179
This ensures normal optimization passes run for forked functions.
Test Plan: Imported from OSS
Differential Revision: D20907253
Pulled By: zdevito
fbshipit-source-id: 72cfa9f82643214b1ef3de24697d163a9a24b29c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36168
This makes it match what eager mode uses as the keyword name.
Currently _requires_grad will not appear in serialization because
it is not listed as kwarg only. There is a small chance there is a model
that has never been run in eager mode that uses the _requires_grad name,
but this is rare enough that I don't think we need to worry about it unless
something breaks in testing.
Test Plan: Imported from OSS
Differential Revision: D20902557
Pulled By: zdevito
fbshipit-source-id: 605cf5371b4fc15ec1b4e8a12f9660d723530de4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36419
Since we call waitForThreadLocalPendingRRefs per-RPC, construct it
already-satisfied in the common empty case, to avoid extra mutex/cv work.
Also, naming consistency for recording_.
ghstack-source-id: 101975739
Test Plan: ctr_mobile_feed, buck test mode/dev-nosan caffe2/test/...
Differential Revision: D20977879
fbshipit-source-id: e321a33127e4b5797e44e039839c579057e778e5
Summary:
It was called twice, but the result of the first invocation was not used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36453
Differential Revision: D20993535
Pulled By: yf225
fbshipit-source-id: 4d85207a936b846866424903d7622905f3fddd36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36282
The reason to do this explicitly in the tool is that we don't want to capture warmup in profiling (as well as input cloning). So instead we make the benchmarking code explicitly aware of the profiler.
Example output:
```
I0408 16:06:40.300040 85516 throughput_benchmark-inl.h:106] Using Autograd profiler. Trace will be saved to /tmp/tmpt0gsz85y
I0408 16:06:40.302232 85516 throughput_benchmark-inl.h:111] Starting threads
I0408 16:06:40.302258 85524 throughput_benchmark-inl.h:78] Starting forward thread 1
I0408 16:06:40.302259 85525 throughput_benchmark-inl.h:78] Starting forward thread 2
I0408 16:06:40.302261 85523 throughput_benchmark-inl.h:78] Starting forward thread 0
I0408 16:06:40.302259 85526 throughput_benchmark-inl.h:78] Starting forward thread 3
I0408 16:06:40.412879 85525 throughput_benchmark-inl.h:88] Shutting down forward thread 2. Total number of finished threads: 1
I0408 16:06:40.412971 85523 throughput_benchmark-inl.h:88] Shutting down forward thread 0. Total number of finished threads: 2
I0408 16:06:40.412989 85526 throughput_benchmark-inl.h:88] Shutting down forward thread 3. Total number of finished threads: 3
I0408 16:06:40.413033 85524 throughput_benchmark-inl.h:88] Shutting down forward thread 1. Total number of finished threads: 4
I0408 16:06:40.413056 85516 throughput_benchmark-inl.h:123] Finished benchmark
Average latency per example: 443.256us
Total number of iterations: 1000
Total number of iterations per second (across all threads): 9024.12
Total time: 110.814ms
```
Test Plan: Imported from OSS
Differential Revision: D20987125
Pulled By: ezyang
fbshipit-source-id: 1f8980c3a5a0abdc268c7a16c99aa9ea868689eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35313
The intention of D16955662 was to print a warning when a single-layer LSTM has an (ignored) dropout specified. I ran into this warning with one of our models, but instead of a warning I got "name 'warnings' is not defined". The linter could have called out that problem on the original diff, not sure why it didn't.
Test Plan: Before this diff JITing a particular model in f176977725 yielded "name 'warnings' is not defined". After this diff f176980937 gets past that point (failing in an unrelated downstream workflow).
Reviewed By: jianyuh
Differential Revision: D20611822
fbshipit-source-id: 99d90f4830f3b15ddbf1e2146e2cc014ef26c2ab
Summary:
Bazel puts generated files in its private hermetic builds, but for some reason also searches for files in `torch/csrcs/*/generated/` folders.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36417
Test Plan: Use the same folder to compile pytorch using cmake and bazel
Differential Revision: D20987580
Pulled By: malfet
fbshipit-source-id: 36d15ba3ce0d0c7ea923ddef902bd500f2578430
Summary:
This partially addresses https://github.com/pytorch/pytorch/issues/33568 by disabling clamp for complex inputs until an appropriate solution can be implemented. test_complex_unsupported in test_torch.py is extended to validate this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36373
Differential Revision: D20984435
Pulled By: mruberry
fbshipit-source-id: 49fd2e1e3a309f6a948585023953bae7ce3734c8
Summary:
We open sourced the FakeLowp ops as a reference implementation of fp16 ops. This PR makes it buildable.
```
USE_CUDA=0 USE_ROCM=0 USE_FAKELOWP=ON python setup.py install
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36170
Test Plan:
Build Onnxifi library in Glow.
```
cp ${GLOW}/build/lib/Onnxifi/libonnxifi-glow.so ${MY_PATH}/ibonnxifi.so
LD_LIBRARY_PATH=${MY_PATH}/ibonnxifi.so python pytorch/caffe2/python/fakelowp/test_sls_nnpi_fp16.py
```
It doesn't run successfully right now because we need to open source the glow gflags and some other ops like `FbgemmPack`.
Reviewed By: houseroad
Differential Revision: D20980681
Pulled By: yinghai
fbshipit-source-id: 6dd31883a985850a77261bcc527029479bbc303f
Summary:
Partially addresses https://github.com/pytorch/pytorch/issues/36374 by disabling min and max for complex inputs. test_complex_unsupported in test_torch.py is extended to validate this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36377
Differential Revision: D20964661
Pulled By: mruberry
fbshipit-source-id: 79606c2e88c17c702543f4af75847d2460586c2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33313
Instead of just remembering the number of arguments and iterating over the stack,
the DispatchKeyExtractor now remembers the exact locations of the dispatch relevant arguments
(i.e. Tensor arguments) and only looks at those.
ghstack-source-id: 101908386
Test Plan: unit tests, benchmarks
Differential Revision: D19748549
fbshipit-source-id: b5b9ff2233b3507e0b600460f422912cfa9e3f0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35488
-
The original problem why those existed was a SIOF (see the multi-line comment that is deleted in this PR).
However, I think this SIOF situation only happened for caffe2 kernels exposed to PyTorch and those now use a different mechanism that shouldn't cause the SIOF anymore (they now create the caffe2 kernel instance on each call instead of storing it in the functor). If this PR passes CI, I'm assuming that the SIOF doesn't exist anymore and we can simplify this code.
ghstack-source-id: 101933838
Test Plan: waitforsandcastle
Differential Revision: D20676093
fbshipit-source-id: 462e11f75f45d9012095d87f447be88416f5dcdc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36406
As title. Move the related operators so that they are available from lite interpreter.
ghstack-source-id: 101944177
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: ayush29feb
Differential Revision: D20958833
fbshipit-source-id: a755d4d662b9757d8d425b7a25f519aaad1fd330
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36118
Callbacks registered with the autograd engine Future in the
distributed engine have a non-trivial amount of business logic. Its entirely
possible that we throw exceptions in these callbacks resulting in those not
being propagated back to the client (since the appropriate future was not
marked as completed).
In this PR, I've added appropriate try-catch blocks to ensure we always mark
the appropriate Future with an error.
ghstack-source-id: 101904294
Test Plan: Tested by simulating an exception.
Differential Revision: D20885521
fbshipit-source-id: b6b6f5994a5fb439e40ec7c585435b6dfe7ddb8e
Summary:
So that XLA can run all tests by setting env `PYTORCH_TEST_PATH` instead of patching a diff. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36321
Differential Revision: D20946635
Pulled By: ailzhang
fbshipit-source-id: 55ab7db7fd93063ad495a0c23a903218a29625a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36394
Those are remains from the time when c10 was being constructed. They've fulfilled their goal of making sure that the c10 library supports all needed corner cases and those corner cases are now covered by actual ops. We don't need these experimental ops anymore.
ghstack-source-id: 101933837
Test Plan: CI
Differential Revision: D20965279
fbshipit-source-id: ff46f2482ff58ca3fa955288083b12ec2066938e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36409
Pull Request resolved: https://github.com/pytorch/glow/pull/4409
Since glow OSS doesn't really ship with python, it's much easier to do it in pytorch. All the glow dependency can be done though LD_LIBRARY_PATH in OSS.
Test Plan:
```
buck test caffe2/caffe2/python/fakelowp:
```
Reviewed By: amylittleyang
Differential Revision: D20969308
fbshipit-source-id: 06a02d23f4972a92beb18e1d052e27d8724539d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36350
Adds CUDA kernels for hardswish in order to unblock use in training.
Test Plan:
added test coverage for forward pass
ran this script for various input sizes to test backward pass against a manual Hardswish module: https://gist.github.com/vkuzo/30e196b059427725817f2ee934ed0384
Imported from OSS
Differential Revision: D20955590
fbshipit-source-id: 635706fbf18af9a4205f2309f3314f2996df904d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36371
It allows to drop circular dependency and remove unknown_symbols in Buck build.
It'd be good to get rid of GetCpuId all together in favor of cpuinfo, but it's not really blocking anything
Reviewed By: malfet
Differential Revision: D20958000
fbshipit-source-id: ed17a2a90a51dc1adf9e634af56c85f0689f8f29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36296
When there's no overload name, the operator name string should be "name", instead of "name.".
Test Plan: Imported from OSS
Differential Revision: D20966759
Pulled By: iseeyuan
fbshipit-source-id: b4b31923c7ec5cdca8ac919bd6a84ba51afb6cd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35002
I was running into some memory issues once I enabled QAT and I found some opportunities to in-place operations. In particular, looks like we can do the ReLUs in-place and the bias addition seems to also work inline. The multiplication operation right above the bias addition is *not* eligible because there's a bifurcation to produce conv_orig.
Reviewed By: jerryzh168
Differential Revision: D20523080
fbshipit-source-id: 4a94047dee0136f4014a328374896b28f561e41f
Summary:
Second attempt at the reduction frontend for the TensorExpr compiler. Has two APIs, a simple version for common reduction types and a customizable Reducer fronted which allows specifying initializer, reduction interaction via lambda and body via lambda.
Simple API looks like so:
```
Buffer b(BufHandle("b", {10}), kInt);
Tensor* c = Reduce("sum", {}, Sum(b), {{10, "m"}});
```
An example of specializing a Sum to do Matmul:
```
Buffer tA(BufHandle("tA", {M, K}), kFloat);
Buffer tB(BufHandle("tB", {K, N}), kFloat);
Sum matmul([&](ParameterList& v) {
ExprHandle m = v[0];
ExprHandle n = v[1];
ExprHandle k = v[2];
return tA(m, k) * tB(k, n);
});
Tensor* mm = Reduce("mm", {{M, "m"}, {N, "n"}}, matmul, {{K, "k"}});
```
A fully specialized Reduction:
```
VarHandle searchValue("searchValue", kInt);
Buffer b(BufHandle("b", {4, 10}), kInt);
Reducer anyEqSV(
ExprHandle(0),
[](ExprHandle a, ExprHandle b) {
return CompareSelect::make(a, 1, 1, b, kEQ);
},
[&](ParameterList& v) {
return CompareSelect::make(b.call(v), searchValue, kEQ);
});
Tensor* any = Reduce("anyEqual", {{4, "i"}}, anyEqSV, {{10, "j"}});
```
---
Until lowering, Reductions are held in a compound form for easier optimization:
```
VarHandle m("m", kInt);
Buffer b(BufHandle("b", {2, 3, m}), kFloat);
Tensor* c = Reduce("sum", {{2, "l"}, {3, "n"}}, Sum(b), {{m, "m"}});
LoopNest loop({c});
std::cout << *loop.root_stmt() << "\n";
```
```
for (int l = 0; l < 2; l++) {
for (int n = 0; n < 3; n++) {
for (int m = 0; m < m_1; m++) {
sum[l, n] = ReduceOp(sum[l, n] = float(0);, (sum[l, n]) + (b[l, n, m]), {m});
}
}
}
```
```
loop.prepareForCodegen();
std::cout << *loop.root_stmt() << "\n";
```
```
for (int l = 0; l < 2; l++) {
for (int n = 0; n < 3; n++) {
sum[(0 + l * (1 * 3)) + n * 1] = float(0);
for (int m = 0; m < m_1; m++) {
sum[(0 + l * (1 * 3)) + n * 1] = (sum[(0 + l * (1 * 3)) + n * 1]) + (b[((0 + l * ((1 * m_1) * 3)) + n * (1 * m_1)) + m * 1]);
}
}
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35866
Differential Revision: D20965577
Pulled By: nickgg
fbshipit-source-id: afe506c90db794447180056417013bcaf0e2c049
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36329
The same header guard was used in two different header files (not sure if this was intentional.)
Test Plan: CI Tests
Reviewed By: jspark1105
Differential Revision: D20946512
fbshipit-source-id: dd0190943a8c90059d480f15c05f3bfcce956acd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36391
Without it I get
```
ImportError: /data/users/ezyang/pytorch-tmp/torch/lib/libtorch_python.so: undefined symbol: _ZN5torch3jit18checkDoubleInRangeEd
```
when I build with DEBUG=1
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20964292
Pulled By: ezyang
fbshipit-source-id: b2569f5813c6490de51372e70029648a36891e7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36259
Re-enable test disabled Related to #36129, which should be fixed by an
earlier PR #36103.
Test Plan: Imported from OSS
Differential Revision: D20933100
fbshipit-source-id: aca4e3b0b83a581fe58760b6730255b3176f41fc
Summary:
Per title. A test is added to test_type_promotion for the behavior. This behavior is consistent with NumPy's.
For complex inputs to `abs` the result is cast to float after the computation since the computation of abs must be performed on the original complex tensor. While `std::abs` returns a float value when called on complex inputs, returning a FloatTensor directly would require additional loop instantiations in TensorIterator. This may be worthwhile to pursue in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35871
Differential Revision: D20961711
Pulled By: mruberry
fbshipit-source-id: 232f62cf64caa4154eb2194969efa51d2082d842
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35426
Use selective build with the full set of operators (vs. manually register each used op with "_" prefix).
Lite interpreter relies on JIT operator dispatch. In future we still need JIT operator dispatch dispatch ops that are not registered in c10.
Currently the selective build is for c10/aten dispatch in BUCK. There is JIT selective code-gen in OSS but not ported to BUCK yet.
This diff is also porting the selective code-gen in BUCK.
* The selected op list is passed to gen_jit_dispatch.py.
* The list passed to gen_jit_dispatch is the top-level ops (USED_PT_OPS) only, because the selective c10/aten dispatch already registered other ops that are called from the top-level ops.
ghstack-source-id: 101885215
(Note: this ignores all push blocking failures!)
Test Plan:
1. In Python, run torch.jit.export_opnames(scripted_M_mod)
2. Append the operator names into fbcode/caffe2/pt_ops.bzl and the BUCK target.
3. Run
```
buck run xplat/caffe2/fb/lite_predictor:lite_predictor_bi -- --model=/home/myuan/temp/bi_pytext_0315.bc --input_dims "1,4" --input_type int64 --pytext_len=4
```
Should provide expected results.
In addition, the size of the generated code for JIT registration, for example, ```register_aten_ops_0.cpp```, should be significantly reduced (from ~250 KB to ~80KB). The non-selected op registration schema are still kept, but the registration functor is replaced by ```DUMMY_OPERATION```
Reviewed By: ljk53
Differential Revision: D20408831
fbshipit-source-id: ec75dd762c4613aeda3b2094f5dad11804dc9492
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36297
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/343
We moved FakeFP16 back to close source and kept `RoundToFloat16` function in "fbgemm/FbgemmConvert.h".
This is because FakeFP16 introduced dependency on MKL in the FBGEMM core. Also it doesn't seem to be needed for open source, as it is not used anywhere.
Test Plan: CI
Reviewed By: jspark1105
Differential Revision: D20937962
fbshipit-source-id: 9487a9fd2282b6df2f754c22bea36f2255a5c791
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36093
Unwrap any tuples (including NamedTuples) in the module forward
function input list to be arglist.
1. Supports multiple tuple inputs, and traces their use through CallMethods and
TupleIndex
2. Does not unwrap inner use of other tuples that did not show up in the
original toplevel graph inputs
We work from the ScriptModule level instead of the Graph level because:
1. If the ScriptModule was previously called with the original set of inputs, the GraphExecutor caches the ExecutionPlan (specifically, ArgumentSpecCreator is derived from the Graph and type check the inputs passed in)
2. Since we are changing this graph's inputs, we clone the module and clear the GraphExecutor.
Since we work from ScriptModule level, we cannot take advantage of jit level syntactic sugar like run_pass(), so I jit exposed this as a cpp extension. Let me know if there are other ideas about this.
Test Plan:
buck test caffe2/torch/fb/model_transform:signature_translation_test
Todo: Verify use in bento
Untranslated graph:
```
> graph(%self : __torch__.test_jit.SparseNNWrapper,
> %inputs.1 : NamedTuple(dense : Tensor, sparse : Dict(int, Tensor))):
> %2 : __torch__.test_jit.SparseNN = prim::GetAttr[name="main_module"](%self)
> %4 : Tensor = prim::CallMethod[name="forward"](%2, %inputs.1) # /data/users/ansha/fbsource/fbcode/buck-out/dev/gen/caffe2/test/jit#binary,link-tree/test_jit.py:12141:23
> return (%4)
```
Translated graph:
```
> graph(%self : __torch__.test_jit.___torch_mangle_1.SparseNNWrapper,
> %inputs.1_0 : Tensor,
> %inputs.1_1 : Dict(int, Tensor)):
> %2 : __torch__.test_jit.___torch_mangle_2.SparseNN = prim::GetAttr[name="main_module"](%self)
> %3 : Tensor = prim::CallMethod[name="forward"](%2, %inputs.1_0, %inputs.1_1) # /data/users/ansha/fbsource/fbcode/buck-out/dev/gen/caffe2/test/jit#binary,link-tree/test_jit.py:12141:23
> return (%3)
```
Reviewed By: houseroad
Differential Revision: D20313673
fbshipit-source-id: fddd07c9537dc8b6f480a14d697bea10ecc74470
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35997
When the number of blocks is large enough, we are already achieving
blalanced SM allocation. But we still should keep the number of inputs
per thread large, because thread reduce is cheap.
Benchmark for Half on V100:
https://github.com/zasdfgbnm/things/blob/master/2020Q2/reduction-benchmark.ipynb
On large tensor, it is: 1.37ms vs 1.25ms
Test Plan: Imported from OSS
Differential Revision: D20927533
Pulled By: ngimel
fbshipit-source-id: 40df52e439cc1c01cda66c6195b600f301c5e984
Summary:
This PR addresses Issue https://github.com/pytorch/pytorch/issues/36279.
Previously, printing of complex tensors would sometimes yield extra spaces before the elements as shown below:
```
print(torch.tensor([[1 + 1.340j, 3 + 4j], [1.2 + 1.340j, 6.5 + 7j]], dtype=torch.complex64))
```
would yield
```
tensor([[(1.0000 + 1.3400j),
(3.0000 + 4.0000j)],
[(1.2000 + 1.3400j),
(6.5000 + 7.0000j)]], dtype=torch.complex64)
```
This occurs primarily because when the max width for the element is being assigned, the formatter's max_width is calculated prior to truncating the float values. As a result, ```self.max_width``` would end up being much longer than the final length of the element string to be printed.
I address this by adding a boolean variable that checks if a complex tensor contains only ints and change the control flow for calculating ```self.max_width``` accordingly.
Here are some sample outputs of both float and complex tensors:
```
tensor([[0., 0.],
[0., 0.]], dtype=torch.float64)
tensor([[(0.+0.j), (0.+0.j)],
[(0.+0.j), (0.+0.j)]], dtype=torch.complex64)
tensor([1.2000, 1.3400], dtype=torch.float64)
tensor([(1.2000+1.3400j)], dtype=torch.complex64)
tensor([[(1.0000+1.3400j), (3.0000+4.0000j)],
[(1.2000+1.3400j), (6.5000+7.0000j)]], dtype=torch.complex64)
tensor([1.0000, 2.0000, 3.0000, 4.5000])
tensor([(1.+2.j)], dtype=torch.complex64)
```
cc ezyang anjali411 dylanbespalko
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36331
Differential Revision: D20955663
Pulled By: anjali411
fbshipit-source-id: c26a651eb5c9db6fcc315ad8d5c1bd9f4b4708f7
Summary:
AnyType wasn't listed as a mutable type, so the assertion triggered (yay!). Also update the `isMutableTypeInternal(from) != isMutableTypeInternal` logic to be more encompassing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36178
Differential Revision: D20922356
Pulled By: eellison
fbshipit-source-id: 7060a62b18e98dc24b6004a66225c196aadb566e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35279
Supported benchmarking pytorch jit self-contained models.
* By specifying flag `--no_inputs=True`, the binary supports benchmarking self-contained torchscript model (model runs without inputs, `model.forward()`)
* This allows moving data preparation part outside of this binary.
Reviewed By: kimishpatel
Differential Revision: D20585639
fbshipit-source-id: c28e50503534c90023c1430479d26f1c1ce740b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36019
Once the autograd engine is finished with a GraphTask it would call
`markCompleted` on the Future. This could trigger callbacks on the Future that
could throw exceptions.
If one of the callbacks did throw an exception, we would call setErrorIfNeeded,
which would be no-op since the Future is already marked as completed. This
would effectively mean we would be swallowing exceptions. To avoid this, we do
the following:
1) Rethrow the exception in `mark_graph_task_completed`.
2) In `setErrorIfNeeded`, log the error if we are ignoring it.
ghstack-source-id: 101607329
Test Plan: Verified appropriate logging.
Differential Revision: D20854806
fbshipit-source-id: 76bdf403cfd6d92f730ca1483ad5dba355f83e58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36319
On the way to resolving #35216.
This is a fix for just the master branch but once this goes in,
I'll send a cherry-pick to release/1.5
The problem is that we were not calling `format` on a string that had
templates (e.g., '{input}', '{dim}'). This change makes it so that we
call format on the entire docstring for `torch.min`.
Test Plan:
- The `torch.max` docs are OK:
https://pytorch.org/docs/master/torch.html#torch.max and don't need
changing.
- `torch.min` docs, before this change: see second screenshot in #35216.
- after this change: <Insert link here on github>

Differential Revision: D20946702
Pulled By: zou3519
fbshipit-source-id: a1a28707e41136a9bb170c8a4191786cf037a0c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36223
Previously #35714
There are a lot of unboxed only defs. We're committed to removing
them at the end of the half but as I am about to do a lot of porting
to the new API, let's get them into a form where they're easy to
remove. This is a new overload impl_UNBOXED that will pass
the function pointer straight to CppFunction::makeUnboxedOnly
I don't attempt to make the _UNBOXED API complete; in particular,
catchall declarations don't get this sugar (as there are very few
of them).
To get some coverage of _UNBOXED API for code analysis, I switched
one of our unboxed tests to be an impl rather than a def. This
shouldn't materially affect coverage.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20929259
Pulled By: ezyang
fbshipit-source-id: 72d2061b6c8a6afbcd392b47f53ade18de2f9184
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36222
Reland of #35706, with fixes to code analyzer.
It is extremely common to define implementations of operators at a
specific dispatch key, so we add an overload to impl specifically for
this case. I then delete most uses of torch::dispatch
dispatch_autograd call sites can't make use of this overload. So
instead the new preferred way to specify something as autograd is to
pass kAutograd as the dispatch key (short form, analogous to kCPU/kCUDA
which we support today).
I flip flopped about whether or not kAutograd should have the type
DispatchKey or some other type (to help better encapsulate the
DispatchKey enum); this is more direct and I can't think of any
BC problems from this usage.
Some other reorganization I did:
- I renamed all of the worker functions in op_registration to have
a leading underscore and made them private, just to make it more
clear what the public versus private API were (the private API
shouldn't be used by users because it doesn't come with && overloads)
Note that this means I needed to adjust the regex in the
code analyzer, because
- In a few places where I was touching lines already, I replaced
full DispatchKey typed out enums with shorter kFoo names, similar
to kAutograd but I didn't publish these globally.
- Code analyzer now prints a unified diff, and in the other order
(because I tend to think of the diff as reporting how the /new/ result
is different)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20929256
Pulled By: ezyang
fbshipit-source-id: c69b803d2b3a1a8aff70e14da33d3adec5239f13
Summary:
Adds handling of constant branches to the TensorExpr IR Simplifier. This covers both IfThenElse and Cond when the condition expression is a known constant (e.g. `IfThenElse(1, X, Y) => X`), or when both arms of the branch are the same (e.g. `IfThenElse(Y, X, X) => X`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36257
Differential Revision: D20947777
Pulled By: nickgg
fbshipit-source-id: 974379e42a6d65ce3e7178622afb62d36ad4e380
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31966
This has three parts:
* When `--caffe2_handle_executor_threads_exceptions` is set when a parallel execution step throws an exception it can hang waiting for async nets to finish. This adds cancellation code to cancel any async nets.
* This makes the exceptions returned from parallel workers pass a std::exception_ptr so the stack trace can be recorded with folly::SmartExceptionTracer.
* Define Cancel method at NetBase level to avoid pulling in unsupported AsyncSchedulingNet for fbandroid.
Test Plan:
Added unit tests for plan_executor
buck test //caffe2/caffe2:caffe2_test_cpu
buck test //caffe2/caffe2:caffe2_test_cpu -- PlanExecutorTest --stress-runs 100
Reviewed By: boryiingsu
Differential Revision: D19320177
fbshipit-source-id: d9939fcea1317751fa3de4172dfae7f781b71b75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36325
return the scale of the input tensor
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py
Imported from OSS
Differential Revision: D20947338
fbshipit-source-id: 71fc15fce815972d23804ff7cf936da997e71dc0
Summary:
This PR completely refactors the code lowering process from our IR to CUDA. Before we had one giant step that would go from a relatively high level IR straight to CUDA, now we're lowering this first into concepts like ForLoop, IfThenElse, TensorIndex, Allocate. This lowering will allow us to do more complex code lowering like reductions and unrolling. Unrolling will quickly follow this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36199
Reviewed By: dzhulgakov
Differential Revision: D20925220
Pulled By: soumith
fbshipit-source-id: 8f621c694c68a1aad8653e625d7287fe2d8b35dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34527
Adding support for prune_delays and prune ratios in Adagrad optimizer.
Test Plan:
Tested via unit tests in masked_adagrad_optimizer_test. Added unit test for prune_delay versions of MaskedAdagrad
buck build caffe2/caffe2/fb/optimizers:masked_adagrad_optimizer_test; buck-out/gen/caffe2/caffe2/fb/optimizers/masked_adagrad_optimizer_test#binary.par
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- 'test_pruning'
All Dper tests passed https://our.intern.facebook.com/intern/testinfra/testrun/7599824380741217
Reviewed By: chocjy
Differential Revision: D20313419
fbshipit-source-id: 5c2c8d4e0fc2ec538bcd6f145c6b87a2381f90f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36267
This makes PythonOp throw the original python exception instead of wrapping it in a c10::Error type. This allows throwing exceptions from Python and preserving the type when they're caught again in Python. This is important for structured logging and handling non-retryable error types.
Test Plan: buck test caffe2/caffe2/python:python_op_test
Reviewed By: wenqicaofb
Differential Revision: D20928098
fbshipit-source-id: 001747f022c657b420f8450b84d64f4d57f6cdf6
Summary:
At title. Found that `THBlas_(swap)` was never be used. So I remove it from repo. Please help review patch, and any suggestions are welcomed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35033
Differential Revision: D20918998
Pulled By: albanD
fbshipit-source-id: 93af8429231421185db0ccdfdd44e349a8f68c67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36239
ProcessGroupAgent and ThriftAgent threads were joined at shutdown, but RpcAgent threads were joined by the destructor. This PR joins all threads at shutdown by using a pattern similar to `start` in RPC.
The derived classes implement a `shutdownImpl` class that cleans up backend-specific state. RpcAgent implements `shutdown` which cleans up generic state and calls the underlying `shutdownImpl`. The atomic running is now set and unset by RpcAgent so backends do not need to mutate it.
ghstack-source-id: 101820415
Test Plan: Ensured this works with `test_duplicate_name` (in which RpcAgent is constructed but PGA is not), and selected `rpc_spawn` and `dist_autograd_spawn` tests with TSAN. Checking Build Bot and CI as well, and continuing to test more with TSAN on devserver (currently running into memory issues).
Reviewed By: jjlilley
Differential Revision: D20902666
fbshipit-source-id: 5dbb5fc92ba66f75614c050bb10b10810770ab12
Summary:
In the IR Simplifier we were not treating multiply by zero specially, which meant some constant expressions were stored in formats that were not constant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36287
Differential Revision: D20937497
Pulled By: nickgg
fbshipit-source-id: 528e430313ea048524d7a4a0256eef4a0297438b
Summary:
This reverts commit 8afa001d898914a48d6b9e3d944a99607d2819c1 and made a few improvements including the following items.
1. return `std::string` for `get_module_base_name`
2. eliminate `module should always be true` warning
3. do `SymInitialize` and `SymCleanup` once to save time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36205
Reviewed By: malfet
Differential Revision: D20919672
Pulled By: ezyang
fbshipit-source-id: 0063a478779feb106459af48063485ef676008a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36302
used 1/sqrt(x) vs rsqrt(x)
Test Plan:
tested with the seed from testwarden 1586230820
tested without the seed
Differential Revision: D20939672
fbshipit-source-id: c7be030c4ae42e78765edda2ce1ad2e213a46030
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35693
Adds utility functions to quantized int types of vec256 to calculate
horizontal sums and sums of squares using avx2 intrinsics.
This is useful for quantized implementations of various normalization
layers (LayerNorm, GroupNorm, InstanceNorm), where we need to calculate
the mean and variance of a layer of quantized ints.
Test Plan:
Adhoc c++ tester for the correctness of the avx2 functions:
https://gist.github.com/vkuzo/0380f450793cd5c05abbeacb6d3883ae
Run with:
```
-lstdc++ -mavx2 -lm -ldl -o main main.cpp && ./main
```
The integration bits and performance will be tested in the next PR in the stack
where we will hook quantized Layernorm to use this.
Imported from OSS
Differential Revision: D20768804
fbshipit-source-id: 4720dd358dde0dabbab8e1a33a67be55925d98f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36284
ATen/gen.py's `force_schema_registration` flag was added in #34622 to unblock c10 boxing for custom build,
as full-JIT frontend expects certain op schemas are always registered (the actual op implementation can be
skipped if it's not used).
The flag didn't work together with `per_op_registration` flag, which was added for FB BUCK selective build.
This PR made it work with `per_op_registration` flag, by moving schema registrations to a separate file.
This way, internal full-JIT can include the new source file while lite-JIT can ignore it. OSS custom build
should still work as before.
Updated table of codegen flags and 5 build configurations that are related to mobile:
```
+--------------------------------------+-----------------------------------------------------------------------------+--------------------------------------------+
| | Open Source | FB BUCK |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| | Default Build | Custom Build w/ Stat-Disp | Custom Build w/ Dyna-Disp | Full-JIT | Lite-JIT |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| Dispatch Type | Static | Static | Dynamic | Dynamic | Dynamic |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| ATen/gen.py | | | | | |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| --op_registration_whitelist | unset | used root ops | closure(used root ops) | unset | closure(possibly used ops) |
| --backend_whitelist | CPU Q-CPU | CPU Q-CPU | CPU Q-CPU | CPU Q-CPU | CPU Q-CPU |
| --per_op_registration | false | false | false | true | true |
| --force_schema_registration | false | true | true | true | true (output unused) |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| tools/setup_helpers/generate_code.py | | | | | |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| --disable-autograd | true | true | true | false | WIP |
| --selected-op-list-path | file(used root ops) | file(used root ops) | file(used root ops) | unset | unset |
| --selected-op-list (WIP) | unset | unset | unset | unset | used root ops |
| --force_schema_registration (WIP) | false | true | true | true | false |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
```
ghstack-source-id: 101840182
Test Plan:
- check OSS CI;
- patch D20577433 on top of this change to make sure test passes on it;
- check mobile build size bot;
Differential Revision: D20932484
fbshipit-source-id: 5028a6f90f2c7ee66fc70c562643b536a32b4d33
Summary:
See issue [https://github.com/pytorch/pytorch/issues/33494 Complex number printing inconsistent with float](https://github.com/pytorch/pytorch/issues/33494).
Changes introduces an optional argument in Formatter's ```format``` function to discern whether a tensor is a float tensor or not. This way, there is consistency between float tensors and complex tensors so that the complex tensors print in the same manner as float tensors:
- Only a decimal point and no zeros for integer values.
- Trailing zeros only if the value is truly a float.
- White space introduced to fill the gap so that +/- symbols and commas align.
Here are some example outputs.
```
print(torch.zeros((2,2), dtype=torch.float64))
```
yields
```
tensor([[0., 0.],
[0., 0.]], dtype=torch.float64)
```
```
print(torch.zeros((2,2), dtype=torch.complex64))
```
previously yielded
```
tensor([[(0.0000 + 0.0000j), (0.0000 + 0.0000j)],
[(0.0000 + 0.0000j), (0.0000 + 0.0000j)]], dtype=torch.complex64)
```
and now yields
```
tensor([[(0 + 0.j), (0 + 0.j)],
[(0 + 0.j), (0 + 0.j)]], dtype=torch.complex64)
```
This new print version is more consistent with float tensor's pretty print.
The following example mixes integer and decimals:
```
print(torch.tensor([[1 + 1.340j, 3 + 4j], [1.2 + 1.340j, 6.5 + 7j]], dtype=torch.complex64))
```
This yields:
```
tensor([[ (1.0000 + 1.3400j),
(3.0000 + 4.0000j)],
[ (1.2000 + 1.3400j),
(6.5000 + 7.0000j)]], dtype=torch.complex64)
```
The following example
```
torch.tensor([1,2,3,4.5])
```
yields
```
tensor([1.0000, 2.0000, 3.0000, 4.5000]) .
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35841
Differential Revision: D20893848
Pulled By: anjali411
fbshipit-source-id: f84c533b8957a1563602439c07e60efbc79691bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36230
To make `at::Generator` compatible with `IValue` this PR replaces `std::shared_ptr<c10::GeneratorImpl>` with `c10::intrusive_ptr<c10::GeneratorImpl>`
Differential Revision: D20923377
Pulled By: pbelevich
fbshipit-source-id: 3cb4214900023d863e5f2fe4ea63ec8aeb30936a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36248
Add basic index/length checks to MergeMultiScalarFeatureTensors to avoid segfaults.
But I don't really understand this op: what would cause this mismatch (see test plan) -- would iike to add it to the assertion description.
Reviewed By: houseroad
Differential Revision: D20912048
fbshipit-source-id: 29ef8c4bd261a48d64cbef6aa4f0306d7f058e71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36292
As reported in https://github.com/pytorch/pytorch/issues/36120,
sparse_coo_tensor has some expensive checks and we were using that to shallow
copy a sparse tensor in AccumulateGrad. This can be avoided by using
_sparse_tensor_coo_unsafe since we're just reusing the indices and values from
a valid sparse tensor to shallow copy it.
Using the benchmark code mentioned in
https://github.com/pytorch/pytorch/issues/36120, these are the results:
1) 65.1 ms on master with this PR.
2) 127.5 ms for PyTorch 1.4
3) 916.5 ms on master without this patch.
ghstack-source-id: 101817209
Test Plan: waitforbuildbot
Differential Revision: D20935573
fbshipit-source-id: 4661bc779c06b47b5eb677e3fd4e192d1e3cba77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36275
Calling a TorchScript function from within RPC was added after initial
support for the profiler with RPC, hence, we were not recording torchscript
funtions invoked under RPC correctly. This diff passes the `RecordFunction` to
the `_invoke_torchscript..` calls similar to what is done for builtin and UDFs.
However, this is only a temporary solution. We will be removing the use of
`RecordFunction` as a standalone in the RPC code in
https://github.com/pytorch/pytorch/pull/35055. This diff is to unblock
recording of torchscript functions in the meantime.
ghstack-source-id: 101800134
Test Plan:
Added tests for calling a script function with builtin, sync, and
asyc. The output looks like below:
```
------ --------------- --------------- --------------- --------------- ---------------
> Name Self CPU
total % Self CPU total CPU total % CPU total CPU time avg Number of Calls
> ---------------------------------------------------------------------------------------------------------- ---------
------ --------------- --------------- --------------- --------------- ---------------
> rpc_sync#__torch__.torch.testing._internal.distributed.rpc.rpc_test.my_script_func(worker1 -> worker2) 99.92%
1.056s 99.92% 1.056s 1.056s 1
> select 0.04%
383.661us 0.04% 383.661us 95.915us 4
> fill_ 0.02%
210.966us 0.02% 210.966us 52.741us 4
> to 0.00%
26.276us 0.00% 26.276us 26.276us 1
> empty 0.02%
159.802us 0.02% 159.802us 79.901us 2
> set_ 0.01%
93.818us 0.01% 93.818us 93.818us 1
> ---------------------------------------------------------------------------------------------------------- ---------
------ --------------- --------------- --------------- --------------- ---------------
> Self CPU time total: 1.057s
```
Note that we use `torch.jit._qualified_name` to get the name of the script fn.
Differential Revision: D20930453
fbshipit-source-id: c6d940aa44fcd9dd8a1a29c156aa19e0d8428d60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36212
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/342
So that we can let vendor use this as a reference for fp16 emulated ops.
Will modify the dependent TARGETS and CMakefiles.
Test Plan:
```
buck test deeplearning/fbgemm:
```
Reviewed By: hyuen
Differential Revision: D20911460
fbshipit-source-id: bb8a43e13591f295727fe1ecc74eca4ca85ab5b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36254
These future use changes were all landed yesterday as part of the future
refactoring, quickly reverted due to an observed OOM, but now being relanded, since
they've since been tested to be benign.
ghstack-source-id: 101776613
Test Plan:
buck test mode/dev-nosan caffe2/test/...
not ooming: buck run mode/opt -c=python.package_style=inplace //caffe2/torch/fb/training_toolkit/examples:ctr_mbl_feed_integration -- prod
Differential Revision: D20924010
fbshipit-source-id: 28872e488df34c7a886bcd659fa7e9914639d306
Summary:
Because `torch_python` is supposed to be thin wrapper around `torch`
In this PR, all invocation of functions from nccl library are moved from python_nccl.cpp (which is part of torch_python) to nccl.cpp (which is part of torch_cuda)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36193
Test Plan: CI
Differential Revision: D20930047
Pulled By: malfet
fbshipit-source-id: 7f278610077df6ac5dc3471c1a1b5d51e653ef9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35844
Also, bitwise operators can operate on the underlying __m256i
representation directly instead of making expensive conversions to
float16.
Test Plan: Imported from OSS
Differential Revision: D20927639
Pulled By: ngimel
fbshipit-source-id: 148c503df090580c8504f0df8d6ed2648d614120
Summary:
This is a realand of https://github.com/pytorch/pytorch/pull/36196
Before the fix bazel spews following multi-line warning for every single caffe2 operator:
```
In file included from ./c10/util/logging_is_google_glog.h:50,
from ./c10/util/Logging.h:26,
from ./caffe2/core/logging.h:2,
from ./caffe2/core/blob.h:13,
from ./caffe2/core/operator.h:18,
from ./caffe2/sgd/adadelta_op.h:1,
from caffe2/sgd/adadelta_op.cc:1:
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h: In instantiation of 'std::string* google::Check_LTImpl(const T1&, const T2&, const char*) [with T1 = int; T2 = long unsigned int; std::string = std::__cxx11::basic_string<char>]':
./caffe2/core/operator.h:192:5: required from 'const T& caffe2::OperatorBase::Input(int, caffe2::DeviceType) [with T = caffe2::Tensor; caffe2::DeviceType = c10::DeviceType]'
./caffe2/core/operator.h:890:48: required from 'const caffe2::Tensor& caffe2::Operator<Context>::Input(int, caffe2::DeviceType) [with Context = caffe2::CPUContext; caffe2::DeviceType = c10::DeviceType]'
./caffe2/sgd/adadelta_op.h:87:5: required from 'bool caffe2::SparseAdadeltaOp<Context>::RunOnDevice() [with Context = caffe2::CPUContext]'
./caffe2/sgd/adadelta_op.h:85:8: required from here
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h:722:32: warning: comparison of integer expressions of different signedness: 'const int' and 'const long unsigned int' [-Wsign-compare]
722 | DEFINE_CHECK_OP_IMPL(Check_LT, < )
| ^
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h:148:53: note: in definition of macro 'GOOGLE_PREDICT_TRUE'
148 | #define GOOGLE_PREDICT_TRUE(x) (__builtin_expect(!!(x), 1))
| ^
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h:722:1: note: in expansion of macro 'DEFINE_CHECK_OP_IMPL'
722 | DEFINE_CHECK_OP_IMPL(Check_LT, < )
| ^~~~~~~~~~~~~~~~~~~~
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36224
Test Plan: CI
Differential Revision: D20919506
Pulled By: malfet
fbshipit-source-id: b8b4b7c62dcbc109b30165b19635a6ef30033e73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35170
Looks like this was renamed by accident in 0cbd7fa46f2
Test Plan:
Unit test.
Imported from OSS
Differential Revision: D20783298
fbshipit-source-id: 8fcc146284af022ec1afe8d651baf6721b190ad3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36173
Previously we were ignoring the conv bias during training if it existed
This PR adds the bias from the conv op during the conv+bn fusion process
Test Plan:
python test/quantization/test_quantization.py
Imported from OSS
Differential Revision: D20921613
fbshipit-source-id: eacb2ccf9107f413ac4ef23163ba914af9b90924
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35198
The need for this tool was motivated by #28883. In the past, we have
done ad-hoc benchmarking, but it's time for something more structured.
It would be nice to add more model architectures so that we can get a
full picture of the performance impact of a code change simply by
running this suite a few times.
Test Plan: Imported from OSS
Differential Revision: D20591296
Pulled By: mrshenli
fbshipit-source-id: ee66ce0ebca02086453b02df0a94fde27ab4be49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35421
This PR makes it so that we don't have to rebuild the entire alias db each time we remove a node in alias analysis.
Test Plan: Imported from OSS
Differential Revision: D20922470
Pulled By: eellison
fbshipit-source-id: 9f43ed6dc743bf8a6b84a4aa38cff7059d46741d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33297
Allowing mutated values as inputs but not outputs has the effect of buffering up all mutated values as inputs to the graph. Just as we values which escape scope as graph inputs but not graph outputs - we should also allow values that get mutated. In both cases, the contract is that that the functional graph cannot write to graph inputs.
Without this patch, if there is a single write to the Tensor wildcard set it would disable all optimization.
Test Plan: Imported from OSS
Differential Revision: D20607175
Pulled By: eellison
fbshipit-source-id: c698e7cf3374e501cd5d835663991026a113ec6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35608
Various quantization options in SparseAdagradOp is only for experimental purposes and was unnecessarily complicating the code.
Moving these options back to internal code, merge into SparseSimdAdagradStochasticQuantOp, and change the name to SparseSimdAdagradFakeQuantOp
Test Plan: CI
Differential Revision: D20720426
fbshipit-source-id: 34c8fdea49f239c795f63e978ab13c8f535609d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36113
As part of debugging https://github.com/pytorch/pytorch/issues/35863,
I discovered that the unit test would timeout during clean shutdown.
Looking into this further, it looks like there is a race in
`_on_leader_follower_report_shutdown_intent` when multiple followers call the
same method on the leader.
To fix this, I've ensured we have an appropriate lock in
`_on_leader_follower_report_shutdown_intent` to guard against this.
I ran the test 500 times to validate that this fix works.
Closes#35863
ghstack-source-id: 101641463
Test Plan:
1) waitforbuildbot
2) Ran the test 500 times.
Differential Revision: D20884373
fbshipit-source-id: 9d580e9892adffc0c9a4c2e832881fb291a1ff16
Summary:
Since workflow configures pytorch with 'USE_NCCL` set to 0, we can not tidy those files
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36249
Differential Revision: D20926213
Pulled By: malfet
fbshipit-source-id: 69c051b7d22fb5f19147a7955782a7de5137f740
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35631
Bundling sample inputs with our models with a standardized interface
will make it possible to write benchmarking and code-coverage tools that
call all models in a uniform way. The intent is to make this a standard
for mobile models within Facebook. Putting it in torch/utils so tests
can run on GitHub and because it might be useful for others as well.
`augment_model_with_bundled_inputs` is the primary entry point. See
its docstring for usage information and the test for some example uses.
One design question I had was how much power should be available for
automatic deflating and inflating of inputs. The current scheme gives
some automatic handling and a reasonable escape hatch
("_bundled_input_inflate_format") for top-level tensor arguments, but no
automatic support for (e.g.) tensors in tuples or long strings. For
more complex cases, we have the ultimate escape hatch of just defining
_generate_bundled_inputs in the model.
Another design question was whether to add the inputs to the model or
wrap the model in a wrapper module that had these methods and delegated
calls to `forward`. Because models can have other exposed methods and
attributes, the wrapped seemed too onerous.
Test Plan: Unit test.
Differential Revision: D20925013
Pulled By: dreiss
fbshipit-source-id: 4dbbb4cce41e5752133b4ecdb05e1c92bac6b2d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35630
Prefix underscored for now because the semantics of this method can be
confusing. It adds a new attribute to the *type*, which can be shared
by several objects.
Test Plan:
Next diff in stack uses it, and has unit tests.
Imported from OSS
Differential Revision: D20904253
fbshipit-source-id: dcbf60eacf0e0e075c19238165aa33954aa73b5f
Summary:
`cuda` metapackage install both kernel driver + runtime libraries + toolchain, while `cuda-toolkit` metapackage as name suggests installs only toolchain + library headers.
This reduces install dependencies time for `clang-tidy` step by 60+ sec
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36241
Test Plan: CI
Differential Revision: D20923839
Pulled By: malfet
fbshipit-source-id: 1e773285222bed179973449573215fcaee1983de
Summary:
Support `aten::div` in `PropagateCompleteShapeOnNode`.
complete shape propagation on `aten::div` is disabled, because shape inference
relies on running node to propagate shape. For `aten::div` we run into
deviding-by-zero problem.
However, shape propagation for pointwise operatoins should be identical. We
would be able to swap the operation for `aten::div` with `aten::mul`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35051
Differential Revision: D20921359
Pulled By: eellison
fbshipit-source-id: 344371f34724a1b6bb2f853ebb4cef80423a4f9f
Summary:
Add support for the TensorExpr IR Simplifier to factorize common terms on either side of a Div node. e.g. `(8 * x) / (4 * y) => (2 * x) / y`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36154
Differential Revision: D20910580
Pulled By: nickgg
fbshipit-source-id: ee071d93bc4711b1e710be312de599d18ab506f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36220
The torch::utils::Future change from yesterday may have introduced a reference cycle,
leading to OOM on PS. This change reverts the lambda capture changes with
torch::utils::Future until we can analyze further.
ghstack-source-id: 101756106
Test Plan: ctr mobile feed: buck run mode/opt -c=python.package_style=inplace //caffe2/torch/fb/training_toolkit/examples:ctr_mbl_feed_integration -- prod-preset
Differential Revision: D20918904
fbshipit-source-id: d637f2370aa72c1765b98f3b9e10eb969a025624
Summary:
Modified messages in the check of default options for the Adam optimizer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36161
Differential Revision: D20920140
Pulled By: yf225
fbshipit-source-id: e697ef1741d4dd86f7f18dc0be2c3b4bd3894d8f
Summary:
By removing the calls of `size` that were effectively nops, I've managed to make `bincount_cpu` run around 6 times faster on my machine. EDIT: (Running Windows 10, I'm suspecting this may be a Windows-specific bug)
For histogramming 1e7 samples with 1e5 bins, best of 20 with 10 runs each
Before: 3.201189
After: 0.466188
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35822
Differential Revision: D20919885
Pulled By: ezyang
fbshipit-source-id: 1657056d69a02f1e61434f4cc8fa800f8d4e1fe8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36151
Python 2 has reached end-of-life and is no longer supported by PyTorch. To avoid confusing behavior when trying to use PyTorch with Python 2, detect this case early and fail with a clear message. This commit covers `import torch` only and not C++ for now.
Test Plan: waitforsandcastle
Reviewed By: dreiss
Differential Revision: D20894381
fbshipit-source-id: a1073b7a648e07cf10cda5a99a2cf4eee5a89230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36206
nothing wrong with the code, adding appropriate casts
to keep the compiler happy
Test Plan:
build //sigrid/...
tests in the same directory
buck test //glow/glow/tests/fakelowp/...
Reviewed By: jspark1105
Differential Revision: D20911279
fbshipit-source-id: 086ef028006a53048e1cfbe9dbc6c4bdd18fb259
Summary:
In a comprehension like:
```
def f()->int:
i = 1
x = [i for i in range(7)]
return i
```
the variables inside the comprehension do not write to the function environment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36105
Differential Revision: D20880699
Pulled By: eellison
fbshipit-source-id: 40af0f7470e0baeff7ef158cb461bf85c816d169
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36177
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20904241
Pulled By: ezyang
fbshipit-source-id: b13584dfdb1f852e451b1295c0d4cd4a7f53712f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36198
Original commit changeset: 4476a810dfe7
With the previous diff, when user sets KMP_AFFINITY, it will be ignored when OMP_NUM_THREADS is 1. That could cause performance regression.
Test Plan: n/a
Reviewed By: ilia-cher
Differential Revision: D20909628
fbshipit-source-id: 5738f99aa61072337146257a68189d3d03ad39f7
Summary:
Otherwise, while bazel spews following multi-line warning for every single caffe2 operator:
```
In file included from ./c10/util/logging_is_google_glog.h:50,
from ./c10/util/Logging.h:26,
from ./caffe2/core/logging.h:2,
from ./caffe2/core/blob.h:13,
from ./caffe2/core/operator.h:18,
from ./caffe2/sgd/adadelta_op.h:1,
from caffe2/sgd/adadelta_op.cc:1:
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h: In instantiation of 'std::string* google::Check_LTImpl(const T1&, const T2&, const char*) [with T1 = int; T2 = long unsigned int; std::string = std::__cxx11::basic_string<char>]':
./caffe2/core/operator.h:192:5: required from 'const T& caffe2::OperatorBase::Input(int, caffe2::DeviceType) [with T = caffe2::Tensor; caffe2::DeviceType = c10::DeviceType]'
./caffe2/core/operator.h:890:48: required from 'const caffe2::Tensor& caffe2::Operator<Context>::Input(int, caffe2::DeviceType) [with Context = caffe2::CPUContext; caffe2::DeviceType = c10::DeviceType]'
./caffe2/sgd/adadelta_op.h:87:5: required from 'bool caffe2::SparseAdadeltaOp<Context>::RunOnDevice() [with Context = caffe2::CPUContext]'
./caffe2/sgd/adadelta_op.h:85:8: required from here
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h:722:32: warning: comparison of integer expressions of different signedness: 'const int' and 'const long unsigned int' [-Wsign-compare]
722 | DEFINE_CHECK_OP_IMPL(Check_LT, < )
| ^
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h:148:53: note: in definition of macro 'GOOGLE_PREDICT_TRUE'
148 | #define GOOGLE_PREDICT_TRUE(x) (__builtin_expect(!!(x), 1))
| ^
bazel-out/k8-fastbuild/bin/external/com_github_glog/_virtual_includes/glog/glog/logging.h:722:1: note: in expansion of macro 'DEFINE_CHECK_OP_IMPL'
722 | DEFINE_CHECK_OP_IMPL(Check_LT, < )
| ^~~~~~~~~~~~~~~~~~~~
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36196
Differential Revision: D20909696
Pulled By: malfet
fbshipit-source-id: 16723355f473379ba9da6d3c33bd561b9724800a
Summary:
This should be faster than allocating one mutex, flag and conditional variable per task.
Using `std::atomic<size_t>` to count remaing tasks is not sufficient,
because modification of remaining counter and signalling conditional variable must happen atomically,
otherwise `wait()` might get invoked after `notify_one()` was called.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36159
Test Plan: CI
Differential Revision: D20905411
Pulled By: malfet
fbshipit-source-id: facaf599693649c3f43edafc49f369e90d2f60de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36084https://github.com/pytorch/pytorch/pull/30330 added support to abort the call to a `RecvWork` created by `recvAnysource`, but there is an additional call to `pg_->recv()` to actually get the tensor sent over the wire (the previous call is the preamble for the tensor). This adds support to be able to abort this call as well in `::shutdown()`, which can be used to avoid hangs during ungraceful shutdown.
Added an internal test case in `ProcessGroupAgentTest` to ensure that an appropriate error message is raised when this happens.
ghstack-source-id: 101689402
Test Plan:
Added test in ProcessGroupAgentTest. We also add a basic config that allows us to control whether to abort the call to `pg->recv()` and `pg->recvAnysource()` in `FailingWaitProcessGroupGloo`.
Run test binary:
```buck build mode/dev-nosan //caffe2/torch/fb/distributed/thriftRpcBackend/test:ProcessGroupAgentTest --keep-going
~/fbcode/buck-out/gen/caffe2/torch/fb/distributed/thriftRpcBackend/test/ProcessGroupAgentTest
```
P128567144
Differential Revision: D20632764
fbshipit-source-id: c0b3c391fd3e0ae711661ad99f309ee4d93f6582
Summary:
This PR introduces frame ids that will allow us to associate profiling information with its corresponding run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33788
Differential Revision: D20164897
Pulled By: Krovatkin
fbshipit-source-id: 8172ff9f4d188b339e2ff98a80bbe4a2b306a8aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35849
This change harmonizes some aspects of the api.
- torch::utils::Future callback should have no args, like ivalue::future.
Many of the lines of this change are related to fixing that up downstream.
No args makes the api simpler to use, particularly since many/most of the
downstream use cases ignore the passed-in args. It's simple enough to
appropriately capture the future in the lambda if necessary.
- Add error/hasError methods to ivalue::Future.
- Use c10::optional underneath for error to ivalue::Future.
- Change markCompleted(error) to setError(error) to ivalue::Future.
- Add setValue(FutureError) version to torch::utils::Future
ghstack-source-id: 101684435
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D20803251
fbshipit-source-id: e3d925287bd9a80d649843eef5f270163f448269
Summary:
Full details in task: https://our.intern.facebook.com/intern/tasks/?t=64776265
With pytroch 1.5+ we remove python2 support from PyTorch. All documentation under docs/ and on the pytorch.org website needs to remove Python 2 references.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36114
Differential Revision: D20901746
Pulled By: jlin27
fbshipit-source-id: 07f8dc8e6fab0b232e5048a63079cab0c433c85f
Summary:
Resubmit of https://github.com/pytorch/pytorch/pull/35424, only this time I run optimizations in the right order so the PR description is actually true.
This speeds up the inlining pass of FairSeq model from 180s -> 13s, and MaskRCNN model from 5s -> 1.5s.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35562
Differential Revision: D20738922
Pulled By: eellison
fbshipit-source-id: 1439cf9d1f0bc780e2d64a744694f8b3b7ba4b70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36078
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20873442
Pulled By: ezyang
fbshipit-source-id: c576432b1016beb735dca0b9a8bebb752f764ca8
Summary:
Make it possible to report the C++ exceptions in console.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36039
Differential Revision: D20885968
Pulled By: ezyang
fbshipit-source-id: 6ad3822af31e5a64c4a93f16627fbefb7750e1c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35835
Make compilable with Clang 9 and GCC 9.
Test Plan: Compile with Clang 9 and GCC 9
Differential Revision: D20800182
fbshipit-source-id: dd9474640270de0ad6392641513a7f2fa970d6e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36082
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20874618
Pulled By: ezyang
fbshipit-source-id: b6f12100a247564428eb7272f803a03c9cad3a97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36005
Getting ovrsource pytorch working, requires single source list across ovrsource and fbsource to avoid build failures every time the source list changes.
This diff factors out libtorch_python_sources into a separate function (needs to be function because it uses glob which is disallowed at global scope)
Test Plan: CI
Reviewed By: malfet
Differential Revision: D20852072
fbshipit-source-id: 0e8ae3f6605e090e3ffdd6aa227fac905e7d9877
Summary:
NCCL library is built using [CUDA separate compilation](https://devblogs.nvidia.com/separate-compilation-linking-cuda-device-code/), which consists of building intermediate CUDA binaries and then linking them into GPU code that could be executed on device. Intermediate CUDA code is stored in `__nv_relfatbin` section, and code that can be launched is stored in `.nv_fatbin`. When `nvcc` is used to link executable/shared library, it removes those intermediate binaries, but default host linker is not aware of that and therefore it is kept inside host executable. Help compiler by removing `__nv_relfatbin` sections from object file inside `libncc_static.a`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35843
Test Plan: Build pytorch with CUDA and run `test_distributed.py`
Differential Revision: D20882224
Pulled By: malfet
fbshipit-source-id: f23dd4aa416518324cb38b9bd6846e73a1c7dd21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36094
The condition variable waiting in the RPC retry thread must be notified after setting the atomic running to False. This will cause ensure the thread is joinable, and allow `rpc.shutdown` to function correctly
ghstack-source-id: 101538860
Test Plan: build bot
Differential Revision: D20854763
fbshipit-source-id: b92050712a1e6c31d4dd3b3d98f32ef8dee0f2f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35731
Changes relu and relu6 to point to the functional implementations here.
The previous behavior tested the time to create the module, but didn't actually run the
function (I noticed this when adding the new input sizes and seeing
the measured time not change).
Test Plan:
run the benchmark, the time now changes as expected with input size for
these.
Imported from OSS
Differential Revision: D20875542
fbshipit-source-id: 3a6278a7a861437d613c1e30698a58175a8e8555
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35729
* there were a few quantized activations which had implementations but not benchmarks, adds them
* adds the input sizes from `unary_tests.py` here, so we can compare fairly from fp to quantized implementations of activations
Test Plan:
```
python -m pt.qactivation_test
```
Imported from OSS
Differential Revision: D20875544
fbshipit-source-id: f55a66422233b96f0791c85b05476596d5d72b5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34753
This improves support for exceptions and capturing stack traces in caffe2 async nets. We generally want to use exceptions everywhere we can in order to preserve stack information. It also makes the exception timestamp more accurate so multiple exceptions at the same time can be correctly ordered.
Test Plan: Updated the tests to use the new error semantics + adds a test to ensure the stack is correctly propagated through deferrable async scheduling.
Reviewed By: andrewwdye
Differential Revision: D20449887
fbshipit-source-id: 047fdf1bd52fd7c7c1f3fde77df9a27ed9e288e7
Summary:
Enables bfloat16 type for add_out of sparse tensors. Also enabled it for coalesce() which is used in unit test reference checking.
iotamudelta ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35978
Differential Revision: D20874142
Pulled By: ezyang
fbshipit-source-id: af8d2f4bc5f5cc3bb7f8cb1e3c688669ba3d13b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35474
I had previously tried to optimize getMutableTypePtr calls by not recursing through container types, but it turns out there are a few uses of container types which refine their contained elements.
This attempt was in #35301
Now I am optimizing calls by caching TypePtr -> Mutable TypePtr conversions. Now that we are doing caching none of the functions marked as const are really const anymore. Previously many of the const functions actually mutated internal state, such as rebuildWriteCache.
one kind of annoying thing is that there is a general api for querying mutability isMutableType that doesn't use the cache, and one internal that does, isMutableTypeInternal. It would be nice if I could call isMutableType within alias analysis and it would dispatch to the internal function, but I'm not sure how to do that.
getMutableTypePtr showed up as 12% of the first run of FairSeq, so this is a function worth optimizing.
Test Plan: Imported from OSS
Differential Revision: D20873493
Pulled By: eellison
fbshipit-source-id: 1b42bb58ba4142c118a6bc47a26978cd7fd0ac79
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/36002
Test Plan: Run cmake and observe there are no warning in stdout nor in `CMakeCache.txt`
Differential Revision: D20872854
Pulled By: malfet
fbshipit-source-id: 8a61b63b3d564e597e7a62dd913c97bc64b183b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35885
For the ops I added recently, ensure all the typehints are
present, so that JIT can script them.
We might want to look into a test for this in the future.
Test Plan:
scripting works for all of them now:
https://gist.github.com/vkuzo/1d92fdea548ad596310fffcbe95e4438
Imported from OSS
Differential Revision: D20818431
fbshipit-source-id: 0de61eaf70c08d625128c6fffd05788e6e5bb920
Summary:
allwu Leave it to you for further investigation and enable it back.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36053
Differential Revision: D20865286
Pulled By: lly-zero-one
fbshipit-source-id: b3e44b1343b66944aaa5a0a3909c8b5e9390c52f
Summary:
Fixing size, as the aten op has updated to support 0 inputs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35984
Reviewed By: hl475
Differential Revision: D20858214
Pulled By: houseroad
fbshipit-source-id: 8ad0a0174a569455e89da6798eed403c8b162a47
Summary:
When applying the float16 dynamic quantization with
```
model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.float16
)
print(model)
```
there is an issue when we try to print the model. Basically we cannot print the `qscheme` information for float16 weight (It is not per-tensor or per-channel quantization defined for int8 dynamic quantization).
Before this PR:
```
Traceback (most recent call last):
File "dlrm_s_pytorch.py", line 860, in <module>
print(dlrm)
File "/home/jianyuhuang/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1142, in __repr__
mod_str = repr(module)
File "/home/jianyuhuang/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1142, in __repr__
mod_str = repr(module)
File "/home/jianyuhuang/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1136, in __repr__
extra_repr = self.extra_repr()
File "/home/jianyuhuang/miniconda3/lib/python3.7/site-packages/torch/nn/quantized/dynamic/modules/linear.py", line 55, in extra_repr
self.in_features, self.out_features, self.weight().qscheme()
RuntimeError: Could not run 'aten::qscheme' with arguments from the 'CPUTensorId' backend. 'aten::qscheme' is only available for these back
ends: [QuantizedCPUTensorId, VariableTensorId].
```
After this PR:
```
(4): DynamicQuantizedLinear(
in_features=2, out_features=1, dtype=torch.float16
(_packed_params): LinearPackedParams()
)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36044
Differential Revision: D20860811
Pulled By: jianyuh
fbshipit-source-id: d1405a185f46a8110e6d27982b40534c854f4d1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36007
Tracing is not needed in Pytorch Mobile client. Disabling it has a couple of benefits:
1. It's a pre-requisite to build lite interpreter.
2. It saves the code size for full jit and Federated learning (around 600k).
Solution: use PYTORCH_DISABLE_TRACING to disable it. It's better than passing an argument to code-gen because:
1. It's a single-point change in the code template for both VariableType and VariableFactories.
2. code-gen does not handle VariableTypeManual.cpp. The macro is need there anyway.
ghstack-source-id: 101529401
Test Plan: CI
Reviewed By: ljk53
Differential Revision: D20852558
fbshipit-source-id: c28cec9f90208974acfa351ec9aec3fabbbb8aac
Summary:
Notes:
1. didn't name them as _copy_real and _copy_imag because it's desirable (but not necessary) to have these methods as tensor methods.
2. replaced old .real() and .imag() instances with _copy_real() and _copy_imag() methods
3. didn't add documentation because we plan to remove these methods when we add real and imag as tensor attributes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35879
Differential Revision: D20841760
Pulled By: anjali411
fbshipit-source-id: 7267e6fbaab9a5ce426e9396f12238994666b0dd
Summary:
There was a permutation operation missing in each of the complex vector files. I also added some test cases, the last two of which fail under the current implementation. This PR fixes that: all the testcases pass.
Fixes https://github.com/pytorch/pytorch/issues/35532
dylanbespalko
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35715
Differential Revision: D20857024
Pulled By: anjali411
fbshipit-source-id: 4eecd8f0863faa838300951626f26b89e6cc9c6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35411
The file and class names in ATen/core/boxing were quite confusing.
Let's rename them for readability.
Also move function schema inference out of the boxing logic into op_registration.h where it belongs.
ghstack-source-id: 101539206
Test Plan: waitforsandcastle
Differential Revision: D20653621
fbshipit-source-id: 6a79c73d5758bee1e072d543c030913b18a69c7c
Summary:
This supersedes https://github.com/pytorch/pytorch/pull/35698.
`abs` is a C-style function that takes only integral argument
`std::abs` is polymorphic and can be applied to both integral and floating point types
This PR also increases `kBatchSize` in `test_optimizer_xor` function in `test/cpp/api/optim.cpp` to fix `OptimTest.XORConvergence_LBFGS` failure under ASAN.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35974
Test Plan: CI
Reviewed By: pbelevich
Differential Revision: D20853570
Pulled By: yf225
fbshipit-source-id: 6135588df2426c5b974e4e097b416955d1907bd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35994
prim::rpc_async was optimized out if we don't takes its returned future and wait on the future.
Test Plan: `
Differential Revision: D7850846
fbshipit-source-id: e4e46506ab608f2e072027d6c10c49a4d784b14a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35193
PR #34275 / D20266240 caused size regression.
PR #35148 / D20578316 reverted partially to fix the regression.
With buck selective build landed it should no longer cause size regression. This diff relands the reverted part of the original diff.
ghstack-source-id: 100641910
Test Plan: CI
Differential Revision: D20586305
fbshipit-source-id: 6f314d6c13d1a557b314123a5ca350ab88441e95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34249
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20834164
Pulled By: bhosmer
fbshipit-source-id: 67586512df6b30869a8a77149fde6ff27beab81e
Summary:
Looks like the branch was force pushed, lets update this to a commit that exists
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35988
Differential Revision: D20849115
Pulled By: seemethere
fbshipit-source-id: 2f1202dcddef834d0b75a46e1202aa30b0176ac9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35168
Sometimes when a saved model isn't working, it's nice to be able to look
at the contents of the pickle files. Unfortunately, pickletools output
isn't particularly readable, and unpickling is often either not possible
or runs so much post-processing code that it's not possible to tell
exactly what is present in the pickled data.
This script uses a custom Unpickler to unpickle (almost) any data into
stub objects that have no dependency on torch or any other runtime types
and suppress (almost) any postprocessing code.
As a convenience, the wrapper can search through zip files, supporting
command lines like
`python -m torch.utils.show_pickle /path/to/model.pt1@*/data.pkl`
When the module is invoked as main, we also install a hack in pprint to
allow semi-resonable formatting of our stub objects.
Test Plan: Ran it on a data.pkl, constants.pkl, and a debug pkl
Differential Revision: D20842550
Pulled By: dreiss
fbshipit-source-id: ef662d8915fc5795039054d1f8fef2e1c51cf40a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35892
A couple recent property additions were missing, plus we weren't
distinguishing between defaults and bona fide property values.
Test Plan: Imported from OSS
Differential Revision: D20834147
Pulled By: bhosmer
fbshipit-source-id: 26a7e433414e0cde1eee2a9a67472f03ba970897
Summary:
Just run `./tools/clang_format.py --verbose` and `git commit --all`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35969
Test Plan: CI
Differential Revision: D20845626
Pulled By: malfet
fbshipit-source-id: 0ae9a91dfa33417a021e7e9d233baba4188daf81
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35951
Change generate_code to keep folder structure the same regardless of whether install path is provide
Amend build_variables.bzl accordingly
Another preliminary step to merge https://github.com/pytorch/pytorch/pull/35220
Test Plan: CI
Reviewed By: EscapeZero, seemethere
Differential Revision: D20839410
fbshipit-source-id: 02297560a7e48aa7c6271f7a8517fc4a1ab35271
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35913
The pass itself is still disabled by default, but with this change we
don't need to register it as a custom pass anymore. It allows us to
control its behavior with env variables more easily.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D20827189
Pulled By: ZolotukhinM
fbshipit-source-id: e74d90b5e46422e7ab7bc40974a805220da50fbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35763
Adds inference function and test for ScatterAssign
Test Plan: Updated unit test
Reviewed By: yyetim, shunting1986
Differential Revision: D20501079
fbshipit-source-id: 7ec6ef0127a151250dd699c90c2b80c35cfb1fe4
Summary:
This enables the serialization part of this change (the deserialization stuff is already landed #33255)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35741
Pulled By: driazati
Differential Revision: D20758124
fbshipit-source-id: e2cdefa99c3bec991491e5e967e7f1661ca7ffd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35904
Currently this optimization means transform conv2d and linears to
prepacked(xnnpack) equivalent.
Test Plan: buck run fbsource//xplat/caffe2:optimize_for_mobile -- --model="/tmp/inpainting_fbnet.pt"
Reviewed By: AshkanAliabadi
Differential Revision: D20824433
fbshipit-source-id: 88d5c0d21b77911f95f018b03398b0df758ab0d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35903
Eval mode must be set for module freezing, which is required for prepack
folding.
Test Plan: Test locally by transforming a model. As shown in the diff above this one.
Reviewed By: AshkanAliabadi
Differential Revision: D20824420
fbshipit-source-id: 6c226f44cca317b0333fb580ebbfd060128ae919
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35190
The following are the main changes:
- The main logic of C++ API parity test mechanism is moved from `test/test_cpp_api_parity.py` to `test/cpp_api_parity/module_impl_check.py` and `test/cpp_api_parity/functional_impl_check.py`, so that there is a clear separation between module tests and functional tests, although they still share a lot of common utility functions which are all in `test/cpp_api_parity/utils.py`.
- Module init tests (i.e. testing whether C++ module accepts the same constructor options as the corresponding Python module) is removed and will be added again in the future.
- `cpp_constructor_args` / `cpp_options_args` / `cpp_function_call` are added as appropriate to all test params dict in `torch/testing/_internal/common_nn.py`, to indicate how to run C++ API parity test for this test params dict.
Test Plan: Imported from OSS
Differential Revision: D20588198
Pulled By: yf225
fbshipit-source-id: 11238c560c8247129584b9b49df73fff40c4d81d
Summary:
Some more cleanup now that we no longer support python2 or 3.5 on master and eventually PyTorch 1.6 release.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35677
Differential Revision: D20838097
Pulled By: orionr
fbshipit-source-id: 95d553a1e8769f3baa395e0bc6d4ce7cd93236e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35916
quantize_per_tensor can now accept list of tensors.
Needed for operators like LSTM and cat
Test Plan: Imported from OSS
Differential Revision: D20830388
fbshipit-source-id: 73f81cf6b7c7614ef19a73b721bc57cf33211345
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35894
Insert new TensorListObserver only for weight input of dynamic LSTM
This is because we are currently not observing the activation inputs in graph mode.
Activation tensors are dynamically quantized within the aten::qlinear_dynamic op
Test Plan:
python test/quantization/test_quantize_script.py
Imported from OSS
Differential Revision: D20830387
fbshipit-source-id: 81bd197ee509df41bd7622ed09fa3f199a37573b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35893
LSTM operator inputs have tensor list for activations and weights.
In graph mode we need a new observer to work with tensor list
Test Plan:
python test/quantization/test_quantization.py ObserverTest
Imported from OSS
Differential Revision: D20830389
fbshipit-source-id: 4790f8932ae3d38446c1d942a2b3780aa91e3022
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35943
This change will add message to tell why the concrete Module type is not a subtype of the Interface type, by telling the missing method name. For example, users may have forgot to tag that method with torch.jit.export.
Test Plan: `
Differential Revision: D7993693
fbshipit-source-id: 1a5b1d9ef483e5e120ab53c2427586560fbb9bcd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35422
This would make `intdiv_256` a much more generic template that can easily accommodate other types of binary operators in the future. The operator becomes "out-of-place" because this would make it easier to substitute with other operators, and compilers should have no problem optimizing this.
Test Plan: Imported from OSS
Differential Revision: D20826861
Pulled By: ngimel
fbshipit-source-id: a6d0706cc1a585063426e988d9982bad402a9b36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35339
CPU version converts integers to their unsigned version first. The CUDA
version should also do it.
Also added tests for this.
Test Plan: Imported from OSS
Differential Revision: D20826862
Pulled By: ngimel
fbshipit-source-id: 164c84cfd931d8c57177a038c1bb8b6f73134d07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35422
This would make `intdiv_256` a much more generic template that can easily accommodate other types of binary operators in the future. The operator becomes "out-of-place" because this would make it easier to substitute with other operators, and compilers should have no problem optimizing this.
Test Plan: Imported from OSS
Differential Revision: D20824641
Pulled By: ngimel
fbshipit-source-id: ec93f7b23eb7196f3791f4d07092ce12c254b6e0
Summary:
It needs a hint how to hash `enum class` in `std::unordered_map`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35935
Test Plan: CI
Differential Revision: D20837750
Pulled By: malfet
fbshipit-source-id: 4208ee4bfa2e3cfbedf5b92bf18031225bf9dfa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35350
Currently we call input.contiguous() on the input tensor resulting in an
unecessary allocation and copy in cases where the input is not contiguous
with regards to the requested memory format. The reason is that in such
scenarios, this call re-allocates and copies the input tensor into
contiguous storage, only for this newly allocated tensor to be used as
the source of another copy to the final destination. Instead, if we copy
into the destination directly in such circumstances, we will save an
allocation and a copy.
Differential Revision: D20656798
Test Plan: Imported from OSS
Pulled By: AshkanAliabadi
fbshipit-source-id: 3f8c51df4d1fd386fa9473e7024621a7b7c6e86c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35850
1. Clamping values were not being propagated through all the structures
and hence were not being serialized.
2. Moved to using Scalar for min/max instead of float. Reason being, the
fusion for hardtanh_ does not work. During sub graph rewrite we direct
values from hardtanh_ to preacking ops, but since they expect float
values, the types conflict and we cannot serialize the model.
Test Plan: Imported from OSS
Differential Revision: D20807523
fbshipit-source-id: 57d6b2e4b65afd9510a0f3ba9365333b768977f5
Summary:
In Summary specify whether CUDA code is compiled with separate compilation enabled
Also, correctly handle space-separate TORCH_NVCC_FLAGS when adding them to NVCC_CUDA_FLAGS
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35726
Test Plan: CI + local build with TORCH_NVCC_FLAGS set to "-Xfatbin -compress-all"
Differential Revision: D20830885
Pulled By: malfet
fbshipit-source-id: 0e0ecab4a97b6c8662a2c4bfc817857da9f32201
Summary:
Clear profiling information before it gets used by passes before guard insertion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35814
Differential Revision: D20800599
Pulled By: Krovatkin
fbshipit-source-id: 978d71c22e1880dc888e7e75e7c25501c573333f
Summary:
The image is actually using Python 3.7.2 so we should reflect that
within our circleci configs
Should fix any issues related to `libtorch*gcc5_4` jobs.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35912
Reviewed By: orionr
Differential Revision: D20827149
Pulled By: seemethere
fbshipit-source-id: 72917b35f6d176ce1f5bc999d6808b9f1d9944f2
Summary:
Per title. Tests of integer division are unchanged.
The intent of this PR is to eliminate warning noise as users see our integer div deprecation warning and try to update their programs to be conformant. In particular, some CUDA indexing operations could perform a deprecated integer division, possibly confusing users.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35862
Differential Revision: D20817957
Pulled By: mruberry
fbshipit-source-id: b9fa15922c9bcea3cb08c0402ea2515feec137c9
Summary: aten::dequantize.self is the only missing op in spark spot int8 model
Test Plan: same as D20761873
Reviewed By: iseeyuan
Differential Revision: D20785654
fbshipit-source-id: 19a3394370af58012ed0dedcc458f3633d921527
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35848
This class so far was used from Python binding only. As a result, testing in c++ only environment is not currently possible. More specifically, adding inputs requires using
py::args and py::kwargs. This PR fixes this by adding another addInput function to ScriptModuleBenchmark class.
Test Plan: Imported from OSS
Differential Revision: D20820772
Pulled By: ilia-cher
fbshipit-source-id: f1ea1b7baa637b297cc0dec5ca6375f6caff21f5
Summary:
The original behavior of pytorch c10d only supports built-in c10d backends, such as
nccl/gloo/mpi. This patch is used to extend the c10d capability to support dynamically
loading 3rd party communication libraries which are derived from ProcessGroup base class.
related RFC is in: https://github.com/pytorch/pytorch/issues/27955
Through this way, user just need specify a 3rd party c10d backend name when invoking
torch.distributed.init_process_group(). The proposed logic will try to load corresponding
c10d backend cpp extension automatically. as for how to develop a new 3rd party c10d backend
through cpp extension, pls refer to test/cpp_extensions/cpp_c10d_extension.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28068
Differential Revision: D19174838
Pulled By: agolynski
fbshipit-source-id: 3409a504a43ce7260e6f9d1207c00e87471fac62
Summary: Properly load node inputs as placeholders during onnxifi checkGraphCompatibility only if they are non-weigth inputs to the node
Test Plan:
`buck test glow:`
PASS: 2286
FAIL: 0
SKIP: 456
Reviewed By: jfix71
Differential Revision: D20823088
fbshipit-source-id: 76215b2c0c3934e36714201c7e716e8f95463e6d
Summary:
Someone messaged me abt this when a better error msg would have solved their problem
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35888
Differential Revision: D20819538
Pulled By: eellison
fbshipit-source-id: 95d124bfd162e1747dcdf7a981703a279a5dfaa6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35794
### Summary
As PyTorch has gone in production on iOS for about week, we've spotted a few crashes (90 out of 20.3k ) related to DispatchStub.h. The major part of the crash log is pasted below (full crash information can be found at `bunnylol logview 1d285dc9172c877b679d0f8539da58f0`):
```
FBCameraFramework void at::native::DispatchStub<void (*)(at::TensorIterator&, c10::Scalar), at::native::add_stub>::operator()<at::TensorIterator&, c10::Scalar&>(c10::DeviceType, at::TensorIterator&, c10::Scalar&)(DispatchStub.h:0)
+FBCameraFramework at::native::add(at::Tensor const&, at::Tensor const&, c10::Scalar)(BinaryOps.cpp:53)
+FBCameraFramework at::CPUType::add_Tensor(at::Tensor const&, at::Tensor const&, c10::Scalar)(CPUType.cpp:55)
+FBCameraFramework at::add(at::Tensor const&, at::Tensor const&, c10::Scalar)(Functions.h:1805)
+FBCameraFramework [inlined] c10::intrusive_ptr<c10::TensorImpl, c10::UndefinedTensorImpl>::intrusive_ptr(c10::intrusive_ptr<c10::TensorImpl, c10::UndefinedTensorImpl>&&)(intrusive_ptr.h:0)
+FBCameraFramework [inlined] c10::intrusive_ptr<c10::TensorImpl, c10::UndefinedTensorImpl>::intrusive_ptr(c10::intrusive_ptr<c10::TensorImpl, c10::UndefinedTensorImpl>&&)(intrusive_ptr.h:221)
+FBCameraFramework [inlined] at::Tensor::Tensor(at::Tensor&&)(TensorBody.h:93)
+FBCameraFramework [inlined] at::Tensor::Tensor(at::Tensor&&)(TensorBody.h:93)
+FBCameraFramework c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >::operator()(at::Tensor, at::Tensor, c10::Scalar)(kernel_lambda.h:23)
+FBCameraFramework [inlined] c10::guts::infer_function_traits<c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> > >::type::return_type c10::detail::call_functor_with_args_from_stack_<c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >, false, 0ul, 1ul, 2ul>(c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >*, std::__1::vector<c10::IValue, c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >*::allocator<std::__1::vector> >*, c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >*::integer_sequence<unsigned long, 0ul, 1ul, 2ul>)(kernel_functor.h:210)
+FBCameraFramework [inlined] c10::guts::infer_function_traits<c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> > >::type::return_type c10::detail::call_functor_with_args_from_stack<c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >, false>(c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >*, std::__1::vector<c10::IValue, c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >*::allocator<std::__1::vector> >*)(kernel_functor.h:218)
+FBCameraFramework c10::detail::make_boxed_from_unboxed_functor<c10::detail::WrapRuntimeKernelFunctor_<(anonymous namespace)::$_3, at::Tensor, c10::guts::typelist::typelist<at::Tensor, at::Tensor, c10::Scalar> >, false, void>::call(c10::OperatorKernel*, c10::OperatorHandle const&, std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >*)(kernel_functor.h:250)
+FBCameraFramework [inlined] (anonymous namespace)::variable_fallback_kernel(c10::OperatorHandle const&, std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >*)(VariableFallbackKernel.cpp:32)
+FBCameraFramework void c10::KernelFunction::make_boxed_function<&((anonymous namespace)::variable_fallback_kernel(c10::OperatorHandle const&, std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >*))>(c10::OperatorKernel*, c10::OperatorHandle const&, std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >*)(KernelFunction_impl.h:21)
+FBCameraFramework torch::jit::mobile::InterpreterState::run(std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >&)(interpreter.cpp:0)
+FBCameraFramework torch::jit::mobile::Function::run(std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >&) const(function.cpp:59)
+FBCameraFramework torch::jit::mobile::Module::run_method(std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >)(module.cpp:51)
+FBCameraFramework [inlined] torch::jit::mobile::Module::forward(std::__1::vector<c10::IValue, std::__1::allocator<c10::IValue> >)(module.h:28)
```
The problem is `compare_exchange_weak` is not guaranteed to be successful in one shot, as described in [C++ Concurrency in Action (2nd Edition)](https://livebook.manning.com/book/c-plus-plus-concurrency-in-action-second-edition/chapter-5/79). This might result in `cpu_dispatch_ptr` being null pointer in concurrent situations, thus leading to the crash. As suggested in the book, due to spurious failure, the `compare_exchange_weak` is typically used in a loop. There is also a [stackoverflow discussion](https://stackoverflow.com/questions/25199838/understanding-stdatomiccompare-exchange-weak-in-c11) about this. Feel free to drop comments below if there is a better option.
### The original PR
- [Enhance DispatchStub to be thread safe from a TSAN point of view](https://github.com/pytorch/pytorch/pull/32148)
### Test Plan
- Keep observing the crash reports in QE
Test Plan: Imported from OSS
Differential Revision: D20808751
Pulled By: xta0
fbshipit-source-id: 52f5c865b70c59b332ef9f0865315e76d97f6eaa
Summary:
This is mostly just so VS Code will stop yelling at me.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35765
Differential Revision: D20787435
Pulled By: robieta
fbshipit-source-id: c8173399328e6da60a07bfcb4b62e91f7f4fe34a
Summary:
This variable hasn't been updated in a long time since it usually just
gets overwritten by whatever is in the setup.py but let's set the
default to something a bit more in-line with what we're actually
building.
Closes https://github.com/pytorch/pytorch/issues/35210
cc ksasso1028
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35260
Differential Revision: D20818302
Pulled By: seemethere
fbshipit-source-id: 530fe137e45be1d0ac0233525c80f7099c17b05a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35834
This handles the cases we did not handle before in AND and OR statements:
static_true || <unknown> -> static_true
static_false && <unknown> -> static_false
Test Plan: Imported from OSS
Differential Revision: D20801125
Pulled By: zdevito
fbshipit-source-id: 0ef94c3a14c7af91580fc5248a4ccfd9e8d6d481
Summary:
qadd calls contiguous on input tensors. This by default does contiguous in NCHW
format (for 4D tensors). We should call
.contiguous(input.suggest_memory_format())
Output allocation also done NCHW format. This results in the subsequent conv
having to do memcpy for NHWC format.
Both of this leads to majority of the time spent in qadd in copying in FBNET_A
model.
Fixing these reduces runtime on S8 phone to 15ms from 17. Reducing the gap
between c2 and PT latency from ~24% to ~9.5%.
Also note that the contract for ops is that they return output tensor in same
format as the input memory format.
Test Plan:
Apply on top of diff D20721889.
bento console --file mobile-vision/projects/model_zoo/scripts/run_create_model_benchmark.py
Note: There are many calls to .contiguous without format specification in
aten/src/ATen/native/quantized/cpu.
All those should be replaced with .contiguous(input.suggest_memory_format())
whenever applicable (Most likely applicable to all elementwise ops)
Also same should apply for output allocation.
Reviewed By: dreiss
Differential Revision: D20794692
fbshipit-source-id: 6b81012497721d48e7d6a5efcc402f315b1dfe77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35800
This PR includes the following changes:
* Introduce a new `Expr` type `Buf`: it plays a similar to `Var` role, but also has dimensions.
* Use the new `Buf` class in `Store` and `Load` instead of `Var` for specifying where to store to or load from. `Buf` contains the dimensions info of the buffer we're loading/storing to and hence we are able to keep N-d indexes without flattening them into a 1-d index ([x,y] vs [x+y*W]).
* Flattening of the indexes is now a separate pass that is executed in `LoopNest::prepareForCodegen` - backends still expect indexes to be flattened, and this PR preserves that.
* `Tensor` now contains a `Buf` instead of `Var`, and thus Tensor now has the dimensions info (previously it was a property of a `Function`, not a `Tensor`). This brings us closer to Tensor being a combination of Buffer + Function, where Buffer specifies iteration domain and the Function defines a computation.
TODOs:
* Consider merging `Buffer` with `Buf` or `BufHandle`. It seems that we don't need all of them.
* Harden the logic of how we create buffers in fuser pass. Currently it seems that sometimes we don't set dimensions.
* Use `Buf` in `Allocate` and `Free`.
* Make it clearer that `Function` doesn't "own" dimensions info and that dimensions are a property of a Tensor, not a Function.
Differential Revision: D20789005
Test Plan: Imported from OSS
Reviewed By: zheng-xq
Pulled By: ZolotukhinM
fbshipit-source-id: e04188d1d297f195f1c46669c614557d6bb6cde4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35857
This fixes a lot of common ops for InferBlobShapesAndTypes as well as adds support for testing the inferred shapes and types of gradient ops.
Ops:
* Concat
* Split
* LeakyReLU
* Relu
* Prelu
* Gelu
* Elu
* Sinh, Tanh, Cosh
* Abs
* ... and a number of other simple element wise ops
Test Plan:
Added support to hypothesis test to check the shape and type of gradient ops.
Enabled it for all the ops I fixed the shape and type inference for.
buck test caffe2/caffe2/python/operator_test:
Reviewed By: pradeepd24
Differential Revision: D20806284
fbshipit-source-id: 77f796d9ff208e09e871bdbadf9a0a7c196b77f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35740
For one of the quantized CV model, the avg_pool3d operation is more than 6x slower than C2 implementation. The reason behind this comes from the following aspects:
- function access inside the loop (such as ```q_scale()``` and ```q_zero_point()```)
- additional data copy in ```Vec256::store``` and ```at::quantize_vec```
This diff resolves the above issue with the following measures:
- lift function access outside the loops
- add an 8-lane path in ```QuantizeAvx2``` to replace ```at::quantize_vec```
- in addition, interchanges c-loop to the innermost for better memory locality.
Test Plan:
buck test //caffe2/test:quantized
Performance Before (n x h x w x c = 4 x 56 x 56 x ch):
```
type c=2 c=4 c=15 c=24 c=48 c=128 c=256
torch.qint8 903.08 us 1373.39 us 2297.97 us 636.72 us 864.98 us 1618.72 us 2908.47 us
torch.quint8 911.93 us 1429.39 us 2315.59 us 623.08 us 844.17 us 1522.28 us 2711.08 us
torch.qint32 897.77 us 1346.97 us 3846.41 us 6211.92 us 11977.74 us 34348.23 us 62927.48 us
```
Performance After:
```
type c=2 c=4 c=15 c=24 c=48 c=128 c=256
torch.qint8 123.29 us 176.00 us 348.90 us 99.02 us 132.73 us 267.17 us 513.43 us
torch.quint8 123.76 us 171.90 us 338.17 us 97.92 us 131.06 us 260.09 us 521.16 us
torch.qint32 102.97 us 172.57 us 559.31 us 814.03 us 1606.11 us 4164.89 us 10041.52 us
```
Reviewed By: lly-zero-one
Differential Revision: D20711888
fbshipit-source-id: a71dd55639500f4a036eee96c357737cff9d33db
Summary:
**Summary:** This PR contains the infrastructure of a new CUDA fuser. This CUDA fuser is based on many of the same principles of TensorExpressions and Halide, however the implementation is ground up. The fusion pass itself is similar to the default CUDA fuser, however, it has undergone some refactoring and is using the new code generation infrastructure. For those who are interested in how the code generation in this PR works, I would recommend reviewing _test/cpp/jit/test_gpu_fusion.cpp_ as well as the long comment section at the beginning of _torch/csrc/jit/codegen/cuda/transform_replay.h_ One of the largest differences between our approach and that of TVM/Halide, is the concept of "TensorView". TensorView from a high level should be thought of similarly to how we think of working with Tensors in PyTorch. It's an N-D object which can undergo transformations that change its dimensionality. Dimensionality changes are done through the operations split/merge/reorder/computeAt. These transformations are similar to split/fuse/reorder/compute_at of TVM, they modify how a tensor is iterated over to generate GPU code. Interestingly, in our scheme these transformations are applied to tensors and only impact how that tensor is generated.
**Warning:** This PR is purposefully not feature complete with the current fuser. We wanted to separate out the infrastructure from the fusion capabilities. Once in, smaller incremental PRs will be submitted to expand capabilities of the fuser.
**Short term goals:**
Parity with current CUDA fuser (including performance):
- Dynamic shapes (no recompilation)
- Implicit handling of braodcast (broadcasted tensors are treated as tensors of the braodcasted size in the generated code)
- Dropout
**Mid-term goals:**
- Transposes fused with pointwise operations where transpose involves only 2 axes (across the fused operation).
- 1-D reductions fused with pointwise operations
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34785
Reviewed By: ZolotukhinM
Differential Revision: D20650977
Pulled By: soumith
fbshipit-source-id: ee39c95a880e1b9822e874ed4cc180971572bf63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35714
There are a lot of unboxed only defs. We're committed to removing
them at the end of the half but as I am about to do a lot of porting
to the new API, let's get them into a form where they're easy to
remove. This is a new overload impl_UNBOXED that will pass
the function pointer straight to CppFunction::makeUnboxedOnly
I don't attempt to make the _UNBOXED API complete; in particular,
catchall declarations don't get this sugar (as there are very few
of them).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20775782
Pulled By: ezyang
fbshipit-source-id: c5e804c69f5961c9d4862f6c5dbbe4c524cc32cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35706
It is extremely common to define implementations of operators at a
specific dispatch key, so we add an overload to impl specifically for
this case. I then delete most uses of torch::dispatch
dispatch_autograd call sites can't make use of this overload. So
instead the new preferred way to specify something as autograd is to
pass kAutograd as the dispatch key (short form, analogous to kCPU/kCUDA
which we support today).
I flip flopped about whether or not kAutograd should have the type
DispatchKey or some other type (to help better encapsulate the
DispatchKey enum); this is more direct and I can't think of any
BC problems from this usage.
Some other reorganization I did:
- I renamed all of the worker functions in op_registration to have
a leading underscore and made them private, just to make it more
clear what the public versus private API were (the private API
shouldn't be used by users because it doesn't come with && overloads)
- In a few places where I was touching lines already, I replaced
full DispatchKey typed out enums with shorter kFoo names, similar
to kAutograd but I didn't publish these globally.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20775783
Pulled By: ezyang
fbshipit-source-id: e45b289e5d1f86c180b24cf14c63cf4459ab5337
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35838
It may be flaky.
Test Plan: Imported from OSS
Differential Revision: D20807409
Pulled By: gchanan
fbshipit-source-id: f085d05bcb6a04d304f3cd048c38d2e8453125d6
Summary:
Adds capabilities to the TensorExpr IR Simplifier to simplify down Round + Mod patterns (e.g. `(x/y)*y + x%y => x`) via means of lifting integer rounding into a temporary `RoundOff` node.
This integrates with existing simplification mechanisms (folding, factorization, reordering, etc) to allow simplification of compound expressions: e.g. `20 * (x / (16 / 2)) * 2 + (11 % 6) * (x % (7+1)) => 5 * x.`.
Tests: ran tensorexpr cpp and python tests, ran a hpc benchmark and verified results and time didn't regress.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35683
Differential Revision: D20811316
Pulled By: nickgg
fbshipit-source-id: 0cd6a517fb9548b3bc689768304b97375df5ac58
Summary:
Adding `test_tensorexpr.py` to our CI. There's a few complications: the first one is that we now always run `SimpleIREVal` as a part of simplifier, so the counts will always be greater than one. We can potentially invest some effort to differentiate between a real codegen call to `SimpleIREval` and calls in simplifier, but it's probably not that important and the second change to turn not being able to retrieve a counter into a default value of 0 since the test are structured to test for either an llvm or simpleireval backends, so it only seems appropriate to not fail the test too early.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35776
Differential Revision: D20799333
Pulled By: Krovatkin
fbshipit-source-id: 2a94ff98e647180c6e6aea141a411c3376c509f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35554
We attach a callback to our RPC send attempts that schedule a retry
upon failure. This PR only schedules the retry if the agent is running.
ghstack-source-id: 101332815
Differential Revision: D20612615
fbshipit-source-id: e1bbb3f162101bce7eb46bad512c9e5dc6d531cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35556
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35542
Apply explicit vectorization to lstm_unit operator.
Enabled by -DENABLE_VECTORIZATION=1
This optimization requires vector library support and was tested with Intel SVML & clang.
However, compiler which support OpenMP4.5 with omp simd extention should also benefit.
After the code changes
In file included from caffe2/caffe2/operators/lstm_unit_op.cc:1:
caffe2/caffe2/operators/lstm_unit_op.h:60:1: remark: vectorized loop (vectorization width: 8, interleaved count: 1) [-Rpass=loop-vectorize]
VECTOR_LOOP for (int d = 0; d < D; ++d) {
caffe2/caffe2/operators/lstm_unit_op.h:60:1: remark: vectorized loop (vectorization width: 8, interleaved count: 1) [-Rpass=loop-vectorize]
caffe2/caffe2/operators/lstm_unit_op.h:112:1: remark: vectorized loop (vectorization width: 8, interleaved count: 1) [-Rpass=loop-vectorize]
VECTOR_LOOP for (int d = 0; d < D; ++d) {
Test Plan:
Check failures at OSS CI
- No build failures related to this change
- Failing tests are:
- py3.6-clang7-rocmdeb-ubuntu16.04-test2
>RuntimeError: fft: ATen not compiled with MKL support
- caffe2_onnx_ort2_py3_6_clang7_ubuntu16_04_test -
>gradient_check_test.py::TestMakeTwo
Exited with code exit status 1
- pytorch_macos_10_13_py3_test , Test errors like:
> ERROR [0.014s]: test_boolean_indexing_weirdness_cpu (__main__.NumpyTestsCPU)
RuntimeError: shape mismatch: indexing tensors could not be broadcast together with shapes [0], [2]
- caffe2_onnx_ort1_py3_6_clang7_ubuntu16_04_test
- No failure info
Reviewed By: jspark1105
Differential Revision: D20484640
fbshipit-source-id: 8fb82dbd6698c8de3e0bbbc0b48d15b70e36ca94
Summary:
This PR would fix https://github.com/pytorch/pytorch/issues/35202, fix GPU part of https://github.com/pytorch/pytorch/issues/24823, be related to https://github.com/pytorch/pytorch/issues/24870.
Here is the origin of this problem.
1. Like those in https://github.com/pytorch/pytorch/issues/35202, with large numbers in grid like `grid.min() == -10059144 grid.max()==67680944`; or `nan, inf, 1.0E20` in https://github.com/pytorch/pytorch/issues/24823,
4d39aeec27/aten/src/ATen/native/cuda/GridSampler.cu (L309-L321)
`ix, iy` will be unnormalized to very large numbers, exceed the bound of INT_MAX.
Then, those `ix_nw, iy_nw` variables will be cast to INT_MAX, and some other variables with "+1" will be INT_MIN.
2. However, these INT_MAX, INT_MIN should not big problems, because
4d39aeec27/aten/src/ATen/native/cuda/GridSampler.cu (L358-L362)4d39aeec27/aten/src/ATen/native/cuda/GridSampler.cuh (L202-L205)
these `within_bounds_2d` functions are supposed to guard the if-statement, prevent the illegal memory access, and leave those output values as zero (padding_modes='zeros').
3. Now here comes the problem, `within_bounds_2d` is set to "inline". We found that those `+1` statement and `>=0` statement may cause compiler to "optimize" the code, that is:
```cpp
int B = something;
int a = something;
int b = a + 1;
bool r = (b >= 0 && b < B);
```
will be compiled into assembly code like
```cpp
int B = something;
int a = something;
bool r1 = (a > -2)
int b = a + 1;
bool r2 = (b < B);
bool r = r1 && r2;
```
This looks nice, but when a = INT_MAX, `a+1` causes Undefined Behavior. Typically, we get b = INT_MIN, then the boolean result from compiled assembly will be true. The `within_bounds_2d` no longer guards us from the illegal memory access.
4. There could be different ways to fix this bug. For example, we may set all of the "ix_nw, iy_nw" values to `int64_t`. That would be a potential performance issue, and doesn't prevent those examples in https://github.com/pytorch/pytorch/issues/24823 with 1E20 in grid.
One minimal fix that I found is to restrict `within_bounds_2d` from being inlined. Thus, compiler won't optimize those `a+1` and `a>=0` code together.
I did a short performace test, just to make sure this forced noinline solution won't cause regression. The performance script can be found at
a6f8bce522/grid-sample/grid-sample.ipynb.
For this `__attribute__((noinline))` macro, I have tested that on nvcc, and there was no problem. I'm not sure if that also works on clang.
cc csarofeen ptrblck ngimel bnehoran zasdfgbnm SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35506
Differential Revision: D20799304
Pulled By: ngimel
fbshipit-source-id: fc70289b35039fad954908a990ab0a2f16fbfcb2
Summary:
Otherwise, it will print some message when hipcc is not found.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35789
Differential Revision: D20793089
Pulled By: ezyang
fbshipit-source-id: 4b3cb29fb1d74a1931603ee01e669013ccae9685
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35476
A few things:
- Add new callUnboxedRedispatch function which can be used to do a
redispatch when you don't want to add a type id to the excluded
set. This will recompute the dispatch key but ignore everything
including and before the currentDispatchKey
- Add FULL_AFTER constructor to DispatchKeySet; used to implement
redispatch.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D20680518
Test Plan: Imported from OSS
Pulled By: ezyang
fbshipit-source-id: ecd7fbdfa916d0d2550a5b19dd3ee4a9f2272457
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35769
This fixes a bug where correct end user API usage can still trigger
a warning because we don't preserve the invariants DispatchTable
was previously expecting to be done. So now, OperatorEntry is
the source of truth, and it just whacks DispatchTable until its
the correct state. OperatorEntry does the user-facing checking.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20772383
Pulled By: ezyang
fbshipit-source-id: 167d249a826d7b02361ba0a44571813c829649c1
Summary:
ROCm 2.10 has a hdot implementation. Use it and enable test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30431
Differential Revision: D20776784
Pulled By: ezyang
fbshipit-source-id: a192a701eb418dac2015e300563ade691c24903e
Summary:
Since the last one was apparently reverted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35530
Differential Revision: D20777341
Pulled By: ezyang
fbshipit-source-id: 6aaaf2a0755359074ae3d0efe32018d78dafe976
Summary:
1- Added support for constant folding onnx::ReduceL1 and onnx::ReduceL2
2- Fixed constant folding for slice as onnx::Slice opset 11 supports negative axes and indices
3- Updated export of select opset 11
4- Separated test environment for test_utility_functions as environment variables could be overwritten by caffe2 quantization tests on CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35280
Reviewed By: hl475
Differential Revision: D20626140
Pulled By: houseroad
fbshipit-source-id: 39667c7852eeaa97d9da23f53da52760d3670ecf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35523
In this PR we extend ThreadLocalState to cover dispatch keys and
ThreadLocalDebugInfo and move it from JIT interpreter down to
thread management (at::launch) and autograd (backward threads) code
Test Plan: unit tests (CI)
Reviewed By: dzhulgakov
Differential Revision: D20615714
fbshipit-source-id: 16a9fc96a25cb6c2629230b1187fbf78786ac565
Summary: This diff fixes the issues with current handling of debug information passed along the execution of the model. (For example, it is possible that multiple calls to the debug guard may override each other)
Test Plan: CI test/cpp/jit
Reviewed By: dzhulgakov
Differential Revision: D20602775
fbshipit-source-id: 4683957954028af81a1a0f1f12b243650230c9bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35005
This is one of the ad-hoc IValue equality implementations that should be
replaced with `operator==`.
Test Plan: Imported from OSS
Differential Revision: D20537900
Pulled By: suo
fbshipit-source-id: 5f31ee2386f9d0b33f2bc047a39351191f4d81b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34986
Previously we were reluctant to define equality for IValues, as it's not
totally straightforward. But the vacuum this created basically forced
people to define their own equality comparisons for their own purposes.
We have at least 3 in PyTorch itself, and 2 others outside that I know
of.
These implementations are generally wrong, so we should just bite the
bullet and define equality canonically.
Test Plan: Imported from OSS
Differential Revision: D20537901
Pulled By: suo
fbshipit-source-id: 8d770a31bf6de6f3b38f9826bf898d62c0ccf34e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35720
When modules are saved, all relevant types are serialized according to
their qualified name with a compilation unit. Since qualified names are
guaranteed to be unique within a compilation unit, this normally works
fine.
On load, all types are registered in a compilation unit owned by the
script::Module. Type names are not unique across compilation units, so
if you load two modules with colliding type names, make them submodules
of yet another module, and save that module, there is the potential of a
name collision. See the added tests for examples if that description is
confusing.
The solution is to unique type names when serializing code by mangling
them if we detect a name collision.
Test Plan: Imported from OSS
Differential Revision: D20749423
Pulled By: suo
fbshipit-source-id: a8827ff1d4a89f3e7964dbbb49b4381863da3e6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35718
Because NamedType is not a concrete type (it's just an interface), it
has no corresponding TypeKind and thus no default `cast()` behavior.
Adding a specialization that does the right thing.
Test Plan: Imported from OSS
Differential Revision: D20749425
Pulled By: suo
fbshipit-source-id: 6ccab1cca26fd2b2805189fcf2305d99ae28145a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35717
We need to provide calling code the ability to customize how type names
are printed. Will be used to mangle names in python_print, stacked on
top.
Test Plan: Imported from OSS
Differential Revision: D20749424
Pulled By: suo
fbshipit-source-id: f110ab569c81e8934487295cd67009fc626ac194
Summary:
In NumPy, calling np.imag on a real-valued tensors returns a non-writable tensor (view) of zeros. In PyTorch we don't support non-writeable tensors (or views), so we can either return a writable tensor or error.
If we do the former, that may confuse people who try to write to the imaginary part of a real-valued tensor, and may cause a BC issue if we do support non-writable tensors. This PR errors to provide us flexibility implementation the solution we'd like in the future, while protecting users from unexpected behavior today.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35728
Differential Revision: D20760687
Pulled By: mruberry
fbshipit-source-id: f60d445746cc75ba558804c853993d9e4621dad3
Summary:
This is a follow up from https://github.com/pytorch/pytorch/pull/34520, which removed specialized list ops. This removes templating from list ops.
it also has one minor other change, which is to move `aten::len(t[]) -> int` to `aten::len(Any[]) -> int` so that heterogenous tuples can be called with `len()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35768
Differential Revision: D20772943
Pulled By: eellison
fbshipit-source-id: bc36a00920bc94ca8c5aa9eb7d5d7a640388ffbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35550
Avoid clearing data before copying into the string buffer in a few cases.
ghstack-source-id: 101020139
Test Plan: buck test mode/dev-nosan caffe2/test/cpp/jit/...
Differential Revision: D20699725
fbshipit-source-id: 14dce40dbebdd64fd0d60372cad1b642602205db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34109
This change adds glue to GraphExecutor to give the RPC server
access to the future-based Interpreter::runAsync() api.
Previously, if a server encounted a TorchScript continuation-based block
with fork/wait, it would simply block in the server thread until the handler
completed, since it uses the synchronous Interpreter::run() api.
With the ivalue::Future returned by the Interpreter, we can run the
TorchScript code asynchronously from c++ simply by connecting its
callback to the server callback.
We add test cases to cover the new logic, both rpc_async and remote.
ghstack-source-id: 101245438
Test Plan: buck test mode/dev-nosan caffe2/test/distributed/rpc/...
Differential Revision: D20194321
fbshipit-source-id: 16785ec5d9ed0b16cb1ffab0a9771a77de30fcb0
Summary:
These packages are now part of the base docker image.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35676
Differential Revision: D20777497
Pulled By: ezyang
fbshipit-source-id: aa9dba905dc376b1462910bc2c4a385d77d7aa0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35764
So that Glow knows what input is constant.
We probably need to do similar things to torch_glow though.
Test Plan:
```
buck build caffe2/caffe2/opt/custom:glow_net_transform
```
Reviewed By: jackm321
Differential Revision: D20770514
fbshipit-source-id: d398eb8eddbdbba21ccb5b4ac9cb335e4b27b8b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35632
This is handy to make sure the settings you have match your expectations. Here is an example output I have got:
```
I0328 15:55:12.336715 41258 throughput_benchmark-inl.h:23] ATen/Parallel:
at::get_num_threads() : 1
at::get_num_interop_threads() : 14
OpenMP 201511 (a.k.a. OpenMP 4.5)
omp_get_max_threads() : 1
Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications
mkl_get_max_threads() : 1
Intel(R) MKL-DNN v0.21.1 (Git Hash 7d2fd500bc78936d1d648ca713b901012f470dbc)
std:🧵:hardware_concurrency() : 28
Environment variables:
OMP_NUM_THREADS : 1
MKL_NUM_THREADS : [not set]
ATen parallel backend: OpenMP
```
Test Plan: Imported from OSS
Differential Revision: D20731331
Pulled By: ezyang
fbshipit-source-id: 5be7ffb23db49b1771c2f563b5d84180c3a0ba7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35704
Due to not clearing nodes_to_delete_, when we try to write graph rewrite
pass with multiple patterns, this is observed:
IndexError: vector::_M_range_check: __n (which is 0) >= this->size() (which is 0)
Test Plan:
The PR stacked on top of this run into this error in the unit test.
Imported from OSS
Differential Revision: D20746593
fbshipit-source-id: 9b55604f49ff2ee2a81a61827880cb679c44607a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35331
When the function called by remote() throws, it seems sensible to
surface that exeption when rref.to_here() is called.
