Summary:
CircleCI by default, chooses to run 0 jobs on tags meaning that when we
tag a build that no job is run if a dependent job does not contain the
correct filters.
This adds an explicit configuration to run the setup job on every branch
and every tag that CircleCI can run on.
For more information on CircleCI filters and what they do (and more
importantly what they do not do) visit:
https://circleci.com/docs/2.0/configuration-reference/#filters-1
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35013
Differential Revision: D20535560
Pulled By: seemethere
fbshipit-source-id: 7ee5dddbc0a9416fd76ed198e5447318c53e1873
Summary:
Per title.
In the future we want to make div(), the division operator, and addcdiv perform true division as in Python 3, NumPy, and JAX. To do this without silently breaking users we plan to:
- Warn (once) in 1.5 when a user performs integer division using div or addcdiv
- RuntimeError in 1.6 when a user attempts to perform integer division using div or addcdiv
- Always perform true division in 1.7 using div, /, and addcdiv
Users can use true_divide or floor_divide today to explicitly specify the type of division they like.
A test for this behavior is added to test_type_promotion. Unfortunately, because we are only warning once (to avoid a deluge) the test only uses maybeWarns Regex.
The XLA failure is real but will be solved by https://github.com/pytorch/pytorch/pull/34552. I'll be sure to land that PR first to avoid temporarily breaking the XLA build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34570
Differential Revision: D20529211
Pulled By: mruberry
fbshipit-source-id: 65af5a9641c5825175d029e8413c9e1730c661d0
Summary:
And few typos
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34791
Test Plan: CI
Differential Revision: D20524879
Pulled By: malfet
fbshipit-source-id: 58fa03bd6356979e77cd1bffb6370d41a177c409
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34980
We were passing sample inputs to `torch.jit.script` (as if it was
`torch.jit.trace`), but this parameter was treated as an optional
`optimize` parameter. That parameter is deprecated and that caused a
warning.
Differential Revision: D20520369
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 87b40a5e35bfc4a3d7a5d95494632bfe117e40b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34638
Fixes: https://github.com/pytorch/pytorch/issues/27643
This PR manages notifying workers in the event of a failure during distributed autograd. Gracefully handles propagating errors across all nodes in the backward pass and sets state in the local autograd engines accordingly.
(Note: this ignores all push blocking failures!)
Test Plan: Added 2 new tests checking errors when they are thrown in an intermediate node during distributed autograd. Ensured that all existing distributed autograd tests pass.
Differential Revision: D20164420
fbshipit-source-id: 3d4ed74230969ac70bb763f1b5b1c16d979f66a2
Summary:
`GetEmptyStringAlreadyInited` invocation pattern in protobuf generated header files chanegd to
`:PROTOBUF_NAMESPACE_ID::internal::GetEmptyStringAlreadyInited`, where `PROTOBUF_NAMESPACE_ID` is defined in `protobuf/port_def.inc` as `google::protobuf`
This likely to have changed around protobuf-3.8.x time, but I've only tested it using protobuf-3.11.4
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35008
Test Plan: Update `third-party/protobuf` submodule to 3.11.4, compile and run `pattern_net_transform_test`
Differential Revision: D20526949
Pulled By: malfet
fbshipit-source-id: fddaa3622c48ad883612c73c40a20d306d88d66b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34988
In https://github.com/pytorch/pytorch/pull/31893, we introduced a confirmedUsers_ map in RRefContext.
For the case that the fork is shared from the owner, there is no `pendingUsers_` intermediate phase for this fork, we should put this fork into `confirmedUsers_` immediately.
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
```
Differential Revision: D7735909
fbshipit-source-id: 14c36a16486f0cc9618dcfb111fe5223781b647d
Summary:
1. Removed LossClosureOptimizer, and merged Optimizer into OptimizerBase (and renamed the merged class to Optimizer)
2. Merged the LBFGS-specific serialize test function and the generic test_serialize_optimizer function.
3. BC-compatibility serialization test for LBFGS
4. Removed mentions of parameters_ in optimizer.cpp, de-virtualize all functions
5. Made defaults_ optional argument in all optimizers except SGD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34957
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20518647
Pulled By: anjali411
fbshipit-source-id: 4760d1d29df1784e2d01e2a476d2a08e9df4ea1c
Summary:
**Summary**
This commit parallelizes the invocation of `clang-format` on all files
in `tools/clang_format_new.py` using `asyncio`.
**Testing**
Ran and timed the script.
*Before*
```
$ time ./tools/clang_format_new.py --diff
...
real 0m7.615s
user 0m6.012s
sys 0m1.634s
```
*After*
```
$ time ./tools/clang_format_new.py --diff
...
Some files not formatted correctly
real 0m2.156s
user 0m8.488s
sys 0m3.201s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34750
Differential Revision: D20523133
Pulled By: SplitInfinity
fbshipit-source-id: 509741a0b4fcfcdcd7c5a45654e3453b4874d256
Summary:
There are three guards related to mobile build:
* AutoGradMode
* AutoNonVariableTypeMode
* GraphOptimizerEnabledGuard
Today we need set some of these guards before calling libtorch APIs because we customized mobile build to only support inference (for both OSS and most FB use cases) to optimize binary size.
Several changes were made since 1.3 release so there are already inconsistent uses of these guards in the codebase. I did a sweep of all mobile related model loading & forward() call sites, trying to unify the use of these guards:
Full JIT: still set all three guards. More specifically:
* OSS: Fixed a bug of not setting the guard at model load time correctly in Android JNI.
* FB: Not covered by this diff (as we are using mobile interpreter for most internal builds).
Lite JIT (mobile interpreter): only needs AutoNonVariableTypeMode guard. AutoGradMode doesn't seem to be relevant (so removed from a few places) and GraphOptimizerEnabledGuard definitely not relevant (only full JIT has graph optimizer). More specifically:
* OSS: At this point we are not committed to support Lite-JIT. For Android it shares the same code with FB JNI callsites.
* FB:
** JNI callsites: Use the unified LiteJITCallGuard.
** For iOS/C++: manually set AutoNonVariableTypeMode for _load_for_mobile() & forward() callsites.
Ideally we should avoid having to set AutoNonVariableTypeMode for mobile interpreter. It's currently needed for dynamic dispatch + inference-only mobile build (where variable kernels are not registered) - without the guard it will try to run `variable_fallback_kernel` and crash (PR #34038). The proper fix will take some time so using this workaround to unblock selective BUCK build which depends on dynamic dispatch.
PS. The current status (of having to set AutoNonVariableTypeMode) should not block running FL model + mobile interpreter - if all necessary variable kernels are registered then it can call _load_for_mobile()/forward() against the FL model without setting the AutoNonVariableTypeMode guard. It's still inconvenient for JAVA callsites as it's set unconditionally inside JNI methods.
Test Plan: - CI
Reviewed By: xta0
Differential Revision: D20498017
fbshipit-source-id: ba6740f66839a61790873df46e8e66e4e141c728
Summary: Add transfer_learning_blob_name_mappings into layer_model_helper to support layer model transfer learning
Reviewed By: mraway
Differential Revision: D20286298
fbshipit-source-id: de3e029611d843f38d3f42ecd4148358f7e14a2b
Summary:
(Updated per review feedback)
`torch.floor_divide` is currently a function that can operate on two tensors or a tensor and a scalar (scalar x scalar floor division is handled natively by Python and the JIT has a builtin function for it). This PR updates it to:
- have an out variant: `floor_divide(x, y, out=z)`
- be a method on a tensor: `x.floor_divide(y)`
- have an in-place variant: `x.floor_divide_(y)`
- work with sparse tensors
Tests are added to test_sparse.py and test_torch.py for these new behaviors.
In addition, this PR:
- cleans up the existing sparse division and true_division code and improves their error message
- adds testing of sparse true_division to test_sparse.py
- extends existing floor_divide testing in test_torch to run on CUDA, too, not just the CPU
Unfortunately, making floor_divide a method requires breaking backwards compatibility, and floor_divide has been added to the BC whitelist since this is international. The BC issue is that the first parameter name to torch.floor_divide is changing from input to self. If you previously called torch.floor_divide with keyword arguments, e.g. torch.floor_divide(input=x, other=y), you will need to update to torch.floor_divide(self=x, other=y), or the more common torch.floor_divide(x, y).
The intent of this PR is to allow floor_divide to be substituted for division (torch.div, /) wherever division was previously used. In 1.6 we expect torch.div to perform true_division, and floor_divide is how users can continue to perform integer division with tensors.
There are two potential follow-up issues suggested by this PR:
- the test framework might benefit from additional tensor construction classes, like one to create dividends and divisors for multiple dtypes
- the test framework might benefit from a universal function test class. while methods have reasonable coverage as part of test_torch.py's TestTensorOp tests, function coverage is spotty. Universal functions are similar enough it should be possible to generate tests for them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34552
Differential Revision: D20509850
Pulled By: mruberry
fbshipit-source-id: 2cd3c828aad67191c77f2ed8470411e246f604f8
Summary:
This is causing failures on my Windows build
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34926
Differential Revision: D20501850
Pulled By: smessmer
fbshipit-source-id: 92c72dd657b27b1786952dbdccfceff99f4ba743
Summary:
This pull request updates the Torchvision commit to use ROCm enabled torchvision in `.jenkins/pytorch/test.sh`.
Pytorch tests:
```
test_SyncBatchNorm_process_group (__main__.TestDistBackend)
test_alexnet (jit.test_models.TestModels)
test_script_module_script_resnet (jit.test_models.TestModels)
test_script_module_trace_resnet18 (jit.test_models.TestModels)
test_torchvision_smoke (__main__.TestTensorBoardPytorchGraph)
```
in `test2` were skipped because torchvision was not installed in `test2` instead it was installed in `test1`. The PR moved torchvision test to correct place and thereby enabling the above mentioned tests.
cc: ezyang iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34909
Differential Revision: D20515333
Pulled By: ezyang
fbshipit-source-id: 69439756a687ba441c1f8107233b4dbc1e108387
Summary:
Per title.
Currently torch.full will always (attempt to) produce a float tensor. This is inconsistent with NumPy in (at least) two cases:
- When integral fill values (including bool) are given
- When complex fill values are given
For example:
```
np.full((1, 2), 1).dtype
: dtype('int64')
np.full((1, 2), (1 + 1j)).dtype
: dtype('complex128')
```
Whereas in PyTorch
```
torch.full((1, 2), 1).dtype
: torch.float32
torch.full((1, 2), (1 + 1j)).dtype
: RuntimeError: value cannot be converted to type float without overflow: (1,1)
```
This PR begins the process of deprecating our current behavior of returning float tensors (by default) when given integer fill values by warning the user that integer fill values will require explicitly specifying the dtype or out kwargs in 1.6, and in 1.7 the behavior will change to return a LongTensor by default (BoolTensor for bool values). The intermediate 1.6 release is to prevent changing the behavior silently and unexpectedly.
The PR also implements inference for complex types. So that with it:
```
torch.full((1, 2), (1 + 1j)).dtype
: torch.complex64
```
The complex type inference returns a ComplexFloat tensor when given a complex fill value (and no dtype or out kwarg is specified), unless the default dtype is Double, in which case a ComplexDouble tensor is returned.
A test for these behaviors is added to test_torch.py.
Implementation note:
This PR required customizing full's dispatch because currently in eager codegen the TensorOptions object passed to functions improperly sets has_dtype() to true, even if the user did not explicitly provide a dtype. torch.arange already worked around this issue with its own custom implementation. The JIT, however, does pass a properly constructed TensorOptions object.
Future Work:
This PR does not extend torch.full's complex type inference to ONNX. This seems unlikely to come up and will be a clear error if it does. When integer type inference is added to torch.full, however, then porting the behavior to ONNX may be warranted. torch.arange ported its complex type promotion logic to ONNX, for example.
Additionally, this PR mostly leaves existing call sites in PyTorch that would trigger this warning intact. This is to be more minimal (since the PR is BC breaking). I will submit a separate PR fixing PyTorch's call sites.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34709
Differential Revision: D20509387
Pulled By: mruberry
fbshipit-source-id: 129593ba06a1662032bbbf8056975eaa59baf933
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34315
previously we register quantization parameter attributes using debugName of
the observed value, but debugName is not unique, this PR addresses this problem
by making attribute names unique
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20504455
fbshipit-source-id: 6dd83bdfc4e4dc77ad3af3d5b48750fb01b2fce1
Summary:
Initial integration of eager autocasting, supporting out-of-place ops only for easier review.
Relevant issue/RFC: https://github.com/pytorch/pytorch/issues/25081
In-place ops and ops with user-supplied `out=...` can certainly be supported as well (my initial WIP https://github.com/pytorch/pytorch/pull/29552 handled many) but require substantially more complex special casing in the autocasting backend and tests. Support for these ops (much of which has already been written) will be broken into later PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32140
Differential Revision: D20346700
Pulled By: ezyang
fbshipit-source-id: 12d77b3917310186fbddf11c59b2794dc859131f
Summary:
This PR would fix https://github.com/pytorch/pytorch/issues/34736. Both code snippet in that issue can now execute normally. More tests are also added.
This PR is a follow-up on https://github.com/pytorch/pytorch/issues/34519, where one variable was mistakenly missed when updating the max_pool2d kernel.
This PR also uses accumulate type of scalar_t in the backward kernel, which resolves the numerical precision issue when stride < kernel_size on fp16.
cc csarofeen ptrblck jjsjann123 VitalyFedyunin ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34934
Differential Revision: D20512062
Pulled By: VitalyFedyunin
fbshipit-source-id: a461ebbb3e3684aa183ae40e38d8f55bb6f4fee1
Summary:
Throwing from destructor leads to undefined behaviour (most often to segault)
So it's better to leak memory then segault
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34756
Test Plan: Run `test_pytorch_onnx_caffe2`
Differential Revision: D20504228
Pulled By: malfet
fbshipit-source-id: 7a05776fea9036f602e95b8182f8493cb5886dab
Summary:
(Updated per review feedback)
`torch.floor_divide` is currently a function that can operate on two tensors or a tensor and a scalar (scalar x scalar floor division is handled natively by Python and the JIT has a builtin function for it). This PR updates it to:
- have an out variant: `floor_divide(x, y, out=z)`
- be a method on a tensor: `x.floor_divide(y)`
- have an in-place variant: `x.floor_divide_(y)`
- work with sparse tensors
Tests are added to test_sparse.py and test_torch.py for these new behaviors.
In addition, this PR:
- cleans up the existing sparse division and true_division code and improves their error message
- adds testing of sparse true_division to test_sparse.py
- extends existing floor_divide testing in test_torch to run on CUDA, too, not just the CPU
Unfortunately, making floor_divide a method requires breaking backwards compatibility, and floor_divide has been added to the BC whitelist since this is international. The BC issue is that the first parameter name to torch.floor_divide is changing from input to self. If you previously called torch.floor_divide with keyword arguments, e.g. torch.floor_divide(input=x, other=y), you will need to update to torch.floor_divide(self=x, other=y), or the more common torch.floor_divide(x, y).
The intent of this PR is to allow floor_divide to be substituted for division (torch.div, /) wherever division was previously used. In 1.6 we expect torch.div to perform true_division, and floor_divide is how users can continue to perform integer division with tensors.
There are two potential follow-up issues suggested by this PR:
- the test framework might benefit from additional tensor construction classes, like one to create dividends and divisors for multiple dtypes
- the test framework might benefit from a universal function test class. while methods have reasonable coverage as part of test_torch.py's TestTensorOp tests, function coverage is spotty. Universal functions are similar enough it should be possible to generate tests for them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34552
Differential Revision: D20497453
Pulled By: mruberry
fbshipit-source-id: ac326f2007d8894f730d1278fef84d63bcb07b5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34903
Reattempt of D20461609
Moving 2/4-bit SLS and row-wise 2/4-bit conversion operator to open source to be used by DLRM
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20495304
fbshipit-source-id: 66a99677583f50fd40e29c514710c7b1a8cdbc29
Summary:
Follow-ups after this PR:
* Remove `LossClosureOptimizer`, and merge `Optimizer` into `OptimizerBase` (and rename the merged class to Optimizer)
* Merge the LBFGS-specific serialize test function and the generic `test_serialize_optimizer` function, possibly by passing a bool `has_only_global_state` flag into the `test_serialize_optimizer` function to denote whether `size()` should be equal to 1 or 2?
* https://github.com/pytorch/pytorch/pull/34564#discussion_r393780303
* It seems that we don't have the equivalent `XORConvergence_LBFGS` test like the other optimizers, and it would be good to add one
* Remove mentions of `parameters_` in optimizer.cpp, de-virtualize all functions, and remove the `OptimizerBase(std::vector<Tensor> parameters)` constructor from `OptimizerBase`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34564
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20495701
Pulled By: anjali411
fbshipit-source-id: 6d35286d2decb6f7dff93d9d3e57515770666622
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34896
Make TorchScript support calling ref.owner() to get owner worker id and calling ref.owner_name() to get owner worker name.
Differential Revision: D7652208
fbshipit-source-id: a60125bb316ac2cf19a993cbd2affc933c0af7c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34413
In this diff we have made various improvements to ProcessGroupAgent in order to accomodate edge and error cases such as a "non-clean" shutdown (shutdowns in which we abort RPC as quickly as possible, and don't wait for all pending work across all RPC agents to be completed):
1. Catch and log exceptions in `enqueueRecv`. This prevents us from calling `std::terminate()` in a different thread and logs an error message indicating the issue. With this we no longer have crashes caused by exceptions in this thread during non-graceful shutdown.
2. Provide cleaner error messages everywhere (and use `c10::str` where possible). One example is in `agent::send()`.
3. Add the ability to abort pending sends that cause blocking waits in `handleSend`. The reason we need to abort this is since during a non-graceful shutdown, we could become blocked waiting for these since there is no guarantee the remote end is still active and this would result in a long wait and eventual timeout. We abort these by adding them to a map, and go through this map during `shutdown()`.
4. Fix flaky tests: `test_handle_send_exceptions` and `test_backward_node_failure` and `test_backward_node_failure_python_udf`. These tests were flaky since they dealt with non-graceful shutdown of workers which has chances for a bunch of edge cases explained above.
We have also refactored `createExceptionResponse`, `enqueueRecv`, and some test functions for the above reasons in this diff.
For testing:
Ensured that the tests are no longer flaky with 500 tests runs. Previously, these tests were flaky and disabled. Also added a unit test in the internal `ProcessGroupAgentTest.cpp`.
ghstack-source-id: 100311598
Test Plan: Ensured that the tests are no longer flaky with 500 tests runs. Previously, these tests were flaky and disabled. Also added a unit test in the internal `ProcessGroupAgentTest.cpp`.
Reviewed By: mrshenli
Differential Revision: D20269074
fbshipit-source-id: de9cad7f7185f9864ffbb6b14cd8ca9f6ff8f465
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34901
init_pg is needed for dist.barrier call, otherwise default process group may not be found for some rpc backend
ghstack-source-id: 100319642
Test Plan: unit test
Differential Revision: D20495321
fbshipit-source-id: a44241bd2ff6e1404eee9b241270a94e9fd114d0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/34714 (using the discussed solution). Thanks to jjabo for flagging and suggesting this.
Instead of expanding `probs` to prepend `sample_shape`, it is better to use the `num_samples` argument to `torch.multinomial` instead, which is faster and consumes lesser memory.
Existing tests should cover this. I have profiled this on different inputs and the change results in faster `.sample` (e.g. 100X faster on the example in the issue), or at worst is similar to what we have now with the default `sample_shape` argument.
cc. fritzo, alicanb, ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34900
Differential Revision: D20499065
Pulled By: ngimel
fbshipit-source-id: e5be225e3e219bd268f5f635aaa9bf7eca39f09c
Summary:
This makes PyTorch compileable(but not linkable) with `CUDA_SEPARABLE_COMPILATION` option enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34899
Test Plan: CI
Differential Revision: D20501050
Pulled By: malfet
fbshipit-source-id: 02903890a827fcc430a26f397d4d05999cf3a441
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34871
We used to configure root logger in RPC module. A stream handler is added to `root.handlers`. This is not desired behavior for pytorch users. We should instead keep the root logger handler list untouched.
We can configure the logger local to the rpc module, set it's log level, so it doesn't use it's ancestor, which is usually the root which has no stream handlers in most cases.
https://docs.python.org/3/library/logging.html#logging.Logger.setLevel
And add a stream handler to make it output to stdout, even if the root handlers is not configured and has an empty list.
https://docs.python.org/3/library/logging.html#logging.Logger.addHandlerhttps://docs.python.org/3/library/logging.handlers.html#logging.StreamHandler
ghstack-source-id: 100322141
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_wait_all_workers
```
Differential Revision: D7677493
fbshipit-source-id: 88a66079e7348c79a7933e3527701917cbebb7ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34607
Adds quantized version of hardsigmoid activation.
Note: not implementing the _ and .out versions is
currently intended, because the implementation changes the scale and
zp and it's nice to not allow the user to specify scale
and zp. Lmk if we should handle this differently.
Test Plan:
tests
benchmarks
Imported from OSS
Differential Revision: D20480546
fbshipit-source-id: 9febcb44afd920125ed2ca4900492f0b712078ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34843
Currently, we use not_ok_to_boxing to filter Dimname that can not be
converted/constructed to IValue. The correct way should be SNIFAE the
constructor of IValue.
(Note: this ignores all push blocking failures!)
Test Plan:
PyTorch compiled after the code change.
All unit test passed
Imported from OSS
Differential Revision: D20494886
fbshipit-source-id: 91dfba6a41a3ae2d6ceba9d4124cbf612ea3f080
Summary:
Filing this PR since we are in the process of migrating ROCm CI to ROCm version 3.1. This patch is to ensure the correct functionality of float <-> bfloat16 conversion in rocm3.1. `std::isnan` regresses with rocm3.1.
iotamudelta ezyang
cc: ashishfarmer (original author of this patch)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34664
Differential Revision: D20440972
Pulled By: ezyang
fbshipit-source-id: 1ccb911c88f05566d94e01878df6c70cf7f31242
Summary:
Was originally not a requirement but we should add it back here since
it's required on import and we require it anyways for our conda
packages.
Tested with:
```
❯ pkginfo -f requires_dist *.whl
requires_dist: ['numpy']
```
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34510
Differential Revision: D20352125
Pulled By: seemethere
fbshipit-source-id: 383e396fe500ed7043d83c3df57d1772d0fff1e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34665
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20493861
Pulled By: ezyang
fbshipit-source-id: 4215e3037a16be460f20cfc2859be5ee074128d3
Summary:
Thi PR implement channel last upsampling nearest for 2D/3D.
This is supposed to be faster, plus, avoids converting formats going in
and out of operator.
Will post benchmarking numbers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34597
Test Plan: python test/test_nn.py TestNN.test_upsamplingNearest3d_channels_last
Differential Revision: D20390583
Pulled By: kimishpatel
fbshipit-source-id: e0162fb97604a261887f38fc957d3f787c80954e
Summary:
If arguments of `ENDIF()` block are non-empty, they should match corresponding `IF()` BLOCK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34886
Test Plan: CI
Differential Revision: D20494631
Pulled By: malfet
fbshipit-source-id: 5fed86239b4a0cb4b3aedd02c950c1b800199d2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34842
This PR (hopefully the last one of such kind) is merging changes from a
side branch where tensor expessions based fuser work has been done so
far. This PR is is a squashed version of changes in the side branch,
which is available here: https://github.com/bertmaher/pytorch
Differential Revision: D20478208
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 21556e009f1fd88099944732edba72ac40e9b9c0
Summary:
For batch_norm inference contiguous case, we can get a better performance by manually vectorize it.
Test script:
``` X
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
for n in [1, 10, 100]:
for c in [1, 10, 100]:
for hw in [1, 10, 200]:
m = nn.BatchNorm2d(c, affine=False)
m.eval()
input = torch.randn(20, c, hw, hw)
# warm up
for i in range(200):
output = m(input)
fwd_t = 0
for j in range(1000):
t1 = time.time()
output = m(input)
t2 = time.time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 1000 * 1000
print("size = (%d, %d, %d, %d); compute time is %.4f(ms)" % (n, c, hw, hw, fwd_avg))
```
Before:
```
size = (1, 1, 1, 1); compute time is 0.0110(ms)
size = (1, 1, 10, 10); compute time is 0.0123(ms)
size = (1, 1, 200, 200); compute time is 0.8166(ms)
size = (1, 10, 1, 1); compute time is 0.0107(ms)
size = (1, 10, 10, 10); compute time is 0.0257(ms)
size = (1, 10, 200, 200); compute time is 8.7533(ms)
size = (1, 100, 1, 1); compute time is 0.0122(ms)
size = (1, 100, 10, 10); compute time is 0.1619(ms)
size = (1, 100, 200, 200); compute time is 123.5674(ms)
size = (10, 1, 1, 1); compute time is 0.0109(ms)
size = (10, 1, 10, 10); compute time is 0.0123(ms)
size = (10, 1, 200, 200); compute time is 0.5629(ms)
size = (10, 10, 1, 1); compute time is 0.0107(ms)
size = (10, 10, 10, 10); compute time is 0.0253(ms)
size = (10, 10, 200, 200); compute time is 8.7817(ms)
size = (10, 100, 1, 1); compute time is 0.0120(ms)
size = (10, 100, 10, 10); compute time is 0.1655(ms)
size = (10, 100, 200, 200); compute time is 123.2488(ms)
size = (100, 1, 1, 1); compute time is 0.0109(ms)
size = (100, 1, 10, 10); compute time is 0.0123(ms)
size = (100, 1, 200, 200); compute time is 0.5740(ms)
size = (100, 10, 1, 1); compute time is 0.0108(ms)
size = (100, 10, 10, 10); compute time is 0.0257(ms)
size = (100, 10, 200, 200); compute time is 8.7201(ms)
size = (100, 100, 1, 1); compute time is 0.0122(ms)
size = (100, 100, 10, 10); compute time is 0.1628(ms)
size = (100, 100, 200, 200); compute time is 123.1739(ms)
```
After:
```
size = (1, 1, 1, 1); compute time is 0.0105(ms)
size = (1, 1, 10, 10); compute time is 0.0114(ms)
size = (1, 1, 200, 200); compute time is 0.5771(ms)
size = (1, 10, 1, 1); compute time is 0.0105(ms)
size = (1, 10, 10, 10); compute time is 0.0160(ms)
size = (1, 10, 200, 200); compute time is 6.9851(ms)
size = (1, 100, 1, 1); compute time is 0.0122(ms)
size = (1, 100, 10, 10); compute time is 0.0848(ms)
size = (1, 100, 200, 200); compute time is 98.6758(ms)
size = (10, 1, 1, 1); compute time is 0.0105(ms)
size = (10, 1, 10, 10); compute time is 0.0115(ms)
size = (10, 1, 200, 200); compute time is 0.2690(ms)
size = (10, 10, 1, 1); compute time is 0.0105(ms)
size = (10, 10, 10, 10); compute time is 0.0159(ms)
size = (10, 10, 200, 200); compute time is 6.6946(ms)
size = (10, 100, 1, 1); compute time is 0.0123(ms)
size = (10, 100, 10, 10); compute time is 0.0854(ms)
size = (10, 100, 200, 200); compute time is 98.7327(ms)
size = (100, 1, 1, 1); compute time is 0.0107(ms)
size = (100, 1, 10, 10); compute time is 0.0116(ms)
size = (100, 1, 200, 200); compute time is 0.2681(ms)
size = (100, 10, 1, 1); compute time is 0.0104(ms)
size = (100, 10, 10, 10); compute time is 0.0159(ms)
size = (100, 10, 200, 200); compute time is 6.7507(ms)
size = (100, 100, 1, 1); compute time is 0.0124(ms)
size = (100, 100, 10, 10); compute time is 0.0852(ms)
size = (100, 100, 200, 200); compute time is 98.6866(ms)
```
For real modle Resnext101, we can also get **~20%** performance improvement for large batch size,
Test script:
```
import torch
import torchvision
import torch
import time
torch.manual_seed(0)
#torch.set_num_threads(1)
model = torchvision.models.resnext101_32x8d().eval()
for batch_size in [1, 64]:
input = torch.randn(batch_size, 3, 224, 224)
#warm up
with torch.no_grad():
for i in range(5):
output = model(input)
fwd_t = 0
for i in range(10):
t1 = time.time()
output = model(input)
t2 = time.time()
fwd_t = fwd_t + (t2 - t1)
time_fwd_avg = fwd_t / 10 * 1000
print("Throughput of resnext101 with batch_size = %d is %10.2f (imgs/s)" % (batch_size, batch_size * 1000/ time_fwd_avg ))
```
Before:
```
Throughput of resnext101 with batch_size = 1 is 7.89 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 13.02 (imgs/s)
num_threads =1
Throughput of resnext101 with batch_size = 1 is 2.97 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 2.75 (imgs/s)
```
After:
```
Throughput of resnext101 with batch_size = 1 is 8.95 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 15.52 (imgs/s)
num_threads = 1
Throughput of resnext101 with batch_size = 1 is 3.10 (imgs/s)
Throughput of resnext101 with batch_size = 64 is 2.88 (imgs/s)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34530
Differential Revision: D20479560
Pulled By: ngimel
fbshipit-source-id: 2e788ebcd814556116c90553ec61159eeffb3c16
Summary:
AT_CHECK has been deprecated and provides no more features than
TORCH_CHECK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34846
Differential Revision: D20481339
Pulled By: mrshenli
fbshipit-source-id: 1777e769a069a78e03118270294e5e273d516ca7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34663
Been bitten by this so many times. Never more.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20425480
Pulled By: ezyang
fbshipit-source-id: c4489efacc4149c9b57d1b8207cc872970c2501f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34783
Moving 2/4-bit SLS and row-wise 2/4-bit conversion operator to open source to be used by DLRM
Test Plan: CI
Reviewed By: yinghai
Differential Revision: D20461609
fbshipit-source-id: b3ef73ff10f2433afe06ffa73fe1145282d9ec4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34792
it is not thread safe to initiate script module in multiple threads.
for both test_remote_script_module and test_torchscript_functions_not_supported, it is possible that client thread is initiating MyScriptModule while server thread is initiating it as well in the same rank process.
removing MyScriptModule instatiation in client thread, it is not needed actually.
ghstack-source-id: 100266609
Test Plan: unit tests
Differential Revision: D20463234
fbshipit-source-id: 6ff70ad90fa50b0b44c78df2495b4bcaabb4487b
Summary:
To speed up compilation time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34811
Test Plan: CI
Differential Revision: D20476992
Pulled By: malfet
fbshipit-source-id: 922cde93783fbfc04854851d7a05a635d5239792
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34844
QNNPACK max_pool2d operator does not support ceil_mode so this can cause crashes in the kernel when it is set to true.
We default to the server implementation when ceil_mode is set to true
Test Plan:
python test/test_quantized.py
Imported from OSS
Differential Revision: D20478701
fbshipit-source-id: 7962444ac493f5c3c32a9aa1a7be465e8b84ccc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33719
We were seeing a strange error where gathering profiler events (specifically `parse_cpu_trace` in `profiler.py`) would fail with the error:
`IndexError: pop from empty list`.
It turned out that this was because for one particular `Event`, there was a pop recorded but not a push. Instead of the `push` event being completely missing, it was overwritten by a completely different event.
After a bunch of debugging, and trying several hypotheses, it turns out that this was a race condition in `RangeEventList::record`. What happened was that different threads would call into `RangeEventList::record` on the same event list instance, and one record would stomp over the data written by the other one. Somehow the data written was a valid `Event` so the error did not manifest itself until the profiler realized a `pop` was missing a matching `push` in the python code.
I fixed this by adding a lock to serialize writes to `RangeEventList::record`.
This PR also makes a small change to pass in the `RecordFunction` name into `popRange`. It makes the debugging easier when investigating the events recorded.
Differential Revision: D20071125
fbshipit-source-id: 70b51a65bcb833a7c88b7462a978fd3a39265f7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34497
Use a thread_local table to intercept UserRRefs created during user
function args deserialization, and then wait for confirmations of
those UserRRefs before launching the given user function.
Differential Revision: D20347464
Test Plan: Imported from OSS
Pulled By: mrshenli
fbshipit-source-id: 087484a2d2f03fbfb156752ab25653f39b412a07
Summary:
PyTorch expand allows size with -1 dim value. -1 dim value means to infer the dimension from input tensor. This can be exported to ONNX expand with 1 dim value since ONNX expand supports two-way broadcast.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34069
Reviewed By: hl475
Differential Revision: D20195532
Pulled By: houseroad
fbshipit-source-id: c90e7d51b9d7422c09c5ed6e135ca8263105b8c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34545
This is for common operator coverage, since this is widely used. A future PR
will add the quantized version.
Some initial questions for reviewers, since it's my first FP operator
diff:
* do we need a backwards.out method for this?
* do we need CUDA? If yes, should it be this PR or is it ok to split
Test Plan:
```
// test
python test/test_torch.py TestTorchDeviceTypeCPU.test_hardsigmoid_cpu_float32
// benchmark
python -m pt.hardsigmoid_test
...
Forward Execution Time (us) : 40.315
Forward Execution Time (us) : 42.603
```
Imported from OSS
Differential Revision: D20371692
fbshipit-source-id: 95668400da9577fd1002ce3f76b9777c6f96c327
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34625
These templated function calls are not specifying the template args correctly. The first arg is the index type, not the array data type. That means, right now it's using `T` as the index type as well, which will break if we do a template specialization for uint8_t. If we omit both, it will correctly infer that the index type is `int` and the data type is `T`.
Reviewed By: BIT-silence
Differential Revision: D20358728
fbshipit-source-id: 8cbd8eeb14bce602c02eb6fce2cc141f0121fa24
Summary:
This test is flaky on my computer, the error is:
```
AssertionError: tensor(1.3351e-05) not less than or equal to 1e-05
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34764
Differential Revision: D20476006
Pulled By: ezyang
fbshipit-source-id: dad7e702275346070552c8a98765c37e6ca2c197
Summary:
Replacing <ATen/core/Tensor.h> with <<ATen/core/TensorBody.h> speeds up compilation of caffe2 operators by 15%
For example, it reduces pool_op.cu compilation from 18.8s to 16s
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34810
Test Plan: CI
Differential Revision: D20472230
Pulled By: malfet
fbshipit-source-id: e1b261cc24ff577f09e2d5f6428be2063c6d4a8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34230
This PR adds some benchmarks that we used to assess tensor expressions performance.
Differential Revision: D20251830
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: bafd66ce32f63077e3733112d854f5c750d5b1af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34228
This PR adds LLVM codegen to tensor expressions. LLVM is added as an
optional build dependency specified with `USE_LLVM=<path_to_llvm>`
variable. If this variable is not set or LLVM is not found in the
specified path, the LLVM codegen is completely disabled.
Differential Revision: D20251832
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 77e203ab4421eb03afc64f8da17e0daab277ecc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34227
This PR adds a CUDA support to tensor expressions.
Differential Revision: D20251836
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: ab36a55834cceff30c8371fef6cca1054a32f017
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34226
LLVM and Cuda backends are added in subsequent PRs, so at this point the fuser is pretty useless, but it still can be tested and its logic is not going to change with addition of the codegens.
Differential Revision: D20251838
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 82b0d221fa89904ed526689d02a6c7676a8ce8de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34224
Our development has been happening on a side branch `pytorch_fusion` in
`bertmaher/pytorch` fork. This PR moves changes to the core classes
representing expressions and transformations on them.
At this moment, the tensor expressions are only used in tests.
Subsequent PRs add LLVM and CUDA codegen for tensor expressions and
implement fuser on top of these.
This PR is huge as it is a squashed version of changes in the side
branch. It is not practical to pull changes one by one from the branch,
so here is the squashed version. If you're interested in seeing the
history of changes, please refer to https://github.com/bertmaher/pytorch
Differential Revision: D20251835
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 1a871acc09cf3c6f7fb4af40d408cdbb82dc7dab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33981
Okay it turns out that https://github.com/pytorch/pytorch/pull/29342
deletes actually useful things from the resulting Python module. In
particular, people like having `ignore`'d methods attached so that they
can invoke them from python.
Test Plan: Imported from OSS
Differential Revision: D20171650
Pulled By: suo
fbshipit-source-id: 71862e932c6a56cd055d0cff6657887ee0ceb9a8
Summary:
This PR refactors RNN / GRU / LSTM layers in C++ API to exactly match the implementation in Python API.
**BC-breaking changes:**
- Instead of returning `RNNOutput`, RNN / GRU forward method now returns `std::tuple<Tensor, Tensor>`, and LSTM forward method now returns `std::tuple<Tensor, std::tuple<Tensor, Tensor>>`, matching Python API.
- RNN / LSTM / GRU forward method now accepts the same inputs (input tensor and optionally hidden state), matching Python API.
- RNN / LSTM / GRU layers now have `forward_with_packed_input` method which accepts `PackedSequence` as input and optionally hidden state, matching the `forward(PackedSequence, ...)` variant in Python API.
- RNN / LSTM / GRU layers no longer have these fields: `w_ih` / `w_hh` / `b_ih` / `b_hh`. Instead, to access the weights and biases of the gates, users should do e.g. `rnn->named_parameters()["weight_ih_l0"]`, which mirrors the Python API `rnn.weight_ih_l0`.
- In `RNNOptions`
- `tanh()` / `relu()` / `activation` are removed. Instead, `nonlinearity` is added which takes either `torch::kTanh` or `torch::kReLU`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `LSTMOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `GRUOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
The majority of the changes in this PR focused on refactoring the implementations in `torch/csrc/api/src/nn/modules/rnn.cpp` to match the Python API. RNN tests are then changed to reflected the revised API design.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34322
Differential Revision: D20458302
Pulled By: yf225
fbshipit-source-id: ffff2ae1ddb1c742c966956f6ad4d7fba03dc54d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34280
To have prim ops searchable for lite interpreter, overloaded names need to be added for the operators with the same name but different schema. For example, aten::add in register_prim_ops.cpp. The difference is a combination of args and output type.
`"aten::add(str a, str b) ->str"`
`"aten::add(int a, int b) ->int"`
`"aten::add(float a, float b) ->float"`
`"aten::add(int a, float b) ->float"`
`"aten::add(float a, int b) ->float"`
`"aten::add(Scalar a, Scalar b) ->Scalar"`
Solution:
Use the argument type and/or output type (the same to the existing overloaded names). The overloaded name should be minimum as long as the operators can be differentiated. For other operators please look into the source code change for details.
`"aten::add.str(str a, str b) ->str"`
`"aten::add.int(int a, int b) ->int"`
`"aten::add.float(float a, float b) ->float"`
`"aten::add.int_float(int a, float b) ->float"`
`"aten::add.float_int(float a, int b) ->float"`
`"aten::add.Scalar_Scalar(Scalar a, Scalar b) ->Scalar"`
Test Plan: Imported from OSS
Differential Revision: D20456997
Pulled By: iseeyuan
fbshipit-source-id: 2c3dc324b4a4e045559f62c6cc2a10fbb9a72dcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33604
For our current RPC agents, this PR disallows sending CUDA tensors
over RPC and asks users to copy them explicitly to CPU. Currently, this seems
to be the easiest contract to guarantee for our current RPC agents, otherwise
if we do support this transparently it gets a little tricky in terms of whether
a CUDA tensor on the client should be sent to CPU/GPU of the remote end and
also which GPU device on the remote end.
In the future, the TensorPipe RPC agent can have its own specific handling of
CUDA tensors.
Closes https://github.com/pytorch/pytorch/issues/28881
ghstack-source-id: 100166120
Test Plan: waitforbuildbot
Differential Revision: D20020183
fbshipit-source-id: ca4d43d2a24e8fcd3a60b21e654aa0e953e756cb
Summary:
So that in the future we can make policy accept an offset calculator in its constructor for the support of non-contiguous tensors.
The `elementwise_kernel_helper` is now very general and it can handle any cases:
```C++
template<typename func_t, typename policy_t>
__device__ inline void elementwise_kernel_helper(func_t f, policy_t policy) {
using traits = function_traits<func_t>;
using return_t = typename traits::result_type;
using args_t = typename traits::ArgsTuple;
int idx = blockIdx.x;
return_t results[thread_work_size];
cuda9::workaround::enable_default_constructor<args_t> args_[thread_work_size];
args_t *args = reinterpret_cast<args_t *>(&args_);
// load
policy.load(args, idx);
// compute
#pragma unroll
for (int i = 0; i < thread_work_size; i++) {
if (policy.check_inbounds(i)) {
results[i] = c10::guts::apply(f, args[i]);
}
}
// store
policy.store(results, idx);
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33720
Differential Revision: D20459652
Pulled By: ngimel
fbshipit-source-id: aa8b122e0e8c6e08ab354785e04753ff778882e2
Summary:
https://github.com/pytorch/pytorch/issues/34563 accidentally introduced a lint error due to an unused import. This PR removes this import.
Jit tests run as expected after this change:
```
> python test/test_jit.py
.....
Ran 2435 tests in 100.077s
OK (skipped=140, expected failures=1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34778
Differential Revision: D20459708
Pulled By: tugrulince
fbshipit-source-id: bb742085fafc849ff3d9507d1557556e01fbeb4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34762
So far it's by luck that we somehow include "caffe2/core/tensor.h" before including "caffe2/caffe2/quantization/server/fbgemm_pack_blob.h". This is not safe and this diff fixes it.
Test Plan: unittest
Reviewed By: jianyuh
Differential Revision: D20455352
fbshipit-source-id: 777dae32a23d0ec75fd7e5e1627426b5a5f81f5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34547
This enables threading by passing a threadpool to xnnpack ops.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20370553
fbshipit-source-id: 4db08e73f8c69b9e722b0e11a00621c4e229a31a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34319
Removes prepacking ops and install them as attributes of the top level
module. Needs to run freezing as the first pass.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20290726
fbshipit-source-id: 633ceaa867ff7d5c8e69bd814c0362018394cb3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34048
Rewrites the graph to insert xnnpack prepack and packed run ops for
conv2d and linear.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20185658
fbshipit-source-id: c4c073c912ad33e822e7beb4ed86c9f895129d55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34047
This PR integrates the added xnnpack conv2d and linear op via
custom class registration for packed weights. The packed struct
is serializable.
Test Plan:
python test test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20185657
fbshipit-source-id: fc7e692d8f913e493b293b02d92f4e78536d7698
Summary:
This PR refactors RNN / GRU / LSTM layers in C++ API to exactly match the implementation in Python API.
**BC-breaking changes:**
- Instead of returning `RNNOutput`, RNN / GRU forward method now returns `std::tuple<Tensor, Tensor>`, and LSTM forward method now returns `std::tuple<Tensor, std::tuple<Tensor, Tensor>>`, matching Python API.
- RNN / LSTM / GRU forward method now accepts the same inputs (input tensor and optionally hidden state), matching Python API.
- RNN / LSTM / GRU now has `forward_with_packed_input` method which accepts `PackedSequence` as input and optionally hidden state, matching the `forward(PackedSequence, ...)` variant in Python API.
- In `RNNOptions`
- `tanh()` / `relu()` / `activation` are removed. Instead, `nonlinearity` is added which takes either `torch::kTanh` or `torch::kReLU`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `LSTMOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
- In `GRUOptions`
- `layers` -> `num_layers`
- `with_bias` -> `bias`
The majority of the changes in this PR focused on refactoring the implementations in `torch/csrc/api/src/nn/modules/rnn.cpp` to match the Python API. RNN tests are then changed to reflected the revised API design.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34322
Differential Revision: D20311699
Pulled By: yf225
fbshipit-source-id: e2b60fc7bac64367a8434647d74c08568a7b28f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34629
Add support for sigmoid in the conversion flow through onnx
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_quantized_sigmoid
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_small_model
Imported from OSS
Differential Revision: D20433680
fbshipit-source-id: 95943e14637d294122e4d102c5c19c06d27064c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33945
Add mapping for this operator in symbolics
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_max_pool2d
Imported from OSS
Differential Revision: D20433681
fbshipit-source-id: 88f02ade698262a6f8824671830bc1f7d40bbfa6
Summary:
This PR adds `RNNCell` / `LSTMCell` / `GRUCell` layers to the C++ frontend, with implementations exactly matching the Python API equivalent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34400
Differential Revision: D20316859
Pulled By: yf225
fbshipit-source-id: bb7cee092622334043c0d0fd0fcb4e75e707699c
Summary:
as title, for bringing up the quantized video model. Will add the batch_norm_relu test in another PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34702
Differential Revision: D20436092
Pulled By: lly-zero-one
fbshipit-source-id: 116bd306f7880bfd763d8575654fbd6c92818338
Summary:
Since we've added CUDA 10.2, it is time to retire CUDA 10.0
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34726
Differential Revision: D20453081
Pulled By: seemethere
fbshipit-source-id: fd5bb35325a5f1577d0f0404d16cd7dfe34c86ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34671
Like the python arg parser, this tries to convert to the schema in order.
It introduces schema_match_exception which gets thrown when the schema doesn't match,
allowing the overload handler to try the next option.
Behavior will not 100% match the schema argument parser but should work for
simple cases using custom binding.
Test Plan: Imported from OSS
Differential Revision: D20432206
Pulled By: zdevito
fbshipit-source-id: 280839a2205ea3497db3a9b5741fccc1e2bff9a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34677
1. Remove remaining uses of `script::` namespace from the codebase,
2. Add one more typedef for `script::ExtraFilesMap` which is part of the
public interface.
Pull Request resolved: #34580
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D20431739
Pulled By: suo
fbshipit-source-id: a29d369c755b6506c53447ca1f286b6339222c9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34190
inplace modification of ClassType might affect other tests, so we want to do non-inplace modifications.
Actually the inplace argument will be removed soon.
Test Plan:
ci
Imported from OSS
Differential Revision: D20451765
fbshipit-source-id: e87ad528c4e7f84f5774b94a8e3e85568269682d
Summary:
Per https://github.com/pytorch/pytorch/issues/19161 PyTorch is incompatible with 3.6.0 due to the missing `PySlice_Unpack`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34724
Test Plan: CI + try to load pytorch binary using python-3.6.0
Differential Revision: D20449052
Pulled By: malfet
fbshipit-source-id: 2c787fc64f5d1377c7f935ad2f3c77f46723d7dd
Summary:
This PR is related to [https://github.com/pytorch/pytorch/issues/33953](https://github.com/pytorch/pytorch/issues/33953).
I've created a directory `type_hint_tests` for the example as suggested by zou3519 [here](https://github.com/pytorch/pytorch/issues/33953#issuecomment-597716405). This directory is supposed to contain examples over which mypy will run. I've added the test in `test/test_type_hints.py`.
The test can simply be invoked by
```
$ python3 test/test_type_hints.py
Fail to import hypothesis in common_utils, tests are not derandomized
.b'test/type_hint_tests/size.py:7: error: Tuple index out of range\ntest/type_hint_tests/size.py:8: error: Tuple index out of range\n'
.
----------------------------------------------------------------------
Ran 2 tests in 13.660s
OK
```
Note that I've not made the change of fixing the stub to show that the test works. The issue can be fixed by changing definition of Size in `class Size(Tuple[_int, ...]): ... ` in `/torch/__init__.pyi.in`.
After changing the `Size` definition, the test passes.
```
$ python3 test/test_type_hints.py
Fail to import hypothesis in common_utils, tests are not derandomized
.b''
.
----------------------------------------------------------------------
Ran 2 tests in 19.382s
OK
```
I will do that once i get approval from zou3519. This is an initial implementation, please provide your suggestions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34595
Differential Revision: D20441817
Pulled By: zou3519
fbshipit-source-id: 00a434adf5bca813960f4efea38aa6d6953fe85f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34706
as title
Test Plan: test in stacked diff
Reviewed By: csummersea
Differential Revision: D20436618
fbshipit-source-id: e51ef0a22708425cd296c05f4089fe8c98eda90a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34511
With https://github.com/pytorch/pytorch/pull/34122/files, issues
with using record_function context manager and profiling RPCs were fixed. This
adds a test case to verify that we can use RPC with the `record_function`
decorator.
ghstack-source-id: 100109932
Test Plan: Unit test change
Differential Revision: D20352242
fbshipit-source-id: d6429e4352ad3b8d874dc0f27b23ecb6202e6b2b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34723
Add min function to cuda math compat
Test Plan: unittest
Reviewed By: houseroad
Differential Revision: D20444517
fbshipit-source-id: 1a93343cc57249ef1101eeb7ef373266f6a2873a
Summary:
This commit adds a reference hash for the linux64 clang-format binary and in
doing so, enables this script to be used on Linux machines.
Test Plan:
Ran the script.
```
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ export http_proxy=fwdproxy:8080
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ export https_proxy=fwdproxy:8080
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ python3 ./tools/clang_format_new.py --diff
Downloading clang-format to /data/users/meghanl/fbsource/fbcode/caffe2/.clang-format-bin
0% |################################################################| 100%
Using clang-format located at /data/users/meghanl/fbsource/fbcode/caffe2/.clang-format-bin/clang-format
meghanl@devvm1517:caffe2 (ff25240c|remote/master)$ echo $?
1
```
A non-zero return code indicates that `clang-format` will make changes.
Reviewed By: suo
Differential Revision: D20434291
fbshipit-source-id: fa13766e9d94720d4b0d8a540d2f1507e788f7a5
Summary:
- Clarify that `torch.distributed.autograd.backwards()` does not use the current thread local autograd context, instead it looks it up based on the context_id passed in
- Clarify the same for `torch.distributeed.optimizer.optim.step()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34670
Differential Revision: D20427645
Pulled By: rohan-varma
fbshipit-source-id: a1a88de346cdd4dbe65fb2b7627157f86fd2b6a3
Summary:
With this PR, we can now support left and right shift operators in the JIT engine for <int, int> and <Tensor, int>.
Updated tests pass as expected:
```
> python test/test_jit.py
...
Ran 2427 tests in 84.861s
OK (skipped=139, expected failures=1)
```
Running the following code with Python results in the output below:
```
> cat ~/expressions.py
import torch
torch.jit.script
def fn(a, b):
# type: (int, int)
return (
a << b, # supported
b >> a, # supported
a & b,
a | b,
a ^ b
)
print(fn.graph)
```
```
> python ~/expressions.py
graph(%a.1 : int,
%b.1 : int):
%4 : int = aten::leftshift(%a.1, %b.1) # /home/ince/expressions.py:7:8
%7 : int = aten::rightshift(%b.1, %a.1) # /home/ince/expressions.py:8:8
%10 : int = aten::__and__(%a.1, %b.1) # /home/ince/expressions.py:9:8
%13 : int = aten::__or__(%a.1, %b.1) # /home/ince/expressions.py:10:8
%16 : int = aten::__xor__(%a.1, %b.1) # /home/ince/expressions.py:11:8
%17 : (int, int, int, int, int) = prim::TupleConstruct(%4, %7, %10, %13, %16)
return (%17)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34563
Differential Revision: D20434209
Pulled By: tugrulince
fbshipit-source-id: 886386c59755106e17b84778b8e495b80a6269cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34623
The bandaid of "AT_WARN" keeps introducing new warnings. Let's get rid
of it entirely.
Close#34502
Test Plan: Imported from OSS
Differential Revision: D20420112
Pulled By: albanD
fbshipit-source-id: 7160c113cb4deb2d2f50a375356f423fe5e86f50
Summary:
How this actually works:
1. Get's a list of URLs from anaconda for pkgs to download, most
likely from pytorch-test
2. Download all of those packages locally in a temp directory
3. Upload all of those packages, with a dry run upload by default
This, along with https://github.com/pytorch/pytorch/issues/34500 basically completes the scripting work for the eventual promotion pipeline.
Currently testing with:
```
TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 PYTORCH_CONDA_FROM=pytorch scripts/release/promote/conda_to_conda.sh
```
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34659
Differential Revision: D20432687
Pulled By: seemethere
fbshipit-source-id: c2a99f6cbc6a7448e83e666cde11d6875aeb878e
Summary:
…ithout lapack
LAPACK is needed for `at::svd``, which is called from `pinverse()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34686
Test Plan: CI + local run
Differential Revision: D20442637
Pulled By: malfet
fbshipit-source-id: b3531ecc1197b0745ddcf50febb7fb4a7700d612
Summary:
This PR would fix https://github.com/pytorch/pytorch/issues/33988 and fix https://github.com/pytorch/pytorch/issues/34083.
Previously, the max_pool2d_nhwc kernels used a shared memory with size proportional to the tensor size (c \* h \* w). When the tensor size is too large, the kernel launch fails.
This PR follows the guidance in AdaptiveAvgPool2d_nhwc by increasing the number of grid_x with split in "C" dimension. With that change, there will be a maximum limit in the shared memory size (which is less than 48 kb) regardless of tensor size.
A benchmark can be found at [here](0b98146089/max-pool2d/max-pool2d.ipynb). TL;DR barely any performance drop is found.
cc csarofeen ptrblck jjsjann123 VitalyFedyunin
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34519
Differential Revision: D20388848
Pulled By: VitalyFedyunin
fbshipit-source-id: 9454f385f9315afaab4a05303305578bbcd80b87
Summary:
- `torch::nn::functional` functions must provide example for how to use the corresponding functional options
- `torch::nn::functional` functions must link to the corresponding functional options
- remove `TORCH_NN_FUNCTIONAL_USE_MODULE_OPTIONS` macro, and put `torch::nn::functional` options docs inside the functional namespace, right above functional declaration
- `torch::nn::functional` options docs should not link back to torch::nn layers. Instead, they should have links to `torch::nn::functional::xxx`
----
This PR is BC-breaking in the following way:
`TORCH_NN_FUNCTIONAL_USE_MODULE_OPTIONS` macro is removed, and user should explicitly write
```cpp
namespace functional {
using SomeFuncOptions = SomeModuleOptions;
} // namespace functional
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34688
Differential Revision: D20431251
Pulled By: yf225
fbshipit-source-id: 7d4f27dca3aad2a1e523690927d7afb261b9d308
Summary: Last diff enabled operator stats for non-production build including AIBench. But the operator latency is off: https://our.intern.facebook.com/intern/aibench/details/414567479798816 as it is representing operator execution end time, and as the threadLocalDebugInfo was not set, the start time is 0. So this diff is fixing it by creating a new ThreadLocalDebugInfo object when op starts to run and store the model information for logging.
Test Plan:
```buck run mode/mac aibench:run_bench_macos -- -b aibench/specifications/models/pytorch/pytext/pytext_mobile_inference.json --platform android --framework pytorch --remote --devices SM-G960F-8.0.0-26```
https://our.intern.facebook.com/intern/aibench/details/922804117425407
```buck run mode/mac aibench:run_bench_macos -- -b aibench/specifications/models/pytorch/fbnet/fbnet_mobile_inference.json --platform android --framework pytorch --remote --devices SM-G960F-8.0.0-26```
https://our.intern.facebook.com/intern/aibench/details/593403202250750
Reviewed By: xta0
Differential Revision: D20436388
fbshipit-source-id: 740bc94c3f51daef6af9b45c1ed7a708f5fc8836
Summary:
- Update API calls `backward` and `optim.step` now that we require `context_id`
- Add notes to clarify purpose of distributed autograd context (this was a source of confusion in some feedback)
- Add note that details why optimizer requires context_id
- Clearly specify that we don't have SMART mode yet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34657
Differential Revision: D20427667
Pulled By: rohan-varma
fbshipit-source-id: 5f8a3539ccf648a78e9e9a0dfdfe389c678b1606
Summary:
Now that lists are no longer specialized, we can register only one operator for list ops that are generic to their element type.
This PR reorgs lists into three sets of ops:
- CREATE_GENERIC_LIST_OPS
- CREATE_SPECIALIZED_LIST_OPS
- CREATE_COMPARATOR_LIST_OPS_SPECIALIZED (we didn't bind certain specialized ops to Tensor)
This is important to land quickly because mobile is finalizing its bytecode soon, after which we could not remove these ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34520
Reviewed By: iseeyuan
Differential Revision: D20429775
Pulled By: eellison
fbshipit-source-id: ae6519f9b0f731eaa2bf4ac20736317d0a66b8a0
Summary:
**Summary**
This commit adds `tools/clang_format_new.py`, which downloads a platform-appropriate
clang-format binary to a `.gitignored` location, verifies the binary by comparing its
SHA1 hash to a reference hash (also included in this commit), and runs it on all files
matched a specific regex in a list of whitelisted subdirectories of pytorch.
This script will eventually replace `tools/clang_format.py`.
**Testing**
Ran the script.
*No Args*
```
pytorch > ./tools/clang_format.py
Downloading clang-format to /Users/<user>/Desktop/pytorch/.clang-format-bin
0% |################################################################| 100%
Using clang-format located at /Users/<user>/Desktop/pytorch/.clang-format-bin/clang-format
> echo $?
0
> git status
<bunch of files>
```
`--diff` *mode*
```
> ./tools/clang_format.py --diff
Using clang-format located at /Users/<user>/Desktop/pytorch/.clang-format-bin/clang-format
Some files are not formatted correctly
> echo $?
1
<format files using the script>
> ./tools/clang_format.py --diff
Using clang-format located at /Users/<user>/Desktop/pytorch/.clang-format-bin/clang-format
All files are formatted correctly
> echo $?
0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34566
Differential Revision: D20431290
Pulled By: SplitInfinity
fbshipit-source-id: 3966f769cfb923e58ead9376d85e97127415bdc6
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33927
Test Plan:
test will be added in later PRs
Imported from OSS
Differential Revision: D20354879
fbshipit-source-id: 03976f4b86c46dbdc4e45764a1e72f1a3855a404
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34652
Split from D20006007 because it needs to synced to open source and also for easy testing & landing.
Test Plan:
```
buck test caffe2/caffe2/fb/tvm:test_tvm_transform
```
CI
Reviewed By: yinghai
Differential Revision: D20414037
fbshipit-source-id: 6e17dd9f8cffe87bc59c6e3cc6fd1f8d8def926b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34635
For custom op, it's removed in EliminateDeadCode IR optimization step, causing wrong training result.
EliminateDeadCode decides to remove it, because it has no output, so output is used. Also, it has no side effect, and has no untracked mutation, which is not true, custom op can have untracked mutation.
The if statement here only allows aten and prim operator to have untracked mutation, which should be removed.
ghstack-source-id: 100001319
Test Plan:
```
buck test mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_jit
buck build mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_jit \
&& buck-out/gen/caffe2/torch/fb/distributed/pytorch/tests/test_jit\#binary.par -r test_use_dense_adagrad_step
```
Reviewed By: wanchaol
Differential Revision: D7440221
fbshipit-source-id: e424417ab397d90075884c7050c59dfc5c84cf77
Summary:
Changelog:
- The magma implementation of small singular square batch matrices had a bug that resulted in nan values in the LU factorization result. This has been fixed in MAGMA 2.5.2. This PR removes the existing patch that was a temporary workaround for this bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34357
Test Plan: - Existing tests for det and lu should pass
Differential Revision: D20422879
Pulled By: seemethere
fbshipit-source-id: 8dd7a30b5c31fc5b844e0a11965efd46067e936a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34626
We need to check has_storage() before looking at it in
cloneSparseTensors(), to avoid gratuitously throwing.
Ideally, we'd add a test for this (I wrote one up but had to disable it),
but won't work until JIT Pickler supports sparse tensors.
ghstack-source-id: 100018077
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcAgent/...
Differential Revision: D20399971
fbshipit-source-id: 5debfa8140eb1f949d37336330223962cc320abc
Summary:
This PR enables bfloat16 type for
- Embedding, Index, Sigmoid Ops used in [DLRM](https://github.com/facebookresearch/dlrm)
- Miscellaneous ops like comparison ops, arange op used in unit tests
- Rename types list with the pattern `*_with_bfloat16` in `test_torch.py` to avoid confusion
iotamudelta ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34630
Differential Revision: D20405093
Pulled By: ezyang
fbshipit-source-id: aa9538acf81b3a5a9a46ce5014529707fdf25687
Summary:
Now that lists are no longer specialized, we can register only one operator for list ops that are generic to their element type.
This PR reorgs lists into three sets of ops:
- CREATE_GENERIC_LIST_OPS
- CREATE_SPECIALIZED_LIST_OPS
- CREATE_COMPARATOR_LIST_OPS_SPECIALIZED (we didn't bind certain specialized ops to Tensor)
This is important to land quickly because mobile is finalizing its bytecode soon, after which we could not remove these ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34520
Differential Revision: D20368543
Pulled By: eellison
fbshipit-source-id: ad0c6d70d2a6be6ff0e948d6786052167fc43e27
Summary:
This is a redo of https://github.com/pytorch/pytorch/pull/33791, which was reverted because it introduced a flaky test. The test was flaky and only flaky on Python3.5 because of dict order randomization.
I've fixed the issue with tests clobbering each other in b539fec and removed the override tests for `torch.nn.functional.tanh` and `torch.nn.functional.sigmoid`, which are deprecated and shouldn't be overridable in e0d7402. I also verified that no more test clobbering is happening.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34240
Differential Revision: D20252442
Pulled By: cpuhrsch
fbshipit-source-id: 069568e342a41c90e1dc76cbf85ba4aed47f24be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31893
In order to resolve the issue summarized in https://github.com/pytorch/pytorch/issues/31325.
The overal solution is to proactively send out delete fork messages from user nodes, before user nodes detecting rref leaks.
As the first step, we want to have a weak ref tracker to track all user rrefs.
ghstack-source-id: 100023142
Test Plan:
V22 is the version that make User to wait on delete UseerRRef message.
# Unit tests
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_nested_rref_stress --stress-runs 100
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_nested_rref_stress
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par - r test_rref_forward_chain
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_non_garbage_collected_user_rref_due_to_local_circular_dependency
```
Reviewed By: mrshenli
Differential Revision: D19292254
fbshipit-source-id: 92c3e8d0b00f183c5e22f163bdca482cc25a1ce9
Summary:
This PR is BC-breaking in the following way:
- The deprecated `torch::nn::BatchNorm` is removed in favor of `torch::nn::BatchNorm{1,2,3}d`
- The deprecated `torch::nn::FeatureDropout` is removed in favor of `torch::nn::Dropout{2,3}d`
- The deprecated `torch::nn::modules_ordered_dict` is removed. User should do `Sequential sequential({{"m1", MyModule(1)}, {"m2", MyModule(2)}})` instead.
- The deprecated `torch::nn::init::Nonlinearity` is removed, in favor of the following enums:
- `torch::kLinear`
- `torch::kConv1D`
- `torch::kConv2D`
- `torch::kConv3D`
- `torch::kConvTranspose1D`
- `torch::kConvTranspose2D`
- `torch::kConvTranspose3D`
- `torch::kSigmoid`
- `torch::kTanh`
- `torch::kReLU`
- `torch::kLeakyReLU`
- The deprecated `torch::nn::init::FanMode` is removed, in favor of the following enums:
- `torch::kFanIn`
- `torch::kFanOut`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34508
Differential Revision: D20351601
Pulled By: yf225
fbshipit-source-id: cca0cd112f29a31bb023e348ca8f82780e42bea3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34267
Adds quantized ELU.
Test Plan:
```
python test/test_quantized.py TestQuantizedOps.test_qelu
```
still need to benchmark, saving that for after the review comments
Imported from OSS
Differential Revision: D20370953
fbshipit-source-id: fe941bf966f72dd9eee2c4b2ef45fe7afb50c866
Summary:
`torch.nn.functional.interpolate` was written as a builtin op when we scripted the standard library, because it has four possible overloads. As a result, whenever we make a change to `interpolate`, we need to make changes in two places, and it also makes it impossible to optimize the interpolate op. The builtin is tech debt.
I talked with ailzhang, and the symbolic script changes are good to remove (i guess that makes a third place we needed to re-implement interpolate).
I'm trying to get rid of unneccessary builtin operators because we're standardizing mobile bytecode soon, so we should try to get this landed as soon as possible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34514
Differential Revision: D20391089
Pulled By: eellison
fbshipit-source-id: abc84cdecfac67332bcba6b308fca4db44303121
Summary:
Make sure that there could not be more than one instance of either `torch::autograd::Engine` or `torch::autograd::python::PythonEngine`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34567
Test Plan: CI
Differential Revision: D20390622
Pulled By: malfet
fbshipit-source-id: c90595032afc88f552dee52901361b58b282dc1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34515
Once upon a time we thought this was necessary. In reality it is not, so
removing it.
For backcompat, our public interface (defined in `api/`) still has
typedefs to the old `script::` names.
There was only one collision: `Pass` as a `Stmt` and `Pass` as a graph
transform. I renamed one of them.
Test Plan: Imported from OSS
Differential Revision: D20353503
Pulled By: suo
fbshipit-source-id: 48bb911ce75120a8c9e0c6fb65262ef775dfba93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34588
I constructed the patch by deleting OperatorOptions and then rerouting
all queries for AliasAnalysisKind to FunctionSchema. Some of the
behavior is kind of bogus: we really shouldn't be mutating FunctionSchema
after the fact, but that won't get fixed until we actually switch to
true schema merging.
Reland of https://github.com/pytorch/pytorch/pull/34160
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20387079
Pulled By: ezyang
fbshipit-source-id: d189f7a6ad8cd186b88b6fbfa3f189994eea14e8
Summary:
TensorIterator is already checking partial overlap, so there is no trivial UB, but TensorITerator allows full overlap, and it is not a bad idea to skip the memcpy in such case.
fixes: https://github.com/pytorch/pytorch/issues/34525
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34548
Differential Revision: D20371643
Pulled By: ngimel
fbshipit-source-id: ff9e2e872537010afe040204e008b2499af963ad
Summary:
This PR updates C++ API torch::nn layer docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34522
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20380832
Pulled By: yf225
fbshipit-source-id: ee99a838ec05c6ce2a23aa97555707e507d09958
Summary:
**Summary**
This commit modifies the JIT implementation of `Tensor.tolist` so that it
can be called on GPU-resident Tensors as well. If the Tensors is not on the
CPU when the operator is invoked, it is copied to the CPU before doing any
of the rest of the work to convert it into a list.
**Testing**
This commit adds GPU versions of some of the existing CPU tests for this
feature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34554
Differential Revision: D20392604
Pulled By: SplitInfinity
fbshipit-source-id: 69c17b98d866428c19d683588046169538aaf1e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34598
as above
Test Plan:
test.txt
```
what time is it now
could you set a reminder at 7 am
waht is the weather today
```
example json
```
{
"model": {
"category": "CNN",
"description": "Assistant Mobile Inference",
"files": {
"model": {
"filename": "model.pt1",
"location": "//everstore/GICWmAB2Znbi_mAAAB0P51IPW8UrbllgAAAP/model.pt1",
"md5": "c0f4b29c442bbaeb0007fb0ce513ccb3"
},
"data": {
"filename": "input.txt",
"location": "/home/pengxia/test/input.txt",
"md5": "c0f4b29c442bbaeb0007fb0ce513ccb3"
}
},
"format": "pytorch",
"framework": "pytorch",
"kind": "deployment",
"name": "Assistant Mobile Inference"
},
"tests": [
{
"command": "{program} --model {files.model} --input_dims \"1\" --input_type NLUType --warmup {warmup} --iter 5 --input_file {files.data} --report_pep true",
"identifier": "{ID}",
"metric": "delay",
"iter": 15,
"warmup": 2,
"log_output": true
}
]
}
```
iter = 5 (--iter 5 ) *3(3 lintes in the test.txt) = 15
arbabu123 I will provide a wrapper to compute the iter in future.
run following command
```
buck run aibench:run_bench -- -b aibench/specifications/models/pytorch/fbnet/assistant_mobile_inference.json --platform android/full_jit --framework pytorch --remote --devices SM-G960U-8.0.0-26
```
results
https://our.intern.facebook.com/intern/aibench/details/275259559594003
**Note: this is compatible with the existing examples.**
Reviewed By: kimishpatel, ljk53
Differential Revision: D20389285
fbshipit-source-id: 80165ef394439a307ac7986cf540a80fdf3d85d6
Summary:
If SELECTED_OP_LIST is specified as a relative path in command line, CMake build will fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33942
Differential Revision: D20392797
Pulled By: ljk53
fbshipit-source-id: dffeebc48050970e286cf263bdde8b26d8fe4bce
Summary:
When a system has ROCm dev tools installed, `scripts/build_mobile.sh` tried to use it.
This PR fixes looking up unused ROCm library when building libtorch mobile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34478
Differential Revision: D20388147
Pulled By: ljk53
fbshipit-source-id: b512c38fa2d3cda9ac20fe47bcd67ad87c848857
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34150
In the distributed setting we commonly have tests in which there are errors where one process
exits but the other do not (since they are for example waiting for work from
the process that exited). Currently, when this situation happens we do not
handle this well, and wait for process 0 to timeout. This results in wasted
time waiting for test errors and a less helpful "Process 0 timed out..." error
message when the error was actually something else.
This diff fixes the issue by checking for exited subprocesses and terminating
the test when we see a subprocess that has exited uncleanly. We still enforce
timeouts and return when all processes have exited cleantly in the happy path.
ghstack-source-id: 99921462
Test Plan:
All distributed tests + tested by writing tests that should trigger
the unclean subprocess detection, and verified that we exit quickly instead of
waiting for the entire timeout.
Differential Revision: D20231032
fbshipit-source-id: 3e0d4a20925b7d1098ec4c40ffcc66845425dd62
Summary:
This PR implements the following linear algebra algorithms for low-rank matrices:
- [x] Approximate `A` as `Q Q^H A` - using Algorithm 4.4 from [Halko et al, 2009](http://arxiv.org/abs/0909.4061).
+ exposed as `torch.lowrank.get_approximate_basis(A, q, niter=2, M=None) -> Q`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] SVD - using Algorithm 5.1 from [Halko et al, 2009](http://arxiv.org/abs/0909.4061).
+ uses `torch.lowrank.get_approximate_basis`
+ exposed as `torch.svd_lowrank(A, q=6, niter=2, M=None) -> (U, S, V)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] PCA - using `torch.svd_lowrank`
+ uses `torch.svd_lowrank`
+ exposed as `torch.pca_lowrank(A, center=True, q=None, niter=2) -> (U, S, V)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices, uses non-centered sparse matrix algorithm
+ [x] documentation
- [x] generalized eigenvalue solver using the original LOBPCG algorithm [Knyazev, 2001](https://epubs.siam.org/doi/abs/10.1137/S1064827500366124)
+ exposed as `torch.lobpcg(A, B=None, k=1, method="basic", ...)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] generalized eigenvalue solver using robust LOBPCG with orthogonal basis selection [Stathopoulos, 2002](https://epubs.siam.org/doi/10.1137/S1064827500370883)
+ exposed as `torch.lobpcg(A, B=None, k=1, method="ortho", ...)`
+ [x] dense matrices
+ [x] batches of dense matrices
+ [x] sparse matrices
+ [x] documentation
- [x] generalized eigenvalue solver using the robust and efficient LOBPCG Algorithm 8 from [Duersch et al, 2018](https://epubs.siam.org/doi/abs/10.1137/17M1129830) that switches to orthogonal basis selection automatically
+ the "ortho" method improves iterations so rapidly that in the current test cases it does not make sense to use the basic iterations at all. If users will have matrices for which basic iterations could improve convergence then the `tracker` argument allows breaking the iteration process at user choice so that the user can switch to the orthogonal basis selection if needed. In conclusion, there is no need to implement Algorithm 8 at this point.
- [x] benchmarks
+ [x] `torch.svd` vs `torch.svd_lowrank`, see notebook [Low-rank SVD](https://github.com/Quansight/pearu-sandbox/blob/master/pytorch/Low-rank%20SVD.ipynb). In conclusion, the low-rank SVD is going to be useful only for large sparse matrices where the full-rank SVD will fail due to memory limitations.
+ [x] `torch.lobpcg` vs `scipy.sparse.linalg.lobpcg`, see notebook [LOBPCG - pytorch vs scipy](https://github.com/Quansight/pearu-sandbox/blob/master/pytorch/LOBPCG%20-%20pytorch%20vs%20scipy.ipynb). In conculsion, both implementations give the same results (up to numerical errors from different methods), scipy lobpcg implementation is generally faster.
+ [x] On very small tolerance cases, `torch.lobpcg` is more robust than `scipy.sparse.linalg.lobpcg` (see `test_lobpcg_scipy` results)
Resolves https://github.com/pytorch/pytorch/issues/8049.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29488
Differential Revision: D20193196
Pulled By: vincentqb
fbshipit-source-id: 78a4879912424595e6ea95a95e483a37487a907e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34160
I constructed the patch by deleting OperatorOptions and then rerouting
all queries for AliasAnalysisKind to FunctionSchema. Some of the
behavior is kind of bogus: we really shouldn't be mutating FunctionSchema
after the fact, but that won't get fixed until we actually switch to
true schema merging.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20282846
Pulled By: ezyang
fbshipit-source-id: ba7bca6e8adc3365789639b88e54c4e881b1692e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33838
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20227875
Pulled By: ezyang
fbshipit-source-id: 319855b1f0fa436f9ed5256d2106b07f20e6b833
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34556
According to
https://github.com/pytorch/pytorch/pull/34012#discussion_r388581548,
this `at::globalContext().setQEngine(at::QEngine::QNNPACK);` call isn't
really necessary for mobile.
In Context.cpp it selects the last available QEngine if the engine isn't
set explicitly. For OSS mobile prebuild it should only include QNNPACK
engine so the default behavior should already be desired behavior.
It makes difference only when USE_FBGEMM is set - but it should be off
for both OSS mobile build and internal mobile build.
Test Plan: Imported from OSS
Differential Revision: D20374522
Pulled By: ljk53
fbshipit-source-id: d4e437a03c6d4f939edccb5c84f02609633a0698
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34559
We check the use_count for indices and values when we avoid a clone
for sparse tensors. The sparse tensor grad itself might have a higher refcount
due to DDP hooks/dist autograd structures holding refs, but the indices and
values inside the sparse tensor should always have a refcount of 1.
ghstack-source-id: 99900534
Test Plan: waitforbuildbot
Differential Revision: D20375239
fbshipit-source-id: 6a654549d13071ab3451cef94259caf7627b575c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34505
A thread could hold GIL when calling PythonRpcHandler::getInstance(),
meantime another thread could have been doing static data
initialization by calling `new PythonRpcHandler()`, inside of which GIL is
also required. Static data initialization is thread-safe, so the thread
holding the GIL will wait for the other thread to finish static data
initializating before going forward. Because the initialization can't
proceed without GIL, there is a deadlock. We ask the calling thread to
release GIL to avoid this situation.
ghstack-source-id: 99893858
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_spawn -- 'test_backward_simple_script_call \(test_dist_autograd_spawn\.DistAutogradTestWithSpawn\)' --stress-runs 100
```
Differential Revision: D7490489
fbshipit-source-id: 76f63cc7bedf088d3dbff288f53aa0bd33749255
Summary:
Stacked PRs
* #33474 - [jit] Remove list specializations from pickler
* **#33255 - [jit] Add type tags to lists/dicts in pickle**
This adds a global call to `torch.jit._pickle.restore_type_tags` for
lists and dicts so that we can preserve their types after serialization.
](https://our.intern.facebook.com/intern/diff/20346780/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33255
Pulled By: driazati
Differential Revision: D20346780
fbshipit-source-id: c8534954ef4adb2e3c880401acbee30cd284f3db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34560
These jobs don't have next phase so we don't really need commit the
docker images.
Should also fix issue #34557.
Test Plan: Imported from OSS
Differential Revision: D20375308
Pulled By: ljk53
fbshipit-source-id: 328cb428fcfb0fbb79b2a233b5f52607158c983c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34376
Vectorized implementation of qmul. qmul is now ~16x faster on my development machine. This implementation works for qint8, quint8 and qint32. Also added some commonly used operations, such as multiply operator, requantize operation etc., to qint vector classes for future use.
```
#!/usr/bin/env python
import time
import torch
import torch.nn as nn
torch.set_num_threads(1)
# print(torch.__config__.parallel_info())
A = torch.rand(1, 54, 54, 256)
B = torch.rand(1, 54, 54, 256)
scale = .05
zero_point = 50
for dtype in [torch.quint8, torch.qint8]:
qA = torch.quantize_per_tensor(A, scale=scale, zero_point=zero_point,
dtype=dtype)
qB = torch.quantize_per_tensor(B, scale=scale, zero_point=zero_point,
dtype=dtype)
NITER = 1000
s = time.time()
for i in range(NITER):
out = torch.ops.quantized.mul(qA, qB, scale=scale, zero_point=zero_point)
time_per_iter = (time.time() - s) / NITER
print('dtype: {} time per iter ms: {:.3f}'.format(dtype, time_per_iter * 1000))
```
### Before
dtype: torch.quint8 time per iter ms: 6.714
dtype: torch.qint8 time per iter ms: 6.780
### After
dtype: torch.quint8 time per iter ms: 0.431
dtype: torch.qint8 time per iter ms: 0.417
### Test
Modified qmul tests to include qint8 and qint32 data types.
python test/test_quantized.py TestQuantizedOps.test_qmul_relu_same_qparams
python test/test_quantized.py TestQuantizedOps.test_qmul_relu_different_qparams
python test/test_quantized.py TestQuantizedOps.test_qmul_broadcast
ghstack-source-id: 99862681
Differential Revision: D20308515
fbshipit-source-id: 4fa65b2ba433cfd59260fc183a70f53a6fcc36b4
Summary:
**Summary**
There is often a need to create a Tensor when writing IR by hand for JIT
optimisation pass unit tests. The only options for this today are real
Tensor creation functions like `aten::ones`. Any test that uses these functions
must also use the same default arguments as the Python/C++ API, which means
that all of the tests have to be updated when the API is updated. This commit
introduces a new primitive, `prim::MakeTestTensor` with schema `() -> Tensor` that
should be used in unit tests instead of real Tensor creation functions. This new
primitive has no public-facing API, so the maintenance burden is much lower.
