**Overview**
This PR switches the order of freeing the unsharded `FlatParameter` (`self._free_unsharded_flat_param()`) and switching to use the sharded `FlatParameter` (`self._use_sharded_flat_param()`). This is to prevent "use-after_free"-type bugs where for `param.data = new_data`, `param` has its metadata intact but not its storage, causing an illegal memory access for any instrumentation that depends on its storage. (`param` is an original parameter and `new_data` is either a view into the sharded `FlatParameter` or `torch.empty(0)` depending on the sharding and rank.)
**Details**
To see why simply switching the order of the two calls is safe, let us examine the calls themselves:
652457b1b7/torch/distributed/fsdp/flat_param.py (L1312-L1339)652457b1b7/torch/distributed/fsdp/flat_param.py (L1298-L1310)
- `_free_unsharded_flat_param()` does not make any assumption that `self.flat_param`'s data is the sharded `FlatParameter` (i.e. `_local_shard`).
- The sharded `FlatParameter` (i.e. `_local_shard`) is always present in memory, which means that FSDP can use sharded views at any time, including before freeing the unsharded data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94859
Approved by: https://github.com/zhaojuanmao, https://github.com/fegin
Fixes#94353
This PR adds examples and further info to the in-place and out-of-place masked scatter functions' documentation, according to what was proposed in the linked issue. Looking forward to any suggested changes you may have as I continue to familiarize myself with PyTorch 🙂
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94545
Approved by: https://github.com/lezcano
Add triton support for ROCm builds of PyTorch.
* Enables inductor and dynamo when rocm is detected
* Adds support for pytorch-triton-mlir backend
* Adds check_rocm support for verify_dynamo.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94660
Approved by: https://github.com/malfet
With the release of ROCm 5.3 hip now supports a hipGraph implementation.
All necessary backend work and hipification is done to support the same functionality as cudaGraph.
Unit tests are modified to support a new TEST_GRAPH feature which allows us to create a single check for graph support instead of attempted to gather the CUDA level in annotations for every graph test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88202
Approved by: https://github.com/jithunnair-amd, https://github.com/pruthvistony, https://github.com/malfet
Following the same logic of preloading cudnn and cublas from the pypi folder in multi-arch disributions, where Pure-lib vs Plat-lib matters, this PR adds the logic for the rest of the cuda pypi libraries that were integrated.
I have tested this PR by running the code block locally and installing/uninstalling nvidia pypi libraries:
```
import sys
import os
def _preload_cuda_deps():
"""Preloads cudnn/cublas deps if they could not be found otherwise."""
# Should only be called on Linux if default path resolution have failed
cuda_libs = {
'cublas': 'libcublas.so.11',
'cudnn': 'libcudnn.so.8',
'cuda_nvrtc': 'libnvrtc.so.11.2',
'cuda_runtime': 'libcudart.so.11.0',
'cuda_cupti': 'libcupti.so.11.7',
'cufft': 'libcufft.so.10',
'curand': 'libcurand.so.10',
'cusolver': 'libcusolver.so.11',
'cusparse': 'libcusparse.so.11',
'nccl': 'libnccl.so.2',
'nvtx': 'libnvToolsExt.so.1',
}
cuda_libs_paths = {lib_folder: None for lib_folder in cuda_libs.keys()}
for path in sys.path:
nvidia_path = os.path.join(path, 'nvidia')
if not os.path.exists(nvidia_path):
continue
for lib_folder, lib_name in cuda_libs.items():
candidate_path = os.path.join(nvidia_path, lib_folder, 'lib', lib_name)
if os.path.exists(candidate_path) and not cuda_libs_paths[lib_folder]:
cuda_libs_paths[lib_folder] = candidate_path
if all(cuda_libs_paths.values()):
break
if not all(cuda_libs_paths.values()):
none_libs = [lib for lib in cuda_libs_paths if not cuda_libs_paths[lib]]
raise ValueError(f"{', '.join(none_libs)} not found in the system path {sys.path}")
_preload_cuda_deps()
```
I don't have access to a multi-arch environment, so if somebody could verify a wheel with this patch on a multi-arch distribution, that would be great!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94355
Approved by: https://github.com/atalman
If the input to operator.not_ is a tensor, I want to convert the operator to a torch.logical_not. This allows the following test case to pass. Beforehand it resulted in the error `NotImplementedError("local_scalar_dense/item NYI for torch.bool")`
```
def test_export_tensor_bool_not(self):
def true_fn(x, y):
return x + y
def false_fn(x, y):
return x - y
def f(x, y):
return cond(not torch.any(x), true_fn, false_fn, [x, y])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94626
Approved by: https://github.com/voznesenskym
Fixes#91824
This PR add a new dynamo backend registration mechanism through ``entry_points``. The ``entry_points`` of a package is provides a way for the package to reigster a plugin for another one.
The docs of the new mechanism:
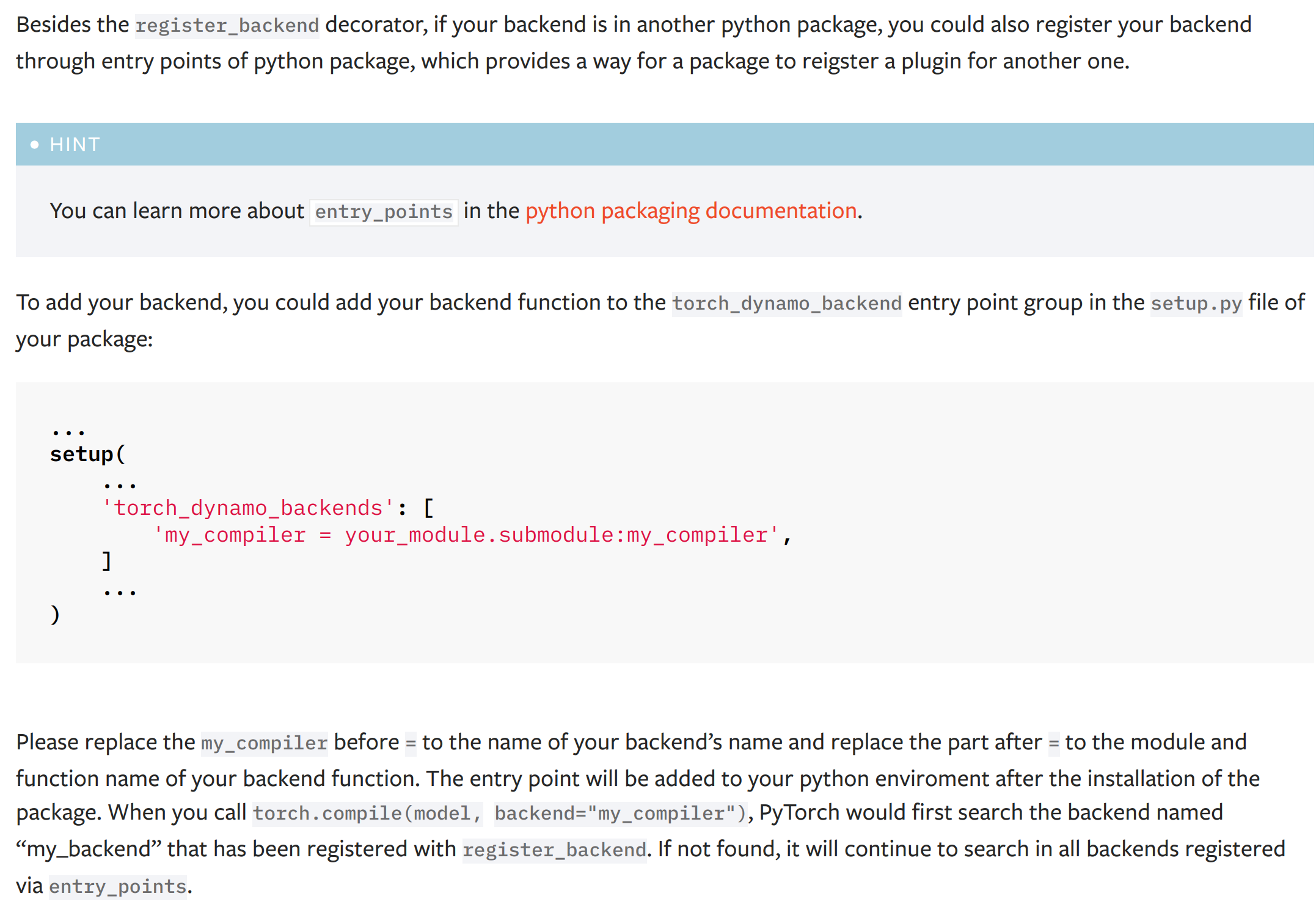
(the typo '...named "my_backend" that has been..." has been fixed to '...named "my_compiler" that has been...')
# Discussion
## About the test
I did not add a test for this PR as it is hard either to install a fack package during a test or manually hack the entry points function by replacing it with a fake one. I have tested this PR offline with the hidet compiler and it works fine. Please let me know if you have any good idea to test this PR.
## About the dependency of ``importlib_metadata``
This PR will add a dependency ``importlib_metadata`` for the python < 3.10 because the modern usage of ``importlib`` gets stable at this python version (see the documentation of the importlib package [here](https://docs.python.org/3/library/importlib.html)). For python < 3.10, the package ``importlib_metadata`` implements the feature of ``importlib``. The current PR will hint the user to install this ``importlib_metata`` if their python version < 3.10.
## About the name and docs
Please let me know how do you think the name ``torch_dynamo_backend`` as the entry point group name and the documentation of this registration mechanism.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93873
Approved by: https://github.com/malfet, https://github.com/jansel
Fixes https://github.com/pytorch/pytorch/issues/93890
We do the following:
1. fix __init__constructor for `AutocastModeVariable` with exisiting `mode` while copying
2. `resume_execution` is made aware of constant args (`target_values`), by storing said args in `ReenterWith`. To propagate between subgraphs (in straightline code), we also store the constant args in the downstream's `code_options["co_consts"]` if not already.
---
Future work:
1. handle instantiating context manager in non-inlineable functions. Simultaneously fix nested grad mode bug.
2. generalize to general `ContextManager`s
3. generalize to variable arguments passed to context manager, with guards around the variable.
---
Actually, if we look at the repro: 74592a43d0/test/dynamo/test_repros.py (L1249), we can see that the method in this PR doesn't work for graph breaks in function calls, in particular, in function calls that don't get inlined.
Why inlining functions with graph breaks is hard:
- When we handle graph breaks, we create a new code object for the remainder of the code. It's hard to imagine doing this when you are inside a function, then we need a frame stack. And we just want to deal with the current frame as a sequence of straight line codes.
Why propagating context manager information is hard:
- If we do not inline the function, the frame does not contain any information about the parent `block_stack` or `co_consts`. So we cannot store it on local objects like the eval frame. It has to be a global object in the output_graph.
---
Anyway, I'm starting to see clearly that dynamo must indeed be optimized for torch use-case. Supporting more general cases tends to run into endless corner-cases and caveats.
One direction that I see as viable to handle function calls which have graph breaks and `has_tensor_in_frame` is stick with not inlining them, while installing a global `ContextManagerManager`, similar to the `CleanupManager` (which cleans up global variables). We can know which context managers are active at any given point, so that we can install their setup/teardown code on those functions and their fragments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94137
Approved by: https://github.com/yanboliang
The `requirement.txt` file is in the PyTorch directory. The instructions to `clone` and `cd` to the PyTorch directory are in the later section under Get the PyTorch Source. So, the instructions as such gives an error that requirement.txt is not found.
```ERROR: Could not open requirements file: .. No such file or directory: 'requirements.txt' ```
This PR clarifies the usage of the command.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94155
Approved by: https://github.com/malfet
GraphModules that were created during DDPOptimizer graph breaking
lacked `compile_subgraph_reason`, which caused an exception when
running .explain().
Now the reason is provided and users can use .explain() to find out
that DDPOptimizer is causing graph breaks.
Fixes#94579
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94749
Approved by: https://github.com/voznesenskym
This restructures the magic methods so that there is a stub `add` that calls the metaprogrammed `_add`. With this change, `SymNode.add` can now show up in stack traces, which is a huge benefit for profiling.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94410
Approved by: https://github.com/Chillee
Changes:
* Add `simplified` kwarg to let you only render guards that are nontrivial (excludes duck sizing)
* Make a list of strings valid for sources, if you just have some variable names you want to bind to
* Add test helper `show_guards` using these facilities, switch a few tests to it
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94404
Approved by: https://github.com/Chillee
This patch started with only the change in `torch/_prims_common/__init__.py`. Unfortunately, this change by itself fails tests. The reason it fails tests is sym_max produces sympy.Max expression, which impedes our ability to actually reason symbolically about the resulting expressions. We much prefer to insert a guard on `l > 1` and get a Sympy expression without Max in it, if we can. In the upcoming unbacked SymInts PR, we can't necessarily do this, but without unbacked SymInts, we always can.
To do this, we introduce `alternate_impl_if_hinted_methods`. The idea is that if all of the arguments into max/min have hints, we will just go ahead and introduce a guard and then return one argument or the other, depending on the result. This is done by rewrapping the SymNode into SymInt/SymFloat and then running builtins.min/max, but we also could have just manually done the guarding (see also https://github.com/pytorch/pytorch/pull/94365 )
However, a very subtle problem emerges when you do this. When we do builtins min/max, we return the argument SymNode directly, without actually allocating a fresh SymNode. Suppose we do a min-max with a constant (as is the case in `sym_max(l, 1)`. This means that we can return a constant SymNode as the result of the computation. Constant SymNodes get transformed into regular integers, which then subsequently trigger the assert at https://github.com/pytorch/pytorch/pull/94400/files#diff-03557db7303b8540f095b4f0d9cd2280e1f42f534f67d8695f756ec6c02d3ec7L620
After thinking about this a bit, I think the assert is wrong. It should be OK for SymNode methods to return constants. The reason the assert was originally added was that ProxyTensorMode cannot trace a constant return. But this is fine: if you return a constant, no tracing is necessary; you know you have enough guards that it is guaranteed to be a constant no matter what the input arguments are, so you can burn it in. You might also be wondering why a change to SymNode method affects the assert from the dispatch mode dispatch: the call stack typically looks like SymNode.binary_magic_impl -> SymProxyTensorMode -> SymNode.binary_magic_impl again; so you hit the binary_magic_impl twice!
No new tests, the use of sym_max breaks preexisting tests and then the rest of the PR makes the tests pass again.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94400
Approved by: https://github.com/Chillee
The expression `argv + [f'--junit-xml-reruns={test_report_path}'] if TEST_SAVE_XML else []` evaluates to the empty list when `TEST_SAVE_XML` is false and would need parentheses.
Instead simplify the code by appending the argument when required directly where `test_report_path` is set.
Note that `.append()` may not be used as that would modify `argv` and in turn `UNITTEST_ARGS` which might have undesired side effects.
Without this patch `pytest.main()` would be called, i.e. no arguments which will try to discover all tests in the current working directory which ultimately leads to (many) failures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94589
Approved by: https://github.com/clee2000, https://github.com/Neilblaze
**Overview**
This refactors module materialization (i.e. meta device or `torchdistX` deferred initialization) to compute the parameter and buffer names as needed instead of pre-computing them. These are needed to reacquire references to the states (e.g. `module.get_parameter(param_name)`) after materialization since the materialization may create new variables.
This refactor simplifies `_get_fully_sharded_module_to_states()` (the core function for "pseudo auto wrapping") to better enable lowest common ancestor (LCA) module computation for shared parameters, for which tracking parameter and buffer names may complicate the already non-obvious implementation.
**Discussion**
The tradeoff is a worst case quadratic traversal over modules if materializing all of them. However, since (1) the number of modules is relatively small, (2) the computation per module in the quadratic traversal is negligible, (3) this runs only once per training session, and (4) module materialization targets truly large models, I think this tradeoff is tolerable.
**For Reviewers**
- `_init_param_handle_from_module()` initializes _one_ `FlatParamHandle` from a fully sharded module and represents the module wrapper code path. For this code path, there is no need to reacquire references to the parameters/buffers for now since the managed parameters are only computed after materialization. This works because the managed parameters have a simple definition: any parameter in the local root module's tree excluding those already marked as flattened by FSDP. Similarly, FSDP marks buffers to indicate that they have already been processed (synced if `sync_module_states`).
- `_init_param_handles_from_module()` initializes _all_ `FlatParamHandle`s from a fully sharded module and represents the composable code path. For this code path, we must reacquire references to parameters/buffers because each logical wrapping is specified as a list of parameters/buffers to group together by those variables and because materialization may create new variables.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94196
Approved by: https://github.com/rohan-varma
Hi!
I've been fuzzing different pytorch modules, and found a few crashes inside one of them.
Specifically, I'm talking about a module for interpreting the JIT code and a function called `InterpreterState::run()`. Running this function with provided crash file results in a crash, which occurs while calling `dim()` on a `stack` with 0 elements ([line-686](abc54f9314/torch/csrc/jit/runtime/interpreter.cpp (L686))). The crash itself occurs later, when std::move is called with incorrect value of type `IValue`.
The second crash is similar and occurs on [line 328](abc54f9314/torch/csrc/jit/runtime/interpreter.cpp (LL328C15-L328C48)), where `reg(inst.X + i - 1) = pop(stack);` is executed. The error here is the same, `Stack stack` might not contain enough elements.
The third crash occurs on [line 681](abc54f9314/torch/csrc/jit/runtime/interpreter.cpp (L681)). The problem here is the same as for previous crashes. There are not enough elements in the stack.
In addition to these places, there are many others (in the same function) where border checking is also missing. I am not sure what is the best way to fix these problems, however I suggest adding a boundary check inside each of these case statement.
All tests were performed on this pytorch version: [abc54f93145830b502400faa92bec86e05422fbd](abc54f9314)
### How to reproduce
1. To reproduce the crash, use provided docker: [Dockerfile](https://github.com/ispras/oss-sydr-fuzz/tree/master/projects/pytorch)
2. Build the container: `docker build -t oss-sydr-fuzz-pytorch-reproduce .`
3. Copy these crash files to the current directory:
- [crash-4f18c5128c9a5a94343fcbbd543d7d6b02964471.zip](https://github.com/pytorch/pytorch/files/10674143/crash-4f18c5128c9a5a94343fcbbd543d7d6b02964471.zip)
- [crash-55384dd7c9689ed7b94ac6697cc43db4e0dd905a.zip](https://github.com/pytorch/pytorch/files/10674147/crash-55384dd7c9689ed7b94ac6697cc43db4e0dd905a.zip)
- [crash-06b6125d01c5f91fae112a1aa7dcc76d71b66576.zip](https://github.com/pytorch/pytorch/files/10674152/crash-06b6125d01c5f91fae112a1aa7dcc76d71b66576.zip)
4. Run the container: ``docker run --privileged --network host -v `pwd`:/homedir --rm -it oss-sydr-fuzz-pytorch-reproduce /bin/bash``
5. And execute the binary: `/jit_differential_fuzz /homedir/crash-4f18c5128c9a5a94343fcbbd543d7d6b02964471`
After execution completes you will see this stacktrace:
```asan
=36==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x6060001657f8 at pc 0x00000060bc91 bp 0x7fff00b33380 sp 0x7fff00b33378
READ of size 4 at 0x6060001657f8 thread T0
#0 0x60bc90 in c10::IValue::IValue(c10::IValue&&) /pytorch_fuzz/torch/include/ATen/core/ivalue.h:214:43
#1 0xc20e7cd in torch::jit::pop(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/aten/src/ATen/core/stack.h:102:12
#2 0xc20e7cd in torch::jit::dim(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/torch/csrc/jit/mobile/promoted_prim_ops.cpp:119:20
#3 0xc893060 in torch::jit::InterpreterStateImpl::runImpl(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/torch/csrc/jit/runtime/interpreter.cpp:686:13
#4 0xc85c47b in torch::jit::InterpreterStateImpl::run(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/torch/csrc/jit/runtime/interpreter.cpp:1010:9
#5 0x600598 in runGraph(std::shared_ptr<torch::jit::Graph>, std::vector<at::Tensor, std::allocator<at::Tensor> > const&) /jit_differential_fuzz.cc:66:38
#6 0x601d99 in LLVMFuzzerTestOneInput /jit_differential_fuzz.cc:107:25
#7 0x52ccf1 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15
#8 0x516c0c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6
#9 0x51c95b in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9
#10 0x545ef2 in main /llvm-project/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#11 0x7f9ec069a082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082)
#12 0x51152d in _start (/jit_differential_fuzz+0x51152d)
0x6060001657f8 is located 8 bytes to the left of 64-byte region [0x606000165800,0x606000165840)
allocated by thread T0 here:
#0 0x5fd42d in operator new(unsigned long) /llvm-project/compiler-rt/lib/asan/asan_new_delete.cpp:95:3
#1 0xa16ab5 in void std::vector<c10::IValue, std::allocator<c10::IValue> >::_M_realloc_insert<c10::IValue&>(__gnu_cxx::__normal_iterator<c10::IValue*, std::vector<c10::IValue, std::allocator<c10::IValue> > >, c10::IValue&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:440:33
#2 0xa168f1 in c10::IValue& std::vector<c10::IValue, std::allocator<c10::IValue> >::emplace_back<c10::IValue&>(c10::IValue&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/vector.tcc:121:4
#3 0xc89b53c in torch::jit::InterpreterStateImpl::runImpl(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/torch/csrc/jit/runtime/interpreter.cpp:344:19
#4 0xc85c47b in torch::jit::InterpreterStateImpl::run(std::vector<c10::IValue, std::allocator<c10::IValue> >&) /pytorch_fuzz/torch/csrc/jit/runtime/interpreter.cpp:1010:9
#5 0x600598 in runGraph(std::shared_ptr<torch::jit::Graph>, std::vector<at::Tensor, std::allocator<at::Tensor> > const&) /jit_differential_fuzz.cc:66:38
#6 0x601d99 in LLVMFuzzerTestOneInput /jit_differential_fuzz.cc:107:25
#7 0x52ccf1 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15
#8 0x516c0c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6
#9 0x51c95b in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9
#10 0x545ef2 in main /llvm-project/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#11 0x7f9ec069a082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082)
SUMMARY: AddressSanitizer: heap-buffer-overflow /pytorch_fuzz/torch/include/ATen/core/ivalue.h:214:43 in c10::IValue::IValue(c10::IValue&&)
Shadow bytes around the buggy address:
0x0c0c80024aa0: fd fd fd fd fd fd fd fa fa fa fa fa 00 00 00 00
0x0c0c80024ab0: 00 00 00 fa fa fa fa fa fd fd fd fd fd fd fd fd
0x0c0c80024ac0: fa fa fa fa fd fd fd fd fd fd fd fd fa fa fa fa
0x0c0c80024ad0: fd fd fd fd fd fd fd fd fa fa fa fa fd fd fd fd
0x0c0c80024ae0: fd fd fd fd fa fa fa fa 00 00 00 00 00 00 00 00
=>0x0c0c80024af0: fa fa fa fa fd fd fd fd fd fd fd fd fa fa fa[fa]
0x0c0c80024b00: 00 00 00 00 00 00 00 00 fa fa fa fa fa fa fa fa
0x0c0c80024b10: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0c80024b20: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0c80024b30: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x0c0c80024b40: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==36==ABORTING
```
6. Executing the remaining crashes gives similar crash reports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94298
Approved by: https://github.com/davidberard98
- To check for Memory Leaks in `test_mps.py`, set the env-variable `PYTORCH_TEST_MPS_MEM_LEAK_CHECK=1` when running test_mps.py (used CUDA code as reference).
- Added support for the following new python interfaces in MPS module:
`torch.mps.[empty_cache(), set_per_process_memory_fraction(), current_allocated_memory(), driver_allocated_memory()]`
- Renamed `_is_mps_on_macos_13_or_newer()` to `_mps_is_on_macos_13_or_newer()`, and `_is_mps_available()` to `_mps_is_available()` to be consistent in naming with prefix `_mps`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94646
Approved by: https://github.com/malfet
Summary:
We have tests testing package level migration correctness for torch AO migration.
After reading the code, I noticed that these tests are not testing anything
additional on top of the function level tests we already have.
An upcoming user warning PR will break this test, and it doesn't seem worth fixing.
As long as the function level tests pass, 100% of user functionality will
be tested. Removing this in a separate PR to keep PRs small.
Test plan:
```
python test/test_quantization.py -k AOMigration
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94422
Approved by: https://github.com/jcaip
Summary:
This test case is dead code. A newer version of this code
exists in `test/quantization/ao_migration/test_quantization.py`. I
think this class must have been mistakenly left during a refactor.
Deleting it.
Test plan: CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94420
Approved by: https://github.com/jerryzh168
Hopefully fixes#89205.
This is another version of #90847 where it was reverted because it increases the compile-time significantly.
From my discussion with @ngimel in https://github.com/pytorch/pytorch/pull/93153#issuecomment-1409051528, it seems the option of jiterator would be very tricky if not impossible.
So what I did was to optimize the compile-time in my computer.
To optimize the build time, first I compile the pytorch as a whole, then only change the `LogcumsumexpKernel.cu` file to see how it changes the compile time.
Here are my results for the compilation time of only the `LogcumsumexpKernel.cu` file in my computer:
- Original version (without any complex implementations): 56s (about 1 minute)
- The previous PR (#90847): 13m 57s (about 14 minutes)
- This PR: 3m 35s (about 3.5 minutes)
If the previous PR increases the build time by 30 mins in pytorch's computer, then this PR reduces the increment of build time to about 6 mins. Hopefully this is an acceptable level of build-time increase.
What I did was (sorted by how significant it reduces the build time from the most significant one):
- Substituting `log(x)` to `log1p(x - 1)`. This is applied in the infinite case, so we don't really care about precision.
- Implementing complex exponential manually
tag: @malfet, @albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94310
Approved by: https://github.com/Skylion007, https://github.com/malfet
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
This is another try(first is https://github.com/pytorch/pytorch/pull/94172) to fix the warning message when running inductor CPU path:
```
l. Known situations this can occur are inference mode only compilation involving resize_ or prims (!schema.hasAnyAliasInfo() INTERNAL ASSERT FAILED); if your situation looks different please file a bug to PyTorch.
Traceback (most recent call last):
File "/home/xiaobing/pytorch-offical/torch/_functorch/aot_autograd.py", line 1377, in aot_wrapper_dedupe
fw_metadata, _out = run_functionalized_fw_and_collect_metadata(flat_fn)(
File "/home/xiaobing/pytorch-offical/torch/_functorch/aot_autograd.py", line 578, in inner
flat_f_outs = f(*flat_f_args)
File "/home/xiaobing/pytorch-offical/torch/_functorch/aot_autograd.py", line 2455, in functional_call
out = Interpreter(mod).run(*args[params_len:], **kwargs)
File "/home/xiaobing/pytorch-offical/torch/fx/interpreter.py", line 136, in run
self.env[node] = self.run_node(node)
File "/home/xiaobing/pytorch-offical/torch/fx/interpreter.py", line 177, in run_node
return getattr(self, n.op)(n.target, args, kwargs)
File "/home/xiaobing/pytorch-offical/torch/fx/interpreter.py", line 294, in call_module
return submod(*args, **kwargs)
File "/home/xiaobing/pytorch-offical/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/xiaobing/pytorch-offical/torch/_inductor/mkldnn.py", line 344, in forward
return self._conv_forward(input, other, self.weight, self.bias)
File "/home/xiaobing/pytorch-offical/torch/_inductor/mkldnn.py", line 327, in _conv_forward
return torch.ops.mkldnn._convolution_pointwise_(
File "/home/xiaobing/pytorch-offical/torch/_ops.py", line 499, in __call__
return self._op(*args, **kwargs or {})
File "/home/xiaobing/pytorch-offical/torch/_inductor/overrides.py", line 38, in __torch_function__
return func(*args, **kwargs)
File "/home/xiaobing/pytorch-offical/torch/_ops.py", line 499, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: !schema.hasAnyAliasInfo() INTERNAL ASSERT FAILED at "/home/xiaobing/pytorch-offical/aten/src/ATen/FunctionalizeFallbackKernel.cpp":32, please report a bug to PyTorch. mutating and aliasing ops should all have codegen'd kernels
While executing %self_layer2_0_downsample_0 : [#users=2] = call_module[target=self_layer2_0_downsample_0](args = (%self_layer1_1_conv2, %self_layer2_0_conv2), kwargs = {})
Original traceback:
File "/home/xiaobing/vision/torchvision/models/resnet.py", line 100, in forward
identity = self.downsample(x)
| File "/home/xiaobing/vision/torchvision/models/resnet.py", line 274, in _forward_impl
x = self.layer2(x)
| File "/home/xiaobing/vision/torchvision/models/resnet.py", line 285, in forward
return self._forward_impl(x)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94581
Approved by: https://github.com/jgong5, https://github.com/jansel
Fixes#87219
Implements new ``repeat_interleave`` function into ``aten/src/ATen/native/mps/operations/Repeat.mm``
Adds it to ``aten/src/ATen/native/native_functions.yaml``
Adds new test ``test_repeat_interleave`` to ``test/test_mps/py``
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88649
Approved by: https://github.com/kulinseth
Applies the remaining flake8-comprehension fixes and checks. This changes replace all remaining unnecessary generator expressions with list/dict/set comprehensions which are more succinct, performant, and better supported by our torch.jit compiler. It also removes useless generators such as 'set(a for a in b)`, resolving it into just the set call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94676
Approved by: https://github.com/ezyang
This is my commandeer of https://github.com/pytorch/pytorch/pull/82154 with a couple extra fixes.
The high level idea is that when we start profiling we see python frames which are currently executing, but we don't know what system TID created them. So instead we defer the TID assignment, and then during post processing we peer into the future and use the system TID *of the next* call on that Python TID.
As an aside, it turns out that CPython does some bookkeeping (ee821dcd39/Include/cpython/pystate.h (L159-L165), thanks @dzhulgakov for the pointer), but you'd have to do some extra work at runtime to know how to map their TID to ours so for now I'm going to stick to what I can glean from post processing alone.
As we start observing more threads it becomes more important to be principled about how we start up and shut down. (Since threads may die while the profiler is running.) #82154 had various troubles with segfaults that wound up being related to accessing Python thread pointers which were no longer alive. I've tweaked the startup and shutdown interaction with the CPython interpreter and it should be safer now.
Differential Revision: [D42336292](https://our.internmc.facebook.com/intern/diff/D42336292/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91684
Approved by: https://github.com/chaekit
Summary:
Update XNNPACK to 51a987591a6fc9f0fc0707077f53d763ac132cbf (51a987591a)
Update the corresponding CMake and BUCK rules, as well as the generate_wrapper.py for the new version.
Due to XNNPACK having already changed a lot. We need to update XNNPACK in this time for many reasons. Firstly, XNNAPCK has updated a lot, and developers' community has re-factored codes' such as API changes. We can see from their cmakefile.txt to see there are many changes! Thus, in order to follow up upstream. We need to update xnnpack at this time. It is very crucial for our future development. Also, many projects are relying on newer versions of XNNPACK, so we probably need to update XNNPACK third-party libs at this time. we have some api changes of XNNPACK, so we also need to update them in this time. We also update target building files and generate-wrapper.py file to make this process more automatically. The original target files have some files which are missing, so we add them into buck2 building files so that it can build and test XNNPACK successfully.
Test Plan:
buck2 build //xplat/third-party/XNNPACK:operators
buck2 build //xplat/third-party/XNNPACK:XNNPACK
buck2 test fbcode//caffe2/test:xnnpack_integration
Reviewed By: digantdesai
Differential Revision: D43092938
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94330
Approved by: https://github.com/digantdesai, https://github.com/albanD
Currently we don't enable fusion of mutation ops in any case (we introduce a `StarDep` to prevent fusion with any upstream readers, to ensure the kernel mutating the buffer is executing after them).
This results in cases like [this](https://gist.github.com/mlazos/3dcfd416033b3459ffea43cb91c117c9) where even though all of the other readers have been fused into a single kernel, the `copy_` is left by itself.
This PR introduces `WeakDep` and a pass after each fusion to see if after fusion there are other dependencies on the upstream fused node which already guarantee that this kernel is fused after the prior readers, if there are, the `WeakDep` is pruned and the kernel performing the mutation can be fused with the upstream kernel. This will allow Inductor to fuse epilogue `copy_`s introduced by functionalization on inference graphs.
[before code](https://gist.github.com/mlazos/3369a11dfd1b5cf5bb255313b710ef5b)
[after code](https://gist.github.com/mlazos/1005d8aeeba56e3a3e1b70cd77773c53)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94110
Approved by: https://github.com/jansel
I applied some flake8 fixes and enabled checking for them in the linter. I also enabled some checks for my previous comprehensions PR.
This is a follow up to #94323 where I enable the flake8 checkers for the fixes I made and fix a few more of them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94601
Approved by: https://github.com/ezyang
- This PR is a prerequisite for the upcoming Memory Leak Detection PR.
- Enable global manual seeding via `torch.manual_seed()` + test case
- Add `torch.mps.synchronize()` to wait for MPS stream to finish + test case
- Enable the following python interfaces for MPS:
`torch.mps.[get_rng_state(), set_rng_state(), synchronize(), manual_seed(), seed()]`
- Added some test cases in test_mps.py
- Added `mps.rst` to document the `torch.mps` module.
- Fixed the failure with `test_public_bindings.py`
Description of new files added:
- `torch/csrc/mps/Module.cpp`: implements `torch._C` module functions for `torch.mps` and `torch.backends.mps`.
- `torch/mps/__init__.py`: implements Python bindings for `torch.mps` module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94417
Approved by: https://github.com/albanD
Fixes#87374
@kulinseth and @albanD This makes the MPSAllocator call the MPSAllocatorCallbacks when getting a free buffer and a first try on allocating fails. User can register callbacks that might free a few buffers and an allocation will be retried.
The reason why we need the `recursive_mutex` is that since callbacks are supposed to free memory, they will eventually call free_buffer() that will lock the same `mutex` that's used for allocation. This approach is similar what's used with the `FreeMemoryCallback` in the `CUDACachingAllocator`.
This PR tries to be as minimal as possible, but there could be some additional improvements cleanups, like:
- In current main, there's no way callbacks can be called, so we could probably rename the callback registry to something reflect the same naming in the CudaAllocator:
996cc1c0d0/c10/cuda/CUDACachingAllocator.h (L14-L24)
- Review the EventTypes here:
996cc1c0d0/aten/src/ATen/mps/MPSAllocator.h (L18-L23)
- And IMHO a nice improvement would be if callbacks could be aware of AllocParams, so they can decide to be more agressive or not depending on how much memory is requested. So I'd pass AllocParams in the signature of the executeCallback instance:
996cc1c0d0/aten/src/ATen/mps/MPSAllocator.h (L25)
Let me know if you think we could sneak those changes into this PR or if it's better to propose them in other smaller PR's.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94133
Approved by: https://github.com/kulinseth, https://github.com/razarmehr, https://github.com/albanD
The other `Autograd[Backend]` keys all have fallthrough kernels registered to them, but `AutogradMeta` was missing the fallthrough kernel.
This is a problem for custom ops that don't have autograd support, if you try to run them with meta tensors. If you have a custom op, and register a CPU and a Meta kernel, then:
(1) if you run the op with cpu tensors, it will dispatch straight to the CPU kernel (as expected)
(2) if you run the op with meta tensors, you will error - because we don't have a fallthrough registered to the AutogradMeta key, we will try to dispatch to the AutogradMeta key and error, since the op author hasn't provided an autograd implementation.
Here's a repro that I confirmed now works:
```
import torch
from torch._dispatch.python import enable_python_dispatcher
from torch._subclasses.fake_tensor import FakeTensorMode
lib = torch.library.Library("test", "DEF")
impl_cpu = torch.library.Library("test", "IMPL", "CPU")
impl_meta = torch.library.Library("test", "IMPL", "Meta")
def foo_impl(x):
return x + 1
lib.define("foo(Tensor a) -> Tensor")
impl_meta.impl("foo", foo_impl)
impl_cpu.impl("foo", foo_impl)
with enable_python_dispatcher():
a = torch.ones(2, device='meta')
print("@@@@@")
b = torch.ops.test.foo.default(a)
print(b)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94603
Approved by: https://github.com/ezyang, https://github.com/albanD
Fixes#88951
The output shape of upsample is computed through `(i64)idim * (double)scale` and then casted back to `i64`. If the input scale is ill-formed (say negative number as #88951) which makes `(double)(idim * scale)` to be out of the range for `i64`, the casting will be an undefined behaviour.
To fix it, we just check if `(double)(idim * scale)` can fit into `i64`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94290
Approved by: https://github.com/malfet
Summary:
- Remove redundant bool casts from scatter/gather
- Make the workarounds for scatter/gather (for bool/uint8 data types) OS specific - use them only in macOS Monterey, ignore them starting with macOS Ventura
- Make all tensors ranked in scatter
Fixes following tests:
```
test_output_match_slice_scatter_cpu_bool
test_output_match_select_scatter_cpu_bool
test_output_match_diagonal_scatter_cpu_bool
test_output_match_repeat_cpu_bool
test_output_match_rot90_cpu_bool
etc..
```
Still failing on macOS Monterey (needs additional investigation):
```
test_output_match_scatter_cpu_bool
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94464
Approved by: https://github.com/kulinseth
* CI Test environment to install onnx and onnx-script.
* Add symbolic function for `bitwise_or`, `convert_element_type` and `masked_fill_`.
* Update symbolic function for `slice` and `arange`.
* Update .pyi signature for `_jit_pass_onnx_graph_shape_type_inference`.
Co-authored-by: Wei-Sheng Chin <wschin@outlook.com>
Co-authored-by: Ti-Tai Wang <titaiwang@microsoft.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94564
Approved by: https://github.com/abock
- Also fix FP16 correctness issues in several other ops by lowering their FP16 precision in the new list `FP16_LOW_PRECISION_LIST`.
- Add atol/rtol to the `AssertEqual()` of Gradient tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94567
Approved by: https://github.com/kulinseth
# Summary
- Adds type hinting support for SDPA
- Updates the documentation adding warnings and notes on the context manager
- Adds scaled_dot_product_attention to the non-linear activation function section of nn.functional docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94008
Approved by: https://github.com/cpuhrsch
To match nodes within the graph, the matcher currently flattens the arguments and compares each argument against each other. However, if it believes that a list input contains all literals, it will not flatten the list and will instead compare the list directly against each other. It determines if a list is a literal by checking if the first element is a node. However this doesn't work in some cases (like the test cases I added).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94375
Approved by: https://github.com/SherlockNoMad
Fixes#88940
According to the [doc](https://pytorch.org/docs/stable/generated/torch.index_select.html):
1. "The returned tensor has the same number of dimensions as the original tensor (`input`). "
2. "The `dim`th dimension has the same size as the length of `index`; other dimensions have the same size as in the original tensor."
These two conditions cannot be satisfied at the same time if the `input` is a scalar && `index` has multiple values: because a scalar at most holds one element (according to property 1, the output is a scalar), it is impossible to satisfy "The `dim`th dimension has the same size as the length of `index`" when `index` has multiple values.
However, currently, if we do so we either get:
1. Buffer overflow with ASAN;
2. Or (w/o ASAN) silently returns outputs that is not consistent with the doc (`x.index_select(0, torch.Tensor([0, 0, 0]).int())` returns `x`).
As a result, we should explicitly reject such cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94347
Approved by: https://github.com/malfet
### Motivation of this PR
This patch is to migrate `spmm_reduce` from `torch-sparse` (a 3rd party dependency for PyG) to `torch`, which is a response to the initial proposal for fusion of **Gather, Apply Scatter** in Message Passing of GNN inference/training. https://github.com/pytorch/pytorch/issues/71300
**GAS** is the major step for Message Passing, the behavior of **GAS** can be classified into 2 kinds depending on the storage type of `EdgeIndex` which records the connections of nodes:
* COO: the hotspot is `scatter_reduce`
* CSR: the hotspot is `spmm_reduce`
The reduce type can be choose from: "max", "mean", "max", "min".
extend `torch.sparse.mm` with an `reduce` argument, maps to `torch.sparse_mm.reduce` internally.
`sparse_mm_reduce` is registered under the TensorTypeId of `SparseCsrCPU`, and this operator requires an internal interface `_sparse_mm_reduce_impl` which has dual outputs:
* `out` - the actual output
* `arg_out` - records output indices in the non zero elements if the reduce type is "max" or "min", this is only useful for training. So for inference, it will not be calculated.
### Performance
Benchmark on GCN for obgn-products on Xeon single socket, the workload is improved by `4.3x` with this patch.
Performance benefit for training will be bigger, the original backward impl for `sum|mean` is sequential; the original backward impl for `max|min` is not fused.
#### before:
```
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
torch_sparse::spmm_sum 97.09% 56.086s 97.09% 56.088s 6.232s 9
aten::linear 0.00% 85.000us 1.38% 795.485ms 88.387ms 9
aten::matmul 0.00% 57.000us 1.38% 795.260ms 88.362ms 9
aten::mm 1.38% 795.201ms 1.38% 795.203ms 88.356ms 9
aten::relu 0.00% 50.000us 0.76% 440.434ms 73.406ms 6
aten::clamp_min 0.76% 440.384ms 0.76% 440.384ms 73.397ms 6
aten::add_ 0.57% 327.801ms 0.57% 327.801ms 36.422ms 9
aten::log_softmax 0.00% 23.000us 0.10% 55.503ms 18.501ms 3
```
#### after
```
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::spmm_sum 87.35% 11.826s 87.36% 11.827s 1.314s 9
aten::linear 0.00% 92.000us 5.87% 794.451ms 88.272ms 9
aten::matmul 0.00% 62.000us 5.87% 794.208ms 88.245ms 9
aten::mm 5.87% 794.143ms 5.87% 794.146ms 88.238ms 9
aten::relu 0.00% 53.000us 3.35% 452.977ms 75.496ms 6
aten::clamp_min 3.35% 452.924ms 3.35% 452.924ms 75.487ms 6
aten::add_ 2.58% 348.663ms 2.58% 348.663ms 38.740ms 9
aten::argmax 0.42% 57.473ms 0.42% 57.475ms 14.369ms 4
aten::log_softmax 0.00% 22.000us 0.39% 52.605ms 17.535ms 3
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83727
Approved by: https://github.com/jgong5, https://github.com/cpuhrsch, https://github.com/rusty1s, https://github.com/pearu
`combine_t` is the type used to represent the number of elements seen so far as
a floating point value (acc.nf). It is always used in calculations with other
values of type `acc_scalar_t` so there is no performance gained by making this a
separate template argument. Furthermore, when calculating the variance on CUDA
it is always set to `float` which means values are unnecessarily truncated
before being immediately promoted to `double`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94522
Approved by: https://github.com/ngimel
Per @ezyang's advice, added magic sym_int method. This works for 1.0 * s0 optimization, but can't evaluate `a>0` for some args, and still misses some optimization that model rewrite achieves, so swin still fails
(rewrite replaces `B = int(windows.shape[0] / (H * W / window_size / window_size))` with `B = (windows.shape[0] // int(H * W / window_size / window_size))` and model passes)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94365
Approved by: https://github.com/ezyang
Fixes batchnorm forward/backward pass and layer_norm:
Batchnorm Forward pass:
```
- fix batch_norm_mps_out key
- return 1/sqrt(var+epsilon) instead of var
- return empty tensor for mean and var if train is not enabled
- remove native_batch_norm from block list
```
Batchnorm Backward pass:
```
- add revert caculation for save_var used in backward path
- add backward test for native_batch_norm and _native_batch_norm_legit
```
Layer norm:
```
- remove the duplicate calculation from layer_norm_mps
- enable native_layer_norm backward test
- raise atol rtol for native_layer_norm
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94351
Approved by: https://github.com/razarmehr
Hi!
I've been fuzzing different pytorch modules, and found a few crashes.
Specifically, I'm talking about `schema_type_parser.cpp` and `irparser.cpp`. Inside these files, different standard conversion functions are used (such as `stoll`, `stoi`, `stod`, `stoull`). However, default `std` exceptions, such as `std::out_of_range`, `std::invalid_argument`, are not handled.
Some of the crash-files:
1. [crash-493db74c3426e79b2bf0ffa75bb924503cb9acdc.zip](https://github.com/pytorch/pytorch/files/10237616/crash-493db74c3426e79b2bf0ffa75bb924503cb9acdc.zip) - crash source: schema_type_parser.cpp:272
2. [crash-67bb5d34ca48235687cc056e2cdeb2476b8f4aa5.zip](https://github.com/pytorch/pytorch/files/10237618/crash-67bb5d34ca48235687cc056e2cdeb2476b8f4aa5.zip) - crash source: schema_type_parser.cpp:240
3. [crash-0157bca5c41bffe112aa01f3b0f2099ca4bcc62f.zip](https://github.com/pytorch/pytorch/files/10307970/crash-0157bca5c41bffe112aa01f3b0f2099ca4bcc62f.zip) - crash source: schema_type_parser.cpp:179
4. [crash-430da923e56adb9569362efa7fa779921371b710.zip](https://github.com/pytorch/pytorch/files/10307972/crash-430da923e56adb9569362efa7fa779921371b710.zip) - crash source: schema_type_parser.cpp:196
The provided patch adds exception handlers for `std::invalid_argument` and `std::out_of_range`, to rethrow these exceptions with `ErrorReport`.
### How to reproduce
1. To reproduce the crash, use provided docker: [Dockerfile](https://github.com/ispras/oss-sydr-fuzz/blob/master/projects/pytorch/Dockerfile)
2. Build the container: `docker build -t oss-sydr-fuzz-pytorch-reproduce .`
3. Copy crash file to the current directory
5. Run the container: ``docker run --privileged --network host -v `pwd`:/homedir --rm -it oss-sydr-fuzz-pytorch-reproduce /bin/bash``
6. And execute the binary: `/irparser_fuzz /homedir/crash-67bb5d34ca48235687cc056e2cdeb2476b8f4aa5`
After execution completes you will see this error message:
```txt
terminate called after throwing an instance of 'std::out_of_range'
what(): stoll
```
And this stacktrace:
```asan
==9626== ERROR: libFuzzer: deadly signal
#0 0x5b4cf1 in __sanitizer_print_stack_trace /llvm-project/compiler-rt/lib/asan/asan_stack.cpp:87:3
#1 0x529627 in fuzzer::PrintStackTrace() /llvm-project/compiler-rt/lib/fuzzer/FuzzerUtil.cpp:210:5
#2 0x50f833 in fuzzer::Fuzzer::CrashCallback() /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:233:3
#3 0x7ffff7c3741f (/lib/x86_64-linux-gnu/libpthread.so.0+0x1441f)
#4 0x7ffff7a5700a in raise (/lib/x86_64-linux-gnu/libc.so.6+0x4300a)
#5 0x7ffff7a36858 in abort (/lib/x86_64-linux-gnu/libc.so.6+0x22858)
#6 0x7ffff7e74910 (/lib/x86_64-linux-gnu/libstdc++.so.6+0x9e910)
#7 0x7ffff7e8038b (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa38b)
#8 0x7ffff7e803f6 in std::terminate() (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa3f6)
#9 0x7ffff7e806a8 in __cxa_throw (/lib/x86_64-linux-gnu/libstdc++.so.6+0xaa6a8)
#10 0x7ffff7e7737d in std::__throw_out_of_range(char const*) (/lib/x86_64-linux-gnu/libstdc++.so.6+0xa137d)
#11 0xbd0579 in long long __gnu_cxx::__stoa<long long, long long, char, int>(long long (*)(char const*, char**, int), char const*, char const*, unsigned long*, int) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/ext/string_conversions.h:86:2
#12 0xc10f9c in std::__cxx11::stoll(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, unsigned long*, int) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/basic_string.h:6572:12
#13 0xc10f9c in torch::jit::SchemaTypeParser::parseRefinedTensor()::$_2::operator()() const::'lambda'()::operator()() const /pytorch_fuzz/torch/csrc/jit/frontend/schema_type_parser.cpp:240:25
#14 0xc10f9c in void c10::function_ref<void ()>::callback_fn<torch::jit::SchemaTypeParser::parseRefinedTensor()::$_2::operator()() const::'lambda'()>(long) /pytorch_fuzz/c10/util/FunctionRef.h:43:12
#15 0xbfbb27 in torch::jit::SchemaTypeParser::parseList(int, int, int, c10::function_ref<void ()>) /pytorch_fuzz/torch/csrc/jit/frontend/schema_type_parser.cpp:424:7
#16 0xc0ef24 in torch::jit::SchemaTypeParser::parseRefinedTensor()::$_2::operator()() const /pytorch_fuzz/torch/csrc/jit/frontend/schema_type_parser.cpp:236:9
#17 0xc0ef24 in void c10::function_ref<void ()>::callback_fn<torch::jit::SchemaTypeParser::parseRefinedTensor()::$_2>(long) /pytorch_fuzz/c10/util/FunctionRef.h:43:12
#18 0xbfbb27 in torch::jit::SchemaTypeParser::parseList(int, int, int, c10::function_ref<void ()>) /pytorch_fuzz/torch/csrc/jit/frontend/schema_type_parser.cpp:424:7
#19 0xbff590 in torch::jit::SchemaTypeParser::parseRefinedTensor() /pytorch_fuzz/torch/csrc/jit/frontend/schema_type_parser.cpp:209:3
#20 0xc02992 in torch::jit::SchemaTypeParser::parseType() /pytorch_fuzz/torch/csrc/jit/frontend/schema_type_parser.cpp:362:13
#21 0x9445642 in torch::jit::IRParser::parseVarWithType(bool) /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:111:35
#22 0x944ff4c in torch::jit::IRParser::parseOperatorOutputs(std::vector<torch::jit::VarWithType, std::allocator<torch::jit::VarWithType> >*)::$_0::operator()() const /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:138:21
#23 0x944ff4c in void std::__invoke_impl<void, torch::jit::IRParser::parseOperatorOutputs(std::vector<torch::jit::VarWithType, std::allocator<torch::jit::VarWithType> >*)::$_0&>(std::__invoke_other, torch::jit::IRParser::parseOperatorOutputs(std::vector<torch::jit::VarWithType, std::allocator<torch::jit::VarWithType> >*)::$_0&) /usr/bin/../lib/gcc/x86_64-linux-gnu/10/../../../../include/c++/10/bits/invoke.h:60:14
#24 0x94463a7 in torch::jit::IRParser::parseList(int, int, int, std::function<void ()> const&) /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:498:7
#25 0x94460a5 in torch::jit::IRParser::parseOperatorOutputs(std::vector<torch::jit::VarWithType, std::allocator<torch::jit::VarWithType> >*) /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:137:3
#26 0x944c1ce in torch::jit::IRParser::parseOperator(torch::jit::Block*) /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:384:3
#27 0x944bf56 in torch::jit::IRParser::parseOperatorsList(torch::jit::Block*) /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:362:5
#28 0x9444f5f in torch::jit::IRParser::parse() /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:482:3
#29 0x94448df in torch::jit::parseIR(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::Graph*, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, torch::jit::Value*, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, torch::jit::Value*> > >&) /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:94:5
#30 0x944526e in torch::jit::parseIR(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, torch::jit::Graph*) /pytorch_fuzz/torch/csrc/jit/ir/irparser.cpp:99:3
#31 0x5e3ebd in LLVMFuzzerTestOneInput /irparser_fuzz.cc:43:5
#32 0x510d61 in fuzzer::Fuzzer::ExecuteCallback(unsigned char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerLoop.cpp:611:15
#33 0x4fac7c in fuzzer::RunOneTest(fuzzer::Fuzzer*, char const*, unsigned long) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:324:6
#34 0x5009cb in fuzzer::FuzzerDriver(int*, char***, int (*)(unsigned char const*, unsigned long)) /llvm-project/compiler-rt/lib/fuzzer/FuzzerDriver.cpp:860:9
#35 0x529f62 in main /llvm-project/compiler-rt/lib/fuzzer/FuzzerMain.cpp:20:10
#36 0x7ffff7a38082 in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x24082)
#37 0x4f559d in _start (/irparser_fuzz+0x4f559d)
```
Following these steps with the remaining crashes will give you almost the same results.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94295
Approved by: https://github.com/davidberard98
Summary:
This PR tries to decompose the operators in torch.ops.quantized_decomposed namespace to more
primitive aten operators, this would free us from maintaining the semantics of the quantize/dequantize
operators, which can be expressed more precises in terms of underlying aten operators
Note: this PR just adds them to the decomposition table, we haven't enable this by default yet
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_q_dq_decomposition
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93312
Approved by: https://github.com/vkuzo, https://github.com/SherlockNoMad
This is the second times I spot this error on the new Windows non-ephemeral runners, so let's get it fixed.
The error https://github.com/pytorch/pytorch/actions/runs/4130018165/jobs/7136942722 was during 7z-ing the usage log artifact on the runners:
```
WARNING: The process cannot access the file because it is being used by another process.
usage_log.txt
```
The locking process is probably the monitoring script. This looks very similar to the issue on MacOS pet runners in which the monitoring script is not killed sometime.
I could try to kill the process to unlock the file. But then not being able to upload the usage log here is arguably ok too. So I think it would be easier to just ignore the locked file and move on.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94483
Approved by: https://github.com/clee2000
Calculate nonzero count directly in the nonzero op.
Additionally, synchronize before entering nonzero op to make sure all previous operations finished (output shape is allocated based on the count_nonzero count)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94442
Approved by: https://github.com/kulinseth
Refcounting is hard. (Citation needed.) https://github.com/pytorch/pytorch/pull/81242 introduced a corner case where we would over incref when breaking out due to max (128) depth. https://github.com/pytorch/pytorch/pull/85847 ostensibly fixed a segfault, but in actuality was over incref-ing because PyEval_GetFrame returns a borrowed reference while `PyFrame_GetBack` returns a strong reference.
Instead of squinting really hard at the loops, it's much better to use the RAII wrapper and do the right thing by default.
I noticed the over incref issue because of a memory leak where Tensors captured by the closure of a function would be kept alive by zombie frames.
Differential Revision: [D42184394](https://our.internmc.facebook.com/intern/diff/D42184394/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91646
Approved by: https://github.com/albanD
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
Summary:
Previously prepare_fx returns an ObservedGraphModule and convert_fx returns a QuantizedGraphModule,
this is to preserve the attributes since torch.fx.GraphModule did not preserve them, after https://github.com/pytorch/pytorch/pull/92062
we are preserving `model.meta`, so we can store the attributes in model.meta now to preserve them.
With this, we don't need to create a new type of GraphModule in these functions and can use GraphModule directly, this
is useful for quantization in pytorch 2.0 flow, if other transformations are using GraphModule as well, the quantization passes will be composable with them
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
python test/test_quantization.py TestQuantizePT2E
Imported from OSS
Differential Revision: D42979722
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94412
Approved by: https://github.com/vkuzo
Summary:
https://github.com/pytorch/pytorch/pull/94170 broke some Meta-only tests because it broke the following syntax:
```
import torch.nn.intrinsic
_ = torch.nn.intrinsic.quantized.dynamic.*
```
This broke with the name change because the `ao` folder is currently doing lazy import loading, but the original folders are not.
For now, just unbreak the folders needed for the tests to pass. We will follow-up with ensuring this doesn't break for other folders in a future PR.
Test plan:
```
python test/test_quantization.py -k AOMigrationNNIntrinsic.test_modules_no_import_nn_intrinsic_quantized_dynamic
```
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94458
Approved by: https://github.com/jerryzh168
Summary:
The caching allocator can be configured to round memory allocations in order to reduce fragmentation. Sometimes however, the overhead from rounding can be higher than the fragmentation it helps reduce.
We have added a new stat to CUDA caching allocator stats to help track if rounding is adding too much overhead and help tune the roundup_power2_divisions flag:
- "requested_bytes.{current,peak,allocated,freed}": memory requested by client code, compare this with allocated_bytes to check if allocation rounding adds too much overhead
Test Plan: Added test case in caffe2/test/test_cuda.py
Differential Revision: D40810674
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88575
Approved by: https://github.com/zdevito
Summary:
There are a few races/permission errors in file creation, fixing
OSS:
1. caffe2/torch/_dynamo/utils.py, get_debug_dir: multiple process may conflict on it even it's using us. Adding pid to it
2. caffe2/torch/_dynamo/config.py: may not be a right assumption that we have permission to cwd
Test Plan: sandcastle
Differential Revision: D42905908
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93407
Approved by: https://github.com/soumith, https://github.com/mlazos
Summary: Need to re-register the underscored function in order to have the op present in predictor. This is because older models have been exported with the underscored version.
Test Plan: See if predictor tests pass?
Reviewed By: cpuhrsch
Differential Revision: D43138338
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94452
Approved by: https://github.com/cpuhrsch
Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
`dsa_add_new_assertion_failure` is currently causing duplicate definition issues. Possible solutions:
1. Put the device code in a .cu file - requires device linking, which would be very painful to get setup.
2. inline the code - could cause bloat, especially since a function might include many DSAs.
3. Anonymous namespace - balances the above two. Putting the code in a .cu file would ensure that there's a single copy of the function, but it's hard to setup. Inlining the code would cause bloat. An anonymous namespace is easy to setup and produces a single copy of the function per translation unit, which allows the function to be called many times without bloat.
Differential Revision: D42998295
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94064
Approved by: https://github.com/ezyang
- fix num_output_dims calculation
- fix median_out_mps key
- cast tensor sent to sortWithTensor and argSortWithTensor
- note down same issue for unique
- unblock median from blocklist
- adding test_median_int16 test
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94489
Approved by: https://github.com/razarmehr
Changes:
1. `typing_extensions -> typing-extentions` in dependency. Use dash rather than underline to fit the [PEP 503: Normalized Names](https://peps.python.org/pep-0503/#normalized-names) convention.
```python
import re
def normalize(name):
return re.sub(r"[-_.]+", "-", name).lower()
```
2. Import `Literal`, `Protocal`, and `Final` from standard library as of Python 3.8+
3. Replace `Union[Literal[XXX], Literal[YYY]]` to `Literal[XXX, YYY]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94490
Approved by: https://github.com/ezyang, https://github.com/albanD
Part of fixing #88098
## Context
This is 1/3 PRs to address issue 88098 (move label check failure logic from `check_labels.py` workflow to `trymerge.py` mergebot. Due to the messy cross-script imports and potential circular dependencies, it requires some refactoring to the scripts before, the functional PR can be cleanly implemented.
## What Changed
1. Extract extracts label utils fcns to a `label_utils.py` module from the `export_pytorch_labels.py` script.
2. Small improvements to naming, interface and test coverage
## Note to Reviewers
This series of PRs is to replace the original PR https://github.com/pytorch/pytorch/pull/92682 to make the changes more modular and easier to review.
* 1st PR: this one
* 2nd PR: https://github.com/Goldspear/pytorch/pull/2
* 3rd PR: https://github.com/Goldspear/pytorch/pull/3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94179
Approved by: https://github.com/ZainRizvi
inductor/test_torchinductor suite is not running as part of the CI. I have triaged this down to a bug in the arguments supplied in test/run_test.py
Currently test_inductor runs the test suites as:
`PYTORCH_TEST_WITH_INDUCTOR=0 python test/run_test.py --include inductor/test_torchinductor --include inductor/test_torchinductor_opinfo --verbose`
Which will only set off the test_torchinductor_opinfo suite
Example from CI logs: https://github.com/pytorch/pytorch/actions/runs/3926246136/jobs/6711985831#step:10:45089
```
+ PYTORCH_TEST_WITH_INDUCTOR=0
+ python test/run_test.py --include inductor/test_torchinductor --include inductor/test_torchinductor_opinfo --verbose
Ignoring disabled issues: []
/var/lib/jenkins/workspace/test/run_test.py:1193: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
if torch.version.cuda is not None and LooseVersion(torch.version.cuda) >= "11.6":
Selected tests:
inductor/test_torchinductor_opinfo
Prioritized test from test file changes.
reordering tests for PR:
prioritized: []
the rest: ['inductor/test_torchinductor_opinfo']
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92833
Approved by: https://github.com/seemethere
When TorchScript Value has an optional tensor, `dtype()` or `scalarType()` is not available and raise (by design).
The symbolic `_op_with_optional_float_cast` must check whether the tensor is otpional or not before calling the scalar type resolution API. This PR fixes that
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94427
Approved by: https://github.com/abock, https://github.com/shubhambhokare1
Per @ezyang's advice, added magic sym_int method. This works for 1.0 * s0 optimization, but can't evaluate `a>0` for some args, and still misses some optimization that model rewrite achieves, so swin still fails
(rewrite replaces `B = int(windows.shape[0] / (H * W / window_size / window_size))` with `B = (windows.shape[0] // int(H * W / window_size / window_size))` and model passes)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94365
Approved by: https://github.com/ezyang
Currently there is a potential conflict for `GLIBCXX_USE_CXX11_ABI` configuration if users don't explicitly set this variable.
In `caffe2/CMakeLists.txt`, if the variable is not set, an `abi checker` will be used to retrieve the ABI configuration from compiler.
https://github.com/pytorch/pytorch/blob/master/caffe2/CMakeLists.txt#L1165-L1183
However, in 'torch/csrc/Module.cpp`, if the variable is not set, it will be set to `0`. The conflict happens when the default ABI of the compiler is `1`.
https://github.com/pytorch/pytorch/blob/master/torch/csrc/Module.cpp#L1612
This PR eliminate this uncertainty and potential conflict.
The ABI will be checked and set in `CMakeLists.txt`, and pass the value to `caffe2/CMakeLists.txt`. Meanwhile, in case the `caffe2/CMakeLists.txt` is directly invoked from a `cmake` command, The original GLIBC check logic is kept in this file.
If users doesn't explicitly assign a value to `GLIBCXX_USE_CXX11_ABI`, the `abi checker` will be executed and set the value accordingly. If the `abi checker` failed to compile or execute, the value will be set to `0`. If users explicitly assigned a value, then the provided value will be used.
Moreover, if `GLIBCXX_USE_CXX11_ABI` is set to `0`, the '-DGLIBCXX_USE_CXX11_ABI=0' flag won't be appended to `CMAKE_CXX_FLAGS`. Thus, whether to use ABI=0 or ABI=1 fully depends on compiler's default configuration. It could cause an issue that even users explicitly set `GLIBCXX_USE_CXX11_ABI` to `0`, the compiler still builds the binaries with ABI=1.
https://github.com/pytorch/pytorch/blob/master/CMakeLists.txt#L44-L51
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94306
Approved by: https://github.com/malfet
# Summary
Add more checks around shape constraints as well as update the sdp_utils to properly catch different head_dims between qk and v for flash_attention which is not supported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94274
Approved by: https://github.com/cpuhrsch
- Fix wrong results in AvgPool2D when `count_include_pad=True`
- Fix issues with adaptive average and max pool2d
- Remove the redundant blocking copies from `AdaptiveMaxPool2d`
- Add `divisor` to cached string key to avoid conflicts
- Add test case when both `ceil_mode` and `count_include_pad` are True (previously failed).
- Clean up redundant code
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94348
Approved by: https://github.com/kulinseth
Historically, we work out `size_hint` by working it out on the fly by doing a substitution on the sympy expression with the `var_to_val` mapping. With this change, we also maintain the hint directly on SymNode (in `expr._hint`) and use it in lieu of Sympy substitution when it is available (mostly guards on SymInt, etc; in particular, in idiomatic Inductor code, we typically manipulate Sympy expressions directly and so do not have a way to conveniently maintain hints.)
While it's possible this will give us modest performance improvements, this is not the point of this PR; the goal is to make it easier to carefully handle unbacked SymInts, where hints are expected not to be available. You can now easily test if a SymInt is backed or not by checking `symint.node.hint is None`.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94201
Approved by: https://github.com/voznesenskym
Supports the following with dynamic shapes:
```python
for element in tensor:
# do stuff with element
```
Approach follows what's done when `call_range()` is invoked with dynamic shape inputs: guard on tensor size and continue tracing with a real size value from `dyn_dim0_size.evaluate_expr()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94326
Approved by: https://github.com/ezyang
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
All this time, PyTorch and ONNX has different strategy for None in output. And in internal test, we flatten the torch outputs to see if the rest of them matched. However, this doesn't work anymore in scripting after Optional node is introduced, since some of None would be kept.
#83184 forces script module to keep all Nones from Pytorch, but in ONNX, the model only keeps the ones generated with Optional node, and deletes those meaningless None.
This PR uses Optional node to keep those meaningless None in output as well, so when it comes to script module result comparison, Pytorch and ONNX should have the same amount of Nones.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84789
Approved by: https://github.com/BowenBao
Fix#82589
Why:
1. **full_check** works in `onnx::checker::check_model` function as it turns on **strict_mode** in `onnx::shape_inference::InferShapes()` which I think that was the intention of this part of code.
2. **strict_mode** catches failed shape type inference (invalid ONNX model from onnx perspective) and ONNXRUNTIME can't run these invalid models, as ONNXRUNTIME actually rely on ONNX shape type inference to optimize ONNX graph. Why we don't set it True for default? >>> some of existing users use other platform, such as caffe2 to run ONNX model which doesn't need valid ONNX model to run.
3. This PR doesn't change the original behavior of `check_onnx_proto`, but add a warning message for those models which can't pass strict shape type inference, saying the models would fail on onnxruntime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83186
Approved by: https://github.com/justinchuby, https://github.com/thiagocrepaldi, https://github.com/jcwchen, https://github.com/BowenBao
Add `collect_ciflow_labels.py` that automatically extracts all labels from workflow files and adds the to pytorch-probot.yml
Same script can also be used to validate that all tags are referenced in the config
Add this validation to quickchecks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94368
Approved by: https://github.com/jeanschmidt
Summary:
This PR tries to decompose the operators in torch.ops.quantized_decomposed namespace to more
primitive aten operators, this would free us from maintaining the semantics of the quantize/dequantize
operators, which can be expressed more precises in terms of underlying aten operators
Note: this PR just adds them to the decomposition table, we haven't enable this by default yet
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_q_dq_decomposition
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93312
Approved by: https://github.com/vkuzo, https://github.com/SherlockNoMad
**Problem**: For a tensor `x`, you can assign `x.my_attr = 3.14` and then later access it. Dynamo does not support this right now; it errors out with an AttributError (it was broken in #91840).
**Fix**: This fixes the problem by catching AttributeErrors in dynamo if we try to access an attr that does not exist on a standard torch.Tensor.
**Tests**: Added tests for accessing and setting attributes to make sure dynamo does not error out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94332
Approved by: https://github.com/yanboliang
While discussing a possible addition of `assert_not_close` to the API (See #90005 later in the stack), it became clear that we should have an intermediate function that returns a bool-ish value that one can assert on. This PR introduces this function as `are_equal` as replacement for `assert_equal`. Interface is the same, but instead of raising in case a comparison failed, we return the `ErrorMeta`'s of all failures and leave it to the caller to handle. Note that this only applies to errors raised during the comparison stage. Everything else, e.g. only setting `atol` *or* `rtol`, will raise just as before.
We decided to keep this private for now unless there is user demand. The largest issue that needs to be solved before this can become public is the return type: if we have something like `torch.testing.are_close` we are targeting two uses cases:
1. Using it to branch inside code like `if are_close(...):`
2. Using it to assert closeness inside a test like `assert are_close(...)`. This is the default way to assert something with `pytest`
To do that, the return type has to be bool-ish, i.e. being an instance of `bool` or implementing `__bool__`. Plus, `bool(are_close()) is True` needs to be the if the inputs are close and `False` otherwise. The current logic of `are_close` satisfies the former, but violates the latter. In case everything is close, we return an empty list, but `bool([]) is False`.
Directly using an instance of `bool` would work for the requirements above, but then we would have no option to add diagnositics to the error. Meaning `assert are_close()` would work, but would be non-descriptive.
Using `Tuple[bool, str]` would work in general, but is quite dangerous and unexpected: since all non-empty tuples evaluate to `True`, this can easily hide bugs if the user is not super careful:
```pycon
>>> close = (False, "error message with diagnostics")
>>> assert close[0]
AssertionError: error message with diagnostics
>>> assert close
```
One possible solution here would be a thin custom object:
```py
class Close:
def __init__(self, flag:bool, msg: str = "") -> None:
self._flag = flag
self._msg = msg
def __bool__(self):
return self._flag
def __str__(self):
return self._msg
```
Now we can do something like
```pycon
close = Close(False, "error message with diagnostics") # coming from are_close
>>> if not close:
... print("It works!")
It works!
>>> assert close
AssertionError
>>> assert close, close # This looks weird, but does its job
AssertionError: error message with diagnostics
```
But this means we introduce another abstraction that the user has to deal with.
To reiterate, we are not going to make `are_close` public until there is user demand, since none of the options above is without flaws.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90004
Approved by: https://github.com/mruberry, https://github.com/malfet
tldr; this should fix some minor perf regressions that were caused by adding more as_strided() calls in aot autograd.
This PR adds a new context manager, `torch.autograd._set_view_replay_enabled()`.
Context: AOT Autograd has special handling for "outputs that alias graph intermediates". E.g. given this function:
```
def f(x):
y = torch.mul(x, 2)
out = y.view(-1)
return out
```
AOT Autograd will do the following:
```
def fn_to_compile(x):
y = torch.mul(x, 2)
out = y.view(-1)
# return the graph intermediate
return y, out
compiled_fn = compile(fn_to_compile)
def wrapper(x):
y, out = compiled_fn(x)
# regenerate the alias of the graph intermediate
return out._view_func(y)
```
What's annoying is that `out._view_func()` will result in a `.as_strided` call, because `out` is an ordinary runtime tensor. This (likely?) caused a perf regression, because when running the backward, out `as_strided_backward()` is slower than our `view_backward()`.
In this PR, I added some TLS for instructing autograd to do view replay instead of as_strided, even when given a normal tensor. I'm definitely interested in thoughts from autograd folks (cc @albanD @soulitzer). A few points that I want to bring up:
(1) One reason that this API seems generally useful to me is because of the case where you `torch.compile()` a function, and you pass in two inputs that alias each other, and mutate one of the inputs. Autograd is forced to add a bunch of as_strided() calls into the graph when this happens, but this would give users an escape hatch for better compiled perf in this situation
(2) To be fair, AOT Autograd probably won't need this TLS in the long term. There's a better (more complicated) solution, where AOT Autograd manually precomputes the view chain off of graph intermediates during tracing, and re-applies them at runtime. This is kind of complicated though and feels lower priority to implement immediately.
(3) Given all of that I made the API private, but lmk what you all think.
This is a followup of https://github.com/pytorch/pytorch/pull/92255.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92588
Approved by: https://github.com/ezyang, https://github.com/albanD
Change the dynamo benchmark timeout from hard code to a parameter with default value 1200ms, cause the hard code 1200ms timeout led some single thread mode model crashed on CPU platform. With the parameter, users can specify the timeout freely.
Fixes#94281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94284
Approved by: https://github.com/malfet
Optimize unnecessary collection cast calls, unnecessary calls to list, tuple, and dict, and simplify calls to the sorted builtin. This should strictly improve speed and improve readability.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94323
Approved by: https://github.com/albanD
Copied the type hints from the other context managers.
Not sure how to add type hints for `clone` since it returns the same class. The `Self` type isn't introduced until Python 3.11 and mypy just recently added support for it. Could also use `"inference_mode"` with quotes to avoid using it before it's declared, or `from __future__ import annotations` to allow its use without quotes. Or we could just skip it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94223
Approved by: https://github.com/albanD
One of the side effect of this is that this is not properly skipped on 3.11
As a side note, it was very surprising to find testing-specific code in `torch._dynamo` and not `torch.testing`...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94312
Approved by: https://github.com/ezyang
Summary:
This diff introduced the core components needed for the Vulkan Graph runtime.
* ComputeGraph data structure
* Value data structure
* Copy node
* Add node with option for prepacked weights
Test Plan:
Run the `delegate_experiment` binary.
```
buck run --target-platforms ovr_config//platform/macos:arm64-fbsource -c pt.vulkan_use_gpu_diagnostics=1 :delegate_experimentAppleMac\#macosx-arm64
```
Differential Revision: D42614155
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94222
Approved by: https://github.com/salilsdesai
Applies some more harmless pyupgrades. This one gets rid of deprecated aliases in unit_tests and more upgrades yield for loops into yield from generators which are more performance and propagates more information / exceptions from original generator. This is the modern recommended way of forwarding generators.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94309
Approved by: https://github.com/albanD
Fast path execution of a few binary ops in fake tensor, to speed up trace time. When testing `python benchmarks/dynamo/timm_models.py --accuracy --timing --backend aot_eager --dynamic-shapes --float32 --only hrnet_w18`, I get the following trace speedup.
Before:
```
cuda eval hrnet_w18 PASS
TIMING: entire_frame_compile:53.97591 backend_compile:33.60832
STATS: call_* op count: 1369 | FakeTensor.__torch_dispatch__:4995 | FakeTensorMode.__torch_dispatch__:89985 | ProxyTorchDispatchMode.__torch_dispatch__:3010
```
After:
```
cuda eval hrnet_w18 PASS
TIMING: entire_frame_compile:40.18931 backend_compile:25.28828
STATS: call_* op count: 1369 | FakeTensor.__torch_dispatch__:4995 | FakeTensorMode.__torch_dispatch__:69478 | attempt fast:4399 | fast is_contiguous:4399 | ProxyTorchDispatchMode.__torch_dispatch__:3010
```
My experiment notebook can be found at https://docs.google.com/document/d/1_dTIQUwjIVnEWmiFAavJQYVF8uzXqD9Dk6b9gGQLF_U/edit#
This is not the "most" optimized version of the code; compared with Horace/Voz roofline experiment:
```
diff --git a/torch/_subclasses/fake_tensor.py b/torch/_subclasses/fake_tensor.py
index e3bf545f3b8..395942c6ffe 100644
--- a/torch/_subclasses/fake_tensor.py
+++ b/torch/_subclasses/fake_tensor.py
@@ -774,6 +774,10 @@ class FakeTensorMode(TorchDispatchMode):
def __torch_dispatch__(self, func, types, args=(), kwargs=None):
kwargs = kwargs if kwargs else {}
+ with no_dispatch():
+ if func in {aten.mul.Tensor, aten.add.Tensor, aten.sub.Tensor, aten.relu.default}:
+ return FakeTensor(self, torch.empty(args[0].shape, device='meta'), device='cuda')
+
if func == torch.ops.prim.device.default:
assert len(args) == 1 and isinstance(args[0], FakeTensor)
if args[0].fake_mode.in_kernel_invocation:
```
I am still leaving about 5s of trace time improvement on the table (3s of which is attributable to not yet handling relu.)
The implementation here is based off of https://github.com/pytorch/pytorch/pull/93118/ but I modeled the short circuit logic off of TensorIterator's implementation, for ease of code review and correctness verification. However, there are some important divergences:
* Traditional fast setup in TensorIterator only short circuits if the shapes of all input elements are equal. On hrnet_w18, only 5% of fastpath'ed binary operators actually satisfy this. So instead, I compute the broadcasted shape, but then I only allow the fast path if (1) at least one input tensor has a shape that is exactly the output size, and (2) all the tensors are contiguous (or if all the tensors are channels last).
* I had to manually adjust the logic to handle wrapped numbers (which ordinarily are handled by wrapping into tensors). I think I got this right.
Some evidence that this heuristic is correct is here in: https://gist.github.com/ezyang/b22fa7b72b7349137211d8dc7041f758 I exhaustively test all dim=3 tensors with sizes [1, 2] and show that we get the same significant strides between PrimTorch and the new algorithm. In fact, there ARE differences between this algorithm and PrimTorch, but in fact this algorithm agrees with TensorIterator where PrimTorch is wrong (sample case: size=(1, 1, 2), stride=(1, 1, 1), stride=(1, 1, 1))
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94047
Approved by: https://github.com/eellison
# Summary
- Adds a large parameter sweep for testing the various configs a user can call sdpa with and compares the deviation of the fused kernels vs the eager math fallback to test for correctness.
- Sm86 + head_dim==128 is throwing an IMA for memory efficient attention. We add a filter for use_mem_efficient_attention(). This has since been fixed in the upstream Xformers version but will likely not make it for branch cut.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94009
Approved by: https://github.com/cpuhrsch
Skip gather/blit calls in case of strided output - this prevents:
- allocating additional memory for the output
- additional transpose for both the input and output
Fixes:
```
x = torch.rand((256,10), device='mps')
x = x.permute(1,0)
x.exp()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94260
Approved by: https://github.com/razarmehr
Fixes TestConsistency masked_fill for bool data type.
Casting a tensor > 1 to MPSDataTypeBool will result in 0 instead of 1. This change manually casts the scalar to a value of 0 or 1 when casting a non-boolean tensor to a boolean tensor:
```
(inputDataType == MPSDataTypeBool) ? !!value.to<double>() : value.to<double>()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94263
Approved by: https://github.com/razarmehr
There are cases when the arrayViewTensor API cannot be used to solve the view operations, such as when a view dimension is bigger than the base dimension of the tensor, e.g:
```
base shape: [1, 768, 512, 2] // we cannot slice the base shape in any way to result in first dimension `2`
view shape: [2, 384, 512, 1]
```
On such cases, we need to fallback on the gather code (that detects this is a slice followed by a reshape) to solve this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94278
Approved by: https://github.com/razarmehr
## Problem history
There seems to always have been a bug in `_vec_log_softmax_lastdim `.
In particular, there were two issues with it -
#### Bug 1
Before AVX512 support was added, `CHUNK_SIZE` had been heuristically chosen in `_vec_log_softmax_lastdim`:
`CHUNK_SIZE = (128 / sizeof(scalar_t)) * Vec::size();`
It was `256` for float32, bfloat16, and float16.
When AVX512 support was added, `CHUNK_SIZE` became `512`.
The rationale behind determining `CHUNK_SIZE` has not been described, and seems flawed, since the number of OpenMP threads used currently depends upon it.
#### Bug 2
`grain_size` had been defined as `internal::GRAIN_SIZE / (16 * dim_size * CHUNK_SIZE)`
So, `grain_size` was usually 0, as it was `8 / (dim_size)`, so, it's always replaced by `CHUNK_SIZE`, viz. 256.
Since `256` was always the `grain_size` for `at::parallel_for`, few threads were used in certain cases.
#### Problem caused by bugs
With `outer_size` of say, 700, only 3 threads would have been used with AVX2, irrespective of the value of `dim_size`!
When AVX512 support was added, since `CHUNK_SIZE` became `512`, only 2 threads were used if `outer_dim` was 700.
In the Transformers training example, `log_softmax` was computed on the last dim of a tensor of shape `(700, 23258)`.
AVX512 thus appeared to be quite slower, cloaking the actual issue that even AVX2 performance for the kernel was quite poor due to inefficient work distribution amongst OpenMP threads.
## Solution
Distribute work more efficiently, which would result in higher performance for both AVX2 & AVX512 than now,
and fixes the regression observed with AVX512 (AVX512 kernel would now be faster than its AVX2 counterpart).
## Benchmarks
##### Machine-config:
Intel(R) Xeon(R) Platinum 8371HC CPU (Cooper Lake)
One socket of 26 physical cores was used.
Intel OpenMP & tcmalloc were preloaded.
Example of a command to run benchmark:
`ATEN_CPU_CAPABILITY=avx512 KMP_AFFINITY=granularity=fine,verbose,compact,1,0 KMP_BLOCKTIME=1 KMP_SETTINGS=1 MKL_NUM_THREADS=26 OMP_NUM_THREADS=26 numactl --membind=0 --cpunodebind=0 python3.8 -m pt.softmax_test --test_name LogSoftmax_N1024_seq_len23258_dim1_cpu`
Benchmark | Old implementation time (us) | New implementation time (us) | Speedup ratio (old/new)
-- | -- | -- | --
LogSoftmax_N1024_seq_len23258_dim1_cpu AVX2 | 11069.281 | 2651.186 | 4.17x
LogSoftmax_N1024_seq_len23258_dim1_cpu AVX512 | 18292.928 | 2586.550| 7.07x
LogSoftmax_N700_seq_len23258_dim1_cpu AVX2 | 9611.902 | 1762.833 | 5.452x
LogSoftmax_N700_seq_len23258_dim1_cpu AVX512 | 12168.371 | 1717.824 | 7.08x
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85398
Approved by: https://github.com/jgong5, https://github.com/mingfeima, https://github.com/peterbell10, https://github.com/lezcano
As found in #92709, thanks to @ngimel and @jansel, currently `torch.Tensor.fn` points to `UserDefinedObjectVariable` rather than `TorchVariable`. The root cause is due to https://github.com/pytorch/pytorch/pull/92709#pullrequestreview-1273357406. To prevent this, build `TorchVariable` of `torch.Tensor.fn` pointing to `torch.ops.aten.fn`.
This issue propagates to `torch.Tensor.fn` causing graph break with `nopython=True`.
```python
import torch
import torch._dynamo as dynamo
#op = torch.ops.aten.abs_ # no graph break
op = torch.Tensor.abs_ # graph break
args = torch.empty(10)
def foo(args):
return op(args)
opt_foo = dynamo.optimize("inductor", nopython=True)(foo)
y_ = opt_foo(args)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93243
Approved by: https://github.com/jansel
Move `ShardingFilterIterDataPipe` into a dedicated file.
Also, propose to have a dedicated parent class (`_ShardingIterDataPipe`) for sharding data pipe, as this seems more like a "system/engine-level" datapipe that gives strong hints to RS on how to execute, and needs first-class citizen treatment in RS (compared with other "user-level" datapipe that are mostly composable `Callable[[Iterable], Iterable]`. So we don't need to based on whether `is_shardable` and `apply_sharding` are presented in DataPipe in `graph_settings.py`. But open to other discussions.
Open question: Should
[ShardingRoundRobinDispatcherIterDataPipe](01fc762003/torchdata/datapipes/iter/util/sharding.py (L16-L17)) also be considered as a `_ShardingIterDataPipe`? (e.g. this sharding is executed by replicating (the metadata), while `ShardingRoundRobinDispatcherIterDataPipe` hints too expensive to replicate so requires round robin data exchange/dispatch).
Differential Revision: D43014692
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94095
Approved by: https://github.com/ejguan, https://github.com/NivekT
Summary:
There are three things that happens in the current prepare code,
(1). user express their intention of how they want the model to be quantized with QConfigMapping, we translate that to
node.meta["target_dtype_info"]
(2). we validate the setting against BackendConfig
(3). insert observers based on the validated node.meta["target_dtype_info"]
previously (2) and (3) are mixed together, this PR tries to move (2) closer to (1), with one edge case left, this refactor
moves us closer to our target design for quantization in pytorch 2.0 export path
this is a follow up PR for https://github.com/pytorch/pytorch/pull/92641
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94011
Approved by: https://github.com/vkuzo
When FSDP is used with other parallelism (e.g., TorchRec), some parameters that are not managed by FSDP may not reside on all the ranks (TorchRec is model parallelism). When `use_orig_params=True` , FSDP will synchronize the FQNs among ranks. As a result, a rank may get the FQNs that the rank does not actually own. If the FQN belongs to a TorchRec managed parameter, FSDP has to ignore the parameter state. Otherwise FSDP does not know how to store the state.
This PR add the logic to ignore the parameters that are not managed by FSDP and are not on the rank.