Doing this only involves simple modifications:
- we need the OwnerRRef to keep around an optional<string>
for the error
- add an OwnerRRef setError() method that's parallel to setValue(),
and plumb through the logic
We add rpc_tests to verify that the exception is propagated properly.
ghstack-source-id: 101136900
Test Plan:
buck test mode/dev-nosan caffe2/test/distributed/rpc:rpc_spawn
buck test mode/dev-nosan caffe2/test/distributed/rpc/jit:rpc_spawn
Differential Revision: D20634078
fbshipit-source-id: b5b13fdb85cdf6a43f42347d82eabae1635368ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35431
Resolving z-a-f's comments on earlier PRs on making
the docblocks easier to read.
Test Plan:
render the new docblocks in http://rst.aaroniles.net/
CI
Imported from OSS
Differential Revision: D20658668
fbshipit-source-id: 5ea4a21d6b8dc9d744e2f4ede2f9d5d799fb902f
Summary:
This moves libtorch to Python 3.6 and cleans up other CircleCI config for the removal of python2.
Going to see if all tests pass on this and will also land before https://github.com/pytorch/pytorch/pull/35677
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35700
Differential Revision: D20767830
Pulled By: orionr
fbshipit-source-id: 0d5a8224b65829cc2b08a5844707e0c0e079421a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35711
As title
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20747290
fbshipit-source-id: fc9fced744cc8f0c61a671cb4b424ff067c2573d
Summary:
caffe2 uses `-I` all over the place, but really we should use the Buck built-in version of this
Alternatively, the `exported_header` clean up means we need to standardize to a single path
Test Plan:
```
buck build caffe2:torch-cpp-cpu
buck build caffe2/...
```
Reviewed By: malfet
Differential Revision: D19150098
fbshipit-source-id: e99aaf69d6c474afaedbd5f693a7736d3d67aafc
Summary:
NumPy doesn't allow complex inputs to floor, ceil, or trunc, and without careful deliberation I don't think PyTorch should, either: is it intuitive that these functions apply to both the real and imaginary parts of complex tensors, or only to the real parts?
This PR disables these functions for complex inputs so we don't prematurely commit a particular behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35592
Differential Revision: D20757796
Pulled By: mruberry
fbshipit-source-id: fdc53ac161fca7ad94c9280c3f5cf9c7c40c7f2c
Summary:
I hit this exception when including the registration code with `torch::class_` in a header file, which was included in multiple cpp files and thus called this twice. It could be helpful to improve the error msg here to indicate what exactly happened.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35568
Differential Revision: D20759476
Pulled By: rohan-varma
fbshipit-source-id: 680f6a8abb4453cd7a311cda1e2a03f81e7f7442
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34710
Extending RecordFunction API to support new recording scopes (such as TorchScript functions), as well as giving more flexibility to set sampling rate.
Test Plan: unit test (test_misc.cpp/testRecordFunction)
Reviewed By: gdankel, dzhulgakov
Differential Revision: D20158523
fbshipit-source-id: a9e0819d21cc06f4952d92d43246587c36137582
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35586
This pass fuses the choose_qparams-quant-dequant sequence
Fusion for weight tensor is the same as static quant.
Test Plan:
python test/test_quantize_script.py
Imported from OSS
Differential Revision: D20755680
fbshipit-source-id: b7443770642b6e6fa0fa9da8a44637e9b2d4df70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35448
Add _choose_qparams_per_tensor which returns scale and zero_point similar to the dynamic quantization in the operator
Test Plan:
python test/test_quantize_script.py
Imported from OSS
Differential Revision: D20755679
fbshipit-source-id: c9066d8f1bb3e331809be26c4be806faafc9b981
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35398
This disables namespaced c10::import which is broken with custom
mobile op builds. This is to help prevent people from accidentally
breaking the custom mobile build in a mysterious way; if they use
the longform version it will work. Fixing the analyzer is tracked
in https://github.com/pytorch/pytorch/issues/35397
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20680519
Pulled By: ezyang
fbshipit-source-id: a18ac8df7e72bf399807870beedb828131273e48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35724
When statically linking BLAS, this results in a second useless copy of
MKL in libtorch_cuda.so
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20758165
Pulled By: ezyang
fbshipit-source-id: 5a82a23c053f440b659f2ac2aaaf3c9d5ec69971
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35558
This is to have a more fine grained support for general ops,
e.g. for sort, the first output will have pass through inputs and the second op does not need to be quantized
so we'll have a check for that
Test Plan:
.
Imported from OSS
Differential Revision: D20752128
fbshipit-source-id: 825c4c393910a88ecb12e24e9a2f3b05c5d5a7ab
Summary:
`abs` is a C-style function that takes only integral argument
`std::abs` is polymorphic and can be applied to both integral and floating point types
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35698
Test Plan: CI
Differential Revision: D20749588
Pulled By: malfet
fbshipit-source-id: b6640af67587650786366fe3907384bc8803069f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35708
these are not actually needed and it breaks the normal include guard that selects correct Half implementation
Test Plan: CI green
Reviewed By: malfet
Differential Revision: D20744681
fbshipit-source-id: 70e3667593c987434415ad8ac3b68828875fc3fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35248
register aten ops in lite interpreter for detectron2go models. Also set catchAllKernel for some ops since the model requires different DispatchKey.
(Note: this ignores all push blocking failures!)
Test Plan:
(whole stack)
buck build -c user.ndk_cxxflags='-g1' -c caffe2.expose_op_to_c10=1 //xplat/caffe2/fb/pytorch_predictor:maskrcnnAndroid#android-armv7
Reviewed By: iseeyuan
Differential Revision: D20528762
fbshipit-source-id: 4da4699fe547a63b0c664fe666a8a688f1ab8c6c
Summary:
https://github.com/pytorch/pytorch/issues/34891 caused a 15 minute regression in XLA test timing when it inadvertently added this test to XLA -- I think it was intended to only add this test to CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35709
Test Plan: The XLA test job should return from ~75 to ~60 minutes.
Reviewed By: malfet
Differential Revision: D20748176
Pulled By: yns88
fbshipit-source-id: b50227a35bcbf2915b4f2013e2a4705e905d0118
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35541
When the OMP_NUM_THREADS is set to 1, we don't need to launch the parallel_for function on an OpenMP thread since there is no intra-op parallelism. By avoiding that, we can reduce the unnecessary context switches.
Test Plan: internal
Reviewed By: ilia-cher
Differential Revision: D20680465
fbshipit-source-id: 4476a810dfe7bf268fcd58fd00afb89ba61644cf
Summary:
The current config on `master` yields the following errors when build from source on Windows with CMake and Visual Studio 2019.
```
Severity Code Description Project File Line Suppression State
Error LNK2001 unresolved external symbol \?warp_size@cuda@at@YAHXZ\ torch D:\AI\pytorch\build_libtorch\caffe2\LINK 1
Severity Code Description Project File Line Suppression State
Error LNK1120 1 unresolved externals torch D:\AI\pytorch\build_libtorch\bin\Release\torch.dll 1
Severity Code Description Project File Line Suppression State
Error LNK2001 unresolved external symbol \?warp_size@cuda@at@YAHXZ\ caffe2_observers D:\AI\pytorch\build_libtorch\modules\observers\LINK 1
Severity Code Description Project File Line Suppression State
Error LNK1120 1 unresolved externals caffe2_observers D:\AI\pytorch\build_libtorch\bin\Release\caffe2_observers.dll 1
Severity Code Description Project File Line Suppression State
Error LNK2001 unresolved external symbol \?warp_size@cuda@at@YAHXZ\ caffe2_detectron_ops_gpu D:\AI\pytorch\build_libtorch\modules\detectron\LINK 1
Severity Code Description Project File Line Suppression State
Error LNK1120 1 unresolved externals caffe2_detectron_ops_gpu D:\AI\pytorch\build_libtorch\bin\Release\caffe2_detectron_ops_gpu.dll 1
```
This change at least fixes the above errors in that specific setting. Do you think it makes sense to get this merged or will it break other settings?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35659
Differential Revision: D20735907
Pulled By: ezyang
fbshipit-source-id: eb8fa1e69aaaa5af2da3a76963ddc910bb716479
Summary:
This causes ambiguity and can be triggered sometimes (e.g., by https://github.com/pytorch/pytorch/issues/35217). Explicitly convert them to float.
error: conditional expression is ambiguous; 'const
hip_impl::Scalar_accessor<float, Native_vec_, 0>' can be converted to
'float' and vice versa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35593
Differential Revision: D20735663
Pulled By: ezyang
fbshipit-source-id: ae6a38a08e59821bae13eb0b9f9bdf21a008d5c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35555
Att. So that we can lower the SparseLengthsSum* part of SparseLengthsSum*Sparse. We update the tying policy between Gather and SparsLengthsWeightSum* so that we don't bother lowering a single Gather into the backend, which is inefficient to execute on card and creates bubbles between continuous lowering graphs.
Test Plan:
```
buck test glow/fb/test:test_onnxifinnpi
```
Reviewed By: ipiszy
Differential Revision: D20688525
fbshipit-source-id: cb8e38239057ff13a8d385ed09d0d019421de78b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35522
We will need to apply this transform pass onto the net before lowering to Glow.
Test Plan:
```
buck test caffe2/caffe2/opt/custom:split_slss_test
```
Reviewed By: ipiszy
Differential Revision: D20688451
fbshipit-source-id: 22c0f5d0dcf97cc51cdc86bfc0abd90328ad5f2c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35507
We want to split up the SparseLengthsSumSparse op into an indirection op and the SparseLengthsSum op so that we can lower the later part. The indirection part is a plain impl now.
Test Plan:
```
for i in `seq 10`; do buck test caffe2/caffe2/python/operator_test:lengths_reducer_fused_nbit_rowwise_ops_test -- test_sparse_lengths_sum_rowwise_sparse; done
```
Reviewed By: jspark1105
Differential Revision: D20683478
fbshipit-source-id: 509effe88719d20aa0c4783bbe0ce1f183ee473c
Summary:
Looks like there is a bug in CUDA device linker, but kernels that uses `thust::sort_by_key` can not be linked with other kernels
Solve the problem by splitting 5 thrust-heavy .cu files into `__torch_cuda_sp` library which is statically linked into `torch_cuda`
For default compilation workflow it should not make any difference.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35581
Test Plan: Compile with `-DCUDA_SEPARABLE_COMPILATION=YES` and observe library size difference: 310Mb before, 173Mb after if compiled for sm_75
Differential Revision: D20741379
Pulled By: malfet
fbshipit-source-id: e9083968324c113e44a39df0de356d79af8e7057
Summary:
Setting device could be expensive, especially when a debugger is present. We should check the device are different before we set.
cc: ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35438
Differential Revision: D20664084
Pulled By: ngimel
fbshipit-source-id: 2440b4c9d96c41b4a19d5b1e8e1756fa40f090f0
Summary:
Add `--gtest_output=xml:/path/to/artifact-metadata-folder` to scripts invoking unit tests
Add artifacts metadata to windows test jobs
Install `unittest-xml-reporting` and add IN_CIRCLECI environment variable to remote python test results on Windows
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35590
Test Plan: Results should eventually be published to: https://circleci.com/build-insights/gh/pytorch/pytorch/master
Differential Revision: D20742687
Pulled By: malfet
fbshipit-source-id: baae60bdb0a4fb8d4f0d2baa77c65402fa2b99ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35599
We don't check if the ready queue was empty before
https://github.com/pytorch/pytorch/pull/33157 because the CPU worker's
queue might not be empty, but after #33157, we try to check if the owner
thread's ready_queue empty after inline exeuction.
This might not always hold true, imagine the following case:
The CPU thread that calls backward() and the GPU device thread, the Graph is like:
GraphRoot(CPU) -> ComputeNode(GPU)
in both thread_main, they are decrementing `--local_graph_task->outstanding_tasks_` to zero together, and then both thread will enter `if (graph_task_completed(local_graph_task))`, CPU thread will break out and finish and check if local_ready_queue is empty, the GPU thread will send a dummy task to CPU thread ready queue as it think the graph_task finished on its own thread (it actually finished on both threads together). So there will be cases that there's a dummy task remains in the queue.
This happens very rare and non-deterministic, but it might get triggered when we run many jobs in the CI. Remove the check to fix the flakiness
Test Plan: Imported from OSS
Differential Revision: D20739778
Pulled By: wanchaol
fbshipit-source-id: 75a671762650a188f44720625d53f0873617c684
Summary:
Define `store_test_results` attribute in CircleCI yamls
Install `unittest-xml-reporting` and define `IN_CIRCLECI` environment variable to trigger test runners to save results to XML
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35687
Differential Revision: D20739831
Pulled By: malfet
fbshipit-source-id: 6a7bbf19f93c32766963f5edad191ad8ca316ff8
Summary:
test_python_all_except_nn
+ /usr/bin/python3.6 test/run_test.py --exclude test_nn test_jit_simple
test_jit_legacy test_jit_fuser_legacy --verbose --bring-to-front
test_quantization test_quantized test_quantized_tensor
test_quantized_nn_mods --determine-from=
test_nn continues to be run as part of test1 target
This will allows us to run run_test.py and correctly disabling these sets for ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35230
Differential Revision: D20735851
Pulled By: ezyang
fbshipit-source-id: 255d21374c9605c8f8b6ffa1b08f58fb10d8e543
Summary:
Does the same things as D19658565 but for Caffe2 models.
From investigation https://fb.quip.com/PbgsAEmoJVuf the model id that predictor uses and the model id saved inside the model don't match. Common reason is recurring fluent2 jobs but there are others.
Since model_id from predictor is what the rest of datasets use, it's way more useful imho. I've considered adding both ids, but it'd require additional piping and I don't think it's that useful.
Test Plan: unittests added
Reviewed By: houseroad
Differential Revision: D20630599
fbshipit-source-id: 3e6d0cb0b6f8c8b6ae5935138f55ae7a2ff60653
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35647
Since we have enabled the unit test for FBNet on iOS, it'll block people from landing due to the missing support for selective build. This PR adds the missing ops in PyTorchPlaygronud to support FBNet.
ghstack-source-id: 101098537
allow-large-files
Test Plan: - `buck test PyTorchPlayground`
Reviewed By: iseeyuan
Differential Revision: D20723020
fbshipit-source-id: dc4443f50bb39166dbf45ca159bb32d5b45d2eea
Summary:
Reland of https://github.com/pytorch/pytorch/pull/35061 ; removed
the get qualified type name magic from debug strings to work around
MSVC 2017 bug.
Main points of the new API:
- You can register implementations (impl) without having to specify a schema.
- Registrations are commutative, so no matter what order your static
initializers run, you end up with the same end result.
op_registration_test.cpp contains a reasonably comprehensive accounting
for the available API surface
How does this implementation proceed? The basic concept is to relax the
internal invariants of Dispatcher data structures to allow the
possibility that a FunctionSchema is not specified in an Operator.
- DispatchKeyExtractor has an uninitialized state where it doesn't look
for dispatch keys in any arguments of the stack. It can have a
schema (de)registered to itself post facto with
registerSchema/unregisterSchema.
- DispatchTable has a new constructor taking only an OperatorName for
the uninitialized state. It can have a schema (de)registered to itself
post facto with registerSchema/unregisterSchema
- OperatorDef maintains counts of both defs and well as defs_and_impls.
defs_and_impls keeps track of the outstanding impl registrations; you
may have impl registrations but no defs. If there are no defs (no
schema), the operator is not returned by findSchema. A new
findOperatorByName fucntion unconditionally returns the OperatorHandle
even if there's no schema. OperatorHandle::hasSchema can be used
to check if the operator has schema.
- Replaced 'registerKernel' with 'registerImpl', which is the new
interface for directly registering kernels without implementations.
- Because 'registerImpl' no longer requires an OperatorHandle, change
'registerDef' to only return a RegistrationHandleRAII. This is marginally
less efficient (since we're doing two hash table lookups on a registration
now), but this won't matter in the long term, and probably doesn't
matter now either.
- Rename registerBackendFallbackKernel to registerFallback (this exposed
a bunch of places where we're improperly directly interfacing with Dispatcher;
we need to add this capability to the true public API)
- All code generated internal registrations are switched to use the new
API. This includes VariableType registrations (which previously
weren't converted) and the mobile autograd stuff
- Switch the new-style def()/impl() APIs to interact directly with Dispatcher,
rather than indirecting through the old API
- We deleted alias analysis kind merging entirely. As a nod to BC, it's
possible to define a full schema with alias analysis kind, and then
later do another full schema def with missing alias analysis kind, but
the opposite direction is not allowed. We can remove this entirely
following the plan at https://github.com/pytorch/pytorch/issues/35040
- Schema matching is moved inside the dispatcher, because we might not
be able to immediately schema match at the point of an impl() (because
we don't have the schema yet). To do this, we store the inferred
function schema inside a KernelEntry, so we can check it when we get
the real schema.
- Registered kernel functions now store a debug string which
can be used to more easily identify them. Tests use this to
distinguish between multiple distinct registrations; regular
invocations get only very basic information.
Because we need our static initializers to work no matter what order
they're run, the testing strategy on this PR is quite involved.
The general concept:
- Bind a (very gimped) version of the dispatcher API from Python,
so that we can easily write a more complex testing harness
using expect tests.
- For series of registrations we want to test, exhaustively
test every possible permutation of registrations (and
deregistrations), and show that the intermediate states
agree no matter what path is taken.
- Intermediate states are rendered using a new dumpState()
debugging method that prints the internal state of the
dispatcher. This method may be generally useful for people
who want to see what's in the dispatcher.
- Simultaneously, add a new invariant testing function which
checks that the internal invariants of the dispatcher are
upheld (so we don't have to print internal implementation
details of the dispatcher)
The testing framework found a few bugs in development. For example,
here is a case where we registered schema too early, before checking
if it was valid:
```
Traceback (most recent call last):
File "test/test_dispatch.py", line 164, in test_def_impl_schema_mismatch
], raises=True)
File "test/test_dispatch.py", line 135, in commute
results=results, raises=raises)
File "test/test_dispatch.py", line 83, in run_permutation
.format(ctor_order[:i], op_ix))
File "test/test_dispatch.py", line 59, in check_invariants
.format(expected_provenance, actual_provenance)
AssertionError: 'name[16 chars]ema: (none)\ncatchall: boxed unboxed :: (Tenso[18 chars]0)\n' != 'name[16 chars]ema: test::foo(Tensor x, Tensor y) -> (Tensor)[53 chars]0)\n'
name: test::foo
- schema: (none)
+ schema: test::foo(Tensor x, Tensor y) -> (Tensor)
catchall: boxed unboxed :: (Tensor _0) -> (Tensor _0)
: expected from running ctors (1,); actual from running ctors (1,) and then failing to run ctor 0 (did this failure leave the dispatcher in a wedged state? it shouldn't!)
```
There are also C++ smoketests for the API. These tests comprehensively
cover the C++ API surface of the new operator registration API, but
don't check very hard if the API does the right thing (that's what
test_dispatch.py is for)
Some miscellaneous changes which could have been split into other
PRs, but I was too lazy to do so:
- Add torch::jit::parseName (mirroring parseSchema/parseSchemaOrName)
- Add cloneWithName functionality to FunctionSchema
- Unconditionally generate schema registration, even when type_method_dispatch
is a dict. The one exception is for manual registrations....
- Add fallback, CppFunction::makeFallthrough and
CppFunction::makeFromBoxedFunction to public API of op_registration, so we can
stop calling internal registerImpl directly
- Add new syntax sugar dispatch_autograd for registering autograd kernels
- Minor OperatorName cleanup, storing OperatorName in DispatchTable
and defining operator<< on OperatorName
- Refactored the op registration API to take FunctionSchema directly.
We now do namespacing by post facto fixing up the OperatorName
embedded in FunctionSchema. This also means that you can
now do torch::import("ns1").def("ns2::blah") and have the ns2
override ns1 (although maybe this is not the correct behavior.)
- New torch::schema public API, for attaching alias analysis kind
annotation kinds. This meant we had to template up some function
signatures which previously took const char*. There's now a nice
comment explaining this strategy.
- torch::import now takes std::string which means we can use
the namespacing from Python
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35629
Differential Revision: D20724551
Pulled By: ezyang
fbshipit-source-id: befa46a1affb4ec4ae1fb39e3564a63695a6ca41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34015
Remove warning
```
caffe2/aten/src/ATen/native/cuda/BatchLinearAlgebra.cu(1400): warning: variable "info" was set but never used
```
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20181160
fbshipit-source-id: 31d44522a558fe7c2661a84dd6c35eb9d05b757a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34016
Remove warning
```
caffe2/aten/src/ATen/native/cuda/Reduce.cuh(654): warning: integer conversion resulted in a change of sign
```
When acc_ptr_ != nullptr , numerator_ and denominator_ must have been initialized.
Other minor changes:
* Make member variables of AccumulationBuffer private
* size_factor_ is used nowhere.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D20181169
fbshipit-source-id: e4d023f7fa0692e62be21cfbd971cad8dfb69ea4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34836
Once SigridHashOp argument is supplied, I realized the shape inference is still wrong because the argument is not supplied in the debug_ssa. Thanks to yinghai, I didn't fix the converter, fixing it in this diff
Test Plan:
Run the binary, and checked the exported op
op {
input: "sequential_250/parallel/normalization/dper_feature_normalization/sparse_features_processor/sparse_feature_transform/gather_ranges_GSF_IDLIST_COOCCUR_APP_ID_NEKO_ORGANIC_1D_7D_INSTALL_V1/gathered_values_0"
output: "sequential_250/parallel/normalization/dper_feature_normalization/sparse_features_processor/sparse_feature_transform/sequential_1/hash_feature_ids/SigridHash:0_0"
type: "SigridHash"
arg {
name: "salt"
i: 0
}
arg {
name: "maxValue"
i: 100000
}
arg {
name: "hashIntoInt32"
i: 1
}
arg {
name: "net_pos"
i: 3
}
}
it now have hashIntInt32
Reviewed By: yinghai
Differential Revision: D20457057
fbshipit-source-id: 023ade5e66df82037a8f2da3174383dda8aff230
Summary:
The current implementations of torch.real and torch.imag are not NumPy compatible. In particular:
- torch.real on a real tensor does not return the real tensor, like contiguous
- torch.real on a complex tensor does not return a real-valued view of the real part
- torch.imag on a complex tensor does not return a real-valued view of the imaginary part
- torch.Tensor.real and torch.Tensor.imag exist as methods, but in NumPy they are writable attributes
This PR makes the functions NumPy compatible by removing the method variants and out kwarg, restricting them to work on only real tensors, and updating the behavior of torch.real to return its input. New tests are added to test_torch.py to verify the behavior, a couple existing complex tests are skipped, and the documentation is updated to reflect the change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35560
Differential Revision: D20714568
Pulled By: mruberry
fbshipit-source-id: 5dd092f45757b620c8426c829dd15ee997246a26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35420
This PR makes `aten::relu` a general op that doesn't require observation
This means we also need to change the logic to support skipping intermediate values because
this breaks `conv - relu` pattern if it is not followed by something that is quantizable
since `conv` is quantizable, but we decide to skip observing between conv and relu.
We changed the old `skip_values` to a new `delay_observation_map_` which records information that
allow us to delay the observation of certain values until later points. In the case of `conv - relu`
pattern, we delayed the observation of output of `conv` and observe the output of `relu` instead.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20655309
fbshipit-source-id: 37dbe8a5e2f4cd7582ed67c405f9cf437dd00dbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35061
Main points of the new API:
- You can register implementations (impl) without having to specify a schema.
- Registrations are commutative, so no matter what order your static
initializers run, you end up with the same end result.
op_registration_test.cpp contains a reasonably comprehensive accounting
for the available API surface
How does this implementation proceed? The basic concept is to relax the
internal invariants of Dispatcher data structures to allow the
possibility that a FunctionSchema is not specified in an Operator.
- DispatchKeyExtractor has an uninitialized state where it doesn't look
for dispatch keys in any arguments of the stack. It can have a
schema (de)registered to itself post facto with
registerSchema/unregisterSchema.
- DispatchTable has a new constructor taking only an OperatorName for
the uninitialized state. It can have a schema (de)registered to itself
post facto with registerSchema/unregisterSchema
- OperatorDef maintains counts of both defs and well as defs_and_impls.
defs_and_impls keeps track of the outstanding impl registrations; you
may have impl registrations but no defs. If there are no defs (no
schema), the operator is not returned by findSchema. A new
findOperatorByName fucntion unconditionally returns the OperatorHandle
even if there's no schema. OperatorHandle::hasSchema can be used
to check if the operator has schema.
- Replaced 'registerKernel' with 'registerImpl', which is the new
interface for directly registering kernels without implementations.
- Because 'registerImpl' no longer requires an OperatorHandle, change
'registerDef' to only return a RegistrationHandleRAII. This is marginally
less efficient (since we're doing two hash table lookups on a registration
now), but this won't matter in the long term, and probably doesn't
matter now either.
- Rename registerBackendFallbackKernel to registerFallback (this exposed
a bunch of places where we're improperly directly interfacing with Dispatcher;
we need to add this capability to the true public API)
- All code generated internal registrations are switched to use the new
API. This includes VariableType registrations (which previously
weren't converted) and the mobile autograd stuff
- Switch the new-style def()/impl() APIs to interact directly with Dispatcher,
rather than indirecting through the old API
- We deleted alias analysis kind merging entirely. As a nod to BC, it's
possible to define a full schema with alias analysis kind, and then
later do another full schema def with missing alias analysis kind, but
the opposite direction is not allowed. We can remove this entirely
following the plan at https://github.com/pytorch/pytorch/issues/35040
- Schema matching is moved inside the dispatcher, because we might not
be able to immediately schema match at the point of an impl() (because
we don't have the schema yet). To do this, we store the inferred
function schema inside a KernelEntry, so we can check it when we get
the real schema.
- Registered kernel functions now store a debug string which
can be used to more easily identify them. There's some best
effort stuff based on __FUNCSIG__ but this is only really
capable of reporting types and not function symbols. Tests
use this to distinguish between multiple distinct registrations.
Because we need our static initializers to work no matter what order
they're run, the testing strategy on this PR is quite involved.
The general concept:
- Bind a (very gimped) version of the dispatcher API from Python,
so that we can easily write a more complex testing harness
using expect tests.
- For series of registrations we want to test, exhaustively
test every possible permutation of registrations (and
deregistrations), and show that the intermediate states
agree no matter what path is taken.
- Intermediate states are rendered using a new dumpState()
debugging method that prints the internal state of the
dispatcher. This method may be generally useful for people
who want to see what's in the dispatcher.
- Simultaneously, add a new invariant testing function which
checks that the internal invariants of the dispatcher are
upheld (so we don't have to print internal implementation
details of the dispatcher)
The testing framework found a few bugs in development. For example,
here is a case where we registered schema too early, before checking
if it was valid:
```
Traceback (most recent call last):
File "test/test_dispatch.py", line 164, in test_def_impl_schema_mismatch
], raises=True)
File "test/test_dispatch.py", line 135, in commute
results=results, raises=raises)
File "test/test_dispatch.py", line 83, in run_permutation
.format(ctor_order[:i], op_ix))
File "test/test_dispatch.py", line 59, in check_invariants
.format(expected_provenance, actual_provenance)
AssertionError: 'name[16 chars]ema: (none)\ncatchall: boxed unboxed :: (Tenso[18 chars]0)\n' != 'name[16 chars]ema: test::foo(Tensor x, Tensor y) -> (Tensor)[53 chars]0)\n'
name: test::foo
- schema: (none)
+ schema: test::foo(Tensor x, Tensor y) -> (Tensor)
catchall: boxed unboxed :: (Tensor _0) -> (Tensor _0)
: expected from running ctors (1,); actual from running ctors (1,) and then failing to run ctor 0 (did this failure leave the dispatcher in a wedged state? it shouldn't!)
```
There are also C++ smoketests for the API. These tests comprehensively
cover the C++ API surface of the new operator registration API, but
don't check very hard if the API does the right thing (that's what
test_dispatch.py is for)
Some miscellaneous changes which could have been split into other
PRs, but I was too lazy to do so:
- Add torch::jit::parseName (mirroring parseSchema/parseSchemaOrName)
- Add cloneWithName functionality to FunctionSchema
- Unconditionally generate schema registration, even when type_method_dispatch
is a dict. The one exception is for manual registrations....
- Add fallback, CppFunction::makeFallthrough and
CppFunction::makeFromBoxedFunction to public API of op_registration, so we can
stop calling internal registerImpl directly
- Add new syntax sugar dispatch_autograd for registering autograd kernels
- Minor OperatorName cleanup, storing OperatorName in DispatchTable
and defining operator<< on OperatorName
- Refactored the op registration API to take FunctionSchema directly.
We now do namespacing by post facto fixing up the OperatorName
embedded in FunctionSchema. This also means that you can
now do torch::import("ns1").def("ns2::blah") and have the ns2
override ns1 (although maybe this is not the correct behavior.)
- New torch::schema public API, for attaching alias analysis kind
annotation kinds. This meant we had to template up some function
signatures which previously took const char*. There's now a nice
comment explaining this strategy.
- torch::import now takes std::string which means we can use
the namespacing from Python
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20680520
Pulled By: ezyang
fbshipit-source-id: 5d39a28e4ec7c73fe4b1fb2222e865ab65e188f5
Summary:
https://github.com/pytorch/pytorch/pull/35127 was landed and reverted because I missed a test fail (oops). I have found and fixed the issue, which was due to zero terms being introduced after the point that filtered them out (usually required NAN/INF, e.g. x / INF => 0).
See https://github.com/pytorch/pytorch/pull/35127 for more info.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35415
Reviewed By: ZolotukhinM
Differential Revision: D20702957
Pulled By: nickgg
fbshipit-source-id: 119eb41e9fa676bd78e3d1df99297a47ae312185
Summary:
The Torch algorithms for linspace and logspace conceptually compute each of their values using:
`start_value + step_value * idx`
[And NumPy does the same,](cef4dc9d91/numpy/core/function_base.py (L24)) except NumPy then [sets the last value in its array directly.](cef4dc9d91/numpy/core/function_base.py (L162)) This is because the above computation is unstable when using floats, and NumPy's contract, like PyTorch's, is that the last element in the array is the stop value.
In PyTorch there can be a divergence between the computed last value and the actual value. One user reported case was:
`torch.linspace(-0.031608279794, 0.031531572342, 257, dtype=torch.float32)`
Which causes a difference of 3.7253e-09 between the last value as set by NumPy and computed by PyTorch. After this PR the difference is zero.
Instead of simply setting the last element of the tensor, this PR updates the kernels with a "symmetric" algorithm that sets the first and last array elements without requiring an additional kernel launch on CUDA. The performance impact of this change seems small. I tested with a step sizes of 2^8 and 2^22, and all timing differences were imperceptible except for 2^22 on CPU, which appears to have suffered ~5% slowdown. I think that's an acceptable performance hit for the improved precision when we consider the context of linspace.
An alternative would be to simply set the last element, as NumPy does, on CPU. But I think it's preferable to keep the CPU and CUDA algorithms aligned and keep the algorithm symmetric. In current PyTorch, for example, torch.linspace starts generating values very similar to NumPy, but as the index increases so do the errors, giving our current implementation a "left bias."
Two tests are added to test_torch.py for this behavior. The linspace test will fail on current PyTorch, but the logspace test will succeed since its more complex computation needs wider error bars.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35461
Differential Revision: D20712539
Pulled By: mruberry
fbshipit-source-id: 2c1257c8706f4cdf080ff0331bbf2f7041ab9adf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35142
supporting swap dequant for prim::If nodes, this includes detecting
all blocks of prim::If ends with dequantize, deleting these dequantize
and inserting new dequantize for the output of prim::If
Test Plan:
see next PR that enables swap dequant for interpolate: https://github.com/pytorch/pytorch/pull/35130
Imported from OSS
Differential Revision: D20655307
fbshipit-source-id: 4fd53fbde8e169b7d98251e72ca37a29acdeb295
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35141
This is preparing for the support of prim::If in SwapDeQuant
Test Plan:
.
Imported from OSS
Differential Revision: D20655300
fbshipit-source-id: 0c66cab37f3f46dd34217a7b99a4d25a159c8487
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35135
This in preperation for the support of prim::If in SwapDeQuant
Test Plan:
.
Imported from OSS
Differential Revision: D20655296
fbshipit-source-id: d8507e0020096940e14bc0fb7bde6a22ce706b72
Summary:
Introduce DISABLED_ON_WINDOWS macro, that adds `DISABLED_` prefix to string if compiled for Win32
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35549
Test Plan: CI
Differential Revision: D20700915
Pulled By: malfet
fbshipit-source-id: adddfe2db89b7139093ceef6899862bce0adcf2d
Summary:
Oneline fix to lara-hdr 's PR https://github.com/pytorch/pytorch/pull/30169.
Default `dtype` value should be set when `dtype is None` rather than when `dtype is not None`.
I didn't make an issue for this as such a small change but I have been using this locally in order to export a model with opset 11 (opset 10 still works).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35467
Differential Revision: D20686048
Pulled By: mruberry
fbshipit-source-id: 726a5f9c0711c7a79b171fe98b602cdef27f9b31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35395
as title
ghstack-source-id: 101035263
Test Plan: CI
Differential Revision: D20632634
fbshipit-source-id: 737e353982b325e73da3825b130aae6b11dbcfe7
Summary:
This one doesn't actually do anything so we don't need an op for it.
It is used inside `torch.nn.functional.unfold` which is already tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34509
Pulled By: driazati
Differential Revision: D20676445
fbshipit-source-id: b72d1308bdec593367ec4e14bf9a901d0b62e1cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27510
We could delete polyfill typing bc requirements.txt require user to
install typing as a dependency whether in py2 or py3, so those typing
actually not getting used either ways.
Test Plan: Imported from OSS
Differential Revision: D20673393
fbshipit-source-id: ea5276824c6e275c1f991f8c12329040b0058d2b
Summary:
Fixes#29035
Previously we were missing a case for namedtuples in our Python value resolution logic, so they were just getting resolved as regular Python values, hence the `OSError`s in the linked issue
](https://our.intern.facebook.com/intern/diff/20653496/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35409
Pulled By: driazati
Differential Revision: D20653496
fbshipit-source-id: b5db1a11e918175aa02fda92993d233695417c56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35218
We should express the ownership semantics directly here. Using
`shared_ptr` makes it too easy to leak ownership by inadvertently
storing a copy.
Test Plan: Imported from OSS
Differential Revision: D20682673
Pulled By: suo
fbshipit-source-id: 32002ee515eb8bb7b37e6d0aac3c0695df4eec79
Summary:
Ignore mixed upper-case/lower-case style for now
Fix space between function and its arguments violation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35574
Test Plan: CI
Differential Revision: D20712969
Pulled By: malfet
fbshipit-source-id: 0012d430aed916b4518599a0b535e82d15721f78
Summary:
As a followup to https://github.com/pytorch/pytorch/pull/35042 this removes python2 from setup.py and adds Python 3.8 to the list of supported versions. We're already testing this in CircleCI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35539
Differential Revision: D20709060
Pulled By: orionr
fbshipit-source-id: 5d40bc14cb885374fec370fc7c5d3cde8769039a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35073
We want to do constant propagation for quantize_per_tensor/quantize_per_channel
which will produce results that's consumed by these ops, and since we need to
make sure the output of the node has no writer before constant prop through the node,
the consumer needs to be pure as well.
Test Plan:
see next PR
Imported from OSS
Differential Revision: D20655310
fbshipit-source-id: 3e33662224c21b889c8121b823f8ce0b7da75eed
Summary:
So that packages are correctly marked when looking through the html
pages.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35309
Differential Revision: D20626737
Pulled By: seemethere
fbshipit-source-id: 0fad3d99f0b0086898939fde94ddbbc9861d257e
Summary:
Let see if it makes both test branches a bit more balanced
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35540
Test Plan: CI
Differential Revision: D20704642
Pulled By: malfet
fbshipit-source-id: 4e2ab5a80adfe78620206d4eaea30207194379cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34248
This argument will no longer exist in positional form when MemoryFormat
is moved into TensorOptions by codegen, so we must stop using it when
we make calls from C++. This diff eliminates all direct positional
calls, making them be passed in using TensorOptions.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20683398
Pulled By: bhosmer
fbshipit-source-id: 6928cfca67abb22fbc667ecc2af8453d93489bd6
Summary:
Since we've done the branch cut for 1.5.0 we should bump nightlies to 1.6.0
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35495
Differential Revision: D20697043
Pulled By: seemethere
fbshipit-source-id: 3646187a5e729994138bf2c68625f25f11430b3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35519
Fix include of THHalf.h to be TH/THHalf.h. Makes the include consistent with the rest of caffe2.
Test Plan: CI
Differential Revision: D20685997
fbshipit-source-id: 893b6e96e4f1a1e7306ba2e40e4e8ee738f0344f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35545
Looks like we have never printed a quantized Tensor in cpp before
(Note: this ignores all push blocking failures!)
Test Plan:
.
Imported from OSS
Differential Revision: D20699748
fbshipit-source-id: 9d029815c6e75f626afabf92194154efc83f5545
Summary:
Skip tests that take more than finish under a sec normally but take 20+ min under ASAN
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35533
Test Plan: CI
Differential Revision: D20700245
Pulled By: malfet
fbshipit-source-id: 7620b12d3aba1bafb2baa9073fa27c4a0b3dd9eb
Summary:
Fixes incorrect usages of symbol annotations including:
1. Exporting or importing a function/class in an anonymous namespace.
2. Exporting or importing a function/class implementation in a header file. However, by removing the symbol annotations, they are now local symbols. If they need to be remain global, I can move the implementations to the source file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35364
Differential Revision: D20670031
Pulled By: ezyang
fbshipit-source-id: cd8018dee703e2424482c27fe9608e040d8105b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34555
This is sometimes necessary, such as when T=int and the step size is of
type double.
Test Plan: Imported from OSS
Differential Revision: D20687063
Pulled By: ezyang
fbshipit-source-id: 33086d4252d06e7539733a9b1b3d6774e177b6da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35244
add roi_align_rotated op to lite interpreter for detectron2go model
(Note: this ignores all push blocking failures!)
Test Plan: try to run model in https://home.fburl.com/~stzpz/text_det/fbnet_300_20/
Reviewed By: iseeyuan
Differential Revision: D20560485
fbshipit-source-id: a81f3a590b9cc5a02d4da676b3cfa52b0e0a68c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35247
add a leading "_" to register quantized ops for lite interpreter. They are needed by d2go model
(Note: this ignores all push blocking failures!)
Test Plan:
(whole stack)
buck build -c user.ndk_cxxflags='-g1' -c caffe2.expose_op_to_c10=1 //xplat/caffe2/fb/pytorch_predictor:maskrcnnAndroid#android-armv7
Reviewed By: iseeyuan
Differential Revision: D20528760
fbshipit-source-id: 5b26d075456641b02d82f15a2d19f2266001f23b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34674
Two changes to make sure the op_names dumped in export_opnames() are consistent to what are actually used in bytecode.
* Inline graph before dumping the operator names.
* Use code of the graph (which is used in bytecode) instead of the nodes of graph.
Test Plan: Imported from OSS
Differential Revision: D20610715
Pulled By: iseeyuan
fbshipit-source-id: 53fa9c3b36f4f242b7f2b99b421f4adf20d4b1f6
Summary:
My PR https://github.com/pytorch/pytorch/pull/33020 changed subgraph_utils made subgraph utils non-deterministic by using a set instead of a vector for closed over values. This broke a downstream glow test. We're in the process of working with glow to not rely on the subgraph input order, but in the interim make it ordered again to fix the test.
An alternative is to use a `set` instead of a vector, but I don't particularly like committing to fixed ordering for the subgraph, especially for things like if nodes and while loops where an order doesn't really have any meaning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35508
Differential Revision: D20683959
Pulled By: eellison
fbshipit-source-id: bb39b29fef2904e52b9dc42be194bb57cbea59c4
Summary:
## Motivation
This PR upgrades MKL-DNN from v0.20 to DNNL v1.2 and resolves https://github.com/pytorch/pytorch/issues/30300.
DNNL (Deep Neural Network Library) is the new brand of MKL-DNN, which improves performance, quality, and usability over the old version.
This PR focuses on the migration of all existing functionalities, including minor fixes, performance improvement and code clean up. It serves as the cornerstone of our future efforts to accommodate new features like OpenCL support, BF16 training, INT8 inference, etc. and to let the Pytorch community derive more benefits from the Intel Architecture.
<br>
## What's included?
Even DNNL has many breaking changes to the API, we managed to absorb most of them in ideep. This PR contains minimalist changes to the integration code in pytorch. Below is a summary of the changes:
<br>
**General:**
1. Replace op-level allocator with global-registered allocator
```
// before
ideep::sum::compute<AllocForMKLDNN>(scales, {x, y}, z);
// after
ideep::sum::compute(scales, {x, y}, z);
```
The allocator is now being registeted at `aten/src/ATen/native/mkldnn/IDeepRegistration.cpp`. Thereafter all tensors derived from the `cpu_engine` (by default) will use the c10 allocator.
```
RegisterEngineAllocator cpu_alloc(
ideep::engine::cpu_engine(),
[](size_t size) {
return c10::GetAllocator(c10::DeviceType::CPU)->raw_allocate(size);
},
[](void* p) {
c10::GetAllocator(c10::DeviceType::CPU)->raw_deallocate(p);
}
);
```
------
2. Simplify group convolution
We had such a scenario in convolution where ideep tensor shape mismatched aten tensor: when `groups > 1`, DNNL expects weights tensors to be 5-d with an extra group dimension, e.g. `goihw` instead of `oihw` in 2d conv case.
As shown below, a lot of extra checks came with this difference in shape before. Now we've completely hidden this difference in ideep and all tensors are going to align with pytorch's definition. So we could safely remove these checks from both aten and c2 integration code.
```
// aten/src/ATen/native/mkldnn/Conv.cpp
if (w.ndims() == x.ndims() + 1) {
AT_ASSERTM(
groups > 1,
"Only group _mkldnn_conv2d weights could have been reordered to 5d");
kernel_size[0] = w.get_dim(0) * w.get_dim(1);
std::copy_n(
w.get_dims().cbegin() + 2, x.ndims() - 1, kernel_size.begin() + 1);
} else {
std::copy_n(w.get_dims().cbegin(), x.ndims(), kernel_size.begin());
}
```
------
3. Enable DNNL built-in cache
Previously, we stored DNNL jitted kernels along with intermediate buffers inside ideep using an LRU cache. Now we are switching to the newly added DNNL built-in cache, and **no longer** caching buffers in order to reduce memory footprint.
This change will be mainly reflected in lower memory usage from memory profiling results. On the code side, we removed couple of lines of `op_key_` that depended on the ideep cache before.
------
4. Use 64-bit integer to denote dimensions
We changed the type of `ideep::dims` from `vector<int32_t>` to `vector<int64_t>`. This renders ideep dims no longer compatible with 32-bit dims used by caffe2. So we use something like `{stride_.begin(), stride_.end()}` to cast parameter `stride_` into a int64 vector.
<br>
**Misc changes in each commit:**
**Commit:** change build options
Some build options were slightly changed, mainly to avoid name collisions with other projects that include DNNL as a subproject. In addition, DNNL built-in cache is enabled by option `DNNL_ENABLE_PRIMITIVE_CACHE`.
Old | New
-- | --
WITH_EXAMPLE | MKLDNN_BUILD_EXAMPLES
WITH_TEST | MKLDNN_BUILD_TESTS
MKLDNN_THREADING | MKLDNN_CPU_RUNTIME
MKLDNN_USE_MKL | N/A (not use MKL anymore)
------
**Commit:** aten reintegration
- aten/src/ATen/native/mkldnn/BinaryOps.cpp
Implement binary ops using new operation `binary` provided by DNNL
- aten/src/ATen/native/mkldnn/Conv.cpp
Clean up group convolution checks
Simplify conv backward integration
- aten/src/ATen/native/mkldnn/MKLDNNConversions.cpp
Simplify prepacking convolution weights
- test/test_mkldnn.py
Fixed an issue in conv2d unit test: it didn't check conv results between mkldnn and aten implementation before. Instead, it compared the mkldnn with mkldnn as the default cpu path will also go into mkldnn. Now we use `torch.backends.mkldnn.flags` to fix this issue
- torch/utils/mkldnn.py
Prepack weight tensor on module `__init__` to achieve better performance significantly
------
**Commit:** caffe2 reintegration
- caffe2/ideep/ideep_utils.h
Clean up unused type definitions
- caffe2/ideep/operators/adam_op.cc & caffe2/ideep/operators/momentum_sgd_op.cc
Unify tensor initialization with `ideep::tensor::init`. Obsolete `ideep::tensor::reinit`
- caffe2/ideep/operators/conv_op.cc & caffe2/ideep/operators/quantization/int8_conv_op.cc
Clean up group convolution checks
Revamp convolution API
- caffe2/ideep/operators/conv_transpose_op.cc
Clean up group convolution checks
Clean up deconv workaround code
------
**Commit:** custom allocator
- Register c10 allocator as mentioned above
<br><br>
## Performance
We tested inference on some common models based on user scenarios, and most performance numbers are either better than or on par with DNNL 0.20.
ratio: new / old | Latency (batch=1 4T) | Throughput (batch=64 56T)
-- | -- | --
pytorch resnet18 | 121.4% | 99.7%
pytorch resnet50 | 123.1% | 106.9%
pytorch resnext101_32x8d | 116.3% | 100.1%
pytorch resnext50_32x4d | 141.9% | 104.4%
pytorch mobilenet_v2 | 163.0% | 105.8%
caffe2 alexnet | 303.0% | 99.2%
caffe2 googlenet-v3 | 101.1% | 99.2%
caffe2 inception-v1 | 102.2% | 101.7%
caffe2 mobilenet-v1 | 356.1% | 253.7%
caffe2 resnet101 | 100.4% | 99.8%
caffe2 resnet152 | 99.8% | 99.8%
caffe2 shufflenet | 141.1% | 69.0% †
caffe2 squeezenet | 98.5% | 99.2%
caffe2 vgg16 | 136.8% | 100.6%
caffe2 googlenet-v3 int8 | 100.0% | 100.7%
caffe2 mobilenet-v1 int8 | 779.2% | 943.0%
caffe2 resnet50 int8 | 99.5% | 95.5%
_Configuration:
Platform: Skylake 8180
Latency Test: 4 threads, warmup 30, iteration 500, batch size 1
Throughput Test: 56 threads, warmup 30, iteration 200, batch size 64_
† Shufflenet is one of the few models that require temp buffers during inference. The performance degradation is an expected issue since we no longer cache any buffer in the ideep. As for the solution, we suggest users opt for caching allocator like **jemalloc** as a drop-in replacement for system allocator in such heavy workloads.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32422
Test Plan:
Perf results: https://our.intern.facebook.com/intern/fblearner/details/177790608?tab=Experiment%20Results
10% improvement for ResNext with avx512, neutral on avx2
More results: https://fb.quip.com/ob10AL0bCDXW#NNNACAUoHJP
Reviewed By: yinghai
Differential Revision: D20381325
Pulled By: dzhulgakov
fbshipit-source-id: 803b906fd89ed8b723c5fcab55039efe3e4bcb77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35042
Removing python2 tests and some compat code in torch.jit. Check if dependent projects and external tests have any issues after these changes.
Test Plan: waitforsandcastle
Reviewed By: suo, seemethere
Differential Revision: D18942633
fbshipit-source-id: d76cc41ff20bee147dd8d44d70563c10d8a95a35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35393
this was being created inside the lock scope, but we don't need to
hold the lock for this.
ghstack-source-id: 100953426
Test Plan: CI
Differential Revision: D20632225
fbshipit-source-id: dbf6746f638b7df5fefd9bbfceaa6b1a542580e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35491
The goal of this diff is to avoid having to set AutoNonVariableTypeMode guard
in client code that uses custom mobile build. The guard was necessary because
custom mobile build might not include variable kernels, in which AutoNonVariableTypeMode
guard is usually set. It's hard to enforce all callsites to follow this rule, so
we make this change to simplify it.
Another goal of the diff is to not break FL where real variable kernels are
registered.
ghstack-source-id: 100944553
Test Plan:
- With stacked diff, tested lite-trainer with MnistModel:
```
buck run xplat/caffe2/fb/lite_trainer:lite_trainer \
-c pt.disable_gen_tracing=1 \
-- --model=/home/liujiakai/ptmodels/MnistModel.bc
```
- Will test with the papaya sample app.
Differential Revision: D20643627
fbshipit-source-id: 37ea937919259c183809c2b7acab0741eff84d33
Summary:
1. Removed LossClosureOptimizer, and merged Optimizer into OptimizerBase (and renamed the merged class to Optimizer)
2. Merged the LBFGS-specific serialize test function and the generic test_serialize_optimizer function.
3. BC-compatibility serialization test for LBFGS
4. Removed mentions of parameters_ in optimizer.cpp, de-virtualize all functions
5. Made defaults_ optional argument in all optimizers except SGD
**TODO**: add BC-breaking notes for this PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34957
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20678162
Pulled By: yf225
fbshipit-source-id: 74e062e42d86dc118f0fbaddd794e438b2eaf35a
Summary:
Desugar prim::shape to aten::size so that passes don't need to reason about both ops. Serialized models still resolve to `prim::shape` so this doesn't break BC.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34286
Differential Revision: D20316818
Pulled By: eellison
fbshipit-source-id: d1585687212843f51e9396e07c108f5c08017818
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35433
Make RRef TorchScript API the same as RRef Python API.
Differential Revision: D7923050
fbshipit-source-id: 62589a429bcaa834b55db6ae8cfb10c0a2ee01ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35430
This fixes and adds tests for several commonly used operators.
There's some formatting differences due to running clang-format on one of the files.
Test Plan: buck test //caffe2/caffe2/fb/operators:hypothesis_test //caffe2/caffe2/python/operator_test:utility_ops_test //caffe2/caffe2/python/operator_test:concat_split_op_test
Reviewed By: yyetim
Differential Revision: D20657405
fbshipit-source-id: 51d86d0834003b8ac8d6acb5149ae13d7bbfc6ab
Summary:
Looks like there is a bug in CUDA device linker, but kernels that uses `thust::sort_by_key` can not be linked with other kernels
Solve the problem by splitting 5 thrust-heavy .cu files into `__torch_cuda_sp` library which is statically linked into `torch_cuda`
For default compilation workflow it should not make any difference.
Test Plan: Compile with `-DCUDA_SEPARABLE_COMPILATION=YES` and observe library size difference: 310Mb before, 173Mb after if compiled for sm_75
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34863
Differential Revision: D20683972
Pulled By: malfet
fbshipit-source-id: bc1492aa9d1d2d21c48e8764a8a7b403feaec5da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35455
In graph mode we need to observer the activation tensor for dynamic quantization. This observer should behave the same way as the quantization functions called in the dynamic operator.
Currently for qlinear_dynamic we call quant_utils::ChooseQuantizationParams which has its own logic for calculating scale and zero_point.
We mimic those calculations in the new observer.
Test Plan:
python test/test_quantization.py ObserverTest
Imported from OSS
Differential Revision: D20664586
fbshipit-source-id: e987ea71fff777c21e00c498504e6586e92568a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35164
As title
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20581853
fbshipit-source-id: 393ddd9487cd965c465eaa49e1509863618a6048
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35302
This is an error in modular builds.
Test Plan: CI
Reviewed By: igorsugak
Differential Revision: D20591224
fbshipit-source-id: 44e8e1be9e54b94f7b54be6bdeb4260a763667ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33157
This PR enables graph level thread parallelism on CPU for the Autograd
Engine. It replace https://github.com/pytorch/pytorch/pull/29574 for the
reason of task level parallelism drawbacks with the existing autograd
system.
Fixes https://github.com/pytorch/pytorch/issues/18333
The graph level parallelism on CPU design:
1. Remove the single CPU thread that init in the Engine itself and allow
the owning thread (which calls Engine::execute) to drive the Engine
execution so that we could let outer threading to enable thread
parallelism.
2. Maintain a separate ReadyQueue per CPU thread, and stash the
ReadyQueue for different devices/threads into the thread local
shared_ptr, the Engine itself will memorize the shared_ptr of the
ReadyQueue to different devices (other than CPU)
3. The CPU thread local ReadyQueue is initialized per CPU thread
Engine::execute call (or `backward()`, `grad()` call), and memorized
the shared_ptr into the GraphTask since every `backward()` call have
its own GraphTask
4. Cross device NodeTask push is accomplished by 2 and 3. we can refer
to device's ReadyQueue from Engine, and CPU's ReadyQueue from
GraphTask, which means if we can push to a different ReadyQueue
according to the device
5. Termination of the CPU thread: if we mark the graph_task as
completed, we will exit the while loop and terminate the current
backward execution, because it's guranteed that all other NodeTasks
is finished before we mark a GraphTask as complete
6. re-entrant thread logic keeps the same, reentrant thread detection is
similar as before, we set the worker_device to NO_DEVICE initially
and set to CPU afterward to detect if this is a reentrant call or not.
7. we still have the reentrant thread pool that create new threads if it's
a deep reentrant case, and reuse the ReadyQueue with the parent thread
for performance.
Since we introduce the thread parallelism on CPU, we have to ensure the
thread safety of the GraphTask. This is not a problem if we execute all
forward in different threads since we will build separate GraphTask in
different threads, and each GraphTask is a separate instance that share
nothing, i.e. Hogwild training on CPU should be fine on this case.
But there might be case that user would like to do some part of the task in
a single thread, and do the rest of work in several threads
concurrently, so thread safety is crucial in those cases. The thread
safety strategy for the multithread autograd is as follows:
1. Add a mutex to protect thread safety in Autograd Node/Function, and
hold the lock for different data racing cases
2. Lock the mutex during Node::apply(), this is to ensure Node that
writing to the shared variable are not racing across threads (i.e.
AccumulateGrad and custom C++ Autograd Node if writing to shared
variables )
3. Lock the mutex during Node::release_variables(), this serve the
purpose that when we release saved_variables from one thread, no
other threads can call the Node::apply(), this ensures the variable
references from other threads aren't dangling.
4. If we don't release any variables and no shared data read/write in
the Node i.e. purely functional, we don't lock the mutex
This way we could protect the thread safety on Autograd Node, but we
could still not protect the thread safety on Node pre/post C++ hooks
(python hooks are automatically thread safe), we rely on the user to
write thread safe C++ hooks if they want the hook to be correctly
applied in multithreading environment.
**User visiable changes**:
There're not too much user visiable changes, since we use the owning
thread to drive the autograd execution, user could write their own
threading code and does not block on the Autograd engine, some behaviors
that user should be aware of:
**Non-determinism**:
if we are calling backward() on multiple thread concurrently but with
shared inputs (i.e. Hogwild CPU training). Since parameters are automatically shared across threads, gradient accumulation might become non-deterministic on backward calls across threads, because two backward calls might access and try to accumulate the same .grad attribute. This is technically not safe, and it might result in racing condition and the result might be invalid to use.
But this is expected pattern if user are using the multithreading
approach to drive the whole training process but using shared
parameters, user who use multithreading should have the threading model
in mind and should expect this to happen. User should use the functional
interface `torch.autograd.grad()` to calculate the gradients instead of
`backward()` on loss.
**Graph retaining**:
If part of the autograd graph is shared between threads, i.e. run first
part of forward single thread, then run second part in multiple threads,
then the first part of graph is shared. In this case different threads execute grad() or backward() on the same graph might
have issue of destroying the graph on the fly of one thread, and the
other thread will crash in this case. We will error out to the user
similar to what call `backward()` twice with out `retain_graph=True`, and let the user know they should use `retain_graph=True`.
**TODOs**:
[ ] benchmark the PR with example models and datasets to demonstrate
the performance gain in CPU training
[ ] ensure that we don't regress the single thread autograd performance
**Follow ups**:
[ ] a correct and tight integration with distributed autograd
[ ] try to unify the thread pool between JIT and Autograd, and see if
there's unifying pattern that we could apply universally
Test Plan: Imported from OSS
Differential Revision: D20236771
Pulled By: wanchaol
fbshipit-source-id: 1e0bd4eec14ffebeffdb60b763b8d6f0e427eb64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35259
This PR added tests as part of https://github.com/pytorch/pytorch/issues/34367
It covers:
Re-entrant -> Test simple re-entrant
Re-entrant -> Test stack overflow escape mechanism
Test Plan: Imported from OSS
Differential Revision: D20611828
Pulled By: wanchaol
fbshipit-source-id: 2c55f2a0e3244f11b7153956b0d844e1992e5c80
Summary:
**Summary**
`asyncio.run` is supported only after 3.7 and that too, provisionally so.
This commit replaces the use of `asyncio.run` in `tools/clang_format.py`
with an approximation that works in both 3.6 and 3.7.
**Testing**
Ran the script with both `python3.6` and `python3.7`.
```
$ python3.6 tools/clang_format.py --diff
...
Some files not formatted correctly
$
```
```
$ python3.7 tools/clang_format.py --diff
...
Some files not formatted correctly
$
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35501
Differential Revision: D20681947
Pulled By: SplitInfinity
fbshipit-source-id: 43e13aa85f79396bec1f12ee1e80eff90dbed5db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35246
register caffe2 mask-rcnn ops in lite interpreter. It requires a leading "_" in the name.
(Note: this ignores all push blocking failures!)
Test Plan: buck build -c caffe2.expose_op_to_c10=1 //xplat/caffe2:mask_rcnn_opsAndroid
Reviewed By: iseeyuan
Differential Revision: D20528758
fbshipit-source-id: 459668a0c6cdc6aec85cb561d7acce2a5291b421
Summary:
`gather` turns out to be much faster than `index_select` for this function. (Anywhere from 2-10x faster across my testing.) We do have to match the shape for the generated indices, however this does not affect performance since `.expand` does not copy the underlying buffer.
I experimented with a custom kernel, but the improvement over this implementation didn't justify the approach since it would have added significant complexity and reduced the use of shared infrastructure in the PyTorch codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35243
Differential Revision: D20629914
Pulled By: robieta
fbshipit-source-id: 7841b6a40ffd2b32e544f54ef2529904d76864b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35496
This commit modifies the clang-format workflow so that it prints
the output of `tools/clang_format.py` to stdout instead of piping
it to a file. This way, the issues encountered by the script
(e.g. which files are not formatted correctly) will be visible
in the CI window.
Testing:
CI
Test Plan: Imported from OSS
Differential Revision: D20678729
Pulled By: SplitInfinity
fbshipit-source-id: 8b437c2cf2779de0245c1b4301c57b4ee0dcad6d
Summary:
Use std::list instead of std::vector to avoid iterating over list of registered listeners
Also, fix formatting
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35486
Differential Revision: D20677764
Pulled By: malfet
fbshipit-source-id: d2a545454a29a12bbbf4aa62d9f8c4029a109e6c
Summary:
This commit allows one to use an environment variable to enable the fuser in torch/csrc/jit/tensorexpr/
```
PYTORCH_TENSOREXPR=1 python benchmark.py
```
This commit also changes the registration to happen by default, removing the requirement for the python exposed "_jit_register_tensorexpr_fuser"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35341
Reviewed By: ZolotukhinM
Differential Revision: D20676348
Pulled By: bwasti
fbshipit-source-id: 4c997cdc310e7567c03905ebff72b3e8a4c2f464
Summary:
On most Linux distros `python` still points to python-2.x
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35490
Differential Revision: D20676691
Pulled By: malfet
fbshipit-source-id: 0d4519b83cfebb108edc0628bf036a541247584e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35239
This commit adds a new GitHub workflow that checks if a pull request
has any formatting issues using `tools/clang_format.py`.
Testing:
Literally in prod.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D20605802
Pulled By: SplitInfinity
fbshipit-source-id: 8dd6517dd907d7b6a3d9e9dd3969b666fbebb709
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35115
This commit runs the newly added tools/clang_format.py on the JIT
codebase and includes all of the formatting changes thus produced.
Testing:
Ran the script, CI.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D20568523
Pulled By: SplitInfinity
fbshipit-source-id: e09bdb982ccf090eecfb7c7b461b8d0681eef82b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35114
This commit replaces clang_format.py with clang_format_new.py, a
new and improved script that downloads, verifies and runs a platform-appropriate
clang-format binary on files in a predefined set of whitelisted directories.
Testing:
Ran the script.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D20568450
Pulled By: SplitInfinity
fbshipit-source-id: 3bd782dfc211a053c5b419fd4318d38616b5fd16
Summary:
This speeds up the inlining pass of FairSeq model from 180s -> 13s.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35424
Differential Revision: D20657271
Pulled By: eellison
fbshipit-source-id: 7a9006858c2f1b157f5a3f36ed2b3774cc186de8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35425
Prior to this commit, dist_optimizer_test.py uses torch.manual_seed(0)
to set RNG state. However, multiple RPC threads from the same
process share the same RNG instance. Therefore, even though we
reset the RNG state before every torch.rand usage, background RPC
thread could still mess up draw order in the RNG, leading to
non-deterministic behavior. This commit address this problem by
avoid using the default RNG.
Test Plan: Imported from OSS
Differential Revision: D20657589
Pulled By: mrshenli
fbshipit-source-id: 0f45b11a902317f15f3ee8448bc240f5723075a5
Summary:
Request to update ROCm CI dockers to release 3.1
Changes required to the PyTorch source base attached:
* switch to the fast path for the Caffe2 ReLU operator
* switch to the new hipMemcpyWithStream(stream) API to replace hipMemcpyAsync(stream) && hipStreamSynchronize(stream) paradigm in an optimized fashion
* disable two regressed unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33930
Differential Revision: D20589048
Pulled By: ezyang
fbshipit-source-id: 568f40c1b90f311eb2ba57f02a9901114d8364af
Summary:
As described in https://github.com/pytorch/pytorch/issues/33934, the current attribute error in `nn.Module`'s properties are wrong.
```python
from torch import nn
class MyModule(nn.Module):
property
def something(self):
hey = self.unknown_function()
return hey
model = MyModule()
print(model.something)
```
This raises `AttributeError: 'MyModule' object has no attribute 'something'` when what we want is `AttributeError: MyModule instance has no attribute 'unknown_function'`.
This fixes this issue and will make properties much easier to debug !
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34324
Differential Revision: D20645563
Pulled By: ezyang
fbshipit-source-id: 130f861851bdbef43803569a5ce9e24d2b942179
Summary:
This reverts commit d7a7bcb0428273fa54a836b52e750608ebe7e4de.
The previous commit is not useful because torch_global_deps doesn't include any external dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35355
Differential Revision: D20653036
Pulled By: ezyang
fbshipit-source-id: 6d2e2f90952ca865b27b649a6ff9114ada8ea78c
Summary:
Issue https://github.com/pytorch/pytorch/issues/24596
This PR moves `mm` cuda to ATen. The internal `addmmImpl` that was used as the base of the old TH version of `mm` cuda is also ported.
This PR also sets up `addmm` cuda to be fairly easily ported to ATen in a future PR, since TH `mm` and `addmm` used the same `addmmImpl` function at their core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34891
Differential Revision: D20650713
Pulled By: ngimel
fbshipit-source-id: 692aba1bbae65a18d23855b5e101446082d64c66
Summary:
Sometimes submodule URL may have changed between commits. Let Dockerfile
also sync submodules before updating.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35423
Differential Revision: D20658464
Pulled By: ngimel
fbshipit-source-id: 9c101338437f9e86432d3502766858fa5156a800
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35261
Uses the RECORD_FUNCTION macro to profile the amount of time in
dist_autograd and ensure that it shows up in the profiler output. Since
dist_autograd.backward() is blocking, we can avoid stuffing the RecordFunction
into a callback. This does not support profiling the RPCs that are created when
gradients are forwarded over to other nodes; this can be added in a follow up
diff.
ghstack-source-id: 100723408
Test Plan: Added a UT.
Differential Revision: D20611653
fbshipit-source-id: f9718cf488398a1c7b63ac3841bd2f4549082c8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35167
The purpose of this PR is to move `normal`/`normal_`/`normal_out` to `native/DistributionTemplates.h`, `native/cpu/DistributionTemplates.h` and `native/cuda/DistributionTemplates.h` to make it reusable for custom RNG, see cpu_rng_test.cpp as an example of custom RNG.
Test Plan: Imported from OSS
Differential Revision: D20588248
Pulled By: pbelevich
fbshipit-source-id: 7ee60be97f81522cd68894ff1389007c05130a60
Summary:
1. Removed LossClosureOptimizer, and merged Optimizer into OptimizerBase (and renamed the merged class to Optimizer)
2. Merged the LBFGS-specific serialize test function and the generic test_serialize_optimizer function.
3. BC-compatibility serialization test for LBFGS
4. Removed mentions of parameters_ in optimizer.cpp, de-virtualize all functions
5. Made defaults_ optional argument in all optimizers except SGD
**TODO**: add BC-breaking notes for this PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34957
Differential Revision: D20645945
Pulled By: yf225
fbshipit-source-id: 383588065bf1859b38f0ad0a25d93d41e153c96e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35265
In graph mode we need to observer the activation tensor for dynamic quantization. This observer should behave the same way as the quantization functions called in the dynamic operator.
Currently for qlinear_dynamic we call quant_utils::ChooseQuantizationParams which has its own logic for calculating scale and zero_point.
We mimic those calculations in the new observer.
Test Plan:
python test/test_quantization.py ObserverTest
Imported from OSS
Differential Revision: D20630988
fbshipit-source-id: 7e7aca77590f965dcb423a705e68d030aaf98550
Summary:
Adding ops to the list based on our discussion. :D
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35399
Differential Revision: D20651393
Pulled By: ailzhang
fbshipit-source-id: 8cf9026d10c0d74117953dbb68ebc2f537be956a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35232
Some prim operators, like profile and fusion, are not used in mobile (at least in short term). They are coupled with JIT code. Put them in a separate file (register_prim_ops_fulljit.cpp).
ghstack-source-id: 100807055
Test Plan: buck build //xplat/caffe2:torch
Reviewed By: dreiss
Differential Revision: D20408827
fbshipit-source-id: 9013093357cf75723ef00c34bbfdb6b7ea40a4cf
Summary:
Same to `else`, `endif` and `elseif`.
Also prefer lowercase over uppercase ones
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35343
Test Plan: None at all
Differential Revision: D20638789
Pulled By: malfet
fbshipit-source-id: 8058075693185e66f5dda7b825b725e139d0d000
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35066Closes#24965
Prior to this commit, final_callbacks_ are cleared on exit of ANY
backward. When using reentrant backward, the last backward would
remove all callbacks from the engine. However, this might lead to
unexpected behavior. For example, the application could install
a final callback after forward, and expecting this callback to fire
when all gradients are ready. If there is a renentrant backward on
a subgraph, it would fire the callback and delete it on exit,
meaning that when fired, not all gradients are ready.
**Failed Attempt**
The 1st attempt was trying to move the callback to the GraphTask
in engine::execute(). However, this failed because more callbacks
could be installed during backward pass.
**Current Solution**
Final callbacks are stored as a member variable in the GraphTask.
* Insertion: use the thread_local current_graph_task to find the
target GraphTask, and append final callback.
* Deletion: final callbacks have the same lifetime as a GraphTask
* Execution: Use the GraphTask provided in the argument to find
final callbacks.
Test Plan: Imported from OSS
Differential Revision: D20546474
Pulled By: mrshenli
fbshipit-source-id: d3f3449bb5af9f8703bcae63e6b52056cd535f11
Summary:
I don't know why reduce_scatter collective operation is not documented so I add it to the document.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35274
Differential Revision: D20645850
Pulled By: mrshenli
fbshipit-source-id: 0a4458bff1a4e15a4593dd4dcc25e4e0f6e2265d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/34191
`at::native::radixSelect` basically uses integer comparison which creates a defined ordering of non-finite float values. This isn't compatible with IEEE float comparison, so mixing the two leads to unwritten values in the output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35253
Differential Revision: D20645554
Pulled By: ezyang
fbshipit-source-id: 651bcb1742ed67086ec89cc318d862caae65b981
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35361
If the inputs we are bundling together will be consumed by ops from the same partition, we can assign the Split and Half2Float ops to the that partition too. Otherwise, we do nothing.
Reviewed By: bangshengtang
Differential Revision: D20639777
fbshipit-source-id: 4032abb9178f3b44a85e4789ddf5ad5624245e3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35311
This must have snuck in since a couple PRs updated this same area and
the merge conflict was not resolved properly.
ghstack-source-id: 100770387
Test Plan: CI
Differential Revision: D20602683
fbshipit-source-id: 22134069194b4095dd3be920e4e7f4437dac06f0
Summary:
Currently constant folding is only enabled for ONNX opset versions 9 to 11. This PR enables it for the new ONNX opset 12.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34823
Reviewed By: hl475
Differential Revision: D20627629
Pulled By: houseroad
fbshipit-source-id: 7501d8ab8295751c0e9a02752d8908a35d8a0454
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35235
For dynamic quantization in graph mode, we need an operator that returns the qparams of the tensor
similar to the linear_dynamic quantized op
Test Plan:
python test/test_quantized_tensor.py TestQuantizedTensor.test_choose_qparams
Imported from OSS
Differential Revision: D20608793
fbshipit-source-id: b923b2620421b32d05f4097db0d6153d53198221
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35353
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35324
When the OMP_NUM_THREADS is set to 1, we don't need to launch the parallel_for function on an OpenMP thread since there is no intra-op parallelism. By avoiding that, we can reduce the unnecessary context switches.
Test Plan: internal
Reviewed By: ilia-cher
Differential Revision: D20638734
fbshipit-source-id: 0d5a6537aa2fc35d8d0904c3b9e734e52585eee7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35346
weight scale op doesn't have GPU impl. This is breaking OSS CI from D20506032. Making it cpu only
Test Plan: OSS CI
Reviewed By: ustctf
Differential Revision: D20637440
fbshipit-source-id: 9aa6cce63ce637ab7856788e5d02f527decb2a26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34070
The first step to make all operators available for lite interpreter. The original code used manual registration for lite interpreter ops with a "_" prefix, for two reasons:
1. To minimize the build size.
2. To avoid duplicate registration in OSS (majorly feature testing and unit tests).
Now since we have more and more models to support, the manual registration way is not practical. To make this process automatic while keeping the binary size under control, we plan to:
1. Make all necessary ops callable from lite interpreter.
2. The binary size would be increased because of step 1. Use ljk53 's custom build to selectively build the binary with ops used in specific models. The ops will be automatically collected using get_opnames.
3. The temporary "register_mobile_ops.cpp" can be removed.
Test Plan: Imported from OSS
Differential Revision: D20291596
Pulled By: iseeyuan
fbshipit-source-id: 553b4699619cd71fea20658f3bc8c2d48852ef5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33199
Remove list appends when we can match them with a list construction. This helps create a larger functional graph
Test Plan: Imported from OSS
Differential Revision: D20603187
Pulled By: eellison
fbshipit-source-id: a60e933b457479d40960994d8ffdf39ef49eaf6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33186
This helps create larger functional graphs. It has the potential to increase memory use, so in order to land this on by default we would probably also do a reuse of buffers pass.
This is currently O(n * | Removed Nodes | ) because we have to rebuild the alias Db each time we make a change. This pass is critical to creating functional graphs, so this might be a compelling use case to build incremental updates to alias Db.
Test Plan: Imported from OSS
Differential Revision: D20603189
Pulled By: eellison
fbshipit-source-id: 105db52bf38e02188ca6df6d36294466d3309a0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33020
This is a pass to create functional blocks. The other PRs in the stack help avoid some of the limitations that are are often found in graphs. It's possible that this would work well with a graph that is frozen. Follow up work items that will help this pass:
- We don't currently have any capacity in alias analysis to tell whether a Value that came from the wildcard set "re-escapes" back into the wildcard set.
- More comments on the semantics of the graph and correctness conditions
- We could consider using dynamic dag if the perf of this is a limitation.
- potential make Functional Graphs Functional Blocks instead, so that we do not repeatedly copy constants, also to make IR read easier.
Test Plan: Imported from OSS
Differential Revision: D20603188
Pulled By: eellison
fbshipit-source-id: 6822a6e65f4cc2676f8f6445fe8aa1cb858ebeeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35356
Fix a few typos in dataset_ops
(Note: this ignores all push blocking failures!)
Test Plan: .
Reviewed By: yinghai
Differential Revision: D20554176
fbshipit-source-id: 8565f4b34f5d304696adb1c06d4596921938de8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35324
When the OMP_NUM_THREADS is set to 1, we don't need to launch the parallel_for function on an OpenMP thread since there is no intra-op parallelism. By avoiding that, we can reduce the unnecessary context switches.
Test Plan: internal
Reviewed By: ilia-cher
Differential Revision: D20630949
fbshipit-source-id: 0b6f1ba5b535dafedb16742145a70cc4bb4872a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34820
Adds quantized version of hardswish, for common quantized operator coverage.
Note:
* we carry over scale and zero_point from the input to the output, because the
range of the output is unbounded if x > 0
* we also skip the .out function to not allow the user to specify a custom
scale+zp (flexible on this).
Test Plan:
```
python test/test_quantized.py
https://gist.github.com/vkuzo/f9b579315ed7f5fdb24839e3218d8465
```
Imported from OSS
Differential Revision: D20472905
fbshipit-source-id: 0f2a83e9f5f7b43485fa46caf30e756dc5d492a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34747
Adds the hardswish FP operator from MobileNetV3 to PyTorch. This is for
common operator coverage, since this is widely used. A future PR will
add the quantized version. CUDA is saved for a future PR as well.
Test Plan:
tests pass:
```
python test/test_torch.py TestTorchDeviceTypeCPU.test_hardswish_cpu_float32
```
microbenchmark:
https://gist.github.com/vkuzo/b10d3b238f24e58c585314e8b5385aca
(batch_size == 1: 11.5GiB/s, batch_size == 4: 11.9GiB/s)
Imported from OSS
Differential Revision: D20451404
fbshipit-source-id: c7e13c9ab1a83e27a1ba18182947c82c896efae2
Summary:
A new version of the IR simplifier used by the jit/tensorexpr fuser. This is capable of simplifying expressions containing (shock) multiple variables, eg:
```(m * (1 * n_1) + (n + 1)) - (m * (1 * n_1) + n) => 1```
Similar to the previous IR Simplifier it uses a two stage approach:
1. Traverse the tree combining subtree's of commutable operations in to a flat structure. In this implementation we have two intermediate Exprs: Term (expressing products of sub expressions) and Polynomial (expressing sums of sub expressions).
2. Traverse the tree expanding Term's and Polynomials into their component operators.
Using the example above we execute with a process like this to simplify:
```
(m * (1 * n_1) + (n + 1)) - (m * (1 * n_1) + n)
# Using PolynomialTransformer:
=> Sub(Add(Mul(m, Mul(1, n_1)), Add(n, 1)), Add(Mul(m, Mul(1, n_1)), n))
=> Sub(Polynomial(Term(m, n_1), n, 1), Polynomial(Term(m, n_1), n))
=> Polynomial(Term(m, n_1), Term(-1, m, n_1), n, -n, 1)
=> Polynomial(1)
# Using TermExpander
=> 1
```
The IRSimplifier supports arithmetic simplifications of operators Add, Sub and Mul and constant folding of all binary Exprs and Intrinsics, but does not attempt expansion of multiplication of Polynomials to the canonical form since that generally leads to less efficient representations. It will do scalar factorization if it results in removal of operators, and will merge chains of multilane primitives (such as Broadcast and Ramp) down into a single operator. The ir_simplifier unit tests are a short tour of its capabilities.
The existing simplifier has a bug where it will sometimes reorder operations on floating point types which are not associative. This causes (at least) the pyhpc equation_of_state benchmark to produce incorrect results. I have fixed that issue in this version and verified that that benchmark produces the same results with and without the simplifier.
Tests: all cpp & py tensorexpr tests, and pyphc benchmark:
```
benchmarks.equation_of_state
============================
Running on CPU
size backend calls mean stdev min 25% median 75% max Δ
------------------------------------------------------------------------------------------------------------------
4,194,304 pytorch 10 0.246 0.002 0.243 0.245 0.246 0.248 0.250 1.000
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35127
Differential Revision: D20624571
Pulled By: nickgg
fbshipit-source-id: e49049377beee69e02dcf26eb922bef1447ae776
Summary:
Stacked PRs
* #34938 - [jit] Remove stray `script`
* **#34935 - [jit] Add lazy script decorator**
Some users maintain libraries of code that is largely trace-able but not
script-able. However, some functions may need to be `torch.jit.script`ed if
they contain control flow so the tracer will use the compiler version.
This however impacts library start up time as in #33418, so this PR adds
a workaround in the form of a `torch.jit._lazy_script_while_tracing`
that will only initialize the compiler if the function is called while
actually tracing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34935
Pulled By: driazati
Differential Revision: D20569778
fbshipit-source-id: d87c88c02b1abc86b283729ab8db94285d7d4853
Summary:
I will need it for https://github.com/pytorch/pytorch/pull/34004
The `mutable` qualifier allows a lambda to capture some values, and modify its own copy. This would be useful for random kernels: we capture a `state` of RNG, initialize it when it first run, and the initialized stated will be used later:
```C++
gpu_kernel(iter, [state, initialized](scalar_t arg) mutable -> scalar_t {
if (!initialized) {
curand_init(..., state);
initialized = true;
}
return some_math(curand_uniform(state), arg);
}
```
The `operator()` of `mutable` lambda is not `const`, so we can not pass it as constant reference. It can not be called inside a non-`mutable` lambda either.
Example usage:
```C++
auto t = at::empty({4096}, kCUDA);
float thread_work_index_ = 0;
auto iter = TensorIterator::nullary_op(t);
gpu_kernel(iter, [thread_work_index_]GPU_LAMBDA() mutable -> float {
return thread_work_index_++;
});
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35015
Differential Revision: D20624698
Pulled By: ngimel
fbshipit-source-id: 06e3987793451cd514181d20252510297e2d28a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35296
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20624843
Pulled By: ezyang
fbshipit-source-id: 9028f1dd62d0c25e916eb4927fd8dd6acbd88886
Summary:
Otherwise, VC++ will warn that every exposed C++ symbol, for example:
```
include\c10/core/impl/LocalDispatchKeySet.h(53): warning C4251: 'c10::impl::LocalDispatchKeySet::included_': class 'c10::DispatchKeySet' needs to have dll-interface to be used by clients of struct 'c10::impl::LocalDispatchKeySet'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35272
Test Plan: CI
Differential Revision: D20623005
Pulled By: malfet
fbshipit-source-id: b635b674159bb9654e4e1a1af4394c4f36fe35bd
Summary:
Simplifies `cpu_scatter_gather_base_kernel` to accept only binary operations and spares them from doing redundant checks.
CC v0dro
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34690
Differential Revision: D20604814
Pulled By: ngimel
fbshipit-source-id: 5e22c2f39a8e2861dc763454c88796d1aa38d2eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35223
Adding tests as part of
https://github.com/pytorch/pytorch/issues/34367.
This test covers
"Mixed with errors" ->
"Reentrant on same device" ->
"Make child error before parent finishes"
ghstack-source-id: 100725947
Test Plan: waitforbuildbot
Differential Revision: D20603127
fbshipit-source-id: 08484b0a98053491459e076bdd23caf042c47150
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35283https://github.com/pytorch/pytorch/issues/34260
Deadlock on destructing py::error_already_set.
There are request callback impls in Python, where Python exceptions could be thrown. For releasing Python exception py::objects, GIL must be held.
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork && \
buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par \
-r test_torchscript_functions_not_supported
```
Differential Revision: D7753253
fbshipit-source-id: 4bfaaaf027e4254f5e3fedaca80228c8b4282e39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34553
This allows vectorized looping in a serial iteration over
TensorIterator.
Test Plan: Imported from OSS
Differential Revision: D20604238
Pulled By: ezyang
fbshipit-source-id: 61c451dac91d47cde7e1a937b271ab78c79e05d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35240
This makes it so that if we have an old serialized TorchBind class, we don't try to load it in and instead rely on the ClassType that's in memory.
ghstack-source-id: 100703946
Test Plan: buck test mode/dev-nosan //caffe2/torch/fb/predictor/model_repo/tests:ai_infra_representative_model_shard_6_test -- 'RepresentativeModelTest\/ShardedRepresentativeModelTest\.RunModel\/0'
Reviewed By: zdevito
Differential Revision: D20605681
fbshipit-source-id: 5403f68937f822914c701d9c80573f0b4a93e83b
Summary:
Per title. See related https://github.com/pytorch/pytorch/pull/34570.
In PyTorch 1.7 the plan is for torch.div and Python's division operator to perform "true" division, like Python 3, JAX, and NumPy. To facilitate this change, this PR expands true_divide to be a method so it can cover all of torch.div's use cases.
New true_divide tests are added to test_torch.py, test_type_promotion.py, and test_sparse.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34794
Differential Revision: D20545507
Pulled By: mruberry
fbshipit-source-id: 55286f819716c8823d1930441a69008560ac2bd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34345
prim::ListConstruct is similar to an op that doesn't require observation
we want to make sure we can propagate observed property through it
Test Plan:
this will be tested when we add support for cat
https://github.com/pytorch/pytorch/pull/34346
Imported from OSS
Differential Revision: D20524455
fbshipit-source-id: b5f8e0c8776d48d588aeba6735de06dcd308560e
Summary:
Clamp input tensor values to [3, 3] to limit how small `tanh` gradint can get
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35196
Test Plan: CI + `bin/test_jit --gtest_filter=JitTest.ADFormulas --gtest_repeat=60000 --gtest_break_on_failure`
Differential Revision: D20611256
Pulled By: malfet
fbshipit-source-id: 8640faa5d8567d6c6df8cc5df80c2e65407116eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34845
This PR allows PyNode to persist the error message so that any pure C++
thread that runs autograd with custom Python autograd function can successfully
catpure the error message without maintaining a initial PyThreadState.
Test Plan: Imported from OSS
Differential Revision: D20480685
Pulled By: wanchaol
fbshipit-source-id: 0488ea5a4df9a33b53ac5d0d59000c41ab6cb748
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35090
As a preparation to open source fp16 + stochastic rounding SparseAdagrad and fused SparseAdagrad
Other minor changes:
* Removed template parameters T that are not actually used
* Removed unnecessary anonymous namespaces used in header files
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20552770
fbshipit-source-id: 224fdca15ea786620ce88e33cbcbf97661423538
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34804
We want to replicate the quantize node for return values in blocks of prim::If
in order to create the quantization patterns.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20524453
fbshipit-source-id: 2268ac555f646158f4e1ffc98ccc8101d7504194
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35252
The torch::from_blob() syntax without a deleter syntax is relatively
dangerous and explicitly assumes that the caller will correctly persist
the tensor bits for as long as necessary.
We were at one point correctly persisting the send tensor bits in
process_group_agent, but with the early-return codepaths are not
doing so any longer.
This change switches to a more robust approach where we instead just use
the torch::from_blob-with-deleter syntax, and use std::move to avoid
a copy. There's an extra malloc, but that's effectively free compared with
the rest of the work involved here. And it means we don't have to worry
about the Tensor memory vanishing from underneath the send anymore.
The initial motivation here was dist_autograd_node_failure flakiness.
While the motivating case is handleSend(), we also fix handlePendingMessage().
ghstack-source-id: 100704883
Test Plan:
existing test coverage, e.g.
buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcBackend/test:ProcessGroupAgentTest
Differential Revision: D20607028
fbshipit-source-id: cf9966c5aa9472830cfefaf7fc2f92af9b52630d
Summary:
Found an issue where the git describe wasn't properly executed since the
binary_populate_env.sh script was being executed from a different
directory.
'git -C' forces the describe to run in the running directory for the
script which should contain the correct git information
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35065
Differential Revision: D20603172
Pulled By: seemethere
fbshipit-source-id: b19112ce4cb2dc45fbb3f84dedc4f1d3f2259748
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34943
Follow up to address Jeremy's and Shen's comments on
https://github.com/pytorch/pytorch/pull/34413:
1) Continue trying even if one `agent->send()` fails when cleaning up dist
autograd ctx
2) Use RAII for lock in process group agent `handleSend`
3) Return bool instead of int in `ProcessGroupAgent::handleRecv` to determine
if the count should be incremented
4) Move recvCounts increment in timed out future processing to be within the
block that ensures the future already doesn't have an error.
ghstack-source-id: 100681746
Test Plan: CI
Differential Revision: D20506065
fbshipit-source-id: 14a2820b3ae7a65edd103f0b333c4bc21e821235
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34786
1) Rename 'HashIValue' to 'HashAliasedIValue'
2) Added Object case in getSubValues function
3) Hashes tensors to their storage
4) Added Dict case in orverrideGradient
5) nit clean up
Test Plan: Imported from OSS
Differential Revision: D20585270
Pulled By: bzinodev
fbshipit-source-id: f580f3cb80dd5623088a014efd5f0f5ccc1659c0
Summary:
add `id` function so to give uses a way of keeping a `seen` set of nn modules.
n practice, this is only used between values of `T` and `T` or `T` and `Optional[T]`, so in this implementation I made it so that None is the only value that can be zero. Python also only guarantees `id()` gives semantically meaningful results for pointer types.
EDIT: now only allowing id on class types
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34975
Reviewed By: driazati
Differential Revision: D20599564
Pulled By: eellison
fbshipit-source-id: 3c6666a9b9b0258198adc70969dd6332e3375e4f
Summary:
`FilterDescriptor` is missing a `TORCH_CUDA_API`, so this symbol is not exported from `torch_cuda.so`, and users could have trouble building cpp_extension when using cudnn.
cc: ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35131
Differential Revision: D20604439
Pulled By: ezyang
fbshipit-source-id: c57414fc8a9df9cb1e910e2ec0a48cfdbe7d1779
Summary:
When `unittest.main()` is invoked with custom testRunner, verbosity settings for the runner must be set manually
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35224
Test Plan: CI
Differential Revision: D20605896
Pulled By: malfet
fbshipit-source-id: 79fc6f55911189b6d8a4bc83bd2390c94bd69e5e
Summary:
iotamudelta Test passed three iterations on the CI, no flakiness detected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35124
Differential Revision: D20604748
Pulled By: ezyang
fbshipit-source-id: ed013ca27f38a3610108421932245b494fac28c0
Summary:
Sometimes it is important to run code with thread sanitizer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35197
Test Plan: CI
Differential Revision: D20605005
Pulled By: malfet
fbshipit-source-id: bcd1a5191b5f859e12b6df6737c980099b1edc36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35221
When weight is reused, we only need to insert one observer for the weight
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20602492
fbshipit-source-id: e003e6316f6615f3526f0d00fb7b722148b4749b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35231Fixes#35213
(Note: this ignores all push blocking failures!)
Test Plan: `mypy -c "import torch; ten = torch.tensor([1.0, 2.0, 3.0]); print(7 + ten)"` should not produce any warnings
Differential Revision: D20604924
Pulled By: pbelevich
fbshipit-source-id: 53a293a99b3f2ab6ca5516b31f3a92f67eb67a39
Summary:
The following code
```python
a = torch.randn(42,)
b = a.cuda(non_blocking=True)
```
will be **blocked** in the current master, and will **not be blocked** in pytorch 1.4 release. This can be verified by a `nvprof --print-api-trace python script.py` profiling. It is causing performance issue.
I isolated the problem, and jjsjann123 & ptrblck pointed out the fix. Thanks!
cc csarofeen ptrblck jjsjann123 VitalyFedyunin ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35144
Differential Revision: D20601163
Pulled By: ngimel
fbshipit-source-id: edd2b1dabd8e615c106188f30ddb3e763bde7471
Summary:
- replace the old build variables NO_CUDA and NO_DISTRIBUTED in CONTRIBUTING.md with the new USE_CUDA and USE_DISTRIBUTED versions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34831
Differential Revision: D20512659
Pulled By: colesbury
fbshipit-source-id: 2d6cb6fd35886eec0b4b1c94f568b5137407c551
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34571
Previously we added wrong values to observed_values_ and also it is
not used to check if a value is observed or not
Test Plan:
.
Imported from OSS
Differential Revision: D20519605
fbshipit-source-id: 6038b2539bcf7d679b7fe5c5a284b81a979934ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34414
Previously we insert observers for Graph(graph is a wrapper around a Block),
this PR added insertObservers for Block, so that the code can work for the nodes that have sub blocks.
Test Plan:
.
Imported from OSS
Differential Revision: D20519604
fbshipit-source-id: 1908913ea7f0898cd7b4f2edd1f81cdfedf8a211
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34411
To make sure dequantize and the node that uses the dequantized value reside in the
block, so that we can do quant fusion
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20519603
fbshipit-source-id: 3e4c68d0a73142716e19ea6a64ae3a5d6d51fa41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34349
Set the output type of dequantize node to the type of original value
this is to fix swap dequantize tensor list
Test Plan:
.
Imported from OSS
Differential Revision: D20504456
fbshipit-source-id: 9064d7d598a4310e27e2914a072097526448a02c
Summary:
In C++, casting a floating point value to an integer dtype is undefined when the value is outside the dtype's dynamic range. For example, casting 300.5 to Int8 is undefined behavior because the maximum representable Int8 value is 127, and 300.5 > 127.
PyTorch, like NumPy, deliberately allows and makes these casts, however, and when we do this we trigger undefined behavior that causes our sanitizers to (correctly) complain. I propose skipping this sanitization on our cast function.
The history of this PR demonstrates the issue, showing a single CI failure in the ASAN build when a test is added that converts a large float value to an integral value. The current PR shows a green CI after the sanitization is skipped.
There are alternatives to skipping this sanitization:
- Clamping or otherwise converting floats to the dynamic range of integral types they're cast to
- Throwing a runtime error if a float value is outside the dynamic range of the integral type it's cast to (this would not be NumPy compatible)
- Declaring programs in error if they perform these casts (this is technically true)
- Preventing this happening in PyTorch proper so the ASAN build doesn't fail
None of these alternatives seems particularly appealing, and I think it's appropriate to skip the sanitization because our behavior is deliberate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35086
Differential Revision: D20591163
Pulled By: mruberry
fbshipit-source-id: fa7a90609c73c4c627bd39726a7dcbaeeffa1d1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35179
Transitive dependencies are calculated in python script for both OSS custom build and BUCK selective build, so change the c++ analyzer to take -closure=false by default and remove the param from callsites.
ghstack-source-id: 100637068
Test Plan: CI
Differential Revision: D20586462
fbshipit-source-id: 195849b71cda6228a49ecd2215d3fb8b4da7f708
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34774
This PR provides pybind11's `type_caster<at::Generator>` that allows mapping `at::Generator` instance returned from user-defined method to python `torch::Generator`, defined as `THPGenerator ` c++ class.
This allows 1) defining custom RNG in c++ extension 2) using custom RNG in python code.
`TestRNGExtension.test_rng` shows how to use custom RNG defined in `rng_extension.cpp`
Test Plan: Imported from OSS
Differential Revision: D20549451
Pulled By: pbelevich
fbshipit-source-id: 312a6deccf8228f7f60695bbf95834620d52f5eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35010
semantics.
This PR moves all the xnnpack specific interfces to a generic interface.
Accordingly removes xnnpac specific reference from API and some variable
names.
What has not yet changed:
TODO:
USE_XNNPACK is still used. This can be removed where no XNNPACK
specific things are done. e.g., RegisterOpContext.cpp and
xnnpack_rewrite.cpp.
Also the filename and structure also remains. Some of the generic class
definition can be moved non-XNNPACK specific folder.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20526416
fbshipit-source-id: 2e1725345c44bbb26bdc448097a7384eca121387
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35163
This PR is BC-breaking in the following way:
Renaming:
- `torch::nn::functional::MultiLabelMarginLossFuncOptions` -> `torch::nn::functional::MultilabelMarginLossFuncOptions`
- `torch::nn::functional::MultiLabelSoftMarginLossFuncOptions` -> `torch::nn::functional::MultilabelSoftMarginLossFuncOptions`
Reason for renaming: to be consistent with the corresponding functional name after camel case to snake case conversion (e.g. the `multilabel_margin_loss` functional should use `MultilabelMarginLossFuncOptions` as options)
Test Plan: Imported from OSS
Differential Revision: D20582598
Pulled By: yf225
fbshipit-source-id: 0f5bdb8249d901b310875a14320449a2fdfa8ecd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34468
This PR prepares `at::Generator` for pybind11's `type_caster<at::Generator>` which is required to implement custom RNG in python. The following changes are done:
1. `at::Generator` was moved to `c10::GeneratorImpl` (similar to `c10::TensorImpl`)
2. `at::Generator` was recreated as a holder of `std::shared_ptr<c10::GeneratorImpl>` (similar to `at::Tensor` that holds `c10::intrusive_ptr<c10::TensorImpl>`)
3. Most of `at::Generator*` usages were replaced with `at::Generator`
TBD: replacing `Generator generator = nullptr` with `{}` requires JIT changes(adding Generator to IValue?)
Differential Revision: D20549420
Pulled By: pbelevich
fbshipit-source-id: 4c92a40eab8f033b359bb6c93f4cd84b07ee8d4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35148
PR #34275 (commit 064c47845380715e290eb335919a18fe3821ee83) causes size
regression for BUCK build before BUCK selective build is enabled.
This PR reverts partially (adding back #ifndef USE_STATIC_DISPATCH) to
fix the size regression. Will wait for BUCK selective build change to
land and soak then revert this revert.
Test Plan: Imported from OSS
Differential Revision: D20578316
Pulled By: ljk53
fbshipit-source-id: 694f01ec7a69fe3758a389e22e9de20ecd867962
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34348
We need this function to do swap dequantize for prim::ListConstruct since
the output of prim::ListConstruct is a list of Tensors
Test Plan:
.
Imported from OSS
Differential Revision: D20504454
fbshipit-source-id: e6155e37da98e2219a6f79737cd46fe32a509c9f
Summary: Att
Test Plan: Updated C2 importer test in stack.
Reviewed By: yinghai, bangshengtang
Differential Revision: D20527162
fbshipit-source-id: cf3d59089b651565db74f2a52af01f26fdfcbca6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35025
This PR fixes `F::interpolate` and `torch::nn::Upsample` implementation to match the Python API implementation.
**This PR is BC-breaking in the following way:**
There are changes to `UpsampleOptions` and `InterpolateFuncOptions`:
- `size` is changed from `std::vector<int64_t>` to `c10::optional<std::vector<int64_t>>`. If you want to pass a list of `int64_t` to this argument, you must pass it as `std::vector<int64_t>`.
- `scale_factor` is changed from `std::vector<double>` to `c10::optional<std::vector<double>>`. If you want to pass a list of `double` to this argument, you must pass it as `std::vector<double>`.
**TODO**: cherry-pick this PR into v1.5 release branch.
Test Plan: Imported from OSS
Differential Revision: D20559892
Pulled By: yf225
fbshipit-source-id: ac18609e351a9f2931eaeced8966b9491b2995f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35023
This PR fixes Conv and ConvTranspose implementation to match the Python API implementation.
**TODO**: cherry-pick this PR into v1.5 release branch.
Test Plan: Imported from OSS
Differential Revision: D20559889
Pulled By: yf225
fbshipit-source-id: 53783a7398ef968ec6d25b6f568fde44907417c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35022
This PR fixes `AdaptiveAvgPool{2,3}d` and `AdaptiveMaxPool{2,3}d` implementation to match the Python API implementation. Particularly, `output_size` is changed to accept `c10::nullopt` in its elements, matching the Python API behavior.
**TODO**: cherry-pick this PR into v1.5 release branch.
Test Plan: Imported from OSS
Differential Revision: D20559890
Pulled By: yf225
fbshipit-source-id: ccddbd278dd39165cf1dda11fc0e49387c76dbef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35039
This is the initial step towards merging ivalue future and rpc future
Test Plan: Imported from OSS
Differential Revision: D20537164
Pulled By: wanchaol
fbshipit-source-id: d4f148c88e49ed6b0881ca4b4dd945ea24166183
Summary:
The protobuf bazel definitions are incompatible with recent bazel
versions, so as a prerequisite for any bazel build of pytorch, a more
recent protobuf must be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34662
Differential Revision: D20570425
Pulled By: malfet
fbshipit-source-id: ed4de3eb3fe05f076df93db7175954e797791300
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35028
removes these methods that are not used anywhere in the codebase. With this we can also remove public declaration of TORCH_API popRange and TORCH_API pushRange since those were the only use cases.
ghstack-source-id: 100560207
Test Plan: CI
Differential Revision: D20531148
fbshipit-source-id: 8ceaf64449c77259a582a38b1137827ff1ab07f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33636
Fixes https://github.com/pytorch/pytorch/issues/32119, https://github.com/pytorch/pytorch/issues/26116,
https://github.com/pytorch/pytorch/issues/33072
Makes RRef control messages idempotent and enables sending with retries for distributed autograd cleanup and RRef internal messages.
In order to effectively test whether these RRef and distributed autograd cleanup work with network failures/retries, I implemented an RPC Agent with a faulty send function, and enabled running tests using this as a third backend (in addition to Thrift and PGA). The tests using this backend are in a separate class (the test cases are similar but with minor changes to ensure short-running tests wait for retried RPCs to finish).
This faulty RPC Agent is pretty configurable. The tests can configure which messages types to fail, and how many messages to fail, but going forward, other RPC functionality can be overriden with faulty methods to test with failures injected.
Differential Revision: D20019236
fbshipit-source-id: 540a977e96b2e29aa0393ff12621fa293fe92b48
Summary:
PR #32521 has several issues with mobile builds:
1. It didn't work with static dispatch (which OSS mobile build currently uses);
2. PR #34275 fixed 1) but it doesn't fix custom build for #32521;
3. manuallyBoxedKernel has a bug with ops which only have catchAllKernel: 2d7ede5f71
Both 1) and 2) have similar root cause - some JIT side code expects certain schemas to be registered in JIT registry.
For example: considering this code snippet: https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/frontend/builtin_functions.cpp#L10
```
auto scalar_operators_source = CodeTemplate(
R"SCRIPT(
def mul(a : ${Scalar}, b : Tensor) -> Tensor:
return b * a
...
```
It expects "aten::mul.Scalar(Tensor self, Scalar other) -> Tensor" to be registered in JIT - it doesn't necessarily need to call the implementation, though; otherwise it will fail some type check: https://github.com/pytorch/pytorch/pull/34013#issuecomment-592982889
Before #32521, all JIT registrations happen in register_aten_ops_*.cpp generated by gen_jit_dispatch.py.
After #32521, for ops with full c10 templated boxing/unboxing support, JIT registrations happen in TypeDefault.cpp/CPUType.cpp/... generated by aten/gen.py, with c10 register API via RegistrationListener in register_c10_ops.cpp. However, c10 registration in TypeDefault.cpp/CPUType.cpp/... are gated by `#ifndef USE_STATIC_DISPATCH`, thus these schemas won't be registered in JIT registry when USE_STATIC_DISPATCH is enabled.
PR #34275 fixes the problem by moving c10 registration out of `#ifndef USE_STATIC_DISPATCH` in TypeDefault.cpp/CPUType.cpp/..., so that all schemas can still be registered in JIT. But it doesn't fix custom build, where we only keep c10 registrations for ops used by specific model directly (for static dispatch custom build) and indirectly (for dynamic dispatch custom build). Currently there is no way for custom build script to know things like "aten::mul.Scalar(Tensor self, Scalar other) -> Tensor" needs to be kept, and in fact the implementation is not needed, only schema needs to be registered in JIT.
Before #32521, the problem was solved by keeping a DUMMY placeholder for unused ops in register_aten_ops_*.cpp: https://github.com/pytorch/pytorch/blob/master/tools/jit/gen_jit_dispatch.py#L326
After #32521, we could do similar thing by forcing aten/gen.py to register ALL schema strings for selective build - which is what is PR is doing.
Measured impact on custom build size (for MobileNetV2):
```
SELECTED_OP_LIST=MobileNetV2.yaml scripts/build_pytorch_android.sh armeabi-v7a
```
Before: 3,404,978
After: 3,432,569
~28K compressed size increase due to including more schema strings.
The table below summarizes the relationship between codegen flags and 5 build configurations that are related to mobile:
```
+--------------------------------------+-----------------------------------------------------------------------------+--------------------------------------------+
| | Open Source | FB BUCK |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| | Default Build | Custom Build w/ Stat-Disp | Custom Build w/ Dyna-Disp | Full-JIT | Lite-JIT |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| Dispatch Type | Static | Static | Dynamic | Dynamic (WIP) | Dynamic (WIP) |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| ATen/gen.py | | | | | |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| --op_registration_whitelist | unset | used root ops | closure(used root ops) | unset | closure(possibly used ops) |
| --backend_whitelist | CPU Q-CPU | CPU Q-CPU | CPU Q-CPU | CPU Q-CPU | CPU Q-CPU |
| --per_op_registration | false | false | false | false | true |
| --force_schema_registration | false | true | true | false | false |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| tools/setup_helpers/generate_code.py | | | | | |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
| --disable-autograd | true | true | true | false | WIP |
| --selected-op-list-path | file(used root ops) | file(used root ops) | file(used root ops) | unset | WIP |
| --disable_gen_tracing | false | false | false | false | WIP |
+--------------------------------------+---------------------+---------------------------+---------------------------+---------------+----------------------------+
```
Differential Revision: D20397421
Test Plan: Imported from OSS
Pulled By: ljk53
fbshipit-source-id: 906750949ecacf68ac1e810fd22ee99f2e968d0b
Summary:
PR #32521 broke static dispatch because some ops are no longer
registered in register_aten_ops_*.cpp - it expects the c10 registers in
TypeDefault.cpp / CPUType.cpp / etc to register these ops. However, all
c10 registers are inside `#ifndef USE_STATIC_DISPATCH` section.
To measure the OSS mobile build size impact of this PR:
```
# default build: SELECTED_OP_LIST=MobileNetV2.yaml scripts/build_pytorch_android.sh armeabi-v7a
# mobilenetv2 custom build: scripts/build_pytorch_android.sh armeabi-v7a
```
- Before this PR, Android AAR size for arm-v7:
* default build: 5.5M;
* mobilenetv2 custom build: 3.2M;
- After this PR:
* default build: 6.4M;
* mobilenetv2 custom build: 3.3M;
It regressed default build size by ~1M because more root ops are
registered by c10 registers, e.g. backward ops which are filtered out by
gen_jit_dispatch.py for inference-only mobile build.
mobilenetv2 custom build size regressed by ~100k presumably because
the op whitelist is not yet applied to things like BackendSelectRegister.
Differential Revision: D20266240
Test Plan: Imported from OSS
Pulled By: ljk53
fbshipit-source-id: 97a9a06779f8c62fe3ff5cce089aa7fa9dee3c4a
Summary:
This is try to parallelize index_put accumulate path for float type on CPU. cpu_atomic_add_float is implemented by using atomic_compare_exchange_strong function.
for [DLRM](https://github.com/facebookresearch/dlrm) benchmark, _index_put_impl_ function time can be reduced from 827.741ms to 116.646ms for 1000 batches
Add a parameter "grain_size" to TensorIterator::for_each to fine tune the index_put performance
The default value of grain_size is internal::GRAIN_SIZE. The index_put grain size is tuned to 3000 and cpu_kernel_vec grain size is tuned to 1024. The following is the grain size impact on the DLRM ops
( _index_put_impl_ based on index_put been parallellized with cpu_atomic_add_float):
| Op Name | without small grain_size | with 1024 as grain_size in cpu_kernel_vec and 3000 in cpu_index_kernel |
|-----------------|----------:|----------:|
| add_ | 11.985s | 11.601s |
| mm | 9.706s | 9.518s |
| addmm | 5.380s | 5.247s |
| _embedding_bag | 2.992s | 2.663s |
| _embedding_bag_backward | 1.330s | 1.354s |
| threshold_backward | 686.920ms | 659.169ms |
| _index_put_impl_ | 489.411ms | 116.646ms |
| bmm | 413.129ms | 362.967ms |
| zero_ | 379.659ms | 310.623ms |
| add | 205.904ms | 171.111ms |
| cat | 187.101ms | 175.621ms |
| Self CPU time total (s) | 36.544 | 34.742 |
| Average ms per iteration | 38.25 | 36.44 |
The more reason for grain size tuning, please further look at [PR#30803](https://github.com/pytorch/pytorch/issues/30803)
to get the DLRM performance here, please also have a look at
[PR#23057](https://github.com/pytorch/pytorch/pull/23057), [PR#24385](https://github.com/pytorch/pytorch/pull/24385) and [PR#27804](https://github.com/pytorch/pytorch/pull/27804)
and expose the env vars as below:
```
export LD_PRELOAD=$HOME/anaconda3/lib/libjemalloc.so (conda install jemalloc)
export KMP_BLOCKTIME=1
export KMP_AFFINITY="granularity=fine,compact,1,0"
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29705
Differential Revision: D19777742
Pulled By: VitalyFedyunin
fbshipit-source-id: a8222fe6089b6bf56b674e35f790508ad05385c0
Summary:
This PR adds a preprocessing step in Conv2dBatchNorm folding.
It traverses the module to check if the bias of Conv2d module is set to
None. If it is, it assume that this a traced module and insert
Optional[Tensor] type bias.
Furthermore it insert getAttr for bias in the forward graph and fixes
_convolution op to take values from getAttr.
It also fixes parametere extraction from BN module which may not
have weight and bias attributes if affine was set to False. In scripted
mode such a BN module will get weight and bias attributes set to None.
For the case of eps it gets const propagated in tracing. This is also
fixed.