**Testing**
This commit updates the alias analysis and DCE tests to use `prim::MakeTestTensor` instead of
`aten::rand`, `aten::ones`, and `aten::zeros`.
```
$ ./bin/test_jit
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = *-*_CUDA:*_MultiCUDA
[==========] Running 75 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 75 tests from JitTest
[ RUN ] JitTest.ADFormulas
[ OK ] JitTest.ADFormulas (82 ms)
[ RUN ] JitTest.Attributes
[ OK ] JitTest.Attributes (0 ms)
...
...
...
[ RUN ] JitTest.LiteInterpreterPrim
[ OK ] JitTest.LiteInterpreterPrim (0 ms)
[ RUN ] JitTest.LiteInterpreterLoadOrigJit
[ OK ] JitTest.LiteInterpreterLoadOrigJit (2 ms)
[----------] 75 tests from JitTest (150 ms total)
[----------] Global test environment tear-down
[==========] 75 tests from 1 test case ran. (150 ms total)
[ PASSED ] 75 tests.
```
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33500.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34334
Differential Revision: D20296437
Pulled By: SplitInfinity
fbshipit-source-id: df4e7b0881ae4913424e5a409bfa171a61c3e568
Summary:
Attempt to build pytorch with ASAN on system with gcc-8 fails due to the mismatch system compilation flags.
Address the issue by using original compiler to build `torch._C` extension
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34549
Test Plan: Run `.jenkins/pytorch/build-asan.sh` on FC-30
Differential Revision: D20373781
Pulled By: malfet
fbshipit-source-id: 041c8d25f96b4436385a5e0eb6fc46e9b5fdf3f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26125
We already had some optimization implementation using AVX2 for improve the quantized kernel performance. In this diff, we want to enable the runtime dispatch.
Test Plan:
Sandcastle build and test
Also test with a python binary calling into vectorized op.
torch.__config__.show()
PyTorch built with:
- GCC 4.2
- clang 8.0.20181009
- Intel(R) Math Kernel Library Version 2017.0.3 Product Build 20170413 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v0.18.1 (Git Hash N/A)
- OpenMP 1
- **CPU capability usage: AVX2**
- Build settings:
Reviewed By: jamesr66a
Differential Revision: D17337251
fbshipit-source-id: 8e22d10011a12a4eaf54cea3485353eb1811d828
Summary:
**This PR is BC-breaking in the following way:**
In RMSpropOptions:
1. learning_rate is renamed to lr.
**Test plan before 1.5 release:**
Test that in 1.5 we can load a C++ RMSprop optimizer that was serialized in 1.4, and their states are the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33450
Differential Revision: D20366623
Pulled By: anjali411
fbshipit-source-id: 83250be9b583a766927e0e22a4de8b0765379451
Summary: I'm using this code in an internal Android build, and std::to_string doesn't work in our internal Android builds yet.
Test Plan: Internal build.
Reviewed By: ljk53
Differential Revision: D20234221
fbshipit-source-id: 8fd61235bf9b487e07a1459c452830e732c7afb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33427
This PR is an attempt to avoid clone for sparse tensors similar to how
we avoid clone for dense tensors currently.
As per my understanding even if the 'indices' and 'values' of a sparse tensor
are non-continguous, operations like 'add' are still supported. As a result,
the major change in this PR is to use create a shallow copy instead of clone()
for sparse tensors.
ghstack-source-id: 99838375
Test Plan: waitforbuildbot
Differential Revision: D19926698
fbshipit-source-id: b5a3f36c2aa273e17f8b7a9f09c1ea00e7478109
Summary:
We updated the default jobs to run in a different PR but neglected to
update this script as well.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34498
Differential Revision: D20368420
Pulled By: seemethere
fbshipit-source-id: 240171b18f397095e3a8d57de3a29d1d2e891d85
Summary:
In DataParallel, replica parameters are not leaves (because they are computed via broadcast from master parameters), and should be treated as such. Fixes https://github.com/pytorch/pytorch/issues/33552
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33907
Differential Revision: D20150199
Pulled By: ngimel
fbshipit-source-id: 5965d4115b6b3a8433063126ff6269567872fbeb
Summary:
The include list seems to be copied from somewhere else, and some totally unrelated files are included.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34528
Differential Revision: D20358622
Pulled By: ngimel
fbshipit-source-id: d8a6260f5f77b0eabdbd68e3728873efd632d9bc
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31342
Test Plan: unit test
Differential Revision: D19131704
fbshipit-source-id: 4e91d5933635ee2c7c301caf89a5a7009c5cb7c8
Summary:
Tries to fix https://github.com/pytorch/pytorch/issues/33562 by raising `std::runtime_error` instead of `std::domain_error`.
* The Python tests already expect `RuntimeError` so this shouldn't affect Python users of PyTorch.
* If someone out there is using C10 or ATen from C++ and tries to catch `std::domain_error` specifically, this fix would break their code. Hopefully that's not the case.
Alternative to this PR is someone try to really get to the bottom of why `std::domain_error` isn't being caught.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34301
Differential Revision: D20344579
Pulled By: ezyang
fbshipit-source-id: d5f3045085a2f75b71b864335ebf44991d0cad80
Summary:
cuDNN needs it, MIOpen doesn't. However, since it seems to be the PyTorch preference to not introduce ROCm-specific logic in the python layer, we need to add a C++ function to detect if rnn weight flattening is needed.
This PR will be needed to fix the rnn unit test errors arising for PR https://github.com/pytorch/pytorch/issues/33837.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34265
Differential Revision: D20345105
Pulled By: ezyang
fbshipit-source-id: a2588a6e2ac6f7d1edf2b7872bc6a879a7df96ec
Summary:
This PR enables bfloat16 type for loss criterion ops(and the ops they depend on) and few miscellaneous ops required to train resnet50.
iotamudelta ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34469
Differential Revision: D20348856
Pulled By: ezyang
fbshipit-source-id: 0a8f06c2169cfa3c9cf319120e27150170095f6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33896Fixes#32625. Previously, we'd receive an error message if we have a
custom function return a view of an input in a no_grad block:
```
class Alias(Function):
staticmethod
def forward(ctx, x):
return x[:]
staticmethod
def backward(ctx, gx):
return gx
inp = torch.rand(2, requires_grad=True)
with torch.no_grad():
# Used to error out
output = Alias.apply(inp)
```
After this change, the error no longer happens. The behavior changes to
become consistent to if we had implemented an operator that does the
same thing as the custom function:
- the output requires_grad
- we are able to detect (and error out) if the user tries to modify the
output in-place outside of the no_grad block.
Test Plan: - new test
Differential Revision: D20345601
Pulled By: zou3519
fbshipit-source-id: 7f95b4254f52ddbf989d26f449660403bcde1c78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33875Fixes#33675.
I added a `current_node_name` argument to AnomalyMetadata::print_stack.
This is a mandatory arg because I found only one callsite and making it
a default arg on a virtual function can be confusing.
Test Plan:
- Tested locally:
https://gist.github.com/zou3519/09937387c83efc76e1700374d5c9c9d9
- I don't know how to add a test for this: the message is printed to
stderr but it isn't an exception nor a warning. I considered capturing
the stderr of a subprocess but that seems like asking for flakiness.
Differential Revision: D20349399
Pulled By: zou3519
fbshipit-source-id: 7585ddffe2bf9e1081f4028a9c44de783978a052
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33214
Distributed autograd had some custom logic in terms of how we
accumulated gradients. This was mostly done early on to enable basic
functionality. Although, in the long term we should merge this logic with what
we have in the local autograd engine. A lot of work has gone into ensuring we
accumulate grads correctly and efficiently and we should reuse that as a
starting point.
We can investigate if we need further custom logic for distributed autograd
later on if we need additional optimizations.
In this PR I've merged the gradient accumulation logic and also the gradient
hooks. As a result, now gradient hooks are called in distributed autograd as
well.
ghstack-source-id: 99838019
Test Plan: waitforbuildbot
Differential Revision: D19843284
fbshipit-source-id: 7923d7e871fb6afd3e98dba7de96606264dcb5f3
Summary:
This PR resolves https://github.com/pytorch/pytorch/issues/22534 by adding a converter for the `torch.nn.functional.one_hot` function, and covering it with a test.
Are there other places this should be tested?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34454
Reviewed By: hl475
Differential Revision: D20354255
Pulled By: houseroad
fbshipit-source-id: 84224c1610b2cc7986c91441c65647ddc090750d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33807
afaik this is unused, so removing it from the source tree. RIP :(
Test Plan: Imported from OSS
Differential Revision: D20122118
Pulled By: suo
fbshipit-source-id: cb45943f5b9f969482301a2f9fe540326dbc78f2
Summary:
See NumPy's division documentation here: https://numpy.org/doc/1.18/reference/generated/numpy.divide.html#numpy.divide.
True division is the same as PyTorch's default division except when both inputs are integer or bool tensors. In the latter case the inputs are (conceptually) cast to the default floating type before the division is performed.
The function is implemented for dense and sparse tensors and supports exporting to ONNX from PyTorch's eager mode or JIT traces. The function is inherently incompatible with exporting to ONNX via JIT script, and is another datapoint suggesting we should deprecate exporting scripted graphs to ONNX.
Tests are added for the type promotion, named tensor, and ONNX export behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34236
Reviewed By: houseroad
Differential Revision: D20334087
Pulled By: mruberry
fbshipit-source-id: 83d00d886f46f713215d7d9e02ffd043164c57f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34321
Mostly cosmetic as we can infer the shape anyway. It can remove a lot of the noise in the log though.
Note that weight sharing doesn't work yet. I'll add another diff to address this.
Reviewed By: houseroad
Differential Revision: D20290841
fbshipit-source-id: fe6f9b60d05dbe150af15b5d9d7a69fd902e12cc
Summary:
This allows us to enable some double-based pdist tests running into accrued error from casting down to float previously.
Addresses https://github.com/pytorch/pytorch/issues/33128
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34103
Differential Revision: D20343279
Pulled By: ezyang
fbshipit-source-id: a2da768259fab34ef326976283b7a15bebbbb979
Summary:
I think this was added when we couldn't compile the function itself. now we can.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34171
Differential Revision: D20269960
Pulled By: eellison
fbshipit-source-id: 0a60458d639995d9448789c249d405343881b304
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33853
Quant fusion relies on inline, but inline will break the CallFunction("linaer", ...) into a if block
it will be hard to recognize this block and swap it with quantized::linear, in order to
preserve the op, we will swap all quantized functional linear into aten::linear.
They might produce different backward graph, but this is called in the step before we get quantized
model, so it shouldn't affect anything.
We'll integrate this with convert_script later in the new "finalize_quant" API
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20343873
fbshipit-source-id: 423e03bf893b79267d2dc97bc997ee1bfe54ec0f
Summary:
Custom classes via torchbind requires runtime type information.
We are trying to enable custom class based graph rewrite for XNNPACK in
this stacked PRs: https://github.com/pytorch/pytorch/pull/34047.
They require RTTI enabled for mobile. Mobile builds are failing
currently without it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34368
Differential Revision: D20306155
Pulled By: kimishpatel
fbshipit-source-id: 52c61ff5467a619e8f51708a05258eee35dd0a56
Summary:
Previously when emitting subscripts we only emitted actual values, but
now they may sometimes emit a `ModuleValue`, so it should stay as a
`SugaredValue`. This allows for the result of the subscript to be
treated as a real module (i.e. you can just do `self.modlist[1](inputs)`
instead of `self.modlist[1].forward(inputs)`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34320
Pulled By: driazati
Differential Revision: D20345642
fbshipit-source-id: 2bedf9a454af747b704422f6bbb8370cbdf4bf61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34398
As part of PR 34109, it was suggested that we track the number of outstanding
async calls for RPC DebugInfo, particularly if we move towards using
at::launch() threads on occasion for continuations.
This particular aspect of the change was distinct from the main purpose of the
diff, and started getting bigger, so split this functionality out as a separate diff.
For completeness, we track client_active_calls, server_active_calls,
server_active_async_calls, and write some very basic unittest coverage.
ghstack-source-id: 99708836
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcBackend/...
Differential Revision: D20314994
fbshipit-source-id: 2f7c75d5c511b27ed0c09c7b8a67b6fb49df31a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34410
### Summary
Currently, the iOS jobs are not being run on PRs anymore. This is because all iOS jobs have specified the `org-member` as a context which used to include all pytorch members. But seems like recently this rule has changed. It turns out that only users from the admin group or builder group can have access right to the context values. https://circleci.com/gh/organizations/pytorch/settings#contexts/2b885fc9-ef3a-4b86-8f5a-2e6e22bd0cfe
This PR will remove `org-member` from the iOS simulator build which doesn't require code signing. For the arm64 builds, they'll only be run on master, not on PRs anymore.
### Test plan
- The iOS simulator job should be able to appear in the PR workflow
Test Plan: Imported from OSS
Differential Revision: D20347270
Pulled By: xta0
fbshipit-source-id: 23f37d40160c237dc280e0e82f879c1d601f72ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33481
We have to propagate observed property of values through ops like max_pool2d, flatten and
avoid inserting duplicated observers.
For example:
```
x1 = self.conv(x)
x2 = maxpool(x1)
x3 = self.conv(x2)
```
If x1 is observed, we should propagate this information through maxpool and
we should consider x2 as observed as well.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20261897
fbshipit-source-id: 7de354a3ccb2b6e1708f5c743d4d9f7272691a93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34354
The condition `NOT INTERN_BUILD_MOBILE AND NOT BUILD_CAFFE2_MOBILE` was
added in #27086, but seems it's always false on current master:
BUILD_CAFFE2_MOBILE is ON by default - the name is a little bit misleading -
it is ON even when it's building non-mobile PyTorch/Caffe2. It is OFF only
when it's building PyTorch mobile, where INTERN_BUILD_MOBILE is ON.
And when it's building PyTorch mobile, it won't build caffe2/operators
at all (by setting BUILD_CAFFE2_OPS OFF: https://github.com/pytorch/pytorch/blob/master/CMakeLists.txt#L345)
So I imagine the real intention is to skip when it's building Caffe2 mobile.
We can simply remove the deprecating BUILD_CAFFE2_MOBILE condition.
Test Plan: Imported from OSS
Differential Revision: D20345298
Pulled By: ljk53
fbshipit-source-id: d2cb4e2248fc209d63b2843e0f12e577e323def4
Summary:
`ConcreteModuleTypeBuilder` used to keep parameters together with all others attributes in an `unordered_map` often leading to reordering them while building up the type. Parameter order is semantically meaningful, so we need to preserve it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34131
Differential Revision: D20331542
Pulled By: suo
fbshipit-source-id: 5b860025f7902654d6099751d3fb14b12f6f5a67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34382
The previous implementation was handling both newWithStorage and newWithSize, which doesn't make much sense.
Test Plan: Imported from OSS
Differential Revision: D20311056
Pulled By: gchanan
fbshipit-source-id: 2696a4566e6203c98338c86cbf4c236bd18d7c49
Summary:
One example in the current docs for `torch::nn::ModuleList` doesn't compile, and this PR fixes it.
Fixes https://github.com/pytorch/pytorch/issues/32414.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34463
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20331120
Pulled By: yf225
fbshipit-source-id: 50bb078fe1a900c9114d5434e92dc40ee13b52bf
Summary:
Fixes https://github.com/pytorch/pytorch/issues/25845.
**Test Plan:**
Check `pytorch_cpp_doc_push` CI job, and see if there is `classat_1_1_tensor` generated (similar to `structat_1_1native_1_1_convolution_descriptor`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34467
Differential Revision: D20338190
Pulled By: yf225
fbshipit-source-id: 52dc05af5e0d742e740de5576d0d2b3e17ef28dd
Summary:
Addresses https://github.com/pytorch/pytorch/issues/5442.
Per title (and see issue). A test is added to test_torch.py to verify the behavior.
Update (with new behavior):
NumPy arrays can be non-writeable (read-only). When converting a NumPy array to a Torch tensor the storage is shared, but the tensor is always writable (PyTorch doesn't have a read-only tensor). Thus, when a non-writeable NumPy array is converted to a PyTorch tensor it can be written to.
In the past, PyTorch would silently copy non-writeable NumPy arrays and then convert those copies into tensors. This behavior violates the from_numpy contract, however, which promises that the tensor and the array share memory.
This PR adds a warning message when a non-writeable NumPy array is converted into a Torch tensor. This will not break any networks, but will make end users aware of the behavior. They can work-around the warning message by marking their NumPy arrays as writeable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33615
Differential Revision: D20289894
Pulled By: mruberry
fbshipit-source-id: b76df0077399eb91038b12a6bf1917ef38c2cafd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34162
This avoids the "worker{}".format(..) in our unit tests to something
cleaner.
ghstack-source-id: 99713074
Test Plan: waitforbuildbot
Differential Revision: D20233533
fbshipit-source-id: 5cff952ca68af5a6d26dc5cc01463cf7756d83d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33921
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.intern.facebook.com/intern/diff/D20153092/)!
Test Plan: Imported from OSS
Differential Revision: D20177227
Pulled By: jamesr66a
fbshipit-source-id: 87f3e484c4f873d60f76f50f6789c1b4a73bdfde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33900
These functions don't require any libtorch-specific functionality, so move them into the header so they're included in the ATen build
Test Plan: Imported from OSS
Differential Revision: D20175874
Pulled By: jamesr66a
fbshipit-source-id: 1efab1b60e196a635e6c6afadb042b63771170f0
Summary:
This commit fixes overlapping keywords in the CPP Docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34142
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20319949
Pulled By: yf225
fbshipit-source-id: e7bb2efdc286c85792c6f18a260c3bba33c54008
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34393
Clean up the list
Test Plan: CI
Reviewed By: hl475
Differential Revision: D20300530
fbshipit-source-id: 50e7da0a9f8295eff33590982f32f84abee96d9c
Summary:
This PR fixed documentation for `torch.add` with alpha. It also fixed these deprecated python calls `torch.add` and `torch.addmm` in tests, which may affect performance in *test/test_sparse.py* and *test/test_nn.py*.
cc csarofeen ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33935
Differential Revision: D20313320
Pulled By: ngimel
fbshipit-source-id: fb08413d7e244865952e3fc0e1be7f1794ce4e9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33717
Because of the special treatment of operator names for lite interpreter, all the operators used in lite interpreter are still prepended by "_". Add the necessary registrations for MNIST model. All the ops with autograd capability are included in torch_mobile_train. After rebase the selective build from D19649074 can be utilized to strip the unused ops.
Note that this diff is for feasibility test. The training accuracy are not covered in the test.
ghstack-source-id: 97780066
Test Plan:
```
buck run xplat/caffe2/fb/lite_trainer:lite_trainer -c pt.disable_gen_tracing=1 -c pt.static_dispatch=0 -- --model=/path/MnistModel.bc
```
{F227898221}
Reviewed By: dreiss
Differential Revision: D19743201
fbshipit-source-id: cacadd76f3729faa0018d147a69466bbf54312fd
Summary:
Please merge after https://github.com/pytorch/pytorch/pull/33073
With that PR, we are now trying different algorithms when OOM, so hopefully there will be some algo working at low memory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34259
Differential Revision: D20310094
Pulled By: ngimel
fbshipit-source-id: bccd8162bd06a0e54ac6f42a7fd9a5b766f92cd7
Summary:
Improves explanation of non-determinism when running on GPUs. Adds info about `torch.nn.BCELoss` operating non-deterministically on GPUs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33795
Differential Revision: D20284880
Pulled By: ngimel
fbshipit-source-id: d543959636d261a80c234150304344b19a37ba5d
Summary:
We don't release binaries for macOS with CUDA support so we should just
remove it from our regular PR pipeline
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34333
Differential Revision: D20312565
Pulled By: seemethere
fbshipit-source-id: 376228680aa0e814d1b37f1ff63b7d1262515e44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34378
This fixes strange symbol mangling mismatch beteen `DECLARE_DISPATCH(qbatch_norm_fn, qbatch_norm_stub)` and `REGISTER_DISPATCH(qbatch_norm_stub, &q_batch_norm_kernel<false>);` if code is build on Windows with clang
Test Plan: CI + build PyTorch on Windows using clang
Reviewed By: EscapeZero
Differential Revision: D20309550
fbshipit-source-id: e97c7c3b6fee2e41ea6b2f8167ce197aec404e3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34099
This change effectively applies into IValue's future impl a few fixes
we discovered when using the torch::utils::Future<T> impl.
The parallel impls should probably eventually be merged, but until then:
- Don't hold the lock when invoking the callbacks. This makes
it effectively impossible (deadlocks) to call value() to get
the value from inside the callback.
- We discovered that it was slightly cleaner in practice to
notify condition variables prior to invoking callbacks
(best to unblock paused threads ASAP, before spawning new work).
- Fix some var naming inconsistency.
- Add a some caffe2 cpp test coverage.
ghstack-source-id: 99336569
Test Plan:
```
buck test mode/dev //caffe2/test/cpp/jit:jit -- 'JitTest\.IValueFuture'
```
Differential Revision: D20203278
fbshipit-source-id: 6e805ba547899dab9aab458e4b23049db31f930e
Summary:
Currently testing against the older release `1.4.0` with:
```
PYTORCH_S3_FROM=nightly TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 scripts/release/promote/libtorch_to_s3.sh
PYTORCH_S3_FROM=nightly TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 scripts/release/promote/wheel_to_s3.sh
```
These scripts can also be used for `torchvision` as well which may make the release process better there as well.
Later on this should be made into a re-usable module that can be downloaded from anywhere and used amongst all pytorch repositories.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34274
Test Plan: sandcastle_will_deliver
Differential Revision: D20294419
Pulled By: seemethere
fbshipit-source-id: c8c31b5c42af5096f09275166ac43d45a459d25c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34159
This fixes `comparison of integers of different sign` warnings
Test Plan: CI
Reviewed By: EscapeZero
Differential Revision: D20232085
fbshipit-source-id: 8f325be54395be54c704335cb7edf2ec7ef75e75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34318
Stop checking whether we have AMD GPU devices on the host, because we may be constructing a net on a machine without GPU, and run the net on another one with GPU
Reviewed By: ajauhri
Differential Revision: D20269562
fbshipit-source-id: 1f561086cacdcead3ce7c03c2d02c25336c8b11a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34017
Remove warning
```
caffe2/aten/src/THC/generic/THCTensorMathBlas.cu(437): warning: statement is unreachable
caffe2/aten/src/THC/generic/THCTensorMathBlas.cu(271): warning: variable "transpose_m1" was set but never used
caffe2/aten/src/THC/generic/THCTensorMathBlas.cu(271): warning: variable "transpose_m2" was set but never used
```
Test Plan: CI
Reviewed By: ngimel
Differential Revision: D20181179
fbshipit-source-id: 3665912ba55bffbd8b4555f8a6803e57a502c103
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34018
Remove warning
```
caffe2/c10/util/ArrayRef.h(278): warning: attribute does not apply to any entity
```
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D20181191
fbshipit-source-id: 58bd168a87a94fec925c7cde8b8d728a4257446c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34183https://github.com/pytorch/pytorch/pull/33263 enhanced the RRef Python constructor to infer most types, by `jit::tryToInferType(..)`.
But this helper function can't infer `ScriptModule` type due to `ScriptModule`'s special per-Module type singleton logic, so it's still not possible for an Python-created RRef to know the JIT type of it's contained `ScriptModule`.
Instead of inferring the specific type of a Module, which could leads to too many candidate types (due to Module's multiple inheritance possibility), it's more straightforward to set it's type as a user-specified `ModuleInterface` type.
We added an optional argument `type_hint` for users to mark an `RRef` for what `ModuleInterface` type it's holds.
ghstack-source-id: 99649379
(Note: this ignores all push blocking failures!)
Test Plan:
Aspects that need to be confirmed in the test cases
https://fb.quip.com/aGxRAh2lCg05
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_create_local_script_class_rref
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_create_local_script_module_rref
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_return_local_script_class_rref_in_py_and_use_in_script
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_return_local_script_module_rref_in_py_and_use_in_script
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_torchscript_function_exception
```
Differential Revision: D7065050
fbshipit-source-id: e10210c0996622969e499e4a35b0659b36787c1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34217
LegacyNoScalar variants cause 0-dim tensors to behave like 1-dim tensors.
LegacyAll variants cause 0-dim tensors to behave like 1-dim tensors, and numel == 0 tensors to be treated like 0-dimensional tensors.
This this was done by codemod, these are often unneeded and often translated incorrectly to ATen.
Test Plan: Imported from OSS
Differential Revision: D20249577
Pulled By: gchanan
fbshipit-source-id: 6f2876d3e479562c9323f3629357a73a47869150
Summary:
The init-list form of `at::indexing::Slice` (i.e. `tensor.index({{1, None, 2}, ...})` instead of `tensor.index({Slice(1, None, 2), ...})`) in C++ API can be easily confused with the list-form indexing in Python API (e.g. `tensor[[1, 3, 2], ...]`), which is not good from readability perspective. This PR removes the init-list form of `at::indexing::Slice` to make the API less confusing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34255
Test Plan: Imported from GitHub, without a `Test Plan:` line.
Differential Revision: D20290166
Pulled By: yf225
fbshipit-source-id: abbcbeca0b179219e5e1f196a33ef8aec87ebb76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34203
Currently cmake and mobile build scripts still build libcaffe2 by
default. To build pytorch mobile users have to set environment variable
BUILD_PYTORCH_MOBILE=1 or set cmake option BUILD_CAFFE2_MOBILE=OFF.
PyTorch mobile has been released for a while. It's about time to change
CMake and build scripts to build libtorch by default.
Changed caffe2 CI job to build libcaffe2 by setting BUILD_CAFFE2_MOBILE=1
environment variable. Only found android CI for libcaffe2 - do we ever
have iOS CI for libcaffe2?
Test Plan: Imported from OSS
Differential Revision: D20267274
Pulled By: ljk53
fbshipit-source-id: 9d997032a599c874d62fbcfc4f5d4fbf8323a12e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34122
Earlier work added support for async rpc cases when RecordFunction's
end callbacks might be called in a different thread; in addition some
extra care was needed to handle pointer to parent function;
This PR makes RecordFunction aware of potentially multiple threads in
use, as well as removes unused parent() call and restricts current()
RecordFunction to scope-based record functions (RECORD_FUNCTION macro)
Test Plan: unit tests
Differential Revision: D20297709
Pulled By: ilia-cher
fbshipit-source-id: 46a59e1b2eea0bbd8a59630385e193b38d30f9d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33978
We can directly pass user_callbale to rpc_async API in TorchScript. There is no need to have private API for taking qualified name.
ghstack-source-id: 99600360
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_torchscript_functions_not_supported
```
Differential Revision: D7420993
fbshipit-source-id: 228c15b21848e67418fab780e3fd6a1c6da5142d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34278
This diff helps check all the ops not supported by lite_interpreter.
Helpful mainly to find all the ops that need to be added instead of adding them
one by one.
Test Plan:
buck run caffe2/binaries:lite_interpreter_model_load --
--model=<bytecode-model-path>
Reviewed By: iseeyuan
Differential Revision: D20266341
fbshipit-source-id: 5a6c7a5bc52f910cea82a72045870da8105ccb87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34118
Previously calc_per_channel_qparams was using for loops and python primitives, which called `item` many times causing slowdown during training.
These changes uses torch primitives on the tensor to speed up the operation over 60x
Perf results on MobileNetV2 during training using autograd profiler
FP32 forward call -
Self CPU time total: 47.222ms
CUDA time total: 124.001ms
before change
FakeQuant Model -
Self CPU time total: 19.107s
CUDA time total: 27.177s
after change
FakeQuant Model -
Self CPU time total: 404.667ms
CUDA time total: 446.344ms
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D20287841
fbshipit-source-id: 6b706b8206e0d0da3c3c217b014e8da5b71b870d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34232
By default `torch.zeros` creates the tensor on GPU. Need to specify the device argument to get it to work correctly on GPU during QAT.
Test Plan:
1. Tested by running QAT on GPU
2. python test/test_quantization.py
Imported from OSS
Differential Revision: D20286351
fbshipit-source-id: 745723c85d902870c56c1c7492f26cb027ae9dc6
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/31336https://github.com/pytorch/pytorch/issues/1664
Sometimes cuDNN heuristics return algorithms that can not be used. Instead of just using the first algorithm returned, we should try these algorithms one by one until one of them succeed.
Benchmark:
https://github.com/zasdfgbnm/things/blob/master/2020Q1/conv-benchmark.ipynb
```python
i = torch.randn(256, 3, 256, 256).cuda()
c = torch.nn.Conv2d(3, 3, 3, 3).cuda()
%timeit c(i); torch.cuda.synchronize()
```
before vs after = 498 vs 490 µs
The performance is improved I guess because, before this PR, we always call the heuristics to get the algorithm, but after this PR, we only do at the first time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33073
Differential Revision: D20284755
Pulled By: ngimel
fbshipit-source-id: b03af37c75939ca50c2cb401c706ba26914dd10e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33294
1. Serialize bytecode of __setstate__ and run it when loading the model.
2. One use case is quantization. To test this use case a few operators are registered temporarily for lite interpreter. The "_" prefix registration will be removed when the operators are all migrated to mobile.
Test Plan: Imported from OSS
Differential Revision: D20162898
Pulled By: iseeyuan
fbshipit-source-id: 7a3180807bf38fbce594d86993896861f12bb58c
Summary:
Among all ONNX tests, ONNXRuntime tests are taking the most time on CI (almost 60%).
This is because we are testing larger models (mainly torchvision RCNNs) for multiple onnx opsets.
I decided to divide tests between two jobs for older/newer opsets. This is now reducing the test time from 2h to around 1h10mins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33242
Reviewed By: hl475
Differential Revision: D19866498
Pulled By: houseroad
fbshipit-source-id: 446c1fe659e85f5aef30efc5c4549144fcb5778c
Summary:
**Summary**
There is often a need to create a Tensor when writing IR by hand for JIT
optimisation pass unit tests. The only options for this today are real
Tensor creation functions like `aten::ones`. Any test that uses these functions
must also use the same default arguments as the Python/C++ API, which means
that all of the tests have to be updated when the API is updated. This commit
introduces a new primitive, `prim::MakeTestTensor` with schema `() -> Tensor` that
should be used in unit tests instead of real Tensor creation functions. This new
primitive has no public-facing API, so the maintenance burden is much lower.
**Testing**
This commit updates the alias analysis and DCE tests to use `prim::MakeTestTensor` instead of
`aten::rand`, `aten::ones`, and `aten::zeros`.
```
$ ./bin/test_jit
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = *-*_CUDA:*_MultiCUDA
[==========] Running 75 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 75 tests from JitTest
[ RUN ] JitTest.ADFormulas
[ OK ] JitTest.ADFormulas (82 ms)
[ RUN ] JitTest.Attributes
[ OK ] JitTest.Attributes (0 ms)
...
...
...
[ RUN ] JitTest.LiteInterpreterPrim
[ OK ] JitTest.LiteInterpreterPrim (0 ms)
[ RUN ] JitTest.LiteInterpreterLoadOrigJit
[ OK ] JitTest.LiteInterpreterLoadOrigJit (2 ms)
[----------] 75 tests from JitTest (150 ms total)
[----------] Global test environment tear-down
[==========] 75 tests from 1 test case ran. (150 ms total)
[ PASSED ] 75 tests.
```
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33500.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33914
Differential Revision: D20150304
Pulled By: SplitInfinity
fbshipit-source-id: c88f5289055a02dc20b7a5dcdf87469f9816d020
Summary:
Currently, putting `outputs: List[Tensor]` instead of `outputs: List[Tensor] = []` in your JITed code results in:
```
Traceback (most recent call last):
File "custom_lstms.py", line 453, in <module>
test_script_stacked_bidir_rnn(5, 2, 3, 7, 4)
File "custom_lstms.py", line 404, in test_script_stacked_bidir_rnn
rnn = script_lstm(input_size, hidden_size, num_layers, bidirectional=True)
File "custom_lstms.py", line 62, in script_lstm
other_layer_args=[LSTMCell, hidden_size * dirs, hidden_size]))
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1267, in script
return torch.jit._recursive.create_script_module(obj, torch.jit._recursive.infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 305, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 348, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/apaszke/pytorch/torch/jit/__init__.py", line 1612, in _construct
init_fn(script_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 340, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, infer_methods_to_compile)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 317, in create_script_module_impl
stubs = stubs_fn(nn_module)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 511, in infer_methods_to_compile
stubs.append(make_stub_from_method(nn_module, method))
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 41, in make_stub_from_method
return make_stub(func)
File "/home/apaszke/pytorch/torch/jit/_recursive.py", line 34, in make_stub
ast = torch.jit.get_jit_def(func, self_name="RecursiveScriptModule")
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 173, in get_jit_def
return build_def(ctx, py_ast.body[0], type_line, self_name)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 206, in build_def
build_stmts(ctx, body))
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 129, in build_stmts
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 129, in <listcomp>
stmts = [build_stmt(ctx, s) for s in stmts]
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 181, in __call__
return method(ctx, node)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 294, in build_AnnAssign
rhs = build_expr(ctx, stmt.value)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 180, in __call__
raise UnsupportedNodeError(ctx, node)
File "/home/apaszke/pytorch/torch/jit/frontend.py", line 116, in __init__
source_range = ctx.make_range(offending_node.lineno,
AttributeError: 'NoneType' object has no attribute 'lineno'
```
This patch makes the error message more reasonable:
```
torch.jit.frontend.UnsupportedNodeError: annotated assignments without assigned value aren't supported:
File "custom_lstms.py", line 221
# type: (Tensor, Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]
inputs = reverse(input.unbind(0))
outputs: List[Tensor]
~ <--- HERE
for i in range(len(inputs)):
out, state = self.cell(inputs[i], state)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34133
Differential Revision: D20249076
Pulled By: ezyang
fbshipit-source-id: 40ec34ad38859f9fe56f379d3f8d08644b00fab9
Summary: I don't know why, but this segfaults on rocm.
Test Plan: Can only be tested on master
Reviewed By: mrshenli
Differential Revision: D20286011
fbshipit-source-id: dde952449bf54ae459d36020f3e3db6fa087b39f
Summary:
This PR enables bfloat16 type for pooling ops on ROCm. Also adds bfloat16 implementation of atomicAdd since pooling ops use it.
Note: Changes in the lambda function blocks is only indentation as it is now wrapped inside `AT_SKIP_BFLOAT16_IF_NOT_ROCM` macro.
iotamudelta ezyang bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34166
Differential Revision: D20263421
Pulled By: ezyang
fbshipit-source-id: 3f4199ec57522e638ec29f45e22c6ec919b7816d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34184
Add mobile custom build with static dispatch & dynamic dispatch to CI.
Most of mobile code analysis CI should be covered by the custom build +
dynamic dispatch flow, so changing it to running on master only.
Test Plan: Imported from OSS
Differential Revision: D20241774
Pulled By: ljk53
fbshipit-source-id: f34c5748735c536ab6b42c8eb1429d8bbdaefd62
Summary:
There was an error in
https://github.com/pytorch/pytorch/pull/30724/files that resulted in
export_chrome_trace generating invalid JSON. This only came up when the
profiler is run with use_cuda=True from what it looks like. In the future, we
should have tests that ensure we generate valid JSON because we no longer use
the json library.
ghstack-source-id: 99508836
Test Plan: Added a unit test.
Differential Revision: D20237040
fbshipit-source-id: 510befbdf4ec39632ac56544afcddee6c8cc3aca
Summary:
Separating CUDA fuser from CPU fuser.
1. New node in IR - prim::CudaFusionGroup:
This enables the cuda fuser to co-exist along side the old fuser. Allows us
to incrementally build and expand cuda fuser.
2. copied FuseGraph optimization passes to CudaFuserGraph:
We will re-factor & reuse Chunk/Concat in the old fuser logic, which is
handled in the optimization pass at this moment. Unfortunately many code in
the pass is tightly binded with the legacy fuser, which makes code sharing
difficult.
The CudaFusionGraph will support only a subset of operations comparing to
legacy fuser (CUDA only). It is registered as a custom pass post fusion via
```torch._C._jit_register_cuda_fuser()```
To have it in effect, you should also turn off fusion on GPU via
```torch._C._jit_override_can_fuse_on_gpu(False)```
3. We don't have codegen in this PR yet (WIP). Currently we just fall back to
the old fuser.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33527
Differential Revision: D20171598
Pulled By: ZolotukhinM
fbshipit-source-id: 9a3c0f06f46da7eaa80ae7551c04869f5b03ef71
Summary:
[This check](019ffdca31/torch/csrc/jit/ir/alias_analysis.cpp (L772)) wasn't being triggered for None outputs of tuples, because `mustBeNone` would return false if `num_outputs != 1`. This caused an assertion to fail in alias analysis. It's kind of a convoluted case to repro and I wasn't able to make a succinct one, but I tested internally and it fixed the bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34268
Differential Revision: D20261539
Pulled By: eellison
fbshipit-source-id: 95edea10e2971727cfd3f3bc2b6bdf9dbadca6a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34284
Python 3.5 only supports function type hints.
Variable type hints are introduced in Python 3.6.
So these tests with JIT type hints will fail with "Syntax Error" in Python 3.5 environment.
ghstack-source-id: 99542199
Test Plan: `
Differential Revision: D7348891
fbshipit-source-id: c4c71ac021f35b5e6f7ce4d3e6af10dd1d2600cc
Test Plan: Can only really be tested in PyTorch master
Reviewed By: mrshenli
Differential Revision: D20260023
fbshipit-source-id: b5444c376894bfccd6524cf04a71cf76eea72275
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33852
This fixes an issue for QAT models. During eval if we call `prepare_qat` and `convert` before calling `load_state_dict` it throws an error because the weight info (num channels) is not updated in the observer module.
It is not an issue for per-tensor case
Fixes issue #33830
Test Plan:
python test/test_quantization.py EagerModePostTrainingQuantTest.test_eval_after_train
python test/test_quantization.py EagerModeQuantizationAwareTrainingTest.test_eval_after_train
Imported from OSS
Differential Revision: D20212996
fbshipit-source-id: a04af8fe4df2e555270ae4d6693f5777d86f8a46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34072
This diff helps check all the ops not supported by lite_interpreter.
Helpful mainly to find all the ops that need to be added instead of adding them
one by one.
Test Plan:
buck run caffe2/binaries:lite_interpreter_model_load --
--model=<bytecode-model-path>
Reviewed By: iseeyuan
Differential Revision: D20194092
fbshipit-source-id: 0d596cd0204308027194af7ed738551d0c32a374
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34187
Noticed that a recent PR broke Android/iOS CI but didn't break mobile
build with host toolchain. Turns out one mobile related flag was not
set on PYTORCH_BUILD_MOBILE code path:
```
"set(INTERN_DISABLE_MOBILE_INTERP ON)"
```
First, move the INTERN_DISABLE_MOBILE_INTERP macro below, to stay with
other "mobile + pytorch" options - it's not relevant to "mobile + caffe2"
so doesn't need to be set as common "mobile" option;
Second, rename PYTORCH_BUILD_MOBILE env-variable to
BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN - it's a bit verbose but
becomes more clear what it does - there is another env-variable
"BUILD_PYTORCH_MOBILE" used in scripts/build_android.sh, build_ios.sh,
which toggles between "mobile + pytorch" v.s. "mobile + caffe2";
Third, combine BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN with ANDROID/IOS
to avoid missing common mobile options again in future.
Test Plan: Imported from OSS
Differential Revision: D20251864
Pulled By: ljk53
fbshipit-source-id: dc90cc87ffd4d0bf8a78ae960c4ce33a8bb9e912
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34215
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20251538
Pulled By: ezyang
fbshipit-source-id: c419f0ce869aca4dede7e37ebd274a08632d10bf
Summary:
Effectively backporting c5c00c119f before that PR lands
The bug didn't manifesting itself earlier because MkldnnConv2d constructor didn't reorder the weights. So the issue was arising only on second serialization/deserialization. This also fixes the constructor to deliver better perf right away.
Note, that I still serialize 5d tensor - it was the previous behavior, we have to handle it anyway and with https://github.com/pytorch/pytorch/issues/32422 the output of `mkldnn_reorder_conv2d_weight` will always be 4d.
cc pinzhenx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34115
Reviewed By: wanchaol
Differential Revision: D20224685
Pulled By: dzhulgakov
fbshipit-source-id: 24ca9227c4eb4c139096a64ae348808d7478d7dc
Summary:
We get seg fault without this in using XNNPACK.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34087
Differential Revision: D20199787
Pulled By: kimishpatel
fbshipit-source-id: d3d274e7bb197461632b21688820cd4c10dcd819
Summary:
This PR aims at improving `UpSample` performance with `mode='nearest'` on 1D 2D and 3D, both inference and training are covered. Current implementation from 'ATen' doesn't have parallelization.
1. single socket inference speedup for 1d, 2d and 3d: **63x, 57x, 46x**.
2. single core inference speedup for 1d, 2d and 3d: **5.9x, 4.6x, 3.4x**.
3. dual sockets training speedup for 1d, 2d and 3d: **38x, 33x, 65x**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31452
Differential Revision: D20077828
Pulled By: VitalyFedyunin
fbshipit-source-id: a7815cf2ae344696067d2ec63bd4f4e858eaafff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33849
For integral types, there is no need to manipulate with
`reinterpret_cast` and therefore a cleaner implementation is available.
This might also be helpful on some less optimized compilers or on a less optimized arch (while a
test on gcc 8.3 x64 shows no difference in performance).
Test Plan: Imported from OSS
Differential Revision: D20222675
Pulled By: VitalyFedyunin
fbshipit-source-id: 875890d1479f8abab4c4a19d934fe9807d12dfd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33817
Then, nullopt denotes catch all, whereas everything else is specific to
a DispatchKey. I can delete the second copy of methods when I do this.
This refactor should be pushed all the way to the frontend but I am doing
it one step at a time.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20125163
Pulled By: ezyang
fbshipit-source-id: 026075a4bab81b0bd88b07f0800f6e6bbeb2166a
Summary:
Remove Int8Relu in quantized model
Suppress log warnings if verbose is false
Test Plan: TBD
Reviewed By: yinghai
Differential Revision: D20202474
fbshipit-source-id: 995ef8e665d8edeee810eedac831440b55271a7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33715
Tracing codes depend on the full JIT, which is not available in lite interpreter. Use `-c pt.disable_gen_tracing=1` to turn off generating tracing part.
ghstack-source-id: 99252322
Test Plan:
```
buck build xplat/caffe2:torch -c pt.disable_gen_tracing=1
```
The tracing part of generated/VariableType_?.cpp will not be generated.
Reviewed By: smessmer
Differential Revision: D19684577
fbshipit-source-id: a1e5b80eca5e51c7bf72b5cc8f0e36c2135fabc2
Summary:
When docs are built, conf.py points to a _templates-stable/layout.html that does not exist.
Adding this file here so future stable docs will build with Google Analytics tags and without the unstable able that is in _templates/layout.html
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33770
Differential Revision: D20164895
Pulled By: jlin27
fbshipit-source-id: 5fca9f9b825b1484dab52e2b2d91f92ae6372371
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33329
# Use case
```
torch.jit.script
def send_rpc_async(dst_worker_name, user_callable_qual_name, tensor):
# type: (str, str, Tensor) -> None
rpc._rpc_async_torchscript(
dst_worker_name, user_callable_qual_name, args=(tensor,)
)
```
# Problem
```
torch.jit.frontend.NotSupportedError: keyword-arg expansion is not supported:
File "/data/users/shihaoxu/fbsource/fbcode/buck-out/dev/gen/caffe2/test/distributed/rpc/rpc_spawn#binary,link-tree/torch/distributed/rpc/api.py", line 722
args = args if args else ()
kwargs = kwargs if kwargs else {}
fut = _invoke_rpc_torchscript(to, qualified_name, *args, **kwargs)
~~~~~~ <--- HERE
return fut
```
# Solution
Register `rpc.rpc_async(..)` as a JIT operator to handle variable-length argument list.
# Plan
This PR is the required changes to make `rpc.rpc_async(..)` a JIT prim operator, which can dynamically handle different number of arguments.
- Register "prim::rpc_async" as a `Symbol` in "interned_string.h"
- Add a if branch in "python_sugared_value.cpp" `toSugarValue(py::object, ..)` entry utility function to set up how JIT frontend convert `torch.distributed.rpc.rpc_async(..)` Python function (Python object) into a `SpecialFormValue` (IR SugaredValue).
- Add a switch case for "prim::rpc_aynsc" Symbol in "ir_emitter.cpp" and `emitApplySpecialForm(..)` to set up how JIT compiler provides inputs to the "prim::rpc_aynsc" Operator.
- Register "prim::rpc_async" as a `jit::Operator` and provide implementation in "register_distributed_ops.cpp".
Notice, since the distributed module is an optional part when building PyTorch. The code to be added in this PR should be wrapped within preprocessing maco.
```
#ifdef USE_DISTRIBUTED
new code here
#endif
```
Test Plan:
Items that need to be confirmed in the test cases
https://fb.quip.com/DCvdA9ZLjeO0
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork \
\
&& buck-out/gen/caffe2/test/distributed/rpc/jit/rpc_fork\#binary.par -r test_call_python_function_remotely_from_script_not_supported
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_spawn
```
```
buck test mode/dev-nosan //caffe2/caffe2/python/operator_test:layer_norm_op_test-2.7 -- test_layer_norm_op_jit
```
Differential Revision: D5738300
fbshipit-source-id: a4604fe762e00be062dc8232ca9790df31fb2074
Summary:
`unpickler.cpp` depends on the mobile type parser all the time, so include it regardless of whether it's a mobile build or not
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34180
Pulled By: driazati
Differential Revision: D20241881
fbshipit-source-id: a998dd2b3f1c7f58e55bb7851dc595c8ddf9eacb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34055
Enable custom mobile build with dynamic dispatch for OSS build.
It calls a python util script to calculate transitive dependencies from
the op dependency graph and the list of used root ops, then pass the
result as the op registration whitelist to aten codegen, so that only
these used ops are registered and kept at link time.
For custom build with dynamic dispatch to work correctly, it's critical
to have the accurate list of used ops. Current assumption is that only
those ops referenced by TorchScript model are used. It works well if
client code doesn't call libtorch API (e.g. tensor methods) directly;
otherwise the extra used ops need to be added to the whitelist manually,
as shown by the HACK in prepare_model.py.
Also, if JIT starts calling extra ops independent of specific model,
then the extra ops need to be added to the whitelist as well.
Verified the correctness of the whole process with MobileNetV2:
```
TEST_CUSTOM_BUILD_DYNAMIC=1 test/mobile/custom_build/build.sh
```
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D20193327
Pulled By: ljk53
fbshipit-source-id: 9d369b8864856b098342aea79e0ac8eec04149aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32814
We skip quantization for the intermediate values for patterns like `Conv - ReLU`,
but currently we didn't skip quantizing the input/output of the graphs of matched modules,
since we now changed the way we add observers, this also needs to be updated.
Test Plan:
python test/test_jit.py -- 'TestJit.test_insert_observers_skip_values'
Imported from OSS
Differential Revision: D20208785
fbshipit-source-id: ce30f2c4c8ce737500d0b41357c80ec8b33aecf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34168
Redo D19153199. It was reverted because it broke CI, due to the change of `AT_ASSERTM` to `TORCH_INTERNAL_ASSERT_DEBUG_ONLY`. Two problems:
1) bug in `TORCH_INTERNAL_ASSERT_DEBUG_ONLY` about MSVC. I'm sending another diff to fix this bug.
2) BlobTest was expecting `Blob::template Get<T>()` to throw when there is a type mismatch.
For now I'll leave `AT_ASSERTM` as it is.
Test Plan:
```
buck test mode/dev //caffe2/caffe2:caffe2_test_cpu -- 'BlobTest' --run-disabled
buck test mode/opt //caffe2/caffe2:caffe2_test_cpu -- 'BlobTest' --run-disabled
```
Reviewed By: yinghai
Differential Revision: D20235225
fbshipit-source-id: 594dad97c03c419afaa8f9023408bc5a119b3cfa
Summary:
This PR aims to improve the interoperability with [CuPy](https://github.com/cupy/cupy/pulls).
Instead of having two separate and conflicting memory pools. With this PR, CuPy can directly alloc memory from the PyTorch allocator by means of this proposal https://github.com/cupy/cupy/pull/3126
We would like to gather feedback to know if this approach makes sense for PyTorch, or other alternative designs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33860
Differential Revision: D20212788
Pulled By: ngimel
fbshipit-source-id: bc1e08a66da1992d26021147bf645dc65239581c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34157
`[[noreturn]` only conficts with CUDA __asert_fail defition if clang is used if host compiler
Test Plan: CI
Reviewed By: EscapeZero
Differential Revision: D20232088
fbshipit-source-id: 7182c28a15278e03175865cd0c87410c5de5bf2c
Summary:
Stacked PRs
* #33474 - [jit] Remove list specializations from pickler
* **#33255 - [jit] Add type tags to lists/dicts in pickle**
This adds a global call to `torch.jit._pickle.restore_type_tags` for
lists and dicts so that we can preserve their types after serialization.
](https://our.intern.facebook.com/intern/diff/19868637/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33255
Pulled By: driazati
Reviewed By: xman1979, Tianshu-Bao
Differential Revision: D19868637
fbshipit-source-id: 2f1826e6679a786ca209198690269f399a542c04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34081
Before this commit, applications have to do the following to configure
number of threads in ProcessGroup RPC backend:
```
op = ProcessGroupRpcBackendOptions()
op.rpc_timeout = rpc_timeout
op.init_method = init_method
op.num_send_recv_threads = 32
init_rpc(...., rpc_backend_options=op)
```
After this commit, it can be simplified to:
```
init_rpc(...., rpc_backend_options=ProcessGroupRpcBackendOptions(num_send_recv_threads=32))
```
Fixes#34075
Test Plan: Imported from OSS
Differential Revision: D20227344
Pulled By: mrshenli
fbshipit-source-id: def4318e987179b8c8ecca44d7ff935702c8a6e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34169
Valgrind have no insight how memory is being initialized by ioctls()
Test Plan: CI
Reviewed By: seemethere
Differential Revision: D20235974
fbshipit-source-id: 46413afa4842e7d42582bbbda903438b1d98691f
Summary:
Related issue: https://github.com/pytorch/pytorch/issues/34079
I don't know how much we care about the difference between `-G` and `-lineinfo` in `DEBUG` vs `REL_WITH_DEB_INFO`, but since `-G` never worked, let's just use `-lineinfo` on both `DEBUG` and `REL_WITH_DEB_INFO`. This would resolve the failure in `DEBUG=1` build. Locally tested to work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34153
Reviewed By: ljk53
Differential Revision: D20232049
Pulled By: ngimel
fbshipit-source-id: 4e48ff818850ba911298b0cc159522f33a305aaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33825
Partially addresses #20376
I do this by overriding assertEqual in classes that opt into
this. This means I have to fix#33821. The fix is a little
unsatisfactory as idiomatic Python 2 super() calls don't work
(since the class is no longer in scope); hopefully this will just
work when we go to Python 3.
General approach taken:
- A lot of dtype mismatches are because we specified tensor constants
that infer to some dtype, but the actual dtype needed is something else.
Those are easy, just annotate the tensor() constructor (often a legacy
Tensor/FloatTensor call) with dtype
- There are a few cases where the promotion rules are nontrivial. Some of them
I just typed out the expected promotion rules manually (based on trial
and error)
- There are some more complex cases; if it gets too hairy I just
set exact_dtype=False and nope the fuck out
I don't have time to do it for all the other classes. But the setup
should work if people just incrementally add the overrides to classes,
and then eventually flip the default.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20125791
Pulled By: ezyang
fbshipit-source-id: 389c2d1efbd93172af02f13e38ac5e92fe730c57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33926
The UnboundBuffer calls here are already protected by a mutex. We only
need to hold the lock while writing the shared structures completed_ and
exception_.
ghstack-source-id: 99315427
Test Plan:
CI
CI
Differential Revision: D20154546
fbshipit-source-id: d1b74508c917b21acdcd0f6a914eb0455437ca0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33987
There was an error in
https://github.com/pytorch/pytorch/pull/30724/files that resulted in
`export_chrome_trace` generating invalid JSON. This only came up when the
profiler is run with `use_cuda=True` from what it looks like. In the future, we
should have tests that ensure we generate valid JSON because we no longer use
the json library.
Test Plan: Add UT to validate JSON.
Differential Revision: D20171428
fbshipit-source-id: ec135a154ce33f62b78d98468174dce4cf01fedf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33569
Clang reported a few places where a call to `fmaxType` is ambiguous. In all cases one of the arguments is `double` and another is `float`. Fix the error by creating a proper value 0 and remove the unneeded `ZERO_MACRO` code.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20006926
fbshipit-source-id: ca6cfacd57459b1c48eb5080b822d9509b03544d
Summary: make use of springhill's fma on SpatialBatchnorm
Test Plan:
re-enabled the unit test, ran it a couple of times
pending: net runner
Reviewed By: amylittleyang
Differential Revision: D20227767
fbshipit-source-id: 7c601f185940249c0a32bdf95d74a20552cd2625
Summary:
1. randn and normal_ methods will work for complex tensors after this PR
2. added an internal function for viewing complex tensors as float tensors which enables us to reuse functions defined for float tensors for complex tensors with change in arguments passed(like size, standard deviation in case of normal_). currently the resultant new float tensor doesn't share the storage with the input complex tensor which means that the version counter wouldn't be updated if any function is called on this resultant tensor, but once the dtype entry is removed from the storage class, this issue will be resolved.
Side notes:
1. didn't add a separate header for the util functions because of this issue https://github.com/pytorch/pytorch/issues/20686#issuecomment-593002293
2. we should eventually have a public API method view_complex_as_float once (2) mentioned above gets resolved
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34037
Differential Revision: D20221793
Pulled By: anjali411
fbshipit-source-id: a78f5e83d6104e2f55e0b250c4ec32e8d29a14eb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33182
This adds private API functions that developers of types that implement `__torch_function__` can use to ensure full coverage of the subset of the PyTorch API that can be overrided.
I've refactored some of the code in the tests into a new `torch._overrides.get_overridable_functions` function. I've also changed `TENSOR_LIKE_TORCH_OVERRIDES` into `torch._overrides.get_testing_overrides` and `IGNORED_TORCH_FUNCTIONS` into `torch._overrides.get_ignored_functions`. Making these two static global variables in the tests into functions should allow rewriting their implementation to construct their return values instead of just statically defining the return value as is done here. Currently that is blocked on not being able to inspect function signatures of compiled kernels in PyTorch (see https://github.com/pytorch/pytorch/issues/28233). See the docs I've added for usage examples of these new functions. I also refactored the existing override tests to make use of these new functions, which should be a good forcing function to make sure they're kept up-to-date.
Finally, while working on this I discovered that `TestTorchFunctionOverrides.test_mean` and `TestTorchFunctionOverrides.test_mm` weren't ever being run because they were getting clobbered by the other dynamically generated override tests. I fixed that by renaming the tests and then fixing the actual test code. I've verified that all the subclassing semantics is correct and that the updated test answers are correct. I'm happy to put the fixes to the existing tests in as a separate pull request if that would be easier to review.
ping cpuhrsch since the feature request originally came from them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33791
Differential Revision: D20195053
Pulled By: cpuhrsch
fbshipit-source-id: 1585f4e405f5223932b410eae03a288dc8eb627e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33834
This changes how we report Tracebacks to make them more clear when
there are both serialized and non-serialized ranges. It now looks like:
```
Traceback (most recent call last):
File "foo.py", line 25, in <module>
s2(a, b)
File "/scratch/zdevito/pytorch/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript, serialized code (most recent call last):
File "code/__torch__.py", line 7, in forward
x: Tensor,
y: Tensor) -> Tensor:
return (self).bar(x, y, )
~~~~~~~~~ <--- HERE
def bar(self: __torch__.Moo,
x: Tensor,
File "code/__torch__.py", line 11, in bar
x: Tensor,
y: Tensor) -> Tensor:
_0 = (self).baz(x, y, )
~~~~~~~~~ <--- HERE
_1 = torch.ones([3], dtype=None, layout=None, device=None, pin_memory=None)
return torch.add(_0, _1, alpha=1)
File "code/__torch__.py", line 17, in baz
x: Tensor,
y: Tensor) -> Tensor:
return torch.add(x, y, alpha=1)
~~~~~~~~~ <--- HERE
Traceback of TorchScript, original code (most recent call last):
File "foo.py", line 11, in forward
def forward(self, x, y):
return self.bar(x, y)
~~~~~~~~ <--- HERE
File "foo.py", line 9, in bar
def bar(self, x, y):
return self.baz(x, y) + torch.ones(3)
~~~~~~~~ <--- HERE
File "foo.py", line 7, in baz
def baz(self, x, y):
return x + y
~~~~~ <--- HERE
RuntimeError: The size of tensor a (4) must match the size of tensor b (5) at non-singleton dimension 1
```
It follows Python convension of having the most important information last
and reading from the bottom up.
Changes:
* Moved the error message to the end, to copy Python
* Report original traceback separate from serialized traceback
* Make sure root functions have names in the interpreter trace.
Test Plan: Imported from OSS
Differential Revision: D20126136
Pulled By: zdevito
fbshipit-source-id: fd01f9985e5d74e04c4d064c02e8bc320f4fac13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33901
After this change, the pytest profile looks like:
4.83s call test/test_torch.py::TestTorch::test_fft_ifft_rfft_irfft
4.23s call test/test_torch.py::TestTorch::test_var_dim
4.22s call test/test_torch.py::TestTorch::test_std_dim
4.19s call test/test_torch.py::TestTorch::test_max
4.06s call test/test_torch.py::TestTorch::test_min
3.60s call test/test_torch.py::TestTorchDeviceTypeCPU::test_cdist_norm_batch_cpu
2.62s call test/test_torch.py::TestTorchDeviceTypeCPU::test_pow_cpu
2.60s call test/test_torch.py::TestTorch::test_matmul_small_brute_force_1d_Nd
And the entire CPU-only test suite can be run in 88s on my Intel(R) Xeon(R) CPU
E5-2650 v4 @ 2.20GHz
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20222288
Pulled By: ezyang
fbshipit-source-id: 4224a9117f42566e290ae202881d76f1545cebec
Summary:
Add vectorization to dropout kernels for both reads & writes. Moved the `masked_scale_kernel` implementation to `TensorIterator` to pick up recent autovectorization additions by zasdfgbnm , and wrote a vectorized specialization of the dropout training kernel (along with some fairly conservative dispatch logic).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33879
Differential Revision: D20222853
Pulled By: ngimel
fbshipit-source-id: 711f56ca907fbc792a10d4bf069c28adab7d6ad7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34038
Mobile build doesn't include autograd/VariableType dispatch. As the
result AutoNonVariableTypeMode needs to be set in mobile runtime.
With static dispatch this works is done inside generated jit-dispatch
code - AutoNonVariableTypeMode needs to be set on per-op basis. Setting
it globally or setting it for wrong ops might break some `is_variable()`
checks in the codebase.
Thanks to the unification of Variable class and Tensor class, all
is_variable() checks have been removed, so AutoNonVariableTypeMode can
be set globally now.
We never tested inference-only mobile build with dynamic dispatch. It
seems that dynamic dispatch also requires setting AutoNonVariableTypeMode
for our mobile build (where VariableType functions are not registered).
Verified the end-to-end test works with this change:
```
TEST_CUSTOM_BUILD_DYNAMIC=1 test/mobile/custom_build/build.sh
```
Test Plan: Imported from OSS
Differential Revision: D20193329
Pulled By: ljk53
fbshipit-source-id: cc98414d89d12463dc82b0cdde0b6160dafc0349
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34012
Today some mobile simulator tests only run on landed PRs and it requires
setting up special build environment to repro errors locally.
The goal of the PR is to do end-to-end mobile custom build & integration
tests with host toolchain (using same CMake options as mobile build). This
way, non-mobile engineers can capture & debug mobile related build issues
much more easily.
There are three custom build types that this script supports:
1. `TEST_DEFAULT_BUILD=1 ./build.sh` - it is similar to the prebuilt libtorch
libraries released for Android and iOS (same CMake build options + host
toolchain), which doesn't contain autograd function nor backward ops thus is
smaller than full LibTorch.
2. `TEST_CUSTOM_BUILD_STATIC=1 ./build.sh` - it further optimizes libtorch
size by only including ops used by a specific model.
3. `TEST_CUSTOM_BUILD_DYNAMIC=1 ./build.sh` - similar as 2) except that it
relies on the op dependency graph (instead of static dispatch) to calculate
and keep all transitively dependent ops by the model.
Type 2) will be deprecated by type 3) in the future.
Type 3) custom build has not been fully supported yet so it's expected to fail.
Replacing existing mobile build CI to run Type 1) build & integration test.
Test Plan: Imported from OSS
Differential Revision: D20193328
Pulled By: ljk53
fbshipit-source-id: 48c14cae849fde86e27123f00f9911996c1cf40e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33277
Currently we insert observer in the called graph, which is incorrect since graphs can be shared
and the decision of whether to insert observer or not might dependend on where the graph is called.
For example, for a call sequence `self.conv1(self.conv2(x))`, we can't inserting observer correctly
if `self.conv1` and `self.conv2` are sharing the same type in the current implementation, because we insert
observer in the graph of the forward method of Conv2d right now and this call sequence requires us to insert
only one observer for the output of self.conv1/input of self.conv2.
We'll need to insert observers for input/output values of the graph in call site instead.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20208787
fbshipit-source-id: 739e1d877639c0d0ed24e573bbd36211defa6836
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34105
make parallel_net_test.cc chronos conforming.
exclude gtest asserts that check thrown exceptions when exceptions are disabled.
Test Plan: CI green
Differential Revision: D20153525
fbshipit-source-id: 7371e559da948f46773fed09e3a23a77411d59e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33548
Mostly just moved code.
Index dim and number of indices checks are added to make checks idential to index_add_cpu_
This is a resubmit of #30573, which got reverted.
Test Plan: Imported from OSS
Differential Revision: D20002248
Pulled By: gchanan
fbshipit-source-id: 46df4047cb3fc1dff37a15b83c70b2cbb7a6460b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33819
These conditions are for the specific implementation, the fallback implementation works without these checks. So use that if any of these checks isn't true.
Resubmit of https://github.com/pytorch/pytorch/pull/33419 (which got reverted due to a problem with XLA, but which now has been fixed)
ghstack-source-id: 99333280
Test Plan: Test included
Differential Revision: D20121460
fbshipit-source-id: c1056b8e26751e24078bbe80c7cb4b223bcca7cb
Summary:
The new added mixture_same_family should support cdf if the family has cdf implemented.
This is very useful for flow models where cdf of mixture of gassian/logistic is used to model flow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33408
Differential Revision: D20191552
Pulled By: ezyang
fbshipit-source-id: 0bfd7973aa335c162919398a12ddec7425712297
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33729
ReshapeOp is doing some useless movements of data between CPU and GPU, which results in crazy amount of kernel calls from this operator. Which makes this operator ridiculosly slow compared to BatchMatMul for cases of pretty cheap models (for example on some versions of GAT).
This diff is moving ReshapeOp to leverage CPU storage and reduce amount of kernel calls from num_dims + 3 calls for case of 3-D
tensor to 2 calls.
Test Plan:
Unit-tests are still passing.
TODO: perf testing
Reviewed By: akyrola
Differential Revision: D19659491
fbshipit-source-id: 2341b21e57208b988169f2df5fb598be3dc8acb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34102
if nvcc is invoked with clang host compiler, it will fail with the following error due to the decorators mismatch defined in cuda and c10:
```
error: attribute "noreturn" did not appear on original declaration
```
Test Plan: Build pytorch with clang
Reviewed By: EscapeZero
Differential Revision: D20204951
fbshipit-source-id: ff7cef0db43436e50590cb4bbf1ae7302c1440fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34107
Updates linter to only lint for python3 instead of linting for python2
Test Plan: good_testplan
Reviewed By: orionr
Differential Revision: D20205395
fbshipit-source-id: 1fa34e5fdf15f7aed96a66d2ce824a7337ee6218
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34035
Bug for the conditon check in https://github.com/pytorch/pytorch/pull/24342, realized we don't have tests in either
python or cpp to catch this, so added testes for both python and cpp.
Thanks hczhu on capturing it!
Test Plan: Imported from OSS
Differential Revision: D20198837
Pulled By: wanchaol
fbshipit-source-id: 33846a14c0a8e7aac2e8328189d10c38a0d7e6ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34092
Disable op in transform map until we get bitwise matching to ice-ref
Test Plan: CI
Reviewed By: hyuen
Differential Revision: D20177936
fbshipit-source-id: e316384184cb264852e63e5edce721a8614742d1
Summary:
## What this will do:
When the repository is tagged the current nightly build pipelines will run and upload to the `test` subdirectory in our S3 bucket for `download.pytorch.org`. Will also upload to the correct organization on anaconda [pytorch-nightly](https://anaconda.org/pytorch-test)
This is only meant for release candidates and will actually not run on any tag that does not match the release candidate regex.
This has been tested on a small scale with: 3ebe0ff2f8
## Related PRs:
* `.circleci: Divert packages to test channel on tag`: https://github.com/pytorch/pytorch/pull/33842
* `.cirlceci: Swap PYTORCH_BUILD_VERSION if on tag`: https://github.com/pytorch/pytorch/pull/33326
## Work to be done later:
- [ ] Figure out how to remove manual step of updating s3 html indices.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34078
Differential Revision: D20204104
Pulled By: seemethere
fbshipit-source-id: 685630e8a04b19fc17374585e9228a13a8c3e407
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33513
These tests require gloo so like the other tests, they should be
skipped if not building with gloo. Otherwise they crash on Mac if not built
with gloo currently.
verified that it does not crash anymore with this PR.
ghstack-source-id: 99303707
Test Plan: Built on Mac and verified that the tests do not fail.
Differential Revision: D19976908
fbshipit-source-id: 6a2a70c3eab83efd0e188e86cabe56de4a869f4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33954
fixes caffe2/core/module_test.cc on windows
misc lint fixes.
Test Plan: CI green
Reviewed By: malfet
Differential Revision: D20153512
fbshipit-source-id: aeae84a028e26edd65c7218611e3c49a8d9bb8c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33938
Making sure we don't silently ignore exceptions from the tasks in the
thread pool
Test Plan: python setup.py clean && python setup.py develop install
Differential Revision: D20178603
Pulled By: ilia-cher
fbshipit-source-id: 34971032205a1a53fb7419ed84ebb986f9e959ad
Summary:
In the examples of `BCEWithLogitsLoss`, `0.999` is passed as the prediction value. The value `0.999` seems to be a probability, but actually it's not. I think it's better to pass a value that is greater than 1, not to confuse readers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34053
Differential Revision: D20195456
Pulled By: ezyang
fbshipit-source-id: 3abbda6232ee1ab141d202d0ce1177526ad59c53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33955
unit tests on windows (clang and cl) were crashing on exit due to racing with static variable destruction.
Test Plan: CI green
Differential Revision: D20153587
fbshipit-source-id: 22e35e591660d49f3a755f93d0c14d7a023ebb2a
Summary:
I think this warning isn't true anymore, and the NCCL backend works without PyTorch needing to be built from source.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34051
Differential Revision: D20195310
Pulled By: ezyang
fbshipit-source-id: 14f879a8c43ea5efdbdf0f638792ea2b90011f4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33957
lots of small preprocessor warning cleanup for windows
Test Plan: CI green
Reviewed By: malfet, albanD
Differential Revision: D20153582
fbshipit-source-id: 18fd61c466fd1f55ededdae4448b3009a9cedc04
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33899
In the issue, we have
```
TypeError("expected %s (got %s)", dispatch_key, toString(other.key_set()).c_str());
```
which results in `dispatch_key` being interpreted as a c-string by `sprintf`. Adding `__attrbute__((format))` to the `TypeError` constructor allows gcc or clang to detect this at compile time. Then `-Werror=format` makes it a hard error at compile time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34019
Differential Revision: D20194842
Pulled By: ezyang
fbshipit-source-id: fa4448916c309d91e3d949fa65bb3aa7cca5c6a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33959
make sure clang on windows uses correct attributes.
add support for cl.exe style pragma attributes
Test Plan: CI green
Differential Revision: D20153548
fbshipit-source-id: bfbfd374e8f5e7d7b8598453c3ca2b6693a425f1
Summary:
1. As RRef has been added as a JIT type in https://github.com/pytorch/pytorch/issues/32992, we no longer need to skip them
2. Nightly now knows about Any
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34071
Reviewed By: houseroad
Differential Revision: D20196963
Pulled By: mrshenli
fbshipit-source-id: 1ea79c5682e8be9087b9cb74104e1b914c3fc456
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33958
look for clang intrinsic headers on windows
Test Plan: CI green
Differential Revision: D20153573
fbshipit-source-id: c87da3b0e9950d3df0bf8350df8ae592064d6613
Summary:
This patch enables folding GetAttr nodes with their corresponding
values. _jit_pass_freeze_module API returns a new TorchScipt module
where all function calls and get attributes are inlined.
Usage:
frozen_model = torch._C._freeze_module(scrited_model._c)
frozen_model.forward(...)
This API currently optimizes the forward method. We will follow up to
to preserve and optimize methods and attributes that are annotated as
torch.jit.interface.
Several future improvements to JIT optimizations are required to maximize
clean up/de-sugar the graph and eliminate redundancies.
Ideally, we want to produce a graph that can easily be lowered to
GLOW and other low-level backends.
__
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32178
Differential Revision: D19419640
Pulled By: bzinodev
fbshipit-source-id: 52baffaba9bca2cd60a8e747baa68d57711ad42b
Summary:
Currently if we run
```bash
DEBUG=1 ONNX_ML=0 MAX_JOBS=8 CMAKE_CXX_COMPILER_LAUNCHER=ccache CMAKE_C_COMPILER_LAUNCHER=ccache CMAKE_CUDA_COMPILER_LAUNCHER=ccache USE_OPENMP=0 USE_DISTRIBUTED=0 USE_MKLDNN=0 USE_NCCL=0 USE_CUDA=1 USE_CUDNN=0 USE_STATIC_CUDNN=0 USE_NNPACK=0 USE_QNNPACK=0 USE_FBGEMM=0 BUILD_TEST=0 TORCH_CUDA_ARCH_LIST="6.1" python setup.py develop --cmake-only
```
then `touch build/CMakeCache.txt` (which adjusting build options will
do), then `python setup.py develop`, the following error message will
show up:
```
CMake Error at build/clog-source/CMakeLists.txt:249 (ADD_SUBDIRECTORY):
ADD_SUBDIRECTORY not given a binary directory but the given source
directory "/home/hong/wsrc/pytorch/build/clog-source" is not a subdirectory
of "/home/hong/wsrc/pytorch/build/clog-source". When specifying an
out-of-tree source a binary directory must be explicitly specified.
```
This is due to a conflict between our cpuinfo submodule and XNNPACK's
external clog dependency. Moving our cpuinfo upward and setting
CLOG_SOURCE_DIR resolves the issue.
---
Also reverted https://github.com/pytorch/pytorch/issues/33947 , where `CLOG_SOURCE_DIR` as an option is not quite appropriate (given that cpuinfo uses its included clog subdir) and the setting of this variable should be a bit later when the dir of cpuinfo is known.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33922
Differential Revision: D20193572
Pulled By: ezyang
fbshipit-source-id: 7cdbdc947a6c7e0ef10df33feccb5b20e1b3ba43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33977
Removing python2 from operator_test so we can retire python2 support for PyTorch.
Test Plan: waitforsandcastle
Reviewed By: seemethere
Differential Revision: D20129500
fbshipit-source-id: d4c82e4acfc795be9bec6a162c713e37ffb9f5ff
Summary:
This PR would fix https://github.com/pytorch/pytorch/issues/33345.
The original CUDA kernel looks good. I changed most appearances of `int` to `int64_t` to avoid the CUDA memory access issue. Removed the two `TORCH_CHECK`. Added a unit test.
cc csarofeen ngimel ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33753
Differential Revision: D20185005
Pulled By: ngimel
fbshipit-source-id: ef0abdc12ea680e10fe6b85266e2773c7a272f0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33705
The fact that there were two overloads appears to be a historical
artifact that dates back to when goldsborough originally added these
bindings in the first place. If TensorOptions is made optional,
then you only need one overload, not two, as they are exactly redundant
with each other. When MemoryFormat was added, it was made a little
harder to do this, as the C++ syntax at::empty_like(t, memory_format) would
not work if you collapsed the overload; but now it works because TensorOptions
supports MemoryFormat.
The upshot is, I can get rid of all the overloads and just have one overload.
Amazingly, this change is backwards compatible, as the test attests. While
I was at it, I also deleted the overload name from the functions entirely.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20073355
Pulled By: bhosmer
fbshipit-source-id: c6a8908213b32ccf6737ea864d135e2cce34f56b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33704
This diff adds MemoryFormat field to TensorOptions, and teaches
all kernels that take TensorOptions to respect it, but doesn't
teach the codegen about it. As such, it is now possible to specify
memory_format using TensorOptions syntax, e.g.,
at::empty_like(tensor, at::memory_format(MemoryFormat::Contiguous))
in the C++ API, but there isn't any other user visible effect.
The intended end state of this diff stack is to eliminate the
explicit MemoryFormat? arguments from native functions, but
as this change has BC implications I'd prefer to do it separately.
So this starts things off with a non-BC breaking addition to the
API. For all internal functions that are not bound by codegen,
I switch them to exclusively using TensorOptions (eliminating
MemoryFormat); there's only a few, mostly quantized and to().
To keep things screwed down in the short term, it is a HARD ERROR
to specify both the explicit MemoryFormat argument as well as
TensorOptions. This caught a few errors in my diff where I needed
to modify memory format settings and then call code later, esp
in empty_like.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20073356
Pulled By: bhosmer
fbshipit-source-id: 18d310d7ee7cf2ee182994104652afcfc9d613e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33960
test helper functions should be out of test function. it is possible process 2 launches test functions slower than process 1, and process 1 sends request to run a helper function on process 2. process 2 may have not compile the helper function yet when process 2 starts to serve processs 1's request, and thus may return error like "attempted to get undefined function"
ghstack-source-id: 99205620
Test Plan: test_remote_script_module was flaky for thrift backend in my local stress test runs, due to error "attempted to get undefined function". With fix in this diff, stress runs passed
Differential Revision: D20167969
fbshipit-source-id: 8a2b9cd7bd62462e24bdbcb69ad32dca745d6956
Summary:
HashNode and CompareNode are useful functions for hanlding jit::Node. This is to unblock https://github.com/pytorch/glow/pull/4235.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34045
Reviewed By: houseroad
Differential Revision: D20184733
Pulled By: yinghai
fbshipit-source-id: 6c829f2f111a490fd2d85017475c1731cd97fb20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33992
resubmit of https://github.com/pytorch/pytorch/pull/33369 with tweaks on when the rref type being created to ensure ivalue->type() hold the correct RRef type inside of inner element type.
Test Plan: Imported from OSS
Differential Revision: D20175043
Pulled By: wanchaol
fbshipit-source-id: a08b178e989c995632374e6c868d23c5a85526ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33536
Simple fix, merge the identical string literals that were being inlined into every wrapper for ops that don't support named tensors. E.g.
```
Tensor all(const Tensor & self, int64_t dim, bool keepdim) {
if (self.has_names()) {
AT_ERROR(
"all is not yet supported with named tensors. Please drop names via "
"`tensor = tensor.rename(None)`, call the op with an unnamed tensor, "
"and set names on the result of the operation.");
}
const OptionalDeviceGuard device_guard(device_of(self));
return at::native::all(self, dim, keepdim);
}
```
becomes
```
Tensor all(const Tensor & self, int64_t dim, bool keepdim) {
if (self.has_names()) {
AT_ERROR("all", named_tensors_unsupported_error);
}
const OptionalDeviceGuard device_guard(device_of(self));
return at::native::all(self, dim, keepdim);
}
```
Also updated the generated file comments to include the source template names, e.g.
```
// generated by aten/src/ATen/gen.py from TypeDefault.cpp
```
Test Plan: Imported from OSS
Differential Revision: D19993407
Pulled By: bhosmer
fbshipit-source-id: 88395a649e6ba53191332344123555c217c5eb40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33975
Currently the code analysis script doesn't go beyond the scope of the
registration API call, i.e. calling registration via a wrapper will not
be covered by the analysis - currently the new API is essentially a
wrapper around old API.
Simply adding the new API signature to the registration API pattern can
solve the problem for now. We might need change the analyzer code if
things change significantly in the future.
Test Plan:
- update test project to use the new API;
- run analyzer against pytorch codebase;
Differential Revision: D20169549
Pulled By: ljk53
fbshipit-source-id: c7925fa0486eee18f07e791a38c32152fee59004
Summary:
Mainly renaming pthread_create of C2, the only one referred internally in NNPACK, that
is conflicting, to pthread_create_c2.
Removed 2 other conflicting symbols that are not used internally at all.
Pointing XNNPACK to original repo instead of the fork.
Copy pasted the new interface and implementation to
caff2/utils/threadpool, so that for internal builds we compile against
this.
When threadpool is unified this will be removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33869
Differential Revision: D20140580
Pulled By: kimishpatel
fbshipit-source-id: de70df0af9c7d6bc065e85ede0e1c4dd6a9e6be3
Summary:
This bug has been hit a couple times recently. We need to handle all bivariant types, not just optional, when asserting mutability/immutability of pointed-to elements in alias analysis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33952
Differential Revision: D20166025
Pulled By: eellison
fbshipit-source-id: cf3df9897a639641ef8303a08ba2b13523d01ef1
Summary:
Fixes#30775
This adds TorchScript implementations (copied from `python_variable.cpp`) for the remainin `Tensor` properties that were missing from the jit, in addition to a test that ensures new properties will trigger a failure so we can decide whether we want to add them as well.