Differential Revision: [D42982778](https://our.internmc.facebook.com/intern/diff/D42982778/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94129
Approved by: https://github.com/rohan-varma
List all missing ops rather than early termination
Test on device
Logcat lists all operators:
```
12-06 00:23:36.523 8299 8299 F DEBUG : Abort message: 'terminating with uncaught exception of type c10::Error: Following ops cannot be found: [aten::max_pool2d, aten::conv2d]. Please check if the operator library is included in the build. If built with selected ops, check if these ops are in the list. If you are a Meta employee, please see fburl.com/missing_ops for a fix. Or post it in https://discuss.pytorch.org/c/mobile/ ()
12-06 00:23:36.523 8299 8299 F DEBUG : Exception raised from initialize_operators at xplat/caffe2/torch/csrc/jit/mobile/function.cpp:89 (most recent call first):
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94205
Approved by: https://github.com/JacobSzwejbka
This PR will prevent a crash in `test_output_match_nan_to_num_cpu_float16`, that would otherwise happen with the upcoming updates to MPS Framework in Ventura (in API `logicalANDWithPrimaryTensor()`). The fix is backwards compatible with Monterey too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94220
Approved by: https://github.com/malfet
- Fix correctness issues with nll_loss_backward(), smooth_l1_loss_backward() and cross_entropy_backward() by taking grad_output into account when computing those loss ops
- Add numel()==0 check to prevent crashes
- Clean up and formatting
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94226
Approved by: https://github.com/kulinseth
This reverts commit f3bf46e801dec2637751224fd6e27fbf97453bc6.
Reverted https://github.com/pytorch/pytorch/pull/94163 on behalf of https://github.com/huydhn due to Sorry for reverting your PR. But I suspect that it causes flaky SIGSEGV failure for linux-bionic-py3.8-clang9 / test (crossref) job in trunk. For example, 05397b1250
Despite my initial attempt to clean up MacOS runner as best as I could (https://github.com/pytorch/test-infra/pull/2100, https://github.com/pytorch/test-infra/pull/2102), the runner in question `i-09df3754ea622ad6b` (yes, the same one) still had its free space gradually dropping from 10GB (after cleaning conda and pip packages few days ago) to only 5.2GB today: 4207d3c330
I have a gotcha moment after logging into the runner and the direct root cause is right before my eyes. I forgot to look at the processes running there:
```
501 7008 1 0 13Jan23 ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_3912838018 --no-capture-output python3 -m tools.stats.monitor
501 30351 30348 0 18Jan23 ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_3953492510 --no-capture-output python3 -m tools.stats.monitor
501 36134 36131 0 19Jan23 ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_3956679232 --no-capture-output python3 -m tools.stats.monitor
501 36579 36576 0 Mon11PM ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_4048875121 --no-capture-output python3 -m tools.stats.monitor
501 37096 37093 0 20Jan23 ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_3971130804 --no-capture-output python3 -m tools.stats.monitor
501 62770 62767 0 27Jan23 ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_4025485821 --no-capture-output python3 -m tools.stats.monitor
501 82293 82290 0 20Jan23 ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_3969944513 --no-capture-output python3 -m tools.stats.monitor
501 95762 95759 0 26Jan23 ttys001 0:00.11 /Users/ec2-user/runner/_work/_temp/miniconda/bin/python /Users/ec2-user/runner/_work/_temp/miniconda/bin/conda run -p /Users/ec2-user/runner/_work/_temp/conda_environment_4012836881 --no-capture-output python3 -m tools.stats.monitor
```
There were many leftover `tools.stats.monitor` processes there. After pkill them all, an extra 45GB of free space was immediately free up. Same situation could be seen on other MacOS pet runners too, i.e. `i-026bd028e886eed73`.
At the moment, it's unclear to me what edge case could cause this as the step to stop the monitoring script should always be executed, may be it received an invalid PID somehow. However, the safety net catch-all solution would be to cleanup all leftover processes on MacOS pet runner before running the workflow (similar to what is done in Windows https://github.com/pytorch/pytorch/pull/93914)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94127
Approved by: https://github.com/clee2000, https://github.com/ZainRizvi
We've been seeing linter failures when the `apt-get install doxygen` command fails to install due to network errors, and the workflow doesn't get retried since it's in a non-retryable step
This PR moves it to a retryable step
It also marks a deterministic step as nonretryable, since retrying that one will never change the output
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94199
Approved by: https://github.com/huydhn, https://github.com/malfet
Since `.data` creates a new Tensor and thus a new python object, this check checks the id of temporary objects and thus always succeed given the current behavior of python's allocator:
```
>>> import torch
>>> print(id(torch.rand(2)) == id(torch.rand(3)))
True
```
I change it here to make sure they look at the same memory.
If you want to check that they are the same python object, I can change it to `is`. Let me know!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94097
Approved by: https://github.com/malfet
We now always have a `__getstate__`/`__setstate__` pair AND the `__dict__` attribute is lazily initialized. So we need to support that in our serialization code.
A quick audit of the rest doesn't look like the new `__getstate__` is too problematic. But maybe the test suite will bring more things to light.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94096
Approved by: https://github.com/ezyang, https://github.com/malfet
…g scalars
Fixes#93784, #93225
Ideally, clamp decomp should live in refs or _decomp, but this reversed our current decomposition flow of `clamp_min` -> `clamp` -> lowering, so to keep changes to minimum, I'm leaving it in inductor for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94157
Approved by: https://github.com/ezyang
By moving guard string assembly into dynamo's default behavior and letting code_parts do the work, we can have much better shape guard failures.
Before this fix, the guard failure in the test would look like:
```
'x.size()[1] == x.size()[0] and x.stride()[0] == x.[264 chars]!= 1' != 'x.size()[0] < 3'
- x.size()[1] == x.size()[0] and x.stride()[0] == x.size()[0] and x.stride()[1] == 1 and x.storage_offset() == 0 and y.size()[0] == x.size()[0] and y.size()[1] == x.size()[0] and y.stride()[0] == x.size()[0] and y.stride()[1] == 1 and y.storage_offset() == 0 and x.size()[0] < 3 and x.size()[0] != 0 and x.size()[0] != 1
+ x.size()[0] < 3
```
now it is
```
"x.size()[0] < 3"
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93894
Approved by: https://github.com/ezyang
This allows unet to be compiled with symbolic shapes (but it still fails accuracy, lol).
Output sizes are always integer, there's no need to pretend they are ever float. Recomputing scale factors still used nominally float sizes converted to int, we might as well do it from the start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94123
Approved by: https://github.com/ezyang
We greatly simplify the handing of OpenMP in CMake by using caffe2::openmp target thoroughly. We follow the old behavior by defaulting to MKL OMP library and detecting OMP flags otherwise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91576
Approved by: https://github.com/malfet
Summary:
Followup after https://github.com/pytorch/pytorch/pull/93267
Generated by running:
```
for i in *.cu; do sed -i -e "s/constexpr char/CONSTEXPR_EXCEPT_WIN_CUDA char/" $i; done
```
Otherwise, attempts to compile using VS-15.9 results in:
```
D:\pytorch\aten\src\aten\native\cuda\laguerre_polynomial_l.cu(17): fatal error C1001: An internal error has occurred in the compiler.
(compiler file 'msc1.cpp', line 1518)
To work around this problem, try simplifying or changing the program near the locations listed above.
Please choose the Technical Support command on the Visual C++
Help menu, or open the Technical Support help file for more information
Internal Compiler Error in D:\VC\Tools\MSVC\14.16.27023\bin\Hostx64\x64\cl.exe. You will be prompted to send an error report to Microsoft later.
INTERNAL COMPILER ERROR in 'D:\VC\Tools\MSVC\14.16.27023\bin\Hostx64\x64\cl.exe'
Please choose the Technical Support command on the Visual C++
Help menu, or open the Technical Support help file for more information
```
Test Plan: CI
Differential Revision: D43011140
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94091
Approved by: https://github.com/seemethere
There are some occurrences when clang-tidy linter fails flakily with the following error, which is very weird:
```
>>> Lint for FILE:
Error (CLANGTIDY) command-failed
Failed due to FileNotFoundError:
[Errno 2] No such file or directory: '.lintbin/clang-tidy'
```
For examples,
* 0a93e6db5a
* 203b2cad3e
The binary is definitely there as the log shows that it has been downloaded successfully from S3. Looking a bit closer, I notice that the linter uses `os.chdir` to jump around between the workspace and the build folder. And it also refers to the binary with the relative path `.lintbin/clang-tidy` which doesn't exist in the latter. AFAIK, the current working directory is per process (https://stackoverflow.com/questions/16388400/what-is-a-thread-specific-os-chdir-and-mkdir-in-python), so I suspect that there is a race here where one thread chdir into build while another thread tries to lint another file. Thus the fix to use the absolute path to clang-tidy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94093
Approved by: https://github.com/malfet
currently the test
```
pytest test/distributed/test_multi_threaded_pg.py -vs
```
has errors
```
Traceback (most recent call last):
File "/private/home/howardhuang/.conda/envs/pytorch/lib/python3.9/threading.py", line 980, in _bootstrap_inner
self.run()
File "/private/home/howardhuang/.conda/envs/pytorch/lib/python3.9/threading.py", line 917, in run
self._target(*self._args, **self._kwargs)
File "/private/home/howardhuang/pytorch-projects/pytorch/torch/testing/_internal/common_distributed.py", line 1029, in _run
self._tls.precision = TestCase._precision
AttributeError: 'TestCollectivesWithBaseClass' object has no attribute '_tls'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93883
Approved by: https://github.com/awgu, https://github.com/wanchaol
These backends have been broken for some time. I tried to get them
running again, but as far as I can tell they are not maintained.
Installing torch_tensorrt downgrades PyTorch to 1.12. If I manually
bypass that downgrade, I get import errors from inside fx2trt. Fixes that
re-add these are welcome, but it might make sense to move these wrappers
to the torch_tensorrt repo once PyTorch 2.0 support is added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93822
Approved by: https://github.com/frank-wei
Before:
```
(/home/ezyang/local/a/pytorch-env) [ezyang@devgpu020.ftw1 ~/local/a/pytorch (ab0e3db0)]$ python benchmarks/dynamo/timm_models.py --accuracy --timing --backend aot_eager --dynamic-shapes --float32 --only hrnet_w18
cuda eval hrnet_w18 PASS
TIMING: entire_frame_compile:54.19504 backend_compile:33.86702
STATS: call_* op count: 1369 | FakeTensor.__torch_dispatch__:72549 | FakeTensorMode.__torch_dispatch__:115542 | ProxyTorchDispatchMode.__torch_dispatch__:3103
```
After
```
(/home/ezyang/local/a/pytorch-env) [ezyang@devgpu020.ftw1 ~/local/a/pytorch (ab0e3db0)]$ python benchmarks/dynamo/timm_models.py --accuracy --timing --backend aot_eager --dynamic-shapes --float32 --only hrnet_w18
cuda eval hrnet_w18 PASS
TIMING: entire_frame_compile:53.97591 backend_compile:33.60832
STATS: call_* op count: 1369 | FakeTensor.__torch_dispatch__:4995 | FakeTensorMode.__torch_dispatch__:89985 | ProxyTorchDispatchMode.__torch_dispatch__:3010
```
It doesn't really help end-to-end wall time all that much, but it does cut the number of calls to FakeTensor.__torch_dispatch__ by an order of magnitude, which hopefully has other positive effects.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93946
Approved by: https://github.com/eellison, https://github.com/albanD
`isposinf` and `isneginf` currently fallback in inductor. Here, I
enable the existing decompositions to work with inductor.
`isinf` can also be written with aten functions, however I don't add
it to inductor's decompositions because `isinf` is lowered to
`tl.libdevice.isinf` in triton.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93951
Approved by: https://github.com/lezcano
Common issue when paralleling with `TensorIterator`, if the problem size is described as [M, N, K] and [M, N] is reflected in TensorIterator (with K being folded), `grain_size` should also be divided by K.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94025
Approved by: https://github.com/XiaobingSuper
Two small changes that I'm bundling together because one of them needs to touch fbcode and I'm not sure how to do stacked diffs + internal changes + land before release cut.
Remove allow_meta from ctor, and allow by default: we should be able to trace through meta with fake tensors, so in some senses it's a bit weird to expose to user to disallow this. However, it's still useful debug wise to error from time to time, so I've added an option to the config that will get back previous behavior.
Remove `throw_on_data_dependent_ops=True`: this was intended as a temporary behavior as we were smoothing things turning on the erroring. There are no uses anywhere of `throw_on_data_dependent_ops=False` I could find.
These are technically backward-incompatble, but fake tensor is new since the last release / in a private namespace, and I don't want to release it with baggage that would be hard to remove later.
Fix for https://github.com/pytorch/pytorch/issues/92877.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93993
Approved by: https://github.com/bdhirsh, https://github.com/ezyang
It's not available as system dependency, so assume that it is installed
using Anaconda
Also, clang on MacOS does not recognize `-fopenmp` flag, but according
to https://mac.r-project.org/openmp/ and local experiments `-Xclang
-fopenmp` always works
Test plan:
Following should run and return true
```python
import torch
def foo(x: torch.Tensor) -> torch.Tensor:
return torch.sin(x) + torch.cos(x)
if __name__=="__main__":
x = torch.rand(3, 3)
x_eager = foo(x)
x_pt2 = torch.compile(foo)(x)
print(torch.allclose(x_eager, x_pt2))
```
Skip number of tests that fail on x86 MacOS (for example rsqrt for bool type and `test_pixel_shuffle_channels_last_cpu` on machines that do not support AVX2)
Tweak few tests to use double precision when running on CPU, as type promotion for accumulator types is broken.
TODO: Fix PyTorch for M1 compilation with OpenMP, bundle `omp.h` into the package and use it instead.
Fixes https://github.com/pytorch/pytorch/issues/90362
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93895
Approved by: https://github.com/jansel, https://github.com/jgong5
As @peterbell10 pointed out, it was giving incorrect results for `compression_ratio`
and `compression_latency` when you used `--diff-branch`.
This fixes this by running a separate subprocess for each branch to make sure you are not being affected by run for other branch.
Also added a couple of more significant figures
to numbers in summary table.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93989
Approved by: https://github.com/jansel
This PR abstracts some reduction utils on CPU, which can be shared by multiple reduction operators, such as `scatter_reduce`, `segment_reduce`, `spmm_reduce`.
No functional change or performance change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92284
Approved by: https://github.com/ezyang
Summary:
Adds a compare weights NS API using a single model.
Note: this is not intended for wide usage, so testing is limited
to specific functions our customers care about. The main reason for adding this
is because existing customers of NS are using the old `compare_weights` API,
and we'd like to move everyone to a single-model API style.
Once all the customers are moved over, we can delete all the old NS code.
Test plan:
```
python test/test_quantization.py -k NShadows.test_extract_weights_linear
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92058
Approved by: https://github.com/jerryzh168
Summary:
This PR reimplements the old `add_loggers(name_a, model_a, name_b, model_b)`
API in a single-model API style, similar to PNP. This allows for memory
efficiency savings of not having to load two models.
Test plan:
```
python test/test_quantization.py -k NShadows.test_add_loggers
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91639
Approved by: https://github.com/jerryzh168
## `pip install -r requirements.txt` in build-from-source documentation
This line
81b5eff3c3/README.md (L182-L188)
Is outdated. Let's default to `requirements.txt`
### My problem
Without touching this codebase for years I'm trying to build repo for local development and run unit tests. I go to `build from source => Contributing.md`. I immediately run into various problems.
* [Contributing.md](https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#developing-pytorch) suggests one way of setting up environment different from [README.md#from-source](https://github.com/pytorch/pytorch/blob/master/README.md#from-source) that does not work for me.
* [README.md#from-source](https://github.com/pytorch/pytorch/blob/master/README.md#from-source) suggests a different set of dependencies than [`requirements.txt`](https://github.com/pytorch/pytorch/blob/master/requirements.txt), many of which are unnecessary, and there's still missing ones to run unit tests.
* Dependencies in `requirements.txt` are needed to run unit tests
So there's competing, inlined and outdated equally confident recommendations on how to set up. https://github.com/pytorch/pytorch/pull/91850 tries to remove one recommendation, this PR tries to make the default one simpler.
### Goals
* Improve society somewhat 😁
* Remove a dead end roundtrip in the developer onboarding funnel
* Update a duplicated & outdated line of documentation
* Two broken things => one broken thing
* Improve doc maintainability and nudge us to a productive discussion of what `requirements.txt` is there for.
### Non-goals
* Give a definite recommendation how to set up your machine for local development. I read the instructions in readme at this moment as an outline on how to do it.
* Say that `requirements.txt` is a definite guide to dependencies, I know it's not (but probably should be)
### Background
* Dependency handling/reproducibility in this repo is tricky! See geist of [this](fdbbd20f32/.github/requirements/README.md). There's many different sets of dependencies with different setups for different environments.
* There's been great attempts of _"one requirements.txt to rule them all"_ which got halted https://github.com/pytorch/pytorch/pull/60697/ see https://github.com/pytorch/pytorch/issues/61375
* The unofficial `requirements.txt` file seem to be .circleci/docker/requirements-ci.txt https://github.com/pytorch/pytorch/issues/72556
* Unofficial _"how to build from source"_ docs seem to be here https://github.com/pytorch/pytorch/tree/master/.circleci#how-to-build-a-binary-locally
### Considered alternatives
* a) Point only to python dependencies in `requirements.txt` **(Chosen option)**
```
conda install cmake ninja
pip install -r requirements.txt
```
This guarantees `python setup.py` to run (on my machine) and gets me one step closer to be able to `python test/run_test.py`
* b) Only add whats needed to `python setup.py install`. Point to `Contributing.md` for explanations on how to run tests (which doesn't exactly mention how yet).
```
conda create -n pytorch-source python cmake ninja pyyaml typing_extensions
conda activate pytorch-source
python setup.py develop
```
* c) Add dependencies needed to run (most) unit tests
I assume _"Install from source"_ describes how to "install so I can do development.". This is why we recommend `python setup.py develop`. Doing development implies running unit tests.
```
conda create -n pytorch-source python cmake ninja pytest click
conda activate pytorch-source
pip install -r requirements.txt xdoctest
python setup.py develop
python test/run_test.py --keep-going
```
This still eclectically goes outside the simple principle _"Use dependencies in requirements.txt"_ without solving the whole problem. Instructions to get tests to run is not the goal of this PR.
* d) Point to ex [`.circleci/docker/requirements-ci.txt`](https://github.com/pytorch/pytorch/blob/master/.circleci/docker/requirements-ci.txt) or any of the system-specific sets of pinned requirements like [`requirements-{conda-env-macOS-ARM64}.txt`](https://github.com/pytorch/pytorch/blob/master/.github/requirements/conda-env-macOS-ARM64)
I don't want to jump into this rabbit hole.
<details>
<summary>My system according to setup.py when verifying it runs</summary>
```
Target system: Darwin-21.6.0
Target processor: arm64
Host system: Darwin-21.6.0
Host processor: arm64
Detected C compiler: AppleClang @ /Library/Developer/CommandLineTools/usr/bin/cc
CMake: 3.22.1
Make program: /opt/homebrew/Caskroom/miniconda/base/envs/pytorch-source/bin/ninja
Python version : 3.10.8
Python executable : /opt/homebrew/Caskroom/miniconda/base/envs/pytorch-source/bin/python
Pythonlibs version : 3.10.8
Python library : /opt/homebrew/Caskroom/miniconda/base/envs/pytorch-source/lib/libpython3.10.a
Python includes : /opt/homebrew/Caskroom/miniconda/base/envs/pytorch-source/include/python3.10
Python site-packages: lib/python3.10/site-packages
```
</details>
See details in comments below.
[skip ci]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91861
Approved by: https://github.com/malfet, https://github.com/ZainRizvi
This is really hard to debug, the faulty runner already disappeared by the time I tried to login. However, I figure out a way to get all the processes that could potentially hold the workspace by running:
```
choco install sysinternals -y
handle64.exe C:\actions-runner\_work\pytorch\pytorch\test\test-reports\
```
This gives me a better list of processes to kill.
```
PS C:\Windows\system32> handle64.exe C:\actions-runner\_work\pytorch\pytorch\test\test-reports\
Nthandle v5.0 - Handle viewer
Copyright (C) 1997-2022 Mark Russinovich
Sysinternals - www.sysinternals.com
python.exe pid: 1672 type: File 574: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
python.exe pid: 4604 type: File 6C8: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
python.exe pid: 4604 type: File 6CC: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
ninja.exe pid: 4764 type: File 468: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
ninja.exe pid: 4764 type: File 5F4: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
cl.exe pid: 5336 type: File 468: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
cl.exe pid: 5336 type: File 5F4: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
nvcc.exe pid: 1680 type: File 468: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
nvcc.exe pid: 1680 type: File 5F4: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
cmd.exe pid: 976 type: File 468: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
cmd.exe pid: 976 type: File 5F4: C:\actions-runner\_work\pytorch\pytorch\test\test-reports\test_cpp_extensions_jit_r04_oc2b.log
```
Crossing my fingers to have this working
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93914
Approved by: https://github.com/clee2000
Fixes#92676
`arange` infers the output dtype from the argument types, but in order to reduce
falling back to ATen, inductor preferred to cast whole number float arguments to
int which gave the wrong output dtype. Instead, this decomposes floating point
arange into the prim equivalent for integers.
This also changes the signature of `prims.arange` to
```python
prims.iota(length, *, start, step, **factory_kwargs)
```
which only supports integers arguments. This is done because calculating the
output size from `start, end, step` is surprisingly complex and liable to off by
one errors so should not be duplicated in each backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93353
Approved by: https://github.com/ngimel, https://github.com/lezcano
Fixes#93351
The existing code guesses that `tmp3` is probably a `float`, and so truncates
any `double` values
```cpp
float tmp3 = 0.0;
if(tmp2)
{
auto tmp4 = in_ptr0[i0];
tmp3 = tmp4;
}
```
The proposed change is to generate a lambda expression that represents the body
of the masked operation, and infer the type from the return value:
```cpp
auto tmp3 = [&]
{
auto tmp4 = in_ptr0[i0];
return tmp4;
}
;
auto tmp5 = tmp2 ? tmp3() : static_cast<decltype(tmp3())>(0.0);
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93842
Approved by: https://github.com/jgong5, https://github.com/Valentine233, https://github.com/jansel
Fixes#93391
Thank you to the PyTorch Distributed team for your invaluable contributions to the PyTorch ecosystem, your work is immensely impressive and inspiring!
As mentioned in #93391, in preparing the downstream package I maintain ([finetuning-scheduler](https://github.com/speediedan/finetuning-scheduler)) to support PyTorch 2.0's version of FSDP, I noticed modules that include multiple persistent buffers were not having their state properly transformed during saving of `state_dict`s.
The issue was that the post-state_dict hook codepath shared by the `FULL_STATE_DICT` and `SHARDED_STATE_DICT` `_state_dict_type`s ([`_common_unshard_post_state_dict_hook`](332d55d3df/torch/distributed/fsdp/_state_dict_utils.py (L158))) was inadvertently referencing a local variable (`buffer`) that was used in a [prior transformation](332d55d3df/torch/distributed/fsdp/_state_dict_utils.py (L231)), instead of the `buffers` variable that should have been referenced in the iteration context:
332d55d3df/torch/distributed/fsdp/_state_dict_utils.py (L251-L253)
In this case, modules with a single persistent buffer or without mixed precision enabled would be unaffected. With multiple buffers and mixed precision enabled however, the issue may appear stochastically in proportion to the ratio of persistent buffers that have compatible dimensions (since the value of the last buffer visited in the ``buffer_names`` ``Set`` is copied to all buffers and the ``Set`` iteration order will of course vary)
```bash
File ".../pytorch/torch/nn/modules/module.py", line 2028, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for FullyShardedDataParallel:
size mismatch for _fsdp_wrapped_module.1._fsdp_wrapped_module.running_mean: copying a param with shape torch.Size([]) from checkpoint, the shape in current model is torch.Size([10]).
```
To both address this issue and enhance coverage to avoid similar issues, this PR fixes the aforementioned typo and adds an additional set of basic tests that validate `state_dict` saving and loading for modules with persistent buffers in various contexts.
I found that adding another model along with additional buffer-specific logic to adapt [`test_basic_save_and_load_state_dict`](76b683b008/test/distributed/fsdp/test_fsdp_state_dict.py (L439)) for the purposes of this coverage seemed to increase complexity of that test to an undesirable degree.
Instead of adding additional complexity to that existing test, I've added a new test ``test_buffers_save_and_load_state_dict`` that does basic validation of ``state_dict`` saving and loading with mixed precision, ``state_dict_type`` and CPU offloading parameterization. Certainly let me know if you prefer I extend the logic of/add the persistent buffers model into the existing basic ``state_dict`` test, I'm happy to do so, just thought it was cleaner this way. Also, I thought doubling the number of tests with a ``use_orig_params`` parameterization or by testing additional different non-default buffer mixed precision data types was computationally imprudent but let me know if you'd like me to add those tests as well.
The only other notable test change is that I've refactored ``TestFSDPStateDict._compare_models`` to accommodate both ``buffers`` and ``parameters`` comparisons without code duplication.
Thanks again to the PyTorch Distributed team for your exceptional contributions. I've got some more to do adapting my package for 2.0's FSDP but it's been a delight so far thanks to your superlative work!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93396
Approved by: https://github.com/rohan-varma, https://github.com/awgu, https://github.com/fegin
Fixes#93019
Since PyTorch regularly breaks binary compatibility, `torchvision` must be
compiled with the exact same version of PyTorch. If not, then importing it may
cause mysterious failures at runtime due to binary incompatibility.
This fixes the issue by delaying the `make_fallback` call for
`torchvision.roi_align` until the operator appears in a graph being lowered, by
which point the user must have imported torchvision themself.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93027
Approved by: https://github.com/jansel
**Overview**
- This PR refactors the `summon_full_params()` unit tests to prepare for `unshard_params()` by consolidating redundant tests and improving others.
- This PR enables `CPUOffload(offload_params=True)` + `NO_SHARD` + `writeback=True`.
- This PR provides an improved error message when calling `summon_full_params()` from an invalid context (i.e. from forward, backward, or in `summon_full_params()`).
**Details**
<details>
<summary>Existing Unit Tests</summary>
`test_summon_full_param_writeback()` with `world_size=1`
`test_summon_full_param_writeback()` with `world_size=2`
- Tests that `writeback=True` persists write and that `writeback=False` does not persist write when modifying a root FSDP instance's `flat_param` (`modify_outer=True`) or a non-root FSDP instance's `flat_param` (`modify_outer=False`); additionally configures with `mixed_precision` and `use_orig_params`
- `CPUOffload(offload_params=True)` + `world_size=1` is not tested because it is not supported.
- The write inside `summon_full_params()` is on the `flat_param` itself, which is not the expected usage.
`test_summon_full_param_shard_value()`
- Tests that reconstructing the `flat_param` (by re-flattening and chunking parameters) inside `summon_full_params()` gives the same as the originally constructed `flat_param` when using a single FSDP instance
- This test seems to exercise the FSDP sharding algorithm, not the specification of `summon_full_params()`. The only relevant part being implicitly tested is that `model.parameters()` order is preserved.
- This test assumes the current FSDP sharding algorithm.
`test_summon_full_param_recursive()`
- Tests that `recurse=True` recursively applies to all FSDP instances and that `recurse=False` does not
- This test assumes the current FSDP sharding algorithm.
`test_cannot_summon_full_params_from_forward()`
`test_cannot_summon_full_params_from_backward()`
- Tests that calling `summon_full_params()` from inside the forward or backward raises an error
- The error message leaks `FlatParamHandle` to the user. I provided a better error in this PR.
`test_summon_full_params_respects_reshard_after_forward()`
- Tests that calling `summon_full_params()` after forward preserves whether the padded unsharded `flat_param` data is freed or not (like `reshard_after_forward`)
- This test depends on FSDP internals (`flat_param._full_param_padded.storage().size()`).
`test_summon_single_param()`
- Tests that writing to padding with `writeback=True` does not persist those writes (doing so by using a singleton `(1, 1)` parameter that gets flattened and padded to `(2,)`)
- This test name is misleading.
`test_summon_full_params_equivalence()`
- Tests `writeback`, `rank0_only`, and `offload_to_cpu` with `writeback=not rank0_only`, using `CPUOffload(offload_params=True)` and including a `torch.cuda._sleep(int(1e6))` _after_ the write in `summon_full_params()`
- The PR introducing this test said that the `torch.cuda._sleep(int(1e6))` exercised the stream synchronization in `summon_full_params()`--namely that the current stream waits for the all-gather stream after all-gathering the parameters. I did not follow conceptually how that works since the `torch.cuda._sleep()` call happens after both the all-gather and write and is in the default stream, which seems to be after the relevant ops. If we clarify this, I can re-incorporate this into the unit tests. Doing so is not a high priority since `summon_full_params()` unshards in the default stream now and does not require stream synchronization.
- This unit test has overlap with `test_summon_full_param_writeback()` and can be coalesced.
`test_summon_from_non_fsdp()`
- Tests calling `summon_full_params()` with default args on a non-FSDP root module exposes the original parameters correctly
- This test actually covers much of the specification since checking for original parameter equivalence includes shape, value, device, etc. checking.
`test_reshard_outside_forward_backward_iteration()`
- Tests that calling `summon_full_params()` after forward preserves whether the padded unsharded `flat_param` data is freed or not (like `reshard_after_forward`) and that calling `summon_full_params()` after backward preserves that the padded unsharded `flat_param` data are freed; additionally configures `mixed_precision`
- This test strictly dominates `test_summon_full_params_respects_reshard_after_forward()` in strictness since it includes the check after backward as well.
`test_params_are_unflattenned()`
- Tests that original parameters are exposed with the unflattened shape factoring in `rank0_only` (e.g. including that nonzero ranks reshard early when `rank0_only=True`) and that with `offload_to_cpu=True`, the `flat_param`s are moved back to GPU after exiting the context; additionally configures `mixed_precision`
`test_params_count_and_value()`
- Tests that original parameters are all exposed and with the correct values factoring in `rank0_only` (e.g. including that nonzero ranks do not expose the original parameters when `rank0_only=True`) and that with `offload_to_cpu=True`, the `flat_param`s are moved back to GPU after exiting the context; additionally configures `mixed_precision`
`test_raises_rank0_with_writeback()`
- Tests that `rank0_only` + `writeback=True` raises an error
`test_named_parameters_buffers()`
- Tests that `named_parameters()` and `named_buffers()` return clean names (without FSDP prefixes) inside `summon_full_params()`
`test_with_grads_core()`
- Tests `with_grads=True` by comparing against DDP
`test_with_grads_none_grads()`
- Tests `with_grads=True` when ranks' `FlatParameter`s have `None` gradient
</details>
<details>
<summary>New Unit Tests</summary>
`test_unshard_params_writeback_no_shard()` (with `world_size=1`)
`test_unshard_params_writeback()` (with `world_size=2`)
- Tests the `writeback` argument (using the default value for all others)
`test_unshard_params_param_data_no_shard()` (with `world_size=1`)
`test_unshard_params_param_data()` (with `world_size=2`)
- Tests that parameters are exposed correctly for `recurse=True` and all other argument configs for a non-FSDP root module
`test_unshard_singleton_param_writeback()`
- Tests `writeback=True` for a singleton parameter, which includes testing that writing to padding does not persist
`test_unshard_params_respects_reshard()`
- Tests that unsharding parameters respects the expected reshard behavior between forward and backward as well as after backward
`test_unshard_params_recurse()`
- Tests the `recurse` argument (using default for all others)
`test_offload_to_cpu_no_shard_raises()`
- Tests that `offload_to_cpu=True` with `NO_SHARD` raises an error
</details>
<details>
<summary>Summary of Unit Test Changes</summary>
- `test_summon_full_param_writeback` -> `test_unshard_params_writeback()`
- `test_summon_full_params_equivalence()`, `test_params_are_unflattenned()`, `test_params_count_and_value()` -> `test_unshard_params_param_data()`
- `test_summon_full_params_respects_reshard_after_forward()`, `test_reshard_outside_forward_backward_iteration()` -> `test_unshard_params_respects_reshard()`
- `test_summon_full_param_recursive()` -> `test_unshard_params_recurse()`
- `test_named_parameters_and_buffers()` unchanged
- `test_with_grads_core()` unchanged
- `test_with_grads_none_grads()` unchanged
- `test_cannot_summon_full_params_from_forward()`, `test_cannot_summon_full_params_from_backward()` -> `test_unshard_params_from_forward_raises()`, `test_unshard_params_from_backward_raises()`
- `test_raises_rank0_with_writeback()` -> `test_rank0_only_with_writeback_raises()`
- `test_offload_to_cpu_no_shard_raises()` new
- `test_summon_full_param_shard_value()` removed
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92298
Approved by: https://github.com/rohan-varma
**Overview**
This PR stack will add support for unsharding FSDP's sharded parameters for `fully_shard`. This PR takes the first step by doing some internal refactoring.
- The existing API for wrapper FSDP is the static method `summon_full_params()`, which calls into the helper `_summon_full_params()`.
- This PR refactors:
- `summon_full_params()` core logic to `_unshard_params()`
- `_summon_full_params()` to `_unshard_params_recurse()`, which has a `recurse: bool` argument
- Previous `_unshard_params()` to `_unshard_fsdp_state_params()`, which applies to a single FSDP state
**Details**
- This PR introduces `_get_fsdp_states_with_modules()` and `_get_root_fsdp_states_with_modules()`, which additionally return the modules along with the FSDP states. The modules are needed for handling `FlatParameter` registration.
- We may be able to remove this if we clean up the `use_orig_params=True` vs. `False` code paths because for `True`, the `FlatParameter` is not registered, meaning that it does not need to be de-registered.
- Since `fully_shard` requires `use_orig_params=True`, we may not need `_get_fsdp_states_with_modules()` and `_get_root_fsdp_root_modules()`; however, I prefer to make the separation of FSDP state and module explicit for now for clarity.
**Follow-Ups**
- `writeback=True` and `rank0_only=True` raises an error. The previous explanation was:
> is not supported, as model parameter shapes will be different across ranks, and writing to them can lead to inconsistencies across ranks when the context is exited.
I am not exactly sure what the different model parameter shapes refers to. However, I believe that we can support `writeback=True` and `rank0_only=True` by broadcasting the `FlatParameter` from rank 0 in the `finally`, writing back, and freeing. This should not increase the peak memory since rank 0 already holds the unsharded `FlatParameter` in GPU memory before writing back and nonzero ranks do not have any other unsharded `FlatParameter`s in GPU memory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92297
Approved by: https://github.com/rohan-varma
# Summary
This PR creates _flash_attention_backward and _scaled_dot_product_flash_attention_backward native functions and registers them to the respective derivatives.yaml.
The goal is to replicate the torch.autograd.Function defined in the FlashAttention repo [here](33e0860c9c/flash_attn/flash_attn_interface.py (L126)) natively in PyTorch. One thing that we don't have access to is ctx.save_for_backward in native PyTorch so in order to save these variables I extended the returned objects from the forward functions.
### MetaFunctions
I also updated the FlashAttention meta functions to mirror the real outputs now. As well I added a meta registration for backwards. I have an XLMR training script and while eager training now works with FlashAttention compiling this module fails with the inductor error down below.
### Questions?
Performance issues vs mem efficient when using torch.nn.mha_forward
TorchCompile -> See purposed solution below.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92917
Approved by: https://github.com/cpuhrsch
We sometimes put ShapeEnv on GraphModule, and code in our testing
utils assume that you can deepcopy a GraphModule, so it's good
for ShapeEnv to be deepcopy'able too. This is done by making the
TLS module-wide rather than per-ShapeEnv. We never really have
multiple ShapeEnv so this is a good trade.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93403
Approved by: https://github.com/jbschlosser
Fixes https://github.com/pytorch/pytorch/issues/61655
The test is flaky and fails whenever `test_jit_cuda_archflags` is run. The latter `test_jit_cuda_archflags` was slow test in the old Windows runner. It's currently running again on trunk due to the problem with populating slow-test JSON file ~Interestingly, its performance is getting better in the new Windows G5 runner and it becomes a borderline slow test, where it run sometimes~. Whenever it runs, the next test `test_jit_cuda_extension` will fail.
* Build and load different CUDA arch modules from `test_jit_cuda_archflags` in separate processes to avoid importing them into the current one. The test only checks the build artifacts. Importing them cause `test_jit_cuda_extension` to fail as describe in https://github.com/pytorch/pytorch/issues/61655
* Clean up the temp build dir on Windows. Windows CUDA runner is non-ephemeral, so it's better to clean thing up properly to avoid any funny business the next time the runner is used
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93332
Approved by: https://github.com/davidberard98
Fixes https://github.com/pytorch/pytorch/issues/89421
The strategy is to patch the given function wrapped with `@torch.fx.wrap` so that if a tensor tracer is active, we will `proxy_call` the function.
`proxy_call` will also skip certain checks if the function to proxy call is not a torch op (checked with `isinstance(.., OpOverload)`.
@IvanYashchuk @ezyang @Chillee
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93273
Approved by: https://github.com/ezyang
We used to have ASAN shard 4 and 5 running in 4xlarge because they timed out. With the current issue with test time collecting, I guess the shard allocation has been changed, and there are now timeout from shard 1 to 3. It's better to just have all shards using the same runner for consistency
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93879
Approved by: https://github.com/clee2000
**Background:** Before this PR, support in dynamo for tensor attributes (e.g. `x.H`, `x.T`, ...) need to be individually implemented one-by-one. This could potentially lead to errors, e.g. if the implementation in [variables/tensor.py](21c7c7c72f/torch/_dynamo/variables/tensor.py (L160)) differs from the implementation from a direct call to the attribute. For attributes that were not special-cased in tensor.py, dynamo tracing would fail. This PR adds generic support for tensor attributes that return tensors without needing to specially handle them. (Notably, for x.real and x.imag, which previously weren't supported).
**In this PR:** This directly creates a proxy node for a `"call_function"` node with `target=getattr`, and feeds it into wrap_fx_proxy. This will produce a TensorVariable for the attribute returned.
This also removes the implementations for H, T, mH, mT which were broken (previously `torch.relu(x.T)` would fail). They now fall back to this default implementation (for which `torch.relu(x.T)` passes).
**Further context**:
* Ed's original suggestion in [90463](https://github.com/pytorch/pytorch/pull/90463#discussion_r1043398340) is to use `torch.Tensor.H.__get__(x)`. I wasn't able to get this to work; fx compilation fails with `getset_descriptor does not have attribute __module__`. Basically, the `__module__` attribute which is available on most python attributes, is not available on `getset_descriptor` objects. (i.e., these are implemented in C++ as attributes on torch.Tensor, so they don't obey some assumptions made by fx)
* Although both tensor attributes and methods (like `x.relu()`) both go through this, this PR should only handle attributes (e.g. see the `"getset_descriptor"` in variables/tensor.py). Methods are handled already by by GetAttrVariable.
* Prior to this PR, we already returned GetAttrVariables for unsupported attrs: the parent caller would catch the NotImplementedError and fallback to returning a GetAttrVariable. But if this GetAttrVariable was ever passed into a torch.\* function (as it could quite possibly be, since most of these attrs are tensors), it would fail because its proxy node would be missing an [example_value](https://github.com/pytorch/pytorch/blob/master/torch/_dynamo/utils.py#L1017). So: before, for some tensor x, `x.real` would work fine; but `torch.relu(x.real)` would fail.
**Testing**: added tests in test_misc.py for x.real, x.imag, x.T, x.real.T.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91840
Approved by: https://github.com/ezyang
Summary:
This PR adds in support for LSTM Structured Pruning.
- Adds in LSTMSaliencyPruner, an implemented pruner that splits the packed weights, finds the appropriate mask for each piece individually based on saliency, and then combines to create an overall mask for the LSTM.
- Adds in pruning functions for LSTM pruning, which will split the weights, apply the masks, and then recombine the pruned weights. Works for both single and multiple-layer LSTMs.
Also added a basic pattern to the default set of of patterns for
LSTM -> Linear pruning
LSTM -> LayerNorm -> Linear pruning
Adds in test to check that LSTM pruning works, as well as for LSTMSaliencyPruner
Test Plan:
`python test/test_ao_sparsity.py -- TestBaseStructuredSparsifier.test_prune_lstm_linear_single_layer`
`python test/test_ao_sparsity.py -- TestBaseStructuredSparsifier.test_prune_lstm_linear_multiple_layer`
`python test/test_ao_sparsity.py -- TestBaseStructuredSparsifier.test_prune_lstm_layernorm_linear_single_layer`
`python test/test_ao_sparsity.py -- TestBaseStructuredSparsifier.test_prune_lstm_layernorm_linear_multiple_layer`
`python test/test_ao_sparsity.py -- TestSaliencyPruner.test_lstm_saliency_pruner_update_mask`
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D42199001](https://our.internmc.facebook.com/intern/diff/D42199001)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90801
Approved by: https://github.com/jerryzh168
Summary: `USE_CUDA` is needed in the bazel definitions to ensure that `USE_CUDA` is applied everywhere it should be.
We also fix some test code to use the correct properties.
Test Plan: Sandcastle
Differential Revision: D42616147
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92640
Approved by: https://github.com/ezyang
Summary:
Before this PR, PNP added shadow loggers to insides of
the shadow wrapper modules.
This PR moves those loggers to the parent module.
There are a couple of benefits:
1. this will unbreak features of quantization API which don't support loggers (such as hardcoding model output to be quantized)
2. this makes it easier to look at the parent graph and visualize what is logged, since now all the logging is in the same graph
3. this will make it easier to implement features such as propagation error calculation in the future
Test plan:
```
python test/test_quantization.py -k NShadows
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91428
Approved by: https://github.com/jerryzh168
Summary:
Changes the PNP test cases to use QNNPACK. The only reason is because
I'm switching to Mac M1 as my primary machine, which supports QNNPACK
but not fbgemm, and it's convenient for me to be able to run these
locally.
PNP itself is not backend specific, so it does not matter which backend
the functionality is tested on.
Test plan:
```
python test/test_quantization.py -k NShadows
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91421
Approved by: https://github.com/jerryzh168
upload_test_stats keeps failing b/c it can't handle when the id is workflow-<workflow_id> so add a try catch for this.
Add retries to get_workflow_job_id to try and reduce the number of times the id can't be found
Failure to upload test stats and inability to get the job id cause our sharding infra and slow test infra (probably also flaky test detection) to be less effective. This does not completely resolve the issue since we do rely on the job id
Failure to get the workflow job id happens tragically often, hopefully retries will help
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93401
Approved by: https://github.com/huydhn
https://github.com/pytorch/pytorch/issues/91536. One issue mentioned torch.inv is pretty slow for large batches with small matrices on cuda.
I checked the CPU implementations and found we have an optimize opportunity.
For torch.inv, the CPU pass chooses to solve it by `lu_factor` + `lu_solve`.
The `lu_factor` loop on `batch_size` dimension and the parallel happened inside lapack
- For small matrix, the computational complexity is too tiny to parallel inside lapack.
- Even for large matrix, the parallelization efficiency is not good in lapack ( it performs worse than using at::parallel outside)
- Only for small batch size + small matrix size, the omp overhead will take too large overhead.
Based on the above observations, using at::parallel outside on lu_factor will have a pretty large benefit.
Here is the code/data collected on 32 core ICX system.
```python
import torch
import time
def bench(bs, r):
x = torch.randn(int(bs), r, r)
start = time.time()
for i in range(100):
y1 = torch.linalg.lu_factor(x)
end = time.time()
print(r, bs)
print(end - start)
print((end - start)/(r**3))
for r in (4, 16, 64):
for bs in (1e2, 1e4, 1e6):
bench(bs, r)
```
| bs/rank | 100/4 | 10000/4 | 1000000/4 | 100/16 | 10000/16| 1000000/16| 100/64| 10000/64| 1000000/64|
| ---- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| parallel inside lapack | 0.0028 |1.077 | 11.99|0.0163 | 1.5260|153.17 |0.2021|20.93 | 1877|
| parallel outside lapack | 0.0087 | 0.0247 | 1.566| 0.0044|0.1678 |17.63|0.038|2.311 | 208.6|
|speed up ratio| 0.32x | 43.6x | 7.65x|3.70x |9.09x |8.69x |5.32x |9.06x |9x |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93037
Approved by: https://github.com/lezcano
`@torch.jit.unused` and `@torch.jit.ignore` do not allow to keep in torch scripted class member function, that has non scriptable declaration (e.g. return type)
Adding FunctionModifier _DROP to allow fully skip those functions from scripting and keep them in the code of the scripted class.
E.g. it can be used for:
```
@torch.jit._drop
def __fx_create_arg__(self, tracer: torch.fx.Tracer) -> torch.fx.node.Argument:
# torch.fx classes are not scriptable
return tracer.create_node(
"call_function",
CFX,
args=(tracer.create_arg(self.features),),
kwargs={},
)
def __iter__(self) -> Iterator[torch.Tensor]:
return iter(self.a)
```
Testing:
Added test case in `test/jit/test_types.py` with non-scriptable type annotations (fx.* classes) that fails before fix and passes after.
```
python test/test_jit.py
```
Differential Revision: [D42774830](https://our.internmc.facebook.com/intern/diff/D42774830)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93012
Approved by: https://github.com/davidberard98
**Summary**
X86 quantization backend (qengine) with oneDNN kernels has not been validated on OS other than Linux. So, let it fall back to fbgemm if OS is not Linux. This makes sure the behavior is the same on Windows/Mac as the previous default fbgemm qengine on x86 CPUs.
**Test plan**
CI checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93218
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Fixes https://github.com/pytorch/pytorch/issues/93245
This failure starts to happen recently. `tempfile.mkdtemp()` has already created the temporary directory, so removing it with `shutil.rmtree`, then recreating it with `os.makedirs` doesn't make much sense to me. The flaky problem here is that `shutil.rmtree` could fail to remove the temporary directory sometimes. Here is the error:
```
======================================================================
ERROR [1.814s]: test_load_rowwise_to_colwise_thread_count_2 (__main__.TestDistributedReshardOnLoad)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_distributed.py", line 539, in wrapper
self._join_processes(fn)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_distributed.py", line 765, in _join_processes
self._check_return_codes(elapsed_time)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_distributed.py", line 810, in _check_return_codes
raise RuntimeError(error)
RuntimeError: Process 0 exited with error code 10 and exception:
Traceback (most recent call last):
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_distributed.py", line 663, in run_test
getattr(self, test_name)()
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_distributed.py", line 541, in wrapper
fn()
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 252, in instantiated_test
test(self, **param_kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/distributed/_shard/sharded_tensor/__init__.py", line 94, in wrapper
func(self, *args, **kwargs)
File "/var/lib/jenkins/workspace/test/distributed/checkpoint/test_file_system_checkpoint_cpu.py", line 364, in test_load_rowwise_to_colwise
os.makedirs(path)
File "/opt/conda/envs/py_3.8/lib/python3.8/os.py", line 223, in makedirs
mkdir(name, mode)
FileExistsError: [Errno 17] File exists: '/tmp/tmps5rxw4hb'
```
If the temporary directory really needs to be cleaned up, another way would be to remove everything underneath it, but leave the folder alone.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93302
Approved by: https://github.com/kumpera
**Summary**
For onednn quant backend only.
QConv weight may be reordered to another blocked format if input shape is changed at runtime. It's a bug that group info is not retained for such reordering. This may lead to wrong shape of weight after reordering. This PR fixes this bug.
**Test plan**
python test/test_quantization.py -k test_conv_reorder_issue_onednn
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91934
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
From PR: https://github.com/pytorch/pytorch/pull/58691, Replacing the second input of `Gather` 0 to 1 affects other innocent Nodes. In Issue #91526 onnx::range starts from 0, the 0 is changed by this mechanism, as it's shared with onnx::Gather. This PR intends to create a whole independent Constant 0 for replacement. NOTE: The PR passes all existing RNN tests locally in case CI doesn't include RNN test.
~~TODO: test~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93120
Approved by: https://github.com/BowenBao
This PR changes the op registration to a better mechanism, now
we require the directly overload registration instead of the op
key str, this have several benefits:
1. We ensure that the op registration registers the correct op, which
means it would be faild if the op registration become wrong (this PR
already fixing several op registration errors as we use direct
OpOverload registration
2. If the overload name get changed/deleted, we immediately know it at
the source code compilation level, which is safer
3. This also keep it consistents with the op registration mechanism with
other tensor subclasses within PyTorch
Differential Revision: [D42876250](https://our.internmc.facebook.com/intern/diff/D42876250)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90735
Approved by: https://github.com/XilunWu, https://github.com/fduwjj
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused ConvAddReLU2d module for onednn backend, which will be used for int8 inference with onednn backend. Cannot call this module with other quantization backends otherwise an error is thrown.
**Test plan**
```
python -m pytest test_quantization.py -k test_conv2d_add_relu
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91154
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused `ConvAdd2d` module for onednn backend, which will be used for int8 inference with onednn backend. Cannot call this module with other quantization backends otherwise an error is thrown.
**Test plan**
```
python -m pytest test_quantization.py -k test_conv2d_add
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91152
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Summary:
Avoid dereferencing element [0] if the vector is empty.
___
In ```transferInputOutputBackends```, one of the rewrite passes for Vulkan ```optimize_for_mobile```, an out of bounds access happens when trying to insert a backend transfer for an input if that input's ```uses()``` is empty. This diff corrects that issue.
Test Plan:
Run tests
___
Phabricator + CI Tests
Reviewed By: SS-JIA
Differential Revision: D41296037
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92918
Approved by: https://github.com/SS-JIA, https://github.com/kirklandsign
The previous sentence seemed to imply that sparse may not always be helpful, ie, your execution time may increase when using sparse. But the docs mentioned otherwise.
A simple re-ordering of two words in the documentation to better align with the contextual sentiment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93258
Approved by: https://github.com/cpuhrsch
Like #89924#91083#85097 added new extra dependencies on nvidia-*. They are linux x86_64 (GPU) only packages, but were not marked as such, causing issues installing pytorch 1.13 via Poetry (and possibly other tools that follow PyPI's metadata API) on Linux aarch64 systems. This "fixes" the issue by adding the `and platform_machine == 'x86_64'` marker on these dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93066
Approved by: https://github.com/malfet
Previously, Dynamo faked support for item() when `capture_scalar_outputs` was True by representing it internally as a Tensor. With dynamic shapes, this is no longer necessary; we can represent it directly as a SymInt/SymFloat. Do so. Doing this requires you to use dynamic shapes; in principle we could support scalar outputs WITHOUT dynamic shapes but I won't do this unless someone hollers for it.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Differential Revision: [D42885775](https://our.internmc.facebook.com/intern/diff/D42885775)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93150
Approved by: https://github.com/voznesenskym
This PR almost a no-op, as most of the logic resides in the builder repo, namely:
6342242c508f361d91e1
Remove `conda-forge` channel dependency for test job, but add `malfet` channel for 3.11 testing (as numpy is not in default channel yet)
Build and upload following dependencies to `pytorch-nightly` channel:
```
anaconda copy --to-owner pytorch-nightly malfet/numpy/1.23.5
anaconda copy --to-owner pytorch-nightly malfet/numpy-base/1.23.5
anaconda copy --to-owner pytorch-nightly malfet/mkl-service/2.4.0
anaconda copy --to-owner pytorch-nightly malfet/mkl_random/1.2.2
anaconda copy --to-owner pytorch-nightly malfet/mkl_fft/1.3.1
anaconda copy --to-owner pytorch-nightly malfet/sympy/1.11.1
anaconda copy --to-owner pytorch-nightly malfet/mpmath/1.2.1
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93186
Approved by: https://github.com/atalman, https://github.com/ZainRizvi
Summary: We originally cleared the cache of the converter to avoid memory leaks; now that the cache uses a weak map this is no longer necessary. Clearing of the cache caused an error in an interaction with the minifier because the minifier uses delayed compilation, so the cleanup had occurred before inductor was invoked.
Test Plan: Memory regression is being checked via dashboard and on master.
Differential Revision: D42858624
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93304
Approved by: https://github.com/ezyang
Every now and then, the python docs push will fail because the base branch (pytorchbot/base) is too old and accumulates commits that might cause the cla check to fail. Pushing to the base branch will prevent it from being old.
The site branch cannot be used because the following push to site will cause the pr to be closed, preventing us from getting the cla check the next day, which is what happened to https://github.com/pytorch/pytorch.github.io/pull/1157 when I was trying to figure this out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93305
Approved by: https://github.com/huydhn
In file: combinatorics.py, the comparison of Collection length creates a logical short circuit.
if isinstance(self.sampler, Sized) and len(self.sampler) >= 0:
Here, the right side of the comparison will always return true.
I suggested that the Collection length check should be removed since this is redundant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93025
Approved by: https://github.com/albanD
We'll rely on the underlying fake tensor to raise an error in these cases. We only raise the error if there is an input to the data dependent operation that is a real tensor (and thus we are at risk of accidentally burning in real values)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93265
Approved by: https://github.com/albanD
periodic debug builds are actually running against Python-3.10
Remove Python version specifier from libtorch builds, as it kind of
irrelevant (libtorch is C++ only build, so Python version should not
matter)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93327
Approved by: https://github.com/kit1980
This must wait for the forward compatibility period since it requires the
`cuda::_exchange_device` primitive for TorchScript. Also since TorchScript
doesn't support inheritance, we can't just inherit from `_DeviceGuard` here.
This saves around 2 us per `with` statement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91127
Approved by: https://github.com/ngimel
**Summary**
Previously, we use `DNNL_RUNTIME_S32_VAL` as the `zero point` for `src` in both weight prepack and convolution forward to ensure the same block format of weight is used. The problem is `DNNL_RUNTIME_S32_VAL` may query out a different block format weight comparing with the true `zero point` for `src`. It makes oneDNN convolution into `jit` path instead of `brgconv` path. Here we will use the true `zero point` for `src` to create pd and make reorder if it's a different block format weight as weight prepack generated.
**Test Plan**
```
python -m pytest quantization/core/test_quantized_op.py::TestQuantizedConv::test_conv_transpose_reorder_issue_onednn
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90818
Approved by: https://github.com/Xia-Weiwen, https://github.com/jgong5, https://github.com/jerryzh168
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused conv2d_add_relu op for onednn backend, which will be used for int8 inference with onednn backend. Cannot call this op with other quantization backends otherwise an error is thrown.
**Test Plan**
```
python -m pytest test_quantization.py::TestQuantizedConv
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90364
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
This added the numpy typing plugin to mypy config so that we could
use it for DeviceMesh typing annotations
Please see https://github.com/pytorch/pytorch/pull/92931 about why we need this. For example, we are currently saving the DeviceMesh's mesh field as torch.Tensor, where when we do sth like:
```python
with FakeTensorMode():
device_mesh = DeviceMesh("cuda", torch.arange(4))
```
It would throw error because FakeTensorMode or any TorchDispatchMode tracks every tensor creation and interactions. While DeviceMesh just want to save a nd-array to record the mesh topology, and would like to avoid the interaction with subsystems like FakeTensor, so we want to support saving `mesh` as numpy array instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92930
Approved by: https://github.com/ezyang, https://github.com/malfet
Summary:
D38543798
Enabled Memopt previously to fix a bug with memory planner
Mirroring the changes we made Internally to OSS
Test Plan: OSS CI
Reviewed By: digantdesai
Differential Revision: D42782958
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93097
Approved by: https://github.com/digantdesai
Summary: For backend/PG plugin, use `ProcessGroup.BackendType.CUSTOM` to avoid uninitialized variable during `pg._register_backend` later
Test Plan: CI/CD and internal tests
Differential Revision: D42793222
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93129
Approved by: https://github.com/H-Huang
Summary: Handwritten out ops should have feature parity with the codegend ones. This means they should resize out to the appropriate size. Q. Why are these handwritten instead of codegend anyway? Q2. Wheres a good spot to put the resize and copy helpers since they are reused in the codegend out kernels
Test Plan: ci.
Differential Revision: D42177051
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91194
Approved by: https://github.com/ezyang
Summary:
Changes node.meta["target_dtype_info"] to store observer/fake_quant constructors instead of (dtype, is_dynamic),
so that in the future user can provide configure this by themselves, follow up refactors:
(1). generalized structure for "target_dtype_info": right now, we have "input_act_obs_or_fq_ctr", "weight_obs_or_fq_ctr", "bias_obs_or_fq_ctr", "output_obs_or_fq_ctr"
this works OK for current use cases, and users are using a different config to specify which input is weight and which input is bias, to generalize it
we should just expose an api that allow users to specify either a dictionary from input_index to obs_or_fq_ctr, and output_index to obs_or_fq_ctr, e.g.
e.g. out1, (out2, out3) = op(arg0, (arg1, arg2))
"input_act_obs_or_fq_ctr" = {0: obs1, 1: obs2}
"output_act_obs_or_fq_ctr" = {0: obs3, 1: obs4}
note that this would not allow configuring obs/fq for nested structures
or have a config that mimics the structure of arguments and output, e.g. out1, (out2, out3) = op(arg0, (arg1, arg2)), we can have
"input_act_obs_or_fq_ctr" = (obs1, (obs2, obs3))
"output_act_obs_or_fq_ctr" = (obs4, (obs5, obs6))
(2). use these observer/fq directly for inserting observers instead of using qconfig
(3). clean up the TODOs in the code base
Test Plan:
python test/test_quantization.py TestQuantizeFx
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92641
Approved by: https://github.com/jcaip
Fixes #ISSUE_NUMBER
currently they are failing due things like
```
ERROR: An error occurred during the fetch of repository 'tf_runtime':
Traceback (most recent call last):
File "/var/lib/jenkins/workspace/xla/third_party/tensorflow/third_party/repo.bzl", line 73, column 33, in _tf_http_archive_impl
ctx.download_and_extract(
Error in download_and_extract: java.io.IOException: Error downloading [3367783466.tar.gz, 3367783466.tar.gz] to /home/jenkins/.cache/bazel/_bazel_jenkins/b463291cb8b07b4bfde1e3a43733cd1a/external/tf_runtime/temp17509854002229755553/3367783466dff91b8b283d61c7fe8abc9e7bbb80.tar.gz: Checksum was 4d2fc38d8b6edd1a478ea2fcb88491eeaf7378e5ffe9f4e3eb3b821df1d1c5ba but wanted 5e6bab71ce31b4b56105ac4567f8bffa5f5b3de7ad3064638297249e69375623
```
so I move to unstable until we investigate and fix
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93296
Approved by: https://github.com/huydhn
This allows it so that ONLY when the users don't set anything for foreach or fused do we switch the default and cascades adam so that we default to fused, then foreach, then single-tensor.
To clarify:
* if the user puts True in foreach _only_, it will run the foreach implementation.
* if the user puts True in fused _only_, it will run the fused implementation.
* if the user puts True in foreach AND for fused, it will run the fused implementation.
And:
* if the user puts False in foreach _only_, it will run the single tensor implementation.
* if the user puts False in fused _only_, it will still run the single tensor implementation.
* if the user puts False in foreach AND for fused, it will run the single tensor implementation.
I also didn't trust myself that much with the helper function, so I ran some local asserts on _default_to_fused_or_foreach. The only point left to really test is the type(p) -- torch.Tensor but I think the distributed tests will catch that in CI.
```
cuda_only_fp_list = [
torch.rand((1, 2), device="cuda", dtype=torch.float32),
torch.rand((1, 2), device="cuda", dtype=torch.float64),
torch.rand((1, 2), device="cuda", dtype=torch.float16),
torch.rand((1, 2), device="cuda", dtype=torch.bfloat16),
]
cuda_only_int_list = [
torch.randint(1024, (1, 2), device="cuda", dtype=torch.int64),
]
cpu_list = [
torch.rand((1, 2), device="cpu", dtype=torch.float32),
torch.rand((1, 2), device="cpu", dtype=torch.float64),
torch.rand((1, 2), device="cpu", dtype=torch.float16),
]
none_list = [None]
# differentiable should always make it return false for both
assert _default_to_fused_or_foreach([cuda_only_fp_list], True, True) == (False, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list], True, False) == (False, False)
# cpu lists should always make it return false for both
assert _default_to_fused_or_foreach([cuda_only_fp_list, cpu_list], False, True) == (False, False)
assert _default_to_fused_or_foreach([cpu_list], False, True) == (False, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cpu_list], False, False) == (False, False)
assert _default_to_fused_or_foreach([cpu_list], False, False) == (False, False)
# has fused triggers correctly
assert _default_to_fused_or_foreach([cuda_only_fp_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list], False, False) == (False, True)
# ints always goes to foreach
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list], False, True) == (False, True)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list], False, False) == (False, True)
# Nones don't error
assert _default_to_fused_or_foreach([cuda_only_fp_list, none_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list, none_list], False, True) == (False, True)
assert _default_to_fused_or_foreach([none_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([none_list], False, False) == (False, True)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93184
Approved by: https://github.com/albanD
We want to make TorchRec sharded models TorchScriptable.
TorchRec sharded models uses generic types Awaitable[W] and LazyAwaitable[W] (https://github.com/pytorch/torchrec/blob/main/torchrec/distributed/types.py#L212).
In sharded model those types are used instead of contained type W, having the initialization function that produces object of type W.
At the moment when the first attribute of W is requested - `LazyAwaitable[W]` will call its initialization function (on the same stack), cache the result inside and work transparently as an object of W. So we can think about it as a delayed object initialization.
To support this behavior in TorchScript - we propose a new type to TorchScript - `Await`.
In eager mode it works the same as `LazyAwaitable[W]` in TorchRec, being dynamically typed - acting as a type `W` while it is `Await[W]`.
Within torchscript it is `Await[W]` and can be only explicitly converted to W, using special function `torch.jit.awaitable_wait(aw)`.
Creation of this `Await[W]` is done via another special function `torch.jit.awaitable(func, *args)`.
The semantic is close to `torch.jit.Future`, fork, wait and uses the same jit mechanics (inline fork Closures) with the difference that it does not start this function in parallel on fork. It only stores as a lambda inside IValue that will be called on the same thread when `torch.jit.awaitable_wait` is called.
For example (more examples in this PR `test/jit/test_await.py`)
```
def delayed(z: Tensor) -> Tensor:
return Tensor * 3
@torch.jit.script
def fn(x: Tensor):
aw: Await[int] = torch.jit._awaitable(delayed, 99)
a = torch.eye(2)
b = torch.jit._awaitable_wait(aw)
return a + b + x
```
Functions semantics:
`_awaitable(func -> Callable[Tuple[...], W], *args, **kwargs) -> Await[W]`
Creates Await object, owns args and kwargs. Once _awaitable_wait calls, executes function func and owns the result of the function. Following _awaitable_wait calls will return this result from the first function call.
`_awaitable_wait(Await[W]) -> W`
Returns either cached result of W if it is not the first _awaitable_wait call to this Await object or calls specified function if the first.
`_awaitable_nowait(W) -> Await[W]`
Creates trivial Await[W] wrapper on specified object To be type complaint for the corner cases.
Differential Revision: [D42502706](https://our.internmc.facebook.com/intern/diff/D42502706)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90863
Approved by: https://github.com/davidberard98
We would handle py::error_already_set correctly from pybind11 bindings,
but not from our regular TH bindings, which meant that anything from
an inner pybind11 function call was getting unconditionally transformed
into a RuntimeError. Not too many cases where we do this, but
PySymNodeImpl was one of them.
To test this, I need to raise a non-RuntimeError from a function which
is invoked from pybind11 and then propagated to a non-pybind11 call
site. I introduce GuardOnDataDependentSymNode for expressly this
purpose (this is how I discovered the bug anyway.)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93238
Approved by: https://github.com/Skylion007, https://github.com/albanD
Not only is this change usually shorter and more readable, it also can yield better performance. size() is not always a constant time operation (such as on LinkedLists), but empty() always is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93236
Approved by: https://github.com/malfet
Scalar is a union type of [int, float, bool], it's only needed for the representation of operation schema.
During export, we always have the concrete argument. As ex.Argument is already an union type, we don't need Scalar type anymore.
Example
Here's the schema for aten.add.Scalar
```
add.Scalar(Tensor self, Scalar other, Scalar alpha=1) -> Tensor
```
A fx.node
```
add_tensor: f32[s0, s0] = torch.ops.aten.add.Scalar(arg0, 1.1)
```
would be exported as
```
Node(
op='call_function',
target='aten.add.Tensor',
args=[
Argument(as_tensor=TensorArgument(name='arg0')),
Argument(as_float=1.1)
],
outputs=[
ReturnArgument(as_tensor=TensorArgument(name='add_tensor'))
]
)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93211
Approved by: https://github.com/suo
Node can only be 'call_function' ops
'placeholder' and 'output' are serialized as inputs and outputs of the Graph
'get_attr' is not needed anymore, as it's an implicit lookup from GraphModule's parameters/buffers
'call_method' and 'call_module' is not supported, as it's not used in the canonical FX Graph
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93208
Approved by: https://github.com/suo, https://github.com/Neilblaze
Fixes#92831
This PR fixes a test failure of `TestTorch.test_from_buffer` on a big-endian machine. The root cause of this failure is that current `THPStorage_fromBuffer` does not perform endian handling correctly on a big-endian.
In `THPStorage_fromBuffer`, the given buffer is stored as machine native-endian. Thus, if the specified byte order (e.g. `big`) is equal to machine native-endian, swapping elements should not be performed. However, in the current implementation, [`decode*BE()`](https://github.com/pytorch/pytorch/blob/master/torch/csrc/utils/byte_order.cpp#L72-L109) always swaps elements regardless of machine native-endian (i.e. these methods assume buffer is stored as little-endian).
Thus, this PR uses the following approaches:
- if the specified byte order (e.g. `big`) is equal to machine native-endian, call `decode*LE()` that does not swap elements by passing `torch::utils::THP_LITTLE_ENDIAN` to `THP_decode*Buffer()`.
- if the specified byte order (e.g. `big`) is not equal to machine native-endian, call `decode*BE()` that always swap elements by passing `torch::utils::THP_BIG_ENDIAN` to `THP_decode*Buffer()`.
After applying this PR to the master branch, I confirmed that the test passes on a big-endian machine.
```
% python test/test_torch.py TestTorch.test_from_buffer
/home/ishizaki/PyTorch/master/test/test_torch.py:6367: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
self.assertEqual(torch.ByteStorage.from_buffer(a).tolist(), [1, 2, 3, 4])
...
/home/ishizaki/PyTorch/master/test/test_torch.py:6396: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
self.assertEqual(bytes.tolist(), [1, 2, 3, 4])
.
----------------------------------------------------------------------
Ran 1 test in 0.021s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92834
Approved by: https://github.com/ezyang
This goes together with https://github.com/pytorch/test-infra/pull/1548 to clean up MacOS M1 runner after the workflow finishes. I'm referring to my test branch here to test https://github.com/pytorch/test-infra/pull/1548. Once that PR is merged, I will switch to the main branch, i.e. `pytorch/test-infra/.github/actions/setup-miniconda@main` and `pytorch/test-infra/.github/actions/check-disk-space@main`
In the future, if there are more steps need to be done after MacOS workflow finishes, this can be also be refactored into a separate action like `teardown-linux`. There is only one step at the moment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93126
Approved by: https://github.com/ZainRizvi
This optimizes an edge case where some compute-only ops (e.g. add)
could end up in an orphan graph at the input side due to the bucket
for the next graph being full already. The fix is to fuse this
graph (which is "empty" in parameter count) together with the adjoining
"full" bucket.
Note: i encountered this when trying to repro some suspected duplicate
argument errors, but this is unrelated and I have not yet repro'd
a duplicate arg issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93162
Approved by: https://github.com/davidberard98
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused `conv2d_add` op for onednn backend, which will be used for int8 inference with onednn backend. Cannot call this op with other quantization backends otherwise an error is thrown.
**Test Plan**
```
python -m pytest test_quantization.py::TestQuantizedConv
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90262
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Exponential distribution is continuous. Fixes CPU MKL exponential implementation to exclude integer dtypes.
```python
import torch
dtypes = [torch.uint8, torch.int8, torch.int16, torch.int32, torch.int64]
for dtype in dtypes:
x = torch.empty(10000, dtype=dtype).exponential_() # should fail !
print("dtype: ", x.dtype, "sum: ", x.sum())
```
### Additional Context
Related to #92709. This issue propagates to OpInfo of exponential.
```
AssertionError: The supported dtypes for exponential on device type cpu are incorrect!
The following dtypes worked in forward but are not listed by the OpInfo: {torch.int64, torch.uint8, torch.int8, torch.int16, torch.int32}.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92891
Approved by: https://github.com/CaoE, https://github.com/jgong5, https://github.com/ngimel
Rely on CI.
Avoid issues such as:
```
Traceback (most recent call last):
File "<string>", line 38, in <module>
File "<string>", line 36, in __run
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/re_cwd/buck-out/v2/gen/fbcode/2841b324ed9b88dd/caffe2/torchgen/__gen_executorch__/gen_executorch#link-tree/torchgen/gen_executorch.py", line 690, in <module>
main()
File "/re_cwd/buck-out/v2/gen/fbcode/2841b324ed9b88dd/caffe2/torchgen/__gen_executorch__/gen_executorch#link-tree/torchgen/gen_executorch.py", line 626, in main
parsed_yaml, custom_ops_parsed_yaml = parse_yaml_files(
File "/re_cwd/buck-out/v2/gen/fbcode/2841b324ed9b88dd/caffe2/torchgen/__gen_executorch__/gen_executorch#link-tree/torchgen/gen_executorch.py", line 505, in parse_yaml_files
translate_native_yaml(
File "/re_cwd/buck-out/v2/gen/fbcode/2841b324ed9b88dd/caffe2/torchgen/__gen_executorch__/gen_executorch#link-tree/torchgen/gen_executorch.py", line 448, in translate_native_yaml
for e in native_es:
TypeError: 'NoneType' object is not iterable
```
Differential Revision: [D42729435](https://our.internmc.facebook.com/intern/diff/D42729435)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92938
Approved by: https://github.com/JacobSzwejbka
Summary:
This is no longer needed, we can use dtype to decide whether an observer is needed or not
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92589
Approved by: https://github.com/jcaip
for some tensor x, x.type(torch.FloatTensor) will essentially do the same thing as x.to(torch.float). x.type can be called with at least 3 types of inputs:
* a string "torch.FloatTensor"
* a dtype torch.float
* a tensor type torch.FloatTensor
the third option (torch.FloatTensor) fails in fx, because fx cannot trace torch.FloatTensor objects. So this PR will replace the torch.FloatTensor type with a string "torch.FloatTensor"
Why not fix this in fx? Well, it's possible, but I'm not sure a nice way to do it. We would want to update [torch.fx.node.BaseArgumentTypes](d88bc38b0c/torch/fx/node.py (L17)) to contain torch.FloatTensor etc. We could hard-code a list of tensor types there (the types vary depending on build type, e.g. whether or not cuda tensors are available), but that's not great in case our hardcoded list differs from the actual list registered by python_tensor.cpp. Another option is to dynamically populate the list of types with `Union[tuple(...)])`, and fill the tuple with `torch._tensor_classes` (which is directly populated by python_tensor.cpp), but apparently this breaks most typecheckers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93043
Approved by: https://github.com/jansel
removes this unused var, the overall buffer comm hook feature is also not being used, we should deprecate / remove it as it is still a private API.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93128
Approved by: https://github.com/awgu
Not super important, but it is nice for the logs because the logs now say "the action timed out" instead of "the action was cancelled". It also makes the job status "failure" instead of "cancelled"
also adds timeout minutes as an input for rocm and mac tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93084
Approved by: https://github.com/huydhn
Summary:
As a follow up in https://github.com/pytorch/pytorch/pull/92664 (D42619405 (e6a8267cf5)), clean up the TRITON_CACHE_DIR settings. There are a few places touching TRITON_CACHE_DIR:
1. triton/fb/triton_util.py: when import triton
2. caffe2/torch/_inductor/codecache.py
3. caffe2/torch/_inductor/triton_ops/autotune.py
4. triton/triton/python/triton/compiler.py
IIUC there are two entry points:
* kernel.run(args): 1 -> 3 -> 4
* async_compile(kernel): 1 -> 2 -> 3 -> 4
* calling triton jit-annoated func directly: 4
I'm removing the TRITON_CACHE_DIR in 1 and 2.
Test Plan: Run local repro
Differential Revision: D42694374
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92879
Approved by: https://github.com/jansel
**Summary**
This work continues with https://github.com/pytorch/pytorch/pull/83784 by @vkuzo and includes all the changes in that PR.
Quote from https://github.com/pytorch/pytorch/pull/83784:
> Issue #83658 reports that ops followed by a certain pattern of `view` and `size` ops were not quantized correctly by FX graph mode quantization.
Before this PR, the "size" op was in the "op shares qparams with input" category, and the code assumed that the input of this op has the same dtype as its output. This led to incorrectly propagating the `int` dtype as the output of whichever op was preceding the `view` op, which in turn made that op blocklisted from quantization.
> The fix is to create a new category of ops which work on different dtypes of tensors but are not observed. This PR does so for `size`, and also for `shape` since it works the same way.
**Note**: This PR needs https://github.com/pytorch/pytorch/pull/91297 to be landed first otherwise there is a UT failure.
**Test plan**
```
python test/test_quantization.py -k test_linear_size_view
python test/test_quantization.py -k test_linear_shape_view
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90001
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Summary: We are trying to add a new feature for quantized gradient computation which enables backward() function for QNNPACK
Test Plan: buck2 test //caffe2/test/quantization:quantization -- test_qlinear_qnnpack_free_memory_and_unpack
Differential Revision: D40927291
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92714
Approved by: https://github.com/digantdesai, https://github.com/jianyuh
Also skip `test_roi_align_dynamic_shapes` for cuda as introduced by https://github.com/pytorch/pytorch/pull/92667. With Torchvision properly installed, the test fails with the following error:
```
2023-01-26T04:46:58.1532060Z test_roi_align_dynamic_shapes_cuda (__main__.CudaTests) ... /var/lib/jenkins/workspace/test/inductor/test_torchinductor.py:266: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
2023-01-26T04:46:58.1532195Z buffer = torch.as_strided(x, (x.storage().size(),), (1,), 0).clone()
2023-01-26T04:46:58.1532383Z test_roi_align_dynamic_shapes_cuda errored - num_retries_left: 3
2023-01-26T04:46:58.1532479Z Traceback (most recent call last):
2023-01-26T04:46:58.1532725Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 1155, in run_node
2023-01-26T04:46:58.1532821Z return node.target(*args, **kwargs)
2023-01-26T04:46:58.1533056Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_ops.py", line 499, in __call__
2023-01-26T04:46:58.1533160Z return self._op(*args, **kwargs or {})
2023-01-26T04:46:58.1533304Z RuntimeError: Cannot call sizes() on tensor with symbolic sizes/strides
```
https://github.com/pytorch/pytorch/issues/93054 reveals a blindspot in the CI where Torchvision was only installed in the first and second shard. The above test should show that failure as part of https://github.com/pytorch/pytorch/pull/92667, but then it was skipped because Torchvision was not installed (in the 3rd shard) for `test_roi_align` to run. The test is still skipped here, but in a more explicit way.
Fixes https://github.com/pytorch/pytorch/issues/93054
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93108
Approved by: https://github.com/clee2000, https://github.com/jjsjann123, https://github.com/nkaretnikov
Summary:
One of such places where circular reference can occur is: _load_state_dict_pre_hooks contains a _WrappedHook, _WrappedHook has a weakref to the same module.
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93038
Approved by: https://github.com/jerryzh168
My first attempt to fix `Library not loaded: @rpath/libzstd.1.dylib` issue on MacOS M1 in https://github.com/pytorch/pytorch/pull/91142 provides some additional logs about flaky error but doesn't fix the issue as I see some of them recently, for example
* e4d83d54a6
Looking at the log, I can see that:
* CMAKE_EXEC correctly points to `CMAKE_EXEC=/Users/ec2-user/runner/_work/_temp/conda_environment_3971491892/bin/cmake`
* The library is there under the executable rpath
```
ls -la /Users/ec2-user/runner/_work/_temp/conda_environment_3971491892/bin/../lib
...
2023-01-20T23:22:03.9761370Z -rwxr-xr-x 2 ec2-user staff 737776 Apr 22 2022 libzstd.1.5.2.dylib
2023-01-20T23:22:03.9761630Z lrwxr-xr-x 1 ec2-user staff 19 Jan 20 22:47 libzstd.1.dylib -> libzstd.1.5.2.dylib
...
```
Then calling cmake after that suddenly uses the wrong cmake from miniconda package cache:
```
2023-01-20T23:22:04.0636880Z + cmake ..
2023-01-20T23:22:04.1924790Z dyld[85763]: Library not loaded: @rpath/libzstd.1.dylib
2023-01-20T23:22:04.1925540Z Referenced from: /Users/ec2-user/runner/_work/_temp/miniconda/pkgs/cmake-3.22.1-hae769c0_0/bin/cmake
```
This is weird, so my second attempt will be more explicit and use the correct cmake executable in `CMAKE_EXEC`. May be something manipulates the global path in between making ` /Users/ec2-user/runner/_work/_temp/miniconda/pkgs/cmake-3.22.1-hae769c0_0/bin/cmake` comes first in the PATH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92737
Approved by: https://github.com/ZainRizvi
**Summary**
For onednn quantization backend only.
Currently, FX fusion requires that all separate ops in a fused module/op have the same `qconfig`. To support `linear - leaky_relu` and `linear - tanh` fusion with onednn backend, we previously explicitly set the same `qconfig` to `linear`, `leaky_relu` and `tanh`. However, this brings two problems:
- It breaks fusion of `linear - relu` since `relu` does not have the same `qconfig` as `linear` does. And it does not look good if we set `qconfig` to all these ops. They should use a global `qconfig` by default.
- `Tanh` requires `fixed_qparams_qconfig` otherwise it is not quantized. So, we cannot set another `qconfig` to `tanh`.
Looks like there is not a straightforward way to solve the problems. This PR fixes them by the following:
- Do not set `qconfig` to these ops so that these ops use a global `qconfig` and `linear - relu` and `linear - leaky_relu` can be fused correctly.
- Set the same `qconfig` to `linear` and `tanh` manually by users when they want to fuse `linear - tanh` with onednn backend.
A known issue still exists: users cannot fuse `linear - tanh` and quantize standalone `tanh` at the same time.
**Test plan**
python test/test_quantization.py -k test_qconfig_dict_with_fused_modules
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91297
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
As per title.
Additionally we also introduce support for:
- Rectangular block sizes which are powers of 2 and at least 16 (triton's `dot` limitation).
- Batch support with broadcasting for either of the arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88078
Approved by: https://github.com/cpuhrsch
Fixes https://github.com/pytorch/pytorch/issues/92283
The repro now works:
```python
import torch
import torch.func
import torch.nn as nn
x = torch.randn(3, device='cuda')
y = torch.randn(1, 3, device='cuda')
def fn(x, y):
# previously output of dropout used to be incorrect [B, 3] (B=1) and thus `mean(1)` used to fail
# post the fix output of dropout is [B, 1, 3] and `mean(1)` works.
return x + nn.functional.dropout(y, 0.3).mean(1)
o = torch.func.vmap(fn, in_dims=(0, None), randomness='different')(x, y)
```
**NOTE**:
`native_dropout_batching_rule(const Tensor& tensor, double p, c10::optional<bool> train)` was called only for CUDA tensor. Hence this issue only affected CUDA tensors and not CPU tensors
Ref:
a6ac922eab/aten/src/ATen/functorch/PyTorchOperatorHacks.cpp (L251-L258)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92975
Approved by: https://github.com/Chillee, https://github.com/Skylion007
This PR is the first step towards refactors the build for nvfuser in order to have the coegen being a standalone library.
Contents inside this PR:
1. nvfuser code base has been moved to `./nvfuser`, from `./torch/csrc/jit/codegen/cuda/`, except for registration code for integration (interface.h/interface.cpp)
2. splits the build system so nvfuser is generating its own `.so` files. Currently there are:
- `libnvfuser_codegen.so`, which contains the integration, codegen and runtime system of nvfuser
- `nvfuser.so`, which is nvfuser's python API via pybind. Python frontend is now exposed via `nvfuser._C.XXX` instead of `torch._C._nvfuser`
3. nvfuser cpp tests is currently being compiled into `nvfuser_tests`
4. cmake is refactored so that:
- nvfuser now has its own `CMakeLists.txt`, which is under `torch/csrc/jit/codegen/cuda/`.
- nvfuser backend code is not compiled inside `libtorch_cuda_xxx` any more
- nvfuser is added as a subdirectory under `./CMakeLists.txt` at the very end after torch is built.
- since nvfuser has dependency on torch, the registration of nvfuser at runtime is done via dlopen (`at::DynamicLibrary`). This avoids circular dependency in cmake, which will be a nightmare to handle. For details, look at `torch/csrc/jit/codegen/cuda/interface.cpp::LoadingNvfuserLibrary`
Future work that's scoped in following PR:
- Currently since nvfuser codegen has dependency on torch, we need to refactor that out so we can move nvfuser into a submodule and not rely on dlopen to load the library. @malfet
- Since we moved nvfuser into a cmake build, we effectively disabled bazel build for nvfuser. This could impact internal workload at Meta, so we need to put support back. cc'ing @vors
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89621
Approved by: https://github.com/davidberard98
Summary:
Currently, we define some C++ functions in one C++ Python extension
which are used by another. This happens to work, but isn't guaranteed to.
This diff moves these functions to a separate C++ library rule to fix this.
Test Plan: CI
Differential Revision: D42552515
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92325
Approved by: https://github.com/kit1980, https://github.com/Skylion007
Summary:
Makes torch.package debugging more transparent by
1. Pointing out not implictily externed modules in the standard library.
2. Creating a debug mode for users to find the source of broken modules.
Test Plan: Run package tests
Differential Revision: D42728753
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92939
Approved by: https://github.com/kurman
to make them agnostic of ubuntu version, ROCm version and python minor version.
This should help avoid frequent updates to the docker image tags when upgrading ROCm version in PyTorch CI, which has creation of new ECR tags as a blocking step.
Reference: https://github.com/pytorch/pytorch/pull/88297#issuecomment-1307873280
The BUILD_ENVIRONMENT flag will continue to specify the exact versions for the above, in case it is needed for debug. @malfet @seemethere Hope that's not going away, otherwise we might have a harder time debugging issues where we need to figure out these environment details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90694
Approved by: https://github.com/malfet
Fixes#92043.
I'm following numpy's implementation as suggested by @min-jean-cho.
I found out that this implementation still produces overflow if we're working with numbers greater than `finfo.max / 2`, but this is still much better than the previous implementation where it gets overflow with numbers greater than `finfo.max ** 0.5`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92539
Approved by: https://github.com/lezcano
Attempts to fix#92656
BC-breaking! This changes the default of zero_grad in optim and in nn to default set grads to None instead of zero tensors. We are changing the default because there are proven perf wins and existing code has typically not regressed due to this change. (will probably have to flesh out this note more).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92731
Approved by: https://github.com/ngimel
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom):
* __->__ #92986
When running compiled submods for the purpose of producing outputs to pass
to the compilation step for the next submod, we use fake parameters and
assume fake inputs, but we forgot to activate our fake_mode during execution.
This caused certain edge cases where tensors other than activations or parameters
got created during execution, such as scalar->tensor expansion in the case
of executing torch.where(tensor, scalar, scalar).
Also add a test and clarify behavior of DDPOptimizer via comments.