Few tests cases are added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34932
Test Plan:
python test/test_jit.py TestJit.test_foldbn_trivial
python test/test_jit.py TestJit.test_foldbn_trivial_nobias
python test/test_jit.py TestJit.test_foldbn_in_submodule
python test/test_jit.py TestJit.test_foldbn_shared_classtype
python test/test_jit.py TestJit.test_foldbn_complex_cases
python test/test_jit.py TestJit.test_nofoldbn_complex_cases
Differential Revision: D20536478
Pulled By: kimishpatel
fbshipit-source-id: 4e842976a380d0575a71001bb4481390c08c259e
Summary:
We should recommend DDP instead of DP. Hope we can also cherry-pick this for 1.5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35063
Differential Revision: D20549621
Pulled By: ngimel
fbshipit-source-id: 86b1b2134664065cc6070ea4212895f993eaf543
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32313
`torch::autograd::profiler::pushCallback()`, `torch::jit::setPrintHandler` should be called only once, not before every loading
`JITCallGuard guard;` not needed before loading module and has no effect
Test Plan: Imported from OSS
Differential Revision: D20559676
Pulled By: IvanKobzarev
fbshipit-source-id: 70cce5d2dda20a00b378639725294cb3c440bad2
Summary:
add `id` function so to give uses a way of keeping a `seen` set of nn modules.
n practice, this is only used between values of `T` and `T` or `T` and `Optional[T]`, so in this implementation I made it so that None is the only value that can be zero. Python also only guarantees `id()` gives semantically meaningful results for pointer types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34975
Differential Revision: D20549677
Pulled By: eellison
fbshipit-source-id: cca5ed4ef013f7540f93abf49f91f9830dfdca14
Summary:
This adds the `trunc_normal_` function to `torch.nn.init` which allows for modifying tensors in-place to values drawn from a truncated normal distribution. I chose to use the inverse CDF method to implement this. I have included the appropriate code in `test_nn.py` for verifying that the values are from the correct distribution.
Reasons I chose this method:
1. Easily implemented to operate on memory in place, as the other initializers are.
1. No resampling delays
1. This method's main weakness is unlikely to be an issue. While the inverse CDF method can fail to generate the correct distribution when `b < mean` or `mean < a`, I expect users will choose `a` and `b` so that `a < mean < b`. This method is extremely effective in this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32397
Differential Revision: D20550996
Pulled By: ezyang
fbshipit-source-id: 298a325043a3fd7d1e24d266e3b9b6cc14f81829
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34394
# SWA operator
In this diff, we added a new operator `SWA` which will be used in `AdaGradOptimizer`.
The algorithm looks like:
{F230902995}
# Background
In our testings, we found that this operator could improve our models' reproducibility a lot. (KT: 0.86 -> .92)
So we hope to land this operator and in future, enable this by default in our Models.
Test Plan:
Local build `aml.dper3:30f068668cfb408fbb40141fb17129f2` and bento kernel.
- Local test: n215857
- f174600345
Reviewed By: chocjy
Differential Revision: D20165239
fbshipit-source-id: c03cdd048cb10b091e5f06323f4c0f3999f95d8a
Summary:
Because `this` must be valid while `Engine::main_thread` is running, at least for non-reentrant worker threads
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34529
Test Plan: Run `test_api --gtest-filter=ModulesTest.InstanceNorm1d` in a loop
Differential Revision: D20552717
Pulled By: malfet
fbshipit-source-id: a0197671db1b7b1499dda675e43e0826f368bf0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34755
This diff disallows to use python pickler to pickle RRef. RRef can only be pickled in the scope of RPC call using _InternalRPCPickler.
ghstack-source-id: 100481337
Test Plan: unit tests
Differential Revision: D20453806
fbshipit-source-id: ebd4115ee01457ba6958cde805afd0a87c686612
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34976
Previously, we are dropping the original device option info when we override the operator conversion function.
Test Plan:
```
buck test caffe2/caffe2/opt:converter_nomigraph_test
```
Reviewed By: ipiszy
Differential Revision: D20507277
fbshipit-source-id: 66b5eab07d18651eff27dab2a809cd04872ac224
Summary:
resubmit D20464855 and also Fix the broken test due to D20464855
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35080
Differential Revision: D20551174
Pulled By: lly-zero-one
fbshipit-source-id: 5a0547a64365c556c3a677a9512423047497cc85
Summary:
torch.mm is exported as Gemm operator in ONNX and both have an optional input: out.
out is considered as broadcastable in Gemm and during graph optimization the optional input (out) would get selected. Since out is optional, in case when it is not defined in torch.mm that would result in the following exception:
IndexError: vector::_M_range_check: __n (which is 2) >= this->size() (which is 2)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34661
Reviewed By: hl475
Differential Revision: D20496398
Pulled By: houseroad
fbshipit-source-id: e677aef0a6aefb1f83a54033153aaabe5c23bc0f
Summary:
Given that complex types have also been vectorized, there is no need to
handle complex types differently in fill.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34973
Differential Revision: D20551014
Pulled By: ezyang
fbshipit-source-id: e0cb519aa17f90b7a2d70700b32b80acb0d41b14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35037Closes#34960
Cannot reproduce the test failure in dev server, local machine, and
the CI env that captured the failure. However, the failed test takes
very long (~10sec) in MacOS, so reducing the number of iterations to
make it lighter.
Re-enable the test and will monitor if the error occurs again.
Test Plan: Imported from OSS
Differential Revision: D20536272
Pulled By: mrshenli
fbshipit-source-id: 577822574e5f6271f1cbb14b56c68c644291713e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34689
rref JIT pickling is only allowed inside rpc calls. enforcing this by adding a thread local variable isInRpcCall and set it as True when converting rpc requests or responses to message, before calling JIT::pickle(). Inside JIT::pickle(), it allowes to pickle RRef only when the isInRpcCall is true.
ghstack-source-id: 100481001
Test Plan: unit tests
Differential Revision: D20429826
fbshipit-source-id: dbc04612ed15de5d6c7d75a4732041ccd4ef3f8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34985
IValue is part of the overall runtime system, not just the JIT. So it
should be tested in the ATen tests.
The real motivation though is so that I can use gtest directly, not the
hacked-up version the JIT uses.
Test Plan: Imported from OSS
Differential Revision: D20537902
Pulled By: suo
fbshipit-source-id: 09897e015ecde24aa8996babeaa08d98db90ef0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34856
This PR adds Python-like equality comparisons to our List type.
- `operator==` performs equality by value.
- `is` performs equality by identity.
The overall goal is that I want to define equality on `IValue` to avoid
people implementing their own broken versions. So, we should have
equality reasonably defined on all types that `IValue` can be.
smessmer raises the concern that C++ people expect `operator==` on
reference types to test identity. I think that's a reasonable concern,
but in practice, it seems that people are defining equality functions to
do it by value anyway, just poorly. My claim is that if we just tell
people that TorchScript types behave like Python types, it will not be
super confusing.
Test Plan: Imported from OSS
Differential Revision: D20483462
Pulled By: suo
fbshipit-source-id: ba2909daa6778924293ed6ef456ab9fc84215442
Summary:
Because `past` is used in `caffe2.python.core`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35057
Test Plan: CI
Differential Revision: D20547042
Pulled By: malfet
fbshipit-source-id: cad2123c7b88271fea37f21e616df551075383a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34912
max_pool2d quantized op actually shows up as aten::max_pool2d
Test Plan:
python test/test_pytorch_onnx_caffe2_quantized.py
Imported from OSS
Differential Revision: D20497780
fbshipit-source-id: 5524ae41676c2d6de1ae3544fe36ac24f2a77b19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34994
Use the fast path for NCHW input tensor
Test Plan: run the pool unit tests
Differential Revision: D20522082
fbshipit-source-id: 6e834425d06fbb1a105d851c2c36ef73df9de08f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34828
python 3.5 does not ensure ordering of dictionary keys, this was added
in python 3.6+. Fixing this so the test is no longer flaky in 3.5. Tested by
500 stresstests with python 3.5
ghstack-source-id: 100426555
Test Plan: 500 stress tests in python 3.5
Differential Revision: D20474996
fbshipit-source-id: 89b614a32363d1e7f3f7a4f27bec4fd7d507721d
Summary:
As title, we want to support the BN2d_relu and BN3d_relu
Test to be added!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34795
Differential Revision: D20464855
Pulled By: lly-zero-one
fbshipit-source-id: 57090d427053c9c94c1b387b33740a7e61261a9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34991
The definition for the partition to be run on CPU is that it will contain an empty device_id list. We chose this over an op with no partitioning info because
1. Backward compatible with models that don't have partitioning info
2. Being explicit can flush out issues in earlier stage.
Test Plan:
```
LD_LIBRARY_PATH=third-party-buck/platform007/build/fb-nnpi/lib ./sigrid/predictor/tests/scripts/launch_ads_test_predictor.sh -g --nnpi --force_models=175742819_0 --sigrid_force_model_dir=$HOME/models/ --smc_server_port=7447 --glow-num-devices=1 --glow_interpreter_memory=$((256<<20)) --caffe2_fbgemm_fake_fp16_clamp --glow_global_fp16 --glow_clip_fp16 --glow_global_fused_scale_offset_fp16 --fbgemm_deserialize_to_original_format --caffe2_dump_input_of_type=Onnxifi --caffe2_logging_print_tensor --caffe2_predictor_use_memonger=no --onnxifi_debug_mode=true --caffe2_dump_input_with_recordio --caffe2_predictor_onnxifi_max_batch_size=32 --caffe2_predictor_onnxifi_max_seq_size=9600 --glow_onnxifi_backend=Interpreter --onnxifi_blacklist_ops=SparseLengthsSum,SparseLengthsWeightedSum --glow_dump_graph
```
Now it hits a new error.
Reviewed By: ipiszy
Differential Revision: D20503167
fbshipit-source-id: 5a609760130bd1131e299ce85b7824cbcbdf1f09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34360
The distributed autograd context sets up a thread local context id
which is used to perform appropriate book keeping and autograd recording of RPC
functions in the forward pass.
However, if we use torch.jit._fork within the distributed autograd context, the
code executed within torch.jit._fork will lose this context since it is run in
a separate JIT thread and the thread local is not set in that thread.
To fix this problem, we pass in the distributed autograd context to
torch.jit._fork similar to what we did in
https://github.com/pytorch/pytorch/pull/16101.
ghstack-source-id: 100445465
Test Plan: waitforbuildbot
Differential Revision: D20301352
fbshipit-source-id: aa3fffe69c2b40722c66213351a4e0d77484a621
Summary:
Adds a new promotion pipeline for both our wheel packages hosted on S3
as well as our conda packages hosted on anaconda.
Promotion is only run on tags that that match the following regex:
/v[0-9]+(\.[0-9]+)*/
Example:
v1.5.0
The promotion pipeline is also only run after a manual approval from
someone within the CircleCI security context "org-member"
> NOTE: This promotion pipeline does not cover promotion of packages that
> are published to PyPI, this is an intentional choice as those
> packages cannot be reverted after they have been published.
TODO: Write a proper testing pipeline for this
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34993
Differential Revision: D20539497
Pulled By: seemethere
fbshipit-source-id: 104772d3c3898d77a24ef9bf25f7dbd2496613df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34959
Adds quantized implementation of hardsigmoid.
Original PR was https://github.com/pytorch/pytorch/pull/34607 and had to
be reverted for a test breakage, trying again.
Test Plan:
tests
benchmarks
Imported from OSS
Differential Revision: D20514212
fbshipit-source-id: cc7ae3b67757e2dde5c313c05ce60a0f2625d961
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34499
RangeEventList::allocBlock currently iterates through `blocks`, which
we serialize access to and accumulates them into `result`. Instead of doing
this, we can swap with an empty `forward_list` in constant time, and then
unlock, and use this local list in order to populate `result`.
ghstack-source-id: 100426115
Test Plan: existing profiler tests pass
Differential Revision: D20346423
fbshipit-source-id: 0e567b56049daa371051ccec6c5d1630a92db15f
Summary: So that Glow can use this info to do actual function partitioning.
Reviewed By: jfix71
Differential Revision: D20502439
fbshipit-source-id: 0ade94b49b49172dc9370d1fc96454ade52ff269
Summary:
CircleCI by default, chooses to run 0 jobs on tags meaning that when we
tag a build that no job is run if a dependent job does not contain the
correct filters.
This adds an explicit configuration to run the setup job on every branch
and every tag that CircleCI can run on.
For more information on CircleCI filters and what they do (and more
importantly what they do not do) visit:
https://circleci.com/docs/2.0/configuration-reference/#filters-1
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35013
Differential Revision: D20535560
Pulled By: seemethere
fbshipit-source-id: 7ee5dddbc0a9416fd76ed198e5447318c53e1873
Summary:
Per title.
In the future we want to make div(), the division operator, and addcdiv perform true division as in Python 3, NumPy, and JAX. To do this without silently breaking users we plan to:
- Warn (once) in 1.5 when a user performs integer division using div or addcdiv
- RuntimeError in 1.6 when a user attempts to perform integer division using div or addcdiv
- Always perform true division in 1.7 using div, /, and addcdiv
Users can use true_divide or floor_divide today to explicitly specify the type of division they like.
A test for this behavior is added to test_type_promotion. Unfortunately, because we are only warning once (to avoid a deluge) the test only uses maybeWarns Regex.
The XLA failure is real but will be solved by https://github.com/pytorch/pytorch/pull/34552. I'll be sure to land that PR first to avoid temporarily breaking the XLA build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34570
Differential Revision: D20529211
Pulled By: mruberry
fbshipit-source-id: 65af5a9641c5825175d029e8413c9e1730c661d0
Summary:
And few typos
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34791
Test Plan: CI
Differential Revision: D20524879
Pulled By: malfet
fbshipit-source-id: 58fa03bd6356979e77cd1bffb6370d41a177c409
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34980
We were passing sample inputs to `torch.jit.script` (as if it was
`torch.jit.trace`), but this parameter was treated as an optional
`optimize` parameter. That parameter is deprecated and that caused a
warning.
Differential Revision: D20520369
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 87b40a5e35bfc4a3d7a5d95494632bfe117e40b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34638
Fixes: https://github.com/pytorch/pytorch/issues/27643
This PR manages notifying workers in the event of a failure during distributed autograd. Gracefully handles propagating errors across all nodes in the backward pass and sets state in the local autograd engines accordingly.
(Note: this ignores all push blocking failures!)
Test Plan: Added 2 new tests checking errors when they are thrown in an intermediate node during distributed autograd. Ensured that all existing distributed autograd tests pass.
Differential Revision: D20164420
fbshipit-source-id: 3d4ed74230969ac70bb763f1b5b1c16d979f66a2
Summary:
`GetEmptyStringAlreadyInited` invocation pattern in protobuf generated header files chanegd to
`:PROTOBUF_NAMESPACE_ID::internal::GetEmptyStringAlreadyInited`, where `PROTOBUF_NAMESPACE_ID` is defined in `protobuf/port_def.inc` as `google::protobuf`
This likely to have changed around protobuf-3.8.x time, but I've only tested it using protobuf-3.11.4
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35008
Test Plan: Update `third-party/protobuf` submodule to 3.11.4, compile and run `pattern_net_transform_test`
Differential Revision: D20526949
Pulled By: malfet
fbshipit-source-id: fddaa3622c48ad883612c73c40a20d306d88d66b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34988
In https://github.com/pytorch/pytorch/pull/31893, we introduced a confirmedUsers_ map in RRefContext.
For the case that the fork is shared from the owner, there is no `pendingUsers_` intermediate phase for this fork, we should put this fork into `confirmedUsers_` immediately.
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
```
Differential Revision: D7735909
fbshipit-source-id: 14c36a16486f0cc9618dcfb111fe5223781b647d
Summary:
1. Removed LossClosureOptimizer, and merged Optimizer into OptimizerBase (and renamed the merged class to Optimizer)
2. Merged the LBFGS-specific serialize test function and the generic test_serialize_optimizer function.
3. BC-compatibility serialization test for LBFGS
4. Removed mentions of parameters_ in optimizer.cpp, de-virtualize all functions
5. Made defaults_ optional argument in all optimizers except SGD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34957
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20518647
Pulled By: anjali411
fbshipit-source-id: 4760d1d29df1784e2d01e2a476d2a08e9df4ea1c
Summary:
**Summary**
This commit parallelizes the invocation of `clang-format` on all files
in `tools/clang_format_new.py` using `asyncio`.
**Testing**
Ran and timed the script.
*Before*
```
$ time ./tools/clang_format_new.py --diff
...
real 0m7.615s
user 0m6.012s
sys 0m1.634s
```
*After*
```
$ time ./tools/clang_format_new.py --diff
...
Some files not formatted correctly
real 0m2.156s
user 0m8.488s
sys 0m3.201s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34750
Differential Revision: D20523133
Pulled By: SplitInfinity
fbshipit-source-id: 509741a0b4fcfcdcd7c5a45654e3453b4874d256
Summary:
There are three guards related to mobile build:
* AutoGradMode
* AutoNonVariableTypeMode
* GraphOptimizerEnabledGuard
Today we need set some of these guards before calling libtorch APIs because we customized mobile build to only support inference (for both OSS and most FB use cases) to optimize binary size.
Several changes were made since 1.3 release so there are already inconsistent uses of these guards in the codebase. I did a sweep of all mobile related model loading & forward() call sites, trying to unify the use of these guards:
Full JIT: still set all three guards. More specifically:
* OSS: Fixed a bug of not setting the guard at model load time correctly in Android JNI.
* FB: Not covered by this diff (as we are using mobile interpreter for most internal builds).
Lite JIT (mobile interpreter): only needs AutoNonVariableTypeMode guard. AutoGradMode doesn't seem to be relevant (so removed from a few places) and GraphOptimizerEnabledGuard definitely not relevant (only full JIT has graph optimizer). More specifically:
* OSS: At this point we are not committed to support Lite-JIT. For Android it shares the same code with FB JNI callsites.
* FB:
** JNI callsites: Use the unified LiteJITCallGuard.
** For iOS/C++: manually set AutoNonVariableTypeMode for _load_for_mobile() & forward() callsites.
Ideally we should avoid having to set AutoNonVariableTypeMode for mobile interpreter. It's currently needed for dynamic dispatch + inference-only mobile build (where variable kernels are not registered) - without the guard it will try to run `variable_fallback_kernel` and crash (PR #34038). The proper fix will take some time so using this workaround to unblock selective BUCK build which depends on dynamic dispatch.
PS. The current status (of having to set AutoNonVariableTypeMode) should not block running FL model + mobile interpreter - if all necessary variable kernels are registered then it can call _load_for_mobile()/forward() against the FL model without setting the AutoNonVariableTypeMode guard. It's still inconvenient for JAVA callsites as it's set unconditionally inside JNI methods.
Test Plan: - CI
Reviewed By: xta0
Differential Revision: D20498017
fbshipit-source-id: ba6740f66839a61790873df46e8e66e4e141c728
Summary: Add transfer_learning_blob_name_mappings into layer_model_helper to support layer model transfer learning
Reviewed By: mraway
Differential Revision: D20286298
fbshipit-source-id: de3e029611d843f38d3f42ecd4148358f7e14a2b
Summary:
(Updated per review feedback)
`torch.floor_divide` is currently a function that can operate on two tensors or a tensor and a scalar (scalar x scalar floor division is handled natively by Python and the JIT has a builtin function for it). This PR updates it to:
- have an out variant: `floor_divide(x, y, out=z)`
- be a method on a tensor: `x.floor_divide(y)`
- have an in-place variant: `x.floor_divide_(y)`
- work with sparse tensors
Tests are added to test_sparse.py and test_torch.py for these new behaviors.
In addition, this PR:
- cleans up the existing sparse division and true_division code and improves their error message
- adds testing of sparse true_division to test_sparse.py
- extends existing floor_divide testing in test_torch to run on CUDA, too, not just the CPU
Unfortunately, making floor_divide a method requires breaking backwards compatibility, and floor_divide has been added to the BC whitelist since this is international. The BC issue is that the first parameter name to torch.floor_divide is changing from input to self. If you previously called torch.floor_divide with keyword arguments, e.g. torch.floor_divide(input=x, other=y), you will need to update to torch.floor_divide(self=x, other=y), or the more common torch.floor_divide(x, y).
The intent of this PR is to allow floor_divide to be substituted for division (torch.div, /) wherever division was previously used. In 1.6 we expect torch.div to perform true_division, and floor_divide is how users can continue to perform integer division with tensors.
There are two potential follow-up issues suggested by this PR:
- the test framework might benefit from additional tensor construction classes, like one to create dividends and divisors for multiple dtypes
- the test framework might benefit from a universal function test class. while methods have reasonable coverage as part of test_torch.py's TestTensorOp tests, function coverage is spotty. Universal functions are similar enough it should be possible to generate tests for them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34552
Differential Revision: D20509850
Pulled By: mruberry
fbshipit-source-id: 2cd3c828aad67191c77f2ed8470411e246f604f8
Summary:
This is causing failures on my Windows build
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34926
Differential Revision: D20501850
Pulled By: smessmer
fbshipit-source-id: 92c72dd657b27b1786952dbdccfceff99f4ba743
Summary:
This pull request updates the Torchvision commit to use ROCm enabled torchvision in `.jenkins/pytorch/test.sh`.
Pytorch tests:
```
test_SyncBatchNorm_process_group (__main__.TestDistBackend)
test_alexnet (jit.test_models.TestModels)
test_script_module_script_resnet (jit.test_models.TestModels)
test_script_module_trace_resnet18 (jit.test_models.TestModels)
test_torchvision_smoke (__main__.TestTensorBoardPytorchGraph)
```
in `test2` were skipped because torchvision was not installed in `test2` instead it was installed in `test1`. The PR moved torchvision test to correct place and thereby enabling the above mentioned tests.
cc: ezyang iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34909
Differential Revision: D20515333
Pulled By: ezyang
fbshipit-source-id: 69439756a687ba441c1f8107233b4dbc1e108387
Summary:
Per title.
Currently torch.full will always (attempt to) produce a float tensor. This is inconsistent with NumPy in (at least) two cases:
- When integral fill values (including bool) are given
- When complex fill values are given
For example:
```
np.full((1, 2), 1).dtype
: dtype('int64')
np.full((1, 2), (1 + 1j)).dtype
: dtype('complex128')
```
Whereas in PyTorch
```
torch.full((1, 2), 1).dtype
: torch.float32
torch.full((1, 2), (1 + 1j)).dtype
: RuntimeError: value cannot be converted to type float without overflow: (1,1)
```
This PR begins the process of deprecating our current behavior of returning float tensors (by default) when given integer fill values by warning the user that integer fill values will require explicitly specifying the dtype or out kwargs in 1.6, and in 1.7 the behavior will change to return a LongTensor by default (BoolTensor for bool values). The intermediate 1.6 release is to prevent changing the behavior silently and unexpectedly.
The PR also implements inference for complex types. So that with it:
```
torch.full((1, 2), (1 + 1j)).dtype
: torch.complex64
```
The complex type inference returns a ComplexFloat tensor when given a complex fill value (and no dtype or out kwarg is specified), unless the default dtype is Double, in which case a ComplexDouble tensor is returned.
A test for these behaviors is added to test_torch.py.
Implementation note:
This PR required customizing full's dispatch because currently in eager codegen the TensorOptions object passed to functions improperly sets has_dtype() to true, even if the user did not explicitly provide a dtype. torch.arange already worked around this issue with its own custom implementation. The JIT, however, does pass a properly constructed TensorOptions object.
Future Work:
This PR does not extend torch.full's complex type inference to ONNX. This seems unlikely to come up and will be a clear error if it does. When integer type inference is added to torch.full, however, then porting the behavior to ONNX may be warranted. torch.arange ported its complex type promotion logic to ONNX, for example.
Additionally, this PR mostly leaves existing call sites in PyTorch that would trigger this warning intact. This is to be more minimal (since the PR is BC breaking). I will submit a separate PR fixing PyTorch's call sites.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34709
Differential Revision: D20509387
Pulled By: mruberry
fbshipit-source-id: 129593ba06a1662032bbbf8056975eaa59baf933
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34315
previously we register quantization parameter attributes using debugName of
the observed value, but debugName is not unique, this PR addresses this problem
by making attribute names unique
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20504455
fbshipit-source-id: 6dd83bdfc4e4dc77ad3af3d5b48750fb01b2fce1
Summary:
Initial integration of eager autocasting, supporting out-of-place ops only for easier review.
Relevant issue/RFC: https://github.com/pytorch/pytorch/issues/25081
In-place ops and ops with user-supplied `out=...` can certainly be supported as well (my initial WIP https://github.com/pytorch/pytorch/pull/29552 handled many) but require substantially more complex special casing in the autocasting backend and tests. Support for these ops (much of which has already been written) will be broken into later PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32140
Differential Revision: D20346700
Pulled By: ezyang
fbshipit-source-id: 12d77b3917310186fbddf11c59b2794dc859131f
Summary:
This PR would fix https://github.com/pytorch/pytorch/issues/34736. Both code snippet in that issue can now execute normally. More tests are also added.
This PR is a follow-up on https://github.com/pytorch/pytorch/issues/34519, where one variable was mistakenly missed when updating the max_pool2d kernel.
This PR also uses accumulate type of scalar_t in the backward kernel, which resolves the numerical precision issue when stride < kernel_size on fp16.
cc csarofeen ptrblck jjsjann123 VitalyFedyunin ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34934
Differential Revision: D20512062
Pulled By: VitalyFedyunin
fbshipit-source-id: a461ebbb3e3684aa183ae40e38d8f55bb6f4fee1
Summary:
Throwing from destructor leads to undefined behaviour (most often to segault)
So it's better to leak memory then segault
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34756
Test Plan: Run `test_pytorch_onnx_caffe2`
Differential Revision: D20504228
Pulled By: malfet
fbshipit-source-id: 7a05776fea9036f602e95b8182f8493cb5886dab
Summary:
(Updated per review feedback)
`torch.floor_divide` is currently a function that can operate on two tensors or a tensor and a scalar (scalar x scalar floor division is handled natively by Python and the JIT has a builtin function for it). This PR updates it to:
- have an out variant: `floor_divide(x, y, out=z)`
- be a method on a tensor: `x.floor_divide(y)`
- have an in-place variant: `x.floor_divide_(y)`
- work with sparse tensors
Tests are added to test_sparse.py and test_torch.py for these new behaviors.
In addition, this PR:
- cleans up the existing sparse division and true_division code and improves their error message
- adds testing of sparse true_division to test_sparse.py
- extends existing floor_divide testing in test_torch to run on CUDA, too, not just the CPU
Unfortunately, making floor_divide a method requires breaking backwards compatibility, and floor_divide has been added to the BC whitelist since this is international. The BC issue is that the first parameter name to torch.floor_divide is changing from input to self. If you previously called torch.floor_divide with keyword arguments, e.g. torch.floor_divide(input=x, other=y), you will need to update to torch.floor_divide(self=x, other=y), or the more common torch.floor_divide(x, y).
The intent of this PR is to allow floor_divide to be substituted for division (torch.div, /) wherever division was previously used. In 1.6 we expect torch.div to perform true_division, and floor_divide is how users can continue to perform integer division with tensors.
There are two potential follow-up issues suggested by this PR:
- the test framework might benefit from additional tensor construction classes, like one to create dividends and divisors for multiple dtypes
- the test framework might benefit from a universal function test class. while methods have reasonable coverage as part of test_torch.py's TestTensorOp tests, function coverage is spotty. Universal functions are similar enough it should be possible to generate tests for them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34552
Differential Revision: D20497453
Pulled By: mruberry
fbshipit-source-id: ac326f2007d8894f730d1278fef84d63bcb07b5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34903
Reattempt of D20461609
Moving 2/4-bit SLS and row-wise 2/4-bit conversion operator to open source to be used by DLRM
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20495304
fbshipit-source-id: 66a99677583f50fd40e29c514710c7b1a8cdbc29
Summary:
Follow-ups after this PR:
* Remove `LossClosureOptimizer`, and merge `Optimizer` into `OptimizerBase` (and rename the merged class to Optimizer)
* Merge the LBFGS-specific serialize test function and the generic `test_serialize_optimizer` function, possibly by passing a bool `has_only_global_state` flag into the `test_serialize_optimizer` function to denote whether `size()` should be equal to 1 or 2?
* https://github.com/pytorch/pytorch/pull/34564#discussion_r393780303
* It seems that we don't have the equivalent `XORConvergence_LBFGS` test like the other optimizers, and it would be good to add one
* Remove mentions of `parameters_` in optimizer.cpp, de-virtualize all functions, and remove the `OptimizerBase(std::vector<Tensor> parameters)` constructor from `OptimizerBase`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34564
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20495701
Pulled By: anjali411
fbshipit-source-id: 6d35286d2decb6f7dff93d9d3e57515770666622
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34896
Make TorchScript support calling ref.owner() to get owner worker id and calling ref.owner_name() to get owner worker name.
Differential Revision: D7652208
fbshipit-source-id: a60125bb316ac2cf19a993cbd2affc933c0af7c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34413
In this diff we have made various improvements to ProcessGroupAgent in order to accomodate edge and error cases such as a "non-clean" shutdown (shutdowns in which we abort RPC as quickly as possible, and don't wait for all pending work across all RPC agents to be completed):
1. Catch and log exceptions in `enqueueRecv`. This prevents us from calling `std::terminate()` in a different thread and logs an error message indicating the issue. With this we no longer have crashes caused by exceptions in this thread during non-graceful shutdown.
2. Provide cleaner error messages everywhere (and use `c10::str` where possible). One example is in `agent::send()`.
3. Add the ability to abort pending sends that cause blocking waits in `handleSend`. The reason we need to abort this is since during a non-graceful shutdown, we could become blocked waiting for these since there is no guarantee the remote end is still active and this would result in a long wait and eventual timeout. We abort these by adding them to a map, and go through this map during `shutdown()`.
4. Fix flaky tests: `test_handle_send_exceptions` and `test_backward_node_failure` and `test_backward_node_failure_python_udf`. These tests were flaky since they dealt with non-graceful shutdown of workers which has chances for a bunch of edge cases explained above.
We have also refactored `createExceptionResponse`, `enqueueRecv`, and some test functions for the above reasons in this diff.
For testing:
Ensured that the tests are no longer flaky with 500 tests runs. Previously, these tests were flaky and disabled. Also added a unit test in the internal `ProcessGroupAgentTest.cpp`.
ghstack-source-id: 100311598
Test Plan: Ensured that the tests are no longer flaky with 500 tests runs. Previously, these tests were flaky and disabled. Also added a unit test in the internal `ProcessGroupAgentTest.cpp`.
Reviewed By: mrshenli
Differential Revision: D20269074
fbshipit-source-id: de9cad7f7185f9864ffbb6b14cd8ca9f6ff8f465
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34901
init_pg is needed for dist.barrier call, otherwise default process group may not be found for some rpc backend
ghstack-source-id: 100319642
Test Plan: unit test
Differential Revision: D20495321
fbshipit-source-id: a44241bd2ff6e1404eee9b241270a94e9fd114d0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/34714 (using the discussed solution). Thanks to jjabo for flagging and suggesting this.
Instead of expanding `probs` to prepend `sample_shape`, it is better to use the `num_samples` argument to `torch.multinomial` instead, which is faster and consumes lesser memory.
Existing tests should cover this. I have profiled this on different inputs and the change results in faster `.sample` (e.g. 100X faster on the example in the issue), or at worst is similar to what we have now with the default `sample_shape` argument.
cc. fritzo, alicanb, ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34900
Differential Revision: D20499065
Pulled By: ngimel
fbshipit-source-id: e5be225e3e219bd268f5f635aaa9bf7eca39f09c
Summary:
This makes PyTorch compileable(but not linkable) with `CUDA_SEPARABLE_COMPILATION` option enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34899
Test Plan: CI
Differential Revision: D20501050
Pulled By: malfet
fbshipit-source-id: 02903890a827fcc430a26f397d4d05999cf3a441
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34871
We used to configure root logger in RPC module. A stream handler is added to `root.handlers`. This is not desired behavior for pytorch users. We should instead keep the root logger handler list untouched.
We can configure the logger local to the rpc module, set it's log level, so it doesn't use it's ancestor, which is usually the root which has no stream handlers in most cases.
https://docs.python.org/3/library/logging.html#logging.Logger.setLevel
And add a stream handler to make it output to stdout, even if the root handlers is not configured and has an empty list.
https://docs.python.org/3/library/logging.html#logging.Logger.addHandlerhttps://docs.python.org/3/library/logging.handlers.html#logging.StreamHandler
ghstack-source-id: 100322141
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_wait_all_workers
```
Differential Revision: D7677493
fbshipit-source-id: 88a66079e7348c79a7933e3527701917cbebb7ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34607
Adds quantized version of hardsigmoid activation.
Note: not implementing the _ and .out versions is
currently intended, because the implementation changes the scale and
zp and it's nice to not allow the user to specify scale
and zp. Lmk if we should handle this differently.
Test Plan:
tests
benchmarks
Imported from OSS
Differential Revision: D20480546
fbshipit-source-id: 9febcb44afd920125ed2ca4900492f0b712078ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34843
Currently, we use not_ok_to_boxing to filter Dimname that can not be
converted/constructed to IValue. The correct way should be SNIFAE the
constructor of IValue.
(Note: this ignores all push blocking failures!)
Test Plan:
PyTorch compiled after the code change.
All unit test passed
Imported from OSS
Differential Revision: D20494886
fbshipit-source-id: 91dfba6a41a3ae2d6ceba9d4124cbf612ea3f080
Summary:
Filing this PR since we are in the process of migrating ROCm CI to ROCm version 3.1. This patch is to ensure the correct functionality of float <-> bfloat16 conversion in rocm3.1. `std::isnan` regresses with rocm3.1.
iotamudelta ezyang
cc: ashishfarmer (original author of this patch)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34664
Differential Revision: D20440972
Pulled By: ezyang
fbshipit-source-id: 1ccb911c88f05566d94e01878df6c70cf7f31242
Summary:
Was originally not a requirement but we should add it back here since
it's required on import and we require it anyways for our conda
packages.
Tested with:
```
❯ pkginfo -f requires_dist *.whl
requires_dist: ['numpy']
```
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34510
Differential Revision: D20352125
Pulled By: seemethere
fbshipit-source-id: 383e396fe500ed7043d83c3df57d1772d0fff1e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34665
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20493861
Pulled By: ezyang
fbshipit-source-id: 4215e3037a16be460f20cfc2859be5ee074128d3
Summary:
Thi PR implement channel last upsampling nearest for 2D/3D.
This is supposed to be faster, plus, avoids converting formats going in
and out of operator.
Will post benchmarking numbers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34597
Test Plan: python test/test_nn.py TestNN.test_upsamplingNearest3d_channels_last
Differential Revision: D20390583
Pulled By: kimishpatel
fbshipit-source-id: e0162fb97604a261887f38fc957d3f787c80954e
Summary:
If arguments of `ENDIF()` block are non-empty, they should match corresponding `IF()` BLOCK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34886
Test Plan: CI
Differential Revision: D20494631
Pulled By: malfet
fbshipit-source-id: 5fed86239b4a0cb4b3aedd02c950c1b800199d2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34842
This PR (hopefully the last one of such kind) is merging changes from a
side branch where tensor expessions based fuser work has been done so
far. This PR is is a squashed version of changes in the side branch,
which is available here: https://github.com/bertmaher/pytorch
Differential Revision: D20478208
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 21556e009f1fd88099944732edba72ac40e9b9c0
Summary:
For batch_norm inference contiguous case, we can get a better performance by manually vectorize it.
Test script:
``` X
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
for n in [1, 10, 100]:
for c in [1, 10, 100]:
for hw in [1, 10, 200]:
m = nn.BatchNorm2d(c, affine=False)
m.eval()
input = torch.randn(20, c, hw, hw)
# warm up
for i in range(200):
output = m(input)
fwd_t = 0
for j in range(1000):
t1 = time.time()
output = m(input)
t2 = time.time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 1000 * 1000
print("size = (%d, %d, %d, %d); compute time is %.4f(ms)" % (n, c, hw, hw, fwd_avg))
```
Before:
```
size = (1, 1, 1, 1); compute time is 0.0110(ms)
size = (1, 1, 10, 10); compute time is 0.0123(ms)
size = (1, 1, 200, 200); compute time is 0.8166(ms)
size = (1, 10, 1, 1); compute time is 0.0107(ms)
size = (1, 10, 10, 10); compute time is 0.0257(ms)
size = (1, 10, 200, 200); compute time is 8.7533(ms)
size = (1, 100, 1, 1); compute time is 0.0122(ms)
size = (1, 100, 10, 10); compute time is 0.1619(ms)
size = (1, 100, 200, 200); compute time is 123.5674(ms)
size = (10, 1, 1, 1); compute time is 0.0109(ms)
size = (10, 1, 10, 10); compute time is 0.0123(ms)
size = (10, 1, 200, 200); compute time is 0.5629(ms)
size = (10, 10, 1, 1); compute time is 0.0107(ms)
size = (10, 10, 10, 10); compute time is 0.0253(ms)
size = (10, 10, 200, 200); compute time is 8.7817(ms)
size = (10, 100, 1, 1); compute time is 0.0120(ms)
size = (10, 100, 10, 10); compute time is 0.1655(ms)
size = (10, 100, 200, 200); compute time is 123.2488(ms)
size = (100, 1, 1, 1); compute time is 0.0109(ms)
size = (100, 1, 10, 10); compute time is 0.0123(ms)
size = (100, 1, 200, 200); compute time is 0.5740(ms)
size = (100, 10, 1, 1); compute time is 0.0108(ms)
size = (100, 10, 10, 10); compute time is 0.0257(ms)
size = (100, 10, 200, 200); compute time is 8.7201(ms)
size = (100, 100, 1, 1); compute time is 0.0122(ms)
size = (100, 100, 10, 10); compute time is 0.1628(ms)
size = (100, 100, 200, 200); compute time is 123.1739(ms)
```
After:
```
size = (1, 1, 1, 1); compute time is 0.0105(ms)
size = (1, 1, 10, 10); compute time is 0.0114(ms)
size = (1, 1, 200, 200); compute time is 0.5771(ms)
size = (1, 10, 1, 1); compute time is 0.0105(ms)
size = (1, 10, 10, 10); compute time is 0.0160(ms)
size = (1, 10, 200, 200); compute time is 6.9851(ms)
size = (1, 100, 1, 1); compute time is 0.0122(ms)
size = (1, 100, 10, 10); compute time is 0.0848(ms)
size = (1, 100, 200, 200); compute time is 98.6758(ms)
size = (10, 1, 1, 1); compute time is 0.0105(ms)
size = (10, 1, 10, 10); compute time is 0.0115(ms)
size = (10, 1, 200, 200); compute time is 0.2690(ms)
size = (10, 10, 1, 1); compute time is 0.0105(ms)
size = (10, 10, 10, 10); compute time is 0.0159(ms)
size = (10, 10, 200, 200); compute time is 6.6946(ms)
size = (10, 100, 1, 1); compute time is 0.0123(ms)
size = (10, 100, 10, 10); compute time is 0.0854(ms)
size = (10, 100, 200, 200); compute time is 98.7327(ms)
size = (100, 1, 1, 1); compute time is 0.0107(ms)
size = (100, 1, 10, 10); compute time is 0.0116(ms)
size = (100, 1, 200, 200); compute time is 0.2681(ms)
size = (100, 10, 1, 1); compute time is 0.0104(ms)
size = (100, 10, 10, 10); compute time is 0.0159(ms)
size = (100, 10, 200, 200); compute time is 6.7507(ms)
size = (100, 100, 1, 1); compute time is 0.0124(ms)
size = (100, 100, 10, 10); compute time is 0.0852(ms)
size = (100, 100, 200, 200); compute time is 98.6866(ms)
```
For real modle Resnext101, we can also get **~20%** performance improvement for large batch size,
Test script:
```
import torch
import torchvision
import torch
import time
torch.manual_seed(0)
#torch.set_num_threads(1)
model = torchvision.models.resnext101_32x8d().eval()
for batch_size in [1, 64]:
input = torch.randn(batch_size, 3, 224, 224)
#warm up
with torch.no_grad():
for i in range(5):
output = model(input)
fwd_t = 0
for i in range(10):
t1 = time.time()
output = model(input)
t2 = time.time()
fwd_t = fwd_t + (t2 - t1)
time_fwd_avg = fwd_t / 10 * 1000
print("Throughput of resnext101 with batch_size = %d is %10.2f (imgs/s)" % (batch_size, batch_size * 1000/ time_fwd_avg ))
```
Before:
```
Throughput of resnext101 with batch_size = 1 is 7.89 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 13.02 (imgs/s)
num_threads =1
Throughput of resnext101 with batch_size = 1 is 2.97 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 2.75 (imgs/s)
```
After:
```
Throughput of resnext101 with batch_size = 1 is 8.95 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 15.52 (imgs/s)
num_threads = 1
Throughput of resnext101 with batch_size = 1 is 3.10 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 2.88 (imgs/s)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34530
Differential Revision: D20479560
Pulled By: ngimel
fbshipit-source-id: 2e788ebcd814556116c90553ec61159eeffb3c16
Summary:
AT_CHECK has been deprecated and provides no more features than
TORCH_CHECK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34846
Differential Revision: D20481339
Pulled By: mrshenli
fbshipit-source-id: 1777e769a069a78e03118270294e5e273d516ca7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34663
Been bitten by this so many times. Never more.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20425480
Pulled By: ezyang
fbshipit-source-id: c4489efacc4149c9b57d1b8207cc872970c2501f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34783
Moving 2/4-bit SLS and row-wise 2/4-bit conversion operator to open source to be used by DLRM
Test Plan: CI
Reviewed By: yinghai
Differential Revision: D20461609
fbshipit-source-id: b3ef73ff10f2433afe06ffa73fe1145282d9ec4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34792
it is not thread safe to initiate script module in multiple threads.
for both test_remote_script_module and test_torchscript_functions_not_supported, it is possible that client thread is initiating MyScriptModule while server thread is initiating it as well in the same rank process.
removing MyScriptModule instatiation in client thread, it is not needed actually.
ghstack-source-id: 100266609
Test Plan: unit tests
Differential Revision: D20463234
fbshipit-source-id: 6ff70ad90fa50b0b44c78df2495b4bcaabb4487b
Summary:
To speed up compilation time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34811
Test Plan: CI
Differential Revision: D20476992
Pulled By: malfet
fbshipit-source-id: 922cde93783fbfc04854851d7a05a635d5239792
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34844
QNNPACK max_pool2d operator does not support ceil_mode so this can cause crashes in the kernel when it is set to true.
We default to the server implementation when ceil_mode is set to true
Test Plan:
python test/test_quantized.py
Imported from OSS
Differential Revision: D20478701
fbshipit-source-id: 7962444ac493f5c3c32a9aa1a7be465e8b84ccc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33719
We were seeing a strange error where gathering profiler events (specifically `parse_cpu_trace` in `profiler.py`) would fail with the error:
`IndexError: pop from empty list`.
It turned out that this was because for one particular `Event`, there was a pop recorded but not a push. Instead of the `push` event being completely missing, it was overwritten by a completely different event.
After a bunch of debugging, and trying several hypotheses, it turns out that this was a race condition in `RangeEventList::record`. What happened was that different threads would call into `RangeEventList::record` on the same event list instance, and one record would stomp over the data written by the other one. Somehow the data written was a valid `Event` so the error did not manifest itself until the profiler realized a `pop` was missing a matching `push` in the python code.
I fixed this by adding a lock to serialize writes to `RangeEventList::record`.
This PR also makes a small change to pass in the `RecordFunction` name into `popRange`. It makes the debugging easier when investigating the events recorded.
Differential Revision: D20071125
fbshipit-source-id: 70b51a65bcb833a7c88b7462a978fd3a39265f7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34497
Use a thread_local table to intercept UserRRefs created during user
function args deserialization, and then wait for confirmations of
those UserRRefs before launching the given user function.
Differential Revision: D20347464
Test Plan: Imported from OSS
Pulled By: mrshenli
fbshipit-source-id: 087484a2d2f03fbfb156752ab25653f39b412a07
Summary:
PyTorch expand allows size with -1 dim value. -1 dim value means to infer the dimension from input tensor. This can be exported to ONNX expand with 1 dim value since ONNX expand supports two-way broadcast.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34069
Reviewed By: hl475
Differential Revision: D20195532
Pulled By: houseroad
fbshipit-source-id: c90e7d51b9d7422c09c5ed6e135ca8263105b8c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34545
This is for common operator coverage, since this is widely used. A future PR
will add the quantized version.
Some initial questions for reviewers, since it's my first FP operator
diff:
* do we need a backwards.out method for this?
* do we need CUDA? If yes, should it be this PR or is it ok to split
Test Plan:
```
// test
python test/test_torch.py TestTorchDeviceTypeCPU.test_hardsigmoid_cpu_float32
// benchmark
python -m pt.hardsigmoid_test
...
Forward Execution Time (us) : 40.315
Forward Execution Time (us) : 42.603
```
Imported from OSS
Differential Revision: D20371692
fbshipit-source-id: 95668400da9577fd1002ce3f76b9777c6f96c327
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34625
These templated function calls are not specifying the template args correctly. The first arg is the index type, not the array data type. That means, right now it's using `T` as the index type as well, which will break if we do a template specialization for uint8_t. If we omit both, it will correctly infer that the index type is `int` and the data type is `T`.
Reviewed By: BIT-silence
Differential Revision: D20358728
fbshipit-source-id: 8cbd8eeb14bce602c02eb6fce2cc141f0121fa24
Summary:
This test is flaky on my computer, the error is:
```
AssertionError: tensor(1.3351e-05) not less than or equal to 1e-05
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34764
Differential Revision: D20476006
Pulled By: ezyang
fbshipit-source-id: dad7e702275346070552c8a98765c37e6ca2c197
Summary:
Replacing <ATen/core/Tensor.h> with <<ATen/core/TensorBody.h> speeds up compilation of caffe2 operators by 15%
For example, it reduces pool_op.cu compilation from 18.8s to 16s
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34810
Test Plan: CI
Differential Revision: D20472230
Pulled By: malfet
fbshipit-source-id: e1b261cc24ff577f09e2d5f6428be2063c6d4a8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34230
This PR adds some benchmarks that we used to assess tensor expressions performance.
Differential Revision: D20251830
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: bafd66ce32f63077e3733112d854f5c750d5b1af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34228
This PR adds LLVM codegen to tensor expressions. LLVM is added as an
optional build dependency specified with `USE_LLVM=<path_to_llvm>`
variable. If this variable is not set or LLVM is not found in the
specified path, the LLVM codegen is completely disabled.
Differential Revision: D20251832
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 77e203ab4421eb03afc64f8da17e0daab277ecc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34227
This PR adds a CUDA support to tensor expressions.
Differential Revision: D20251836
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: ab36a55834cceff30c8371fef6cca1054a32f017
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34226
LLVM and Cuda backends are added in subsequent PRs, so at this point the fuser is pretty useless, but it still can be tested and its logic is not going to change with addition of the codegens.
Differential Revision: D20251838
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 82b0d221fa89904ed526689d02a6c7676a8ce8de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34224
Our development has been happening on a side branch `pytorch_fusion` in
`bertmaher/pytorch` fork. This PR moves changes to the core classes
representing expressions and transformations on them.
At this moment, the tensor expressions are only used in tests.
Subsequent PRs add LLVM and CUDA codegen for tensor expressions and
implement fuser on top of these.
This PR is huge as it is a squashed version of changes in the side
branch. It is not practical to pull changes one by one from the branch,
so here is the squashed version. If you're interested in seeing the
history of changes, please refer to https://github.com/bertmaher/pytorch
Differential Revision: D20251835
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 1a871acc09cf3c6f7fb4af40d408cdbb82dc7dab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33981
Okay it turns out that https://github.com/pytorch/pytorch/pull/29342
deletes actually useful things from the resulting Python module. In
particular, people like having `ignore`'d methods attached so that they
can invoke them from python.
Test Plan: Imported from OSS
Differential Revision: D20171650
Pulled By: suo
fbshipit-source-id: 71862e932c6a56cd055d0cff6657887ee0ceb9a8
Summary:
This PR refactors RNN / GRU / LSTM layers in C++ API to exactly match the implementation in Python API.
**BC-breaking changes:**
- Instead of returning `RNNOutput`, RNN / GRU forward method now returns `std::tuple<Tensor, Tensor>`, and LSTM forward method now returns `std::tuple<Tensor, std::tuple<Tensor, Tensor>>`, matching Python API.
- RNN / LSTM / GRU forward method now accepts the same inputs (input tensor and optionally hidden state), matching Python API.
- RNN / LSTM / GRU layers now have `forward_with_packed_input` method which accepts `PackedSequence` as input and optionally hidden state, matching the `forward(PackedSequence, ...)` variant in Python API.
- RNN / LSTM / GRU layers no longer have these fields: `w_ih` / `w_hh` / `b_ih` / `b_hh`. Instead, to access the weights and biases of the gates, users should do e.g. `rnn->named_parameters()["weight_ih_l0"]`, which mirrors the Python API `rnn.weight_ih_l0`.
- In `RNNOptions`
- `tanh()` / `relu()` / `activation` are removed. Instead, `nonlinearity` is added which takes either `torch::kTanh` or `torch::kReLU`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `LSTMOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `GRUOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
The majority of the changes in this PR focused on refactoring the implementations in `torch/csrc/api/src/nn/modules/rnn.cpp` to match the Python API. RNN tests are then changed to reflected the revised API design.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34322
Differential Revision: D20458302
Pulled By: yf225
fbshipit-source-id: ffff2ae1ddb1c742c966956f6ad4d7fba03dc54d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34280
To have prim ops searchable for lite interpreter, overloaded names need to be added for the operators with the same name but different schema. For example, aten::add in register_prim_ops.cpp. The difference is a combination of args and output type.
`"aten::add(str a, str b) ->str"`
`"aten::add(int a, int b) ->int"`
`"aten::add(float a, float b) ->float"`
`"aten::add(int a, float b) ->float"`
`"aten::add(float a, int b) ->float"`
`"aten::add(Scalar a, Scalar b) ->Scalar"`
Solution:
Use the argument type and/or output type (the same to the existing overloaded names). The overloaded name should be minimum as long as the operators can be differentiated. For other operators please look into the source code change for details.
`"aten::add.str(str a, str b) ->str"`
`"aten::add.int(int a, int b) ->int"`
`"aten::add.float(float a, float b) ->float"`
`"aten::add.int_float(int a, float b) ->float"`
`"aten::add.float_int(float a, int b) ->float"`
`"aten::add.Scalar_Scalar(Scalar a, Scalar b) ->Scalar"`
Test Plan: Imported from OSS
Differential Revision: D20456997
Pulled By: iseeyuan
fbshipit-source-id: 2c3dc324b4a4e045559f62c6cc2a10fbb9a72dcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33604
For our current RPC agents, this PR disallows sending CUDA tensors
over RPC and asks users to copy them explicitly to CPU. Currently, this seems
to be the easiest contract to guarantee for our current RPC agents, otherwise
if we do support this transparently it gets a little tricky in terms of whether
a CUDA tensor on the client should be sent to CPU/GPU of the remote end and
also which GPU device on the remote end.
In the future, the TensorPipe RPC agent can have its own specific handling of
CUDA tensors.
Closes https://github.com/pytorch/pytorch/issues/28881
ghstack-source-id: 100166120
Test Plan: waitforbuildbot
Differential Revision: D20020183
fbshipit-source-id: ca4d43d2a24e8fcd3a60b21e654aa0e953e756cb
Summary:
So that in the future we can make policy accept an offset calculator in its constructor for the support of non-contiguous tensors.
The `elementwise_kernel_helper` is now very general and it can handle any cases:
```C++
template<typename func_t, typename policy_t>
__device__ inline void elementwise_kernel_helper(func_t f, policy_t policy) {
using traits = function_traits<func_t>;
using return_t = typename traits::result_type;
using args_t = typename traits::ArgsTuple;
int idx = blockIdx.x;
return_t results[thread_work_size];
cuda9::workaround::enable_default_constructor<args_t> args_[thread_work_size];
args_t *args = reinterpret_cast<args_t *>(&args_);
// load
policy.load(args, idx);
// compute
#pragma unroll
for (int i = 0; i < thread_work_size; i++) {
if (policy.check_inbounds(i)) {
results[i] = c10::guts::apply(f, args[i]);
}
}
// store
policy.store(results, idx);
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33720
Differential Revision: D20459652
Pulled By: ngimel
fbshipit-source-id: aa8b122e0e8c6e08ab354785e04753ff778882e2
Summary:
https://github.com/pytorch/pytorch/issues/34563 accidentally introduced a lint error due to an unused import. This PR removes this import.
Jit tests run as expected after this change:
```
> python test/test_jit.py
.....
Ran 2435 tests in 100.077s
OK (skipped=140, expected failures=1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34778
Differential Revision: D20459708
Pulled By: tugrulince
fbshipit-source-id: bb742085fafc849ff3d9507d1557556e01fbeb4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34762
So far it's by luck that we somehow include "caffe2/core/tensor.h" before including "caffe2/caffe2/quantization/server/fbgemm_pack_blob.h". This is not safe and this diff fixes it.
Test Plan: unittest
Reviewed By: jianyuh
Differential Revision: D20455352
fbshipit-source-id: 777dae32a23d0ec75fd7e5e1627426b5a5f81f5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34547
This enables threading by passing a threadpool to xnnpack ops.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20370553
fbshipit-source-id: 4db08e73f8c69b9e722b0e11a00621c4e229a31a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34319
Removes prepacking ops and install them as attributes of the top level
module. Needs to run freezing as the first pass.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20290726
fbshipit-source-id: 633ceaa867ff7d5c8e69bd814c0362018394cb3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34048
Rewrites the graph to insert xnnpack prepack and packed run ops for
conv2d and linear.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20185658
fbshipit-source-id: c4c073c912ad33e822e7beb4ed86c9f895129d55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34047
This PR integrates the added xnnpack conv2d and linear op via
custom class registration for packed weights. The packed struct
is serializable.
Test Plan:
python test test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20185657
fbshipit-source-id: fc7e692d8f913e493b293b02d92f4e78536d7698
Summary:
This PR refactors RNN / GRU / LSTM layers in C++ API to exactly match the implementation in Python API.
**BC-breaking changes:**
- Instead of returning `RNNOutput`, RNN / GRU forward method now returns `std::tuple<Tensor, Tensor>`, and LSTM forward method now returns `std::tuple<Tensor, std::tuple<Tensor, Tensor>>`, matching Python API.
- RNN / LSTM / GRU forward method now accepts the same inputs (input tensor and optionally hidden state), matching Python API.
- RNN / LSTM / GRU now has `forward_with_packed_input` method which accepts `PackedSequence` as input and optionally hidden state, matching the `forward(PackedSequence, ...)` variant in Python API.
- In `RNNOptions`
- `tanh()` / `relu()` / `activation` are removed. Instead, `nonlinearity` is added which takes either `torch::kTanh` or `torch::kReLU`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `LSTMOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `GRUOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
The majority of the changes in this PR focused on refactoring the implementations in `torch/csrc/api/src/nn/modules/rnn.cpp` to match the Python API. RNN tests are then changed to reflected the revised API design.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34322
Differential Revision: D20311699
Pulled By: yf225
fbshipit-source-id: e2b60fc7bac64367a8434647d74c08568a7b28f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34629
Add support for sigmoid in the conversion flow through onnx
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_quantized_sigmoid
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_small_model
Imported from OSS
Differential Revision: D20433680
fbshipit-source-id: 95943e14637d294122e4d102c5c19c06d27064c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33945
Add mapping for this operator in symbolics
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_max_pool2d
Imported from OSS
Differential Revision: D20433681
fbshipit-source-id: 88f02ade698262a6f8824671830bc1f7d40bbfa6
Summary:
This PR adds `RNNCell` / `LSTMCell` / `GRUCell` layers to the C++ frontend, with implementations exactly matching the Python API equivalent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34400
Differential Revision: D20316859
Pulled By: yf225
fbshipit-source-id: bb7cee092622334043c0d0fd0fcb4e75e707699c
Summary:
as title, for bringing up the quantized video model. Will add the batch_norm_relu test in another PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34702
Differential Revision: D20436092
Pulled By: lly-zero-one
fbshipit-source-id: 116bd306f7880bfd763d8575654fbd6c92818338
Summary:
Since we've added CUDA 10.2, it is time to retire CUDA 10.0
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34726
Differential Revision: D20453081
Pulled By: seemethere
fbshipit-source-id: fd5bb35325a5f1577d0f0404d16cd7dfe34c86ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34671
Like the python arg parser, this tries to convert to the schema in order.
It introduces schema_match_exception which gets thrown when the schema doesn't match,
allowing the overload handler to try the next option.
Behavior will not 100% match the schema argument parser but should work for
simple cases using custom binding.
Test Plan: Imported from OSS
Differential Revision: D20432206
Pulled By: zdevito
fbshipit-source-id: 280839a2205ea3497db3a9b5741fccc1e2bff9a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34677
1. Remove remaining uses of `script::` namespace from the codebase,
2. Add one more typedef for `script::ExtraFilesMap` which is part of the
public interface.
Pull Request resolved: #34580
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D20431739
Pulled By: suo
fbshipit-source-id: a29d369c755b6506c53447ca1f286b6339222c9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34190
inplace modification of ClassType might affect other tests, so we want to do non-inplace modifications.
Actually the inplace argument will be removed soon.
Test Plan:
ci
Imported from OSS
Differential Revision: D20451765
fbshipit-source-id: e87ad528c4e7f84f5774b94a8e3e85568269682d
Summary:
Per https://github.com/pytorch/pytorch/issues/19161 PyTorch is incompatible with 3.6.0 due to the missing `PySlice_Unpack`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34724
Test Plan: CI + try to load pytorch binary using python-3.6.0
Differential Revision: D20449052
Pulled By: malfet
fbshipit-source-id: 2c787fc64f5d1377c7f935ad2f3c77f46723d7dd
Summary:
This PR is related to [https://github.com/pytorch/pytorch/issues/33953](https://github.com/pytorch/pytorch/issues/33953).
I've created a directory `type_hint_tests` for the example as suggested by zou3519 [here](https://github.com/pytorch/pytorch/issues/33953#issuecomment-597716405). This directory is supposed to contain examples over which mypy will run. I've added the test in `test/test_type_hints.py`.
The test can simply be invoked by
```
$ python3 test/test_type_hints.py
Fail to import hypothesis in common_utils, tests are not derandomized
.b'test/type_hint_tests/size.py:7: error: Tuple index out of range\ntest/type_hint_tests/size.py:8: error: Tuple index out of range\n'
.
----------------------------------------------------------------------
Ran 2 tests in 13.660s
OK
```
Note that I've not made the change of fixing the stub to show that the test works. The issue can be fixed by changing definition of Size in `class Size(Tuple[_int, ...]): ... ` in `/torch/__init__.pyi.in`.
After changing the `Size` definition, the test passes.
```
$ python3 test/test_type_hints.py
Fail to import hypothesis in common_utils, tests are not derandomized
.b''
.
----------------------------------------------------------------------
Ran 2 tests in 19.382s
OK
```
I will do that once i get approval from zou3519. This is an initial implementation, please provide your suggestions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34595
Differential Revision: D20441817
Pulled By: zou3519
fbshipit-source-id: 00a434adf5bca813960f4efea38aa6d6953fe85f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34706
as title
Test Plan: test in stacked diff
Reviewed By: csummersea
Differential Revision: D20436618
fbshipit-source-id: e51ef0a22708425cd296c05f4089fe8c98eda90a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34511
With https://github.com/pytorch/pytorch/pull/34122/files, issues
with using record_function context manager and profiling RPCs were fixed. This
adds a test case to verify that we can use RPC with the `record_function`
decorator.
ghstack-source-id: 100109932
Test Plan: Unit test change
Differential Revision: D20352242
fbshipit-source-id: d6429e4352ad3b8d874dc0f27b23ecb6202e6b2b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34723
Add min function to cuda math compat
Test Plan: unittest
Reviewed By: houseroad
Differential Revision: D20444517
fbshipit-source-id: 1a93343cc57249ef1101eeb7ef373266f6a2873a
Summary:
This commit adds a reference hash for the linux64 clang-format binary and in
doing so, enables this script to be used on Linux machines.
Test Plan:
Ran the script.
```
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ export http_proxy=fwdproxy:8080
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ export https_proxy=fwdproxy:8080
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ python3 ./tools/clang_format_new.py --diff
Downloading clang-format to /data/users/meghanl/fbsource/fbcode/caffe2/.clang-format-bin
0% |################################################################| 100%
Using clang-format located at /data/users/meghanl/fbsource/fbcode/caffe2/.clang-format-bin/clang-format
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ echo $?
1
```
A non-zero return code indicates that `clang-format` will make changes.
Reviewed By: suo
Differential Revision: D20434291
fbshipit-source-id: fa13766e9d94720d4b0d8a540d2f1507e788f7a5
Summary:
- Clarify that `torch.distributed.autograd.backwards()` does not use the current thread local autograd context, instead it looks it up based on the context_id passed in
- Clarify the same for `torch.distributeed.optimizer.optim.step()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34670
Differential Revision: D20427645
Pulled By: rohan-varma
fbshipit-source-id: a1a88de346cdd4dbe65fb2b7627157f86fd2b6a3
Summary:
With this PR, we can now support left and right shift operators in the JIT engine for <int, int> and <Tensor, int>.
Updated tests pass as expected:
```
> python test/test_jit.py
...
Ran 2427 tests in 84.861s
OK (skipped=139, expected failures=1)
```
Running the following code with Python results in the output below:
```
> cat ~/expressions.py
import torch
torch.jit.script
def fn(a, b):
# type: (int, int)
return (
a << b, # supported
b >> a, # supported
a & b,
a | b,
a ^ b
)
print(fn.graph)
```
```
> python ~/expressions.py
graph(%a.1 : int,
%b.1 : int):
%4 : int = aten::leftshift(%a.1, %b.1) # /home/ince/expressions.py:7:8
%7 : int = aten::rightshift(%b.1, %a.1) # /home/ince/expressions.py:8:8
%10 : int = aten::__and__(%a.1, %b.1) # /home/ince/expressions.py:9:8
%13 : int = aten::__or__(%a.1, %b.1) # /home/ince/expressions.py:10:8
%16 : int = aten::__xor__(%a.1, %b.1) # /home/ince/expressions.py:11:8
%17 : (int, int, int, int, int) = prim::TupleConstruct(%4, %7, %10, %13, %16)
return (%17)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34563
Differential Revision: D20434209
Pulled By: tugrulince
fbshipit-source-id: 886386c59755106e17b84778b8e495b80a6269cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34623
The bandaid of "AT_WARN" keeps introducing new warnings. Let's get rid
of it entirely.
Close#34502
Test Plan: Imported from OSS
Differential Revision: D20420112
Pulled By: albanD
fbshipit-source-id: 7160c113cb4deb2d2f50a375356f423fe5e86f50
Summary:
How this actually works:
1. Get's a list of URLs from anaconda for pkgs to download, most
likely from pytorch-test
2. Download all of those packages locally in a temp directory
3. Upload all of those packages, with a dry run upload by default
This, along with https://github.com/pytorch/pytorch/issues/34500 basically completes the scripting work for the eventual promotion pipeline.
Currently testing with:
```
TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 PYTORCH_CONDA_FROM=pytorch scripts/release/promote/conda_to_conda.sh
```
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34659
Differential Revision: D20432687
Pulled By: seemethere
fbshipit-source-id: c2a99f6cbc6a7448e83e666cde11d6875aeb878e
Summary:
…ithout lapack
LAPACK is needed for `at::svd``, which is called from `pinverse()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34686
Test Plan: CI + local run
Differential Revision: D20442637
Pulled By: malfet
fbshipit-source-id: b3531ecc1197b0745ddcf50febb7fb4a7700d612
Summary:
This PR would fix https://github.com/pytorch/pytorch/issues/33988 and fix https://github.com/pytorch/pytorch/issues/34083.
Previously, the max_pool2d_nhwc kernels used a shared memory with size proportional to the tensor size (c \* h \* w). When the tensor size is too large, the kernel launch fails.
This PR follows the guidance in AdaptiveAvgPool2d_nhwc by increasing the number of grid_x with split in "C" dimension. With that change, there will be a maximum limit in the shared memory size (which is less than 48 kb) regardless of tensor size.
A benchmark can be found at [here](0b98146089/max-pool2d/max-pool2d.ipynb). TL;DR barely any performance drop is found.
cc csarofeen ptrblck jjsjann123 VitalyFedyunin
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34519
Differential Revision: D20388848
Pulled By: VitalyFedyunin
fbshipit-source-id: 9454f385f9315afaab4a05303305578bbcd80b87
Summary:
- `torch::nn::functional` functions must provide example for how to use the corresponding functional options
- `torch::nn::functional` functions must link to the corresponding functional options
- remove `TORCH_NN_FUNCTIONAL_USE_MODULE_OPTIONS` macro, and put `torch::nn::functional` options docs inside the functional namespace, right above functional declaration
- `torch::nn::functional` options docs should not link back to torch::nn layers. Instead, they should have links to `torch::nn::functional::xxx`
----
This PR is BC-breaking in the following way:
`TORCH_NN_FUNCTIONAL_USE_MODULE_OPTIONS` macro is removed, and user should explicitly write
```cpp
namespace functional {
using SomeFuncOptions = SomeModuleOptions;
} // namespace functional
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34688
Differential Revision: D20431251
Pulled By: yf225
fbshipit-source-id: 7d4f27dca3aad2a1e523690927d7afb261b9d308
Summary: Last diff enabled operator stats for non-production build including AIBench. But the operator latency is off: https://our.intern.facebook.com/intern/aibench/details/414567479798816 as it is representing operator execution end time, and as the threadLocalDebugInfo was not set, the start time is 0. So this diff is fixing it by creating a new ThreadLocalDebugInfo object when op starts to run and store the model information for logging.
Test Plan:
```buck run mode/mac aibench:run_bench_macos -- -b aibench/specifications/models/pytorch/pytext/pytext_mobile_inference.json --platform android --framework pytorch --remote --devices SM-G960F-8.0.0-26```
https://our.intern.facebook.com/intern/aibench/details/922804117425407
```buck run mode/mac aibench:run_bench_macos -- -b aibench/specifications/models/pytorch/fbnet/fbnet_mobile_inference.json --platform android --framework pytorch --remote --devices SM-G960F-8.0.0-26```
https://our.intern.facebook.com/intern/aibench/details/593403202250750
Reviewed By: xta0
Differential Revision: D20436388
fbshipit-source-id: 740bc94c3f51daef6af9b45c1ed7a708f5fc8836
Summary:
- Update API calls `backward` and `optim.step` now that we require `context_id`
- Add notes to clarify purpose of distributed autograd context (this was a source of confusion in some feedback)
- Add note that details why optimizer requires context_id
- Clearly specify that we don't have SMART mode yet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34657
Differential Revision: D20427667
Pulled By: rohan-varma
fbshipit-source-id: 5f8a3539ccf648a78e9e9a0dfdfe389c678b1606
Summary:
Now that lists are no longer specialized, we can register only one operator for list ops that are generic to their element type.
This PR reorgs lists into three sets of ops:
- CREATE_GENERIC_LIST_OPS
- CREATE_SPECIALIZED_LIST_OPS
- CREATE_COMPARATOR_LIST_OPS_SPECIALIZED (we didn't bind certain specialized ops to Tensor)
This is important to land quickly because mobile is finalizing its bytecode soon, after which we could not remove these ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34520
Reviewed By: iseeyuan
Differential Revision: D20429775
Pulled By: eellison
fbshipit-source-id: ae6519f9b0f731eaa2bf4ac20736317d0a66b8a0
Summary:
**Summary**
This commit adds `tools/clang_format_new.py`, which downloads a platform-appropriate
clang-format binary to a `.gitignored` location, verifies the binary by comparing its
SHA1 hash to a reference hash (also included in this commit), and runs it on all files
matched a specific regex in a list of whitelisted subdirectories of pytorch.
This script will eventually replace `tools/clang_format.py`.
**Testing**
Ran the script.
*No Args*
```
pytorch > ./tools/clang_format.py
Downloading clang-format to /Users/<user>/Desktop/pytorch/.clang-format-bin
0% |################################################################| 100%
Using clang-format located at /Users/<user>/Desktop/pytorch/.clang-format-bin/clang-format
> echo $?
0
> git status
<bunch of files>
```
`--diff` *mode*
```
> ./tools/clang_format.py --diff
Using clang-format located at /Users/<user>/Desktop/pytorch/.clang-format-bin/clang-format
Some files are not formatted correctly
> echo $?
1
<format files using the script>
> ./tools/clang_format.py --diff
Using clang-format located at /Users/<user>/Desktop/pytorch/.clang-format-bin/clang-format
All files are formatted correctly
> echo $?
0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34566
Differential Revision: D20431290
Pulled By: SplitInfinity
fbshipit-source-id: 3966f769cfb923e58ead9376d85e97127415bdc6
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33927
Test Plan:
test will be added in later PRs
Imported from OSS
Differential Revision: D20354879
fbshipit-source-id: 03976f4b86c46dbdc4e45764a1e72f1a3855a404
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34652
Split from D20006007 because it needs to synced to open source and also for easy testing & landing.
Test Plan:
```
buck test caffe2/caffe2/fb/tvm:test_tvm_transform
```
CI
Reviewed By: yinghai
Differential Revision: D20414037
fbshipit-source-id: 6e17dd9f8cffe87bc59c6e3cc6fd1f8d8def926b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34635
For custom op, it's removed in EliminateDeadCode IR optimization step, causing wrong training result.
EliminateDeadCode decides to remove it, because it has no output, so output is used. Also, it has no side effect, and has no untracked mutation, which is not true, custom op can have untracked mutation.
The if statement here only allows aten and prim operator to have untracked mutation, which should be removed.
ghstack-source-id: 100001319
Test Plan:
```
buck test mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_jit
buck build mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_jit \
&& buck-out/gen/caffe2/torch/fb/distributed/pytorch/tests/test_jit\#binary.par -r test_use_dense_adagrad_step
```
Reviewed By: wanchaol
Differential Revision: D7440221
fbshipit-source-id: e424417ab397d90075884c7050c59dfc5c84cf77
Summary:
Changelog:
- The magma implementation of small singular square batch matrices had a bug that resulted in nan values in the LU factorization result. This has been fixed in MAGMA 2.5.2. This PR removes the existing patch that was a temporary workaround for this bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34357
Test Plan: - Existing tests for det and lu should pass
Differential Revision: D20422879
Pulled By: seemethere
fbshipit-source-id: 8dd7a30b5c31fc5b844e0a11965efd46067e936a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34626
We need to check has_storage() before looking at it in
cloneSparseTensors(), to avoid gratuitously throwing.
Ideally, we'd add a test for this (I wrote one up but had to disable it),
but won't work until JIT Pickler supports sparse tensors.
ghstack-source-id: 100018077
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcAgent/...
Differential Revision: D20399971
fbshipit-source-id: 5debfa8140eb1f949d37336330223962cc320abc
Summary:
This PR enables bfloat16 type for
- Embedding, Index, Sigmoid Ops used in [DLRM](https://github.com/facebookresearch/dlrm)
- Miscellaneous ops like comparison ops, arange op used in unit tests
- Rename types list with the pattern `*_with_bfloat16` in `test_torch.py` to avoid confusion
iotamudelta ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34630
Differential Revision: D20405093
Pulled By: ezyang
fbshipit-source-id: aa9538acf81b3a5a9a46ce5014529707fdf25687
Summary:
Now that lists are no longer specialized, we can register only one operator for list ops that are generic to their element type.
This PR reorgs lists into three sets of ops:
- CREATE_GENERIC_LIST_OPS
- CREATE_SPECIALIZED_LIST_OPS
- CREATE_COMPARATOR_LIST_OPS_SPECIALIZED (we didn't bind certain specialized ops to Tensor)
This is important to land quickly because mobile is finalizing its bytecode soon, after which we could not remove these ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34520
Differential Revision: D20368543
Pulled By: eellison
fbshipit-source-id: ad0c6d70d2a6be6ff0e948d6786052167fc43e27
Summary:
This is a redo of https://github.com/pytorch/pytorch/pull/33791, which was reverted because it introduced a flaky test. The test was flaky and only flaky on Python3.5 because of dict order randomization.
I've fixed the issue with tests clobbering each other in b539fec and removed the override tests for `torch.nn.functional.tanh` and `torch.nn.functional.sigmoid`, which are deprecated and shouldn't be overridable in e0d7402. I also verified that no more test clobbering is happening.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34240
Differential Revision: D20252442
Pulled By: cpuhrsch
fbshipit-source-id: 069568e342a41c90e1dc76cbf85ba4aed47f24be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31893
In order to resolve the issue summarized in https://github.com/pytorch/pytorch/issues/31325.
The overal solution is to proactively send out delete fork messages from user nodes, before user nodes detecting rref leaks.
As the first step, we want to have a weak ref tracker to track all user rrefs.
ghstack-source-id: 100023142
Test Plan:
V22 is the version that make User to wait on delete UseerRRef message.
# Unit tests
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_nested_rref_stress --stress-runs 100
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_nested_rref_stress
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par - r test_rref_forward_chain
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_non_garbage_collected_user_rref_due_to_local_circular_dependency
```
Reviewed By: mrshenli
Differential Revision: D19292254
fbshipit-source-id: 92c3e8d0b00f183c5e22f163bdca482cc25a1ce9
Summary:
This PR is BC-breaking in the following way:
- The deprecated `torch::nn::BatchNorm` is removed in favor of `torch::nn::BatchNorm{1,2,3}d`
- The deprecated `torch::nn::FeatureDropout` is removed in favor of `torch::nn::Dropout{2,3}d`
- The deprecated `torch::nn::modules_ordered_dict` is removed. User should do `Sequential sequential({{"m1", MyModule(1)}, {"m2", MyModule(2)}})` instead.
- The deprecated `torch::nn::init::Nonlinearity` is removed, in favor of the following enums:
- `torch::kLinear`
- `torch::kConv1D`
- `torch::kConv2D`
- `torch::kConv3D`
- `torch::kConvTranspose1D`
- `torch::kConvTranspose2D`
- `torch::kConvTranspose3D`
- `torch::kSigmoid`
- `torch::kTanh`
- `torch::kReLU`
- `torch::kLeakyReLU`
- The deprecated `torch::nn::init::FanMode` is removed, in favor of the following enums:
- `torch::kFanIn`
- `torch::kFanOut`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34508
Differential Revision: D20351601
Pulled By: yf225
fbshipit-source-id: cca0cd112f29a31bb023e348ca8f82780e42bea3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34267
Adds quantized ELU.
Test Plan:
```
python test/test_quantized.py TestQuantizedOps.test_qelu
```
still need to benchmark, saving that for after the review comments
Imported from OSS
Differential Revision: D20370953
fbshipit-source-id: fe941bf966f72dd9eee2c4b2ef45fe7afb50c866
Summary:
`torch.nn.functional.interpolate` was written as a builtin op when we scripted the standard library, because it has four possible overloads. As a result, whenever we make a change to `interpolate`, we need to make changes in two places, and it also makes it impossible to optimize the interpolate op. The builtin is tech debt.
I talked with ailzhang, and the symbolic script changes are good to remove (i guess that makes a third place we needed to re-implement interpolate).
I'm trying to get rid of unneccessary builtin operators because we're standardizing mobile bytecode soon, so we should try to get this landed as soon as possible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34514
Differential Revision: D20391089
Pulled By: eellison
fbshipit-source-id: abc84cdecfac67332bcba6b308fca4db44303121
Summary:
Make sure that there could not be more than one instance of either `torch::autograd::Engine` or `torch::autograd::python::PythonEngine`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34567
Test Plan: CI
Differential Revision: D20390622
Pulled By: malfet
fbshipit-source-id: c90595032afc88f552dee52901361b58b282dc1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34515
Once upon a time we thought this was necessary. In reality it is not, so
removing it.
For backcompat, our public interface (defined in `api/`) still has
typedefs to the old `script::` names.
There was only one collision: `Pass` as a `Stmt` and `Pass` as a graph
transform. I renamed one of them.
Test Plan: Imported from OSS
Differential Revision: D20353503
Pulled By: suo
fbshipit-source-id: 48bb911ce75120a8c9e0c6fb65262ef775dfba93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34588
I constructed the patch by deleting OperatorOptions and then rerouting
all queries for AliasAnalysisKind to FunctionSchema. Some of the
behavior is kind of bogus: we really shouldn't be mutating FunctionSchema
after the fact, but that won't get fixed until we actually switch to
true schema merging.
Reland of https://github.com/pytorch/pytorch/pull/34160
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20387079
Pulled By: ezyang
fbshipit-source-id: d189f7a6ad8cd186b88b6fbfa3f189994eea14e8
Summary:
TensorIterator is already checking partial overlap, so there is no trivial UB, but TensorITerator allows full overlap, and it is not a bad idea to skip the memcpy in such case.
fixes: https://github.com/pytorch/pytorch/issues/34525
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34548
Differential Revision: D20371643
Pulled By: ngimel
fbshipit-source-id: ff9e2e872537010afe040204e008b2499af963ad
Summary:
This PR updates C++ API torch::nn layer docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34522
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20380832
Pulled By: yf225
fbshipit-source-id: ee99a838ec05c6ce2a23aa97555707e507d09958
Summary:
**Summary**
This commit modifies the JIT implementation of `Tensor.tolist` so that it
can be called on GPU-resident Tensors as well. If the Tensors is not on the
CPU when the operator is invoked, it is copied to the CPU before doing any
of the rest of the work to convert it into a list.
**Testing**
This commit adds GPU versions of some of the existing CPU tests for this
feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34554
Differential Revision: D20392604
Pulled By: SplitInfinity
fbshipit-source-id: 69c17b98d866428c19d683588046169538aaf1e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34598
as above
Test Plan:
test.txt
```
what time is it now
could you set a reminder at 7 am
waht is the weather today
```
example json
```
{
"model": {
"category": "CNN",
"description": "Assistant Mobile Inference",
"files": {
"model": {
"filename": "model.pt1",
"location": "//everstore/GICWmAB2Znbi_mAAAB0P51IPW8UrbllgAAAP/model.pt1",
"md5": "c0f4b29c442bbaeb0007fb0ce513ccb3"
},
"data": {
"filename": "input.txt",
"location": "/home/pengxia/test/input.txt",
"md5": "c0f4b29c442bbaeb0007fb0ce513ccb3"
}
},
"format": "pytorch",
"framework": "pytorch",
"kind": "deployment",
"name": "Assistant Mobile Inference"
},
"tests": [
{
"command": "{program} --model {files.model} --input_dims \"1\" --input_type NLUType --warmup {warmup} --iter 5 --input_file {files.data} --report_pep true",
"identifier": "{ID}",
"metric": "delay",
"iter": 15,
"warmup": 2,
"log_output": true
}
]
}
```
iter = 5 (--iter 5 ) *3(3 lintes in the test.txt) = 15
arbabu123 I will provide a wrapper to compute the iter in future.
run following command
```
buck run aibench:run_bench -- -b aibench/specifications/models/pytorch/fbnet/assistant_mobile_inference.json --platform android/full_jit --framework pytorch --remote --devices SM-G960U-8.0.0-26
```
results
https://our.intern.facebook.com/intern/aibench/details/275259559594003
**Note: this is compatible with the existing examples.**
Reviewed By: kimishpatel, ljk53
Differential Revision: D20389285
fbshipit-source-id: 80165ef394439a307ac7986cf540a80fdf3d85d6
Summary:
If SELECTED_OP_LIST is specified as a relative path in command line, CMake build will fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33942
Differential Revision: D20392797
Pulled By: ljk53
fbshipit-source-id: dffeebc48050970e286cf263bdde8b26d8fe4bce
Summary:
When a system has ROCm dev tools installed, `scripts/build_mobile.sh` tried to use it.
This PR fixes looking up unused ROCm library when building libtorch mobile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34478
Differential Revision: D20388147
Pulled By: ljk53
fbshipit-source-id: b512c38fa2d3cda9ac20fe47bcd67ad87c848857
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34150
In the distributed setting we commonly have tests in which there are errors where one process
exits but the other do not (since they are for example waiting for work from
the process that exited). Currently, when this situation happens we do not
handle this well, and wait for process 0 to timeout. This results in wasted
time waiting for test errors and a less helpful "Process 0 timed out..." error
message when the error was actually something else.
This diff fixes the issue by checking for exited subprocesses and terminating
the test when we see a subprocess that has exited uncleanly. We still enforce
timeouts and return when all processes have exited cleantly in the happy path.
ghstack-source-id: 99921462
Test Plan:
All distributed tests + tested by writing tests that should trigger
the unclean subprocess detection, and verified that we exit quickly instead of
waiting for the entire timeout.
Differential Revision: D20231032
fbshipit-source-id: 3e0d4a20925b7d1098ec4c40ffcc66845425dd62
Summary:
This PR implements the following linear algebra algorithms for low-rank matrices:
- [x] Approximate `A` as `Q Q^H A` - using Algorithm 4.4 from [Halko et al, 2009](http://arxiv.org/abs/0909.4061).
+ exposed as `torch.lowrank.get_approximate_basis(A, q, niter=2, M=None) -> Q`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] SVD - using Algorithm 5.1 from [Halko et al, 2009](http://arxiv.org/abs/0909.4061).
+ uses `torch.lowrank.get_approximate_basis`
+ exposed as `torch.svd_lowrank(A, q=6, niter=2, M=None) -> (U, S, V)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] PCA - using `torch.svd_lowrank`
+ uses `torch.svd_lowrank`
+ exposed as `torch.pca_lowrank(A, center=True, q=None, niter=2) -> (U, S, V)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices, uses non-centered sparse matrix algorithm
+ [x] documentation
- [x] generalized eigenvalue solver using the original LOBPCG algorithm [Knyazev, 2001](https://epubs.siam.org/doi/abs/10.1137/S1064827500366124)
+ exposed as `torch.lobpcg(A, B=None, k=1, method="basic", ...)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] generalized eigenvalue solver using robust LOBPCG with orthogonal basis selection [Stathopoulos, 2002](https://epubs.siam.org/doi/10.1137/S1064827500370883)
+ exposed as `torch.lobpcg(A, B=None, k=1, method="ortho", ...)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] generalized eigenvalue solver using the robust and efficient LOBPCG Algorithm 8 from [Duersch et al, 2018](https://epubs.siam.org/doi/abs/10.1137/17M1129830) that switches to orthogonal basis selection automatically
+ the "ortho" method improves iterations so rapidly that in the current test cases it does not make sense to use the basic iterations at all. If users will have matrices for which basic iterations could improve convergence then the `tracker` argument allows breaking the iteration process at user choice so that the user can switch to the orthogonal basis selection if needed. In conclusion, there is no need to implement Algorithm 8 at this point.
- [x] benchmarks
+ [x] `torch.svd` vs `torch.svd_lowrank`, see notebook [Low-rank SVD](https://github.com/Quansight/pearu-sandbox/blob/master/pytorch/Low-rank%20SVD.ipynb). In conclusion, the low-rank SVD is going to be useful only for large sparse matrices where the full-rank SVD will fail due to memory limitations.
+ [x] `torch.lobpcg` vs `scipy.sparse.linalg.lobpcg`, see notebook [LOBPCG - pytorch vs scipy](https://github.com/Quansight/pearu-sandbox/blob/master/pytorch/LOBPCG%20-%20pytorch%20vs%20scipy.ipynb). In conculsion, both implementations give the same results (up to numerical errors from different methods), scipy lobpcg implementation is generally faster.
+ [x] On very small tolerance cases, `torch.lobpcg` is more robust than `scipy.sparse.linalg.lobpcg` (see `test_lobpcg_scipy` results)
Resolves https://github.com/pytorch/pytorch/issues/8049.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29488
Differential Revision: D20193196
Pulled By: vincentqb
fbshipit-source-id: 78a4879912424595e6ea95a95e483a37487a907e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34160
I constructed the patch by deleting OperatorOptions and then rerouting
all queries for AliasAnalysisKind to FunctionSchema. Some of the
behavior is kind of bogus: we really shouldn't be mutating FunctionSchema
after the fact, but that won't get fixed until we actually switch to
true schema merging.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20282846
Pulled By: ezyang
fbshipit-source-id: ba7bca6e8adc3365789639b88e54c4e881b1692e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33838
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20227875
Pulled By: ezyang
fbshipit-source-id: 319855b1f0fa436f9ed5256d2106b07f20e6b833
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34556
According to
https://github.com/pytorch/pytorch/pull/34012#discussion_r388581548,
this `at::globalContext().setQEngine(at::QEngine::QNNPACK);` call isn't
really necessary for mobile.
In Context.cpp it selects the last available QEngine if the engine isn't
set explicitly. For OSS mobile prebuild it should only include QNNPACK
engine so the default behavior should already be desired behavior.
It makes difference only when USE_FBGEMM is set - but it should be off
for both OSS mobile build and internal mobile build.
Test Plan: Imported from OSS
Differential Revision: D20374522
Pulled By: ljk53
fbshipit-source-id: d4e437a03c6d4f939edccb5c84f02609633a0698
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34559
We check the use_count for indices and values when we avoid a clone
for sparse tensors. The sparse tensor grad itself might have a higher refcount
due to DDP hooks/dist autograd structures holding refs, but the indices and
values inside the sparse tensor should always have a refcount of 1.
ghstack-source-id: 99900534
Test Plan: waitforbuildbot
Differential Revision: D20375239
fbshipit-source-id: 6a654549d13071ab3451cef94259caf7627b575c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34505
A thread could hold GIL when calling PythonRpcHandler::getInstance(),
meantime another thread could have been doing static data
initialization by calling `new PythonRpcHandler()`, inside of which GIL is
also required. Static data initialization is thread-safe, so the thread
holding the GIL will wait for the other thread to finish static data
initializating before going forward. Because the initialization can't
proceed without GIL, there is a deadlock. We ask the calling thread to
release GIL to avoid this situation.
ghstack-source-id: 99893858
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_spawn -- 'test_backward_simple_script_call \(test_dist_autograd_spawn\.DistAutogradTestWithSpawn\)' --stress-runs 100
```
Differential Revision: D7490489
fbshipit-source-id: 76f63cc7bedf088d3dbff288f53aa0bd33749255
Summary:
Stacked PRs
* #33474 - [jit] Remove list specializations from pickler
* **#33255 - [jit] Add type tags to lists/dicts in pickle**
This adds a global call to `torch.jit._pickle.restore_type_tags` for
lists and dicts so that we can preserve their types after serialization.
](https://our.intern.facebook.com/intern/diff/20346780/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33255
Pulled By: driazati
Differential Revision: D20346780
fbshipit-source-id: c8534954ef4adb2e3c880401acbee30cd284f3db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34560
These jobs don't have next phase so we don't really need commit the
docker images.
Should also fix issue #34557.
Test Plan: Imported from OSS
Differential Revision: D20375308
Pulled By: ljk53
fbshipit-source-id: 328cb428fcfb0fbb79b2a233b5f52607158c983c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34376
Vectorized implementation of qmul. qmul is now ~16x faster on my development machine. This implementation works for qint8, quint8 and qint32. Also added some commonly used operations, such as multiply operator, requantize operation etc., to qint vector classes for future use.
```
#!/usr/bin/env python
import time
import torch
import torch.nn as nn
torch.set_num_threads(1)
# print(torch.__config__.parallel_info())
A = torch.rand(1, 54, 54, 256)
B = torch.rand(1, 54, 54, 256)
scale = .05
zero_point = 50
for dtype in [torch.quint8, torch.qint8]:
qA = torch.quantize_per_tensor(A, scale=scale, zero_point=zero_point,
dtype=dtype)
qB = torch.quantize_per_tensor(B, scale=scale, zero_point=zero_point,
dtype=dtype)
NITER = 1000
s = time.time()
for i in range(NITER):
out = torch.ops.quantized.mul(qA, qB, scale=scale, zero_point=zero_point)
time_per_iter = (time.time() - s) / NITER
print('dtype: {} time per iter ms: {:.3f}'.format(dtype, time_per_iter * 1000))
```
### Before
dtype: torch.quint8 time per iter ms: 6.714
dtype: torch.qint8 time per iter ms: 6.780
### After
dtype: torch.quint8 time per iter ms: 0.431
dtype: torch.qint8 time per iter ms: 0.417
### Test
Modified qmul tests to include qint8 and qint32 data types.
python test/test_quantized.py TestQuantizedOps.test_qmul_relu_same_qparams
python test/test_quantized.py TestQuantizedOps.test_qmul_relu_different_qparams
python test/test_quantized.py TestQuantizedOps.test_qmul_broadcast
ghstack-source-id: 99862681
Differential Revision: D20308515
fbshipit-source-id: 4fa65b2ba433cfd59260fc183a70f53a6fcc36b4
Summary:
**Summary**
There is often a need to create a Tensor when writing IR by hand for JIT
optimisation pass unit tests. The only options for this today are real
Tensor creation functions like `aten::ones`. Any test that uses these functions
must also use the same default arguments as the Python/C++ API, which means
that all of the tests have to be updated when the API is updated. This commit
introduces a new primitive, `prim::MakeTestTensor` with schema `() -> Tensor` that
should be used in unit tests instead of real Tensor creation functions. This new
primitive has no public-facing API, so the maintenance burden is much lower.
**Testing**
This commit updates the alias analysis and DCE tests to use `prim::MakeTestTensor` instead of
`aten::rand`, `aten::ones`, and `aten::zeros`.
```
$ ./bin/test_jit
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = *-*_CUDA:*_MultiCUDA
[==========] Running 75 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 75 tests from JitTest
[ RUN ] JitTest.ADFormulas
[ OK ] JitTest.ADFormulas (82 ms)
[ RUN ] JitTest.Attributes
[ OK ] JitTest.Attributes (0 ms)
...
...
...
[ RUN ] JitTest.LiteInterpreterPrim
[ OK ] JitTest.LiteInterpreterPrim (0 ms)
[ RUN ] JitTest.LiteInterpreterLoadOrigJit
[ OK ] JitTest.LiteInterpreterLoadOrigJit (2 ms)
[----------] 75 tests from JitTest (150 ms total)
[----------] Global test environment tear-down
[==========] 75 tests from 1 test case ran. (150 ms total)
[ PASSED ] 75 tests.
```
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33500.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34334
Differential Revision: D20296437
Pulled By: SplitInfinity
fbshipit-source-id: df4e7b0881ae4913424e5a409bfa171a61c3e568
Summary:
Attempt to build pytorch with ASAN on system with gcc-8 fails due to the mismatch system compilation flags.
Address the issue by using original compiler to build `torch._C` extension
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34549
Test Plan: Run `.jenkins/pytorch/build-asan.sh` on FC-30
Differential Revision: D20373781
Pulled By: malfet
fbshipit-source-id: 041c8d25f96b4436385a5e0eb6fc46e9b5fdf3f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26125
We already had some optimization implementation using AVX2 for improve the quantized kernel performance. In this diff, we want to enable the runtime dispatch.
Test Plan:
Sandcastle build and test
Also test with a python binary calling into vectorized op.
torch.__config__.show()
PyTorch built with:
- GCC 4.2
- clang 8.0.20181009
- Intel(R) Math Kernel Library Version 2017.0.3 Product Build 20170413 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v0.18.1 (Git Hash N/A)
- OpenMP 1
- **CPU capability usage: AVX2**
- Build settings:
Reviewed By: jamesr66a
Differential Revision: D17337251
fbshipit-source-id: 8e22d10011a12a4eaf54cea3485353eb1811d828
Summary:
**This PR is BC-breaking in the following way:**
In RMSpropOptions:
1. learning_rate is renamed to lr.
**Test plan before 1.5 release:**
Test that in 1.5 we can load a C++ RMSprop optimizer that was serialized in 1.4, and their states are the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33450
Differential Revision: D20366623
Pulled By: anjali411
fbshipit-source-id: 83250be9b583a766927e0e22a4de8b0765379451
Summary: I'm using this code in an internal Android build, and std::to_string doesn't work in our internal Android builds yet.
Test Plan: Internal build.
Reviewed By: ljk53
Differential Revision: D20234221
fbshipit-source-id: 8fd61235bf9b487e07a1459c452830e732c7afb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33427
This PR is an attempt to avoid clone for sparse tensors similar to how
we avoid clone for dense tensors currently.
As per my understanding even if the 'indices' and 'values' of a sparse tensor
are non-continguous, operations like 'add' are still supported. As a result,
the major change in this PR is to use create a shallow copy instead of clone()
for sparse tensors.
ghstack-source-id: 99838375
Test Plan: waitforbuildbot
Differential Revision: D19926698
fbshipit-source-id: b5a3f36c2aa273e17f8b7a9f09c1ea00e7478109
Summary:
We updated the default jobs to run in a different PR but neglected to
update this script as well.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34498
Differential Revision: D20368420
Pulled By: seemethere
fbshipit-source-id: 240171b18f397095e3a8d57de3a29d1d2e891d85
Summary:
In DataParallel, replica parameters are not leaves (because they are computed via broadcast from master parameters), and should be treated as such. Fixes https://github.com/pytorch/pytorch/issues/33552
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33907
Differential Revision: D20150199
Pulled By: ngimel
fbshipit-source-id: 5965d4115b6b3a8433063126ff6269567872fbeb
Summary:
The include list seems to be copied from somewhere else, and some totally unrelated files are included.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34528
Differential Revision: D20358622
Pulled By: ngimel
fbshipit-source-id: d8a6260f5f77b0eabdbd68e3728873efd632d9bc
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31342
Test Plan: unit test
Differential Revision: D19131704
fbshipit-source-id: 4e91d5933635ee2c7c301caf89a5a7009c5cb7c8
Summary:
Tries to fix https://github.com/pytorch/pytorch/issues/33562 by raising `std::runtime_error` instead of `std::domain_error`.
* The Python tests already expect `RuntimeError` so this shouldn't affect Python users of PyTorch.
* If someone out there is using C10 or ATen from C++ and tries to catch `std::domain_error` specifically, this fix would break their code. Hopefully that's not the case.
Alternative to this PR is someone try to really get to the bottom of why `std::domain_error` isn't being caught.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34301
Differential Revision: D20344579
Pulled By: ezyang
fbshipit-source-id: d5f3045085a2f75b71b864335ebf44991d0cad80
Summary:
cuDNN needs it, MIOpen doesn't. However, since it seems to be the PyTorch preference to not introduce ROCm-specific logic in the python layer, we need to add a C++ function to detect if rnn weight flattening is needed.
This PR will be needed to fix the rnn unit test errors arising for PR https://github.com/pytorch/pytorch/issues/33837.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34265
Differential Revision: D20345105
Pulled By: ezyang
fbshipit-source-id: a2588a6e2ac6f7d1edf2b7872bc6a879a7df96ec
Summary:
This PR enables bfloat16 type for loss criterion ops(and the ops they depend on) and few miscellaneous ops required to train resnet50.
iotamudelta ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34469
Differential Revision: D20348856
Pulled By: ezyang
fbshipit-source-id: 0a8f06c2169cfa3c9cf319120e27150170095f6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33896Fixes#32625. Previously, we'd receive an error message if we have a
custom function return a view of an input in a no_grad block:
```
class Alias(Function):
staticmethod
def forward(ctx, x):
return x[:]
staticmethod
def backward(ctx, gx):
return gx
inp = torch.rand(2, requires_grad=True)
with torch.no_grad():
# Used to error out
output = Alias.apply(inp)
```
After this change, the error no longer happens. The behavior changes to
become consistent to if we had implemented an operator that does the
same thing as the custom function:
- the output requires_grad
- we are able to detect (and error out) if the user tries to modify the
output in-place outside of the no_grad block.
Test Plan: - new test
Differential Revision: D20345601
Pulled By: zou3519
fbshipit-source-id: 7f95b4254f52ddbf989d26f449660403bcde1c78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33875Fixes#33675.
I added a `current_node_name` argument to AnomalyMetadata::print_stack.
This is a mandatory arg because I found only one callsite and making it
a default arg on a virtual function can be confusing.
Test Plan:
- Tested locally:
https://gist.github.com/zou3519/09937387c83efc76e1700374d5c9c9d9
- I don't know how to add a test for this: the message is printed to
stderr but it isn't an exception nor a warning. I considered capturing
the stderr of a subprocess but that seems like asking for flakiness.
Differential Revision: D20349399
Pulled By: zou3519
fbshipit-source-id: 7585ddffe2bf9e1081f4028a9c44de783978a052
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33214
Distributed autograd had some custom logic in terms of how we
accumulated gradients. This was mostly done early on to enable basic
functionality. Although, in the long term we should merge this logic with what
we have in the local autograd engine. A lot of work has gone into ensuring we
accumulate grads correctly and efficiently and we should reuse that as a
starting point.
We can investigate if we need further custom logic for distributed autograd
later on if we need additional optimizations.
In this PR I've merged the gradient accumulation logic and also the gradient
hooks. As a result, now gradient hooks are called in distributed autograd as
well.
ghstack-source-id: 99838019
Test Plan: waitforbuildbot
Differential Revision: D19843284
fbshipit-source-id: 7923d7e871fb6afd3e98dba7de96606264dcb5f3
Summary:
This PR resolves https://github.com/pytorch/pytorch/issues/22534 by adding a converter for the `torch.nn.functional.one_hot` function, and covering it with a test.
Are there other places this should be tested?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34454
Reviewed By: hl475
Differential Revision: D20354255
Pulled By: houseroad
fbshipit-source-id: 84224c1610b2cc7986c91441c65647ddc090750d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33807
afaik this is unused, so removing it from the source tree. RIP :(
Test Plan: Imported from OSS
Differential Revision: D20122118
Pulled By: suo
fbshipit-source-id: cb45943f5b9f969482301a2f9fe540326dbc78f2
Summary:
See NumPy's division documentation here: https://numpy.org/doc/1.18/reference/generated/numpy.divide.html#numpy.divide.
True division is the same as PyTorch's default division except when both inputs are integer or bool tensors. In the latter case the inputs are (conceptually) cast to the default floating type before the division is performed.
The function is implemented for dense and sparse tensors and supports exporting to ONNX from PyTorch's eager mode or JIT traces. The function is inherently incompatible with exporting to ONNX via JIT script, and is another datapoint suggesting we should deprecate exporting scripted graphs to ONNX.
Tests are added for the type promotion, named tensor, and ONNX export behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34236
Reviewed By: houseroad
Differential Revision: D20334087
Pulled By: mruberry
fbshipit-source-id: 83d00d886f46f713215d7d9e02ffd043164c57f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34321
Mostly cosmetic as we can infer the shape anyway. It can remove a lot of the noise in the log though.
Note that weight sharing doesn't work yet. I'll add another diff to address this.
Reviewed By: houseroad
Differential Revision: D20290841
fbshipit-source-id: fe6f9b60d05dbe150af15b5d9d7a69fd902e12cc
Summary:
This allows us to enable some double-based pdist tests running into accrued error from casting down to float previously.
Addresses https://github.com/pytorch/pytorch/issues/33128
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34103
Differential Revision: D20343279
Pulled By: ezyang
fbshipit-source-id: a2da768259fab34ef326976283b7a15bebbbb979
Summary:
I think this was added when we couldn't compile the function itself. now we can.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34171
Differential Revision: D20269960
Pulled By: eellison
fbshipit-source-id: 0a60458d639995d9448789c249d405343881b304
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33853
Quant fusion relies on inline, but inline will break the CallFunction("linaer", ...) into a if block
it will be hard to recognize this block and swap it with quantized::linear, in order to
preserve the op, we will swap all quantized functional linear into aten::linear.
They might produce different backward graph, but this is called in the step before we get quantized
model, so it shouldn't affect anything.
We'll integrate this with convert_script later in the new "finalize_quant" API
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20343873
fbshipit-source-id: 423e03bf893b79267d2dc97bc997ee1bfe54ec0f
Summary:
Custom classes via torchbind requires runtime type information.
We are trying to enable custom class based graph rewrite for XNNPACK in
this stacked PRs: https://github.com/pytorch/pytorch/pull/34047.
They require RTTI enabled for mobile. Mobile builds are failing
currently without it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34368
Differential Revision: D20306155
Pulled By: kimishpatel
fbshipit-source-id: 52c61ff5467a619e8f51708a05258eee35dd0a56
Summary:
Previously when emitting subscripts we only emitted actual values, but
now they may sometimes emit a `ModuleValue`, so it should stay as a
`SugaredValue`. This allows for the result of the subscript to be
treated as a real module (i.e. you can just do `self.modlist[1](inputs)`
instead of `self.modlist[1].forward(inputs)`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34320
Pulled By: driazati
Differential Revision: D20345642
fbshipit-source-id: 2bedf9a454af747b704422f6bbb8370cbdf4bf61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34398
As part of PR 34109, it was suggested that we track the number of outstanding
async calls for RPC DebugInfo, particularly if we move towards using
at::launch() threads on occasion for continuations.
This particular aspect of the change was distinct from the main purpose of the
diff, and started getting bigger, so split this functionality out as a separate diff.
For completeness, we track client_active_calls, server_active_calls,
server_active_async_calls, and write some very basic unittest coverage.
ghstack-source-id: 99708836
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcBackend/...
Differential Revision: D20314994
fbshipit-source-id: 2f7c75d5c511b27ed0c09c7b8a67b6fb49df31a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34410
### Summary
Currently, the iOS jobs are not being run on PRs anymore. This is because all iOS jobs have specified the `org-member` as a context which used to include all pytorch members. But seems like recently this rule has changed. It turns out that only users from the admin group or builder group can have access right to the context values. https://circleci.com/gh/organizations/pytorch/settings#contexts/2b885fc9-ef3a-4b86-8f5a-2e6e22bd0cfe
This PR will remove `org-member` from the iOS simulator build which doesn't require code signing. For the arm64 builds, they'll only be run on master, not on PRs anymore.
### Test plan
- The iOS simulator job should be able to appear in the PR workflow
Test Plan: Imported from OSS
Differential Revision: D20347270
Pulled By: xta0
fbshipit-source-id: 23f37d40160c237dc280e0e82f879c1d601f72ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33481
We have to propagate observed property of values through ops like max_pool2d, flatten and
avoid inserting duplicated observers.
For example:
```
x1 = self.conv(x)
x2 = maxpool(x1)
x3 = self.conv(x2)
```
If x1 is observed, we should propagate this information through maxpool and
we should consider x2 as observed as well.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20261897
fbshipit-source-id: 7de354a3ccb2b6e1708f5c743d4d9f7272691a93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34354
The condition `NOT INTERN_BUILD_MOBILE AND NOT BUILD_CAFFE2_MOBILE` was
added in #27086, but seems it's always false on current master:
BUILD_CAFFE2_MOBILE is ON by default - the name is a little bit misleading -
it is ON even when it's building non-mobile PyTorch/Caffe2. It is OFF only
when it's building PyTorch mobile, where INTERN_BUILD_MOBILE is ON.
And when it's building PyTorch mobile, it won't build caffe2/operators
at all (by setting BUILD_CAFFE2_OPS OFF: https://github.com/pytorch/pytorch/blob/master/CMakeLists.txt#L345)
So I imagine the real intention is to skip when it's building Caffe2 mobile.
We can simply remove the deprecating BUILD_CAFFE2_MOBILE condition.
Test Plan: Imported from OSS
Differential Revision: D20345298
Pulled By: ljk53
fbshipit-source-id: d2cb4e2248fc209d63b2843e0f12e577e323def4
Summary:
`ConcreteModuleTypeBuilder` used to keep parameters together with all others attributes in an `unordered_map` often leading to reordering them while building up the type. Parameter order is semantically meaningful, so we need to preserve it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34131
Differential Revision: D20331542
Pulled By: suo
fbshipit-source-id: 5b860025f7902654d6099751d3fb14b12f6f5a67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34382
The previous implementation was handling both newWithStorage and newWithSize, which doesn't make much sense.
Test Plan: Imported from OSS
Differential Revision: D20311056
Pulled By: gchanan
fbshipit-source-id: 2696a4566e6203c98338c86cbf4c236bd18d7c49
Summary:
One example in the current docs for `torch::nn::ModuleList` doesn't compile, and this PR fixes it.
Fixes https://github.com/pytorch/pytorch/issues/32414.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34463
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20331120
Pulled By: yf225
fbshipit-source-id: 50bb078fe1a900c9114d5434e92dc40ee13b52bf
Summary:
Fixes https://github.com/pytorch/pytorch/issues/25845.
**Test Plan:**
Check `pytorch_cpp_doc_push` CI job, and see if there is `classat_1_1_tensor` generated (similar to `structat_1_1native_1_1_convolution_descriptor`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34467
Differential Revision: D20338190
Pulled By: yf225
fbshipit-source-id: 52dc05af5e0d742e740de5576d0d2b3e17ef28dd
Summary:
Addresses https://github.com/pytorch/pytorch/issues/5442.
Per title (and see issue). A test is added to test_torch.py to verify the behavior.
Update (with new behavior):
NumPy arrays can be non-writeable (read-only). When converting a NumPy array to a Torch tensor the storage is shared, but the tensor is always writable (PyTorch doesn't have a read-only tensor). Thus, when a non-writeable NumPy array is converted to a PyTorch tensor it can be written to.
In the past, PyTorch would silently copy non-writeable NumPy arrays and then convert those copies into tensors. This behavior violates the from_numpy contract, however, which promises that the tensor and the array share memory.
This PR adds a warning message when a non-writeable NumPy array is converted into a Torch tensor. This will not break any networks, but will make end users aware of the behavior. They can work-around the warning message by marking their NumPy arrays as writeable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33615
Differential Revision: D20289894
Pulled By: mruberry
fbshipit-source-id: b76df0077399eb91038b12a6bf1917ef38c2cafd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34162
This avoids the "worker{}".format(..) in our unit tests to something
cleaner.
ghstack-source-id: 99713074
Test Plan: waitforbuildbot
Differential Revision: D20233533
fbshipit-source-id: 5cff952ca68af5a6d26dc5cc01463cf7756d83d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33921
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.intern.facebook.com/intern/diff/D20153092/)!
