* Make zeros argument of torch.where same dtype as other argument
* Added check for torch.where on CPU that both arguments have same dtype
* Changes based on PR comments
* Fix flake8
* Fixed test for CUDA
* Changes basen on PR comments
* Changes based on PR review
* preserve original tensoriterator behavior when not explicitly promoting
Summary:
Cherry-picking of https://github.com/pytorch/pytorch/pull/28231 to
1.3.1 branch.
Fix: https://github.com/pytorch/pytorch/issues/28010
A mixed-type index assignment that would have been an error in 1.2 was unintentionally made possible (with incorrect results) in 1.3. This PR restores the original behavior.
This is BC-breaking because:
```
a = torch.ones(5, 2, dtype=torch.double)
b = torch.zeros(5, dtype=torch.int)
a[:, [1]] = b.unsqueeze(-1)
```
now raises an error (as in 1.2) whereas it did not in 1.3.
* Compute correct strides after type promotion (#28253)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28253
Instead of trying to fix strides after changing dtypes, wait until after
promotion to set them.
fixes: https://github.com/pytorch/pytorch/issues/27824
fixes: https://github.com/pytorch/pytorch/issues/28502
Test Plan: Imported from OSS
Differential Revision: D18124950
Pulled By: nairbv
fbshipit-source-id: e4db90b2a6bb0f5d49cb388e0cd1971303c6badd
Summary:
People get confused with partial support otherwise: https://github.com/pytorch/pytorch/issues/27811#27729
Suggestions on where else put warnings are welcomed (probably in tutorials - cc SethHWeidman )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27829
Differential Revision: D17910931
Pulled By: dzhulgakov
fbshipit-source-id: 37a169a4bef01b94be59fe62a8f641c3ec5e9b7c
Organize APIs logically in subsections. Fix typos.
This is the v1.3.0 version of a 3 Part PR originally made to master PR: https://github.com/pytorch/pytorch/pull/27677/
originally by @dzhulgakov
* docstring only formatting changes in the quantize.py and fake_quantization.py files to render better in HTML.
* docstring change on observer.py as well
* just kind of tweaking the docstrings a bit more.
* switching to r""" for the mult-line string. Per Zafar's suggestion.
* trying to resolve the merge conflict soumith saw
* trying to avoid a conflict when this gets merged back to master
* Cherry picked in changes from Jessica's branch.
Consolidate all quantization docs in quantization.rst. Add a link to quantization docs from torch.rst. Order quantization.rst alphabetically in index.rst
* Fix Quantized reference
* Add prose for Quantized Functions in the torch.nn docs
* Remove Quantization section
* Updates to index for v1.3.0
* Update "Package Reference" to "Python API"
* Add in torchaudio and torchtext reference links so they show up across all docs not just the main page
* Add "Other Languages" section, add in C++ docs, add in Javadocs
* Add link to XLA docs under Notes: http://pytorch.org/xla/
* Doc tests caught that we'd somehow dropped documenting a few functions like
result_type, can_cast, promote_types
* Add javasphinx extension
* Add javadocs for v1.3.0
* Delete Tensor-Tensor_float32 because it is not public
* Delete Tensor-Tensor_float64 because it is not public
* Delete Tensor-Tensor_int32 because it is not public
* Delete Tensor-Tensor_int64 because it is not public
* Delete Tensor-Tensor_int8 because it is not public
* Delete Tensor-Tensor_uint8 because it is not public
* Add reference to DType and TensorImageUtils
This PR updates the docs CI. After this is merged, we open a PR from
1.3.0 -> master. That open PR will build docs on this branch and push
them to pytorch.github.io:site-v1.3.0. This is done in dry_run mode
so the pushing won't actually happen; I will follow up with a
subsequent change to drop dry_run mode after verifying that everything
builds correctly.
`docs/source/named_tensor.rst` is the entry point; most users will land
either here or the named tensor tutorial when looking to use named
tensors. We should strive to make this as readable, concise, and understandable
as possible.
`docs/source/name_inference.rst` lists all of the name inference rules.
It should be clear but it's hard to make it concise.
Please let me know if anything doesn't make sense and please propose
alternative wordings and/or restructuring to improve the documentation.
This should ultimately get cherry-picked into the 1.3 branch as one
monolithic commit so it would be good to get all necessary changes made
in this PR and not have any follow ups.
Test Plan:
- built and reviewed locally with `cd docs/ && make html`.
ghstack-source-id: dc2ca7a204f86d4849bd45673c189d5bbddcb32c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27173
Summary:
All of the test cases move into a base class that is extended by the
intrumentation test and a new "HostTests" class that can be run in
normal Java. (Some changes to the build script and dependencies are
required before the host test can actually run.)
ghstack-source-id: fe1165b513241b92c5f4a81447f5e184b3bfc75e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27453
Test Plan: Imported from OSS
Reviewed By: IvanKobzarev
Differential Revision: D17800410
fbshipit-source-id: 1184f0caebdfa219f4ccd1464c67826ac0220181
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27396
Observer that estimates moving averages of min and max values per batch, more suited for quantization aware training instead of minmax observers that track extremal values across batches
ghstack-source-id: 91369018
Test Plan:
buck test caffe2/test:quantization -- 'test_per_tensor_observers \(test_quantization\.ObserverTest\)' --print-passing-details
buck test caffe2/test:quantization -- 'test_per_channel_observers \(test_quantization\.ObserverTest\)' --print-passing-details
Differential Revision: D17727213
fbshipit-source-id: 024a890bf3dd0bf269d8bfe61f19871d027326f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27298
PR #26908 toggles NonVariableTypeMode in ATen dispatcher, which is where
USE_STATIC_DISPATCH takes place.
This causes an issue with numel() as it gets called through the dispatch mode and probably not getting inlined.
Also the thread local state is expensive to read/write so many times and this kills perf.
PR #27274 is another approach to fix this and has more details.
Test Plan:
Quantized mobilenetV2 perf before this change
Main run finished. Milliseconds per iter: 28.6782. Iters per second: 34.8696
Perf after this change
Main run finished. Milliseconds per iter: 22.2585. Iters per second: 44.9267
Imported from OSS
Differential Revision: D17742565
fbshipit-source-id: 43c6045cc001c46916ba339555c9d809a2537eff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27151
We need to be ab le to handle observers with no min/max data correctly as models sometimes have modules that do not get any data.
ghstack-source-id: 91113403
Test Plan:
buck test caffe2/test:quantization -- test_minmax_observer
buck test caffe2/test:quantization -- test_per_channel_minmax_observer
buck test caffe2/test:quantization --test_histogram_observer
Reviewed By: csummersea
Differential Revision: D17690828
fbshipit-source-id: e95709333ea0f66d79ddb8141b7cba5a83347dbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26992
Run the same test for FBGEMM and QNNPACK backends.
Checks that QNNPACK or FBGEMM are supported before running it (using supported_qengines)
Test Plan:
python test/test_quantized.py TestQuantizedLinear
python test/test_quantized.py TestQuantizedConv
python test/test_quantized_models.py
python test/test_quantized_nn_mods.py
Imported from OSS
Differential Revision: D17689171
fbshipit-source-id: e11c0a5e41f5f4e6836a614a5b61e4db3c5e384b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26457
Enhancement to fuse module to support sequentials, fuse list can now be just like the state dict.
Also add support for Conv-Relu and linear-relu fusion
Also support inplace and out of place fusion of models.
ghstack-source-id: 91076386
Test Plan:
buck test caffe2/test:quantization -- 'test_fusion_sequential_model_train \(test_quantization\.FusionTest\)' --print-passing-details
buck test caffe2/test:quantization -- 'test_fusion_sequential_model_eval \(test_quantization\.FusionTest\)' --print-passing-details
Differential Revision: D17466382
fbshipit-source-id: 0a548f8f4c366f3ecc59db693bac725ccd62328e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27113
Fix bug in fake quant control of observer and fake-quantize operations.
Add test to ensure that features work as expected
ghstack-source-id: 91071181
Test Plan: buck test mode/dev-nosan caffe2/test:fake_quant -- test_fake_quant_control
Differential Revision: D17678875
fbshipit-source-id: 2912ad8b6e674daa1d129f7a7c6f27d8c1b4f93b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26612
Add support for add relu functional module, this allows for fusion of add and relu quantized operations
ghstack-source-id: 91055976
Test Plan: buck test caffe2/test:quantization -- 'test_functional_module \(test_quantization\.FunctionalModuleTest\)' --print-passing-details
Differential Revision: D17518268
fbshipit-source-id: e1e8b4655d6b32405863ab9d1c7da111fb4343cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26624
For QAT we need to be able to control batch norm for all modules from the top. Adding helper functions to enable/disable batch norm freezing during training
ghstack-source-id: 91008297
Test Plan: buck test caffe2/test:quantization -- --print-passing-details
Differential Revision: D17512199
fbshipit-source-id: f7b981e2b1966ab01c4dbb161030177274a998b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26516
ghstack-source-id: 90982010
Test Plan:
Integrate per-channel support into conv and linear modules.
The following tests pass:
buck test caffe2/test:quantized -- 'test_linear_api \(test_quantized_nn_mods\.ModuleAPITest\)' --print-passing-details
buck test caffe2/test:quantized -- 'test_conv_api \(test_quantized_nn_mods\.ModuleAPITest\)' --print-passing-details
buck test caffe2/test:quantized -- 'test_float_quant_compare_per_channel \(test_quantized_models\.ModelNumerics\)' --print-passing-details
Differential Revision: D17342622
fbshipit-source-id: f0d618928e3d9348672c589a6b7a47049c372a2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27002
This was taking a significant amount of time in my benchmarks with larger output sizes (e.g. final output projection in a language classification model)
Test Plan: Imported from OSS
Differential Revision: D17641765
Pulled By: jamesr66a
fbshipit-source-id: b0ef30767eec9774fc503bb51fed039222026bba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27304
The ellipsis version of `align_to` only works if it is called as a
method. To prevent any confusion, this PR disables `torch.align_to` (but
keeps `Tensor.align_to`.
Test Plan: - [namedtensor ci]
Differential Revision: D17743809
Pulled By: zou3519
fbshipit-source-id: cf5c53dcf45ba244f61bb1e00e4853de5db6c241
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27274
This is yet another fix to address #26764.
PR #26908 toggles NonVariableTypeMode in ATen dispatcher, which is where
USE_STATIC_DISPATCH takes place thus it's most logically sound place to do
such tweaks.
However, we observed nontrivial perf regression due to this fix. Turns out
the numel() tensor method gets called in several for-loops thus incurs ~7M
thread_local updates in a single forward call:
```
7173330 numel
558 size
416 q_scale
302 _empty_affine_quantized
288 contiguous
257 q_zero_point
216 qscheme
173 empty
110 set_
105 as_strided
104 permute
...
```
As numel() is not called from a single place so a natural workaround is to
update function_wrapper.py so that it only adds the guard on gen_namespace_function()
case and ignore the gen_tensor_method() case. But some tensor methods are actually
being called from JIT side directly (e.g. "aten::eq_" -> "(self).eq_") so the
only "band aid" left on the table is to insert guard on JIT->aten path as originally
did on #26868 - this is a simplified version of it as it doesn't hurt to extend the
NonVariableMode scope a little bit to also cover stack drop/pack calls.
On Android we only expose JIT API so we don't need worry about TensorMethods being
called directly. On iOS we don't provide a wrapper yet but we can mention this caveat
in the doc. Hopefully by the time it's widely used we can finish Variable/Tensor
unification and remove all these hacks.
Test Plan:
- Verified it runs quantized/fp32 MobileNetV2 models;
- Verified it fixes the perf regression (revert #26908 separately);
Differential Revision: D17732489
Pulled By: ljk53
fbshipit-source-id: c14ca66aebc6b6f17ad6efac7ca47f9487c98de5
Previously, we would only test named tensors if:
1) we built with BUILD_NAMEDTENSOR=1
2) TEST_NAMEDTENSOR=1 is in the environment.
This PR makes it so that we ALWAYS test named tensors. This is OK
because all the release binaries should be able to run the named tensor
tests and be green; otherwise, there is something wrong.
Summary:
This PR serialize autograd ops into its own namespace by turning the
serialization op name into torch.autograd.op, this is to keep the
original code namespace rather than turning all to the global namespace,
this will be more properly handled in the future when we handle the module
namespace. This change also preserve BC until we have namespace handling
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27293
This doesn't turn on 3.5 signal, but it makes it so that [test all]
will include it if you do request it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17738741
Pulled By: ezyang
fbshipit-source-id: 2b1af4d7bf26fd84a593fde292d6bfa2aabc1148
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26861
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17712801
Pulled By: ezyang
fbshipit-source-id: 504594452e6594d79e41856ce5177ab370dc26f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27061
Previously the cronjobs were run on master, but now the nightly builds
count as "PRs" so we must whitelist them from should_run calculation.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17669066
Pulled By: ezyang
fbshipit-source-id: 3b92bf1d09aefa7ef524ea93dfa8c6f566161887
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/26038
Somewhere between v1.1 and master `nonzero` become `abstract` and was marked as differentiable (by mistake) we need to but them into TH section of `tools/autograd/derivatives.yaml ` to fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26980
Differential Revision: D17632276
Pulled By: VitalyFedyunin
fbshipit-source-id: d6cabcc53348af6148cea5a1bd1af2ef12547373
The current logic is buggy, and will fail in the following situation:
Thread A: check optimized_graph_, it is empty.
Thread A: claim the mutex in order to initialize optimized_graph_.
Thread A: copy graph_ into optimized_graph_.
Thread A: start running optimizations on optimized_graph_.
Thread B: check optimized_graph_, it is not empty.
Thread B: start using optimized_graph_.
BUG: Thread B is using the graph while it's still being mutated by
Thread A.
[ghstack-poisoned]
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26390
`quantize_script`: top level API for graph mode quantization
Test Plan:
there are some known issues, we can enable test after all known issues are fixed.
Imported from OSS
Differential Revision: D17645132
fbshipit-source-id: 61f261d5607409d493b39a2f4e05ebd017279f6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26978
We can add them later if there is a need.
Test Plan:
ci
Imported from OSS
Differential Revision: D17643009
fbshipit-source-id: 053ec65c4acc03371aab4760793282682f039933
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26848
att
Test Plan:
ci
Imported from OSS
Differential Revision: D17636399
fbshipit-source-id: 7a2bc99a5dd7120c3b7de2adc72c772cb0759066
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26839
att
Test Plan:
ci
Imported from OSS
Differential Revision: D17643010
fbshipit-source-id: 5768b70410b7bdfdbee734d3a00296e5b1ad30d5
Summary:
Previously we did not throw if an input to `range` was a non-integer.
We also typed the result from `int ** int` as an integer but returned a float value. The return type should be a float, because if the exponent is negative `int ** int` returns a float.
Batching these two PRs together because it is easier to land and we're almost at the branch cut.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26926
Differential Revision: D17643039
Pulled By: eellison
fbshipit-source-id: b49203a9d420417e1307bbb653d2e33cd9e530e3
Summary:
Fixes https://github.com/pytorch/pytorch/issues/8817
This rewrites `argmax` and `argmin` to use `TensorIterator` as suggested by ngimel in https://github.com/pytorch/pytorch/issues/8817. To support this, the reduction operation is now passed the index along with the current element. I also had to change a few places where the input and output tensor `dtype`s were assumed to be the same.
Unfortunatley, this isn't enough to reimplement the variants of `min` and `max` that return indices. There are several places where multiple tensor outputs are assumed to all have the same `dtype` and so returning `pair<scalar_t, int64_t>` for `ops.project` isn't possible.
#### Performance Results
**Edit:** These timings are invalid, see below for a better perf comparison
Timings reported by [`argmax.py`](https://gist.github.com/SsnL/6898c240d22faa91da16fc41359756a2):
```
cuda : 0.1432
cpu : 26.976
numpy: 2.1350
```
So, the `TensorIterator` reductions are much faster on the GPU but significantly slower on the CPU. `htop` shows the cpu kernel using 4 cores for the cpu reduction so it's not clear what the issue is there.
Should I just revert to the old implementation on CPU or is it worth investigating further? I see that other `TensorIterator` cpu reductions are similarly faster in `numpy` e.g. `max`, `mean` `std`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26181
Differential Revision: D17631979
Pulled By: pbelevich
fbshipit-source-id: 58424818ef32cef031d436cb6191e9a6ca478581
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26867
Use caffe2::Int8Quantize for pytorch mobile. Currently this is only implemented for uint8 tensors and runs using NEON intrinsics.
For all other cases it falls back to naive pytorch quantize_val implementation.
Previously, naive implementation of quantize_val is slow on mobile, taking up more than 50% of the execution time.
Results
Before
aten::quantize_per_tensor 42.893 ms
Total model runtime 70.5ms
After
aten::quantize_per_tensor 0.340 ms
Total model runtime 27.5ms
Test Plan:
Tested current python tests work python test/test_quantized.py TestQNNPackOps
Also tested using quantized mobilenetV2 on mobile and compared output
Imported from OSS
Differential Revision: D17638732
fbshipit-source-id: 76445d1e415e6e502d05ba5b900e5e1d875fc1b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27001
This unconditional log line spams the logs enough that it's a drag on cpu and will eventually fill up logs.
Test Plan: Allow unit test and automated testing to give feedback.
Reviewed By: jspark1105
Differential Revision: D17638140
fbshipit-source-id: 4e8a44bda31327ba7e797f7579a9e3bf866eef7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26938
They were accidentally removed in #26020
Test Plan: Imported from OSS
Differential Revision: D17632120
Pulled By: pbelevich
fbshipit-source-id: d62f2b5635fb4976fd4eda2f2015fdf67138a0c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26912
group name is used as prefix in the c10d store and without a consistent name process group cannot be initialized.
When process group doesn't have an explicit name (only WORLD (default) process group can have an explicit name), we use global _group_counter to generate the name. We need to reset the counter on destruction to allow consistent value to be generated when we re-create process groups after some trainers recover from failure.
Test Plan: existing tests passed
Reviewed By: mrshenli
Differential Revision: D17594268
fbshipit-source-id: 17f4d2746584dadaa5d468085d871ff3e95a1c84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26985
Produce better error message when `calculate_qparams` doesn't return
something we expect. It should return a Tuple of two tensors.
Test Plan:
ci
Imported from OSS
Differential Revision: D17636252
fbshipit-source-id: 6caee48134f46d2f25dec3fa655e99c15043a67f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26995
Fix current setup, exclude fbjni - we can not use independently pytorch_android:package, for example for testing `gradle pytorch_android:cAT`
But for publishing it works as pytorch_android has dep on fbjni that will be also published
For other cases - we have 2 fbjni.so - one from native build (CMakeLists.txt does add_subdirectory(fbjni_dir)), and from dependency ':fbjni'
We need both of them as ':fbjni' also contains java classes
As a fix: keep excluding for publishing tasks (bintrayUpload, uploadArchives), but else - pickFirst (as we have 2 sources of fbjni.so)
# Testing
gradle cAT works, fbjni.so included
gradle bintrayUpload (dryRun==true) - no fbjni.so
Test Plan: Imported from OSS
Differential Revision: D17637775
Pulled By: IvanKobzarev
fbshipit-source-id: edda56ba555678272249fe7018c1f3a8e179947c
Summary:
- This PR together with #26908 attempt to address issue #26764 (`Issue 1` mentioned below).
- Current flow without USE_STATIC_DISPATCH (for server build):
```
S1. jit::load()
a. JIT calls variable_factories.h methods to instantiate variable instances.
b. JIT calls some ATen methods during intitalization, e.g.: conv_prepack, q_scale.
b.1 First runs corresponding `Operation` in generated register_aten_ops_xxx.cpp, which calls `at::` functions, then calls ATen dispatcher.
b.2 ATen dispatcher dispatches to corresponding VariableType methods.
b.3 VariableType method uses `AutoNonVariableTypeMode` guard before calling into ATen implementation, as ATen generally expects `CHECK(!is_variable())`.
b.4 VariableType method uses `as_variable` to wrap the results.
x. Somewhere in JIT it expects `CHECK(is_variable())` - not sure before/after S1.a / S1.b.
S2. module::forward()
a. JIT interpreter calls some ATen methods (via JIT registry).
a.1 - a.4: same as S1.b.1 - S1.b.4.
x. Different from S1.x, seems JIT doesn't expect `CHECK(is_variable())` during the entire `forward()` call.
```
- Current flow with USE_STATIC_DISPATCH (for mobile build):
```
M1. jit::load()
a. JIT calls variable_factories.h methods to instantiate variable instances.
b. JIT calls some ATen methods during intitalization, e.g.: conv_prepack, q_scale.
b.1 First runs corresponding `Operation` in generated register_aten_ops_xxx.cpp, which calls `at::` functions, then calls ATen dispatcher.
b.2 ATen dispatcher dispatches to corresponding ATen implementation directly.
// Issue 1: NO VariableType methods / `AutoNonVariableTypeMode` so `CHECK(!is_variable())` in ATen will fail!
// (Hypothetical) Issue 2: NO `as_variable()` to wrap result as variable. M1.x will fail if is ever used to check this result.
x. Somewhere in JIT it expects `CHECK(is_variable())` - not sure before/after M1.a / M1.b.
M2. module::forward() // PR #26477 wraps this call with `AutoNonVariableTypeMode` guard.
a. JIT interpreter calls some ATen methods (via JIT registry).
a.1 same as M1.b.1, calls into register_aten_ops_xxx.cpp.
a.2 same as M1.b.2, calls ATen implementation directly.
// `CHECK(!is_variable())` in ATen won't fail thanks to the outer scope `AutoNonVariableTypeMode` guard.
x. Same as above, seems JIT never expects `CHECK(is_variable())` during the entire `forward()` call.
```
- Wrong solution: if we wrap M1 with `AutoNonVariableTypeMode`, it will solve `Issue 1` for some models but will fail M1.x for some other models.
- Proposed solution:
I feel the root cause is that mobile build doesn't have `VariableType` as a barrier sitting between JIT and ATen to convert between is_variable() and !is_variable().
Without `VariableType` the best alternative place to put a barrier is M1.b.2 as Edward did in #26908.
For some reason we also need toggle variable state for c10 ops: this is what this PR does. We haven't figured how non-mobile build works without this logic so it's kinda bandaid for now.
This PR doesn't try to address (Hypothetical) Issue 2 as I haven't seen it. PR #26477 can be replaced by #26908 + this PR but we can keep it until M2.x is no longer true.
- Ultimate solution:
After Variable and Tensor are completely merged: #23032 then is_variable() checks can be changed to requires_grad() checks and all problems will be solved. We can clean up these hacks by then.
- References:
* Effect of `AutoNonVariableTypeMode`: all `is_variable()` inside current thread scope returns false:
https://github.com/pytorch/pytorch/blob/master/c10/core/TensorImpl.h#L811
* Effect of `as_variable`: https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/VariableTypeUtils.h#L159
It calls `make_variable`: https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/variable.h#L539
Test Plan: - Load and run MobileNetV2 fp32 & int8 models.
Differential Revision: D17595179
Pulled By: ljk53
fbshipit-source-id: ed417ba6b696d722ea04fe18adf6b38ababa6b7c
Summary:
Bumping up the `producer_version` in exported ONNX models in view of the next release. Updating tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26976
Reviewed By: hl475
Differential Revision: D17631902
Pulled By: houseroad
fbshipit-source-id: 6d58964657402ac23963c49c07fcc813386aabf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26897
TORCH_INTERNAL_ASSERT("foo") doesn't do what you think it does :)
I'll try to do a fix to catch it in the compiler, but for now - let's fix usages
Found them using regex:
```
ag --cpp "TORCH_(CHECK|INTERNAL_ASSERT)\([ \n]*\"" --multiline
```
Test Plan: Imported from OSS
Differential Revision: D17624299
Pulled By: dzhulgakov
fbshipit-source-id: 74f05737ef598fd92b5e61541ee36de2405df23d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26968
To make implementations of an operator more robust, we should have a
separate "named area" where name propagation happens and an "unnamed
area" where the implementation is. Right now, many functions are
implemented without an "unnamed area". The problem with that is that if
someone modifies the implementation, it is very easy to break
namedtensor support by using a helper function that does not propagate
names correctly. The test coverage for named tensors is also
insufficient to catch such breakages.
This PR modifies some named tensor implementations to have separate
"named area" and "unnamed area". The following implementations were
changed:
- dropout, softmax, log_softmax, bernoulli
- dot, mm, addmm, addmv, mv
Test Plan: - [namedtensor ci]
Differential Revision: D17627920
Pulled By: zou3519
fbshipit-source-id: 9300ac3962219b1fcd8c4c8705a2cea6f8c9d23d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26975
ExportModule doesn't exist in mobile libtorch.a, it doesn't fail for
regular mobile build guess _save_for_mobile was stripped altogether.
But for host toolchain with different linker flag this will fail.
Add #if macro as Module::save.
Test Plan: - scripts/build_mobile.sh works;
Differential Revision: D17629869
Pulled By: ljk53
fbshipit-source-id: 7d3cebe0a7c3f7b56928eb5a9d9c9174403fe6e5
Summary:
This PR contains the following:
1. Fix ambiguous overload problem when `torch::tensor({{1, 2}})` is used:
```
../test/cpp/api/tensor.cpp: In member function ‘virtual void TensorTest_MultidimTensorCtor_Test::TestBody()’:
../test/cpp/api/tensor.cpp:202:41: error: call of overloaded ‘tensor(<brace-enclosed initializer list>)’ is ambiguous
auto tensor = torch::tensor({{1, 2}});
^
In file included from ../caffe2/../torch/csrc/api/include/torch/types.h:7:0,
from ../caffe2/../torch/csrc/api/include/torch/detail/static.h:4,
from ../caffe2/../torch/csrc/api/include/torch/nn/pimpl.h:4,
from ../caffe2/../torch/csrc/api/include/torch/nn/module.h:3,
from ../caffe2/../torch/csrc/api/include/torch/nn/cloneable.h:3,
from ../test/cpp/api/support.h:7,
from ../test/cpp/api/tensor.cpp:2:
../torch/csrc/autograd/generated/variable_factories.h:177:644: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<unsigned char>)
../torch/csrc/autograd/generated/variable_factories.h:177:1603: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<signed char>)
../torch/csrc/autograd/generated/variable_factories.h:177:2562: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<short int>)
../torch/csrc/autograd/generated/variable_factories.h:177:3507: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<int>)
../torch/csrc/autograd/generated/variable_factories.h:177:4450: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<long int>)
../torch/csrc/autograd/generated/variable_factories.h:177:5404: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<float>)
../torch/csrc/autograd/generated/variable_factories.h:177:6354: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<double>)
../torch/csrc/autograd/generated/variable_factories.h:177:7630: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<bool>)
../torch/csrc/autograd/generated/variable_factories.h:177:9224: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<c10::Half>)
../torch/csrc/autograd/generated/variable_factories.h:177:10838: note: candidate: at::Tensor torch::tensor(c10::ArrayRef<c10::BFloat16>)
In file included from ../caffe2/../torch/csrc/api/include/torch/types.h:7:0,
from ../caffe2/../torch/csrc/api/include/torch/detail/static.h:4,
from ../caffe2/../torch/csrc/api/include/torch/nn/pimpl.h:4,
from ../caffe2/../torch/csrc/api/include/torch/nn/module.h:3,
from ../caffe2/../torch/csrc/api/include/torch/nn/cloneable.h:3,
from ../test/cpp/api/support.h:7,
from ../test/cpp/api/tensor.cpp:2:
../torch/csrc/autograd/generated/variable_factories.h:193:19: note: candidate: at::Tensor torch::tensor(torch::detail::InitListTensor)
inline at::Tensor tensor(detail::InitListTensor list_init_tensor) {
^
```
After this PR, the multidim tensor constructor `torch::tensor(...)` should be ready for general use.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26890
Differential Revision: D17632608
Pulled By: yf225
fbshipit-source-id: 2e653d4ad85729d052328a124004d64994bec782
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26934
Disable cudnn transpose for int types
Did experiment with int + 4d/5d
Test Plan: buck test mode/dev-nosan caffe2/caffe2/python/operator_test:utility_ops_test
Reviewed By: houseroad
Differential Revision: D17607176
fbshipit-source-id: 83b9f9cf654b33d68b657f1b5a17d9bbd06df529
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26520
Hooks to enable control of observer and fake quant that can be used by model.apply() to control fake quant during QAT
ghstack-source-id: 90897063
Test Plan: buck test caffe2/test:quantization -- --print-passing-details
Differential Revision: D17491155
fbshipit-source-id: 80ff0d7a1ac35c96e054b4f0165a73c56c2f53cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26966
Without this, you may allocate intermediates which are non-variables
when you should allocate variables.
Should help with discussion in #26868.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17629863
Pulled By: ezyang
fbshipit-source-id: 0dd9b218d3fc2dbbbbd9b1712db8ab4dac16ea22
Summary:
Kernel launch did not have the stream argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26946
Test Plan: should be covered by current tests
Differential Revision: D17629397
Pulled By: ngimel
fbshipit-source-id: f91a72d0908b5672c6df045c9df49bf1d48a5ac9
Summary:
The QuantizedAVx2 does not support the int32 type. We switch to use at::quantize_vec function instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26854
Differential Revision: D17609872
Pulled By: llyfacebook
fbshipit-source-id: b4a77d93ce0ebfef696506b5cdbe3e91fe44bb36
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/24192 by including the private field `iteration_` in SGD optimizer serialization. Under the hood, `iteration_` is serialized into an `IValue`, then stored in a JIT module as an attribute.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26906
Differential Revision: D17628359
Pulled By: yf225
fbshipit-source-id: beec1367459e973a1c9080dc86f502e4c7bc5ebd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26830Fixes#26817
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17608535
Pulled By: ezyang
fbshipit-source-id: 18b47af508bd606391b1e6436cefe586b9926ace
Summary:
ONNX does not support dictionaries for inputs and output. The reason is that the arg flattening and unflattening does not handle Dictionary types.
This PR adds flattening/unflattening support for dictionaries and strings.
However this feature should be handled with caution for input dictionaries; and users need to verify their dict inputs carefully, and keep in mind that dynamic lookups are not available.
This PR will allow exporting cases where models have dictionnary outputs (detection and segmentation models in torchvision), and where dictionary inputs are used for model configurations (MultiScaleRoiAlign in torchvision).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25889
Reviewed By: hl475
Differential Revision: D17613605
Pulled By: houseroad
fbshipit-source-id: c62da4f35e5dc2aa23a85dfd5e2e11f63e9174db
Summary:
In some version of python, then_net and else_net may switch the order. Let's make sure we are iterating the right arg node.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26931
Reviewed By: hl475
Differential Revision: D17614829
Pulled By: houseroad
fbshipit-source-id: 3f1b4eb91ecf4d808f58c34896d3e628aa2e0af0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26877
Add batch_size == 0 testings of other DNNLOWP operators not covered by the other diffs.
Test Plan: CI
Reviewed By: jianyuh
Differential Revision: D17596315
fbshipit-source-id: ddf5325f422402cafacbef9114314d92c49fc284
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26898
This diff removes call sites using the old depth-wise conv fbgemm interface in Caffe2.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D17515368
fbshipit-source-id: 7200cf12ddac1103402e690596c58f378f95b1e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26882
Reduce binary size by 500kb by making TypeDerived and VariableType anonymous namespaces instead of classes. TypeDefault is also a namespace now but can't be anonymous because VariableType calls into it.his also has the nice side effect that VariableType.h and ${TypeDerived.h} are much smaller because they don't have to list the operator declarations anymore.
ghstack-source-id: 90865080
Test Plan: Measure libtorch.so size
Differential Revision: D17599686
fbshipit-source-id: da3c6641060b7410a7808f36a0a18ee3246ce2d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26878
Before, for each function signature used in one or more ops, there's a template instantiation that creates the FunctionSchema object for it. As we've seen in the past, all these vector<> constructors in the FunctionSchema object take quite some binary size.
With this PR, we now create an intermediate constexpr std::array that has minimal binary size and can be embedded into the executable, then at runtime we will run a small piece of code that constructs the vector<>'s from it.
This reduces libtorch.so binary size by 800kb
ghstack-source-id: 90842811
Test Plan: measure libtorch.so size
Differential Revision: D17597752
fbshipit-source-id: 53442b565a7747c0d0384b2e3b845729c3daddfd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26869
Having a lot of shared_ptr<Functor> cost us ~1.1MB of binary size in libtorch.so.
This PR fixes that.
ghstack-source-id: 90842812
Test Plan: measure libtorch.so size
Differential Revision: D17595674
fbshipit-source-id: 05151047ee8e85c05205b7510a33915ba98bab58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26827
The templates there had a binary size impact of ~20MB. This PR fixes that.
ghstack-source-id: 90842814
Test Plan: build it and see binary size of libtorch.so go down from 95MB to 70MB.
Differential Revision: D17566642
fbshipit-source-id: 57bebffce8e036675a452434bc1a9733f5f2cf6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26911
Check if QNNPACK is present as a backend (should always be present on mobile).
If it is present then set the backend to QNNPACK
Test Plan:
Test on mobile
./speed_benchmark_torch --model mobilenet_quantized_scripted.pt --input_dims="1,3,224,224" --input_type=float --warmup=5 --iter 20 --print_output True
Imported from OSS
Differential Revision: D17613908
fbshipit-source-id: af96722570a0111f13d69c38ccca52416ea5e460
Summary:
https://github.com/pytorch/pytorch/issues/24593https://github.com/pytorch/pytorch/issues/24727
**torch.lt(Tensor a, Tensor b)**
will compute common dtype (highest) based on inputs and then compare values. The result will be Bool tensor
```
>>> x = torch.tensor([0], dtype=torch.int)
>>> y = torch.tensor([0.5], dtype=torch.double)
>>> x < y
tensor([True])
```
Previously it was impossible to make comparison of two tensors with different dtype.
**torch.lt(Tensor a, Tensor b, out=c)**
will compute common dtype (highest) based on inputs and then compare values. The result can be populated only to Bool tensor
```
>>> x = torch.tensor([0], dtype=torch.int)
>>> y = torch.tensor([0.5], dtype=torch.double)
>>> z = torch.empty([1], dtype=torch.bool)
>>> torch.lt(x, y, out=z)
tensor([True])
```
Previously it was impossible to make comparison of two tensors with different dtype. Also previously the result dtype could be Bool and Byte(deprecated). Currently it will accept only Bool result.
**a.lt_(Tensor b)**
Expects that a and b has same dtype, otherwise it's possible to get an overflow(Example: 'a' is uint8, 'b' is float32. 'a' will be promoted to float32 and the result will be also float32. Then it will be casted back to uint8 so potential for overflow). Will not compute common dtype. Result will have type of a.
```
>>> x = torch.tensor([0], dtype=torch.double)
>>> y = torch.tensor([0.5], dtype=torch.double)
>>> x < y
tensor([True])
```
Works similar to previous implementation.
**torch.lt(Tensor a, Scalar b)**
will check if there is no overflow when converting b to the same type as a. Then will compute common dtype and compare.
```
>>> x = torch.tensor([0], dtype=torch.double)
>>> x < 0.5
tensor([True])
>>> x = torch.tensor([0], dtype=torch.int)
>>> x < 0.5
tensor([True])
```
Fix https://github.com/pytorch/pytorch/issues/22301.
**torch.lt(Tensor a, Scalar b, out=c)**
will check if there is no overflow when converting b to the same type as a. Then will compute common dtype and compare. The result can be populated only to Bool tensor
```
>>> x = torch.tensor([0], dtype=torch.double)
>>> torch.lt(x, 0.5, out=z)
tensor([True])
```
Previously the result dtype could be Bool and Byte(deprecated). Currently it will accept only Bool result. The rest works similar to previous implementation.
**torch.lt_(Tensor a, Scalar b)**
will check if there is no overflow when converting b to the same type as a. Then will compute common dtype and compare. Result will have type of a.
```
>>> x = torch.tensor([0], dtype=torch.int)
>>> x.lt_(1)
tensor([1], dtype=torch.int32)
>>> x = torch.tensor([0], dtype=torch.int)
>>> x.lt_(1.0)
tensor([1], dtype=torch.int32)
```
Works similar to previous implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25998
Differential Revision: D17431853
Pulled By: ifedan
fbshipit-source-id: b5effc6a5d9b32da379395b32abc628b604faaf7
Summary:
Currently when a Vec256<T> (base) object contains -0.0, Vec256<T>::abs()
would not produce 0.0, but -0.0 instead. This commit fixes this issue.
This bug will mostly affect CPUs without AVX support, such as ARM,
PowerPC, and older Intel models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26422
Differential Revision: D17607346
fbshipit-source-id: e8d4595f0e88ad93018a61f89b9e3dcada485358
Summary:
Proposed change:
Check whether sccache is available before running it to show statistics.
(If not available, simply skip it. Showing these stats isn't mandatory to build.)
https://github.com/pytorch/pytorch/issues/26058
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26059
Differential Revision: D17364967
Pulled By: vincentqb
fbshipit-source-id: 0250c6ba5573bc0b292ae8e2188b3e1fa700409e
Summary:
A little benchmarking shows real improvements.
Benchmarking script:
```python
import timeit
for n, t in [(10_000, 8000),
(100_000, 800)]:
for dtype in ('torch.float', 'torch.double'):
print(f'================ dtype {dtype}, {t} times ================================')
for op in ('sin', 'sinh', 'cos', 'cosh', 'tan'):
print(f'a.{op}() (a.numel() == {n}) for {t} times')
print(timeit.timeit(f'a.{op}()',
setup=f'import torch; a = torch.arange({n}, device="cpu", dtype={dtype})',
number=t))
```
RHEL 7.7, Debug build, gcc 8.3, turbo off:
Before this commit:
```
================ dtype torch.float, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
2.690067914001702
a.sinh() (a.numel() == 10000) for 8000 times
7.025003784001456
a.cos() (a.numel() == 10000) for 8000 times
2.691191975001857
a.cosh() (a.numel() == 10000) for 8000 times
6.7473940790005145
a.tan() (a.numel() == 10000) for 8000 times
39.14060311800131
================ dtype torch.double, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
5.442704386001424
a.sinh() (a.numel() == 10000) for 8000 times
6.778444146999391
a.cos() (a.numel() == 10000) for 8000 times
5.429267812000035
a.cosh() (a.numel() == 10000) for 8000 times
6.625128638002934
a.tan() (a.numel() == 10000) for 8000 times
6.888564799002779
================ dtype torch.float, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
2.343601189000765
a.sinh() (a.numel() == 100000) for 800 times
6.4455943499997375
a.cos() (a.numel() == 100000) for 800 times
2.3377084899984766
a.cosh() (a.numel() == 100000) for 800 times
6.357531049001409
a.tan() (a.numel() == 100000) for 800 times
46.93665131099988
================ dtype torch.double, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
5.122997600999952
a.sinh() (a.numel() == 100000) for 800 times
6.233409892000054
a.cos() (a.numel() == 100000) for 800 times
5.071856587001093
a.cosh() (a.numel() == 100000) for 800 times
6.0974346790026175
a.tan() (a.numel() == 100000) for 800 times
6.5203832980005245
```
After this commit:
```
================ dtype torch.float, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
1.5905082239987678
a.sinh() (a.numel() == 10000) for 8000 times
6.8216283560032025
a.cos() (a.numel() == 10000) for 8000 times
1.630263119997835
a.cosh() (a.numel() == 10000) for 8000 times
6.738510535000387
a.tan() (a.numel() == 10000) for 8000 times
1.7482984089983802
================ dtype torch.double, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
2.0000513029990543
a.sinh() (a.numel() == 10000) for 8000 times
6.876631892999285
a.cos() (a.numel() == 10000) for 8000 times
2.0672772910002095
a.cosh() (a.numel() == 10000) for 8000 times
6.678993797999283
a.tan() (a.numel() == 10000) for 8000 times
2.3625312719996145
================ dtype torch.float, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
1.2381345620015054
a.sinh() (a.numel() == 100000) for 800 times
6.400261008999223
a.cos() (a.numel() == 100000) for 800 times
1.284327255001699
a.cosh() (a.numel() == 100000) for 800 times
6.332740200999979
a.tan() (a.numel() == 100000) for 800 times
1.392364119998092
================ dtype torch.double, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
1.6348750549987017
a.sinh() (a.numel() == 100000) for 800 times
6.312609101998532
a.cos() (a.numel() == 100000) for 800 times
1.700102185997821
a.cosh() (a.numel() == 100000) for 800 times
6.141731683001126
a.tan() (a.numel() == 100000) for 800 times
1.9891383869980928
```
RHEL 7.7, Release build, gcc 8.3, turbo off:
Before this commit:
```
================ dtype torch.float, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
1.0220722929989279
a.sinh() (a.numel() == 10000) for 8000 times
0.9413958889999776
a.cos() (a.numel() == 10000) for 8000 times
1.013564700999268
a.cosh() (a.numel() == 10000) for 8000 times
0.9127178879971325
a.tan() (a.numel() == 10000) for 8000 times
25.249723791999713
================ dtype torch.double, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
3.3466339340011473
a.sinh() (a.numel() == 10000) for 8000 times
0.909793314000126
a.cos() (a.numel() == 10000) for 8000 times
3.4019737700000405
a.cosh() (a.numel() == 10000) for 8000 times
0.918371007002861
a.tan() (a.numel() == 10000) for 8000 times
4.902741645997594
================ dtype torch.float, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
0.9870414770011848
a.sinh() (a.numel() == 100000) for 800 times
0.9038734009991458
a.cos() (a.numel() == 100000) for 800 times
0.9786967349973565
a.cosh() (a.numel() == 100000) for 800 times
0.8774048919985944
a.tan() (a.numel() == 100000) for 800 times
30.299459709000075
================ dtype torch.double, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
3.3855797659998643
a.sinh() (a.numel() == 100000) for 800 times
0.8303290260009817
a.cos() (a.numel() == 100000) for 800 times
3.3702223940017575
a.cosh() (a.numel() == 100000) for 800 times
0.822016927999357
a.tan() (a.numel() == 100000) for 800 times
4.889868417001708
```
After this commit:
```
================ dtype torch.float, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
0.542676458000642
a.sinh() (a.numel() == 10000) for 8000 times
0.90598970100109
a.cos() (a.numel() == 10000) for 8000 times
0.6119738140005211
a.cosh() (a.numel() == 10000) for 8000 times
0.902145998999913
a.tan() (a.numel() == 10000) for 8000 times
0.7713400800021191
================ dtype torch.double, 8000 times ================================
a.sin() (a.numel() == 10000) for 8000 times
0.609621113002504
a.sinh() (a.numel() == 10000) for 8000 times
0.8993683010012319
a.cos() (a.numel() == 10000) for 8000 times
0.6876834479990066
a.cosh() (a.numel() == 10000) for 8000 times
0.8859291590015346
a.tan() (a.numel() == 10000) for 8000 times
0.9243346840012236
================ dtype torch.float, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
0.5219837559998268
a.sinh() (a.numel() == 100000) for 800 times
0.8755807839988847
a.cos() (a.numel() == 100000) for 800 times
0.5899826130007568
a.cosh() (a.numel() == 100000) for 800 times
0.8757360769996012
a.tan() (a.numel() == 100000) for 800 times
0.7496912290007458
================ dtype torch.double, 800 times ================================
a.sin() (a.numel() == 100000) for 800 times
0.578619064999657
a.sinh() (a.numel() == 100000) for 800 times
0.7951330530013365
a.cos() (a.numel() == 100000) for 800 times
0.6442456569966453
a.cosh() (a.numel() == 100000) for 800 times
0.7975544330001867
a.tan() (a.numel() == 100000) for 800 times
0.875703464000253
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26431
Differential Revision: D17470502
fbshipit-source-id: 82e930993c7b2827b04cbe5f9a962913a6069b62
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26757
This doesn't switch any open source builds or CI.
The internal fbcode build is C++17 already for quite some time, but in CUDA code, we had it restricted to C++11.
This diff changes that to C++14.
Because this doesn't change anything open source, the risk of this is low.
ghstack-source-id: 90728524
Test Plan: waitforsandcastle
Differential Revision: D17558142
fbshipit-source-id: 9cfd47e38e71d5a2fdae2f535c01f281bf007d9a
Summary:
The current Bernoulli distribution sampler is slightly off in that it returns true slightly too often. This is most obvious at very low p values, like p = 0, although it theoretically occurs at every probability. See https://github.com/pytorch/pytorch/issues/26807.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26864
Differential Revision: D17610459
Pulled By: ezyang
fbshipit-source-id: 28215ff820a6046822513f284793e7b850d38438
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26907
Somehow CircleCI broke this on update to their OS X workers;
the error looks like
/bin/bash: line 1: PROMPT_COMMAND: unbound variable
I'm not sure if I've killed all the occurrences that are necessary,
let's see!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17607486
Pulled By: ezyang
fbshipit-source-id: 5e9a7ff69d4b18e759965bf97c67d38404841187
Summary:
Changelog:
- Selectively assign compute_uv in the at::svd used internally in the implementation of at::nuclear_norm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26303
Test Plan:
- Add tests in common_method_invocations.py
Refixes: https://github.com/pytorch/pytorch/issues/18275
Differential Revision: D17605357
Pulled By: ezyang
fbshipit-source-id: d87d60afe678e2546dca6992ea66f2daeb6b0346
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26758
This PR changes the order in which we import classes and functions so
that is is no longer necessary for them to defined in order in a file,
or for there to be proper import statements in the exported file.
Actually importing a function/class now is driven by the need to resolve
the entity during unpickling, type resolution, or value resolution.
While this should allow significant simplification to the code that
serializes classes, this work has not been done yet in order to avoid
inevitable forward compat issues in the transition period.
Notes:
* Individual functions have been replaced with a SourceImporter object
that exposes a resolveType method. This method loads the type if
it has not been loaded yet, potentially parsing (but not loading)
the file it exists in if that file hasn't been parsed yet.
* Some legacy functionality needed to be added as a method to this object
since the old format still used some of this logic for class resolution.
Test Plan: Imported from OSS
Differential Revision: D17558989
Pulled By: zdevito
fbshipit-source-id: 7eae3470bcbd388c4de463e3462d527776ed46c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26367
This is necessary for boxed fallback, as boxed fallback must
live inside the templated code. Error reporting code never
has to be in templated code, so that stays in the C++ file.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17448556
Pulled By: ezyang
fbshipit-source-id: 8244589251e359886dbfcd1c306ae6c033c7a222
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26857
Previously, ATenDispatch took TensorTypeId and returned a function pointer, to
avoid requiring a direct dependence on Tensor (which would have caused a header
cycle). Thanks to the work of Sebastian, it is now possible to include
TensorBody.h without inducing a cycle; so we can now replace this indirect
implementation with a more direct implementation of unboxedCall and move most of
the implementation details into ATenDispatch (simplifying generated code). This
is a necessary prerequisite for boxed fallback work I want to do, as I want to
handle generation of boxing from inside ATenDispatch, not generated code.
Unfortunately, we still need to generate the multidispatch list in
function_wrapper.py to accommodate c10 dispatcher.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17602540
Pulled By: ezyang
fbshipit-source-id: 6927e66924405f5bf5cb67f1b57e49bc9a0f58ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26824
These ops are named after the bitwise reduction ops in MPI.
This is based on the work done by knottb in #22449.
Closes#22449.
Test Plan: Imported from OSS
Differential Revision: D17600210
Pulled By: pietern
fbshipit-source-id: 44c7041ce01bc5de170a4591c5a696e4f24431ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26809
resize_as_ shouldn't do multiple dispatch on its second argument. Because it
currently has per CPU/CUDA dispatch, however, it will do proper dispatch on all
arguments. Bad!
There is only a very minor downside to this patch which is we have an extra
dynamic dispatch now.
Thank you Ailing for reporting this problem.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17581324
Pulled By: ezyang
fbshipit-source-id: e62cbb6cf497a7d6e53c4a24b905fef7a29b0826
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26782
At least we should be consistent on top-level APIs and prepare/convert/etc.
Logic is inplace=False by default but top-level APIs take care of doing fewer copies.
Also renames always-inplace methods like add_observer to have underscore in the end.
One fix for MinMaxObserver was triggered by deepcopy surfacing that we were accidentally keeping autograd around
Test Plan: Imported from OSS
Differential Revision: D17595956
Pulled By: dzhulgakov
fbshipit-source-id: 801f9f5536b553f24c7a660064dd6fce685edd65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26849
We were having division-by-zero errors when one of the input tensor dimension is 0 . Examples: P111481720 and P111481374
This diff adds unit tests for empty input tensors and fixes division-by-zero errors in the partition function.
Test Plan: buck test caffe2/caffe2/quantization/server:concat_dnnlowp_op_test -- --stress-runs=100
Reviewed By: jianyuh
Differential Revision: D17574566
fbshipit-source-id: 1d2c21308bde99b3c4f2da82f53201eec42b5d8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26851
Add codegen option to remove backward ops from jit-op-registry as they are not
likely to be used for inference only mobile build.
Measured ARM-v7 AAR build size change: 5,804,182 -> 5,331,219.
Test Plan: - build and integrate with demo app;
Differential Revision: D17587422
Pulled By: ljk53
fbshipit-source-id: 08c0fc7a710698a0d4baaf16bbb73cb812b1126a
Summary:
This diff implemented at::parallel_for()/parallel_reduce() and other
ATen/Parallel.h APIs for mobile using caffe2::ThreadPool.
caffe2::ThreadPool doesn't support submitting individual tasks
separately and running them in parallel - all tasks need to be submit in
one batch which will lock the thread pool until all of them finish - as a
result we didn't wrap caffe2::ThreadPool with TaskThreadPoolBase interface
and reuse at::parallel_for() implementation in ParallelNative.h. Because
of this constraint, intraop_launch() / intraop_launch_future() are not
supported yet.
This diff doesn't touch inter-ops pool - it's still default native c10
thread pool. Will work on it when it's widely used.
Test Plan: - This is early draft to receive feedback. Will do more thorough tests.
Differential Revision: D17543412
Pulled By: ljk53
fbshipit-source-id: 53a3259409c7207d837b9135d87d8daa6ad15e30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26828
Pickle serialization for quantized modules is currently broken by https://github.com/pytorch/pytorch/issues/24045, so let's be loud and fail if the user tries to do it
Test Plan: Imported from OSS
Differential Revision: D17579127
Pulled By: jamesr66a
fbshipit-source-id: 3deccac7e4590c6f648f22bb79c57badf3bf0487
Summary:
An attempt to enable double backward for non-cudnn LSTM and GRU (see https://github.com/pytorch/pytorch/issues/25315, https://github.com/pytorch/pytorch/issues/20449). RNN works already because it does not rely on fused kernels.
This does not implement double backward function itself, because that is pretty hard to spell out. Instead, it implements backward using differentiable operations, so that double backward can be done automatically.
The good: seems to work, no effect on performance on the usual case without double backward. because fused lstm backward is used.
The bad: Performance of backward and, especially, double backward, is pretty bad. Scripting would still be a preferred way if we want a performant solution. Performance and/or memory use can be slightly improved if in-place variants can be used for sigmoid_backward and tanh_backward to avoid cat in the end, but I'm not yet sure it's possible, and in any case it is only slight improvement.
The ugly: I could not figure out a way to reuse workspace that contains the sum of the gates with the applied sigmoid and tanh operations, so that's probably another perf and memory hit.
cc soumith, albanD. If you think this approach is viable, I can extend to GRU and RNN.
Thanks to mcarilli whose approach to double backward in weight norm I copied.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26660
Test Plan: added tests to check gradgrad for GRU and LSTM with cudnn disabled.
Differential Revision: D17581489
Pulled By: ngimel
fbshipit-source-id: efd204289e9a0e94d94896a0b3bff5cf6246cafa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25187
The bytecode export flow: dump the bytecode format for the light weighted interpreter.
* The bytecode is generated without input spec optimization. It would be more generic (input independent) with no obvious performance degradation (to be tested).
* Main API: torch::jit::script::Module::save(filename, extra_files, bool *bytecode_format* = false).
* Both bytecode and module object are exported in pickle format.
* The module object (in data.pkl) is the same as the original JIT model.
* The serializer is dependent on pickle only (no protobuf or Json).
* The major functionality is forked in ScriptModuleSerializer2::serialize().
* The test loader is test_bc_export.cpp.
* Simple APIs are added in Code and its implementation to get necessary information (instructions, operators and constants).
* Since there's no dependency on graph/node, GetAttr is promoted from an operator to first-class instruction (https://github.com/pytorch/pytorch/pull/25151) .
* Some definitions (instructions, writeArchive, etc) that are shared by full JIT and bytecode are pulled out of the local namespace (https://github.com/pytorch/pytorch/pull/25148).
The output layout looks like:
* folders of methods.
* In each method folder (for example, forward/):
* bytecode.pkl: instructions and operators
* constants{.pkl,/}: constant list in constants.pkl. If there are tensors in constants, the binary tensor files in constants/ folder.
* data{.pkl,/}: the module object, with binary tensor files in data/ folder. The same as in torchscript.
Test Plan: Imported from OSS
Differential Revision: D17076411
fbshipit-source-id: 46eb298e7320d1e585b0101effc0fcfd09219046
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26829
The TensorIterator loop for `copy_` uses operations that are currently
unsupported by named tensors. The solution is to wrap `copy_` in a
function that does the name propagation and ignore names when running
the implementation of `copy_`. There is no test case because I'm not
sure how to trigger the incorrect behavior, but there is definitely code
in CUDA copy that doesn't support named tensors (expand_as isn't
supported):
aaf30cdf36/aten/src/ATen/native/cuda/Copy.cu (L141-L148)
Test Plan: - [namedtensor ci]
Differential Revision: D17577310
Pulled By: zou3519
fbshipit-source-id: e11c52243800e1331fad738084304badcfd51ae2
Summary:
cpuinfo_initialize() was not implemented for s390 arch.
cpuinfo calls are x86 specific to determine vector extensions AVX, AVX512 etc.
Without this patch an unnecessary error log is printed in s390 arch:
Error in cpuinfo: processor architecture is not supported in cpuinfo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26265
Differential Revision: D17452301
Pulled By: izdeby
fbshipit-source-id: 9ca485550385c26dec18aac5953c887f1ffbfb7a
Summary:
We find a bug about `std::tuple` with nvcc.
In C++11, `std::tuple` constructor is constexpr in libstdc++, but is not constexpr in libc++.
c36b77fcda/aten/src/ATen/native/cuda/Loops.cuh (L109-L111)
The lines have occurred crashes in CUDA with a message `scan failed with synchronize`. It is a error message of cuda initialization.
The purpose of this PR is fixed for loop in nvcc and libc++ by not using `std::tuple`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25553
Differential Revision: D17582118
Pulled By: yf225
fbshipit-source-id: d6f62ed46c2415b48eb49f8a051cf3c0e7cb23ce
Summary:
Default encoding when using torch.load to 'utf-8'
This commit provides changes for cases where user tries to torch.load
a pickled module with non-ASCII characters in the docstring as
discussed in https://github.com/pytorch/pytorch/issues/21743. The default encoding was changed from 'ascii'
to 'utf-8'. Documentation for `torch.load` was updated and two tests
(loading py2 unicode module with unicode in it; error throwing when
user explicitly sets wrong encoding) were written.
~~This commit provides changes for better error handling in cases
where user tries to `torch.load` a pickled module with non-ASCII
characters in the docstring as discussed in https://github.com/pytorch/pytorch/issues/21743.~~
Ping ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26421
Differential Revision: D17581633
Pulled By: yf225
fbshipit-source-id: f8e77dcf7907092771149aad8ede6cfb73c21620
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26815
This PR adds named tensor support for:
- any, all, `bitwise_not(_)`, cumprod, cumsum, `logical_not`
In addition, it adds smoke tests for a variety of tensor attributes and
fns:
- is_shared, is_signed
- retain_grad, register_hook
Test Plan: - [namedtensor ci]
Differential Revision: D17575905
Pulled By: zou3519
fbshipit-source-id: 37bfa327e68112c5bf0f6bf1f467a527f50fa1c4
Summary:
function_ref is pulled over from LLVM. It is to callables what StringRef is to strings.
This allows it to be substantially lighter weight, particularly in code size. That comes
at the cost of not being usable in situations where the callable's lifetime is shorter
than the function_ref. This means it is suitable for callback-like scenarios, but not
for situations where the callable needs to be stored. In converting TensorIterator,
I only encountered one situation that required refactoring to comply with function_ref's
constraints.
In my local Release build, this reduces the size of libtorch by 4MB, from 70MB->66MB.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26592
Differential Revision: D17516202
fbshipit-source-id: 267476891f767f4827a4d38149f70e5035c56c48
Summary:
This PR makes the following improvements:
1. Add `forward_with_indices` method to all C++ MaxPool modules, to return the max indices along with the outputs. (We can't make two `forward` methods that return different types based on input, because that will break the type deduction of `torch::detail::return_type_of_forward_t`)
2. Add `max_poolNd_with_indices` to `torch::nn::functional`, to be used when indices of the max values are needed. (We can't merge this with `torch::nn::functional::max_poolNd` because the return type of `max_poolNd` has to be defined statically).
3. Improve `pretty_print` of C++ MaxPoolNd and AvgPoolNd modules to match the Python `extra_repr`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26521
Differential Revision: D17507358
Pulled By: yf225
fbshipit-source-id: b6c0e2b27b38378cdc0c75f4bfc797b3c6b17cd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26453
Previously, schema matching would incorrectly widen typevar bindings
when later occurrences were supertypes of earlier ones. This allowed
callsites like `floatlist.append(tensor.item())` to pass the typechecker,
causing a runtime assert (issue #24856).
An earlier, reverted fix (#25136) insisted on strict equality across all
occurrences of a typevar, necessitating explicit casts around Scalar-typed
arguments to int- or float-typed parameters, like `tensor.item()` above.
This was per the original type system design, but turned out to break
existing user code that relied on the de facto dynamic downcast. (The
error required a specialized list representation.)
The current fix includes the prevention of typevar widening, but
adds logic to insert implicit conversions from Scalar to float or int
as needed to satisfy a matched schema.
Test Plan: Imported from OSS
Differential Revision: D17470598
Pulled By: bhosmer
fbshipit-source-id: d260dbf3cd78b9c2f2229bc61afc84e1910b5659
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26704
nccl 2.1.15 isn't available for CUDA 10.1 and 2.4.8 isn't available for cuda 9.1 :(
ghstack-source-id: 90714191
Test Plan: build docker images on Jenkins
Differential Revision: D17543120
fbshipit-source-id: 882c5a005a9a3ef78f9209dea9dcec1782060b25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26496
It is a BAD BAD idea to deploy Docker versions which are not deployed
(per ossci-job-dsl) because those versions will get GC'ed after two
weeks. At the moment, there is no verification that your Docker version
is deployed. This adds an Azure job to check this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17575100
Pulled By: ezyang
fbshipit-source-id: 8df2331c6e6899c585bc2917b55e8955908b0e4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26751
### Summary
We're going to use the AWS s3 bucket - `s3://ossci-ios` to store the release binary. To release the cocoapods, we can follow the steps below:
1. Open a fake PR to trigger the CI job that pulls the code from the 1.3.0 tag branch and does the building and uploading.
2. Verify the binary locally - Run tests on both arm64 and simulator
3. Publish the cocoapods officially
### Test plan
- podspec lint command succeeds
- `pod spec lint --verbose --allow-warnings --no-clean --use-libraries --skip-import-validation`
Test Plan: Imported from OSS
Differential Revision: D17577131
Pulled By: xta0
fbshipit-source-id: 55fee918ecc5c4e0b6d714488a12351b4370afac
Summary:
Output tensors doesn't need to be copied during type promotion as we are not using any data from them. Simple allocation gives steady 10% performance gain.
BEFORE
```
In [1]: x = torch.randn(64, 2048, 7,7)
In [2]: y = torch.randn(64, 2048, 7,7, dtype=torch.float64)
In [3]: timeit x.add_(y)
77.3 ms ± 257 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
AFTER
```
In [1]: x = torch.randn(64, 2048, 7,7)
In [2]: y = torch.randn(64, 2048, 7,7, dtype=torch.float64)
In [3]: timeit x.add_(y)
68.2 ms ± 713 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26816
Differential Revision: D17573455
Pulled By: VitalyFedyunin
fbshipit-source-id: 47286abce5e7e665eb61e46ae358c896e945bef2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26583
Adds a function that uses the nccl api to get the version code. Converts it to a readable version. Will be
used for logging NCCL version in exception messages.
Test Plan: See above
Differential Revision: D17473200
fbshipit-source-id: 4881ed5221b397f2f967262668c2b376b6bf3c64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26290Fixes#26206
Happily, I also can delete the dead Dense***Tensor cases, since they
are for the defunct THS backend.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17404368
Pulled By: ezyang
fbshipit-source-id: 79d71ad40c4325c9f52d2825aceb65074d2e20e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26784
Previously we are using empty to generate test tensors, this PR changes the test tensors to use
randint so that we can test things properly
Also added a set_sizes_and_strides and removed .contiguous() in int_repr function to preserve the
original size and strides
Test Plan:
python test/test_quantized_tensor.py
Imported from OSS
Differential Revision: D17566575
fbshipit-source-id: 89379fb09b500dd156118e6ee0709df59f169990
Summary:
- Separates device type from default (test) device
- Adds multidevice decorator
- Updates generic tests to use multidevice decorator where applicable
TorchXLA wants to change the default test device based on the test environment. Separating the device type and the default (test) device enables that functionality.
Additionally, many existing tests only run on multiple devices and are required, as a consequence, to make CUDA-specific API calls. The multidevice decorator simplifies the existing code and limits the CUDA dependency. Eventually this should let us run multidevice tests on multiple device types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26594
Test Plan: tests were manually run with the CUDA test device set to 'cuda:1'.
Differential Revision: D17568910
Pulled By: mruberry
fbshipit-source-id: c442f748a31a970be8c21deb12a67c3b315c1128
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26773
att
Test Plan:
ci
Imported from OSS
Differential Revision: D17563673
fbshipit-source-id: 5a6fb4238b6886695c2d25db11fec22ebe5d0c08
Summary:
Resubmit of https://github.com/pytorch/pytorch/pull/25980.
Our old serialization was in tar (like `resnet18-5c106cde.pth` was in this format) so let's only support automatically unzip if checkpoints are zipfiles.
We can still manage to get it work with tarfile, but let's delay it when there's an ask.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26723
Differential Revision: D17551795
Pulled By: ailzhang
fbshipit-source-id: 00b4e7621f1e753ca9aa07b1fe356278c6693a1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26718
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17549623
Pulled By: ezyang
fbshipit-source-id: 8880c09d85a15b2a63dcf0c242ba6a2dd941decb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26360
This is not just for aesthetics: this include blocks the inclusion
of headers like ivalue.h from ATenDispatch.h (as it causes an
include cycle.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17429163
Pulled By: ezyang
fbshipit-source-id: 03feb210c12bc891d95bbb5a11ffd694ec05005c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26118
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17404367
Pulled By: ezyang
fbshipit-source-id: 14a16baa4b59f97182725092531a54603f3d92b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25914
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17284083
Pulled By: ezyang
fbshipit-source-id: 430ac7ea2bd042b1f4bb874e53679d0fde326dec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26563
This adds name inference rules for pre-existing logsumexp, mode,
kthvalue, and median ops. Also adds overloads so that they can take
`Dimname` dimensions.
There are a lot of min/max overloads. This PR adds name inference to
the following overloads for (both) min and max:
- min(Tensor, int dim)
- min(Tensor, Dimname dim)
- min(Tensor) (full reduction)
Test Plan: - new tests and [namedtensor ci]
Differential Revision: D17557050
Pulled By: zou3519
fbshipit-source-id: a099a0ef04ad90d021a38a0668fc44902e1c7171
Summary:
Currently, we export invalid ONNX models when size() is used with a negative dim.
This PR fixes the issue and allows exporting these models to ONNX (ex: input.size(-1)).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26436
Reviewed By: hl475
Differential Revision: D17565905
Pulled By: houseroad
fbshipit-source-id: 036bc384b25de77506ef9fbe24ceec0f7e3cff8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26778
- Add support for linear and cubic interpolate in opset 11.
- Add support for 1d and 3d interpolate in nearest mode for opset 7 and 8.
- Add tests for all cases of interpolate in ORT tests (nearest/linear/cubic, 1d/2d/3d, upsample/downsample).
Original PR resolved: https://github.com/pytorch/pytorch/pull/24805
Reviewed By: hl475
Differential Revision: D17564911
Pulled By: houseroad
fbshipit-source-id: 591e1f5b361854ace322eca1590f8f84d29c1a5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26543
Also adds a test for logical_xor (it already had named tensor support
but there was no test)
Test Plan: - [namedtensor ci]
Differential Revision: D17501403
Pulled By: zou3519
fbshipit-source-id: 49be15580be9fb520e25a8020164e5a599d22d40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26745
This file doesn't appear to be included by default on GCC 7.3 and
causes compilation to fail. Adding this include fixes compilation.
Test Plan: Imported from OSS
Differential Revision: D17566444
Pulled By: pietern
fbshipit-source-id: 9afb3d4596e424efc5a6ea6ab3b1cffdb2b41fbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26518
Skip Dequantize() modules for QAT alone. For fake quant insertion, DeQuantize() is a no-op and we should not be inserting fake-quant.
ghstack-source-id: 90704220
Test Plan:
buck test caffe2/test:quantization -- --print-passing-details
Tests in test_quantization pass with changes:
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/281475121296989
Summary (total time 73.03s):
PASS: 28
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D17439333
fbshipit-source-id: f716c23500324ae08c8d104ee2c9587fa6926571
Summary:
Rename old mobile_threadpool() API, replace it with a new version that
returns caffe2::ThreadPool instead of pthreadpool_t.
Test Plan: - builds
Differential Revision: D17543413
Pulled By: ljk53
fbshipit-source-id: a3effd24e8ce9d677a2a04ebe6b6e1582e6f0a65
Summary:
This PR includes the following improvements:
1. Add comments for limitations of the multidim tensor factory function `torch::tensor(...)`, noting the fact that `torch::tensor({})` and mixed data type such as `torch::tensor({{bool, 2.0}})` are not supported at the moment. (I will also update https://pytorch.org/cppdocs/notes/tensor_creation.html to include usage examples for the multidim tensor factory function `torch::tensor(...)`)
2. Rename `ListInitTensor` to `InitListTensor`, for better naming consistency.
This addresses reviews in https://github.com/pytorch/pytorch/pull/26210. I will work on a separate PR to move the factory function to `at::`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26756
Differential Revision: D17560136
Pulled By: yf225
fbshipit-source-id: eb8b45226e999784da48f75cc8953a998582df99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26760
Follow-up of D17514003 . Change Caffe2 code to use the new PackedDepthWiseConvMatrix interface.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D17514350
fbshipit-source-id: 691d9f1fd35bdb7dd8ba152287f3a34359dc1f4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26558
Previously, name inference gets called after dimensions are wrapped.
This PR makes it so that name inference always wraps dimensions so that
it can be called anywhere. Ideally we would only wrap dimensions once,
but many of our operators wrap dimensions in weird places.
Wrapping dimensions in name inference is pretty inexpensive and only
happens for named tensors (name inference does not run on unnamed
tensors.)
Test Plan: - [namedtensor ci]
Differential Revision: D17557049
Pulled By: zou3519
fbshipit-source-id: 68c5636489e233dbf2588ab6ad4e379a6fe4c8ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26636
This PR defines a lot of dimname overloads so that when named tensor
support is added for those operators, we will not have to modify the
autogenerated TensorMethods.h, thereby avoiding potential merge
conflicts in the future.
Overloads were added for the following:
- all
- any
- argmax
- argmin
- cumsum
- cumprod
- index_copy
- kthvalue
- mode
- permute
- squeeze
- index_add
- index_fill
- scatter
- scatter_add
- index_select
- gather
- sort
- argsort
Test Plan: - [namedtensor ci]
Differential Revision: D17522984
Pulled By: zou3519
fbshipit-source-id: eca6dea819ba4e4e43b71b700d5cf09176f00061
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25429
Previously we are using empty to generate test tensors, this PR changes the test tensors to use
randint so that we can test things properly
Also added a set_sizes_and_strides and removed .contiguous() in int_repr function to preserve the
original size and strides
Test Plan:
python test/test_quantized_tensor.py
Imported from OSS
Differential Revision: D17559660
fbshipit-source-id: d4ce81d577296c1137270fdaa6b1359fb703896f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26656
Updating the NDK to r18 or newer triggers a path in our CI scripts so that we now build with clang instead of gcc.
Google discontinued the gcc support for android quite a while ago, clang is the only way forward.
ghstack-source-id: 90698985
Test Plan: CI
Reviewed By: dreiss
Differential Revision: D17533570
fbshipit-source-id: 5eef4d5a539d8bb1a6682f000d0b5d33b3752819
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26506
[pytorch] [distributed] Made test forgiving to allow rpc agent to return one of the two errors.
ghstack-source-id: 90667534
Test Plan: Made sure pg based UT works.
Differential Revision: D17488899
fbshipit-source-id: 41f76cf4b4a0ca5e651a5403d6e67b639f0b9c4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26696
att
Test Plan:
ci
Imported from OSS
Differential Revision: D17558701
fbshipit-source-id: 96ef87db74bd1a5d4ddc69867ae71d78c0df83fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26738
someone may use torch._export directly. Here we change the onnx_export_type's default value to None,
and if it's pytorch onnx caffe2 bundle, we set it to ONNX_ATEN_FALLBACK, otherwise, it's ONNX.
Test Plan: ci
Reviewed By: hl475
Differential Revision: D17546452
fbshipit-source-id: 38e53926e2b101484bbbce7b58ebcd6af8c42438
Summary:
- Normalization mean and std specified as parameters instead of hardcode
- imageYUV420CenterCropToFloat32Tensor before this change worked only with square tensors (width==height) - added generalization to support width != height with all rotations and scalings
- javadocs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26690
Differential Revision: D17556006
Pulled By: IvanKobzarev
fbshipit-source-id: 63f3321ea2e6b46ba5c34f9e92c48d116f7dc5ce
Summary:
- Add support for linear and cubic interpolate in opset 11.
- Add support for 1d and 3d interpolate in nearest mode for opset 7 and 8.
- Add tests for all cases of interpolate in ORT tests (nearest/linear/cubic, 1d/2d/3d, upsample/downsample).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24805
Reviewed By: hl475
Differential Revision: D17330801
Pulled By: houseroad
fbshipit-source-id: 1bdefff9e72f5e70c51f4721e1d7347478b7505b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26728
Use Caffe2::mobile_threadpool() in linear and conv operators
Perf
Without threadpool - 76ms
With threadpool - 41 ms
Test Plan:
python test/test_quantized.py TestQNNPackOps
Imported from OSS
Differential Revision: D17553510
fbshipit-source-id: dd5b06f526f65d87727ec7e3dad0a5fa74cba9f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26554
Previously, in `TCPStore`'s constructor we did not pass in a timeout to
the `connect` function, which thus used the default timeout (-1, so infinite).
But the timeout variable in `TCPStore.cpp `is configurable by the user and set to
be 300 seconds by default, so we should be passing this into the connect function.
Test Plan: see above.
Differential Revision: D17486779
fbshipit-source-id: 42d38a3b8d492d9e9ff09110990a8e4a3a1292b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26694
Previously we would not properly populate `errorDesc` for:
```
./torch/jit/__init__.py:13:1: F401 'torch.nn.ModuleList' imported but unused
```
because we wanted only letters and spaces. Be more permissive
Test Plan: Imported from OSS
Differential Revision: D17551999
Pulled By: suo
fbshipit-source-id: b82567df1fa3c9729e7427dc3461bedfb40933dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26681
att
Test Plan:
ci
Imported from OSS
Differential Revision: D17542833
fbshipit-source-id: 653e906b0e146763609c69ef0de7f9cf38621586
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26581
We're currently inlining immediate values of the constants directly into
IR when we generate it providing no way to access these values by their
names later. This change registers such values as atrtibutes of the
module so that they are not lost after IR generation.
Differential Revision: D17513451
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: cf8f9b450e7178692211abd905ffd2d7ce5a6ce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26680
This was introduced before under the assumption that we'll have a qconv_per_tensor_affine
and a qconv_per_channel_affine, but turns out we don't have these, so we'll remove
thse functions.
Test Plan:
python test/test_jit.py 'TestJit.test_quant_fusion'
Imported from OSS
Differential Revision: D17542607
fbshipit-source-id: b90ce5738170f0922bdc2eb1c4dbecd930f68a48
Summary:
This is a follow-up PR for https://github.com/pytorch/pytorch/pull/23284. In that PR we had removed changing the default behavior for `keep_initializers_as_input` argument to the export API. With this PR we are enabling that change in that if `keep_initializers_as_input` is not specified then value/behavior for this argument is chosen automatically depending on whether the export type is ONNX or not.
This was part of the earlier PR was removed for further review. The test points have also been updated.
This change may fail some internal tests which may require explicitly setting `keep_initializers_as_input=True` to preserve old behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26146
Reviewed By: hl475
Differential Revision: D17369677
Pulled By: houseroad
fbshipit-source-id: 2aec2cff50d215714ee8769505ef24d2b7865a11
Summary:
- Ports all CUDA tests to TestAutogradDeviceType except those using multiple devices
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26708
Differential Revision: D17549435
Pulled By: mruberry
fbshipit-source-id: b564186444201d1351934b6a7d21f67bdfca6e3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26709
Polishes implementation from #25975. Primarily, we use NoopObserver to communicate that weights need to be quantized to float16. The very top-level API (quantize_dynamic) stays the same with `dtype` argument but the implementation follows the common flow.
One can argue that dynamic fp16 quantization doesn't really fit into the 'observer' mechanism. It's in fact not ideal, but it's better to have the same flow than branching on both dtype and qconfig.
Test Plan: Imported from OSS
Differential Revision: D17544103
Pulled By: dzhulgakov
fbshipit-source-id: 6af3f18c35929a1a53ea734079c005f656e4925f
Summary:
Current integer scalar exps are always cast to double. This commit avoids cast if the tensor is also
integral and the scalar is positive to speed up.
Benchmark (Debian Buster, g++ 8, Intel(R) Xeon(R) E-2136 CPU @ 3.30GHz 0 0:0 3300.00 MHz , Debug
build, Turbo turned off):
```python
import timeit
for n, t in [(1000, 13000),
(10_000, 1300)]:
for e in (2, 3, 4):
for dtype in ('torch.int16', 'torch.int32', 'torch.int64'):
print(f'a.pow({e}) (a.numel() == {n}) for {t} times')
print(f'dtype {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a.pow({e})',
setup=f'import torch; a = torch.arange({n}, device="cpu", dtype={dtype})',
number=t))
```
Before:
```
a.pow(2) (a.numel() == 1000) for 13000 times
dtype torch.int16, 13000 times 1.6958350749996498
a.pow(2) (a.numel() == 1000) for 13000 times
dtype torch.int32, 13000 times 0.7989626339999631
a.pow(2) (a.numel() == 1000) for 13000 times
dtype torch.int64, 13000 times 0.7973162800003593
a.pow(3) (a.numel() == 1000) for 13000 times
dtype torch.int16, 13000 times 1.8660746679997828
a.pow(3) (a.numel() == 1000) for 13000 times
dtype torch.int32, 13000 times 0.8101709959996697
a.pow(3) (a.numel() == 1000) for 13000 times
dtype torch.int64, 13000 times 0.8135280149999744
a.pow(4) (a.numel() == 1000) for 13000 times
dtype torch.int16, 13000 times 5.010833072999958
a.pow(4) (a.numel() == 1000) for 13000 times
dtype torch.int32, 13000 times 4.801007671999741
a.pow(4) (a.numel() == 1000) for 13000 times
dtype torch.int64, 13000 times 3.963344578000033
a.pow(2) (a.numel() == 10000) for 1300 times
dtype torch.int16, 1300 times 1.6216251330001796
a.pow(2) (a.numel() == 10000) for 1300 times
dtype torch.int32, 1300 times 0.5672429639998882
a.pow(2) (a.numel() == 10000) for 1300 times
dtype torch.int64, 1300 times 0.5544572270000572
a.pow(3) (a.numel() == 10000) for 1300 times
dtype torch.int16, 1300 times 1.656308512999658
a.pow(3) (a.numel() == 10000) for 1300 times
dtype torch.int32, 1300 times 1.502670819999821
a.pow(3) (a.numel() == 10000) for 1300 times
dtype torch.int64, 1300 times 0.5757876879997639
a.pow(4) (a.numel() == 10000) for 1300 times
dtype torch.int16, 1300 times 4.775718216999849
a.pow(4) (a.numel() == 10000) for 1300 times
dtype torch.int32, 1300 times 4.754745475000163
a.pow(4) (a.numel() == 10000) for 1300 times
dtype torch.int64, 1300 times 3.737249878000057
```
After:
```
a.pow(2) (a.numel() == 1000) for 13000 times
dtype torch.int16, 13000 times 1.1006453190002503
a.pow(2) (a.numel() == 1000) for 13000 times
dtype torch.int32, 13000 times 1.0849009019998448
a.pow(2) (a.numel() == 1000) for 13000 times
dtype torch.int64, 13000 times 1.093259106000005
a.pow(3) (a.numel() == 1000) for 13000 times
dtype torch.int16, 13000 times 1.0859826279997833
a.pow(3) (a.numel() == 1000) for 13000 times
dtype torch.int32, 13000 times 1.1076840900000207
a.pow(3) (a.numel() == 1000) for 13000 times
dtype torch.int64, 13000 times 1.0755480369998622
a.pow(4) (a.numel() == 1000) for 13000 times
dtype torch.int16, 13000 times 1.918211066999902
a.pow(4) (a.numel() == 1000) for 13000 times
dtype torch.int32, 13000 times 1.9183043200000611
a.pow(4) (a.numel() == 1000) for 13000 times
dtype torch.int64, 13000 times 1.930021430999659
a.pow(2) (a.numel() == 10000) for 1300 times
dtype torch.int16, 1300 times 0.7271483560002707
a.pow(2) (a.numel() == 10000) for 1300 times
dtype torch.int32, 1300 times 0.7289002070001516
a.pow(2) (a.numel() == 10000) for 1300 times
dtype torch.int64, 1300 times 0.7267536800000016
a.pow(3) (a.numel() == 10000) for 1300 times
dtype torch.int16, 1300 times 0.7301799359997858
a.pow(3) (a.numel() == 10000) for 1300 times
dtype torch.int32, 1300 times 0.7289195180001116
a.pow(3) (a.numel() == 10000) for 1300 times
dtype torch.int64, 1300 times 0.7270008230002531
a.pow(4) (a.numel() == 10000) for 1300 times
dtype torch.int16, 1300 times 1.5354506029998447
a.pow(4) (a.numel() == 10000) for 1300 times
dtype torch.int32, 1300 times 1.528263066999898
a.pow(4) (a.numel() == 10000) for 1300 times
dtype torch.int64, 1300 times 1.5369428439998956
```
---
Best viewed with whitespace changes turned off
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26020
Differential Revision: D17485400
Pulled By: VitalyFedyunin
fbshipit-source-id: 3a16b074825a5aab0f7e7af3d8100f9e4b7011a3
Summary:
There is an issue with the torchvision version not matching the pytorch version if one builds the docker from a tag, see issue https://github.com/pytorch/pytorch/issues/25917. The current solution requires one to re-init the submodules or manually change the version of torchvision. This PR allows one to build the docker image without torchvision, which not only fixes the above mentioned bug but also frees non-image pytorch users from the tyranny of torchvision 😆.
In all seriousness, for NLP researchers especially torchvision isn't a necessity for pytorch and all non-essential items shouldn't be in the docker. This option removes one extra thing that can go wrong.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26168
Differential Revision: D17550001
Pulled By: soumith
fbshipit-source-id: 48b8b9e22b75eef3afb392c618742215d3920e9d
Summary:
This ensures that `F::cosine_similarity` and `F::pairwise_distance` can be used simply by including `torch/torch.h` and set `namespace F = torch::nn::functional`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26559
Differential Revision: D17507421
Pulled By: yf225
fbshipit-source-id: f895dde3634d5c8ca66ee036903e327e5cdab6b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26685
This prevents XLA from picking up on named tensor APIs. I ran into some
problems while attempting to support dimname overloads in XLA; since we
don't need the first iteration of named tensors to work with XLA this is
OK.
Test Plan: - run CI.
Differential Revision: D17538893
Pulled By: zou3519
fbshipit-source-id: 93d579c93f5b1dc68541c07c4a3d61792859507d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26417
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17548776
Pulled By: ezyang
fbshipit-source-id: 8c79893ee4216780edb838671e701de5518c4cd0
Summary:
FindCUDNN.cmake and cuda.cmake have done the detection. This commit deletes `tools/setup_helpers/cudnn.py` as it is no longer needed.
Previously in https://github.com/pytorch/pytorch/issues/25482, one test failed because TensorRT detects cuDNN differently, and there may be situations we can find cuDNN but TensorRT cannot. This is fixed by passing our detection result down to TensorRT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25876
Differential Revision: D17346270
Pulled By: ezyang
fbshipit-source-id: c1e7ad4a1cb20f964fe07a72906f2f002425d894
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26489
This basically fixes Inline(recurse=true) and makes it a default. One
reservation against running inlining recursively in the original
implementation was that we might hit a quadratic behavior, but in this
implementation it's not an issue since we're inlining only already
inlined graphs and as we recursively descend the call tree we're caching
graphs we've already optimized.
Test Plan: Imported from OSS
Differential Revision: D17485744
Pulled By: ZolotukhinM
fbshipit-source-id: 2ed7bdc69863b90a8c10a385d63f8e7c9e7b05f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26488
Currently the main use case for this graph is inlining and that's the
only optimization we perform. We probably should run more cleanups on
this graph in future.
Test Plan: Imported from OSS
Differential Revision: D17485745
Pulled By: ZolotukhinM
fbshipit-source-id: 7b30c9ba47b4e5fff3591a0063560bfeb68f2164
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26571
We will need a mutex for computing optimized graph too, which will be
implemented in subsequent commits.
Test Plan: Imported from OSS
Differential Revision: D17510883
Pulled By: ZolotukhinM
fbshipit-source-id: 273b25426785e50f67a103204de98f6ed14182db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26487
The way it is implemented currently is bad because while we're inlining
to a graph G, we are also mutating all the graphs that are being
inlined. The problem is that the graphs we're inlining are usually the
original graphs of functions, so we're silently changing them behind the
scenes, and we don't have a way to recover 'unoptimized' graphs
afterwards.
Test Plan: Imported from OSS
Differential Revision: D17485748
Pulled By: ZolotukhinM
fbshipit-source-id: 6094ef56077240e9379d4c53680867df1b6e79ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26658
By SFINAE'ing the lambda registration to only kernels that aren't stackbased kernels,
an attempt to register a stackbased lambda kernel will correctly fallback to the stackbased registration function and work as expected.
ghstack-source-id: 90610843
Test Plan: unit tests
Differential Revision: D17533871
fbshipit-source-id: 1bfe3106b0576d46798a51bdaa5b7b5508164766
Summary:
- Moves several tests to TestNNDeviceType
- Merges helper base with TestNNDeviceType
<s>- Enables non-default stream for TestNN (like recent updates to TestTorch and TestCUDA)</s>
Reverted non-default stream due to failure of test_variable_sequence_cuda (main.TestNN).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26638
Differential Revision: D17543899
Pulled By: mruberry
fbshipit-source-id: 001fa191f5fe424f2e7adc378b8fb5ee7f264f16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26676
Just makes it more user-friendly to be able to pass any floating point or int point values to scales or zero_points for per-channel quantization. It matches behavior or per tensor quantizer where those arguments are scalars (not tensors) and thus automatic casting is applied.
Test Plan: Imported from OSS
Differential Revision: D17537051
Pulled By: dzhulgakov
fbshipit-source-id: e955ccdb5b4691828a559dc8f1ed7de54b6d12c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26675
Based on offline poll, we're very unlikely to have multi-axis quantized tensors in the foreseeable future. Let's simplify API and just return int instead of list. It also matches the singular `axis` name.
Test Plan: Imported from OSS
Differential Revision: D17537052
Pulled By: dzhulgakov
fbshipit-source-id: 676abc3b251d288468aaed467b5e5ca4063b98b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26243
This is an attempt to fix _empty_per_channel_affine_quantized to be more sane. It's a factory function that nevertheless receives a Tensor argument and it throws the codegen off course.
Before people did a hacky workaround of appending _like to the function name to trick codegen, it also required non-natural argument order.
This PR explicitly allows to override the 'category' of the function to make codegen do the right thing. Now name and the argument order (in C++) make more sense.
Test Plan: Imported from OSS
Differential Revision: D17443221
Pulled By: dzhulgakov
fbshipit-source-id: c98c1c74473d8cbf637f511d26ceb949d8ae2a1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26677
This diff adds OpProfile proto into ProfDAGProtos to support storing operation cost. During performance estimation idx, net_name, type, and exec_time will be stored in this proto.
Test Plan:
```
buck test caffe2/caffe2/fb/net_transforms/tests/:stats_collector_test
buck test caffe2/caffe2/fb/net_transforms/tests/:perf_estimator_test
buck run caffe2/caffe2/fb/distribute/snntest/cogwheel/:cogwheel_snntest_offline_training_simple_online_training
```
Reviewed By: heslami
Differential Revision: D17533791
fbshipit-source-id: a339c8eadcac891aa631daaf64522b69876b5045
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26679
making it more explicit that it's a factory function.
Test Plan:
ci
Imported from OSS
Differential Revision: D17540861
fbshipit-source-id: bf66c87d6afad411afd5620cf2143a8f5596ad6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26609
Previously, we were globbing all of ATen/core and excluding specific files.
However, this frequently resulted in new files being missed, and PyTorch
diffs triggering Caffe2 builds. Now, instead, we will list the ATen/core
files that are required for Caffe2.
Test Plan: Ran internal Caffe2Go unit test.
Reviewed By: smessmer
Differential Revision: D17504740
fbshipit-source-id: 5b9bf7a6e8fa7848b2dfd375246d32630ca40cd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26678
making it more explicit that it's a factory function.
Test Plan:
ci
Imported from OSS
Differential Revision: D17540862
fbshipit-source-id: 14c5a4dcc7bb85ae849c9e4e0882601005e2ed3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26562
I was trying to be too clever with GITHUB_HEAD_REF...
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D17538517
Pulled By: suo
fbshipit-source-id: 82c71ee3c6edb299ac8eb73675d96967e00a29f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26620
This change updates torch.backend.quantized.engine to accept string ("fbgemm"/"qnnpack"/"none" for now).
set_qengine and get_qengine return an int which represents the at::QEngine enum
Test Plan:
python test/test_torch.py
Imported from OSS
Differential Revision: D17533582
fbshipit-source-id: 5103263d0d59ff37d43dec27243cb76ba8ba633f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26640
Remove some code that we forgot to remove before
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D17538669
fbshipit-source-id: 9614e45f6e5ad6f2fe2b4936deb23d0ffdfcd86a
Summary:
This PR does a few small improvements to hub:
- add support `verbose` option in `torch.load`. Note that this mutes hitting cache message but keeps the message of first download as suggested. fixes https://github.com/pytorch/pytorch/issues/24791
- add support loading state dict from tar file or zip file in `torch.hub.load_state_dict_from_url`.
- add `torch.hub.download_url_to_file` as public API, and add BC bit for `_download_url_to_file`.
- makes hash check in filename optional through `check_hash`, many users don't have control over the naming, relaxing this constraint could potentially avoid duplicating download code on user end.
- move pytorch CI off `pytorch/vision` and use `ailzhang/torchhub_example` as a dedicated test repo. fixes https://github.com/pytorch/pytorch/issues/25865
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25980
Differential Revision: D17495679
Pulled By: ailzhang
fbshipit-source-id: 695df3e803ad5f9ca33cfbcf62f1a4f8cde0dbbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26145
This is step towards isinstance type refinement.
It primarily does yak shaving in compiler.cpp to unify the handling
of special case behavior that occurs in conditional expressions:
* Handling type refinement as part of emission.
* Handling `is None` static-if specialization.
It introduces a CondValue object that is a Value that also has
additional type refinements that are true when that Value is true,
and potentialy a static-true/false value that, if set, will cause if
statements to be handled statically, omitting typechecking of the other side.
This ends up expanding some behavior, for instance `is None` specialization
used to happen only for single expressions, but now works through
boolean logic.
Test Plan: Imported from OSS
Differential Revision: D17359500
Pulled By: zdevito
fbshipit-source-id: ce93804496c8b4c3197a5966bc28c608465fda64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26339
Serializes per-channel tensor in both torch.serialization and jit. Since we didn't bind Quantizer properly yet, I chose to save a tuple representing quantizer settings. To avoid recursive tensor serialization calls, I'm using tuple instead of tensor to store scales and zero points.
driazati - please check the serialization logic. Is there a good test that compares that JIT serialization and python serialization are equivalent? (I haven't tested it yet)
Test Plan: Imported from OSS
Differential Revision: D17443222
Pulled By: dzhulgakov
fbshipit-source-id: a34758de1ffd2ec1cdc5355f5baf95284a4ccf4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26524
This creates an NHWC specialization for `quantized::cat` that kicks in when all inputs are `NHWC`. This ensures the correct layout is propagated downstream as well as is an optimized implementation specifically for this data layout
Benchmark script based on Squeezenet shapes:
```
import torch, time
torch.manual_seed(0)
# NHWC
sizes = [
(1, 54, 54, 64),
(1, 54, 54, 128),
(1, 26, 26, 128),
(1, 26, 26, 256),
(1, 12, 12, 256)
]
for size in sizes:
x = torch.rand(*size)
y = torch.rand(*size)
qX = torch.quantize_linear(x, 0.01, 3, torch.qint8).permute([0, 3, 1, 2])
qY = torch.quantize_linear(y, 0.01, 3, torch.qint8).permute([0, 3, 1, 2])
ref = torch.cat([qX.dequantize(), qY.dequantize()], dim=1)
NITER = 1000
s = time.time()
for i in range(NITER):
out = torch.ops.quantized.cat([qX, qY], dim=1, scale=0.01, zero_point=3)
time_per_iter = (time.time() - s) / NITER
print('time per iter ms', time_per_iter * 1000)
print('gb/s', (qX.numel() + qY.numel() + out.numel()) * qX.element_size() / time_per_iter / 1e9)
torch.testing.assert_allclose(out.dequantize(), ref)
```
Before this change
```
time per iter ms 0.6898486614227295
gb/s 1.0821156026605054
time per iter ms 1.5480577945709229
gb/s 0.9644291093239284
time per iter ms 0.3180875778198242
gb/s 1.0881028500775023
time per iter ms 0.6702737808227539
gb/s 1.032748139350315
time per iter ms 0.13010454177856445
gb/s 1.1333655073392244
```
After this change
```
time per iter ms 0.11604785919189453
gb/s 6.432656364350577
time per iter ms 0.15956878662109375
gb/s 9.356416324360508
time per iter ms 0.040181636810302734
gb/s 8.613685939027139
time per iter ms 0.06564664840698242
gb/s 10.544696748392909
time per iter ms 0.018549680709838867
gb/s 7.949247337814738
```
Test Plan: Imported from OSS
Differential Revision: D17503593
Pulled By: jamesr66a
fbshipit-source-id: ec5d57ad8fbcb3fd9379e8bd370abd29d386f953
Summary:
At the moment we have the same names for PR jobs and nightly jobs and results as we see on https://ezyang.github.io/pytorch-ci-hud/build/pytorch-master:
pytorch_linux_xenial_py3_clang5_android_ndk_r19c_arm_v7a_build-1
pytorch_linux_xenial_py3_clang5_android_ndk_r19c_arm_v7a_build-2
=> adding nightly_ prefix for nightly jobs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26652
Differential Revision: D17533456
Pulled By: IvanKobzarev
fbshipit-source-id: 586f48dc361c9143d8223e6742bbe78ef96b64fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26654
As per python contract, __getattr__ can only throw AttributeError. Throwing something else breaks hasattr() and causes upstream issues.
Similar bug was in pytorch earlier.
Test Plan: builds
Differential Revision: D17529471
fbshipit-source-id: bb6ac6c9e3be8b80fa2967e6a2e293afd1594cf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26648
Previously:
- `Tensor.align_to(*names)` only works on fully named tensors. In addition, the
desired ordering `names` must not have any None-names.
- `Tensor.align_to(*names)` accepted `...`, but expanded it based on
position. i.e., in `tensor.align_to('N', ..., 'C', 'H')`, `...` expand
to `*tensor.names[1:-2]`. This is wildly incorrect: see the following
concrete example.
```
tensor = tensor.refine_names('N', 'C', 'H, 'W')
tensor.align_to('W', ...) # ... expands to 'C', 'H, 'W'
```
This PR changes it so that `...` in `tensor.align_to` grabs all
unmentioned dimensions from `tensor`, in the order that they appear.
`align_to` is the only function that takes ellipsis that requires this
change. This is because all other functions (`refine_to`) require their
list of names to work in a positional manner, but `align_to` lets the
user reorder dimensions.
This does not add very much overhead to `align_to`, as shown in the
following benchmark. However, in the future, we should resolve to make
these operations faster; align_to should be as fast as view but isn't
most likely due to Python overhead.
```
[ins] In [2]: import torch
...: named = torch.randn(3, 3, 3, 3, names=('N', 'C', 'H', 'W'))
...: unnamed = torch.randn(3, 3, 3, 3)
...: %timeit unnamed[:]
...: %timeit unnamed.view(-1)
...: %timeit named.align_to(...)
...: %timeit named.align_to('N', 'C', 'H', 'W')
31 µs ± 126 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
43.8 µs ± 146 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
69.6 µs ± 142 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
66.1 µs ± 1.13 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Test Plan:
- new tests [namedtensor ci]
allows the user to transpose and permute dimensions.
Differential Revision: D17528207
Pulled By: zou3519
fbshipit-source-id: 4efc70329f84058c245202d0b267d0bc5ce42069
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26633
This will enable named tensor CI on all pull requests. Previously, named
tensor CI only ran on master.
This is essential for the experimental release because we would like to
prevent failures in the named tensor tests. In addition, when
cherry-picking changes to the release branch, the first signals appear
on the pull requests and it is good to be able to tell that something is
wrong before the cherry-pick is merged.
Test Plan:
- run CI
- check that the named tensor build / tests are indeed running on this
PR.
Differential Revision: D17523064
Pulled By: zou3519
fbshipit-source-id: d8d09bf584f1293bd3cfd43bf710d84f87d766ae
Summary:
- Makes test_indexing.py device generic
- Removes test_indexing_cuda.py
Note: a couple tests in test_indexing.py were already CPU and CUDA tests, meaning these tests were run multiple times when CUDA was available. Genericizing test_indexing.py corrects this and lets these tests be run on other device types, like XLA, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26634
Differential Revision: D17529001
Pulled By: mruberry
fbshipit-source-id: e71ba28d947749255a0aceeb7b77a42c4811439d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26632
### Summary
This script builds the TestApp (located in ios folder) to generate an iOS x86 executable via the `xcodebuild` toolchain on macOS. The goal is to provide a quick way to test the generated static libraries to see if there are any linking errors. The script can also be used by the iOS CI jobs. To run the script, simply see description below:
```shell
$ruby scripts/xcode_ios_x86_build.rb --help
-i, --install path to the cmake install folder
-x, --xcodeproj path to the XCode project file
```
### Note
The script mainly deals with the iOS simulator build. For the arm64 build, I haven't found a way to disable the Code Sign using the `xcodebuiild` tool chain (XCode 10). If anyone knows how to do that, please feel free to leave a comment below.
### Test Plan
- The script can build the TestApp and link the generated static libraries successfully
- Don't break any CI job
Test Plan: Imported from OSS
Differential Revision: D17530990
Pulled By: xta0
fbshipit-source-id: f50bef7127ff8c11e884c99889cecff82617212b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26492
Previous definition of observers was quite clumsy - with things like `default_observer()()`. This PR strips a way a lot of craft and allows to pass just class names directly. In order to override default arguments either `functools.partial` can be used or convenient wrapper `MyObserver.with_args(x=1)` is provided.
Also rename `QConfig_dynamic` to `QConfigDynamic` because it violates the naming convention.
Test Plan: Imported from OSS
Differential Revision: D17521265
Pulled By: dzhulgakov
fbshipit-source-id: ba9df19b368641acf4093c43df9990796284fd9e
Summary:
Resolves issue https://github.com/pytorch/pytorch/issues/24585 .
Btw, there are two ways to define unary operator support:
1. Use `IMPLEMENT_UNARY_OP_VEC_CUDA(someunaryop)` in `aten/src/ATen/UnaryOps.cpp` and in `native_functions.yaml` have:
```
- func: someunaryop(Tensor self) -> Tensor
use_c10_dispatcher: full
supports_named_tensor: True
variants: method, function
dispatch:
CPU: someunaryop
CUDA: someunaryop
```
2. Or, in `aten/src/ATen/UnaryOps.cpp` have
```
Tensor& someunaryop_out(Tensor& result, const Tensor& self) { return unary_op_impl_out(result, self, someunaryop_stub); }
Tensor someunaryop(const Tensor& self) { return unary_op_impl(self, someunaryop_out); }
Tensor& someunaryop_(Tensor& self) { return unary_op_impl_(self, someunaryop_out); }
```
and in `native_functions.yaml` (note that `dispatch` section is removed):
```
- func: someunaryop(Tensor self) -> Tensor
use_c10_dispatcher: full
supports_named_tensor: True
variants: method, function
```
It turns out that the way 1 is 3% more performant than the way 2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26600
Differential Revision: D17527166
Pulled By: ezyang
fbshipit-source-id: 112ba298ad3f67d04078b921859e73dcd184852b
Summary:
Changelog:
- Remove `torch.gels` which was deprecated in v1.2.0
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26480
Test Plan: - No tests were changed and all callsites for `torch.gels` where modified to `torch.lstsq` when `torch.lstsq` was introduced
Differential Revision: D17527207
Pulled By: zou3519
fbshipit-source-id: 28e2fa3a3bf30eb6b9029bb5aab198c4d570a950
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26548
This makes the naming more consistent with PyTorch's API. The original
concern was that `tensor.rename` might make the operation seem like it
is in-place. However, we have many "verb" APIs: `tensor.add(other)`, for
example, doesn't add other to tensor in-place, but `tensor.add_(other)`
does.
`tensor.rename_` does exactly the same place as `tensor.rename`, but
in-place.