For `some_tensor`, adds:
* `some_tensor.T`
* `some_tensor.ndim`
* `some_tensor.is_leaf`
* `some_tensor.name`
](https://our.intern.facebook.com/intern/diff/20153288/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33906
Pulled By: driazati
Differential Revision: D20153288
fbshipit-source-id: 2ddc48a14267077bc176065267e5ce52181b3d6b
Summary:
This adds some machinery so that we use Python to resolve types to a value and the corresponding resolution logic in `annotations.py` instead of using the string.
This PR also `slowTests` a random test since it was taking > 1 min whereas all the other tests take < 10 seconds.
Fixes#31864Fixes#31950
](https://our.intern.facebook.com/intern/diff/20144407/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29623
Pulled By: driazati
Differential Revision: D20144407
fbshipit-source-id: ef3699f6b86039d8b4646ffc42c21bd1132d1681
Summary:
This PR prepares us to allow XLA use `XLAPreAutograd` to override compound ops.
To do this we'll need to pass all ops, with additional infomation about whether it's compound or not for XLA to parse.
Companion PR: https://github.com/pytorch/xla/pull/1698
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33908
Differential Revision: D20149585
Pulled By: ailzhang
fbshipit-source-id: a93140e8a34548fcabcea454386d15df58177c1d
Summary:
With the profiling executor enabled the fuser won't be invoked until the second pass over a script function, so some of these tests weren't correctly comparing the fused output with the interpreter output. I've used the `checkScript` method where applicable, which seems to do the right thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33944
Test Plan: Locally inject obvious errors into the fuser and verify that the updated tests fail when they're supposed to.
Differential Revision: D20162320
Pulled By: bertmaher
fbshipit-source-id: 4a2f3f2d2ff1d81f23db504dc8cd0d5417bdcc50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33559
For sm_60+ CUDA supports `atomicAdd(double*, double*)` function and for lower compute capabilities the CUDA C Programming Guide [1] suggest a user implementation as in this code. On the other side, Clang's CUDA wrappers unconditionally define this function, regardless of compute capability, and merit an error if it actually get's used.
So the problem is: when Clang is used for < sm_60, CUDA's `atomicAdd(double*, double*)` cannot be used and it cannot be redeclared in standard compliant C++.
Workaround the problem by using Clang's `enable_if` attribute [2], which has a side effect of function redeclaration.
1. https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#atomic-functions
2. https://clang.llvm.org/docs/AttributeReference.html#enable-if
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20005113
fbshipit-source-id: d0d4bd6514f201af9cdeba1229bd9b798df0d02e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33556
Fix several places exposed by Clang where order of member initializer list doesn't actually match the actual initialization order. The fix is to simply reorder member initializer lists.
Also accepted formatting changes suggested by clang-format linter.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20004834
fbshipit-source-id: b61c7c3f1fe8413bbb3512f6b62177a3ddf67682
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33947
XNNPACK was downloading clog because we weren't setting CLOG_SOURCE_DIR.
Actually, it was downloading cpuinfo and pointing to the copy of clog
within that. So let's just point to the copy of clog within the cpuinfo
submodule we already have.
(Note: this ignores all push blocking failures!)
Test Plan:
Ran cmake and didn't see any downloading.
Verified that our clog is the same as the one that was being downloaded
with `diff -Naur`.
Differential Revision: D20169656
Pulled By: suo
fbshipit-source-id: ba0f7d1535f702e504fbc4f0102e567f860db94b
Summary:
This PR comes from discussion with albanD in https://fb.quip.com/npBHAXaPfnbu. Main goal is to clarify view ops with general outplace/inplace ops and remind users about the difference.
For reference this information is only available in code which is internal and hard to find. Also changes to this list actually affect users so we think it's better to expose it as public information. It's also helpful for new backend like XLA when implementing PyTorch ops. 19bbb4fccb/tools/autograd/gen_autograd.py (L32-L68)
Please feel free to comment!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32560
Differential Revision: D20161069
Pulled By: ailzhang
fbshipit-source-id: b5f1fd4353fe7594a427784db288aeb5a37dc521
Summary:
This PR move glu to Aten(CPU).
Test script:
```
import torch
import torch.nn.functional as F
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n // 2, device=device)
for i in range(1000):
output = F.glu(input)
output.backward(grad_output)
for n in [10, 100, 1000, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n // 2, device=device)
for i in range(10000):
t1 = _time()
output = F.glu(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test device: **skx-8180.**
Before:
```
input size(128, 10) forward time is 0.04 (ms); backwad avg time is 0.08 (ms).
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.14 (ms).
input size(128, 1000) forward time is 0.11 (ms); backwad avg time is 0.31 (ms).
input size(128, 10000) forward time is 1.52 (ms); backwad avg time is 2.04 (ms).
```
After:
```
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.05 (ms).
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.09 (ms).
input size(128, 1000) forward time is 0.07 (ms); backwad avg time is 0.17 (ms).
input size(128, 10000) forward time is 0.13 (ms); backwad avg time is 1.03 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24707, https://github.com/pytorch/pytorch/issues/24708.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33179
Differential Revision: D19839835
Pulled By: VitalyFedyunin
fbshipit-source-id: e4d3438556a1068da2c4a7e573d6bbf8d2a6e2b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32521
Not all ops support the templated unboxing wrappers yet. For the ones that don't,
let's use the codegen'ed unboxing wrappers from register_aten_ops.cpp, but register
them with c10 directly instead of JIT.
The `use_c10_dispatcher` setting in `native_functions.yaml` now has a new option 'with_codegenerated_unboxing_wrapper' which means we take the codegened unboxing wrapper from register_aten_ops.cpp and stuff it into c10. This new argument is the default, 'unboxed_only' is not the default anymore. For the (very few) ops that don't support boxed dispatch yet (i.e. ops taking TensorOptions arguments), we set them to 'unboxed_only' and they follow the old behavior of having register_aten_ops.cpp register the jit op.
Next steps here are (1) to make TensorOptions work with boxed dispatch and remove the `unboxed_only` option from `use_c10_dispatcher`, so that all ops go through the new path and (2) make the new path template-only and remove codegen from it (see https://github.com/pytorch/pytorch/issues/32366).
First experiments show that
- For a small JITted model that calls add (i.e. a op with just two arguments that are both tensors) on two tensors in a loop, we see a 2-4% performance improvement (~35-50ns) when compared to the old path. This is a simple op that takes two tensor arguments and no non-tensor arguments, so iterating over it in boxed dispatch is cheap.
- For a small JITted model that calls avgpool1d (i.e. an op that has one tensor arg and 5 non-tensor args) on a tensor in a loop, we see a 3-4% performance regression (~60ns) when compared to the old path. This is an op that takes only one tensor argument and then 6 non-tensor arguments. Unboxed dispatch doesn’t have to look at those but boxed dispatch still needs to iterate over them.
This performance difference is likely due to boxed dispatch iterating over all arguments in a loop and unboxed dispatch not having to look at non-tensor arguments.
ghstack-source-id: 99161484
Test Plan: unit tests that call existing ops through JIT
Differential Revision: D18672405
fbshipit-source-id: bf2a7056082dfad61e7e83e9eeff337060eb6944
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33732
move and forward instead of copy
Benchmarks:
A microbenchmark calling the add operation on two tensors in a tight loop shows a 5% improvement in performance.
No visible change for a model like resnet that does more work in its kernels.
ghstack-source-id: 99161486
Test Plan: benchmarks
Differential Revision: D20082642
fbshipit-source-id: eeac59686f8621dd5eaa85d61e6d219bba48c847
Summary:
hard to get right locally...I can build the docs but never quite match what it looks like live. the bullet point indentation was just an oversight.
Removing `Returns:` formatting tabs because they take up a lot of space when rendered and add no clarity. Some functions in Pytorch [do use them](https://pytorch.org/docs/master/torch.html#torch.eye), but [many don't bother](https://pytorch.org/docs/master/torch.html#torch.is_tensor), so apparently some people shared my feelings (Not using them is in line with existing practice).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33832
Differential Revision: D20135581
Pulled By: ngimel
fbshipit-source-id: bc788a7e57b142f95c4fa5baf3fe01f94c45abd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33563
When NVCC or Clang are driving CUDA compilation many math functions are declared by default, with a small difference: Clang marks them as `__device__` only, while NVCC uses both `__host__` and `__device__`. This makes every un-elaborated `min` or `max` function call from a `__host__` function generate a syntax error when Clang is used.
Fix the errors by using `std::min` and `std::max` from `<algorithm>`, since C++14 they are `constexpr` and can be used in the `__device__` code [1].
1. https://llvm.org/docs/CompileCudaWithLLVM.html#algorithm
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: ngimel
Differential Revision: D20005795
fbshipit-source-id: 98a3f35e8a96c15d3ad3d2066396591f5cca1696
Summary:
- Modified assertEqual to handle complex tensors
- added a test in test_torch.py to test torch.zeros
- added dispatch for complex for index_kernel, index_put_kernel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33773
Differential Revision: D20135553
Pulled By: anjali411
fbshipit-source-id: f716604535c0447ecffa335b0fc843431397c988
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33273
- Move the check for bias to valueNeedsToBeQuantized
- Move TORCH_CHECK inside the functions for checking if a value is bias or weight
Test Plan:
.
Imported from OSS
Differential Revision: D20123595
fbshipit-source-id: 4b805d57dcaf41a6436506d021dd5f6518bc88fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33263
This PR allow PyRRef local creation to inspect the pyobject, if it
founds that we could turn it to an IValue, turn to an IValue first,
otherwise hold it as a PyObjectType
Test Plan:
Imported from OSS
https://fb.quip.com/aGxRAh2lCg05
Differential Revision: D19871243
Pulled By: wanchaol
fbshipit-source-id: ae5be3c52fb1e6db33c64e64ef64bc8b9ea63a9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33576
`throw` statement at the end of `constexpr` is ill-formed according to Clang. It happens when Clang is driving CUDA compilation and compiles for device the effected code. Due to its compilation model it requires host code to be well-formed even when compiling for device.
Fix the error by guarding the entire definition of `type_index_impl` with `__CUDA_ARCH__` check.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Execute tests on devgpu:
```
buck test mode/dev-nosan -j 8 //caffe2/caffe2/python/operator_test/... //caffe2/test:cuda
```
Reviewed By: smessmer
Differential Revision: D20008881
fbshipit-source-id: b0dc9abf0dc308b8b8637b54646a0411baf7fef3
Summary:
The way it works on the Anaconda distribution of Python 3.8 is a bit different. Loading DLLs explicitly (e.g. `ctype.CDLL`) relies on paths appended by `os.add_dll_directory`. But if you try to load DLLs implicitly (e.g. `from torch._C import *`), it will rely on `PATH`.
Fixes https://github.com/pytorch/vision/issues/1916.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33856
Differential Revision: D20150080
Pulled By: soumith
fbshipit-source-id: cdbe76c138ea259ef7414c6634d4f7e0b1871af3
Summary:
**Summary**
This commit adds an implementation of `Tensor.tolist()` to the JIT interpreter.
**Testing**
This commit adds several unit tests that test that this function works correctly for
0D, 1D, 2D and 3D tensors of type `float`, `int` and `bool`.
```
(base) meghanl-mbp:pytorch meghanl$ python test/test_jit.py TestList.test_to_list -v
Fail to import hypothesis in common_utils, tests are not derandomized
test_to_list (jit.test_list_dict.TestList)
Unit tests for Tensor.tolist() function. ... ok
----------------------------------------------------------------------
Ran 1 test in 0.329s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33472
Differential Revision: D20109738
Pulled By: SplitInfinity
fbshipit-source-id: a6e3fee5e3201d5e1f0c4ca45048488ae2bf5e33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33806
as title
Test Plan: Imported from OSS
Differential Revision: D20122117
Pulled By: suo
fbshipit-source-id: 209d29ed2c873181140c9fb5cdc305c200ce4008
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33885Fixes: #32835Fixes: #5834
Can not combine with CUDA's implementation as each of them requires individual `std::once_flag` as well as different `forked_autograd_child` functions. CUDA version relays to python module, autograd uses TORCH_CHECK to report error to python and cpp.
Test Plan: Imported from OSS
Differential Revision: D20144024
Pulled By: VitalyFedyunin
fbshipit-source-id: e7cf30568fff5110e9df7fe5b23f18ed992fa17f
Summary:
In *_like functions we call
`globalLegacyTypeDispatch().initForDispatchKeySet(c10::detail::multi_dispatch_key_set(self, options));` -> `dispatchKeyToBackend` and thus this change.
`self` has both `XLAPreAutograd` and `XLATensorId` in key set.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33848
Differential Revision: D20135898
Pulled By: ailzhang
fbshipit-source-id: a8585f39f3fa77b53718f20d3144f4f2f3cb8e53
Summary:
Conda registers a suffixed slash as a new user so it was failing to
upload the anaconda packages.
In the future this should be handled through a single variable that can
be used for both but until then this will have to do.
Bug was introduced in https://github.com/pytorch/pytorch/issues/33842
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33903
Differential Revision: D20148679
Pulled By: seemethere
fbshipit-source-id: 27c95f5d906ce84aa34bf5d76fd6f1ef5df08fb9
Summary:
…/xla this will result in a failure since it is comparing a XLA tensor with a CPU tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33635
Differential Revision: D20043517
Pulled By: ailzhang
fbshipit-source-id: d84038ea675e4d4a9c02e7a8b0924bdb12f40501
Summary:
`.data` calls are unsafe and should not be used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33874
Differential Revision: D20141059
Pulled By: izdeby
fbshipit-source-id: 8e11afc74f0cb04f5b18b458068fb813a6d51708
Summary:
**Summary**
There is often a need to create a Tensor when writing IR by hand for JIT
optimisation pass unit tests. The only options for this today are real
Tensor creation functions like `aten::ones`. Any test that uses these functions
must also use the same default arguments as the Python/C++ API, which means
that all of the tests have to be updated when the API is updated. This commit
introduces a new primitive, `prim::MakeTestTensor` with schema `() -> Tensor` that
should be used in unit tests instead of real Tensor creation functions. This new
primitive has no public-facing API, so the maintenance burden is much lower.
**Testing**
This commit updates the alias analysis and DCE tests to use `prim::MakeTestTensor` instead of
`aten::rand`, `aten::ones`, and `aten::zeros`.
```
$ ./bin/test_jit
CUDA not available. Disabling CUDA and MultiCUDA tests
Note: Google Test filter = *-*_CUDA:*_MultiCUDA
[==========] Running 75 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 75 tests from JitTest
[ RUN ] JitTest.ADFormulas
[ OK ] JitTest.ADFormulas (82 ms)
[ RUN ] JitTest.Attributes
[ OK ] JitTest.Attributes (0 ms)
...
...
...
[ RUN ] JitTest.LiteInterpreterPrim
[ OK ] JitTest.LiteInterpreterPrim (0 ms)
[ RUN ] JitTest.LiteInterpreterLoadOrigJit
[ OK ] JitTest.LiteInterpreterLoadOrigJit (2 ms)
[----------] 75 tests from JitTest (150 ms total)
[----------] Global test environment tear-down
[==========] 75 tests from 1 test case ran. (150 ms total)
[ PASSED ] 75 tests.
```
**Fixes**
This pull request fixes https://github.com/pytorch/pytorch/issues/33500.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33595
Differential Revision: D20127441
Pulled By: SplitInfinity
fbshipit-source-id: 56da4f23ac46335227254f606c6481718108f378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33173
How to deal with ops that’s defined for both floating point and quantized Tensor?
Category of ops: the ones that doesn’t require observers, which means the quantization parameters(scale/zero_point) of the output of this op can be inferred from the quantization parameters of inputs.
For example:
avg_pool, max_pool, flatten, transpose, upsample
Another related topic to previous one is how do we deal with things like adaptive_avg_pool2d that does not require to be observed and it works with quantized tensor as well? If we insert quant/dequant for them, even the quant fusion becomes a numerically changing operation because the scale/zero_point for input and output are different.
Proposal
We can swap the operator with dequantize whenever we see it. For example, for pattern
Let’s say aten::general_op is defined for both floating point and quantized
%r = aten::conv(...)
%q = quantize(%r)
%dq = dequantize(%q)
%f = aten::general_op(%dq)
...
We detect that all inputs of aten::general_op is produced by dequantize, we’ll first delete all the dequantize for the inputs and then insert dequantize for each use of the output of the aten::general_op, note that this should work generally for all the case we might encounter.
After transformation we’ll have:
%r = aten::conv(...)
%q = quantize(%r)
%x = aten::general_op(%q)
%f = dequantize(%x)
...
1. Multiple inputs
1. We need to make sure all inputs of the aten::general_op are produced by dequantize before we do this transformation
2. Input used by multiple operators
1. We already did this by inserting dequantize for each use of the value
3. Output used by multiple operators
1. We’ll reuse the code that inserts dequantize(might need some refactor)
Note that current concat does not belong to this category right now since it does not inherit quantization parameters from inputs.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20123590
fbshipit-source-id: de2febe1f37e4079457a23acaeccbc6d9c9e1f8a
Summary:
I've been using pytorch with type hintings, and I found errors that can be easily fixed. So I'm creating this PR to fix type bugs.
I expected below code should be type-checked without any errors.
```python
import torch
from torch.nn import Linear
from torch.autograd import Variable
from torch.optim import AdamW
from torch.utils import hooks
# nn.Module should have training attribute
module = Linear(10, 20)
module.training
# torch should have dtype bfloat16
tensor2 = torch.tensor([1,2,3], dtype=torch.bfloat16)
# torch.Tensor.cuda should accept int or str value
torch.randn(5).cuda(1)
torch.tensor(5).cuda('cuda:0')
# optimizer should have default attribute
module = Linear(10, 20)
print(AdamW(module.weight).default)
# torch.Tensor should have these boolean attributes
torch.tensor([1]).is_sparse
torch.tensor([1]).is_quantized
torch.tensor([1]).is_mkldnn
# Size class should tuple of int
a, b = torch.tensor([[1,2,3]]).size()
# check modules can be accessed
torch.nn.parallel
torch.autograd.profiler
torch.multiprocessing
torch.sparse
torch.onnx
torch.jit
torch.hub
torch.random
torch.distributions
torch.quantization
torch.__config__
torch.__future__
torch.ops
torch.classes
# Variable class's constructor should return Tensor
def fn_to_test_variable(t: torch.Tensor):
return None
v = Variable(torch.tensor(1))
fn_to_test_variable(v)
# check RemovableHandle attributes can be accessed
handle = hooks.RemovableHandle({})
handle.id
handle.next_id
# check torch function hints
torch.is_grad_enabled()
```
But current master branch raises errors. (I checked with pyright)
```
$ pyright test.py
Searching for source files
Found 1 source file
test.py
12:45 - error: 'bfloat16' is not a known member of module
15:21 - error: Argument of type 'Literal[1]' cannot be assigned to parameter 'device' of type 'Optional[device]'
'int' is incompatible with 'device'
Cannot assign to 'None'
16:22 - error: Argument of type 'Literal['cuda:0']' cannot be assigned to parameter 'device' of type 'Optional[device]'
'str' is incompatible with 'device'
Cannot assign to 'None'
23:19 - error: Cannot access member 'is_sparse' for type 'Tensor'
Member 'is_sparse' is unknown
24:19 - error: Cannot access member 'is_quantized' for type 'Tensor'
Member 'is_quantized' is unknown
25:19 - error: Cannot access member 'is_mkldnn' for type 'Tensor'
Member 'is_mkldnn' is unknown
32:7 - error: 'autograd' is not a known member of module
33:7 - error: 'multiprocessing' is not a known member of module
34:7 - error: 'sparse' is not a known member of module
35:7 - error: 'onnx' is not a known member of module
36:7 - error: 'jit' is not a known member of module
37:7 - error: 'hub' is not a known member of module
38:7 - error: 'random' is not a known member of module
39:7 - error: 'distributions' is not a known member of module
40:7 - error: 'quantization' is not a known member of module
41:7 - error: '__config__' is not a known member of module
42:7 - error: '__future__' is not a known member of module
44:7 - error: 'ops' is not a known member of module
45:7 - error: 'classes' is not a known member of module
60:7 - error: 'is_grad_enabled' is not a known member of module
20 errors, 0 warnings
Completed in 1.436sec
```
and below list is not checked as errors, but I think these are errors too.
* `nn.Module.training` is not boolean
* return type of `torch.Tensor.size()` is `Tuple[Unknown]`.
---
related issues.
https://github.com/pytorch/pytorch/issues/23731, https://github.com/pytorch/pytorch/issues/32824, https://github.com/pytorch/pytorch/issues/31753
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33762
Differential Revision: D20118884
Pulled By: albanD
fbshipit-source-id: 41557d66674a11b8e7503a48476d4cdd0f278eab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33603
This function returns ScalarType based on its value. This is helpful
to avoid code generated in aten_op.h has returned Scalars depending on
arg self to determine its type.
Test Plan: Imported from OSS
Differential Revision: D20100218
Pulled By: ezyang
fbshipit-source-id: 337729a7559e6abb3a16b2a563a2b92aa96c7016
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33510
Previously, we would fill in TensorOption with defaults whenever an
item was missing from both the left and right side of the merge. This
is morally incorrect: if we don't have an item on the left or right,
we should keep the entry empty (so the downstream user can apply
the appropriate defaulting rule).
I don't think this caused any bugs, but I noticed this error when
working on a later patch in my diff stack.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20001775
Pulled By: ezyang
fbshipit-source-id: 88139fc268b488cd1834043584a0d73f46c8ecaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33505
This shouldn't change semantics, but it has the benefit of making
torch::empty_like(x, dtype(kFloat)) actually work (previously, this
would just ignore all of the properties from x).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20001776
Pulled By: ezyang
fbshipit-source-id: ba81186d3293abc65da6130b2684d42e9e675208
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32289
This has been fixed upstream as of Python 3.8.2. I think the easiest and least invasive way to ameliorate this is to catch the error condition and print a more informative error asking the user to update their Python version. It might be possible to buffer the data into memory and then read from memory, but that would be an invasive change and might cause memory exhaustion for very large models.
Suggestions for alternate fixes or ways to improve the error message wording are very welcome.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33824
Differential Revision: D20131722
Pulled By: ezyang
fbshipit-source-id: a6e3fbf4bf7f9dcce5772b36f7a622cbf14b5ae4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33610
Our pybind definitions for several RPC functions didn't release GIL
once we were processing stuff in C++.
This PR adds asserts that we release GIL appropriately and adds
py::gil_scoped_release and py::gil_scoped_acquire in the appropriate places.
ghstack-source-id: 99066749
Test Plan: waitforbuildbot
Differential Revision: D20025847
fbshipit-source-id: 57a778cba0336cf87352b07c89bbfb9254c4bdd7
Summary:
Stacked PRs
* **#33578 - [jit] Unify augmented assign handling**
* #32993 - [jit] Fix aug assign for non-tensor attributes
We handle augmented assignments to `Select` and `Var` statements differently, but the actual in place update is the same for both, so this PR factors it out into a method so we don't have 2 code paths doing the same thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33578
Pulled By: driazati
Differential Revision: D20127647
fbshipit-source-id: 94f37acbd2551498de9d2ca09a514508266f7d31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33711Fixed#33480
This makes `dist_autograd.backward` and `dist_optimizer.step` functional by making the user explicitly pass in the `context_id` as opposed to relying on the confusing thread_local context_id.
This diff incorporates these API changes and all places where these functions are called.
More concretely, this code:
```
with dist_autograd.context():
# Forward pass.
dist_autograd.backward([loss.sum()])
dist_optim.step()
```
should now be written as follows:
```
with dist_autograd.context() as context_id:
# Forward pass.
dist_autograd.backward(context_id, [loss.sum()])
dist_optim.step(context_id)
```
Test Plan: Ensuring all existing dist_autograd and dist_optimizer tests pass with the new API. Also added a new test case for input checking.
Differential Revision: D20011710
fbshipit-source-id: 216e12207934a2a79c7223332b97c558d89d4d65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33531
We already insert dequantize for each use of the value, but there might still be cases where we only
see the value is used multiple times after inline. This pass adds the support to replicate dequantize
after inline to ensure output of dequantize is only used by one node, which is necessary to preserve all
quantization patterns like `dequant - conv - quant`
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D20123591
fbshipit-source-id: 6edb10a4566538bcf9379d332233f870372b7a63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33779
This should eliminate random warnings and print spew from test_jit.
It also fixes a bug where we weren't properly comparing captured outputs
(!)
Test Plan: Imported from OSS
Differential Revision: D20124224
Pulled By: suo
fbshipit-source-id: 9241d21fdf9470531b0437427b28e325cdf08d3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33369
This PR add RRef type infer rule when we try to infer a type from a
pyobject, this allow script module attributes could contain a rref,
(i.e. List[RRefs] as a module attribute)
Test Plan: Imported from OSS
Differential Revision: D19918320
Pulled By: wanchaol
fbshipit-source-id: e5fd99c0ba5693b22ed48f0c0550b5e1dac89990
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33504
Fix resolution fo functions that are bound onto torch in torch/functional.py. This does not fix compilation of all of those functions, those will be done in follow ups. Does torch.stft as a start.
Fixes#21478
Test Plan: Imported from OSS
Differential Revision: D20014591
Pulled By: eellison
fbshipit-source-id: bb362f1b5479adbb890e72a54111ef716679d127
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29495
This PR adds support for `_modules`, making it so we no longer need to special case support for `nn.Sequential`. I was getting internal errors around the previous approach using `self.define()`, so i am adding this PR as part of the stack.
Fix for https://github.com/pytorch/pytorch/issues/28998
Test Plan: Imported from OSS
Differential Revision: D18412561
Pulled By: eellison
fbshipit-source-id: a8b24ebee39638fccf63b2701f65f8bb0de84faa
Summary:
This sets up PIP_UPLOAD_FOLDER to point to the correct channel for
release candidates as opposed to nightlies.
Removes an old safety check that's not needed anymore for devtoolset3
And provides a nice default for PIP_UPLOAD_FOLDER, which should clear up
confusion on where it's initially set
This is a stepping stone towards the promotable pipeline.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33842
Differential Revision: D20130791
Pulled By: seemethere
fbshipit-source-id: dac94ef46299574c36c08c968dd36faddeae6363
Summary:
port `masked_fill` from TH to ATen with TensorIterator.
single core performance roughly stays the same, single socket performance has **3~16x** boost.
`masked_fill` is missing from https://github.com/pytorch/pytorch/issues/24507
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33330
Differential Revision: D20098812
Pulled By: VitalyFedyunin
fbshipit-source-id: ff20712ffc00cc665550997abcfdfb8916c18e40
Summary:
Print a complete and comprehensive error message with a description of the issue when an op is missing during ONNX export (previously an ambiguous "key not in registry" error was thrown which was not helpful for the user to understand the failure).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33593
Reviewed By: hl475
Differential Revision: D20052213
Pulled By: houseroad
fbshipit-source-id: ae3010a97efdab26effad5e4a418e9cc41f5b04e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33735
This apparently used to create a new storage, but I couldn't find anywhere in the code where this actually happens.
Changing it to an assert to see what happens.
Test Plan: Imported from OSS
Differential Revision: D20084029
Pulled By: gchanan
fbshipit-source-id: e9c4db115a25fc2e17a3b166c1ff5a0e6b56d690
Summary:
Stacked PRs
* **#33578 - [jit] Unify augmented assign handling**
* #32993 - [jit] Fix aug assign for non-tensor attributes
We handle augmented assignments to `Select` and `Var` statements differently, but the actual in place update is the same for both, so this PR factors it out into a method so we don't have 2 code paths doing the same thing.
](https://our.intern.facebook.com/intern/diff/20010383/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33578
Pulled By: driazati
Differential Revision: D20010383
fbshipit-source-id: 52e559ce907e95e5c169ab9d9690d0d235db36f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30426
This PR adds `assert_tensor_equal` and `assert_tensor_not_equal` to `test/cpp/api/support.h`, as better functions for testing whether two tensors are equal / not equal.
Test Plan: Imported from OSS
Differential Revision: D18695900
Pulled By: yf225
fbshipit-source-id: c19b9bc4c4e84d9f444015023649d27618fcbdf5
Summary:
This might lead to silent undefined behaviour (e.g. with out-of-bound indices). This affects `test_multinomial_invalid_probs_cuda` which is now removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32719
Test Plan:
* Build with VERBOSE=1 and manually inspect `less ndebug.build.log | grep 'c++' | grep -v -- -DNDEBUG` (only with nina on Linux)
* CI
Fixes https://github.com/pytorch/pytorch/issues/22745
Differential Revision: D20104340
Pulled By: yf225
fbshipit-source-id: 2ebfd7ddae632258a36316999eeb5c968fb7642c
Summary:
Thanks to pjh5 for continued use of his account to upload binaries but I
think we can start using a bot account now for this.
Just a draft until we can ensure the env variables get injected correctly and the token can actually upload
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33786
Differential Revision: D20122423
Pulled By: seemethere
fbshipit-source-id: 0444584831a40ae730325d258935f6d1b873961b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/23925
This fixes the incorrect gradients returned by `F.grid_sample` at image borders under `"border"` and `"reflection"` padding modes.
At nondifferentiable points, the choice of which gradient to return among its super- or subgradients is rather arbitrary and generally does not affect training. Before this change, however, a bug in the code meant that the gradient returned at the exact borders was not selected from among the super- or subgradients.
The gradient is now set to zero at the borders, which is a defensible choice for both the `"border"` and `"reflection"` padding modes:
* For `"border"` padding, this effectively means that the exact borders of the image are now considered out of bounds, and therefore receive zero gradient.
* For `"reflection"` padding, this effectively treats the exact borders as extrema.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32829
Differential Revision: D20118564
Pulled By: soumith
fbshipit-source-id: ef8571ff585be35ab1b90a922af299f53ab9c095
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33765
quantize and dequantize methods now make use of multiple threads. This makes use of shz0116's recent parallelization of quantize/dequantize routines in FBGEMM.
Fixes:
https://github.com/pytorch/pytorch/issues/32006https://github.com/pytorch/FBGEMM/issues/142
Alternative to https://github.com/pytorch/pytorch/pull/30153
```
#!/usr/bin/env python
import time
import torch
import torch.nn as nn
torch.set_num_threads(4)
# print(torch.__config__.parallel_info())
W = torch.rand(1, 54, 54, 256)
NITER = 1000
s = time.time()
for i in range(NITER):
W_q = torch.quantize_per_tensor(W, scale=1.0, zero_point = 0, dtype=torch.quint8)
time_per_iter = (time.time() - s) / NITER
print('quantize time per iter ms', time_per_iter * 1000)
s = time.time()
for i in range(NITER):
W_deq = W_q.dequantize()
time_per_iter = (time.time() - s) / NITER
print('dequantize time per iter ms', time_per_iter * 1000)
```
### With 1 thread
quantize time per iter ms 0.22633790969848633
dequantize time per iter ms 0.6573665142059326
### With 4 threads
quantize time per iter ms 0.0905618667602539
dequantize time per iter ms 0.19511842727661133
ghstack-source-id: 98935895
Test Plan: python test/test_quantized.py
Reviewed By: jspark1105
Differential Revision: D20098521
fbshipit-source-id: bd8c45761b4651fcd5b20b95759e3868a136c048
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33667
Pass shared_ptr properly according to C++ guidances. Thank kimishpatel for pointing it out.
Test Plan: Imported from OSS
Differential Revision: D20111001
Pulled By: iseeyuan
fbshipit-source-id: 213a0f950a7f3b9199d789dc0155911f6102d77a
Summary:
Also, windows memory failures responsible for the earlier reversion have been fixed.
This PR (initially) contains 2 commits:
* a revert of the revert
* all changes to implement the original Apex scale update heuristic, squashed into a single commit for easier diff review
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33366
Differential Revision: D20099026
Pulled By: ngimel
fbshipit-source-id: 339b9b6bd5134bf055057492cd1eedb7e4461529
Summary:
Fixes an issue with `cdist` backward calculation for large inputs for the euclidean case.
The grid size when launching the kernel exceeded the 2^16 limit for the second dimension, resulting in `RuntimeError: CUDA error: invalid configuration argument`
Code to reproduce:
```
h, w, d = 800, 1216, 12
n = 133
A = torch.randn(n, d).cuda()
B = torch.randn(h, w, d).cuda()
A.requires_grad = True
B.requires_grad = True
B = B.reshape(-1, d).contiguous()
dist = torch.cdist(A, B)
loss = dist.sum()
loss.backward()
```
Thanks to tkerola for the bug report, reproduction and suggesting a solution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31167
Differential Revision: D20035605
Pulled By: ngimel
fbshipit-source-id: ae28ba4b549ee07a8bd937bb1de2438dc24eaa17
Summary:
removed padding and dilation from LPPool2d Doc as the function dose not support padding and dilation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33714
Differential Revision: D20097021
Pulled By: ngimel
fbshipit-source-id: fc1c2d918b32f4b45c7e6e6bd93f018e867a628f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33749
Disable printing of the histogram when dump to make the log cleaner.
Test Plan: CI
Reviewed By: amylittleyang
Differential Revision: D20087735
fbshipit-source-id: 5421cd9d25c340d92f29ce63fed2a58aefef567d
Summary:
Most of the function implementation and test code are translated from the Python version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33652
Differential Revision: D20052211
Pulled By: yf225
fbshipit-source-id: ce6767db54364f91ef4f06674239a12278c2752a
Summary:
The function originally comes from 4279f99847/tensorflow/python/ops/summary_op_util.py (L45-L68)
As its comment says:
```
# In the past, the first argument to summary ops was a tag, which allowed
# arbitrary characters. Now we are changing the first argument to be the node
# name. This has a number of advantages (users of summary ops now can
# take advantage of the tf name scope system) but risks breaking existing
# usage, because a much smaller set of characters are allowed in node names.
# This function replaces all illegal characters with _s, and logs a warning.
# It also strips leading slashes from the name.
```
This function is only for compatibility with TF's operator name restrictions, and is therefore no longer valid in pytorch. By removing it, tensorboard summaries can use more characters in the names.
Before:
After:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33133
Differential Revision: D20089307
Pulled By: ezyang
fbshipit-source-id: 3552646dce1d5fa0bde7470f32d5376e67ec31c6
Summary:
CMake only views the first item of `CC` and `CXX` as executable. So calling `sccache.exe` directly won't work. Using a shim executable resolves this problem.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33745
Differential Revision: D20100397
Pulled By: soumith
fbshipit-source-id: 3a130d30dd548b7c2e726c064e66ae4fccb30c44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32813
We need to separate the step to make the logic more clear
and also to find all the values we want to skip in advance
without the interference of inserted observers
Test Plan:
.
Imported from OSS
Differential Revision: D20087841
fbshipit-source-id: ec3654ca561c0d4e2c05011988bb9ecc8671c5c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33225
This removes a redundant assert statement in `record_function_ops`. In
the else branch in question, we are guaranteed to have `current == &rec`, so
this assert will never fire.
Although, maybe we should add an assert failure when `current == &rec` since it
seems that `current` should always be profiler::record_function_exit.
ghstack-source-id: 98852219
Test Plan: Existing autograd profiler UTs past
Differential Revision: D19849145
fbshipit-source-id: 2014a0d3b9d11e5b64942a54e0fb45e21f46cfa2
Summary:
**Summary**
This commit adds a script that fetches a platform-appropriate `clang-format` binary
from S3 for use during PyTorch development. The goal is for everyone to use the exact
same `clang-format` binary so that there are no formatting conflicts.
**Testing**
Ran the script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33644
Differential Revision: D20076598
Pulled By: SplitInfinity
fbshipit-source-id: cd837076fd30e9c7a8280665c0d652a33b559047
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33431
Some elementwise operators don't have shape and type inference specified for the output tensor: `BitwiseOr`, `BitwiseAnd`, `BitwiseXor`, `Not`, `Sign`.
This change fixes this issue:
- For `Not` and `Sign` operators, the output has the same type and shape as the input, so `IdenticalTypeAndShapeOfInput` function is used to specify that.
- For bitwise operators created by `CAFFE2_SCHEMA_FOR_BINARY_BITWISE_OP` macro, the type and shape inference rules should be the same as for other binary element-wise operators, so `TensorInferenceFunction(ElementwiseOpShapeInference)` is used to specify that.
Also some tests were modified to ensure that the shape and type are inferred (`ensure_outputs_are_inferred` parameter)
Test Plan:
```
CAFFE2_ASSERT_SHAPEINFERENCE=1 buck test caffe2/caffe2/python/operator_test:elementwise_ops_test
CAFFE2_ASSERT_SHAPEINFERENCE=1 buck test caffe2/caffe2/python/operator_test:math_ops_test
```
Note that the tests have to be executed with `CAFFE2_ASSERT_SHAPEINFERENCE=1` in order to fail upon shape inference failure.
Reviewed By: idning
Differential Revision: D19880164
fbshipit-source-id: 5d7902e045d79e5669e5e98dfb13a39711294939
Summary:
Resolve https://github.com/pytorch/pytorch/issues/33699
`torch/__init__.pyi` will be generated like
```python
# TODO: One downside of doing it this way, is direct use of
# torch.tensor.Tensor doesn't get type annotations. Nobody
# should really do that, so maybe this is not so bad.
class Tensor:
requires_grad: _bool = ...
grad: Optional[Tensor] = ...
# some methods here...
overload
def bernoulli_(self, p: _float=0.5, *, generator: Generator=None) -> Tensor: ...
def bfloat16(self) -> Tensor: ...
def bincount(self, weights: Optional[Tensor]=None, minlength: _int=0) -> Tensor: ...
# some methods here...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33747
Differential Revision: D20090316
Pulled By: ngimel
fbshipit-source-id: b9ce4c0d4ef720c94ccac0a0342a012e8cf3af0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33696
This changes two tests:
- The batchnorm inference cannot change the memory format of the weights as they are 1D. So this is removed.
- The batchnorm test now run both in affine and not affine mode.
- I added back the test for type errors using .data. In particular, `.data` allows to change the type of a Tensor inplace (very bad, never do it!) but since it is possible, we should test it until .data is removed.
cc Enealor who did the first version of the PR.
Test Plan: Imported from OSS
Differential Revision: D20069241
Pulled By: albanD
fbshipit-source-id: a0348f40c44df38d654fb2a2b2b526d9d42f598a
Summary:
The following script reproduces the hang
```py
import multiprocessing, logging
logger = multiprocessing.log_to_stderr()
logger.setLevel(multiprocessing.SUBDEBUG)
import torch
class Dataset:
def __len__(self):
return 23425
def __getitem__(self, idx):
return torch.randn(3, 128, 128), idx % 100
ds = Dataset()
trdl = torch.utils.data.DataLoader(ds, batch_size=64, num_workers=300, pin_memory=True, shuffle=True)
for e in range(1000):
for ii, (x, y) in enumerate(trdl):
print(f'tr {e: 5d} {ii: 5d} avg y={y.mean(dtype=torch.double).item()}')
if ii % 2 == 0:
print("="*200 + "BEFORE ERROR" + "="*200)
1/0
```
The process will hang at joining the putting thread of `data_queue` in **main process**. The root cause is that too many things are put in the queue from the **worker processes**, and the `put` at 062ac6b472/torch/utils/data/dataloader.py (L928) is blocked at background thread. The `pin_memory_thread` exits from the set `pin_memory_thread_done_event`, without getting the `(None, None)`. Hence, the main process needs the same treatment as the workers did at
062ac6b472/torch/utils/data/_utils/worker.py (L198) .
After the patch, the script finishes correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33721
Differential Revision: D20089209
Pulled By: ezyang
fbshipit-source-id: e73fbfdd7631afe1ce5e1edd05dbdeb7b85ba961
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33419
These conditions are for the specific implementation, the fallback implementation works without these checks. So use that if any of these checks isn't true.
ghstack-source-id: 98836075
Test Plan: Previously got error for special case where k=0 which has gone. The error was in some complicated autograd, and I'm not sure how and where an simple regression test should be added.
Differential Revision: D19941103
fbshipit-source-id: e1c85d1e75744b1c51ad9b71c7b3211af3c5bcc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33727
Some small changes to adagrad (tiny bit faster, though there is more interesting diff in the stack on this).
Test Plan: Part of the stack
Reviewed By: chocjy
Differential Revision: D20029499
fbshipit-source-id: 7f4fddb9288d7881ef54673b17a0e19ef10d64c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33537
Cases of embeddings smaller than 128, we can get a bit more compute by
allocating less threads per block.
Test Plan: Unit-test, benchmark.
Reviewed By: xianjiec
Differential Revision: D19969594
fbshipit-source-id: 6cc6b14fc61302804bed9093ea3591f21e3827d8
Summary:
This PR adds the following items:
- **1st item**: `ArrayRef<TensorIndex>` and `std::initializer_list<TensorIndex>` overloads for `Tensor::index` and `Tensor::index_put_`, to be used specifically for multi-dim indexing purpose.
Design rationale:
* C++ `Tensor::index` and `Tensor::index_put_` are both existing tensor APIs, and they currently (before this PR) only accept a list of tensors (i.e. `ArrayRef<Tensor>`) as indices. If we change their signatures to also accept non-tensors as indices (i.e. `ArrayRef<TensorIndex>`, and `TensorIndex` is convertible from `Tensor` / `Slice` / `None` / `Ellipsis`), it would slow down the original code path (since now it has to go through more steps), which is undesirable.
To get around this problem, the proposed solution is to keep the original `ArrayRef<Tensor>` overload, and add `ArrayRef<TensorIndex>` and `std::initializer_list<TensorIndex>` overloads to `Tensor::index` and `Tensor::index_put_`. This way, the original code path won’t be affected, and the tensor multi-dim indexing API is only used when the user explicitly pass an `ArrayRef<TensorIndex>` or a braced-init-list of `TensorIndex`-convertible types to `Tensor::index` and `Tensor::index_put_` .
Note that the above proposed solution would still affect perf for the user’s original `Tensor::index` or `Tensor::index_put_` call sites that use a braced-init-list of tensors as input, e.g. `tensor.index({...})` or `tensor.index_put_({...}, value)`, since now such function calls would take the multi-dim indexing path instead of the original advanced indexing path. However, there are only two instances of this in our codebase (one in ATen cpp test, one in a C++ API nn init function), and they can be easily changed to explicitly use `ArrayRef<Tensor>` as input (I changed them in this PR). For external user’s code, since this is part of the C++ frontend which is still considered experimental, we will only talk about this change in the release note, and ask users to switch to using `ArrayRef<Tensor>` explicitly if they want to keep using the original advanced indexing code path.
- **2nd item**: Mechanisms for parsing `ArrayRef<TensorIndex>` indices and performing indexing operations (mirroring the functions in `torch/csrc/autograd/python_variable_indexing.cpp`).
- **3rd item**: Simple tests to demonstrate that the `Tensor::index()` and `Tensor::index_put_()` APIs work. I will add more tests after the first few PRs are reviewed.
- **4th item**: Merge Python/C++ indexing code paths, for code simplicity. I tested locally and found that there is no perf regression resulting from the merge. I will get more concrete numbers for common use cases when we settle on the overall design.
This PR supersedes https://github.com/pytorch/pytorch/pull/30425.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32841
Differential Revision: D19919692
Pulled By: yf225
fbshipit-source-id: 7467e64f97fc0e407624809dd183c95ea16b1482
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33722
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding native implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Test Plan:
Build: CI
Functionality: Not exposed
Reviewed By: dreiss
Differential Revision: D20069796
Pulled By: AshkanAliabadi
fbshipit-source-id: d46c1c91d4bea91979ea5bd46971ced5417d309c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32812
We'll error out for the case we can't handle inside the function,
instead of checking each time in the callsite
Test Plan:
.
Imported from OSS
Differential Revision: D20087846
fbshipit-source-id: ae6d33a94adf29c4df86d67783e7ef8753c91f90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32891
- Add JitDistAutoGradTest into fork/spawn test launcher
- Add JitRpcTest into fork/spawn test launcher
ghstack-source-id: 98900090
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_spawn
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_spawn
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_fork_thrift
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_spawn
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:rpc_spawn_thrift
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_fork
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_fork_thrift
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_spawn
buck test mode/dev-nosan //caffe2/test/distributed/rpc/jit:dist_autograd_spawn_thrift
```
Differential Revision: D5785394
fbshipit-source-id: 335a85424d22f1a83874be81a8139499c9a68ce2
Summary:
This PR improves performance of EmbeddingBag on cuda by removing 5 kernel launches (2 of those are synchronizing memcopies).
- 2 memcopies are checking values of offsets[0] and offsets[-1] to be in expected range (0 for the former, less than number of indices for the latter). It seems strange to check only those 2 values, if users are providing invalid offsets, invalid values can be anywhere in the array, not only the first and last element. After this PR, the checks are skipped on cuda, the first value is forced to 0, if the last value is larger than expected, cuda kernel will assert. It is less nice than ValueError, but then again, the kernel could have asserted if other offset values were invalid. On the cpu, the checks are moved inside the cpu implementation from functional.py, and will throw RuntimeError instead of ValueError.
- 3 or 4 initializations (depending on the mode) of the output tensors with .zeros() are unnecessary, because every element of those tensors is written to, so their data can be uninitialized on the start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33589
Reviewed By: jianyuh
Differential Revision: D20078011
Pulled By: ngimel
fbshipit-source-id: 2fb2e2080313af64adc5cf1b9fc6ffbdc6efaf16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33359
Updated alias analysis kind to FROM_SCHEMA so input tensors can be marked as nonmutable
when appropriate, allowing for constant folding of these tensors.
Needed to update the schemas of the _out variants with annotations to mark the output input
tensor as aliased and mutable.
Test Plan:
```
import torch
class M(torch.nn.Module):
def __init__(self):
super(M, self).__init__()
def forward(self, x):
w = torch.tensor([3], dtype=torch.float)
w = torch.quantize_per_tensor(w, 1.0, 0, torch.qint8)
y = torch.tensor([3], dtype=torch.float)
y = torch.quantize_per_tensor(w, 1.0, 0, torch.qint8)
return torch.ops.quantized.add_out(x, w, y)
m = torch.jit.script(M())
torch._C._jit_pass_constant_propagation(m.graph)
print(m.graph)
```
```
graph(%self : __torch__.___torch_mangle_9.M,
%x.1 : Tensor):
%11 : int = prim::Constant[value=12]() # <ipython-input-11-1dd94c30cb58>:9:49
%9 : float = prim::Constant[value=1.]() # <ipython-input-11-1dd94c30cb58>:9:41
%10 : int = prim::Constant[value=0]() # <ipython-input-11-1dd94c30cb58>:9:46
%36 : QInt8(1) = prim::Constant[value={3}]()
%y.2 : Tensor = aten::quantize_per_tensor(%36, %9, %10, %11) # <ipython-input-11-1dd94c30cb58>:11:12
%24 : Tensor = quantized::add_out(%x.1, %36, %y.2) # <ipython-input-11-1dd94c30cb58>:12:15
return (%24)
```
As expected, the aten::quantize_per_tensor() for w is now folded. The aten::quantize_per_tensor()
for y is not folded, since that tensor is aliased/modified.
Differential Revision: D19910667
fbshipit-source-id: 127071909573151dc664500d363399e3643441b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32809
This is a refactor to help further changes to quantization.cpp
We want some operations on the graph happen before we call insertObserver for invoked methods,
especially `addIntermediateValuesToSkipObserver` since we want to skip the input of the ReLU
module in `Conv - ReLU` pattern.
Test Plan:
test_jit.py
test_quantization.py
Imported from OSS
Differential Revision: D20087844
fbshipit-source-id: 28b7fa0c7ce9e254ab9208eb344893fb705e14d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33464
I added a python-exposed knob to register this pass in custom passes pipeline. If the knob is not used, the pass is not registered and thus not run at all.
Differential Revision: D19958217
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: fecdd98567fcda069fbdf8995c796899a3dbfa5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33682
Previously, there were two API's for CPU and CUDA. This change keeps one top level API, i.e `fake_quantize_per_tensor_affine` and `fake_quantize_per_channel_affine` and uses the device type to dispatch to different backends (CPU and CUDA).
CPU kernel implementation is in QuantizedOpKernels.cpp
CUDA kernel implementation is in fake_quantize_core.cu
Test Plan:
python test/test_fake_quant.py
Benchmark Results for CPU
FakeQuantize tensor of size (2, 256, 128, 128)
Before:
per tensor quant ms 9.905877113342285
per channel quant ms 74.93825674057007
After:
per tensor quant ms 6.028120517730713
per channel quant ms 44.91588592529297
Imported from OSS
Differential Revision: D20072656
fbshipit-source-id: 0424f763775f88b93380a452e3d6dd0c90cb814b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32379
Folding Conv2d - BatchNorm2d modules means recalculate the weight and bias of Conv2d module by incorproating the parameters
of BatchNorm2d, and also change the method calls to calling only forward of Conv2d module, this involves change of both module
types and graph because the bias of Conv2d is a parameter when it has value and is an attribute when it is
None(since JIT code has assumption of prameter being Tensor in multiple places), therefore
we'll need to remove the bias attribute when it is None and add a bias attribute later. Since ClassType might be shared, we separate
remove and add in separate steps and also keep track of the processed graph to avoid modifying the graph and type multiple times.
However we'll have to record the slot index of bias as well so we can replay the slot removal on other instances of Conv2d module.
Test Plan:
tbd
Imported from OSS
Differential Revision: D20078719
fbshipit-source-id: cee5cf3764f3e0c0a4a2a167b78dbada2e3835cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33695
I'm not sure how this stuck around, but it has no effect.
Test Plan: Imported from OSS
Differential Revision: D20068867
Pulled By: gchanan
fbshipit-source-id: 79191338a8bc7a195e2b7265005ca6f00aab3818
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33626
For DDP we require the attributes to be registered as buffers. By doing this the value is broadcast from one device to the rest.
Test Plan:
Tested on actual model on GPU
Imported from OSS
Differential Revision: D20038839
fbshipit-source-id: 82e829fc3baca0b3262c3894a283c375eb08a4a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33205
A number of important use-cases are implemented:
- def(schema): defines a schema, with no implementation (alias
inferred from schema, by default)
- def(schema, fn_ptr): registers fn_ptr as a catch-all kernel
for the operation
- def(schema, lambda): registers lambda as a catch-all kernel
for the operation
- def(schema, torch::dispatch(dispatch_key, fn)), and
def(schema, torch::dispatch(device_type, fn)): registers
the function to only be executed when dispatch_key/device_type
is selected for use
- def(schema, TORCH_OPTIMIZED_FN(fn)): registers the function
as unboxed only, using the inline syntax
All of our code generated registrations in ATen are switched to
the new API.
Some aspects of the API which are not fully implemented:
- It's still not valid to omit the schema when registering a function
pointer, due to #32549
- Although it's possible to take advantage of top-level namespaces
ala torch::import("aten"), we don't use it because this results
in worse code (as we have to cat everything back together). This
is not an essential problem, we just need the internals to be less
stupid.
There are some aspects of the API which don't semantically make sense,
but I chose not to fix them in this PR:
- For some reason, TORCH_OPTIMIZED_FN uses the *runtime* wrapper to
do wrapping, rather than the compile time one which inlines the
function in. This means that there isn't any reason we should be
passing in the function pointer as a template argument; a regular
old argument ought to have worked fine. This is seemingly
consistent with the current API though; needs further investigation.
- There's no reason to optional<DispatchKey>, DispatchKey would
work just fine (use DispatchKey::Undefined for the nullopt case)
In the long term, we should swap the wrapper around: the new-style
API has the real implementation, and the old-style API is backwards
compatibility. However, this implies a lot of internal refactoring,
so I decided to short circuit around it to get this in faster
Ancillary changes:
- I stopped moving optional<DispatchKey>, it's literally just two
words, pass it by value please.
- Needed to add a & qualified version of RegisterOps::op, since
I'm storing RegisterOps as a member inside the new style
Namespace and I cannot conveniently get a rvalue reference
to it in that situation. (BTW, register_ = std::move(register_)
really doesn't work, don't try it!)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19856626
Pulled By: ezyang
fbshipit-source-id: 104de24b33fdfdde9447c104853479b305cbca9a
Summary: Used by segmentation model.
Test Plan: Ran segmentation model on mobile.
Reviewed By: iseeyuan
Differential Revision: D19881378
fbshipit-source-id: 87f00058050fd173fbff1e88987ce09007622b83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32959
in rpc torch script call path, we need to pickle/unpickle rref, this diff is added to make jit pickler/unpickler be able to pickle/unpickle rref. It is similar to what is implemented for PyRef::pickle() and PyRef::unpickle().
The pickling/unpickling design assumes it is always coupled with RPC calls. It is not needed to checkpoint a model with rref, before checkpointing the model, user should call ref.to_here() to get value inside rref.
The pickling process is:
1. push torch.distributed.rpc.rref global string
1. call rref.fork() and create rrefForkData, which is a few IDs and type str of the value held inside the rref, the IDs includes rref id, fork id, caller work id, callee work id, owner work id
2. push the rrefForkData
The unpickling process is:
1. read torch.distributed.rpc.rref global string, and retrieve the cached global lamda function
2. the globa lamda function will get rrefForkData
3. if callee is also owner work id, then get owner rref based on Ids inside rrefFork data and return the ownerRRef
4. if callee is not owner work id, then create user rref using the rrefForkData and return the userRRef
5. meanwhile owner rref will be notified and do reference counting correctly
During unpickling, a type_resolver is needed to parse type str. This type_resolver has python dependency, so we get it from rpc_agent, and pass it to unpickler during construction. So we added a type_resolver argumenmt to jit unpickler constructor in this diff.
ghstack-source-id: 98814793
Test Plan: unit test
Differential Revision: D19713293
fbshipit-source-id: 4fd776cdd4ce8f457c4034d79acdfb4cd095c52e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33570
In this PR, we are a bit more careful about avoiding zero-ing the output. Analysis as follows:
1) `mm` doesn't need zero_ because it never calls scal, which is the underlying problem.
2) for `mv`, which does call scal (in certain cases), we can just move the zeroing to where it would actually be a problem, namely when the scalar value is 0.
In this case we just run the non-BLAS version of the code.
Test Plan: Imported from OSS
Differential Revision: D20007665
Pulled By: gchanan
fbshipit-source-id: 1f3a56954501aa9b2940d2f4b35095b2f60089a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31666
List of changes:
1) Fix a case where torch.mv was not handling NaNs correctly. In particular, with a transposed tensor and expanded vector, NaNs in the output are kept, even if beta = 0.
This is handled in the `out=` case by zero-ing out the passed-in Tensor, but this can happen just the same with the non-out variant if the allocated tensor happens to have a NaN.
Also adds tests for this case.
NOTE: we zero out the output tensor in all cases for mv and mm, even though this is probably overkill. I didn't find another case where this would be a problem, but the old code at least
attempted to do this for all mv and mm calls and I didn't add comprehensive testing to be sure that it's not a problem.
2) on CPU: move mv, mv_out, mm, mm_out to be direct wrappers on _th_addmv, _th_addmm, rather than having their own wrappers in Declarations.cwrap.
Ths is to remove the magic around cpu_zero from the codegen, which simplifies the codegen and makes testing this easier.
Test Plan: Imported from OSS
Differential Revision: D19239953
Pulled By: gchanan
fbshipit-source-id: 27d0748d215ad46d17a8684696d88f4cfd8a917e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33645
Fix bug where we were trying to get a schema for prim::Constant, which is not registered as an operator.
ghstack-source-id: 98785729
Test Plan: buck test mode/dev //pytext/models/test:scripted_seq2seq_generator_test -- 'test_generator \(pytext\.models\.test\.scripted_seq2seq_generator_test\.ScriptedSeq2SeqGeneratorTest\)'
Differential Revision: D20050833
fbshipit-source-id: cc38510b0135b750fdf57fb9c1e66ce1d91ee128
Summary:
The current logic for vectorized/unrolled operations in CUDALoops.cuh applies bounds checking to loads and stores, [but not to the actual functor's execution](16d6c17845/aten/src/ATen/native/cuda/CUDALoops.cuh (L264)). In other words, for a block acting on the tail of a tensor that doesn't require the whole block to participate in memory transactions, many threads execute their functor on uninitialized data. For functors that only communicate with the outside world via the bounds-checked loads and stores, that's ok. The threads acting on garbage data never actually write their results. But [my proposed inf/nan checking kernel](https://github.com/pytorch/pytorch/pull/33366/files#diff-9701a2b34900195d160bdc234e001b79R70-R79) has the additional side effect of writing to a `found_inf` flag in global memory. For irregularly-shaped tensors where tail threads execute the functor on garbage data, these threads would sometimes see and report spurious infs/nans.
In general, we can't guarantee functors won't have side effects. For safety (and efficiency) we should apply bounds checking to the functor execution as well as the loads and stores.
Is it possible that other elementwise kernels (in addition to the strided/vectorized implementation) are also executing functors unconditionally? That would cause similar failures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33642
Differential Revision: D20062985
Pulled By: ngimel
fbshipit-source-id: 65b8d75a001ce57865ed1c0cf89105d33f3f4dd4
Summary:
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding **native** implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Reviewed By: dreiss
Differential Revision: D19521853
Pulled By: AshkanAliabadi
fbshipit-source-id: 99a1fab31d0ece64961df074003bb852c36acaaa
Summary:
Removes almost every usage of `.data` in test_torch to address part of https://github.com/pytorch/pytorch/issues/33629.
Lines 4706-4710 had to be refactored to allow this. The changed test is fundamentally the same, as it appears to be meant to confirm that using an input of a different type than the weight causes an appropriate error.
There is one remaining usage of `.data`, and it is on line 5132. This was left as the `set_` and `resize_` methods still mention `.data` explicitly. I figure the right time to remove this is when those methods have their runtime errors updated.
Note: ~~some tests are skipped locally, and so I am still verifying that nothing has been obviously broken.~~ Appears to be passing early tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33638
Differential Revision: D20062288
Pulled By: albanD
fbshipit-source-id: 672a6d7a20007baedb114a20bf1ddcf6c4c0a16a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33666
it's caused by a revert. So let's skip it.
Test Plan: ci
Reviewed By: hl475
Differential Revision: D20057382
fbshipit-source-id: d71af8efe68b31befcef5dddc372540e8a8ae2ac
Summary:
The same header `<torch/nn/functional/conv.h>` is included twice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33656
Differential Revision: D20056913
Pulled By: yf225
fbshipit-source-id: b1563035c9821731b99c26eec130ff0b9cc627a7
Summary:
Addresses https://github.com/pytorch/pytorch/issues/33300.
Calling .numpy() on a CUDA or non-strided (e.g. sparse) tensor segfaults in current PyTorch. This fixes the segfaults and throws the appropriate TypeError, as was intended.
Two tests, one in test_cuda.py and the other in test_sparse.py, are added to verify the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33612
Differential Revision: D20038210
Pulled By: mruberry
fbshipit-source-id: 265531dacd37c392232fd3ec763489a62ef54795
Summary: Skip the test to unblock dper fbpkg push
Test Plan: buck test //caffe2/caffe2:caffe2_test_cpu -- 'DBSeekTest\.RocksDB' --run-disabled
Reviewed By: cheshen1
Differential Revision: D20043418
fbshipit-source-id: 05ceb2cea08722a671fa211d73680fd4b78f354c
Summary:
this adds enough infrastructure to run bailout checks in `checkScript`. I'll need to figure out the best way to enable it for nightly builds now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32802
Differential Revision: D19974718
Pulled By: Krovatkin
fbshipit-source-id: 40485503f6d3ae14edcce98e1eec1f0559f3ad08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33632
* `inline_container.h` was unnecessarily exposing all includers to caffe2 headers via `caffe2/core/logging.h`
* Add msvc version of hiding unused warnings.
* Make sure clang on windows does not use msvc pragmas.
* Don't redefine math macro.
Test Plan: CI green
Differential Revision: D20017046
fbshipit-source-id: 230a9743eb88aee08d0a4833680ec2f01b7ab1e9
Summary: The first run of the net is noisy sometimes - just run it twice.
Reviewed By: cheshen1
Differential Revision: D20039274
fbshipit-source-id: 639e65646bf52f3efe1ecd4bbcd0e413d9389b29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33529
Current version goes through GPU -> CPU -> GPU copy and is pretty slow: ~19 ms
for 1M elements with 20 possible buckets based on benchmark.
This new version is ~0.2 on the same
Test Plan: benchmark + unit-test
Reviewed By: chocjy
Differential Revision: D19969518
fbshipit-source-id: 51889bc9a232b6d45d9533e53b7b7f4531da481f
Summary:
The detection of the env variable ONNX_ML has been properly handled in tools/setup_helpers/cmake.py,
line 242.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33424
Differential Revision: D20043991
Pulled By: ezyang
fbshipit-source-id: 91d1d49a5a12f719e67d9507cc203c8a40992f03
Summary:
…have different argument types"
This reverts commit 05fb160048b71c1b8b00d2083a08618318158c1a.
Please go to https://github.com/pytorch/pytorch/pull/33558 and check the CUDA9 on CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33553
Differential Revision: D20017575
Pulled By: ngimel
fbshipit-source-id: a5fd78eea00c7b0925ab21fd90a7daeb66725f1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33097
Previously, we had to specify full types because the functions we registering
might be overloaded, and the type was necessary to resolve the ambiguity. I
disambiguate all of these names by mangling the names of the methods we
place on CPUType/CUDAType/TypeDefault with the overload name (these are
*internal* wrappers which are not user visible), and then can strip
the generation of full function types from the registration.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19837898
Pulled By: ezyang
fbshipit-source-id: 5f557184f6ec84cb0613d4eb2e33b83fd1712090
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33093
In #30187 the aliasAnalysis field on operator registration was updated
so that alias analysis could be specified in only some registration call
sites, rather than requiring it be consistently specified in all call
sites. With this change, we can eliminate the requirement that all
registrations specify aliasAnalysis; as long as we know *one* site
specifies the correct aliasAnalysis, we don't have to specify it
any of the other sites.
In this patch, the "one site" is TypeDefault.cpp (previously we only
generated these stub declarations for manually registered functions,
but now we generate the stubs for everything). Then I delete aliasAnalysis
anywhere we register an op for an existing function (which is a lot
of places).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19837897
Pulled By: ezyang
fbshipit-source-id: 26a7fbc809ec1553da89ea5c0361f3e81526d4c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33216
All tensor expressions belong to a kernel arena and are freed when the
arena is destroyed. Until it is destroyed, all expressions stay valid.
Test Plan: Imported from OSS
Differential Revision: D19848382
Pulled By: ZolotukhinM
fbshipit-source-id: a581ea2b635b9ba2cc53949616a13d8d3a47caae
Summary:
This pull request has changes for:
1. Enabling a torch module with HIP code to be compiled by cpp_extensions.py
2. Fixes for hipify module to be able to be used by a torch extension
cc: ezyang iotamudelta jeffdaily
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32669
Differential Revision: D20033893
Pulled By: zou3519
fbshipit-source-id: fd6ddc8cdcd3930f41008636bb2bc9dd26cdb008
Summary:
this is a follow up PR to https://github.com/pytorch/pytorch/issues/33602:
torch/nn/utils/rnn.html:
`pack_padded_sequence` has a confusing and incomplete description of the `enforce_sorted` param. Currently it goes:
```
enforce_sorted (bool, optional): if ``True``, the input is expected to
contain sequences sorted by length in a decreasing order. If
``False``, this condition is not checked. Default: ``True``.
```
The second part "this condition is not checked" (1) makes no sense since the alluded to condition is not described and (2) it's incomplete as it doesn't reflect the important part, that it actually does the sorting. I think it should say something like:
```
enforce_sorted (bool, optional): if ``True``, the input is expected to
contain sequences sorted by length in a decreasing order. If
``False``, the input will get sorted unconditionally. Default: ``True``.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33617
Differential Revision: D20035131
Pulled By: albanD
fbshipit-source-id: 654382eb0cb62b5abc78497faa5b4bca42db5fda
Summary:
This adds `__torch_function__` support for all functions in `torch.functional` and `torch.nn.functional`.
The changes to C++ code and codegen scripts are to facilitate adding `__torch_function__` support for the native functions in `torch._C._nn`. Note that I moved the `handle_torch_function` C++ function to a header that both `python_torch_functions.cpp` and `python_nn_functions.cpp` include. The changes to `python_nn_functions.cpp` mirror the changes I made to `python_torch_functions.cpp` when `__torch_function__` support was first added in https://github.com/pytorch/pytorch/issues/27064. Due to the somewhat different way the `torch._C` and `torch._C._nn` namespaces are initialized I needed to create a new static reference to the `torch._C._nn` namespace (`THPNNVariableFunctions`). I'm not sure if that is the best way to do this. In principle I could import these namespaces in each kernel and avoid the global variable but that would have a runtime cost.
I added `__torch_function__` support to the Python functions in `torch.nn.functional` following the approach in https://github.com/pytorch/pytorch/issues/32194.
I re-enabled the test that checks if all functions in the `torch` namespace are explicitly tested for `__torch_function__` support. I also generalized the check to work for `torch.functional` and `torch.nn.functional` as well. This test was explicitly disabled in https://github.com/pytorch/pytorch/issues/30730 and I'm happy to disable it again if you think that's appropriate. I figured now was as good a time as any to try to re-enable it.
Finally I adjusted the existing torch API tests to suppress deprecation warnings and add keyword arguments used by some of the code in `torch.nn.functional` that were missed when I originally added the tests in https://github.com/pytorch/pytorch/issues/27064.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32799
Differential Revision: D19956809
Pulled By: ezyang
fbshipit-source-id: 40d34e0109cc4b9f3ef62f409d2d35a1d84e3d22
Summary:
This is generating a considerable amount of warning, due to the fact
that the header file is included in multiple places.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33524
Differential Revision: D20006604
Pulled By: ezyang
fbshipit-source-id: 0885cd2a708679ba5eeabb172366eb4c5a3bbef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33572
This reverts commit 687a7e4a2566861c53c8fb53a80b198465168b38.
Original PR #33305
Reland with BC tests whitelisted. See https://github.com/pytorch/pytorch/issues/33580 for reasoning why this change is not actually BC breaking.
Test Plan: Imported from OSS
Differential Revision: D20011011
Pulled By: ezyang
fbshipit-source-id: 116374efc93af12b8ad738a0989d6f0daa9569e2
Summary:
IIUC Python does not guarantee when an object is garbage collected. So it is possible that, some other test running before `TestCuda.test_memory_stats` creates object which is only garbage collected during `TestCuda.test_memory_stats`, causing mem stats to change and causing this test to fail. This kind of failure is very hard to debug (it took me and mcarilli and ptrblck quite a while to figure out what is happening), and it is the root cause of mcarilli's gradient scaling PR https://github.com/pytorch/pytorch/pull/26512 failing on Windows.
cc: csarofeen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33575
Differential Revision: D20009260
Pulled By: ngimel
fbshipit-source-id: 62f2716aefac3aa6c7d1898aa8a78e6b8aa3075a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33517
I don't think any mobile model uses SparseCPU backend yet so we can skip
generating dispatch code for this backend type.
This will help reduce mobile code size with dynamic dispatch turned on,
roughly ~100K for uncompressed iOS: D19616007 +413K v.s. D19616016 +319K.
It probably doesn't affect much static dispatch build size as the unused
static dispatch methods will be stripped by linker in the end.
ghstack-source-id: 98615810
Test Plan: - CI & BuildSizeBot
Reviewed By: linbinyu
Differential Revision: D19978633
fbshipit-source-id: 27bf6ada2ba98482084cf23724cf400b538b0a03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33557
We should add GIL asserts in some places to keep assumptions documented.
This just adds one in an exception codepath as a placeholder for more.
This change also moves a #define from a .h to the .cpp to reduce scope.
ghstack-source-id: 98673532
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D20005387
fbshipit-source-id: b7eff54a6f1dd69d199f8ca05cdb3001c50b37c4
Summary:
The `not inline_everything` check was causing the jitter check to be skipped whenever we emitted a function. thanks SplitInfinity for pointing this out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33468
Differential Revision: D19975934
Pulled By: eellison
fbshipit-source-id: 03faf8d2fd93f148100d8cf49cb67b8e15cf1f04
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32863, (together with https://github.com/pytorch/pytorch/issues/33310 for the `TensorIterator` reductions)
This adds 64-bit indexed kernels for `THC_reduceDimIndex` and uses `THCTensor_canUse32BitIndexMath` to switch between the two at runtime.
I have a test for this locally but haven't included it here because `max` is much slower than `argmax`. To the point where the test takes several minutes to call max on just one `2**32` element tensor. That seems excessive, even for a slow test but I can push it if preferred.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33405
Differential Revision: D20010769
Pulled By: ezyang
fbshipit-source-id: a8a86f662598d5fade4d90448436418422c699a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33574
Sprinkle with Clang identification macro places that otherwise would cause build errors when Clang is used to drive the CUDA compilation.
Note: `__clang__` is defined when either Clang is used as host compiler by NVCC or when Clang drives the compilation. `__CUDA__` is defined only for the latter case.
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
```
Reviewed By: BIT-silence
Differential Revision: D20007440
fbshipit-source-id: 53caa70695b99461a3910d41dc71a9f6d0728a75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33555
A quick fix for the PyText model (in internal production) on the new bytecode format.
Test Plan: Imported from OSS
Differential Revision: D20008266
Pulled By: iseeyuan
fbshipit-source-id: 1916bd0bf41093898713c567c7f6fa546b9ea440
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33554
NVCC/GCC accepts the existing syntax, but not Clang which requires a proper escape. Here `%laneid` is one of the many registers that CUDA's pseudo-asm provides [1]. And using the extra `%` doesn't change the semantics, as PTX expects `%laneid` value after it's processed by the asm tool.
1. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
Test Plan:
```lang=bash
buck build mode/opt -c fbcode.cuda_use_clang=true //fblearner/flow/projects/dper:workflow
buck build mode/opt //fblearner/flow/projects/dper:workflow
Reviewed By: bddppq
Differential Revision: D20003621
fbshipit-source-id: 8e550e55a3455925e7bd92c6df3e504b5d38c2dc
Summary:
We need to run a peephole before constant propagation in the profiling pipeline, so we fold `prim::shape` for inputs with complete tensor types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33337
Differential Revision: D19905624
Pulled By: Krovatkin
fbshipit-source-id: 80fff067941556053847ddc7afe0fd1c7a89a3ba
Summary:
Changelog:
- Add a check to ensure that all inputs to `where` lie on the same device
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33432
Test Plan:
- Added test_where_invalid_device
Fixes https://github.com/pytorch/pytorch/issues/33422
Differential Revision: D19981115
Pulled By: VitalyFedyunin
fbshipit-source-id: 745896927edb53f61f3dd48ba9e1e6cd10d35434
Summary:
Adam and AdamW are missing parameter validation for weight_decay. Other optimisers have this check present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33126
Differential Revision: D19860366
Pulled By: vincentqb
fbshipit-source-id: 286d7dc90e2f4ccf6540638286d2fe17939648fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32990
right now remote torchscript call can not call to itself, this diff is to support this in the same way as how is supported when calling remote python call to itself
ghstack-source-id: 98599082
Test Plan: unit test
Differential Revision: D19731910
fbshipit-source-id: 6495db68c3eaa58812aa0c5c1e72e8b6057dc5c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33347
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19975410
Pulled By: ezyang
fbshipit-source-id: eb729870c2d279d7d9ca43c92e514fe38dedb06d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33305
The current TensorOptions code is written to exactly extract out
TensorOptions based on exact struct match, including default arguments.
That meant that tril_indices/triu_indices which had a different
default argument didn't match, and thus needed a special case.
I resolve this special case by instead replacing the explicit long
default argument with a None default argument, and then adjusting
the actual implementations to select the correct dtype when none
was specified. I think the general rule I'm following here is that
it is always acceptable to replace an explicit default argument,
with a None argument (assuming the backend will compute it appropriately);
the documentation gets modestly worse, but everything that was
previously expressible continues to be expressible. Maybe later
we should switch the default argument back to long, but for now
the simplification in code is worth it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19975411
Pulled By: ezyang
fbshipit-source-id: 996598759bed9e8d54fe61e19354ad038ed0e852
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33426
Make 2/4/8-bit fused rowwise conversion operators more general to work for N-dim tensors
Test Plan: CI
Reviewed By: ellie-wen
Differential Revision: D19943136
fbshipit-source-id: 47008544dd7e1d11a346d34f35449e0fcc0e7ee0
Summary:
We want to run ONNX checker only when selected operator type is ONNX, and nowhere else. This PR updates the logic in the exporter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33522
Reviewed By: hl475
Differential Revision: D19983954
Pulled By: houseroad
fbshipit-source-id: 15db726321637a96fa110051cc54e9833e201133
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33523
When using `ThreadPool::setNumThreads` to set the number of threads, it should not exceed the number of big cores. Otherwise, the performance could degrade significantly.
Test Plan:
```
cd ~/fbsource/xplat
buck test caffe2:caffe2_testAndroid
```
Reviewed By: dreiss
Differential Revision: D19779267
fbshipit-source-id: 4e980e8a0ccc2f37e1c8ed16e2f4651d72924dbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33434
Reland of https://github.com/pytorch/pytorch/pull/33325, since the
unit test was flaky and failed on land.
To ensure that the test is not flaky, I bumped the timeout so the rendezvous
does not timeout (timing out the rendezvous in 1s led to the flakiness). I also
generalized our mechanism for retrying on errors to include retrying on errors
due to timeout in rendezvous.
ghstack-source-id: 98558377
Test Plan: Added UT test_tcp_store_timeout_set
Differential Revision: D19935390
fbshipit-source-id: 56ccf8c333dd2f954a33614d35cd1642d4e9473a
Summary:
Since the tensor iterator supports the broadcast, we will just remove the assertion on input shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30442
Differential Revision: D19976562
Pulled By: lly-zero-one
fbshipit-source-id: 91b27fc8b2570f29d110c6df26eacdd16f587b9f
Summary:
The quantizer use std::vector to save per_channel scales and zero_points, but when query scales(zero_points), it requires to return tensor. These lead to use std::vector to initialize tensors and it dose cost lots of time. So I change quantizer to save per_channel scales and zero_points by using tensor directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31040
Differential Revision: D19701070
Pulled By: jerryzh168
fbshipit-source-id: 9043f16c44b74dd8289b8474e540171765a7f92a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33365
This adds functionality for re-trying RPC's that are sent with the function sendWithRetries(). It adds RPC's that will potentially need to be retried to a sorted map that contains the timeout at which to retry the RPC and associated metadata. A separate thread iteratively removes the earliest retry-able RPC from the map, sleeps until the corresponding time point, re-tries the RPC, and adds to the map again with a future timeout.
GitHub Issue: https://github.com/pytorch/pytorch/issues/32124
Per the first 4 milestones, the following will be addressed in future PR's:
* enabling RPC Retries for RRef internal messages
Differential Revision: D19915694
fbshipit-source-id: 4a520e32d5084ebcf90e97fd9f26867115a35c0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33508
Ever since we switched to not inlining by default, some users have
complained since they relied on inlining occuring to, e.g. process the
graph with some other tool. Add an inlined_graph for convenience in
those cases.
Test Plan: Imported from OSS
Differential Revision: D19977638
Pulled By: suo
fbshipit-source-id: fe1fa92ff888959203d5d1995930d488b5f9e24c
Summary:
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/297
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33250
As Title says. FBGEMM has recently added the support for Windows.
ghstack-source-id: 97932881
Test Plan: CI
Reviewed By: jspark1105
Differential Revision: D19738268
fbshipit-source-id: e7f3c91f033018f6355edeaf6003bd2803119df4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33515
Previously, if we had a `ModuleDict` with the same value types but
different names for keys, they would share types under certain
conditions. This only happens for `ModuleDict`, because in other cases
a simple Python class check invalidates the class.
Test Plan: Imported from OSS
Differential Revision: D19978552
Pulled By: suo
fbshipit-source-id: f31b2af490064f89b70aa35f83ba740ddaf2a77a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32839
As mentioned in the updated comment in `variable.h`, this disambiguate code like:
```python
base = torch.rand(10, requires_grad=True)
with torch.no_grad():
view = base[1]
view.copy_(var)
torch.autograd.grad(base.sum(), var) # <- what should it return?
```
Given that there is no consensus of what should happen here (does the gradient flow through the view in the no_grad or not). This special case is detected and forbidden.
As mentionned in the error message:
- If you want it to be tracked: move both out of the no_grad
- If do not want them to be tracked, move both inside the no_grad
This implies that any custom Function that returns views does not allow inplace modification on its output. I'll add a PR to the stack to relax this to be a DeprecationWarning for now. And we will make it into an actual error for 1.6
This replaces https://github.com/pytorch/pytorch/pull/26607
cc sublee
Test Plan: Imported from OSS
Differential Revision: D19814114
Pulled By: albanD
fbshipit-source-id: ff2c9d97c8f876d9c31773a2170e37b06d88bed7
Summary:
This fixes https://github.com/pytorch/pytorch/issues/33001.
When subtracting 1 from a empty array, instead of being `-1` as seems to be expected in the later code (while loop), because `size()` seems to be unsigned, it becomes a very large number. This causes a segfault during the while loop later in the code where it tries to access a empty array.