Fixes#92941
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92986
Approved by: https://github.com/bdhirsh
The unused variable in `fmha_api.cpp` [here](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/transformers/cuda/flash_attn/fmha_api.cpp#L313) was causing build failures (internally) due to to the `-Wunused-variable` flag being used. For example:
```
[2023-01-24T20:32:00.241-08:00] Stderr: aten/src/ATen/native/transformers/cuda/flash_attn/fmha_api.cpp:313:25: error: unused variable 'rng_engine_inputs' [-Werror,-Wunused-variable]
[CONTEXT] [2023-01-24T20:32:00.241-08:00] at::PhiloxCudaState rng_engine_inputs;
[CONTEXT] [2023-01-24T20:32:00.241-08:00] ^
[2023-01-24T21:09:33.507-08:00] Stderr: aten/src/ATen/native/transformers/cuda/flash_attn/fmha_api.cpp:313:25: error: unused variable 'rng_engine_inputs' [-Werror,-Wunused-variable]
[CONTEXT] [2023-01-24T21:09:33.507-08:00] at::PhiloxCudaState rng_engine_inputs;
[CONTEXT] [2023-01-24T21:09:33.507-08:00]
```
This PR removes that unused variable. Mirroring this same patch made by @drisspg internally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93024
Approved by: https://github.com/drisspg
This is a follow up from the previous PR: https://github.com/pytorch/pytorch/pull/88449 , to move the dynamo/TorchXLA bridge from pytorch repo to xla repo.
Overall the dynamo/TorchXLA integration has the following four layers of code
- pybind layer: This is the bottom layer containing various pybind APIs as the foundation. This part resident in xla repo
- bridge layer: build upon the pybind layer to implement the trace once functionality. This layer and it's corresponding unit test are in pytorch repro previously. This PR (and the corresponding xla pr https://github.com/pytorch/xla/pull/4476 ) moves them to the xla repo.
- dynamo backend registration: this a thin layer registers 4 dynamo backends (training/inference/trace_once/trace_everytime). It remains in pytorch repo.
- benchmark script: the torchbench.py script in dynamo is adapted so it can be used in dynamo/TorchXLA integration. This one remains in pytorch repo.
We think the new code organization is cleaner.
I'll wait for the xla PR in first before trying to merge this one.
Tests
1. run the unit tests moved to the xla repo
2. Test for inference: `GPU_NUM_DEVICES=1 python benchmarks/dynamo/torchbench.py --randomize-input --performance --trace-on-xla --backend=torchxla_trace_once --only resnet18`
3. Test for training: `GPU_NUM_DEVICES=1 python benchmarks/dynamo/torchbench.py --randomize-input --performance --trace-on-xla --training --backend=aot_torchxla_trace_once --only resnet18 --collect-outputs`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92601
Approved by: https://github.com/wconstab
I noticed that `torch.log1p` is ridiculously slow compared to `torch.log`
on CPU, and looking at the assembly it seems vsLog1p doesn't use any
vector instructions. I saw the same for abs, though AFAICT this is
dead code anyway as `abs` is implemented with `cpu_kernel_vec`.
Locally I see a 14x speedup in `torch.log1p`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92113
Approved by: https://github.com/jgong5
This gives some speedups for kernels implemented with `at::vml`:
- Make vml ops serial and use `TensorIterator.for_each` for better parallism
with discontiguous tensors
- Reduce buffer size for discontiguous data to 8 KiB to increase chance of
fitting in L1d cache, but is still wide enough to utilize AVX-512.
- Avoid a copy if only one of input and output is discontiguous
There is no change for contiguous tensors, but I see significant speedup for
the following benchmarks:
```
import torch
a = torch.randn(2*10**6, device="cpu")
%timeit a.view(100, 20000)[:,::2].sqrt()
%timeit a.view(200, 10000)[::2].sqrt()
```
For discontiguous last dimension I see a 27x speedup and for discontiguous
batch dimension I see an 8x speedup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91963
Approved by: https://github.com/jgong5
ids for composite workflows are really strange, both the calling step and the step in the composite workflow need an id, but when they're different, the calling step's id takes precedence
Should fix test uploading problem
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93001
Approved by: https://github.com/huydhn
When there is an original parameter with 1D shape that is fully assigned to one rank, then its `param.shape == view.shape` in `_use_unsharded_grad_views()`. In that case, we still want to check whether `param.dtype == view.dtype` and bypass as necessary.
The previous PR had an additional `and not self.uses_sharded_strategy` because the unit test did not require the check for sharded strategies, and I was conservatively adding a minimal fix. This was happenstance and because there was no 1D parameter fully assigned to one rank. Including the bias in the linear layer achieves that case, and removing the `and not self.uses_sharded_strategy` is necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92874
Approved by: https://github.com/zhaojuanmao
# Summary
Add support for fused attention kernels (FlashAttention and memory-efficient attention) on Windows. Previously we could not do this because the fixes required c++17 to do this but we have since update the PyTorch standard.
This PR:
- Changes invocations of unsigned long to the fixed width integer type
- Adds in the #define FP16_SWITCH(COND, ...) which has been added to the flash_attention main branch
- Changes the some macros used within mem-efficient attention code in order to work around the VA_ARG discrepancy between clang/gcc and msvc. An alternative would be setting the global flag Zc:preprocessor
- Selectively applies /Zc:lambda to only the mem-efficient sources since applying this globally caused quantization files to not compile
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91909
Approved by: https://github.com/cpuhrsch
The issue was first solved in [/pull/91371] for CI/CD, but the main Dockerfile in the repo root still has this issue for people trying to test build custom image manually.
Without it the build fails at installing miniconda
```
#14 3.802 Preparing transaction: ...working... done
#14 4.087 Executing transaction: ...working... done
#14 5.713 /root/miniconda.sh: 438: /root/miniconda.sh: [[: not found
#14 5.713
#14 5.713 Installing * environment...
#14 5.713
#14 5.714 /root/miniconda.sh: 444: /root/miniconda.sh: [[: not found
#14 6.050
#14 6.050 CondaFileIOError: '/opt/conda/pkgs/envs/*/env.txt'. [Errno 2] No such
file or directory: '/opt/conda/pkgs/envs/*/env.txt'
#14 6.050
```
With the modification, locally tested build successfully with `make -f ./docker.Makefile` as instructed in the README
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92702
Approved by: https://github.com/seemethere, https://github.com/malfet
Add bionic-py3.11-clang9, and move vulkan testing to it. Test only fx and jit for the time being (will add more in followup PRs)
Do not install numba, is it's not yet available for python-3.11
Change installed mkl version as the one installed before was incompatible with numpy
TODO: Remove `-c malfet` when required packages become available on default conda channel, namely `numpy`, `setuptools`, `coverage`, `mypy-exensions`, `typing-extensions`, `psutils` and `pyyaml`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92787
Approved by: https://github.com/albanD
In 3.11 bytecode size is not constant, so in order to get from `f_lasti` to opcode index, one need to search for the closes offset in disassembled instructions.
Update `_patch_function` to construct code with all the properties that exist in 3.11 runtime.
Update `_torchscript_schema_to_signature` to mark `from` named arg as positional argument only, as this is a reserved keyword in Python and as such checked by `inspect` package in 3.11
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92895
Approved by: https://github.com/albanD
You can easily test this by adding
```
@patch.object(config.triton, "convolution", "triton")
```
to test_convolution1 but it takes a long time to autotune so
I don't want to add it to the unit tests.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92870
Approved by: https://github.com/albanD
Summary:
Regularize mask handling for attn_mask and key_padding_mask
* Update documentation to remove reference to byte masks (which were deprecated long ago)
* Introduce check and warn about deprecation if attn_mask and key_padding_mask types mismatch
* Convert all masks to float before combining
* Combine by adding
Test Plan: sandcastle & github CI
Differential Revision: D42653215
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92733
Approved by: https://github.com/ngimel, https://github.com/drisspg
Follow up from: Quansight-Labs/numpy_pytorch_interop#3
This PR adds support for NumPy scalars for `torch.asarray`.
**Before:** treats the scalar as an object that implements the buffer protocol. Thus, interprets the data as the default data type (`float32`)
```python
>>> torch.asarray(numpy.float64(0.5))
tensor([0.0000, 1.7500])
```
**After:** identifies the NumPy scalar, and does the "right" thing. i.e. creates a 0-dimensional tensor from the NumPy array that doesn't share its memory
```python
>>> torch.asarray(numpy.float64(0.5))
tensor(0.5000, dtype=torch.float64)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90914
Approved by: https://github.com/lezcano, https://github.com/mruberry
For the cudagraphs implementation, we would like to reuse objects that are defined in python across the forward and backward. The backward is run in a different thread, so to handle this we add an api for copying over arbitrary python objects in pytorch's thread local state, in the same way that C++ objects are copied over currently.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89169
Approved by: https://github.com/albanD
My first attempt to fix `Library not loaded: @rpath/libzstd.1.dylib` issue on MacOS M1 in https://github.com/pytorch/pytorch/pull/91142 provides some additional logs about flaky error but doesn't fix the issue as I see some of them recently, for example
* e4d83d54a6
Looking at the log, I can see that:
* CMAKE_EXEC correctly points to `CMAKE_EXEC=/Users/ec2-user/runner/_work/_temp/conda_environment_3971491892/bin/cmake`
* The library is there under the executable rpath
```
ls -la /Users/ec2-user/runner/_work/_temp/conda_environment_3971491892/bin/../lib
...
2023-01-20T23:22:03.9761370Z -rwxr-xr-x 2 ec2-user staff 737776 Apr 22 2022 libzstd.1.5.2.dylib
2023-01-20T23:22:03.9761630Z lrwxr-xr-x 1 ec2-user staff 19 Jan 20 22:47 libzstd.1.dylib -> libzstd.1.5.2.dylib
...
```
Then calling cmake after that suddenly uses the wrong cmake from miniconda package cache:
```
2023-01-20T23:22:04.0636880Z + cmake ..
2023-01-20T23:22:04.1924790Z dyld[85763]: Library not loaded: @rpath/libzstd.1.dylib
2023-01-20T23:22:04.1925540Z Referenced from: /Users/ec2-user/runner/_work/_temp/miniconda/pkgs/cmake-3.22.1-hae769c0_0/bin/cmake
```
This is weird, so my second attempt will be more explicit and use the correct cmake executable in `CMAKE_EXEC`. May be something manipulates the global path in between making ` /Users/ec2-user/runner/_work/_temp/miniconda/pkgs/cmake-3.22.1-hae769c0_0/bin/cmake` comes first in the PATH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92737
Approved by: https://github.com/ZainRizvi
Follow-up of #89582 to drop flags like `CUDA11OrLater` in tests. Note that in some places it appears that `TEST_WITH_ROCM` is _implicitly_ guarded against via the `CUDA11OrLater` version check, based on my best-guess of how `torch.version.cuda` would behave in ROCM builds, so I've added `not TEST_WITH_ROCM` in cases where ROCM wasn't previously explicitly allowed.
CC @ptrblck @malfet @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92605
Approved by: https://github.com/ngimel
### Background
Early on in this process of integrating the FlashAttention code into core we were speaking with Tri and we came to the conclusion that the main branch of Flash Attention wasn't suitable for integration. We instead went with a [refactored version](https://github.com/HazyResearch/flash-attention/tree/cutlass) that more heavily depended upon cutlass.
That is the current version of FlashAttention in PyTorch. However there are some limitations with that branch.
- No backward support for SDPA
- Not as performant for some large MHA setups.
### Sumary
This PR pulls in the latest version of the main branch of [FlashAttention](https://github.com/HazyResearch/flash-attention/tree/main). It does not register the backward for the aten function SDPA_flash_attn. That will be done in a follow up PR.
### Changeset
A few changes were made to the original code for PyTorch.
- Flattened one layer of folder structure. (This is to match the the existing FlashAttention in core structure)
- Remove return_softmax param and change mha_fwd signature. Since the SDPA in core public function does not support need_weights we remove this argument.
- Add a lot of `#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >=530` around sections of code that will not compile for architecture less or equal to 520. Most of these blocks of code are half based asm or _hmul2 operations. An example update
```cpp
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >=530
float f;
asm volatile("cvt.f32.f16 %0, %1;\n" : "=f"(f) : "h"(h));
return f;
#else
assert(false);
return 0;
#endif
}
```
- Remove any blocksparse functions and files. And comment out utility functions that are used in the blockspase kernels written for FlashAttention since we did not pull in those functions.
- Update gemm_cl in **/gemm.h to:
``` c++
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
using InstructionShape = cutlass::gemm::GemmShape<16, 8, 16>;
#elif defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 750
using InstructionShape = cutlass::gemm::GemmShape<16, 8, 8>;
#else
assert(0);
// THIS IS NOT CORRECT BUT THE ASSERT WILL STOP THIS
using InstructionShape = cutlass::gemm::GemmShape<16, 8, 8>;
// TD [2022-06-02] We don't support Volta (SM70) yet.
#endif
```
### Reasoning:
FlashAttention is only designed to run on gpus that support sm7.5 or later. However PyTorch is generally build and released using `TORCH_CUDA_ARCH_LIST=5.2,..,8.6`. This means that source code must be compilable for these lower archs even if it is not run. But how are we sure that it won't be run? That should be handled by the runtime dispatch mechanism, specifically here: [check_arch](d70ed68162/aten/src/ATen/native/transformers/cuda/sdp_utils.h (L308))
There is however one edge case for building from source:
User specifies TORCH_CUDA_ARCH_LIST={something less than 7.5} and they are running on a gpu that is >= 7.5 This will cause the runtime dispatcher to think it is okay to run FlashAttention even though the compiled code is bogus.
I tested this with arch=5.3 on an a100 and get the following result:` RuntimeError: CUDA error: no kernel image is available for execution on the device` coming from torch.rand.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91994
Approved by: https://github.com/cpuhrsch
Fixes#88470
I added the "method" keyword in `aten/src/ATen/native/native_functions.yaml` for the function `where` with Scalar Overload.
This way, you can now use `Tensor.where()` with a scalar parameter the same way `torch.where()` can.
I added a test in `test/test_torch.py` as requested.
It uses the `where()` method on a tensor and then checks it has the same results as the `torch.where()` function.
The test is roughly the same as the one provided by the author of the issue.
PS: this is the second PR I make to resolve this issue, the first one is #92747. I had troubles with commit signatures and is therefore closed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92849
Approved by: https://github.com/albanD
# Summary
In preparation for pt 2.0 launch this PR updates SDPA's API and makes the function a nn.funcitonal public function.
## Changes
### API
Previously the the function signature was:
`scaled_dot_product_attention(query, key, value, attn_mask=None, need_attn_weights=False, dropout_p=0.0, is_causal=False) -> (Tensor, Tensor)`
Updated signature:
`scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False) -> Tensor`
This PR removes the need_attn_weights optional boolean variable and updates the return type to a singular tensor.
#### Reasoning:
The main goal of this function is to provide an easy interface for users to call into fused attention kernels e.g. (FlashAttention). The fused kernels do not currently support arbitrary attn_mask or dropout but there is a PR to mem-efficient attention to enable these. We want to have the API surface ready for when the backing kernels get updated.
The fused kernels save on memory usage by not materializing the weights and it is unlikely that a fast fused implementation will enable this feature so we are removing.
Discussed with folks at FAIR/Xformers and +1 this API change.
#### Make function Public
In preparation for the pt 2.0 launch we make the function public to start to generate user feedback
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92189
Approved by: https://github.com/cpuhrsch
How the old retains_grad hooks was implemented:
- retains_grad hooks are stored on the autograd_meta, as entries in a vector
- upon registration, a wrapper hook CppFunctionTensorPreHook is created to wrap that vector, and then that wrapper hook is registered to the grad_fn, i.e., by appending it to a vector of retains_grad hooks on the grad_fn
- upon in-place, for the old grad_fn we set the retains_grad hook to nullptr, so that even though the old grad_fn still references the vector, the vector contains a single nullptr. For the new grad_fn, we create a new wrapper hook around the vector (storing the single retains_grad hook) on autograd_meta.
The new retains_grad hook implementation:
- we store std::function by value, and we store it on the grad_fn rather than the autograd_meta
- a single grad_fn can have multiple outputs, so it can potentially hold multiple retains_grad hooks. We use an unordered_map (previously a vector).
- on in-place we remove the hook from the old grad_fn and put it in the new grad_fn (small implication of this change is that we we now need to have access to both the old grad_fn and new grad_fn, this isn't a problem)
Other details:
- CppFunctionTensorPreHook took a shared_ptr to vector of std::function. In our new implementation, we add a new wrapper hook CppFunctionSingleTensorPreHook, which takes a single std::function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92604
Approved by: https://github.com/albanD
Saw some places we missed some old requirements that are no longer necessary (dataclasses and future). Testing to see if all the CIs still work. We don't need dataclasses anymore now that we are on Python >= 3.7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92763
Approved by: https://github.com/ezyang
--diff_main renamed to --diff-branch BRANCH and now works again
Summary table splits results per branch.
csv output now has column with branch name when run in this mode
Added --progress flag so you can track how many models are going to be
run.
Example output:
```
$ python benchmarks/dynamo/torchbench.py --quiet --performance --backend inductor --float16 --batch-size-file $(realpath benchmarks/dynamo/torchbench_models_list.txt) --filter 'alexnet|vgg16' --progress --diff viable/strict
Running model 1/2
batch size: 1024
cuda eval alexnet dynamo_bench_diff_branch 1.251x p=0.00
cuda eval alexnet viable/strict 1.251x p=0.00
Running model 2/2
batch size: 128
cuda eval vgg16 dynamo_bench_diff_branch 1.344x p=0.00
cuda eval vgg16 viable/strict 1.342x p=0.00
Summary for tag=dynamo_bench_diff_branch:
speedup gmean=1.30x mean=1.30x
abs_latency gmean=24.09x mean=25.26x
compilation_latency mean=2.0 seconds
compression_ratio mean=0.9x
Summary for tag=viable/strict:
speedup gmean=1.30x mean=1.30x
abs_latency gmean=24.11x mean=25.29x
compilation_latency mean=0.5 seconds
compression_ratio mean=1.0x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92713
Approved by: https://github.com/jansel
If a state is not associated with any parameter, `FSDP.optim_state_dict` should still save it. The current implementation to determine whether a state is associated with a parameter is not completely correct and can cause `use_orig_params=True` have extra states.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92744
Approved by: https://github.com/awgu
This reverts commit 59071ab1e71891d480ab77af0d619bc5e01094c2.
It breaks `quantization.jit.test_ondevice_quantization.TestOnDeviceDynamicPTQFinalize`, which is not run in OSS, but is mandatory for internal CI.
We pass `fully_sharded_module`, not `root_module`, after recent refactoring to unify composable and wrapper FSDP for now. This PR removes the comment explaining why before we passed in `root_module`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92739
Approved by: https://github.com/mrshenli
Fixes#92808
This PR fixes SIGSEGV on a big-endian machine when reading pickle data.
The root cause is not to convert `size`, which is read from a file, from little-endian to big-endian while `size` is used in a method. The fix is to convert `size` on a big-endian machine instead of `nbytes`.
I confirmed that the program in the issue works w/o SIGSEGV and the test passes, with this fix in master branch.
```
$ python test/test_autograd.py TestAutograd.test_pickle
.
----------------------------------------------------------------------
Ran 1 test in 0.010s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92810
Approved by: https://github.com/malfet
Replace cpp string comparisons with more efficient equality operators. These string comparisons are not just more readable, but they also allow for short-circuiting for faster string equality checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92765
Approved by: https://github.com/ezyang
Apply clang-tidy readability-data-pointer fixits. This essentially uses the data() method when possible instead of the less readable `&vec[0]` to get the address of the underlying backing implementation. Not only is this more readable, it is safer as it allows you to retrieve the pointer even when the std::vector or std::string is empty without throwing an index error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92755
Approved by: https://github.com/ezyang
Since the CI exclusions are hard-coded in our script, we might as well require them to match exactly. This solved some head scratching where I was like, "this model is not obviously excluded, why is it not showing up in CI."
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92761
Approved by: https://github.com/jansel
When integrating AOT logging with TorchInductor trace, the ability to print graphs to the console if the user specified any of the env vars was removed (in favor of using TORCH_COMPILE_DEBUG). This restores this by checking if the user set any of the aot debug variables *before* setting up the remainder of the logging, and adding a stream to stdout if any of those env vars are set.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92720
Approved by: https://github.com/Chillee
This changes TensorImpl to store SymBool instead of bool. However, it doesn't actually compute these quantities symbolically (outside of some top level disjunctions.) The purpose of this PR is to make it easier to diagnose performance problems in the next PR, as after this change we can switch to guardless implementations without modifying TensorImpl.h
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92229
Approved by: https://github.com/Skylion007, https://github.com/albanD
Summary:
It looks we have some race in the cache directory for triton codegen, when we have multiple processes on the same host:
1. Rank A and B cannot find the code in cache (/tmp/uid/triton/cache) and start compilation separately
2. Most of the times the codegen is the same; but rarely it may produce different llir and different shared memory (in our case it's 544 and 2560, both are valid for the llir/ptx generated). See repro D42584580
3. They both write the compiled so and metadata into the local cache folder, with the same directory name (same hash, without considering device id). There will be a race here even if they grab the file lock, because it only locks each file but not the entire transaction
4. We then load the so and meta data back from the file. What happens can be we load so from rank A and shared memory from rank B and they mismatch.
Test Plan:
Run the faulty program to double check
```
[trainer5]: cache dir: /tmp/root/4951/triton/cache/198ef4405d2e525acd20d5c2d01ad099
[trainer1]: cache dir: /tmp/root/4947/triton/cache/198ef4405d2e525acd20d5c2d01ad099
```
Differential Revision: D42619405
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92664
Approved by: https://github.com/bertmaher, https://github.com/ngimel, https://github.com/jansel
We have known for a while that we should in principle support SymBool as a separate concept from SymInt and SymFloat ( in particular, every distinct numeric type should get its own API). However, recent work with unbacked SymInts in, e.g., https://github.com/pytorch/pytorch/pull/90985 have made this a priority to implement. The essential problem is that our logic for computing the contiguity of tensors performs branches on the passed in input sizes, and this causes us to require guards when constructing tensors from unbacked SymInts. Morally, this should not be a big deal because, we only really care about the regular (non-channels-last) contiguity of the tensor, which should be guaranteed since most people aren't calling `empty_strided` on the tensor, however, because we store a bool (not a SymBool, prior to this PR it doesn't exist) on TensorImpl, we are forced to *immediately* compute these values, even if the value ends up not being used at all. In particular, even when a user allocates a contiguous tensor, we still must compute channels-last contiguity (as some contiguous tensors are also channels-last contiguous, but others are not.)
This PR implements SymBool, and makes TensorImpl use SymBool to store the contiguity information in ExtraMeta. There are a number of knock on effects, which I now discuss below.
* I introduce a new C++ type SymBool, analogous to SymInt and SymFloat. This type supports logical and, logical or and logical negation. I support the bitwise operations on this class (but not the conventional logic operators) to make it clear that logical operations on SymBool are NOT short-circuiting. I also, for now, do NOT support implicit conversion of SymBool to bool (creating a guard in this case). This does matter too much in practice, as in this PR I did not modify the equality operations (e.g., `==` on SymInt) to return SymBool, so all preexisting implicit guards did not need to be changed. I also introduced symbolic comparison functions `sym_eq`, etc. on SymInt to make it possible to create SymBool. The current implementation of comparison functions makes it unfortunately easy to accidentally introduce guards when you do not mean to (as both `s0 == s1` and `s0.sym_eq(s1)` are valid spellings of equality operation); in the short term, I intend to prevent excess guarding in this situation by unit testing; in the long term making the equality operators return SymBool is probably the correct fix.
* ~~I modify TensorImpl to store SymBool for the `is_contiguous` fields and friends on `ExtraMeta`. In practice, this essentially meant reverting most of the changes from https://github.com/pytorch/pytorch/pull/85936 . In particular, the fields on ExtraMeta are no longer strongly typed; at the time I was particularly concerned about the giant lambda I was using as the setter getting a desynchronized argument order, but now that I have individual setters for each field the only "big list" of boolean arguments is in the constructor of ExtraMeta, which seems like an acceptable risk. The semantics of TensorImpl are now that we guard only when you actually attempt to access the contiguity of the tensor via, e.g., `is_contiguous`. By in large, the contiguity calculation in the implementations now needs to be duplicated (as the boolean version can short circuit, but the SymBool version cannot); you should carefully review the duplicate new implementations. I typically use the `identity` template to disambiguate which version of the function I need, and rely on overloading to allow for implementation sharing. The changes to the `compute_` functions are particularly interesting; for most of the functions, I preserved their original non-symbolic implementation, and then introduce a new symbolic implementation that is branch-less (making use of our new SymBool operations). However, `compute_non_overlapping_and_dense` is special, see next bullet.~~ This appears to cause performance problems, so I am leaving this to an update PR.
* (Update: the Python side pieces for this are still in this PR, but they are not wired up until later PRs.) While the contiguity calculations are relatively easy to write in a branch-free way, `compute_non_overlapping_and_dense` is not: it involves a sort on the strides. While in principle we can still make it go through by using a data oblivious sorting network, this seems like too much complication for a field that is likely never used (because typically, it will be obvious that a tensor is non overlapping and dense, because the tensor is contiguous.) So we take a different approach: instead of trying to trace through the logic computation of non-overlapping and dense, we instead introduce a new opaque operator IsNonOverlappingAndDenseIndicator which represents all of the compute that would have been done here. This function returns an integer 0 if `is_non_overlapping_and_dense` would have returned `False`, and an integer 1 otherwise, for technical reasons (Sympy does not easily allow defining custom functions that return booleans). The function itself only knows how to evaluate itself if all of its arguments are integers; otherwise it is left unevaluated. This means we can always guard on it (as `size_hint` will always be able to evaluate through it), but otherwise its insides are left a black box. We typically do NOT expect this custom function to show up in actual boolean expressions, because we will typically shortcut it due to the tensor being contiguous. It's possible we should apply this treatment to all of the other `compute_` operations, more investigation necessary. As a technical note, because this operator takes a pair of a list of SymInts, we need to support converting `ArrayRef<SymNode>` to Python, and I also unpack the pair of lists into a single list because I don't know if Sympy operations can actually validly take lists of Sympy expressions as inputs. See for example `_make_node_sizes_strides`
* On the Python side, we also introduce a SymBool class, and update SymNode to track bool as a valid pytype. There is some subtlety here: bool is a subclass of int, so one has to be careful about `isinstance` checks (in fact, in most cases I replaced `isinstance(x, int)` with `type(x) is int` for expressly this reason.) Additionally, unlike, C++, I do NOT define bitwise inverse on SymBool, because it does not do the correct thing when run on booleans, e.g., `~True` is `-2`. (For that matter, they don't do the right thing in C++ either, but at least in principle the compiler can warn you about it with `-Wbool-operation`, and so the rule is simple in C++; only use logical operations if the types are statically known to be SymBool). Alas, logical negation is not overrideable, so we have to introduce `sym_not` which must be used in place of `not` whenever a SymBool can turn up. To avoid confusion with `__not__` which may imply that `operators.__not__` might be acceptable to use (it isn't), our magic method is called `__sym_not__`. The other bitwise operators `&` and `|` do the right thing with booleans and are acceptable to use.
* There is some annoyance working with booleans in Sympy. Unlike int and float, booleans live in their own algebra and they support less operations than regular numbers. In particular, `sympy.expand` does not work on them. To get around this, I introduce `safe_expand` which only calls expand on operations which are known to be expandable.
TODO: this PR appears to greatly regress performance of symbolic reasoning. In particular, `python test/functorch/test_aotdispatch.py -k max_pool2d` performs really poorly with these changes. Need to investigate.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92149
Approved by: https://github.com/albanD, https://github.com/Skylion007
Fix for this issue surfaced from the discuss forum: https://discuss.pytorch.org/t/cuda-error-cublas-status-not-supported-when-calling-cublasltmatmul-from-torch-nn-functional-linear/170214
Note that PyTorch builds before #71200 should not be affected as there was no `cublasLt` dispatch path. Additionally, the provided repro has the quirk of using a 3D input, which means it will not dispatch to `cublasLt`-backed `addmm` until builds that include #72728. Changing the input to 2D by trivially removing the size `1` dimension will surface the failure on builds after #71200.
Interestingly, the use-case where _all_ inputs are 2-byte aligned are supported (runs without crashing), but when some are > 2-byte and some are == 2-byte are not. This behavior suggests that the `cuBlastLt` heuristics are incorrect, as the heuristic function has visibility of the raw pointer values via the descriptors when it is called.
We will follow up with `cuBlasLt` but this fix is needed to prevent unnecessary crashes for now.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92201
Approved by: https://github.com/ngimel
Summary:
This is in preparation for quantize_pt2e API where we allow programability for users to set how
they want to quantize their model
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizePT2E
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92574
Approved by: https://github.com/jcaip
Summary:
easy fix on formatting. for example,
> BackendCompilerFailed: compile_fx raised RuntimeError: Sizes of tensors must match except in dimension 0. Expected {common_length} but got {length} for tensor number {tensor_idx} in the list
Reviewed By: Yuzhen11
Differential Revision: D42491648
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92124
Approved by: https://github.com/malfet
Before
```python
tmp0 = 2.0
tmp2 = tl.libdevice.pow(tmp0, tmp1)
```
After
```python
tmp1 = tl.libdevice.exp2(tmp0)
```
I've benchmarked on CPU and CUDA with the following examples
```
@torch._dynamo.optimize()
def exp2(x):
return torch.pow(2, x)
@torch._dynamo.optimize()
def logaddexp2(a, b):
m = torch.maximum(a, b)
return m + torch.log2(1 + torch.pow(2, -torch.abs(a-b)))
```
triton is able to specialize `pow(2, x)` such that this makes
no difference, but on CPU I see a surprisingly large speedup.
| device | Function | Master (us) | This PR (us) | Speedup |
|--------|-----------|-------------|--------------|---------|
| CUDA | exp2 | 64 | 63 | 1.0 |
| | logaddexp | 109 | 107 | 1.0 |
| CPU | exp2 | 220 | 40 | 5.5 |
| | logaddexp | 282 | 140 | 2.0 |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92632
Approved by: https://github.com/lezcano, https://github.com/ngimel
Previously, we only create the directory in rank 0. Therefore, if running on multihosts with multiple GPUs, we would run into issues of "No such file or directory".
This is the fix for it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92553
Approved by: https://github.com/kumpera
Sample value from the test case `test_export_with_stack_trace`
node.target | node.meta["source_fn"]
-- | --
aten.randn.default | <built-in method randn of type object at 0x7f8683263108>
aten.t.default | < built-in function linear >
aten.mm.default | < built-in function linear >
aten.cos.default | <built-in method cos of type object at 0x7f8683263108>
aten.relu.default | relu
aten.add.Tensor | < built-in function add >
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92399
Approved by: https://github.com/jerryzh168, https://github.com/yanboliang
This removes the now-redundant `_squeeze_multiple` helpers and instead decomposes into a single call to `aten::squeeze.dims` which also has the effect of reducing the lowered graph size in inductor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91602
Approved by: https://github.com/ngimel
This replaces `log2(1 + x)` with `log1p(x) * (1 / log(2))` which improves
precision when `x` is small by avoiding the truncation from calculating
`(1 + x) - 1`. Noting that `x` is always `<= 1` in this formula.
This also replaces `pow(2, x)` with `exp2(x)` which improves performance,
particularly on CPU where the constant value cannot be inlined into Sleef.
With numel=1e7 for example, I see a 1.35x speedup on CPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92116
Approved by: https://github.com/lezcano
This reverts commit 4386f317b92a400cabc6a25b5849466475eec1a9.
Reverted https://github.com/pytorch/pytorch/pull/92608 on behalf of https://github.com/ZainRizvi due to test_aot_autograd_symbolic_exhaustive_unsafe_split_cpu_float32 (__main__.TestEagerFusionOpInfoCPU) is failing consistently since this PR was merged
Another PR towards solving #89205.
What's in this PR:
* The implementation of forward `logcumsumexp` for complex numbers in CPU & CUDA
* The tests on forward call of `logcumsumexp` for complex numbers
* The implementation of backward `logcumsumexp` for complex numbers
What's missing:
* The test on backward gradient of `logcumsumexp` (it complaints `RuntimeError: logcumsumexp does not support automatic differentiation for outputs with complex dtype.` and I don't know how to solve the error and I don't know where to put the test for the backward computation). If possible, I'd like this to be done in this PR.
It's really tricky to handle the edge cases here (i.e. the ones involving `inf`), but I've tried my best to put some comments explaining the reasonings of my decisions in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90847
Approved by: https://github.com/albanD
For micro-bench op `aten.elu.default` in TIMM, the performance is not good even though with vectorization. `Elu` uses `expm1` as a sub-op. It turns out that inductor invokes sleef `expm1` function while aten decomposes it with `exp - 1`. The former one performs worse than the latter one. This PR decomposes `expm1` for cpp vectorization to make performance come back.
Performance data for eager v.s. inductor:
<html xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns="http://www.w3.org/TR/REC-html40">
<head>
<meta name=ProgId content=Excel.Sheet>
<meta name=Generator content="Microsoft Excel 15">
<link id=Main-File rel=Main-File
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip.htm">
<link rel=File-List
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip_filelist.xml">
</head>
<body link=blue vlink=purple>
<html xmlns:v="urn:schemas-microsoft-com:vml"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns="http://www.w3.org/TR/REC-html40">
<head>
<meta name=ProgId content=Excel.Sheet>
<meta name=Generator content="Microsoft Excel 15">
<link id=Main-File rel=Main-File
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip.htm">
<link rel=File-List
href="file:///C:/Users/xuanliao/AppData/Local/Temp/msohtmlclip1/01/clip_filelist.xml">
</head>
<body link=blue vlink=purple>
suite | improved_ratio_speedup | speedup_old | RSD(3) | speedup_new | RSD(3)
-- | -- | -- | -- | -- | --
timm | 114.38% | 0.803447768 | 8.39% | 1.722458 | 27.74%
</body>
</html>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92289
Approved by: https://github.com/jgong5, https://github.com/jansel
Summary:
This PR supports the following feature for QConfigMapping:
```
qconfig_mapping = QConfigMapping().set_object_type(torch.nn.Conv2d, qconfig)
backend_config = get_qnnpack_pt2e_backend_config()
m = prepare_pt2e(m, qconfig_mapping, example_inputs, backend_config)
```
which means users want to set the qconfig for all calls to `torch.nn.Conv2d` to use `qconfig`, note this is only verified for the case when the module is broken down to a single aten op right now, e.g. torch.nn.Conv2d will be torch.ops.aten.convolution op when traced through. will need to support more complicated modules that is broken down to multiple operators later, e.g. (MaxPool)
Test Plan:
python test/test_quantization.py TestQuantizePT2E.test_qconfig_module_type
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92355
Approved by: https://github.com/jcaip
This PR splits `test_fully_shard.py` into `fully_shard/test_fully_shard<...>.py`. This should help improve readability and avoid some future rebase conflicts.
The only other real change is resolving a `TODO` for using `run_subtests` in the model checkpointing unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92296
Approved by: https://github.com/mrshenli
Fixes#88098
### What Changed
* Moved `check_label.py` logic into `trymerge.py`
* Refactored relevant unittests
* ~~Dropped~~ Refactored `check_label.py` ci job
### Tests
`python .github/scripts/test_trymerge.py`
`python .github/scripts/test_check_labels.py`
`make lint & lintrunner -a`
### Notes to reviewers
This PR replaces the [original PR](https://github.com/pytorch/pytorch/pull/92225) to workaround the sticky EasyCLA failure mark on its first commit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92309
Approved by: https://github.com/ZainRizvi
`TORCH_CHECK_TENSOR_ALL(cond, ...)` is a wrapper around `TORCH_CHECK` which allows the condition argument to be a tensor, batched or unbatched. `cond` can be a boolean tensor of any size. If any element is False, or if `cond.numel() == 0`, then `TORCH_CHECK_TENSOR_ALL` raises an error
Part of #72948
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89097
Approved by: https://github.com/zou3519
Fixing XLA test job flaky with sccache failing to start with a timeout error, for example:
* https://github.com/pytorch/pytorch/actions/runs/3953719143/jobs/6770489428
* https://github.com/pytorch/pytorch/actions/runs/3952860712/jobs/6769339620
* https://github.com/pytorch/pytorch/actions/runs/3946315315/jobs/6754126326
XLA test job actually builds XLA as part of the test ~~, so it needs sccache~~
* Register sccache epilogue before starting sccache, so that any errors when starting sccache can be printed
* Add `-e SKIP_SCCACHE_INITIALIZATION=1` to `_linux_test` workflow, this is the same flag used in `_linux_build` workflow. Quoted the reason from the build script:
> sccache --start-server seems to hang forever on self hosted runners for GHA so let's just go ahead and skip the --start-server altogether since it seems as though sccache still gets used even when the sscache server isn't started explicitly
* Also fix the code alignment in `.jenkins/pytorch/common-build.sh`
* We don't even use sccache in XLA test job, but there is an S3 cache used by bazel there (`XLA_CLANG_CACHE_S3_BUCKET_NAME=ossci-compiler-clang-cache-circleci-xla`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92587
Approved by: https://github.com/malfet, https://github.com/ZainRizvi
This reverts commit e525f433e15de1f16966901604a8c4c662828a8a.
Original PR: #85849
Fixes #ISSUE_NUMBER
In addition to reverting the revert, this PR:
- defines the virtual destructor of FunctionPreHook in the header. Why? Presumably the internal build imports the header from somewhere, but does not have function_hooks.cpp (where the virtual destructor was previously defined) in the same compilation unit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92559
Approved by: https://github.com/albanD
The `tensor_properties` field of the `ShardedTensorMetadata` dataclass is a reference to a `TensorProperties` object. However, the field is set to `field(default=TensorProperties())` instead of `field(default_factory=TensorProperties)`. This causes an error when using Python 3.11 or later:
```python
ValueError: mutable default <class 'torch.distributed._shard.sharded_tensor.metadata.TensorProperties'> for field tensor_properties is not allowed: use default_factory
```
This change in dataclass behavior was introduced in [bpo-44674: Use unhashability as a proxy for mutability for default dataclass __init__ arguments](https://github.com/python/cpython/pull/29867).
The current use of `default` instead of `default_factory` also means that all `ShardedTensorMetadata` objects created without specifying `tensor_properties` will share the same `TensorProperties` object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91795
Approved by: https://github.com/fduwjj
As per title.
Additionally we also introduce support for:
- Rectangular block sizes which are powers of 2 and at least 16 (triton's `dot` limitation).
- Batch support with broadcasting for either of the arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88078
Approved by: https://github.com/cpuhrsch
This PR is more of an RFC asking whether we intend to maintain parallelnative in the long term or to allow it to become community-supported.
If we want to maintain parallelnative, then let's close this PR.
If we do not, then we should remove it from trunk workflows into periodic (or just remove entirely).
Why shouldn't we just allow it to continue on CI regardless?
It adds friction to development! If we do support it, I think the friction is good--it prevents users from breaking what we support! But if not, then it is just another job users have to wait for before landing or another vector for flakiness to arise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92567
Approved by: https://github.com/malfet
I count the number of sub-graphs (for tiny-GPT2 in huggingface) by
```
class GraphCaptureCompiler:
def __init__(self):
self.captured_graphs = []
def compile(self, gm, example_inputs):
self.captured_graphs.append(gm)
return gm
compiler = GraphCaptureCompiler()
torch._dynamo.optimize(compiler, nopython=True)(Wrapper(fn))(*args)
```
Although `len(compiler.captured_graphs)` is 2, no error was thrown during the compilation. This observation conflicts with `nopython=True`. After some digging, I found a check is missed before making graph break. This PR adds it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90970
Approved by: https://github.com/ezyang, https://github.com/jansel, https://github.com/thiagocrepaldi
Mitigates https://github.com/pytorch/pytorch/issues/91469
Changes:
- ~once_differentiable can now be parametrized to print a custom error message~
- instead of once_differentiable, we do the backward inside another custom Function, which makes sure the graph is connected, but also makes sure to error on double backward
- we now explicitly error when doing double backward with torch.compile + aot_autograd instead of being silently incorrect. ~The niceness of the error message can vary depending on whether your grad_outputs are passed, or whether you are doing `.grad()` or `.backward()`.~
Unchanged:
- doing backward inside compiled function is still allowed. It currently causes a graph break and is equivalent to doing backward outside the compiled function. It might be nice to disallow this explicitly as well, but that can be done in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92348
Approved by: https://github.com/albanD
* flatten the workflows into just jobs in order to give more specific links (link to the specific job that failed instead of just pull), this should make it easier to implement bypass certain failures in the future
* try catch of MandatoryChecksMissingError from find_matching_merge_rule should fix error where merge loops instead of raising runtime error when trunk job fails
* remove usage of on_green and mandatory_only flags just in case. on_green and force are the only two behaviors we currently use
* fail if ghstack pr has non ghstack change, tested locally with #92177 but unsure how to write tests b/c requires use of repo._run_git
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92097
Approved by: https://github.com/huydhn, https://github.com/ZainRizvi
Summary:
A lot of other libraries have their own `xyz::Tensor` data structure. Under some rare cases, when they interop with torch, there will be compilation error such as
```
torch/csrc/api/include/torch/data/samplers/random.h(49): error: "Tensor" is ambiguous
```
Making some of the `Tensor` namespace clear will resolve this.
Test Plan: CI
Differential Revision: D42538675
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92266
Approved by: https://github.com/Skylion007, https://github.com/malfet
It turns out our old max/min implementation didn't do anything, because `__max__` and `__min__` are not actually magic methods in Python. So I give 'em the `sym_` treatment, similar to the other non-overrideable builtins.
NB: I would like to use `sym_max` when computing contiguous strides but this appears to make `python test/functorch/test_aotdispatch.py -v -k test_aot_autograd_symbolic_exhaustive_nn_functional_max_pool2d_cpu_float32` run extremely slowly. Needs investigating.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92107
Approved by: https://github.com/albanD, https://github.com/voznesenskym, https://github.com/Skylion007
After the previous fix to limit the CPU and memory used by Bazel, I see one case today where the runner runs out of memory in a "proper" way with exit code 137 0c8f4b5893. So, the memory usage must be close to limit of an 2xlarge instance. It makes sense to preemptively use 4xlarge now (like XLA)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92340
Approved by: https://github.com/clee2000
Changes in details:
- Fix and update some out-of-date type hints in `_functorch/make_functional.py`.
- ~Explicitly use `OrderedDict` for order-sensitive mappings.~
In `create_names_map()`, `_swap_state()`, and `FunctionalModuleWithBuffers.__init__()`, the unordered `dict` was used. The key order should be preserved for `dict.items()` while it is required to `zip` with a tuple of `params`/`buffers`. Although since Python 3.6, the built-in dictionary is insertion ordered ([PEP 468](https://peps.python.org/pep-0468)). Explicit is better than implicit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91579
Approved by: https://github.com/zou3519
This PR:
- Updates the docs to say it is deprecated
- Raises a UserWarning
- Changes most of the callsites inside PyTorch to use
torch.func.functional_call, minus the test_stateless testing.
The motivation behind this is that we can now align behind a single
functional_call API in PyTorch.
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92280
Approved by: https://github.com/albanD
This PR:
- adds deprecation warnings when calling the functorch APIs
- adds documentation saying that those APIs are deprecated
It does this by creating thin wrappers around the original APIs that (1)
raise deprecation warnings and (2) have an additional line in their
documentation that they are deprecated.
NB:
- Python surpresses DeprecationWarning, so we use UserWarning instead.
Test Plan:
- New tests
- the functorch.* APIs are still tested for correctness because that's
what test/functorch/* use (as opposed to directly calling the
torch.func.* APIs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92279
Approved by: https://github.com/albanD, https://github.com/soulitzer
`torch.func.stack_module_state` is our replacement for
`functorch.combine_state_for_ensemble`. The most common usage for
combine_state_for_ensemble is to
- create stacked parameters and buffers
- use vmap to run the forward pass
- use regular PyTorch autograd to run the backward pass (e.g.,
Tensor.backwrd)
- optimize directly over the stacked parameters (this is more performant
than optimizing over the unstacked parameters).
Right now, stack_module_state returns stacked parameters that cannot be
optimized directly (only leaf tensors can have a .grad field); this PR
fixes that by turning the stacked parameters back into leaf tensors.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92278
Approved by: https://github.com/soulitzer
`log1p` offers better precision near zero since `(1 + x) - 1` truncates any
values less than the float epsilon to zero. For `soft_margin_loss` this also
requires one fewer kernel invocation which for numel=1e7 gives me a 1.2x speedup
on CUDA and a 1.1x speedup on CPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92114
Approved by: https://github.com/ngimel, https://github.com/lezcano
> Reopen of https://github.com/pytorch/pytorch/pull/90354
**Summary**
Onednn quantization backend switch to new API in `third_party/ideep`.
- `struct forward_params` for conv/deconv are changed. Modify primitive cache accordingly.
- Use new versions of `prepare` and `compute` API. Fp32 and int8 paths separated. The old ones will be deprecated.
- Now `ideep::tensor::reorder_if_differ_in` supports block-to-block reorder. Use it instead of defining a util function `onednn_utils::try_reorder`.
- For new API of transposed convolution, we can use a flag to keep weight desc align with oneDNN thus needless to transpose it explicitly in PyTorch.
- Use `is_channels_last` flag to specify layout of src/dst when querying expected weight desc.
It won't impact correctness. Performance should be unaffected or slightly better.
FBGEMM and QNNPACK backends are not affected.
Performance results are given below.
1. End-to-end performance of static quantized models (from torchvision)
(throughput: fps, higher is better)

2. Op benchmark of dynamic quantized linear
(Latency: ms, lower is better)

Test method & env:
- Intel(R) Xeon(R) Platinum 8358 CPU @ 2.60GHz
- Run multi-instances on a single node. Use one core for each instance.
- Use Jemalloc and Intel OpenMP
**Test plan**
python test/test_quantization.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91056
Approved by: https://github.com/jgong5
Currently the biasadd of MKL SGEMM was executed using OpenMP macro, this will lead to a performance issue if the SGEMM size is very small (e.g., M = 1, K = 80, N = 256) when we are using many threads.
The reason is that in such case `num_task < num_thread`, and the task cost is too small (e.g., ~1-2 cycles for memcpy), the thread synchronization cost would be very large. Thus it is better to use `at::parallel_for` to run on the main thread directly.
Packed MKL SGEMM (1x80x256) | OpenMP biasadd | `at::parallel_for` biasadd
-- | -- | --
Latency | 2000 us | 21 us
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92300
Approved by: https://github.com/XiaobingSuper, https://github.com/jgong5
This PR adds FSDP and composable API files to `.lintrunner.toml` so that (1) lintrunner enforces that those files are formatted and (2) `lintrunner f` formats those files for you.
There are two requirements here (see https://github.com/pytorch/pytorch/wiki/lintrunner for details):
1. Install lintrunner:
```
pip install lintrunner
lintrunner init
```
2. `lintrunner f` before you finalize your PR, which would now be enforced by CI after this PR.
The code changes in this PR outside of `.lintrunner.toml` are the result of `lintrunner f`.
---
I only plan to land this PR if all of the composable API developers agree that this is something that makes sense and is not too intrusive to the workflow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90873
Approved by: https://github.com/yhcharles, https://github.com/mrshenli, https://github.com/rohan-varma
This PR:
- registers all of the codegened Nodes to the torch._C._functions module, this is where special nodes like AccumulateGrad are already registered.
- creates a autograd.graph.Node abstract base class that all of the newly registered nodes subclass from. We make the subclassing happen by implementing the ``__subclasshook__`` method
- enables static type checking to work and also enables Sphinx to generate documentation for the Node and its methods
- handles both the custom Function and codegened cases
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91475
Approved by: https://github.com/albanD
Summary: After D41587318 introduced new pytorch randomization, filament2 training failed due to chunk size is 0. We gated the new change to external only to fix filament2 package
Test Plan: f402461641 the flow has training successfully finished
Reviewed By: izaitsevfb
Differential Revision: D42501726
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92190
Approved by: https://github.com/izaitsevfb
As per title.
Additionally we also introduce support for:
- Rectangular block sizes which are powers of 2 and at least 16 (triton's `dot` limitation).
- Batch support with broadcasting for either of the arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88078
Approved by: https://github.com/cpuhrsch
Fixes#52664. Checks if the attribute is a property that defines a setter and uses fset in __setattr__ rather than registering an inaccessible module / parameter.
This is BC-breaking as the attribute setters on nn.Module properties used to be ignored and now will be called properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92044
Approved by: https://github.com/albanD
Cleaning FQN for `FullyShardedDataParallel(use_orig_params=True)` can cause some discrepancies with respect to the FQN compared to manually looping over `named_modules()` and `named_parameters()` together.
There is no requirement for the FQNs to be clean when using wrapper FSDP + `use_orig_params=True`. We can leave clean FQNs to `fully_shard`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91767
Approved by: https://github.com/zhaojuanmao
Addresses: https://github.com/pytorch/pytorch/issues/35802
Design doc: https://docs.google.com/document/d/19xSib7FFknRQ5f3ptGFUmiOt3BrgXSUlTQH2xMcZJYg/edit#
### Changes in this PR
#### Implementation
- We have now have 3 fields: pre_hooks, retains_grad_hooks, and tensor_pre_hooks so that we can more precisely define their ordering and when they are executed.
- Since retains grad uses an entirely new field, we cannot reuse the old retains grad, logic. We refactor retains grad to call directly into the variable.cpp logic. Other logic in variable.cpp that handle cpp hooks must also be updated.
#### Hooks ordering and execution:
- Defines pre-hooks registered on tensor to run before pre-hooks registered on grad_fn
- Updates pre-hooks registered on tensor to always run, even if they are the inputs= to .grad()
- Post hooks (and pre hooks) can now observe the modifications to gradient by the tensor pre hook
#### Retains grad hooks
- retains grad hooks always execute last, even if there are other tensor pre-hooks registered
#### Unchanged:
- pre_hooks registered to grad_fn aren't expected to execute if they are the inputs= to .grad()
Follow ups:
- simplify retains_grad field to not be a vector, since it always holds a single hook
- potentially merge capture hooks with tensor pre hooks, this would involve some additional refactoring since
- python hooks registered to tensor behavior on in-place is still wrong
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85849
Approved by: https://github.com/albanD
Ref #70924
This addresses part 1 of the issue, allowing `torch.squeeze` to be
passed a tuple of dimensions. e.g.
```python
x.squeeze(0).squeeze(0)
```
can now be written
```python
x.squeeze((0, 1))
```
(assuming x has at least 2 dimensions)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89017
Approved by: https://github.com/albanD
This PR removes the autograd.Function extension feature flag. This was
previously used for development of the functorch <> autograd.Function
interaction.
It's been in master for long enough with the feature flag defaulting to
True, so it's time to remove it.
Test Plan:
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92026
Approved by: https://github.com/soulitzer
functorch used to have a switch that enables/disables autograd.Function.
That switch now enables/disables torch.autograd.function._SingleLevelFunction, so
I've renamed it accordingly.
We could just delete the switch because users should not be directly
working with torch.autograd.function._SingleLevelFunction. However,
it was useful for debugging when something went wrong when I was
implementing the autograd.Function <> functorch interaction, so I want
to keep it around as a debugging tool for a while since the code is
already there.
Test Plan:
- updated tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92025
Approved by: https://github.com/soulitzer
We don't actually need `output_shapes` to implement
`generate_vmap_rule=True` support for autograd.Function.
- We need this in the vjp (backward) case because autograd automatically
reduces grad_inputs to inputs and we need to replicate that behavior.
In order to replicate that behavior, we recorded the original input
shapes so we know how to reduce the grad_input.
- There is no such behavior for forward-mode AD, so we don't need to
pass an `output_shapes` to reductify.
This PR simplifies the API of `reductify` and `reductify_leaf`. Instead
of accepting `input_shape_without_bdim` and `allow_expanded_grad`, we
now combine these into a single argument,
`reduce_to_input_shape_without_bdim`.
- if it is None, then we don't do anything
- if it is not-None and a shape, then we will reduce the grad to the
provided shape.
Test Plan:
- updated original unittests
- wait for test suite
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92024
Approved by: https://github.com/soulitzer
This PR:
- adds a nice error message if the user doesn't follow the API of the
vmap staticmethod correctly. That is, the user must return two
arguments from the vmap staticmethod API: (outputs, out_dims), and
out_dims must be a PyTree with either the same structure as `outputs`
our be broadcastable to the same structure as `outputs`.
- Fixes an edge case for out_dims=None. out_dims is allowed to be None,
but wrap_outputs_maintaining_identity was treating "None" as "This is
not the vmap case"
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92023
Approved by: https://github.com/soulitzer
This PR:
- changes generate_vmap_rule to either be True or False. Previously it
could be True, False, or not set. This simplifies the implementation a
bit.
- changes the vmap staticmethod to always be on the autograd.Function
rather than sometimes defined.
This is how the other staticmethod (forward, backward, jvp) are
implemented and allows us to document it.
There are 4 possible states for the autograd.Function w.r.t. to the
above:
- generate_vmap_rule is True, vmap staticmethod overriden. This raises
an error when used with vmap.
- generate_vmap_rule is False, vmap staticmethod overriden. This is
valid.
- generate_vmap_rule is True, vmap staticmethod not overriden. This is
valid.
- generate_vmap_rule is False, vmap staticmethod not overriden. This
raises an error when used with vmap.
Future:
- setup_context needs the same treatment, but that's a bit tricker to
implement.
Test Plan:
- new unittest
- existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91787
Approved by: https://github.com/soulitzer
Time comparison between using MultithreadedTestCase and MultiProcessTestCase on op db tests is amazing!
using MultiThreadTestCase on a AWS dev node:
```
time pytest test/distributed/_tensor/test_dtensor_ops.py
============= 175 passed, 42 skipped, 397 xfailed in 80.30s (0:01:20) =======
real 1m22.330s
user 1m38.782s
sys 0m18.762s
```
MultiProcessTestCase spends from 40mins to more than 1h, even if using pytest parallel testing tools.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92198
Approved by: https://github.com/XilunWu
This PR did a full rewrite of MultiThreadedTestCase, to make it more
aligned with the MultiProcessTestCase, also changed how it do spawning
and testing, so that we could embed thread local states when running
tests.
This PR enables device_type tests to work with MultiThreadedTestCase
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91650
Approved by: https://github.com/XilunWu
This PR refactors the threaded PG logic to enable multiple sub pg
creation under the world threaded pg, and allow the case where
we can call collectives together on different subpgs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91649
Approved by: https://github.com/XilunWu
Consider the following example:
```python
def fn(x):
y = torch.full_like(x, 1.2, dtype=torch.int64)
return x + y
```
In eager this truncates 1.2 to 1, then adds it to `x`. However, in
inductor the literal "1.2" is used verbatim and the result is off by
0.2. This fixes the issue by respecting the dtype argument to `ops.constant`
and truncating accordingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92093
Approved by: https://github.com/lezcano, https://github.com/jansel
Summary: This adds a new MTIA DeviceType which is associated with the MTIA DispatchKey and will be used for the Meta in-house training and inference accelerators.
Test Plan: All CI should pass.
Differential Revision: D42526044
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92232
Approved by: https://github.com/ezyang
Summary: Fix a fp64 version of model failed-to-run issue when convert_element_type
appears in the model. The failure can cause some numerical difference
recognized as accuracy error since the fp64 baseline result is not
available, and thus distracts Minifier from finding a real culprit for
accuracy error.
See the discussion in https://github.com/pytorch/torchdynamo/issues/1812
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92036
Approved by: https://github.com/ngimel
Inspired by #92156 , I realized our generated TensorBody.h has many methods that do an unnecessary copies. Scalar is backed by a ptr and is therefore not trivially copyable and care should be assigned over ownership of the params. Since it's a template, clang-tidy was never run on it in a way that was able to propogate the changes back to the source code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92162
Approved by: https://github.com/ezyang
As titled. To register a custom op into Executorch, we need:
* `custom_ops.yaml`, defines the operator schema and the corresponding native function.
* `custom_ops.cpp`, defines the kernel.
* `RegisterDispatchKeyCustomOps.cpp`, a template to register operator into PyTorch.
Added a new test for custom ops. The custom op `custom::add_3.out` takes 3 tensors and add them together. The test makes sure it is registered correctly and then verifies the outcome is correct.
Differential Revision: [D42204263](https://our.internmc.facebook.com/intern/diff/D42204263/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91291
Approved by: https://github.com/ezyang
Old behavior would have adadelta foreach sending tensors to the slow path if they were not all the same dtype nor on the same device.
This PR adds grouping for adadelta optimizer so that it would run foreach in batches, allowing more users to benefit from foreach perf.
Of course, we should ensure that the new implementation works, so there are new tests to ensure this behavior is not broken.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92048
Approved by: https://github.com/albanD
This clang-tidy check is disabled globally due to false positives on containers, but there are a few places here where adding clang-tidy would actually improve performance (by allowing STL containers to use the move operator / assignment)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92156
Approved by: https://github.com/ngimel
It's empty at the moment, but would tentatively include ROCm trunk jobs. This adopts the same practice we have for inductor where it's run for every commit on trunk, and on PR with `ciflow/unstable` label
- [x] Allow `ciflow/unstable` as a valid tag https://github.com/pytorch/test-infra/pull/1394
- [x] Create the unstable workflow on PyTorch https://github.com/pytorch/pytorch/pull/92106
- [ ] Gather reliability metrics of ROCm runner
- [ ] Decide if we want to move ROCMs trunk jobs to the unstable workflow
- [ ] Add redness metrics for the unstable workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92106
Approved by: https://github.com/ZainRizvi
This PR adds the `_profile_using_dynolog` function to `torch/__init__.py`. The `_profile_using_dynolog` method allows registering the optimizer step post hook. This is required to collect iteration based traces using dynolog.
Other related changes for tests to pass:
1. Updated `optimizer.pyi`
1. Updated `overrides.py`
1. The test `test_kineto_profiler_multiple_steppers` in `test_profiler.py` has been broken down into two cases:
- `test_kineto_profiler_multiple_steppers_with_override_True` : this test uses the override argument
- `test_kineto_profiler_multiple_steppers_with_override_False` : this test uses the environment variable
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90101
Approved by: https://github.com/albanD
--whole-archive is a linker option(notice, that flag is passed as -Wl,--whole-archive), and -force_load is indeed available on MacOS platform (below is the quote from man ld):
-force_load path_to_archive
Loads all members of the specified static archive library. Note:
-all_load forces all members of all archives to be loaded. This
option allows you to target a specific archive.
Quote from malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91736
Approved by: https://github.com/larryliu0820
As we live in C++17 world
This is a functional no-op, just
- `s/namespace at { namespace native {/namespace at::native {/`
- `s/namespace torch { namespace jit {/namespace torch::jit {/`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92100
Approved by: https://github.com/izaitsevfb
Adds a PyInstDecoder object that handles the differences in bytecode
added in 3.11. Basically some instructions have inline caches which
change the size of the instruction, so calculating the next instruction
is slightly different.
fixes#91246
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91290
Approved by: https://github.com/albanD
Fixes#91654.
Currently, the `hook` parameters of `nn.Module.register_forward_pre_hook` and `nn.Module.register_forward_hook` are typed as `Callable[..., None]`, which 1) does not enable the validation of the signature of `hook` and 2) incorrectly restricts the return type of `hook`, which the docstrings of these methods themselves state can be non-`None`.
The typing of the first parameter of `hook` as `TypeVar("T", bound="Module")` allows the binding of `Callable` whose first parameter is a subclass of `Module`.
---
Here are some examples of:
1. forward hooks and pre-hook hooks being accepted by mypy according to the new type hints
2. mypy throwing errors d.t. incorrect `hook` signatures
3. false negatives of pre-hooks being accepted as forward hooks
4. false negatives of hooks with kwargs being accepted irrespective of the value provided for `with_kwargs`
```python
from typing import Any, Dict, Tuple
import torch
from torch import nn
def forward_pre_hook(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
) -> None:
...
def forward_pre_hook_return_input(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
) -> Tuple[torch.Tensor, ...]:
...
def forward_pre_hook_with_kwargs(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
kwargs: Dict[str, Any],
) -> None:
...
def forward_pre_hook_with_kwargs_return_input(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
kwargs: Dict[str, Any],
) -> Tuple[Tuple[torch.Tensor, ...], Dict[str, Any]]:
...
def forward_hook(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
output: torch.Tensor,
) -> None:
...
def forward_hook_return_output(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
output: torch.Tensor,
) -> torch.Tensor:
...
def forward_hook_with_kwargs(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
kwargs: Dict[str, Any],
output: torch.Tensor,
) -> None:
...
def forward_hook_with_kwargs_return_output(
module: nn.Linear,
args: Tuple[torch.Tensor, ...],
kwargs: Dict[str, Any],
output: torch.Tensor,
) -> torch.Tensor:
...
model = nn.Module()
# OK
model.register_forward_pre_hook(forward_pre_hook)
model.register_forward_pre_hook(forward_pre_hook_return_input)
model.register_forward_pre_hook(forward_pre_hook_with_kwargs, with_kwargs=True)
model.register_forward_pre_hook(forward_pre_hook_with_kwargs_return_input, with_kwargs=True)
model.register_forward_hook(forward_hook)
model.register_forward_hook(forward_hook_return_output)
model.register_forward_hook(forward_hook_with_kwargs, with_kwargs=True)
model.register_forward_hook(forward_hook_with_kwargs_return_output, with_kwargs=True)
# mypy(error): [arg-type]
model.register_forward_pre_hook(forward_hook)
model.register_forward_pre_hook(forward_hook_return_output)
model.register_forward_pre_hook(forward_hook_with_kwargs)
model.register_forward_pre_hook(forward_hook_with_kwargs_return_output)
model.register_forward_hook(forward_pre_hook)
model.register_forward_hook(forward_pre_hook_return_input)
# false negatives
model.register_forward_hook(forward_pre_hook_with_kwargs)
model.register_forward_hook(forward_pre_hook_with_kwargs_return_input)
model.register_forward_pre_hook(forward_pre_hook_with_kwargs, with_kwargs=False)
model.register_forward_pre_hook(forward_pre_hook_with_kwargs_return_input, with_kwargs=False)
...
```
---
Though it is not functional as of mypy 0.991, the ideal typing of these methods would use [`typing.Literal`](https://mypy.readthedocs.io/en/stable/literal_types.html#literal-types):
```python
T = TypeVar("T", bound="Module")
class Module:
@overload
def register_forward_hook(
self,
hook: Callable[[T, Tuple[Any, ...], Any], Optional[Any]],
*,
prepend: bool = ...,
with_kwargs: Literal[False] = ...,
) -> RemovableHandle:
...
@overload
def register_forward_hook(
self,
hook: Callable[[T, Tuple[Any, ...], Dict[str, Any], Any], Optional[Any]],
*,
prepend: bool = ...,
with_kwargs: Literal[True] = ...,
) -> RemovableHandle:
...
def register_forward_hook(...):
...
```
which would:
1. validate the signature of `hook` according to the corresponding literal value provided for `with_kwargs` (and fix the false negative examples above)
2. implicitly define the [fallback `bool` signature](https://github.com/python/mypy/issues/6113#issuecomment-1266186192) e.g. to handle if a non-literal is provided for `with_kwargs`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92061
Approved by: https://github.com/albanD
This PR is a copy of https://github.com/pytorch/pytorch/pull/90849 that merge was reverted.
The PR adds "check sparse tensor invariants" flag to Context that when enabled will trigger sparse tensor data invariants checks in unsafe methods of constructing sparse COO/CSR/CSC/BSR/BSC tensors. The feature includes the following changes to UI:
`torch.sparse.check_sparse_tensor_invariants` class provides different ways to enable/disable the invariant checking.
`torch.sparse_coo/csr/csc/bsr/bsc/compressed_tensor` functions have a new optional argument `check_invariants` to enable/disable the invariant checks explicitly. When the `check_invariants` argument is specified, the global state of the feature is temporarily overridden.
The PR fixes https://github.com/pytorch/pytorch/issues/90833
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92094
Approved by: https://github.com/cpuhrsch
The output of Torchbench model `doctr_det_predictor` on CPU is a `numpy ndarray`. When running the accuracy benchmark of this model, the below error is raised: `RuntimeError: unsupported type: ndarray`.
Repro CMD:
```bash
python benchmarks/dynamo/torchbench.py --accuracy --float32 -dcpu -n50 --inductor --no-skip --dashboard --only doctr_det_predictor --batch_size 1 --threads 1
```
This PR adds the support to compare `numpy ndarray` in the dynamo utils.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91870
Approved by: https://github.com/jgong5, https://github.com/Chillee
Very low probability, but it is possible to have all values positive throughout the
execution of this test model. The test tries to fake an incorrect export by replacing
relu's output with its input. However, the behavior of the model is the same when
values are all positive. Hence leading to false test failure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92105
Approved by: https://github.com/titaiwangms
Summary: This commit moves the API specification section of
the BackendConfig tutorial to the docstrings, which is a more
suitable place for this content. This change also reduces some
duplication. There is no new content added in this change.
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91999
Approved by: https://github.com/vkuzo, https://github.com/jerryzh168
### Changelist
* Change Windows TORCH_CUDA_ARCH_LIST from `7.0` to `8.6` to compatible with NVIDIA A10G TPU
* Correctly disable some tests that requires flash attention, which is not available on Windows at the moment. This has been fixed by https://github.com/pytorch/pytorch/pull/91979
* G5 runner has `AMD EPYC 7R32` CPU, not an Intel one
* This seems to change the behavior of `GetDefaultMobileCPUAllocator` in `cpu_profiling_allocator_test`. This might need to be investigated further (TODO: TRACKING ISSUE). In the meantime, the test has been updated accordingly to use `GetDefaultCPUAllocator` correctly instead of `GetDefaultMobileCPUAllocator` for mobile build
* Also one periodic test `test_cpu_gpu_parity_nn_Conv3d_cuda_float32` fails with Tensor not close error when comparing grad tensors between CPU and GPU. This is fixed by turning off TF32 for the test.
### Performance gain
* (CURRENT) p3.2xlarge - https://hud.pytorch.org/tts shows each Windows CUDA shards (1-5 + functorch) takes about 2 hours to finish (duration)
* (NEW RUNNER) g5.4xlarge - The very rough estimation of the duration is 1h30m for each shard, meaning a half an hour gain (**25%**)
### Pricing
On demand hourly rate:
* (CURRENT) p3.2xlarge: $3.428. Total = Total hours spent on Windows CUDA tests * 3.428
* (NEW RUNNER) g5.4xlarge: $2.36. Total = Total hours spent on Windows CUDA tests * Duration gain (0.75) * 2.36
So the current runner is not only more expensive but is also slower. Switching to G5 runners for Windows should cut down the cost by (3.428 - 0.75 * 2.36) / 3.428 = **~45%**
### Rolling out
https://github.com/pytorch/test-infra/pull/1376 needs to be reviewed and approved to ensure the capacity of the runner before PR can be merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91727
Approved by: https://github.com/ZainRizvi, https://github.com/malfet, https://github.com/seemethere
I'm seeing quite a number of runner errors "i-NUMBER lost communication with the server. Verify the machine is running and has a healthy network connection. Anything in your workflow that terminates the runner process, starves it for CPU/Memory, or blocks its network access can cause this error" with Bazel build and test job, i.e. https://hud.pytorch.org/hud/pytorch/pytorch/master/1?per_page=50&name_filter=bazel
The job runs on normal `linux.2xlarge` runner. As the error doesn't occur with any other jobs running on the same type of runner with the exception of XLA. I suspect that this is due to a resource constraint crashing the runner. So this PR sets a limit to the amount of memory and CPU and bazel can use. Even if bazel crashes, i.e. with OOM error, it's still better than crashing the whole runner and losing all the logs.
Example failures:
* 33e3c9ac67
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92056
Approved by: https://github.com/ZainRizvi
Description:
- output memory format is matching input for bicubic2d
Problem: output tensor's memory format does not match input format for bicubic2d
```python
import torch
i = torch.rand(1, 3, 32, 32).contiguous(memory_format=torch.channels_last)
assert i.is_contiguous(memory_format=torch.channels_last)
o = torch.nn.functional.interpolate(i, size=(4, 4), mode="bicubic")
assert o.is_contiguous(memory_format=torch.channels_last), f"Should be channels last but given channels first ({o.is_contiguous(memory_format=torch.contiguous_format)})"
> AssertionError: Should be channels last but given channels first (True)
```
Related PR fixing bilinear ops: https://github.com/pytorch/pytorch/pull/53535 (cc @VitalyFedyunin @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10 @bdhirsh )
Discovered together with @NicolasHug while working on https://github.com/pytorch/pytorch/tree/interpolate_uint8_images_linear_cpu_support_dev
- Updated code to match grad input / output memory formats
- temporary tensor creation matches memory format in `separable_upsample_generic_Nd_kernel_impl`
- Updated tests
- Added missing forward AD support for bicubic with antialiasing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90470
Approved by: https://github.com/NicolasHug, https://github.com/lezcano
Fix https://github.com/pytorch/torchdynamo/issues/1915
This PR adds the vectorization support for transposed operations in TorchInductor CPP backend. It contains the following changes:
1. `CppTile2DKernelChecker` is added to check the eligibility of applying the optimization. We only addresss a narrow set of situations. All of the following conditions should be met: 1) There exists one and only one fp32 load/store with outer loop var having contiguous buffer accesses. 2) When a load/store doesn't have contiguous access in an outer loop var, the access should be vectorizable from the inner-most dim. 3) No reduction. More scenarios/operations would be supported in the future PRs.
2. If `CppTile2DKernelChecker` reports the optimization is doable, `CppKernelProxy` would split/tile the loops from both the outer loop var having contiguous buffer access and the inner-most loop var.
3. The main loop split from the outer loop var is further split at the inner-most level and then handled by `CppTile2DKernel` and `CppTile2DTailKernel` which generate the transposed load/store. The former kernel does the vectorized transposed load/store on tiles and then does vectorized load/store/compute along the inner-most loop axis. The vectorized transpose micro-kernel implementation borrows/refers to that from FBGEMM. The latter kernel simply does scalar operations.
4. The tail loop split from the outer loop var directly calls `CppKernel` with scalar operations.
Next steps:
1. Support vectorized transpose with smaller tile size at one dim but bigger tile size at the other, e.g., 3x784.
2. Support reduction vectorized on the outer loop var (contiguous from outer loop var, not with inner-most loop var)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91532
Approved by: https://github.com/EikanWang, https://github.com/jansel
This adds `torch.cuda._DeviceGuard` which is a stripped down version of
`torch.cuda.device` with lower overhead. To do this, it only accepts `int` as
the device so we don't need to call `_get_device_index` and is implemented
with a new C++ helper `torch._C._cuda_exchangeDevice` that allows
`_DeviceGuard.__enter__` to be just a single function call. On my machine,
I see a drop from 3.8us of overhead to 0.94 us with this simple benchmark:
```python
def set_device():
with torch.cuda.device(0):
pass
%timeit set_device()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91045
Approved by: https://github.com/ngimel, https://github.com/anijain2305
Cleaning FQN for `FullyShardedDataParallel(use_orig_params=True)` can cause some discrepancies with respect to the FQN compared to manually looping over `named_modules()` and `named_parameters()` together.
There is no requirement for the FQNs to be clean when using wrapper FSDP + `use_orig_params=True`. We can leave clean FQNs to `fully_shard`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91767
Approved by: https://github.com/zhaojuanmao
This makes some minor fixes to ensure that `use_orig_params=True`, `no_sync()`, and mixed precision work together for `FULL_SHARD`, `SHARD_GRAD_OP`, and `NO_SHARD`.
The added unit test only checks that dtypes are correct since for FP16, it is hard to test for numeric parity against a baseline.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91193
Approved by: https://github.com/zhaojuanmao
Closes https://github.com/pytorch/pytorch/issues/90838.
To make mixed precision precise internally, https://github.com/pytorch/pytorch/pull/90660 changed the implementation to save `_orig_param_dtype`, `_low_prec_param_dtype`, and `_reduce_dtype` explicitly. However, these are computed at FSDP construction time, so it does not allow the user to change the model dtype after FSDP construction time but before lazy initialization. This PR recomputes those dtype attributes as needed if the model dtype changes in that window.
Note that any mixed precision settings specified by the user take precedence over the model dtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91192
Approved by: https://github.com/zhaojuanmao
#75854
A naive attempt at working around the limitations of using a single 64-bit integer to pack `stream_id`, `device_index`, and `device_type`.
Stills needs sanity checks, testing, and minimization of BC-breaking changes.
Currently a Holder for the `StreamData3` struct is used for `IValue` compatibility. While doing this seems to work for `ivalue.h` and `ivalue_inl.h`, this doesn't seem to be naively working for the JIT CUDA stream wrapper? (Something about ambiguous calls if an `intrusive_ptr` to `c10::ivalue::StreamData3Holder` is used as the return type for `pack()`. It turns out that the methods required to access the fields for rematerializing a CUDA Stream are basically already present anyway, so `pack` is simply removed in the wrapper for now and the methods to access the required fields are called directly.
CC @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81596
Approved by: https://github.com/ezyang
### Target and Background
This PR is improving the performance of `sampled_addmm` on CPU device. This is part of effort for improving PyG performance on CPU for GNN training/inference.
The current implementation is a reference design which converts `SparseCSR` tensor back to dense tensor and then do the addmm and convert back to `SparseCSR` again: this is going to be very slow and won't be able to run most of the datasets under https://github.com/snap-stanford/ogb (convert to dense would trigger `OOM`).
### Benchmarks
Right now we don't have any hands-on benchmark or workload to test this since this operator is not used in PyG yet. I fetched the dataset from `ogb-products` where:
* number of nodes: 2.4 * 10^6
* number of edges: 1.26 * 10^8
* number of features: 128
So if we store the **adjacency matrix** is dense, it is going to be 2.4 * 2.4 * 4 * 10^12 bytes, this will be OOB on current code. I abstract the first 1k rows to compare, **1100x** speedup:
CPU: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz, dual socket, 20 cores per socket.
```
### before: run 1000 rows from the whole dataset
sampled_addmm: running dataset ogb-products first 1000 rows: each iter takes 1212.000 ms!
### after: run 1000 rows from the whole dataset
sampled_addmm: running dataset ogb-products first 1000 rows: each iter takes 1.102 ms!
### after: run the whole dataset
sampled_addmm: running dataset ogb-products (the whole dataset) 2449029 rows: each iter takes 873.306 ms!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90978
Approved by: https://github.com/pearu, https://github.com/cpuhrsch
In control_flow.cond(), we unwrap arguments' proxy by using
get_proxy_slot() call which call a lambda in the end to get the stored
proxy. For SymInt and SymFloat we hide the proxy under a thunk instead
of storing proxy on .proxy attribute diretly, therefore we need to
special case SymInt for unwrapping here.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91907
Approved by: https://github.com/ezyang
This PR fixes 2 bugs with CUDA `_foreach_norm`:
1. Wrong norm when tensors are larger than kChunkSize = 65536
```
>>> torch._foreach_norm([torch.ones(60000, device="cuda") for _ in range(1)])
(tensor(244.9490, device='cuda:0', grad_fn=<NotImplemented>),)
>>> torch._foreach_norm([torch.ones(70000, device="cuda") for _ in range(1)])
(tensor(256., device='cuda:0', grad_fn=<NotImplemented>),)
>>> torch.ones(60000, device="cuda").norm()
tensor(244.9490, device='cuda:0', grad_fn=<LinalgVectorNormBackward0>)
>>> torch.ones(70000, device="cuda").norm()
tensor(264.5751, device='cuda:0', grad_fn=<LinalgVectorNormBackward0>)
```
2. Error when a tensor numel is smaller than the number of tensors
```
>> torch._foreach_norm([torch.ones(9, device="cuda") for _ in range(10)])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: select(): index 9 out of range for tensor of size [9] at dimension 0
```
This bug could have been caught by tests if `PYTORCH_TEST_WITH_SLOW` was 1, because it would have tested tensors of size 300*300=90000. It's not enabled by default, does someone know if it's ever enabled?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91844
Approved by: https://github.com/ngimel
Summary:
This is a fix for the following issue:
"When two nodes in a model have the same dTypes / node.target, the torch quantization prepare_fx flow does not check for duplicates and tries to do a custom module swap twice. When it attempts the swap the same target for a second time, the swap_custom_module_to_observed detects the observed module instead of the float module class on the target, and fails on an assertion. "
The added unit test demonstrates a simple example where it fails in absence of this fix.
Test Plan: buck test mode/dev //caffe2/test:quantization_fx -- --exact 'caffe2/test:quantization_fx - test_custom_module_class_input_has_duplicate_nodes (quantization.fx.test_quantize_fx.TestQuantizeFx)'
Reviewed By: vkuzo
Differential Revision: D42023273
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91905
Approved by: https://github.com/jerryzh168
Handle tensor default func/method args when inlining
Previously, when inlining a function, its default arguments
were only wrapped with VariableTrackers if non-tensor. Now,
tensor default args are also handled by adding them to the
parent InstructionTranslator as an attribute.
- also patches up a missing source in nnmodule call_function,
needed to properly guard on a default arg in its methods
- adds new 'DefaultsSource' type which guards either a `__defaults__`
or `__kwdefaults__` entry on a function
Fixes#90361https://github.com/pytorch/torchdynamo/issues/1968
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90575
Approved by: https://github.com/voznesenskym
**Motivation**
When adding support for default args (#90575), a lot of VariableTrackers missing sources were encountered. Currently, in a lot of cases it seems OK to skip the source for VariableTrackers created (especially during inlining), but that assumption breaks down when inlining functions with default arguments.
**Summary** of changes
- propagate the self.source of the VariableBuilder to the new variables being built, which seems like it was an omission previously
- Add SuperSource to track usages of super(), so that SuperVariables can support function calls with default args
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91729
Approved by: https://github.com/ezyang
3 fixes made to control_flow.map:
1. argument list won't accept torch.nn.Module anymore, only Tensors.
2. during tracing we call new_empty from the returned sample output
instead xs to correctly inherit tensor metadata.
3. for FakeTensorMode we implement map() using new_empty() as well
instead of torch.stack() to preserve symbolic shape output.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91906
Approved by: https://github.com/tugsbayasgalan
On classic pyg user case for message passing, `gather` has `index` tensor in a broadcasted shape, e.g. with shape `5000, 128` and stride `[1, 0]`. That indicated gather is done on each row of the self tensor. The current implementation will try to parallel on the inner dimension which is bad performance for CPU and unable to be vectorized.
This PR addressed this use case and optimize in a similar manner to index_select, parallel on outer dimension of `index` and do vectorized copy on inner dimension.
Performance benchmarking on Xeon Icelake single socket on `GCN`: the `gather` reduced from `150.787ms` to `10.926ms`, after this optimization, `gather` will no longer be the major bottleneck for training of GNN models when `EdgeIndex` is in COO format.
for more details, please refer to https://github.com/pyg-team/pytorch_geometric/issues/4891#issuecomment-1288423705
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87586
Approved by: https://github.com/rusty1s, https://github.com/malfet
Basically the same as #88644, to fix warnings like `ptxas warning : Value of threads per SM for entry _ZN2at6native13reduce_kernelILi512ELi1ENS0_8ReduceOpIfNS0_10NormTwoffEEjfLi4EEEEEvT1_ is out of range. .minnctapersm will be ignored`
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91972
Approved by: https://github.com/ngimel
Fixes 14k github models: https://github.com/jansel/pytorch-jit-paritybench/blob/master/generated/test_Sanster_lama_cleaner.py#L2392
Error
```
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/guards.py", line 263, in CONSTANT_MATCH
self.EQUALS_MATCH(guard)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/guards.py", line 197, in EQUALS_MATCH
assert istype(
AssertionError: float64
```
```np.float``` is unspecialized by default, which has guard on ```TYPE_MATCH```. However, it will be baked when being used in control flow, which has guard on ```EQUALS_MATCH```. We should make ```EQUALS_MATCH``` support ```np.float```.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91991
Approved by: https://github.com/jansel
Summary: * when we try to port py obj of script module/obj to c++, `tryToInferType` is flawed in providing type inference metadata. but change it would break normal torch.jit.script flow, so we try extract the ivalue in the py obj value.
Test Plan: NA
Reviewed By: PaliC
Differential Revision: D41749823
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91776
Approved by: https://github.com/842974287
This is implementing an idea from @lezcano : if we have a generated triton kernel with `xnumel=1`, then `xmask` is just `0<1` and can be dropped from all `load`/`store`/`where`.
The `xnumel=1` case actually comes up relatively often when code for reductions is being generated. @lezcano reported some performance gains in micro-benchmarks (see comment below) and it is a very simple change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91254
Approved by: https://github.com/jansel, https://github.com/ngimel
I'm at a loss to explain why this happens, but not setting the manifest file explicitly in the linker fixes it.
### Testing locally
* With `/MANIFESTFILE:bin\torch_python.dll.manifest`
```
C:\PROGRA~2\MICROS~2\2019\BUILDT~1\VC\Tools\MSVC\1428~1.293\bin\Hostx64\x64\link.exe /nologo @CMakeFiles\torch_python.rsp /out:bin\torch_python.dll /implib:lib\torch_python.lib /pdb:bin\torch_python.pdb /dll /version:0.0 /machine:x64 /ignore:4049 /ignore:4217 /ignore:4099 /INCREMENTAL:NO /NODEFAULTLIB:LIBCMT.LIB -WHOLEARCHIVE:C:/actions-runner/_work/pytorch/pytorch/build/lib/onnx.lib /MANIFEST /MANIFESTFILE:bin\torch_python.dll.manifest
LINK : fatal error LNK1000: Internal error during CImplib::EmitImportThunk
```
* Work fine without the flag
```
C:\PROGRA~2\MICROS~2\2019\BUILDT~1\VC\Tools\MSVC\1428~1.293\bin\Hostx64\x64\link.exe /nologo @CMakeFiles\torch_python.rsp /out:bin\torch_python.dll /implib:lib\torch_python.lib /pdb:bin\torch_python.pdb /dll /version:0.0 /machine:x64 /ignore:4049 /ignore:4217 /ignore:4099 /INCREMENTAL:NO /NODEFAULTLIB:LIBCMT.LIB -WHOLEARCHIVE:C:/actions-runner/_work/pytorch/pytorch/build/lib/onnx.lib /MANIFEST
```
In both case, the `/MANIFEST` flag is set, so the manifest file is there. In the latter case, the filename comes by appending `.manifest` suffix to `bin\torch_python.dll`. Thus, it's still correctly be `bin\torch_python.dll.manifest`. Weird.
```
C:\actions-runner\_work\pytorch\pytorch>ls -la build/bin/torch_*
-rwxr-xr-x 1 runneruser 197121 246796288 Jan 11 04:30 build/bin/torch_cpu.dll
-rw-r--r-- 1 runneruser 197121 381 Jan 11 04:26 build/bin/torch_cpu.dll.manifest
-rwxr-xr-x 1 runneruser 197121 9728 Jan 11 03:55 build/bin/torch_global_deps.dll
-rw-r--r-- 1 runneruser 197121 381 Jan 11 03:55 build/bin/torch_global_deps.dll.manifest
-rwxr-xr-x 1 runneruser 197121 11746816 Jan 11 04:31 build/bin/torch_python.dll
-rw-r--r-- 1 runneruser 197121 381 Jan 11 04:30 build/bin/torch_python.dll.manifest
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91988
Approved by: https://github.com/malfet, https://github.com/Blackhex, https://github.com/ZainRizvi
I see https://github.com/pytorch/pytorch/issues/53103 says this might be problematic, but I'm a bit confused at this point, because it looks like ModuleList does in fact already adhere to the Sequence API
The big win here is that for homogenous ModuleLists, you now get typing for individual members, e.g.