Test Plan: - [namedtensor ci]
Differential Revision: D17502021
Pulled By: zou3519
fbshipit-source-id: 6a5b93136a820075013cd1e30fb8fc6b9d77d7d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25582
There are a lot of min/max overloads. This PR adds name inference to
the following overloads for (both) min and max:
- min(Tensor, int dim)
- min(Tensor, Dimname dim)
- min(Tensor) (full reduction)
Test Plan: - new tests [namedtensor ci]
Differential Revision: D17521607
Pulled By: zou3519
fbshipit-source-id: 303e3cef22916dbc9da6a092d4f23e39e74c39e4
Summary:
This takes a lot of pressure off of the C++ typechecker as well as generating much more
efficient and smaller code. In my not-super-rigorous testing, compile time for
register_prim_ops.cpp went from 68s to 35s, and the size of libtorch went from 72MB to 70MB.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26560
Differential Revision: D17507305
fbshipit-source-id: 8bbd2c08304739432efda96da71f0fa80eb7668b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26586
Use the backend engine flag to call QNNPACK for quantized ops.
Test Plan: python test/test_quantized.py TestQNNPACKOps
Differential Revision: D17515129
Pulled By: supriyar
fbshipit-source-id: 951e90205aa19581ea006a91d9514fc7a94409ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26432
Move unpickler related codes from pickler.h/cpp to unpickler.h/cpp. In import flow we link to unpickler only.
Test Plan: Imported from OSS
Differential Revision: D17465410
fbshipit-source-id: 9d34629aa05bc0b45383e8f809c87baa186c9804
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26576
to match `quantize_per_tensor`
Test Plan:
ci
Imported from OSS
Differential Revision: D17517439
fbshipit-source-id: 8c20f9b5d2a50d0e42e4444994b0987e6204ac56
Summary:
In this PR, we tried to fix the windows build issue of d17437015.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26580
Differential Revision: D17517341
Pulled By: llyfacebook
fbshipit-source-id: db726596aa8f7c992c5a7ddc2781dc3aa0312284
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26599
These fail due to tolerance in equality comparison. Disable them for now.
ghstack-source-id: 90553855
Test Plan: unit tests
Differential Revision: D17517085
fbshipit-source-id: a4d9278e356318719ccd84047404915a97944f52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26575
To keep consistent with `quantize_per_tensor` we also
rename `quantize_linear_per_channel` to `quantize_per_channel`
Test Plan:
ci
Imported from OSS
Differential Revision: D17517360
fbshipit-source-id: 3af7d8f0fbe99148b79fcb1ad2fe811f776590cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26593
This broke due to a merge conflict between my diffs and ezyang's multi dispatch diff being reverted and then relanded.
ghstack-source-id: 90549856
Test Plan: unit tests
Differential Revision: D17515837
fbshipit-source-id: c0bfd5f159ee4de80035079a1a2f39d5beafec41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26425
Currently the scalar type is hardcoded for weight and normal tensor
but what we want is to get it from corresponding observer module
Test Plan:
there are some known issues right now,
will test e2e later when all the issues are fixed
Imported from OSS
Differential Revision: D17504459
fbshipit-source-id: f5a21789c2ebeb60bff4acc777db80170063c9f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26574
Since we also have `quantized::linear`, `quantize_linear` sounds
confusing, so we plan to rename it before the branch cut
Test Plan:
ci
Imported from OSS
Differential Revision: D17514876
fbshipit-source-id: 01d9005e6ec8cb9950b9d8bba122109c389641d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26589
Just for better debugging purpose.
Test Plan: Dump the net and check the dim type info is in the pb_txt.
Reviewed By: dreamingleo
Differential Revision: D17505931
fbshipit-source-id: ceba4c3849eb271c22227fa07a05d5bcb07344a5
Summary:
2 ^ 31 is 29, which is not a big number. Corrected to 2 ** 31.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26491
Differential Revision: D17494296
fbshipit-source-id: 83d320e8fb6d1b7df41e4474933a98107c8e4129
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26272
```
use_c10_dispatcher: 'unboxed_only'
```
This is the previous implementation. The operator is registered with c10, but only in its unboxed form. No boxing wrapper is generated.
```
use_c10_dispatcher: 'full'
```
This does everything done by 'unboxed_only', but additionally creates a boxing wrapper so the op can be called through the c10 dispatcher using a boxed operator call.
This only changes registration, not the calling path. These operators are still called through the unboxed function pointer.
The final goal is to have 'full' for all operators, but this isn't immediately going to work for all ops.
[namedtensor ci]
ghstack-source-id: 90459907
Test Plan: unit tests
Differential Revision: D17393317
fbshipit-source-id: d629edfb3baede8c4ac869aa1886e512782ed2aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26337
- Factor out boxing and unboxing functionality from the c10 dispatcher into a c10::KernelFunction class
- Move that class and everything else it depends on into ATen/core/boxing
- This also allows us to get rid of c10::KernelCache. Instead, we now store a pointer to the unboxed functor in c10::KernelFunction.
- We're also getting rid of the DispatchTableEntry struct and instead store KernelFunction directly.
- To make this work, we need to change the dispatcher calling API from Dispatcher::lookup().callBoxed/callUnboxed and OperatorEntry::lookup().callBoxed/callUnboxed to Dispatcher::callBoxed/callUnboxed and OperatorEntry::callBoxed/callUnboxed.
ghstack-source-id: 90459911
Test Plan: unit tests
Differential Revision: D17416607
fbshipit-source-id: fd221f1d70eb3f1b4d33092eaa7e37d25684c934
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26565
For OSS mobile build we should keep QNNPACK off and PYTORCH_QNNPACK on
as we don't include caffe2 ops that use third_party/QNNPACK.
Update android/iOS build script to include new libraries accordingly.
Test Plan: - CI build
Differential Revision: D17508918
Pulled By: ljk53
fbshipit-source-id: 0483d45646d4d503b4e5c1d483e4df72cffc6c68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26503
[pytorch] [distributed] Corrected variable name and added test
ghstack-source-id: 90454793
Test Plan: Made sure pg based UT works.
Differential Revision: D17488846
fbshipit-source-id: 6e6cba110a6f61ee1af3d37c5a41c69701de1a8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26525
Create a util function to avoid boilerplate code as we are adding more
libraries.
Test Plan: - build CI;
Differential Revision: D17495394
Pulled By: ljk53
fbshipit-source-id: 9e19f96ede4867bdff5157424fa68b71e6cff8bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26335
Use the backend engine flag to call QNNPACK for quantized ops.
Test Plan:
python test/test_quantized.py TestQNNPACKOps
Imported from OSS
Differential Revision: D17504331
fbshipit-source-id: 35cb2189067ac5cc6a7307179ef0335d1cec7b8f
Summary:
Mainly want to resolve comments from https://github.com/pytorch/pytorch/pull/25830.
Overall, we want to provide a recording observer for recording the runtime tensor values of activation path in order to debug the numerical accuracy loss offline.
According to the feedback from https://github.com/pytorch/pytorch/issues/25830, it might be better to record all the observers in a dict and query the dict to get corresponding tensor values. hx89 is working on how to insert the recording observers into model under debug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26413
Differential Revision: D17506502
Pulled By: llyfacebook
fbshipit-source-id: 3ab90dc78920e7ec3fa572c2a07327a9991c530a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26541
`torch.pow` already supports named tensors; every one of its constituent
codepaths propagates names:
- TensorIterator propagates names
- resize_as_ and fill_ propagate names (exponent == 0 or base == 1)
- resize_as_ and copy_ propagate names (exponent == 1)
This PR adds `supports_named_tensor = True` to the pow overloads,
enabling `pow` to take named tensors.
Test Plan: - [namedtensor ci]
Differential Revision: D17501402
Pulled By: zou3519
fbshipit-source-id: 07ee91d685e55dd58bbbb3a3fc9e185de8bb7515
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26493
resize_ and resize_as_ are low level functions that are not meant to be
used as a part of the regular PyTorch user's routine. However, they are
used to implement a lot of our operations: `out=` functionality is
implemented by resizing an output to be the correct size.
To keep in line with already implemented `out=` functionality, we do the
following:
- resize_as_(self, other) propagates names according to `out=` functionality.
This means that if self doesn't have names, then we propagate
other.names. If self does have names, they must be equal to other.names.
In addition, resize_ cannot resize a named tensor to anything but the same size.
Test Plan: - [namedtensor ci]
Differential Revision: D17501404
Pulled By: zou3519
fbshipit-source-id: e396e7fba55e1419355933925226d02dccb03012
Summary:
USE_STATIC_DISPATCH needs to be exposed as we don't hide header files
containing it for iOS (yet). Otherwise it's error-prone to request all
external projects to set the macro correctly on their own.
Also remove redundant USE_STATIC_DISPATCH definition from other places.
Test Plan:
- build android gradle to confirm linker can still strip out dead code;
- integrate with demo app to confirm inference can run without problem;
Differential Revision: D17484260
Pulled By: ljk53
fbshipit-source-id: 653f597acb2583761b723eff8026d77518007533
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25426
Add embedding table 4bit quantization support.
* add the conversion from fp32 to int4.
* using brew to pass the context so that the 4bit operators are added when generating the predictor net.
Reviewed By: kennyhorror, chocjy
Differential Revision: D16859892
fbshipit-source-id: a06c3f0b56a7eabf9ca4a2b2cb6c63735030d70b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26307
Add support for FP32 bias. Re-quantize bias during time time based on input scale.
If the value of input scale changes in the packed struct we requantize the bias with the updated input scale.
Test Plan: python test/test_quantized.py TestQNNPackOps
Differential Revision: D17504253
Pulled By: supriyar
fbshipit-source-id: 49fe36a0bee91aaeb085db28eec4ded8c684dcf4
Summary:
C++ `nn::Distance` tests can take advantage of the newly released multi-dimensional tensor constructor https://github.com/pytorch/pytorch/pull/26210 to simplify the tensor constructions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26539
Differential Revision: D17501041
Pulled By: yf225
fbshipit-source-id: 21d5f95ab3ec02227115c823c581218cee2ce458
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26366
Changes:
- `NameType::NORMAL` -> `NameType::BASIC`
- `Dimname::is_wildcard` -> `Dimname::isWildcard()`
- `Dimname::is_normal` -> `Dimname::isBasic()`.
- `at::is_valid_identifier` -> `Dimname::isValidName(string)`
- `at::match`, `at::unify` are now methods on `Dimname`.
I am adopting CamelCase for struct members of a named tensor related
struct.
Test Plan: - [namedtensor ci]
Differential Revision: D17484757
Pulled By: zou3519
fbshipit-source-id: 21c128e5025e81513e14d34506a7d7744caefdc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26479
This PR doesn't delete the code for them yet because it takes some effort to
determine what to delete. I will send a followup PR fully deleting
tagged names, but this PR disables their creation.
Test Plan: - [namedtensor ci]
Differential Revision: D17484758
Pulled By: zou3519
fbshipit-source-id: 451409e36eac98ffee1b98884d0f675bb5d46c9d
Summary:
With this PR, we establish the following conventions:
1. Options in C++ module / optimizer constructors should always be `const SomeOptions&` type, not `SomeOptions` type.
2. The options constructor arg should always be named `options_`, not `options`, to not be confused with the module / optimizer's internal field `options`.
3. We never use `std::move` to assign `options_` to the module / optimizer's internal field `options` in the constructor definition. Instead, we simply use `options(options_)`.
Here is the reasoning:
We might be tempted to declare the constructor as `SomeModule(SomeOptions options_)` and have `options(std::move(options_))` in the member initialization list. However, this can be a dangerous design because the constructor might use `options_` to set values for other member fields in the member initialization list (e.g. 8317f75b79/torch/csrc/api/include/torch/optim/lbfgs.h (L30-L34)), and use-after-move can cause hard-to-debug problems.
Instead, we choose to explicitly use `const SomeOptions&` type for `options_`, and never use `std::move` to assign it to the internal `options` field. This way we have stronger guarantee on the validity of `options_` at any point in the constructor.
Notable exceptions to the above conventions:
1. C++ Embedding module doesn't adhere to the conventions now, which will be fixed after https://github.com/pytorch/pytorch/pull/26358 is landed.
2. C++ dataloader and dataset classes likely need similar changes. We will do it when we start to work on dataloader/dataset parity.
Thanks ShahriarSS for discovering the options usage inconsistency! 🚀
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26483
Differential Revision: D17500451
Pulled By: yf225
fbshipit-source-id: 49361a3519e4ede933789db75731d40144f0b617
Summary:
When used as annotations on Python functions, `NamedTuple`s go through our Python annotation -> type mapping which previously had no way of lookup up `NamedTuple`s (which are created lazily by checking if the type has certain properties, so the lookup is creating the `TupleType` from scratch). This PR threads through the necessary data to make them work.
Fixes#26437
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26443
Pulled By: driazati
Differential Revision: D17486441
fbshipit-source-id: a6bbb543ff05a5abe61f1a7f68db9ecdb652b358
Summary:
If the `Union` contains a non-class type, `issubclass` would fail, this
adds a check for that case
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26312
Pulled By: driazati
Differential Revision: D17486465
fbshipit-source-id: c513cef3bbc038f15c021eb0c1bf36be0df1eb90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26515
Fix patterns of `prepack` and `permute` after recent changes
to `quantized::conv2d` and `quantized::conv2d_prepack`
Test Plan:
python test/test_jit.py 'TestJit.test_quant_fusion'
Imported from OSS
Differential Revision: D17502573
fbshipit-source-id: 1a719fd610e8ea9dc16075abaa042556e1edbceb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26364
Per https://github.com/pytorch/pytorch/issues/25769, we sometimes get
an infinite loop when `TCPStore` calls `tcputil::connect`, and the server
continually returns `ECONNRESET` or `ECONNREFUSED`. If a proper timeout is passed
in, we guard against this by throwing an exception once the timeout has passed.
Testing: Tested with modifying `TCPStore` to connect to an invalid port, thus getting
`ECONNREFUSED`. If a valid timeout is passed in, the function correctly throws an
exception. Steps below:
1) in TCPStore.cpp's constructor, replace the `connect` call with this line:
`storeSocket_ = tcputil::connect(tcpStoreAddr_, 1, true, std::chrono::milliseconds(3000));`
2) Build the `TCPStoreTest` binary.
3) Run the binary. Expected output:
```
terminate called after throwing an instance of 'std::runtime_error'
what(): Connecting to TCP store timed out.
Aborted (core dumped)
```
ghstack-source-id: 90480086
Test Plan: See above.
Differential Revision: D17430164
fbshipit-source-id: 1482aca72fcc3ddb95ea25649ec057edda5d1934
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26501
Instead of considering only the TensorTypeSet of the first argument, we collect all Tensor and TensorList arguments and union them together before computing the dispatch type id.
XLA companion patch at https://github.com/pytorch/xla/pull/1031
Billing of changes:
* ATenDispatch fallback code (i.e., what gets run if there is no entry for a function in the table) now lives out-of-line in a function `getFallbackOp`. This gave me an opportunity to write a more detailed error message, providing information about what registrations were available. There is a TODO in the fallback code, suggesting that we could automatically redispatch in the event that there is no handler for the key. But this is a bit of a design question, because it's not clear if automatic redispatch would cover up errors in the dispatch table (i.e., there *should* have been something registered at some key, but there wasn't.)
* Collection of Tensor/TensorList arguments is done using the trusty old IterArgs helper class. A minor bit of refactoring I had to do to get here was move the IterArgs functionality in torch/csrc/utils/variadic.h into ATen/core. There's some refactoring due on that file too (it has copies of some C++ helper pieces which already live in c10--you can't actually move the whole thing because it is literally incompatible with other code in the codebase). So instead of calling `type_set()` to get the type set of the dispatch argument, now we just call `at::detail::multi_dispatch_tensor_type_set` on all of the tensor/tensor list arguments.
* The code generator is adjusted to codegen collection of arguments as needed. There is a little bit of a hack in the code generator to turn 'self' arguments into '*this'. I think this may be duplicated with some logic somewhere else but I have to double check.
The new generated code looks like this:
```
inline Tensor & Tensor::copy_(const Tensor & src, bool non_blocking) const {
static auto table = globalATenDispatch().getOpTable("aten::copy_(Tensor(a!) self, Tensor src, bool non_blocking=False) -> Tensor(a!)");
return table->getOp<Tensor & (Tensor &, const Tensor &, bool)>(at::detail::multi_dispatch_tensor_type_set(*this, src))(const_cast<Tensor&>(*this), src, non_blocking);
}
```
The key difference is that previously we wrote `type_set()` as argument to getOp; now it is a call to `multi_dispatch_tensor_type_set` which collects the type ids together.
After turning on multi-dispatch, I had to refactor existing code which previously dispatched one place, but now dispatches somewhere else. The primary component affected by this is sparse.
* Binary operations (add/sub/mul/div/addmm) now dispatch to sparse kernels even if you did add(dense, sparse). So I delete all the sparse handling code from dense kernels, and bulk up the sparse error handling to handle when the first argument is dense. In the case of addmm, I can eliminate the bridge code entirely (well, not quite: more on this below). I also updated the dispatch on sparse to actually point at sparse kernels. Pay special attention to the handling of `div_` by scalar: previously this logic lived in the "dense" `div_` implementation, but there is actually not any sparse kernel we dispatch to. I solved this particular problem by making a redispatch, but another valid approach would have been to add specific dispatches for sparse div on scalar. This codepath is poorly tested because it is only exercised from C++.
* One minor annoyance is that because I now want separate dispatch for dense and sparse, I also need to replicate the `add`, `add_`, `add_out` trifecta on the sparse side. I opted for a compromise here: I wrote new a new `add_sparse` trifecta, but reused the implementation between CPU and CUDA. This means that I hav to do another dispatch once I get to `add_out`. The alternative would have been to do twice as many copies for CPU and CUDA (thereby eliminating the extra dispatch) but that seemed distinctly not worth it.
* A lot of kernels in sparse assumed that the dispatch argument must be sparse. This is no longer true with dispatch, so I converted the asserts into plain error checking. This also means that we've perturbed the error message in the case of TestSparseOneOff.test_cuda_sparse_cpu_dense_add (I just updated the saved error message)
* `addmm` is a little bit even more special: the bridge code also handled broadcasting. I replicated the broadcasting logic between CPU and CUDA implementations to avoid an extra dispatch.
* `_sparse_addmm` gave me a bit of trouble, because I had forgotten why we had `torch.sparse.addmm` in the first place. But in the end, its changes followed along with the structural changes I made in addmm. I opted for an extra dispatch here for simplicity.
* c10d has some Variable-Tensor confusion in its sparse code. I've worked around it by judiciously inserting "no variable type" guards, but a more correct fix would be to just solve the confusion entirely.
Benchmark:
Apply the following patch to the base commit and this commit:
```
diff --git a/aten/src/ATen/native/Const.cpp b/aten/src/ATen/native/Const.cpp
new file mode 100644
index 0000000000..b66f4d3ece
--- /dev/null
+++ b/aten/src/ATen/native/Const.cpp
@@ -0,0 +1,10 @@
+#include <ATen/ATen.h>
+
+namespace at {
+namespace native {
+
+Tensor _const5(const Tensor& self, const Tensor& second, const Tensor& third, const Tensor& fourth, const Tensor& fifth) {
+ return self;
+}
+
+}} // namespace at::native
diff --git a/aten/src/ATen/native/native_functions.yaml b/aten/src/ATen/native/native_functions.yaml
index b494ed7950..fddae638bb 100644
--- a/aten/src/ATen/native/native_functions.yaml
+++ b/aten/src/ATen/native/native_functions.yaml
@@ -5878,3 +5878,9 @@
dispatch:
CPU: im2col_backward_cpu
CUDA: im2col_backward_cuda
+
+# For benchmarking
+- func: _const5(Tensor self, Tensor second, Tensor third, Tensor fourth, Tensor fifth) -> Tensor
+ variants: function
+ dispatch:
+ CPU: _const5
```
Comparisons with timeit:
One-argument, representative case:
Before:
```
In [6]: %timeit x.reshape(1, 1)
1.46 µs ± 1.38 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [7]: %timeit x.reshape(1, 1)
1.48 µs ± 29.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [8]: %timeit x.reshape(1, 1)
1.52 µs ± 61.9 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
After:
```
In [3]: %timeit x.reshape(1, 1)
1.42 µs ± 1.34 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit x.reshape(1, 1)
1.43 µs ± 1.01 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit x.reshape(1, 1)
1.42 µs ± 0.982 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
Five-argument, synthetic case (we expect, with enough Tensor arguments, for there to be a slowdown, as we scale `O(n)` with number of arguments, compared to old dispatcher which is `O(1)` with number of arguments):
Before:
```
In [1]: import torch
In [2]: x = torch.zeros(1)
In [3]: %timeit torch._const5(x, x, x, x, x)
949 ns ± 1.3 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit torch._const5(x, x, x, x, x)
954 ns ± 1.96 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit torch._const5(x, x, x, x, x)
947 ns ± 0.601 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
After:
```
In [3]: %timeit torch._const5(x, x, x, x, x)
985 ns ± 9.11 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit torch._const5(x, x, x, x, x)
984 ns ± 1.17 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit torch._const5(x, x, x, x, x)
988 ns ± 0.555 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D17499154
Pulled By: ezyang
fbshipit-source-id: 8ea237c2e935134b0f4f8d6cfd89c6a93037c02c
Summary:
These are intentionally not yet used by the encoder to avoid backcompat issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26454
Differential Revision: D17480844
fbshipit-source-id: e88ae7f5b94e32c7f12341a750aa4b9f7374bfb7
Summary:
test_wrapped_number was calling torch.set_default_tensor_type('torch.FloatTensor'), which was setting the default tensor types for all following tests until a class boundary (with unittest) or until end of file (with pytest). Tests that don't expect the default tensor type to be set this way were then failing if run afterwards.
This fixes the issue by copying the default_tensor_type decorator from test_nn and using that instead with test_wrapped_number. The decorator correctly resets the default tensor type after the test has run.
This fixes the many errors encountered when running pytest test_jit.py.
Note: test_wrapped_number was introduced in https://github.com/pytorch/pytorch/issues/22273.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26523
Differential Revision: D17495283
Pulled By: mruberry
fbshipit-source-id: ab518c78b7706af7cb1c2d1c17823d311178996d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26504
[pytorch] [distributed] Make distructor virtual for class with virtual function
Not having virtual distructor may lead to a memory leak.
ghstack-source-id: 90454880
Test Plan: Made sure pg based UT works.
Differential Revision: D17488876
fbshipit-source-id: 5fdc55e175fd2b22e931b740c36cb1feed454066
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26498
We should allocate an empty tensor as a result tensor when performing
binary ops. Currently some ops use `empty_like(self)` as the initial
result tensor before passing it into TensorIterator. This is not very
efficient because TensorIterator may resize the tensor due to
broadcasting, causing more memory allocation. By using an empty tensor
as the result tensor, we only need to allocate/resize memory once as
opposed to twice.
Also fixes https://github.com/pytorch/pytorch/issues/26495. The bug
there is that the implementation of `pow` is missing a resize in one
case.
Test Plan:
- new test
- run tests
Differential Revision: D17500025
Pulled By: zou3519
fbshipit-source-id: bff4949af5e75541c04669b961bcf2e1ec456faf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25975
We would like to add the FP16 weight support for the dynamic quantized LSTM.
Test Plan:
buck test mode/dev caffe2/test:quantization -- 'test_quantized_rnn \(test_quantization\.PostTrainingDynamicQuantTest\)' --print-passing-details
```
[jianyuhuang@devvm794.ftw3.facebook.com: ~/fbsource/fbcode/caffe2/test] $ buck test mode/dev caffe2/test:quantization
-- 'test_quantized_rnn \(test_quantization\.PostTrainingDynamicQuantTest\)' --print-passing-details
Building: finished in 13.4 sec (100%) 8134/8134 jobs, 81 updated
Total time: 13.9 sec
Trace available for this run at /tmp/testpilot.20190910-210241.2092790.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision c86e65add357582accb6ec0be23b92c8a2c510bd fbpkg ca46e8f5b26c451a8b0b2462c11bb61d at Mon Sep 9
22:16:37 2019 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/696/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/1125900050322971
✓ caffe2/test:quantization - test_quantized_rnn (test_quantization.PostTrainingDynamicQuantTest) 0.183 1/1 (passed)
Test output:
> test_quantized_rnn (test_quantization.PostTrainingDynamicQuantTest) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 0.184s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/1125900050322971
Summary (total time 4.35s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
Differential Revision: D17299116
fbshipit-source-id: 7fe91ece25867f2c0496f1b63fb1041e6b815166
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26477
- At inference time we need turn off autograd mode and turn on no-variable
mode since we strip out these modules for inference-only mobile build.
- Both flags are stored in thread-local variables so we cannot simply
set them to false glboally.
- Add "autograd/grad_mode.h" header to all-in-one header 'torch/script.h'
to reduce friction for iOS engs who might need do this manually in their
project.
P.S. I tried to hide AutoNonVariableTypeMode in codegen but figured it's not
very trivial (e.g. there are manually written part not covered by codegen).
Might try it again later.
Test Plan: - Integrate with Android demo app to confirm inference runs correctly.
Differential Revision: D17484259
Pulled By: ljk53
fbshipit-source-id: 06887c8b527124aa0cc1530e8e14bb2361acef31
Summary:
Serialization.cpp fails on big endian machines.
This patch fixes the endian bugs and also makes the pytorch
model files portable across different endian architectures.
x86 generated model file can be read on s390 arch.
First problem, is serialization.cpp forgets to convert "size" value
of the storage elements to the native byte order.
torch.load throws an assertion as a result
(see the first stack trace below).
Second problem is when it reads the model from storage (doRead)
it decodes values to little endian which is the wrong order
on a big endian machine. The decode should be
to THP_nativeByteOrder() instead
(see the model dump below)
```loaded_model = torch.load( opt.model_file, map_location=torch.device("cpu"))
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 422, in load
return _load(f, map_location, pickle_module, **pickle_load_args)
File "/usr/local/lib/python3.6/dist-packages/torch/serialization.py", line 616, in _load
deserialized_objects[key]._set_from_file(f, offset, f_should_read_directly)
RuntimeError: storage has wrong size: expected 2305843009213693952 got 32
(the very long number is actually 32 in the wrong endianness)
```
Model file load on x86 (correct output)
```>>> import torch
>>> torch.load('400f2k_best.model', map_location=torch.device("cpu"))
{'epoch': 24, 'model_type': 'emb_aec', 'classifier_model': OrderedDict([('model.0.weight', tensor([[ 2.4608e-01, -1.1174e-01, -1.0854e-01, 4.0124e-01, -1.5261e-02,
-1.2206e-01, 1.3229e-01, -1.2615e-01, -5.2773e-01, 2.6333e-01,
-3.1462e-03, -1.4902e-01, 9.8545e-02, -1.5789e-01, -2.2625e-01,
-1.0776e-01, -9.0895e-02, -3.8530e-01, 9.1152e-01, -3.9720e-01,
-8.5848e-01, -4.7837e-02, -1.5178e-01, 8.5023e-02, 1.5013e-01,
-9.9294e-02, -2.7422e-01, -4.3986e-01, -4.4297e-01, -3.9570e-01,
```
Model file load on s390x (wrong endianness; notice the exponents)
```>>> import torch
>>> torch.load( "400f2k_best.model", map_location=torch.device("cpu"))
{'epoch': 24, 'model_type': 'emb_aec', 'classifier_model': OrderedDict([('model.0.weight', tensor([[ 9.2780e+21, -9.7722e-11, 4.1350e+33, 7.782e+34, 4.2056e-31,
9.0784e+18, 1.1846e-32, 3.3320e-32, -4.8288e-28, -7.2679e+12,
1.5379e-16, -5.2604e+12, -4.7240e+17, 4.6092e-21, -1.8360e-20,
-2.7712e-31, 1.4548e-16, -2.5089e-27, 7.9094e-10, 7.1977e+34,
1.1930e+26, 8.4536e+15, 2.7757e+23, -5.8455e-10, -1.5611e+09,
-1.1311e-23, 6.6451e+19, -2.0970e+20, 3.4878e-19, -1.0857e-12,
7.8098e+22, 5.3998e-35],
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26383
Differential Revision: D17480891
fbshipit-source-id: f40569c7b9c4a1935dceb41f1a2508ce21ea3491
Summary:
At the moment it includes https://github.com/pytorch/pytorch/pull/26219 changes. That PR is landing at the moment, afterwards this PR will contain only javadocs.
Applied all dreiss comments from previous version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26149
Differential Revision: D17490720
Pulled By: IvanKobzarev
fbshipit-source-id: f340dee660d5ffe40c96b43af9312c09f85a000b
Summary:
In schema matching we allow a homogenous tuple to be matched to list arguments. This logic wasn't yet extended for vartype lists, causing stuff like `len((1, 2, 3))` to fail.
Fix for https://github.com/pytorch/pytorch/issues/20500
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25944
Differential Revision: D17482510
Pulled By: eellison
fbshipit-source-id: aa63318c27a01d965a7a7b68ce8bec638168dc26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26478
### Summary
Since QNNPACK [doesn't support bitcode](7d2a4e9931/scripts/build-ios-arm64.sh (L40)), I'm going to disable it in our CMake scripts. This won't hurt any existing functionalities, and will only affect the build size. Any application that wants to integrate our framework should turn off bitcode as well.
### Test plan
- CI job works
- LibTorch.a can be compiled and run on iOS devices
Test Plan: Imported from OSS
Differential Revision: D17489020
Pulled By: xta0
fbshipit-source-id: 950619b9317036cad0505d8a531fb8f5331dc81f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/26076. mruberry if https://github.com/pytorch/pytorch/issues/26248 goes in soon, I'll rebase after it, otherwise this should go in because it's a bug fix.
Side note: cdist backward testing is very light and I suspect is not testing all the code paths, but that's a separate issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26254
Test Plan: added test for the affected size to test_autograd.py. Streams are tested by existing tests.
Differential Revision: D17480945
Pulled By: ngimel
fbshipit-source-id: 0f18c9fd05e462d22c410a2ebddc2bcc9580582d
Summary:
Makes c10::Dict Ordered and bins binds the OrderedDict() and dict() constructor into torchscript. For the case of the empty constructor dict() i typed it as [str, Tensor] because:
• we're almost dropping support for python 2, at which point all dicts are ordered
• then it's more conventional to write x : Dict[int, int] = {} which is already supported
• It is possible to construct an arbitrarily typed empty OrderedDict through
OrderedDict(torch.jit.annotate(List[Tuple[key, value]], [])
We could consider dropping the no inputs aten::dict constructor since then the types would be more explicit.
This replaces https://github.com/pytorch/pytorch/issues/26170 and https://github.com/pytorch/pytorch/pull/26372 b/c ghstack was poisioned and i had to resubmit
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26465
Differential Revision: D17481604
Pulled By: eellison
fbshipit-source-id: d2d49795a518c3489881afac45d070e5262c5849
Summary:
The implementation of several modules in C++ frontend currently has calls to `options.name_`, which is bad practice because `options.name_` should be a private options field and we should use `options.name()` to access its value. This PR makes `options.name_` actually private and changes all callsites of `options.name_` to `options.name()`.
After this change, we can change all module options to have a map as the underlying data structure, and require that all options must be able to be stored in `c10::IValue`. These changes together would make serializing module options much easier.
Note that this PR is BC-breaking in the following way:
Previously, calling `options.name_` in C++ module implementation works because `options.name_` was a public field. After this PR, `options.name_` becomes private, and to get the value of `options.name_` we should call `options.name()`, and to set the value of `options.name_` we should call `options.name(new_value)`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26419
Differential Revision: D17481507
Pulled By: yf225
fbshipit-source-id: 93e4ed0e1d79ef57104ad748809d03e25da61ed3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25824
Use github actions for flake8. This is nice because it makes it easier
to create inline annotations for lint violations.
It ends up looking like this:
https://github.com/suo/pytorch/pull/21/files
Test Plan: Imported from OSS
Differential Revision: D17487007
Pulled By: suo
fbshipit-source-id: 663094ea2bbbdb1da5b7e5d294c70735a319d5e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26468
Instead of considering only the TensorTypeSet of the first argument, we collect all Tensor and TensorList arguments and union them together before computing the dispatch type id.
XLA companion patch at https://github.com/pytorch/xla/pull/1031
Billing of changes:
* ATenDispatch fallback code (i.e., what gets run if there is no entry for a function in the table) now lives out-of-line in a function `getFallbackOp`. This gave me an opportunity to write a more detailed error message, providing information about what registrations were available. There is a TODO in the fallback code, suggesting that we could automatically redispatch in the event that there is no handler for the key. But this is a bit of a design question, because it's not clear if automatic redispatch would cover up errors in the dispatch table (i.e., there *should* have been something registered at some key, but there wasn't.)
* Collection of Tensor/TensorList arguments is done using the trusty old IterArgs helper class. A minor bit of refactoring I had to do to get here was move the IterArgs functionality in torch/csrc/utils/variadic.h into ATen/core. There's some refactoring due on that file too (it has copies of some C++ helper pieces which already live in c10--you can't actually move the whole thing because it is literally incompatible with other code in the codebase). So instead of calling `type_set()` to get the type set of the dispatch argument, now we just call `at::detail::multi_dispatch_tensor_type_set` on all of the tensor/tensor list arguments.
* The code generator is adjusted to codegen collection of arguments as needed. There is a little bit of a hack in the code generator to turn 'self' arguments into '*this'. I think this may be duplicated with some logic somewhere else but I have to double check.
The new generated code looks like this:
```
inline Tensor & Tensor::copy_(const Tensor & src, bool non_blocking) const {
static auto table = globalATenDispatch().getOpTable("aten::copy_(Tensor(a!) self, Tensor src, bool non_blocking=False) -> Tensor(a!)");
return table->getOp<Tensor & (Tensor &, const Tensor &, bool)>(at::detail::multi_dispatch_tensor_type_set(*this, src))(const_cast<Tensor&>(*this), src, non_blocking);
}
```
The key difference is that previously we wrote `type_set()` as argument to getOp; now it is a call to `multi_dispatch_tensor_type_set` which collects the type ids together.
After turning on multi-dispatch, I had to refactor existing code which previously dispatched one place, but now dispatches somewhere else. The primary component affected by this is sparse.
* Binary operations (add/sub/mul/div/addmm) now dispatch to sparse kernels even if you did add(dense, sparse). So I delete all the sparse handling code from dense kernels, and bulk up the sparse error handling to handle when the first argument is dense. In the case of addmm, I can eliminate the bridge code entirely (well, not quite: more on this below). I also updated the dispatch on sparse to actually point at sparse kernels. Pay special attention to the handling of `div_` by scalar: previously this logic lived in the "dense" `div_` implementation, but there is actually not any sparse kernel we dispatch to. I solved this particular problem by making a redispatch, but another valid approach would have been to add specific dispatches for sparse div on scalar. This codepath is poorly tested because it is only exercised from C++.
* One minor annoyance is that because I now want separate dispatch for dense and sparse, I also need to replicate the `add`, `add_`, `add_out` trifecta on the sparse side. I opted for a compromise here: I wrote new a new `add_sparse` trifecta, but reused the implementation between CPU and CUDA. This means that I hav to do another dispatch once I get to `add_out`. The alternative would have been to do twice as many copies for CPU and CUDA (thereby eliminating the extra dispatch) but that seemed distinctly not worth it.
* A lot of kernels in sparse assumed that the dispatch argument must be sparse. This is no longer true with dispatch, so I converted the asserts into plain error checking. This also means that we've perturbed the error message in the case of TestSparseOneOff.test_cuda_sparse_cpu_dense_add (I just updated the saved error message)
* `addmm` is a little bit even more special: the bridge code also handled broadcasting. I replicated the broadcasting logic between CPU and CUDA implementations to avoid an extra dispatch.
* `_sparse_addmm` gave me a bit of trouble, because I had forgotten why we had `torch.sparse.addmm` in the first place. But in the end, its changes followed along with the structural changes I made in addmm. I opted for an extra dispatch here for simplicity.
* c10d has some Variable-Tensor confusion in its sparse code. I've worked around it by judiciously inserting "no variable type" guards, but a more correct fix would be to just solve the confusion entirely.
Benchmark:
Apply the following patch to the base commit and this commit:
```
diff --git a/aten/src/ATen/native/Const.cpp b/aten/src/ATen/native/Const.cpp
new file mode 100644
index 0000000000..b66f4d3ece
--- /dev/null
+++ b/aten/src/ATen/native/Const.cpp
@@ -0,0 +1,10 @@
+#include <ATen/ATen.h>
+
+namespace at {
+namespace native {
+
+Tensor _const5(const Tensor& self, const Tensor& second, const Tensor& third, const Tensor& fourth, const Tensor& fifth) {
+ return self;
+}
+
+}} // namespace at::native
diff --git a/aten/src/ATen/native/native_functions.yaml b/aten/src/ATen/native/native_functions.yaml
index b494ed7950..fddae638bb 100644
--- a/aten/src/ATen/native/native_functions.yaml
+++ b/aten/src/ATen/native/native_functions.yaml
@@ -5878,3 +5878,9 @@
dispatch:
CPU: im2col_backward_cpu
CUDA: im2col_backward_cuda
+
+# For benchmarking
+- func: _const5(Tensor self, Tensor second, Tensor third, Tensor fourth, Tensor fifth) -> Tensor
+ variants: function
+ dispatch:
+ CPU: _const5
```
Comparisons with timeit:
One-argument, representative case:
Before:
```
In [6]: %timeit x.reshape(1, 1)
1.46 µs ± 1.38 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [7]: %timeit x.reshape(1, 1)
1.48 µs ± 29.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [8]: %timeit x.reshape(1, 1)
1.52 µs ± 61.9 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
After:
```
In [3]: %timeit x.reshape(1, 1)
1.42 µs ± 1.34 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit x.reshape(1, 1)
1.43 µs ± 1.01 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit x.reshape(1, 1)
1.42 µs ± 0.982 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
Five-argument, synthetic case (we expect, with enough Tensor arguments, for there to be a slowdown, as we scale `O(n)` with number of arguments, compared to old dispatcher which is `O(1)` with number of arguments):
Before:
```
In [1]: import torch
In [2]: x = torch.zeros(1)
In [3]: %timeit torch._const5(x, x, x, x, x)
949 ns ± 1.3 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit torch._const5(x, x, x, x, x)
954 ns ± 1.96 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit torch._const5(x, x, x, x, x)
947 ns ± 0.601 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
After:
```
In [3]: %timeit torch._const5(x, x, x, x, x)
985 ns ± 9.11 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit torch._const5(x, x, x, x, x)
984 ns ± 1.17 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit torch._const5(x, x, x, x, x)
988 ns ± 0.555 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bddppq
Differential Revision: D17481256
Pulled By: ezyang
fbshipit-source-id: b3206936b4ca8938d45ea90fd71422e0d80b5f96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26242
According to https://github.com/pytorch/pytorch/issues/19092 we always keep NCHW order and do handling inside the kernels. This PR fixes it for activations of the qconv by using MemoryLayout mechanism - activations stay logically as NCHW but strided as NHWC.
Note, that this version is more aggressive than eventual MemoryLayout mechanism - the QConv's output is always NHWC regardless of the input striding. I think it's ok as we don't have NCHW quantized kernels anyway - so the very first conv would magically switch the order, but I'm open to suggestions. Btw, it doesn't change behavior - same happens today in master because of the explicit permute() call.
Test Plan: Imported from OSS
Differential Revision: D17443218
Pulled By: dzhulgakov
fbshipit-source-id: cfd136ae0465acd8d8c26ffad87385dac9c88726
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26241
According to https://github.com/pytorch/pytorch/issues/19092 we always keep NCHW order and do handling inside the kernels. This PR fixes it for weights of the qconv by using MemoryLayout mechanism.
Test Plan: Imported from OSS
Differential Revision: D17443219
Pulled By: dzhulgakov
fbshipit-source-id: ce0eb92034a9977b3303dafab8b0414575171062
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26240
In particular adds support for empty/empty_like which is needed for memory layouts to work.
Test Plan: Imported from OSS
Differential Revision: D17443220
Pulled By: dzhulgakov
fbshipit-source-id: 9c9e25981999c0edaf40be104a5741e9c62a1333
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26415
We do dynamic quantization for bias right now, remove this in pattern
Test Plan:
python test/test_jit.py 'TestJit.test_quant_fusion'
Imported from OSS
Differential Revision: D17465555
fbshipit-source-id: 5e229cbc6ae85ea4ce727b3479993d79747d7792
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26439
C10_MOBILE / FEATURE_TORCH_MOBILE are checked in EnableNamedTensor.h but
NamedTensor.h includes it at very beginning - for internal build it's
fine as C10_MOBILE / FEATURE_TORCH_MOBILE are set as compiler flags, but
for cmake build it relies on c10/macros/Macros.h header to derive these
macros from other macros like __ANDROID__, so it won't work as expected.
Test Plan:
- build locally;
- will check CI;
Differential Revision: D17466581
Pulled By: ljk53
fbshipit-source-id: 317510bcc077782ec2d22e23b1aaa0cb77cb73a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26395
This diff makes each SummaryWriter write into its own unique directory.
Reviewed By: orionr
Differential Revision: D17441500
fbshipit-source-id: d284fcf0e7e7a7214e644349e345f1de0e1a1aba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26466
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17480533
Pulled By: ezyang
fbshipit-source-id: 5532bd50aaea284ebb208feb949b5a6aca6be458
Summary:
Follow up to https://github.com/pytorch/pytorch/pull/25664, add `class_type[ind] = val`. Like `__getitem__`, `__setitem__` has a custom compilation path so it wasn't added with the rest of the magic methods.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25750
Differential Revision: D17428725
Pulled By: eellison
fbshipit-source-id: ff3767ef41515baf04b0c0f5c896dbd3f1d20cd3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25653
Instead of considering only the TensorTypeSet of the first argument, we collect all Tensor and TensorList arguments and union them together before computing the dispatch type id.
Billing of changes:
* ATenDispatch fallback code (i.e., what gets run if there is no entry for a function in the table) now lives out-of-line in a function `getFallbackOp`. This gave me an opportunity to write a more detailed error message, providing information about what registrations were available. There is a TODO in the fallback code, suggesting that we could automatically redispatch in the event that there is no handler for the key. But this is a bit of a design question, because it's not clear if automatic redispatch would cover up errors in the dispatch table (i.e., there *should* have been something registered at some key, but there wasn't.)
* Collection of Tensor/TensorList arguments is done using the trusty old IterArgs helper class. A minor bit of refactoring I had to do to get here was move the IterArgs functionality in torch/csrc/utils/variadic.h into ATen/core. There's some refactoring due on that file too (it has copies of some C++ helper pieces which already live in c10--you can't actually move the whole thing because it is literally incompatible with other code in the codebase). So instead of calling `type_set()` to get the type set of the dispatch argument, now we just call `at::detail::multi_dispatch_tensor_type_set` on all of the tensor/tensor list arguments.
* The code generator is adjusted to codegen collection of arguments as needed. There is a little bit of a hack in the code generator to turn 'self' arguments into '*this'. I think this may be duplicated with some logic somewhere else but I have to double check.
After turning on multi-dispatch, I had to refactor existing code which previously dispatched one place, but now dispatches somewhere else. The primary component affected by this is sparse.
* Binary operations (add/sub/mul/div/addmm) now dispatch to sparse kernels even if you did add(dense, sparse). So I delete all the sparse handling code from dense kernels, and bulk up the sparse error handling to handle when the first argument is dense. In the case of addmm, I can eliminate the bridge code entirely (well, not quite: more on this below). I also updated the dispatch on sparse to actually point at sparse kernels. Pay special attention to the handling of `div_` by scalar: previously this logic lived in the "dense" `div_` implementation, but there is actually not any sparse kernel we dispatch to. I solved this particular problem by making a redispatch, but another valid approach would have been to add specific dispatches for sparse div on scalar. This codepath is poorly tested because it is only exercised from C++.
* One minor annoyance is that because I now want separate dispatch for dense and sparse, I also need to replicate the `add`, `add_`, `add_out` trifecta on the sparse side. I opted for a compromise here: I wrote new a new `add_sparse` trifecta, but reused the implementation between CPU and CUDA. This means that I hav to do another dispatch once I get to `add_out`. The alternative would have been to do twice as many copies for CPU and CUDA (thereby eliminating the extra dispatch) but that seemed distinctly not worth it.
* A lot of kernels in sparse assumed that the dispatch argument must be sparse. This is no longer true with dispatch, so I converted the asserts into plain error checking. This also means that we've perturbed the error message in the case of TestSparseOneOff.test_cuda_sparse_cpu_dense_add (I just updated the saved error message)
* `addmm` is a little bit even more special: the bridge code also handled broadcasting. I replicated the broadcasting logic between CPU and CUDA implementations to avoid an extra dispatch.
* `_sparse_addmm` gave me a bit of trouble, because I had forgotten why we had `torch.sparse.addmm` in the first place. But in the end, its changes followed along with the structural changes I made in addmm. I opted for an extra dispatch here for simplicity.
* c10d has some Variable-Tensor confusion in its sparse code. I've worked around it by judiciously inserting "no variable type" guards, but a more correct fix would be to just solve the confusion entirely.
Benchmark:
Apply the following patch to the base commit and this commit:
```
diff --git a/aten/src/ATen/native/Const.cpp b/aten/src/ATen/native/Const.cpp
new file mode 100644
index 0000000000..b66f4d3ece
--- /dev/null
+++ b/aten/src/ATen/native/Const.cpp
@@ -0,0 +1,10 @@
+#include <ATen/ATen.h>
+
+namespace at {
+namespace native {
+
+Tensor _const5(const Tensor& self, const Tensor& second, const Tensor& third, const Tensor& fourth, const Tensor& fifth) {
+ return self;
+}
+
+}} // namespace at::native
diff --git a/aten/src/ATen/native/native_functions.yaml b/aten/src/ATen/native/native_functions.yaml
index b494ed7950..fddae638bb 100644
--- a/aten/src/ATen/native/native_functions.yaml
+++ b/aten/src/ATen/native/native_functions.yaml
@@ -5878,3 +5878,9 @@
dispatch:
CPU: im2col_backward_cpu
CUDA: im2col_backward_cuda
+
+# For benchmarking
+- func: _const5(Tensor self, Tensor second, Tensor third, Tensor fourth, Tensor fifth) -> Tensor
+ variants: function
+ dispatch:
+ CPU: _const5
```
Comparisons with timeit:
One-argument, representative case:
Before:
```
In [6]: %timeit x.reshape(1, 1)
1.46 µs ± 1.38 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [7]: %timeit x.reshape(1, 1)
1.48 µs ± 29.8 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [8]: %timeit x.reshape(1, 1)
1.52 µs ± 61.9 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
After:
```
In [3]: %timeit x.reshape(1, 1)
1.42 µs ± 1.34 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit x.reshape(1, 1)
1.43 µs ± 1.01 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit x.reshape(1, 1)
1.42 µs ± 0.982 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
Five-argument, synthetic case (we expect, with enough Tensor arguments, for there to be a slowdown, as we scale `O(n)` with number of arguments, compared to old dispatcher which is `O(1)` with number of arguments):
Before:
```
In [1]: import torch
In [2]: x = torch.zeros(1)
In [3]: %timeit torch._const5(x, x, x, x, x)
949 ns ± 1.3 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit torch._const5(x, x, x, x, x)
954 ns ± 1.96 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit torch._const5(x, x, x, x, x)
947 ns ± 0.601 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
After:
```
In [3]: %timeit torch._const5(x, x, x, x, x)
985 ns ± 9.11 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [4]: %timeit torch._const5(x, x, x, x, x)
984 ns ± 1.17 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [5]: %timeit torch._const5(x, x, x, x, x)
988 ns ± 0.555 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17265918
Pulled By: ezyang
fbshipit-source-id: 221efe4e86a40f36abc81e2ebceaa7e251c90b3d
Summary:
- Moves all ROCm-requiring test_torch tests to TestTorchDeviceType
- Moves test_stft and test_lu from test_cuda
- Moves many CUDA-only test_torch tests to TestTorchDeviceType
- Combines several test_torch CPU tests with their CUDA variants
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26435
Differential Revision: D17470469
Pulled By: mruberry
fbshipit-source-id: 90bb7fc09465c53eb2ab8da52eb2c2509775c16f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26061
This is in preparation for actually emitting a dynamic isinstance check instruction.
It re-arranges the logic so that all the types and properties to check
against are in a flat list. In the future this flat list will be encoded
into an actual instruction if we determine that we cannot perform
the check statically.
Test Plan: Imported from OSS
Differential Revision: D17332062
Pulled By: zdevito
fbshipit-source-id: 4c0b65436f8e030170d469fe747e79de24bb24eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26211
Currently QNNPACK does not have an unpack function like FBGEMM does.
In order to be able to script quantized models for mobile, we need to save unpacked weights.
This change stores the original weights and bias in the opaque struct and simply returns it when unpack is called
Test Plan:
python test/test_quantized.py TestQNNPackOps.test_qconv_unpack
python test/test_quantized.py TestQNNPackOps.test_qlinear_unpack
Imported from OSS
Differential Revision: D17464430
fbshipit-source-id: 83ad5a2556dcf13245a1047feef6cfb489c9ef69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25675
This will be used to support OrderedDict in python. Modifies the existing `flat_hash_map` to preserve insertion and deletion order.
Test Plan: Imported from OSS
Differential Revision: D17440131
Pulled By: eellison
fbshipit-source-id: c7a6a290c8471627f5a061c0cca8e98ff131c9b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26371
This is just so the PR making the flat hash map preserve order is easier to review
Replaces https://github.com/pytorch/pytorch/pull/25674 bc ghstack was poisoned and i had to resubmit
Test Plan: Imported from OSS
Differential Revision: D17440132
Pulled By: eellison
fbshipit-source-id: 8a4f640d070d85795261cb3a129518c72096e9ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25887
ghstack-source-id: 90383258
Add per channel observer to compute the qparams for each channel.
Test Plan:
buck test mode/dev caffe2/test:quantization -- 'test_per_channel_minmax_observer'
buck test mode/dev caffe2/test:quantization -- 'test_per_channel_minmax_observer_scriptable'
Differential Revision: D17137226
fbshipit-source-id: 0b1c93e3cbcda86f5c4e30f7cd94c670f2665063
Summary:
Added support for gelu in symbolic opset9 + op and ORT tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24475
Reviewed By: hl475
Differential Revision: D17088708
Pulled By: houseroad
fbshipit-source-id: 9d2f9d7d91481c57829708793d88f786d6c3956f
Summary:
These are intentionally not yet used by the encoder to
avoid backcompat issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25786
Differential Revision: D17374409
fbshipit-source-id: 17971b26e48429c68b7fa8126d7ed56ff80b5d68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26440
As we are optimizing build size for Android/iOS, it starts diverging
from default build on several build options, e.g.:
- USE_STATIC_DISPATCH=ON;
- disable autograd;
- disable protobuf;
- no caffe2 ops;
- no torch/csrc/api;
...
Create this build_mobile.sh script to 'simulate' mobile build mode
with host toolchain so that people who don't work on mobile regularly
can debug Android/iOS CI error more easily. It might also be used to
build libtorch on devices like raspberry pi natively.
Test Plan:
- run scripts/build_mobile.sh -DBUILD_BINARY=ON
- run build_mobile/bin/speed_benchmark_torch on host machine
Differential Revision: D17466580
Pulled By: ljk53
fbshipit-source-id: 7abb6b50335af5b71e58fb6d6f9c38eb74bd5781
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26444
Original commit changeset: 6276a011a373
Test Plan: Revert of recent change that was breaking a test. Test plan is that build no longer breaks verified manually.
Differential Revision: D17467067
fbshipit-source-id: bf866f4dc0f08af249d92cebc9846623d44224f6
Summary:
fbjni is used during linking `libpytorch.so` and is specified in `pytorch_android/CMakeLists.txt` and as a result its included as separate `libfbjni.so` and is included to `pytorch_android.aar`
We also have java part of fbjni and its connected to pytorch_android as gradle dependency which contains `libfbjni.so`
As a result when we specify gradle dep `'org.pytorch:pytorch_android'` (it has libjni.so) and it has transitive dep `'org.pytorch:pytorch_android_fbjni'` that has `libfbjni.so` and we will have gradle ambiguity error about this
Fix - excluding libfbjni.so from pytorch_android.aar packaging, using `libfbjni.so` from gradle dep `'org.pytorch:pytorch_android_fbjni'`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26382
Differential Revision: D17468723
Pulled By: IvanKobzarev
fbshipit-source-id: fcad648cce283b0ee7e8b2bab0041a2e079002c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26227
In the previous implementation of composite lr, the lr_scale for each sub policy will be rewritten by the last lr_scale.
Due to another bug in unittest (where policy_lr_scale being the same for all sub policies), this bug was not detected by unittest...
Fix: add an additional field in CompositeLearningRateItem so that we store lr_scale values for all sub policies
If fix unittest, the error in previous implementation:
https://fburl.com/testinfra/ikdbnmey
With the fix,
https://fburl.com/testinfra/m694ehl1
Test Plan:
unittest
buck test caffe2/caffe2/python/operator_test:learning_rate_op_test -- test_composite_learning_rate_op
Reviewed By: chocjy, alex1o1o7cloud
Differential Revision: D17380363
fbshipit-source-id: 161e9cb71bb2ea7f0734a3361e270616057a08e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26224
We need to make sure they are Constant before we can do folding
Test Plan:
python test/test_jit.py 'TestJit.test_fold_quantize'
Imported from OSS
Differential Revision: D17462530
fbshipit-source-id: 2e02f980e0e7f28014d2f813035975dfc69cacd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26152
This change adds the support to call QNNPACK using the refactored API for Conv2d operators
Test Plan:
python test/test_quantized.py TestQNNPackOps.test_qconv_qnnpack
Imported from OSS
Differential Revision: D17459892
fbshipit-source-id: d20b3e8b81dd403541cb2b9164731448ca229695
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26381
Was looking through this definition and saw that it has 2 identical
definitions of get_worker_id. Tested by ensuring that all tests in
`test/test_rpc.py` still pass.
ghstack-source-id: 90347452
Test Plan: See above
Differential Revision: D17439495
fbshipit-source-id: 9a78340f7aefa5797e0ae837fbcfe24ebe3a775d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26223
add filter function to runGraph, if the function returns false for given `Match`,
the we'll skip the rewrite.
Test Plan:
will test in later PR that adds extra filtering on Constant nodes
Imported from OSS
Differential Revision: D17462529
fbshipit-source-id: 52abe52cb3e729a3871f7a60eddd5275060af36a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25447
When we unpickle IValues, we lose type information for List[T]
and Dict[K, V]. We can restore this information using the static
type information contained in the top-level Module/Class type.
This ensures that even after serialization we can always get the
dynamic type of an ivalue using its type() method.
Test Plan: Imported from OSS
Differential Revision: D17127872
Pulled By: zdevito
fbshipit-source-id: 1ffb5e37a7c35c71ac9d3fb7b2edbc7ce3fbec72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25439
This introduces a type() method on IValue that returns the tagged type
of the IValue. The intention is that this value is always present/accurate,
making it possible for clients to recover the Type from an IValue.
Currently our APIs here are incomplete: they can sometimes recover a type but not always.
This PR adds the function, and cleans up remaining cases where Lists/Dicts are not
tagged. However, this information does not survive serialization unchanged.
A second PR will use the type information in the ClassType being serialized
to fixup the serialized ivalues to have the correct types again.
After this patch it will be save to remove our incomplete APIs for recovering types.
Test Plan: Imported from OSS
Differential Revision: D17125595
Pulled By: zdevito
fbshipit-source-id: 71c8c1a0e44762647e8f15f45d8ed73af8e6cb92
Summary:
This pass tries to resolve scalar type mismatch issues between input tensors introduced by the implicit type conversions on scalars.
e.g. https://github.com/pytorch/pytorch/issues/23724
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24378
Reviewed By: hl475
Differential Revision: D17088682
Pulled By: houseroad
fbshipit-source-id: 3de710f70c3b70b9f76fd36a7c4c76e168dbc756
Summary:
- Adds dtypes, dtypesIfCPU, and dtypesIfCUDA decorators.
- Eliminates the need for nontest members to be defined in an inherited base.
- Updates one test to use the decorators and updates TestTorchDeviceType with helpers.
This PR appears to be hanging the ROCm build, which is not entirely surprising. See https://github.com/pytorch/pytorch/issues/26394, which demonstrates that the ROCm build can be hung by commenting out a Python test that was never run on ROCm.
gchanan - what type list, if any, do you want to expose? I imagine most test suites will define their own lists like today. SCALAR_TYPES, QUANTIZED_TYPES, and ALL_TYPES seem reasonable to me. DOCUMENTED_TENSOR_TYPES will be removed, of course.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26375
Test Plan: Edit is to tests themselves.
Differential Revision: D17462294
Pulled By: mruberry
fbshipit-source-id: f8259ec66709749b1bf8077efc737676af901436
Summary:
This PR has been updated. Since ORIGINAL PR comment below.
ROCm CI builds have been hanging as we've been refactoring tests, even when these refactors seem entirely innocuous. This PR started by commenting out test_stft, for example, a Python test never run on ROCm, and that was sufficient to reliably hang the ROCm build in CI.
Putting ROCm tests back on the default stream appears to remove this hang. So this PR now does that. This is likely to unblock development.
ORIGINAL: Some test changes appear to be causing ROCm builds to hang in CI. This PR is an attempt to diagnose the source of the hang.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26394
Test Plan: Change is to test themselves.
Differential Revision: D17456678
Pulled By: mruberry
fbshipit-source-id: 38d00d01c64b5055c1dfed01687ce3e1c9372887
Summary:
- There are some missing casts.
- Functions like ::log, ::sin will potentially always invoke the double version on host. For
example, compiling the following code:
```c++
#include <cmath>
float log_float(float f) {
return ::logf(f);
}
double log_double(double f) {
return ::log(f);
}
float log_float2(float f) {
return ::log(f);
}
float log_float3(float f) {
return std::log(f);
}
```
using `g++ -c -O3` leads to:
log_float(float):
jmp logf
log_double(double):
jmp log
log_float2(float):
subq $8, %rsp
cvtss2sd %xmm0, %xmm0
call log
addq $8, %rsp
cvtsd2ss %xmm0, %xmm0
ret
log_float3(float):
jmp logf
Note that log_float2 delegates the call to the double version of log
(surrounded by cast), while log_float3 delegates the call correctly to
logf. See https://godbolt.org/z/KsRWwW
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25791
Differential Revision: D17452312
Pulled By: izdeby
fbshipit-source-id: 6276a011a373cd7cb144f9ecd84116aa206e7d1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26352
"named_guard: P" is the same as "supports_named_tensor: !P".
Also changed the error message to be more understandable to users.
Test Plan:
- `TEST_NAMEDTENSOR=1 pytest test/test_namedtensor.py -v`
- [namedtensor ci]
Differential Revision: D17426234
Pulled By: zou3519
fbshipit-source-id: 4cab780e6e29e184e79cdd3690f41df9ebb2ecb5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26353
### Summary
As the new iOS building script has been landed, this PR will clean up some redundant code for the PR jobs.
### Test Plan
- Don't break any existing CI jobs
- Don't break the old iOS CI jobs
Test Plan: Imported from OSS
Differential Revision: D17457253
Pulled By: xta0
fbshipit-source-id: 0d85117533a62d0b9b7b859b0044fd4388c3c9d4
Summary:
Currently calc_erfinv's float version on CPU is missing. This commit adds the float version (by templating).
I also used this opportunity to clean up calc_erfinv a bit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26070
Reviewed By: ezyang
Differential Revision: D17368024
Pulled By: VitalyFedyunin
fbshipit-source-id: 00cc3097f340022b3788143e6c12b01c35d72f13
Summary:
# Problem
If there is not enough number of thread in the RPC Agent thread pool. Some circular dependent works could cause deadlock.
The current to way to get around this deadlock is to provide abundant number of threads.
# Solution
as titled
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26313
Differential Revision: D17405491
Pulled By: xush6528
fbshipit-source-id: a1d9b6a84db0371cd4b63328fa00f651c0808485
Summary:
per https://github.com/pytorch/pytorch/issues/22226, The current sparse allreduce in ProcessGroupGloo pads the indices and values tensors to the maximum length across all processes and then performs a regular allgather (because they'll have equal size across processes). Instead, we can use allgatherv. This is mostly a win for memory usage if there is severe size imbalance between processes.
close https://github.com/pytorch/pytorch/issues/22226
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23917
Test Plan:
buck run mode/dev-nosan caffe2/test:c10d -- test_c10d.ProcessGroupGlooTest.test_sparse_allreduce_basics
buck run mode/dev-nosan caffe2/test:c10d -- test_c10d.ProcessGroupGlooTest.test_sparse_allreduce_basics_cuda
buck run mode/dev-nosan caffe2/test:c10d -- test_c10d.ProcessGroupGlooTest.test_sparse_allreduce_checks
Differential Revision: D16664985
Pulled By: zhaojuanmao
fbshipit-source-id: e7d3c0770cbc09f9175b3027b527e95053724843
Summary:
ignore the folder and its children ios/TestApp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26399
Differential Revision: D17451239
Pulled By: houseroad
fbshipit-source-id: d6ba666bf955454eca4a10c00784ee5947a70f59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26350
Python 3 lets us use `...` to perform indexing. Semantically, `...`
means "the rest of the unspecified dimensions". For example, while
indexing, one can do (for 5D `tensor`) `tensor[0, 0, ..., 0]` and
the `...` is expanded into `tensor[0, 0, :, :, 0]`.
Previously, we were using '*' to represent a similar behavior in names.
For example, `tensor.refine_names` supports things like the following:
```
x = torch.randn(2, 3, 4, 5, 6)
x_out = x.refine_names('*', 'H', 'W') # refine only the last two
dimensions
```
This PR changes it so that named tensor API functions recognize `'...'`
(in Python 2 and Python 3) and `...` (in Python 3 exclusively) instead
of `'*'`.
Test Plan: - [namedtensor ci]
Differential Revision: D17424666
Pulled By: zou3519
fbshipit-source-id: 003182879fd38ced3fea051217572a457cdaf7cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26349
The directory holds a lot of private helper functions that help
implement named tensor functionality. Instead of naming each helper
function with a leading underscore, I change the name of the import to
`_namedtensor_internals` to signal it should not be used directly.
Test Plan: - [namedtensor ci]
Differential Revision: D17424178
Pulled By: zou3519
fbshipit-source-id: 8f7b74346765759303480e581038a661021acf53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26147
We may try to unpickle a byte string in py3 that was pickled from py2. Therefore we need to add encoding latin1.
Reviewed By: kennyhorror
Differential Revision: D17305677
fbshipit-source-id: c0c8a51909629a65eb72bb81cccfbabaee9f8d01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24022
In histogram observer add an approximation for L2 error minimization for selecting min/max.
By selecting new min/max, we filter out outliers in input distribution.
This follows the implementation of NormMinimization::NonlinearQuantizationParamsSearch in caffe2/quantization/server/norm_minimization.cc
ghstack-source-id: 90298789
Test Plan: buck test mode/dev caffe2/test:quantization -- 'test_histogram_observer'
Differential Revision: D16713239
fbshipit-source-id: 82631ba47974e25689c9c66bc3088117090e26d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25658
This unflattens `dim` according to the shape specified in `namedshape`.
`namedshape` may be either an OrderedDict or an iterable of (name, size)
tuples.
Future:
- It is possible to make it take a dict in Python >= 3.6 because those are
ordered by default, but I'll leave that task for the future.
Test Plan: - new tests [namedtensor ci]
Differential Revision: D17192655
Pulled By: zou3519
fbshipit-source-id: fd9bd2f462c23a4df1c23d66f2aa95076ff1b160
Summary:
The Pickler previously had a distinction between tensors that would be inlined in 1 pickle binary (matching the format of `torch.save()`) and tensors that are saved elsewhere with only a reference stored in the binary. This PR moves that distinction out to `torch::pickle_save` to match the eager Python interface.
The change can be seen in `register_prim_ops.cpp` where the call to `jit::pickle` is now `torch::pickle_save`
](https://our.intern.facebook.com/intern/diff/17175215/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25502
Pulled By: driazati
Differential Revision: D17175215
fbshipit-source-id: 8c9a21327cc79eaf6a0e488ea99e305be52f82b1
Summary:
ROCm CI jobs are running on Jenkins. They have the "-test{1,2}" parts in "JOB_BASE_NAME", not "BUILD_ENVIRONMENT".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26380
Differential Revision: D17439523
Pulled By: bddppq
fbshipit-source-id: 31e2a986d1b7ea40c90ab399a3c1e0a328ae3a92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26135
This change adds the support to call QNNPACK using the refactored API for Linear operators (Fully Connected)
It also has certain cmake changes to enable builing and using pytorch_qnnpack inside aten
I have disabled USE_QNNPACK in CMakeLists.txt. Enabling it results in picking kernels from third_party/QNNPACK during runtime since the function names are the same.
Test Plan:
python test/test_quantized.py TestQNNPackOps.test_qlinear_qnnpack
Imported from OSS
Differential Revision: D17434885
fbshipit-source-id: 084698026938f4529f61d12e86dfe82534ec73dd
Summary:
Fix the regex (requires enabling extglob) for two digit clang releases.
While there, also fix it for three digit releases with the hope that I
do not need to touch it for some time.
Unfortunately, this regex requires extglob to be enabled in the shell.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25409
Differential Revision: D17431786
Pulled By: bddppq
fbshipit-source-id: a50b2ff525d9b6046deae9c8725c92d67119599a
Summary:
In schema matching we allow a homogenous tuple to be matched to list arguments. This logic wasn't yet extended for vartype lists, causing stuff like `len((1, 2, 3))` to fail.
Fix for https://github.com/pytorch/pytorch/issues/20500
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25944
Differential Revision: D17431514
Pulled By: eellison
fbshipit-source-id: 2ad98bab15eaa496471df651572735eb35183323
Summary:
Inserting markers using the nvtx-equivalent API is not supported yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26300
Differential Revision: D17425573
Pulled By: bddppq
fbshipit-source-id: 4df6c695ba07ab68e7f4dc2f77edde06f78fdac7
Summary:
This is the first step of adding CI for bc breaking changes detection of function shcemas.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26321
Reviewed By: hl475
Differential Revision: D17425468
Pulled By: houseroad
fbshipit-source-id: b4bb36e5597043407c943b5b8dfe2b1ac3248cb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26261
### Summary
Previously we have enabled the CI jobs for Pull Requests and nightly build
- **#25840 [iOS][Circle CI] Add PR jobs for iOS builds**
- **#26074 [IOS][CIRCLE CI] Nightly jobs for iOS builds**
The testing phase is missing in the nightly build process. Although we are able to generate the build and upload it to the AWS, there is no way to know whether the binary is valid or not (there could be a linking error). To add the test phase to the process, we need
1. Put a dummy test App in the repo.
2. After the build jobs finishes, manually link the static libs to the dummy app to produce an executable using the xcode tool chain.
3. If there is no linking error, then upload the binaris to AWS. If there is an error, then stops the following process and reports an error in CI.
The second and third steps depends on the first step which needs to be landed first.
### Test Plan
- Don't break any existing CI jobs
Test Plan: Imported from OSS
Differential Revision: D17408929
Pulled By: xta0
fbshipit-source-id: e391da242639943005453d1318795f981034cc72
Summary:
Was confused by the wrong message while debugging.
Turns out cpu version is wrong on comparison direction and gpu version is printing wrong number in addition to that.
This fix should make the error message correct.
jjsjann123 for tracking
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26325
Differential Revision: D17408969
Pulled By: soumith
fbshipit-source-id: 0d9330e00aaabcb3e8e893b37a6a53fb378171c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26259
This wasn't called from anywhere (confirmed by grep)
ghstack-source-id: 90222268
Test Plan: waitforsandcastle
Differential Revision: D17391417
fbshipit-source-id: 77c395f2f7104995f6af6e3e20d3f615223085b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26255
Add some more ops that work fine without needing fixes
[namedtensor ci]
ghstack-source-id: 90222272
Test Plan: unit tests
Differential Revision: D17390980
fbshipit-source-id: 0eeae69a409a8cfd9195b71053c1f6202ddd3509
Summary:
This PR aims to re-organize C++ API `torch::nn` folder structure in the following way:
- Every module in `torch/csrc/api/include/torch/nn/modules/` (except `any.h`, `named_any.h`, `modulelist.h`, `sequential.h`, `embedding.h`) has a strictly equivalent Python file in `torch/nn/modules/`. For example:
`torch/csrc/api/include/torch/nn/modules/pooling.h` -> `torch/nn/modules/pooling.py`
`torch/csrc/api/include/torch/nn/modules/conv.h` -> `torch/nn/modules/conv.py`
`torch/csrc/api/include/torch/nn/modules/batchnorm.h` -> `torch/nn/modules/batchnorm.py`
`torch/csrc/api/include/torch/nn/modules/sparse.h` -> `torch/nn/modules/sparse.py`
- Containers such as `any.h`, `named_any.h`, `modulelist.h`, `sequential.h` are moved into `torch/csrc/api/include/torch/nn/modules/container/`, because their implementations are too long to be combined into one file (like `torch/nn/modules/container.py` in Python API)
- `embedding.h` is not renamed to `sparse.h` yet, because we have another work stream that works on API parity for Embedding and EmbeddingBag, and renaming the file would cause conflict. After the embedding API parity work is done, we will rename `embedding.h` to `sparse.h` to match the Python file name, and move the embedding options out to options/ folder.
- `torch/csrc/api/include/torch/nn/functional/` is added, and the folder structure mirrors that of `torch/csrc/api/include/torch/nn/modules/`. For example, `torch/csrc/api/include/torch/nn/functional/pooling.h` contains the functions for pooling, which are then used by the pooling modules in `torch/csrc/api/include/torch/nn/modules/pooling.h`.
- `torch/csrc/api/include/torch/nn/options/` is added, and the folder structure mirrors that of `torch/csrc/api/include/torch/nn/modules/`. For example, `torch/csrc/api/include/torch/nn/options/pooling.h` contains MaxPoolOptions, which is used by both MaxPool modules in `torch/csrc/api/include/torch/nn/modules/pooling.h`, and max_pool functions in `torch/csrc/api/include/torch/nn/functional/pooling.h`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26262
Differential Revision: D17422426
Pulled By: yf225
fbshipit-source-id: c413d2a374ba716dac81db31516619bbd879db7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26060
This PR enables BUILD_NAMEDTENSOR by default. This is done via including
a header, `c10/core/EnableNamedTensor`, that sets `BUILD_NAMEDTENSOR`.
In the future, the plan is to get rid of the flag entirely: we can
incrementally delete usages after this PR goes in.
This PR also maintains the namedtensor ci vs regular ci distinction.
`test/test_namedtensor.py` only runs if TEST_NAMEDTENSOR=1 is specified.
TEST_NAMEDTENSOR=1 is set on the namedtensor ci. I'll remove this
distinction later and send out an announcement about it; devs will be
responsible for named tensor failures after that.
The initial reason why we had the BUILD_NAMEDTENSOR flag was so that we
could quickly prototype named tensor features without worrying about
adding overhead to the framework. The overheads can be categorized as
memory overhead and performance overhead.
Memory overhead: named tensors adds 1 additional word per Tensor. This
is because TensorImpl stores a `unique_ptr<NamedTensorMetaInterface>`
field. This is not a lot of overhead.
Performance overhead: At all entry points to name inference, we check
if inputs to an op are named. If inputs are not named, we short-circuit
and don't do name inference. These calls should therefore be as
efficient as error-checking code and not take up a lot of time.
My plan is to benchmark a few functions and then post the results in a
comment to this PR.
Test Plan: - [namedtensor ci]
Differential Revision: D17331635
Pulled By: zou3519
fbshipit-source-id: deed901347448ae2c26066c1fa432e3dc0cadb92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26298
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17420724
Pulled By: ezyang
fbshipit-source-id: b8e651d0dfe7abec5615e849bdd5d1a19feb7b40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26285
I renamed:
THTensor_(std / var) -> THTensor(std_single / var_single)
THTensor(stdall / varall) -> THTensor(std_all, var_all)
because I reversed the meaning of the bias/unbiased parameters (to match ATen) and type checking wouldn't catch failures.
Test Plan: Imported from OSS
Differential Revision: D17397227
Pulled By: gchanan
fbshipit-source-id: 244fe878d4e1045620137c00fbaea6e6f919fc8d
Summary:
Follow-up to gh-25483, more of the same fixes for warnings like:
```
../torch/csrc/autograd/python_variable.cpp:503:31: warning: cast between incompatible function types from ‘PyObject* (*)(THPVariable*)’ {aka ‘_object* (*)(THPVariable*)’} to ‘getter’ {aka ‘_object* (*)(_object*, void*)’} [-Wcast-function-type]
503 | {"_backward_hooks", (getter)THPVariable_get_backwards_hooks, (setter)THPVariable_set_backwards_hooks, nullptr, nullptr},
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
```
This takes the build log output for a full rebuild with GCC 9.1 from ~10,000 to ~7,000 lines.
`clang-tidy` is going to complain, no way around that - see discussion at the end of gh-25483.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26104
Differential Revision: D17396831
Pulled By: ezyang
fbshipit-source-id: d71696bfe4dbe25519e4bcb7753151c118bd39f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25788
Previously, I thought that _lazy_init held the GIL throughout initialization, so
I could write the code in a single-threaded manner. This is not true; it
releases the GIL at various points, which make it possible for another thread to
race with initialization.
The correct fix is to add locking for the initialization section, so other
threads wait until the first thread finishes initializing before being let
in. There is some subtlety with how to handle lazy calls, which will call
_lazy_init reentrantly; this is handled using TLS that lets you know if you
are the initializing thread (and therefore reentrant calls are OK.)
Fixes#16559
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17366348
Pulled By: ezyang
fbshipit-source-id: 99b982709323e2370d03c127c46d87be97495916
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25908
Original commit changeset: f6e961e88c01
device_option propagation is completely broken in Caffe2 for cases when pass through operators are used. As an example Gather operator don't have gradient and passes through it's inputs, which results in incorrect detection of the components for sparse parameter aggregation (component will be empty instead of the real device).
This diff is trying to fix this issue.
Original diff had a problem, that Caffe2 is not handling cases when device option is present, but contains only metadata (for example one for auto-generated reduction ops in backward pass). This diff is addressing this issue by merging device options during the backward pass
Test Plan:
1. net_transform is finally working with Gather + FloatToHalf transformed model instead of failing because of incorrect number of components.
2. New unit-test.
3. Verify that previously broken benchmark is now passing
ezyang do you have suggestions what else I should test?
Reviewed By: ezyang
Differential Revision: D17281528
fbshipit-source-id: 4a1bc386f29f6a34fbf8008effde9d4890abebfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26289
It's not possible to refer to values of local variables otherwise.
ghstack-source-id: 90160797
Test Plan: The code compiles.
Differential Revision: D17397702
fbshipit-source-id: 49c74c44c88f197264603e4978e3d60bf199f6ac
Summary:
Changelog:
- Modify existing implementation of pinverse to support batching on inputs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26095
Test Plan: - Added tests in test_pinverse to test batched implementation
Differential Revision: D17408092
Pulled By: soumith
fbshipit-source-id: bba95eb193ce33a94ecfaf74da270d34b435e4af
Summary:
It appears to be a bug with test_arange, which wasn't revealed with older version of onnxruntime.
TLDR. The test tries to update exported onnx model to accept dynamic sized input, however it is written incorrectly such that the exported model input is still fixed sized. Meanwhile, the version of ort in CI doesn't validate if model input size matches with input data, so this error was not found.
Affecting ci in https://github.com/pytorch/pytorch/pull/25797
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26320
Reviewed By: hl475
Differential Revision: D17406442
Pulled By: houseroad
fbshipit-source-id: a09ad4b925ccbed0b71342f5aaa7878e1c4a5a2d
Summary:
- Adds new decorators for skipping on ROCm, skipping on MKL, running only on the CPU and running only on CUDA
- Makes decorator skip semantics consistent
- Adds CUDA default stream requirement to MAGMA decorator
- Creates TestAutogradDeviceType
Note this PR originally moved test_cdist, but moving it caused failures in CI. There may be an undiagnosed issue with cdist or the test. The issue does not reproduce locally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26248
Test Plan: Change is to tests themselves.
Differential Revision: D17410386
Pulled By: mruberry
fbshipit-source-id: 8459df44f2a00f0e71680fbe713587a01d4b0300
Summary:
After offline discussion with dzhulgakov :
- In future we will introduce creation of byte signed and byte unsigned dtype tensors, but java has only signed byte - we will have to add some separation for it in method names ( java types and tensor types can not be clearly mapped) => Returning type in method names
- fixes in error messages
- non-static method Tensor.numel()
- Change Tensor toString() to be more consistent with python
Update on Sep 16:
Type renaming on java side to uint8, int8, int32, float32, int64, float64
```
public abstract class Tensor {
public static final int DTYPE_UINT8 = 1;
public static final int DTYPE_INT8 = 2;
public static final int DTYPE_INT32 = 3;
public static final int DTYPE_FLOAT32 = 4;
public static final int DTYPE_INT64 = 5;
public static final int DTYPE_FLOAT64 = 6;
```
```
public static Tensor newUInt8Tensor(long[] shape, byte[] data)
public static Tensor newInt8Tensor(long[] shape, byte[] data)
public static Tensor newInt32Tensor(long[] shape, int[] data)
public static Tensor newFloat32Tensor(long[] shape, float[] data)
public static Tensor newInt64Tensor(long[] shape, long[] data)
public static Tensor newFloat64Tensor(long[] shape, double[] data)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26219
Differential Revision: D17406467
Pulled By: IvanKobzarev
fbshipit-source-id: a0d7d44dc8ce8a562da1a18bd873db762975b184
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26311
We are currently unable to deploy models due to D16955662 changing function signature of ```quantized_lstm(``` but the function call here (https://fburl.com/diffusion/e4wrmx83) not passing the newly added ```use_dynamic``` param.
Here is the details of the error: P111215482
```
E0916 12:36:16.423516 1149877 ExceptionTracer.cpp:214] exception stack complete
terminate called after throwing an instance of 'torch::jit::script::ErrorReport'
what():
Arguments for call are not valid.
The following operator variants are available:
aten::quantized_lstm(Tensor input, Tensor[] hx, Tensor[] params, bool has_biases, int num_layers, float dropout, bool train, bool bidirectional, bool batch_first, *, int? dtype=None) -> (Tensor, Tensor, Tensor):
Keyword argument use_dynamic unknown.
```
This diff fixes that.
Test Plan:
Running quantization tests after.
```buck test mode/dev caffe2/test:jit -- 'test_quantization_modules \(test_jit\.TestScript\)'```
https://our.intern.facebook.com/intern/testinfra/testrun/5910974518872494
Also, currently building a package (language_technology.translation.jedi.scripts:35c3643) and testing this (f138747078).
f138771702
Reviewed By: jhcross
Differential Revision: D17404451
fbshipit-source-id: 390d2ce1ecbdd63a07a8f16c80e4c3ac25ab0a99
Summary:
pytorch builds fail on 390 architecture because
in simd.h the ifdef macros default to an x86 asm instruction.
This patchs adds an ifdef __s390x__ to be able to build on s390.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26233
Differential Revision: D17392714
Pulled By: soumith
fbshipit-source-id: 037672bfea64fc5e52da2390d93b973534137c12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26204
Support quant fusion for `matmul` with bias to `quantized::linear`.
Test Plan:
python test/test_jit.py 'TestJit.test_quant_fusion'
Imported from OSS
Differential Revision: D17380073
fbshipit-source-id: 00014469a852cc5d5b66469fc4b8d05eafba1e3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26282
Since this isn't the end-user API anymore, we shouldn't have defaults.
Test Plan: Imported from OSS
Differential Revision: D17397153
Pulled By: gchanan
fbshipit-source-id: d44040bec0ee9c70734a53ebcc10a96f12226a29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26166
There were 2 variants to create a new device. One to do so based the
name of a network interface, and one to do so based on a hostname or
address. In the latter, if the address was not specified, it would
lookup the local hostname and try to resolve that. If that failed, the
process would crash.
In this default path, we now try to lookup and use the local hostname,
and if that fails we fallback to using the loopback address.
If the local hostname doesn't resolve to an address that we can bind
to, it is very likely that this process won't join other processes
over the network, and that the user is trying to run a local test.
If this assumption is wrong, the user can override the default
interface selection by setting the environment variable
`GLOO_SOCKET_IFNAME` to the name of the external network interface.
I tested this by changing the local hostname to a bogus name and
confirmed that default initialization works as expected.
Closes#26049.
Test Plan: Imported from OSS
Differential Revision: D17397898
Pulled By: pietern
fbshipit-source-id: 95a2467761d89df87b520d6e5837b92184b0dc12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26077
As per #26071, we would like to get rid of the calls to Variable(
where possible. This diff removes the calls in the test file test_nn.py. The
unit tests should all still pass as expected.
ghstack-source-id: 90086624
Test Plan: tests in `test_nn.py` should all pass.
Differential Revision: D17336484
fbshipit-source-id: 43fc7bd0b0be835ae89d06162ce1cbe4e0056d91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26237
Calling a lot of `std::string` constructors is horrible for binary size, see t53997334.
Using `const char*` instead should make the binary size much smaller.
ghstack-source-id: 90145501
Test Plan: size checks on the diff
Differential Revision: D17386002
fbshipit-source-id: c5420adf225e535396e806a0df92419a7e2ad3e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26257
In native_functions.yaml, all overloads must have unique overload names.
This PR fixes `flatten` to have unique names for the overloads.
Test Plan: - tested locally, but also [namedtensor ci]
Differential Revision: D17391243
Pulled By: zou3519
fbshipit-source-id: aaef654953b4275c43b9d7bd949c46bd011f6c73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26252
Original commit changeset: 1375774f24c2
Testing to see if this is somehow the source of hangs on ROCm builds.
Test Plan: Change is to tests themselves. This diff is for testing the ROCm hang, however.
Differential Revision: D17390575
fbshipit-source-id: a6ffd5eb1df3971b99b6d42271a8d3d501ac79c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26250
Exclude some ops from the c10 dispatcher that don't work with it yet.
ghstack-source-id: 90138046
Test Plan: waitforsandcastle
Reviewed By: zou3519
Differential Revision: D17390117
fbshipit-source-id: a87fb3048aeba2c3293b95d610ddb8e94369f8fe
Summary:
- Adds SkipCUDAIfRocm and skipCPUIfNoMkl decorators, ports corresponding tests
- Changes "SkipIf" input semantics for consistency
- Removes torchtest, which has been replaced with this new generic framework
- Refactors some common parts out of CUDA tests to TestTorchDeviceType
- Ensures all MAGMA tests run on default stream by putting the skipCUDANonDefaultStreamIf in the skipCUDAIfNoMagma decorator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26244
Differential Revision: D17389060
Pulled By: mruberry
fbshipit-source-id: 1375774f24c2266049e6d4b899e7300ddf32eac8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26130
Since we now just use TensorTypeId::VariableTensorId, there's no need to treat autograd kernels any differently.
ghstack-source-id: 90130457
Test Plan: unit tests
Differential Revision: D17353873
fbshipit-source-id: d4468506a5366bc5e7429144b090b3e78af9de62
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23668
- The eager mode frontend now calls operators who are defined in native_functions.yaml with `use_c10_dispatcher: True` through the c10 dispatcher and not anymore through globalATenDispatch().
- These operators aren't registered with globalAtenDispatch anymore, only on c10 now.
- Backend extensions calling globalATenDispatch().registerOp() to add their own kernels still work, this function will forward the registration to the c10 dispatcher for them.
ghstack-source-id: 90130455
Test Plan: benchmarks at https://docs.google.com/document/d/1gpzKZcFf1JJameY1vKxF7Cloul9s6D8HKIK2_Pp1hFo/edit#
Differential Revision: D16603133
fbshipit-source-id: 991f17b355e9c78c5e86fee4fa381df7ab98ac82
Summary:
If source code is not available due to packaging (e.g. sources are compiled to .pyc), TorchScript produces very obscure error message. This tries to make it nicer and allow to customize message by overriding _utils_internal.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25415
Test Plan: Really hard to unittest properly. Did one off testing by compiling to .pyc and checking the message.
Differential Revision: D17118238
Pulled By: dzhulgakov
fbshipit-source-id: 3cbfee0abddc8613000680548bfe0b8ed52a36b0
Summary:
This PR moves many tests in test_torch.py to the generic device type framework. This means that many CUDA tests now run in test_torch.py and there is greater consistency in how tests for many device types are written.
One change is that all MAGMA tests are run on the default stream due to intermittent instability running MAGMA on the non-default stream. This is a known issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26232
Test Plan:
While this PR edits the tests itself, it was validated using two independent methods:
(1) The code was reviewed and it was verified that all deleted functions were actually moved.
(2) The output of the TestTorch CI was reviewed and test outputs were matched before and after this PR.
Differential Revision: D17386370
Pulled By: mruberry
fbshipit-source-id: 843d14911bbd52e8aac6861c0d9bc3d0d9418219
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26222
### Summary
The last generation of armv7s device is Phone 5C. As discussed with David offline, we decided not to support iOS armv7s devices.
### Test plan
- CI finishes successfully
- Builds can be run only on X86_64 and arm64 devices
Test Plan: Imported from OSS
Differential Revision: D17385308
Pulled By: xta0
fbshipit-source-id: f883999aed18224ea3386b1f016964a33270fa34
Summary:
This test can sometimes fail in CI.
I suspect this flakiness is because the test asks a CUDA stream to record an event, fails to synchronize the CPU with that stream, then checks if the event is recorded on the CPU. There is no guarantee this will have happened.
This one-line change preserves the intent of the test while ensuring the GPU has recorded the event before the CPU queries it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26231
Differential Revision: D17382110
Pulled By: mruberry
fbshipit-source-id: 35b701f87f41c24b208aafde48bf10e1a54de059
Summary:
This PR addresses https://github.com/pytorch/pytorch/issues/24851 by...
1. lets device types easily register themselves for testing
2. lets tests be written to run on multiple devices and with multiple dtypes
3. provides a mechanism to instantiate those tests so they are discoverable and filterable by unittest and pytest
It refactors three tests from test_torch.py to demonstrate how to use it.
`test_diagonal` is the simplest example. Most tests just need to be modified to accept 'device' as an argument. The framework will then instantiate `test_diagonal_cpu` and `test_diagonal_cuda` (when CUDA is available) which call `test_diagonal` with the appropriate 'device' argument.
`test_neg` also has dtype variants. It accepts both 'device' and 'dtype' as arguments, and the dtypes it runs with are specified with the 'dtypes' decorator. Dtypes can be specified for all device types and particular device types. The framework instantiates tests like `test_neg_cpu_torch.float`.
`test_inverse` has device-specific dependencies. These dependencies are expressed with the sugary 'skipCUDAIfNoMagma' and 'skipCPUIfNoLapack' decorators. These decorators are device-specific so CPU testing is not skipped if Magma is not installed, and there conditions may be checked after or before the test case has been initialized. This means that skipCUDAIfNoMagma does not initialize CUDA. In fact, CUDA is only initialized if a CUDA test is run.
These instantiated tests may be run as usual and with pytest filtering it's easy to run one test on all device types, run all the tests for a particular device type, or run a device type and dtype combination.
See the note "Generic Device-Type Testing" for more detail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25967
Differential Revision: D17381987
Pulled By: mruberry
fbshipit-source-id: 4a639641130f0a59d22da0efe0951b24b5bc4bfb
Summary:
we intend to be conservative, and will relax the checks in future if necessary.
So far, we consider the following three conditions as backward compatible:
1) two schemas are equal
2) two schemas have same number of arguments, and this schema's
arguments are backward compatible with the corresponding ones in
argument list of old_schema.
3) this schema has m argument, old_argument has n argument, m > n.
the first n arguments of this schema are backward compatible with
the corresponding arguments of old_schema. the remaning arguments
must be either OptionalType or provide default values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23409
ghstack-source-id: 90111021
Test Plan: buck test //caffe2/test:function_schema
Reviewed By: hl475
Differential Revision: D16505203
fbshipit-source-id: e4099537776a60e8945e5c3cd57fa861f3598a9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23959
Add histogram observer that records the running histogram of tensor values along with min/max values.
ghstack-source-id: 90076996
Test Plan:
Added a test test_histogram_observer
buck test mode/dev caffe2/test:quantization -- 'test_histogram_observer'
buck test mode/dev caffe2/test:quantization -- 'test_observer_scriptable'
Differential Revision: D16692835
fbshipit-source-id: 0f047d3349cb9770fad4a2b6cb346c51d9e99cd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25974
Previously we observe all the Tensor values, but what we want is actually
observing only the ones that can be quantized.
Test Plan:
python test/test_jit.py
python test/test_quantizer.py
Imported from OSS
Differential Revision: D17348986
fbshipit-source-id: 55be0d73862a0e7eb1e7fd882d16e0d830618b63
Summary:
Applying dzhulgakov review comments
org.pytorch.Tensor:
- dims renamed to shape
- typeCode to dtype
- numElements to numel
newFloatTensor, newIntTensor... to newTensor(...)
Add support of dtype=long, double
Resorted in code byte,int,float,long,double
For if conditions order float,int,byte,long,double as I expect that float and int branches will be used more often
Tensor.toString() does not have data, only numel (data buffer capacity)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26183
Differential Revision: D17374332
Pulled By: IvanKobzarev
fbshipit-source-id: ee93977d9c43c400b6c054b6286080321ccb81bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26089
### Summary
A couple of changes
1. Replace the source link with the newly nightly build address
2. Remove module support for Swift and Objective-C
3. Expose all static libraries instead of archiving them into one single library. This is because those static libraries might contain object files that have the same name, e.g. `init.c.o` in both `libcupinfo.a` and `libqnnpack.a`. If we archive them into one using this `libtool -static` command, by default, it only picks one object file and discards the others, which could result in undefined symbols when linking the executable. The change here is to expose all the static libraries and let the linker decide which one to use.
### Test Plan
- pod spec lint succeed
- `pod spec lint --verbose --allow-warnings --no-clean --use-libraries --skip-import-validation`
Test Plan: Imported from OSS
Differential Revision: D17363037
Pulled By: xta0
fbshipit-source-id: ba77b0001b58e6e2353d8379d932db598166d37d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26074
### Summary
This PR creates a nightly job for iOS builds. The job will generate a couple of static libraries that contains three architectures(x86, arm64, armv7s) and upload them to AWS s3.
### Note
The test phase in this job is missing right now, meaning if there is a linking error, we won't be able to know it. To add the test jobs, we have to put a dummy test App in the repo and manually link the libraries to the app after the build finishes. This will be done in the next following PRs
Test Plan: Imported from OSS
Differential Revision: D17363066
Pulled By: xta0
fbshipit-source-id: 5beeb4263af5722f0a852297023f37aaea9ba4b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26131
Changes in this PR:
- For each operator with use_c10_dispatcher: True, additionally generate a c10 registration line in TypeDefault.cpp, CPUType.cpp, and other backend files.
- This doesn't change globalATenDispatch yet, the c10 registration is purely additional and the operator calling path doesn't change. A diff further up the stack will change these things.
- Enable the use_c10_dispatcher: True flag for about ~70% of operators
- This also changes the c10->jit operator export because ATen ops are already exported to JIT directly and we don't want to export the registered c10 ops because they would clash
- For this, we need a way to recognize if a certain operator is already moved from ATen to c10, this is done by generating a OpsAlreadyMovedToC10.cpp file with the list. A diff further up in the stack will also need this file to make sure we don't break the backend extension API for these ops.
Reasons for some ops to be excluded (i.e. not have the `use_c10_dispatcher` flag set to true):
- `Tensor?(a!)` (i.e. optional tensor with annotations) not supported in c++ function schema parser yet
- `-> void` in native_functions.yaml vs `-> ()` expected by function schema parser
- out functions have different argument order in C++ as in the jit schema
- `Tensor?` (i.e. optional tensor) doesn't work nicely with undefined tensor sometimes being undefined tensor and sometimes being None.
- fixed-size arrays like `int[3]` not supported in c10 yet
These will be fixed in separate diffs and then the exclusion tag will be removed.
ghstack-source-id: 90060748
Test Plan: a diff stacked on top uses these registrations to call these ops from ATen
Differential Revision: D16603131
fbshipit-source-id: 315eb83d0b567eb0cd49973060b44ee1d6d64bfb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25947
Previously, the c10 dispatcher didn't allow having a catch-all kernel and backend specific kernels at the same time.
This is also the long term goal. But to make the current XLA implementation work, we need to allow them to overwrite these ops with XLA variants.
This diff changes that so that ops can have both, catchall and backend specific kernels, and will call into the catchall kernel if there is no more specific kernel registered.
This is also the current behavior of globalATenDispatch.
ghstack-source-id: 90049398
Test Plan: unit tests
Differential Revision: D17293036
fbshipit-source-id: f2d5928e904c1dc9b6b89e9bb468debe48a4056c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26114
With this diff, the operator schema or name can be specified as part of the options objects:
```
static auto registry = torch::RegisterOperators()
.op(torch::RegisterOperators::options().schema("my_op").kernel(&kernel))
.op(...);
```
This does not break backwards compatibility, all old APIs are kept as shorthands.
This (a) makes the API more consistent, accumulating all options into the options objects and not treating schema special anymore, and (b) this is required for allowing the c10 dispatcher to forward registration calls to ATenDispatch for ops that are still on that dispatcher, see plan in https://github.com/pytorch/pytorch/issues/24132
ghstack-source-id: 90049402
Test Plan: unit tests
Differential Revision: D17350383
fbshipit-source-id: cbb8f33a52dccb2a4522753e7b5ac8ba35b908fd
Summary:
The main part is to switch at::Tensor creation from usage of `torch::empty(torch::IntArrayRef(...))->ShareExternalPointer(...) to torch::from_blob(...)`
Removed explicit set of `device CPU` as `at::TensorOptions` by default `device CPU`
And renaming of local variables removing `input` prefix to make them shorter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25973
Differential Revision: D17356837
Pulled By: IvanKobzarev
fbshipit-source-id: 679e099b8aebd787dbf8ed422dae07a81243e18f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25625
We want to fold the quantize op for weights/bias into module to avoid quantizing weights on the fly.
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D17208889
fbshipit-source-id: 1854b8953b065855d210bc1166533c08ca264354
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26153
I am suspecting that our multithreaded test-system causes issue with dyndep, if two places try to concurrently InitOpsLibrary. So perhaps we just guard this by a lock. This is just a guess-fix, as it is impossible to repro.
Test Plan: sandcastle
Reviewed By: bddppq
Differential Revision: D17361310
fbshipit-source-id: 596634a2098b18881abbd26a5a727a5ba0d03b6e
Summary:
Because of 'return NotImplemented', __contains__ return True when the element is not a number.
bool(NotImplemented) == True
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24156
Differential Revision: D16829895
Pulled By: zou3519
fbshipit-source-id: 9d3d58025b2b78b33a26fdfcfa6029d0d049f11f
Summary:
local build is slow... test in CI...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26083
Differential Revision: D17346949
Pulled By: ailzhang
fbshipit-source-id: f552d1a4be55ad4e2bd915af7c5a2c1b6667c446
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25610
They don't do anything anymore, since this isn't the end-user interface.
Test Plan: Imported from OSS
Differential Revision: D17172495
Pulled By: gchanan
fbshipit-source-id: a380d970f0836ed85eb9ac2aa42eb73655d775aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26159
The snippets for working with Homebrew were duplicated across binary
builds, macOS builds, and iOS builds. In #25336, the CircleCI
configuration version was updated to version 2.1, which supports
parameterized commands. This means we no longer have to use YAML
tricks to duplicate stanzas and instead can natively define a series
of reusable steps.
Motivation for doing this is that the macOS binary builds were still
using the slow `brew update` instead of `git fetch` (see #25988).
[test macos]
[test wheel]
Test Plan: Imported from OSS
Differential Revision: D17366538
Pulled By: pietern
fbshipit-source-id: 194c0f37c1dc999705f3ba97fdabf4ff18728d93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24352
Enable chainable schedulers as requested in #13022 by implementing the changes mentioned below from [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513370208).
* Changing the behavior of schedulers to the chainable formula when available
* Using the closed form whenever epoch is different from None until the next release with a deprecation warning
* Making `get_computed_values` the supported way of obtaining the last computed learning rate by the scheduler (see [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513940729) for new syntax)
* Returning a deprecation warning when invoking the undocumented get_lr function (see [comment](https://github.com/pytorch/pytorch/pull/21800#discussion_r294305485)) referring to `get_computed_values`, and deprecating it in the next release.
* `CosineAnnealingWarmRestart` still takes an epoch parameter as it is the only one with a mechanic relying on fractional epoch
* `MultiplicativeLR` is consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
# #20527
### Before
The user calls scheduler with a constant epoch either across loops or in the same loop.
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
# Scheduler with sometimes-constant epoch number
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
lr_scheduler.step(epoch)
print(optimizer.param_groups[0]['lr'])
```
### After
If the user wants to step
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
last_epoch = -1
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
# Check if epoch number has changed manually
if epoch-last_epoch > 0:
lr_scheduler.step()
last_epoch = epoch
print(epoch, scheduler.get_computed_values())
```
# #22107
### Before
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Scheduler computes and returns new learning rate, leading to unexpected behavior
print(i, scheduler.get_lr())
scheduler.step()
```
### After
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Returns last computed learning rate by scheduler
print(i, lr_scheduler.get_computed_values())
lr_scheduler.step()
```
Test Plan: Imported from OSS
Differential Revision: D17349760
Pulled By: vincentqb
fbshipit-source-id: 0a6ac01e2a6b45000bc6f9df732033dd81f0d89f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26106
Previously, in the named tensors build, an operator is marked as
non-traceable if ANY of its overloads are named tensor overloads. This
breaks the tracer for things like torch.full (has a names= overload for
named tensor) and tensor.sum (has a Dimname overload for named tensor).
This PR fixes the problem by putting the "no tracer support" logic into
the location where the tracer attempts to construct a graph by adding a
Dimname/DimnameList argument to a node.
Test Plan:
- new test in test_jit.py to check if torch.full is traceable
- new test in test_namedtensor.py to check what happens when someone
tries to trace a function that uses named tensor APIs.
- [namedtensor ci]
Differential Revision: D17353452
Pulled By: zou3519
fbshipit-source-id: b0b843c8357ffe54baee6e8df86db914f0b1ece4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25843
`tensor.align_to(*names)` permutes the dimensions of `tensor` and adds
additional 1-sized dimensions such that the output tensor has dimensions
in the same order as `names`. All dimensions of `tensor` must be
present in `names`, in addition, this function requires that all dims of
`tensor` be named.
`tensor.align_as(other)` is equivalent to
`tensor.align_to(*other.names)`.
I'm planning on changing `torch.align_tensors(*tensors)` to align closer
to these semantics because there didn't seem to be a clear use case for the old
semantics that preserve unnamed dimensions. That will come in a future
change.
Test Plan: - new tests [namedtensor ci]
Differential Revision: D17255549
Pulled By: zou3519
fbshipit-source-id: 1e437ad81e9359b4d5bd0e7e64c3a1be441fc3e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25842
`tensor.refine_names(*names)` takes `tensor` and attempts to name its
dimensions `names` out-of-place. If a dimension `i` already had a name,
then it cannot be changed (so tensor.names[i] must equal names[i]);
if the original dimension did not have a name, then the new name
(names[i]) can be anything.