This issue seemed to happen only on the pi with the following example code: `v = torch.FloatTensor(1, 135).fill_(0); v[0, [1]] += 2`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33456
Differential Revision: D19963711
Pulled By: ezyang
fbshipit-source-id: 1dbddd59a5df544cd7e025fc540c9efe2c4e19f4
Summary:
This was old code that isn't tested and is broken, it should have been
deleted in #24874
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33453
Pulled By: driazati
Differential Revision: D19961403
fbshipit-source-id: 94c52360460194d279dad5b0ea756ee366f525e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32880
The PR below made it impossible to construct a SourceRange without a
context, so get rid of its optional-ness
Test Plan: Imported from OSS
Differential Revision: D19670923
Pulled By: suo
fbshipit-source-id: 05936fca2a3d5e613313ade9287b2210bc4a3ccd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32879
An error report without a SourceRange context is bad, because it doesn't
tell the user where something happened. Delete the default constructor
to make it harder to create errors like this (you can still use a fake
SourceRange if you absolutely need to).
Also clean up the only case where the default constructor was used.
Test Plan: Imported from OSS
Differential Revision: D19670924
Pulled By: suo
fbshipit-source-id: 46888a86e5d32b84c8d6d52c0c8d70243722b14a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33440
The constructors make a copy without `std::move` in the initializer list.
Test Plan:
Confirmed manually that without this change, the `data()` pointer of
the vector changes. With this change it does not, as intended.
Reviewed By: mrshenli
Differential Revision: D19948685
fbshipit-source-id: ee4f22e29894b858ad86068722dc2f4651987517
Summary:
There are large models such as GPT2-large which cannot be exported with the current exporter because of the 2GB protobuf limit (e.g. see https://github.com/pytorch/pytorch/issues/19277). ONNX spec specifies a special format for large (> 2GB) models. This PR adds support for exporting large models in ONNX large model format in the PyTorch-ONNX exporter.
This is the first PR for this feature that enables the end-to-end execution. Tests for large model export have been added. We may need follow-up PRs to refine this workflow based on user feedback.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33062
Reviewed By: hl475
Differential Revision: D19782292
Pulled By: houseroad
fbshipit-source-id: e972fcb066065cae6336aa91c03023d9c41c88bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32885
Currently Tensor bias is registered as parameter and None bias is registered as attribute.
We need the type annotation because when we try to fold ConvBn in graph mode quantization we'll
remove the None bias attribute and add a Tensor bias attribute, without type annotation the
bias Value in the graph will be marked with different type in these two cases, so we have rewrite the
graph to change the type as well in that case. But with type annotation we don't need to modify the graph
since both cases the bias value will have type `Tensor?`
Test Plan:
.
Imported from OSS
Differential Revision: D19844710
fbshipit-source-id: 52438bc72e481ab78560533467f9379a8b0b0cfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33265
This removes the need for isinstance to keep trace of list and tuple
separately by introducing AnyListType and AnyTupleType into the JIT
type system to be the common supertype of any lists or tuples.
This allows us to remove the weird flags from the interpreter for
the isinstance operator.
Test Plan: Imported from OSS
Differential Revision: D19883933
Pulled By: zdevito
fbshipit-source-id: f998041b42d8b4554c5b99f4d95d1d42553c4d81
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32889
Common primitive ops that have special inputs make it very hard to
serialize the bytecode for mobile because information about how the
op behaves is hidden in the Node*. This changes how we handle the following
ops so that they are encoded as their own interpreter bytecodes.
```
USES NODE: prim::TupleUnpack(...) -> (...)
USES NODE: prim::TupleSlice(...) -> (...)
USES NODE: prim::TupleConstruct(...) -> (...)
USES NODE: prim::ListUnpack(...) -> (...)
USES NODE: prim::ListConstruct(...) -> (...)
USES NODE: prim::DictConstruct(...) -> (...)
USES NODE: prim::Constant() -> (...)
USES NODE: prim::isinstance(...) -> (...)
USES NODE: prim::CreateObject(...) -> (...)
USES NODE: prim::fork(...) -> (...)
USES NODE: aten::warn(str message, *, int stacklevel=2) -> () # need stack level information, so ideally in interpreter so it can look at the stack
```
This leaves a state where the _only_ remaining Node*-consuming builtins
are things that are only introduced during JIT optimization and will
not appear in mobile code.
Serialization of bytecode can now be made to directly write the CodeImpl
object without modification.
Test Plan: Imported from OSS
Differential Revision: D19673157
Pulled By: zdevito
fbshipit-source-id: 7b8c633d38a4c783b250fbdb222705e71a83ad26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32804
Constants are interpreter primitives so the op was not actually used.
This cleans up some of the logic around it.
This also fixes constant prop such that failures to look up an op
do not silently stop constant propagation. Instead, only errors
inside the op implementation itself will do this.
Test Plan: Imported from OSS
Differential Revision: D19673156
Pulled By: zdevito
fbshipit-source-id: 7beee59a6a67a6c2f8261d86bd505280fefa999e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32791
When a registered operator has varags (ends with ... in its schema),
the interpreter now appends the number of arguments to the top of
the stack before invoking the operator. This allows the removal of more
uses of Node* in the interpreter.
This PR also then cleans up the constructors for Operator to make
it more likely someone chooses the correct one. After making these ops:
```
USES NODE: prim::TupleUnpack(...) -> (...)
USES NODE: prim::TupleSlice(...) -> (...)
USES NODE: prim::TupleConstruct(...) -> (...)
USES NODE: prim::ListUnpack(...) -> (...)
USES NODE: prim::ListConstruct(...) -> (...)
USES NODE: prim::DictConstruct(...) -> (...)
USES NODE: prim::Constant() -> (...)
USES NODE: prim::isinstance(...) -> (...)
USES NODE: prim::CreateObject(...) -> (...)
USES NODE: prim::fork(...) -> (...)
USES NODE: aten::warn(str message, *, int stacklevel=2) -> () # need stack level information, so ideally in interpreter so it can look at the stack
```
Into interpreter primitives, we can remove all but two constructors for operators:
one that is (schema_string, operation), and one that is (symbol, op_creator) for
the remaining weird primitives.
Test Plan: Imported from OSS
Differential Revision: D19673158
Pulled By: zdevito
fbshipit-source-id: 95442a001538a6f53c1db4a210f8557ef118de66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33368
reorganizing files that describe sources to ensure the same list is used for both fbcode and ovrsource targets. (BUCK vs TARGETS)
Test Plan: CI green
Reviewed By: malfet
Differential Revision: D19803036
fbshipit-source-id: 69c1fa10877c3f0c0e9c1517784949c3c9939710
Summary:
Closes https://github.com/pytorch/pytorch/issues/30027
The idea here is that you can bind a function with `pybind11` in a single line and without modifying the function:
```cpp
m.def("foo", foo, py::call_guard<torch::PyWarningHandler>());
```
Where warnings are handled by the [`call_guard`](https://pybind11.readthedocs.io/en/stable/advanced/functions.html#call-guard) and exceptions are handled by the `pybind11` exception translator. To do this, I have added support for handling C++ exceptions in `torch::PyWarningHandler`'s destructor without setting the python error state before hand.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30588
Differential Revision: D19905626
Pulled By: albanD
fbshipit-source-id: 90c0a5e298b123cc0c8ab9c52c91be4e96ea47c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33358
We just translate this code to ATen.
Test Plan: Imported from OSS
Differential Revision: D19911114
Pulled By: gchanan
fbshipit-source-id: 2279e63bb7006f7253620417937e3ce9301e0cdb
Summary:
## problem
```python
class LambdaLR(_LRScheduler):
"""Sets the learning rate of each parameter group to the initial lr
times a given function. When last_epoch=-1, sets initial lr as lr.
Args:
optimizer (Optimizer): Wrapped optimizer.
lr_lambda (function or list): A function which computes a multiplicative
factor given an integer parameter epoch, or a list of such
functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
Example:
>>> # Assuming optimizer has two groups.
>>> lambda1 = lambda epoch: epoch // 30
>>> lambda2 = lambda epoch: 0.95 ** epoch
>>> scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()
"""
```
`LambdaLR` takes a lambda that returns a float and takes a int, or a list of such lambdas.
## related issue
Resolve https://github.com/pytorch/pytorch/issues/32645
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33271
Differential Revision: D19878665
Pulled By: vincentqb
fbshipit-source-id: 50b16caea13de5a3cbd187e688369f33500499d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33346Fixes#33091
This PR lets users control the number of workers that cpp extensions
uses through the environment variable `MAX_JOBS`. If the environment
variable is a non-negative integer we use that many threads; otherwise,
ninja falls back to the default.
I chose to use the name `MAX_JOBS` because we use it in PyTorch already
to control the number of workers PyTorch builds with. There is a risk
that users of cpp extensions already have `MAX_JOBS` set but we are
hoping that that risk is small and/or it means semantically the same
thing.
Test Plan: - tested locally
Differential Revision: D19911645
Pulled By: zou3519
fbshipit-source-id: d20ed42de4f845499ed38f1a1c73e9ccb620f780
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33008
Corrects D19373507 to allow valid use cases that fail now. Multiplies batch size by the number of elements in a group to get the correct number of elements over which statistics are computed.
**Details**:
The current implementation disallows GroupNorm to be applied to tensors of shape e.g. `(1, C, 1, 1)` to prevent cases where statistics are computed over 1 element and thus result in a tensor filled with zeros.
However, in GroupNorm the statistics are calculated across channels. So in case where one has an input tensor of shape `(1, 256, 1, 1)` for `GroupNorm(32, 256)`, the statistics will be computed over 8 elements and thus be meaningful.
One use case is [Atrous Spatial Pyramid Pooling (ASPPPooling)](791c172a33/torchvision/models/segmentation/deeplabv3.py (L50)), where GroupNorm could be used in place of BatchNorm [here](791c172a33/torchvision/models/segmentation/deeplabv3.py (L55)). However, now this is prohibited and results in failures.
Proposed solution consists in correcting the computation of the number of elements over which statistics are computed. The number of elements per group is taken into account in the batch size.
Test Plan: check that existing tests pass
Reviewed By: fmassa
Differential Revision: D19723407
fbshipit-source-id: c85c244c832e6592e9aedb279d0acc867eef8f0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33395
By default the GPU fuser stays enabled, but this function allows to
manually disable it. It will be useful for working on other
implementations of fuser.
Test Plan: Imported from OSS
Differential Revision: D19926911
Pulled By: ZolotukhinM
fbshipit-source-id: 7ea9d1dd7821453d640f81c487b63e1d585123c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33027
This PR allows default arguments in module's forward method to be skipped when module is used in `torch::nn::Sequential`, by introducing the `FORWARD_HAS_DEFAULT_ARGS` macro and requiring that all modules that have default arguments in its forward method must have a corresponding `FORWARD_HAS_DEFAULT_ARGS` macro call.
Fixes issue mentioned in https://github.com/pytorch/pytorch/issues/30931#issuecomment-564144468.
Test Plan: Imported from OSS
Differential Revision: D19777815
Pulled By: yf225
fbshipit-source-id: 73282fcf63377530063e0092a9d84b6c139d2e32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33026
This PR contains necessary changes to prepare for https://github.com/pytorch/pytorch/pull/33027. It exposes the following classes to public:
1. `torch::nn::AnyValue`, because if the user has optional arguments in their module's forward method, they must also use the `FORWARD_HAS_DEFAULT_ARGS` macro and pass in the default values for those optional arguments wrapped by `torch::nn::AnyValue`.
2. `torch::nn::AnyModuleHolder`, because `torch::nn::Module` needs to declare it as a friend class for it to be able to access `torch::nn::Module`'s protected methods such as `_forward_has_default_args` / `_forward_num_required_args` / `_forward_populate_default_args`.
Test Plan: Imported from OSS
Differential Revision: D19777814
Pulled By: yf225
fbshipit-source-id: 1c9d5aa24f0689154752c426a83ee98f64c9d02f
Summary:
Although `gpu_kernel_with_index` might look like a quite general helper function at first look, it actually isn't.
The problem is not only 32bit indexing, but something more fundamental: `TensorIterator` reorder dims and shapes, so if you have non-contiguous tensor such as `torch.empty(5, 5).t()` , the index won't be correct. Since the whole point of `TensorIterator` is to manipulate shapes/strides to speedup loops, it is fundamentally impossible to get the correct linear index without tons of efforts.
Currently, the range factories are not failing on an `out=non_contiguous_tensor` is because it is so lucky that `has_internal_overlap` is stupid enough to return everything not contiguous as `TOO_HARD`.
Since `gpu_kernel_with_index` is not general, we should move it from `Loops.cuh` to `RangeFactories.cu`. And since the kernel is so simple to implement, it makes no sense to use `TensorIterator` which goes through tons of unnecessary checks like `compute_dtypes`.
`torch.range` is not tested for 64bit-indexing, and I will file a new PR to remove it (it was supposed to be removed at 0.5).
Benchmark:
The device is GTX-1650, I don't have a good GPU at home.
Code:
```python
import torch
print(torch.__version__)
for i in range(100):
torch.randn(1000, device='cuda')
torch.cuda.synchronize()
for i in range(15, 29):
%timeit torch.arange(2 ** i, device='cuda'); torch.cuda.synchronize()
```
Before:
```
1.5.0a0+c37a9b8
11.9 µs ± 412 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
12.7 µs ± 309 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
19.6 µs ± 209 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
28.9 µs ± 923 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
48.4 µs ± 1.64 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
85.7 µs ± 1.46 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
162 µs ± 1.09 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
312 µs ± 9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
618 µs ± 15.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.22 ms ± 9.91 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
2.45 ms ± 97.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.9 ms ± 155 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
10.1 ms ± 378 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
After:
```
1.5.0a0+7960d19
11 µs ± 29.6 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
12.4 µs ± 550 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
18.4 µs ± 230 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
27.6 µs ± 10.9 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
46.2 µs ± 18.6 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
83.3 µs ± 5.61 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
158 µs ± 373 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
307 µs ± 1.44 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
603 µs ± 112 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.2 ms ± 1.05 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
2.4 ms ± 23.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
4.77 ms ± 25.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
9.51 ms ± 933 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33370
Differential Revision: D19925990
Pulled By: ngimel
fbshipit-source-id: f4a732fe14a5582b35a56618941120d62e82fdce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33147
The log mentioned that it is aborting communicators even if
`blockingWait_` was false. This was incorrect, and I updated the logging to
reflect the appropriate behavior.
ghstack-source-id: 98025017
Test Plan: waitforbuildbot
Differential Revision: D19817967
fbshipit-source-id: fb3415af2cc99eb20981ceaa5203c0a1880fd6f3
Summary:
Add quant_scheme_generator that will be used to interface with dper.
Also updated two related functions:
- Add batch_size option to save_local_dataset() in dataset utils to be more flexible.
Test Plan:
Tested in the stacked diff D19747206.
buck test deeplearning/numeric_suite/toolkit/test:int8_static_utils_test
Reviewed By: csummersea
Differential Revision: D19745159
fbshipit-source-id: a4ac1ef0ffdddc68bdf5e209ae801b8c475d0b96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32974
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/286
Re-attempt of D18805426 . Decided to be consistent with PyTorch Adagrad
There was an inconsistency in the order of operation between scalar and SIMD code when we compute Adagrad. This diff make them consistent by doing w += lr * grad / (sqrt(moment) + epsilon) in Adagrad and w += lr / (sqrt(moment) + epsilon) * grad in RowWiseSparseAdagrad.
The Adagrad order is consistent with PyTorch (see aten/src/ATen/native/cpu/PointwiseOpsKernel.cpp addcmul_cpu_kernel function). The RowWiseSparseAdagrad order is to make compute more efficient. In RowWiseSparseAdagrad, lr / (sqrt(moment) + epsilon) is shared among all elements in the row
And, we're not going to use FMA to be consistent with PyTorch (even though it provides a little accuracy benefit)
Test Plan: CI
Reviewed By: wx1988
Differential Revision: D19342865
fbshipit-source-id: e950c16f2e1c4a2f2a3ef53b1705db373c67f341
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33325
Closes https://github.com/pytorch/pytorch/issues/32924. There was a bug where for TCPStore, we would not respect the timeout passed into `init_process_group` while constructing the TCPStore. Instead, we'd set the timeout after the rendezvous created the store, meaning that we used the default timeout of 300s while connecting to the server. This diff passes the timeout passed into `init_process_group` to rendezvous so that it can be passed into the constructor for TCPStore, so that we can use the right timeout at construction time.
Question: Should we make this change for FileStore as well? Currently the FileStore constructor does not take in a timeout at all.
ghstack-source-id: 98401875
Test Plan: Added a UT
Differential Revision: D19871946
fbshipit-source-id: dd002180c4c883216645b8a97cc472c6116ac117
Summary: in dper2, local net is hard-coded by whitelisting some layers. Add SparseFeatureGating related layers to local net explicitly.
Test Plan:
* workflow: f167812211
* QRT: fall back looks normal
{F228442018}
Differential Revision: D19852280
fbshipit-source-id: 6fecc3d745c3f742d029575a7b9fe320618f1863
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33387
CI is broken. Skip two functions to fix the problem.
Test Plan: ci
Reviewed By: hl475
Differential Revision: D19926249
fbshipit-source-id: a46d1465c59de8616d2af5fb0b9cc18532359f88
Summary:
Fixes the `TensorIterator` parts of https://github.com/pytorch/pytorch/issues/32863 (THC is still broken)
`TensorIterator::split` now keeps track of the `view_offsets` into the full tensor range. With this, I can take the base offset for the reduced dimension and translate partial results from the sub-iter into the index range of the full tensor. This happens only once for each intermediate result, so we should still benefit from the performance of 32-bit indexing in loops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33310
Differential Revision: D19906136
Pulled By: ngimel
fbshipit-source-id: 3372ee4b8d5b115a53be79aeafc52e80ff9c490b
Summary:
Globally define
```C++
constexpr int num_threads = C10_WARP_SIZE * 2;
constexpr int thread_work_size = 4;
constexpr int block_work_size = thread_work_size * num_threads;
```
and kill all the template arguments passing these values.
These are effectively global, but we are now passing them around by template arguments, causing many inconvenience in coding.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33308
Differential Revision: D19907250
Pulled By: ngimel
fbshipit-source-id: 4623b69baea7e6e77f460ffdfa07cf9f8cba588a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32962
As per gchanan's comments on
https://github.com/pytorch/pytorch/pull/30445, I've used
`torch.set_default_dtype` in test_data_parallel instead of specifying
dtype=torch.double everywhere. Also, renamed dtype2prec to dtype2prec_DONTUSE
ghstack-source-id: 98388429
Test Plan: waitforbuildbot
Differential Revision: D19714374
fbshipit-source-id: eb55bbca33881625636ba9ea6dd4cb692f25668e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33261
It was requested in #33114.
Test Plan: Imported from OSS
Differential Revision: D19910600
Pulled By: ZolotukhinM
fbshipit-source-id: 827f1744b97f386065a21d1ba5d82c1f90edbe46
Summary:
docker cp was erroring out, so lets just use volume mounts instead which
should hopefully be more consistent
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33355
Differential Revision: D19913948
Pulled By: seemethere
fbshipit-source-id: 059ddd36a8162f946cfea451b5dcd1706f1209e9
Summary:
Basically just fills out PYTORCH_BUILD_VERSION to the correct version
baesd on the git tag.
This makes it so that we don't have to continually edit this file
when doing releases.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33326
Differential Revision: D19911035
Pulled By: seemethere
fbshipit-source-id: e27105f3e193a49dd68452d8f60232f8a132acad
Summary:
This PR renames `at::Tensor::base()` to `at::Tensor::_base()`, to achieve parity with Python `torch.Tensor._base` API.
----
This PR is BC-breaking in the following way:
Previously, to get the tensor that this tensor is a view of, the user would call `tensor.base()` in C++. Now, they must call `tensor._base()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33316
Differential Revision: D19905687
Pulled By: yf225
fbshipit-source-id: 949d97b707b2c82becb99ac89e9ac24359d183e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33318
### Summary
Recently, we have a [discussion](https://discuss.pytorch.org/t/libtorch-on-watchos/69073/14) in the forum about watchOS. This PR adds the support for building watchOS libraries.
### Test Plan
- `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=WATCHOS ./scripts/build_ios.sh`
Test Plan: Imported from OSS
Differential Revision: D19896534
Pulled By: xta0
fbshipit-source-id: 7b9286475e895d9fefd998246e7090ac92c4c9b6
Summary:
For both the Caffe2 and PyTorch backends, enable 3D convolutions through MIOpen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33067
Reviewed By: BIT-silence
Differential Revision: D19880495
Pulled By: bddppq
fbshipit-source-id: 8f6f970910654c1c5aa871b48a04c1054875691c
Summary:
Exporting Split with a dynamic list of split_sizes is not supported.
This PR enables export using onnx SplitToSequence + SequenceAt
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33161
Reviewed By: hl475
Differential Revision: D19860152
Pulled By: houseroad
fbshipit-source-id: 300afedc22b01923efb23acd1a3627aa146bb251
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32602
This adds functionality for re-trying RPC's that are sent with the function `sendWithRetries()`. It adds RPC's that will potentially need to be retried to a sorted map that contains the timeout at which to retry the RPC and associated metadata. A separate thread iteratively removes the earliest retry-able RPC from the map, sleeps until the corresponding time point, re-tries the RPC, and adds to the map again with a future timeout.
GitHub Issue: https://github.com/pytorch/pytorch/issues/32124
Per the first 3 milestones, the following will be addressed in future PR's:
* enabling RPC Retries for RRef internal messages
Differential Revision: D19560159
fbshipit-source-id: 40cd86f9a25dc24367624d279a3b9720b20824cf
Summary:
Addressing issue https://github.com/pytorch/pytorch/issues/18125
This implements a mixture distributions, where all components are from the same distribution family. Right now the implementation supports the ```mean, variance, sample, log_prob``` methods.
cc: fritzo and neerajprad
- [x] add import and `__all__` string in `torch/distributions/__init__.py`
- [x] register docs in docs/source/distributions.rst
### Tests
(all tests live in tests/distributions.py)
- [x] add an `Example(MixtureSameFamily, [...])` to the `EXAMPLES` list,
populating `[...]` with three examples:
one with `Normal`, one with `Categorical`, and one with `MultivariateNormal`
(to exercise, `FloatTensor`, `LongTensor`, and nontrivial `event_dim`)
- [x] add a `test_mixture_same_family_shape()` to `TestDistributions`. It would be good to test this with both `Normal` and `MultivariateNormal`
- [x] add a `test_mixture_same_family_log_prob()` to `TestDistributions`.
- [x] add a `test_mixture_same_family_sample()` to `TestDistributions`.
- [x] add a `test_mixture_same_family_shape()` to `TestDistributionShapes`
### Triaged for follup-up PR?
- support batch shape
- implement `.expand()`
- implement `kl_divergence()` in torch/distributions/kl.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22742
Differential Revision: D19899726
Pulled By: ezyang
fbshipit-source-id: 9c816e83a2ef104fe3ea3117c95680b51c7a2fa4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33156
When dist_autograd_spawn_thrift's 'test_backward_node_failure_python_udf' test is
run, it was encountering a TSAN error related to holding the mutex while the
underlying datastructure was being dealloced.
In this change, we simply get a shared_ptr<> reference to the future, and
set_exception() without having the lock held, to avoid deallocing underneath
the lock.
ghstack-source-id: 98303434
Test Plan: buck test mode/opt-tsan //caffe2/test/distributed/rpc:dist_autograd_spawn_thrift -- 'test_backward_node_failure_python_udf \(test_dist_autograd_spawn\.DistAutogradTestWithSpawn\)'
Differential Revision: D19821362
fbshipit-source-id: 82f735e33f8e608552418ae71592400fa3621e40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33332
We check the input shape of lengths and indices of SLS and add an attribute if they are the same.
Test Plan:
```
buck test glow/fb/test/numerics:test_operator_onnxifinnpi -- test_slws_fused_8bit_rowwise_length1_graph
```
Reviewed By: ipiszy
Differential Revision: D19874903
fbshipit-source-id: 06b643b5351d0ba19ba209b5a5b599fbb38b1dfc
Summary:
Container `Module`s, including `ModuleList`, `ParameterList` and `ParameterDict`, should not be called like a regular `Module`.
This PR add error messages for these special modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29991
Differential Revision: D19698535
Pulled By: ezyang
fbshipit-source-id: fe156a0bbb033041086734b38f8c6fde034829bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32432
Use JIT'ed fp16 SLS in D19477209 from Caffe2 operators
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D19477208
fbshipit-source-id: ef2ccba10f5f4c475166141bf09c266dedb92d38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33323
skip the tests until it is fixed
Test Plan: ci
Reviewed By: hl475
Differential Revision: D19894675
fbshipit-source-id: 1cfc153577bf021171f4412115d84719beae7a91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33190
This enable the initial RRef type to be used inside TorchScript, user
could pass a python RRef into a torchscript function and call to_here
inside. Specifically, this PR:
- Add RRef schema type parsing
- Add python interop for RRef in Python and into JIT
- register to_here op in register_distributed_ops
More support for RRef in TorchScript will be added in future PRs
Test Plan: Imported from OSS
Differential Revision: D19871244
Pulled By: wanchaol
fbshipit-source-id: 7eca6c491a84666b261c70806254b705603bd663
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32992
This PR add RRef to IValue and the JIT type system.
- The RRefInterface abstract class inherit from intrusive_ptr_target,
this made the RRef class can be hold in ivalue as intrusive_ptr
- Add RRefType as a JIT type, it's a container type similar to
future type.
Test Plan: Imported from OSS
Differential Revision: D19871242
Pulled By: wanchaol
fbshipit-source-id: cb80ca32605096f9a42ef147109fb368a7c1d4d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33189
Add RRefInterface to Aten/Core, which will later be used by IValue
Switch all the rpc code base to use intrusive_ptr instead of shared_ptr,
so that we could add it to IValue.
Actual adding to IValue and JIT will be in next PR
Test Plan: Imported from OSS
Differential Revision: D19871241
Pulled By: wanchaol
fbshipit-source-id: d7e1fd04b46320e0f26c18591b49c92ad30a4032
Summary:
See https://discuss.pytorch.org/t/bugs-about-torch-from-numpy-array/43312.
This update incorporates albanD 's suggestion into the error message, saving future users from having to ask or look on the forums if they encounter this issue and don't mind making their arrays contiguous.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33254
Differential Revision: D19885808
Pulled By: mruberry
fbshipit-source-id: 8f0fd994cf8c088bf3c3940ab4dfb3ddbc5b3ede
Summary: update this mapping with thte int4 sls ops so we can run netrunner
Test Plan: testing with net_runner
Reviewed By: jfix71
Differential Revision: D19879826
fbshipit-source-id: eac84b10e2365c21cb8a7cfbf3123e26a9945deb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32957
Closes https://github.com/pytorch/pytorch/issues/29703. If there is a
gloo timeout and `recvWork->wait()` times out in `listenLoop()`,
processGroupagent crashes since there is an unhandled exception in a thread.
This catches the exception and exits the listen loop. In a follow up diff, we
will enhance these error conditions so that if users attempt to send RPCs
again, they are notified that the RPC agent was in a bad state and it was
shutdown.
This PR also adds a new option, `processGroupTimeout` to PG agent's backend
options. This allows us to control the gloo timeout.
ghstack-source-id: 98236783
Test Plan: Added a unit test.
Differential Revision: D19678979
fbshipit-source-id: 3895ae754f407b84aca76c6ed3cb087d19178c40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26410
I only ported the CPU forward implementation for now to try a CPU-only benchmark.
Test Plan: Imported from OSS
Differential Revision: D17454519
Pulled By: gchanan
fbshipit-source-id: ff757cf972c5627074fea2f92a670129007a49f4
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32008
This is similar to CaoZhongZ's patch which runs on all OpenMP threads in the team and selectively exits early to scale the number of threads active. I have also restored the `if` clause from before https://github.com/pytorch/pytorch/issues/26963 so that running on 1 thread should still avoid additional synchronisation.
One comment is that this does slightly change the meaning of `at::get_num_threads` inside of a `parallel_for` loop since it's not guaranteed that the function was called on that many threads. I've looked at the uses within ATen and couldn't see anything that would be problematic. There are a few places in `quantized` that seem to make this assumption but they always use a grain size of 1 so should be safe:
d9e99ab544/aten/src/ATen/native/quantized/cpu/qconv.cpp (L436-L437)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32875
Differential Revision: D19775823
Pulled By: VitalyFedyunin
fbshipit-source-id: 4f843b78cdb9e2766339590d728923786a00af6d
Summary:
- Clean up error checking code
- Avoid unecessary floating-point computation
- Use float instead of double when possible to avoid massive cast in the tensor
- Use bool instead of uint8_t for clear Boolean purpose
- Improve error message
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32665
Differential Revision: D19601920
Pulled By: VitalyFedyunin
fbshipit-source-id: 0c6c6b5ff227b1437a6c1bae79b2c4135a13cd37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33011
I also reordered some of the keys in non-semantic ways to make the
organizational grouping mroe clear.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19796584
Pulled By: ezyang
fbshipit-source-id: 3083abadb47e9f382b9fbe981af0b34203c6ea4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33080
Quantized batch norm for cases where batch norm cannot be fused with conv.
AVX2 implementation is from Caffe2.
Test Plan:
python test/test_quantized.py TestQuantizedOps.test_batch_norm
Imported from OSS
Differential Revision: D19861927
fbshipit-source-id: bd8cd101fc063cb6358132ab7c651a160999293c
Summary:
If a value has the type None, we can always replace it with a None constant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33264
Differential Revision: D19878695
Pulled By: eellison
fbshipit-source-id: 5d0e7ffb37c5747997df093fec3183039d8dff4d
Summary:
For reasons similar to https://github.com/pytorch/pytorch/issues/33021. Note that the support of half type has
not been available in any releases yet so it should be safe to remove (All forward ones concerning this PR were added in daef363b15c8a3aaaed09892004dc655df76ff81 and 8cb05e72c69fdd837548419770f3f1ba9807c16d)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33206
Differential Revision: D19861137
Pulled By: ezyang
fbshipit-source-id: 38a3a398a716a782c26a611c56ddeab7eb7ac79e
Summary:
When building with FFMPEG, I encountered compilation error due to missing include/library.
I also find the change in video_input_op.h will improve build on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27589
Differential Revision: D19700351
Pulled By: ezyang
fbshipit-source-id: feff25daa43bd2234d5e75c66b9865b672a8fb51
Summary:
This PR implements the gradient scaling API that mruberry, jjsjann123, ngimel, zdevito, gchanan and I have been discussing. Relevant issue/RFC: https://github.com/pytorch/pytorch/issues/25081.
Volume-wise, this PR is mostly documentation and tests. The Python API (found entirely in `torch/cuda/amp/amp_scaler.py`) is lightweight . The exposed functions are intended to make the implementation and control flow of gradient scaling convenient, intuitive, and performant.
The API is probably easiest to digest by looking at the documentation and examples. `docs/source/amp.rst` is the homepage for the Automatic Mixed Precision package. `docs/source/notes/amp_examples.rst` includes several examples demonstrating common but not-immediately-obvious use cases. Examples are backed by tests in `test_cuda.py` (and thankfully the tests pass :P).
Two small utility kernels have been added in `native/cuda/AmpKernels.cu` to improve performance and avoid host-device synchronizations wherever possible.
Existing optimizers, both in the wild and in Pytorch core, do not need to change to use the scaling API.
However, the API was also designed to establish a contract between user scripts and optimizers such that writers of _new_ custom optimizers have the control points they need to implement fast, optionally sync-free updates. User scripts that obey the scaling API can drop such custom optimizers in and reap performance benefits without having to change anything aside from the optimizer constructor itself. [I know what the contract with custom optimizers should be](35829f24ef/torch/cuda/amp/amp_scaler.py (L179-L184)), but I'm waiting for review on the rest of the API before I go about documenting it (it will be given a dedicated section in `docs/source/notes/amp_examples.rst`.
Currently, the gradient scaling examples do not include the auto-casting API as discussed in https://github.com/pytorch/pytorch/issues/25081. The gradient scaling API is intended to be orthogonal/modular relative to autocasting. Without auto-casting the gradient scaling API is fully use-_able_, but not terribly use-_ful_, so it's up to you guys whether you want to wait until auto-casting is ready before merging the scaling API as well.
### Todo
- [ ] How do I get c10 registered status for my two custom kernels? They're very simple.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26512
Differential Revision: D19859905
Pulled By: mruberry
fbshipit-source-id: bb8ae6966214718dfee11345db824389e4286923
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33174
Closes https://github.com/pytorch/pytorch/issues/32780. It looks like
this is the only callsite where we do `_get_current_rpc_agent().foo()`, and we
can do this directly in the pybind layer to save some overhead.
ghstack-source-id: 98200664
Test Plan: All UTs should pass.
Differential Revision: D19828786
fbshipit-source-id: 5c34a96b5a970e57e6a1fdf7f6e54c1f6b88f3d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33125
Provide histogram collection and weights prepacking interface for Dper to auto quantize the Ads models.
Test Plan:
buck test mode/opt deeplearning/numeric_suite/toolkit/test:int8_static_utils_test
buck test mode/opt deeplearning/numeric_suite/toolkit/test:histogram_utils_test
Reviewed By: amylittleyang
Differential Revision: D19794819
fbshipit-source-id: 6a4f4a6684da0977b7df2feed8a4b961db716da8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33251
Somehow this was preventing `c10::Error` exceptions from ever being thrown on windows when `defined(NDEBUG) == false`. Kinda scary.
Test Plan: sandcastle green, made sure `intrusive_ptr_test.cpp` (givenStackObject_whenReclaimed_thenCrashes) passed inside ovrsource using `mode/win/dev-debug`
Reviewed By: malfet
Differential Revision: D19865667
fbshipit-source-id: c32d5752025c043e57d16c6d14a94b069bed0bc3
Summary:
Stacked PRs
* #32955 - [jit] Fix flipped PackedSequence outputs in script
* **#32953 - [jit] Support properties on `Device`**
PyTorch devices have a `index` and `type` property. This PR adds support for both to TorchScript
](https://our.intern.facebook.com/intern/diff/19849320/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32953
Pulled By: driazati
Differential Revision: D19849320
fbshipit-source-id: ce845258c6110058dd9ea1f759ef74b7ed2e786e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32739
As Title says.
ghstack-source-id: 98061467
Test Plan: CI
Differential Revision: D19610810
fbshipit-source-id: f9621cd7d780769941ed77974b19c5226d4b2b30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33243
If a file does not exist in an archive, PyTorchStreamReader throws an exception. However, when PyTorchStreamReader is destructed another exception is thrown while processing the first exception. As a result of this double exception there is SIGABORT.
Thanks dreiss for catching this bug and suggesting the fix. It happened when he used _load_for_mobile to load a torch script file without bytecode session. A unittest is added to test this case.
Test Plan: Imported from OSS
Differential Revision: D19859205
Pulled By: iseeyuan
fbshipit-source-id: 8f96b6256f1a1f933fce1c256d64604c7e9269e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32761
This replaces ImplicitTensorToNum with result-specific operators like
IntImplicit, FloatImplicit, or ScalarImplicit. Note that ScalarImplicit
was not correctly implemented before and this PR fixes the lapse.
This does not change on-disk serialization because these operators are not
serialized directly but written as eg. `annotated(int, foo)`.
Test Plan: Imported from OSS
Differential Revision: D19615385
Pulled By: zdevito
fbshipit-source-id: 48575f408e8219d2ec5b46936fc2aa691f283976
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32682
This moves code around so that operator.h/cpp no longer requires a full
definition of Node* nor does it include alias analysis or the pretty printer.
This should make it possible to include in the mobile build.
Functionality for checking if operators match Node and to look up
and operator for a Node have moved to the Node object.
Test Plan: Imported from OSS
Differential Revision: D19615386
Pulled By: zdevito
fbshipit-source-id: e38bdf29971183597ef940d061c06ba56e71d9c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33050
Following what gchanan proposed in #30480
- If the (logical) shapes of mean and std are broadcastable, we broadcast them for the output
Done in tensor iterator already.
- If the (logical) shapes of mean and std are not broadcastable and they have the same number of elements, we fall back to the old behavior (pick the shape of mean)
Done by reshape std to the same shape of mean.
- If the (logical) shapes of mean and std are not broadcastable and don't have the same number of elements, we error out.
Done by tensor iterator already.
Test Plan: Imported from OSS
Differential Revision: D19771186
Pulled By: glaringlee
fbshipit-source-id: a0b71063c7f5fdda2d4ceb84e06384414d7b4262
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33194
### Summary
The iOS x86_64 job has been failed for a few days. I haven't found the root cause, but seems like updating the torchvision to its latest version can fix the problem
### Test Plan
- the x86_64 job works
Test Plan: Imported from OSS
Differential Revision: D19845079
Pulled By: xta0
fbshipit-source-id: 5034e252600b6704b860d68c371a65bef4cf37fc
Summary:
There are cases when we want to recover from CUDA OOM, for example, some cuDNN algorithms use huge workspace and we want to recover from OOM to pick a different algorithm, in such cases, there is no reason to catch all errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33056
Differential Revision: D19795359
Pulled By: ezyang
fbshipit-source-id: a34e23bf6d172dc0257389251dafef5b38d27d2b
Summary:
Resolves issue https://github.com/pytorch/pytorch/issues/31603
- A minor spelling typo is corrected: "suitible" --> "suitable"
- A minor quality of life improvement is added: the data format strings are better rendered as fixed width to indicate that they are string constants. "CHW" --> "`CHW`"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31604
Differential Revision: D19697293
Pulled By: ezyang
fbshipit-source-id: ee38b0d4c9ca8a233ac9243c310d9a3b42ad6f32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33184
dnnlowp specific code shouldn't be in the default FC in the first place
Test Plan: Just removing #ifdef #endif
Reviewed By: jianyuh
Differential Revision: D19835301
fbshipit-source-id: 7880cf298bedb3f0bc407d140d342124663ea4a7
Summary:
Collect activation histograms along the model evaluation and aggregate all the histograms from multiple threads/readers into one file
The original functionality of bulk_eval workflow is still valid. The output predictions and extra blobs will be exported to a hive table, which will be very useful for numerical debugging.
Test Plan:
FBL
```flow-cli canary dper.workflows.bulk_eval.export --mode dbg --parameters-file experimental/summerdeng/sparsenn/bulk_eval_input_configs.json --run-as-secure-group team_ai_system_sw_hw_co-design --entitlement gpu_prod --name "Histogram collection with caffe2 logging. Attach histogram observer to the predict net. Use small model 102343030. "
```
f163861773
When the flow is done, we can get all the histogram files under the specified dir. For example:
```
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6ca65cc0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6cde8a80
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6d144840
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6d4a9600
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6da303c0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6dd1c800
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6e0855c0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6e3e0380
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6e95a140
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6eafcf00
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6ed1a100
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6f094ec0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6f561c80
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6f783a40
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb6fccb7c0
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7003d580
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb703ae340
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7084ae80
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb70bc1c40
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb70f43a00
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb70ff7680
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb71361300
-rw-rw-r--. 1 185754 185754 3945012 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb716df0c0
-rw-rw-r--. 1 185754 185754 4024538 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7199c780
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb71b72f00
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72330000
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72598100
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb7290d880
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72b03980
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb72f1f160
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fcb8bcee9e0
-rw-rw-r--. 1 185754 185754 3944091 Jan 23 09:45 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.0x7fd51b457260
-rw-rw-r--. 1 185754 185754 4026659 Jan 23 09:51 /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.final
```
The aggregated histogram file is /mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.final. It can be loaded to the following auto quant workflow for int8 static quantization.
######## Code refactoring ########
Moved the utility functions to process activation histograms to the deeplearning/numeric_suite/toolkit:hist_processor and add the dependency in dper.
We also had a hist_compiler in the caffe2/caffe2/fb/fbgemm/numerical_debugger/python_utils/hist_compiler.py. Also refactored the code to reuse the utility functions in deeplearning/numeric_suite/toolkit:hist_processor.
The histograms from bulk_eval and the hist_compiler are identical.
/mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.compiled.bak
/mnt/vol/gfsadslearner-frc3c01/fblearner_flow/users/summerdeng/sparsenn/bulk_eval.txt.final.bak
Reviewed By: hx89
Differential Revision: D19270090
fbshipit-source-id: c7ecb4f2bbf1ea725c52e903356ad9a7b9ad73ac
Summary:
fixes a compiler warning:
```
torch/aten/src/ATen/native/cuda/MaxUnpooling.cu.cc(402):
warning: variable "batchSize" was set but never used
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32294
Differential Revision: D19697277
Pulled By: ezyang
fbshipit-source-id: b9821be325826dc4785cad7994803b54f1711a0c
Summary:
The extra dashes are breaking the link here
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31760
Differential Revision: D19697301
Pulled By: ezyang
fbshipit-source-id: 65de026b9016dc8689c9dac9efb8aafd00b535cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30352
1) tbb forwards us ident through parameter, we don't need to capture it.
2) tbb is being passed steps <= 0 which is bad.
Taken from TBB documentation:
```
The index type must be an integral type. The loop must not wrap around. The step value must be positive. If omitted, it is implicitly 1.
```
I have a build that uses `TBB_USE_DEBUG=1` and there are currently a lot of issues with PyTorch use.
Is TBB version not tested very much right now?
ghstack-source-id: 94459382
Test Plan: CI green
Differential Revision: D18666029
fbshipit-source-id: d5aa8327b03181d349e1964f9c8211298c433d6a
Summary:
1. Use C10_WARP_SIZE instead of hardcoded value "32".
2. `getNumThreads` returns a minimum of 32 for CUDA, which is same as the warp size in CUDA. However, for HIP, it returns a minimum of 16, which is less than the warp size (64) in HIP. This creates an issue in the [reduce function](14548c2d5b/aten/src/ATen/native/cuda/Normalization.cuh (L115)) when it zeroes out the other entries in shared memory [here](14548c2d5b/aten/src/ATen/native/cuda/Normalization.cuh (L137)): since `blockDim.x` is at least equal to the warp size in CUDA, this never zeroes out `shared[0]`, but for HIP, since `blockDim.x` could be 16 or 32, which is less than the warp size (64), this results in `blockDim.x * blockDim.y` being potentially less than the warp size for small cases, which then zeroes out `shared[0]` as well. This results in an erroneous output of zero for the reduce function on ROCm (depending on how the block dimensions are set).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33098
Differential Revision: D19837355
Pulled By: bddppq
fbshipit-source-id: ea526acd82ec08b1acb25be860b7e663c38ff173
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33083
Added more recommendations, some notes and warning
Test Plan: cd docs ; make html
Differential Revision: D19829133
Pulled By: ilia-cher
fbshipit-source-id: b9fbd89f5875b3ce35cc42ba75a3b44bb132c506
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30982
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
-----------
In this PR:
Updating the templates.
-----------
Test Plan: Imported from OSS
Differential Revision: D18912680
Pulled By: izdeby
fbshipit-source-id: 9e3828e42ee5c3aefbf3729f4a8d6db813f2e7c3
Summary:
They were probably mistakenly added as we do not intend to support Half
on CPUs in general and in these situations Half type would probably be
significantly slower than their float and double counterpart due to the
lack of vectorization and the need of additional casting.
cc XiaobingSuper
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33021
Differential Revision: D19795152
Pulled By: VitalyFedyunin
fbshipit-source-id: b19796db88880a46557e1b2fd06e584d46093562
Summary:
This PR aims at improving `cat` performance on CPU.
Current `cat` logic from `TH` module has no parallelization when the input tensor array are all contiguous.
This code also try to reuse the same `TensorIterator` as much as possible, in order to reduce overhead of creating `TensorIterator`, this is helpful when the slice of copy is not large enough.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30806
Differential Revision: D19275026
Pulled By: VitalyFedyunin
fbshipit-source-id: 756e9b86891f725c256b0a6981887ff06d88b053
Summary:
Currently `torch.pdist` yields an illegal CUDA memory access for batch sizes >= 46342 as reported by SsnL in https://github.com/pytorch/pytorch/issues/30583.
Thanks for the minimal code reproduction, btw! ;)
Reason for this bug:
The calculation if `i` in the [`pdist_kerne_cuda_impl`](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L112)) might overflow, if a tensor with a `batch size >= 46342` is passed to `torch.pdist`.
Detailed description:
* `result` is resizes as ` n * (n - 1) / 2 = 1073767311` ([line of code](46ad80c839/aten/src/ATen/native/Distance.cpp (L140)))
* `grid` is initialized as `result.numel()` ([line of code](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L246)))
* `k` is assigned to the `blockIdx.x` as an `int32` ([line of code](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L108)))
* `i` is calculated using `2 * k >= 2147534622` ([line of code](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L112))), which overflows, since `2147534622 > 2147483647 (int32_max)`.
Using `const int64_t k = blockIdx.x;` would solve the illegal memory access. This seems also be done for [`cdist_kernel_cuda_impl`](46ad80c839/aten/src/ATen/native/cuda/DistanceKernel.cu (L198-L201)).
However, we might expect a slowdown, so I've timed the current PyTorch master vs. this PR:
(tested with `x = torch.randn(x.size(0), 128)` on a V100)
|x.size(0) | int32 idx | int64 idx | slowdown |
|----------|-----------|-----------|----------|
| 50000 | - | 4.4460 | - |
| 25000 | 1.02522 | 1.10869 | 7.53% |
| 12500 | 0.25182 | 0.27277 | 7.68% |
| 6250 | 0.06291 | 0.06817 | 7.72% |
| 3125 | 0.01573 | 0.01704 | 7.69% |
| 1562 | 0.00393 | 0.00426 | 7.75% |
While checking the backward kernel, it seems I'm triggering another error with a size limit of
```python
x = torch.randn(1449, 1, device='cuda', requires_grad=True)
out = torch.pdist(x)
out.mean().backward()
> RuntimeError: CUDA error: invalid configuration argument
```
, while `[<=1448, 1]` works.
I'll take another look at this issue. Let me know, if the potential fix should go into this PR or if I should open a new issue.
CC ngimel, csarofeen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31593
Differential Revision: D19825571
Pulled By: ngimel
fbshipit-source-id: ace9ccab49f3cf0ce894cdb6daef0795e2e8ec03
Summary:
`where` is special because the arguments do not have the same type, which does not satisfy the assumption in modern https://github.com/pytorch/pytorch/pull/32383. I migrate it to TensorIterator so that there is something to test that this case is not broken. Currently, this case fallback to using legacy (not vectorized, not unrolled) code. It should be supported in the future when I cleanup `Loops.cuh`.
I also move some sharing part of `CUDALoops.cuh` and `ROCmLoops.cuh` into `Loops.cuh` so that to logic for checking whether `func_t` has the same arg types could be shared.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32984
Differential Revision: D19825127
Pulled By: ngimel
fbshipit-source-id: bbf4682349d96b4480c4d657f3c18a3a67a9bf17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32985
This can be useful in many situations to decide whether all elements are
zeros or non-zeros, such as elu as shown in #32986 .
Test Plan: Imported from OSS
Differential Revision: D19794549
Pulled By: VitalyFedyunin
fbshipit-source-id: 1be1c863d69b9a19fdcfcdd7cb52343066f740d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30981
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
-----------
In this PR:
Extended DispatchKeyExtractor logic to expect TensorOptions.
-----------
Test Plan: Imported from OSS
Differential Revision: D18912684
Pulled By: izdeby
fbshipit-source-id: 25cf1c397caa14272ca65b4003f1f03ff282ea77
Summary:
When an error is raised and `__exit__` in a context manager returns `True`, the error is suppressed; otherwise the error is raised. No return value should be given to maintain the default behavior of context manager.
Fixes https://github.com/pytorch/pytorch/issues/32639. The `get_lr` function was overridden with a function taking an epoch parameter, which is not allowed. However, the relevant error was not being raised.
```python
In [1]: import torch
...:
...: class MultiStepLR(torch.optim.lr_scheduler._LRScheduler):
...: def __init__(self, optimizer, gamma, milestones, last_epoch = -1):
...: self.init_lr = [group['lr'] for group in optimizer.param_groups]
...: self.gamma = gamma
...: self.milestones = milestones
...: super().__init__(optimizer, last_epoch)
...:
...: def get_lr(self, step):
...: global_step = self.last_epoch #iteration number in pytorch
...: gamma_power = ([0] + [i + 1 for i, m in enumerate(self.milestones) if global_step >= m])[-1]
...: return [init_lr * (self.gamma ** gamma_power) for init_lr in self.init_lr]
...:
...: optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
...: scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
```
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-7fad6ba050b0> in <module>
14
15 optimizer = torch.optim.SGD([torch.rand(1)], lr = 1)
---> 16 scheduler = MultiStepLR(optimizer, gamma = 1, milestones = [10, 20])
<ipython-input-1-7fad6ba050b0> in __init__(self, optimizer, gamma, milestones, last_epoch)
6 self.gamma = gamma
7 self.milestones = milestones
----> 8 super().__init__(optimizer, last_epoch)
9
10 def get_lr(self, step):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in __init__(self, optimizer, last_epoch)
75 self._step_count = 0
76
---> 77 self.step()
78
79 def state_dict(self):
~/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/optim/lr_scheduler.py in step(self, epoch)
141 print("1a")
142 # try:
--> 143 values = self.get_lr()
144 # except TypeError:
145 # raise RuntimeError
TypeError: get_lr() missing 1 required positional argument: 'step'
```
May be related to https://github.com/pytorch/pytorch/issues/32898.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32997
Differential Revision: D19737731
Pulled By: vincentqb
fbshipit-source-id: 5cf84beada69b91f91e36b20c3278e9920343655
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30573
Mostly just moved code.
Index dim and number of indices checks are added to make checks idential to index_add_cpu_
ghstack-source-id: 98010129
Test Plan: existing tests
Differential Revision: D18749922
fbshipit-source-id: d243be43a3b6a9b9591caf0c35ef2fb6ec0d3ead
Summary:
Bazelisk automatically reads `.bazelversion` file and install the required version of Bazel. This saves us from updating CI script everytime we need a Bazel upgrade.
Use clang-8 for consistency with pytorch/xla repo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33036
Differential Revision: D19820819
Pulled By: ailzhang
fbshipit-source-id: 1560ec225cd037a811769a509a704b0df77ea183
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33102
Add a simple main() to build code analyzer as a binary. This enables
easier integration with FB internal build environment.
ghstack-source-id: 97958658
Test Plan: - CI
Differential Revision: D19798560
Pulled By: ljk53
fbshipit-source-id: 126230e3bf7568046a309e8a6785230f820e0222
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31998
This change builds on recent torch::from_blob() changes to avoid Tensor
copies on send in more cases.
Particularly, this change adds an enabled option to assume if the Tensor
Storage's DataPtr has a non-trivial deleter, then the Tensor does in fact
manage the underlying memory. And hence we can reference the Tensor's Storage
via an IOBuf that is referenced while sending, saving a Tensor copy.
We add appropriate test cases, particularly re: torch::from_blob() which
would have been problematic would recent changes.
ghstack-source-id: 97778619
Test Plan: buck test mode/dev caffe2/torch/fb/distributed/wireSerializer/test/...
Reviewed By: satgera
Differential Revision: D19306682
fbshipit-source-id: 05f56efb2d5d6279ae4b54dfcbba0f729c2c13fa
Summary:
## Several flags
`/MP[M]`: It is a flag for the compiler `cl`. It leads to object-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
`/maxcpucount:[M]`: It is a flag for the generator `msbuild`. It leads to project-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
`/p:CL_MPCount=[M]`: It is a flag for the generator `msbuild`. It leads the generator to pass `/MP[M]` to the compiler.
`/j[M]`: It is a flag for the generator `ninja`. It leads to object-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
## Reason for the change
1. Object-level multiprocessing is preferred over project-level multiprocessing.
2. ~For ninja, we don't need to set `/MP` otherwise M * M processes will be spawned.~ Actually, it is not correct because in ninja configs, there are only one source file in the command. Therefore, the `/MP` switch should be useless.
3. For msbuild, if it is called through Python configuration scripts, then `/p:CL_MPCount=[M]` will be added, otherwise, we add `/MP` to `CMAKE_CXX_FLAGS`.
4. ~It may be a possible fix for https://github.com/pytorch/pytorch/issues/28271, https://github.com/pytorch/pytorch/issues/27463 and https://github.com/pytorch/pytorch/issues/25393. Because `/MP` is also passed to `nvcc`.~ It is probably not true. Because `/MP` should not be effective given there is only one source file per command.
## Reference
1. https://docs.microsoft.com/en-us/cpp/build/reference/mp-build-with-multiple-processes?view=vs-2019
2. https://github.com/Microsoft/checkedc-clang/wiki/Parallel-builds-of-clang-on-Windows
3. https://blog.kitware.com/cmake-building-with-all-your-cores/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33120
Differential Revision: D19817227
Pulled By: ezyang
fbshipit-source-id: f8d01f835016971729c7a8d8a0d1cb8a8c2c6a5f
Summary:
Another pull request to follow up issue https://github.com/pytorch/pytorch/issues/32531.
Here I implemented the backward operation for `torch.eig` with a condition that all the eigenvalues are real.
This pull request is independent of my another pull request https://github.com/pytorch/pytorch/issues/32932, which means that there is no dependency between this PR and my another PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33090
Differential Revision: D19814347
Pulled By: albanD
fbshipit-source-id: 2fae30964e97987abb690544df8240aedeae56e8
Summary:
`assertWarnsRegex` now prints out any warnings that it caught while failing to find a matching warning. This makes it easier to debug tests by just looking at the CI logs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33099
Differential Revision: D19800021
Pulled By: ezyang
fbshipit-source-id: 1c31ae785c8ffc5d47619aff6597e479263be2de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33069
This PR adds the following:
- Warn when a non-input Tensor is given to `mark_dirty()` as it is not needed.
- Raise an error if we modify inplace an input that is a view and that we have multiple output. This setting is not handled by `CopySlices` and will raise a cryptic error during the backward.
- Raise an error if an input is modified inplace but not returned. That will prevent the graph rewrite from being done correctly.
Test Plan: Imported from OSS
Differential Revision: D19791563
Pulled By: albanD
fbshipit-source-id: 4d8806c27290efe82ef2fe9c8c4dc2b26579abd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33068
The version counter is already tracked if we use pytorch's functions but not if the user unpack the Tensor and modifies it by hand or with a third party library.
Test Plan: Imported from OSS
Differential Revision: D19791564
Pulled By: albanD
fbshipit-source-id: a73c0f73d8fd0c0e5bf838f14bed54fa66937840
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31768, second attempt of https://github.com/pytorch/pytorch/issues/32870
DataParallel creates replicas of the original `nn.Module` with the parameters duplicated onto the destination devices. Calling `backwards` will propagate gradients onto the original module parameters but calling `zero_grad` on the replica module doesn't clear the gradients from the parent module. However, any replica using backwards was broken anyway since the replica's parameters are not leaf nodes in autograd. So, we should issue a warning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33064
Differential Revision: D19790178
Pulled By: albanD
fbshipit-source-id: 886f36640acef4834a6fa57a26ce16b42ff0e9ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32979
Since we use prepacked weights in the Fp16 FCs and future Int8 FCs in production Ads models, we provide the python utils to inspect the unpacked format of the weights for debugging purpose. The main interfaces are the following:
```
from deeplearning.numeric_suite.toolkit import packed_weights_inspector
# inspect fp16 packed weights
unpacked_fp16_weights = packed_weights_inspector.extract_fp16_fc_packed_weights(fp16_weight_blob_name)
# inspect int8 packed weights
unpacked_int8_weights, qparams = packed_weights_inspector.extract_int8_fc_packed_weights(int8_weight_blob_name)
```
Test Plan:
```
buck test mode/opt deeplearning/numeric_suite/toolkit/test:packed_weights_inspector_test
```
Reviewed By: amylittleyang
Differential Revision: D19724474
fbshipit-source-id: e937672b3722e61bc44c2587aab2288a86aece9a
Summary:
If using nn.functional avg_pool, stride is an optional arg. If not provided, it is set to kernel_size.
This PR fixes the export of avg_pool with default stride.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33017
Reviewed By: hl475
Differential Revision: D19759604
Pulled By: houseroad
fbshipit-source-id: b0352db6fbaf427f4cff9ba8a942efdeb39b6f02
Summary:
Fix internal error message due to old version of hypothesis
test_suite = self.load_tests()
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/__fb_test_main__.py", line 678, in load_tests
suite = loader.load_all()
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/__fb_test_main__.py", line 467, in load_all
__import__(module_name, level=0)
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/test_quantization.py", line 45, in <module>
hu.assert_deadline_disabled()
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/torch/testing/_internal/hypothesis_utils.py", line 322, in assert_deadline_disabled
assert settings().deadline is None
File "/data/sandcastle/boxes/eden-trunk-hg-fbcode-fbsource/fbcode/buck-out/dev/gen/caffe2/test/quantization#binary,link-tree/hypothesis/_settings.py", line 127, in __getattr__
raise AttributeError('settings has no attribute %s' % (name,))
AttributeError: settings has no attribute deadline
Test Plan: buck test mode/dev //caffe2/test:quantization -- --run-disabled runs successfully
Differential Revision: D19795232
fbshipit-source-id: ef1d8be20b4be30e1cfad4cd5019c4779a5f4568
Summary:
split requires an int input, however in tracing operators such as
size(axis) return a tensor, which is different behavior than when not
tracing. As such need to modify split to handle these cases.
Fixes https://github.com/pytorch/pytorch/issues/27551
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32493
Reviewed By: hl475
Differential Revision: D19538254
Pulled By: houseroad
fbshipit-source-id: c8623009de5926aa38685e08121f4b48604bd8c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33070
`start_method` parameter is intentionally ignored for `mp.spawn()`. Document this fact and point the user to `start_processes` if they want to use a different `start_method`.
Test Plan:
Warning message looks like:
```
main.py:8: UserWarning: This method only supports start_method=spawn (got: fork).
To use a different start_method use:
torch.multiprocessing.start_process(...)
warnings.warn(msg)
```
Reviewed By: ailzhang
Differential Revision: D19780235
fbshipit-source-id: 4599cd18c3ba6cc401810efe4f390290ffa8023b
Summary:
Currently, custom ops are registered for a specific opset version.
For example, all torchvision custom ops are registered for opset 11, and cannot be exported into higher opset versions. This PR extends op registration to higher opset versions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32943
Reviewed By: hl475
Differential Revision: D19739406
Pulled By: houseroad
fbshipit-source-id: dd8b616de3a69a529d135fdd02608a17a8e421bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32506
In this PR, we've introduced a `retain_graph` parameter to distributed
autograd similar to `torch.autograd.backward`.
In terms of design, this parameter is sent over RPC to all nodes and is used to
create the GraphTask on the local nodes. This enables us to run
`dist_autograd.backward()` multiple times in the same context.
The use case currently for this is to benchmark only the backward pass for
distributed autograd. We'd like to measure the QPS for the backward pass and as
a result, running a single forward pass and multiple backward passes in a loop
is one way to benchmark backward pass performance.
ghstack-source-id: 97868900
Test Plan: waitforbuildbot
Differential Revision: D19521288
fbshipit-source-id: 7ad8521059fd400d7b5a6ab77ce56e1927ced90a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33060
Noticed this when tracking down a partially-related SIGSEGV.
If inserting a non-present key into a memoized map, don't re-calculate it twice
(probably safer that way anyway).
ghstack-source-id: 97904485
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D19778008
fbshipit-source-id: 95b1d708c034a54b96a22ccbdffb24f72d08dffd
Summary:
the rand N like function had required args which were not being used.
As such modified the method signature to give default values so when
scripting does not provide these arguments which are not even being
used, no error is thrown.
Additionally modified the const checker for handling prim::Constant as
well
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32830
Reviewed By: hl475
Differential Revision: D19731715
Pulled By: houseroad
fbshipit-source-id: a3cacb3977eecb88b122e0ceb654fdbf1c8286c1
Summary:
Supporting the below case. Previously index for copy_ was only considered as constant integer, where as it could be a tensor input as well.
```python
class InPlaceIndexedAssignment(torch.nn.Module):
def forward(self, data, index, new_data):
data[index] = new_data
return data
data = torch.zeros(3, 4)
index = torch.tensor(1)
new_data = torch.arange(4).to(torch.float32)
torch.onnx.export(InPlaceIndexedAssignment(), (data, index, new_data), 'inplace_assign.onnx', opset_version=11)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32801
Reviewed By: hl475
Differential Revision: D19731666
Pulled By: houseroad
fbshipit-source-id: 08703fdccd817f901282e19847e259d93929e702
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32243
Following what gchanan proposed in #30480
- If the (logical) shapes of mean and std are broadcastable, we broadcast them for the output
Done in tensor iterator already.
- If the (logical) shapes of mean and std are not broadcastable and they have the same number of elements, we fall back to the old behavior (pick the shape of mean)
Done by reshape std to the same shape of mean.
- If the (logical) shapes of mean and std are not broadcastable and don't have the same number of elements, we error out.
Done by tensor iterator already.
Test Plan: Imported from OSS
Differential Revision: D19417087
Pulled By: glaringlee
fbshipit-source-id: 1c4bc7df923110a803620b9e2abd11a7151fc33e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31768
`DataParallel` creates replicas of the original `nn.Module` with the parameters duplicated onto the destination devices. Calling `backwards` will propagate gradients onto the original module parameters but calling `zero_grad` on the replica module doesn't clear the gradients from the parent module,
~breaking any model that uses `backward`-`zero_grad` in its `forward`. I fix this by patching the replica module so that `zero_grad` clears grads on the parent as well.~
However, any replica using backwards was broken anyway since the replica's parameters are not leaf nodes in autograd. So, we should raise a warning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32870
Differential Revision: D19730209
Pulled By: ezyang
fbshipit-source-id: cb9b2cb0c2e0aca688ce0ff3e56b40fbd2aa3c66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32495
Background
------------------------------
Previously, ninja was used to compile+link inline cpp_extensions and
ahead-of-time cpp_extensions were compiled with distutils. This PR adds
the ability to compile (but not link) ahead-of-time cpp_extensions with ninja.
The main motivation for this is to speed up cpp_extension builds: distutils
does not make use of parallelism. With this PR, using the new option, on my machine,
- torchvision compilation goes from 3m43s to 49s
- nestedtensor compilation goes from 2m0s to 28s.
User-facing changes
------------------------------
I added a `use_ninja` flag to BuildExtension. This defaults to
`True`. When `use_ninja` is True:
- it will attempt to use ninja.
- If we cannot use ninja, then this throws a warning and falls back to
distutils.
- Situations we cannot use ninja: Windows (NYI, I'll open a new issue
for this), if ninja cannot be found on the system.
Implementation Details
------------------------------
This PR makes this change in two steps. Please me know if it would be
easier to review this if I split this up into a stacked diff.
Those changes are:
1) refactor _write_ninja_file to separate the policy (what compiler flags
to pass) from the mechanism (how to write the ninja file and do compilation).
2) call _write_ninja_file and _run_ninja_build while building
ahead-of-time cpp_extensions. These are only used to compile objects;
distutils still handles the linking.
Change 1: refactor _write_ninja_file to seperate policy from mechanism
- I split _write_ninja_file into: _write_ninja_file and
_write_ninja_file_to_build_library
- I renamed _build_extension_module to _run_ninja_build
Change 2: Call _write_ninja_file while building ahead-of-time
cpp_extensions
- _write_ninja_file_and_compile_objects calls _write_ninja_file to only
build object files.
- We monkey-patch distutils.CCompiler.compile to call
_write_ninja_files_and_compile_objects
- distutils still handles the linking step. The linking step is not a
bottleneck so it was not a concern.
- This change only works on unix-based systems. Our code for windows
goes down a different codepath and I did not want to mess with that.
- If a system does not support ninja, we raise a warning and fall back
to the original compilation path.
Test Plan
------------------------------
Adhoc testing
- I built torchvision using pytorch master and printed out the build
commands. Next, I used this branch to build torchvision and looked at
the ninja file. I compared the ninja file with the build commands and
asserted that they were functionally the same.
- I repeated the above for pytorch/nestedtensor.
PyTorch test suite
- I split `test_cpp_extensions` into `test_cpp_extensions_aot` and
`test_cpp_extensions_jit`. The AOT (ahead-of-time) version tests
ahead-of-time and the JIT version tests just-in-time (not to be confused
with TorchScript)
- `test_cpp_extensions_aot` gets run TWICE by run_test.py, once with
a module that was built with ninja, and once with a module that was
built without ninja.
- run_test.py asserts that when we are building with use_ninja=True,
ninja is actually available on the system.
Test Plan: Imported from OSS
Differential Revision: D19730432
Pulled By: zou3519
fbshipit-source-id: 819590d01cf65e8da5a1e8019b8b3084792fee90
Summary:
This will allow us to incrementally enable more tests for scripting as we put in fixes. houseroad spandantiwari
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32654
Reviewed By: hl475
Differential Revision: D19583401
Pulled By: houseroad
fbshipit-source-id: 8dc05e4784df819c939dffdf33b00cbb80bfa364
Summary:
Stacked PRs
* #32958 - Make zip serialization the default
* **#32244 - Fix some bugs with zipfile serialization**
It includes the following changes:
* Split up tests so that we can test both serialization methods
* Loading something within a buffer doesn't work anymore, so those tests are only on the old serialization method (it's possible but introduces a big slowdown since it requires a linear scan of the entire zipfile to find the magic number at the end)
* Call `readinto` on a buffer if possible instead of `read` + a copy
* Disable CRC-32 checks on read (there was some issue where miniz said the CRC was wrong but `zipinfo` and `unzip` said the zip file was fine)
](https://our.intern.facebook.com/intern/diff/19418935/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32244
Pulled By: driazati
Reviewed By: eellison
Differential Revision: D19418935
fbshipit-source-id: df140854f52ecd04236225417d625374fd99f573
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32895
When a particular rank calls `ncclCommAbort` on a communicator, it is
important to ensure all other ranks call `ncclCommAbort` on their respective
communicators. If this is not done, the other ranks could get stuck causing the
GPU to spin with 100% utilization.
To alleviate this issue, whenever any rank calls `ncclCommAbort` we put the
unique communicator id in the store. The NCCL watchdog thread then monitors the
store and aborts any communicators found in the store as "aborted".
A few more general fixes in this PR:
1) Use std::shared_ptr for the store in PrefixStore. PrefixStore was using a
reference to the store and when that reference went out of scope the store
object it was holding onto was invalid. This caused a segfault in the watchdog
thread.
2) Enhanced logging for the watchdog thread.
Test Plan: waitforbuildbot
Differential Revision: D19638159
fbshipit-source-id: 596cd87c9fe6d4aeaaab4cb7319cc37784d06eaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32941
The Python grammar allows single-statement one-line functions. So we
should allow it in the string parser.
Test Plan: Imported from OSS
Differential Revision: D19704153
Pulled By: suo
fbshipit-source-id: 8c06cc9c600aa2a9567b484a1ecc0360aad443e3
Summary:
Enabling the RCCL test on rocm by adding a temporary grace period to clean up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32340
Differential Revision: D19744459
Pulled By: xw285cornell
fbshipit-source-id: 1af3b64113a67f93e622d010ddd3020e5d6c8bc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32982
For masked_scatter_ and masked_fill_ (which already have manually written wrappers), move the broadcasting logic into the manually written wrappers.
Test Plan: Imported from OSS
Differential Revision: D19726830
Pulled By: gchanan
fbshipit-source-id: 1f6e55e19c1314a76e43946b14d58f147c0f8204
Summary:
The way we currently dispatch argmax/argmin to out-of-source devices is bad and caused issues, e.g it doesn't work well when the input requires grad. https://github.com/pytorch/xla/issues/1585.
Making argmax/argmin dispatch at device level resolves it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32961
Differential Revision: D19726826
Pulled By: ailzhang
fbshipit-source-id: f7fb445fd8e7691524afcc47d24d8e6b0171d10c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32788
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628643
Pulled By: ezyang
fbshipit-source-id: 7099b08eff37913144b961dda00b070bd4b939d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32787
Gets rid of a longstanding TODO. TensorList unwrap is only used for cat, which
means we can assume that the inputs are dense, and do something similar to how
we do the dense tensor wrapping above.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628642
Pulled By: ezyang
fbshipit-source-id: 3264439407585fb97995a9a2302c2913efecb421
Summary:
The PR https://github.com/pytorch/pytorch/pull/31791 adds support for float[] constant, which affects some cases of ONNX interpolate support.
This PR adds float[] constants support in ONNX, updates interpolate in ONNX, and re-enable the disabled tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32554
Reviewed By: hl475
Differential Revision: D19566596
Pulled By: houseroad
fbshipit-source-id: 843f62c86126fdf4f9c0117b65965682a776e7e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32936
Closes https://github.com/pytorch/pytorch/issues/32732. Currently if a
UDF run in RPC throws an exception such as ValueError or TypeError, we wrap
this in a RemoteException on the callee side. When raising this on the caller
side, we currently raise a vanilla Exception. This diff changes it so that the
correct exception is thrown. Tested by changing the current rpc tests to assert
on the right type of error rather than just the base `Exception`.
ghstack-source-id: 97706957
Test Plan: Modified unit test.
Differential Revision: D19700434
fbshipit-source-id: e451b772ea6aecc1d2e109e67e7f932eb9151f15
Summary:
Checks the size of each tensor passed to `torch.stack` before calling `cat` to address https://github.com/pytorch/pytorch/issues/29510. This is done in the `get_stack_input` function as that is a common path. The function now compares the size of each tensor in the TensorList to the size of the first tensor and throws an exception when the sizes are not equal.
To compare:
```
x = torch.zeros([1, 2])
y = torch.zeros([1, 3])
torch.stack([x, y]) # Errors due to size differences
```
Current error:
```
RuntimeError: invalid argument 0: Sizes of tensors must match
except in dimension 0. Got 2 and 3 in dimension 2 at (path)\aten\src\TH/generic/THTensor.cpp:612
```
New error:
```
RuntimeError: stack expects each tensor to be equal size, but
got [1, 2] at entry 0 and [1, 3] at entry 1
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32931
Differential Revision: D19700110
Pulled By: ezyang
fbshipit-source-id: 7e18bb00fa2c137e418e340d719b6b76170b83e3
Summary:
It was causing a build error when compiling on MINGW64
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32015
Differential Revision: D19697296
Pulled By: ezyang
fbshipit-source-id: 71e58783c48f8e99755c091b2027d59740dfca47
Summary:
Closes gh-31771
Also note that the `epoch` attribute is *only* used as a manual seed in each iteration (so it could easily be changed/renamed). Seeding consecutive iterations with `[0, 1, 2, ...]` is low-entropy, however in practice it probably doesn't matter when using the sampler in combination with a dataloader (because there won't be enough data nor epochs to run into statistical issues
due to low-entropy seeding). So leaving that as is.
Rendered docstring:
<img width="534" alt="image" src="https://user-images.githubusercontent.com/98330/73701250-35134100-46e9-11ea-97b8-3baeb60fcb37.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32951
Differential Revision: D19729333
Pulled By: ezyang
fbshipit-source-id: 3ddf90a3828b8bbae88aa2195a5d0b7d8ee1b066
Summary:
two instances of if -> it in torch.nn.modules.batchnorm.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29797
Differential Revision: D19698613
Pulled By: ezyang
fbshipit-source-id: 7312b2333f227113e904dfa91db90d00e525affb
Summary:
TensorBoard tests using SummaryWriter() may fail with a pandas import
complaint if TensorFlow packages are installed in the same python
environment as PyTorch:
Traceback (most recent call last):
File "test_tensorboard.py", line 212, in test_writer
with self.createSummaryWriter() as writer:
File "test_tensorboard.py", line 64, in createSummaryWriter
return SummaryWriter(temp_dir)
...
File "[...]/site-packages/pandas/core/arrays/categorical.py", line 52, in <module>
import pandas.core.algorithms as algorithms
AttributeError: module 'pandas' has no attribute 'core'
The exact failure may depend on the pandas version. We've also seen:
File "[...]/site-packages/pandas/core/arrays/categorical.py", line 9, in <module>
import pandas.compat as compat
AttributeError: module 'pandas' has no attribute 'compat'
The module import chain leading to the failure is tensorboard imports
tensorflow imports tensorflow_estimator imports pandas. pandas includes
a submodule named 'bottleneck', whose name collides with the PyTorch
'test/bottleneck/' subdirectory.
So IF tensorboard, tensorflow, tensorflow_estimator, and pandas are
installed in the python environment AND IF testing is run from within
PyTorch's 'test/' directory (or maybe just with 'test/' in PYTHONPATH,
etc.), then TensorBoard tests using SummaryWriter() will fail.
Rename the 'bottleneck/' directory slightly to avoid the name collision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29650
Differential Revision: D19698638
Pulled By: ezyang
fbshipit-source-id: cb59342ed407cb37aefc833d67f768a8809129ac
Summary:
With fedora negativo17 repo, the cudnn headers are installed in /usr/include/cuda directory, along side with other cuda libraries.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31755
Differential Revision: D19697262
Pulled By: ezyang
fbshipit-source-id: be80d3467ffb90fd677d551f4403aea65a2ef5b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32897
Moving the default static instance into the method to achieve the same purpose.
ghstack-source-id: 97570792
Test Plan: - CI
Reviewed By: dreiss
Differential Revision: D19674566
fbshipit-source-id: 27f54da66dd7667c34905eddaac6579e64aa1118
Summary:
Understanding which ops return views and which return tensors with new storage is a common user issue, and an issue for developers connecting accelerators to PyTorch, too. This generic test suite verifies that ops which should return views do (and a few ops that shouldn't don't). The documentation has also been updated for .t(), permute(), unfold(), and select() to clarify they return views.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32512
Differential Revision: D19659454
Pulled By: mruberry
fbshipit-source-id: b4334be9b698253a979e1bb8746fdb3ca24aa4e3
Summary:
1. Allows both the memory_format of weight & input to dictate the output
memory_format.
2. Provides utility function to recursively convert memory_format of Conv2d and
ConvTranspose2d layers. This allows easy model conversion and ensures that lost
memory_format through incompatible layers could be restored at Convolution-like
layer, where significant performance boost is expected on later generation CUDA
devices.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32482
Differential Revision: D19647903
Pulled By: VitalyFedyunin
fbshipit-source-id: 62c96ff6208ff5e84fae1f55b63af9a010ad199a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32888
This kills ~1500 lines of generated code by doing the following:
1) Stop binding _th_clone, which isn't used anymore.
2) Move allocation code out of the switch, because it doesn't need to be there, example:
Now:
```
auto dispatch_scalar_type = infer_scalar_type(self);
auto result_ = c10::make_intrusive<TensorImpl, UndefinedTensorImpl>(c10::Storage(scalarTypeToTypeMeta(dispatch_scalar_type), 0, allocator(), true),DispatchKey::CPUTensorId).release();
auto result = Tensor(c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl>::reclaim(result_));
switch (dispatch_scalar_type) {
case ScalarType::Bool: {
...
case ScalarType::Byte: {
...
```
Before:
```
auto dispatch_scalar_type = infer_scalar_type(self);
switch(dispatch_scalar_type) {
case ScalarType::Bool: {
auto result_ = c10::make_intrusive<TensorImpl, UndefinedTensorImpl>(caffe2::TypeMeta::Make<bool>(), 0, allocator(), true),DispatchKey::CPUTensorId).release();
auto result = Tensor(c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl>::reclaim(result_));
case ScalarType::Byte: {
auto result_ = c10::make_intrusive<TensorImpl, UndefinedTensorImpl>(caffe2::TypeMeta::Make<byte>(), 0, allocator(), true),DispatchKey::CPUTensorId).release();
auto result = Tensor(c10::intrusive_ptr<TensorImpl, UndefinedTensorImpl>::reclaim(result_));
```
Note there's one extra lookup from ScalarType -> TypeMeta, but that can go away once we are able to put everything in a dispatch macro.
3) Prepare for more moves out of the switch by using dispatch_scalar_type where we would have used an explicit ScalarType::Name
More moves are currently blocked by "real" types needing to map scalar_type -> C++ type. Dispatch macros can solve that, but I'll need to wrap the actual TH calls in templates so the entire
thing can be done via dispatch.
4) Kill some codegen that isn't used anymore: ALLOC_WRAP, is_actual_return_long.
Test Plan: Imported from OSS
Differential Revision: D19672613
Pulled By: gchanan
fbshipit-source-id: 753f480842d11757e10182e43b471bd3abaa5446
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32952
When the Async() version of clearAndWaitForOutstandingRpcs() was written,
we didn't yet have the generic Future<T> class, and hadn't worked out our
error model fully.
This change fixes that method to properly propagate the first encountered error
to the future, using a bool+CAS.
ghstack-source-id: 97665749
Test Plan: existing test coverage, buck test mode/dev-nosan caffe2/test/...
Differential Revision: D19710337
fbshipit-source-id: 66ce5593a94a16ea624930dbb9409917ef5cfd5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32935
Mock away the content of onnxified net with some low cost ops so that we can still mimic the input/output transfer while doing minimal work on the card.
Test Plan:
```
buck run glow/fb/test:sparsenn_test -- --gtest_filter='SparseNNTest.vanillaC2' --onnxifi_debug_mode --onnxifi_loop_test_mode --nocaffe2_predictor_use_memonger
```
Differential Revision: D19631971
fbshipit-source-id: f970c55ccb410702f479255eeb750e01e3f8c2ae
Summary:
Should fix https://github.com/pytorch/pytorch/issues/32346 hopefully. Now when _flat_weights list is updated, `None` elements are appended to it if some weights are missing, subsequent `setattr` calls for the missing weights should repair _flat_weights and make it suitable to use in the backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32939
Differential Revision: D19710990
Pulled By: ngimel
fbshipit-source-id: c978c7519464e94beeffa9bc33b9172854a2f298
Summary:
The default value is removed because it is explained right below.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32945
Reviewed By: soumith
Differential Revision: D19706567
Pulled By: ailzhang
fbshipit-source-id: 1b7cc87991532f69b81aaae2451d944f70dda427
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32907
All op-specific information used in this logic was available to the
parser itself, so the check can be done in that context, no codegen
needed.