`ModuleList([Linear(), Linear(), Linear()])[1]` properly has type `Linear`
If this looks good, I can do a followup PR to do similarly for `ModuleDict` and `Parameter[List,Dict]`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89135
Approved by: https://github.com/albanD
In preparation for https://github.com/pytorch/pytorch/pull/89621.
The build changes in #89621 would require re-writing the internal build
in order to get NVFuser support. As-is, #89621 would disable NVFuser in
the internal build; so I would need to add some internal-only changes
associated with the internal copy of the PR (not visible from github) to
fix the internal build.
However, I don't think NVFuser is actually being used internally
anywhere at the moment, so it may be easier to land #89621 as is, and
then we can fix the internal build later if needed. To verify that, I
want to land this PR instead to flush out any issues caused by disabling
NVFuser. If the PR lands without issues, then we can move on to landing #89621.
If the PR breaks things internally, then it will need to be reverted;
and that will probably be easier than having to revert and reland #89621.
Differential Revision: [D42398050](https://our.internmc.facebook.com/intern/diff/D42398050)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91836
Approved by: https://github.com/jjsjann123
fast_sigmoid uses fast_tanh under the hood which is not precise;
the op outputs are treated as probability-like numbers;
in a reeeally small percentage of cases the outputs fell out of acceptable range for probabilities
Test Plan: ci
Differential Revision: D42445821
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91993
Approved by: https://github.com/davidberard98
Fixes#90652
Previously, we had assumed that the only way to call `handle_torch_function_no_python_arg_parser` was through the Python key. This is no longer true with FakeTensor. Specifically `_like` functions will call `.device()` on FakeTensors when the args list is being parsed. In order to respect that the mode stack shouldn't run when the python key is off, this just adds that a check that the python key is on/the torch_function equivalent to that function
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91573
Approved by: https://github.com/ezyang
The eager implementation of softmax supports computation along zero dimensions, but many of the other implementations did not, including:
* decompositions & refs (this was causing dynamo failures)
* forward AD for logsumexp
* MPS log_softmax_backward
This PR handles the `input.numel() == 0` cases separately to avoid running `amax()`, which fails for zero dimensions, and updates opinfos.
example of "computation along zero dimensions":
```python
# example of where
import torch
t = torch.rand((4, 0, 0))
print("~")
print(torch.nn.functional.softmax(t, dim=-1)) # this passes
print("~")
torch._refs.softmax(t, dim=-1) # this fails
print("~")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91322
Approved by: https://github.com/lezcano
# Summary
Memory efficient attention is a non deterministic algorithm.
This PR ensures that the sdp_choice will allow for mem-efficient to be used as the backend to SDPA if we are in warn only mode. Otherwise if we have enabled determinism and and set warn_only to False sdp_choice will not return memory efficient attention as the backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91979
Approved by: https://github.com/cpuhrsch
In `peephole` pass, user nodes of output of `prim::PackPadded` are modified to consume
the input of `prim::PackPadded` instead. Hence the logic in shape type inference. However
only the first output requires this workaround.
Fixes#91528
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91829
Approved by: https://github.com/titaiwangms
### Motivation of this PR
This PR is targeting at improving performance of `scatter_add` for GNN usage scenarios on PyG. Currently only CPU optimizations is covered.
`Message Passing` is the major step in GNN learning which means exchanging/aggregating info between nodes. And from the perf point of view, if the `EdgeIndex` is stored as [2, num_edges], `scatter_reduce` would be a major perf hotspot on current pytorch implementations.
To be more specific, in the process of message passing, `scatter_add` is used in a very similar way as `index_select`, except that the `self` tensor is written into while `index_select` is only reading. Therefore, the `index` tensor passed to `scatter_add` is an expanded tensor on dim0, which means all the rest of dims would end up with the same value.
### Algorithm
Current impl on scatter would do parallel on the inner dims for such case which would cause bad perf: non-contiguous memory access pattern and non-vectorized.
This PR did sorting on the `index` to solve the write conflicts if we directly parallel on dim0. The algorithm is equivalent to:
* convert memory format from `COO` to `CSR`
* do spmm reduce
### Perf improvement
The benchmark comes from https://github.com/pyg-team/pytorch_geometric/tree/master/examples, `python reddit.py` which runs model SAGE on dataset reddit.
CPU type: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz
` aten::scatter_add_` has been reduced from **37.797s** to **5.989s**:
* breakdown before
```
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::scatter_add_ 49.00% 37.797s 49.00% 37.797s 41.445ms 912
aten::index_select 19.74% 15.223s 19.74% 15.227s 6.678ms 2280
aten::linear 0.01% 5.706ms 15.04% 11.602s 12.721ms 912
aten::addmm 6.62% 5.108s 7.92% 6.112s 13.403ms 456
aten::matmul 0.00% 2.339ms 7.10% 5.475s 12.006ms 456
```
* breakdown after
```
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::index_select 32.41% 14.677s 32.42% 14.681s 6.439ms 2280
aten::linear 0.01% 6.665ms 26.43% 11.968s 13.123ms 912
aten::addmm 11.76% 5.328s 13.76% 6.232s 13.667ms 456
aten::scatter_add_ 13.22% 5.989s 13.22% 5.989s 6.566ms 912
aten::matmul 0.01% 2.303ms 12.63% 5.720s 12.543ms 456
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82703
Approved by: https://github.com/jgong5, https://github.com/ezyang
test-times.json uses the job name as the key, but when looking up the the times in CI, the BUILD_ENVIRONMENT is used because we don't have a good way of getting the job name (it usually turns out to be just "test" or "build" instead of "linux-cuda..."), so having the job names match the BUILD_ENVIRONMENT is necessary for sharding to work
Another solution might be to make the lookup more robust or look up the job name similar to how we get the job id.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91512
Approved by: https://github.com/huydhn, https://github.com/ZainRizvi, https://github.com/malfet
This reverts commit c55293d64099ac4380f5e3955a891d1d7924f327.
Reverted https://github.com/pytorch/pytorch/pull/90869 on behalf of https://github.com/huydhn due to Crossref error cannot just simply be ignored because it would break trunk for every commits after this, i.e. fd0030fe74. The failure would need to be handled gracefully, i.e. adding an XFAIL for example
This PR adds "check sparse tensor invariants" flag to Context that when enabled will trigger sparse tensor data invariants checks in unsafe methods of constructing sparse COO/CSR/CSC/BSR/BSC tensors. The feature includes the following changes to UI:
- `torch.enable_check_sparse_tensor_invariants` and `torch.is_check_sparse_tensor_invariants_enabled` functions to globally enable/disable the invariant checks and to retrieve the state of the feature, respectively
- `torch.sparse_coo/csr/csc/bsr/bsc/compressed_tensor` functions have a new optional argument `check_invariants` to enable/disable the invariant checks explicitly. When the `check_invariants` argument is specified, the global state of the feature is temporarily overridden.
The PR also fixes https://github.com/pytorch/pytorch/issues/90833
# Main issue
*The following content is outdated after merging the PRs in this ghstack but kept for the record.*
The importance of this feature is that when enabling the invariants checks by default, say, via
<details>
```
$ git diff
diff --git a/torch/__init__.py b/torch/__init__.py
index c8543057c7..19a91d0482 100644
--- a/torch/__init__.py
+++ b/torch/__init__.py
@@ -1239,3 +1239,8 @@ if 'TORCH_CUDA_SANITIZER' in os.environ:
# Populate magic methods on SymInt and SymFloat
import torch.fx.experimental.symbolic_shapes
+
+# temporarily enable sparse tensor arguments validation in unsafe
+# constructors:
+
+torch._C._set_check_sparse_tensor_invariants(True)
```
</details>
a massive number of test failures/errors occur in test_sparse_csr.py tests:
```
$ pytest -sv test/test_sparse_csr.py
<snip>
==== 4293 failed, 1557 passed, 237 skipped, 2744 errors in 69.71s (0:01:09) ====
```
that means that we are silently constructing sparse compressed tensors that do not satisfy the sparse tensor invariants. In particular, the following errors are raised:
```
AssertionError: "resize_as_sparse_compressed_tensor_: self and src must have the same layout" does not match "expected values to be a strided and contiguous tensor"
RuntimeError: CUDA error: device-side assert triggered
RuntimeError: `col_indices[..., crow_indices[..., i - 1]:crow_indices[..., i]] for all i = 1, ..., nrows are sorted and distinct along the last dimension values` is not satisfied.
RuntimeError: expected col_indices to be a strided and contiguous tensor
RuntimeError: expected row_indices to be a strided and contiguous tensor
RuntimeError: expected values to be a strided and contiguous tensor
RuntimeError: for_each: failed to synchronize: cudaErrorAssert: device-side assert triggered
RuntimeError: tensor dimensionality must be sum of batch, base, and dense dimensionalities (=0 + 2 + 0) but got 3
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90849
Approved by: https://github.com/amjames, https://github.com/cpuhrsch
Many of the previous inductive cases were wrong (e.g. `abs`, `sq`, `div` and `truediv`).
We rewrite it using the mathematical terms that allow to prove the relevant upper
and lower bounds.
Note that the inductive step can be seen as a not-too-difficult optimisation problem
with constraints, hence the naming of the functions.
For many of the other functions, we also simplify the formulas, which will be useful
when this code is generalised to work with symbolic shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91601
Approved by: https://github.com/jansel, https://github.com/eellison
Fixes https://github.com/pytorch/pytorch/issues/86975
If the destination is a strided MPS tensor and the source is a CPU tensor, we cannot perform a blit directly to copy the memory from the CPU tensor into the MPS tensor. We need to scatter the data into the right indices.
```
a1 = torch.Tensor([[1,2],[3,4], [5,6]]).to(torch.device("mps"))
b1 = torch.Tensor([-1, -1])
a1[1:,1] = b1 # strided MPS destination / contiguous CPU source
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91784
Approved by: https://github.com/kulinseth
Solve contiguous view tensors using arrayViews directly instead of performing blit or gather.
E.g in case of the following example:
```
x = torch.tensor([1,2,3,4], device="mps')
y = x[2:]
r = y + 2
```
Previously, `y` would be materialized using a gather or a blit. With this change, the memory of `y` is aliased directly using arrayViews, thus skipping the need for blit or gather.
Fixes pytorch#85297, pytorch#86048
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91743
Approved by: https://github.com/razarmehr, https://github.com/kulinseth
### Target and Background
This PR is improving the performance of `sampled_addmm` on CPU device. This is part of effort for improving PyG performance on CPU for GNN training/inference.
The current implementation is a reference design which converts `SparseCSR` tensor back to dense tensor and then do the addmm and convert back to `SparseCSR` again: this is going to be very slow and won't be able to run most of the datasets under https://github.com/snap-stanford/ogb (convert to dense would trigger `OOM`).
### Benchmarks
Right now we don't have any hands-on benchmark or workload to test this since this operator is not used in PyG yet. I fetched the dataset from `ogb-products` where:
* number of nodes: 2.4 * 10^6
* number of edges: 1.26 * 10^8
* number of features: 128
So if we store the **adjacency matrix** is dense, it is going to be 2.4 * 2.4 * 4 * 10^12 bytes, this will be OOB on current code. I abstract the first 1k rows to compare, **1100x** speedup:
CPU: Intel(R) Xeon(R) Gold 6248 CPU @ 2.50GHz, dual socket, 20 cores per socket.
```
### before: run 1000 rows from the whole dataset
sampled_addmm: running dataset ogb-products first 1000 rows: each iter takes 1212.000 ms!
### after: run 1000 rows from the whole dataset
sampled_addmm: running dataset ogb-products first 1000 rows: each iter takes 1.102 ms!
### after: run the whole dataset
sampled_addmm: running dataset ogb-products (the whole dataset) 2449029 rows: each iter takes 873.306 ms!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90978
Approved by: https://github.com/pearu, https://github.com/cpuhrsch
@bypass-github-export-checks
Pointwise Conv2d is one of the ops which we want to benchmark using different Vulkan Shaders (```conv2d_pw_2x2``` vs ```conv2d_pw_1x1```) with
The configs are copied from Conv2d with the kernel parameter removed.
I considered just using the same configs but ignoring the provided kernel and hardcoding the kernel to 1 when initializing nn.Conv2d, but then in the op benchmark title, it would say kernel=3 even if though that would not be the case.
Differential Revision: [D42303453](https://our.internmc.facebook.com/intern/diff/D42303453/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91918
Approved by: https://github.com/mcr229
@bypass-github-export-checks
This diff allows for adding entries to the shader registry by specifying which op names and registry keys should map to a template codegen Shader in the codegen Shader's glslt and params yaml files.
This can be done by
- adding a REGISTER_FOR entry which maps to either a tuple of (op name, list of registry keys) or null to the YAML file, and
- adding a ```REGISTER_FOR = $REGISTER_FOR``` line to the ShaderInfo comment in the glslt file
Ex.
YAML File:
```
conv2d_pw:
parameter_names_with_default_values:
...
REGISTER_FOR:
- !!python/tuple ["conv2d_pw", ["catchall"]]
parameter_values:
- ...
REGISTER_FOR: null
```
GLSLT File:
```
...
* REGISTER_FOR = $REGISTER_FOR
...
```
This diff also registers the conv2d_pw_2x2 Shader under ```'conv2d_pw → 'catchall'``` in the registry and uses ```VK_REGISTRY_KERNEL``` to retrieve the shader by look up in the registry
The shader registry generated in spv.cpp now looks like
```
ShaderRegistry shader_registry = {
{"conv2d", {{"catchall", "conv2d"}}},
{"conv2d_pw", {{"catchall", "conv2d_pw_2x2"}}}};
```
and the generated conv2d_p2_KxK.glsl files look like:
K=1
```
...
/*
* TILE_SIZE = (1, 1, 1)
* WEIGHT_STORAGE = TEXTURE_2D
* WEIGHT_STORAGE_LAYOUT = OC4,IC4,4ic,4oc
* BIAS_STORAGE = TEXTURE_2D
* REGISTER_FOR = None
*/
...
```
K=2
```
...
/*
* TILE_SIZE = (2, 2, 1)
* WEIGHT_STORAGE = TEXTURE_2D
* WEIGHT_STORAGE_LAYOUT = OC4,IC4,4ic,4oc
* BIAS_STORAGE = TEXTURE_2D
* REGISTER_FOR = ('conv2d_pw', ['catchall'])
*/
...
```
Differential Revision: [D42198560](https://our.internmc.facebook.com/intern/diff/D42198560/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91916
Approved by: https://github.com/mcr229
@bypass-github-export-checks
This diff allows for adding entries to the shader registry by specifying which op names and registry keys should map to a Shader in the Shader's glsl file.
This can be done by adding a REGISTER_FOR line with a tuple of (op name, list of registry keys) to the ShaderInfo comment in the glsl file
Ex.
```
REGISTER_FOR = ('conv2d', ['catchall', ...])
```
This diff also registers the conv2d Shader under ```'conv2d → 'catchall'``` in the registry and uses ```VK_REGISTRY_KERNEL``` to retrieve the shader by look up in the registry
The shader registry generated in spv.cpp now looks like
```
ShaderRegistry shader_registry = {
{"conv2d", {{"catchall", "conv2d"}}}};
```
Differential Revision: [D42197400](https://our.internmc.facebook.com/intern/diff/D42197400/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91915
Approved by: https://github.com/mcr229
@bypass-github-export-checks
We want to be able to look-up which shader to use in a registry given a particular op/algorithm name, which is what this diff enables. This is done with the newly added ```shader_registry``` map and ```look_up_shader_info``` function.
After this change, Shaders can be retrieved either with the ```VK_KERNEL``` macro, which gets the Shader with a specified name directly, or with the ```VK_REGISTRY_KERNEL``` macro, which looks up what Shader should be used for a specified algorithm name in the registry.
For now, the registry is empty and unused. In the next diffs in this stack, I will be adding support for registering a shader in the registry in GLSL and GLSLT + Params Yaml files.
I also
- Adjusted the formatting of spv.h and spv.cpp so that they are closer to what clang wants, which makes them easier to read. (proper indentation, proper order of includes, etc.)
- Moved the codegen spv/registry code from at::native::vulkan to at::native::vulkan::api (since registry.cpp / .h are in ```ATen/native/vulkan/api```)
Now spv.h looks like
```
#pragma once
#include <ATen/native/vulkan/api/Types.h>
#include <ATen/native/vulkan/api/vk_api.h>
#include <c10/util/flat_hash_map.h>
#include <string>
namespace at {
namespace native {
namespace vulkan {
namespace api {
struct ShaderInfo;
} // namespace api
typedef ska::flat_hash_map<std::string, api::ShaderInfo> ShaderListing;
typedef ska::flat_hash_map<std::string, std::string> RegistryKeyMap;
typedef ska::flat_hash_map<std::string, RegistryKeyMap> ShaderRegistry;
extern const ShaderListing shader_infos;
extern ShaderRegistry shader_registry;
inline const ShaderListing& get_shader_infos() {
return shader_infos;
}
inline ShaderRegistry& get_shader_registry() {
return shader_registry;
}
} // namespace vulkan
} // namespace native
} // namespace at
```
and spv.cpp looks like
```
#include <ATen/native/vulkan/api/Shader.h>
#include <ATen/native/vulkan/spv.h>
#include <stdint.h>
#include <vector>
namespace at {
namespace native {
namespace vulkan {
namespace {
const uint32_t adaptive_avg_pool2d_bin[] = {
119734787,
...
};
...
const uint32_t conv2d_pw_2x2_bin[] = {
119734787,
...
};
} // namespace
const ShaderListing shader_infos = {
{"adaptive_avg_pool2d",
api::ShaderInfo(
"vulkan.adaptive_avg_pool2d",
adaptive_avg_pool2d_bin,
3204,
{VK_DESCRIPTOR_TYPE_STORAGE_IMAGE,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER},
std::vector<uint32_t>(),
api::StorageType::UNKNOWN,
api::StorageType::UNKNOWN)},
...
{"conv2d_pw_2x2",
api::ShaderInfo(
"vulkan.conv2d_pw_2x2",
conv2d_pw_2x2_bin,
7736,
{VK_DESCRIPTOR_TYPE_STORAGE_IMAGE,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER,
VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER},
{2, 2, 1},
api::StorageType::TEXTURE_2D,
api::StorageType::TEXTURE_2D)}};
ShaderRegistry shader_registry = {
};
} // namespace vulkan
} // namespace native
} // namespace at
```
(Full File: P594112814)
Differential Revision: [D41594453](https://our.internmc.facebook.com/intern/diff/D41594453/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91914
Approved by: https://github.com/mcr229
@bypass-github-export-checks
To include custom locations when building with buck, use a ```-c gen_vulkan_spv.additional_glsl_paths="..."``` flag where ... is a list of filegroups and source directory paths separated by spaces,
ex. to include the sources added in D41413913, you would use
```
buck build ... -c gen_vulkan_spv.additional_glsl_paths="//xplat/caffe2:test_glsl_src_path_a test_src/a //xplat/caffe2:test_glsl_src_path_b test_src/b"
```
(as shown in the test plan)
Differential Revision: [D41413914](https://our.internmc.facebook.com/intern/diff/D41413914/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D41413914/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91913
Approved by: https://github.com/mcr229
Summary:
This PR adds in SaliencyPruner, an implementation of L1 norm pruning for structured pruning, as well as additional tests for the SaliencyPruner
The README.md references this file but I forgot to add it in earlier when writing the tutorial.
Test Plan:
```
python test/test_ao_sparsity.py -- TestSaliencyPruner
```
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91814
Approved by: https://github.com/jerryzh168
patches the missing pin_memory argument on full::meta_impl. This is not a functional break, but it does give test failure, which asserts on no warning. vvv
`python test/test_nvfuser_dynamo.py -k test_batch_norm_implicit_dtype_promotion`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91541
Approved by: https://github.com/malfet
I'm not sure why this was left out in the first place as all adjacent operations have both Half and BFloat16. Things seem to work as expected and this enables `relu6` to be used in bfloat16 training. Hardtanh backward is super simple and precision is not relevant.
```
import torch
x_fp32 = torch.tensor([-1,2,4,7], requires_grad=True, dtype=torch.float32, device="cuda")
x_bf16 = torch.tensor([-1,2,4,7], requires_grad=True, dtype=torch.bfloat16, device="cuda")
torch.nn.functional.relu6(x_fp32).sum().backward()
torch.nn.functional.relu6(x_bf16).sum().backward()
assert (x_fp32.grad == x_bf16.grad).all()
```
Previously would fail with:
```
Traceback (most recent call last):
File "test_hardtanh_patch.py", line 5, in <module>
torch.nn.functional.relu6(x_bf16).sum().backward()
File ".../lib/python3.8/site-packages/torch/_tensor.py", line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File ".../lib/python3.8/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: "hardtanh_backward_cuda" not implemented for 'BFloat16'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91511
Approved by: https://github.com/ngimel
This reverts commit 9945a78a94bd9907c05b102984c7233faa44ad14.
Reverted https://github.com/pytorch/pytorch/pull/90463 on behalf of https://github.com/ZainRizvi due to This is causing test failures: FAILED inductor/test_torchinductor_opinfo.py::TestInductorOpInfoCUDA::test_comprehensive_linalg_pinv_singular_cuda_float64 - RuntimeError: unexpected success linalg.pinv.singular, torch.float64, cuda
Currently, most of the reduction ops are flattening the input tensor to 1D to perform the operation.
This change removes the flattening of the tensors / the unranked placeholders and adds support for multi axes in all the reduction ops.
- Fixes reduction ops with correctness and shape issues.
- Fixes masked.argmax / masked.argmin. In case of passing inf to argmax / argmin, MPS will return nan as index for these numbers. Casting this nan to Long will make it -1. This change avoids negative values by clamping them to 0 (matching CPU results).
TestConsistency issues fixed:
```
std
var
amax
amin
sum
prod
mean
count_nonzero
masked.amax
masked.amin
masked.mean
masked.prod
masked.std
masked.sum
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91734
Approved by: https://github.com/kulinseth
The pattern can't be matched if one attribute is `_param_constant1` and the other is `_param_constant0`
Large graph:
```
# call_function addmm_default aten.addmm.default (_param_constant1, ph_0, _tensor_constant0) {}
```
Pattern graph
```
# call_function addmm_default aten.addmm.default (_param_constant0, ph_0, _tensor_constant0) {}
```
Differential Revision: [D42316574](https://our.internmc.facebook.com/intern/diff/D42316574/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91657
Approved by: https://github.com/SherlockNoMad
We are using the idiom
```py
sys.path.insert(0, path)
# do something
sys.path.remove(path)
```
three times in `torch.hub`. This is a textbook case for using a context manager. In addition, by using `try` / `finally` we can enforce the Python path is back in its original state even if the actual action raises an exception:
```py
import sys
path = "/tmp"
# PR
try:
sys.path.insert(0, path)
try:
# Any exception raised while performing the actual functionality
raise Exception
finally:
sys.path.remove(path)
except Exception:
assert path not in sys.path
# main
try:
sys.path.insert(0, path)
# Any exception raised while performing the actual functionality
raise Exception
sys.path.remove(path)
except Exception:
assert path in sys.path
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75786
Approved by: https://github.com/NicolasHug
We should not allow creating a derived source (e.g. AttrSource), without a valid base source.
It's more reliable to check this in the source `__init__` or `__post_init__` than asserting we have a valid source before passing that to an AttrSource() call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91711
Approved by: https://github.com/voznesenskym
This is needed to support `enum.Enum` derived classes in Python-3.11
that adds `_new_member_` to classdict, see:
15c44789bb/Lib/enum.py (L529)
Following snippet illustrates the problem with the previous iteration of
the code on 3.11:
```python
from enum import Enum
import inspect
class Color(Enum):
RED = 1
GREEN = 2
def print_routines(cls):
print(cls.__name__)
for name in cls.__dict__:
fn = getattr(cls, name)
if inspect.isroutine(fn):
print(name, fn, f"has_globals: {hasattr(fn, '__globals__')}")
print_routines(Color)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91805
Approved by: https://github.com/albanD, https://github.com/suo
Summary: We don't care about params/buffers being mutated in dynamo export, so it is safe to always convert them to faketensor
Test Plan: CI
Differential Revision: D42353789
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91742
Approved by: https://github.com/qihqi
# Summary
This PR updates the second return value from SDPA to return an empty tensor of size 0 not what it would be if need_attn_weights is True. Also updates the meta function to account for this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91782
Approved by: https://github.com/cpuhrsch
- Fixed the memory leak with the `malloc()`
- Introduced shortened data type strings (optional) to avoid getting extra long cached graph string keys with ops such as cat_out()
- Fixed data type issues in Monterey
- Removed the unused `use_scalar_value` argument from `getTensorsStringKey()`
- Clean up and refactoring
Fixes#89353
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91786
Approved by: https://github.com/kulinseth
This PR refactors the loop related data structure to support the loop split at a given depth. Before this PR, the loop split is always supported at the inner-most level. With this PR, it is possible to support tiling at outer levels and at more than one levels. The `LoopNest` data structure is extended to support loop splits at various levels and renamed to `LoopNestWithSplit`. The `codegen_loops` function is also rewritten to be general to support arbitrary kernels set at the leaves of the loop structure.
This PR also improves the handling of reduction loops with split. The main loop and tail loop now work on their own reduction variables in parallel without data dependency as previous do. With this, two workarounds can be removed in the `CppVecKernel`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91397
Approved by: https://github.com/EikanWang, https://github.com/jansel
setup.py clean now won't remove paths matching .gitignore patterns across the entire OS. Instead, now only files from the repository will be removed.
`/build_*` had to be removed from .gitignore because with the wildcard fixed, build_variables.bzl file was deleted on cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91503
Approved by: https://github.com/soumith
#84624 introduces an update on `torch.norm` [dispatch logic](eaa43d9f25/torch/functional.py (L1489)) which now depends on `layout`. Resulting in regressions to export related operators from TorchScript.
This PR resolves the regression by partially supporting a subset use case of `prim::layout` (only `torch.strided`), `aten::__contains__` (only constants) operators. It requires much more effort to properly support other layouts, e.g. `torch.sparse_coo`. Extending JIT types, and supporting related family of ops like `aten::to_sparse`. This is out of the scope of this PR.
Fixes#83661
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91660
Approved by: https://github.com/justinchuby, https://github.com/kit1980
- Workaround for MaxPool when ceilMode=true
- Workaround for ChannelsLast memory format
- Workaround for divisor_override in AvgPool ops
- Enabled count_include_pad parameter for AvgPool
- Refactoring and clean up of duplicate code
- Enable MaxPool tests in TestConsistency
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91519
Approved by: https://github.com/kulinseth, https://github.com/malfet
**Summary**:
When converting a ref module into a quant module, `_lower_static_weighted_ref_module` pass assumes the `ref_node` only has 1 input node, and only remove the first `dequant` node. We add a check in this PR to ensure this is the case for `_lower_static_weighted_ref_module` pass.
**Test Plan**:
We only add a check in this PR, there is no new added test case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90157
Approved by: https://github.com/Xia-Weiwen, https://github.com/jgong5, https://github.com/jerryzh168
We've already shown some promising perf result by integrating dynamo with torchxla for inference. To provide consistent UX for training and for inference, in this PR we try to enable training for dynamo/torchxla.
Training is trickier than inference and we may not expect much perf gains since
1. in training case, torchxla only generate a single combined graph for fwd/bwd/optimizer while in `torchxla_trace_once` bridge we added in dynamo, due to how AOT_Autograd works, we will generate 3 graphs: one for forward, one for backward and one for the optimizer. XLA favors larger graph to do more optimizations.
2. in training case, tracing overhead can be overlapped with computation. Tracing overhead is not as a big deal for training as for inference. After all training cares more about throughput while inference cares more about latency.
3. in training case, people can increase batch size to 'mitigate' the tracing overhead. Increase batch size does not change tracing overhead, thus it shows like the tracing overhead 'per example' reduces.
But we still want to add training support to dynamo/torchxla to make the work complete.
We added '--iterations-per-run' argument to control how may iterations we do per measure/device sync. This is to understand the impact of item 2 above.
Results:
With '--iterations-per-run' equals to 1, here are the perf numbers:
```
+-------------------------+--------------------+-------------------------+
| Model | XLA (trace once) | XLA (trace everytime) |
+=========================+====================+=========================+
| resnet18 | 0.91 | 0.959 |
+-------------------------+--------------------+-------------------------+
| resnet50 | 0.917 | 0.932 |
+-------------------------+--------------------+-------------------------+
| resnext50_32x4d | 0.912 | 0.905 |
+-------------------------+--------------------+-------------------------+
| alexnet | 1.038 | 0.974 |
+-------------------------+--------------------+-------------------------+
| mobilenet_v2 | 0.881 | 0.835 |
+-------------------------+--------------------+-------------------------+
| mnasnet1_0 | 0.903 | 0.931 |
+-------------------------+--------------------+-------------------------+
| vgg16 | 0.914 | 0.967 |
+-------------------------+--------------------+-------------------------+
| BERT_pytorch | 1.359 | 0.84 |
+-------------------------+--------------------+-------------------------+
| timm_vision_transformer | 1.288 | 0.893 |
+-------------------------+--------------------+-------------------------+
| geomean | 1.0006 | 0.913794 |
+-------------------------+--------------------+-------------------------+
```
Overall it looks like graph break indeed cause perf loss. But for BERT_pytorch and timm_vision_transformer we still see perf gain. We need do more experiments with larger '--iterations-per-run'
NOTE:
In torchbench.py I added the following code to do a few workaround:
```
from myscripts import workaround # TODO will remove this line before landing
```
Here are the content of workaround.py:
```
import torch
from torch import nn
import os
# override max_pool2d with avg_pool2d
if os.environ.get("REPLACE_MAXPOOL", "0") == "1":
torch.nn.MaxPool2d = torch.nn.AvgPool2d
```
It work around a few issues we found
1. MaxPool2d does not work for training in dynamo/torchxla: https://github.com/pytorch/torchdynamo/issues/1837 . WIP fix from Brian in https://github.com/pytorch/pytorch/pull/90226 , https://github.com/pytorch/xla/pull/4276/files (WIP)
2. recent change ( this PR https://github.com/pytorch/pytorch/pull/88697 ) in op decomposition cause batch_norm ops to fallback in torchxla. Fix from jack in https://github.com/pytorch/xla/pull/4282#event-7969608134 . (confirmed the fix after adding Deduper to handle duplicated return from fx graph generated by AOTAutograd)
3. we have issue to handle dropout because of random seed out of sync issue. Here is the fix: https://github.com/pytorch/xla/pull/4293 (confirmed the fix)
Example command:
```
REPLACE_MAXPOOL=1 USE_FAKE_TENSOR=0 GPU_NUM_DEVICES=1 python benchmarks/dynamo/torchbench.py --randomize-input --performance --trace-on-xla --training --backend=aot_torchxla_trace_once --only vgg16
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88449
Approved by: https://github.com/wconstab, https://github.com/qihqi, https://github.com/malfet
This removes the now-redundant `_squeeze_multiple` helpers and instead decomposes into a single call to `aten::squeeze.dims` which also has the effect of reducing the lowered graph size in inductor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91602
Approved by: https://github.com/ngimel
Small refactor to remove any code used by vTensor under the `op/` folder to appropriate locations in the `api/` folder. Also remove vTensor from the `ops` namespace, it now resides in the higher level `at::native::vulkan` namespace which will also be used for the Graph data structures in the future.
This is the last step required for vTensor to be able to moved to the api folder.
Differential Revision: [D42052680](https://our.internmc.facebook.com/intern/diff/D42052680/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91023
Approved by: https://github.com/salilsdesai
This is needed for MLIR rewrite
This replaces
```
xindex = xoffset + tl.reshape(tl.arange(0, XBLOCK), [XBLOCK, 1])
```
with
```
xindex = xoffset + tl.arange(0, XBLOCK)[:, None]
```
so code is a bit more readable, and compiles with master triton (which doesn't currently support first construct).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91722
Approved by: https://github.com/desertfire
This diff removes all dependencies on ATen from the vTensor class, in preparation for moving the class to the `api/` folder so that it can be part of the core library (i.e. part of the `torch_vulkan_api` target introduced in the below diff which should have no dependencies on ATen.
Most notably, the constructor of `vTensor` is changed to
```
vTensor(
api::Context* context,
IntArrayRef sizes,
const c10::ScalarType dtype = c10::kFloat,
const api::StorageType storage_type = api::StorageType::TEXTURE_3D,
const c10::MemoryFormat memory_format = c10::MemoryFormat::Contiguous);
```
Instead of accepting a `TensorOptions` argument, since `TensorOptions` is a part of ATen. The majority of changes in this diff are due to updating vTensor construction to use the new constructor.
Differential Revision: [D42049862](https://our.internmc.facebook.com/intern/diff/D42049862/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91022
Approved by: https://github.com/kimishpatel
- Implemented following new ops: upsample_nearest1d_backward
upsample_nearest_exact1d
upsample_nearest_exact1d_backward
- Moved Upsample code from Shape.mm to Upsample.mm
- Fallback to CPU for nearest mode on Monterey
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91669
Approved by: https://github.com/malfet
This diff isolates the core components of the Pytorch Vulkan backend into its own target (`//xplat/caffe2:torch_vulkan_api`). The main motivation for this is to create a library that does not have a dependency on the ATen library which can then be used to build a graph mode runtime for Vulkan for Executorch.
In addition to introducing the new target, this diff also removes some references to external dependencies in the `api/` folder so that files in that folder are completely self contained.
Differential Revision: [D42038817](https://our.internmc.facebook.com/intern/diff/D42038817/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D42038817/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91021
Approved by: https://github.com/kirklandsign
The code produced by the lowering and the decomposition is now the same
modulo a casting to `float32`. This casting is necessary as otherwise
the tests do not pass due to accuracy errors. We prefer accuracy over
speed here, given that this is an associative scan, and thus it's prone
to numerical errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91621
Approved by: https://github.com/ngimel
Fixes#91404
As expected
```python
import torch
from functorch import vmap
x = torch.randn(32, 3, 3, 3)
y = vmap(torch.trace)(x)
print(y)
```
Now gives the exact same runtime error as eager mode
```
(sourcetorch) ubuntu@ip-172-31-39-26:~/test$ python functorch_test_pos.py
Traceback (most recent call last):
File "functorch_test_pos.py", line 4, in <module>
y = vmap(torch.trace)(x)
File "/home/ubuntu/pytorch/torch/_functorch/vmap.py", line 420, in wrapped
return _flat_vmap(
File "/home/ubuntu/pytorch/torch/_functorch/vmap.py", line 39, in fn
return f(*args, **kwargs)
File "/home/ubuntu/pytorch/torch/_functorch/vmap.py", line 605, in _flat_vmap
batched_outputs = func(*batched_inputs, **kwargs)
RuntimeError: trace: expected a matrix, but got tensor with dim 3
```
Equivalent eager code
```python
import torch
x = torch.randn(32, 3, 3, 3)
results = []
for xi in x:
y = torch.trace(xi)
results.append(y)
```
```
(sourcetorch) ubuntu@ip-172-31-39-26:~/test$ python functorch_test_neg.py
Traceback (most recent call last):
File "functorch_test_neg.py", line 5, in <module>
y = torch.trace(xi)
RuntimeError: trace: expected a matrix, but got tensor with dim 3
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91679
Approved by: https://github.com/zou3519
Continuation of #79979.
Fixes#79161
This PR does the following:
* Expands the `parametrize_fn()` signature from returning a 3-tuple of `(test, test_name, param_kwargs)` to returning a 4-tuple of `(test, test_name, param_kwargs, decorator_fn)`. Expected signature for the addition is `decorator_fn(param_kwargs) -> List[decorator]` i.e. given the full set of test params, return a list of decorators to apply.
* `modules`, `ops`, and `parametrize` now fit the new signature, returning `decorator_fn`s instead of applying decorators themselves.
* `instantiate_parametrized_tests()` and `instantiate_device_type_tests()` now call the returned `decorator_fn`, passing in the full set of `param_kwargs` (after composition + `device` / `dtype` additions) and applying the returned decorators.
* Composing multiple `parametrize_fn`s also composes the corresponding `decorator_fn`s; the composed `decorator_fn` simply concatenates the decorator lists returned by the constituents.
* Expands `DecorateInfo.is_active` to support callables:
```python
DecorateInfo(
unittest.expectedFailure, "TestOps", "test_python_ref_executor",
device_type='cuda', active_if=lambda params: params['executor'] == 'nvfuser'
),
```
* Adds several tests to `test/test_testing.py` ensuring proper decoration using `@parametrize`, `@modules`, and `@ops`.
* (minor) Fixes a couple `ModuleInfo` naming oddities uncovered during testing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91658
Approved by: https://github.com/malfet
When we run the node with fake value for tensor.item, it would previously error because the utility method doesn't know how to handle placeholder node. The tensor we are calling item can be input from user will be placeholder in the graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91668
Approved by: https://github.com/voznesenskym
Fixes#90940. This PR revamps how tests are run in parallel as well as device visibility at the docker container and within the run_test.py test runner.
First, running multiple test modules concurrently on the same GPU was causing instability for ROCm runners manifesting as timeouts. ROCm runners have at least 1 GPU each, but often 2 or more. This PR allows NUM_PROCS to be set equal to the number of devices available, but also takes care to set HIP_VISIBLE_DEVICES to avoid oversubscribing any GPU.
Second, we had introduced env vars `-e ROCR_VISIBLE_DEVICES` (#91031) to prepare for two GHA runners per CI node, to split up the GPU visibility at the docker level between the two runners. This effort wasn't fully realized; to date, we haven't had more than one runner per CI host. We abandon this effort in favor of all GPUs being visible to a single runner and managing GPU resources as stated above.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91137
Approved by: https://github.com/kit1980, https://github.com/huydhn, https://github.com/pruthvistony
Ref #70924
This addresses part 1 of the issue, allowing `torch.squeeze` to be
passed a tuple of dimensions. e.g.
```python
x.squeeze(0).squeeze(0)
```
can now be written
```python
x.squeeze((0, 1))
```
(assuming x has at least 2 dimensions)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89017
Approved by: https://github.com/albanD
addmm_cuda_lt failed for some corner cases, so far we can not reproduce the corner cases in the unit tests, seems that the failures do not only depend on matrices' shape and strides. For now, add an environment variable to allow users disable this kernel for such corner cases.
**See the case one with more error logs:**
RuntimeError: 0CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling cublasLtMatmul with transpose_mat1 1 transpose_mat2 0 m 80 n 1024 k 160 mat1_ld 160 mat2_ld 160 result_ld 80 abcType 14 computeType 68 scaleType 0 result_shape 1024 80 result_stride 80 1 self_shape 80 self_stride 1 mat1_shape 1024 160 mat1_stride 160 1 mat2_shape 160 80 mat2_stride 1 160
Exception raised from gemm_and_bias at fbcode/caffe2/aten/src/ATen/cuda/CUDABlas.cpp:1071 (most recent call first):
**another case with more error logs:**
RuntimeError: 0CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling cublasLtMatmul with transpose_mat1 1 transpose_mat2 0 m 16 n 16384 k 48 mat1_ld 48 mat2_ld 48 result_ld 16 abcType 14 computeType 68 scaleType 0 result_shape 16384 16 result_stride 16 1 self_shape 16 self_stride 1 mat1_shape 16384 48 mat1_stride 48 1 mat2_shape 48 16 mat2_stride 1 48
Exception raised from gemm_and_bias at fbcode/caffe2/aten/src/ATen/cuda/CUDABlas.cpp:1071 (most recent call first):
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91436
Approved by: https://github.com/ngimel
This PR:
- Updates autograd.Function.forward docs to reflect how you either
define a forward with ctx or a separate forward and setup_context
- Updates the "Extending Autograd" docs to suggest the usage of
autograd.Function with separate forward and setup_context. This should
be the default because there is a low barrier to go from this to
an autograd.Function that is fully supported by functorch transforms.
- Adds a new "Extending torch.func with autograd.Function" doc that
explains how to use autograd.Function with torch.func. It also
explains how to use generate_vmap_rule and how to manually write a
vmap staticmethod.
While writing this, I noticed that the implementation of
setup_context staticmethod/generate_vmap_rule/vmap staticmethod are a
bit inconsistent with the other method/attributes on autograd.Function:
- https://github.com/pytorch/pytorch/issues/91451
- I'm happy to fix those if we think it is a problem, either in this PR
or a followup (this PR is getting long, I want some initial docs
out that I can point early adopters at, and fixing the problems in the
future isn't really BC-breaking).
Test Plan:
- view docs preview
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91452
Approved by: https://github.com/soulitzer
Summary:
This diff is reverting D42051833
D42051833 has been identified to be causing the following test or build failures:
Tests affected:
- [//xplat/pytorch_models/build/MultitaskPeopleSegmentation/v7020:MultitaskPeopleSegmentation7020_testAndroid-64bit - runAllTests (com.facebook.xplat.XplatTestRunner)](https://www.internalfb.com/intern/test/281475056077477/)
- [//xplat/pytorch_models/build/MultitaskPeopleSegmentation/v4020:PYTORCH_MODEL_testAndroid-64bit - runAllTests (com.facebook.xplat.XplatTestRunner)](https://www.internalfb.com/intern/test/844425007913475/)
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1478566
Here are the tasks that are relevant to this breakage:
T93205881: 15 tests started failing for oncall ai_infra_mobile_platform in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Differential Revision: D42090396
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91458
Approved by: https://github.com/kit1980
Fixes https://github.com/pytorch/functorch/issues/1087
It looks like there are `306` rules that should be looked into
```
test/functorch/test_vmap_registrations.py .x.....xxxxxxx.x.x.x.x.x.x.x.x........xx.x.x..x.x.xxx...xxxx.x.x.x........x.........xxxxx..x..x.....xx...xx.....xxx.xxxxxxxxxxxxxxxxx.. [ 24%]
.........x.x......x.xxxxxx..x..xx.x.xxx.x.......x.xxx.xx..xxx.xxx...xxxxx.x....xxxxxxxxxxxxxxx....xx.xxx.xx.x...xx...xx...xxxxxx...xxxxx..x...xxxxxxxxxxxx..xx..xx.xx.x..xxxx..xx [ 56%]
.xx..x.x....xxxxxx.x.xx...xxxxx.xx...x..x.x.xx...xx.xxxxxx.xxxxxx..x........xxxxxxxx..xxxxxxxx..xx.xxxxxxxxxxxxxxxxxxxxxxx..........xxxx.xxxx.........xxxxxxxx..xxx..xxx.x.x.x.xx [ 88%]
xx.xxx.x......xxx.x.xxxxxxxx....x......xxxxxxxxx.xx.x.x.x.......xx [100%]
=================================================================== 249 passed, 1185 deselected, 306 xfailed in 3.17s ===================================================================
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91367
Approved by: https://github.com/zou3519
Summary:
This diff is reverting D42257039
D42257039 has been identified to be causing the following test or build failures:
Tests affected:
- [assistant/neural_dm/rl/modules/tests:action_mask_classifier_test - main](https://www.internalfb.com/intern/test/281475048940766/)
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1493969
Here are the tasks that are relevant to this breakage:
T93770103: 1 test started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: weiwangmeta
Differential Revision: D42272391
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91548
Approved by: https://github.com/kit1980
These functions will be legacy functions. We deprecate them, but we also
take this chance to dispatch to a more efficient and consistent implementation.
Doing so should help writing a conversion rule for these to be able to
remove them once and for all
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81763
Approved by: https://github.com/ngimel
Fixes copies into slices where the input data type is different than the output dtype.
This change removes the cast done before scatter, so we don't have to allocate additional memory to perform the casting. Scatter handles the casting directly now.
device = "mps"
shape = (4, 4)
tensor = torch.randint(10, shape, device=device)
tensor_before = tensor.clone()
res = torch.empty(shape[0], shape[1] * 2, device=device)[:, ::2].copy_(tensor)
torch.testing.assert_close(tensor, tensor_before)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91197
Approved by: https://github.com/razarmehr
Apply clang-tidy fixups to prefer member initializer and modernize-pass-by-value. This is a mostly a noop, but it should make a few ctors slighlty more readable and more efficient. Also drops in some missing moves that prevents a lot of unnecessary copying.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91538
Approved by: https://github.com/ezyang
Follow-up of #86167 ; The number of pools was mistakenly ignored and the default workspace size appears to be too small to match selected cuBLAS kernels before the explicit allocation change.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89027
Approved by: https://github.com/ngimel
Small optimization for the hot path when thrashing the cache with dynamic shapes; in most cases we don't need the fallback generator so we can omit it unless needed later.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90811
Approved by: https://github.com/ngimel
Bumps [protobuf](https://github.com/protocolbuffers/protobuf) from 3.20.1 to 3.20.2.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/protocolbuffers/protobuf/releases">protobuf's releases</a>.</em></p>
<blockquote>
<h2>Protocol Buffers v3.20.2</h2>
<h1>C++</h1>
<ul>
<li>Reduce memory consumption of MessageSet parsing</li>
<li>This release addresses a <a href="https://github.com/protocolbuffers/protobuf/security/advisories/GHSA-8gq9-2x98-w8hf">Security Advisory for C++ and Python users</a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="a20c65f2cd"><code>a20c65f</code></a> Updating changelog</li>
<li><a href="c49fe79af9"><code>c49fe79</code></a> Updating version.json and repo version numbers to: 20.2</li>
<li><a href="806d7e4ce6"><code>806d7e4</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/protocolbuffers/protobuf/issues/10544">#10544</a> from deannagarcia/3.20.x</li>
<li><a href="ae718b3902"><code>ae718b3</code></a> Add missing includes</li>
<li><a href="b4c395aaed"><code>b4c395a</code></a> Apply patch</li>
<li><a href="6439c5c013"><code>6439c5c</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/protocolbuffers/protobuf/issues/10531">#10531</a> from protocolbuffers/deannagarcia-patch-7</li>
<li><a href="22c79e6e4c"><code>22c79e6</code></a> Update version.json</li>
<li><a href="c1a2d2ec29"><code>c1a2d2e</code></a> Fix python release on macos (<a href="https://github-redirect.dependabot.com/protocolbuffers/protobuf/issues/10512">#10512</a>)</li>
<li><a href="a826282e15"><code>a826282</code></a> Merge pull request <a href="https://github-redirect.dependabot.com/protocolbuffers/protobuf/issues/10505">#10505</a> from deannagarcia/3.20.x</li>
<li><a href="7639a710e1"><code>7639a71</code></a> Add version file</li>
<li>Additional commits viewable in <a href="https://github.com/protocolbuffers/protobuf/compare/v3.20.1...v3.20.2">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
- `@dependabot use these labels` will set the current labels as the default for future PRs for this repo and language
- `@dependabot use these reviewers` will set the current reviewers as the default for future PRs for this repo and language
- `@dependabot use these assignees` will set the current assignees as the default for future PRs for this repo and language
- `@dependabot use this milestone` will set the current milestone as the default for future PRs for this repo and language
You can disable automated security fix PRs for this repo from the [Security Alerts page](https://github.com/pytorch/pytorch/network/alerts).
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91540
Approved by: https://github.com/huydhn
The main changes are:
1. Remove outdated checks for old compiler versions because they can't support C++17.
2. Remove outdated CMake checks because it now requires 3.18.
3. Remove outdated CUDA checks because we are moving to CUDA 11.
Almost all changes are in CMake files for easy audition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90599
Approved by: https://github.com/soumith
**What does this PR do?**
This PR refactor `_optim_utils.py` to use `_FSDPState` instead of `FullyShardedDataParallel` class. This change enables the support of optim state_dict for `fully_shard`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91234
Approved by: https://github.com/rohan-varma
Whenever you guard on something, you're supposed to tell GuardBuilder about it, so GuardBuilder knows that it has to actually bind it in scope when it creates the guard function. But shape env guards bypass that mechanism completely. Well, now they don't.
For the most part, this didn't matter in practice, because we usually had a `TENSOR_MATCH` guard floating around that made sure that the guard stayed live. But if we ever eliminate those guards (e.g., because we build it into the shape guard directly; something we'll probably want to do when https://github.com/pytorch/pytorch/pull/89707 goes online) then this will indeed matter.
One complication: some of the shape env guards are on globals. You have to make sure to shunt the usage to the correct guard builder in that case. Maybe it would be better if we refactored things so there is only one GuardBuilder. Not sure.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91058
Approved by: https://github.com/voznesenskym
I'm going to need this in the follow up PR. Instead of storing only Source.name() in Symbol, I now store a full on Source. Lots of replumbing reoccurs. In particular:
- Move Source to torch._guards to break cycles
- I have to add TensorPropertySource and NegateSource to handle x.size()[0] and -x codegen that I was doing with string manipulation previously
- I tighten up invariants so that I never pass source=None; instead I pass ConstantSource (these are constant sources right) and test for that rather than source being missing. I think this is more parsimonious
- Some mypy wobbles from new imports
I didn't move LocalSource and friends to torch._guards, but I ended up needing to access them in a few places. The main annoyance with moving these is that then I also need to move the bytecode codegen stuff, and that's not so easy to move without bringing in the kitchen sink.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91057
Approved by: https://github.com/albanD, https://github.com/voznesenskym, https://github.com/zou3519
Summary: There was a patch to not raise SOFT_ASSERT in debug builds. Update this test to match it.
Test Plan: This test passes after this patch.
Differential Revision: D42270123
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91464
Approved by: https://github.com/robieta
Docs copy-pasted from functorch docs with minor adjustments. We are
keeping the functorch docs for BC, though that's up for debate -- we
could also just say "see .. in torch.func" for some, but not all doc
pages (we still want to keep around any examples that use
make_functional so that users can tell what the difference between that
and the new functional_call is).
Test Plan:
- docs preview
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91319
Approved by: https://github.com/samdow
Applies so more fixes to headers that may have been missed before for performance optimization.cc @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10 @EikanWang @ezyang since this more in the series of the clang-tidy fixup
This is PR fixes 3 main issues:
1. Use emplacement more in headers
1. Avoid unnecessary copies and use const ref when possible
1. Default any special functions when possible to make them potentially trivial and more readable.
1. There is also one change in this PR that tries to prevent unnecessary math promotion, the rest of these changes are in another PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91445
Approved by: https://github.com/ezyang
This applies some more clang-tidy fixups. Particularly, this applies the modernize loops and modernize-use-transparent-functors checks. Transparent functors are less error prone since you don't have to worry about accidentally specifying the wrong type and are newly available as of C++17.
Modern foreach loops tend be more readable and can be more efficient to iterate over since the loop condition is removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91449
Approved by: https://github.com/ezyang
Setting a timeout value when testing multiprocess DataLoader to prevent ASAN jobs timing out after 4 hours.
We are seeing multiple timeout issue running ASAN tests on HUD https://hud.pytorch.org/hud/pytorch/pytorch/master/1?per_page=50&name_filter=asan for examples
* Without mem leak check enabled https://github.com/pytorch/pytorch/actions/runs/3794216079/jobs/6455118197
* With mem leak check https://github.com/pytorch/pytorch/actions/runs/3792743994/jobs/6449356306
Looking a bit closer into the test, the hanging happens when multiprocess DataLoader is used in `test_utils`. Here is the snapshot of those processes when I log into the hang runner:
```
UID PID PPID C STIME TTY TIME CMD
jenkins 1 0 0 Dec28 pts/0 00:00:00 bash
jenkins 8 0 0 Dec28 pts/1 00:00:00 sh -c pip install dist/torch-2.0.0a0+git97db9fd-cp37-cp37m-linux_x86_64.whl[opt-einsum] && .jenkins/pytorch/test.sh
jenkins 20 8 0 Dec28 pts/1 00:00:00 /bin/bash .jenkins/pytorch/test.sh
jenkins 764 20 0 Dec28 pts/1 00:00:07 python test/run_test.py --exclude-jit-executor --exclude-distributed-tests --shard 5 5 --verbose
jenkins 788 764 0 Dec28 pts/1 00:00:00 /opt/conda/bin/python -c from multiprocessing.semaphore_tracker import main;main(6)
jenkins 3743 764 0 Dec28 pts/1 00:00:05 /opt/conda/bin/python -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=7, pipe_handle=11) --multiprocessing-fork
jenkins 3766 3743 0 Dec28 pts/1 00:00:06 /opt/conda/bin/python -bb test_utils.py -v --import-slow-tests --import-disabled-tests
jenkins 3878 3766 0 Dec28 pts/1 00:00:06 /opt/conda/bin/python -bb test_utils.py -v --import-slow-tests --import-disabled-tests
jenkins 3879 3766 0 Dec28 pts/1 00:00:00 /opt/conda/bin/python -bb test_utils.py -v --import-slow-tests --import-disabled-tests
jenkins 3880 3766 0 Dec28 pts/1 00:00:00 /opt/conda/bin/python -bb test_utils.py -v --import-slow-tests --import-disabled-tests
jenkins 3881 3766 0 Dec28 pts/1 00:00:00 /opt/conda/bin/python -bb test_utils.py -v --import-slow-tests --import-disabled-tests
jenkins 3893 0 0 01:45 pts/2 00:00:00 /bin/bash
jenkins 3904 3893 0 01:46 pts/2 00:00:00 ps -ef
```
The specific hanging test was `test_random_seed` which spawned 4 subprocesses to load data. After I killed one of them, the test could continue and printed the following stacktrace:
```
test_random_seed (__main__.TestDataLoaderUtils) ... [W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
ERROR (9345.840s)
test_random_seed (__main__.TestDataLoaderUtils) ... test_random_seed errored - num_retries_left: 3
Traceback (most recent call last):
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 1134, in _try_get_data
data = self._data_queue.get(timeout=timeout)
File "/opt/conda/lib/python3.7/multiprocessing/queues.py", line 104, in get
if not self._poll(timeout):
File "/opt/conda/lib/python3.7/multiprocessing/connection.py", line 257, in poll
return self._poll(timeout)
File "/opt/conda/lib/python3.7/multiprocessing/connection.py", line 414, in _poll
r = wait([self], timeout)
File "/opt/conda/lib/python3.7/multiprocessing/connection.py", line 921, in wait
ready = selector.select(timeout)
File "/opt/conda/lib/python3.7/selectors.py", line 415, in select
fd_event_list = self._selector.poll(timeout)
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/_utils/signal_handling.py", line 66, in handler
_error_if_any_worker_fails()
RuntimeError: DataLoader worker (pid 3878) is killed by signal: Terminated.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "test_utils.py", line 469, in test_random_seed
x2 = run()
File "test_utils.py", line 464, in run
return next(iter(dataloader))
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 635, in __next__
data = self._next_data()
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 1330, in _next_data
idx, data = self._get_data()
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 1296, in _get_data
success, data = self._try_get_data()
File "/opt/conda/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 1147, in _try_get_data
raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str)) from e
RuntimeError: DataLoader worker (pid(s) 3878) exited unexpectedly
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
[W ParallelNative.cpp:230] Warning: Cannot set number of intraop threads after parallel work has started or after set_num_threads call when using native parallel backend (function set_num_threads)
ok (0.137s)
```
This doesn't fix the issue which I'll need to follow up to see why they hang. However, this should allow the test to terminate gracefully and report errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91476
Approved by: https://github.com/kit1980
This should help address https://github.com/pytorch/pytorch/issues/67002. At the end of these tests, any temp file `/dev/shm/torch_*` are cleaned up, but somehow it might take longer than 0.5s to finish causing the test to fail. So, the PR tries to increase this max waiting time to 5s while polling for the result every 0.5s as before
### Testing
`pytest test_multiprocessing.py -k test_fs --verbose --flake-finder` to run `test_fs`, `test_fs_is_shared`, `test_fs_pool`, `test_fs_preserve_sharing`, and `test_fs_sharing` 50 times on a dynamo shard. All passes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91459
Approved by: https://github.com/kit1980, https://github.com/ZainRizvi, https://github.com/atalman
The autograd.Function <> functorch interaction is in a mostly completed
state now. There are some minor action items remaining
(https://github.com/pytorch/pytorch/issues/90224), but I want to enable
the feature by default so that PyTorch CI / other parties / etc can
begin testing to see if there is any impact on the original
autograd.Function API (there shouldn't be).
The longer-term plan for the feature flag is:
- keep it around until at least the next release (so that people can
turn off the feature if it breaks something in existing code)
- delete the flag then (either before or after the release, I haven't
decided yet)
Test Plan:
- new test
- wait for CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91441
Approved by: https://github.com/albanD, https://github.com/soulitzer
rebasing certain merged prs results in the rebased branch pointing at the target branch b/c git believes the pr has already been included in the branch. Git does not replay the changes onto the target branch because the change is already in the target branch
This usually affects PRs with only 1 commit (more commits -> trymerge squashes them when merged -> git believes that the change is not in the target branch b/c the squashed commit is different from the individual changes).
It might also affect ghstack changes b/c behind the scenes the ghstack PRs are all contained within one commit on the orig branch, but I'm not sure about this.
helps w/ https://github.com/pytorch/test-infra/issues/836
looks like https://github.com/clee2000/random-testing/pull/44#issuecomment-1363439534
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91337
Approved by: https://github.com/ZainRizvi
This PR moves the definitions for:
* `sym_int`
* `sym_ceil` (used only for `sym_int`)
* `sym_floor` (used only for `sym_int`)
* `sym_float`
from `torch/fx/experimental/symbolic_shapes.py` to `torch/__init__.py`, where `SymInt` and `SymFloat` are already defined.
This removes the need for several in-line imports, and enables proper JIT script gating for #91318. I'm very open to doing this in a better way!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91317
Approved by: https://github.com/ezyang, https://github.com/anijain2305
Fixes#91107
Added `softmax` docs in
- `pytorch/torch/_tensor_docs.py`
- `pytorch/torch/_torch_docs.py `
- `pytorch/docs/XXX.rst` files. Here XXX represents all those files where I made the change
Although I have added `softmax` in `docs` directory, I was not sure which files/folders required the edits so there could be issues
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91292
Approved by: https://github.com/lezcano
NumPy versions 1.22 and 1.23 (and their respective bugfix releases included) have a buggy implementation of the Dlpack deleter that doesn't account for no-GIL contexts. Since we now release the GIL when deallocating tensors in `THPVariable_clear`, this leads to a failure of internal consistency checks when freeing a Dlpack-backed tensor from NumPy.
This PR adds a check for the buggy NumPy versions and overrides the `DlManagedTensor` deleter to reacquire the GIL before deallocation.
### Rationale for this implementation
The version check was added to `tensor_numpy.h/cpp` as it seemed like a more logical location for it than creating a new translation unit. The overriding of the deleter was originally attempted by directly modifying `at::fromDlpack`, but the lack of a build dependency on the Python C API in A10 prevented that. So, I extended the A10 Dlpack API instead to additionally accept a custom deleter functor.
Fixes#88082
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89759
Approved by: https://github.com/albanD
This function is an auxiliary function for `torch.norm`. This particular
overload was not even used or tested. I hope it's not used internally
either. If it is, we can simply drop this PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81762
Approved by: https://github.com/ngimel
### Motivation
When dim is -1 and the slice of source or result is noncontiguous, original `index_add` is slow as it uses add for the sliced tensor, which is serial on index and parallel on sliced tensor to avoid write conflict. Doing parallel on the sliced tensor is not optimal as the size of sliced tensor may be not big enough to parallel and also causes multiple parallelizations.
`scatter_add ` is used to speedup for this case as `scatter_add ` parallels on the outer dimension of input and is serial on the inner dimension to avoid write conflict. `scatter_add ` only need one parallel and the size of outer dimensions is bigger to do parallel.
### Testing
- Single core:
Before:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 2.82E-03 | 2.11E-03
[10, 128, 50, 50] | 0.023604 | 0.023794
After:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 9.30E-04 | 1.66E-03
[10, 128, 50, 50] | 0.005995 | 0.010003
- Single socket (28 cores):
Before:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 2.96E-03 | 2.52E-03
[10, 128, 50, 50] | 0.012208 | 0.012568
After:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 7.44E-05 | 1.33E-04
[10, 128, 50, 50] | 0.000333 | 0.000469
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88729
Approved by: https://github.com/mingfeima, https://github.com/jgong5, https://github.com/malfet
Noticed the toSymFloat / toSymInt overloads always copied the internal pointer of an ivalue even if it was an rvalue unlike other overloads (like toTensor). This fixes that issue by adding the appropriate methods needed to facilitate that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91405
Approved by: https://github.com/ezyang
initialise the members boolean_ and integer_ of at::indexing::TensorIndex to false and 0 respectively, because the compiler generated copy-ctor accesses them which is UB. This resolves a compile time warning, a runtime error from UBSan + gcc, and a runtime error from MSVC when compiling debug.
Fixes#90951
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91399
Approved by: https://github.com/bdhirsh
Support for jvp is very similar to support for backward():
- We need to vmap over a version of the original autograd.Function's jvp
method that does not take ctx as input.
- On the output, we need to reductify to ensure the output tangent has
the same shape as the output. This reductify does not have the
extra reduction semantics, because PyTorch forward-mode AD requires the
output tangent to have the same exact shape as the output.
- setup_context needs to tell us the bdims of the saved_tensors
(necessary for vmap over jvp_no_context), as well
as the output shapes (necessary for reductify).
Test Plan:
- Added jvp support to the *GenVmapAutogradFunction
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91211
Approved by: https://github.com/soulitzer
This PR adds the following tests. They will be useful as test cases for
generate_vmap_rule=True and jvp (to come soon)
- test_jvpvmap
- test_jvpvmapvmap
- test_vmapjvpvmap
- test_jvpjvpvmap
- test_jvpvjpvmap
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91206
Approved by: https://github.com/soulitzer
This reverts commit 57dcd93c4103c6db043f341a0242596a42188081.
Reverted https://github.com/pytorch/pytorch/pull/91371 on behalf of https://github.com/kit1980 due to trunk / cuda11.6-py3.10-gcc7-sm86 / test (slow, 1, 2, linux.g5.4xlarge.nvidia.gpu) started to fail after this PR with mypy error
Summary:
As title.
Saw this while working on another diff.
`storage` won't be defined in the `else` case. But this causes pyre to freak out.
Test Plan: Unit tests.
Differential Revision: D41751229
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90306
Approved by: https://github.com/PaliC
Fixes https://github.com/pytorch/pytorch/issues/91041
There's a bug in our boxed reduction batching rules for a very specific
case: vmap over a Tensor of shape [1] for an operation where the
output rank is supposed to be less than the input rank, e.g.
```
x = torch.tensor([10.], device=device)
y = vmap(lambda x: x.sum(0))(x)
```
The boxed reduction batching rule handles three types of "reduction"
operations:
- reduction operations with an optional keepdim argument, which
specifies if the output should have the same or smaller rank than the
input
- reduction operations without a keepdim arg that morally have keepdim=True (like cumsum --
which never actually modifies the rank of the tensor but is still a
"reduction" since it sums a bunch of things together)
- reduction operations without a keepdim arg that morally have
keepdim=False. (just torch.count_nonzero).
Furthermore, PyTorch has special handling for scalar tensors (e.g.
tensors of shape []). It is valid to do
`torch.sum(torch.tensor(10.), dim=0)`.
This PR updates the `boxed_reduction_batch_rule` to handle the
interaction between the three kinds of reduction and the scalar tensor
cases correctly. Concretely, it:
- introduces additional templates to `boxed_reduction_batch_rule` for
what type of "keepdim" reduction this is.
- splits the old REDUCTION_BOXED macro (which was a good default) into
REDUCTION_NO_KEEPDIM_ARG and REDUCTION_WITH_KEEPDIM_ARG (which are also
opionated defaults) and uses them.
Test Plan:
- Given an input of shape [], our vmap OpInfo test suite only produces
a Tensor of shape [B] with B = 2. At first glance this doesn't look
sufficient to test this case (vmap over Tensor[1]), but the claim is
that it is because the boxed_reduction_batch_rule is agnostic to the shape
of the dimension being vmapped over. Previously it was not due to
the semantics of `squeeze`; this PR adds internal asserts to make it agnostic.
- there is a light test for vmap over the Tensor of shape [1] for
torch.sum as a sanity check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91109
Approved by: https://github.com/samdow
…c10d
Fixes a broken header filters from #90699 and applies a few more clang-tidy fixes that are relevant from c10 and c10d. The header filter pattern was actually broken and the clang-tidy include pattern was redundant. Also fixed a few bugs in torch/distributed/c10d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91178
Approved by: https://github.com/ezyang
This `is_forward_ad` isn't propagated, which leads to this line creating a
slow-gradcheck failure on master:
```
if not is_forward_ad and any(o.is_complex() for o in outputs):
raise ValueError("Expected output to be non-complex. get_numerical_jacobian no "
"longer supports functions that return complex outputs.")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91391
Approved by: https://github.com/albanD
## Problem
When models have a lot of complex repeated layers, `print(module)` output becomes unfeasible to work with. For example, current output of `__repr__` for `t5-small` is `715 ` lines long.
## Solution
Using better `__repr__` it becomes `135`. For `t5-large`, current `__repr__` prints `1411` lines. Better `__repr__` — `135`. Same numer as for t5-small, because most of the layers are just repeated. For `EleutherAI/gpt-j-6B` number of lines reduces form `483` to just `24`.
Here's how it works: when ModuleList items have exactly the same `__repr__` instead of printing both of them, it prints f`N x {repr(item)}`. Current code supports cases when the same ModuleList has multiple repeating items, which is especially useful when first/last layer of a block is different from the reset of them.
Better `__repr__` should make model prints smaller, more beautiful and significantly more useful by highlighting the difference between repeated blocks instead of losing it in a wall of text.
## Motivating real-life example.
You can try it out in this [colab notebook](https://colab.research.google.com/drive/1PscpX_K1UemIDotl2raC4QMy_pTqDq7p?usp=sharing).
Current `__repr__` of gpt-j-6b output it too big to add it to this PR description:
```
GPTJModel(
(wte): Embedding(50400, 4096)
(drop): Dropout(p=0.0, inplace=False)
(h): ModuleList(
(0): GPTJBlock(
(ln_1): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(attn): GPTJAttention(
(attn_dropout): Dropout(p=0.0, inplace=False)
(resid_dropout): Dropout(p=0.0, inplace=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(out_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): GPTJMLP(
(fc_in): Linear(in_features=4096, out_features=16384, bias=True)
(fc_out): Linear(in_features=16384, out_features=4096, bias=True)
(act): NewGELUActivation()
(dropout): Dropout(p=0.0, inplace=False)
)
)
(1): GPTJBlock(
(ln_1): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(attn): GPTJAttention(
(attn_dropout): Dropout(p=0.0, inplace=False)
(resid_dropout): Dropout(p=0.0, inplace=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(out_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): GPTJMLP(
(fc_in): Linear(in_features=4096, out_features=16384, bias=True)
(fc_out): Linear(in_features=16384, out_features=4096, bias=True)
(act): NewGELUActivation()
(dropout): Dropout(p=0.0, inplace=False)
)
)
(2): GPTJBlock(
...
```
Better `__repr__` output looks like this:
```
GPTJModel(
(wte): Embedding(50400, 4096)
(drop): Dropout(p=0.0, inplace=False)
(h): ModuleList(
(0-27): 28 x GPTJBlock(
(ln_1): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(attn): GPTJAttention(
(attn_dropout): Dropout(p=0.0, inplace=False)
(resid_dropout): Dropout(p=0.0, inplace=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(out_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): GPTJMLP(
(fc_in): Linear(in_features=4096, out_features=16384, bias=True)
(fc_out): Linear(in_features=16384, out_features=4096, bias=True)
(act): NewGELUActivation()
(dropout): Dropout(p=0.0, inplace=False)
)
)
)
(ln_f): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90452
Approved by: https://github.com/albanD
This helps with kernels that make use of caching like mid-range softmax
which reads the data three times.
Selecting `eviction_policy=evict_first` in the last loop of the softmax
operation seems to give a 7-10% speed-up vs. selecting `evict_last` which
was the previous option. I'll put up some benchmarks soon™.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91316
Approved by: https://github.com/ngimel
Fixes#91107
Added `softmax` docs in
- `pytorch/torch/_tensor_docs.py`
- `pytorch/torch/_torch_docs.py `
- `pytorch/docs/XXX.rst` files. Here XXX represents all those files where I made the change
Although I have added `softmax` in `docs` directory, I was not sure which files/folders required the edits so there could be issues
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91292
Approved by: https://github.com/lezcano
Found this issue from [weekly running 7k github models](https://github.com/pytorch/torchdynamo/issues/1884). This caused regression on pass rate, there are 25 models failed due to this issue.
The reason is argument ```cx``` of ```aten._cudnn_rnn``` can be ```None```, but it doesn't handle well in meta registration, so throws the following error:
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1059, in run_node
return nnmodule(*args, **kwargs)
File "/scratch/ybliang/work/repos/pytorch/torch/nn/modules/module.py", line 1482, in _call_impl
return forward_call(*args, **kwargs)
File "/scratch/ybliang/work/repos/pytorch/torch/nn/modules/rnn.py", line 477, in forward
result = _VF.rnn_tanh(input, hx, self._flat_weights, self.bias, self.num_layers,
File "/scratch/ybliang/work/repos/pytorch/torch/_subclasses/fake_tensor.py", line 916, in __torch_dispatch__
r = func(*args, **kwargs)
File "/scratch/ybliang/work/repos/pytorch/torch/_ops.py", line 284, in __call__
return self._op(*args, **kwargs or {})
File "/scratch/ybliang/work/repos/pytorch/torch/_meta_registrations.py", line 2108, in _cudnn_rnn
cy = cx.new_empty(0 if cx is None else cell_shape)
AttributeError: 'NoneType' object has no attribute 'new_empty'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91333
Approved by: https://github.com/ezyang
To help resolve issues like:
```
++ python3 .github/scripts/get_workflow_job_id.py 3736406815 i-08b8fd3e605729ed9
+ GHA_WORKFLOW_JOB_ID=
Warning: Attempt 2 failed. Reason: Child_process exited with error code 1
```
This should only happen when github actions is experiencing degraded service
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91145
Approved by: https://github.com/malfet
This PR adds functionalization path for torch.cond. As it is the first pass, we only functionalize for very restrictive use cases. We explicitly restrict following:
- Output of each branch aliasing input
- In-place mutation on inputs given to each branch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89966
Approved by: https://github.com/zou3519
Builds up sympy expressions computing the lower and upper bound of ranges, and then finds `op.to_dtype(x, torch.int64)` nodes whose dominated values can all be computed in a lower precision. I haven't gotten all the way to work with dynamic shapes but it should be a fairly small change. There's still additional work to get torchinductor to work with large tensors (see https://github.com/pytorch/torchdynamo/issues/1819) because we would need to add explicit dtype annotations to int64 which we're not doing right now.
Fix for https://github.com/pytorch/torchdynamo/issues/1293.
Performance Before OpBench aten.upsample_bilinear2d.vec float32:
(25th %, 50th %, 75th %)
Before
[0.7521964636710751, 0.8645357996607477, 2.8746003906598494]
After:
[0.9511363478204263, 1.0295566597806718, 3.2662165264101755]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91028
Approved by: https://github.com/jansel
CUDA 12 introduces behavioral changes in `cudaSetDevice`. In the old version it would just set the device to be used for kernel launches and memory allocations without creating a CUDA context. Now, in CUDA 12, every time `cudaSetDevice` is called for the first time it creates a CUDA context. See issue #91122.
The autograd engine iterates over all devices and sets them:
f8b348c1fc/torch/csrc/autograd/engine.cpp (L1399-L1402)f8b348c1fc/torch/csrc/autograd/engine.cpp (L349)
Which causes pollution of CUDA contexts on sibling devices.
This PR introduces a workaround this issue by conditionally setting the device.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91191
Approved by: https://github.com/ngimel
It turns out that we *do* need to update *_scatter ops to return the exact same strides as their inputs. I added a test to `test/test_functionalization.py`, which now trips thanks to Ed's functionalization stride debugging check. It only actually ends up tripping silent correctness if you try to .backward() on that function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91029
Approved by: https://github.com/ezyang
Use curly braces even after single line `if`
Use whitespace between `if` and condition
Use `c10::irange`
Also, use `c10::multiply_integers` instead of explicit for loop of elements of `IntArrayRef`
Do not pass `num_input_dims` to `set_apparent_shapes` as it is always equal to the length of `input_shape` array
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91221
Approved by: https://github.com/kit1980, https://github.com/huydhn
See #91122
Summary:
Some APIs are deprecated in newer version of CUDA.
* cudaGraphInstantiate:
From:
```
cudaGraphInstantiate ( cudaGraphExec_t* pGraphExec, cudaGraph_t graph, cudaGraphNode_t* pErrorNode, char* pLogBuffer, size_t bufferSize )
```
To
```
__host__cudaError_t cudaGraphInstantiate ( cudaGraphExec_t* pGraphExec, cudaGraph_t graph, unsigned long long flags = 0 )
```
* cudaProfilerInitialize: deprecated in cuda 11 and removed in cuda 12
Test Plan: GH CI
Differential Revision: D41469051
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91050
Approved by: https://github.com/jianyuh
Summary:
1) Setting torch.backends.cudnn.deterministic to True helps to
eliminate the eager_variance failures seen on CI
2) Skip Triton failure instead of retry
3) Some minor script cleanup is also included in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91283
Approved by: https://github.com/anijain2305
This PR is a new version of #89566, fixing a test failure.
Couldn't get ghstack to colaborate on updating that PR after re-opening,
so started a new one.
This changes the way masks for loads/stores are computed in triton backend of inductor.
New approach is to iterate over all variables used in indexing expression and add the corresponding mask variables to the set that will be used. For indexing variables like `x0`, `y1` and `r3` it adds `xmask`, `ymask` and `rmask` respectively.
For indexing variables like `tmp5` (i.e., indirect indexing), it uses the new `mask_vars` attribute of the corresponding `TritonCSEVariable` object, which is populated when variable is created.
I started working on this with the aim of fixing https://github.com/pytorch/torchdynamo/issues/1654, which meanwhile was fixed by #89524 with a different approach, making this change less necessary. However note that #89524 fixes the issue by broadcasting the indices that are being loaded to a larger size, while this approach fixes it by making the mask have only the necessary terms.
Relative to #89566, the only change is to not include the mask variables
of arguments when the function being called is `tl.where`. The reason
being that `tl.where` is often used precisely to make sure the output
variable has valid values.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91241
Approved by: https://github.com/ngimel
Use Prims to implement group_norm, group_norm_backward and mean_var
Use `torch._ops.ops` instead of `torch.ops` in numerous subpackages in
order to be able to make them importable from `torch/backend/mps/__init__.py` as this alias is defined in
15af4b1cee/torch/__init__.py (L1095)
is executed last during init process.
Add `__all__` to `torch/backends/mps/__init__.py` as well as alias all imports as private
Add `TestNNMPS.test_group_norm_backward` that validates no NaNs are generated during the backward pass
Fixes https://github.com/pytorch/pytorch/issues/88331
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91190
Approved by: https://github.com/albanD
This change aims to make bazel build more embeeding-friendly.
Namely, when PyTorch is included as an external repo in another project, it is usually included like this
```
native.local_repository(
name = "pytorch",
path = ...,
repo_mapping = repo_mapping,
)
```
Or
```
http_archive(
name = "pytorch",
urls = ...
repo_mapping = repo_mapping,
)
```
In this case, references to `@//` would resolve to the top-level WORKSPACE that includes PyTorch.
That makes upgrades harder because we need to carry around this patch.
Note that under some edge-case circumstances even `//` resolves to the top-level `WORKSPACE`.
This change makes the embedding of the bazel build easier without compromising anything for the main repo, since the `@pytorch//` still refers to the same thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89660
Approved by: https://github.com/kit1980
**What does this PR do?**
This PR refactors FSDP optimizer state_dict APIs to accept `NamedOptimizer` as the input optimizer. The key difference is that the state_dict returned by `NamedOptimizer` is already keyed as FQN. This PR majorly changes the internal mapping to allows the optimizer state_dict to be keyed as FQN.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91160
Approved by: https://github.com/fduwjj, https://github.com/rohan-varma
### Motivation
When dim is -1 and the slice of source or result is noncontiguous, original `index_add` is slow as it uses add for the sliced tensor, which is serial on index and parallel on sliced tensor to avoid write conflict. Doing parallel on the sliced tensor is not optimal as the size of sliced tensor may be not big enough to parallel and also causes multiple parallelizations.
`scatter_add ` is used to speedup for this case as `scatter_add ` parallels on the outer dimension of input and is serial on the inner dimension to avoid write conflict. `scatter_add ` only need one parallel and the size of outer dimensions is bigger to do parallel.
### Testing
- Single core:
Before:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 2.82E-03 | 2.11E-03
[10, 128, 50, 50] | 0.023604 | 0.023794
After:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 9.30E-04 | 1.66E-03
[10, 128, 50, 50] | 0.005995 | 0.010003
- Single socket (28 cores):
Before:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 2.96E-03 | 2.52E-03
[10, 128, 50, 50] | 0.012208 | 0.012568
After:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 7.44E-05 | 1.33E-04
[10, 128, 50, 50] | 0.000333 | 0.000469
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88729
Approved by: https://github.com/mingfeima, https://github.com/jgong5, https://github.com/malfet
Fixes#90500
The change here checks for parameter changes at the beginning of each `forward()` call; if the parameters are found to be different tensors than last time, `self._flat_weights` is re-initialized with the new values. Thus, swapping parameter values using `stateless.functional_call()` will re-initialize `self._flat_weights` during the `forward()` call, and the provided parameters will be used for module computation as expected.
NB: There are still some changes needed for symbolic shapes to work with `nn.GRU` (will address in a follow-up PR).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91111
Approved by: https://github.com/ezyang, https://github.com/albanD
Summary:
After this change, if the querypool_flushed_shader_log test fails:
1) The test continues after the first failure and checks all three (Because ASSERT was changed to EXPECT)
2) The op names which are compared to vulkan.add, vulkan.sub, and vulkan.mul are shown (rather than not showing what the wrong op name was) (Because we use ..._EQ(a, b) instead of just checking ...(a == b))
This change makes it easier to debug future failures to querypool_flushed_shader_log (it helped me when one of my diffs broke the test)
Test Plan:
Vulkan API Test
- https://www.internalfb.com/intern/aibench/details/959371570734292
Reviewed By: SS-JIA
Differential Revision: D42186371
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91259
Approved by: https://github.com/SS-JIA
**What does this PR do?**
This PR splits the FSDP optim_state_dict APIs into common implementation parts that are shared for different frontend APIs (we have many now and will consolidate them gradually). This PR also add `_optim_state_dict_post_hook` and `_load_optim_state_dict_pre_hook` for the integration with `NamedOptimzer`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90798
Approved by: https://github.com/rohan-varma, https://github.com/awgu
This reverts commit d6fc2d82ca616f87d9fef49e84e6d4ff6976292f.
Reverted https://github.com/pytorch/pytorch/pull/91018 on behalf of https://github.com/kit1980 due to After this PR, inductor / cuda11.6-py3.10-gcc7-sm86 / test fails every time with CUDA out of memory during OPTForCausalLM
I realized test_fused_optimizers used a helper that was written for foreach, so we were not testing fused at all. This PR fixes that test so we actually test fused adam.
The explicitly adding fused=False is to set the stage for my later changes (but should be a no-op here).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91228
Approved by: https://github.com/albanD, https://github.com/soulitzer
Essentially the same change as #67946, except that the default is to disallow reduced precision reductions in `BFloat16` GEMMs (for now). If performance is severely regressed, we can change the default, but this option appears to be necessary to pass some `addmm` `BFloat16` tests on H100.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89172
Approved by: https://github.com/ngimel
Allow _apply_optim_in_backward to work with DDP.
Example:
```
dist.init_process_group("nccl", rank=rank, world_size=2)
torch.cuda.set_device(rank)
e = enc().cuda(rank)
_apply_optimizer_in_backward(
optimizer_class=torch.optim.SGD,
params=e.parameters(),
optimizer_kwargs={"lr": 0.03},
)
e = DDP(e, device_ids=[rank])
inp = torch.randn(1, 10, device=rank)
e(inp).sum().backward()
```
Constraints:
1. Custom communication hook not yet supported
2. _apply_optim_in_backward needs to be called _before_ wrapping model in DDP.
3. DDP will remove the gradient hooks _apply_optim_in_backward registers, so these gradient hooks will not be fired and cannot be used.
4. All DDP managed parameters have grads set to None by default once optimizer is applied. There is no support for setting only some parameter grads to None, this must be done manually by user (and DDP_OVERLAPPED_OPTIM_SET_GRADS_TO_NONE=0 needs to be set.)
Differential Revision: [D41329694](https://our.internmc.facebook.com/intern/diff/D41329694/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D41329694/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89194
Approved by: https://github.com/zhaojuanmao
The `multiplicationWithPrimaryTensor` and/or `scatterWithDataTensor` api has issues with handling two f16 tensor inputs, resulting in zeros outputs. With int16 or int64 inputs, there are issues as well.
This PR conditionally casts inputs to f32 if they're not and then casts the output back to the source's datatype.
Fixes#82645.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88542
Approved by: https://github.com/kulinseth
I'm going to need this in the follow up PR. Instead of storing only Source.name() in Symbol, I now store a full on Source. Lots of replumbing reoccurs. In particular:
- Move Source to torch._guards to break cycles
- I have to add TensorPropertySource and NegateSource to handle x.size()[0] and -x codegen that I was doing with string manipulation previously
- I tighten up invariants so that I never pass source=None; instead I pass ConstantSource (these are constant sources right) and test for that rather than source being missing. I think this is more parsimonious
- Some mypy wobbles from new imports
I didn't move LocalSource and friends to torch._guards, but I ended up needing to access them in a few places. The main annoyance with moving these is that then I also need to move the bytecode codegen stuff, and that's not so easy to move without bringing in the kitchen sink.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91057
Approved by: https://github.com/albanD, https://github.com/voznesenskym
The idea is to make ShapeEnv guards less of a one-off special snowflake, and integrate it more closely with the regular builder infrastructure. But it is not so easy: the shape env code has to live after tensor match code, because we need to know that the values in question are tensors before we start matching on them. So we introduce a new `shape_env_code` field to put the special shape env code, so we can add it to the final constructed code after tensor.
Everything else works the obvious way. There's a new ShapeEnvSource for constructing the singleton SHAPE_ENV guard that drives the shape env guard construction. I added some more docs and also made the printed code for guards include the enclosing lambda for more clarity.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91055
Approved by: https://github.com/albanD, https://github.com/voznesenskym
## Job
Test running on most CI jobs.
## Test binary
* `test_main.cpp`: entry for gtest
* `test_operator_registration.cpp`: test cases for gtest
## Helper sources
* `operator_registry.h/cpp`: simple operator registry for testing purpose.
* `Evalue.h`: a boxed data type that wraps ATen types, for testing purpose.
* `selected_operators.yaml`: operators Executorch care about so far, we should cover all of them.