`tensor.refine_names(*names)` also accepts a glob '*' that greedily selects
names from `tensor`. Here are some examples:
- `Tensor[None].refine_names('N') -> Tensor[N]`
- `Tensor[N].refine_names('N') -> Tensor[N]`
- `Tensor[N].refine_names('D') -> Error!`
- `Tensor[N].refine_names(None) -> Error!`
- `Tensor[None, None].refine_names('*', D) -> Tensor[None, D]`
Test Plan: - new tests [namedtensor ci]
Differential Revision: D17255548
Pulled By: zou3519
fbshipit-source-id: fdbdb3a12f24fbe37ce1e53ed09dc8a42589d928
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25624
First fuse the splitted op into aten::linear and then fuse
`dequant - aten::linear - quant` into quantized linear op
Test Plan:
python test/test_jit.py 'TestJit.quant_fusion'
Imported from OSS
Differential Revision: D17208891
fbshipit-source-id: 864b19fabab2e8e6f8f8ad35eb3dbbf2d5fdb8c4
Summary:
To give better signal to the user, we will now always create the TensorBoard tests classes and just disable tests if TensorBoard is not installed.
cc lanpa sanekmelnikov natalialunova pietern
[test macos]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26005
Reviewed By: sanekmelnikov
Differential Revision: D17352430
Pulled By: orionr
fbshipit-source-id: 87a592064f4768ffded76a3d666a8e508a1ef164
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25623
Port over fuse_linear pass from pytorch/tvm project, we'll need this
in backend specific quantization pass to match aten::linear and swap
it with quantized linear
Test Plan:
python test/test_jit.py 'TestJit.test_fuse_linear'
Imported from OSS
Differential Revision: D17208890
fbshipit-source-id: f4ff3889ae4525797d3b986f46ae37e50ea49116
Summary:
This PR adds ```unregister_module``` to ```nn::Module``` and ```erase``` function to ```OrderedDict```.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26088
Differential Revision: D17360058
Pulled By: yf225
fbshipit-source-id: f1f375b4751317da85b8da1458e092fe2405ceec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25505
Support for quantizing all the methods called by forward method, including
child module methods and other methods in the current module
It relies on module level constant prop, we need to figure out a way to do constant prop
for these methods as well. We can either do constant prop in the module level or do constant
prop in the quantization function, but this will need some discussion.
Test Plan:
python test/test_jit.py 'TestJit.insert_quant_dequant'
python test/test_quantizer.py
Imported from OSS
Differential Revision: D17208887
fbshipit-source-id: 21749457b21b00a6edada290c26324e2fb210b10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25504
Skip inserting duplicate observers for values observed
in forward method of a child module or other methods in
the current module.
Test Plan:
python test/test_jit.py -- 'TestJit.insert_observers'
python test/test_jit.py -- 'TestJit.insert_observers_child_qconfig'
python test/test_jit.py -- 'TestJit.insert_observers_skip_values'
Imported from OSS
Differential Revision: D17208888
fbshipit-source-id: e04f1c22ab1c4f410933a17a3ef31acf5f217323
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26113
After https://github.com/pytorch/pytorch/pull/16914, passing in an
argument such as "build_deps" (i.e. python setup.py build_deps develop) is
invalid since it gets picked up as an invalid argument.
ghstack-source-id: 90003508
Test Plan:
Before, this script would execute "python setup.py build_deps
develop", which errored. Now it executes "python setup.py develop" without an
error. Verified by successfully running the script on devgpu. In setup.py,
there is already a `RUN_BUILD_DEPS = True` flag.
Differential Revision: D17350359
fbshipit-source-id: 91278c3e9d9f7c7ed8dea62380f18ba5887ab081
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25984
Link static libtorch libraries into pytorch.so (API library for android)
with "-Wl,--gc-sections" flag to remove unused symbols in libtorch.
Test Plan:
- full gradle CI with stacked PR;
- will check final artifacts.tgz size change;
Differential Revision: D17312859
Pulled By: ljk53
fbshipit-source-id: 99584d15922867a7b3c3d661ba238a6f99f43db5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25897
It doesn't hurt to set all variables unconditionally.
And we can create link to lib directory instead of specific files - this
way it's easier to switch between dynamic/static library names.
Test Plan:
- check android gradle CI;
- use stack diff to check all 4 architectures on PR;
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25897
Differential Revision: D17307240
Pulled By: ljk53
fbshipit-source-id: c975085ddda852ef7da1c29935c2f6a28d797e5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25607
Since we don't generate these as end-user bindings, and we no longer reorder based on this property, we can just get rid of the property.
Test Plan: Imported from OSS
Differential Revision: D17172500
Pulled By: gchanan
fbshipit-source-id: f84fd8bb2b13598501897f56871b21339585d844
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25606
This just complicates the codegen for no benefit.
Test Plan: Imported from OSS
Differential Revision: D17172498
Pulled By: gchanan
fbshipit-source-id: d2f50e45400ac0336792422518e03dbae3a1bedc
Summary:
This basically works a simple filter as you suggested ZolotukhinM
`export PYTORCH_JIT_LOG_LEVEL=guard_elimination` will print all `GRAPH_DUMP` and `GRAPH_UPDATE` statements.
`export PYTORCH_JIT_LOG_LEVEL=>guard_elimination:>alias_analysis` will print all `GRAPH_DUMP`, `GRAPH_UPDATE` **and** `GRAPH_DEBUG` statements in `guard_elimination.cpp` **and** in `alias_analysis.cpp`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25895
Differential Revision: D17309090
Pulled By: Krovatkin
fbshipit-source-id: 8fa9e67cc9af566b084d66cc15223633fda08444
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26080
Will be used in c2 ctr_mbl_feed model to PyTorch conversion
Test Plan: Unit test
Reviewed By: yinghai
Differential Revision: D17337604
fbshipit-source-id: a90d9f5dc38301608d1562c6f2418e7f4616e753
Summary:
cc: gchanan zou3519
I will look into why this is failing spuriously.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26108
Differential Revision: D17348399
Pulled By: zou3519
fbshipit-source-id: aed4ccfc3f106692d4e32acc029740309570b0c3
Summary:
While this isn't ideal as it might print out the same source every time a function is run; it's still easier to go and tweak python code to reduce loop counts, than to insert `std::cout` and recompile cpp code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25868
Differential Revision: D17318386
Pulled By: Krovatkin
fbshipit-source-id: 928ba6543204042924ab41a724635594709630de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26050
Throws a warning once when someone attempts to attach names to a tensor.
This is guaranteed to happen at the callsite `set_named_tensor_meta`.
Test Plan: - run tests [namedtensor ci]
Differential Revision: D17331634
Pulled By: zou3519
fbshipit-source-id: 44f5e5c95acd9c7ba543c1210a3b1314aab348f0
Summary:
Enable one unit test that passes now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25956
Differential Revision: D17298150
Pulled By: bddppq
fbshipit-source-id: 8763e71ad7ef80be915fe93a3471b29f27f3f0a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25734
[pytorch] Dynamic registration of RPC backends
Allow non-pg rpc backends to be plugged in as a backend.
ghstack-source-id: 89938296
Differential Revision: D17183789
fbshipit-source-id: 885fed12d80b82b60f9a125f78302a161e708089
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25680
Add a runtime flag to choose between FBGEMM and QNNPACK when compiled with both.
The flag can be set by using torch.backends.quantized.engine = torch.fbgemm/torch.qnnpack or ctx::setPreferredQuantizedEngine(at::QEngine)
ghstack-source-id: 89935643
Test Plan: Verified torch.backends.quantized.engine works
Differential Revision: D17198233
fbshipit-source-id: e5449d06f4136385e0e6d18bd4237f8654a61672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25976
As recommended in https://github.com/pytorch/pytorch/pull/25877/files#r322956051:
> We should move more of these toward using BytesIO. Using files in tests is generally considered bad practice because it introduces syscalls and dependencies on the execution environment, and thus can cause test flakiness/instability.
ghstack-source-id: 89929947
Test Plan: CI
Differential Revision: D17310441
fbshipit-source-id: ba97cce4224225df45ff44062f1bc8ebefb25922
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26075
att, remove verbose argument to reduce noice in the logs
Test Plan:
ci
Imported from OSS
Differential Revision: D17335935
fbshipit-source-id: 2e4289e838bf4489dcad8d5533353eebcff0d481
Summary:
This change adds a new prepack and run function for FC and Convolution operators in QNNPACK.
The new functions added are `PackBMatrix`, `qnnpackLinear`, `PrePackConvWeights` and `qnnpackConv`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25862
Test Plan:
QNNPACK unit tests
fully-connected-test
convolution-test
Differential Revision: D17299260
Pulled By: supriyar
fbshipit-source-id: fdc4e2d5f1232675acd153f3efb9d17ed8628a54
Summary:
Just a tiny fix to make debugging easier (output errors to stderr and include in the exception message)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25809
Reviewed By: zrphercule
Differential Revision: D17329957
Pulled By: houseroad
fbshipit-source-id: 0d73dd9f62c735fbc5096e6a7c0e5f58e4cd90ae
Summary:
This PR adds Average Pool module to C++ front-end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25800
Differential Revision: D17318094
Pulled By: yf225
fbshipit-source-id: c914c0e802bbe5f1d1f0a21a669c28bc956899db
Summary:
Now that backward reuses forward streams calls to backward no longer need to be explicitly synced (in the great majority of cases). This is an opportunity to enable the _do_cuda_non_default_stream flag, which this PR does for test_cuda.py and test_distributions.py, where the flag was previously defined but set to false.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25989
Test Plan: Test changes the entire test suite, so the test suite is the test plan.
Differential Revision: D17329233
Pulled By: mruberry
fbshipit-source-id: 52f65b5ed53de26e35e6d022658d7fac22609f6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25948
Previously, test/test_namedtensor.py is skipped if pytorch was not
compiled with BUILD_NAMEDTENSOR. Now, we skip test/test_namedtensor.py
if pytorch was not compiled with BUILD_NAMEDTENSOR or if
TEST_NAMEDTENSOR is not set.
This is done in preparation for turning on BUILD_NAMEDTENSOR=1 permanently;
at that point we will use TEST_NAMEDTENSOR to differentiate between the
named tensor ci and the regular ci.
Test Plan:
- [namedtensor ci] (and check that the named tensor tests are actually
running).
Differential Revision: D17300132
Pulled By: zou3519
fbshipit-source-id: 928f71f4d50445680b6ae1aa54b8857bc92e4d08
Summary:
Changelog:
- De-duplicate the code in tests for torch.solve, torch.cholesky_solve, torch.triangular_solve
- Skip tests explicitly if requirements aren't met for e.g., if NumPy / SciPy aren't available in the environment
- Add generic helpers for these tests in test/common_utils.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25733
Test Plan:
- All tests should pass to confirm that the change is not erroneous
Clears one point specified in the discussion in https://github.com/pytorch/pytorch/issues/24333.
Differential Revision: D17315330
Pulled By: zou3519
fbshipit-source-id: c72a793e89af7e2cdb163521816d56747fd70a0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25938
It doesn't matter whether or not we expose these for namedtensor /
non-namedtensor builds.
Test Plan: - [namedtensor ci]
Differential Revision: D17291249
Pulled By: zou3519
fbshipit-source-id: a5aac77469e28198f63967396e2bdb1ec15bad97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25993
These imports fail the test suite if they're not installed, even if we
don't end up testing tensorboard.
[test macos]
Test Plan: Imported from OSS
Differential Revision: D17318588
Pulled By: pietern
fbshipit-source-id: febad497ecb3fd292317f68fc2439acd893ccd67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25988
Running `brew update` used to take over 6 minutes. Now it completes in
about 30 seconds.
Test Plan: Imported from OSS
Differential Revision: D17318585
Pulled By: pietern
fbshipit-source-id: 75956aebc887cb29dbc2bc7efbf823243f18ab01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25928
Improved error message
ghstack-source-id: 89854172
Test Plan:
if given the input of wrong dimension, the message earlier
```
[QConv2D] each dimension of output tensor should be greater than 0
```
message now
```
Given groups=1, weight of size 20, 5, 5, 1, expected input (NHWC) 10, 1, 32, 32 to have 1 channels, but got 32 channels instead
```
Reviewed By: jianyuh
Differential Revision: D17287290
fbshipit-source-id: d91573d6d69f2a5e0e615ffbd47a0bd233636a0b
Summary:
These unit tests pass after landing all the warp size awareness patches.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25963
Differential Revision: D17319124
Pulled By: bddppq
fbshipit-source-id: 22f5d5f1ca9c67e66a7ccf983b2d2f889a74e729
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25977
Call add_subdirectory() explicitly before NNPACK/QNNPACK with
EXCLUDE_FROM_ALL property so that pthreadpool target won't be installed
by default for libtorch mobile build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25977
Test Plan: Imported from OSS
Differential Revision: D17312083
Pulled By: ljk53
fbshipit-source-id: 79851d0aa9402c5b9287ef4bbd8d7fd3a341497d
Summary:
This PR is about add torch.backends.mkldnn.enabled flag said in https://github.com/pytorch/pytorch/issues/25186 which can be used disable mkldnn at runtime step as torch.backends.cudnn.enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25459
Differential Revision: D17258926
Pulled By: ezyang
fbshipit-source-id: e179ad364cc608fdaa7d0f37e2e762ceb5eda598
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25934
att
Test Plan:
python test test/test_quantized_nn_mods.py
Imported from OSS
Differential Revision: D17318270
fbshipit-source-id: afb39f79e01e4d36a55dd17648c25e0743de1d42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25950
I feel that is a more natural order
Test Plan:
python test/test_quantizer.py
Imported from OSS
Differential Revision: D17294963
fbshipit-source-id: ed8ffdfe788a5e81966bda856e8d046ab68ee229
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25597
We now take advantage of the new bitset representation TensorTypeSet to store "Variable-ness" of a tensor directly in the dispatch key. We introduce a new thread local TensorTypeSet "excluded" and replace the previous thread local boolean with it; we no longer have to query `is_variable()` to do dispatch (I didn't delete `is_variable`, because there are still a lot of uses of it). The key change is in `dispatchTypeId`.
Knock-on effects:
* Because Variable is now a TensorTypeId, I can eliminate the out-of-line registration `registerVariableOp` for variables; instead, make the registrar take a TensorTypeId (instead of a Backend) and you just register under the Variable key.
* Tensors aren't really ever created with Variable information initialized correctly at the start; instead, a tensor "becomes" a Variable because we set its `autograd_meta_`. These setters now correctly setup invariants on the dispatch type set. The new invariant is that if `autograd_meta_ != nullptr`, then `type_set().has(TensorTypeId::VariableTensorId)`.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17265919
Pulled By: ezyang
fbshipit-source-id: a90a7ed14f5cb1086137483ae3d0646fcd4c42d0
Summary:
yf225 This is L1Loss module. I don't think that ```_Loss``` and ```_WeightedLoss``` as base Python classes do anything. First one sets reduction type and also takes in ```reduce``` parameter which is deprecated. The second one only registers ```weight``` parameter. I don't think that we should keep this structure. What do you think?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25902
Differential Revision: D17307045
Pulled By: yf225
fbshipit-source-id: ad3eda2ee8dcf4465054b376c1be89b39d11532f
Summary:
Besides common understanding, the only occurrence of calc_digamma is in UnaryOpsKernel.cpp, which clearly sees the float version of calc_digamma as returning float type (and the double version of calc_digamma as returning double type).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25488
Reviewed By: ezyang
Differential Revision: D17172379
Pulled By: VitalyFedyunin
fbshipit-source-id: 56facd45564cff019d572138c0d541a0bdded5c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25905
Now that we can detect and recover from failures in NCCL we should
allow processes that are started at different times (and perhaps have
had previous NCCL process group instances), to eventually be part of
the same process group. Keeping track of group names in global
variables prevents that, because the processes will be out of sync.
This commit removes the global group name maps and defers
responsibility of isolating access to the same store from multiple
process groups to the store itself. Users can use `c10d::PrefixStore`
to derive new store instances whose keyspace is scoped to some
prefix. Functionally, this is identical to keeping a global map and
using a group name, but also gives more flexibility to the front-end
API to reset state and have processes that have started at different
times to join the same process group.
ghstack-source-id: 89804865
Test Plan: Tests pass.
Differential Revision: D17281416
fbshipit-source-id: eab3b48463a9b0ef24aedeca76e2bb970b9f33ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25911
The check is practically equivalent to checking for equivalence with
POLLIN (because the constant is a single bit and poll(2) is asked to
check for POLLIN). On macOS, if a client disconnects, POLLHUP will be
set as well, and the check fails. Instead of performing the check and
letting it fail, we can simply run the `query` function and catch
exceptions, in case we see EOF.
Test Plan: Imported from OSS
Differential Revision: D17313301
Pulled By: pietern
fbshipit-source-id: 00c5a69043f70848ef632d53f8e046dc69e15650
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25867
The test can fail if this is run as a stress test. Increase the
threshold to significantly decrease the probability of failure.
ghstack-source-id: 89743661
Test Plan: Tests pass.
Differential Revision: D17266101
fbshipit-source-id: af514eff305783e4a970ac30c3ebdb02fbdcf4c5
Summary:
This PR addresses issue https://github.com/pytorch/pytorch/issues/7601.
Currently models that use streams explicitly in forward have to do a lot of extra work to make backwards respect those streams. This PR extends the (recently added) input tracing (see TypeAndShape) to record the devices and streams of inputs. The autograd engine then uses this metadata to enact the expected stream parallelism without extra work from the user.
For example, a model with forward declared like (original example courtesy of ngimel):
```
def forward(self,x):
x0 = x.clone()
torch._C._cuda_setStream(self.stream1._cdata)
y0 = self.fc1(x0)
self.event1.record(stream = torch.cuda.current_stream())
torch._C._cuda_setStream(self.stream2._cdata)
y1 = self.fc2(x)
self.event2.record(stream = torch.cuda.current_stream())
self.stream2.wait_event(self.event1)
return y0 + y1
```
currently will backward on a single stream. With this change the kernels will go on the streams they are assigned in forward and both forward and backward will (for appropriate sizes) run the fc1 and fc2 kernels simultaneously.
The crux of this change is, as mentioned, an expansion of the TypeAndShape tracing and a relatively simple change to the autograd engine to use cuda events for stream synchronization. To make this efficient I also added a new AutoGPUAndStream class, exposed getting and setting streams on devices, and removed InputBuffer's AutoGPU (it's now redundant). While making these modifications I also fixed AutoGPU to check before setting the GPU when it's destroyed and to use THCudaCheck instead of its custom error handler. These changes mean that an often excessive cudaSetDevice() is not being called when inputs are added to a buffer.
In addition to allowing users to easily set and use streams that are respected in both forward and backward, this change may encourage modules to do the same and the expanded tracing might allow further optimizations in the autograd engine. (apaszke, for example, now after initial enumeration we know the number of devices that will be used by a graph task, which might help provide a sense of the "level of parallelism" we should expect.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8354
Test Plan: Two tests were added specifically for this behavior.
Differential Revision: D17275980
Pulled By: mruberry
fbshipit-source-id: 92bd50ac782ffa973b159fcbbadb7a083802e45d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25954
Add torch.nn.LSTM into the default dynamic quantize mappings. We will by default dynamic quantize LSTM when we apply the quantize_dynamic API.
ghstack-source-id: 89839673
Test Plan: CI
Differential Revision: D17294958
fbshipit-source-id: 824aceef821276b3e28c52ce3bebafaf9b0a0833
Summary:
Currently we compute common dtype for TensorIterator based on all inputs and outputs. It can be a problem when dtype of the outputs should be different from dtype of inputs. (Example torch.eq)
We also have `dont_compute_common_dtype` method that allows us to avoid a computation of a common dtype for all inputs and outputs.
This PR will give the ability to compute common dtype based only on inputs using `compute_common_dtype_only_for_inputs`. Also it will provide a simple method `input_dtype(int arg=0) that will give the ability to dispatch based on input's dtype.
```
AT_DISPATCH_ALL_TYPES(iter.input_dtype(), ...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25593
Differential Revision: D17286352
Pulled By: ifedan
fbshipit-source-id: a94fb608acd2763120992fe85b8dfd02ff21f9ba
Summary:
Add support for nn.ModuleDict in script. This is needed to support torchvision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25715
Differential Revision: D17301826
Pulled By: eellison
fbshipit-source-id: 541b5477e980f519a8c3bbb1be91dac227f6d00f
Summary:
This PR simplifies header inclusion in `test/cpp/api/modules.cpp`, so that when we add a new `torch::nn` module and add the test in `modules.cpp`, we can check that the new module's header is included in `torch/torch.h`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25921
Differential Revision: D17303220
Pulled By: yf225
fbshipit-source-id: 327db0ff2f075d52e7b594b3dffc5a59441e0931
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25958
Should have cleaned up the remaining protobuf dependencies before landing PR #25896.
Test Plan: - CI build;
Reviewed By: dreiss
Differential Revision: D17296949
Pulled By: ljk53
fbshipit-source-id: 20c444e63900c7fa054db3cc757d3f18614af630
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25424
Test Plan
- new tests [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17120399
Pulled By: zou3519
fbshipit-source-id: 93d7944f2ec4c5a7256f505323b879af706131df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25742
python rpc handler right now is namespace + global variable, changed it to be singleton class as it can gurantee deterministic order of variable destruction. for namespace + global variable, we hit a process exit crash issue because global variables have dependencies and they are not destructed as expected
ghstack-source-id: 89809889
Test Plan: unit test passed
Differential Revision: D17097999
fbshipit-source-id: 5a5d003925dba1a7ea1caf3b7c28ff9e24c94a21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25896
Similar change as PR #25822.
Test Plan:
- Updated CI to use the new script.
- Will check pytorch android CI output to make sure it builds libtorch
instead of libcaffe2.
Reviewed By: dreiss
Differential Revision: D17279722
Pulled By: ljk53
fbshipit-source-id: 93abcef0dfb93df197fabff29e53d71db5674255
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25894
NNPack/QNNPack both depend on a third-party library "pthreadpool". There
are two versions of "pthreadpool" implementation, one is the default
implementation under third-party/pthreadpool, the other is caffe2 custom
implementation under caffe2/utils/threadpool. Both implementations share
the same interface (as defined by pthreadpool headers).
Usually only one version of pthreadpool should be linked into libtorch.
If QNNPACK_CUSTOM_THREADPOOL/NNPACK_CUSTOM_THREADPOOL are set to true,
then QNNPack/NNPack will not link third-party/pthreadpool - they will
expect the caller (libtorch) to link correct version of pthreadpool;
otherwise they will bring in the default pthreadpool implementation.
Looks like libtorch cmake already sets both macros to true in
Dependencies.cmake and External/nnpack.cmake. And currently libtorch
mobile build includes the caffe2/utils/threadpool pthreadpool
implementation. So it shouldn't try to explicitly link default
pthreadpool target in aten/CMake in this AT_NNPACK_ENABLED section.
Test Plan:
- Before this diff, libtorch.so links libpthreadpool.a:
```
LINK_LIBRARIES = lib/libc10.so lib/libqnnpack.a lib/libnnpack.a
lib/libcpuinfo.a -llog -ldl -lm lib/libnnpack.a lib/libpthreadpool.a
lib/libcpuinfo.a lib/libclog.a -llog -latomic -lm
```
- After this diff, libtorch.so no longer links libpthreadpool.a:
```
LINK_LIBRARIES = lib/libc10.so lib/libqnnpack.a lib/libnnpack.a
lib/libcpuinfo.a -llog -ldl -lm lib/libnnpack.a lib/libcpuinfo.a
lib/libclog.a -llog -latomic -lm
```
- Tried the following combinations to make sure things work as expected:
* remove caffe2/utils/threadpool, remove libpthreadpool: link error;
* keep caffe2/utils/threadpool, remove libpthreadpool: no link error;
* remove caffe2/utils/threadpool, add back libpthreadpool: no link error;
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25894
Reviewed By: dreiss
Differential Revision: D17279723
Pulled By: ljk53
fbshipit-source-id: ae5aa7ca7283a276ecf1e2140bad0a6af3efdb3a
Summary:
Also change documentation to reflect both the CUDA and ROCm facts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25937
Differential Revision: D17291453
Pulled By: bddppq
fbshipit-source-id: ee1d7a34f3ad6c05a8f1564d4f9e516e497f2199
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25740
Previously we had `omit_method_bodies`, `omit_attr_values` and
`omit_param_values`. They were called the same in the python bindings
and it was hard to remember their proper spelling. This PR changes them
to `code`, `attrs`, and `params` which are might easier to remember. It
also flips their meaning - now they enable printing instead of disabling
it. I also changed the default values to 'print all' from 'print
nothing', as that's the most usual way of using it.
Test Plan: Imported from OSS
Differential Revision: D17217517
Pulled By: ZolotukhinM
fbshipit-source-id: fa56e478a732ffd685d885f11c9da0457cd03d16
Summary:
Use the new C10_WARP_SIZE macro to make the sparse coalesce kernel warp size aware.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25918
Differential Revision: D17286442
Pulled By: bddppq
fbshipit-source-id: a079f012c32e5786b49b2a6973019d847ee11897
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25881
Add Dropout to blacklist to avoid the error in eager mode quantization.
ghstack-source-id: 89759536
Test Plan: Test locally in python notebook.
Reviewed By: jianyuh
Differential Revision: D17270826
fbshipit-source-id: bcf43483976740564d7f407838f25c2dbb67b016
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25308
Instead of storing a single TensorTypeId in a Tensor, we store a bitset of tensor type IDs in a Tensor, TensorTypeSet. This class comes with some unit tests. This is in preparation for making Variable a TensorTypeId. In order to help flush out places where this makes a semantic difference, we rename `Tensor::type_id()` to `Tensor::type_set()` and smoke out all of the locations where this was semantically meaningful.
Because the new tensor type set is 64-bits, this increases the size of Tensor by a word.
Listing of semantic changes:
* Many TensorImpl related constructors just propagate TensorTypeId to a parent constructor. These are pretty simple to adjust.
* Backend extensions are now in the business of explicitly constructing a TensorTypeSet and then passing it in. This is probably OK for now but when Variable drops, these dispatch IDs may get immediately overwritten to have Variable set.
* `sparseTensorSetToDeviceType` and similar functions previously did an equality test with TensorTypeId, to determine what an appropriate device type is. This equality is now replaced with a set inclusion test. This is valid, under the assumption that we don't ever have weird sets like "this tensor is simultaneously a sparse CPU tensor and a sparse CUDA tensor", which will be true in the short term plan of adding Variable to the dispatch ID.
* `impl::dispatchTypeId` was generally introduced for cases where we legitimately need to convert from `TensorTypeSet -> TensorTypeId` in a dispatch related manner. At the moment, the implementation is trivial, but they will soon be adjusted to handle TLS. I've tried to make these call sites as forwards compatible as possible:
* `checked_tensor_unwrap` and co now use `dispatchTypeId`. When Variable is added to the type set, these will always be called in a context where the Variable type ID is disabled, so we will get the correct underlying tensor type ID.
* Uses of `Backend` in dispatch are now replaced with `TensorTypeSet`. The general heuristic here for whether or not to accept a `TensorTypeId` or `TensorTypeSet` is that we want to make the generated code as simple as possible. It is easier to retrieve a `TensorTypeSet`, so that's a more appropriate API in these cases.
* In some cases, I could not conveniently switch an implementation to the new semantics, because it was blocked on some other refactor. In this case, I introduced `legacyExtractTypeId`, which gives what would be a BC-compatible `TensorTypeSet` to `TensorTypeId` implementation that will continue to report the same values it would have prior to this change. This is **different** from `dispatchTypeId`, because this function does NOT respect TLS; it always ignores Variable type IDs.
* c10 dispatcher tests, which are oblivious to Variable dispatch, use this BC function (actually, they use `extractTypeId`, an overload for Tensor.
* The implementation of `new_*` methods heavily relies on tensor type ID, I chose not to unwind this. PR to refactor this at https://github.com/pytorch/pytorch/pull/25475
* Slicing also relies on tensor type ID, see `torch/csrc/autograd/python_variable_indexing.cpp` (though in some cases in this file, I was able to replace use of tensor type ID with TensorOptions)
* In some cases, there is an equality test on tensor type ID which would be better done by testing "tensor axes". In those cases, I replaced those equality tests with more equality tests.
* Example: `torch/csrc/nn/type_checks.h`
* There is a total punt in `torch/csrc/tensor/python_tensor.cpp` where "instance of" checking is done via dispatch ids. In general, the Variable-ness of a tensor doesn't participate in instanceof testing. It's not entirely clear what to do here.
* Instead of storing `Backend` in `VariableInfo`, we now just store Layout.
c10 dispatcher test updates were done with:
```
:%s/\([^ ]\+\)\.type_id()/extractTypeId(\1)/g
:%s/\([^( ]\+\)->type_id()/extractTypeId(*\1)/g
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25308
Differential Revision: D17092791
Test Plan: sandcastle and ossci
Reviewed By: bwasti
Pulled By: ezyang
fbshipit-source-id: 22207d14fe62dd31ee19cc5011af22e3d9aabb5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25816
On Android we will release a small set of native APIs designed for mobile use
cases. All of needed libtorch c++ APIs are called from inside this JNI bridge:
android/pytorch_android/src/main/cpp/pytorch_jni.cpp
With NO_EXPORT set for android static library build, it will hide all
original TORCH, CAFFE2, TH/ATen APIs, which will allow linker to strip
out unused ones from mobile library when producing DSO.
If people choose to directly build libtorch DSO then it will still keep
all c++ APIs as the mobile API layer is not part of libtorch build (yet).
Test Plan:
- build libtorch statically and link into demo app;
- confirm that linker can strip out unused APIs;
Differential Revision: D17247237
Pulled By: ljk53
fbshipit-source-id: de668216b5f2130da0d6988937f98770de571c7a
Summary:
This is the first of a series of changes to reduce build size by cutting
autograd functions from mobile build.
When INTERN_DISABLE_AUTOGRAD is set:
* On CMake side we exclude Functions.h/cpp, VariableType*.h/cpp,
VariableTypeManual.cpp from the build process. Still keep variable_factories.h
as we rely on it to create variables instead of tensors.
* In source code we gate a couple autograd references (in autograd/variable.cpp)
with C10_MOBILE (technically we should use a dedicated c macro but its
maintenance cost is higher than cmake macro as we have several build systems
to change).
* Pass --disable-autograd flag to codegen script, which will stop generating
Functions/VariableType code. And for variable_factories.h it will stop
generating tracing code.
Edit: in this diff we will keep Functions.h/cpp to avoid changing source code.
Why we need this change if it's already not calling VariableType and autograd
stuff with USE_STATIC_DISPATCH=ON for mobile?
It's trying to reduce static library size for iOS build, for which it's
relatively harder to strip size with linker approach.
Why we need make involved change into codegen script?
There isn't a global config system in codegen - autograd/env.py provides similar
functionality but it says not adding anything there.
Test Plan:
- will check CI;
- test mobile build in sample app;
Differential Revision: D17202733
Pulled By: ljk53
fbshipit-source-id: 5701c6639b39ce58aba9bf5489a08d30d1dcd299
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25815
Don't need call these global registerers when USE_STATIC_DISPATCH is
set as they will keep all aten functions at link time.
Should solely rely on jit/generated/register_aten_ops* to keep "interface"
aten functions (which are directly called from JIT), and rely on
STATIC_DISPATCH + linker to keep all other aten functions that are
transitively needed by the "interface" functions.
Test Plan:
- build and run in the demo app;
- with stacked diff to shrink registered "interface" functions, linker
can strip out unused aten implementations;
Differential Revision: D17247236
Pulled By: ljk53
fbshipit-source-id: 1feb5fbb8b9cfa057b9ba8bf3f2967f40980c917
Summary:
These are test failures due to `-Werror` in `test/cpp_extensions/setup.py` that look like:
```
$ python test/run_test.py -i cpp_extensions
Test executor: ['/home/rgommers/anaconda3/envs/pytorch-gcc91/bin/python']
Running test_cpp_extensions ... [2019-08-29 02:19:03.421117]
running install
running build
running build_py
creating build
creating build/lib.linux-x86_64-3.6
creating build/lib.linux-x86_64-3.6/torch_test_cpp_extension
copying torch_test_cpp_extension/__init__.py -> build/lib.linux-x86_64-3.6/torch_test_cpp_extension
running build_ext
building 'torch_test_cpp_extension.cpp' extension
creating build/temp.linux-x86_64-3.6
gcc -pthread -B /home/rgommers/anaconda3/envs/pytorch-gcc91/compiler_compat -Wl,--sysroot=/ -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -Wstrict-prototypes -fPIC -I/home/rgommers/code/pytorch/torch/include -I/home/rgommers/code/pytorch/torch/include/torch/csrc/api/include -I/home/rgommers/code/pytorch/torch/include/TH -I/home/rgommers/code/pytorch/torch/include/THC -I/home/rgommers/anaconda3/envs/pytorch-gcc91/include/python3.6m -c extension.cpp -o build/temp.linux-x86_64-3.6/extension.o -g -Werror -DTORCH_API_INCLUDE_EXTENSION_H -DTORCH_EXTENSION_NAME=cpp -D_GLIBCXX_USE_CXX11_ABI=1 -std=c++11
cc1plus: warning: command line option ‘-Wstrict-prototypes’ is valid for C/ObjC but not for C++
In file included from /home/rgommers/code/pytorch/torch/include/c10/core/MemoryFormat.h:5,
from /home/rgommers/code/pytorch/torch/include/ATen/core/Tensor.h:5,
from /home/rgommers/code/pytorch/torch/include/ATen/Tensor.h:2,
from /home/rgommers/code/pytorch/torch/include/ATen/Context.h:4,
from /home/rgommers/code/pytorch/torch/include/ATen/ATen.h:5,
from /home/rgommers/code/pytorch/torch/include/torch/csrc/api/include/torch/types.h:3,
from /home/rgommers/code/pytorch/torch/include/torch/csrc/api/include/torch/data/dataloader_options.h:4,
from /home/rgommers/code/pytorch/torch/include/torch/csrc/api/include/torch/data/dataloader/base.h:3,
from /home/rgommers/code/pytorch/torch/include/torch/csrc/api/include/torch/data/dataloader/stateful.h:3,
from /home/rgommers/code/pytorch/torch/include/torch/csrc/api/include/torch/data/dataloader.h:3,
from /home/rgommers/code/pytorch/torch/include/torch/csrc/api/include/torch/data.h:3,
from /home/rgommers/code/pytorch/torch/include/torch/csrc/api/include/torch/all.h:4,
from /home/rgommers/code/pytorch/torch/include/torch/extension.h:4,
from extension.cpp:1:
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = long int]’:
/home/rgommers/code/pytorch/torch/include/c10/core/TensorImpl.h:1464:34: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<long int>::Data’ from ‘std::initializer_list<long int>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
103 | : Data(Vec.begin() == Vec.end() ? static_cast<T*>(nullptr) : Vec.begin()),
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = unsigned char]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<unsigned char>::Data’ from ‘std::initializer_list<unsigned char>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = signed char]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<signed char>::Data’ from ‘std::initializer_list<signed char>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = short int]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<short int>::Data’ from ‘std::initializer_list<short int>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = int]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<int>::Data’ from ‘std::initializer_list<int>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = float]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<float>::Data’ from ‘std::initializer_list<float>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = double]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<double>::Data’ from ‘std::initializer_list<double>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = bool]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<bool>::Data’ from ‘std::initializer_list<bool>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = c10::Half]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<c10::Half>::Data’ from ‘std::initializer_list<c10::Half>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h: In instantiation of ‘constexpr c10::ArrayRef<T>::ArrayRef(const std::initializer_list<_Tp>&) [with T = c10::BFloat16]’:
/home/rgommers/code/pytorch/torch/include/ATen/NativeFunctions.h:47:1: required from here
/home/rgommers/code/pytorch/torch/include/c10/util/ArrayRef.h:103:39: error: initializing ‘c10::ArrayRef<c10::BFloat16>::Data’ from ‘std::initializer_list<c10::BFloat16>::begin’ does not extend the lifetime of the underlying array [-Werror=init-list-lifetime]
cc1plus: all warnings being treated as errors
error: command 'gcc' failed with exit status 1
Traceback (most recent call last):
File "test/run_test.py", line 438, in <module>
main()
File "test/run_test.py", line 430, in main
raise RuntimeError(message)
RuntimeError: test_cpp_extensions failed!
```
The warnings look valid, the code isn't guaranteed to work (although in practice it does seem to). Using `std::begin` keeps the underlying array for the `initializer_list` going out of scope.
Note that the same warning is reported in https://github.com/pytorch/vision/issues/1173#issuecomment-517308733 (Cc ShahriarSS)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25384
Differential Revision: D17113146
Pulled By: ezyang
fbshipit-source-id: 477c414481fb3664a8cb92728f4111e6317b309e
Summary:
This best preserves accuracy, while erfinvf() should be used for half and float.
This is also consistent with the implementation before the migration: https://github.com/pytorch/pytorch/issues/24943
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25337
Differential Revision: D17102333
Pulled By: zou3519
fbshipit-source-id: 5178cff534cf5f10d86ab04d4b6c1779ffedf49e
Summary:
Currently we have different checks for multinomial method on CPU and CUDA. This PR will make them consistent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25595
Differential Revision: D17236163
Pulled By: ifedan
fbshipit-source-id: 7718173bdaf216e8eb636c2a5b9c5939b975325b
Summary:
What dist_check.py does is largely merely determining whether we should
use set "USE_IBVERBS" to ON or OFF when the user sets "USE_GLOO_IBVERBS"
to ON. But this is unnecessary, because this complicated determination
will always be overrided by gloo:
2101e02cea/cmake/Dependencies.cmake (L19-L28)
Since dist_check.py becomes irrelevant, this commit also simplifies the
setting of `USE_DISTRIBUTED` (by removing its explicit setting in Python scripts), and deprecate `USE_GLOO_IBVERBS` in favor
of `USE_IBVERBS`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25879
Differential Revision: D17282395
Pulled By: pietern
fbshipit-source-id: a10735f50728d89c3d81fd57bcd26764e7f84dd1
Summary:
Introduce a C10_WARP_SIZE define in Macros.h
For kernels that had ifdef-ing of WARP_SIZE for ROCm vs CUDA, use said macro. This is no functional change - we merely refactor to unify on one WARP_SIZE definition.
I hope we can encourage use of this macro over more WARP_SIZE definitions being sprinkled across the code base (or numerically hard-coded).
Some kernels remain that have their own WARP_SIZE definitions but did not satisfy above condition. They will be fixed in follow-up PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25884
Differential Revision: D17276662
Pulled By: bddppq
fbshipit-source-id: cef8e77a74ae2e5de10df816ea80b25cb2bab713
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25782
Enable variable size embedding for dot processor. We split the embedding matrix into multiple towers, based on the embedding size and perform dot product in a loop over each of the towers and finally concatenate all the dot product outputs.
Test Plan:
buck test //caffe2/caffe2/fb/dper/layer_models/tests/split_1:
https://our.intern.facebook.com/intern/testinfra/testrun/3659174703037560
Specific unit tests --
buck test //caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_per_feature_emb_dim
https://our.intern.facebook.com/intern/testinfra/testrun/3377699726358808
Reviewed By: chenshouyuan
Differential Revision: D16690811
fbshipit-source-id: 8f5bce5aa5b272f5f795d4ac32bba814cc55210b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25263
This adds an api to return true in script and false in eager, which together with ignore allows guarding of not yet supported JIT features. Bikeshedding requested please.
cc zou3519
```
def foo():
if not torch.jit.is_scripting():
return torch.linear(...)
else:
return addmm(...)
```
Test Plan: Imported from OSS
Differential Revision: D17272443
Pulled By: eellison
fbshipit-source-id: de0f769c7eaae91de0007b98969183df93a91f42
Summary:
Changelog:
- Simplify generation of singular matrices to just constructing a constant matrix instead of a random singular matrix using random_square_matrix_of_rank, which is susceptible to numerical issues
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25773
Test Plan:
- test_det_logdet_slogdet_batched should pass
Fixes https://github.com/pytorch/pytorch/issues/25172
cc: branfosj hartb
Apologies for the delay.
Differential Revision: D17261059
Pulled By: soumith
fbshipit-source-id: 8f991e2cb8c0e9dccad363d4785075213088e58a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25869
The c10 code for tracing was not disabling tracing when calling the op like it should have. This caused really weird errors where we were recording tensors for ops called within a given c10 op implementation, and making tracing fail
Test Plan: Imported from OSS
Differential Revision: D17275748
Pulled By: jamesr66a
fbshipit-source-id: b4e89ae5a954a1f476c9e5b8bf405bdc621f0323
Summary:
This PR makes the following improvements to C++ API parity test harness:
1. Remove `options_args` since we can get the list of options from the Python module constructor args.
2. Add test for mapping `int` or `tuple` in Python module constructor args to `ExpandingArray` in C++ module options.
3. Use regex to split up e.g. `(1, {2, 3}, 4)` into `['1', '{2, 3}', '4']` for `cpp_default_constructor_args`.
4. Add options arg accessor tests in `_test_torch_nn_module_ctor_args`.
We will be able to merge https://github.com/pytorch/pytorch/pull/24160 and https://github.com/pytorch/pytorch/pull/24860 after these improvements.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25828
Differential Revision: D17266197
Pulled By: yf225
fbshipit-source-id: 96d0d4a2fcc4b47cd1782d4df2c9bac107dec3f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25847
### Summary
The Podspec file for iOS OSS release. This podspec contains the C++ header files and a static library that supports three architectures.
Please ignore the link for `s.source` for now, as I'm still working on the CI nightly build. This is a temporary link for testing purpose.
### Note
Previously I have a cocoapods release proposal - https://github.com/pytorch/pytorch/pull/25543 which contains two podspec files. However, for the time being, we haven't decided whether we want to release the Objective-C API wrapper or not. Please review and refer to this one if you have questions.
Test Plan: Imported from OSS
Differential Revision: D17262459
Pulled By: xta0
fbshipit-source-id: 4cc60787a41beab14cf9b1c0e9ab62b8b14603c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25822
### Summary
Since protobuf has been removed from mobile, the `build_host_protoc.sh` can be removed from `build_ios.sh` as well. However, the old caffe2 mobile build still depend on it, therefore, I introduced this `BUILD_PYTORCH_MOBILE` flag to gate the build.
- iOS device build
```
BUILD_PYTORCH_MOBILE=1 IOS_ARCH=arm64 ./scripts/build_ios.sh
BUILD_PYTORCH_MOBILE=1 IOS_ARCH=armv7s ./scripts/build_ios.sh
```
- iOS simulator build
```
BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=SIMULATOR ./scripts/build_ios.sh
```
### Test Plan
All device and simulator builds run successfully
Test Plan: Imported from OSS
Differential Revision: D17264469
Pulled By: xta0
fbshipit-source-id: f8994bbefec31b74044eaf01214ae6df797816c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25840
### Summary:
The CI jobs for iOS builds are missing, this PR creates a workflow which will two PR jobs:
- pytorch_ios_10_2_1_x86_64_build
- pytorch_ios_10_2_1_arm64_build
### Note:
Those two jobs will not store any artifacts nor upload any binary files, which will be done in the next PR.
Test Plan:
- The jobs can be triggered by any PR.
- The jobs can be run successfully.
Differential Revision: D17255504
Pulled By: xta0
fbshipit-source-id: 5c56e85c7ccf6339a3e0ffd11eedd925f137adc8
Summary:
Enabled torch.nn.functional.log_softmax and torch.nn.CrossEntropyLoss for bfloat16 data type.
In order to do that, following dependency have to be enabled.
- RNE (round to nearest even)
- AccumulateType
- bfloat16 arithmetic operator overload
Also, we implement std::numeric_limits fully support for bfloat16 data type
background for dependency:
- RNE vs truncate
From torch.nn.CrossEntropyLoss test. input_size=(128, 1000)
RNE result:
float output: tensor(7.3981, dtype=torch.float32, grad_fn=<NllLossBackward>)
bfloat16 output: tensor(7.3125, dtype=torch.bfloat16, grad_fn=<NllLossBackward>)
truncate result:
float output: tensor(7.3981, dtype=torch.float32, grad_fn=<NllLossBackward>)
bfloat16 output: tensor(5.8750, dtype=torch.bfloat16, grad_fn=<NllLossBackward>)
- scalar_t vs AccumulateType (AccumulateType of bfloat16 is float)
AccumulateType is essential to keep accuracy, especially for reduction related operation.
we have verified it with both local case and real topology. It turns out that bfloat16 type accumulator would cause huge relative error when elements number is large, even more than 50%.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24457
Differential Revision: D17113018
Pulled By: ezyang
fbshipit-source-id: 8d61297ca118f9b5c6730a01efcf3a3704d2f206
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25793
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17259049
Pulled By: ezyang
fbshipit-source-id: 03bf2f28bfd584250ae8feddf4933522ea331b0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24242
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17162837
Pulled By: ezyang
fbshipit-source-id: 7bfa92eb151d13fd60cb525475056b363d1254f9
Summary:
__ldg is only available for CC3.5 and above, add default implementation for CC3.0 platform.
This PR along with jcooky's PR of ecdf4564d4. make the pytorch master HEAD build and runs properly for CC3.0 platform(such as Retina MacBook Pro of Late 2013).
I test the mnist example from pytorch/examples with the wheel built, the test accuracy ends with 99% after 10 Epochs with GT 750M CC3.0 platform. CC3.0 platform decrease training time into about 1/5 of its cpu counterpart.
```
(pytorch) SamuelFdeMBP:mnist sfeng$ pip list | grep torch
pytorch-sphinx-theme 0.0.24 /Users/sfeng/GH/pytorch_110/docs/src/pytorch-sphinx-theme
torch 1.3.0a0+a332583
torchvision 0.5.0a0+0bd7080
(pytorch) SamuelFdeMBP:mnist sfeng$ date && time python main.py && date
日 9 8 07:17:38 CST 2019
/Users/sfeng/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch/cuda/__init__.py:132: UserWarning:
Found GPU0 GeForce GT 750M which is of cuda capability 3.0.
PyTorch no longer supports this GPU because it is too old.
The minimum cuda capability that we support is 3.5.
warnings.warn(old_gpu_warn % (d, name, major, capability[1]))
Train Epoch: 1 [0/60000 (0%)] Loss: 2.300039
......
Train Epoch: 10 [59520/60000 (99%)] Loss: 0.007440
Test set: Average loss: 0.0322, Accuracy: 9895/10000 (99%)
real 2m39.962s
user 4m13.625s
sys 0m9.672s
日 9 8 07:20:18 CST 2019
(pytorch) SamuelFdeMBP:mnist sfeng$ date && time python main.py --no-cuda && date
日 9 8 07:20:40 CST 2019
Train Epoch: 1 [0/60000 (0%)] Loss: 2.300039
Train Epoch: 1 [640/60000 (1%)] Loss: 2.213470
Train Epoch: 1 [1280/60000 (2%)] Loss: 2.170460
......
Train Epoch: 10 [58880/60000 (98%)] Loss: 0.005681
Train Epoch: 10 [59520/60000 (99%)] Loss: 0.007686
Test set: Average loss: 0.0319, Accuracy: 9894/10000 (99%)
real 12m6.604s
user 75m53.129s
sys 3m41.744s
日 9 8 07:32:47 CST 2019
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25825
Differential Revision: D17252176
Pulled By: soumith
fbshipit-source-id: 70bf84ae6380be86b56344b161a52fb06a53a1b2
Summary:
Fixes ~5000 lines of warnings like:
```
In file included from ../aten/src/TH/TH.h:4,
from ../torch/csrc/Storage.cpp:11:
../torch/csrc/Storage.h:6:39: warning: cast between incompatible function types from ‘PyObject* (*)(THPStorage*)’ {aka ‘_object* (*)(THPStorage*)’} to ‘getter’ {aka ‘_object* (*)(_object*, void*)’} [-Wcast-function-type]
6 | #define THPStorage_(NAME) TH_CONCAT_4(THP,Real,Storage_,NAME)
| ^~~
caffe2/aten/src/TH/THGeneral.h:154:37: note: in definition of macro ‘TH_CONCAT_4_EXPAND’
154 | #define TH_CONCAT_4_EXPAND(x,y,z,w) x ## y ## z ## w
| ^
../torch/csrc/Storage.h:6:27: note: in expansion of macro ‘TH_CONCAT_4’
6 | #define THPStorage_(NAME) TH_CONCAT_4(THP,Real,Storage_,NAME)
| ^~~~~~~~~~~
../torch/csrc/generic/Storage.cpp:299:22: note: in expansion of macro ‘THPStorage_’
299 | {"device", (getter)THPStorage_(device), nullptr, nullptr, nullptr},
| ^~~~~~~~~~~
../torch/csrc/Storage.h:6:39: warning: cast between incompatible function types from ‘PyObject* (*)(THPStorage*)’ {aka ‘_object* (*)(THPStorage*)’} to ‘getter’ {aka ‘_object* (*)(_object*, void*)’} [-Wcast-function-type]
6 | #define THPStorage_(NAME) TH_CONCAT_4(THP,Real,Storage_,NAME)
| ^~~
caffe2/aten/src/TH/THGeneral.h:154:37: note: in definition of macro ‘TH_CONCAT_4_EXPAND’
154 | #define TH_CONCAT_4_EXPAND(x,y,z,w) x ## y ## z ## w
| ^
../torch/csrc/Storage.h:6:27: note: in expansion of macro ‘TH_CONCAT_4’
6 | #define THPStorage_(NAME) TH_CONCAT_4(THP,Real,Storage_,NAME)
| ^~~~~~~~~~~
```
This issue and the fix is very similar to how CPython fixed it, see https://bugs.python.org/issue33012.
There's still more of these warnings left, but this fixes the majority of them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25483
Differential Revision: D17149824
Pulled By: ezyang
fbshipit-source-id: 353560a4f76070fa7482608e9532b60205d16798
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25707
The retry logic dealt with ECONNREFUSED to deal with the client being
started before the server. It didn't yet deal with the server being
started but having its listen backlog exhausted. This may happen when
starting many processes that all try to connect at the same time.
The server implementation uses blocking I/O to read and write entire
messages, so it may take a bit longer to call `accept(2)` on new
connections compared to a fully event driven approach.
This commit both increases the default listen backlog on the server
side and implements retries on ECONNRESET after `connect(2)`.
Test Plan: Imported from OSS
Differential Revision: D17226958
Pulled By: pietern
fbshipit-source-id: 877a7758b29286e06039f31b5c900de094aa3100
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25778
I don't know how this ever compiled, it was caught by an internal test.
Do we not set DEBUG when compiling in debug mode in OSS?
Test Plan
- [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17228393
Pulled By: zou3519
fbshipit-source-id: 441ad716a369ee99be4723318cf78e394f98becf
Summary:
When the given input size is larger than expected, `weight_sizes` is `k`-length but only has `weight_dim` numbers. And it causes the confusing error message:
```
RuntimeError: Expected 4-dimensional input for 4-dimensional
weight 256 5 3 3 3987964488216321853 94670871813000,
but got 6-dimensional input of size [1, 61, 1, 5, 64, 64] instead
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25146
Differential Revision: D17233651
Pulled By: soumith
fbshipit-source-id: c6ddfa45e854f9b95ca253052f8bc358e35fd9d4
Summary:
The motivation for this move, and our long-term commitment to maintaining and integrating this code into ATen is described in the issue below:
https://github.com/pytorch/pytorch/issues/25621
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25500
Test Plan:
QNNPack unit tests, as follows:
OSS:
x86:
mkdir build; cd build; cmake ..; make all -j16 && make test
All 26 unit tests pass, both when built with ADD_DEFINITIONS(-DPYTORCH_QNNPACK_RUNTIME_QUANTIZATION=0) and ADD_DEFINITIONS(-DPYTORCH_QNNPACK_RUNTIME_QUANTIZATION=1)
ARM:
Make sure you have an android device available to adb either through one world or directly connected.
To compile and push do
$> adb shell mkdir /data/qnnpack && ./scripts/build-android-arm64.sh && adb push ./build/android/arm64-v8a/*-test /data/qnnpack
To execute tests, first $> adb shell to login into the device, then run all the tests by
$> for t in $(ls /data/qnnpack); do /data/qnnpack/$t; done
Repeat the exact same process with ADD_DEFINITIONS(-DPYTORCH_QNNPACK_RUNTIME_QUANTIZATION=0), and ADD_DEFINITIONS(-DPYTORCH_QNNPACK_RUNTIME_QUANTIZATION=1)
Repeat the exact same process with ./scripts/build-android-armv7.sh for AARCH32.
Reviewed By: ljk53
Differential Revision: D17194732
Pulled By: AshkanAliabadi
fbshipit-source-id: 9e627338ebd63aa917a36b717618c0643ccf40c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25802
Test script
```
import torch
def foo(x, y):
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
return x
scripted = torch.jit.script(foo)
scripted.save('foo.zip')
loaded = torch.jit.load('foo.zip')
loaded(torch.rand(3, 4), torch.rand(4, 5))
```
Before this change
```
RuntimeError: The size of tensor a (4) must match the size of tensor b (5) at non-singleton dimension 1
The above operation failed in interpreter, with the following stack trace:
at code/__torch__.py:7:9
op_version_set = 1
class PlaceholderModule(Module):
__parameters__ = []
def forward(self: __torch__.PlaceholderModule,
x: Tensor,
y: Tensor) -> Tensor:
x0 = torch.add(x, y, alpha=1)
~~~~~~~~~ <--- HERE
x1 = torch.add(x0, y, alpha=1)
x2 = torch.add(x1, y, alpha=1)
x3 = torch.add(x2, y, alpha=1)
x4 = torch.add(x3, y, alpha=1)
x5 = torch.add(x4, y, alpha=1)
x6 = torch.add(x5, y, alpha=1)
x7 = torch.add(x6, y, alpha=1)
x8 = torch.add(x7, y, alpha=1)
x9 = torch.add(x8, y, alpha=1)Compiled from code at /home/jamesreed/print_test.py:5:8
def foo(x, y):
x = x + y
~~~~~ <--- HERE
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
```
After this change
```
RuntimeError: The size of tensor a (4) must match the size of tensor b (5) at non-singleton dimension 1
The above operation failed in interpreter, with the following stack trace:
at code/__torch__.py:7:9
op_version_set = 1
class PlaceholderModule(Module):
__parameters__ = []
def forward(self: __torch__.PlaceholderModule,
x: Tensor,
y: Tensor) -> Tensor:
x0 = torch.add(x, y, alpha=1)
~~~~~~~~~ <--- HERE
x1 = torch.add(x0, y, alpha=1)
x2 = torch.add(x1, y, alpha=1)
x3 = torch.add(x2, y, alpha=1)
x4 = torch.add(x3, y, alpha=1)
x5 = torch.add(x4, y, alpha=1)
x6 = torch.add(x5, y, alpha=1)
x7 = torch.add(x6, y, alpha=1)
x8 = torch.add(x7, y, alpha=1)
x9 = torch.add(x8, y, alpha=1)
Compiled from code at /home/jamesreed/print_test.py:5:8
def foo(x, y):
x = x + y
~~~~~ <--- HERE
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
x = x + y
```
Test Plan: Imported from OSS
Differential Revision: D17250599
Pulled By: jamesr66a
fbshipit-source-id: 56266dcbf2c2287dc8ced7b9463ed42ef5f1167c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25812
as title
Test Plan:
```
[huaminli@devvm2388.ftw3 ~/fbsource/fbcode] buck run mode/dev-nosan caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --operators None --iterations 3
```
last few lines of the output P109238440
Reviewed By: mingzhe09088
Differential Revision: D17246792
fbshipit-source-id: d93ee5f404164d32210968997c6ea63b82058d2a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25728
Two quick fixes:
1) windows doesn't seem to like std::locale, so that got removed.
2) at::empty should call the non-named-tensor overload if the tensor
doesn't have names to avoid re-dispatching. In the long term we'll merge
the at::empty names and no-names overloads.
Test Plan
- [namedtensor ci], but the windows thing isn't easy to test without
running BUILD_NAMEDTENSOR=1 on windows.
Test Plan: Imported from OSS
Differential Revision: D17212059
Pulled By: zou3519
fbshipit-source-id: 58da5ab96d53c4844237ca10fa1b2de4b1052a0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25672
There are three overloads:
1) flatten(tensor, int start_dim, int end_dim, Dimname out_dim)
2) flatten(tensor, Dimname start_dim, Dimname end_dim, Dimname out_dim)
3) flatten(tensor, DimnameList dims, Dimname out_dim)
`flatten` joins all the dimensions between start_dim and end_dim into
one dimension. The name of the output dimension is specified by
`out_dim`.
In the case where flatten takes a list of `dims` to flatten, all the
dimensions in `dims` must be in consecutive order.
Test Plan: - new tests [namedtensor ci]
Differential Revision: D17192656
Pulled By: zou3519
fbshipit-source-id: 55d2b23358bd77cbef299f66701a8da8cd194f4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25731
I didn't notice this before, but the QuantizeAvx2 routine was requantizing only a single vector of 8 floats into 1/4 of a 256-bit int8 register. This switches it to use a specialization that goes from 4 float vectors into a whole int8 vector, borrowed from C2
Test Plan: Imported from OSS
Differential Revision: D17214413
Pulled By: jamesr66a
fbshipit-source-id: 1d6fc556e43739e9a4b0dba5df2332beb1b3795b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25203
device_option propagation is completely broken in Caffe2 for cases when pass
through operators are used. As an example Gather operator don't have gradient
and passes through it's inputs, which results in incorrect detection of the
components for sparse parameter aggregation (component will be empty instead of
the real device).
This diff is trying to fix this issue.
Test Plan:
net_transform is finally working with Gather + FloatToHalf transformed model
instead of failing because of incorrect number of components.
Reviewed By: dzhulgakov
Differential Revision: D16936041
fbshipit-source-id: 916551b933469f04e32ddf86ec4b2c07f76c9176
Summary:
# Problem
ProcessGroupAgent used in test_rpc has SIGSEGV on exiting.
# Solution
It was because the python module was unpexceted destructed twice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25458
Test Plan: Run prototype tests on top of this diff.
Differential Revision: D17127093
Pulled By: xush6528
fbshipit-source-id: 4b86cd8465e8cca6fce1c163e78160a2386fa9c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25667
Relax scale and zero-point for activations to ensure that fbgemm implementations of conv and linear do not saturate due to 16 bit intermediate accumulation.
Add test to verify precision of numerics of quantized model with updated observer. This test catches errors in
handling layouts for quantized ops in addition to saturation/quantization errors.
ghstack-source-id: 89587942
Test Plan:
buck test caffe2/test:quantized -- 'test_float_quant_compare \(test_quantized_models\.ModelNumerics\)' --print-passing-details
Passes when SQNR > 35 dB
buck test caffe2/test:quantization -- 'test_minmax_observer \(test_quantization\.ObserverTest\)' --print-passing-details
Passes with additional coverage for observer changes
Differential Revision: D17140498
fbshipit-source-id: 42c58e726bb0b0f51890590ee2525428f9a8d24e
Summary:
expose necessary functions to python, and add round-way tests for
function schema str() and parsing functions.
We iterate over all the registered function schemas and get the string,
then parse the string. We compare the schema generated from parsing with
the original one, and make sure they are equal.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23208
ghstack-source-id: 89638026
Test Plan: buck test //caffe2/test:function_schema
Reviewed By: zrphercule
Differential Revision: D16435471
fbshipit-source-id: 6961ab096335eb88a96b132575996c24090fd4c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25781
To prepare for removing the BUILD_NAMEDTENSOR flag, I am attempting to
remove BUILD_NAMEDTENSOR out of header areas.
Test Plan:
- [namedtensor ci]
- Tested building locally with USE_STATIC_DISPATCH=1. Previously, in
https://github.com/pytorch/pytorch/pull/25721, this change had caused a
dependency cycle while building with that on.
Differential Revision: D17229490
Pulled By: zou3519
fbshipit-source-id: 22fbd5e2770374ab321c13542fa321a2bf7d3101
Summary:
`torch.nn` modules in Python save their kwarg options directly as module object attributes, while `torch::nn` modules in C++ save their options inside the `options` field of the module object. This PR tries to map between these two (by using the newly added `options_args` list to discover options arguments in Python module), to make sure options equivalence is properly checked.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25784
Differential Revision: D17238609
Pulled By: yf225
fbshipit-source-id: 2febd277ddcbe3ab458ac3feaaf93e4c94bb5b98
Summary:
This fixes the empty graph problem since pytorch 1.2
To prevent such things happen, we have to make the test harder.
There 3 levels of verification.
lv 1. make sure that the graph is saved to some event file. <--currently here
lv 2. make sure the file can be read by tensorboard.
lv 3. make sure the graph in tensorboard is human-friendly.
I think (3) must be involved by a human.
(2) is possible, but it will be useless if we want to use lv 3 directly.
cc orionr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25599
Reviewed By: sanekmelnikov
Differential Revision: D17229276
Pulled By: orionr
fbshipit-source-id: b39f2f1805ee0b3a456b2c69d97e6e3622f5220e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25780
support "trainer:0", "server:1" format
Test Plan:
# Unit tests
```
buck test mode/dev-nosan caffe2/test:rpc
```
Differential Revision: D17228907
fbshipit-source-id: a6e759f4364548454ab0f2907707e738997bbf38
Summary:
Change the doc of torch.where. The parameters are x and y instead of input and other
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25554
Differential Revision: D17227193
Pulled By: soumith
fbshipit-source-id: 96d8a6f60ae8e788648247320ae715d0058de2b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25711
This function renames the dimensions of a tensor out-of-place. Because
of that, I think `tensor.renamed(...)` is a clearer name: `view_names`
has the connotation that we can use names to `view` our tensors with a
"different shape", but what this function really does is let us rename a
tensor no matter the previous names.
`tensor.names_`, the in-place version of this, is unchanged for now.
However, we might delete this or not advertise it if it has no use case
and also because its naming is a little inconsistent with `tensor.renamed`.
Test Plan: - [namedtensor ci]
Differential Revision: D17206515
Pulled By: zou3519
fbshipit-source-id: 67053951fcc8130c84566b5ebbdce35ef619c90d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25513
Randomized tests are flaky, this PR derandomized some of them
Test Plan:
python test/test_fake_quant.py
python test/test_quantized_nn_mods.py
Imported from OSS
Differential Revision: D17221273
fbshipit-source-id: f6978704ba0139071c26f443e923955a2f849832
Summary:
Undefined preprocessor macros being evaluated cause
errors on some compilers/configs. There is an ungated define in caffe2
which is inconsistent with the rest of the file and should be
fixed anyway because it's causing issues in ovrsource.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25729
Test Plan: contbuilds
Differential Revision: D17211552
Pulled By: akrieger
fbshipit-source-id: 499b123894b255f37ff68079c4ba3650b1599a5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25650
This PR removes protobuf dependencies from mobile build altogether:
- caffe2/proto: protobuf files, including caffe2.proto and torch.proto;
- caffe2 components that depend on caffe2.proto, including most part of
caffe2/core, caffe2/utils;
- libprotobuf / libprotobuf-lite dependencies;
- protobuf compiler;
- some utils class, e.g.: netdef_converter.cpp;
- introduce a macro to disable third_party/onnx which depends on protobuf;
Test Plan:
- builds;
- link with demo app to make sure it can load and run a model in pickle format;
Differential Revision: D17183548
Pulled By: ljk53
fbshipit-source-id: fe60b48674f29c4a9b58fd1cf8ece44191491531
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25428
Added bias as an optional param to the quantized_linear_prepack function.
Bias is quantized during runtime using input scale and weight scale.
ghstack-source-id: 89601399
Test Plan: python test/run_test.py --exclude nn --verbose --bring-to-front quantization quantized quantized_tensor quantized_nn_mods quantizer
Differential Revision: D17121304
fbshipit-source-id: 8adb0e55e4aed0a5430aaa2c8639c8ad1639c85a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25755
PR #25721 breaks mobile CI (with USE_STATIC_DISPATCH=1) due to circular
header dependency.
Move 'ATen/core/Tensor.h' back into '#ifdef BUILD_NAMEDTENSOR' to work
around the CI issue.
Test Plan: - build android library locally
Differential Revision: D17223997
Pulled By: ljk53
fbshipit-source-id: d8b5fd26e332953f1b592758fc76947ea2af94dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25759
In #25260, USE_DISTRIBUTED was defaulted to OFF for Windows and macOS
only. The Android builds didn't run for the PR and started to fail
when it was merged to master. It turns out the mobile builds
explicitly disable USE_DISTRIBUTED but only after the USE_DISTRIBUTED
option, and derivative dependent options were defined. The result
being that USE_GLOO was enabled while USE_DISTRIBUTED was disabled.
This commit ensures that USE_DISTRIBUTED defaults to OFF unless the
build is for a supported platform.
ghstack-source-id: 89613698
Test Plan: N/A
Differential Revision: D17224842
fbshipit-source-id: 459039b79ad5240e81dfa3caf486858d6e77ba4b
Summary:
FindCUDNN.cmake and cuda.cmake have done the detection. This commit deletes `tools/setup_helpers/cudnn.py` as it is no longer needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25482
Differential Revision: D17226408
Pulled By: ezyang
fbshipit-source-id: abd9cd0244cabea1f5d9f93f828d632d77c8dd5e
Summary: To test the int8 ads models on CPU and accelerators with the ads replayer, we need to load the PREPACKING_INIT_NET_TYPE in the int8 model to initialize the int8 w_packed blobs.
Test Plan:
Ads replayer test.
P74811059
Reviewed By: zrphercule
Differential Revision: D16518888
fbshipit-source-id: cee212710ad37d9e491c970b25b2fe484373e5e4
Summary:
It doesn't seem to be used anywhere once down to CMake in this repo or any submodules
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25720
Differential Revision: D17225088
Pulled By: pietern
fbshipit-source-id: a24b080e6346a203b345e2b834fe095e3b9aece0
Summary:
Adds a '-m' flag to torch.distributed.launch that allows users to launch python modules using launch instead of specifying the full file path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24910
Differential Revision: D17221653
Pulled By: pietern
fbshipit-source-id: 5c6453ed266fd121103b11caab303e3f9404227d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25670
This is part of the effort to get rid of protobuf dependency for
libtorch mobile build.
embedding_lookup_idx.cc is used by ATen/EmbeddingBag.cpp. It indirectly
includes caffe2.pb.h but doesn't really need it. Clean up the headers to
unblock no-protobuf mobile build.
The broader problem is that many common headers in pytorch/caffe2 directly
or indirectly include caffe2.pb.h. After landing the stack of changes to
remove protobuf from OSS libtorch mobile build, it's going to constraint
how ATen and other parts of pytorch use caffe2 components: it will break
OSS mobile CI if a PR introduces a dependency to a caffe2 file that
indirectly includes caffe2.pb.h. We will need to tease out caffe2.pb.h
dependencies like in this diff, or do a refactor to replace protobuf
generated types.
Chatted with gchanan and ezyang to confirm that there is no plan to
add more dependencies to caffe2 components from ATen in near future,
so this should be fine.
Test Plan: - build locally with stacked diffs
Differential Revision: D17191913
Pulled By: ljk53
fbshipit-source-id: 1248fe6424060a8bedcf20e73942b7500ae5e815
Summary:
So we can iterate over the operator registry, and check the backward compatiblity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23207
ghstack-source-id: 89570438
Test Plan: ci and the round trip tests added in the last diff
Reviewed By: zrphercule
Differential Revision: D16434335
fbshipit-source-id: 86a66d746a1f122a8aafe39e936606d6ba7ef362
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25442
This make the tensor key in dict works in serialzation by comparing the
tensor keys TensorImpl address directly. Given that we just want to
ensure the ordering be stable when iterating, it should be good enough,
we will need careful consideration if we want to stick with python 3.7
insertion order
Test Plan: Imported from OSS
Differential Revision: D17216377
fbshipit-source-id: 80df17dc2fa9eddd73a66e3979d7f8d7934660c0
Summary:
Improve handling of mixed-type tensor operations.
This PR affects the arithmetic (add, sub, mul, and div) operators implemented via TensorIterator (so dense but not sparse tensor ops).
For these operators, we will now promote to reasonable types where possible, following the rules defined in https://github.com/pytorch/pytorch/issues/9515, and error in cases where the cast would require floating point -> integral or non-boolean to boolean downcasts.
The details of the promotion rules are described here:
https://github.com/nairbv/pytorch/blob/promote_types_strict/docs/source/tensor_attributes.rst
Some specific backwards incompatible examples:
* now `int_tensor * float` will result in a float tensor, whereas previously the floating point operand was first cast to an int. Previously `torch.tensor(10) * 1.9` => `tensor(10)` because the 1.9 was downcast to `1`. Now the result will be the more intuitive `tensor(19)`
* Now `int_tensor *= float` will error, since the floating point result of this operation can't be cast into the in-place integral type result.
See more examples/detail in the original issue (https://github.com/pytorch/pytorch/issues/9515), in the above linked tensor_attributes.rst doc, or in the test_type_promotion.py tests added in this PR:
https://github.com/nairbv/pytorch/blob/promote_types_strict/test/test_type_promotion.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22273
Reviewed By: gchanan
Differential Revision: D16582230
Pulled By: nairbv
fbshipit-source-id: 4029cca891908cdbf4253e4513c617bba7306cb3
Summary:
As of ROCm 2.6, we support hiprtc - the HIP runtime compilation API. Enable the jit fusion feature depending on the existence of such an API. This entails
* new hipification rules for API_RTC
* add hiprtc APIs to the shim loader
* update cmake infrastructure to find the hiprtc library (it is part of the HIP package)
* enabling of unit tests in the jit_fuser test set
* special casing in resource strings for HIP - the typedefs CUDA requires would be redundant
* for now disable the occupancy calculation we do not support yet and hard-code
Thanks to t-vi for working with me on getting this integration done!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22872
Differential Revision: D17207425
Pulled By: bddppq
fbshipit-source-id: 93409f3051ad0ea06afacc2239fd6c402152debe
Summary:
Add magic method for `class_type[index]`. Since the compiler has custom logic for indexing this was not included with the other magic methods.
Fix for https://github.com/pytorch/pytorch/issues/25637
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25664
Differential Revision: D17214996
Pulled By: eellison
fbshipit-source-id: bf77f70851f6c3487147da710cc996624492a0c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25721
Context: I am starting to work on removing the BUILD_NAMEDTENSOR flag.
Here is the approach:
- Move the macro out of header areas
- Include a new `enable_namedtensor.h` header that does a `#ifndef
BUILD_NAMEDTENSOR #define BUILD_NAMEDTENSOR`.
- Include `enable_namedtensor.h` where necessary. This only really needs
to happen in two files (c10/TensorImpl.h, ATen/Dimname.h).
- Incrementally delete usages of the BUILD_NAMEDTENSOR macro later.
The alternative is to straight up delete all instances of
BUILD_NAMEDTENSOR. This alternative could be disruptive, lead to merge
conflicts, and isn't incremental.
Along with the above, some work needs to be done on feature flagging
named tensors, and merging the namedtensor CI with the regular CI, and
communicating with devs. This work will too be done incrementally.
Test Plan
- [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17210913
Pulled By: zou3519
fbshipit-source-id: c73f128b976bb90212639e8f2a3ad2a6a52b8e0c
Summary:
All of the code examples should now run as unit tests, save for those
that require interaction (i.e. show `pdb` usage) and those that use
CUDA.
`save` had to be moved before `load` in `jit/__init__.py` so `load`
could use the file generated by `save`
](https://our.intern.facebook.com/intern/diff/17192417/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25668
Pulled By: driazati
Differential Revision: D17192417
fbshipit-source-id: 931b310ae0c3d2cc6affeabccae5296f53fe42bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25628
We figured that base_lr is negative in learning_rate_functors.h. So using fabs(base_lr) for cyclical learning rate multiplier
computation.
Test Plan: Canary: f135306794
Reviewed By: chenshouyuan
Differential Revision: D17167635
fbshipit-source-id: e7fb55835f9fc07712edd63e81f1cf355e05b9f4
Summary:
old (a)
new (a! -> b)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23206
ghstack-source-id: 89570435
Test Plan: cont build and the round trip tests in the last diff
Reviewed By: zrphercule
Differential Revision: D16433909
fbshipit-source-id: b5b018e839935cccbb1fb446070afd1cb9379bb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25725
After landing #25260 the macOS wheel builds started to fail. It turns
out that if not specified, the setup helpers default USE_DISTRIBUTED
to true on all platforms except Windows.
This commit updates that such that USE_DISTRIBUTED only defaults to
true on Linux. More work is needed to enable it by default on macOS.
[test wheel]
ghstack-source-id: 89571701
Test Plan: N/A
Differential Revision: D17211695
fbshipit-source-id: 185db2e3425e45e6b76bd09d70a84e57327ca20f
Summary:
Before https://github.com/pytorch/pytorch/issues/24879, `bitwise_not` calls into `at::bitwise_not_out` which goes through a device dispatch. But after the PR it's dispatched directly to `at::native::bitwise_not_out` which only has cpu and cuda impls. Skipping `at::` dispatch indeed broke XLA but XLA didn't have unary tests. We didn't notice it until a test has been added in https://github.com/pytorch/xla/pull/986. :P
Trying to fix the breakage in this PR to save a revert.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25689
Differential Revision: D17201071
Pulled By: ailzhang
fbshipit-source-id: 0ca560a14a2ec6141f3795479c6dcb460e3805b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25169
See #23110 for RRef design details. This commit only implements
RRef as return value for builtin operators, and RRef will communicate
between a user and the owner. More specifically, a RRef is first
created on the `dist.remote` caller, which is a user of the RRef.
Then the RRef user sends and notification to the owner to report
the fork to the owner, and the owner uses a shared_ptr to keep
the RRef alive. When the user RRef is destructed on the caller,
another notification will be sent to the owner, and the owner
can then drop it's RRef as well.
Test Plan: Imported from OSS
Differential Revision: D17048343
Pulled By: mrshenli
fbshipit-source-id: 9dd3b3d0e4fd214c76fecdbed746a6d3029b3efd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25696
Move the flag from CI to CMake so it's less magic and can be reused by
iOS build as well.
Test Plan: - will check CI
Differential Revision: D17202734
Pulled By: ljk53
fbshipit-source-id: da4f150cbcf2bb5624def386ce3699eff2a7446f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25695
Rename codegen variables to better reflect its semantics.
As we are going to change other parts of codegen for mobile build, e.g.
autograd, it would be more clear to use more specific names instead of
calling everything 'mobile'.
Test Plan: - will check CI
Differential Revision: D17202732
Pulled By: ljk53
fbshipit-source-id: b2953c0914f25f9a1de00be89a09a6372cc5b614
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25503
Previously we only insert observers for forward methods, this PR
extends the support to all observers. It will insert
duplicated observers right now, we'll remove them in next PR.
Test Plan:
python test/test_jit.py -- 'TestJit.insert_observers'
Imported from OSS
Differential Revision: D17208886
fbshipit-source-id: 04084c8f42c56cb66a11968987a15752f532ac04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25262
Preserve the type of ignore'd functions on serialization. Currently we first compile an ignore'd function with it's annotated type when first compiling, but do not preserve it. This is important for being able to compile models with not-yet-supported features in JIT.
```
torch.jit.ignore
def unsupported(x):
return x
def foo():
if not torch.jit._is_scripting():
return torch.linear(...)
else:
return unsupported(...)
```
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D17199043
Pulled By: eellison
fbshipit-source-id: 1196fd94c207b9fbee1087e4b2ef7d4656a6647f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25678
As an effort to unify fbgemm and qnnpack at the dispatcher level, we need to have a generic name for the quantized backed ops.
Currently FBGEMM is guarded by the USE_FBGEMM macro and QNNPACK uses USE_QNNPACK.
ghstack-source-id: 89518961
Test Plan: buck test caffe2/test:quantized
Differential Revision: D17194364
fbshipit-source-id: 5960aedff6b8cb89eb3872c39b74caf54c0fbf20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25673
We recently moved new_empty into ATen. new_empty doesn't support named
tensors (in fact, it was hackily supporting named tensors before). This
fixes the named tensor test by changing all uses of `new_empty` to
`empty`.
Named tensor support for `new_empty` will come eventually, but it might
be a little tricky.
Test Plan: - [namedtensor ci]
Differential Revision: D17206043
Pulled By: zou3519
fbshipit-source-id: 1697bd1d63e7cb344f3d459a29af0fcb9696ea49
Summary:
In facebookincubator/gloo#212, a libuv based Gloo transport was introduced,
which allows us to use Gloo on macOS (and later perhaps also Windows). This
commit updates CMake code to enable building with USE_DISTRIBUTED=1 on macOS.
A few notes:
* The Caffe2 ops are not compiled, for they depend on `gloo::transport::tcp`.
* The process group implementation uses `gloo::transport::tcp` on Linux (because of `epoll(2)` on Linux and `gloo::transport::uv` on macOS).
* The TCP store works but sometimes crashes on process termination.
* The distributed tests are not yet run.
* The nightly builds don't use `USE_DISTRIBUTED=1`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25260
Reviewed By: mrshenli
Differential Revision: D17202381
Pulled By: pietern
fbshipit-source-id: ca80a82e78a05b4154271d2fb0ed31c8d9f26a7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25671
To decouple string_utils.h from types.h and protobuf headers.
Logically GetDimFromOrderString seems to be more similiar to
StringToStorageOrder comparing to other string_utils functions.
Test Plan: - Will check all internal/external CI jobs.
Reviewed By: yinghai
Differential Revision: D17191912
Pulled By: ljk53
fbshipit-source-id: fe555feef27bfd74c92b6297c12fb668252ca9ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25649
Continue the work of PR #25493 to remove dependencies of generated
protobuf headers from jit/import.cpp.
Instead of adding intrusive #if/#else to gate the legacy functions,
moving them into a separate file. Keep the ScriptModuleDeserializer
structure as otherwise it will require a lot of interface changes.
There is not much state to copy from ScriptModuleDeserializer as it only
extracts extra_files before calling into LEGACY_deserialize. There is
no state to copy back into ScriptModuleDeserializer either as it directly
returns script::Module.
Test Plan:
- builds;
- with stacked PR to remove protobuf from cmake;
- load and run ResNet-18 in model.json format with non-mobile build;
- load and run ResNet-18 in pickle format with mobile build;
Differential Revision: D17183549
Pulled By: ljk53
fbshipit-source-id: 2947b95659cd16046d9595fb118d22acc179b3ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25651
Most of the bianries are not useful/compilable for mobile. Consolidate the gating
logic and move to the beginning of the file.
Test Plan: - make sure BUILD_BINARY=ON works for both mobile and non-mobile builds;
Differential Revision: D17183550
Pulled By: ljk53
fbshipit-source-id: a8179f4e80999271bf43b5d97798abc713c59843
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25686
From the new runs, we found some ops that we can increase the shape size to reduce the variance
Test Plan:
```
[huaminli@devvm2388.ftw3 ~/fbsource/fbcode] buck run mode/dev-nosan caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --operators None --iterations 3
```
last few lines of the output P108624830
Reviewed By: mingzhe09088
Differential Revision: D17199623
fbshipit-source-id: a9277509f6d3e6503d3086b3b02f87eebd953239
Summary:
This PR adds Python/C++ API parity tracker at `test/cpp_api_parity/parity-tracker.md`, which currently shows parity status for `torch.nn` modules.
A good amount of line changes here is moving `new_criterion_tests` from `test_nn.py` to `common_nn.py`, so that it can be used in `test_cpp_api_parity.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25289
Differential Revision: D17188085
Pulled By: yf225
fbshipit-source-id: 33d12fb1a4de2d9147ed09380973f361a3981fdf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25596
Giving up on trying to limit this to just a py2 dependency
Test Plan: Imported from OSS
Differential Revision: D17171063
Pulled By: jamesr66a
fbshipit-source-id: 5df35fd128f3051dd9c6709f7d45323fedc12e65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25598
att
Test Plan:
CI
Imported from OSS
Differential Revision: D17192467
fbshipit-source-id: 9ee93b02cc293bb71ed114534d92eedda3ddee88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25475
I got sucked into this rabbit hole when I was trying to understand
what I should do with TensorTypeId occurrences in
torch/csrc/utils/tensor_new.cpp. I eventually concluded that all of my problems
were because Tensor.new_empty was hand implemented and not actually a native
function. So I made it a native function.
There are a bunch of other new_* functions which should get this
treatment, but I'm sending out this PR just to show how it can
be done.
The general recipe:
1. Implement a concept of TensorOptions merging (TensorOptions::merge_in).
This represents the notion of taking a tensor, but "overriding" some
of its values with specific overrides. One subtlety here is how
devices get merged; see the comments for what our existing behavior is,
and how I preserve it.
2. Implement new_empty as a native function, using options merging.
3. Add another special case to Python binding generation to treat new_*
similar to *_like (i.e., handle TensorOptions correctly). The logic
here is probably wrong, actually; we should codegen TensorOptions
correctly no matter what happens, but new_empty follows the same
pattern as empty_like so I opted not to touch this code too much.
4. Delete the now defunct manual binding code.
5. Delete manual type annotations that are no longer necessary since
we're going through native.
I didn't handle memory format correctly here. I don't know if this function
should accept memory format; prior memory format patches didn't add support
for memory format to new_like. If we had put memory format in TensorOptions
this wouldn't have been a question.
ghstack-source-id: 89294185
Test Plan: sandcastle & ossci
Differential Revision: D17133000
fbshipit-source-id: 00f4e98bd5174f6fd54e8aba2910ea91824771d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25338
As an effort to unify fbgemm and qnnpack at the dispatcher level, we need to have a generic name for the quantized backed ops.
Currently FBGEMM is guarded by the USE_FBGEMM macro and QNNPACK uses USE_QNNPACK.
TBD: Use compile time macro or run_time to switch between fbgemm and qnnpack.
ghstack-source-id: 89454244
Test Plan: buck test caffe2/test:quantized
Differential Revision: D17097735
fbshipit-source-id: 447112a7a421387724d3e29b8fd8412dfb1c373a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25361
Previously we had a different None object for each type T so that
unwrap optional could still recover the type T from it. After a few
months of having this conversion behavior, it has become clear that
only the unwrap optional operators cause this problem. Furthermore, it
is beneficial to have NoneType <: Optional[T] because this is how IValues
work (in particular the None IValue is not tagged). This patch makes the
necessary changes to do this. In particular it special cases unwrap optional
in export so that it annotates the None to make sure we can recover the type.
This also changes how matching and evaluating type values work so that we
can consider None matchable to type Optional[T], eventhough we cannot
derive T from that match.
Test Plan: Imported from OSS
Differential Revision: D17103072
Pulled By: zdevito
fbshipit-source-id: 37678ed3e5ce54f2eb3ee4dff2734a39f0bee028
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25545
This re-uses the infrastructure from ATen/native/cpu, which compiles kernels multiple times for different instruction sets and dispatches dynamically based on the CPU's capability flags at runtime. This ensures we use the most optimal quantized kernel for the given machine
Test Plan: Imported from OSS
Differential Revision: D17166369
Pulled By: jamesr66a
fbshipit-source-id: 8c8393f99365e1408819bbaf254c1b5734a34b70
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex)
Note: These changes do not support AVX/SSE operations on complex tensors.
Changes so far:
- [x] Added complex support of torch.empty.
- [x] Added complex support of CopyKernels
- [x] Added complex support of BinaryOp kernels
Once these changes are applied the rest of the kernels are pretty easy.
ezyang
I have fixed the issues in the original [PR: 25373](https://github.com/pytorch/pytorch/pull/25373).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25534
Differential Revision: D17188390
Pulled By: ezyang
fbshipit-source-id: ade9fb00b2caa89b0f66a4de70a662b62db13a8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25411
We provide a full example in Transformer.py in comments section.
Test Plan: N/A
Reviewed By: zhangguanheng66
Differential Revision: D17116514
fbshipit-source-id: b8fd331bef7a626e52f3347c88adba21b1f43ec5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25440
See the comments deleted for what this PR is all about
Test Plan: Imported from OSS
Differential Revision: D17125690
Pulled By: suo
fbshipit-source-id: a4a2f541a3e161f9c15b51df475130e7bf683cf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25617
This was causing some build issues if you included c10 but not torch
Test Plan: Imported from OSS
Differential Revision: D17173352
Pulled By: suo
fbshipit-source-id: 8b6f65b6cdefea716598dec2909bbeb511f881b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25652
The clang-tidy driver script generates a chunk whitelist per file so
that it only shows errors for lines that were actually changed. If a
change removes the chunk the count is equal to 0. If the chunk happens
to be at the start of the file, and the start position is equal 0,
clang-tidy fails to run. This change filters out those chunks.
Test Plan: Imported from OSS
Differential Revision: D17184188
Pulled By: pietern
fbshipit-source-id: b6c2d9dca4d52cd6bf4b186603545312726fb00b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25604
In this initial version:
- autograd ignores all names.
- tensor.grad is unnamed, unless the user manually assigns to it.
- if a grad tensor has any names, perhaps the user was hoping for some
alignment-checking behavior that named tensor offers for other ops. We
raise a warning in this case.
Future: do some more extensive checking to see if this actually works in
all cases.
Test Plan:
- [namedtensor ci]
- Check a warning is raised if a grad tensor has names.
- Check tensor.grad field is unnamed.
- Check that we can perform backward on an op that doesn't explictly
support names in backward. `sigmoid` is one such op.
Differential Revision: D17171788
Pulled By: zou3519
fbshipit-source-id: 64837fde94d8269610b6d3539ac025516dbe1df4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23888
This is an alternative to https://github.com/pytorch/pytorch/pull/23684.
Instead of splitting a bunch of headers into declaration and definition, we change tensor includes to only include the tensor declaration when the tensor definition isn't needed.
ghstack-source-id: 89357687
Test Plan: waitforsandcastle
Differential Revision: D16673569
fbshipit-source-id: fa1d92809b05de7910a8c2dc2f55abe071ca63bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25620
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25602
Enable rocThrust with hipCUB and rocPRIM for ROCm. They are the ROCm implementations of the thrust and cub APIs and replace the older hip-thrust and cub-hip packages going forward. ROCm 2.5 is the first release to contain the new packages as an option, as of 2.6 they will be the only available option.
Add hipification rules to correctly hipify thrust::cuda to thrust::hip and cub:: to hipcub:: going forward. Add hipification rules to hipify specific cub headers to the general hipcub header.
Infrastructure work to correctly find, include and link against the new packages. Add the macro definition to choose the HIP backend to Thrust.
Since include chains are now a little different from CUDA's Thrust, add includes for functionality used where applicable.
Skip four tests that fail with the new rocThrust for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21864
Reviewed By: xw285cornell
Differential Revision: D16940768
Pulled By: bddppq
fbshipit-source-id: 3dba8a8f1763dd23d89eb0dd26d1db109973dbe5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25569
Test Plan
- new tests [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17159121
Pulled By: zou3519
fbshipit-source-id: c68bdb543155488aa3634f908bd576e5c30c8d77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25564
There are a number of ops that get called while printing tensors
depending on how large the tensors are. This PR makes it so that before
we attempt to format tensor data for printing, we drop the names of the
tensor (if there are any). This is easier than supporting named tensors
for all of those ops (which should happen eventually).
Test Plan: - new test [namedtensor ci]
Differential Revision: D17158872
Pulled By: zou3519
fbshipit-source-id: 282023837645b8cb16a4d93896a843dd598fc738
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25157
Add the dynamic quantized LSTM module.
TODO (separate PRs):
- Serialization.
- Bias can be Null.
ghstack-source-id: 89443731
Test Plan:
buck test mode/dev caffe2/test:quantization -- 'test_quantized_rnn \(test_quantization\.PostTrainingDynamicQuantTest\)' --print-passing-details
```
[jianyuhuang@devvm2816.prn3.facebook.com: ~/fbsource/fbcode/caffe2/test] $ buck test mode/dev caffe2/test:quantization -- 'test_quantized_rnn \(test_q
uantization\.PostTrainingDynamicQuantTest\)' --print-passing-details
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 1.4 sec
Building: finished in 4.0 sec (100%) 8122/8122 jobs, 2 updated
Total time: 5.5 sec
Trace available for this run at /tmp/testpilot.20190902-164918.1275502.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision b61bc0e3b71033578eddfe0a28b0739bc685663f fbpkg 3b1c1aed1c534c0cb161a981eca6e2f0 at Sun Sep 1 20:58:52 2019 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/690/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/2251799823877227
✓ caffe2/test:quantization - test_quantized_rnn (test_quantization.PostTrainingDynamicQuantTest) 1.048 1/1 (passed)
Test output:
> test_quantized_rnn (test_quantization.PostTrainingDynamicQuantTest) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 1.049s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/2251799823877227
Summary (total time 5.53s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
Differential Revision: D16955662
fbshipit-source-id: 61cf1a74913105fa02e44b3941813eabac0006b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25563
Before, for binary ops, name inference occurred after shape checks. This
defeats the purposes for names because the names are supposed to tell
the user that i.e. their tensors are misaligned or that they are adding
incompatible tensors.
This PR changes TensorIterator so that names are computed before shape checks and
propagated after the binary ops are finished. In order to support this,
this PR makes the following changes:
- adds a `names_` field to TensorIterator, similar to `shape_`. This is
necessary to hold the output names, that are computed in
`compute_names`, until they are used in `propagate_names_to_outputs()`.
Test Plan: Imported from OSS
Differential Revision: D17158869
Pulled By: zou3519
fbshipit-source-id: 0caa90f7a93e4d9bdb2549cd330cc3abd2258868
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25568
Test Plan
- new test [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17159069
Pulled By: zou3519
fbshipit-source-id: fbc185ea5865b128508451096b742ac18e467670
Summary:
Changelog:
- We had 65535 as a common magic number for several linalg routines as a batch size limit. This PR explicitly assigns them to a variable to minimize possible errors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25524
Test Plan:
- All existing tests should pass to confirm that the modification is correct
This is a follow-up of the suggestion in https://github.com/pytorch/pytorch/issues/24438.
Differential Revision: D17171842
Pulled By: zou3519
fbshipit-source-id: a9ed5000f47614b8aa792c577f30b30475e0ac4b
Summary:
`self` isn't necessary for `index` backward, we only need the shape of
`self`. Changing derivatives.yaml to use `zeros_like(self)` triggers a
codepath in the codegen to only save the shape.
Fixes https://github.com/pytorch/pytorch/issues/24853.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25594
Test Plan:
- I added a new test that is adapted from the code in
https://github.com/pytorch/pytorch/issues/24853. I'm not sure what a
more minimal example would look like because the bug is hard to trigger
because of how autograd handles differential views.
Differential Revision: D17168645
Pulled By: zou3519
fbshipit-source-id: 11f270fed7370730984a93e4316dd937baa351a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25566
masked_select returns a tensor with None names. However, it broadcasts
its inputs so we need to perform a check that they are broadcastable.
Test Plan: - new tests [namedtensor ci]
Differential Revision: D17159071
Pulled By: zou3519
fbshipit-source-id: ad201f3f73bc54163ede1ba3d906d2409ebef475
Summary:
Changelog:
- Iterate over mini batches of 262140 matrices (maximum)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24438
Test Plan:
- Added slow tests to test the behavior in test_torch and test_cuda
Fixes https://github.com/pytorch/pytorch/issues/24403
Differential Revision: D17175603
Pulled By: soumith
fbshipit-source-id: 1abb0a1e92494cf43ef4ba9efb54a919cd18bfef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25507
It doesn't seem to be used.
Test Plan: Imported from OSS
Differential Revision: D17163584
Pulled By: gchanan
fbshipit-source-id: 7409cc06bf84863bd14aea060c755d0f162d2aec
Summary:
Changelog:
- Enable broadcasting of RHS and LHS tensors for lu_solve. This means that you can now have RHS with size `3 x 2` and LHS with size `4 x 3 x 3` for instance
- Remove deprecated behavior of having 2D tensors for RHS. Now all tensors have to have a last dimension which equals the number of right hand sides
- Modified docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24333
Test Plan: - Add tests for new behavior in test_torch.py with a port to test_cuda.py
Differential Revision: D17165463
Pulled By: zou3519
fbshipit-source-id: cda5d5496ddb29ed0182bab250b5d90f8f454aa6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25575
For both scatter and gather, only the source and destination rank,
respectively, need to supply a list of tensors. The `scatter_list` and
`gather_list` arguments were mandatory, however, and this has resulted
in some confusion. This commit makes both the `scatter_list` and
`gather_list`, and the `src` and `dst` arguments optional.
Closes#25463.
Test Plan: Imported from OSS
Differential Revision: D17164253
fbshipit-source-id: a16bc208c87a1c96163c1a86d4a7ca8634a26f95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25431
I put the name propagation logic in a central place, `make_reduction`,
that creates a TensorIterator for the reduction. This lets us implement
name inference rules for mean, std, var, std_mean, and var_mean.
Test Plan
- new tests [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17123577
Pulled By: zou3519
fbshipit-source-id: 2d47080a40da0c4bcabbb3df71ffa8fbeb7a14c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25405
This PR adds schemas to native_functions.yaml, core/Tensor.h, and
core/TensorMethods.h for Dimname/DimnameList overloads for the following
functions:
- min, max, max_values, min_values
- mean, meadian
- logsumexp, std, var, norm
The actual implementations will come in a later PR. I am accumulating
all the addtional schemas and changes to core/{Tensor|TensorMethods}.h
in this PR so that there is only one point of failure for potential
merge conflicts.
Test Plan: - Check that all pytorch builds still build. [namedtensor ci]
Differential Revision: D17116333
Pulled By: zou3519
fbshipit-source-id: fd666d60109a311767169261afbec0fd85cc00c8
Summary:
Adds links to torchaudio and torchtext to docs index. We should eventually evolve this to bring the audio and text docs builds in like torchvision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24245
Differential Revision: D17163539
Pulled By: soumith
fbshipit-source-id: 5754bdf7579208e291e53970b40f73ef119b758f
Summary:
This should work both on VS and Ninja.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25556
Differential Revision: D17162045
Pulled By: ezyang
fbshipit-source-id: 18c3d62e9ba93bf603f3a5310087fac77be4a974
Summary:
addresses https://github.com/pytorch/pytorch/issues/25427, see issue discussion for more context.
message conversion to unicode is a potential source of flakiness, passing in as kwarg instead of to `prec` is both more clear and resilient to being broken in the future.
cc mrshenli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25557
Differential Revision: D17160343
Pulled By: pietern
fbshipit-source-id: af071fecc04c7e0a6658694dc0d76472193f8e78
Summary:
`test_allreduce_coalesced_checks` is skipped if no GPU/not compiled with `CUDA` support. This PR moves the checks involving `.cuda()` to their own tests, since the others are still valid with or without CUDA.
cc pietern mrshenli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25555
Differential Revision: D17160337
Pulled By: pietern
fbshipit-source-id: 4c5e6db44d2728ca43784b85131e890d3d003bcd
Summary:
I think...
I'm having issues building the site, but it appears to get rid of the error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25544
Differential Revision: D17157327
Pulled By: ezyang
fbshipit-source-id: 170235c52008ca78ff0d8740b2d7f5b67397b614
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25509
Trying to reduce the number of build parameters to simplify the config.
This one is purely derived from the build environment, so we can have
the CI scripts just compute it.
Test Plan: Imported from OSS
Differential Revision: D17143343
Pulled By: suo
fbshipit-source-id: 7837607b7b18a9233fd8657dc9c63539c0194110
Summary:
Fixes https://github.com/pytorch/pytorch/issues/25304.
The possible cause for the failure could have been the fact that `at::empty` was creating a tensor with very small values or 0, which led to `cumdist` not summing to a positive number.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25539
Differential Revision: D17156212
Pulled By: ezyang
fbshipit-source-id: ee8039e576bf76a2266aeb7e9537337d635e0f8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25382
The formatted code swapped the inclusion order around in
ProcessGroupNCCLTest.cpp, causing a compilation failure in
`ATen/cuda/CUDAMultiStreamGuard.h`.
To fix this, this commit also includes a fix to the include list in
`ATen/cuda/CUDAMultiStreamGuard.h`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25382
Test Plan: Imported from OSS
Differential Revision: D17152634
Pulled By: pietern
fbshipit-source-id: c7b74d65a10dce5d602a98dc23fe2810235f932d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24876
This contains very basic functionality of adding 'send' autograd
function to our autograd graph. The purpose of this change is to validate the
basic structure proposed here makes sense. Once this makes sense, we can build
upon this to address more complicated scenarios. At a high level we've added
the following functionality:
1) Define a very simple 'SendRpcBackwards' autograd function.
2) Attach this function to appropriate tensors when we call an RPC.
3) Store the send function in our distributed autograd context.
ghstack-source-id: 89359708
Test Plan: unit tests.
Differential Revision: D16903255
fbshipit-source-id: 6c04794a8e58b199795404225fd9da0c1440460e
Summary:
This PR excises the last of SymbolicVariable. There should be no change in functionality. One new test for addmm fusion was added. A case where the peephole optimizer might convert a scalar argument remains untested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25077
Test Plan: Refactors existing code so mostly covered by current tests. One test for addmm fusion was added.
Differential Revision: D17145334
Pulled By: mruberry
fbshipit-source-id: 6b68faf764f9ee8398b55c43110228ed9faf81eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25441
1) There was a bug in https://github.com/pytorch/pytorch/pull/25012, where the
tests which needed to be skipped for return code checking was incorrect.
2) Added proper setup and teardown for the nccl_error tests.
3) Ensure AssertionError is not ignored for tests that skip return code
checking.
ghstack-source-id: 89317660
Test Plan: unit tests
Differential Revision: D17125824
fbshipit-source-id: 317ec39942b93e40ab847246b3a5129919ba2ac4
Summary:
Gradle tasks for publishing to bintray and jcenter, mavencentral; snapshot buidls go to oss.sonatype.org
Those gradle changes adds tasks:
bintrayUpload - publishing on bintray, in 'facebook' org
uploadArchives - uploading to maven repos
Gradle tasks are copied from facebook open sourced libraries like https://github.com/facebook/litho, https://github.com/facebookincubator/spectrum
To do the publishing we need to provide somehow (e.g. in ~/.gradle/gradle.properties)
```
signing.keyId=
signing.password=
signing.secretKeyRingFile=
bintrayUsername=
bintrayApiKey=
bintrayGpgPassword=
SONATYPE_NEXUS_USERNAME=
SONATYPE_NEXUS_PASSWORD=
```
android/libs/fbjni is submodule, to be able to add publishing tasks to it (it needs to be published as separate maven dependency) - I created `android/libs/fbjni_local` that has only `build.gradle` with release tasks.
pytorch_android dependency for ':fbjni' changed from implementation -> api as implementation treated as 'private' dependency which is translated to scope=runtime in maven pom file, api works as 'compile'
Testing:
it's already published on bintray with version 0.0.4 and can be used in gradle files as
```
repositories {
maven {
url "https://dl.bintray.com/facebook/maven"
}
}
dependencies {
implementation 'com.facebook:pytorch_android:0.0.4'
implementation 'com.facebook:pytorch_android_torchvision:0.0.4'
}
```
It was published in com.facebook group
I requested sync to jcenter from bintray, that usually takes 2-3 days
Versioning added version suffixes to aar output files and circleCI jobs for android start failing as they expected just pytorch_android.aar pytorch_android_torchvision.aar, without any version
To avoid it - I changed circleCI android jobs to zip *.aar files and publish as single artifact with name artifacts.zip, I will add kostmo to check this part, if circleCI jobs finish ok - everything works :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25351
Reviewed By: kostmo
Differential Revision: D17135886
Pulled By: IvanKobzarev
fbshipit-source-id: 64eebac670bbccaaafa1b04eeab15760dd5ecdf9
Summary: It's failing in the FB internal build because we don't enable that op.