Test Plan: Imported from OSS
Differential Revision: D20177227
Pulled By: jamesr66a
fbshipit-source-id: 87f3e484c4f873d60f76f50f6789c1b4a73bdfde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33900
These functions don't require any libtorch-specific functionality, so move them into the header so they're included in the ATen build
Test Plan: Imported from OSS
Differential Revision: D20175874
Pulled By: jamesr66a
fbshipit-source-id: 1efab1b60e196a635e6c6afadb042b63771170f0
Summary:
This commit fixes overlapping keywords in the CPP Docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34142
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20319949
Pulled By: yf225
fbshipit-source-id: e7bb2efdc286c85792c6f18a260c3bba33c54008
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34393
Clean up the list
Test Plan: CI
Reviewed By: hl475
Differential Revision: D20300530
fbshipit-source-id: 50e7da0a9f8295eff33590982f32f84abee96d9c
Summary:
This PR fixed documentation for `torch.add` with alpha. It also fixed these deprecated python calls `torch.add` and `torch.addmm` in tests, which may affect performance in *test/test_sparse.py* and *test/test_nn.py*.
cc csarofeen ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33935
Differential Revision: D20313320
Pulled By: ngimel
fbshipit-source-id: fb08413d7e244865952e3fc0e1be7f1794ce4e9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33717
Because of the special treatment of operator names for lite interpreter, all the operators used in lite interpreter are still prepended by "_". Add the necessary registrations for MNIST model. All the ops with autograd capability are included in torch_mobile_train. After rebase the selective build from D19649074 can be utilized to strip the unused ops.
Note that this diff is for feasibility test. The training accuracy are not covered in the test.
ghstack-source-id: 97780066
Test Plan:
```
buck run xplat/caffe2/fb/lite_trainer:lite_trainer -c pt.disable_gen_tracing=1 -c pt.static_dispatch=0 -- --model=/path/MnistModel.bc
```
{F227898221}
Reviewed By: dreiss
Differential Revision: D19743201
fbshipit-source-id: cacadd76f3729faa0018d147a69466bbf54312fd
Summary:
Please merge after https://github.com/pytorch/pytorch/pull/33073
With that PR, we are now trying different algorithms when OOM, so hopefully there will be some algo working at low memory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34259
Differential Revision: D20310094
Pulled By: ngimel
fbshipit-source-id: bccd8162bd06a0e54ac6f42a7fd9a5b766f92cd7
Summary:
Improves explanation of non-determinism when running on GPUs. Adds info about `torch.nn.BCELoss` operating non-deterministically on GPUs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33795
Differential Revision: D20284880
Pulled By: ngimel
fbshipit-source-id: d543959636d261a80c234150304344b19a37ba5d
Summary:
We don't release binaries for macOS with CUDA support so we should just
remove it from our regular PR pipeline
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34333
Differential Revision: D20312565
Pulled By: seemethere
fbshipit-source-id: 376228680aa0e814d1b37f1ff63b7d1262515e44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34378
This fixes strange symbol mangling mismatch beteen `DECLARE_DISPATCH(qbatch_norm_fn, qbatch_norm_stub)` and `REGISTER_DISPATCH(qbatch_norm_stub, &q_batch_norm_kernel<false>);` if code is build on Windows with clang
Test Plan: CI + build PyTorch on Windows using clang
Reviewed By: EscapeZero
Differential Revision: D20309550
fbshipit-source-id: e97c7c3b6fee2e41ea6b2f8167ce197aec404e3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34099
This change effectively applies into IValue's future impl a few fixes
we discovered when using the torch::utils::Future<T> impl.
The parallel impls should probably eventually be merged, but until then:
- Don't hold the lock when invoking the callbacks. This makes
it effectively impossible (deadlocks) to call value() to get
the value from inside the callback.
- We discovered that it was slightly cleaner in practice to
notify condition variables prior to invoking callbacks
(best to unblock paused threads ASAP, before spawning new work).
- Fix some var naming inconsistency.
- Add a some caffe2 cpp test coverage.
ghstack-source-id: 99336569
Test Plan:
```
buck test mode/dev //caffe2/test/cpp/jit:jit -- 'JitTest\.IValueFuture'
```
Differential Revision: D20203278
fbshipit-source-id: 6e805ba547899dab9aab458e4b23049db31f930e
Summary:
Currently testing against the older release `1.4.0` with:
```
PYTORCH_S3_FROM=nightly TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 scripts/release/promote/libtorch_to_s3.sh
PYTORCH_S3_FROM=nightly TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 scripts/release/promote/wheel_to_s3.sh
```
These scripts can also be used for `torchvision` as well which may make the release process better there as well.
Later on this should be made into a re-usable module that can be downloaded from anywhere and used amongst all pytorch repositories.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34274
Test Plan: sandcastle_will_deliver
Differential Revision: D20294419
Pulled By: seemethere
fbshipit-source-id: c8c31b5c42af5096f09275166ac43d45a459d25c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34159
This fixes `comparison of integers of different sign` warnings
Test Plan: CI
Reviewed By: EscapeZero
Differential Revision: D20232085
fbshipit-source-id: 8f325be54395be54c704335cb7edf2ec7ef75e75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34318
Stop checking whether we have AMD GPU devices on the host, because we may be constructing a net on a machine without GPU, and run the net on another one with GPU
Reviewed By: ajauhri
Differential Revision: D20269562
fbshipit-source-id: 1f561086cacdcead3ce7c03c2d02c25336c8b11a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34017
Remove warning
```
caffe2/aten/src/THC/generic/THCTensorMathBlas.cu(437): warning: statement is unreachable
caffe2/aten/src/THC/generic/THCTensorMathBlas.cu(271): warning: variable "transpose_m1" was set but never used
caffe2/aten/src/THC/generic/THCTensorMathBlas.cu(271): warning: variable "transpose_m2" was set but never used
```
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D20181179
fbshipit-source-id: 3665912ba55bffbd8b4555f8a6803e57a502c103
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34018
Remove warning
```
caffe2/c10/util/ArrayRef.h(278): warning: attribute does not apply to any entity
```
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20181191
fbshipit-source-id: 58bd168a87a94fec925c7cde8b8d728a4257446c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34183https://github.com/pytorch/pytorch/pull/33263 enhanced the RRef Python constructor to infer most types, by `jit::tryToInferType(..)`.
But this helper function can't infer `ScriptModule` type due to `ScriptModule`'s special per-Module type singleton logic, so it's still not possible for an Python-created RRef to know the JIT type of it's contained `ScriptModule`.
Instead of inferring the specific type of a Module, which could leads to too many candidate types (due to Module's multiple inheritance possibility), it's more straightforward to set it's type as a user-specified `ModuleInterface` type.
We added an optional argument `type_hint` for users to mark an `RRef` for what `ModuleInterface` type it's holds.
ghstack-source-id: 99649379
(Note: this ignores all push blocking failures!)
Test Plan:
Aspects that need to be confirmed in the test cases
https://fb.quip.com/aGxRAh2lCg05
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_create_local_script_class_rref
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_create_local_script_module_rref
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_return_local_script_class_rref_in_py_and_use_in_script
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_return_local_script_module_rref_in_py_and_use_in_script
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_torchscript_function_exception
```
Differential Revision: D7065050
fbshipit-source-id: e10210c0996622969e499e4a35b0659b36787c1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34217
LegacyNoScalar variants cause 0-dim tensors to behave like 1-dim tensors.
LegacyAll variants cause 0-dim tensors to behave like 1-dim tensors, and numel == 0 tensors to be treated like 0-dimensional tensors.
This this was done by codemod, these are often unneeded and often translated incorrectly to ATen.
Test Plan: Imported from OSS
Differential Revision: D20249577
Pulled By: gchanan
fbshipit-source-id: 6f2876d3e479562c9323f3629357a73a47869150
Summary:
The init-list form of `at::indexing::Slice` (i.e. `tensor.index({{1, None, 2}, ...})` instead of `tensor.index({Slice(1, None, 2), ...})`) in C++ API can be easily confused with the list-form indexing in Python API (e.g. `tensor[[1, 3, 2], ...]`), which is not good from readability perspective. This PR removes the init-list form of `at::indexing::Slice` to make the API less confusing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34255
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20290166
Pulled By: yf225
fbshipit-source-id: abbcbeca0b179219e5e1f196a33ef8aec87ebb76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34203
Currently cmake and mobile build scripts still build libcaffe2 by
default. To build pytorch mobile users have to set environment variable
BUILD_PYTORCH_MOBILE=1 or set cmake option BUILD_CAFFE2_MOBILE=OFF.
PyTorch mobile has been released for a while. It's about time to change
CMake and build scripts to build libtorch by default.
Changed caffe2 CI job to build libcaffe2 by setting BUILD_CAFFE2_MOBILE=1
environment variable. Only found android CI for libcaffe2 - do we ever
have iOS CI for libcaffe2?
Test Plan: Imported from OSS
Differential Revision: D20267274
Pulled By: ljk53
fbshipit-source-id: 9d997032a599c874d62fbcfc4f5d4fbf8323a12e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34122
Earlier work added support for async rpc cases when RecordFunction's
end callbacks might be called in a different thread; in addition some
extra care was needed to handle pointer to parent function;
This PR makes RecordFunction aware of potentially multiple threads in
use, as well as removes unused parent() call and restricts current()
RecordFunction to scope-based record functions (RECORD_FUNCTION macro)
Test Plan: unit tests
Differential Revision: D20297709
Pulled By: ilia-cher
fbshipit-source-id: 46a59e1b2eea0bbd8a59630385e193b38d30f9d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33978
We can directly pass user_callbale to rpc_async API in TorchScript. There is no need to have private API for taking qualified name.
ghstack-source-id: 99600360
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_torchscript_functions_not_supported
```
Differential Revision: D7420993
fbshipit-source-id: 228c15b21848e67418fab780e3fd6a1c6da5142d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34278
This diff helps check all the ops not supported by lite_interpreter.
Helpful mainly to find all the ops that need to be added instead of adding them
one by one.
Test Plan:
buck run caffe2/binaries:lite_interpreter_model_load --
--model=<bytecode-model-path>
Reviewed By: iseeyuan
Differential Revision: D20266341
fbshipit-source-id: 5a6c7a5bc52f910cea82a72045870da8105ccb87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34118
Previously calc_per_channel_qparams was using for loops and python primitives, which called `item` many times causing slowdown during training.
These changes uses torch primitives on the tensor to speed up the operation over 60x
Perf results on MobileNetV2 during training using autograd profiler
FP32 forward call -
Self CPU time total: 47.222ms
CUDA time total: 124.001ms
before change
FakeQuant Model -
Self CPU time total: 19.107s
CUDA time total: 27.177s
after change
FakeQuant Model -
Self CPU time total: 404.667ms
CUDA time total: 446.344ms
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D20287841
fbshipit-source-id: 6b706b8206e0d0da3c3c217b014e8da5b71b870d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34232
By default `torch.zeros` creates the tensor on GPU. Need to specify the device argument to get it to work correctly on GPU during QAT.
Test Plan:
1. Tested by running QAT on GPU
2. python test/test_quantization.py
Imported from OSS
Differential Revision: D20286351
fbshipit-source-id: 745723c85d902870c56c1c7492f26cb027ae9dc6
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/31336https://github.com/pytorch/pytorch/issues/1664
Sometimes cuDNN heuristics return algorithms that can not be used. Instead of just using the first algorithm returned, we should try these algorithms one by one until one of them succeed.
Benchmark:
https://github.com/zasdfgbnm/things/blob/master/2020Q1/conv-benchmark.ipynb
```python
i = torch.randn(256, 3, 256, 256).cuda()
c = torch.nn.Conv2d(3, 3, 3, 3).cuda()
%timeit c(i); torch.cuda.synchronize()
```
before vs after = 498 vs 490 µs
The performance is improved I guess because, before this PR, we always call the heuristics to get the algorithm, but after this PR, we only do at the first time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33073
Differential Revision: D20284755
Pulled By: ngimel
fbshipit-source-id: b03af37c75939ca50c2cb401c706ba26914dd10e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33294
1. Serialize bytecode of __setstate__ and run it when loading the model.
2. One use case is quantization. To test this use case a few operators are registered temporarily for lite interpreter. The "_" prefix registration will be removed when the operators are all migrated to mobile.
Test Plan: Imported from OSS
Differential Revision: D20162898
Pulled By: iseeyuan
fbshipit-source-id: 7a3180807bf38fbce594d86993896861f12bb58c
Summary:
Among all ONNX tests, ONNXRuntime tests are taking the most time on CI (almost 60%).
This is because we are testing larger models (mainly torchvision RCNNs) for multiple onnx opsets.
I decided to divide tests between two jobs for older/newer opsets. This is now reducing the test time from 2h to around 1h10mins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33242
Reviewed By: hl475
Differential Revision: D19866498
Pulled By: houseroad
fbshipit-source-id: 446c1fe659e85f5aef30efc5c4549144fcb5778c
Summary:
**Summary**
There is often a need to create a Tensor when writing IR by hand for JIT
optimisation pass unit tests. The only options for this today are real
Tensor creation functions like `aten::ones`. Any test that uses these functions
must also use the same default arguments as the Python/C++ API, which means
that all of the tests have to be updated when the API is updated. This commit
introduces a new primitive, `prim::MakeTestTensor` with schema `() -> Tensor` that
should be used in unit tests instead of real Tensor creation functions. This new
primitive has no public-facing API, so the maintenance burden is much lower.
**Testing**
This commit updates the alias analysis and DCE tests to use `prim::MakeTestTensor` instead of
`aten::rand`, `aten::ones`, and `aten::zeros`.
```
$ ./bin/test_jit
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = *-*_CUDA:*_MultiCUDA
[==========] Running 75 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 75 tests from JitTest
[ RUN ] JitTest.ADFormulas
[ OK ] JitTest.ADFormulas (82 ms)
[ RUN ] JitTest.Attributes
[ OK ] JitTest.Attributes (0 ms)
...
...
...
[ RUN ] JitTest.LiteInterpreterPrim
[ OK ] JitTest.LiteInterpreterPrim (0 ms)
[ RUN ] JitTest.LiteInterpreterLoadOrigJit
[ OK ] JitTest.LiteInterpreterLoadOrigJit (2 ms)
[----------] 75 tests from JitTest (150 ms total)
[----------] Global test environment tear-down
[==========] 75 tests from 1 test case ran. (150 ms total)
[ PASSED ] 75 tests.
```
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33500.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33914
Differential Revision: D20150304
Pulled By: SplitInfinity
fbshipit-source-id: c88f5289055a02dc20b7a5dcdf87469f9816d020
Summary:
Currently, putting `outputs: List[Tensor]` instead of `outputs: List[Tensor] = []` in your JITed code results in:
```
Traceback (most recent call last):
File "custom_lstms.py", line 453, in <module>
test_script_stacked_bidir_rnn(5, 2, 3, 7, 4)
File "custom_lstms.py", line 404, in test_script_stacked_bidir_rnn
rnn = script_lstm(input_size, hidden_size, num_layers, bidirectional=True)
File "custom_lstms.py", line 62, in script_lstm
other_layer_args=[LSTMCell, hidden_size * dirs, hidden_size]))
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1267, in script
return torch.jit._recursive.create_script_module(obj, torch.jit._recursive.infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 305, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 317, in create_script_module_impl
stubs = stubs_fn(nn_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 511, in infer_methods_to_compile
stubs.append(make_stub_from_method(nn_module, method))
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 41, in make_stub_from_method
return make_stub(func)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 34, in make_stub
ast = torch.jit.get_jit_def(func, self_name="RecursiveScriptModule")
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 173, in get_jit_def
return build_def(ctx, py_ast.body[0], type_line, self_name)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 206, in build_def
build_stmts(ctx, body))
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 129, in build_stmts
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 129, in <listcomp>
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 181, in __call__
return method(ctx, node)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 294, in build_AnnAssign
rhs = build_expr(ctx, stmt.value)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 180, in __call__
raise UnsupportedNodeError(ctx, node)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 116, in __init__
source_range = ctx.make_range(offending_node.lineno,
AttributeError: 'NoneType' object has no attribute 'lineno'
```
This patch makes the error message more reasonable:
```
torch.jit.frontend.UnsupportedNodeError: annotated assignments without assigned value aren't supported:
File "custom_lstms.py", line 221
# type: (Tensor, Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]
inputs = reverse(input.unbind(0))
outputs: List[Tensor]
~ <--- HERE
for i in range(len(inputs)):
out, state = self.cell(inputs[i], state)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34133
Differential Revision: D20249076
Pulled By: ezyang
fbshipit-source-id: 40ec34ad38859f9fe56f379d3f8d08644b00fab9
Summary: I don't know why, but this segfaults on rocm.
Test Plan: Can only be tested on master
Reviewed By: mrshenli
Differential Revision: D20286011
fbshipit-source-id: dde952449bf54ae459d36020f3e3db6fa087b39f
Summary:
This PR enables bfloat16 type for pooling ops on ROCm. Also adds bfloat16 implementation of atomicAdd since pooling ops use it.
Note: Changes in the lambda function blocks is only indentation as it is now wrapped inside `AT_SKIP_BFLOAT16_IF_NOT_ROCM` macro.
iotamudelta ezyang bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34166
Differential Revision: D20263421
Pulled By: ezyang
fbshipit-source-id: 3f4199ec57522e638ec29f45e22c6ec919b7816d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34184
Add mobile custom build with static dispatch & dynamic dispatch to CI.
Most of mobile code analysis CI should be covered by the custom build +
dynamic dispatch flow, so changing it to running on master only.
Test Plan: Imported from OSS
Differential Revision: D20241774
Pulled By: ljk53
fbshipit-source-id: f34c5748735c536ab6b42c8eb1429d8bbdaefd62
Summary:
There was an error in
https://github.com/pytorch/pytorch/pull/30724/files that resulted in
export_chrome_trace generating invalid JSON. This only came up when the
profiler is run with use_cuda=True from what it looks like. In the future, we
should have tests that ensure we generate valid JSON because we no longer use
the json library.
ghstack-source-id: 99508836
Test Plan: Added a unit test.
Differential Revision: D20237040
fbshipit-source-id: 510befbdf4ec39632ac56544afcddee6c8cc3aca
Summary:
Separating CUDA fuser from CPU fuser.
1. New node in IR - prim::CudaFusionGroup:
This enables the cuda fuser to co-exist along side the old fuser. Allows us
to incrementally build and expand cuda fuser.
2. copied FuseGraph optimization passes to CudaFuserGraph:
We will re-factor & reuse Chunk/Concat in the old fuser logic, which is
handled in the optimization pass at this moment. Unfortunately many code in
the pass is tightly binded with the legacy fuser, which makes code sharing
difficult.
The CudaFusionGraph will support only a subset of operations comparing to
legacy fuser (CUDA only). It is registered as a custom pass post fusion via
```torch._C._jit_register_cuda_fuser()```
To have it in effect, you should also turn off fusion on GPU via
```torch._C._jit_override_can_fuse_on_gpu(False)```
3. We don't have codegen in this PR yet (WIP). Currently we just fall back to
the old fuser.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33527
Differential Revision: D20171598
Pulled By: ZolotukhinM
fbshipit-source-id: 9a3c0f06f46da7eaa80ae7551c04869f5b03ef71
Summary:
[This check](019ffdca31/torch/csrc/jit/ir/alias_analysis.cpp (L772)) wasn't being triggered for None outputs of tuples, because `mustBeNone` would return false if `num_outputs != 1`. This caused an assertion to fail in alias analysis. It's kind of a convoluted case to repro and I wasn't able to make a succinct one, but I tested internally and it fixed the bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34268
Differential Revision: D20261539
Pulled By: eellison
fbshipit-source-id: 95edea10e2971727cfd3f3bc2b6bdf9dbadca6a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34284
Python 3.5 only supports function type hints.
Variable type hints are introduced in Python 3.6.
So these tests with JIT type hints will fail with "Syntax Error" in Python 3.5 environment.
ghstack-source-id: 99542199
Test Plan: `
Differential Revision: D7348891
fbshipit-source-id: c4c71ac021f35b5e6f7ce4d3e6af10dd1d2600cc
Test Plan: Can only really be tested in PyTorch master
Reviewed By: mrshenli
Differential Revision: D20260023
fbshipit-source-id: b5444c376894bfccd6524cf04a71cf76eea72275
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33852
This fixes an issue for QAT models. During eval if we call `prepare_qat` and `convert` before calling `load_state_dict` it throws an error because the weight info (num channels) is not updated in the observer module.
It is not an issue for per-tensor case
Fixes issue #33830
Test Plan:
python test/test_quantization.py EagerModePostTrainingQuantTest.test_eval_after_train
python test/test_quantization.py EagerModeQuantizationAwareTrainingTest.test_eval_after_train
Imported from OSS
Differential Revision: D20212996
fbshipit-source-id: a04af8fe4df2e555270ae4d6693f5777d86f8a46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34072
This diff helps check all the ops not supported by lite_interpreter.
Helpful mainly to find all the ops that need to be added instead of adding them
one by one.
Test Plan:
buck run caffe2/binaries:lite_interpreter_model_load --
--model=<bytecode-model-path>
Reviewed By: iseeyuan
Differential Revision: D20194092
fbshipit-source-id: 0d596cd0204308027194af7ed738551d0c32a374
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34187
Noticed that a recent PR broke Android/iOS CI but didn't break mobile
build with host toolchain. Turns out one mobile related flag was not
set on PYTORCH_BUILD_MOBILE code path:
```
"set(INTERN_DISABLE_MOBILE_INTERP ON)"
```
First, move the INTERN_DISABLE_MOBILE_INTERP macro below, to stay with
other "mobile + pytorch" options - it's not relevant to "mobile + caffe2"
so doesn't need to be set as common "mobile" option;
Second, rename PYTORCH_BUILD_MOBILE env-variable to
BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN - it's a bit verbose but
becomes more clear what it does - there is another env-variable
"BUILD_PYTORCH_MOBILE" used in scripts/build_android.sh, build_ios.sh,
which toggles between "mobile + pytorch" v.s. "mobile + caffe2";
Third, combine BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN with ANDROID/IOS
to avoid missing common mobile options again in future.
Test Plan: Imported from OSS
Differential Revision: D20251864
Pulled By: ljk53
fbshipit-source-id: dc90cc87ffd4d0bf8a78ae960c4ce33a8bb9e912
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34215
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20251538
Pulled By: ezyang
fbshipit-source-id: c419f0ce869aca4dede7e37ebd274a08632d10bf
Summary:
Effectively backporting c5c00c119f before that PR lands
The bug didn't manifesting itself earlier because MkldnnConv2d constructor didn't reorder the weights. So the issue was arising only on second serialization/deserialization. This also fixes the constructor to deliver better perf right away.
Note, that I still serialize 5d tensor - it was the previous behavior, we have to handle it anyway and with https://github.com/pytorch/pytorch/issues/32422 the output of `mkldnn_reorder_conv2d_weight` will always be 4d.
cc pinzhenx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34115
Reviewed By: wanchaol
Differential Revision: D20224685
Pulled By: dzhulgakov
fbshipit-source-id: 24ca9227c4eb4c139096a64ae348808d7478d7dc
Summary:
We get seg fault without this in using XNNPACK.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34087
Differential Revision: D20199787
Pulled By: kimishpatel
fbshipit-source-id: d3d274e7bb197461632b21688820cd4c10dcd819
Summary:
This PR aims at improving `UpSample` performance with `mode='nearest'` on 1D 2D and 3D, both inference and training are covered. Current implementation from 'ATen' doesn't have parallelization.
1. single socket inference speedup for 1d, 2d and 3d: **63x, 57x, 46x**.
2. single core inference speedup for 1d, 2d and 3d: **5.9x, 4.6x, 3.4x**.
3. dual sockets training speedup for 1d, 2d and 3d: **38x, 33x, 65x**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31452
Differential Revision: D20077828
Pulled By: VitalyFedyunin
fbshipit-source-id: a7815cf2ae344696067d2ec63bd4f4e858eaafff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33849
For integral types, there is no need to manipulate with
`reinterpret_cast` and therefore a cleaner implementation is available.
This might also be helpful on some less optimized compilers or on a less optimized arch (while a
test on gcc 8.3 x64 shows no difference in performance).
Test Plan: Imported from OSS
Differential Revision: D20222675
Pulled By: VitalyFedyunin
fbshipit-source-id: 875890d1479f8abab4c4a19d934fe9807d12dfd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33817
Then, nullopt denotes catch all, whereas everything else is specific to
a DispatchKey. I can delete the second copy of methods when I do this.
This refactor should be pushed all the way to the frontend but I am doing
it one step at a time.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20125163
Pulled By: ezyang
fbshipit-source-id: 026075a4bab81b0bd88b07f0800f6e6bbeb2166a
Summary:
Remove Int8Relu in quantized model
Suppress log warnings if verbose is false
Test Plan: TBD
Reviewed By: yinghai
Differential Revision: D20202474
fbshipit-source-id: 995ef8e665d8edeee810eedac831440b55271a7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33715
Tracing codes depend on the full JIT, which is not available in lite interpreter. Use `-c pt.disable_gen_tracing=1` to turn off generating tracing part.
ghstack-source-id: 99252322
Test Plan:
```
buck build xplat/caffe2:torch -c pt.disable_gen_tracing=1
```
The tracing part of generated/VariableType_?.cpp will not be generated.
Reviewed By: smessmer
Differential Revision: D19684577
fbshipit-source-id: a1e5b80eca5e51c7bf72b5cc8f0e36c2135fabc2
Summary:
When docs are built, conf.py points to a _templates-stable/layout.html that does not exist.
Adding this file here so future stable docs will build with Google Analytics tags and without the unstable able that is in _templates/layout.html
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33770
Differential Revision: D20164895
Pulled By: jlin27
fbshipit-source-id: 5fca9f9b825b1484dab52e2b2d91f92ae6372371
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33329
# Use case
```
torch.jit.script
def send_rpc_async(dst_worker_name, user_callable_qual_name, tensor):
# type: (str, str, Tensor) -> None
rpc._rpc_async_torchscript(
dst_worker_name, user_callable_qual_name, args=(tensor,)
)
```
# Problem
```
torch.jit.frontend.NotSupportedError: keyword-arg expansion is not supported:
File "/data/users/shihaoxu/fbsource/fbcode/buck-out/dev/gen/caffe2/test/distributed/rpc/rpc_spawn#binary,link-tree/torch/distributed/rpc/api.py", line 722
args = args if args else ()
kwargs = kwargs if kwargs else {}
fut = _invoke_rpc_torchscript(to, qualified_name, *args, **kwargs)
~~~~~~ <--- HERE
return fut
```
# Solution
Register `rpc.rpc_async(..)` as a JIT operator to handle variable-length argument list.
# Plan
This PR is the required changes to make `rpc.rpc_async(..)` a JIT prim operator, which can dynamically handle different number of arguments.
- Register "prim::rpc_async" as a `Symbol` in "interned_string.h"
- Add a if branch in "python_sugared_value.cpp" `toSugarValue(py::object, ..)` entry utility function to set up how JIT frontend convert `torch.distributed.rpc.rpc_async(..)` Python function (Python object) into a `SpecialFormValue` (IR SugaredValue).
- Add a switch case for "prim::rpc_aynsc" Symbol in "ir_emitter.cpp" and `emitApplySpecialForm(..)` to set up how JIT compiler provides inputs to the "prim::rpc_aynsc" Operator.
- Register "prim::rpc_async" as a `jit::Operator` and provide implementation in "register_distributed_ops.cpp".
Notice, since the distributed module is an optional part when building PyTorch. The code to be added in this PR should be wrapped within preprocessing maco.
```
#ifdef USE_DISTRIBUTED
new code here
#endif
```
Test Plan:
Items that need to be confirmed in the test cases
https://fb.quip.com/DCvdA9ZLjeO0
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
\
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_call_python_function_remotely_from_script_not_supported
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_spawn
```
```
buck test mode/dev-nosan //caffe2/caffe2/python/operator_test:layer_norm_op_test-2.7 -- test_layer_norm_op_jit
```
Differential Revision: D5738300
fbshipit-source-id: a4604fe762e00be062dc8232ca9790df31fb2074
Summary:
`unpickler.cpp` depends on the mobile type parser all the time, so include it regardless of whether it's a mobile build or not
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34180
Pulled By: driazati
Differential Revision: D20241881
fbshipit-source-id: a998dd2b3f1c7f58e55bb7851dc595c8ddf9eacb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34055
Enable custom mobile build with dynamic dispatch for OSS build.
It calls a python util script to calculate transitive dependencies from
the op dependency graph and the list of used root ops, then pass the
result as the op registration whitelist to aten codegen, so that only
these used ops are registered and kept at link time.
For custom build with dynamic dispatch to work correctly, it's critical
to have the accurate list of used ops. Current assumption is that only
those ops referenced by TorchScript model are used. It works well if
client code doesn't call libtorch API (e.g. tensor methods) directly;
otherwise the extra used ops need to be added to the whitelist manually,
as shown by the HACK in prepare_model.py.
Also, if JIT starts calling extra ops independent of specific model,
then the extra ops need to be added to the whitelist as well.
Verified the correctness of the whole process with MobileNetV2:
```
TEST_CUSTOM_BUILD_DYNAMIC=1 test/mobile/custom_build/build.sh
```
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D20193327
Pulled By: ljk53
fbshipit-source-id: 9d369b8864856b098342aea79e0ac8eec04149aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32814
We skip quantization for the intermediate values for patterns like `Conv - ReLU`,
but currently we didn't skip quantizing the input/output of the graphs of matched modules,
since we now changed the way we add observers, this also needs to be updated.
Test Plan:
python test/test_jit.py -- 'TestJit.test_insert_observers_skip_values'
Imported from OSS
Differential Revision: D20208785
fbshipit-source-id: ce30f2c4c8ce737500d0b41357c80ec8b33aecf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34168
Redo D19153199. It was reverted because it broke CI, due to the change of `AT_ASSERTM` to `TORCH_INTERNAL_ASSERT_DEBUG_ONLY`. Two problems:
1) bug in `TORCH_INTERNAL_ASSERT_DEBUG_ONLY` about MSVC. I'm sending another diff to fix this bug.
2) BlobTest was expecting `Blob::template Get<T>()` to throw when there is a type mismatch.
For now I'll leave `AT_ASSERTM` as it is.
Test Plan:
```
buck test mode/dev //caffe2/caffe2:caffe2_test_cpu -- 'BlobTest' --run-disabled
buck test mode/opt //caffe2/caffe2:caffe2_test_cpu -- 'BlobTest' --run-disabled
```
Reviewed By: yinghai
Differential Revision: D20235225
fbshipit-source-id: 594dad97c03c419afaa8f9023408bc5a119b3cfa
Summary:
This PR aims to improve the interoperability with [CuPy](https://github.com/cupy/cupy/pulls).
Instead of having two separate and conflicting memory pools. With this PR, CuPy can directly alloc memory from the PyTorch allocator by means of this proposal https://github.com/cupy/cupy/pull/3126
We would like to gather feedback to know if this approach makes sense for PyTorch, or other alternative designs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33860
Differential Revision: D20212788
Pulled By: ngimel
fbshipit-source-id: bc1e08a66da1992d26021147bf645dc65239581c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34157
`[[noreturn]` only conficts with CUDA __asert_fail defition if clang is used if host compiler
Test Plan: CI
Reviewed By: EscapeZero
Differential Revision: D20232088
fbshipit-source-id: 7182c28a15278e03175865cd0c87410c5de5bf2c
Summary:
Stacked PRs
* #33474 - [jit] Remove list specializations from pickler
* **#33255 - [jit] Add type tags to lists/dicts in pickle**
This adds a global call to `torch.jit._pickle.restore_type_tags` for
lists and dicts so that we can preserve their types after serialization.
](https://our.intern.facebook.com/intern/diff/19868637/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33255
Pulled By: driazati
Reviewed By: xman1979, Tianshu-Bao
Differential Revision: D19868637
fbshipit-source-id: 2f1826e6679a786ca209198690269f399a542c04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34081
Before this commit, applications have to do the following to configure
number of threads in ProcessGroup RPC backend:
```
op = ProcessGroupRpcBackendOptions()
op.rpc_timeout = rpc_timeout
op.init_method = init_method
op.num_send_recv_threads = 32
init_rpc(...., rpc_backend_options=op)
```
After this commit, it can be simplified to:
```
init_rpc(...., rpc_backend_options=ProcessGroupRpcBackendOptions(num_send_recv_threads=32))
```
Fixes#34075
Test Plan: Imported from OSS
Differential Revision: D20227344
Pulled By: mrshenli
fbshipit-source-id: def4318e987179b8c8ecca44d7ff935702c8a6e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34169
Valgrind have no insight how memory is being initialized by ioctls()
Test Plan: CI
Reviewed By: seemethere
Differential Revision: D20235974
fbshipit-source-id: 46413afa4842e7d42582bbbda903438b1d98691f
Summary:
Related issue: https://github.com/pytorch/pytorch/issues/34079
I don't know how much we care about the difference between `-G` and `-lineinfo` in `DEBUG` vs `REL_WITH_DEB_INFO`, but since `-G` never worked, let's just use `-lineinfo` on both `DEBUG` and `REL_WITH_DEB_INFO`. This would resolve the failure in `DEBUG=1` build. Locally tested to work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34153
Reviewed By: ljk53
Differential Revision: D20232049
Pulled By: ngimel
fbshipit-source-id: 4e48ff818850ba911298b0cc159522f33a305aaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33825
Partially addresses #20376
I do this by overriding assertEqual in classes that opt into
this. This means I have to fix#33821. The fix is a little
unsatisfactory as idiomatic Python 2 super() calls don't work
(since the class is no longer in scope); hopefully this will just
work when we go to Python 3.
General approach taken:
- A lot of dtype mismatches are because we specified tensor constants
that infer to some dtype, but the actual dtype needed is something else.
Those are easy, just annotate the tensor() constructor (often a legacy
Tensor/FloatTensor call) with dtype
- There are a few cases where the promotion rules are nontrivial. Some of them
I just typed out the expected promotion rules manually (based on trial
and error)
- There are some more complex cases; if it gets too hairy I just
set exact_dtype=False and nope the fuck out
I don't have time to do it for all the other classes. But the setup
should work if people just incrementally add the overrides to classes,
and then eventually flip the default.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20125791
Pulled By: ezyang
fbshipit-source-id: 389c2d1efbd93172af02f13e38ac5e92fe730c57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33926
The UnboundBuffer calls here are already protected by a mutex. We only
need to hold the lock while writing the shared structures completed_ and
exception_.
ghstack-source-id: 99315427
Test Plan:
CI
CI
Differential Revision: D20154546
fbshipit-source-id: d1b74508c917b21acdcd0f6a914eb0455437ca0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33987
There was an error in
https://github.com/pytorch/pytorch/pull/30724/files that resulted in
`export_chrome_trace` generating invalid JSON. This only came up when the
profiler is run with `use_cuda=True` from what it looks like. In the future, we
should have tests that ensure we generate valid JSON because we no longer use
the json library.
Test Plan: Add UT to validate JSON.
Differential Revision: D20171428
fbshipit-source-id: ec135a154ce33f62b78d98468174dce4cf01fedf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33569
Clang reported a few places where a call to `fmaxType` is ambiguous. In all cases one of the arguments is `double` and another is `float`. Fix the error by creating a proper value 0 and remove the unneeded `ZERO_MACRO` code.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20006926
fbshipit-source-id: ca6cfacd57459b1c48eb5080b822d9509b03544d
Summary: make use of springhill's fma on SpatialBatchnorm
Test Plan:
re-enabled the unit test, ran it a couple of times
pending: net runner
Reviewed By: amylittleyang
Differential Revision: D20227767
fbshipit-source-id: 7c601f185940249c0a32bdf95d74a20552cd2625
Summary:
1. randn and normal_ methods will work for complex tensors after this PR
2. added an internal function for viewing complex tensors as float tensors which enables us to reuse functions defined for float tensors for complex tensors with change in arguments passed(like size, standard deviation in case of normal_). currently the resultant new float tensor doesn't share the storage with the input complex tensor which means that the version counter wouldn't be updated if any function is called on this resultant tensor, but once the dtype entry is removed from the storage class, this issue will be resolved.
Side notes:
1. didn't add a separate header for the util functions because of this issue https://github.com/pytorch/pytorch/issues/20686#issuecomment-593002293
2. we should eventually have a public API method view_complex_as_float once (2) mentioned above gets resolved
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34037
Differential Revision: D20221793
Pulled By: anjali411
fbshipit-source-id: a78f5e83d6104e2f55e0b250c4ec32e8d29a14eb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33182
This adds private API functions that developers of types that implement `__torch_function__` can use to ensure full coverage of the subset of the PyTorch API that can be overrided.
I've refactored some of the code in the tests into a new `torch._overrides.get_overridable_functions` function. I've also changed `TENSOR_LIKE_TORCH_OVERRIDES` into `torch._overrides.get_testing_overrides` and `IGNORED_TORCH_FUNCTIONS` into `torch._overrides.get_ignored_functions`. Making these two static global variables in the tests into functions should allow rewriting their implementation to construct their return values instead of just statically defining the return value as is done here. Currently that is blocked on not being able to inspect function signatures of compiled kernels in PyTorch (see https://github.com/pytorch/pytorch/issues/28233). See the docs I've added for usage examples of these new functions. I also refactored the existing override tests to make use of these new functions, which should be a good forcing function to make sure they're kept up-to-date.
Finally, while working on this I discovered that `TestTorchFunctionOverrides.test_mean` and `TestTorchFunctionOverrides.test_mm` weren't ever being run because they were getting clobbered by the other dynamically generated override tests. I fixed that by renaming the tests and then fixing the actual test code. I've verified that all the subclassing semantics is correct and that the updated test answers are correct. I'm happy to put the fixes to the existing tests in as a separate pull request if that would be easier to review.
ping cpuhrsch since the feature request originally came from them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33791
Differential Revision: D20195053
Pulled By: cpuhrsch
fbshipit-source-id: 1585f4e405f5223932b410eae03a288dc8eb627e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33834
This changes how we report Tracebacks to make them more clear when
there are both serialized and non-serialized ranges. It now looks like:
```
Traceback (most recent call last):
File "foo.py", line 25, in <module>
s2(a, b)
File "/scratch/zdevito/pytorch/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript, serialized code (most recent call last):
File "code/__torch__.py", line 7, in forward
x: Tensor,
y: Tensor) -> Tensor:
return (self).bar(x, y, )
~~~~~~~~~ <--- HERE
def bar(self: __torch__.Moo,
x: Tensor,
File "code/__torch__.py", line 11, in bar
x: Tensor,
y: Tensor) -> Tensor:
_0 = (self).baz(x, y, )
~~~~~~~~~ <--- HERE
_1 = torch.ones([3], dtype=None, layout=None, device=None, pin_memory=None)
return torch.add(_0, _1, alpha=1)
File "code/__torch__.py", line 17, in baz
x: Tensor,
y: Tensor) -> Tensor:
return torch.add(x, y, alpha=1)
~~~~~~~~~ <--- HERE
Traceback of TorchScript, original code (most recent call last):
File "foo.py", line 11, in forward
def forward(self, x, y):
return self.bar(x, y)
~~~~~~~~ <--- HERE
File "foo.py", line 9, in bar
def bar(self, x, y):
return self.baz(x, y) + torch.ones(3)
~~~~~~~~ <--- HERE
File "foo.py", line 7, in baz
def baz(self, x, y):
return x + y
~~~~~ <--- HERE
RuntimeError: The size of tensor a (4) must match the size of tensor b (5) at non-singleton dimension 1
```
It follows Python convension of having the most important information last
and reading from the bottom up.
Changes:
* Moved the error message to the end, to copy Python
* Report original traceback separate from serialized traceback
* Make sure root functions have names in the interpreter trace.
Test Plan: Imported from OSS
Differential Revision: D20126136
Pulled By: zdevito
fbshipit-source-id: fd01f9985e5d74e04c4d064c02e8bc320f4fac13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33901
After this change, the pytest profile looks like:
4.83s call test/test_torch.py::TestTorch::test_fft_ifft_rfft_irfft
4.23s call test/test_torch.py::TestTorch::test_var_dim
4.22s call test/test_torch.py::TestTorch::test_std_dim
4.19s call test/test_torch.py::TestTorch::test_max
4.06s call test/test_torch.py::TestTorch::test_min
3.60s call test/test_torch.py::TestTorchDeviceTypeCPU::test_cdist_norm_batch_cpu
2.62s call test/test_torch.py::TestTorchDeviceTypeCPU::test_pow_cpu
2.60s call test/test_torch.py::TestTorch::test_matmul_small_brute_force_1d_Nd
And the entire CPU-only test suite can be run in 88s on my Intel(R) Xeon(R) CPU
E5-2650 v4 @ 2.20GHz
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20222288
Pulled By: ezyang
fbshipit-source-id: 4224a9117f42566e290ae202881d76f1545cebec
Summary:
Add vectorization to dropout kernels for both reads & writes. Moved the `masked_scale_kernel` implementation to `TensorIterator` to pick up recent autovectorization additions by zasdfgbnm , and wrote a vectorized specialization of the dropout training kernel (along with some fairly conservative dispatch logic).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33879
Differential Revision: D20222853
Pulled By: ngimel
fbshipit-source-id: 711f56ca907fbc792a10d4bf069c28adab7d6ad7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34038
Mobile build doesn't include autograd/VariableType dispatch. As the
result AutoNonVariableTypeMode needs to be set in mobile runtime.
With static dispatch this works is done inside generated jit-dispatch
code - AutoNonVariableTypeMode needs to be set on per-op basis. Setting
it globally or setting it for wrong ops might break some `is_variable()`
checks in the codebase.
Thanks to the unification of Variable class and Tensor class, all
is_variable() checks have been removed, so AutoNonVariableTypeMode can
be set globally now.
We never tested inference-only mobile build with dynamic dispatch. It
seems that dynamic dispatch also requires setting AutoNonVariableTypeMode
for our mobile build (where VariableType functions are not registered).
Verified the end-to-end test works with this change:
```
TEST_CUSTOM_BUILD_DYNAMIC=1 test/mobile/custom_build/build.sh
```
Test Plan: Imported from OSS
Differential Revision: D20193329
Pulled By: ljk53
fbshipit-source-id: cc98414d89d12463dc82b0cdde0b6160dafc0349
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34012
Today some mobile simulator tests only run on landed PRs and it requires
setting up special build environment to repro errors locally.
The goal of the PR is to do end-to-end mobile custom build & integration
tests with host toolchain (using same CMake options as mobile build). This
way, non-mobile engineers can capture & debug mobile related build issues
much more easily.
There are three custom build types that this script supports:
1. `TEST_DEFAULT_BUILD=1 ./build.sh` - it is similar to the prebuilt libtorch
libraries released for Android and iOS (same CMake build options + host
toolchain), which doesn't contain autograd function nor backward ops thus is
smaller than full LibTorch.
2. `TEST_CUSTOM_BUILD_STATIC=1 ./build.sh` - it further optimizes libtorch
size by only including ops used by a specific model.
3. `TEST_CUSTOM_BUILD_DYNAMIC=1 ./build.sh` - similar as 2) except that it
relies on the op dependency graph (instead of static dispatch) to calculate
and keep all transitively dependent ops by the model.
Type 2) will be deprecated by type 3) in the future.
Type 3) custom build has not been fully supported yet so it's expected to fail.
Replacing existing mobile build CI to run Type 1) build & integration test.
Test Plan: Imported from OSS
Differential Revision: D20193328
Pulled By: ljk53
fbshipit-source-id: 48c14cae849fde86e27123f00f9911996c1cf40e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33277
Currently we insert observer in the called graph, which is incorrect since graphs can be shared
and the decision of whether to insert observer or not might dependend on where the graph is called.
For example, for a call sequence `self.conv1(self.conv2(x))`, we can't inserting observer correctly
if `self.conv1` and `self.conv2` are sharing the same type in the current implementation, because we insert
observer in the graph of the forward method of Conv2d right now and this call sequence requires us to insert
only one observer for the output of self.conv1/input of self.conv2.
We'll need to insert observers for input/output values of the graph in call site instead.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20208787
fbshipit-source-id: 739e1d877639c0d0ed24e573bbd36211defa6836
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34105
make parallel_net_test.cc chronos conforming.
exclude gtest asserts that check thrown exceptions when exceptions are disabled.
Test Plan: CI green
Differential Revision: D20153525
fbshipit-source-id: 7371e559da948f46773fed09e3a23a77411d59e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33548
Mostly just moved code.
Index dim and number of indices checks are added to make checks idential to index_add_cpu_
This is a resubmit of #30573, which got reverted.
Test Plan: Imported from OSS
Differential Revision: D20002248
Pulled By: gchanan
fbshipit-source-id: 46df4047cb3fc1dff37a15b83c70b2cbb7a6460b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33819
These conditions are for the specific implementation, the fallback implementation works without these checks. So use that if any of these checks isn't true.
Resubmit of https://github.com/pytorch/pytorch/pull/33419 (which got reverted due to a problem with XLA, but which now has been fixed)
ghstack-source-id: 99333280
Test Plan: Test included
Differential Revision: D20121460
fbshipit-source-id: c1056b8e26751e24078bbe80c7cb4b223bcca7cb
Summary:
The new added mixture_same_family should support cdf if the family has cdf implemented.
This is very useful for flow models where cdf of mixture of gassian/logistic is used to model flow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33408
Differential Revision: D20191552
Pulled By: ezyang
fbshipit-source-id: 0bfd7973aa335c162919398a12ddec7425712297
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33729
ReshapeOp is doing some useless movements of data between CPU and GPU, which results in crazy amount of kernel calls from this operator. Which makes this operator ridiculosly slow compared to BatchMatMul for cases of pretty cheap models (for example on some versions of GAT).
This diff is moving ReshapeOp to leverage CPU storage and reduce amount of kernel calls from num_dims + 3 calls for case of 3-D
tensor to 2 calls.
Test Plan:
Unit-tests are still passing.
TODO: perf testing
Reviewed By: akyrola
Differential Revision: D19659491
fbshipit-source-id: 2341b21e57208b988169f2df5fb598be3dc8acb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34102
if nvcc is invoked with clang host compiler, it will fail with the following error due to the decorators mismatch defined in cuda and c10:
```
error: attribute "noreturn" did not appear on original declaration
```
Test Plan: Build pytorch with clang
Reviewed By: EscapeZero
Differential Revision: D20204951
fbshipit-source-id: ff7cef0db43436e50590cb4bbf1ae7302c1440fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34107
Updates linter to only lint for python3 instead of linting for python2
Test Plan: good_testplan
Reviewed By: orionr
Differential Revision: D20205395
fbshipit-source-id: 1fa34e5fdf15f7aed96a66d2ce824a7337ee6218
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34035
Bug for the conditon check in https://github.com/pytorch/pytorch/pull/24342, realized we don't have tests in either
python or cpp to catch this, so added testes for both python and cpp.
Thanks hczhu on capturing it!
Test Plan: Imported from OSS
Differential Revision: D20198837
Pulled By: wanchaol
fbshipit-source-id: 33846a14c0a8e7aac2e8328189d10c38a0d7e6ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34092
Disable op in transform map until we get bitwise matching to ice-ref
Test Plan: CI
Reviewed By: hyuen
Differential Revision: D20177936
fbshipit-source-id: e316384184cb264852e63e5edce721a8614742d1
Summary:
## What this will do:
When the repository is tagged the current nightly build pipelines will run and upload to the `test` subdirectory in our S3 bucket for `download.pytorch.org`. Will also upload to the correct organization on anaconda [pytorch-nightly](https://anaconda.org/pytorch-test)
This is only meant for release candidates and will actually not run on any tag that does not match the release candidate regex.
This has been tested on a small scale with: 3ebe0ff2f8
## Related PRs:
* `.circleci: Divert packages to test channel on tag`: https://github.com/pytorch/pytorch/pull/33842
* `.cirlceci: Swap PYTORCH_BUILD_VERSION if on tag`: https://github.com/pytorch/pytorch/pull/33326
## Work to be done later:
- [ ] Figure out how to remove manual step of updating s3 html indices.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34078
Differential Revision: D20204104
Pulled By: seemethere
fbshipit-source-id: 685630e8a04b19fc17374585e9228a13a8c3e407
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33513
These tests require gloo so like the other tests, they should be
skipped if not building with gloo. Otherwise they crash on Mac if not built
with gloo currently.
verified that it does not crash anymore with this PR.
ghstack-source-id: 99303707
Test Plan: Built on Mac and verified that the tests do not fail.
Differential Revision: D19976908
fbshipit-source-id: 6a2a70c3eab83efd0e188e86cabe56de4a869f4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33954
fixes caffe2/core/module_test.cc on windows
misc lint fixes.
Test Plan: CI green
Reviewed By: malfet
Differential Revision: D20153512
fbshipit-source-id: aeae84a028e26edd65c7218611e3c49a8d9bb8c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33938
Making sure we don't silently ignore exceptions from the tasks in the
thread pool
Test Plan: python setup.py clean && python setup.py develop install
Differential Revision: D20178603
Pulled By: ilia-cher
fbshipit-source-id: 34971032205a1a53fb7419ed84ebb986f9e959ad
Summary:
In the examples of `BCEWithLogitsLoss`, `0.999` is passed as the prediction value. The value `0.999` seems to be a probability, but actually it's not. I think it's better to pass a value that is greater than 1, not to confuse readers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34053
Differential Revision: D20195456
Pulled By: ezyang
fbshipit-source-id: 3abbda6232ee1ab141d202d0ce1177526ad59c53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33955
unit tests on windows (clang and cl) were crashing on exit due to racing with static variable destruction.
Test Plan: CI green
Differential Revision: D20153587
fbshipit-source-id: 22e35e591660d49f3a755f93d0c14d7a023ebb2a
Summary:
I think this warning isn't true anymore, and the NCCL backend works without PyTorch needing to be built from source.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34051
Differential Revision: D20195310
Pulled By: ezyang
fbshipit-source-id: 14f879a8c43ea5efdbdf0f638792ea2b90011f4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33957
lots of small preprocessor warning cleanup for windows
Test Plan: CI green
Reviewed By: malfet, albanD
Differential Revision: D20153582
fbshipit-source-id: 18fd61c466fd1f55ededdae4448b3009a9cedc04
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33899
In the issue, we have
```
TypeError("expected %s (got %s)", dispatch_key, toString(other.key_set()).c_str());
```
which results in `dispatch_key` being interpreted as a c-string by `sprintf`. Adding `__attrbute__((format))` to the `TypeError` constructor allows gcc or clang to detect this at compile time. Then `-Werror=format` makes it a hard error at compile time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34019
Differential Revision: D20194842
Pulled By: ezyang
fbshipit-source-id: fa4448916c309d91e3d949fa65bb3aa7cca5c6a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33959
make sure clang on windows uses correct attributes.
add support for cl.exe style pragma attributes
Test Plan: CI green
Differential Revision: D20153548
fbshipit-source-id: bfbfd374e8f5e7d7b8598453c3ca2b6693a425f1
Summary:
1. As RRef has been added as a JIT type in https://github.com/pytorch/pytorch/issues/32992, we no longer need to skip them
2. Nightly now knows about Any
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34071
Reviewed By: houseroad
Differential Revision: D20196963
Pulled By: mrshenli
fbshipit-source-id: 1ea79c5682e8be9087b9cb74104e1b914c3fc456
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33958
look for clang intrinsic headers on windows
Test Plan: CI green
Differential Revision: D20153573
fbshipit-source-id: c87da3b0e9950d3df0bf8350df8ae592064d6613
Summary:
This patch enables folding GetAttr nodes with their corresponding
values. _jit_pass_freeze_module API returns a new TorchScipt module
where all function calls and get attributes are inlined.
Usage:
frozen_model = torch._C._freeze_module(scrited_model._c)
frozen_model.forward(...)
This API currently optimizes the forward method. We will follow up to
to preserve and optimize methods and attributes that are annotated as
torch.jit.interface.
Several future improvements to JIT optimizations are required to maximize
clean up/de-sugar the graph and eliminate redundancies.
Ideally, we want to produce a graph that can easily be lowered to
GLOW and other low-level backends.
__
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32178
Differential Revision: D19419640
Pulled By: bzinodev
fbshipit-source-id: 52baffaba9bca2cd60a8e747baa68d57711ad42b
Summary:
Currently if we run
```bash
DEBUG=1 ONNX_ML=0 MAX_JOBS=8 CMAKE_CXX_COMPILER_LAUNCHER=ccache CMAKE_C_COMPILER_LAUNCHER=ccache CMAKE_CUDA_COMPILER_LAUNCHER=ccache USE_OPENMP=0 USE_DISTRIBUTED=0 USE_MKLDNN=0 USE_NCCL=0 USE_CUDA=1 USE_CUDNN=0 USE_STATIC_CUDNN=0 USE_NNPACK=0 USE_QNNPACK=0 USE_FBGEMM=0 BUILD_TEST=0 TORCH_CUDA_ARCH_LIST="6.1" python setup.py develop --cmake-only
```
then `touch build/CMakeCache.txt` (which adjusting build options will
do), then `python setup.py develop`, the following error message will
show up:
```
CMake Error at build/clog-source/CMakeLists.txt:249 (ADD_SUBDIRECTORY):
ADD_SUBDIRECTORY not given a binary directory but the given source
directory "/home/hong/wsrc/pytorch/build/clog-source" is not a subdirectory
of "/home/hong/wsrc/pytorch/build/clog-source". When specifying an
out-of-tree source a binary directory must be explicitly specified.
```
This is due to a conflict between our cpuinfo submodule and XNNPACK's
external clog dependency. Moving our cpuinfo upward and setting
CLOG_SOURCE_DIR resolves the issue.
---
Also reverted https://github.com/pytorch/pytorch/issues/33947 , where `CLOG_SOURCE_DIR` as an option is not quite appropriate (given that cpuinfo uses its included clog subdir) and the setting of this variable should be a bit later when the dir of cpuinfo is known.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33922
Differential Revision: D20193572
Pulled By: ezyang
fbshipit-source-id: 7cdbdc947a6c7e0ef10df33feccb5b20e1b3ba43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33977
Removing python2 from operator_test so we can retire python2 support for PyTorch.
Test Plan: waitforsandcastle
Reviewed By: seemethere
Differential Revision: D20129500
fbshipit-source-id: d4c82e4acfc795be9bec6a162c713e37ffb9f5ff
Summary:
This PR would fix https://github.com/pytorch/pytorch/issues/33345.
The original CUDA kernel looks good. I changed most appearances of `int` to `int64_t` to avoid the CUDA memory access issue. Removed the two `TORCH_CHECK`. Added a unit test.
cc csarofeen ngimel ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33753
Differential Revision: D20185005
Pulled By: ngimel
fbshipit-source-id: ef0abdc12ea680e10fe6b85266e2773c7a272f0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33705
The fact that there were two overloads appears to be a historical
artifact that dates back to when goldsborough originally added these
bindings in the first place. If TensorOptions is made optional,
then you only need one overload, not two, as they are exactly redundant
with each other. When MemoryFormat was added, it was made a little
harder to do this, as the C++ syntax at::empty_like(t, memory_format) would
not work if you collapsed the overload; but now it works because TensorOptions
supports MemoryFormat.
The upshot is, I can get rid of all the overloads and just have one overload.
Amazingly, this change is backwards compatible, as the test attests. While
I was at it, I also deleted the overload name from the functions entirely.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20073355
Pulled By: bhosmer
fbshipit-source-id: c6a8908213b32ccf6737ea864d135e2cce34f56b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33704
This diff adds MemoryFormat field to TensorOptions, and teaches
all kernels that take TensorOptions to respect it, but doesn't
teach the codegen about it. As such, it is now possible to specify
memory_format using TensorOptions syntax, e.g.,
at::empty_like(tensor, at::memory_format(MemoryFormat::Contiguous))
in the C++ API, but there isn't any other user visible effect.
The intended end state of this diff stack is to eliminate the
explicit MemoryFormat? arguments from native functions, but
as this change has BC implications I'd prefer to do it separately.
So this starts things off with a non-BC breaking addition to the
API. For all internal functions that are not bound by codegen,
I switch them to exclusively using TensorOptions (eliminating
MemoryFormat); there's only a few, mostly quantized and to().
To keep things screwed down in the short term, it is a HARD ERROR
to specify both the explicit MemoryFormat argument as well as
TensorOptions. This caught a few errors in my diff where I needed
to modify memory format settings and then call code later, esp
in empty_like.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20073356
Pulled By: bhosmer
fbshipit-source-id: 18d310d7ee7cf2ee182994104652afcfc9d613e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33960
test helper functions should be out of test function. it is possible process 2 launches test functions slower than process 1, and process 1 sends request to run a helper function on process 2. process 2 may have not compile the helper function yet when process 2 starts to serve processs 1's request, and thus may return error like "attempted to get undefined function"
ghstack-source-id: 99205620
Test Plan: test_remote_script_module was flaky for thrift backend in my local stress test runs, due to error "attempted to get undefined function". With fix in this diff, stress runs passed
Differential Revision: D20167969
fbshipit-source-id: 8a2b9cd7bd62462e24bdbcb69ad32dca745d6956
Summary:
HashNode and CompareNode are useful functions for hanlding jit::Node. This is to unblock https://github.com/pytorch/glow/pull/4235.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34045
Reviewed By: houseroad
Differential Revision: D20184733
Pulled By: yinghai
fbshipit-source-id: 6c829f2f111a490fd2d85017475c1731cd97fb20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33992
resubmit of https://github.com/pytorch/pytorch/pull/33369 with tweaks on when the rref type being created to ensure ivalue->type() hold the correct RRef type inside of inner element type.
Test Plan: Imported from OSS
Differential Revision: D20175043
Pulled By: wanchaol
fbshipit-source-id: a08b178e989c995632374e6c868d23c5a85526ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33536
Simple fix, merge the identical string literals that were being inlined into every wrapper for ops that don't support named tensors. E.g.
```
Tensor all(const Tensor & self, int64_t dim, bool keepdim) {
if (self.has_names()) {
AT_ERROR(
"all is not yet supported with named tensors. Please drop names via "
"`tensor = tensor.rename(None)`, call the op with an unnamed tensor, "
"and set names on the result of the operation.");
}
const OptionalDeviceGuard device_guard(device_of(self));
return at::native::all(self, dim, keepdim);
}
```
becomes
```
Tensor all(const Tensor & self, int64_t dim, bool keepdim) {
if (self.has_names()) {
AT_ERROR("all", named_tensors_unsupported_error);
}
const OptionalDeviceGuard device_guard(device_of(self));
return at::native::all(self, dim, keepdim);
}
```
Also updated the generated file comments to include the source template names, e.g.
```
// generated by aten/src/ATen/gen.py from TypeDefault.cpp
```
Test Plan: Imported from OSS
Differential Revision: D19993407
Pulled By: bhosmer
fbshipit-source-id: 88395a649e6ba53191332344123555c217c5eb40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33975
Currently the code analysis script doesn't go beyond the scope of the
registration API call, i.e. calling registration via a wrapper will not
be covered by the analysis - currently the new API is essentially a
wrapper around old API.
Simply adding the new API signature to the registration API pattern can
solve the problem for now. We might need change the analyzer code if
things change significantly in the future.
Test Plan:
- update test project to use the new API;
- run analyzer against pytorch codebase;
Differential Revision: D20169549
Pulled By: ljk53
fbshipit-source-id: c7925fa0486eee18f07e791a38c32152fee59004
Summary:
Mainly renaming pthread_create of C2, the only one referred internally in NNPACK, that
is conflicting, to pthread_create_c2.
Removed 2 other conflicting symbols that are not used internally at all.
Pointing XNNPACK to original repo instead of the fork.
Copy pasted the new interface and implementation to
caff2/utils/threadpool, so that for internal builds we compile against
this.
When threadpool is unified this will be removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33869
Differential Revision: D20140580
Pulled By: kimishpatel
fbshipit-source-id: de70df0af9c7d6bc065e85ede0e1c4dd6a9e6be3
Summary:
This bug has been hit a couple times recently. We need to handle all bivariant types, not just optional, when asserting mutability/immutability of pointed-to elements in alias analysis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33952
Differential Revision: D20166025
Pulled By: eellison
fbshipit-source-id: cf3df9897a639641ef8303a08ba2b13523d01ef1
Summary:
Fixes#30775
This adds TorchScript implementations (copied from `python_variable.cpp`) for the remainin `Tensor` properties that were missing from the jit, in addition to a test that ensures new properties will trigger a failure so we can decide whether we want to add them as well.
For `some_tensor`, adds:
* `some_tensor.T`
* `some_tensor.ndim`
* `some_tensor.is_leaf`
* `some_tensor.name`
](https://our.intern.facebook.com/intern/diff/20153288/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33906
Pulled By: driazati
Differential Revision: D20153288
fbshipit-source-id: 2ddc48a14267077bc176065267e5ce52181b3d6b
Summary:
This adds some machinery so that we use Python to resolve types to a value and the corresponding resolution logic in `annotations.py` instead of using the string.
This PR also `slowTests` a random test since it was taking > 1 min whereas all the other tests take < 10 seconds.
Fixes#31864Fixes#31950
](https://our.intern.facebook.com/intern/diff/20144407/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29623
Pulled By: driazati
Differential Revision: D20144407
fbshipit-source-id: ef3699f6b86039d8b4646ffc42c21bd1132d1681
Summary:
This PR prepares us to allow XLA use `XLAPreAutograd` to override compound ops.
To do this we'll need to pass all ops, with additional infomation about whether it's compound or not for XLA to parse.
Companion PR: https://github.com/pytorch/xla/pull/1698
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33908
Differential Revision: D20149585
Pulled By: ailzhang
fbshipit-source-id: a93140e8a34548fcabcea454386d15df58177c1d
Summary:
With the profiling executor enabled the fuser won't be invoked until the second pass over a script function, so some of these tests weren't correctly comparing the fused output with the interpreter output. I've used the `checkScript` method where applicable, which seems to do the right thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33944
Test Plan: Locally inject obvious errors into the fuser and verify that the updated tests fail when they're supposed to.
Differential Revision: D20162320
Pulled By: bertmaher
fbshipit-source-id: 4a2f3f2d2ff1d81f23db504dc8cd0d5417bdcc50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33559
For sm_60+ CUDA supports `atomicAdd(double*, double*)` function and for lower compute capabilities the CUDA C Programming Guide [1] suggest a user implementation as in this code. On the other side, Clang's CUDA wrappers unconditionally define this function, regardless of compute capability, and merit an error if it actually get's used.
So the problem is: when Clang is used for < sm_60, CUDA's `atomicAdd(double*, double*)` cannot be used and it cannot be redeclared in standard compliant C++.
Workaround the problem by using Clang's `enable_if` attribute [2], which has a side effect of function redeclaration.
1. https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#atomic-functions
2. https://clang.llvm.org/docs/AttributeReference.html#enable-if
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20005113
fbshipit-source-id: d0d4bd6514f201af9cdeba1229bd9b798df0d02e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33556
Fix several places exposed by Clang where order of member initializer list doesn't actually match the actual initialization order. The fix is to simply reorder member initializer lists.
Also accepted formatting changes suggested by clang-format linter.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20004834
fbshipit-source-id: b61c7c3f1fe8413bbb3512f6b62177a3ddf67682
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33947
XNNPACK was downloading clog because we weren't setting CLOG_SOURCE_DIR.
Actually, it was downloading cpuinfo and pointing to the copy of clog
within that. So let's just point to the copy of clog within the cpuinfo
submodule we already have.
(Note: this ignores all push blocking failures!)
Test Plan:
Ran cmake and didn't see any downloading.
Verified that our clog is the same as the one that was being downloaded
with `diff -Naur`.
Differential Revision: D20169656
Pulled By: suo
fbshipit-source-id: ba0f7d1535f702e504fbc4f0102e567f860db94b
Summary:
This PR comes from discussion with albanD in https://fb.quip.com/npBHAXaPfnbu. Main goal is to clarify view ops with general outplace/inplace ops and remind users about the difference.
For reference this information is only available in code which is internal and hard to find. Also changes to this list actually affect users so we think it's better to expose it as public information. It's also helpful for new backend like XLA when implementing PyTorch ops. 19bbb4fccb/tools/autograd/gen_autograd.py (L32-L68)
Please feel free to comment!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32560
Differential Revision: D20161069
Pulled By: ailzhang
fbshipit-source-id: b5f1fd4353fe7594a427784db288aeb5a37dc521
Summary:
This PR move glu to Aten(CPU).
Test script:
```
import torch
import torch.nn.functional as F
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n // 2, device=device)
for i in range(1000):
output = F.glu(input)
output.backward(grad_output)
for n in [10, 100, 1000, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n // 2, device=device)
for i in range(10000):
t1 = _time()
output = F.glu(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test device: **skx-8180.**
Before:
```
input size(128, 10) forward time is 0.04 (ms); backwad avg time is 0.08 (ms).
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.14 (ms).
input size(128, 1000) forward time is 0.11 (ms); backwad avg time is 0.31 (ms).
input size(128, 10000) forward time is 1.52 (ms); backwad avg time is 2.04 (ms).
```
After:
```
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.05 (ms).
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.09 (ms).
input size(128, 1000) forward time is 0.07 (ms); backwad avg time is 0.17 (ms).
input size(128, 10000) forward time is 0.13 (ms); backwad avg time is 1.03 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24707, https://github.com/pytorch/pytorch/issues/24708.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33179
Differential Revision: D19839835
Pulled By: VitalyFedyunin
fbshipit-source-id: e4d3438556a1068da2c4a7e573d6bbf8d2a6e2b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32521
Not all ops support the templated unboxing wrappers yet. For the ones that don't,
let's use the codegen'ed unboxing wrappers from register_aten_ops.cpp, but register
them with c10 directly instead of JIT.
The `use_c10_dispatcher` setting in `native_functions.yaml` now has a new option 'with_codegenerated_unboxing_wrapper' which means we take the codegened unboxing wrapper from register_aten_ops.cpp and stuff it into c10. This new argument is the default, 'unboxed_only' is not the default anymore. For the (very few) ops that don't support boxed dispatch yet (i.e. ops taking TensorOptions arguments), we set them to 'unboxed_only' and they follow the old behavior of having register_aten_ops.cpp register the jit op.
Next steps here are (1) to make TensorOptions work with boxed dispatch and remove the `unboxed_only` option from `use_c10_dispatcher`, so that all ops go through the new path and (2) make the new path template-only and remove codegen from it (see https://github.com/pytorch/pytorch/issues/32366).
First experiments show that
- For a small JITted model that calls add (i.e. a op with just two arguments that are both tensors) on two tensors in a loop, we see a 2-4% performance improvement (~35-50ns) when compared to the old path. This is a simple op that takes two tensor arguments and no non-tensor arguments, so iterating over it in boxed dispatch is cheap.
- For a small JITted model that calls avgpool1d (i.e. an op that has one tensor arg and 5 non-tensor args) on a tensor in a loop, we see a 3-4% performance regression (~60ns) when compared to the old path. This is an op that takes only one tensor argument and then 6 non-tensor arguments. Unboxed dispatch doesn’t have to look at those but boxed dispatch still needs to iterate over them.
This performance difference is likely due to boxed dispatch iterating over all arguments in a loop and unboxed dispatch not having to look at non-tensor arguments.
ghstack-source-id: 99161484
Test Plan: unit tests that call existing ops through JIT
Differential Revision: D18672405
fbshipit-source-id: bf2a7056082dfad61e7e83e9eeff337060eb6944
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33732
move and forward instead of copy
Benchmarks:
A microbenchmark calling the add operation on two tensors in a tight loop shows a 5% improvement in performance.
No visible change for a model like resnet that does more work in its kernels.
ghstack-source-id: 99161486
Test Plan: benchmarks
Differential Revision: D20082642
fbshipit-source-id: eeac59686f8621dd5eaa85d61e6d219bba48c847
Summary:
hard to get right locally...I can build the docs but never quite match what it looks like live. the bullet point indentation was just an oversight.
Removing `Returns:` formatting tabs because they take up a lot of space when rendered and add no clarity. Some functions in Pytorch [do use them](https://pytorch.org/docs/master/torch.html#torch.eye), but [many don't bother](https://pytorch.org/docs/master/torch.html#torch.is_tensor), so apparently some people shared my feelings (Not using them is in line with existing practice).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33832
Differential Revision: D20135581
Pulled By: ngimel
fbshipit-source-id: bc788a7e57b142f95c4fa5baf3fe01f94c45abd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33563
When NVCC or Clang are driving CUDA compilation many math functions are declared by default, with a small difference: Clang marks them as `__device__` only, while NVCC uses both `__host__` and `__device__`. This makes every un-elaborated `min` or `max` function call from a `__host__` function generate a syntax error when Clang is used.
Fix the errors by using `std::min` and `std::max` from `<algorithm>`, since C++14 they are `constexpr` and can be used in the `__device__` code [1].
1. https://llvm.org/docs/CompileCudaWithLLVM.html#algorithm
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20005795
fbshipit-source-id: 98a3f35e8a96c15d3ad3d2066396591f5cca1696
Summary:
- Modified assertEqual to handle complex tensors
- added a test in test_torch.py to test torch.zeros
- added dispatch for complex for index_kernel, index_put_kernel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33773
Differential Revision: D20135553
Pulled By: anjali411
fbshipit-source-id: f716604535c0447ecffa335b0fc843431397c988
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33273
- Move the check for bias to valueNeedsToBeQuantized
- Move TORCH_CHECK inside the functions for checking if a value is bias or weight
Test Plan:
.
Imported from OSS
Differential Revision: D20123595
fbshipit-source-id: 4b805d57dcaf41a6436506d021dd5f6518bc88fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33263
This PR allow PyRRef local creation to inspect the pyobject, if it
founds that we could turn it to an IValue, turn to an IValue first,
otherwise hold it as a PyObjectType
Test Plan:
Imported from OSS
https://fb.quip.com/aGxRAh2lCg05
Differential Revision: D19871243
Pulled By: wanchaol
fbshipit-source-id: ae5be3c52fb1e6db33c64e64ef64bc8b9ea63a9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33576
`throw` statement at the end of `constexpr` is ill-formed according to Clang. It happens when Clang is driving CUDA compilation and compiles for device the effected code. Due to its compilation model it requires host code to be well-formed even when compiling for device.
Fix the error by guarding the entire definition of `type_index_impl` with `__CUDA_ARCH__` check.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: smessmer
Differential Revision: D20008881
fbshipit-source-id: b0dc9abf0dc308b8b8637b54646a0411baf7fef3
Summary:
The way it works on the Anaconda distribution of Python 3.8 is a bit different. Loading DLLs explicitly (e.g. `ctype.CDLL`) relies on paths appended by `os.add_dll_directory`. But if you try to load DLLs implicitly (e.g. `from torch._C import *`), it will rely on `PATH`.
Fixes https://github.com/pytorch/vision/issues/1916.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33856
Differential Revision: D20150080
Pulled By: soumith
fbshipit-source-id: cdbe76c138ea259ef7414c6634d4f7e0b1871af3
Summary:
**Summary**
This commit adds an implementation of `Tensor.tolist()` to the JIT interpreter.
**Testing**
This commit adds several unit tests that test that this function works correctly for
0D, 1D, 2D and 3D tensors of type `float`, `int` and `bool`.
```
(base) meghanl-mbp:pytorch meghanl$ python test/test_jit.py TestList.test_to_list -v
Fail to import hypothesis in common_utils, tests are not derandomized
test_to_list (jit.test_list_dict.TestList)
Unit tests for Tensor.tolist() function. ... ok
----------------------------------------------------------------------
Ran 1 test in 0.329s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33472
Differential Revision: D20109738
Pulled By: SplitInfinity
fbshipit-source-id: a6e3fee5e3201d5e1f0c4ca45048488ae2bf5e33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33806
as title
Test Plan: Imported from OSS
Differential Revision: D20122117
Pulled By: suo
fbshipit-source-id: 209d29ed2c873181140c9fb5cdc305c200ce4008
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33885Fixes: #32835Fixes: #5834
Can not combine with CUDA's implementation as each of them requires individual `std::once_flag` as well as different `forked_autograd_child` functions. CUDA version relays to python module, autograd uses TORCH_CHECK to report error to python and cpp.
Test Plan: Imported from OSS
Differential Revision: D20144024
Pulled By: VitalyFedyunin
fbshipit-source-id: e7cf30568fff5110e9df7fe5b23f18ed992fa17f
Summary:
In *_like functions we call
`globalLegacyTypeDispatch().initForDispatchKeySet(c10::detail::multi_dispatch_key_set(self, options));` -> `dispatchKeyToBackend` and thus this change.
`self` has both `XLAPreAutograd` and `XLATensorId` in key set.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33848
Differential Revision: D20135898
Pulled By: ailzhang
fbshipit-source-id: a8585f39f3fa77b53718f20d3144f4f2f3cb8e53
Summary:
Conda registers a suffixed slash as a new user so it was failing to
upload the anaconda packages.
In the future this should be handled through a single variable that can
be used for both but until then this will have to do.
Bug was introduced in https://github.com/pytorch/pytorch/issues/33842
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33903
Differential Revision: D20148679
Pulled By: seemethere
fbshipit-source-id: 27c95f5d906ce84aa34bf5d76fd6f1ef5df08fb9
Summary:
…/xla this will result in a failure since it is comparing a XLA tensor with a CPU tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33635
Differential Revision: D20043517
Pulled By: ailzhang
fbshipit-source-id: d84038ea675e4d4a9c02e7a8b0924bdb12f40501
Summary:
`.data` calls are unsafe and should not be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33874
Differential Revision: D20141059
Pulled By: izdeby
fbshipit-source-id: 8e11afc74f0cb04f5b18b458068fb813a6d51708
Summary:
**Summary**
There is often a need to create a Tensor when writing IR by hand for JIT
optimisation pass unit tests. The only options for this today are real
Tensor creation functions like `aten::ones`. Any test that uses these functions
must also use the same default arguments as the Python/C++ API, which means
that all of the tests have to be updated when the API is updated. This commit
introduces a new primitive, `prim::MakeTestTensor` with schema `() -> Tensor` that
should be used in unit tests instead of real Tensor creation functions. This new
primitive has no public-facing API, so the maintenance burden is much lower.
**Testing**
This commit updates the alias analysis and DCE tests to use `prim::MakeTestTensor` instead of
`aten::rand`, `aten::ones`, and `aten::zeros`.
```
$ ./bin/test_jit
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = *-*_CUDA:*_MultiCUDA
[==========] Running 75 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 75 tests from JitTest
[ RUN ] JitTest.ADFormulas
[ OK ] JitTest.ADFormulas (82 ms)
[ RUN ] JitTest.Attributes
[ OK ] JitTest.Attributes (0 ms)
...
...
...
[ RUN ] JitTest.LiteInterpreterPrim
[ OK ] JitTest.LiteInterpreterPrim (0 ms)
[ RUN ] JitTest.LiteInterpreterLoadOrigJit
[ OK ] JitTest.LiteInterpreterLoadOrigJit (2 ms)
[----------] 75 tests from JitTest (150 ms total)
[----------] Global test environment tear-down
[==========] 75 tests from 1 test case ran. (150 ms total)
[ PASSED ] 75 tests.
```
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33500.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33595
Differential Revision: D20127441
Pulled By: SplitInfinity
fbshipit-source-id: 56da4f23ac46335227254f606c6481718108f378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33173
How to deal with ops that’s defined for both floating point and quantized Tensor?
Category of ops: the ones that doesn’t require observers, which means the quantization parameters(scale/zero_point) of the output of this op can be inferred from the quantization parameters of inputs.
For example:
avg_pool, max_pool, flatten, transpose, upsample
Another related topic to previous one is how do we deal with things like adaptive_avg_pool2d that does not require to be observed and it works with quantized tensor as well? If we insert quant/dequant for them, even the quant fusion becomes a numerically changing operation because the scale/zero_point for input and output are different.
Proposal
We can swap the operator with dequantize whenever we see it. For example, for pattern
Let’s say aten::general_op is defined for both floating point and quantized
%r = aten::conv(...)
%q = quantize(%r)
%dq = dequantize(%q)
%f = aten::general_op(%dq)
...
We detect that all inputs of aten::general_op is produced by dequantize, we’ll first delete all the dequantize for the inputs and then insert dequantize for each use of the output of the aten::general_op, note that this should work generally for all the case we might encounter.
After transformation we’ll have:
%r = aten::conv(...)
%q = quantize(%r)
%x = aten::general_op(%q)
%f = dequantize(%x)
...
1. Multiple inputs
1. We need to make sure all inputs of the aten::general_op are produced by dequantize before we do this transformation
2. Input used by multiple operators
1. We already did this by inserting dequantize for each use of the value
3. Output used by multiple operators
1. We’ll reuse the code that inserts dequantize(might need some refactor)
Note that current concat does not belong to this category right now since it does not inherit quantization parameters from inputs.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20123590
fbshipit-source-id: de2febe1f37e4079457a23acaeccbc6d9c9e1f8a
Summary:
I've been using pytorch with type hintings, and I found errors that can be easily fixed. So I'm creating this PR to fix type bugs.
I expected below code should be type-checked without any errors.
```python
import torch
from torch.nn import Linear
from torch.autograd import Variable
from torch.optim import AdamW
from torch.utils import hooks
# nn.Module should have training attribute
module = Linear(10, 20)
module.training
# torch should have dtype bfloat16
tensor2 = torch.tensor([1,2,3], dtype=torch.bfloat16)
# torch.Tensor.cuda should accept int or str value
torch.randn(5).cuda(1)
torch.tensor(5).cuda('cuda:0')
# optimizer should have default attribute
module = Linear(10, 20)
print(AdamW(module.weight).default)
# torch.Tensor should have these boolean attributes
torch.tensor([1]).is_sparse
torch.tensor([1]).is_quantized
torch.tensor([1]).is_mkldnn
# Size class should tuple of int
a, b = torch.tensor([[1,2,3]]).size()
# check modules can be accessed
torch.nn.parallel
torch.autograd.profiler
torch.multiprocessing
torch.sparse
torch.onnx
torch.jit
torch.hub
torch.random
torch.distributions
torch.quantization
torch.__config__
torch.__future__
torch.ops
torch.classes
# Variable class's constructor should return Tensor
def fn_to_test_variable(t: torch.Tensor):
return None
v = Variable(torch.tensor(1))
fn_to_test_variable(v)
# check RemovableHandle attributes can be accessed
handle = hooks.RemovableHandle({})
handle.id
handle.next_id
# check torch function hints
torch.is_grad_enabled()
```
But current master branch raises errors. (I checked with pyright)
```
$ pyright test.py
Searching for source files
Found 1 source file
test.py
12:45 - error: 'bfloat16' is not a known member of module
15:21 - error: Argument of type 'Literal[1]' cannot be assigned to parameter 'device' of type 'Optional[device]'
'int' is incompatible with 'device'
Cannot assign to 'None'
16:22 - error: Argument of type 'Literal['cuda:0']' cannot be assigned to parameter 'device' of type 'Optional[device]'
'str' is incompatible with 'device'
Cannot assign to 'None'
23:19 - error: Cannot access member 'is_sparse' for type 'Tensor'
Member 'is_sparse' is unknown
24:19 - error: Cannot access member 'is_quantized' for type 'Tensor'
Member 'is_quantized' is unknown
25:19 - error: Cannot access member 'is_mkldnn' for type 'Tensor'
Member 'is_mkldnn' is unknown
32:7 - error: 'autograd' is not a known member of module
33:7 - error: 'multiprocessing' is not a known member of module
34:7 - error: 'sparse' is not a known member of module
35:7 - error: 'onnx' is not a known member of module
36:7 - error: 'jit' is not a known member of module
37:7 - error: 'hub' is not a known member of module
38:7 - error: 'random' is not a known member of module
39:7 - error: 'distributions' is not a known member of module
40:7 - error: 'quantization' is not a known member of module
41:7 - error: '__config__' is not a known member of module
42:7 - error: '__future__' is not a known member of module
44:7 - error: 'ops' is not a known member of module
45:7 - error: 'classes' is not a known member of module
60:7 - error: 'is_grad_enabled' is not a known member of module
20 errors, 0 warnings
Completed in 1.436sec
```
and below list is not checked as errors, but I think these are errors too.
* `nn.Module.training` is not boolean
* return type of `torch.Tensor.size()` is `Tuple[Unknown]`.
---
related issues.
https://github.com/pytorch/pytorch/issues/23731, https://github.com/pytorch/pytorch/issues/32824, https://github.com/pytorch/pytorch/issues/31753
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33762
Differential Revision: D20118884
Pulled By: albanD
fbshipit-source-id: 41557d66674a11b8e7503a48476d4cdd0f278eab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33603
This function returns ScalarType based on its value. This is helpful
to avoid code generated in aten_op.h has returned Scalars depending on
arg self to determine its type.
Test Plan: Imported from OSS
Differential Revision: D20100218
Pulled By: ezyang
fbshipit-source-id: 337729a7559e6abb3a16b2a563a2b92aa96c7016
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33510
Previously, we would fill in TensorOption with defaults whenever an
item was missing from both the left and right side of the merge. This
is morally incorrect: if we don't have an item on the left or right,
we should keep the entry empty (so the downstream user can apply
the appropriate defaulting rule).
I don't think this caused any bugs, but I noticed this error when
working on a later patch in my diff stack.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20001775
Pulled By: ezyang
fbshipit-source-id: 88139fc268b488cd1834043584a0d73f46c8ecaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33505
This shouldn't change semantics, but it has the benefit of making
torch::empty_like(x, dtype(kFloat)) actually work (previously, this
would just ignore all of the properties from x).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20001776
Pulled By: ezyang
fbshipit-source-id: ba81186d3293abc65da6130b2684d42e9e675208
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32289
This has been fixed upstream as of Python 3.8.2. I think the easiest and least invasive way to ameliorate this is to catch the error condition and print a more informative error asking the user to update their Python version. It might be possible to buffer the data into memory and then read from memory, but that would be an invasive change and might cause memory exhaustion for very large models.
Suggestions for alternate fixes or ways to improve the error message wording are very welcome.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33824
Differential Revision: D20131722
Pulled By: ezyang
fbshipit-source-id: a6e3fbf4bf7f9dcce5772b36f7a622cbf14b5ae4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33610
Our pybind definitions for several RPC functions didn't release GIL
once we were processing stuff in C++.
This PR adds asserts that we release GIL appropriately and adds
py::gil_scoped_release and py::gil_scoped_acquire in the appropriate places.
ghstack-source-id: 99066749
Test Plan: waitforbuildbot
Differential Revision: D20025847
fbshipit-source-id: 57a778cba0336cf87352b07c89bbfb9254c4bdd7
Summary:
Stacked PRs
* **#33578 - [jit] Unify augmented assign handling**
* #32993 - [jit] Fix aug assign for non-tensor attributes
We handle augmented assignments to `Select` and `Var` statements differently, but the actual in place update is the same for both, so this PR factors it out into a method so we don't have 2 code paths doing the same thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33578
Pulled By: driazati
Differential Revision: D20127647
fbshipit-source-id: 94f37acbd2551498de9d2ca09a514508266f7d31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33711Fixed#33480
This makes `dist_autograd.backward` and `dist_optimizer.step` functional by making the user explicitly pass in the `context_id` as opposed to relying on the confusing thread_local context_id.
This diff incorporates these API changes and all places where these functions are called.
More concretely, this code:
```
with dist_autograd.context():
# Forward pass.
dist_autograd.backward([loss.sum()])
dist_optim.step()
```
should now be written as follows:
```
with dist_autograd.context() as context_id:
# Forward pass.
dist_autograd.backward(context_id, [loss.sum()])
dist_optim.step(context_id)
```
Test Plan: Ensuring all existing dist_autograd and dist_optimizer tests pass with the new API. Also added a new test case for input checking.
Differential Revision: D20011710
fbshipit-source-id: 216e12207934a2a79c7223332b97c558d89d4d65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33531
We already insert dequantize for each use of the value, but there might still be cases where we only
see the value is used multiple times after inline. This pass adds the support to replicate dequantize
after inline to ensure output of dequantize is only used by one node, which is necessary to preserve all
quantization patterns like `dequant - conv - quant`
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20123591
fbshipit-source-id: 6edb10a4566538bcf9379d332233f870372b7a63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33779
This should eliminate random warnings and print spew from test_jit.
It also fixes a bug where we weren't properly comparing captured outputs
(!)
Test Plan: Imported from OSS
Differential Revision: D20124224
Pulled By: suo
fbshipit-source-id: 9241d21fdf9470531b0437427b28e325cdf08d3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33369
This PR add RRef type infer rule when we try to infer a type from a
pyobject, this allow script module attributes could contain a rref,
(i.e. List[RRefs] as a module attribute)
Test Plan: Imported from OSS
Differential Revision: D19918320
Pulled By: wanchaol
fbshipit-source-id: e5fd99c0ba5693b22ed48f0c0550b5e1dac89990
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33504
Fix resolution fo functions that are bound onto torch in torch/functional.py. This does not fix compilation of all of those functions, those will be done in follow ups. Does torch.stft as a start.
Fixes#21478
Test Plan: Imported from OSS
Differential Revision: D20014591
Pulled By: eellison
fbshipit-source-id: bb362f1b5479adbb890e72a54111ef716679d127
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29495
This PR adds support for `_modules`, making it so we no longer need to special case support for `nn.Sequential`. I was getting internal errors around the previous approach using `self.define()`, so i am adding this PR as part of the stack.
Fix for https://github.com/pytorch/pytorch/issues/28998
Test Plan: Imported from OSS
Differential Revision: D18412561
Pulled By: eellison
fbshipit-source-id: a8b24ebee39638fccf63b2701f65f8bb0de84faa
Summary:
This sets up PIP_UPLOAD_FOLDER to point to the correct channel for
release candidates as opposed to nightlies.
Removes an old safety check that's not needed anymore for devtoolset3
And provides a nice default for PIP_UPLOAD_FOLDER, which should clear up
confusion on where it's initially set
This is a stepping stone towards the promotable pipeline.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33842
Differential Revision: D20130791
Pulled By: seemethere
fbshipit-source-id: dac94ef46299574c36c08c968dd36faddeae6363
Summary:
port `masked_fill` from TH to ATen with TensorIterator.
single core performance roughly stays the same, single socket performance has **3~16x** boost.
`masked_fill` is missing from https://github.com/pytorch/pytorch/issues/24507
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33330
Differential Revision: D20098812
Pulled By: VitalyFedyunin
fbshipit-source-id: ff20712ffc00cc665550997abcfdfb8916c18e40
Summary:
Print a complete and comprehensive error message with a description of the issue when an op is missing during ONNX export (previously an ambiguous "key not in registry" error was thrown which was not helpful for the user to understand the failure).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33593
Reviewed By: hl475
Differential Revision: D20052213
Pulled By: houseroad
fbshipit-source-id: ae3010a97efdab26effad5e4a418e9cc41f5b04e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33735
This apparently used to create a new storage, but I couldn't find anywhere in the code where this actually happens.
Changing it to an assert to see what happens.
Test Plan: Imported from OSS
Differential Revision: D20084029
Pulled By: gchanan
fbshipit-source-id: e9c4db115a25fc2e17a3b166c1ff5a0e6b56d690
Summary:
Stacked PRs
* **#33578 - [jit] Unify augmented assign handling**
* #32993 - [jit] Fix aug assign for non-tensor attributes
We handle augmented assignments to `Select` and `Var` statements differently, but the actual in place update is the same for both, so this PR factors it out into a method so we don't have 2 code paths doing the same thing.
](https://our.intern.facebook.com/intern/diff/20010383/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33578
Pulled By: driazati
Differential Revision: D20010383
fbshipit-source-id: 52e559ce907e95e5c169ab9d9690d0d235db36f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30426
This PR adds `assert_tensor_equal` and `assert_tensor_not_equal` to `test/cpp/api/support.h`, as better functions for testing whether two tensors are equal / not equal.
Test Plan: Imported from OSS
Differential Revision: D18695900
Pulled By: yf225
fbshipit-source-id: c19b9bc4c4e84d9f444015023649d27618fcbdf5
Summary:
This might lead to silent undefined behaviour (e.g. with out-of-bound indices). This affects `test_multinomial_invalid_probs_cuda` which is now removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32719
Test Plan:
* Build with VERBOSE=1 and manually inspect `less ndebug.build.log | grep 'c++' | grep -v -- -DNDEBUG` (only with nina on Linux)
* CI
Fixes https://github.com/pytorch/pytorch/issues/22745
Differential Revision: D20104340
Pulled By: yf225
fbshipit-source-id: 2ebfd7ddae632258a36316999eeb5c968fb7642c
Summary:
Thanks to pjh5 for continued use of his account to upload binaries but I
think we can start using a bot account now for this.
Just a draft until we can ensure the env variables get injected correctly and the token can actually upload
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33786
Differential Revision: D20122423
Pulled By: seemethere
fbshipit-source-id: 0444584831a40ae730325d258935f6d1b873961b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/23925
This fixes the incorrect gradients returned by `F.grid_sample` at image borders under `"border"` and `"reflection"` padding modes.
At nondifferentiable points, the choice of which gradient to return among its super- or subgradients is rather arbitrary and generally does not affect training. Before this change, however, a bug in the code meant that the gradient returned at the exact borders was not selected from among the super- or subgradients.
The gradient is now set to zero at the borders, which is a defensible choice for both the `"border"` and `"reflection"` padding modes:
* For `"border"` padding, this effectively means that the exact borders of the image are now considered out of bounds, and therefore receive zero gradient.
* For `"reflection"` padding, this effectively treats the exact borders as extrema.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32829
Differential Revision: D20118564
Pulled By: soumith
fbshipit-source-id: ef8571ff585be35ab1b90a922af299f53ab9c095
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33765
quantize and dequantize methods now make use of multiple threads. This makes use of shz0116's recent parallelization of quantize/dequantize routines in FBGEMM.
Fixes:
https://github.com/pytorch/pytorch/issues/32006https://github.com/pytorch/FBGEMM/issues/142
Alternative to https://github.com/pytorch/pytorch/pull/30153
```
#!/usr/bin/env python
import time
import torch
import torch.nn as nn
torch.set_num_threads(4)
# print(torch.__config__.parallel_info())
W = torch.rand(1, 54, 54, 256)
NITER = 1000
s = time.time()
for i in range(NITER):
W_q = torch.quantize_per_tensor(W, scale=1.0, zero_point = 0, dtype=torch.quint8)
time_per_iter = (time.time() - s) / NITER
print('quantize time per iter ms', time_per_iter * 1000)
s = time.time()
for i in range(NITER):
W_deq = W_q.dequantize()
time_per_iter = (time.time() - s) / NITER
print('dequantize time per iter ms', time_per_iter * 1000)
```
### With 1 thread
quantize time per iter ms 0.22633790969848633
dequantize time per iter ms 0.6573665142059326
### With 4 threads
quantize time per iter ms 0.0905618667602539
dequantize time per iter ms 0.19511842727661133
ghstack-source-id: 98935895
Test Plan: python test/test_quantized.py
Reviewed By: jspark1105
Differential Revision: D20098521
fbshipit-source-id: bd8c45761b4651fcd5b20b95759e3868a136c048
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33667
Pass shared_ptr properly according to C++ guidances. Thank kimishpatel for pointing it out.
Test Plan: Imported from OSS
Differential Revision: D20111001
Pulled By: iseeyuan
fbshipit-source-id: 213a0f950a7f3b9199d789dc0155911f6102d77a
Summary:
Also, windows memory failures responsible for the earlier reversion have been fixed.
This PR (initially) contains 2 commits:
* a revert of the revert
* all changes to implement the original Apex scale update heuristic, squashed into a single commit for easier diff review
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33366
Differential Revision: D20099026
Pulled By: ngimel
fbshipit-source-id: 339b9b6bd5134bf055057492cd1eedb7e4461529
Summary:
Fixes an issue with `cdist` backward calculation for large inputs for the euclidean case.
The grid size when launching the kernel exceeded the 2^16 limit for the second dimension, resulting in `RuntimeError: CUDA error: invalid configuration argument`
Code to reproduce:
```
h, w, d = 800, 1216, 12
n = 133
A = torch.randn(n, d).cuda()
B = torch.randn(h, w, d).cuda()
A.requires_grad = True
B.requires_grad = True
B = B.reshape(-1, d).contiguous()
dist = torch.cdist(A, B)
loss = dist.sum()
loss.backward()
```
Thanks to tkerola for the bug report, reproduction and suggesting a solution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31167
Differential Revision: D20035605
Pulled By: ngimel
fbshipit-source-id: ae28ba4b549ee07a8bd937bb1de2438dc24eaa17
Summary:
removed padding and dilation from LPPool2d Doc as the function dose not support padding and dilation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33714
Differential Revision: D20097021
Pulled By: ngimel
fbshipit-source-id: fc1c2d918b32f4b45c7e6e6bd93f018e867a628f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33749
Disable printing of the histogram when dump to make the log cleaner.
Test Plan: CI
Reviewed By: amylittleyang
Differential Revision: D20087735
fbshipit-source-id: 5421cd9d25c340d92f29ce63fed2a58aefef567d
Summary:
Most of the function implementation and test code are translated from the Python version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33652
Differential Revision: D20052211
Pulled By: yf225
fbshipit-source-id: ce6767db54364f91ef4f06674239a12278c2752a
Summary:
The function originally comes from 4279f99847/tensorflow/python/ops/summary_op_util.py (L45-L68)
As its comment says:
```
# In the past, the first argument to summary ops was a tag, which allowed
# arbitrary characters. Now we are changing the first argument to be the node
# name. This has a number of advantages (users of summary ops now can
# take advantage of the tf name scope system) but risks breaking existing
# usage, because a much smaller set of characters are allowed in node names.
# This function replaces all illegal characters with _s, and logs a warning.
# It also strips leading slashes from the name.
```
This function is only for compatibility with TF's operator name restrictions, and is therefore no longer valid in pytorch. By removing it, tensorboard summaries can use more characters in the names.
Before:
After:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33133
Differential Revision: D20089307
Pulled By: ezyang
fbshipit-source-id: 3552646dce1d5fa0bde7470f32d5376e67ec31c6
Summary:
CMake only views the first item of `CC` and `CXX` as executable. So calling `sccache.exe` directly won't work. Using a shim executable resolves this problem.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33745
Differential Revision: D20100397
Pulled By: soumith
fbshipit-source-id: 3a130d30dd548b7c2e726c064e66ae4fccb30c44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32813
We need to separate the step to make the logic more clear
and also to find all the values we want to skip in advance
without the interference of inserted observers
Test Plan:
.
Imported from OSS
Differential Revision: D20087841
fbshipit-source-id: ec3654ca561c0d4e2c05011988bb9ecc8671c5c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33225
This removes a redundant assert statement in `record_function_ops`. In
the else branch in question, we are guaranteed to have `current == &rec`, so
this assert will never fire.
Although, maybe we should add an assert failure when `current == &rec` since it
seems that `current` should always be profiler::record_function_exit.
ghstack-source-id: 98852219
Test Plan: Existing autograd profiler UTs past
Differential Revision: D19849145
fbshipit-source-id: 2014a0d3b9d11e5b64942a54e0fb45e21f46cfa2
Summary:
**Summary**
This commit adds a script that fetches a platform-appropriate `clang-format` binary
from S3 for use during PyTorch development. The goal is for everyone to use the exact
same `clang-format` binary so that there are no formatting conflicts.
**Testing**
Ran the script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33644
Differential Revision: D20076598
Pulled By: SplitInfinity
fbshipit-source-id: cd837076fd30e9c7a8280665c0d652a33b559047
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33431
Some elementwise operators don't have shape and type inference specified for the output tensor: `BitwiseOr`, `BitwiseAnd`, `BitwiseXor`, `Not`, `Sign`.
This change fixes this issue:
- For `Not` and `Sign` operators, the output has the same type and shape as the input, so `IdenticalTypeAndShapeOfInput` function is used to specify that.
- For bitwise operators created by `CAFFE2_SCHEMA_FOR_BINARY_BITWISE_OP` macro, the type and shape inference rules should be the same as for other binary element-wise operators, so `TensorInferenceFunction(ElementwiseOpShapeInference)` is used to specify that.
Also some tests were modified to ensure that the shape and type are inferred (`ensure_outputs_are_inferred` parameter)
Test Plan:
```
CAFFE2_ASSERT_SHAPEINFERENCE=1 buck test caffe2/caffe2/python/operator_test:elementwise_ops_test
CAFFE2_ASSERT_SHAPEINFERENCE=1 buck test caffe2/caffe2/python/operator_test:math_ops_test
```
Note that the tests have to be executed with `CAFFE2_ASSERT_SHAPEINFERENCE=1` in order to fail upon shape inference failure.
Reviewed By: idning
Differential Revision: D19880164
fbshipit-source-id: 5d7902e045d79e5669e5e98dfb13a39711294939
Summary:
Resolve https://github.com/pytorch/pytorch/issues/33699
`torch/__init__.pyi` will be generated like
```python
# TODO: One downside of doing it this way, is direct use of
# torch.tensor.Tensor doesn't get type annotations. Nobody
# should really do that, so maybe this is not so bad.
class Tensor:
requires_grad: _bool = ...
grad: Optional[Tensor] = ...
# some methods here...
overload
def bernoulli_(self, p: _float=0.5, *, generator: Generator=None) -> Tensor: ...
def bfloat16(self) -> Tensor: ...
def bincount(self, weights: Optional[Tensor]=None, minlength: _int=0) -> Tensor: ...
# some methods here...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33747
Differential Revision: D20090316
Pulled By: ngimel
fbshipit-source-id: b9ce4c0d4ef720c94ccac0a0342a012e8cf3af0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33696
This changes two tests:
- The batchnorm inference cannot change the memory format of the weights as they are 1D. So this is removed.
- The batchnorm test now run both in affine and not affine mode.
- I added back the test for type errors using .data. In particular, `.data` allows to change the type of a Tensor inplace (very bad, never do it!) but since it is possible, we should test it until .data is removed.
cc Enealor who did the first version of the PR.
Test Plan: Imported from OSS
Differential Revision: D20069241
Pulled By: albanD
fbshipit-source-id: a0348f40c44df38d654fb2a2b2b526d9d42f598a
Summary:
The following script reproduces the hang
```py
import multiprocessing, logging
logger = multiprocessing.log_to_stderr()
logger.setLevel(multiprocessing.SUBDEBUG)
import torch
class Dataset:
def __len__(self):
return 23425
def __getitem__(self, idx):
return torch.randn(3, 128, 128), idx % 100
ds = Dataset()
trdl = torch.utils.data.DataLoader(ds, batch_size=64, num_workers=300, pin_memory=True, shuffle=True)
for e in range(1000):
for ii, (x, y) in enumerate(trdl):
print(f'tr {e: 5d} {ii: 5d} avg y={y.mean(dtype=torch.double).item()}')
if ii % 2 == 0:
print("="*200 + "BEFORE ERROR" + "="*200)
1/0
```
The process will hang at joining the putting thread of `data_queue` in **main process**. The root cause is that too many things are put in the queue from the **worker processes**, and the `put` at 062ac6b472/torch/utils/data/dataloader.py (L928) is blocked at background thread. The `pin_memory_thread` exits from the set `pin_memory_thread_done_event`, without getting the `(None, None)`. Hence, the main process needs the same treatment as the workers did at
062ac6b472/torch/utils/data/_utils/worker.py (L198) .
After the patch, the script finishes correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33721
Differential Revision: D20089209
Pulled By: ezyang
fbshipit-source-id: e73fbfdd7631afe1ce5e1edd05dbdeb7b85ba961
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33419
These conditions are for the specific implementation, the fallback implementation works without these checks. So use that if any of these checks isn't true.
ghstack-source-id: 98836075
Test Plan: Previously got error for special case where k=0 which has gone. The error was in some complicated autograd, and I'm not sure how and where an simple regression test should be added.
Differential Revision: D19941103
fbshipit-source-id: e1c85d1e75744b1c51ad9b71c7b3211af3c5bcc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33727
Some small changes to adagrad (tiny bit faster, though there is more interesting diff in the stack on this).
Test Plan: Part of the stack
Reviewed By: chocjy
Differential Revision: D20029499
fbshipit-source-id: 7f4fddb9288d7881ef54673b17a0e19ef10d64c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33537
Cases of embeddings smaller than 128, we can get a bit more compute by
allocating less threads per block.
Test Plan: Unit-test, benchmark.
Reviewed By: xianjiec
Differential Revision: D19969594
fbshipit-source-id: 6cc6b14fc61302804bed9093ea3591f21e3827d8
Summary:
This PR adds the following items:
- **1st item**: `ArrayRef<TensorIndex>` and `std::initializer_list<TensorIndex>` overloads for `Tensor::index` and `Tensor::index_put_`, to be used specifically for multi-dim indexing purpose.
Design rationale:
* C++ `Tensor::index` and `Tensor::index_put_` are both existing tensor APIs, and they currently (before this PR) only accept a list of tensors (i.e. `ArrayRef<Tensor>`) as indices. If we change their signatures to also accept non-tensors as indices (i.e. `ArrayRef<TensorIndex>`, and `TensorIndex` is convertible from `Tensor` / `Slice` / `None` / `Ellipsis`), it would slow down the original code path (since now it has to go through more steps), which is undesirable.
To get around this problem, the proposed solution is to keep the original `ArrayRef<Tensor>` overload, and add `ArrayRef<TensorIndex>` and `std::initializer_list<TensorIndex>` overloads to `Tensor::index` and `Tensor::index_put_`. This way, the original code path won’t be affected, and the tensor multi-dim indexing API is only used when the user explicitly pass an `ArrayRef<TensorIndex>` or a braced-init-list of `TensorIndex`-convertible types to `Tensor::index` and `Tensor::index_put_` .
Note that the above proposed solution would still affect perf for the user’s original `Tensor::index` or `Tensor::index_put_` call sites that use a braced-init-list of tensors as input, e.g. `tensor.index({...})` or `tensor.index_put_({...}, value)`, since now such function calls would take the multi-dim indexing path instead of the original advanced indexing path. However, there are only two instances of this in our codebase (one in ATen cpp test, one in a C++ API nn init function), and they can be easily changed to explicitly use `ArrayRef<Tensor>` as input (I changed them in this PR). For external user’s code, since this is part of the C++ frontend which is still considered experimental, we will only talk about this change in the release note, and ask users to switch to using `ArrayRef<Tensor>` explicitly if they want to keep using the original advanced indexing code path.
- **2nd item**: Mechanisms for parsing `ArrayRef<TensorIndex>` indices and performing indexing operations (mirroring the functions in `torch/csrc/autograd/python_variable_indexing.cpp`).
- **3rd item**: Simple tests to demonstrate that the `Tensor::index()` and `Tensor::index_put_()` APIs work. I will add more tests after the first few PRs are reviewed.
- **4th item**: Merge Python/C++ indexing code paths, for code simplicity. I tested locally and found that there is no perf regression resulting from the merge. I will get more concrete numbers for common use cases when we settle on the overall design.
This PR supersedes https://github.com/pytorch/pytorch/pull/30425.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32841
Differential Revision: D19919692
Pulled By: yf225
fbshipit-source-id: 7467e64f97fc0e407624809dd183c95ea16b1482
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33722
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding native implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Test Plan:
Build: CI
Functionality: Not exposed
Reviewed By: dreiss
Differential Revision: D20069796
Pulled By: AshkanAliabadi
fbshipit-source-id: d46c1c91d4bea91979ea5bd46971ced5417d309c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32812
We'll error out for the case we can't handle inside the function,
instead of checking each time in the callsite
Test Plan:
.
Imported from OSS
Differential Revision: D20087846
fbshipit-source-id: ae6d33a94adf29c4df86d67783e7ef8753c91f90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32891
- Add JitDistAutoGradTest into fork/spawn test launcher
- Add JitRpcTest into fork/spawn test launcher
ghstack-source-id: 98900090
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_spawn
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_spawn
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork_thrift
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_spawn
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_spawn_thrift
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_fork_thrift
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_spawn
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_spawn_thrift
```
Differential Revision: D5785394
fbshipit-source-id: 335a85424d22f1a83874be81a8139499c9a68ce2
Summary:
This PR improves performance of EmbeddingBag on cuda by removing 5 kernel launches (2 of those are synchronizing memcopies).
- 2 memcopies are checking values of offsets[0] and offsets[-1] to be in expected range (0 for the former, less than number of indices for the latter). It seems strange to check only those 2 values, if users are providing invalid offsets, invalid values can be anywhere in the array, not only the first and last element. After this PR, the checks are skipped on cuda, the first value is forced to 0, if the last value is larger than expected, cuda kernel will assert. It is less nice than ValueError, but then again, the kernel could have asserted if other offset values were invalid. On the cpu, the checks are moved inside the cpu implementation from functional.py, and will throw RuntimeError instead of ValueError.
- 3 or 4 initializations (depending on the mode) of the output tensors with .zeros() are unnecessary, because every element of those tensors is written to, so their data can be uninitialized on the start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33589
Reviewed By: jianyuh
Differential Revision: D20078011
Pulled By: ngimel
fbshipit-source-id: 2fb2e2080313af64adc5cf1b9fc6ffbdc6efaf16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33359
Updated alias analysis kind to FROM_SCHEMA so input tensors can be marked as nonmutable
when appropriate, allowing for constant folding of these tensors.
Needed to update the schemas of the _out variants with annotations to mark the output input
tensor as aliased and mutable.
Test Plan:
```
import torch
class M(torch.nn.Module):
def __init__(self):
super(M, self).__init__()
def forward(self, x):
w = torch.tensor([3], dtype=torch.float)
w = torch.quantize_per_tensor(w, 1.0, 0, torch.qint8)
y = torch.tensor([3], dtype=torch.float)
y = torch.quantize_per_tensor(w, 1.0, 0, torch.qint8)
return torch.ops.quantized.add_out(x, w, y)
m = torch.jit.script(M())
torch._C._jit_pass_constant_propagation(m.graph)
print(m.graph)
```
```
graph(%self : __torch__.___torch_mangle_9.M,
%x.1 : Tensor):
%11 : int = prim::Constant[value=12]() # <ipython-input-11-1dd94c30cb58>:9:49
%9 : float = prim::Constant[value=1.]() # <ipython-input-11-1dd94c30cb58>:9:41
%10 : int = prim::Constant[value=0]() # <ipython-input-11-1dd94c30cb58>:9:46
%36 : QInt8(1) = prim::Constant[value={3}]()
%y.2 : Tensor = aten::quantize_per_tensor(%36, %9, %10, %11) # <ipython-input-11-1dd94c30cb58>:11:12
%24 : Tensor = quantized::add_out(%x.1, %36, %y.2) # <ipython-input-11-1dd94c30cb58>:12:15
return (%24)
```
As expected, the aten::quantize_per_tensor() for w is now folded. The aten::quantize_per_tensor()
for y is not folded, since that tensor is aliased/modified.