## Templates
* `NativeFunctions.h`: for generating headers for native functions. (not compiled in the test, since we will be using `libtorch`)
* `RegisterCodegenUnboxedKernels.cpp`: for registering boxed operators.
* `Functions.h`: for declaring operator C++ APIs. Generated `Functions.h` merely wraps `ATen/Functions.h`.
## Build files
* `CMakeLists.txt`: generate code to register ops.
* `build.sh`: driver file, to be called by CI job.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89596
Approved by: https://github.com/ezyang
Design document:
https://docs.google.com/document/d/1bIQkWXy3J35_20c_a5kchikabBW5M8_uRAhl0BIMwU4/edit
This PR adds a `generate_vmap_rule` option (default False) to autograd.Function.
By setting it to True, a user promises to us that their autograd.Function's
{forward, backward, jvp}, if defined, only uses PyTorch operations, in addition to the other
limitations of autograd.Function+functorch (such as the user not
capturing any Tensors being transformed over from outside of the
autograd.Function).
Concretely, the approach is:
- we update `custom_function_call` to accept an additional
`generate_vmap_rule` argument.
- The vmap rule for `custom_function_call` and `generate_vmap_rule=True`
is: we construct a vmapped version of the autograd.Function and dispatch
on it.
- The vmapped version of the autograd.Function can be thought of like
the following: if we have an autograd.Function Foo, then
VmappedFoo.apply(in_dims, ...) has the same semantics as
vmap(Foo.apply, in_dims...)
- VmappedFoo's forward, setup_context, and backward staticmethod are
vmapped versions of Foo's staticmethods.
- See the design doc for more motivation and explanation
Test Plan:
- This PR introduces additional autograd.Function with the suffix "GenVmap" to
autograd_function_db.
- There are also some minor UX tests
Future:
- jvp support
- likely more testing to come, but please let me know if you have
cases that you want me to test here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90966
Approved by: https://github.com/soulitzer
As seen in
https://docs.google.com/document/d/1bIQkWXy3J35_20c_a5kchikabBW5M8_uRAhl0BIMwU4/edit
`reductify_leaf(grad_input, ...)` is a helper function that processes a
single grad_input Tensor. The reason why we need it is:
- the grad_input has some optional bdim
- the input has some optional bdim
- if these are different, we need to coerce the grad_input into having
the same shape as the input, either by reducing or expanding the
grad_input.
Note that there is a special case in autograd that the user is allowed
to return a grad_input Tensor that is an expanded version of the
original input tensor. In this case, autograd automatically reduces
grad_input to the same shape as the input. Unfortunately this logic
doesn't work when bdims are involved, so we manually handle it in
`reductify_leaf`.
Test Plan:
- tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90965
Approved by: https://github.com/soulitzer
As seen in
https://docs.google.com/document/d/1bIQkWXy3J35_20c_a5kchikabBW5M8_uRAhl0BIMwU4/edit
`restore_vmap` is a private helper function. It is vmap but has the
following
differences:
- instead of returning outputs, it returns an (outputs, out_dims) tuple.
out_dims is a pytree of shape shape as outputs and contains Optional[int]
specifying where the vmapped dimension, if it exists, is in the
corresponding output.
- does no validation on in_dims or inputs (vmap expects at least one
Tensor to be vmapped).
restore_vmap allows for no inputs to have the vmap dimension
- does no validation on outputs (vmap expects only Tensor outputs)
restore_vmap allows for return of arbitrary outputs (not just
Tensors)
Test Plan:
- added some simple test to test restore_vmap
- I am OK with restore_vmap not being a part of vmap right now -- the
implementation of vmap rarely changes and it is a bit difficult to
refactor vmap in a way that restore_vmap is a subroutine.
Other questions:
- Bikeshedding the `restore_vmap` name
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90963
Approved by: https://github.com/samdow, https://github.com/soulitzer
Otherwise, Nested Tensor kernels won't sync with current stream, resulting in flaky unit tests in test_nestedtensor.py.
This is the second time the wrong streams have been used in NestedTensor code. See #84134 for another example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91180
Approved by: https://github.com/mikaylagawarecki
1. Add param_group check logic and unit test
2. Remove unnecessary check for conditional param update
3. Return the param_group from the inner optimizer so that when param_group is None or not all params are specified, we still return the expected result.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91147
Approved by: https://github.com/fegin
Use ROCR_VISIBLE_DEVICES to limit GPU visibility, in preparation for CI node upgrade to ROCm5.3 KFD and UB22.04.
### PROBLEM
After upgrading some of our CI nodes to UB22.04 and ROCm5.3KFD, rocminfo doesn't work inside the docker container if we use the following flags: `--device=/dev/dri/renderD128 --device=/dev/dri/renderD129`. It gives the error:
```
+ rocminfo
ROCk module is loaded
Failed to set mem policy for GPU [0x6b0d]
hsa api call failure at: /long_pathname_so_that_rpms_can_package_the_debug_info/src/rocminfo/rocminfo.cc:1140
Call returned HSA_STATUS_ERROR_OUT_OF_RESOURCES: The runtime failed to allocate the necessary resources. This error may also occur when the core runtime library needs to spawn threads or create internal OS-specific events.
```
### WORKAROUND
Use `--device=/dev/dri` instead, and use `ROCR_VISIBLE_DEVICES` to limit GPU visibility inside container.
### BACKGROUND OF ORIGINAL CODE
We introduced these flags to prepare for 2 runners per CI node, to split up the GPU visibility among the runners: https://github.com/pytorch/pytorch/blame/master/.github/actions/setup-rocm/action.yml#L58
That effort - 2 runners per CI node - is still pending, and we might need to revisit this patch when we try to enable that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91031
Approved by: https://github.com/jeffdaily, https://github.com/malfet
This is to address the recent flakiness issue on MacOS ARM64 https://hud.pytorch.org/failure/Library%20not%20loaded%3A%20%40rpath%2Flibzstd.1.dylib.
From what I see, the immediate cause is that `cmake` exec under `/Users/ec2-user/runner/_work/_temp/miniconda/pkgs/cmake-3.22.1-hae769c0_0/bin/` is used instead of the expected one under the temp CONDA_ENV, i.e. `/Users/ec2-user/runner/_work/_temp/conda_environment_3736476178/bin`. I'm not quite sure what is the reason behind this flaky behavior, so I want to try a catch-all fix by setting the cmake PATH correctly
This PR also prints some debugging information w.r.t cmake PATH, and cleans up some legacy code in `macos-test.sh` script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91142
Approved by: https://github.com/ZainRizvi
This PR supports nesting `replicate` in `fully_shard`.
- The PR achieves this by treating `replicate`-annotated modules are ignored modules. This means that all submodules in the `replicate`-annotated module's subtree are ignored, including nested `fully_shard`-annotated modules, which is the desired behavior.
---
This PR reworks some tree traversal.
One end goal is for `state._handles` to follow the same order for both the wrapper and composable paths. This implies that `_get_fsdp_handles()` returns the same value for both paths.
- The helper function `_get_fully_sharded_module_to_states()` now follows a left-to-right DFS from each fully sharded module instead of a BFS. The left-to-right DFS follows `.modules()` order.
- The composable auto "wrap" initialization function `_init_param_handles_from_module()` follows the reverse left-to-right DFS order. As noted in the code comments, this initialization order is a valid reverse topological sort, but it differs from the wrapper path. This is the _only_ difference with respect to initialization order through the entire process.
```
mod: Module(
submod1: Submodule()
submod2: Submodule(
subsubmod: Subsubmodule(),
),
)
```
For left-to-right DFS, the order is `mod`, `submod1`, `submod2`, `subsubmod`. (For context, right-to-left DFS would be `mod`, `submod2`, `subsubmod`, `submod1`. In other words, the left-to-right vs. right-to-left corresponds to `.children()` vs. `reversed(.children())` respectively.) Then, reverse left-to-right DFS is `subsubmod`, `submod2`, `submod1`, `mod`, which is a valid initialization order. However, the wrapper auto wrap initialization order would be `submod1`, `subsubmod`, `submod2`, `mod` since it directly follows a left-to-right DFS and initializes as a part of the recursive DFS logic.
- At the end of `_init_param_handles_from_module()`, we reverse the newly populated `state._handles`, so this is the reverse reverse left-to-right DFS order, which is equivalent to the left-to-right DFS order. Thus, `state._handles` has the same order for both paths.
Another goal is for `_get_fsdp_states()` to not traverse into any submodule that is annotated with an API that is not compatible with `fully_shard` (e.g. `replicate`). To achieve this while preserving that `_get_fsdp_states()` follows `.modules()` order, we again use a left-to-right DFS.
The reason the DFSs may look strange is because I implemented them non-recursively, which requires a stack.
- `test_get_fully_sharded_module_to_states()` in `test_utils.py` checks the traversal order of `_get_fully_sharded_module_to_states()`.
- `test_policy()` in `test_fully_shard.py` checks the traversal order returned by `_get_fsdp_handles()`.
---
Due to a circular dependency issue, we must move the graph/tree traversal helpers to their own file `_traversal_utils.py`, and any usages must import the entire file like `import torch.distributed.fsdp._traversal_utils as traversal_utils` instead of `from torch.distributed.fsdp._traversal_utils import ...`.
The cycle comes from the fact that the traversals require `_composable()`, which requires `_get_registry()` from `composable/contract.py`, which when imported, imports `composable/fully_shard.py`, which requires the traversals.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91044
Approved by: https://github.com/mrshenli
This adds a note to explain how to do traversal in the new code base. These traversal helper methods were introduced in [1/N], [3/N], and [5/N].
I am working on updating the traversal helpers to account for other composable APIs (e.g. `replicate`). The rule is that the traversal should not proceed into an incompatible API's tree. This will be needed for `fully_shard` to be above `replicate`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90959
Approved by: https://github.com/mrshenli
This PR adds manual "wrapping" support for `fully_shard`. For example, for
```
fully_shard(mod.sub)
fully_shard(mod)
```
`mod.sub` and `mod` will share the same FSDP data structures.
To have parity with wrapper FSDP, this PR only checks support for when each manual application of `fully_shard` passes `policy=None`. Hybrid auto / manual wrapping is not in scope for this PR since it is not supported for wrapper FSDP either. I can follow up to either add support properly or raise and error early.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90874
Approved by: https://github.com/mrshenli
For `limit_all_gathers`, if we do not enforce that they all have the same value, then the entire semantics guaranteed by the `bool` can be violated. It could be as if none of them set that value to be `True`.
For `use_orig_params`, optimizer state dict assumes that the value is the same for all FSDP instances.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90871
Approved by: https://github.com/mrshenli
This allows to know at any point during the backward pass what is running and where the Node currently running was created at:
```python
import torch
from torch.utils._python_dispatch import TorchDispatchMode
from torch.autograd import detect_anomaly
class MyMode(TorchDispatchMode):
def __torch_dispatch__(self, func, types, args, kwargs=None):
node = torch._C._current_autograd_node()
print(f"Running {func} from within {node}")
if node is not None:
print("The Node was created at:")
print("\n ".join(node.metadata["traceback_"]))
return func(*args, **kwargs or {})
with MyMode(), detect_anomaly():
print("FW")
a = torch.rand(10, requires_grad=True)
b = a.mul(2)
b = b.div(3)
b = b.sum()
print("BW")
b.backward()
```
Gives
```
$ python foo.py
foo.py:15: UserWarning: Anomaly Detection has been enabled. This mode will increase the runtime and should only be enabled for debugging.
with MyMode(), detect_anomaly():
FW
Running aten.rand.default from within None
Running aten.mul.Tensor from within None
Running aten.div.Tensor from within None
Running aten.sum.default from within None
BW
Running aten.ones_like.default from within None
Running aten.expand.default from within <SumBackward0 object at 0x7fa40c0c6dc0>
The Node was created at:
File "foo.py", line 20, in <module>
b = b.sum()
Running aten.isnan.default from within <SumBackward0 object at 0x7fa40c0c6500>
The Node was created at:
File "foo.py", line 20, in <module>
b = b.sum()
Running aten.any.default from within <SumBackward0 object at 0x7fa32b23a780>
The Node was created at:
File "foo.py", line 20, in <module>
b = b.sum()
Running aten._local_scalar_dense.default from within <SumBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 20, in <module>
b = b.sum()
Running aten.div.Tensor from within <DivBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 19, in <module>
b = b.div(3)
Running aten.isnan.default from within <DivBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 19, in <module>
b = b.div(3)
Running aten.any.default from within <DivBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 19, in <module>
b = b.div(3)
Running aten._local_scalar_dense.default from within <DivBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 19, in <module>
b = b.div(3)
Running aten.mul.Tensor from within <MulBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 18, in <module>
b = a.mul(2)
Running aten.isnan.default from within <MulBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 18, in <module>
b = a.mul(2)
Running aten.any.default from within <MulBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 18, in <module>
b = a.mul(2)
Running aten._local_scalar_dense.default from within <MulBackward0 object at 0x7fa40c0c9190>
The Node was created at:
File "foo.py", line 18, in <module>
b = a.mul(2)
Running aten.detach.default from within <AccumulateGrad object at 0x7fa40c0c9730>
The Node was created at:
File "foo.py", line 18, in <module>
b = a.mul(2)
Running aten.detach.default from within <AccumulateGrad object at 0x7fa40c0c94b0>
The Node was created at:
File "foo.py", line 18, in <module>
b = a.mul(2)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90867
Approved by: https://github.com/soulitzer
### Motivation
When dim is -1 and the slice of source or result is noncontiguous, original `index_add` is slow as it uses add for the sliced tensor, which is serial on index and parallel on sliced tensor to avoid write conflict. Doing parallel on the sliced tensor is not optimal as the size of sliced tensor may be not big enough to parallel and also causes multiple parallelizations.
`scatter_add ` is used to speedup for this case as `scatter_add ` parallels on the outer dimension of input and is serial on the inner dimension to avoid write conflict. `scatter_add ` only need one parallel and the size of outer dimensions is bigger to do parallel.
### Testing
- Single core:
Before:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 2.82E-03 | 2.11E-03
[10, 128, 50, 50] | 0.023604 | 0.023794
After:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 9.30E-04 | 1.66E-03
[10, 128, 50, 50] | 0.005995 | 0.010003
- Single socket (28 cores):
Before:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 2.96E-03 | 2.52E-03
[10, 128, 50, 50] | 0.012208 | 0.012568
After:
shape | fp32 / s | bf16 / s
-- | -- | --
[10, 128, 20, 20] | 7.44E-05 | 1.33E-04
[10, 128, 50, 50] | 0.000333 | 0.000469
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88729
Approved by: https://github.com/mingfeima, https://github.com/jgong5, https://github.com/malfet
Fix the failure when building PyTorch from source code using CUDA 12
```
In file included from /home/jianyuhuang/Work/Github/pytorch/c10/cuda/CUDAFunctions.h:12,
from /home/jianyuhuang/Work/Github/pytorch/c10/cuda/CUDAStream.h:10,
from /home/jianyuhuang/Work/Github/pytorch/c10/cuda/CUDAGraphsC10Utils.h:3,
from /home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.h:5,
from /home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp:2:
/home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp: In member function ‘void at::cuda::CUDAGraph::capture_end()’:
/home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp:168:75: warning: converting to non-pointer type ‘long long unsigned int’ from NULL [-Wconversion-null]
AT_CUDA_CHECK(cudaGraphInstantiate(&graph_exec_, graph_, NULL, NULL, 0));
^
/home/jianyuhuang/Work/Github/pytorch/c10/cuda/CUDAException.h:31:42: note: in definition of macro ‘C10_CUDA_CHECK’
C10_UNUSED const cudaError_t __err = EXPR; \
^~~~
/home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp:168:5: note: in expansion of macro ‘AT_CUDA_CHECK’
AT_CUDA_CHECK(cudaGraphInstantiate(&graph_exec_, graph_, NULL, NULL, 0));
^~~~~~~~~~~~~
/home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp:168:75: error: too many arguments to function ‘cudaError_t cudaGraphInstantiate(CUgraphExec_st**, cudaGraph_t, long long unsigned int)’
AT_CUDA_CHECK(cudaGraphInstantiate(&graph_exec_, graph_, NULL, NULL, 0));
^
/home/jianyuhuang/Work/Github/pytorch/c10/cuda/CUDAException.h:31:42: note: in definition of macro ‘C10_CUDA_CHECK’
C10_UNUSED const cudaError_t __err = EXPR; \
^~~~
/home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp:168:5: note: in expansion of macro ‘AT_CUDA_CHECK’
AT_CUDA_CHECK(cudaGraphInstantiate(&graph_exec_, graph_, NULL, NULL, 0));
^~~~~~~~~~~~~
In file included from /home/jianyuhuang/Work/Github/pytorch/c10/cuda/CUDAStream.h:6,
from /home/jianyuhuang/Work/Github/pytorch/c10/cuda/CUDAGraphsC10Utils.h:3,
from /home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.h:5,
from /home/jianyuhuang/Work/Github/pytorch/aten/src/ATen/cuda/CUDAGraph.cpp:2:
/usr/local/cuda/include/cuda_runtime_api.h:11439:39: note: declared here
extern __host__ cudaError_t CUDARTAPI cudaGraphInstantiate(cudaGraphExec_t *pGraphExec, cudaGraph_t graph, unsigned long long flags __dv(0));
^~~~~~~~~~~~~~~~~~~~
ninja: build stopped: subcommand failed.
```
```
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp: In function ‘void torch::cuda::shared::initCudartBindings(PyObject*)’:
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:34:13: error: ‘cudaOutputMode_t’ was not declared in this scope
py::enum_<cudaOutputMode_t>(
^~~~~~~~~~~~~~~~
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:34:13: note: suggested alternative: ‘cudaGraphNode_t’
py::enum_<cudaOutputMode_t>(
^~~~~~~~~~~~~~~~
cudaGraphNode_t
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:34:29: error: template argument 1 is invalid
py::enum_<cudaOutputMode_t>(
^
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:38:30: error: ‘cudaKeyValuePair’ was not declared in this scope
.value("KeyValuePair", cudaKeyValuePair)
^~~~~~~~~~~~~~~~
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:39:21: error: ‘cudaCSV’ was not declared in this scope
.value("CSV", cudaCSV);
^~~~~~~
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:39:21: note: suggested alternative: ‘cudart’
.value("CSV", cudaCSV);
^~~~~~~
cudart
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:99:7: error: ‘cudaProfilerInitialize’ was not declared in this scope
cudaProfilerInitialize);
^~~~~~~~~~~~~~~~~~~~~~
/home/jianyuhuang/Work/Github/pytorch/torch/csrc/cuda/shared/cudart.cpp:99:7: note: suggested alternative: ‘cudaProfilerStart’
cudaProfilerInitialize);
^~~~~~~~~~~~~~~~~~~~~~
cudaProfilerStart
ninja: build stopped: subcommand failed.
```
After these fixes, we can see CUDA 12 is successfully built with OSS PyTorch instructions.
USE_CUDA=1 python setup.py develop 2>&1 | tee compile.log
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91118
Approved by: https://github.com/ngimel, https://github.com/brad-mengchi
Ensures that load_state_dict for fully_shard works:
- Don't add back FSDP prefix
- Small fix to ensure mixed precision check for buffers work
Follow ups:
- state_dict_type does not work, blocking rank0_only and CPU offload as well as other state dict implementations
- No testing when wrapped with AC, using mixed precision, integration with distributed checkpoint, etc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90945
Approved by: https://github.com/awgu
Summary: As FX passes of permute fusion run before functionalization, it might be safer to replace `graph.eliminate_dead_code()` with `graph.erase_node()` to avoid cases that `graph.eliminate_dead_code()` might remove mutation nodes
Test Plan: Unit Tests & CI
Reviewed By: jansel
Differential Revision: D41904755
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91014
Approved by: https://github.com/jansel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90880
# Summary
Enables multiple step trackers. Currently we only had one place to mark that a step() has occurred in the program. This was via pytorch profiler step().
We are now working on adding an Optimizer step hook - https://github.com/pytorch/pytorch/issues/88446
- This could mean programs that already call profiler.step() every iteration can end up double incrementing steps
- If a model uses multiple optimizers we can also have double or more counting of the step.
## Solution
We fix this by adding a layer of abstraction before calling step() to the kineto library. The idea is to maintain steps per requester in a dictionary
```
{
"ProfilerStep": 100, # triggered by profiler step() call
"Optimizer1Step": 100, # Optimizer 1 or 2 are just examples, could be SGD, Adam etc
"Optimizer2Step": 100,
}
```
To figure out the global step count just take max on the dict values (100).
```
{
"ProfilerStep": 100,
"Optimizer1Step": 101, # Optimizer1 got incremented first say
"Optimizer2Step": 100,
}
```
Then global step count is 101
## Calling kineto
We only call the kineto step() function when global count increments.
# Test Plan:
Added a unit test
buck2 run mode/dev-nosan caffe2/test:profiler
Differential Revision: D41751157
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90880
Approved by: https://github.com/chaekit
This PR sets up torch.func and populates it with the following APIs:
- grad
- grad_and_value
- vjp
- jvp
- jacrev
- jacfwd
- hessian
- functionalize
- vmap
It also renames all instances of `functorch` in the APIs for those docs
to `torch.func`.
We rewrite the `__module__` fields on some of the above APIs so that the
APIs fit PyTorch's public api definition.
- For an API to be public, it must have a `__module__` that points to a
public PyTorch submodule. However, `torch._functorch.eager_transforms`
is not public due to the leading underscore.
- The solution is to rewrite `__module__` to point to where the API is
exposed (torch.func). This is what both Numpy and JAX do for their
APIs.
- h/t pmeier in
https://github.com/pytorch/pytorch/issues/90284#issuecomment-1348595246
for idea and code
- The helper function, `exposed_in`, is confined to
torch._functorch/utils for now because we're not completely sure if
this should be the long-term solution.
Implication for functorch.* APIs:
- functorch.grad is the same object as torch.func.grad
- this means that the functorch.grad docstring is actually the
torch.func.grad docstring and will refer to torch.func instead of
functorch.
- This isn't really a problem since the plan on record is to deprecate
functorch in favor of torch.func. We can fix these if we really want,
but I'm not sure if a solution is worth maintaining.
Test Plan:
- view docs preview
Future:
- vmap should actually just be torch.vmap. This requires an extra step
where I need to test internal callsites, so, I'm separating it into a
different PR.
- make_fx should be in torch.func to be consistent with `import
functorch`. This one is a bit more of a headache to deal with w.r.t.
public api, so going to deal with it separately.
- beef up func.rst with everything else currently on the functorch
documention website. func.rst is currently just an empty shell.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91016
Approved by: https://github.com/samdow
I count the number of sub-graphs (for tiny-GPT2 in huggingface) by
```
class GraphCaptureCompiler:
def __init__(self):
self.captured_graphs = []
def compile(self, gm, example_inputs):
self.captured_graphs.append(gm)
return gm
compiler = GraphCaptureCompiler()
torch._dynamo.optimize(compiler, nopython=True)(Wrapper(fn))(*args)
```
Although `len(compiler.captured_graphs)` is 2, no error was thrown during the compilation. This observation conflicts with `nopython=True`. After some digging, I found a check is missed before making graph break. This PR adds it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90970
Approved by: https://github.com/ezyang, https://github.com/jansel
Previously we would abort() but this is annoying when you're running
pytest or something. Don't hard crash.
It would be nice to apply this treatment to the other uses of CHECK
macro in this file, but it was just guards that was bothering me.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91053
Approved by: https://github.com/jansel
Fixes https://github.com/pytorch/torchdynamo/issues/1995
Running `python benchmarks/dynamo/timm_models.py --performance --float32 -dcuda --output=out.csv --training --inductor --only bad_model_name` gives
```
Traceback (most recent call last):
File "benchmarks/dynamo/timm_models.py", line 338, in <module>
main(TimmRunnner())
File "/scratch/williamwen/work/pytorch/benchmarks/dynamo/common.py", line 1660, in main
return maybe_fresh_cache(run, args.cold_start_latency and args.only)(
File "/scratch/williamwen/work/pytorch/benchmarks/dynamo/common.py", line 833, in inner
return fn(*args, **kwargs)
File "/scratch/williamwen/work/pytorch/benchmarks/dynamo/common.py", line 2000, in run
) = runner.load_model(device, model_name, batch_size=batch_size)
File "benchmarks/dynamo/timm_models.py", line 215, in load_model
raise RuntimeError(f"Failed to load model '{model_name}'")
RuntimeError: Failed to load model 'bad_model_name'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91049
Approved by: https://github.com/ezyang
## Logic to handle custom ops
We generate files for custom ops, so that they can be registered into PyTorch.
Generated files:
* `Register{dispatch_key}CustomOps.cpp` (dispatch_key = CPU), it's basically the same as vanilla PyTorch `RegisterCPU.cpp`. The only difference is that we bind to native functions directly.
* `Register{dispatch_key}Stub.cpp` (dispatch_key = CPU), register placeholder kernels for custom ops. Only used when there's no custom op kernel available.
As an example:
```cpp
namespace {
at::Tensor & wrapper_out_unsqueeze_out(const at::Tensor & self, int64_t dim, at::Tensor & out) {
// No device check
// DeviceGuard omitted
return torch::executor::native::unsqueeze_out(self, dim, out);
}
} // anonymous namespace
TORCH_LIBRARY_IMPL(aten, CPU, m) {
m.impl("unsqueeze.out",
TORCH_FN(wrapper_out_unsqueeze_out));
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90099
Approved by: https://github.com/ezyang
This PR adds `unboxing.py` which converts a `EValue` (similar to `IValue`) to its corresponding C++ type, based on the `ExecutorchCppSignature`.
Added unit tests to it in `test_executorch_unboxing.py`. Notice that this unboxing logic should work for both ATen types and Executorch types, hence the unit tests are parametrized.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90098
Approved by: https://github.com/ezyang
@bypass-github-export-checks
This change ensures that vulkan event start/end times are correctly synced with their parent CPU times.
This sometimes requires increasing CPU event durations (to fully contain their child events) and delaying CPU event start times (to prevent overlaps), so this should not be used unless Vulkan events are being profiled and it is ok to use this modified timestamp/duration information instead of the the original information.
Differential Revision: [D39893109](https://our.internmc.facebook.com/intern/diff/D39893109/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39893109/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90672
Approved by: https://github.com/kimishpatel
@bypass-github-export-checks
This change ensures that parent/child relationships between vulkan events and their corresponding CPU events are established correctly. (Previously, if a vulkan event's duration was too long, it would not be made a child correctly).
This could be merged in with the preceding diff, but I wanted to separate it for now because I'm not sure what the most appropriate way to pass through the events and adjust the in_tree_building_ flag (the way I have it now seems a bit awkward), so keeping it separate for now makes it easier to understand/fix. Taylor if you have feedback on this let me know.
Differential Revision: [D40084788](https://our.internmc.facebook.com/intern/diff/D40084788/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90671
Approved by: https://github.com/kimishpatel
@bypass-github-export-checks
This diff enables passing processing events in the profiler. Passing the events from QueryPool, and making sure vulkan events align with parent CPU events correctly will be handled later in this diff stack.
This diff was made by forking Taylor's scaffolding diff, D39779878, with a few changes:
- Rebasing + resolving merge conflicts
- Fixing (i.e. removing) auto import of profiler/containers.h
- Changing the activity type to CPU_OP which makes the vulkan events appear on chrometrace
- Moving timestamp adjustment scaffolding to D39893109
Differential Revision: [D39834805](https://our.internmc.facebook.com/intern/diff/D39834805/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90852
Approved by: https://github.com/mcr229
@bypass-github-export-checks
We want to avoid tossing shader log entries when we reset the query pool so that the old entires can be used by the profiler after gathering all profiling data is done.
```get_shader_name_and_execution_duration_ns``` is used for accessing shader names/durations after they are flushed. It will be used with the torch profiler.
Differential Revision: [D40119621](https://our.internmc.facebook.com/intern/diff/D40119621/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90668
Approved by: https://github.com/kimishpatel
1. No need to move inputs/activations to devices for every nested FSDP instance
2. it also breaks the case when some nested FSDP instances have newly added inputs/activations in the signatures of submodules wrapped by nested FSDP instances, args_tuple[0] and kargs_tuple[0] are not correct to get the inputs/activations for these nested instances
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91078
Approved by: https://github.com/mrshenli, https://github.com/rohan-varma
Motivations for this change:
1. TorchRec returns inconsistent results on `m.named_parameters()`
and `m.m1.named_parameters()` if m1 is a `ShardedModule`. Basically,
`ShardedModule` appears in `m.named_modules()`, but its parameters
are not in `m.named_parameters()`. As a result, when we identify
`ShardedModule` and pass them as `ignored_modules` to FSDP, FSDP
complains about key error in `_get_ignored_params`.
2. If users are manually wrapping submodules with FSDP, it could be
easier for them to keep a global set of ignored parameters, instead
of create a new collection for every FSDP invocation.
Given the above two reasons, we allow FSDP to have ignored modules
out of the wrapped root module.
Differential Revision: [D42132394](https://our.internmc.facebook.com/intern/diff/D42132394)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91079
Approved by: https://github.com/awgu
**Summary**
This PR adds fused `QLinearTanh` module for onednn backend, which will be used for int8 inference with onednn backend. Cannot call this module with other quantization backends otherwise an error is thrown.
**Test plan**
python test_quantization.py TestStaticQuantizedModule
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88923
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Fixes#88652
In the CPU implementation of linspace of integral types, `base` type in vectorized implementation is `int64_t`, which will drop the precision when `base` comes from a floating number. Meanwhile, its vectorized implementation tends to suffer from the catastrophic cancellation of floating point arithemtic since both the `base (start + step * idx)` and the `step` are not exact. Its scalar implementation is fine since start is always an integer and the result would be truncated to integer as well.
Therefore, in this PR , we will skip the vectorized implementation since the vec doesn't contribute to performance anyway. And now the behaviors between CPU and GPU are the same. In some cases, the results are the same as numpy's. In some other cases, the results are different from numpy's, but it is not related to the devices (CPU and GPU). https://github.com/pytorch/pytorch/issues/81996#issuecomment-1192980485
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89048
Approved by: https://github.com/mingfeima, https://github.com/jgong5, https://github.com/albanD
This PR adds `@comptime`, a decorator that causes a given function to be executed at compile time when Dynamo is symbolically evaluating their program. To query the Dynamo state, we offer a public ComptimeContext API which provides a limited set of APIs for querying Dynamo's internal state. We intend for users to use this API and plan to keep it stable. Here are some things you can do with it:
* You want to breakpoint Dynamo compilation when it starts processing a particular line of user code: give comptime a function that calls breakpoint
* You want to manually induce a graph break for testing purposes; give comptime a function that calls unimplemented
* You want to perform a debug print, but you don't want to induce a graph break; give comptime a function that prints.
* You can print what the symbolic locals at a given point in time are.
* You can print out the partial graph the Dynamo had traced at this point.
* (My original motivating use case.) You want to add some facts to the shape env, so that a guard evaluation on an unbacked SymInt doesn't error with data-dependent. Even if you don't know what the final user API for this should be, with comptime you can hack out something quick and dirty. (This is not in this PR, as it depends on some other in flight PRs.)
Check out the tests to see examples of comptime in action.
In short, comptime is a very powerful debugging tool that lets you drop into Dynamo from user code, without having to manually jerry-rig pdb inside Dynamo to trigger after N calls.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90983
Approved by: https://github.com/jansel
1. If user uses amp to run bfloat16 models, `torch.autocast` will
keep module paramters in acc dtype which will leave `gamma` and`beta`
in float while input/output will be in bfloat16.
2. If user explicitly cast the model to bfloat16,
the input/output and gamma/beta will all be in bfloat16.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81852
Approved by: https://github.com/jgong5, https://github.com/malfet
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused `linear-tanh` op for `onednn` backend, which will be used for int8 inference with `onednn` backend. Linear-tanh is found in models like CGAN.
Cannot call this op with other quantization backends otherwise an error is thrown.
**Test Plan**
python test_quantization.py TestQuantizedLinear
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88879
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Apply clang-tidy check modernize-use-emplace. This is slightly more efficient by using an inplace constructor and is the recommended style in parts of the codebase covered by clang-tidy. This just manually applies the check to rest of the codebase. Pinging @ezyang as this is related to my other PRs he reviewed like #89000
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91077
Approved by: https://github.com/ezyang
Currently the `torch.backends.cudnn.benchmark_limit` setting ignores the validity/status of proposed cuDNN frontend execution plans because we do not know if they will complete successfully until execution is attempted. However, there are rare cases where the majority of execution plans fail and a fallback plan is needed (e.g., in the case of extremely small pointer alignment on the input tensors). If the limit is too small to include a working fallback plan, we currently bail out prematurely without checking the plans exhaustively.
The fix is to defer applying the `benchmark_limit` setting until we are sure that plans will execute successfully, but this requires changes to the cuDNN frontend timing function. This PR adds a hacked version of the cuDNN frontend timing function for now, with the intent that we can switch to the upstream cuDNN frontend implementation once this functionality is added.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91032
Approved by: https://github.com/ngimel
Summary:
This PR introduces the top level APIs for quantization support in PyTorch 2.0 Export stack
* torch.ao.quantization.quantize_pt2e.prepare_pt2e
Takes a model that is captured by the PyTorch 2.0 export (torchdynamo full graph mode) and prepares the model for calibration
for post training quantization
* torch.ao.quantization.quantize_pt2e.convert_pt2e
Takes a calibrated model and converts that to a reference quantized model that can be lowered later to quantized operator libraries or delegation modules
Also added a backend config for the qnnpack_pt2e backend:
* torch.ao.quantization.backend_config.get_qnnpack_pt2e_backend_config
Note: everything related to quantize_pt2e are experimental (prototype), and we don't have any bc guarantees
Test Plan:
python test/test_quantization.py TestQuantizePT2EModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91035
Approved by: https://github.com/HDCharles
This should fix hf_Longformer, AllenaiLongformerBase, and tacotron2 with dynamic shapes. Example repro:
```
TORCHDYNAMO_DYNAMIC_SHAPES=1 AOT_DYNAMIC_SHAPES=1 python benchmarks/dynamo/torchbench.py --accuracy --backend aot_eager --training --only hf_Longformer
```
used to fail with:
```
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [4, 1024, 12, 513]], which is output 0
of AsStridedBackward0, is at version 6; expected version 4 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient,
with torch.autograd.set_detect_anomaly(True).
```
The problem is that:
(1) when we have a tensor from the forward, whose sizes are needed the backward, we were saving the actual tensor for backward, and directly grabbing the sizes off of it inside of the backward graph (bad for perf)
(2) If that tensor happens to be a graph input that gets mutated, we end up with the above error. Autograd yells at you if you try to save a tensor for backward, and later mutate it.
I confirmed that this problem doesn't happen for the min cut partitioner.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91012
Approved by: https://github.com/ezyang
This PR adds the following OpInfo tests:
- vmap x vjp x vmap
- vjp x vmap x vmap
- vjp x vjp x vmap
These OpInfo tests only run for the autograd_function_db. In general,
testing composition of two transforms is sufficient to convince
ourselves that functorch works on a given operator.
The autograd.Function testing (especially the upcoming
generate_vmap_rule) didn't feel rigorous enough to me, so I added these
additional tests to convince myself.
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90962
Approved by: https://github.com/samdow, https://github.com/soulitzer
This PR:
- adds VmapInterpreter.randomness. This returns the randomness option
the user provided in vmap(..., randomness=...)
- adds randomness in the info object passed to the vmap staticmethod of
autograd.Function. This is so that the user can handle random operations
on their own terms (if randomness="error", and if the autograd.Function
has random operations, then it is the user's responsiblity to raise an
error).
Test Plan:
- updated unittest
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90789
Approved by: https://github.com/samdow, https://github.com/soulitzer
Tracing `torch.backends.cudnn.is_acceptable(Tensor) -> bool:` fails with:
```
...
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/functions.py", line 196, in call_function
return super(UserFunctionVariable, self).call_function(tx, args, kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/functions.py", line 67, in call_function
return tx.inline_user_function_return(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 426, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 1698, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 1752, in inline_call_
tracer.run()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 485, in run
and self.step()
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 455, in step
getattr(self, inst.opname)(inst)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 281, in wrapper
return inner_fn(self, inst)
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 912, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/symbolic_convert.py", line 389, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/torch.py", line 431, in call_function
tensor_variable = wrap_fx_proxy(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/builder.py", line 662, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/scratch/dberard/dynamo38/pytorch/torch/_dynamo/variables/builder.py", line 820, in wrap_fx_proxy_cls
raise AssertionError(
AssertionError: torch.* op returned non-Tensor bool call_function <function is_acceptable at 0x7f00deefb790>
```
So instead, evaluate `is_acceptable()` and convert the result to a constant. The result of `is_acceptable(tensor) -> bool` depends on:
* dtype/device of the input tensor (this should already be guarded)
* properties of the build & whether cudnn is available
* some global state that gets initialized during the first call to `torch.backends.cudnn._init()` (this is NOT guarded in this PR)
Note: this fixes tts_angular with FSDP. This was an issue with FSDP because FSDP modules are interpreted as UnspecializedNNModules, and UnspecializedNNModules try to inline calls. In comparison, NNModules (e.g. when the tts_angular model is not wrapped in FSDP) do not inline calls and instead evaluate subsequent calls. In subsequent calls, cudnn.is_acceptable would be skipped by eval_frame.py:catch_errors because it is not in an allowlist.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90323
Approved by: https://github.com/jansel
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88330
### Implementation
Move backend-specific (NCCL, Gloo, etc) collective implementations to corresponding `Backend` class. Update ProcessGroup to support multiple backends and use dispatcher to calls backends based on tensor device type.
### Changes
#### c++ changes (ProcessGroup files, `Ops.cpp`, `init.cpp`)
- Update pybind definitions for new process group base class and new backend class
- Update pybinded backend class with collective definitions to keep BC with Python PG instances (e.g. `dist.ProcessGroupGloo`, `dist.ProcessGroupNCCL`) which are used in tests
- Switch `ProcessGroupGloo`, `ProcessGroupNCCL`, `ProcessGroupMPI`, `ProcessGroupUCC` to derive from the `Backend` class.
- Update CPU/CUDA `Ops.cpp` and `OpsImpl.cpp` to perform this dispatching by querying the backend using the device type
- Update internal dispatched implementation of `barrier` to use a tensor which allows operation to be dispatched.
- Update `allgather` collective to use `TensorList`. For some reason it was using the default implementation of `allgather` rather than dispatching it correctly. I still don't understand why and had originally filed an issue in 85122.
#### python changes (`distributed_c10d.py`, test files)
- Add BackendConfig class to specify the default configurations of backends and `get_backend_config()` API
- `get_backend()` deprecation warning
- `init_process_group` how returns a generic `ProcessGroup` object, it contains a list of backends (the ones stated above) which it will dispatch operations to.
- `new_group` updated to return the same as above
- Update `test_c10d_gloo.py`, Update `DistributedDataParallelTest` to use `init_process_group`, Update `ReducerTest`, update `test_broadcast_coalesced_gloo` to move from PG instance and gloo options
- Update `test_c10d_nccl.py`, Update `DistributedDataParallelTest` to use `init_process_group`
- Specific tests updated: `test_Backend_enum_class`
### Changes missing
- lazy initialization of backends
- support parsing of BackendConfig
### open questions
- Pure Python PG extensions (https://github.com/pytorch/pytorch/pull/66338)
# Example
This is a basic script (using 2 backends within a process group)
```python
# python -m torch.distributed.run --nnodes=1 --nproc_per_node=2 basic_scenario.py
import torch.distributed as dist
import torch
import os
if __name__ == "__main__":
rank = os.environ.get("RANK")
# initialize with both gloo and nccl
dist.init_process_group()
# with gloo
dist.all_reduce(torch.tensor([1.0]))
print(f"Rank {rank} finished")
# with nccl
dist.all_reduce(torch.tensor([1.0], device=f"cuda:{rank}"))
```
Test Plan: Imported from OSS
Differential Revision: D42069829
Pulled By: H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90997
Approved by: https://github.com/awgu, https://github.com/fduwjj
Adds a set of generated tests for `AOTAutograd` using the `ModuleInfo` db, analogous to the `OpInfo`-based tests. Includes the following changes:
* Adds a `TestEagerFusionModuleInfo` test class, with both symbolic and non-symbolic tests, just like the OpInfo tests.
* Test logic "functionalizes" the module under test and calls into the now-factored-out verification logic the OpInfo tests use to compare compiled vs. non-compiled function outputs / grads.
* Adds a `decorateForModules(decorator, module_set)` utility to `test/functorch/common_utils.py` to handle xfails, skips, etc. The pre-existing logic is specific to ops, and I didn't want to duplicate all that, so I kept additions minimal with this function.
* Bunch of xfails to get everything passing; haven't looked deeply into all these yet. #90500 is relevant for the RNN failures.
* Fixes a bug in the `ModuleInfo` entry for `NLLLoss` to ensure sample input has the requested `requires_grad` setting (was causing spurious test failures).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90980
Approved by: https://github.com/ezyang
Summary: Introduce causal mask
This PR introduces a causal mask option _causal_mask (as well as causal mask detection if attn_mask is provided), since current custom kernels do not support arbitrary masks.
Test Plan: sandcastle & github ci/cd
Differential Revision: D41723137
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90508
Approved by: https://github.com/albanD
- This PR introduces `_get_fsdp_root_states(state: _FSDPState, module: nn.Module)` to return all states that are FSDP root in the module tree rooted at `module`.
- This requires passing in both `state` and `module` because it must call `_lazy_init()` to check for root-ness, which requires that signature.
- This PR moves the one internal usage of `FullyShardedDataParallel.fsdp_modules(root_only=True)` to use `_get_fsdp_root_states()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90862
Approved by: https://github.com/rohan-varma
This PR removes the "communication module" (comm. module / `comm_module`) concept from the FSDP code base since it causes disproportionate confusion compared to its benefit for now.
Instead, we introduce the term "fully sharded module" as the single concept to unify the wrapper and non-wrapper code paths. The definition is presented in a note at the top of `flat_param.py`. I reproduce it here:
---
We define the **"fully sharded module"** to be the original `nn.Module` that owns a `FlatParamHandle`. It is the *single* module logically responsible for the *single* unshard/reshard pair for the handle's `FlatParameter` for a given forward or backward pass. The fully sharded module should be passed to the `FlatParamHandle` constructor.
For the wrapper code path:
- The `FullyShardedDataParallel` module wrapping the fully sharded module runs the unshard/reshard on behalf of the fully sharded module by overriding `nn.Module.forward`.
- The fully sharded module is exactly the module passed to the `FullyShardedDataParallel` constructor's `module` argument and is saved in `_fsdp_wrapped_module`.
For the non-wrapper code path:
- Hooks registered on the fully sharded module run the unshard/reshard.
- The fully sharded module may either be the direct argument to `fully_shard` or a submodule chosen by the provided wrapping policy.
---
After this PR, `handle.flat_param._fqns`, `_param_infos`, and `_shared_param_infos` all prefix names from the same module, namely the fully sharded module. This should make state dict less confusing.
---
As an example, consider:
```
mod: Module(
sub1: Submodule(
subsub1: Subsubmodule(),
subsub2: Subsubmodule(),
),
sub2: Submodule(
subsub1: Subsubmodule(),
subsub2: Subsubmodule(),
),
)
```
For wrapper FSDP manual wrap:
```
mod.sub1 = FSDP(mod.sub1)
mod.sub2 = FSDP(mod.sub2)
mod = FSDP(mod)
```
For wrapper FSDP auto wrap:
```
mod = FSDP(mod, auto_wrap_policy=ModuleWrapPolicy({Submodule}))
```
(WIP) For non-wrapper FSDP manual wrap:
```
fully_shard(mod.sub1)
fully_shard(mod.sub2)
fully_shard(mod)
```
For non-wrapper FSDP auto wrap:
```
fully_shard(mod, policy=ModuleWrapPolicy({Submodule}))
```
The fully sharded module **in all cases** are `mod`, `mod.sub1`, `mod.sub2`, and notably, `subsub1` and `subsub2`s are not fully sharded modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90933
Approved by: https://github.com/rohan-varma
Fixes https://github.com/pytorch/torchdynamo/issues/1717, https://github.com/pytorch/torchdynamo/issues/1990
<s>TODO: add test with multiple devices, figure out extra context initialization</s>
Problems:
<s>It still initializes context on 0-th device that it shouldn't, I'll take a look where that happens and fix before landing</s>
It adds a python device context manages, that is absurdly slow and takes ~2.5 us (should be nanoseconds). That's not a problem for real models, because it'll be called just once, but it is a bit of an inconvenience for microbenchmarking, we should make that context manager more performant (won't fix in this PR)
It still can have bugs for graphs that run on multiple devices and can have buffers incorrectly shared between multiple device by memory reuse, if that happens that'll need to be solved separately.
Generated code:
```
def call(args):
arg0_1, arg1_1 = args
args.clear()
with torch.cuda.device(1):
buf0 = empty_strided((4, ), (1, ), device='cuda', dtype=torch.float32)
stream1 = get_cuda_stream(1)
triton_fused_div_0.run(arg0_1, arg1_1, buf0, 4, grid=grid(4), stream=stream1)
del arg0_1
del arg1_1
return (buf0, )
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90934
Approved by: https://github.com/wconstab
This change introduces a mechanism to test onnx export based on sample inputs registered in OpInfo, similar to how MPS and other components of pytorch are tested. It provides test coverage on ops and dtypes previously unattainable with manually created test models. This is the best way for us to discover gaps in the exporter support, especially for ops with partial existing support.
This test is adapted from https://github.com/pytorch/pytorch/blob/master/test/test_mps.py
This PR also
- Update sqrt to support integer inputs to match pytorch behavior
- Add pytest-subtests for unittest subtests support in the new test file
I only enabled very few ops: `t`, `ceil` and `sqrt` because otherwise too many things will fail due to (1) unsupported dtypes in the exporter (2) unimplemented dtype support in onnxruntime (3) unexpected input to verification.verify.
Subsequent PRs should improve `verification.verify` first for it to accept any legal input to a pytorch model, then incrementally fix the symbolic functions to enable more test cases.
Fixes#85363
Design #88118
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86182
Approved by: https://github.com/BowenBao
This PR migrates all internal usages of `FullyShardedDataParallel.fsdp_modules(root_only=False)` to `_get_fsdp_states()`. This is to unify the code paths for composable and wrapper FSDP.
This PR _does not_ change the usages in test files. This is because we should revisit those usages separately as a way to track which functionality for which we have not tested composable FSDP.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90861
Approved by: https://github.com/rohan-varma
I started refactoring unit tests to use `_get_fsdp_states()` instead of `FullyShardedDataParallel.fsdp_modules()` but realized we should not do that for now. This is just a change I made while doing that. `entry` is not descriptive. Let us explicitly say `fsdp_module`. `for fsdp_module in FSDP.fsdp_modules(module)` is a proper idiom.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90864
Approved by: https://github.com/rohan-varma
- This PR introduces `_get_fsdp_states(module: nn.Module) -> List[_FSDPState]` to prepare for `fully_shard` manual "wrapping".
- ~~I place it in `_runtime_utils.py`, not `_common_utils.py`, because in a follow-up PR, I will add `_get_root_fsdp_states()`, which requires `_lazy_init()`. I concluded that it would be preferred to have both of these getters be in the same place than to have them split, even if that means that `_get_fsdp_states()` is in `_runtime_utils.py`.~~ Due to circular import issues, I think I should still put it in `_common_utils.py`.
- This PR changes `FullyShardedDataParallel.fsdp_modules()` to be backed by `_get_fsdp_states()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90860
Approved by: https://github.com/rohan-varma
People's general tendency is to read from top to bottom. Leverage that at the right moment to help them realize that there's a troubleshooting section they can use if they get stuck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90927
Approved by: https://github.com/ZainRizvi
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused `QLinearLeakyReLU` module for onednn backend, which will be used for int8 inference with onednn backend. Cannot call this module with other quantization backends otherwise an error is thrown.
**Test plan**
python test_quantization.py TestStaticQuantizedModule
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88661
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Summary:
This PR introduces the top level APIs for quantization support in PyTorch 2.0 Export stack
* torch.ao.quantization.quantize_pt2e.prepare_pt2e
Takes a model that is captured by the PyTorch 2.0 export (torchdynamo full graph mode) and prepares the model for calibration
for post training quantization
* torch.ao.quantization.quantize_pt2e.convert_pt2e
Takes a calibrated model and converts that to a reference quantized model that can be lowered later to quantized operator libraries or delegation modules
Also added a backend config for the qnnpack_pt2e backend:
* torch.ao.quantization.backend_config.get_qnnpack_pt2e_backend_config
Note: everything related to quantize_pt2e are experimental (prototype), and we don't have any bc guarantees
Test Plan:
python test/test_quantization.py TestQuantizePT2EModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90971
Approved by: https://github.com/HDCharles
GraphArgs worked fairly well, but it was still missing sources
sometimes. Now, we maintain an auxiliary data structure which we
MUST populate whenever we fakeify a tensor / allocate a bare SymInt.
This should guarantee once and for all that every symbol is available.
Should fix swin_base_patch4_window7_224.
While I was at it, I moved fakeification utility back to builder
as it was only used at once call site.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90911
Approved by: https://github.com/voznesenskym
Summary: There was an OOM issue in two internal models when turning on padding bmm with dim m and n with shape padding optimization, so added a flag to turned on/off for the internal models. The issue was gone now so removing the flag.
Differential Revision: D42074557
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90937
Approved by: https://github.com/ngimel
Summary:
1. use pytree to allow any input format for make_graphed_callables
2. add allow_unused_input argument for make_graphed_callables
Test Plan: buck2 test mode/dev-nosan //caffe2/test:cuda -- --print-passing-details
Differential Revision: D42077976
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90941
Approved by: https://github.com/ngimel
This PR is to fix the segfault reported at https://github.com/pytorch/pytorch/issues/89677, this is a `double free` issue caused by `invalid read`.
The reported issue broke at slow path for `EmbeddingBag` on float32, at [EmbeddingBag.cpp#L451](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/EmbeddingBag.cpp#L451)
Root cause is that `add_indices` has index which exceeds range of `output_data`, for the reported case.
The offsets are given as
```
{0, 6, 12, 15, 25, 32, 40, 42, 46, 53, 53}
```
The `indices` has 55 elements and `offsets[-1] != indices.size(0)`.
When `include_last_offset` is true, the `output` will be in the shape of {offsets.size(0) - 1, weight.sizes()[1]}, which will be {10, 5}.
Originally, `add_indices` will be (i re-arange the 1D tensor by rows, so here 10 rows in total)
```
### this is 55 elements
0 0 0 0 0 0
1 1 1 1 1 1
2 2 2
3 3 3 3 3 3 3 3 3 3
4 4 4 4 4 4 4
5 5 5 5 5 5 5 5
6 6
7 7 7 7
8 8 8 8 8 8 8
10 10
```
The last row has index of 10 which is out of range of output tensor whose size is [10, 5].
The reason is `make_offset2bag` at [EmbeddingBag.cpp#L66](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/EmbeddingBag.cpp#L66) would give the following `offset2bag`:
```
### this is 55 + 1 elements:
0 0 0 0 0 0 1
0 0 0 0 0 1
0 0 1
0 0 0 0 0 0 0 0 0 1
0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 1
0 0 0 1
0 0 0 0 0 0 2
0 0
```
Notice for index 53, it is added twice.
The fix is ignore the last index from `offsets` when `include_last_offset` is true, also this behavior aligns with CUDA, quote from https://github.com/pytorch/pytorch/pull/57208#issuecomment-1021727378
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90358
Approved by: https://github.com/ezyang
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused `QLinearLeakyReLU` module for onednn backend, which will be used for int8 inference with onednn backend. Cannot call this module with other quantization backends otherwise an error is thrown.
**Test plan**
python test_quantization.py TestStaticQuantizedModule
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88661
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
Reset the rng in hf before generating input and loading model, this makes the huggingface inputs+weights deterministic depending on the seed of the rng. This matches the behavior of the other test suites.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90936
Approved by: https://github.com/desertfire
For parameter mixed precision, we cast the inputs to the low precision parameter dtype. If the input has tensors that require gradient, then we must cast them in place in order for them to receive a gradient. The cast should be tracked by autograd (e.g. with `grad_fn` equal to `ToCopyBackward0`). This removes the `torch.no_grad` context when calling `_apply_to_tensors`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90921
Approved by: https://github.com/mrshenli, https://github.com/rohan-varma
Summary:
This PR introduces the top level APIs for quantization support in PyTorch 2.0 Export stack
* torch.ao.quantization.quantize_pt2e.prepare_pt2e
Takes a model that is captured by the PyTorch 2.0 export (torchdynamo full graph mode) and prepares the model for calibration
for post training quantization
* torch.ao.quantization.quantize_pt2e.convert_pt2e
Takes a calibrated model and converts that to a reference quantized model that can be lowered later to quantized operator libraries or delegation modules
Also added a backend config for the qnnpack_pt2e backend:
* torch.ao.quantization.backend_config.get_qnnpack_pt2e_backend_config
Note: everything related to quantize_pt2e are experimental (prototype), and we don't have any bc guarantees
Test Plan:
python test/test_quantization.py TestQuantizePT2EModels
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90802
Approved by: https://github.com/qihqi
Currently the default `ops` handler expects strings as arguments and
just formats them into a function call template string. For complex
expressions, this can lead to exponential growth in terms. Say for
example you have:
```python
def fn(a):
for _ in range(3)
a = ops.mul(a, a)
return a
```
You might expect `inner_fn_str` to contain 1 load and 3 multiplies,
but instead you find 8 loads and 7 multiplies:
```python
load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0) * load(arg_0, i0)
```
This type of blowup is present in the lowering for
`max_pool2d_with_indices_backward` which in #pytorch/torchdynamo#1352
was reported to have caused the entire compilation to hang.
This PR fixes the issue by formatting the string as a series of assignments to
variables, so for the example above, we now get:
```
tmp0 = load(arg_0, i0)
tmp1 = tmp0 * tmp0
tmp2 = tmp1 * tmp1
tmp3 = tmp2 * tmp2
return tmp3
```
Which corresponds to sequence of `ops` calls made.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88933
Approved by: https://github.com/jansel
In the context of hybrid sharding strategies, we only need to enforce the same process groups among the instances using a hybrid sharding strategy, not all instances. We can even mix and match the two different hybrid sharding strategies. This PR relaxes the validation to support this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90846
Approved by: https://github.com/rohan-varma
**Summary**
Onednn quantization backend switch to new API in `third_party/ideep`.
- `struct forward_params` for conv/deconv are changed. Modify primitive cache accordingly.
- Use new versions of `prepare` and `compute` API. Fp32 and int8 paths separated. The old ones will be deprecated.
- Now `ideep::tensor::reorder_if_differ_in` supports block-to-block reorder. Use it instead of defining a util function `onednn_utils::try_reorder`.
- For new API of transposed convolution, we can use a flag to keep weight desc align with oneDNN thus needless to transpose it explicitly in PyTorch.
- Use `is_channels_last` flag to specify layout of src/dst when querying expected weight desc.
It won't impact correctness. Performance should be unaffected or slightly better.
FBGEMM and QNNPACK backends are not affected.
Performance results are given below.
1. End-to-end performance of static quantized models (from torchvision)
(throughput: fps, higher is better)

2. Op benchmark of dynamic quantized linear
(Latency: ms, lower is better)

Test method & env:
- Intel(R) Xeon(R) Platinum 8358 CPU @ 2.60GHz
- Run multi-instances on a single node. Use one core for each instance.
- Use Jemalloc and Intel OpenMP
**Test plan**
python test/test_quantization.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90354
Approved by: https://github.com/jgong5
In the prior patch, I just YOLOed a mutable mapping implementation.
Many edge cases were not handled correctly. In this PR, I just
copy paste the WeakKeyDictionary from CPython and the hacked it up
to use WeakIdRef instead of weakref.ref. You can see each line
I changed with the comment CHANGED; there aren't many.
Being exactly API compatible with WeakKeyDictionary means I can also
rob all of the tests from CPython, which I also did for
test/test_weak.py
How to review? You could either try taking the delta from CPython
(recommended), or review everything from scratch (not recommended).
Can post diff representing delta on request.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90825
Approved by: https://github.com/albanD
Fixes#74177
Since RNN code use static variables to cache state, we store an atomic_flag in RNG generator to notify new seed changes and generate new random state for RNN. The additional cost is that the it must check the atomic_flag each time to ensure reproducibility. This may be ugly but it is the best way currently without large code refactoring
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90522
Approved by: https://github.com/ngimel
I made an important mistake here when thinking `not result.skipped` mean that the current test wasn't skipped.
Similar to `result.failures` or `result.errors`, `result.skipped` is that it's a list including all the skipped messages so far in the test suite (https://docs.python.org/3/library/unittest.html#unittest.TestResult). As such, the correct way to check if the current test was skipped is to compare `skipped_before` and `len(result.skipped)` after running the test in the same way as failures and errors are handled. If they are the same, the test isn't skipped.
### Testing
`python test/run_test.py -i test_autograd --verbose` to confirm that the disabled test `test_profiler_seq_nr` is run 50 times always in rerun mode
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90888
Approved by: https://github.com/clee2000
## Pitch
Change input args type from `std::tuple` to `std::vector` to reduce the compilation time.
## Description
`std::tie()` takes quite a long time during the compilation when the input args number grows.
For example, for a graph from the `PegasusForConditionalGeneration` model with 318 input args, the compilation of `std::tie` for the args is about 10s. By changing to std::vector, the compilation time of arg assignment is reduced to less than 1s.
### Code before:
```cpp
at::Tensor call_0(std::tuple<at::Tensor&, at::Tensor&> args) {
at::Tensor arg0_1, arg1_1;
std::tie(arg0_1, arg1_1) = args;
...
return buf0;
}
```
### Code after:
```cpp
at::Tensor call_0(std::vector<at::Tensor> args) {
at::Tensor arg0_1, arg1_1;
arg0_1 = args[0];
arg1_1 = args[1];
...
return buf0;
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90754
Approved by: https://github.com/jgong5, https://github.com/jansel
Summary:
This is useful for debugging what autocast is doing when
it's running on top of torchdynamo, without this the Python dispatch
key for autocast prints as `???`.
Test Plan:
```
import torch
dir(torch._C.DispatchKey)
// the autocast keys show up now
```
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90821
Approved by: https://github.com/ezyang
Summary: The existing BackendConfig fusion pattern
uses a "reversed nested tuple" format that is highly
unintuitive. For example,
```
linear-relu -> (nn.ReLU, nn.Linear)
conv-bn-relu -> (nn.ReLU, (nn.BatchNorm2d, nn.Conv2d))
```
This pattern format also complicates the signatures
of the user specified "fuser methods", which needed
to accept arguments in reverse nested order to match
the patterns:
```
def fuse_linear_relu(is_qat, relu, linear):
...
def fuse_conv_bn_relu(is_qat, relu, bn_conv):
(bn, conv) = bn_conv
...
```
Instead, this commit introduces a new pattern format that
simply specifies the ops in forward order with no nesting:
```
linear-relu -> (nn.Linear, nn.ReLU)
conv-bn-relu -> (nn.Conv2d, nn.BatchNorm2d, nn.ReLU)
def fuse_linear_relu(is_qat, linear, relu):
...
def fuse_conv_bn_relu(is_qat, conv, bn, relu):
...
```
Note that the legacy "reversed nested tuple" is still
used internally since it is more general. In the
future, we should replace it with the format used in
the subgraph rewriter in `torch.fx`, and simplify the
existing pattern matching code to handle the new
format added in this commit.
BC-breaking Notes:
Before:
```
import torch as nn
import torch.ao.nn.intrinsic as nni
from torch.ao.quantization.backend_config import BackendPatternConfig
def fuse_linear_relu(is_qat, relu, bn_conv):
(bn, conv) = bn_conv
return nni.ConvBnReLU2d(conv, bn, relu)
config = BackendPatternConfig((nn.ReLU, (nn.BatchNorm2d, nn.Conv2d))) \
.set_dtype_configs(...) \
.set_fuser_method(fuse_conv_bn_relu) \
.set_fused_module(nni.ConvBnReLU2d)
```
After:
```
def fuse_linear_relu(is_qat, conv, bn, relu):
return nni.ConvBnReLU2d(conv, bn, relu)
config = BackendPatternConfig((nn.Conv2d, nn.BatchNorm2d, nn.ReLU)) \
.set_dtype_configs(...) \
.set_fuser_method(fuse_conv_bn_relu) \
.set_fused_module(nni.ConvBnReLU2d)
```
OR (for backward-compatibility)
```
def fuse_linear_relu(is_qat, relu, bn_conv):
(bn, conv) = bn_conv
return nni.ConvBnReLU2d(conv, bn, relu)
config = BackendPatternConfig() \
._set_pattern_complex_format((nn.ReLU, (nn.BatchNorm2d, nn.Conv2d))) \
.set_dtype_configs(...) \
.set_fuser_method(fuse_conv_bn_relu) \
.set_fused_module(nni.ConvBnReLU2d) \
._set_use_legacy_pattern_format(True)
```
Before:
```
backend_config.configs # returns Dict[Pattern, BackendPatternConfig]
```
After:
```
backend_config.configs # returns List[BackendPatternConfig]
```
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestBackendConfig
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Differential Revision: [D41954553](https://our.internmc.facebook.com/intern/diff/D41954553)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90698
Approved by: https://github.com/vkuzo, https://github.com/jerryzh168
Changes:
- Allow multiple `sharding_filter` in the pipeline as long as they are not on the same branch
- [x] Add test
Example:
```mermaid
graph TD;
DP1-->sharding_filter_1;
sharding_filter_1-->DP3;
DP2-->sharding_filter_2;
sharding_filter_2-->DP4;
DP3-->DP4;
DP4-->output;
```
In order to properly shard `DP1` and `DP2`, we should allow multiple `sharding_filter`s
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90769
Approved by: https://github.com/NivekT
This PR
- Removes `_module_to_handles` since it is no longer used. We instead use `_comm_module_to_handles`.
- Removes `HandleConfig` and stores its fields directly as attributes on `FlatParamHandle`.
- Uses the term `fqn`/`fqns` uniformly in `flat_param.py` instead of `prefixed_param_name` / `prefixed_param_names`.
- Clarifies some documentation.
I am including all of these BE items in the same PR to save CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90840
Approved by: https://github.com/rohan-varma
Retry of #90591, which is a retry of #89595. Reverted due to dependency PR breaking internal fbcode.
## Forked BaseCppType
Created a module for Executorch: `torchgen.executorch`.
## In `torchgen.executorch.api.types.types`:
* Define `BaseCppType` with `torch::executor` namespace.
## In `torchgen.executorch.api.et_cpp`:
* Help generate `NamedCType` for `ExecutorchCppSignature` arguments.
## In `torchgen.executorch.api.types.signatures`:
* Define the signature using these types. (`ExecutorchCppSignature`)
## In `torchgen.executorch.api.types.__init__`:
* Suppress flake8 error for `import *`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90781
Approved by: https://github.com/ezyang
Retry of #90590, which is a retry of #89594. Original PR reverted due to internal breakage.
This PR fixes the breakage by adding a default value to the new argument.
This PR allows `get_native_function_declarations` API to take a function as argument. This function should take `NativeFunction` as input and emit code for native function declaration. By default it is `dest.compute_native_function_declaration`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90780
Approved by: https://github.com/ezyang
Give a unique prefix to all steps in lint.yml which catch valid linter errors. This will let retrybot identify lint.yml steps which should not be retried.
This is a prelude to https://github.com/pytorch/test-infra/pull/1275 which extends the retry-on-failure behavior to all PRs in addition to trunk.
This hadn't been an issue previously since we would always only linter failures on `master`, where linter failures were always safe to retry since legitimate linter failures there are virtually non-existent
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90705
Approved by: https://github.com/huydhn, https://github.com/malfet
It turns out it is possible to break cycles by not directly importing a
module:
- there's a problem that torch.jit imports torch._ops and torch._ops
import torch.jit
- there's another problem that torch.autograd.function imports
custom_function_call but torch._functorch.autograd_function imports
torch.autograd.function
The "better" way to handle all of this is to do some large refactoring so
that torch._functorch.autograd_function imports some file that has
_SingleLevelAutogradFunction and then have torch.autograd.function
depend on torch.functorch.autograd_function... (and ditto for torch.jit
vs torch._ops), but I'm scared to move code around too much for BC
reasons and the fix in this PR works well.
Test Plan:
- import torch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90415
Approved by: https://github.com/albanD, https://github.com/soulitzer
This PR adds functorch.jvp support for autograd.Function. It does so by
adding a jvp rule for custom_function_call.
For a regular PyTorch operation (like at::sin), the VariableType kernel:
- re-dispatches to at::sin
- calls the jvp rule for at::sin
The jvp rule for custom_function_call does just that. It constructs a
new autograd.Function (because the above logic already exists). Inside
the forward, it re-dispatches to custom_function_call. In the jvp rule,
it just calls whatever the jvp rule is supposed to be.
Since this logic is really close to the custom_function_call_grad, I
just put them together.
Test Plan:
- added jvp rules to the autograd.Function in autograd_function_db
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90077
Approved by: https://github.com/albanD, https://github.com/soulitzer
For reductions, the code string in the codegen stage and the execution stage are different due to `\`.
- The code string gotten from `code.getvalue()` (`code` is an `IndentedBuffer`) in codegen stage:
```
#pragma omp declare reduction(argmax : struct IndexValue_1 :\
omp_out.value = omp_in.value < omp_out.value ? omp_out.value : omp_in.value,\
omp_out.index = omp_in.value < omp_out.value ? omp_out.index : omp_in.index)\
initializer(omp_priv = {0, -std::numeric_limits<float>::infinity()})
```
- The code string loaded during the execution (`\` will be escaped):
```
#pragma omp declare reduction(argmax : struct IndexValue_1 : omp_out.value = omp_in.value < omp_out.value ? omp_out.value : omp_in.value, omp_out.index = omp_in.value < omp_out.value ? omp_out.index : omp_in.index) initializer(omp_priv = {0, -std::numeric_limits<float>::infinity()})
```
Thus we can't get the same hash value for these two pieces of code.
This PR adds a function to make the transformation escape the backslash in the codegen stage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88561
Approved by: https://github.com/jgong5, https://github.com/jansel, https://github.com/desertfire
Previously, we planned to lift the parameters and weights while exporting and implement our own transformer to "unlift" the lifted weights and params back to the graph as attributes. But this is bit challenging because:
- We need to maintain correct ordering for weights and parameters that are passed as inputs so that we know how to map them back.
- Some weights are unused in the graph, so our transformer needs to be aware of which weights and parameters are not used in the graph. And we need to distinguish which are real user input and which are parameters.
- There can be more edge cases we haven't seen in other models yet.
I am aware that @Chillee and @bdhirsh mentioned that functionalization won't work with fake-tensor attributes but this is fine for the short term as we don't expect users to be modifying weights and params in inference mode. In fact, we explicitly disable attribute mutation in torchdynamo export mode right now.
Given above condition, it might be ok to just fakify params when we need. I use a flag to guard against this change.
Differential Revision: [D41891201](https://our.internmc.facebook.com/intern/diff/D41891201)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90417
Approved by: https://github.com/eellison
1) don't codegen maxpool backward, it's exceedingly slow
2) better determine reduction variables for more accurate hints
3) deterministic iteration order for reduction arguments, take into account all full size reduction argument, for hints break ties to outer reduction
fixes#1653
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89616
Approved by: https://github.com/jansel, https://github.com/Chillee
**Why this PR?**
For the composable APIs implementation, sometimes the internal APIs may not have the application (FSDP, DDP) root module but only the local module. One example is the state_dict/optimizer_state_dict implementation of FSDP. These APIs are designed to start with the root module of the model. It is tricky for these APIs to tell whether a random submodule is managed by either DDP or FSDP.
It will be useful to have APIs like:
`_get_module_state(module)`: return the composable state if this module is managed by composable API.
`_get_module_fsdp_state(module)`: return the FSDP state if this module is managed by FSDP.
**What does this PR propose?**
1. Make `_State` out of `_composable` module so that `FullyShardedDataParallel` can inherit from it.
2. A global `_module_state_mapping: Dict[nn.Module, _State]` that keeps the mapping of all submodules (not just root module) to the state.
3. Create `_get_module_state(module)` to look up `_module_state_mapping`.
4. Create `_get_module_fsdp_state(module)` that uses `_get_module_state(module)` to get the state then verifies if the state is `_FSDPState`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89147
Approved by: https://github.com/awgu
`no_sync()` introduces a separate case where a `FlatParameter` maintains an _unsharded_ gradient, instead of a _sharded_ one. This PR fixes `no_sync()` with `use_orig_params=True` by dealing with this separate case.
The existing `use_orig_params=False` already bypasses the built-in parameter/gradient size check, where the `flat_param` is sharded, while the `flat_param.grad` is unsharded. For `use_orig_params=True`, we need to use the same `.data` hack to side step the size check that we used to side step the dtype check for `keep_low_precision_grads=True`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90546
Approved by: https://github.com/rohan-varma
**What:**
This PR add the optim state_dict support of `use_orig_params` with rank0_only is False. rank0_only support will be added in a following PR. The design of this PR focus on the simplicity and may not have good performance, especially for optim state_dict loading. Since optim state_dict loading is only called once in the beginning of the training, performance is not the major concern.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89900
Approved by: https://github.com/awgu, https://github.com/rohan-varma
TF32 is not supported on ROCm and hence the torch/profiler/_pattern_matcher.py FP32MatMulPattern should return False for ROCm instead of checking the results of torch.cuda.get_arch_list(). Depending on the gfx arch running the test, test_profiler.py's test_profiler_fp32_matmul_pattern (__main__.TestExperimentalUtils) will fail otherwise.
Signed-off-by: Jagadish Krishnamoorthy <jagdish.krishna@gmail.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84077
Approved by: https://github.com/jeffdaily, https://github.com/kit1980
Co-authored with @rohan-varma.
**Overview**
This adds preliminary `state_dict()` support for `fully_shard`.
- The only explicit branching between composable and wrapper code paths happens in the state dict hook registration, which is inevitable.
- We introduce a `_comm_module_prefix` to match the FQNs between the two code paths. This is needed since for composable, the FQNs are prefixed from the local FSDP root, whereas for state dict purposes, we want them to be prefixed from the comm. module. Thus, we need this `_comm_module_prefix` to be stripped during state dict.
- In my understanding, the alternative to not use the `prefix` argument in `state_dict()` does not support the case when `fully_shard` is applied to a submodule (i.e. not the global root module) since we still need _part_ of `prefix` then.
**Follow-Ups**
- We can retire the `functools.partial` usage once @fegin's PR lands.
- We should add more thorough testing (e.g. sharded state dict, save and load together etc.).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90767
Approved by: https://github.com/rohan-varma, https://github.com/fegin
cuSPARSE v12.0 has started to use const pointers for the descriptors, from `cusparse.h` (documentation is incorrect):
```cpp
typedef struct cusparseSpVecDescr const* cusparseConstSpVecDescr_t;
typedef struct cusparseDnVecDescr const* cusparseConstDnVecDescr_t;
typedef struct cusparseSpMatDescr const* cusparseConstSpMatDescr_t;
typedef struct cusparseDnMatDescr const* cusparseConstDnMatDescr_t;
```
Changing also the function signature for the corresponding destructors to accept a const pointer. This PR adds `ConstCuSparseDescriptorDeleter` working with `cusparseStatus_t (*destructor)(const T*)`.
Some algorithm enums were deprecated during CUDA 11 and removed in CUDA 12, I replaced the following occurences
```
CUSPARSE_CSRMM_ALG1 -> CUSPARSE_SPMM_CSR_ALG1
CUSPARSE_COOMM_ALG1 -> CUSPARSE_SPMM_COO_ALG1
CUSPARSE_COOMM_ALG2 -> CUSPARSE_SPMM_COO_ALG2
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90765
Approved by: https://github.com/cpuhrsch
Summary:
Inductor can't fuse pointwise into the output of concat, but it can
fuse into the inputs, and that's the same thing. So we hoist pointwise through
a concat (followed by an optional series of views).
Test Plan: New unit test
Differential Revision: D41901656
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90743
Approved by: https://github.com/jiawenliu64, https://github.com/jansel
A "life handle" is a pointer-to-boolean that says whether or not a
TensorWrapper is alive. A TensorWrapper is alive if we are currently
inside of its corresponding transform. An Interpreter is alive if we are
currently inside of its corresponding transform. I.e., for vmap(f)(x),
the BatchedTensor(x, level=1) is alive inside of the execution of f; and
the corresponding VmapInterpreter is alive inside of f.
Previously, there was a global map of level to life handle. It is
possible to get into a state where we have multiple levels that refer to
different Interpreters (if the implementation of an operator calls into
functorch) and that messes up the global map.
This PR changes it so that
- every Interpreter holds a life handle that says if it is alive
- to construct a TensorWrapper, one must either (a) directly pass it a life
handle, or (b) one must create the TensorWrapper when the corresponding
Interpreter is on the stack (and we will automatically grab the life
handle by indexing into the DynamicLayerStack with the level)
(a) is more robust so I changed most of our C++ callsites to do that.
(b) feels a bit hacky to me, but it seems fine for now:
- It'll raise a nice error message if the interpreter isn't on the stack
- all of our Python callsites already follow this convention (we construct
TensorWrappers after pushing the Interpreter onto the stack).
The alternative to (b) is that we always do (a), which we can do in the
future if (b) runs us into any problems.
Test Plan:
- all functorch tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90317
Approved by: https://github.com/samdow
Motivation
- These were previously defined in functorch. They are not
functorch-specific, so I'm moving them to torch.autograd.forward_ad and
the autograd python bindings.
- I need this to avoid some of my cyclic import problems.
Should these be public APIs? Probably. Though this needs discussion, so
punting it to the future.
Test Plan:
- moved the tests of these from test/functorch/test_eager_transforms.py
to test/test_autograd.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90240
Approved by: https://github.com/soulitzer
This PR adds a `vmap` staticmethod to autograd.Function and a
corresponding vmap kernel for custom_function_call. These two items mean
that autograd.Function with a vmap staticmethod can be used with vmap.
```py
class NumpyMul(torch.autograd.Function)
staticmethod
def forward(x, y):
return torch.tensor(to_numpy(x) * to_numpy(y), device=x.device)
staticmethod
def setup_context(ctx, outputs, x, y):
ctx.save_for_backward(x, y)
staticmethod
def backward(ctx, grad_output):
x, y = ctx.saved_tensors
gx = None
if isinstance(x, torch.Tensor) and x.requires_grad:
gx = NumpyMul.apply(grad_output, y)
gy = None
if isinstance(y, torch.Tensor) and y.requires_grad:
gy = NumpyMul.apply(grad_output, x)
return gx, gy
staticmethod
def vmap(info, in_dims, x, y):
x_bdim, y_bdim = in_dims
x = x.movedim(x_bdim, -1) if x_bdim else x.unsqueeze(-1)
y = y.movedim(y_bdim, -1) if y_bdim else y.unsqueeze(-1)
result = NumpyMul.apply(x, y)
result = result.movedim(-1, 0)
return result, 0
```
API Spec
- the staticmethod takes two arguments (info, in_dims) as well as the
unexpanded inputs (x, y).
- If we think about it as `vmap(info, in_dims, *args)`, `in_dims` is a
pytree with the same tree structure as args. It has None if the arg is
not being vmapped over and an integer vmapped dimension index if it is.
- `info` is an object with metadata about the vmap. It currently has one
field, `info.batch_size`. In the future we can extend this by adding
things like the randomness information.
- If there is a single vmap going on, (x, y) are NOT BatchedTensors,
they've already been unpacked.
- We expect the user to return a `(outputs, out_dims)` tuple. `out_dims`
must "broadcast" to the same pytree structure as `outputs`.
Semantics
- vmap(NumpyMul.apply)(x) will apply the vmap staticmethod if there is
one and will never actually run NumpyMul.forward.
- In order for the autograd.Function to support nested vmap (e.g.,
`vmap(vmap(NumpyMul.apply))(x)`, then the vmap staticmethod must call
into operations that vmap understands (i.e. PyTorch operators or more
autograd.Function).
At a high level, this PR:
- adds a vmap rule for custom_function_call
Testing
- Added some tests for in_dims and info
- Added vmap staticmethod to most of the autograd.Function in
autograd_function_db and sent them through functorch's vmap-related
OpInfo tests
Future
- Better error messages if the user gets the return contract wrong. I
didn't include them in this PR because it might involve a refactor of
some of the existing code in functorch/_src/vmap.py that will add
~200LOC to the PR, but LMK if you'd prefer it here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90037
Approved by: https://github.com/samdow, https://github.com/soulitzer
This PR reworks the internal handling of parameter and gradient reduction mixed precision, cleans up the post-backward hook logic, and adds some minor changes to the communication hooks.
**Overview**
This PR addresses everything in https://github.com/pytorch/pytorch/issues/90657 except renaming `keep_low_precision_grads` to `keep_grads_in_reduce_dtype` since that is BC breaking. I recommend reading the issue before preceding.
For `MixedPrecision(param_dtype, reduce_dtype, ...)`, the exact rule for parameter and gradient reduction mixed precision that we are following is:
> If `param_dtype is not None` and `reduce_dtype is None`, then we infer `reduce_dtype = param_dtype`. Otherwise, we take `param_dtype` and `reduce_dtype` as is.
This PR enforces that, at the `FlatParamHandle` level, `handle._config.fwd_bwd_param_dtype` and `handle._config.reduce_dtype` are never `None`. The way to check if mixed precision is enabled is to compare against the original parameter dtype, which is now stored in `handle._orig_param_dtype`. It is no longer to check against `None`.
This avoids ambiguous cases such as when the user passes `MixedPrecision(param_dtype=torch.float32)`. In that case, our existing implementation mistakenly thinks that parameter mixed precision is enabled and either relies on no-ops silently or errors (such as one case reported by MosaicML).
**Additional Details**
- We remove `FullyShardedDataParallel._mixed_precision_enabled_for_params`, `FullyShardedDataParallel._mixed_precision_enabled_for_reduce`, and `FullyShardedDataParallel._mixed_precision_keep_low_precision_grads` since they are not used.
- The unit test `test_meta_device_with_mixed_precision()` exercises a tricky edge case with meta device initialization, `apply()` (calling into `summon_full_params()`), and `param_dtype=torch.float32` for a nested wrapping case, where each nested instance has parameters.
- We include some minor fixes/improvements to the communication hook implementation.
**Follow-Ups**
- We should get rid of `HandleConfig` and store its fields as attributes on `FlatParamHandle` directly.
- Rename `keep_low_precision_grads` to `keep_grads_in_reduce_dtype`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90660
Approved by: https://github.com/zhaojuanmao
## Summary
Torch.compile was previously not working for transformerencoder because torch.SDPA calls a native function on tensors that returns an int. This PR instead creates a dispatch stub for the function called in order to not create a separate fx node for this native function.
As well this pr adds meta functions for the fused kerenels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90576
Approved by: https://github.com/cpuhrsch
Summary: Only the pattern part, will leave the delegation example to Chen
Test Plan: buck run executorch/exir/tests:quant_lowering_custom_backend_pass -- "executorch.exir.tests.test_quant_lowering_custom_backend_pass.TestQuantLoweringCustomBackendPass.test_quantized_linear_dynamic"
Reviewed By: cccclai
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90640
Approved by: https://github.com/cccclai
#85303 added a patch to `torch.testing.assert_close` to handle `torch.storage.TypedStorage`'s. This change is not reflected in the docs and is not intended for the public API. This PR removes the patch ones again and moves the behavior to `TestCase.assertEqual` instead. Meaning, `TypedStorage`'s are again not supported by the public API, but the behavior is the same for all internal use cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89557
Approved by: https://github.com/kurtamohler, https://github.com/mruberry
Summary: A cast to int was added in
https://github.com/pytorch/pytorch/pull/45630 to make mypy not complain.
However this leads to unexpected behavior where the histogram doesn't
actually capture the full range of activation values.
note1: the test_histogram_observer_against_reference test was secretly
broken, on master. The random parameters that normally get run apparently don't cause a test failure but if you make a loop repeatedly run the test, it would
eventually fail. This was due to in some cases
sum(<tensor>)!=torch.sum(<tensor>).item(). I was not able to reproduce
this with a toy example but running this test in a loop and editing
either observer to print the calculation for 'total' would break the
test and show different behaviors. Fixing this test was necessary to
land this PR since the changing histogram bounds changed things enough
that this test would error.
note2: updating histogram observer breaks some BC tests unless I regenerate the
model using the HistogramObserver from this PR
Test Plan: python test/test_quantization.py TestHistogramObserver.test_histogram_observer_correct_numel
python test/test_quantization -k histogram
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90355
Approved by: https://github.com/vkuzo
@mlazos: skips `item()` calls if compiling with dynamo, by defining a helper function `_get_value` which either returns the result of `.item()` or the scalar cpu tensor if compiling with dynamo. This was done because removing `item()` calls significantly regresses eager perf. Additionally, `_dispatch_sqrt` calls the appropriate sqrt function (math.sqrt, or torch.sqrt).
Fixes https://github.com/pytorch/torchdynamo/issues/1083
This PR will no longer be needed once symint support is default.
This PR closes all remaining graph breaks in the optimizers (!!)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88173
Approved by: https://github.com/albanD
Applies various automated fixes that reduces the number of spurious copies in torch, aten, and c10. I also inlined any default dtors that would have made the type trivially destructible.
Follow up to #89000
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90629
Approved by: https://github.com/ezyang
The big idea is to add `create_unbacked_symfloat` and `create_unbacked_symint` to ShapeEnv, allowing you to allocate symbolic floats/ints corresponding to data you don't know about at compile time. Then, instead of immediately erroring out when you try to call local_scalar_dense on a FakeTensor, we instead create a fresh symint/symfloat and return that.
There a bunch of odds and ends that need to be handled:
* A number of `numel` calls converted to `sym_numel`
* When we finally return from item(), we need to ensure we actually produce a SymInt/SymFloat when appropriate. The previous binding code assumed that you would have to get a normal Python item. I add a pybind11 binding for Scalar (to PyObject only) and refactor the code to use that. There is some trickiness where you are NOT allowed to go through c10::SymInt if there isn't actually any SymInt involved. See comment.
* One of our unit tests tripped an implicit data dependent access which occurs when you pass a Tensor as an argument to a sizes parameter. This is also converted to support symbolic shapes
* We now support tracking bare SymInt/SymFloat returns in proxy tensor mode (this was already in symbolic-shapes branch)
* Whenever we allocate an unbacked symint, we record the stack trace it was allocated at. These get printed when you attempt data dependent access on the symint (e.g., you try to guard on it)
* Subtlety: unbacked symints are not necessarily > 1. I added a test for this.
These unbacked symints are not very useful right now as you will almost always immediately raise an error later when you try to guard on them. The next logical step is adding an assertion refinement system that lets ShapeEnv learn facts about unbacked symints so it can do a better job eliding guards that are unnecessary.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90624
Approved by: https://github.com/Skylion007, https://github.com/voznesenskym
* Skip a unittest that needs FFT if not built with FFT
* Mark a test with "slow": `python test/test_ops.py -k TestCompositeComplianceCUDA.test_forward_ad_svd_lowrank_cuda_float32` took >5min on my machine.