Test Plan: buck test //xplat/caffe2:caffe2_testAndroid
Reviewed By: supriyar
Differential Revision: D17139694
fbshipit-source-id: 8091b71ff826466f3e2e1b4d6f87b9b50d1def20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25449
Currently Variable and Tensor are still not 100% merged. There are
various places in ATen/TH codebase where it asserts input type to be
Variable/Tensor.
Usually when input type is Variable it will dispatch function calls to
corresponding generated VariableType methods, where it converts input
Variable type to Tensor type with "unpack()" before calling into LegacyTHFunctions
and then converts result from Tensor type back to Variable type with "as_variable()".
However, when USE_STATIC_DISPATCH mode is enabled, it no longer dispatches function
calls to VariableType methods. This way, Variable inputs will remain as
Variable instances when they reach LegacyTHFunctions and fail the "checked_tensor_unwrap"
asserts. And there are a couple other failed asserts because of similar reason.
There are several options to address this problem with USE_STATIC_DISPATCH:
1. Wait until Variable and Tensor are fully merged as planned in https://github.com/pytorch/pytorch/issues/23032;
2. Create Tensors instead of Variables upfront on caller side (JIT);
3. Fix downstream asserts in ATen/TH to tolerant Variable inputs when AutoGrad is disabled;
Option 1 will still take some time; Option 2 was tried before and caused
a lot problems; Option 3 needs to be conducted case by case as it can be
dangerous to remove asserts before 100% merge happens.
After digging into it a bit more, turns out NonVariableTypeMode not only controls how
it dispatches, but also controls TensorImpl.is_variable() result. So the
problem can be addressed by:
1. Set AutoNonVariableTypeMode mode right before calling forward();
2. Make sure all inputs/params are created as Variable, e.g.:
A. should use torch::ones() to create test input tensor instead of at::ones();
B. should not set AutoNonVariableTypeMode before torch::jit::load() call;
This diff applied these changes to speed benchmark to proof how it works.
Test Plan:
- Build speed benchmark binary for Android:
```
./scripts/build_android.sh \
-DBUILD_BINARY=ON \
-DBUILD_CAFFE2_MOBILE=OFF \
-DUSE_STATIC_DISPATCH=ON \
-DCMAKE_PREFIX_PATH=$(python -c 'from distutils.sysconfig import get_python_lib; print(get_python_lib())') \
-DPYTHON_EXECUTABLE=$(python -c 'import sys; print(sys.executable)')
```
- Push binaries and model to Android device:
```
adb push build_android/bin/speed_benchmark_torch /data/local/tmp
adb push resnet.pb /data/local/tmp
```
- Run inference on device:
```
/data/local/tmp # ./speed_benchmark_torch --model=resnet.pb \
--input_dims="1,3,224,224" --input_type=float --print_output=true
```
Differential Revision: D17128567
Pulled By: ljk53
fbshipit-source-id: 58cc49ff35d21fefc906172cc3271f984eeb29f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25485
I recently enabled binary build macro for android CI in PR #25368 as I started
adding new binaries for android. But seems it's fragile, e.g.: PR #25230 failed
android-armv8 CI but passed armv7/x86-32/x86-64. Currently it only runs
x86-32 for PR so the armv8 failure was not captured before landing.
Similar problem might happen for other PRs so I think we should just
disable it for now to avoid breaking master CI. The android binaries are
for local testing purpose anyway. We can re-enable it when it becomes
more stable.
Test Plan:
- will check CI;
Imported from OSS
Differential Revision: D17137006
fbshipit-source-id: 2b7901f79e83c77ff82c14a0da3500b9416314b6
Summary:
`-Wimplicit-fallthrough` is enabled for recent GCC versions, and there's about 1000 lines of warnings in the build output with GCC 9.1 like:
```
/home/rgommers/code/pytorch/aten/src/THCUNN/FeatureLPPooling.cu: In function ‘bool runFeatureLPPoolingUpdateOutput(THCState*, const THCDeviceTensor<T, 4>&, THCDeviceTensor<T, 4>&, float, int, int) [with T = c10::Half]’:
/home/rgommers/code/pytorch/aten/src/THCUNN/FeatureLPPooling.cu:474:10: warning: this statement may fall through [-Wimplicit-fallthrough=]
474 | L2_WIDTH_CASE(2);
| ^~~~~~
/home/rgommers/code/pytorch/aten/src/THCUNN/FeatureLPPooling.cu:475:1: note: here
475 | L2_WIDTH_CASE(3);
| ^
...
/home/rgommers/code/pytorch/aten/src/THCUNN/FeatureLPPooling.cu:639:11: warning: this statement may fall through [-Wimplicit-fallthrough=]
639 | LP_WIDTH_CASE(15);
| ^~~~~~
/home/rgommers/code/pytorch/aten/src/THCUNN/FeatureLPPooling.cu:640:1: note: here
640 | LP_WIDTH_CASE(16);
| ^
```
Fix by ending each case statement with `break;`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25451
Differential Revision: D17131254
Pulled By: ezyang
fbshipit-source-id: 55b513620438cbbf86052f22d799d790b0633fa2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25467
Use Layout/Device more directly in these cases.
ghstack-source-id: 89289651
Test Plan: sandcastle and ossci
Differential Revision: D17131883
fbshipit-source-id: ab3c6d1c879b7f26f20a2378364c852dc37508fc
Summary:
Doesn't really add much functionality, since inputs to `tuple()` which we can statically infer the output size is pretty much just tuples. Does improve the error message though.
Fix for https://github.com/pytorch/pytorch/issues/24000
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25474
Differential Revision: D17133800
Pulled By: eellison
fbshipit-source-id: 41a052895e6ed24a384ec6f8aef0a6769ac094e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25446
Parameterize the CircleCI config. So now instead of ~1zillion job specs, there are only a handful, like `pytorch_linux_build` and such. The workflow definition feeds in the appropriate parameters that actually control job behavior.
[Diff](https://gist.github.com/suo/12a48efd36948fc71bdb5c719682a64c) of the `circleci config process` output shows that the actual jobs generated are identical, except for some empty env vars being set.
Differential Revision: D17133395
Test Plan: Imported from OSS
Pulled By: suo
fbshipit-source-id: e6d79268b05c91d5079670992bdf4a99e6dc2807
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25354
It doesn't seem to be used anymore.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D17101577
Pulled By: gchanan
fbshipit-source-id: b7c00de8c05bff1336d2012fd7b6f97709391e17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25477
We want to increase `in_c, out_c` so that the metric reported back are more stable
Test Plan:
```[huaminli@devvm2388.ftw3 ~/fbsource/fbcode] buck run mode/dev-nosan caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --operators None --iterations 3
```
runs fine on my devserver, last couple lines of output P107448746
Reviewed By: mingzhe09088
Differential Revision: D17133043
fbshipit-source-id: 0b989a530cbfe3d608471a30ae4bbda10e5216ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25352
It doesn't appear to be necessary anymore; assuming this works I'll kill the codegen in a follow-up PR.
Test Plan: Imported from OSS
Differential Revision: D17101573
Pulled By: gchanan
fbshipit-source-id: bd3d1724ee5c659185a161b1e291e30af52f0a8a
Summary:
PR to compare shapes of `outputs` and `grad_outputs` in `torch.autograd.grad()`.
> grad_outputs should be a sequence of length matching output containing the pre-computed gradients w.r.t. each of the outputs.
resolve https://github.com/pytorch/pytorch/issues/17893
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25349
Differential Revision: D17119931
Pulled By: CamiWilliams
fbshipit-source-id: 86c9089e240ca0cea5f4ea8ec7bcff95f9d8cf53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24331
Currently our logs are something like 40M a pop. Turning off warnings and turning on verbose makefiles (to see the compile commands) reduces this to more like 8M. We could probably reduce log size more but verbose makefile is really useful and we'll keep it turned on for Windows.
Some findings:
1. Setting `CMAKE_VERBOSE_MAKEFILE` inside CMakelists.txt itself as suggested in https://github.com/ninja-build/ninja/issues/900#issuecomment-417917630 does not work on Windows. Setting `-DCMAKE_VERBOSE_MAKEFILE=1` does work (and we respect this environment variable.)
2. The high (`/W3`) warning level is by default on MSVC is due to cmake inserting this in the default flags. On recent versions of cmake, CMP0092 can be used to disable this flag in the default set. The string replace trick sort of works, but the standard snippet you'll find on the internet won't disable the flag from nvcc. I inspected the CUDA cmake code and verified it does respect CMP0092
3. `EHsc` is also in the default flags; this one cannot be suppressed via a policy. The string replace trick seems to work...
4. ... however, it seems nvcc implicitly inserts an `/EHs` after `-Xcompiler` specified flags, which means that if we add `/EHa` to our set of flags, you'll get a warning from nvcc. So we probably have to figure out how to exclude EHa from the nvcc flags set (EHs does seem to work fine.)
5. To suppress warnings in nvcc, you must BOTH pass `-w` and `-Xcompiler /w`. Individually these are not enough.
The patch applies these things; it also fixes a bug where nvcc verbose command printing doesn't work with `-GNinja`.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17131746
Pulled By: ezyang
fbshipit-source-id: fb142f8677072a5430664b28155373088f074c4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25089
Previously, when the tracer encountered a scripted function (or method), it
inlined the function into the graph. Now, we emit a CallFunction or
CallMethod node instead.
Test Plan: Imported from OSS
Reviewed By: zdevito
Differential Revision: D16987936
Pulled By: suo
fbshipit-source-id: a3e38a4621f3504909ec0542865dc7e381c243d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25425
1. Properly invalidate memory locations when we change the points-to
set.
2. Don't build a new indexToElementMap in toString(), just use
`MemoryDag::fromIndex`
3. Fix transitive wildcard assignment
Test Plan: Imported from OSS
Differential Revision: D17126402
Pulled By: suo
fbshipit-source-id: cbd99027d2e78fd333dbf030172d3b7ac4df8349
Summary:
This is a fix for a potential ONNX export issue with SyncBatchNorm where irrespective of the value of momentum, the value for momentum in ONNX BN node is always 0. The details are captured in https://github.com/pytorch/pytorch/issues/18525.
The fix in this PR for `SyncBatchNorm` is very similar to the fix that went in https://github.com/pytorch/pytorch/pull/18764 for `BatchNorm` (I think this site was just missed).
Please note that there are no ONNX test points added for this, because SyncBatchNorm works exclusively with tensors on GPU and the ONNX test passes are CPU only. If there's a way to add a test point, please let me know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24995
Differential Revision: D17085570
Pulled By: dzhulgakov
fbshipit-source-id: 162d428673c269efca4360fb103854b7319ec204
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25408
Change exception to warning so that observer can be called with no data and still provide a scale and zero-point.
ghstack-source-id: 89267768
Test Plan:
buck test mode/dev caffe2/test:quantization -- 'test_minmax_observer'
buck test mode/dev caffe2/test:quantization -- 'test_observer_scriptable'
Differential Revision: D17116524
fbshipit-source-id: db4d76e882b57f23161dced846df3a0760194a41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25229
The binaries don't build when BUILD_CAFFE2_MOBILE=OFF (libtorch mode)
in which case we don't include caffe2/predictor which is needed by
predictor_verifier.cc.
Add BUILD_BINARY=ON to libtorch android CI script to make sure binaries
can be compiled for libtorch android as we will add speed benchmark
binary for it.
Test Plan:
- Verified BUILD_BINARY=ON works with BUILD_CAFFE2_MOBILE=OFF and ON.
- Will check CI builds.
Differential Revision: D17067217
Pulled By: ljk53
fbshipit-source-id: 2a28139d9d25ff738be7b49b24849c9d300ef9a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24195
It is not efficient to use a string destination name in every
send. Moreover, when we add RRef later, RpcAgent will frequently check
RRef ownership. It will be slow as well if we have to go though string
comparison every time. This commit assigns each RpcAgent a unique
integer ID. In the Python send API, applications can provide either
destination name or id. If it is a string name, it will be converted to
id by calling the get_id(workerName) API.
Test Plan: Imported from OSS
Differential Revision: D16770241
Pulled By: mrshenli
fbshipit-source-id: fa56128a77a02a402dc6682474bc301dc1b7f43d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25370
Removes some checking code that is copied from insert_observers pass
Test Plan:
python test/test_jit.py 'TestJit.test_insert_quant_dequant'
Imported from OSS
Differential Revision: D17106633
fbshipit-source-id: 3c39be89dbf58dc6ffd63e1ee1283eba65243ea6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25281
We want to skip inserting observers for the Tensors that's between the two
ops that will be fused, e.g. Conv -> ReLU, this PR just added this pattern,
but new patterns can be easily added in the future.
Test Plan:
python test test/test_jit.py -- 'TestJit.test_insert_observers_skip_values'
Imported from OSS
Differential Revision: D17106037
fbshipit-source-id: 49697f4d9598a461edc62a2b4148495764a99574
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25276
We add the per channel quantization support for the quantized linear operator, based on the recent added per channel quantization APIs in https://github.com/pytorch/pytorch/pull/24935 and https://github.com/pytorch/pytorch/pull/24934.
ghstack-source-id: 89267515
Test Plan:
buck test mode/dev caffe2/test:quantized -- 'test_qlinear_unpack \(test_quantized\.TestQuantizedLinear\)' --print-passing-details
```
[jianyuhuang@devvm6560.prn2.facebook.com: ~/fbsource/fbcode/caffe2/test] $ buck test mode/dev caffe2/test:quantized -- 'test_qlinear_unpack \(test_quantized\.TestQuantizedLinear\)' --print-passing-details
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 1.3 sec
Building: finished in 5.7 sec (100%) 8114/8114 jobs, 0 updated
Total time: 7.0 sec
Trace available for this run at /tmp/testpilot.20190827-141824.842847.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision c4cde854bae419be71282b0f92bf2d57a9203003 fbpkg f45bf410f1694a6882727cf03961702b at Mon Aug 26 22:10:29 2019 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/686/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/5629499540372523
✓ caffe2/test:quantized - test_qlinear_unpack (test_quantized.TestQuantizedLinear) 0.996 1/1 (passed)
Test output:
> test_qlinear_unpack (test_quantized.TestQuantizedLinear) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 0.997s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/5629499540372523
Summary (total time 5.05s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
buck test mode/dev caffe2/test:quantized -- 'test_qlinear \(test_quantized\.TestQuantizedLinear\)' --print-passing-details
```
[jianyuhuang@devvm6560.prn2.facebook.com: ~/fbsource/fbcode/caffe2/test] $ buck test mode/dev caffe2/test:quantized -- 'test_qlinear \(test_quantized\.TestQuantizedLinear\)' --print-passing-details
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 0.9 sec
Building: finished in 6.4 sec (100%) 8114/8114 jobs, 2 updated
Total time: 7.3 sec
Trace available for this run at /tmp/testpilot.20190827-141631.836596.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision c4cde854bae419be71282b0f92bf2d57a9203003 fbpkg f45bf410f1694a6882727cf03961702b at Mon Aug 26 22:10:29 2019 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/686/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/1125900049005601
✓ caffe2/test:quantized - test_qlinear (test_quantized.TestQuantizedLinear) 2.893 1/1 (passed)
Test output:
> test_qlinear (test_quantized.TestQuantizedLinear) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 2.893s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/1125900049005601
Summary (total time 6.78s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
buck test mode/dev caffe2/test:quantized -- 'test_qlinear \(test_quantized\.TestDynamicQuantizedLinear\)' --print-passing-details
```
[jianyuhuang@devvm6560.prn2.facebook.com: ~/fbsource/fbcode/caffe2/test] $ buck test mode/dev caffe2/test:quantized -- 'test_qlinear \(test_quantized\.TestDynamicQuantizedLinear\)' --print-passing-details
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 1.7 sec
Building: finished in 4.9 sec (100%) 8118/8118 jobs, 2 updated
Total time: 6.6 sec
Trace available for this run at /tmp/testpilot.20190829-153630.613647.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision f39465ac7f6b26840c8cbd0ae5e367fb8a60ec24 fbpkg cf4e6efcd2fa4642b6f8c26a9bd98d67 at Tue Aug 27 21:58:47 2019 by twsvcscm from /usr/local/fbprojects/packages/testinfra.testpilot/687/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/4222124657066806
✓ caffe2/test:quantized - test_qlinear (test_quantized.TestDynamicQuantizedLinear) 3.377 1/1 (passed)
Test output:
> test_qlinear (test_quantized.TestDynamicQuantizedLinear) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 3.378s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/4222124657066806
Summary (total time 8.18s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
Differential Revision: D17057818
fbshipit-source-id: 9ad8b9120fd0d9933ca81c132da61b53e2c91b9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25432
Test fails without width argument (it was dropped from hypothesis).
Temporarily skipping until fixed.
ghstack-source-id: 89260995
Test Plan: N/A
Differential Revision: D17123571
fbshipit-source-id: 2fc934a005959a300c6a962d8507cf0aaa137be5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25400
Bring in fixes for clamp operator and tests
Test Plan: CI
Reviewed By: dreiss
Differential Revision: D17100464
fbshipit-source-id: b071a8266dbdef19aa7d58a66c43bfa97d59ce02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25332
This method makes reference to a deprecated class, we now delete it.
This deletion was somewhat involved. Pre-existing use sites of
toType:
- Tensor::cpu()/cuda()/hip()
- native::type_as
- SummaryOps: toType(CPU(kDouble)) translated into to(kDouble) as weights
is an input argument and therefore assumed to be on CPU already. Similar
for CUDA.
- TensorTransformations: toType(CUDA(kLong)) translated into cuda(), as
the inputs are actually already the correct dtype, and this translation is just to move them to CUDA
- Adjusted native_test to take TensorOptions instead of
DeprecatedTypeProperties, killing toType along the way in favor of to
- Some tests for toType with UndefinedType which I just deleted
- CopyBackwards stores TensorOptions now instead of
DeprecatedTypeProperties
ghstack-source-id: 89177526
Test Plan: sandcastle and ossci
Differential Revision: D17096824
fbshipit-source-id: 964e5a073b9d37594e911d8bca98c9eab5766826
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16382
Adding an Int8TransposeOp that inherits from TransposeOp.
Small refactoring to normal TransposeOp to move main logic into a TransposeImpl
function.
Test Plan: int8_test.cc
Reviewed By: supriyar
Differential Revision: D13822715
fbshipit-source-id: a4d61bdf8e4e1d3f2e30b86d325810ed44c21635
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25345
Test Plan
- New tests [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17101486
Pulled By: zou3519
fbshipit-source-id: 58e803b042056ee6abab8551517f74078f2b81d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25334
1) There was a bug in https://github.com/pytorch/pytorch/pull/25012, where the
tests which needed to be skipped for return code checking was incorrect.
2) Added proper setup and teardown for the nccl_error tests.
3) Ensure AssertionError is not ignored for tests that skip return code
checking.
Test Plan: unit tests
Differential Revision: D17003555
fbshipit-source-id: 0e0429367fb6dae251b74e9f8b2baa67a48a0d22
Summary:
Introducing circleCI jobs for pytorch_android gradle builds, the ultimate goal of it at the moment - to run:
```
gradle assembleRelease -p ~/workspace/android/pytorch_android assembleRelease
```
To assemble android gradle build (aar) we need to have results of libtorch-android shared library with headers for 4 android abis, so pytorch_android_gradle_build requires 4 jobs
```
- pytorch_android_gradle_build:
requires:
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_x86_32_build
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_x86_64_build
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_arm_v7a_build
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_arm_v8a_build
```
All jobs use the same base docker_image, differentiate them by committing docker images with different android_abi -suffixes (like it is now for xla and namedtensor): (it's in `&pytorch_linux_build_defaults`)
```
if [[ ${BUILD_ENVIRONMENT} == *"namedtensor"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-namedtensor
elif [[ ${BUILD_ENVIRONMENT} == *"xla"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-xla
elif [[ ${BUILD_ENVIRONMENT} == *"-x86"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-x86
elif [[ ${BUILD_ENVIRONMENT} == *"-arm-v7a"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-arm-v7a
elif [[ ${BUILD_ENVIRONMENT} == *"-arm-v8a"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-arm-v8a
elif [[ ${BUILD_ENVIRONMENT} == *"-x86_64"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-x86_64
else
export COMMIT_DOCKER_IMAGE=$output_image
fi
```
pytorch_android_gradle_build job copies headers and libtorch.so, libc10.so results from libtorch android docker images, to workspace first and to android_abi=x86 docker image afterwards, to run there final gradle build calling `.circleci/scripts/build_android_gradle.sh`
For PR jobs we have only `pytorch_linux_xenial_py3_clang5_android_ndk_r19c_x86_32_build` libtorch android build => it will have separate gradle build `pytorch_android_gradle_build-x86_32` that does not do docker copying,
it calls the same `.circleci/scripts/build_android_gradle.sh` which has only-x86_32 logic by condition on BUILD_ENVIRONMENT:
`[[ "${BUILD_ENVIRONMENT}" == *-gradle-build-only-x86_32* ]]`
And has filtering to un only for PR as for other runs we will have the full build. Filtering checks `-z "${CIRCLE_PULL_REQUEST:-}"`
```
- run:
name: filter_run_only_on_pr
no_output_timeout: "5m"
command: |
echo "CIRCLE_PULL_REQUEST: ${CIRCLE_PULL_REQUEST:-}"
if [ -z "${CIRCLE_PULL_REQUEST:-}" ]; then
circleci step halt
fi
```
Updating docker images to the version with gradle, android_sdk, openjdk - jenkins job with them https://ci.pytorch.org/jenkins/job/pytorch-docker-master/339/
pytorch_android_gradle_build successful run: https://circleci.com/gh/pytorch/pytorch/2604797#artifacts/containers/0
pytorch_android_gradle_build-x86_32 successful run: https://circleci.com/gh/pytorch/pytorch/2608945#artifacts/containers/0
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25286
Reviewed By: kostmo
Differential Revision: D17115861
Pulled By: IvanKobzarev
fbshipit-source-id: bc88fd38b38ed0d0170d719fffa375772bdea142
Summary:
Here is a PR adding ```ModuleList``` to ```modules.h``` so that it can be used by including ```torch/torch.h```.
yf225 edit: Closes https://github.com/pytorch/pytorch/issues/25293.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25346
Differential Revision: D17115013
Pulled By: yf225
fbshipit-source-id: 38a1848b9a8272fa411865dfc83b76d10c5789a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25336
1. Remove versions from workflows
2. Escape heredoc `<<` used in shells
3. Replace "." with "_" in binary job names (we already do the same for other jobs)
4. (Bonus), fix `should_run_job.py` it so that commits with `[ci]` don't accidentally skip all jobs
Let's see if it works
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25336
Test Plan: Imported from OSS
Differential Revision: D17114619
Pulled By: suo
fbshipit-source-id: 722606ad862af565cd0ba4bb539daeb9d8f5da71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25339
This is to get rid of backend-specific dispatch in modules; this autograd function is no longer backend specific so
doesn't need to be in a backend specific location.
Test Plan: Imported from OSS
Differential Revision: D17101576
Pulled By: gchanan
fbshipit-source-id: f4f0bd3ecc2d4dbd8cdfedbaabcadb8c603d2507
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25326
And also uses self._backend, which I'm trying to kill or at least drastically reduce.
Test Plan: Imported from OSS
Differential Revision: D17097303
Pulled By: gchanan
fbshipit-source-id: f55d7df2a668425978499d4a4338b23ba6cf1b90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25323
They don't seem to be used anymore.
Test Plan: Imported from OSS
Differential Revision: D17097302
Pulled By: gchanan
fbshipit-source-id: dc1133e32586818a9b2e2b7560d259d36c7b36f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25280
`ATen/core/Tensor.h` and `ATen/core/TensorMethods.h` both depend on
Dimname.h and NamedTensor.h. Therefore `Dimname.h` and `NamedTensor.h`
should really be in `ATen/core`. It's not a problem right now because
this dependency chain (core files cannot depend on non-core files) isn't
enforced in our OSS builds, but it is necessary to resolve this before
removing the BUILD_NAMEDTENSOR flag.
Test Plan
- [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17087195
Pulled By: zou3519
fbshipit-source-id: f06e4268d91fabadb04b41d5b78fb0e530f030fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25375
Either MSVC or the Windows headers have a PURE macro defined and will replace
any occurrences of the PURE token in code with an empty string. Replace
AliasAnalysisKind::PURE with AliasAnalysisKind::PURE_FUNCTION.
Note: this is bc breaking.
ghstack-source-id: 89202222
Test Plan: unit tests
Differential Revision: D17107743
fbshipit-source-id: 899a20651ba32d50691956b5424b351586c21cec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25252
Our model going forward for extensions will be that you will have to
get an allocation of an ID in our system. This is how things work
in practice today; we're just simplifying our underlying registration
since there is no need to have distributed registration.
There are some codemods in this diff:
```
codemod --extensions cpp,h,cc,cuh,py,in --exclude-paths=c10/core/TensorTypeId.h '([A-Za-z]+?)TensorId\(\)' 'TensorTypeId::\1TensorId'
codemod --extensions cpp,h,cc,cuh,py,in 'TensorTypeIds::undefined\(\)' 'TensorTypeId::UndefinedTensorId'
codemod --extensions cpp 'TensorType1\(\)' 'TensorTypeId::CPUTensorId'
codemod --extensions cpp 'TensorType2\(\)' 'TensorTypeId::CUDATensorId'
codemod --extensions cpp 'TensorType3\(\)' 'TensorTypeId::XLATensorId'
codemod --extensions cpp 'TensorType1' 'CPUTensorId'
codemod --extensions cpp 'TensorType2' 'CUDATensorId'
codemod --extensions cpp 'TensorType3' 'XLATensorId'
```
The main hand-written changes are in c10/core/TensorTypeId.h
Other manual fixes:
- aten/src/ATen/core/op_registration/op_registration.cpp - stop using
std::string operator+
- aten/src/ATen/function_wrapper.py - handle a hardcoded TypeId() that
wasn't caught by codemod
- torch/csrc/tensor/python_tensor.h - fix now incorrect forward declaration
of TensorTypeId
- aten/src/ATen/core/op_registration/ - remove out-of-line registration
Differential Revision: D17072001
Test Plan: ossci and sandcastle
Pulled By: ezyang
fbshipit-source-id: c641515fd0604c045c54fbb1d6b1b950f45e89d1
Summary:
…default value
Addresses https://github.com/pytorch/pytorch/issues/24962. A valid (and the default) value for the `device` parameter in the `cuda` method is `None`. Type signature was returning invalid linter errors in PyCharm. Verified fix in latest PyCharm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25018
Differential Revision: D17098520
Pulled By: VitalyFedyunin
fbshipit-source-id: d83eb9976f09c75b4a033cb49c81d972e3fd37c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25322
As far as I can tell, none of these are actually used anymore.
Test Plan: Imported from OSS
Differential Revision: D17097301
Pulled By: gchanan
fbshipit-source-id: 649ee0fd549f6e2a875faef7c32b19c70bb969b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25282
For now it will be used in quantization, but it can be used as a
standalone pass too.
Couple of things are not finished at this moment:
- Batchnorm.eps value is hardcoded. This is bad and wrong, but we cannot
access fields listed in __constants__ from IR now. Once we fix this, we
should remove the hardcoded value.
- We do not remove Batchnorm submodules from the parent module even when
they were merged into a Conv. Once we figure out API for removing
attributes and modules, we should fix this.
Test Plan: Imported from OSS
Differential Revision: D17086611
Pulled By: ZolotukhinM
fbshipit-source-id: d58a947a3b2205d8f3629d693b70b9ad2b5a9102
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25069
This PR changes the API of insert_observers to use qconfig_dict,
full functionality support will come in later PRs
Test Plan:
```
python test/test_quantizer.py
python test/test_jit.py
```
Imported from OSS
Differential Revision: D17001135
fbshipit-source-id: 16df6fa521fcc0c9e268a375be8e1a630e77011a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25151
The prim::GetAttr operator depends on node. However, in lite interpreter there will be no node dependency. Promote the operator to a first-class instruction.
Test Plan: Imported from OSS
Differential Revision: D17076412
fbshipit-source-id: 8de20978445bb598634c5462e66e4459dcd567be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25148
Instructions will be used in lite interpreter as well. Pull it out of interpreter.cpp, so that the lite interpreter doesn't have to compile with interpreter.cpp.
Test Plan: Imported from OSS
Differential Revision: D17076413
fbshipit-source-id: 99b3d8d27a96823a4a4dde6b2337ee44635e34cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25265
This ensures that the output strides match the input strides. Previously, we would degenerate down to slow scalar code because the call to _empty_affine_quantize would produce a tensor with different strides than the operands. When this mismatch occurs, TensorIterator uses the scalar code. This fixes that
Benchmark script:
```
import torch, time
x = torch.rand(1, 56, 56, 256)
y = torch.rand(1, 56, 56, 256)
qX = torch.quantize_linear(x, 0.1, 128, torch.quint8)
qY = torch.quantize_linear(y, 0.1, 128, torch.quint8)
s = time.time()
for i in range(1000):
x + y
print('float contig', time.time() - s)
s = time.time()
for i in range(1000):
torch.ops.quantized.add(qX, qY, 0.5, 1)
print('quantized contig', time.time() - s)
x = torch.rand(1, 56, 56, 256)
y = torch.rand(1, 56, 56, 256)
qX = torch.quantize_linear(x, 0.1, 128, torch.quint8).permute([0, 3, 1, 2])
qY = torch.quantize_linear(y, 0.1, 128, torch.quint8).permute([0, 3, 1, 2])
x = x.permute([0, 3, 1, 2])
y = y.permute([0, 3, 1, 2])
s = time.time()
for i in range(1000):
x + y
print('float strided', time.time() - s)
s = time.time()
for i in range(1000):
torch.ops.quantized.add(qX, qY, 0.5, 1)
print('quantized strided', time.time() - s)
```
Before this change
```
$ OMP_NUM_THREADS=1 python cmp.py
float contig 0.4625673294067383
quantized contig 1.8083674907684326
float strided 0.46366071701049805
quantized strided *8.30056643486023*
```
After this change
```
$ OMP_NUM_THREADS=1 python cmp.py
float contig 0.48703694343566895
quantized contig 2.0587124824523926
float strided 0.4711723327636719
quantized strided *2.0382332801818848*
```
Test Plan: Imported from OSS
Differential Revision: D17077811
Pulled By: jamesr66a
fbshipit-source-id: 25f52743081162122dfc9eb4bc39185d4cc4ba3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25052
Previously we would not inline nested functions, now we do.
Test Plan: Imported from OSS
Differential Revision: D16973848
Pulled By: suo
fbshipit-source-id: 94aa0b6f84a2577a663f4e219f930d2c6396d585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24875
As per https://github.com/pytorch/pytorch/issues/23110, each autograd pass
would be assigned a unique autograd_context_id. In this change we introduce a
DistAutogradContainer per worker which holds information for each autograd pass
currently running.
DistAutogradContainer has a map from the autograd_context_id to
DistAutogradContext (which holds all the relevant information for the autograd
pass). DistAutogradContext currently only stores the autograd_context_id and
more information would be added to it later as we build out the rest of the
framework.
The autograd_context_id is a 64 bit globally unique integer where the first 16
bits are the worker_id and next 48 bits are auto-incrementing for uniqueness.
Sample python code on how this would be used for distributed autograd:
```
import torch.distributed.autograd as dist_autograd
worker_id = 0
dist_autograd.init(worker_id)
with dist_autograd.context() as context_id:
# forward pass...
# backward pass...
# optimizer step...
```
ghstack-source-id: 89119248
Test Plan: unit tests.
Differential Revision: D16356694
fbshipit-source-id: d1a8678da0c2af611758dbb5d624d554212330ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25136
Previously we were calling unifyType to match typevars at callsites.
unifyType actually does merging (e.g. to handle control flow joins)
so its effect at callsites was bivariance, allowing typevar bindings
to widen as new concrete types were encountered in arguments.
Fixes issue #24856
Strip refinements when doing invariant matching on type vars.
Previous change (bivariance to invariance) makes type matching
sensitive to the addition of type refinements. Use unshapedType
to avoid considering refinements when doing matching.
Test Plan: Imported from OSS
Differential Revision: D17078081
Pulled By: bhosmer
fbshipit-source-id: 54476469679af698cfe9bd020a39de31271f52cc
Summary:
Hi,
I noticed after v1.2.0 the implement of LBFGS optimizer has been changed. In this new implement, the return condition has been changed from the sum of the gradients to the max value in the gradients (see: b15d91490a/torch/optim/lbfgs.py (L313)). But the default tolerance_grad parameter has not been changed (which is too large for max of gradients), so this result in lots of my old codes not optimizing or only optimizing for one or two steps.
So, I came up this pull request to suggest that changing this tolerance_grad to a smaller value
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25240
Differential Revision: D17102713
Pulled By: vincentqb
fbshipit-source-id: d46acacdca1c319c1db669f75da3405a7db4a7cb
Summary:
Don't throw in constant propagation, since the op we're running may not be reached. Previously we would only only catch `C10::Error`; however it's hard to maintain that the entire codebase doesn't throw any other types of errors, and some errors map nicely to python errors, like `std::index_error` to IndexError.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25270
Differential Revision: D17102545
Pulled By: eellison
fbshipit-source-id: 9fd485821743ad882e5c6fc912ca47b0b001b0e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25259
Switching to tensorboard instead of tensorflow
Test Plan: went through instructions in [fbsource/fbcode/caffe2/caffe2/contrib/tensorboard/tensorboard.md] to make sure everything is working (using/not using tensorboard/tensorflow)
Reviewed By: orionr
Differential Revision: D17059111
fbshipit-source-id: aaa26dec840fb517b3bc7dc988f3a8c54566d356
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25178
Previously, we were using torch/csrc/utils/memory.h. This switches those
headers to be c10/util/C++17.h.
Context: ATen and torch are the same library now, so one can call code
in torch from ATen. However, I haven't seen an example of that yet
(aside from the named tensor code that uses make_unique from torch). In
this PR I try to maintain the ATen / torch separation just in case it
matters.
Test Plan
- Check that code compiles [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17051453
Pulled By: zou3519
fbshipit-source-id: 44b6393a748bdb1e671ecb1e9a615c33202e8515
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25177
Test Plan
- new tests [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17051452
Pulled By: zou3519
fbshipit-source-id: 7259cdb7ba7f480035528cf3c60ef6d051e42db5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25123
The approach is different for CPU and CUDA. In particular:
- in CPU, I added a name inference rule to bmm_out
- in CUDA, bmm calls THCTensor_(baddbmm) so I added a name inference
rule to that.
When one calls baddbmm on CPU or CUDA, it'll error out with NYI due to
named_guard: True on it in native_functions.yaml. I'm not planning on
implementing baddbmm soon because it's a little tricky to add it to CPU
and bmm is more commonly used function.
Test Plan
- new tests [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D16998073
Pulled By: zou3519
fbshipit-source-id: 8dc01898964318717911f28eebd6cdfffc7dfcf2
Summary:
Related: https://github.com/pytorch/pytorch/issues/24927#issuecomment-524608021
`fork` inherits lock state. So if we happen to unfortunately fork when the `SharedCache` lock is held. We could deadlock in the child process when some code tries to acquire it.
Following pytorch multiprocessing library design, this patch resets the lock to a new object after fork. A similar example from python core lib for `multiprocessing.Queue` is :
```py
class Queue(object):
def __init__(self, ...):
...
self._after_fork()
if sys.platform != 'win32':
register_after_fork(self, Queue._after_fork)
def _after_fork(self):
debug('Queue._after_fork()')
self._notempty = threading.Condition(threading.Lock())
self._buffer = collections.deque()
self._thread = None
self._jointhread = None
self._joincancelled = False
self._closed = False
self._close = None
self._send_bytes = self._writer.send_bytes
self._recv_bytes = self._reader.recv_bytes
self._poll = self._reader.poll
```
d4d60134b2/Lib/multiprocessing/queues.py (L54-L78)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25158
Differential Revision: D17091227
Pulled By: soumith
fbshipit-source-id: ee7130f47d7bbd42fc34a2598f1f6974d8d7cdb7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25313
`sign` was recently ported from TH to ATen, undoing some named tensor
changes and breaking the CI named tensor test. This PR re-enables named tensor
for `sign`.
Test Plan
- [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D17093439
Pulled By: zou3519
fbshipit-source-id: 11185ad88a0eaf56078b94e9547bbbd6d02d0aab
Summary:
Using `TORCH_WARN_ONCE` for `Tensor.data<T>()` is still causing deadlocks internally. According to Dima: "So the problem seems to be in TORCH_WARN/c10::Warning::warn which produces a warning - we setup a wrapper that sends the message back to python land. But doing so requires acquiring GIL and it somehow deadlocks. In general using TORCH_WARN in so low-level API is dangerous as there's no guarantee whether we're running under GIL or not."
In order to avoid causing accidental deadlocks in other code including external extensions, the use of `TORCH_WARN_ONCE` in `Tensor.data<T>()` is changed to `C10_DEPRECATED_MESSAGE` in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25319
Reviewed By: dzhulgakov
Differential Revision: D17094933
Pulled By: yf225
fbshipit-source-id: e29dc35187f73ca7865cfa5a9ecde708cd237c58
Summary:
Moving so that `new_criterion_tests` can be used from `test_cpp_api_parity.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25333
Differential Revision: D17097188
Pulled By: yf225
fbshipit-source-id: 7f7905cc6799bca8dc6b3c9cc43995313c6bc058
Summary:
addresses https://github.com/pytorch/pytorch/issues/21640 for CPU tensors and the Gloo backend.
Questions:
- ~~currently takes `AllreduceOptions`, since all of the options are the same. Would it be better to make a new `AllreduceCoalescedOptions` class?~~
- ~~I decided to inherit from `ProcessGroupGloo::AsyncWork` instead of `AsyncAllreduceWork` to shorten the inheritance chain a bit and for consistency with existing classes. However, this means that the two `getFunction` methods are copy-pasted. Would inheriting from `AsyncAllreduceWork` be preferable?~~
- ~~should the work class be named `AsyncCoalescedAllreduceWork` or `AsyncAllreduceCoalescedWork`?~~
thank you!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24949
Differential Revision: D17055580
Pulled By: mrshenli
fbshipit-source-id: e63b5fcaec6021053ea960776a09ee8cf11d1ec2
Summary:
Fixing https://github.com/pytorch/pytorch/issues/24750
```
DEBUG = 0
OMP_NUM_THREADS = 1
import torch
base = torch.randn(1000000)
exp = torch.randn(1000000)
out = torch.empty_like(base)
timeit base.pow(0) +30x
old 6.26 ms ± 35.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 213 µs ± 3.38 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(1/3) +6x
old 56 ms ± 911 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.41 ms ± 237 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit base.pow(-1/3) +6x
old 57 ms ± 1.65 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.49 ms ± 293 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit base.pow(1/2) +6x
old 4.04 ms ± 14.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 620 µs ± 3.35 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(-1/2) +5x
old 6.56 ms ± 43 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 1.24 ms ± 19.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(1) no diff
old 322 µs ± 4.7 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
new 331 µs ± 7.26 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(-1) +3.5x
old 2.48 ms ± 15.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 717 µs ± 130 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(2) no diff
old 328 µs ± 7.42 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
new 324 µs ± 4.93 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(-2) +3.5x
old 2.45 ms ± 11.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 662 µs ± 3.83 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(3) +7x
old 2.39 ms ± 60.7 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 334 µs ± 7.26 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit base.pow(-3) +9x
old 93.7 ms ± 5.27 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 10.3 ms ± 666 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit base.pow(123456.789) +5x
old 46.5 ms ± 418 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.68 ms ± 325 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit base.pow(-123456.789) +5x
old 46.5 ms ± 784 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 10 ms ± 541 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit base.pow(exp) +6x
old 60.6 ms ± 4 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.7 ms ± 379 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit torch.pow(0, exp) no diff
old 18.3 ms ± 859 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 21.2 ms ± 333 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
timeit torch.pow(1, exp) +30x
old 6.01 ms ± 81.6 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 203 µs ± 1.08 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit torch.pow(-1, exp) +3x
old 30.8 ms ± 5.51 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.67 ms ± 441 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit torch.pow(42, exp) +8x
old 80.1 ms ± 1.57 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.51 ms ± 103 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit torch.pow(-42, exp) +2x
old 21.8 ms ± 4.37 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.5 ms ± 89.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit torch.pow(0, exp, out=out) no diff
old 20.2 ms ± 3.04 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 22.1 ms ± 648 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
timeit torch.pow(1, exp, out=out) +30x
old 6.7 ms ± 397 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
new 203 µs ± 4.64 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
timeit torch.pow(-1, exp, out=out) +3x
old 32.5 ms ± 3.61 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.4 ms ± 99.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit torch.pow(42, exp, out=out) +10x
old 91 ms ± 7.45 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 9.64 ms ± 291 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
timeit torch.pow(-42, exp, out=out) +2.5x
old 25.9 ms ± 5.03 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
new 10.1 ms ± 698 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
BC: enforce stronger shape requirements on the output tensor (out= keyword argument) and do not allow output tensor to be resized if it is also used as one of the inputs.
BC: enforce stronger integer tensor base power integer exponent requirement on CPU and CUDA: `Integers to negative integer powers are not allowed.`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23492
Differential Revision: D16731583
Pulled By: pbelevich
fbshipit-source-id: 4e5bf689357fe82a19371e42d48abbb7b4c1c3ca
Summary:
Adds documentation for `nn.functional.bilinear`, as requested in https://github.com/pytorch/pytorch/issues/9886.
The format follows that of `nn.functional.linear`, and borrows from `nn.bilinear` in its description of `Tensor` shapes.
I am happy to add more extensive documentation (e.g. "Args," "Example(s)"). From what I gather, the format of comments is inconsistent across functions in `nn.functional.py` and between modules (e.g. `nn.functional` and `nn`). It's my first PR, so guidance for contributing documentation and other code would be greatly appreciated!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24951
Differential Revision: D17091261
Pulled By: soumith
fbshipit-source-id: efe2ad764700dfd6f30eedc03de4e1cd0d10ac72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25268
The AT_FORALL AND macros with mistakenly already include Half, which differs from the Dispatch macros.
This change shouldn't have any effect.
Test Plan: Imported from OSS
Differential Revision: D17079747
Pulled By: gchanan
fbshipit-source-id: 635eb167722ce850d6c1949fac652de4dddf32ee
Summary:
They are not supposed to be copied.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24932
Differential Revision: D16940997
Pulled By: gchanan
fbshipit-source-id: 6f16211ec57f8db6baec86e17288c8050c89cab5
Summary:
1. upgrade MKL-DNN to v0.20.3
2. allow user to change the capability of primitive cache in mkldnn-bridge by environment value LRU_CACHE_CAPACITY
3. support to fill all tensor elements by one scalar
4. fix the link issue if build with private MKLML other than pre-installed MKL
5. add rnn support in mkldnn-bridge
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22910
Differential Revision: D16365998
Pulled By: VitalyFedyunin
fbshipit-source-id: b8d2bb454cbfbcd4b8983b1a8fa3b83e55ad01c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25212
In eager mode, all modules need to work with input tensors that can change qparams dynamically. This issue https://github.com/pytorch/pytorch/issues/23874 will address this via FBGEMM modifications. This is a work around before that.
ghstack-source-id: 89118038
Test Plan:
buck test caffe2/test:quantized -- 'test_conv_api \(test_quantized_nn_mods\.ModuleAPITest\)' --print-passing-details
Summary (total time 65.86s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D17064471
fbshipit-source-id: 3c192442b19bf2d9d88d4e52de6c24dc134a846f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25283
Return a message instead of void from rpc udf
This is to help thrift style rpc where there is no need for explicit send for a response.
We need to figure out how to solve the non-blocking callback case but don't want to block the thrift backed rpc agent implementation till then.
ghstack-source-id: 89130305
Differential Revision: D16825072
fbshipit-source-id: 75cb1c9aa5a10363b1c6b12cd21c50d7047d2268
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25295
As Title says.
Test Plan: CI
Reviewed By: hl475
Differential Revision: D17089457
fbshipit-source-id: b45ca24decd6033e7e207f17540d486df6ef2ddc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24863
Add the sparse feature name in logging for ease of debugging
Test Plan:
./buck-out/gen/caffe2/caffe2/fb/dper/layer_models/sparse_nn/pooling_test#binary.par -r test_simple_sum_pooling_named_exception
Another test for id_score_list. the original sparse_key is equivalent to get_key(self.input_record)()
P98343716
./buck-out/gen/caffe2/caffe2/python/layers_test-2.7#binary.par -r test_get_key
Reviewed By: chocjy
Differential Revision: D16901964
fbshipit-source-id: 2523de2e290aca20afd0b909111541d3d152a588
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25228
This adds a facility to isSubtypeOf for it to explain why a type is
not a subtype of something else. It is used in situations where it
is not clear from the types python_str alone why the relationship
is now true. Because of subtle interaction between default arguments,
overloads, and virtual methods, it uses isSubtypeOfExt for the extended
version to avoid requiring readers to understand the interaction.
Test Plan: Imported from OSS
Differential Revision: D17066673
Pulled By: zdevito
fbshipit-source-id: 4de7c40fbf7f9eeae045d33a89a038538cf87155
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25227
Adds cases to NamedType serialization to so that interfaces are written.
Similar implementation to NamedTuples
Test Plan: Imported from OSS
Differential Revision: D17066674
Pulled By: zdevito
fbshipit-source-id: fda5419260fad29e8c4ddb92de1d3447d621d982
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25226
Given the current structure, it is easier to just call different functions
to get the desired behavior.
Test Plan: Imported from OSS
Differential Revision: D17066672
Pulled By: zdevito
fbshipit-source-id: 88e76c5ee870d9d1e9887aebcac5e7873fabe6b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25258
this is the first commit in a series to add interfaces to JIT.
Interfaces allow the specification through a blank python class of an
abstract interface that can be used in type annotations for Script functions.
If a TorchScript class implements all the methods in the interface with
the appropriate types, then it is implicitly considered to implement
that interface.
Follows required:
* implementation of serialization
* implementation in the parser frontend
* better error reporting for explaining why a class does not meet an
interface specification.
Test Plan: Imported from OSS
Differential Revision: D17079963
Pulled By: zdevito
fbshipit-source-id: a9986eeba2d4fdedd0064ce7d459c0251480a5a0
Summary:
When a closure was declared that always throw'd we would erroneously propagate the ExitThrows status to the block in which it was declared, causing us to remove the subsequent code in the block. [this code](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/script/exit_transforms.cpp#L462) was meant to handle this case, however it didn't handle the case when we were transforming Loops and the prim::Function wasn't a target block.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25278
Differential Revision: D17084780
Pulled By: eellison
fbshipit-source-id: ee31a4cc243653f615e4607ece29cdac8ef5710e
Summary:
This PR adds `TORCH_WARN_ONCE` macro, and use it in `Tensor.data<T>()`.
cc. gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25207
Differential Revision: D17066263
Pulled By: yf225
fbshipit-source-id: 411c6ccc8326fb27ff885fee4638df8b5ba4d449
Summary:
This PR linked to https://github.com/pytorch/pytorch/issues/22806 moving sign function to ATen.
sign(x) supports bool, and vectorized operation on CPU.
sign(NaN) is defined to return 0.
sign(bool) is a no-op, the resulting tensor will holds the same values than the input one.
- [x] CPU Backend
- [x] CUDA Backend
- [x] Bring support for bool dtype
- [x] Bring support for Half dtype
- [x] Add test for NaN
- [x] Add test for bool dtype
- [x] Delete legacy implementation in THTensorMoreMath.cpp
Performances:
```python
timeit -s 'import torch; x = torch.randn((1000, 1000))' -n 1000 'torch.sign(x)'
timeit -s 'import torch; x = torch.randn((1000, 1000), device="cuda")' -n 1000 'torch.sign(x); torch.cuda.synchronize()'
```
| device | before | after |
| :-------------: | :-------------: | :-----: |
| CPU | 1.24 msec | 33.9 usec |
| GPU | 680 usec | 7.13 usec |
| CPU (1 thread) | 0.82 msec | 0.73 msec |
| GPU (1 thread) | 16.1 used | 15.9 usec |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22861
Differential Revision: D16503452
Pulled By: VitalyFedyunin
fbshipit-source-id: a87ce7fff139642ef4ed791f15873074ad0d53af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24103
This change adds a quantized add and maxpool2d operation for pytorch mobile.
These operators follow the structure of qnnpack in terms of create/setup and run calls. The plan to refactor QNNPACK to make it more functional is currently for FC and Conv ops where the cost of create/setup is high.
For ops like add and maxpool the cost of calling create and setup in each operator invocation is negligible.
Once we migrate FC and Conv QNNPACK ops to be functional in nature, we will consider changing these ops as well to make it consistent.
ghstack-source-id: 88997042
Test Plan:
python test/test_quantized.py TestQNNPackOps.test_qnnpack_add
python test/test_quantized.py TestQNNPackOps.test_qnnpack_maxpool2d
Differential Revision: D16734190
fbshipit-source-id: 5152aed88e8bbe4f701dba4886eac989bdcefe8f
Summary:
We have environment variable USE_CUDNN with self-explanatory name. However cpp code is compiled based on cpp macro definition AT_CUDNN_ENABLED, which is defined as:
```
IF (NOT AT_CUDA_ENABLED OR NOT CUDNN_FOUND)
MESSAGE(STATUS "CuDNN not found. Compiling without CuDNN support")
set(AT_CUDNN_ENABLED 0)
ELSE()
include_directories(SYSTEM ${CUDNN_INCLUDE_DIRS})
set(AT_CUDNN_ENABLED 1)
ENDIF()
```
So, even if USE_CUDNN is set to 0, cpp is compiled with cuDNN if cmake finds cuDNN in the system. I actually tested it and was very surprised when I was debugging cuDNN code which I built with USE_CUDNN=0. I believe that cmake code above should look like this:
`IF (NOT AT_CUDA_ENABLED OR NOT CUDNN_FOUND OR NOT USE_CUDNN) ...`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25037
Differential Revision: D17048683
Pulled By: pbelevich
fbshipit-source-id: 48afa19eaae0bba2ffd49c1f68db0b4efd5cf85e
Summary:
In current pytorch/master we have only libtorch android build for static libraries for armv7
This change adds the same builds with shared library to circleCI, abis: x86, x86_64, arm
-v7a, arm-v8a
In pytorch_build_data.py I added new AndroidAbiConfigNode:
class AndroidAbiConfigNode(TreeConfigNode):
def init2(self, node_name):
self.props["android_abi"] = node_name
def child_constructor(self):
return ImportantConfigNode
That can be children of
ExperimentalFeatureConfigNode
And it results:
("android", [
("r19c", [
("3.6", [
("android_abi", [XImportant("x86")]),
("android_abi", [XImportant("x86_64")]),
("android_abi", [XImportant("arm-v7a")]),
("android_abi", [XImportant("arm-v8a")]),
])
]),
]),
As all parameters are used for docker_image_name generation, while I wanted to use the same docker image for all android jobs - I introduced in Conf.parms_list_ignored_for_docker_image in pytorch_build_definitions.py
It contains parameters that will not be joined to docker_image but used for job name generation and build_environment generation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25192
Reviewed By: kostmo
Differential Revision: D17078465
Pulled By: IvanKobzarev
fbshipit-source-id: c87534a45fb92c395e0dd3471213d42d3613c604
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25223
Before this PR, it shows the following warning:
```
> caffe2/aten/src/ATen/core/Tensor.h:297: UserWarning: Tensor.data<T>() is deprecated. Please use Tensor.data_ptr<T>() instead.
> TORCH_WARN("Tensor.data<T>() is deprecated. Please use Tensor.data_ptr<T>() instead.");
> caffe2/aten/src/ATen/core/Tensor.h:297: UserWarning: Tensor.data<T>() is deprecated. Please use Tensor.data_ptr<T>() instead.
> TORCH_WARN("Tensor.data<T>() is deprecated. Please use Tensor.data_ptr<T>() instead.");
```
After this PR, the warning message should disappear.
ghstack-source-id: 89113498
Test Plan: CI
Differential Revision: D17066471
fbshipit-source-id: e4fec964b5333ff968c8cf218286d4a8ab8dbe54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25133
This is driven by benchmarks I did for moving ATen ops to the c10 operator library.
Improvements:
- tell the compiler that the error cases are unlikely so it can optimize code better
- optimize cache layout of LeftRight.
ghstack-source-id: 88907294
Test Plan: unit tests
Differential Revision: D16998010
fbshipit-source-id: 0e3cbff0a4983133a4447ec093444f5d85dd61d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25001
Seems QScheme and Quantizer class type has 1-1 mapping, so use it to compare whether
two quantizers are equal instead of using dynamic_cast.
This way the code can remain mobile friendly as our internal mobile build doesn't
enable rtti by default.
ghstack-source-id: 88925243
Test Plan:
- builds;
- will check CI tests;
Differential Revision: D16951501
fbshipit-source-id: 585b354f64e5188fd34f01d456c91cec232ba6b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25195
The test will fila for large samples adue to deadline constraint in the hypothesis framework.
Test Plan: Imported from OSS
Differential Revision: D17059087
Pulled By: zafartahirov
fbshipit-source-id: 915f46ecae61de1b384136c14da25ee875d1c02d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25249
See #25097
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17071632
Pulled By: ezyang
fbshipit-source-id: 1c5ad7204f1d30f5c67d682fbb083608e067cb2a
Summary:
Currently they sit together with other code in cuda.cmake. This commit is the first step toward cleaning up cuDNN detection in our build system.
Another attempt to https://github.com/pytorch/pytorch/issues/24293, which breaks manywheels build because it does not handle `USE_STATIC_CUDNN` properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24938
Differential Revision: D17070920
Pulled By: ezyang
fbshipit-source-id: a4d017a3505c102d9c435a73ae62332e4336c52e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24474
torch.dot is a little weird. It ignores the names of its inputs to be
consistent with the rest of our matrix multiplication functions.
I've written the implementation using a helper function that is also
used by other matrix multiplication functions so that it is easy to
change the behavior.
Test Plan
- new tests [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D16915802
Pulled By: zou3519
fbshipit-source-id: 628a6de1935357022cc92f4d23222736a70bb070
Summary:
Not meant to be a landing blocker or anything like that. This only lets me setup some more effective email filters, hopefully allowing me to discover the current changes earlier and be more responsive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25231
Differential Revision: D17070735
Pulled By: soumith
fbshipit-source-id: 171c8dcd48edf64a9dc3367015e4166baa860c0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25211
P
Change dtypes of all tensors in testqat to double precision. Without this change, the backward pass showed small mismatches the root cause of which wasnt clear. With this change, the numerics match to a precision of 1e-10 and this test is useful and provides a tight check on numerics.
ghstack-source-id: 89041119
Test Plan:
buck test caffe2/test:quantized -- 'test_conv_bn_relu \(test_qat\.IntrinsicQATModuleTest\)' --print-passing-details
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/3377699726578151
✓ caffe2/test:quantized - test_conv_bn_relu (test_qat.IntrinsicQATModuleTest) 17.777 1/1 (passed)
Test output:
> test_conv_bn_relu (test_qat.IntrinsicQATModuleTest) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 17.778s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/3377699726578151
Summary (total time 22.03s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D17064183
fbshipit-source-id: 7f6d5d2b71430b6aaf4f6d741b56a2bd1247ac29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24999
As described in previous PR, we are doing module level observer rather
than global observer now, so majority of code are deprecated. But we
still keeps some logic that is independent of this decision in the new
code.
Test Plan:
.
Imported from OSS
Differential Revision: D17001138
fbshipit-source-id: b456f80d587a61e368c626e7e8ac2a4f1282268b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24998
Original graph mode was developed at the time when we don't have conrete API of qconfig yet and
it has a global observer module which is passed around during the whole quantization flow,
we have a much clearer picture of quantization API now, and we are going to use a per Tensor
observer design, just like in eager mode. This PR removes the deprecated tests, next PR will
remove deprecated code.
Test Plan:
```
python test/test_quantizer.py
```
Imported from OSS
Differential Revision: D17001140
fbshipit-source-id: 87f342cfa8ea6b45606372c51dbfc493065a737a
Summary:
Initial commit of pytorch_android_torchvision that has utility methods for
android.media.Image, YUV_420_888 format (camera output) -> Tensor(Float) with torchvision format, normalized by ImageNet mean,std
Bitmap -> Tensor(Float) torchvision format
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25185
Reviewed By: dreiss
Differential Revision: D17053008
Pulled By: IvanKobzarev
fbshipit-source-id: 6bf7a39615bf876999982b06925e7444700e284b
Summary:
Tensor has getDataAsFloatArray(), we also support Int and Byte Tensors,
adding symmetric methods for Int and Byte, that will throw
IllegalStateException if called for not appropriate type
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25183
Reviewed By: dreiss
Differential Revision: D17052674
Pulled By: IvanKobzarev
fbshipit-source-id: 1d44944461ad008e202e382152cd0690c61124f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24471
mv(Tensor[M, N], Tensor[O]) ignores the names of N and O and returns a
tensor with names [M].
Test Plan: - new tests [namedtensor ci]
Differential Revision: D16915805
Pulled By: zou3519
fbshipit-source-id: d7d47903f249f85ef3be8a188d51993834bf5f55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24469
tensor.expand(*sizes) returns a tensor with names equal to tensor.names
plus unnamed padding in the beginning dimensions.
For example, Tensor[H, W].expand(10, 2, 128, 128) -> Tensor[None, None,
H, W].
Test Plan: - new tests [namedtensor ci]
Differential Revision: D16915804
Pulled By: zou3519
fbshipit-source-id: 77ac97f42e9959d7f6d358c5286e3dc27488e33d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25059
This fixes the cases where a type annotated with optional cannot
be conditionally assigned to none:
```
x : Optional[int] = 4
if ...:
x = None
```
Test Plan: Imported from OSS
Differential Revision: D16975166
Pulled By: zdevito
fbshipit-source-id: 5a7a81224d08b9447e1f4d957fcd882091e02f32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24306
Featuring:
- a new way of writing name inference tests. At some point I'll migrate
the older tests over.
- The out= variants aren't implemented. This is because they are a
little weird: the output gets resized, but I haven't throught through
what semantics that should have.
Test Plan: - new tests [namedtensor ci]
Differential Revision: D16915801
Pulled By: zou3519
fbshipit-source-id: 29ae2ee414c7d98e042965458c5dccef7ddbd4dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24921
Let `unnamed = torch.randn(1, 1, 1)` and `named = torch.randn(1, 1,
names=('N', 'C'))`.
Previously, there was a bug where `unnamed + named` would error out.
This happened because `unify_from_right(unnamed.opt_names(),
named.opt_names())` would return `named.names()`, which was propagated
to the output tensor. However, the output tensor has dim 3, but
`names.names()` only has 2 elements, so the code would throw an error.
The solution implemented in this PR is to stop trying to do premature
optimization. If all inputs to an operation doesn't have names, then
don't run name inference. However, if any inputs do, then materialize
the names and run name inference.
It's possible to make this more efficient for the case where some inputs
are named and some aren't, but we should benchmark these cases
and determine if it is necessary for it to be more efficient.
Test Plan: - new tests [namedtensor ci]
Differential Revision: D16930710
Pulled By: zou3519
fbshipit-source-id: 0de73c803c8b0f9a1c2d80684b9a47cccba91cbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25189
Change dtypes of all tensors in testqat to double precision. Without this change, the backward pass showed small mismatches the root cause of which wasnt clear. With this change, the numerics match to a precision of 1e-10 and this test is useful and provides a tight check on numerics.
ghstack-source-id: 88999698
Test Plan:
buck test caffe2/test:quantized -- 'test_conv_bn_relu \(test_qat\.IntrinsicQATModuleTest\)' --print-passing-details
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/3377699726578151
✓ caffe2/test:quantized - test_conv_bn_relu (test_qat.IntrinsicQATModuleTest) 17.777 1/1 (passed)
Test output:
> test_conv_bn_relu (test_qat.IntrinsicQATModuleTest) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 17.778s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/3377699726578151
Summary (total time 22.03s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D17053634
fbshipit-source-id: e19d555adee29b49bff873fcc01f527e8272f1c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24923
Replace exception with warning for un initialized min/max values to support creation of quantized models without observers.
ghstack-source-id: 89003800
Test Plan: Replace error message with warning for observers
Differential Revision: D16923660
fbshipit-source-id: 9927ed4e4ee977c1388595ddef042204f71076a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24789
In eager mode, all modules need to work with input tensors that can change qparams dynamically. This issue https://github.com/pytorch/pytorch/issues/23874 will address this via FBGEMM modifications. This is a work around before that.
ghstack-source-id: 89003798
Test Plan:
buck test caffe2/test:quantized -- 'test_conv_api \(test_quantized_nn_mods\.ModuleAPITest\)' --print-passing-details
Summary (total time 65.86s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D16852280
fbshipit-source-id: 988f8ff91616eddf511e71926aa7d2d0f1938188
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23913
This PR bind torch.autograd.backward and tensor.backward to TorchScript,
and make aliasing to the conservative for these two ops, this is mainly
because backward op might write to every input tensors in the graph
Test Plan: Imported from OSS
Differential Revision: D16923272
fbshipit-source-id: 8a4016c62e00d00e0dee3d8c599d3aca220202f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24426
Added following pass:
- _jit_pass_insert_quant_dequant: removes observer modules and calls, insert
quantize_linear-int_repr-_dequantize_linear calls for activation, weight and bias,
the scale of bias is calculated from the scale of input activation and weight
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D17001141
fbshipit-source-id: e81faac697a9c0df862adc5aa8ca2aa9e4ae5fd9
Summary:
This PR adds test harness for checking Python / C++ API parity for `torch.nn.Module` subclasses. Under the hood, we use JIT tracing to transfer `nn.Module` state from Python to C++, so that we can test initialization / forward / backward on Python / C++ modules with the same parameters and buffers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23852
Differential Revision: D16830204
Pulled By: yf225
fbshipit-source-id: 9b5298c0e8cd30e341a9f026e6f05604a82d6002
Summary:
[Not in need of review at this time]
Support focal loss in MTML (effectively dper2 in general) as described in https://arxiv.org/pdf/1708.02002.pdf. Adopt approach similar to Yuchen He's WIP diff D14008545
Test Plan:
Passed the following unit tests
buck test //caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_lr_loss_based_focal_loss
buck test //caffe2/caffe2/fb/dper/layer_models/tests:mtml_test_2 -- test_mtml_with_lr_loss_based_focal_loss
buck test //caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_lr_loss_based_focal_loss_with_stop_grad_in_focal_factor
Passed ./fblearner/flow/projects/dper/canary.sh; URL to track workflow runs: https://fburl.com/fblearner/446ix5q6
Model based on V10 of this diff
f133367092
Baseline model
f133297603
Protobuf of train_net_1 https://our.intern.facebook.com/intern/everpaste/?color=0&handle=GEq30QIFW_7HJJoCAAAAAABMgz4Jbr0LAAAz
Reviewed By: hychyc90, ellie-wen
Differential Revision: D16795972
fbshipit-source-id: 7bacae3e2255293d337951c896e9104208235f33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25083
I missed this in the last PR
Test Plan: Imported from OSS
Differential Revision: D17005372
Pulled By: jamesr66a
fbshipit-source-id: 1200a6cd88fb9051aed8baf3162a9f8ffbf65189
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25075
This change adds a special behavior to subgraph matcher to allow it to
match calls to modules. Namely, when a node in the pattern graph has a
'match::module' type, it is considered 'match' only when the
corresponding node in the target graph is a 'prim::GetAttr' obtaining a
submodule which type matches the type specified in 'name' attribute of
the 'match::module' node.
Currently when comparing the expected module type we check if the string
specified in 'name' prefixes qualified name of the module GetAttr
returns. In future when qualified name format is better defined we will
probably change it for the exact comparison.
Why do we want this? In some cases we would like to perform fusion on a
module level rather than on a graph-level. A popular example of such
fusion would be Conv-BN. It is inpractical to match batchnorm on
graph-evel because that would mean we woudl need to specify its full
and exact implementation in the pattern graph. If we match on the
CallMethod level, however, the problem becomes trivial.
The feature added in this PR allows to detect patterns with 'CallMethod'
nodes, which in its turn allows us to use subgraph rewriter to replace
such patterns with some node (or nodes). I expect that a usual approach
would be to use subgraph-rewriter to replace all matches with some
artificial node and then in additional pass replace such nodes with
calls to another module or something else. It is not possible at the
moment to use subgraph-rewriter to add a call to a method of a new
module, because it can not add a new submodule, but we probably would
add a higher level API to do that.
Test Plan: Imported from OSS
Differential Revision: D16978652
Pulled By: ZolotukhinM
fbshipit-source-id: 37307a5ec65cf4618ad8eb595ef5f8ae656e2713
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25098
Use the same optimization we used for Sum operator in Add when broadcast is not used and inputs are uint8_t.
The optimization uses AVX2 instruction and use fp32 (instead of pure fixed point arithmetic). It does introduce numerical difference but only for minor cases like tie-breaking when rounding.
Test Plan: buck test caffe2/caffe2/quantization/server:elementwise_add_dnnlowp_op_test
Reviewed By: jianyuh
Differential Revision: D16985776
fbshipit-source-id: 8097503dd55f7d39857b3e4102db0f91327a6f55
Summary: It's needed by fp16 SLS.
Test Plan: The lowering works but NNPI doesn't seem to support fp16 SLS yet.
Reviewed By: zrphercule
Differential Revision: D16996047
fbshipit-source-id: e830e4926b416cb7770975838baf17a88dde6d91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25119
Make `defaultSchemaFor` an anonymous function and move it + its caller
into function.cpp
Purely mechanical changes
Test Plan: Imported from OSS
Differential Revision: D16994147
Pulled By: suo
fbshipit-source-id: 96da8b3527eea37ad7beae433122384303a010c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25118
This allows people to temporarily disable a job from running on PRs. We
should use this only if there is a long-running breakage that can't be
fixed in a simple way.
Test Plan: Imported from OSS
Differential Revision: D16994074
Pulled By: suo
fbshipit-source-id: 6aa9c618057c126d16065e53a60204665d8ff0eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24944
As Title says, we would like to make the EmbeddingLookup APIs take offsets rather than lengths to match the PyTorch's EmbeddingBag.
ghstack-source-id: 88883902
Test Plan:
python hp_emblookup_codegen.py --use-offsets
Check the benchmark in D16990830.
Reviewed By: jspark1105
Differential Revision: D16924271
fbshipit-source-id: 7fac640c8587db59fd2304bb8e8d63c413f27cb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25044
Bring in Windows fixes, new microkernels, and zero-batch support.
Test Plan: CI
Reviewed By: supriyar
Differential Revision: D16946393
fbshipit-source-id: 3047eb73f1980e4178b795a20d53e744f176c2d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24914
There are two helpers, Tensor::names(), and Tensor::opt_names().
- Tensor::names() always returns a DimnameList; if the tensor doesn't have
names, it returns a DimnameList of all `None` names.
- Tensor::opt_names() returns an optional<DimnameList>: it returns
names if the tensor has names allocated, otherwise, nullopt.
Tensor::opt_names() is more of an implementation detail. It is
recommended that devs use Tensor::has_names() and Tensor::names()
because those result in a cleaner API.
This PR also cleans up callsites of Tensor::opt_names() to use
Tensor::names() where applicable.
Finally, this PR also adds impl::get_names(TensorImpl*), which is the
analogous function for TensorImpl*. (Tensor::opt_names() <->
impl::get_opt_names(TensorImpl*)).
Test Plan: - run existing tests. [namedtensor ci]
Differential Revision: D16919767
Pulled By: zou3519
fbshipit-source-id: ef30c9427a3d8e978d2e6d01c7f74f5174ccd52c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24907
This better reflects the semantics because Tensor::opt_names() returns
an `optional<DimnameList>`, not just a DimnameList.
Also rename `impl::get_names` to `impl::get_opt_names` (that is the
`TensorImpl*` variant of `Tensor::opt_names()`.
Test Plan
- run existing tests [namedtensor ci]
gh-metadata: pytorch pytorch 24907 gh/zou3519/110/head
Test Plan: Imported from OSS
Differential Revision: D16919768
Pulled By: zou3519
fbshipit-source-id: 094d404576b3f4b39629d0204e51c6ef48ee006e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24885
Store a static pre-allocated vector of names. When one calls
`default_names`, it gives a const reference to some amount of these
names.
Also make clearer the maximum number of dimensions we support for named
tensors. Right now it is 64 but that number is easy to change. 64
follows some internal pytorch maximum number of dimensions;
TensorIterator reduce ops have a limit of 64 dims.
Test Plan: - new tests [namedtensor ci]
Differential Revision: D16915803
Pulled By: zou3519
fbshipit-source-id: 931741b199456f8976882b82f25ab5af6dcd108b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25055
An ATen kernel registered with the c10 dispatcher doesn't need a cache,
so let's not call a cache creator function when the kernel is looked up.
ghstack-source-id: 88834902
Test Plan: unit tests
Differential Revision: D16974248
fbshipit-source-id: 5f9e65d706ec5f836804cb6e5f693f5a01f66714
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25121
Turns out there is a more idiomatic way to use azure variables. This
also fixes clang-tidy failing on master
Test Plan: Imported from OSS
Differential Revision: D16994595
Pulled By: suo
fbshipit-source-id: 5c5b1b47ced57cff85c4302cde43ff8c8c3f54c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25056
For some combinations of key and entry ordering (and only on an OSX
build) dict.pop() would return a value other than the popped one,
failing test_pop in test_jit.py. Caused by erase() mutating the
iterator returned from find(), fixed by dereferencing it first.
Test Plan: Imported from OSS
Differential Revision: D16975020
Pulled By: bhosmer
fbshipit-source-id: ce84e9aed6b90010121c0ef5d6c9ed8d2d1356b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25078
Our script is set up to only run on lines generated by diffing your branch against the base branch.
But we were using `$TRAVIS_BRANCH` to refer to the target branch, which was causing the script to diff against master, generating many spurious lines of diff output to be clang-tidy'd
Test Plan: Imported from OSS
Differential Revision: D16993054
Pulled By: suo
fbshipit-source-id: 7bffa890f6a1a2d5566ef01b9798c4eb86d8169f
Summary:
https://github.com/pytorch/FBGEMM (USE_FBGEMM is ON by default for x86, x86_64)
Build libtorch for android_abi x86_64 fails due to this.
Turning it off for android builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25113
Reviewed By: dreiss
Differential Revision: D16992459
Pulled By: IvanKobzarev
fbshipit-source-id: 3cf35a67043288cb591cc3b23c261258c28cf304
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24942
NamesMode determines whether or not to ignore the names field of
TensorImpl. In particular, when it is disabled, all tensors are treated
as unnamed.
Test Plan: - New tests [namedtensor ci]
Differential Revision: D16930708
Pulled By: zou3519
fbshipit-source-id: 867b31c4daff4e1eabafea45ed489efda4471efb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25099
As title says
ghstack-source-id: 88875870
Test Plan: CI
Differential Revision: D16986248
fbshipit-source-id: 2a0de41e89e413a32957b12308e5e6f48715477f
Summary:
TLDR; initial commit of android java-jni wrapper of pytorchscript c++ api
The main idea is to provide java interface for android developers to use pytorchscript modules.
java API tries to repeat semantic of c++ and python pytorchscript API
org.pytorch.Module (wrapper of torch::jit::script::Module)
- static Module load(String path)
- IValue forward(IValue... inputs)
- IValue runMethod(String methodName, IValue... inputs)
org.pytorch.Tensor (semantic of at::Tensor)
- newFloatTensor(long[] dims, float[] data)
- newFloatTensor(long[] dims, FloatBuffer data)
- newIntTensor(long[] dims, int[] data)
- newIntTensor(long[] dims, IntBuffer data)
- newByteTensor(long[] dims, byte[] data)
- newByteTensor(long[] dims, ByteBuffer data)
org.pytorch.IValue (semantic of at::IValue)
- static factory methods to create pytorchscript supported types
Examples of usage api could be found in PytorchInstrumentedTests.java:
Module module = Module.load(path);
IValue input = IValue.tensor(Tensor.newByteTensor(new long[]{1}, Tensor.allocateByteBuffer(1)));
IValue output = module.forward(input);
Tensor outputTensor = output.getTensor();
ThreadSafety:
Api is not thread safe, all synchronization must be done on caller side.
Mutability:
org.pytorch.Tensor buffer is DirectBuffer with native byte order, can be created with static factory methods specifing DirectBuffer.
At the moment org.pytorch.Tensor does not hold at::Tensor on jni side, it has: long[] dimensions, type, DirectByteBuffer blobData
Input tensors are mutable (can be modified and used for the next inference),
Uses values from buffer on the momment of Module#forward or Module#runMethod calls.
Buffers of input tensors is used directly by input at::Tensor
Output is copied from output at::Tensor and is immutable.
Dependencies:
Jni level is implemented with usage of fbjni library, that was developed in Facebook,
and was already used and opensourced in several opensource projects,
added to the repo as submodule from personal account to be able to switch submodule
when fbjni will be opensourced separately.
ghstack-source-id: b39c848359a70d717f2830a15265e4aa122279c0
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25084
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25105
Reviewed By: dreiss
Differential Revision: D16988107
Pulled By: IvanKobzarev
fbshipit-source-id: 41ca7c9869f8370b8504c2ef8a96047cc16516d4
Summary:
The semantic of the _auto-convert GPU arrays that support the __cuda_array_interface__ protocol_ has changed a bit.
It used to throw an exception when using `touch.as_tensor(...,device=D)` where `D` is a CUDA device not used in `__cuda_array_interface__`. Now, this is supported and will result in an implicit copy.
I do not what have changes but `from_blob()` now supports that the input and the output device differ.
I have updated the tests to reflect this, which fixes https://github.com/pytorch/pytorch/issues/24968
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25017
Differential Revision: D16986240
Pulled By: soumith
fbshipit-source-id: e6f7e2472365f924ca155ce006c8a9213f0743a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25065
Using global atomic variables is bad because sending the same AST through
the compiler twice will produce different graphs. This makes it a
member of the translation struct.
Test Plan: Imported from OSS
Differential Revision: D16975355
Pulled By: zdevito
fbshipit-source-id: 23e15ffd58937a207898a4c4bed82628237e3c2e
Summary:
I presume this is what was intended.
cc t-vi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25011
Differential Revision: D16980939
Pulled By: soumith
fbshipit-source-id: c55b22e119f3894bd124eb1dce4f92a719ac047a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25051
In #24355 I factored out a function for creating a prefix in jit_log,
but I made a copypasta error there: the prefix stringstream was
initialized from the input string instead of an empty string.
Test Plan: Imported from OSS
Differential Revision: D16974156
Pulled By: ZolotukhinM
fbshipit-source-id: 014fe0e3366e85e984a6936ec9bb17f571107f6e
Summary:
Overal context: open-source BlackBoxPredictor as the entry
point for inference in Caffe2 (thread safe abstraction for Caffe2
inference). This should be used in ThroughputBenchmark for the purpose
of framework comparison
This specific diff:
There should be no harm in moving transformation code to
OSS. On the advantages side we will be able to compare production
Caffe2 setup with PyTorch in the most fair way via
ThroughputBenchmark. This approach avoid any complicated
transformation regirstries. Building those proper would be significant
engineering effort as well as production risk. In the past we had SEVs
related to transforms being turned off due to various refactors. Given
that we don't plan to build any other significant investments into
transformation logic except existing ones (like TVM and Glow), and
those also relate to open-source technologies, I came up to the
conclusion of moving to OSS the whole thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23350
ghstack-source-id: 87121538
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24928
Test Plan: waitforsandcastle
Differential Revision: D16445133
Pulled By: salexspb
fbshipit-source-id: a93106489611dfe427b0f144717bc720d04e47f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24989
This fixes the cases where a type annotated with optional cannot
be conditionally assigned to none:
```
x : Optional[int] = 4
if ...:
x = None
```
Test Plan: Imported from OSS
Differential Revision: D16949314
Pulled By: zdevito
fbshipit-source-id: 7f63d88b30a3f5b024c2a539aa74967c9202af00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25005
Seeing a bunch of failures in TSAN mostly with the following error:
```
ThreadSanitizer: starting new threads after multi-threaded fork is not
supported. Dying (set die_after_fork=0 to override)
```
TSAN is unsafe to use in a multi-threaded program after fork() and setting
die_after_fork can lead to deadlocks. As a result, I'm disabling tsan.
ghstack-source-id: 88765698
Differential Revision: D16954347
fbshipit-source-id: 18895cd82b5052938284b46479d8470af2d74a06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25012
Resubmitting https://github.com/pytorch/pytorch/pull/22907 with build fix.
This change adds the following functionality:
1) WorkNCCL isCompleted, isSuccess methods check for NCCL errors and set the
appropriate exception.
2) Added a watchdog thread to ProcessGroupNCCL which checks for errors in the
cached communicators and removes them from the cache.
3) Use ncclCommAbort in NCCLComm destructor since ncclCommDestroy can block
forever waiting for work.
4) Added a simulate_nccl_errors.py script to simulate NCCL errors.
https://github.com/pytorch/pytorch/issues/17882
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22907
Test Plan: 1) Run the simulate_nccl_errors.py to verify NCCL errors are caught.
Differential Revision: D16958078
fbshipit-source-id: 662b0b8b8ee250e2b6d15bdfc9306d71c4f66219
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24994
Use C10_MOBILE to gate CustomClass lookup logic for mobile build, which uses
typeid() and requires "-frtti" which is off by default for internal mobile build.
Not sure whether we ever need CustomClass for internal use cases. Feel the change
is not too intrusive - but I'm willing to hear others' thoughts.
ghstack-source-id: 88754932
Reviewed By: dreiss
Differential Revision: D16951430
fbshipit-source-id: 445f47ee4e9c16260e2fd2c43f5684cea602e3d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24964
To reduce complications in quantized kernel implementation, we decided not to
have symmetric quantizer, since it can be expressed by affine quantizer,
but we will still have symmetric quantization qscheme in frontend, and user
can still specify tensors to be symmetrically quantized, while the actual quantized
Tensor represetation will only have affine quantization.
Differential Revision: D16965114
fbshipit-source-id: 0e9a5a00131878a302e211fda65a1aa427204eea
Summary:
This fixes https://github.com/pytorch/pytorch/issues/22970. Specifically, `torch.distributions.uniform.Uniform.log_prob()` now works even if `value` is passed as a python float.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23017
Differential Revision: D16383258
Pulled By: vincentqb
fbshipit-source-id: 26943c33431d6da6f47e0897d6eda1c5f5541d28
Summary:
In the examples for creating an instance of the Transformer module, src and tgt parameters (from forward) were added which are not present in the __init__ .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24837
Differential Revision: D16938065
Pulled By: zhangguanheng66
fbshipit-source-id: 7b2d2180d95ddb65930ad83c87c926e35f2bf521
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24351
**Context:**
I was doing some exploration on APIs for jit script module internals.
I found there can be a bug(cannot cast Module to Slot) when I try to check size of sub_modules in one module. (please also provide suggestions if you think my diff is not optimal or wrong)
See the following:
for (auto m1 : module.get_modules()) { // module is the module loading from P79892263.
std::cout << "test module " << " " << m1.get_modules().size() << "\n";
}
With this change, its going to return 0 (expected)
Without this change, the following error will throw: P79892732
Also, I put a RFC here since I am looking for some ideas for any tests I should add, and where I should add those tests.
Reviewed By: smessmer
Differential Revision: D16803759
fbshipit-source-id: 1e2ae6b69d9790c700119d2d0b9f9f85f41616d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25006
Builds without sccache or ccache would run into issues since
`CACHE_WRAPPER_DIR` would not be set. As a result `CUDA_NVCC_EXECUTABLE` would
be set to /nvcc and the build would fail.
ghstack-source-id: 88766907
Differential Revision: D16954651
fbshipit-source-id: fea41da52dc9f8f03e6356d348f5900978db3651
Summary:
Resolves: https://github.com/pytorch/pytorch/issues/20785
Addresses https://github.com/pytorch/pytorch/issues/24470 for `affine_grid`
Subsumes and closes: https://github.com/pytorch/pytorch/pull/24878 and likewise closes: https://github.com/pytorch/pytorch/issues/24821
Adds the `align_corners` option to `grid_sample` and `affine_grid`, paralleling the option that was added to `interpolate` in version 0.4.0.
In short, setting `align_corners` to `False` allows these functions to be resolution agnostic.
This ensures, for example, that a grid generated from a neural net trained to warp 1024x1024 images will also work to warp the same image upsampled/downsampled to other resolutions like 512x512 or 2048x2048 without producing scaling/stretching artifacts.
Refer to the documentation and https://github.com/pytorch/pytorch/issues/20785 for more details.
#### BC-Breaking Changes
- **Important**: BC-Breaking change because of new default for `align_corners`
The old functionality can still be achieved by setting `align_corners=True`, but the default is now set to `align_corners=False`, since this is the more correct setting, and since this matches the default setting of `interpolate`.
- **Should not cause BC issues**: BC-Breaking change for pathological use case
2D affine transforms on 1D coordinates and 3D affine transforms on 2D coordinates (that is, when one of the spatial dimensions has an empty span) are ill-defined, and not an intended use case of `affine_grid`. Whereas before, all grid point components along such dimension were set arbitrarily to `-1` (that is, before multiplying be the affine matrix), they are now all set instead to `0`, which is a much more consistent and defensible arbitrary choice. A warning is triggered for such cases.
#### Documentation
- Update `affine_grid` documentation to express that it does indeed support 3D affine transforms. This support was already there but not documented.
- Add documentation warnings for BC-breaking changes in `grid_sample` and `affine_grid` (see above).
#### Refactors
- `affine_grid` no longer dispatches to cuDNN under any circumstances.
The decision point for when the cuDNN `affine_grid_generator` is compatible with the native PyTorch version and when it fails is a headache to maintain (see [these conditions](5377478e94/torch/nn/_functions/vision.py (L7-L8))). The native PyTorch kernel is now used in all cases.
- The kernels for `grid_sample` are slightly refactored to make maintenance easier.
#### Tests
Two new tests are added in `test_nn.py`:
- `test_affine_grid_error_checking` for errors and warnings in `affine_grid`
- `test_affine_grid_3D` for testing `affine_grid`'s 3D functionality. The functionality existed prior to this, but wasn't tested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24929
Differential Revision: D16949064
Pulled By: ailzhang
fbshipit-source-id: b133ce0d47a2a5b3e2140b9d05fb05fca9140926
Summary:
This PR adds deprecation message for `tensor.data<T>()` (91d94e7d41), and changes all call sites of `tensor.data<T>()` to `tensor.data_ptr<T>()` in PyTorch core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24886
Differential Revision: D16924576
Pulled By: yf225
fbshipit-source-id: 0943d6be73245c7c549c78597b74c3b07fa24440
Summary:
Another pass over the docs, this covers most of the remaining stuff
* content updates for new API
* adds links to functions instead of just names
* removes some useless indentations
* some more code examples + `testcode`s
](https://our.intern.facebook.com/intern/diff/16847964/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24445
Pulled By: driazati
Differential Revision: D16847964
fbshipit-source-id: cd0b403fe4a89802ce79289f7cf54ee0cea45073
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24425
- _jit_pass_prepare_quant: clone the observer module in argument and insert that to the
module we want to quantize, insert observer calls for the Tensor values we want to observe
Differential Revision: D16933120
fbshipit-source-id: 7248de6132429ba943a09831a76486f7a3cd52a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24980
We'll need this internally, so just updating the open source version. the other optimizers have this argument anyways.
Test Plan: Imported from OSS
Differential Revision: D16945279
Pulled By: li-roy
fbshipit-source-id: 0b8cc86f15387cd65660747899d3d7dd870cff27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24955
Some third-party code relies on this default constructor. It's not
invalid to construct an OuputArchive with an indepednent CU, so
restoring it.
Test Plan: Imported from OSS
Differential Revision: D16935254
Pulled By: suo
fbshipit-source-id: 40b6494e36d10c5009b3031648bee96b2e38b49a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24882
Previously, looking up a kernel accidentally copied the DispatchTableEntry, which has as its member a std::function cache creator function.
Being an std::function, it was expensive to copy and cost us more than 50ns on each op call.
This diff fixes this by not copying DispatchTableEntry anymore.
ghstack-source-id: 88611173
Differential Revision: D16910530
fbshipit-source-id: 44eeaa7f6ffead940b4a124f0c31d8ef71404db3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24792
This will prevent the circular dependencies in the future
Differential Revision: D16868861
Test Plan: Imported from OSS
Pulled By: zafartahirov
fbshipit-source-id: 92cf77094b2c56560d380c1fd1df8e1e24a86359
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24940
We're missing an include for named tensors in templates/TypeDefault.h.
Test Plan: - run ci [namedtensor ci]
Differential Revision: D16930709
Pulled By: zou3519
fbshipit-source-id: c15d631761a78d5e50fe265a3129239e72042a83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24871
Bind the torch.autograd.grad function into TorchScript so that well
formed inputs can directly call this from a TorchScript function.
This also change the serliazation a bit, it fixes a small bug where node
output type can never be tensor type in prim::ListConstruct(only its elementype can be), and add the case where we need to annotate the ListType if the element type is optional type to preserve type information when reimport
Differential Revision: D16923273
fbshipit-source-id: 151cc13411c8c287def35b4e65122d9fc083ccfd
Summary:
Use explicit versioned nightly whl such that to provide coverage of ONNX updates not in release yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24414
Differential Revision: D16940810
Pulled By: bddppq
fbshipit-source-id: 7bf76554898958e0f48883a1da7a3bdc781be7f8
Summary:
This hasn't been edited in a while and doesn't work anymore. Its use
case is also served pretty well by `script_module.code`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24874
Pulled By: driazati
Differential Revision: D16941025
fbshipit-source-id: 11acd05cea5e44eeb1d48188a2de645669b21610
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24850
### Summary
There are 1373 header files in total that have been installed on mobile, many of which are not being used. Take ATen for example, there are 165 header files in total. Folders like `cuda/`, `cudann`, `miopen`, etc are not needed. This PR will remove 33 unnecessary header files as well as some cuda files.
### Test Plan
- `build_ios.sh` finished successfully
- `libtorch.a` can be compiled and run on mobile
Test Plan: Imported from OSS
Differential Revision: D16897314
Pulled By: xta0
fbshipit-source-id: 54e046936439a549fe633ec791a10a2a3d36fa8b
Summary:
Stacked PRs
* #24445 - [jit] Misc doc updates #2
* **#24435 - [jit] Add docs to CI**
This integrates the [doctest](http://www.sphinx-doc.org/en/master/usage/extensions/doctest.html) module into `jit.rst` so that we can run our code examples as unit tests. They're added to `test_jit.py` under the `TestDocs` class (which takes about 30s to run). This should help prevent things like #24429 from happening in the future. They can be run manually by doing `cd docs && make doctest`.
* The test setup requires a hack since `doctest` defines everything in the `builtins` module which upsets `inspect`
* There are several places where the code wasn't testable (i.e. it threw an exception on purpose). This may be resolvable, but I'd prefer to leave that for a follow up. For now there are `TODO` comments littered around.
](https://our.intern.facebook.com/intern/diff/16840882/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24435
Pulled By: driazati
Differential Revision: D16840882
fbshipit-source-id: c4b26e7c374cd224a5a4a2d523163d7b997280ed
Summary:
This change adds the following functionality:
1) WorkNCCL isCompleted, isSuccess methods check for NCCL errors and set the
appropriate exception.
2) Added a watchdog thread to ProcessGroupNCCL which checks for errors in the
cached communicators and removes them from the cache.
3) Use ncclCommAbort in NCCLComm destructor since ncclCommDestroy can block
forever waiting for work.
4) Added a simulate_nccl_errors.py script to simulate NCCL errors.
https://github.com/pytorch/pytorch/issues/17882
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22907
Test Plan: 1) Run the simulate_nccl_errors.py to verify NCCL errors are caught.
Differential Revision: D16220638
fbshipit-source-id: fbc8881ea0c38a4d09a77045691e36557b7b0b25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24259
Follow up to https://github.com/pytorch/pytorch/pull/23886, add the same overload api specified in PEP 484 to module methods to reduce the friction of adding method overloads that was brought up in #23266.
The usage is:
```
torch.jit.overload
def add(self, y: int) -> int: ...
torch.jit.overload
def add(self, y: float) -> float: ...
def add():
...
```
Test Plan: Imported from OSS
Differential Revision: D16921304
Pulled By: eellison
fbshipit-source-id: 784e2f26f7ca9a330a434a603c86b53725c3dc71
Summary:
As in https://github.com/pytorch/pytorch/issues/23439, some descriptions of arguments in `_torch_docs.py` have been replaced by `common_args`, it would be helpful to check if any descriptions can be replaced for new docs in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24161
Differential Revision: D16889293
Pulled By: ezyang
fbshipit-source-id: bf6f581494482d6eb32e634f73e84a4586766230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24342
Right now the two APIs that provided in autograd package only have
python bindings and we could not call them either in C++ API or in
TorchScript. This PR make these two APIs available purely in C++ (with
preserving semantics) and can be used in C++ API and TorchScript
Differential Revision: D16923271
fbshipit-source-id: 049d6fbd94cd71ecc08b2716f74d52ac061f861e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24367
NamesMode determines whether or not to ignore the names field of
TensorImpl. In particular, when it is disabled, all tensors are treated
as unnamed.
Test Plan: - New tests [namedtensor ci]
Differential Revision: D16915806
Pulled By: zou3519
fbshipit-source-id: 21f7ff1eadebd678d6cd9a16ff25dd6134272b76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24889
Trying to fix#2575. [Here](https://gist.github.com/suo/7b0bc4b49d3c9e095b9f7eef8fa7c6e8) is all TLS in libtorch.so (thanks ezyang for figuring how to find this)
I noticed that `CallbackManager::sample_zero_one()::gen` has size 5000,
which seems bigger than the other ones. So make it heap-allocated
instead.
Caveat: I have no idea if this will actually fix anything, or whether
making this variable heap-allocated is a bad idea.
Test Plan: Imported from OSS
Differential Revision: D16912540
Pulled By: suo
fbshipit-source-id: 71eb0391bf4c6e85b090f8650a2fbfc2107f2707
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24284
This PR finishes the unification of all Tensor types into a single object.
ProfiledTensorType is renamed to TensorType and the old TensorType is
deleted.
Notes:
* Fixes bug in merge for VaryingShape by changing its representation to an
optional list of optional ints.
* Removes ProfiledTensorType::create(type) invocations that can now
simply be expect calls on tensor type.
Test Plan: Imported from OSS
Differential Revision: D16794034
Pulled By: zdevito
fbshipit-source-id: 10362398d0bb166d0d385d74801e95d9b87d9dfc
Summary:
~~In case of tensor indexing with a scalar index, index_select returns a tensor with the same rank as the input. To match this behavior in ONNX, we make index a 1D tensor so that with a gather
it also produces a tensor with the same rank as the input.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23507
Differential Revision: D16586805
Pulled By: bddppq
fbshipit-source-id: 8f5d964d368873ec372773a29803b25f29a81def
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24138
catch exception thrown on server, send the exception message back to client and rethrow it.
Reviewed By: mrshenli
Differential Revision: D16748748
fbshipit-source-id: ce18b3ea1b1d28645ec292f58aa0c818d93e559e
Summary:
Currently they sit together with other code in cuda.cmake. This commit
is the first step toward cleaning up cuDNN detection in our build system.
Another attempt to https://github.com/pytorch/pytorch/issues/24293, which breaks manywheels build because it does not handle `USE_STATIC_CUDNN`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24784
Differential Revision: D16914345
Pulled By: ezyang
fbshipit-source-id: fd261478c01d879dc770c1f1a56b17cc1a587be2
Summary:
```
[1/1424] Building NVCC (Device) object caffe2/CMakeFiles/torch.dir/operators/torch_generated_weighted_sample_op.cu.obj
CMake Warning (dev) at torch_generated_weighted_sample_op.cu.obj.Release.cmake:82 (set):
Syntax error in cmake code at
C:/Users/Ganzorig/pytorch/build/caffe2/CMakeFiles/torch.dir/operators/torch_generated_weighted_sample_op.cu.obj.Release.cmake:82
when parsing string
C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1/include;C:/Users/Ganzorig/pytorch/aten/src;C:/Users/Ganzorig/pytorch/build;C:/Users/Ganzorig/pytorch;C:/Users/Ganzorig/pytorch/cmake/../third_party/googletest/googlemock/include;C:/Users/Ganzorig/pytorch/cmake/../third_party/googletest/googletest/include;;C:/Users/Ganzorig/pytorch/third_party/protobuf/src;C:/Users/Ganzorig/pytorch/cmake/../third_party/benchmark/include;C:/Users/Ganzorig/pytorch/cmake/../third_party/eigen;C:/Users/Ganzorig/Anaconda3/envs/code/include;C:/Users/Ganzorig/Anaconda3/envs/code/lib/site-packages/numpy/core/include;C:/Users/Ganzorig/pytorch/cmake/../third_party/pybind11/include;C:/Users/Ganzorig/pytorch/cmake/../third_party/cub;C:/Users/Ganzorig/pytorch/build/caffe2/contrib/aten;C:/Users/Ganzorig/pytorch/third_party/onnx;C:/Users/Ganzorig/pytorch/build/third_party/onnx;C:/Users/Ganzorig/pytorch/third_party/foxi;C:/Users/Ganzorig/pytorch/build/third_party/foxi;C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1/include;C:/Users/Ganzorig/pytorch/caffe2/../torch/csrc/api;C:/Users/Ganzorig/pytorch/caffe2/../torch/csrc/api/include;C:/Program Files/NVIDIA Corporation/NvToolsExt/include;C:/Users/Ganzorig/pytorch/caffe2/aten/src/TH;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src/TH;C:/Users/Ganzorig/pytorch/caffe2/../torch/../aten/src;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src;C:/Users/Ganzorig/pytorch/build/aten/src;C:/Users/Ganzorig/pytorch/caffe2/../torch/../aten/src;C:/Users/Ganzorig/pytorch/build/caffe2/../aten/src;C:/Users/Ganzorig/pytorch/build/caffe2/../aten/src/ATen;C:/Users/Ganzorig/pytorch/build/aten/src;C:/Users/Ganzorig/pytorch/caffe2/../torch/csrc;C:/Users/Ganzorig/pytorch/caffe2/../torch/../third_party/miniz-2.0.8;C:/Users/Ganzorig/pytorch/caffe2/../torch/csrc/api;C:/Users/Ganzorig/pytorch/caffe2/../torch/csrc/api/include;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src/TH;C:/Users/Ganzorig/pytorch/aten/src/TH;C:/Users/Ganzorig/pytorch/aten/src;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src;C:/Users/Ganzorig/pytorch/build/aten/src;C:/Users/Ganzorig/pytorch/aten/src;C:/Users/Ganzorig/pytorch/aten/../third_party/catch/single_include;C:/Users/Ganzorig/pytorch/aten/src/ATen/..;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src/ATen;C:/Users/Ganzorig/pytorch/third_party/miniz-2.0.8;C:/Users/Ganzorig/pytorch/caffe2/core/nomnigraph/include;C:/Users/Ganzorig/pytorch/caffe2/;C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1/include;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src/TH;C:/Users/Ganzorig/pytorch/aten/src/TH;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src/THC;C:/Users/Ganzorig/pytorch/aten/src/THC;C:/Users/Ganzorig/pytorch/aten/src/THCUNN;C:/Users/Ganzorig/pytorch/aten/src/ATen/cuda;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src/TH;C:/Users/Ganzorig/pytorch/aten/src/TH;C:/Users/Ganzorig/pytorch/aten/src;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src;C:/Users/Ganzorig/pytorch/build/aten/src;C:/Users/Ganzorig/pytorch/aten/src;C:/Users/Ganzorig/pytorch/aten/../third_party/catch/single_include;C:/Users/Ganzorig/pytorch/aten/src/ATen/..;C:/Users/Ganzorig/pytorch/build/caffe2/aten/src/ATen;C:/Users/Ganzorig/pytorch/third_party/protobuf/src;C:/Users/Ganzorig/pytorch/c10/../;C:/Users/Ganzorig/pytorch/build;C:/Users/Ganzorig/pytorch/third_party/cpuinfo/include;C:/Users/Ganzorig/pytorch/third_party/FP16/include;C:/Users/Ganzorig/pytorch/third_party/foxi;C:/Users/Ganzorig/pytorch/third_party/foxi;C:/Users/Ganzorig/pytorch/third_party/onnx;C:/Users/Ganzorig/pytorch/build/third_party/onnx;C:/Users/Ganzorig/pytorch/build/third_party/onnx;C:/Users/Ganzorig/pytorch/c10/cuda/../..;C:/Users/Ganzorig/pytorch/build;C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1/include;C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1/include;C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1/include;C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1\include;C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.1/include
Invalid escape sequence \i
Policy CMP0010 is not set: Bad variable reference syntax is an error. Run
"cmake --help-policy CMP0010" for policy details. Use the cmake_policy
command to set the policy and suppress this warning.
This warning is for project developers. Use -Wno-dev to suppress it.
```
Compared to https://github.com/pytorch/pytorch/issues/24044 , this commit moves the fix up, and uses [bracket arguments](https://cmake.org/cmake/help/v3.12/manual/cmake-language.7.html#bracket-argument).
PR also sent to upstream: https://gitlab.kitware.com/cmake/cmake/merge_requests/3679
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24420
Differential Revision: D16914193
Pulled By: ezyang
fbshipit-source-id: 9f897cf4f607502a16dbd1045f2aedcb49c38da7
Summary:
This PR removes SymbolicVariable from all tests as well as the specialize_autogradzero and canonicalize_ops passes. These passes used SymbolicVariable in a relatively simple way compared to its few remaining uses.