No change in the warning behavior itself, mod minor formatting tweak -
passes existing tests. Saves like ~275K binary size on mac:
```
-rwxr-xr-x 1 bhosmer 1876110778 16502064 Feb 1 00:43 torch/lib/libtorch_python.dylib
-rwxr-xr-x 1 bhosmer 1876110778 16247888 Feb 1 00:44 torch/lib/libtorch_python.dylib
```
[codegen diff](https://github.com/bhosmer/scratch/compare/deprecation_warning_before...deprecation_warning_after)
More important than the size savings is the minimization of codegen. Ideally the generated artifact should express distinctive per-op properties in as minimal a form as practically possible - e.g. here instead of generating check-and-warn behavior into every binding, we generate only the data that triggers the behavior in the parser. (And actually we were generating it already.)
Test Plan: Imported from OSS
Differential Revision: D19679928
Pulled By: bhosmer
fbshipit-source-id: cf0140573118430720c6b797c762fe5be98acd86
Summary:
The `BatchNorm*` part of the issue (see gh-12013) seems to have been fixed in the master branch and these tests would make it concrete.
However I would appreciate comments on https://github.com/pytorch/pytorch/issues/12013#issuecomment-575871264 on whether the current behaviour is satisfactory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32384
Differential Revision: D19704154
Pulled By: ngimel
fbshipit-source-id: 1bbbbf1ae1215a460b22cf26e6b263e518ecf60b
Summary:
SpatialBNFakeLoweredFp16NNPI
this is the fake operator for SpatialBN that gets lowered into add/mul/div, etc.
Test Plan: test_spatialbn
Reviewed By: tracelogfb, amylittleyang
Differential Revision: D19658680
fbshipit-source-id: 2abddbcd9a2023ac75c494f20eaac2051b7139dc
Summary:
Fix for constant folding flaky tests
Looks like the constant folding test modules are sometimes exported with ONNX_ATEN op export type, which is causing the CI failures.
I'm unable to repro this issue locally, but my guess is that the op export param is being overwritten on CI build at some point.
This PR sets the op export type and hopefully fixes the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32546
Reviewed By: hl475
Differential Revision: D19606919
Pulled By: houseroad
fbshipit-source-id: 31793d6857bbbf99b43b4a7c22a045a56ae19e44
Summary:
e.g. `tensor[torch.tensor([0, 1, 0], dtype=torch.bool)]`
Previously the mask is of type uint8. Both uint8 and bool should be supported for export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32445
Reviewed By: hl475
Differential Revision: D19610713
Pulled By: houseroad
fbshipit-source-id: 8df636e0c3cb0b82919a689242a962c79220209c
Summary:
I noticed the description of the initialization of convolutional modules is inconsistent with the actual implementation. There are two such cases:
1) `k` in the initialization of ConvTranspose modules is not dependent on the input channels but on the output channels (`kaiming_uniform_` uses the size of the second dimension of `weight` which is transposed in the first two dimensions).
2) Both the normal convolutions and the transposed ones use `k` divided by `groups`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30079
Differential Revision: D19698511
Pulled By: ezyang
fbshipit-source-id: 1ba938fbbd97663eaf29fd1245872179d2761fff
Summary:
* New ops supported for exporting.
* Updates on support for tensor indexing and dynamic list of tensors.
* lara-hdr, spandantiwari Should we also include updates on torchvision support in this page?
cc houseroad, neginraoof Please review if I have missed anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32805
Reviewed By: hl475
Differential Revision: D19635699
Pulled By: houseroad
fbshipit-source-id: b6be4fce641f852dcbceed20b4433f4037d8024a
Summary:
The need for this is felt because sometimes we change a build script and change the `std=c++XX` flag, which does not get caught until the compilation has progressed for a while.
https://github.com/pytorch/pytorch/issues/31757
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32819
Differential Revision: D19697205
Pulled By: ezyang
fbshipit-source-id: b045a1d15e24c4c6007b5d1464756051d32bf911
Summary:
This PR fixes type hints for `torch.optim.optimizer.Optimizer` object, issue also reported in https://github.com/pytorch/pytorch/issues/23731
To test things I used following optimiser implementation, that is fully covered with type hints:
```python
from typing import Optional, Callable, Union, Iterable
from torch import Tensor
from torch.optim.optimizer import Optimizer
OptClosure = Optional[Callable[[], float]]
_params_t = Union[Iterable[Tensor], Iterable[dict]]
class SGD(Optimizer):
def __init__(self, params: _params_t, lr: float = 0.1) -> None:
defaults = dict(lr=lr)
super(SGD, self).__init__(params, defaults)
def __setstate__(self, state: dict) -> None:
super(SGD, self).__setstate__(state)
def step(self, closure: OptClosure = None) -> Optional[float]:
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad.data
p.data.add_(-group['lr'], d_p)
return loss
```
Without fix `mypy` reports bunch of inconsistencies in types and missing properties:
```bash
$ mypy torch_optimizer/sgd.py
torch_optimizer/sgd.py:14: error: Too many arguments for "__init__" of "Optimizer"
torch_optimizer/sgd.py:17: error: "__setstate__" undefined in superclass
torch_optimizer/sgd.py:19: error: Return type "Optional[float]" of "step" incompatible with return type "None" in supertype "Optimizer"
torch_optimizer/sgd.py:24: error: "SGD" has no attribute "param_groups"
Found 4 errors in 1 file (checked 1 source file)
```
with fix not issues:
```bash
$ mypy torch_optimizer/sgd.py
Success: no issues found in 1 source file
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32900
Differential Revision: D19697175
Pulled By: ezyang
fbshipit-source-id: d5e2b3c421f69da3df8c32b3d53b4b6d15d61a41
Summary:
Add `torch.jit.is_scripting` to the list of CondValues, or values that if they are an input to a if statement we only compile one side of the if. I'm not sure if we actually want this PR.
Pros:
- Makes it easier to add features that are not yet supported in TorchScript (like has_torch_function)
- The current idiom of writing `torch.jit.is_scripting` and factoring out the block to a function annotated with `torch.jit.ignore` is functionally equivalent and much more cumbersome
Cons:
- Makes it easier to add features that are not yet supported in TorchScript
- Perhaps is confusing as a reader what is being compiled. Potentially could give all caps name or otherwise change name to make it more visually stand out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32871
Differential Revision: D19670383
Pulled By: eellison
fbshipit-source-id: 5257b0bd23c66f199d59a7f2c911e948301e5588
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32847
Add support for join on List of strings in TorchScript.
Test Plan:
(pytorch) smummadi@smummadi-mbp pytorch % python test/test_jit_string.py
Fail to import hypothesis in common_utils, tests are not derandomized
.
Ran 1 test in 1.090s
OK
Differential Revision: D19650809
fbshipit-source-id: 387a8f0e3cc3111fd3dadd3d54c90fc8c7774cf9
Summary:
Closes https://github.com/pytorch/pytorch/issues/27368.
Previously, if a function `'func` did not exist on worker A but existed in B, and the user ran `rpc.rpc_sync(A, func)`, A would crash with a segmentation fault since it is not able to find the function. B would eventually timeout since RPCs by default time out in 60s.
At the root this comes from an unhandled exception when trying to deserialize the `PythonUDF` to run.
This PR makes it so that we can recover from this error, and A reports back a `RemoteException` to B indicating that the function was not found. Now, A will no longer crash and B can handle the exception appropriately and with more information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32726
Differential Revision: D19648825
Pulled By: rohan-varma
fbshipit-source-id: 53847f4bfb68187db41c61d69ddac13613e814b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32749
The test was flaky since the message from owner RRef confirming fork would arrive after the test checked whether the pending User RRefs map was empty - leading to an assertion error. This diff creates a utility function that should be used by any test to wait for this message to complete processing before doing any assertions related to the pending User RRefs map.
GitHub Issue: https://github.com/pytorch/pytorch/issues/30988
Test Plan: Stress tested `test_rref_context_debug_info` 200 times.
Differential Revision: D19612289
fbshipit-source-id: 57a7c19b1cf792b94c263d3efbbbb6da60c07d07
Summary:
Power and x86 are giving slightly different results when scaling images up using `torch.nn.functional.interpolate` and when using OpenCV's `resize`. This is causing `test_upsampling_not_recompute_scale_factor` to fail on Power, but not x86. This changes the expected value to what OpenCV on Power produces if the test case is running on Power as well.
See https://github.com/pytorch/pytorch/issues/31915
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32786
Differential Revision: D19672053
Pulled By: ezyang
fbshipit-source-id: 3497f852bdc6d782646773792f9107c857c7b806
Summary:
If there was a namedtuple with immutable constant inputs, that was also the input / output of a function which expected a namedtuple it would fail. Fix by using namedtuple constructor on serialization. (no one has run into this bug yet).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32873
Differential Revision: D19668807
Pulled By: eellison
fbshipit-source-id: bae33506e53b6a979b4e65a3e7c989b1408c98f4
Summary:
This PR solves Issue https://github.com/pytorch/pytorch/issues/32750.
- Changes function prod_kernel_impl to use `out_t` argument instead of `scalar_t` (which caused the garbage output for FP16 input and FP32 output tensor type).
- Adds test case for `torch.prod` (for CUDA): tests both `torch.prod` and `torch.tensor.prod`. Checks all the combinations for dtypes: `torch.float16` and `torch.float32`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32831
Differential Revision: D19664666
Pulled By: ngimel
fbshipit-source-id: c275363355c832899f10325043535949cd12b2f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32738
This is to simplify the codegen layer, with the goal of making it simple enough to just check in.
Test Plan: Imported from OSS
Differential Revision: D19610927
Pulled By: gchanan
fbshipit-source-id: 760734f579b1f655775e6d270918c361985f3743
Summary:
To suppress a clang-tidy warning:
torch/csrc/jit/script/builtin_functions.cpp#L89
[performance-for-range-copy] warning: loop variable is copied but only
used as const reference; consider making it a const reference
Also make the const qualifier of scalar explicit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32852
Differential Revision: D19663277
Pulled By: ezyang
fbshipit-source-id: f4ec5688d3cbea9a5f40db6063b7d111b0bf0cce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32849
We learned that Android NDK's gcc + gnustl combination might produce a
use-after-free for thread_local variables with non-trivial destructors.
This PR removes such a thread_local use case from error_report.cpp for mobile build,
which is the only case included in mobile lite-JIT build.
ghstack-source-id: 97491327
Test Plan: - CI
Reviewed By: dreiss
Differential Revision: D19652702
fbshipit-source-id: ee8d316ad5c6e6c8a8006eb25f3bba1618dd7e6d
Summary:
I didn't see any use case where the functor of `gpu_kernel_with_index` needs to have argument other than the index. Merge conflict with https://github.com/pytorch/pytorch/pull/32755.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32777
Differential Revision: D19646381
Pulled By: ngimel
fbshipit-source-id: 81d2be74170457e39943274e3689845e83758bfa
Summary:
The Python document <https://www.python.org/dev/peps/pep-0263/> gives
all examples using lowercase letters. Although it doesn't say
straightly, the following paragraph seems to indicate that uppercase
letters aren't legitimate:
> If a source file uses both the UTF-8 BOM mark signature and a magic encoding comment, the only allowed encoding for the comment is 'utf-8'. Any other encoding will cause an error.
My Emacs also complains about the uppercase letters every time I save
the file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32850
Differential Revision: D19663281
Pulled By: ezyang
fbshipit-source-id: 48127d3c2fd6e22dd732a2766913735136ec2ebc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32771
It's a patch to #32621, make the api private.
Test Plan: Imported from OSS
Differential Revision: D19657307
Pulled By: iseeyuan
fbshipit-source-id: e604a0cbed6a1e61413daaafc65bea92b90f1f5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32753
Functions to be bound as an Aten operator could not have Python dependency.
This is to refactor and remove Python dependency.
ghstack-source-id: 97485800
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_script_functions_not_supported
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_script_functions_not_supported
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck-out/gen/caffe2/test/distributed/rpc/dist_autograd_fork\#binary.par -r test_backward_simple_script_call
```
Differential Revision: D5741675
fbshipit-source-id: 31ee60955be8d815d0773f3699e3ff2f1f9d8849
Summary:
Make batch norm with empty inputs return zero parameter gradients. Now batch norm, group norm and convolutions now return zero grads for parameters, so make tests check that. Fixes some bullet points in https://github.com/pytorch/pytorch/issues/12013 (interpolate is not fixed by this PR, is being fixed in other PRs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32820
Differential Revision: D19651470
Pulled By: ngimel
fbshipit-source-id: 96fdd085f9b0e98e91217dd2ac1f30f9c482b8be
Summary:
Remove `needs_dynamic_casting` from TensorIterator and move it to `Loops.cuh`.
The original design of `needs_dynamic_casting` is fundamentally flawed: it injects logics into TensorIterator and uses a bunch of boolean values to test whether the dynamic casting is needed. This makes it very fragile, as the TensorIterator is so complicated and it is easy to introduce unnecessary dynamic casts. It also makes the `gpu_kernel` very unflexible, differently cases needs to manipulate TensorIterator to make it work.
For example, currently
```python
torch.zeros(10, device='cuda').mul_(0.9)
```
needs dynamic cast, but it shouldn't.
Testing whether dynamic casting is needed could be easy: just compare the dtypes of the lambda with the dtypes of operands. If they don't match, then dynamically cast, otherwise don't cast.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32755
Differential Revision: D19644092
Pulled By: ngimel
fbshipit-source-id: 130bb8bd78d20c2ed1bdfc9d9fb451eb0f0c7e55
Summary:
Should fix https://github.com/pytorch/pytorch/issues/29744 by falling back to native batch norm implementation, if cudnn cannot execute the provided shape.
Shape numbers were verified for cudnn 7.6.5.32 with tensor shapes:
```python
# for spatial bn
x = torch.Size([880801, 256, 5])
x = torch.Size([65535, 256, 5])
x = torch.Size([880801, 64, 4, 4])
x = torch.Size([65535, 64, 4, 4])
# for per-act bn
x = torch.Size([131070, 2048])
x = torch.Size([262136, 2048])
```
for `training()` and `eval()` mode using `torch.float32` and `torch.float16`.
I've increased the shape of our current smoke test to, but I can also add all use cases of the support matrix, if wanted.
CC ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32763
Differential Revision: D19644328
Pulled By: ngimel
fbshipit-source-id: c2151bf9fe6bac79b8cbc69cff517a4b0b3867aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32843
fix the ci by skipping aten::join
Test Plan: ci
Reviewed By: hl475
Differential Revision: D19650584
fbshipit-source-id: 4446eef568ded334217ff9205a795daffebe41a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32734
VariableTensorId is the only key with this treatment today,
but BackendSelect and CompoundOp are coming soon.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628091
Pulled By: ezyang
fbshipit-source-id: 250753f90528fa282af7a18d8d2f7736382754bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32729
When working on the vmap prototype I noticed that this was helpful
as it lets me easily initialize a no-op guard, if I need to do it
at constructor time (which I usually do, because the guards don't
have move constructors).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628092
Pulled By: ezyang
fbshipit-source-id: d6259a3f70d287cdac2e4a5f3984e2880f19bdc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32728
It doesn't have much to do with tensors anymore.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19628093
Pulled By: ezyang
fbshipit-source-id: 4d57111cdf44ba347bec8a32bb5b4b47a83c1eaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32807
After this commit, RRefContext no longer depends on pybind.
Test Plan: Imported from OSS
Differential Revision: D19636316
Pulled By: mrshenli
fbshipit-source-id: 88faa101c32e9019e979ae8e5da6706e49842726
Summary:
This PR updates how RNNs handle their "flat weights." In particular, it allows for only some flat weights to be "materialized" when apply is called, and it updates the flattening behavior to only apply if all flat weights are (1) materialized, (2) share a dtype and (3) are acceptable to cuDNN.
One test is modified and another created to test these changes. One practical effect of this change is that weight norm can be successfully applied to a module BEFORE that module is moved to an accelerator. Previously doing so would throw an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32563
Differential Revision: D19602725
Pulled By: mruberry
fbshipit-source-id: d8f9441d17815c8c9ba15b256d4be36f784a3cf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32574
Previously, we ignored alias annotations when deriving argument mutability
and instead recognized particular signature patterns (in-place, out variant)
and assigned mutability accordingly. Op signatures that didn't fit these
patterns would error (e.g. see #30526, which this fixes).
No change in the generated binding code.
Code changes:
1. in function_wrapper.py, fix the mutability derivation logic used when creating an argument's c++ type property. Note that we temporarily need to trap a special case and apply the old logic, see code comment for details.
2. in gen_jit_dispatch.py, update logic that assumed only one mutable Tensor argument per declaration. Happily this mostly was accomplished by bypassing some now-redundant signature regeneration machinery. Another special case here requires that we keep the old machinery around temporarily.
Test Plan: Imported from OSS
Differential Revision: D19564875
Pulled By: bhosmer
fbshipit-source-id: 5637a9672923676d408c9586f3420bcc0028471a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29986
Previously in addition to generating a python binding for each op,
we would generate an almost-trivial helper for each overload.
This PR eliminates the helpers, simplifying codegen logic a bit and
reducing the source-level indirection by a step.
Perf should be unchanged.
codegen diff: 1f2f07fb60
Note: in the interests of keeping the diff contained, there's only
some light cleanup here beyond what's necessary for the codegen changes.
Plan is to do some more substantial refactoring in followup PRs that
leave generated code unchanged.
Test Plan: Imported from OSS
Differential Revision: D18567980
Pulled By: bhosmer
fbshipit-source-id: eb9a81babb4489abd470842757af45580d4c9906
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32785
Add PythonRpcHandler::handleExceptionWithGIL() so that in PyRRef::localValue(),
we don't need to release the GIL and re-acquire the following line.
ghstack-source-id: 97418465
Test Plan: existing test coverage
Differential Revision: D19626195
fbshipit-source-id: db694d04b078811f819626789e1e86f1b35adb5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32757
This PR updates the main quantize_dynamic API to use QNNPACK backend for mobile
Test Plan:
python test/test_quantization.py PostTrainingDynamicQuantTest.test_quantized_rnn
Imported from OSS
Differential Revision: D19632220
fbshipit-source-id: b4c51485c281d088524101b97c84dd806438b597
Summary:
when using scripting, there was an error in attempting to access a
specific element from within the size tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32652
Reviewed By: hl475
Differential Revision: D19610726
Pulled By: houseroad
fbshipit-source-id: bca49927bbe71dbe7e7d7edf301908fe79e089b5
Summary: Add support for join on List of strings in TorchScript.
Test Plan:
(pytorch) smummadi@smummadi-mbp pytorch % python test/test_jit_string.py
Fail to import hypothesis in common_utils, tests are not derandomized
.
----------------------------------------------------------------------
Ran 1 test in 1.090s
OK
Differential Revision: D19611800
fbshipit-source-id: cef66356abc14dfd100a806d25dd1a8bc9af0a11
Summary:
When running the ctr_mbl_feed, we've encountered hang issue related to the rendezvous handshake based on zeus. It was mitigated by this diff https://our.intern.facebook.com/intern/diff/D19167151/.
This diff resolves the race condition by adding a reference to the rendezvous handler.
Test Plan: x7340282797
Reviewed By: yifuwang
Differential Revision: D19627293
fbshipit-source-id: 560af289db8ef6cf8d6f101f95ec27d5a361fd04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32745
Some parameters (like `bias` in conv) are optional. To achieve this
previously, you had to add `bias` as a constant, which would invoke some
pretty weird behavior in the frontend, summarized as:
```
if bias is not None:
add it as a parameter normally
else: # bias is None
add it as a constant with the value None
```
There are several things bad about this:
1. Bias is not a constant. Marking it `__constants__` is confusing.
2. It basically relies on an implementation detail (the frontend
processes parameters before constants) to work.
Okay, whatever. I don't even know why we did this originally, but
getting rid of it doesn't break anything, so I assume improved NoneType
refinement has made this a non-issue.
Note on perf: this will make no difference; if bias was `None` it's still
folded out today, if bias is a Tensor it would be added as a parameter
both before and after this change
Test Plan: Imported from OSS
Differential Revision: D19628634
Pulled By: suo
fbshipit-source-id: d9128a09c5d096b938fcf567b8c23b09ac9ab37f
Summary:
resubmitting https://github.com/pytorch/pytorch/issues/32612 after a merge gone wrong. Enables convolution with an empty batch or number of channels for all flavors of convolution (grouped convolution, convTranspose). Would make https://github.com/pytorch/pytorch/issues/31658 unnecessary. Also returns zero gradients for the parameters, that's necessary for correct DDP operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32709
Differential Revision: D19627968
Pulled By: ngimel
fbshipit-source-id: 7359759bd05ff0df0eb658cac55651c607f1b59f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32683
Pull Request resolved: https://github.com/pytorch/glow/pull/4079
Similar to D17768404, we changed the EmbeddingBag operator for 8-bit fused version to add the option to include the last offset and parallelize the op.
ghstack-source-id: 97404645
Test Plan:
To generate the AVX2 code (`embedding_lookup_fused_8bit_rowwise_idx_avx2.cc`):
```
python hp_emblookup_codegen.py --fused --use-offsets
```
To test the correctness:
```
buck test //caffe2/torch/fb/sparsenn:test -- test_embedding_bag_byte_rowwise_offsets --print-passing-details
```
Reviewed By: yinghai
Differential Revision: D19592761
fbshipit-source-id: f009d675ea3f2228f62e9f86b7ccb94700a0dfe0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32704
-Werror is too aggressive check for test cpp extensions because it fails even on deprecation warnings which is are included from core codebase.
Fixes#32136
Test Plan: Imported from OSS
Differential Revision: D19620190
Pulled By: pbelevich
fbshipit-source-id: 0e91566eb5de853559bb59e68a02b0bb15e7341b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32116
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579875
Pulled By: ezyang
fbshipit-source-id: 00393c9dc101967c79231bfae36b23b7b80135fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32114
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579876
Pulled By: ezyang
fbshipit-source-id: d09a231ba891403a06eae0c2203e0ad7dd6d3a12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32112
It turns out we already removed these from the CPU version; copy
the changes over.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579874
Pulled By: ezyang
fbshipit-source-id: e40efbf94e128fd81421b227b76dd9c9c0256d96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32727
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19621858
Pulled By: ezyang
fbshipit-source-id: 5112c849252478d8249de4f8c8c5a2d6caf60672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32557
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579853
Pulled By: ezyang
fbshipit-source-id: 45f83a7a5ead0344e4c13526abb5fafdedaed4a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32533
Applies renames based on comments in #32439. I also updated some
other documentation and variable names while I was at it.
Fixes#32435.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19579854
Pulled By: ezyang
fbshipit-source-id: 85021a92a2a84501f49ee5c16318f81f5df64f8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32043
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19621910
Pulled By: ezyang
fbshipit-source-id: dce00a56ff679548fd9f467661c3c54c71a3dd4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32748
This is to follow up PR #30630, we need to have GIL when calling jit::toPyObject(), for some binded functions need to be taged with GIL release if underneath C++ codes requires GIL. so
1. pyRef::to_here() and pyRef::local_value() added GIL
2. pyRef::pickle and pyRef::unpickle() added GIL release tag
3. in request_callback_impl, also added GIL as needed
4. for typeParser, use cached jitCompilationUnit_, also clean it up in cleanUp() function
ghstack-source-id: 97373011
Test Plan: unit test
Differential Revision: D19612337
fbshipit-source-id: 4d09f9b52ba626545ae7d31fea6b671301ed3890
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32567
As a first change to support proguard.
even if these methods could be not called from java, on jni level we register them and this registration will fail if methods are stripped.
Adding DoNotStrip to all native methods that are registered in OSS.
After integration of consumerProguardFiles in fbjni that prevents stripping by proguard DoNotStrip it will fix errors with proguard on.
Test Plan: Imported from OSS
Differential Revision: D19624684
Pulled By: IvanKobzarev
fbshipit-source-id: cd7d9153e9f8faf31c99583cede4adbf06bab507
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for CUDA complex numbers is here: [pytorch-cuda-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cuda-strided-complex)
Changes:
[x] Fixed performance issue raise in https://github.com/pytorch/pytorch/issues/30704 so that non-complex numbers do not call `conj()` and `real()`.
[x] Fixed tensor_to_numpy() conversion likely broken by a `checkBackend()` in https://github.com/pytorch/pytorch/issues/27064.
[x] Fixed some ReduceOps and TensorCompare Ops that recently added a `checkBackend()`.
- `checkBackend()` is replaced with a device type check and a layout check.
- This ensures the ComplexCPU Type ID is supported.
[x] Added AVX support for complex `exp()`, as requested in https://github.com/pytorch/pytorch/issues/755
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30871
Differential Revision: D19200726
Pulled By: ezyang
fbshipit-source-id: d7e1be0b0a89c5d6e5f4a68ce5fcd2adc5b88277
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32325
The purpose of this PR is to enable PyTorch dispatching on `at::Generator*` parameters and demonstrate how it can be used in cpp extensions to implement custom RNG.
1. `CustomRNGKeyId` value added to DispatchKey enum and `DispatchKeySet key_set_` added to `at::Generator`
2. The overloaded `operator()(at::Generator* gen)` added to MultiDispatchKeySet.
3. The existing CPUGenerator and CUDAGenerator class are supplied with CPUTensorId and CUDATensorId dispatch keys
4. The implementation of CPU's `cauchy_kernel`(as an example, because it's already moved to ATen) was templatized and moved to `ATen/native/cpu/DistributionTemplates.h` to make it available for cpp extensions
5. Minor CMake changes to make native/cpu tensors available for cpp extensions
6. RegisterCustomRNG test that demonstrates how CustomCPUGenerator class can be implemented and how custom_rng_cauchy_ native function can be registered to handle Tensor::cauchy_ calls.
Test Plan: Imported from OSS
Differential Revision: D19604558
Pulled By: pbelevich
fbshipit-source-id: 2619f14076cee5742094a0be832d8530bba72728
Summary:
These codes are implemented twice at different places by different people, we should merge them together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32730
Differential Revision: D19622023
Pulled By: ezyang
fbshipit-source-id: a9cbda31428b335bf28a7e4050f51f58e787b94f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32659
Applies linter to RPC test files so that we can use linter shortcuts
without getting unnecessary changes to the whole file.
ghstack-source-id: 97361237
Test Plan: No actual changes.
Differential Revision: D19584742
fbshipit-source-id: a11ce74ee0e2817e6f774fff7c39bcab06e99307
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32657
The goal here is to simplify the codegen enough that we can just handwrite the bindings, so anything in here is "bad".
Test Plan: Imported from OSS
Differential Revision: D19584521
Pulled By: gchanan
fbshipit-source-id: 93005b178228c52a1517e911adde2e2fe46d66a5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32722
Checked using [this](https://godbolt.org/z/uAaE9R) that it gives the correct assembly.
Test Plan: Imported from OSS
Differential Revision: D19610012
Pulled By: albanD
fbshipit-source-id: 4d1cb812951ae03d412a0fba3c80730f0d286e1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32326
Now that we have type-level granularity we can improve `mayContainAlias` queries. Each new values is initialized as containing the wildcard set of each contained mutable type. Whenever a value is added to a container it is set to the wildcard set. Now, to check if any two values contain overlapping values, we can just check if the `containedMemoryLocations` of two sets overlap.
Test Plan: Imported from OSS
Differential Revision: D19563262
Pulled By: eellison
fbshipit-source-id: c6d7489749c14b2054a6d50ef75baca699ada471
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32251
Previously wildcard sets were associated by TypeKind, meaning all Lists were in one alias set, all Classes were in one alias set, etc. We can improve analysis by bucketing wildcard sets by TypePtr instead. Any two mutable types which can unify should be in the same wildcard set bucket.
This also allows us do much simpler `mayContainAlias` analysis, and also improves `analyzeConservative` analysis because now we can recurse through all contained memory locations and mark writes, instead of just recursing only level deep in contained elements.
Test Plan: Imported from OSS
Differential Revision: D19563263
Pulled By: eellison
fbshipit-source-id: 371a37d1a8596abc6c53f41c09840b6c140ea362
Summary: ATT. Since the infra is there.
Test Plan: run it
Reviewed By: amylittleyang
Differential Revision: D19605250
fbshipit-source-id: c68be4d7963afa4fa5f8f60c90f1913605eae516
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32501
This diff will address https://github.com/pytorch/pytorch/issues/24699
We ask the input `lambda` to be >= 0 to be same as https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.random.exponential.html#numpy-random-exponential. This does not exist in the previous implementation.
Benchmark I am using PT operator microbenchmark
```
================================================================================
Before the change, Program Output:
================================================================================
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: exponential_
# Mode: Eager
# Name: exponential__M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 21311.746
================================================================================
After the change, Program Output:
================================================================================
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: exponential_
# Mode: Eager
# Name: exponential__M512_N512_cpu
# Input: M: 512, N: 512, device: cpu
Forward Execution Time (us) : 20919.914
================================================================================
```
Test Plan: Sandcastle and Github tests
Reviewed By: BIT-silence
Differential Revision: D19518700
fbshipit-source-id: 0e79cb6a999c1278eb08b0d94cf61b119c85a36c
Summary:
Included the ONNX model checker code in the ONNX export
this will force onnx checker to run for all models that get exported.
This should help with validating exported models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32298
Reviewed By: hl475
Differential Revision: D19538251
Pulled By: houseroad
fbshipit-source-id: eb20b124fe59200048f862ddaf20f6c59a0174d5
Summary:
This method is pretty hot. In an internal workload, this single
call to at() accounted for ~2% of overall cycles.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31627
Reviewed By: yinghai
Differential Revision: D19607779
Pulled By: qizzzh
fbshipit-source-id: 1684919049a35fdad686d8396c7dce7243ab92d4
Summary:
Stacked PRs
* #32244 - Make zip serialization the default
* **#32241 - Split serialization tests to their own file**
This makes them all easier to run as a batch. This PR is just a code move / fixing up imports. There are still some serialization tests in `test_torch.py` as part of `TestDeviceType`.
](https://our.intern.facebook.com/intern/diff/19415826/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32241
Pulled By: driazati
Differential Revision: D19415826
fbshipit-source-id: a3f6cfe1626ff2f9b9631c409bf525bd32e4639b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32675
It's good to have one location to do the mapping.
Test Plan: Everything still runs.
Reviewed By: amylittleyang
Differential Revision: D19590354
fbshipit-source-id: d8c0d14e4bdf27da3e13bd4d161cd135d6e3822b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32656
Fixes these flaky tests.
Test Plan: Run the test 500 times and verify that it succeeds every time.
Differential Revision: D19584453
fbshipit-source-id: 07cbc4914211f274182ac0fa74bb5ef6d43392d1
Summary:
Both `test_wait_all_workers` and `test_wait_all_workers_and_shutdown` test the same pattern of initialize RPC, call `_wait_all_workers`, and `rpc.shutdown(graceful=False)`.
`test_wait_all_workers` seems to be more thorough since it tests one worker driving and the others waiting on it as well.
We shouldn't have duplicate test so removing this `test_wait_all_workers_and_shutdown`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32588
Differential Revision: D19566294
Pulled By: rohan-varma
fbshipit-source-id: b69519d169b3964649d47ad75532bda5de538241
Summary:
Done by just editing `.circleci/cimodel/data/dimensions.py` to include `3.8` and then regenerated using `.circleci/regenerate.sh`
cc kostmo, mingbowan, ezyang, soumith
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31948
Differential Revision: D19602069
Pulled By: seemethere
fbshipit-source-id: ac57fde9d0c491c7d948a3f5944c3cb324d403c0
Summary:
This handles a corner case when a user schedules second bailout after the first one and the first one doesn't fire.
Alternatively, we could go back to the implementation that uses a hash set to remember the indices of bailouts that need to fire.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32672
Differential Revision: D19596872
Pulled By: Krovatkin
fbshipit-source-id: 41dcc374cd2501ac20a9892fb31a9c56d6640258
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32621
Export the "_save_for_mobile" method to Python so that the bytecode format for lite interpreter can be added or updated to the original script model.
It's the first step of python binding for lite interpreter, as discussed in this [internal post](https://fb.workplace.com/groups/1144215345733672/permalink/1478900738931796/) and offline.
Next step is to export the load_for_mobile and run method of mobile module, so that users could verify the mobile model from Python.
Test: use the following python script to display the bytecode part of the updated model file.
```
#!/usr/bin/env python3
import sys
import pickle
import pprint
import zipfile
class FakeObject(object):
def __init__(self, module, name, args):
self.module = module
self.name = name
self.args = args
self.state = None
def __repr__(self):
state_str = "" if self.state is None else f"(state={self.state!r})"
return f"{self.module}.{self.name}{self.args!r}{state_str}"
def __setstate__(self, state):
self.state = state
class FakeClass(object):
def __init__(self, module, name):
self.module = module
self.name = name
self.__new__ = self.fake_new
def __repr__(self):
return f"{self.module}.{self.name}"
def __call__(self, *args):
return FakeObject(self.module, self.name, args)
def fake_new(self, *args):
return FakeObject(self.module, self.name, args)
class DumpUnpickler(pickle._Unpickler):
def find_class(self, module, name):
return FakeClass(module, name)
def persistent_load(self, pid):
return FakeObject("pers", "obj", (pid,))
def main(argv):
zfile = zipfile.ZipFile(argv[1])
names = [i for i in zfile.namelist() if "bytecode.pkl" in i]
if not names:
print("bytecode.pkl not found.")
return
with zfile.open(names[0], "r") as handle:
value = DumpUnpickler(handle).load()
pprint.pprint(value)
if __name__ == "__main__":
sys.exit(main(sys.argv))
```
Test Plan: Imported from OSS
Differential Revision: D19596359
Pulled By: iseeyuan
fbshipit-source-id: 19a4a771320f95217f5b0f031c2c04db7b4079a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32642
Previously, if we defined `__setstate__` but not `__getstate__`, we
would segfault. This PR turns that into a comprehensible error message
(and improves another error message as well).
Fixes https://github.com/pytorch/pytorch/issues/25886
Test Plan: Imported from OSS
Differential Revision: D19596463
Pulled By: suo
fbshipit-source-id: dbe76bc36bc747d65fb0223184c009e0e9ba072c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32653
This test was flaky since the watchdog thread could abort the
communicator instead of the thread calling `wait()`. As a result, we could
actually see `NCCL error` instead of `Operation timed out` on the user end.
ghstack-source-id: 97250714
Test Plan: waitforbuildbot
Differential Revision: D19583003
fbshipit-source-id: 5c07326d1a16f214dcdbabed97ca613e0a5b42b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32635
With the source of truth of current RPC agent moved to C++ world, there is no point of passing current RPC agent from Python world to C++ world.
ghstack-source-id: 97293316
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_process_group_debug_info
```
Differential Revision: D5703519
fbshipit-source-id: ef7c28bdb1efd293eb6cafe0b0fca7ca80fa08a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32633
There were 2 sources of current RPC agent.
- One is in Python world, `torch.distributedrpc.api._agent`.
- The other is in C++ world, `RpcAgent::defaultRpcAgent_`
Setting Python `_agent` to `None`, does not necessarily reset the C++ `defaultRpcAgent_` to `nullptr`.
i.e.
```
torch.distributedrpc.api._agent = None
```
does not translate to
```
RpcAgent::defaultRpcAgent_ = nullptr
```
This PR is to remove this ambiguity, and use the C++ pointer as source of truth.
The solution is to leverage a pybind11 behavior that it implicitly casts C++ `shared_ptr<RpcAgent>(nullptr)` to Python `None`.
ghstack-source-id: 97293315
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_duplicate_name
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_process_group_debug_info
```
```
buck test mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_remote_module
buck test mode/dev-nosan //caffe2/torch/fb/distributed/modules/tests:test_sharded_embedding
buck test mode/dev-nosan //caffe2/torch/fb/distributed/modules/tests:test_sharded_pairwise_attention_pooling
buck test mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_rpc
```
Differential Revision: D5733066
fbshipit-source-id: b3e6032ee975f19ca556497edbbf40b517b25be8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32624
We need this PR to resolve the issue mentioned in https://github.com/pytorch/pytorch/issues/31325#issuecomment-574918917.
The solution is for each `_wait_all_workers()` call, there is a sequence ID added, to identify different calls.
ghstack-source-id: 97277591
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_wait_all_workers
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_wait_all_workers
```
Differential Revision: D5739520
fbshipit-source-id: a64131e09c365179624700514422f5375afe803f
Summary:
This PR updates how RNNs handle their "flat weights." In particular, it allows for only some flat weights to be "materialized" when apply is called, and it updates the flattening behavior to only apply if all flat weights are (1) materialized, (2) share a dtype and (3) are acceptable to cuDNN.
One test is modified and another created to test these changes. One practical effect of this change is that weight norm can be successfully applied to a module BEFORE that module is moved to an accelerator. Previously doing so would throw an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32563
Differential Revision: D19562258
Pulled By: mruberry
fbshipit-source-id: 4fef006e32cdfd8e3e3d519fc2ab5fc203dd7b36
Summary:
This PR adds support for 0-dim batch size input for `torch.nn.functional.interpolate` for various modes of interpolation.
Fixes part of gh-12013
CC: rgommers ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32400
Differential Revision: D19557090
Pulled By: ezyang
fbshipit-source-id: 6822f148bb47bfbcacb5e03798bf2744f24a2a32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32476
This makes the handling of FORWARD_AUTOGRAD_REQ in request_callback
nonblocking. Processing this message requires unwrapping the message with
autograd information, processing the original message, and sending back the
message with autograd information wrapped. This makes the processing the
original message nonblocking by grabbing a future to it and marking the parent
future as completed when this one completes.
ghstack-source-id: 97221251
Test Plan: `test_rpc_spawn.py` and `test_dist_autograd_spawn.py` both pass.
Differential Revision: D19509501
fbshipit-source-id: 84ad2f9c5305ed11ed9bb0144b1aaf5f8698cd2b
Summary:
Changes the linspace functions to be more consistent as requested in https://github.com/pytorch/pytorch/issues/31991. The code has also been updated to avoid an early rounding error; the line `scalar_t step = (scalar_end - scalar_start) / static_cast<static_t>(steps-1)` can result in `step = 0` for integer scalars, and this gives unintended results. I examined the new output using
```
import torch
types = [torch.uint8, torch.int8, torch.short, torch.int, torch.long, torch.half, torch.float, torch.double]
print('Testing linspace:')
for type in types:
print(type, torch.linspace(-2, 2, 10, dtype=type))
```
which returns
```
Testing linspace:
torch.uint8 tensor([254, 254, 254, 255, 255, 0, 0, 1, 1, 2], dtype=torch.uint8)
torch.int8 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2], dtype=torch.int8)
torch.int16 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2], dtype=torch.int16)
torch.int32 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2], dtype=torch.int32)
torch.int64 tensor([-2, -2, -2, -1, -1, 0, 0, 1, 1, 2])
torch.float16 tensor([-2.0000, -1.5557, -1.1113, -0.6670, -0.2227, 0.2227, 0.6660, 1.1113,
1.5547, 2.0000], dtype=torch.float16)
torch.float32 tensor([-2.0000, -1.5556, -1.1111, -0.6667, -0.2222, 0.2222, 0.6667, 1.1111,
1.5556, 2.0000])
torch.float64 tensor([-2.0000, -1.5556, -1.1111, -0.6667, -0.2222, 0.2222, 0.6667, 1.1111,
1.5556, 2.0000], dtype=torch.float64)
```
which is the expected output: `uint8` overflows as it should, and the result of casting from a floating point to an integer is correct.
This PR does not change the logspace function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32218
Differential Revision: D19544224
Pulled By: ngimel
fbshipit-source-id: 2bbf2b8552900eaef2dcc41b6464fc39bec22e0b
Summary:
This test case had been using the tensor
```
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
```
which is not an invertible tensor and causes the test case to fail, even if magma gets initialized just fine. This change uses a tensor that is invertible, and the inverse doesn't include any elements that are close to zero to avoid floating point rounding errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32547
Differential Revision: D19572316
Pulled By: ngimel
fbshipit-source-id: 1baf3f8601b2ba69fdd6678d7a3d86772d01edbe
Summary:
A constructor of `nn.Parameter` has default values on `data` and `requires_grad`, but in type stub, there are no default values.
Resolve https://github.com/pytorch/pytorch/issues/32481
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32617
Differential Revision: D19571397
Pulled By: ngimel
fbshipit-source-id: fd14298aa472b7575221229cecf5a56f8c84f531
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32451
This PR adds a few new parameters to ATen codegen script:
```
1. op_registration_whitelist
Can be used to filter op registrations for selective build;
2. type_whitelist
Can be used to filter types (CPUType, CUDAType, ...) for selective build;
3. per_op_registration
When set it will group function registrations by op name and write to separate files;
```
1 & 2 are introduced for mobile custom build without relying on static dispatch;
3 is introduced to solve custom build with multi-library / multi-model (needed by FB
internal build - see more details: https://fb.quip.com/ZVh1AgOKW8Vv).
These flags should work independently with each other (and independent to USE_STATIC_DISPATCH).
Not setting them should have no effect compared to master.
ghstack-source-id: 97214788
Test Plan: - tested all 3 params with FB internal build changes.
Differential Revision: D19427919
fbshipit-source-id: a381fe5f768fe2e9196563787f08eb9f18316e83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32275
Currently TypeDerived (e.g. `CPUType::`) methods are declared and
defined in anonymous namespace as they are only called from c10
dispatcher - except for STATIC_DISPATCH mode, where they can be directly
called from Functions.h.
We plan to generate c10 op registration into separate files for internal
xplat/BUCK build, thus we need declare these methods in non-anonymous
namespace.
I feel it's easier to simply change it unconditionally, unless there are
some side effect I'm not aware of - `TypeDefault::` methods are in
non-anonymous namespace anyway.
ghstack-source-id: 97214789
Test Plan: - CI
Differential Revision: D19426692
Pulled By: ljk53
fbshipit-source-id: 44aebba15f5e88ef4acfb623844f61d735016959
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32466
It's a follow-up work of https://github.com/pytorch/pytorch/pull/32197.
In https://github.com/pytorch/pytorch/pull/32197, `rpc.sync_rpc(..) `and `rpc.rpc_async(..)` support taking a TorchScript annotated Python function as the user function for RPC.
This PR extend along this direction by making `rpc.remote(..)` support taking a TorchScript annotated Python function as well.
ghstack-source-id: 97211168
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork -- test_script_function_exception
buck build mode/dev-nosan //caffe2/test/distributed/rpc:rpc_fork
buck-out/gen/caffe2/test/distributed/rpc/rpc_fork\#binary.par -r test_script_function_exception
```
```
buck test mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork -- test_backward_simple_script_call
buck build mode/dev-nosan //caffe2/test/distributed/rpc:dist_autograd_fork
buck-out/gen/caffe2/test/distributed/rpc/dist_autograd_fork\#binary.par -r test_backward_simple_script_call
```
Differential Revision: D19440633
fbshipit-source-id: d37f6dcdc0b80d35ac7bcba46ad6f9b831c3779b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32479
Run dynamic quantization on mobile (similar to FBGEMM). Currently only implemented on linear operator
Test Plan:
python test/test_quantized.py TestDynamicQuantizedLinear.test_qlinear
Imported from OSS
Differential Revision: D19542980
fbshipit-source-id: c9f6e5e8ded4d62ae0f2ed99e478c8307dde22ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32571
The watchdog thread would erase an element and call `it--` (implicitly
relying on `it++` in the for loop to position correctly). Although, `it--`
would cause undefined behavior if the iterator is pointing to begin(). As a
result, I've modified the logic to update the iterator appropriately.
I've also enhanced the watchdog thread to catch and log exceptions.
ghstack-source-id: 97150763
Test Plan: waitforbuildbot
Differential Revision: D19551365
fbshipit-source-id: 426835819ad8d467bccf5846b04d14442a342f78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32548
As Title says.
ghstack-source-id: 97175523
Test Plan: CI
Differential Revision: D19541893
fbshipit-source-id: 96dce6964e6a89393d4159401a59672f041f51d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32371
After we add constants to ClassType, we didn't update clone to
clone the constants, this PR adds the support
fixes: https://github.com/pytorch/pytorch/issues/32368
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D19564378
fbshipit-source-id: dbb13fb889d6ea9291034313b1f3c9aff4748bda
Summary:
It looks like the jit Future does not have a `wait()` anymore and this throws an error when trying to run this code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32336
Differential Revision: D19559922
Pulled By: rohan-varma
fbshipit-source-id: a5aa67990595e98e0682a20cf5aced17c2ae85bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32380
We'll clone the module first and then fold conv bn and return a new
module
Test Plan:
.
Imported from OSS
Differential Revision: D19508033
fbshipit-source-id: 328e91a2c9420761c904a7f2b62dab4cfaaa31ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32374
Moving all fold conv bn code to a class to prepare for making
it work with shared ClassType
Test Plan:
compiles
Imported from OSS
Differential Revision: D19508032
fbshipit-source-id: 4e9cf714111305d2b5474d4506507078f69f0c84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32556
Out of caution, avoid assuming that there's never a failure in a couple of
request_calback_impl case handlers, but rather propagate the error.
ghstack-source-id: 97128697
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D19544685
fbshipit-source-id: 67c55626960bd42a5b0dec7841e8ba44ab059eb9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31990
This PR does three things:
- Add a new `allow_rebase_history` flag to the differentiable views. If set, trying to rebase their history will raise an error.
- Make sure that the codegen functions verify this flag before doing inplace operations so that they fail before doing the inplace modification.
- Make sure the codegen functions set this flag properly when we don't support rebasing the history of the output.
The codegen change can be found [here](4bf180caa0).
Test Plan: Imported from OSS
Differential Revision: D19409649
Pulled By: albanD
fbshipit-source-id: a2b41c2d231e952ecfe162bdb6bad620ac595703
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32044
Fix the list of views in the codegen:
- Move `narrow` out of the autograd functions since it's now implemented with slice.
- Add `split_with_sizes` that was missing from the list
- Remove special formulas for both `split` and `split_with_sizes`. Both used not to be considered as views. When they are, all the rnn code breaks because it uses them in an invalid way. The generic formula will generate one `narrow` Node for each output. Which is always valid.
The diff for the generated code can be found [here](https://github.com/pytorch/pytorch/compare/16eff6e...albanD:06d6e85) (outdated for last commit)
Test Plan: Imported from OSS
Differential Revision: D19409648
Pulled By: albanD
fbshipit-source-id: 5ebc4c978af500403f7f008c0231b7db0cabab26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32525
Before calling static code analyzer we need link all bitcode files into
a single module. Current approach is a bit hacky: cmake still calls "ar"
to pack bitcode files into archives, then we manually unpack these
archives and call llvm-link.
Turns out libtorch_cpu.a contains a few files with same name, e.g.:
```
aten/src/ATen/native/SoftMax.cpp
aten/src/ATen/native/mkldnn/SoftMax.cpp
```
"ar x" will only keep one of them and cause inaccurate analysis result.
Use this temporary hack to workaround the problem. Ideally should merge
this step into cmake (e.g. directly calling llvm-link to produce target
output?).
Differential Revision: D19530533
Pulled By: ljk53
fbshipit-source-id: 94b292c241abaaa0ff4a23059882abdc3522971e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32539
Before: if something in `_modules` was `None`, we would barf. This is
incorrect because it's allowed for users to put `None` there, in case a
module is optional.
This case ought to be handled correctly during scripting. Fixes https://github.com/pytorch/pytorch/issues/32469
Test Plan: Imported from OSS
Differential Revision: D19552346
Pulled By: suo
fbshipit-source-id: aba7fdc19fd84d195c81cdaca8a75013a8626a8b
Summary:
This API seems to be quite useful to make sure all bailouts in a graph are triggered. I used it for testing torchvision models and I was wondering if this might be something we might actually want to have? zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32518
Differential Revision: D19553147
Pulled By: Krovatkin
fbshipit-source-id: 7542c99051588b622091aec6d041c70731ca5d26
Summary:
## Commit Message:
Refactors Dockerfile to be as parallel as possible with caching and adds a new Makefile to build said Dockerfile.
Also updated the README.md to reflect the changes as well as updated some of the verbage around running our latest Docker images.
Adds the new Dockerfile process to our CircleCI workflows
## How to build:
Building the new images is pretty simple, just requires `docker` > 18.06 since the new build process relies on `buildkit` caching and multi-stage build resolving.
### Development images
For `runtime` images:
```
make -f docker.Makefile runtime-image
```
For `devel` images:
```
make -f docker.Makefile devel-image
```
Builds are tagged as follows:
```bash
docker.io/${docker_user:-whoami}/pytorch:$(git describe --tags)-${image_type}
```
Example:
```
docker.io/seemethere/pytorch:v1.4.0a0-2225-g9eba97b61d-runtime
```
### Official images
Official images are the ones hosted on [`docker.io/pytorch/pytorch`](https://hub.docker.com/r/pytorch/pytorch)
To do official images builds you can simply add set the `BUILD_TYPE` variable to `official` and it will do the correct build without building the local binaries:
Example:
```
make -f docker.Makefile BUILD_TYPE=official runtime-image
```
## How to push:
Pushing is also super simple (And will automatically tag the right thing based off of the git tag):
```
make -f docker.Makefile runtime-push
make -f docker.Makefile devel-push
```
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32515
Differential Revision: D19558619
Pulled By: seemethere
fbshipit-source-id: a06b25cd39ae9890751a60f8f36739ad6ab9ac99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32569
If the dict's contained types cannot be inferred from its contents (for
example, `Dict[str, Tensor]` vs. `Dict[str, Optional[Tensor]]`), we must
explicitly annotate the type.
Also this removes some special handling that omits annotations on empty
containers that have the default type. It makes the code more complex
for not too much value, and was wrong for dicts anyway.
Test Plan: Imported from OSS
Differential Revision: D19551016
Pulled By: suo
fbshipit-source-id: c529b112e72c10f509a6bc0f5876644caa1be967
Summary:
Pull Request resolved: https://github.com/pytorch/glow/pull/4049
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27477
We would like to add the intra-op parallelization support for the EmbeddingBag operator.
This should bring speedup for the DLRM benchmark:
https://github.com/pytorch/pytorch/pull/24385
Benchmark code:
```
from __future__ import absolute_import, division, print_function, unicode_literals
import torch
import time
eb = torch.nn.EmbeddingBag(1000000, 64, mode='sum')
input = torch.LongTensor(1500).random_(0, 1000000)
offsets = torch.zeros(64, dtype=torch.int64)
niter = 10000
s = time.time()
for _ in range(niter):
out = eb(input, offsets)
time_per_iter = (time.time() - s) / niter
print('time_per_iter', time_per_iter)
print('GB/s', (input.numel() * 64 * 4 + out.numel() * 4) / time_per_iter / 1e9)
```
The following results are single core on Skylake T6:
- Before our change (with the original caffe2::EmbeddingLookup)
time_per_iter 6.313693523406982e-05
GB/s 6.341517821789133
- After our change using the EmbeddingLookupIdx API which takes the offsets instead of lengths.
time_per_iter 5.7627105712890626e-05
GB/s 6.947841559053659
- With Intel's PR: https://github.com/pytorch/pytorch/pull/24385
time_per_iter 7.393271923065185e-05
GB/s 5.415518381664018
For multi-core performance, because Clang doesn't work with OMP, I can only see the single-core performance on SKL T6.
ghstack-source-id: 97124557
Test Plan:
With D16990830:
```
buck run mode/dev //caffe2/caffe2/perfkernels:embedding_bench
```
With D17750961:
```
buck run mode/opt //experimental/jianyuhuang/embeddingbag:eb
buck run mode/opt-lto //experimental/jianyuhuang/embeddingbag:eb
```
OSS test
```
python run_test.py -i nn -- TestNNDeviceTypeCPU.test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu
```
Buck test
```
buck test mode/dev-nosan //caffe2/test:nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets_cpu"
OMP_NUM_THREADS=3 buck test mode/opt -c pytorch.parallel_backend=tbb //caffe2/test:nn -- "test_EmbeddingBag_per_sample_weights_and_new_offsets" --print-passing-details
```
Generate the AVX2 code for embedding_lookup_idx_avx2.cc:
```
python hp_emblookup_codegen.py --use-offsets
```
Differential Revision: D17768404
fbshipit-source-id: 8dcd15a62d75b737fa97e0eff17f347052675700
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30630
This remove template and all the specializations it have in rpc, we
universally use IValue as the inner value since we support making python
object to be hold inside IValue.
This will also ensure that we have the correct type information when
creating the RRef, we use the return type from the schema when creating
userRRef and OwnerRRef, it will enable IValue to always have the correct
type if the IValue is the RRef object (next PR)
Test Plan: Imported from OSS
Differential Revision: D19502235
fbshipit-source-id: 0d5decae8a9767e0893f3b8b6456b231653be3c5
Summary:
Capsule Type doesn't appear in the IR, it is purely used in the runtime. So we should not have to handle it node hashing... Let's see if this breaks anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32540
Differential Revision: D19541357
Pulled By: eellison
fbshipit-source-id: 905ed9f89cf6d03b45ddb4fde02adfa149b477f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32260
This makes it so you can actually pass the custom class as an arg to ScriptFunctions
Test Plan: Imported from OSS
Differential Revision: D19424252
Pulled By: jamesr66a
fbshipit-source-id: c3530186619655781dedbea03c2ad321aaff1cb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32205
to be filled
Test Plan:
python test_jit.py
Imported from OSS
Differential Revision: D19508031
fbshipit-source-id: cbf03d34e52eae62595c34fde6ec645cb6744ad9
Summary:
There was a user who did this and it would seg fault.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32503
Differential Revision: D19538481
Pulled By: eellison
fbshipit-source-id: dc3752028b9eff6ac88c025e8a2b5f8fd44ce32f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31531
As suggested by suo , add unit test on torch.jit.export_opnames with interface. A submodule is annotated as interface and assigned to an instance, and then re-assigned to another instance. Make sure the operator names are also updated.
Test Plan: Imported from OSS
Differential Revision: D19539129
Pulled By: iseeyuan
fbshipit-source-id: 71a76ae7790cdd577618ca278afdb132727f08dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32295
Fix for https://github.com/pytorch/pytorch/issues/32045
Calling into the engine with the GIL can deadlock because:
- worker thread initialization acquires the GIL
- Any Node / hook can be a python function that will acquire the GIL
The choice was made here to raise an error as one of the advantage of using cpp extensions with python is to be able to release the GIL. So we prefer to educate users to do it rather than doing it under the hook.
Test Plan: Imported from OSS
Differential Revision: D19430979
Pulled By: albanD
fbshipit-source-id: e43f57631885f12e573da0fc569c03a943cec519
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31126
Gloo device creator registry is throwing warning that confuses users - https://fb.workplace.com/groups/1405155842844877/permalink/3217491788277931/
Create C10_DEFINE_SHARED_REGISTRY_WITHOUT_WARNING API to skip such warning
Test Plan:
{F224342749}
Tested both `C10_DEFINE_SHARED_REGISTRY` and `C10_DEFINE_SHARED_REGISTRY_WITHOUT_WARNING`.
Make sure nothing breaks
Reviewed By: d4l3k
Differential Revision: D18904783
fbshipit-source-id: 0e0065d530956249a18325d4ed3cb58dec255d4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30445
Create distributed and rpc directories under caffe/test for better management
of unit tests.
Differential Revision: D18702786
fbshipit-source-id: e9daeed0cfb846ef68806f6decfcb57c0e0e3606
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32271
Use the 2-stage EmbeddingSpMDM interface in D19425982 to reduce the overhead of code cache lookup and lock contention.
Fix an issue in sparse_lengths_sum_benchmarks generating empty indices when average length is small like 1.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D19425987
fbshipit-source-id: d5c5f0d46e0072403901809c31d516fa0f4b9b31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32448
Using binary search to compute the value for the given quantile among the input tensors.
Test Plan: Newly added unittests;
Reviewed By: jspark1105
Differential Revision: D19487604
fbshipit-source-id: 0dc6627b78d1310ac35b3f1d53b89cc89a697ece
Summary:
While putting finishing touches on the gradient scaling PR (https://github.com/pytorch/pytorch/pull/26512), I discovered my multi-GPU test (which uses `to()` to transfer tensors between devices) was intermittently failing with bad numerics. I knew it was going to be [a weird case from the start](https://www.imdb.com/title/tt8946378/quotes/qt4868203) and spent a week descending into madness. It turns out, for backward ops that create gradients on a different device from the device on whose stream the op is executed, the streaming backward synchronizations in [input_buffer.cpp](https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/input_buffer.cpp#L46-L83) do not properly tell later ops to wait on the population/creation of those gradients. For example, a cross-device `to()` backward (CopyBackward Node) enqueues a cudaMemcpyAsync on the current stream of the source (incoming gradient's) device, then [syncs getCurrentCUDAStream on the destination device with the cudaMemcpyAsync](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Copy.cu#L76). However, `input_buffer.cpp` in such cases ([case (3)](https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/input_buffer.cpp#L77-L81)) was not properly telling `opt_consumer_stream` to wait on the current stream of the destination device (`var`'s device).
Circumstances needed to repro in current master (see [my test](https://github.com/pytorch/pytorch/compare/master...mcarilli:backward_to_race_fix#diff-e68a7bc6ba14f212e5e7eb3727394b40R1901)):
- 2 devices, with non-default streams used for forward-pass ops on both devices (which is the default behavior in test_cuda.py)
- A `to()` that transfers a tensor requiring grad from one device to another
- A backward pass that routes back through to()'s backward (aka CopyBackward).
Under these circumstances, backward ops following CopyBackward on CopyBackward's destination device (aka the original forward-pass source device) race with the device-to-device transfer, and execute using partially-transferred data.
The present PR fixes the race condition and ensures that later ops wait on the CopyBackward transfer. This PR should also make streaming backward safe for other backward ops that span devices, as long as they play nice and populate any new gradients they create using the "current stream" of the device(s) on which they create those gradients.
There are a couple minor issues where I'm not sure of the best approach:
- Should we guard onto the var's device for the entire body of InputBuffer::add?
- I'm fairly sure we need to `recordStream` on `var` if the consumer stream is different from the stream on which (we expect) `var` was created, but calling `c10::cuda::CUDACachingAllocator::recordStream` in input_buffer.cpp might break CPU-only builds. I couldn't find a different API call to record streams that seemed CPU-build-agnostic. Could I wrap the call with a macro?
Thanks to mruberry for helpful suggestions and also the organization/naming of the stream pool and streaming backward code that allowed me to (just barely) wrap my head around the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31930
Differential Revision: D19517617
Pulled By: mruberry
fbshipit-source-id: 183d5460aefa5d27366b465b0473b80ec80fa044
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32491
This PR enables IValue to be able to hold a pure PyObject by adding a
new enum tag, a new jit_type to denote PyObject existance in IValue and
the JIT type system. We don't and not plan to expose this to user.
This is the basic piece that enable ivalue to be adopted broader like
making RRef always hold IValue, it might also simplify some compiler
logic
ghstack-source-id: 97039980
Test Plan: Imported from OSS
Differential Revision: D19502234
fbshipit-source-id: 90be001706d707d376cfbea25980fd82980df84a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32475
As title
Test Plan: CI
Reviewed By: houseroad
Differential Revision: D19508778
fbshipit-source-id: fd9ad63607535980505d155f3e3c3b7c6b95daf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32203
The type is needed for allowing multiple qconfig configurations for shared
ClassType, see next PR for more details
Test Plan:
.
Imported from OSS
Differential Revision: D19508027
fbshipit-source-id: a3df29dab3038bfa88c55dda98a3e8a78e99e5a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31841
Add Tuple Constants to JIT. The constraint here is that all elements of a tuple must themself be insertable as a a constant. Previously tuples were special cased in constant propagation, but now that there are more passes that are inserted constants, such as freezing, we should just have tuples be representable as constants.
Test Plan: Imported from OSS
Differential Revision: D19439514
Pulled By: eellison
fbshipit-source-id: 3810ba08ee349fa5598f4b53ea64525996637b1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31840
The next PR in this stack makes tuples insertable as constants, so we can remove special handling of tuples in constant propagation.
Test Plan: Imported from OSS
Differential Revision: D19439515
Pulled By: eellison
fbshipit-source-id: c58f153157f1d4eee4c1242decc4f36e41c1aa05
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31839
There are a number of improvements that can be made to `mayContainAlias`, which I would like to do in follow ups. For now, this is an easy one.
Test Plan: Imported from OSS
Differential Revision: D19439516
Pulled By: eellison
fbshipit-source-id: 0042fb7eaae6cfb4916bf95dc38280517a4bd987
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32256
Previously two unrelated modules loaded from torch.jit.load
would compare equal because we only considered their data_ attributes which
are initialized blank in torch.jit.load. This changes ConcreteModuleType
to distinguish when the data_ attribute is blank vs when it is empty.
This replaces the poisoned logic.
ghstack-source-id: 96755797
Test Plan: oss
Differential Revision: D19423055
fbshipit-source-id: 79d6a50a3731c6eeb8466ba2a93702b49264bba0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32202
Move some helper functions in ModuleUseDeduper for public use
Test Plan:
.
Imported from OSS
Differential Revision: D19508034
fbshipit-source-id: 2e8e05eff6f3bbcfe6936598371e4afa72f9b11f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32226
right now if users call torch.dist.all_reduce() on dense tensors, outputs are put in input tensors. but if users call torch.dist.all_reduce() on sparse tensors, outputs are neither returned explicitly to users nor are put in input tensors.
To make torch.dist.all_reduce() API have same behavior on both dense tensors and sparse tensors, this diff is made to make torch.dist.all_reduce() on sparse tensors to put output in input tensors as well. This is acheived by simply calling input_sparse.copy_(output_sparse), see PR https://github.com/pytorch/pytorch/pull/9005 that implemented copy_ for sparse tensors.
close#31413
ghstack-source-id: 96984228
Test Plan: unit test
Differential Revision: D19192952
fbshipit-source-id: 2dd31dc057f20cc42b44b9e55df864afa2918c33
Summary:
fix `torch.eq()` entry example to match the current output (boolean, instead of uint8)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32399
Differential Revision: D19498104
Pulled By: ezyang
fbshipit-source-id: e7ec1263226766a5c549feed16d22f8f172aa1a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32439
This adds c10::fallthrough_kernel which is a special boxed function which
can be used to implement fallthrough behavior at a dispatch key. A fallthrough
kernel will redispatch to the next valid dispatch key. It is implemented
in such a way that it costs no more to fallthrough than it does to go
straight to the actual implementation of the kernel.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D19503886
Test Plan: Imported from OSS
Pulled By: ezyang
fbshipit-source-id: 6ee05bd815c4ef444e612d19f62312dbb76f2787
Summary:
We will now use USE_*, BUILD_* consistently. The backward compatibility
for NO_* and WITH_* is hereby removed in this commit, as promised in the
comment (next release is beyond Feb 20):
# Before we run the setup_helpers, let's look for NO_* and WITH_* variables and hotpatch environment with the USE_*
# equivalent The use of NO_* and WITH_* is deprecated and will be removed in Feb 20, 2020.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32447
Differential Revision: D19515536
Pulled By: ezyang
fbshipit-source-id: 2f2c51e6d4674af690b190a1f0397b8f596b6a15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31408
We'll error out when a graph is quantized with different QSchemes.
This only occurs when we have two modules that have same types (e.g. two Conv2d modules initialized with
same arguments) and quantized with two configs that would produce different quantized graphs, for example
per tensor affine and per channel affine. This is a rare case, so it should be OK to skip for now.
Actual support will come later.
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D19162366
fbshipit-source-id: 798f06d0ddef0c8458237ce88b62159cc77eec8b
Summary:
Fix https://github.com/pytorch/pytorch/issues/24723.
Benchmark script :
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000]:
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(1000):
input.log_normal_()
for n in [1, 10, 100, 1000]:
fwd_t = 0
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(10000):
t1 = _time()
input.log_normal_()
t2 = _time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.4f (ms)." % (n, fwd_avg))
```
Test Device: skx-8180.
Before:
```
input size(128, 1) forward time is 0.0114 (ms).
input size(128, 10) forward time is 0.1021 (ms).
input size(128, 100) forward time is 1.0081 (ms).
input size(128, 1000) forward time is 10.1831 (ms).
```
After:
```
input size(128, 1) forward time is 0.0108 (ms).
input size(128, 10) forward time is 0.0969 (ms).
input size(128, 100) forward time is 0.9804 (ms).
input size(128, 1000) forward time is 9.6131 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31854
Differential Revision: D19314586
Pulled By: pbelevich
fbshipit-source-id: 2ea1d9a2c505e36aca9e609b52ccb3e8caf2ba8f
Summary:
While working on https://github.com/pytorch/pytorch/issues/31768 and trying to add tests for `DataParallel`, I discovered that:
- `test_data_parallel.py` can't be run through `run_test.py`
- running it with `pytest` fails with many name errors
`test_data_parallel.py` seems to have been split from `test_nn.py` in https://github.com/pytorch/pytorch/issues/28297 but not in a state where it can actually be run. Presumably `DataParallel` hasn't been tested by CI in the time since.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32428
Differential Revision: D19499345
Pulled By: ezyang
fbshipit-source-id: f9b748a99a5c85fc6675c22506cf10bbfd9c8a4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32148
TSAN would complain about multiple threads reading and writing to the
`cpu_dispatch_ptr` without any sort of synchronization. Although, this is a
valid issue from a TSAN point of view, there wasn't a correctness issue since
both threads would compute the same value.
In order to fix this, I've used std::atomic for cpu_dispatch_ptr with relaxed
ordering guarantees.
ghstack-source-id: 96989435
Test Plan: Verify the TSAN tests pass.
Differential Revision: D19386082
fbshipit-source-id: 1ff0893e02529eddd06b2855d9565edf1bbf1196
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31896
Test Plan: Added new tests to QNNPACK's test suite to cover the new use case. All new tests are passing.
Reviewed By: supriyar
Differential Revision: D19443250
Pulled By: AshkanAliabadi
fbshipit-source-id: fa7b1cffed7266a3c198eb591d709f222141a152
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32338
Timed out ops could linger around if the user doesn't actually call
`wait()` on that OP. As result, to fix this I've introduced the following
functionality in this PR:
1. Keep track of all outstanding work in ProcessGroupNCCL.
2. Enhance NCCL watchdog to sweep through all outstanding work and perform the
following operations:
i. If the work has timed out, abort all communicators for that work and
remove them from the cache.
ii. If the communicators for the work receive an error, abort the
communicators and remove them from the cache.
iii. If the work has completed (successfully/unsuccessfully), remove it from
the list of outstanding work.
ghstack-source-id: 96895704
Test Plan: waitforbuildbot
Differential Revision: D19401625
fbshipit-source-id: 8f6f277ba2750a1e1aa03cdbc76e8c11862e7ce5
Summary:
Without this, dlopen won't look in the proper directory for dependencies
(like libtorch and fbjni).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32247
Test Plan:
Build libpytorch_jni.dylib on Mac, replaced the one from the libtorch
nightly, and was able to run the Java demo.
Differential Revision: D19501498
Pulled By: dreiss
fbshipit-source-id: 13ffdff9622aa610f905d039f951ee9a3fdc6b23
Summary:
The current version check doesn't use proper lexicographic comparison and so will break for future versions of cuSPARSE with `CUSPARSE_VER_MAJOR > 10` and `CUSPARSE_VER_MINOR < 2`. Also, my cusparse headers for CUDA 9 don't seem to include version macros at all, so added `if !defined` to be explicit about that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32405
Differential Revision: D19499412
Pulled By: ezyang
fbshipit-source-id: 1593bf1e5a4aae8b75bb3b350d016cc6c3b9c009
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30842
We'd like to profile the time spent on GIL acqusiition to debug
performance issues.
Test Plan: Unit tests pass.
Differential Revision: D18837590
fbshipit-source-id: 925968f71c5fb96b8cd93f1eab4647602d2617d1
Summary:
These jobs were taking forver to run so we decided it's only really
worth it to run it on master.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32378
Differential Revision: D19499301
Pulled By: seemethere
fbshipit-source-id: 22cac5b5baee84e44607a16daeb77048cb0f5974
Summary:
Currently, setting `USE_CUDNN=0` has no effect and any cudnn library found on your system will be used anyway. This is especially problematic when your system has multiple CUDA versions installed, and you are building with a version that lacks a matching cudnn. CMake will find any other cudnn versions and you end up with both CUDA versions added to your compiler include paths.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32404
Differential Revision: D19499425
Pulled By: ezyang
fbshipit-source-id: a9b3f6f9dc22033481c3c1c5999b1a7ef98468cb
Summary:
qlinear/qconv to be consistent with data update.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32254
Differential Revision: D19422929
Pulled By: kimishpatel
fbshipit-source-id: 595a4f7d6fde4978c94f3e720ec8645f3f2bdb7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32197
This is to reland https://github.com/pytorch/pytorch/pull/30063, the main change is to match a general exception and grep "pickle" error word in "test_script_functions_not_supported" unit test, as Python 3.5 and Python 3.6 throw different types of errors with different error message for the rpc call in the unit test.
[test all]This diff makes following changes:
1. Providing a new set of python rpc privated APIs, they can accept an annotated TorchScript call and this call can be serialized, deserialized and executed in C++ without GIL. These privated APIs will be binded to JIT in the future, and they are different from public APIs as future JIT binded private APIs will be able to accept qualified_name, not callables. These private APIs are subject to be deprecated once JIT supports torch script function to be a JIT type.
Also, these APIs require torch script function to be defined and annotated by users in python land, it can not be script class/module constructor or class/module methods.
2. This diff also allows public rpc APIs to accept an annotated TorchScript call and execute code path that above private APIs ran on. Therefore if users invoke an annotated TorchScript call over RPC, this call can be serialized, deserialized and executed in C++ without GIL as well.
3. The above private APIs call a newly defined C++ function to make rpc torch script call to be serialized, deserialized and executed in C++ land. This C++ function returns an ivalue::Future. so that in follow up diff this C++ function can be called when these privated APIs are binded to JIT.
4. script_call.cpp/.h and request_callback_impl.cpp files are refactored accordingly so that torch script call and builtin call can share same message type and codes.
5. refactored deserializeResponse() and added a new utility to deserizalize response to IValue
ghstack-source-id: 96879167
ghstack-source-id: 96879167
Test Plan: unit test
Differential Revision: D19402374
fbshipit-source-id: 04efcc7c167d08a6503f29efe55e76f2be4b2c5e
Summary:
This should be covered under recursive script now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32235
Pulled By: driazati
Differential Revision: D19414889
fbshipit-source-id: 85f8132401dbe44c9dbaef7c0350110f90eb9843
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32276
Include mobile interpreter in mobile code analysis pass, which has some
manually registered ops in temporary namespaces.
The mobile interpreter is still under development and these ops will be
removed in the future. This is a temporary step for internal build
experiment.
Test Plan: Imported from OSS
Differential Revision: D19426818
Pulled By: ljk53
fbshipit-source-id: 507453dc801e5f93208f1baea12400beccda9ca5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32242
TSAN and fork don't play well together, so skip this test if we're
building under TSAN. It will still run in other modes.
Differential Revision: D19416113
fbshipit-source-id: 7e88d63a843356372160c2524c05e8fd1706553e
Summary:
Unchecked cast just refines the type of a value, the value stays the same, so the output should alias the input.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32309
Differential Revision: D19439037
Pulled By: eellison
fbshipit-source-id: fe6902d0d9a5a9ef5e9c13e1dbd056576d8c327e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32323
### Summary
Since we have released the custom build in 1.4.0, it's time to setup a CI for that. This PR adds a new iOS job to the iOS builds. To save time, It only runs the arm64 build.
### Test Plan
- Don't break any iOS jobs
- Custom Build works.
Test Plan: Imported from OSS
Differential Revision: D19451342
Pulled By: xta0
fbshipit-source-id: 9de305c004fc795710ecf01d436ef4792c07760c
Summary:
Distributed data parallel can not broadcast None so when we prepare the model for QAT and trying to save the model it will error out.
fixes: https://github.com/pytorch/pytorch/issues/32082
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32318
Differential Revision: D19434801
Pulled By: jerryzh168
fbshipit-source-id: ee70abe4c3dcdd3506fb7dd0316aee2fb1705469
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32138
I personally prefer `throw std::runtime_error("BOOM")`, but we should
probably have asserts here now that it is gtest. Also ensures that the correct
exceptions are thrown by the `testSignal` tests.
ghstack-source-id: 96811000
Differential Revision: D19382905
fbshipit-source-id: 1b00dd70524d03c8bd6f48715baa5070a7985467
Summary:
This is another implementation of the maximum bailout depth.
The first version was implemented in https://github.com/pytorch/pytorch/pull/31521
This one has advantages that
* the bailout depth only exists in `CodeImpl` which seems to be an appropriate place to keep it in.
* threading many objects is reduced to threading through CodeImpl and getPlanFor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32073
Differential Revision: D19443432
Pulled By: Krovatkin
fbshipit-source-id: 898384bb2308a1532a50a33d9e05cfca504711e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32134
These tests weren't written in the most correct way and were often
flaky. It was tricky to identify these tests as flaky until we moved this file
to use gtest.
The gist of the issue is that the test previously would not coordinate sends
and recvs properly. For example, we created a single thread to test an
abortRecv and a successful recv. A separate sender thread was used to send 2
messages. What could go wrong here is that the first send could successfully
complete, resulting in the receiving end processing the message before it gets
the abort signal. In this case we would have an error in the test.
ghstack-source-id: 96806879
Differential Revision: D19379395
fbshipit-source-id: 24782ccaf6e6ec6b445378b29d5f10f901e0dee6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31901
ncclCommAbort is not thread safe, so adding a lock for it
ghstack-source-id: 96829715
Test Plan: unit tests
Differential Revision: D19293869
fbshipit-source-id: 711b4a07605d6e5a81577247d2f90a78041c1809
Summary:
After we removed `Specialize_AutogradZero` from the optimization pipeline of the simple executor mode, we don't need to mark any inputs as undefined in `autodiff`. Also, `needsGradient` in `graph_executor.cpp` never runs on graph with profiling information, so I removed that code as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32106
Differential Revision: D19374238
Pulled By: Krovatkin
fbshipit-source-id: 4223d3efe3c904a55a28471e5ae9593017ce3e07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32321
Updating the test to test more meaningful sematics
Test Plan:
[xintchen@devvm6308.prn2 ~/fbsource/fbcode] buck test mode/dev //caffe2:ATen-core-test -- 'OperatorRegistrationTest\.whenRegisteringCPUTensorType_thenCanOnlyCallUnboxedWithCPUTensorIdDispatchKey'
Building: finished in 0.4 sec (100%) 517/517 jobs, 0 updated
Total time: 0.5 sec
Trace available for this run at /tmp/testpilot.20200116-132729.2541763.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision e5f315ebe0508d11fc281fa4b4f7b43d2ef1c003 fbpkg 67e8eb96914f400db234fd9af70fdcde at Wed Jan 15 23:38:32 2020 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/762/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/6192449492430045
✓ caffe2:ATen-core-test - OperatorRegistrationTest.whenRegisteringCPUTensorType_thenCanOnlyCallUnboxedWithCPUTensorIdDispatchKey 0.002 1/1 (passed)
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/6192449492430045
Summary (total time 1.15s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D19436345
fbshipit-source-id: c1f2383d62627aa4507616b8905ceb42ac563e9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32316
### Summary
Since the Custom Build has been released in 1.4.0, it's time setup CI. To do that, we need
1. Add a python script to generate the yaml file
2. Add new build scripts to circle CI (arm64 only).
### Test Plan
- Don't break the current iOS CIs
Test Plan: Imported from OSS
Differential Revision: D19437362
Pulled By: xta0
fbshipit-source-id: 395e27a582c43663af88d11b1ef974a4687e672c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32168
We move the exception raising into the function, saving us a
big pile of instructions for raising the stack.
After this stack of changes, the compiler is willing to inline, e.g.,
`c10::KernelFunction::callUnboxed<at::Tensor, at::Tensor const&>(c10::OperatorHandle const&, at::Tensor const&) const::__func__`
(whereas previously it refused to do so.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392948
Pulled By: ezyang
fbshipit-source-id: d5edab00cae48444b308e74438a17a421532c08f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32121
This reduces code size in the call sites of this function (of which
there are many: one for every operator call) since we no longer have
to construct std::string at the site.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392951
Pulled By: ezyang
fbshipit-source-id: 8bc43d46ba635380ff9f8989f7557fdd74b552cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32118
This reduces code size and makes the calling function more likely to inline.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392950
Pulled By: ezyang
fbshipit-source-id: 5e3829cca5604407229f93c2486eb9a325581ea2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32117
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19392949
Pulled By: ezyang
fbshipit-source-id: 7f579e45d49bddeab36b8dd1a90c83224a368ac8
Summary:
For ppc64le, we no longer plan to run regular builds on Python 2.7, and we wish to stop
publicizing the build status for those two builds (ppc64le/CPU and ppc64le/GPU each on py27).
This pull request simply removes the build status links for these two builds, replacing them
with a generic dash character (consistent with other un-publicized builds within the table).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32315
Differential Revision: D19435939
Pulled By: soumith
fbshipit-source-id: c9f31e7acba83e42f6a758ac011bbef36fd8aaa0
Summary:
x || ( !x && y ) <=> to x || y
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32201
Differential Revision: D19429334
Pulled By: ezyang
fbshipit-source-id: 044dc46c2d9a7e180aa1795703c0097b0c7c3585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32198
creating a method called "callUnboxedWithDispatchKey".