* Skip a flaky test that's marked "expectedFailure", similar to #90233
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90609
Approved by: https://github.com/soumith
This lowers the `reduce_dtype` retrieval to the `handle` instead of the `state` in preparation for `fully_shard`, and this adds a guard to avoid a no-op `to()` call.
Note that this change pretty much gets overridden in following PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90615
Approved by: https://github.com/rohan-varma
Use register_state_dict_pre_hook in FSDP to simplify state_dict implementations & remove hacks. This removes `def state_dict` entirely and paves the path for composable API as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90436
Approved by: https://github.com/fegin
This saves a data structure `_stream_to_name: Dict[torch.cuda.Stream, str]` that maps each FSDP stream to its name. This can help in debugging by checking `_stream_to_name[torch.cuda.current_stream()]` to see if it is `"default"` or `"unshard"` in the post-backward hook for example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90611
Approved by: https://github.com/rohan-varma
Optimizes the nccl python bindings to reserve space when converting PythonObject* into Tensors. This should reduce the number of unnecessary allocations in the nccl bindings as the std::vector grows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88203
Approved by: https://github.com/ezyang
Applies some more missing std::move found by static analysis. This should improve performance and reduce unnecessary copies. This PR only targets ATen for now.
And before you ask about the edits, std::move is optimal in a ternary operator as copy ellision cannot happen one. The best thing is probably rewriting it as an if else, but ultimately this should be performant enough.
Followup to #88512 and #88514
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89000
Approved by: https://github.com/ezyang
Instead of inferring shape mappings from a bunch of data structures that were plumbed in InstructionTranslator, we instead work out mappings by just iterating over the GraphArgs and mapping symbols to arguments as they show up. If multiple argument sizes/strides/offset map to the same symbol, this means they are duck sized, so we also generate extra equality tests that they must be equal. Finally, we generate 0/1 specialization guards. The resulting code is much shorter, and I think also easier to understand.
TODO: Delete all the tensor ref tracking code, it's unnecessary
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90528
Approved by: https://github.com/voznesenskym
So, uh, I have a new strategy for generating dupe guards, one where I don't actually need to allocate symints for every tensor that is fakeified. So I'm reverting the changes I made from earlier PRs in this one.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90381
Approved by: https://github.com/voznesenskym
Wow, I had to sweat so much to get this PR out lol.
This PR enforces the invariant that whenever we allocate SymInts as part of fakeification, the SymInt is associated with a Source, and in fact we store the string source name on SymbolWithSourceName. We use 'sname' as the shorthand for source name, as 'name' is already used by sympy to name symbols.
In order to store source names, we have to plumb source names from Dynamo to PyTorch. This made doing this PR a bit bone crushing, because there are many points in the Dynamo codebase where we are improperly converting intermediate tensors into fake tensors, where there is no source (and there cannot be, because it's a frickin' intermediate tensor). I've fixed all of the really awful cases in earlier PRs in the stack. This PR is just plumbing in source names from places where we do have it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90295
Approved by: https://github.com/voznesenskym
Summary:
This pull request makes some LazyGraphExecutor private data structures protected such that XLAGraphExecutor can reuse them.
Here is the list:
1. DeviceLocker.
2. DeviceLockerArena.
3. DataCacheArena. In addition, it also introduces LazyGraphExecutor::ResetTrimCounter() such that XLAGraphExecutor can reuse the trim counter.
Test Plan:
CI.
P.S. This is to re-land #90457.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90598
Approved by: https://github.com/JackCaoG
Retry of #89595. Accidentally closed.
## Forked `BaseCppType`
Created a module for Executorch: `torchgen.executorch`.
In `torchgen.executorch.api.types.types`:
* Define `BaseCppType` with `torch::executor` namespace.
In `torchgen.executorch.api.et_cpp`:
* Help generate `NamedCType` for `ExecutorchCppSignature` arguments.
In `torchgen.executorch.api.types.signatures`:
* Define the signature using these types. (`ExecutorchCppSignature`)
In `torchgen.executorch.api.types.__init__`:
* Suppress flake8 error for `import *`.
Differential Revision: [D41501836](https://our.internmc.facebook.com/intern/diff/D41501836/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90591
Approved by: https://github.com/iseeyuan
A retry of #89487. Accidentally closed.
## Split `torchgen.api.types` into `types_base`, `types` and `signatures`.
In `types_base`:
* Created base class `CType`. `BaseCType` and `ConstRefCType` etc are inheriting `CType`.
* Only keep abstract type model definitions, such as `BaseCppType`.
In `types`:
* Define `BaseCppType` with `at` and `c10` namespaces.
* All the signatures using these types.
In `signatures`:
* Define all the signatures.
In `__init__`:
* `from ... import *`, suppress flake8 error.
Differential Revision: [D41455634](https://our.internmc.facebook.com/intern/diff/D41455634/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D41455634/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90589
Approved by: https://github.com/iseeyuan
Variable length arguments can overflow the arena being used to keep overhead
low for torch dims. If we hit this case, we know the amount of work being done
is already relatively big, so we just fallback to standard memory allocation.
Fixes#88586
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88596
Approved by: https://github.com/ezyang
This adds a d3-based interactive visualization for exploring the memory
allocation traces that the caching allocator can capture. This visualization
code can also be attached to kineto trace information in the future to also
provide visualization for the memory events captured there, which come with
addition information about the graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90348
Approved by: https://github.com/robieta
Summary: Modified replace_pattern in the subgraph rewriter to return a list of pairs of matches along with their corresponding replacement nodes in the modified graph (`List[Tuple[Match, List[Node]]]`). This allows us to easily modify the replaced nodes, including setting the metadata.
Test Plan: CI
Differential Revision: D41737056
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90244
Approved by: https://github.com/SherlockNoMad
Summary:
Optimize the shape padding in the following perspectives:
- Add BFloat16 support for AMP training and Float16 support for inference
- Optimize microbenchmark to avoid peak memory issue, and include profiling memory ops to make more accurate decision
- Add a flag to turn off/on padding dims N and M in `torch.bmm` due to expensive memory copy of `.contiguous` to avoid peak memory issues in internal models
Test Plan: CI
Differential Revision: D41724868
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90425
Approved by: https://github.com/jianyuh
Continuation after https://github.com/pytorch/pytorch/pull/90163.
Here is a script I used to find all the non-existing arguments in the docstrings (the script can give false positives in presence of *args/**kwargs or decorators):
_Edit:_
I've realized that the indentation is wrong for the last `break` in the script, so the script only gives output for a function if the first docstring argument is wrong. I'll create a separate PR if I find more issues with corrected script.
``` python
import ast
import os
import docstring_parser
for root, dirs, files in os.walk('.'):
for name in files:
if root.startswith("./.git/") or root.startswith("./third_party/"):
continue
if name.endswith(".py"):
full_name = os.path.join(root, name)
with open(full_name, "r") as source:
tree = ast.parse(source.read())
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
all_node_args = node.args.args
if node.args.vararg is not None:
all_node_args.append(node.args.vararg)
if node.args.kwarg is not None:
all_node_args.append(node.args.kwarg)
if node.args.posonlyargs is not None:
all_node_args.extend(node.args.posonlyargs)
if node.args.kwonlyargs is not None:
all_node_args.extend(node.args.kwonlyargs)
args = [a.arg for a in all_node_args]
docstring = docstring_parser.parse(ast.get_docstring(node))
doc_args = [a.arg_name for a in docstring.params]
clean_doc_args = []
for a in doc_args:
clean_a = ""
for c in a.split()[0]:
if c.isalnum() or c == '_':
clean_a += c
if clean_a:
clean_doc_args.append(clean_a)
doc_args = clean_doc_args
for a in doc_args:
if a not in args:
print(full_name, node.lineno, args, doc_args)
break
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90505
Approved by: https://github.com/malfet, https://github.com/ZainRizvi
The old `temp_dir` is created under `PWD`. But `PWD` may not be writable and in general is not a good place to create temporary directories. Use the standard `tempfile` instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89826
Approved by: https://github.com/soumith
Fixes#88074
Several datapipes have their lengths cached on being executed for the first time. However, source datapipes might change in length (most prominently, whenever `apply_sharding` is called). The behaviour is counter-intuitive because we do not expect `__len__` to have side-effects.
This PR makes `__len__` dynamically computed.
Changes:
- Add note to the `datapipes` README that `__len__` should be dynamic and why.
- Remove caching of length computations in `ConcaterIterDataPipe`, `MultiplexerIterDataPipe`, `ZipperIterDataPipe`, `BatcherIterDataPipe`, `ConcaterMapDataPipe`, and `BatcherMapDataPipe`.
- This required removal of the `length` attribute in setstate/getstate of `MultiplexerIterDataPipe`. I am unsure whether to remove this completely and risk breaking saved checkpoints (as I did) or whether to just ignore the `length` of the loaded `state`.
- This also means the classes above no longer have a `length` attribute. I have found no uses of this, though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88302
Approved by: https://github.com/NivekT
Summary:
This pull request makes some LazyGraphExecutor private data structures protected such that XLAGraphExecutor can reuse them.
Here is the list:
1. DeviceLocker.
2. DeviceLockerArena.
3. DataCacheArena.
In addition, it also introduces LazyGraphExecutor::ResetTrimCounter() such that XLAGraphExecutor can reuse the trim counter.
Test Plan:
CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90457
Approved by: https://github.com/JackCaoG
- Adds `log_level` to aot's config
- Outputs log to `<graph_name>_<log_level>.log` in aot_torchinductor subfolder of the debug directory
- Modifies the Inductor debug context to use the graph name when naming the folder instead of the os pid
- Adds `TORCH_COMPILE_DEBUG` flag to enable it, (as well as separate dynamo and inductor logs)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88987
Approved by: https://github.com/Chillee
This PR changes the way masks for loads/stores are computed in triton backend of inductor.
New approach is to iterate over all variables used in indexing expression and add the corresponding mask variables to the set that will be used. For indexing variables like `x0`, `y1` and `r3` it adds `xmask`, `ymask` and `rmask` respectively.
For indexing variables like `tmp5` (i.e., indirect indexing), it uses the new `mask_vars` attribute of the corresponding `TritonCSEVariable` object, which is populated when variable is created.
I started working on this with the aim of fixing https://github.com/pytorch/torchdynamo/issues/1654, which meanwhile was fixed by #89524 with a different approach, making this change less necessary. However note that #89524 fixes the issue by broadcasting the indices that are being loaded to a larger size, while this approach fixes it by making the mask have only the necessary terms.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89566
Approved by: https://github.com/jansel, https://github.com/ngimel
Doing some tests with all Optimizer and LRScheduler classes in optim package, I noticed a couple of mistakes in type annotations, so created a pull request to fix them.
- In Optimizer class, incorrectly named parameter `default` instead of `defaults` in pyi file
- In SGD class, type for `maximize` and `differentiable` not available in either py or pyi files
I don't know if there is a plan to move all types from pyi to py files, so wasn't too sure where to fix what.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90216
Approved by: https://github.com/janeyx99
Rewrite inplace addcdiv to a div, mul and inplace add to avoid graph break
Rewrite inplace add to a mul and inplace add to avoid graph break
Needed to close optimizer graph breaks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90330
Approved by: https://github.com/jansel
Summary: To get source for a particular module, the "correct" thing to do is to check the module's spec and use `get_source` if it's a SourceFileLoader, since subclasses may look elsewhere than the `__file__`, and the spec will give the source of truth. For torch packager, however, we prefer to use linecache, but the loader could still change the file, so we figure out the file for the module using the spec's loader rather than using `module.__file__`, if possible.
Test Plan: This code path will get exercised by CI. Also added a test for remapped files.
Differential Revision: D41412983
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90258
Approved by: https://github.com/PaliC
Summary:
We should not fork in deploy when initializing torch.
Traceback (most recent call last):
File "<string>", line 38, in <module>
File "<string>", line 36, in __run
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/fbcode/platform010/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/data/users/zyan/fbsource/buck-out/v2/gen/fbcode/104a4d5c3a690252/multipy/runtime/__test_py__/test_py#link-tree/multipy/runtime/test_py.py", line 61, in <module>
import torch # has to be done serially otherwise things will segfault
File "/data/users/zyan/fbsource/buck-out/v2/gen/fbcode/104a4d5c3a690252/multipy/runtime/__test_py__/test_py#link-tree/torch/__init__.py", line 158, in <module>
platform.system() != 'Windows':
File "/usr/local/fbcode/platform010/lib/python3.8/platform.py", line 891, in system
return uname().system
File "/usr/local/fbcode/platform010/lib/python3.8/platform.py", line 857, in uname
processor = _syscmd_uname('-p', '')
File "/usr/local/fbcode/platform010/lib/python3.8/platform.py", line 613, in _syscmd_uname
output = subprocess.check_output(('uname', option),
Test Plan: override a local script run trigger init and set `subprocess.check_output` to None
Reviewed By: yinghai, houseroad
Differential Revision: D41848592
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90492
Approved by: https://github.com/PaliC
Happy to split this PR more if it helps.
This PR adds functorch.grad support for autograd.Function. There's a lot
going on; here is the high level picture and there are more details as
comments in the code.
Mechanism (PyOperator)
- Somehow, autograd.Function needs to dispatch with functorch. This is
necessary because every layer of functorch needs to see the
autograd.Function; grad layers need to preserve the backward pass.
- The mechanism for this is via PyOperator. If functorch transforms are
active, then we wrap the autograd.Function in a `custom_function_call`
PyOperator where we are able to define various rules for functorch
transforms.
- `custom_function_call` has a rule for the functorch grad transform.
autograd.Function changes
- I needed to make some changes to autograd.Function to make this work.
- First, this PR splits autograd.Function into a _SingleLevelFunction
(that works with a single level of functorch transform) and
autograd.Function (which works with multiple levels). This is necessary
because functorch's grad rule needs some way of specifying a backward
pass for that level only.
- This PR changes autograd.Function's apply to eitehr call
`custom_function_call` (if functorch is active) or super().apply (if
functorch isn't active).
Testing
- Most of this PR is just testing. It creates an autograd.Function
OpInfo database that then gets passed to the functorch grad-based tests
(grad, vjp, vjpvjp).
- Since functorch transform tests are autogenerated from OpInfo tests,
this is the easiest way to test various autograd.Function with
functorch.
Future
- jvp and vmap support coming next
- better error message (functorch only supports autograd.Function that
have the optional setup_context staticmethod)
- documentation to come when we remove the feature flag
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89860
Approved by: https://github.com/soulitzer
Adds a setup_context staticmethod to autograd.Function.
If it exists, then the user splits the ctx-specific logic from the
forward() and puts it in the setup_context staticmethod.
Docs will come later when we remove the feature flag.
Test Plan:
- some light tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89859
Approved by: https://github.com/soulitzer
This PR adds a private runtime feature flag for the feature work we're going
to do with extending autograd.Function. The motivation of the feature flag
is:
- to guard the feature against unsuspecting users
- control the release of the feature to when we are ready to release it
We might not even need the feature flag (because we hope to have the
work done in the next month), but it is good practice and it does touch
currently public API (autograd.Function).
Concretely, "autograd.Function extension" refers to:
- adding an optional `setup_context` staticmethod to autograd.Function
- adding an optional `vmap` staticmethod to autograd.Function
- autograd.Function support for functorch
Test Plan:
- new test that the feature flag works
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89858
Approved by: https://github.com/soulitzer
Summary:
This pull request makes some tweaks on LazyTensor class such that it's easier for XLATensor to inherit.
1. It replaces data_ptr() with data() which now returns a const shared_ptr& type.
2. It adds a temporary ctor to LazyTensor::Data such that XLATensor::Data can easily inherits it.
3. It moves LazyTensor(std::shared_ptr<Data>) and SetTensorData(at::Tensor) to protected for XLATensor to access.
Test Plan:
CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90363
Approved by: https://github.com/JackCaoG
The function signature in its current state is ambiguous.
Its an inline function that is also declared to be imported from the DLL.
which leaves it subject to compilers decision to choose one or the other and depending on what the compiler/linker may choose we may get one of the two behaviors for the `aten::init_num_threads` call:
1. Once-per-dll-in-a-thread (if its inlined)
2. Once-per-thread (if its imported)
I suspect once-per-dll-in-a-thread is already the case currently because it being tagged inline
So removing the inline will simply make it a little more consistent and clear.
The function exists to avoid repeated calls to aten::init_num_threads.
Being in an "internal" namespace, the function isnt expected to be called by external plugins which means that the "once-per-dll-in-a-thread" behavior isn't that much of a problem anyway
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89511
Approved by: https://github.com/malfet
Adds 2 new hybrid sharding strategy to FSDP:
1. HYBRID_SHARD: applies zero-3 style sharding within a node, and data parallel across
2. HYBRID_SHARD_ZERO2: applies zero-2 style sharding within a node, and data parallel across
These are useful for medium sized models and aim to decrease communication volume, tests and benchmarks will be run to understand which workloads are optimal under which sharding strategy.
Hybrid sharding in general works by sharding the model using a process group within a single node, and creating intra-node process groups for replication / data parallelism. The user either needs to pass in a tuple of these process groups, or None, and we generate the process groups appropriately.
** Acknowledgements **
- @awgu 's excellent prototype: 5ad3a16d48
- @liangluofb For ideation, feedback, and initial implementation and experimentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89915
Approved by: https://github.com/awgu
This makes the signature of `torch.masked.std` and `var` more consistent with the global namespace variant and also updates the sample inputs to repurpose the existing `sample_inputs_std_var` inputs which fully exercise the `correction` argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87118
Approved by: https://github.com/cpuhrsch
I believe that @mrshenli used `ModuleWrapPolicy({UnitModule})` when applying `fully_shard` to `UnitModule`s because `policy=None` was not supported. However, he added that support in a previous PR, so this PR simplifies to using `policy=None` to make the intention more clear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90400
Approved by: https://github.com/mrshenli
- This PR introduces a new concept, the _communication module_ (denoted `comm_module`), that represents the module responsible for the unshard/reshard pair for a `FlatParamHandle`. This is well-defined because the current design assumes that each `FlatParamHandle` only has _one_ unshard/reshard pair for either the forward or backward pass.
- For the wrapper code path, the `comm_module` is exactly the module already being passed to the `FlatParamHandle` constructor.
- For the composable code path, the `comm_module` is not necessarily the module already being passed to the `FlatParamHandle`. This is because the module already being passed is always the local FSDP root module to give complete FQNs, instead of local FQNs. Distinguishing the communication module from the local FSDP root module can provide more flexibility for non-recursive wrapping designs in the future.
- This PR adds a unit test `test_unshard_reshard_order` that explicitly checks that `_unshard` and `_reshard` are called in the exactly the same order across the two code paths.
- This PR does not fix `test_checkpoint_fsdp_submodules_use_reentrant`. However, the error message changes, so this PR accommodates that.
- The error is now the same as if we used the equivalent wrapper FSDP:
```
test_model.u1 = FSDP(test_model.u1, use_orig_params=True)
test_model.u2 = FSDP(test_model.u2, use_orig_params=True)
```
- The error is also the same as if we used wrapper FSDP with `use_orig_params=False`, so it is not unique to `use_orig_params=True`.
---
**`comm_module` Example**
```
model = Model(
seq1: nn.Sequential(
nn.Linear
nn.ReLU
nn.Linear
nn.ReLU
)
seq2: nn.Sequential(
nn.Linear
nn.ReLU
nn.Linear
nn.ReLU
)
)
policy = ModuleWrapPolicy({nn.Sequential})
fully_shard(model, policy=policy)
FullyShardedDataParallel(model, auto_wrap_policy=policy)
```
- This policy constructs two `FlatParamHandle`s, one for `seq1` and one for `seq2`.
- `FullyShardedDataParallel` will pass `seq1` and `seq2` as the `module` argument to the two `FlatParamHandle`s, respectively.
- `fully_shard()` will pass `model` as the `module` argument to every `FlatParamHandle`.
- `FullyShardedDataParallel` will pass `seq1` and `seq2` as the `comm_module` argument to the two `FlatParamHandle`s, respectively.
- `fully_shard()` will pass `seq1` and `seq2` as the `comm_module` argument to the two `FlatParamHandle`s, respectively.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90387
Approved by: https://github.com/mrshenli
Unlike for FSDP, where we already diverged to using per-test-file models, let us try to use the same set of models for the composable API effort. This can improve debugging efficiency because we know which module structures we support and which we do not _across all of our composable APIs_.
This PR had to perform some surgery for `test_materialize_meta_module`. Writing a correct parameter initialization function for meta device initialization is not easy, and we should revisit this. The old implementation, which followed the style of the previous unit tests--namely, using `module.to_empty()`--is actually incorrect for nested FSDP applications because `module.to_empty()` will re-initialize already materialized parameters and the module materialization proceeds bottom up. The existing unit test in `test_fsdp_meta.py` passes because it sets every parameter to ones (`self.weight.fill_(1)`), which is idempotent to re-initialization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90386
Approved by: https://github.com/mrshenli
The `PositiveDefiniteTransform` is required to transform from an unconstrained space to positive definite matrices, e.g. to support testing the Wishart mode in #76690. It is a simple extension of the `LowerCholeskyTransform`.
I've also added a small test that ensures the generated data belong to the domain of the associated transform. Previously, the data generated for the inverse transform of the `LowerCholeskyTransform` wasn't part of the domain, and the test only passed because the comparison uses `equal_nan=True`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76777
Approved by: https://github.com/lezcano, https://github.com/fritzo, https://github.com/soumith
Summary:
This PR implements `prune` in BaseStructuredSparsifier:
`prune` is a function that takes in a model with structured sparsity parametritizations (the result of `prepare`) and will return a resized model with the masked out weights removed.
`prune` is defined by a mapping from **patterns** to different **pruning functions**.
- **patterns** are just sequences of operations, for example `(nn.Linear, activation, nn.Linear)`
- **pruning functions** are functions that take in an matched pattern as args and will resize the appropriate layer sizes and weights.
```
def prune_linear_activation_linear(linear1, activation, linear2):
pass
```
- This is one line in the pattern config `(nn.Linear, activation, nn.Linear): prune_linear_activation_linear`
At a high level `prune` works by finding instances of the graph that match different patterns and then calling the mapped pruning functions on those matched patterns.
This is unlike the previous code which attempted to do both at the same time.
There may be some gaps in the patterns compared to the previous implementation, but the conversion functionality support should be the same.
Currently we have pruning functions for the following patterns:
- linear -> linear
- linear -> activation -> linear
- conv2d -> conv2d
- conv2d -> activation -> conv2d
- conv2d -> activation -> pool -> conv2d
- conv2d -> pool -> activation -> conv2d
- conv2d -> adaptive pool -> flatten -> linear
Added in MyPy type hints as well for the prune_functions.
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89777
Approved by: https://github.com/vkuzo
Prior to this change, the symbolic_fn `layer_norm` (before ONNX version 17) always lose precision when eps is smaller than Float type, while PyTorch always take eps as Double. This PR adds `onnx::Cast` into eps related operations to prevent losing precision during the calculation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89869
Approved by: https://github.com/BowenBao
This is the last PR for integrating 2D into core distributed.
This PR does the following:
1. Add optimizer.py: this adds ability to load a state_dict in conjunction with FSDP sharded optimzer state.
2. Update default_planner.py to support 2D checkpoint.
3. Add test_fsdp_optim_state.py as a unit test for No. 1.
4. Fix bug in torch/testing/_internal/distributed/checkpoint_utils.py
5. Rename the filename for the APIs that should be private. Will organize and cleanup further in following PRs. #90328
Docstring and integration test will be added in the following PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90212
Approved by: https://github.com/wanchaol
Summary:
This will make sure we don't run into an internal assert for clang tsan which has a cap of 63 on concurrently held lock count.
Seems like it is failing with 64 since the comparison is `<`, so setting it to 63 here.
```
llvm-project/compiler-rt/lib/sanitizer_common/sanitizer_deadlock_detector.h:67 "((n_all_locks_)) < (((sizeof(all_locks_with_contexts_)/sizeof((all_locks_with_contexts_)[0]))))"
```
Created from CodeHub with https://fburl.com/edit-in-codehub
Test Plan:
CI
Sandcastle run
Reviewed By: kimishpatel, salilsdesai
Differential Revision: D41444710
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89453
Approved by: https://github.com/mcr229
Summary:
This diff introduces a set of changes that makes it possible for the host to get assertions from CUDA devices. This includes the introduction of
**`CUDA_KERNEL_ASSERT2`**
A preprocessor macro to be used within a CUDA kernel that, upon an assertion failure, writes the assertion message, file, line number, and possibly other information to UVM (Managed memory). Once this is done, the original assertion is triggered, which places the GPU in a Bad State requiring recovery. In my tests, data written to UVM appears there before the GPU reaches the Bad State and is still accessible from the host after the GPU is in this state.
Messages are written to a multi-message buffer which can, in theory, hold many assertion failures. I've done this as a precaution in case there are several, but I don't actually know whether that is possible and a simpler design which holds only a single message may well be all that is necessary.
**`TORCH_DSA_KERNEL_ARGS`**
This preprocess macro is added as an _argument_ to a kernel function's signature. It expands to supply the standardized names of all the arguments needed by `C10_CUDA_COMMUNICATING_KERNEL_ASSERTION` to handle device-side assertions. This includes, eg, the name of the pointer to the UVM memory the assertion would be written to. This macro abstracts the arguments so there is a single point of change if the system needs to be modified.
**`c10::cuda::get_global_cuda_kernel_launch_registry()`**
This host-side function returns a singleton object that manages the host's part of the device-side assertions. Upon allocation, the singleton allocates sufficient UVM (Managed) memory to hold information about several device-side assertion failures. The singleton also provides methods for getting the current traceback (used to identify when a kernel was launched). To avoid consuming all the host's memory the singleton stores launches in a circular buffer; a unique "generation number" is used to ensure that kernel launch failures map to their actual launch points (in the case that the circular buffer wraps before the failure is detected).
**`TORCH_DSA_KERNEL_LAUNCH`**
This host-side preprocessor macro replaces the standard
```
kernel_name<<<blocks, threads, shmem, stream>>>(args)
```
invocation with
```
TORCH_DSA_KERNEL_LAUNCH(blocks, threads, shmem, stream, args);
```
Internally, it fetches the UVM (Managed) pointer and generation number from the singleton and append these to the standard argument list. It also checks to ensure the kernel launches correctly. This abstraction on kernel launches can be modified to provide additional safety/logging.
**`c10::cuda::c10_retrieve_device_side_assertion_info`**
This host-side function checks, when called, that no kernel assertions have occurred. If one has. It then raises an exception with:
1. Information (file, line number) of what kernel was launched.
2. Information (file, line number, message) about the device-side assertion
3. Information (file, line number) about where the failure was detected.
**Checking for device-side assertions**
Device-side assertions are most likely to be noticed by the host when a CUDA API call such as `cudaDeviceSynchronize` is made and fails with a `cudaError_t` indicating
> CUDA error: device-side assert triggered CUDA kernel errors
Therefore, we rewrite `C10_CUDA_CHECK()` to include a call to `c10_retrieve_device_side_assertion_info()`. To make the code cleaner, most of the logic of `C10_CUDA_CHECK()` is now contained within a new function `c10_cuda_check_implementation()` to which `C10_CUDA_CHECK` passes the preprocessor information about filenames, function names, and line numbers. (In C++20 we can use `std::source_location` to eliminate macros entirely!)
# Notes on special cases
* Multiple assertions from the same block are recorded
* Multiple assertions from different blocks are recorded
* Launching kernels from many threads on many streams seems to be handled correctly
* If two process are using the same GPU and one of the processes fails with a device-side assertion the other process continues without issue
* X Multiple assertions from separate kernels on different streams seem to be recorded, but we can't reproduce the test condition
* X Multiple assertions from separate devices should be all be shown upon exit, but we've been unable to generate a test that produces this condition
Differential Revision: D37621532
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84609
Approved by: https://github.com/ezyang, https://github.com/malfet
Summary:
In this logic, we are traversing the entries to find the module for STACK_GLOBAL entries.
According to 2837241f22/Lib/pickletools.py (L1799) we need to look for GET, BINGET and LONG_BINGET.
So this diff updates that. Also while testing, I found some cases of empty modules, for cases such as tanh. For this I added the option to skip processing when this is the case.
Test Plan: Tested with f392778829
Differential Revision: D41748595
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90223
Approved by: https://github.com/PaliC
The original implementation of cond() operator support in dynamo operated by recursively calling export() on the inner subgraph. This is problematic for a number of reasons:
* My original motivating reason: the original implementation had to play tricks to feed real tensors to the recursive export call, which means that it doesn't work well with tracing with dynamic shapes (where we MUST stay in fake tensors to accurately track dynamic shapes across the cond invocation)
* If there are pending side effects, the recursive export() call won't see those side effects (as they are only tracked by Dynamo, not actually applied to the Python environment.) You can see an example where dynamo cond tracing does the wrong thing at https://github.com/pytorch/pytorch/pull/90208
* If there were side effects inside the true/false branch, these side effects were silently lost (as the export only returns the graph of tensor operations, and not any of the residual Python bytecodes necessary to reapply any side effects.) This could have substantive effects on the export of subsequent parts of the model, as those parts of the models could rely on the side effects.
* It was not possible to track NN module accesses inside the true/false branches, necessitating a hack where the NN module was explicitly passed in as an input to cond https://github.com/pytorch/pytorch/pull/87020#issuecomment-1338842844 which doesn't really make any sense from a backend compilation perspective
* Guards induced from the inside of the true/false branch were not properly propagated to the top level guards; they were just silently dropped (in fact, the original implementation checked that the true/false branch produce the same guards which... is not useful? Like, I don't think that actually is even necessary for correctness)
This PR replaces the old implementation with a new implementation based on graphstate checkpointing. The basic idea is to process a cond(), we checkpoint the state of our interpreter, run the true branch, rollback to our checkpoint, run the false branch, rollback to our checkpoint and then merge the changes from both of the checkpoints. I require the true/false branches to have exactly the same side effects, but union their guards.
Some of the details:
* Dynamo is too aggressive with tracking side effects when processing closures, c.f. https://github.com/pytorch/torchdynamo/pull/233/files#r1040480078 The basic problem is whenever I define a closure, this immediately counts as a side effect, even if I didn't actually mutate anything. This triggered on the nested cond export example. To prevent this from happening, I optimistically avoid tracking side effects, but if a STORE_DEREF happens, I restart analysis with the relevant Source.name() added to `mutated_closure_cell_contents` so we start tracking on closure allocation. This is enough to fix the relevant test.
* For the most part, I assert that the graph states must be equivalent after applying the true/false branches. During debugging, I found it useful to be able to compare two graph states and give a better description about what the divergence was. You can test this using the `diff()` method I've added to a few structures.
* The implementation now supports NestedUserFunctionVariable, which is nice as it allows the true/false branches to be defined closer to the cond implementation.
* I fixed the naming of the true/false subgraphs; previously they were named `name_0`, `name_1`, now they are named `cond_true_0` and `cond_false_0`
* I added `name_to_input` to the saved graph state. I don't actually know if this is necessary, but it seemed like a good idea.
* I have to play some tricks to get the speculating execution of the true/false branch to record into a subgraph. After a careful read of OutputGraph, I found that what would work is overriding graph with a fresh Graph that we want to write things into, and manually setting up the inputs/outputs. It's a little delicate as you have to make sure you reset the Graph to its original before you restore a checkpoint, as checkpoints don't actually save graph for efficiency, and just undo changes on the graph. This capability may usefully get refactored to OutputGraph but I didn't do it in this PR for simplicity.
There are some further problems with the cond() implementation that I leave for future work. Most of these were preexisting with the original implementation.
* Not a problem per se, but if an NN module is used by both the true/false branch, it will show up in the final graph twice (since it has to be a submodule of the GraphModule that makes use of it.) I hope the export pipeline can deal with this.
* List of tensor output for cond is not supported.
* The true/false return values may not have consistent sizes/dims/etc, and we don't check them for consistency.
* If we modify fake tensors in the true/false branches, we aren't rolling them back, c.f. https://github.com/pytorch/torchdynamo/issues/1840
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90286
Approved by: https://github.com/voznesenskym
Get rid of std::iterator inheritance/references for `c10::DictIterator`, `c10::IListRefIterator` and `c10::ListIterator`
Followup after https://github.com/pytorch/pytorch/pull/90174
Fixes deprecation warning and extension compilation failures using VC++
that raises following errors:
```
C:\actions-runner\_work\pytorch\pytorch\build\win_tmp\build\torch\include\ATen/core/IListRef.h(517): error C4996: 'std::iterator<std::bidirectional_iterator_tag,T,ptrdiff_t,T *,T &>::value_type': warning STL4015: The std::iterator class template (used as a base class to provide typedefs) is deprecated in C++17. (The <iterator> header is NOT deprecated.) The C++ Standard has never required user-defined iterators to derive from std::iterator. To fix this warning, stop deriving from std::iterator and start providing publicly accessible typedefs named iterator_category, value_type, difference_type, pointer, and reference. Note that value_type is required to be non-const, even for constant iterators. You can define _SILENCE_CXX17_ITERATOR_BASE_CLASS_DEPRECATION_WARNING or _SILENCE_ALL_CXX17_DEPRECATION_WARNINGS to acknowledge that you have received this warning.
C:\actions-runner\_work\pytorch\pytorch\build\win_tmp\build\torch\include\ATen/core/List.h(169): error C4996: 'std::iterator<std::random_access_iterator_tag,T,ptrdiff_t,T *,T &>::difference_type': warning STL4015: The std::iterator class template (used as a base class to provide typedefs) is deprecated in C++17. (The <iterator> header is NOT deprecated.) The C++ Standard has never required user-defined iterators to derive from std::iterator. To fix this warning, stop deriving from std::iterator and start providing publicly accessible typedefs named iterator_category, value_type, difference_type, pointer, and reference. Note that value_type is required to be non-const, even for constant iterators. You can define _SILENCE_CXX17_ITERATOR_BASE_CLASS_DEPRECATION_WARNING or _SILENCE_ALL_CXX17_DEPRECATION_WARNINGS to acknowledge that you have received this warning.
```
Discovered while working on https://github.com/pytorch/pytorch/pull/85969
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90379
Approved by: https://github.com/ezyang, https://github.com/dagitses
Continuation of https://github.com/pytorch/pytorch/pull/88207
A compile time guard was preventing ActivityType::CUDA from being available on rocm. This caused both the GPU_FALLBACK and CUDA modes to be active at the same time. So operators were being charged gpu time for the hipEventRecord ranges and the actual kernel execution times. This caused incorrect (and often negative) cuda times, in e.g. table().
Previously a cmake variable was not being propagated to a '-D', causing an issue on Windows, which uses cuda but not cupti.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89785
Approved by: https://github.com/jeffdaily, https://github.com/malfet
Fixes https://github.com/pytorch/torchdynamo/issues/1959, #90260
However, I wasn't able to make existing stride tests fail before the fix, even though I'm comparing all, not just significant strides.
Separately running refs on meta tensors produces wrong strides as shown in #90260, however, it looks like in meta tests some other way of computing meta info is used (I've been running
```
pytest -s -v test/test_meta.py -k test_meta_outplace_expand_cuda_float64
```
and verified that it has sample input that should fail, and that it indeed compares all the strides, but the produced `meta_rs` results somehow still had correct strides).
Edit: @SherlockNoMad helped me figure out how to fail the tests, and now I've set the correct ops for checking. `expand` fails for some test inputs because it special-cases 0-dim input case, correctly modeling it in prims would require a lot of changes, so skipping that for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90341
Approved by: https://github.com/SherlockNoMad
Summary: cuda:: is a ambiguous namespace. Make it explicit c10::cuda
Differential Revision: D41469007
/caffe2/caffe2/core/context_gpu.cu(564): error: "caffe2::cuda" is ambiguous/caffe2/caffe2/core/context_gpu.cu(564): error: expected a ";"/caffe2/caffe2/core/context_gpu.cu(568): warning #12-D: parsing restarts here after previous syntax error
Remark: The warnings can be suppressed with "-diag-suppress <warning-number>"/caffe2/caffe2/core/context_gpu.cu(569): error: "caffe2::cuda" is ambiguous/caffe2/caffe2/core/context_gpu.cu(628): error: "caffe2::cuda" is ambiguous
4 errors detected in the compilation of "/caffe2/caffe2/core/context_gpu.cu".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89534
Approved by: https://github.com/malfet
Summary:
- Registered vulkan_prepack::create_qconv2d_context to the QuantizedCPU backend.
- Registered vulkan_prepack::run_qconv2d_context to the Vulkan backend.
- Added function test_quantized_conv2d, in order to test Vulkan Quantized Conv2d with QUInt8 activation, weight and bias (all QUInt8).
- Added multiples tests for vulkan quantized conv2d (regular, depthwise and pointwise). All these tests make use of the test_quantized_conv2d function.
This function tests the correctness of vulkan quantized conv2d, by comparing the following two processes:
(we start with randomly generated float cpu tensors)
- random float cpu tensors -> to vulkan -> quantize them -> apply vulkan conv2d quantized op -> dequantize result -> to cpu
- random float cpu tensors -> quantize them -> dequantize -> apply cpu floating point conv2d op on dequantized tensors -> quantize result -> dequantize
This function takes three boolean flags that modify its behavior:
- prepacking:
- if false, then we directly call at::native::vulkan::ops::quantized_conv2d
- if true, then we call vulkan_prepack::create_qconv2d_context and vulkan_prepack::run_qconv2d_context.
- compute_quantization_params & random_quantization_params:
- if both are false, all quantization params are fixed (given as input)
- if compute_quantization_params is true, all params are computed
- if random_quantization_params is true, the input params are random and the output params are computed.
(compute_quantization_params takes precedence over random_quantization_params)
Test Plan:
On Mac
```
cd ~/fbsource
buck1 run -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
On Android
```
cd ~/fbsource
buck1 build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_quantized_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_quantized_api_test
adb shell "/data/local/tmp/vulkan_quantized_api_test"
```
Reviewed By: SS-JIA
Differential Revision: D41047096
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90012
Approved by: https://github.com/salilsdesai
Summary:
Copying QInt8 and QInt32 from cpu to vulkan:
- Added shader nchw_to_image_int8
- Added shader nchw_to_image_int32
Copying QInt8 and QInt32 from vulkan to cpu
Note: This functionality is currently disabled until issues on Android are resolved.
- Added shader image_to_nchw_int32
- QInt8 works with the same existing image_to_nchw_quantized shaders
Added multiple tests for each supported dtype:
- cpu_to_vulkan_and_dequantize:
These tests check the correctness of copying quantized cpu tensor to vulkan by comparing the output of the following:
- cpu float tensor -> quantize -> to vulkan -> dequantize -> to cpu
- cpu float tensor -> quantize -> dequantize
- cpu_to_vulkan_and_vulkan_to_cpu
(currently disabled until copying vulkan quantized to cpu is enabled):
These tests check the correctness of copying from cpu to vulkan and from vulkan to cpu by creating a random cpu float tensor, quantizing it, then copying it to vulkan, then back to cpu and comparing the output tensor to the original quantized tensor.
- quantize_per_tensor_and_vulkan_to_cpu
(currently disabled until copying vulkan quantized to cpu is enabled):
These tests check the correctness of copying quantized tensor from vulkan to cpu by comparing the output of the following:
- cpu float tensor -> to vulkan -> quantize -> to cpu
- cpu float tensor -> quantize
Test Plan:
On Mac
```
cd ~/fbsource
buck1 run -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
On Android
```
cd ~/fbsource
buck1 build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_quantized_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_quantized_api_test
adb shell "/data/local/tmp/vulkan_quantized_api_test"
```
Reviewed By: kimishpatel
Differential Revision: D41654287
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90357
Approved by: https://github.com/SS-JIA
**Motivation:**
Add a helper to map from the FQN to the corresponding flat_param. The helper will directly get flat_param from fsdp_state and flat_handler as flat_param is not registered to the module if `use_orig_params` is True.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89899
Approved by: https://github.com/awgu
We have an older torch.vmap implementation. It is no longer supported.
It still needs to exist somewhere for the sake of BC with
torch.autograd.functional.
This PR makes it clear what files are meant for implementing the old
vmap implementation. I've seen a couple of PRs recently adding support
for the old vmap implementation, so this will lessen the confusion.
Test Plan:
- CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90324
Approved by: https://github.com/samdow
Summary:
This PR implements `prune` in BaseStructuredSparsifier:
`prune` is a function that takes in a model with structured sparsity parametritizations (the result of `prepare`) and will return a resized model with the masked out weights removed.
`prune` is defined by a mapping from **patterns** to different **pruning functions**.
- **patterns** are just sequences of operations, for example `(nn.Linear, activation, nn.Linear)`
- **pruning functions** are functions that take in an matched pattern as args and will resize the appropriate layer sizes and weights.
```
def prune_linear_activation_linear(linear1, activation, linear2):
pass
```
- This is one line in the pattern config `(nn.Linear, activation, nn.Linear): prune_linear_activation_linear`
At a high level `prune` works by finding instances of the graph that match different patterns and then calling the mapped pruning functions on those matched patterns.
This is unlike the previous code which attempted to do both at the same time.
There may be some gaps in the patterns compared to the previous implementation, but the conversion functionality support should be the same.
Currently we have pruning functions for the following patterns:
- linear -> linear
- linear -> activation -> linear
- conv2d -> conv2d
- conv2d -> activation -> conv2d
- conv2d -> activation -> pool -> conv2d
- conv2d -> pool -> activation -> conv2d
- conv2d -> adaptive pool -> flatten -> linear
Added in MyPy type hints as well for the prune_functions.
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89777
Approved by: https://github.com/vkuzo
This PR introduces a new function we can pass to torch._dynamo.optimize - guard_failure_fn. Usage is in the PR, and the one stacked on top of it, but the gist of it is that it emits failed guard reason strings alongside code. This is useful for tests and debugging, as it gives far finer grained assertions and control than the compile counter alone.
This is a resubmit of https://github.com/pytorch/pytorch/pull/90129
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90371
Approved by: https://github.com/ezyang
Summary: This commit moves helper functions that are not core
to the convert logic out of convert.py, which was more than
1000 lines. This helps with readability since a new developer
won't have to scroll through hundreds of lines of util functions
to understand the core logic. There should be no change in
functionality in this commit.
BC-breaking notes: The following helper functions that were
previously exposed under the `torch.ao.quantization.fx.convert`
namespace are now made private. Many of these are moved to the
new convert_utils.py
```
convert_custom_module
convert_standalone_module
convert_weighted_module
get_module_path_and_prefix,
has_none_qconfig,
insert_dequantize_node,
is_conversion_supported,
maybe_recursive_remove_dequantize,
replace_observer_or_dequant_stub_with_dequantize_node,
restore_state,
run_weight_observers,
```
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90189
Approved by: https://github.com/jerryzh168
Summary:
importing torch.fb seemed like a good idea, but we don't always have
torch.fb inside fbcode. Testing for torch.version.git_version is more
reliable, since we'll never have a git_version inside fbcode, which is an hg
repo.
Test Plan: `buck2 run mode/dev-nosan //caffe2/test/inductor:smoke`
Reviewed By: soumith, jansel
Differential Revision: D41777058
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90312
Approved by: https://github.com/soumith
Currently the stride and offset are determined by substituting 1 and 0 for
different indices, which will fail for any expression that doesn't match the
expected stride calculation. Instead, this uses `sympy.match` and returns `None`
for any variables used in non-standard index calculation, e.g. `torch.roll`
which uses `ModularIndexing`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90184
Approved by: https://github.com/jansel
Currently there is `test_vertical_fusion1` which fuses entirely during
the lowering stage and no buffers are realized. This adds
`test_scheduler_vertical_fusion1` which is the same test but with
several intermediate calculations realized so the scheduler is left
to do the fusion.
To support the test, this PR also adds:
- `metrics.ir_nodes_pre_fusion` which when compared with
`generated_kernel_count` tells us how many nodes were fused.
- `torch._test_inductor_realize` which is an identity operator in
eager, but under inductor also forces the input to be realized.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90014
Approved by: https://github.com/jansel
Summary:
Before this diff, copying of vulkan quantized tensors to cpu was broken. This was mainly caused because the shader only works properly with specific global and local work group sizes, and those specific sizes had been modified in earlier refactoring.
As part of this fix, an optimized version of the shader that performs the copying was written, to take advantage of the special case when the plane size (x*y) is multiple of 4).
After fixing this, and writing comprehensive tests, it was discovered that the copying still has issues on Android for specific input sizes, e.g. [1, 1, 11, 17]. These issues are currently unresolved, so, copying of quantized vulkan tensors to cpu has been disabled.
What is contained in this diff?
- Fix for existing issue
- New optimized shader (image_to_nchw_quantized_mul4)
- New comprehensive tests (which have been disabled)
- Disable the copying of quantized vulkan tensors to cpu until issues on Android are fixed.
Test Plan:
On Mac
```
cd ~/fbsource
buck1 run -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
On Android
```
cd ~/fbsource
buck1 build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_quantized_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_quantized_api_test
adb shell "/data/local/tmp/vulkan_quantized_api_test"
```
Reviewed By: kimishpatel
Differential Revision: D41047098
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90275
Approved by: https://github.com/kimishpatel
Summary: One common cause of jit unscriptability issue is loss of node type annotations on local names after one or several FX transform(s). One way to improve the type coverage is to eagerly annotate the type for `getitem` nodes from its parent sequence node. This diff introduces an fx pass to do that.
Test Plan:
```
buck2 test //caffe2/test:fx_experimental
```
Reviewed By: xush6528
Differential Revision: D41749744
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90237
Approved by: https://github.com/xush6528
The old code didn't actually fakeify traceable tensor subclasses at the
time they are added as a GraphArg to the module; now we do, by ignoring
the subclass during fakeification and relying on Dynamo to simulate
the subclass on top. See comments for more details.
BTW, this codepath is super broken, see filed issues linked on the
inside.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90009
Approved by: https://github.com/wconstab, https://github.com/voznesenskym
A recent PR deprecated `torch.testing.assert_allclose` in favor of `torch.testing.assert_close` and left a `TODO`. This PR follows up to confirm that we do intend to have `check_dtype=False`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90251
Approved by: https://github.com/rohan-varma
`FSDP.clip_grad_norm_()` is tested separately in `test_fsdp_clip_grad_norm.py`. This PR removes the dead non-run code from `common_fsdp.py` and `test_fsdp_core.py` related to `clip_grad_norm_()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90250
Approved by: https://github.com/rohan-varma
Observed by @aazzolini, some op might have Optional[Tensor] returns
where it return None (i.e. native_layer_norm_backward), it's a mismatch
between C++ aten op signature and python None, but we need to handle it
in the python side
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90241
Approved by: https://github.com/aazzolini
**Summary**
Post op fusion can reduce data movement overhead and improve inference performance. This PR adds fused `linear-leaky_relu` op for `onednn` backend, which will be used for int8 inference with `onednn` backend. Cannot call this op with other quantization backends otherwise an error is thrown.
**Test Plan**
python test_quantization.py TestQuantizedLinear
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88478
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
- Add `full` nvprim to support factory functions because the full reference uses `empty` and `fill` while we have a full factory function.
- Change `full_like` reference to call `full` to avoid defining another nvprim.
- Enable support for new_zeros to enable `cudnn_batch_norm` decomposition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89230
Approved by: https://github.com/kevinstephano, https://github.com/mruberry
I need to rebase later after Shen's PRs land.
The idea is to only register the pre/post-forward hook on the _root modules_ among the modules that consume a `FlatParameter`. (Yes, the term _root module_ is heavily overloaded. We may want to clarify that at some point. Here, _root_ is being used in the graph sense, meaning parent-less, and the scope is only among the modules consuming a `FlatParameter`.)
This avoids unnecessary pre/post-forward hooks running, which would lead to errors because the unshard is not truly idempotent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90201
Approved by: https://github.com/mrshenli, https://github.com/rohan-varma
This PR get rids of torchgen FunctionSchema parsing and parse
it manually, it should resolve torchgen package issue and also
provide some perf wins when running DTensor eagerly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90106
Approved by: https://github.com/awgu
In pytorch, the optim state_dict will always use number to index optimizer state_dict for parameters.
Now composability workstream need a FQN based way to index optimizer state_dict for parameters..
For example, SGD optimizer might have something in its `state_dict` like:
```
{'state':
{0:
{'momentum_buffer': tensor(...)},
{1:
{'momentum_buffer': tensor(...)},
...
}
'param_groups':
[{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'differentiable': False, 'params': [0, 1, 2, 3, 4, 5, 6, 7]}]
}
```
And in NamedOptimizer we want the `state_dict` can be:
```
{'state':
{'net1.0.weight':
{'momentum_buffer': tensor(...)},
{'net1.0.bias':
{'momentum_buffer': tensor(...)},
...
}
'param_groups':
[{'lr': 0.001, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'differentiable': False, 'params': ['net1.0.weight', 'net1.0.bias', 'net2.0.weight', 'net2.0.bias', 'net3.weight', 'net3.bias', 'net4.1.weight', 'net4.1.bias']}]
}
```
We also want to support load_state_dict to enable optim `state_dict` override for NameOptimizer.
For the next couple PR/diffs, we also need to:
1. To make `NamedOptimizer` working with FSDP (like registering a hook for model wrapped with FSDP) and other PTD/PT components.
2. Make `NamedOptimizer` works well with apply_optim_in_backward
3. Upstream also `CombinedOptimizer`.
Differential Revision: [D41432088](https://our.internmc.facebook.com/intern/diff/D41432088/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D41432088/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89480
Approved by: https://github.com/rohan-varma
Not sure why, but top-level `using namespace` directive causes VC++ fail with (if C++17 standard is used, but everything is fine with C++14):
```
C:\actions-runner\_work\pytorch\pytorch\third_party\pybind11\include\pybind11\detail\../pytypes.h(1520): error C2872: 'attr': ambiguous symbol
C:\actions-runner\_work\pytorch\pytorch\aten\src\ATen/core/interned_strings.h(349): note: could be 'c10::attr'
C:\actions-runner\_work\pytorch\pytorch\torch/csrc/jit/ir/ir.h(75): note: or 'torch::jit::attr'
C:\actions-runner\_work\pytorch\pytorch\cmake\..\third_party\pybind11\include\pybind11/pybind11.h(1094): note: see reference to function template instantiation 'pybind11::str pybind11::str::format<_Ty1&>(_Ty1 &) const' being compiled
with
[
_Ty1=pybind11::handle
]
```
Solve this by replacing global `using namespace torch::jit;` with
specific usages of objects/methods from namespaces
Another prep change for https://github.com/pytorch/pytorch/70188
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90228
Approved by: https://github.com/kit1980, https://github.com/albanD
When not using ordered dictionary, it can result in parameter values have
different order for each specialization. This can result shader names which are
not consistent in their naming and meaning of the template parameter values
that appear in the meaning of their names.
For example if you have:
conv2d_pw:
default_values:
- X: 1
- Y: 2
parameter_values:
- Y: 3
Default parameter value can generate shader with 'my_shader_1x2' where 1x2 is
for X, Y parameters respectively. Then,
for non default values, of which there is only 1, we have Y=3 and with existing
implementation you can end up genreating shader with 'my_shader_3x1'. Here 3 is
for Y and 1 is for X. This leads to confusing shader names.
THis diff fixes this by
1. using ordered dict.
2. non default values are updated by first copying default values and then
updating them.
Differential Revision: [D41006639](https://our.internmc.facebook.com/intern/diff/D41006639/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89951
Approved by: https://github.com/salilsdesai
Fixes https://github.com/pytorch/torchdynamo/issues/1928
For `ModularIndexing` we generate indexing code with `//` and `%` operators. When `ModularIndexing` base is negative (that can happen after valid simplifications), `//` in triton produces wrong results https://github.com/openai/triton/issues/619/. For `//` op coming from pytorch, we have codegen workarounds, but I'm reluctant to apply these workarounds to very common indexing computation patterns, both for code readability and perf considerations.
Similarly, we replace `ModularIndexing` with `IndexingDiv` when we can prove that base is small, but those assumptions break when `ModularIndexing` base is negative (`ModularIndexing` is always positive, `IndexingDiv` isn't).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89933
Approved by: https://github.com/jansel
… as equivalent replacements for std::is_pod and std::is_pod_v because they are deprecated in C++20.
When consuming libtorch header files in a project that uses C++20, there are warnings about std::is_pod being deprecated. This patch fixes that issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88918
Approved by: https://github.com/ezyang
Fixes: https://github.com/pytorch/data/issues/865
I will add another PR in torchdata to validate this change would solve the infinite datapipe problem (I have tested locally). This is one of the most annoying stack of PRs cause by separation between TorchData and PyTorch.
There is a case that `file.close` is never called because when generator function has never reached to the end. A simple example would be `zip` two datepipes with different length. The longer DataPipe would never reach the end of generator and then it will be cleaned up by `gc`. So, the line of `file.close` is not executed. (This is the reason that Vitaly has to create this [hack](4451eb24e6/torch/utils/data/datapipes/iter/combining.py (L573-L583)) to retrieve all remaining data to make sure generator function is fully executed)
However, this hack introduces another problem where an infinite datapipe would make `zip` never end as it would try to deplete the infinite iterator. See: https://github.com/pytorch/data/issues/865
So, in this PR, I am adding a `try-finally` clause to make sure the `file.close` is always executed during the destruction of `generator` object. Then, we don't need the hack within `zip` any more.
Differential Revision: [D41699469](https://our.internmc.facebook.com/intern/diff/D41699469)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89974
Approved by: https://github.com/NivekT, https://github.com/wenleix
```
[130/1102] Building CXX object caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cudnn/LossCTC.cpp.o
/home/gaoxiang/nvfuser5/aten/src/ATen/native/cudnn/LossCTC.cpp:97:11: warning: use of bitwise '&' with boolean operands [-Wbitwise-instead-of-logical]
(target_lengths[b] < 256) & (target_lengths[b] <= input_lengths[b]);
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
&&
/home/gaoxiang/nvfuser5/aten/src/ATen/native/cudnn/LossCTC.cpp:97:11: note: cast one or both operands to int to silence this warning
1 warning generated.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90131
Approved by: https://github.com/kit1980
The documentation of `torch.rand` was missing the `generator` keyword argument in the function signature. However, the argument is explained in the documentation and `torch.rand` accepts that argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90071
Approved by: https://github.com/janeyx99
Summary:
This diff is reverting D41682843
D41682843 has been identified to be causing the following test or build failures:
Tests affected:
- https://www.internalfb.com/intern/test/281475048939643/
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1444954
Here are the tasks that are relevant to this breakage:
T93770103: 5 tests started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: zyan0, atuljangra, YazhiGao
Differential Revision: D41710749
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90132
Approved by: https://github.com/awgu
There is a case that `file.close` is never called because when generator function has never reached to the end. A simple example would be `zip` two datepipes with different length. The longer DataPipe would never reach the end of generator and then it will be cleaned up by `gc`. So, the line of `file.close` is not executed. (This is the reason that Vitaly has to create this [hack](4451eb24e6/torch/utils/data/datapipes/iter/combining.py (L573-L583)) to retrieve all remaining data to make sure generator function is fully executed)
However, this hack introduces another problem where an infinite datapipe would make `zip` never end as it would try to deplete the infinite iterator. See: https://github.com/pytorch/data/issues/865
So, in this PR, I am adding a `try-finally` clause to make sure the `file.close` is always executed during the destruction of `generator` object. Then, we don't need the hack within `zip` any more.
Differential Revision: [D41699470](https://our.internmc.facebook.com/intern/diff/D41699470)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89973
Approved by: https://github.com/NivekT
This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90091
Approved by: https://github.com/anijain2305, https://github.com/ezyang
Summary:
This PR aligns the "eager" mode of the structured pruning flow with the existing unstructured pruning flow.
The base pruner has been moved from and has been renamed from BasePruner to BaseStructuredPruner
`torch/ao/pruning/_experimental/pruner/base_pruner.py -> /torch/ao/pruning/_experimental/pruner/base_structured_pruner.py`
Support for pruning batchnorm modules in the config have been removed, so now the structured pruning code can use more of the BaseSparsifier logic and we don't need to override as many functions.
Since we aim to only support a single flow, we have only updated ZeroesParametrizations (FakeStructuredSparsity) and BiasHook.
The parameterizations have also been rewritten to use a bool mask tensor for keeping track of pruned rows, instead of using sets before.
This better aligns structured and unstructured sparsity.
The BaseStructuredSparsifier tests have also been updated to reflect the above changes. I also removed `squash_mask` tests because they were breaking CI and `squash_mask` is no longer used.
We will migrate the structured pruning code out of this folder in a later PR.
Test Plan:
```
python test/test_ao_sparsity -- TestBaseStructuredPruner
```
Reviewers:
z-a-f vkuzo
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88436
Approved by: https://github.com/vkuzo
Summary: Previously we explicitly set a qconfig for ops
like conv and linear in the default QConfigMapping. However,
this makes it difficult for user to override the global and
have the new global take effect for basic ops. This commit
removes these explicit settings so the user can simply run
the following to quantize these ops.
```
qconfig_mapping = get_default_qconfig_mapping()
qconfig_mapping.set_global(my_qconfig)
```
There is no change in behavior for the default use case
of not setting anything on the default QConfigMapping.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_default_qconfig_mapping_override_global
Reviewers: vkuzo, jerryzh168
Subscribers: vkuzo, jerryzh168
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90066
Approved by: https://github.com/vkuzo, https://github.com/jerryzh168
For PyTorch FSDP, the only way that gradients are in low precision is if `keep_low_precision_grads=True` or if the user turns on AMP. This PR adds tests for the former and improves the documentation for `clip_grad_norm_()`, especially around these non-full-precision cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90028
Approved by: https://github.com/rohan-varma
For any `flat_param.data = flat_param.to(...)` or `flat_param.grad.data = flat_param.grad.to(...)`, we must also refresh sharded parameter/gradient views, respectively, if the storage changes.
For `keep_low_precision_grads=True` and a sharded strategy, we cast the gradient back to the low precision using `.data` to bypass the PyTorch check that a parameter and its gradient have the same dtype. For `use_orig_params=True` before this PR, the gradient would incorrectly still be in full precision, not low precision, since we did not refresh views (this can actually be considered a memory leak since we have two copies of the gradient now, one in low precision and one in full precision). This PR refreshes the views.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90027
Approved by: https://github.com/mrshenli
Fix errors from [7k github models](https://github.com/pytorch/torchdynamo/issues/1884)
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1062, in get_fake_value
return wrap_fake_exception(
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 739, in wrap_fake_exception
return fn()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1063, in <lambda>
lambda: run_node(tx.output, node, args, kwargs, nnmodule)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1112, in run_node
raise RuntimeError(
RuntimeError: Failed running call_function <function einsum at 0x7fd8f246a4c0>(*('i,j->ij', FakeTensor(FakeTensor(..., device='meta', size=(4,)), cpu), FakeTensor(FakeTensor(..., device='meta', size=(2,)), cuda:0)), **{}):
Unhandled FakeTensor Device Propagation for aten.mul.Tensor, found two different devices cpu, cuda:0
(scroll up for backtrace)
```
The root cause is: ```tensor.type()``` should return ```torch.cuda.FloatTensor``` rather than ```torch.FloatTensor``` if it's on GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90021
Approved by: https://github.com/jansel
This commit had inconsistent internal land and pr merged. This caused merge conflicts that required revert in both places, normalize the internal commit stack, and then re-land properly.
Original commit: #88384 (011452a2a1c745d4b12f83f89eca039f482d134b)
Inconsistent revert: #90018 (8566aa7c0b4bdca50bf85ca14705b4304de030b3)
Revert of the inconsistent revert to restore healthy state (or re-land of the original commit): cf3c3f22804be6909e54fc09e07f891ab0886774
Landing the correct, internally congruent revert of the original commit: (This PR) #90055 (TBD)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90055
Approved by: https://github.com/DanilBaibak, https://github.com/malfet
- Add graph index to the profile information of the Inductor kernel for better debugability.
The generated code for different graphs could produce kernels with the same name. The side effect is that it is hard to identify the portion of E2E performance for these kernels because the profiler will aggregate the performance with the same kernel name regardless of different graphs. Hence, this PR added the graph index to the profile information to address this limitation.
- Label arbitrary code ranges for `eager` and `opt` modes for better debugability
The profile information of dynamo benchmarks mixes the eager mode and opt mode. It is hard to separate the range for different modes. This PR added eager and opt marks to the profile information to address this limitation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90008
Approved by: https://github.com/jgong5, https://github.com/jansel
Motivation: for Timm model, there is always use customer-defined BN which using F.batch_norm: https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/layers/norm_act.py#L26, and the fx graph will be like:
```
------------- ---------------------- --------------------------------------- --------------------------------------------------------------------------------------------------------- --------
placeholder x x () {}
call_module self_conv self_conv (x,) {}
get_attr self_bn_running_mean_1 self_bn_running_mean () {}
get_attr self_bn_running_var self_bn_running_var () {}
get_attr self_bn_weight self_bn_weight () {}
get_attr self_bn_bias self_bn_bias () {}
call_function batch_norm <function batch_norm at 0x7f07196cdf70> (self_conv, self_bn_running_mean_1, self_bn_running_var, self_bn_weight, self_bn_bias, False, 0.1, 1e-05) {}
call_module self_bn_drop self_bn_drop (batch_norm,)
```
the original conv+bn folding path doesn't work for **F.batch_norm**, but for **F.batch_norm** case, if its' parameters are const(attr of the module and will not be updated), we can also do the const folding's optimization. This PR will enable it and will improve the Timm models' performance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89746
Approved by: https://github.com/jgong5, https://github.com/jansel
Summary:
This PR adds support for matching patterns that has multiple arguments, it's needed for quantization in PyTorch 2.0 early prototype
Before this PR, we only support patterns like:
```
x -> conv -> bn -> relu
(relu, (bn, conv))
```
where each operator has a single node, the code breaks when we want to match a pattern that has an op that has multiple arguments, such as:
```
shape \
transpose -> reshape -> output ->
```
where `reshape` has two arguments
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_match_pattern_with_multiple_args
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89986
Approved by: https://github.com/vkuzo
Summary:
The deleter of the operator's unique_ptr doesn't get called unless the unique_ptr is created after the op has been created
This fixes the problem reported in
https://fb.workplace.com/groups/pytorch.edge.users/posts/1210708329799458/
Test Plan:
# Testing memory leak fix
**With test code added in D41487340:**
```
cd ~/fbsource/xplat
buck run caffe2/aten/src/ATen/native/quantized/cpu/qsoftmax_test:qsoftmax_test
```
Before this diff:
```
==2060866==ERROR: LeakSanitizer: detected memory leaks
Direct leak of 608 byte(s) in 1 object(s) allocated from:
#0 0x41bcd27 in calloc (/data/users/salilsdesai/fbsource/buck-out/gen/aab7ed39/xplat/caffe2/aten/src/ATen/native/quantized/cpu/qsoftmax_test/qsoftmax_test+0x41bcd27)
#1 0x405b692 in pytorch_qnnp_create_softargmax_nc_q8 xplat/caffe2/aten/src/ATen/native/quantized/cpu/qnnpack/src/softargmax.c:77
Indirect leak of 1024 byte(s) in 1 object(s) allocated from:
#0 0x41bcb7f in malloc (/data/users/salilsdesai/fbsource/buck-out/gen/aab7ed39/xplat/caffe2/aten/src/ATen/native/quantized/cpu/qsoftmax_test/qsoftmax_test+0x41bcb7f)
#1 0x405b6a8 in pytorch_qnnp_create_softargmax_nc_q8 xplat/caffe2/aten/src/ATen/native/quantized/cpu/qnnpack/src/softargmax.c:85
SUMMARY- AddressSanitizer: 1632 byte(s) leaked in 2 allocation(s).
```
After this diff:
- No errors
___
# Testing op correctness
```
cd ~/fbsource/fbcode
buck test caffe2/test/quantization:quantization -- test_qsoftmax
```
Passes
- https://www.internalfb.com/intern/testinfra/testconsole/testrun/2814749908834332/
Differential Revision: D41487341
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89544
Approved by: https://github.com/mcr229
Summary: Added randomized test for quantized add, sub, mul and div
Test Plan:
On Mac
```
cd ~/fbsource
buck1 run -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
On Android
```
cd ~/fbsource
buck1 build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_quantized_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_quantized_api_test
adb shell "/data/local/tmp/vulkan_quantized_api_test"
```
Differential Revision: D41047094
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89578
Approved by: https://github.com/digantdesai
`torch.compile` can be used either as decorator or to optimize model directly, for example:
```
@torch.compile
def foo(x):
return torch.sin(x) + x.max()
```
or
```
mod = torch.nn.ReLU()
optimized_mod = torch.compile(mod, mode="max-autotune")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89607
Approved by: https://github.com/soumith
Summary: This commit renames fx/quantization_patterns.py
to fx/quantize_handler.py, and fx/fusion_patterns.py to
fx/fuse_handler.py. This is because these files contain
only QuantizeHandler and FuseHandler respectively, so the
new names are more descriptive. A future commit will
further break BC by removing all the empty *QuantizeHandler
classes.
BC-breaking notes:
The following classes under the
`torch.ao.quantization.fx.quantization_patterns` namespace
are migrated to the `torch.ao.quantization.fx.quantize_handler`
namespace:
```
QuantizeHandler
BinaryOpQuantizeHandler
CatQuantizeHandler
ConvReluQuantizeHandler
LinearReLUQuantizeHandler
BatchNormQuantizeHandler
EmbeddingQuantizeHandler
RNNDynamicQuantizeHandler
DefaultNodeQuantizeHandler
FixedQParamsOpQuantizeHandler
CopyNodeQuantizeHandler
GeneralTensorShapeOpQuantizeHandler
CustomModuleQuantizeHandler
StandaloneModuleQuantizeHandler
```
The following classes under the
`torch.ao.quantization.fx.fusion_patterns` namespace are
migrated to the `torch.ao.quantization.fx.fuse_handler`
namespace:
```
DefaultFuseHandler
FuseHandler
```
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89872
Approved by: https://github.com/jerryzh168
The ignored modules are still using the original precision, which
leads to the following error.
```
RuntimeError: mat1 and mat2 must have the same dtype
```
This is not blocking me at the moment, but the fix seems not too
hard. We can add a pre-forward hook to each ignored module to
convert activations to original precision, and a post-forward hook
to convert it back to the specified precision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89971
Approved by: https://github.com/awgu
We may need to express guards on the size/stride/storage offset of
a tensor, but we cannot do this if it's already been duck sized.
This PR guarantees that we allocate a symbol (or negation of the
symbol) whenever we ask to create a SymInt, and propagates this
symbol to SymNode so that Dynamo can look at it (not in this PR).
This PR doesn't actually add guards, nor does Dynamo do anything
with these symbols.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89879
Approved by: https://github.com/albanD
This set tracks symbols which we know are definitely not 0/1, and thus
can be further simplified when we try to work out their static value
without guards. Right now, all allocated symbols are in this set,
but we will later add symbols which don't uphold this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89871
Approved by: https://github.com/albanD
See code comment for details. I also had to do some extra fixes:
* `run_functionalized_fw_and_collect_metadata` now is able to handle duplicated arguments
* `aot_wrapper_dedupe` now always returns boxed compiled functions
* `aot_wrapper_dedupe` is now applied to inference compiler along with autograd compiler (preexisting)
Fixes https://github.com/pytorch/torchdynamo/issues/1939
Fixes DebertaV2ForQuestionAnswering DebertaForMaskedLM DebertaForQuestionAnswering DebertaV2ForMaskedLM
Repro command:
```
python benchmarks/dynamo/huggingface.py --performance --float32 -dcuda --training --inductor --no-skip --dashboard --only DebertaForQuestionAnswering --cold_start_latency
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89896
Approved by: https://github.com/bdhirsh
This was separated out from the previous PR to decouple. Since not all builds include `torch.distributed`, we should define the globals in the dynamo file and import to distributed instead of vice versa. Unlike the version from the previous PR, this PR prefixes the globals with `_` to future proof against `_dynamo/` eventually becoming public.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89913
Approved by: https://github.com/wconstab
Preparation for the next PR in this stack: #89559.
I replaced
- `self.assertTrue(torch.equal(...))` with `self.assertEqual(..., rtol=0, atol=0, exact_device=True)`,
- the same for `self.assertFalse(...)` with `self.assertNotEqual(...)`, and
- `assert torch.equal(...)` with `torch.testing.assert_close(..., rtol=0, atol=0)` (note that we don't need to set `check_device=True` here since that is the default).
There were a few instances where the result of `torch.equal` is used directly. In that cases I've replaced with `(... == ...).all().item()` while sometimes also dropping the `.item()` depending on the context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89527
Approved by: https://github.com/mruberry
After our failed attempt to remove `assert_allclose` in #87974, we decided to add it to the documentation after all. Although we drop the expected removal date, the function continues to be deprecated in favor of `assert_close`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89526
Approved by: https://github.com/mruberry
I've tried to soft-enforce this manually already, albeit with a line length of 120. This just adds it to the CI. Note that this only applies to `torch/testing/*.py` and thus everything under `torch/testing/_internal/**/*` is *not* affected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89525
Approved by: https://github.com/kit1980
When you are writing a meta function, you cannot call item() on the tensor because there is no real data on the tensor and it will fail. The error message was not very good in this case, see also https://github.com/pytorch/pytorch/issues/89959
This PR takes a brute force approach to resolving the problem: just manually define meta implementations for the naughty functions that are calling item(). However, this results in a lot of code duplication. The easiest way to avoid this situation is to rewrite the decomps so they don't call item. It should not be that difficult to use direct tensors on your operations, as scalar tensors can broadcast too.
I could only test this with `buck test @mode/opt -c python.package_style=inplace //executorch/backends/test:test_backends` in internal with D41555454. Test coverage needs to be improved, otherwise don't blame us when we break you.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89958
Approved by: https://github.com/jerryzh168
1. If user uses amp to run bfloat16 models, `torch.autocast` will
keep module paramters in acc dtype which will leave `gamma` and`beta`
in float while input/output will be in bfloat16.
2. If user explicitly cast the model to bfloat16 such as:
```
x = torch.randn(n, t, c).bfloat16()
ln = nn.LayerNorm(c).bfloat16()
y = ln(x)
```
The input/output and gamma/beta will all be in bfloat16.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81851
Approved by: https://github.com/ezyang
Summary: Helper functions for producing random inputs/scale/zero points and also computing suitable scale and zero points of a tensor, used in the testing of quantized ops.
Test Plan:
On Mac
```
cd ~/fbsource
buck1 run -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
On Android
```
cd ~/fbsource
buck1 build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_quantized_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_quantized_api_test
adb shell "/data/local/tmp/vulkan_quantized_api_test"
```
Reviewed By: kimishpatel
Differential Revision: D41595034
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89922
Approved by: https://github.com/digantdesai
Differential Revision: [D40351062](https://our.internmc.facebook.com/intern/diff/D40351062)
For mkldnn quantization path, we will do weight prepack using dummy data to query the expected weight format, the packed weight's format may differ from the real input case(the weight format depends on the input's shape), and there will have a block weight to block weight reorder if the packed weight format differs with the expected weight format. The mkldnn may meet the following issue when doing such reorder(test on ICX machine):
```
test_conv_reorder_issue_onednn
torch.ops.quantized.conv2d(qx, w_packed, output_scale=1.0, output_zero_point=0)
File "/home/weiwen/.conda/envs/int8-dev/lib/python3.9/site-packages/torch/_ops.py", line 472, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: could not create a primitive descriptor for a reorder primitive
```
This PR will fix it: if the block weight to block weight reorder is failed, we will reorder the block weight to plain weight first, and then reorder the plain weight to the target block weight.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86876
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
To fix https://github.com/pytorch/pytorch/issues/77507
Originally `utils::RowwiseMoments<BFloat16>` will still accululate on BFloat16,
which is not only slow but also introducing additional rounding errors.
This patch will do accumulation on float for the bfloat16 inputs:
each of bfloat16 vec (size 16) will be converted to two float vec (size 8),
and accumulated on m1(mean) and m2(rstd) vecs which are all float vecs.
No effect on float performance, will improve bfloat16 performance:
* avx512 single socket:
```
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.215 ms; bf16: 0.178 ms
```
* avx512 single core:
```
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.618 ms; bf16: 2.309 ms
```
* avx2 single socket:
```
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.527 ms; bf16: 0.458 ms
```
* avx2 single core:
```
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.416 ms; bf16: 3.524 ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84405
Approved by: https://github.com/jgong5
This PR attemps to fix the following pyre error:
```
Incompatible parameter type [6]: In call
`dist.fsdp.fully_sharded_data_parallel.FullyShardedDataParallel.__init__`,
for 7th parameter `auto_wrap_policy` expected
`Optional[typing.Callable[..., typing.Any]]` but got
`Optional[_FSDPPolicy]`.
```
Besides, this also removes the type inconsistency in code and docstring.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89930
Approved by: https://github.com/awgu
Add dynamo smoke tests to CI, which checks for python/torch/cuda versions and runs simple dynamo examples on a few backends, including inductor. Smoke tests will run on dynamo and inductor shards.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89302
Approved by: https://github.com/malfet
Summary:
When `ref_node.args` is empty, the QAT will throw index out of range. Here is an example, line 574 is using `tensors = ....` in torch.cat func, which will be treated as `kwargs`
{F800357376}
f388506954
To fix the issue, we will use the value of the first kwarg if args is empty
Test Plan: f388545532
Reviewed By: bigning, lyoka
Differential Revision: D41396771
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89778
Approved by: https://github.com/lyoka, https://github.com/houseroad
Previously, `assert_functionalization` only took in uni-Tensor-parameter functions. This PR beefs up the check to allow for functions that take multiple parameters.
This PR also changes the test_instance_norm test to check that the multiparam change works.
## Test plan
Locally tested, CI should also pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89798
Approved by: https://github.com/samdow
# Motivate
We need to add XPU backend to support torch.save and torch.load when parameter _use_new_zipfile_serialization=False.
# Solution
We give a design via wrap data as a tensor:
>1. and use an in-place copy for H2D
>2. directly call a tensor.to() for D2H.
This can help us:
>1. unify the generic code for all backends.
>2. support all the non-CPU device backends.
# Additional Context
No need more UT.
test/test_serialization.py will cover this code change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89679
Approved by: https://github.com/ezyang
I made a pass over Linjian's `_symbolic_trace.py` and tidied it up a bit. Aside from simple stylistic changes, this PR makes the following changes:
- Save `visited_params: Set[nn.Parameter]` to avoid linear overhead to check a parameter already being visited when appending to the parameter execution order list (`param_forward_order`)
- Move the tracer patching logic to a class `_ExecOrderTracer` to have a reference to `self.exec_info` without having a fragmented 2-step initialization (like the old `_init_execution_info(root_module)` plus `_patch_tracer(tracer, root_module, execution_info)`)
- Define `_ParamUsageInfo` to formalize the `Tuple[nn.Module, List[str, nn.Parameter]]` elements being mapped to in the execution info `dict`, and clarify the documentation regarding what this represents
- Change the unit test to use `TestCase`, not `FSDPTest`, to avoid initializing a process group
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89917
Approved by: https://github.com/zhaojuanmao, https://github.com/fegin
This PR makes two minor changes: It (1) moves the recently-added module annotation logic for dynamo support to a separate file `torch/distributed/fsdp/_dynamo_utils.py` and ~~(2) saves the annotated attribute names to global variables `FSDP_MANAGED_MODULE` and `FSDP_USE_ORIG_PARAMS`~~.
Update: Since the distributed package may not be included in some builds, it is not safe to import from `torch.distributed...` to a file in `_dynamo/`. I will not include change (2) in this PR. The alternative is to define those globals (privately) in the dynamo file and import from there in the FSDP file.
- The first change is mainly a personal choice, where I wanted to avoid the dynamo explanation from dominating the FSDP constructor space-wise. I added the `(see function for details)` to the inline comment to forward interested readers.
- The second change follows the custom we have taken in the past for such attributes (e.g. `FSDP_FLATTENED`). My understanding (in the past as well as currently) is that this is a good practice.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89890
Approved by: https://github.com/wconstab
This PR extends the `Tensor.to_sparse()` method to `Tensor.to_sparse(layout=None, blocksize=None)` in a BC manner (`layout=None` means `layout=torch.sparse_coo`).
In addition, the PR adds support for the following conversions:
- non-hybrid/hybrid COO tensor to CSR or CSC or a COO tensor
- short, bool, byte, char, bfloat16, int, long, half CSR tensor to a BSR tensor
and fixes the following conversions:
- hybrid COO to COO tensor
- non-batch/batch hybrid BSR to BSR or BSC tensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89502
Approved by: https://github.com/amjames, https://github.com/cpuhrsch
I am in the habit now to run `ufmt format test/distributed/fsdp` before committing, and this changed `test_fsdp_checkpoint.py`. I separated this into its own PR. This change should be safe to force merge to save CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89916
Approved by: https://github.com/mrshenli
Moving to train mode for TIMM models and also raising batch size for accuracy testing.
Raising batch size seems to remove a lot of noise/instability coming from batch_norm decomposition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89780
Approved by: https://github.com/ngimel
This PR includes:
Changes from @kumpera (https://github.com/pytorch/pytorch/pull/86327): adding MultiThreaded FileSystemWriter for distributed checkpointing, which adds two knobs to FileSystemWriter: thread_count and per_thread_copy_ahead. This increases up to 50% performance improvement on 32 GPUS workloads on AWS.
Add parametrize tests to /test/distributed/_shard/checkpoint/test_file_system_checkpoint.py and /test/distributed/_shard/checkpoint/test_file_system_checkpoint_cpu.py
Modify @with_comms in ShardedTensorTestBase to take in *args and **kwargs.
Tests:
```
python3 test/distributed/checkpoint/test_file_system_checkpoint_cpu.py
```
test/distributed/checkpoint/test_file_system_checkpoint.py(GPU tests) runs fine locally but would timeout on CI. We will use thread-based PG and update this test in following PR.
[T134844615]
## Add docstring and update comments in the following PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87987
Approved by: https://github.com/fduwjj
Originally `cpu/moments_utils.h` uses namespace of at::native::utils,
this file contains `Vectorized<>`, in order to make it properly vectorized
on different archs, need to use anonymous namespace or inline namespace.
Otherwise it would be linked to scalar version of the code.
This PR is to fix vectorization issue from `RowwiseMoments` which is used to calculate `mean` and `rstd` in norm layers.
Attach benchmark data, generally fp32 will get 2-3x speedup and bf16 has larger speedup.
This patch will improves layer_norm (input size 32x128x1024) float32 inference:
* avx512 single socket: 2.1x
```bash
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.439 ms; bf16: 2.479 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.210 ms; bf16: 0.770 ms
```
* avx512 single core: 3.2x
```bash
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 6.308 ms; bf16: 39.765 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 2.661 ms; bf16: 12.267 ms
```
* avx2 single socket: 2.3x
```bash
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 1.248 ms; bf16: 8.487 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 0.540 ms; bf16: 2.030 ms
```
* avx2 single core: 2.5x
```bash
before: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 10.792 ms; bf16: 66.366 ms
after: LayerNorm((1024,), eps=1e-05, elementwise_affine=True) : 32x128x1024: fp32: 4.349 ms; bf16: 19.252 ms
```
Attached some original VTune profiling results here to further indicate the issue:
1. original bottlenecks
we can see `RowwiseMomentsImpl<>` takes majority of the runtime here.
2. Instruction level breakdown of `RowwiseMomentsImpl<>`
we can see it's all **scalar** instructions here.
3. after the fix, the bottlenecks
getting better.
4. after the fix, Instruction level breakdown of `RowwiseMomentsImpl<>`
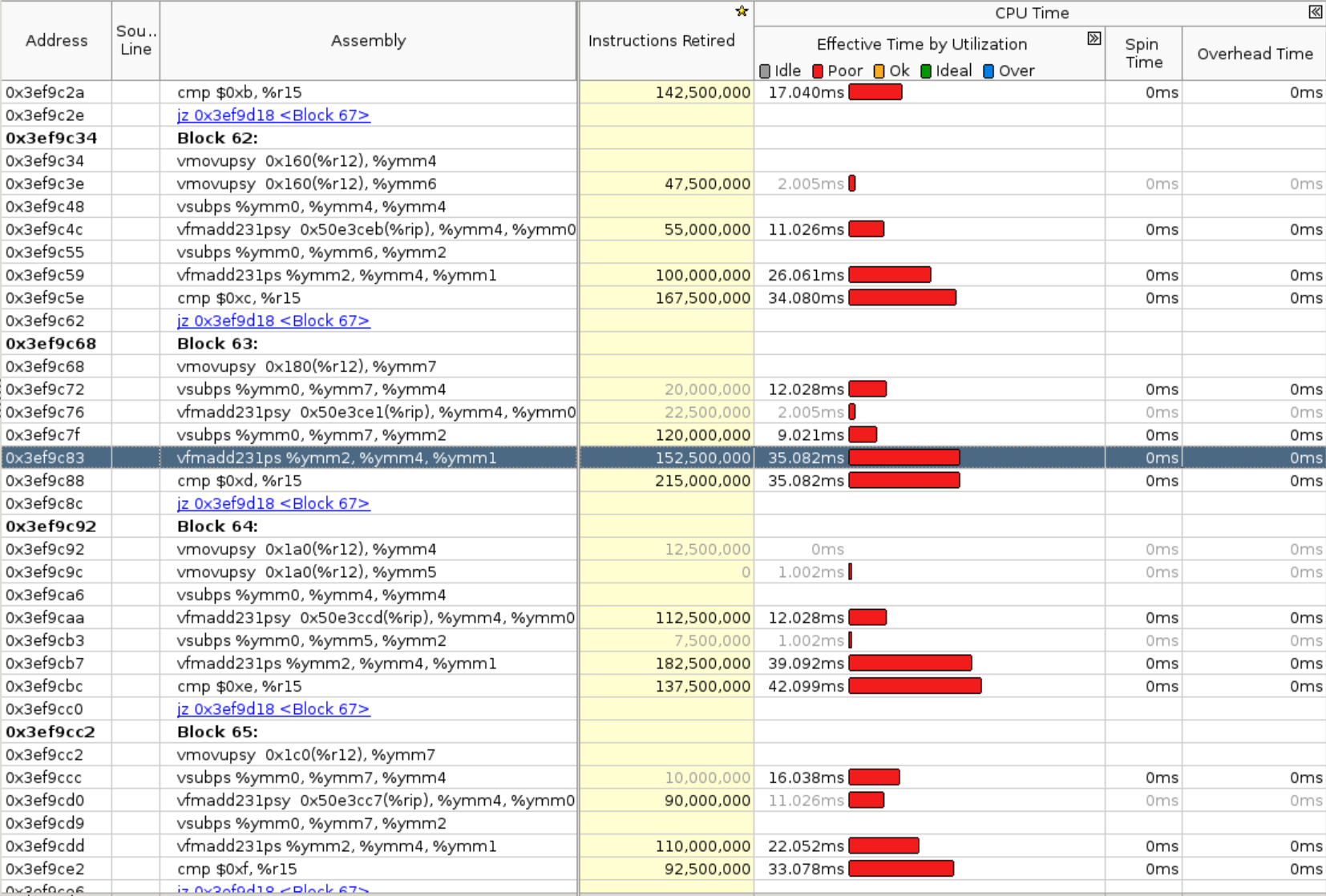
now it is all **vectorized** instructions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84404
Approved by: https://github.com/jgong5
To reuse memory when allocating the unsharded `FlatParameter` in the unshard stream, we only need to block the CPU thread on the preceding free event (i.e. `event.synchronize()`) before allocating the unsharded memory, which happens in `handle.unshard()`. Notably, this can be done after the pre-unshard logic, which at most performs _sharded_ allocations (low precision shard or H2D sharded `FlatParameter` copy) in its own pre-unshard stream. This enables the pre-unshard to overlap with any pending ops.