Removing SymbolicVariable means graphs must be constructed by other methods. IRParser was preferred for tests, but tests requiring pointers to graph internals or differentiation use direct construction instead. See https://github.com/pytorch/pytorch/issues/23989, which was discovered during this process, for why IRParser cannot be used when differentiation is required. Direct construction was also used in the updated passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24007
Test Plan: Only refactors existing tests and preserves current checks; no additional testing needed.
Differential Revision: D16906045
Pulled By: mruberry
fbshipit-source-id: b67df4611562cd7618f969890e2b6840750c7266
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23799
Before, we inlined as part of the initial IR generation process, which
has a few disadvantages:
1. It loses information about what nodes came from which function/method
calls. Other parties who want to implement transformations on the
function/module level don't have a reliable way of doing so.
2. It duplicates a ton of code if we are inlining the same
function/method a tons of times.
After this PR: inline is deferred to the optimization stage, so
optimizations that rely on inlining will still work. But things get
serialized with the function/method calls in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23799
Differential Revision: D16652819
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Pulled By: suo
fbshipit-source-id: a11af82aec796487586f81f5a9102fefb6c246db
Summary:
This PR templatizes `Tensor.data_ptr()`, to prepare for the deprecation of `Tensor.data<T>()` and introduction of `Tensor.data()` that has the same semantics as `Variable.data()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24847
Differential Revision: D16906061
Pulled By: yf225
fbshipit-source-id: 8f9db9fd105b146598a9d759aa4b4332011da8ea
Summary:
Added support for cumsum in symbolic opset 11 + op and ORT tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24476
Differential Revision: D16896780
Pulled By: bddppq
fbshipit-source-id: b52355796ee9f37004c9258f710688ad4b1ae8a2
Summary:
This PR removes the following operators to symbolic script:
- add
- sub
- mul
- div
- threshold
- clamp
- addmm
- comparison ops (lt, le, ge, ...)
- fmod
- remainder
- max_pool2d_with_indices
Additionally, the view and reshape operations were removed from autodiff.cpp (they were already written in symbolic script).
The functionality of these operators is mostly preserved, except clamp and threshold have been modified to be gradient preserving at the boundary. Moving clamp also changed the graph tested in test_jit.py, which I think is expected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23794
Test Plan: Existing tests provided sufficient coverage.
Differential Revision: D16902986
Pulled By: mruberry
fbshipit-source-id: 478f2a59d9a5b0487fc523fd594cb775cb617525
Summary:
Fixes https://github.com/pytorch/pytorch/issues/8212
This fix is based on the idea that in-place ops(e.g. add_(...)) and out ops(e.g. tensor.add(..., out=...)) must check that the output tensor does not partially overlap with any of it's input tensors. Otherwise the result of such op is unexpected to the user. Since TensorIterator is a common backend for such ops and it's already used to check output self-overlapping, this fix is implemented in the same place.
MemOverlapStatus enum class is introduced to model two tensors overlapped state:
- TOO_HARD if at least one of them is not contiguous
- FULL if both are contiguous and share exactly the same memory array [data(), data() + numel() *itemsize()]
- PARTIAL is both are contiguous but underlying memory is shared partially, in other words memory arrays overlap but not identical.
- NO if both are contiguous but have independent non overlapping memory arrays
Performance test of clone/addcmul_/addcdiv_ with check_mem_overlaps:
a = torch.empty(10000000, device='cpu')
b = torch.randn(10000000, device='cpu')
timeit a.copy_(b)
master: 10.3 ms ± 429 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
branch: 10.2 ms ± 946 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
a = torch.empty(10000000, device='cuda')
b = torch.randn(10000000, device='cuda')
timeit a.copy_(b)
master: 373 µs ± 97.9 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
branch: 373 µs ± 120 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
a = torch.randn(1000000, device='cpu')
b = torch.randn(1000000, device='cpu')
c = torch.randn(1000000, device='cpu')
timeit a.addcmul_(b, c)
master: 2.02 ms ± 212 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
branch: 2.11 ms ± 200 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
a = torch.randn(1000000, device='cuda')
b = torch.randn(1000000, device='cuda')
c = torch.randn(1000000, device='cuda')
timeit a.addcmul_(b, c)
master: 72.6 µs ± 627 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
branch: 72.4 µs ± 18.1 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
a = torch.randn(1000000, device='cpu')
b = torch.randn(1000000, device='cpu')
c = torch.randn(1000000, device='cpu')
timeit a.addcdiv_(b, c)
master: 2.19 ms ± 583 µs per loop (mean ± std. dev. of 7 runs, 1000 loop each)
branch: 1.97 ms ± 125 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
a = torch.randn(1000000, device='cuda')
b = torch.randn(1000000, device='cuda')
c = torch.randn(1000000, device='cuda')
timeit a.addcdiv_(b, c)
master: 71.3 µs ± 1.98 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
branch: 71.7 µs ± 3.96 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
a = torch.empty(100, device='cpu')
b = torch.randn(100, device='cpu')
timeit a.copy_(b)
master: 12.1 µs ± 1.11 µs per loop (mean ± std. dev. of 7 runs, 100000 loops each)
branch: 11.1 µs ± 61.1 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
a = torch.empty(100, device='cuda')
b = torch.randn(100, device='cuda')
timeit a.copy_(b)
master: 20.9 µs ± 1.62 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
branch: 22.8 µs ± 2.63 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
a = torch.randn(100, device='cpu')
b = torch.randn(100, device='cpu')
c = torch.randn(100, device='cpu')
timeit a.addcmul_(b, c)
master: 24.1 µs ± 2.7 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
branch: 24 µs ± 91.6 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
a = torch.randn(100, device='cuda')
b = torch.randn(100, device='cuda')
c = torch.randn(100, device='cuda')
timeit a.addcmul_(b, c)
master: 34.5 µs ± 4.82 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
branch: 29.8 µs ± 496 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
a = torch.randn(100, device='cpu')
b = torch.randn(100, device='cpu')
c = torch.randn(100, device='cpu')
timeit a.addcdiv_(b, c)
master: 21.3 µs ± 210 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
branch: 23.8 µs ± 403 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
a = torch.randn(100, device='cuda')
b = torch.randn(100, device='cuda')
c = torch.randn(100, device='cuda')
timeit a.addcdiv_(b, c)
master: 30.3 µs ± 257 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
branch: 31.8 µs ± 214 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24058
Differential Revision: D16767892
Pulled By: pbelevich
fbshipit-source-id: 0cdaaa471d003a2886b1736f8985842226b8493a
Summary:
Changelog:
- Enable torch.eye for bool and float16 dtypes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24148
Test Plan:
- Tests added in test_torch.py for all available devices and dtypes (except torch.bfloat16)
Fixes https://github.com/pytorch/pytorch/issues/24088
Differential Revision: D16891048
Pulled By: ezyang
fbshipit-source-id: 3e86fe271bd434300c396e63f82c1a1f3adac2b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24357
SparseNormalize does not need to know the gradient value to the lookup table, only the indices of the embeddings that need to be updated. By removing this input, we allow SparseNormalize to be used alongside SparseAdagradFusion
Differential Revision: D16809919
fbshipit-source-id: cc19692ba4dea8854663ae1ed8cf9365e90c99bc
Summary:
Do not use the explicit CAS loop. This will perform better if there is
any contention. Since this feature is ROCm-only, the HIP layer provides no
helper function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24854
Differential Revision: D16902292
Pulled By: ezyang
fbshipit-source-id: df192063c749f2b39f8fc304888fb0ae1070f20e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24499
We are attempting to subscript a variable `kernel_size` that may not be
an iterable in the `conv.py` module currently. This leads to errors unless the
user passes in an iterable for kernel_size. D16830855 changed
`self.kernel_size` to be a pair type, but did not actually use the variable.
We want to use `self.kernel_size` which is a pair even if the user passed in an int for `kernel_size` so that we stop having the subscripting error.
Differential Revision: D16859809
fbshipit-source-id: cd2a5497e89d88e518ca7b8a97bf9e69803ee2ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24502
Files in distributed.rpc package mixes snake camel names. This
commit cleans that up and all files use snake names now.
ghstack-source-id: 88548990
Reviewed By: xush6528
Differential Revision: D16860155
fbshipit-source-id: 3a22a89bf6c4e11aac5849564fc53296a04d6a8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24827
We already cache the node's schema, but alias analysis wants operators.
This ends up being almost 70% of the on-cpu time optimizing a large
graph.
Here's some results on a [sample model](https://gist.github.com/suo/63ab9638516002176f94553a37060f61)
(the units are seconds).
Before:
```
compiled in: 20.256319999694824
first run in: 313.77824568748474
```
After:
```
compiled in: 18.8815860748291
first run in: 42.58739233016968
```
More than a 7x speedup! Still slower than I'd like though so I'll keep
digging.
Test Plan: Imported from OSS
Differential Revision: D16887540
Pulled By: suo
fbshipit-source-id: 2449be2898889d00ac094c3896e37b0e6a8c5f08
Summary:
Resolves: https://github.com/pytorch/pytorch/issues/20785
Adds the `align_corners` option to `grid_sample` and `affine_grid`, paralleling the option that was added to `interpolate` in version 0.4.0.
In short, setting `align_corners` to `False` allows these functions to be resolution agnostic.
This ensures, for example, that a grid generated from a neural net trained to warp 1024x1024 images will also work to warp the same image upsampled/downsampled to other resolutions like 512x512 or 2048x2048 without producing scaling/stretching artifacts.
Refer to the documentation and https://github.com/pytorch/pytorch/issues/20785 for more details.
**Important**: BC-Breaking Change because of new default
The old functionality can still be achieved by setting `align_corners=True`, but the default is now set to `align_corners=False`, since this is the more correct setting, and since this matches the default setting of `interpolate`.
The vectorized 2D cpu version of `grid_sampler` is refactored a bit. I don’t suspect that this refactor would affect the runtime much, since it is mostly done in inlined functions, but I may be wrong, and this has to be verified by profiling.
~The tests are not yet updated to reflect the new default. New tests should probably also be added to test both settings of `align_corners`.~ _Tests are now updated._
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23923
Differential Revision: D16887357
Pulled By: ailzhang
fbshipit-source-id: ea09aad7853ef16536e719a898db8ba31595daa5
Summary:
This is a follow-up to gh-23408. No longer supported are any arches < 3.5 (numbers + 'Fermi' and 'Kepler+Tegra').
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24442
Differential Revision: D16889283
Pulled By: ezyang
fbshipit-source-id: 3c0c35d51b7ac7642d1be7ab4b0f260ac93b60c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24801
This is to fix the ODR-violations in fbcode static builds, which have been broken for several months.
This PR is unfortunately quite large, but the changes are only mechanical:
1. Tests defined in header files -> tests defined in cpp files
2. Remove the `torch::jit::testing` namespace -> `torch::jit`.
3. Single `test.h` file that aggregates all tests.
4. Separate out files for gtest and python versions of the tests instead of using a build flag
5. Add a readme for how to add a new test, and explaining a bit about why the cpp tests are the way they are.
Test Plan: Imported from OSS
Differential Revision: D16878605
Pulled By: suo
fbshipit-source-id: 27b5c077dadd990a5f74e25d01731f9c1f491603
Summary:
The derivative of the symmetric eigendecomposition was previously a triangular matrix.
Changelog:
- Modify the derivative of symeig from a triangular matrix to a symmetric matrix with reason specified as a comment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23018
Test Plan: - Existing gradcheck and gradgradchecks are ported to test_autograd to verify that the change is correct. Input to symeig is symmetrized before passing
Differential Revision: D16859070
Pulled By: ezyang
fbshipit-source-id: 2d075abdf690909f80781764cfaf938b581d0ef6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24448
The setting `--durations=10` was hard-coded, which is annoying as I
don't necessarily care. A good alternative to get the same behavior is:
```
python run_tests.py --pytest -- --durations=10
```
Test Plan: Imported from OSS
Differential Revision: D16876380
Pulled By: suo
fbshipit-source-id: 1e14d366db45b6b9bf4a4ab1633b0f6ece29f6bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23968
Existing ProcessGroupAgent uses a single thread to send all messages, and
a single thread to listen and process all received messages. This causes
both performance issues and also prevents nested RPCs. For example, when
running nested RPC A->B->A->B, the second recv on B cannot start until
the first recv on B finishes. If the second recv is triggered by a nested
RPC in the first recv, it will deadlock. Ideally, we should expose sth like
responder or FutureResult to the Python land to support nested asynchronous
UDFs.
This diff adds a shared ThreadPool for send and recv. Send use it do send
out messages, and recv use it to process received messages. There is still
a dedicated thread to listen for incoming messages and add it to task queue.
There are two goals: 1) speed up ProcessGroupAgent 2) use ThreadPool as a
temporary solution for (a small number of) nested RPCs
ghstack-source-id: 88476246
Differential Revision: D16695091
fbshipit-source-id: fd18a5c65e7fcd1331b73d1287673e6e10d2dd86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24374
This is a duplicate to bring back #23704 with diff revision D16634539
Test Plan: Imported from OSS
Differential Revision: D16818664
Pulled By: zafartahirov
fbshipit-source-id: c8f7965356555a6a995eaeea6820ea62cbbea6fd
Summary:
This lets you mark a class so that it won't be recursively compiled.
This also runs up against a weird thing on the UX side, that to ignore a
module you have to `ignore` its `forward()` method but to ignore a
class you use `ignore` on the class declaration. The `ignore` on the
class declaration matches the use of `script` for script classes but is
confusing to those that don't know the difference between script classes
/ modules.
](https://our.intern.facebook.com/intern/diff/16770068/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23614
Pulled By: driazati
Differential Revision: D16770068
fbshipit-source-id: bee9a9e88b6c798ce779f622c4f929adae4eaf45
Summary:
Previously we weren't clearing the stack, so any failures that didn't
stop the program stayed around in the stack and would show up if
something else accessed the stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23458
Pulled By: driazati
Differential Revision: D16866719
fbshipit-source-id: 29739b11f79de91c6468129da1bdcbf3c53b42d9
Summary:
`binary_populate_env.sh` is used by `binary_linux_test`, and for libtorch with new ABI we need to run the tests on a docker image different from `soumith/manylinux-cudaXX`. In such cases, we should respect the actual DOCKER_IMAGE value defined in the CircleCI job description.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24787
Differential Revision: D16867976
Pulled By: yf225
fbshipit-source-id: dc0a68bffc5789249ae14491ef485c7cc2fc1c34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23906
The 1-off error is expected for the average pool due to double rounding.
Increasing unittest precision tolerance to 1.0 to avoid failing.
Test Plan: Imported from OSS
Differential Revision: D16678044
Pulled By: zafartahirov
fbshipit-source-id: 4e73934e4379b1d108af649ec77053998e44c560
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24393
Ability to register hook on a variable, similar to python autograd API. register_hook will take a function as argument and create a CppFunctionPreHook similar to PyFunctionPreHook.
It will return the index of the hook which can be passed to remove_hook to disable the hook.
Test Plan: Added tests.
Differential Revision: D16861722
fbshipit-source-id: d08047f932e38c7bde04283a18b2d0311c8ad604
Summary:
Empty and empty_like return uninitialized tensors with specific sizes.
The values in the tensor cannot be predicted, that's why tests in test_pytorch_onnx_onnxruntime.py and test_pytorch_onnx_caffe2.py are not added.
The tests in test_operators.py verify the onnx graph and output shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24166
Differential Revision: D16831571
Pulled By: bddppq
fbshipit-source-id: b2500f36ced4735da9a8418d87a39e145b74f63a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24433
bounds checker was only used once per instruction. If a read in the
middle of an instruction went of the end of the stream, it would just
read invalid memory. This replaces bounds checker with just one
guarded read function.
Test Plan: Imported from OSS
Differential Revision: D16836178
Pulled By: zdevito
fbshipit-source-id: a7f70d0f293bf26c3220a12bafb8a06678931016
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24040
This diff fixes failed test in test_tensorboard.py:
- fixed test_image_with_boxes: tests compares serialized protobuf Summary object with image against expected serialized protobuf in file. Turns out that comparing images string by string might not work (e.g. if they were serialized with different versions of image library) - images can be equal, though due to differences in metadata or compression methods actual strings might differ. Changed to compare images using == from PIL.Image
Reviewed By: orionr
Differential Revision: D16715831
fbshipit-source-id: 7dd4a7cfc8e63767ed727656f1891edd273d95da
Summary:
This patch writes documentation for `Tensor.record_stream()`, which is not a documented API currently. I've discussed publishing it with colesbury in https://github.com/pytorch/pytorch/issues/23729.
The documentation is based on [the introduction at `CUDACachingAllocator.cpp`](25d1496d58/c10/cuda/CUDACachingAllocator.cpp (L47-L50)). ~~I didn't explain full details of the life cycle of memory blocks or stream awareness of the allocator for the consistent level of details with other documentations.~~ I explained about the stream awareness in a note block.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24078
Differential Revision: D16743526
Pulled By: zou3519
fbshipit-source-id: 05819c3cc96733e2ba93c0a7c0ca06933acb22f3
Summary:
Some files have inproper executable permissions (which git tracks). This
commit adds a test in CI to ensure that executable permissions are off
for files that shouldn't have such a permission. This also ensures fixes
such as https://github.com/pytorch/pytorch/issues/21305 are complied in the future.
---
Disclaimer: I'm the author of flake8-executable, and I've been using it
on my end for over a month and thus I think it should be stable enough.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24214
Differential Revision: D16783437
Pulled By: ezyang
fbshipit-source-id: 018e55798f1411983c65444e6304a25c5763cd19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24439
many literatures mentioned BPR is useful for improving recommendation quality. Add a BPR loss so that we can train TTSN with it. Would like to see if it can improve retrieval models.
reference: https://arxiv.org/pdf/1205.2618.pdf
Reviewed By: dragonxlwang
Differential Revision: D16812513
fbshipit-source-id: 74488c714a37ccd10e0666d225751a845019eb94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24454
We want to change the place of wipe_cache. From what we observed, the original place does not help.
Reviewed By: mingzhe09088
Differential Revision: D16853205
fbshipit-source-id: 1f6224a52433cbe15c0d27000b4ac140fb9cd4c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24418Fixes#24394
The observer is not added correctlty, because one of the conditions is not met.
Test Plan: Imported from OSS
Differential Revision: D16833951
Pulled By: zafartahirov
fbshipit-source-id: bb4699e6a1cf6368c7278272a68e5e7c6d3f59a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24431
Pickle's fully-qualified name lookup would fail when trying to serialize QConfig_dynamic since the __name__ on the instance would refer to the wrong class name
Test Plan: Imported from OSS
Differential Revision: D16835705
Pulled By: jamesr66a
fbshipit-source-id: e146835cbe10b08923d77298bc93b0f5b0ba37c5
Summary:
The old behavior was to always use `sm_30`. The new behavior is:
- For building via a setup.py, check if `'arch'` is in `extra_compile_args`. If so, don't change anything.
- If `TORCH_CUDA_ARCH_LIST` is set, respect that (can be 1 or more arches)
- Otherwise, query device capability and use that.
To test this, for example on a machine with `torch` installed for py37:
```
$ git clone https://github.com/pytorch/extension-cpp.git
$ cd extension-cpp/cuda
$ python setup.py install
$ cuobjdump --list-elf build/lib.linux-x86_64-3.7/lltm_cuda.cpython-37m-x86_64-linux-gnu.so
ELF file 1: lltm.1.sm_61.cubin
```
Existing tests in `test_cpp_extension.py` for `load_inline` and for compiling via `setup.py` in test/cpp_extensions/ cover this.
Closes gh-18657
EDIT: some more tests:
```
from torch.utils.cpp_extension import load
lltm = load(name='lltm', sources=['lltm_cuda.cpp', 'lltm_cuda_kernel.cu'])
```
```
# with TORCH_CUDA_ARCH_LIST undefined or an empty string
$ cuobjdump --list-elf /tmp/torch_extensions/lltm/lltm.so
ELF file 1: lltm.1.sm_61.cubin
# with TORCH_CUDA_ARCH_LIST = "3.5 5.2 6.0 6.1 7.0+PTX"
$ cuobjdump --list-elf build/lib.linux-x86_64-3.7/lltm_cuda.cpython-37m-x86_64-linux-gnu.so
ELF file 1: lltm_cuda.cpython-37m-x86_64-linux-gnu.1.sm_35.cubin
ELF file 2: lltm_cuda.cpython-37m-x86_64-linux-gnu.2.sm_52.cubin
ELF file 3: lltm_cuda.cpython-37m-x86_64-linux-gnu.3.sm_60.cubin
ELF file 4: lltm_cuda.cpython-37m-x86_64-linux-gnu.4.sm_61.cubin
ELF file 5: lltm_cuda.cpython-37m-x86_64-linux-gnu.5.sm_70.cubin
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23408
Differential Revision: D16784110
Pulled By: soumith
fbshipit-source-id: 69ba09e235e4f906b959fd20322c69303240ee7e
Summary:
The issue is that `python setup.py install` will fail right at the end
of the build, with:
```
File "setup.py", line 380, in run
report('-- Detected cuDNN at ' + CUDNN_LIBRARY + ', ' + CUDNN_INCLUDE_DIR)
TypeError: must be str, not NoneType
```
This is due to `USE_CUDNN` being True, but CUDNN library and include dir
not being auto-detected. On this distro, the CUDA install goes into
`/opt/cuda/` while CUDNN goes into `/usr/lib`.
```
$ locate libcudnn.so
...
/usr/lib/libcudnn.so
/usr/lib/libcudnn.so.7
/usr/lib/libcudnn.so.7.6.1
$ locate libcublas.so # targets/... symlinked from /opt/cuda/lib64
...
/opt/cuda/targets/x86_64-linux/lib/libcublas.so
```
One could work around this by setting `CUDNN_LIB_DIR`, but that's
annoying and you only find out after running into this.
The path is added after `CUDA_HOME`, so should not be a problem on
systems which have multiple CUDA installs and select one via `CUDA_HOME`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24300
Differential Revision: D16839323
Pulled By: soumith
fbshipit-source-id: 5285fff604584ccfbe6368c5ee5a066f8fc10802
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24257
Type subclassing was used to support our old hierarchy of
Tensor types. Now that we have one tensor type it is not needed.
This removes:
* isSubclass, since it is now always false.
* type slicing, which was only needed for subclasses.
* AutogradZeroTensor, which is folded into ProfiledTensorType
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D16794035
Pulled By: zdevito
fbshipit-source-id: 9a3e6101df0d51029a5e667a9c9137d2ae119aa7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24348
Partition + GatherByKeys pair is pretty handy for implementing strategy where
part of the keys will be on local machine, while part of the keys will end up
on the remote machin (for cases when there is exactly 1 id).
Reviewed By: aazzolini
Differential Revision: D16802988
fbshipit-source-id: 4c7ac97fc0db3ce88575fccab0c7bf69dcbef965
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24330
In principle, we should be able to use the MSVC generator
to do a Windows build, but with the latest build of our
Windows AMI, this is no longer possible. An in-depth
investigation about why this is no longer working should
occur in https://github.com/pytorch/pytorch/issues/24386
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24330
Test Plan: Imported from OSS
Differential Revision: D16828794
Pulled By: ezyang
fbshipit-source-id: fa826a8a6692d3b8d5252fce52fe823eb58169bf
Summary:
The corresponding numpy_dtype_to_aten is public already so this
should be fine. Tests still pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23943
Differential Revision: D16690742
Pulled By: soumith
fbshipit-source-id: 81431a3316509cff8a9122e10e8f6a362bbcc9c0
Summary:
This is a bunch of changes to the docs for stylistic changes,
correctness, and updates to the new script API / recent TorchScript
changes (i.e. namedtuple)
For reviewers, ping me to see a link of the rendered output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24371
Pulled By: driazati
Differential Revision: D16832417
fbshipit-source-id: a28e748cf1b590964ca0ae2dfb5d8259c766a203
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24384
So that we can use them in other functions.
Reviewed By: yinghai
Differential Revision: D16824289
fbshipit-source-id: 3cb33cfa9a5c479a63db6438aef518209bdfb1f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24350
`TK_NAMED_TUPLE_DEF` shouldn't exist, because NamedTuples are not
distinct syntactic things. The fact that NamedTuples and Classes are
treated differently is a property of our implementation, not the
language grammar.
This PR kills it and re-uses `CLASS_DEF` instead.
Test Plan: Imported from OSS
Differential Revision: D16825273
Pulled By: suo
fbshipit-source-id: f6d97d7e4fbdf789fd777f514eac97f32e2bbae2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24349
Methods that derive a new class type from the old one need to copy the
`method_` field as well as the attributes.
Test Plan: Imported from OSS
Differential Revision: D16825274
Pulled By: suo
fbshipit-source-id: 938334e0733d2a89f00ec46984cbd5beecb4c786
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23753
Add intrinsic(fused) module mappings in quantize.py to enable mapping fused modules
in both QAT and post PTQ
Differential Revision: D16820749
fbshipit-source-id: 07de76a4f09b44bde8b193c103eac02c22b875b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24183
-----------
Fix: Enabled masked select/scatter/fill for BFloat16 on CPU
Test: via unit tests
Test Plan: Imported from OSS
Differential Revision: D16763461
Pulled By: izdeby
fbshipit-source-id: fe733635a2064e5a088a108ff77c2a1a1487a27c
Summary:
Removes older `torch.stack`-based logic in favor of `torch.diagonal()` and `torch.diag_embed()`.
I see 100x speedup in my application, where my batched matrix has shape `(800, 32 ,32)`.
```py
import torch
from torch.distributions import constraints, transform_to
x = torch.randn(800, 32, 32, requires_grad=True)
# Before this PR:
%%timeit
transform_to(constraints.lower_cholesky)(x).sum().backward()
# 579 ms ± 34.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# After this PR:
%%timeit
transform_to(constraints.lower_cholesky)(x).sum().backward()
# 4.5 ms ± 241 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24131
Differential Revision: D16764035
Pulled By: ezyang
fbshipit-source-id: 170cdb0d924cdc94cd5ad3b75d1427404718d437
Summary:
This diff is to support python user defined function over rpc for https://github.com/pytorch/pytorch/issues/23110, work flow is like this:
1. pickle python udf
2. pass pickle to C++
3. C++ pass over rpc from client to server
4. server call runPythonUDF() python function to unpickle and run python udf and pickle the udf result using python embedder
6. pass back serialized result from server to client
7. client call loadPythonUDFResult() python function to unpickle result
7. return it to python
right now, put rpc_sync_builtin() and rpc_async_builtin() as temporary interfaces for builtin operator remote calls, they accept qualified name string, this interface can execute builtin operators in C++ land.
rpc_sync() and rpc_async() accept python callables only right now, it could be user define python functions or builtin operator python functions, the python functions will be executed in python land.
once we can resolve builtin operator python callables to qualified name string, we can merge rpc_sync_builtin() into rpc_sync() then
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23569
Test Plan: unit tests
Differential Revision: D16390764
Pulled By: zhaojuanmao
fbshipit-source-id: 2cf2c22a979646830b5581bd75eabf8b3cca564c
Summary:
Assert that there's no multiple written-to to a single memory location, which
caused corrupted output.
Fixed batched matrix trlu logic, which relies on the previous copy behavior to
support tensors with stride 0 at leading dimension.
This fixes the issue proposed at: https://github.com/pytorch/pytorch/issues/23063
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23574
Differential Revision: D16600717
Pulled By: ezyang
fbshipit-source-id: e41e14f03eccf97398b64ba43647110beb1529e6
Summary:
Variables such as `device` and `sparse` in for loops should be used in tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24075
Differential Revision: D16763073
Pulled By: ezyang
fbshipit-source-id: 8735cbc8d9ed695db8489cfc949c895180a7b826
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24361
Currently we only support Conv in kernel but have entrance for both type using one same class
It is time make change
Reviewed By: csummersea
Differential Revision: D16604713
fbshipit-source-id: b98d39a2c7960707cd50ba27e43dce73f741eeeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24232
As suggested in https://github.com/pytorch/pytorch/pull/23128#discussion_r306650311, we will make the keys of default_qconfig_dict as `torch.nn.Linear`. That is, we will do the dynamic quantization on the `torch.nn.Linear` by default, if the user just specify `torch.quantize_dynamic(model)`.
ghstack-source-id: 88287089
Differential Revision: D16781191
fbshipit-source-id: 991a5e151a9ea32b879d6897cd9862855d747135
Summary:
We found the following dimension mismatch issues when running the BERT model with the dynamic quantization:
```
Traceback (most recent call last):
File "bert.py", line 75, in <module>
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 539, in __call__
result = self.forward(*input, **kwargs)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 709, in forward
head_mask=head_mask)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 539, in __call__
result = self.forward(*input, **kwargs)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 437, in forward
layer_outputs = layer_module(hidden_states, attention_mask, head_mask[i])
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 539, in __call__
result = self.forward(*input, **kwargs)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 415, in forward
attention_outputs = self.attention(hidden_states, attention_mask, head_mask)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 539, in __call__
result = self.forward(*input, **kwargs)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 372, in forward
self_outputs = self.self(input_tensor, attention_mask, head_mask)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 539, in __call__
result = self.forward(*input, **kwargs)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 303, in forward
query_layer = self.transpose_for_scores(mixed_query_layer)
File "/home/jianyuhuang/anaconda3/lib/python3.7/site-packages/pytorch_transformers/modeling_bert.py", line 296, in transpose_for_scores
return x.permute(0, 2, 1, 3)
RuntimeError: number of dims don't match in permute
```
Before the quantization, the dimension of ```x``` in ```transpose_for_scores``` is ```[1, 14, 12, 64]```;
After the quantization, the dimension of ```x``` in ```transpose_for_scores``` is ```[14, 12, 64]```.
There is a dimension mismatch on the output of the ```torch.ops.quantized.fbgemm_linear_dynamic``` operators. The first dimension is missing, which cause the issues with the abvove permute.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23330
ghstack-source-id: 88287092
Differential Revision: D16463334
fbshipit-source-id: 4bdb836d1df31ba7c0bd44e3339aabdc8b943ae1
Summary:
TensorIterator was incorrectly moving the stride 0 dimension to the
inner-most dim in the assignment:
a[idx] = b
Note that the corresponding read was still fast:
c = a[idx]
This was noticed by adamlerer
```
import torch
import time
import sys
N = 300000
torch.set_num_threads(1)
a = torch.zeros(N, 128)
b = torch.zeros(N, 128)
idx = torch.arange(N)
%timeit c = a[idx] # before and after: ~91.3 ms
%timeit a[idx] = b # before: 4.38 sec after: 44.1 ms
```
Note that the indexed read is slower than the indexed assignment on
my computer because the read has to allocate a new output (which is
zero'ed by the kernel). The indexed assignment doesn't allocate any new
Tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24083
Differential Revision: D16805440
Pulled By: colesbury
fbshipit-source-id: 70a2e74ae79691afbfa9f75b3d7d1e6806f603f5
Summary:
Stacked PRs
* #24258 - [jit] Add `trace_module` to docs
* **#24208 - [jit] Cleanup documentation around `script` and `trace`**
Examples / info was duplicated between `ScriptModule`, `script`, and
`trace`, so this PR consolidates it and moves some things around to make
the docs more clear.
For reviewers, if you want to see the rendered output, ping me for a
link
](https://our.intern.facebook.com/intern/diff/16746236/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24208
Pulled By: driazati
Differential Revision: D16746236
fbshipit-source-id: fac3c6e762a31c897b132b8421baa8d4d61f694c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24298
This helps in situations like when you have `__{g,s}etstate__` on an `nn.Module` and you'd like to trace the module, but still preserve the serialization methods to make the module semantically correct
Test Plan: Imported from OSS
Differential Revision: D16799800
Pulled By: jamesr66a
fbshipit-source-id: 91c2957c94c9ec97a486ea376b2a3e3a821270af
Summary:
We want to use the Module type as the key for the qconfig_dict for the module replacement during the quantization.
Before this Diff, to dynamic quantize the BERT model, we have to specify each layer:
```
qconfig_dict = {
'encoder.layer.0.attention.self.query': default_qconfig,
'encoder.layer.0.attention.self.key': default_qconfig,
'encoder.layer.0.attention.self.value': default_qconfig,
'encoder.layer.0.attention.output.dense': default_qconfig,
'encoder.layer.0.intermediate.dense': default_qconfig,
'encoder.layer.0.output.dense': default_qconfig,
'encoder.layer.1.attention.self.query': default_qconfig,
'encoder.layer.1.attention.self.key': default_qconfig,
'encoder.layer.1.attention.self.value': default_qconfig,
'encoder.layer.1.attention.output.dense': default_qconfig,
'encoder.layer.1.intermediate.dense': default_qconfig,
'encoder.layer.1.output.dense': default_qconfig,
...
}
```
After this Diff, we only need the following
```
qconfig_dict = {
torch.nn.Linear : default_qconfig
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23212
ghstack-source-id: 88287091
Reviewed By: zafartahirov
Differential Revision: D16436542
fbshipit-source-id: 11fbe68ee460560c1a7cdded63581eb7a00e5a89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23963
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16695160
Pulled By: ezyang
fbshipit-source-id: dc8fd1f0c7096fcd4eb48ce42069307915052a77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23961
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16695162
Pulled By: ezyang
fbshipit-source-id: 28eca6920bd1b4e72286b4ab859cf513dcd0db44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23960
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16695161
Pulled By: ezyang
fbshipit-source-id: 36d1777467bbe3f8842736c570b029b72954e027
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23954
There is only one substantive change: when stride.size() == 1,
we expand it to size 2. However, I also took the opportunity
to give a better error message.
Testing here is bare minimum, because I'm in a hurry. Just make
sure C++ API with all size 1 inputs works.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16695163
Pulled By: ezyang
fbshipit-source-id: 31674bf97db67e60e4232514c88a72be712bd9ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24087
Added name inference rules for softmax and log_softmax.
Added the overloads for Dimname dim to softmax and log_softmax.
Test Plan: - [namedtensor ci]
Differential Revision: D16763391
Pulled By: zou3519
fbshipit-source-id: 676a14666d42441eb7d3c9babef7461c7b78d290
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24028
Previously, torch.abs(tensor, out=out) would ignore the names of the
`out` tensor and overwrite them with the names of `tensor`.
This patch changes the behavior to the following:
1) If `out` does not have names, then overwite them with `tensor.names`.
2) If `out` does have names, then check that `out.names` equals
`tensor.names`.
This patch also includes the following clean ups:
- renamed `default_names` to `FIXME_default_names` because it is
inefficient and needs to be fixed.
- Renamed impl::internal_get_names / impl::internal_has_names to
impl::get_names / impl::set_names. Devs should feel free to use them, so
I removed the internal_ prefix.
- Moved internal_set_names to NamedTensor.{h, cpp}. These functions
still have the internal_ prefix because their use requires caution.
Test Plan: - [namedtensor ci]
Differential Revision: D16763387
Pulled By: zou3519
fbshipit-source-id: 57dcc7c759246def0db2746d1dca8eddd5e90049
Summary:
Rename decorator to `for_all_device_types` as `test_` prefixed name recognized as test in some environments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24337
Differential Revision: D16806807
Pulled By: VitalyFedyunin
fbshipit-source-id: 3132366046e183329ba5838a4bc29441fdb5bd4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24282
This moves a test from Python to cpp, and in doing so lets us clean up a
bunch of otherwise unused code.
Test Plan: Imported from OSS
Differential Revision: D16800562
Pulled By: suo
fbshipit-source-id: ebc29bb81f4fb2538081fa309ead1739980f1093
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24281
These are not just classes anymore, rename
Test Plan: Imported from OSS
Differential Revision: D16800564
Pulled By: suo
fbshipit-source-id: 8b8d508944c26a8916fc7642df43f22583dfcf82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24280
This simplifies the groundwork for serializing functions.
Test Plan: Imported from OSS
Differential Revision: D16800560
Pulled By: suo
fbshipit-source-id: 129b32dddb39494daeade33c87d76248486a86b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24279
As title. I want to let children be able to define how to get their own
name
Test Plan: Imported from OSS
Differential Revision: D16800563
Pulled By: suo
fbshipit-source-id: 6a12ffef96b0dfa5543c5463386170de7726ad58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24278
We had a lot of redundant methods. Killing them.
Test Plan: Imported from OSS
Differential Revision: D16800561
Pulled By: suo
fbshipit-source-id: 60acc1d5b0f34130a1f66a1e5bc7df364a5feb57
Summary:
Previously we didn't handle list comprehensions where the expression produced a different type than the input list.
`[float(x) for x in [1, 2, 3]`
Fix for https://github.com/pytorch/pytorch/issues/24239
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24271
Differential Revision: D16806564
Pulled By: eellison
fbshipit-source-id: 1af6a174b9d17a6ea7154511133c12c691eb9188
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24311
Now you can run tests with `pytest -n auto test/test_jit.py` to get
tests to run in parallel. On my devfair in opt mode, this takes < 30
seconds, which is a huge improvement.
The actual changes are places where we hard-coded certain things that
got changed due to how pytest-xdist distributes tests:
1. Warnings are filtered after they are tripped once, so
`test_trace_warn` shouldn't rely on warning counts.
2. various file/save things hardcoded paths inappropraitely
Test Plan: Imported from OSS
Differential Revision: D16801256
Pulled By: suo
fbshipit-source-id: 62a3543dd7448a7d23bdef532953d06e222552ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23983
While testing I realized that model layers can extract different types of features from the same column. For example, MultifeedFeaturesTransform uses float and ID list features from the "features" column.
get_accessed_features returns a map from column to AccessedFeatures, and AccessedFeatures only has the feature IDs for one feature type. This is incompatible with have multiple types of features per column, one type ends up overwriting another in the map.
To fix this, I've modified get_accessed_features to return a map from column to a list of AccessedFeatures objects.
Reviewed By: itomatik
Differential Revision: D16693845
fbshipit-source-id: 2099aac8dc3920dd61de6b6ad5cf343c864803bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24262
Previously for onnxifi_blacklist_ops option, we figure out the net_pos based on the order of ops in the net. But this logic is wrong if the net already has net_pos assigned and we may end up blacklisting unintended ops. Fix this issue to always assign net_pos before computing any blacklist.
Reviewed By: yinghai
Differential Revision: D16789166
fbshipit-source-id: 2d08a7737d417822f2209adb4dcb24dbb258ff90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23973
Without loss of generality, I describe the API for `tensor.view_names`.
`tensor.names_` has an analogous API.
`tensor.view_names(*names)` returns a view on tensor with named dims `names`.
`names` must be of length `tensor.dim()`; otherwise, if '*' is in `names`,
then it (known as the "glob") is expanded greedily to be equal to the
corresponding names from `tensor.names`.
For example,
```
>>> x = torch.empty(2, 3, 5, 7, names=('N', 'C', 'H', 'W'))
>>> x.view_names('*', 'height', 'width').names
('N', 'C', 'height', 'width')
>>> x.view_names('batch', '*', 'width').names
('batch', 'C', 'H', 'width')
```
tensor.view_names(**rename_map) returns a view on tensor that has
renamed dims as specified in the mapping `rename_map`.
For example,
```
>>> x = torch.empty(2, 3, 5, 7, names=('N', 'C', 'H', 'W'))
>>> x.view_names(W='width', H='height').names
('N', 'C', 'height', 'width')
```
These are different(!!!) from the C++ API, which only allows the
following:
- tensor.view_names(optional<DimnameList>)
C++ API parity for named tensors is not important right now; I am
punting that to the future.
Test Plan: - [namedtensor ci]
Differential Revision: D16710916
Pulled By: zou3519
fbshipit-source-id: 7cb8056c0fb4c97b04c3a2d1dd0f737e0a67ce34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23962
This change should make the semantics clearer.
`tensor.names_(names)` sets tensor.names to be `names`.
`tensor.view_names(names)` returns a view of the tensor with names
`names`.
Test Plan
- [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D16710915
Pulled By: zou3519
fbshipit-source-id: c82fa9812624d03c86f7be84b0a460e3c047aaa0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23804
`output = tensor.align_to(names)` returns a view of `tensor` such that
`output.names = names`. Dimensions with the same names in `tensor` and
`output` have the same sizes; dimensions with new names have size 1.
The following must be true for this operation to succeed:
1) tensor.names must be a subsequence (not necessarily contiguous) of `names`
2) Aligning tensor.names to names must not change the absolute position from the
right of any unnamed dimension.
In practice, these constraints mean that aligning cannot transpose
names.
Some examples:
- Tensor[C].align_to(C) -> Tensor[C]
- Tensor[N].align_to([N, C]) -> Tensor[N, C]
- Tensor[H, W].align_to([N, H, W, C]) -> Tensor[N, H, W, C]
- Tensor[None].align_to([N, None]) -> Tensor[N, None]
- Tensor[N].align_to([N, None None]) -> Tensor[N, None, None]
Examples of error cases:
- Tensor[W, H].align_to([N, H, W, C]) -> Error (not a subsequence)
- Tensor[None, H].align_to([None, H, W]) -> Error (would change the
absolute position from the right of a None dimension)
`torch.align_tensors(*tensors)` aligns the named dimensions of each
tensor according to the alignment rules so that they can be used in an
operation. More concretely, it aligns each tensor to the
longest names among the names of the tensors in `tensors`.
This allows users to emulate "broadcasting by names", which is one of
the things named tensors tries to enable. Here is an example:
```
imgs: Tensor[N, C, H, W]
scale: Tensor[N]
// Doesn't work because we do broadcasting by alignment by default
imgs * scale
// Does work
imgs, scale = torch.align_tensors(imgs, scale)
imas * scale
```
Future:
- Consider allowing broadcasting by names by default.
Test Plan:
- The diff looks pretty large but more than half of it is testing.
- new tests [namedtensor ci]
Differential Revision: D16657927
Pulled By: zou3519
fbshipit-source-id: e2f958bf5146c8ee3b694aba57d21b08e928a4e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24108
`torch.empty_like(tensor)` and `tensor.clone()` both propagate names to
the output tensor.
As a part of this change, I fixed the empty(..., names=) overload to
include the `memory_format` argument in the normal `empty` declaration
in native_functions.yaml.
Test Plan: - [namedtensor ci]
Differential Revision: D16763392
Pulled By: zou3519
fbshipit-source-id: c7b2bc058d26a515a5fd8deef22c2acb290c8816
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24107
In the short term, we implement this by having overloads for each of
these functions. In the long term, the plan is to move DimnameList to
TensorOptions so that we do not have to duplicate work.
Also fixes the implementation of empty. If there are no names, we should
just return an unnamed tensor instead of telling the user we don't
support their backend/layout.
Test Plan: - [namedtensor ci]
Differential Revision: D16763393
Pulled By: zou3519
fbshipit-source-id: 7324a6b157187d4f74abc5459052f3323a417412
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24030
The cmake arg - `USE_QNNPACK` was disabled for iOS build due to its lack of support for building multiple archs(armv7;armv7s;arm64) simultaneously.To enable it, we need to specify the value of IOS_ARCH explicitly in the build command:
```
./scripts/build_ios.sh \
-DIOS_ARCH=arm64 \
-DBUILD_CAFFE2_MOBILE=OFF \
```
However,the iOS.cmake will overwirte this value according to the value of `IOS_PLATFORM`. This PR is a fix to this problem.
Test Plan:
- `USE_QNNPACK` should be turned on by cmake.
- `libqnnpack.a` can be generated successfully.
- `libortch.a` can be compiled and run successfully on iOS devices.
<img src="https://github.com/xta0/AICamera-ObjC/blob/master/aicamera.gif?raw=true" width="400">
Differential Revision: D16771014
Pulled By: xta0
fbshipit-source-id: 4cdfd502cb2bcd29611e4c22e2efdcdfe9c920d3
Summary:
- ~~Add a unit test for the Dynamic Quantized Linear operator (```torch.fbgemm_linear_quantize_weight```, ```torch.fbgemm_pack_quantized_matrix```, and ```torch.fbgemm_linear_int8_weight```) in ```test_quantized.py```.~~ Move this to D16404027 for a separate review.
- Add the Dynamic Quantized Linear module in ```torch/nn/quantized/modules/linear.py```. ~~This is in a rudimentary stage. Will add more functions later~~.
- Add the torch.quantize logic (prepare, eval, convert) for dynamic quantization.
- Add a unit test for the Dynamic Quantized Linear module in ```test_nn_quantized.py```.
- Add a unit test for the Model-level Quantization API
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23128
ghstack-source-id: 88257232
Differential Revision: D16258664
fbshipit-source-id: 4be3ac39ee27c088b341c741d3f09f51d5a23ef0
Summary:
Which was added in https://github.com/pytorch/pytorch/issues/16412.
Also make some CUDNN_* CMake variables to be build options so as to avoid direct reading using `$ENV` from environment variables from CMake scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24044
Differential Revision: D16783426
Pulled By: ezyang
fbshipit-source-id: cb196b0013418d172d0d36558995a437bd4a3986
Summary:
As suggested in https://github.com/pytorch/pytorch/pull/22891, we will add an overload for torch.fbgemm_linear_int8_weight (dynamic quantized version of linear function) that takes PackedLinearWeight as input and is pretty much the same in signature as regular aten::linear.
The previous Diff D16381552 is reverted because `quantize_linear` expects the scale to be `float`, and the zero_point to be `int`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23464
ghstack-source-id: 88257231
Differential Revision: D16527741
fbshipit-source-id: 66585f668c6e623c50514eb11633bb711d8767f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24201
It turns out that the `run_test` script uses a blacklist of "exclude" tests and tests if the test name [starts with](https://github.com/pytorch/pytorch/blob/master/test/run_test.py#L342) the given blacklist item. `nn` was passed as a blacklist item in CI, and that meant that not only was test_nn skipped, but also test_nn_quantized. This renames the test to avoid this situation, and imo puts it in a better position lexicographically next to the other quantization tests.
Test Plan: Imported from OSS
Differential Revision: D16772820
Pulled By: jamesr66a
fbshipit-source-id: 4cde0729b48ae3e36fcedab9c98197831af82dde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24202
tensor.set_names(names) is the out-of-place variant of
tensor.set_names_(names). This naming is probably confusing so I am
taking any and all suggestions.
Test Plan: - run tests [namedtensor ci]
Differential Revision: D16773014
Pulled By: zou3519
fbshipit-source-id: 61024303c1a34db631cc4cb2c53757345e40d72c
Summary:
Existing code adds two enumerators to the set instead of forming their union.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23974
Differential Revision: D16732762
Pulled By: ezyang
fbshipit-source-id: 787737b7cf4b97ca4e2597e2da4a6ade863ce85c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24171
There can be up to 24, instead of 16, intersections (including duplications) returned from rotated_rect_intersection_pts, which caused errors of num <= 16 assertions in https://fburl.com/scuba/mzmf49xc (thanks to Ananth's report) when the boxes are extremely close (e.g., the newly added unit test case)
Differential Revision: D16760676
fbshipit-source-id: 289c25ef82c094d98bfe570c5d35c055e49703cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24182
-----
Fix: Enabled comparison operations for BFloat16 on CPU
Test: via unit tests
Test Plan: Imported from OSS
Differential Revision: D16763460
Pulled By: izdeby
fbshipit-source-id: 885ff9006d3bd60bb945147c3b86f97cd0d26f7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24196
Observer returns output with no changes for post training quant. This unifies observer semantics for QAT and PTQ.
ghstack-source-id: 88140887
Differential Revision: D16768277
fbshipit-source-id: fae7c94e3dc0eeda363e9982b3865a15113e11bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24077
This replaces all uses of DimensionedTensorType with ProfiledTensorType.
For places where we propagate shape information, we still follow the
dimension-only propagation rules, meaning that even if full size information
is known on inputs the outputs will only have dimension information.
This fixes several bugs in existing implentations that this change uncovered:
* requires_grad was not propgated correctly across loops
* requires_grad on ProfiledTensorType returned false when requires_grad information
is unknown but the conservative result is true
* some equality code on ProfiledTensorType contained bugs.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D16729581
Pulled By: zdevito
fbshipit-source-id: bd9f823c1c6b1d06a236a1b5b2b2fcdf0245edce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23635
It appears it is the same complexity to add new modules using a base class and using a generation script.
Test Plan: Imported from OSS
Differential Revision: D16593364
Pulled By: zafartahirov
fbshipit-source-id: 852dcf41f3dfa2a89152042b8e61d0b6defa8feb
Summary:
This PR introduce `pytorchtest.test_all_device_types()` decorator which helps to write CPU, CUDA tests faster, iterating single test through all available devices
Simple `test_var_mean_some_dims` becomes
```
test_var_mean_some_dims (__main__.TestTorch) ... ok
test_var_mean_some_dims_cpu (__main__.TestTorch) ... ok
test_var_mean_some_dims_cuda (__main__.TestTorch) ... ok
```
```python
class pytorchtest():
"""Allows to generate and run per-device unittests.
This decorator class allows to generate and run per-device unittest.
Example:
class _TestTorchMixin(pytorchtest):
pytorchtest.test_all_device_types()
def test_zeros_like(self, device):
expected = torch.zeros((100, 100,), device=device)
Will execute:
test_zeros_like (__main__.TestTorch) ... skipped 'Look at test_zeros_like_cpu, test_zeros_like_cuda results.'
test_zeros_like_cpu (__main__.TestTorch) ... ok
test_zeros_like_cuda (__main__.TestTorch) ... ok
To work properly, test class should be inherited from the `pytorchtest`.
test_all_device_types decorator does not guarantee proper functionality in
combination with other decorators.
Please do not extend this decorator to support other cases (such as dtype,
layouts, etc) without consulting with bigger group. Devices is the special
case as build flags control additions/removals (see
https://github.com/pytorch/pytorch/pull/23824 for the reference).
"""
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23824
Differential Revision: D16716959
Pulled By: VitalyFedyunin
fbshipit-source-id: ba39af0f9bce2c4a64da421bbc24d6a1c1d9139d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23846
This moves a test from Python to cpp, and in doing so lets us clean up a
bunch of otherwise unused code.
Test Plan: Imported from OSS
Differential Revision: D16684390
Pulled By: suo
fbshipit-source-id: fca81ca14d1ac9e4d6b47ae5eecaa42b38d69147
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23845
These are not just classes anymore, rename
Test Plan: Imported from OSS
Differential Revision: D16684391
Pulled By: suo
fbshipit-source-id: af0024c0b7fbcca68785ec3fc6dc288ec46a1b84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23697
This simplifies the groundwork for serializing functions.
Test Plan: Imported from OSS
Differential Revision: D16611884
Pulled By: suo
fbshipit-source-id: 620d3446cb353befde090a81a250cdd2d5e35aa8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23696
As title. I want to let children be able to define how to get their own
name
Test Plan: Imported from OSS
Differential Revision: D16611885
Pulled By: suo
fbshipit-source-id: 620b22c314eddf95159546810e1a00b1646663b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23691
We had a lot of redundant methods. Killing them.
Test Plan: Imported from OSS
Differential Revision: D16611883
Pulled By: suo
fbshipit-source-id: a32c0a8b8b7e909b386a70abb0827c26cbd37e20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23689
We store methods, no reason to try to lock the CU to find a method on a
class type
Test Plan: Imported from OSS
Differential Revision: D16610045
Pulled By: suo
fbshipit-source-id: d84ad81faa42c4e2da20b666fa3645e22f11dac3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24206
`unicode_literals` messes up python2 when the literals are put in `__all__`, because the python interpreter expects str and not unicode for elements in an import statement. This fixes that
Test Plan: Imported from OSS
Differential Revision: D16774391
Pulled By: jamesr66a
fbshipit-source-id: fee2562f58b2e2c6480726d8809696961a37c8dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23658
**How things work for caffe2:**
Caffe2 Ops -> NNPACK/QNNPACK -> pthreadpool_compute_1/2/3/4d_tiled -> pthreadpool_compute_1d (caffe2 shim) -> caffe2::ThreadPool
**Before this PR:**
Pytorch Ops -> NNPACK/QNNPACK -> pthreadpool_compute_1/2/3/4d_tiled -> pthreadpool_compute_1d (third_party implementation without mobile optimization)
caffe2::ThreadPool is optimized for mobile. This change leverages this logic for pytorch mobile as a temporary solution improve pytorch mobile perf. It is guarded by the C10_MOBILE macro.
For server side we return nullptr.
**Plan for next steps:**
Implement a mobile version of "at::parallel_for" which uses caffe2::ThreadPool internally so all ATen/TH multithreading usage is mobile optimized.
Refactor QNNPACK and/or pthreadpool to explicitly using "at::parallel_for" primitive to replace pthreadpool_compute_1d for Pytorch.
After QNNPACK is refactored, we will delete the mobile_threadpool() API.
ghstack-source-id: 88073396
Reviewed By: dreiss
Differential Revision: D16594020
fbshipit-source-id: 9f94600756d5f86d24a12a2fd7df3eebd0994f1d
Summary:
**Patch Description**:
Update the docs to reflect one no longer needs to install tensorboard nightly, as Tensorboard 1.14.0 was [released last week](https://github.com/tensorflow/tensorboard/releases/tag/1.14.0).
**Testing**:
Haven't actually tested pytorch with tensorboard 1.14 yet. I'll update this PR once I have.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22026
Differential Revision: D16772136
Pulled By: orionr
fbshipit-source-id: 2e1e17300f304f50026837abbbc6ffb25704aac0
Summary:
These were incorrect and didn't run before
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24191
Pulled By: driazati
Differential Revision: D16770604
fbshipit-source-id: 0d8547185871f7f4b1e44c660e45699ed8240900
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24184
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16764168
Pulled By: ezyang
fbshipit-source-id: cc252a860fd7e4b7fb2b95c5d9fcdbf6935ffeb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24029
The cmake toolchain file for building iOS is currently in `/third-pary/ios-cmake`. Since the upstream is not active anymore, It's better to maintain this file ourselves moving forward.This PR is also the prerequisite for enabling QNNPACK for iOS.
Test Plan:
- The `libtorch.a` can be generated successfully
- The `libtorch.a` can be compiled and run on iOS devices
<img src="https://github.com/xta0/AICamera-ObjC/blob/master/aicamera.gif?raw=true" width="400">
Differential Revision: D16770980
Pulled By: xta0
fbshipit-source-id: 1ed7b12b3699bac52b74183fa7583180bb17567e
Summary:
Starting ONNX IR version 4, the initializers in the ONNX graph do not have to be inputs of the graphs. This constraint, which existed in IR version 3 and earlier, was relaxed in IR version 4. This PR provides an API level argument to allow ONNX export with the relaxed constraint of IR version 4, i.e. provides the option to not include initializers as inputs. This allows backends/runtimes to do certain optimizations, such as constant folding, better.
*Edit*: After discussion with houseroad we have the following behavior. For any OperatorExportType, except OperatorExportTypes.ONNX, the current status of export is maintained in this PR by default. However, the user can override it by setting the `keep_initializers_as_inputs` argument to the export API. But when exporting to ONNX, i.e. OperatorExportType is OperatorExportTypes.ONNX, the current status is changed in that by default the initializers are NOT part of the input. Again, the default can be overridden by setting the `keep_initializers_as_inputs` argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23284
Differential Revision: D16459961
Pulled By: bddppq
fbshipit-source-id: b8f0270dfaba47cdb8e04bd4cc2d6294f1cb39cf
Summary:
Improve error messages by showing the relevant function call that failed.
Before:
```
>>> torch.ones(1, dtype=torch.float) < torch.ones(1, dtype=torch.double)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Expected object of scalar type Float but got scalar type Double for argument https://github.com/pytorch/pytorch/issues/2 'other'
```
After:
```
>>> torch.ones(1, dtype=torch.float) < torch.ones(1, dtype=torch.double)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Expected object of scalar type Float but got scalar type Double for argument https://github.com/pytorch/pytorch/issues/2 'other' in call to _th_lt
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24187
Differential Revision: D16769167
Pulled By: nairbv
fbshipit-source-id: 4992eb4e86bdac2ab8805cc5356f7f92c63e1255
Summary:
This PR deletes `WeakScriptModuleProxy` and uses `ScriptModule` directly and moves the recursive script stuff into `torch/jit/_recursive.py`. The first commit is just moving code, the latter 2 contain the actual changes
](https://our.intern.facebook.com/intern/diff/16712340/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23398
Pulled By: driazati
Reviewed By: eellison
Differential Revision: D16712340
fbshipit-source-id: f907efcec59bb2694c079ab655304324c125e9bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24106
Test Plan
- Code reading. assertTensorDataAndNamesEqual isn't used in this commit
but it'll be used in future commits.
- [namedtensor ci]
Test Plan: Imported from OSS
Differential Revision: D16763390
Pulled By: zou3519
fbshipit-source-id: 170e27ebc4d79aca939c5d101489b20faedc6133
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24105
tensor.set_names(names) is the out-of-place variant of
tensor.set_names_(names). This naming is probably confusing so I am
taking any and all suggestions.
Test Plan: - run tests [namedtensor ci]
Differential Revision: D16763388
Pulled By: zou3519
fbshipit-source-id: 4b2fb3acc0514515e7ca805dbc5c3d4a9bd96317
Summary:
Some interfaces of schedulers defined in lr_scheduler.py are missing in lr_scheduler.pyi.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23934
Differential Revision: D16726622
Pulled By: ezyang
fbshipit-source-id: 45fd2d28fbb658c71f6fcd33b8997d6ee8e2b17d
Summary:
Doing these one at a time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24100
Differential Revision: D16753599
Pulled By: suo
fbshipit-source-id: cfd317a2463cf6792758abe04c0f01a146a7ec47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24048
Add `__{g,s}etstate__ methods on `nnq.Linear` for JIT (and torch.{save,load} serialization).
Unfortunately, this unearthed a bug in serialization documented in https://github.com/pytorch/pytorch/issues/24045. The check that triggered the bug has been disabled pending a fix
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D16728347
Pulled By: jamesr66a
fbshipit-source-id: c3b850be3b831f4c77cec3c2df626151b2af8b34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24047
Add `_{save_to,load_from}_state_dict` methods to `nnq.Linear` that explicitly deal with conversions from the Python attributes to the serialized state dict form
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D16728346
Pulled By: jamesr66a
fbshipit-source-id: 182c9f5069d509147dc9020b341b6cb87505fe7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24046
`nnq.Linear` was a confusing mess of buffers/attributes and Tensor/not tensor members. This PR reworks it to consistently have only Python attributes, with the conversions handled explicitly by state_dict or __{get,set}state__ methods (added in PRs further up the stack
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D16728345
Pulled By: jamesr66a
fbshipit-source-id: 47468b776b428fca2409bb55c8b161afb68a3379
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24136
This diff aims to reduce the execution of benchmark_all_test which runs all the supported operator benchmarks. In the default run, only one shape of each operator will be benchmarked. The rest of the benchmarks can be triggered with tag_filter flag.
Reviewed By: hl475
Differential Revision: D16736448
fbshipit-source-id: 33bd86f6fc2610f87f24240ad559fb11d3e35e89
Summary:
This was previously buggy and not being displayed on master. This fixes
the issues with the script to generate the builtin function schemas and
moves it to its own page (it's 6000+ lines of schemas)
Sphinx looks like it will just keep going if it hits errors when importing modules, we should find out how to turn that off and put it in the CI
This also includes some other small fixes:
* removing internal only args from `script()` and `trace()` docs, this also requires manually keeping these argument lists up to date but I think the cleanliness is worth it
* removes outdated note about early returns
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24056
Pulled By: driazati
Differential Revision: D16742406
fbshipit-source-id: 9102ba14215995ffef5aaafcb66a6441113fad59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23665
For many ATen ops, c10 can't generate boxed kernel versions yet.
We need to allow kernels that have only unboxed versions for them to be registerable with c10.
ghstack-source-id: 88050429
Differential Revision: D16603132
fbshipit-source-id: 84cae4a514da104f5035d23a4059ca6197469f9c
Summary:
The c10 dispatcher now also stores a `void*` pointer to the unboxed kernel function and this kernel function can be called if the call site knows the exact kernel signature.
It is not clear if this API will survive in the long term, but in the short term this allows an easier migration from ATen to c10 and is supposed to replace ATenDispatch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23447
ghstack-source-id: 88050435
Differential Revision: D16521939
fbshipit-source-id: 7e570df5a721defc677c3cc91758651dbe06ce1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23834
Re-expot of reverted PR https://github.com/pytorch/pytorch/pull/23810 with the bug fixed
A previous diff removed the special casing for aten:: and prim:: ops in alias analysis and implements alias analysis purely
based on the AliasAnalysisKind. To be sure it doesn't break our existing code base, it added asserts that make sure that
our existing aten:: and prim:: ops set the correct AliasAnalysisKind.
However, we don't need that restriction for future ops. Since we are now certain all existing cases are set up correctly,
we can remove these assertions.
ghstack-source-id: 88050427
Differential Revision: D16657239
fbshipit-source-id: 8a7606da8e9bd961bf47e3e1587b622a9c247ec6
Summary:
This PR:
- Moves clamp from autodiff cpp to symbolic script
- Adds an additional tuple lowering pass to the graph executor
- Updates clamp backwards to be maximally gradient preserving
Moving clamp to symbolic script presented two challenges:
- When the backward graph is defined the branch taken in the conditional is known, but communicating this information to the Jit is a little tricky. It turns out the Jit has a quirk where variables that can be None at the time of graph instantiation are treated as constants, so testing min and max against None lets the Jit instantiate only one path branch. It might be more natural to select different backward functions for these cases, but that is not yet supported.
- Moving clamp to symbolic script introduced an extra tuple construction and immediate unpacking which prevented fusion. This was dealt with by adding an additional tuple removal pass. This issue could appear whenever a symbolic script's return value was defined in an if statement, which made the Jit see the unpacked tuple as being constructed from an if, not a TupleConstruct. The graph is later optimized but tuple lowering was not performed again after these optimizations.
Moving clamp to symbolic script also adds some explicit conversions to float in graphs which it appears, but these seem harmless.
If clamp were simply moved to symbolic script then its backward graphs would look like this:
`graph(%0 : Float(*, *),
%1 : AutogradZeroTensor,
%2 : Float(*, *),
%3 : int[]?,
%4 : Scalar?,
%5 : int):
%6 : None = prim::Constant() # <string>:5:31
%7 : float = aten::Float(%5) # <string>:12:37
%8 : Float(*, *) = prim::FusionGroup_0(%0, %2, %7)
%9 : (Float(*, *), None, None) = prim::TupleConstruct(%8, %6, %6)
%10 : Float(*, *), %11 : None, %12 : None = prim::TupleUnpack(%9)
return (%10)
with prim::FusionGroup_0 = graph(%0 : Float(*, *),
%1 : Float(*, *),
%2 : float):
%3 : Bool(*, *) = aten::le(%1, %2) # <string>:12:29
%mask.5 : Float(*, *) = aten::type_as(%3, %1) # <string>:12:29
%5 : Float(*, *) = aten::mul(%0, %mask.5) # <string>:13:28
return (%5)`
And adding the additional pass to remove tuples eliminates the prim::TupleConstruct and prim::TupleUnpack. Keeping these included previously would cause test_fuser_iou to fail because multiple fusion groups would be created. Since https://github.com/pytorch/pytorch/issues/23372 this test is disabled, however. When enabled the relevant portion of its graph is now:
`%59 : float = aten::Float(%26) # <string>:314:38
%60 : float = aten::Float(%27) # <string>:314:61
%61 : int[] = aten::size(%14) # <string>:41:99
%62 : int[] = aten::size(%11) # <string>:42:100
%63 : int[] = aten::size(%15) # <string>:41:99
%64 : int[] = aten::size(%12) # <string>:42:100
%65 : Tensor, %66 : Tensor, %67 : Tensor, %68 : Tensor, %69 : Tensor, %70 : Tensor, %71 : Tensor, %72 : Tensor, %73 : Double(*, *) = prim::FusionGroup_0(%w.1, %13, %16, %23, %h.1, %54, %inter.1, %0, %12, %15, %18, %17, %29, %11, %14, %60, %59)
%74 : Tensor = aten::_grad_sum_to_size(%73, %53)
%75 : Tensor = aten::_grad_sum_to_size(%73, %52)
%grad_self.10 : Tensor = aten::_grad_sum_to_size(%65, %61) # <string>:41:30
%grad_other.10 : Tensor = aten::_grad_sum_to_size(%66, %62) # <string>:42:31
%78 : Tensor = prim::FusionGroup_1(%grad_self.10, %74, %36)
%79 : Tensor = prim::FusionGroup_2(%grad_other.10, %75, %44)
%grad_self.14 : Tensor = aten::_grad_sum_to_size(%67, %21) # <string>:33:30
%grad_other.14 : Tensor = aten::_grad_sum_to_size(%68, %22) # <string>:34:31
%grad_self.12 : Tensor = aten::_grad_sum_to_size(%69, %63) # <string>:41:30
%grad_other.12 : Tensor = aten::_grad_sum_to_size(%70, %64) # <string>:42:31
%grad_self.16 : Tensor = aten::_grad_sum_to_size(%71, %19) # <string>:33:30
%grad_other.16 : Tensor = aten::_grad_sum_to_size(%72, %20) # <string>:34:31
%86 : Tensor, %87 : Tensor = prim::FusionGroup_3(%grad_self.12, %grad_self.16, %74, %39)
%88 : Tensor, %89 : Tensor = prim::FusionGroup_4(%grad_other.12, %grad_other.16, %75, %47)
return (%79, %88, %89, %78, %86, %87, %grad_self.14, %grad_other.14)`
Which I think is expected/desired.
Finally, this implementation of clamp backwards is "maximally gradient preserving," which simply means that elements on the boundary now receive gradients. For example, if an element of a tensor is 5 and the clamp is to [2, 5], then that element will now receive a gradient. The prior implementation would zero these gradients. See https://github.com/pytorch/pytorch/issues/7002 for a discussion on preserving gradients.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23927
Test Plan: Existing tests provided sufficient coverage.
Differential Revision: D16739740
Pulled By: mruberry
fbshipit-source-id: c94291d20e1f3f25197afc7b74dc61aeb204b074
Summary:
This is try to reduce the overhead on the index_select on CPU path at DLRM (https://github.com/facebookresearch/dlrm). To make src as contiguous can make it go into the parallelied path in Tensor indexSelect function
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23055
Differential Revision: D16603913
Pulled By: ezyang
fbshipit-source-id: baaa02f184a8e70f1193e5d96ada195a46d140b9
Summary:
This patch fixes the following error:
```
In file included from /path/to/lib/python3.6/site-packages/numpy/core/include/numpy/arrayobject.h:4:0,
from ../torch/csrc/utils/numpy_stub.h:19,
from ../torch/csrc/utils/tensor_numpy.cpp:2:
../torch/csrc/utils/tensor_numpy.cpp: In function 'bool torch::utils::is_numpy_scalar(PyObject*)':
../torch/csrc/utils/tensor_numpy.cpp:223:11: error: 'PyInt_Check' was not declared in this scope
return (PyArray_IsIntegerScalar(obj) ||
^
../torch/csrc/utils/tensor_numpy.cpp:225:1: warning: control reaches end of non-void function [-Wreturn-type]
}
^```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24042
Differential Revision: D16732545
Pulled By: ezyang
fbshipit-source-id: 8d73d228b88b4a95daedcd7a4ef81c268830792e
Summary:
1. Prefixed underscores to any `DataLoaderIter` attribute that is not part of the data loader ctor argument list.
2. Prefixed `DataLoader.dataset_kind` with underscore because it only makes sense with the private enum `_DatasetKind`, and is an implementation detail.
3. Disallow setting `DataLoader.dataset` and `DataLoader.batch_sampler` after initializing a `DataLoader` because they affect other attributes in `__init__`.
These changes should not have major BC breaking effect since the big changes are on the iterator class and most users don't even store it. I GitHub searched `pin_memory_thread` and (while I didn't look through all result pages) results I see are forks of pytorch and blog posts on how data loader works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23744
Differential Revision: D16732507
Pulled By: ezyang
fbshipit-source-id: 9f04d000b4200b8047f31eaa3473780b66cebd26
Summary:
Changelog:
- When number of batches = 1, dispatch to trsm instead of trsm_batched in MAGMA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23953
Test Plan: - All triangular_solve tests should pass to ensure that the change is valid
Differential Revision: D16732590
Pulled By: ezyang
fbshipit-source-id: 7bbdcf6daff8a1af905df890a458ddfedc01ceaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23803
Custom `forward()` can return a `Variable` in case of single outputs instead of returning a `variable_list` of size 1.
Test Plan: Modified tests involving single output forward functions.
Reviewed By: ezyang
Differential Revision: D16673857
Pulled By: ezyang
fbshipit-source-id: c96d9473b48ad99e6736a68d334b333a917498b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24019
Permutes are done inside the module. We don't need them outside.
Setting of scale/zero_point has changed.
Reviewed By: jianyuh
Differential Revision: D16712437
fbshipit-source-id: e3cedf9d63347fbf8070d1a65a196e6d4b2833fc
Summary:
scale and zero_point name should match with what's used in other methods of the class.
Closes https://github.com/pytorch/pytorch/issues/23881
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23991
Test Plan: buck build mode/opt caffe2/benchmarks/operator_benchmark/pt:qconv_test --show-output
Reviewed By: jianyuh
Differential Revision: D16703956
Pulled By: dskhudia
fbshipit-source-id: 5e894bd84caaa20dc7639d4885d59a72f27d8ec2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23746
`torch.empty_like(tensor)` and `tensor.clone()` both propagate names to
the output tensor.
As a part of this change, I fixed the empty(..., names=) overload to
include the `memory_format` argument in the normal `empty` declaration
in native_functions.yaml.
Test Plan: - [namedtensor ci]
Differential Revision: D16647821
Pulled By: zou3519
fbshipit-source-id: 43b261f3456b6bf5fca7b6313e659b259a2ba66d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23743
In the short term, we implement this by having overloads for each of
these functions. In the long term, the plan is to move DimnameList to
TensorOptions so that we do not have to duplicate work.
Test Plan: - [namedtensor ci]
Differential Revision: D16647820
Pulled By: zou3519
fbshipit-source-id: c6c53c5f26a86b730cbc4d4eb69907ac0e08fc65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23801
Test Plan
- Code reading. assertTensorDataAndNamesEqual isn't used in this commit
but it'll be used in future commits.
- [namedtensor ci]
gh-metadata: pytorch pytorch 23801 gh/zou3519/90/head
Test Plan: Imported from OSS
Differential Revision: D16667816
Pulled By: zou3519
fbshipit-source-id: 66519cd5d17bda4c4304a1bc6e2a03ae59d49e39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23624
tensor.set_names(names) is the out-of-place variant of
tensor.set_names_(names). This naming is probably confusing so I am
taking any and all suggestions.
Test Plan:
- run tests [namedtensor ci]
gh-metadata: pytorch pytorch 23624 gh/zou3519/86/head
Differential Revision: D16621830
Pulled By: zou3519
fbshipit-source-id: f8a3837d3a370b41210e938369348dcbb4aee53a
Summary:
These implicit fallthroughs lead to the following warning on g++ 7, because g++ could not recognize the implicit `abort` call in `LOG(FATAL)`. We suppress by adding explicit `return`s.
/home/hong/wsrc/pytorch/caffe2/utils/math_cpu.cc: In function void
caffe2::math::GemmEx(CBLAS_TRANSPOSE, CBLAS_TRANSPOSE, int
, int, int, T, const T*, int, const T*, int, T, T*, int, Context*) [with
T = float; Context = caffe2::CPUContext; Engine = caf
fe2::DefaultEngine]:
/home/hong/wsrc/pytorch/c10/util/logging_is_not_google_glog.h:98:10:
warning: this statement may fall through [-Wimplicit-fall
through=]
::c10::MessageLogger((char*)__FILE__, __LINE__, n).stream()
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/home/hong/wsrc/pytorch/caffe2/utils/math_cpu.cc:179:11: note: in
expansion of macro LOG
LOG(FATAL) << "Unexpected CBLAS_TRANSPOSE for trans_B";
^
/home/hong/wsrc/pytorch/caffe2/utils/math_cpu.cc:182:5: note: here
case CblasTrans: {
^~~~
In file included from /home/hong/wsrc/pytorch/c10/util/Logging.h:28:0,
from /home/hong/wsrc/pytorch/caffe2/core/logging.h:2,
from /home/hong/wsrc/pytorch/caffe2/core/types.h:9,
from /home/hong/wsrc/pytorch/caffe2/utils/math.h:17,
from
/home/hong/wsrc/pytorch/caffe2/utils/math_cpu.cc:14:
/home/hong/wsrc/pytorch/c10/util/logging_is_not_google_glog.h:98:10:
warning: this statement may fall through [-Wimplicit-fall
through=]
::c10::MessageLogger((char*)__FILE__, __LINE__, n).stream()
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/home/hong/wsrc/pytorch/caffe2/utils/math_cpu.cc:202:11: note: in
expansion of macro LOG
LOG(FATAL) << "Unexpected CBLAS_TRANSPOSE for trans_B";
^
/home/hong/wsrc/pytorch/caffe2/utils/math_cpu.cc:205:5: note: here
default:
^~~~~~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24053
Differential Revision: D16732530
Pulled By: ezyang
fbshipit-source-id: 90373879f25b52efca5bf151c7ed58d6ad19d925
Summary:
Not sure whether 34c0043aaee971a0539c8c3c49c4839f67ae001d still makes sense.
`USE_SYSTEM_EIGEN_INSTALL` is OFF by default (as set in CMakeLists.txt). If a user wants to change this build option, I don't see any reason to force them to do it in `CMakeCache.txt`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23990
Differential Revision: D16732569
Pulled By: ezyang
fbshipit-source-id: 4604b4a1d5857552ad02e76aee91641aea48801a
Summary:
CPU and CUDA testing code are largely the same.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23526
Reviewed By: ezyang
Differential Revision: D16586271
Pulled By: VitalyFedyunin
fbshipit-source-id: 91c70c05789120fde4718ce955de243087a8c993
Summary:
Without metadata(datatype) for the new output, exporter won't be able to perform implicit scalar datatype casting. This PR covers a large portion of this common issue seen in many exported models, e.g. https://github.com/pytorch/pytorch/issues/23724
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23809
Reviewed By: ezyang
Differential Revision: D16707640
Pulled By: bddppq
fbshipit-source-id: 3de985c6b580b9c9ebaec08085c7443bd8d9c7f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23645
Previously, every module would get its own CompilationUnit when saving
from the C++ frontend. That's bad because nothing checks that they have
uniquely qualified names or mangles them to make them unique.
This was okay when we were doing model.json, but once we serialize
modules like classes this will cause an error on import (when we try to
re-define the same class a bunch of times.
Test Plan: Imported from OSS
Differential Revision: D16597709
Pulled By: suo
fbshipit-source-id: 0412efd5acfcac26d03f6ed5b5a7dfc023163bc3
Summary:
as title, the op can be used to update Length blob values in cuda.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23995
Reviewed By: xianjiec
Differential Revision: D16684065
fbshipit-source-id: da562334c8b61a5e54c3aa78156ce5caff619e60
Summary:
Currently when reading CMakeCache.txt, only `VAR:TYPE=VAL` can be matched.
This works well for CMake-generated lines, but a user may add a line
without specifying type (`VAR=VAL`), which is totally legitimate in the
eyes of CMake. This improvements in regex ensure that `VAR:TYPE=VAL` is
also matched. The situation of `"VAR":TYPE=VAL` is also corrected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23745
Differential Revision: D16726514
Pulled By: ezyang
fbshipit-source-id: 6c50150d58926563837cf77d156c24d644666ef0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24052
This will make things show up in the azure pipelines output
Test Plan: Imported from OSS
Differential Revision: D16723846
Pulled By: suo
fbshipit-source-id: d78cbf476be74ccfb28d6e1b21d66b6641d36e26
Summary:
Move `_overload` to `_jit_internal.py` so that it can be imported in nn/functional.py for `conv`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24049
Differential Revision: D16723339
Pulled By: eellison
fbshipit-source-id: 527e6069dbfa81f8133c405be5350a8c76873a12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24014
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16714081
Pulled By: ezyang
fbshipit-source-id: d346fbe8a54d5c182f81d2b908b1cdf191e3d822
Summary:
Enable Add, sub, mul, and div on CPU for bfloat16 type.
Tested via unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22851
Differential Revision: D16256757
Pulled By: izdeby
fbshipit-source-id: 8b62f7581fc0ca0d2cff48ab40d877a9fcf70a5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23891
This adds an initial set of testing coverage for quantization that checks if the modules can be scripted. Testing for tracing and serialization is forthcoming
Test Plan: Imported from OSS
Differential Revision: D16698045
Pulled By: jamesr66a
fbshipit-source-id: 96d80d938b816220af72359165a7b96d998a30c9
Summary:
I accidentally removed this in a merge, breaking a test. Fix for master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24003
Differential Revision: D16707108
Pulled By: eellison
fbshipit-source-id: 8b59f46e7932b88a7ae246a261c4daf17f23995f
Summary:
https://github.com/pytorch/pytorch/pull/23228 caused build failure on OSX, because rpc.h is included as long as USE_DISTRIBUTED=1, but rpc/init.cpp (and others) is only included when NOT APPLE. So, it cannot find python_functions defined in init.cpp on MacOS. This PR attempt to fix it by wrapping rpc.h with USE_C10D, which is only set when NOT APPLE.
I tried this fix locally and it works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23998
Differential Revision: D16706087
Pulled By: mrshenli
fbshipit-source-id: d04fe6717a181a3198289cdef51439708c2e291d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23886
This is a series of PRs that will allow us to support adding [padding to conv](https://github.com/pytorch/pytorch/pull/22484) and also reduce the friction of adding method overloads that was brought up in https://github.com/pytorch/pytorch/pull/23266.
Support for overloaded functions following the specification in [PEP 484](https://www.python.org/dev/peps/pep-0484/#function-method-overloading).
The usage is:
```
torch.jit.overload
def add(x: int, y: int) -> int: ...
torch.jit.overload
def add(x: float, y: float) -> float: ...
def add:
return x + y
```
Follow up PRs:
- Add same API for methods
- A couple of cleanups for functions:
- don't require default params specified on the overload as well
- potentially error if invocation could be matched to multiple overloads. now it just chooses the first one, mypy does the same thing currently
Test Plan: Imported from OSS
Differential Revision: D16694863
Pulled By: eellison
fbshipit-source-id: f94f2933bc1c97fa58f31846acfe962b0630068c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23885
This is a series of PRs that will allow us to support adding [padding to conv](https://github.com/pytorch/pytorch/pull/22484) and also reduce the friction of adding method overloads that was brought up in https://github.com/pytorch/pytorch/pull/23266.
This PR only compiles one if branch if the condition is an isinstance check. This is consistent with what mypy does; it does not report errors if a branch can be determined statically to be unreachable.
```
def foo(x):
# type: (int) -> int
if isinstance(x, str):
return x["1"]
return x + 1
reveal_type(foo) # no error, shows int -> int
```
Test Plan: Imported from OSS
Differential Revision: D16697092
Pulled By: eellison
fbshipit-source-id: d3eb4925cd16d551515ac6ff620a69897dbec130
Summary:
`python_requires` helps the installer choose the correct version of this package for the user's running Python.
This is especially necessary when dropping Python 2 (https://github.com/pytorch/pytorch/issues/23795) but is useful now too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23863
Differential Revision: D16692908
Pulled By: soumith
fbshipit-source-id: 3c9ba2eb1d1cf12763d6284daa4f18f605abb373
Summary:
Before calling `__setstate__` when loading a module, we need to disable
the optimizer since the module's type does not match the values on the
stack (all the tensors will be `UndefinedTensor`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23698
Pulled By: driazati
Differential Revision: D16690935
fbshipit-source-id: 71e2238fd25cd16271af478ef21a3cf4e514a462
Summary:
Simplifying https://github.com/pytorch/pytorch/issues/23793: The dependency relationship between
{INSTALL,BUILD}_TEST is already properly handled in CMakeLists.txt. All
we need to do is to pass down INSTALL_TEST.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23806
Differential Revision: D16691833
Pulled By: soumith
fbshipit-source-id: 7607492b2d82db3f79b174373a92e2810a854a61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23898
These files were not following the clang-format style and as a result, some files (such as TensorFactories.cpp) were extremely hard to read and modify.
Test Plan: Imported from OSS
Differential Revision: D16684724
Pulled By: jamesr66a
fbshipit-source-id: 0600c6dddc778481af5bef798e77072fb7e988aa
Summary:
Otherwise you may see errors like
```
Exception ignored in: <function _MultiProcessingDataLoaderIter.__del__ at 0x000001F99F5CB9D8>
Traceback (most recent call last):
File "C:\Users\Divyansh J\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py", line 883, in __del__
self._shutdown_workers()
File "C:\Users\Divyansh J\Anaconda3\envs\pytorch\lib\site-packages\torch\utils\data\dataloader.py", line 860, in _shutdown_workers
if self.workers_status[worker_id]:
IndexError: list index out of range
```
e.g. https://discuss.pytorch.org/t/how-to-construct-dataset-with-iterator-for-multi-process-dataloader/49612/5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23761
Differential Revision: D16644687
Pulled By: soumith
fbshipit-source-id: a60e847431264525079456ff422317af1ac2be4b
Summary:
When we're emitting an if node, if one branch exits allow variables in the other branch to escape scope. This is using the same machinery that already exists for early returns so there are minimal changes to the compiler. Most of the changes are in the exit_transform pass so we don't create terrible graphs when exceptions exist. In a follow up PR i will add a writeup of the transform pass to docs since this should be the last change made to it for a while.
This will allow assertions to refine Optional types, as well as allow JIT to understand things like:
```
def foo(x):
if x == 1:
raise Exception()
else:
a = 1
return a
```
If you look in nn/functional.py, like 3/4 of the TODOs are this issue. One note is that if a function always throws, I accepted whatever the annotation for the return type is if it exists and otherwise set it to None. This is consistent with what mypy does.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23565
Differential Revision: D16679572
Pulled By: eellison
fbshipit-source-id: e58c9e9ddaeb13144c803d90e2beae253c851f7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22956
As Title says: remove the extra function arguments for better engineering.
Differential Revision: D16297724
fbshipit-source-id: a31be17708d13508c4ce9a3ce7eb5238e8d17984
Summary:
Many descriptions of arguments could be replaced by items in the template such as `factory_common_args`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23439
Differential Revision: D16688527
Pulled By: ezyang
fbshipit-source-id: 406ce45d72e297f46b5fa9ea5472b3284c8d4324
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23895
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16688489
Pulled By: ezyang
fbshipit-source-id: a56d0180a0bc57775badd9e31ea3d441d5fd4f88
Summary:
Use the supported way to differentiate and automatically switch between hip-clang and hcc hipification in build_amd.py.
Cleaned up from PR https://github.com/pytorch/pytorch/issues/23699
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23835
Differential Revision: D16659661
Pulled By: vincentqb
fbshipit-source-id: 05a4250ceb28beda7a7bf73a46c5dc46f6e852bc
Summary:
This is a similar issue as TestCuda.test_events_wait.
PyTorch test sets a policy() method to assertLeaksNoCudaTensors.
Whenever a test is run, assertLeaksNoCudaTensors is called,
which in turn calls CudaMemoryLeakCheck, which in turn calls
initialize_cuda_context_rng, where it executes torch.randn
on each device, where a kernel is launched on each device.
Since the kernel may not finish on device 0, the first assertion
self.assertTrue(s0.query()) fails.
The fix is to insert
torch.cuda.synchronize(d0)
torch.cuda.synchronize(d1)
at the beginning of the test so that previously launched kernels finish before the real
test begins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23912
Differential Revision: D16688599
Pulled By: ezyang
fbshipit-source-id: 3de2b555e99f5bbd05727835b9d7c93a026a0519
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/23480.
I only verified that the schedule reaches the restart at the expected step as specified in the issue, it would be good to have someone else verify correctness here.
Script:
```
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(torch.optim.SGD([torch.randn(1, requires_grad=True)], lr=0.5), T_0=1, T_mult=2)
for i in range(9):
print(i)
print(scheduler.get_lr())
scheduler.step()
```
Output:
```
0
[0.5]
1
[0.5]
2
[0.25]
3
[0.5]
4
[0.42677669529663687]
5
[0.25]
6
[0.07322330470336313]
7
[0.5]
8
[0.4809698831278217]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23833
Differential Revision: D16657251
Pulled By: gchanan
fbshipit-source-id: 713973cb7cbfc85dc333641cbe9feaf917718eb9
Summary:
Features:
* sync and async RPC for builtin operators
* RpcAgent API
* ProcessGroupAgent implementation
Goal:
* have a minimum working and testable RPC implementation
* make sure the RpcAgent API is sufficient for future ThriftAgent and TensorPipeAgent implementation
* For tensor pipe implementation, it might allocate multiple underlying communication channels with different types, and might also use streaming serialization/deserialization for large tensors. To support this requirement, the current implementation only convert a BuiltinOp into a Message which contains a byte vector and a tensor table. It is up to the RpcAgent implementation to determine how it would like to serialize a Message object.
* For ThriftAgent, as Thrift has it own request/response matching solution, the Message.id is no longer necessary. Hence the id can be dropped during serialization. All it needs to do is to pass the response Message object to the Future returned by send(...).
* support blocking and non-blocking RequestCallback
* blocking means the callback won't return before sending out the response
* non-blocking can be achieved by enqueue the `(from, request, RpcAgent&)` tuple and use a different thread to process them. That is why there is an `RpcAgent&` arg in the param list.
We are not exporting this diff until we finalize distributed autograd design and publish the API review publicly.
https://fb.quip.com/FabTAZKVgQpf
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23228
ghstack-source-id: 87816717
Reviewed By: zhaojuanmao
Differential Revision: D15194693
fbshipit-source-id: 7adb600796613cde6073db6c227451b89940ecaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23893
Set `caffe2_tvm_min_ops` to 8 for production and tests.
Reviewed By: yinghai
Differential Revision: D16659420
fbshipit-source-id: ef33b37e2a5128e502a6b8df306914a409f13c2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23879
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16670379
Pulled By: ezyang
fbshipit-source-id: c498f8362760bdf8526c59043db3276f99e3ccc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23858
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23718
Changes:
- Enable tests for quantization test files in `run_tests.py`
- Remove `__future__` imports from `torch/nn/qat/modules/__init__.py`, since `unicode_literals` messes up imports on python2 because the elements in `__all__` will be Unicode and not string
- Skip PostTrainingQuantTests if the build doesn't have FBGEMM (only a small subset of targets in tests) or if testing under UBSAN (the suppression file doesn't seem to work)
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D16639467
Pulled By: jamesr66a
fbshipit-source-id: 532766797c216976dd7e07d751f768ff8e0fc207
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23837
This is a temporary workaround to an issue in MKL-DNN's Convolution backwards implementation: https://github.com/pytorch/pytorch/issues/23825
It is only used to enable testing quantization
Test Plan: Imported from OSS
Differential Revision: D16659081
Pulled By: jamesr66a
fbshipit-source-id: de18ebe98dec2a042f28b23373e20da2b44a42a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23848
Problem:
In experiment running feed model 127607201 (/mnt/public/tracelog/feed_repro2/127607201_0.predictor), encountered blob dimensionality mismatch error when running onnxified net. This is due to the model initializing input blobs in current workspace with blob size 0, and onnxifi() falsely identified those input blobs as weight blobs and assigned wrong dimension.
Solution:
Add option to pass correct weight blob names to onnxifi() instead of using all blobs in current workspace.
Reviewed By: yinghai
Differential Revision: D16661396
fbshipit-source-id: cabe44db6b64e6538bef4b65e380312214b3ba9f
Summary:
formatting in advance of pr that touches this file bc there is a lot of formatting noise :'(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23840
Differential Revision: D16659311
Pulled By: eellison
fbshipit-source-id: 7dedaccf9b9c455f97efdcce1c58515eb155d261
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23784
Backward path does nothing during the gradient path when the input as empty, as
a result workspace can preserve gradient values from previous iteration and get
inconsistent inputs for some of the backward pass operators. This diff should
fix this disrepancy by always reinitializing output during the backward path.
Reviewed By: dzhulgakov
Differential Revision: D16646096
fbshipit-source-id: 8ca68dfad17a63fc87c033cce7b36b40bd77245c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23788
We be using Azure Pipelines now, matey!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16648527
Pulled By: ezyang
fbshipit-source-id: d05326c4971fd392868f2a70aa0a9be9c7280f86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23708
Resolves https://github.com/pytorch/pytorch/issues/23631
We always treat dtypes as number types, and we have the conversion logic of dtype->int64_t present in toSugaredValue. So if a dtype appears in a statement being compiled, it's properly converted to its long ScalarType equivalent. However, this logic was missing in `toIValue`, thus making taking dtypes as attributes broken
Test Plan: Imported from OSS
Differential Revision: D16617222
Pulled By: jamesr66a
fbshipit-source-id: 4b10e5795f9c142c2fd9fa1b5d60f6374f5218e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23752
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16657471
Pulled By: ezyang
fbshipit-source-id: 4d8fcde1d10d4b078c76c643adb6d4a4fc1259c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23779
Mangling is two underscores, not one :(. We want this method to be
private so that inheritors who define a `__construct` do not interfere
with Module initialization
Test Plan: Imported from OSS
Differential Revision: D16645156
Pulled By: suo
fbshipit-source-id: b9060cb35bfaa0391ff200b63fb78b1ac15fee39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23791
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16657447
Pulled By: ezyang
fbshipit-source-id: a4a5f5abef72146a52a76cfab629f8c105949bb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23792
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16648539
Pulled By: ezyang
fbshipit-source-id: f713fca6d428c03ed31aad18464c92265fb81420
Summary:
Use the supported way to differentiate and automatically switch between hip-clang and hcc hipification in build_amd.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23699
Differential Revision: D16627326
Pulled By: vincentqb
fbshipit-source-id: 977003174395fb69cf0c96c89232bd6214780cd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23810
A previous diff removed the special casing for aten:: and prim:: ops in alias analysis and implements alias analysis purely
based on the AliasAnalysisKind. To be sure it doesn't break our existing code base, it added asserts that make sure that
our existing aten:: and prim:: ops set the correct AliasAnalysisKind.
However, we don't need that restriction for future ops. Since we are now certain all existing cases are set up correctly,
we can remove these assertions.
ghstack-source-id: 87733626
Differential Revision: D15996322
fbshipit-source-id: df27ed95397bbe58a76b6b2c2e9808fcfde35294
Summary:
Define 4D tensor as stored in channels last memory format, when dimensions order is NCHW and C-strides < W-strides < H-strides < N-strides (If size of any dimension is equal to 1, this dimension strides value is not taken into account).
Channels last contiguous tensor is channel last tensor which occupies contiguous memory block. So x.is_contiguous(memory_format=torch.channels_last) checks if tensor is channels last contiguous.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23391
Differential Revision: D16601414
Pulled By: VitalyFedyunin
fbshipit-source-id: 8d098e7eec2f00fb1d12261bc240b3645d4f5b73
Summary:
This allows `INSTALL_*` to pass through to cmake.
Additional fix is that if `INSTALL_TEST` is specified, it wont use `BUILD_TEST` as the default value for `INSTALL_TEST`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23793
Differential Revision: D16648668
Pulled By: soumith
fbshipit-source-id: 52c2a0d8033bc556355b87a6731a577940de9859
Summary:
cpu binary builds are built with cu100 docker image now instead of cu80
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23772
Differential Revision: D16644224
Pulled By: soumith
fbshipit-source-id: 5af09aba149c13fadbd4146172e7da038f2f4261
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23680
Now when initializing a ScriptModule during the torch.jit.load()
process, there is already a cpp module backing the thing. That means
that setting training will overwrite whatever the initialized
ScriptModule had.
This PR splits apart the common "set up internal state" part of the
Module __init__ and calls that from ScriptModule.__init__ and
Module.__init__, leaving the "nn.Module-specific" part (setting
`self.training`) for the nn.Module __init__
Test Plan: Imported from OSS
Differential Revision: D16606959
Pulled By: suo
fbshipit-source-id: f7ea6b36551ff4e4472b7685f65731d5cfab87fd
Summary:
We can now have any valid zero points for weight and activation for conv2d kernel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23541
Test Plan:
buck test mode/dev caffe2/test:quantized -- 'test_qconv\ \(test_quantized.TestQuantizedConv\)' --print-passing-details
```
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/3377699723897843
✓ caffe2/test:quantized - test_qconv (test_quantized.TestQuantizedConv) 68.528 1/1 (passed)
Test output:
> test_qconv (test_quantized.TestQuantizedConv) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 68.529s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/3377699723897843
Summary (total time 74.97s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
Differential Revision: D16556515
Pulled By: dskhudia
fbshipit-source-id: 6e2ee9ddc58f9dc8a3f8b25918bb7955f0655073
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23590
This diff adds CPU% and Virtual Memory computation by default to AIBench when doing mobile remote run
Reviewed By: llyfacebook
Differential Revision: D16469619
fbshipit-source-id: 670f3549c830a36bc456a57f2ea668f9f82dd15a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23566
Currently if we use dynamic quantization we don't have the access to the internally quantized inputs and output for debugging.
To make the debugging easier, this diff adds a debug feature to expose the quantized X, W and Y for debugging if debug outputs are attached to the operator and caffe2_dnnlowp_force_slow_path flag is set.
The quantized inputs and output are exposed as the extra outputs.
The example Int8FC op with debug outputs appended looks like:
```
op {
input: "X"
input: "W"
input: "b"
output: "Y"
output: "X_q"
output: "W_q"
output: "Y_q"
name: ""
type: "Int8FC"
arg {
name: "axis"
i: 1
}
...
}
```
Next need to expose the quantization parameters.
Reviewed By: jspark1105
Differential Revision: D16566753
fbshipit-source-id: acd855a172ee7993ddba8808f2af81b628ff9c02
Summary:
On my testcase, this reduces the uncompressed size of TorchScript
debug info from 281KB to 76KB. With zip compression enabled, this
saves about 2.5KB of final size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23741
Differential Revision: D16624128
fbshipit-source-id: ce45659d6b20d40608ace05639b69b93696b00d9
Summary:
I have some test code in there as well, along with a script "test_libtorch" to run it. You'll need to modify `test_libtorch` to point to where you have `pytorch` built. I currently require that `pybind11` is included as a subdirectory of the test, but added it to the `.gitignore` to make this reviewable.
Currently, something like this works:
```cpp
struct Foo {
int x, y;
Foo(): x(2), y(5){}
Foo(int x_, int y_) : x(x_), y(y_) {}
void display() {
cout<<"x: "<<x<<' '<<"y: "<<y<<endl;
}
int64_t add(int64_t z) {
return (x+y)*z;
}
};
static auto test = torch::jit::class_<Foo>("Foo")
.def(torch::jit::init<int64_t, int64_t>())
.def("display", &Foo::display)
.def("add", &Foo::add)
.def("combine", &Foo::combine);
```
with
```py
torch.jit.script
def f(x):
val = torch._C.Foo(5, 3)
val.display()
print(val.add(3))
```
results in
```
x: 5 y: 3
24
```
Current issues:
- [x] The python class created by torchscript doesn't interactly properly with the surrounding code.
```
torch.jit.script
def f(x):
val = torch._C.Foo(5, 3)
return val
```
- [x] Doesn't properly take in non-pointer classes. Can't define this function signature in cpp (We don't want to support this I believe).
```cpp
void combine(Foo x) {
```
- [x] Has some issues with memory for blobs when constructing multiple objects (fix constant propagation pass to not treat capsules as the same object).
```py
torch.jit.script
def f(x):
val = torch._C.Foo(5, 3)
val2 = torch._C.Foo(100, 0)
val.display()
print(val.add(3))
```
- [ ] Can't define multiple constructors (need to define overload string. Currently not possible since we don't support overloaded methods).
- [x] `init` is a little bit different syntax than `pybind`. `.init<...>()` instead of `.def(py::init<>())`
- [x] I couldn't figure out how to add some files into the build so they'd be copied to the `include/` directories, so I symlinked them manually.
- [ ] Currently, the conversion from Python into Torchscript doesn't work.
- [ ] Torchbind also currently requires Python/Pybind dependency. Fixing this would probably involve some kind of macro to bind into Python when possible.
- [ ] We pass back into Python by value, currently. There's no way of passing by reference.
- [x] Currently can only register one method with the same type signature. This is because we create a `static auto opRegistry`, and the function is templated on the type signature.
Somewhat blocked on https://github.com/pytorch/pytorch/pull/21177. We currently use some structures that will be refactored by his PR (namely `return_type_to_ivalue` and `ivalue_to_arg_type`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21098
Differential Revision: D16634872
Pulled By: Chillee
fbshipit-source-id: 1408bb89ea649c27d560df59e2cf9920467fe1de
Summary:
Added a number of opset10 tests from Caffe2 to ORT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22993
Differential Revision: D16467954
Pulled By: bddppq
fbshipit-source-id: 0b92694c7c0213bdf8e77e6f8e07e6bc8a85170a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23747
This reverts commit 6a3ebdbbc529da79125423839bf18f527a706ab8
"Remove all conda 3.5 nightly configs" but not the smoketest
removal.
Test Plan: Imported from OSS
Differential Revision: D16632992
Pulled By: ezyang
fbshipit-source-id: 5c6dcf1510b84359a1760cfa216edea610563ad5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23577
This diff is fixing a model size issue introduced in #23291. After that PR, the model size after in8 quantization is the same as that of the original unquantized model. The reason is that we save original weight for int8 quantization even when that's not needed anymore. This diff fixes that by only saving original weight for fp16 quantization path.
Reviewed By: llyfacebook
Differential Revision: D16557619
fbshipit-source-id: f924ae8d155a0d525b86a7440b3c7147d5bead0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23679
Full Canary: https://fburl.com/fblearner/sa1pkpya
Add LambdaRank DCG Loss Option
* when use_idcg_normalization == true, regular LambdaRank with NDCG loss
* when use_idcg_normalization == false, gradient and loss functions are not normalized by idcg.
Differential Revision: D16605459
fbshipit-source-id: a16f071e69516974e48d27bef4ca179019ca4ae7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23623
This is a quick, not-user-facing check for if pytorch was built with BUILD_NAMEDTENSOR=1.
Test Plan:
- run tests [namedtensor ci]
gh-metadata: pytorch pytorch 23623 gh/zou3519/85/head
Differential Revision: D16621829
Pulled By: zou3519
fbshipit-source-id: d7e1161dc176bab2c1f953265722daeba1e63102
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23628
More tests for autograd::Fuction based on python tests from test_autograd.py
Test Plan: Imported from OSS
Differential Revision: D16600992
fbshipit-source-id: 0cb8bfbcff315111dc4936e837ff859d0a1e251d
Summary:
Feature includes
- Log message if bind(2) fail
- Make collective work with single process context
- Use hipStreamCreateWithFlags instead of hipStreamCreateWithPriority
- Add RCCl support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23400
Differential Revision: D16623110
Pulled By: bddppq
fbshipit-source-id: e75cd8d2e2cad551ad0b0a08667320d7036b78bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23734
In the latest run on AI-PEP, there are 6 tests out of 342 which has more than 7% variation. Around 20 tests which has variations between 4% to 7%. The rest are within 4%. This diff tries to further reduce the variation to 4% for all tests.