Also adding tests to make sure it works.
Test Plan: buck test mode/dev //caffe2:ATen-core-test
Differential Revision: D19402815
fbshipit-source-id: b206cf04b1216fbbd5b54ac79aef495cb0c1be06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32232
Previously, we were using `operator<<` as the default way of printing
IValue constants during serialization. The semantics of `operator<<`
were ill-defined; and this bit us in particular with strings and lack of
quoting.
This PR defines the role of `operator<<`: much like Python `str()`, it
is intended to produce a human-readable-ish representation for
debugging purposes.
This PR also defines a new `repr()` function on IValue that is intended
to produce a valid Python expression that can be used to recreate an
object with the same value. `repr()` is not defined on all IValue kinds
(notably tensors!) for this reason.
Test Plan: Imported from OSS
Differential Revision: D19417036
Pulled By: suo
fbshipit-source-id: c102d509eaf95a28b6a62280bc99ca6f09603de5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31456
External request https://discuss.pytorch.org/t/jit-android-debugging-the-model/63950
By default torchscript print function goes to stdout. For android it is not seen in logcat by default.
This change propagates it to logcat.
Test Plan: Imported from OSS
Differential Revision: D19171405
Pulled By: IvanKobzarev
fbshipit-source-id: f9c88fa11d90bb386df9ed722ec9345fc6b25a34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32208
### Summary
Since the master branch will generate `libtorch_cpu.a`, which is different from the release branch. This PR will skip the missing libs before archiving them.
### Test Plan
- don't break the nightly build
Test Plan: Imported from OSS
Differential Revision: D19420042
Pulled By: xta0
fbshipit-source-id: fb28df17b7e95d5c7fdf5f3a21bece235d7be17c
Summary:
An example of a model with such leaf nodes is faster_rcnn model. This PR helps optimizing onnx ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32077
Reviewed By: hl475
Differential Revision: D19399622
Pulled By: houseroad
fbshipit-source-id: 35c628c6f1514b79f1bcf7982c25f0f4486f8941
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32224
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19416878
Pulled By: ezyang
fbshipit-source-id: 0205d0635658a3328128dcaad94bbbef505342be
Summary:
Introduce ProcessGroup::allgather_base. No implementation yet: plan to add it one PG backend at a time in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31892
Test Plan: No functional changes, no tests yet.
Differential Revision: D19290739
Pulled By: agolynski
fbshipit-source-id: c2f4947d2980995724c539de7c6d97618e1ba11a
Summary:
torch.onnx.export docs contain two descriptions for 'example_outputs' arg.
So combined the information for it with the description with the parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31826
Differential Revision: D19274928
Pulled By: zou3519
fbshipit-source-id: cbcce0a79c51784c1d7aa8981aab8aac118ca9b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31713
- In case the callbacks are heavy/slow, the other threads should be able to start work on the value of the future after the current thread moves the value and unlock the mutex.
- `completed()` is not inlined. Avoid function call overhead.
ghstack-source-id: 96694593
Test Plan: tdb
Differential Revision: D5624371
fbshipit-source-id: 5762e6e894d20108ec9afedd1a6e64bcd97ee3fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31970
Now that the ClassType can be shared among different module instances, we'll
preserve the sharing in clone as well, that is if the original module has
a ClassType that is shared, we'll clone this ClassType once and share it between
different module instances as well.
Test Plan:
build/test/test_jit
Imported from OSS
Differential Revision: D19406251
fbshipit-source-id: 2881c695f6e718e5432040a3817cf187a62017bf
Summary:
"in_features" and "out_features" are not defined. Possibly a typo. They should be "input_features" and "output_features" instead
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31682
Differential Revision: D19251685
Pulled By: zou3519
fbshipit-source-id: ac9e524e792a1853a16e8876d76b908495d8f35e
Summary:
Just update the comment to make it accurate.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32222
Differential Revision: D19410428
Pulled By: albanD
fbshipit-source-id: ad13596382613c2728e674a47049ea4f563964b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32187Fixes#32058. Previously we would build documentation during the pytorch
linux cuda build. We don't actually need to do this because we have a
dedicated python_doc_build job that builds the docs. With this change,
the CUDA build should run ~10 minutes faster, giving devs faster signal.
Test Plan: - Check the CUDA (10.1) build on this PR, make sure it doesn't build the docs.
Differential Revision: D19400417
Pulled By: zou3519
fbshipit-source-id: e8fb2b818146f33330e06760377a9afbc18a71ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32185
Previously we would unify the contained types of dictionaries, however this breaks type safety.
```
torch.jit.script
def test(input: Dict[str, None], cond):
if cond:
out = input
else:
out: {"1": 1}
out["hi"] = 3
```
This would only occur if a dictionary is being re-assigned across an if condition with different contained types, which is pretty unlikely. I tested `model_backward_compatibility` for all fb models and this didn't break anything. This PR is a precursor to alias analysis changes.
Also fixes `Future` type unification. Because `Future` is an immutable type, it is okay to unify the contained type.
Test Plan: Imported from OSS
Differential Revision: D19398585
Pulled By: eellison
fbshipit-source-id: ebc8812cdf5b6dba37b1cfbc2edc7d8c467b258c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32179
Tensors are used as keys in dictionaries, so we need to annotate that key insertion into a dictionary inserts the key into the wildcard set. Also fixes bug with `listCopyAndSort` not copying the input list.
Test Plan: Imported from OSS
Differential Revision: D19397555
Pulled By: eellison
fbshipit-source-id: 17acdc22ff5e2dda44fd25c80450396f5592095e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32086
np.clip(1, num_indices // 2, 10) -> np.clip(num_indices // 2, 1, 10)
Also change batchsize -> num_rows to match with what the variable actually does
Test Plan: CI
Reviewed By: hx89
Differential Revision: D19361521
fbshipit-source-id: 9ce864c7d7da046dc606afa5207da677ccf80f52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32104
Fixes these warnings:
```
xplat\caffe2\caffe2Windows#header-mode-symlink-tree-only,headers\caffe2\operators\quantized\int8_conv_op.h(96,17): warning: use 'template' keyword to treat 'data' as a dependent template name
W.t.data<uint8_t>(),
^
template
xplat\caffe2\caffe2Windows#header-mode-symlink-tree-only,headers\caffe2\operators\quantized\int8_conv_op.h(97,17): warning: use 'template' keyword to treat 'data' as a dependent template name
B.t.data<int32_t>(),
^
template
```
Test Plan: Tested locally with clang-cl and CI for other toolchains
Reviewed By: boguscoder
Differential Revision: D19353563
fbshipit-source-id: c28afb8c1ad72fd77ef82556ba89fcf09100d1f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32190
We need a backend-agnostic mechanism to do barrier-like operation before locally destroy RRef context and shutdown RPC Agent.
- Sort worker names.
- Elect the first name as the leader in the ordered worker names.
- Followers reports therir intent to synchronize to the leader.
- Leader also reports to itself, when `_wait_all_workers()` called.
- If all workers report their intent to proceed, leader send the command to every one to proceed.
ghstack-source-id: 96693296
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_leak
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn
buck-out/gen/caffe2/test/rpc_spawn\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_spawn\#binary.par -r test_rref_leak
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_worker_id
```
# Stress runs
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_heavy_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_heavy_rpc --stress-runs 10
```
Differential Revision: D19399908
fbshipit-source-id: 1dee607cd49adafe88534621a1c85e2736e2f595
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32133
We should do this to better debug the test.
Differential Revision: D19375479
fbshipit-source-id: 8c2bf61bae605a38252bb793b091ade479bea11a
Summary:
Currently, libtorch build and test are not running in macOS CI. This PR fixes the issue.
**Test Plan:**
Check that libtorch build and test are running again in macOS CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32072
Differential Revision: D19391909
Pulled By: yf225
fbshipit-source-id: 1ab345b099869f78e1124f1a8bd185fa51371b6a
Summary:
This was not tested before, fixes#32139 (which was actually a false positive, functions with kwargs but without defaults on those kwargs are supported). This PR adds testing for both cases and cleans up the error reporting.
](https://our.intern.facebook.com/intern/diff/19385828/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32146
Pulled By: driazati
Differential Revision: D19385828
fbshipit-source-id: 5eab74df6d02f8e1d7ec054cafb44f909f9d637e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32147
### Summary
Got some security warnings regarding the ruby dependencies. This diff updates the packages in Gemfile.
```
GitHub has detected that a package defined in the ios/TestApp/Gemfile.lock file of the pytorch/pytorch repository contains a security vulnerability.
Package name: excon
Affected versions: < 0.71.0
Fixed in version: 0.71.0
Severity: LOW
Identifier(s):
GHSA-q58g-455p-8vw9
CVE-2019-16779
```
### Test Plan
- Won't affect the existing iOS CI jobs
Test Plan: Imported from OSS
Differential Revision: D19400087
Pulled By: xta0
fbshipit-source-id: 34b548d136cfd6b68fcc53bf0b243461bd7afd64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32170
Stack from [ghstack](https://github.com/ezyang/ghstack):
Change the overload name from passing by const ref to by value and move.
* **#32170 Fix the passing-by-ref constructor of OperatorName.**
Test Plan: Imported from OSS
Differential Revision: D19396225
Pulled By: iseeyuan
fbshipit-source-id: e946c47647e1f8d23d7565cfe93f487845e7f24c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31912
### Summary
Clean up the logs from pip-install.
### Test Plan
- Don't break the iOS simulator build
Test Plan: Imported from OSS
Differential Revision: D19395526
Pulled By: xta0
fbshipit-source-id: a638a209cab801ce90c8615e7ea030b1ab0939f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32149
This is an attempt at clarifying some of the preprocessor boolean logic that was getting more and more complicated. The previous logic used constexpr with nvcc on clang; which we were getting compiler failures on in ovrsource with mode/linux/* (based on platform007).
Test Plan:
ovrsource xplat/caffe2 compiles
fbsource sandcastle green
Differential Revision: D19385409
fbshipit-source-id: 60a02bae9854388b87510afdd927709673a6c313
Summary:
Continuation of https://github.com/pytorch/pytorch/issues/31514, fixes https://github.com/pytorch/pytorch/issues/28430
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32009
Test Plan:
I verified that the deprecation warnings only occur once on a relevant workflow. Built with:
```
buck build mode/opt //vision/fair/detectron2/tools:train_net
```
Ran with:
```
DETECTRON2_ENV_MODULE=detectron2.fb.env ~/local/train_net.par --config-file configs/quick_schedules/retinanet_R_50_FPN_instant_test.yaml --num-gpus 1 SOLVER.IMS_PER_BATCH 2
```
Inspected log:
```
[01/14 07:28:13 d2.engine.train_loop]: Starting training from iteration 0
buck-out/opt/gen/caffe2/generate-code=python_variable_methods.cpp/python_variable_methods.cpp:1299: UserWarning: This overload of add is deprecated:
add(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add(Tensor other, Number alpha)
buck-out/opt/gen/caffe2/generate-code=python_variable_methods.cpp/python_variable_methods.cpp:1334: UserWarning: This overload of add_ is deprecated:
add_(Number alpha, Tensor other)
Consider using one of the following signatures instead:
add_(Tensor other, Number alpha)
[01/14 07:28:25 d2.utils.events]: eta: 0:00:10 iter: 19 total_loss: 1.699 loss_cls: 1.185 loss_box_reg: 0.501 time: 0.5020 data_time: 0.0224 lr: 0.000100 max_mem: 3722M
[01/14 07:28:35 fvcore.common.checkpoint]: Saving checkpoint to ./output/model_final.pth
```
Differential Revision: D19373523
Pulled By: ezyang
fbshipit-source-id: 75756de129645501f43ecc4e3bf8cc0f78c40b90
Summary:
`test_init_ops` calls `orthogonal_` which fails without lapack (this test was just missing a skip condition)
The cpp tests would fail with a `undefined symbol` error if run with `BUILD_TESTS=0`, so this PR skips them if that flag is `0`
](https://our.intern.facebook.com/intern/diff/19320064/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31965
Pulled By: driazati
Differential Revision: D19320064
fbshipit-source-id: d1dcd36714107688ded25a414e8969abe026bd03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30063
This diff makes following changes:
1. Providing a new set of python rpc privated APIs, they can accept an annotated TorchScript call and this call can be serialized, deserialized and executed in C++ without GIL. These privated APIs will be binded to JIT in the future, and they are different from public APIs as future JIT binded private APIs will be able to accept qualified_name, not callables. These private APIs are subject to be deprecated once JIT supports torch script function to be a JIT type.
Also, these APIs require torch script function to be defined and annotated by users in python land, it can not be script class/module constructor or class/module methods.
2. This diff also allows public rpc APIs to accept an annotated TorchScript call and execute code path that above private APIs ran on. Therefore if users invoke an annotated TorchScript call over RPC, this call can be serialized, deserialized and executed in C++ without GIL as well.
3. The above private APIs call a newly defined C++ function to make rpc torch script call to be serialized, deserialized and executed in C++ land. This C++ function returns an ivalue::Future. so that in follow up diff this C++ function can be called when these privated APIs are binded to JIT.
4. script_call.cpp/.h and request_callback_impl.cpp files are refactored accordingly so that torch script call and builtin call can share same message type and codes.
5. refactored deserializeResponse() and added a new utility to deserizalize response to IValue
ghstack-source-id: 96638829
Test Plan: unit test
Differential Revision: D18482934
fbshipit-source-id: bd82a0d820c47a8e45b2e7c616eca06573f7d7ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31830
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19330312
Pulled By: ezyang
fbshipit-source-id: fe2e53e732e946088e983ec45fed2393436f0517
Summary:
While ONNX does not currently directly support the Dim operation on a
tensor, we can provide the same functionality with two ONNX operations.
This allows us to support Dim for all opsets. It may be adventageous to
add support for Dim into a future ONNX opset, and use that for more
efficient code.
While testing dim op found that there is an issue with empty blocks
withing if statements. Modified graph generation to prevent generation
of empty if blocks.
Fixes https://github.com/pytorch/pytorch/issues/27569
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31928
Reviewed By: hl475
Differential Revision: D19376602
Pulled By: houseroad
fbshipit-source-id: 111682b058a5341f5cca6c1a950c83ae412a4c6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31674
The motivation of this PR was to fix the problem where we would see
"Address already in use" issues for TCPStoreTest due to port conflicts. To
resolve this:
1. We can now pass in port 0 for TCPStore and retrieve the port it actually
bound to using a new getPort() API.
2. Added a `wait` flag to TCPStore constructor indicating whether or not it
should wait for workers (defaults to true).
3. Made `waitForWorkers` a public API to ensure that we can construct TCPStore
without waiting and wait for workers separately. This helps in TCPStoreTest to
ensure we can retrieve the port and pass it to the client stores.
ghstack-source-id: 96486845
Test Plan: waitforbuildbot
Differential Revision: D19240947
fbshipit-source-id: 7b1d1cb2730209fac788764845f1dbbe73d75d9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32102
Previously, the docs CI depended on our CUDA xenial py3 build. This
meant that the turnaround time to get signal for docs was very slow
(I've seen builds that go as much as 3 hours).
Fortunately, the docs CI do not (and should not!) rely on CUDA. This
PR changes it so that the docs CI runs on a CPU-only machine.
Fixes#29995
Test Plan:
- Check CI status on this PR by reading logs for the python and cpp docs
builds.
- I built the docs locally, once for CPU, and once for CUDA, and
verified (via diff) that the pages were exactly the same)
Differential Revision: D19374078
Pulled By: zou3519
fbshipit-source-id: 3eb36f692c3c0632d2543d3439c822d51a87b809
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31978
Currently we keep a `mangleIndex_` that's intenral to compilation unit and
just increment the index when we found the original name is mangled, this doesn't
guarantee the new name is not defined.
This PR fixes the problem by querying whether the new name is defined or not.
fixes: https://github.com/pytorch/pytorch/issues/31268
Test Plan:
fixes the issue
Imported from OSS
Differential Revision: D19350535
fbshipit-source-id: fe3262b2838d4208ab72e2cd4a5970b3a792ae86
Summary:
Currently, libtorch build and test are not running in macOS CI. This PR fixes the issue.
**Test Plan:**
Check that libtorch build and test are running again in macOS CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32072
Differential Revision: D19373615
Pulled By: yf225
fbshipit-source-id: 28686ef5895358a2b60db46b1946f21c58c6a18e
Summary:
Currently cumprod crashes for tensors with non-empty dimensions but with zero elements, which could happen when some dimension is zero. This commit fixes the error by checking both dim() and numel() in cumprod backward
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32070
Differential Revision: D19373200
Pulled By: ezyang
fbshipit-source-id: d8ecde33f3330b40a7c611f6faa3b1d707ef2a9a
Summary:
This PR adds a more complete list of pytorch header files to be installed at build time. It also fixes one instance of including a header from local src directory instead of installed directory.
A more complete set of headers enable other modules to correctly work with pyTorch built for ROCm.
cc: ezyang bddppq iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32076
Differential Revision: D19372933
Pulled By: ezyang
fbshipit-source-id: 3b5f3241c001fa05ea448c359a706ce9a8214aa0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30734
What are specialized lists?
The IValues that hold List[int], List[Tensor], and List[AnythingElse] are different C++ types.
e.g. List[int] has a std::vector<int> while List[AnythingElse] holds a std::vector<IValue>.
Why do we have specialized lists?
When we first created the JIT we needed to bind the ATen C++ API which has std::vector<int>,
std::vector<Tensor> as inputs. The easiest way to match this API was to make our IValues contain
these same types. Conversion was just unwrapping the IValue, very easy and cheap.
What is the problem with specialized lists?
We end up with significant special cases through the compiler. Other types like Dict are not
specialized. So in the Pickler, for instance, there is a single piece of logic to handle
their serialization. For Lists, we end up with multiple cases. Furthermore, it doesn't
match Python, leading to problems along translation boundaries. Our pickle serialization
is slightly different than python, so it is harder to load objects from our IValue serialization
as Python values.
They also make it harder to provide an easy-to-use user API. We'd like to match pybind11 for C++
bindings to TorchScript. This would entail having a single torch::List class (untemplated)
that can be used to construct inputs. This is made much harder if the underlying ivalue needs
to be different depending on the type inside the list. The ideal case would be to have a constructor like
```
template<typename T>
List(std::vector<T> foo);
```
It would then set up the type tags correctly based on type T, without the need for passing tags.
Do specialized lists improve perf?
Not in a way we have been able to measure. Our major concern initially was having to translate
a std::vector<IValue> to std::vector<int> to call ATen functions. This was especially a concern
for aten::_convolution which takes a number of mostly-constant lists of integers. However,
when we measure the effect of actually having to do this conversion for an aten::_convolution,
it does not take measurable time (benchmark results below).
This is true even if you use a trivial convolution (e.g. 1x1x1), and comment out the actual convolution code.
What are the issues removing them?
This PR removes list specialization but keeps the serialization format, and IValue APIs almost exactly
the same. The only visible change is that toTensorListRef and family have turned into toTensorVector
because they now return by value a copy of the list as a vector.
Further PRs can then clean up the complexity issues that arose from speclization. This will likely
involve removing the isTensorList/isIntList functions, and refactoring the code that used them to
work generically. At some point we will also change serialization to no longer write specialized
lists in the pickle binary. This is forward incompatible, so will go in its own PR.
Benchmark:
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
class MnistNet(nn.Module):
def __init__(self):
super(MnistNet, self).__init__()
self.conv1 = nn.Conv2d(1, 1, kernel_size=1)
self.conv2 = nn.Conv2d(1, 1, kernel_size=1)
def forward(self, x):
for i in range(10):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
return x
model = MnistNet()
x = torch.rand(1, 1, 1, 1)
r = torch.jit.trace(model, x )
r(x)
r(x)
r(x)
r(x)
print(torch.jit.last_executed_optimized_graph())
while True:
b = time.time()
for i in range(100):
r(x)
e = time.time()
print(e - b)
```
Results (no observable difference):
```
Before (actual conv)
0.13251137733459473
0.13260436058044434
0.13276338577270508
0.1327497959136963
0.13250041007995605
0.13270330429077148
0.13290190696716309
0.13265132904052734
0.13274288177490234
0.1326758861541748
0.13253355026245117
0.13254785537719727
0.13260746002197266
0.13285017013549805
0.13264012336730957
0.132490873336792
0.13280034065246582
0.13243484497070312
0.1325232982635498
0.1326127052307129
0.13264131546020508
0.13274383544921875
0.13298296928405762
0.1326909065246582
-------------------
After (actual conv)
0.13127517700195312
0.13150334358215332
0.13092470169067383
0.13102364540100098
0.13134360313415527
0.13155555725097656
0.13314104080200195
0.13151955604553223
0.13160037994384766
0.1315293312072754
0.13137340545654297
0.13148093223571777
0.131455659866333
0.1327371597290039
0.13134026527404785
0.13152337074279785
0.13151192665100098
0.13165974617004395
0.13403725624084473
0.13251852989196777
0.13135504722595215
0.1315624713897705
0.1317615509033203
0.1314380168914795
0.13157200813293457
--------------------
The following replace the convolution operator with a no-op, to show
that even if the conv op was made faster, then we still would not see
a difference:
Before (fake conv)
0.0069539546966552734
0.0069522857666015625
0.007120847702026367
0.007344722747802734
0.007689952850341797
0.007932662963867188
0.00761723518371582
0.007501363754272461
0.007532835006713867
0.007141828536987305
0.007174253463745117
0.007114410400390625
0.007071495056152344
------------------
After (fake conv)
0.007458209991455078
0.007337093353271484
0.007268190383911133
0.007313251495361328
0.007306575775146484
0.007468700408935547
0.0073091983795166016
0.007308483123779297
0.007538318634033203
0.007356882095336914
0.007464170455932617
0.007372140884399414
```
Test Plan: Imported from OSS
Differential Revision: D18814702
Pulled By: zdevito
fbshipit-source-id: 0371c73b63068fdc12f24b801371ea90f23531a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31381
This PR adds support for being able to profile both sync and async RPCs, so that users can use the autograd profiler and be able to view metrics such as RPC latency and number of calls in the profiler output.
The way this is implemented is by using the existing `RecordFunction` class provided by the autograd profiler. We create a `RecordFunction` instance when sending an RPC, if autograd profiling is enabled. We also invoke the starting callbacks on this `RecordFunction` instance, this does things such as start the CPU timer. This instance is then persisted across the lifetime of the RPC by attaching it to the `Future` created by the RPC. When the RPC is finished (i.e. when `future->markComplete()` is called), we run the `RecordFunction` instance's end callbacks, which among other things, stops the timer so that we get the correct RPC latency.
The `RecordFunction` and relevant callbacks in `profiler.cpp` are modified slightly to support running end callbacks from a different thread (which is needed since futures are marked as completed by a different thread than the main RPC thread). By default, the autograd profiler uses a `thread_local` list of `Events` and `thread_id`. However, since we'd like to run the `RecordFunction`'s callbacks from a different thread, we would like to access the list of `Events` created by the original thread. This is done by attaching the `thread_id` for the event to the `RecordFunction`, and then looking up the event with that thread in `all_event_lists` (see the changes in `profiler.cpp`). To ensure that the original behavior does not change in the profiler, this described behavior is only run when a user calls `setOverrideThreadId()` on the `RecordFunction` object.
ghstack-source-id: 96527291
Test Plan: Added a unit test.
Differential Revision: D19053322
fbshipit-source-id: 9a27a60c809fc4fdb16fa5d85085f3b6b21abfbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32016
The previously logic will raise exception when there is query in url when rank or world_size is specified
The fix will parse the url and stitch rank and world_size into url.query and regenerate the url.
Test Plan: f161291877
Differential Revision: D19337929
fbshipit-source-id: 6bb3a07716dda5233553804000b706052ff18db8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30424
`at::indexing::TensorIndex` is used for converting C++ tensor indices such as `{None, "...", Ellipsis, 0, true, {1, None, 2}, torch::tensor({1, 2})}` into its equivalent `std::vector<TensorIndex>`, so that further tensor indexing operations can be performed using the supplied indices.
Test Plan: Imported from OSS
Differential Revision: D18695902
Pulled By: yf225
fbshipit-source-id: d73e14a411cdbec815866b02e75ffd71a9186e89
Summary:
Per discussion with Fei Tian, we need to add a `scale_init_value` to scale down the output of normalization such as batch-norm and layer-norm.
Currently we have `sparse_normalization_options` to normalize embedding pooling output. By default, scale = 1.0, we found it's better to set scale from 0.025 to 0.1 https://fb.quip.com/MiKUAibEaYhH
Besides, I am removing the tags from normalizers because it makes more sense to calculate norm ops in distributed trainers, not ps.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31983
Test Plan:
Testing LN and BN after sum-pooling --
baseline f160348514
LN: f160348609
BN: f160348710
{F226106518}
Layer norm after sum-pooling fwd_net https://fburl.com/sa4j207n
Layer norm after dot-prod fwd_net https://fburl.com/twggwyvb
## Unit Tests
Testing normalization after pooling
```
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_sparse_pooling_batch_normalization
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_dense_sparse_pooling_batch_normalization
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_sparse_pooling_layer_normalization
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test_4 -- test_dense_sparse_pooling_layer_normalization
```
Testing normalization after dot-prod
```
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_last_layer_use_batch_norm
buck test caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_last_layer_use_layer_norm
```
Differential Revision: D19277618
Pulled By: SilunWang
fbshipit-source-id: ea323e33e3647ba55d2e808ef09d94ad7b45b934
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31023
Adds support to catch exceptions in ProcessGroupAgent::enqueueSend and
report them in the future by marking the future as completed with an exception
indicating the error. An example of when this could happen is if the receiving
side aborts when the sender is sending the message, previously, we would hang
until the timeout is hit, and the original exception would be lost.
ghstack-source-id: 96498386
Test Plan: Added a relevant unit test: `test_sender_exceptions` in rpc_test.py
Differential Revision: D18901981
fbshipit-source-id: 08de26936c4ad45b837219a247088cbea644c04c
Summary:
Custom build and internal build will depend on the analysis result so
let's make sure it doesn't break.
Tested locally with LLVM-5.0, LLVM-7 and LLVM-8.
Test Plan: - check CI result
Differential Revision: D18894637
Pulled By: ljk53
fbshipit-source-id: 657854e4bed85a84907e3b6638d158823a56ec80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32027
The test was added in #30985 for #28313. Seems the fix only works for
Python3 but doesn't work on Python2. The current Python2 CI docker image
doesn't have `dill` module installed at all so it's not captured.
I'm trying to build and push new CI docker image which has `dill` installed
and I verified it's the latest version 0.3.1.1 but the fix doesn't seem
to work and blocks me from upgrading image version. It works for Python3
docker image though...
Here is a succeeded job with old image (no dill installed):
https://app.circleci.com/jobs/github/pytorch/pytorch/4192688
Here is a failed job with new image (dill installed):
https://app.circleci.com/jobs/github/pytorch/pytorch/4192679
This PR bypasses the test for Py2 to unblock docker image change. We
can figure out a proper fix for Py2 later.
Test Plan: Imported from OSS
Differential Revision: D19341451
Pulled By: ljk53
fbshipit-source-id: d5768de8cbaf1beba8911da76f4942b8f210f2d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32011
Run into build problem with Ninja + code analysis build as follows:
```
The install of the torch_global_deps target requires changing an RPATH from
the build tree, but this is not supported with the Ninja generator unless
on an ELF-based platform.
```
Seems we don't need build the target for static build mode?
Verified code analyzer works with the patch.
Test Plan: Imported from OSS
Differential Revision: D19336818
Pulled By: ljk53
fbshipit-source-id: 37f45a9392c45ce92c1df40d739b23954e50a13a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31972
Since eager mode quantization requires many user modifications, we can't
consistently quantize a given model by just changing qconfig_dict, therefore
the top level `qconfig_dict` is not that useful.
fixes: https://github.com/pytorch/pytorch/issues/31549
Test Plan:
.
Imported from OSS
Differential Revision: D19330691
fbshipit-source-id: 8aee6e5249e0c14e8a363ac1a83836e88887cd7d
Summary:
Instead of a mixture of direct calls to library provided atomicAdd calls, such as float atomicAdd(float*, float) and calls provided internally, such as void atomicAdd(long*, long), abstract to one API void gpuAtomicAdd(T*, T) in THCAtomics.cuh for the PyTorch backend.
The advantage of this approach is that it allows us to more easily distinguish between capabiltiies of different platforms (and their versions). Additionally, the abstraction of void returning atomicAdds allows us to, in the future, support fast HW instructions on some platforms that will not return the previous value.
Call sites that do not satisfy above conditions and are either highly platform specific (__half2 atomicAdd fast path in one operator) or require the return explicitly (some int atomicAdd invocations) are left untouched. The Caffe2 backend also remains untouched.
While here, add a bunch of includes of THCAtomics.cuh that were missing before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31992
Differential Revision: D19330220
Pulled By: ezyang
fbshipit-source-id: d6ab73ec5168c77e328faeef6c6f48eefba00861
Summary:
This was missing and resulted in the incorrect `name` passed into `_to_worker_info` not being printed out in the error message.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31969
Differential Revision: D19331927
Pulled By: rohan-varma
fbshipit-source-id: e74d47daec3224c2d9b9da3c0a6404cfa67baf65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31858
Trying to upgrade docker image but ran into the following error:
```
Running test_nn ... [2020-01-04 18:05:12.537860]
Traceback (most recent call last):
File "test_nn.py", line 45, in <module>
from common_cuda import TEST_CUDA, TEST_MULTIGPU, TEST_CUDNN, TEST_CUDNN_VERSION
File "/var/lib/jenkins/workspace/test/common_cuda.py", line 16, in <module>
import numba.cuda
File "/opt/conda/lib/python3.6/site-packages/numba/__init__.py", line 178, in <module>
_ensure_llvm()
File "/opt/conda/lib/python3.6/site-packages/numba/__init__.py", line 100, in _ensure_llvm
raise ImportError(msg)
ImportError: Numba requires at least version 0.30.0 of llvmlite.
Installed version is 0.28.0.
```
Test Plan: Imported from OSS
Differential Revision: D19282923
Pulled By: ljk53
fbshipit-source-id: bdeefbf4f6c0c97df622282f76e77eb1eadba436
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31031
This activation will be needed for the LSTM implementation.
Also includes the QNNPack implementation.
Test Plan: Imported from OSS
Differential Revision: D19334280
Pulled By: z-a-f
fbshipit-source-id: ae14399765a47afdf9b1e072d3967c24ff473e8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31857
According to mingbowan we will change to use string docker image
version because the tag is no longer an integer since we move the docker
image build job to circle CI:
http://ossci-docker.s3-website.us-east-1.amazonaws.com/pytorch.html
Test Plan: - with stacked PR
Differential Revision: D19282726
Pulled By: ljk53
fbshipit-source-id: 7a12ae89a11cf15163b905734d50fed6dc98cb07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31995Fixes#31906.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19331259
Pulled By: ezyang
fbshipit-source-id: 5d24bf3555e632211a9b6f8e50ff241603c18b3d
Summary:
Fix for https://github.com/pytorch/pytorch/issues/19420
So after actually writing a C++ JSON dumping class I figured that
a faster and cleaner way would be simply rewrite the Python without
the JSON module since the JSON that we need to output is so simple.
For now I decided to not touch the `parse_cpu_trace` function since
only changing `export_chrome_trace` shows a 4x speedup.
Here's the script I used for benchmarking:
``` python
import time
import torch
x = torch.ones(2, 2)
start = time.time()
with torch.autograd.profiler.profile() as prof:
for _ in range(10000):
x * x
for i in range(50):
prof.export_chrome_trace("trace.json")
stop = time.time()
print(stop-start)
```
master branch (using json dump) -> 8.07515025138855
new branch (without json dump) -> 2.0943689346313477
I checked the trace file generated in the [test](https://github.com/pytorch/pytorch/blob/master/test/test_autograd.py#L2659)
and it does work fine.
Please let me know what you think.
If you still insist on the C++ version I can send a new patch soon enough.
CC ezyang rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30724
Differential Revision: D19298955
Pulled By: ezyang
fbshipit-source-id: b0d7324ea5f90884ab8a00dd272f3aa3d9bc0427
Summary:
Fix https://github.com/pytorch/pytorch/issues/24704.
Benchmark script :
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000]:
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(1000):
input.geometric_(0.5)
for n in [1, 10, 100, 1000]:
fwd_t = 0
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(10000):
t1 = _time()
input.geometric_(0.5)
t2 = _time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.4f (ms)." % (n, fwd_avg))
```
Test device: **skx-8180**.
Before:
```
input size(128, 1) forward time is 0.0092 (ms).
input size(128, 10) forward time is 0.0802 (ms).
input size(128, 100) forward time is 0.7994 (ms).
input size(128, 1000) forward time is 7.8403 (ms).
```
After:
```
input size(128, 1) forward time is 0.0088 (ms).
input size(128, 10) forward time is 0.0781 (ms).
input size(128, 100) forward time is 0.7815 (ms).
input size(128, 1000) forward time is 7.7163 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31878
Differential Revision: D19314510
Pulled By: ezyang
fbshipit-source-id: 2d95bf9938c8becf280890acf9e37223ddd08a39
Summary:
VitalyFedyunin, This PR is about port LogSigmoid activation to Aten:
Test script:
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
m = nn.LogSigmoid()
#warm up
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
**Before:**
```
input size(128, 1) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.10 (ms); backwad avg time is 0.03 (ms).
input size(128, 100) forward time is 0.90 (ms); backwad avg time is 0.09 (ms).
input size(128, 1000) forward time is 9.04 (ms); backwad avg time is 0.87 (ms).
```
**After:**
```
input size(128, 1) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 0.28 (ms); backwad avg time is 0.07 (ms).
```
**OMP_NUM_THREADS=1:**
```
Before:
input size(128, 1) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.10 (ms); backwad avg time is 0.03 (ms).
input size(128, 100) forward time is 0.88 (ms); backwad avg time is 0.10 (ms).
input size(128, 1000) forward time is 8.72 (ms); backwad avg time is 0.81 (ms).
After:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.07 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 0.63 (ms); backwad avg time is 0.15 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24724, https://github.com/pytorch/pytorch/issues/24725.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30958
Differential Revision: D19275111
Pulled By: ezyang
fbshipit-source-id: bbfe82e58fb27a4fb21c1914c6547a9050072e5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31962
I added precision tests for CUDA half, float, and double.
The precision for CUDA half seems bad, but I checked the numbers against
previous versions of pytorch. The output of CUDA Half linspace+logspace
are exactly the same when compared with 1.2.0.
Test Plan: - Run CI
Differential Revision: D19320182
Pulled By: zou3519
fbshipit-source-id: 38d3d4dea2807875ed0b0ec2b93b19c10a289988
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31162
This should help us resolve a multitude of weird segfaults and crashes
when PyTorch is imported along with other packages. Those would often
happen because libtorch symbols were exposed globally and could be used
as a source of relocations in shared libraries loaded after libtorch.
Fixes#3059.
Some of the subtleties in preparing this patch:
* Getting ASAN to play ball was a pain in the ass. The basic problem is that when we load with `RTLD_LOCAL`, we now may load a library multiple times into the address space; this happens when we have custom C++ extensions. Since the libraries are usually identical, this is usually benign, but it is technically undefined behavior and UBSAN hates it. I sprayed a few ways of getting things to "work" correctly: I preload libstdc++ (so that it is seen consistently over all library loads) and added turned off vptr checks entirely. Another possibility is we should have a mode where we use RTLD_GLOBAL to load _C, which would be acceptable in environments where you're sure C++ lines up correctly. There's a long comment in the test script going into more detail about this.
* Making some of our shared library dependencies load with `RTLD_LOCAL` breaks them. OpenMPI and MKL don't work; they play linker shenanigans to look up their symbols which doesn't work when loaded locally, and if we load a library with `RLTD_LOCAL` we aren't able to subsequently see it with `ctypes`. To solve this problem, we employ a clever device invented by apaszke: we create a dummy library `torch_global_deps` with dependencies on all of the libraries which need to be loaded globally, and then load that with `RTLD_GLOBAL`. As long as none of these libraries have C++ symbols, we can avoid confusion about C++ standard library.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D19262579
Test Plan: Imported from OSS
Pulled By: ezyang
fbshipit-source-id: 06a48a5d2c9036aacd535f7e8a4de0e8fe1639f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31161
Previously, it wasn't necessary to specify `DT_NEEDED` in C++ extensions on Linux (aka pass `-l` flags) because all of the symbols would have already been loaded with `RTLD_GLOBAL`, so there wouldn't be any undefined symbols. But when we switch to loading `_C` with `RTLD_LOCAL`, it's now necessary for all the C++ extensions to know what libraries to link with. The resulting code is clearer and more uniform, so it's wins all around.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262578
Pulled By: ezyang
fbshipit-source-id: a893cc96f2e9aad1c064a6de4f7ccf79257dec3f
Summary:
special case for norm out where p == 2. Instead of calling `pow`,
we use multiplication as a faster code path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31903
Differential Revision: D19312749
Pulled By: ngimel
fbshipit-source-id: 73732b7b37a243a14438609784795b920271a0b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31800
If we know that two constants are the same object, we can ignore other constraints and pool them together. This fixes an issue introduced by the other PR where quantization relied on constant pooling happening for correctness.
Test Plan: Imported from OSS
Differential Revision: D19269499
Pulled By: eellison
fbshipit-source-id: 9d4396125aa6899cb081863d463d4f024135cbf4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31501
We have a number of places in our code base where we should be checking if it's safe to change the alias relationship between two sets of values. This PR adds an api to Alias Db to consolidate the logic, and refactors Constant Pooling and `CSE` to use the new api. Next steps: add api usage in peephole.cpp where applicable.
Happy to bikeshed `AliasDb::safeToChangeAliasingRelationship`. Previously I suggested `AliasDb::safeToIntroduceAliasing`, however that's not quite accurate, because this API also handles when it is unsafe to remove aliasing.
Alternate suggestions: `safeToChangeAliasing`, `validToChangeAliasing`, `validToChangeAliasingRelationship`
Related: https://github.com/pytorch/pytorch/issues/28360
Test Plan: Imported from OSS
Differential Revision: D19254413
Pulled By: eellison
fbshipit-source-id: 17f7f52ad2d1526d303132767cbbb32f8189ae15
Summary:
This is a first pass attempt at documenting `IValue` to help with problems like in #17165. Most users are probably concerned with
* how to make an `IValue` that matches the input type to their graph (most of the constructors are pretty self explanatory, so as long as they are in the docs I think its enough)
* how to extract the results after running their graph (there is a small note on the behavior of `.toX()` based on confusions we've had in the past)
Preview:
https://driazati.github.io/pytorch_doc_previews/31904/api/structc10_1_1_i_value.html#exhale-struct-structc10-1-1-i-value
There are also some random CSS fixes to clean up the style.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31904
Pulled By: driazati
Differential Revision: D19318733
fbshipit-source-id: b29dae3349d5a7ea5a3b8e09cd23f7ff8434edb4
Summary:
This hooks up `inspect` so that Python functions get their parameters
names attached instead of naming them `0, 1, 2, ...`. This also fixes
issue #28537 where `ignore` functions were improperly typing `self`.
](https://our.intern.facebook.com/intern/diff/19256434/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29300
Pulled By: driazati
Differential Revision: D19256434
fbshipit-source-id: 6a1fe7bd0afab708b8439517798955d0abfeb44c
Summary:
Stacked PRs
* **#31908 - Remove C++ docs contributing page**
* #31905 - Add doc previewing instructions
We should have 1 source of truth for contribution instructions (CONTRIBUTING.md).
This PR moves the instructions from the C++ doc pages there instead of having its
own separate page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31908
Pulled By: driazati
Differential Revision: D19296366
fbshipit-source-id: c1daf004259342bd09e09dea3b80e34db47066ec
Summary:
Stacked PRs
* #31908 - Remove C++ docs contributing page
* **#31905 - Add doc previewing instructions**
This adds some instructions on how to get started with Github pages you can show reviewers your documentation changes. Hopefully we can delete this eventually and build docs automatically on relevant PRs in CI.
](https://our.intern.facebook.com/intern/diff/19296364/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31905
Pulled By: driazati
Differential Revision: D19296364
fbshipit-source-id: df47fa1a8d7be029c3efcf6521298583ad9f7a95
Summary:
Fix https://github.com/pytorch/pytorch/issues/24684.
Benchmark script :
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
#warm up
for n in [10, 100, 1000]:
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(1000):
input.cauchy_()
for n in [1, 10, 100, 1000]:
fwd_t = 0
input = torch.randn(128, n, requires_grad=False, device=device)
for i in range(10000):
t1 = _time()
input.cauchy_()
t2 = _time()
fwd_t = fwd_t + (t2 -t1)
fwd_avg = fwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.4f (ms)." % (n, fwd_avg))
```
Test device: **skx-8180**.
Before:
```
input size(128, 1) forward time is 0.0071 (ms).
input size(128, 10) forward time is 0.0596 (ms).
input size(128, 100) forward time is 0.5798 (ms).
input size(128, 1000) forward time is 5.8395 (ms).
```
After:
```
input size(128, 1) forward time is 0.0070 (ms).
input size(128, 10) forward time is 0.0583 (ms).
input size(128, 100) forward time is 0.5714 (ms).
input size(128, 1000) forward time is 5.7674 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31824
Differential Revision: D19314411
Pulled By: ezyang
fbshipit-source-id: 58098546face3e5971b023f702cfe44ff1cccfbc
Summary:
VitalyFedyunin, This PR is about port Softplus activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Softplus()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.12 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.18 (ms).
CPU:
input size(128, 100) forward time is 1.16 (ms); backwad avg time is 0.69 (ms).
input size(128, 10000) forward time is 60.19 (ms); backwad avg time is 31.86 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
input size(128, 100) forward time is 0.43 (ms); backwad avg time is 0.16 (ms).
input size(128, 10000) forward time is 1.65 (ms); backwad avg time is 0.83 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) forward time is 0.53 (ms); backwad avg time is 0.28 (ms).
input size(128, 10000) forward time is 51.33 (ms); backwad avg time is 25.48 (ms).
After:
input size(128, 100) forward time is 0.44 (ms); backwad avg time is 0.16 (ms).
input size(128, 10000) forward time is 42.05 (ms); backwad avg time is 13.97 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24633, https://github.com/pytorch/pytorch/issues/24634, https://github.com/pytorch/pytorch/issues/24766, https://github.com/pytorch/pytorch/issues/24767.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30504
Differential Revision: D19274913
Pulled By: ezyang
fbshipit-source-id: 21b29e8459dcba5a040cc68333887b45a858328e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31897
Previous version only use avx2. The _simd version uses avx512 if CPU is capable of that.
Test Plan: Unitttest
Reviewed By: tracelogfb
Differential Revision: D19291499
fbshipit-source-id: 3b1ee0ba756e5c9defbd5caf7f68982d9b2ca06c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31031
This activation will be needed for the LSTM implementation.
Also includes the QNNPack implementation.
Test Plan: Imported from OSS
Differential Revision: D18903453
Pulled By: z-a-f
fbshipit-source-id: 0050b1cebb1ddb179b7ecbcb114fe70705070f67
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31412
The root cause is `plan_caches` being resized in one thread while another holds a reference to an existing `CuFFTParamsLRUCache` which then becomes invalidated.
I was able to reproduce the crash very reliably without this fix applied and no longer see it. Being a race condition, it's hard to say for sure though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31861
Differential Revision: D19312314
Pulled By: ezyang
fbshipit-source-id: 06e4561128d503f2d70cdfe1982be0f3db2a8cf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31313
This is a bugfix. The reason we couldn't enable the constexpr-ness for it before is that it was buggy,
and without constexpr it crashed at runtime and not at compile time which seems to have passed our CI unfortunately...
ghstack-source-id: 96380160
Test Plan: Now it works even when enabling constexpr for it
Differential Revision: D19087471
fbshipit-source-id: 28be107389f4507d35d08eab4b089a405690529b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31026
This is error prone and probably wrong. Since we don't use LeftRight on the hot path anymore, let's remove this.
ghstack-source-id: 96369644
Test Plan: none
Differential Revision: D18902165
fbshipit-source-id: 7b9478cd7cc071f403d75da20c7c889c27248b5c
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31911
Test Plan:
* CI builds including GPU and OSS-build tests
* The `defined(__HIP_DEVICE_COMPILE__) ` instance a few lines below is proof that this is a define/undef flag, not a define01 flag
Reviewed By: hlu1
Differential Revision: D19296560
fbshipit-source-id: 1c45069aec534b0bf4a87751a74680675c985e06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31147
The goal here is to add more tests of the current behavior of the autograd to make sure no regressions are introduced when modifying it.
Do let me know if you think of other corner cases I missed.
Test Plan: Imported from OSS
Differential Revision: D19301082
Pulled By: albanD
fbshipit-source-id: 2cb07dcf99e56eb1f2c56a179796f2e6042d5a2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31888
We need a backend-agnostic mechanism to do barrier-like operation before locally destroy RRef context and shutdown RPC Agent.
- Sort worker names.
- Elect the first name as the leader in the ordered worker names.
- Followers reports therir intent to synchronize to the leader.
- Leader also reports to itself, when `_wait_all_workers()` called.
- If all workers report their intent to proceed, leader send the command to every one to proceed.
ghstack-source-id: 96386210
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_leak
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_worker_id
```
# Stress runs
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_heavy_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_heavy_rpc --stress-runs 10
```
Differential Revision: D19290954
fbshipit-source-id: cdb22203c2f27b5e0d0ad5b2d3b279d438c22dcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31917
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19301480
Pulled By: ezyang
fbshipit-source-id: fcce8868733965b9fbd326b4ec273135759df377
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31351
Clang 4 needs the c10:: namespace specifier on fully_qualified_type_name_impl() to work correctly.
Also, let's add an error message for people using clang 3 and earlier, we don't support those compilers anymore but before this PR, they got a crappy message.
ghstack-source-id: 96380163
Test Plan: testinprod
Differential Revision: D19135587
fbshipit-source-id: c206b56240b36e5c207fb2b69c389bb39f1e62aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30916
These macros said "make it constexpr if we're in C++14". Since we're now always C++14, we can just say "constexpr" isntead.
ghstack-source-id: 96369584
Test Plan: waitforsandcastle
Differential Revision: D18869635
fbshipit-source-id: f41751e4e26fad6214ec3a98db2d961315fd73ff
Summary: I think this was wrong before?
Test Plan: Not sure.
Reviewed By: IvanKobzarev
Differential Revision: D19221358
fbshipit-source-id: 27e675cac15dde29e026305f4b4e6cc774e15767
Summary:
These were returning incorrect data before. Now we make a contiguous copy
before converting to Java. Exposing raw data to the user might be faster in
some cases, but it's not clear that it's worth the complexity and code size.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221361
fbshipit-source-id: 22ecdad252c8fd968f833a2be5897c5ae483700c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31584
These were returning incorrect data before.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221360
fbshipit-source-id: b3f01de086857027f8e952a1c739f60814a57acd
Summary: These are valid tensors.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221362
fbshipit-source-id: fa9af2fc539eb7381627b3d473241a89859ef2ba
Summary:
As in title, this PR will disable the `--quiet` flag used in the CI as a workaround to a timeout hitting Mac OS CI. Circle CI works by timing out when no text has been printed for 10 min.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31900
Differential Revision: D19302899
Pulled By: bwasti
fbshipit-source-id: 145647da983ee06f40794bda1abd580ea45a0019
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31222
- When constructing torch::from_blob() in the case where the deleter is a nop, switch to using a nullptr context in the DataPtr (with a nop deleter)
- No real extra memory/cpu requirements here, actually saves a minor alloc.
Why? Trying to get a signal that a Tensor might contain non-owned memory from
torch::from_blob(), by detecting the nullptr context.
ghstack-source-id: 96336078
Test Plan:
buck test mode/dev caffe2/test/cpp/api/...
buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18992119
fbshipit-source-id: 4eea642f82d0858b57fdfc6995364a760c10567d
Summary:
For now I'm just removing the decorators from all of the currently overridable functions in `torch.functional`. This means they are no longer overridable, however this should fix the benchmark regressions reported in https://github.com/pytorch/pytorch/issues/30831. Moving forward we'll be looking at reducing the overhead of the python-level override mechanism and failing that, re-implementing all of these operators in C++.
cc hl475
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30839
Differential Revision: D18838848
Pulled By: ezyang
fbshipit-source-id: 22b8015d7b2f7a947f1ebc9632c998e081b48ad8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31343
Fix an issue in TorchScript tracing for modules with `c10::List<at::Tensor>` as an output. TensorList was not supported properly.
Test Plan: unit tests
Reviewed By: wanchaol
Differential Revision: D18850722
fbshipit-source-id: 87a223104d1361fe754d55deceeb1e8bbcad629b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31508
This PR builds on top of https://github.com/pytorch/pytorch/pull/31230
to ensure that distributed autograd doesn't block an RPC thread anymore during
the backward pass.
I've also added a unit test where all ranks hammer rank 0 without about 60
backward calls (which would cause a deadlock earlier), but now such a test
passes without any issues.
ghstack-source-id: 96345097
Test Plan: waitforbuildbot
Differential Revision: D19188749
fbshipit-source-id: b21381b38175699afd0f9dce1ddc8ea6a220f589
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28430
The unpythonic signatures for functions such as `torch.addcdiv` are already seperated in [`deprecated.yaml`] and the signatures marked as deprecated in `PythonArgParser`. However, nothing was done with this information previously. So, this now emits a warning when the deprecated signatures are used.
One minor complication is that if all arguments are passed as keyword args then there is nothing to differentiate the deprecated overload. This can lead to false warnings being emitted. So, I've also modified `PythonArgParser` to prefer non-deprecated signatures.
[`deprecated.yaml`]: https://github.com/pytorch/pytorch/blob/master/tools/autograd/deprecated.yaml
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31514
Differential Revision: D19298735
Pulled By: ezyang
fbshipit-source-id: 03cb78af17658eaab9d577cd2497c6f413f07647
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31909https://github.com/pytorch/pytorch/pull/31230 introduced a bug where
we would end up calling `graph_task_post_processing` twice for reentrant
backward calls (once when we mark the future completed and then we we called
graph_task_post_processing in execute_with_graph_task).
This PR fixes the issues by verifying the future we return in that case is
completed and we remove the call to graph_task_post_processing.
In addition to that I added a test that reproduced the problem and verified it
is fixed by this PR.
ghstack-source-id: 96349102
Test Plan: waitforbuildbot
Differential Revision: D19296363
fbshipit-source-id: dc01a4e95989709ad163bb0357b1d191ef5a4fb2
Summary:
In order to support Ubuntu18.04, some changes to the scripts are required.
* install dependencies with -y flag
* mark install noninteractive
* install some required dependencies (gpg-agent, python3-distutils, libidn11)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31886
Differential Revision: D19300586
Pulled By: bddppq
fbshipit-source-id: d7fb815a3845697ce63af191a5bc449d661ff1de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31236
It is not compiled on Windows
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262581
Pulled By: ezyang
fbshipit-source-id: 80bfa553333a946f00291aaca6ad26313caaa9e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31707
Change the initialization value for FC weight init and sparse embedding lookup init.
Previous default initialization is uniform(-\sqrt(1/input_dim), \sqrt(1/input_dim)); Now pass into a flexible hyperparameter, say \alpha into it, to change into uniform(-\sqrt(\alpha/input_dim), \sqrt(\alpha/input_dim));
Reviewed By: chonglinsun
Differential Revision: D18825615
fbshipit-source-id: 4c5f2e07f2b3f5d642fd96d64dbf68892ebeb30b
Summary:
The error message produced by AT_ASSERT() in gather() encouraged users to file a bug report ("please report a bug to PyTorch..."). The assertion should be a regular argument check since it can be triggered by passing tensors with different dimensionality, e.g. `torch.cuda.comm.gather([torch.rand(1, device='cuda'), torch.rand(1, 1, device='cuda')])`.
See: https://github.com/pytorch/pytorch/issues/26400
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27456
Differential Revision: D19300270
Pulled By: ezyang
fbshipit-source-id: ec87d225e23445020b377521e0daccceb4748215
Summary:
This PR adds bfloat16 support for convolutions on ROCm.
- Intergrates MIOpen bfloat16 convolution support into PyTorch
- Enables bfloat16 convolution for non-miopen paths, i.e THCUNN, native hip kernels
- Enables bfloat16 type for probability distribution functions(this is included in this PR since conv unit tests use bfloat16 random number generators)
Native cuda kernels for convolution and random functions will be compiled for CUDA as well.
iotamudelta bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30948
Differential Revision: D19274164
Pulled By: ezyang
fbshipit-source-id: c0888a6ac72a2c5749b1ebb2195ac6f2209996be
Summary:
Compared to cuDNN bias, PyTorch add has the following advantage:
- faster, especially for backward (see: https://github.com/zasdfgbnm/things/blob/master/2019/conv-backward-profile.md)
- handles 64bit indexing automatically
- has less code, less maintenance effort
ngimel I submit this PR early so the CI could start building it. But I have not tested it locally yet (still waiting for compiling).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31524
Differential Revision: D19264244
Pulled By: ngimel
fbshipit-source-id: cb483d378a6d8bce0a05c3643a796e544bd8e8f0
Summary:
Closes https://github.com/pytorch/pytorch/issues/31497
This allows `torch.no_grad` and `torch.enable_grad` to be used as decorators for generator functions. In which case it disables/enables grad only inside the body of the generator and restores the context outside of the generator.
https://github.com/pytorch/pytorch/issues/31497 doesn't include a complete reproducer but the included test with `torch.is_grad_enabled` show this is working where it failed before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31792
Differential Revision: D19274971
Pulled By: albanD
fbshipit-source-id: fde6d3fd95d76c8d324ad02db577213a4b68ccbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31157
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262583
Pulled By: ezyang
fbshipit-source-id: 8fb87b41ab53770329b38e1e2fe679fb868fee12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31155
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262584
Pulled By: ezyang
fbshipit-source-id: 147ac5a9c36e813ea9a2f68b498880942d661be5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31152
Per apaszke: I can't find any reasonable references to libIRC online, so
I decided to remove this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D19262582
Pulled By: ezyang
fbshipit-source-id: a1d47462427a3e0ca469062321d608e0badf8548
Summary:
This change is required for cases like:
x[1:] = data or x[:3] = data
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31552
Reviewed By: hl475
Differential Revision: D19238815
Pulled By: houseroad
fbshipit-source-id: 56c9837d86b341ea92b0a71d55034ce189d12e6c
Summary:
For backend integration, backend (e.g. Glow) needs to check the content of the tensor to determine whether it is a legit byte tensor or some special packed format. This provides a convenient interface for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31290
Reviewed By: jackm321, qizzzh
Differential Revision: D19069684
Pulled By: yinghai
fbshipit-source-id: 63360fa2c4d32695fe9767a40027d446d63efdd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31803
Refactored the following fairly similar functions:
1. `test_context_cleanup_tensor_with_grad`
2. `test_context_cleanup_tensor_no_grad`
3. `test_context_cleanup_no_tensors`
by creating a helper function `context_cleanup_test_helper` that can be invoked with the appropriate arguments.
Test Plan: Verified by running tests.
Differential Revision: D19269246
fbshipit-source-id: bfb42b078ad56b97ceeecf0d68b4169768c2c453
Summary:
When calling the add_images() method on the tensorboard SummaryWriter with a uint8 NCHW tensor, the tensor is incorrectly scaled, resulting in overflow behavior. This leads to incorrect images being displayed in tensorboard.
Issue: https://github.com/pytorch/pytorch/issues/31459
Local Testing (ran this code with and without the PR changes and printed scale_factor):
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x=torch.tensor([[[[1, 2, 3], [4, 5, 6]]]], dtype=torch.uint8)
writer.add_images("images", x)
Before- scale_factor: 255, After- scale_factor: 1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31778
Differential Revision: D19289189
Pulled By: anjali411
fbshipit-source-id: 350a1650337244deae4fd8f8b7fb0e354ae6986b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31230
A major issue with distributed autograd currently is that we block an
RPC thread when we call Engine::execute_with_graph_task.
To resolve this issue, I've made modifications to the local autograd engine
such that `execute_with_graph_task` returns a Future instead. The `execute()`
methods for Engine::execute() and DistEngine::execute() still wait() on this
Future which ensures there is no change in behavior yet.
In follow up PRs we can modify the distributed autograd engine to take
advantage of this Future.
Closes#26359
ghstack-source-id: 96298057
Test Plan: waitforbuildbot
Differential Revision: D18999709
fbshipit-source-id: 388f54467fd2415a0acb7df17bd063aedc105229
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30710
We need a backend-agnostic mechanism to do barrier-like operation before locally destroy RRef context and shutdown RPC Agent.
- Sort worker names.
- Elect the first name as the leader in the ordered worker names.
- Followers reports therir intent to synchronize to the leader.
- Leader also reports to itself, when `_wait_all_workers()` called.
- If all workers report their intent to proceed, leader send the command to every one to proceed.
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork -- test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_wait_all_workers$
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_leak
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rref_forward_chain
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_wait_all_workers
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_wait_all_workers$
```
# Stress runs
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_light_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_stress_heavy_rpc --stress-runs 10
```
```
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift -- test_stress_heavy_rpc --stress-runs 10
```
# Debug
```
buck test mode/dev-nosan caffe2/test:rpc_fork -- test_shutdown
```
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork -- test_clean_context_during_backward
buck build mode/dev-nosan //caffe2/test:dist_autograd_fork
buck-out/gen/caffe2/test/dist_autograd_fork\#binary.par -r test_clean_context_during_backward
```
https://our.intern.facebook.com/intern/testinfra/diagnostics/281475127895800.844424945328750.1575664368/
```
I1206 12:27:47.491420 185619 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
I1206 12:27:47.493880 185630 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
I1206 12:27:47.494526 185625 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
I1206 12:27:47.495390 185636 process_group_agent.cpp:211] Shutting down ProcessGroupAgent.
E1206 12:27:47.544198 185627 pair.cc:642] 1 --->>> 0, read ERROR: AsyncSocketException: Network error, type = Network error, errno = 104 (Connection reset by peer)
E1206 12:27:47.544203 185633 pair.cc:642] 2 --->>> 0, read ERROR: AsyncSocketException: Network error, type = Network error, errno = 104 (Connection reset by peer)
E1206 12:27:47.544210 185639 pair.cc:642] 3 --->>> 0, read ERROR: AsyncSocketException: Network error, type = Network error, errno = 104 (Connection reset by peer)
```
This should mean the UDF in the request has been run, so Python proceeded and ran to `_agent.shutdown()`.
While the RpcAgents on followers wanted to send back the response, but the leader has closed RPC.
Need to re-trigger "pytorch_rpc-buck" to reproduce the rare-seen issue.
Differential Revision: D18643137
fbshipit-source-id: d669d4fc9ad65ed48bed1329a4eb1c32ba51323c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30612
The first version to move prim ops to c10 registration. After the reviewers are fine with the initial changes, more operators will be moved in the same style.
Test Plan: Imported from OSS
Differential Revision: D19237648
Pulled By: iseeyuan
fbshipit-source-id: c5a519604efffb80564a556536f17d829f71d9f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29220
Support for accessing constant is added in previous
PRs, this PR re-enables the foldbn tests
Test Plan:
test_jit.py
Imported from OSS
Differential Revision: D18846848
fbshipit-source-id: 90ceaf42539ffee80b984e0d8b2420da66c263c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29219
We added class constant in previous PRs, this PR allows access to
class constant in the object API
Test Plan:
build/bin/test_jit
python test/test_jit.py
Imported from OSS
Differential Revision: D18846851
fbshipit-source-id: 888a6517d5f747d1f8ced283c0c2c30b2f6c72c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30787
This is needed when we fuse conv bn modules,
where we need to rewrite a constant bias (None) of conv to an attribute
bias of Tensor
Test Plan:
build/bin/test_jit
Imported from OSS
Differential Revision: D18846850
fbshipit-source-id: 9fd5fe85d93d07226e180b75d2e068fe00ca25fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31012
- getConstant should throw when the item is not found
- add another getConstant which takes slot index as argument
Test Plan:
test_class_type.cpp
Imported from OSS
Differential Revision: D18898418
fbshipit-source-id: d3a23a4896fdbf5fa98e1c55c9c4d6205840014b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31845
ArrayRef is trivially copyable and should be passed by value. Removing
unnecessary `&`s.
Test Plan: Imported from OSS
Differential Revision: D19278523
Pulled By: suo
fbshipit-source-id: 026db693ea98d19246b02c48d49d1929ecb6478e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29218
We need to be able to access constant in module.
Test Plan:
tbd
Imported from OSS
Differential Revision: D18846847
fbshipit-source-id: 22d2c485c3c449bc14ad798f6e1a0c64fc8fb346
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31255
This test had 2 issues. A timeout would occasionally happen due to a timeout of 50ms, and CUDA could would get compiled and run on CPU, leading to errors. This PR fixes those issues.
Differential Revision: D19028231
fbshipit-source-id: e50752228affe0021e7c0caa83bce78d76473759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31575
We need a new exception class specifically for the enforce_finite operator, because we need to map it to a specific python exception ExitException, not the RuntimeError type that all c10::Errors get mapped to by default. This diff includes:
- Define c10::EnforceFiniteNotMet
- API CAFFE_ENFORCE_FINITE to throw c10::EnforceFiniteNotMet
- Map from c10::EnforceFiniteNotMet to python ExitException
- Apply CAFFE_ENFORCE_FINITE in caffe2 op
Test Plan:
- integration test pass: https://fburl.com/fblearner/xwkzbqyo
- integration test with D19213617: https://fburl.com/fblearner/479y4jrj Generate error message as desired
- Example:
- Original error message f157597803
{F225477055}
- Updated error message (with D19213617 to generate the error): f158571327
{F225477071}
Reviewed By: zheng-xq
Differential Revision: D19206240
fbshipit-source-id: bd256862801d5957a26b76d738edf4e531f03827
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31583
But rather use `float *`, which is alredy registered
Test Plan: CI
Reviewed By: xianjiec
Differential Revision: D19221405
fbshipit-source-id: eb8eabcf828745022bc1e4185a0e65abd19a8f04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31813
Closes https://github.com/pytorch/pytorch/issues/31804. We were using
an `std::vector` for the key for a map that keeps track of futures to mark them
if they timeout, but we can instead use an `unordered_set`. This results in a
faster lookup in the code block where we remove futureIDs from this set when
they complete successfully. Previously we were finding them via a linear
`std::find`. Switching it to a constant time find will help performance in the
case where a large number of futures are scheduled to time out at the same
time, or if there is no timeout enforced.
To benchmark a rough perf improvement, I created 50k futures with the same
timeout. Before this PR, the lookup `std::find(futuresAtTime.begin(),
futuresAtTime.end(), id)` took ~200us, now it takes 1us.
ghstack-source-id: 96251355
Test Plan: Unit tests pass.
Differential Revision: D19269798
fbshipit-source-id: 1a0fa84a478ee27a16ab0b9fa6f5413b065a663e
Summary:
This PR aims at improving `index_select` performance on CPU with `TensorIterator`.
The code has equally effective optimization for both contiguous tensor and non-contiguous tensor.
The code will try to parallel inner loop in case the slice of copy is large enough, otherwise it will parallel on outer loop.
Thus both the user scenarios from DLRM (from `Embedding`) and Fairseq transformer is covered.
1. for contiguous input, single socket: **1.25x** performance speedup
2. for non-contiguous input, single socket: **799x** performance speedup
3. for contiguous input, single core: same performance
4. for non-contiguous input, single core: **31x** performance speedup
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30598
Differential Revision: D19266892
Pulled By: VitalyFedyunin
fbshipit-source-id: 7aaf8e2c861b4a96250c968c4dd95c8d2c5b92d7
Summary:
VitalyFedyunin, this PR is about port rrelu activation to Aten:
Test script:
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
return time.time()
device = "cpu"
m = nn.RReLU(0.1, 0.3).train()
# for inference
#m = nn.RReLU(0.1, 0.3).eval()
#warm up
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [1, 10, 100, 1000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.randn(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
**Before:**
```
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.03 (ms).
input size(128, 10) forward time is 0.03 (ms); backwad avg time is 0.04 (ms).
input size(128, 100) forward time is 0.17 (ms); backwad avg time is 0.06 (ms).
input size(128, 1000) forward time is 1.45 (ms); backwad avg time is 0.07 (ms).
inferecne:
input size(128, 1) forward time is 0.01 (ms).
input size(128, 10) forward time is 0.01 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.15 (ms).
```
**After:**
```
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.03 (ms).
input size(128, 10) forward time is 0.03 (ms); backwad avg time is 0.04 (ms).
input size(128, 100) forward time is 0.17 (ms); backwad avg time is 0.07 (ms).
input size(128, 1000) forward time is 1.43 (ms); backwad avg time is 0.08 (ms).
inferecne:
input size(128, 1) forward time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.03 (ms).
```
**OMP_NUM_THREADS=1:**
```
Before:
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.15 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 1.45 (ms); backwad avg time is 0.14 (ms).
inferecne:
input size(128, 1) forward time is 0.01 (ms).
input size(128, 10) forward time is 0.01 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.20 (ms).
After:
Training:
input size(128, 1) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10) forward time is 0.02 (ms); backwad avg time is 0.02 (ms).
input size(128, 100) forward time is 0.15 (ms); backwad avg time is 0.03 (ms).
input size(128, 1000) forward time is 1.43 (ms); backwad avg time is 0.15 (ms).
inferecne:
input size(128, 1) forward time is 0.01 (ms).
input size(128, 10) forward time is 0.02 (ms).
input size(128, 100) forward time is 0.02 (ms).
input size(128, 1000) forward time is 0.06 (ms).
```
Fix https://github.com/pytorch/pytorch/issues/24755, https://github.com/pytorch/pytorch/issues/24756.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31094
Differential Revision: D19270936
Pulled By: VitalyFedyunin
fbshipit-source-id: 11bb3236b1037a558022d3777d1f9a429af2bffe
Summary:
Currently `cumsum` crashes for tensors with non-empty dimensions but with zero elements, which could happen when some dimension is zero. This commit fixes the error by checking both `dim()` and `numel()` in cumsum backward
Fixes https://github.com/pytorch/pytorch/issues/31515
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31694
Reviewed By: mrshenli
Differential Revision: D19266613
Pulled By: leedtan
fbshipit-source-id: 9407e0aa55440fed911c01a3580bb6c5eab62a16
Summary:
The original `check-and-act` style can raise `FileExistsError` when multiple processes are jit-compiling the extension on the same node.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30956
Differential Revision: D19262570
Pulled By: ezyang
fbshipit-source-id: bb18c72e42648770b47f9378ac7c3929c3c03efc
Summary:
This dramatically reduces the number of instantiations and eliminates
~900KB of code from my local build of libtorch_cpu.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31683
Differential Revision: D19258364
Pulled By: resistor
fbshipit-source-id: addb921a26289978ffd14c203325ca7e35a4515b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31539
Adding this metric primarily because it is needed to unblock unit
tests for https://github.com/pytorch/pytorch/pull/31381. It also may be useful
to look at this metric to see the number of pending RRef forks that currently
exist.
ghstack-source-id: 96230360
Test Plan: Modified the relevant unit test.
Differential Revision: D19204158
fbshipit-source-id: 016345e52cd02cc5f46837bffd8d589ba8575f29
Summary:
Add support to print op dependence as python code so that both custom
build script and BUCK can import it without yaml parser.
Test Plan:
- generate the file:
```
ANALYZE_TORCH=1 FORMAT=py DEPLOY=1 tools/code_analyzer/build.sh -closure=false
```
- load the file in python:
```
python
>>> from tools.code_analyzer.generated.torch import TORCH_DEPS
>>> print(TORCH_DEPS)
```
Differential Revision: D18894639
Pulled By: ljk53
fbshipit-source-id: e304d0525a07a13cf6e8a9317cd22637200d044c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31215
Install LLVM-dev package for code analysis CI job: #30937
LLVM-dev package is not related to android NDK but the whole code
analysis thing is for mobile custom build so choose this docker image.
Test Plan: - wait docker image to build?
Differential Revision: D19193223
Pulled By: ljk53
fbshipit-source-id: 54a79daf8d98fa7c8b9eed11f519e1c7b1614be8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31588
Per title. This test can sometimes fail with a different error regex
than the one that is currently tested, so add this error regex to make the test
pass consistently.
Differential Revision: D19222275
fbshipit-source-id: 89c95276d4d9beccf9e0961f970493750d78a96b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31668
This also removes an annoying warning about change of sign conversion
Test Plan: Run unit tests
Reviewed By: ezyang
Differential Revision: D19238631
fbshipit-source-id: 29b50abac635e530d5b0453c3a0f36a4573fbf5b
Summary:
In the long string, formalstring thinks it is good to have a name.
When using dict, literal is better for readability and faster than dict constructor.
I always appreciate your efforts in creating the world's best frameworks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31352
Differential Revision: D19191967
Pulled By: ngimel
fbshipit-source-id: 21f063b163b67de8cf9761a4db5991f74318e991
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31676
Facebook:
Previously we assumed mask is passed in as a tensor which is not feasible for sparse parameter.
Here we allow to pass in the mask through db path which requires the masks to be stored in some db first.
Test Plan: unit tests
Reviewed By: ellie-wen
Differential Revision: D18928753
fbshipit-source-id: 75ca894de0f0dcd64ce17b13652484b3550cbdac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31675
This test could be flaky since there could be inflight RPC requests as
part of startup which might not have finished. As a result, if they finish
between the different calls to retrieve debug_info, there could be a problem
since we would report separate information. As a result, we wait to ensure
the metrics stabilize to avoid flakiness.
ghstack-source-id: 96188488
Test Plan: waitforbuildbot
Differential Revision: D19242588
fbshipit-source-id: 8f3db7e7365acbd3742e6ec0c2ddcca68f27db9e
Summary:
- Fixes https://github.com/pytorch/pytorch/issues/31672
- Adds Bfloat16 dispatch to the indexing operations that were missing it
- index_put on cuda does not have bfloat16 dispatch, because I'm not sure bfloat16 math ops work on cuda
Note: `index_put_` with `accum=True` is enabled for `bool`, which does not make much sense, but I'm not the one who started it, so this behavior is preserved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31692
Differential Revision: D19249561
Pulled By: ngimel
fbshipit-source-id: 1269196194f7b9f611b32be198c001704731a78f
Summary:
Change log:
- [x] Change the order of arguments position of torch.std and torch.std_mean in doc.
- [x] Correct a spelling mistake of torch.std_mean in doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31677
Differential Revision: D19247372
Pulled By: ngimel
fbshipit-source-id: 8685f5207c39be524cdc81250430beac9d75f330
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28942
The new abstract RRef class contains only user-facing RRef APIs.
It will be later moved to a common folder so that it can be shared
by jit and distributed packages to provide TorchScript support.
Test Plan: Imported from OSS
Differential Revision: D18240590
Pulled By: mrshenli
fbshipit-source-id: ac28cfc2c8039ab7131b537b2971ed4738710acb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31641
Assuming mask is provided as a tensor
Test Plan: unit test
Reviewed By: ellie-wen
Differential Revision: D18928737
fbshipit-source-id: a4f3dd51769c2b56e5890043e91c18e6128be082
Summary:
7zip and cmake are part of base image, no need to re-install. Remove the install step can make build/test more stable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30897
Differential Revision: D19232961
Pulled By: mingbowan
fbshipit-source-id: fa3bbd1325839a2a977bf13fdbd97fda43793b8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31612
Count the number recent update on rows. Exponential decay is applied on the counter with decay rate r, such that
r^{counter_halflife} = 0.5;
If counter_halflife is nonpositive, this operator is turned off.
Test Plan: added unittest
Reviewed By: chocjy
Differential Revision: D19217921
fbshipit-source-id: 96d850123e339212cc0e0ef352ea8a1b1bf61dfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31602
Pull Request resolved: https://github.com/pytorch/glow/pull/3943
Zero length input is something we hit fairly frequently in practice. Previous handling of global TensorPool involves two locks per input (acquire and reclaim). Here we use a specialized anchor tensor to host zero length input. Note that it is only padded to max sequence length. If necessary, an easy extension can be added to pad to max `InputPlaceholder.getType().size()`.
Reviewed By: jfix71
Differential Revision: D19192467
fbshipit-source-id: cafdc1eb7bf9b9d6ead04a0243b0be838f6b71cd
Summary:
Earlier cudnn version doesn't support grouped convolution in NHWC well. Legit
configuration in later cudnn version might return CUDNN_STATUS_NOT_SUPPORTED.
We are falling back to NCHW when runtime check of cudnn version is < 7.6.0 to
keep the logic simple.
Note:
We might update the heuristics, 7.6.0 is very conservative.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31444
Differential Revision: D19232414
Pulled By: VitalyFedyunin
fbshipit-source-id: 4c2d79ed347c49cd388bbe5b2684dbfa233eb2a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31260
1. Update the LiteLM dataset conversion script (fbcode/pytext/fb/tools/lite_lm_dataset_to_tensorproto.py)
2. Created a benchmark json file for byte-aware lstm word model (xplat/aibench/specifications/models/caffe2/assistant/lite_lm_len5.json)
3. In order to run the model -- created an int64 Tensor for the model, added batch gather ops to the BUCK file
Test Plan:
```
1. Create tensorproto of the model input
buck run mode/opt //pytext/fb/tools:byte_lm_dataset_to_tensorproto -- --in-path /mnt/vol/pytext/smart_keyboard/aibench/test_5.txt --out-path /mnt/vol/pytext/smart_keyboard/aibench/byteAwareWordLM/ --hidden_dim 203 --layers_num 2 --max_seq_len 64 --max_byte_len 15
2. Run the aibench command
buck run fbsource//xplat/aibench:run_bench -- -b aibench/specifications/models/caffe2/assistant/lm_byte_lstm_len5.json --remote --devices SM-G960U-8.0.0-26
```
Reviewed By: gardenia22
Differential Revision: D17785682
fbshipit-source-id: 351c3c8bae16449e72ac641522803b23a83349be
Summary:
Originally, we only print one broken schema. With this changeset, all the broken schemas are printed out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31628
Reviewed By: hl475
Differential Revision: D19231444
Pulled By: houseroad
fbshipit-source-id: 3dd5b4609a6a9a9046e95f2f30deb9beeb5dcd56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31490
When this happens, a dense tensor is constructed from a sparse constructor.
Fixes: https://github.com/pytorch/pytorch/issues/16154
Test Plan: Imported from OSS
Reviewed By: cpuhrsch, mrshenli
Differential Revision: D19196498
Pulled By: gchanan
fbshipit-source-id: 57a6324833e35f3e62318587ac74267077675b93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30784
Instead of putting experimental Masked*Adagrad to OSS, we decided to change D18805278 .
Test Plan: CI
Reviewed By: chocjy
Differential Revision: D18824265
fbshipit-source-id: 3d893fe6c441f2ff7af4c497cf81b9c49363e7a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31582
D19124934 removed a dummy pointer passed to strtod_c() that's used only for Android (https://fburl.com/diffusion/zkv34jf1). Without it, jit parsing on Android start throwing SIGSEGV due to null pointer dereferencing. This diff adds the dummy pointer back.
Test Plan: Tests
Reviewed By: driazati, shoumikhin
Differential Revision: D19221071
fbshipit-source-id: 2e230c3fbfa873c3f7b92f73c87ee766ac182115
Summary:
Basically the same as https://github.com/pytorch/pytorch/pull/31379 except for that I write a separate function `split_batch_dim_to_32bit_out` for the logic. This function could also be used for convolution forward, and I will rebase this PR after https://github.com/pytorch/pytorch/issues/31379 get merged and then change `raw_cudnn_convolution_forward_out` to use `split_batch_dim_to_32bit_out` here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31510
Differential Revision: D19210563
Pulled By: ngimel
fbshipit-source-id: e20bb82b6360aa2c0e449e127188c93f44e1e9b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31517
This is going to be used by upsample (which currently uses magic values to represent optionals).
For now, we just introduce a fake function for testing (torch._test_optional_float(x)).
Test Plan: Imported from OSS
Differential Revision: D19198721
Pulled By: gchanan
fbshipit-source-id: 0a1382fde0927c5d277d02d62bfb31fb574b8c74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31533
Fixes this test that was flaky and has been disabled (see
https://github.com/pytorch/pytorch/issues/31112)
ghstack-source-id: 96038999
Test Plan: Run the test 1000 times and ensure that it passes.
Differential Revision: D19203366
fbshipit-source-id: 7978cbb8ca0989a0a370a36349cdd4db3bb8345b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31380
For being able to profile async RPCs, we attach a `RecordFunction` object to the future that is created during the RPC to persist it across the lifetime of the RPC (this is implemented in the next PR: ). Since we'd only like to do this when profiling is enabled, this PR adds an enabled API to the autograd profiler.
ghstack-source-id: 96053933
Test Plan: Modified unit test.
Differential Revision: D19050391
fbshipit-source-id: aa382110e69d06b4a84c83b31d2bec2d8a81ba10
Summary:
I don't see any reason for not doing so, because it is a common error that people forget to set the stream. And I don't think there is a reason for not running on the current stream.
This is just for cublas, cusparse and cudnn should be modified also.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31537
Differential Revision: D19206908
Pulled By: ngimel
fbshipit-source-id: ba2b2b74e9847f0495c76dbc778751a9f23f8b36
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/22496
This is just a first step towards the support of 64bit convolution on CUDA. In the forward of convolution, if the total tensor size is larger than 2^31, then we split it on the batch dimension. I want to get some review feedback before moving forward for the same splitting approach for backward.