Differential Revision: D19910667
fbshipit-source-id: 127071909573151dc664500d363399e3643441b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32809
This is a refactor to help further changes to quantization.cpp
We want some operations on the graph happen before we call insertObserver for invoked methods,
especially `addIntermediateValuesToSkipObserver` since we want to skip the input of the ReLU
module in `Conv - ReLU` pattern.
Test Plan:
test_jit.py
test_quantization.py
Imported from OSS
Differential Revision: D20087844
fbshipit-source-id: 28b7fa0c7ce9e254ab9208eb344893fb705e14d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33464
I added a python-exposed knob to register this pass in custom passes pipeline. If the knob is not used, the pass is not registered and thus not run at all.
Differential Revision: D19958217
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: fecdd98567fcda069fbdf8995c796899a3dbfa5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33682
Previously, there were two API's for CPU and CUDA. This change keeps one top level API, i.e `fake_quantize_per_tensor_affine` and `fake_quantize_per_channel_affine` and uses the device type to dispatch to different backends (CPU and CUDA).
CPU kernel implementation is in QuantizedOpKernels.cpp
CUDA kernel implementation is in fake_quantize_core.cu
Test Plan:
python test/test_fake_quant.py
Benchmark Results for CPU
FakeQuantize tensor of size (2, 256, 128, 128)
Before:
per tensor quant ms 9.905877113342285
per channel quant ms 74.93825674057007
After:
per tensor quant ms 6.028120517730713
per channel quant ms 44.91588592529297
Imported from OSS
Differential Revision: D20072656
fbshipit-source-id: 0424f763775f88b93380a452e3d6dd0c90cb814b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32379
Folding Conv2d - BatchNorm2d modules means recalculate the weight and bias of Conv2d module by incorproating the parameters
of BatchNorm2d, and also change the method calls to calling only forward of Conv2d module, this involves change of both module
types and graph because the bias of Conv2d is a parameter when it has value and is an attribute when it is
None(since JIT code has assumption of prameter being Tensor in multiple places), therefore
we'll need to remove the bias attribute when it is None and add a bias attribute later. Since ClassType might be shared, we separate
remove and add in separate steps and also keep track of the processed graph to avoid modifying the graph and type multiple times.
However we'll have to record the slot index of bias as well so we can replay the slot removal on other instances of Conv2d module.
Test Plan:
tbd
Imported from OSS
Differential Revision: D20078719
fbshipit-source-id: cee5cf3764f3e0c0a4a2a167b78dbada2e3835cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33695
I'm not sure how this stuck around, but it has no effect.
Test Plan: Imported from OSS
Differential Revision: D20068867
Pulled By: gchanan
fbshipit-source-id: 79191338a8bc7a195e2b7265005ca6f00aab3818
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33626
For DDP we require the attributes to be registered as buffers. By doing this the value is broadcast from one device to the rest.
Test Plan:
Tested on actual model on GPU
Imported from OSS
Differential Revision: D20038839
fbshipit-source-id: 82e829fc3baca0b3262c3894a283c375eb08a4a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33205
A number of important use-cases are implemented:
- def(schema): defines a schema, with no implementation (alias
inferred from schema, by default)
- def(schema, fn_ptr): registers fn_ptr as a catch-all kernel
for the operation
- def(schema, lambda): registers lambda as a catch-all kernel
for the operation
- def(schema, torch::dispatch(dispatch_key, fn)), and
def(schema, torch::dispatch(device_type, fn)): registers
the function to only be executed when dispatch_key/device_type
is selected for use
- def(schema, TORCH_OPTIMIZED_FN(fn)): registers the function
as unboxed only, using the inline syntax
All of our code generated registrations in ATen are switched to
the new API.
Some aspects of the API which are not fully implemented:
- It's still not valid to omit the schema when registering a function
pointer, due to #32549
- Although it's possible to take advantage of top-level namespaces
ala torch::import("aten"), we don't use it because this results
in worse code (as we have to cat everything back together). This
is not an essential problem, we just need the internals to be less
stupid.
There are some aspects of the API which don't semantically make sense,
but I chose not to fix them in this PR:
- For some reason, TORCH_OPTIMIZED_FN uses the *runtime* wrapper to
do wrapping, rather than the compile time one which inlines the
function in. This means that there isn't any reason we should be
passing in the function pointer as a template argument; a regular
old argument ought to have worked fine. This is seemingly
consistent with the current API though; needs further investigation.
- There's no reason to optional<DispatchKey>, DispatchKey would
work just fine (use DispatchKey::Undefined for the nullopt case)
In the long term, we should swap the wrapper around: the new-style
API has the real implementation, and the old-style API is backwards
compatibility. However, this implies a lot of internal refactoring,
so I decided to short circuit around it to get this in faster
Ancillary changes:
- I stopped moving optional<DispatchKey>, it's literally just two
words, pass it by value please.
- Needed to add a & qualified version of RegisterOps::op, since
I'm storing RegisterOps as a member inside the new style
Namespace and I cannot conveniently get a rvalue reference
to it in that situation. (BTW, register_ = std::move(register_)
really doesn't work, don't try it!)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19856626
Pulled By: ezyang
fbshipit-source-id: 104de24b33fdfdde9447c104853479b305cbca9a
Summary: Used by segmentation model.
Test Plan: Ran segmentation model on mobile.
Reviewed By: iseeyuan
Differential Revision: D19881378
fbshipit-source-id: 87f00058050fd173fbff1e88987ce09007622b83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32959
in rpc torch script call path, we need to pickle/unpickle rref, this diff is added to make jit pickler/unpickler be able to pickle/unpickle rref. It is similar to what is implemented for PyRef::pickle() and PyRef::unpickle().
The pickling/unpickling design assumes it is always coupled with RPC calls. It is not needed to checkpoint a model with rref, before checkpointing the model, user should call ref.to_here() to get value inside rref.
The pickling process is:
1. push torch.distributed.rpc.rref global string
1. call rref.fork() and create rrefForkData, which is a few IDs and type str of the value held inside the rref, the IDs includes rref id, fork id, caller work id, callee work id, owner work id
2. push the rrefForkData
The unpickling process is:
1. read torch.distributed.rpc.rref global string, and retrieve the cached global lamda function
2. the globa lamda function will get rrefForkData
3. if callee is also owner work id, then get owner rref based on Ids inside rrefFork data and return the ownerRRef
4. if callee is not owner work id, then create user rref using the rrefForkData and return the userRRef
5. meanwhile owner rref will be notified and do reference counting correctly
During unpickling, a type_resolver is needed to parse type str. This type_resolver has python dependency, so we get it from rpc_agent, and pass it to unpickler during construction. So we added a type_resolver argumenmt to jit unpickler constructor in this diff.
ghstack-source-id: 98814793
Test Plan: unit test
Differential Revision: D19713293
fbshipit-source-id: 4fd776cdd4ce8f457c4034d79acdfb4cd095c52e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33570
In this PR, we are a bit more careful about avoiding zero-ing the output. Analysis as follows:
1) `mm` doesn't need zero_ because it never calls scal, which is the underlying problem.
2) for `mv`, which does call scal (in certain cases), we can just move the zeroing to where it would actually be a problem, namely when the scalar value is 0.
In this case we just run the non-BLAS version of the code.
Test Plan: Imported from OSS
Differential Revision: D20007665
Pulled By: gchanan
fbshipit-source-id: 1f3a56954501aa9b2940d2f4b35095b2f60089a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31666
List of changes:
1) Fix a case where torch.mv was not handling NaNs correctly. In particular, with a transposed tensor and expanded vector, NaNs in the output are kept, even if beta = 0.
This is handled in the `out=` case by zero-ing out the passed-in Tensor, but this can happen just the same with the non-out variant if the allocated tensor happens to have a NaN.
Also adds tests for this case.
NOTE: we zero out the output tensor in all cases for mv and mm, even though this is probably overkill. I didn't find another case where this would be a problem, but the old code at least
attempted to do this for all mv and mm calls and I didn't add comprehensive testing to be sure that it's not a problem.
2) on CPU: move mv, mv_out, mm, mm_out to be direct wrappers on _th_addmv, _th_addmm, rather than having their own wrappers in Declarations.cwrap.
Ths is to remove the magic around cpu_zero from the codegen, which simplifies the codegen and makes testing this easier.
Test Plan: Imported from OSS
Differential Revision: D19239953
Pulled By: gchanan
fbshipit-source-id: 27d0748d215ad46d17a8684696d88f4cfd8a917e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33645
Fix bug where we were trying to get a schema for prim::Constant, which is not registered as an operator.
ghstack-source-id: 98785729
Test Plan: buck test mode/dev //pytext/models/test:scripted_seq2seq_generator_test -- 'test_generator \(pytext\.models\.test\.scripted_seq2seq_generator_test\.ScriptedSeq2SeqGeneratorTest\)'
Differential Revision: D20050833
fbshipit-source-id: cc38510b0135b750fdf57fb9c1e66ce1d91ee128
Summary:
The current logic for vectorized/unrolled operations in CUDALoops.cuh applies bounds checking to loads and stores, [but not to the actual functor's execution](16d6c17845/aten/src/ATen/native/cuda/CUDALoops.cuh (L264)). In other words, for a block acting on the tail of a tensor that doesn't require the whole block to participate in memory transactions, many threads execute their functor on uninitialized data. For functors that only communicate with the outside world via the bounds-checked loads and stores, that's ok. The threads acting on garbage data never actually write their results. But [my proposed inf/nan checking kernel](https://github.com/pytorch/pytorch/pull/33366/files#diff-9701a2b34900195d160bdc234e001b79R70-R79) has the additional side effect of writing to a `found_inf` flag in global memory. For irregularly-shaped tensors where tail threads execute the functor on garbage data, these threads would sometimes see and report spurious infs/nans.
In general, we can't guarantee functors won't have side effects. For safety (and efficiency) we should apply bounds checking to the functor execution as well as the loads and stores.
Is it possible that other elementwise kernels (in addition to the strided/vectorized implementation) are also executing functors unconditionally? That would cause similar failures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33642
Differential Revision: D20062985
Pulled By: ngimel
fbshipit-source-id: 65b8d75a001ce57865ed1c0cf89105d33f3f4dd4
Summary:
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding **native** implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Reviewed By: dreiss
Differential Revision: D19521853
Pulled By: AshkanAliabadi
fbshipit-source-id: 99a1fab31d0ece64961df074003bb852c36acaaa
Summary:
Removes almost every usage of `.data` in test_torch to address part of https://github.com/pytorch/pytorch/issues/33629.
Lines 4706-4710 had to be refactored to allow this. The changed test is fundamentally the same, as it appears to be meant to confirm that using an input of a different type than the weight causes an appropriate error.
There is one remaining usage of `.data`, and it is on line 5132. This was left as the `set_` and `resize_` methods still mention `.data` explicitly. I figure the right time to remove this is when those methods have their runtime errors updated.
Note: ~~some tests are skipped locally, and so I am still verifying that nothing has been obviously broken.~~ Appears to be passing early tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33638
Differential Revision: D20062288
Pulled By: albanD
fbshipit-source-id: 672a6d7a20007baedb114a20bf1ddcf6c4c0a16a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33666
it's caused by a revert. So let's skip it.
Test Plan: ci
Reviewed By: hl475
Differential Revision: D20057382
fbshipit-source-id: d71af8efe68b31befcef5dddc372540e8a8ae2ac
Summary:
The same header `<torch/nn/functional/conv.h>` is included twice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33656
Differential Revision: D20056913
Pulled By: yf225
fbshipit-source-id: b1563035c9821731b99c26eec130ff0b9cc627a7
Summary:
Addresses https://github.com/pytorch/pytorch/issues/33300.
Calling .numpy() on a CUDA or non-strided (e.g. sparse) tensor segfaults in current PyTorch. This fixes the segfaults and throws the appropriate TypeError, as was intended.
Two tests, one in test_cuda.py and the other in test_sparse.py, are added to verify the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33612
Differential Revision: D20038210
Pulled By: mruberry
fbshipit-source-id: 265531dacd37c392232fd3ec763489a62ef54795
Summary: Skip the test to unblock dper fbpkg push
Test Plan: buck test //caffe2/caffe2:caffe2_test_cpu -- 'DBSeekTest\.RocksDB' --run-disabled
Reviewed By: cheshen1
Differential Revision: D20043418
fbshipit-source-id: 05ceb2cea08722a671fa211d73680fd4b78f354c
Summary:
this adds enough infrastructure to run bailout checks in `checkScript`. I'll need to figure out the best way to enable it for nightly builds now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32802
Differential Revision: D19974718
Pulled By: Krovatkin
fbshipit-source-id: 40485503f6d3ae14edcce98e1eec1f0559f3ad08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33632
* `inline_container.h` was unnecessarily exposing all includers to caffe2 headers via `caffe2/core/logging.h`
* Add msvc version of hiding unused warnings.
* Make sure clang on windows does not use msvc pragmas.
* Don't redefine math macro.
Test Plan: CI green
Differential Revision: D20017046
fbshipit-source-id: 230a9743eb88aee08d0a4833680ec2f01b7ab1e9
Summary: The first run of the net is noisy sometimes - just run it twice.
Reviewed By: cheshen1
Differential Revision: D20039274
fbshipit-source-id: 639e65646bf52f3efe1ecd4bbcd0e413d9389b29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33529
Current version goes through GPU -> CPU -> GPU copy and is pretty slow: ~19 ms
for 1M elements with 20 possible buckets based on benchmark.
This new version is ~0.2 on the same
Test Plan: benchmark + unit-test
Reviewed By: chocjy
Differential Revision: D19969518
fbshipit-source-id: 51889bc9a232b6d45d9533e53b7b7f4531da481f
Summary:
The detection of the env variable ONNX_ML has been properly handled in tools/setup_helpers/cmake.py,
line 242.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33424
Differential Revision: D20043991
Pulled By: ezyang
fbshipit-source-id: 91d1d49a5a12f719e67d9507cc203c8a40992f03
Summary:
…have different argument types"
This reverts commit 05fb160048b71c1b8b00d2083a08618318158c1a.
Please go to https://github.com/pytorch/pytorch/pull/33558 and check the CUDA9 on CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33553
Differential Revision: D20017575
Pulled By: ngimel
fbshipit-source-id: a5fd78eea00c7b0925ab21fd90a7daeb66725f1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33097
Previously, we had to specify full types because the functions we registering
might be overloaded, and the type was necessary to resolve the ambiguity. I
disambiguate all of these names by mangling the names of the methods we
place on CPUType/CUDAType/TypeDefault with the overload name (these are
*internal* wrappers which are not user visible), and then can strip
the generation of full function types from the registration.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19837898
Pulled By: ezyang
fbshipit-source-id: 5f557184f6ec84cb0613d4eb2e33b83fd1712090
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33093
In #30187 the aliasAnalysis field on operator registration was updated
so that alias analysis could be specified in only some registration call
sites, rather than requiring it be consistently specified in all call
sites. With this change, we can eliminate the requirement that all
registrations specify aliasAnalysis; as long as we know *one* site
specifies the correct aliasAnalysis, we don't have to specify it
any of the other sites.
In this patch, the "one site" is TypeDefault.cpp (previously we only
generated these stub declarations for manually registered functions,
but now we generate the stubs for everything). Then I delete aliasAnalysis
anywhere we register an op for an existing function (which is a lot
of places).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19837897
Pulled By: ezyang
fbshipit-source-id: 26a7fbc809ec1553da89ea5c0361f3e81526d4c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33216
All tensor expressions belong to a kernel arena and are freed when the
arena is destroyed. Until it is destroyed, all expressions stay valid.
Test Plan: Imported from OSS
Differential Revision: D19848382
Pulled By: ZolotukhinM
fbshipit-source-id: a581ea2b635b9ba2cc53949616a13d8d3a47caae
Summary:
This pull request has changes for:
1. Enabling a torch module with HIP code to be compiled by cpp_extensions.py
2. Fixes for hipify module to be able to be used by a torch extension
cc: ezyang iotamudelta jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32669
Differential Revision: D20033893
Pulled By: zou3519
fbshipit-source-id: fd6ddc8cdcd3930f41008636bb2bc9dd26cdb008
Summary:
this is a follow up PR to https://github.com/pytorch/pytorch/issues/33602:
torch/nn/utils/rnn.html:
`pack_padded_sequence` has a confusing and incomplete description of the `enforce_sorted` param. Currently it goes:
```
enforce_sorted (bool, optional): if ``True``, the input is expected to
contain sequences sorted by length in a decreasing order. If
``False``, this condition is not checked. Default: ``True``.
```
The second part "this condition is not checked" (1) makes no sense since the alluded to condition is not described and (2) it's incomplete as it doesn't reflect the important part, that it actually does the sorting. I think it should say something like:
```
enforce_sorted (bool, optional): if ``True``, the input is expected to
contain sequences sorted by length in a decreasing order. If
``False``, the input will get sorted unconditionally. Default: ``True``.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33617
Differential Revision: D20035131
Pulled By: albanD
fbshipit-source-id: 654382eb0cb62b5abc78497faa5b4bca42db5fda
Summary:
This adds `__torch_function__` support for all functions in `torch.functional` and `torch.nn.functional`.
The changes to C++ code and codegen scripts are to facilitate adding `__torch_function__` support for the native functions in `torch._C._nn`. Note that I moved the `handle_torch_function` C++ function to a header that both `python_torch_functions.cpp` and `python_nn_functions.cpp` include. The changes to `python_nn_functions.cpp` mirror the changes I made to `python_torch_functions.cpp` when `__torch_function__` support was first added in https://github.com/pytorch/pytorch/issues/27064. Due to the somewhat different way the `torch._C` and `torch._C._nn` namespaces are initialized I needed to create a new static reference to the `torch._C._nn` namespace (`THPNNVariableFunctions`). I'm not sure if that is the best way to do this. In principle I could import these namespaces in each kernel and avoid the global variable but that would have a runtime cost.
I added `__torch_function__` support to the Python functions in `torch.nn.functional` following the approach in https://github.com/pytorch/pytorch/issues/32194.
I re-enabled the test that checks if all functions in the `torch` namespace are explicitly tested for `__torch_function__` support. I also generalized the check to work for `torch.functional` and `torch.nn.functional` as well. This test was explicitly disabled in https://github.com/pytorch/pytorch/issues/30730 and I'm happy to disable it again if you think that's appropriate. I figured now was as good a time as any to try to re-enable it.
Finally I adjusted the existing torch API tests to suppress deprecation warnings and add keyword arguments used by some of the code in `torch.nn.functional` that were missed when I originally added the tests in https://github.com/pytorch/pytorch/issues/27064.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32799
Differential Revision: D19956809
Pulled By: ezyang
fbshipit-source-id: 40d34e0109cc4b9f3ef62f409d2d35a1d84e3d22
Summary:
This is generating a considerable amount of warning, due to the fact
that the header file is included in multiple places.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33524
Differential Revision: D20006604
Pulled By: ezyang
fbshipit-source-id: 0885cd2a708679ba5eeabb172366eb4c5a3bbef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33572
This reverts commit 687a7e4a2566861c53c8fb53a80b198465168b38.
Original PR #33305
Reland with BC tests whitelisted. See https://github.com/pytorch/pytorch/issues/33580 for reasoning why this change is not actually BC breaking.
Test Plan: Imported from OSS
Differential Revision: D20011011
Pulled By: ezyang
fbshipit-source-id: 116374efc93af12b8ad738a0989d6f0daa9569e2
Summary:
IIUC Python does not guarantee when an object is garbage collected. So it is possible that, some other test running before `TestCuda.test_memory_stats` creates object which is only garbage collected during `TestCuda.test_memory_stats`, causing mem stats to change and causing this test to fail. This kind of failure is very hard to debug (it took me and mcarilli and ptrblck quite a while to figure out what is happening), and it is the root cause of mcarilli's gradient scaling PR https://github.com/pytorch/pytorch/pull/26512 failing on Windows.
cc: csarofeen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33575
Differential Revision: D20009260
Pulled By: ngimel
fbshipit-source-id: 62f2716aefac3aa6c7d1898aa8a78e6b8aa3075a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33517
I don't think any mobile model uses SparseCPU backend yet so we can skip
generating dispatch code for this backend type.
This will help reduce mobile code size with dynamic dispatch turned on,
roughly ~100K for uncompressed iOS: D19616007 +413K v.s. D19616016 +319K.
It probably doesn't affect much static dispatch build size as the unused
static dispatch methods will be stripped by linker in the end.
ghstack-source-id: 98615810
Test Plan: - CI & BuildSizeBot
Reviewed By: linbinyu
Differential Revision: D19978633
fbshipit-source-id: 27bf6ada2ba98482084cf23724cf400b538b0a03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33557
We should add GIL asserts in some places to keep assumptions documented.
This just adds one in an exception codepath as a placeholder for more.
This change also moves a #define from a .h to the .cpp to reduce scope.
ghstack-source-id: 98673532
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D20005387
fbshipit-source-id: b7eff54a6f1dd69d199f8ca05cdb3001c50b37c4
Summary:
The `not inline_everything` check was causing the jitter check to be skipped whenever we emitted a function. thanks SplitInfinity for pointing this out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33468
Differential Revision: D19975934
Pulled By: eellison
fbshipit-source-id: 03faf8d2fd93f148100d8cf49cb67b8e15cf1f04
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32863, (together with https://github.com/pytorch/pytorch/issues/33310 for the `TensorIterator` reductions)
This adds 64-bit indexed kernels for `THC_reduceDimIndex` and uses `THCTensor_canUse32BitIndexMath` to switch between the two at runtime.
I have a test for this locally but haven't included it here because `max` is much slower than `argmax`. To the point where the test takes several minutes to call max on just one `2**32` element tensor. That seems excessive, even for a slow test but I can push it if preferred.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33405
Differential Revision: D20010769
Pulled By: ezyang
fbshipit-source-id: a8a86f662598d5fade4d90448436418422c699a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33574
Sprinkle with Clang identification macro places that otherwise would cause build errors when Clang is used to drive the CUDA compilation.
Note: `__clang__` is defined when either Clang is used as host compiler by NVCC or when Clang drives the compilation. `__CUDA__` is defined only for the latter case.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Reviewed By: BIT-silence
Differential Revision: D20007440
fbshipit-source-id: 53caa70695b99461a3910d41dc71a9f6d0728a75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33555
A quick fix for the PyText model (in internal production) on the new bytecode format.
Test Plan: Imported from OSS
Differential Revision: D20008266
Pulled By: iseeyuan
fbshipit-source-id: 1916bd0bf41093898713c567c7f6fa546b9ea440
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33554
NVCC/GCC accepts the existing syntax, but not Clang which requires a proper escape. Here `%laneid` is one of the many registers that CUDA's pseudo-asm provides [1]. And using the extra `%` doesn't change the semantics, as PTX expects `%laneid` value after it's processed by the asm tool.
1. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
Reviewed By: bddppq
Differential Revision: D20003621
fbshipit-source-id: 8e550e55a3455925e7bd92c6df3e504b5d38c2dc
Summary:
We need to run a peephole before constant propagation in the profiling pipeline, so we fold `prim::shape` for inputs with complete tensor types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33337
Differential Revision: D19905624
Pulled By: Krovatkin
fbshipit-source-id: 80fff067941556053847ddc7afe0fd1c7a89a3ba
Summary:
Changelog:
- Add a check to ensure that all inputs to `where` lie on the same device
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33432
Test Plan:
- Added test_where_invalid_device
Fixes https://github.com/pytorch/pytorch/issues/33422
Differential Revision: D19981115
Pulled By: VitalyFedyunin
fbshipit-source-id: 745896927edb53f61f3dd48ba9e1e6cd10d35434
Summary:
Adam and AdamW are missing parameter validation for weight_decay. Other optimisers have this check present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33126
Differential Revision: D19860366
Pulled By: vincentqb
fbshipit-source-id: 286d7dc90e2f4ccf6540638286d2fe17939648fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32990
right now remote torchscript call can not call to itself, this diff is to support this in the same way as how is supported when calling remote python call to itself
ghstack-source-id: 98599082
Test Plan: unit test
Differential Revision: D19731910
fbshipit-source-id: 6495db68c3eaa58812aa0c5c1e72e8b6057dc5c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33347
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19975410
Pulled By: ezyang
fbshipit-source-id: eb729870c2d279d7d9ca43c92e514fe38dedb06d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33305
The current TensorOptions code is written to exactly extract out
TensorOptions based on exact struct match, including default arguments.
That meant that tril_indices/triu_indices which had a different
default argument didn't match, and thus needed a special case.
I resolve this special case by instead replacing the explicit long
default argument with a None default argument, and then adjusting
the actual implementations to select the correct dtype when none
was specified. I think the general rule I'm following here is that
it is always acceptable to replace an explicit default argument,
with a None argument (assuming the backend will compute it appropriately);
the documentation gets modestly worse, but everything that was
previously expressible continues to be expressible. Maybe later
we should switch the default argument back to long, but for now
the simplification in code is worth it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19975411
Pulled By: ezyang
fbshipit-source-id: 996598759bed9e8d54fe61e19354ad038ed0e852
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33426
Make 2/4/8-bit fused rowwise conversion operators more general to work for N-dim tensors
Test Plan: CI
Reviewed By: ellie-wen
Differential Revision: D19943136
fbshipit-source-id: 47008544dd7e1d11a346d34f35449e0fcc0e7ee0
Summary:
We want to run ONNX checker only when selected operator type is ONNX, and nowhere else. This PR updates the logic in the exporter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33522
Reviewed By: hl475
Differential Revision: D19983954
Pulled By: houseroad
fbshipit-source-id: 15db726321637a96fa110051cc54e9833e201133
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33523
When using `ThreadPool::setNumThreads` to set the number of threads, it should not exceed the number of big cores. Otherwise, the performance could degrade significantly.
Test Plan:
```
cd ~/fbsource/xplat
buck test caffe2:caffe2_testAndroid
```
Reviewed By: dreiss
Differential Revision: D19779267
fbshipit-source-id: 4e980e8a0ccc2f37e1c8ed16e2f4651d72924dbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33434
Reland of https://github.com/pytorch/pytorch/pull/33325, since the
unit test was flaky and failed on land.
To ensure that the test is not flaky, I bumped the timeout so the rendezvous
does not timeout (timing out the rendezvous in 1s led to the flakiness). I also
generalized our mechanism for retrying on errors to include retrying on errors
due to timeout in rendezvous.
ghstack-source-id: 98558377
Test Plan: Added UT test_tcp_store_timeout_set
Differential Revision: D19935390
fbshipit-source-id: 56ccf8c333dd2f954a33614d35cd1642d4e9473a
Summary:
Since the tensor iterator supports the broadcast, we will just remove the assertion on input shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30442
Differential Revision: D19976562
Pulled By: lly-zero-one
fbshipit-source-id: 91b27fc8b2570f29d110c6df26eacdd16f587b9f
Summary:
The quantizer use std::vector to save per_channel scales and zero_points, but when query scales(zero_points), it requires to return tensor. These lead to use std::vector to initialize tensors and it dose cost lots of time. So I change quantizer to save per_channel scales and zero_points by using tensor directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31040
Differential Revision: D19701070
Pulled By: jerryzh168
fbshipit-source-id: 9043f16c44b74dd8289b8474e540171765a7f92a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33365
This adds functionality for re-trying RPC's that are sent with the function sendWithRetries(). It adds RPC's that will potentially need to be retried to a sorted map that contains the timeout at which to retry the RPC and associated metadata. A separate thread iteratively removes the earliest retry-able RPC from the map, sleeps until the corresponding time point, re-tries the RPC, and adds to the map again with a future timeout.
GitHub Issue: https://github.com/pytorch/pytorch/issues/32124
Per the first 4 milestones, the following will be addressed in future PR's:
* enabling RPC Retries for RRef internal messages
Differential Revision: D19915694
fbshipit-source-id: 4a520e32d5084ebcf90e97fd9f26867115a35c0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33508
Ever since we switched to not inlining by default, some users have
complained since they relied on inlining occuring to, e.g. process the
graph with some other tool. Add an inlined_graph for convenience in
those cases.
Test Plan: Imported from OSS
Differential Revision: D19977638
Pulled By: suo
fbshipit-source-id: fe1fa92ff888959203d5d1995930d488b5f9e24c
Summary:
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/297
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33250
As Title says. FBGEMM has recently added the support for Windows.
ghstack-source-id: 97932881
Test Plan: CI
Reviewed By: jspark1105
Differential Revision: D19738268
fbshipit-source-id: e7f3c91f033018f6355edeaf6003bd2803119df4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33515
Previously, if we had a `ModuleDict` with the same value types but
different names for keys, they would share types under certain
conditions. This only happens for `ModuleDict`, because in other cases
a simple Python class check invalidates the class.
Test Plan: Imported from OSS
Differential Revision: D19978552
Pulled By: suo
fbshipit-source-id: f31b2af490064f89b70aa35f83ba740ddaf2a77a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32839
As mentioned in the updated comment in `variable.h`, this disambiguate code like:
```python
base = torch.rand(10, requires_grad=True)
with torch.no_grad():
view = base[1]
view.copy_(var)
torch.autograd.grad(base.sum(), var) # <- what should it return?
```
Given that there is no consensus of what should happen here (does the gradient flow through the view in the no_grad or not). This special case is detected and forbidden.
As mentionned in the error message:
- If you want it to be tracked: move both out of the no_grad
- If do not want them to be tracked, move both inside the no_grad
This implies that any custom Function that returns views does not allow inplace modification on its output. I'll add a PR to the stack to relax this to be a DeprecationWarning for now. And we will make it into an actual error for 1.6
This replaces https://github.com/pytorch/pytorch/pull/26607
cc sublee
Test Plan: Imported from OSS
Differential Revision: D19814114
Pulled By: albanD
fbshipit-source-id: ff2c9d97c8f876d9c31773a2170e37b06d88bed7
Summary:
This fixes https://github.com/pytorch/pytorch/issues/33001.
When subtracting 1 from a empty array, instead of being `-1` as seems to be expected in the later code (while loop), because `size()` seems to be unsigned, it becomes a very large number. This causes a segfault during the while loop later in the code where it tries to access a empty array.
This issue seemed to happen only on the pi with the following example code: `v = torch.FloatTensor(1, 135).fill_(0); v[0, [1]] += 2`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33456
Differential Revision: D19963711
Pulled By: ezyang
fbshipit-source-id: 1dbddd59a5df544cd7e025fc540c9efe2c4e19f4
Summary:
This was old code that isn't tested and is broken, it should have been
deleted in #24874
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33453
Pulled By: driazati
Differential Revision: D19961403
fbshipit-source-id: 94c52360460194d279dad5b0ea756ee366f525e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32880
The PR below made it impossible to construct a SourceRange without a
context, so get rid of its optional-ness
Test Plan: Imported from OSS
Differential Revision: D19670923
Pulled By: suo
fbshipit-source-id: 05936fca2a3d5e613313ade9287b2210bc4a3ccd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32879
An error report without a SourceRange context is bad, because it doesn't
tell the user where something happened. Delete the default constructor
to make it harder to create errors like this (you can still use a fake
SourceRange if you absolutely need to).
Also clean up the only case where the default constructor was used.
Test Plan: Imported from OSS
Differential Revision: D19670924
Pulled By: suo
fbshipit-source-id: 46888a86e5d32b84c8d6d52c0c8d70243722b14a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33440
The constructors make a copy without `std::move` in the initializer list.
Test Plan:
Confirmed manually that without this change, the `data()` pointer of
the vector changes. With this change it does not, as intended.
Reviewed By: mrshenli
Differential Revision: D19948685
fbshipit-source-id: ee4f22e29894b858ad86068722dc2f4651987517
Summary:
There are large models such as GPT2-large which cannot be exported with the current exporter because of the 2GB protobuf limit (e.g. see https://github.com/pytorch/pytorch/issues/19277). ONNX spec specifies a special format for large (> 2GB) models. This PR adds support for exporting large models in ONNX large model format in the PyTorch-ONNX exporter.
This is the first PR for this feature that enables the end-to-end execution. Tests for large model export have been added. We may need follow-up PRs to refine this workflow based on user feedback.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33062
Reviewed By: hl475
Differential Revision: D19782292
Pulled By: houseroad
fbshipit-source-id: e972fcb066065cae6336aa91c03023d9c41c88bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32885
Currently Tensor bias is registered as parameter and None bias is registered as attribute.
We need the type annotation because when we try to fold ConvBn in graph mode quantization we'll
remove the None bias attribute and add a Tensor bias attribute, without type annotation the
bias Value in the graph will be marked with different type in these two cases, so we have rewrite the
graph to change the type as well in that case. But with type annotation we don't need to modify the graph
since both cases the bias value will have type `Tensor?`
Test Plan:
.
Imported from OSS
Differential Revision: D19844710
fbshipit-source-id: 52438bc72e481ab78560533467f9379a8b0b0cfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33265
This removes the need for isinstance to keep trace of list and tuple
separately by introducing AnyListType and AnyTupleType into the JIT
type system to be the common supertype of any lists or tuples.
This allows us to remove the weird flags from the interpreter for
the isinstance operator.
Test Plan: Imported from OSS
Differential Revision: D19883933
Pulled By: zdevito
fbshipit-source-id: f998041b42d8b4554c5b99f4d95d1d42553c4d81
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32889
Common primitive ops that have special inputs make it very hard to
serialize the bytecode for mobile because information about how the
op behaves is hidden in the Node*. This changes how we handle the following
ops so that they are encoded as their own interpreter bytecodes.
```
USES NODE: prim::TupleUnpack(...) -> (...)
USES NODE: prim::TupleSlice(...) -> (...)
USES NODE: prim::TupleConstruct(...) -> (...)
USES NODE: prim::ListUnpack(...) -> (...)
USES NODE: prim::ListConstruct(...) -> (...)
USES NODE: prim::DictConstruct(...) -> (...)
USES NODE: prim::Constant() -> (...)
USES NODE: prim::isinstance(...) -> (...)
USES NODE: prim::CreateObject(...) -> (...)
USES NODE: prim::fork(...) -> (...)
USES NODE: aten::warn(str message, *, int stacklevel=2) -> () # need stack level information, so ideally in interpreter so it can look at the stack
```
This leaves a state where the _only_ remaining Node*-consuming builtins
are things that are only introduced during JIT optimization and will
not appear in mobile code.
Serialization of bytecode can now be made to directly write the CodeImpl
object without modification.
Test Plan: Imported from OSS
Differential Revision: D19673157
Pulled By: zdevito
fbshipit-source-id: 7b8c633d38a4c783b250fbdb222705e71a83ad26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32804
Constants are interpreter primitives so the op was not actually used.
This cleans up some of the logic around it.
This also fixes constant prop such that failures to look up an op
do not silently stop constant propagation. Instead, only errors
inside the op implementation itself will do this.
Test Plan: Imported from OSS
Differential Revision: D19673156
Pulled By: zdevito
fbshipit-source-id: 7beee59a6a67a6c2f8261d86bd505280fefa999e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32791
When a registered operator has varags (ends with ... in its schema),
the interpreter now appends the number of arguments to the top of
the stack before invoking the operator. This allows the removal of more
uses of Node* in the interpreter.
This PR also then cleans up the constructors for Operator to make
it more likely someone chooses the correct one. After making these ops:
```
USES NODE: prim::TupleUnpack(...) -> (...)
USES NODE: prim::TupleSlice(...) -> (...)
USES NODE: prim::TupleConstruct(...) -> (...)
USES NODE: prim::ListUnpack(...) -> (...)
USES NODE: prim::ListConstruct(...) -> (...)
USES NODE: prim::DictConstruct(...) -> (...)
USES NODE: prim::Constant() -> (...)
USES NODE: prim::isinstance(...) -> (...)
USES NODE: prim::CreateObject(...) -> (...)
USES NODE: prim::fork(...) -> (...)
USES NODE: aten::warn(str message, *, int stacklevel=2) -> () # need stack level information, so ideally in interpreter so it can look at the stack
```
Into interpreter primitives, we can remove all but two constructors for operators:
one that is (schema_string, operation), and one that is (symbol, op_creator) for
the remaining weird primitives.
Test Plan: Imported from OSS
Differential Revision: D19673158
Pulled By: zdevito
fbshipit-source-id: 95442a001538a6f53c1db4a210f8557ef118de66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33368
reorganizing files that describe sources to ensure the same list is used for both fbcode and ovrsource targets. (BUCK vs TARGETS)
Test Plan: CI green
Reviewed By: malfet
Differential Revision: D19803036
fbshipit-source-id: 69c1fa10877c3f0c0e9c1517784949c3c9939710
Summary:
Closes https://github.com/pytorch/pytorch/issues/30027
The idea here is that you can bind a function with `pybind11` in a single line and without modifying the function:
```cpp
m.def("foo", foo, py::call_guard<torch::PyWarningHandler>());
```
Where warnings are handled by the [`call_guard`](https://pybind11.readthedocs.io/en/stable/advanced/functions.html#call-guard) and exceptions are handled by the `pybind11` exception translator. To do this, I have added support for handling C++ exceptions in `torch::PyWarningHandler`'s destructor without setting the python error state before hand.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30588
Differential Revision: D19905626
Pulled By: albanD
fbshipit-source-id: 90c0a5e298b123cc0c8ab9c52c91be4e96ea47c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33358
We just translate this code to ATen.
Test Plan: Imported from OSS
Differential Revision: D19911114
Pulled By: gchanan
fbshipit-source-id: 2279e63bb7006f7253620417937e3ce9301e0cdb
Summary:
## problem
```python
class LambdaLR(_LRScheduler):
"""Sets the learning rate of each parameter group to the initial lr
times a given function. When last_epoch=-1, sets initial lr as lr.
Args:
optimizer (Optimizer): Wrapped optimizer.
lr_lambda (function or list): A function which computes a multiplicative
factor given an integer parameter epoch, or a list of such
functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
Example:
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
"""
```
`LambdaLR` takes a lambda that returns a float and takes a int, or a list of such lambdas.
## related issue
Resolve https://github.com/pytorch/pytorch/issues/32645
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33271
Differential Revision: D19878665
Pulled By: vincentqb
fbshipit-source-id: 50b16caea13de5a3cbd187e688369f33500499d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33346Fixes#33091
This PR lets users control the number of workers that cpp extensions
uses through the environment variable `MAX_JOBS`. If the environment
variable is a non-negative integer we use that many threads; otherwise,
ninja falls back to the default.
I chose to use the name `MAX_JOBS` because we use it in PyTorch already
to control the number of workers PyTorch builds with. There is a risk
that users of cpp extensions already have `MAX_JOBS` set but we are
hoping that that risk is small and/or it means semantically the same
thing.
Test Plan: - tested locally
Differential Revision: D19911645
Pulled By: zou3519
fbshipit-source-id: d20ed42de4f845499ed38f1a1c73e9ccb620f780
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33008
Corrects D19373507 to allow valid use cases that fail now. Multiplies batch size by the number of elements in a group to get the correct number of elements over which statistics are computed.
**Details**:
The current implementation disallows GroupNorm to be applied to tensors of shape e.g. `(1, C, 1, 1)` to prevent cases where statistics are computed over 1 element and thus result in a tensor filled with zeros.
However, in GroupNorm the statistics are calculated across channels. So in case where one has an input tensor of shape `(1, 256, 1, 1)` for `GroupNorm(32, 256)`, the statistics will be computed over 8 elements and thus be meaningful.
One use case is [Atrous Spatial Pyramid Pooling (ASPPPooling)](791c172a33/torchvision/models/segmentation/deeplabv3.py (L50)), where GroupNorm could be used in place of BatchNorm [here](791c172a33/torchvision/models/segmentation/deeplabv3.py (L55)). However, now this is prohibited and results in failures.
Proposed solution consists in correcting the computation of the number of elements over which statistics are computed. The number of elements per group is taken into account in the batch size.
Test Plan: check that existing tests pass
Reviewed By: fmassa
Differential Revision: D19723407
fbshipit-source-id: c85c244c832e6592e9aedb279d0acc867eef8f0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33395
By default the GPU fuser stays enabled, but this function allows to
manually disable it. It will be useful for working on other
implementations of fuser.
Test Plan: Imported from OSS
Differential Revision: D19926911
Pulled By: ZolotukhinM
fbshipit-source-id: 7ea9d1dd7821453d640f81c487b63e1d585123c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33027
This PR allows default arguments in module's forward method to be skipped when module is used in `torch::nn::Sequential`, by introducing the `FORWARD_HAS_DEFAULT_ARGS` macro and requiring that all modules that have default arguments in its forward method must have a corresponding `FORWARD_HAS_DEFAULT_ARGS` macro call.
Fixes issue mentioned in https://github.com/pytorch/pytorch/issues/30931#issuecomment-564144468.
Test Plan: Imported from OSS
Differential Revision: D19777815
Pulled By: yf225
fbshipit-source-id: 73282fcf63377530063e0092a9d84b6c139d2e32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33026
This PR contains necessary changes to prepare for https://github.com/pytorch/pytorch/pull/33027. It exposes the following classes to public:
1. `torch::nn::AnyValue`, because if the user has optional arguments in their module's forward method, they must also use the `FORWARD_HAS_DEFAULT_ARGS` macro and pass in the default values for those optional arguments wrapped by `torch::nn::AnyValue`.
2. `torch::nn::AnyModuleHolder`, because `torch::nn::Module` needs to declare it as a friend class for it to be able to access `torch::nn::Module`'s protected methods such as `_forward_has_default_args` / `_forward_num_required_args` / `_forward_populate_default_args`.
Test Plan: Imported from OSS
Differential Revision: D19777814
Pulled By: yf225
fbshipit-source-id: 1c9d5aa24f0689154752c426a83ee98f64c9d02f
Summary:
Although `gpu_kernel_with_index` might look like a quite general helper function at first look, it actually isn't.
The problem is not only 32bit indexing, but something more fundamental: `TensorIterator` reorder dims and shapes, so if you have non-contiguous tensor such as `torch.empty(5, 5).t()` , the index won't be correct. Since the whole point of `TensorIterator` is to manipulate shapes/strides to speedup loops, it is fundamentally impossible to get the correct linear index without tons of efforts.
Currently, the range factories are not failing on an `out=non_contiguous_tensor` is because it is so lucky that `has_internal_overlap` is stupid enough to return everything not contiguous as `TOO_HARD`.
Since `gpu_kernel_with_index` is not general, we should move it from `Loops.cuh` to `RangeFactories.cu`. And since the kernel is so simple to implement, it makes no sense to use `TensorIterator` which goes through tons of unnecessary checks like `compute_dtypes`.
`torch.range` is not tested for 64bit-indexing, and I will file a new PR to remove it (it was supposed to be removed at 0.5).
Benchmark:
The device is GTX-1650, I don't have a good GPU at home.
Code:
```python
import torch
print(torch.__version__)
for i in range(100):
torch.randn(1000, device='cuda')
torch.cuda.synchronize()
for i in range(15, 29):
%timeit torch.arange(2 ** i, device='cuda'); torch.cuda.synchronize()
```
Before:
```
1.5.0a0+c37a9b8
11.9 µs ± 412 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
12.7 µs ± 309 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
19.6 µs ± 209 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
28.9 µs ± 923 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
48.4 µs ± 1.64 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
85.7 µs ± 1.46 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
162 µs ± 1.09 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
312 µs ± 9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
618 µs ± 15.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.22 ms ± 9.91 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
2.45 ms ± 97.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.9 ms ± 155 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
10.1 ms ± 378 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
After:
```
1.5.0a0+7960d19
11 µs ± 29.6 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
12.4 µs ± 550 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
18.4 µs ± 230 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
27.6 µs ± 10.9 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
46.2 µs ± 18.6 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
83.3 µs ± 5.61 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
158 µs ± 373 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
307 µs ± 1.44 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
603 µs ± 112 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.2 ms ± 1.05 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
2.4 ms ± 23.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.77 ms ± 25.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
9.51 ms ± 933 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33370
Differential Revision: D19925990
Pulled By: ngimel
fbshipit-source-id: f4a732fe14a5582b35a56618941120d62e82fdce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33147
The log mentioned that it is aborting communicators even if
`blockingWait_` was false. This was incorrect, and I updated the logging to
reflect the appropriate behavior.
ghstack-source-id: 98025017
Test Plan: waitforbuildbot
Differential Revision: D19817967
fbshipit-source-id: fb3415af2cc99eb20981ceaa5203c0a1880fd6f3
Summary:
Add quant_scheme_generator that will be used to interface with dper.
Also updated two related functions:
- Add batch_size option to save_local_dataset() in dataset utils to be more flexible.
Test Plan:
Tested in the stacked diff D19747206.
buck test deeplearning/numeric_suite/toolkit/test:int8_static_utils_test
Reviewed By: csummersea
Differential Revision: D19745159
fbshipit-source-id: a4ac1ef0ffdddc68bdf5e209ae801b8c475d0b96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32974
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/286
Re-attempt of D18805426 . Decided to be consistent with PyTorch Adagrad
There was an inconsistency in the order of operation between scalar and SIMD code when we compute Adagrad. This diff make them consistent by doing w += lr * grad / (sqrt(moment) + epsilon) in Adagrad and w += lr / (sqrt(moment) + epsilon) * grad in RowWiseSparseAdagrad.
The Adagrad order is consistent with PyTorch (see aten/src/ATen/native/cpu/PointwiseOpsKernel.cpp addcmul_cpu_kernel function). The RowWiseSparseAdagrad order is to make compute more efficient. In RowWiseSparseAdagrad, lr / (sqrt(moment) + epsilon) is shared among all elements in the row
And, we're not going to use FMA to be consistent with PyTorch (even though it provides a little accuracy benefit)
Test Plan: CI
Reviewed By: wx1988
Differential Revision: D19342865
fbshipit-source-id: e950c16f2e1c4a2f2a3ef53b1705db373c67f341
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33325
Closes https://github.com/pytorch/pytorch/issues/32924. There was a bug where for TCPStore, we would not respect the timeout passed into `init_process_group` while constructing the TCPStore. Instead, we'd set the timeout after the rendezvous created the store, meaning that we used the default timeout of 300s while connecting to the server. This diff passes the timeout passed into `init_process_group` to rendezvous so that it can be passed into the constructor for TCPStore, so that we can use the right timeout at construction time.
Question: Should we make this change for FileStore as well? Currently the FileStore constructor does not take in a timeout at all.
ghstack-source-id: 98401875
Test Plan: Added a UT
Differential Revision: D19871946
fbshipit-source-id: dd002180c4c883216645b8a97cc472c6116ac117
Summary: in dper2, local net is hard-coded by whitelisting some layers. Add SparseFeatureGating related layers to local net explicitly.
Test Plan:
* workflow: f167812211
* QRT: fall back looks normal
{F228442018}
Differential Revision: D19852280
fbshipit-source-id: 6fecc3d745c3f742d029575a7b9fe320618f1863
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33387
CI is broken. Skip two functions to fix the problem.
Test Plan: ci
Reviewed By: hl475
Differential Revision: D19926249
fbshipit-source-id: a46d1465c59de8616d2af5fb0b9cc18532359f88
Summary:
Fixes the `TensorIterator` parts of https://github.com/pytorch/pytorch/issues/32863 (THC is still broken)
`TensorIterator::split` now keeps track of the `view_offsets` into the full tensor range. With this, I can take the base offset for the reduced dimension and translate partial results from the sub-iter into the index range of the full tensor. This happens only once for each intermediate result, so we should still benefit from the performance of 32-bit indexing in loops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33310
Differential Revision: D19906136
Pulled By: ngimel
fbshipit-source-id: 3372ee4b8d5b115a53be79aeafc52e80ff9c490b
Summary:
Globally define
```C++
constexpr int num_threads = C10_WARP_SIZE * 2;
constexpr int thread_work_size = 4;
constexpr int block_work_size = thread_work_size * num_threads;
```
and kill all the template arguments passing these values.
These are effectively global, but we are now passing them around by template arguments, causing many inconvenience in coding.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33308
Differential Revision: D19907250
Pulled By: ngimel
fbshipit-source-id: 4623b69baea7e6e77f460ffdfa07cf9f8cba588a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32962
As per gchanan's comments on
https://github.com/pytorch/pytorch/pull/30445, I've used
`torch.set_default_dtype` in test_data_parallel instead of specifying
dtype=torch.double everywhere. Also, renamed dtype2prec to dtype2prec_DONTUSE
ghstack-source-id: 98388429
Test Plan: waitforbuildbot
Differential Revision: D19714374
fbshipit-source-id: eb55bbca33881625636ba9ea6dd4cb692f25668e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33261
It was requested in #33114.
Test Plan: Imported from OSS
Differential Revision: D19910600
Pulled By: ZolotukhinM
fbshipit-source-id: 827f1744b97f386065a21d1ba5d82c1f90edbe46
Summary:
docker cp was erroring out, so lets just use volume mounts instead which
should hopefully be more consistent
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33355
Differential Revision: D19913948
Pulled By: seemethere
fbshipit-source-id: 059ddd36a8162f946cfea451b5dcd1706f1209e9
Summary:
Basically just fills out PYTORCH_BUILD_VERSION to the correct version
baesd on the git tag.
This makes it so that we don't have to continually edit this file
when doing releases.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33326
Differential Revision: D19911035
Pulled By: seemethere
fbshipit-source-id: e27105f3e193a49dd68452d8f60232f8a132acad
Summary:
This PR renames `at::Tensor::base()` to `at::Tensor::_base()`, to achieve parity with Python `torch.Tensor._base` API.
----
This PR is BC-breaking in the following way:
Previously, to get the tensor that this tensor is a view of, the user would call `tensor.base()` in C++. Now, they must call `tensor._base()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33316
Differential Revision: D19905687
Pulled By: yf225
fbshipit-source-id: 949d97b707b2c82becb99ac89e9ac24359d183e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33318
### Summary
Recently, we have a [discussion](https://discuss.pytorch.org/t/libtorch-on-watchos/69073/14) in the forum about watchOS. This PR adds the support for building watchOS libraries.
### Test Plan
- `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=WATCHOS ./scripts/build_ios.sh`
Test Plan: Imported from OSS
Differential Revision: D19896534
Pulled By: xta0
fbshipit-source-id: 7b9286475e895d9fefd998246e7090ac92c4c9b6
Summary:
For both the Caffe2 and PyTorch backends, enable 3D convolutions through MIOpen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33067
Reviewed By: BIT-silence
Differential Revision: D19880495
Pulled By: bddppq
fbshipit-source-id: 8f6f970910654c1c5aa871b48a04c1054875691c
Summary:
Exporting Split with a dynamic list of split_sizes is not supported.
This PR enables export using onnx SplitToSequence + SequenceAt
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33161
Reviewed By: hl475
Differential Revision: D19860152
Pulled By: houseroad
fbshipit-source-id: 300afedc22b01923efb23acd1a3627aa146bb251
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32602
This adds functionality for re-trying RPC's that are sent with the function `sendWithRetries()`. It adds RPC's that will potentially need to be retried to a sorted map that contains the timeout at which to retry the RPC and associated metadata. A separate thread iteratively removes the earliest retry-able RPC from the map, sleeps until the corresponding time point, re-tries the RPC, and adds to the map again with a future timeout.
GitHub Issue: https://github.com/pytorch/pytorch/issues/32124
Per the first 3 milestones, the following will be addressed in future PR's:
* enabling RPC Retries for RRef internal messages
Differential Revision: D19560159
fbshipit-source-id: 40cd86f9a25dc24367624d279a3b9720b20824cf
Summary:
Addressing issue https://github.com/pytorch/pytorch/issues/18125
This implements a mixture distributions, where all components are from the same distribution family. Right now the implementation supports the ```mean, variance, sample, log_prob``` methods.
cc: fritzo and neerajprad
- [x] add import and `__all__` string in `torch/distributions/__init__.py`
- [x] register docs in docs/source/distributions.rst
### Tests
(all tests live in tests/distributions.py)
- [x] add an `Example(MixtureSameFamily, [...])` to the `EXAMPLES` list,
populating `[...]` with three examples:
one with `Normal`, one with `Categorical`, and one with `MultivariateNormal`
(to exercise, `FloatTensor`, `LongTensor`, and nontrivial `event_dim`)
- [x] add a `test_mixture_same_family_shape()` to `TestDistributions`. It would be good to test this with both `Normal` and `MultivariateNormal`
- [x] add a `test_mixture_same_family_log_prob()` to `TestDistributions`.
- [x] add a `test_mixture_same_family_sample()` to `TestDistributions`.
- [x] add a `test_mixture_same_family_shape()` to `TestDistributionShapes`
### Triaged for follup-up PR?
- support batch shape
- implement `.expand()`
- implement `kl_divergence()` in torch/distributions/kl.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22742
Differential Revision: D19899726
Pulled By: ezyang
fbshipit-source-id: 9c816e83a2ef104fe3ea3117c95680b51c7a2fa4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33156
When dist_autograd_spawn_thrift's 'test_backward_node_failure_python_udf' test is
run, it was encountering a TSAN error related to holding the mutex while the
underlying datastructure was being dealloced.
In this change, we simply get a shared_ptr<> reference to the future, and
set_exception() without having the lock held, to avoid deallocing underneath
the lock.
ghstack-source-id: 98303434
Test Plan: buck test mode/opt-tsan //caffe2/test/distributed/rpc:dist_autograd_spawn_thrift -- 'test_backward_node_failure_python_udf \(test_dist_autograd_spawn\.DistAutogradTestWithSpawn\)'
Differential Revision: D19821362
fbshipit-source-id: 82f735e33f8e608552418ae71592400fa3621e40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33332
We check the input shape of lengths and indices of SLS and add an attribute if they are the same.
Test Plan:
```
buck test glow/fb/test/numerics:test_operator_onnxifinnpi -- test_slws_fused_8bit_rowwise_length1_graph
```
Reviewed By: ipiszy
Differential Revision: D19874903
fbshipit-source-id: 06b643b5351d0ba19ba209b5a5b599fbb38b1dfc
Summary:
Container `Module`s, including `ModuleList`, `ParameterList` and `ParameterDict`, should not be called like a regular `Module`.
This PR add error messages for these special modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29991
Differential Revision: D19698535
Pulled By: ezyang
fbshipit-source-id: fe156a0bbb033041086734b38f8c6fde034829bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32432
Use JIT'ed fp16 SLS in D19477209 from Caffe2 operators
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D19477208
fbshipit-source-id: ef2ccba10f5f4c475166141bf09c266dedb92d38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33323
skip the tests until it is fixed
Test Plan: ci
Reviewed By: hl475
Differential Revision: D19894675
fbshipit-source-id: 1cfc153577bf021171f4412115d84719beae7a91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33190
This enable the initial RRef type to be used inside TorchScript, user
could pass a python RRef into a torchscript function and call to_here
inside. Specifically, this PR:
- Add RRef schema type parsing
- Add python interop for RRef in Python and into JIT
- register to_here op in register_distributed_ops
More support for RRef in TorchScript will be added in future PRs
Test Plan: Imported from OSS
Differential Revision: D19871244
Pulled By: wanchaol
fbshipit-source-id: 7eca6c491a84666b261c70806254b705603bd663
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32992
This PR add RRef to IValue and the JIT type system.
- The RRefInterface abstract class inherit from intrusive_ptr_target,
this made the RRef class can be hold in ivalue as intrusive_ptr
- Add RRefType as a JIT type, it's a container type similar to
future type.
Test Plan: Imported from OSS
Differential Revision: D19871242
Pulled By: wanchaol
fbshipit-source-id: cb80ca32605096f9a42ef147109fb368a7c1d4d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33189
Add RRefInterface to Aten/Core, which will later be used by IValue
Switch all the rpc code base to use intrusive_ptr instead of shared_ptr,
so that we could add it to IValue.
Actual adding to IValue and JIT will be in next PR
Test Plan: Imported from OSS
Differential Revision: D19871241
Pulled By: wanchaol
fbshipit-source-id: d7e1fd04b46320e0f26c18591b49c92ad30a4032
Summary:
See https://discuss.pytorch.org/t/bugs-about-torch-from-numpy-array/43312.
This update incorporates albanD 's suggestion into the error message, saving future users from having to ask or look on the forums if they encounter this issue and don't mind making their arrays contiguous.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33254
Differential Revision: D19885808
Pulled By: mruberry
fbshipit-source-id: 8f0fd994cf8c088bf3c3940ab4dfb3ddbc5b3ede
Summary: update this mapping with thte int4 sls ops so we can run netrunner
Test Plan: testing with net_runner
Reviewed By: jfix71
Differential Revision: D19879826
fbshipit-source-id: eac84b10e2365c21cb8a7cfbf3123e26a9945deb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32957
Closes https://github.com/pytorch/pytorch/issues/29703. If there is a
gloo timeout and `recvWork->wait()` times out in `listenLoop()`,
processGroupagent crashes since there is an unhandled exception in a thread.
This catches the exception and exits the listen loop. In a follow up diff, we
will enhance these error conditions so that if users attempt to send RPCs
again, they are notified that the RPC agent was in a bad state and it was
shutdown.
This PR also adds a new option, `processGroupTimeout` to PG agent's backend
options. This allows us to control the gloo timeout.
ghstack-source-id: 98236783
Test Plan: Added a unit test.
Differential Revision: D19678979
fbshipit-source-id: 3895ae754f407b84aca76c6ed3cb087d19178c40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26410
I only ported the CPU forward implementation for now to try a CPU-only benchmark.
Test Plan: Imported from OSS
Differential Revision: D17454519
Pulled By: gchanan
fbshipit-source-id: ff757cf972c5627074fea2f92a670129007a49f4
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32008
This is similar to CaoZhongZ's patch which runs on all OpenMP threads in the team and selectively exits early to scale the number of threads active. I have also restored the `if` clause from before https://github.com/pytorch/pytorch/issues/26963 so that running on 1 thread should still avoid additional synchronisation.
One comment is that this does slightly change the meaning of `at::get_num_threads` inside of a `parallel_for` loop since it's not guaranteed that the function was called on that many threads. I've looked at the uses within ATen and couldn't see anything that would be problematic. There are a few places in `quantized` that seem to make this assumption but they always use a grain size of 1 so should be safe:
d9e99ab544/aten/src/ATen/native/quantized/cpu/qconv.cpp (L436-L437)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32875
Differential Revision: D19775823
Pulled By: VitalyFedyunin
fbshipit-source-id: 4f843b78cdb9e2766339590d728923786a00af6d
Summary:
- Clean up error checking code
- Avoid unecessary floating-point computation
- Use float instead of double when possible to avoid massive cast in the tensor
- Use bool instead of uint8_t for clear Boolean purpose
- Improve error message
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32665
Differential Revision: D19601920
Pulled By: VitalyFedyunin
fbshipit-source-id: 0c6c6b5ff227b1437a6c1bae79b2c4135a13cd37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33011
I also reordered some of the keys in non-semantic ways to make the
organizational grouping mroe clear.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19796584
Pulled By: ezyang
fbshipit-source-id: 3083abadb47e9f382b9fbe981af0b34203c6ea4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33080
Quantized batch norm for cases where batch norm cannot be fused with conv.
AVX2 implementation is from Caffe2.
Test Plan:
python test/test_quantized.py TestQuantizedOps.test_batch_norm
Imported from OSS
Differential Revision: D19861927
fbshipit-source-id: bd8cd101fc063cb6358132ab7c651a160999293c
Summary:
If a value has the type None, we can always replace it with a None constant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33264
Differential Revision: D19878695
Pulled By: eellison
fbshipit-source-id: 5d0e7ffb37c5747997df093fec3183039d8dff4d
Summary:
For reasons similar to https://github.com/pytorch/pytorch/issues/33021. Note that the support of half type has
not been available in any releases yet so it should be safe to remove (All forward ones concerning this PR were added in daef363b15c8a3aaaed09892004dc655df76ff81 and 8cb05e72c69fdd837548419770f3f1ba9807c16d)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33206
Differential Revision: D19861137
Pulled By: ezyang
fbshipit-source-id: 38a3a398a716a782c26a611c56ddeab7eb7ac79e
Summary:
When building with FFMPEG, I encountered compilation error due to missing include/library.
I also find the change in video_input_op.h will improve build on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27589
Differential Revision: D19700351
Pulled By: ezyang
fbshipit-source-id: feff25daa43bd2234d5e75c66b9865b672a8fb51
Summary:
This PR implements the gradient scaling API that mruberry, jjsjann123, ngimel, zdevito, gchanan and I have been discussing. Relevant issue/RFC: https://github.com/pytorch/pytorch/issues/25081.
Volume-wise, this PR is mostly documentation and tests. The Python API (found entirely in `torch/cuda/amp/amp_scaler.py`) is lightweight . The exposed functions are intended to make the implementation and control flow of gradient scaling convenient, intuitive, and performant.
The API is probably easiest to digest by looking at the documentation and examples. `docs/source/amp.rst` is the homepage for the Automatic Mixed Precision package. `docs/source/notes/amp_examples.rst` includes several examples demonstrating common but not-immediately-obvious use cases. Examples are backed by tests in `test_cuda.py` (and thankfully the tests pass :P).
Two small utility kernels have been added in `native/cuda/AmpKernels.cu` to improve performance and avoid host-device synchronizations wherever possible.
Existing optimizers, both in the wild and in Pytorch core, do not need to change to use the scaling API.
However, the API was also designed to establish a contract between user scripts and optimizers such that writers of _new_ custom optimizers have the control points they need to implement fast, optionally sync-free updates. User scripts that obey the scaling API can drop such custom optimizers in and reap performance benefits without having to change anything aside from the optimizer constructor itself. [I know what the contract with custom optimizers should be](35829f24ef/torch/cuda/amp/amp_scaler.py (L179-L184)), but I'm waiting for review on the rest of the API before I go about documenting it (it will be given a dedicated section in `docs/source/notes/amp_examples.rst`.
Currently, the gradient scaling examples do not include the auto-casting API as discussed in https://github.com/pytorch/pytorch/issues/25081. The gradient scaling API is intended to be orthogonal/modular relative to autocasting. Without auto-casting the gradient scaling API is fully use-_able_, but not terribly use-_ful_, so it's up to you guys whether you want to wait until auto-casting is ready before merging the scaling API as well.
### Todo
- [ ] How do I get c10 registered status for my two custom kernels? They're very simple.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26512
Differential Revision: D19859905
Pulled By: mruberry
fbshipit-source-id: bb8ae6966214718dfee11345db824389e4286923
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33174
Closes https://github.com/pytorch/pytorch/issues/32780. It looks like
this is the only callsite where we do `_get_current_rpc_agent().foo()`, and we
can do this directly in the pybind layer to save some overhead.
ghstack-source-id: 98200664
Test Plan: All UTs should pass.
Differential Revision: D19828786
fbshipit-source-id: 5c34a96b5a970e57e6a1fdf7f6e54c1f6b88f3d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33125
Provide histogram collection and weights prepacking interface for Dper to auto quantize the Ads models.
Test Plan:
buck test mode/opt deeplearning/numeric_suite/toolkit/test:int8_static_utils_test
buck test mode/opt deeplearning/numeric_suite/toolkit/test:histogram_utils_test
Reviewed By: amylittleyang
Differential Revision: D19794819
fbshipit-source-id: 6a4f4a6684da0977b7df2feed8a4b961db716da8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33251
Somehow this was preventing `c10::Error` exceptions from ever being thrown on windows when `defined(NDEBUG) == false`. Kinda scary.
Test Plan: sandcastle green, made sure `intrusive_ptr_test.cpp` (givenStackObject_whenReclaimed_thenCrashes) passed inside ovrsource using `mode/win/dev-debug`
Reviewed By: malfet
Differential Revision: D19865667
fbshipit-source-id: c32d5752025c043e57d16c6d14a94b069bed0bc3
Summary:
Stacked PRs
* #32955 - [jit] Fix flipped PackedSequence outputs in script
* **#32953 - [jit] Support properties on `Device`**
PyTorch devices have a `index` and `type` property. This PR adds support for both to TorchScript
](https://our.intern.facebook.com/intern/diff/19849320/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32953
Pulled By: driazati
Differential Revision: D19849320
fbshipit-source-id: ce845258c6110058dd9ea1f759ef74b7ed2e786e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32739
As Title says.
ghstack-source-id: 98061467
Test Plan: CI
Differential Revision: D19610810
fbshipit-source-id: f9621cd7d780769941ed77974b19c5226d4b2b30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33243
If a file does not exist in an archive, PyTorchStreamReader throws an exception. However, when PyTorchStreamReader is destructed another exception is thrown while processing the first exception. As a result of this double exception there is SIGABORT.
Thanks dreiss for catching this bug and suggesting the fix. It happened when he used _load_for_mobile to load a torch script file without bytecode session. A unittest is added to test this case.
Test Plan: Imported from OSS
Differential Revision: D19859205
Pulled By: iseeyuan
fbshipit-source-id: 8f96b6256f1a1f933fce1c256d64604c7e9269e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32761
This replaces ImplicitTensorToNum with result-specific operators like
IntImplicit, FloatImplicit, or ScalarImplicit. Note that ScalarImplicit
was not correctly implemented before and this PR fixes the lapse.
This does not change on-disk serialization because these operators are not
serialized directly but written as eg. `annotated(int, foo)`.
Test Plan: Imported from OSS
Differential Revision: D19615385
Pulled By: zdevito
fbshipit-source-id: 48575f408e8219d2ec5b46936fc2aa691f283976
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32682
This moves code around so that operator.h/cpp no longer requires a full
definition of Node* nor does it include alias analysis or the pretty printer.
This should make it possible to include in the mobile build.
Functionality for checking if operators match Node and to look up
and operator for a Node have moved to the Node object.
Test Plan: Imported from OSS
Differential Revision: D19615386
Pulled By: zdevito
fbshipit-source-id: e38bdf29971183597ef940d061c06ba56e71d9c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33050
Following what gchanan proposed in #30480
- If the (logical) shapes of mean and std are broadcastable, we broadcast them for the output
Done in tensor iterator already.
- If the (logical) shapes of mean and std are not broadcastable and they have the same number of elements, we fall back to the old behavior (pick the shape of mean)
Done by reshape std to the same shape of mean.
- If the (logical) shapes of mean and std are not broadcastable and don't have the same number of elements, we error out.
Done by tensor iterator already.
Test Plan: Imported from OSS
Differential Revision: D19771186
Pulled By: glaringlee
fbshipit-source-id: a0b71063c7f5fdda2d4ceb84e06384414d7b4262
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33194
### Summary
The iOS x86_64 job has been failed for a few days. I haven't found the root cause, but seems like updating the torchvision to its latest version can fix the problem
### Test Plan
- the x86_64 job works
Test Plan: Imported from OSS
Differential Revision: D19845079
Pulled By: xta0
fbshipit-source-id: 5034e252600b6704b860d68c371a65bef4cf37fc
Summary:
There are cases when we want to recover from CUDA OOM, for example, some cuDNN algorithms use huge workspace and we want to recover from OOM to pick a different algorithm, in such cases, there is no reason to catch all errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33056
Differential Revision: D19795359
Pulled By: ezyang
fbshipit-source-id: a34e23bf6d172dc0257389251dafef5b38d27d2b
Summary:
Resolves issue https://github.com/pytorch/pytorch/issues/31603
- A minor spelling typo is corrected: "suitible" --> "suitable"
- A minor quality of life improvement is added: the data format strings are better rendered as fixed width to indicate that they are string constants. "CHW" --> "`CHW`"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31604
Differential Revision: D19697293
Pulled By: ezyang
fbshipit-source-id: ee38b0d4c9ca8a233ac9243c310d9a3b42ad6f32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33184
dnnlowp specific code shouldn't be in the default FC in the first place
Test Plan: Just removing #ifdef #endif
Reviewed By: jianyuh
Differential Revision: D19835301
fbshipit-source-id: 7880cf298bedb3f0bc407d140d342124663ea4a7
Summary:
Collect activation histograms along the model evaluation and aggregate all the histograms from multiple threads/readers into one file
The original functionality of bulk_eval workflow is still valid. The output predictions and extra blobs will be exported to a hive table, which will be very useful for numerical debugging.
Test Plan:
FBL
```flow-cli canary dper.workflows.bulk_eval.export --mode dbg --parameters-file experimental/summerdeng/sparsenn/bulk_eval_input_configs.json --run-as-secure-group team_ai_system_sw_hw_co-design --entitlement gpu_prod --name "Histogram collection with caffe2 logging. Attach histogram observer to the predict net. Use small model 102343030. "
```
f163861773
When the flow is done, we can get all the histogram files under the specified dir. For example:
```
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6ca65cc0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6cde8a80
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6d144840
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6d4a9600
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6da303c0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6dd1c800
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6e0855c0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6e3e0380
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6e95a140
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6eafcf00
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6ed1a100
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6f094ec0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6f561c80
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6f783a40
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6fccb7c0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7003d580
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb703ae340
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7084ae80
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb70bc1c40
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb70f43a00
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb70ff7680
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb71361300
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb716df0c0
-rw-rw-r--. 1 185754 185754 4024538 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7199c780
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb71b72f00
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72330000
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72598100
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7290d880
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72b03980
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72f1f160
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb8bcee9e0
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fd51b457260
-rw-rw-r--. 1 185754 185754 4026659 Jan 23 09:51 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.final
```
The aggregated histogram file is /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.final. It can be loaded to the following auto quant workflow for int8 static quantization.
######## Code refactoring ########
Moved the utility functions to process activation histograms to the deeplearning/numeric_suite/toolkit:hist_processor and add the dependency in dper.
We also had a hist_compiler in the caffe2/caffe2/fb/fbgemm/numerical_debugger/python_utils/hist_compiler.py. Also refactored the code to reuse the utility functions in deeplearning/numeric_suite/toolkit:hist_processor.
The histograms from bulk_eval and the hist_compiler are identical.
/mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.compiled.bak
/mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.final.bak
Reviewed By: hx89
Differential Revision: D19270090
fbshipit-source-id: c7ecb4f2bbf1ea725c52e903356ad9a7b9ad73ac
Summary:
fixes a compiler warning:
```
torch/aten/src/ATen/native/cuda/MaxUnpooling.cu.cc(402):
warning: variable "batchSize" was set but never used
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32294
Differential Revision: D19697277
Pulled By: ezyang
fbshipit-source-id: b9821be325826dc4785cad7994803b54f1711a0c
Summary:
The extra dashes are breaking the link here
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31760
Differential Revision: D19697301
Pulled By: ezyang
fbshipit-source-id: 65de026b9016dc8689c9dac9efb8aafd00b535cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30352
1) tbb forwards us ident through parameter, we don't need to capture it.
2) tbb is being passed steps <= 0 which is bad.
Taken from TBB documentation:
```
The index type must be an integral type. The loop must not wrap around. The step value must be positive. If omitted, it is implicitly 1.
```
I have a build that uses `TBB_USE_DEBUG=1` and there are currently a lot of issues with PyTorch use.
Is TBB version not tested very much right now?
ghstack-source-id: 94459382
Test Plan: CI green
Differential Revision: D18666029
fbshipit-source-id: d5aa8327b03181d349e1964f9c8211298c433d6a
Summary:
1. Use C10_WARP_SIZE instead of hardcoded value "32".
2. `getNumThreads` returns a minimum of 32 for CUDA, which is same as the warp size in CUDA. However, for HIP, it returns a minimum of 16, which is less than the warp size (64) in HIP. This creates an issue in the [reduce function](14548c2d5b/aten/src/ATen/native/cuda/Normalization.cuh (L115)) when it zeroes out the other entries in shared memory [here](14548c2d5b/aten/src/ATen/native/cuda/Normalization.cuh (L137)): since `blockDim.x` is at least equal to the warp size in CUDA, this never zeroes out `shared[0]`, but for HIP, since `blockDim.x` could be 16 or 32, which is less than the warp size (64), this results in `blockDim.x * blockDim.y` being potentially less than the warp size for small cases, which then zeroes out `shared[0]` as well. This results in an erroneous output of zero for the reduce function on ROCm (depending on how the block dimensions are set).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33098
Differential Revision: D19837355
Pulled By: bddppq
fbshipit-source-id: ea526acd82ec08b1acb25be860b7e663c38ff173
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33083
Added more recommendations, some notes and warning
Test Plan: cd docs ; make html
Differential Revision: D19829133
Pulled By: ilia-cher
fbshipit-source-id: b9fbd89f5875b3ce35cc42ba75a3b44bb132c506
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30982
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
-----------
In this PR:
Updating the templates.
-----------
Test Plan: Imported from OSS
Differential Revision: D18912680
Pulled By: izdeby
fbshipit-source-id: 9e3828e42ee5c3aefbf3729f4a8d6db813f2e7c3
Summary:
They were probably mistakenly added as we do not intend to support Half
on CPUs in general and in these situations Half type would probably be
significantly slower than their float and double counterpart due to the
lack of vectorization and the need of additional casting.
cc XiaobingSuper
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33021
Differential Revision: D19795152
Pulled By: VitalyFedyunin
fbshipit-source-id: b19796db88880a46557e1b2fd06e584d46093562
Summary:
This PR aims at improving `cat` performance on CPU.
Current `cat` logic from `TH` module has no parallelization when the input tensor array are all contiguous.
This code also try to reuse the same `TensorIterator` as much as possible, in order to reduce overhead of creating `TensorIterator`, this is helpful when the slice of copy is not large enough.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30806
Differential Revision: D19275026
Pulled By: VitalyFedyunin
fbshipit-source-id: 756e9b86891f725c256b0a6981887ff06d88b053
Summary:
Currently `torch.pdist` yields an illegal CUDA memory access for batch sizes >= 46342 as reported by SsnL in https://github.com/pytorch/pytorch/issues/30583.
Thanks for the minimal code reproduction, btw! ;)
Reason for this bug:
The calculation if `i` in the [`pdist_kerne_cuda_impl`](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L112)) might overflow, if a tensor with a `batch size >= 46342` is passed to `torch.pdist`.
Detailed description:
* `result` is resizes as ` n * (n - 1) / 2 = 1073767311` ([line of code](46ad80c839/aten/src/ATen/native/Distance.cpp (L140)))
* `grid` is initialized as `result.numel()` ([line of code](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L246)))
* `k` is assigned to the `blockIdx.x` as an `int32` ([line of code](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L108)))
* `i` is calculated using `2 * k >= 2147534622` ([line of code](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L112))), which overflows, since `2147534622 > 2147483647 (int32_max)`.
Using `const int64_t k = blockIdx.x;` would solve the illegal memory access. This seems also be done for [`cdist_kernel_cuda_impl`](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L198-L201)).
However, we might expect a slowdown, so I've timed the current PyTorch master vs. this PR:
(tested with `x = torch.randn(x.size(0), 128)` on a V100)
|x.size(0) | int32 idx | int64 idx | slowdown |
|----------|-----------|-----------|----------|
| 50000 | - | 4.4460 | - |
| 25000 | 1.02522 | 1.10869 | 7.53% |
| 12500 | 0.25182 | 0.27277 | 7.68% |
| 6250 | 0.06291 | 0.06817 | 7.72% |
| 3125 | 0.01573 | 0.01704 | 7.69% |
| 1562 | 0.00393 | 0.00426 | 7.75% |
While checking the backward kernel, it seems I'm triggering another error with a size limit of
```python
x = torch.randn(1449, 1, device='cuda', requires_grad=True)
out = torch.pdist(x)
out.mean().backward()
> RuntimeError: CUDA error: invalid configuration argument
```
, while `[<=1448, 1]` works.
I'll take another look at this issue. Let me know, if the potential fix should go into this PR or if I should open a new issue.
CC ngimel, csarofeen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31593
Differential Revision: D19825571
Pulled By: ngimel
fbshipit-source-id: ace9ccab49f3cf0ce894cdb6daef0795e2e8ec03
Summary:
`where` is special because the arguments do not have the same type, which does not satisfy the assumption in modern https://github.com/pytorch/pytorch/pull/32383. I migrate it to TensorIterator so that there is something to test that this case is not broken. Currently, this case fallback to using legacy (not vectorized, not unrolled) code. It should be supported in the future when I cleanup `Loops.cuh`.
I also move some sharing part of `CUDALoops.cuh` and `ROCmLoops.cuh` into `Loops.cuh` so that to logic for checking whether `func_t` has the same arg types could be shared.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32984
Differential Revision: D19825127
Pulled By: ngimel
fbshipit-source-id: bbf4682349d96b4480c4d657f3c18a3a67a9bf17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32985
This can be useful in many situations to decide whether all elements are
zeros or non-zeros, such as elu as shown in #32986 .
Test Plan: Imported from OSS
Differential Revision: D19794549
Pulled By: VitalyFedyunin
fbshipit-source-id: 1be1c863d69b9a19fdcfcdd7cb52343066f740d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30981
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
-----------
In this PR:
Extended DispatchKeyExtractor logic to expect TensorOptions.
-----------
Test Plan: Imported from OSS
Differential Revision: D18912684
Pulled By: izdeby
fbshipit-source-id: 25cf1c397caa14272ca65b4003f1f03ff282ea77
Summary:
When an error is raised and `__exit__` in a context manager returns `True`, the error is suppressed; otherwise the error is raised. No return value should be given to maintain the default behavior of context manager.
Fixes https://github.com/pytorch/pytorch/issues/32639. The `get_lr` function was overridden with a function taking an epoch parameter, which is not allowed. However, the relevant error was not being raised.
```python
In [1]: import torch
...:
...: class MultiStepLR(torch.optim.lr_scheduler._LRScheduler):
...: def __init__(self, optimizer, gamma, milestones, last_epoch = -1):
...: self.init_lr = [group['lr'] for group in optimizer.param_groups]
...: self.gamma = gamma
...: self.milestones = milestones
...: super().__init__(optimizer, last_epoch)
...:
...: def get_lr(self, step):
...: global_step = self.last_epoch #iteration number in pytorch
...: gamma_power = ([0] + [i + 1 for i, m in enumerate(self.milestones) if global_step >= m])[-1]
...: return [init_lr * (self.gamma ** gamma_power) for init_lr in self.init_lr]
...:
...: optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
...: scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
```
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-7fad6ba050b0> in <module>
14
15 optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
---> 16 scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
<ipython-input-1-7fad6ba050b0> in __init__(self, optimizer, gamma, milestones, last_epoch)
6 self.gamma = gamma
7 self.milestones = milestones
----> 8 super().__init__(optimizer, last_epoch)
9
10 def get_lr(self, step):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in __init__(self, optimizer, last_epoch)
75 self._step_count = 0
76
---> 77 self.step()
78
79 def state_dict(self):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in step(self, epoch)
141 print("1a")
142 # try:
--> 143 values = self.get_lr()
144 # except TypeError:
145 # raise RuntimeError
TypeError: get_lr() missing 1 required positional argument: 'step'
```
May be related to https://github.com/pytorch/pytorch/issues/32898.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32997
Differential Revision: D19737731
Pulled By: vincentqb
fbshipit-source-id: 5cf84beada69b91f91e36b20c3278e9920343655
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30573
Mostly just moved code.
Index dim and number of indices checks are added to make checks idential to index_add_cpu_
ghstack-source-id: 98010129
Test Plan: existing tests
Differential Revision: D18749922
fbshipit-source-id: d243be43a3b6a9b9591caf0c35ef2fb6ec0d3ead
Summary:
Bazelisk automatically reads `.bazelversion` file and install the required version of Bazel. This saves us from updating CI script everytime we need a Bazel upgrade.
Use clang-8 for consistency with pytorch/xla repo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33036
Differential Revision: D19820819
Pulled By: ailzhang
fbshipit-source-id: 1560ec225cd037a811769a509a704b0df77ea183
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33102
Add a simple main() to build code analyzer as a binary. This enables
easier integration with FB internal build environment.
ghstack-source-id: 97958658
Test Plan: - CI
Differential Revision: D19798560
Pulled By: ljk53
fbshipit-source-id: 126230e3bf7568046a309e8a6785230f820e0222
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31998
This change builds on recent torch::from_blob() changes to avoid Tensor
copies on send in more cases.
Particularly, this change adds an enabled option to assume if the Tensor
Storage's DataPtr has a non-trivial deleter, then the Tensor does in fact
manage the underlying memory. And hence we can reference the Tensor's Storage
via an IOBuf that is referenced while sending, saving a Tensor copy.
We add appropriate test cases, particularly re: torch::from_blob() which
would have been problematic would recent changes.
ghstack-source-id: 97778619
Test Plan: buck test mode/dev caffe2/torch/fb/distributed/wireSerializer/test/...
Reviewed By: satgera
Differential Revision: D19306682
fbshipit-source-id: 05f56efb2d5d6279ae4b54dfcbba0f729c2c13fa
Summary:
## Several flags
`/MP[M]`: It is a flag for the compiler `cl`. It leads to object-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
`/maxcpucount:[M]`: It is a flag for the generator `msbuild`. It leads to project-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
`/p:CL_MPCount=[M]`: It is a flag for the generator `msbuild`. It leads the generator to pass `/MP[M]` to the compiler.
`/j[M]`: It is a flag for the generator `ninja`. It leads to object-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
## Reason for the change
1. Object-level multiprocessing is preferred over project-level multiprocessing.
2. ~For ninja, we don't need to set `/MP` otherwise M * M processes will be spawned.~ Actually, it is not correct because in ninja configs, there are only one source file in the command. Therefore, the `/MP` switch should be useless.
3. For msbuild, if it is called through Python configuration scripts, then `/p:CL_MPCount=[M]` will be added, otherwise, we add `/MP` to `CMAKE_CXX_FLAGS`.
4. ~It may be a possible fix for https://github.com/pytorch/pytorch/issues/28271, https://github.com/pytorch/pytorch/issues/27463 and https://github.com/pytorch/pytorch/issues/25393. Because `/MP` is also passed to `nvcc`.~ It is probably not true. Because `/MP` should not be effective given there is only one source file per command.
## Reference
1. https://docs.microsoft.com/en-us/cpp/build/reference/mp-build-with-multiple-processes?view=vs-2019
2. https://github.com/Microsoft/checkedc-clang/wiki/Parallel-builds-of-clang-on-Windows
3. https://blog.kitware.com/cmake-building-with-all-your-cores/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33120
Differential Revision: D19817227
Pulled By: ezyang
fbshipit-source-id: f8d01f835016971729c7a8d8a0d1cb8a8c2c6a5f
Summary:
Another pull request to follow up issue https://github.com/pytorch/pytorch/issues/32531.
Here I implemented the backward operation for `torch.eig` with a condition that all the eigenvalues are real.
This pull request is independent of my another pull request https://github.com/pytorch/pytorch/issues/32932, which means that there is no dependency between this PR and my another PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33090
Differential Revision: D19814347
Pulled By: albanD
fbshipit-source-id: 2fae30964e97987abb690544df8240aedeae56e8
Summary:
`assertWarnsRegex` now prints out any warnings that it caught while failing to find a matching warning. This makes it easier to debug tests by just looking at the CI logs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33099
Differential Revision: D19800021
Pulled By: ezyang
fbshipit-source-id: 1c31ae785c8ffc5d47619aff6597e479263be2de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33069
This PR adds the following:
- Warn when a non-input Tensor is given to `mark_dirty()` as it is not needed.
- Raise an error if we modify inplace an input that is a view and that we have multiple output. This setting is not handled by `CopySlices` and will raise a cryptic error during the backward.
- Raise an error if an input is modified inplace but not returned. That will prevent the graph rewrite from being done correctly.
Test Plan: Imported from OSS
Differential Revision: D19791563
Pulled By: albanD
fbshipit-source-id: 4d8806c27290efe82ef2fe9c8c4dc2b26579abd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33068
The version counter is already tracked if we use pytorch's functions but not if the user unpack the Tensor and modifies it by hand or with a third party library.
Test Plan: Imported from OSS
Differential Revision: D19791564
Pulled By: albanD
fbshipit-source-id: a73c0f73d8fd0c0e5bf838f14bed54fa66937840
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31768, second attempt of https://github.com/pytorch/pytorch/issues/32870
DataParallel creates replicas of the original `nn.Module` with the parameters duplicated onto the destination devices. Calling `backwards` will propagate gradients onto the original module parameters but calling `zero_grad` on the replica module doesn't clear the gradients from the parent module. However, any replica using backwards was broken anyway since the replica's parameters are not leaf nodes in autograd. So, we should issue a warning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33064
Differential Revision: D19790178
Pulled By: albanD
fbshipit-source-id: 886f36640acef4834a6fa57a26ce16b42ff0e9ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32979
Since we use prepacked weights in the Fp16 FCs and future Int8 FCs in production Ads models, we provide the python utils to inspect the unpacked format of the weights for debugging purpose. The main interfaces are the following:
```
from deeplearning.numeric_suite.toolkit import packed_weights_inspector
# inspect fp16 packed weights
unpacked_fp16_weights = packed_weights_inspector.extract_fp16_fc_packed_weights(fp16_weight_blob_name)
# inspect int8 packed weights
unpacked_int8_weights, qparams = packed_weights_inspector.extract_int8_fc_packed_weights(int8_weight_blob_name)
```
Test Plan:
```
buck test mode/opt deeplearning/numeric_suite/toolkit/test:packed_weights_inspector_test
```
Reviewed By: amylittleyang
Differential Revision: D19724474
fbshipit-source-id: e937672b3722e61bc44c2587aab2288a86aece9a
Summary:
If using nn.functional avg_pool, stride is an optional arg. If not provided, it is set to kernel_size.
This PR fixes the export of avg_pool with default stride.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33017
Reviewed By: hl475
Differential Revision: D19759604
Pulled By: houseroad
fbshipit-source-id: b0352db6fbaf427f4cff9ba8a942efdeb39b6f02
Summary:
Fix internal error message due to old version of hypothesis
test_suite = self.load_tests()
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/__fb_test_main__.py", line 678, in load_tests
suite = loader.load_all()
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/__fb_test_main__.py", line 467, in load_all
__import__(module_name, level=0)
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/test_quantization.py", line 45, in <module>
hu.assert_deadline_disabled()
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/torch/testing/_internal/hypothesis_utils.py", line 322, in assert_deadline_disabled
assert settings().deadline is None
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/hypothesis/_settings.py", line 127, in __getattr__
raise AttributeError('settings has no attribute %s' % (name,))
AttributeError: settings has no attribute deadline
Test Plan: buck test mode/dev //caffe2/test:quantization -- --run-disabled runs successfully
Differential Revision: D19795232
fbshipit-source-id: ef1d8be20b4be30e1cfad4cd5019c4779a5f4568
Summary:
split requires an int input, however in tracing operators such as
size(axis) return a tensor, which is different behavior than when not
tracing. As such need to modify split to handle these cases.
Fixes https://github.com/pytorch/pytorch/issues/27551
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32493
Reviewed By: hl475
Differential Revision: D19538254
Pulled By: houseroad
fbshipit-source-id: c8623009de5926aa38685e08121f4b48604bd8c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33070
`start_method` parameter is intentionally ignored for `mp.spawn()`. Document this fact and point the user to `start_processes` if they want to use a different `start_method`.
Test Plan:
Warning message looks like:
```
main.py:8: UserWarning: This method only supports start_method=spawn (got: fork).
To use a different start_method use:
torch.multiprocessing.start_process(...)
warnings.warn(msg)
```
Reviewed By: ailzhang
Differential Revision: D19780235
fbshipit-source-id: 4599cd18c3ba6cc401810efe4f390290ffa8023b
Summary:
Currently, custom ops are registered for a specific opset version.
For example, all torchvision custom ops are registered for opset 11, and cannot be exported into higher opset versions. This PR extends op registration to higher opset versions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32943
Reviewed By: hl475
Differential Revision: D19739406
Pulled By: houseroad
fbshipit-source-id: dd8b616de3a69a529d135fdd02608a17a8e421bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32506
In this PR, we've introduced a `retain_graph` parameter to distributed
autograd similar to `torch.autograd.backward`.
In terms of design, this parameter is sent over RPC to all nodes and is used to
create the GraphTask on the local nodes. This enables us to run
`dist_autograd.backward()` multiple times in the same context.
The use case currently for this is to benchmark only the backward pass for
distributed autograd. We'd like to measure the QPS for the backward pass and as
a result, running a single forward pass and multiple backward passes in a loop
is one way to benchmark backward pass performance.
ghstack-source-id: 97868900
Test Plan: waitforbuildbot
Differential Revision: D19521288
fbshipit-source-id: 7ad8521059fd400d7b5a6ab77ce56e1927ced90a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33060
Noticed this when tracking down a partially-related SIGSEGV.
If inserting a non-present key into a memoized map, don't re-calculate it twice
(probably safer that way anyway).
ghstack-source-id: 97904485
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D19778008
fbshipit-source-id: 95b1d708c034a54b96a22ccbdffb24f72d08dffd
Summary:
the rand N like function had required args which were not being used.
As such modified the method signature to give default values so when
scripting does not provide these arguments which are not even being
used, no error is thrown.
Additionally modified the const checker for handling prim::Constant as
well
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32830
Reviewed By: hl475
Differential Revision: D19731715
Pulled By: houseroad
fbshipit-source-id: a3cacb3977eecb88b122e0ceb654fdbf1c8286c1
Summary:
Supporting the below case. Previously index for copy_ was only considered as constant integer, where as it could be a tensor input as well.
```python
class InPlaceIndexedAssignment(torch.nn.Module):
def forward(self, data, index, new_data):
data[index] = new_data
return data
data = torch.zeros(3, 4)
index = torch.tensor(1)
new_data = torch.arange(4).to(torch.float32)
torch.onnx.export(InPlaceIndexedAssignment(), (data, index, new_data), 'inplace_assign.onnx', opset_version=11)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32801
Reviewed By: hl475
Differential Revision: D19731666
Pulled By: houseroad
fbshipit-source-id: 08703fdccd817f901282e19847e259d93929e702
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32243
Following what gchanan proposed in #30480
- If the (logical) shapes of mean and std are broadcastable, we broadcast them for the output
Done in tensor iterator already.
- If the (logical) shapes of mean and std are not broadcastable and they have the same number of elements, we fall back to the old behavior (pick the shape of mean)
Done by reshape std to the same shape of mean.
- If the (logical) shapes of mean and std are not broadcastable and don't have the same number of elements, we error out.
Done by tensor iterator already.
Test Plan: Imported from OSS
Differential Revision: D19417087
Pulled By: glaringlee
fbshipit-source-id: 1c4bc7df923110a803620b9e2abd11a7151fc33e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31768
`DataParallel` creates replicas of the original `nn.Module` with the parameters duplicated onto the destination devices. Calling `backwards` will propagate gradients onto the original module parameters but calling `zero_grad` on the replica module doesn't clear the gradients from the parent module,
~breaking any model that uses `backward`-`zero_grad` in its `forward`. I fix this by patching the replica module so that `zero_grad` clears grads on the parent as well.~
However, any replica using backwards was broken anyway since the replica's parameters are not leaf nodes in autograd. So, we should raise a warning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32870
Differential Revision: D19730209
Pulled By: ezyang
fbshipit-source-id: cb9b2cb0c2e0aca688ce0ff3e56b40fbd2aa3c66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32495
Background
------------------------------
Previously, ninja was used to compile+link inline cpp_extensions and
ahead-of-time cpp_extensions were compiled with distutils. This PR adds
the ability to compile (but not link) ahead-of-time cpp_extensions with ninja.
The main motivation for this is to speed up cpp_extension builds: distutils
does not make use of parallelism. With this PR, using the new option, on my machine,
- torchvision compilation goes from 3m43s to 49s
- nestedtensor compilation goes from 2m0s to 28s.
User-facing changes
------------------------------
I added a `use_ninja` flag to BuildExtension. This defaults to
`True`. When `use_ninja` is True:
- it will attempt to use ninja.
- If we cannot use ninja, then this throws a warning and falls back to
distutils.
- Situations we cannot use ninja: Windows (NYI, I'll open a new issue
for this), if ninja cannot be found on the system.
Implementation Details
------------------------------
This PR makes this change in two steps. Please me know if it would be
easier to review this if I split this up into a stacked diff.
Those changes are:
1) refactor _write_ninja_file to separate the policy (what compiler flags
to pass) from the mechanism (how to write the ninja file and do compilation).
2) call _write_ninja_file and _run_ninja_build while building
ahead-of-time cpp_extensions. These are only used to compile objects;
distutils still handles the linking.
Change 1: refactor _write_ninja_file to seperate policy from mechanism
- I split _write_ninja_file into: _write_ninja_file and
_write_ninja_file_to_build_library
- I renamed _build_extension_module to _run_ninja_build
Change 2: Call _write_ninja_file while building ahead-of-time
cpp_extensions
- _write_ninja_file_and_compile_objects calls _write_ninja_file to only
build object files.
- We monkey-patch distutils.CCompiler.compile to call
_write_ninja_files_and_compile_objects
- distutils still handles the linking step. The linking step is not a
bottleneck so it was not a concern.
- This change only works on unix-based systems. Our code for windows
goes down a different codepath and I did not want to mess with that.
- If a system does not support ninja, we raise a warning and fall back
to the original compilation path.
Test Plan
------------------------------
Adhoc testing
- I built torchvision using pytorch master and printed out the build
commands. Next, I used this branch to build torchvision and looked at
the ninja file. I compared the ninja file with the build commands and
asserted that they were functionally the same.
- I repeated the above for pytorch/nestedtensor.
PyTorch test suite
- I split `test_cpp_extensions` into `test_cpp_extensions_aot` and
`test_cpp_extensions_jit`. The AOT (ahead-of-time) version tests
ahead-of-time and the JIT version tests just-in-time (not to be confused
with TorchScript)
- `test_cpp_extensions_aot` gets run TWICE by run_test.py, once with
a module that was built with ninja, and once with a module that was
built without ninja.
- run_test.py asserts that when we are building with use_ninja=True,
ninja is actually available on the system.
Test Plan: Imported from OSS
Differential Revision: D19730432
Pulled By: zou3519
fbshipit-source-id: 819590d01cf65e8da5a1e8019b8b3084792fee90
Summary:
This will allow us to incrementally enable more tests for scripting as we put in fixes. houseroad spandantiwari
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32654
Reviewed By: hl475
Differential Revision: D19583401
Pulled By: houseroad
fbshipit-source-id: 8dc05e4784df819c939dffdf33b00cbb80bfa364
Summary:
Stacked PRs
* #32958 - Make zip serialization the default
* **#32244 - Fix some bugs with zipfile serialization**
It includes the following changes:
* Split up tests so that we can test both serialization methods
* Loading something within a buffer doesn't work anymore, so those tests are only on the old serialization method (it's possible but introduces a big slowdown since it requires a linear scan of the entire zipfile to find the magic number at the end)
* Call `readinto` on a buffer if possible instead of `read` + a copy
* Disable CRC-32 checks on read (there was some issue where miniz said the CRC was wrong but `zipinfo` and `unzip` said the zip file was fine)
](https://our.intern.facebook.com/intern/diff/19418935/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32244
Pulled By: driazati
Reviewed By: eellison
Differential Revision: D19418935
fbshipit-source-id: df140854f52ecd04236225417d625374fd99f573
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32895
When a particular rank calls `ncclCommAbort` on a communicator, it is
important to ensure all other ranks call `ncclCommAbort` on their respective
communicators. If this is not done, the other ranks could get stuck causing the
GPU to spin with 100% utilization.
To alleviate this issue, whenever any rank calls `ncclCommAbort` we put the
unique communicator id in the store. The NCCL watchdog thread then monitors the
store and aborts any communicators found in the store as "aborted".
A few more general fixes in this PR:
1) Use std::shared_ptr for the store in PrefixStore. PrefixStore was using a
reference to the store and when that reference went out of scope the store
object it was holding onto was invalid. This caused a segfault in the watchdog
thread.
2) Enhanced logging for the watchdog thread.
Test Plan: waitforbuildbot
Differential Revision: D19638159
fbshipit-source-id: 596cd87c9fe6d4aeaaab4cb7319cc37784d06eaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32941
The Python grammar allows single-statement one-line functions. So we
should allow it in the string parser.
Test Plan: Imported from OSS
Differential Revision: D19704153
Pulled By: suo
fbshipit-source-id: 8c06cc9c600aa2a9567b484a1ecc0360aad443e3
Summary:
Enabling the RCCL test on rocm by adding a temporary grace period to clean up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32340
Differential Revision: D19744459
Pulled By: xw285cornell
fbshipit-source-id: 1af3b64113a67f93e622d010ddd3020e5d6c8bc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32982
For masked_scatter_ and masked_fill_ (which already have manually written wrappers), move the broadcasting logic into the manually written wrappers.
Test Plan: Imported from OSS
Differential Revision: D19726830
Pulled By: gchanan
fbshipit-source-id: 1f6e55e19c1314a76e43946b14d58f147c0f8204
Summary:
The way we currently dispatch argmax/argmin to out-of-source devices is bad and caused issues, e.g it doesn't work well when the input requires grad. https://github.com/pytorch/xla/issues/1585.
Making argmax/argmin dispatch at device level resolves it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32961
Differential Revision: D19726826
Pulled By: ailzhang
fbshipit-source-id: f7fb445fd8e7691524afcc47d24d8e6b0171d10c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32788
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628643
Pulled By: ezyang
fbshipit-source-id: 7099b08eff37913144b961dda00b070bd4b939d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32787
Gets rid of a longstanding TODO. TensorList unwrap is only used for cat, which
means we can assume that the inputs are dense, and do something similar to how
we do the dense tensor wrapping above.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628642
Pulled By: ezyang
fbshipit-source-id: 3264439407585fb97995a9a2302c2913efecb421
Summary:
The PR https://github.com/pytorch/pytorch/pull/31791 adds support for float[] constant, which affects some cases of ONNX interpolate support.
This PR adds float[] constants support in ONNX, updates interpolate in ONNX, and re-enable the disabled tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32554
Reviewed By: hl475
Differential Revision: D19566596
Pulled By: houseroad
fbshipit-source-id: 843f62c86126fdf4f9c0117b65965682a776e7e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32936
Closes https://github.com/pytorch/pytorch/issues/32732. Currently if a
UDF run in RPC throws an exception such as ValueError or TypeError, we wrap
this in a RemoteException on the callee side. When raising this on the caller
side, we currently raise a vanilla Exception. This diff changes it so that the
correct exception is thrown. Tested by changing the current rpc tests to assert
on the right type of error rather than just the base `Exception`.
ghstack-source-id: 97706957
Test Plan: Modified unit test.
Differential Revision: D19700434
fbshipit-source-id: e451b772ea6aecc1d2e109e67e7f932eb9151f15
Summary:
Checks the size of each tensor passed to `torch.stack` before calling `cat` to address https://github.com/pytorch/pytorch/issues/29510. This is done in the `get_stack_input` function as that is a common path. The function now compares the size of each tensor in the TensorList to the size of the first tensor and throws an exception when the sizes are not equal.
To compare:
```
x = torch.zeros([1, 2])
y = torch.zeros([1, 3])
torch.stack([x, y]) # Errors due to size differences
```
Current error:
```
RuntimeError: invalid argument 0: Sizes of tensors must match
except in dimension 0. Got 2 and 3 in dimension 2 at (path)\aten\src\TH/generic/THTensor.cpp:612
```
New error:
```
RuntimeError: stack expects each tensor to be equal size, but
got [1, 2] at entry 0 and [1, 3] at entry 1
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32931
Differential Revision: D19700110
Pulled By: ezyang
fbshipit-source-id: 7e18bb00fa2c137e418e340d719b6b76170b83e3
Summary:
It was causing a build error when compiling on MINGW64
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32015
Differential Revision: D19697296
Pulled By: ezyang
fbshipit-source-id: 71e58783c48f8e99755c091b2027d59740dfca47
Summary:
Closes gh-31771
Also note that the `epoch` attribute is *only* used as a manual seed in each iteration (so it could easily be changed/renamed). Seeding consecutive iterations with `[0, 1, 2, ...]` is low-entropy, however in practice it probably doesn't matter when using the sampler in combination with a dataloader (because there won't be enough data nor epochs to run into statistical issues
due to low-entropy seeding). So leaving that as is.
Rendered docstring:
<img width="534" alt="image" src="https://user-images.githubusercontent.com/98330/73701250-35134100-46e9-11ea-97b8-3baeb60fcb37.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32951
Differential Revision: D19729333
Pulled By: ezyang
fbshipit-source-id: 3ddf90a3828b8bbae88aa2195a5d0b7d8ee1b066
Summary:
two instances of if -> it in torch.nn.modules.batchnorm.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29797
Differential Revision: D19698613
Pulled By: ezyang
fbshipit-source-id: 7312b2333f227113e904dfa91db90d00e525affb
Summary:
TensorBoard tests using SummaryWriter() may fail with a pandas import
complaint if TensorFlow packages are installed in the same python
environment as PyTorch:
Traceback (most recent call last):
File "test_tensorboard.py", line 212, in test_writer
with self.createSummaryWriter() as writer:
File "test_tensorboard.py", line 64, in createSummaryWriter
return SummaryWriter(temp_dir)
...
File "[...]/site-packages/pandas/core/arrays/categorical.py", line 52, in <module>
import pandas.core.algorithms as algorithms
AttributeError: module 'pandas' has no attribute 'core'
The exact failure may depend on the pandas version. We've also seen:
File "[...]/site-packages/pandas/core/arrays/categorical.py", line 9, in <module>
import pandas.compat as compat
AttributeError: module 'pandas' has no attribute 'compat'
The module import chain leading to the failure is tensorboard imports
tensorflow imports tensorflow_estimator imports pandas. pandas includes
a submodule named 'bottleneck', whose name collides with the PyTorch
'test/bottleneck/' subdirectory.
So IF tensorboard, tensorflow, tensorflow_estimator, and pandas are
installed in the python environment AND IF testing is run from within
PyTorch's 'test/' directory (or maybe just with 'test/' in PYTHONPATH,
etc.), then TensorBoard tests using SummaryWriter() will fail.
Rename the 'bottleneck/' directory slightly to avoid the name collision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29650
Differential Revision: D19698638
Pulled By: ezyang
fbshipit-source-id: cb59342ed407cb37aefc833d67f768a8809129ac
Summary:
With fedora negativo17 repo, the cudnn headers are installed in /usr/include/cuda directory, along side with other cuda libraries.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31755
Differential Revision: D19697262
Pulled By: ezyang
fbshipit-source-id: be80d3467ffb90fd677d551f4403aea65a2ef5b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32897
Moving the default static instance into the method to achieve the same purpose.
ghstack-source-id: 97570792
Test Plan: - CI
Reviewed By: dreiss
Differential Revision: D19674566
fbshipit-source-id: 27f54da66dd7667c34905eddaac6579e64aa1118
Summary:
Understanding which ops return views and which return tensors with new storage is a common user issue, and an issue for developers connecting accelerators to PyTorch, too. This generic test suite verifies that ops which should return views do (and a few ops that shouldn't don't). The documentation has also been updated for .t(), permute(), unfold(), and select() to clarify they return views.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32512
Differential Revision: D19659454
Pulled By: mruberry
fbshipit-source-id: b4334be9b698253a979e1bb8746fdb3ca24aa4e3
Summary:
1. Allows both the memory_format of weight & input to dictate the output
memory_format.
2. Provides utility function to recursively convert memory_format of Conv2d and
ConvTranspose2d layers. This allows easy model conversion and ensures that lost
memory_format through incompatible layers could be restored at Convolution-like
layer, where significant performance boost is expected on later generation CUDA
devices.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32482
Differential Revision: D19647903
Pulled By: VitalyFedyunin
fbshipit-source-id: 62c96ff6208ff5e84fae1f55b63af9a010ad199a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32888
This kills ~1500 lines of generated code by doing the following:
1) Stop binding _th_clone, which isn't used anymore.
2) Move allocation code out of the switch, because it doesn't need to be there, example:
Now:
```
auto dispatch_scalar_type = infer_scalar_type(self);
auto result_ = c10::make_intrusive<TensorImpl, UndefinedTensorImpl>(c10::Storage(scalarTypeToTypeMeta(dispatch_scalar_type), 0, allocator(), true),DispatchKey::CPUTensorId).release();
auto result = Tensor(c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl>::reclaim(result_));
switch (dispatch_scalar_type) {
case ScalarType::Bool: {
...
case ScalarType::Byte: {
...
```
Before:
```
auto dispatch_scalar_type = infer_scalar_type(self);
switch(dispatch_scalar_type) {
case ScalarType::Bool: {
auto result_ = c10::make_intrusive<TensorImpl, UndefinedTensorImpl>(caffe2::TypeMeta::Make<bool>(), 0, allocator(), true),DispatchKey::CPUTensorId).release();
auto result = Tensor(c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl>::reclaim(result_));
case ScalarType::Byte: {
auto result_ = c10::make_intrusive<TensorImpl, UndefinedTensorImpl>(caffe2::TypeMeta::Make<byte>(), 0, allocator(), true),DispatchKey::CPUTensorId).release();
auto result = Tensor(c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl>::reclaim(result_));
```
Note there's one extra lookup from ScalarType -> TypeMeta, but that can go away once we are able to put everything in a dispatch macro.
3) Prepare for more moves out of the switch by using dispatch_scalar_type where we would have used an explicit ScalarType::Name
More moves are currently blocked by "real" types needing to map scalar_type -> C++ type. Dispatch macros can solve that, but I'll need to wrap the actual TH calls in templates so the entire
thing can be done via dispatch.
4) Kill some codegen that isn't used anymore: ALLOC_WRAP, is_actual_return_long.
Test Plan: Imported from OSS
Differential Revision: D19672613
Pulled By: gchanan
fbshipit-source-id: 753f480842d11757e10182e43b471bd3abaa5446
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32952
When the Async() version of clearAndWaitForOutstandingRpcs() was written,
we didn't yet have the generic Future<T> class, and hadn't worked out our
error model fully.