With this change, I believe that we should use `limit_all_gathers=True` all the time to stay true to FSDP's proposed memory semantics.
If a user wants to set `limit_all_gathers=False`, that would mean that he/she wants to overlap ops that are issued after the unshard logic's all-gather with ops that are pending at the time when FSDP _would_ block the CPU thread via `event.synchronize()`.
- If the user is willing to not reuse memory for that all-gather, then the user may as well have applied `NO_SHARD` and optionally ZeRO-1 (if this niche is important, then maybe we should consider hardening ZeRO-1). This is because now the unsharded memory for the all-gather additionally contributes to peak memory since it cannot reuse memory.
- If the user wanted to reuse memory for that all-gather, then we needed to block the CPU thread. There is no way around that given the caching allocator semantics.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89057
Approved by: https://github.com/mrshenli
We do not need to have the pre-unshard and unshard streams wait for the computation stream because we are not using the pre-unshard or unshard streams in `clip_grad_norm_()`.
The other change is simply avoiding a loop to get `grads`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89308
Approved by: https://github.com/mrshenli
**Overview**
This PR removes an outdated TODO:
```
# TODO (awgu): When exposing the original parameters, we need to also
# use this attribute to prevent re-synchronizing parameters.
```
**Justification**
We only pass `managed_params` to `_sync_module_params_and_buffers()`, where `managed_params` is defined as
```
managed_params = list(_get_orig_params(root_module, state._ignored_params))
```
This `_get_orig_params()` call excludes parameters already flattened by FSDP. Thus, `_sync_module_params_and_buffers()` will not re-sync already-synchronized parameters. Each parameter appears in `managed_params` for some FSDP instance exactly once and hence is only synchronized once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89217
Approved by: https://github.com/mrshenli
Improve the test_nested_dict.py test:
1. Add comments to show flatten_dict and mapping result.
2. Update test_mapping unit test to ensure the key value pair matching in mapping.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89854
Approved by: https://github.com/H-Huang
Summary: `ExprGroup::getMergeCandidates()` had a logic bug. The vector being initialized had its arguments mis-ordered. This didn't trigger a build warning because the warning about implicit cast from an integral type to `bool` wasn't enabled.
Test Plan: `buck test fbsource//arvr/mode/win/vs2019/cuda11/opt fbsource//arvr/mode/hybrid_execution //arvr/libraries/neural_net_inference/TorchScript/...`
Differential Revision: D41488939
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89551
Approved by: https://github.com/davidberard98, https://github.com/jjsjann123
Summary:
This is to make sure the description texts are wrapping around code, instead of being displayed as a single line
Test Plan:
visual inspections
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89795
Approved by: https://github.com/andrewor14
The issue for `test_2d_parallel.py` is that `DTensor` does not support the idiom `param.data = view` where `view` is a `DTensor`. To work around this, we do not preserve the parameter variable `param` and instead create a new parameter variable altogether via `nn.Parameter(view)`. Preserving the parameter variable when unsharded was not a strict requirement -- it just made sense to do that if we are already doing that when _sharded_, where it _is_ a strict requirement to support the optimizer step. The sharded case is not an issue for 2D because sharded implies local tensor, not `DTensor`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89845
Approved by: https://github.com/zhaojuanmao
Avoids
```
$ python foo.py
Traceback (most recent call last):
File "foo.py", line 3, in <module>
a = torch.cuda.Stream()
File "/home/albandes/local/pytorch/3.8_debug_source/torch/cuda/streams.py", line 34, in __new__
return super(Stream, cls).__new__(cls, priority=priority, **kwargs)
TypeError: object.__new__() takes exactly one argument (the type to instantiate)
```
And now gets
```
$ python foo.py
Traceback (most recent call last):
File "foo.py", line 3, in <module>
a = torch.cuda.Stream()
File "/home/albandes/local/pytorch/3.8_debug_source/torch/cuda/streams.py", line 34, in __new__
return super(Stream, cls).__new__(cls, priority=priority, **kwargs)
File "/home/albandes/local/pytorch/3.8_debug_source/torch/cuda/_utils.py", line 44, in err_fn
raise RuntimeError(
RuntimeError: Tried to instantiate dummy base class Stream
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89592
Approved by: https://github.com/soumith
Summary: The recommended way to use QConfigMapping is through
`get_default_qconfig_mapping`. However, the docs still references
usages that use `QConfigMapping().set_global(...)`. This doesn't
actually work well in practice when the model has fixed qparams
ops for example. This commit updates these usages.
Reviewers: vkuzo
Subscribers: vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87299
Approved by: https://github.com/jerryzh168
Summary: Previously under torch/ao/quantization we have
backend_config/utils.py and fx/backend_config_utils.py, which
was confusing. This commit deletes the latter and moves
everything there to more suitable util files.
BC-breaking note: The following public APIs under the
`torch.ao.quantization.fx.backend_config_utils` namespace
are removed in this commit.
```
get_quantize_handler_cls
get_fusion_pattern_to_fuse_handler_cls
get_native_quant_patterns
get_pattern_to_quantize_handlers
```
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89810
Approved by: https://github.com/jerryzh168
This reverts commit faa032c5e58502de6ea461e531109d2acc22e56a.
Reverted https://github.com/pytorch/pytorch/pull/89694 on behalf of https://github.com/clee2000 due to broke periodic b/c they take ~2.5 hrs, also broke mem leak check b/c its slow, should probably look into having this be a parameter
This assert was accidentally made stricter when transitioning from per-FSDP-instance training state to per-handle training state. This PR relaxes it again, which should restore compatibility for some reentrant AC plus FSDP cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89791
Approved by: https://github.com/zhaojuanmao
Summary: The example in the BackendConfig docstring and the README
was not runnable. This fixes a typo (`bias_type` -> `bias_dtype`),
removes the call to an internal helper function, and adds an
additional BackendPatternConfig to make the example BackendConfig
more realistic and useful.
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89319
Approved by: https://github.com/jerryzh168
This will be the last disruptive functorch internals change.
Why are we moving these files?
- As a part of rationalizing functorch we are moving the code in
functorch/_src to torch/_functorch
- This is so that we can offer the functorch APIs as native PyTorch APIs
(coming soon) and resolve some internal build issues.
Why are we moving all of these files at once?
- It's better to break developers all at once rather than many times
Test Plan:
- wait for tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88756
Approved by: https://github.com/ezyang
Update previous recursive logic.
Continue setting training attribute only if the slot is an object and a module.
For the corresponding JIT module, they get the module list first and set module one by one. there is method to get all modules iteratively, instead of recursively.
This change patch one fix to set training attribute for `model_f269583363.ptl`. Another patch is needed, because current lite interpreter doesn't have the correct type when loading object with setstate.
Differential Revision: [D41466417](https://our.internmc.facebook.com/intern/diff/D41466417/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89488
Approved by: https://github.com/iseeyuan
During accuracy minification, minifier can create graphs which can cause assertion failures. This PR catches such assertions and let minifier move on, instead of getting stuck in minifying this issue.
It is possible that such graphs point to some real-although-unrelated issue. So, printing an assertion to flag and debug if needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89739
Approved by: https://github.com/mlazos
copy_graphstate is called a ton, this makes copy_graphstate a lot faster, helps with https://github.com/pytorch/torchdynamo/issues/1803
tag each graph node with a timestamp, when checkpointing store the timestamp, when restoring remove nodes older than the timestamp stored in the state. This essentially has the same behavior as the original impl, just doesn't copy the whole graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89232
Approved by: https://github.com/jansel
Adding a memory_tracker API to show operator level memory traces for allocated_memory, active_memory and reserved memory stats, it gave the summary about top 20 operators that generate memories as well.
The implementation mainly uses torchDispatchMode and module hooks to get traces and add markers.
Will add following up PRs:
1. allow tracing more than 1 iteration
2. dump json data for visualization
3. add unit test for DDP training
4. add unit test for FSDP training
5. add unit test for activation checkpointing + DDP/FSDP training
6. add traces for activation memories and top operators that generate activation memories
7. print summaries for more breakdowns like model size, optimizer states, etc
8. add traces for temporary memories or memories consumed by cuda streams or nccl library if possible
9. connect the tool with OOM memory debugging
10. add dynamic programming (dp) algorithm to find best activation checkpointing locations based on the operator level activation memory traces
11. add same traces & dp algorithm for module level memory stats, as FSDP wrapping depends on module level memories, for some model users/not model authors, if they have to apply activation checkpointing on module level, they need module level memory traces as well
======================================================
Current test result for the memory_tracker_example.py on notebook:
Top 20 ops that generates memory are:
bn1.forward.cudnn_batch_norm.default_0: 98.0009765625MB
maxpool.forward.max_pool2d_with_indices.default_0: 74.5MB
layer1.0.conv1.backward.max_pool2d_with_indices_backward.default_0: 49.0MB
layer1.0.bn1.forward.cudnn_batch_norm.default_1: 24.5009765625MB
layer1.0.bn2.forward.cudnn_batch_norm.default_2: 24.5009765625MB
layer1.1.bn1.forward.cudnn_batch_norm.default_3: 24.5009765625MB
layer1.1.bn2.forward.cudnn_batch_norm.default_4: 24.5009765625MB
layer1.2.bn1.forward.cudnn_batch_norm.default_5: 24.5009765625MB
layer1.2.bn2.forward.cudnn_batch_norm.default_6: 24.5009765625MB
layer1.0.conv1.forward.convolution.default_1: 24.5MB
layer1.0.conv2.forward.convolution.default_2: 24.5MB
layer1.1.conv1.forward.convolution.default_3: 24.5MB
layer1.1.conv2.forward.convolution.default_4: 24.5MB
layer1.2.conv1.forward.convolution.default_5: 24.5MB
layer1.2.conv2.forward.convolution.default_6: 24.5MB
maxpool.backward.threshold_backward.default_32: 23.5MB
layer2.0.downsample.backward.convolution_backward.default_26: 12.2802734375MB
layer2.0.bn1.forward.cudnn_batch_norm.default_7: 12.2509765625MB
layer2.0.bn2.forward.cudnn_batch_norm.default_8: 12.2509765625MB
layer2.0.downsample.1.forward.cudnn_batch_norm.default_9: 12.2509765625MB
<img width="1079" alt="Screen Shot 2022-11-10 at 10 03 06 AM" src="https://user-images.githubusercontent.com/48731194/201172577-ddfb769c-fb0f-4962-80df-92456b77903e.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88825
Approved by: https://github.com/awgu
With combining FSDP with reentrant checkpointing, the post backward
hook might run twice, and then hit [this
error](e20ec44544/torch/distributed/fsdp/_runtime_utils.py (L487)).
This is because reentrant backward uses nested autograd GraphTasks.
The inner GraphTask is not aware of the outer one and therefore
will flush pending `AccumulateGrad` invocations on exit, which in
turn triggers the post backward hooks registered by FSDP. Later,
the outer GraphTask will trigger that again, leading to the above
error.
PR #89791 relaxes the FSDP training state check, but we still run
into grad value check failures occasionally. Therefore, this PR only
lands the test for non-reentrant test, and we can enable the
reentrant test when the accuracy issues are addressed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89781
Approved by: https://github.com/rohan-varma
- This is a strict requirement given the way dynamo+FSDP is implemented,
but isn't convenient to assert.
- By plumbing use_orig_param field on all wrapped modules, we can
do this assertion inside dynamo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89523
Approved by: https://github.com/awgu
Performance benchmarks on 6 popular models from 1-64 GPUs compiled with
torchinductor show performance gains or parity with eager, and showed
regressions without DDPOptimizer. *Note: resnet50 with small batch size shows a regression with optimizer, in part due to failing to compile one subgraph due to input mutation, which will be fixed.
(hf_Bert, hf_T5_large, hf_T5, hf_GPT2_large, timm_vision_transformer, resnet50)
Correctness checks are implemented in CI (test_dynamo_distributed.py),
via single-gpu benchmark scripts iterating over many models
(benchmarks/dynamo/torchbench.py/timm_models.py/huggingface.py),
and via (multi-gpu benchmark scripts in torchbench)[https://github.com/pytorch/benchmark/tree/main/userbenchmark/ddp_experiments].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88523
Approved by: https://github.com/davidberard98
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
This PR adds an option `config.profiler_mark_wrapper_call` (disabled by default) to mark the duration of wrapper call in the PyTorch profiler. This makes it easy to identify the duration and start/end of each wrapper call in the profiler output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89674
Approved by: https://github.com/jansel
Summary stat diff was reporting diff between previous day and the day before that, instead of today and previous day. Issue was because summary stats were not uploaded to the archive before the summary stat differ was run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89789
Approved by: https://github.com/anijain2305
This ensures that all elements of `FlatParameter._params` and `FlatParameter._shared_params` are `nn.Parameter`s (as expected). This was violated by the local tensor of a `DTensor` when using 2D parallelism. To fix the breakage, we simply wrap with `nn.Parameter` if needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89782
Approved by: https://github.com/fduwjj
This PR moves nested_dict and its test to torch.distributed.checkpoint. This is a pre-req for enabling 2D checkpoint.
This provides the functionality to flatten a nested dict and unflatten a flattened dict.
Docstring will be added in the following PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89537
Approved by: https://github.com/fduwjj, https://github.com/wanchaol
This PR moves nested_tensors to torch.distributed.checkpoint. This is a pre-req for enabling 2D checkpoint.
This flattens sharded tensors in state_dict. It is used when saving and loading FSDP SHARDED_STATE_DICT.
Docstring, individual and integration test will be added in the following PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89501
Approved by: https://github.com/wanchaol
Fixes#87894
This PR adds a warning if captured graph is empty (consists of zero nodes).
The example snippet where would it be useful:
```python
import torch
x = torch.randn(10)
z = torch.zeros(10)
g = torch.cuda.CUDAGraph()
with torch.cuda.graph(g):
z = x * x
# Warn user
```
and in #87894
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88754
Approved by: https://github.com/ezyang
Summary: Fixed bug on pack_biases, where the weight scale and zero point were being assigned to the bias.
Test Plan:
On Mac
```
cd ~/fbsource
buck1 run -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAppleMac\#macosx-arm64
```
On Android
```
cd ~/fbsource
buck1 build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 -c pt.vulkan_full_precision=1 //xplat/caffe2:pt_vulkan_quantized_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_quantized_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_quantized_api_test
adb shell "/data/local/tmp/vulkan_quantized_api_test"
```
Reviewed By: SS-JIA
Differential Revision: D41350358
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89568
Approved by: https://github.com/salilsdesai
When using SciPy >= 1.7 wishart_log_prob runs into singular samples which means there are `inf`s in `batched_prop` and `unbatched_prop`.
The difference of 2 `inf`s is `nan` which will fail the `equal(0` check.
However passing the tensors directly to `assertEqual` is not only supported but the correct way as it will handle `inf` values etc.
Change the same code in 2 more tests:
- test_multivariate_normal_log_prob
- test_lowrank_multivariate_normal_log_prob
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87977
Approved by: https://github.com/soulitzer
Disabling Gradscaler because
1) Benchmark setup runs 2 iterations of fwd-bwd. So, not useful.
2) Current setup shares grad_scaler for eager and dynamo model,
which is bad as Gradscaler has state and can adjust the scaling
factor between eager and dynamo run, making accuracy check
harder.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89741
Approved by: https://github.com/ngimel
Summary:
https://github.com/pytorch/pytorch/pull/89122 introduces internal compatibility issues with torchdeploy. However, GetPythonFramesFunction() never worked with torchdeploy, so this PR simply reverts to the original behavior of skipping the function if torchdeploy is used as a forward fix.
Test Plan:
Running failed tests in T128123281
```
buck2 test @//mode/opt //multipy/runtime:test_deploy -- --exact 'multipy/runtime:test_deploy - TorchpyTest.TaggingRace' --run-disabled
buck2 test mode/dev //multipy/runtime/testdev:test_deploy_from_python -- --exact 'multipy/runtime/testdev:test_deploy_from_python - multipy.runtime.testdev.test_deploy_from_python.TestDeployFromPython: test_deploy_from_python'
```
Differential Revision: D41414263
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89315
Approved by: https://github.com/kurman
Strategy taken from voz's #89392 but my implementation strategy
is a bit different.
If a fake tensor is provided, we use its FakeTensorMode
(and more importantly, its ShapeEnv--this is what is tested
in the new unit test). Only one tensor needs to be fake;
if nothing is fake we just make a fresh mode as before.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89670
Approved by: https://github.com/voznesenskym
This is extracted from voz's #89392
Previously, the implementation did some half-assed caching where it
returned a callable, that when invoked for the first time, actually
performed the compilation. Delaying the compilation like this...
seems totally unnecessary? To make matters worse, this has cost
(we have to check if we hit the cache) and unsound (because the
compiled function may not be valid for other arguments.)
So instead, we ask user to provide arguments, and compile everything
immediately.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89669
Approved by: https://github.com/voznesenskym, https://github.com/Chillee
There was a lot of strangeness in how AOTAutograd backends were previously defined. This refactor replaces the strangeness with something simple and straightforward. The improvements:
- There is no longer a footgun aot_autograd "backend" which doesn't actually work. No more mistyping `torch._dynamo.optimize("aot_autograd")` when you meant "aot_eager"
- Deleted aot_print because it's annoying and anyway there's no uses of it
- Instead of having BOTH the backend Subgraph and AotAutogradStrategy, there is now only an aot_autograd function which takes the kwargs to configure AOTAutograd, and then gives you a compiler function that does AOTAutograd given those kwargs. Easy.
- The primary downside is that we are now eagerly populating all of the kwargs, and that can get us into import cycle shenanigans. Some cycles I resolved directly (e.g., we now no longer manually disable the forward function before passing it to aot_autograd; aot_autograd it does it for us), but for getting inductor decompositions I had to make it take a lambda so I could lazily populate the decomps later.
New code is 130 lines shorter!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89736
Approved by: https://github.com/anjali411, https://github.com/albanD
I am not aware of any users of `FullyShardedDataParallel` that pass arguments after `process_group` positionally. I.e., I believe users pass arguments as keyword arguments. This PR formalizes this for `fully_shard()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89573
Approved by: https://github.com/mrshenli
- This PR registers the FSDP root pre-forward hook as a module forward pre-hook following the recently added support for kwargs for those hooks.
- This PR also passes `prepend=True` for the normal (not root) pre-forward hook. This is not strictly required for this PR, but I believe it is needed for composability with activation checkpointing. (We want to run FSDP logic on the outside and AC logic on the inside, just like how we recommend `FSDP(AC(module))` for the wrapper versions.)
Fun fact: I originally chose the `[FSDP()]` prefix in the PR titles when we still referred to composable FSDP as functional-like FSDP, in which case `FSDP()` approximated "functional FSDP". I am preserving this usage to make searching for PRs relating to composable FSDP easier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89572
Approved by: https://github.com/mrshenli
It's kind of intractable to enable mypy everywhere at the moment,
because there are a lot of errors, and also mypy is really slow
for some reason. I just want enough types to explain the public
types for user compiler calls, going through typing the _C.dynamo
bindings along the way. This is a first step for this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89731
Approved by: https://github.com/suo
A few things in this PR, that I found useful while debugging some
recent issues:
- We now allocate an aot_id to each aot_function/aot_module invocation,
and print it whenever we report error messages and graph output
logging. Check the comment for why this sort of thing is useful,
and also why it's different from nth_graph. This number is now
incorporated into aot_graph_name
- I noticed that nth_graph only gets incremented when backwards is
compiled. Because backwards is compiled lazily, this means that
multiple forward graphs would have gotten the same ID! I change
nth_graph to always increment to avoid confusion here.
- I added a simple describe_input function, which makes use of
num_params_buffers to tell the user if the input index they're
looking at is a param/buffer or an input. With the help of
https://github.com/pytorch/pytorch/pull/89709 we could give
even more detailed information about inputs (we could also
easily give detailed information about parameters if we stored
a mapping of index to parameter name, but I didn't need this
when debugging so I'll let someone else add it if they need
it.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89710
Approved by: https://github.com/bdhirsh
It's a lot easier to debug problems in the Dynamo optimization pass if
you aren't actually triggering a multiprocessing run. Keep these tests
around.
I think the other tests can probably get this treatment too, leaving
this to future work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89721
Approved by: https://github.com/voznesenskym
It turns out that instead of having a giant blobby aot_dispatch_autograd
function, we can factor it into a series of wrapper functions, each
of which successively guarantees more invariants on the inner
compilation function until the final inner function is quite trivial.
How exactly you have to wrap the input user functions and the output
compiled functions can be expressed concisely in Haskell, so I've
included the Haskell formulation in code comments.
This PR shows how to do this for input deduplication. Dealing with the
rest of the view handling is left to future work.
This PR should also be a slight performance improvement as deduplicating
is skipped entirely when there are no duplicate inputs.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89701
Approved by: https://github.com/bdhirsh
I audited the pattern matches on the enum and it didn't
look like this one should apply there.
Sorry, no test, I know this matters on symbolic-shapes branch
but I haven't had time to extract out a minimal reproducer.
Take my word for it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89711
Approved by: https://github.com/jansel
There are various Tensors created in the backward pass which do not correspond to parameters. We don't want to mark these as gradients, but we do still want to convey as much information as possible. Thus, this PR introduces an AUTOGRAD_DETAIL category. (Which can be grouped with GRADIENT in visualization if one wishes to take a coarse grained view of the world.)
Differential Revision: [D40868661](https://our.internmc.facebook.com/intern/diff/D40868661/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88926
Approved by: https://github.com/chaekit
Up until now the unit tests for category assignment have been narrowly scoped to specific checks on specific Tensors. However as we start to reach reasonable levels of category assignment it's useful to supplement those tests with higher level summary tests to inspect the larger graph and confirm that it makes sense. (It will also be necessary for some categories like activations where it is tedious to record all relevant Tensors.)
The general structure of these tests is to capture a model invocation with `__torch_dispatch__` and then cross reference those inputs and outputs with the categories assigned by the memory profiler.
Differential Revision: [D40868659](https://our.internmc.facebook.com/intern/diff/D40868659/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88653
Approved by: https://github.com/chaekit
Following the pattern of earlier PRs, we use two methods to extract parameters. The primary one is the Python tracer; both nn.Module and optim.Optimizer collect parameters and in most cases that is sufficient. As a fallback we can analyze the data flow graph and deduce likely parameters based on gradient computation and updates.
Parameter identification has a circular interaction with input identification. Inputs are defined as "not part of the core forward-backward-update loop", but we need inputs for the parameter identification fallback to give us a proxy for the forward pass. Thus, we mark parameters from the python tracer which limits which Tensors get marked as inputs. While not necessary, it adds a bit of robustness. (As shown by the strengthening of the input unit tests.)
Differential Revision: [D40238619](https://our.internmc.facebook.com/intern/diff/D40238619/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87568
Approved by: https://github.com/chaekit
It is surprisingly difficult to identify the leaves of the data flow graph. The issue is that inputs and pre-existing parameters look identical until parameter identification takes place. It's not too bad for training since Autograd lets us differentiate between them however I still want the tool to do something reasonable in inference.
Some of this will be ameliorated when a later PR pulls in parameters from python tracing. The current approach is passable, but I will continue to mull over refinements.
Differential Revision: [D40220388](https://our.internmc.facebook.com/intern/diff/D40220388/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87567
Approved by: https://github.com/chaekit
Semantic assignment will be built up as a series of passes which gradually pin down the regions of a trace. For this reason it is important to be very meticulous in the assignment of categories.
We begin with gradients as they are both straightforward to identify and foundational to subsequent analysis. There are two mechanisms that the profiler can use to tag gradients, each with their own advantages and limitations. The first is direct inspection of the op graph which is generic but predicated on certain features of the Autograd engine. (And therefore not necessarily exhaustive.) The second approach is direct instrumentation via the python tracer. This method relies requires that gradients be attached to an nn.Module parameter and can miss corner cases such as `set_to_none=True` due to the cache structure of the python tracer. Combined these two approaches provide very high coverage.
Temporaries are more straightforward; we can easily add them by trivial local inspection of a data flow node.
Because this is the first PR in the end-to-end section most of the code is building the scaffolding for category bookkeeping and unit testing. (The actual gradient extraction was covered in an earlier PR.)
Differential Revision: [D40220389](https://our.internmc.facebook.com/intern/diff/D40220389/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87566
Approved by: https://github.com/chaekit
The semantic meaning of a Tensor is tightly coupled to its lineage. The data flow graph allows us to identify temporary Tensors, masks, inputs, activations, and more. However one important nuance is that Tensors must be versioned; operations which mutate their inputs can also change the semantic meaning of said inputs.
It is challenging to assemble a complete picture of the data flow in a PyTorch model because ops can, and often do, recursively call into other ops. For the purpose of memory profiling this is an implementation detail, so instead we traverse the op tree to identify top level ops and allocations and then coalesce their children, folding inputs and outputs into the top level Node.
Differential Revision: [D40220391](https://our.internmc.facebook.com/intern/diff/D40220391/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87006
Approved by: https://github.com/chaekit
The preexisting logic here added in
https://github.com/pytorch/functorch/pull/970 was very peculiar: if top_kwargs
was non-empty, then the inner compiled function supports kwargs. Naively, this
would leave you to expect that there is some sort of correlation between
top_kwargs and kwargs. But in fact, they're completely unrelated! top_kwargs
is the AOTAutograd configuration knobs (e.g., fw_compiler/bw_compiler), but
kwargs is the RUNTIME kwargs that are to be passed to the compiled function.
But (1) we don't support this (the function to be compiled only takes a list
of tensors) and (2) even if we did support it, conditioning on whether or not
you had passed AOTAutograd configuration kwargs to support kwargs at runtime
is bonkers.
So delete it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89664
Approved by: https://github.com/voznesenskym
There is only one call site for compiler_fn, so we can safely delay
wrapping verify correctness to here. This will help later when we
change the backend compiler calling convention to pass fake tensors
(but I need to pass real tensors here.)
This is adapted from voz's changes at https://github.com/pytorch/pytorch/pull/89392
but with less changes to the substantive logic. I only moved the relevant
inner implementation; there are no changes otherwise.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89662
Approved by: https://github.com/voznesenskym
A previous version of this patch graph breaks when torch.tensor fails, but that causes
```
PYTORCH_TEST_WITH_DYNAMO=1 python test/nn/test_embedding.py -k test_embedding_bag_1D_padding_idx_cpu_float32
```
to start failing. Probably another latent bug that needs investigating.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89645
Approved by: https://github.com/albanD
This PR is about enabled weight prepack using the MKLDNN tensor:
1. enable fake tensor mode for MKLDNN tensor input.
2. make convolution fusion kernel support MKLDNN tensor input.
3. do the weight prepack at FX fusion step.
For better performance, we always use channels_last for CPU convolution path. because we test that the channels_last path can get a better performance than block input path, and also avoid the activation's layout conversion(plain to block, block to plain), currently, there only need plain to plain format conversion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88988
Approved by: https://github.com/jgong5, https://github.com/jansel
This is a slight regression: RAdam and Adagrad don't appear to
trace at all under fake tensors. But I think this is a more accurate
reflection of the current state of affairs.
Along the way fix some problems on the fake tensor path.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89643
Approved by: https://github.com/anjali411
I'm not really sure what desertfire's intended follow up was
on https://github.com/pytorch/pytorch/pull/87490 because when I remove
the unsupported() call, dynamo tests pass. But the change here is
conservative and I think strictly better than the current situation.
The idea is to force fake tensor pop on for the test, and then just
observe that we are doing a graph break. Clearly, export doesn't work,
so I manually xfail it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89641
Approved by: https://github.com/anjali411
Previously, we hackily wrapped unspecialized integers into
tensors and treated them as tensor inputs. Sometimes, downstream
operations would not be able to deal with the tensor input. Now,
we wrap them into SymInt, so more correct overload selection occurs.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89639
Approved by: https://github.com/anjali411
One PR towards #89205.
The content is mostly from PR #38465, but slightly changed the expression to make it faster.
Here are some benchmarking code:
```c++
#include <complex>
#include <iostream>
#include <chrono>
// main.cc
template<typename T> inline std::complex<T> log1p_v0(const std::complex<T> &z) {
// this PR
T x = z.real();
T y = z.imag();
T theta = std::atan2(y, x + T(1));
T r = x * (x + T(2)) + y * y;
return {T(0.5) * std::log1p(r), theta};
}
template<typename T> inline std::complex<T> log1p_v1(const std::complex<T> &z) {
// PR #38465
T x = z.real();
T y = z.imag();
std::complex<T> p1 = z + T(1);
T r = std::abs(p1);
T a = std::arg(p1);
T rm1 = (x * x + y * y + x * T(2)) / (r + 1);
return {std::log1p(rm1), a};
}
template<typename T>
inline std::complex<T> log1p_v2(const std::complex<T> &z) {
// naive, but numerically inaccurate
return std::log(T(1) + z);
}
int main() {
int n = 1000000;
std::complex<float> res(0.0, 0.0);
std::complex<float> input(0.5, 2.0);
auto start = std::chrono::system_clock::now();
for (int i = 0; i < n; i++) {
res += log1p_v0(input);
}
auto end = std::chrono::system_clock::now();
auto elapsed = end - start;
std::cout << "time for v0: " << elapsed.count() << '\n';
start = std::chrono::system_clock::now();
for (int i = 0; i < n; i++) {
res += log1p_v1(input);
}
end = std::chrono::system_clock::now();
elapsed = end - start;
std::cout << "time for v1: " << elapsed.count() << '\n';
start = std::chrono::system_clock::now();
for (int i = 0; i < n; i++) {
res += log1p_v2(input);
}
end = std::chrono::system_clock::now();
elapsed = end - start;
std::cout << "time for v2: " << elapsed.count() << '\n';
std::cout << res << '\n';
}
```
Compiling the script with command `g++ main.cc` produces the following results:
```
time for v0: 237812271
time for v1: 414524941
time for v2: 360585994
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89214
Approved by: https://github.com/lezcano
Summary:
After counters are reset, getters' behaviors are inconsistent. To improve that, here I 1) move the validation of CounterData into CounterData::IsValid such that it's better encapsulated, 2) divide getters into two groups: a) MetricsArena::GetCounter() and b) MetricsArena::ForEachCounter(), and route MetricsArena::GetCounterNames() and CreateMetricReport() to use b.
This is paired with pytorch/xla#4217.
Test Plan:
PJRT_DEVICE=CPU python xla/test/test_metrics.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89608
Approved by: https://github.com/JackCaoG
Summary:
This PR deprecates the `compute_dtype` field on observers, and replaces
it with the `is_dynamic` field on observers. This is better aligned
with the reference model spec.
Test plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85431
Approved by: https://github.com/jerryzh168
E.g. `test_cpp_extensions_aot_ninja` fails as it includes `vec.h` which requires the vec/vsx/* headers and `sleef.h`. The latter is also required for AVX512 builds on non MSVC compilers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85547
Approved by: https://github.com/kit1980
This PR add tests to verify the behavior of number of outputs returns by an XLA graph. The understanding from this PR will help us fix https://github.com/pytorch/torchdynamo/issues/1908 and enable training for dynamo/torchxla integration eventually. Send this PR separately so Jack could help verify if the behavior is expected and play with it.
List some code snippets here since their behavior is not straightforward at a first glance:
```
def forward(self, a, b, c):
"""
The XLA graph will only return the first 2 items
"""
return a + b, a + c, b
```
```
def forward(self, a, b, c):
"""
Inplace update on b cause it to be returned in XLA graph
"""
b.zero_()
return a + b, a + c, b
```
```
def forward(self, a, b, c):
"""
Even if we return b twice, the XLA graph only return b once.
"""
b.zero_()
return a + b, a + c, b, b
```
Here are what observed by the added tests:
1. XLA does not return outputs that are also inputs -- if the tensor is not inplace updated. At first glance people may feel curious why should we consider this kind of 'non-realistic' corner case. But this kind of graphs indeed shows up in AOTAutograd. The main reason is AOTAutograd lift all model parameters/buffers as graph input and may return some of them. Check ***test_direct_return***
2. if a tensor is inplace updated, XLA will still return it as graph output even if it's also an input. The only difference compared to item 1 is, the inplace updating on the tensor cause it being returned. This happens for BatchNorm2d since the running_mean/variance tensors will be inplace updated during training. Check ***test_direct_return_with_inplace_update***
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89536
Approved by: https://github.com/jansel
Set `cmake.dir` to `/usr/local` in `.circleci/scripts/build_android_gradle.sh `
Prep change for raising compiler standard to C++17: cmake-3.18 is the first one to support CUDA17 language
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89570
Approved by: https://github.com/atalman
Using the same repro from the issue (but with BatchNorm2D)
Rectifies native_batch_norm schema by splitting the schema into 2:
1. one will have NON-optional alias-able running_mean and running_var inputs
2. the other will just not have those parameters at all (no_stats variation)
**Calling for name suggestions!**
## test plan
I've added tests in test_functionalization.py as well as an entry in common_method_invocations.py for `native_batch_norm_legit`
CI should pass.
## next steps
Because of bc/fc reasons, we reroute native_batch_norm to call our new schemas ONLY through the python dispatcher, but in 2 weeks or so, we should make `native_batch_norm_legit` the official batch_norm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88697
Approved by: https://github.com/albanD
`JIT_LOG` checks if logging was enabled for that particular file and when it isn't it doesn't output anything. Since the test checks for the size of `test_stream` it fails. I believe forcing the file to have logging enabled to see if the stream is being correctly set during test makes no sense so this patches just forcibly outputs and checks if it worked.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82722
Approved by: https://github.com/davidberard98
I have found the reason why uploading tests stats fails for rerun disabled workflow, for example https://github.com/pytorch/pytorch/actions/runs/3522896778/jobs/5917765699. The problem is that the pytest XML file is now too big to be processed quickly (x50 bigger). Unlike unittest, `pytest-flakefinder` used by rerun disabled tests for test_ops includes skipped messages multiple times (50 times by default, retrying and skipping). This slows down the upload test stats script too much (O(n)) because it tries to gather all the stats. On the other hand, `check_disabled_tests` doesn't suffer from the same issue because it ignores all these skipped messages.
This is a quick fix to skip test reports from rerun disabled tests workflow when trying to upload test stats.
I'll try to fix this properly later in the way we use pytest-flakefinder. From what I see, a zipped test report from rerun disabled test is only few MB ([example](https://gha-artifacts.s3.amazonaws.com/pytorch/pytorch/3521687954/1/artifact/test-reports-test-default-1-2-linux.2xlarge_9636028803.zip)), but will balloon up to a much bigger XML file after extracting from a dozen to a few hundred MB (text). The size of the zipped file is not a big immediate problem
### Testing
[3521687954](https://github.com/pytorch/pytorch/actions/runs/3521687954) is an example workflow with rerun disabled tests and mem leak check. The script can now finish when running locally:
* `upload_test_stats` finishes around 3+ minutes
```
time python -m tools.stats.upload_test_stats --workflow-run-id 3521687954 --workflow-run-attempt 1 --head-branch master
...
Writing 8925 documents to S3
Done!
Writing 1760 documents to S3
Done!
Writing 1675249 documents to S3
Done!
python3 -m tools.stats.upload_test_stats --workflow-run-id 3521687954 1 185.69s user 12.89s system 75% cpu 4:22.82 total
```
* `check_disabled_tests` finishes within 3 minutes
```
time python -m tools.stats.check_disabled_tests --workflow-run-id 3521687954 --workflow-run-attempt 1 --repo pytorch/pytorch
...
python -m tools.stats.check_disabled_tests --workflow-run-id 3521687954 1 154.19s user 4.17s system 97% cpu 2:42.50 total
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89548
Approved by: https://github.com/clee2000
Fixes#88985
By default, `maybe_wrap_dim` allows through `dim=0` or `dim=-1`
for scalar tensors which leads to an invalid dimension being used to
index into `tensor.sizes()` as in the code sample from the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89234
Approved by: https://github.com/mruberry
Relands #89031
Per title. We now set strides from fx graph only for convolutions and mm, which is a hack, but bmm in some cases caused extra copy, and there is no obvious way to fix that, we should rethink the strides anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89530
Approved by: https://github.com/Chillee
Summary:
Goal
Add `all_reduce` collective to multi-threaded ProcessGroup added in D40236769 (6663ae5537).
Code Motion
Added `allreduce` collective to ProcessLocalGroup (a subclass of c10d ProcessGroup).
What's Next
Add a DDP test utilizing the new allreduce op.
Generalize `allreduce` to allow other `ReduceOp`s besides `SUM`.
Test Plan:
cd fbcode/caffe2
buck2 test mode/dev //caffe2/test/distributed:multi_threaded
Differential Revision: D41046606
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89043
Approved by: https://github.com/wanchaol
Currently it falls through to a call to `storage()`, which the IPU doesn't support.
I've made the minimal change here for ease of merging (this'd help us if it was in for 1.13.1), however...
**QUESTION**: Is there any reason why `not torch._C._has_storage(self)` needs to *also* be guarded on `self.device.type == privateuseone`? in other words, could the condition for using `clone` not be this?
```python
self.is_sparse
or self.device.type
in ["lazy", "xla", "mps", "ort", "meta", "hpu", "ipu"]
or not torch._C._has_storage(self)
or (type(self) is not Tensor and self.data_ptr() == 0)
```
If the condition fails, the very next thing is a call to `self._typed_storage()` which will fail, so it feels to me like *any* case without storage shouldn't fall through to the `storage()` call.
The original PR for adding the 'no storage and device is `PrivateUse1`' condition ([86557](https://github.com/pytorch/pytorch/pull/86557)) doesn't discuss whether this could be broadened.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89129
Approved by: https://github.com/albanD
This is a group of bug fixes for [7k github models](https://github.com/pytorch/torchdynamo/issues/1884), it would fix 30+ model tests.
* Support ```tensor.type()```.
* Support ```tensor.get_device()```.
* Support ```torch.nn.functional._Reduction.get_enum```.
* Support ```torch._utils._get_device_index()```.
* Fallback ```tensor.data_ptr()```.
* ```FakeTensor``` always returns 0
* For no fake tensor propagation, we ```clone``` the input tensor, which makes no sense to track the original ```data_ptr```. And I don't think this is a very popular API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89486
Approved by: https://github.com/jansel
This reverts commit 9fd00f194ae4e28948a9a03a6382c20dde04e4fd.
Reverted https://github.com/pytorch/pytorch/pull/89174 on behalf of https://github.com/robieta due to For some reason this is interacting badly with NVFuser. I think it is instability in kineto, but until we figure out what's going on reverting is a necessary evil.
Fixes#43144
This uses the Backend system added by [82682](https://github.com/pytorch/pytorch/pull/82682) to change allocators dynamically during the code execution. This will allow us to use RMM, use CUDA managed memory for some portions of the code that do not fit in GPU memory. Write static memory allocators to reduce fragmentation while training models and improve interoperability with external DL compilers/libraries.
For example, we could have the following allocator in c++
```c++
#include <sys/types.h>
#include <cuda_runtime_api.h>
#include <iostream>
extern "C" {
void* my_malloc(ssize_t size, int device, cudaStream_t stream) {
void *ptr;
std::cout<<"alloc "<< size<<std::endl;
cudaMalloc(&ptr, size);
return ptr;
}
void my_free(void* ptr) {
std::cout<<"free "<<std::endl;
cudaFree(ptr);
}
}
```
Compile it as a shared library
```
nvcc allocator.cc -o alloc.so -shared --compiler-options '-fPIC'
```
And use it from PyTorch as follows
```python
import torch
# Init caching
# b = torch.zeros(10, device='cuda')
new_alloc = torch.cuda.memory.CUDAPluggableAllocator('alloc.so', 'my_malloc', 'my_free')
old = torch.cuda.memory.get_current_allocator()
torch.cuda.memory.change_current_allocator(new_alloc)
b = torch.zeros(10, device='cuda')
# This will error since the current allocator was already instantiated
torch.cuda.memory.change_current_allocator(old)
```
Things to discuss
- How to test this, needs compiling external code ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86786
Approved by: https://github.com/albanD
This PR fixes convolution when using `torchdynamo` with dynamic shapes.
**Problem:** there are some `tensor.sizes()` calls in a few error messages. As a result, an uninformative error message was being displayed.
```python
@torch._dynamo.optimize("eager")
def foo(inp, w):
return F.conv2d(inp, w)
inp = torch.rand((1, 1, 32, 32))
w = torch.rand((1, 2, 3, 3))
# |
# |--------- incorrect shape!
foo(inp, w)
```
-----
**Before this PR:**
```python
Traceback (most recent call last):
File "torch/_dynamo/utils.py", line 1076, in run_node
return node.target(*args, **kwargs)
File "torch/_subclasses/fake_tensor.py", line 867, in __torch_dispatch__
op_impl_out = op_impl(self, func, *args, **kwargs)
File "torch/_subclasses/fake_tensor.py", line 445, in conv
conv_backend = torch._C._select_conv_backend(**kwargs)
RuntimeError: Cannot call sizes() on tensor with symbolic sizes/strides
```
**After this PR:**
```python
Traceback (most recent call last):
File "torch/_dynamo/utils.py", line 1076, in run_node
return node.target(*args, **kwargs)
File "torch/_subclasses/fake_tensor.py", line 867, in __torch_dispatch__
op_impl_out = op_impl(self, func, *args, **kwargs)
File "torch/_subclasses/fake_tensor.py", line 445, in conv
conv_backend = torch._C._select_conv_backend(**kwargs)
RuntimeError: Given groups=1, weight of size [1, s1, s2, s2], expected input[1, 1, s0, s0] to have s1 channels, but got 1 channels instead
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89549
Approved by: https://github.com/ezyang
Summary:
att, after this PR we can produce quantize_per_channel and dequantize_per_channel ops (typically used for quantizing weights)
in the reference flow using decomposed tensor
Test Plan:
python test/test_quantization.py -k test__convert_to_reference_decomposed_fx_per_channel_quant
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89270
Approved by: https://github.com/vkuzo
When FBGEMM is not used (either manually disabled or on platforms such as POWER where it isn't supported at all) the fallback code requests a `data_ptr<float>` on a `Tensor` object returned by `to(ScalarType::Float)` in the same line. This object will be destroyed at the end of the line leading to a dangling pointer.
On some platforms this manifests in wrong results being returned as the memory gets overwritten. On other platforms anything may happen due to this being undefined behavior, although most likely it will just crash or continue to return semi-random results which may even happen to be correct (when the memory is not reused yet)
Fix this by binding the temporary object (or initial object) to a const value reference which extents its lifetime and getting the `data_ptr` from that.
Fixes#84748
This bug was introduced by a seemingly unrelated change in #64081 hence ccing @d1jang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84750
Approved by: https://github.com/kimishpatel
The idea is to add a custom handler to Functionalize key in Python
dispatcher that runs the functionalized version along side a non
functionalized version, and checks that their outputs agree in the
end. (Technically, for metadata mutation we should also check the
inputs, but for now we're relying on those functions returning self.)
I turned this on for test_functionalize.py (new TestCrossRefFunctionalize)
and found a bunch of failures that look legit.
This probably doesn't interact that nicely if you're also tracing at
the same time, probably need more special logic for that (directly,
just disabling tracing for when we create the nested fake tensor mode,
but IDK if there's a more principled way to organize this.)
There are some misc fixups which I can split if people really want.
- xfail_inherited_tests moved to test common_utils
- Bindings for _dispatch_tls_set_dispatch_key_included,
_dispatch_tls_is_dispatch_key_included and _functionalization_reapply_views_tls
- Type stubs for _enable_functionalization, _disable_functionalization
- all_known_overloads utility to let you iterate over all OpOverloads
in all namespaces. Iterator support on all torch._ops objects to let
you iterate over their members.
- suspend_functionalization lets you temporarily disable functionalization mode
in a context
- check_metadata_matches for easily comparing outputs of functions and see
if they match (TODO: there are a few copies of this logic, consolidate!)
- _fmt for easily printing the metadata of a tensor without its data
- _uncache_dispatch for removing a particular dispatch key from the cache,
so that we force it to regenerate
- check_significant_strides new kwarg only_cuda to let you also do stride
test even when inputs are not CUDA
- Functionalize in torch._C.DispatchKey
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89498
Approved by: https://github.com/malfet
Switch GCC/Clang max versions to be exclusive as the `include/crt/host_config.h` checks the major version only for the upper bound. This allows to be less restrictive and match the checks in the aforementioned header.
Also update the versions using that header in the CUDA SDKs.
Follow up to #82860
I noticed this as PyTorch 1.12.1 with CUDA 11.3.1 and GCC 10.3 was failing in the `test_cpp_extensions*` tests.
Example for CUDA 11.3.1 from the SDK header:
```
#if __GNUC__ > 11
// Error out
...
#if (__clang_major__ >= 12) || (__clang_major__ < 3) || ((__clang_major__ == 3) && (__clang_minor__ < 3))
// Error out
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86360
Approved by: https://github.com/ezyang
closes#35643
This PR is mostly borrowed from #82042. Thanks @Padarn for implementing
the first version and debugging into the errors.
Based on the discussion in #82042 this PR adds a with_kwargs
argument to register_forward_pre_hook and register_forward_hook
methods. When the arg is set to true, the provided hook must accept
kwargs args. Under the hook, this PR adds a
`_forward_pre_hooks_with_kwargs` and a `_forward_hook_with_kwargs`
set to keep track of which hooks accept kwargs.
Differential Revision: [D41431111](https://our.internmc.facebook.com/intern/diff/D41431111)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89389
Approved by: https://github.com/soulitzer
- Avoid fx graph rewrite that replaces certain ops with ones using
triton random
- Keep track of replacement ops using triton random, so it is possible
to not disable all replacements when using fallback_random
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89515
Approved by: https://github.com/ngimel
Replace the remaining hand-written code in vec256_float_vsx.h by calls to Sleef functions similar to what was done in #59382 & #82646 after #41541
This fixes wrong results for e.g. `sin(1e20)`.
Fixes#85978
To fix#85978 I only needed to do the sin/cos functions to make the test pass but to not encounter the same issue again and again (see the previous PRs and issues) I checked the whole file for similar functions where a Sleef function could be used and changed those too. In the diff I've noticed the faulty whitespace so to make this complete I fixed that too, so it should now be done.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86453
Approved by: https://github.com/malfet
The test may fail due to slightly different values caused by different order of matrizes in SGEMM:
> Mismatched elements: 1 / 50 (2.0%)
> Greatest absolute difference: 1.430511474609375e-05 at index (4, 5) (up to 1e-05 allowed)
> Greatest relative difference: 4.65393206065873e-06 at index (4, 5) (up to 1.3e-06 allowed)
Observed on POWER (ppc64le)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86365
Approved by: https://github.com/mruberry, https://github.com/kit1980
Summary:
split the is_decomposed logic for `_replace_observer_with_quantize_dequantize_node` in a separate function and added support for dynamic quantization in the decomposed version of this function.
In case of dynamic quantization, we'll produce the following reference quantized pattern in decomposed mode:
```
x -> choose_qparams -> quantize_per_tensor -> dequantize_per_tensor -> linear
```
Test Plan:
python test/test_quantization.py -k test__convert_to_reference_decomposed_fx_dynamic_quant
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89248
Approved by: https://github.com/vkuzo
This PR moves traverse and its test to torch.distributed.checkpoint. This is a pre-req for enabling 2D checkpoint.
This is used when flatten nested dict and flatten sharded tensors.
Docstring and comments will be added in the following PRs.
Test:
```
python3 test/distributed/_tensor/parallel/test_2d_parallel.py
```
and CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89398
Approved by: https://github.com/wanchaol
Summary: This permute copy change seems to be causing huge regressions on machines without AVX512. Revert to mitigate. This shouldn't be problematic since the improvement from changing it was super small anyways.
Differential Revision: D41450088
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89463
Approved by: https://github.com/hlu1
In #87741 we added the inference support for dynamo/torchxla integration. Later on in #88449 we attempt to add the training support. That attempt is not smooth because
- we try 2 things together
1. let dynamo trace the model on xla rather than eager
2. enable training
- It turns out neither of these two tasks are trivial enough.
Furthermore, item 2 (enable training) depends on item 1 (tracing on xla). We enable training via AOTAutograd. AOTAutograd lift all model parameters/buffers as graph inputs. Without item 1 being done, we would need copy all graph inputs (including model parameters/buffers) from eager device to xla devices. That hurts performance a lot. Have a cache to map eager parameter to XLA parameter does not solve the problem since the update on either will not sync automatically to the other. They will easily go out of sync.
This PR let dynamo trace the model on XLA rather than eager. This is a preparation step to enabling training.
Also, tracing on XLA makes the data movement more efficient. We see 1.5x geomean speedup compared to previous 1.38x.
```
+-------------------------+--------------------+-------------------------+
| Model | XLA (trace once) | XLA (trace everytime) |
+=========================+====================+=========================+
| resnet18 | 1.38 | 1.008 |
+-------------------------+--------------------+-------------------------+
| resnet50 | 1.227 | 0.998 |
+-------------------------+--------------------+-------------------------+
| resnext50_32x4d | 1.544 | 1.008 |
+-------------------------+--------------------+-------------------------+
| alexnet | 1.085 | 1.045 |
+-------------------------+--------------------+-------------------------+
| mobilenet_v2 | 2.028 | 1.013 |
+-------------------------+--------------------+-------------------------+
| mnasnet1_0 | 1.516 | 0.995 |
+-------------------------+--------------------+-------------------------+
| squeezenet1_1 | 0.868 | 1.01 |
+-------------------------+--------------------+-------------------------+
| vgg16 | 1.099 | 1.008 |
+-------------------------+--------------------+-------------------------+
| BERT_pytorch | 3.26 | 1.027 |
+-------------------------+--------------------+-------------------------+
| timm_vision_transformer | 2.182 | 1.015 |
+-------------------------+--------------------+-------------------------+
| geomean | 1.50389 | 1.01261 |
+-------------------------+--------------------+-------------------------+
```
Example command
```
GPU_NUM_DEVICES=1 python benchmarks/dynamo/torchbench.py --randomize-input --performance --trace-on-xla --only resnet18 --backend=torchxla_trace_once
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88904
Approved by: https://github.com/wconstab, https://github.com/JackCaoG, https://github.com/jansel
This PR moves dedup_tensors and its test to torch.distributed.checkpoint. This is a pre-req for enabling 2D checkpoint.
This removes duplicated shards in list of SavePlan. It is used when saving DT with replicated placement.
Docstring and comments will be added in the following PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89399
Approved by: https://github.com/wanchaol
When looking into Rockset data for disabled test unittest, for example `testAdd`, I see that it's re-run only 3 times instead of 50+ times as expected under rerun-disabled -test mode
```
[
{
"name": "testAdd",
"classname": "TestLazyReuseIr",
"filename": "lazy/test_reuse_ir.py",
"flaky": false,
"num_green": 3,
"num_red": 0
}
]
```
It turns out that I made a mistake mixing `RERUN_DISABLED_TESTS` and `report_only` into `(RERUN_DISABLED_TESTS or report_only) and num_retries_left < MAX_NUM_RETRIES` in https://github.com/pytorch/pytorch/pull/88646. The retrying logic for successful tests under rerun-disabled-tests mode is never executed because num_retries_left would be equal to MAX_NUM_RETRIES (not smaller) if the very first run successes. Thus, the sample test `testAdd` finishes right away (1 success count)
* `report_only` and `RERUN_DISABLED_TESTS` are 2 different things and shouldn't be mixed together. RERUN_DISABLED_TESTS has the higher priority.
* We also don't want to retry skipped tests under rerun-disabled-tests mode because they are only skipped due to `check_if_enable` check `Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run`
### Testing
* CI https://github.com/pytorch/pytorch/actions/runs/3518228784 generates https://gha-artifacts.s3.amazonaws.com/pytorch/pytorch/3518228784/1/artifact/test-reports-test-default-4-4-linux.4xlarge.nvidia.gpu_9627285587.zip in which `testAdd` is correctly called multiple times and `TestLazyReuseIr` is skipped correctly
* Locally
```
# export CI=1
# export PYTORCH_RETRY_TEST_CASES=1
# export PYTORCH_OVERRIDE_FLAKY_SIGNAL=1
# export PYTORCH_TEST_RERUN_DISABLED_TESTS=1
$ python test/run_test.py --verbose -i lazy/test_reuse_ir
Ignoring disabled issues: []
Selected tests:
lazy/test_reuse_ir
Prioritized test from test file changes.
reordering tests for PR:
prioritized: []
the rest: ['lazy/test_reuse_ir']
Downloading https://raw.githubusercontent.com/pytorch/test-infra/generated-stats/stats/slow-tests.json to /Users/huydo/Storage/mine/pytorch/test/.pytorch-slow-tests.json
Downloading https://raw.githubusercontent.com/pytorch/test-infra/generated-stats/stats/disabled-tests-condensed.json to /Users/huydo/Storage/mine/pytorch/test/.pytorch-disabled-tests.json
parallel (file granularity) tests:
lazy/test_reuse_ir
serial (file granularity) tests:
Ignoring disabled issues: []
Ignoring disabled issues: []
Running lazy/test_reuse_ir ... [2022-11-21 13:21:07.165877]
Executing ['/Users/huydo/miniconda3/envs/py3.9/bin/python', '-bb', 'lazy/test_reuse_ir.py', '-v', '--import-slow-tests', '--import-disabled-tests', '--rerun-disabled-tests'] ... [2022-11-21 13:21:07.166279]
Expand the folded group to see the log file of lazy/test_reuse_ir
##[group]PRINTING LOG FILE of lazy/test_reuse_ir (/Users/huydo/Storage/mine/pytorch/test/test-reports/lazy-test_reuse_ir_6cf_dxa1)
Running tests...
----------------------------------------------------------------------
Test results will be stored in test-reports/python-unittest/lazy.test_reuse_ir
testAdd (__main__.TestLazyReuseIr) ... ok (1.215s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 50
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 49
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 48
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 47
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 46
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 45
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 44
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 43
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 42
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 41
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 40
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 39
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 38
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 37
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 36
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 35
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 34
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 33
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 32
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 31
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 30
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 29
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 28
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 27
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 26
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 25
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 24
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 23
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 22
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 21
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 20
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 19
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 18
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 17
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 16
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 15
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 14
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 13
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 12
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 11
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 10
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 9
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 8
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 7
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 6
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 5
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 4
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 3
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 2
ok (0.001s)
testAdd (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 1
ok (0.001s)
testAddSub (__main__.TestLazyReuseIr) ... testAdd succeeded - num_retries_left: 0
skip: Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run (0.001s)
testAddSubFallback (__main__.TestLazyReuseIr) ... skip: Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run (0.001s)
testBatchNorm (__main__.TestLazyReuseIr) ... skip: Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run (0.001s)
----------------------------------------------------------------------
Ran 54 tests in 1.264s
OK (skipped=3)
```
Here is the sample rockset query
```
WITH added_row_number AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY name, classname, filename ORDER BY _event_time DESC) AS row_number
FROM
commons.rerun_disabled_tests
)
SELECT
name,
classname,
filename,
flaky,
num_green,
num_red
FROM
added_row_number
WHERE
row_number = 1
AND name = 'testAdd'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89454
Approved by: https://github.com/clee2000
Handling constant data for xnnpack delegation. This allows us to handle new modules like such:
```
class Module(torch.nn.Module):
def __init__(self):
super().__init__()
self._constant = torch.ones(4, 4, 4)
def forward(self, x):
return x + self._constant
```
this is the precursor work to handling convolution, as we need to serialize constant data(weights)
Differential Revision: [D41050349](https://our.internmc.facebook.com/intern/diff/D41050349/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89445
Approved by: https://github.com/digantdesai
This has been flaky on macOS for a while ([hud](https://hud.pytorch.org/failure/RuntimeError%3A%20test_ops_fwd_gradients%20failed)) and I can reproduce this locally. The issue was raised by https://github.com/pytorch/pytorch/issues/66033 and it seems to point to macos itself https://github.com/graphia-app/graphia/issues/33. So switching to single thread when running `test_ops_fwd_gradients` on macOS as a mitigation for the flaky tests.
### Testing
`pytest test_ops_fwd_gradients.py -k test_fn_fwgrad_bwgrad -vv --flake-finder` to run all `test_fn_fwgrad_bwgrad` tests 50 times to make sure they all pass (no flaky anymore)
https://hud.pytorch.org/tests shows that `test_ops_fwd_gradients` on macOS takes about 15m to finish or 8 minute if using 2 shards like in the test. There is no obvious difference in the test duration:
```
2022-11-21T21:34:18.6078080Z Running test_ops_fwd_gradients ... [2022-11-21 21:34:18.600663]
2022-11-21T21:34:21.6805770Z Executing ['/Users/runner/work/_temp/conda_environment_3517515737/bin/python', '-bb', 'test_ops_fwd_gradients.py', '-v', '--use-pytest', '-vv', '-rfEX', '-x', '--reruns=2', '--shard-id=0', '--num-shards=2', '-k=not _linalg_cholesky_', '--import-slow-tests', '--import-disabled-tests'] ... [2022-11-21 21:34:21.680156]
2022-11-21T21:34:21.6806380Z Ignoring disabled issues: []
2022-11-21T21:34:21.6815250Z Executing ['/Users/runner/work/_temp/conda_environment_3517515737/bin/python', '-bb', 'test_ops_fwd_gradients.py', '-v', '--use-pytest', '-vv', '-rfEX', '-x', '--reruns=2', '--shard-id=1', '--num-shards=2', '-k=not _linalg_cholesky_', '--import-slow-tests', '--import-disabled-tests'] ... [2022-11-21 21:34:21.681174]
2022-11-21T21:34:21.6815830Z Ignoring disabled issues: []
.....
2022-11-21T21:40:42.2422700Z =============================== warnings summary ===============================
.....
2022-11-21T21:40:42.2424670Z - generated xml file: /Users/runner/work/pytorch/pytorch/test/test-reports/python-pytest/test_ops_fwd_gradients/test_ops_fwd_gradients-47b619449ea7db1f.xml -
2022-11-21T21:40:42.2424850Z = 831 passed, 596 skipped, 5 deselected, 17 xfailed, 1 warning in 374.54s (0:06:14) =
.....
2022-11-21T21:42:00.1923310Z =============================== warnings summary ===============================
.....
2022-11-21T21:42:00.1925370Z - generated xml file: /Users/runner/work/pytorch/pytorch/test/test-reports/python-pytest/test_ops_fwd_gradients/test_ops_fwd_gradients-d24ee6419a602a6e.xml -
2022-11-21T21:42:00.1925540Z = 828 passed, 603 skipped, 7 deselected, 20 xfailed, 1 warning in 452.94s (0:07:32) =
....
2022-11-21T21:42:09.9035670Z FINISHED PRINTING LOG FILE of test_ops_fwd_gradients (/Users/runner/work/pytorch/pytorch/test/test-reports/test_ops_fwd_gradients_ha_3rfhb)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89410
Approved by: https://github.com/soulitzer
When we create fake tensors, we may call operators that introduce
guards, to accurately reconstruct views. But these guards are spurious:
if a user is able to present a tensor that "looks the same", they have
implicitly fulfilled the contract that the view is creatable.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89349
Approved by: https://github.com/voznesenskym
Fix bugs in [7k github models](https://github.com/pytorch/torchdynamo/issues/1884).
* Legacy code still use ```tensor.data```, I think we can use ```tensor.detach``` to rewrite, not sure if there is anything I didn't anticipate.
* Support ```tensor.layout```.
The root cause of these issues are: dynamo wraps unimplemented ```tensor.x``` call into ```GetAttrVariable(TensorVariable, x)```, but this op was not inserted into FX graph. Hence, during the fake tensor propagation, it throws ```KeyError: 'example_value` ```.
For these two popular attributes, Dynamo should support them anyway. However, if dynamo should support ___all___ ```tensor.x``` call and not fallback to ```GetAttrVariable```, I think it's debatable.
If I turn off fake tensor propagation, it works well even not including this fix. So I'm curious if we should improve the fake propagation to cover similar cases. cc @mlazos @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @jansel @eellison
```
Traceback (most recent call last):
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/convert_frame.py", line 404, in _compile
out_code = transform_code_object(code, transform)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/bytecode_transformation.py", line 341, in transform_code_object
transformations(instructions, code_options)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/convert_frame.py", line 392, in transform
tracer.run()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 1523, in run
super().run()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 389, in run
and self.step()
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 359, in step
getattr(self, inst.opname)(inst)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 193, in wrapper
return inner_fn(self, inst)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 865, in CALL_FUNCTION_KW
self.call_function(fn, args, kwargs)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/symbolic_convert.py", line 301, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/torch.py", line 407, in call_function
tensor_variable = wrap_fx_proxy(
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/builder.py", line 636, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/variables/builder.py", line 676, in wrap_fx_proxy_cls
example_value = get_fake_value(proxy.node, tx)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1024, in get_fake_value
args, kwargs = torch.fx.node.map_arg((node.args, node.kwargs), visit)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 613, in map_arg
return map_aggregate(a, lambda x: fn(x) if isinstance(x, Node) else x)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 621, in map_aggregate
t = tuple(map_aggregate(elem, fn) for elem in a)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 621, in <genexpr>
t = tuple(map_aggregate(elem, fn) for elem in a)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 627, in map_aggregate
return immutable_dict((k, map_aggregate(v, fn)) for k, v in a.items())
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 627, in <genexpr>
return immutable_dict((k, map_aggregate(v, fn)) for k, v in a.items())
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 631, in map_aggregate
return fn(a)
File "/scratch/ybliang/work/repos/pytorch/torch/fx/node.py", line 613, in <lambda>
return map_aggregate(a, lambda x: fn(x) if isinstance(x, Node) else x)
File "/scratch/ybliang/work/repos/pytorch/torch/_dynamo/utils.py", line 1022, in visit
return n.meta["example_value"]
KeyError: 'example_value\n\nfrom user code:\n File "./generated/test_BayesWatch_pytorch_prunes.py", line 108, in forward\n return torch.zeros([x.size()[0], self.channels, x.size()[2] // self.spatial, x.size()[3] // self.spatial], dtype=x.dtype, layout=x.layout, device=x.device)\n\nSet torch._dynamo.config.verbose=True for more information\n\n\nYou can suppress this exception and fall back to eager by setting:\n torch._dynamo.config.suppress_errors = True\n'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89257
Approved by: https://github.com/jansel
1. `aten.div.Tensor_mode` should allow broadcasting
2. `div` can use `ELEMENTWISE_TYPE_PROMOTION_KIND.INT_TO_FLOAT`
3. `prims.div` on integers should be truncating division
4. Add lowering for `true_divide` which is aliased to `div`
5. register lowering for inplace version of `div_mode`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88603
Approved by: https://github.com/ngimel
Summary:
This Diff ports the torchbench.py script from torchdynamo to torchbench to support the development of internal models.
Currently, only works with the `--only` option, and can only test one model at a time.
Note that the noisy logs are from upstream model code, not the benchmark code.
In the internal environment, `torch._dynamo.config.base_dir` is not writable, so we add an option to specify the output directory.
Test Plan:
```
$ buck2 run mode/opt //caffe2/benchmarks/dynamo:torchbench -- --performance --only ads_dhen_5x --part over --output-directory /tmp/tb-test/
cuda eval ads_dhen_5x
1/ 1 +0 frames 2s 1 graphs 1 graph calls 412/ 411 = 100% ops 100% time
```
```
$ buck2 run mode/opt //caffe2/benchmarks/dynamo:torchbench -- --performance --only cmf_10x --part over --output-directory /tmp/tb-test/
cuda eval cmf_10x
1/ 1 +0 frames 1s 1 graphs 1 graph calls 306/ 305 = 100% ops 100% time
```
Reviewed By: jansel
Differential Revision: D41294311
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89239
Approved by: https://github.com/jansel
`config.compile_threads` gets the number of compile threads via `min(32,os.cpu_count())` while `os.cpu_count()` is the total number of cpu cores in the system, not the available ones. This would cause compile thread contention when the available cpu cores are less than `min(32,os.cpu_count())`, e.g., available cpu cores are limited with numactl or taskset, making the compilation very slow. This PR tries to use `len(os.sched_getaffinity(0))` if `os.sched_getaffinity` is available which returns the available number of cpu cores.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89377
Approved by: https://github.com/soumith
**Summary**
The update includes API changes and optimzations to reduce framework overhead, which will benefit all mkldnn (onednn) ops in JIT mode and inductor CPU backend, etc. These benefits will be seen after switching to new ideep API by future PRs.
**Test plan**
For correctness, all UTs that call mkldnn ops, including test_ops.py, test_mkldnn*.py, test_quantization.py, etc.
For performance, TorchBench has been run and no regression is found. Results are shown below.
- Intel (R) Xeon (R) IceLake with 40 cores
- Use multi-instance
- Using tcmalloc & Intel OMP
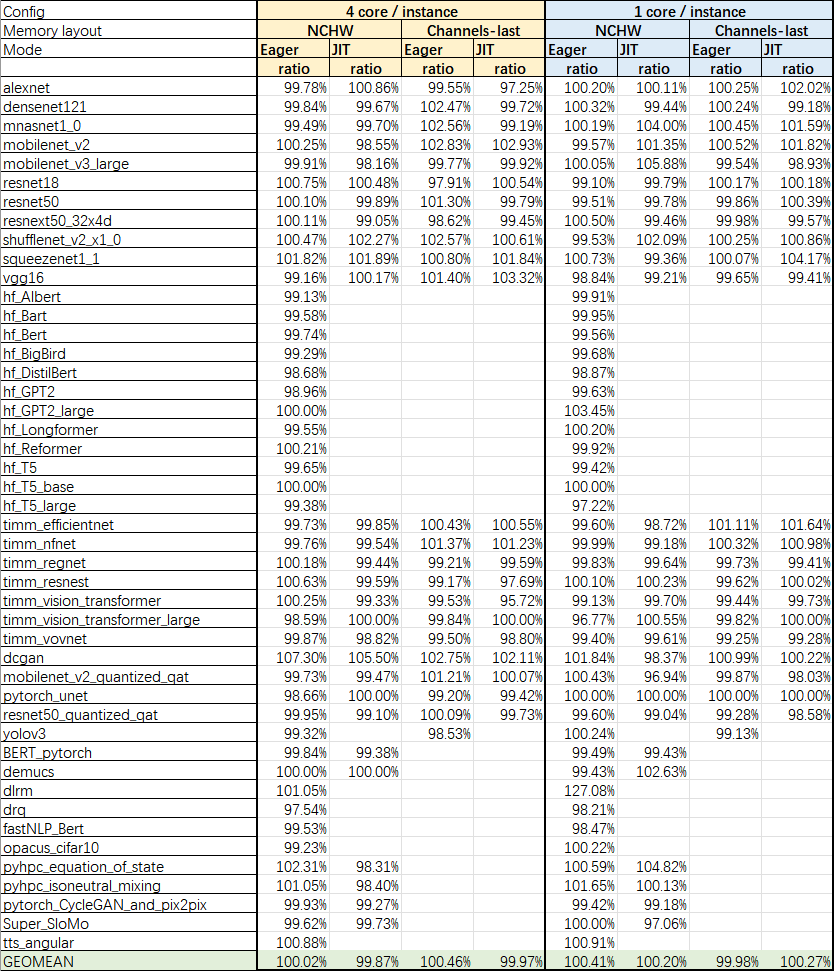
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87966
Approved by: https://github.com/jgong5, https://github.com/XiaobingSuper
This PR is targeting to automatically enable vectorization optimization for TorchInductor. It refined the semantics of `config.cpp.simdlen`.
Originally, `None` means to disable vectorization while a specific value means the number of elements to be vectorized once time. But it depends on the data. Regarding 256bit SVE/SIMD ISA for ARM and X86, the `simdlen` should be 16 for Float while 32 for BFloat. Hence, this PR defined the `simdlen` as the bit width. The detailed semantics are as follows.
- **_simdlen = None_**: Automatically determine the SIMD bit width. Detect HW information and pick the proper vectorization ISA. Specific for X86, the priority of AVX512 is higher than AVX2.
- **_simdlen <=1_**: Explicitly disable SIMD
- **_simdlen > 1_**: Explicitly specify the SIMD bit width. It equals the disabled semantic if the bit width does not match the ISA width.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89263
Approved by: https://github.com/jgong5, https://github.com/jansel
By itself, libdevice version of erf has the same perf as our decomposition, but in real workloads it leads to better fusion groups (due to fewer ops in the fused kernel).
Bonus: a few fp64 test skips removed, because our decomposition wasn't accurate enough for fp64, but libdevice version is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89388
Approved by: https://github.com/jansel
This ensures that subsequent link commands involving mkl libraries
know where to find the libraries if they are in a non-standard
location (which is the case if you installed mkl via conda, which
is what our standard instructions recommend.)
This is kind of a hack, because the MKL libraries are not actually
guaranteed to be in $MKL_ROOT/lib (they are for the conda install
though). The real fix is to properly use the MKL targets from
FindMKL.cmake but thats its own can of fish. See
https://github.com/pytorch/pytorch/issues/73008
This fixes https://github.com/pytorch/audio/issues/2784
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89359
Approved by: https://github.com/soumith
`setType` API is not respected in current exporter because the graph-level shape type inference simply overrides every NOT ONNX Op shape we had from node-level shape type inference. To address this issue, this PR (1) makes custom Op with `setType` **reliable** in ConstantValueMap to secure its shape/type information in pass: _C._jit_pass_onnx. (2) If an invalid Op with shape/type in pass: _C._jit_pass_onnx_graph_shape_type_inference(graph-level), we recognize it as reliable.
1. In #62856, The refactor in onnx.cpp made regression on custom Op, as that was the step we should update custom Op shape/type information into ConstantValueMap for remaining Ops.
2. Add another condition besides IsValidONNXNode for custom Op setType in shape_type_inference.cpp. If all the node output has shape (not all dynamic), we say it's custom set type.
3. ~However, this PR won't solve the [issue](https://github.com/pytorch/pytorch/issues/87738#issuecomment-1292831219) that in the node-level shape type inference, exporter invokes the warning in terms of the unknow custom Op, since we process its symbolic_fn after this warning, but it would have shape/type if setType is used correctly. And that will be left for another issue to solve. #84661~ Add `no_type_warning` in UpdateReliable() and it only warns if non ONNX node with no given type appears.
Fixes#81693Fixes#87738
NOTE: not confident of this not breaking anything. Please share your thoughts if there is a robust test on your mind.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88622
Approved by: https://github.com/BowenBao
Summary:
This is needed for choose qparams, but previously it is not configurable, and in the reference quantization flow
with decomposed Tensor, we are making this explicit
Test Plan:
tested in future PR
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89267
Approved by: https://github.com/vkuzo
Make mutation faster to speed up tracing optimizers, helps with https://github.com/pytorch/torchdynamo/issues/1803
`replace_all` no longer iterates over the entire variable tracker data structure every time a mutation is performed
Each variable tracker internally keeps a set of contained mutable variable trackers, to provide a hint to `replace_all`. This is populated with a call to `apply` from `__post_init__` in the base `VariableTracker`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89170
Approved by: https://github.com/jansel
Summary:
`RuntimeError: Invalid function argument. Expected parameter "tensor_list" to be of type List[torch.Tensor].`
to
`RuntimeError: Invalid function argument. Expected parameter "input_tensor_list" to be of type List[torch.Tensor].`
Test Plan: sandcastle
Differential Revision: D41405238
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89294
Approved by: https://github.com/awgu
Summary:
We want to introduce an experimental control flow op: map() to export some models as FX graphs correctly.
Some calrification on basic requirements we have in mind:
1. This op can nest cond() and other control flow primitives internally.
2. We don't necessarily need loop carried dependencies for the models we've seen.
3. This map() op can handle dynamically shaped tensor as input and return dynamically shaped output based on input shapes.
4. We should be able to pass through additional arguments to the loop body as extra arguments.
In this diff we introduce a new control flow op `map()` which has the following semantics:
```
def map(f: Callable, xs: Tensor, *args):
# one possible implementation:
return torch.stack([f(x, *args) for x in xs])
```
Test Plan:
pytest functorch/test_control_flow.py
CI
Differential Revision: D41165796
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88767
Approved by: https://github.com/zou3519
Summary: Some nodes lost the type annotation during `split_module`, causing the submodels to be un-scriptable. This is because compiler always infer Tensor type, which is wrong for non-Tensor types. We attempt to infer type annotation for `getitem` node to improve scriptability.
Test Plan:
```
buck2 test //caffe2/test:fx_experimental
```
Differential Revision: D41037819
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88510
Approved by: https://github.com/xush6528
Summary:
I saw the following issue only on Windows build in PR #88767:
```
RuntimeError: AttributeError: 'SymNode' object has no attribute 'torch::impl::PythonSymNodeImpl::ge'
```
It's only on Windows because we get the attributes of SymNode in C++ with
`__FUNCTION__` macro, which is not in C++ standard, therefore has platform specific behavior.
In this case, MSVC will include a function's namespace and class name, which is not intended here.
Instead we should use `__func__`. see: https://en.cppreference.com/w/cpp/language/function#Function_definition
godbolt example to show the difference: https://godbolt.org/z/PGfvecxPx
Test Plan:
CI
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89264
Approved by: https://github.com/ezyang
Summary: The `-weak_framework` flag is no longer necessary, Buck will weakly link frameworks depending on the `target_sdk_version` of the binary being linked.
Test Plan:
Compare IG load commands before and after change with P553208168
```
load command difference in Instagram.app/Frameworks/InstagramXplatFramework.framework/InstagramXplatFramework
--- /tmp/tmpvd97s2v0 2022-11-16 12:13:54.082910598 -0800
+++ /tmp/tmpj20r_4ca 2022-11-16 12:13:54.082910598 -0800
@@ -9,7 +9,7 @@
/System/Library/Frameworks/CoreHaptics.framework/CoreHaptics (compatibility version 1.0.0, current version 1.0.0, weak)
/System/Library/Frameworks/CoreImage.framework/CoreImage (compatibility version 1.0.0, current version 5.0.0)
/System/Library/Frameworks/CoreLocation.framework/CoreLocation (compatibility version 1.0.0, current version 2780.0.17)
- /System/Library/Frameworks/CoreML.framework/CoreML (compatibility version 1.0.0, current version 1.0.0, weak)
+ /System/Library/Frameworks/CoreML.framework/CoreML (compatibility version 1.0.0, current version 1.0.0)
/System/Library/Frameworks/CoreMedia.framework/CoreMedia (compatibility version 1.0.0, current version 1.0.0)
/System/Library/Frameworks/CoreServices.framework/CoreServices (compatibility version 1.0.0, current version 1226.0.0)
/System/Library/Frameworks/CoreTelephony.framework/CoreTelephony (compatibility version 1.0.0, current version 0.0.0)
@@ -33,9 +33,9 @@
/System/Library/Frameworks/Security.framework/Security (compatibility version 1.0.0, current version 60420.40.34)
/System/Library/Frameworks/SystemConfiguration.framework/SystemConfiguration (compatibility version 1.0.0, current version 1241.40.2)
/System/Library/Frameworks/UIKit.framework/UIKit (compatibility version 1.0.0, current version 6109.1.108)
- /System/Library/Frameworks/UserNotifications.framework/UserNotifications (compatibility version 1.0.0, current version 1.0.0, weak)
+ /System/Library/Frameworks/UserNotifications.framework/UserNotifications (compatibility version 1.0.0, current version 1.0.0)
/System/Library/Frameworks/VideoToolbox.framework/VideoToolbox (compatibility version 1.0.0, current version 1.0.0)
- /System/Library/Frameworks/WebKit.framework/WebKit (compatibility version 1.0.0, current version 614.2.9, weak)
+ /System/Library/Frameworks/WebKit.framework/WebKit (compatibility version 1.0.0, current version 614.2.9)
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1319.0.0)
/usr/lib/libbz2.1.0.dylib (compatibility version 1.0.0, current version 1.0.8)
/usr/lib/libc++.1.dylib (compatibility version 1.0.0, current version 1300.32.0)
```
Both these changes are correct, WebKit is available from 8.0, UserNotifications from 10.0 and CoreML from 11.0. Instagram has a deployment target of 12.4.
Reviewed By: ebgraham
Differential Revision: D41348639
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89233
Approved by: https://github.com/malfet
Summary: In both eager and FX graph mode quantization,
`torch.ao.nn.quantizable.LSTM` is used as an observed custom module,
which is responsible for inserting its own observers. By default,
the user specifies a single QConfig for the custom module (either
through QConfigMapping or by setting the "qconfig" attribute"),
and all inner ops will [inherit this
QConfig](dc00bb51b8/torch/ao/nn/quantizable/modules/rnn.py (L366-L378))
and use the same observer/fake_quantize constructors.
Today, users who wish to override this behavior must extend
`torch.ao.nn.quantizable.LSTM` and write a lot of custom code
to manually assign the QConfigs to the inner ops. This commit
alleviates this burden on the user by providing a helper function
to assign QConfigs with custom observers. An example use case of
this is providing a reference implementation for a backend kernel
that hardcodes qparams for efficiency.
Example usage:
```
import torch
from torch.ao.quantization import get_default_qconfig_mapping
from torch.ao.quantization.fx.custom_config import (
PrepareCustomConfig,
ConvertCustomConfig,
)
class MyModel(torch.nn.Module):
...
class UserLSTM(torch.ao.nn.quantizable.LSTM):
@classmethod
def from_float(cls, other):
assert isinstance(other, cls._FLOAT_MODULE)
linear_output_obs_ctr = FixedQParamsObserver.with_args(
scale=2 ** -11, zero_point=2 ** 15, dtype=torch.qint32)
sigmoid_obs_ctr = FixedQParamsObserver.with_args(
scale=2 ** -16, zero_point=0, dtype=torch.qint32)
tanh_obs_ctr = FixedQParamsObserver.with_args(
scale=2 ** -15, zero_point=2 ** 15, dtype=torch.qint32)
cell_state_obs_ctr = FixedQParamsObserver.with_args(
scale=2 ** -11, zero_point=0, dtype=torch.qint32)
hidden_state_obs_ctr = FixedQParamsObserver.with_args(
scale=2 ** -7, zero_point=2 ** 7, dtype=torch.quint8)
return torch.ao.quantization.utils._get_lstm_with_individually_observed_parts(
float_lstm=other,
linear_output_obs_ctr=linear_output_obs_ctr,
sigmoid_obs_ctr=sigmoid_obs_ctr,
tanh_obs_ctr=tanh_obs_ctr,
cell_state_obs_ctr=cell_state_obs_ctr,
hidden_state_obs_ctr=hidden_state_obs_ctr,
)
qconfig_mapping = get_default_qconfig_mapping()
example_inputs = (torch.rand(5, 3, 50), torch.rand(1, 3, 50), torch.randn(1, 3, 50))
prepare_custom_config = PrepareCustomConfig() \
.set_float_to_observed_mapping(torch.nn.LSTM, UserLSTM)
convert_custom_config = ConvertCustomConfig() \
.set_observed_to_quantized_mapping(UserLSTM, torch.ao.nn.quantized.LSTM)
model = MyModel()
model = prepare_fx(model, qconfig_mapping, example_inputs, prepare_custom_config=prepare_custom_config)
model(*example_inputs) # calibrate
model = convert_fx(model, convert_custom_config=convert_custom_config)
model(*example_inputs)
```
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_static_lstm_with_custom_fixed_qparams
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88456
Approved by: https://github.com/jerryzh168, https://github.com/vkuzo
We add most in-place references in a generic way. We also implement a
wrapper to implement the annoying interface that `nn.functional`
nonlinearities have.
We fix along the way a couple decompositions for some non-linearities by
extending the arguments that the references have.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88117
Approved by: https://github.com/mruberry
The previous behaviour would call `resize_` on 0-sized elements even
when their size was correct. This would make some test fail, as resize_
may be an in-place operation and it's not supported by some subsystems
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88116
Approved by: https://github.com/mruberry
The `__name__` field of some binary reference functions was wrong. We
fix this to be consistent with unary reference functions. In the future,
we should probably make the binary reference wrapper return a wrapper
itself to avoid all those calls to `partial`.
This change helps performing some homogeneous treatment of functions by
their name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88115
Approved by: https://github.com/mruberry
Summary: tests are failing due to code packaged with trained models calling now defunct function names (is_activation_post_process).
this diff maintains BC temporarily until the cached code can be refreshed
Test Plan: no functional change
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89260
Approved by: https://github.com/jerryzh168
Summary: The op exposed should be qparams, and then we have concerns about prims not being supported so make q and dq ops that take in tensors
Test Plan: unit test
Differential Revision: D41382580
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89236
Approved by: https://github.com/jerryzh168
This readme was deleted here: https://github.com/pytorch/pytorch/pull/73224 I chatted with the author, who doesn't remember exactly why it was deleted but suspects it was due either to out of date contents or because of the upcoming migration to github actions.
With that said, we have references to this readme through our circleci directory, and since we do still have a lot of circleci workflows I feel this readme still adds a lot of value. (I recently did some CI tasks that required me to dig this readme up in order to solve a problem).
I recommend we restore this file with a warning that its contents may be out of date, until our CircleCI workflows are entirely migrated to Github Actions
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85598
Approved by: https://github.com/clee2000, https://github.com/malfet
## Summary ⚡
**Aim**: Add support for aten::median for MPS backend (Fixes#87220)
This is fresh clean PR from the previous [PR](https://github.com/pytorch/pytorch/pull/88554)
- Implementing the new median function in aten/src/ATen/native/mps/operations/ReduceOps.mm
- Adding it to aten/src/ATen/native/native_functions.yaml
- Adding it to existing test_median
### **this will works like this** 🪶
median of entire input tensor on MPS
`torch.median(mps_inputTensor)`
median of along a dim
`torch.median(mps_inputTensor, dim=[int], keepdim=[Bool])`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88807
Approved by: https://github.com/kulinseth
- This would remove the hard-coded check within `_ChildDataPipe`.
- Add `get_length_by_instance` to parent class to make sure there is a chance that child DataPipe can have different lengths
- Prevent Error when `__del__` executed when the object has already been removed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89216
Approved by: https://github.com/NivekT
Introduce `_eval_no_call` method, that evaluates statement only if it
does not contain any calls(done by examining the bytecode), thus preventing command injection exploit
Added simple unit test to check for that
`torch.jit.annotations.get_signature` would not result in calling random
code.
Although, this code path exists for Python-2 compatibility, and perhaps
should be simply removed.
Fixes https://github.com/pytorch/pytorch/issues/88868
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89189
Approved by: https://github.com/suo
This reverts commit 2b131b1d43b10a2a005f3f042f920a62501e4e2d.
Reverted https://github.com/pytorch/pytorch/pull/88736 on behalf of https://github.com/kit1980 due to Inductor tests are failing with AttributeError: module 'torch._inductor.codecache' has no attribute 'valid_vec_isa_list'
This reverts commit e686b8c3ba93cb7caa314c78bf84dbd2d7df9683.