There are real-world use cases that even when N=1 the input is still larger than 2^31. For this case, the splitting would be complicated, so I am planning to modify `use_cudnn` to just dispatch to the slow fallback kernel in PyTorch in a later PR.
Update: `later PR` is https://github.com/pytorch/pytorch/pull/31383
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31379
Differential Revision: D19192018
Pulled By: ngimel
fbshipit-source-id: c26ecc56319ac67c4d5302ffed246b8d9b5eb972
Summary:
get rid of f-string, somehow we still have python2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31536
Differential Revision: D19204187
Pulled By: mingbowan
fbshipit-source-id: da8e17e4dccdd6fd1b0e92eb4740f5a09a8a4209
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30195
1. Added flavorDimensions 'build' local/nightly
to be able to test the latest nightlies
```
cls && gradle clean test_app:installMobNet2QuantNightlyDebug -PABI_FILTERS=x86 --refresh-dependencies && adb shell am start -n org.pytorch.testapp.mobNet2Quant/org.pytorch.testapp.MainActivity
```
2. To be able to change all new model setup editing only `test_app/build.gradle`
Inlined model asset file names to `build.gradle`
Extracted input tensor shape to `build.gradle` (BuildConfig)
Test Plan: Imported from OSS
Differential Revision: D18893394
Pulled By: IvanKobzarev
fbshipit-source-id: 1fae9989d6f4b02afb42f8e26d0f3261d7ca929b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31407
Remove observers in the end instead of before quantize tensor
since we still need them to find the quantization paramters for each module instance
Test Plan:
.
Imported from OSS
Differential Revision: D19162367
fbshipit-source-id: f817af87183f6c42dc97becea85ddeb7e050e2b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31406
Previously we record quantization parameters for a given value when we collect the observer nodes,
but actually the quantization parameter can vary depending on each module instance, to achieve
that, we need to delay the call to later stage and only record the `Value*` that's needed
in `collectObserverNodesAndValueToQuantize` function
Test Plan:
.
Imported from OSS
Differential Revision: D19162369
fbshipit-source-id: e0f97e322d18a281bf15b6c7bbb04c3dfacb512f
Summary:
The Python C API documentation states "Access to the [PyObject]
members must be done by using the macros Py_REFCNT and Py_TYPE."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31388
Differential Revision: D19161790
Pulled By: colesbury
fbshipit-source-id: ac9a3738c913ad290a6d3460d0d657ec5c13b711
Summary:
This is the first stab at running profile-insensitive optimizations on pre-profiled graphs. Running those optimizations has a potential to simplify graphs greatly before GuardElimination and GuardElimination should be able to remove more guards.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31392
Differential Revision: D19173639
Pulled By: Krovatkin
fbshipit-source-id: 2485a2a598c10f9b5445efb30b16439ad4551b3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31470
Optimize performance of these two operators.
Additionally use nearbyint instead of round to be consistent with 4-bit embedding table quantization.
Reviewed By: hyuen
Differential Revision: D19072103
fbshipit-source-id: efe96f14aeff7958cceb453ed625d3fd693891ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31455
In 15.9, __FUNCSIG__ unwraps using definitions as well as preserves noexcept qualifiers
Test Plan: Build caffe2 on Windows using VS2017
Differential Revision: D19166204
fbshipit-source-id: b6c5f70e5262d13adf585f77b92223cf5f1e78dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30429
also fix a bug in uncoalesced division
General approach here is that we:
* compute the common dtype based on input tensors
* error if the output tensor is specified and the common type can't be cast back to the output type (e.g. for inplace ops)
* convert input tensor (values) to the common dtype
* perform the op as normal (computing at the common dtype instead of the result type).
* convert/copy the result values back to that of the result tensor (for in-place ops).
For uncoalesced division we need to coalesce, because an integral tensor with values=[1,1] at the same index divided by 2 would give 1/2 + 1/2 =0 instead of 2/2=1.
Test Plan: Imported from OSS
Differential Revision: D19143223
Pulled By: nairbv
fbshipit-source-id: 480fa334c0b2b3df046818f2342cfd4e2d9d892a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31507
This script is used to generate a model with bound shape inference and
blob reorder, which are requirements for big model loading on T17.
1. Load existing model.
2. Do bound shape inference and blob reorder (put embedding blobs at the end).
3. Save the modified model.
Test Plan:
Generated a new moel and tested on NNPI.
P124181047 (mismatch is AA variance)
Reviewed By: ipiszy
Differential Revision: D19165467
fbshipit-source-id: c3522fc5dc53b7ec652420558e9e8bf65a1ccfae
Summary:
https://github.com/pytorch/pytorch/pull/30330 got rid of the need to send a `MessageType::SHUTDOWN` message, so we can now remove the logic/utils for this type of message.
I think we can also delete the enum entry in the `enum MessageType`, but we may want to keep it in case the logic in https://github.com/pytorch/pytorch/pull/30710 is ever moved to C++.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31270
Test Plan: All existing unit tests pass
Differential Revision: D19146983
Pulled By: rohan-varma
fbshipit-source-id: 35b185411f9446d7d4dfc37a6cb5477cf041e647
Summary:
Fixes a bad merge that is breaking distributed tests on master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31492
Pulled By: driazati
Differential Revision: D19180978
fbshipit-source-id: f69f525e2c7f61194686f07cf75db00eb642882f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31293
Previously we check the number of elements in scale to determine if we are using per channel quantization,
but we should get qscheme information from observer module directly and we'll expose this information
to caller as well
Test Plan:
.
Imported from OSS
Differential Revision: D19146669
fbshipit-source-id: ea430eeae0ef8f441be39aa6dcc1bb530b065554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31473
Mitigates #6313
A common use case for the autograd profiler is to use it to run over an
entire model, including dataloading. The following will crash:
- run autograd profiler in CUDA mode
- Use a multi-worker DataLoader (presumably with the 'fork' spawn
method)
- because the autograd profiler initializes CUDA and forking after CUDA is
initialized is bad.
This PR puts in a nice error message when this happens so that users
aren't too confused. The new error message looks like:
https://gist.github.com/zou3519/903f15c3e86bad4585b7e5ce14cc1b70
Test Plan:
- Tested locally.
- I didn't add a test case for this because it's hard to write a test
case that doesn't completely stop the rest of our test suite from
running.
Differential Revision: D19178080
Pulled By: zou3519
fbshipit-source-id: c632525ba1f7b168324f1aa55416e5250f56a086
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31484
See https://github.com/pytorch/pytorch/issues/26123 for context.
Previously, when someone googles for `pytorch "adaptive_max_pool2d"`,
https://pytorch.org/docs/stable/_modules/torch/nn/modules/pooling.html
is the first result. This PR changes the docs build script to exclude
all such generated source docs under `_modules/` from Google.
It does this by doing a search for `<head>` and then appending
`<meta name="robots" content="noindex">`.
The [google developer
docs](https://support.google.com/webmasters/answer/93710?hl=en) suggest
that this is the right way to prevent google from indexing the page.
In the future, when the CI
builds documentation (both master and stable docs), the newly created
docs under _modules will have the meta noindex tag.
Test Plan:
- I ran `find "$install_path/_modules" -name "*.html" -print0 | xargs -0
sed -i '/<head>/a \ \ <meta name="robots" content="noindex">'` on a docs
build locally and checked that it does indeed append the meta noindex
tag after `<head>`.
- In a few days we should rerun the search to see if these pages are
still being indexed.
Differential Revision: D19180300
Pulled By: zou3519
fbshipit-source-id: 5f5aa95a85dd9f065607c2a16f4cdd24ed699a83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31436
Tensor::has_names is slower than it should be for unnamed tensors
because of the following:
- it always tries to access the TLS for NamesMode. Unnamed tensors don't
need to peek at NamesMode to determine if they have names or not.
- There is some virtual function being called because TensorImpl is in
c10 and NamedTensorMeta is in libtorch.
This PR short-circuits Tensor::has_names for unnamed tensors by
checking if the underlying TensorImpl hold a pointer to NamedTensorMeta
or not. If the NamedTensorMeta is nullptr; then the tensor is definitely
unnamed.
Benchmarks:
- I have a dedicated benchmarking machine where I isolate a single CPU
and make sure it runs at a fixed frequency.
- I benchmarked torch.add, which calls `tensor::has_names` three times.
- The TL;DR is that torch.add between size-1 unnamed tensors gets sped up
~200ns after this change which is a 9% improvement.
- Before, on my machine:
https://gist.github.com/zou3519/dfd648a1941d584711d850754e0694bc
- After on my machine:
https://gist.github.com/zou3519/e78f0d8980b43d0d9c3e3e78ecd0d4d5
Test Plan: - run tests
Differential Revision: D19166510
Pulled By: zou3519
fbshipit-source-id: 1888a4e92d29152a5e3b778a95e531087e532f53
Summary:
Reference: https://github.com/pytorch/pytorch/issues/23159
Currently we don't support reduction operations for dim>=64 and we should give a descriptive RuntimeError indicating the same
Diff: D19179039
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31476
Differential Revision: D19179039
Pulled By: anjali411
fbshipit-source-id: 58568f64627bf3df6b3e00a1498544c030e74a0e
Summary:
Reference: https://github.com/pytorch/pytorch/issues/31385
In the current documentation for NLLLoss, it's unclear what `y` refers to in the math section of the loss description. There was an issue(https://github.com/pytorch/pytorch/issues/31295) filed earlier where there was a confusion if the loss returned for reduction=mean is right or not, perhaps because of lack in clarity of formula symbol description in the current documentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31488
Differential Revision: D19181391
Pulled By: anjali411
fbshipit-source-id: 8b75f97aef93c92c26ecbce55b3faf2cd01d3e74
Summary:
The current numba version doesn't appear to actually work with our numba-cuda tests (numba.cuda.is_available()) fails.
Previous attempts to upgrade were blocked by https://github.com/numba/numba/issues/4368.
It's a bit unclear to me, but I believe 0.46.0 fixes the above version. I'm verify that we catch that issue in CI via https://github.com/pytorch/pytorch/pull/31434.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31435
Differential Revision: D19166865
Pulled By: gchanan
fbshipit-source-id: e01fa48c577e35de178423db7a7f79ac3dd3894d
Summary:
Previously we would only catch `py::cast_error` which led to incomprehensible error messages like: `TypeError: 'NoneType' object is not iterable`. We are running arbitrary pybind code here, and not doing anything with the error message, so we should be less restrictive with the types of errors we catch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31398
Differential Revision: D19166655
Pulled By: eellison
fbshipit-source-id: 84db8b3714c718b475913f2f4bb6f19e62f2d9ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31011
`getAttribute` is supposed to throw when there the attribute is not
found rather than return a `nullptr`.
Test Plan:
.
Imported from OSS
Differential Revision: D18898417
fbshipit-source-id: 0fe7d824b978ad19bb5ef094d3aa560e9fc57f87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31357
If a user selects a subset of a Tensor and sends it in an RPC, we were sending
the whole original Tensor Storage over the network.
While this sounds reasonable, in practice, we observed view-like Tensors being sent
over rpc, where only 1% of the data in the provided Tensor's Storage was
actually used/needed.
The simple solution here is to just force a clone in the serializer code if we see that
less than (arbitrary) half the bits are used, and the tensor is more than a nominal few KB.
Add related tests to ensure this doesn't break.
An alternate approach would be to modify the Pickler. That said, since Pickler is shared by more
components, the logic might be harder to tailor appropriately at that layer (particularly
given that the Pickler has explicit logic to share a single Storage* among several Tensors
that commonly point to the same Storage*).
It's possible that we might want to further refine the basic thresholds in this change.
In practice, we've seen a mostly bimodal distribution thus far for the percent of Tensor
Storage referred by a Tensor in observed rpcs (i.e. either 90%+ or sub-10% of the Storage
referenced), hence the existing 50% threshold here is probably not an unreasonable
starting point.
ghstack-source-id: 95925474
Test Plan: buck test mode/dev caffe2/test/cpp/rpc/...
Differential Revision: D19137056
fbshipit-source-id: e2b3a4dd0cc6e1de820fd0740aa1d59883dbf8d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31393
pytorch build was set up with the include paths (-I) relative to fbcode/. This works well for fbcode builds, but doesn't work for the new fbcode_deps args for xplat build targets that work across xplat and fbcode. When these targets are built, the include paths need to be relative to fbsource, so fbcode/ suffix needs to be added to those paths.
Longer term, to properly fix this, we need to use raw_headers with public_include_directories specified for all of these targets.
Test Plan: buck test mode/dev //papaya/integration/service/local/test:mnist_federated_system_test -- 'MnistFederatedSystemTest\.test' --run-disabled
Reviewed By: mzlee
Differential Revision: D19148465
fbshipit-source-id: a610e84bf4cad5838e54e94bae71b957c4b6d4b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31346
This makes it so that if profiling is enabled/disabled from a different thread while a RecordFunction span is active via an op it doesn't crash the process.
We currently see when using torch.distributed.rpc to enable/disable profiling on other nodes while other things are running.
Test Plan: buck test //caffe2/test:autograd -- test_record_function
Reviewed By: albanD
Differential Revision: D19133258
fbshipit-source-id: 30712b06c6aa051789948de2918dcfb9b78967ba
Summary:
Fixes#27495
This adds builtins as another piece of a concrete type. They're separate from normal functions since they represent the `BuiltinFunction` sugared value (which is a direct call to a builtin op). It also moves the builtins related logic from `jit/__init__.py` to `jit/_builtins.py` so it can be used from `jit/_recursive.py` to look up functions in the builtins table.
](https://our.intern.facebook.com/intern/diff/19149779/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31269
Pulled By: driazati
Differential Revision: D19149779
fbshipit-source-id: d4e5e5d7d7d528b75a2f503e6004394251a4e82d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24341
ConvTransposeOp doesn't crash for zero-batch, but it doesn't modify the output blob. This leads to buggy behaviour especially when running the same network twice using different input, or backprop during training.
Seems `ConvTransposeUnpoolBase<Context>::GetOutputSize` works for zero-batch, so I remove the check for `input.numel() > 0`, and reshape the output blob before returning.
For CudnnConvTransposeGradientOp, it's a bit verbose to set `dfilter` and `dbias`, it's a seems the Cudnn can handle it, so simply remove the `X.numel() == 0` branch.
Test Plan: buck test mode/dev-nosan caffe2/caffe2/python/operator_test:conv_transpose_test -- --run-disabled
Reviewed By: BIT-silence
Differential Revision: D16807606
fbshipit-source-id: 0d72c5bd8f2e03c34465e7b530cca548d9bdd5e1
Summary:
Stacked PRs
* #29940 - [jit] Fix parsing of big float literals
* **#29935 - [jit] Fix hex literal parsing**
* #29931 - [jit] Throw a better error for int too big for int64_t
Previously these were all parsed as `0`
](https://our.intern.facebook.com/intern/diff/19124944/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29935
Pulled By: driazati
Differential Revision: D19124944
fbshipit-source-id: 1ee0c1dee589933363a5efba069a2cfaf94373c5
Summary:
Add a section for unsupported ops, and modules. Automatically generate the properties and attributes that aren't bound, and for ops that have semantic mismatches set up tests so the docs stay up to date.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31329
Differential Revision: D19164472
Pulled By: eellison
fbshipit-source-id: 46290bb8a64d9de928cfb1eda5ff4558c3799c88
Summary:
Fix: https://github.com/pytorch/pytorch/issues/24631, https://github.com/pytorch/pytorch/issues/24632, https://github.com/pytorch/pytorch/issues/24764, https://github.com/pytorch/pytorch/issues/24765
Port of TH SoftMarginCriterion to ATen using un-fused tensor operators but with custom backward code. This is a follow-up/fixc of reverted PR https://github.com/pytorch/pytorch/issues/27673.
Benchmark results:
CPU became faster, GPU slower. To reach previous TH perf probably manual fusion is necessary.
### WITH patch
```
CPU warmup 1000 took 7.997200009413064e-05
CPU warmup 10000 took 0.0008116499957395718
CPU warmup 100000 took 0.0012691459996858612
CPU warmup TOTAL time 0.0021982479956932366
CPU forward 1000 took 7.320100849028677e-05
CPU forward 10000 took 0.00015837099635973573
CPU forward 100000 took 0.0010471990099176764
CPU forward 1000000 took 0.01238470000680536
CPU forward 10000000 took 0.12747182900784537
CPU forward 100000000 took 1.2076255190040683
CPU forward TOTAL time 1.3488940890092636
CPU for- & backward 1000 took 0.00032587299938313663
CPU for- & backward 10000 took 0.0006926299975020811
CPU for- & backward 100000 took 0.002146183993318118
CPU for- & backward 1000000 took 0.019158899012836628
CPU for- & backward 10000000 took 0.2957490350090666
CPU for- & backward 100000000 took 1.7630806300003314
CPU for- & backward TOTAL time 2.081367089995183
GPU warmup 1000 took 0.0004558280052151531
GPU warmup 10000 took 0.0002567449992056936
GPU warmup 100000 took 0.0001593509950907901
GPU warmup TOTAL time 0.0009442300070077181
GPU forward 1000 took 0.00015061900194268674
GPU forward 10000 took 0.00015258099301718175
GPU forward 100000 took 0.00015409699699375778
GPU forward 1000000 took 0.0008183339959941804
GPU forward 10000000 took 0.004424853003001772
GPU forward 100000000 took 0.04356115800328553
GPU forward TOTAL time 0.04938192600093316
GPU for- & backward 1000 took 0.0008062430133577436
GPU for- & backward 10000 took 0.0006074949924368411
GPU for- & backward 100000 took 0.0007091690058587119
GPU for- & backward 1000000 took 0.001022183001623489
GPU for- & backward 10000000 took 0.009945805999450386
GPU for- & backward 100000000 took 0.0944173600000795
GPU for- & backward TOTAL time 0.28060428200114984
```
### WITHOUT patch
```
CPU warmup 1000 took 6.394000956788659e-05
CPU warmup 10000 took 0.00038220599526539445
CPU warmup 100000 took 0.0034939230099553242
CPU warmup TOTAL time 0.003981974994530901
CPU forward 1000 took 4.7855006414465606e-05
CPU forward 10000 took 0.000347569992300123
CPU forward 100000 took 0.003367935001733713
CPU forward 1000000 took 0.03605044000141788
CPU forward 10000000 took 0.35935167300340254
CPU forward 100000000 took 3.630371332008508
CPU forward TOTAL time 4.029640004009707
CPU for- & backward 1000 took 0.00028494100843090564
CPU for- & backward 10000 took 0.0006738200027029961
CPU for- & backward 100000 took 0.0051178760040784255
CPU for- & backward 1000000 took 0.04925115800870117
CPU for- & backward 10000000 took 0.7172313440096332
CPU for- & backward 100000000 took 5.441953932997421
CPU for- & backward TOTAL time 6.21466830400459
GPU warmup 1000 took 0.001803738996386528
GPU warmup 10000 took 0.00041877900366671383
GPU warmup 100000 took 0.0003870719956466928
GPU warmup TOTAL time 0.0026561370032140985
GPU forward 1000 took 0.00037833399255760014
GPU forward 10000 took 0.00038825398951303214
GPU forward 100000 took 0.0003841099969577044
GPU forward 1000000 took 0.0007090550061548129
GPU forward 10000000 took 0.0016171559982467443
GPU forward 100000000 took 0.013463679002597928
GPU forward TOTAL time 0.017010531009873375
GPU for- & backward 1000 took 0.0007374050037469715
GPU for- & backward 10000 took 0.0006343529967125505
GPU for- & backward 100000 took 0.0006375070079229772
GPU for- & backward 1000000 took 0.0007550300069851801
GPU for- & backward 10000000 took 0.002672752001672052
GPU for- & backward 100000000 took 0.023170708998804912
GPU for- & backward TOTAL time 0.20251446698966902
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28135
Differential Revision: D18001447
Pulled By: VitalyFedyunin
fbshipit-source-id: ad90dc1cca42dcaf3ea9e17e4f8fd79cee0a293e
Summary:
VitalyFedyunin, This PR is about port LeakyReLU activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.LeakyReLU()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.14 (ms).
input size(128, 10000) forward time is 4.21 (ms); backwad avg time is 8.02 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.07 (ms).
input size(128, 10000) forward time is 1.98 (ms); backwad avg time is 6.21 (ms)
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.04 (ms).
input size(128, 10000) forward time is 0.03 (ms); backwad avg time is 0.09 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10000) forward time is 0.47 (ms); backwad avg time is 1.02 (ms).
```
How to set the numbers of thread? using following script:
```
num_threads=$1
script=$2
last_core=`expr $num_threads - 1`
echo "using $num_threads OMP threads"
echo "bind cores to 0~$last_core"
export OMP_NUM_THREADS=$num_threads
export KMP_AFFINITY=granularity=fine,compact,1,0
numactl --physcpubind=0-$last_core --membind=0 python $script
```
and run .**/run.sh num_threads test.py**.
Fixes https://github.com/pytorch/pytorch/issues/24583#24584https://github.com/pytorch/pytorch/issues/24720#24721
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29899
Differential Revision: D18816231
Pulled By: VitalyFedyunin
fbshipit-source-id: afb1e43a99317d17f50cff1b593cd8f7a0a83da2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31335
When an error occurs in a net we end up cancelling all the async ops. If one error occurs it's highly likely other errors will occur as well.
Typically we see:
1. SendOp failed due to a network error
2. async scheduling cancels all other ops via `SetFinished("Cancelled");`
3. Another SendOp fails due to a network error and crashes the process when the exception is thrown.
This changes caffe2 ops to allow failing twice.
Test Plan: buck test //caffe2/caffe2:caffe2_test_cpu
Reviewed By: andrewwdye
Differential Revision: D19106548
fbshipit-source-id: 4b7882258a240894cc16d061a563c83a3214d3d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31404
Multiple "trainers" could each create different instances of DistributedOptimizer, which means we can still have a race condition unless we do a trully global per worker lock.
ghstack-source-id: 95874624
Test Plan: run unit tests -- unfortunatelly due to the non-deterministic behavior it's not clear how to unit test this properly.
Differential Revision: D19154248
fbshipit-source-id: fab6286c17212f534f1bd1cbdf9f0de002d48c74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31292
att
Also we need to do this check after we call `insertObservers` on invoked modules
as well since qconfig can be None for parent module while being valid for invoked modules
Test Plan:
.
Imported from OSS
Differential Revision: D19146668
fbshipit-source-id: be6811353d359ed3edd5415ced29a4999d86650b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31364
clang-cl defines both `_MSC_VER` and `__clang__`. Names are mangled clang style though. calling `extract` with the wrong name mangling pattern will throw `std::logic_error`. This crashes on Windows when `get_fully_qualified_type_name` is called because it is marked with `noexcept`.
Test Plan: Windows builds no longer crash on startup.
Reviewed By: mattjgalloway
Differential Revision: D19142064
fbshipit-source-id: 516b9b63daeff30f5c097d192b0971c7a42db57e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31020
Before, the recursive scripting process re-did the concrete type
inference process for every submodule call. This changes things so that
the concrete type inference process only occurs once (at the top level),
and we re-use all the inferred concrete types while recursively
compiling submodules.
This is both more efficient (we don't do n^2 work inferring concrete
types) and less bug-prone (since we infer the concrete type only once,
there is no possibility of a mismatch).
Test Plan: Imported from OSS
Differential Revision: D18904110
Pulled By: suo
fbshipit-source-id: 6560b85ae29fe5e9db1ee982dbf8bc222614b8d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31019
No more `recurisve_script`, just direct calls to `create_script_module`.
This reduces the number of pathways through the frontend, and the
uniformity is useful for a future PR.
Test Plan: Imported from OSS
Differential Revision: D18904113
Pulled By: suo
fbshipit-source-id: 7de061dfef0cbdfc9376408fc6c1167b81803f01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31018
Properties are now disallowed so this hack is no longer necessary
Test Plan: Imported from OSS
Differential Revision: D18904112
Pulled By: suo
fbshipit-source-id: 83448da677082d59355729bb72d9f9f4c31ea756
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31017
This arg is now derivable from another one. So we don't need to pass
both
Test Plan: Imported from OSS
Differential Revision: D18904111
Pulled By: suo
fbshipit-source-id: ea74ea9c2ae83d9e0e6977b0eb6629f53545e2e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31401
As title, just a mechanical change
Test Plan: Imported from OSS
Differential Revision: D19152965
Pulled By: suo
fbshipit-source-id: 6bb27df7c8f542c55110286c156358ba0936269f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31373
Just some housekeeping
Test Plan: Imported from OSS
Differential Revision: D19145987
Pulled By: suo
fbshipit-source-id: ae8142dab2bddcf0b628c27c426ca26334c48238
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31372
Keeping it current with the latest changes.
Test Plan: Imported from OSS
Differential Revision: D19145986
Pulled By: suo
fbshipit-source-id: 88122e66fa87a354ef8e87faffe58551074e3f03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31214
This set up the basic infrastructure for distributed autograd and rpc to
bind their operators to TorchScript, since the whole distributed package
is builtin behind the `USE_DISTRIBUTED` flag, we separate the
registration and build it only when the flag is on.
Test Plan: Imported from OSS
Differential Revision: D19137160
fbshipit-source-id: ff47dc4c380ebe273fe0eea9e5e3fccfbd6466d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30918
This is a C++14 feature we can use now
ghstack-source-id: 95811482
Test Plan: waitforsandcastle
Differential Revision: D18869636
fbshipit-source-id: b5b3d78b61b6ceb2deda509131f8502e95b1d057
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30530
Switch some mentions of "C++11" in the docs to "C++14"
ghstack-source-id: 95812049
Test Plan: testinprod
Differential Revision: D18733733
fbshipit-source-id: b9d0490eb3f72bad974d134bbe9eb563f6bc8775
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31071
Previously the profiler would think Tensors would require grad, even
when the no_grad flag is enabled during execution. This makes the profiling
and guards respect the no_grad flag, which eliminates extra differentiable
graphs that appear in the backward graph (where no_grad is typically enabled).
Test Plan: Imported from OSS
Differential Revision: D18915468
Pulled By: zdevito
fbshipit-source-id: 1ae816a16ab78ae5352825cc6b4a68ed7681a089
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30978
This particular approach queries our issue tracker for test titles that
match the following format:
```
DISABLED test_async_grad_guard_with_grad (jit.test_async.TestAsync)
```
And then skips the python test for them. There is 1 second timeout so
if the internet flakes we still run the test suite, without disabling any
tests.
This is intended as a quick fix, similar to ninja unland, to get to a green
master. Long term test disables should go into the code.
Test Plan: Imported from OSS
Pulled By: zdevito
Differential Revision: D18890532
fbshipit-source-id: fe9447e59a6d5c9ad345f7c3ff15d63b6d2a09e2
Summary:
Upgrade IR version from 4 to 6, below is change doc from ONNX. The upgrade should be backward compatible.
```
// IR VERSION 5 published on March 18, 2019
// - Add message TensorAnnotation.
// - Add quantization annotation in GraphProto to map tensor with its scale and zero point quantization parameters.
IR_VERSION_2019_3_18 = 0x0000000000000005;
// IR VERSION 6 published on Sep 19, 2019
// - Add support for sparse tensor constants stored in model.
// - Add message SparseTensorProto
// - Add sparse initializers
IR_VERSION = 0x0000000000000006;
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31025
Reviewed By: hl475
Differential Revision: D18935444
Pulled By: houseroad
fbshipit-source-id: 9ba47f9657fa1a668db291cf04af07d5e8d73c21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31334
The wipe cache logic was introduced hoping to reduce the variations in the benchmark results. Based on our experiments result, it didn't actually help with that. In addition, several engineers had encountered the issue of missing cpuinfo.h which was used in the wipe cache logic. So this diff removes that feature to ensure smooth installation and running of the op bench.
Test Plan:
```
buck run caffe2/benchmarks/operator_benchmark/pt:add_test -- --iterations 1
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: add
# Mode: Eager
# Name: add_M1_N1_K1_cpu
# Input: M: 1, N: 1, K: 1, device: cpu
Forward Execution Time (us) : 111.192
A/B test also pass Benchmark Run #2476535015
Reviewed By: hl475
Differential Revision: D19126970
fbshipit-source-id: 9b1ab48c121838836ba6e0ae664a48fe2d18efdd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31206
Improvement on #25525.
- DistAutogradContext::getKnownWorkerIds() returns a unordered_map as temp value. No need to copy this temp value A into another temp value B.
ghstack-source-id: 95736296
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork -- test_worker_ids_recorded
```
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork_thrift -- test_context_cleanup_tensor_with_grad
```
Differential Revision: D5707771
fbshipit-source-id: 9fea83dc69b02047aef8b02a73028a260ac0be40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30915
Since we now have C++14, we don't need these c10::guts helpers anymore
ghstack-source-id: 95777609
Test Plan: waitforsandcastle
Differential Revision: D18869639
fbshipit-source-id: 97716f932297c64c6e814410ac47b444c33d4e2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31217
It doesn't seem to be used.
Test Plan: Imported from OSS
Differential Revision: D18986642
Pulled By: gchanan
fbshipit-source-id: 96d615df82731d2224d403ab6e2cad6d4c6674fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30917
This is a C++14 feature, we can use this now.
ghstack-source-id: 95255753
Test Plan: waitforsandcastle
Differential Revision: D18869637
fbshipit-source-id: dd02036b9faeaffa64b2d2d305725443054da31b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30501
**Motivation**:
In current state output of libtorch Module forward,runMethod is mem copied to java ByteBuffer, which is allocated, at least in some versions of android, on java heap. That could lead to intensive garbage collection.
**Change**:
Output java tensor becomes owner of output at::Tensor and holds it (as `pytorch_jni::TensorHybrid::tensor_` field) alive until java part is not destroyed by GC. For that org.pytorch.Tensor becomes 'Hybrid' class in fbjni naming and starts holding member field `HybridData mHybridData;`
If construction of it starts from java side - java constructors of subclasses (we need all the fields initialized, due to this `mHybridData` is not declared final, but works as final) call `this.mHybridData = super.initHybrid();` to initialize cpp part (`at::Tensor tensor_`).
If construction starts from cpp side - cpp side is initialiaed using provided at::Tensor with `makeCxxInstance(std::move(tensor))` and is passed to java method `org.pytorch.Tensor#nativeNewTensor` as parameter `HybridData hybridData`, which holds native pointer to cpp side.
In that case `initHybrid()` method is not called, but parallel set of ctors of subclasses are used, which stores `hybridData` in `mHybridData`.
Renaming:
`JTensor` -> `TensorHybrid`
Removed method:
`JTensor::newAtTensorFromJTensor(JTensor)` becomes trivial `TensorHybrid->cthis()->tensor()`
Test Plan: Imported from OSS
Differential Revision: D18893320
Pulled By: IvanKobzarev
fbshipit-source-id: df94775d2a010a1ad945b339101c89e2b79e0f83
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31271
This fixes copy kernel speed regression introduced in https://github.com/pytorch/pytorch/issues/29631.
The previous implementation forces the compiler to instantiate `static_cast_with_inter_type` because it is passed as an argument of a function. This behavior makes it impossible for compilers to do optimizations like automatic vectorization, and, function call itself is expensive compared to a single casting instruction.
To check the change, run
```
readelf -Ws /home/xgao/anaconda3/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so | grep static_cast_with_inter_type
```
On nightly build, we have output
```
168217: 0000000001852bf0 5 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsdE5applyEd
168816: 0000000001852d30 33 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIfEaE5applyEa
168843: 00000000018531f0 7 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIblE5applyEl
168930: 0000000001852c20 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIslE5applyEl
168935: 00000000018528d0 124 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIfNS_4HalfEE5applyES1_
169023: 0000000001852f30 17 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdEhE5applyEh
169713: 00000000018525c0 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIahE5applyEh
170033: 0000000001852c10 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsiE5applyEi
170105: 0000000001852bd0 5 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIshE5applyEh
170980: 0000000001852fc0 27 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdES1_IfEE5applyES3_
171398: 0000000001852810 13 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIdbE5applyEb
171574: 00000000018532e0 35 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIbNS_8BFloat16EE5applyES1_
171734: 0000000001852b20 6 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIlSt7complexIdEE5applyES2_
172422: 0000000001853350 54 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_8BFloat16EaE5applyEa
172704: 00000000018533c0 38 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_8BFloat16EfE5applyEf
172976: 0000000001852890 10 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIflE5applyEl
173038: 0000000001852f80 9 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdEfE5applyEf
173329: 00000000018531c0 20 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIbfE5applyEf
173779: 00000000018524d0 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIhiE5applyEi
174032: 0000000001852960 14 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIfNS_8BFloat16EE5applyES1_
174334: 0000000001852d60 29 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIfEdE5applyEd
174470: 0000000001852c60 124 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsNS_4HalfEE5applyES1_
174770: 0000000001852bc0 15 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIlNS_8BFloat16EE5applyES1_
176408: 0000000001853980 144 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_4HalfEbE5applyEb
176475: 0000000001852790 128 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIdNS_4HalfEE5applyES1_
....
```
And after this PR, we get empty output
```
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31279
Differential Revision: D19075587
Pulled By: ngimel
fbshipit-source-id: c20088241f39fa40c1d055f0a46eb5b9ece52e71
Summary:
Closes https://github.com/pytorch/pytorch/issues/31198, see the issue for more details. We throw an error when `local_value()` is called on a non-owned rref, but the incorrect node name is printed in the error message. This PR fixes that and adds a relevant unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31199
Differential Revision: D19072014
Pulled By: rohan-varma
fbshipit-source-id: 760c20bfd2fbf286eaaca19500469509a575cfec
Summary:
Make the following changes:
- When there are more than 10k errors, cuda-memcheck only shows 10k errors, in this case we shouldn't raise an Exception
- Add UNDER_CUDA_MEMCHECK environment to allow disabling `pin_memory` tests when running cuda-memcheck.
- Add a `--ci` command option, when turned on, then this script would run output to stdout instead of writing a file, and exit with an error if cuda-memcheck fails
- Add a `--nohang` command option. When turned on, then hang would be treated as pass instead of error
- Do simple filtering on the test to run: if `'cpu'` in the test name but not `'cuda'` is not in the test name
- Add `--split` and `--rank` to allowing splitting the work (NVIDIA CI has a limitation of 3 hours, we have to split the work to satisfy this limitation)
- The error summary could be `ERROR SUMMARY: 1 error`, or `ERROR SUMMARY: 2 errors`, the tail could be `error` or `errors`, it is not of the same length. The script is fixed to handle this case.
- Ignore errors from `cufft`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29243
Differential Revision: D18941701
Pulled By: mruberry
fbshipit-source-id: 2048428f32b66ef50c67444c03ce4dd9491179d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31276
Change assert --> CUDA_ASSERT_KERNEL to avoid hip undefined __assert_fail()
This is similar to https://github.com/pytorch/pytorch/pull/13902 in caffe2 land.
Test Plan: wait for CI to clear
Reviewed By: bddppq
Differential Revision: D19047582
fbshipit-source-id: 34703b03786c8eee9c78d2459eb54bde8dc21a57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30391
A Type parser to parse the python string of a Type. For example,
"Tuple[str, Optional[float], Dict[str, List[Tensor]], int]".
Please refer to test_type_parser.cpp for the usage.
One of the use cases is in lite interpreter, types needs to be serialized (directly calling the python_str() of the Type) and deserialized (calling parseType(str)).
Test Plan: Imported from OSS
Differential Revision: D18924268
Pulled By: iseeyuan
fbshipit-source-id: 830d411563abfbeec023f01e7f8f4a1796f9a59a
Summary:
https://github.com/pytorch/pytorch/issues/28294 DDP should not set grad for globally unused parameters
DDP currently computes the param to bucket mapping upfront, and allreduce grads for all params in every iteration. Even if params are unused, it will just set grad to zero. With such behavior, optimizer cannot tell if a param indeed has a zero grad or it is not used in the current iteration. This could trigger convergence problems for optimizers with weight decay and momentum such as SGD. However, DDP cannot simply set grad to None for local unused parameters, as local unused parameters might be used in other processes, and hence we still need to allreduce its grad. Instead DDP should figure out the globally unused parameters and skip touching their grad in the end of backward.
Implementation summary:
* Add locally used parameter map for each model replica.
* Mark the locally unused parameters in the end of forward and then reduce to get the globally unused parameters.
* In the end of backward skip touching grad for those globally unused parameters.
* Add a unit test test_global_local_unused_params_grad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28883
Differential Revision: D18491530
Pulled By: mrshenli
fbshipit-source-id: 24e9b5f20df86c34ddbf9c7106250fd6ce186699
Summary:
Fixes https://github.com/pytorch/pytorch/pull/28378#issuecomment-562597033
To reproduce the failure I had to downgrade to `cmake 3.9` (Ubuntu 18 uses 3.10 apparently). These older `cmake` versions unfortunately don't seem to allow `target_link_libraries(INTERFACE)` to be used with imported libraries. Switching back to `set_property(TARGET)` fixes the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30935
Differential Revision: D18956912
Pulled By: albanD
fbshipit-source-id: a2b728ee3268599a428b7878c988e1edef5d9dda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26618
Implement a mechanism to get type names at compile time
In a future diff, I'm planning to introduce this to caffe2::TypeMeta and a few other places.
ghstack-source-id: 95337871
Test Plan: unit tests
Differential Revision: D17519253
fbshipit-source-id: e14017f962fd181d147accb3f53fa8d6ee42a3f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31200
We do not hipify these files when doing out of place.
Test Plan: wait for CI to clear.
Differential Revision: D18963683
fbshipit-source-id: eeba8597143f26417d0a8181a4c746139afefa24
Summary:
Tests for unique_dim will be refactored in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31211
Differential Revision: D19034968
Pulled By: ngimel
fbshipit-source-id: 855d326b37638b5944f11fbbce03394cf000daf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31207
Cleanup after #30914.
In #30914, `autogradContext->addKnownWorkerId(dst);` was moved out of `addSendRpcBackward()`.
So `addSendRpcBackward()` does not need `dstId` as it's argument anymore.
ghstack-source-id: 95509218
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork -- test_context_cleanup_tensor_no_grad
```
Differential Revision: D5742365
fbshipit-source-id: accd041a594ec18d369231f5590289828d87baa7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31224
If a future coming back to a rpc_agent server is satisfied with an
exception, ensure this information is propagated back over the wire.
ghstack-source-id: 95522418
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcBackend/...
Differential Revision: D18979185
fbshipit-source-id: 99848ae805cc2d48948809a238f61a2e0ef234c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31128
When operation times out due to some errors that are not detected by nccl communicators, ncclCommWatchdog can not check this time out error and thus can not abort ncclComms accordingly. So explicitly abort ncclComms here before throwing this timed out exception to users, after this, ncclCommWatchdog can detect nccl communicators are aborted and clean up devNCCLCommMap_ accordingly. if throwing timed out excepiton without aborting nccl communicators here, it was observed that CUDA GPU will have 100% utilization and can not run new events successfully.
ghstack-source-id: 95528488
Test Plan: newly revised test _test_nccl_errors_blocking passed with the changes in this diff; the reviesed test failed withtout the changes in this diff
Reviewed By: isunjin
Differential Revision: D18928607
fbshipit-source-id: be65a05ce4ff005f0c7fed36ae8e28903e8ffe2b
Summary:
It was a random coding exercise so I wasn't putting much effort into it; but, I was like "hey is the current intrusive_ptr implementation optimized enough?" so I compared it with shared_ptr (using std::shared_from_this).
My benchmark result shows that intrusive_ptr is actually slower. On my macbook the speed is:
```
---------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------
BM_IntrusivePtrCtorDtor 14 ns 14 ns 52541902
BM_SharedPtrCtorDtor 10 ns 10 ns 71898849
BM_IntrusivePtrArray 14285 ns 14112 ns 49775
BM_SharedPtrArray 13821 ns 13384 ns 51602
```
Wanted to share the results so someone could probably take a look if interested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30810
Reviewed By: yinghai
Differential Revision: D18828785
Pulled By: bddppq
fbshipit-source-id: 202e9849c9d8a3da17edbe568572a74bb70cb6c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30175
fbjni was opensourced and java part is published as 'com.facebook.fbjni:fbjni-java-only:0.0.3'
switching to it.
We still need submodule fbjni inside the repo (which is already pointing to https://github.com/facebookincubator/fbjni) for so linking.
**Packaging changes**:
before that `libfbjni.so` came from pytorch_android_fbjni dependency, as we also linked fbjni in `pytorch_android/CMakeLists.txt` - it was built in pytorch_android, but excluded for publishing. As we had 2 libfbjni.so there was a hack to exclude it for publishing and resolve duplication locally.
```
if (rootProject.isPublishing()) {
exclude '**/libfbjni.so'
} else {
pickFirst '**/libfbjni.so'
}
```
After this change fbjni.so will be packaged inside pytorch_android.aar artefact and we do not need this gradle logic.
I will update README in separate PR after landing previous PR to readme(https://github.com/pytorch/pytorch/pull/30128) to avoid conflicts
Test Plan: Imported from OSS
Differential Revision: D18982235
Pulled By: IvanKobzarev
fbshipit-source-id: 5097df2557858e623fa480625819a24a7e8ad840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29579
Per #28923, this diff is to move Future<Message> to torch::utils and extend it to be Future<T>, most of implementations are copied from FutureMessage and ivalue::Future. merge ivalue::Future with Future<T> will be done separately.
The main difference between Future<T> and FutureMessage is the error handling, instead of checking message type inside Future to handle error, this future<T> owns has_error_ and error_ states.
also this future passes value_, has_error_ and error_ states to callbacks for easily read future states.
In next diff, a torch script rpc async API will be created, before the API returns, it will create an ivalue::Future and passes it to Future<T>'s call back where state of ivalue::Future will be set. In this way, the torch script rpc async API can still return a ivalue::Future and call wait() to get its state appropriately afterwards.
ghstack-source-id: 95479525
Test Plan: unit tests
Differential Revision: D18263023
fbshipit-source-id: 48a65712656a72c2feb0bb3ec8b308c0528986a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31212
To be able to use this function more broadly.
Test Plan: unit tests
Reviewed By: jackm321
Differential Revision: D18978913
fbshipit-source-id: d998dc7c7f9540f491a8a4bc5d6d25d9c3bf8764
Summary:
Update ONNX Flatten to accept negative indices in opset 11.
With this change, some cases of flatten do not rely on the input rank being available.
Fixes : https://github.com/pytorch/pytorch/issues/30512 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30751
Reviewed By: hl475
Differential Revision: D18946904
Pulled By: houseroad
fbshipit-source-id: a6fa30a9182fff92211e505a19325525c6112f19
Summary:
all jobs are currently running with "--dry-run", so you can verify if the jobs are doing the right thing. i'll remove the flag and make it runs every hour same as on Jenkins once this PR is approved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30996
Differential Revision: D18971001
Pulled By: mingbowan
fbshipit-source-id: 2384bdb50ebdf47aad265395f26be3843f0ce05e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31163
The purpose is to unblock integration with TorchScript. Currently,
an OwnerRRef will be created by either a remote call or a to_here
call, whichever arrives first. However, when making RRef an IValue,
we need to know the type of value held by the RRef, which is
retrived by checking the return type of the TorchScript function.
The TorchScript function is only avaible during the remote call
but not in the to_here() call. Hence, an OwnerRRef can only be
created when processing a remote call. This commit implements this
behavior by introducing a conditional variable for every OwnerRRef
in the RRefContext, and let the to_here() call and PyRRef::unpickle
block on the CV until the value is ready.
Test Plan: Imported from OSS
Differential Revision: D18949591
Pulled By: mrshenli
fbshipit-source-id: 17513c6f1fd766885ea8e1cd38f672a403fa4222
Summary:
Remove most of the testing for `weak_script`, since we removed it. Refactor a few of the existing tests to use recursive scripting api.
Fix for https://github.com/pytorch/pytorch/issues/23965
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31193
Differential Revision: D18966291
Pulled By: eellison
fbshipit-source-id: 6b1e18c293f55017868a14610d87b69be42bde12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31127
Original commit changeset: d22448b90843
On Skylake T6:
Single Core:
(Note that our benchmark generates batch_size=47 for first case and batch_size=56 for the second case. In spite of that, the vectorized version is still faster than the original reference C version without vectorization.)
- Before the PR:
```
native_layer_norm 0.81% 5.884ms 0.81% 5.884ms 122.580us NaN 0.000us 0.000us 48 [[47, 1, 1024], [1024], [1024]]
```
- After the PR:
```
native_layer_norm 0.68% 5.053ms 0.68% 5.053ms 105.272us NaN 0.000us 0.000us 48 [[56, 1, 1024], [1024], [1024]]
```
20 Cores:
- Before the PR:
```
native_layer_norm 1.65% 41.682ms 1.65% 41.682ms 868.365us NaN 0.000us 0.000us 48 [[61, 64, 1024], [1024], [1024]]
```
- After the PR:
```
native_layer_norm 1.34% 33.829ms 1.34% 33.829ms 704.771us NaN 0.000us 0.000us 48 [[61, 64, 1024], [1024], [1024]]
```
ghstack-source-id: 95420889
Test Plan:
buck test mode/dev-nosan //caffe2/test:nn -- "LayerNorm"
buck test mode/dev-nosan //caffe2/test:nn -- "test_LayerNorm_1d_no_elementwise_affine_eval"
python run_test.py -i nn -- TestNN.test_LayerNorm_1d_no_elementwise_affine_eval
Differential Revision: D18936428
fbshipit-source-id: 8cae33d35fb338b5ac49b1597c2709152612d6e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31088
Original issue:
https://github.com/pytorch/pytorch/issues/31027
The problem is that for the stacks of PRs for non-leaf PRs circleCI does not set environment variable `CIRCLE_PULL_REQUEST` which is used to filter out some jobs that should run only on `master`.
(Android job for master includes alll 4 abis (x86, x86_64, armeabi-v7a, arm64-v8a) and gradle build tries to get results from all 4 abis, for PRs we run only x86 build for resources economy. Thats why not filtered master android job fails as abis apart x86 were not scheduled)
env variable `CIRCLE_BRANCH ` is set fine and can be used as a workaround to distinguish that this is PR (published with ghstack).
Test Plan: Imported from OSS
Differential Revision: D18966385
Pulled By: IvanKobzarev
fbshipit-source-id: 644c5ef07fcf2d718b72695da2cc303da8b94ef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31117
After this diff, we will have completely removed the named tensor
feature flagging. This means that named tensors are always on and that
there is no mechanism to turn them off. There should be no more follow-up
diffs.
I performed the deletion of the header with
```
find . -type f -print0 | xargs -0 sed -i '/#include
<ATen\/core\/EnableNamedTensor.h>/d'
```
Test Plan: - wait for CI
Differential Revision: D18934952
Pulled By: zou3519
fbshipit-source-id: 253d059074b910fef15bdf885ebf71e0edf5bea5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31116
Changelist:
- remove BUILD_NAMEDTENSOR macro
- remove torch._C._BUILD_NAMEDTENSOR
- remove all python behavior that relies on torch._C._BUILD_NAMEDTENSOR
Future:
- In the next diff, I will remove all usages of
ATen/core/EnableNamedTensor.h since that header doesn't do anything
anymore
- After that, we'll be done with the BUILD_NAMEDTENSOR removal.
Test Plan: - run CI
Differential Revision: D18934951
Pulled By: zou3519
fbshipit-source-id: 0a0df0f1f0470d0a01c495579333a2835aac9f5d
Summary:
Resubmit of https://github.com/pytorch/pytorch/pull/30356 and https://github.com/pytorch/pytorch/pull/31014 :'(
The last commit contains the fix. There was an internal FBcode error not able to compile the previous `impl_default->second.equal(default_val.second))` line. I tried various fixes in C++ internally but couldn't figure anything out. This is a good example of the programming costs of going from python -> c++ for different types of objects, because the conceptual overhead has expanded in scope from (python) -> (python, c++, pybind).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31123
Differential Revision: D18936128
Pulled By: eellison
fbshipit-source-id: 7d8fd66a6dd4a3e9838f3a0b68c219b6565a9462
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30909
`fold_prepack` doesn't work anymore after we change `scale`, `zero_point`
to be attributes, but since the freeze API is coming up, I don't want to
spend time to make this work since this will be thrown away later.
Test Plan:
.
Imported from OSS
Differential Revision: D18864537
fbshipit-source-id: 649e6b91f2b04b8babacc0afb6bc1530ed7259d3
Summary:
**Patch Description**
Round out the rest of the optimizer types in torch.optim by creating the stubs for the rest of them.
**Testing**:
I ran mypy looking for just errors in that optim folder. There's no *new* mypy errors created.
```
$ mypy torch/optim | grep optim
$ git checkout master; mypy torch/optim | wc -l
968
$ git checkout typeoptims; mypy torch/optim | wc -l
968
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31130
Reviewed By: stephenroller
Differential Revision: D18947145
Pulled By: vincentqb
fbshipit-source-id: 5b8582223833b1d9123d829acc1ed8243df87561
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30355
- Make processTimedOutFutures hold lock.
- Reduce unnecessary scan on future and future timeout maps.
- Reduce the scope of lock at a spot.
- Avoid repeatedly wake up if user set timeout = 0.
ghstack-source-id: 95409528
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork -- test_rpc_timeouts
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_rpc_timeouts
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_rpc_timeouts
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_rpc_timeouts
```
Differential Revision: D5516149
fbshipit-source-id: 4bb0bd59fa31d9bfaef9f07ac0126782da17f762
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31164
We have a small number of internal projects that still are on Python 2.
Until we can figure out how to get rid of them, we need to continue
supporting Python 2 for PyTorch.
Test Plan: Imported from OSS
Differential Revision: D18949698
Pulled By: suo
fbshipit-source-id: 4a9d7e4306ed81576e05f243de472937a2bb1176
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31151
same as title. I am not sure why this was not added in the first place.
Test Plan: wait for build to succeed.
Reviewed By: bddppq, xw285cornell
Differential Revision: D18880216
fbshipit-source-id: 8b17d4fbd5dd08c28c52df8b1da77b69d56d65dc
Summary:
Currently, both `Conv{1,2,3}dOptions` and `ConvTranspose{1,2,3}dOptions` are aliases of the `ConvOptions<{1,2,3}>` class, which causes confusion because the `ConvOptions` class has parameters such as `transposed` that shouldn't be exposed to the end user. (This has caused issues such as https://github.com/pytorch/pytorch/issues/30931.) This PR makes the following improvements:
1. Rename the original `torch::nn::ConvOptions<N>` class to `torch::nn::detail::ConvNdOptions<N>` class, to signify that it's an implementation detail and should not be used publicly.
2. Create new classes `torch::nn::ConvOptions<N>` and `torch::nn::ConvTransposeOptions<N>`, which have parameters that exactly match the constructor of `torch.nn.Conv{1,2,3}d` and `torch.nn.ConvTranspose{1,2,3}d` in Python API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31005
Differential Revision: D18898048
Pulled By: yf225
fbshipit-source-id: 7663d646304c8cb004ca7f4aa4e70d3612c7bc75
Summary:
Fix for https://github.com/pytorch/pytorch/issues/30015
We had a model that failed in shape propagation because we could not unify `Tensor` and `Optional[BoolTensor]`. Tensor not subtyping Optional[BoolTensor] was correct, but we should have unified those two types to `Optional[Tensor]`.
The fix here is that for immutable types containers (Optional, Tuple Type), we should be attempting to unify with complete shape information, and if that fails, then try to unify those types with unshaped types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31076
Differential Revision: D18921802
Pulled By: eellison
fbshipit-source-id: aa6890277470c60b349ed1da4d81cc5d71d377f6
Summary:
Adding support for the new ATen op floor_divide which was introduced in https://github.com/pytorch/pytorch/pull/30493/files.
This operation is used in Torchvision/FasterRCNN-MaskRCNN, which are now failing after the new op was introduced.
This PR fixes the failure.
cc: neginraoof
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31081
Reviewed By: houseroad
Differential Revision: D18945316
Pulled By: eellison
fbshipit-source-id: 09919c237d618ce7db293c7770f48f7304949dcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31086
This change leverages the new future response framework so that server
threads don't block until setValue is called. Particulurly, we add a
getFuture() method to OwnerRRef so that we get a future that is satisfied
once setValue is called.
ghstack-source-id: 95402273
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18925272
fbshipit-source-id: 2caf51019e5b5fd7ec45539544780067deb28610
Summary:
Previously list elements were only unified for tensor lists.
This improves error messages and expands the unification logic
to include all types.
](https://our.intern.facebook.com/intern/diff/18837726/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30777
Pulled By: driazati
Differential Revision: D18837726
fbshipit-source-id: c4d275562a8429700987569426d694faa8f6002e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31137
Our Test CI is broken because:
- hypothesis recently did a new release that reorganized their internal
modules
- we were importing something from their internal module structure.
This PR fixes the CI by doing the following:
- import SearchStrategy from the correct (public) location
- Pin the hypothesis version to avoid future surprises.
In the long term, we should stop install hypothesis every time the CI
runs and instead install it as a part of our docker build process. See
https://github.com/pytorch/pytorch/issues/31136 for details.
Test Plan:
- I tested this locally; before this PR test/test_nn.py fails to run but
after it does run.
- Wait for CI
Differential Revision: D18940817
Pulled By: zou3519
fbshipit-source-id: c1ef78faa5a33ddf4d923f947c03cf075a590bb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31069
Just to clarify that they are still experimental.
Test Plan: Imported from OSS
Differential Revision: D18920496
Pulled By: suo
fbshipit-source-id: d2f3014592a01a21f7fc60a4ce46dd0bfe5e19e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30994
The flakiness we saw was due to missing barriers(), which caused
states leaked into previous or subsequent checks. This commit
attempts fix this problem by adding barriers before and after each
check.
Test Plan: Imported from OSS
Differential Revision: D18893457
Pulled By: mrshenli
fbshipit-source-id: 42bcc12efa7e6e43e2841ef23e4bc2543b0236c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19705
Optimizing for a case when there's a consecutive dims that are not broadcasted followed by another consecutive dims that are broadcasted.
For example, MulGradient(["dC", "A", "B"], ["dA", "dB"], broadcast=True, axis=0) where A.shape == dC.shape == [9508, 80] and B.shape == [80] .
Test Plan:
In SKL T6,
Running mul_gradient_benchmark without this optimization
Operator #0 (dA, MulGradient) 11.9119 ms/iter
After this optimization,
Operator #0 (dA, MulGradient) 0.672759 ms/iter
Need to land D15291800 before to fix the unit test error
Reviewed By: dmudiger
Differential Revision: D15075415
fbshipit-source-id: 0f97be17cf8f1dacbafa34cd637fb8bc1c5e5387
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30979
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
--------------
In this PR:
Add tracing support for optional Device and Layout types.
--------------
Test Plan: Imported from OSS
Differential Revision: D18912685
Pulled By: izdeby
fbshipit-source-id: 4a9514ce2eee0041f9bc96636d3ddb4f077675e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30980
This stack is a first step toward an effort to fix, clean up and simplify code generation logic. �Please see the master [task](https://github.com/pytorch/pytorch/issues/30405) to see related discussions and all the known issues.
Main focus of these changes is TensorOptions in code generation.
Goals:
- Remove TensorOptions from generated code wherever it's possible. Leave it only in python/C++ API layers.
- Refactor TensorOptions logic to a single place.
- Log all discovered issues.
Non goals:
- Fix Everything!
- Remove all the hacks in code generation scripts.
- Clean up and defector all code generation scripts.
--------------
In this PR:
Add a test to check that C++ API behavior stays the same after all the changes.
While working on it a bug related to `requires_grad` was found and logged in the master task.
--------------
Test Plan: Imported from OSS
Differential Revision: D18912681
Pulled By: izdeby
fbshipit-source-id: 19772a37c92dde820839b79055f348689b99fa77
Summary:
This makes `nn.Transformer` usable from TorchScript. It preserves backwards compatibility via `__setstate__` on the encoder/decoder.
Fixes https://github.com/pytorch/pytorch/issues/24173
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28561
Differential Revision: D18124753
Pulled By: driazati
fbshipit-source-id: 7314843e5aa9c9bf974c4672e4edb24ed8ef4a6f
Summary:
VitalyFedyunin, This PR is about port ELU activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.ELU()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.09 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.28 (ms); backwad avg time is 0.18 (ms).
input size(128, 10000) forward time is 23.53 (ms); backwad avg time is 14.46 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.16 (ms); backwad avg time is 0.08 (ms).
input size(128, 10000) forward time is 15.53 (ms); backwad avg time is 6.60 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100) forward time is 0.24 (ms); backwad avg time is 0.17 (ms).
input size(128, 10000) forward time is 0.73 (ms); backwad avg time is 1.11 (ms).
OMP_NUM_THREADS=1
input size(128, 100) forward time is 0.15 (ms); backwad avg time is 0.07 (ms).
input size(128, 10000) forward time is 14.40 (ms); backwad avg time is 6.00 (ms).
```
How to set the numbers of thread? using following script:
```
num_threads=$1
script=$2
last_core=`expr $num_threads - 1`
echo "using $num_threads OMP threads"
echo "bind cores to 0~$last_core"
export OMP_NUM_THREADS=$num_threads
export KMP_AFFINITY=granularity=fine,compact,1,0
numactl --physcpubind=0-$last_core --membind=0 python $script
```
and run .**/run.sh num_threads test.py**.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29275
Differential Revision: D18587389
Pulled By: VitalyFedyunin
fbshipit-source-id: bea8f3f006c6893090f863d047c01886d195437a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31047
Changelist:
- remove BUILD_NAMEDTENSOR from .cu files
- remove BUILD_NAMEDTENSOR special handling in function_wrapper.py
- remove BUILD_NAMEDTENSOR from cpp_extension.py. This code actually
did nothing because we always compile with BUILD_NAMEDTENSOR.
Test Plan: - run tests
Differential Revision: D18908442
Pulled By: zou3519
fbshipit-source-id: b239e24de58580adaf3cef573350773a38b1e4f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29104
We would like to provide the vectorized implementation for layer norm. This PR reuses https://github.com/pytorch/pytorch/pull/23349.
Test Plan:
buck test mode/dev-nosan //caffe2/test:nn -- "LayerNorm"
buck test mode/dev-nosan //caffe2/test:nn -- "test_LayerNorm_1d_no_elementwise_affine_eval"
python run_test.py -i nn -- TestNN.test_LayerNorm_1d_no_elementwise_affine_eval
Differential Revision: D18293522
fbshipit-source-id: f4cfed6e62bac1b43ee00c32b495ecc836bd9ec5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31100
This appears to not work right now. Disabling pending an investigation.
Test Plan: Imported from OSS
Differential Revision: D18928777
Pulled By: suo
fbshipit-source-id: 63089131bad98902979e5cf4373732c85badef9d
Summary:
Exported weight_norm is incorrectly reducing over axis 0 as well when dim is set to 0.
Previous test case only covers weight with size(0) == 1, which yields the same result whether reduced over or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31015
Reviewed By: hl475
Differential Revision: D18900894
Pulled By: houseroad
fbshipit-source-id: 19004f51933b37f848dbe4138e617a7a8e35a9ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30912
Add a new data type ZERO_COLLISION_HASH .
Test Plan: ci
Reviewed By: boryiingsu
Differential Revision: D18843626
fbshipit-source-id: b2d8280f13c78b4a656cf95822198df59de7b64c
Summary:
Peephole optimize out type refinements when they are no longer refining the type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31024
Differential Revision: D18920958
Pulled By: eellison
fbshipit-source-id: 6d05d9812b9f9dcf001de760a78a2042fb832773
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31068
Let's get it out of the early parts now that the recursive API has been
around for a while
Test Plan: Imported from OSS
Differential Revision: D18920498
Pulled By: suo
fbshipit-source-id: 6f4389739dd9e7e5f3014811b452249cc21d88e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30637
RequestCallback api currently forces work to be always synchronous, which,
as we scale, means we're going to need to throw large number of (mostly
blocked) threads at the rpc problem. For some activities like dependent
autograd rpcs, there's not a necessary reason to block in these threads.
In this change, the RequestCallback api is updated to return a
shared_ptr<FutureMessage> rather than a Message:
std::shared_ptr<FutureMessage> operator()(Message& request) const;
With a futures-style api, RPC ops that wish to be async can then be async,
while short-lived blocking functions (or Python UDFs) can just block.
In this change, we keep all of the current ops as synchronous (i.e. we block
and then return a completed FutureMessage). We also update the rpc_agents in
a manner compatible with this sort of parallelism.
Here, we only want to incur overhead when we use the async behavior.
Some modest extra cost seems unavoidable here (e.g. the allocation for the
std::make_shared<>), but we can trivially detect the synchronous/completed
case in the rpc_agent and avoid the extra thread-switches/etc. in that case.
ghstack-source-id: 95287026
Test Plan:
- Basic: buck test mode/dev-nosan caffe2/test/...
- Additional testcase in ThriftRpcAgentTest for deferred work.
Differential Revision: D18774322
fbshipit-source-id: cf49922a71707cfb1726de16f93af23b160385d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30887
Support to convert quantized concat from pytorch to caffe2
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_cat
Imported from OSS
Differential Revision: D18855676
fbshipit-source-id: 5d0cf3f03c61819e168b080afa368b1255d0419c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30683
Assume that a node can work with autograd only if it is not a fusion
group and in prim or aten namespaces.
Test Plan: CI
Reviewed By: lly-zero-one
Differential Revision: D18795171
Pulled By: ilia-cher
fbshipit-source-id: 301090557e330b58be70e956784f7f0dc343c684
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29357
As title
Test Plan: Imported from OSS
Reviewed By: pritamdamania87
Differential Revision: D18920562
Pulled By: suo
fbshipit-source-id: b5dd559cfb0ba6c64b9ccf3655417afb56a7b472
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29353
First step to killing Python 2 everywhere. I don't really know that much
about the caffe2 circle jobs so I left them alone for now.
Test Plan: Imported from OSS
Differential Revision: D18920563
Pulled By: suo
fbshipit-source-id: b37d8427a6ecd4b8a7e16c1ff948e0ce13b5798f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31057
The current signature basically will always fail to type check, because
mypy enforces that the subclass method's input types must be "wider"
than their superclass method's input types (i.e. they can vary
contravariantly). And nothing is wider than `Any`.
This change makes it so that any input params are allowed in
`forward()`. Fixes#29099
Test Plan: Imported from OSS
Differential Revision: D18918034
Pulled By: suo
fbshipit-source-id: 9940e9f769b55d580d9d7f23abf6f88edb92627f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31030
DistAutogradContext held a shared_ptr reference to RecvRpcBackward and
RecvRpcBackward held a shared_ptr reference to the context. This circular
dependency caused significant memory leaks. As a result, I'm changing the
reference in RecvRpcBackward to be a weak_ptr.
Test Plan: waitforbuildbot
Differential Revision: D18896389
fbshipit-source-id: e5bc588b6f998885854e3a67de1e82452e8475ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30874
These have all been disabled at this point, so there is no difference in the generated code.
Test Plan: Imported from OSS
Differential Revision: D18855990
Pulled By: gchanan
fbshipit-source-id: 03796b2978e23ef9060063f33241a1cbb39f1cf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30926
Calling the JITed FBGEMM kernel for Fused 8 Bit Sparse Length Sum (Fused8BitRowwiseEmbeddingLookup)
Test Plan:
buck test mode/dbg //caffe2/caffe2/python:lengths_reducer_fused_8bit_rowwise_ops_test
All tests pass.
Reviewed By: jspark1105
Differential Revision: D18058128
fbshipit-source-id: 0dfa936eb503712c39e53748e015fc156afde86f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29766
Add FbgemmPackTranspose op to support the packing on FCTransposed weights
Add FCTransposed to FbFCPacked transformation to Dper fp16 exporter
Test Plan:
```
buck test mode/opt caffe2/caffe2/fb/fbgemm:fb_fc_packed_op_test
```
```
buck test mode/opt caffe2/caffe2/python:layers_test
```
Differential Revision: D18482306
fbshipit-source-id: e8f1947b3d0d04892293509ebf88742f5f0f5997
Summary:
After several discussions, we agreed not to put any extra safety check for recordStream as either the check will cause failures in certain scenarios or there is no need to throw for user errors.
As a summary, it simply does what is described in https://github.com/pytorch/pytorch/issues/27405, check if a tensor is indeed allocated by a CUDACachingAllocator instance, if it is, then throw internal error if a block can not be retrieved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30870
Differential Revision: D18851669
Pulled By: yxia11
fbshipit-source-id: c2f01798cd24f1fd0f35db8764057d5d333dab95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30894
This PR begins the process of removing BUILD_NAMEDTENSOR macros. There
will be followups.
Reasons for removing the macros:
- BUILD_NAMEDTENSOR is always on and has been on since pytorch 1.3.0.
- Since we don't test building without it, it is useless to keep around.
- Code becomes nicer to read without the macros
Reasons for not removing the macros:
- potential for feature flagging
Now, I argue against needing to feature flag. The main reason why we
might want to feature flag is if we need to disable the feature.
We'd need a fast switch to disable the feature if someone discovers
in the future that named tensors caused some regression in some existing workflows.
In https://github.com/pytorch/pytorch/pull/25798, I did a variety of
macro- and micro- benchmarks to determine the performance impact of named
tensors on regular tensors.
[The
microbenchmarks](https://github.com/pytorch/pytorch/pull/25798#issuecomment-529014810)
were not very stable, and running the
microbenchmarks for more iterations doesn't actually help because the
noise is not distributed in a nice way. Instead of microbenchmarks I ran
a [profiler
(perf)](https://github.com/pytorch/pytorch/pull/25798#issuecomment-555707645)
to estimate how much overhead named tensors add to unnamed code. I
estimated the overhead to be less than 100ns for `add` and even smaller
for `mm`; there are ways to optimize even futher if we find this to be a
problem.
[Initial
macrobenchmarks](https://github.com/pytorch/pytorch/pull/25798#issuecomment-530539104)
were also not very stable. I ran imagenet for some number of epochs. To
make them more stable, I got rid of the data loading (which seemed to
vary between runs). [In some benchmarkers without data
loading](https://github.com/pytorch/pytorch/pull/25798#issuecomment-562214053),
we can see that the results are less noisy now. These results support
no noticeable regressions in speed.
Test Plan: - wait for CI
Differential Revision: D18858543
Pulled By: zou3519
fbshipit-source-id: 08bf3853a9f506c6b084808dc9ddd1e835f48c13
Summary:
Adds `torch.floor_divide` following the numpy's `floor_divide` api. I only implemented the out-of-place version, I can add the inplace version if requested.
Also fixes https://github.com/pytorch/pytorch/issues/27512
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30493
Differential Revision: D18896211
Pulled By: eellison
fbshipit-source-id: ee401c96ab23a62fc114ed3bb9791b8ec150ecbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30802
Change shape_hints from map<string, TensorShape> to ShapeInfoMap to catch dimType info from model file.
Reviewed By: ipiszy
Differential Revision: D18821486
fbshipit-source-id: c5d9ed72e158d3698aba38900aeda00f776745b4
Summary:
Updated to export API:
When calling this API, a dict containing the custom opsets (domain and version) used to export the model could be provided.
We allow registering one custom opset (domain, version) per ONNX opset. So, when exporting an operator from a custom domain, users need to pass this pair. Default custom opset version is 1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29752
Reviewed By: hl475
Differential Revision: D18703662
Pulled By: houseroad
fbshipit-source-id: 84d22557d132b526169051193d730761798fce60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30356
This finishes up the `torch.jit.overload` api for free-functions.
- defaults now required on the implementation function itself
- fully follows [overload spec](https://mypy.readthedocs.io/en/latest/more_types.html#function-overloading) such that the following is supported
```
overload
def mouse_event(x1: int, y1: int) -> ClickEvent: ...
def mouse_event(x1: int,
y1: int,
x2: Optional[int] = None,
y2: Optional[int] = None): ...
```
Note: `jit.overload` isn't supported yet for UDT, but is support for modules. This PR doesn't make the same changes for modules, if reviewers think I should include them then I could do so in a follow up PR or wait to land this. Since that's still an internal api I think it's fine, and the changes here would allow us to expose `torch.jit.overload` on free functions.
Test Plan: Imported from OSS
Differential Revision: D18864774
Pulled By: eellison
fbshipit-source-id: 6c566738bd6f0551a000a9ea8d56e403636b7856
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30749
Add check to schemas that the schema is sane.
I removed the defaults from symbolic_script because they were in some cases wrong and don't actually do anything. At the point they're invoked the forward should already have matched all arguments.
Test Plan: Imported from OSS
Differential Revision: D18864775
Pulled By: eellison
fbshipit-source-id: 273d7e96d65b8a3d3de72e2d7bfcdf2417046c6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30877
Previously, when the environment tried to reassign variables which had been assigned to "inf" or "nan" it would fail because they are not simple values. Constant prop exposed this, a test was failing internally because of it.
Test Plan: Imported from OSS
Reviewed By: Krovatkin
Differential Revision: D18861016
Pulled By: eellison
fbshipit-source-id: b9b72978a26a0b00b13bf8ea7685825551f5a541
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30544
Run Constant Propagation upon compilation only on ops with non-aliasing inputs and outputs. This speeds up the first run of `torchvision.models.resnet18` by over 50% and speeds up compilation by about 25% (although the effects didn't seem additive with with https://github.com/pytorch/pytorch/pull/30503, so I'm going to land this PR first and then see if caching still has a sizable impact).
Running constant prop only with non-aliasing types does a lot of graph cleanup by removing constant ifs and a bunch of other smaller ops. It also avoids all the jitter problems we had when we tried running full constant prop previously. Bc it is idempotent it doesn't jitter, and it doesn't jitter graphs constructed from tracing because tracing doesn't emit any ops that only involve non-aliasing inputs.
Full constant prop isn't idempotent because what ops are run depends on the state of mutation in alias db, which will often change upon successive iterations of constant propagation, and bc it affects graphs constructed from tracing.
Edit: if we were okay with running constant propagation on graphs constructed from tracing (potentially making them hard to debug), an alternative would be to run constant propagation until the graph reaches a fixed point.
Test Plan: Imported from OSS
Differential Revision: D18833607
Pulled By: eellison
fbshipit-source-id: 92a0adb4882d67ed5a0db5c279f5e122aeeba54a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30543
`shouldAnnotate` doesn't make make a ton of sense as a public api
Test Plan: Imported from OSS
Differential Revision: D18833608
Pulled By: eellison
fbshipit-source-id: 460ee05d0fa91b1edc640c037be2a6ee8eaf50a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30853
Right now we print one element tuple as `(val)`, and it will
be interpreted as `val` in parsing, this PR changes it
to `(val,)` so we can recognize the one element tuple in parsing
Test Plan:
.
Imported from OSS
Differential Revision: D18846849
fbshipit-source-id: 42959b9190c2567ef021a861497077c550324b7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30859
We can dictionary of quantization parameters to simplify the code
handling these things a bit
Test Plan:
.
Imported from OSS
Differential Revision: D18849023
fbshipit-source-id: 09e9860b2656a1affa8776016e16794529bcee3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30927
Classes that are used virtually (e.g. have virtual methods) must have a virtual destructor or bad things happen
ghstack-source-id: 95144736
Test Plan: waitforsandcastle
Differential Revision: D18870351
fbshipit-source-id: 333af4e95469fdd9103aa9ef17b40cbc4a343f82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30519
Re-enable them and write a few additional ones
ghstack-source-id: 95143051
Test Plan: unit tests
Differential Revision: D18729561
fbshipit-source-id: 8cefd8320913d72a450a3324bfd7c88faed072d7
Summary:
VitalyFedyunin, This PR is about port Softshrink activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Softshrink()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.12 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.18 (ms).
CPU:
input size(128, 100) forward time is 0.19 (ms); backwad avg time is 0.23 (ms).
input size(128, 10000) forward time is 17.23 (ms); backwad avg time is 16.83 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU:
input size(128, 100) forward time is 0.08 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 0.32 (ms); backwad avg time is 0.08 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) forward time is 0.08 (ms); backwad avg time is 0.10 (ms).
input size(128, 10000) forward time is 7.58 (ms); backwad avg time is 7.91 (ms).
After:
input size(128, 100) forward time is 0.08 (ms); backwad avg time is 0.02 (ms).
input size(128, 10000) forward time is 7.30 (ms); backwad avg time is 1.02 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30229
Differential Revision: D18810054
Pulled By: VitalyFedyunin
fbshipit-source-id: e19074824396570db45ba488ae4f9fe1b07a5839
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30914
When tensors don't require grad, we don't call `addSendRpcBackward`, where we record known workerIDs to clean up the dist autograd context later. But since https://github.com/pytorch/pytorch/pull/29781, we always include the autograd context ID in RPCs, even if tensors do not require grad. So, it could be possible that we don't release the contexts on some nodes.
This can contribute to OOMs since the contexts will not be cleaned up in this case, which can be checking by running the unit test without this patch. We can fix this issue by moving the `addKnownWorkerIds` call to the `getMessageWithAutograd` function.
ghstack-source-id: 95178561
Test Plan: Added a unit test: `test_context_cleanup_tensor_no_grad`
Differential Revision: D18869191
fbshipit-source-id: b80f66bfd0dd7d01960abe1691d3f44095bb1b2b
Summary:
This simplifies the generated code a bit, saving about 40K off of libtorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30466
Differential Revision: D18836215
Pulled By: resistor
fbshipit-source-id: ad75c9e04783bb29cc06afd2022f73f9625dd52b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30715
Changed caffe2/caffe2/TARGETS file to define USE_FBGEMM for x86 and USE_SSE_ONLY is not defined.
Test Plan: buck test caffe2/caffe2:caffe2_test_cpu -- Float16
Reviewed By: jianyuh
Differential Revision: D18806067
fbshipit-source-id: 1b44b90a9f6dc3c27f81a46038c0f7542ed2bab3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30642
Adding a couple of basic metrics for distributed autograd which would
help in determining stuckness.
ghstack-source-id: 95156189
Test Plan: waitforbuildbot
Differential Revision: D18776478
fbshipit-source-id: a0556ad6fe2b7c3cd0082ee2350c1c78cafaaec5
Summary:
- [x] Add more comments and refactor the logic of `ReshapeToAdvancedIndexingFormat`
- [x] Add more description here. Cases that are/aren't supported, and how they are supported.
- [x] Need to merge this PR https://github.com/pytorch/pytorch/issues/27186 to enable testing inplace operators.
We are now supporting exporting aten::copy_ and aten::index_put to ONNX.
Here's a breakdown of the different cases in PyTorch code.
```
# Case 1: Scalar Indices
x[0, 1, 2] = data
# Case 2: Slice Indices
x[1:3, :, ::2] = data
# Case 3: Ellipsis Indices
x[..., 0] = data
# Case 4: Tensor Indices
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
x[ind1, ind2] = data
# Case 5: Mixing all the above cases
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
x[1:3, ind1, ind2, ..., 3] = data
```
Limitations:
Tensor indices must be consecutive, and 1-d tensors.
```
# Supported
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
x[ind1, ind2] = data
# Not supported
ind1 = torch.tensor([0, 2])
ind2 = torch.tensor([1, 1])
ind3 = torch.tensor([[0], [1]])
x[ind1, :, ind2] = data
x[ind3] = data
```
Negative indices are not supported.
```
# Not supported
x[-1] = data
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26941
Differential Revision: D17951030
Pulled By: houseroad
fbshipit-source-id: 4357777072f53aa0bc4b297aa1ee53457a7f8dec
Summary:
```python
record_function('my_func')
def f(x, y):
return x + y
with profile() as p:
f(1, 2)
print(prof.key_averages().table())
```
```
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
my_func 85.42% 86.796us 87.27% 88.670us 88.670us 1
------------------------------------ --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 101.606us
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30861
Differential Revision: D18857993
Pulled By: bddppq
fbshipit-source-id: eb6b8e2a8d4f3a7f8e5b4cb3da1ee3320acb1ae7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30904
When we sent tensors over RPC, on the server side we would call
addRecvRpcBackward which would call `set_history` on all tensors. This was
incorrect and set the `requires_grad` flag on tensors that didn't actually need
grad.
To fix this, we only attach autograd edges to tensors that need grads.
ghstack-source-id: 95113672
ghstack-source-id: 95113999
Test Plan: waitforbuildbot
Differential Revision: D18828561
fbshipit-source-id: d8942b76e9e4c567f8f1821f125c00d275ea0f90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30892
Fixes all outstanding lints and actually installs a properly configured
flake8
Test Plan: Imported from OSS
Differential Revision: D18862825
Pulled By: suo
fbshipit-source-id: 08e9083338a7309272e17bb803feaa42e348aa85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30906
Add mobile module observer to measure performance of each method run.
ghstack-source-id: 95120194
Test Plan:
Run pytext model through BI cloaking flow on lite-interpreter and verify logs are sent:
1. buck install -r fb4a
2. Go to internal setting and find MobileConfig, search for android_bi_infra_cloaking_iab_models and set the following params:
a. sample_rate: 1.0
b. enabled: true
c. use_bytedoc_pytorch_model: true
d. use_bytedoc_caffe2_model: false
e. use_full_jit: false
3. Go back to new feed and scroll down until find an ads which will direct you to offsite webpage;
4. Click on the ads, wait for the offsite ads loads;
5. Click back to news feed;
6. Go to scuba table: https://fburl.com/scuba/4fghwp0b and see all the operator runs have been logged:
{F223456981}
Reviewed By: ljk53
Differential Revision: D18702116
fbshipit-source-id: a9f07eee684e3022cef5ba3c5934f30f20192a85
Summary:
Copy-paste comment from code for reasoning:
```
# NOTE [ IterableDataset and __len__ ]
#
# For `IterableDataset`, `__len__` could be inaccurate when one naively
# does multi-processing data loading, since the samples will be duplicated.
# However, no real use case should be actually using that behavior, so
# it should count as a user error. We should generally trust user
# code to do the proper thing (e.g., configure each replica differently
# in `__iter__`), and give us the correct `__len__` if they choose to
# implement it (this will still throw if the dataset does not implement
# a `__len__`).
#
# To provide a further warning, we track if `__len__` was called on the
# `DataLoader`, save the returned value in `self._len_called`, and warn
# if the iterator ends up yielding more than this number of samples.
```
Fixes https://github.com/pytorch/pytorch/issues/30184
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23587
Differential Revision: D18852625
Pulled By: ailzhang
fbshipit-source-id: aea8d4d70c7f21aaa69b35908a6f43026493d826
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30908
Same as title.