This change fixes that method to properly propagate the first encountered error
to the future, using a bool+CAS.
ghstack-source-id: 97665749
Test Plan: existing test coverage, buck test mode/dev-nosan caffe2/test/...
Differential Revision: D19710337
fbshipit-source-id: 66ce5593a94a16ea624930dbb9409917ef5cfd5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32935
Mock away the content of onnxified net with some low cost ops so that we can still mimic the input/output transfer while doing minimal work on the card.
Test Plan:
```
buck run glow/fb/test:sparsenn_test -- --gtest_filter='SparseNNTest.vanillaC2' --onnxifi_debug_mode --onnxifi_loop_test_mode --nocaffe2_predictor_use_memonger
```
Differential Revision: D19631971
fbshipit-source-id: f970c55ccb410702f479255eeb750e01e3f8c2ae
Summary:
Should fix https://github.com/pytorch/pytorch/issues/32346 hopefully. Now when _flat_weights list is updated, `None` elements are appended to it if some weights are missing, subsequent `setattr` calls for the missing weights should repair _flat_weights and make it suitable to use in the backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32939
Differential Revision: D19710990
Pulled By: ngimel
fbshipit-source-id: c978c7519464e94beeffa9bc33b9172854a2f298
Summary:
The default value is removed because it is explained right below.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32945
Reviewed By: soumith
Differential Revision: D19706567
Pulled By: ailzhang
fbshipit-source-id: 1b7cc87991532f69b81aaae2451d944f70dda427
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32907
All op-specific information used in this logic was available to the
parser itself, so the check can be done in that context, no codegen
needed.
No change in the warning behavior itself, mod minor formatting tweak -
passes existing tests. Saves like ~275K binary size on mac:
```
-rwxr-xr-x 1 bhosmer 1876110778 16502064 Feb 1 00:43 torch/lib/libtorch_python.dylib
-rwxr-xr-x 1 bhosmer 1876110778 16247888 Feb 1 00:44 torch/lib/libtorch_python.dylib
```
[codegen diff](https://github.com/bhosmer/scratch/compare/deprecation_warning_before...deprecation_warning_after)
More important than the size savings is the minimization of codegen. Ideally the generated artifact should express distinctive per-op properties in as minimal a form as practically possible - e.g. here instead of generating check-and-warn behavior into every binding, we generate only the data that triggers the behavior in the parser. (And actually we were generating it already.)
Test Plan: Imported from OSS
Differential Revision: D19679928
Pulled By: bhosmer
fbshipit-source-id: cf0140573118430720c6b797c762fe5be98acd86
Summary:
The `BatchNorm*` part of the issue (see gh-12013) seems to have been fixed in the master branch and these tests would make it concrete.
However I would appreciate comments on https://github.com/pytorch/pytorch/issues/12013#issuecomment-575871264 on whether the current behaviour is satisfactory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32384
Differential Revision: D19704154
Pulled By: ngimel
fbshipit-source-id: 1bbbbf1ae1215a460b22cf26e6b263e518ecf60b
Summary:
SpatialBNFakeLoweredFp16NNPI
this is the fake operator for SpatialBN that gets lowered into add/mul/div, etc.
Test Plan: test_spatialbn
Reviewed By: tracelogfb, amylittleyang
Differential Revision: D19658680
fbshipit-source-id: 2abddbcd9a2023ac75c494f20eaac2051b7139dc
Summary:
Fix for constant folding flaky tests
Looks like the constant folding test modules are sometimes exported with ONNX_ATEN op export type, which is causing the CI failures.
I'm unable to repro this issue locally, but my guess is that the op export param is being overwritten on CI build at some point.
This PR sets the op export type and hopefully fixes the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32546
Reviewed By: hl475
Differential Revision: D19606919
Pulled By: houseroad
fbshipit-source-id: 31793d6857bbbf99b43b4a7c22a045a56ae19e44
Summary:
e.g. `tensor[torch.tensor([0, 1, 0], dtype=torch.bool)]`
Previously the mask is of type uint8. Both uint8 and bool should be supported for export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32445
Reviewed By: hl475
Differential Revision: D19610713
Pulled By: houseroad
fbshipit-source-id: 8df636e0c3cb0b82919a689242a962c79220209c
Summary:
I noticed the description of the initialization of convolutional modules is inconsistent with the actual implementation. There are two such cases:
1) `k` in the initialization of ConvTranspose modules is not dependent on the input channels but on the output channels (`kaiming_uniform_` uses the size of the second dimension of `weight` which is transposed in the first two dimensions).
2) Both the normal convolutions and the transposed ones use `k` divided by `groups`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30079
Differential Revision: D19698511
Pulled By: ezyang
fbshipit-source-id: 1ba938fbbd97663eaf29fd1245872179d2761fff
Summary:
* New ops supported for exporting.
* Updates on support for tensor indexing and dynamic list of tensors.
* lara-hdr, spandantiwari Should we also include updates on torchvision support in this page?
cc houseroad, neginraoof Please review if I have missed anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32805
Reviewed By: hl475
Differential Revision: D19635699
Pulled By: houseroad
fbshipit-source-id: b6be4fce641f852dcbceed20b4433f4037d8024a
Summary:
The need for this is felt because sometimes we change a build script and change the `std=c++XX` flag, which does not get caught until the compilation has progressed for a while.
https://github.com/pytorch/pytorch/issues/31757
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32819
Differential Revision: D19697205
Pulled By: ezyang
fbshipit-source-id: b045a1d15e24c4c6007b5d1464756051d32bf911
Summary:
This PR fixes type hints for `torch.optim.optimizer.Optimizer` object, issue also reported in https://github.com/pytorch/pytorch/issues/23731
To test things I used following optimiser implementation, that is fully covered with type hints:
```python
from typing import Optional, Callable, Union, Iterable
from torch import Tensor
from torch.optim.optimizer import Optimizer
OptClosure = Optional[Callable[[], float]]
_params_t = Union[Iterable[Tensor], Iterable[dict]]
class SGD(Optimizer):
def __init__(self, params: _params_t, lr: float = 0.1) -> None:
defaults = dict(lr=lr)
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state: dict) -> None:
super(SGD, self).__setstate__(state)
def step(self, closure: OptClosure = None) -> Optional[float]:
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
p.data.add_(-group['lr'], d_p)
return loss
```
Without fix `mypy` reports bunch of inconsistencies in types and missing properties:
```bash
$ mypy torch_optimizer/sgd.py
torch_optimizer/sgd.py:14: error: Too many arguments for "__init__" of "Optimizer"
torch_optimizer/sgd.py:17: error: "__setstate__" undefined in superclass
torch_optimizer/sgd.py:19: error: Return type "Optional[float]" of "step" incompatible with return type "None" in supertype "Optimizer"
torch_optimizer/sgd.py:24: error: "SGD" has no attribute "param_groups"
Found 4 errors in 1 file (checked 1 source file)
```
with fix not issues:
```bash
$ mypy torch_optimizer/sgd.py
Success: no issues found in 1 source file
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32900
Differential Revision: D19697175
Pulled By: ezyang
fbshipit-source-id: d5e2b3c421f69da3df8c32b3d53b4b6d15d61a41
Summary:
Add `torch.jit.is_scripting` to the list of CondValues, or values that if they are an input to a if statement we only compile one side of the if. I'm not sure if we actually want this PR.
Pros:
- Makes it easier to add features that are not yet supported in TorchScript (like has_torch_function)
- The current idiom of writing `torch.jit.is_scripting` and factoring out the block to a function annotated with `torch.jit.ignore` is functionally equivalent and much more cumbersome
Cons:
- Makes it easier to add features that are not yet supported in TorchScript
- Perhaps is confusing as a reader what is being compiled. Potentially could give all caps name or otherwise change name to make it more visually stand out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32871
Differential Revision: D19670383
Pulled By: eellison
fbshipit-source-id: 5257b0bd23c66f199d59a7f2c911e948301e5588
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32847
Add support for join on List of strings in TorchScript.
Test Plan:
(pytorch) smummadi@smummadi-mbp pytorch % python test/test_jit_string.py
Fail to import hypothesis in common_utils, tests are not derandomized
.
Ran 1 test in 1.090s
OK
Differential Revision: D19650809
fbshipit-source-id: 387a8f0e3cc3111fd3dadd3d54c90fc8c7774cf9
Summary:
Closes https://github.com/pytorch/pytorch/issues/27368.
Previously, if a function `'func` did not exist on worker A but existed in B, and the user ran `rpc.rpc_sync(A, func)`, A would crash with a segmentation fault since it is not able to find the function. B would eventually timeout since RPCs by default time out in 60s.
At the root this comes from an unhandled exception when trying to deserialize the `PythonUDF` to run.
This PR makes it so that we can recover from this error, and A reports back a `RemoteException` to B indicating that the function was not found. Now, A will no longer crash and B can handle the exception appropriately and with more information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32726
Differential Revision: D19648825
Pulled By: rohan-varma
fbshipit-source-id: 53847f4bfb68187db41c61d69ddac13613e814b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32749
The test was flaky since the message from owner RRef confirming fork would arrive after the test checked whether the pending User RRefs map was empty - leading to an assertion error. This diff creates a utility function that should be used by any test to wait for this message to complete processing before doing any assertions related to the pending User RRefs map.
GitHub Issue: https://github.com/pytorch/pytorch/issues/30988
Test Plan: Stress tested `test_rref_context_debug_info` 200 times.
Differential Revision: D19612289
fbshipit-source-id: 57a7c19b1cf792b94c263d3efbbbb6da60c07d07
Summary:
Power and x86 are giving slightly different results when scaling images up using `torch.nn.functional.interpolate` and when using OpenCV's `resize`. This is causing `test_upsampling_not_recompute_scale_factor` to fail on Power, but not x86. This changes the expected value to what OpenCV on Power produces if the test case is running on Power as well.
See https://github.com/pytorch/pytorch/issues/31915
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32786
Differential Revision: D19672053
Pulled By: ezyang
fbshipit-source-id: 3497f852bdc6d782646773792f9107c857c7b806
Summary:
If there was a namedtuple with immutable constant inputs, that was also the input / output of a function which expected a namedtuple it would fail. Fix by using namedtuple constructor on serialization. (no one has run into this bug yet).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32873
Differential Revision: D19668807
Pulled By: eellison
fbshipit-source-id: bae33506e53b6a979b4e65a3e7c989b1408c98f4
Summary:
This PR solves Issue https://github.com/pytorch/pytorch/issues/32750.
- Changes function prod_kernel_impl to use `out_t` argument instead of `scalar_t` (which caused the garbage output for FP16 input and FP32 output tensor type).
- Adds test case for `torch.prod` (for CUDA): tests both `torch.prod` and `torch.tensor.prod`. Checks all the combinations for dtypes: `torch.float16` and `torch.float32`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32831
Differential Revision: D19664666
Pulled By: ngimel
fbshipit-source-id: c275363355c832899f10325043535949cd12b2f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32738
This is to simplify the codegen layer, with the goal of making it simple enough to just check in.
Test Plan: Imported from OSS
Differential Revision: D19610927
Pulled By: gchanan
fbshipit-source-id: 760734f579b1f655775e6d270918c361985f3743
Summary:
To suppress a clang-tidy warning:
torch/csrc/jit/script/builtin_functions.cpp#L89
[performance-for-range-copy] warning: loop variable is copied but only
used as const reference; consider making it a const reference
Also make the const qualifier of scalar explicit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32852
Differential Revision: D19663277
Pulled By: ezyang
fbshipit-source-id: f4ec5688d3cbea9a5f40db6063b7d111b0bf0cce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32849
We learned that Android NDK's gcc + gnustl combination might produce a
use-after-free for thread_local variables with non-trivial destructors.
This PR removes such a thread_local use case from error_report.cpp for mobile build,
which is the only case included in mobile lite-JIT build.
ghstack-source-id: 97491327
Test Plan: - CI
Reviewed By: dreiss
Differential Revision: D19652702
fbshipit-source-id: ee8d316ad5c6e6c8a8006eb25f3bba1618dd7e6d
Summary:
I didn't see any use case where the functor of `gpu_kernel_with_index` needs to have argument other than the index. Merge conflict with https://github.com/pytorch/pytorch/pull/32755.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32777
Differential Revision: D19646381
Pulled By: ngimel
fbshipit-source-id: 81d2be74170457e39943274e3689845e83758bfa
Summary:
The Python document <https://www.python.org/dev/peps/pep-0263/> gives
all examples using lowercase letters. Although it doesn't say
straightly, the following paragraph seems to indicate that uppercase
letters aren't legitimate:
> If a source file uses both the UTF-8 BOM mark signature and a magic encoding comment, the only allowed encoding for the comment is 'utf-8'. Any other encoding will cause an error.
My Emacs also complains about the uppercase letters every time I save
the file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32850
Differential Revision: D19663281
Pulled By: ezyang
fbshipit-source-id: 48127d3c2fd6e22dd732a2766913735136ec2ebc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32771
It's a patch to #32621, make the api private.
Test Plan: Imported from OSS
Differential Revision: D19657307
Pulled By: iseeyuan
fbshipit-source-id: e604a0cbed6a1e61413daaafc65bea92b90f1f5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32753
Functions to be bound as an Aten operator could not have Python dependency.
This is to refactor and remove Python dependency.
ghstack-source-id: 97485800
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_script_functions_not_supported
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_script_functions_not_supported
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck-out/gen/caffe2/test/distributed/rpc/dist_autograd_fork\#binary.par -r test_backward_simple_script_call
```
Differential Revision: D5741675
fbshipit-source-id: 31ee60955be8d815d0773f3699e3ff2f1f9d8849
Summary:
Make batch norm with empty inputs return zero parameter gradients. Now batch norm, group norm and convolutions now return zero grads for parameters, so make tests check that. Fixes some bullet points in https://github.com/pytorch/pytorch/issues/12013 (interpolate is not fixed by this PR, is being fixed in other PRs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32820
Differential Revision: D19651470
Pulled By: ngimel
fbshipit-source-id: 96fdd085f9b0e98e91217dd2ac1f30f9c482b8be
Summary:
Remove `needs_dynamic_casting` from TensorIterator and move it to `Loops.cuh`.
The original design of `needs_dynamic_casting` is fundamentally flawed: it injects logics into TensorIterator and uses a bunch of boolean values to test whether the dynamic casting is needed. This makes it very fragile, as the TensorIterator is so complicated and it is easy to introduce unnecessary dynamic casts. It also makes the `gpu_kernel` very unflexible, differently cases needs to manipulate TensorIterator to make it work.
For example, currently
```python
torch.zeros(10, device='cuda').mul_(0.9)
```
needs dynamic cast, but it shouldn't.
Testing whether dynamic casting is needed could be easy: just compare the dtypes of the lambda with the dtypes of operands. If they don't match, then dynamically cast, otherwise don't cast.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32755
Differential Revision: D19644092
Pulled By: ngimel
fbshipit-source-id: 130bb8bd78d20c2ed1bdfc9d9fb451eb0f0c7e55
Summary:
Should fix https://github.com/pytorch/pytorch/issues/29744 by falling back to native batch norm implementation, if cudnn cannot execute the provided shape.
Shape numbers were verified for cudnn 7.6.5.32 with tensor shapes:
```python
# for spatial bn
x = torch.Size([880801, 256, 5])
x = torch.Size([65535, 256, 5])
x = torch.Size([880801, 64, 4, 4])
x = torch.Size([65535, 64, 4, 4])
# for per-act bn
x = torch.Size([131070, 2048])
x = torch.Size([262136, 2048])
```
for `training()` and `eval()` mode using `torch.float32` and `torch.float16`.
I've increased the shape of our current smoke test to, but I can also add all use cases of the support matrix, if wanted.
CC ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32763
Differential Revision: D19644328
Pulled By: ngimel
fbshipit-source-id: c2151bf9fe6bac79b8cbc69cff517a4b0b3867aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32843
fix the ci by skipping aten::join
Test Plan: ci
Reviewed By: hl475
Differential Revision: D19650584
fbshipit-source-id: 4446eef568ded334217ff9205a795daffebe41a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32734
VariableTensorId is the only key with this treatment today,
but BackendSelect and CompoundOp are coming soon.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628091
Pulled By: ezyang
fbshipit-source-id: 250753f90528fa282af7a18d8d2f7736382754bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32729
When working on the vmap prototype I noticed that this was helpful
as it lets me easily initialize a no-op guard, if I need to do it
at constructor time (which I usually do, because the guards don't
have move constructors).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628092
Pulled By: ezyang
fbshipit-source-id: d6259a3f70d287cdac2e4a5f3984e2880f19bdc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32728
It doesn't have much to do with tensors anymore.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628093
Pulled By: ezyang
fbshipit-source-id: 4d57111cdf44ba347bec8a32bb5b4b47a83c1eaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32807
After this commit, RRefContext no longer depends on pybind.
Test Plan: Imported from OSS
Differential Revision: D19636316
Pulled By: mrshenli
fbshipit-source-id: 88faa101c32e9019e979ae8e5da6706e49842726
Summary:
This PR updates how RNNs handle their "flat weights." In particular, it allows for only some flat weights to be "materialized" when apply is called, and it updates the flattening behavior to only apply if all flat weights are (1) materialized, (2) share a dtype and (3) are acceptable to cuDNN.
One test is modified and another created to test these changes. One practical effect of this change is that weight norm can be successfully applied to a module BEFORE that module is moved to an accelerator. Previously doing so would throw an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32563
Differential Revision: D19602725
Pulled By: mruberry
fbshipit-source-id: d8f9441d17815c8c9ba15b256d4be36f784a3cf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32574
Previously, we ignored alias annotations when deriving argument mutability
and instead recognized particular signature patterns (in-place, out variant)
and assigned mutability accordingly. Op signatures that didn't fit these
patterns would error (e.g. see #30526, which this fixes).
No change in the generated binding code.
Code changes:
1. in function_wrapper.py, fix the mutability derivation logic used when creating an argument's c++ type property. Note that we temporarily need to trap a special case and apply the old logic, see code comment for details.
2. in gen_jit_dispatch.py, update logic that assumed only one mutable Tensor argument per declaration. Happily this mostly was accomplished by bypassing some now-redundant signature regeneration machinery. Another special case here requires that we keep the old machinery around temporarily.
Test Plan: Imported from OSS
Differential Revision: D19564875
Pulled By: bhosmer
fbshipit-source-id: 5637a9672923676d408c9586f3420bcc0028471a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29986
Previously in addition to generating a python binding for each op,
we would generate an almost-trivial helper for each overload.
This PR eliminates the helpers, simplifying codegen logic a bit and
reducing the source-level indirection by a step.
Perf should be unchanged.
codegen diff: 1f2f07fb60
Note: in the interests of keeping the diff contained, there's only
some light cleanup here beyond what's necessary for the codegen changes.
Plan is to do some more substantial refactoring in followup PRs that
leave generated code unchanged.
Test Plan: Imported from OSS
Differential Revision: D18567980
Pulled By: bhosmer
fbshipit-source-id: eb9a81babb4489abd470842757af45580d4c9906
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32785
Add PythonRpcHandler::handleExceptionWithGIL() so that in PyRRef::localValue(),
we don't need to release the GIL and re-acquire the following line.
ghstack-source-id: 97418465
Test Plan: existing test coverage
Differential Revision: D19626195
fbshipit-source-id: db694d04b078811f819626789e1e86f1b35adb5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32757
This PR updates the main quantize_dynamic API to use QNNPACK backend for mobile
Test Plan:
python test/test_quantization.py PostTrainingDynamicQuantTest.test_quantized_rnn
Imported from OSS
Differential Revision: D19632220
fbshipit-source-id: b4c51485c281d088524101b97c84dd806438b597
Summary:
when using scripting, there was an error in attempting to access a
specific element from within the size tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32652
Reviewed By: hl475
Differential Revision: D19610726
Pulled By: houseroad
fbshipit-source-id: bca49927bbe71dbe7e7d7edf301908fe79e089b5
Summary: Add support for join on List of strings in TorchScript.
Test Plan:
(pytorch) smummadi@smummadi-mbp pytorch % python test/test_jit_string.py
Fail to import hypothesis in common_utils, tests are not derandomized
.
----------------------------------------------------------------------
Ran 1 test in 1.090s
OK
Differential Revision: D19611800
fbshipit-source-id: cef66356abc14dfd100a806d25dd1a8bc9af0a11
Summary:
When running the ctr_mbl_feed, we've encountered hang issue related to the rendezvous handshake based on zeus. It was mitigated by this diff https://our.intern.facebook.com/intern/diff/D19167151/.
This diff resolves the race condition by adding a reference to the rendezvous handler.
Test Plan: x7340282797
Reviewed By: yifuwang
Differential Revision: D19627293
fbshipit-source-id: 560af289db8ef6cf8d6f101f95ec27d5a361fd04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32745
Some parameters (like `bias` in conv) are optional. To achieve this
previously, you had to add `bias` as a constant, which would invoke some
pretty weird behavior in the frontend, summarized as:
```
if bias is not None:
add it as a parameter normally
else: # bias is None
add it as a constant with the value None
```
There are several things bad about this:
1. Bias is not a constant. Marking it `__constants__` is confusing.
2. It basically relies on an implementation detail (the frontend
processes parameters before constants) to work.
Okay, whatever. I don't even know why we did this originally, but
getting rid of it doesn't break anything, so I assume improved NoneType
refinement has made this a non-issue.
Note on perf: this will make no difference; if bias was `None` it's still
folded out today, if bias is a Tensor it would be added as a parameter
both before and after this change
Test Plan: Imported from OSS
Differential Revision: D19628634
Pulled By: suo
fbshipit-source-id: d9128a09c5d096b938fcf567b8c23b09ac9ab37f
Summary:
resubmitting https://github.com/pytorch/pytorch/issues/32612 after a merge gone wrong. Enables convolution with an empty batch or number of channels for all flavors of convolution (grouped convolution, convTranspose). Would make https://github.com/pytorch/pytorch/issues/31658 unnecessary. Also returns zero gradients for the parameters, that's necessary for correct DDP operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32709
Differential Revision: D19627968
Pulled By: ngimel
fbshipit-source-id: 7359759bd05ff0df0eb658cac55651c607f1b59f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32683
Pull Request resolved: https://github.com/pytorch/glow/pull/4079
Similar to D17768404, we changed the EmbeddingBag operator for 8-bit fused version to add the option to include the last offset and parallelize the op.
ghstack-source-id: 97404645
Test Plan:
To generate the AVX2 code (`embedding_lookup_fused_8bit_rowwise_idx_avx2.cc`):
```
python hp_emblookup_codegen.py --fused --use-offsets
```
To test the correctness:
```
buck test //caffe2/torch/fb/sparsenn:test -- test_embedding_bag_byte_rowwise_offsets --print-passing-details
```
Reviewed By: yinghai
Differential Revision: D19592761
fbshipit-source-id: f009d675ea3f2228f62e9f86b7ccb94700a0dfe0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32704
-Werror is too aggressive check for test cpp extensions because it fails even on deprecation warnings which is are included from core codebase.
Fixes#32136
Test Plan: Imported from OSS
Differential Revision: D19620190
Pulled By: pbelevich
fbshipit-source-id: 0e91566eb5de853559bb59e68a02b0bb15e7341b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32116
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579875
Pulled By: ezyang
fbshipit-source-id: 00393c9dc101967c79231bfae36b23b7b80135fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32114
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579876
Pulled By: ezyang
fbshipit-source-id: d09a231ba891403a06eae0c2203e0ad7dd6d3a12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32112
It turns out we already removed these from the CPU version; copy
the changes over.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579874
Pulled By: ezyang
fbshipit-source-id: e40efbf94e128fd81421b227b76dd9c9c0256d96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32727
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19621858
Pulled By: ezyang
fbshipit-source-id: 5112c849252478d8249de4f8c8c5a2d6caf60672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32557
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579853
Pulled By: ezyang
fbshipit-source-id: 45f83a7a5ead0344e4c13526abb5fafdedaed4a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32533
Applies renames based on comments in #32439. I also updated some
other documentation and variable names while I was at it.
Fixes#32435.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579854
Pulled By: ezyang
fbshipit-source-id: 85021a92a2a84501f49ee5c16318f81f5df64f8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32043
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19621910
Pulled By: ezyang
fbshipit-source-id: dce00a56ff679548fd9f467661c3c54c71a3dd4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32748
This is to follow up PR #30630, we need to have GIL when calling jit::toPyObject(), for some binded functions need to be taged with GIL release if underneath C++ codes requires GIL. so
1. pyRef::to_here() and pyRef::local_value() added GIL
2. pyRef::pickle and pyRef::unpickle() added GIL release tag
3. in request_callback_impl, also added GIL as needed
4. for typeParser, use cached jitCompilationUnit_, also clean it up in cleanUp() function
ghstack-source-id: 97373011
Test Plan: unit test
Differential Revision: D19612337
fbshipit-source-id: 4d09f9b52ba626545ae7d31fea6b671301ed3890
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32567
As a first change to support proguard.
even if these methods could be not called from java, on jni level we register them and this registration will fail if methods are stripped.
Adding DoNotStrip to all native methods that are registered in OSS.
After integration of consumerProguardFiles in fbjni that prevents stripping by proguard DoNotStrip it will fix errors with proguard on.
Test Plan: Imported from OSS
Differential Revision: D19624684
Pulled By: IvanKobzarev
fbshipit-source-id: cd7d9153e9f8faf31c99583cede4adbf06bab507
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for CUDA complex numbers is here: [pytorch-cuda-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cuda-strided-complex)
Changes:
[x] Fixed performance issue raise in https://github.com/pytorch/pytorch/issues/30704 so that non-complex numbers do not call `conj()` and `real()`.
[x] Fixed tensor_to_numpy() conversion likely broken by a `checkBackend()` in https://github.com/pytorch/pytorch/issues/27064.
[x] Fixed some ReduceOps and TensorCompare Ops that recently added a `checkBackend()`.
- `checkBackend()` is replaced with a device type check and a layout check.
- This ensures the ComplexCPU Type ID is supported.
[x] Added AVX support for complex `exp()`, as requested in https://github.com/pytorch/pytorch/issues/755
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30871
Differential Revision: D19200726
Pulled By: ezyang
fbshipit-source-id: d7e1be0b0a89c5d6e5f4a68ce5fcd2adc5b88277
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32325
The purpose of this PR is to enable PyTorch dispatching on `at::Generator*` parameters and demonstrate how it can be used in cpp extensions to implement custom RNG.
1. `CustomRNGKeyId` value added to DispatchKey enum and `DispatchKeySet key_set_` added to `at::Generator`
2. The overloaded `operator()(at::Generator* gen)` added to MultiDispatchKeySet.
3. The existing CPUGenerator and CUDAGenerator class are supplied with CPUTensorId and CUDATensorId dispatch keys
4. The implementation of CPU's `cauchy_kernel`(as an example, because it's already moved to ATen) was templatized and moved to `ATen/native/cpu/DistributionTemplates.h` to make it available for cpp extensions
5. Minor CMake changes to make native/cpu tensors available for cpp extensions
6. RegisterCustomRNG test that demonstrates how CustomCPUGenerator class can be implemented and how custom_rng_cauchy_ native function can be registered to handle Tensor::cauchy_ calls.
Test Plan: Imported from OSS
Differential Revision: D19604558
Pulled By: pbelevich
fbshipit-source-id: 2619f14076cee5742094a0be832d8530bba72728
Summary:
These codes are implemented twice at different places by different people, we should merge them together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32730
Differential Revision: D19622023
Pulled By: ezyang
fbshipit-source-id: a9cbda31428b335bf28a7e4050f51f58e787b94f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32659
Applies linter to RPC test files so that we can use linter shortcuts
without getting unnecessary changes to the whole file.
ghstack-source-id: 97361237
Test Plan: No actual changes.
Differential Revision: D19584742
fbshipit-source-id: a11ce74ee0e2817e6f774fff7c39bcab06e99307
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32657
The goal here is to simplify the codegen enough that we can just handwrite the bindings, so anything in here is "bad".
Test Plan: Imported from OSS
Differential Revision: D19584521
Pulled By: gchanan
fbshipit-source-id: 93005b178228c52a1517e911adde2e2fe46d66a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32722
Checked using [this](https://godbolt.org/z/uAaE9R) that it gives the correct assembly.
Test Plan: Imported from OSS
Differential Revision: D19610012
Pulled By: albanD
fbshipit-source-id: 4d1cb812951ae03d412a0fba3c80730f0d286e1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32326
Now that we have type-level granularity we can improve `mayContainAlias` queries. Each new values is initialized as containing the wildcard set of each contained mutable type. Whenever a value is added to a container it is set to the wildcard set. Now, to check if any two values contain overlapping values, we can just check if the `containedMemoryLocations` of two sets overlap.
Test Plan: Imported from OSS
Differential Revision: D19563262
Pulled By: eellison
fbshipit-source-id: c6d7489749c14b2054a6d50ef75baca699ada471
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32251
Previously wildcard sets were associated by TypeKind, meaning all Lists were in one alias set, all Classes were in one alias set, etc. We can improve analysis by bucketing wildcard sets by TypePtr instead. Any two mutable types which can unify should be in the same wildcard set bucket.
This also allows us do much simpler `mayContainAlias` analysis, and also improves `analyzeConservative` analysis because now we can recurse through all contained memory locations and mark writes, instead of just recursing only level deep in contained elements.
Test Plan: Imported from OSS
Differential Revision: D19563263
Pulled By: eellison
fbshipit-source-id: 371a37d1a8596abc6c53f41c09840b6c140ea362
Summary: ATT. Since the infra is there.
Test Plan: run it
Reviewed By: amylittleyang
Differential Revision: D19605250
fbshipit-source-id: c68be4d7963afa4fa5f8f60c90f1913605eae516
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32501
This diff will address https://github.com/pytorch/pytorch/issues/24699
We ask the input `lambda` to be >= 0 to be same as https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.random.exponential.html#numpy-random-exponential. This does not exist in the previous implementation.
Benchmark I am using PT operator microbenchmark
```
================================================================================
Before the change, Program Output:
================================================================================
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: exponential_
# Mode: Eager
# Name: exponential__M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 21311.746
================================================================================
After the change, Program Output:
================================================================================
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: exponential_
# Mode: Eager
# Name: exponential__M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 20919.914
================================================================================
```
Test Plan: Sandcastle and Github tests
Reviewed By: BIT-silence
Differential Revision: D19518700
fbshipit-source-id: 0e79cb6a999c1278eb08b0d94cf61b119c85a36c
Summary:
Included the ONNX model checker code in the ONNX export
this will force onnx checker to run for all models that get exported.
This should help with validating exported models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32298
Reviewed By: hl475
Differential Revision: D19538251
Pulled By: houseroad
fbshipit-source-id: eb20b124fe59200048f862ddaf20f6c59a0174d5
Summary:
This method is pretty hot. In an internal workload, this single
call to at() accounted for ~2% of overall cycles.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31627
Reviewed By: yinghai
Differential Revision: D19607779
Pulled By: qizzzh
fbshipit-source-id: 1684919049a35fdad686d8396c7dce7243ab92d4
Summary:
Stacked PRs
* #32244 - Make zip serialization the default
* **#32241 - Split serialization tests to their own file**
This makes them all easier to run as a batch. This PR is just a code move / fixing up imports. There are still some serialization tests in `test_torch.py` as part of `TestDeviceType`.
](https://our.intern.facebook.com/intern/diff/19415826/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32241
Pulled By: driazati
Differential Revision: D19415826
fbshipit-source-id: a3f6cfe1626ff2f9b9631c409bf525bd32e4639b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32675
It's good to have one location to do the mapping.
Test Plan: Everything still runs.
Reviewed By: amylittleyang
Differential Revision: D19590354
fbshipit-source-id: d8c0d14e4bdf27da3e13bd4d161cd135d6e3822b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32656
Fixes these flaky tests.
Test Plan: Run the test 500 times and verify that it succeeds every time.
Differential Revision: D19584453
fbshipit-source-id: 07cbc4914211f274182ac0fa74bb5ef6d43392d1
Summary:
Both `test_wait_all_workers` and `test_wait_all_workers_and_shutdown` test the same pattern of initialize RPC, call `_wait_all_workers`, and `rpc.shutdown(graceful=False)`.
`test_wait_all_workers` seems to be more thorough since it tests one worker driving and the others waiting on it as well.
We shouldn't have duplicate test so removing this `test_wait_all_workers_and_shutdown`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32588
Differential Revision: D19566294
Pulled By: rohan-varma
fbshipit-source-id: b69519d169b3964649d47ad75532bda5de538241
Summary:
Done by just editing `.circleci/cimodel/data/dimensions.py` to include `3.8` and then regenerated using `.circleci/regenerate.sh`
cc kostmo, mingbowan, ezyang, soumith
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31948
Differential Revision: D19602069
Pulled By: seemethere
fbshipit-source-id: ac57fde9d0c491c7d948a3f5944c3cb324d403c0
Summary:
This handles a corner case when a user schedules second bailout after the first one and the first one doesn't fire.
Alternatively, we could go back to the implementation that uses a hash set to remember the indices of bailouts that need to fire.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32672
Differential Revision: D19596872
Pulled By: Krovatkin
fbshipit-source-id: 41dcc374cd2501ac20a9892fb31a9c56d6640258
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32621
Export the "_save_for_mobile" method to Python so that the bytecode format for lite interpreter can be added or updated to the original script model.
It's the first step of python binding for lite interpreter, as discussed in this [internal post](https://fb.workplace.com/groups/1144215345733672/permalink/1478900738931796/) and offline.
Next step is to export the load_for_mobile and run method of mobile module, so that users could verify the mobile model from Python.
Test: use the following python script to display the bytecode part of the updated model file.
```
#!/usr/bin/env python3
import sys
import pickle
import pprint
import zipfile
class FakeObject(object):
def __init__(self, module, name, args):
self.module = module
self.name = name
self.args = args
self.state = None
def __repr__(self):
state_str = "" if self.state is None else f"(state={self.state!r})"
return f"{self.module}.{self.name}{self.args!r}{state_str}"
def __setstate__(self, state):
self.state = state
class FakeClass(object):
def __init__(self, module, name):
self.module = module
self.name = name
self.__new__ = self.fake_new
def __repr__(self):
return f"{self.module}.{self.name}"
def __call__(self, *args):
return FakeObject(self.module, self.name, args)
def fake_new(self, *args):
return FakeObject(self.module, self.name, args)
class DumpUnpickler(pickle._Unpickler):
def find_class(self, module, name):
return FakeClass(module, name)
def persistent_load(self, pid):
return FakeObject("pers", "obj", (pid,))
def main(argv):
zfile = zipfile.ZipFile(argv[1])
names = [i for i in zfile.namelist() if "bytecode.pkl" in i]
if not names:
print("bytecode.pkl not found.")
return
with zfile.open(names[0], "r") as handle:
value = DumpUnpickler(handle).load()
pprint.pprint(value)
if __name__ == "__main__":
sys.exit(main(sys.argv))
```
Test Plan: Imported from OSS
Differential Revision: D19596359
Pulled By: iseeyuan
fbshipit-source-id: 19a4a771320f95217f5b0f031c2c04db7b4079a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32642
Previously, if we defined `__setstate__` but not `__getstate__`, we
would segfault. This PR turns that into a comprehensible error message
(and improves another error message as well).
Fixes https://github.com/pytorch/pytorch/issues/25886
Test Plan: Imported from OSS
Differential Revision: D19596463
Pulled By: suo
fbshipit-source-id: dbe76bc36bc747d65fb0223184c009e0e9ba072c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32653
This test was flaky since the watchdog thread could abort the
communicator instead of the thread calling `wait()`. As a result, we could
actually see `NCCL error` instead of `Operation timed out` on the user end.
ghstack-source-id: 97250714
Test Plan: waitforbuildbot
Differential Revision: D19583003
fbshipit-source-id: 5c07326d1a16f214dcdbabed97ca613e0a5b42b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32635
With the source of truth of current RPC agent moved to C++ world, there is no point of passing current RPC agent from Python world to C++ world.
ghstack-source-id: 97293316
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_process_group_debug_info
```
Differential Revision: D5703519
fbshipit-source-id: ef7c28bdb1efd293eb6cafe0b0fca7ca80fa08a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32633
There were 2 sources of current RPC agent.
- One is in Python world, `torch.distributedrpc.api._agent`.
- The other is in C++ world, `RpcAgent::defaultRpcAgent_`
Setting Python `_agent` to `None`, does not necessarily reset the C++ `defaultRpcAgent_` to `nullptr`.
i.e.
```
torch.distributedrpc.api._agent = None
```
does not translate to
```
RpcAgent::defaultRpcAgent_ = nullptr
```
This PR is to remove this ambiguity, and use the C++ pointer as source of truth.
The solution is to leverage a pybind11 behavior that it implicitly casts C++ `shared_ptr<RpcAgent>(nullptr)` to Python `None`.
ghstack-source-id: 97293315
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_duplicate_name
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_process_group_debug_info
```
```
buck test mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_remote_module
buck test mode/dev-nosan //caffe2/torch/fb/distributed/modules/tests:test_sharded_embedding
buck test mode/dev-nosan //caffe2/torch/fb/distributed/modules/tests:test_sharded_pairwise_attention_pooling
buck test mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_rpc
```
Differential Revision: D5733066
fbshipit-source-id: b3e6032ee975f19ca556497edbbf40b517b25be8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32624
We need this PR to resolve the issue mentioned in https://github.com/pytorch/pytorch/issues/31325#issuecomment-574918917.
The solution is for each `_wait_all_workers()` call, there is a sequence ID added, to identify different calls.
ghstack-source-id: 97277591
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_wait_all_workers
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_wait_all_workers
```
Differential Revision: D5739520
fbshipit-source-id: a64131e09c365179624700514422f5375afe803f
Summary:
This PR updates how RNNs handle their "flat weights." In particular, it allows for only some flat weights to be "materialized" when apply is called, and it updates the flattening behavior to only apply if all flat weights are (1) materialized, (2) share a dtype and (3) are acceptable to cuDNN.
One test is modified and another created to test these changes. One practical effect of this change is that weight norm can be successfully applied to a module BEFORE that module is moved to an accelerator. Previously doing so would throw an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32563
Differential Revision: D19562258
Pulled By: mruberry
fbshipit-source-id: 4fef006e32cdfd8e3e3d519fc2ab5fc203dd7b36
Summary:
This PR adds support for 0-dim batch size input for `torch.nn.functional.interpolate` for various modes of interpolation.
Fixes part of gh-12013
CC: rgommers ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32400
Differential Revision: D19557090
Pulled By: ezyang
fbshipit-source-id: 6822f148bb47bfbcacb5e03798bf2744f24a2a32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32476
This makes the handling of FORWARD_AUTOGRAD_REQ in request_callback
nonblocking. Processing this message requires unwrapping the message with
autograd information, processing the original message, and sending back the
message with autograd information wrapped. This makes the processing the
original message nonblocking by grabbing a future to it and marking the parent
future as completed when this one completes.
ghstack-source-id: 97221251
Test Plan: `test_rpc_spawn.py` and `test_dist_autograd_spawn.py` both pass.
Differential Revision: D19509501
fbshipit-source-id: 84ad2f9c5305ed11ed9bb0144b1aaf5f8698cd2b
Summary:
Changes the linspace functions to be more consistent as requested in https://github.com/pytorch/pytorch/issues/31991. The code has also been updated to avoid an early rounding error; the line `scalar_t step = (scalar_end - scalar_start) / static_cast<static_t>(steps-1)` can result in `step = 0` for integer scalars, and this gives unintended results. I examined the new output using
```
import torch
types = [torch.uint8, torch.int8, torch.short, torch.int, torch.long, torch.half, torch.float, torch.double]
print('Testing linspace:')
for type in types:
print(type, torch.linspace(-2, 2, 10, dtype=type))
```
which returns
```
Testing linspace:
torch.uint8 tensor([254, 254, 254, 255, 255, 0, 0, 1, 1, 2], dtype=torch.uint8)
torch.int8 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2], dtype=torch.int8)
torch.int16 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2], dtype=torch.int16)
torch.int32 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2], dtype=torch.int32)
torch.int64 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2])
torch.float16 tensor([-2.0000, -1.5557, -1.1113, -0.6670, -0.2227, 0.2227, 0.6660, 1.1113,
1.5547, 2.0000], dtype=torch.float16)
torch.float32 tensor([-2.0000, -1.5556, -1.1111, -0.6667, -0.2222, 0.2222, 0.6667, 1.1111,
1.5556, 2.0000])
torch.float64 tensor([-2.0000, -1.5556, -1.1111, -0.6667, -0.2222, 0.2222, 0.6667, 1.1111,
1.5556, 2.0000], dtype=torch.float64)
```
which is the expected output: `uint8` overflows as it should, and the result of casting from a floating point to an integer is correct.
This PR does not change the logspace function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32218
Differential Revision: D19544224
Pulled By: ngimel
fbshipit-source-id: 2bbf2b8552900eaef2dcc41b6464fc39bec22e0b
Summary:
This test case had been using the tensor
```
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
```
which is not an invertible tensor and causes the test case to fail, even if magma gets initialized just fine. This change uses a tensor that is invertible, and the inverse doesn't include any elements that are close to zero to avoid floating point rounding errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32547
Differential Revision: D19572316
Pulled By: ngimel
fbshipit-source-id: 1baf3f8601b2ba69fdd6678d7a3d86772d01edbe
Summary:
A constructor of `nn.Parameter` has default values on `data` and `requires_grad`, but in type stub, there are no default values.
Resolve https://github.com/pytorch/pytorch/issues/32481
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32617
Differential Revision: D19571397
Pulled By: ngimel
fbshipit-source-id: fd14298aa472b7575221229cecf5a56f8c84f531
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32451
This PR adds a few new parameters to ATen codegen script:
```
1. op_registration_whitelist
Can be used to filter op registrations for selective build;
2. type_whitelist
Can be used to filter types (CPUType, CUDAType, ...) for selective build;
3. per_op_registration
When set it will group function registrations by op name and write to separate files;
```
1 & 2 are introduced for mobile custom build without relying on static dispatch;
3 is introduced to solve custom build with multi-library / multi-model (needed by FB
internal build - see more details: https://fb.quip.com/ZVh1AgOKW8Vv).
These flags should work independently with each other (and independent to USE_STATIC_DISPATCH).
Not setting them should have no effect compared to master.
ghstack-source-id: 97214788
Test Plan: - tested all 3 params with FB internal build changes.
Differential Revision: D19427919
fbshipit-source-id: a381fe5f768fe2e9196563787f08eb9f18316e83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32275
Currently TypeDerived (e.g. `CPUType::`) methods are declared and
defined in anonymous namespace as they are only called from c10
dispatcher - except for STATIC_DISPATCH mode, where they can be directly
called from Functions.h.
We plan to generate c10 op registration into separate files for internal
xplat/BUCK build, thus we need declare these methods in non-anonymous
namespace.
I feel it's easier to simply change it unconditionally, unless there are
some side effect I'm not aware of - `TypeDefault::` methods are in
non-anonymous namespace anyway.
ghstack-source-id: 97214789
Test Plan: - CI
Differential Revision: D19426692
Pulled By: ljk53
fbshipit-source-id: 44aebba15f5e88ef4acfb623844f61d735016959
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32466
It's a follow-up work of https://github.com/pytorch/pytorch/pull/32197.
In https://github.com/pytorch/pytorch/pull/32197, `rpc.sync_rpc(..) `and `rpc.rpc_async(..)` support taking a TorchScript annotated Python function as the user function for RPC.
This PR extend along this direction by making `rpc.remote(..)` support taking a TorchScript annotated Python function as well.
ghstack-source-id: 97211168
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_script_function_exception
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_script_function_exception
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork -- test_backward_simple_script_call
buck build mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck-out/gen/caffe2/test/distributed/rpc/dist_autograd_fork\#binary.par -r test_backward_simple_script_call
```
Differential Revision: D19440633
fbshipit-source-id: d37f6dcdc0b80d35ac7bcba46ad6f9b831c3779b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32479
Run dynamic quantization on mobile (similar to FBGEMM). Currently only implemented on linear operator
Test Plan:
python test/test_quantized.py TestDynamicQuantizedLinear.test_qlinear
Imported from OSS
Differential Revision: D19542980
fbshipit-source-id: c9f6e5e8ded4d62ae0f2ed99e478c8307dde22ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32571
The watchdog thread would erase an element and call `it--` (implicitly
relying on `it++` in the for loop to position correctly). Although, `it--`
would cause undefined behavior if the iterator is pointing to begin(). As a
result, I've modified the logic to update the iterator appropriately.
I've also enhanced the watchdog thread to catch and log exceptions.
ghstack-source-id: 97150763
Test Plan: waitforbuildbot
Differential Revision: D19551365
fbshipit-source-id: 426835819ad8d467bccf5846b04d14442a342f78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32548
As Title says.
ghstack-source-id: 97175523
Test Plan: CI
Differential Revision: D19541893
fbshipit-source-id: 96dce6964e6a89393d4159401a59672f041f51d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32371
After we add constants to ClassType, we didn't update clone to
clone the constants, this PR adds the support
fixes: https://github.com/pytorch/pytorch/issues/32368
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D19564378
fbshipit-source-id: dbb13fb889d6ea9291034313b1f3c9aff4748bda
Summary:
It looks like the jit Future does not have a `wait()` anymore and this throws an error when trying to run this code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32336
Differential Revision: D19559922
Pulled By: rohan-varma
fbshipit-source-id: a5aa67990595e98e0682a20cf5aced17c2ae85bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32380
We'll clone the module first and then fold conv bn and return a new
module
Test Plan:
.
Imported from OSS
Differential Revision: D19508033
fbshipit-source-id: 328e91a2c9420761c904a7f2b62dab4cfaaa31ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32374
Moving all fold conv bn code to a class to prepare for making
it work with shared ClassType
Test Plan:
compiles
Imported from OSS
Differential Revision: D19508032
fbshipit-source-id: 4e9cf714111305d2b5474d4506507078f69f0c84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32556
Out of caution, avoid assuming that there's never a failure in a couple of
request_calback_impl case handlers, but rather propagate the error.
ghstack-source-id: 97128697
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D19544685
fbshipit-source-id: 67c55626960bd42a5b0dec7841e8ba44ab059eb9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31990
This PR does three things:
- Add a new `allow_rebase_history` flag to the differentiable views. If set, trying to rebase their history will raise an error.
- Make sure that the codegen functions verify this flag before doing inplace operations so that they fail before doing the inplace modification.
- Make sure the codegen functions set this flag properly when we don't support rebasing the history of the output.
The codegen change can be found [here](4bf180caa0).
Test Plan: Imported from OSS
Differential Revision: D19409649
Pulled By: albanD
fbshipit-source-id: a2b41c2d231e952ecfe162bdb6bad620ac595703
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32044
Fix the list of views in the codegen:
- Move `narrow` out of the autograd functions since it's now implemented with slice.
- Add `split_with_sizes` that was missing from the list
- Remove special formulas for both `split` and `split_with_sizes`. Both used not to be considered as views. When they are, all the rnn code breaks because it uses them in an invalid way. The generic formula will generate one `narrow` Node for each output. Which is always valid.
The diff for the generated code can be found [here](https://github.com/pytorch/pytorch/compare/16eff6e...albanD:06d6e85) (outdated for last commit)
Test Plan: Imported from OSS
Differential Revision: D19409648
Pulled By: albanD
fbshipit-source-id: 5ebc4c978af500403f7f008c0231b7db0cabab26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32525
Before calling static code analyzer we need link all bitcode files into
a single module. Current approach is a bit hacky: cmake still calls "ar"
to pack bitcode files into archives, then we manually unpack these
archives and call llvm-link.
Turns out libtorch_cpu.a contains a few files with same name, e.g.:
```
aten/src/ATen/native/SoftMax.cpp
aten/src/ATen/native/mkldnn/SoftMax.cpp
```
"ar x" will only keep one of them and cause inaccurate analysis result.
Use this temporary hack to workaround the problem. Ideally should merge
this step into cmake (e.g. directly calling llvm-link to produce target
output?).
Differential Revision: D19530533
Pulled By: ljk53
fbshipit-source-id: 94b292c241abaaa0ff4a23059882abdc3522971e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32539
Before: if something in `_modules` was `None`, we would barf. This is
incorrect because it's allowed for users to put `None` there, in case a
module is optional.
This case ought to be handled correctly during scripting. Fixes https://github.com/pytorch/pytorch/issues/32469
Test Plan: Imported from OSS
Differential Revision: D19552346
Pulled By: suo
fbshipit-source-id: aba7fdc19fd84d195c81cdaca8a75013a8626a8b
Summary:
This API seems to be quite useful to make sure all bailouts in a graph are triggered. I used it for testing torchvision models and I was wondering if this might be something we might actually want to have? zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32518
Differential Revision: D19553147
Pulled By: Krovatkin
fbshipit-source-id: 7542c99051588b622091aec6d041c70731ca5d26
Summary:
## Commit Message:
Refactors Dockerfile to be as parallel as possible with caching and adds a new Makefile to build said Dockerfile.
Also updated the README.md to reflect the changes as well as updated some of the verbage around running our latest Docker images.
Adds the new Dockerfile process to our CircleCI workflows
## How to build:
Building the new images is pretty simple, just requires `docker` > 18.06 since the new build process relies on `buildkit` caching and multi-stage build resolving.
### Development images
For `runtime` images:
```
make -f docker.Makefile runtime-image
```
For `devel` images:
```
make -f docker.Makefile devel-image
```
Builds are tagged as follows:
```bash
docker.io/${docker_user:-whoami}/pytorch:$(git describe --tags)-${image_type}
```
Example:
```
docker.io/seemethere/pytorch:v1.4.0a0-2225-g9eba97b61d-runtime
```
### Official images
Official images are the ones hosted on [`docker.io/pytorch/pytorch`](https://hub.docker.com/r/pytorch/pytorch)
To do official images builds you can simply add set the `BUILD_TYPE` variable to `official` and it will do the correct build without building the local binaries:
Example:
```
make -f docker.Makefile BUILD_TYPE=official runtime-image
```
## How to push:
Pushing is also super simple (And will automatically tag the right thing based off of the git tag):
```
make -f docker.Makefile runtime-push
make -f docker.Makefile devel-push
```
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32515
Differential Revision: D19558619
Pulled By: seemethere
fbshipit-source-id: a06b25cd39ae9890751a60f8f36739ad6ab9ac99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32569
If the dict's contained types cannot be inferred from its contents (for
example, `Dict[str, Tensor]` vs. `Dict[str, Optional[Tensor]]`), we must
explicitly annotate the type.
Also this removes some special handling that omits annotations on empty
containers that have the default type. It makes the code more complex
for not too much value, and was wrong for dicts anyway.
Test Plan: Imported from OSS
Differential Revision: D19551016
Pulled By: suo
fbshipit-source-id: c529b112e72c10f509a6bc0f5876644caa1be967
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/4049
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27477
We would like to add the intra-op parallelization support for the EmbeddingBag operator.
This should bring speedup for the DLRM benchmark:
https://github.com/pytorch/pytorch/pull/24385
Benchmark code:
```
from __future__ import absolute_import, division, print_function, unicode_literals
import torch
import time
eb = torch.nn.EmbeddingBag(1000000, 64, mode='sum')
input = torch.LongTensor(1500).random_(0, 1000000)
offsets = torch.zeros(64, dtype=torch.int64)
niter = 10000
s = time.time()
for _ in range(niter):
out = eb(input, offsets)
time_per_iter = (time.time() - s) / niter
print('time_per_iter', time_per_iter)
print('GB/s', (input.numel() * 64 * 4 + out.numel() * 4) / time_per_iter / 1e9)
```
The following results are single core on Skylake T6:
- Before our change (with the original caffe2::EmbeddingLookup)
time_per_iter 6.313693523406982e-05
GB/s 6.341517821789133
- After our change using the EmbeddingLookupIdx API which takes the offsets instead of lengths.
time_per_iter 5.7627105712890626e-05
GB/s 6.947841559053659
- With Intel's PR: https://github.com/pytorch/pytorch/pull/24385
time_per_iter 7.393271923065185e-05
GB/s 5.415518381664018
For multi-core performance, because Clang doesn't work with OMP, I can only see the single-core performance on SKL T6.
ghstack-source-id: 97124557
Test Plan:
With D16990830:
```
buck run mode/dev //caffe2/caffe2/perfkernels:embedding_bench
```
With D17750961:
```
buck run mode/opt //experimental/jianyuhuang/embeddingbag:eb
buck run mode/opt-lto //experimental/jianyuhuang/embeddingbag:eb
```
OSS test
```
python run_test.py -i nn -- TestNNDeviceTypeCPU.test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu
```
Buck test
```
buck test mode/dev-nosan //caffe2/test:nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu"
OMP_NUM_THREADS=3 buck test mode/opt -c pytorch.parallel_backend=tbb //caffe2/test:nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets" --print-passing-details
```
Generate the AVX2 code for embedding_lookup_idx_avx2.cc:
```
python hp_emblookup_codegen.py --use-offsets
```
Differential Revision: D17768404
fbshipit-source-id: 8dcd15a62d75b737fa97e0eff17f347052675700
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30630
This remove template and all the specializations it have in rpc, we
universally use IValue as the inner value since we support making python
object to be hold inside IValue.
This will also ensure that we have the correct type information when
creating the RRef, we use the return type from the schema when creating
userRRef and OwnerRRef, it will enable IValue to always have the correct
type if the IValue is the RRef object (next PR)
Test Plan: Imported from OSS
Differential Revision: D19502235
fbshipit-source-id: 0d5decae8a9767e0893f3b8b6456b231653be3c5
Summary:
Capsule Type doesn't appear in the IR, it is purely used in the runtime. So we should not have to handle it node hashing... Let's see if this breaks anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32540
Differential Revision: D19541357
Pulled By: eellison
fbshipit-source-id: 905ed9f89cf6d03b45ddb4fde02adfa149b477f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32260
This makes it so you can actually pass the custom class as an arg to ScriptFunctions
Test Plan: Imported from OSS
Differential Revision: D19424252
Pulled By: jamesr66a
fbshipit-source-id: c3530186619655781dedbea03c2ad321aaff1cb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32205
to be filled
Test Plan:
python test_jit.py
Imported from OSS
Differential Revision: D19508031
fbshipit-source-id: cbf03d34e52eae62595c34fde6ec645cb6744ad9
Summary:
There was a user who did this and it would seg fault.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32503
Differential Revision: D19538481
Pulled By: eellison
fbshipit-source-id: dc3752028b9eff6ac88c025e8a2b5f8fd44ce32f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31531
As suggested by suo , add unit test on torch.jit.export_opnames with interface. A submodule is annotated as interface and assigned to an instance, and then re-assigned to another instance. Make sure the operator names are also updated.
Test Plan: Imported from OSS
Differential Revision: D19539129
Pulled By: iseeyuan
fbshipit-source-id: 71a76ae7790cdd577618ca278afdb132727f08dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32295
Fix for https://github.com/pytorch/pytorch/issues/32045
Calling into the engine with the GIL can deadlock because:
- worker thread initialization acquires the GIL
- Any Node / hook can be a python function that will acquire the GIL
The choice was made here to raise an error as one of the advantage of using cpp extensions with python is to be able to release the GIL. So we prefer to educate users to do it rather than doing it under the hook.
Test Plan: Imported from OSS
Differential Revision: D19430979
Pulled By: albanD
fbshipit-source-id: e43f57631885f12e573da0fc569c03a943cec519
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31126
Gloo device creator registry is throwing warning that confuses users - https://fb.workplace.com/groups/1405155842844877/permalink/3217491788277931/
Create C10_DEFINE_SHARED_REGISTRY_WITHOUT_WARNING API to skip such warning
Test Plan:
{F224342749}
Tested both `C10_DEFINE_SHARED_REGISTRY` and `C10_DEFINE_SHARED_REGISTRY_WITHOUT_WARNING`.
Make sure nothing breaks
Reviewed By: d4l3k
Differential Revision: D18904783
fbshipit-source-id: 0e0065d530956249a18325d4ed3cb58dec255d4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30445
Create distributed and rpc directories under caffe/test for better management
of unit tests.
Differential Revision: D18702786
fbshipit-source-id: e9daeed0cfb846ef68806f6decfcb57c0e0e3606
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32271
Use the 2-stage EmbeddingSpMDM interface in D19425982 to reduce the overhead of code cache lookup and lock contention.
Fix an issue in sparse_lengths_sum_benchmarks generating empty indices when average length is small like 1.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D19425987
fbshipit-source-id: d5c5f0d46e0072403901809c31d516fa0f4b9b31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32448
Using binary search to compute the value for the given quantile among the input tensors.
Test Plan: Newly added unittests;
Reviewed By: jspark1105
Differential Revision: D19487604
fbshipit-source-id: 0dc6627b78d1310ac35b3f1d53b89cc89a697ece
Summary:
While putting finishing touches on the gradient scaling PR (https://github.com/pytorch/pytorch/pull/26512), I discovered my multi-GPU test (which uses `to()` to transfer tensors between devices) was intermittently failing with bad numerics. I knew it was going to be [a weird case from the start](https://www.imdb.com/title/tt8946378/quotes/qt4868203) and spent a week descending into madness. It turns out, for backward ops that create gradients on a different device from the device on whose stream the op is executed, the streaming backward synchronizations in [input_buffer.cpp](https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/input_buffer.cpp#L46-L83) do not properly tell later ops to wait on the population/creation of those gradients. For example, a cross-device `to()` backward (CopyBackward Node) enqueues a cudaMemcpyAsync on the current stream of the source (incoming gradient's) device, then [syncs getCurrentCUDAStream on the destination device with the cudaMemcpyAsync](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Copy.cu#L76). However, `input_buffer.cpp` in such cases ([case (3)](https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/input_buffer.cpp#L77-L81)) was not properly telling `opt_consumer_stream` to wait on the current stream of the destination device (`var`'s device).
Circumstances needed to repro in current master (see [my test](https://github.com/pytorch/pytorch/compare/master...mcarilli:backward_to_race_fix#diff-e68a7bc6ba14f212e5e7eb3727394b40R1901)):
- 2 devices, with non-default streams used for forward-pass ops on both devices (which is the default behavior in test_cuda.py)
- A `to()` that transfers a tensor requiring grad from one device to another
- A backward pass that routes back through to()'s backward (aka CopyBackward).
Under these circumstances, backward ops following CopyBackward on CopyBackward's destination device (aka the original forward-pass source device) race with the device-to-device transfer, and execute using partially-transferred data.
The present PR fixes the race condition and ensures that later ops wait on the CopyBackward transfer. This PR should also make streaming backward safe for other backward ops that span devices, as long as they play nice and populate any new gradients they create using the "current stream" of the device(s) on which they create those gradients.
There are a couple minor issues where I'm not sure of the best approach:
- Should we guard onto the var's device for the entire body of InputBuffer::add?
- I'm fairly sure we need to `recordStream` on `var` if the consumer stream is different from the stream on which (we expect) `var` was created, but calling `c10::cuda::CUDACachingAllocator::recordStream` in input_buffer.cpp might break CPU-only builds. I couldn't find a different API call to record streams that seemed CPU-build-agnostic. Could I wrap the call with a macro?
Thanks to mruberry for helpful suggestions and also the organization/naming of the stream pool and streaming backward code that allowed me to (just barely) wrap my head around the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31930
Differential Revision: D19517617
Pulled By: mruberry
fbshipit-source-id: 183d5460aefa5d27366b465b0473b80ec80fa044
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32491
This PR enables IValue to be able to hold a pure PyObject by adding a
new enum tag, a new jit_type to denote PyObject existance in IValue and
the JIT type system. We don't and not plan to expose this to user.
This is the basic piece that enable ivalue to be adopted broader like
making RRef always hold IValue, it might also simplify some compiler
logic
ghstack-source-id: 97039980
Test Plan: Imported from OSS
Differential Revision: D19502234
fbshipit-source-id: 90be001706d707d376cfbea25980fd82980df84a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32475
As title
Test Plan: CI
Reviewed By: houseroad
Differential Revision: D19508778
fbshipit-source-id: fd9ad63607535980505d155f3e3c3b7c6b95daf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32203
The type is needed for allowing multiple qconfig configurations for shared
ClassType, see next PR for more details
Test Plan:
.
Imported from OSS
Differential Revision: D19508027
fbshipit-source-id: a3df29dab3038bfa88c55dda98a3e8a78e99e5a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31841
Add Tuple Constants to JIT. The constraint here is that all elements of a tuple must themself be insertable as a a constant. Previously tuples were special cased in constant propagation, but now that there are more passes that are inserted constants, such as freezing, we should just have tuples be representable as constants.
Test Plan: Imported from OSS
Differential Revision: D19439514
Pulled By: eellison
fbshipit-source-id: 3810ba08ee349fa5598f4b53ea64525996637b1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31840
The next PR in this stack makes tuples insertable as constants, so we can remove special handling of tuples in constant propagation.
Test Plan: Imported from OSS
Differential Revision: D19439515
Pulled By: eellison
fbshipit-source-id: c58f153157f1d4eee4c1242decc4f36e41c1aa05
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31839
There are a number of improvements that can be made to `mayContainAlias`, which I would like to do in follow ups. For now, this is an easy one.
Test Plan: Imported from OSS
Differential Revision: D19439516
Pulled By: eellison
fbshipit-source-id: 0042fb7eaae6cfb4916bf95dc38280517a4bd987
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32256
Previously two unrelated modules loaded from torch.jit.load
would compare equal because we only considered their data_ attributes which
are initialized blank in torch.jit.load. This changes ConcreteModuleType
to distinguish when the data_ attribute is blank vs when it is empty.
This replaces the poisoned logic.
ghstack-source-id: 96755797
Test Plan: oss
Differential Revision: D19423055
fbshipit-source-id: 79d6a50a3731c6eeb8466ba2a93702b49264bba0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32202
Move some helper functions in ModuleUseDeduper for public use
Test Plan:
.
Imported from OSS
Differential Revision: D19508034
fbshipit-source-id: 2e8e05eff6f3bbcfe6936598371e4afa72f9b11f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32226
right now if users call torch.dist.all_reduce() on dense tensors, outputs are put in input tensors. but if users call torch.dist.all_reduce() on sparse tensors, outputs are neither returned explicitly to users nor are put in input tensors.
To make torch.dist.all_reduce() API have same behavior on both dense tensors and sparse tensors, this diff is made to make torch.dist.all_reduce() on sparse tensors to put output in input tensors as well. This is acheived by simply calling input_sparse.copy_(output_sparse), see PR https://github.com/pytorch/pytorch/pull/9005 that implemented copy_ for sparse tensors.
close#31413
ghstack-source-id: 96984228
Test Plan: unit test
Differential Revision: D19192952
fbshipit-source-id: 2dd31dc057f20cc42b44b9e55df864afa2918c33
Summary:
fix `torch.eq()` entry example to match the current output (boolean, instead of uint8)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32399
Differential Revision: D19498104
Pulled By: ezyang
fbshipit-source-id: e7ec1263226766a5c549feed16d22f8f172aa1a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32439
This adds c10::fallthrough_kernel which is a special boxed function which
can be used to implement fallthrough behavior at a dispatch key. A fallthrough
kernel will redispatch to the next valid dispatch key. It is implemented
in such a way that it costs no more to fallthrough than it does to go
straight to the actual implementation of the kernel.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D19503886
Test Plan: Imported from OSS
Pulled By: ezyang
fbshipit-source-id: 6ee05bd815c4ef444e612d19f62312dbb76f2787
Summary:
We will now use USE_*, BUILD_* consistently. The backward compatibility
for NO_* and WITH_* is hereby removed in this commit, as promised in the
comment (next release is beyond Feb 20):
# Before we run the setup_helpers, let's look for NO_* and WITH_* variables and hotpatch environment with the USE_*
# equivalent The use of NO_* and WITH_* is deprecated and will be removed in Feb 20, 2020.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32447
Differential Revision: D19515536
Pulled By: ezyang
fbshipit-source-id: 2f2c51e6d4674af690b190a1f0397b8f596b6a15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31408
We'll error out when a graph is quantized with different QSchemes.
This only occurs when we have two modules that have same types (e.g. two Conv2d modules initialized with
same arguments) and quantized with two configs that would produce different quantized graphs, for example
per tensor affine and per channel affine. This is a rare case, so it should be OK to skip for now.
Actual support will come later.
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D19162366
fbshipit-source-id: 798f06d0ddef0c8458237ce88b62159cc77eec8b
Summary:
Fix https://github.com/pytorch/pytorch/issues/24723.
Benchmark script :
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000]:
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(1000):
input.log_normal_()
for n in [1, 10, 100, 1000]:
fwd_t = 0
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(10000):
t1 = _time()
input.log_normal_()
t2 = _time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.4f (ms)." % (n, fwd_avg))
```
Test Device: skx-8180.
Before:
```
input size(128, 1) forward time is 0.0114 (ms).
input size(128, 10) forward time is 0.1021 (ms).
input size(128, 100) forward time is 1.0081 (ms).
input size(128, 1000) forward time is 10.1831 (ms).
```
After:
```
input size(128, 1) forward time is 0.0108 (ms).
input size(128, 10) forward time is 0.0969 (ms).
input size(128, 100) forward time is 0.9804 (ms).
input size(128, 1000) forward time is 9.6131 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31854
Differential Revision: D19314586
Pulled By: pbelevich
fbshipit-source-id: 2ea1d9a2c505e36aca9e609b52ccb3e8caf2ba8f
Summary:
While working on https://github.com/pytorch/pytorch/issues/31768 and trying to add tests for `DataParallel`, I discovered that:
- `test_data_parallel.py` can't be run through `run_test.py`
- running it with `pytest` fails with many name errors
`test_data_parallel.py` seems to have been split from `test_nn.py` in https://github.com/pytorch/pytorch/issues/28297 but not in a state where it can actually be run. Presumably `DataParallel` hasn't been tested by CI in the time since.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32428
Differential Revision: D19499345
Pulled By: ezyang
fbshipit-source-id: f9b748a99a5c85fc6675c22506cf10bbfd9c8a4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32148
TSAN would complain about multiple threads reading and writing to the
`cpu_dispatch_ptr` without any sort of synchronization. Although, this is a
valid issue from a TSAN point of view, there wasn't a correctness issue since
both threads would compute the same value.
In order to fix this, I've used std::atomic for cpu_dispatch_ptr with relaxed
ordering guarantees.
ghstack-source-id: 96989435
Test Plan: Verify the TSAN tests pass.
Differential Revision: D19386082
fbshipit-source-id: 1ff0893e02529eddd06b2855d9565edf1bbf1196
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31896
Test Plan: Added new tests to QNNPACK's test suite to cover the new use case. All new tests are passing.
Reviewed By: supriyar
Differential Revision: D19443250
Pulled By: AshkanAliabadi
fbshipit-source-id: fa7b1cffed7266a3c198eb591d709f222141a152
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32338
Timed out ops could linger around if the user doesn't actually call
`wait()` on that OP. As result, to fix this I've introduced the following
functionality in this PR:
1. Keep track of all outstanding work in ProcessGroupNCCL.
2. Enhance NCCL watchdog to sweep through all outstanding work and perform the
following operations:
i. If the work has timed out, abort all communicators for that work and
remove them from the cache.
ii. If the communicators for the work receive an error, abort the
communicators and remove them from the cache.
iii. If the work has completed (successfully/unsuccessfully), remove it from
the list of outstanding work.
ghstack-source-id: 96895704
Test Plan: waitforbuildbot
Differential Revision: D19401625
fbshipit-source-id: 8f6f277ba2750a1e1aa03cdbc76e8c11862e7ce5
Summary:
Without this, dlopen won't look in the proper directory for dependencies
(like libtorch and fbjni).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32247
Test Plan:
Build libpytorch_jni.dylib on Mac, replaced the one from the libtorch
nightly, and was able to run the Java demo.
Differential Revision: D19501498
Pulled By: dreiss
fbshipit-source-id: 13ffdff9622aa610f905d039f951ee9a3fdc6b23
Summary:
The current version check doesn't use proper lexicographic comparison and so will break for future versions of cuSPARSE with `CUSPARSE_VER_MAJOR > 10` and `CUSPARSE_VER_MINOR < 2`. Also, my cusparse headers for CUDA 9 don't seem to include version macros at all, so added `if !defined` to be explicit about that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32405
Differential Revision: D19499412
Pulled By: ezyang
fbshipit-source-id: 1593bf1e5a4aae8b75bb3b350d016cc6c3b9c009
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30842
We'd like to profile the time spent on GIL acqusiition to debug
performance issues.
Test Plan: Unit tests pass.
Differential Revision: D18837590
fbshipit-source-id: 925968f71c5fb96b8cd93f1eab4647602d2617d1
Summary:
These jobs were taking forver to run so we decided it's only really
worth it to run it on master.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32378
Differential Revision: D19499301
Pulled By: seemethere
fbshipit-source-id: 22cac5b5baee84e44607a16daeb77048cb0f5974
Summary:
Currently, setting `USE_CUDNN=0` has no effect and any cudnn library found on your system will be used anyway. This is especially problematic when your system has multiple CUDA versions installed, and you are building with a version that lacks a matching cudnn. CMake will find any other cudnn versions and you end up with both CUDA versions added to your compiler include paths.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32404
Differential Revision: D19499425
Pulled By: ezyang
fbshipit-source-id: a9b3f6f9dc22033481c3c1c5999b1a7ef98468cb
Summary:
qlinear/qconv to be consistent with data update.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32254
Differential Revision: D19422929
Pulled By: kimishpatel
fbshipit-source-id: 595a4f7d6fde4978c94f3e720ec8645f3f2bdb7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32197
This is to reland https://github.com/pytorch/pytorch/pull/30063, the main change is to match a general exception and grep "pickle" error word in "test_script_functions_not_supported" unit test, as Python 3.5 and Python 3.6 throw different types of errors with different error message for the rpc call in the unit test.
[test all]This diff makes following changes:
1. Providing a new set of python rpc privated APIs, they can accept an annotated TorchScript call and this call can be serialized, deserialized and executed in C++ without GIL. These privated APIs will be binded to JIT in the future, and they are different from public APIs as future JIT binded private APIs will be able to accept qualified_name, not callables. These private APIs are subject to be deprecated once JIT supports torch script function to be a JIT type.
Also, these APIs require torch script function to be defined and annotated by users in python land, it can not be script class/module constructor or class/module methods.
2. This diff also allows public rpc APIs to accept an annotated TorchScript call and execute code path that above private APIs ran on. Therefore if users invoke an annotated TorchScript call over RPC, this call can be serialized, deserialized and executed in C++ without GIL as well.
3. The above private APIs call a newly defined C++ function to make rpc torch script call to be serialized, deserialized and executed in C++ land. This C++ function returns an ivalue::Future. so that in follow up diff this C++ function can be called when these privated APIs are binded to JIT.
4. script_call.cpp/.h and request_callback_impl.cpp files are refactored accordingly so that torch script call and builtin call can share same message type and codes.
5. refactored deserializeResponse() and added a new utility to deserizalize response to IValue
ghstack-source-id: 96879167
ghstack-source-id: 96879167
Test Plan: unit test
Differential Revision: D19402374
fbshipit-source-id: 04efcc7c167d08a6503f29efe55e76f2be4b2c5e
Summary:
This should be covered under recursive script now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32235
Pulled By: driazati
Differential Revision: D19414889
fbshipit-source-id: 85f8132401dbe44c9dbaef7c0350110f90eb9843
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32276
Include mobile interpreter in mobile code analysis pass, which has some
manually registered ops in temporary namespaces.
The mobile interpreter is still under development and these ops will be
removed in the future. This is a temporary step for internal build
experiment.
Test Plan: Imported from OSS
Differential Revision: D19426818
Pulled By: ljk53
fbshipit-source-id: 507453dc801e5f93208f1baea12400beccda9ca5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32242
TSAN and fork don't play well together, so skip this test if we're
building under TSAN. It will still run in other modes.
Differential Revision: D19416113
fbshipit-source-id: 7e88d63a843356372160c2524c05e8fd1706553e
Summary:
Unchecked cast just refines the type of a value, the value stays the same, so the output should alias the input.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32309
Differential Revision: D19439037
Pulled By: eellison
fbshipit-source-id: fe6902d0d9a5a9ef5e9c13e1dbd056576d8c327e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32323
### Summary
Since we have released the custom build in 1.4.0, it's time to setup a CI for that. This PR adds a new iOS job to the iOS builds. To save time, It only runs the arm64 build.
### Test Plan
- Don't break any iOS jobs
- Custom Build works.
Test Plan: Imported from OSS
Differential Revision: D19451342
Pulled By: xta0
fbshipit-source-id: 9de305c004fc795710ecf01d436ef4792c07760c
Summary:
Distributed data parallel can not broadcast None so when we prepare the model for QAT and trying to save the model it will error out.
fixes: https://github.com/pytorch/pytorch/issues/32082
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32318
Differential Revision: D19434801
Pulled By: jerryzh168
fbshipit-source-id: ee70abe4c3dcdd3506fb7dd0316aee2fb1705469
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32138
I personally prefer `throw std::runtime_error("BOOM")`, but we should
probably have asserts here now that it is gtest. Also ensures that the correct
exceptions are thrown by the `testSignal` tests.
ghstack-source-id: 96811000
Differential Revision: D19382905
fbshipit-source-id: 1b00dd70524d03c8bd6f48715baa5070a7985467
Summary:
This is another implementation of the maximum bailout depth.
The first version was implemented in https://github.com/pytorch/pytorch/pull/31521
This one has advantages that
* the bailout depth only exists in `CodeImpl` which seems to be an appropriate place to keep it in.
* threading many objects is reduced to threading through CodeImpl and getPlanFor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32073
Differential Revision: D19443432
Pulled By: Krovatkin
fbshipit-source-id: 898384bb2308a1532a50a33d9e05cfca504711e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32134
These tests weren't written in the most correct way and were often
flaky. It was tricky to identify these tests as flaky until we moved this file
to use gtest.
The gist of the issue is that the test previously would not coordinate sends
and recvs properly. For example, we created a single thread to test an
abortRecv and a successful recv. A separate sender thread was used to send 2
messages. What could go wrong here is that the first send could successfully
complete, resulting in the receiving end processing the message before it gets
the abort signal. In this case we would have an error in the test.
ghstack-source-id: 96806879
Differential Revision: D19379395
fbshipit-source-id: 24782ccaf6e6ec6b445378b29d5f10f901e0dee6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31901
ncclCommAbort is not thread safe, so adding a lock for it
ghstack-source-id: 96829715
Test Plan: unit tests
Differential Revision: D19293869
fbshipit-source-id: 711b4a07605d6e5a81577247d2f90a78041c1809
Summary:
After we removed `Specialize_AutogradZero` from the optimization pipeline of the simple executor mode, we don't need to mark any inputs as undefined in `autodiff`. Also, `needsGradient` in `graph_executor.cpp` never runs on graph with profiling information, so I removed that code as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32106
Differential Revision: D19374238
Pulled By: Krovatkin
fbshipit-source-id: 4223d3efe3c904a55a28471e5ae9593017ce3e07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32321
Updating the test to test more meaningful sematics
Test Plan:
[xintchen@devvm6308.prn2 ~/fbsource/fbcode] buck test mode/dev //caffe2:ATen-core-test -- 'OperatorRegistrationTest\.whenRegisteringCPUTensorType_thenCanOnlyCallUnboxedWithCPUTensorIdDispatchKey'
Building: finished in 0.4 sec (100%) 517/517 jobs, 0 updated
Total time: 0.5 sec
Trace available for this run at /tmp/testpilot.20200116-132729.2541763.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision e5f315ebe0508d11fc281fa4b4f7b43d2ef1c003 fbpkg 67e8eb96914f400db234fd9af70fdcde at Wed Jan 15 23:38:32 2020 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/762/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/6192449492430045
✓ caffe2:ATen-core-test - OperatorRegistrationTest.whenRegisteringCPUTensorType_thenCanOnlyCallUnboxedWithCPUTensorIdDispatchKey 0.002 1/1 (passed)
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/6192449492430045
Summary (total time 1.15s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D19436345
fbshipit-source-id: c1f2383d62627aa4507616b8905ceb42ac563e9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32316
### Summary
Since the Custom Build has been released in 1.4.0, it's time setup CI. To do that, we need
1. Add a python script to generate the yaml file
2. Add new build scripts to circle CI (arm64 only).
### Test Plan
- Don't break the current iOS CIs
Test Plan: Imported from OSS
Differential Revision: D19437362
Pulled By: xta0
fbshipit-source-id: 395e27a582c43663af88d11b1ef974a4687e672c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32168
We move the exception raising into the function, saving us a
big pile of instructions for raising the stack.
After this stack of changes, the compiler is willing to inline, e.g.,
`c10::KernelFunction::callUnboxed<at::Tensor, at::Tensor const&>(c10::OperatorHandle const&, at::Tensor const&) const::__func__`
(whereas previously it refused to do so.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392948
Pulled By: ezyang
fbshipit-source-id: d5edab00cae48444b308e74438a17a421532c08f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32121
This reduces code size in the call sites of this function (of which
there are many: one for every operator call) since we no longer have
to construct std::string at the site.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392951
Pulled By: ezyang
fbshipit-source-id: 8bc43d46ba635380ff9f8989f7557fdd74b552cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32118
This reduces code size and makes the calling function more likely to inline.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392950
Pulled By: ezyang
fbshipit-source-id: 5e3829cca5604407229f93c2486eb9a325581ea2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32117
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392949
Pulled By: ezyang
fbshipit-source-id: 7f579e45d49bddeab36b8dd1a90c83224a368ac8
Summary:
For ppc64le, we no longer plan to run regular builds on Python 2.7, and we wish to stop
publicizing the build status for those two builds (ppc64le/CPU and ppc64le/GPU each on py27).
This pull request simply removes the build status links for these two builds, replacing them
with a generic dash character (consistent with other un-publicized builds within the table).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32315
Differential Revision: D19435939
Pulled By: soumith
fbshipit-source-id: c9f31e7acba83e42f6a758ac011bbef36fd8aaa0
Summary:
x || ( !x && y ) <=> to x || y
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32201
Differential Revision: D19429334
Pulled By: ezyang
fbshipit-source-id: 044dc46c2d9a7e180aa1795703c0097b0c7c3585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32198
creating a method called "callUnboxedWithDispatchKey".
Also adding tests to make sure it works.
Test Plan: buck test mode/dev //caffe2:ATen-core-test
Differential Revision: D19402815
fbshipit-source-id: b206cf04b1216fbbd5b54ac79aef495cb0c1be06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32232
Previously, we were using `operator<<` as the default way of printing
IValue constants during serialization. The semantics of `operator<<`
were ill-defined; and this bit us in particular with strings and lack of
quoting.
This PR defines the role of `operator<<`: much like Python `str()`, it
is intended to produce a human-readable-ish representation for
debugging purposes.
This PR also defines a new `repr()` function on IValue that is intended
to produce a valid Python expression that can be used to recreate an
object with the same value. `repr()` is not defined on all IValue kinds
(notably tensors!) for this reason.
Test Plan: Imported from OSS
Differential Revision: D19417036
Pulled By: suo
fbshipit-source-id: c102d509eaf95a28b6a62280bc99ca6f09603de5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31456
External request https://discuss.pytorch.org/t/jit-android-debugging-the-model/63950
By default torchscript print function goes to stdout. For android it is not seen in logcat by default.
This change propagates it to logcat.
Test Plan: Imported from OSS
Differential Revision: D19171405
Pulled By: IvanKobzarev
fbshipit-source-id: f9c88fa11d90bb386df9ed722ec9345fc6b25a34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32208
### Summary
Since the master branch will generate `libtorch_cpu.a`, which is different from the release branch. This PR will skip the missing libs before archiving them.
### Test Plan
- don't break the nightly build
Test Plan: Imported from OSS
Differential Revision: D19420042
Pulled By: xta0
fbshipit-source-id: fb28df17b7e95d5c7fdf5f3a21bece235d7be17c
Summary:
An example of a model with such leaf nodes is faster_rcnn model. This PR helps optimizing onnx ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32077
Reviewed By: hl475
Differential Revision: D19399622
Pulled By: houseroad
fbshipit-source-id: 35c628c6f1514b79f1bcf7982c25f0f4486f8941
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32224
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19416878
Pulled By: ezyang
fbshipit-source-id: 0205d0635658a3328128dcaad94bbbef505342be
Summary:
Introduce ProcessGroup::allgather_base. No implementation yet: plan to add it one PG backend at a time in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31892
Test Plan: No functional changes, no tests yet.
Differential Revision: D19290739
Pulled By: agolynski
fbshipit-source-id: c2f4947d2980995724c539de7c6d97618e1ba11a
Summary:
torch.onnx.export docs contain two descriptions for 'example_outputs' arg.
So combined the information for it with the description with the parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31826
Differential Revision: D19274928
Pulled By: zou3519
fbshipit-source-id: cbcce0a79c51784c1d7aa8981aab8aac118ca9b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31713
- In case the callbacks are heavy/slow, the other threads should be able to start work on the value of the future after the current thread moves the value and unlock the mutex.
- `completed()` is not inlined. Avoid function call overhead.
ghstack-source-id: 96694593
Test Plan: tdb
Differential Revision: D5624371
fbshipit-source-id: 5762e6e894d20108ec9afedd1a6e64bcd97ee3fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31970
Now that the ClassType can be shared among different module instances, we'll
preserve the sharing in clone as well, that is if the original module has
a ClassType that is shared, we'll clone this ClassType once and share it between
different module instances as well.
Test Plan:
build/test/test_jit
Imported from OSS
Differential Revision: D19406251
fbshipit-source-id: 2881c695f6e718e5432040a3817cf187a62017bf
Summary:
"in_features" and "out_features" are not defined. Possibly a typo. They should be "input_features" and "output_features" instead
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31682
Differential Revision: D19251685
Pulled By: zou3519
fbshipit-source-id: ac9e524e792a1853a16e8876d76b908495d8f35e
Summary:
Just update the comment to make it accurate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32222
Differential Revision: D19410428
Pulled By: albanD
fbshipit-source-id: ad13596382613c2728e674a47049ea4f563964b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32187Fixes#32058. Previously we would build documentation during the pytorch
linux cuda build. We don't actually need to do this because we have a
dedicated python_doc_build job that builds the docs. With this change,
the CUDA build should run ~10 minutes faster, giving devs faster signal.
Test Plan: - Check the CUDA (10.1) build on this PR, make sure it doesn't build the docs.
Differential Revision: D19400417
Pulled By: zou3519
fbshipit-source-id: e8fb2b818146f33330e06760377a9afbc18a71ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32185
Previously we would unify the contained types of dictionaries, however this breaks type safety.
```
torch.jit.script
def test(input: Dict[str, None], cond):
if cond:
out = input
else:
out: {"1": 1}
out["hi"] = 3
```
This would only occur if a dictionary is being re-assigned across an if condition with different contained types, which is pretty unlikely. I tested `model_backward_compatibility` for all fb models and this didn't break anything. This PR is a precursor to alias analysis changes.
Also fixes `Future` type unification. Because `Future` is an immutable type, it is okay to unify the contained type.
Test Plan: Imported from OSS
Differential Revision: D19398585
Pulled By: eellison
fbshipit-source-id: ebc8812cdf5b6dba37b1cfbc2edc7d8c467b258c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32179
Tensors are used as keys in dictionaries, so we need to annotate that key insertion into a dictionary inserts the key into the wildcard set. Also fixes bug with `listCopyAndSort` not copying the input list.
Test Plan: Imported from OSS
Differential Revision: D19397555
Pulled By: eellison
fbshipit-source-id: 17acdc22ff5e2dda44fd25c80450396f5592095e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32086
np.clip(1, num_indices // 2, 10) -> np.clip(num_indices // 2, 1, 10)
Also change batchsize -> num_rows to match with what the variable actually does
Test Plan: CI
Reviewed By: hx89
Differential Revision: D19361521
fbshipit-source-id: 9ce864c7d7da046dc606afa5207da677ccf80f52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32104
Fixes these warnings:
```
xplat\caffe2\caffe2Windows#header-mode-symlink-tree-only,headers\caffe2\operators\quantized\int8_conv_op.h(96,17): warning: use 'template' keyword to treat 'data' as a dependent template name
W.t.data<uint8_t>(),
^
template
xplat\caffe2\caffe2Windows#header-mode-symlink-tree-only,headers\caffe2\operators\quantized\int8_conv_op.h(97,17): warning: use 'template' keyword to treat 'data' as a dependent template name
B.t.data<int32_t>(),
^
template
```
Test Plan: Tested locally with clang-cl and CI for other toolchains
Reviewed By: boguscoder
Differential Revision: D19353563
fbshipit-source-id: c28afb8c1ad72fd77ef82556ba89fcf09100d1f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32190
We need a backend-agnostic mechanism to do barrier-like operation before locally destroy RRef context and shutdown RPC Agent.
- Sort worker names.
- Elect the first name as the leader in the ordered worker names.
- Followers reports therir intent to synchronize to the leader.
- Leader also reports to itself, when `_wait_all_workers()` called.
- If all workers report their intent to proceed, leader send the command to every one to proceed.
ghstack-source-id: 96693296
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_leak
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn
buck-out/gen/caffe2/test/rpc_spawn\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_spawn\#binary.par -r test_rref_leak
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_worker_id
```
# Stress runs
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_heavy_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_heavy_rpc --stress-runs 10
```
Differential Revision: D19399908
fbshipit-source-id: 1dee607cd49adafe88534621a1c85e2736e2f595
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32133
We should do this to better debug the test.
Differential Revision: D19375479
fbshipit-source-id: 8c2bf61bae605a38252bb793b091ade479bea11a
Summary:
Currently, libtorch build and test are not running in macOS CI. This PR fixes the issue.
**Test Plan:**
Check that libtorch build and test are running again in macOS CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32072
Differential Revision: D19391909
Pulled By: yf225
fbshipit-source-id: 1ab345b099869f78e1124f1a8bd185fa51371b6a
Summary:
This was not tested before, fixes#32139 (which was actually a false positive, functions with kwargs but without defaults on those kwargs are supported). This PR adds testing for both cases and cleans up the error reporting.
](https://our.intern.facebook.com/intern/diff/19385828/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32146
Pulled By: driazati
Differential Revision: D19385828
fbshipit-source-id: 5eab74df6d02f8e1d7ec054cafb44f909f9d637e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32147
### Summary
Got some security warnings regarding the ruby dependencies. This diff updates the packages in Gemfile.
```
GitHub has detected that a package defined in the ios/TestApp/Gemfile.lock file of the pytorch/pytorch repository contains a security vulnerability.
Package name: excon
Affected versions: < 0.71.0
Fixed in version: 0.71.0
Severity: LOW
Identifier(s):
GHSA-q58g-455p-8vw9
CVE-2019-16779
```
### Test Plan
- Won't affect the existing iOS CI jobs
Test Plan: Imported from OSS
Differential Revision: D19400087
Pulled By: xta0
fbshipit-source-id: 34b548d136cfd6b68fcc53bf0b243461bd7afd64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32170
Stack from [ghstack](https://github.com/ezyang/ghstack):
Change the overload name from passing by const ref to by value and move.
* **#32170 Fix the passing-by-ref constructor of OperatorName.**
Test Plan: Imported from OSS
Differential Revision: D19396225
Pulled By: iseeyuan
fbshipit-source-id: e946c47647e1f8d23d7565cfe93f487845e7f24c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31912
### Summary
Clean up the logs from pip-install.
### Test Plan
- Don't break the iOS simulator build
Test Plan: Imported from OSS
Differential Revision: D19395526
Pulled By: xta0
fbshipit-source-id: a638a209cab801ce90c8615e7ea030b1ab0939f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32149
This is an attempt at clarifying some of the preprocessor boolean logic that was getting more and more complicated. The previous logic used constexpr with nvcc on clang; which we were getting compiler failures on in ovrsource with mode/linux/* (based on platform007).
Test Plan:
ovrsource xplat/caffe2 compiles
fbsource sandcastle green
Differential Revision: D19385409
fbshipit-source-id: 60a02bae9854388b87510afdd927709673a6c313
Summary:
Continuation of https://github.com/pytorch/pytorch/issues/31514, fixes https://github.com/pytorch/pytorch/issues/28430
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32009
Test Plan:
I verified that the deprecation warnings only occur once on a relevant workflow. Built with:
```
buck build mode/opt //vision/fair/detectron2/tools:train_net
```
Ran with:
```
DETECTRON2_ENV_MODULE=detectron2.fb.env ~/local/train_net.par --config-file configs/quick_schedules/retinanet_R_50_FPN_instant_test.yaml --num-gpus 1 SOLVER.IMS_PER_BATCH 2
```
Inspected log:
```
[01/14 07:28:13 d2.engine.train_loop]: Starting training from iteration 0
buck-out/opt/gen/caffe2/generate-code=python_variable_methods.cpp/python_variable_methods.cpp:1299: UserWarning: This overload of add is deprecated:
add(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add(Tensor other, Number alpha)
buck-out/opt/gen/caffe2/generate-code=python_variable_methods.cpp/python_variable_methods.cpp:1334: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, Number alpha)
[01/14 07:28:25 d2.utils.events]: eta: 0:00:10 iter: 19 total_loss: 1.699 loss_cls: 1.185 loss_box_reg: 0.501 time: 0.5020 data_time: 0.0224 lr: 0.000100 max_mem: 3722M
[01/14 07:28:35 fvcore.common.checkpoint]: Saving checkpoint to ./output/model_final.pth
```
Differential Revision: D19373523
Pulled By: ezyang
fbshipit-source-id: 75756de129645501f43ecc4e3bf8cc0f78c40b90
Summary:
`test_init_ops` calls `orthogonal_` which fails without lapack (this test was just missing a skip condition)
The cpp tests would fail with a `undefined symbol` error if run with `BUILD_TESTS=0`, so this PR skips them if that flag is `0`
](https://our.intern.facebook.com/intern/diff/19320064/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31965
Pulled By: driazati
Differential Revision: D19320064
fbshipit-source-id: d1dcd36714107688ded25a414e8969abe026bd03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30063
This diff makes following changes:
1. Providing a new set of python rpc privated APIs, they can accept an annotated TorchScript call and this call can be serialized, deserialized and executed in C++ without GIL. These privated APIs will be binded to JIT in the future, and they are different from public APIs as future JIT binded private APIs will be able to accept qualified_name, not callables. These private APIs are subject to be deprecated once JIT supports torch script function to be a JIT type.
Also, these APIs require torch script function to be defined and annotated by users in python land, it can not be script class/module constructor or class/module methods.
2. This diff also allows public rpc APIs to accept an annotated TorchScript call and execute code path that above private APIs ran on. Therefore if users invoke an annotated TorchScript call over RPC, this call can be serialized, deserialized and executed in C++ without GIL as well.
3. The above private APIs call a newly defined C++ function to make rpc torch script call to be serialized, deserialized and executed in C++ land. This C++ function returns an ivalue::Future. so that in follow up diff this C++ function can be called when these privated APIs are binded to JIT.
4. script_call.cpp/.h and request_callback_impl.cpp files are refactored accordingly so that torch script call and builtin call can share same message type and codes.
5. refactored deserializeResponse() and added a new utility to deserizalize response to IValue
ghstack-source-id: 96638829
Test Plan: unit test
Differential Revision: D18482934
fbshipit-source-id: bd82a0d820c47a8e45b2e7c616eca06573f7d7ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31830
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19330312
Pulled By: ezyang
fbshipit-source-id: fe2e53e732e946088e983ec45fed2393436f0517
Summary:
While ONNX does not currently directly support the Dim operation on a
tensor, we can provide the same functionality with two ONNX operations.
This allows us to support Dim for all opsets. It may be adventageous to
add support for Dim into a future ONNX opset, and use that for more
efficient code.
While testing dim op found that there is an issue with empty blocks
withing if statements. Modified graph generation to prevent generation
of empty if blocks.
Fixes https://github.com/pytorch/pytorch/issues/27569
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31928
Reviewed By: hl475
Differential Revision: D19376602
Pulled By: houseroad
fbshipit-source-id: 111682b058a5341f5cca6c1a950c83ae412a4c6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31674
The motivation of this PR was to fix the problem where we would see
"Address already in use" issues for TCPStoreTest due to port conflicts. To
resolve this:
1. We can now pass in port 0 for TCPStore and retrieve the port it actually
bound to using a new getPort() API.
2. Added a `wait` flag to TCPStore constructor indicating whether or not it
should wait for workers (defaults to true).
3. Made `waitForWorkers` a public API to ensure that we can construct TCPStore
without waiting and wait for workers separately. This helps in TCPStoreTest to
ensure we can retrieve the port and pass it to the client stores.
ghstack-source-id: 96486845
Test Plan: waitforbuildbot
Differential Revision: D19240947
fbshipit-source-id: 7b1d1cb2730209fac788764845f1dbbe73d75d9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32102
Previously, the docs CI depended on our CUDA xenial py3 build. This
meant that the turnaround time to get signal for docs was very slow
(I've seen builds that go as much as 3 hours).
Fortunately, the docs CI do not (and should not!) rely on CUDA. This
PR changes it so that the docs CI runs on a CPU-only machine.
Fixes#29995
Test Plan:
- Check CI status on this PR by reading logs for the python and cpp docs
builds.
- I built the docs locally, once for CPU, and once for CUDA, and
verified (via diff) that the pages were exactly the same)
Differential Revision: D19374078
Pulled By: zou3519
fbshipit-source-id: 3eb36f692c3c0632d2543d3439c822d51a87b809
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31978
Currently we keep a `mangleIndex_` that's intenral to compilation unit and
just increment the index when we found the original name is mangled, this doesn't
guarantee the new name is not defined.
This PR fixes the problem by querying whether the new name is defined or not.
fixes: https://github.com/pytorch/pytorch/issues/31268
Test Plan:
fixes the issue
Imported from OSS
Differential Revision: D19350535
fbshipit-source-id: fe3262b2838d4208ab72e2cd4a5970b3a792ae86
Summary:
Currently, libtorch build and test are not running in macOS CI. This PR fixes the issue.
**Test Plan:**
Check that libtorch build and test are running again in macOS CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32072
Differential Revision: D19373615
Pulled By: yf225
fbshipit-source-id: 28686ef5895358a2b60db46b1946f21c58c6a18e
Summary:
Currently cumprod crashes for tensors with non-empty dimensions but with zero elements, which could happen when some dimension is zero. This commit fixes the error by checking both dim() and numel() in cumprod backward
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32070
Differential Revision: D19373200
Pulled By: ezyang
fbshipit-source-id: d8ecde33f3330b40a7c611f6faa3b1d707ef2a9a
Summary:
This PR adds a more complete list of pytorch header files to be installed at build time. It also fixes one instance of including a header from local src directory instead of installed directory.
A more complete set of headers enable other modules to correctly work with pyTorch built for ROCm.
cc: ezyang bddppq iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32076
Differential Revision: D19372933
Pulled By: ezyang
fbshipit-source-id: 3b5f3241c001fa05ea448c359a706ce9a8214aa0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30734
What are specialized lists?
The IValues that hold List[int], List[Tensor], and List[AnythingElse] are different C++ types.
e.g. List[int] has a std::vector<int> while List[AnythingElse] holds a std::vector<IValue>.
Why do we have specialized lists?
When we first created the JIT we needed to bind the ATen C++ API which has std::vector<int>,
std::vector<Tensor> as inputs. The easiest way to match this API was to make our IValues contain
these same types. Conversion was just unwrapping the IValue, very easy and cheap.
What is the problem with specialized lists?
We end up with significant special cases through the compiler. Other types like Dict are not
specialized. So in the Pickler, for instance, there is a single piece of logic to handle
their serialization. For Lists, we end up with multiple cases. Furthermore, it doesn't
match Python, leading to problems along translation boundaries. Our pickle serialization
is slightly different than python, so it is harder to load objects from our IValue serialization
as Python values.
They also make it harder to provide an easy-to-use user API. We'd like to match pybind11 for C++
bindings to TorchScript. This would entail having a single torch::List class (untemplated)
that can be used to construct inputs. This is made much harder if the underlying ivalue needs
to be different depending on the type inside the list. The ideal case would be to have a constructor like
```
template<typename T>
List(std::vector<T> foo);
```
It would then set up the type tags correctly based on type T, without the need for passing tags.
Do specialized lists improve perf?
Not in a way we have been able to measure. Our major concern initially was having to translate
a std::vector<IValue> to std::vector<int> to call ATen functions. This was especially a concern
for aten::_convolution which takes a number of mostly-constant lists of integers. However,
when we measure the effect of actually having to do this conversion for an aten::_convolution,
it does not take measurable time (benchmark results below).
This is true even if you use a trivial convolution (e.g. 1x1x1), and comment out the actual convolution code.
What are the issues removing them?
This PR removes list specialization but keeps the serialization format, and IValue APIs almost exactly
the same. The only visible change is that toTensorListRef and family have turned into toTensorVector
because they now return by value a copy of the list as a vector.
Further PRs can then clean up the complexity issues that arose from speclization. This will likely
involve removing the isTensorList/isIntList functions, and refactoring the code that used them to
work generically. At some point we will also change serialization to no longer write specialized
lists in the pickle binary. This is forward incompatible, so will go in its own PR.
Benchmark:
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet, self).__init__()
self.conv1 = nn.Conv2d(1, 1, kernel_size=1)
self.conv2 = nn.Conv2d(1, 1, kernel_size=1)
def forward(self, x):
for i in range(10):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
return x
model = MnistNet()
x = torch.rand(1, 1, 1, 1)
r = torch.jit.trace(model, x )
r(x)
r(x)
r(x)
r(x)
print(torch.jit.last_executed_optimized_graph())
while True:
b = time.time()
for i in range(100):
r(x)
e = time.time()
print(e - b)
```
Results (no observable difference):
```
Before (actual conv)
0.13251137733459473
0.13260436058044434
0.13276338577270508
0.1327497959136963
0.13250041007995605
0.13270330429077148
0.13290190696716309
0.13265132904052734
0.13274288177490234
0.1326758861541748
0.13253355026245117
0.13254785537719727
0.13260746002197266
0.13285017013549805
0.13264012336730957
0.132490873336792
0.13280034065246582
0.13243484497070312
0.1325232982635498
0.1326127052307129
0.13264131546020508
0.13274383544921875
0.13298296928405762
0.1326909065246582
-------------------
After (actual conv)
0.13127517700195312
0.13150334358215332
0.13092470169067383
0.13102364540100098
0.13134360313415527
0.13155555725097656
0.13314104080200195
0.13151955604553223
0.13160037994384766
0.1315293312072754
0.13137340545654297
0.13148093223571777
0.131455659866333
0.1327371597290039
0.13134026527404785
0.13152337074279785
0.13151192665100098
0.13165974617004395
0.13403725624084473
0.13251852989196777
0.13135504722595215
0.1315624713897705
0.1317615509033203
0.1314380168914795
0.13157200813293457
--------------------
The following replace the convolution operator with a no-op, to show
that even if the conv op was made faster, then we still would not see
a difference:
Before (fake conv)
0.0069539546966552734
0.0069522857666015625
0.007120847702026367
0.007344722747802734
0.007689952850341797
0.007932662963867188
0.00761723518371582
0.007501363754272461
0.007532835006713867
0.007141828536987305
0.007174253463745117
0.007114410400390625
0.007071495056152344
------------------
After (fake conv)
0.007458209991455078
0.007337093353271484
0.007268190383911133
0.007313251495361328
0.007306575775146484
0.007468700408935547
0.0073091983795166016
0.007308483123779297
0.007538318634033203
0.007356882095336914
0.007464170455932617
0.007372140884399414
```
Test Plan: Imported from OSS
Differential Revision: D18814702
Pulled By: zdevito
fbshipit-source-id: 0371c73b63068fdc12f24b801371ea90f23531a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31381
This PR adds support for being able to profile both sync and async RPCs, so that users can use the autograd profiler and be able to view metrics such as RPC latency and number of calls in the profiler output.
The way this is implemented is by using the existing `RecordFunction` class provided by the autograd profiler. We create a `RecordFunction` instance when sending an RPC, if autograd profiling is enabled. We also invoke the starting callbacks on this `RecordFunction` instance, this does things such as start the CPU timer. This instance is then persisted across the lifetime of the RPC by attaching it to the `Future` created by the RPC. When the RPC is finished (i.e. when `future->markComplete()` is called), we run the `RecordFunction` instance's end callbacks, which among other things, stops the timer so that we get the correct RPC latency.
The `RecordFunction` and relevant callbacks in `profiler.cpp` are modified slightly to support running end callbacks from a different thread (which is needed since futures are marked as completed by a different thread than the main RPC thread). By default, the autograd profiler uses a `thread_local` list of `Events` and `thread_id`. However, since we'd like to run the `RecordFunction`'s callbacks from a different thread, we would like to access the list of `Events` created by the original thread. This is done by attaching the `thread_id` for the event to the `RecordFunction`, and then looking up the event with that thread in `all_event_lists` (see the changes in `profiler.cpp`). To ensure that the original behavior does not change in the profiler, this described behavior is only run when a user calls `setOverrideThreadId()` on the `RecordFunction` object.
ghstack-source-id: 96527291
Test Plan: Added a unit test.
Differential Revision: D19053322
fbshipit-source-id: 9a27a60c809fc4fdb16fa5d85085f3b6b21abfbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32016
The previously logic will raise exception when there is query in url when rank or world_size is specified
The fix will parse the url and stitch rank and world_size into url.query and regenerate the url.
Test Plan: f161291877
Differential Revision: D19337929
fbshipit-source-id: 6bb3a07716dda5233553804000b706052ff18db8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30424
`at::indexing::TensorIndex` is used for converting C++ tensor indices such as `{None, "...", Ellipsis, 0, true, {1, None, 2}, torch::tensor({1, 2})}` into its equivalent `std::vector<TensorIndex>`, so that further tensor indexing operations can be performed using the supplied indices.
Test Plan: Imported from OSS
Differential Revision: D18695902
Pulled By: yf225
fbshipit-source-id: d73e14a411cdbec815866b02e75ffd71a9186e89
Summary:
Per discussion with Fei Tian, we need to add a `scale_init_value` to scale down the output of normalization such as batch-norm and layer-norm.
Currently we have `sparse_normalization_options` to normalize embedding pooling output. By default, scale = 1.0, we found it's better to set scale from 0.025 to 0.1 https://fb.quip.com/MiKUAibEaYhH
Besides, I am removing the tags from normalizers because it makes more sense to calculate norm ops in distributed trainers, not ps.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31983
Test Plan:
Testing LN and BN after sum-pooling --
baseline f160348514
LN: f160348609
BN: f160348710
{F226106518}
Layer norm after sum-pooling fwd_net https://fburl.com/sa4j207n
Layer norm after dot-prod fwd_net https://fburl.com/twggwyvb
## Unit Tests
Testing normalization after pooling
```
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_sparse_pooling_batch_normalization
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_dense_sparse_pooling_batch_normalization
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_sparse_pooling_layer_normalization
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_dense_sparse_pooling_layer_normalization
```
Testing normalization after dot-prod
```
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_last_layer_use_batch_norm
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_last_layer_use_layer_norm
```
Differential Revision: D19277618
Pulled By: SilunWang
fbshipit-source-id: ea323e33e3647ba55d2e808ef09d94ad7b45b934
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31023
Adds support to catch exceptions in ProcessGroupAgent::enqueueSend and
report them in the future by marking the future as completed with an exception
indicating the error. An example of when this could happen is if the receiving
side aborts when the sender is sending the message, previously, we would hang
until the timeout is hit, and the original exception would be lost.
ghstack-source-id: 96498386
Test Plan: Added a relevant unit test: `test_sender_exceptions` in rpc_test.py
Differential Revision: D18901981
fbshipit-source-id: 08de26936c4ad45b837219a247088cbea644c04c
Summary:
Custom build and internal build will depend on the analysis result so
let's make sure it doesn't break.
Tested locally with LLVM-5.0, LLVM-7 and LLVM-8.
Test Plan: - check CI result
Differential Revision: D18894637
Pulled By: ljk53
fbshipit-source-id: 657854e4bed85a84907e3b6638d158823a56ec80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32027
The test was added in #30985 for #28313. Seems the fix only works for
Python3 but doesn't work on Python2. The current Python2 CI docker image
doesn't have `dill` module installed at all so it's not captured.
I'm trying to build and push new CI docker image which has `dill` installed
and I verified it's the latest version 0.3.1.1 but the fix doesn't seem
to work and blocks me from upgrading image version. It works for Python3
docker image though...
Here is a succeeded job with old image (no dill installed):
https://app.circleci.com/jobs/github/pytorch/pytorch/4192688
Here is a failed job with new image (dill installed):
https://app.circleci.com/jobs/github/pytorch/pytorch/4192679
This PR bypasses the test for Py2 to unblock docker image change. We
can figure out a proper fix for Py2 later.
Test Plan: Imported from OSS
Differential Revision: D19341451
Pulled By: ljk53
fbshipit-source-id: d5768de8cbaf1beba8911da76f4942b8f210f2d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32011
Run into build problem with Ninja + code analysis build as follows:
```
The install of the torch_global_deps target requires changing an RPATH from
the build tree, but this is not supported with the Ninja generator unless
on an ELF-based platform.
```
Seems we don't need build the target for static build mode?
Verified code analyzer works with the patch.
Test Plan: Imported from OSS
Differential Revision: D19336818
Pulled By: ljk53
fbshipit-source-id: 37f45a9392c45ce92c1df40d739b23954e50a13a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31972
Since eager mode quantization requires many user modifications, we can't
consistently quantize a given model by just changing qconfig_dict, therefore
the top level `qconfig_dict` is not that useful.
fixes: https://github.com/pytorch/pytorch/issues/31549
Test Plan:
.
Imported from OSS
Differential Revision: D19330691
fbshipit-source-id: 8aee6e5249e0c14e8a363ac1a83836e88887cd7d
Summary:
Instead of a mixture of direct calls to library provided atomicAdd calls, such as float atomicAdd(float*, float) and calls provided internally, such as void atomicAdd(long*, long), abstract to one API void gpuAtomicAdd(T*, T) in THCAtomics.cuh for the PyTorch backend.