Each test has to run predefined_minimum_secs seconds before exiting. Increasing that value makes all tests run longer. Based on the experimental results, we will see what's the right value to use.
Reviewed By: hl475
Differential Revision: D16622361
fbshipit-source-id: d4c034f64b1d64e1cffd67ffbced7d8cd4449d69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23465
We decided not to allow user to use qconfig_dict to do quantization
since that API is not robust.
Differential Revision: D16611504
fbshipit-source-id: b0d1d311b32c990a165c480f50e9ce3d68b785b5
Summary:
MultiProcessTestCase will be useful for both c10d and rpc tests. So, this diff extracts that class and some common decorators to a separate file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23660
Reviewed By: pietern
Differential Revision: D16602865
Pulled By: mrshenli
fbshipit-source-id: 85ad47dfb8ba187b7debeb3edeea5df08ef690c7
Summary:
Adds new people and reorders sections to make more sense
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23693
Differential Revision: D16618230
Pulled By: dzhulgakov
fbshipit-source-id: 74191b50c6603309a9e6d14960b7c666eec6abdd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23692
Before tests took ~40s to finish, with this change it's ~2s.
Test Plan: Imported from OSS
Differential Revision: D16611479
Pulled By: ZolotukhinM
fbshipit-source-id: 391235483029d2ab860fcc4597ce84f4964025f1
Summary:
Move CPU implementation of the `addcmul` operator to Aten ( https://github.com/pytorch/pytorch/issues/22797 )
### before
```python
In [11]: timeit x.addcmul(a, b)
1.31 ms ± 18.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
### after
```python
In [9]: timeit x.addcmul(a, b)
588 µs ± 22.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Adding custom code for the case when `value == 1`, doesn't provide significant performance gain.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22874
Differential Revision: D16359348
Pulled By: VitalyFedyunin
fbshipit-source-id: 941ead835672fca78a1fcc762da052e64308b111
Summary:
add setup metadata to help PyPI flesh out content on pypi package page.
Apparently this might help flesh out the "Used By" feature according to driazati
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22085
Differential Revision: D16604703
Pulled By: soumith
fbshipit-source-id: ddb4f7ba7c24fdf718260aed28cc7bc9afb46de9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23654
Default configuration at time of writing is CUDA 10 (but
with 10.1 coming soon)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16601097
Pulled By: ezyang
fbshipit-source-id: c8368355ce1521c01b0ab2a14b1cd0287f554e66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23611
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16601098
Pulled By: ezyang
fbshipit-source-id: febb5a822854b91d5b3d942e6bf71b4ae9f1f15c
Summary:
Currently once user has set `USE_NATIVE_ARCH` to OFF, they will never be able to turn it on for MKLDNN again by simply changing `USE_NATIVE_ARCH`. This commit fixes this issue.
Following up 09ba4df031ed51e05724bb490d4d6fc52b3b1ac6
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23608
Differential Revision: D16599600
Pulled By: ezyang
fbshipit-source-id: 88bbec1b1504b5deba63e56f78632937d003a1f6
Summary:
We need this to be able to register them with the c10 dispatcher.
The overload names are based on one-letter-per-argument-type.
Script used to change native_functions.yaml and derivatives.yaml: P75630718
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23532
ghstack-source-id: 87539687
Differential Revision: D16553437
fbshipit-source-id: a1d0f10c42d284eba07e2a40641f71baa4f82ecf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23618
For example: `save_for_backward({Variable(), x, Variable()})` should be allowed, so that this is consistent with the python API behaviour.
Test Plan: Added a test similar to the python test `test_save_none_for_backward` from test_autograd.py.
Differential Revision: D16589402
fbshipit-source-id: 847544ad8fc10772954d8629ad5a62bfdc1a66c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23630
This is temporary, won't be needed with the new serialization format.
But for now, since the main module gets its name from the archive name,
we need this for safety, other wise something like
`torch.jit.save("torch.pt") will break things.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D16592404
Pulled By: suo
fbshipit-source-id: b538dc3438a80ea7bca14d84591ecd63f4b1289f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23557
As title states this enables any tensors defined by the user to be outputs, including activations
Reviewed By: yinghai
Differential Revision: D16362993
fbshipit-source-id: b7dc8412c88c46fcf67a3b3953dc4e4c2db8c4aa
Summary:
`is_pinned` was moved to native_functions.yaml, disabling it for named
tensors. This PR re-enables its usage for named tensors.
I wrote a named inference rule for torch.clone(), but something happened
to it. Disable it for now so we can get the namedtensor ci to be green.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23597
Test Plan: - run tests [namedtensor ci]
Differential Revision: D16581771
Pulled By: zou3519
fbshipit-source-id: 498018cdc55e269bec80634b8c0a63ba5c72914b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23572
### **(The stack from #23020 was moved into this PR)**
Adding API for custom autograd operations, with user defined forward and backward, [like in python](https://pytorch.org/docs/stable/notes/extending.html#extending-torch-autograd).
The custom operation should be a subclass of Function, with static forward and backward functions. `forward()` can accept any arguments similar to the Python API and `backward()` should accept a variable list as an argument.
Both `forward()` and `backward() `accept a AutogradContext* which can be used to share data between them.
Variables can be saved in the context using `save_for_backward()` and other data can be saved in the map `save` in the form of `<std::string, at::IValue>` pairs. Variables saved in forward can be accessed with `get_saved_variables()`.
Example usage:
```
class MyFunction : public Function<MyFunction> {
public:
static variable_list forward(AutogradContext *ctx, int n, Variable var) {
// Save data for backward in context
ctx->saved_data["n"] = n;
return {var};
}
static variable_list backward(AutogradContext *ctx, variable_list grad_output) {
// Use data saved in forward
auto n = ctx->saved_data["n"].toInt();
return {grad_output[0]*n};
}
};
```
Then, it can be used with:
```
Variable x;
MyFunction::apply(6, x);
```
Also AutogradContext has methods to mark outputs as non differentiable and mark inputs as dirty similar to the [Python API](ff23a02ac4/torch/autograd/function.py (L26)).
Test Plan: Added tests for the custom autograd function API based on test_autograd.py. Currently only the tests for the basic functionality have been added. More tests will be added later.
Differential Revision: D16583428
fbshipit-source-id: 0bd42f19ce37bcd99d3080d16195ad74d40d0413
Summary:
### Summary
The iOS build was broken after this PR 👉 [23195](https://github.com/pytorch/pytorch/pull/23195/files) was merged, as there are two files still have dependency on ONNX.
- `test.cpp` in `test/cpp/jit`
- `export.cpp` in `torch/csrc/jit`
This PR is to remove ONNX completely from mobile build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23546
Test Plan:
- The `build_ios.sh` finished successfully.
- The `libtorch.a` can be compiled and run on iOS devices
Differential Revision: D16558236
Pulled By: xta0
fbshipit-source-id: b7ff1db750698cfd5a72d5cb0b9f2f378e315077
Summary:
Changelog:
- Add batching for det / logdet / slogdet operations
- Update derivative computation to support batched inputs (and consequently batched outputs)
- Update docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22909
Test Plan:
- Add a `test_det_logdet_slogdet_batched` method in `test_torch.py` to test `torch.det`, `torch.logdet` and `torch.slogdet` on batched inputs. This relies on the correctness of `torch.det` on single matrices (tested by `test_det_logdet_slogdet`). A port of this test is added to `test_cuda.py`
- Add autograd tests for batched inputs
Differential Revision: D16580988
Pulled By: ezyang
fbshipit-source-id: b76c87212fbe621f42a847e3b809b5e60cfcdb7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23376
This uses master version of sphinxcontrib-katex as it only
recently got prerender support.
Fixes#20984
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16582064
Pulled By: ezyang
fbshipit-source-id: 9ef24c5788c19572515ded2db2e8ebfb7a5ed44d
Summary:
Changelog:
- Use narrow instead of narrow_copy while returning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23591
Test Plan:
- All tests should pass to ensure that the change is correct
Fixes https://github.com/pytorch/pytorch/issues/23580
Differential Revision: D16581174
Pulled By: ezyang
fbshipit-source-id: 1b6bf7d338ddd138ea4c6aa6901834dd202ec79c
Summary:
accidently calls clone, but what we want is creating an empty tensor and set storage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23452
ghstack-source-id: 87438096
Differential Revision: D16442756
fbshipit-source-id: 6d5663f82c9bd4e9de8fc846c52992477843af6a
Summary:
Previously these were left out which would lead to confusing messages,
now it looks something like:
```
torch.jit.frontend.UnsupportedNodeError: import statements aren't
supported
:
at ../test.py:13:9
def bad_fn(self):
import pdb
~~~~~~ <--- HERE
'__torch__.X' is being compiled since it was called from 'fn'
at ../test.py:16:12
def fn(x):
return X(10)
~~~~ <--- HERE
```
Fixes#23453
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23454
Pulled By: driazati
Differential Revision: D16567930
fbshipit-source-id: 251b6f91f37a2816e06bb4c803f9bc172fa1d91b
Summary:
API operators now routed to `at::native::resize_as_*_` and `at::native::clone` accordingly.
Internal `THTensor_(resizeAs)`, `THCTensor_(resizeAs)`, `THTensor_(newClone)` and `THCTensor_(newClone)` remains to support older TH code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23027
Differential Revision: D16362304
Pulled By: VitalyFedyunin
fbshipit-source-id: 4c1e8516da685f3fdea632ff791d143f27aeebeb
Summary:
Changelog:
- Rename `gels` to `lstsq`
- Fix all callsites
- Rename all tests
- Create a tentative alias for `lstsq` under the name `gels` and add a deprecation warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23460
Test Plan: - All tests should pass to confirm that the patch is correct
Differential Revision: D16547834
Pulled By: colesbury
fbshipit-source-id: b3bdb8f4c5d14c7716c3d9528e40324cc544e496
Summary:
Only check for cmake dependencies we directly depend on (e.g., hipsparse but not rocsparse)
Use cmake targets for ROCm where possible.
While there, update the docker CI build infrastructure to only pull in packages by name we directly depend on (anticipating the demise of, e.g., miopengemm). I do not anticipate a docker rebuild to be necessary at this stage as the changes are somewhat cosmetic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23527
Differential Revision: D16561010
Pulled By: ezyang
fbshipit-source-id: 87cd9d8a15a74caf9baca85a3e840e9d19ad5d9f
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
LARGE: 66
MEDIUM: 649
XLARGE: 1
Updated actions:
From LARGE to MEDIUM: 18
From LARGE to XLARGE: 2
From MEDIUM to LARGE: 20
From XLARGE to LARGE: 1
Differential Revision: D16559356
fbshipit-source-id: a51ef034265649314661ab0e283089a069a20437
Summary:
When a user tries to change metadata of a tensor created from `.data` or `.detach()`, we currently shows an error message "<function_name> is not allowed on Tensor created from .data or .detach()". However, this error message doesn't suggest what the right fix should look like. This PR improves the error message.
Closes https://github.com/pytorch/pytorch/issues/23393.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23504
Differential Revision: D16547415
Pulled By: yf225
fbshipit-source-id: 37f4a0385442e2b0966386fb14d3d938ecf4230c
Summary:
Previously these were left out which would lead to confusing messages,
now it looks something like:
```
torch.jit.frontend.UnsupportedNodeError: import statements aren't
supported
:
at ../test.py:13:9
def bad_fn(self):
import pdb
~~~~~~ <--- HERE
'__torch__.X' is being compiled since it was called from 'fn'
at ../test.py:16:12
def fn(x):
return X(10)
~~~~ <--- HERE
```
Fixes#23453
](https://our.intern.facebook.com/intern/diff/16526027/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23454
Pulled By: driazati
Differential Revision: D16526027
fbshipit-source-id: 109f2968430dbf51ee91b1b3409badfd557d19a4
Summary:
Use the recursive script API in the existing docs
TODO:
* Migration guide for 1.1 -> 1.2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21612
Pulled By: driazati
Differential Revision: D16553734
fbshipit-source-id: fb6be81a950224390bd5d19b9b3de2d97b3dc515
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23521
non-fbgemm path should have the same arguments as fbgemm path.
Reviewed By: jianyuh
Differential Revision: D16547637
fbshipit-source-id: bb00d725fb968cbee32defb8facd2799a7e79bb4
Summary:
This resolves two issues in one shot:
- sub shouldn't be available for bool type.
- When sub is applied to an unsupported type, the current error messages
shows "add_cpu/add_cuda is not implemented for [type]". They should be
"sub_cpu/sub_cuda" instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23519
Differential Revision: D16548770
Pulled By: izdeby
fbshipit-source-id: fe404a2a97b8d11bd180ec41364bf8e68414fb15
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23417
Test Plan:
cd docs; make html
Imported from OSS
Differential Revision: D16523781
Pulled By: ilia-cher
fbshipit-source-id: d6c09e8a85d39e6185bbdc4b312fea44fcdfff06
Summary:
No real change on the CI since currently the default latest is 0.4.0. houseroad bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23517
Differential Revision: D16550375
Pulled By: bddppq
fbshipit-source-id: a669b8af678c79c4d6909300b28458fe6b7cd30c
Summary:
There is an internal fbcode assert that fails if i do not add these checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23511
Differential Revision: D16545606
Pulled By: eellison
fbshipit-source-id: cd3a799850bae8f052f9d81c1e4a2678fda19317
Summary:
PyTorch test sets a policy() method to assertLeaksNoCudaTensors.
Whenever a test is run, assertLeaksNoCudaTensors is called,
which in turn calls CudaMemoryLeakCheck, which in turn calls
initialize_cuda_context_rng, where it executes torch.randn
on each device, where a kernel is launched on each device.
Since the kernel may not finish on device 1, the assertion
self.assertTrue(s1.query()) fails.
The fix is to insert
torch.cuda.synchronize(d0)
torch.cuda.synchronize(d1)
at the beginning of the test so that previously launched kernels finish before the real
test begins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23520
Differential Revision: D16547701
Pulled By: soumith
fbshipit-source-id: 42ad369f909d534e15555493d08e9bb99dd64b6a
Summary:
Add a sorting policy to ChunkDataset.
This is considered an advanced parameter for developers who want to apply a 'sorting policy' to the chunk data before sampling into minibatch.
Different than the collate method, this policy is applied on the chunk level instead of minibatch level. When a chunk of data is loaded (multiple chunks if cross_chunk_shuffle_count_ is greater than 1), this policy is targeting to the full loaded data. It will be useful if developers want to perform some pre-processing (like bucketing) to the chunk data before example sampler samples the data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23053
Differential Revision: D16537692
Pulled By: colesbury
fbshipit-source-id: cd21ed40ab787a18b8c6dd304e5b806a7a45e6ba
Summary:
Thanks adefazio for the feedback, adding a note to the Contribution guide so that folks don't start working on code without checking with the maintainers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23513
Differential Revision: D16546685
Pulled By: soumith
fbshipit-source-id: 1ee8ade963703c88374aedecb8c9e5ed39d7722d
Summary:
This modernizes distributions code by replacing a few uses of `.contiguous().view()` with `.reshape()`, fixing a sample bug in the `Categorical` distribution.
The bug is exercised by the following test:
```py
batch_shape = (1, 2, 1, 3, 1)
sample_shape = (4,)
cardinality = 2
logits = torch.randn(batch_shape + (cardinality,))
dist.Categorical(logits=logits).sample(sample_shape)
# RuntimeError: invalid argument 2: view size is not compatible with
# input tensor's size and stride (at least one dimension spans across
# two contiguous subspaces). Call .contiguous() before .view().
# at ../aten/src/TH/generic/THTensor.cpp:203
```
I have verified this works locally, but I have not added this as a regression test because it is unlikely to regress (the code is now simpler).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23328
Differential Revision: D16510678
Pulled By: colesbury
fbshipit-source-id: c125c1a37d21d185132e8e8b65241c86ad8ad04b
Summary:
Currently there is no way to build MKLDNN more optimized than sse4. This commit let MKLDNN build respect USE_NATIVE_ARCH.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23445
Differential Revision: D16542275
Pulled By: ezyang
fbshipit-source-id: 550976531d6a52db9128c0e3d4589a33715feee2
Summary:
- MSVC_Z7_OVERRIDE has already handled in CMakeLists.txt. No need to process it for once more in the Python scripts.
- Option MSVC_Z7_OVERRIDE should be visible to the user only if MSVC is used.
- Move the setting of "/EHa" flag to CMakeLists.txt, where other MSVC-specific flags are processed. This also further prepares the removal of redundant cflags setup in Python build scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23455
Differential Revision: D16542274
Pulled By: ezyang
fbshipit-source-id: 4d3b8b07161478bbba8a21feb6ea24c9024e21ac
Summary:
Closes gh-16955.
Closes https://github.com/pytorch/vision/issues/977
On Linux both `lib64` and `lib` may be present (symlinked). The reports
seem to all be about macOS, but it seems like this is also possibly more
robust on Linux and can't hurt. So not treating platforms differently.
Note that Eigen has a similar check in its CMake:
```
if(CUDA_64_BIT_DEVICE_CODE AND (EXISTS "${CUDA_TOOLKIT_ROOT_DIR}/lib64"))
link_directories("${CUDA_TOOLKIT_ROOT_DIR}/lib64")
else()
link_directories("${CUDA_TOOLKIT_ROOT_DIR}/lib")
endif()
```
There may be other issues for building from source on macOS, can't test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23491
Differential Revision: D16538973
Pulled By: soumith
fbshipit-source-id: cc309347b7d16e718e06878d3824d0a6e40b1019
Summary:
Currently set_rng_state and get_rng_state do not accept string as their parameters. This commit let them accept strings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23448
Differential Revision: D16527172
Pulled By: soumith
fbshipit-source-id: 8f9a2129979706e16877cc110f104770fbbe952c
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
MEDIUM: 981
LARGE: 56
Updated actions:
From MEDIUM to LARGE: 10
From LARGE to MEDIUM: 3
From LARGE to XLARGE: 1
Differential Revision: D16532427
fbshipit-source-id: c58bf59e6c571627b3994f8cdfa79758fb85892b
Summary:
(1) Add `COMMON_MSVC_FLAGS` to the flags in the ninja codepath
(2) Add `/EHsc` to `COMMON_MSVC_FLAG`
(3) Remove `-fPIC` and `-std=c++11` from the flags in the windows codepath
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23472
Differential Revision: D16532993
Pulled By: soumith
fbshipit-source-id: bc2d983f5f8b4eae9c7385bf170f155679e92e87
Summary:
Add `sorted` keyword to JIT for lists and dicts. This desugars to a list copy and a call to `list.sort()`. Since we don't have interfaces yet I implement it in terms of `list.sort()`. When we do we can re-visit implementing this op in a different manner.
The test fails bc of a fix to specialized lists which is landing here: https://github.com/pytorch/pytorch/pull/23267
Ignore the first commit because it is formatting, plz use clang_format ppl :'(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23274
Differential Revision: D16527323
Pulled By: eellison
fbshipit-source-id: aed8faef23cb790b9af036cd6c1b9b1d7066345d
Summary:
Scatter is unnecessary if only using one device, and it breaks on some custom data structures like namedtuple, so would like to avoid :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22384
Differential Revision: D16428208
Pulled By: soumith
fbshipit-source-id: eaa3876b2b95c1006ccaaacdb62f54c5280e730c
Summary:
This is part of the effort to shrink OSS libtorch mobile build size.
We shouldn't need Module::save function on mobile - it depends on
csrc/jit/export.cpp which then depends on ONNX. By gating these two
methods we can avoid these dependencies for libtorch mobile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23415
ghstack-source-id: 87288228
Reviewed By: dreiss
Differential Revision: D16511143
fbshipit-source-id: fd031f91fcf9b7be54cbe1436506965af94ab537
Summary:
Add early returns to JIT with minimal changes to compiler.cpp and an IR->IR pass that will transform the graph so that there is only one return value.
In compiler.cpp, record when a block will exit so that in the following example will work:
```
if cond:
a = torch.zeros([2])
else:
return 2
a += 2
...
```
To match block outputs with values that will not be used, like in the above example with `a`, I add a Bottom Type that subtypes everything else. This allows shape propagation to continue to work, and makes it so that we don't need many extra nodes filling up the graph.
The IR transform currently doesn't work on Loops, I didn't add that to this PR to avoid too much complexity, but will add it as a stack (and it should be very little extra code). the IR transform is commented at the top of the file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19179
Differential Revision: D16519819
Pulled By: eellison
fbshipit-source-id: 322a27f69966d1fd074ebe723c3e948b458b0e68
Summary:
Adds qtensor specific fields to the proto file so that they get serialized into the model.json
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23356
ghstack-source-id: 87263428
Differential Revision: D16473237
fbshipit-source-id: bf5b51d0863d036d30a1644a3c3b74516468224b
Summary:
As pointed out by SsnL in https://github.com/pytorch/pytorch/issues/20910, when clone destination is different from the module's device,
`Cloneable` currently calls `clone()` and then `to()` on every parameter and buffer, where the first clone is unnecessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20995
Differential Revision: D15517353
Pulled By: mrshenli
fbshipit-source-id: 6b6dc01560540a63845663f863dea0a948021fa5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23442
Replace the argument name from `operator` to `operators` which can take a list of operators to test.
Reviewed By: hl475
Differential Revision: D16520779
fbshipit-source-id: 94284a87c64471793e319f5bd3143f89b9a192bb
Summary:
When an exception occurs in one of the modules passed to `parallel_apply()`, it is caught and re-raised in the main thread. This preserves the original exception type and message, but has the traceback point at the position where it's re-raised, rather than the original point of failure.
This PR saves the exception information required to generate the traceback, and includes the original traceback in the message of the exception raised in the main thread.
Before:
```
...
File ".../torch/nn/parallel/data_parallel.py", line 153, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File ".../torch/nn/parallel/parallel_apply.py", line 84, in parallel_apply
raise output
RuntimeError: expected type torch.FloatTensor but got torch.cuda.FloatTensor
```
After:
```
...
File ".../torch/nn/parallel/data_parallel.py", line 153, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File ".../torch/nn/parallel/parallel_apply.py", line 88, in parallel_apply
''.join(traceback.format_exception(*exc_info)))
RuntimeError: Caught exception in replica 0. Original traceback and message:
Traceback (most recent call last):
...
File "../models/foo.py", line 319, in bar
baz = asdf / ghij[:, np.newaxis]
RuntimeError: expected type torch.FloatTensor but got torch.cuda.FloatTensor
```
I took care to raise an exception of the original type (in case the main code checks for that), but replaced the message. It helped me find a bug that did not occur outside `data_parallel()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18055
Differential Revision: D16444972
Pulled By: zhangguanheng66
fbshipit-source-id: ec436c9d4677fad18106a8046cfa835a20a101ce
Summary:
Don't automatically unwrap top layer DataParalllel for users. Instead, we provide useful error information and tell users what action to take.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23365
Reviewed By: zrphercule
Differential Revision: D16514273
Pulled By: houseroad
fbshipit-source-id: f552de5c53fb44807e9d9ad62126c98873ed106e
Summary:
The conda compiler are gcc/c++ 7.3.0, but have custom version strings
for clarity:
x86_64-conda_cos6-linux-gnu-cc
x86_64-conda_cos6-linux-gnu-c++
Using these compilers to build a C++ or CUDA extension now gives this warning (unnecessarily):
```
!! WARNING !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Your compiler (/home/rgommers/anaconda3/envs/pytorch-nightly/bin/x86_64-conda_cos6-linux-gnu-c++) is not compatible with the compiler Pytorch was
built with for this platform, which is g++ on linux.
...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23396
Differential Revision: D16500637
Pulled By: soumith
fbshipit-source-id: 5b2fc3593e22e9a7d07dc2c0456dbb4934ffddb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23104
ghstack-source-id: 87247148
As suggested in https://github.com/pytorch/pytorch/pull/22891, we will add an overload for ```torch.fbgemm_linear_int8_weight``` (dynamic quantized version of linear function) that takes PackedLinearWeight as input and is pretty much the same in signature as regular aten::linear.
Differential Revision: D16381552
fbshipit-source-id: 1ccc4174fd02c546eee328940ac4b0da48fc85e8
Summary:
adding qconv+relu and qlinear+relu modules in nn/_intrinsic/quantized
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23410
Test Plan:
Extended tests to test these new modules as well
buck test mode/dev caffe2/test:quantized -- 'test_linear_api' --print-passing-details
```
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/2251799820197379
✓ caffe2/test:quantized - test_linear_api (test_nn_quantized.ModuleAPITest) 4.055 1/1 (passed)
Test output:
> test_linear_api (test_nn_quantized.ModuleAPITest)
> test API functionality for nn.quantized.linear and nn._intrinsic.quantized.linear_relu ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 4.056s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/2251799820197379
Summary (total time 10.66s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
buck test mode/dev caffe2/test:quantized -- 'test_conv_api' --print-passing-details
```
Running 2 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/4785074607089664
✓ caffe2/test:quantized - test_conv_api (test_quantized_conv.QuantizedConvTest) 5.195 1/2 (passed)
Test output:
> test_conv_api (test_quantized_conv.QuantizedConvTest)
> Tests the correctness of the conv functional. ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 5.195s
>
> OK
✓ caffe2/test:quantized - test_conv_api (test_nn_quantized.ModuleAPITest) 10.616 2/2 (passed)
Test output:
> test_conv_api (test_nn_quantized.ModuleAPITest)
> Tests the correctness of the conv module. ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 10.616s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/4785074607089664
Summary (total time 17.31s):
PASS: 2
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
``
Differential Revision: D16505333
Pulled By: dskhudia
fbshipit-source-id: 04f45cd0e76dc55f4694d558b913ab2958b7d727
Summary:
This is still work in progress.
There are several more items to add to complete this doc, including
- [x] LHS indexing, index assignments.
- [x] Tensor List.
- [x] ~Shape/Type propagation.~
- [x] FAQs
Please review and share your thoughts, feel free to add anything that you think should be included as well. houseroad spandantiwari lara-hdr neginraoof
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23185
Differential Revision: D16459647
Pulled By: houseroad
fbshipit-source-id: b401c005f848d957541ba3b00e00c93ac2f4609b
Summary:
They should be forwarded by their actual type, not their rvalue reference.
This looked like perfect forwarding but actually wasn't.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23412
ghstack-source-id: 87214575
Reviewed By: dzhulgakov
Differential Revision: D16507872
fbshipit-source-id: 2b20a37df83067dd53e917fe87407ad687bb147c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21211
There are cases where the `init` method used to create inputs can exit with error. When this happens, that specific input should be skipped.
Reviewed By: zheng-xq
Differential Revision: D15466410
fbshipit-source-id: 55e86764b2ec56f7730349ff1df6e50efc0239d7
Summary:
Align the Argument's operator<< with parser,
additional support:
1) List size
2) real default value
3) Alias information
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23203
ghstack-source-id: 87118985
Reviewed By: zrphercule
Differential Revision: D16433188
fbshipit-source-id: aea5711f93feacd94d1732e2f0d61218a31a0c5c
Summary:
The builder pattern doesn't seem to work well with return-value-optimization.
This saves ~100 ns in the construction of TensorIterator::binary_op.
```
import torch
x = torch.rand(1)
y = torch.rand(1)
z = torch.rand(1)
%timeit torch.add(x, y, out=z) # ~1.76 us vs ~1.88 us on my machine
```
cc resistor zheng-xq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23329
Differential Revision: D16495070
Pulled By: VitalyFedyunin
fbshipit-source-id: 8ce116075fa4c7149dabfcdfa25885c1187c8e2f
Summary:
The legacy iOS build script (`build_ios.sh`) is still working, but the output is in caffe2, not Pytorch. To enable the Pytorch iOS build, we can set the value of `BUILD_CAFFE2_MOBILE` to `NO`, and turn on another cmake arg - `INTERN_BUILD_MOBILE` ljk53 has created for Android.
There is a trivial issue in `used_kernel.cpp` that will cause the compiling error when running `build_ios.sh`, as it uses a `system`API that has been deprecated since iOS 11. The fix below is to bypass this file since it's not needed by mobile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23293
Test Plan:
The `build_ios.sh` completed successfully, and all the generated static libraries can be compiled and linked successfully on iOS devices.
### Build script
```shell
./scripts/build_ios.sh \
-DBUILD_CAFFE2_MOBILE=OFF \
-DCMAKE_PREFIX_PATH=$(python -c 'from distutils.sysconfig import get_python_lib; print(get_python_lib())') \
-DPYTHON_EXECUTABLE=$(python -c 'import sys; print(sys.executable)')
```
Differential Revision: D16456100
Pulled By: xta0
fbshipit-source-id: 38c73e1e3a0c219a38ddc28b31acc181690f34e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22175
- Rename AliasAnalysisKind::DEFAULT to AliasAnalysisKind::CONSERVATIVE
- Introduce AliasAnalysisKind::FROM_SCHEMA that means the alias annotations of the schema should be honored
- Introduce AliasAnalysisKind::INTERNAL_SPECIAL_CASE to be able to run assertions that internal special cased ops are treated correctly
- aten:: and prim:: ops are not treated as special cases anymore, but just use AliasAnalysisKind::FROM_SCHEMA
- There's a set of assertions to ensure that aten:: and prim:: ops are all correctly set up to use AliasAnalysisKind::FROM_SCHEMA. Once this PR lands and passes all tests, we will remove those assertions and open up for the possibility of different AliasAnalysisKind settings for aten:: and prim:: ops
Differential Revision: D15929595
fbshipit-source-id: 7c6a9d4d29e13b8c9a856062cd6fb3f8a46a2e0d
Summary:
torch::List recently received some polishing that now also is done for Dict. This should be done before the PyTorch 1.2 release because of backwards compatibility.
- Dict is just a reference type, so "const Dict" should have the same capabilities as "Dict", constness is not guaranteed in any way.
- DictIterator gets comparison operators <, <=, >, >=
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23344
ghstack-source-id: 87170304
Differential Revision: D16468800
fbshipit-source-id: 2978c3b9cdcfb2cfb3f26516b15bd455d9a48ba9
Summary:
This check is not needed. Even if it were, the assignment is clobbered anyway.
Closes#23300.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23370
ghstack-source-id: 87157671
Differential Revision: D16485329
fbshipit-source-id: 8ccac79e81f5e0d0d20099d550411c161f58c233
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22808
- Use ```size_to_dim_```.
- ```mod``` is not in the scope. Should be ```module```.
Reviewed By: mingzhe09088
Differential Revision: D16225799
fbshipit-source-id: 9a263227d2d508eefdfddfee15fd0822819de946
Summary:
all cases should be prim ops, but let's support it. it will expect variadic return schema to be prim::PythonOp(...) -> ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23199
ghstack-source-id: 87113845
Differential Revision: D16431635
fbshipit-source-id: 798b6957ce5d800f7fcf981c86fdcb009cd77a78
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/22833
grad_sum_to_size does not commute with AutogradAdd after all because it turns the broadcasting AutogradAdd into a broadcasting add.
Chillee did actually do most of the tracking down to the fusion of grad_sum_to_size and pinging me when he had found the cause. Thank you!
About the choice of removing the fusion completely instead of being more precise:
- We do have grad_sum_to_size elimination which works for cases where broadcasting does not actually happen in the forward, so the cases where the fusing of grad_sum_to_size is actually beneficial is much smaller than when initially proposed.
- There will be less fusion, in terms of the tests, IOU stops being fully fused. I vaguely think that it is a case we could handle with refined logic.
- Keeping it would add complexity in checking when to merge fusion groups to the complexities that this PR removes.
- The future of fusion probably lies more in more complete solutions including reductions (TVM or KeOps or our own or ...).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23372
Differential Revision: D16489930
Pulled By: soumith
fbshipit-source-id: bc0431b0d3eda264c401b634675872c4ce46f0f4
Summary:
Instead, defer its default value to CMakeLists.txt
NO_FBGEMM has already been handled in tools/setup_helpers/env.py
(although deprecated)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23314
Differential Revision: D16493580
Pulled By: ezyang
fbshipit-source-id: 7255eb1df5e8a6dd0362507d68da0986a9ed46e2
Summary:
This is a small fix on top of gh-23348, which fixed the libtorch
nightly build timeouts.
For the latest nighly build (25 July), see
https://circleci.com/workflow-run/33d0a24a-b77c-4a8f-9ecd-5646146ce684
The only failures are these uploads, which is because `aws s3 cp`
can only deal with one file at a time. The only way to make it do
multiple files at once is:
```
aws s3 cp . "$s3_dir" --exclude "*" --include "libtorch-*.zip" --recursive --acl public-read
```
which is much more verbose. executing one `cp` per file should be fine,
and this is also what's done in `binary_macos_upload.sh`
Closes gh-23039
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23368
Differential Revision: D16488853
Pulled By: soumith
fbshipit-source-id: 6dc04b4de2f6cd2de5ae9ad57a6e980f56896498
Summary:
With this change you can now list multiple interfaces separated by
comma. ProcessGroupGloo creates a single Gloo context for every device
in the list (a context represents a connection to every other
rank). For every collective that is called, it will select the context
in a round robin fashion. The number of worker threads responsible for
executing the collectives is set to be twice the number of devices.
If you have a single physical interface, and wish to employ increased
parallelism, you can also specify
`GLOO_SOCKET_IFNAME=eth0,eth0,eth0,eth0`. This makes ProcessGroupGloo
use 4 connections per rank, 4 I/O threads, and 8 worker threads
responsible for executing the collectives.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22978
ghstack-source-id: 87006270
Differential Revision: D16339962
fbshipit-source-id: 9aa1dc93d8e131c1714db349b0cbe57e9e7266f1
Summary:
Illegal instruction is encountered in pre-built package in MKL-DNN. https://github.com/pytorch/pytorch/issues/23231
To avoid such binary compatibility issue, the HostOpts option in MKL-DNN is disabled in order to build MKL-DNN for generic arch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23292
Differential Revision: D16488773
Pulled By: soumith
fbshipit-source-id: 9e13c76fb9cb9338103cb767d7463c10891d294a
Summary:
This is step 1 in trying to get rid of constants that are set prior to
executing the test runner. All setup logic should be concentrated in
the setupClass() function of the TestCase subclass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23223
ghstack-source-id: 87005260
Reviewed By: zhaojuanmao
Differential Revision: D16439147
fbshipit-source-id: 7a929ad4b1c8e368e33d1165becbd4d91220882c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23347
This diff replaces uint8 with int8 to match with the underlying kernel implementation. When we do int8 quantization, we are computing with uint8 (input activation) * int8 (weight) -> uint8 (output activation). The weight is quantized into int8.
Reviewed By: jianyuh
Differential Revision: D16469435
fbshipit-source-id: a697655b0e97833fc601e5980970aec4dba53c39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23354
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16474254
Pulled By: ezyang
fbshipit-source-id: 0dd7ce02e1aa1a42a24d2af066ebd0ac5206c9a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23325Fixes#19990
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16473826
Pulled By: ezyang
fbshipit-source-id: 466db2c22fabd7b574f0a08aec67a18318ddb431
Summary:
Proposed PR for
https://github.com/pytorch/pytorch/issues/23342
Disables execution of QNNpack tests if IS_PPC.
Basically this parallels the same skipping of tests for IS_WINDOWS as well, which is already present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23343
Differential Revision: D16469218
Pulled By: soumith
fbshipit-source-id: 80b651d00e5d413e359cf418f79e20d74cd9c8e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23317
Print out the kind type when fail to export
Reviewed By: zrphercule
Differential Revision: D16462641
fbshipit-source-id: 27157c0bd597362f90ac8cfb33e1808bac0ec48b
Summary:
fix https://github.com/pytorch/pytorch/issues/21044
Bicubic interpolation can cause overshoot.
Opencv keeps results dtype aligned with input dtype:
- If input is uint8, the result is clamped [0, 255]
- If input is float, the result is unclamped.
In Pytorch case, we only accept float input, so we'll keep the result unclamped, and add some notes so that users can explicitly call `torch.clamp()` when necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23321
Differential Revision: D16464796
Pulled By: ailzhang
fbshipit-source-id: 177915e525d1f54c2209e277cf73e40699ed1acd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23257
Overal context: open-source BlackBoxPredictor as the entry
point for inference in Caffe2 (thread safe abstraction for Caffe2
inference). This should be used in ThroughputBenchmark for the purpose
of framework comparison
This specific diff:
There should be no harm in moving transformation code to
OSS. On the advantages side we will be able to compare production
Caffe2 setup with PyTorch in the most fair way via
ThroughputBenchmark. This approach avoid any complicated
transformation regirstries. Building those proper would be significant
engineering effort as well as production risk. In the past we had SEVs
related to transforms being turned off due to various refactors. Given
that we don't plan to build any other significant investments into
transformation logic except existing ones (like TVM and Glow), and
those also relate to open-source technologies, I came up to the
conclusion of moving to OSS the whole thing.
Reviewed By: zrphercule
Differential Revision: D16428124
fbshipit-source-id: b35deada5c015cd97b91ae12a7ea4aac53bd14b8
Summary:
Covering fleet-wide profiling, api logging, etc.
It's my first time writing rst, so suggestions are definitely welcomed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23010
Differential Revision: D16456721
Pulled By: dzhulgakov
fbshipit-source-id: 3d3018f41499d04db0dca865bb3a9652d8cdf90a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23291
This diff implements LSTM with FP16 weights based on FBGEMM.
At a high level, here are the steps:
1. Quantize and pack weight in every layer of LSTM
2. Pass weights from step 1 to the ATen `quantized_lstm` function which does matrix multiplication with FP16 weight. The following code shows the dtype of each variable used in MM:
Y = X * W + B
(fp32, fp32, fp16, fp32)
Reviewed By: jianyuh
Differential Revision: D16389595
fbshipit-source-id: c26ae4e153c667a941f4af64e9d07fc251403cee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22733
This refactor changes the conv module to avoid the usage of the functional ops.
Reviewed By: jerryzh168
Differential Revision: D15835572
fbshipit-source-id: f2294cd708fbe8372eb3a15cc60d83777d4f7029
Summary:
It used to be run with comm_size=8, which causes flaky results in a
stress run. The flakiness was caused by too many listening sockets
being created by Gloo context initialization (8 processes times 7
sockets times 20-way concurrency, plus TIME_WAIT).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23221
ghstack-source-id: 86995596
Reviewed By: d4l3k
Differential Revision: D16437834
fbshipit-source-id: 998d0e2b087c0ab15eca64e308059c35e1b51e7b
Summary:
I manually went through all functions in `torch.*` and corrected any mismatch between the arguments mentioned in doc and the ones actually taken by the function. This fixes https://github.com/pytorch/pytorch/issues/8698.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22973
Differential Revision: D16419602
Pulled By: yf225
fbshipit-source-id: 5562c9b0b95a0759abee41f967c45efacf2267c2
Summary:
Currently the build type is decided by the environment variable DEBUG
and REL_WITH_DEB_INFO. This commit also lets CMAKE_BUILD_TYPE be
effective. This makes the interface more consistent with CMake. This
also prepares https://github.com/pytorch/pytorch/issues/22776.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22875
Differential Revision: D16281663
Pulled By: ezyang
fbshipit-source-id: 952f92aad85ff59f1c7abe8256eca8a4a0936026
Summary:
Rehash of https://github.com/pytorch/pytorch/issues/22322 .
Given that python 2.7 will be EOL'd on Jan 1, 2020 and we have models depending on python3.5+, we'd like to update the ROCm CI across the board to python3.6.
This PR adds the skip tests and some semantic changes for PyTorch.
Added pattern match skip for anything but the ROCm CI compared to #223222 for the python find step in the PyTorch build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23088
Differential Revision: D16448261
Pulled By: bddppq
fbshipit-source-id: 69ece1a213418d9abf1444c496dce1c190ee07c8
Summary:
there are a lot of formatting changes which makes other diffs to these PRs noisy & hard to read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23283
Differential Revision: D16453590
Pulled By: eellison
fbshipit-source-id: 97b4bf1dbbbfb09c44c57402f61ea27287060044
Summary:
In Python, `register_module` / `register_parameter` / `register_buffer` method in `nn.Module` is public. This PR makes those APIs public for C++ `nn::Module` as well. Closes https://github.com/pytorch/pytorch/issues/23140.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23196
Differential Revision: D16440239
Pulled By: yf225
fbshipit-source-id: e0eff6e1db592961fba891ec417dc74fa765e968
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23272
We see significant performance improvements by limiting concurrency
at caffe2 level on mobile. This diff enables setting the number of caffe2
workspaces used during rnn inference.
Reviewed By: akyrola
Differential Revision: D16448611
fbshipit-source-id: 28abaddb4ea60bacb084ceb28cb7a4d1e67ccc17
Summary:
Support exporting
* Standard tensor indexing like
```
x = torch.ones(4, 5)
ind = torch.tensor([0, 1])
return x[ind]
```
* [Advanced indexing](https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html#advanced-indexing) like
```
x = torch.ones(4,5,6,7,8)
ind1 = torch.tensor([0, 1])
ind2 = torch.tensor([[3], [2]])
ind3 = torch.tensor([[2, 2], [4, 5]])
return x[2:4, ind1, None, ind2, ind3, :]
```
It would be ideal if ONNX can natively support indexing in future opsets, but for opset <= 10 it will always need this kind of workarounds.
There are still various limitations, such as not supporting advanced indexing with negative indices, not supporting mask indices of rank > 1, etc. My feeling is that these are less common cases that requires great effort to support using current opset, and it's better to not make the index export more cumbersome than it already is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21716
Reviewed By: zrphercule
Differential Revision: D15902199
Pulled By: houseroad
fbshipit-source-id: 5f1cc687fc9f97da18732f6a2c9dfe8f6fdb34a6
Summary:
Previously we weren't specializing the list returned from `dict.keys()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23267
Differential Revision: D16448512
Pulled By: eellison
fbshipit-source-id: fcd2a37ac680bdf90219b099a94aa36a80f4067c
Summary:
Overal context: open-source BlackBoxPredictor as the entry
point for inference in Caffe2 (thread safe abstraction for Caffe2
inference). This should be used in ThroughputBenchmark for the purpose
of framework comparison
This specific diff:
There should be no harm in moving transformation code to
OSS. On the advantages side we will be able to compare production
Caffe2 setup with PyTorch in the most fair way via
ThroughputBenchmark. This approach avoid any complicated
transformation regirstries. Building those proper would be significant
engineering effort as well as production risk. In the past we had SEVs
related to transforms being turned off due to various refactors. Given
that we don't plan to build any other significant investments into
transformation logic except existing ones (like TVM and Glow), and
those also relate to open-source technologies, I came up to the
conclusion of moving to OSS the whole thing.
Reviewed By: bertmaher
Differential Revision: D16367134
fbshipit-source-id: fc6bacc1be3ff6336beb57cdad58168d3a2b8c28
Summary:
per https://github.com/pytorch/pytorch/issues/22260, default number of open mp threads are spawned to be the same of number of cores available, for multi processing data parallel cases, too many threads may be spawned and could overload the CPU, resulting in performance regression.
so set OMP_NUM_THREADS = number of CPU processors/number of processes in default to neither overload or waste CPU threads
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22501
Test Plan:
1. without and with this change, example codes result in same result
python ~/local/fbsource-fbcode/fbcode/caffe2/torch/distributed/launch.py --nproc_per_node=2 pytorch/examples/yanlizhao/distributed_launch_example.py
Setting OMP_NUM_THREADS environment variable for each process to be: 24, which
is max(1, num_cpus / num_processes), you can further tune the variable for optimal performance in your application if needed.
final loss = tensor(0.5211, device='cuda:0', grad_fn=<MseLossBackward>)
Differential Revision: D16092225
Pulled By: zhaojuanmao
fbshipit-source-id: b792a4c27a7ffae40e4a59e96669209c6a85e27f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23003
torch.quantization.fuse_module and torch.nn._intrinsic convRelu and LinearRelu
Fusion function to combine specific modules: (conv,bn) and (conv,bn,relu).
In all cases, replace modules in place. The first module is replaced with the _intrinsic fused module and the remaining modules are replaced by nn.Identity.
Support both training and eval. For training, the modules are "fused" with a sequential container. This is to allow for further module swaps for quantization aware training.
Also add: torch.nn._intrinsic for convRelu and LinearRelu.
TODO: Add tests for _intrinsic modules.
Conv BN fusion code is based on DsKhudia's implementation
Differential Revision: D16199720
fbshipit-source-id: 95fb9ffe72b361d280313b2ec57de2acd4f9dda2
Summary:
This adds a replace_module method to the C++ api. This is needed to be able to replace modules.
The primary use case I am aware of is to enable finetuning of models.
Given that finetuning is fairly popular these days, I think it would be good to facilitate this in the C++ api as well.
This has been reported by Jean-Christophe Lombardo on the [forums](https://discuss.pytorch.org/t/finetuning-a-model-on-multiple-gpu-in-c/49195).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22546
Differential Revision: D16440289
Pulled By: yf225
fbshipit-source-id: c136f914b8fc5c0f1975d877ea817fda5c851cda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23022
will be tested in later diffs.
Added LinearReLU module for qat, allows conversion from torch.nn._intrisic.LinearReLU to torch.nn._intrinsic.qat.LinearReLU
Reviewed By: zafartahirov
Differential Revision: D16286800
fbshipit-source-id: 84cce3551d46e649781b9b6107d4076e10e51018
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23181
We can't run dead code elimination after erasing number types because dce relies on graph invariants that erase_number_types breaks.
Reviewed By: houseroad
Differential Revision: D16427819
fbshipit-source-id: d1b98a74d2558b14d4be692219691149689a93d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23180
This pass needs to be run later because it breaks jit graph invariants and the lower_all_tuples pass still needs a valid jit graph.
Reviewed By: houseroad
Differential Revision: D16427680
fbshipit-source-id: 427c7e74c59a3d7d62f2855ed626cf6258107509
Summary:
Creating an untyped generic list is deprecated, we always want type information to be present.
This fixes test cases and removes one that used lists with ambigious types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23192
ghstack-source-id: 86972891
Differential Revision: D16431482
fbshipit-source-id: 4ca5cd142118a3f0a4dcb8cd77383127c54abb29
Summary:
---
How does the current code subsume all detections in the deleted `nccl.py`?
- The dependency of `USE_NCCL` on the OS and `USE_CUDA` is handled as dependency options in `CMakeLists.txt`.
- The main NCCL detection happens in [FindNCCL.cmake](8377d4b32c/cmake/Modules/FindNCCL.cmake), which is called by [nccl.cmake](8377d4b32c/cmake/External/nccl.cmake). When `USE_SYSTEM_NCCL` is false, the previous Python code defer the detection to `find_package(NCCL)`. The change in `nccl.cmake` retains this.
- `USE_STATIC_NCCL` in the previous Python code simply changes the name of the detected library. This is done in `IF (USE_STATIC_NCCL)`.
- Now we only need to look at how the lines below line 20 in `nccl.cmake` are subsumed. These lines list paths to header and library directories that NCCL headers and libraries may reside in and try to search these directories for the key header and library files in turn. These are done by `find_path` for headers and `find_library` for the library files in `FindNCCL.cmake`.
* The call of [find_path](https://cmake.org/cmake/help/v3.8/command/find_path.html) (Search for `NO_DEFAULT_PATH` in the link) by default searches for headers in `<prefix>/include` for each `<prefix>` in `CMAKE_PREFIX_PATH` and `CMAKE_SYSTEM_PREFIX_PATH`. Like the Python code, this commit sets `CMAKE_PREFIX_PATH` to search for `<prefix>` in `NCCL_ROOT_DIR` and home to CUDA. `CMAKE_SYSTEM_PREFIX_PATH` includes the standard directories such as `/usr/local` and `/usr`. `NCCL_INCLUDE_DIR` is also specifically handled.
* Similarly, the call of [find_library](https://cmake.org/cmake/help/v3.8/command/find_library.html) (Search for `NO_DEFAULT_PATH` in the link) by default searches for libraries in directories including `<prefix>/lib` for each `<prefix>` in `CMAKE_PREFIX_PATH` and `CMAKE_SYSTEM_PREFIX_PATH`. But it also handles the edge cases intended to be solved in the Python code more properly:
- It only searches for `<prefix>/lib64` (and `<prefix>/lib32`) if it is appropriate on the system.
- It only searches for `<prefix>/lib/<arch>` for the right `<arch>`, unlike the Python code searches for `lib/<arch>` in a generic way (e.g., the Python code searches for `/usr/lib/x86_64-linux-gnu` but in reality systems have `/usr/lib/x86_64-some-customized-name-linux-gnu`, see https://unix.stackexchange.com/a/226180/38242 ).
---
Regarding for relevant issues:
- https://github.com/pytorch/pytorch/issues/12063 and https://github.com/pytorch/pytorch/issues/2877: These are properly handled, as explained in the updated comment.
- https://github.com/pytorch/pytorch/issues/2941 does not changes NCCL detection specifically for Windows (it changed CUDA detection).
- b7e258f81ef61d19b884194cdbcd6c7089636d46 A versioned library detection is added, but the order is reversed: The unversioned library becomes preferred. This is because normally unversioned libraries are linked to versioned libraries and preferred by users, and local installation by users are often unversioned. Like the document of [find_library](https://cmake.org/cmake/help/v3.8/command/find_library.html) suggests:
> When using this to specify names with and without a version suffix, we recommend specifying the unversioned name first so that locally-built packages can be found before those provided by distributions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22930
Differential Revision: D16440275
Pulled By: ezyang
fbshipit-source-id: 11fe80743d4fe89b1ed6f96d5d996496e8ec01aa
Summary:
Some overlap with https://github.com/pytorch/pytorch/pull/21716 regarding caffe2 nonzero. Will rebase the other one accordingly whichever gets merged first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22601
Reviewed By: zrphercule
Differential Revision: D16224660
Pulled By: houseroad
fbshipit-source-id: dbfd1b8776cb626601e0bf83b3fcca291806e653
Summary:
https://github.com/pytorch/pytorch/issues/20153
I believe you need 2 passes for this. Take this example
```python
torch.jit.script
def f():
x = torch.ones(10, 9, 8, 7, 6)
return x[..., None, None].shape
```
which results in `[10, 9, 8, 7, 6, 1, 1]`
vs
```
torch.jit.script
def f():
x = torch.ones(10, 9, 8, 7, 6)
return x[..., None, None, :].shape
```
which results in `[10, 9, 8, 7, 1, 1, 6]`
After only processing `x[..., None, None` we don't know whether we should be creating a new dimension at the end of the dimension list or somewhere in the middle. What we do depends on the elements to the right of it.
Thus, I do 2 passes - one to collect all the dimensions that the index operations operate on, and another that executes the index operations.
This still doesn't work for an ellipse index followed by a tensor index, but it wasn't working previously either.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22905
Differential Revision: D16433558
Pulled By: Chillee
fbshipit-source-id: c1b303cb97b1af8b6e405bad33495ef3b4c27c4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23182
This fixes the issue seen in D16390551
Changing the load op to take in shapes vector needs changes in lots of places (almost all usages of load op).
Instead this is a small and safe change where the behavior is unchanged if we are loading multiple blobs and when loading a single blob without shape information.
If you are loading just one blob and the shape information is provided, then this returns the right shape info back.
For all other cases, behavior is unchanged as before we introduced the issue.
This fixes the issue reported by Andrey in D16229465
Reviewed By: boryiingsu
Differential Revision: D16428140
fbshipit-source-id: 8ef6705ab2efb346819489e1f166e23269f7ef8a
Summary:
fbgemm requires a AVX512 which requires a more recent compiler, so this also switches all the nightlies from devtoolset3 to devtoolset7. Since CUDA 9.0 doesn't support devtoolset7, we also switch from CUDA 9.0 to CUDA 9.2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22784
Differential Revision: D16428165
Pulled By: pjh5
fbshipit-source-id: c1af3729d8edce88a96fa9069d4c5a1808c25f99
Summary:
We need a way to figure get a complete list fo features that are used in training a model. One way to do this is to make it possible to get the list of features used in each Model Layer. Then once the model is complete we can go through the layers and aggregate the features.
I've introduced a function to expose that information here, get_accessed_features, and implemented it in the FeatureSparseToDense layer to start with.
I've tried to include the minimum amount of information to make this useful, while making it easy to integrate into the variety of model layers. This is, for example, why AccessedFeatures does not contain feature_names which is not always present in a model layer. I debated whether or not to include feature_type, but I think that's useful enough, and easy enough to figure out in a model layer, that it's worth including.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23036
Test Plan:
Added a unit test to verify the behavior of get_accessed_features in FeatureSparseToDense.
aml_dper2-fblearner-flow-integration-tests failed due to a known issue D16355865
aml_dper3-fblearner-flow-integration-tests failed due to a known issue T47197113
I verified no tests in the integration tests failed to issues other than those known ones.
DPER2 canaries: https://fburl.com/fblearner/1217voga
Reviewed By: volkhin
Differential Revision: D16365380
Pulled By: kevinwilfong
fbshipit-source-id: 2dbb4d832628180336533f29f7d917cbad171950
Summary:
I ran into the following error when trying to pass a Python int as an arg to `torch::jit::createStackForSchema`, and I think it is due to the missing support for `NumberType` in [toIValue](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/pybind_utils.h#L448).
> RuntimeError: Missing cases in toIValue for type: Scalar! File a bug report. (toIValue at ../torch/csrc/jit/pybind_utils.h:449)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22817
Differential Revision: D16276006
Pulled By: mrshenli
fbshipit-source-id: 7f63519bb37219445e836ec1f51ca4f98bf52c44
Summary:
Bumping up the producer_version in exported ONNX models in view of the next release. Updating tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23120
Reviewed By: zrphercule
Differential Revision: D16420917
Pulled By: houseroad
fbshipit-source-id: 6686b10523c102e924ecaf96fd3231240b4219a9
Summary:
`pickle` supports this and a lot of the quantized use cases for get/set
state follow this pattern
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23119
Pulled By: driazati
Differential Revision: D16391234
fbshipit-source-id: 9f63e0a1679daa61b17aa64b5995e2be23b07b50
Summary:
Previously we looked at the stack frame of the function that called
`script` to resolve variables. This doesn't work if someone calls script
with a function defined somewhere else that references captured
variables. We already have a mechanism to look at the closed over
variables for a function, so this changes the `rcb` to use that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22270
Pulled By: driazati
Differential Revision: D16391346
fbshipit-source-id: ad9b314ae86c249251b106079e76a5d7cf6c04c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23166
Changing the load op to take in shapes vector needs changes in lots of places (almost all usages of load op).
Instead this is a small and safe change where the behavior is unchanged if we are loading multiple blobs and when loading a single blob without shape information.
If you are loading just one blob and the shape information is provided, then this returns the right shape info back.
For all other cases, behavior is unchanged as before we introduced the issue.
This fixes the issue reported by Andrey in D16229465
Reviewed By: boryiingsu
Differential Revision: D16390551
fbshipit-source-id: 1055b481a7a9e83021209e59f38a7cc0b49003cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23077
Although the difference between running from python and this is not much if we
have forward method's loop long enough (like 1000 in this case).
Reviewed By: mingzhe09088
Differential Revision: D16122343
fbshipit-source-id: 5c1d1b98ae82c996baf9d42bcd04995e2ba60c78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23076
Tracing based and non tracing based added
Reviewed By: mingzhe09088
Differential Revision: D16097280
fbshipit-source-id: 3a137092f7ccc3dd2d29d95e10178ec89d3ce892
Summary:
Update ScatterWeightedSum op when there exists only one weighted X to update slice of Y which is usually the case when the op is used for gradient update. The changes remove the copy overhead and seeing significant operator performance improvement
- 25 - 50% improvment on CUDA based on input configuration
- ~50% improvement on ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23087
Differential Revision: D16385194
Pulled By: bddppq
fbshipit-source-id: 3189e892940fb9c26305269eb0d47479b9b71af0
Summary:
This is a small patch to not overwrite unchanged files to help a bit with building.
It is not as incremental as one might like, given that one has to pass `--out-of-place-only` to not run into the patching and things.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23112
Differential Revision: D16402623
Pulled By: bddppq
fbshipit-source-id: 531ce0078bc716ae31bd92c5248080ef02a065b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22765
the pooling signature is the same as the non-quantized one. Adding it to the native_functions.yaml
Reviewed By: jerryzh168
Differential Revision: D16102608
fbshipit-source-id: 7627ad8f02a231f488b74d1a245b853f89d9c419
Summary:
USE_{C11,MSC,GCC}_ATOMICS are not used in PyTorch or submodules. Now we remove their underlying detection code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23089
Differential Revision: D16402750
Pulled By: ezyang
fbshipit-source-id: fde84b958eb0b5b4d3f0406acefa92ab30ea43be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21749
This is the first version without "requantization"
Reviewed By: jerryzh168
Differential Revision: D15807940
fbshipit-source-id: 19bb0482abed8ed9d1521a3fa1f15bda8e6a6a7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23096
nets can have states that depends on the rest of the state in the Workspace. Hence, they should be destructed first.
Reviewed By: ajyu
Differential Revision: D16382987
fbshipit-source-id: 3fd030ba206e2d0e897abb9e31c95bdaeb9482b7
Summary:
Add support for quantization aware training in eager mode
Modifications to Post training flow:
## Prepare
* Fusion: e.g. (Conv, Bn) → ConvBn (float)
* Swapping: To insert fake_quant to weight, we need to swap the float modules that has weight with different qat modules, e.g. Conv → torch.nn.qat.Conv , ConvBn → torch.nn._intrinsic.qat.ConvBn
```
* previously we were thinking about modify the weight in forward_pre hook and change it back in forward_hook:
* def forward_pre_hook(self, input):
self.float_weight = self.weight
self.weight = self.fake_quantize(self.float_weight)
def forward_hook(self, input):
self.weight = self.float_weight
```
* Assignments to self.weight are needed because we can’t change forward function and in forward function they are using self.weight.
* But we will need to keep two copies of weight in this case, so it’s probably better to just swap the module
* So we want to just swap Conv to torch.nn.qat.Conv and Linear to torch.nn.qat.Linear
* qat modules will have fake_quant for output and weights inserted in forward function
## Convert
* flow should be identical to ptq, but the swapping dictionary is slightly different since modules are changed in prepare step.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23082
ghstack-source-id: 86824650
Differential Revision: D16379374
fbshipit-source-id: 7d16d1acd87025065a24942ff92abf18e9fc8070
Summary:
Overal context: open-source BlackBoxPredictor as the entry
point for inference in Caffe2 (thread safe abstraction for Caffe2
inference). This should be used in ThroughputBenchmark for the purpose
of framework comparison
This specific diff:
There should be no harm in moving transformation code to
OSS. On the advantages side we will be able to compare production
Caffe2 setup with PyTorch in the most fair way via
ThroughputBenchmark. This approach avoid any complicated
transformation regirstries. Building those proper would be significant
engineering effort as well as production risk. In the past we had SEVs
related to transforms being turned off due to various refactors. Given
that we don't plan to build any other significant investments into
transformation logic except existing ones (like TVM and Glow), and
those also relate to open-source technologies, I came up to the
conclusion of moving to OSS the whole thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22877
Test Plan:
did a bunch of unit tests locally and now
waitforsandcaslte
AdFinder canary:
https://our.intern.facebook.com/intern/ads/canary/419623727275650390
adindexer:
https://our.intern.facebook.com/intern/ads/canary/419623750891549182
prospector:
https://our.intern.facebook.com/intern/ads/canary/419644899887610977https://our.intern.facebook.com/intern/ads/canary/419645123742738405
Differential Revision: D16267765
Pulled By: salexspb
fbshipit-source-id: 776a1cd5415e0695eae28254b3f155e7a9bd8c2b
Summary:
1. Fix out of range memory access for reduction on all dimensions for non-packed
tensor.
2. Enabling launch config that maps block width to reduction on fastest striding
dimension. This mapping was previously only active when reducing on fastest
striding dimension of packed tensor, which is not necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22827
Differential Revision: D16271897
Pulled By: zdevito
fbshipit-source-id: 20763f6cf9a58e44ffc0e7ec27724dfec8fe2c5d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/22389
In most cases we only import `PIL` methods when we need them, but we missed a spot.
cc lanpa natalialunova sanekmelnikov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23023
Reviewed By: sanekmelnikov
Differential Revision: D16373492
Pulled By: orionr
fbshipit-source-id: b08bf8a9b5a861390eadf62eda21ac055777180f
Summary:
This PR fixes the invalid None return when calling get_all_math_dtype(device='cuda').
Issue came from the __append__ method which doesn't have any return value used in `return dtypes.append(...)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23028
Differential Revision: D16362732
Pulled By: colesbury
fbshipit-source-id: 0bbc30a0c663749d768159f1bc37b99f7263297b
Summary:
This PR aims at improving BERT performance on CPU by using `mkldnn` inner product for `nn.Linear()`.
The current logic is to use `mkldnn` only when `input` tensor is of mkldnn layout. This PR loosens this condition, `mkldnn` will be used for `nn.Linear()` when `input` tensor is of dense layout. The aten tensor is viewed inplace in `mkldnn` without additional memory copy.
1. when `input.dim() >= 3` , it is viewed as 2d tensor. e.g. `[T, N, C]` is treated as `[TN, C]`;
2. when `input` is not contiguous, it is copied so as to be contiguous. `mkldnn` inner product can't handle non-contiguous memory.
With this PR, BERT on `glue/MRPC` inference (batch size = 1) on Xeon 6148 single socket (20 cores@2.5GHz) improves by `44%`:
1. before (unit: iterations/sec):
```bash
408/408 [00:24<00:00, 16.69it/s]
```
2. after (unit: iterations/sec):
```bash
408/408 [00:16<00:00, 24.06it/s]
```
The latency reduces from `59.92 ms` to `41.56ms` correspondingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21851
Differential Revision: D16056334
Pulled By: dzhulgakov
fbshipit-source-id: 9b70ed58323b5e2f3f4e3ebacc766a74a8b68a8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22732
Add support for quantization aware training in eager mode
Modifications to Post training flow:
## Prepare
* Fusion: e.g. (Conv, Bn) → ConvBn (float)
* Swapping: To insert fake_quant to weight, we need to swap the float modules that has weight with different qat modules, e.g. Conv → torch.nn.qat.Conv , ConvBn → torch.nn._intrinsic.qat.ConvBn
```
* previously we were thinking about modify the weight in forward_pre hook and change it back in forward_hook:
* def forward_pre_hook(self, input):
self.float_weight = self.weight
self.weight = self.fake_quantize(self.float_weight)
def forward_hook(self, input):
self.weight = self.float_weight
```
* Assignments to self.weight are needed because we can’t change forward function and in forward function they are using self.weight.
* But we will need to keep two copies of weight in this case, so it’s probably better to just swap the module
* So we want to just swap Conv to torch.nn.qat.Conv and Linear to torch.nn.qat.Linear
* qat modules will have fake_quant for output and weights inserted in forward function
## Convert
* flow should be identical to ptq, but the swapping dictionary is slightly different since modules are changed in prepare step.
Reviewed By: zafartahirov
Differential Revision: D16199356
fbshipit-source-id: 62aeaf47c12c62a87d9cac208f25f7592e245d6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22714
We need this module for add fake_quant for weight
Reviewed By: zafartahirov
Differential Revision: D16193585
fbshipit-source-id: ed6c04ecf574ca1fe1dcded22c225da05976f7a3
Summary:
When working on https://github.com/pytorch/pytorch/pull/22762, we discovered that we haven't actually deprecated legacy autograd function. This PR puts up the deprecation warning for 1.2, with the goal to remove legacy function support completely in the near future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22922
Differential Revision: D16363916
Pulled By: yf225
fbshipit-source-id: 4b554010a3d1f87a3fa45cc1aa29d019c8f1033c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22950
Print quantized tensor by first dequantizing it and then printing. Also print the scale, zero_point. size and type of tensor.
Reviewed By: jerryzh168
Differential Revision: D16286397
fbshipit-source-id: 2d6fb1796e5b329a77c022b18af0a39f6edde0d7
Summary:
We are planning to put up a deprecation warning for legacy autograd function in 1.2: https://github.com/pytorch/pytorch/pull/22922. This PR removes all usage of legacy function in PyTorch core and test suite, to prepare for the eventual removal of legacy function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22925
Differential Revision: D16344834
Pulled By: yf225
fbshipit-source-id: 8bf4cca740398835a08b7a290f3058c3e46781ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22316
Adding the quantized ReLU to the native_functions.yamp, as it has the same signature as non-quantized relu
Reviewed By: jerryzh168
Differential Revision: D16038441
fbshipit-source-id: 1cfbb594eb9bca1b7ec49ca486defcf1908b0d26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22966
We want to implement "trimmed lasso" for feature selection with learnable and regularizable weights. Trimmed lasso is a simple yet powerful improved version from traditional lasso. More reference can be found at https://arxiv.org/abs/1708.04527 and http://proceedings.mlr.press/v97/yun19a.html. For quick and necessary intro, please refer to P1-3 of the paper at https://arxiv.org/abs/1708.04527.
Given n weights, traditional lasso sums up all weights' l1 norms. The trimmed lasso takes an input integer k (how many weights you want to select from n) and only sums over the smallest n - k weights. Given lambda as the regularization constant, the penalty term is only on the smallest n - k weights, but not other larger weights. If lambda becomes larger than certain threshold, the smallest n - k weights are shrunk to zero. That means we have those weights "dropped". With this property, the number k is the number of weights left after lasso, which we can easily control.
Meanwhile, we further support all available regularization in a single interface. Current supported regularizers on weights include no reg, l1, l2, elastic, trimmed l1, elastic with trimmed l1, group l1, and logbarrier.
Differential Revision: D16326492
fbshipit-source-id: 6e1fd75606005d9bc09d6650435c96a7984ba69c
Summary:
Given that python 2.7 will be EOL'd on Jan 1, 2020 and we have models depending on python3.5+, we'd like to update the ROCm CI across the board to python3.6.
This PR adds the skip tests and some semantic changes for PyTorch.
Open tasks/questions:
* RoiAlignTest.CheckCPUGPUEqual fails in the Caffe2 unit tests. Is this something expects / can be skipped?
* for testing, I've used update-alternatives on CentOS/Ubuntu to select python == python 3.6. Is this the preferred way?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22322
Differential Revision: D16199862
Pulled By: ezyang
fbshipit-source-id: 46ca6029a232f7d23f3fdb5efc33ae39a379fca8
Summary:
Fixes https://github.com/pytorch/pytorch/issues/21935 by using the integer floor division that was introduced for convolution shapes in https://github.com/pytorch/pytorch/issues/9640. Without this fix, the pooling operators can produce a 1-element output in cases they shouldn't.
Disclaimer: I couldn't properly test it locally (it's not picking up the modified version for some reason). I'm marking this WIP until I checked what the CI tools say...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22304
Differential Revision: D16181955
Pulled By: ezyang
fbshipit-source-id: a2405372753572548b40616d1206848b527c8121
Summary:
This cleans up the `torch.utils.tensorboard` API to remove all kwargs usage (which isn't clear to the user) and removes the "experimental" warning in prep for our 1.2 release.
We also don't need the additional PyTorch version checks now that we are in the codebase itself.
cc ezyang lanpa natalialunova
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21786
Reviewed By: natalialunova
Differential Revision: D15854892
Pulled By: orionr
fbshipit-source-id: 06b8498826946e578824d4b15c910edb3c2c20c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22958
When we use `extension_loader.DlopenGuard()` to dyndep or import modules, it sets a `RTLD_GLOBAL` flag, and restores the original flags after the `yield`. However, if the modules is not there, yield will fail, and the flags won't be restored, creating all kinds of symbol conflict problems.
Reviewed By: bddppq
Differential Revision: D16311949
fbshipit-source-id: 7b9ec6d60423ec5e78cae694b66c2f17493840b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22830
Separating the tensor generation and the generation of the quantization parameters
- Introducing hypothesis filter `assume_not_overflowing`, which makes sure that the generated tensor and qparams play well with each other. **Note: This is an expensive filter!**
- `qtensor` -> Renameed to `tensor`
- `qtensor_conv` -> Renamed to `tensor_conv2d`
- The tensors don't return the quantization parameters anymore, use `qparams` for it
- The `dtypes` argument is just a quantized dtype now.
- The enforcement for zero_point is predefined as before. As before, if set to `None` the zero_point will be sampled. However, if `None`, you can override sampling with `zero_point_min` and `zero_point_max`
- Scale sampling can also be overriden using `scale_min` and `scale_max`
Reviewed By: jerryzh168
Differential Revision: D16234314
fbshipit-source-id: 5b538a5aa9772b7add4f2ce5eff6fd0decd48f8e
Summary:
ONNX uses virtualenv, and PyTorch doesn't. So --user flag is causing problems in ONNX ci...
Fixing it by moving it to pytorch only scripts. And will install ninja in onnx ci separately.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22946
Reviewed By: bddppq
Differential Revision: D16297781
Pulled By: houseroad
fbshipit-source-id: 52991abac61beaf3cfbcc99af5bb1cd27b790485
Summary:
…te argument in macro
Changelog:
- Update note about tensors on CPU for the following MAGMA functions
- magma_(d/s)getrf_gpu and magma_getrf_nopiv_gpu require tensors on CPU for pivots
- magma_(d/s)geqrf2_gpu requires tensors on CPU for elementary reflectors
- magma_(d/s)syevd_gpu requires tensors on CPU for eigenvalues
- Remove dummy tensor in ALLOCATE_ARRAY MACRO
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22618
Test Plan:
- All existing tests should pass to verify that the patch is correct
This PR has been proposed to eliminate confusion due to the previous comments, as indicated in https://github.com/pytorch/pytorch/issues/22573
Differential Revision: D16286198
Pulled By: zou3519
fbshipit-source-id: a5a6ec829084bdb752ca6006b8795227cbaf63b1
Summary:
This fixes up the test suite (mostly just adding `ignore` decorations
to tests that need to call Python function) so that it all passes with
recursive script enabled.
The main user-facing result of this change is that Python functions are
compiled without any decorators, so non-TorchScriptable code must be
decorated with `torch.jit.ignore` (or
`torch.jit.ignore(drop_on_export=True` to maintain the functionality of
the current `ignore`)
Details can be found in #20939
](https://our.intern.facebook.com/intern/diff/16277608/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22887
Pulled By: driazati
Differential Revision: D16277608
fbshipit-source-id: 0abd0dc4291cf40651a1719bff813abb2b559640
Summary:
Motivation:
The forward method of MultiheadAttention has a kwarg a key_padding_mask. This mask is of shape (N,S) where N is batch and S is sequence length. This mask is applied prior to attention softmax where True values in the mask are set to float('-inf'). This allows you to mask position j from attention for all position i in input sequence. It's typically used to mask padded inputs. So for a sample in a batch we will be able to make sure no encoder outputs depend on padding inputs. Currently the Transformer, TransformerEncoder, and TransformerEncoderLayer do not have this kwarg, and only have options for a (S,S), (T,T), and (S,T) masks which are applied equally across the batch for source input, target output, and target-source memory respectively. These masks can't be used for padding and are instead used for things like subsequent masking in language modeling, by masking the attention of position i to position j.
This diff exposes the key_padding_mask to Transformer, TransformerEncoder, and TransformerEncoderLayer forward methods which is ultimately passed to MultiheadAttention forward.
Open question: should we also allow a key_padding_mask for the decoder layer? As padding is usually at the end of each sentence in a batch and sentences are usually decoding from left to right, usually people deal with padding on decoded outputs by just masking those outputs at the loss layer. There might be some scenarios where it's needed though I don't think it would be common. People can also still just subclass and override the layers. We could also pass the input key_padding_mask to the memory <> decoder attention layer. Not sure if that's necessary though because the output of position i from each attention encoder layer won't depend on any masked positions in the input (even if position i is a masked position itself) so there's not really any point in masking position i again.
Adds the key_padding_mask kwarg to Transformer, TransformerEncoder, and TransformerEncoderLayer forward methods.
The standard TransformerEncoderLayer uses a MultiheadAttention layer as self_attn. MultiheadAttention forward method has a key_padding_mask kwarg that allows for masking of values such as padding per sequence in a batch, in contrast to the attn_mask kwarg which is usually of shape (S,S) and applied equally across the batch.
MultiheadAttention calls functional.multi_head_attention_forward, which has the same key_padding_mask kwarg of shape (N,S). Masked (True) values are set to float('-inf').
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22588
Test Plan:
buck test mode/dev caffe2/test:nn -- 'test_transformerencoderlayer \(test_nn\.TestNN\)'
buck test mode/dev caffe2/test:nn -- 'test_Transformer_cell \(test_nn\.TestNN\)'
buck test mode/dev caffe2/test:nn -- 'test_transformer_args_check \(test_nn\.TestNN\)'
Differential Revision: D16112263
Pulled By: lucasgadams
fbshipit-source-id: dc4147dd1f89b55a4c94e8c701f16f0ffdc1d1a2
Summary:
Asterisks start emphases in rst. We should either escape them or put them as interpreted text.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22896
Differential Revision: D16282869
Pulled By: zou3519
fbshipit-source-id: 15ec4286434db55fb8357b1a12e6f70ef54f8c66
Summary:
The sccache wrapping strategy causes problems for at-runtime kernel
compilation of MIOpen kernels. We therefore - after the builds of
caffe2/pytorch are complete - unwrap sccache again by moving the clang-9
actual binary back into its original place.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22743
Differential Revision: D16283329
Pulled By: bddppq
fbshipit-source-id: 4fcdc92be295d5ea9aba75c30e39af1a18a80c13
Summary:
This is achieved by using `cuDevicePrimaryCtxGetState` as a way to check whether a primary context exists on a device. It is not too slow, from this benchmark of a single call to it on CUDA 10.1, Titan Xp, driver 415.27:
```
---------------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------------
BM_cuDevicePrimaryCtxGetState 301 ns 301 ns 2319746
```
Commits:
1. Add `CUDAHooks::getDeviceWithPrimaryContext` which returns a device index with primary context (if exists).
Link `c10/cuda` against `libcuda` for device API calls.
2. Use `getDeviceWithPrimaryContext` to check primary context in `pin_memory`.
Fix `OptionalDeviceGuard` doc.
3. Refactor `test_cuda_primary_ctx.py` to support multiple tests.
Add test for this in that file.
Fixes https://github.com/pytorch/pytorch/issues/21081.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22229
Differential Revision: D16170194
Pulled By: zou3519
fbshipit-source-id: 485a45f211b7844c9e69c63f3b3b75194a796c5d
Summary:
…te argument in macro
Changelog:
- Update note about tensors on CPU for the following MAGMA functions
- magma_(d/s)getrf_gpu and magma_getrf_nopiv_gpu require tensors on CPU for pivots
- magma_(d/s)geqrf2_gpu requires tensors on CPU for elementary reflectors
- magma_(d/s)syevd_gpu requires tensors on CPU for eigenvalues
- Remove dummy tensor in ALLOCATE_ARRAY MACRO
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22618
Test Plan:
- All existing tests should pass to verify that the patch is correct
This PR has been proposed to eliminate confusion due to the previous comments, as indicated in https://github.com/pytorch/pytorch/issues/22573
Differential Revision: D16227440
Pulled By: zou3519
fbshipit-source-id: 97d5537c5da98c0ed3edc4668a09294794fc426b
Summary:
…rides
Changelog:
- Fix behavior of `torch.triu` / `torch.tril` on certain unsqueezed tensors that lead to uninitialized values on CPU
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22730
Test Plan:
- Add tests for these cases in test_triu_tril in test_torch
Fixes https://github.com/pytorch/pytorch/issues/22581
Differential Revision: D16222897
Pulled By: zou3519
fbshipit-source-id: b86b060187797e5cd2a7731421dff1ba2b5c9596
Summary:
Align the behavior of `torch.utils.cpp_extension.CUDA_HOME` with that of `tools.setup_helpers.cuda.CUDA_HOME`.
Typically, I swapped the position of guess 2 and guess 3 in `torch.utils.cpp_extension.CUDA_HOME` .
Fixing issue https://github.com/pytorch/pytorch/issues/22844
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22845
Differential Revision: D16276241
Pulled By: zou3519
fbshipit-source-id: 3b62b439b2f794a6f3637a5fee58991f430985fe
Summary:
We introduced RTTI in recent change: https://github.com/pytorch/pytorch/pull/21613
For internal mobile build we don't enable '-frtti' yet. This diff is trying to replace
RTTI with alternative approach.
According to dzhulgakov we could compare two tensors' type_id directly in most cases -
which is more strict than comparing TensorImpl subclass type as TensorImpl -> type_id
mapping is 1-to-n but it's more proper for this use case.
The only two cases where we can relax direct type comparison (for legacy reason) are:
1. CPUTensor <-> CUDATensor;
2. SparseCPUTensor <-> SparseCUDATensor;
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22773
Differential Revision: D16277696
Pulled By: ljk53
fbshipit-source-id: 043e264fbacc37b7a11af2046983c70ddb62a599
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22892
Think of num_runs as manually run the binary <num_runs> times. Each run runs the operator for many iterations.
Reviewed By: hl475
Differential Revision: D16271597
fbshipit-source-id: b6f509ee0332c70f85bec0d447b84940c5c0cecd
Summary:
Since recursive script creates a ScriptModule from an `nn.Module`,
there's no ties to the original module to pull a type name from, so we
have to explicitly pass it in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22873
Pulled By: driazati
Differential Revision: D16268547
fbshipit-source-id: 902a30e6e36427c6ba7033ded027a29d9dcbc1ee
Summary:
Changelog:
- Port SVD TH implementation to ATen/native/BatchLinearAlgebra.cpp
- Port SVD THC implementation to ATen/native/cuda/BatchLinearAlgebra.cu
- Allow batches of matrices as arguments to `torch.svd`
- Remove existing implementations in TH and THC
- Update doc string
- Update derivatives to support batching
- Modify nuclear norm implementation to use at::svd instead of _batch_svd
- Remove _batch_svd as it is redundant
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21588
Test Plan:
- Add new test suite for SVD in test_torch.py with port to test_cuda.py
- Add tests in common_methods_invocations.py for derivative testing
Differential Revision: D16266115
Pulled By: nairbv
fbshipit-source-id: e89bb0dbd8f2d58bd758b7830d2389c477aa61fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22517
Force anybody creating an untyped Dict to call c10::impl::deprecatedUntypedDict().
This should hopefully make it clear that this is not public API and prevent people from using it.
Reviewed By: dzhulgakov
Differential Revision: D16115214
fbshipit-source-id: 2c8d0e4e375339c699d583995f79c05c59693c3e
Summary:
Introduce Azure Pipelines for the linting checks. This is meant to be equivalent to the existing Travis linting phase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22839
Differential Revision: D16260376
Pulled By: ezyang
fbshipit-source-id: 1e535c3096358be67a0dad4cd920a92082b2d18e
Summary:
As part of the Variable/Tensor merge, `variable.tensor_data()` should be removed in favor of `variable.detach()`. This PR removes `tensor_data()` call sites in Python `Variable()` and `nn.Parameter()` constructor paths.
Note that this PR is BC-breaking in the following way:
- For Python `Variable()` constructor:
Previously, in-place updating a tensor after it's been used to create a Variable does not bump the Variable's version counter, which causes the following problem:
```python
t = torch.ones(2, 3)
v = torch.autograd.Variable(t).requires_grad_()
y = v * v
t.add_(1) # This bumps version counter of `t`
y.sum().backward() # This computes `v`'s gradient incorrectly before this patch, and throws error after this patch
```
After this patch, in-place updating a tensor after it's been used to create a Variable will also bump the Variable's version counter, thus preserving the correctness of the Variable's version counter.
- For Python `nn.Parameter()` constructor:
Previously, in-place updating a tensor after it's been used to create an nn.Parameter does not bump the nn.Parameter's version counter, which causes the following problem:
```python
t = torch.ones(2, 3)
v = torch.nn.Parameter(t)
y = v * v
t.add_(1) # This bumps version counter of `t`
y.sum().backward() # This computes `v`'s gradient incorrectly before this patch, and throws error after this patch
```
After this patch, in-place updating a tensor after it's been used to create an nn.Parameter will also bump the nn.Parameter's version counter, thus preserving the correctness of the nn.Parameter's version counter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22821
Differential Revision: D16258030
Pulled By: yf225
fbshipit-source-id: 9a6d68cea1864893193dbefbb6ef0c1d5ca12d78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22829
Sending out caffe2 load op changes separately since we want pick it to open source.
This change is needed because the shape information of the blobs is determined from the load operator and that shape information is needed in our download_group.
Reviewed By: boryiingsu
Differential Revision: D16229465
fbshipit-source-id: f78b2df9a7f26968d70eca68dde75cd11ab6f7a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22323
This diff adds an interface to use quantized Linear op in JIT.
Reviewed By: jamesr66a
Differential Revision: D16040724
fbshipit-source-id: 90e90aff9973c96ea076ed6a21ae02c349ee2bcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22023
This diff implements Linear operation with fp16 weights based on FBGEMM. At a hight level, we want to perform the following operation:
Y = X * W + B with dtypes:
(fp32, fp32, fp16, fp32)
To do that, three steps are needed:
1. Quantize weights from fp32 to fp16, this is done using `PackedGemmMatrixFP16` in the `fbgemm_pack_gemm_matrix_fp16`
2. Conduct matrix multiplication with quantized weights using `cblas_gemm_compute` in `fbgemm_linear_fp16_weight`
3. Add bias to the result from step2 and return the final Y
Reviewed By: jianyuh
Differential Revision: D15921768
fbshipit-source-id: dc4e5b366f846ce9d58975876940a9b3372b8b8d
Summary:
Add support for breaks and continues in the jit. We do with a Graph transform pre-SSA.
A graph of the form
```
def test():
while i < 5:
if i == 3:
break
i += 1
print(i)
```
has the body of the loop transformed to
```
if i == 3:
did_break = True
else:
did_break = False
if did_break:
loop_exit = True
else:
i += 1
print(i)
loop_exit = i < 5
```
I am going to add more tests but I think it is ready for review now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21692
Differential Revision: D16215807
Pulled By: eellison
fbshipit-source-id: 365102f42de4861d9323caaeb39a96de7619a667
Summary:
This is an extension to the original PR https://github.com/pytorch/pytorch/pull/21765
1. Increase the coverage of different opsets support, comments, and blacklisting.
2. Adding backend tests for both caffe2 and onnxruntime on opset 7 and opset 8.
3. Reusing onnx model tests in caffe2 for onnxruntime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22421
Reviewed By: zrphercule
Differential Revision: D16225518
Pulled By: houseroad
fbshipit-source-id: 01ae3eed85111a83a0124e9e95512b80109d6aee
Summary:
Using PMCTest (https://www.agner.org/optimize/) to measure
TensorIterator construction, this results in ~600 fewer instructions
retired (~300 fewer cycles) for constructing TensorIterator on a 1D
tensor. (Should be roughly ~100 ns, but it's hard to measure that
precisely end-to-end).
```
Before:
Clock Core cyc Instruct Uops L1D Miss
5082 2768 5690 7644 3
After:
Clock Core cyc Instruct Uops L1D Miss
4518 2437 5109 6992 0
```
Note that Instruct is reliable, Core cyc is a little noisy, and Clock
is a little more noisy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22756
Differential Revision: D16207777
Pulled By: VitalyFedyunin
fbshipit-source-id: bcc453a90472d9951a1c123bcb1b7a243fde70ac
Summary:
Speeds up the common case where Tensor is a torch.Tensor (not a
subclass). This reduces the number of executed instructions for a
torch.add(tensor1, tensor2) by ~328 (should be ~65 ns faster).
Note that most of the PythonArgs accessors are too large to be inlined.
We should move most of them to the cpp file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22782
Differential Revision: D16223592
Pulled By: colesbury
fbshipit-source-id: cc20f8989944389d5a5e3fab033cdd70d581ffb1
Summary:
This PR aims at improving `topk()` performance on CPU. This is useful when computing **beam search** during `Transformer` and `BERT`.
Given a tensor x of size `[N, C]`, and we want to apply `x.topk(K)`, the current logic is **sequentially** loop on the dimension of `N` and do **quick select** on the dimension of `C` so as to find out top K elements.
Performance can be further improved from:
- On the dimension of `N`, it can be paralleled
- Maybe a faster sorting algorithm for `topk`. (After a bunch of experimenting, `std::partial_sort` seems to be the most promising)
So i compared 3 versions:
1. vanilla: sequential + quick select
2. reference PR https://github.com/pytorch/pytorch/issues/19737: parallel + quick select
3. this PR: parallel + partial sort
with the following benchmark, on `Xeon 8180, 2*28 cores@2.5 GHz`:
```python
import torch
from time import time
num_iters = 1000
def bench_topk(N=8, C=168560, k=10):
a = torch.randn(N, C)
# warm up
for i in range(100):
torch.topk(a, k)
t = 0
for i in range(num_iters):
a = torch.randn(N, C)
start = time()
value, indice = torch.topk(a, k)
t += time() - start
print("#[%d, %d] times: %f ms" % (N, C, t / num_iters * 1000))
Ns = [10, 20, 30]
Cs = [10000, 20000, 40000, 80000, 160000, 320000]
for n in Ns:
for c in Cs:
bench_topk(N=n, C=c)
```
### vanilla: sequential + quick select
```
#[10, 10000] times: 0.746740 ms
#[10, 20000] times: 1.437399 ms
#[10, 40000] times: 2.832455 ms
#[10, 80000] times: 5.649426 ms
#[10, 160000] times: 11.309466 ms
#[10, 320000] times: 22.798765 ms
#[20, 10000] times: 1.511303 ms
#[20, 20000] times: 2.822024 ms
#[20, 40000] times: 5.564770 ms
#[20, 80000] times: 11.443044 ms
#[20, 160000] times: 22.747731 ms
#[20, 320000] times: 46.234449 ms
#[30, 10000] times: 2.214045 ms
#[30, 20000] times: 4.236179 ms
#[30, 40000] times: 8.418577 ms
#[30, 80000] times: 17.067578 ms
#[30, 160000] times: 33.826214 ms
#[30, 320000] times: 68.109420 ms
```
### reference PR: parallel + quick select
```
#[10, 10000] times: 0.271649 ms
#[10, 20000] times: 0.593016 ms
#[10, 40000] times: 1.133518 ms
#[10, 80000] times: 2.082355 ms
#[10, 160000] times: 4.049928 ms
#[10, 320000] times: 7.321285 ms
#[20, 10000] times: 0.315255 ms
#[20, 20000] times: 0.539054 ms
#[20, 40000] times: 1.000675 ms
#[20, 80000] times: 1.914586 ms
#[20, 160000] times: 4.437122 ms
#[20, 320000] times: 8.822445 ms
#[30, 10000] times: 0.347209 ms
#[30, 20000] times: 0.589947 ms
#[30, 40000] times: 1.102814 ms
#[30, 80000] times: 2.112201 ms
#[30, 160000] times: 5.186837 ms
#[30, 320000] times: 10.523023 ms
```
### this PR: parallel + partial sort
```
#[10, 10000] times: 0.150284 ms
#[10, 20000] times: 0.220089 ms
#[10, 40000] times: 0.521875 ms
#[10, 80000] times: 0.965593 ms
#[10, 160000] times: 2.312356 ms
#[10, 320000] times: 4.759422 ms
#[20, 10000] times: 0.167630 ms
#[20, 20000] times: 0.265607 ms
#[20, 40000] times: 0.471477 ms
#[20, 80000] times: 0.974572 ms
#[20, 160000] times: 3.269645 ms
#[20, 320000] times: 6.538608 ms
#[30, 10000] times: 0.204976 ms
#[30, 20000] times: 0.342833 ms
#[30, 40000] times: 0.589381 ms
#[30, 80000] times: 1.398579 ms
#[30, 160000] times: 3.904077 ms
#[30, 320000] times: 9.681224 ms
```
In summary, `2` is **5x** faster than `vanilla` on average and `3` is **8.6x** faster than `vanilla`.
On `Fairseq Transformer`, the default parameter on dataset `wmt14` would have a `topk` size of `[8, 168560]`, and this operator gets `3x` faster with this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19736
Differential Revision: D16204820
Pulled By: VitalyFedyunin
fbshipit-source-id: ea70562c9149a0d832cf5872a891042ebd74fc63
Summary:
For three 1-D operands, compute_strides now takes 298 instructions instead
of 480. (Saves ~36 ns). We'll want to make Tensor::sizes(), strides(), and
element_size() trivially inlinable to speed this up more.
(Using PMCTest from https://www.agner.org/optimize/ to measure instructions retired)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22779
Differential Revision: D16223595
Pulled By: colesbury
fbshipit-source-id: e4730755f29a0aea9cbc82c2d376a8e6a0c7bce8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22781
The custom op is required to make the op benchmark work with JIT. Running this command `python setup.py install` in the pt_extension directory to install it. It is required.
Reviewed By: hl475
Differential Revision: D16214430
fbshipit-source-id: c9221c532011f9cf0d5453ac8535a6cde65e8376
Summary:
Currently ONNX constant folding (`do_constant_folding=True` arg in `torch.onnx.export` API) supports only opset 9 of ONNX. For opset 10, it is a no-op. This change enables ONNX constant folding for opset 10. Specifically there are three main changes:
1) Turn on constant folding ONNX pass for opset 10.
2) Update support for opset 10 version of `onnx::Slice` op for backend computation during constant folding.
3) Enable constant folding tests in `test/onnx/test_utility_funs.py` for multiple opsets (9 and 10).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22515
Reviewed By: zrphercule
Differential Revision: D16189336
Pulled By: houseroad
fbshipit-source-id: 3e2e748a06e4228b69a18c5458ca71491bd13875
Summary:
1. update on restricting block.z <= 64, compliant to CUDA maximum z-dimension of
a block;
2. clang-format
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22602
Differential Revision: D16203857
Pulled By: ezyang
fbshipit-source-id: 567719ae175681a48eb0f818ca0aba409dca2550
Summary:
Some other environment variables can be added to speed things up for development.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22736
Differential Revision: D16200904
Pulled By: soumith
fbshipit-source-id: 797ef91a863a244a6c96e0adf64d9f9b4c9a9582
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22706
Moved the models used for quantization test from the test_quantization.py file to common_quantization.py
Reviewed By: jerryzh168
Differential Revision: D16189865
fbshipit-source-id: 409b43454b6b3fe278ac16b1affb9085d6ed6835
Summary:
Previously in tracing when we called a script function we would inline the graph and set the graph inputs equal to the types the graph was invoked with.
This breaks for optional arguments invoked with None since we rely on None being set to Optional[T] in schema matching.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22686
Differential Revision: D16186372
Pulled By: eellison
fbshipit-source-id: e25c807c63527bf442eb8b31122d50689c7822f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22694
Move quantization and quantized utility functions for testing to common_quantized.py and common_quantization.py. Addditionally, add a quantized test case base class which contains common methods for checking the results of quantization on modules. As a consequence of the move, fixed the import at the top of test_quantized.py, and test_quantization to use the new utility
Reviewed By: jerryzh168
Differential Revision: D16172012
fbshipit-source-id: 329166af5555fc829f26bf1383d682c25c01a7d9
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/22631
Test Plan:
test suite
Imported from OSS
Differential Revision: D16185040
fbshipit-source-id: 9b83749f6c9cd05d13f54a3bb4801e263293252b
Summary:
After converting BN layers to SyncBN layers, the function will set all `requires_grad = True` regardless of the original requires_grad states. I think it is a bug and have fixed it in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22569
Differential Revision: D16151647
Pulled By: zou3519
fbshipit-source-id: e2ad1886c94d8882485e7fb8be51ad76469ecc67
Summary:
Addressing potential dependency issue by adding forward declaration for OutputArchive/InputArchive.
This change follows the same pattern in base.h in 'torch/csrc/api/include/torch/data/samplers/base.h'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22562
Differential Revision: D16161524
Pulled By: soumith
fbshipit-source-id: d03f8a2ece5629762f9fa8a27b15b0d037e8f07b
Summary:
Also revert the change of cmake.py in
c97829d7011bd59d662f6af9c3a0ec302e7e75fc . The comments are added to
prevent future similar incidents in the future (which has occurred a couple of times in the past).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22641
Differential Revision: D16171763
Pulled By: ezyang
fbshipit-source-id: 5a65f9fbb3c1c798ebd25521932bfde0ad3d16fc
Summary:
No need to `clone` if the expanded size matches original size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22634
Differential Revision: D16171091
Pulled By: ezyang
fbshipit-source-id: 3d8f116398f02952488e321c0ee0ff2868768a0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21209
This diff introduces a new interface to add a list of operators. Here are the steps to add ops using this interface:
- create op_list:
```unary_ops_list = op_bench.op_list(
attr_names=["op_name", "op_function"],
attrs=[
["abs", torch.abs],
["abs_", torch.abs_],
],
)
```
- create a bench class:
```
class UnaryOpBenchmark(op_bench.TorchBenchmarkBase):
def init(self, M, N, op_function):
self.input_one = torch.rand(M, N)
self.op_func = op_function
def forward(self):
return self.op_func(self.input_one)
```
- 3. register those ops
``` op_bench.generate_pt_tests_from_list(unary_ops_list, unary_ops_configs, UnaryOpBenchmark)
```
Reviewed By: zheng-xq
Differential Revision: D15514188
fbshipit-source-id: f09b359cab8175eeb8d51b3ad7bbbcfbc9f6430f
Summary:
The error for `test_error_stack_module`:
```
Traceback (most recent call last):
File "../test.py", line 35, in <module>
scripted = torch.jit.script(M())
File "/home/davidriazati/other/pytorch/torch/jit/__init__.py", line 1119, in script
return _convert_to_script_module(obj)
File "/home/davidriazati/other/pytorch/torch/jit/__init__.py", line 1825, in _convert_to_script_module
raise e
RuntimeError:
d(int x) -> int:
Expected a value of type 'int' for argument 'x' but instead found type 'str'.
:
at ../test.py:11:12
def c(x):
return d("hello") + d(x)
~ <--- HERE
'c' is being compiled since it was called from 'b'
at ../test.py:14:12
def b(x):
return c(x)
~~~ <--- HERE
'b' is being compiled since it was called from 'forward'
at ../test.py:22:16
def forward(self, x):
return b(x)
~~~ <--- HERE
'forward' is being compiled since it was called from 'forward'
at ../test.py:31:20
def forward(self, x):
return x + self.submodule(x)
~~~~~~~~~~~~~~~~ <--- HERE
```
This also unifies our error reporting in the front end with `ErrorReport`
TODO
* Include module names in message, #22207 should make this easy
](https://our.intern.facebook.com/intern/diff/16060781/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22280
Pulled By: driazati
Differential Revision: D16060781
fbshipit-source-id: c42968b53aaddb774ac69d5abbf7e60c23df8eed
Summary:
Some of my qpth users have told me that updating to the latest version of PyTorch and replacing the btrifact/btrisolve calls with the LU ones wasn't working and I didn't believe them until I tried it myself :)
These updates have broken unpivoted LU factorizations/solves on CUDA. The LU factorization code used to return the identity permutation when pivoting wasn't used but now returns all zeros as the pivots. This PR reverts it back to return the identity permutation. I've not yet tested this code as I'm having some trouble compiling PyTorch with this and am hitting https://github.com/pytorch/pytorch/issues/21700 and am not sure how to disable that option.
Here's a MWE to reproduce the broken behavior, and my fix.
```python
torch.manual_seed(0)
n = 4
L = torch.randn(n,n)
A = L.mm(L.t()).unsqueeze(0)
b = torch.randn(1, n)
A_lu_cpu = torch.lu(A)
A_lu_cuda_nopivot = torch.lu(A.cuda(), pivot=False)
A_lu_cuda_pivot = torch.lu(A.cuda(), pivot=True)
print('A_lu_cuda_nopivot\n', A_lu_cuda_nopivot)
print('-----\nA_lu_cuda_pivot\n', A_lu_cuda_nopivot)
x_cpu = b.lu_solve(*A_lu_cpu)
x_cuda_nopivot = b.cuda().lu_solve(*A_lu_cuda_nopivot)
x_cuda_nopivot_fixed = b.cuda().lu_solve(
A_lu_cuda_nopivot[0], torch.arange(1, n+1, device='cuda:0').int())
x_cuda_pivot = b.cuda().lu_solve(*A_lu_cuda_pivot)
print(x_cpu, x_cuda_nopivot, x_cuda_nopivot_fixed, x_cuda_pivot)
```
Output:
```
A_lu_cuda_nopivot
(tensor([[[ 2.8465, -0.7560, 0.8716, -1.7337],
[-0.2656, 5.5724, -1.1316, 0.6678],
[ 0.3062, -0.2031, 1.4206, -0.5438],
[-0.6091, 0.1198, -0.3828, 1.5103]]], device='cuda:0'), tensor([[0, 0, 0, 0]], device='cuda:0', dtype=torch.int32))
-----
A_lu_cuda_pivot
(tensor([[[ 2.8465, -0.7560, 0.8716, -1.7337],
[-0.2656, 5.5724, -1.1316, 0.6678],
[ 0.3062, -0.2031, 1.4206, -0.5438],
[-0.6091, 0.1198, -0.3828, 1.5103]]], device='cuda:0'), tensor([[0, 0, 0, 0]], device='cuda:0', dtype=torch.int32))
(tensor([[-0.3121, -0.1673, -0.4450, -0.2483]]),
tensor([[-0.1661, -0.1875, -0.5694, -0.4772]], device='cuda:0'),
tensor([[-0.3121, -0.1673, -0.4450, -0.2483]], device='cuda:0'),
tensor([[-0.3121, -0.1673, -0.4450, -0.2483]], device='cuda:0'))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22242
Differential Revision: D16049334
Pulled By: ezyang
fbshipit-source-id: 7eacae810d87ffbdf8e07159bbbc03866dd9979d
Summary:
This PR activates faster depthwise convolution kernels for Volta and Turing GPUs using cudnn >= 7600.
The script to benchmark the current PyTorch master branch and this PR branch can be found [here](https://gist.github.com/ptrblck/4590cf20721d8f43296c9903abd4a774).
(50 warmup iterations, 1000 iterations for timing)
I've used https://github.com/pytorch/pytorch/issues/3265 to create a similar benchmark and added a few additional setups.
Since the results are quite long, I've uploaded them in a spreadsheet [here](https://docs.google.com/spreadsheets/d/13ByXcqg7LQUr3DVG3XpLwnJ-CXg3GUZJ3puyTMw9n2I/edit?usp=sharing).
Times are given in ms per iteration.
We've benchmarked this PR on a DGX1 using V100 GPUs.
The current workload check in `check_cudnn_depthwise_workload` is quite long and can be moved to another file, if wanted.
CC ngimel (Thanks for the support while benchmarking it ;) )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22302
Differential Revision: D16115057
Pulled By: ezyang
fbshipit-source-id: bad184658518e73b4d6b849d77e408f5a7a757de
Summary:
Having the NVRTC stub in ATen is necessary to call driver APIs in ATen. This is currently blocking https://github.com/pytorch/pytorch/pull/22229.