Test Plan: Wait for CI to clear.
Reviewed By: bddppq, xw285cornell
Differential Revision: D18862837
fbshipit-source-id: bc34356b85774fc20ba46d321c8a2bb5d5c727f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30890
We've received way too many complaints about this functionality making tests flaky, and it's not providing value to us anyway. Let's cut the shit and kill deadline testing
Test Plan: Imported from OSS
Differential Revision: D18857597
Pulled By: jamesr66a
fbshipit-source-id: 67e3412795ef2fb7b7ee896169651084e434d2f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30858
This is not needed since we have `values_to_qparams_`
Test Plan:
.
Imported from OSS
Differential Revision: D18848992
fbshipit-source-id: dc81f59967a93abdd5562f1010f02de4f4e60db0
Summary: Add mobile operator observer to measure performance of each operator run, the result will also log into QPL event: [MOBILE_OPERATOR_STATS ](https://fburl.com/quicklog/8773a00a).
Test Plan:
Run pytext model through BI cloaking flow on lite-interpreter and verify logs are sent:
1. buck install -r fb4a
2. Go to internal setting and find MobileConfig, search for android_bi_infra_cloaking_iab_models and set the following params:
a. sample_rate: 1.0
b. enabled: true
c. use_bytedoc_pytorch_model: true
d. use_bytedoc_caffe2_model: false
e. use_full_jit: false
3. Go back to new feed and scroll down until find an ads which will direct you to offsite webpage;
4. Click on the ads, wait for the offsite ads loads;
5. Click back to news feed;
6. Go to scuba table: https://fburl.com/scuba/er7t4g9u and see all the operator runs have been logged:
{F223250762}
Reviewed By: ljk53
Differential Revision: D18131224
fbshipit-source-id: 23e2f6e2a9851c04b29511b45dc53f3cce03e8a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30709
Intrusive_ptr doesn't provide a explicit incref method. When a users want to
incref the target, they creates a intrusive_ptr to wrap the target, then makes
a copy which does the actual incref, then release both the first intrusive_ptr
and the copy to prevent decref at deconstruction time. This is very
inefficient. Instead, do the incref/decref directly.
Differential Revision: D18798505
fbshipit-source-id: 524d4f30d07d733df09d54423b044d80e4651454
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30649
Operators in VariableTypeManual are now no longer registered against the VariableTypeId key, but they are registered as compound ops. See https://github.com/pytorch/pytorch/issues/30102 for background.
This also requires the non-variable codegen to ignore them and requires removal of VariableMethodStubs.cpp.
So, because function_wrapper.py now also needs to know which ops are manual, instead of having a hard-coded list in gen_variable_type.cpp for ops with manual implementation, we now have a `manual_kernel_registration` flag in native_functions.yaml that disables the registration of operator kernels for this operator (the schema is still registered). Then, we manually register the right kernels for the operator.
ghstack-source-id: 95082204
Test Plan: unit tests
Differential Revision: D18778191
fbshipit-source-id: 0af6f9e43ff4fb9800ce19b286dfccd0fd22cc41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30552
For upcoming changes to support quantizing shared class type
Test Plan:
.
Imported from OSS
Differential Revision: D18818653
fbshipit-source-id: 393a55db69b20a1c00ffa0157ab568cb097915b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30826
Previously the scalar_check for the reduction None case was:
input.dim() <= 1, but it should be target based, i.e.:
target.dim() == 0. This follows from the "correct cases", i.e.
(N, C) X (N,) -> (N,)
(C,) X () -> ()
Test Plan: Imported from OSS
Differential Revision: D18833660
Pulled By: gchanan
fbshipit-source-id: 26338b842a8311718c4b89da3e2f1b726d5409b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30790
The index_select documentaiton reads:
"The returned tensor has the same number of dimensions as the original tensor (input)."
But the implementation would return a 0-dimensional tensor iff both the input and index were 0-dimensional.
This change makes it so we retuan a 0-dimensional tensor iff the input is 0-dimensional.
Restacked version of: https://github.com/pytorch/pytorch/pull/30502
Test Plan: Imported from OSS
Differential Revision: D18825717
Pulled By: gchanan
fbshipit-source-id: aeb10c5107e748af3e264fbdc81fff5dd4833cc4
Summary:
When converting a contiguous CuPy ndarray to Tensor via `__cuda_array_interface__`, an error occurs due to incorrect handling of default strides. This PR fixes this problem. It makes `torch.tensor(cupy_ndarray)` works for contiguous inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24947
Differential Revision: D18838986
Pulled By: ezyang
fbshipit-source-id: 2d827578f54ea22836037fe9ea8735b99f2efb42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30821
While investigating while our tests didn't catch #30704 I noticed that none
of our tests in method_tests() were being run on CUDA. This diff moves
those tests into the new device-generic test framework so that we also get
CUDA coverage. For expediency, I blacklisted all tests which didn't work
on CUDA (rather than fix them); that's something we can leave for future PRs.
This is done by way of a new expectedFailure gadget.
Note that all occurences of skipIfNoLapack needed to be replaced with
skipCPUIfNoLapack.
I punted for test_jit; it's possible those tests should also run CUDA but a JIT
expert should take a look here.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18840089
Pulled By: ezyang
fbshipit-source-id: 66b613b5024c91d3e391c456bb642be7e73d4785
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30551
To enable quantizing with shared types, we need to insert GetAttr nodes for
quantization parameters since the code might be shared by multiple module instances
and we'd like to make quantized module instance also share the same code but with
different values of attributes.
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D18818652
fbshipit-source-id: fc95623cac59dcedd9e3f95397524eae515e7a11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30837
This test would get very occasional flakes, with an error saying the
RPC timed out. This happened because one worker would still be waiting for the
return value of an RPC, but another worker had already performed its local
shutdown, so it would not have sent the response. This didn't show up in
initial testing since the flakiness is very rare (< 1/100 test runs). This diff
fixes the issue by not erroring if these RPCs timeout. The reason this is okay
is because with a local shutdown, we should not expect for all outstanding RPCs
to be completed, since workers are free to shut down without completing/waiting
on outstanding work.
ghstack-source-id: 95021672
ghstack-source-id: 95021672
Test Plan: Ran the test 1000 times to ensure that it is not flaky.
Differential Revision: D18775731
fbshipit-source-id: 21074e8b4b4bbab2be7b0a59e80cb31bb471ea46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30474
There are some common parts in `isBiasOfConvOrLinear` and `isWeightOfConvOrLinear`, we can factor
them out, the refactor will allow for easier extension of new patterns
Test Plan:
python test/test_jit.py
python test/test_quantization.py
Imported from OSS
Differential Revision: D18795725
fbshipit-source-id: 446463da5e3fa8464db441ed0d9651930487b3b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30679
Caffe2 expects quantized ops to be in NHWC format while pytorch inputs are in NCHW.
Add a jit pass to insert permutes to convert from nchw2nhwc before each conv op and add nhwc2nchw permute after the conv op.
Using graph rewriter to find consecutive redundant permutes and remove them from the graph
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps
Imported from OSS
Differential Revision: D18790518
fbshipit-source-id: 4dd39cf0b31b21f5586c0edfdce2260d4e245112
Summary:
we prefer "_" over "-" in build names, so change checks in test script
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30836
Differential Revision: D18840736
Pulled By: mingbowan
fbshipit-source-id: 6fdf736496225c5f8ab44906d8f4681b7bf894a7
Summary:
VitalyFedyunin, This PR is about port Hardtanh activation to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Hardtanh()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
fwd_t = 0
bwd_t = 0
for i in range(10000):
t1 = _time()
output = m(input)
t2 = _time()
output.backward(grad_output)
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.06 (ms).
input size(128, 10000) forward time is 0.84 (ms); backwad avg time is 0.44 (ms).
```
After:
```
GPU:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.11 (ms).
input size(128, 10000) forward time is 0.06 (ms); backwad avg time is 0.17 (ms).
CPU
input size(128, 100) forward time is 0.02 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 0.61 (ms); backwad avg time is 0.10 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.07 (ms).
input size(128, 10000) forward time is 5.21 (ms); backwad avg time is 5.25 (ms).
After:
input size(128, 100) forward time is 0.01 (ms); backwad avg time is 0.02 (ms).
input size(128, 10000) forward time is 1.09 (ms); backwad avg time is 1.09 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30152
Differential Revision: D18815545
Pulled By: VitalyFedyunin
fbshipit-source-id: d23b6b340a7276457f22dce826bcbe3b341d755f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29944
This particular approach queries our issue tracker for test titles that
match the following format:
```
DISABLED test_async_grad_guard_with_grad (jit.test_async.TestAsync)
```
And then skips the python test for them. There is 1 second timeout so
if the internet flakes we still run the test suite, without disabling any
tests.
This is intended as a quick fix, similar to ninja unland, to get to a green
master. Long term test disables should go into the code.
Test Plan: Imported from OSS
Differential Revision: D18621773
Pulled By: zdevito
fbshipit-source-id: 5532f1d5fa3f83f77fc3597126cbb7dba09a3c33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30825
It didn't verify in the 1-d case that the targets were size 1..
Test Plan: Imported from OSS
Differential Revision: D18833659
Pulled By: gchanan
fbshipit-source-id: 9b0276e7b0423fdaf2ba7cfa34bde541558c61f9
Summary:
We dont have ATen/native/*.h in torch target before, and we would like it to be exposed for external use.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30835
Differential Revision: D18836160
Pulled By: zrphercule
fbshipit-source-id: 7330a9c9d8b65f173cc332b1cfeeb18c7dca20a8
Summary:
This PR adds docs for how we expose declarations in `at::` to `torch::`, to make the semantics more clear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30760
Differential Revision: D18833081
Pulled By: yf225
fbshipit-source-id: eff4d8815c67f681ce3a930ce99771cf2e55dbd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30800
SparseNN benchmark crashed due to this.
Wrap warning handler in a function to avoid siof.
Test Plan: Tested locally, SparseNN benchmark no longer crashes.
Reviewed By: yinghai
Differential Revision: D18826731
fbshipit-source-id: 8fcab8a3f38cc20f775409c0686363af3c27d0a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30769
The TorchConfig.cmake is the public cmake we produce in install folder for
3rd party client code to get all libtorch dependencies easily.
Apparently this build flow is not well covered by our CI (which is focused
on 1st party build / shared libraries?) as the little dummy project for
code analysis testing purpose was broken by #30315 without fail any CI.
Fixed the problem for mobile build and add the dummy project build to mobile
CI as well.
Test Plan: - make sure new CI pass;
Differential Revision: D18825054
Pulled By: ljk53
fbshipit-source-id: 80506f3875ffbc1a191154bb9e3621c621e08b12
Summary:
Fixes https://github.com/pytorch/pytorch/issues/29161.
I looked a bit at the code changes related to this and think I have all of the use cases of `DeprecatedTypeProperties` covered in the message, but suggestions from someone with more context on this would be very much appreciated :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30281
Differential Revision: D18830818
Pulled By: ezyang
fbshipit-source-id: 1a7fcee15354ae09e6644577e7fa33bd26acfe20
Summary:
To support variadic inputs of `checkpoint_sequential` was deprecated at https://github.com/pytorch/pytorch/issues/21006. This case should be warned with `DeprecationWarning` for PyTorch 1.2, but it should be simply failed with `TypeError` since PyTorch 1.3. This patch removes the `DeprecationWarning` for PyTorch 1.2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25985
Differential Revision: D18809875
Pulled By: albanD
fbshipit-source-id: e84dd8629c04979c4b2dc63e8ada94292e8cedd0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30768
The behavior didn't match the documentation, because the documentation (for 'none' reduction) reads:
input X target -> output
(N, C) X (N, C) -> (N,)
(C,) X (C,) -> ()
but the later case would output (1,). This also changes the case to:
() X (C,) -> ()
from:
() X (C,) -> (C,)
which makes more sense with the above formulas.
Restacked version of: https://github.com/pytorch/pytorch/pull/30748
Test Plan: Imported from OSS
Differential Revision: D18821554
Pulled By: gchanan
fbshipit-source-id: 3df77c51cf25648cb5fab62a68b09f49c91dab4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30765
It is already supported in CPU and is pretty easy to add for consistency.
Restacked version of: https://github.com/pytorch/pytorch/pull/30727
Test Plan: Imported from OSS
Differential Revision: D18821557
Pulled By: gchanan
fbshipit-source-id: e6aa3e91000ff3fd63941defc7d30aef58ae2f82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30746
This diff should be safe as long as open source build succeeds and should have no impact to cuda.
Differential Revision: D18811302
fbshipit-source-id: a7adab993816cba51842701898fac5019438b664
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for CUDA complex numbers is here: [pytorch-cuda-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cuda-strided-complex)
Changes so far:
- [x] Added complex support of torch.empty and torch.fill()
- [x] Added complex support of CopyKernels
- The 'static_cast_with_inter_type' template function is specialized for the following cases
- `dest_t = thrust::complex<dest_value_t>`, `src_t = std::complex<src_value_t>`
- `dest_t = std::complex<dest_value_t>`, `src_t = thrust::complex<src_value_t>`
- This handles the compile-time case where `dest_value_t=double` and `src_value_t=float`.
- [x] Added complex support of BinaryOp kernels
- `using thrust_t = typename ztype_cuda<scalar_t>::thrust_t;` converts std::complex<T> ScalarTypes to thrust types and is a no-op of other Scalar Types.
- The operator is performed using complex number support defined in `thrust/complex.h`
- This could be extended to work with ROCm by using `rocm/complex.h`
- [x] Added complex support of UnaryOp kernels
- Added CUDA support for `angle()`, `real()`, `imag()`, `conj()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30295
Differential Revision: D18781954
Pulled By: ezyang
fbshipit-source-id: 25d204c0b8143ee27fda345a5d6a82f095da92a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28443
We're now on C++14, so we don't need the else branch of these ifdef's anymore
ghstack-source-id: 94904074
Test Plan: waitforsandcastle
Differential Revision: D18069136
fbshipit-source-id: f1613cab9a99ee30f99775e4a60a1b06fd0a03ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30550
Right now we have a `InsertQuantDeQuantHelper` for each module, but we need
it to be global because we need to know what graphs have been quantized before
and based on this information we can decide how to handle the module instance.
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D18818651
fbshipit-source-id: bfcaf37094ce20a257171a0c99b05b9348ebc13d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30037
Support quantization for modules with reused submodules, e.g. relu (automatically make unique)
We first do a pass on the graph to find all duplicate uses of the same module, and record the `Value`s of the
module instance, for each of these values we create a new module and change the access to that module.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D18821483
fbshipit-source-id: 1698b981e9e9f0c728d9f03fcbcfbd260151f679
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30473
Invoked `ConstantPooling` and `FuseLinear` pass before
`insertObservers`.
`ConstantPooling` is for cleanning up traced graph, e.g. when we
have to constant node that has the same value, this pass will merge them,
this allows us to have less quantization patterns
`FuseLinear` is to merge the exploded linear function into `aten::linear` so
that we can quantize this function properly. We need to fuse it because right now
the way we recognize weight and bias is by matching the argument position in certain function
calls, e.g. 1st argument of aten::conv2d is weight. Therefore we have to preserve
the bounary of the linear function to recognize the weight of linear. Since in the exploded
linear code, input of addmm is transposed weight rather than the original weight of linear.
ghstack-source-id: 94887831
Test Plan:
This is needed for quantizing traced model tests to pass
Imported from OSS
Differential Revision: D18795722
fbshipit-source-id: 192d9d1e56307e2e1d90e30dce0502e31cb4f829
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30737
Original commit changeset: 2a8b2a3f5401
Reverting this to be safe until we address test failures in T58528495
Test Plan: CI
Reviewed By: wx1988
Differential Revision: D18812384
fbshipit-source-id: 2a3ac554024773022ec827f259127e4c8cffe6e2
Summary:
For system pybind11 installs this is a system header location that should not get installed since it might include other unrelated headers. Since the header is already installed for a system install there's no need to install the headers, so only do the install when we use the bundled pybind11 version.
Closes https://github.com/pytorch/pytorch/issues/29823. Closes https://github.com/pytorch/pytorch/issues/30627.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30758
Differential Revision: D18820189
Pulled By: bddppq
fbshipit-source-id: fcc9fa657897e18c07da090752c912e3be513b17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29217
We want to preserve constant information in ClassType so that
users can access the constants in the module by name.
This is also used later for freezing some attribute(converting
attributes to constant)
Test Plan:
tbd
Imported from OSS
Differential Revision: D18799955
fbshipit-source-id: fbfbcd5d3f7f560368b96e2a87e270c822a3d03a
Summary:
This is a re-do of https://github.com/pytorch/pytorch/issues/27064, which was reverted (b8792c0438). This was landed at the same time as other work that added new operators to the `torch` namespace so the check for whether the `torch` namespace is exhaustively checked for overridability was triggering test failures.
I've temporarily disabled that check and added an explanatory comment that the check will be re-enabled in a future PR that will be merged during a time when the commit velocity on PyTorch is lower.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30730
Differential Revision: D18813270
Pulled By: ezyang
fbshipit-source-id: 70477c4656dca8fea6e7bc59259555041fcfbf68
Summary:
VitalyFedyunin, This PR is about port Tanh backward to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
m = nn.Tanh()
if torch.cuda.is_available():
device = "cuda"
m = m.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
for i in range(1000):
output = m(input)
output.backward(grad_output)
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
grad_output = torch.ones(128, n, device=device)
bwd_t = 0
for i in range(10000):
output = m(input)
t1 = _time()
output.backward(grad_output)
t2 = _time()
bwd_t = bwd_t + (t2 - t1)
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) backwad avg time is %.2f (ms)." % (n, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P40.
Perfromance:
Before:
```
GPU:
input size(128, 100) backwad avg time is 0.12 (ms).
input size(128, 10000) backwad avg time is 0.17 (ms).
CPU
input size(128, 100) backwad avg time is 0.05 (ms).
input size(128, 10000) backwad avg time is 0.35 (ms).
```
After:
```
GPU:
input size(128, 100) backwad avg time is 0.12 (ms).
input size(128, 10000) backwad avg time is 0.17 (ms).
CPU
input size(128, 100) backwad avg time is 0.04 (ms).
input size(128, 10000) backwad avg time is 0.25 (ms).
```
`OMP_NUM_THREADS=1:`
```
Before:
input size(128, 100) backwad avg time is 0.03 (ms).
input size(128, 10000) backwad avg time is 1.85 (ms).
After:
input size(128, 100) backwad avg time is 0.02 (ms).
input size(128, 10000) backwad avg time is 1.16 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30224
Differential Revision: D18810045
Pulled By: VitalyFedyunin
fbshipit-source-id: ab37948ab8f76bdaf9f3d1388562eaf29dacc0ea
Summary: As title
Test Plan: buck test caffe2/caffe2/fb/optimizers:masked_adagrad_test
Reviewed By: chocjy
Differential Revision: D18736639
fbshipit-source-id: d0d73f75228604d3448651bff2cf34ecc21f9ba6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30670
Also turn off scalar_check for grad_input: it isn't necessary because the input can't be 0-dimensional.
Test Plan: Imported from OSS
Differential Revision: D18784523
Pulled By: gchanan
fbshipit-source-id: 246d30970457075a0403dd0089317659a2cd2dd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30669
The inputs can't be 0-d, so we don't need that check in the scalar_check.
Test Plan: Imported from OSS
Differential Revision: D18784524
Pulled By: gchanan
fbshipit-source-id: d44222dffc91880a6e8c7be69e6e146e60040d43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30665
total_weight is a "hidden" output just for autograd, so it's not user visible. The existing test_nn tests cover this (I verified that the new code is executed) and this matches the CPU behavior.
Test Plan: Imported from OSS
Differential Revision: D18782709
Pulled By: gchanan
fbshipit-source-id: 6d1c20eeaeffa14d06f375b37f11e866587f5fa0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30549
Preparing for later refactoring
Test Plan:
.
Imported from OSS
Differential Revision: D18802464
fbshipit-source-id: 0b5afb143549d93eed4c429125d3d5fd253093a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30548
ClassTypes can be shared among different module instances, but previously we assumed
they would be unique, this PR enables the insert_observers pass to work with shared class types
Test Plan:
python test/test_jit.py
python test/test_quantization.py
Imported from OSS
Differential Revision: D18802465
fbshipit-source-id: b782e71e44a043af45577ac2b5c83e695155bb8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30558
Most c10 op registration/invocation cases are generated by aten codegen
following some fixed pattern, but a handful of them were written
manually, mainly for quantized ops. Added these "irregular" cases to the
test project to verify static code analyzer can handle them as well.
Test:
- build and run the test project;
Test Plan: Imported from OSS
Differential Revision: D18811098
Pulled By: ljk53
fbshipit-source-id: 7bdf17175dfec41c56c0d70f124cc96478135bc4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30315
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
This is a reland of https://github.com/pytorch/pytorch/pull/29731 but
I've extracted all of the prep work into separate PRs which can be
landed before this one.
Some things of note:
* torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
* The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/libprotobuf.a(arena.cc.o) is referenced by DSO"
* A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly
* I had to torch_cpu/torch_cuda caffe2_interface_library so that they get whole-archived linked into torch when you statically link. And I had to do this in an *exported* fashion because torch needs to depend on torch_cpu_library. In the end I exported everything and removed the redefinition in the Caffe2Config.cmake. However, I am not too sure why the old code did it in this way in the first place; however, it doesn't seem to have broken anything to switch it this way.
* There's some uses of `__HIP_PLATFORM_HCC__` still in `torch_cpu` code, so I had to apply it to that library too (UGH). This manifests as a failer when trying to run the CUDA fuser. This doesn't really matter substantively right now because we still in-place HIPify, but it would be good to fix eventually. This was a bit difficult to debug because of an unrelated HIP bug, see https://github.com/ROCm-Developer-Tools/HIP/issues/1706Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18790941
Pulled By: ezyang
fbshipit-source-id: 01296f6089d3de5e8365251b490c51e694f2d6c7
Summary:
[Why static dispatch]
Static dispatch was introduced to allow stripping out unused ops at link
time (with “gc-sections” linker flag) for mobile build.
The alternative approaches to do "non-static" dispatch are:
* virtual methods - old ATen dispatcher, which has already been deprecated;
* registry pattern - used by caffe2, c10 and JIT;
However, none of them are “gc-sections” friendly. Global registers are
root symbols - linker cannot strip out any op if we use registry pattern
for mobile.
[Why static dispatch isn’t great]
* One more code path to maintain;
* Need recompile framework to add new backends/ops;
* Doesn’t support AutoGrad yet thus blocks on-device training;
[Static Code Analysis]
This PR introduces a LLVM analysis pass. It takes LLVM bitcode /
assembly as input and generates dependecy graph among aten ops. From a
set of root ops used by a model, we can calculate transitive closure of
all dependent ops, then we can ask codegen to only register these ops.
[Approach]
To generate the dependency graph it searches for 3 types of connections in
LLVM bitcode / assembly:
1) op registration: op name (schema string literal) -> registered function;
2) regular function call: function -> function;
3) op invocation: function -> op name (schema string literal)
For 2) it uses similar algorithm as llvm::LazyCallGraph - not only looks into
call/invoke instructions but also recursively searches for function pointers
in each instruction's operands.
For 1) and 3) it searches for connections between operator name string
literals / function pointers and c10 op registration/invocation API calls in
LLVM IR graph via "use" edges (bi-directional):
1. llvm::Value has "users()" method to get other llvm::Value nodes that use
the value;
2. most of types derive from llvm::User which has "operands()" method to get
other llvm::Value nodes being used by the value;
[Limitation]
For now the search doesn't go beyond the function boundary because the
reference to op name string literals and c10 op registration/invocation
APIs are almost always in the same function.
The script uses regular expression to identify c10 API calls:
* op_schema_pattern="^(aten|quantized|profiler|_test)::[^ ]+"
* op_register_pattern="c10::RegisterOperators::(op|checkSchemaAndRegisterOp_)"
* op_invoke_pattern="c10::Dispatcher::findSchema|callOp"
If we create helper function around c10 API (e.g. the "callOp" method
defined in aten/native), we could simply add them to the regular expression
used to identify c10 API.
[Example]
In the following example, it finds out:
1) the registered function for "quantized:add" operator;
2) one possible call path to at::empty() function;
3) the called operator name "aten::empty":
- "quantized::add"
- c10::detail::wrap_kernel_functor_unboxed_<at::native::(anonymous namespace)::QAdd<false>, at::Tensor (at::Tensor, at::Tensor, double, long)>::call(c10::OperatorKernel*, at::Tensor, at::Tensor, double, long)
- at::native::(anonymous namespace)::QAdd<false>::operator()(at::Tensor, at::Tensor, double, long)
- void at::native::DispatchStub<void (*)(at::Tensor&, at::Tensor const&, at::Tensor const&), at::native::qadd_stub>::operator()<at::Tensor&, at::Tensor const&, at::Tensor const&>(c10::DeviceType, at::Tensor&, at::Tensor const&, at::Tensor const&)
- at::native::DispatchStub<void (*)(at::Tensor&, at::Tensor const&, at::Tensor const&), at::native::qadd_stub>::choose_cpu_impl()
- void at::native::(anonymous namespace)::qadd_kernel<false>(at::Tensor&, at::Tensor const&, at::Tensor const&)
- at::TensorIterator::binary_op(at::Tensor&, at::Tensor const&, at::Tensor const&, bool)
- at::TensorIterator::build()
- at::TensorIterator::fast_set_up()
- at::empty(c10::ArrayRef<long>, c10::TensorOptions const&, c10::optional<c10::MemoryFormat>)
- "aten::empty"
[How do we know it’s correct?]
* Built a test project that contains different op registration/invocation
patterns found in pytorch codebase, including both codegen and non-codegen
cases.
* Tried different optimization flags “-O0”, “-O3” - the result seems to
be stable.
* Filtered by common patterns: “aten::”, “at::”, “at::native”,
“at::CPUType”, “at::TypeDefault” - manually checked the relationship
between function schema strings and corresponding implementations were
captured.
* It can print instruction level data flow and show warning message if it
encounters unexpected cases (e.g.: found 0 or multiple op names per
registration/invocation API call, found 0 registered functions, etc).
* Verified consistent results on different linux / macOs hosts. It can
handle different STL library ABI reliably, including rare corner cases
for short string literals
[Known issues]
* Doesn’t handle C code yet;
* Doesn’t handle overload name yet (all variants are collapsed into the
main op name);
Test Plan:
```
LLVM_DIR=... ANALYZE_TEST=1 CHECK_RESULT=1 scripts/build_code_analyzer.sh
```
Differential Revision: D18428118
Pulled By: ljk53
fbshipit-source-id: d505363fa0cbbcdae87492c1f2c29464f6df2fed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30713
It should use moveToIntrusivePtr.
This function is a very hot one and used a lot in interpreter loop. e.g.
GET_ATTR, SET_ATTR. Making a copy and doing incref/decref caused big overhead.
Reviewed By: yinghai
Differential Revision: D18805212
fbshipit-source-id: 3a9368604f71638a21300ad086739c4b50f0644e
Summary:
Move the shell script into this separate PR to make the original PR
smaller and less scary.
Test Plan:
- With stacked PRs:
1. analyze test project and compare with expected results:
```
ANALYZE_TEST=1 CHECK_RESULT=1 tools/code_analyzer/build.sh
```
2. analyze LibTorch:
```
ANALYZE_TORCH=1 tools/code_analyzer/build.sh
```
Differential Revision: D18474749
Pulled By: ljk53
fbshipit-source-id: 55c5cae3636cf2b1c4928fd2dc615d01f287076a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30467
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
Test Plan: Imported from OSS
Differential Revision: D18801619
Pulled By: iseeyuan
fbshipit-source-id: f9b198d3e82b095daf704ee595d8026ad889bb13
Summary:
With the CI failure caused in 8bbafa0b32d2899ef6101172d62c6049427c977b fixed (incorrect return type of the lambdas in CUDA kernels)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30521
Differential Revision: D18770151
Pulled By: ailzhang
fbshipit-source-id: 02f0fe1d5718c34d24da6dbb5884ee8b247ce39a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30197
This default constructor was added because std::map's operator[]
requires a default constructor. However, instead of using operator[], we can
use emplace and remove the constructor, to ensure that the FutureInfo struct
doesnt get constructed with garbage values.
ghstack-source-id: 94802453
Test Plan: Unit tests pass.
Differential Revision: D18627675
fbshipit-source-id: c4cb000e60081478c0fd7308e17103ebbc4dc554
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30677
Currently you can only add FunctionEvents to FunctionEventAvg. This makes it so you can add multiple FunctionEventAvg objects together. This is useful for merging multiple profiles together such as when dealing with distributed training.
Test Plan:
added unit test
buck test //caffe2/test:autograd -- test_profiler
Reviewed By: bddppq
Differential Revision: D18785578
fbshipit-source-id: 567a441dec885db7b0bd8f6e0ac9a60b18092278
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28389
Intel's OpenMP implementation sets the thread affinity on the first call to an OpenMP function after a fork. By adding an atfork handler we can force this to happen before a user tries to set the affinity in their own DataLoader `worker_init_fn`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29006
Differential Revision: D18782456
Pulled By: ezyang
fbshipit-source-id: ce0b515256da0cf18ceb125e0cdec99a3311bbd3
Summary:
This fixes the second issue reported in https://github.com/pytorch/pytorch/issues/29909 namely, a loop counter is assigned the wrong values after transitioning to a bailout graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30186
Differential Revision: D18646845
Pulled By: Krovatkin
fbshipit-source-id: 1f7c601dd9f35892979385ffa132fb0886a4f203
Summary:
This PR removes `namespace F = torch::nn::functional` from `torch/nn/modules/batchhnorm.h`, so that people don't have to define `torch::nn::functional` as `F` if they don't want to.
Fixes https://github.com/pytorch/pytorch/issues/30682.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30684
Differential Revision: D18795717
Pulled By: yf225
fbshipit-source-id: c9feffbeb632cc6b4ce3e6c22c0a78533bab69ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30659
I could only find one usage of TupleParser and it doesn't seem worth maintaining just for that one usage.
Test Plan: Imported from OSS
Differential Revision: D18795979
Pulled By: nairbv
fbshipit-source-id: 6e50d65fc8fade0944f36ab20d00f1539a3d4cb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30498
Updated Int8SliceOp to accept dim, start and end index similar to Pytorch.
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_slice
Imported from OSS
Differential Revision: D18740519
fbshipit-source-id: 2313f37a4936edb150ce04911b241e591e191801
Summary:
To ensure synchronization between copying of weights in RNN wei buf, and the operation, both the pyTorch operator as well as underlying MIOpen call must be on the same HIP stream. This is also consistent with MIOpen calls in other pyTorch operators
ezyang iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30672
Differential Revision: D18785683
Pulled By: bddppq
fbshipit-source-id: 144611046cb70cfe450680295734203f253ac6e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30345
Skip ProcessGroupGlooAyncTest if there is no CUDA available, otherwise in sandcastle non GPU host the test will abort with failing to load CUDA library
ghstack-source-id: 94771241
Test Plan: test skipped on non GPU host
Differential Revision: D18665322
fbshipit-source-id: 8c7b89aeecc6ec007bee12d864a6058384254e61
Summary:
This improved multi-d microbenchmark by ~100 ns, empty_tensor_restride used to be 13% of iteration time, now about 5%
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30452
Test Plan: Covered by existing tests
Differential Revision: D18704233
Pulled By: ngimel
fbshipit-source-id: be527f09183bc31e9d1f63fd49bfbe0998fe167f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30636
Currently DeQuantStub is still in whitelist because set union has
lower precedence than set difference
fix issue: https://github.com/pytorch/pytorch/issues/29646
Test Plan:
verified locally that we don't attach qconfig for DeQuantStub
Imported from OSS
Differential Revision: D18775275
fbshipit-source-id: 8da07e40963555671b3d4326c9291706103f858e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30327
### Summary
Seems like starting from macOS 10.15, we can no longer get access to the `Downloads` folder in our macOS machines.
```
permissionError: [Errno 1] Operation not permitted: '/Users/distiller/Downloads'
```
The fix is to change the conda download directory to ${HOME}
### Test Plan
- iOS jobs are back to normal
- Don't break other jobs
Test Plan: Imported from OSS
Differential Revision: D18717380
Pulled By: xta0
fbshipit-source-id: cad754076bf4ae5035741aa57a310ad87c76726e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30314
Somehow we forgot to define it!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762356
Pulled By: ezyang
fbshipit-source-id: 28afc605ad986266071e3831049ec8a7f71fd695
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30313
See comments in code about the bug.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762360
Pulled By: ezyang
fbshipit-source-id: 406a01f2f0c3722b381428c89afd67b3c3c19142
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30312
It's not necessary because it's already defined in the header.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762363
Pulled By: ezyang
fbshipit-source-id: 418bf355d460dd171ac449559f20bf55415e54ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30311
multinomial_stub must be in scope to register against it. Somehow,
this works today, but when I split torch_cpu and torch_cuda it
doesn't.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762358
Pulled By: ezyang
fbshipit-source-id: ef9c111292cd02d816af1c94c8bbaadabffaabe5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30310
- Annotate CUDAGenerator.h with correct TORCH_CUDA_API.
This is actually CUDA related functionality with its implementation living
in the cuda/ folder. For some reason it lives at the top level; it
should be moved (but that should be handled in another PR.)
- Add missing TORCH/CAFFE_API annotations to. All of
these functions are used from CUDA code, which means that
we need to correctly annotate them if we split CPU/CUDA code
into separate libraries.
Test Plan: Imported from OSS
Differential Revision: D18762357
Pulled By: ezyang
fbshipit-source-id: c975a8e4f082fe9f4196c2cca40977623caf4148
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30308
Dispatch is declared in non-anonymous namespace, so it definitely
shouldn't be defined in an anonymous namespace. This doesn't seem
to matter today, but it matters when we split libtorch into two
libraries.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762361
Pulled By: ezyang
fbshipit-source-id: 484f0fab183c385dd889db9dad3e48e92e0a3900
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30307
DispatchStub will stop working when I split CPU/CUDA libraries, because
there are some symbols from the templates in DispatchStub stubs which aren't
properly exported and I couldn't figure out how to make them dispatch properly.
This is the only case where DispatchStub is being used to dispatch to CUDA,
anyway.
This partially addresses #29844 but I need to also just completely delete
the CUDA registration logic from DispatchStub entirely.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18762362
Pulled By: ezyang
fbshipit-source-id: bdfa8739c0daf23badf3c5af61890a934af00813
Summary:
Convolution nodes are traced as aten:_convolution and are currently supported in ONNX.
Scripting convolution uses aten:conv<1,2,3>d which are currently not supported in ONNX.
This PR adds the symbolics for aten:conv<1,2,3>d and aten:conv_transpose<1,2,3>d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30618
Reviewed By: hl475
Differential Revision: D18778145
Pulled By: houseroad
fbshipit-source-id: 4af0379f29974a1ce8443024d1d87b3eb8d2dd36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30546
factor out this function for later support of quantizing shared types
Test Plan:
test_jit.py, test_quantization.py
Imported from OSS
Differential Revision: D18776304
fbshipit-source-id: f5a736b0f69019cefe17ec4517da1ae5462f78e1
Summary:
Improve .view() performance by not calling set_ and instead restriding returned alias. This improves performance of .view() operation from ~500ns to ~360 ns
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30554
Test Plan: covered by existing tests
Differential Revision: D18759896
Pulled By: ngimel
fbshipit-source-id: 9757c93158bc55e9c87dc30ac3415ba8f8b849e5
Summary:
This tests seems to only test that we throw exceptions in the `WorkerInfo` constructor when invalid names are passed in, so I don't think we need to complicate by initializing RPC, and exposing ourselves to potential flakiness.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30620
Differential Revision: D18766955
Pulled By: rohan-varma
fbshipit-source-id: 11643de4d57431e5f46e096c7766de3ab0b9b05a
Summary:
Previous behaviour: a user runs tests from `TestCppExtension` class so that `/tmp/torch_extensions` is created under her ownership and not removed afterwards,
then the other user's run of the same tests might result in 'Permission denied' exception upon deleting `/tmp/torch_extensions`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30095
Differential Revision: D18770234
Pulled By: ezyang
fbshipit-source-id: 4c6b972e4c4327a94c8b4bf6b0b9998a01c218bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30527
When we introduced dtype.is_signed we allowed for support of
quantized types, but we're not sure what the correct result should be.
See discussion at https://github.com/pytorch/pytorch/pull/29511
Test Plan: Imported from OSS
Differential Revision: D18765410
Pulled By: nairbv
fbshipit-source-id: c87cfe999b604cfcbbafa561e04d0d5cdbf41e6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30603
Pickler object needs to be kept in scope until data is written out to the
final serialized string. tensorData in particular is a reference to memory
owned by the descoped Pickle object.
Noticed this by inspection. In practice, this potential read-after-free here
is limited to non-cpu tensors, and any such use was very soon after free.
ghstack-source-id: 94756036
Test Plan: existing test suite at buck test mode/dev-nosan caffe2/test:rpc_fork
Differential Revision: D18760463
fbshipit-source-id: 9de890d66626aa48f13ca376dd9bd50b92e0cb00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30354
TCPStoreTest would timeout since the TCPStore constructor for the
server would block the main thread waiting for workers. The workers themselves
were spawned later on once the server store is created. As a result, this test
would always timeout.
To fix the test, I moved the server store to a thread so that the workers can
register with the server in parallel.
In addition to this made a few improvements to tcputils::connect. When
tcputils::connect() encountered an exception, it always looked at `errno` for
the error code. In some cases `errno` could be overwritten and the real error
code would be stored in `std::system_error`. As a result, I've modified the
code to look at the error code in `std::system_error` if we catch an exception
of that type.
ghstack-source-id: 94758939
Test Plan: waitforbuildbot
Differential Revision: D18668454
fbshipit-source-id: d5a3c57b066b094bfecda9a79d9d31bfa32e17f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30529
We started to see build failures for multiple services with top-of-trunk LLVM compiler. The failures point to a warning that was treated as error for implicit conversion from long to double. Per discussion on D18642524, I'm disabling this warning from the containing TARGET file. T58053069 opened for code owner to track this - a proper source code fix and more unit test is needed.
Test Plan: local build, sandcastle
Reviewed By: smessmer
Differential Revision: D18668396
fbshipit-source-id: 28c0ff3258c5ba3afd41a0053f9fe1b356a496a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30490
Add symbolic mapping to Int8AvgPool2d and Int8Reshape op in C2
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps
Imported from OSS
Differential Revision: D18740520
fbshipit-source-id: 1606125500c4b549fbc984e7929b7fd5204396a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30624
These tests were flaky since we would end up calling the 'verify'
methods before some of the RPCs were done. The `check_rpc_done` function might
not guarantee this since set_rpc_done sets an appropriate flag in python which
causes `check_rpc_done` to pass. Although, there are a few steps after that
like attaching the send functions for the response of the RPC that might not
have executed by then.
ghstack-source-id: 94781954
Test Plan: Run the tests 100 times.
Reviewed By: zhaojuanmao
Differential Revision: D18768786
fbshipit-source-id: a14c3f4b27de14fe5ecc6e90854dc52652f769b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30351
Not sure what proper fix is, clang is having trouble with the loop pragmas. This at least gets things compiling.
ghstack-source-id: 94458450
Test Plan: CI passes
Differential Revision: D18665812
fbshipit-source-id: b8a899ce4138010cbe308eaa2c0838dd9e15573f
Summary:
This TOC is manually generated but `CONTRIBUTING.md` seems like its
stable enough for that to be okay
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29671
Pulled By: driazati
Differential Revision: D18771604
fbshipit-source-id: 0d6c9c6cf1083d3be413219d3cead79c2fe5050b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30434
These are all pointwise ops that are implemented correctly wrt shapes in THC.
Test Plan: Imported from OSS
Differential Revision: D18699087
Pulled By: gchanan
fbshipit-source-id: 82cb91b00c77bfaca75be497c87fc7ae52daf46c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30449
There was an inconsistency in the order of operation between scalar and SIMD code when we compute Adagrad.
In this diff we first compute effective_lr = lr / (sqrt(moment) + epsilon) and then multiply with gradient.
Test Plan: CI
Reviewed By: protonu
Differential Revision: D18703416
fbshipit-source-id: 2a8b2a3f5401466549561412bd22f07abac3c598
Summary:
${CMAKE_HOST_SYSTEM_PROCESSOR} get processor name by `uname -p` on linux and `%PROCESSOR_ARCHITECTURE%` on windows
1. %PROCESSOR_ARCHITECTURE% has value in (AMD64|IA64|ARM64) for 64-bit processor, and (x86) for 32-bit processor
2. `uname -p` has value like "(x86_64|i[3-6]+86)"
We cannot tell intel cpu from other cpus by ${CMAKE_HOST_SYSTEM_PROCESSOR}. It is the architecture, not provider.
i. e. Intel CPU i7-9700K CPU on windows get "AMD64"
reference:
[MSDN](https://docs.microsoft.com/zh-cn/windows/win32/winprog64/wow64-implementation-details?redirectedfrom=MSDN)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30564
Differential Revision: D18763031
Pulled By: ezyang
fbshipit-source-id: 11ae20e66b4b89bde1dcf4df6177606a3374c671
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30594
This testcase started breaking, clean up for the build.
ghstack-source-id: 94736837
Test Plan: Unittest disabling change
Differential Revision: D18758635
fbshipit-source-id: 05df1158ff0ccd75e401f352da529fb663b1cae0
Summary:
On the latest master, I get link errors when building one of the tests:
```sh
/home/pbell/git/pytorch/build/../test/cpp/rpc/test_wire_serialization.cpp:23:
undefined reference to `torch::distributed::rpc::wireDeserialize(void const*, unsigned long)'
```
This seems to be caused by PR https://github.com/pytorch/pytorch/issues/29785 not working with `USE_DISTRIBUTED=0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30587
Differential Revision: D18758625
Pulled By: jjlilley
fbshipit-source-id: 0ad0703acdbbac22bb4b8317370fbe2606fcb67e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30491
Our RPC API docs presents the APIs well but misses a general
introduction to the APIs. Readers might be a little lost the first
time landing this page. This commits reorganizes the APIs into
four components from user's perspective, RPC, RRef, dist autograd,
and dist optimizer. It also adds an intro to each and briefly
discribes why we provide those.
Test Plan: Imported from OSS
Differential Revision: D18723294
Pulled By: mrshenli
fbshipit-source-id: 4aced4ab537b070aa780aaaf9724659fd47cb3cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29785
TLDR: This change improves process_group's serialization speed:
Serialize_Tensor64: 12.38us -> 1.99us (~-84%)
Deserialize_Tensor64: 33.89us -> 5.62us (~-84%)
Serialize_Tensor1M: 525.74us -> 285.43us (~-45%)
Deserialize_Tensor1M: 892.61us -> 273.68us (~-70%)
After speaking with the jit team, we had consensus that torch::save()/load()
are somewhat high-overhead for RPC serialization, mostly intended for
persistent disk data.
(Particularly, for large tensors, 35% of the time is spent in CRC checking, even
with the fb-side changes to subsitute 40x faster SSE-accelerated crc checking;
Also, for small tensors, the zip container overhead is considerable, as is the
overhead of lexing/parsing an embedded text python program for each RPC).
The jit team encouraged us to use jit::pickler, with the WriteableTensorData
way of outputting result tensors (not the default side-tensor table, or
with pickling the actual tensors). This ends up just pickling some tensor
metadata, and giving us some tensor blobs that we can mindlessly
blit over the wire (they copy to cpu memory if needed).
There is yet no standardized container format for the pickled data
(there is jit::pickle_save() checked in, but but it's experimental,
no load function is yet provided), but they encouraged us to just use
something sensible for this, and possibly revisit later. For now, I made
the directory headers slightly http-inspired.
Note that serialization is just one component of the pipeline, but that
said, we also see reasonable reductions in end-to-end echo times (noisier):
ProcessGroupAgent_Echo(Tensor_Small) 855.25us -> 492.65us (~-42%)
ProcessGroupAgent_Echo(Tensor_1M) 10.82ms -> 6.94ms (~-35%)
ProcessGroupAgent_Echo(Small_NoTensor) 688.82us -> 301.72us (~-56%)
ProcessGroupAgent_Echo(1MB_NoTensor) 4.65ms -> 3.71ms (~-20%)
I moved the "wire serialization" logic to a separate file to assist with
unittesting.
ghstack-source-id: 94694682
Test Plan:
buck test mode/dev-nosan caffe2/test/cpp/api:serialize
buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18493938
fbshipit-source-id: 07ddfe87dbe56472bc944f7d070627052c94a8f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30330
This is now possible due to previous changes made in `gloo` and `ProcessGroupGloo`. We `abort` the listener thread that is waiting for a message, and join all other threads. The API is changed so that the previous `wait_all_workers` does not destroy the agent, and this is now done in a new `shutdown` method. All callsites are updated appropriately.
ghstack-source-id: 94673884
ghstack-source-id: 94673884
Test Plan: Unit tests pass.
Reviewed By: mrshenli
Differential Revision: D18661775
fbshipit-source-id: 5aaa7c14603e18253394224994f6cd43234301c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30522
This is in preparation for moving the docs push CI jobs to depend on
`pytorch-linux-xenial-py3.6-gcc5.4` rather than
`pytorch-linux-xenial-cuda9-cudnn7-py3`.
Test Plan: Imported from OSS
Differential Revision: D18731108
Pulled By: zou3519
fbshipit-source-id: fd753a5ca818fa73a14e4276c33368a247cc40e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30361
### Summary
By default, the compiler will choose `clock_gettime` for the iOS build. However, that API is not available until iOS 10. Since the Facebook app still supports iOS 9.0, we have to use `gettimeofday` instead.
```shell
xplat/caffe2/torch/csrc/autograd/profiler.h:86:3: error: 'clock_gettime' is only available on iOS 10.0 or newer [-Werror,-Wunguarded-availability]
xplat/caffe2/torch/csrc/autograd/profiler.h:86:17: error: '_CLOCK_MONOTONIC' is only available on iOS 10.0 or newer [-Werror,-Wunguarded-availability]
```
P.S. the open-sourced version is iOS 12.0 and above, so we don't have this problem.
### Test Plan
- buck build works
- Don't break CIs
Test Plan: Imported from OSS
Differential Revision: D18730262
Pulled By: xta0
fbshipit-source-id: fe6d954b8d3c23cbc9d1e25a2e72e0b0c1d4eaa9
Summary:
PyTorch dim and ONNX axis have different meanings.
ONNX only supports log_softmax with dim = -1. Transpose must be added before and after log_softmax to support other cases.
This requires input rank to be known at export time.
Fixes https://github.com/pytorch/pytorch/issues/17918
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30433
Reviewed By: hl475
Differential Revision: D18723520
Pulled By: houseroad
fbshipit-source-id: d0ed3b3f051d08d46495a7abfa854edd120dca3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25768
The round robin process group can be constructed from multiple other
process groups. Every collective call against this new process group
is delegated to the specified process groups in a round robin fashion.
Doing so may benefit performance when calling into multiple NCCL
process groups. Instead of adding support for round-robin usage of
NCCL communicators, we achieve the same without changing the NCCL
process group and adding this wrapper class.
The API to create this round robin process group is a bit harsh. If we
find it adds significant benefit we can revisit and make this a first
class citizen in the torch.distributed module.
ghstack-source-id: 94578376
Test Plan: The newly added test passes.
Reviewed By: chenyangyu1988
Differential Revision: D17226323
fbshipit-source-id: ec9f754b66f33b983fee30bfb86a1c4c5d74767d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30415
This enables subclassing of c10d.Store and implementing its interface in Python.
ghstack-source-id: 94586627
Test Plan: New tests passes.
Reviewed By: vladbelous
Differential Revision: D18693018
fbshipit-source-id: fa1eba4bd11cc09a3d6bf3f35369c885033c63c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29934
Previously, when doing boxed dispatch (e.g. custom ops), the dispatcher manually removed the VariableTensorId flag before dispatching
because custom ops don't have variable kernels.
This is one of the blockers that prevented us from using the boxed dispatch mechanism for ops from native_functions.yaml because they define variable kernels and need them to be called for autograd.
This PR changes that. The dispatcher doesn't remove the VariableTensorId flag anymore.
Instead, to make custom ops work, we implement a variable fallback kernel that is called whenever no other variable kernel was found.
ghstack-source-id: 94618474
Test Plan: unit tests
Differential Revision: D18542342
fbshipit-source-id: a30ae35d98f89f7ae507151f55c42cfbed54a451
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30451
TORCH_CHECK takes __VA_ARGS__ so there is no need to concatenate strings
before calling it. This way it won't call Formatting::print() on the
tensor when STRIP_ERROR_MESSAGES macro is set. Formatting::print() calls
several specific tensor methods that brings in unnecessary inter-op
dependencies for static code analysis.
Test Plan: - builds
Differential Revision: D18703784
Pulled By: ljk53
fbshipit-source-id: 1c0628e3ddcb2fd42c475cb161edbef09dfe8eb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30120
The example given for functional conv2d didn't work. This diff fixes the example in docs so that it works.
Fixes https://github.com/pytorch/pytorch/issues/29649
ghstack-source-id: 94601559
Test Plan: Tried the example locally
Differential Revision: D18604606
fbshipit-source-id: ff1a4f903e2843efe30d962d4ff00e5065cd1d7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30428
Reported issue https://discuss.pytorch.org/t/incomprehensible-behaviour/61710
Steps to reproduce:
```
class WrapRPN(nn.Module):
def __init__(self):
super().__init__()
def forward(self, features):
# type: (Dict[str, Tensor]) -> int
return 0
```
```
#include <torch/script.h>
int main() {
torch::jit::script::Module module = torch::jit::load("dict_str_tensor.pt");
torch::Tensor tensor = torch::rand({2, 3});
at::IValue ivalue{tensor};
c10::impl::GenericDict dict{c10::StringType::get(),ivalue.type()};
dict.insert("key", ivalue);
module.forward({dict});
}
```
ValueType of `c10::impl::GenericDict` is from the first specified element as `ivalue.type()`
It fails on type check in` function_schema_inl.h` !value.type()->isSubtypeOf(argument.type())
as `DictType::isSubtypeOf` requires equal KeyType and ValueType, while `TensorType`s are different.
Fix:
Use c10::unshapedType for creating Generic List/Dict
Test Plan: Imported from OSS
Differential Revision: D18717189
Pulled By: IvanKobzarev
fbshipit-source-id: 1e352a9c776a7f7e69fd5b9ece558f1d1849ea57
Summary:
using `buck build mode/opt mode/no-gpu //experimental/ngimel/benchmark_framework_overheads:cpp_benchmark`
```
devvm497.prn3.facebook.com:/data/users/bwasti/fbsource/fbcode $ ./cpp_benchmark --niter 10000
creating inputs, number of dimensions 1
starting op
benchmarking 10000 iterations
using cpp frontend
elapsed time per iteration 0.90638 us
```
```
devvm497.prn3.facebook.com:/data/users/bwasti/fbsource/fbcode $ ./cpp_benchmark --niter 10000 --disable_variable_dispatch
creating inputs, number of dimensions 1
starting op
benchmarking 10000 iterations
using cpp frontend
elapsed time per iteration 0.775436 us
```
Test Plan: let all tests run
Reviewed By: smessmer
Differential Revision: D18654276
fbshipit-source-id: 362812b2c87ec428448b2ac65baac45f492fdce4
Summary:
This PR add `gpu_kernel_with_index` as an addition to element-wise kernel template. It allows kernel to not only operate on input tensor value, but also each values index(view as 1d, so from 0 to numel) within the lambda.
Direct use case here is to replace thrust::tabulate used in range/arange/linspace. Benifits are:
- thrust::tabulate causes additional unneccessary synchronization on cpu.
- Now it works with tensor iterator, output no longer needs to be contiguous and a memcpy is saved
It can also potentially be reused to add new function to pytorch later, if we see use case both value and index is needed.(for example unify tril/triu into tensor iterator element-wise? add other pattern?)
Known issues:
https://github.com/pytorch/pytorch/pull/23586 is needed to enable non-contiguous case work properly, since overlapping needs to be checked. Currently non-contiguous tensor falls into TOO_HARD. I could write proper check in this file but I figured using exist method is better. jjsjann123
It does not work beyond 32bit indexing. But thrust was erroring on those case too. We could split tensor in caller to enable this. Index changes after split, so it is easier for caller to pass different lambda, and harder for the template to handle it in general.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28175
Differential Revision: D18708649
Pulled By: ngimel
fbshipit-source-id: 382081c96f266ae7b61095fc1f2af41c6b210fa9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30472
Add DoNotStrip to nativeNewTensor method.
ghstack-source-id: 94596624
Test Plan:
Triggered build on diff for automation_fbandroid_fallback_release.
buck install -r fb4a
Tested BI cloaking using pytext lite interpreter.
Obverse that logs are sent to scuba table:
{F223408345}
Reviewed By: linbinyu
Differential Revision: D18709087
fbshipit-source-id: 74fa7a0665640c294811a50913a60ef8d6b9b672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29953
The underlying function handles it correctly.
Test Plan: Imported from OSS
Differential Revision: D18548055
Pulled By: gchanan
fbshipit-source-id: cc2d0ae37d9689423363d115c6a653cb64840528
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29952
The underlying op handles the check correctly.
Test Plan: Imported from OSS
Differential Revision: D18548048
Pulled By: gchanan
fbshipit-source-id: 9ac6fde743408e59ccdfc61bd574ebe6e2862238
Summary:
In ONNX opset 11, a series of sequence ops were added. Operators that are related to Tensor[] in PyTorch can be exported using these sequence ops.
In this PR, unbind/split that produces Tensor[], and __getitem__ that takes Tensor[] as input, are exported correctly to ONNX opset 11.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29136
Reviewed By: hl475
Differential Revision: D18309222
Pulled By: houseroad
fbshipit-source-id: be12c96bf8d0a56900683ef579f1c808c0a1af21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30202
Pytorch Upsample operator has output_size as an argument.
For quantized tensor inputs we cannot get the input_size to calculate the width and height scale factor.
Instead we pass the output_size directly to caffe2 to calculate the scale factors.
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2_quantized.py TestQuantizedOps.test_upsample
Imported from OSS
Differential Revision: D18631478
fbshipit-source-id: 38a39129bc863f4ecf2293acc068e40ab7edc825
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30217
Before this commit, RRefContext throws an error if it detects any
RRef leak during shutdown. However, this requires applications to
make sure that is has freed all references to RRefs in application
code, which can be a bad debugging experience when for large
applications. Besides, this also relies on Python GC to free things
up in time, which might not always be true. After this commit,
RRefContext would ignore leaking RRefs during shutdown, as shutdown
is called when the application has finished training and no longer
care about local states. Hence, it should be OK to just ignore
those leaks and destroy OwnerRRefs. If application would like to
enforce no leaks, just set torch.distributed.rpc.api._ignore_rref_leak
to False.
Test Plan: Imported from OSS
Differential Revision: D18632546
Pulled By: mrshenli
fbshipit-source-id: 2744b2401dafdd16de0e0a76cf8e07777bed0f38
Summary:
The PyTorch exporter does not add any name to the ONNX operators in the exported graph. A common request is to add names to op nodes by default. This helps the readability of the graph in visualization tools such a Netron, or when the ONNX graph is printed as a string. Also, it helps with the debuggability of the ONNX graph.
Therefore this PR adds name to operators in the exporters. The names follow a simple format, <op_type>_<index>. Expect files for tests in `test/onnx/test_operators.py` have been updated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27342
Reviewed By: hl475
Differential Revision: D17790979
Pulled By: houseroad
fbshipit-source-id: 1eaae88b5f51f152735a2ff96e22827837e34d9d
Summary:
This should resolve https://github.com/pytorch/pytorch/issues/29008. This flag has two effects on the tracer.
- Remove the underscroll for inplace operators. E.g.: index_put_ ==> index_put. This is handled in utils.py separately as well.
- Add out as input for backward computation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29466
Reviewed By: hl475
Differential Revision: D18422815
Pulled By: houseroad
fbshipit-source-id: 317b6a3c8a5751fe6fe49d7543e429d281ed0d6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30357
Fix issue https://github.com/pytorch/pytorch/issues/29032 in loading from state dict for observers and fake quant.
ghstack-source-id: 94468814
Test Plan: Ensures that load/save of fake quant and observers with missing keys works correctly.
Differential Revision: D18668517
fbshipit-source-id: 0eda6f47c39102e55977fc548b9a03664f123ad7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30430
When a module isn't a TracedModule, attempt to get name information with `original_name` property on module and default to 'Module' when no such property exists.
Test Plan:
### Change child module to scripted module:
```
model = torchvision.models.alexnet()
model.classifier = torch.jit.script(model.classifier)
```
### Add graph
```
w = SummaryWriter()
w.add_graph(model, torch.rand((2, 3, 224, 224)))
w.close()
```
### No errors
However, graph is disconnected at parts and hard to understand.
{F223327878}
Reviewed By: sanekmelnikov
Differential Revision: D18690836
fbshipit-source-id: 42295d06b7c1d48d5401776dca1e0d12cd64b49d
Summary:
This adds a listing of the parts of the `typing` module that are unsupported
This is also a first pass decisions on features are 'unlikely to be implemented' vs 'not implemented' so they're open to discussion
](https://our.intern.facebook.com/intern/diff/18665628/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30344
Pulled By: driazati
Differential Revision: D18665628
fbshipit-source-id: 22b8ebbde23df03839306cdb4344ca18a44f2c29
Summary:
There is no `out` argument to `argsort` according to the source code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24335
Differential Revision: D16829134
Pulled By: vincentqb
fbshipit-source-id: 8f91154984cd4a753ba1d6105fb8a9bfa0da22b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30362
Right now the qat modules(qat.ConvBn2d, qat.ConvBnReLU2d, qat.Conv2d)
are not convinent to support other dimensions of Conv, this PR refactors
these modules so that we can support Conv1d/Conv3d better
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D18691152
fbshipit-source-id: 5b561e6b054eadd31b98cabdf1ac67a61ee9b805
Summary:
In this PR, we mainly handle the case there are multiple usage of a Value when inserting the quant-dequant pair. This change will add one dequant for each usage of the Value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30145
Differential Revision: D18671600
Pulled By: lly-zero-one
fbshipit-source-id: 61324a98861da85b80dcf7e930381311118ae53b
Summary:
Currently, the way the compare kernels handle dtypes is very funny (this behavior is introduced in https://github.com/pytorch/pytorch/pull/28427 and I just realize it today):
Let's say `a, b` are two float tensors on CUDA.
If you do `a < b`, this is what would happen inside the loop:
- Step 1: Fetch `a` and `b`, dynamically cast them from `float` to `float`. (i.e. check the scalar type to figure out if it needs cast. it doesn't. so do nothing then.)
- Step 2: compute `a < b`, get a `bool` result
- Step 3: statically cast the result into `float`
- Step 3: do a dynamic cast of the result from `float` to `bool` and store the value
And if you do `a.lt_(b)`, this is what would happen:
- Step 1: Fetch `a` and `b`, no casting
- Step 2: compute `a < b`, get a `bool` result
- Step 3: statically cast the result into `float`
- Step 4: store the result to memory, no casting
Although dynamic casting happens on registers, it still hurt the performance a bit (~8%).
This PR fixes this issue. Now for compare kernels, if the output is bool and inputs have the same dtype, then there is no dynamic casting. Otherwise, there will be dynamic casting for each input and output. That is, the dynamic casting behavior of the two cases described above are swapped.
Benchmark on `a < b` for tensor of 1000000000 fp32 elements:
Before https://github.com/pytorch/pytorch/issues/28427 6.35 ms
Current master: 6.88 ms
With this PR: 6.36 ms
Benchmark on `a.lt_(b)` does not show any difference across versions.
Besides this, what worries me most is, with type promotion, the logic for tensor iterator is becoming super complicated, and it is hard to see if one change causes the performance regression of others. I suggest we create scripts that could benchmark tensor iterator entirely, review that code and put it somewhere inside the repository (maybe under `/tools` or `/test/scripts`?), and whenever we are not certain about the performance we could run it to check. (I guess not on this PR but on PRs after the script is done. If there are worries about performance, the author of PRs should run the script manually, and the reviewer should remind PR author to do so if necessary) If this is a good idea, I will send a PR for the script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29743
Differential Revision: D18671269
Pulled By: ngimel
fbshipit-source-id: 89a9c1c8b5fd45d5ae8fe907d65c2fe1a7dfd2dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30208
Adds default arg for init_method so users don't have to pass this in,
and moves it to `RpcBackendOptions` struct. Removes `init_method` arg from rpc.init_rpc. Also fixes some docs.
ghstack-source-id: 94500475
Test Plan: Unit tests pass.
Reviewed By: mrshenli
Differential Revision: D18630074
fbshipit-source-id: 04b7dd7ec96f4c4da311b71d250233f1f262135a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30359
We need this for C++14 support
ghstack-source-id: 94519850
Test Plan: unit tests
Differential Revision: D18668868
fbshipit-source-id: 87e8eadf0e60a1699fba4524aea53b306b9a7f24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29945
Both functions require at least 1 2-dimensional tensor, so can never return an inferred scalar.
Test Plan: Imported from OSS
Differential Revision: D18548056
Pulled By: gchanan
fbshipit-source-id: f99a41d490b9a5ab5717534c92e4f2e848c743e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29923
Note that this changes the behavior of masked_select when both "self" and "mask" are 0-dimensional.
In previous versions of PyTorch, this would return a 0-dimensional tensor. But the documentation reads:
"Returns a new 1-D tensor which indexes the input tensor according to the boolean mask mask which is a BoolTensor."
Test Plan: Imported from OSS
Differential Revision: D18539560
Pulled By: gchanan
fbshipit-source-id: 1637ed2c434fcf8ceead0073aa610581f4a19d21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30320Fixes#30296
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18665704
Pulled By: ezyang
fbshipit-source-id: f09a953137fcc105959382254f9b8886af5aea3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30390
Fix the crashes for c++ not able to find java class through Jni
ghstack-source-id: 94499644
Test Plan: buck install -r fb4a
Reviewed By: ljk53
Differential Revision: D18667992
fbshipit-source-id: aa1b19c6dae39d46440f4a3e691054f7f8b1d42e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30282
The atomic increment/decrements in LeftRight::read() were measurable in perf benchmarks. Let's improve their perf.
ghstack-source-id: 94443230
Test Plan: unit tests, perf benchmarks
Differential Revision: D18650228
fbshipit-source-id: d184ce8288510ab178e7c7da73562609d1ca3c9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29682
This PR re-introduces backend_fallback_test.cpp, which was previously called boxed_fallback_test.cpp and showed how to use the backend fallback API.
ghstack-source-id: 94481314
Test Plan: unit tests
Differential Revision: D18462654
fbshipit-source-id: 3e9b5c8f35c05f9cd795f44a5fefd1a0aaf03509
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29681
Remove callUnboxedOnly() and instead use metaprogramming to figure out if an operator can use a boxed fallback or not.
This enables boxed fallback for ops in native_functions.yaml even if they don't have `use_c10_dispatcher: full` set, as long as they're in the range of supported types.
ghstack-source-id: 94481320
Test Plan: unit tests
Differential Revision: D18462653
fbshipit-source-id: 2955e3c4949267520a1734a6a2b919ef5e9684a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29337
This argument is needed by boxing wrappers so they're able to get a pointer to the corresponding unboxed kernel and call into it.
But if a kernel is registered in a boxed way, we don't need it and should hide this from the API.
This is especially needed for the backend fallback API where users would only be left wondering why this argument is there and what it does.
Also, hiding it allows us to potentially totally remove it in a future refactoring if we find some way to do so.
ghstack-source-id: 94481316
Test Plan: unit tests
Differential Revision: D18361991
fbshipit-source-id: 5cef26c896fe3f2a5db730d3bc79dcd62e7ef492
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29330
This makes for a nicer API, especially in backend fallback kernels who get an OperatorHandle instance and can directly call these methods on it.
ghstack-source-id: 94481322
Test Plan: unit tests stacked on top
Differential Revision: D18357424
fbshipit-source-id: fa8c638335f246c906c8e16186507b4c486afb3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29201
This is required for boxed backend fallback kernels (e.g. lazy, AMP) because they need to know which op was actually called.
ghstack-source-id: 94481313
Test Plan: I will add unit tests in a diff stacked on top
Differential Revision: D18282746
fbshipit-source-id: 339a1bbabd6aff31a587b98f095c75104dfc6f99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30340
We already made OperatorEntry::dispatchTable_ an array to be able to avoid the concurrency primitives there,
but Dispatcher::backendFallbackKernels_ has the same issue. Let's make it a table too.
Since there is some code duplication here, we also factor out the concept of a KernelFunctionTable to be used in both places.
ghstack-source-id: 94481317
Test Plan: unit tests
Differential Revision: D18663426
fbshipit-source-id: ba82ca5c4cae581eea359d5c0c3a5e23b0f8838c
Summary:
In the PR, we enhance the graph-mode quantization for aten::_convolution, which could be generated from tracing path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30245
Differential Revision: D18671597
Pulled By: lly-zero-one
fbshipit-source-id: 78a2470fbb0fe0def55d63c6bda7cbb5c89f7848
Summary:
This PR updates `torch::pickle_save` to use the new zipfile format introduced in #29232 and adds `torch::pickle_load` which can decode the zipfile format. Now that `torch.save/load` use this format as well (if the `_use_new_zipfile_serialization` flag is `True`), raw values saved in Python can be loaded in C++ and vice versa.
Fixes#20356
](https://our.intern.facebook.com/intern/diff/18607087/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30108
Pulled By: driazati
Differential Revision: D18607087
fbshipit-source-id: 067cdd5b1cf9c30ddc7e2e5021a8cceee62d8a14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30367
use the SLS emulations that match the hardware
Test Plan: replayer test
Differential Revision: D18667605
fbshipit-source-id: 89aee630184737b86ecfb09717437e5c7473e42c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30241
We need an API to get all worker infos. This will be used by backend-agnostic `rpc.wait_all_workers()` API.
ghstack-source-id: 94454935
Test Plan:
# Unit tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork -- test_get_worker_infos
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_get_worker_infos
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift -- test_get_worker_infos
buck-out/gen/caffe2/test/rpc_fork_thrift\#binary.par -r test_get_worker_infos
```
Differential Revision: D5693412
fbshipit-source-id: 5123c8248b6d44fd36b8a5f381dbabb2660e6f0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30167
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29164
- Created GlooDeviceFactory to hide device creation details
- Added transport option while on Python interface
The reason of making the factory class is to make it easier to extend gloo transport in the future
Test Plan: Imported from OSS
Reviewed By: satgera, d4l3k
Differential Revision: D18596527
fbshipit-source-id: e8114162ee8d841c0e0769315b48356b37d6ca0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29207
The logic calling c10 ops from JIT did some variable wrapping to make sure all results are always variables.
Thanks to ezyang, this is not needed anymore because everything is a variable now.
ghstack-source-id: 93345590
Test Plan: waitforsandcastle
Differential Revision: D18327507
fbshipit-source-id: 86512c5e19d6972d70f125feae172461c25e3cb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30193
Featuring:
- Added a NoNamesGuard::reset() function that sets NamesMode back to
what it was before the guard. This makes it so that we don't have to
create a new context to run code in an unnamed way.
- Added a diagonal(Tensor, *, Dimname outdim, Dimname dim1, Dimname dim2, int64_t offset=0)
overload. All of the non-tensor arguments are keyword only for
readability purposes; something like `tensor.diagonal("A", "B", "C")`
would be really confusing.
Test Plan: - Added new tests
Differential Revision: D18638363
Pulled By: zou3519
fbshipit-source-id: ea37b52a19535f84a69be38e95e569e88f307381
Summary:
This PR looks for a `constants.pkl` file at the top level in a zip file
in `torch.load`. If found, it calls `torch.jit.load` instead and issues
a warning to call `torch.jit.load` directly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29339
Differential Revision: D18611095
Pulled By: driazati
fbshipit-source-id: f070a02f6b5509054fc3876b3e8356bbbcc183e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29943
This was apparently the same as "pytorch/pytorch-binary-docker-image-ubuntu16.04:latest",
so standardize on that name.
Test Plan:
This PR, which is stacked on top of a commit that puts one of the jobs
using that container into the set of PR builds.
Imported from OSS
Differential Revision: D18653554
fbshipit-source-id: 40e6c52db02265d61e8166bb1211376faccfc53a
2019-11-22 11:39:55 -08:00
2723 changed files with 152809 additions and 55755 deletions
author={Paszke, Adam and Gross, Sam and Chintala, Soumith and Chanan, Gregory and Yang, Edward and DeVito, Zachary and Lin, Zeming and Desmaison, Alban and Antiga, Luca and Lerer, Adam},
booktitle={NIPS Autodiff Workshop},
year={2017}
@incollection{NEURIPS2019_9015,
title = {PyTorch: An Imperative Style, High-Performance Deep Learning Library},
author = {Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and Kopf, Andreas and Yang, Edward and DeVito, Zachary and Raison, Martin and Tejani, Alykhan and Chilamkurthy, Sasank and Steiner, Benoit and Fang, Lu and Bai, Junjie and Chintala, Soumith},
booktitle = {Advances in Neural Information Processing Systems 32},
editor = {H. Wallach and H. Larochelle and A. Beygelzimer and F. d\textquotesingle Alch\'{e}-Buc and E. Fox and R. Garnett},
* Slack: The [PyTorch Slack](https://pytorch.slack.com/) hosts a primary audience of moderate to experienced PyTorch users and developers for general chat, online discussions, collaboration etc. If you are a beginner looking for help, the primary medium is [PyTorch Forums](https://discuss.pytorch.org). If you need a slack invite, please fill this form: https://goo.gl/forms/PP1AGvNHpSaJP8to1
* newsletter: no-noise, one-way email newsletter with important announcements about pytorch. You can sign-up here: https://eepurl.com/cbG0rv
* for brand guidelines, please visit our website at [pytorch.org](https://pytorch.org/)
The current nightly(snapshots) version is the value of `VERSION_NAME` in `gradle.properties` in current folder, at this moment it is `1.4.0-SNAPSHOT`.
The current nightly(snapshots) version is the value of `VERSION_NAME` in `gradle.properties` in current folder, at this moment it is `1.5.0-SNAPSHOT`.
## Building PyTorch Android from Source
@ -49,6 +49,7 @@ For this you can use `./scripts/build_pytorch_android.sh` script.
```
git clone https://github.com/pytorch/pytorch.git
cd pytorch
git submodule update --init --recursive
sh ./scripts/build_pytorch_android.sh
```
@ -59,7 +60,7 @@ The workflow contains several steps:
2\. Create symbolic links to the results of those builds:
`android/pytorch_android/src/main/jniLibs/${abi}` to the directory with output libraries
`android/pytorch_android/src/main/cpp/libtorch_include/${abi}` to the directory with headers. These directories are used to build `libpytorch.so` library that will be loaded on android device.
3\. And finally run `gradle` in `android/pytorch_android` directory with task `assembleRelease`
Script requires that Android SDK, Android NDK and gradle are installed.
We also have to add all transitive dependencies of our aars.
As `pytorch_android` [depends](https://github.com/pytorch/pytorch/blob/master/android/pytorch_android/build.gradle#L62-L63) on `'com.android.support:appcompat-v7:28.0.0'` and `'com.facebook.soloader:nativeloader:0.8.0'`, we need to add them.
(In case of using maven dependencies they are added automatically from `pom.xml`).
At the moment for the case of using aar files directly we need additional configuration due to packaging specific (`libfbjni.so` is packaged in both `pytorch_android_fbjni.aar` and `pytorch_android.aar`).
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
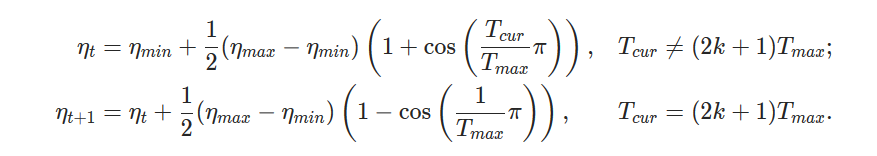{kind=link}
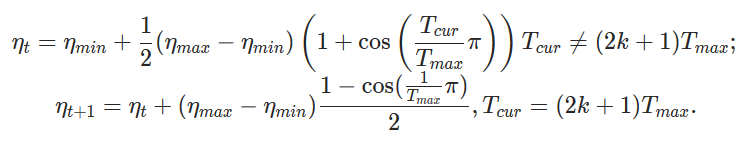{kind=link}
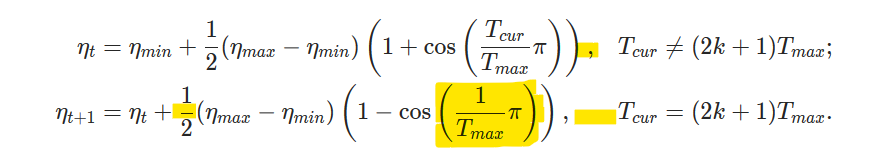{kind=link}
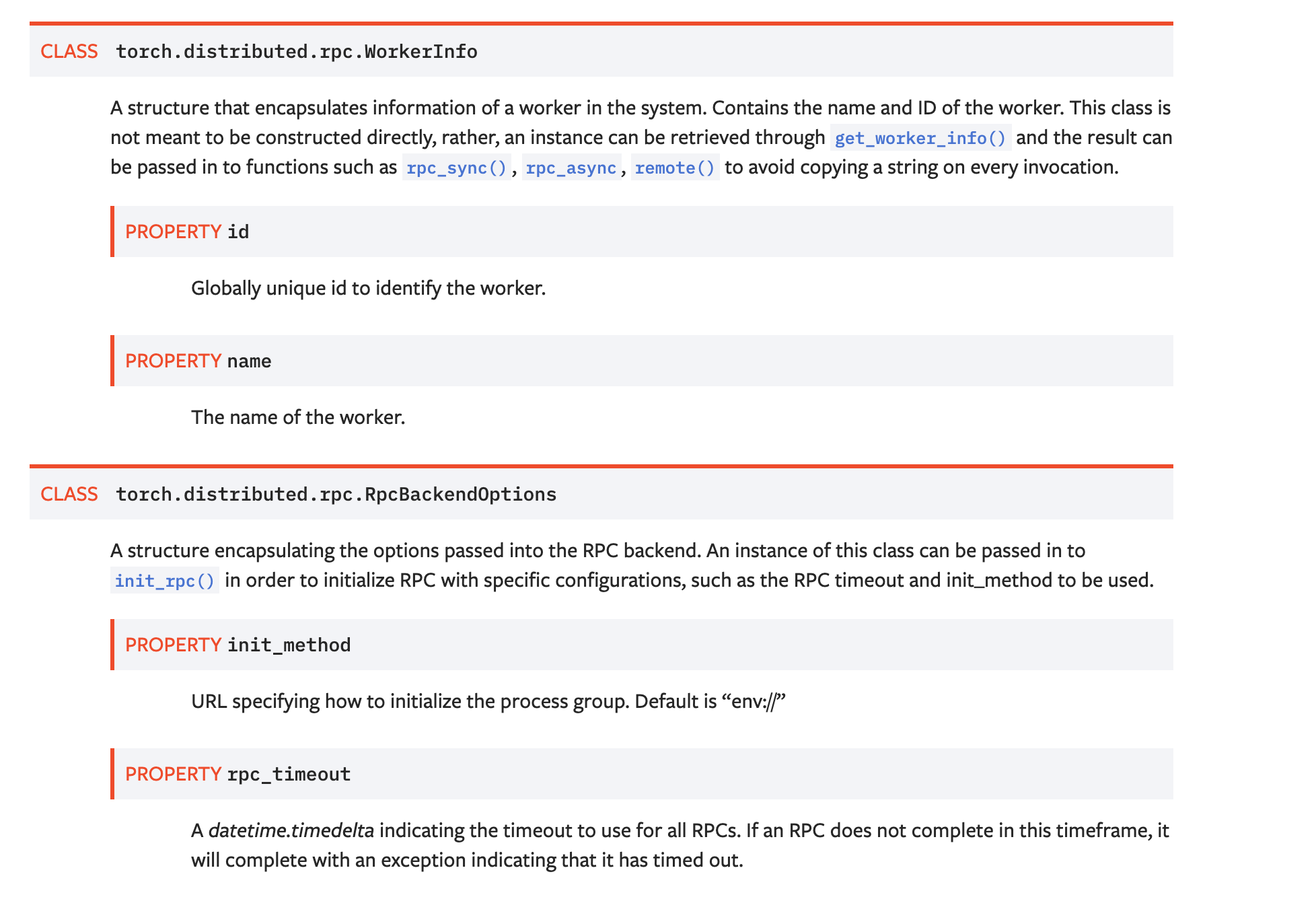{kind=link}