The advantage of this approach is that it allows us to more easily distinguish between capabiltiies of different platforms (and their versions). Additionally, the abstraction of void returning atomicAdds allows us to, in the future, support fast HW instructions on some platforms that will not return the previous value.
Call sites that do not satisfy above conditions and are either highly platform specific (__half2 atomicAdd fast path in one operator) or require the return explicitly (some int atomicAdd invocations) are left untouched. The Caffe2 backend also remains untouched.
While here, add a bunch of includes of THCAtomics.cuh that were missing before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31992
Differential Revision: D19330220
Pulled By: ezyang
fbshipit-source-id: d6ab73ec5168c77e328faeef6c6f48eefba00861
Summary:
This was missing and resulted in the incorrect `name` passed into `_to_worker_info` not being printed out in the error message.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31969
Differential Revision: D19331927
Pulled By: rohan-varma
fbshipit-source-id: e74d47daec3224c2d9b9da3c0a6404cfa67baf65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31858
Trying to upgrade docker image but ran into the following error:
```
Running test_nn ... [2020-01-04 18:05:12.537860]
Traceback (most recent call last):
File "test_nn.py", line 45, in <module>
from common_cuda import TEST_CUDA, TEST_MULTIGPU, TEST_CUDNN, TEST_CUDNN_VERSION
File "/var/lib/jenkins/workspace/test/common_cuda.py", line 16, in <module>
import numba.cuda
File "/opt/conda/lib/python3.6/site-packages/numba/__init__.py", line 178, in <module>
_ensure_llvm()
File "/opt/conda/lib/python3.6/site-packages/numba/__init__.py", line 100, in _ensure_llvm
raise ImportError(msg)
ImportError: Numba requires at least version 0.30.0 of llvmlite.
Installed version is 0.28.0.
```
Test Plan: Imported from OSS
Differential Revision: D19282923
Pulled By: ljk53
fbshipit-source-id: bdeefbf4f6c0c97df622282f76e77eb1eadba436
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31031
This activation will be needed for the LSTM implementation.
Also includes the QNNPack implementation.
Test Plan: Imported from OSS
Differential Revision: D19334280
Pulled By: z-a-f
fbshipit-source-id: ae14399765a47afdf9b1e072d3967c24ff473e8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31857
According to mingbowan we will change to use string docker image
version because the tag is no longer an integer since we move the docker
image build job to circle CI:
http://ossci-docker.s3-website.us-east-1.amazonaws.com/pytorch.html
Test Plan: - with stacked PR
Differential Revision: D19282726
Pulled By: ljk53
fbshipit-source-id: 7a12ae89a11cf15163b905734d50fed6dc98cb07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31995Fixes#31906.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19331259
Pulled By: ezyang
fbshipit-source-id: 5d24bf3555e632211a9b6f8e50ff241603c18b3d
Summary:
Fix for https://github.com/pytorch/pytorch/issues/19420
So after actually writing a C++ JSON dumping class I figured that
a faster and cleaner way would be simply rewrite the Python without
the JSON module since the JSON that we need to output is so simple.
For now I decided to not touch the `parse_cpu_trace` function since
only changing `export_chrome_trace` shows a 4x speedup.
Here's the script I used for benchmarking:
``` python
import time
import torch
x = torch.ones(2, 2)
start = time.time()
with torch.autograd.profiler.profile() as prof:
for _ in range(10000):
x * x
for i in range(50):
prof.export_chrome_trace("trace.json")
stop = time.time()
print(stop-start)
```
master branch (using json dump) -> 8.07515025138855
new branch (without json dump) -> 2.0943689346313477
I checked the trace file generated in the [test](https://github.com/pytorch/pytorch/blob/master/test/test_autograd.py#L2659)
and it does work fine.
Please let me know what you think.
If you still insist on the C++ version I can send a new patch soon enough.
CC ezyang rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30724
Differential Revision: D19298955
Pulled By: ezyang
fbshipit-source-id: b0d7324ea5f90884ab8a00dd272f3aa3d9bc0427
Summary:
Fix https://github.com/pytorch/pytorch/issues/24704.
Benchmark script :
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000]:
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(1000):
input.geometric_(0.5)
for n in [1, 10, 100, 1000]:
fwd_t = 0
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(10000):
t1 = _time()
input.geometric_(0.5)
t2 = _time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.4f (ms)." % (n, fwd_avg))
```
Test device: **skx-8180**.
Before:
```
input size(128, 1) forward time is 0.0092 (ms).
input size(128, 10) forward time is 0.0802 (ms).
input size(128, 100) forward time is 0.7994 (ms).
input size(128, 1000) forward time is 7.8403 (ms).
```
After:
```
input size(128, 1) forward time is 0.0088 (ms).
input size(128, 10) forward time is 0.0781 (ms).
input size(128, 100) forward time is 0.7815 (ms).
input size(128, 1000) forward time is 7.7163 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31878
Differential Revision: D19314510
Pulled By: ezyang
fbshipit-source-id: 2d95bf9938c8becf280890acf9e37223ddd08a39
Summary:
VitalyFedyunin, This PR is about port LogSigmoid activation to Aten:
Test script:
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
m = nn.LogSigmoid()
#warm up
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
**Before:**
```
input size(128, 1) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.10 (ms); backwad avg time is 0.03 (ms).
input size(128, 100) forward time is 0.90 (ms); backwad avg time is 0.09 (ms).
input size(128, 1000) forward time is 9.04 (ms); backwad avg time is 0.87 (ms).
```
**After:**
```
input size(128, 1) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 0.28 (ms); backwad avg time is 0.07 (ms).
```
**OMP_NUM_THREADS=1:**
```
Before:
input size(128, 1) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.10 (ms); backwad avg time is 0.03 (ms).
input size(128, 100) forward time is 0.88 (ms); backwad avg time is 0.10 (ms).
input size(128, 1000) forward time is 8.72 (ms); backwad avg time is 0.81 (ms).
After:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.07 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 0.63 (ms); backwad avg time is 0.15 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24724, https://github.com/pytorch/pytorch/issues/24725.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30958
Differential Revision: D19275111
Pulled By: ezyang
fbshipit-source-id: bbfe82e58fb27a4fb21c1914c6547a9050072e5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31962
I added precision tests for CUDA half, float, and double.
The precision for CUDA half seems bad, but I checked the numbers against
previous versions of pytorch. The output of CUDA Half linspace+logspace
are exactly the same when compared with 1.2.0.
Test Plan: - Run CI
Differential Revision: D19320182
Pulled By: zou3519
fbshipit-source-id: 38d3d4dea2807875ed0b0ec2b93b19c10a289988
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31162
This should help us resolve a multitude of weird segfaults and crashes
when PyTorch is imported along with other packages. Those would often
happen because libtorch symbols were exposed globally and could be used
as a source of relocations in shared libraries loaded after libtorch.
Fixes#3059.
Some of the subtleties in preparing this patch:
* Getting ASAN to play ball was a pain in the ass. The basic problem is that when we load with `RTLD_LOCAL`, we now may load a library multiple times into the address space; this happens when we have custom C++ extensions. Since the libraries are usually identical, this is usually benign, but it is technically undefined behavior and UBSAN hates it. I sprayed a few ways of getting things to "work" correctly: I preload libstdc++ (so that it is seen consistently over all library loads) and added turned off vptr checks entirely. Another possibility is we should have a mode where we use RTLD_GLOBAL to load _C, which would be acceptable in environments where you're sure C++ lines up correctly. There's a long comment in the test script going into more detail about this.
* Making some of our shared library dependencies load with `RTLD_LOCAL` breaks them. OpenMPI and MKL don't work; they play linker shenanigans to look up their symbols which doesn't work when loaded locally, and if we load a library with `RLTD_LOCAL` we aren't able to subsequently see it with `ctypes`. To solve this problem, we employ a clever device invented by apaszke: we create a dummy library `torch_global_deps` with dependencies on all of the libraries which need to be loaded globally, and then load that with `RTLD_GLOBAL`. As long as none of these libraries have C++ symbols, we can avoid confusion about C++ standard library.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D19262579
Test Plan: Imported from OSS
Pulled By: ezyang
fbshipit-source-id: 06a48a5d2c9036aacd535f7e8a4de0e8fe1639f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31161
Previously, it wasn't necessary to specify `DT_NEEDED` in C++ extensions on Linux (aka pass `-l` flags) because all of the symbols would have already been loaded with `RTLD_GLOBAL`, so there wouldn't be any undefined symbols. But when we switch to loading `_C` with `RTLD_LOCAL`, it's now necessary for all the C++ extensions to know what libraries to link with. The resulting code is clearer and more uniform, so it's wins all around.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262578
Pulled By: ezyang
fbshipit-source-id: a893cc96f2e9aad1c064a6de4f7ccf79257dec3f
Summary:
special case for norm out where p == 2. Instead of calling `pow`,
we use multiplication as a faster code path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31903
Differential Revision: D19312749
Pulled By: ngimel
fbshipit-source-id: 73732b7b37a243a14438609784795b920271a0b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31800
If we know that two constants are the same object, we can ignore other constraints and pool them together. This fixes an issue introduced by the other PR where quantization relied on constant pooling happening for correctness.
Test Plan: Imported from OSS
Differential Revision: D19269499
Pulled By: eellison
fbshipit-source-id: 9d4396125aa6899cb081863d463d4f024135cbf4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31501
We have a number of places in our code base where we should be checking if it's safe to change the alias relationship between two sets of values. This PR adds an api to Alias Db to consolidate the logic, and refactors Constant Pooling and `CSE` to use the new api. Next steps: add api usage in peephole.cpp where applicable.
Happy to bikeshed `AliasDb::safeToChangeAliasingRelationship`. Previously I suggested `AliasDb::safeToIntroduceAliasing`, however that's not quite accurate, because this API also handles when it is unsafe to remove aliasing.
Alternate suggestions: `safeToChangeAliasing`, `validToChangeAliasing`, `validToChangeAliasingRelationship`
Related: https://github.com/pytorch/pytorch/issues/28360
Test Plan: Imported from OSS
Differential Revision: D19254413
Pulled By: eellison
fbshipit-source-id: 17f7f52ad2d1526d303132767cbbb32f8189ae15
Summary:
This is a first pass attempt at documenting `IValue` to help with problems like in #17165. Most users are probably concerned with
* how to make an `IValue` that matches the input type to their graph (most of the constructors are pretty self explanatory, so as long as they are in the docs I think its enough)
* how to extract the results after running their graph (there is a small note on the behavior of `.toX()` based on confusions we've had in the past)
Preview:
https://driazati.github.io/pytorch_doc_previews/31904/api/structc10_1_1_i_value.html#exhale-struct-structc10-1-1-i-value
There are also some random CSS fixes to clean up the style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31904
Pulled By: driazati
Differential Revision: D19318733
fbshipit-source-id: b29dae3349d5a7ea5a3b8e09cd23f7ff8434edb4
Summary:
This hooks up `inspect` so that Python functions get their parameters
names attached instead of naming them `0, 1, 2, ...`. This also fixes
issue #28537 where `ignore` functions were improperly typing `self`.
](https://our.intern.facebook.com/intern/diff/19256434/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29300
Pulled By: driazati
Differential Revision: D19256434
fbshipit-source-id: 6a1fe7bd0afab708b8439517798955d0abfeb44c
Summary:
Stacked PRs
* **#31908 - Remove C++ docs contributing page**
* #31905 - Add doc previewing instructions
We should have 1 source of truth for contribution instructions (CONTRIBUTING.md).
This PR moves the instructions from the C++ doc pages there instead of having its
own separate page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31908
Pulled By: driazati
Differential Revision: D19296366
fbshipit-source-id: c1daf004259342bd09e09dea3b80e34db47066ec
Summary:
Stacked PRs
* #31908 - Remove C++ docs contributing page
* **#31905 - Add doc previewing instructions**
This adds some instructions on how to get started with Github pages you can show reviewers your documentation changes. Hopefully we can delete this eventually and build docs automatically on relevant PRs in CI.
](https://our.intern.facebook.com/intern/diff/19296364/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31905
Pulled By: driazati
Differential Revision: D19296364
fbshipit-source-id: df47fa1a8d7be029c3efcf6521298583ad9f7a95
Summary:
Fix https://github.com/pytorch/pytorch/issues/24684.
Benchmark script :
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000]:
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(1000):
input.cauchy_()
for n in [1, 10, 100, 1000]:
fwd_t = 0
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(10000):
t1 = _time()
input.cauchy_()
t2 = _time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.4f (ms)." % (n, fwd_avg))
```
Test device: **skx-8180**.
Before:
```
input size(128, 1) forward time is 0.0071 (ms).
input size(128, 10) forward time is 0.0596 (ms).
input size(128, 100) forward time is 0.5798 (ms).
input size(128, 1000) forward time is 5.8395 (ms).
```
After:
```
input size(128, 1) forward time is 0.0070 (ms).
input size(128, 10) forward time is 0.0583 (ms).
input size(128, 100) forward time is 0.5714 (ms).
input size(128, 1000) forward time is 5.7674 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31824
Differential Revision: D19314411
Pulled By: ezyang
fbshipit-source-id: 58098546face3e5971b023f702cfe44ff1cccfbc
Summary:
VitalyFedyunin, This PR is about port Softplus activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Softplus()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.12 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.18 (ms).
CPU:
input size(128, 100) forward time is 1.16 (ms); backwad avg time is 0.69 (ms).
input size(128, 10000) forward time is 60.19 (ms); backwad avg time is 31.86 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
input size(128, 100) forward time is 0.43 (ms); backwad avg time is 0.16 (ms).
input size(128, 10000) forward time is 1.65 (ms); backwad avg time is 0.83 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) forward time is 0.53 (ms); backwad avg time is 0.28 (ms).
input size(128, 10000) forward time is 51.33 (ms); backwad avg time is 25.48 (ms).
After:
input size(128, 100) forward time is 0.44 (ms); backwad avg time is 0.16 (ms).
input size(128, 10000) forward time is 42.05 (ms); backwad avg time is 13.97 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24633, https://github.com/pytorch/pytorch/issues/24634, https://github.com/pytorch/pytorch/issues/24766, https://github.com/pytorch/pytorch/issues/24767.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30504
Differential Revision: D19274913
Pulled By: ezyang
fbshipit-source-id: 21b29e8459dcba5a040cc68333887b45a858328e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31897
Previous version only use avx2. The _simd version uses avx512 if CPU is capable of that.
Test Plan: Unitttest
Reviewed By: tracelogfb
Differential Revision: D19291499
fbshipit-source-id: 3b1ee0ba756e5c9defbd5caf7f68982d9b2ca06c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31031
This activation will be needed for the LSTM implementation.
Also includes the QNNPack implementation.
Test Plan: Imported from OSS
Differential Revision: D18903453
Pulled By: z-a-f
fbshipit-source-id: 0050b1cebb1ddb179b7ecbcb114fe70705070f67
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31412
The root cause is `plan_caches` being resized in one thread while another holds a reference to an existing `CuFFTParamsLRUCache` which then becomes invalidated.
I was able to reproduce the crash very reliably without this fix applied and no longer see it. Being a race condition, it's hard to say for sure though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31861
Differential Revision: D19312314
Pulled By: ezyang
fbshipit-source-id: 06e4561128d503f2d70cdfe1982be0f3db2a8cf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31313
This is a bugfix. The reason we couldn't enable the constexpr-ness for it before is that it was buggy,
and without constexpr it crashed at runtime and not at compile time which seems to have passed our CI unfortunately...
ghstack-source-id: 96380160
Test Plan: Now it works even when enabling constexpr for it
Differential Revision: D19087471
fbshipit-source-id: 28be107389f4507d35d08eab4b089a405690529b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31026
This is error prone and probably wrong. Since we don't use LeftRight on the hot path anymore, let's remove this.
ghstack-source-id: 96369644
Test Plan: none
Differential Revision: D18902165
fbshipit-source-id: 7b9478cd7cc071f403d75da20c7c889c27248b5c
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31911
Test Plan:
* CI builds including GPU and OSS-build tests
* The `defined(__HIP_DEVICE_COMPILE__) ` instance a few lines below is proof that this is a define/undef flag, not a define01 flag
Reviewed By: hlu1
Differential Revision: D19296560
fbshipit-source-id: 1c45069aec534b0bf4a87751a74680675c985e06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31147
The goal here is to add more tests of the current behavior of the autograd to make sure no regressions are introduced when modifying it.
Do let me know if you think of other corner cases I missed.
Test Plan: Imported from OSS
Differential Revision: D19301082
Pulled By: albanD
fbshipit-source-id: 2cb07dcf99e56eb1f2c56a179796f2e6042d5a2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31888
We need a backend-agnostic mechanism to do barrier-like operation before locally destroy RRef context and shutdown RPC Agent.
- Sort worker names.
- Elect the first name as the leader in the ordered worker names.
- Followers reports therir intent to synchronize to the leader.
- Leader also reports to itself, when `_wait_all_workers()` called.
- If all workers report their intent to proceed, leader send the command to every one to proceed.
ghstack-source-id: 96386210
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_leak
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_worker_id
```
# Stress runs
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_heavy_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_heavy_rpc --stress-runs 10
```
Differential Revision: D19290954
fbshipit-source-id: cdb22203c2f27b5e0d0ad5b2d3b279d438c22dcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31917
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19301480
Pulled By: ezyang
fbshipit-source-id: fcce8868733965b9fbd326b4ec273135759df377
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31351
Clang 4 needs the c10:: namespace specifier on fully_qualified_type_name_impl() to work correctly.
Also, let's add an error message for people using clang 3 and earlier, we don't support those compilers anymore but before this PR, they got a crappy message.
ghstack-source-id: 96380163
Test Plan: testinprod
Differential Revision: D19135587
fbshipit-source-id: c206b56240b36e5c207fb2b69c389bb39f1e62aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30916
These macros said "make it constexpr if we're in C++14". Since we're now always C++14, we can just say "constexpr" isntead.
ghstack-source-id: 96369584
Test Plan: waitforsandcastle
Differential Revision: D18869635
fbshipit-source-id: f41751e4e26fad6214ec3a98db2d961315fd73ff
Summary: I think this was wrong before?
Test Plan: Not sure.
Reviewed By: IvanKobzarev
Differential Revision: D19221358
fbshipit-source-id: 27e675cac15dde29e026305f4b4e6cc774e15767
Summary:
These were returning incorrect data before. Now we make a contiguous copy
before converting to Java. Exposing raw data to the user might be faster in
some cases, but it's not clear that it's worth the complexity and code size.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221361
fbshipit-source-id: 22ecdad252c8fd968f833a2be5897c5ae483700c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31584
These were returning incorrect data before.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221360
fbshipit-source-id: b3f01de086857027f8e952a1c739f60814a57acd
Summary: These are valid tensors.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221362
fbshipit-source-id: fa9af2fc539eb7381627b3d473241a89859ef2ba
Summary:
As in title, this PR will disable the `--quiet` flag used in the CI as a workaround to a timeout hitting Mac OS CI. Circle CI works by timing out when no text has been printed for 10 min.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31900
Differential Revision: D19302899
Pulled By: bwasti
fbshipit-source-id: 145647da983ee06f40794bda1abd580ea45a0019
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31222
- When constructing torch::from_blob() in the case where the deleter is a nop, switch to using a nullptr context in the DataPtr (with a nop deleter)
- No real extra memory/cpu requirements here, actually saves a minor alloc.
Why? Trying to get a signal that a Tensor might contain non-owned memory from
torch::from_blob(), by detecting the nullptr context.
ghstack-source-id: 96336078
Test Plan:
buck test mode/dev caffe2/test/cpp/api/...
buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18992119
fbshipit-source-id: 4eea642f82d0858b57fdfc6995364a760c10567d
Summary:
For now I'm just removing the decorators from all of the currently overridable functions in `torch.functional`. This means they are no longer overridable, however this should fix the benchmark regressions reported in https://github.com/pytorch/pytorch/issues/30831. Moving forward we'll be looking at reducing the overhead of the python-level override mechanism and failing that, re-implementing all of these operators in C++.
cc hl475
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30839
Differential Revision: D18838848
Pulled By: ezyang
fbshipit-source-id: 22b8015d7b2f7a947f1ebc9632c998e081b48ad8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31343
Fix an issue in TorchScript tracing for modules with `c10::List<at::Tensor>` as an output. TensorList was not supported properly.
Test Plan: unit tests
Reviewed By: wanchaol
Differential Revision: D18850722
fbshipit-source-id: 87a223104d1361fe754d55deceeb1e8bbcad629b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31508
This PR builds on top of https://github.com/pytorch/pytorch/pull/31230
to ensure that distributed autograd doesn't block an RPC thread anymore during
the backward pass.
I've also added a unit test where all ranks hammer rank 0 without about 60
backward calls (which would cause a deadlock earlier), but now such a test
passes without any issues.
ghstack-source-id: 96345097
Test Plan: waitforbuildbot
Differential Revision: D19188749
fbshipit-source-id: b21381b38175699afd0f9dce1ddc8ea6a220f589
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28430
The unpythonic signatures for functions such as `torch.addcdiv` are already seperated in [`deprecated.yaml`] and the signatures marked as deprecated in `PythonArgParser`. However, nothing was done with this information previously. So, this now emits a warning when the deprecated signatures are used.
One minor complication is that if all arguments are passed as keyword args then there is nothing to differentiate the deprecated overload. This can lead to false warnings being emitted. So, I've also modified `PythonArgParser` to prefer non-deprecated signatures.
[`deprecated.yaml`]: https://github.com/pytorch/pytorch/blob/master/tools/autograd/deprecated.yaml
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31514
Differential Revision: D19298735
Pulled By: ezyang
fbshipit-source-id: 03cb78af17658eaab9d577cd2497c6f413f07647
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31909https://github.com/pytorch/pytorch/pull/31230 introduced a bug where
we would end up calling `graph_task_post_processing` twice for reentrant
backward calls (once when we mark the future completed and then we we called
graph_task_post_processing in execute_with_graph_task).
This PR fixes the issues by verifying the future we return in that case is
completed and we remove the call to graph_task_post_processing.
In addition to that I added a test that reproduced the problem and verified it
is fixed by this PR.
ghstack-source-id: 96349102
Test Plan: waitforbuildbot
Differential Revision: D19296363
fbshipit-source-id: dc01a4e95989709ad163bb0357b1d191ef5a4fb2
Summary:
In order to support Ubuntu18.04, some changes to the scripts are required.
* install dependencies with -y flag
* mark install noninteractive
* install some required dependencies (gpg-agent, python3-distutils, libidn11)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31886
Differential Revision: D19300586
Pulled By: bddppq
fbshipit-source-id: d7fb815a3845697ce63af191a5bc449d661ff1de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31236
It is not compiled on Windows
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262581
Pulled By: ezyang
fbshipit-source-id: 80bfa553333a946f00291aaca6ad26313caaa9e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31707
Change the initialization value for FC weight init and sparse embedding lookup init.
Previous default initialization is uniform(-\sqrt(1/input_dim), \sqrt(1/input_dim)); Now pass into a flexible hyperparameter, say \alpha into it, to change into uniform(-\sqrt(\alpha/input_dim), \sqrt(\alpha/input_dim));
Reviewed By: chonglinsun
Differential Revision: D18825615
fbshipit-source-id: 4c5f2e07f2b3f5d642fd96d64dbf68892ebeb30b
Summary:
The error message produced by AT_ASSERT() in gather() encouraged users to file a bug report ("please report a bug to PyTorch..."). The assertion should be a regular argument check since it can be triggered by passing tensors with different dimensionality, e.g. `torch.cuda.comm.gather([torch.rand(1, device='cuda'), torch.rand(1, 1, device='cuda')])`.
See: https://github.com/pytorch/pytorch/issues/26400
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27456
Differential Revision: D19300270
Pulled By: ezyang
fbshipit-source-id: ec87d225e23445020b377521e0daccceb4748215
Summary:
This PR adds bfloat16 support for convolutions on ROCm.
- Intergrates MIOpen bfloat16 convolution support into PyTorch
- Enables bfloat16 convolution for non-miopen paths, i.e THCUNN, native hip kernels
- Enables bfloat16 type for probability distribution functions(this is included in this PR since conv unit tests use bfloat16 random number generators)
Native cuda kernels for convolution and random functions will be compiled for CUDA as well.
iotamudelta bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30948
Differential Revision: D19274164
Pulled By: ezyang
fbshipit-source-id: c0888a6ac72a2c5749b1ebb2195ac6f2209996be
Summary:
Compared to cuDNN bias, PyTorch add has the following advantage:
- faster, especially for backward (see: https://github.com/zasdfgbnm/things/blob/master/2019/conv-backward-profile.md)
- handles 64bit indexing automatically
- has less code, less maintenance effort
ngimel I submit this PR early so the CI could start building it. But I have not tested it locally yet (still waiting for compiling).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31524
Differential Revision: D19264244
Pulled By: ngimel
fbshipit-source-id: cb483d378a6d8bce0a05c3643a796e544bd8e8f0
Summary:
Closes https://github.com/pytorch/pytorch/issues/31497
This allows `torch.no_grad` and `torch.enable_grad` to be used as decorators for generator functions. In which case it disables/enables grad only inside the body of the generator and restores the context outside of the generator.
https://github.com/pytorch/pytorch/issues/31497 doesn't include a complete reproducer but the included test with `torch.is_grad_enabled` show this is working where it failed before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31792
Differential Revision: D19274971
Pulled By: albanD
fbshipit-source-id: fde6d3fd95d76c8d324ad02db577213a4b68ccbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31157
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262583
Pulled By: ezyang
fbshipit-source-id: 8fb87b41ab53770329b38e1e2fe679fb868fee12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31155
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262584
Pulled By: ezyang
fbshipit-source-id: 147ac5a9c36e813ea9a2f68b498880942d661be5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31152
Per apaszke: I can't find any reasonable references to libIRC online, so
I decided to remove this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262582
Pulled By: ezyang
fbshipit-source-id: a1d47462427a3e0ca469062321d608e0badf8548
Summary:
This change is required for cases like:
x[1:] = data or x[:3] = data
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31552
Reviewed By: hl475
Differential Revision: D19238815
Pulled By: houseroad
fbshipit-source-id: 56c9837d86b341ea92b0a71d55034ce189d12e6c
Summary:
For backend integration, backend (e.g. Glow) needs to check the content of the tensor to determine whether it is a legit byte tensor or some special packed format. This provides a convenient interface for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31290
Reviewed By: jackm321, qizzzh
Differential Revision: D19069684
Pulled By: yinghai
fbshipit-source-id: 63360fa2c4d32695fe9767a40027d446d63efdd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31803
Refactored the following fairly similar functions:
1. `test_context_cleanup_tensor_with_grad`
2. `test_context_cleanup_tensor_no_grad`
3. `test_context_cleanup_no_tensors`
by creating a helper function `context_cleanup_test_helper` that can be invoked with the appropriate arguments.
Test Plan: Verified by running tests.
Differential Revision: D19269246
fbshipit-source-id: bfb42b078ad56b97ceeecf0d68b4169768c2c453
Summary:
When calling the add_images() method on the tensorboard SummaryWriter with a uint8 NCHW tensor, the tensor is incorrectly scaled, resulting in overflow behavior. This leads to incorrect images being displayed in tensorboard.
Issue: https://github.com/pytorch/pytorch/issues/31459
Local Testing (ran this code with and without the PR changes and printed scale_factor):
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x=torch.tensor([[[[1, 2, 3], [4, 5, 6]]]], dtype=torch.uint8)
writer.add_images("images", x)
Before- scale_factor: 255, After- scale_factor: 1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31778
Differential Revision: D19289189
Pulled By: anjali411
fbshipit-source-id: 350a1650337244deae4fd8f8b7fb0e354ae6986b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31230
A major issue with distributed autograd currently is that we block an
RPC thread when we call Engine::execute_with_graph_task.
To resolve this issue, I've made modifications to the local autograd engine
such that `execute_with_graph_task` returns a Future instead. The `execute()`
methods for Engine::execute() and DistEngine::execute() still wait() on this
Future which ensures there is no change in behavior yet.
In follow up PRs we can modify the distributed autograd engine to take
advantage of this Future.
Closes#26359
ghstack-source-id: 96298057
Test Plan: waitforbuildbot
Differential Revision: D18999709
fbshipit-source-id: 388f54467fd2415a0acb7df17bd063aedc105229
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30710
We need a backend-agnostic mechanism to do barrier-like operation before locally destroy RRef context and shutdown RPC Agent.
- Sort worker names.
- Elect the first name as the leader in the ordered worker names.
- Followers reports therir intent to synchronize to the leader.
- Leader also reports to itself, when `_wait_all_workers()` called.
- If all workers report their intent to proceed, leader send the command to every one to proceed.
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork -- test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers$
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_leak
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_forward_chain
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_wait_all_workers$
```
# Stress runs
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_heavy_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_heavy_rpc --stress-runs 10
```
# Debug
```
buck test mode/dev-nosan caffe2/test:rpc_fork -- test_shutdown
```
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork -- test_clean_context_during_backward
buck build mode/dev-nosan //caffe2/test:dist_autograd_fork
buck-out/gen/caffe2/test/dist_autograd_fork\#binary.par -r test_clean_context_during_backward
```
https://our.intern.facebook.com/intern/testinfra/diagnostics/281475127895800.844424945328750.1575664368/
```
I1206 12:27:47.491420 185619 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
I1206 12:27:47.493880 185630 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
I1206 12:27:47.494526 185625 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
I1206 12:27:47.495390 185636 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
E1206 12:27:47.544198 185627 pair.cc:642] 1 --->>> 0, read ERROR: AsyncSocketException: Network error, type = Network error, errno = 104 (Connection reset by peer)
E1206 12:27:47.544203 185633 pair.cc:642] 2 --->>> 0, read ERROR: AsyncSocketException: Network error, type = Network error, errno = 104 (Connection reset by peer)
E1206 12:27:47.544210 185639 pair.cc:642] 3 --->>> 0, read ERROR: AsyncSocketException: Network error, type = Network error, errno = 104 (Connection reset by peer)
```
This should mean the UDF in the request has been run, so Python proceeded and ran to `_agent.shutdown()`.
While the RpcAgents on followers wanted to send back the response, but the leader has closed RPC.
Need to re-trigger "pytorch_rpc-buck" to reproduce the rare-seen issue.
Differential Revision: D18643137
fbshipit-source-id: d669d4fc9ad65ed48bed1329a4eb1c32ba51323c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30612
The first version to move prim ops to c10 registration. After the reviewers are fine with the initial changes, more operators will be moved in the same style.
Test Plan: Imported from OSS
Differential Revision: D19237648
Pulled By: iseeyuan
fbshipit-source-id: c5a519604efffb80564a556536f17d829f71d9f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29220
Support for accessing constant is added in previous
PRs, this PR re-enables the foldbn tests
Test Plan:
test_jit.py
Imported from OSS
Differential Revision: D18846848
fbshipit-source-id: 90ceaf42539ffee80b984e0d8b2420da66c263c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29219
We added class constant in previous PRs, this PR allows access to
class constant in the object API
Test Plan:
build/bin/test_jit
python test/test_jit.py
Imported from OSS
Differential Revision: D18846851
fbshipit-source-id: 888a6517d5f747d1f8ced283c0c2c30b2f6c72c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30787
This is needed when we fuse conv bn modules,
where we need to rewrite a constant bias (None) of conv to an attribute
bias of Tensor
Test Plan:
build/bin/test_jit
Imported from OSS
Differential Revision: D18846850
fbshipit-source-id: 9fd5fe85d93d07226e180b75d2e068fe00ca25fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31012
- getConstant should throw when the item is not found
- add another getConstant which takes slot index as argument
Test Plan:
test_class_type.cpp
Imported from OSS
Differential Revision: D18898418
fbshipit-source-id: d3a23a4896fdbf5fa98e1c55c9c4d6205840014b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31845
ArrayRef is trivially copyable and should be passed by value. Removing
unnecessary `&`s.
Test Plan: Imported from OSS
Differential Revision: D19278523
Pulled By: suo
fbshipit-source-id: 026db693ea98d19246b02c48d49d1929ecb6478e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29218
We need to be able to access constant in module.
Test Plan:
tbd
Imported from OSS
Differential Revision: D18846847
fbshipit-source-id: 22d2c485c3c449bc14ad798f6e1a0c64fc8fb346
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31255
This test had 2 issues. A timeout would occasionally happen due to a timeout of 50ms, and CUDA could would get compiled and run on CPU, leading to errors. This PR fixes those issues.
Differential Revision: D19028231
fbshipit-source-id: e50752228affe0021e7c0caa83bce78d76473759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31575
We need a new exception class specifically for the enforce_finite operator, because we need to map it to a specific python exception ExitException, not the RuntimeError type that all c10::Errors get mapped to by default. This diff includes:
- Define c10::EnforceFiniteNotMet
- API CAFFE_ENFORCE_FINITE to throw c10::EnforceFiniteNotMet
- Map from c10::EnforceFiniteNotMet to python ExitException
- Apply CAFFE_ENFORCE_FINITE in caffe2 op
Test Plan:
- integration test pass: https://fburl.com/fblearner/xwkzbqyo
- integration test with D19213617: https://fburl.com/fblearner/479y4jrj Generate error message as desired
- Example:
- Original error message f157597803
{F225477055}
- Updated error message (with D19213617 to generate the error): f158571327
{F225477071}
Reviewed By: zheng-xq
Differential Revision: D19206240
fbshipit-source-id: bd256862801d5957a26b76d738edf4e531f03827
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31583
But rather use `float *`, which is alredy registered
Test Plan: CI
Reviewed By: xianjiec
Differential Revision: D19221405
fbshipit-source-id: eb8eabcf828745022bc1e4185a0e65abd19a8f04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31813
Closes https://github.com/pytorch/pytorch/issues/31804. We were using
an `std::vector` for the key for a map that keeps track of futures to mark them
if they timeout, but we can instead use an `unordered_set`. This results in a
faster lookup in the code block where we remove futureIDs from this set when
they complete successfully. Previously we were finding them via a linear
`std::find`. Switching it to a constant time find will help performance in the
case where a large number of futures are scheduled to time out at the same
time, or if there is no timeout enforced.
To benchmark a rough perf improvement, I created 50k futures with the same
timeout. Before this PR, the lookup `std::find(futuresAtTime.begin(),
futuresAtTime.end(), id)` took ~200us, now it takes 1us.
ghstack-source-id: 96251355
Test Plan: Unit tests pass.
Differential Revision: D19269798
fbshipit-source-id: 1a0fa84a478ee27a16ab0b9fa6f5413b065a663e
Summary:
This PR aims at improving `index_select` performance on CPU with `TensorIterator`.
The code has equally effective optimization for both contiguous tensor and non-contiguous tensor.
The code will try to parallel inner loop in case the slice of copy is large enough, otherwise it will parallel on outer loop.
Thus both the user scenarios from DLRM (from `Embedding`) and Fairseq transformer is covered.
1. for contiguous input, single socket: **1.25x** performance speedup
2. for non-contiguous input, single socket: **799x** performance speedup
3. for contiguous input, single core: same performance
4. for non-contiguous input, single core: **31x** performance speedup
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30598
Differential Revision: D19266892
Pulled By: VitalyFedyunin
fbshipit-source-id: 7aaf8e2c861b4a96250c968c4dd95c8d2c5b92d7
Summary:
VitalyFedyunin, this PR is about port rrelu activation to Aten:
Test script:
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
m = nn.RReLU(0.1, 0.3).train()
# for inference
#m = nn.RReLU(0.1, 0.3).eval()
#warm up
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
**Before:**
```
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.03 (ms).
input size(128, 10) forward time is 0.03 (ms); backwad avg time is 0.04 (ms).
input size(128, 100) forward time is 0.17 (ms); backwad avg time is 0.06 (ms).
input size(128, 1000) forward time is 1.45 (ms); backwad avg time is 0.07 (ms).
inferecne:
input size(128, 1) forward time is 0.01 (ms).
input size(128, 10) forward time is 0.01 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.15 (ms).
```
**After:**
```
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.03 (ms).
input size(128, 10) forward time is 0.03 (ms); backwad avg time is 0.04 (ms).
input size(128, 100) forward time is 0.17 (ms); backwad avg time is 0.07 (ms).
input size(128, 1000) forward time is 1.43 (ms); backwad avg time is 0.08 (ms).
inferecne:
input size(128, 1) forward time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.03 (ms).
```
**OMP_NUM_THREADS=1:**
```
Before:
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.15 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 1.45 (ms); backwad avg time is 0.14 (ms).
inferecne:
input size(128, 1) forward time is 0.01 (ms).
input size(128, 10) forward time is 0.01 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.20 (ms).
After:
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.15 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 1.43 (ms); backwad avg time is 0.15 (ms).
inferecne:
input size(128, 1) forward time is 0.01 (ms).
input size(128, 10) forward time is 0.02 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.06 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24755, https://github.com/pytorch/pytorch/issues/24756.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31094
Differential Revision: D19270936
Pulled By: VitalyFedyunin
fbshipit-source-id: 11bb3236b1037a558022d3777d1f9a429af2bffe
Summary:
Currently `cumsum` crashes for tensors with non-empty dimensions but with zero elements, which could happen when some dimension is zero. This commit fixes the error by checking both `dim()` and `numel()` in cumsum backward
Fixes https://github.com/pytorch/pytorch/issues/31515
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31694
Reviewed By: mrshenli
Differential Revision: D19266613
Pulled By: leedtan
fbshipit-source-id: 9407e0aa55440fed911c01a3580bb6c5eab62a16
Summary:
The original `check-and-act` style can raise `FileExistsError` when multiple processes are jit-compiling the extension on the same node.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30956
Differential Revision: D19262570
Pulled By: ezyang
fbshipit-source-id: bb18c72e42648770b47f9378ac7c3929c3c03efc
Summary:
This dramatically reduces the number of instantiations and eliminates
~900KB of code from my local build of libtorch_cpu.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31683
Differential Revision: D19258364
Pulled By: resistor
fbshipit-source-id: addb921a26289978ffd14c203325ca7e35a4515b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31539
Adding this metric primarily because it is needed to unblock unit
tests for https://github.com/pytorch/pytorch/pull/31381. It also may be useful
to look at this metric to see the number of pending RRef forks that currently
exist.
ghstack-source-id: 96230360
Test Plan: Modified the relevant unit test.
Differential Revision: D19204158
fbshipit-source-id: 016345e52cd02cc5f46837bffd8d589ba8575f29
Summary:
Add support to print op dependence as python code so that both custom
build script and BUCK can import it without yaml parser.
Test Plan:
- generate the file:
```
ANALYZE_TORCH=1 FORMAT=py DEPLOY=1 tools/code_analyzer/build.sh -closure=false
```
- load the file in python:
```
python
>>> from tools.code_analyzer.generated.torch import TORCH_DEPS
>>> print(TORCH_DEPS)
```
Differential Revision: D18894639
Pulled By: ljk53
fbshipit-source-id: e304d0525a07a13cf6e8a9317cd22637200d044c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31215
Install LLVM-dev package for code analysis CI job: #30937
LLVM-dev package is not related to android NDK but the whole code
analysis thing is for mobile custom build so choose this docker image.
Test Plan: - wait docker image to build?
Differential Revision: D19193223
Pulled By: ljk53
fbshipit-source-id: 54a79daf8d98fa7c8b9eed11f519e1c7b1614be8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31588
Per title. This test can sometimes fail with a different error regex
than the one that is currently tested, so add this error regex to make the test
pass consistently.
Differential Revision: D19222275
fbshipit-source-id: 89c95276d4d9beccf9e0961f970493750d78a96b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31668
This also removes an annoying warning about change of sign conversion
Test Plan: Run unit tests
Reviewed By: ezyang
Differential Revision: D19238631
fbshipit-source-id: 29b50abac635e530d5b0453c3a0f36a4573fbf5b
Summary:
In the long string, formalstring thinks it is good to have a name.
When using dict, literal is better for readability and faster than dict constructor.
I always appreciate your efforts in creating the world's best frameworks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31352
Differential Revision: D19191967
Pulled By: ngimel
fbshipit-source-id: 21f063b163b67de8cf9761a4db5991f74318e991
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31676
Facebook:
Previously we assumed mask is passed in as a tensor which is not feasible for sparse parameter.
Here we allow to pass in the mask through db path which requires the masks to be stored in some db first.
Test Plan: unit tests
Reviewed By: ellie-wen
Differential Revision: D18928753
fbshipit-source-id: 75ca894de0f0dcd64ce17b13652484b3550cbdac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31675
This test could be flaky since there could be inflight RPC requests as
part of startup which might not have finished. As a result, if they finish
between the different calls to retrieve debug_info, there could be a problem
since we would report separate information. As a result, we wait to ensure
the metrics stabilize to avoid flakiness.
ghstack-source-id: 96188488
Test Plan: waitforbuildbot
Differential Revision: D19242588
fbshipit-source-id: 8f3db7e7365acbd3742e6ec0c2ddcca68f27db9e
Summary:
- Fixes https://github.com/pytorch/pytorch/issues/31672
- Adds Bfloat16 dispatch to the indexing operations that were missing it
- index_put on cuda does not have bfloat16 dispatch, because I'm not sure bfloat16 math ops work on cuda
Note: `index_put_` with `accum=True` is enabled for `bool`, which does not make much sense, but I'm not the one who started it, so this behavior is preserved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31692
Differential Revision: D19249561
Pulled By: ngimel
fbshipit-source-id: 1269196194f7b9f611b32be198c001704731a78f
Summary:
Change log:
- [x] Change the order of arguments position of torch.std and torch.std_mean in doc.
- [x] Correct a spelling mistake of torch.std_mean in doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31677
Differential Revision: D19247372
Pulled By: ngimel
fbshipit-source-id: 8685f5207c39be524cdc81250430beac9d75f330
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28942
The new abstract RRef class contains only user-facing RRef APIs.
It will be later moved to a common folder so that it can be shared
by jit and distributed packages to provide TorchScript support.
Test Plan: Imported from OSS
Differential Revision: D18240590
Pulled By: mrshenli
fbshipit-source-id: ac28cfc2c8039ab7131b537b2971ed4738710acb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31641
Assuming mask is provided as a tensor
Test Plan: unit test
Reviewed By: ellie-wen
Differential Revision: D18928737
fbshipit-source-id: a4f3dd51769c2b56e5890043e91c18e6128be082
Summary:
7zip and cmake are part of base image, no need to re-install. Remove the install step can make build/test more stable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30897
Differential Revision: D19232961
Pulled By: mingbowan
fbshipit-source-id: fa3bbd1325839a2a977bf13fdbd97fda43793b8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31612
Count the number recent update on rows. Exponential decay is applied on the counter with decay rate r, such that
r^{counter_halflife} = 0.5;
If counter_halflife is nonpositive, this operator is turned off.
Test Plan: added unittest
Reviewed By: chocjy
Differential Revision: D19217921
fbshipit-source-id: 96d850123e339212cc0e0ef352ea8a1b1bf61dfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31602
Pull Request resolved: https://github.com/pytorch/glow/pull/3943
Zero length input is something we hit fairly frequently in practice. Previous handling of global TensorPool involves two locks per input (acquire and reclaim). Here we use a specialized anchor tensor to host zero length input. Note that it is only padded to max sequence length. If necessary, an easy extension can be added to pad to max `InputPlaceholder.getType().size()`.
Reviewed By: jfix71
Differential Revision: D19192467
fbshipit-source-id: cafdc1eb7bf9b9d6ead04a0243b0be838f6b71cd
Summary:
Earlier cudnn version doesn't support grouped convolution in NHWC well. Legit
configuration in later cudnn version might return CUDNN_STATUS_NOT_SUPPORTED.
We are falling back to NCHW when runtime check of cudnn version is < 7.6.0 to
keep the logic simple.
Note:
We might update the heuristics, 7.6.0 is very conservative.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31444
Differential Revision: D19232414
Pulled By: VitalyFedyunin
fbshipit-source-id: 4c2d79ed347c49cd388bbe5b2684dbfa233eb2a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31260
1. Update the LiteLM dataset conversion script (fbcode/pytext/fb/tools/lite_lm_dataset_to_tensorproto.py)
2. Created a benchmark json file for byte-aware lstm word model (xplat/aibench/specifications/models/caffe2/assistant/lite_lm_len5.json)
3. In order to run the model -- created an int64 Tensor for the model, added batch gather ops to the BUCK file
Test Plan:
```
1. Create tensorproto of the model input
buck run mode/opt //pytext/fb/tools:byte_lm_dataset_to_tensorproto -- --in-path /mnt/vol/pytext/smart_keyboard/aibench/test_5.txt --out-path /mnt/vol/pytext/smart_keyboard/aibench/byteAwareWordLM/ --hidden_dim 203 --layers_num 2 --max_seq_len 64 --max_byte_len 15
2. Run the aibench command
buck run fbsource//xplat/aibench:run_bench -- -b aibench/specifications/models/caffe2/assistant/lm_byte_lstm_len5.json --remote --devices SM-G960U-8.0.0-26
```
Reviewed By: gardenia22
Differential Revision: D17785682
fbshipit-source-id: 351c3c8bae16449e72ac641522803b23a83349be
Summary:
Originally, we only print one broken schema. With this changeset, all the broken schemas are printed out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31628
Reviewed By: hl475
Differential Revision: D19231444
Pulled By: houseroad
fbshipit-source-id: 3dd5b4609a6a9a9046e95f2f30deb9beeb5dcd56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31490
When this happens, a dense tensor is constructed from a sparse constructor.
Fixes: https://github.com/pytorch/pytorch/issues/16154
Test Plan: Imported from OSS
Reviewed By: cpuhrsch, mrshenli
Differential Revision: D19196498
Pulled By: gchanan
fbshipit-source-id: 57a6324833e35f3e62318587ac74267077675b93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30784
Instead of putting experimental Masked*Adagrad to OSS, we decided to change D18805278 .
Test Plan: CI
Reviewed By: chocjy
Differential Revision: D18824265
fbshipit-source-id: 3d893fe6c441f2ff7af4c497cf81b9c49363e7a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31582
D19124934 removed a dummy pointer passed to strtod_c() that's used only for Android (https://fburl.com/diffusion/zkv34jf1). Without it, jit parsing on Android start throwing SIGSEGV due to null pointer dereferencing. This diff adds the dummy pointer back.
Test Plan: Tests
Reviewed By: driazati, shoumikhin
Differential Revision: D19221071
fbshipit-source-id: 2e230c3fbfa873c3f7b92f73c87ee766ac182115
Summary:
Basically the same as https://github.com/pytorch/pytorch/pull/31379 except for that I write a separate function `split_batch_dim_to_32bit_out` for the logic. This function could also be used for convolution forward, and I will rebase this PR after https://github.com/pytorch/pytorch/issues/31379 get merged and then change `raw_cudnn_convolution_forward_out` to use `split_batch_dim_to_32bit_out` here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31510
Differential Revision: D19210563
Pulled By: ngimel
fbshipit-source-id: e20bb82b6360aa2c0e449e127188c93f44e1e9b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31517
This is going to be used by upsample (which currently uses magic values to represent optionals).
For now, we just introduce a fake function for testing (torch._test_optional_float(x)).
Test Plan: Imported from OSS
Differential Revision: D19198721
Pulled By: gchanan
fbshipit-source-id: 0a1382fde0927c5d277d02d62bfb31fb574b8c74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31533
Fixes this test that was flaky and has been disabled (see
https://github.com/pytorch/pytorch/issues/31112)
ghstack-source-id: 96038999
Test Plan: Run the test 1000 times and ensure that it passes.
Differential Revision: D19203366
fbshipit-source-id: 7978cbb8ca0989a0a370a36349cdd4db3bb8345b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31380
For being able to profile async RPCs, we attach a `RecordFunction` object to the future that is created during the RPC to persist it across the lifetime of the RPC (this is implemented in the next PR: ). Since we'd only like to do this when profiling is enabled, this PR adds an enabled API to the autograd profiler.
ghstack-source-id: 96053933
Test Plan: Modified unit test.
Differential Revision: D19050391
fbshipit-source-id: aa382110e69d06b4a84c83b31d2bec2d8a81ba10
Summary:
I don't see any reason for not doing so, because it is a common error that people forget to set the stream. And I don't think there is a reason for not running on the current stream.
This is just for cublas, cusparse and cudnn should be modified also.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31537
Differential Revision: D19206908
Pulled By: ngimel
fbshipit-source-id: ba2b2b74e9847f0495c76dbc778751a9f23f8b36
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/22496
This is just a first step towards the support of 64bit convolution on CUDA. In the forward of convolution, if the total tensor size is larger than 2^31, then we split it on the batch dimension. I want to get some review feedback before moving forward for the same splitting approach for backward.
There are real-world use cases that even when N=1 the input is still larger than 2^31. For this case, the splitting would be complicated, so I am planning to modify `use_cudnn` to just dispatch to the slow fallback kernel in PyTorch in a later PR.
Update: `later PR` is https://github.com/pytorch/pytorch/pull/31383
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31379
Differential Revision: D19192018
Pulled By: ngimel
fbshipit-source-id: c26ecc56319ac67c4d5302ffed246b8d9b5eb972
Summary:
get rid of f-string, somehow we still have python2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31536
Differential Revision: D19204187
Pulled By: mingbowan
fbshipit-source-id: da8e17e4dccdd6fd1b0e92eb4740f5a09a8a4209
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30195
1. Added flavorDimensions 'build' local/nightly
to be able to test the latest nightlies
```
cls && gradle clean test_app:installMobNet2QuantNightlyDebug -PABI_FILTERS=x86 --refresh-dependencies && adb shell am start -n org.pytorch.testapp.mobNet2Quant/org.pytorch.testapp.MainActivity
```
2. To be able to change all new model setup editing only `test_app/build.gradle`
Inlined model asset file names to `build.gradle`
Extracted input tensor shape to `build.gradle` (BuildConfig)
Test Plan: Imported from OSS
Differential Revision: D18893394
Pulled By: IvanKobzarev
fbshipit-source-id: 1fae9989d6f4b02afb42f8e26d0f3261d7ca929b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31407
Remove observers in the end instead of before quantize tensor
since we still need them to find the quantization paramters for each module instance
Test Plan:
.
Imported from OSS
Differential Revision: D19162367
fbshipit-source-id: f817af87183f6c42dc97becea85ddeb7e050e2b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31406
Previously we record quantization parameters for a given value when we collect the observer nodes,
but actually the quantization parameter can vary depending on each module instance, to achieve
that, we need to delay the call to later stage and only record the `Value*` that's needed
in `collectObserverNodesAndValueToQuantize` function
Test Plan:
.
Imported from OSS
Differential Revision: D19162369
fbshipit-source-id: e0f97e322d18a281bf15b6c7bbb04c3dfacb512f
Summary:
The Python C API documentation states "Access to the [PyObject]
members must be done by using the macros Py_REFCNT and Py_TYPE."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31388
Differential Revision: D19161790
Pulled By: colesbury
fbshipit-source-id: ac9a3738c913ad290a6d3460d0d657ec5c13b711
Summary:
This is the first stab at running profile-insensitive optimizations on pre-profiled graphs. Running those optimizations has a potential to simplify graphs greatly before GuardElimination and GuardElimination should be able to remove more guards.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31392
Differential Revision: D19173639
Pulled By: Krovatkin
fbshipit-source-id: 2485a2a598c10f9b5445efb30b16439ad4551b3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31470
Optimize performance of these two operators.
Additionally use nearbyint instead of round to be consistent with 4-bit embedding table quantization.
Reviewed By: hyuen
Differential Revision: D19072103
fbshipit-source-id: efe96f14aeff7958cceb453ed625d3fd693891ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31455
In 15.9, __FUNCSIG__ unwraps using definitions as well as preserves noexcept qualifiers
Test Plan: Build caffe2 on Windows using VS2017
Differential Revision: D19166204
fbshipit-source-id: b6c5f70e5262d13adf585f77b92223cf5f1e78dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30429
also fix a bug in uncoalesced division
General approach here is that we:
* compute the common dtype based on input tensors
* error if the output tensor is specified and the common type can't be cast back to the output type (e.g. for inplace ops)
* convert input tensor (values) to the common dtype
* perform the op as normal (computing at the common dtype instead of the result type).
* convert/copy the result values back to that of the result tensor (for in-place ops).
For uncoalesced division we need to coalesce, because an integral tensor with values=[1,1] at the same index divided by 2 would give 1/2 + 1/2 =0 instead of 2/2=1.
Test Plan: Imported from OSS
Differential Revision: D19143223
Pulled By: nairbv
fbshipit-source-id: 480fa334c0b2b3df046818f2342cfd4e2d9d892a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31507
This script is used to generate a model with bound shape inference and
blob reorder, which are requirements for big model loading on T17.
1. Load existing model.
2. Do bound shape inference and blob reorder (put embedding blobs at the end).
3. Save the modified model.
Test Plan:
Generated a new moel and tested on NNPI.
P124181047 (mismatch is AA variance)
Reviewed By: ipiszy
Differential Revision: D19165467
fbshipit-source-id: c3522fc5dc53b7ec652420558e9e8bf65a1ccfae
Summary:
https://github.com/pytorch/pytorch/pull/30330 got rid of the need to send a `MessageType::SHUTDOWN` message, so we can now remove the logic/utils for this type of message.
I think we can also delete the enum entry in the `enum MessageType`, but we may want to keep it in case the logic in https://github.com/pytorch/pytorch/pull/30710 is ever moved to C++.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31270
Test Plan: All existing unit tests pass
Differential Revision: D19146983
Pulled By: rohan-varma
fbshipit-source-id: 35b185411f9446d7d4dfc37a6cb5477cf041e647
Summary:
Fixes a bad merge that is breaking distributed tests on master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31492
Pulled By: driazati
Differential Revision: D19180978
fbshipit-source-id: f69f525e2c7f61194686f07cf75db00eb642882f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31293
Previously we check the number of elements in scale to determine if we are using per channel quantization,
but we should get qscheme information from observer module directly and we'll expose this information
to caller as well
Test Plan:
.
Imported from OSS
Differential Revision: D19146669
fbshipit-source-id: ea430eeae0ef8f441be39aa6dcc1bb530b065554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31473
Mitigates #6313
A common use case for the autograd profiler is to use it to run over an
entire model, including dataloading. The following will crash:
- run autograd profiler in CUDA mode
- Use a multi-worker DataLoader (presumably with the 'fork' spawn
method)
- because the autograd profiler initializes CUDA and forking after CUDA is
initialized is bad.
This PR puts in a nice error message when this happens so that users
aren't too confused. The new error message looks like:
https://gist.github.com/zou3519/903f15c3e86bad4585b7e5ce14cc1b70
Test Plan:
- Tested locally.
- I didn't add a test case for this because it's hard to write a test
case that doesn't completely stop the rest of our test suite from
running.
Differential Revision: D19178080
Pulled By: zou3519
fbshipit-source-id: c632525ba1f7b168324f1aa55416e5250f56a086
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31484
See https://github.com/pytorch/pytorch/issues/26123 for context.
Previously, when someone googles for `pytorch "adaptive_max_pool2d"`,
https://pytorch.org/docs/stable/_modules/torch/nn/modules/pooling.html
is the first result. This PR changes the docs build script to exclude
all such generated source docs under `_modules/` from Google.
It does this by doing a search for `<head>` and then appending
`<meta name="robots" content="noindex">`.
The [google developer
docs](https://support.google.com/webmasters/answer/93710?hl=en) suggest
that this is the right way to prevent google from indexing the page.
In the future, when the CI
builds documentation (both master and stable docs), the newly created
docs under _modules will have the meta noindex tag.
Test Plan:
- I ran `find "$install_path/_modules" -name "*.html" -print0 | xargs -0
sed -i '/<head>/a \ \ <meta name="robots" content="noindex">'` on a docs
build locally and checked that it does indeed append the meta noindex
tag after `<head>`.
- In a few days we should rerun the search to see if these pages are
still being indexed.
Differential Revision: D19180300
Pulled By: zou3519
fbshipit-source-id: 5f5aa95a85dd9f065607c2a16f4cdd24ed699a83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31436
Tensor::has_names is slower than it should be for unnamed tensors
because of the following:
- it always tries to access the TLS for NamesMode. Unnamed tensors don't
need to peek at NamesMode to determine if they have names or not.
- There is some virtual function being called because TensorImpl is in
c10 and NamedTensorMeta is in libtorch.
This PR short-circuits Tensor::has_names for unnamed tensors by
checking if the underlying TensorImpl hold a pointer to NamedTensorMeta
or not. If the NamedTensorMeta is nullptr; then the tensor is definitely
unnamed.
Benchmarks:
- I have a dedicated benchmarking machine where I isolate a single CPU
and make sure it runs at a fixed frequency.
- I benchmarked torch.add, which calls `tensor::has_names` three times.
- The TL;DR is that torch.add between size-1 unnamed tensors gets sped up
~200ns after this change which is a 9% improvement.
- Before, on my machine:
https://gist.github.com/zou3519/dfd648a1941d584711d850754e0694bc
- After on my machine:
https://gist.github.com/zou3519/e78f0d8980b43d0d9c3e3e78ecd0d4d5
Test Plan: - run tests
Differential Revision: D19166510
Pulled By: zou3519
fbshipit-source-id: 1888a4e92d29152a5e3b778a95e531087e532f53
Summary:
Reference: https://github.com/pytorch/pytorch/issues/23159
Currently we don't support reduction operations for dim>=64 and we should give a descriptive RuntimeError indicating the same
Diff: D19179039
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31476
Differential Revision: D19179039
Pulled By: anjali411
fbshipit-source-id: 58568f64627bf3df6b3e00a1498544c030e74a0e
Summary:
Reference: https://github.com/pytorch/pytorch/issues/31385
In the current documentation for NLLLoss, it's unclear what `y` refers to in the math section of the loss description. There was an issue(https://github.com/pytorch/pytorch/issues/31295) filed earlier where there was a confusion if the loss returned for reduction=mean is right or not, perhaps because of lack in clarity of formula symbol description in the current documentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31488
Differential Revision: D19181391
Pulled By: anjali411
fbshipit-source-id: 8b75f97aef93c92c26ecbce55b3faf2cd01d3e74
Summary:
The current numba version doesn't appear to actually work with our numba-cuda tests (numba.cuda.is_available()) fails.
Previous attempts to upgrade were blocked by https://github.com/numba/numba/issues/4368.
It's a bit unclear to me, but I believe 0.46.0 fixes the above version. I'm verify that we catch that issue in CI via https://github.com/pytorch/pytorch/pull/31434.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31435
Differential Revision: D19166865
Pulled By: gchanan
fbshipit-source-id: e01fa48c577e35de178423db7a7f79ac3dd3894d
Summary:
Previously we would only catch `py::cast_error` which led to incomprehensible error messages like: `TypeError: 'NoneType' object is not iterable`. We are running arbitrary pybind code here, and not doing anything with the error message, so we should be less restrictive with the types of errors we catch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31398
Differential Revision: D19166655
Pulled By: eellison
fbshipit-source-id: 84db8b3714c718b475913f2f4bb6f19e62f2d9ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31011
`getAttribute` is supposed to throw when there the attribute is not
found rather than return a `nullptr`.
Test Plan:
.
Imported from OSS
Differential Revision: D18898417
fbshipit-source-id: 0fe7d824b978ad19bb5ef094d3aa560e9fc57f87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31357
If a user selects a subset of a Tensor and sends it in an RPC, we were sending
the whole original Tensor Storage over the network.
While this sounds reasonable, in practice, we observed view-like Tensors being sent
over rpc, where only 1% of the data in the provided Tensor's Storage was
actually used/needed.
The simple solution here is to just force a clone in the serializer code if we see that
less than (arbitrary) half the bits are used, and the tensor is more than a nominal few KB.
Add related tests to ensure this doesn't break.
An alternate approach would be to modify the Pickler. That said, since Pickler is shared by more
components, the logic might be harder to tailor appropriately at that layer (particularly
given that the Pickler has explicit logic to share a single Storage* among several Tensors
that commonly point to the same Storage*).
It's possible that we might want to further refine the basic thresholds in this change.
In practice, we've seen a mostly bimodal distribution thus far for the percent of Tensor
Storage referred by a Tensor in observed rpcs (i.e. either 90%+ or sub-10% of the Storage
referenced), hence the existing 50% threshold here is probably not an unreasonable
starting point.
ghstack-source-id: 95925474
Test Plan: buck test mode/dev caffe2/test/cpp/rpc/...
Differential Revision: D19137056
fbshipit-source-id: e2b3a4dd0cc6e1de820fd0740aa1d59883dbf8d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31393
pytorch build was set up with the include paths (-I) relative to fbcode/. This works well for fbcode builds, but doesn't work for the new fbcode_deps args for xplat build targets that work across xplat and fbcode. When these targets are built, the include paths need to be relative to fbsource, so fbcode/ suffix needs to be added to those paths.
Longer term, to properly fix this, we need to use raw_headers with public_include_directories specified for all of these targets.
Test Plan: buck test mode/dev //papaya/integration/service/local/test:mnist_federated_system_test -- 'MnistFederatedSystemTest\.test' --run-disabled
Reviewed By: mzlee
Differential Revision: D19148465
fbshipit-source-id: a610e84bf4cad5838e54e94bae71b957c4b6d4b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31346
This makes it so that if profiling is enabled/disabled from a different thread while a RecordFunction span is active via an op it doesn't crash the process.
We currently see when using torch.distributed.rpc to enable/disable profiling on other nodes while other things are running.
Test Plan: buck test //caffe2/test:autograd -- test_record_function
Reviewed By: albanD
Differential Revision: D19133258
fbshipit-source-id: 30712b06c6aa051789948de2918dcfb9b78967ba
Summary:
Fixes#27495
This adds builtins as another piece of a concrete type. They're separate from normal functions since they represent the `BuiltinFunction` sugared value (which is a direct call to a builtin op). It also moves the builtins related logic from `jit/__init__.py` to `jit/_builtins.py` so it can be used from `jit/_recursive.py` to look up functions in the builtins table.
](https://our.intern.facebook.com/intern/diff/19149779/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31269
Pulled By: driazati
Differential Revision: D19149779
fbshipit-source-id: d4e5e5d7d7d528b75a2f503e6004394251a4e82d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24341
ConvTransposeOp doesn't crash for zero-batch, but it doesn't modify the output blob. This leads to buggy behaviour especially when running the same network twice using different input, or backprop during training.
Seems `ConvTransposeUnpoolBase<Context>::GetOutputSize` works for zero-batch, so I remove the check for `input.numel() > 0`, and reshape the output blob before returning.
For CudnnConvTransposeGradientOp, it's a bit verbose to set `dfilter` and `dbias`, it's a seems the Cudnn can handle it, so simply remove the `X.numel() == 0` branch.
Test Plan: buck test mode/dev-nosan caffe2/caffe2/python/operator_test:conv_transpose_test -- --run-disabled
Reviewed By: BIT-silence
Differential Revision: D16807606
fbshipit-source-id: 0d72c5bd8f2e03c34465e7b530cca548d9bdd5e1
Summary:
Stacked PRs
* #29940 - [jit] Fix parsing of big float literals
* **#29935 - [jit] Fix hex literal parsing**
* #29931 - [jit] Throw a better error for int too big for int64_t
Previously these were all parsed as `0`
](https://our.intern.facebook.com/intern/diff/19124944/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29935
Pulled By: driazati
Differential Revision: D19124944
fbshipit-source-id: 1ee0c1dee589933363a5efba069a2cfaf94373c5
Summary:
Add a section for unsupported ops, and modules. Automatically generate the properties and attributes that aren't bound, and for ops that have semantic mismatches set up tests so the docs stay up to date.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31329
Differential Revision: D19164472
Pulled By: eellison
fbshipit-source-id: 46290bb8a64d9de928cfb1eda5ff4558c3799c88
Summary:
Fix: https://github.com/pytorch/pytorch/issues/24631, https://github.com/pytorch/pytorch/issues/24632, https://github.com/pytorch/pytorch/issues/24764, https://github.com/pytorch/pytorch/issues/24765
Port of TH SoftMarginCriterion to ATen using un-fused tensor operators but with custom backward code. This is a follow-up/fixc of reverted PR https://github.com/pytorch/pytorch/issues/27673.
Benchmark results:
CPU became faster, GPU slower. To reach previous TH perf probably manual fusion is necessary.
### WITH patch
```
CPU warmup 1000 took 7.997200009413064e-05
CPU warmup 10000 took 0.0008116499957395718
CPU warmup 100000 took 0.0012691459996858612
CPU warmup TOTAL time 0.0021982479956932366
CPU forward 1000 took 7.320100849028677e-05
CPU forward 10000 took 0.00015837099635973573
CPU forward 100000 took 0.0010471990099176764
CPU forward 1000000 took 0.01238470000680536
CPU forward 10000000 took 0.12747182900784537
CPU forward 100000000 took 1.2076255190040683
CPU forward TOTAL time 1.3488940890092636
CPU for- & backward 1000 took 0.00032587299938313663
CPU for- & backward 10000 took 0.0006926299975020811
CPU for- & backward 100000 took 0.002146183993318118
CPU for- & backward 1000000 took 0.019158899012836628
CPU for- & backward 10000000 took 0.2957490350090666
CPU for- & backward 100000000 took 1.7630806300003314
CPU for- & backward TOTAL time 2.081367089995183
GPU warmup 1000 took 0.0004558280052151531
GPU warmup 10000 took 0.0002567449992056936
GPU warmup 100000 took 0.0001593509950907901
GPU warmup TOTAL time 0.0009442300070077181
GPU forward 1000 took 0.00015061900194268674
GPU forward 10000 took 0.00015258099301718175
GPU forward 100000 took 0.00015409699699375778
GPU forward 1000000 took 0.0008183339959941804
GPU forward 10000000 took 0.004424853003001772
GPU forward 100000000 took 0.04356115800328553
GPU forward TOTAL time 0.04938192600093316
GPU for- & backward 1000 took 0.0008062430133577436
GPU for- & backward 10000 took 0.0006074949924368411
GPU for- & backward 100000 took 0.0007091690058587119
GPU for- & backward 1000000 took 0.001022183001623489
GPU for- & backward 10000000 took 0.009945805999450386
GPU for- & backward 100000000 took 0.0944173600000795
GPU for- & backward TOTAL time 0.28060428200114984
```
### WITHOUT patch
```
CPU warmup 1000 took 6.394000956788659e-05
CPU warmup 10000 took 0.00038220599526539445
CPU warmup 100000 took 0.0034939230099553242
CPU warmup TOTAL time 0.003981974994530901
CPU forward 1000 took 4.7855006414465606e-05
CPU forward 10000 took 0.000347569992300123
CPU forward 100000 took 0.003367935001733713
CPU forward 1000000 took 0.03605044000141788
CPU forward 10000000 took 0.35935167300340254
CPU forward 100000000 took 3.630371332008508
CPU forward TOTAL time 4.029640004009707
CPU for- & backward 1000 took 0.00028494100843090564
CPU for- & backward 10000 took 0.0006738200027029961
CPU for- & backward 100000 took 0.0051178760040784255
CPU for- & backward 1000000 took 0.04925115800870117
CPU for- & backward 10000000 took 0.7172313440096332
CPU for- & backward 100000000 took 5.441953932997421
CPU for- & backward TOTAL time 6.21466830400459
GPU warmup 1000 took 0.001803738996386528
GPU warmup 10000 took 0.00041877900366671383
GPU warmup 100000 took 0.0003870719956466928
GPU warmup TOTAL time 0.0026561370032140985
GPU forward 1000 took 0.00037833399255760014
GPU forward 10000 took 0.00038825398951303214
GPU forward 100000 took 0.0003841099969577044
GPU forward 1000000 took 0.0007090550061548129
GPU forward 10000000 took 0.0016171559982467443
GPU forward 100000000 took 0.013463679002597928
GPU forward TOTAL time 0.017010531009873375
GPU for- & backward 1000 took 0.0007374050037469715
GPU for- & backward 10000 took 0.0006343529967125505
GPU for- & backward 100000 took 0.0006375070079229772
GPU for- & backward 1000000 took 0.0007550300069851801
GPU for- & backward 10000000 took 0.002672752001672052
GPU for- & backward 100000000 took 0.023170708998804912
GPU for- & backward TOTAL time 0.20251446698966902
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28135
Differential Revision: D18001447
Pulled By: VitalyFedyunin
fbshipit-source-id: ad90dc1cca42dcaf3ea9e17e4f8fd79cee0a293e
Summary:
VitalyFedyunin, This PR is about port LeakyReLU activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.LeakyReLU()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.14 (ms).
input size(128, 10000) forward time is 4.21 (ms); backwad avg time is 8.02 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.07 (ms).
input size(128, 10000) forward time is 1.98 (ms); backwad avg time is 6.21 (ms)
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.04 (ms).
input size(128, 10000) forward time is 0.03 (ms); backwad avg time is 0.09 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10000) forward time is 0.47 (ms); backwad avg time is 1.02 (ms).
```
How to set the numbers of thread? using following script:
```
num_threads=$1
script=$2
last_core=`expr $num_threads - 1`
echo "using $num_threads OMP threads"
echo "bind cores to 0~$last_core"
export OMP_NUM_THREADS=$num_threads
export KMP_AFFINITY=granularity=fine,compact,1,0
numactl --physcpubind=0-$last_core --membind=0 python $script
```
and run .**/run.sh num_threads test.py**.
Fixes https://github.com/pytorch/pytorch/issues/24583#24584https://github.com/pytorch/pytorch/issues/24720#24721
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29899
Differential Revision: D18816231
Pulled By: VitalyFedyunin
fbshipit-source-id: afb1e43a99317d17f50cff1b593cd8f7a0a83da2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31335
When an error occurs in a net we end up cancelling all the async ops. If one error occurs it's highly likely other errors will occur as well.
Typically we see:
1. SendOp failed due to a network error
2. async scheduling cancels all other ops via `SetFinished("Cancelled");`
3. Another SendOp fails due to a network error and crashes the process when the exception is thrown.
This changes caffe2 ops to allow failing twice.
Test Plan: buck test //caffe2/caffe2:caffe2_test_cpu
Reviewed By: andrewwdye
Differential Revision: D19106548
fbshipit-source-id: 4b7882258a240894cc16d061a563c83a3214d3d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31404
Multiple "trainers" could each create different instances of DistributedOptimizer, which means we can still have a race condition unless we do a trully global per worker lock.
ghstack-source-id: 95874624
Test Plan: run unit tests -- unfortunatelly due to the non-deterministic behavior it's not clear how to unit test this properly.
Differential Revision: D19154248
fbshipit-source-id: fab6286c17212f534f1bd1cbdf9f0de002d48c74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31292
att
Also we need to do this check after we call `insertObservers` on invoked modules
as well since qconfig can be None for parent module while being valid for invoked modules
Test Plan:
.
Imported from OSS
Differential Revision: D19146668
fbshipit-source-id: be6811353d359ed3edd5415ced29a4999d86650b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31364
clang-cl defines both `_MSC_VER` and `__clang__`. Names are mangled clang style though. calling `extract` with the wrong name mangling pattern will throw `std::logic_error`. This crashes on Windows when `get_fully_qualified_type_name` is called because it is marked with `noexcept`.
Test Plan: Windows builds no longer crash on startup.
Reviewed By: mattjgalloway
Differential Revision: D19142064
fbshipit-source-id: 516b9b63daeff30f5c097d192b0971c7a42db57e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31020
Before, the recursive scripting process re-did the concrete type
inference process for every submodule call. This changes things so that
the concrete type inference process only occurs once (at the top level),
and we re-use all the inferred concrete types while recursively
compiling submodules.
This is both more efficient (we don't do n^2 work inferring concrete
types) and less bug-prone (since we infer the concrete type only once,
there is no possibility of a mismatch).
Test Plan: Imported from OSS
Differential Revision: D18904110
Pulled By: suo
fbshipit-source-id: 6560b85ae29fe5e9db1ee982dbf8bc222614b8d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31019
No more `recurisve_script`, just direct calls to `create_script_module`.
This reduces the number of pathways through the frontend, and the
uniformity is useful for a future PR.
Test Plan: Imported from OSS
Differential Revision: D18904113
Pulled By: suo
fbshipit-source-id: 7de061dfef0cbdfc9376408fc6c1167b81803f01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31018
Properties are now disallowed so this hack is no longer necessary
Test Plan: Imported from OSS
Differential Revision: D18904112
Pulled By: suo
fbshipit-source-id: 83448da677082d59355729bb72d9f9f4c31ea756
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31017
This arg is now derivable from another one. So we don't need to pass
both
Test Plan: Imported from OSS
Differential Revision: D18904111
Pulled By: suo
fbshipit-source-id: ea74ea9c2ae83d9e0e6977b0eb6629f53545e2e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31401
As title, just a mechanical change
Test Plan: Imported from OSS
Differential Revision: D19152965
Pulled By: suo
fbshipit-source-id: 6bb27df7c8f542c55110286c156358ba0936269f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31373
Just some housekeeping
Test Plan: Imported from OSS
Differential Revision: D19145987
Pulled By: suo
fbshipit-source-id: ae8142dab2bddcf0b628c27c426ca26334c48238
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31372
Keeping it current with the latest changes.
Test Plan: Imported from OSS
Differential Revision: D19145986
Pulled By: suo
fbshipit-source-id: 88122e66fa87a354ef8e87faffe58551074e3f03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31214
This set up the basic infrastructure for distributed autograd and rpc to
bind their operators to TorchScript, since the whole distributed package
is builtin behind the `USE_DISTRIBUTED` flag, we separate the
registration and build it only when the flag is on.
Test Plan: Imported from OSS
Differential Revision: D19137160
fbshipit-source-id: ff47dc4c380ebe273fe0eea9e5e3fccfbd6466d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30918
This is a C++14 feature we can use now
ghstack-source-id: 95811482
Test Plan: waitforsandcastle
Differential Revision: D18869636
fbshipit-source-id: b5b3d78b61b6ceb2deda509131f8502e95b1d057
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30530
Switch some mentions of "C++11" in the docs to "C++14"
ghstack-source-id: 95812049
Test Plan: testinprod
Differential Revision: D18733733
fbshipit-source-id: b9d0490eb3f72bad974d134bbe9eb563f6bc8775
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31071
Previously the profiler would think Tensors would require grad, even
when the no_grad flag is enabled during execution. This makes the profiling
and guards respect the no_grad flag, which eliminates extra differentiable
graphs that appear in the backward graph (where no_grad is typically enabled).
Test Plan: Imported from OSS
Differential Revision: D18915468
Pulled By: zdevito
fbshipit-source-id: 1ae816a16ab78ae5352825cc6b4a68ed7681a089
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30978
This particular approach queries our issue tracker for test titles that
match the following format:
```
DISABLED test_async_grad_guard_with_grad (jit.test_async.TestAsync)
```
And then skips the python test for them. There is 1 second timeout so
if the internet flakes we still run the test suite, without disabling any
tests.
This is intended as a quick fix, similar to ninja unland, to get to a green
master. Long term test disables should go into the code.
Test Plan: Imported from OSS
Pulled By: zdevito
Differential Revision: D18890532
fbshipit-source-id: fe9447e59a6d5c9ad345f7c3ff15d63b6d2a09e2
Summary:
Upgrade IR version from 4 to 6, below is change doc from ONNX. The upgrade should be backward compatible.
```
// IR VERSION 5 published on March 18, 2019
// - Add message TensorAnnotation.
// - Add quantization annotation in GraphProto to map tensor with its scale and zero point quantization parameters.
IR_VERSION_2019_3_18 = 0x0000000000000005;
// IR VERSION 6 published on Sep 19, 2019
// - Add support for sparse tensor constants stored in model.
// - Add message SparseTensorProto
// - Add sparse initializers
IR_VERSION = 0x0000000000000006;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31025
Reviewed By: hl475
Differential Revision: D18935444
Pulled By: houseroad
fbshipit-source-id: 9ba47f9657fa1a668db291cf04af07d5e8d73c21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31334
The wipe cache logic was introduced hoping to reduce the variations in the benchmark results. Based on our experiments result, it didn't actually help with that. In addition, several engineers had encountered the issue of missing cpuinfo.h which was used in the wipe cache logic. So this diff removes that feature to ensure smooth installation and running of the op bench.
Test Plan:
```
buck run caffe2/benchmarks/operator_benchmark/pt:add_test -- --iterations 1
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: add
# Mode: Eager
# Name: add_M1_N1_K1_cpu
# Input: M: 1, N: 1, K: 1, device: cpu
Forward Execution Time (us) : 111.192
A/B test also pass Benchmark Run #2476535015
Reviewed By: hl475
Differential Revision: D19126970
fbshipit-source-id: 9b1ab48c121838836ba6e0ae664a48fe2d18efdd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31206
Improvement on #25525.
- DistAutogradContext::getKnownWorkerIds() returns a unordered_map as temp value. No need to copy this temp value A into another temp value B.
ghstack-source-id: 95736296
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork -- test_worker_ids_recorded
```
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork_thrift -- test_context_cleanup_tensor_with_grad
```
Differential Revision: D5707771
fbshipit-source-id: 9fea83dc69b02047aef8b02a73028a260ac0be40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30915
Since we now have C++14, we don't need these c10::guts helpers anymore
ghstack-source-id: 95777609
Test Plan: waitforsandcastle
Differential Revision: D18869639
fbshipit-source-id: 97716f932297c64c6e814410ac47b444c33d4e2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31217
It doesn't seem to be used.
Test Plan: Imported from OSS
Differential Revision: D18986642
Pulled By: gchanan
fbshipit-source-id: 96d615df82731d2224d403ab6e2cad6d4c6674fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30917
This is a C++14 feature, we can use this now.
ghstack-source-id: 95255753
Test Plan: waitforsandcastle
Differential Revision: D18869637
fbshipit-source-id: dd02036b9faeaffa64b2d2d305725443054da31b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30501
**Motivation**:
In current state output of libtorch Module forward,runMethod is mem copied to java ByteBuffer, which is allocated, at least in some versions of android, on java heap. That could lead to intensive garbage collection.
**Change**:
Output java tensor becomes owner of output at::Tensor and holds it (as `pytorch_jni::TensorHybrid::tensor_` field) alive until java part is not destroyed by GC. For that org.pytorch.Tensor becomes 'Hybrid' class in fbjni naming and starts holding member field `HybridData mHybridData;`
If construction of it starts from java side - java constructors of subclasses (we need all the fields initialized, due to this `mHybridData` is not declared final, but works as final) call `this.mHybridData = super.initHybrid();` to initialize cpp part (`at::Tensor tensor_`).
If construction starts from cpp side - cpp side is initialiaed using provided at::Tensor with `makeCxxInstance(std::move(tensor))` and is passed to java method `org.pytorch.Tensor#nativeNewTensor` as parameter `HybridData hybridData`, which holds native pointer to cpp side.
In that case `initHybrid()` method is not called, but parallel set of ctors of subclasses are used, which stores `hybridData` in `mHybridData`.
Renaming:
`JTensor` -> `TensorHybrid`
Removed method:
`JTensor::newAtTensorFromJTensor(JTensor)` becomes trivial `TensorHybrid->cthis()->tensor()`
Test Plan: Imported from OSS
Differential Revision: D18893320
Pulled By: IvanKobzarev
fbshipit-source-id: df94775d2a010a1ad945b339101c89e2b79e0f83
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31271
This fixes copy kernel speed regression introduced in https://github.com/pytorch/pytorch/issues/29631.
The previous implementation forces the compiler to instantiate `static_cast_with_inter_type` because it is passed as an argument of a function. This behavior makes it impossible for compilers to do optimizations like automatic vectorization, and, function call itself is expensive compared to a single casting instruction.
To check the change, run
```
readelf -Ws /home/xgao/anaconda3/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so | grep static_cast_with_inter_type
```
On nightly build, we have output
```
168217: 0000000001852bf0 5 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsdE5applyEd
168816: 0000000001852d30 33 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIfEaE5applyEa
168843: 00000000018531f0 7 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIblE5applyEl
168930: 0000000001852c20 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIslE5applyEl
168935: 00000000018528d0 124 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIfNS_4HalfEE5applyES1_
169023: 0000000001852f30 17 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdEhE5applyEh
169713: 00000000018525c0 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIahE5applyEh
170033: 0000000001852c10 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsiE5applyEi
170105: 0000000001852bd0 5 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIshE5applyEh
170980: 0000000001852fc0 27 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdES1_IfEE5applyES3_
171398: 0000000001852810 13 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIdbE5applyEb
171574: 00000000018532e0 35 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIbNS_8BFloat16EE5applyES1_
171734: 0000000001852b20 6 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIlSt7complexIdEE5applyES2_
172422: 0000000001853350 54 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_8BFloat16EaE5applyEa
172704: 00000000018533c0 38 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_8BFloat16EfE5applyEf
172976: 0000000001852890 10 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIflE5applyEl
173038: 0000000001852f80 9 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdEfE5applyEf
173329: 00000000018531c0 20 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIbfE5applyEf
173779: 00000000018524d0 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIhiE5applyEi
174032: 0000000001852960 14 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIfNS_8BFloat16EE5applyES1_
174334: 0000000001852d60 29 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIfEdE5applyEd
174470: 0000000001852c60 124 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsNS_4HalfEE5applyES1_
174770: 0000000001852bc0 15 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIlNS_8BFloat16EE5applyES1_
176408: 0000000001853980 144 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_4HalfEbE5applyEb
176475: 0000000001852790 128 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIdNS_4HalfEE5applyES1_
....
```
And after this PR, we get empty output
```
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31279
Differential Revision: D19075587
Pulled By: ngimel
fbshipit-source-id: c20088241f39fa40c1d055f0a46eb5b9ece52e71
Summary:
Closes https://github.com/pytorch/pytorch/issues/31198, see the issue for more details. We throw an error when `local_value()` is called on a non-owned rref, but the incorrect node name is printed in the error message. This PR fixes that and adds a relevant unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31199
Differential Revision: D19072014
Pulled By: rohan-varma
fbshipit-source-id: 760c20bfd2fbf286eaaca19500469509a575cfec
Summary:
Make the following changes:
- When there are more than 10k errors, cuda-memcheck only shows 10k errors, in this case we shouldn't raise an Exception
- Add UNDER_CUDA_MEMCHECK environment to allow disabling `pin_memory` tests when running cuda-memcheck.
- Add a `--ci` command option, when turned on, then this script would run output to stdout instead of writing a file, and exit with an error if cuda-memcheck fails
- Add a `--nohang` command option. When turned on, then hang would be treated as pass instead of error
- Do simple filtering on the test to run: if `'cpu'` in the test name but not `'cuda'` is not in the test name
- Add `--split` and `--rank` to allowing splitting the work (NVIDIA CI has a limitation of 3 hours, we have to split the work to satisfy this limitation)
- The error summary could be `ERROR SUMMARY: 1 error`, or `ERROR SUMMARY: 2 errors`, the tail could be `error` or `errors`, it is not of the same length. The script is fixed to handle this case.
- Ignore errors from `cufft`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29243
Differential Revision: D18941701
Pulled By: mruberry
fbshipit-source-id: 2048428f32b66ef50c67444c03ce4dd9491179d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31276
Change assert --> CUDA_ASSERT_KERNEL to avoid hip undefined __assert_fail()
This is similar to https://github.com/pytorch/pytorch/pull/13902 in caffe2 land.
Test Plan: wait for CI to clear
Reviewed By: bddppq
Differential Revision: D19047582
fbshipit-source-id: 34703b03786c8eee9c78d2459eb54bde8dc21a57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30391
A Type parser to parse the python string of a Type. For example,
"Tuple[str, Optional[float], Dict[str, List[Tensor]], int]".
Please refer to test_type_parser.cpp for the usage.
One of the use cases is in lite interpreter, types needs to be serialized (directly calling the python_str() of the Type) and deserialized (calling parseType(str)).
Test Plan: Imported from OSS
Differential Revision: D18924268
Pulled By: iseeyuan
fbshipit-source-id: 830d411563abfbeec023f01e7f8f4a1796f9a59a
Summary:
https://github.com/pytorch/pytorch/issues/28294 DDP should not set grad for globally unused parameters
DDP currently computes the param to bucket mapping upfront, and allreduce grads for all params in every iteration. Even if params are unused, it will just set grad to zero. With such behavior, optimizer cannot tell if a param indeed has a zero grad or it is not used in the current iteration. This could trigger convergence problems for optimizers with weight decay and momentum such as SGD. However, DDP cannot simply set grad to None for local unused parameters, as local unused parameters might be used in other processes, and hence we still need to allreduce its grad. Instead DDP should figure out the globally unused parameters and skip touching their grad in the end of backward.
Implementation summary:
* Add locally used parameter map for each model replica.
* Mark the locally unused parameters in the end of forward and then reduce to get the globally unused parameters.
* In the end of backward skip touching grad for those globally unused parameters.
* Add a unit test test_global_local_unused_params_grad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28883
Differential Revision: D18491530
Pulled By: mrshenli
fbshipit-source-id: 24e9b5f20df86c34ddbf9c7106250fd6ce186699
Summary:
Fixes https://github.com/pytorch/pytorch/pull/28378#issuecomment-562597033
To reproduce the failure I had to downgrade to `cmake 3.9` (Ubuntu 18 uses 3.10 apparently). These older `cmake` versions unfortunately don't seem to allow `target_link_libraries(INTERFACE)` to be used with imported libraries. Switching back to `set_property(TARGET)` fixes the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30935
Differential Revision: D18956912
Pulled By: albanD
fbshipit-source-id: a2b728ee3268599a428b7878c988e1edef5d9dda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26618
Implement a mechanism to get type names at compile time
In a future diff, I'm planning to introduce this to caffe2::TypeMeta and a few other places.
ghstack-source-id: 95337871
Test Plan: unit tests
Differential Revision: D17519253
fbshipit-source-id: e14017f962fd181d147accb3f53fa8d6ee42a3f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31200
We do not hipify these files when doing out of place.
Test Plan: wait for CI to clear.
Differential Revision: D18963683
fbshipit-source-id: eeba8597143f26417d0a8181a4c746139afefa24
Summary:
Tests for unique_dim will be refactored in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31211
Differential Revision: D19034968
Pulled By: ngimel
fbshipit-source-id: 855d326b37638b5944f11fbbce03394cf000daf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31207
Cleanup after #30914.
In #30914, `autogradContext->addKnownWorkerId(dst);` was moved out of `addSendRpcBackward()`.
So `addSendRpcBackward()` does not need `dstId` as it's argument anymore.
ghstack-source-id: 95509218
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork -- test_context_cleanup_tensor_no_grad
```
Differential Revision: D5742365
fbshipit-source-id: accd041a594ec18d369231f5590289828d87baa7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31224
If a future coming back to a rpc_agent server is satisfied with an
exception, ensure this information is propagated back over the wire.
ghstack-source-id: 95522418
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcBackend/...
Differential Revision: D18979185
fbshipit-source-id: 99848ae805cc2d48948809a238f61a2e0ef234c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31128
When operation times out due to some errors that are not detected by nccl communicators, ncclCommWatchdog can not check this time out error and thus can not abort ncclComms accordingly. So explicitly abort ncclComms here before throwing this timed out exception to users, after this, ncclCommWatchdog can detect nccl communicators are aborted and clean up devNCCLCommMap_ accordingly. if throwing timed out excepiton without aborting nccl communicators here, it was observed that CUDA GPU will have 100% utilization and can not run new events successfully.
ghstack-source-id: 95528488
Test Plan: newly revised test _test_nccl_errors_blocking passed with the changes in this diff; the reviesed test failed withtout the changes in this diff
Reviewed By: isunjin
Differential Revision: D18928607
fbshipit-source-id: be65a05ce4ff005f0c7fed36ae8e28903e8ffe2b
Summary:
It was a random coding exercise so I wasn't putting much effort into it; but, I was like "hey is the current intrusive_ptr implementation optimized enough?" so I compared it with shared_ptr (using std::shared_from_this).
My benchmark result shows that intrusive_ptr is actually slower. On my macbook the speed is:
```
---------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------
BM_IntrusivePtrCtorDtor 14 ns 14 ns 52541902
BM_SharedPtrCtorDtor 10 ns 10 ns 71898849
BM_IntrusivePtrArray 14285 ns 14112 ns 49775
BM_SharedPtrArray 13821 ns 13384 ns 51602
```
Wanted to share the results so someone could probably take a look if interested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30810
Reviewed By: yinghai
Differential Revision: D18828785
Pulled By: bddppq
fbshipit-source-id: 202e9849c9d8a3da17edbe568572a74bb70cb6c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30175
fbjni was opensourced and java part is published as 'com.facebook.fbjni:fbjni-java-only:0.0.3'
switching to it.
We still need submodule fbjni inside the repo (which is already pointing to https://github.com/facebookincubator/fbjni) for so linking.
**Packaging changes**:
before that `libfbjni.so` came from pytorch_android_fbjni dependency, as we also linked fbjni in `pytorch_android/CMakeLists.txt` - it was built in pytorch_android, but excluded for publishing. As we had 2 libfbjni.so there was a hack to exclude it for publishing and resolve duplication locally.
```
if (rootProject.isPublishing()) {
exclude '**/libfbjni.so'
} else {
pickFirst '**/libfbjni.so'
}
```
After this change fbjni.so will be packaged inside pytorch_android.aar artefact and we do not need this gradle logic.
I will update README in separate PR after landing previous PR to readme(https://github.com/pytorch/pytorch/pull/30128) to avoid conflicts
Test Plan: Imported from OSS
Differential Revision: D18982235
Pulled By: IvanKobzarev
fbshipit-source-id: 5097df2557858e623fa480625819a24a7e8ad840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29579
Per #28923, this diff is to move Future<Message> to torch::utils and extend it to be Future<T>, most of implementations are copied from FutureMessage and ivalue::Future. merge ivalue::Future with Future<T> will be done separately.
The main difference between Future<T> and FutureMessage is the error handling, instead of checking message type inside Future to handle error, this future<T> owns has_error_ and error_ states.
also this future passes value_, has_error_ and error_ states to callbacks for easily read future states.
In next diff, a torch script rpc async API will be created, before the API returns, it will create an ivalue::Future and passes it to Future<T>'s call back where state of ivalue::Future will be set. In this way, the torch script rpc async API can still return a ivalue::Future and call wait() to get its state appropriately afterwards.
ghstack-source-id: 95479525
Test Plan: unit tests
Differential Revision: D18263023
fbshipit-source-id: 48a65712656a72c2feb0bb3ec8b308c0528986a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31212
To be able to use this function more broadly.
Test Plan: unit tests
Reviewed By: jackm321
Differential Revision: D18978913
fbshipit-source-id: d998dc7c7f9540f491a8a4bc5d6d25d9c3bf8764
Summary:
Update ONNX Flatten to accept negative indices in opset 11.
With this change, some cases of flatten do not rely on the input rank being available.
Fixes : https://github.com/pytorch/pytorch/issues/30512 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30751
Reviewed By: hl475
Differential Revision: D18946904
Pulled By: houseroad
fbshipit-source-id: a6fa30a9182fff92211e505a19325525c6112f19
Summary:
all jobs are currently running with "--dry-run", so you can verify if the jobs are doing the right thing. i'll remove the flag and make it runs every hour same as on Jenkins once this PR is approved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30996
Differential Revision: D18971001
Pulled By: mingbowan
fbshipit-source-id: 2384bdb50ebdf47aad265395f26be3843f0ce05e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31163
The purpose is to unblock integration with TorchScript. Currently,
an OwnerRRef will be created by either a remote call or a to_here
call, whichever arrives first. However, when making RRef an IValue,
we need to know the type of value held by the RRef, which is
retrived by checking the return type of the TorchScript function.
The TorchScript function is only avaible during the remote call
but not in the to_here() call. Hence, an OwnerRRef can only be
created when processing a remote call. This commit implements this
behavior by introducing a conditional variable for every OwnerRRef
in the RRefContext, and let the to_here() call and PyRRef::unpickle
block on the CV until the value is ready.
Test Plan: Imported from OSS
Differential Revision: D18949591
Pulled By: mrshenli
fbshipit-source-id: 17513c6f1fd766885ea8e1cd38f672a403fa4222
Summary:
Remove most of the testing for `weak_script`, since we removed it. Refactor a few of the existing tests to use recursive scripting api.
Fix for https://github.com/pytorch/pytorch/issues/23965
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31193
Differential Revision: D18966291
Pulled By: eellison
fbshipit-source-id: 6b1e18c293f55017868a14610d87b69be42bde12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31127
Original commit changeset: d22448b90843
On Skylake T6:
Single Core:
(Note that our benchmark generates batch_size=47 for first case and batch_size=56 for the second case. In spite of that, the vectorized version is still faster than the original reference C version without vectorization.)
- Before the PR:
```
native_layer_norm 0.81% 5.884ms 0.81% 5.884ms 122.580us NaN 0.000us 0.000us 48 [[47, 1, 1024], [1024], [1024]]
```
- After the PR:
```
native_layer_norm 0.68% 5.053ms 0.68% 5.053ms 105.272us NaN 0.000us 0.000us 48 [[56, 1, 1024], [1024], [1024]]
```
20 Cores:
- Before the PR:
```
native_layer_norm 1.65% 41.682ms 1.65% 41.682ms 868.365us NaN 0.000us 0.000us 48 [[61, 64, 1024], [1024], [1024]]
```
- After the PR:
```
native_layer_norm 1.34% 33.829ms 1.34% 33.829ms 704.771us NaN 0.000us 0.000us 48 [[61, 64, 1024], [1024], [1024]]
```
ghstack-source-id: 95420889
Test Plan:
buck test mode/dev-nosan //caffe2/test:nn -- "LayerNorm"
buck test mode/dev-nosan //caffe2/test:nn -- "test_LayerNorm_1d_no_elementwise_affine_eval"
python run_test.py -i nn -- TestNN.test_LayerNorm_1d_no_elementwise_affine_eval
Differential Revision: D18936428
fbshipit-source-id: 8cae33d35fb338b5ac49b1597c2709152612d6e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31088
Original issue:
https://github.com/pytorch/pytorch/issues/31027
The problem is that for the stacks of PRs for non-leaf PRs circleCI does not set environment variable `CIRCLE_PULL_REQUEST` which is used to filter out some jobs that should run only on `master`.
(Android job for master includes alll 4 abis (x86, x86_64, armeabi-v7a, arm64-v8a) and gradle build tries to get results from all 4 abis, for PRs we run only x86 build for resources economy. Thats why not filtered master android job fails as abis apart x86 were not scheduled)
env variable `CIRCLE_BRANCH ` is set fine and can be used as a workaround to distinguish that this is PR (published with ghstack).
Test Plan: Imported from OSS
Differential Revision: D18966385
Pulled By: IvanKobzarev
fbshipit-source-id: 644c5ef07fcf2d718b72695da2cc303da8b94ef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31117
After this diff, we will have completely removed the named tensor
feature flagging. This means that named tensors are always on and that
there is no mechanism to turn them off. There should be no more follow-up
diffs.
I performed the deletion of the header with
```
find . -type f -print0 | xargs -0 sed -i '/#include
<ATen\/core\/EnableNamedTensor.h>/d'
```
Test Plan: - wait for CI
Differential Revision: D18934952
Pulled By: zou3519
fbshipit-source-id: 253d059074b910fef15bdf885ebf71e0edf5bea5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31116
Changelist:
- remove BUILD_NAMEDTENSOR macro
- remove torch._C._BUILD_NAMEDTENSOR
- remove all python behavior that relies on torch._C._BUILD_NAMEDTENSOR
Future:
- In the next diff, I will remove all usages of
ATen/core/EnableNamedTensor.h since that header doesn't do anything
anymore
- After that, we'll be done with the BUILD_NAMEDTENSOR removal.
Test Plan: - run CI
Differential Revision: D18934951
Pulled By: zou3519
fbshipit-source-id: 0a0df0f1f0470d0a01c495579333a2835aac9f5d
Summary:
Resubmit of https://github.com/pytorch/pytorch/pull/30356 and https://github.com/pytorch/pytorch/pull/31014 :'(
The last commit contains the fix. There was an internal FBcode error not able to compile the previous `impl_default->second.equal(default_val.second))` line. I tried various fixes in C++ internally but couldn't figure anything out. This is a good example of the programming costs of going from python -> c++ for different types of objects, because the conceptual overhead has expanded in scope from (python) -> (python, c++, pybind).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31123
Differential Revision: D18936128
Pulled By: eellison
fbshipit-source-id: 7d8fd66a6dd4a3e9838f3a0b68c219b6565a9462
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30909
`fold_prepack` doesn't work anymore after we change `scale`, `zero_point`
to be attributes, but since the freeze API is coming up, I don't want to
spend time to make this work since this will be thrown away later.
Test Plan:
.
Imported from OSS
Differential Revision: D18864537
fbshipit-source-id: 649e6b91f2b04b8babacc0afb6bc1530ed7259d3
Summary:
**Patch Description**
Round out the rest of the optimizer types in torch.optim by creating the stubs for the rest of them.
**Testing**:
I ran mypy looking for just errors in that optim folder. There's no *new* mypy errors created.
```
$ mypy torch/optim | grep optim
$ git checkout master; mypy torch/optim | wc -l
968
$ git checkout typeoptims; mypy torch/optim | wc -l
968
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31130
Reviewed By: stephenroller
Differential Revision: D18947145
Pulled By: vincentqb
fbshipit-source-id: 5b8582223833b1d9123d829acc1ed8243df87561
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30355
- Make processTimedOutFutures hold lock.
- Reduce unnecessary scan on future and future timeout maps.
- Reduce the scope of lock at a spot.
- Avoid repeatedly wake up if user set timeout = 0.
ghstack-source-id: 95409528
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork -- test_rpc_timeouts
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rpc_timeouts
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_rpc_timeouts
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_rpc_timeouts
```
Differential Revision: D5516149
fbshipit-source-id: 4bb0bd59fa31d9bfaef9f07ac0126782da17f762
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31164
We have a small number of internal projects that still are on Python 2.
Until we can figure out how to get rid of them, we need to continue
supporting Python 2 for PyTorch.
Test Plan: Imported from OSS
Differential Revision: D18949698
Pulled By: suo
fbshipit-source-id: 4a9d7e4306ed81576e05f243de472937a2bb1176
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31151
same as title. I am not sure why this was not added in the first place.
Test Plan: wait for build to succeed.
Reviewed By: bddppq, xw285cornell
Differential Revision: D18880216
fbshipit-source-id: 8b17d4fbd5dd08c28c52df8b1da77b69d56d65dc
Summary:
Currently, both `Conv{1,2,3}dOptions` and `ConvTranspose{1,2,3}dOptions` are aliases of the `ConvOptions<{1,2,3}>` class, which causes confusion because the `ConvOptions` class has parameters such as `transposed` that shouldn't be exposed to the end user. (This has caused issues such as https://github.com/pytorch/pytorch/issues/30931.) This PR makes the following improvements:
1. Rename the original `torch::nn::ConvOptions<N>` class to `torch::nn::detail::ConvNdOptions<N>` class, to signify that it's an implementation detail and should not be used publicly.
2. Create new classes `torch::nn::ConvOptions<N>` and `torch::nn::ConvTransposeOptions<N>`, which have parameters that exactly match the constructor of `torch.nn.Conv{1,2,3}d` and `torch.nn.ConvTranspose{1,2,3}d` in Python API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31005
Differential Revision: D18898048
Pulled By: yf225
fbshipit-source-id: 7663d646304c8cb004ca7f4aa4e70d3612c7bc75
Summary:
Fix for https://github.com/pytorch/pytorch/issues/30015
We had a model that failed in shape propagation because we could not unify `Tensor` and `Optional[BoolTensor]`. Tensor not subtyping Optional[BoolTensor] was correct, but we should have unified those two types to `Optional[Tensor]`.
The fix here is that for immutable types containers (Optional, Tuple Type), we should be attempting to unify with complete shape information, and if that fails, then try to unify those types with unshaped types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31076
Differential Revision: D18921802
Pulled By: eellison
fbshipit-source-id: aa6890277470c60b349ed1da4d81cc5d71d377f6
Summary:
Adding support for the new ATen op floor_divide which was introduced in https://github.com/pytorch/pytorch/pull/30493/files.
This operation is used in Torchvision/FasterRCNN-MaskRCNN, which are now failing after the new op was introduced.
This PR fixes the failure.
cc: neginraoof
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31081
Reviewed By: houseroad
Differential Revision: D18945316
Pulled By: eellison
fbshipit-source-id: 09919c237d618ce7db293c7770f48f7304949dcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31086
This change leverages the new future response framework so that server
threads don't block until setValue is called. Particulurly, we add a
getFuture() method to OwnerRRef so that we get a future that is satisfied
once setValue is called.
ghstack-source-id: 95402273
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18925272
fbshipit-source-id: 2caf51019e5b5fd7ec45539544780067deb28610
Summary:
Previously list elements were only unified for tensor lists.
This improves error messages and expands the unification logic
to include all types.
](https://our.intern.facebook.com/intern/diff/18837726/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30777
Pulled By: driazati
Differential Revision: D18837726
fbshipit-source-id: c4d275562a8429700987569426d694faa8f6002e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31137
Our Test CI is broken because:
- hypothesis recently did a new release that reorganized their internal
modules
- we were importing something from their internal module structure.
This PR fixes the CI by doing the following:
- import SearchStrategy from the correct (public) location
- Pin the hypothesis version to avoid future surprises.
In the long term, we should stop install hypothesis every time the CI
runs and instead install it as a part of our docker build process. See
https://github.com/pytorch/pytorch/issues/31136 for details.
Test Plan:
- I tested this locally; before this PR test/test_nn.py fails to run but
after it does run.
- Wait for CI
Differential Revision: D18940817
Pulled By: zou3519
fbshipit-source-id: c1ef78faa5a33ddf4d923f947c03cf075a590bb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31069
Just to clarify that they are still experimental.
Test Plan: Imported from OSS
Differential Revision: D18920496
Pulled By: suo
fbshipit-source-id: d2f3014592a01a21f7fc60a4ce46dd0bfe5e19e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30994
The flakiness we saw was due to missing barriers(), which caused
states leaked into previous or subsequent checks. This commit
attempts fix this problem by adding barriers before and after each
check.
Test Plan: Imported from OSS
Differential Revision: D18893457
Pulled By: mrshenli
fbshipit-source-id: 42bcc12efa7e6e43e2841ef23e4bc2543b0236c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19705
Optimizing for a case when there's a consecutive dims that are not broadcasted followed by another consecutive dims that are broadcasted.
For example, MulGradient(["dC", "A", "B"], ["dA", "dB"], broadcast=True, axis=0) where A.shape == dC.shape == [9508, 80] and B.shape == [80] .
Test Plan:
In SKL T6,
Running mul_gradient_benchmark without this optimization
Operator #0 (dA, MulGradient) 11.9119 ms/iter
After this optimization,
Operator #0 (dA, MulGradient) 0.672759 ms/iter
Need to land D15291800 before to fix the unit test error
Reviewed By: dmudiger
Differential Revision: D15075415
fbshipit-source-id: 0f97be17cf8f1dacbafa34cd637fb8bc1c5e5387
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30979
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
--------------
In this PR:
Add tracing support for optional Device and Layout types.
--------------
Test Plan: Imported from OSS
Differential Revision: D18912685
Pulled By: izdeby
fbshipit-source-id: 4a9514ce2eee0041f9bc96636d3ddb4f077675e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30980
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
--------------
In this PR:
Add a test to check that C++ API behavior stays the same after all the changes.
While working on it a bug related to `requires_grad` was found and logged in the master task.
--------------
Test Plan: Imported from OSS
Differential Revision: D18912681
Pulled By: izdeby
fbshipit-source-id: 19772a37c92dde820839b79055f348689b99fa77
Summary:
This makes `nn.Transformer` usable from TorchScript. It preserves backwards compatibility via `__setstate__` on the encoder/decoder.
Fixes https://github.com/pytorch/pytorch/issues/24173
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28561
Differential Revision: D18124753
Pulled By: driazati
fbshipit-source-id: 7314843e5aa9c9bf974c4672e4edb24ed8ef4a6f
Summary:
VitalyFedyunin, This PR is about port ELU activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.ELU()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.09 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.28 (ms); backwad avg time is 0.18 (ms).
input size(128, 10000) forward time is 23.53 (ms); backwad avg time is 14.46 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.16 (ms); backwad avg time is 0.08 (ms).
input size(128, 10000) forward time is 15.53 (ms); backwad avg time is 6.60 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.24 (ms); backwad avg time is 0.17 (ms).
input size(128, 10000) forward time is 0.73 (ms); backwad avg time is 1.11 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.15 (ms); backwad avg time is 0.07 (ms).
input size(128, 10000) forward time is 14.40 (ms); backwad avg time is 6.00 (ms).
```
How to set the numbers of thread? using following script:
```
num_threads=$1
script=$2
last_core=`expr $num_threads - 1`
echo "using $num_threads OMP threads"
echo "bind cores to 0~$last_core"
export OMP_NUM_THREADS=$num_threads
export KMP_AFFINITY=granularity=fine,compact,1,0
numactl --physcpubind=0-$last_core --membind=0 python $script
```
and run .**/run.sh num_threads test.py**.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29275
Differential Revision: D18587389
Pulled By: VitalyFedyunin
fbshipit-source-id: bea8f3f006c6893090f863d047c01886d195437a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31047
Changelist:
- remove BUILD_NAMEDTENSOR from .cu files
- remove BUILD_NAMEDTENSOR special handling in function_wrapper.py
- remove BUILD_NAMEDTENSOR from cpp_extension.py. This code actually
did nothing because we always compile with BUILD_NAMEDTENSOR.
Test Plan: - run tests
Differential Revision: D18908442
Pulled By: zou3519
fbshipit-source-id: b239e24de58580adaf3cef573350773a38b1e4f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29104
We would like to provide the vectorized implementation for layer norm. This PR reuses https://github.com/pytorch/pytorch/pull/23349.