`DynamicLibrary` is also moved as it is used in the stub code, and seems general enough.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22362
Differential Revision: D16131787
Pulled By: ezyang
fbshipit-source-id: add2ee8a8865229578aa00001a00d5a6671e0e73
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
MEDIUM: 488
LARGE: 29
XXLARGE: 2
Updated actions:
From MEDIUM to LARGE: 227
From XLARGE to MEDIUM: 1
From XLARGE to LARGE: 1
From XLARGE to XXLARGE: 1
From LARGE to MEDIUM: 2
From LARGE to XLARGE: 2
Differential Revision: D16161669
fbshipit-source-id: 67a4e0d883ca3f1ca3185a8285903c0961537757
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22143
Like Conv DNNLOWP operator, allow FC to run the slow path to debug numerical issues caused by Intel's int8 instruction that does horizontal addition of 2 int8 multiplication results in 16 bit
Reviewed By: hx89
Differential Revision: D15966885
fbshipit-source-id: c6726376a3e39d341fd8aeb0e54e0450d2af8920
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22174
This is a preliminary change outlining the approach we plan to follow to integrate QNNPACK operators into the pytorch backend. The operators will not be made visible to the user in the python world, so ultimately we will have a function that calls qnnpack backend based on the environment being run on.
The goal of the project is to integrate QNNPACK library with PyTorch to achieve good performance for quantized mobile models.
Reviewed By: ljk53
Differential Revision: D15806325
fbshipit-source-id: c14e1d864ac94570333a7b14031ea231d095c2ae
Summary:
Some duplicated code is removed. It also becomes clear that there is only one special case `div_kernel_cuda` is handling.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22555
Differential Revision: D16152091
Pulled By: zou3519
fbshipit-source-id: bb875370077c1f84efe4b766b3e1acc461e73e6c
Summary:
Fix a grammatical error of the comment in line 233.
change from " Returns an `OrderedDict` of he submodules of this `Module`"
to " Returns an `OrderedDict` of the submodules of this `Module`"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22548
Differential Revision: D16134534
Pulled By: zou3519
fbshipit-source-id: 33b1dd0fbc3a24bef99b6e0192566e2839292842
Summary:
As part of the Variable/Tensor merge, we want to be able to pass Variables into Caffe2 without doing extra shallow copy, to improve performance and also allow for in-place mutations in Caffe2 ops. There are a few approaches outlined in https://github.com/pytorch/pytorch/pull/22418, and this PR is the chosen approach.
Specifically, we can have the assumption that we won't be connecting autograd to C2 gradients at any point (as it's too tricky and not that useful). Therefore, we can pass Variable into Caffe2 ops by requiring that all Variables in Caffe2 don't require grad. For code paths in Caffe2 that might potentially track gradients (e.g. `ScriptModuleOp` and `call_caffe2_op_from_c10`), we use the `torch::NoGradGuard` to make sure gradients are not tracked.
This supersedes https://github.com/pytorch/pytorch/pull/22418.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22473
Differential Revision: D16099042
Pulled By: yf225
fbshipit-source-id: 57efc3c7cfb3048d9abe90e63759acc14ebd2972
Summary:
Forgot to mirror the `nn/ __init__.py` semantics in the new `nn` type stub.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22411
Differential Revision: D16149798
Pulled By: ezyang
fbshipit-source-id: 0ffa256fbdc5e5383a7b9c9c3ae61acd11de1dba
Summary:
`addcmul_out` overwrote the samples, which led to constant values being output by `torch.normal`.
Changelog:
- Replace the `addcmul_out` calls with combo of inplace `mul` and `add` and justification for this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22533
Test Plan:
- Enable tests for test_normal on all devices
Fixes https://github.com/pytorch/pytorch/issues/22529
Differential Revision: D16141337
Pulled By: ezyang
fbshipit-source-id: 567a399042e0adcd154582f362318ce95a244c62
Summary:
Currently specifying different build options in respect to the "USE_"
series is in quite a disarray. There are a lot of build options that
accept three variants: USE_OPTION, WITH_OPTION, and NO_OPTION. Some
build options only accept USE_ and NO_ variant. Some accept only USE_.
This inconsistency is quite confusing and hard to maintain.
To resolve this inconsistency, we can either let all these build options
support all three variants, or we only support the USE_ variant.
This commit makes a step to the latter choice, i.e., deprecates and sets
a date for removing the NO_ and WITH_ variants and keeps only the
USE_ variant. This is likely better than the former solution because:
- NO_ and WITH_ variants are not documented.
- CMakeLists.txt only has the USE_ variants for relevant build options
defined. It would be a surprise that when user pass these variables to
CMake during rebuild and find them ineffective.
- Multiple variants are difficult to maintain.
- The behavior is confusing if more than one variant is passed. For
example, what to be expected if one sets "NO_CUDA=1 USE_CUDA=1"?
The downside is that this will break backward compatibility for existing
build scripts in the future (if they used the undocumented build
options).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22474
Differential Revision: D16149396
Pulled By: ezyang
fbshipit-source-id: 7145b88ad195db2051772b9665dd708dfcf50b7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22477
There is actually no use of uninitialized variable but some compilers are not smart enough to reason about two if branches are already taken together.
Reviewed By: hx89
Differential Revision: D16100211
fbshipit-source-id: 25f01d668063603d7aaa776451afe8a10415d2ea
Summary:
After the Variable/Tensor merge, code paths in ATen need to be able to check whether a tensor requires gradient, and throw errors in places where a `requires_grad=true` tensor is not allowed (such as https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/Utils.h#L76-L78 and https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/SparseTensorImpl.cpp#L86). Since the `GradMode` thread-local variable controls whether a tensor should accumulate gradients, we need to be able to check this variable from ATen when we determine whether a tensor requires gradient, hence the PR to move `GradMode` / `AutoGradMode` / `NoGradGuard` to ATen.
Note that we intentionally don't merge `at::GradMode` and `at::NonVariableTypeMode`, with the following reasoning:
Semantically, `at::GradMode` and `at::NonVariableTypeMode` actually mean different things: `at::GradMode` controls whether a tensor should accumulate gradients, and `at::NonVariableTypeMode` controls whether a Variable should be treated as a non-Variable tensor in type dispatches. There are places whether we *don't* want the tensor to accumulate gradients, but *still* want the Variable to be treated as a Variable. Here is one example:
```python
# torch/tensor.py
with torch.no_grad():
...
new_tensor = self.new() # `at::GradMode` is false at this point
...
```
```cpp
// tools/autograd/templates/python_variable_methods.cpp
static PyObject * THPVariable_new(PyObject* self, PyObject* args, PyObject* kwargs)
{
...
// if we merge `at::GradMode` and `at::NonVariableTypeMode`, since `at::GradMode` is false and `self_.type()` checks `at::GradMode` to decide whether to return non-Variable type, it will return a non-Variable type here, which is not what we want (and throws a "Tensor that was converted to Variable was not actually a Variable" error)
return THPVariable_Wrap(torch::utils::legacy_tensor_new(self_.type(), args, kwargs));
...
}
```
For the above reason, we cannot merge `at::GradMode` and `at::NonVariableTypeMode`, as they have different purposes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18573
Differential Revision: D16134413
Pulled By: yf225
fbshipit-source-id: 6140347e78bc54206506499c264818eb693cdb8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22479
In some cases, for example, when we training on CTR data, we would like to start training from old samples and finish on new recent samples.
This diff add the option to disable the shuffling in DistributedSampler to accommodate this use case.
Reviewed By: soumith
Differential Revision: D16100388
fbshipit-source-id: 35566581f5250040b2db5ec408a63037b47a9f5d
Summary:
Replaces https://github.com/pytorch/pytorch/pull/21501 because ghimport had errors when i tried to import the stack that i couldn't figure out :'(
has the two commits that were previously accepted and the merge commit
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22561
Differential Revision: D16135743
Pulled By: eellison
fbshipit-source-id: f0a98842ccb334c7ceab04d1437e09dc76be0eb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22516
Force anybody creating an untyped Dict to call c10::impl::deprecatedUntypedDict().
This should hopefully make it clear that this is not public API and prevent people from using it.
Differential Revision: D16115215
fbshipit-source-id: 2ef4cb443da1cdf4ebf5b99851f69de0be730b97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22005
When a Dict or List is created with type information, it will remember that.
If at any point later, this list is instantiated to a List<T> with a concrete type, it will assert that T is the correct type.
Differential Revision: D15914462
fbshipit-source-id: a8c3d91cb6d28d0c1ac0b57a4c4c6ac137153ff7
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/22551
Test Plan:
ran test locally
Imported from OSS
Differential Revision: D16132182
fbshipit-source-id: 5b9efbf883efa66c4d8b7c400bdb804ac668a631
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22510
Added a new function to implement clone operation on quantized tensors. Also added a test case which can be tested as shown in test plan.
This change is required to be able to call torch.jit.trace on quantized models.
Clone implementation calls copy_ on QTensor internally.
Differential Revision: D16059576
fbshipit-source-id: 226918cd475521b664ed72ee336a3da8212ddcdc
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/22397
Test Plan:
Added test for reentrant backwards with checkpoint and a test for a recursive backwards function (which should fail if we run all the reentrant tasks recursively in the same thread) and for testing priority of reentrant tasks.
~~Will add a test for priority of reentrant tasks in future pr.~~
Imported from OSS
Differential Revision: D16131955
fbshipit-source-id: 18301d45c1ec9fbeb566b1016dbaf7a84a09c7ac
Summary:
Currently, the **stream** parameter is not set when launching these two kernels: softmax_warp_forward() and softmax_warp_backward(), i.e. the kernels are always put on the default stream, which may fail to respect the stream that was set previously. Add **at::cuda::getCurrentCUDAStream()** as a launch argument to fix this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22470
Differential Revision: D16115051
Pulled By: izdeby
fbshipit-source-id: 38b27e768bb5fcecc1a06143ab5d63b0e68a279e
Summary:
re-apply changes reverted in:
https://github.com/pytorch/pytorch/pull/22412
Also change log_softmax to take positional arguments. Long-term we do want the kwarg-only interface, but seems to currently be incompatible with jit serialization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22456
Differential Revision: D16097159
Pulled By: nairbv
fbshipit-source-id: 8cb73e9ca18fc66b35b873cf4a574b167a578b3d
Summary:
* Deletes all weak script decorators / associated data structures / methods
* In order to keep supporting the standard library in script, this enables recursive script on any function defined in `torch.nn`
* Most changes in `torch/nn` are the result of `ag -Q "weak" torch/nn/ -l | xargs sed -i '/weak/d'`, only `rnn.py` needed manual editing to use the `ignore` and `export` to continue supporting the overloaded `forward` methods
* `Sequential`/`ModuleList` no longer need to be added to constants since they are compiled on demand
This should also fix https://github.com/pytorch/pytorch/issues/22212
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22212
Differential Revision: D15988346
Pulled By: driazati
fbshipit-source-id: af223e3ad0580be895377312949997a70e988e4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22309
This diff enables PT operators to run with JIT mode. Users can control eager and JIT mode using the `use_jit` flag.
In this diff, we are putting operators in a loop and passed it to JIT. One extra step which wraps the operator with the `_consume` op is introduced to avoid dead code elimination optimization in JIT. With that, the reported time includes the real operator execution time plus the `_consume` (directly return input, nothing else if happening inside) op.
Reviewed By: zheng-xq
Differential Revision: D16033082
fbshipit-source-id: e03be89fd5a505e44e81015dfc63db9cd76fb8a1
Summary:
- Fix typo in ```torch/onnx/utils.py``` when looking up registered custom ops.
- Add a simple test case
1. Register custom op with ```TorchScript``` using ```cpp_extension.load_inline```.
2. Register custom op with ```torch.onnx.symbolic``` using ```register_custom_op_symbolic```.
3. Export model with custom op, and verify with Caffe2 backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21321
Differential Revision: D16101097
Pulled By: houseroad
fbshipit-source-id: 084f8b55e230e1cb6e9bd7bd52d7946cefda8e33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21432
This diff introduce a new interface to generate tests based on the metadata of operators.
Reviewed By: ajauhri
Differential Revision: D15675542
fbshipit-source-id: ba60e803ea553d8b9eb6cb2bcdc6a0368ef62b1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22499
Another place where onnx export is running dead code elimination after making the jit graph invalid. Fixing it.
Reviewed By: houseroad
Differential Revision: D16111969
fbshipit-source-id: 5ba80340c06d091988858077f142ea4e3da0638c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22348
This is the last step of LRU hash eviction weight re-init. This diff checks if there's evicted values in sparse_lookup, if so call op created in D15709866 to re-init the values for indicies in evicted_values. Also created gradient op for the operator. The gradient op just passes the output gradient as input gradient.
Reviewed By: itomatik
Differential Revision: D16044736
fbshipit-source-id: 9afb85209b0de1038c5153bcb7dfc5f52e0b2abb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22476
Dead code elimination assumes a valid jit graph because it checks if operators have side effects.
The onnx export path destroys the jit graph right before calling dead code elimination, but it actually doesn't care about side effects.
We can just call dead code elimination and disable side effect lookup and things should work.
Reviewed By: houseroad
Differential Revision: D16100172
fbshipit-source-id: 8c790055e0d76c4227394cafa93b07d1310f2cea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22441
This include doesn't seem to be needed. Remove it to simplify mobile build dependency.
Reviewed By: dreiss
Differential Revision: D16088224
fbshipit-source-id: f6aec21655e259726412e26a006d785912436c2a
Summary:
This has been requested in https://github.com/pytorch/pytorch/issues/20323
(It is still not exactly the same as NumPy, which allows you to pass tensors at mean/std and broadcast them with size, but the present PR is extremely simple and does the main thing people are asking for)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20545
Differential Revision: D15358736
Pulled By: zhangguanheng66
fbshipit-source-id: 762ea5eab5b8667afbac2df0137df017ba6e413c
Summary:
The changes include:
1. Allow key/value to have different number of features with query. It supports the case when key and value have different feature dimensions.
2. Support three separate proj_weight, in addition to a single in_proj_weight. The proj_weight of key and value may have different dimension with that of query so three separate proj_weights are necessary. In case that key and value have same dimension as query, it is preferred to use a single large proj_weight for performance reason. However, it should be noted that using a single large weight or three separate weights is a size-dependent decision.
3. Give an option to use static k and v in the multihead_attn operator (see saved_k and saved_v). Those static key/value tensors can now be re-used when training the model.
4. Add more test cases to cover the arguments.
Note: current users should not be affected by the changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21288
Differential Revision: D15738808
Pulled By: zhangguanheng66
fbshipit-source-id: 288b995787ad55fba374184b3d15b5c6fe9abb5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21927
Add `OUTPUT_PROB` output to CTCBeamSearchDecoderOp to return a probability for each sequence.
Add argument to output top-k instead of top-1 decoded sequences.
Reviewed By: SuperIRabbit
Differential Revision: D15797371
fbshipit-source-id: 737ca5cc4f90a0bcc3660ac9f58519a175977b69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22461
We shouldn't call dead code elimination after EraseNumberTypes because dead code elimination assumes a valid jit graph which EraseNumberTypes just broke.
Let's have it clean up itself isntead.
Reviewed By: houseroad
Differential Revision: D16094656
fbshipit-source-id: f2752277d764e78ab276c57d56b2724b872b136f
Summary:
It's always set to equal USE_NCCL, we made Gloo depending on Caffe2 NCCL
build. See 30da84fbe1614138d6d9968c1475cb7dc459cd4b
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22467
Differential Revision: D16098581
Pulled By: ezyang
fbshipit-source-id: f706ec7cebc2e6315bafca013b669f5a72e04815
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22279
This new operator is used for embedding table weight re-init. After we get the evicted indices, they will be the rows need reseting in embedding table. Then we can create a 1d tensor with default values, and apply this operator to copy the tensor to all evicted rows in embedding table
Will add gradient op in next diff
Reviewed By: itomatik
Differential Revision: D15709866
fbshipit-source-id: 2297b70a7326591524d0be09c73a588da245cc08
Summary:
The sgemm in cuBLAS 9.0 has some issues with sizes above 2M on Maxwell and Pascal architectures. Warn in this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22034
Differential Revision: D15949930
Pulled By: zhangguanheng66
fbshipit-source-id: 0af977ec7900c76328d23898071de9c23778ff8b
Summary:
ROCm is already detected in cmake/public/LoadHIP.cmake. No need to
detect twice. Plus, the Python script read environment variable
ROCM_HOME, but what is really used in CMake scripts is ROCM_PATH -- A
user must specify both environment variables right. Since ROCM_HOME is
undocumented, this commit completely eradicates it.
---
ezyang A remake of https://github.com/pytorch/pytorch/issues/22228 because its dependency has been dismissed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22464
Differential Revision: D16096833
Pulled By: bddppq
fbshipit-source-id: fea461e80ee61ec77fa3a7b476f7aec4fc453d5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22425
Currently, in bound_shape_inference.cc: InferBoundShapeAndType, we firstly infer ops in the order and then infer inputs of concat in reverse order. In ctr_instagram_model tiny version, concat is right before FC, so we can infer the inputs for concat. But in production version, we found there are some ops between concat and FC(or other ops we know the shape), so the shape of these ops cannot be inferred.
This diff is a tmp solution for this problem: infer shape in order and in reverse order repeatly until no more change.
Reviewed By: yinghai, ipiszy
Differential Revision: D16082521
fbshipit-source-id: d5066509368029c6736dce156030adf5c38653d7
Summary:
MKL-DNN is the main library for computation when we use ideep device. It can use kernels implemented by different algorithms (including JIT, CBLAS, etc.) for computation. We add the "USE_MKLDNN_CBLAS" (default OFF) build option so that users can decide whether to use CBLAS computation methods or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19014
Differential Revision: D16094090
Pulled By: ezyang
fbshipit-source-id: 3f0b1d1a59a327ea0d1456e2752f2edd78d96ccc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22004
In future, we want all dicts/lists to store information about the types they contain.
This is only possible if the creation API doesn't allow creating lists/dicts without type information.
This diff removes some call sites that don't specify type information and have it specify type information.
Reviewed By: dzhulgakov
Differential Revision: D15906387
fbshipit-source-id: 64766a2534b52c221e8a5501a85eaad13812e7bd
Summary:
Currently the build system accepts USE_NAMEDTENSOR from the environment
variable and turns it into NAMEDTENSOR_ENABLED when passing to CMake.
This discrepancy does not seem necessary and complicates the build
system. The naming of this build option is also semantically incorrect
("BUILD_" vis-a-vis "USE_"). This commit eradicate this issue before it
is made into a stable release.
The support of NO_NAMEDTENSOR is also removed, since PyTorch has been
quite inconsistent about "NO_*" build options.
---
Note: All environment variables with their names starting with `BUILD_` are currently automatically passed to CMake with no need of an additional wrapper.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22360
Differential Revision: D16074509
Pulled By: zou3519
fbshipit-source-id: dc316287e26192118f3c99b945454bc50535b2ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21389
As titled. To do weight re-init on evicted rows in embedding table, we need to pass the info of the evicted hashed values to SparseLookup, which is the layer model responsible for constructing the embedding table and do pooling.
To pass evicted values, we need to adjust the output record of lru_sparse_hash to include the evicted values, and add optional input to all processors that needs to take in sparse segment. For SparseLookup to get the evicted values, its input record needs to be adjusted. Now the input record can have type IdList/IdScoreList/or a struct of feature + evicted values
Reviewed By: itomatik
Differential Revision: D15590307
fbshipit-source-id: e493881909830d5ca5806a743a2a713198c100c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22241
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20387
glibc has a non-standard function, feenableexcept, that triggers floating-point exception handler . Compared to feclearexcept + fetestexcept , this approach allows us to see precisely where the exception is raised from the stack trace.
Reviewed By: jspark1105
Differential Revision: D15301095
fbshipit-source-id: 94f6e72456b2280f78d7d01c2ee069ae46d609bb
Summary:
empty_like uses the tensor options of `self`, rather than the passed in tensor options. This means it messes up variable/tensor types, and ignores specifications like different dtypes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21978
Differential Revision: D15903948
Pulled By: gchanan
fbshipit-source-id: f29946be01c543f888daef2e99fe928e7b7d9d74
Summary:
# What is this?
This is an implementation of the AdamW optimizer as implemented in [the fastai library](803894051b/fastai/callback.py) and as initially introduced in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101). It decouples the weight decay regularization step from the optimization step during training.
There have already been several abortive attempts to push this into pytorch in some form or fashion: https://github.com/pytorch/pytorch/pull/17468, https://github.com/pytorch/pytorch/pull/10866, https://github.com/pytorch/pytorch/pull/3740, https://github.com/pytorch/pytorch/pull/4429. Hopefully this one goes through.
# Why is this important?
Via a simple reparameterization, it can be shown that L2 regularization has a weight decay effect in the case of SGD optimization. Because of this, L2 regularization became synonymous with the concept of weight decay. However, it can be shown that the equivalence of L2 regularization and weight decay breaks down for more complex adaptive optimization schemes. It was shown in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101) that this is the reason why models trained with SGD achieve better generalization than those trained with Adam. Weight decay is a very effective regularizer. L2 regularization, in and of itself, is much less effective. By explicitly decaying the weights, we can achieve state-of-the-art results while also taking advantage of the quick convergence properties that adaptive optimization schemes have.
# How was this tested?
There were test cases added to `test_optim.py` and I also ran a [little experiment](https://gist.github.com/mjacar/0c9809b96513daff84fe3d9938f08638) to validate that this implementation is equivalent to the fastai implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21250
Differential Revision: D16060339
Pulled By: vincentqb
fbshipit-source-id: ded7cc9cfd3fde81f655b9ffb3e3d6b3543a4709
Summary:
Address the issue raised in https://github.com/pytorch/pytorch/issues/22377.
The PR https://github.com/pytorch/pytorch/issues/22016 introduces a temporary tensor of weights `grad_weight_per_segment` of the same dtype as the end result, which can be a problem when using `float16`.
In this PR, it now use a `float32` temporary tensor when the input is `float16`.
ngimel, can I get you to review? I think I have fixed the issues you have pointed out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22401
Differential Revision: D16077319
Pulled By: mrshenli
fbshipit-source-id: 7cfad7f40b4d41a244052baa2982ab51bbbd7309
Summary:
The CMake modifications include removal of some unnecessary paths
(e.g. find_package(CUDA) and friends) that are no longer used since
c10d is always part of the larger torch build. The macro
`C10D_USE_...` was ambiguous and is now removed in favor of only
having top level `USE_...`. The c10d test suite is changed to include
skip annotations for the tests that depend on Gloo as well.
Now, if you compile with `USE_DISTRIBUTED=1` and `USE_GLOO=0` you get
a functioning build for which the tests actually pass.
Closes https://github.com/pytorch/pytorch/issues/18851.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22257
Differential Revision: D16087993
Pulled By: pietern
fbshipit-source-id: 0cea66bd5cbd9736b06fa1d45ee13a18cab88adb
Summary:
The `assert False` lint error has been causing CI to fail:
./torch/utils/throughput_benchmark.py:14:13: B011 Do not call assert False since python -O removes these calls. Instead callers should raise AssertionError().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22424
Differential Revision: D16083464
Pulled By: bddppq
fbshipit-source-id: 6d96e36c8fcbb391d071b75fe79c22d526c1ba3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22429
Android NDK r20 removes the guard `(__ANDROID_API__ <= __ANDROID_API_O_MR1__)`, so we do it here also. There is insufficient reason to keep these decls undefined for earlier API levels. NDK r15 and earlier don't even define `__ANDROID_API_O_MR1__`, so the preprocessor defaults it to 0 and the guard evaluates as TRUE.
Reviewed By: smeenai, hlu1
Differential Revision: D16084105
fbshipit-source-id: f0857b3eb0573fe219f0d6c5e6583f89e2b5518f
Summary:
This change adds one advanced support for cross-chunk shuffling.
For training with static dataset, the default configuration is at user's disposal. However, in some user cases, over each epoch, new data is added to the current dataset, thus the dataset's size is dynamically changing/increasing. In order to mix the new data and the old data for better random sampling, one approach is to shuffle examples from more than 1 chunks. This feature is supported with this change. By specifying the `cross_chunk_shuffle_count_` on construction, advanced user can specify how many chunks to shuffle example from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22347
Differential Revision: D16081378
Pulled By: zhangguanheng66
fbshipit-source-id: fd001dfb9e66947839adecfb9893156fbbce80d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22413
_jit_pass_erase_number_types invalidates the jit graph but parts of _jit_pass_onnx rely on having a valid jit graph.
This splits _jit_pass_onnx into _jit_pass_onnx_remove_print and _jit_pass_onnx_preprocess_caffe2 (which rely on the valid jit graph), runs these before _jit_pass_erase_number_types,
and then runs the rest of _jit_pass_onnx after _jit_pass_erase_number_types
Reviewed By: houseroad
Differential Revision: D16079890
fbshipit-source-id: ae68b87dced077f76cbf1335ef3bf89984413224
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22334
Improve the function signatures of save_to_db and load_from_db in predictor_exporter.
Reviewed By: akyrola
Differential Revision: D16047208
fbshipit-source-id: a4e947f86e00ef3b3dd32c57efe58f76a38fcec7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22293
Just wrapping C class with nicer python interface which now
ust print dirrectly to get all the data. Later we can add various
visualizations there
Differential Revision: D16023999
fbshipit-source-id: 8436e37e36965821a690035617784dcdc352dcd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22292
as we do atomic fetch_add to validate if a thread should
finish, we should not take the last iteration into account. As a
result total number of iterations should be exactly the same as user
sets via config.num_iters
Now when running a unit test I see exact number of iterations reported
Differential Revision: D16023963
fbshipit-source-id: 3b12ee17276628ecd7b0979f28cd6deb777a1543
Summary:
As part of the Variable/Tensor merge, one invariant for tensor libraries such as ATen / Caffe2 / XLA is that they should only deal with Tensors, not Variables. However, currently in `variable_factories.h` we are potentially passing Variables into those tensor libraries without the `at::AutoNonVariableTypeMode` guard, which will cause those libraries to treat those Variables as Variables (i.e. their `is_variable()` is true), not Tensors.
Consider the following example for `full_like`:
```cpp
inline at::Tensor full_like(const at::Tensor & self, at::Scalar fill_value) {
...
// Both ATen and XLA rely on `at::full_like` to dispatch to library specific implementations.
//
// When `self` is a Variable, since we are not using `at::AutoNonVariableTypeMode`,
// `at::full_like` will also use `self` as a Variable (and it will see that `self.is_variable()` is true),
// which breaks the invariant that ATen / XLA should never deal with Variables.
at::Tensor tensor = at::full_like(self, fill_value, self.options().is_variable(false));
at::Tensor result =
autograd::make_variable_consuming(std::move(tensor), /*requires_grad=*/false);
...
return result;
}
```
Instead, the invariant-preserving implementation would be:
```cpp
inline at::Tensor full_like(const at::Tensor & self, at::Scalar fill_value) {
...
at::Tensor tensor = ([&]() {
at::AutoNonVariableTypeMode non_var_type_mode(true);
// Both ATen and XLA rely on `at::full_like` to dispatch to library specific implementations.
//
// When `self` is a Variable, since we have `at::AutoNonVariableTypeMode` in the scope,
// `at::full_like` will use `self` as a Tensor (and it will see that `self.is_variable()` is false),
// which preserves the invariant that ATen / XLA should only deal with Tensors.
return at::full_like(self, fill_value, self.options().is_variable(false));
})();
at::Tensor result =
autograd::make_variable_consuming(std::move(tensor), /*requires_grad=*/false);
...
return result;
}
```
This PR makes the suggested change for all variable factory functions.
cc. ailzhang This should allow us to remove all `tensor_data()` calls in the XLA codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22364
Differential Revision: D16074862
Pulled By: yf225
fbshipit-source-id: 3deba94b90bec92a757041ec05d604401a30c353
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22285
Previously forward hooks are expected to return None, this PR adds the support to overwrite input and output in `forward_pre_hook` and `forward_hook`, this is used to implement inserting quant/dequant function calls around forward functions.
Differential Revision: D16022491
fbshipit-source-id: 02340080745f22c8ea8a2f80c2c08e3a88e37253
Summary:
As per attached tasks, these are noops and are being deprecated/removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22113
Reviewed By: philipjameson
Differential Revision: D15901131
fbshipit-source-id: 3acf12208f692548afe4844be13717a49d74af32
Summary:
Saying `I` in an err msg is too subjective to be used in a framework.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22369
Differential Revision: D16067712
Pulled By: soumith
fbshipit-source-id: 2a390646bd5b15674c99f65e3c460a7272f508b6
Summary:
`setup.py` recommends setting `USE_QNNPACK=0` and `USE_NNPACK=0` to disable building QNNPACK and NNPACK respectively. However this wasn't reflected correctly because we were looking for `NO_QNNPACK` and `NO_NNPACK`. This PR fixes it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22367
Differential Revision: D16067393
Pulled By: soumith
fbshipit-source-id: 6491865ade9a6d41b7a79d68fd586a7854051f28
Summary:
Say the user inputs reduction=False. Of course, we can't add a bool and a string, so the ValueError itself will error -which is more confusing to the user. Instead, we should use string formatting. I would use `f"{reduction} is not..."` but unsure whether we are ok with using f"" strings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22160
Differential Revision: D15981826
Pulled By: soumith
fbshipit-source-id: 279f34bb64a72578c36bdbabe2da83d2fa4b93d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22319
The onnx pass replacing ints with Tensors produces an invalid JIT graph. It should only be called right before the onnx pass.
Also, it should only be called if we actually export to onnx.
Reviewed By: houseroad
Differential Revision: D16040374
fbshipit-source-id: e78849ee07850acd897fd9eba60b6401fdc4965b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22317
About to add an observer that is also statically initialized in a different
file, so we need to enforce initialization order.
Reviewed By: ilia-cher
Differential Revision: D16012275
fbshipit-source-id: f26e57149a5e326fd34cb51bde93ee99e65403c4
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
MEDIUM: 445
LARGE: 354
Updated actions:
From MEDIUM to LARGE: 21
From LARGE to XLARGE: 34
From LARGE to MEDIUM: 9
From XLARGE to MEDIUM: 1
Differential Revision: D16047893
fbshipit-source-id: 7afab2ef879277f114d67fd1da9f5102ec04ed7f
Summary:
This does not occur in CUDA code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22271
Differential Revision: D16024605
Pulled By: bddppq
fbshipit-source-id: bb4f16bacbdc040faa59751fba97958f4c2d33cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22307
MSVC-specific pragma doesn't silence the warning about throwing constructor and therefore `clang-cl` fails to compile this file. This diff fixes the problem by adding additional check for `clang` compiler.
Reviewed By: smessmer
Differential Revision: D16032324
fbshipit-source-id: 6dbce0ebf0a533d3e42b476294720590b43a8448
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21921
Call FBGEMM kernels to implement quantized linear operator. This operator is used only for inference.
Differential Revision: D15375695
fbshipit-source-id: b9ca6c156fd60481fea83e55603b2897f7bfc3eb
Summary:
Reduction of gradients for unused parameters should happen as soon as
possible, because they potentially block reduction of gradients for
used parameters. This used to happen instantly when
`prepare_for_backward` was called and it found parameters that didn't
contribute. This meant that if you have a model with unused
parameters, and you want to discard the model output (i.e. not call
backward on some loss), reduction of the gradients of those unused
parameters would have been kicked off, and you'd see an error the next
time you called `forward`.
In this commit, this original approach is slightly changed to delay
reduction of the gradients of those unused parameters until the first
autograd hook is called. This means that you can now discard the model
output regardless of the model having unused parameters or not.
This is a prerequisite for making the `find_unused_parameters`
argument to DDP default to `True`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22219
Differential Revision: D16028698
Pulled By: pietern
fbshipit-source-id: c6aec2cd39c4a77746495d9cb1c9fb9c5ac61983
Summary:
This adds the rest of the `dict.???` methods that were missing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21979
Pulled By: driazati
Differential Revision: D16023573
fbshipit-source-id: 3ea9bd905090e2a176af654a8ca98c7d965ea679
Summary:
In talks with smessmer, we decided that it'd be better to put the logic in `list`, as optimal behavior requires knowing `.capacity()`
Results on my cpu (for the benchmark here: https://twitter.com/VahidK/status/1138674536679821312) now look like this:
```
Pytorch batch_gather took 0.018311 seconds.
Pytorch batch_gather jit took 0.013921 seconds.
Pytorch vectorized batch_gather took 0.001384 seconds.
```
Previously, `batch_gather jit` took 3x as long as `batch_gather`.
Some logic taken from https://github.com/pytorch/pytorch/pull/21690. Note that these two PR's are somewhat orthogonal. That PR handles this benchmark by looking at the alias analysis, while this PR specializes for `+=`.
Note that we can't jit the vectorized version as we think `torch.arange` returns a float tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21896
Differential Revision: D15998628
Pulled By: Chillee
fbshipit-source-id: b0085960da4613578b94deb98ac62c0a4532a8c3
Summary:
This is yet another step to disentangle Python build scripts and CMake
and improve their integration (Let CMake handle more build environment
detections, and less by our handcrafted Python scripts).
The processor detection logic also changed a bit: Instead of detecting
whether the system processor is PPC or ARM, this PR changes to detect
Intel CPUs, because this is more precise as MKL only supports Intel
CPUs. The build option `USE_MKLDNN` will also not be presented to
users on non-Intel processors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22215
Differential Revision: D16005953
Pulled By: ezyang
fbshipit-source-id: bf3f74d53609b3f835e280f63a872ff3c9352763
Summary:
When dealing with large scale dataset, it is handy if we can save the dataset status and resume later. Especially in cases where some unexpected crash happens, user don't need to start over the whole dataset from begining. Instead, they can reload it from the last checkpoint.
This change adds support for checkpoint save/load logic in ChunkDataset.
On ChunkDataset construction, user can specify a file name from which to load the checkpoint. If it is empty, default to start from fresh; otherwise the ChunkDataset will 'fast forward' the chunk sampler to the corresponding checkpoint.
The user can also call ChunkDataset::save() to serialize current status to a file, which can be used later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21889
Differential Revision: D16024582
Pulled By: ailzhang
fbshipit-source-id: 1862ab5116f94c9d29da174ce04a91041d06cad5
Summary:
`cmake/public/LoadHIP.cmake` calls `find_package(miopen)`, which uses the CMake module in MIOpen installation (It includes the line `set(miopen_DIR ${MIOPEN_PATH}/lib/cmake/miopen)`). `cmake/Modules/FindMIOpen.cmake` is not used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22244
Differential Revision: D16000771
Pulled By: bddppq
fbshipit-source-id: 07bb40fdf033521e8427fc351715d47e6e30ed34
Summary:
The original name `copy_tensor_data` could be confusing because users are not sure whether it deep-copies data in the tensor's storage or just copies the tensor's metadata. The renaming makes it more clear.
cc. ailzhang This might break XLA build, but I think the renaming makes it more clear why we use `copy_tensor_data` in XLATensorImpl's shallow-copy functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22266
Differential Revision: D16014724
Pulled By: yf225
fbshipit-source-id: f6ee966927d4d65d828b68264b3253b2f8fd768d
Summary:
This adds the rest of the `dict.???` methods that were missing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21979
Pulled By: driazati
Differential Revision: D15999938
fbshipit-source-id: 7bc2a55e3f791015a0ff2e3731703075cf0770ee
Summary:
I learned from https://github.com/pytorch/pytorch/pull/22058 that `worker_kill` is just flaky, regardless of `hold_iter_reference`. So let's disable it altogether for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22208
Differential Revision: D15990307
Pulled By: soumith
fbshipit-source-id: d7d3f4fe7eaac4987f240cb8fd032c73a84157d7
Summary:
As part of the Variable/Tensor merge, we want to gradually remove call sites of `tensor_data()` and the API itself, and instead uses `variable_data()`. This PR removes the `tensor_data()` call in the tensor_to_numpy conversion path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22214
Differential Revision: D15997397
Pulled By: yf225
fbshipit-source-id: 6fcab7b14e138824fc2adb5434512bcf868ca375
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22077
ghimport-source-id: 39cf0a2e66e7fa2b6866af72782a22a4bd025e4c
Test Plan:
- Compared the build/aten/src folder before and after this change
locally and verified they are identical (`diff -r`).
- Wait for CI + Also, [namedtensor ci]
Imported from OSS
Differential Revision: D15941967
Pulled By: zou3519
fbshipit-source-id: d8607df78f48325fba37e0d00fce0ecfbb78cb36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20729
Currently there is no way to specify what scalar types each nn function will support.
This change will allow to specify supported scalar types for each function/backward function and device. By default each function will support Float, Double, Half.
If you want to scpecify any extra supported scalar types, other then default, you will need to change nn.yalm:
- name: _some_func(Tensor self)
cname: SomeFunction
CPU:
forward_scalar_types: ['Float', 'Double', 'Long']
backward_scalar_types: ['Float', 'Double']
Differential Revision: D15423752
fbshipit-source-id: b3c157316d6e629bc39c1b377a3b23c71b1656cf
Summary:
In `torch/csrc/autograd/function.h` we define `torch::autograd::Function`, a (the?) central autograd record-holding class. `Function` is declared public API (`TORCH_API`).
We also define a custom deleter `deleteFunction` which we use throughout PyTorch's own use of `Function`. This trivial PR declares the deleter public API as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22236
Differential Revision: D16001335
Pulled By: yf225
fbshipit-source-id: 6ef0a3630e8f82f277a0e6e26cc64455ef7ee43e
Summary:
we used to not print device when it's on xla. It's sometimes confusing as it looks the same as cpu tensor...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22094
Differential Revision: D15975405
Pulled By: ailzhang
fbshipit-source-id: f19ceb9e26f5f2f6e7d659de12716f0dfe065f42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22084
For DictPtr/ListPtr, default construction was disallowed because it was ambigious if it's supposed to create an empty list or a nullptr.
But since we renamed them to Dict/List, we can now allow default construction without ambiguity.
Differential Revision: D15948098
fbshipit-source-id: 942a9235b51608d1870ee4a2f2f0a5d0d45ec6e6
Summary:
This cleans up the `checkScript` API and some old tests that were hardcoding outputs. It also now runs the Python function when a string is passed in to verify the outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22002
Differential Revision: D15924485
Pulled By: driazati
fbshipit-source-id: ee870c942d804596913601cb411adc31bd988558
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22157
This header uses `std::swap_ranges` function which is defined in `<algorithm>` header (https://en.cppreference.com/w/cpp/algorithm/swap_ranges). Therefore this file isn't guaranteed to compile on all platforms.
This diff fixes the problem by adding the missing header.
Reviewed By: smessmer
Differential Revision: D15971425
fbshipit-source-id: e3edcec131f72d729161f5644ee152f66489201a
Summary:
Changelog:
- Port `symeig` from TH/THC to ATen
- Enable batching of matrix inputs for `symeig`
- Modify derivative computation based on batching
- Update docs to reflect the change
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21858
Test Plan: - Added additional tests in `test_torch.py` (with a port to `test_cuda.py`) and `common_methods_invocations.py` to test if both the port and batching work.
Differential Revision: D15981789
Pulled By: soumith
fbshipit-source-id: ab9af8361f8608db42318aabc8421bd99a1ca7ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21885
If a kernel is defined as a stateful lambda
static auto registry = torch::RegisterOperators().op("my::op", [some_closure] (Tensor a) {...});
this can have very unexpected behavior when kernels are instantiated. There is no guarantee that the state is kept.
In the options based API, state is already disallowed:
// this is a compiler error
static auto registry = torch::RegisterOperators().op("my::op", torch::RegisterOperators::options().kernel([some_closure] (Tensor a) {...}));
but we can't disallow it in the non-options-based API for backwards compatibility reasons.
We can, however, show a deprecation warning. This is what this diff introduces.
Differential Revision: D15867089
fbshipit-source-id: 300fa4772fad8e7d177eb7cb910063d360537a4a
Summary:
Re-implementation of the `embedding_dense_backward_cuda()` and the `embedding_bag_backward_cuda_sum_avg()` functions.
#### Performance
Running a [Mortgage Workflow](https://github.com/EvenOldridge/MortgageWorkflowA) with a block size of 100K on a DXG-2 (single GPU), we see a 270% speedup:
```
Original version: 370,168 example/s
Optimized version: 1,034,228 example/s
```
The original version is bounded by the `EmbeddingBag_accGradParametersKernel_sum_avg`, which takes 70% of the CUDA execution time. In the optimized version, the optimized kernel now takes only 17% of the time.
#### Greater Numerical Stability
An added benefit is greater numerical stability. Instead of doing a flat sum where a single variable are used to accumulate the weights, this code uses two-steps where each GPU-thread computes a sub-result defined by `NROWS_PER_THREAD` before the final result are accumulated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22016
Differential Revision: D15944339
Pulled By: mrshenli
fbshipit-source-id: 398d5f48826a017fc4b31c24c3f8b56d01830bf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22130
Optimize InstanceNormOp forward
For InstanceNormOp on CPU with order = NHWC, N = 128, C = 256, H = 56, W = 56: 183ms -> 115ms.
For InstanceNormOp on GPU with N = 256, C = 256, H = 112, W = 112:
NCHW: 1475ms -> 45ms
NHWC: 1597ms -> 79ms
Reviewed By: houseroad
Differential Revision: D15963711
fbshipit-source-id: 3fa03109326456b9f301514fecbefa7809438d3e
Summary:
In order to select more important features in dot product among a list of candidate sparse features, we can assign one learnable weight on each feature, reweight each feature by multiplying the weight onto its embedding before dot product. We finally select features based on the weight magnitude after training.
We can perform L1 and/or L2 regularization on the weights. To summarize, the weights tend to shrink their values (avoiding overfitting) due to L2 regularization, and some weights will vanish to zero as L1. To avoid sparse feature embedding being ignored due to early collapse of weights, a piece lr warm up policy is used in optimizing regularization term, such that regularization is weak at first stage and gets stronger afterwards (a small lr constant in iters less than threshold 1, a medium lr constant in stage 2, and a final reasonable large lr constant in all iters after threshold 2). The features with nonzero and relatively large weights (in absolute value) will be selected for the module.
We can also apply softmax on the original weights to make it sum to 1. We can even boosting the softmaxed weights by multiply the number of softmax components, which essentially make them sum to the number of softmax components and avergae to 1. In this idea, all the weights are positive and sum to a constant. Regularization is not a must since we can count on the competition between softmax weights themselves to achieve reasonable re-weighting. We expect those weights be more dense, comparing with sparse ones from L1 regularization and we can select features based on top K weights.
Overall, we aim to demonstrate the selected feature set outperform current v0 feature set in experiments. Special acknowledgement goes to Shouyuan Chen, who initiated the work of regularizable weighting.
---
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22176
The diff will export updates to Github repository, as stated below.
{F162787228}
Basically, the updates on the files are summarized as below:
- adding logger messages
`caffe2/python/layer_model_helper.py`
- add ElasticNet regularizer, which combines both L1 and L2 regularization
`caffe2/python/regularizer.py`
- implement piecewarmup, specifically warm up with three constant pieces
`caffe2/sgd/learning_rate_functors.h, caffe2/sgd/learning_rate_op.cc, caffe2/sgd/learning_rate_op.h`
Differential Revision: D15923430
fbshipit-source-id: ee18902cb88c23b1b7b367cc727d690a21e4cda9
Summary:
- PyCQA/flake8-bugbear#53 has been fixed (but not yet closed on their side) and a new version of flake8-bugbear has been released on Mar 28, 2019. Switch CI to use the latest stable version.
- Fix the new B011 errors that flake8-bugbear catches in the current codebase.
---
B011: Do not call assert False since python -O removes these calls. Instead callers should raise AssertionError().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21944
Differential Revision: D15974842
Pulled By: soumith
fbshipit-source-id: de5c2c07015f7f1c50cb3904c651914b8c83bf5c
Summary:
Returning the result of an inplace `squeeze_` in `einsum` (which itself is traced) interacts badly with `autograd.Function`.
I must admit that I'm not 100% certain whether it should be necessary to change this, but I consider this a good change overall.
Fixes: https://github.com/pytorch/pytorch/issues/22072
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22111
Differential Revision: D15974990
Pulled By: soumith
fbshipit-source-id: 477e7f23833f02999085f665c175d062e7d32acd
Summary:
The current error message displays as:
`RuntimeError: index koccurs twice in output`
A whitespace is missing between the index and 'occurs'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21904
Differential Revision: D15878941
Pulled By: colesbury
fbshipit-source-id: 163dda1829bf4956978cd01fd0e751673580722d
Summary:
The bug is that when target_length == 0, there is no preceding BLANK state and the original implementation will lead to out of bound pointer access.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21910
Differential Revision: D15960239
Pulled By: ezyang
fbshipit-source-id: 7bbbecb7bf91842735c14265612c7e5049c4d9b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22088
This diff is similar to D14163001. We need to handle the edge case when add_axis=1.
Reviewed By: jspark1105
Differential Revision: D15949003
fbshipit-source-id: 328d1e07b78b69bde81eee78c9ff5a8fb81f629b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22037
This adds support for sparse gradients to the reducer as well as to
the DistributedDataParallel wrapper. Note that an out of band signal
is needed whether or not a dense parameter (e.g. an embedding) is
expected to receive a sparse gradient or not. This information is
passed to the bucket assignment computation routine and the reducer as
a vector of booleans. Every parameter for which we expect a sparse
gradient is assigned its own bucket, as we cannot easily group
multiple unrelated sparse tensors.
Reviewed By: mrshenli
Differential Revision: D15926383
fbshipit-source-id: 39c0d5dbd95bf0534314fdf4d44b2385d5321aaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22036
Implemented only on ProcessGroupGloo, as an allgather of metadata
(sparse_dim, dense_dim, and nnz), followed by an allgather of indices,
followed by an allgather of values. Once these operations have
finished, all ranks locally compute a reduction over these sparse
tensors. Works for both CPU and CUDA tensors.
This surfaced a problem with the existing assumption of only modifying
tensors that are passed at the call site, because for sparse tensors
we don't know the dimensions of the output tensors before we run the
collective. To deal with this unknown, this commit adds a `result`
function to the `c10d::ProcessGroup::Work` class that returns a vector
of tensors.
It's a bit odd to have to retrieve the result through this function
only for operations on sparse tensors. To make this work irrespective
of tensor layout, we can create a follow-up commit to make all in
place operations make their results accessible through this function
as well. This doesn't break any existing contracts but does have the
potential to add interface ambiguity.
This is a resubmission of #19146.
Reviewed By: mrshenli
Differential Revision: D15926384
fbshipit-source-id: b6ee5d81606bfa8ed63c3d63a9e307613491e0ae
Summary:
This change is backwards incompatible in *C++ only* on mean(), sum(), and prod() interfaces that accepted either of:
```
Tensor sum(IntArrayRef dim, bool keepdim=false) const;
Tensor sum(IntArrayRef dim, ScalarType dtype) const;
```
but now to specify both the dim and dtype will require the keepdim parameter:
```
Tensor sum(IntArrayRef dim, bool keepdim=false, c10::optional<ScalarType> dtype=c10::nullopt) const;
```
[xla ci]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21088
Reviewed By: ailzhang
Differential Revision: D15944971
Pulled By: nairbv
fbshipit-source-id: 53473c370813d9470b190aa82764d0aea767ed74
Summary:
Currently many build options are explicitly passed from Python build scripts to CMake. But this is unecessary, at least for many of them. This commit removes the build options that have the same name in CMakeLists.txt and environment variables (e.g., `USE_REDIS`). Additionally, many build options that are not explicitly passed to CMake are lost.
For `ONNX_ML`, `ONNX_NAMESPACE`, and `BUILDING_WITH_TORCH_LIBS`, I changed their default values in CMake scripts (as consistent with what the `CMake.defines` call meant), to avoid their default values being redundantly set in the Python build scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21877
Differential Revision: D15964996
Pulled By: ezyang
fbshipit-source-id: 127a46af7e2964885ffddce24e1a62995e0c5007
Summary:
This PR tackles issue https://github.com/pytorch/pytorch/issues/18352 .
Progress:
- [x] conv_dilated2d CPU
- [x] conv_dilated3d CPU
- [x] conv_dilated2d CUDA
- [x] conv_dilated3d CUDA
- [x] RocM port
- [x] Port of CUDA gemm and gemv
- [x] Refactored 2d and 3d functions as well as output and gradient computations into a single C++ template function
- [x] Cleanup
+ [x] eliminate forward functions
+ [x] eliminate buffers `columns` and `ones` from functions API
+ [x] eliminate out functions
+ [x] eliminate using `ones`
Note that col2im, im2col, col2vol, vol2col implementations are exposed in `ATen/native/im2col.h` and `ATen/native/vol2col.h`. The corresponding operators (not ported in this PR) should use these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20983
Differential Revision: D15958088
Pulled By: ezyang
fbshipit-source-id: 1897f6e15abbf5710e9413cd1e443c2e1dc7d705
Summary:
This is useful for measuring inference performance of your
models. This is a very basic benchmark for now. We don't support
batching on the benchmark side, no inter and intra op parallelizm is
supported yet, just caller based parallelizm.
Main phylosophy here is that user should be able to provide inputs
from python and just stack them within the benchmark. API should be
exactly the same as passing inputs to module.forward.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20766
Test Plan: Added a new unit test
Differential Revision: D15435461
Pulled By: salexspb
fbshipit-source-id: db08829dc3f4398bb1d8aa16cc4a58b6c72f16c6
Summary:
Previously any assert failures would leave the updated setting, making
the test suite semantics dependent on the order in which the tests are run.
The diff is large only due to the indentation change (might be good to review without whitespace changes).
cc yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22115
Differential Revision: D15960875
Pulled By: soumith
fbshipit-source-id: 9313695277fc2d968786f13371719e03fff18519
Summary:
Apply launch bounds annotations for ROCm as the maximum threads per
block (1024) is higher than the ROCm internal default (256).
Reduce the minBlocksPerMultiprocessor for ROCm to 8 from 16 as this
improves performance in some microbenchmarks by (statistically
significant) 4%.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22081
Differential Revision: D15947426
Pulled By: bddppq
fbshipit-source-id: b4b7015417f99e14dfdedb62639e4d837c38e4fd
Summary:
We can't really test these until we get Python 3.8 in the CI, but these all work locally and won't be invoked at all for Python 3.7 and lower so this should be pretty safe.
Fixes#21710
](https://our.intern.facebook.com/intern/diff/15914735/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22007
Pulled By: driazati
Differential Revision: D15914735
fbshipit-source-id: 83833cebe7e38b162719a4f53cbe52c3fc638edd
Summary:
This was originally introduced between at::Half, which overloaded a number of operators; since this isn't necessary anymore, get rid of it.
Note in many cases, these files still need THCNumerics.cuh (which was included by THCHalfAutoNumerics); I was not careful about isolating these usages.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21878
Differential Revision: D15941236
Pulled By: gchanan
fbshipit-source-id: 65f30a20089fcd618e8f3e9646cf03147a15ccba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21753
- it accidentally didn't move non-IValue-based lists before. This is fixed now.
- it only needs to recreate a T() for IValue-based lists
Reviewed By: resistor
Differential Revision: D15809220
fbshipit-source-id: 944badf1920ee05f0969fff0d03284a641dae4a9
Summary:
Get benefit from the compile time vectorization and multi-threading.
Before:
```python
In [1]: import torch
In [2]: x = torch.randn(1000000)
In [3]: y = torch.randn(1000000)
In [4]: w = 0.7
In [5]: timeit torch.lerp(x, y, w)
2.29 ms ± 23.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
After:
```python
In [1]: import torch
In [2]: x = torch.randn(1000000)
In [3]: y = torch.randn(1000000)
In [4]: w = 0.7
In [5]: timeit torch.lerp(x, y, w)
452 µs ± 1.81 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After with multi-processing:
```python
In [1]: import torch
In [2]: x = torch.randn(1000000)
In [3]: y = torch.randn(1000000)
In [4]: w = 0.7
In [5]: timeit torch.lerp(x, y, w)
167 µs ± 48.8 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22038
Differential Revision: D15941468
Pulled By: VitalyFedyunin
fbshipit-source-id: fa8a5126187df4e6c849452e035b00b22be25739
Summary:
# Motivation
We allow to override JIT module serialization with `__getstate__/__setstate__` in order to cover cases where parameters are not serializable. Use cases include: MKLDNN integration: a388c78350/torch/utils/mkldnn.py (L18-L26)
and also fbgemm prepacked format integration for quantized tensors.
However many Eager scripts use `torch.save(module.state_dict())` form of serialization. There are several ways to make it work:
* make packed_weight itself pickleable (e.g. by binding `__getstate__/__setstate__` on C++ UDT level)
* change: we’d need to allow module buffers to be of arbitrary, non-Tensor types
* pro: no change to state_dict behavior
* cons: might not be directly inspectable by user calling .state_dict(), especially if packed weights represent several tensors fused together
* make packed_weight being proper Tensor layout
* pro: no change to state_dict or buffers behavior
* cons: adding new tensor layouts is pretty costly today
* cons: doesn’t work if multiple tensors are packed in one interleaved representation
* *[this approach]* allow Modules to override state_dict and return regular tensors
* pro: most flexible and hackable
* pro: maintains semantic meaning of statedict as all data necessary to represent module’s state
* cons: complicates state_dict logic
* cons: potential code duplication between `__getstate__/__setstate__`
Based on discussions with zdevito and gchanan we decided to pick latter approach. Rationale: this behavior is fully opt-in and will impact only modules that need it. For those modules the requirement listed above won't be true. But we do preserve requirement that all elements of state_dict are tensors. (https://fburl.com/qgybrug4 for internal discussion)
In the future we might also implement one of the approaches above but those are more involved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21933
Differential Revision: D15937678
Pulled By: dzhulgakov
fbshipit-source-id: 3cb5d1a8304d04def7aabc0969d0a2e7be182367
Summary:
This pull request adds the necessary Windows DLL code to be able to support JIT fusion for CUDA. CPU JIT Fusion isn't supported. This also adds all the non-CPU JIT tests back in on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21861
Differential Revision: D15940939
Pulled By: soumith
fbshipit-source-id: e11f6af1ac258fcfd3a077e6e2f2e6fa38be4ef1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22015
Previous fusion logic only works for operators back-to-back in the linear order of protobuf file.
This diff generalizes to work for any predecessor-successor operators in the graph without any "interfering" use/def of the related blobs.
Reviewed By: csummersea
Differential Revision: D15916709
fbshipit-source-id: 82fe4911a8250845a8bea3427d1b77ce2442c495
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21709
Change the return type from Scalar to double/int64_t so we don't need to do conversion when we call other quantize related aten functions
Differential Revision: D15793003
fbshipit-source-id: 510936c69fa17a4d67340a31ebb03415647feb04
Summary:
This is a modified version of https://github.com/pytorch/pytorch/pull/14705 since commit structure for that PR is quite messy.
1. Add `IterableDataset`.
3. So we have 2 data loader mods: `Iterable` and `Map`.
1. `Iterable` if the `dataset` is an instance of `IterableDataset`
2. `Map` o.w.
3. Add better support for non-batch loading (i.e., `batch_size=None` and `batch_sampler=None`). This is useful in doing things like bulk loading.
3. Refactor `DataLoaderIter` into two classes, `_SingleProcessDataLoaderIter` and `_MultiProcessingDataLoaderIter`. Rename some methods to be more generic, e.g., `get_batch` -> `get_data`.
4. Add `torch.utils.data.get_worker_info` which returns worker information in a worker proc (e.g., worker id, dataset obj copy, etc.) and can be used in `IterableDataset.__iter__` and `worker_init_fn` to do per-worker configuration.
5. Add `ChainDataset`, which is the analog of `ConcatDataset` for `IterableDataset`.
7. Import torch.utils.data in `torch/__init__.py`
9. data loader examples and documentations
10. Use `get_worker_info` to detect whether we are in a worker process in `default_collate`
Closes https://github.com/pytorch/pytorch/issues/17909, https://github.com/pytorch/pytorch/issues/18096, https://github.com/pytorch/pytorch/issues/19946, and some of https://github.com/pytorch/pytorch/issues/13023
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19228
Reviewed By: bddppq
Differential Revision: D15058152
fbshipit-source-id: 9e081a901a071d7e4502b88054a34b450ab5ddde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20673
Add option to bucket-weighted pooling to hash the bucket so that any cardinality score can be used.
Reviewed By: huginhuangfb
Differential Revision: D15003509
fbshipit-source-id: 575a149de395f18fd7759f3edb485619f8aa5363
Summary:
The first attempt and more discussions are available in https://github.com/pytorch/pytorch/issues/19577
#### Goal
Allow toggling DDP gradient synchronization across iterations. With this feature, users may accumulate grads in module variables, and only kick off expensive grad synchronize every a few iterations.
#### Concerns
Our first attempt in https://github.com/pytorch/pytorch/issues/19577 tries to do it using a variable or a function. But apaszke made a good point that it will not be error prone, and favors a context manager instead.
#### Proposed Solution
Instead of providing a `accumulate_grads` variable/function/context, we provide a `DistributedDataParallel.no_sync()` context manager. And it does exactly what the name suggests, i.e., disable DDP grad synchronization within the context. Note that `accumulate_grads` means `no_sync` + no optimizer step, where the latter is not controlled by DDP.
It is true that users need to call another `model(input).backward()` after exiting the context, and this is indeed more verbose. But I think it is OK as one major concern in the previous discussion is to prevent users from running into errors without knowing it. This API should reaffirm the expected behavior, and does not mess up with other use cases if accumulating grads is not required..
The application would then look like:
```python
with ddp.no_sync():
for input in inputs:
ddp(input).backward()
ddp(one_more_input).backward()
optimizer.step()
```
chenyangyu1988 myleott
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21736
Differential Revision: D15805215
Pulled By: mrshenli
fbshipit-source-id: 73405797d1e39965c52016af5cf45b15525ce21c
Summary:
There aren't any substantive changes aside from some test renames (e.g. `TestScript.test_dict_membership` -> `TestDict.test_membership`) and the addition of `TestDict.dict()`.
Adding the rest of the dict ops was making the tests a mess and `TestScript` is already > 10000 lines by itself, so breaking them up should make things cleaner
](https://our.intern.facebook.com/intern/diff/15911383/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22000
Pulled By: driazati
Differential Revision: D15911383
fbshipit-source-id: 614428e03fbc14252f0e9cde74ab9a707169a860
Summary:
The cppdocs build job (originally run on Chronos as a cron job) was frequently broken because it was not run on every PR. This PR moves it to CircleCI and enables it on every PR, so that we can get the build failure signal much earlier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19768
Differential Revision: D15922289
Pulled By: yf225
fbshipit-source-id: e36ef59a2e42f78b7d759ee02f2d94dc90f88fff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19443
This adds support for sparse gradients to the reducer as well as to
the DistributedDataParallel wrapper. Note that an out of band signal
is needed whether or not a dense parameter (e.g. an embedding) is
expected to receive a sparse gradient or not. This information is
passed to the bucket assignment computation routine and the reducer as
a vector of booleans. Every parameter for which we expect a sparse
gradient is assigned its own bucket, as we cannot easily group
multiple unrelated sparse tensors.
Reviewed By: mrshenli
Differential Revision: D15007365
fbshipit-source-id: f298e83fd3ca828fae9e80739e1db89d045c99ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19146
Implemented only on ProcessGroupGloo, as an allgather of metadata
(sparse_dim, dense_dim, and nnz), followed by an allgather of indices,
followed by an allgather of values. Once these operations have
finished, all ranks locally compute a reduction over these sparse
tensors. Works for both CPU and CUDA tensors.
This surfaced a problem with the existing assumption of only modifying
tensors that are passed at the call site, because for sparse tensors
we don't know the dimensions of the output tensors before we run the
collective. To deal with this unknown, this commit adds a `result`
function to the `c10d::ProcessGroup::Work` class that returns a vector
of tensors.
It's a bit odd to have to retrieve the result through this function
only for operations on sparse tensors. To make this work irrespective
of tensor layout, we can create a follow-up commit to make all in
place operations make their results accessible through this function
as well. This doesn't break any existing contracts but does have the
potential to add interface ambiguity.
Reviewed By: mrshenli
Differential Revision: D14889547
fbshipit-source-id: 34f3de4d6a2e09c9eba368df47daad0dc11b333e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21938
After having changed all call sites, we can now remove the old naming scheme.
Reviewed By: zdevito
Differential Revision: D15892402
fbshipit-source-id: 1f5b53a12fa657f6307811e8657c2e14f6285d2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21937
This changes call sites to use the new naming scheme
Reviewed By: zdevito
Differential Revision: D15892404
fbshipit-source-id: 8d32aa90a0ead1066688166478f299fde9c2c133
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21936
This introduces torch::List and torch::Dict as aliases to ListPtr/DictPtr.
After this lands, we can step by step change the call sites to the new naming
and finally remove the old spellings.
Reviewed By: zdevito
Differential Revision: D15892405
fbshipit-source-id: 67b38a6253c42364ff349a0d4049f90f03ca0d44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21806
Dispatcher::findSchema(op_name) now uses a lookup table instead of iterating through the list of operators to find it.
This speeds up op lookup (as in finding the operator handle from the name, not as in finding a kernel when you already have the operator handle)
and it also speeds up op registration since that needs to look if an op with the same name already eists.
Differential Revision: D15834256
fbshipit-source-id: c3639d7b567e4ed5e3627c3ebfd01b7d08b55ac1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21809
Many error messages show dispatch keys, for example when the dispatcher didn't find a kernel to dispatch to.
Previously, this was a string like "CPU" or "CUDA" for known backends and just an arbitrary number for other backends.
Now, tensor type id registration also registers a name for the dispatch key and shows that in the error messages.
There is no API change, just the error messages are better now.
Differential Revision: D15835809
fbshipit-source-id: 4f0c9d0925c6708b02d79c653a2fae75b6623bb9
Summary:
https://github.com/pytorch/pytorch/pull/17072 breaks `model.to(xla_device)`, because moving `model` to XLA device involves changing its parameters' TensorImpl type, and the current implementation of `nn.Module.to()` doesn't support changing module parameters' TensorImpl type:
```python
# 6dc445e1a8/torch/nn/modules/module.py (L192-L208)
def _apply(self, fn):
...
for param in self._parameters.values():
if param is not None:
# Tensors stored in modules are graph leaves, and we don't
# want to create copy nodes, so we have to unpack the data.
param.data = fn(param.data) # NOTE: this doesn't allow changing `param.data`'s TensorImpl type
if param._grad is not None:
param._grad.data = fn(param._grad.data) # NOTE: this doesn't allow changing `param._grad.data`'s TensorImpl type
...
```
yf225 TODO: fix the description here when we finish the implementation
To fix this problem, we introduce a new API `model.to_()` that always assign new tensors to the parameters (thus supporting changing the parameters to any TensorImpl type), and also bump the version counter of the original parameters correctly so that they are invalidated in any autograd graph they participate in.
We also add warning to the current `model.to()` API to inform users about the upcoming behavior change of `model.to()`: in future releases, it would create and return a new model instead of in-place updating the current model.
This unblocks adding XLA to our CI test suite, which also allows XLA to catch up with other changes in our codebase, notably the c10 dispatcher.
[xla ci]
cc. resistor ailzhang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21613
Differential Revision: D15895387
Pulled By: yf225
fbshipit-source-id: b79f230fb06019122a37fdf0711bf2130a016fe6
Summary:
When we pass `fn` to `nn.Module._apply()` and `fn` is an in-place operation, the correct behavior should also include bumping the parameters' and their gradients' version counters. This PR fixes the old incorrect behavior and makes sure the new behavior is right.
Note that this PR is BC-breaking in the following way:
Previously, passing an in-place operation to `nn.Module._apply()` does not bump the module's parameters' and their gradients' version counters. After this PR, the module's parameters' and their gradients' version counters will be correctly bumped by the in-place operation, which will invalidate them in any autograd graph they previously participate in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21865
Differential Revision: D15881952
Pulled By: yf225
fbshipit-source-id: 62f9244a4283a110147e9f20145ff232a5579fbd
Summary:
Added some extra tests for std_mean and var_mean for multiple dims.
Some refactoring of previously created tests based on PR comments: https://github.com/pytorch/pytorch/pull/18731
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20650
Differential Revision: D15396101
Pulled By: ifedan
fbshipit-source-id: d15c3c2c7084a24d6cfea4018173552fcc9c03a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21852
To enable change of q_scale and q_zero_point in `copy_`
Differential Revision: D15793427
fbshipit-source-id: a7040b5b956d161fd6af6176287f4a4aa877c9be
Summary:
The code in `python_sugared_value.cpp` to recursively compile methods
was not being tested, so this adds a test for it and fixes some errors
in it
It was necessary to disable any hooks set since (at least in our tests) they would try to export
a half-finished graph since they were being called on recursively
compiled methods
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21862
Differential Revision: D15860314
Pulled By: driazati
fbshipit-source-id: e8afe9d4c75c345b6e1471072d67c5e335b61337
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21914https://github.com/pytorch/pytorch/pull/21591 added a needed feature to clean up grad accumulator post hooks when the DistributedDataParallel model object is cleaned up. There's a minor typo that causes it to loop infinitely over the first element.
Differential Revision: D15878884
fbshipit-source-id: b7fd0bbd51eb187579d639b1709c6f7b62b85e7a
Summary:
This PR adds support for `in` checks like `key in my_dict`
For now it leaves lists as a follow up due to the changes around `IValue` lists and it needing an `IValue` equality op.
For objects it uses the magic method `__contains__(self, key)`
](https://our.intern.facebook.com/intern/diff/15811203/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21527
Pulled By: driazati
Differential Revision: D15811203
fbshipit-source-id: 95745060394f8a9450efaaf8ab09d9af83bea01e
Summary:
This adds support for inferred attributes (everything except empty lists, dicts, and tuples) as well as using the PEP 526 style annotations on a class, so this eliminates the need for `torch.jit.Attribute`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21379
Differential Revision: D15718537
Pulled By: driazati
fbshipit-source-id: b7481ae3d7ee421613e931b7dc3427ef2a99757f
Summary:
This is a fix for https://github.com/pytorch/pytorch/issues/21469
Currently there is no way to define if backward function released variables when variables were added to a vector. This change will set a flag if function has saved variables and they were released. So we will prevent if somebody will call this function again with already released variables.
Functions that do not have saved variables can be called multiple times for BC
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21533
Differential Revision: D15810481
Pulled By: ifedan
fbshipit-source-id: 5663e0c14f1b65727abc0d078aef348078d6a543
Summary:
This will need a conflict resolution once avg_pool2d() has been merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21732
Differential Revision: D15824923
Pulled By: ezyang
fbshipit-source-id: 83341e0209b660aecf788272079d8135d78b6ff1
Summary:
This was some code I added :^)
Time for me to remove it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21897
Differential Revision: D15873213
Pulled By: Chillee
fbshipit-source-id: 769c3bd71c542be4afddc02dc2f65aa5c751b10d
Summary:
What's the point of having warnings if we never fix them :^)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21898
Differential Revision: D15873280
Pulled By: Chillee
fbshipit-source-id: a8274bab2badd840d36a9d2e1354677a6114ae1d
Summary:
cosine_similarity has two non-tensor parameters, needs some special handling. Add the support for its export in this diff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21884
Reviewed By: zrphercule
Differential Revision: D15866807
Pulled By: houseroad
fbshipit-source-id: a165fbc00c65c44b276df89ae705ca8960349d48
Summary:
```
This replaces the kernel helpers in Loops.h/cuh with the following:
cpu_kernel
cpu_kernel_vec
gpu_kernel
gpu_kernel_with_scalars
These work with functions with any number of input arugments, with the
exception of 'gpu_kernel_with_scalars' which is limited to binary
operations. Previously, we only supported functions of 0, 1, or 2 input
arguments. Adding support for 3 or 4 input argument functions required
significant amount of additional code.
This makes a few other changes:
Remove 'ntensors' from the for_each/serial_for_each loop. Most loops
assume a fixed number of tensors, and the value is accessible from
TensorIterator::ntensors()
Only lift CPU scalars to parameters in 'gpu_kernel_with_scalars'.
Previously, we performed this recursively in gpu_unary_kernel and
gpu_binary_kernel, so something like `torch.add(3, 4, out=cuda_tensor)`
would specialize to a "nullary" kernel. Now, only the first
scalar input is lifted to a kernel parameter. Any additional scalar
inputs are copied to CUDA tensors. Note that operations like `x + 5`
and `5 + x` still work efficiently. This avoids generating an exponential
number of specializations in the number of input arguments.
```
**Performance measurements**
Timing numbers are unchanged for basic elementwise operations. Linked below is a script to measure torch.add perf on PR vs. master CPU+GPU (GCC 7.3):
[miniperf.py](https://gist.github.com/colesbury/4a61893a22809cb0931f08cd37127be4)
**Generated assembly**
cpu_kernel and cpu_kernel_vec still generate good vectorized code with
both GCC 7.3 and GCC 4.8.5. Below is the assembly for the "hot" inner loop of
torch.add as well as an auto-vectorized torch.mul implementation using cpu_kernel/
binary_kernel. (The real torch.mul uses cpu_kernel_vec but I wanted to check that
auto vectorization still works well):
[torch.add GCC 7.3](https://gist.github.com/colesbury/927ddbc71dc46899602589e85aef1331)
[torch.add GCC 4.8](https://gist.github.com/colesbury/f00e0aafd3d1c54e874e9718253dae16)
[torch.mul auto vectorized GCC 7.3](https://gist.github.com/colesbury/3077bfc65db9b4be4532c447bc0f8628)
[torch.mul auto vectorized GCC 4.8](https://gist.github.com/colesbury/1b38e158b3f0aaf8aad3a76963fcde86)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21475
Differential Revision: D15745116
Pulled By: colesbury
fbshipit-source-id: 914277d7930dc16e94f15bf87484a4ef82890f91
Summary:
PR https://github.com/pytorch/pytorch/issues/20685 incorrectly only enabled P2P access for non-contiguous copies.
This can make cudaMemcpy slow for inter-gpu copies, especially on ROCm
devices. I didn't notice a difference on CUDA 10, but ngimel says it's
important for CUDA too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21872
Differential Revision: D15863965
Pulled By: colesbury
fbshipit-source-id: 0a858f3c338fa2a5d05949d7f65fc05a70a9dfe1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21080
Add Huber loss as a new option for regression training (refer to TensorFlow implementation: https://fburl.com/9va71wwo)
# huber loss
def huber(true, pred, delta):
error = abs(true-pred)
loss = 0.5 * min(error, delta)^2 + delta * max(error - delta, 0)
return mean(loss)
As a combination of MSE loss (`x < delta`) and MAE loss (`x >= delta`), the advantage of Huber loss is to reduce the training dependence on outlier.
One thing worth to note is that Huber loss is not 2nd differential at `x = delta`. To further address this problem, one could consider adopt the loss of `LOG(cosh(x))`.
Reviewed By: chintak
Differential Revision: D15524377
fbshipit-source-id: 73acbe2728ce160c075f9acc65a1c21e3eb64e84
Summary:
After fixing https://github.com/pytorch/pytorch/issues/20774 the TRT build was broken
Because of missing annotations, pybind_state_gpu.so was missing symbols, but pybind_state.so did not. It caused a weird combination when trying to import pybind_state_gpu first left system in semi-initialized state and lead to sigsev.
Minimal repro:
```
>>> import ctypes
>>> ctypes.CDLL('/var/lib/jenkins/.local/lib/python2.7/site-packages/caffe2/python/caffe2_pybind11_state_gpu.so')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python2.7/ctypes/__init__.py", line 362, in __init__
self._handle = _dlopen(self._name, mode)
OSError: /var/lib/jenkins/.local/lib/python2.7/site-packages/caffe2/python/caffe2_pybind11_state_gpu.so: undefined symbol: _ZN6caffe219TensorRTTransformer9TransformEPNS_9WorkspaceEPNS_6NetDefERKSt13unordered_mapINSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEENS_11TensorShapeESt4hashISB_ESt8equal_toISB_ESaISt4pairIKSB_SC_EEE
>>> ctypes.CDLL('/var/lib/jenkins/.local/lib/python2.7/site-packages/caffe2/python/caffe2_pybind11_state.so')
Segmentation fault (core dumped)
```
Too lazy to repro locally, let's see if CI passes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21775
Differential Revision: D15829605
Pulled By: dzhulgakov
fbshipit-source-id: 1adb2bde56b0cd68f84cfca67bc050adcf787cd9
Summary:
Following up b811b6d5c03596d789a33d7891b606842e01f7d2
* Use property instead of __setattr__ in CMake.
* Add a comment clarifying when built_ext.run is called.
---
cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21792
Differential Revision: D15860606
Pulled By: umanwizard
fbshipit-source-id: ba1fa07f58d4eac81ac27fa9dc7115d1cdd3dec0
Summary:
https://github.com/pytorch/pytorch/issues/11866 has corrected this issue in function `host_softmax` (aten/src/ATen/native/SoftMax.cpp). But I tried the example proposed in https://github.com/pytorch/pytorch/issues/11752. `log_softmax` is still not working for big logits.
I have looked into the source code, found that example had called `vec_host_softmax_lastdim`, not `host_softmax`.
This code fixes the issue in `_vec_log_softmax_lastdim` and has a test for `log_softmax`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21672
Differential Revision: D15856327
Pulled By: VitalyFedyunin
fbshipit-source-id: 7a1fd3c0a03d366c99eb873e235361e4fcfa7567
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21735
ghimport-source-id: 4a4289693e372880e3d36e579c83d9e8745e70ed
Test Plan:
- I'm not sure how to test this other than making sure it compiles.
- [namedtensor ci]
gh-metadata: pytorch pytorch 21735 gh/zou3519/49/head
Imported from OSS
Differential Revision: D15833456
Pulled By: zou3519
fbshipit-source-id: ea2fa6d5c5f1eb2d7970d47189d6e4fcd947146d
Summary:
kuttas pointed out that the DDP Reducer only needs to remember `uintptr, Function` pairs, and hence does not need a nunordered map as added by https://github.com/pytorch/pytorch/issues/21591. Using a vector should speed it up a bit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21783
Differential Revision: D15854312
Pulled By: mrshenli
fbshipit-source-id: 153ba035b8d658c7878a613f16a42de977d89c43
Summary:
After https://github.com/pytorch/pytorch/pull/17072, we are allowed to pass Variables into ATen ops, thus there is no need to unwrap input variables in the c10 call path.
Note that since Caffe2 still expects inputs to be pure Tensors, we moved the unwrapping logic to the Caffe2 wrapper.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21620
Differential Revision: D15763560
Pulled By: yf225
fbshipit-source-id: 5375f0e51eb320f380ae599ebf98e6b259f0bff8
Summary:
This refactors pybind_utils so we can have all our type-inferring stuff in
1 place (e.g. for #21379)
There is some follow up work to make the error messages better, but I think that's fine to save for another PR.
](https://our.intern.facebook.com/intern/diff/15727002/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21550
Pulled By: driazati
Differential Revision: D15727002
fbshipit-source-id: a6974f2e1e5879f0503a18efc138da31cda7afa2
Summary:
Resolves https://github.com/pytorch/lockdown/issues/18
This implements NamedTuple by taking advantage of the existing `names` field in `TupleType`.
TODO: This currently doesn't retain the NamedTuple-ness through serialization. Discussed with suo offline, we can probably make a way to define an anonymous NamedTuple in script (e.g. `NamedTuple('Foo', [('a', int), ('b', float), ('c', List[float])])` and serialize that
TODO: implement support for calling the constructor with kwargs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21428
Differential Revision: D15741564
Pulled By: jamesr66a
fbshipit-source-id: c077cbcea1880675ca6deb340a9ec78f824a136c
Summary:
when enabling this flag, there were a lot of warnings, this pr focuses on the warnings where this comparison could be affecting array indices, which could be ones most prone to fail
the good news is that I didn't find anything obviously concerning
one degenerate case could be when the matrices we work with are too skinny could run into issues (dim1=1, dim2 needs to hold a big number)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18187
Differential Revision: D14527182
Pulled By: hyuen
fbshipit-source-id: b9f46b6f68ab912c55368961758a7a5af1805555
Summary:
We plan on generating python bindings for C++ ChunkDataset API using the current Pytorch Dataloader class, which must call get_batch() instead of get_batch(size)
This changes doesnt break the current API, just add one more method that will make future extensions easier (WIP)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21797
Differential Revision: D15830522
Pulled By: soumith
fbshipit-source-id: 7208f305b48bf65d2783eaff43ff57a05e62c255
Summary:
Originally, the tests for tensorboard writer are smoke tests only. This PR lets CI compare the output with expected results at low level. The randomness of the tensors in the test are also removed.
ps. I found that how protobuf serializes data differs between different python environment. One method to solve this is to write the data and then read it back instantly. (compare the data at a higher level)
For `add_custom_scalars`, the data to be written is a dictionary. and the serialized result might be different (not `ordereddict`). So only smoke test for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20987
Reviewed By: NarineK, lanpa
Differential Revision: D15804871
Pulled By: orionr
fbshipit-source-id: 69324c11ff823b19960d50def73adff36eb4a2ac
Summary:
Try to fix a sporadic failure on some CIs.
I've run this test hundreds of times on my machine (GeForce 1060, MAGMA) but I cannot reproduce this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21638
Differential Revision: D15827779
Pulled By: ezyang
fbshipit-source-id: 3586075e48907b3b84a101c560a34cc733514a02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21712
Warn when people use unordered_map or vector with IValues. These APIs are deprecated.
The unordered_map API is slow because it requires copying the whole map.
The vector API is slow for some types (e.g. std::string) because for them it also requires copying the whole map.
Also, the vector API would get slow for all types if we decide to switch to SmallVector.
Differential Revision: D15792428
fbshipit-source-id: 1b72406b3a8d56521c862858c9f0ed01e56f2757
Summary:
When kwargs are specified in a test defined via common_method_invocations, it doesn't work if there isn't also a positional argument (`{'foo':'foo'}` without a positional arg generates a python call like: `self.method(, foo=foo)`, erroring on the `,`). I wanted to test something in a different PR and noticed I couldn't.
Also fixed some flake8 warnings I was seeing locally.
I replaced `lambda x: x` with `ident` since it seems a bit cleaner to me, but happy to revert that if others don't agree?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21499
Differential Revision: D15826974
Pulled By: nairbv
fbshipit-source-id: a3f37c80ba2303c7d9ae06241df06c7475b64e36
Summary:
So far, we only have py2 ci for onnx. I think py3 support is important. And we have the plan to add onnxruntime backend tests, which only supports py3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21715
Reviewed By: bddppq
Differential Revision: D15796885
Pulled By: houseroad
fbshipit-source-id: 8554dbb75d13c57b67ca054446a13a016983326c
Summary:
Some data loader tests are flaky on py 2 with the following error
```
Jun 12 22:17:31 Traceback (most recent call last):
Jun 12 22:17:31 File "test_dataloader.py", line 798, in test_iterable_dataset
Jun 12 22:17:31 fetched = sorted([d.item() for d in dataloader_iter])
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 697, in __next__
Jun 12 22:17:31 idx, data = self._get_data()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 664, in _get_data
Jun 12 22:17:31 success, data = self._try_get_data()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 617, in _try_get_data
Jun 12 22:17:31 data = self.data_queue.get(timeout=timeout)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/multiprocessing/queues.py", line 135, in get
Jun 12 22:17:31 res = self._recv()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/multiprocessing/queue.py", line 22, in recv
Jun 12 22:17:31 return pickle.loads(buf)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/pickle.py", line 1382, in loads
Jun 12 22:17:31 return Unpickler(file).load()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/pickle.py", line 858, in load
Jun 12 22:17:31 dispatch[key](self)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/pickle.py", line 1133, in load_reduce
Jun 12 22:17:31 value = func(*args)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/multiprocessing/reductions.py", line 274, in rebuild_storage_fd
Jun 12 22:17:31 fd = multiprocessing.reduction.rebuild_handle(df)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/multiprocessing/reduction.py", line 157, in rebuild_handle
Jun 12 22:17:31 new_handle = recv_handle(conn)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/multiprocessing/reduction.py", line 83, in recv_handle
Jun 12 22:17:31 return _multiprocessing.recvfd(conn.fileno())
Jun 12 22:17:31 OSError: [Errno 4] Interrupted system call
```
Apparently, Python 2.7's `recvfd` calls `recvmsg` without EINTR retry: https://github.com/python/cpython/blob/2.7/Modules/_multiprocessing/multiprocessing.c#L174
So we should call it with an outer try-catch loop.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21723
Differential Revision: D15806247
Pulled By: ezyang
fbshipit-source-id: 16cb661cc0fb418fd37353a1fef7ceeb634f02b7
Summary:
Currently when building extensions, variables such as USE_CUDA, USE_CUDNN are used to determine what libraries should be linked. But we should use what CMake has detected, because:
1. If CMake found them unavailable but the variables say some libraries should be linked, the build would fail.
2. If the first build is made using a set of non-default build options, rebuild must have these option passed to setup.py again, otherwise the extension build process is inconsistent with CMake. For example,
```bash
# First build
USE_CUDA=0 python setup.py install
# Subsequent builds like this would fail, unless "build/" is deleted
python setup.py install
```
This commit addresses the above issues by using variables from CMakeCache.txt when building the extensions.
---
The changes in `setup.py` may look lengthy, but the biggest changed block is mostly moving them into a function `configure_extension_build` (along with some variable names changed to `cmake_cache_vars['variable name']` and other minor changes), because it must be called after CMake has been called (and thus the options used and system environment detected by CMake become available).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21653
Differential Revision: D15824506
Pulled By: ezyang
fbshipit-source-id: 1e1eb7eec7debba30738f65472ccad966ee74028
Summary:
This makes the error thrown in aten_to_numpy_dtype consistent with that in numpy_dtype_to_aten.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21608
Differential Revision: D15816035
Pulled By: gchanan
fbshipit-source-id: 392e8b9ea37003a859e7ed459911a1700fcbd695
Summary:
This PR is intended as a fix for https://github.com/pytorch/pytorch/issues/21644.
It allows the `with emit_nvtx` context manager to take an additional `record_shapes` argument. `record_shapes` is False by default, but if True, the nvtx ranges generated for each autograd op will append additional information about the sizes of Tensors received by that op.
The format of shape information is equivalent to what the CPU-side profiler spits out. For example,
```
M = torch.randn(2, 3)
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 3)
with torch.cuda.profiler.profile():
with torch.autograd.profiler.emit_nvtx(record_shapes=True):
torch.addmm(M, mat1, mat2)
```
produces the following nvtx range label for addmm:

(cf the "Input Shapes" shown in 864cfbc216 (diff-115b6d48fa8c0ff33fa94b8fce8877b6))
I also took the opportunity to do some minor docstring cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21691
Differential Revision: D15816226
Pulled By: gchanan
fbshipit-source-id: b2b01ea10fea61a6409a32b41e85b6c8b4851bed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20924
I found a python3 bug for deserializing caffe2 code. The exception thrown is Unicode related error instead of just decode error, and we need to catch that as well
Reviewed By: ipiszy
Differential Revision: D15293221
fbshipit-source-id: 29820800d1b4cbe5bf3f5a189fe2023e655d0508
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21763
Custom __getattr__ functions can only raise AttributeError. This code throwed NotImplementedError which caused upstream troubles when hasattr() was called.
Differential Revision: D15815176
fbshipit-source-id: 0982e2382de4578d3fc05c5d2a63f624d6b4765e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21446
this is used for easier tracing of iter id when looking at trace diagram
Reviewed By: ilia-cher
Differential Revision: D15628950
fbshipit-source-id: ee75b3bdb14a36abc18c7bddc49d8ec9789b724d
Summary:
```
The stride calculation using OffsetCalculator performs poorly with
MAX_DIMS=25. This reduces MAX_DIMS (after coalescing) to 16 on ROCm.
I think it's unlikely that anyone will exceed this limit. If they do,
we can add additional specializations for ROCm with more dimensions.
```
I'm not sure about the underlying cause. With MAX_DIM=25, the add kernel's params
is ~648 bytes vs. ~424 bytes with MAX_DIM=16. The kernel instruction footprint is
bigger too, but most of these instructions are never executed and most kernel parameters
are never loaded because the typical dimensionality is much smaller.
Mini benchmark here:
https://gist.github.com/colesbury/1e917ae6a0ca9d24712121b92fed4c8f
(broadcasting operations are much faster)
cc iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21754
Reviewed By: bddppq
Differential Revision: D15811906
Pulled By: colesbury
fbshipit-source-id: 063f92c083d26e2ef2edc98df7ff0400f9432b9d
Summary:
Currently multihead attention for half type is broken
```
File "/home/ngimel/pytorch/torch/nn/functional.py", line 3279, in multi_head_attention_forward
attn_output = torch.bmm(attn_output_weights, v)
RuntimeError: Expected object of scalar type Float but got scalar type Half for argument https://github.com/pytorch/pytorch/issues/2 'mat2'
```
because softmax converts half inputs into fp32 inputs. This is unnecessary - all the computations in softmax will be done in fp32 anyway, and the results need to be converted into fp16 for the subsequent batch matrix multiply, so nothing is gained by writing them out in fp32. This PR gets rid of type casting in softmax, so that half works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21658
Differential Revision: D15807487
Pulled By: zhangguanheng66
fbshipit-source-id: 4709ec71a36383d0d35a8f01021e12e22b94992d
Summary:
In this PR, we use `expect` to fill in the token for pytorchbot when doing `git push`, so that we don't need to save the token in the git remote URL.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20459
Differential Revision: D15811676
Pulled By: yf225
fbshipit-source-id: cd3b780da05d202305f76878e55c3435590f15a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21742
Add error message to NotImplementedError so we know which function it is about.
Reviewed By: bddppq
Differential Revision: D15806379
fbshipit-source-id: 14eab9d03aa5b44ab95c5caeadc0e01d51f22188
Summary:
When converting pixel_shuffle to reshape + transpose + reshape, the first reshape should
be:
[N, C * r^2, H, W] => [N, C, r, r, H, W]
in order to match pytorch's implementation (see ATen PixelShuffle.cpp).
This previously wasn't caught by the test case, since it uses C = r = 4. Updated test case to
have C = 2, r = 4.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21486
Reviewed By: houseroad
Differential Revision: D15700945
Pulled By: houseroad
fbshipit-source-id: 47019691fdc20e152e867c7f6fd57da104a12948
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21718
adding a detection method on whether the package is built for AMD.
Reviewed By: bddppq
Differential Revision: D15795893
fbshipit-source-id: 91a21ee76b2273b1032507bdebe57e016717181d
Summary:
**Closes:** Confusing documentation with distributions.Categorical about logits https://github.com/pytorch/pytorch/issues/16291
**Solution**: Changes documentation on the Categorical distribution from `log probabilities` to `event log-odds`. This makes should reduce confusion as raised by this issue, and is consistent with other distributions such as `torch.Binomial`.
More than happy to make any other changes if they fit :).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21707
Differential Revision: D15799181
Pulled By: soumith
fbshipit-source-id: f11acca7a5c130102a3ff6674640235ee5aa69bf
Summary:
- [x] Add tests after https://github.com/pytorch/pytorch/pull/20256 is merged
- Support exporting ScriptModule with inputs/outputs of arbitrarily constructed tuples.
- Moved the assigning of output shapes to after graph conversion to ONNX is completed. By then all tuples in the IR has already been lowered by the pass ```_jit_pass_lower_all_tuples```. If assigning output shapes is required to happen before that, we'll need to hand parse the tuple structures in the graph, and repeat the same logic in ```_jit_pass_lower_all_tuples```. Handling inputs is easier because all tuple information is encoded within the input tensor type.
- Swap the order of ```_jit_pass_lower_all_tuples``` and ```_jit_pass_erase_number_types```. Ops like ```prim::TupleIndex``` relies on index being a scalar. ```_jit_pass_erase_number_types``` will convert these kind of scalars to tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20784
Reviewed By: zrphercule
Differential Revision: D15484171
Pulled By: houseroad
fbshipit-source-id: 4767a84038244c929f5662758047af6cb92228d3
Summary:
This renames the CMake `caffe2` target to `torch`, as well as renaming `caffe2_gpu` to `torch_gpu` (and likewise for other gpu target variants). Many intermediate variables that don't manifest as artifacts of the build remain for now with the "caffe2" name; a complete purge of `caffe2` from CMake variable names is beyond the scope of this PR.
The shell `libtorch` library that had been introduced as a stopgap in https://github.com/pytorch/pytorch/issues/17783 is again flattened in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20774
Differential Revision: D15769965
Pulled By: kostmo
fbshipit-source-id: b86e8c410099f90be0468e30176207d3ad40c821
Summary:
Class member annotations can be marked with `Final[T]` instead of adding them to `__constants__`. `Final` comes from the `typing_extensions` module (which will be used if it is present). If not, the polyfill from `_jit_internal` is exposed as `torch.jit.Final` for users that don't want to install `typing_extensions`.
This keeps around `__constants__` since a lot of code is still using it, but in documentation follow ups we should change the examples to all to use `Final`.
TODO: install typing_extensions on CI, move tests to a Python3 only file when #21489 lands
](https://our.intern.facebook.com/intern/diff/15746274/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21603
Pulled By: driazati
Differential Revision: D15746274
fbshipit-source-id: d2c9b5643b4abba069b130c26fd42714c906ffac
Summary:
This adds support for PEP 526 style annotations on assignments in place of
`torch.jit.annotate()`, so
```python
a = torch.jit.annotate(List[int], [])
```
turns into
```python
a : List[int] = []
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21390
Differential Revision: D15790937
Pulled By: driazati
fbshipit-source-id: 0cc204f7209a79839d330663cc6ba8320d3a4120
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21177
- Integrate c10::ListPtr into IValue and the c10 dispatcher.
- Streamline conversion to/from IValue. Before, we had IValue::to<> and kernel_functor.h had its own ivalue_to_arg_type and return_type_to_ivalue. They are now unified. Also, this means that nested types like Dicts of Lists of Optional of Dict of ... do work as expected now
Differential Revision: D15476433
fbshipit-source-id: bde9df80df20091aa8e6ae17ba7e90abd149b954
Summary:
Accidentally rebased the old PR and make it too messy. Find it here (https://github.com/pytorch/pytorch/pull/19274)
Create a PR for comments. The model is still WIP but I want to have some feedbacks before moving too far. The transformer model depends on several modules, like MultiheadAttention (landed).
Transformer is implemented based on the paper (https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf). Users have the flexibility to build a transformer with self-defined and/or built-in components (i.e encoder, decoder, encoder_layer, decoder_layer). Users could use Transformer class to build a standard transformer model and modify sub-layers as needed.
Add a few unit tests for the transformer module, as follow:
TestNN.test_Transformer_cell
TestNN.test_transformerencoderlayer
TestNN.test_transformerdecoderlayer
TestNN.test_transformer_args_check
TestScript.test_scriptmodule_transformer_cuda
There is another demonstration example for applying transformer module on the word language problem. https://github.com/pytorch/examples/pull/555
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20170
Differential Revision: D15417983
Pulled By: zhangguanheng66
fbshipit-source-id: 7ce771a7e27715acd9a23d60bf44917a90d1d572
Summary:
Currently we don't have any Linux libtorch binary build in the PR CI, which led to nightly build failure such as https://circleci.com/gh/pytorch/pytorch/1939687. This PR adds Linux libtorch CPU binary build to prevent such breakage from happening in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21671
Differential Revision: D15785003
Pulled By: yf225
fbshipit-source-id: d1f2e4235e48296ddecb3367f8e5a0df16f4ea49
Summary:
Fix https://github.com/pytorch/pytorch/issues/20421
`ProcessGroupGloo` only requires input/output tensors to be contiguous. Contiguous tensors might not start from the beginning of the underlying storage, e.g., `chunk(..., dim=0)[1]`. The current implementation passes `tensor.storage().data()` ptr to gloo buffer. This leads to wrong results if the tensor has a non-zero storage offset.
The proposed solution is to use `tensor.data_ptr()` instead. Let's see if this breaks any tests.
cc qijianan777
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21490
Differential Revision: D15768907
Pulled By: mrshenli
fbshipit-source-id: 9d7d1e9baf0461b31187c7d21a4a53b1fbb07397
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21592
We now support groupwise convolutions for qconv2d
Reviewed By: zafartahirov
Differential Revision: D15739239
fbshipit-source-id: 80b9b4fef5b9ee3d22ebecbaf205b970ab3d4250
Summary:
Closes https://github.com/pytorch/pytorch/issues/21344
DDP assigns the original module to the first module replica instead of creating a new one. Then, it creates a new Reducer to add post hooks to sync gradients. However, because every reconstructed DDP instance wraps the same original module, all their reducers will add hooks to the same set of variables. This PR deletes DDP hooks from variables when destructing Reducer, trying to make DDP failure recoverable.
pietern kuttas and I discussed the following solutions:
#### Solution 1
Keep `add_post_hook` API intact, and do a `dynamic_cast` in `del_post_hook` to check hook type. If the type matches Reducer's hook, delete it. As pietern mentioned, this will not work if we create multiple DDP instances from the same original model.
#### Solution 2
Use a counter to generate a unique key for every hook in `Function`, and keep them in a map. return the key to the caller of `add_post_hook`, and ask the caller to provide key if it needs to delete the hook.
Con: this would add extra overhead to `add_post_hook` and every `Function` object.
#### Solution 3 [Current implementation]
kuttas suggests that, instead of generating a unique key, directly using the address of the pointer would be better. In order to avoid messing up dereferencing, let `add_post_hook` to return a `uintptr_t`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21591
Differential Revision: D15745706
Pulled By: mrshenli
fbshipit-source-id: e56d2d48de0c65f6667790ab16337eac7f7d8b76
Summary:
This makes it so we can see the output of prim::Print in environments like iPython notebooks which override sys.stdout
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21625
Differential Revision: D15756793
Pulled By: jamesr66a
fbshipit-source-id: 7d9a14b2e229ed358e784318e9d862677db2c461
Summary:
Emit loop condition as a separate block in loops, then inline them before conversion to SSA. This is needed for breaks & continues where we will inline the condition block after the continue pass and before the break pass.
I also considered emitting a prim::For and a prim::While, but i think it's easier to just have one pathway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21611
Differential Revision: D15775820
Pulled By: eellison
fbshipit-source-id: de17c5e65f6e4a0256a660948b1eb630e41b04fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21606
StoreMatrixInMatrixMarketFormat was able to dump quantized tensors only but sometimes we want to dump float tensors.
Reviewed By: csummersea
Differential Revision: D15741611
fbshipit-source-id: 95b03c2fdf1bd8407f7d925171d9dc9f25677464
Summary:
Stream is not respected on range/linspace/logspace functions, which contributes to https://github.com/pytorch/pytorch/issues/21589 (this is not a complete solution for that issue).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21619
Differential Revision: D15769666
Pulled By: ezyang
fbshipit-source-id: 7c036f7aecb3119430c4d432775cad98a5028fa8
Summary:
Resolves issue https://github.com/pytorch/pytorch/issues/19003
The author of this issue also asked that `cycle_momentum` default to `False` if the optimizer does not have a momentum parameter, but I'm not sure what the best way to do this would be. Silently changing the value based on the optimizer may confuse the user in some cases (say the user explicitly set `cycle_momentum=True` but doesn't know that the Adam optimizer doesn't use momentum).
Maybe printing a warning when switching this argument's value would suffice?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20401
Differential Revision: D15765463
Pulled By: ezyang
fbshipit-source-id: 88ddabd9e960c46f3471f37ea46013e6b4137eaf
Summary:
This adds support for PEP 526 style annotations on assignments in place of
`torch.jit.annotate()`, so
```python
a = torch.jit.annotate(List[int], [])
```
turns into
```python
a : List[int] = []
```
](https://our.intern.facebook.com/intern/diff/15706021/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21390
Pulled By: driazati
Differential Revision: D15706021
fbshipit-source-id: 8bf1459f229d5fd0e16e59953b9656e85a2207fb
Summary:
Ops on a Process Group (pg) instance will hit an error when input/output tensors are created on a different process, because, pg calls `recordStream` on `CUDACachingAllocator` which only knows tensors created within the same process.
The proposed solution is to add a `suppressError` arg (suggestions for better names?) to `recordStream`. See comments in code for arguments.
CC pichuang1984
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21449
Differential Revision: D15689736
Pulled By: mrshenli
fbshipit-source-id: e7fc81b167868f8666536067eaa7ae2c8584d88e
Summary:
1. reduce the overhead of mkldnn-bridge itself
2. remove redundant code and useless APIs
3. provide new operators, including int8 inner_product, ND permute/transpose, elem_add/mul, and etc.
4. improve inner_product to support io format weights without implicit reorder
5. add SoftMax support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20569
Reviewed By: houseroad
Differential Revision: D15558663
Pulled By: bddppq
fbshipit-source-id: 79a63aa139037924e9ffb1069f7e7f1d334efe3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21207
This diff adds 80 PT pointwise unary ops to the benchmark suite. Most of the ops are added using the generate_pt_tests_from_list interface. The rest are handled separately.
Reviewed By: zheng-xq
Differential Revision: D15471597
fbshipit-source-id: 8ea36e292a38b1dc50f064a48c8cd07dbf78ae56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21210
This diff introduces a new path to run op with JIT. There are two steps involved here:
1. Users need to script the op. This should happen in the `init` method.
2. The generated graph from step1 is passed to `jit_forward` which will be executed by the benchmark backend
Reviewed By: zheng-xq
Differential Revision: D15460831
fbshipit-source-id: 48441d9cd4be5d0acebab901f45544616e6ed2ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20723
These classes already existed but only as c10::Dict and c10::OperatorKernel.
Since they're now part of torch::RegisterOperators(), they should also live in the torch namespace.
Differential Revision: D15421575
fbshipit-source-id: d64ebd8664fadc264bbbae7eca1faa182529a32b
Summary:
yf225 helped me discovered that our CI does not run multi-gpu tests in `test_c10d.py`. There are quite a few multi-gpu c10d tests. This PR tries to enable those tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21598
Differential Revision: D15744256
Pulled By: mrshenli
fbshipit-source-id: 0a1524a862946128321f66fc8b7f331eff10e52a
Summary:
Create an uninitialized ivalue. This will be needed for Breaks & Continues to match up if block outputs of values that are guaranteed not to be used but need to escape the block scope. It is not exposed to users.
Was previously part of final returns but I was asked to make a separate PR for it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21387
Differential Revision: D15745124
Pulled By: eellison
fbshipit-source-id: ae6a6f766b4a70a71b9033987a630cfbf044e296
Summary:
For consistency, derivatives.yaml now uses the same schema specification as native_functions.yaml.
Note that there are some small downsides, e.g. changing the default values or return parameter names in native_functions.yaml also now requires updating derivatives.yaml as well. But this has a few nice properties:
1) Able to copy-paste definitions from native_functions to derivatives.