Test Plan:
buck test mode/dev-nosan //caffe2/test:nn -- "LayerNorm"
buck test mode/dev-nosan //caffe2/test:nn -- "test_LayerNorm_1d_no_elementwise_affine_eval"
python run_test.py -i nn -- TestNN.test_LayerNorm_1d_no_elementwise_affine_eval
Differential Revision: D18293522
fbshipit-source-id: f4cfed6e62bac1b43ee00c32b495ecc836bd9ec5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31100
This appears to not work right now. Disabling pending an investigation.
Test Plan: Imported from OSS
Differential Revision: D18928777
Pulled By: suo
fbshipit-source-id: 63089131bad98902979e5cf4373732c85badef9d
Summary:
Exported weight_norm is incorrectly reducing over axis 0 as well when dim is set to 0.
Previous test case only covers weight with size(0) == 1, which yields the same result whether reduced over or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31015
Reviewed By: hl475
Differential Revision: D18900894
Pulled By: houseroad
fbshipit-source-id: 19004f51933b37f848dbe4138e617a7a8e35a9ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30912
Add a new data type ZERO_COLLISION_HASH .
Test Plan: ci
Reviewed By: boryiingsu
Differential Revision: D18843626
fbshipit-source-id: b2d8280f13c78b4a656cf95822198df59de7b64c
Summary:
Peephole optimize out type refinements when they are no longer refining the type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31024
Differential Revision: D18920958
Pulled By: eellison
fbshipit-source-id: 6d05d9812b9f9dcf001de760a78a2042fb832773
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31068
Let's get it out of the early parts now that the recursive API has been
around for a while
Test Plan: Imported from OSS
Differential Revision: D18920498
Pulled By: suo
fbshipit-source-id: 6f4389739dd9e7e5f3014811b452249cc21d88e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30637
RequestCallback api currently forces work to be always synchronous, which,
as we scale, means we're going to need to throw large number of (mostly
blocked) threads at the rpc problem. For some activities like dependent
autograd rpcs, there's not a necessary reason to block in these threads.
In this change, the RequestCallback api is updated to return a
shared_ptr<FutureMessage> rather than a Message:
std::shared_ptr<FutureMessage> operator()(Message& request) const;
With a futures-style api, RPC ops that wish to be async can then be async,
while short-lived blocking functions (or Python UDFs) can just block.
In this change, we keep all of the current ops as synchronous (i.e. we block
and then return a completed FutureMessage). We also update the rpc_agents in
a manner compatible with this sort of parallelism.
Here, we only want to incur overhead when we use the async behavior.
Some modest extra cost seems unavoidable here (e.g. the allocation for the
std::make_shared<>), but we can trivially detect the synchronous/completed
case in the rpc_agent and avoid the extra thread-switches/etc. in that case.
ghstack-source-id: 95287026
Test Plan:
- Basic: buck test mode/dev-nosan caffe2/test/...
- Additional testcase in ThriftRpcAgentTest for deferred work.
Differential Revision: D18774322
fbshipit-source-id: cf49922a71707cfb1726de16f93af23b160385d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30887
Support to convert quantized concat from pytorch to caffe2
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_cat
Imported from OSS
Differential Revision: D18855676
fbshipit-source-id: 5d0cf3f03c61819e168b080afa368b1255d0419c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30683
Assume that a node can work with autograd only if it is not a fusion
group and in prim or aten namespaces.
Test Plan: CI
Reviewed By: lly-zero-one
Differential Revision: D18795171
Pulled By: ilia-cher
fbshipit-source-id: 301090557e330b58be70e956784f7f0dc343c684
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29357
As title
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D18920562
Pulled By: suo
fbshipit-source-id: b5dd559cfb0ba6c64b9ccf3655417afb56a7b472
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29353
First step to killing Python 2 everywhere. I don't really know that much
about the caffe2 circle jobs so I left them alone for now.
Test Plan: Imported from OSS
Differential Revision: D18920563
Pulled By: suo
fbshipit-source-id: b37d8427a6ecd4b8a7e16c1ff948e0ce13b5798f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31057
The current signature basically will always fail to type check, because
mypy enforces that the subclass method's input types must be "wider"
than their superclass method's input types (i.e. they can vary
contravariantly). And nothing is wider than `Any`.
This change makes it so that any input params are allowed in
`forward()`. Fixes#29099
Test Plan: Imported from OSS
Differential Revision: D18918034
Pulled By: suo
fbshipit-source-id: 9940e9f769b55d580d9d7f23abf6f88edb92627f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31030
DistAutogradContext held a shared_ptr reference to RecvRpcBackward and
RecvRpcBackward held a shared_ptr reference to the context. This circular
dependency caused significant memory leaks. As a result, I'm changing the
reference in RecvRpcBackward to be a weak_ptr.
Test Plan: waitforbuildbot
Differential Revision: D18896389
fbshipit-source-id: e5bc588b6f998885854e3a67de1e82452e8475ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30874
These have all been disabled at this point, so there is no difference in the generated code.
Test Plan: Imported from OSS
Differential Revision: D18855990
Pulled By: gchanan
fbshipit-source-id: 03796b2978e23ef9060063f33241a1cbb39f1cf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30926
Calling the JITed FBGEMM kernel for Fused 8 Bit Sparse Length Sum (Fused8BitRowwiseEmbeddingLookup)
Test Plan:
buck test mode/dbg //caffe2/caffe2/python:lengths_reducer_fused_8bit_rowwise_ops_test
All tests pass.
Reviewed By: jspark1105
Differential Revision: D18058128
fbshipit-source-id: 0dfa936eb503712c39e53748e015fc156afde86f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29766
Add FbgemmPackTranspose op to support the packing on FCTransposed weights
Add FCTransposed to FbFCPacked transformation to Dper fp16 exporter
Test Plan:
```
buck test mode/opt caffe2/caffe2/fb/fbgemm:fb_fc_packed_op_test
```
```
buck test mode/opt caffe2/caffe2/python:layers_test
```
Differential Revision: D18482306
fbshipit-source-id: e8f1947b3d0d04892293509ebf88742f5f0f5997
Summary:
After several discussions, we agreed not to put any extra safety check for recordStream as either the check will cause failures in certain scenarios or there is no need to throw for user errors.
As a summary, it simply does what is described in https://github.com/pytorch/pytorch/issues/27405, check if a tensor is indeed allocated by a CUDACachingAllocator instance, if it is, then throw internal error if a block can not be retrieved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30870
Differential Revision: D18851669
Pulled By: yxia11
fbshipit-source-id: c2f01798cd24f1fd0f35db8764057d5d333dab95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30894
This PR begins the process of removing BUILD_NAMEDTENSOR macros. There
will be followups.
Reasons for removing the macros:
- BUILD_NAMEDTENSOR is always on and has been on since pytorch 1.3.0.
- Since we don't test building without it, it is useless to keep around.
- Code becomes nicer to read without the macros
Reasons for not removing the macros:
- potential for feature flagging
Now, I argue against needing to feature flag. The main reason why we
might want to feature flag is if we need to disable the feature.
We'd need a fast switch to disable the feature if someone discovers
in the future that named tensors caused some regression in some existing workflows.
In https://github.com/pytorch/pytorch/pull/25798, I did a variety of
macro- and micro- benchmarks to determine the performance impact of named
tensors on regular tensors.
[The
microbenchmarks](https://github.com/pytorch/pytorch/pull/25798#issuecomment-529014810)
were not very stable, and running the
microbenchmarks for more iterations doesn't actually help because the
noise is not distributed in a nice way. Instead of microbenchmarks I ran
a [profiler
(perf)](https://github.com/pytorch/pytorch/pull/25798#issuecomment-555707645)
to estimate how much overhead named tensors add to unnamed code. I
estimated the overhead to be less than 100ns for `add` and even smaller
for `mm`; there are ways to optimize even futher if we find this to be a
problem.
[Initial
macrobenchmarks](https://github.com/pytorch/pytorch/pull/25798#issuecomment-530539104)
were also not very stable. I ran imagenet for some number of epochs. To
make them more stable, I got rid of the data loading (which seemed to
vary between runs). [In some benchmarkers without data
loading](https://github.com/pytorch/pytorch/pull/25798#issuecomment-562214053),
we can see that the results are less noisy now. These results support
no noticeable regressions in speed.
Test Plan: - wait for CI
Differential Revision: D18858543
Pulled By: zou3519
fbshipit-source-id: 08bf3853a9f506c6b084808dc9ddd1e835f48c13
Summary:
Adds `torch.floor_divide` following the numpy's `floor_divide` api. I only implemented the out-of-place version, I can add the inplace version if requested.
Also fixes https://github.com/pytorch/pytorch/issues/27512
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30493
Differential Revision: D18896211
Pulled By: eellison
fbshipit-source-id: ee401c96ab23a62fc114ed3bb9791b8ec150ecbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30802
Change shape_hints from map<string, TensorShape> to ShapeInfoMap to catch dimType info from model file.
Reviewed By: ipiszy
Differential Revision: D18821486
fbshipit-source-id: c5d9ed72e158d3698aba38900aeda00f776745b4
Summary:
Updated to export API:
When calling this API, a dict containing the custom opsets (domain and version) used to export the model could be provided.
We allow registering one custom opset (domain, version) per ONNX opset. So, when exporting an operator from a custom domain, users need to pass this pair. Default custom opset version is 1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29752
Reviewed By: hl475
Differential Revision: D18703662
Pulled By: houseroad
fbshipit-source-id: 84d22557d132b526169051193d730761798fce60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30356
This finishes up the `torch.jit.overload` api for free-functions.
- defaults now required on the implementation function itself
- fully follows [overload spec](https://mypy.readthedocs.io/en/latest/more_types.html#function-overloading) such that the following is supported
```
overload
def mouse_event(x1: int, y1: int) -> ClickEvent: ...
def mouse_event(x1: int,
y1: int,
x2: Optional[int] = None,
y2: Optional[int] = None): ...
```
Note: `jit.overload` isn't supported yet for UDT, but is support for modules. This PR doesn't make the same changes for modules, if reviewers think I should include them then I could do so in a follow up PR or wait to land this. Since that's still an internal api I think it's fine, and the changes here would allow us to expose `torch.jit.overload` on free functions.
Test Plan: Imported from OSS
Differential Revision: D18864774
Pulled By: eellison
fbshipit-source-id: 6c566738bd6f0551a000a9ea8d56e403636b7856
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30749
Add check to schemas that the schema is sane.
I removed the defaults from symbolic_script because they were in some cases wrong and don't actually do anything. At the point they're invoked the forward should already have matched all arguments.
Test Plan: Imported from OSS
Differential Revision: D18864775
Pulled By: eellison
fbshipit-source-id: 273d7e96d65b8a3d3de72e2d7bfcdf2417046c6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30877
Previously, when the environment tried to reassign variables which had been assigned to "inf" or "nan" it would fail because they are not simple values. Constant prop exposed this, a test was failing internally because of it.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D18861016
Pulled By: eellison
fbshipit-source-id: b9b72978a26a0b00b13bf8ea7685825551f5a541
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30544
Run Constant Propagation upon compilation only on ops with non-aliasing inputs and outputs. This speeds up the first run of `torchvision.models.resnet18` by over 50% and speeds up compilation by about 25% (although the effects didn't seem additive with with https://github.com/pytorch/pytorch/pull/30503, so I'm going to land this PR first and then see if caching still has a sizable impact).
Running constant prop only with non-aliasing types does a lot of graph cleanup by removing constant ifs and a bunch of other smaller ops. It also avoids all the jitter problems we had when we tried running full constant prop previously. Bc it is idempotent it doesn't jitter, and it doesn't jitter graphs constructed from tracing because tracing doesn't emit any ops that only involve non-aliasing inputs.
Full constant prop isn't idempotent because what ops are run depends on the state of mutation in alias db, which will often change upon successive iterations of constant propagation, and bc it affects graphs constructed from tracing.
Edit: if we were okay with running constant propagation on graphs constructed from tracing (potentially making them hard to debug), an alternative would be to run constant propagation until the graph reaches a fixed point.
Test Plan: Imported from OSS
Differential Revision: D18833607
Pulled By: eellison
fbshipit-source-id: 92a0adb4882d67ed5a0db5c279f5e122aeeba54a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30543
`shouldAnnotate` doesn't make make a ton of sense as a public api
Test Plan: Imported from OSS
Differential Revision: D18833608
Pulled By: eellison
fbshipit-source-id: 460ee05d0fa91b1edc640c037be2a6ee8eaf50a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30853
Right now we print one element tuple as `(val)`, and it will
be interpreted as `val` in parsing, this PR changes it
to `(val,)` so we can recognize the one element tuple in parsing
Test Plan:
.
Imported from OSS
Differential Revision: D18846849
fbshipit-source-id: 42959b9190c2567ef021a861497077c550324b7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30859
We can dictionary of quantization parameters to simplify the code
handling these things a bit
Test Plan:
.
Imported from OSS
Differential Revision: D18849023
fbshipit-source-id: 09e9860b2656a1affa8776016e16794529bcee3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30927
Classes that are used virtually (e.g. have virtual methods) must have a virtual destructor or bad things happen
ghstack-source-id: 95144736
Test Plan: waitforsandcastle
Differential Revision: D18870351
fbshipit-source-id: 333af4e95469fdd9103aa9ef17b40cbc4a343f82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30519
Re-enable them and write a few additional ones
ghstack-source-id: 95143051
Test Plan: unit tests
Differential Revision: D18729561
fbshipit-source-id: 8cefd8320913d72a450a3324bfd7c88faed072d7
Summary:
VitalyFedyunin, This PR is about port Softshrink activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Softshrink()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.12 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.18 (ms).
CPU:
input size(128, 100) forward time is 0.19 (ms); backwad avg time is 0.23 (ms).
input size(128, 10000) forward time is 17.23 (ms); backwad avg time is 16.83 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
input size(128, 100) forward time is 0.08 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 0.32 (ms); backwad avg time is 0.08 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) forward time is 0.08 (ms); backwad avg time is 0.10 (ms).
input size(128, 10000) forward time is 7.58 (ms); backwad avg time is 7.91 (ms).
After:
input size(128, 100) forward time is 0.08 (ms); backwad avg time is 0.02 (ms).
input size(128, 10000) forward time is 7.30 (ms); backwad avg time is 1.02 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30229
Differential Revision: D18810054
Pulled By: VitalyFedyunin
fbshipit-source-id: e19074824396570db45ba488ae4f9fe1b07a5839
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30914
When tensors don't require grad, we don't call `addSendRpcBackward`, where we record known workerIDs to clean up the dist autograd context later. But since https://github.com/pytorch/pytorch/pull/29781, we always include the autograd context ID in RPCs, even if tensors do not require grad. So, it could be possible that we don't release the contexts on some nodes.
This can contribute to OOMs since the contexts will not be cleaned up in this case, which can be checking by running the unit test without this patch. We can fix this issue by moving the `addKnownWorkerIds` call to the `getMessageWithAutograd` function.
ghstack-source-id: 95178561
Test Plan: Added a unit test: `test_context_cleanup_tensor_no_grad`
Differential Revision: D18869191
fbshipit-source-id: b80f66bfd0dd7d01960abe1691d3f44095bb1b2b
Summary:
This simplifies the generated code a bit, saving about 40K off of libtorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30466
Differential Revision: D18836215
Pulled By: resistor
fbshipit-source-id: ad75c9e04783bb29cc06afd2022f73f9625dd52b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30715
Changed caffe2/caffe2/TARGETS file to define USE_FBGEMM for x86 and USE_SSE_ONLY is not defined.
Test Plan: buck test caffe2/caffe2:caffe2_test_cpu -- Float16
Reviewed By: jianyuh
Differential Revision: D18806067
fbshipit-source-id: 1b44b90a9f6dc3c27f81a46038c0f7542ed2bab3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30642
Adding a couple of basic metrics for distributed autograd which would
help in determining stuckness.
ghstack-source-id: 95156189
Test Plan: waitforbuildbot
Differential Revision: D18776478
fbshipit-source-id: a0556ad6fe2b7c3cd0082ee2350c1c78cafaaec5
Summary:
- [x] Add more comments and refactor the logic of `ReshapeToAdvancedIndexingFormat`
- [x] Add more description here. Cases that are/aren't supported, and how they are supported.
- [x] Need to merge this PR https://github.com/pytorch/pytorch/issues/27186 to enable testing inplace operators.
We are now supporting exporting aten::copy_ and aten::index_put to ONNX.
Here's a breakdown of the different cases in PyTorch code.
```
# Case 1: Scalar Indices
x[0, 1, 2] = data
# Case 2: Slice Indices
x[1:3, :, ::2] = data
# Case 3: Ellipsis Indices
x[..., 0] = data
# Case 4: Tensor Indices
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
x[ind1, ind2] = data
# Case 5: Mixing all the above cases
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
x[1:3, ind1, ind2, ..., 3] = data
```
Limitations:
Tensor indices must be consecutive, and 1-d tensors.
```
# Supported
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
x[ind1, ind2] = data
# Not supported
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
ind3 = torch.tensor([[0], [1]])
x[ind1, :, ind2] = data
x[ind3] = data
```
Negative indices are not supported.
```
# Not supported
x[-1] = data
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26941
Differential Revision: D17951030
Pulled By: houseroad
fbshipit-source-id: 4357777072f53aa0bc4b297aa1ee53457a7f8dec
Summary:
```python
record_function('my_func')
def f(x, y):
return x + y
with profile() as p:
f(1, 2)
print(prof.key_averages().table())
```
```
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
my_func 85.42% 86.796us 87.27% 88.670us 88.670us 1
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 101.606us
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30861
Differential Revision: D18857993
Pulled By: bddppq
fbshipit-source-id: eb6b8e2a8d4f3a7f8e5b4cb3da1ee3320acb1ae7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30904
When we sent tensors over RPC, on the server side we would call
addRecvRpcBackward which would call `set_history` on all tensors. This was
incorrect and set the `requires_grad` flag on tensors that didn't actually need
grad.
To fix this, we only attach autograd edges to tensors that need grads.
ghstack-source-id: 95113672
ghstack-source-id: 95113999
Test Plan: waitforbuildbot
Differential Revision: D18828561
fbshipit-source-id: d8942b76e9e4c567f8f1821f125c00d275ea0f90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30892
Fixes all outstanding lints and actually installs a properly configured
flake8
Test Plan: Imported from OSS
Differential Revision: D18862825
Pulled By: suo
fbshipit-source-id: 08e9083338a7309272e17bb803feaa42e348aa85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30906
Add mobile module observer to measure performance of each method run.
ghstack-source-id: 95120194
Test Plan:
Run pytext model through BI cloaking flow on lite-interpreter and verify logs are sent:
1. buck install -r fb4a
2. Go to internal setting and find MobileConfig, search for android_bi_infra_cloaking_iab_models and set the following params:
a. sample_rate: 1.0
b. enabled: true
c. use_bytedoc_pytorch_model: true
d. use_bytedoc_caffe2_model: false
e. use_full_jit: false
3. Go back to new feed and scroll down until find an ads which will direct you to offsite webpage;
4. Click on the ads, wait for the offsite ads loads;
5. Click back to news feed;
6. Go to scuba table: https://fburl.com/scuba/4fghwp0b and see all the operator runs have been logged:
{F223456981}
Reviewed By: ljk53
Differential Revision: D18702116
fbshipit-source-id: a9f07eee684e3022cef5ba3c5934f30f20192a85
Summary:
Copy-paste comment from code for reasoning:
```
# NOTE [ IterableDataset and __len__ ]
#
# For `IterableDataset`, `__len__` could be inaccurate when one naively
# does multi-processing data loading, since the samples will be duplicated.
# However, no real use case should be actually using that behavior, so
# it should count as a user error. We should generally trust user
# code to do the proper thing (e.g., configure each replica differently
# in `__iter__`), and give us the correct `__len__` if they choose to
# implement it (this will still throw if the dataset does not implement
# a `__len__`).
#
# To provide a further warning, we track if `__len__` was called on the
# `DataLoader`, save the returned value in `self._len_called`, and warn
# if the iterator ends up yielding more than this number of samples.
```
Fixes https://github.com/pytorch/pytorch/issues/30184
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23587
Differential Revision: D18852625
Pulled By: ailzhang
fbshipit-source-id: aea8d4d70c7f21aaa69b35908a6f43026493d826
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30908
Same as title.
Test Plan: Wait for CI to clear.
Reviewed By: bddppq, xw285cornell
Differential Revision: D18862837
fbshipit-source-id: bc34356b85774fc20ba46d321c8a2bb5d5c727f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30890
We've received way too many complaints about this functionality making tests flaky, and it's not providing value to us anyway. Let's cut the shit and kill deadline testing
Test Plan: Imported from OSS
Differential Revision: D18857597
Pulled By: jamesr66a
fbshipit-source-id: 67e3412795ef2fb7b7ee896169651084e434d2f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30858
This is not needed since we have `values_to_qparams_`
Test Plan:
.
Imported from OSS
Differential Revision: D18848992
fbshipit-source-id: dc81f59967a93abdd5562f1010f02de4f4e60db0
Summary: Add mobile operator observer to measure performance of each operator run, the result will also log into QPL event: [MOBILE_OPERATOR_STATS ](https://fburl.com/quicklog/8773a00a).
Test Plan:
Run pytext model through BI cloaking flow on lite-interpreter and verify logs are sent:
1. buck install -r fb4a
2. Go to internal setting and find MobileConfig, search for android_bi_infra_cloaking_iab_models and set the following params:
a. sample_rate: 1.0
b. enabled: true
c. use_bytedoc_pytorch_model: true
d. use_bytedoc_caffe2_model: false
e. use_full_jit: false
3. Go back to new feed and scroll down until find an ads which will direct you to offsite webpage;
4. Click on the ads, wait for the offsite ads loads;
5. Click back to news feed;
6. Go to scuba table: https://fburl.com/scuba/er7t4g9u and see all the operator runs have been logged:
{F223250762}
Reviewed By: ljk53
Differential Revision: D18131224
fbshipit-source-id: 23e2f6e2a9851c04b29511b45dc53f3cce03e8a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30709
Intrusive_ptr doesn't provide a explicit incref method. When a users want to
incref the target, they creates a intrusive_ptr to wrap the target, then makes
a copy which does the actual incref, then release both the first intrusive_ptr
and the copy to prevent decref at deconstruction time. This is very
inefficient. Instead, do the incref/decref directly.
Differential Revision: D18798505
fbshipit-source-id: 524d4f30d07d733df09d54423b044d80e4651454
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30649
Operators in VariableTypeManual are now no longer registered against the VariableTypeId key, but they are registered as compound ops. See https://github.com/pytorch/pytorch/issues/30102 for background.
This also requires the non-variable codegen to ignore them and requires removal of VariableMethodStubs.cpp.
So, because function_wrapper.py now also needs to know which ops are manual, instead of having a hard-coded list in gen_variable_type.cpp for ops with manual implementation, we now have a `manual_kernel_registration` flag in native_functions.yaml that disables the registration of operator kernels for this operator (the schema is still registered). Then, we manually register the right kernels for the operator.
ghstack-source-id: 95082204
Test Plan: unit tests
Differential Revision: D18778191
fbshipit-source-id: 0af6f9e43ff4fb9800ce19b286dfccd0fd22cc41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30552
For upcoming changes to support quantizing shared class type
Test Plan:
.
Imported from OSS
Differential Revision: D18818653
fbshipit-source-id: 393a55db69b20a1c00ffa0157ab568cb097915b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30826
Previously the scalar_check for the reduction None case was:
input.dim() <= 1, but it should be target based, i.e.:
target.dim() == 0. This follows from the "correct cases", i.e.
(N, C) X (N,) -> (N,)
(C,) X () -> ()
Test Plan: Imported from OSS
Differential Revision: D18833660
Pulled By: gchanan
fbshipit-source-id: 26338b842a8311718c4b89da3e2f1b726d5409b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30790
The index_select documentaiton reads:
"The returned tensor has the same number of dimensions as the original tensor (input)."
But the implementation would return a 0-dimensional tensor iff both the input and index were 0-dimensional.
This change makes it so we retuan a 0-dimensional tensor iff the input is 0-dimensional.
Restacked version of: https://github.com/pytorch/pytorch/pull/30502
Test Plan: Imported from OSS
Differential Revision: D18825717
Pulled By: gchanan
fbshipit-source-id: aeb10c5107e748af3e264fbdc81fff5dd4833cc4
Summary:
When converting a contiguous CuPy ndarray to Tensor via `__cuda_array_interface__`, an error occurs due to incorrect handling of default strides. This PR fixes this problem. It makes `torch.tensor(cupy_ndarray)` works for contiguous inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24947
Differential Revision: D18838986
Pulled By: ezyang
fbshipit-source-id: 2d827578f54ea22836037fe9ea8735b99f2efb42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30821
While investigating while our tests didn't catch #30704 I noticed that none
of our tests in method_tests() were being run on CUDA. This diff moves
those tests into the new device-generic test framework so that we also get
CUDA coverage. For expediency, I blacklisted all tests which didn't work
on CUDA (rather than fix them); that's something we can leave for future PRs.
This is done by way of a new expectedFailure gadget.
Note that all occurences of skipIfNoLapack needed to be replaced with
skipCPUIfNoLapack.
I punted for test_jit; it's possible those tests should also run CUDA but a JIT
expert should take a look here.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18840089
Pulled By: ezyang
fbshipit-source-id: 66b613b5024c91d3e391c456bb642be7e73d4785
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30551
To enable quantizing with shared types, we need to insert GetAttr nodes for
quantization parameters since the code might be shared by multiple module instances
and we'd like to make quantized module instance also share the same code but with
different values of attributes.
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D18818652
fbshipit-source-id: fc95623cac59dcedd9e3f95397524eae515e7a11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30837
This test would get very occasional flakes, with an error saying the
RPC timed out. This happened because one worker would still be waiting for the
return value of an RPC, but another worker had already performed its local
shutdown, so it would not have sent the response. This didn't show up in
initial testing since the flakiness is very rare (< 1/100 test runs). This diff
fixes the issue by not erroring if these RPCs timeout. The reason this is okay
is because with a local shutdown, we should not expect for all outstanding RPCs
to be completed, since workers are free to shut down without completing/waiting
on outstanding work.
ghstack-source-id: 95021672
ghstack-source-id: 95021672
Test Plan: Ran the test 1000 times to ensure that it is not flaky.
Differential Revision: D18775731
fbshipit-source-id: 21074e8b4b4bbab2be7b0a59e80cb31bb471ea46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30474
There are some common parts in `isBiasOfConvOrLinear` and `isWeightOfConvOrLinear`, we can factor
them out, the refactor will allow for easier extension of new patterns
Test Plan:
python test/test_jit.py
python test/test_quantization.py
Imported from OSS
Differential Revision: D18795725
fbshipit-source-id: 446463da5e3fa8464db441ed0d9651930487b3b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30679
Caffe2 expects quantized ops to be in NHWC format while pytorch inputs are in NCHW.
Add a jit pass to insert permutes to convert from nchw2nhwc before each conv op and add nhwc2nchw permute after the conv op.
Using graph rewriter to find consecutive redundant permutes and remove them from the graph
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps
Imported from OSS
Differential Revision: D18790518
fbshipit-source-id: 4dd39cf0b31b21f5586c0edfdce2260d4e245112
Summary:
we prefer "_" over "-" in build names, so change checks in test script
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30836
Differential Revision: D18840736
Pulled By: mingbowan
fbshipit-source-id: 6fdf736496225c5f8ab44906d8f4681b7bf894a7
Summary:
VitalyFedyunin, This PR is about port Hardtanh activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Hardtanh()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.06 (ms).
input size(128, 10000) forward time is 0.84 (ms); backwad avg time is 0.44 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 0.61 (ms); backwad avg time is 0.10 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.07 (ms).
input size(128, 10000) forward time is 5.21 (ms); backwad avg time is 5.25 (ms).
After:
input size(128, 100) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10000) forward time is 1.09 (ms); backwad avg time is 1.09 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30152
Differential Revision: D18815545
Pulled By: VitalyFedyunin
fbshipit-source-id: d23b6b340a7276457f22dce826bcbe3b341d755f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29944
This particular approach queries our issue tracker for test titles that
match the following format:
```
DISABLED test_async_grad_guard_with_grad (jit.test_async.TestAsync)
```
And then skips the python test for them. There is 1 second timeout so
if the internet flakes we still run the test suite, without disabling any
tests.
This is intended as a quick fix, similar to ninja unland, to get to a green
master. Long term test disables should go into the code.
Test Plan: Imported from OSS
Differential Revision: D18621773
Pulled By: zdevito
fbshipit-source-id: 5532f1d5fa3f83f77fc3597126cbb7dba09a3c33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30825
It didn't verify in the 1-d case that the targets were size 1..
Test Plan: Imported from OSS
Differential Revision: D18833659
Pulled By: gchanan
fbshipit-source-id: 9b0276e7b0423fdaf2ba7cfa34bde541558c61f9
Summary:
We dont have ATen/native/*.h in torch target before, and we would like it to be exposed for external use.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30835
Differential Revision: D18836160
Pulled By: zrphercule
fbshipit-source-id: 7330a9c9d8b65f173cc332b1cfeeb18c7dca20a8
Summary:
This PR adds docs for how we expose declarations in `at::` to `torch::`, to make the semantics more clear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30760
Differential Revision: D18833081
Pulled By: yf225
fbshipit-source-id: eff4d8815c67f681ce3a930ce99771cf2e55dbd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30800
SparseNN benchmark crashed due to this.
Wrap warning handler in a function to avoid siof.
Test Plan: Tested locally, SparseNN benchmark no longer crashes.
Reviewed By: yinghai
Differential Revision: D18826731
fbshipit-source-id: 8fcab8a3f38cc20f775409c0686363af3c27d0a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30769
The TorchConfig.cmake is the public cmake we produce in install folder for
3rd party client code to get all libtorch dependencies easily.
Apparently this build flow is not well covered by our CI (which is focused
on 1st party build / shared libraries?) as the little dummy project for
code analysis testing purpose was broken by #30315 without fail any CI.
Fixed the problem for mobile build and add the dummy project build to mobile
CI as well.
Test Plan: - make sure new CI pass;
Differential Revision: D18825054
Pulled By: ljk53
fbshipit-source-id: 80506f3875ffbc1a191154bb9e3621c621e08b12
Summary:
Fixes https://github.com/pytorch/pytorch/issues/29161.
I looked a bit at the code changes related to this and think I have all of the use cases of `DeprecatedTypeProperties` covered in the message, but suggestions from someone with more context on this would be very much appreciated :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30281
Differential Revision: D18830818
Pulled By: ezyang
fbshipit-source-id: 1a7fcee15354ae09e6644577e7fa33bd26acfe20
Summary:
To support variadic inputs of `checkpoint_sequential` was deprecated at https://github.com/pytorch/pytorch/issues/21006. This case should be warned with `DeprecationWarning` for PyTorch 1.2, but it should be simply failed with `TypeError` since PyTorch 1.3. This patch removes the `DeprecationWarning` for PyTorch 1.2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25985
Differential Revision: D18809875
Pulled By: albanD
fbshipit-source-id: e84dd8629c04979c4b2dc63e8ada94292e8cedd0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30768
The behavior didn't match the documentation, because the documentation (for 'none' reduction) reads:
input X target -> output
(N, C) X (N, C) -> (N,)
(C,) X (C,) -> ()
but the later case would output (1,). This also changes the case to:
() X (C,) -> ()
from:
() X (C,) -> (C,)
which makes more sense with the above formulas.
Restacked version of: https://github.com/pytorch/pytorch/pull/30748
Test Plan: Imported from OSS
Differential Revision: D18821554
Pulled By: gchanan
fbshipit-source-id: 3df77c51cf25648cb5fab62a68b09f49c91dab4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30765
It is already supported in CPU and is pretty easy to add for consistency.
Restacked version of: https://github.com/pytorch/pytorch/pull/30727
Test Plan: Imported from OSS
Differential Revision: D18821557
Pulled By: gchanan
fbshipit-source-id: e6aa3e91000ff3fd63941defc7d30aef58ae2f82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30746
This diff should be safe as long as open source build succeeds and should have no impact to cuda.
Differential Revision: D18811302
fbshipit-source-id: a7adab993816cba51842701898fac5019438b664
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for CUDA complex numbers is here: [pytorch-cuda-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cuda-strided-complex)
Changes so far:
- [x] Added complex support of torch.empty and torch.fill()
- [x] Added complex support of CopyKernels
- The 'static_cast_with_inter_type' template function is specialized for the following cases
- `dest_t = thrust::complex<dest_value_t>`, `src_t = std::complex<src_value_t>`
- `dest_t = std::complex<dest_value_t>`, `src_t = thrust::complex<src_value_t>`
- This handles the compile-time case where `dest_value_t=double` and `src_value_t=float`.
- [x] Added complex support of BinaryOp kernels
- `using thrust_t = typename ztype_cuda<scalar_t>::thrust_t;` converts std::complex<T> ScalarTypes to thrust types and is a no-op of other Scalar Types.
- The operator is performed using complex number support defined in `thrust/complex.h`
- This could be extended to work with ROCm by using `rocm/complex.h`
- [x] Added complex support of UnaryOp kernels
- Added CUDA support for `angle()`, `real()`, `imag()`, `conj()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30295
Differential Revision: D18781954
Pulled By: ezyang
fbshipit-source-id: 25d204c0b8143ee27fda345a5d6a82f095da92a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28443
We're now on C++14, so we don't need the else branch of these ifdef's anymore
ghstack-source-id: 94904074
Test Plan: waitforsandcastle
Differential Revision: D18069136
fbshipit-source-id: f1613cab9a99ee30f99775e4a60a1b06fd0a03ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30550
Right now we have a `InsertQuantDeQuantHelper` for each module, but we need
it to be global because we need to know what graphs have been quantized before
and based on this information we can decide how to handle the module instance.
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D18818651
fbshipit-source-id: bfcaf37094ce20a257171a0c99b05b9348ebc13d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30037
Support quantization for modules with reused submodules, e.g. relu (automatically make unique)
We first do a pass on the graph to find all duplicate uses of the same module, and record the `Value`s of the
module instance, for each of these values we create a new module and change the access to that module.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D18821483
fbshipit-source-id: 1698b981e9e9f0c728d9f03fcbcfbd260151f679
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30473
Invoked `ConstantPooling` and `FuseLinear` pass before
`insertObservers`.
`ConstantPooling` is for cleanning up traced graph, e.g. when we
have to constant node that has the same value, this pass will merge them,
this allows us to have less quantization patterns
`FuseLinear` is to merge the exploded linear function into `aten::linear` so
that we can quantize this function properly. We need to fuse it because right now
the way we recognize weight and bias is by matching the argument position in certain function
calls, e.g. 1st argument of aten::conv2d is weight. Therefore we have to preserve
the bounary of the linear function to recognize the weight of linear. Since in the exploded
linear code, input of addmm is transposed weight rather than the original weight of linear.
ghstack-source-id: 94887831
Test Plan:
This is needed for quantizing traced model tests to pass
Imported from OSS
Differential Revision: D18795722
fbshipit-source-id: 192d9d1e56307e2e1d90e30dce0502e31cb4f829
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30737
Original commit changeset: 2a8b2a3f5401
Reverting this to be safe until we address test failures in T58528495
Test Plan: CI
Reviewed By: wx1988
Differential Revision: D18812384
fbshipit-source-id: 2a3ac554024773022ec827f259127e4c8cffe6e2
Summary:
For system pybind11 installs this is a system header location that should not get installed since it might include other unrelated headers. Since the header is already installed for a system install there's no need to install the headers, so only do the install when we use the bundled pybind11 version.
Closes https://github.com/pytorch/pytorch/issues/29823. Closes https://github.com/pytorch/pytorch/issues/30627.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30758
Differential Revision: D18820189
Pulled By: bddppq
fbshipit-source-id: fcc9fa657897e18c07da090752c912e3be513b17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29217
We want to preserve constant information in ClassType so that
users can access the constants in the module by name.
This is also used later for freezing some attribute(converting
attributes to constant)
Test Plan:
tbd
Imported from OSS
Differential Revision: D18799955
fbshipit-source-id: fbfbcd5d3f7f560368b96e2a87e270c822a3d03a
Summary:
This is a re-do of https://github.com/pytorch/pytorch/issues/27064, which was reverted (b8792c0438). This was landed at the same time as other work that added new operators to the `torch` namespace so the check for whether the `torch` namespace is exhaustively checked for overridability was triggering test failures.
I've temporarily disabled that check and added an explanatory comment that the check will be re-enabled in a future PR that will be merged during a time when the commit velocity on PyTorch is lower.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30730
Differential Revision: D18813270
Pulled By: ezyang
fbshipit-source-id: 70477c4656dca8fea6e7bc59259555041fcfbf68
Summary:
VitalyFedyunin, This PR is about port Tanh backward to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Tanh()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
bwd_t = 0
for i in range(10000):
output = m(input)
t1 = _time()
output.backward(grad_output)
t2 = _time()
bwd_t = bwd_t + (t2 - t1)
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) backwad avg time is %.2f (ms)." % (n, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) backwad avg time is 0.12 (ms).
input size(128, 10000) backwad avg time is 0.17 (ms).
CPU
input size(128, 100) backwad avg time is 0.05 (ms).
input size(128, 10000) backwad avg time is 0.35 (ms).
```
After:
```
GPU:
input size(128, 100) backwad avg time is 0.12 (ms).
input size(128, 10000) backwad avg time is 0.17 (ms).
CPU
input size(128, 100) backwad avg time is 0.04 (ms).
input size(128, 10000) backwad avg time is 0.25 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) backwad avg time is 0.03 (ms).
input size(128, 10000) backwad avg time is 1.85 (ms).
After:
input size(128, 100) backwad avg time is 0.02 (ms).
input size(128, 10000) backwad avg time is 1.16 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30224
Differential Revision: D18810045
Pulled By: VitalyFedyunin
fbshipit-source-id: ab37948ab8f76bdaf9f3d1388562eaf29dacc0ea
Summary: As title
Test Plan: buck test caffe2/caffe2/fb/optimizers:masked_adagrad_test
Reviewed By: chocjy
Differential Revision: D18736639
fbshipit-source-id: d0d73f75228604d3448651bff2cf34ecc21f9ba6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30670
Also turn off scalar_check for grad_input: it isn't necessary because the input can't be 0-dimensional.
Test Plan: Imported from OSS
Differential Revision: D18784523
Pulled By: gchanan
fbshipit-source-id: 246d30970457075a0403dd0089317659a2cd2dd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30669
The inputs can't be 0-d, so we don't need that check in the scalar_check.
Test Plan: Imported from OSS
Differential Revision: D18784524
Pulled By: gchanan
fbshipit-source-id: d44222dffc91880a6e8c7be69e6e146e60040d43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30665
total_weight is a "hidden" output just for autograd, so it's not user visible. The existing test_nn tests cover this (I verified that the new code is executed) and this matches the CPU behavior.
Test Plan: Imported from OSS
Differential Revision: D18782709
Pulled By: gchanan
fbshipit-source-id: 6d1c20eeaeffa14d06f375b37f11e866587f5fa0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30549
Preparing for later refactoring
Test Plan:
.
Imported from OSS
Differential Revision: D18802464
fbshipit-source-id: 0b5afb143549d93eed4c429125d3d5fd253093a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30548
ClassTypes can be shared among different module instances, but previously we assumed
they would be unique, this PR enables the insert_observers pass to work with shared class types
Test Plan:
python test/test_jit.py
python test/test_quantization.py
Imported from OSS
Differential Revision: D18802465
fbshipit-source-id: b782e71e44a043af45577ac2b5c83e695155bb8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30558
Most c10 op registration/invocation cases are generated by aten codegen
following some fixed pattern, but a handful of them were written
manually, mainly for quantized ops. Added these "irregular" cases to the
test project to verify static code analyzer can handle them as well.
Test:
- build and run the test project;
Test Plan: Imported from OSS
Differential Revision: D18811098
Pulled By: ljk53
fbshipit-source-id: 7bdf17175dfec41c56c0d70f124cc96478135bc4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30315
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
This is a reland of https://github.com/pytorch/pytorch/pull/29731 but
I've extracted all of the prep work into separate PRs which can be
landed before this one.
Some things of note:
* torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
* The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/libprotobuf.a(arena.cc.o) is referenced by DSO"
* A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly
* I had to torch_cpu/torch_cuda caffe2_interface_library so that they get whole-archived linked into torch when you statically link. And I had to do this in an *exported* fashion because torch needs to depend on torch_cpu_library. In the end I exported everything and removed the redefinition in the Caffe2Config.cmake. However, I am not too sure why the old code did it in this way in the first place; however, it doesn't seem to have broken anything to switch it this way.
* There's some uses of `__HIP_PLATFORM_HCC__` still in `torch_cpu` code, so I had to apply it to that library too (UGH). This manifests as a failer when trying to run the CUDA fuser. This doesn't really matter substantively right now because we still in-place HIPify, but it would be good to fix eventually. This was a bit difficult to debug because of an unrelated HIP bug, see https://github.com/ROCm-Developer-Tools/HIP/issues/1706Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18790941
Pulled By: ezyang
fbshipit-source-id: 01296f6089d3de5e8365251b490c51e694f2d6c7
Summary:
[Why static dispatch]
Static dispatch was introduced to allow stripping out unused ops at link
time (with “gc-sections” linker flag) for mobile build.
The alternative approaches to do "non-static" dispatch are:
* virtual methods - old ATen dispatcher, which has already been deprecated;
* registry pattern - used by caffe2, c10 and JIT;
However, none of them are “gc-sections” friendly. Global registers are
root symbols - linker cannot strip out any op if we use registry pattern
for mobile.
[Why static dispatch isn’t great]
* One more code path to maintain;
* Need recompile framework to add new backends/ops;
* Doesn’t support AutoGrad yet thus blocks on-device training;
[Static Code Analysis]
This PR introduces a LLVM analysis pass. It takes LLVM bitcode /
assembly as input and generates dependecy graph among aten ops. From a
set of root ops used by a model, we can calculate transitive closure of
all dependent ops, then we can ask codegen to only register these ops.
[Approach]
To generate the dependency graph it searches for 3 types of connections in
LLVM bitcode / assembly:
1) op registration: op name (schema string literal) -> registered function;
2) regular function call: function -> function;
3) op invocation: function -> op name (schema string literal)
For 2) it uses similar algorithm as llvm::LazyCallGraph - not only looks into
call/invoke instructions but also recursively searches for function pointers
in each instruction's operands.
For 1) and 3) it searches for connections between operator name string
literals / function pointers and c10 op registration/invocation API calls in
LLVM IR graph via "use" edges (bi-directional):
1. llvm::Value has "users()" method to get other llvm::Value nodes that use
the value;
2. most of types derive from llvm::User which has "operands()" method to get
other llvm::Value nodes being used by the value;
[Limitation]
For now the search doesn't go beyond the function boundary because the
reference to op name string literals and c10 op registration/invocation
APIs are almost always in the same function.
The script uses regular expression to identify c10 API calls:
* op_schema_pattern="^(aten|quantized|profiler|_test)::[^ ]+"
* op_register_pattern="c10::RegisterOperators::(op|checkSchemaAndRegisterOp_)"
* op_invoke_pattern="c10::Dispatcher::findSchema|callOp"
If we create helper function around c10 API (e.g. the "callOp" method
defined in aten/native), we could simply add them to the regular expression
used to identify c10 API.
[Example]
In the following example, it finds out:
1) the registered function for "quantized:add" operator;
2) one possible call path to at::empty() function;
3) the called operator name "aten::empty":
- "quantized::add"
- c10::detail::wrap_kernel_functor_unboxed_<at::native::(anonymous namespace)::QAdd<false>, at::Tensor (at::Tensor, at::Tensor, double, long)>::call(c10::OperatorKernel*, at::Tensor, at::Tensor, double, long)
- at::native::(anonymous namespace)::QAdd<false>::operator()(at::Tensor, at::Tensor, double, long)
- void at::native::DispatchStub<void (*)(at::Tensor&, at::Tensor const&, at::Tensor const&), at::native::qadd_stub>::operator()<at::Tensor&, at::Tensor const&, at::Tensor const&>(c10::DeviceType, at::Tensor&, at::Tensor const&, at::Tensor const&)
- at::native::DispatchStub<void (*)(at::Tensor&, at::Tensor const&, at::Tensor const&), at::native::qadd_stub>::choose_cpu_impl()
- void at::native::(anonymous namespace)::qadd_kernel<false>(at::Tensor&, at::Tensor const&, at::Tensor const&)
- at::TensorIterator::binary_op(at::Tensor&, at::Tensor const&, at::Tensor const&, bool)
- at::TensorIterator::build()
- at::TensorIterator::fast_set_up()
- at::empty(c10::ArrayRef<long>, c10::TensorOptions const&, c10::optional<c10::MemoryFormat>)
- "aten::empty"
[How do we know it’s correct?]
* Built a test project that contains different op registration/invocation
patterns found in pytorch codebase, including both codegen and non-codegen
cases.
* Tried different optimization flags “-O0”, “-O3” - the result seems to
be stable.
* Filtered by common patterns: “aten::”, “at::”, “at::native”,
“at::CPUType”, “at::TypeDefault” - manually checked the relationship
between function schema strings and corresponding implementations were
captured.
* It can print instruction level data flow and show warning message if it
encounters unexpected cases (e.g.: found 0 or multiple op names per
registration/invocation API call, found 0 registered functions, etc).
* Verified consistent results on different linux / macOs hosts. It can
handle different STL library ABI reliably, including rare corner cases
for short string literals
[Known issues]
* Doesn’t handle C code yet;
* Doesn’t handle overload name yet (all variants are collapsed into the
main op name);
Test Plan:
```
LLVM_DIR=... ANALYZE_TEST=1 CHECK_RESULT=1 scripts/build_code_analyzer.sh
```
Differential Revision: D18428118
Pulled By: ljk53
fbshipit-source-id: d505363fa0cbbcdae87492c1f2c29464f6df2fed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30713
It should use moveToIntrusivePtr.
This function is a very hot one and used a lot in interpreter loop. e.g.
GET_ATTR, SET_ATTR. Making a copy and doing incref/decref caused big overhead.
Reviewed By: yinghai
Differential Revision: D18805212
fbshipit-source-id: 3a9368604f71638a21300ad086739c4b50f0644e
Summary:
Move the shell script into this separate PR to make the original PR
smaller and less scary.
Test Plan:
- With stacked PRs:
1. analyze test project and compare with expected results:
```
ANALYZE_TEST=1 CHECK_RESULT=1 tools/code_analyzer/build.sh
```
2. analyze LibTorch:
```
ANALYZE_TORCH=1 tools/code_analyzer/build.sh
```
Differential Revision: D18474749
Pulled By: ljk53
fbshipit-source-id: 55c5cae3636cf2b1c4928fd2dc615d01f287076a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30467
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
Test Plan: Imported from OSS
Differential Revision: D18801619
Pulled By: iseeyuan
fbshipit-source-id: f9b198d3e82b095daf704ee595d8026ad889bb13
Summary:
With the CI failure caused in 8bbafa0b32d2899ef6101172d62c6049427c977b fixed (incorrect return type of the lambdas in CUDA kernels)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30521
Differential Revision: D18770151
Pulled By: ailzhang
fbshipit-source-id: 02f0fe1d5718c34d24da6dbb5884ee8b247ce39a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30197
This default constructor was added because std::map's operator[]
requires a default constructor. However, instead of using operator[], we can
use emplace and remove the constructor, to ensure that the FutureInfo struct
doesnt get constructed with garbage values.
ghstack-source-id: 94802453
Test Plan: Unit tests pass.
Differential Revision: D18627675
fbshipit-source-id: c4cb000e60081478c0fd7308e17103ebbc4dc554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30677
Currently you can only add FunctionEvents to FunctionEventAvg. This makes it so you can add multiple FunctionEventAvg objects together. This is useful for merging multiple profiles together such as when dealing with distributed training.
Test Plan:
added unit test
buck test //caffe2/test:autograd -- test_profiler
Reviewed By: bddppq
Differential Revision: D18785578
fbshipit-source-id: 567a441dec885db7b0bd8f6e0ac9a60b18092278
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28389
Intel's OpenMP implementation sets the thread affinity on the first call to an OpenMP function after a fork. By adding an atfork handler we can force this to happen before a user tries to set the affinity in their own DataLoader `worker_init_fn`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29006
Differential Revision: D18782456
Pulled By: ezyang
fbshipit-source-id: ce0b515256da0cf18ceb125e0cdec99a3311bbd3
Summary:
This fixes the second issue reported in https://github.com/pytorch/pytorch/issues/29909 namely, a loop counter is assigned the wrong values after transitioning to a bailout graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30186
Differential Revision: D18646845
Pulled By: Krovatkin
fbshipit-source-id: 1f7c601dd9f35892979385ffa132fb0886a4f203
Summary:
This PR removes `namespace F = torch::nn::functional` from `torch/nn/modules/batchhnorm.h`, so that people don't have to define `torch::nn::functional` as `F` if they don't want to.
Fixes https://github.com/pytorch/pytorch/issues/30682.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30684
Differential Revision: D18795717
Pulled By: yf225
fbshipit-source-id: c9feffbeb632cc6b4ce3e6c22c0a78533bab69ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30659
I could only find one usage of TupleParser and it doesn't seem worth maintaining just for that one usage.
Test Plan: Imported from OSS
Differential Revision: D18795979
Pulled By: nairbv
fbshipit-source-id: 6e50d65fc8fade0944f36ab20d00f1539a3d4cb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30498
Updated Int8SliceOp to accept dim, start and end index similar to Pytorch.
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_slice
Imported from OSS
Differential Revision: D18740519
fbshipit-source-id: 2313f37a4936edb150ce04911b241e591e191801
Summary:
To ensure synchronization between copying of weights in RNN wei buf, and the operation, both the pyTorch operator as well as underlying MIOpen call must be on the same HIP stream. This is also consistent with MIOpen calls in other pyTorch operators
ezyang iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30672
Differential Revision: D18785683
Pulled By: bddppq
fbshipit-source-id: 144611046cb70cfe450680295734203f253ac6e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30345
Skip ProcessGroupGlooAyncTest if there is no CUDA available, otherwise in sandcastle non GPU host the test will abort with failing to load CUDA library
ghstack-source-id: 94771241
Test Plan: test skipped on non GPU host
Differential Revision: D18665322
fbshipit-source-id: 8c7b89aeecc6ec007bee12d864a6058384254e61
Summary:
This improved multi-d microbenchmark by ~100 ns, empty_tensor_restride used to be 13% of iteration time, now about 5%
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30452
Test Plan: Covered by existing tests
Differential Revision: D18704233
Pulled By: ngimel
fbshipit-source-id: be527f09183bc31e9d1f63fd49bfbe0998fe167f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30636
Currently DeQuantStub is still in whitelist because set union has
lower precedence than set difference
fix issue: https://github.com/pytorch/pytorch/issues/29646
Test Plan:
verified locally that we don't attach qconfig for DeQuantStub
Imported from OSS
Differential Revision: D18775275
fbshipit-source-id: 8da07e40963555671b3d4326c9291706103f858e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30327
### Summary
Seems like starting from macOS 10.15, we can no longer get access to the `Downloads` folder in our macOS machines.
```
permissionError: [Errno 1] Operation not permitted: '/Users/distiller/Downloads'
```
The fix is to change the conda download directory to ${HOME}
### Test Plan
- iOS jobs are back to normal
- Don't break other jobs
Test Plan: Imported from OSS
Differential Revision: D18717380
Pulled By: xta0
fbshipit-source-id: cad754076bf4ae5035741aa57a310ad87c76726e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30314
Somehow we forgot to define it!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762356
Pulled By: ezyang
fbshipit-source-id: 28afc605ad986266071e3831049ec8a7f71fd695
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30313
See comments in code about the bug.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762360
Pulled By: ezyang
fbshipit-source-id: 406a01f2f0c3722b381428c89afd67b3c3c19142
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30312
It's not necessary because it's already defined in the header.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762363
Pulled By: ezyang
fbshipit-source-id: 418bf355d460dd171ac449559f20bf55415e54ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30311
multinomial_stub must be in scope to register against it. Somehow,
this works today, but when I split torch_cpu and torch_cuda it
doesn't.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762358
Pulled By: ezyang
fbshipit-source-id: ef9c111292cd02d816af1c94c8bbaadabffaabe5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30310
- Annotate CUDAGenerator.h with correct TORCH_CUDA_API.
This is actually CUDA related functionality with its implementation living
in the cuda/ folder. For some reason it lives at the top level; it
should be moved (but that should be handled in another PR.)
- Add missing TORCH/CAFFE_API annotations to. All of
these functions are used from CUDA code, which means that
we need to correctly annotate them if we split CPU/CUDA code
into separate libraries.
Test Plan: Imported from OSS
Differential Revision: D18762357
Pulled By: ezyang
fbshipit-source-id: c975a8e4f082fe9f4196c2cca40977623caf4148
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30308
Dispatch is declared in non-anonymous namespace, so it definitely
shouldn't be defined in an anonymous namespace. This doesn't seem
to matter today, but it matters when we split libtorch into two
libraries.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762361
Pulled By: ezyang
fbshipit-source-id: 484f0fab183c385dd889db9dad3e48e92e0a3900
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30307
DispatchStub will stop working when I split CPU/CUDA libraries, because
there are some symbols from the templates in DispatchStub stubs which aren't
properly exported and I couldn't figure out how to make them dispatch properly.
This is the only case where DispatchStub is being used to dispatch to CUDA,
anyway.
This partially addresses #29844 but I need to also just completely delete
the CUDA registration logic from DispatchStub entirely.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762362
Pulled By: ezyang
fbshipit-source-id: bdfa8739c0daf23badf3c5af61890a934af00813
Summary:
Convolution nodes are traced as aten:_convolution and are currently supported in ONNX.
Scripting convolution uses aten:conv<1,2,3>d which are currently not supported in ONNX.
This PR adds the symbolics for aten:conv<1,2,3>d and aten:conv_transpose<1,2,3>d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30618
Reviewed By: hl475
Differential Revision: D18778145
Pulled By: houseroad
fbshipit-source-id: 4af0379f29974a1ce8443024d1d87b3eb8d2dd36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30546
factor out this function for later support of quantizing shared types
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D18776304
fbshipit-source-id: f5a736b0f69019cefe17ec4517da1ae5462f78e1
Summary:
Improve .view() performance by not calling set_ and instead restriding returned alias. This improves performance of .view() operation from ~500ns to ~360 ns
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30554
Test Plan: covered by existing tests
Differential Revision: D18759896
Pulled By: ngimel
fbshipit-source-id: 9757c93158bc55e9c87dc30ac3415ba8f8b849e5
Summary:
This tests seems to only test that we throw exceptions in the `WorkerInfo` constructor when invalid names are passed in, so I don't think we need to complicate by initializing RPC, and exposing ourselves to potential flakiness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30620
Differential Revision: D18766955
Pulled By: rohan-varma
fbshipit-source-id: 11643de4d57431e5f46e096c7766de3ab0b9b05a
Summary:
Previous behaviour: a user runs tests from `TestCppExtension` class so that `/tmp/torch_extensions` is created under her ownership and not removed afterwards,
then the other user's run of the same tests might result in 'Permission denied' exception upon deleting `/tmp/torch_extensions`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30095
Differential Revision: D18770234
Pulled By: ezyang
fbshipit-source-id: 4c6b972e4c4327a94c8b4bf6b0b9998a01c218bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30527
When we introduced dtype.is_signed we allowed for support of
quantized types, but we're not sure what the correct result should be.
See discussion at https://github.com/pytorch/pytorch/pull/29511
Test Plan: Imported from OSS
Differential Revision: D18765410
Pulled By: nairbv
fbshipit-source-id: c87cfe999b604cfcbbafa561e04d0d5cdbf41e6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30603
Pickler object needs to be kept in scope until data is written out to the
final serialized string. tensorData in particular is a reference to memory
owned by the descoped Pickle object.
Noticed this by inspection. In practice, this potential read-after-free here
is limited to non-cpu tensors, and any such use was very soon after free.
ghstack-source-id: 94756036
Test Plan: existing test suite at buck test mode/dev-nosan caffe2/test:rpc_fork
Differential Revision: D18760463
fbshipit-source-id: 9de890d66626aa48f13ca376dd9bd50b92e0cb00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30354
TCPStoreTest would timeout since the TCPStore constructor for the
server would block the main thread waiting for workers. The workers themselves
were spawned later on once the server store is created. As a result, this test
would always timeout.
To fix the test, I moved the server store to a thread so that the workers can
register with the server in parallel.
In addition to this made a few improvements to tcputils::connect. When
tcputils::connect() encountered an exception, it always looked at `errno` for
the error code. In some cases `errno` could be overwritten and the real error
code would be stored in `std::system_error`. As a result, I've modified the
code to look at the error code in `std::system_error` if we catch an exception
of that type.
ghstack-source-id: 94758939
Test Plan: waitforbuildbot
Differential Revision: D18668454
fbshipit-source-id: d5a3c57b066b094bfecda9a79d9d31bfa32e17f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30529
We started to see build failures for multiple services with top-of-trunk LLVM compiler. The failures point to a warning that was treated as error for implicit conversion from long to double. Per discussion on D18642524, I'm disabling this warning from the containing TARGET file. T58053069 opened for code owner to track this - a proper source code fix and more unit test is needed.
Test Plan: local build, sandcastle
Reviewed By: smessmer
Differential Revision: D18668396
fbshipit-source-id: 28c0ff3258c5ba3afd41a0053f9fe1b356a496a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30490
Add symbolic mapping to Int8AvgPool2d and Int8Reshape op in C2
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps
Imported from OSS
Differential Revision: D18740520
fbshipit-source-id: 1606125500c4b549fbc984e7929b7fd5204396a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30624
These tests were flaky since we would end up calling the 'verify'
methods before some of the RPCs were done. The `check_rpc_done` function might
not guarantee this since set_rpc_done sets an appropriate flag in python which
causes `check_rpc_done` to pass. Although, there are a few steps after that
like attaching the send functions for the response of the RPC that might not
have executed by then.
ghstack-source-id: 94781954
Test Plan: Run the tests 100 times.
Reviewed By: zhaojuanmao
Differential Revision: D18768786
fbshipit-source-id: a14c3f4b27de14fe5ecc6e90854dc52652f769b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30351
Not sure what proper fix is, clang is having trouble with the loop pragmas. This at least gets things compiling.
ghstack-source-id: 94458450
Test Plan: CI passes
Differential Revision: D18665812
fbshipit-source-id: b8a899ce4138010cbe308eaa2c0838dd9e15573f
Summary:
This TOC is manually generated but `CONTRIBUTING.md` seems like its
stable enough for that to be okay
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29671
Pulled By: driazati
Differential Revision: D18771604
fbshipit-source-id: 0d6c9c6cf1083d3be413219d3cead79c2fe5050b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30434
These are all pointwise ops that are implemented correctly wrt shapes in THC.
Test Plan: Imported from OSS
Differential Revision: D18699087
Pulled By: gchanan
fbshipit-source-id: 82cb91b00c77bfaca75be497c87fc7ae52daf46c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30449
There was an inconsistency in the order of operation between scalar and SIMD code when we compute Adagrad.
In this diff we first compute effective_lr = lr / (sqrt(moment) + epsilon) and then multiply with gradient.
Test Plan: CI
Reviewed By: protonu
Differential Revision: D18703416
fbshipit-source-id: 2a8b2a3f5401466549561412bd22f07abac3c598
Summary:
${CMAKE_HOST_SYSTEM_PROCESSOR} get processor name by `uname -p` on linux and `%PROCESSOR_ARCHITECTURE%` on windows
1. %PROCESSOR_ARCHITECTURE% has value in (AMD64|IA64|ARM64) for 64-bit processor, and (x86) for 32-bit processor
2. `uname -p` has value like "(x86_64|i[3-6]+86)"
We cannot tell intel cpu from other cpus by ${CMAKE_HOST_SYSTEM_PROCESSOR}. It is the architecture, not provider.
i. e. Intel CPU i7-9700K CPU on windows get "AMD64"
reference:
[MSDN](https://docs.microsoft.com/zh-cn/windows/win32/winprog64/wow64-implementation-details?redirectedfrom=MSDN)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30564
Differential Revision: D18763031
Pulled By: ezyang
fbshipit-source-id: 11ae20e66b4b89bde1dcf4df6177606a3374c671
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30594
This testcase started breaking, clean up for the build.
ghstack-source-id: 94736837
Test Plan: Unittest disabling change
Differential Revision: D18758635
fbshipit-source-id: 05df1158ff0ccd75e401f352da529fb663b1cae0
Summary:
On the latest master, I get link errors when building one of the tests:
```sh
/home/pbell/git/pytorch/build/../test/cpp/rpc/test_wire_serialization.cpp:23:
undefined reference to `torch::distributed::rpc::wireDeserialize(void const*, unsigned long)'
```
This seems to be caused by PR https://github.com/pytorch/pytorch/issues/29785 not working with `USE_DISTRIBUTED=0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30587
Differential Revision: D18758625
Pulled By: jjlilley
fbshipit-source-id: 0ad0703acdbbac22bb4b8317370fbe2606fcb67e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30491
Our RPC API docs presents the APIs well but misses a general
introduction to the APIs. Readers might be a little lost the first
time landing this page. This commits reorganizes the APIs into
four components from user's perspective, RPC, RRef, dist autograd,
and dist optimizer. It also adds an intro to each and briefly
discribes why we provide those.
Test Plan: Imported from OSS
Differential Revision: D18723294
Pulled By: mrshenli
fbshipit-source-id: 4aced4ab537b070aa780aaaf9724659fd47cb3cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29785
TLDR: This change improves process_group's serialization speed:
Serialize_Tensor64: 12.38us -> 1.99us (~-84%)
Deserialize_Tensor64: 33.89us -> 5.62us (~-84%)
Serialize_Tensor1M: 525.74us -> 285.43us (~-45%)
Deserialize_Tensor1M: 892.61us -> 273.68us (~-70%)
After speaking with the jit team, we had consensus that torch::save()/load()
are somewhat high-overhead for RPC serialization, mostly intended for
persistent disk data.
(Particularly, for large tensors, 35% of the time is spent in CRC checking, even
with the fb-side changes to subsitute 40x faster SSE-accelerated crc checking;
Also, for small tensors, the zip container overhead is considerable, as is the
overhead of lexing/parsing an embedded text python program for each RPC).
The jit team encouraged us to use jit::pickler, with the WriteableTensorData
way of outputting result tensors (not the default side-tensor table, or
with pickling the actual tensors). This ends up just pickling some tensor
metadata, and giving us some tensor blobs that we can mindlessly
blit over the wire (they copy to cpu memory if needed).
There is yet no standardized container format for the pickled data
(there is jit::pickle_save() checked in, but but it's experimental,
no load function is yet provided), but they encouraged us to just use
something sensible for this, and possibly revisit later. For now, I made
the directory headers slightly http-inspired.
Note that serialization is just one component of the pipeline, but that
said, we also see reasonable reductions in end-to-end echo times (noisier):
ProcessGroupAgent_Echo(Tensor_Small) 855.25us -> 492.65us (~-42%)
ProcessGroupAgent_Echo(Tensor_1M) 10.82ms -> 6.94ms (~-35%)
ProcessGroupAgent_Echo(Small_NoTensor) 688.82us -> 301.72us (~-56%)
ProcessGroupAgent_Echo(1MB_NoTensor) 4.65ms -> 3.71ms (~-20%)
I moved the "wire serialization" logic to a separate file to assist with
unittesting.
ghstack-source-id: 94694682
Test Plan:
buck test mode/dev-nosan caffe2/test/cpp/api:serialize
buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18493938
fbshipit-source-id: 07ddfe87dbe56472bc944f7d070627052c94a8f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30330
This is now possible due to previous changes made in `gloo` and `ProcessGroupGloo`. We `abort` the listener thread that is waiting for a message, and join all other threads. The API is changed so that the previous `wait_all_workers` does not destroy the agent, and this is now done in a new `shutdown` method. All callsites are updated appropriately.
ghstack-source-id: 94673884
ghstack-source-id: 94673884
Test Plan: Unit tests pass.
Reviewed By: mrshenli
Differential Revision: D18661775
fbshipit-source-id: 5aaa7c14603e18253394224994f6cd43234301c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30522
This is in preparation for moving the docs push CI jobs to depend on
`pytorch-linux-xenial-py3.6-gcc5.4` rather than
`pytorch-linux-xenial-cuda9-cudnn7-py3`.
Test Plan: Imported from OSS
Differential Revision: D18731108
Pulled By: zou3519
fbshipit-source-id: fd753a5ca818fa73a14e4276c33368a247cc40e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30361
### Summary
By default, the compiler will choose `clock_gettime` for the iOS build. However, that API is not available until iOS 10. Since the Facebook app still supports iOS 9.0, we have to use `gettimeofday` instead.
```shell
xplat/caffe2/torch/csrc/autograd/profiler.h:86:3: error: 'clock_gettime' is only available on iOS 10.0 or newer [-Werror,-Wunguarded-availability]
xplat/caffe2/torch/csrc/autograd/profiler.h:86:17: error: '_CLOCK_MONOTONIC' is only available on iOS 10.0 or newer [-Werror,-Wunguarded-availability]
```
P.S. the open-sourced version is iOS 12.0 and above, so we don't have this problem.
### Test Plan
- buck build works
- Don't break CIs
Test Plan: Imported from OSS
Differential Revision: D18730262
Pulled By: xta0
fbshipit-source-id: fe6d954b8d3c23cbc9d1e25a2e72e0b0c1d4eaa9
Summary:
PyTorch dim and ONNX axis have different meanings.
ONNX only supports log_softmax with dim = -1. Transpose must be added before and after log_softmax to support other cases.
This requires input rank to be known at export time.
Fixes https://github.com/pytorch/pytorch/issues/17918
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30433
Reviewed By: hl475
Differential Revision: D18723520
Pulled By: houseroad
fbshipit-source-id: d0ed3b3f051d08d46495a7abfa854edd120dca3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25768
The round robin process group can be constructed from multiple other
process groups. Every collective call against this new process group
is delegated to the specified process groups in a round robin fashion.
Doing so may benefit performance when calling into multiple NCCL
process groups. Instead of adding support for round-robin usage of
NCCL communicators, we achieve the same without changing the NCCL
process group and adding this wrapper class.
The API to create this round robin process group is a bit harsh. If we
find it adds significant benefit we can revisit and make this a first
class citizen in the torch.distributed module.
ghstack-source-id: 94578376
Test Plan: The newly added test passes.
Reviewed By: chenyangyu1988
Differential Revision: D17226323
fbshipit-source-id: ec9f754b66f33b983fee30bfb86a1c4c5d74767d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30415
This enables subclassing of c10d.Store and implementing its interface in Python.
ghstack-source-id: 94586627
Test Plan: New tests passes.
Reviewed By: vladbelous
Differential Revision: D18693018
fbshipit-source-id: fa1eba4bd11cc09a3d6bf3f35369c885033c63c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29934
Previously, when doing boxed dispatch (e.g. custom ops), the dispatcher manually removed the VariableTensorId flag before dispatching
because custom ops don't have variable kernels.
This is one of the blockers that prevented us from using the boxed dispatch mechanism for ops from native_functions.yaml because they define variable kernels and need them to be called for autograd.
This PR changes that. The dispatcher doesn't remove the VariableTensorId flag anymore.
Instead, to make custom ops work, we implement a variable fallback kernel that is called whenever no other variable kernel was found.
ghstack-source-id: 94618474
Test Plan: unit tests
Differential Revision: D18542342
fbshipit-source-id: a30ae35d98f89f7ae507151f55c42cfbed54a451
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30451
TORCH_CHECK takes __VA_ARGS__ so there is no need to concatenate strings
before calling it. This way it won't call Formatting::print() on the
tensor when STRIP_ERROR_MESSAGES macro is set. Formatting::print() calls
several specific tensor methods that brings in unnecessary inter-op
dependencies for static code analysis.
Test Plan: - builds
Differential Revision: D18703784
Pulled By: ljk53
fbshipit-source-id: 1c0628e3ddcb2fd42c475cb161edbef09dfe8eb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30120
The example given for functional conv2d didn't work. This diff fixes the example in docs so that it works.
Fixes https://github.com/pytorch/pytorch/issues/29649
ghstack-source-id: 94601559
Test Plan: Tried the example locally
Differential Revision: D18604606
fbshipit-source-id: ff1a4f903e2843efe30d962d4ff00e5065cd1d7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30428
Reported issue https://discuss.pytorch.org/t/incomprehensible-behaviour/61710
Steps to reproduce:
```
class WrapRPN(nn.Module):
def __init__(self):
super().__init__()
def forward(self, features):
# type: (Dict[str, Tensor]) -> int
return 0
```
```
#include <torch/script.h>
int main() {
torch::jit::script::Module module = torch::jit::load("dict_str_tensor.pt");
torch::Tensor tensor = torch::rand({2, 3});
at::IValue ivalue{tensor};
c10::impl::GenericDict dict{c10::StringType::get(),ivalue.type()};
dict.insert("key", ivalue);
module.forward({dict});
}
```
ValueType of `c10::impl::GenericDict` is from the first specified element as `ivalue.type()`
It fails on type check in` function_schema_inl.h` !value.type()->isSubtypeOf(argument.type())
as `DictType::isSubtypeOf` requires equal KeyType and ValueType, while `TensorType`s are different.
Fix:
Use c10::unshapedType for creating Generic List/Dict
Test Plan: Imported from OSS
Differential Revision: D18717189
Pulled By: IvanKobzarev
fbshipit-source-id: 1e352a9c776a7f7e69fd5b9ece558f1d1849ea57
Summary:
using `buck build mode/opt mode/no-gpu //experimental/ngimel/benchmark_framework_overheads:cpp_benchmark`
```
devvm497.prn3.facebook.com:/data/users/bwasti/fbsource/fbcode $ ./cpp_benchmark --niter 10000
creating inputs, number of dimensions 1
starting op
benchmarking 10000 iterations
using cpp frontend
elapsed time per iteration 0.90638 us
```
```
devvm497.prn3.facebook.com:/data/users/bwasti/fbsource/fbcode $ ./cpp_benchmark --niter 10000 --disable_variable_dispatch
creating inputs, number of dimensions 1
starting op
benchmarking 10000 iterations
using cpp frontend
elapsed time per iteration 0.775436 us
```
Test Plan: let all tests run
Reviewed By: smessmer
Differential Revision: D18654276
fbshipit-source-id: 362812b2c87ec428448b2ac65baac45f492fdce4
Summary:
This PR add `gpu_kernel_with_index` as an addition to element-wise kernel template. It allows kernel to not only operate on input tensor value, but also each values index(view as 1d, so from 0 to numel) within the lambda.
Direct use case here is to replace thrust::tabulate used in range/arange/linspace. Benifits are:
- thrust::tabulate causes additional unneccessary synchronization on cpu.
- Now it works with tensor iterator, output no longer needs to be contiguous and a memcpy is saved
It can also potentially be reused to add new function to pytorch later, if we see use case both value and index is needed.(for example unify tril/triu into tensor iterator element-wise? add other pattern?)
Known issues:
https://github.com/pytorch/pytorch/pull/23586 is needed to enable non-contiguous case work properly, since overlapping needs to be checked. Currently non-contiguous tensor falls into TOO_HARD. I could write proper check in this file but I figured using exist method is better. jjsjann123
It does not work beyond 32bit indexing. But thrust was erroring on those case too. We could split tensor in caller to enable this. Index changes after split, so it is easier for caller to pass different lambda, and harder for the template to handle it in general.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28175
Differential Revision: D18708649
Pulled By: ngimel
fbshipit-source-id: 382081c96f266ae7b61095fc1f2af41c6b210fa9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30472
Add DoNotStrip to nativeNewTensor method.
ghstack-source-id: 94596624
Test Plan:
Triggered build on diff for automation_fbandroid_fallback_release.
buck install -r fb4a
Tested BI cloaking using pytext lite interpreter.
Obverse that logs are sent to scuba table:
{F223408345}
Reviewed By: linbinyu
Differential Revision: D18709087
fbshipit-source-id: 74fa7a0665640c294811a50913a60ef8d6b9b672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29953
The underlying function handles it correctly.
Test Plan: Imported from OSS
Differential Revision: D18548055
Pulled By: gchanan
fbshipit-source-id: cc2d0ae37d9689423363d115c6a653cb64840528
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29952
The underlying op handles the check correctly.
Test Plan: Imported from OSS
Differential Revision: D18548048
Pulled By: gchanan
fbshipit-source-id: 9ac6fde743408e59ccdfc61bd574ebe6e2862238
Summary:
In ONNX opset 11, a series of sequence ops were added. Operators that are related to Tensor[] in PyTorch can be exported using these sequence ops.
In this PR, unbind/split that produces Tensor[], and __getitem__ that takes Tensor[] as input, are exported correctly to ONNX opset 11.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29136
Reviewed By: hl475
Differential Revision: D18309222
Pulled By: houseroad
fbshipit-source-id: be12c96bf8d0a56900683ef579f1c808c0a1af21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30202
Pytorch Upsample operator has output_size as an argument.
For quantized tensor inputs we cannot get the input_size to calculate the width and height scale factor.
Instead we pass the output_size directly to caffe2 to calculate the scale factors.
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_upsample
Imported from OSS
Differential Revision: D18631478
fbshipit-source-id: 38a39129bc863f4ecf2293acc068e40ab7edc825
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30217
Before this commit, RRefContext throws an error if it detects any
RRef leak during shutdown. However, this requires applications to
make sure that is has freed all references to RRefs in application
code, which can be a bad debugging experience when for large
applications. Besides, this also relies on Python GC to free things
up in time, which might not always be true. After this commit,
RRefContext would ignore leaking RRefs during shutdown, as shutdown
is called when the application has finished training and no longer
care about local states. Hence, it should be OK to just ignore
those leaks and destroy OwnerRRefs. If application would like to
enforce no leaks, just set torch.distributed.rpc.api._ignore_rref_leak
to False.
Test Plan: Imported from OSS
Differential Revision: D18632546
Pulled By: mrshenli
fbshipit-source-id: 2744b2401dafdd16de0e0a76cf8e07777bed0f38
Summary:
The PyTorch exporter does not add any name to the ONNX operators in the exported graph. A common request is to add names to op nodes by default. This helps the readability of the graph in visualization tools such a Netron, or when the ONNX graph is printed as a string. Also, it helps with the debuggability of the ONNX graph.
Therefore this PR adds name to operators in the exporters. The names follow a simple format, <op_type>_<index>. Expect files for tests in `test/onnx/test_operators.py` have been updated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27342
Reviewed By: hl475
Differential Revision: D17790979
Pulled By: houseroad
fbshipit-source-id: 1eaae88b5f51f152735a2ff96e22827837e34d9d
Summary:
This should resolve https://github.com/pytorch/pytorch/issues/29008. This flag has two effects on the tracer.
- Remove the underscroll for inplace operators. E.g.: index_put_ ==> index_put. This is handled in utils.py separately as well.
- Add out as input for backward computation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29466
Reviewed By: hl475
Differential Revision: D18422815
Pulled By: houseroad
fbshipit-source-id: 317b6a3c8a5751fe6fe49d7543e429d281ed0d6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30357
Fix issue https://github.com/pytorch/pytorch/issues/29032 in loading from state dict for observers and fake quant.
ghstack-source-id: 94468814
Test Plan: Ensures that load/save of fake quant and observers with missing keys works correctly.
Differential Revision: D18668517
fbshipit-source-id: 0eda6f47c39102e55977fc548b9a03664f123ad7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30430
When a module isn't a TracedModule, attempt to get name information with `original_name` property on module and default to 'Module' when no such property exists.
Test Plan:
### Change child module to scripted module:
```
model = torchvision.models.alexnet()
model.classifier = torch.jit.script(model.classifier)
```
### Add graph
```
w = SummaryWriter()
w.add_graph(model, torch.rand((2, 3, 224, 224)))
w.close()
```
### No errors
However, graph is disconnected at parts and hard to understand.
{F223327878}
Reviewed By: sanekmelnikov
Differential Revision: D18690836
fbshipit-source-id: 42295d06b7c1d48d5401776dca1e0d12cd64b49d
Summary:
This adds a listing of the parts of the `typing` module that are unsupported
This is also a first pass decisions on features are 'unlikely to be implemented' vs 'not implemented' so they're open to discussion
](https://our.intern.facebook.com/intern/diff/18665628/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30344
Pulled By: driazati
Differential Revision: D18665628
fbshipit-source-id: 22b8ebbde23df03839306cdb4344ca18a44f2c29
Summary:
There is no `out` argument to `argsort` according to the source code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24335
Differential Revision: D16829134
Pulled By: vincentqb
fbshipit-source-id: 8f91154984cd4a753ba1d6105fb8a9bfa0da22b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30362
Right now the qat modules(qat.ConvBn2d, qat.ConvBnReLU2d, qat.Conv2d)
are not convinent to support other dimensions of Conv, this PR refactors
these modules so that we can support Conv1d/Conv3d better
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D18691152
fbshipit-source-id: 5b561e6b054eadd31b98cabdf1ac67a61ee9b805
Summary:
In this PR, we mainly handle the case there are multiple usage of a Value when inserting the quant-dequant pair. This change will add one dequant for each usage of the Value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30145
Differential Revision: D18671600
Pulled By: lly-zero-one
fbshipit-source-id: 61324a98861da85b80dcf7e930381311118ae53b
Summary:
Currently, the way the compare kernels handle dtypes is very funny (this behavior is introduced in https://github.com/pytorch/pytorch/pull/28427 and I just realize it today):
Let's say `a, b` are two float tensors on CUDA.
If you do `a < b`, this is what would happen inside the loop:
- Step 1: Fetch `a` and `b`, dynamically cast them from `float` to `float`. (i.e. check the scalar type to figure out if it needs cast. it doesn't. so do nothing then.)
- Step 2: compute `a < b`, get a `bool` result
- Step 3: statically cast the result into `float`
- Step 3: do a dynamic cast of the result from `float` to `bool` and store the value
And if you do `a.lt_(b)`, this is what would happen:
- Step 1: Fetch `a` and `b`, no casting
- Step 2: compute `a < b`, get a `bool` result
- Step 3: statically cast the result into `float`
- Step 4: store the result to memory, no casting
Although dynamic casting happens on registers, it still hurt the performance a bit (~8%).
This PR fixes this issue. Now for compare kernels, if the output is bool and inputs have the same dtype, then there is no dynamic casting. Otherwise, there will be dynamic casting for each input and output. That is, the dynamic casting behavior of the two cases described above are swapped.
Benchmark on `a < b` for tensor of 1000000000 fp32 elements:
Before https://github.com/pytorch/pytorch/issues/28427 6.35 ms
Current master: 6.88 ms
With this PR: 6.36 ms
Benchmark on `a.lt_(b)` does not show any difference across versions.
Besides this, what worries me most is, with type promotion, the logic for tensor iterator is becoming super complicated, and it is hard to see if one change causes the performance regression of others. I suggest we create scripts that could benchmark tensor iterator entirely, review that code and put it somewhere inside the repository (maybe under `/tools` or `/test/scripts`?), and whenever we are not certain about the performance we could run it to check. (I guess not on this PR but on PRs after the script is done. If there are worries about performance, the author of PRs should run the script manually, and the reviewer should remind PR author to do so if necessary) If this is a good idea, I will send a PR for the script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29743
Differential Revision: D18671269
Pulled By: ngimel
fbshipit-source-id: 89a9c1c8b5fd45d5ae8fe907d65c2fe1a7dfd2dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30208
Adds default arg for init_method so users don't have to pass this in,
and moves it to `RpcBackendOptions` struct. Removes `init_method` arg from rpc.init_rpc. Also fixes some docs.
ghstack-source-id: 94500475
Test Plan: Unit tests pass.
Reviewed By: mrshenli
Differential Revision: D18630074
fbshipit-source-id: 04b7dd7ec96f4c4da311b71d250233f1f262135a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30359
We need this for C++14 support
ghstack-source-id: 94519850
Test Plan: unit tests
Differential Revision: D18668868
fbshipit-source-id: 87e8eadf0e60a1699fba4524aea53b306b9a7f24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29945
Both functions require at least 1 2-dimensional tensor, so can never return an inferred scalar.
Test Plan: Imported from OSS
Differential Revision: D18548056
Pulled By: gchanan
fbshipit-source-id: f99a41d490b9a5ab5717534c92e4f2e848c743e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29923
Note that this changes the behavior of masked_select when both "self" and "mask" are 0-dimensional.
In previous versions of PyTorch, this would return a 0-dimensional tensor. But the documentation reads:
"Returns a new 1-D tensor which indexes the input tensor according to the boolean mask mask which is a BoolTensor."
Test Plan: Imported from OSS
Differential Revision: D18539560
Pulled By: gchanan
fbshipit-source-id: 1637ed2c434fcf8ceead0073aa610581f4a19d21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30320Fixes#30296
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18665704
Pulled By: ezyang
fbshipit-source-id: f09a953137fcc105959382254f9b8886af5aea3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30390
Fix the crashes for c++ not able to find java class through Jni
ghstack-source-id: 94499644
Test Plan: buck install -r fb4a
Reviewed By: ljk53
Differential Revision: D18667992
fbshipit-source-id: aa1b19c6dae39d46440f4a3e691054f7f8b1d42e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30282
The atomic increment/decrements in LeftRight::read() were measurable in perf benchmarks. Let's improve their perf.
ghstack-source-id: 94443230
Test Plan: unit tests, perf benchmarks
Differential Revision: D18650228
fbshipit-source-id: d184ce8288510ab178e7c7da73562609d1ca3c9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29682
This PR re-introduces backend_fallback_test.cpp, which was previously called boxed_fallback_test.cpp and showed how to use the backend fallback API.
ghstack-source-id: 94481314
Test Plan: unit tests
Differential Revision: D18462654
fbshipit-source-id: 3e9b5c8f35c05f9cd795f44a5fefd1a0aaf03509
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29681
Remove callUnboxedOnly() and instead use metaprogramming to figure out if an operator can use a boxed fallback or not.
This enables boxed fallback for ops in native_functions.yaml even if they don't have `use_c10_dispatcher: full` set, as long as they're in the range of supported types.
ghstack-source-id: 94481320
Test Plan: unit tests
Differential Revision: D18462653
fbshipit-source-id: 2955e3c4949267520a1734a6a2b919ef5e9684a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29337
This argument is needed by boxing wrappers so they're able to get a pointer to the corresponding unboxed kernel and call into it.
But if a kernel is registered in a boxed way, we don't need it and should hide this from the API.
This is especially needed for the backend fallback API where users would only be left wondering why this argument is there and what it does.
Also, hiding it allows us to potentially totally remove it in a future refactoring if we find some way to do so.
ghstack-source-id: 94481316
Test Plan: unit tests
Differential Revision: D18361991
fbshipit-source-id: 5cef26c896fe3f2a5db730d3bc79dcd62e7ef492
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29330
This makes for a nicer API, especially in backend fallback kernels who get an OperatorHandle instance and can directly call these methods on it.
ghstack-source-id: 94481322
Test Plan: unit tests stacked on top
Differential Revision: D18357424
fbshipit-source-id: fa8c638335f246c906c8e16186507b4c486afb3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29201
This is required for boxed backend fallback kernels (e.g. lazy, AMP) because they need to know which op was actually called.
ghstack-source-id: 94481313
Test Plan: I will add unit tests in a diff stacked on top
Differential Revision: D18282746
fbshipit-source-id: 339a1bbabd6aff31a587b98f095c75104dfc6f99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30340
We already made OperatorEntry::dispatchTable_ an array to be able to avoid the concurrency primitives there,
but Dispatcher::backendFallbackKernels_ has the same issue. Let's make it a table too.
Since there is some code duplication here, we also factor out the concept of a KernelFunctionTable to be used in both places.
ghstack-source-id: 94481317
Test Plan: unit tests
Differential Revision: D18663426
fbshipit-source-id: ba82ca5c4cae581eea359d5c0c3a5e23b0f8838c
Summary:
In the PR, we enhance the graph-mode quantization for aten::_convolution, which could be generated from tracing path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30245
Differential Revision: D18671597
Pulled By: lly-zero-one
fbshipit-source-id: 78a2470fbb0fe0def55d63c6bda7cbb5c89f7848
Summary:
This PR updates `torch::pickle_save` to use the new zipfile format introduced in #29232 and adds `torch::pickle_load` which can decode the zipfile format. Now that `torch.save/load` use this format as well (if the `_use_new_zipfile_serialization` flag is `True`), raw values saved in Python can be loaded in C++ and vice versa.
Fixes#20356
](https://our.intern.facebook.com/intern/diff/18607087/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30108
Pulled By: driazati
Differential Revision: D18607087
fbshipit-source-id: 067cdd5b1cf9c30ddc7e2e5021a8cceee62d8a14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30367
use the SLS emulations that match the hardware
Test Plan: replayer test
Differential Revision: D18667605
fbshipit-source-id: 89aee630184737b86ecfb09717437e5c7473e42c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30241
We need an API to get all worker infos. This will be used by backend-agnostic `rpc.wait_all_workers()` API.
ghstack-source-id: 94454935
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork -- test_get_worker_infos
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_get_worker_infos
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_get_worker_infos
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_get_worker_infos
```
Differential Revision: D5693412
fbshipit-source-id: 5123c8248b6d44fd36b8a5f381dbabb2660e6f0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30167
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29164
- Created GlooDeviceFactory to hide device creation details
- Added transport option while on Python interface
The reason of making the factory class is to make it easier to extend gloo transport in the future
Test Plan: Imported from OSS
Reviewed By: satgera, d4l3k
Differential Revision: D18596527
fbshipit-source-id: e8114162ee8d841c0e0769315b48356b37d6ca0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29207
The logic calling c10 ops from JIT did some variable wrapping to make sure all results are always variables.
Thanks to ezyang, this is not needed anymore because everything is a variable now.
ghstack-source-id: 93345590
Test Plan: waitforsandcastle
Differential Revision: D18327507
fbshipit-source-id: 86512c5e19d6972d70f125feae172461c25e3cb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30193
Featuring:
- Added a NoNamesGuard::reset() function that sets NamesMode back to
what it was before the guard. This makes it so that we don't have to
create a new context to run code in an unnamed way.
- Added a diagonal(Tensor, *, Dimname outdim, Dimname dim1, Dimname dim2, int64_t offset=0)
overload. All of the non-tensor arguments are keyword only for
readability purposes; something like `tensor.diagonal("A", "B", "C")`
would be really confusing.
Test Plan: - Added new tests
Differential Revision: D18638363
Pulled By: zou3519
fbshipit-source-id: ea37b52a19535f84a69be38e95e569e88f307381
Summary:
This PR looks for a `constants.pkl` file at the top level in a zip file
in `torch.load`. If found, it calls `torch.jit.load` instead and issues
a warning to call `torch.jit.load` directly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29339
Differential Revision: D18611095
Pulled By: driazati
fbshipit-source-id: f070a02f6b5509054fc3876b3e8356bbbcc183e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29943
This was apparently the same as "pytorch/pytorch-binary-docker-image-ubuntu16.04:latest",
so standardize on that name.
Test Plan:
This PR, which is stacked on top of a commit that puts one of the jobs
using that container into the set of PR builds.
Imported from OSS
Differential Revision: D18653554
fbshipit-source-id: 40e6c52db02265d61e8166bb1211376faccfc53a
2019-11-22 11:39:55 -08:00
4129 changed files with 366994 additions and 126125 deletions
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
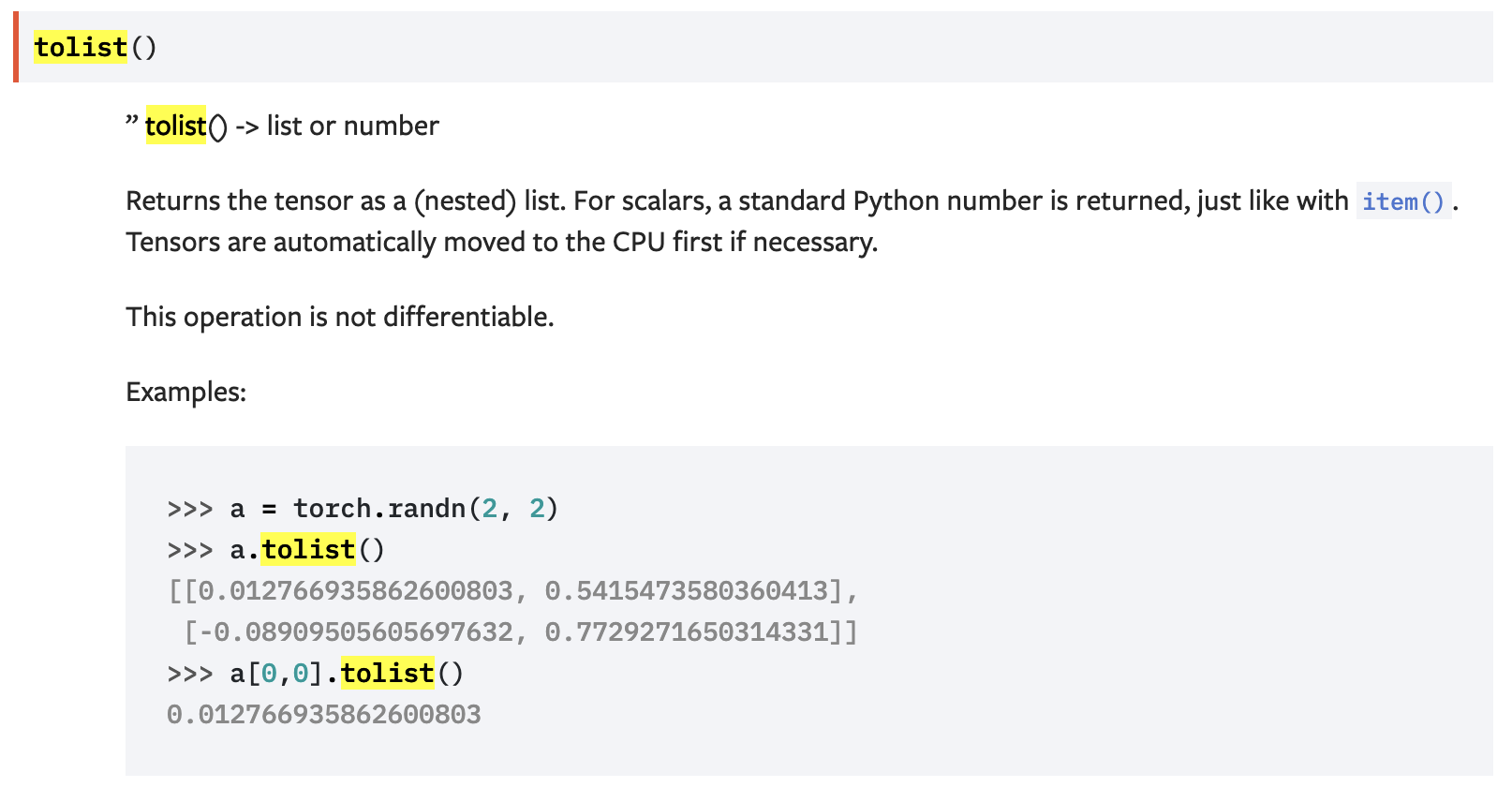{kind=link}
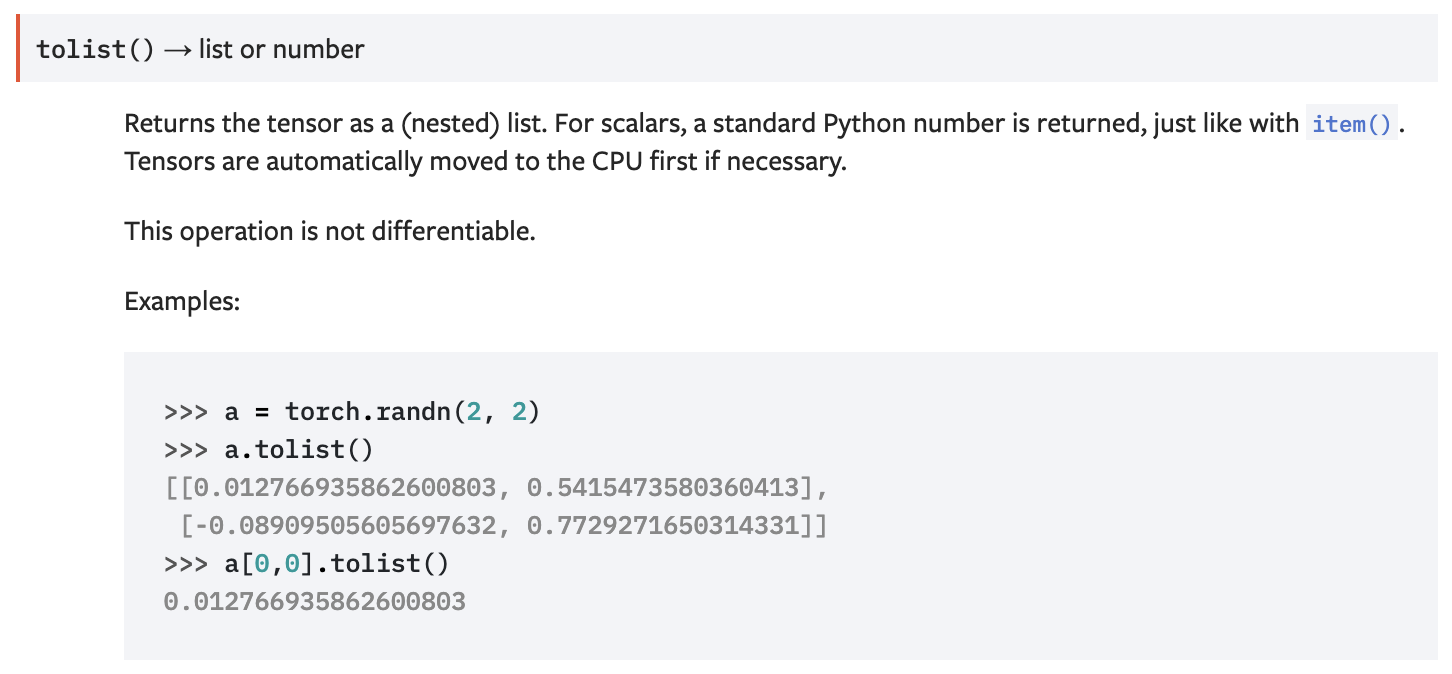{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
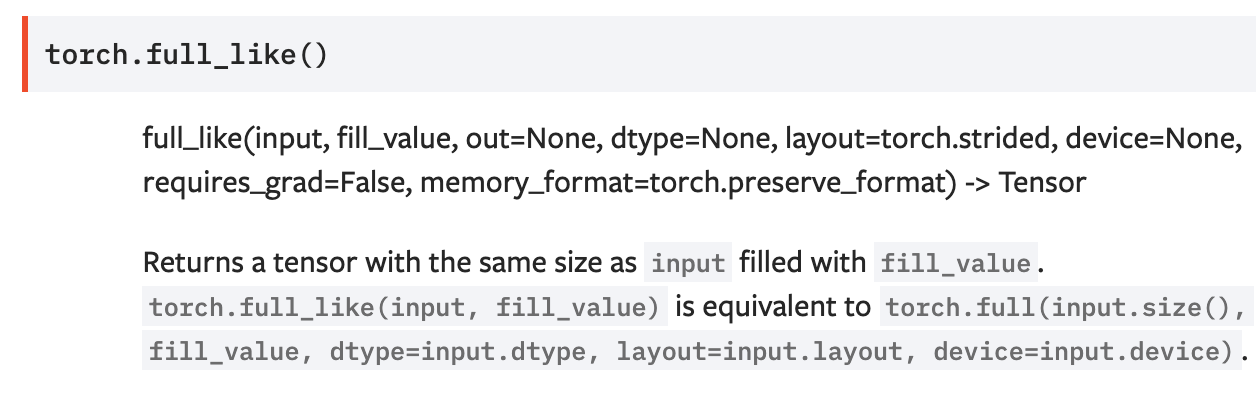{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
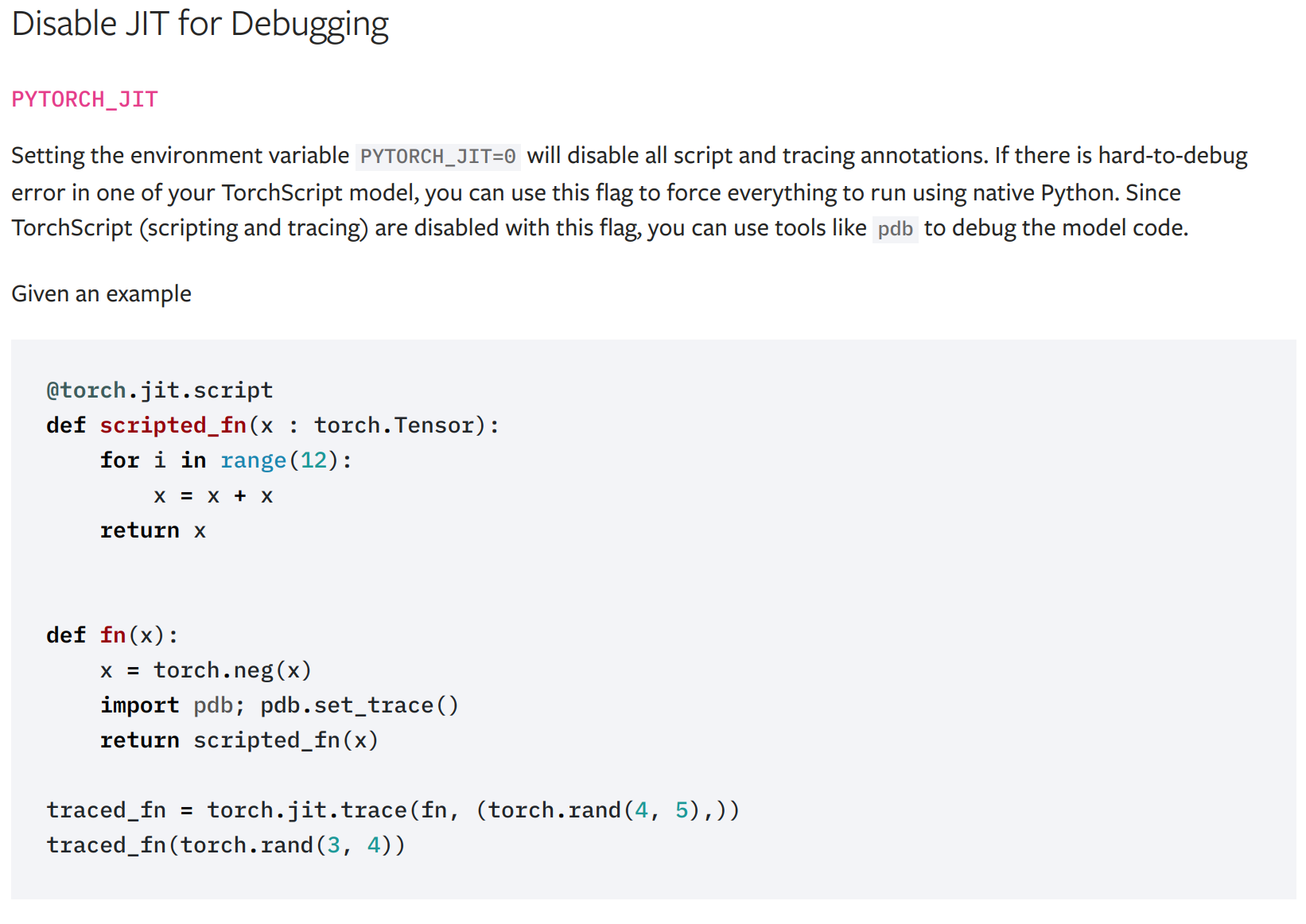{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
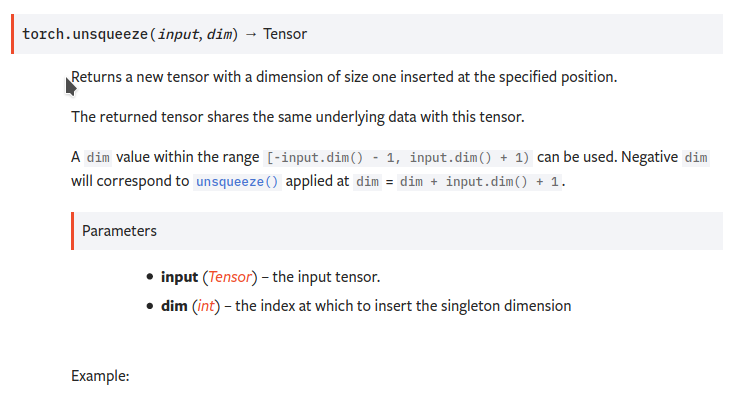{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
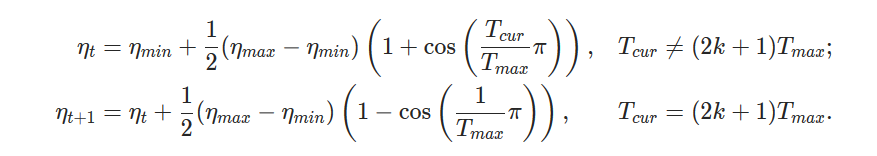{kind=link}
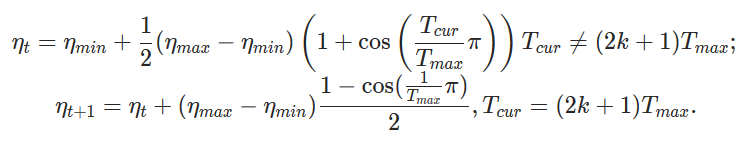{kind=link}
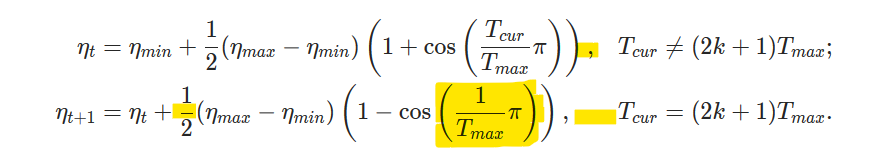{kind=link}
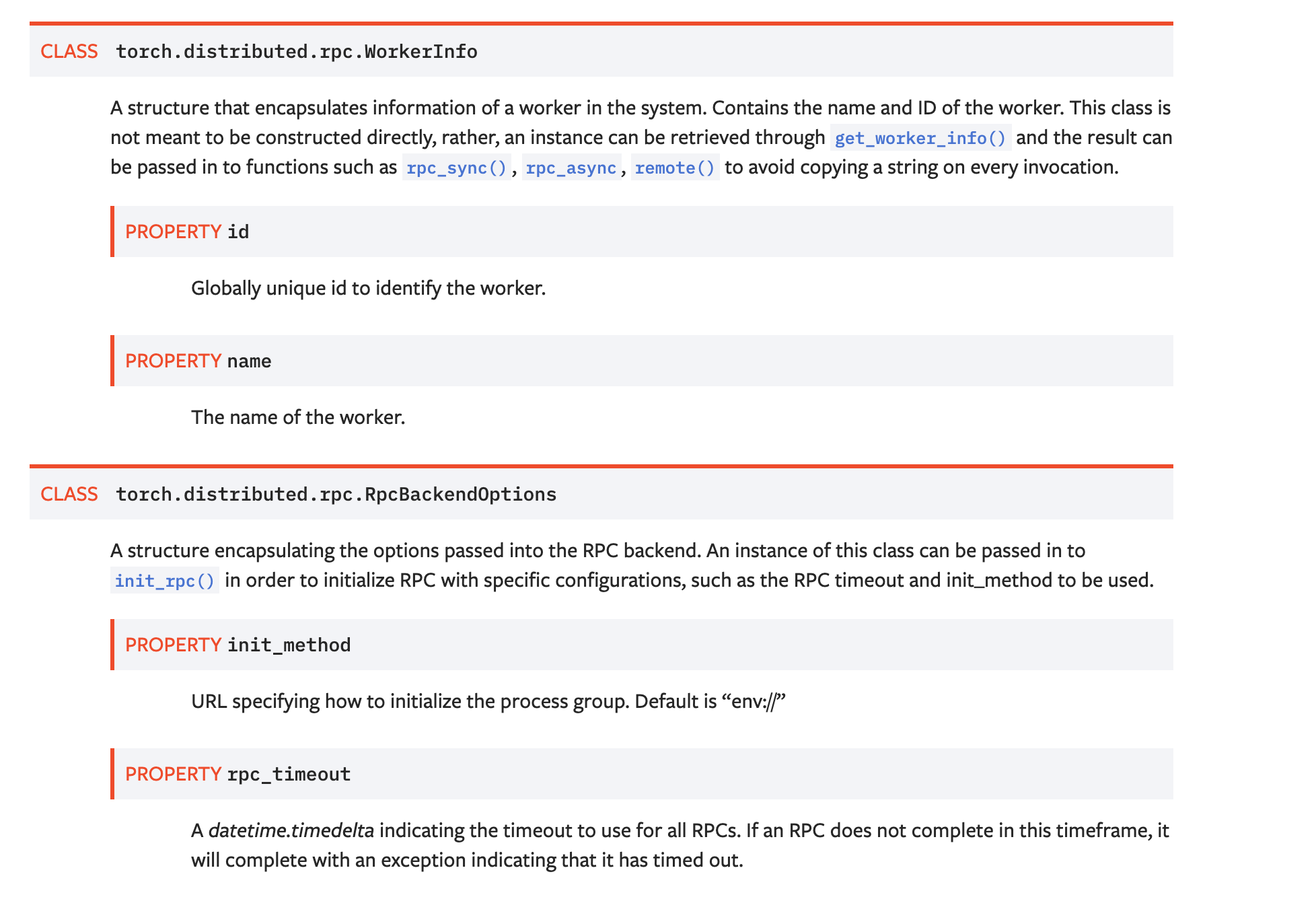{kind=link}