2) Makes it impossible to write derivatives for operators without schemas (e.g. old TH operators).
3) Moves us closer to the ideal situation of co-locating forward and backwards declarations.
Note that this doesn't change any generated code; in particular, this has the same behavior of mapping in-place and out-of-place definitions together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20916
Differential Revision: D15497800
Pulled By: gchanan
fbshipit-source-id: baee5caf56b675ce78dda4aaf6ce6a34575a6432
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21599
We prevented this because c10 ops can't have a backwards yet and calling them with requires_grad=True would do the wrong thing
if the c10 op is not purely implemented by calling other autograd-able ops.
However, it is a valid use case to have c10 ops that just call other autograd-aware ops, and these ops should be callable with requires_grad=True.
This should fix https://github.com/pytorch/pytorch/issues/21584.
Differential Revision: D15744692
fbshipit-source-id: ba665365c850ef63fc9c51498fd69afe49e5d7ec
Summary:
An incorrect increment / decrement caused the samples to not be generated from a multinomial distribution
Changelog:
- Remove the incorrect increment / decrement operation
Fixes#21257, fixes#21508
cc: LeviViana neerajprad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21324
Differential Revision: D15717575
Pulled By: ezyang
fbshipit-source-id: b1154e226d426c0d412d360c15f7c64aec95d101
Summary:
test that wasn't on the CI, but is tested internally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21594
Differential Revision: D15742157
Pulled By: eellison
fbshipit-source-id: 11fc82d1fc0281ffedd674ed96100e0c783c0599
Summary:
This PR addresses some numerical issues of Sigmoid/StickBreakingTransform, where these transforms give +-inf when the unconstrained values move to +-20 areas.
For example, with
```
t = torch.distributions.SigmoidTransform()
x = torch.tensor(20.)
t.inv(t(x)), t.log_abs_det_jacobian(x, t(x))
```
current behaviour the inverse will return `inf` and logdet return `-inf` while this PR makes it to `15.9424` and `-15.9424`.
And for
```
t = torch.distributions.StickBreakingTransform()
x = torch.tensor([20., 20.])
t.inv(t(x)), t.log_abs_det_jacobian(x, t(x))
```
current value is `(inf, nan)` and `-inf` for logdet, while this PR makes it `[16.6355, 71.3942]` and `-47.8272` for logdet.
Although these finite values are wrong and seems unavoidable, it is better than returning `inf` or `nan` in my opinion. This is useful in HMC where despite that the grad will be zero when the unconstrained parameter moves to unstable area (due to clipping), velocity variable will force the parameter move to another area which by chance can move the parameter out of unstable area. But inf/nan can be useful to stop doing inference early. So the changes in this PR might be inappropriate.
I also fix some small issues of `_Simplex` and `_RealVector` constraints where batch shape of the input is not respected when checking validation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20288
Differential Revision: D15742047
Pulled By: ezyang
fbshipit-source-id: b427ed1752c41327abb3957f98d4b289307a7d17
Summary:
This changes our compiler so it first emits Loads & Stores, and then transforms the graph to SSA in a follow up pass. When a variable is set, we emit a prim::Store, and when a variable is referenced, we emit a prim::Load.
```
a = 1
print(a)
```
becomes:
```
%a.1 : int = prim::Constant[value=1]()
prim::Store[name="a"](%a.1)
%a : int = prim::Load[name="a"]()
prim::Print(%a)
```
In the follow up pass, convertToSSA, the values are turned into SSA form with the Loads & Stores removed. This change will enable breaks and continues because you can transform the graph with the variable naming information still intact.
There are still some remaining jitter and edge cases issues that I have to look through, but I think is still ready for eview.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21101
Differential Revision: D15723353
Pulled By: eellison
fbshipit-source-id: 3269934d4bc24ddaf3a87fdd20620b0f954d83d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21382
Concat tensor inference function was not handling correctly the case where axis argument points to the last dimension so input tensors don't need to have the same number of dimensions.
Split tensor inference function was not handling correctly the case where split information is provided as the second input tensor rather than as an argument.
Reviewed By: mdschatz
Differential Revision: D15633148
fbshipit-source-id: d566af44dc882457ee9efe83d2461b28408c2c5d
Summary:
Should be self-explanatory. This `int` variable is overflowing.
Reported in #21526
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21530
Differential Revision: D15719275
Pulled By: umanwizard
fbshipit-source-id: 24e917a00a5b78bc3af29ef3b8b72eea7e89d5d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21556
Optimize batch mm op when broadcast the second input
Reviewed By: houseroad
Differential Revision: D15728914
fbshipit-source-id: c60441d69d4997dd32a3566780496c7ccda5e67a
Summary:
This was looking at the number of elements in the memo table, not the total capacity, and was thus calling reserve() a lot more than it should have
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21542
Reviewed By: driazati
Differential Revision: D15723132
Pulled By: jamesr66a
fbshipit-source-id: 20e1f9099b6a51a33994ea9dbc3f22eb3bc0c8f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21195
The motivation is that, while we shouldn't break USER code for using
deprecated declarations, we should keep our internal code base
deprecation clean.
Differential Revision: D15576968
fbshipit-source-id: fb73a8986a5b60bf49ee18260653100319bb1030
Summary:
namedtensor build + test should run on PRs only if the commit message
includes [namedtensor ci].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21520
Differential Revision: D15718404
Pulled By: zou3519
fbshipit-source-id: ce8b5df2682e795e64958a9d49e2e3c091599b33
Summary:
This should further reduce noise by only clang-formatting the lines you actually touched in the precommit hook.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15657
Differential Revision: D15717337
Pulled By: suo
fbshipit-source-id: 57e65a679a8fdee5c3ff28e241c74ced9398eb0c
Summary:
The new implementation of tracing supports more module. So many error-handling code can be removed by placing the old one (LegacyTracedModule).
cc orionr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21339
Reviewed By: natalialunova
Differential Revision: D15695154
Pulled By: orionr
fbshipit-source-id: af7d35754e9f34bd1a0ad7b72a9ebe276ff8ab98
Summary:
Fixes#12259, needs to make sure tests (see #13766) don't break due to numerical precision issues. Not sure what would need to be adjusted here...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13774
Differential Revision: D15715021
Pulled By: ezyang
fbshipit-source-id: 20ce2beee1b39ebe9f023c5f2b25be53acccb5f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21492
If one async operator failed, async_scheduling net currently only marks all scheduled async operators as finished without cancelling the callbacks.
The new behavior is to cancel the callbacks first, then set event status to finished.
Reviewed By: ilia-cher
Differential Revision: D15702475
fbshipit-source-id: 55a1774d768b2e238bab859b83332f1877a001ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21502
In BenchResult, we keep name, avg_fwd, std_fwd, avg_bwd, and std_bwd. There is no information about the number of each iteration. In this diff, I am adding more info to BenchResult to include the number reported from each iteration.
Reviewed By: wanchaol
Differential Revision: D15706306
fbshipit-source-id: 3f14be4ba91f1f6da473995783bd7af1d067938d
Summary:
This moves `JitTestCase` to its own file so that we can have other jit
test files (ex. `test_jit_py3.py`)
There aren't any code changes, just a move and cleaning up the imports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21491
Pulled By: driazati
Differential Revision: D15703060
fbshipit-source-id: 6082e8b482100bb7b0cd9ae69738f1273e626171
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21230
tsia; we support empty tensor with this diff for reshape operator
Reviewed By: jerryzh168
Differential Revision: D15583356
fbshipit-source-id: 6d44c04e95ca3546509bfb12102e29c878f9a7c7
Summary:
Modify MKLDNN pooling operation to support ceil mode by adjusting the right/bottom padding accordingly. This is done similarly as in Caffe (see discussion https://github.com/pytorch/pytorch/pull/19205#discussion_r276903751).
To make this possible, I split the padding to left and right (top / bottom). This naming is confusing but actually follows mkldnn's own naming for pooling::compute(). We increase the r paddings so that it matches the ceiling mode expected output size.
Strengthened the test case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21310
Reviewed By: bddppq
Differential Revision: D15611664
Pulled By: akyrola
fbshipit-source-id: 46b40015dafef69a8fd5e7b2c261d8dbf448cd20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21393
Result of splitting the base diff. We moved a header from src/* to include/fbgemm/*
Reviewed By: jianyuh
Differential Revision: D15635188
fbshipit-source-id: ad7d0ddba964ff1cb8b2e33f5f98e457a4d2eac9
Summary:
changed `UpsampleBilinearKernel` s.t. the throughput increased 40~50%.
I tested locally with my local test code -- **not pytorch's provided test code** -- because I am having a build problem ( which I made an issue about [here](https://github.com/pytorch/pytorch/issues/19184)). I tested with various tensor sizes and across all the sizes, it should a significant increase in throughput.
1. added `__restrict__`
2. instead of launch as many threads as there are output elements, I launched only `output_height * output_width` may threads and had each thread iterate through the channel and batch dimension.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19306
Differential Revision: D15701840
Pulled By: ezyang
fbshipit-source-id: 53c54d4f4e4a28b58ecc7d7ae6b864cbfc760e27
Summary:
Currently, when the input of MVN is precision matrix, we take inverse to convert the result to covariance matrix. This, however, will easily make the covariance matrix not positive definite, hence will trigger a cholesky error.
For example,
```
import torch
torch.manual_seed(0)
x = torch.randn(10)
P = torch.exp(-(x - x.unsqueeze(-1)) ** 2)
torch.distributions.MultivariateNormal(loc=torch.ones(10), precision_matrix=P)
```
will trigger `RuntimeError: cholesky_cpu: U(8,8) is zero, singular U.`
This PR uses some math tricks ([ref](https://nbviewer.jupyter.org/gist/fehiepsi/5ef8e09e61604f10607380467eb82006#Precision-to-scale_tril)) to only take inverse of a triangular matrix, hence increase the stability.
cc fritzo, neerajprad , SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21366
Differential Revision: D15696972
Pulled By: ezyang
fbshipit-source-id: cec13f7dfdbd06dee94b8bed8ff0b3e720c7a188
Summary:
This PR addresses the problem described in the comment: https://github.com/pytorch/pytorch/pull/20203#issuecomment-499231276
and previously coded bad behaviour:
- a warning was raised all the times when lr schedulling is initialized
Now the code checks that:
- on the second call of `lr_scheduler.step`, ensure that `optimizer.step` has been already called, otherwise raise a warning (as it was done in #20203 )
- if optimizer's step is overridden -> raise once another warning to aware user about the new pattern:
`opt.step()` -> `lrs.step()` as we can not check this .
Now tests check that
- at initialization (`lrs = StepLR(...)`)there is no warnings
- if we replace `optimizer.step` by something else (similarly to the [code of nvidia/apex](https://github.com/NVIDIA/apex/blob/master/apex/amp/_process_optimizer.py#L287)) there is another warning raised.
cc ezyang
PS. honestly I would say that there is a lot of overhead introduced for simple warnings. I hope all these checks will be removed in future `1.2.0` or other versions...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21460
Differential Revision: D15701776
Pulled By: ezyang
fbshipit-source-id: eac5712b9146d9d3392a30f6339cd33d90c497c7
Summary:
Fixes#21026.
1. Improve build docs for Windows
2. Change `BUILD_SHARED_LIBS=ON` for Caffe2 local builds
3. Change to out-source builds for LibTorch and Caffe2 (transferred to #21452)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21190
Differential Revision: D15695223
Pulled By: ezyang
fbshipit-source-id: 0ad69d7553a40fe627582c8e0dcf655f6f63bfdf
Summary:
Another simple bit of syntax that NumPy supports and we don't.
Support int, float, and bool.
```python
>>> torch.randn((2,3), dtype=float)
tensor([[-0.1752, -0.3240, -0.6148],
[ 0.1861, 1.6472, 0.1687]], dtype=torch.float64)
```
A bit confusingly, Python's "float" actually means double, but nothing we can do about that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21215
Differential Revision: D15697012
Pulled By: umanwizard
fbshipit-source-id: 9a38d960a610b8e67023486b0c9265edd3c22246
Summary:
Adds support for recursively compiling `nn.Sequential` and
`nn.ModuleList`. When either is used, it is converted to a
`jit._ConstModuleList` or `jit._ConstSequential` as necessary. Due to
this, we don't need to add it to `__constants__` since it's made
constant on demand.
This PR also moves the recursive script tests out to their own class
`TestRecursiveScript` (the added test is called `test_iterable_modules`)
](https://our.intern.facebook.com/intern/diff/15611738/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21306
Pulled By: driazati
Differential Revision: D15611738
fbshipit-source-id: fac52993990bd2dfad71d044c463a58a3759932a
Summary:
Enable bool tensors for these index methods:
- index_select
- index_copy
- put
- take
- index_fill
Tested via unit tests
TODO:
Enable index_add in a separate PR as it requires more "side" changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21435
Differential Revision: D15684964
Pulled By: izdeby
fbshipit-source-id: 48440e4d44873d70c4577e017dd0d8977e0fa15a
Summary:
`torch.tensor([True, False, True], dtype=torch.bool).sum()` should return **2** instead of **True** as it does now.
Tested via unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21421
Differential Revision: D15674203
Pulled By: izdeby
fbshipit-source-id: b00e3d0ca809c9b92b750adc05632522dad50c74
Summary:
Fixes#19540
CC nmerrill67
C++ data parallel was using Module.clone() to create module replicas on every destination device. However, clone() does not set up gradient edges to point from replicas to the original module. As a result, the gradient will not be aggregated into the original module. This commit fixes the the problem by manually setting gradient edges from every parameter X in every replica to the same parameter X in the original module.
## Failed Attempt
Initially I tried implementing what we did in `replicate.py`, which
1. create module replicas
2. use Python `Broadcast` autograd function to broadcast every parameter in the original module to all destination devices.
3. assign the broadcast result params to module replicas' `_parameters` dict.
This works in Python because derived module member field params (e.g., `Linear.weight`) and base module `_parameters` (e.g., `Linear._parameters['weight']`) are referencing the same parameter instance. Assigning one of them will apply to both. However, in C++, even though I can modify Module's `parameters_ `values and gradient edges to point to the broadcast source, I cannot touch the weight and bias member fields in Linear, because replicate cannot (and should not) add special-case handlers to every different module. (See `Linear` [.h](https://github.com/pytorch/pytorch/blob/master/torch/csrc/api/include/torch/nn/modules/linear.h), [.cpp](https://github.com/pytorch/pytorch/blob/master/torch/csrc/api/src/nn/modules/linear.cpp)) Although they initially point to the same `TensorImpl` instance, after assigning to `Module.parameters_['weight']`, it will be different from `Linear.weight`.
## Solution Options
gchanan and I had several discussions on this issue and figured two solutions to this problem.
### Option One [implemented in this PR]
Replicate the module in two steps:
1. call `Module.clone()` to create a module replica on every destination device.
2. manually setting gradient edges from every parameter in every replica to the same parameter in the original module.
* Pro: Does not need to change any existing module, and relatively easier to implement
* Con: It is a little hackish.
### Options Two
Implement a `Replicatable` class (similar to `Cloneable`), and make it a friend class of `Module`. For more details see `Note [Replicating Modules]` in the code change.
* Pro: Maybe this aligns more with our existing approach implemented in `Cloneable`?
* Con: Require changes to every existing module.
I am inclined to go with option one, because `replicate` will only be used on data parallel. I feel it is too big an overkill if we have to change all existing module implementations due to a data parallel requirement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20910
Differential Revision: D15556426
Pulled By: mrshenli
fbshipit-source-id: aa836290ec657b32742e2bea80bd0ac2404ef3b0
Summary:
Fixed an issue where models can not be loaded in a 32-bit environment like Raspbian.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20900
Differential Revision: D15696709
Pulled By: ezyang
fbshipit-source-id: 37a81f05f235d3b9fc6244e12d3320ced3d1465e
Summary:
Current versions of NVRTC incorrectly map error code 7 to the error string "NVRTC unknown error." This update maps error code 7 to the correct string explicitly in PyTorch. See the documentation at: https://docs.nvidia.com/cuda/nvrtc/index.html#group__error.
This may give us a better idea of the source of NVRTC errors that some community members, like Uber, have reported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21174
Differential Revision: D15696593
Pulled By: ezyang
fbshipit-source-id: f5c7b5876c07b311ab5f2d7c8e375e93273912c6
Summary:
Fixed#21269 by removed the the expected `ValueError` when converting a tensor to a Numpy `int8` array in the Numba interoperability test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21458
Differential Revision: D15696363
Pulled By: ezyang
fbshipit-source-id: f4ee9910173aab0b90a757e75c35925b026d1cc4
Summary:
I inserted default weight and reduction params in binary_cross_entropy_with_logits function . These default params exist in python and binary_cross_entropy function in cpp.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21336
Differential Revision: D15628917
Pulled By: ezyang
fbshipit-source-id: 38e5f53851125238842df1bd71cb6149c8603be1
Summary:
This could serve as a alternative solution to export ```torch.gather``` before something similar goes into ONNX spec. The exported model is verified to be correct against onnxruntime backend. We weren't able to test against Caffe2 backend because it doesn't seem to support OneHot opset9.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21235
Differential Revision: D15613039
Pulled By: houseroad
fbshipit-source-id: 7fc097f85235c071474730233ede7d83074c347f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21440
This diff modifies the output format when ai_pep_format is enabled.
Reviewed By: hl475
Differential Revision: D15681042
fbshipit-source-id: df5f2dbb38d1bd866ca7f74ef4e63459d480be6e
Summary:
We have encountered `std::bad_cast` error when running PyTorch binary built with cxx11 abi on CentOS7, stack trace:
```
#0 0x00007fec10160207 in raise () from /lib64/libc.so.6
#1 0x00007fec101618f8 in abort () from /lib64/libc.so.6
#2 0x00007fec015767d5 in __gnu_cxx::__verbose_terminate_handler() () from /lib64/libstdc++.so.6
#3 0x00007fec01574746 in ?? () from /lib64/libstdc++.so.6
#4 0x00007fec01574773 in std::terminate() () from /lib64/libstdc++.so.6
#5 0x00007fec01574993 in __cxa_throw () from /lib64/libstdc++.so.6
#6 0x00007fec015c94d2 in std::__throw_bad_cast() () from /lib64/libstdc++.so.6
#7 0x00007feb2ab3c2d7 in std::__cxx11::numpunct<char> const& std::use_facet<std::__cxx11::numpunct<char> >(std::locale const&) ()
from /root/.local/lib/python2.7/site-packages/torch/lib/libcaffe2.so
#8 0x00007feb28643d62 in torch::jit::script::strtod_c(char const*, char**) () from /root/.local/lib/python2.7/site-packages/torch/lib/libcaffe2.so
```
We are suspecting this line will get compiled to gcc abi dependent symbol:
```
char decimal_point = std::use_facet<std::numpunct<char>>(std::locale()).decimal_point();
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21293
Differential Revision: D15609910
Pulled By: bddppq
fbshipit-source-id: e247059729863868e4b36d6fec4fcbc36fbc4bb1
Summary:
Fixing an incorrect implementation of the CELU activation function. The existing implementation works by a chance combination of errors that seem to cancel each other out. This change makes the code more readable, aligns the parameter names correctly, and is consistent with the cuda implementation.
I came across this issue while working on version counters... I attempted to specify a gradient in derivatives.yaml for CELU due to a failed test, but the derivative couldn't be specified correctly without fixing the celu implementation.
https://github.com/pytorch/pytorch/pull/20612
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21213
Differential Revision: D15678823
Pulled By: nairbv
fbshipit-source-id: 29fa76b173a66c2c44ed2e0b7959e77f95d19c43
Summary:
This PR is a continuation of #15310, which itself is a continuation of #14845, #14941, & #15293. It should be synced up with the pytorch/master branch as of yesterday.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19465
Differential Revision: D15632268
Pulled By: ezyang
fbshipit-source-id: 8e337e8dc17ac31439935ccb530a7caf77f960e6
Summary:
We want to be able to call stft from a torchscript which requires that stft have a type annotation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21302
Differential Revision: D15607973
Pulled By: cpuhrsch
fbshipit-source-id: c4a5c09cdaafe7e81cf487a3ad216d1b03464a21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21392
as discussed at https://github.com/pytorch/pytorch/pull/21244, we
found some values in log_beta are not properly initialized. This diff will 1)
initialize all log_beta to -inf; 2) fix a tricky compare condition; 3) zero all
the gradient elements corresponding to padding to zero.
Offline experiments show that this diff can fix previous seen NaN loss.
Differential Revision: D15637977
fbshipit-source-id: 477008a5e11aae946bd2aa401ab7e0c513421af0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21398
Module::forward method calls find_method() function potentially in multiple threads.
Internally it calls find_offset() method and reads dict_ object.
If the correspondent name is not in a dictionary thread call insert() method and modifies dict_ object.
At the same time when first thread modifies dict_ object another thread can enter forward()->find_method()->find_offset() path
and access dict_ object for reading while it have been modified -> crash.
Moved mutex protection up to protect both calls find_offset() and insert().
Consider to use C++ 17 shared_mutex locking object instead of recursive_mutex object.
Reviewed By: bddppq
Differential Revision: D15638942
fbshipit-source-id: ca6a453448302a0b3666c87724755fa4e9ce242f
Summary:
Something flaky is going on with `test_inplace_view_saved_output` on Windows.
With my PR #20598 applied, the test fails, even though there is no obvious reason it should be related, so the PR was reverted.
Based on commenting out various parts of my change and re-building, I think the problem is with the name -- renaming everything from `T` to `asdf` seems to make the test stop failing. I can't be sure that this is actually the case though, since I could just be seeing patterns in non-deterministic build output...
I spoke with colesbury offline and we agreed that it is okay to just disable this test on Windows for now and not block landing the main change. He will look into why it is failing.
**Test Plan:** I will wait to make sure the Windows CI suite passes before landing this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21175
Differential Revision: D15566970
Pulled By: umanwizard
fbshipit-source-id: edf223375d41faaab0a3a14dca50841f08030da3
Summary:
Currently tools/build_pytorch_libs.py looks quite convoluted. This commit reorgnizes cmake related functions to a separate file to make the code clearer.
---
This is hopefully helpful for further contribution for better integration with cmake.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21367
Differential Revision: D15636991
Pulled By: soumith
fbshipit-source-id: 44d76e4e77aec0ce33cb32962b6a79a7f82785da
Summary:
This default was incorrect and made printing in python not print file:line:col
This wasn't caught because FileCheck internally uses operator<< to print the graph, which has `true` hardcoded as the value. I've added more comprehensive tests to catch this
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21370
Differential Revision: D15631135
Pulled By: jamesr66a
fbshipit-source-id: c809e06fff4f0174eefeb89062024384b4944ef7
Summary:
I found this significantly speeds up incremental builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21334
Differential Revision: D15632994
Pulled By: suo
fbshipit-source-id: bb4af90f4400bffa90d168d82ff30fece5e3835c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21365
This diff adds new operators to benchmark_all_test so all the supported ops can be built as one binary
Reviewed By: hl475
Differential Revision: D15627328
fbshipit-source-id: b7ca550a279f485102a6a6bd47e4032c7beb9940
Summary:
The original PR (#16071) is not working anymore after `caffe2` and `torch` is unified. What's more, It is making the binary big since the optimizing flag is disabled on a very big project(the `torch` library used to be small, but it now applies on the whole `caffe2` and `caffe2_gpu` library). We need to get it reverted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21335
Differential Revision: D15622163
Pulled By: soumith
fbshipit-source-id: 900bd400106d27a1512eed1e9f2288114f5f41bb
Summary:
This adds a regression test for the bug fix in #21236. Operations
involving CUDA tensors an CPU scalars should not copy the CPU scalar to
the device (because that is slow). They should instead "lift" the scalar
to a kernel parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21253
Reviewed By: bddppq
Differential Revision: D15604080
Pulled By: colesbury
fbshipit-source-id: c14ded5d584499eaa5ea83337ffc50278205f3d6
Summary:
This solves the situation where, for example, someone instantiates LSTM with `dropout=0`, a Python integer. This works fine in Python, but JIT throws a type error because it expected float but got int
Resolves https://github.com/pytorch/lockdown/issues/65
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21304
Differential Revision: D15613153
Pulled By: jamesr66a
fbshipit-source-id: eabff76e3af3de0612583b37dbc5f7eab7e248a4
Summary:
This PR adds support for torch.rand export in the PyTorch ONNX exporter. There are other generator ops that need to be supported for export and they will added in subsequent PRs. This op is needed with priority for a model on our end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20559
Differential Revision: D15379653
Pulled By: houseroad
fbshipit-source-id: d590db04a4cbb256c966f4010a9361ab8eb3ade3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20915
Clean the unary processor code. Some question are added into the comments to seek suggestions.
Reviewed By: pjh5
Differential Revision: D15448502
fbshipit-source-id: ef0c45718c1a06187e3fe2e4e59b7f20c641d9c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21206
This diff change the default test_name to be a globally unique value across tests. With that, users can list all the tests and choose to run a specific test.
Reviewed By: zheng-xq
Differential Revision: D15543508
fbshipit-source-id: 0814ef6a60d41637fed5245e30c282497cf21bb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21149
The diff modifies the interface for PyTorch operators in the benchmark suite
Reviewed By: zheng-xq
Differential Revision: D15433897
fbshipit-source-id: e858183431eb37d90313356716c2de8709372b58
Summary:
This doesn't affect anything because we run constant pooling, and in the case of Closures and Forks creates unnecessary closures over constants.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21229
Differential Revision: D15587764
Pulled By: eellison
fbshipit-source-id: d5609b0a5697071fab5050eb9e03876ab9ebb27a
Summary:
~~This is work in progress due to its dependency on multiple pending PRs.~~
- [x] ONNX: Relax constraint on subgraph input/output type & shape check. https://github.com/onnx/onnx/pull/2009
- [x] PyTorch: Add infra to test_pytorch_onnx_caffe2.py to test ScriptModule models. https://github.com/pytorch/pytorch/pull/20256
This PR should partially resolve https://github.com/pytorch/pytorch/issues/17531. However, ideally we shouldn't need to put cast(and reshape) node to help the conversion for loop condition.
- Added cast node for condition values before entering loop node. The ONNX spec only accepts Bool type, while in PyTorch if the condition value is an output from other node it could potentially have any integral type.
- Tidying up the exported ONNX loop subgraph input type & shape. According to ONNX spec, input "M" is exported as 0-d scalar tensor with type int64. input "Cond" is exported as incomplete tensor of type Bool without shape information. This is because through out the iteration, the rank of condition value is dynamic, either 0-d or 1-d, as long as it holds a single value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20445
Differential Revision: D15534188
Pulled By: houseroad
fbshipit-source-id: d174e778529def05ee666afeee4b8fb27786e320
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21267
Replace AT_ASSERTM with TORCH_CHECK: AT_ASSERTM is deprecated.
Not sure when ```AT_ASSERT``` is dprecated with some new TORCH ASSERT function.
Reviewed By: zafartahirov
Differential Revision: D15599242
fbshipit-source-id: 23f21a9a23dc3c147dc817e6d278066d0832e08d
Summary:
This PR improves performance of advanced indexing backward, partially solving #15245 (performance is still worse than gather, but not by such outrageous margins). Before, using benchmarking harness from #15245, cuda 10/V100:
```
Indexing is faster by at most -270.61607820767887 us on N: 16 D: 256 K: 1
Indexing is slower by at most 11127.466280784833 us on N: 16 D: 4096 K: 4096
```
after:
```
Indexing is faster by at most 23.524456737696028 us on N: 512 D: 4096 K: 4096
Indexing is slower by at most 186.24056029472553 us on N: 16 D: 1024 K: 4096
```
Strategy is to reuse embedding backward kernel, adapting it to handle unindexed dimensions in the beginning by launching additional threadblocks, and also allowing it to handle slices that are bigger than `65K*128`, that is hardly ever a problem for embedding. Still, integer indexing is baked in the kernel, and is important for performance, so for now bigger than 2G element tensors are not supported.
The main savings come from not having to expand index to all unindexed dimensions, and not sorting expanded index with incoming gradient values, but rather only sorting unexpanded index.
There are ways to make sorting overhead smaller (thanks mcarilli for suggestions) but I'll get to it when it becomes a real problem, or rather, when cuda graphs will force us to get rid of thrust::sort calls.
I've also added tests for indexing backward, before tests for index_put_ and indexing backward were non-existent.
This PR also fixes#20457 by casting indices to `self` backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20557
Differential Revision: D15582434
Pulled By: ezyang
fbshipit-source-id: 91e8f2769580588ec7d18823d99a26f1c0da8e2a
Summary:
Stacked on https://github.com/pytorch/pytorch/pull/21217
This adds support for recording file and line information during tracing, by extracting the top Python interpreter frame
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21247
Reviewed By: suo, driazati
Differential Revision: D15594553
Pulled By: jamesr66a
fbshipit-source-id: 72e1b3a46f1dabe3e83a608ec1a7d083bd1720f9
Summary:
Remove Dropout from the opset 10 blacklist.
ONNX Dropout was modified in opset 10, but only the output "mask" was modified, which is not exported in pytorch opset 9. So we can still fallback on the opset 9 op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20710
Differential Revision: D15571248
Pulled By: houseroad
fbshipit-source-id: 15267eb63308a29a435261034b2f07324db1dea6
Summary:
We're not getting much from checking the export strings, and they are noisy and slow development. DIdn't realize they existed until now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21238
Differential Revision: D15604256
Pulled By: eellison
fbshipit-source-id: 488e9401231228cffe132dab99d519563fa63afc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21100
Added multifile flag to write scalar data into separate files. This can slow down dashboard loading.
Reviewed By: orionr
Differential Revision: D15548913
fbshipit-source-id: dd39a7f76f93025d28f14babbf933e39860e6910
Summary:
Loops.h has contains specializations for cases where all the inputs are
contiguous as well as cases where one input is a scalar and all other
inputs are contiguous.
Previously, there were separate checks for each functions that take
zero, one, or two input arguments. This is getting unwieldy, especially
once we add support for functions that take three inputs (#21025).
This requires the use of recursive templates (which have their own
downsides), but this seems better than the alternative.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21106
Differential Revision: D15562430
Pulled By: colesbury
fbshipit-source-id: 5f19ab2212e16e29552887f4585c2b4a70309772
Summary:
Instead of attempting to hardcode calls to "ninja" or "make", we should always let cmake do it. This better integrates build configurations (DEBUG or REL_WITH_DEB_INFO) and better handles the case in which the native build tool is not in PATH (cmake has some capacity to find them and has options for users to specify their locations).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21105
Differential Revision: D15602883
Pulled By: soumith
fbshipit-source-id: 32ac46d438af00e791defde6ae5ac21c437d0bb0
Summary:
Retry #21197
The previous one failed because it uses some Python3 only syntax.
ezyang Do we still have multi-GPU py2 tests? I am curious why the CI tests did not catch this error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21262
Differential Revision: D15598941
Pulled By: mrshenli
fbshipit-source-id: 95f416589448c443685d6d236d205b011998a715
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20883
Add autograd for layer_norm on CPU, after this diff, both PyTorch and jit model can automatically benefit from performance improvement of nn.functional.layer_norm
Reviewed By: zheng-xq
Differential Revision: D15483790
fbshipit-source-id: 94ed3b16ab6d83ca6c254dbcfb224ff7d88837f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20665
Add gelu activation forward on CPU in pytorch
Compare to current python implemented version of gelu in BERT model like
def gelu(self, x):
x * 0.5 * (1.0 + torch.erf(x / self.sqrt_two))
The torch.nn.functional.gelu function can reduce the forward time from 333ms to 109ms (with MKL) / 112ms (without MKL) for input size = [64, 128, 56, 56] on a devvm.
Reviewed By: zheng-xq
Differential Revision: D15400974
fbshipit-source-id: f606b43d1dd64e3c42a12c4991411d47551a8121
Summary:
cc ezyang this is meant to fix the fuser failures on master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21252
Differential Revision: D15594283
Pulled By: jamesr66a
fbshipit-source-id: 85f37e78b2de051c92ade3fe4c44c7530b4542e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21233
It is possible that OnnxifiOp is created in a thread where weights have been cleaned from the workspace, which is legit use case as we can create the backend once and lower all the weights. So we need to extract the weight shape info the first time we create the backend and save it.
Reviewed By: bertmaher, rdzhabarov
Differential Revision: D15587237
fbshipit-source-id: 1f264dc32c0398c42b618e9c41c119eb13e1c9f1
Summary:
Fixes#21108
When grad is disabled, Python autograd function outputs are [wrapped as detached aliases](8cde4c4d22/torch/csrc/autograd/python_function.cpp (L395-L399)), which prevents calling `Tensor.set_()` on them after recent changes in Tensors and Variables. This will hit a problem when users would like to call `rnn.flatten_parameters()` in the forward pass, as the function [calls `set_()`](9d09f5df6c/aten/src/ATen/native/cudnn/RNN.cpp (L669)).
The proposed solution is to avoid using an autograd Broadcast if in no_grad mode.
apsdehal
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21197
Differential Revision: D15577342
Pulled By: mrshenli
fbshipit-source-id: 1a024c572171a3f2daca9454fd3ee6450d112f7c
Summary:
I think there was a typo in #20690 here https://github.com/pytorch/pytorch/pull/20690/files#diff-b47a50873394e38a005b4c1acd151957R130.
Original conditional was ` common_backend == Backend::CUDA && op.tensor.type().backend() == Backend::CPU)`, now it is `op.device.is_cuda() && op.tensor.device().is_cpu()`. It seems that `op.device` and `op.tensor.device()` should be the same, so this conditional is never true. This leads to spurious h2d copies for operations between cuda tensors and cpu scalars, because cpu scalars are now sent to gpu, instead of being passed to lambdas directly.
Unfortunately, I don't know how to test this change, because functionally everything was fine after #20690, it was just a performance regression.
cc colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21236
Differential Revision: D15592754
Pulled By: soumith
fbshipit-source-id: 105bfecc61c222cfdb7294a03c9ecae3cc7f5817
Summary:
`Tensor.is_cuda` and `is_leaf` is not a predicate function but a `bool` attribute. This patch fixes the type hints in `torch/__init__.pyi` for those attributes.
```diff
- def is_cuda(self) -> bool: ...
+ is_cuda: bool
- def is_leaf(self) -> bool: ...
+ is_leaf: bool
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21192
Differential Revision: D15592766
Pulled By: soumith
fbshipit-source-id: 8c4ecd6939df8b8a8a19e1c9db6d40193bca7e4a
Summary:
This makes file-line reporting also work for things loaded using `torch.jit.load()` as well as the string frontend (via `CompilationUnit`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21217
Differential Revision: D15590838
Pulled By: jamesr66a
fbshipit-source-id: 6b6a12574bf9eca0b83f24f0b50535fda5863243
Summary:
Studied why sparse tensor coalesce was slow: issue #10757.
Using nv-prof, and writing a simple benchmark, I determined bulk of the time was used ``kernelTransformReduceInnermostDimIndex``, which is called when sparse tensor is constructed with sparse_coo_tensor when it does sanity check on the minimum and maximum indices. However, we do not need this sanity check because after coalescing the tensor, these min/maxs won't change.
On my benchmark with 1 million non-zeros, the runtime of coalesce. was about 10x from 0.52s to 0.005 sec.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21214
Reviewed By: bddppq
Differential Revision: D15584338
Pulled By: akyrola
fbshipit-source-id: a08378baa018dbd0b45d7aba661fc9aefd3791e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21163
These two backend transformation share some common traits. Therefore we want to reuse the data struct/code as much as possible.
Reviewed By: hlu1
Differential Revision: D15561177
fbshipit-source-id: 35f5d63b2b5b3657f4ba099634fd27c3af545f1b
Summary:
Some of the functions are only used in this file - mark them `static`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21140
Differential Revision: D15578076
Pulled By: Krovatkin
fbshipit-source-id: 71ae67baabebd40c38ecb9292b5b8202ad2b9fc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21152
Migrate existing add benchmark to use the new op front-end
Reviewed By: zheng-xq
Differential Revision: D15325524
fbshipit-source-id: 34e969e1bd289913d881c476711bce9f8ac18a29
Summary:
i will do loops in a follow up after some other changes I am working on have landed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20911
Differential Revision: D15497205
Pulled By: eellison
fbshipit-source-id: 8cac197c6a6045b27b552cbb39e6fc86ca747b18
Summary:
Following on #19747, this implements most of the `torch.jit.script()` changes laid out in #20939.
Still to do:
* Accessing a method from Python does not add it as a `ScriptMethod` (so only `export`ed methods and `forward` are compiled)
* Calling a method other than `forward` on a submodule doesn't work
](https://our.intern.facebook.com/intern/diff/15560490/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20708
Pulled By: driazati
Differential Revision: D15560490
fbshipit-source-id: cc7ef3a1c2772eff9beba5f3e66546d2b7d7198a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21085
Now that torch::jit::RegisterOperators() always passes through to torch::RegisterOperators() (see diffs stacked below this), we can remove the old custom op implementation.
Reviewed By: dzhulgakov
Differential Revision: D15542261
fbshipit-source-id: ef437e6c71950e58fdd237d6abd035826753c2e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21084
- Now AliasAnalysisKind can be set using the torch::RegisterOperators() API
- This also allows us to remove the last place in torch::jit::RegisterOperators that didn't use c10 yet.
Reviewed By: dzhulgakov
Differential Revision: D15542097
fbshipit-source-id: ea127ecf051a5c1e567e035692deed44e04faa9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21181
Implement c10::OperatorOptions as a class to store metadata about operators.
This is meant to replace torch::jit::OperatorOptions.
Reviewed By: dzhulgakov
Differential Revision: D15569897
fbshipit-source-id: 95bf0bf917c1ef2bdf32702405844e1a116d9a64
Summary:
This reduces DenseNet load time by about 25% (down to 5.3s on my laptop) and gets AliasAnalysis out of the profile top hits entirely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21203
Differential Revision: D15578155
fbshipit-source-id: ddbb1ad25c9540b5214702830084aa51cc6fd3cb
Summary:
Adds persistent cuda kernels that speed up SoftMax applied over the fast dimension, i.e. torch.nn.Softmax(dim=-1) and torch.nn.LogSoftmax(dim=-1). When the size is <= 1024, this code is 2-10x faster than the current code, speedup is higher for smaller sizes. This code works for half, float and double tensors with 1024 or fewer elements in the fast dimension. Numerical accuracy is on par with the current code, i.e. relative error is ~1e-8 for float tensors and ~1e-17 for double tensors. Relative error was computed against the CPU code.
The attached image shows kernel time in us for torch.nn.Softmax(dim=-1) applied to a half precision tensor of shape [16384,n], n is plotted along the horizontal axis. Similar uplifts can be seen for the backward pass and for LogSoftmax.
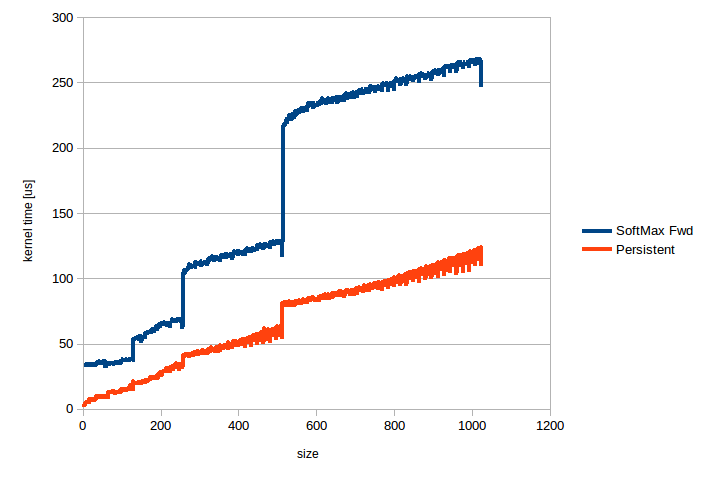
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20827
Differential Revision: D15582509
Pulled By: ezyang
fbshipit-source-id: 65805db37487cebbc4ceefb1a1bd486d24745f80
Summary:
This is a follow up on Jame's PR: https://github.com/pytorch/pytorch/pull/19041. The idea is to replace the legacy `sinh` / `cosh` ops that are being dispatched to TH with the operations defined in `Vec256` for better performance.
benchmark(from Jame's script):
```python
import torch, time
ops = ['sinh', 'cosh']
x = torch.rand(1024, 1024)
NITER = 10000
print('op', 'time per iter (ms)', 'gops/s', 'GB/s', sep='\t')
for op in ops:
s = time.time()
for i in range(NITER):
getattr(x, op)()
elapsed_sec = ((time.time() - s) / NITER)
print(op, elapsed_sec * 1000, (1024*1024/elapsed_sec)/1e9, (1024*1024*4*2) / elapsed_sec / 1e9, sep='\t')
```
code on master:
```
op time per iter (ms) gops/s GB/s
sinh 3.37614369392395 0.3105839369002935 2.484671495202348
cosh 3.480502033233643 0.3012714803748572 2.4101718429988574
```
after change (on Macbook pro 2018):
```
op time per iter (ms) gops/s GB/s
sinh 0.8956503868103027 1.1707425301677301 9.365940241341841
cosh 0.9392147302627564 1.1164390487217428 8.931512389773943
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21115
Reviewed By: ljk53
Differential Revision: D15574580
Pulled By: xta0
fbshipit-source-id: 392546a0df11ed4f0945f2bc84bf5dea2750b60e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21196
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15577123
fbshipit-source-id: d0abeea488418fa9ab212f84b0b97ee237124240
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21169
We should minimize dependency from perfkernels (we were including eigen header files only in cc files not compiled with avx or avx2 options but better to be very strict because it's easy to introduce illegal instruction errors in perfkernels)
Reviewed By: salexspb
Differential Revision: D15563839
fbshipit-source-id: d4b1bca22d7f2e6f20f23664d4b99498e5984586
Summary:
Most important fix: Correct "tensor.rst" to "tensors.rst"
Secondary fix: some minor English spelling/grammar fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21029
Differential Revision: D15523230
Pulled By: umanwizard
fbshipit-source-id: 6052d8609c86efa41a4289cd3a099b2f1037c810
Summary:
Dynamically creating a type at runtime was messing up the MRO and has been causing many other problems. I think it's best to delete it, this causes a regression since
```python
self.linear = nn.Linear(10, 10)
isinstance(self.linear, nn.Linear)
```
will now be `False` again, but this will be fixed once recursive script mode is the default (#20939)
](https://our.intern.facebook.com/intern/diff/15560549/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21107
Pulled By: driazati
Differential Revision: D15560549
fbshipit-source-id: 7bd6b958acb4f353d427d66196bb4ee577ecb1a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21148
The diff modifies the interface for Caffe2 operators in the benchmark suite
Reviewed By: zheng-xq
Differential Revision: D15433888
fbshipit-source-id: c264a95906422d7a26c10b1f9836ba8b35e36b53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21147
This diff introduces a new interface to add PT/C2 operators to the benchmark suite.
The following steps are needed to add a new operator:
1. Specify the input shapes, args to an operator in configs
2. Create a PT/C2 benchmark class which includes ```init``` (create tensors), ```forward``` (specify the operator to be tested.), and ```backward```(gradient of an op.) methods
3. call generate_pt_test/generate_c2_test to create test cases based on configs
Reviewed By: zheng-xq
Differential Revision: D15250380
fbshipit-source-id: 1025a7cf60d2427baa0f3f716455946d3d3e6a27
Summary:
This should pass once https://github.com/pytorch/vision/pull/971 is merged.
To remove torchvision as baseline, we just compare to sum of all param.sum() in pretrained resnet18 model, which means we need to manually update the number only when that pretrained weights are changed, which is generally rare.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21132
Differential Revision: D15563078
Pulled By: ailzhang
fbshipit-source-id: f28c6874149a1e6bd9894402f6847fd18f38b2b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21164
Write a List type to be used in operator kernels. This abstracts away from the concrete list type used (e.g. std::vector vs SmallVector)
and allows us to change these implementation details without breaking the kernel API.
Also, this class allows for handling List<bool>, which would not work with ArrayRef because vector<bool> is a bitset and can't be converted to ArrayRef<bool>.
Reviewed By: ezyang
Differential Revision: D15476434
fbshipit-source-id: 5855ae36b45b70437f996c81580f34a4c91ed18c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21156
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15558784
fbshipit-source-id: 0b194750c423f51ad1ad5e9387a12b4d58d969a9
Summary:
In the previous implementation of triu / tril, we passed the batch size in the 2nd dimension of a grid. This is limited to 65535, which means that performing triu / tril on a tensor with batch size > 65535 will throw an error. This PR removes the dependence on the 2nd dimension, and corresponding non-contiguity constraints.
Changelog:
- Compute offset, row and col in the kernel
- Use 1st dimension of grid alone
- Remove unnecessary contiguity checks on tensors as a result of this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21067
Differential Revision: D15572501
Pulled By: ezyang
fbshipit-source-id: 93851cb661918ce794d43eeb12c8a38762e1358c
Summary:
Resolves https://github.com/pytorch/lockdown/issues/51
This adds support for converting simple f-string literals to calls to `string.format()`. It does not support conversion specifiers or format strings.
This also does not support the string parser frontend, since that implementation would be more involved and likely would require modifying our TorchScript AST
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21037
Reviewed By: zdevito
Differential Revision: D15541183
Pulled By: jamesr66a
fbshipit-source-id: ae9df85e73f646d7219c1349f5b7683becbcef20
Summary:
# Overall Improvements
1. Switched from using `unordered_set` to sparse bitset.
1. Prevent some excessive memory allocations (thanks to resistor )
1. Take advantage of the sparse bitset operations
1. Switch to `flat_hash_map` instead of `unordered_map` in some places.
# Benchmarks (somewhat approximate, best of a couple runs)
1. InceptionNet (load + one forward pass): 19.8->13.3
1. GoogleNet(load + one forward pass): 10.0 -> 7.24
1. DenseNet (only load): 7.3 -> 5.3
I use the `sparse bitset` taken from https://llvm.org/doxygen/SparseBitVector_8h_source.html. I had to make some modifications to use `__builtin_popcountl` and instructions like that instead of other transitive clang dependencies.
## Some notes on our graph topologies
In general, our graphs are very sparse, and most of the components aren't connected. For GoogleNet, we have 200k nodes, we do 2k `mayAlias` queries, and the sum of magnitudes of sets at each node is 500k (ie: every node, on average, reaches 2.5 leaves).
PS: Holy crap macbooks throttle an insane amount with the default fan settings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20899
Differential Revision: D15564612
Pulled By: Chillee
fbshipit-source-id: 2a293a21a9be25f942ca888c8f225cab32bbfcd0
Summary:
Now you can run `python test/run_tests --jit` to run all jit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21161
Differential Revision: D15563912
Pulled By: eellison
fbshipit-source-id: 4bb0285cda4168b72a3dc4bba471485566a59873
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21051
In net transforms, we perform an SSARewrite where we update the 'net_pos' for all the ops in the net. The transform function also takes a unordered set of net positions for blacklisting. It's possible that SSARewrite will change the indexes of the ops so the blacklist is applied to the wrong ops. We fix this issue by having SSARewrite only assign new net_pos if the op doesn't already have one.
Reviewed By: yinghai
Differential Revision: D15532795
fbshipit-source-id: e020492a7b5196a91cdc39d0eda761b1ca612cdb
Summary:
These do not work. We'll save time and cpu until someone has the time to fix these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21153
Differential Revision: D15558601
Pulled By: pjh5
fbshipit-source-id: f9bfe580aa7962a88506f9af0032647f553637a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21027
Previously, we are only able to adjust batch size when output shape has batch size conditioned at its first dim. Although not common, there are cases where we want to slice back the output whose batch size is conditioned on non-first dim, or whose output shape doesn't really has batch size in it but rather is an expression of it. Examples are shapes at the output of `Transpose` or `Tile`. This diff redesigns how we handle the output size. The key is when we run OnnxifiOp, the input shapes are given, and we can actually do a shape inference to derive the real output shapes, no matter how they got transformed. And then we compare the real output shape with max batch sized output shape, dim by dim and use a `Slice` op to cut the max output back to real output shape.
Notice that general `Slice` op is slow and in most of the cases, we still prefer adjusting batch size by shrinking its first dim, which is just an operation on meta info without data allocation/manipulation. Therefore, we add a flag `fast_path` to detect this situation and operate accordingly.
Reviewed By: tracelogfb
Differential Revision: D15515189
fbshipit-source-id: 9c1fff161f82d0bc20eeac07ca4a2756e964e9fd
Summary:
Resolves https://github.com/pytorch/lockdown/issues/29
Examples:
```
import torch
torch.jit.script
def foobar(x):
return torch.blargh(xyz)
==
RuntimeError:
object has no attribute blargh:
at compile.py:5:12
torch.jit.script
def foo(x):
return torch.blargh(x)
~~~~~~~~~~~~ <--- HERE
```
It also gets the correct column number in the case where the original source file has common leading whitespace in front of the callable:
```
import torch
with torch.no_grad():
torch.jit.script
def foo(x):
return torch.blargh(x)
==
RuntimeError:
object has no attribute blargh:
at compile_leading.py:6:24
torch.jit.script
def foo(x):
return torch.blargh(x)
~~~~~~~~~~~~ <--- HERE
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20898
Differential Revision: D15552424
Pulled By: jamesr66a
fbshipit-source-id: 78d0f0de03f7ccbf3e7ea193a1b4eced57ea5d69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20874
A criteria for what should go in Tensor method is whether numpy has it, for this one it does not
so we are removing it as a Tensor method, we can still call it as function.
Python
```
torch.quantize_linear(t, ...), torch.dequantize(t)
```
C++
```
at::quantize_linear(t, ...), at::dequantize(t)
```
Reviewed By: dzhulgakov
Differential Revision: D15477933
fbshipit-source-id: c8aa81f681e02f038d72e44f0c700632f1af8437
Summary:
Following on #19747, this implements most of the `torch.jit.script()` changes laid out in #20939.
Still to do:
* Accessing a method from Python does not add it as a `ScriptMethod` (so only `export`ed methods and `forward` are compiled)
* Calling a method other than `forward` on a submodule doesn't work
](https://our.intern.facebook.com/intern/diff/15546045/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20708
Pulled By: driazati
Differential Revision: D15546045
fbshipit-source-id: c2c8fe179088ffbdad47198e799a456560655b86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20869
Adding support for the functions listed in the title, by implementing the copy kernel.
Differential Revision: D15474060
fbshipit-source-id: 9264df6e442cca1cc5d952e3e5dcc9f4a426f317
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20876
Tell the compiler that assertions are likely to succeed.
This allows the compiler to generate betterr code and optimize for the success case.
Differential Revision: D15480066
fbshipit-source-id: 4485154d66b2ee0ef8a401718712dbd61d811aee
Summary:
Thanks Jonas1312 for validating this workground.
Fixes#20635.
However, I don't know exactly why this one is needed.
The following are my guesses:
1. It is a CUDA bug. Static linking against `cudart` is the default now, so they didn't run enough tests for dynamic ones.
2. It is related to UCRT. But (1)according to msdn, shared DLLs should share the same CRT. (2) The CUDA related objects like `CUDevice` passing to `cudart` are stored on the stack, not the heap. (3) If this is the case, it should always fail, not sometimes. https://docs.microsoft.com/en-us/cpp/c-runtime-library/potential-errors-passing-crt-objects-across-dll-boundaries?view=vs-2019
3. It is a bug of our side. However, I was unable to find it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21062
Differential Revision: D15543557
Pulled By: ezyang
fbshipit-source-id: c23af45ebf582fad93ce5f029af6e1f06cf1d49d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20887
Switch AT_xxx assertion macros to the TORCH_ variants and make sure the separation between TORCH_CHECK and TORCH_INTERNAL_ASSERT makes sense.
Differential Revision: D15484658
fbshipit-source-id: 490ae64cc36946756c30971f1b685048bc5f77da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20940
- `torch.nn._intrinsic` will contain normal(unquantized) fused modules like Conv2DRelu, Conv2DBnRelu, FakeQuantize ops etc.
- `torch.nn._intrinsic` will contain fused and quantized modules like Quantized Conv2DRelu, Quantized LinearRelu etc.
Right now I only added FakeQuantize op in `torch.nn._intrinsic` namespace, we'll have more later
Differential Revision: D15505228
fbshipit-source-id: d380929e38af7a5bcfbea27474d5b80f95d43b03
Summary:
A bunch of modules were missing entries for `__constants__` which was making their `__repr__`s not work. Others had `__constants__` that were not necessary since it was provided by some parent class instead.
Fixes#20978
](https://our.intern.facebook.com/intern/diff/15539518/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21071
Pulled By: driazati
Differential Revision: D15539518
fbshipit-source-id: 24bdd1ef41ef636eefd5d2bad4ab2d79646ed4f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17946
Some of these are probably implementable for exported operators,
but aren't implemented yet and for now it's better to assert than to just return wrong results.
Reviewed By: ezyang
Differential Revision: D14430749
fbshipit-source-id: 2b0037a9ed227a22aa7376a90e6d3d09d3e04707
Summary:
Fixes#18440
I calculate a derived index from `start,stop,step` as `start + step*index`. When `start=0` and `step=1` (the defaults/`range(n)`), this is the same behavior as before.
Unluckily, it seems that we do not optimize out operations like `x*1` or `x+0`. That means that we're doing lots of redundant operations when we don't need to. EDIT: More specifically, it seems like we only do this optimization for (tensor, scalar): https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/passes/peephole.cpp#L128
The most annoying part of this code is calculating the number of iterations, given `start, stop, step`. I ended up going with the formula `(abs(stop-start) + abs(step)-1)//abs(step)`. Other intuitively appealing formulas like `(stop-start + step -1)//step` don't work for negative numbers.
I tried using `SymbolicVariable` for the calculations, but it seems that `symbolicvariable` only outputs ops for `tensors`, not the integers we have.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20795
Differential Revision: D15446869
Pulled By: Chillee
fbshipit-source-id: 6085545ace04e25985c6ac870226f7a651f670d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21035
Fix the dtype error in `dequantize_linear`, it should accept the same dtype argument as `quantize_linear`
Differential Revision: D15521931
fbshipit-source-id: 0114c046a3f1046e42fca49c74c85e487fee8616
Summary:
This PR adds a check that prints a warning if a type annotation prefix isn't what mypy expects.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20884
Differential Revision: D15511043
Pulled By: Krovatkin
fbshipit-source-id: 9038e074807832931faaa5f4e69628f94f51fd72
Summary:
I accidentally added a TF dependency in #20413 by using the from tensorboard.plugins.mesh.summary import _get_json_config import.
I'm removing it at the cost of code duplication.
orionr, Please review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21066
Reviewed By: natalialunova
Differential Revision: D15538746
Pulled By: orionr
fbshipit-source-id: 8a822719a4a9f5d67f1badb474e3a73cefce507f
Summary:
In larger system environment, there's usually a need to store some information about how the model was created (e.g. from which process, workflow, by which user, etc). It's almost like JPEG metadata written by camera.
This PR adds a low-level c++ hook to allow population of additional files in zip container based on environment. The reason to have it a low-level hook instead of top-level API wrapper (e.g. `m.save_with_metadata`) is to capture all usages of the saving API transparently for user.
Let me know if there are concerns.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20863
Differential Revision: D15487941
Pulled By: dzhulgakov
fbshipit-source-id: 120c5a4c9758aa82846bb51a1207f923e3da1333
Summary:
This doesn't have `strace` yet. But still have `faulthandler` to print stack traces at hanging. Also part of an attempt to isolate changes from #19228 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20166
Differential Revision: D15536504
Pulled By: ezyang
fbshipit-source-id: fe6e6e2e9899f30d8167436d7bc62b42883a3356
Summary:
Previously, we didn't work when 2d target tensors had extra columns at the end. Now we just ignore those.
Also fix the confusion in the doc example regarding the number of classes.
Thank you, ypw-rich for the report with reproducing example.
Fixes: #20522
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20971
Differential Revision: D15535481
Pulled By: ezyang
fbshipit-source-id: 397e44e20165fc4fa2547bee9390d4c0b688df93
Summary:
https://github.com/pytorch/pytorch/pull/17783 has made ninja and makefile builds to print out build commands unconditionally, this has made the build log very verbose, e.g. ROCm CI build log becomes >13mb. Large build log make searching for real error hard.
https://github.com/pytorch/pytorch/pull/20508 has reverted the ninja change, and this one reverts the makefile change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21053
Differential Revision: D15533412
Pulled By: bddppq
fbshipit-source-id: ad89b617d06acc670d75d4cf25111a4081e9c95e
Summary:
I've reported inconsistency between `checkpoint_sequential` and `nn.Sequential` at https://github.com/pytorch/pytorch/issues/19260. Both should provide the same input signature but they don't. I think the consistency is important and I agree with apaszke that `nn.Sequential`'s semantics should be kept instead of `checkpoint_sequential`.
I hope `checkpoint_sequential` raises `TypeError` on variadic arguments since PyTorch 1.2.0. But for now, it's okay just to warn as `DeprecationWarning`. I've talked about this approach with soumith.
Please review this pull request. Any comment will be my pleasure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21006
Differential Revision: D15530801
Pulled By: soumith
fbshipit-source-id: 0ceb2cc6a17dcc547d0d00ebaf9df8603be53183
Summary:
gradcheck currently includes a determinism check (although only trying twice and seeing if results match).
This can lead to flaky tests, e.g. in #20971, but also #13818.
This adds nondet_tol for both gradcheck and gradgradcheck. It does not change / reenable any tests yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20980
Differential Revision: D15530129
Pulled By: soumith
fbshipit-source-id: 04d7f85b5b59cd62867820c74b064ba14f4fa7f8
Summary:
Fixes a typo in the CyclicLR docs by adding the lr_scheduler directory and puts in other required arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21021
Differential Revision: D15530109
Pulled By: soumith
fbshipit-source-id: 98781bdab8d82465257229e50fa3bd0015da1286
Summary:
Just an annoying warning that's been popping up a lot.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20964
Differential Revision: D15531064
Pulled By: Chillee
fbshipit-source-id: 9580115676c5e246481054bbfc749a551a3cca5e
Summary:
This PR covers two important points with respect to the QR decomposition:
- batching of input matrices (#7500)
- adding `some` as an option in `torch.qr` akin to NumPy's `mode` option (#10538)
Changelog:
- Enable batching for inputs to `torch.qr`
- Move QR decomposition implementation to ATen (CPU and CUDA)
- Remove existing implementations in TH/THC
- Add a `some` option to `torch.qr` that will enable users to switch between complete and reduced decomposition
- Modify doc strings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20689
Differential Revision: D15529230
Pulled By: soumith
fbshipit-source-id: 16af82b1d2db8a3a758fa8a5f798d83f5f950efb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20603
When we use intra_op_parallel operators, Caffe2 tracing was generating trace only for the master task giving a false impression that a lot of threads are underutilized.
This diff also traces child tasks.
Reviewed By: ilia-cher
Differential Revision: D14820008
fbshipit-source-id: ff4ed203804d86d9231c21c99d869f1ddf1d1ef9
Summary:
Add an option to setup.py to stop the build process once cmake terminates. This leaves users a chance to fine adjust build options. Also update README accordingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21034
Differential Revision: D15530096
Pulled By: soumith
fbshipit-source-id: 71ac6ff8483c3ee77c38d88f0d059db53a7d3901
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20647
The initial assumption was that `qint8` would be unsigned. After introduction of `quint8` and `qint8`, some tests break.
Reviewed By: jerryzh168
Differential Revision: D15332106
fbshipit-source-id: 6ed18da428915aea918a363c5f38754a3c75d06b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20493
This helps distinguish if the op was a quantized op or not.
Reviewed By: salexspb
Differential Revision: D15337854
fbshipit-source-id: 43c7aef143085cfaeb4ec2102a7f36cc454e0e94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20173
Enabled op profiling even when net type is not dag or prof dag. Also added
engine type info to summary.
Reviewed By: salexspb, ilia-cher
Differential Revision: D15177813
fbshipit-source-id: 5be0efeaabc9a961cf1d73b0703749c08bb1adbb
Summary:
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#19587 [jit] Make ScriptModule.training an attribute instead of a parameter**
Remove the hack we had previously where `training` was a buffer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19587
Differential Revision: D15502768
Pulled By: driazati
fbshipit-source-id: 3022f2d57ec6849868f9225d9bc2bfb7828cb318
Summary:
Before we look into supporting `deepcopy` we could at least improve an error msg.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20885
Differential Revision: D15511023
Pulled By: Krovatkin
fbshipit-source-id: 93b8730a2cc663eee0147f14d3341d0606748eaf
Summary:
This #20919 without the changes to aten/src/THC/THCIntegerDivider.cuh
that broke the ROCm build.
cc bddppq
Original summary:
This fixes advanced indexing in cases where there's more than 2^31-1
bytes in the output. The `gpu_index_kernel` was missing the
`can_use_32bit_indexing`/`with_32bit_indexing` check.
This also adds a number of TORCH_INTERNAL_ASSERTS in Loops.cuh,
OffsetCalculator, and IntDivider that sizes are fit in a signed 32-bit
integer.
More comprehensive tests that require a 32 GB GPU are here:
https://gist.github.com/colesbury/e29387f5851521256dff562be07b981e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21019
Differential Revision: D15518477
Pulled By: colesbury
fbshipit-source-id: 4db5626fda76eb58250793e8aa7d4f2832db3a34
Summary:
Fixes#20495 .
Now for
```python
class A(torch.jit.ScriptModule):
def __init__(self):
super(A, self).__init__()
torch.jit.script_method
def forward(self, x):
return x + self.whatisgoingon
class B(A):
def __init__(self):
super(B, self).__init__()
torch.jit.script_method
def bar(self, x):
return x * x
A()
```
it does
```
RuntimeError:
attribute 'whatisgoingon' does not exist:
torch.jit.script_method
def forward(self, x):
return x + self.whatisgoingon
~~~~~~~~~~~~~~~~~~ <--- HERE
```
I added a test in `test_jit.py` as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20779
Differential Revision: D15441138
Pulled By: Chillee
fbshipit-source-id: 88f458c36b5e32a1ffc467b27bbc28a3c5c07321
Summary:
As a part of https://github.com/pytorch/pytorch/pull/20580 I noticed that we had some unusual variable naming in `summary.py`. This cleans it up and also removes some variables that weren't being used.
I'll wait until we have an `add_custom_scalars` test to land this.
cc lanpa natalialunova
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20861
Differential Revision: D15503420
Pulled By: orionr
fbshipit-source-id: 86d105a346198a1ca543d1c5d297804402ab5a0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20880
This clarifies how the momentum parameters should be used.
Reviewed By: soumith
Differential Revision: D15482450
fbshipit-source-id: e3649a38876c5912cb101d8e404abca7c3431766
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20610
Change InferLengthsRangeFill
Add InferGatherRanges
add tests from ClipRangesGatherSigridHash all the way to SparseLengthsWeightedSum
add tests from SigridTransforms all the way to SparseLengthsWeightedSum
e2e test will be added in the following diff
Reviewed By: ipiszy
Differential Revision: D15382730
fbshipit-source-id: a611cd129007a273dfc43955cd99af1c4ed04efd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20938
Dequantize_linear need not be exposed to the front end users.
It will only be used for the jit passes for q-dq insertion and op
substitution.
Differential Revision: D15446097
fbshipit-source-id: a5fbcf2bb72115122c9653e5089d014e2a2e891d
Summary:
Remove the internal functions in multi_head_attention_forward. Those internal functions cause 10-15% performance regression and there is possibly a JIT issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20653
Differential Revision: D15398888
Pulled By: cpuhrsch
fbshipit-source-id: 0a3f053a4ade5009e73d3974fa6733c2bff9d929
Summary:
Changes:
- protobuf has been moved to protocolbuffers/protobuf a while ago.
- cpuinfo has been moved to pytorch/cpuinfo and updated in FBGEMM recently.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20973
Differential Revision: D15511926
Pulled By: soumith
fbshipit-source-id: 2c50373c9b245524f839bd1059870dd2b84e3b81
Summary:
Sometimes users forget using the "--recursive" option when they update submodules. This added check should help expose this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20937
Differential Revision: D15502846
Pulled By: mrshenli
fbshipit-source-id: 34c28a2c71ee6442d16b8b741ea44a18733b1536
Summary:
This changes the progress bars in `_download_url_to_file` from saying things like `49773343.40it/s` to `47.5MB/s`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20908
Differential Revision: D15511223
Pulled By: soumith
fbshipit-source-id: 2422eb5fb486f9ef4bd69c556c4ed1775b8b2860
Summary:
I believe the `True` and `False` in the doc are reversed :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20961
Differential Revision: D15510806
Pulled By: soumith
fbshipit-source-id: 62566bb595e187506b23dedc24892e48f35b1147
Summary:
Fixes#20630
Haven't tested it yet. Let's see if it passes all CI tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20882
Reviewed By: pietern
Differential Revision: D15483561
Pulled By: mrshenli
fbshipit-source-id: 5f0730a04d92906af077b2fe2170b674ca371e6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20868
When `input_boxes_include_bg_cls` is false (which means `input_scores_fg_cls_starting_id` is 0), It doesn't map the class index of score currectly when sorting and limiting the detections over all classes after nms.
Reviewed By: newstzpz
Differential Revision: D15472706
fbshipit-source-id: dc1e808b63ad09fb4bd95acf866771bb3fa92d69
Summary:
This fixes advanced indexing in cases where there's more than 2^31-1
bytes in the output. The `gpu_index_kernel` was missing the
`can_use_32bit_indexing`/`with_32bit_indexing` check.
This also adds a number of TORCH_INTERNAL_ASSERTS in Loops.cuh,
OffsetCalculator, and IntDivider that sizes are fit in a signed 32-bit
integer.
More comprehensive tests that require a 32 GB GPU are here:
https://gist.github.com/colesbury/e29387f5851521256dff562be07b981eFixes#20888
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20919
Differential Revision: D15501945
Pulled By: colesbury
fbshipit-source-id: e876e678e866d2efda8ee92c47a1d2d1310671f0
Summary:
Previously, this used `crepr` afer the decref of `repr`. This is not
allowed because `repr` owns the cached copy of `crepr`.
Let's see if this fixes the contbuild.
See #20926
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20931
Differential Revision: D15501929
Pulled By: colesbury
fbshipit-source-id: 24141ba62df8758d2a3998cf7c2054be09088b6a
Summary:
Bug reported internally at FB:
```python
>>> t=torch.from_numpy(np.empty((0,4)))
>>> t[:,1::2]*=1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Trying to resize storage that is not resizable at ../aten/src/TH/THStorageFunctions.cpp:76
```
This happens because the storage offset of `t[:, 1::2]` is 1, and it has 0 elements. We can fix this by avoiding resizing the storage for no-element arrays.
(We could *also* have avoided it by not modifying the storage index in this case, but I felt this way was more semantically correct -- in general, we should not be assuming it's okay to do anything to the storage when it has zero elements).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20914
Differential Revision: D15497860
Pulled By: umanwizard
fbshipit-source-id: 6af61d73a05edfc5c07ce8be9e530f15bf72e6a9
Summary:
I started adding support for the new **[mesh/point cloud](https://github.com/tensorflow/graphics/blob/master/tensorflow_graphics/g3doc/tensorboard.md)** data type introduced to TensorBoard recently.
I created the functions to add the data, created the appropriate summaries.
This new data type however requires a **Merged** summary containing the data for the vertices, colors and faces.
I got stuck at this stage. Maybe someone can help. lanpa?
I converted the example code by Google to PyTorch:
```python
import numpy as np
import trimesh
import torch
from torch.utils.tensorboard import SummaryWriter
sample_mesh = 'https://storage.googleapis.com/tensorflow-graphics/tensorboard/test_data/ShortDance07_a175_00001.ply'
log_dir = 'runs/torch'
batch_size = 1
# Camera and scene configuration.
config_dict = {
'camera': {'cls': 'PerspectiveCamera', 'fov': 75},
'lights': [
{
'cls': 'AmbientLight',
'color': '#ffffff',
'intensity': 0.75,
}, {
'cls': 'DirectionalLight',
'color': '#ffffff',
'intensity': 0.75,
'position': [0, -1, 2],
}],
'material': {
'cls': 'MeshStandardMaterial',
'roughness': 1,
'metalness': 0
}
}
# Read all sample PLY files.
mesh = trimesh.load_remote(sample_mesh)
vertices = np.array(mesh.vertices)
# Currently only supports RGB colors.
colors = np.array(mesh.visual.vertex_colors[:, :3])
faces = np.array(mesh.faces)
# Add batch dimension, so our data will be of shape BxNxC.
vertices = np.expand_dims(vertices, 0)
colors = np.expand_dims(colors, 0)
faces = np.expand_dims(faces, 0)
# Create data placeholders of the same shape as data itself.
vertices_tensor = torch.as_tensor(vertices)
faces_tensor = torch.as_tensor(faces)
colors_tensor = torch.as_tensor(colors)
writer = SummaryWriter(log_dir)
writer.add_mesh('mesh_color_tensor', vertices=vertices_tensor, faces=faces_tensor,
colors=colors_tensor, config_dict=config_dict)
writer.close()
```
I tried adding only the vertex summary, hence the others are supposed to be optional.
I got the following error from TensorBoard and it also didn't display the points:
```
Traceback (most recent call last):
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/serving.py", line 302, in run_wsgi
execute(self.server.app)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/serving.py", line 290, in execute
application_iter = app(environ, start_response)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/application.py", line 309, in __call__
return self.data_applications[clean_path](environ, start_response)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/wrappers/base_request.py", line 235, in application
resp = f(*args[:-2] + (request,))
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/plugins/mesh/mesh_plugin.py", line 252, in _serve_mesh_metadata
tensor_events = self._collect_tensor_events(request)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/plugins/mesh/mesh_plugin.py", line 188, in _collect_tensor_events
tensors = self._multiplexer.Tensors(run, instance_tag)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/event_processing/plugin_event_multiplexer.py", line 400, in Tensors
return accumulator.Tensors(tag)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/event_processing/plugin_event_accumulator.py", line 437, in Tensors
return self.tensors_by_tag[tag].Items(_TENSOR_RESERVOIR_KEY)
KeyError: 'mesh_color_tensor_COLOR'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20413
Differential Revision: D15500737
Pulled By: orionr
fbshipit-source-id: 426e8b966037d08c065bce5198fd485fd80a2b67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20821
Change registration API. Instead of
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel>()
.dispatchKey(CPUTensorId()));
it is now
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel>(CPUTensorId()));
This binds kernel and dispatch key together, allowing them to be separate from other future configuration options like alias analysis or autograd wrappers.
The semantic problem behind this is that the dispatch key is a *kernel config parameter* and not an *operator config parameter* while things like autograd wrappers, alias info, and actually the kernel itself are *operator config parameters*. And while previously, the different kind of config parameters have been mixed, this diff now separates them.
Before this change, it wouldn't have been well defined if you specified a dispatchKey together with an autogradWrapper or aliasInfo for example.
// what is this supposed to do?
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.aliasInfo(DEFAULT)
.dispatchKey(CPUTensorId()));
If we get more kernel config parameters in the future, we could introduce something like this
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel>(torch::RegisterOperators::kernelOptions()
.dispatchKey(CPUTensorId())
.otherConfig());
but that's overkill as long as dispatch keys are the only kernel config parameter, and we can introduce that later without breaking backwards compatibility.
A nice side effect of this is that people can register multiple kernels to the same operator in the same `.op()` call:
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel1>(CPUTensorId())
.kernel<Kernel2>(CUDATensorId()));
Reviewed By: dzhulgakov
Differential Revision: D15455790
fbshipit-source-id: 1c46bfe676dcacf74cf36bd3f5df3d2c32b8fb11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17818
Some of these are probably implementable for exported operators,
but aren't implemented yet and for now it's better to assert than to just return wrong results.
Reviewed By: ezyang
Differential Revision: D14392459
fbshipit-source-id: bf86e6cb0a7cfefd112a65dc85cc243e57a5ad52
Summary:
This PR also moves Device::validate into the header file, which makes
statements like `Device d = kCPU` effectively free.
Device includes the device's index, so TensorIterator::compute_types
now implicitly checks that all CUDA inputs are on the same GPU.
Previously, this was done ad-hoc in places like TensorIterator::binary_op.
Note that zero-dim Tensor (scalars) are NOT required to be on the
same device as other inputs because they behave almost like Python numbers.
TensorIterator handles copying zero-dim Tensors to the common device.
Prior to this PR, TensorIterator would copy zero-dim Tensors between CPU
and GPU, but not between different GPUs (because Backend didn't encode
the GPU index). This removes that restriction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20690
Differential Revision: D15414826
Pulled By: colesbury
fbshipit-source-id: 1d0ad1f7d663252af36dd4590bcda418c2f7a09f
Summary:
This PR is a eliminates unneeded grad_sum_to_size and in particular speeds up the LSTM backward by allowing better fusion.
It consists of two parts:
- In AutoDiff, record broadcasting sizes only if the broadcast output size is different from the input size, otherwise record None.
- The specialization of Optional arguments (#18407) allows us to then eliminate ` _grad_sum_to_size(t, None)` in the peephole optimization step.
Thus, in the LSTM case, no SumToSize remain in the crucial fusion group. The trick here is that we can specialize on the runtime information from the forward.
I'm testing that different broadcasting situations lead to different graphs.
I didn't move all symbolic_script _grad_sum_to_size to the new logic, but it might be better to do this incrementally, anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18697
Differential Revision: D15482076
Pulled By: wanchaol
fbshipit-source-id: 7f89367e35b8729910077c95c02bccefc8678afb
2019-05-24 11:24:17 -07:00
2968 changed files with 293768 additions and 109054 deletions
2. Persists CircleCI scripts (everything in `.circleci`) into a workspace. Why?
We don't always do a Git checkout on all subjobs, but we usually
still want to be able to call scripts one way or another in a subjob.
Persisting files this way lets us have access to them without doing a
checkout. This workspace is conventionally mounted on `~/workspace`
(this is distinguished from `~/project`, which is the conventional
working directory that CircleCI will default to starting your jobs
in.)
3. Write out the commit message to `.circleci/COMMIT_MSG`. This is so
we can determine in subjobs if we should actually run the jobs or
not, even if there isn't a Git checkout.
CircleCI configuration generator
================================
@ -35,4 +55,450 @@ Future direction
See comment [here](https://github.com/pytorch/pytorch/pull/17323#pullrequestreview-206945747):
In contrast with a full recursive tree traversal of configuration dimensions,
> in the future future I think we actually want to decrease our matrix somewhat and have only a few mostly-orthogonal builds that taste as many different features as possible on PRs, plus a more complete suite on every PR and maybe an almost full suite nightly/weekly (we don't have this yet). Specifying PR jobs in the future might be easier to read with an explicit list when we come to this.
> in the future future I think we actually want to decrease our matrix somewhat and have only a few mostly-orthogonal builds that taste as many different features as possible on PRs, plus a more complete suite on every PR and maybe an almost full suite nightly/weekly (we don't have this yet). Specifying PR jobs in the future might be easier to read with an explicit list when we come to this.
----------------
----------------
# How do the binaries / nightlies / releases work?
### What is a binary?
A binary or package (used interchangeably) is a pre-built collection of c++ libraries, header files, python bits, and other files. We build these and distribute them so that users do not need to install from source.
A **binary configuration** is a collection of
* release or nightly
* releases are stable, nightlies are beta and built every night
* python version
* linux: 2.7m, 2.7mu, 3.5m, 3.6m 3.7m (mu is wide unicode or something like that. It usually doesn't matter but you should know that it exists)
* macos: 2.7, 3.5, 3.6, 3.7
* windows: 3.5, 3.6, 3.7
* cpu version
* cpu, cuda 9.0, cuda 10.0
* The supported cuda versions occasionally change
* operating system
* Linux - these are all built on CentOS. There haven't been any problems in the past building on CentOS and using on Ubuntu
* MacOS
* Windows - these are built on Azure pipelines
* devtoolset version (gcc compiler version)
* This only matters on Linux cause only Linux uses gcc. tldr is gcc made a backwards incompatible change from gcc 4.8 to gcc 5, because it had to change how it implemented std::vector and std::string
### Where are the binaries?
The binaries are built in CircleCI. There are nightly binaries built every night at 9pm PST (midnight EST) and release binaries corresponding to Pytorch releases, usually every few months.
We have 3 types of binary packages
* pip packages - nightlies are stored on s3 (pip install -f <as3url>). releases are stored in a pip repo (pip install torch) (ask Soumith about this)
* conda packages - nightlies and releases are both stored in a conda repo. Nighty packages have a '_nightly' suffix
* libtorch packages - these are zips of all the c++ libraries, header files, and sometimes dependencies. These are c++ only
* shared with dependencies (the only supported option for Windows)
* static with dependencies
* shared without dependencies
* static without dependencies
All binaries are built in CircleCI workflows except Windows. There are checked-in workflows (committed into the .circleci/config.yml) to build the nightlies every night. Releases are built by manually pushing a PR that builds the suite of release binaries (overwrite the config.yml to build the release)
# CircleCI structure of the binaries
Some quick vocab:
* A\**workflow** is a CircleCI concept; it is a DAG of '**jobs**'. ctrl-f 'workflows' on\https://github.com/pytorch/pytorch/blob/master/.circleci/config.yml to see the workflows.
* **jobs** are a sequence of '**steps**'
* **steps** are usually just a bash script or a builtin CircleCI command.* All steps run in new environments, environment variables declared in one script DO NOT persist to following steps*
* CircleCI has a **workspace**, which is essentially a cache between steps of the *same job* in which you can store artifacts between steps.
## How are the workflows structured?
The nightly binaries have 3 workflows. We have one job (actually 3 jobs: build, test, and upload) per binary configuration
3. For each binary configuration, e.g. linux_conda_3.7_cpu there is a
1. smoke_linux_conda_3.7_cpu
1. Downloads the package from the cloud, e.g. using the official pip or conda instructions
2. Runs the smoke tests
## How are the jobs structured?
The jobs are in https://github.com/pytorch/pytorch/tree/master/.circleci/verbatim-sources . Jobs are made of multiple steps. There are some shared steps used by all the binaries/smokes. Steps of these jobs are all delegated to scripts in https://github.com/pytorch/pytorch/tree/master/.circleci/scripts .
* Linux jobs: https://github.com/pytorch/pytorch/blob/master/.circleci/verbatim-sources/linux-binary-build-defaults.yml
* Common shared code (shared across linux and macos): https://github.com/pytorch/pytorch/blob/master/.circleci/verbatim-sources/nightly-binary-build-defaults.yml
* binary_checkout.sh - checks out pytorch/builder repo. Right now this also checks out pytorch/pytorch, but it shouldn't. pytorch/pytorch should just be shared through the workspace. This can handle being run before binary_populate_env.sh
* binary_populate_env.sh - parses BUILD_ENVIRONMENT into the separate env variables that make up a binary configuration. Also sets lots of default values, the date, the version strings, the location of folders in s3, all sorts of things. This generally has to be run before other steps.
* binary_install_miniconda.sh - Installs miniconda, cross platform. Also hacks this for the update_binary_sizes job that doesn't have the right env variables
* binary_run_in_docker.sh - Takes a bash script file (the actual test code) from a hardcoded location, spins up a docker image, and runs the script inside the docker image
### **Why do the steps all refer to scripts?**
CircleCI creates a final yaml file by inlining every <<* segment, so if we were to keep all the code in the config.yml itself then the config size would go over 4 MB and cause infra problems.
### **What is binary_run_in_docker for?**
So, CircleCI has several executor types: macos, machine, and docker are the ones we use. The 'machine' executor gives you two cores on some linux vm. The 'docker' executor gives you considerably more cores (nproc was 32 instead of 2 back when I tried in February). Since the dockers are faster, we try to run everything that we can in dockers. Thus
* linux build jobs use the docker executor. Running them on the docker executor was at least 2x faster than running them on the machine executor
* linux test jobs use the machine executor and spin up their own docker. Why this nonsense? It's cause we run nvidia-docker for our GPU tests; any code that calls into the CUDA runtime needs to be run on nvidia-docker. To run a nvidia-docker you need to install some nvidia packages on the host machine and then call docker with the '—runtime nvidia' argument. CircleCI doesn't support this, so we have to do it ourself.
* This is not just a mere inconvenience. **This blocks all of our linux tests from using more than 2 cores.** But there is nothing that we can do about it, but wait for a fix on circleci's side. Right now, we only run some smoke tests (some simple imports) on the binaries, but this also affects non-binary test jobs.
* linux upload jobs use the machine executor. The upload jobs are so short that it doesn't really matter what they use
* linux smoke test jobs use the machine executor for the same reason as the linux test jobs
binary_run_in_docker.sh is a way to share the docker start-up code between the binary test jobs and the binary smoke test jobs
### **Why does binary_checkout also checkout pytorch? Why shouldn't it?**
We want all the nightly binary jobs to run on the exact same git commit, so we wrote our own checkout logic to ensure that the same commit was always picked. Later circleci changed that to use a single pytorch checkout and persist it through the workspace (they did this because our config file was too big, so they wanted to take a lot of the setup code into scripts, but the scripts needed the code repo to exist to be called, so they added a prereq step called 'setup' to checkout the code and persist the needed scripts to the workspace). The changes to the binary jobs were not properly tested, so they all broke from missing pytorch code no longer existing. We hotfixed the problem by adding the pytorch checkout back to binary_checkout, so now there's two checkouts of pytorch on the binary jobs. This problem still needs to be fixed, but it takes careful tracing of which code is being called where.
# Azure Pipelines structure of the binaries
TODO: fill in stuff
## How are the workflows structured?
TODO: fill in stuff
## How are the jobs structured?
TODO: fill in stuff
# Code structure of the binaries (circleci agnostic)
## Overview
The code that runs the binaries lives in two places, in the normal [github.com/pytorch/pytorch](http://github.com/pytorch/pytorch), but also in [github.com/pytorch/builder](http://github.com/pytorch/builder) , which is a repo that defines how all the binaries are built. The relevant code is
```
# All code needed to set-up environments for build code to run in,
# but only code that is specific to the current CI system
pytorch/pytorch
- .circleci/ # Folder that holds all circleci related stuff
- config.yml # GENERATED file that actually controls all circleci behavior
- verbatim-sources # Used to generate job/workflow sections in ^
- scripts/ # Code needed to prepare circleci environments for binary build scripts
- setup.py # Builds pytorch. This is wrapped in pytorch/builder
- cmake files # used in normal building of pytorch
# All code needed to prepare a binary build, given an environment
# with all the right variables/packages/paths.
pytorch/builder
# Given an installed binary and a proper python env, runs some checks
# to make sure the binary was built the proper way. Checks things like
# the library dependencies, symbols present, etc.
- check_binary.sh
# Given an installed binary, runs python tests to make sure everything
# is in order. These should be de-duped. Right now they both run smoke
# tests, but are called from different places. Usually just call some
# import statements, but also has overlap with check_binary.sh above
- run_tests.sh
- smoke_test.sh
# Folders that govern how packages are built. See paragraphs below
- conda/
- build_pytorch.sh # Entrypoint. Delegates to proper conda build folder
- switch_cuda_version.sh # Switches activate CUDA installation in Docker
- pytorch-nightly/ # Build-folder
- manywheel/
- build_cpu.sh # Entrypoint for cpu builds
- build.sh # Entrypoint for CUDA builds
- build_common.sh # Actual build script that ^^ call into
- wheel/
- build_wheel.sh # Entrypoint for wheel builds
- windows/
- build_pytorch.bat # Entrypoint for wheel builds on Windows
```
Every type of package has an entrypoint build script that handles the all the important logic.
## Conda
Linux, MacOS and Windows use the same code flow for the conda builds.
Conda packages are built with conda-build, see https://conda.io/projects/conda-build/en/latest/resources/commands/conda-build.html
Basically, you pass `conda build` a build folder (pytorch-nightly/ above) that contains a build script and a meta.yaml. The meta.yaml specifies in what python environment to build the package in, and what dependencies the resulting package should have, and the build script gets called in the env to build the thing.
tldr; on conda-build is
1. Creates a brand new conda environment, based off of deps in the meta.yaml
1. Note that environment variables do not get passed into this build env unless they are specified in the meta.yaml
2. If the build fails this environment will stick around. You can activate it for much easier debugging. The “General Python” section below explains what exactly a python “environment” is.
2. Calls build.sh in the environment
3. Copies the finished package to a new conda env, also specified by the meta.yaml
4. Runs some simple import tests (if specified in the meta.yaml)
5. Saves the finished package as a tarball
The build.sh we use is essentially a wrapper around ```python setup.py build``` , but it also manually copies in some of our dependent libraries into the resulting tarball and messes with some rpaths.
The entrypoint file `builder/conda/build_conda.sh` is complicated because
* It works for Linux, MacOS and Windows
* The mac builds used to create their own environments, since they all used to be on the same machine. There’s now a lot of extra logic to handle conda envs. This extra machinery could be removed
* It used to handle testing too, which adds more logic messing with python environments too. This extra machinery could be removed.
## Manywheels (linux pip and libtorch packages)
Manywheels are pip packages for linux distros. Note that these manywheels are not actually manylinux compliant.
`builder/manywheel/build_cpu.sh` and `builder/manywheel/build.sh` (for CUDA builds) just set different env vars and then call into `builder/manywheel/build_common.sh`
The entrypoint file `builder/manywheel/build_common.sh` is really really complicated because
* This used to handle building for several different python versions at the same time. The loops have been removed, but there's still unnecessary folders and movements here and there.
* The script is never used this way anymore. This extra machinery could be removed.
* This used to handle testing the pip packages too. This is why there’s testing code at the end that messes with python installations and stuff
* The script is never used this way anymore. This extra machinery could be removed.
* This also builds libtorch packages
* This should really be separate. libtorch packages are c++ only and have no python. They should not share infra with all the python specific stuff in this file.
* There is a lot of messing with rpaths. This is necessary, but could be made much much simpler if the above issues were fixed.
## Wheels (MacOS pip and libtorch packages)
The entrypoint file `builder/wheel/build_wheel.sh` is complicated because
* The mac builds used to all run on one machine (we didn’t have autoscaling mac machines till circleci). So this script handled siloing itself by setting-up and tearing-down its build env and siloing itself into its own build directory.
* The script is never used this way anymore. This extra machinery could be removed.
* This also builds libtorch packages
* Ditto the comment above. This should definitely be separated out.
Note that the MacOS Python wheels are still built in conda environments. Some of the dependencies present during build also come from conda.
## Windows Wheels (Windows pip and libtorch packages)
The entrypoint file `builder/windows/build_pytorch.bat` is complicated because
* This used to handle building for several different python versions at the same time. This is why there are loops everywhere
* The script is never used this way anymore. This extra machinery could be removed.
* This used to handle testing the pip packages too. This is why there’s testing code at the end that messes with python installations and stuff
* The script is never used this way anymore. This extra machinery could be removed.
* This also builds libtorch packages
* This should really be separate. libtorch packages are c++ only and have no python. They should not share infra with all the python specific stuff in this file.
Note that the Windows Python wheels are still built in conda environments. Some of the dependencies present during build also come from conda.
## General notes
### Note on run_tests.sh, smoke_test.sh, and check_binary.sh
* These should all be consolidated
* These must run on all OS types: MacOS, Linux, and Windows
* These all run smoke tests at the moment. They inspect the packages some, maybe run a few import statements. They DO NOT run the python tests nor the cpp tests. The idea is that python tests on master and PR merges will catch all breakages. All these tests have to do is make sure the special binary machinery didn’t mess anything up.
* There are separate run_tests.sh and smoke_test.sh because one used to be called by the smoke jobs and one used to be called by the binary test jobs (see circleci structure section above). This is still true actually, but these could be united into a single script that runs these checks, given an installed pytorch package.
### Note on libtorch
Libtorch packages are built in the wheel build scripts: manywheel/build_*.sh for linux and build_wheel.sh for mac. There are several things wrong with this
* It’s confusing. Most of those scripts deal with python specifics.
* The extra conditionals everywhere severely complicate the wheel build scripts
* The process for building libtorch is different from the official instructions (a plain call to cmake, or a call to a script)
### Note on docker images / Dockerfiles
All linux builds occur in docker images. The docker images are
* soumith/conda-cuda
* Has ALL CUDA versions installed. The script pytorch/builder/conda/switch_cuda_version.sh sets /usr/local/cuda to a symlink to e.g. /usr/local/cuda-10.0 to enable different CUDA builds
* Also used for cpu builds
* soumith/manylinux-cuda90
* soumith/manylinux-cuda92
* soumith/manylinux-cuda100
* Also used for cpu builds
The Dockerfiles are available in pytorch/builder, but there is no circleci job or script to build these docker images, and they cannot be run locally (unless you have the correct local packages/paths). Only Soumith can build them right now.
### General Python
* This is still a good explanation of python installations https://caffe2.ai/docs/faq.html#why-do-i-get-import-errors-in-python-when-i-try-to-use-caffe2
# How to manually rebuild the binaries
tldr; make a PR that looks like https://github.com/pytorch/pytorch/pull/21159
Sometimes we want to push a change to master and then rebuild all of today's binaries after that change. As of May 30, 2019 there isn't a way to manually run a workflow in the UI. You can manually re-run a workflow, but it will use the exact same git commits as the first run and will not include any changes. So we have to make a PR and then force circleci to run the binary workflow instead of the normal tests. The above PR is an example of how to do this; essentially you copy-paste the binarybuilds workflow steps into the default workflow steps. If you need to point the builder repo to a different commit then you'd need to change https://github.com/pytorch/pytorch/blob/master/.circleci/scripts/binary_checkout.sh#L42-L45 to checkout what you want.
## How to test changes to the binaries via .circleci
Writing PRs that test the binaries is annoying, since the default circleci jobs that run on PRs are not the jobs that you want to run. Likely, changes to the binaries will touch something under .circleci/ and require that .circleci/config.yml be regenerated (.circleci/config.yml controls all .circleci behavior, and is generated using ```.circleci/regenerate.sh``` in python 3.7). But you also need to manually hardcode the binary jobs that you want to test into the .circleci/config.yml workflow, so you should actually make at least two commits, one for your changes and one to temporarily hardcode jobs. See https://github.com/pytorch/pytorch/pull/22928 as an example of how to do this.
# Update the PR, need to force since the commits are different now
git push origin my_branch --force
```
The advantage of this flow is that you can make new changes to the base commit and regenerate the .circleci without having to re-write which binary jobs you want to test on. The downside is that all updates will be force pushes.
## How to build a binary locally
### Linux
You can build Linux binaries locally easily using docker.
```
# Run the docker
# Use the correct docker image, soumith/conda-cuda used here as an example
#
# -v path/to/foo:path/to/bar makes path/to/foo on your local machine (the
# machine that you're running the command on) accessible to the docker
# container at path/to/bar. So if you then run `touch path/to/bar/baz`
# in the docker container then you will see path/to/foo/baz on your local
# machine. You could also clone the pytorch and builder repos in the docker.
#
# If you're building a CUDA binary then use `nvidia-docker run` instead, see below.
#
# If you know how, add ccache as a volume too and speed up everything
# Export whatever variables are important to you. All variables that you'd
# possibly need are in .circleci/scripts/binary_populate_env.sh
# You should probably always export at least these 3 variables
export PACKAGE_TYPE=conda
export DESIRED_PYTHON=3.6
export DESIRED_CUDA=cpu
# Call the entrypoint
# `|& tee foo.log` just copies all stdout and stderr output to foo.log
# The builds generate lots of output so you probably need this when
# building locally.
/builder/conda/build_pytorch.sh |& tee build_output.log
```
**Building CUDA binaries on docker**
To build a CUDA binary you need to use `nvidia-docker run` instead of just `docker run` (or you can manually pass `--runtime=nvidia`). This adds some needed libraries and things to build CUDA stuff.
You can build CUDA binaries on CPU only machines, but you can only run CUDA binaries on CUDA machines. This means that you can build a CUDA binary on a docker on your laptop if you so choose (though it’s gonna take a loong time).
For Facebook employees, ask about beefy machines that have docker support and use those instead of your laptop; it will be 5x as fast.
### MacOS
There’s no easy way to generate reproducible hermetic MacOS environments. If you have a Mac laptop then you can try emulating the .circleci environments as much as possible, but you probably have packages in /usr/local/, possibly installed by brew, that will probably interfere with the build. If you’re trying to repro an error on a Mac build in .circleci and you can’t seem to repro locally, then my best advice is actually to iterate on .circleci :/
But if you want to try, then I’d recommend
```
# Create a new terminal
# Clear your LD_LIBRARY_PATH and trim as much out of your PATH as you
# know how to do
# Install a new miniconda
# First remove any other python or conda installation from your PATH
# Always install miniconda 3, even if building for Python <3
# All MacOS builds use conda to manage the python env and dependencies
# that are built with, even the pip packages
conda create -yn binary python=2.7
conda activate binary
# Export whatever variables are important to you. All variables that you'd
# possibly need are in .circleci/scripts/binary_populate_env.sh
# You should probably always export at least these 3 variables
export PACKAGE_TYPE=conda
export DESIRED_PYTHON=3.6
export DESIRED_CUDA=cpu
# Call the entrypoint you want
path/to/builder/wheel/build_wheel.sh
```
N.B. installing a brand new miniconda is important. This has to do with how conda installations work. See the “General Python” section above, but tldr; is that
1. You make the ‘conda’ command accessible by prepending `path/to/conda_root/bin` to your PATH.
2. You make a new env and activate it, which then also gets prepended to your PATH. Now you have `path/to/conda_root/envs/new_env/bin:path/to/conda_root/bin:$PATH`
3. Now say you (or some code that you ran) call python executable `foo`
1. if you installed `foo` in `new_env`, then `path/to/conda_root/envs/new_env/bin/foo` will get called, as expected.
2. But if you forgot to installed `foo` in `new_env` but happened to previously install it in your root conda env (called ‘base’), then unix/linux will still find `path/to/conda_root/bin/foo` . This is dangerous, since `foo` can be a different version than you want; `foo` can even be for an incompatible python version!
Newer conda versions and proper python hygiene can prevent this, but just install a new miniconda to be safe.
echo NOTE: To run `import torch`, please make sure to activate the conda environment by running `call %CONDA_PARENT_DIR%\Miniconda3\Scripts\activate.bat %CONDA_PARENT_DIR%\Miniconda3` in Command Prompt before running Git Bash.
USE_MKLDNN"Use MKLDNN. Only available on x86 and x86_64."ON
"CPU_INTEL"OFF)
set(MKLDNN_ENABLE_CONCURRENT_EXEC${USE_MKLDNN})
cmake_dependent_option(
USE_MKLDNN_CBLAS"Use CBLAS in MKLDNN"OFF
"USE_MKLDNN"OFF)
option(USE_DISTRIBUTED"Use distributed"ON)
cmake_dependent_option(
USE_MPI"Use MPI for Caffe2. Only available if USE_DISTRIBUTED is on."ON
@ -134,43 +185,94 @@ cmake_dependent_option(
cmake_dependent_option(
USE_GLOO"Use Gloo. Only available if USE_DISTRIBUTED is on."ON
"USE_DISTRIBUTED"OFF)
cmake_dependent_option(
USE_GLOO_IBVERBS"Use Gloo IB verbs for distributed. Only available if USE_GLOO is on."OFF
"USE_GLOO"OFF)
option(USE_TBB"Use TBB"OFF)
# Used when building Caffe2 through setup.py
option(BUILDING_WITH_TORCH_LIBS"Tell cmake if Caffe2 is being built alongside torch libs"OFF)
option(BUILDING_WITH_TORCH_LIBS"Tell cmake if Caffe2 is being built alongside torch libs"ON)
# /Z7 override option
# When generating debug symbols, CMake default to use the flag /Zi.
# However, it is not compatible with sccache. So we rewrite it off.
# But some users don't use sccache; this override is for them.
option(MSVC_Z7_OVERRIDE"Work around sccache bug by replacing /Zi and /ZI with /Z7 when using MSVC (if you are not using sccache, you can turn this OFF)"ON)
cmake_dependent_option(
MSVC_Z7_OVERRIDE"Work around sccache bug by replacing /Zi and /ZI with /Z7 when using MSVC (if you are not using sccache, you can turn this OFF)"ON
@ -159,7 +159,7 @@ If you want to compile with CUDA support, install
- [NVIDIA CUDA](https://developer.nvidia.com/cuda-downloads) 9 or above
- [NVIDIA cuDNN](https://developer.nvidia.com/cudnn) v7 or above
If you want to disable CUDA support, export environment variable `NO_CUDA=1`.
If you want to disable CUDA support, export environment variable `USE_CUDA=0`.
Other potentially useful environment variables may be found in `setup.py`.
If you are building for NVIDIA's Jetson platforms (Jetson Nano, TX1, TX2, AGX Xavier), Instructions to [are available here](https://devtalk.nvidia.com/default/topic/1049071/jetson-nano/pytorch-for-jetson-nano/)
@ -212,27 +212,69 @@ If the version of Visual Studio 2017 is higher than 15.4.5, installing of "VC++
NVTX is a part of CUDA distributive, where it is called "Nsight Compute". For installing it onto already installed CUDA run CUDA installation once again and check the corresponding checkbox.
Be sure that CUDA with Nsight Compute is installed after Visual Studio 2017.
Currently VS 2017, VS 2019 and Ninja are supported as the generator of CMake. If `ninja.exe` is detected in `PATH`, then Ninja will be used as the default generator, otherwise it will use VS 2017.
<br/> If Ninja is selected as the generator, the latest MSVC which is newer than VS 2015 (14.0) will get selected as the underlying toolchain if you have Python > 3.5, otherwise VS 2015 will be selected so you'll have to activate the environment. If you use CMake <= 3.14.2 and has VS 2019 installed, then even if you specify VS 2017 as the generator, VS 2019 will get selected as the generator.
CUDA and MSVC has strong version dependencies, so even if you use VS 2017 / 2019, you will get build errors like `nvcc fatal : Host compiler targets unsupported OS`. For this kind of problem, please install the corresponding VS toolchain in the table below and then you can either specify the toolset during activation (recommended) or set `CUDAHOSTCXX` to override the cuda host compiler (not recommended if there are big version differences).
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
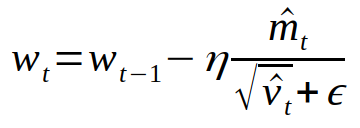{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
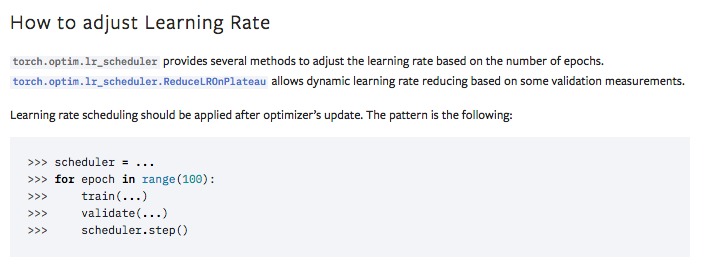{kind=link}