Reverted https://github.com/pytorch/pytorch/pull/89143 on behalf of https://github.com/ZainRizvi due to This seems to be causing the test_make_fx_symbolic_exhaustive_rad2deg_cpu_float32 and test_make_fx_symbolic_exhaustive_inplace_rad2deg_cpu_float32 test to fail across multiple jobs
Fixes#88939
The root cause of the issue is that BF16 cannot accurately represent big integer values. In the test case below, `539` as one of the corner pixel index is wrongly represented as `540` (from fc60a1865e/aten/src/ATen/native/UpSample.h (L271)) and then the access out of the range with this index. Thanks to @malfet for the investigation and initial fix. I also reported an issue https://github.com/pytorch/pytorch/issues/89212 to track the issue of inaccurate integer representation of bf16 that need to be addressed in other places of PyTorch.
```python
import torch
def test():
arg_1 = torch.rand([1, 10, 540, 540], dtype=torch.bfloat16).clone()
res = torch.nn.functional.interpolate(arg_1,2,mode='bilinear',align_corners=True)
test()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89210
Approved by: https://github.com/malfet
Fixes https://github.com/pytorch/torchdynamo/issues/1839
Should I do this for all backends or just inductor?
## Test
On a V100 I got from AWS
```python
from torch._dynamo import optimize
import torch
def fn(x, y):
a = torch.cos(x)
b = torch.sin(y)
return a + b
new_fn = optimize("inductor")(fn)
a = new_fn(torch.Tensor(1),torch.Tensor(1))
print(a)
```
## New logs
```
(sourcetorch) ubuntu@ip-172-31-31-152:~/test$ python test.py
/home/ubuntu/pytorch/torch/_dynamo/eval_frame.py:318: UserWarning: Tensor cores are available but not enabled. Consider setting torch.backends.cuda.matmul.allow_tf32 == True in your python script for speedups
warnings.warn(
tensor([1.3717])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88844
Approved by: https://github.com/ngimel, https://github.com/mlazos, https://github.com/anijain2305
Fixes empty input convolution issue : when input is empty e.g. shape of (0, 3, 3, 4) and weight is channels last format, at::_unsafe_view will raise "view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86521
Approved by: https://github.com/jgong5, https://github.com/malfet
Here we pass XNNExecutor* to compile model so that XNNExecutor can be allocated by runtime. This signature change is for executorch:
```
XNNExecutor compileModel(void* buffer) --> void compileModel(void* buffer, XNNExecutor* executor)
```
The intended usecase for allocating Executor and Compiling the serialized flatbuffer:
```
XNNExecutor* executor = runtime_allocator->allocateList<jit::xnnpack::delegate::XNNExecutor>(1);
XNNCompiler::compileModel(processed.buffer, executor);
```
Differential Revision: [D41208387](https://our.internmc.facebook.com/intern/diff/D41208387/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89090
Approved by: https://github.com/digantdesai
Analyze and upload disabled tests rerun to S3. Note that this only picks up `test-reports` from `rerun_disable_tests` workflows.
### Testing
Running the script manually `python -m tools.stats.check_disabled_tests --workflow-run-id 3473068035 --workflow-run-attempt 1 --repo pytorch/pytorch` and see the files successfully uploaded to s3://ossci-raw-job-status/rerun_disabled_tests/3473068035/1
Rockset collection created https://console.rockset.com/collections/details/commons.rerun_disabled_tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89083
Approved by: https://github.com/clee2000
This PR is targeting to automatically enable vectorization optimization for TorchInductor. It refined the semantics of `config.cpp.simdlen`.
Originally, `None` means to disable vectorization while a specific value means the number of elements to be vectorized once time. But it depends on the data. Regarding 256bit SVE/SIMD ISA for ARM and X86, the `simdlen` should be 16 for Float while 32 for BFloat. Hence, this PR defined the `simdlen` as the bit width. The detailed semantics are as follows.
- **_simdlen = None_**: Automatically determine the SIMD bit width. Detect HW information and pick the proper vectorization ISA. Specific for X86, the priority of AVX512 is higher than AVX2.
- **_simdlen <=1_**: Explicitly disable SIMD
- **_simdlen > 1_**: Explicitly specify the SIMD bit width. It equals the disabled semantic if the bit width does not match the ISA width.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88482
Approved by: https://github.com/jgong5, https://github.com/jansel
This PR adds the first version of the `replicate()` composable API. For this prototype version, I try to reuse as much code from existing `DistributedDataParallel` as possible, and iterate on it in later changes. The basic idea of this prototype is:
- create a `ReplicateState` object. It internally uses a `ParameterList` module to hold all parameters of modules marked by `replicate()` API.
- create an internal `_ddp` object, which reuses existing `DistributedDataParallel` implementation, and wraps the `ParameterList` object
- install pre-forward and after-forward hooks on the root module, which calls methods of `_ddp` to run initialization and forward
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87649
Approved by: https://github.com/zhaojuanmao
Summary:
I found a confusing bug in the PassManager that only happens
when you instantiate one multiple times: it will use old passes and
constraints!
This occurs because the class-level declarations initialize it to an empty list,
but the problem is that class initializers only run once, and are creating class
variables. This means the same empty list was being reused every time, except
after the first time it isn't empty.
The empty list has to be created in `__init__` newly each time or else it'll be shared.
Note that this is the same type of bug as using an empty list as a default parameter, where
it'll reuse the same list pointer and not make it empty each time.
The better way to do this is with either:
* An immutable default parameter like an empty tuple, that you create a new list from: `self.passes = list(passes)`
* Use None and then create the empty list inside `__init__`
I chose the latter as it's less likely to cause a behavior change due to the changed default.
Note that for immutable values like `False` and `1` this doesn't apply as you can't mutate that
value for everyone.
Test Plan:
Added a test to ensure that the pass state is not saved.
Without my change, this test would fail as it would run all of the `2 * x` passes first,
then all of the `3 * x` passes.
Differential Revision: D41327056
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89108
Approved by: https://github.com/angelayi
The core problem that we often have with contiguous/channels-last layouts and convolutions is that Inductor often doesn't do a great job of "preserving" the eager-mode layouts.
So, for example, we'll often have something like
```
a: channels-last
b = foo(a)
c = convolution(a)
```
In eager-mode, `a` would stay channels-last, and we would avoid two transpose copies (one into NHWC and one back into NCHW) within the convolution kernel.
However, Inductor currently sometimes loses the "correct" layout of `b` (not in this simple example, but others). Then, not only will we do a transpose within `foo`, but we'll then immediately transpose it back to do the convolution (and then again once the convolution is done).
This is particularly egregious in `convnext_base`, where there's a lot of mixing of non-channels last tensors and channels-last tensors.
The solution in this PR is to constrain the inputs to `aten.convolution`/`aten.convolution_backward` to match the layouts from eager-mode. This ensures that we'll never do extra transposes *within* `aten.convolution`, which are particularly bad (since Inductor can't fuse them).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89031
Approved by: https://github.com/ngimel, https://github.com/jansel
This is pretty much self explanatory issues
Two typo's in generate generate binary script caused workflows to be generated with invalid parameters:
1 .generated-linux-binary-libtorch-pre-cxx11-master.yml
2 .generated-macos-arm64-binary-wheel-nightly.yml
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89153
Approved by: https://github.com/malfet
Mainly wanted to confirm torchrun works fine with dynamo/ddp,
but it is also a better system than manually launching processes.
Partially addresses issue #1779
New run commands
------------
single process:
python benchmarks/dynamo/distributed.py [args]
multi-gpu (e.g. 2 gpu on one host):
torchrun --nproc_per_node 2 benchmarks/dynamo/distributed.py [args]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89149
Approved by: https://github.com/aazzolini
A number of dashboard improvements:
- Add accuracy failures to warnings section
- Add regression detection to all metrics (speedup, compile time, peak memory), not just accuracy
- Add testing flag to update-dashboard to prevent image/comment uploads
- Add section for comparing summary statistics (passrate, speedup) between 2 most recent reports
- Show names of reports for summary stats diff and regression detection sections
- Remove metric graphs from the comment (they can still be found in the generated text file)
Sample comment: https://github.com/pytorch/torchdynamo/issues/1831#issuecomment-1317565972
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89155
Approved by: https://github.com/anijain2305
Summary: same function in observer and quantize, consolidated to a
single function. Note the definitions were slightly different, I've
changed the definition to be maximally inclusive so that the name of the
function is more accurate
Test Plan: python test/test_public_bindings.py
python test/test_quantization.py
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D40709276](https://our.internmc.facebook.com/intern/diff/D40709276)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87520
Approved by: https://github.com/jcaip
Summary: When the BackendConfig was first introduced,
`overwrite_output_observer` and `overwrite_output_fake_quantize`
were added to ensure fixed qparams ops like `torch.nn.Sigmoid`
and `torch.nn.Tanh` used the correct observers and fake quantizes.
However, this is hacky because the BackendConfig should not set
the observer constructors themselves, but should instead specify
only requirements on the observers.
Later, https://github.com/pytorch/pytorch/pull/80184 added the
correct observers to `get_default_qconfig_mapping` along with
validation logic that throws an error if incorrect observers
were specified. With this change, we no longer need to overwrite
the observers from the BackendConfig, since we expect the user to
pass in the correct observers for these ops.
This commit removes these overwrite observer settings in the
BackendConfig. Instead, we represent the observer constraints for
fixed qparams ops through the existing DTypeWithConstraints
mechanism. Note that, however, to be consistent with other
DTypeWithConstraints checks, we no longer throw an error if an
incorrect observer is specified, but simply ignore the offending
QConfig and log a warning instead. This is the BC-breaking part
of the change.
BC-breaking notes:
```
from torch.ao.quantization.qconfig import default_qconfig
from torch.ao.quantization.quantize_fx import prepare_fx
model = ModelWithFixedQParamsOps()
qconfig_mapping = QConfigMapping().set_global(default_qconfig)
example_inputs = ...
prepare_fx(model, qconfig_mapping, example_inputs)
```
Before this commit, running the above leads to an exception
because the wrong observers are used for fixed qparams ops.
After this commit, the above will only encounter a warning,
and the fixed qparams ops will not be quantized. In both cases,
switching to `get_default_qconfig_mapping` will cause the
fixed qparams ops to be quantized.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88620
Approved by: https://github.com/jerryzh168
The logic used by `mem_leak_check` https://github.com/pytorch/pytorch/pull/88373 is currently not applied to rocm, i.e. 06486cd008 because its workflows don't have the test-config filtering logic yet (linux, mac, and windows all have it already). In another work, rocm tests always run with mem leak check disabled at the moment. We want that but also to run the test with mem leak check enabled periodically one per day. This PR closes that gap
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89046
Approved by: https://github.com/clee2000
This is an interesting one
Since this is an operation that's intrinsically defined on the reals,
we should perform the ops on that dtype always, and just cast to
the desired dtype at the end. This simplifies the decomposition.
Now, I started looking at this one when I started seeing failures on a
test that's added in a later PR. What's going on here is that, by doing
an upcast to a higher dtype and then cast down to integers, sometimes
there's an off-by-one error. I think this is fine, as the decomposition
is more accurate than the original function, which goes in line with
the whole PrimTorch effort.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87203
Approved by: https://github.com/mruberry
Summary: The CPU block in `collective_post` was missing pre & post processing. The reduce-scatter implementaion expects use of pre-processing callback to flatten the input tensors, however, the missing invocation meant grabage values were being passed.
Test Plan: Tested the reduce-scatter collective using PARAM
Reviewed By: eastzone
Differential Revision: D41291592
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89030
Approved by: https://github.com/kingchc, https://github.com/kwen2501
Extend `register_custom_op` to support onnx-script local function. The FunctionProto from onnx-script is represented by custom op and inserted into ModelProto for op execution.
NOTE: I did experiments on >2GB case of a simple model with large initializers:
```python
import torch
class Net(torch.nn.Module):
def __init__(self, B, C):
super().__init__()
self.layer_norm = torch.nn.LayerNorm((B, C), eps=1e-3)
def forward(self, x):
return self.layer_norm(x)
N, B, C = 3, 25000, 25000
model = Net(B, C)
x = torch.randn(N, B, C)
torch.onnx.export(model, x, "large_model.onnx", opset_version=12)
```
And it turns out we won't get model_bytes > 2GB after `_export_onnx` pybind cpp function, as we split initializer in external files in that function, and have serialization before return the model bytes, which protobuf is not allowed to be larger than 2GB at any circumstances.
The test cases can be found in the next PR #86907 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86906
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Fake tensor behaves pretty differently depending on if you have
symbolic shapes or not. This leads to bugs; for example, we
weren't getting correct convolution_backward strides because we
bypassed the correct stride logic in fake tensor on symbolic
shapes.
This PR attempts to unify the two codepaths. I don't manage to
unify everything, but I get most of it. The algorithm is delicate
and I'm still hosing down test failures.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89038
Approved by: https://github.com/anjali411
We will need this to implement a convolution meta function that
is SymInt aware. I use templates so that regular convolution code
is not affected by the change. No tests for symbolic ints directly; that will
come in a subsequent PR which also needs to refactor fake tensors.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89069
Approved by: https://github.com/SherlockNoMad
# Summary
Creates a callable native function that can determine which implementation of scaled dot product will get called. This allows to bump re-order the runtime dispatch of SDP to enable autograd.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89029
Approved by: https://github.com/cpuhrsch
Now that periodic jobs are run under `mem_leak_check` mode with parallelization turning off. It's very easy for `linux-bionic-cuda11.6-py3-gcc7-slow-gradcheck / test` to timeout because one of the shards is very close to the 4h mark.
* 2452e3f99a
* 35e668b5ce
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89079
Approved by: https://github.com/clee2000
This PR teaches PyDispatcher and PyOperator about functorch transforms.
It is important that PyDispatcher/PyOperator dispatch with functorch
transforms, because this is our plan for higher-order operators
(operators that accept functions as arguments). Examples of these
include:
- functorch transforms over the existing cond operator (control flow)
- autograd.Function support for functorch (which I am working towards),
- AOTDispatcher (should be a higher order operator)
Concretely, the problem with teaching PyDispatcher/PyOperator about
functorch is that the stack-based dispatching logic (DynamicLayerStack)
is hidden inside the fallbacks for two dispatch keys
(DynamicLayer{Front, Back}). PyDispatcher doesn't know about C++ boxed
fallbacks, our plan on record for that is that we need to reimplement
all of them in Python (but can call helper functions in C++ to make our
lives easier).
Instead of exposing all of what DynamicLayer{Front, Back} do to python,
this PR takes the approach of re-implementing part of the stack-based
dispatching in Python. The motivation is that this is more sane and
follows what the "ideal" implementation of functorch would have been:
- each transform should be a "mode"
- there should be no TLS dispatch key set hackery. functorch needs to do
this hackery today to re-use VariableType implementations.
This PR:
- exposes the DynamicLayerStack to Python
- The DynamicLayerStack is a stack of Interpreters.
These get exposed to Python as well.
- Interpreters can run operations (Interpreter.process) or lower them to
the next interpreter in the stack (Interpreter.lower)
- To use a PyOperator with functorch transforms, a developer needs to
register a rule for each transform (vmap, grad, jvp, ...).
- The PyOperator API is NOT user-facing. Things like autograd.Function
support for functorch will end up going through the autograd.Function
API.
Question for reviewers:
- Does this design make sense?
- I'm trying to split up the "functorch support for autograd.Function"
work into logical pieces. Would it be better if I didn't? (the full
thing is a bit long - 1000-2000 LOC).
Test Plan:
- new tests that construct PyOperator and compose them with functorch
transforms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88785
Approved by: https://github.com/samdow, https://github.com/soulitzer
Sometimes it's really convenient to run simple models thru the torchbench.py script rather than those from pytorch/benchmark. This PR add the ability to run any model from a specified path by overloading the --only argument.
This PR is split out from #88904
Here is the usage:
Specify the path and class name of the model in format like:
--only=path:<MODEL_FILE_PATH>,class:<CLASS_NAME>
Due to the fact that dynamo changes current working directory,
the path should be an absolute path.
The class should have a method get_example_inputs to return the inputs
for the model. An example looks like
```
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(10, 10)
def forward(self, x):
return self.linear(x)
def get_example_inputs(self):
return (torch.randn(2, 10),)
```
Test command:
```
# python benchmarks/dynamo/torchbench.py --performance --only=path:/pytorch/myscripts/model_collection.py,class:LinearModel --backend=eager
WARNING:common:torch.cuda.is_available() == False, using CPU
cpu eval LinearModel 0.824x p=0.00
```
Content of model_collection.py
```
from torch import nn
import torch
class LinearModel(nn.Module):
"""
AotAutogradStrategy.compile_fn ignore graph with at most 1 call nodes.
Make sure this model calls 2 linear layers to avoid being skipped.
"""
def __init__(self, nlayer=2):
super().__init__()
layers = []
for _ in range(nlayer):
layers.append(nn.Linear(10, 10))
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
def get_example_inputs(self):
return (torch.randn(2, 10),)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89028
Approved by: https://github.com/jansel
A compile time guard was preventing ActivityType::CUDA from being available on rocm. This caused both the GPU_FALLBACK and CUDA modes to be active at the same time. So operators were being charged gpu time for the hipEventRecord ranges and the actual kernel execution times. This caused incorrect (and often negative) cuda times, in e.g. table().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88207
Approved by: https://github.com/malfet, https://github.com/jeffdaily
Print unexpected success as XPASS. I will submit a PR to test-infra so that the log classifier can find these
Ex: https://github.com/pytorch/pytorch/actions/runs/3466368885/jobs/5790424173
```
test_import_hipify (__main__.TestHipify) ... ok (0.000s)
test_check_onnx_broadcast (__main__.TestONNXUtils) ... ok (0.000s)
test_prepare_onnx_paddings (__main__.TestONNXUtils) ... ok (0.000s)
test_load_standalone (__main__.TestStandaloneCPPJIT) ... ok (16.512s)
======================================================================
XPASS [4.072s]: test_smoke (__main__.TestCollectEnv)
----------------------------------------------------------------------
----------------------------------------------------------------------
Ran 31 tests in 24.594s
FAILED (skipped=7, unexpected successes=1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89020
Approved by: https://github.com/huydhn, https://github.com/seemethere
This fixes https://github.com/pytorch/torchdynamo/issues/1515
To fix it, we need to keep track of whether a Triton variable is a scalar (so we can not use a mask when doing indirect loads through them). This requires a way of annotating variable names generated by CSE with properties.
So now CSE will use CSEVariable class to keep track of variables and let backends subclass it so they can annotate them with whatever information they want. TritonCSEVariable is such a subclass that track the `is_scalar` property.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88347
Approved by: https://github.com/jgong5, https://github.com/ngimel
# Registers the derivative for mem efficient backward
- Use gradcheck to test correctness. The kernel is not implemented for fp64 so run checks with bumped tolerances in fp32
- I also made updates based off of Xformer main branch and flash-attention cutlass branch.
- This will enable the fused backward to be called for scaled dot product attention
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88856
Approved by: https://github.com/cpuhrsch
The appropriate annotation for a block of memory is a function of time: an input can be mutated in-place to become an activation, a clever kernel might steal the memory of a detached input (such as a mask) to use as output memory, etc.
We could pessimistically assume that all ops mutate all of their inputs, however inspection of schema allows us to significantly narrow that assumption with minimal effort. Checking schemas also allows us to distinguish between dispatcher ops (which have load bearing semantics) and user annotations with reasonably high precision.
Differential Revision: [D40220390](https://our.internmc.facebook.com/intern/diff/D40220390/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86854
Approved by: https://github.com/chaekit
Summary:
caffe2/test:torch_cuda - test_advanced_indexing_assignment_lazy (test_view_ops.TestViewOpsLAZY)
RuntimeError: TorchScript backend not yet supported in FBCODE/OVRSOURCE builds
File "/usr/local/fbcode/platform010/lib/python3.8/unittest/suite.py", line 163, in _handleClassSetUp
setUpClass()
File "/re_cwd/fbcode/buck-out/opt/gen/caffe2/test/torch_cuda#binary,link-tree/torch/testing/_internal/common_device_type.py", line 506, in setUpClass
torch._lazy.ts_backend.init()
File "/re_cwd/fbcode/buck-out/opt/gen/caffe2/test/torch_cuda#binary,link-tree/torch/_lazy/ts_backend.py", line 6, in init
torch._C._lazy_ts_backend._init()
Test Plan: Rely on CI.
Differential Revision: D41170545
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88786
Approved by: https://github.com/zou3519
The python tracer caches information about module and optimizer state. That means that for subsequent calls, the presence of a Tensor in these fields does not imply that the Tensor is still live; just that it was live during the first call. (I should perhaps rename the fields to something like `stale_parameters` to convey this.) Unless we discard subsequent calls ID assignment get tripped up when it see's a Tensor that was already released.
Differential Revision: [D41226827](https://our.internmc.facebook.com/intern/diff/D41226827/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88917
Approved by: https://github.com/chaekit
[This run](https://github.com/pytorch/pytorch/actions/runs/3432340660/jobs/5721731207) failed claiming that it couldn't detect GPUs on the runner. Inspecting the rocminfo output (higher up in logs) show that it in fact had three GPUs, but the workflow is currently setup to expect either 2 or 4 gpus.
The workflow files currently have no way of specifying wither it'll get a 2 gpu or a 4 gpu machine, so really 2 is all any test can expect to get. [This old PR](https://github.com/pytorch/pytorch/pull/72142/files) shows that historically ROCm runners only had 4 gpus, then later the logic was extended to expect 2 GPU runners as well.
It's not clear how the ROCm runner ended up with 3 gpus instead of 2 or 4 (something for ROCm folks to look into) but there doesn't seem to be a good reason for ROCm workflows to fail if 3 (or 5) gpus ever show up on a machine. This PR makes the workflows resilient to ROCm having these alternate GPU counts
Also filed https://github.com/pytorch/pytorch/issues/89012 against the ROCm team to explore why the runner only had 3 gpus
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89011
Approved by: https://github.com/huydhn
As title, add three things to the schema
1. debug handle for each node
2. file identifier, so we can sanity check we are getting the xnnpack schema flatbuffers file, instead of other random binary
3. extension, so the dumped binary will end up with its own extension like `myschema.xnnpack` (maybe can have a better name) instead of the default extension `.bin`
Differential Revision: [D40906970](https://our.internmc.facebook.com/intern/diff/D40906970/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89033
Approved by: https://github.com/mcr229
Bug:
Previously, `initOutputLayouts()` was called after creating a graph and before merging other nodes. It is a vector with one element. So when a graph contains multiple outputs, e.g. using AOTAutograd compile in my case, layout_propagation pass try to access out of range elements in the vector. Then it comes to the second bug in `useOpaqueLayout()`, the out of range checks the index with the updated output size instead of the size of the vector. Then used `[]` to access the element, which is out of range.
Fixes the above two issues:
1. check the offset is within range with the size of `attr::output_layouts` vector instead of another variable. This check catches the error now.
2. change the place to initial `attr::output_layouts` after node merging. The graph may change with node merging. Thus we moved the initialization in layout_propagation with the complete graph.
Added test time:
`Ran 1 test in 0.383s`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88496
Approved by: https://github.com/jgong5, https://github.com/sanchitintel
Rerun all disabled test to gather their latest result so that we can close disabled tickets automatically. When running under this mode (RERUN_DISABLED_TESTS=true), only disabled tests are run while the rest are skipped `<skipped message="Test is enabled but --rerun-disabled-tests verification mode is set, so only disabled tests are run" type="skip"/>`
The logic is roughly as follows, the test runs multiple times (n=50)
* If the disabled test passes, and it's flaky, do nothing because it's still flaky. In the test report, we'll see the test passes with the following skipped message:
```
<testcase classname="TestMultiprocessing" file="test_multiprocessing.py" line="357" name="test_fs" time="0.000" timestamp="0001-01-01T00:00:00">
<skipped message="{"flaky": True, "num_red": 4, "num_green": 0, "max_num_retries": 3, "rerun_disabled_test": true}" type="skip"/>
</testcase>
```
* If the disabled test passes every single time, and it is not flaky anymore, mark it so that it can be closed later. We will see the test runs and passes, i.e.
```
<testcase classname="TestCommonCUDA" name="test_out_warning_linalg_lu_factor_cuda" time="0.170" file="test_ops.py" />
```
* If the disabled test fails after all retries, this is also expected. So only report this but don't fail the job (because we don't care about red signals here), we'll see the test is skipped (without the `flaky` field), i.e.
```
<testcase classname="TestMultiprocessing" file="test_multiprocessing.py" line="357" name="test_fs" time="0.000" timestamp="0001-01-01T00:00:00">
<skipped message="{"num_red": 4, "num_green": 0, "max_num_retries": 3, "rerun_disabled_test": true}" type="skip"/>
</testcase>
```
This runs at the same schedule as `mem_leak_check` (daily). The change to update test stats, and (potentially) grouping on HUD will come in separated PRs.
### Testing
* pull https://github.com/pytorch/pytorch/actions/runs/3447434434
* trunk https://github.com/pytorch/pytorch/actions/runs/3447434928
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88646
Approved by: https://github.com/clee2000
# Registers the derivative for mem efficient backward
- Use gradcheck to test correctness. The kernel is not implemented for fp64 so run checks with bumped tolerances in fp32
- I also made updates based off of Xformer main branch and flash-attention cutlass branch.
- This will enable the fused backward to be called for scaled dot product attention
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88856
Approved by: https://github.com/cpuhrsch
Fixes#80441
The highlighting in the documentation for torch.linalg.lstsq was incorrect due to a newline that sphinx doesn't parse correctly. Instead of writing the tensors directly, I used randn to generate the tensors. This seems to be more consistent with how other documentation is written.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89013
Approved by: https://github.com/lezcano
Fixes error from 7k github models: https://github.com/jansel/pytorch-jit-paritybench/blob/master/generated/test_arashwan_matrixnet.py
Error:
```
AssertionError: torch.* op returned non-Tensor bool call_function <function is_tensor at 0x7fca94d0faf0>
from user code:
File "/scratch/ybliang/work/repos/pytorch-jit-paritybench/generated/test_arashwan_matrixnet.py", line 749, in scatter
return scatter_map(inputs)
File "/scratch/ybliang/work/repos/pytorch-jit-paritybench/generated/test_arashwan_matrixnet.py", line 741, in scatter_map
assert not torch.is_tensor(obj), 'Tensors not supported in scatter.'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88704
Approved by: https://github.com/jansel
This updates `wrap_pybind_function` to use `invoke` and adds the
`invoke_traits` object which is analogous to `function_traits` but
for member functions it includes the class as an explicit argument.
To test this is working properly, I've also applied it to the
`CUDAGraph` binding code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88932
Approved by: https://github.com/albanD
Fix dashboard comment failure due to the following trace:
```
Traceback (most recent call last):
File "/scratch/anijain/dashboard/work/pytorch/benchmarks/dynamo/runner.py", line 1180, in <module>
DashboardUpdater(args).update()
File "/scratch/anijain/dashboard/work/pytorch/benchmarks/dynamo/runner.py", line 1119, in update
self.comment_on_gh(comment)
File "/scratch/anijain/dashboard/work/pytorch/benchmarks/dynamo/runner.py", line 1096, in comment_on_gh
subprocess.check_call(
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 368, in check_call
retcode = call(*popenargs, **kwargs)
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 349, in call
with Popen(*popenargs, **kwargs) as p:
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 951, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/scratch/anijain/dashboard/env/lib/python3.9/subprocess.py", line 1821, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
OSError: [Errno 7] Argument list too long: '/data/home/anijain/miniconda/bin/gh'
srun: error: a100-st-p4d24xlarge-27: task 0: Exited with exit code 1
```
That is, we were trying to execute a gh command in the OS that was too long.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89002
Approved by: https://github.com/davidberard98
inductor doesn't have prims.squeeze lowering, so this breaks it. Longer term, `squeeze` with multiple dimensions is not a prim, nvfuser implements it with a loop, inductor uses `_squeeze_multiple` helper which turns it into a loop. Prim should accept only a single dimension.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88927
Approved by: https://github.com/eellison
Hello @wconstab! As you saw, `transformer_auto_wrap_policy()` is a misnomer and actually works for any module classes. The PR before this one tries to add a class `ModuleWrapPolicy` that takes in the `module_classes` in its constructor and works just like `transformer_auto_wrap_policy()` without requiring the `functools.partial()`. I hope you do not mind if we update the dynamo benchmarks util file with this migration.
The PR before this one might require some back and forth within FSDP devs, so I apologize for any consequent updates to this PR, which in itself is an easy change. I will request review once we know the previous PR is good for land.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88453
Approved by: https://github.com/wconstab
This fixes excessing recompilation issue in tacotron2 but has few caveats - https://github.com/pytorch/torchdynamo/issues/330
For tacotron2, the repro is something like this
~~~
def inner(x):
return torch.sin(x)
def fn(x):
for _ in range(100):
inner(x)
torch._dynamo.graph_break()
return x
~~~
The problem here is that Dynamo has guards on the TUPLE_ITERATOR_LEN whenever a graph break happens. Therefore, we keep on recompiling.
This PR checks if there is a backedge (helps with while loop) in presence of a graph break. If there is, Dynamo skips processing this frame. Therefore, Dynamo gets called when inner is called, and we compile only once.
Note that, if there was no graph break, we will unroll the original loop, and see one graph with 100 sin operations (just as before, so no changes there).
The caveat is - We are skipping the frame, so if we have something like this
~~~
def fn(x):
for _ in range(100):
# 1000s of lines of PyTorch code
torch._dynamo.graph_break()
return x
~~~
Dynamo will skip processing this frame, and might miss on the optimization.
Completely open for suggestions. Happy to re-implement if there is a better way to handle this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88857
Approved by: https://github.com/jansel, https://github.com/yanboliang
This PR fixes `FSDP.clip_grad_norm_()` for `NO_SHARD`, which previously "double-counted" each gradient `world_size`-many times.
This does not address any discrepancies between `FULL_SHARD` and DDP. (Note that the unit tests do show parity between `FULL_SHARD` and DDP when using `FSDP.clip_grad_norm_()` and `nn.utils.clip_grad_norm_()` respectively on one iteration.)
The added unit test code path tests mixing nested FSDP instances with both `FULL_SHARD` and `NO_SHARD` to ensure that the `local_sharded_norm` and `local_nonsharded_norm` computations are interoperating correctly. I want to test non-FSDP root instance in the future, but this is BC breaking since we need to make `clip_grad_norm_()` a static method, which would require a different method call syntax (`FSDP.clip_grad_norm_(root_module, ...)` vs. `root_module.clip_grad_norm_(...)`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88955
Approved by: https://github.com/zhaojuanmao
Summary: This diff added support for fusing "dq - reshape - q" to a reshape op, the op is needed in wakeword model
Test Plan: buck test executorch/exir/tests:quant_fusion_pass
Reviewed By: qihqi, JacobSzwejbka
Differential Revision: D41111069
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88858
Approved by: https://github.com/JacobSzwejbka
This is an API change, so please review carefully.
With this PR, torchdynamo returns an `OptimizedModule` class object, a subclass of `torch.nn.Module`, when asked to optimize a `nn.Module` object. Most of the methods are redirected to the original `nn.Module`, which is installed as `_mod` in the `OptimizedModule`.
This is helpful for many cases
```
mod = MockModule()
opt_mod = torch._dynamo.optimize()(mod)
print(opt_mod) # Works
opt_mod = opt_mod.to(device="cuda")
print(opt_mod) # Works
opt_mod(input) # Triggers recompile if necessary, earlier we were shedding the TorchDynamo wrapper
opt_mod.parameters() # Refers to the original module
```
Topics unclear to me
* I have overridden many methods to raise NotImplementedError. A careful review of those will be good.
* hooks
* For the optimized forward, should we call torchdynamo optimization on `__call__` or `forward`
* What else to test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88629
Approved by: https://github.com/Chillee, https://github.com/jansel, https://github.com/msaroufim
**BC Breaking Change**
This renames `unwrapped_params` to `nonwrapped_numel`. I prefer `nonwrapped` over `unwrapped` because "unwrap" suggests that some wrapping has been undone. I prefer `numel` over `params` because that is unit of measurement; I think we should keep "params" to refer to `nn.Parameter`s themselves.
This only breaks anything that passes `unwrapped_params` as a keyword argument, but I did not see anything that did that (except the one internal benchmark file but that does not actually depend on our `pytorch` code).
In a follow-up, I want to rename `min_num_params` to `min_nonwrapped_numel` in `size_based_auto_wrap_policy`, which is also BC breaking. Again, this is to differentiate between "params" being `nn.Parameter`s and "numel" being the unit for `param.numel()`.
**Overview**
This PR introduces `ModuleWrapPolicy` as a lightweight layer over the existing `transformer_auto_wrap_policy`. The most common auto wrapping paradigm is:
```
module_classes: Set[Type[nn.Module]] = ...
auto_wrap_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls=module_classes,
)
fsdp_model = FSDP(model, auto_wrap_policy=auto_wrap_policy, ...)
```
Now, users can instead write:
```
auto_wrap_policy = ModuleWrapPolicy(module_classes)
fsdp_model = FSDP(model, auto_wrap_policy=auto_wrap_policy, ...)
```
This hides the unused arguments expected from the callable (`recurse` and `unwrapped_params`/`nonwrapped_numel`).
`ModuleWrapPolicy` inherits from an abstract base class `FSDPPolicy` that expects a `policy` property. This decouples the construct of such `FSDPPolicy` classes and their actual `policy`, which must abide by the `_recursive_wrap` interface. Any existing auto wrap policy can be rewritten as a class that inherits from `FSDPPolicy`, so this approach is fully backward compatible from a functionality perspective.
I call this base class `FSDPPolicy` to generalize over the cases where we may not want to actually perform any nested wrapping. In reality, the policy is meant for constructing `FlatParameter`s, which just happened to be induced by a nested wrapping before. Given this, I am changing the constructor argument in `fully_shard()` to simply `policy` instead of `auto_wrap_policy`.
This PR migrates usages of `transformer_auto_wrap_policy` within our unit test suite to `ModuleWrapPolicy` as much as possible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88450
Approved by: https://github.com/zhaojuanmao
I'm not sure why I thought this assert was valid in the first
place, and there's no comment about it.
The assert is tantamount to saying, "no tensor objects should
become dead via SafePyObject when hermetic mode is on." But
suppose we run a Python GC while we're inside hermetic mode.
This could result in us disposing non-hermetic tensors, which
would hit decref. So the assert seems invalid.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88885
Approved by: https://github.com/anjali411, https://github.com/malfet
Dynamo+AotAutograd needs a way to wrap all tensors (whether
inputs or params/buffers) in FakeTensor wrappers, and
FSDP's mangling of parameters hides them from this wrapping.
This PR unblocks running hf_bert and hf_T5 with FSDP under dynamo, whether using recursive wrapping around transformer layers or only applying FSDP around the whole model. Perf/memory validation and possibly optimization is the next step.
`python benchmarks/dynamo/distributed.py --torchbench_model hf_Bert --fsdp --dynamo aot_eager`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_Bert --fsdp --dynamo aot_eager --fsdp_wrap`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_T5 --fsdp --dynamo aot_eager`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_T5 --fsdp --dynamo aot_eager --fsdp_wrap`
The problem:
Dynamo (Actually aot_autograd) trips up with FSDP becuase it must
wrap all input tensors in FakeTensor wrappers, and it only knows
to wrap graph inputs or named_(parameters, buffers). FSDP's
pre_forward hook sets views (which are not nn.param) into the flatparam
as attrs on the module with the same name as the original param, but
they will not show up in named_parameters.
- in use_orig_params mode, FSDP still de-registers
params during pre-forward hook, then re-registers them
post-forward
- during forward (between the hooks), the params are setattr'd
on the module as regular view tensors, not nn.Parameters
- note: use_orig_params is the recommended way to use FSDP,
and use_orig_params=False is being deprecated. So i only consider
use_orig_params=True for this enablement
The solution:
- adding them to named_buffers is not possible because it interferes
with how FSDP's `_apply` works
- since they are not actual nn.parameters, register_parameter will
complain about registering them
- simply seting `module._parameters[name] = view` seems to be a viable
workaround, despite being hacky, and FSDP code does modify _parameters
directly already.
Note: Manual checkpointing still isn't working with FSDP+dynamo,
so that will have to be addressed in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88781
Approved by: https://github.com/ezyang, https://github.com/awgu
This comes up if you use inplace operators on a slice, e.g.
```python
import torch
a = torch.rand(1000000, device="cuda")
a[::2] *= 2
```
The last line looks as if it should be fully inplace, but is actually
equivalent to:
```python
tmp = a[::2]
tmp *= 2
a[::2] = tmp
```
Which results in `mul_` and `copy_` being called. With this PR, the
redundant copy becomes a no-op and the above example is 2x faster.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88884
Approved by: https://github.com/ngimel
Summary:
Usage of fast math in BatchBoxCox kernel provided different math results between dev and optimized versions which cause few internal test to fail.
For now disabling the compiler optimized version and relying on ATEN vectors
Differential Revision: D41211784
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88875
Approved by: https://github.com/hyuen
**What**
This PR completely removes the `FullyShardedDataParallel` dependency from `_state_dict_utils` -- `_state_dict_utils` now depends only on `_FSDPState` and all the utils modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88637
Approved by: https://github.com/awgu
**What**
`_summon_full_parameters` is required for state_dict. To enable composable FSDP state_dict, `_summon_full_params` must be accessible without FullyShardedDataParall. This PR move the core logic of `_summon_full_params` to `_unshard_params_utils`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88636
Approved by: https://github.com/awgu
Follow-up for #87735
Once again, because BUILD_CAFFE2=0 is not tested for ONNX exporter, one scenario slipped through. A use case where the model can be exported without aten fallback when operator_export_type=ONNX_ATEN_FALLBACK and BUILD_CAFFE2=0
A new unit test has been added, but it won't prevent regressions if BUILD_CAFFE2=0 is not executed on CI again
Fixes#87313
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88504
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
**What This PR Does**
_state_dict_utils currently accesses the FSDP states through module. To enable composable FSDP state_dict, these accesses need to go through _FSDPState. module is still required for most APIs as state_dict has to access per-module information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88635
Approved by: https://github.com/awgu
WIP to fix extremely slow `scatter_add` issue vs. fp16. The current changes seem to improve performance, but it still appears to lag behind the fp16 equivalent.
CC @ngimel @ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84981
Approved by: https://github.com/ngimel
In `FakeTensorMode.__torch_dispatch__`, the output is now always computed by meta kernels in
```python
try:
with in_kernel_invocation_manager(self):
r = func(*args, **kwargs) # <----- "r" can be a real tensor.
except NotImplementedError as not_implemented_error:
# no meta kernel registered, fallback to kernel for the device
if not self.allow_fallback_kernels:
raise not_implemented_error
return run_fallback_kernel(self, func, args, kwargs, not_implemented_error)
return self.wrap_meta_outputs_with_default_device_logic(r, func, args, kwargs)
```
For example, I observed a CPU tensor is generated when executing `aten.addmm` when running `FakeTensorProp`. Therefore, I'd like to allow `FakeTensorMode` to wrap real tensor as `FakeTensor` during the computation. Does this PR look a good direction to fix this problem? If yes, I can go ahead and add some tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88700
Approved by: https://github.com/eellison, https://github.com/ezyang
This is one step toward the ultimate goal: remove the overwritten state_dict in FSDP. All the logic should be either in `pre_state_dict_hook` or `post_state_dict_hook`.
Since current `nn.Module` does not support `pre_state_dict_hook`, this PR mimic `pre_state_dict_hook` by calling the pre hook inside post the hook, effectively ditching all the work done by `nn.Module.state_dict`. Once `pre_state_dict_hook` is supported by `nn.Module`, these pre hook calls can be moved out from the post hooks and be registered to `nn.Module.pre_state_dict_hook`.
The major issue of this temporary solution is that `post_state_dict_hook` is called from the leaf node to the root node. This makes the `module._lazy_init()` invalid as FSDP assumes `_lazy_init()` to be called from the root. As a result, `FSDP.state_dict` currently contains only one logic -- calling `module._lazy_init()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87900
Approved by: https://github.com/rohan-varma
Since we already enforce eval mode for the fast_path, we do not need to also check for a falsy dropout value, as a model trained with dropout will have a non-zero dropout during eval mode, even though it won't be applied.
Fixes#88806
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88831
Approved by: https://github.com/drisspg
Summary: See title. Left Windows out so it still compiles.
Test Plan:
Add a `#fail` below [this line](https://fburl.com/code/p0mlhlw4) and build for various platforms and confirm it fails which proves the `#ifdef` was hit.
```
buck2 build xplat/langtech/tuna/cli:tuclixAndroid
buck2 build xplat/langtech/tuna/cli:tuclix
```
CI/CD for the rest.
Differential Revision: D41054824
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88545
Approved by: https://github.com/qihqi
* Reflect required arguments in method signature for each diagnostic rule. Previous design accepts arbitrary sized tuple which is hard to use and prone to error.
* Removed `DiagnosticTool` to keep things compact.
* Removed specifying supported rule set for tool(context) and checking if rule of reported diagnostic falls inside the set, to keep things compact.
* Initial overview markdown file.
* Change `full_description` definition. Now `text` field should not be empty. And its markdown should be stored in `markdown` field.
* Change `message_default_template` to allow only named fields (excluding numeric fields). `field_name` provides clarity on what argument is expected.
* Added `diagnose` api to `torch.onnx._internal.diagnostics`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87830
Approved by: https://github.com/abock
- Propagates origin fx nodes through inlining during lowering
- Concatenates op names into kernel name
- Adds config to cap the number of ops in the kernel name so they don't get too long
Caveats:
- The ordering in the name may not match the order that the ops are executed in the kernel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88624
Approved by: https://github.com/anijain2305, https://github.com/jansel
This is the on-device runtime work. We modify the compile and execute from our hacky solution from before to what will actually be running at runtime.
First we rebuild our graph from the serialized flatbuffer string. We also introduce a runtime wrapper that inherits CustomClassHolder that allows us to forward along the built xnngraph runtime to our execute function
Once the subgraph object has been rebuilt by our we pass it along to the runtime wrapper for us to forward along to execute
At execute we prep the input/outputs and invoke the runtime using our runtime wrapper. Finally we forward those results to our execution
Differential Revision: [D39413031](https://our.internmc.facebook.com/intern/diff/D39413031/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39413031/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88780
Approved by: https://github.com/digantdesai
If someone is building the project from source they're likely a contributor for which develop will be much more useful. For people that want to try the latest and greatest they can leverage the nightlies
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88507
Approved by: https://github.com/malfet
# Executor Class
Executor object used to wrap our xnn_runtime object. The ideal flow of this object looks as such:
```
executor.set_inputs(vector<tensor> inputs, vector<tensor> outputs)
executor.forward()
```
This will likely be returned by our delegate compile and given over to execute in order to run inference using the xnn runtime
##### Executorch Considerations
```
#include <ATen/Functions.h>
#include <ATen/Utils.h>
```
These Aten functions are included in order to use at::Tensor when setting the inputs, this will change when used for Executorch because we will be switching from at::Tensor to whatever tensor abstraction is used for ET. Seems like they have the same call for `.data_ptr<float>()`, so realistically all logic here will be the same.
ATen/Utils is used for TORCH_CHECK. We will switch to ET_CHECK_MESSAGE for executorch.
Differential Revision: [D40733121](https://our.internmc.facebook.com/intern/diff/D40733121/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88778
Approved by: https://github.com/digantdesai
Summary:
Since `c10::ArrayRef` now support `c10::ArrayRef<const T>`, let's restore `ComputePostOrder` to accept `const Node*` again, which is more suitable for the context of the given helpers.
Test Plan:
CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88773
Approved by: https://github.com/JackCaoG
- Calling `F.pad()` issues a pad kernel from the CPU even if there is no padding needed, which can incur some non-negligible overhead. This PR removes that unnecessary call for the no-padding case.
- This PR also does not zero the newly-allocated sharded gradient tensor before the reduce-scatter if `use_orig_params=True` because there is no need. The reduce-scatter will fill the tensor anyway, and we do not care about the values in the padding. For `use_orig_params=False`, the padding is exposed to the user, so we preserve the existing semantics of zeroing it. I left a to-do to follow-up since we may optimize that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88769
Approved by: https://github.com/zhaojuanmao
As of LLVM 15 typed pointers are going away:
https://llvm.org/docs/OpaquePointers.html. Thus
`getPointerElementType` is no longer legal, since pointers are all
opaque. I don't totally remember why we use it so prolifically, or
whether there's an easy change to get rid of it, or whether we'd need
a significant refactor to carry around `Type`s alongside `Value`s.
But in any case, NNC is deprecated (see: TorchInductor) and will
hopefully be gone before LLVM 16 is a thing. For now, we can apply
the hack of turning off opaque pointer mode on the LLVMContext.
Differential Revision: [D41176215](https://our.internmc.facebook.com/intern/diff/D41176215)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88798
Approved by: https://github.com/desertfire
Hybrid sparse CSR tensors can currently not be compared to strided ones since `.to_dense` does not work:
```py
import torch
from torch.testing._internal.common_utils import TestCase
assertEqual = TestCase().assertEqual
actual = torch.sparse_csr_tensor([0, 2, 4], [0, 1, 0, 1], [[1, 11], [2, 12] ,[3, 13] ,[4, 14]])
expected = torch.stack([actual[0].to_dense(), actual[1].to_dense()])
assertEqual(actual, expected)
```
```
main.py:4: UserWarning: Sparse CSR tensor support is in beta state. If you miss a functionality in the sparse tensor support, please submit a feature request to https://github.com/pytorch/pytorch/issues. (Triggered internally at ../aten/src/ATen/SparseCsrTensorImpl.cpp:54.)
actual = torch.sparse_csr_tensor([0, 2, 4], [0, 1, 0, 1], [[1, 11], [2, 12] ,[3, 13] ,[4, 14]])
Traceback (most recent call last):
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 1098, in assert_equal
pair.compare()
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 619, in compare
actual, expected = self._equalize_attributes(actual, expected)
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 706, in _equalize_attributes
actual = actual.to_dense() if actual.layout != torch.strided else actual
RuntimeError: sparse_compressed_to_dense: Hybrid tensors are not supported
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "main.py", line 10, in <module>
assertEqual(actual, expected)
File "/home/philip/git/pytorch/torch/torch/testing/_internal/common_utils.py", line 2503, in assertEqual
msg=(lambda generated_msg: f"{generated_msg}\n{msg}") if isinstance(msg, str) and self.longMessage else msg,
File "/home/philip/git/pytorch/torch/torch/testing/_comparison.py", line 1112, in assert_equal
) from error
RuntimeError: Comparing
TensorOrArrayPair(
id=(),
actual=tensor(crow_indices=tensor([0, 2, 4]),
col_indices=tensor([0, 1, 0, 1]),
values=tensor([[ 1, 11],
[ 2, 12],
[ 3, 13],
[ 4, 14]]), size=(2, 2, 2), nnz=4,
layout=torch.sparse_csr),
expected=tensor([[[ 1, 11],
[ 2, 12]],
[[ 3, 13],
[ 4, 14]]]),
rtol=0.0,
atol=0.0,
equal_nan=True,
check_device=False,
check_dtype=True,
check_layout=False,
check_stride=False,
check_is_coalesced=False,
)
resulted in the unexpected exception above. If you are a user and see this message during normal operation please file an issue at https://github.com/pytorch/pytorch/issues. If you are a developer and working on the comparison functions, please except the previous error and raise an expressive `ErrorMeta` instead.
```
This adds a temporary hack to `TestCase.assertEqual` to enable this. Basically, we are going through the individual CSR subtensors, call `.to_dense()` on them, and stack everything back together. I opted to not do this in the common machinery, since that way users are not affected by this (undocumented) hack.
I also added an xfailed test that will trigger as soon as the behavior is supported natively so we don't forget to remove the hack when it is no longer needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88749
Approved by: https://github.com/mruberry, https://github.com/pearu
Fixes T135842750 (follow-up for #87377)
## Description
At present, having both `src_key_padding_mask` and `src_mask` at the same time is not supported on the fastpath in Transformer and Multi-Head Attention.
This PR enables using both masks on the fastpath on CPU and GPU: if both masks are passed, we merge them into a 4D mask in Python and change mask type to 2 before passing downstream.
Downstream processing in native code is not changed, as it already supports 4D mask. Indeed, it is done depending on the device:
- on CUDA, by `SoftMax.cu::masked_softmax_cuda`. When mask type is 2, it calls either `dispatch_softmax_forward` -> `softmax_warp_forward` or `at::softmax` (depending on the input size). In both cases 4D mask is supported.
- on CPU, by `SoftMax.cpp::masked_softmax_cpp`. It calls `hosted_softmax` which supports 4D mask.
## Tests
- Extended `test_mask_check_fastpath` to check that fast path is indeed taken in Transformer when two masks are passed
- Added `test_multihead_self_attn_two_masks_fast_path_mock` to check that fast path is taken in MHA when two masks are passed
- Added `test_multihead_self_attn_two_masks_fast_path` to check that fast and slow paths give the same result when two masks are passed in MHA
- `test_masked_softmax_mask_types` now covers mask type 2
- `test_transformerencoderlayer_fast_path` (CPU smoke test) is expanded to the case of both masks provided simultaneously
- `test_masked_softmax_devices_parity` checks that mask type 2 is accepted by CPU and CUDA paths
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88488
Approved by: https://github.com/mikekgfb
Add absolute latency to dashboard, as requested by https://github.com/pytorch/torchdynamo/issues/1833#issuecomment-1302742914
Tested by setting `run.sh` to
```
# Setup the output directory
rm -rf ../test-dynamo-runner-logs-7/
mkdir ../test-dynamo-runner-logs-7/
# Commands for torchbench for device=cuda, dtype=float32 for training and for performance testing
python benchmarks/dynamo/torchbench.py --performance --float32 -dcuda --output=../test-dynamo-runner-logs-7//inductor_torchbench_float32_training_cuda_performance.csv --training --inductor --no-skip --dashboard --only mobilenet_v2 --cold_start_latency
# Commands for torchbench for device=cuda, dtype=float32 for training and for accuracy testing
python benchmarks/dynamo/torchbench.py --accuracy --float32 -dcuda --output=../test-dynamo-runner-logs-7//inductor_torchbench_float32_training_cuda_accuracy.csv --training --inductor --no-skip --dashboard --only mobilenet_v2
```
and running `python benchmarks/dynamo/runner.py --output-dir ../test-dynamo-runner-logs-7/ --dashboard-archive-path /data/home/williamwen/dynamo-runner-logs-copy --training --run --compilers inductor --flag-compilers inductor --suites torchbench --update-dashboard` (need to comment out the `generate_commands` line and change the github issue ID from 681 to something else).
Sample comment: https://github.com/pytorch/torchdynamo/issues/1831#issuecomment-1309645562
NOTE: this change breaks processing old logs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88790
Approved by: https://github.com/anijain2305
Add stride/contiguity constraints to fallbacks so that inputs will be in the right stride permutation for the fallback kernel.
Improves perf of coat_lite_mini from 1.48415536054865 -> 2.010956856330101.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88534
Approved by: https://github.com/ngimel
Pass install channel when building nightly images
Pass `TRITON_VERSION` argument to install triton for nightly images
Fix `generate_pytorch_version.py` to work with unannotated tags and avoid failures like the following:
```
% git checkout nightly
% ./.github/scripts/generate_pytorch_version.py
fatal: No annotated tags can describe '93f15b1b54ca5fb4a7ca9c21a813b4b86ebaeafa'.
However, there were unannotated tags: try --tags.
Traceback (most recent call last):
File "/Users/nshulga/git/pytorch/pytorch-release/./.github/scripts/generate_pytorch_version.py", line 120, in <module>
main()
File "/Users/nshulga/git/pytorch/pytorch-release/./.github/scripts/generate_pytorch_version.py", line 115, in main
print(version_obj.get_release_version())
File "/Users/nshulga/git/pytorch/pytorch-release/./.github/scripts/generate_pytorch_version.py", line 75, in get_release_version
if not get_tag():
File "/Users/nshulga/git/pytorch/pytorch-release/./.github/scripts/generate_pytorch_version.py", line 37, in get_tag
dirty_tag = subprocess.check_output(
File "/Users/nshulga/miniforge3/lib/python3.9/subprocess.py", line 424, in check_output
return run(*popenargs, stdout=PIPE, timeout=timeout, check=True,
File "/Users/nshulga/miniforge3/lib/python3.9/subprocess.py", line 528, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['git', 'describe']' returned non-zero exit status 128.
```
After the change nightly is reported as(due to autolabelling issue,
should be fixed by ttps://github.com/pytorch/test-infra/pull/1047 ):
```
% ./.github/scripts/generate_pytorch_version.py
ciflow/inductor/26921+cpu
```
Even for tagged release commits version generation was wrong:
```
% git checkout release/1.13
% ./.github/scripts/generate_pytorch_version.py
ciflow/periodic/79617-4848-g7c98e70d44+cpu
```
After the fix, it is as expected:
```
% ./.github/scripts/generate_pytorch_version.py
1.13.0+cpu
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88741
Approved by: https://github.com/dagitses, https://github.com/msaroufim
This diff adds the option to use a Buffer to store data for a `vTensor` by passing `StorageType::BUFFER` to the constructor of `vTensor`. To enable this change, the construction of `vTensor` and `vTensorStorage` had to be slightly refactored to properly support strides. To summarize the changes:
* `vTensorStorage` now contains no Tensor metadata (such as tensor sizes, strides, and `TensorOptions`) - it now only contains the image extents (if texture storage is used) and the buffer length. Tensor metadata is now managed by `vTensor`. The reason for this is to allow multiple `vTensor` objects to point to the same `vTensorStorage` but with different metadata which may be a useful feature now that Buffer storage is enabled.
* `vTensor` will now compute the strides upon construction based on the requested sizes and memory layout if Buffer storage is requested. Previously, strides were faked by setting them all to 0 as strides do not apply to image textures (this behavior is preserved for texture storage).
Differential Revision: [D40604163](https://our.internmc.facebook.com/intern/diff/D40604163/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87622
Approved by: https://github.com/digantdesai
- DLRM requires special configuration of embedding layers which are sparse
and not compatible with DDP.
- I could mark the embedding params as ignored in DDP
to make the benchmark pass, but this isn't a representative benchmark.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88712
Approved by: https://github.com/ezyang
Fixes#81690
TODO:
* [x] C++ Unpickler Fix (locally tested pickled in Python and unpickled in C++)
* [x] C++ Pickler Fix (locally tested pickled in C++ and unpickled in Python)
* [x] Do quant_tensor, sparse_tensor, etc require similar changes? (Sparse and Quant don't need this)
* [x] Add Comments
* [x] How to make sure C++ and Python are in sync? (Functions in `pickler.h` help in getting and setting Tensor Metadata (math-bits for now) on a tensor. They are the only place which should handle this.)
Notes:
Quant Tensor don't support complex dtypes and for float they segfault with `_neg_view` : https://github.com/pytorch/pytorch/issues/88484
Sparse Tensor:
```python
>>> a = torch.tensor([[0, 2.], [3j, 0]]).to_sparse()
>>> a.conj().is_conj()
False
>>> a._neg_view()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NotImplementedError: Cannot access storage of SparseTensorImpl
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88182
Approved by: https://github.com/ezyang, https://github.com/anjali411
Summary: Currently fallback kernel in inductor assumes its output is
either a tensor or a tuple/list of tensors. This PR makes it handle more
generic output data structure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88495
Approved by: https://github.com/jansel
Summary:
This test relies on what the root workspace is before any other code
is run. However, some of the test cases change it. If the order the
tests are run is randomized, then the test can fail if run after one
of them.
Having it on its own ensures that it always sees a pristine state.
Test Plan:
Verified locally and confirmed in internal and external CI.
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88682
Approved by: https://github.com/r-barnes, https://github.com/malfet
## Description
Support lowering of channel shuffle in FX by adding its module and functional op to `is_copy_node` list in `torch/ao/quantization/fx/_lower_to_native_backend.py`
## Validation
UTs added to test
- correctness of quantized `ChannelShuffle` module.
- FX lowering of `ChannelShuffle` module and functional `channel_shuffle`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83731
Approved by: https://github.com/jerryzh168
It allows one to SSH faster rather than having to wait for repo clone to
finish.
I.e. right now one usually have to wait for a few minutes fore PyTorch clone is finished, but with this change you can SSH ahead of time (thanks to `setup-ssh` being a composite action
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88715
Approved by: https://github.com/clee2000, https://github.com/izaitsevfb
Summary:
Today when we transform the captured graph in the last step in export(aten_graph=True), we construct a new graph which doesn't have the all the metadata to be preserved, for example, node.meta["val"].
meta["val"] is important for writing passes and analysis on the graph later in the pipeline, we may want to preserve that on placeholder nodes.
Test Plan: test_export.py:test_export_meta_val
Differential Revision: D41110864
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88651
Approved by: https://github.com/tugsbayasgalan, https://github.com/jansel
Summary: This diff modifies the implementation of the select operator so slices of the irregular dimension can be selected (e.g. nt[:,0,:]).
Test Plan:
Added new unit tests to test that the new functions work as intended (see them in diff). To test,
`buck test mode/dev-nosan //caffe2/test:nested`
Differential Revision: D41083993
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88585
Approved by: https://github.com/cpuhrsch
This PR unifies and rationalizes some of the input representation in Result. The current approach of storing separate types in separate vectors is tedious for two types (Tensors and scalars), but would be even more annoying with the addition of TensorLists. A similar disconnection exists with sizes and strides which the user is also expected to zip with tensor_metadata.
I simplified things by moving inputs to a variant and moving sizes and strides into TensorMetadata. This also forced collection of sizes and strides in python tracer which helps to bring it in line with op profiling. Collection of TensorLists is fairly straightforward; `InputOutputEncoder` already has a spot for them (I actually collected them in the original TorchTidy prototype) so it was just a matter of plumbing things through.
Differential Revision: [D40734451](https://our.internmc.facebook.com/intern/diff/D40734451/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87825
Approved by: https://github.com/slgong-fb, https://github.com/chaekit
Part of the current ID assingment algorithm groups any Storages which are associated with the same TensorImpl*. This isn't sound (which I knew but deferred until it actually became a problem) because pointers can be reused by different objects. (ABA problem)
ABA is easy to handle for Storage because we see allocations and frees, but ~TensorImpl is very hot and cannot tolerate profiling code without significant increases in overhead.
This PR narrows the conditions under which ID assignment will join on TensorImpl*. Two storages which are associated with the same TensorImpl* are grouped IFF they were live at the same time. (Note that this still allows storages with disjoint lifetimes to be joined transitively through a third storage which overlaps with both.)
The need for this PR arose in memory profiling. The Python argument parser creates short lived Tensors for (some) scalar arguments which triggers this issue. (Which is stochastic and platform dependent since optimizations like reusing recently freed allocations is implementation defined.) Spurious connections can lead to confusing and long range interactions when building up the memory profile, so it makes sense to harden ID assignment to avoid any issues.
Differential Revision: [D40445121](https://our.internmc.facebook.com/intern/diff/D40445121/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87133
Approved by: https://github.com/slgong-fb, https://github.com/chaekit
Various code cleanup in MPS operations:
- Per @kulinseth suggestion move `mpsSupportsCumsum` to `MPSDevice.h` and rename it to
`is_macos_13_or_newer()`
- Move Ventura MPSGraph new operators to `MPSGraphVenturaOps.h` header
- Use `LookupAs` and `CreateCachedGraphAs` to make code more compact
- Formatting
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88529
Approved by: https://github.com/kulinseth
Summary:
Implement `native_batch_norm.out` for CPU. Reuses the main logic for `native_batch_norm` but extract out the Tensor creation logic for outputs. There are 3 outputs: `output`, `save_mean` and `save_var`. `batch_norm_cpu` calls `batch_norm_cpu_update_stats_template` to get `save_mean` and `save_var`, and then calls into `batch_norm_cpu_transform_input_template` which initializes `output`.
In the implementation of `batch_norm_cpu_out`, I did the following:
* Let `batch_norm_cpu_transform_input_template` to take another argument `output`, ask the call sites to pass in a output Tensor.
* Overload `batch_norm_cpu_update_stats_template` to take `save_mean` and `save_var`, ask the call sites to pass in those Tensors.
* In `batch_norm_cpu_out`, pass `output`, `save_mean` and `save_var` all the way to our new `batch_norm_cpu_transform_input_template` and `batch_norm_cpu_update_stats_template`.
* In `batch_norm_cpu`, prepare for these outputs and call `batch_norm_cpu_out`.
Test Plan: Enable unit tests for `native_batch_norm.out`.
Differential Revision: D40992036
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88604
Approved by: https://github.com/iseeyuan, https://github.com/jjsjann123
Modify the lookup procedure for TorchDynamo caches to keep the head of the single linked list as the most recently used cache entry, which may potentially improve probability for cache hitting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88076
Approved by: https://github.com/jansel
This is a little tricky: there is a diag_embed.out, but its not bound
in Python because it's autogenerated, see https://github.com/pytorch/pytorch/issues/88598
So I can't "just" add the out variant to the ref, as this makes it
inconsistent with the torch API. To workaround this, I mark the ref
as supporting out, but not the original function.
This is useful to do, because it means that diag_embed.out now supports
symbolic shapes. However, this cannot be easily tested because
I can't mark the out variant as being supported in the normal OpInfo test.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88671
Approved by: https://github.com/mruberry
- find_unused_parameters adds a slight overhead, but is required
in cases where users do not manually specify parameters to ignore
which will not receive grads. In some models, some parameters
do not receive grads, and this causes DDP to throw an exception
as it waits for a grad for each parameter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88645
Approved by: https://github.com/soumith
Currently all of the distributed errors are thrown from the `TORCH_CHECK` macro which throws a generic `RuntimeError`. This change introduced a new error type `DistBackendError` which derives from `RuntimeError` to signify there was an error with the backend communication library. This allows for better error handling and analysis at higher levels in the stack. Motivation: https://docs.google.com/document/d/1j6VPOkC6znscliFuiDWMuMV1_fH4Abgdq7TCHMcXai4/edit#heading=h.a9rc38misyx8
Changes:
- introduce new error type
- Update `C10D_NCCL_CHECK`
Sample script to demonstrate new error type
```python
# python -m torch.distributed.run --nproc_per_node=2 <script>.py
import torch
import torch.distributed as dist
if __name__ == "__main__":
dist.init_process_group("nccl")
dist.broadcast(torch.tensor([1, 2, 3]).cuda(), 0)
```
Differential Revision: [D40998803](https://our.internmc.facebook.com/intern/diff/D40998803)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88134
Approved by: https://github.com/rohan-varma
This build uses the wrong BUILD_ENVIRONMENT `pytorch-linux-focal-py3`, thus it hasn't been run for a long time (forgotten). The name was probably the old name of the build environment we used in the past. The convention today doesn't have the `pytorch-` prefix. There is a TODO for this:
> TODO: this condition is never (BUILD_ENVIRONMENT doesn't start with pytorch-), need to fix this.
This is done as part of [T131829540](https://www.internalfb.com/intern/tasks/?t=131829540), where we want
`static_runtime_benchmark` build and test jobs to run in OSS CI to avoid breaking internal
* I also fix some compiler warning errors `-Werror=sign-compare`, `-Werror,-Wunused-const-variable`, and gcc7 compatibility issue along the way because this hasn't been run for a long time.
* Reviving this test also reveals a small bug in `PrepackWeights` test in `test_static_runtime.cc` added recently in https://github.com/pytorch/pytorch/pull/85289. The test refers to an internal ops and should only be run internally. This has been fixed by https://github.com/pytorch/pytorch/pull/87799 (To be merged)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87660
Approved by: https://github.com/malfet
There is a fast path in InputBuffer to steal memory when use count is zero, however it is only used for sparse Tensors. According to Natalia, this is just because it wasn't obvious that there would be a benefit for dense Tensors so there was no reason to live dangerously. However I've noticed large Tensors in internal models which would benefit from this optimization as well.
Differential Revision: [D40946601](https://our.internmc.facebook.com/intern/diff/D40946601/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88339
Approved by: https://github.com/ngimel
Summary: Add an option to disable TORCH_WARN, some op could trigger spammy TOCH_WARN log which is not desired under certain scenario.
Test Plan:
Tested with
-pt.disable_warn = 1 and -pt.disable_warn = 0
verified TORCH_WARN and TORCH_WARN_ONCE are properly handled
tested with
-pt.strip_error_messages = 1, -pt.disable_warn = 0
verified strip error message is respected when warn is printed
Differential Revision: D40321550
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87188
Approved by: https://github.com/kurtamohler, https://github.com/ezyang
Along the way, I undid making sparse/dense dim symint (they're
dimensions, so they should be static.)
Also symintify set_indices_and_values_unsafe
There is a little bit of a nontrivial infra change here: previously, we didn't populate the strides field on sparse tensors. It is now populated with "empty" strides, and this meant that sparse tensors were falsely reporting they were non-overlapping dense/contiguous. I added in a hack to work around this case.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88573
Approved by: https://github.com/anjali411
I'm not sure, what would be the best behaviour here, but it feels a bit strange to perform parts of `float32` computations as `float64` and then downcast them back to `float32`.
Use `at::opmath_type` rather than `at:acc_type` as no accumulation is used in the op.
I don't know much about double vs single precision scalar perf on x86 CPU, but before the change:
```
python -c "import timeit;import torch;x=torch.arange(100, dtype=torch.float32).reshape(1, 1, 10, 10); print(timeit.Timer(stmt='torch.nn.functional.interpolate(x, scale_factor=2.0, mode=\"bilinear\", align_corners=False)', globals={'x':x, 'torch':torch}).timeit())"
11.337517574429512
```
After the change:
```
$ python -c "import timeit;import torch;x=torch.arange(100, dtype=torch.float32).reshape(1, 1, 10, 10); print(timeit.Timer(stmt='torch.nn.functional.interpolate(x, scale_factor=2.0, mode=\"bilinear\", align_corners=False)', globals={'x':x, 'torch':torch}).timeit())"
10.513805857859552
```
I.e. roughly 7% perf degradation (measured on Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz)
NOTE:
- `aten::acc_type<float, false>` yields `double`
- `aten::acc_type<float, true>` return `float`.
Fixes https://github.com/pytorch/pytorch/issues/87968
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88277
Approved by: https://github.com/mingfeima, https://github.com/ngimel, https://github.com/jgong5
I accidentally delete my remote branch, so I need to create a new PR for this fix (instead of updating the reverted PR https://github.com/pytorch/pytorch/pull/88531)
TIL, sudo echo doesn't do that I think it does, the correct syntax should be `echo "1" | sudo tee /sys/bus/pci/devices/$PCI_ID/reset` granting sudo permission to the latter tee command.
### Testing
Due diligence and actually login to `i-07e62045d15df3629` and make sure that the command works
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88605
Approved by: https://github.com/ZainRizvi
Summary: This diff merges both previous implementations of constructors for nested tensors, the one from lists of tensors and the one with arbitrary python lists, adn implements it in pytorch core so no extensions are needed to construct NT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88213
Approved by: https://github.com/cpuhrsch
The latest version 1.11.1 breaks PyTorch CI. A bunch of tests are failing now in master d1ee073041. Curiously, the latest commit 81042d3a53 looks green, but it's good to pin this dependency anyway
https://github.com/pytorch/pytorch/blob/master/.circleci/docker/requirements-ci.txt#L95-L97 has a curious note about ninja and why it's not part of the docker container (need to revisit this later on):
```
#ninja
#Description: build system. Note that it install from
#here breaks things so it is commented out
```
This is one more reason to justify the effort to consolidating all pip and conda dependencies to get rid of this family of issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88548
Approved by: https://github.com/clee2000
Implement various features in https://github.com/pytorch/torchdynamo/issues/1644:
- Upload nightly run logs to /fsx before parsing - for backing up parsing failures.
- Flag models with (1) < 0.95x speedup, (2) > 2min compile time, (3) < 0.9x compression ratio
- Flag models that were passing yesterday but failed today.
- Other small bug fixes.
See https://github.com/pytorch/torchdynamo/issues/1831 for sample outputs.
Also tested by running run.sh:
```bash
# Setup the output directory
rm -rf ../test-dynamo-runner-logs-3/
mkdir ../test-dynamo-runner-logs-3/
# Commands for torchbench for device=cuda, dtype=float32 for training and for performance testing
python benchmarks/dynamo/torchbench.py --performance --float32 -dcuda --output=../test-dynamo-runner-logs-3//inductor_torchbench_float32_training_cuda_performance.csv --training --inductor --no-skip --dashboard --only mobilenet_v2 --cold_start_latency
# Commands for torchbench for device=cuda, dtype=float32 for training and for accuracy testing
python benchmarks/dynamo/torchbench.py --accuracy --float32 -dcuda --output=../test-dynamo-runner-logs-3//inductor_torchbench_float32_training_cuda_accuracy.csv --training --inductor --no-skip --dashboard --only mobilenet_v2
```
with the command
`python benchmarks/dynamo/runner.py --output-dir ../test-dynamo-runner-logs-3/ --dashboard-archive-path /data/home/williamwen/dynamo-runner-logs-copy --training --run --compilers inductor --flag-compilers inductor --suites torchbench --update-dashboard` (need to comment out the `generate_commands` line and change the github issue ID from 681 to something else).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88516
Approved by: https://github.com/anijain2305
I saw some missed optimization opportunities in C10 using std::move and thought I would submit a PR to fix them. There are particularly a lot of them dealing with the symbolic operators which are used in quite a few places including in loops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88512
Approved by: https://github.com/ezyang
Summary:
* Added an error message for when the result is not a PassResult
* Modified the error handling to capture exceptions that happen in the check() function
* consolidated inplace_wrapper and pass_result_wrapper
Test Plan: CI
Differential Revision: D40950135
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88520
Approved by: https://github.com/SherlockNoMad
Summary:
X-link: https://github.com/pytorch/torchrec/pull/781
Move a bunch of globals to instance methods and replace all use to them.
We move all PG related globals under World and use a singleton instance under _world.
This creates an undocumented extension point to inject full control of how how c10d
state behaves.
One simple hack is to change _world to an implementation that uses a threadlocal
and enable per-thread PGs.
It almost get DDP working and the PG is missing an implementation of all_reduce.
This enables notebook usage of PTD, which is a big deal for learning it:
https://gist.github.com/kumpera/32cb051fa26b8cad8bdf671f968dcd68
This change ensures BC by keeping the global variables around and have the default _World wrap it.
I have relinked this diff to a new github PR, so that I can update it. The original PR is
> Pull Request resolved: https://github.com/pytorch/pytorch/pull/86348
Differential Revision: D40236769
Pulled By: yhcharles
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88471
Approved by: https://github.com/gnadathur, https://github.com/rohan-varma
Summary:
D40798763 broke this op. Unfortunately, it wasn't caught at land time due to the recent OSS Static Runtime test problems.
The problem is C++ overload resolution. After D40798763, the int that we were passing to `at::native::tensor_split` was getting implicitly converted to `IntArrayRef`. Fix this by converting the int to a `SymInt` and calling the correct overload.
Test Plan:
```
buck2 test caffe2/benchmarks/static_runtime:static_runtime_cpptest -- Tensor_Split --run-disabled
```
Differential Revision: D40862394
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88113
Approved by: https://github.com/hlu1
This PR is to optimize reduction implementation by `at::vec`. The main idea is as same as the aten implementation.
- Step1: Parallelize and vectorize the reduction implementation
- Step2: Invoke `at::vec::vec_reduce_all` to reduce the vector generated at step 1 to a single scalar
- Step3: Handle the tail elements
For the implementation, we create two kernels - `CppVecKernel` and `CppKernel`. The code block generation is as follows step by step.
- Gen the non-reduction loop - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1008-L1010)
- Gen the reduction initialization both for vectorization and non-vectorization kernel - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1015)
- Gen the reduction loop for the vectorization kernel - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1021-L1023)
- Gen the code to reduce the vector to scalar - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1033)
- Gen the reduction loop for the non-vectorization kernel - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1042)
- Do some post-reduction things like store reduction value - [Code](https://github.com/pytorch/pytorch/blob/gh/EikanWang/9/head/torch/_inductor/codegen/cpp.py#L1049)
```python
# Gen the non-reduction loop
for loop in CppVecKernel.NoneReductionLoop:
# Gen the reduction initialization both for vectorization and non-vectorization kernel
CppVecKernel.ReductionPrefix
# Gen the reduction loop for the vectorization kernel
for loop in CppVecKernel.ReductionLoop
CppVecKernel.Loads
CppVecKernel.Compute
CppVecKernel.Stores
# Gen the code to reduce the vector to scalar
CppVecKernel.ReductionSuffix
# Gen the reduction loop for the non-vectorization kernel
for loop in CppKernel.ReductionLoop
CppKernel.Loads
CppKernel.Compute
CppKernel.Stores
# The reduction is almost finished. To do some post-reduction things like store reduction value.
CppKernel.ReductionSuffix
```
The code snippet for maximum reduction exemplifies the idea. More detailed comments are inlined.
```C++
{
// Declare reduction for at::vec::Vectorized since it is not built-in data type.
#pragma omp declare reduction(+:at::vec::Vectorized<float>:omp_out += omp_in) initializer(omp_priv={{0}})
float tmp4 = 0;
// tmp4_vec is used to vectorize the sum reduction for tmp4
auto tmp4_vec = at::vec::Vectorized<float>(tmp4);
float tmp6 = 0;
// tmp6_vec is used to vectorize the sum reduction for tmp6
auto tmp6_vec = at::vec::Vectorized<float>(tmp6);
#pragma omp parallel num_threads(48)
{
// Parallelize the vectorized reduction
#pragma omp for reduction(+:tmp4_vec) reduction(+:tmp6_vec)
for(long i0=0; i0<192; i0+=1)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 8*i0);
auto tmp1 = at::vec::Vectorized<float>::loadu(in_ptr1 + 8*i0);
auto tmp2 = tmp0 - tmp1;
auto tmp3 = tmp2.abs();
auto tmp5 = tmp2 * tmp2;
tmp4_vec += tmp3;
tmp6_vec += tmp5;
}
// Reduce the tmp4_vec as a scalar and store at tmp4
tmp4 = at::vec::vec_reduce_all<float>([](at::vec::Vectorized<float>& x, at::vec::Vectorized<float>&y) {return x + y;}, tmp4_vec);
// Reduce the tmp6_vec as a scalar and store at tmp6
tmp6 = at::vec::vec_reduce_all<float>([](at::vec::Vectorized<float>& x, at::vec::Vectorized<float>&y) {return x + y;}, tmp6_vec);
// Handle the tail elements that could not be vectorized by aten.
#pragma omp for simd simdlen(4) reduction(+:tmp4) reduction(+:tmp6)
for(long i0=1536; i0<1536; i0+=1)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[i0];
auto tmp2 = tmp0 - tmp1;
auto tmp3 = std::abs(tmp2);
auto tmp5 = tmp2 * tmp2;
tmp4 += tmp3;
tmp6 += tmp5;
}
}
out_ptr0[0] = tmp4;
out_ptr1[0] = tmp6;
}
```
Performance(Measured by operatorbench and the base line of speedup ratio is aten operator performance):
Softmax (1,16,384,384,dim=3) | Speedup ratio (simdlen=None) | Speedup ratio (simdlen=8) + this PR
-- | -- | --
24c | 0.37410838067524177 | 0.9036240100351164
4c | 0.24655829520907663 | 1.0255329993674518
1c | 0.21595768114988007 | 1.000587368005134
HW Configuration:
SKU: SKX Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz
MemTotal: 196708148 kB
MemFree: 89318532 kB
MemBandwidth: 112195.1MB/S
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87356
Approved by: https://github.com/jgong5, https://github.com/jansel
In this PR, we replace OMP SIMD with `aten::vec` to optimize TorchInductor vectorization performance. Take `res=torch.exp(torch.add(x, y))` as the example. The generated code is as follows if `config.cpp.simdlen` is 8.
```C++
extern "C" void kernel(const float* __restrict__ in_ptr0,
const float* __restrict__ in_ptr1,
float* __restrict__ out_ptr0,
const long ks0,
const long ks1)
{
#pragma omp parallel num_threads(48)
{
#pragma omp for
for(long i0=0; i0<((ks0*ks1) / 8); ++i0)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 8*i0);
auto tmp1 = at::vec::Vectorized<float>::loadu(in_ptr1 + 8*i0);
auto tmp2 = tmp0 + tmp1;
auto tmp3 = tmp2.exp();
tmp3.store(out_ptr0 + 8*i0);
}
#pragma omp for simd simdlen(4)
for(long i0=8*(((ks0*ks1) / 8)); i0<ks0*ks1; ++i0)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[i0];
auto tmp2 = tmp0 + tmp1;
auto tmp3 = std::exp(tmp2);
out_ptr0[i0] = tmp3;
}
}
}
```
The major pipeline is as follows.
- Check whether the loop body could be vectorized by `aten::vec`. The checker consists of two parts. [One ](bf66991fc4/torch/_inductor/codegen/cpp.py (L702))is to check whether all the `ops` have been supported. The [other one](355326faa3/torch/_inductor/codegen/cpp.py (L672)) is to check whether the data access could be vectorized.
- [`CppSimdVecKernelChecker`](355326faa3/torch/_inductor/codegen/cpp.py (L655))
- Create the `aten::vec` kernel and original omp simd kernel. Regarding the original omp simd kernel, it serves for the tail loop when the loop is vectorized.
- [`CppSimdVecKernel`](355326faa3/torch/_inductor/codegen/cpp.py (L601))
- [`CppSimdVecOverrides`](355326faa3/torch/_inductor/codegen/cpp.py (L159)): The ops that we have supported on the top of `aten::vec`
- Create kernel
- [`aten::vec` kernel](355326faa3/torch/_inductor/codegen/cpp.py (L924))
- [`Original CPP kernel - OMP SIMD`](355326faa3/torch/_inductor/codegen/cpp.py (L929))
- Generate code
- [`CppKernelProxy`](355326faa3/torch/_inductor/codegen/cpp.py (L753)) is used to combine the `aten::vec` kernel and original cpp kernel
- [Vectorize the most inner loop](355326faa3/torch/_inductor/codegen/cpp.py (L753))
- [Generate code](355326faa3/torch/_inductor/codegen/cpp.py (L821))
Next steps:
- [x] Support reduction
- [x] Vectorize the tail loop with `aten::vec`
- [ ] Support BF16
- [ ] Optimize the loop condition and loop index calculation by replacing `div` with `add`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87068
Approved by: https://github.com/jgong5, https://github.com/jansel
Speeds up autotuning a little bit more (about 90s -> 75s for coat_lite_mini)
@bertmaher, I've put in workaround so that internal doesn't break, but it can be removed once triton is updated internally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88557
Approved by: https://github.com/anijain2305
Ref pytorch/torchdynamo#327
The use of as_strided does require in-memory manipulations, however this
lowering allows those memory ops to be fused with any preceding calculations.
e.g.
```
def f(a, b):
return torch.as_strided_scatter(
a * 8 + 10,
b * 2 - 4,
size=(a.numel() // 2,),
stride=(2,))
```
Before this compiles to two kernels and a call to `aten.as_strided_scatter` and
with this PR it compiles to just two kernels and no additional operator calls.
In theory I think this could be a decomposition, but in practice I saw the
`output_view.copy_(src)` being optimized out in some cases when this was
implemented as a decomposition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88379
Approved by: https://github.com/jansel
Summary:
Upstreaming this as part of sharing common APIs. This is just a plain
move, any changes needed to support DDP / FSDP will come in follow up diffs.
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D40564646
fbshipit-source-id: 619c434e02196812f8d4db1e40d07290e08b18f9
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88539
Approved by: https://github.com/awgu
This also comes with some bug fixes that were uncovered from doing
this:
- Forward device calls to inner tensor in FunctionalTensorWrapper
- Make legacyExtractDispatchKey exclude Functionalize, so that
it can get at the real device type key. This is noncontroversial.
- Stop stripping dense from key set. The reason for this is
FunctionalWrapperTensor may be used in contexts where people
query if it is dense or not. If it doesn't report this correctly
(from the dispatch key), it will cause errors. This caused some
torchbench models to fail when I did one-pass tracing.
- Save and restore reapply views TLS correctly
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88063
Approved by: https://github.com/bdhirsh
- does not intend to support multi-process, as that is more complex
and we have torchbench scripts for that
- currently only works in accuracy mode as this was the main goal,
but could be extended for measuring single-gpu perf impact of
graph breaks
Run with
`python benchmarks/dynamo/torchbench.py --inductor --training --accuracy --only hf_Bert --ddp`
Example output
```
cuda train hf_Bert
[2022-11-04 18:52:08,304] torch._inductor.compile_fx: [WARNING] skipping cudagraphs due to complex input striding
PASS
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88511
Approved by: https://github.com/davidberard98, https://github.com/aazzolini
Summary:
This is a followup to https://github.com/pytorch/pytorch/pull/88354/files#diff-622913fdb49db90d6f3a8ab225b4badb7996023e6498e9f7c6d03fe9f32d0986R836
Reference to self.export got added to InstructionTranslatorBase (i.e. STORE_ATTR) but self.export is populated only for InstructionTranslators.
Here's an example failure
```
File "/scratch/williamwen/work/pytorch/torch/_dynamo/symbolic_convert.py", line 322, in step
getattr(self, inst.opname)(inst)
File "/scratch/williamwen/work/pytorch/torch/_dynamo/symbolic_convert.py", line 844, in STORE_ATTR
not self.export
AttributeError: 'InliningInstructionTranslator' object has no attribute 'export'
```
Let's populate with the base class with export flag.
Test Plan:
python test/dynamo/test_export_mutations.py
python test/dynamo/test_export.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88508
Approved by: https://github.com/tugsbayasgalan
Summary: Bypass "Runtime error: store to misaligned address [...] for type 'uint16_t' (aka 'unsigned short'), which requires 2 byte alignment"
Test Plan:
One of the failing tests, now passes
`buck test fbsource//arvr/mode/platform010/dev-asan fbsource//arvr/libraries/eye/engine:sys_test_eyetrackingenginevisioninterface`
Reviewed By: kimishpatel, salilsdesai
Differential Revision: D40918376
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88276
Approved by: https://github.com/manuelcandales
Summary: This commit fixes the bug where `non_leaf_module_list`
was not respected for activation modules like `torch.nn.Sigmoid`
and `torch.nn.Tanh`. Today, these modules default to
`default_fixed_qparams_range_0to1_fake_quant`, and there is no
way to configure them to use any other activation_post_process
(e.g. FixedQParamsObserver) (see this [mapping](dc00bb51b8/torch/ao/quantization/quantization_mappings.py (L188-L193))).
`non_leaf_module_list` is a "list of non-leaf modules we want
to add observer" (see prepare docstring). If the user explicitly
specified to insert observers for these modules, we should respect
that instead of continuing to use the default.
Test Plan:
python test/test_quantization.py TestQuantizeEagerPTQStatic.test_activations_in_non_leaf_module_list
Reviewers: vkuzo, jerryzh168
Subscribers: vkuzo, jerryzh168
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88498
Approved by: https://github.com/jerryzh168
tbh at this point it might be easier to make a new workflow and copy the relevant jobs...
Changes:
* Disable cuda mem leak check except for on scheduled workflows
* Make pull and trunk run on a schedule which will run the memory leak check
* Periodic will always run the memory leak check -> periodic does not have parallelization anymore
* Concurrency check changed to be slightly more generous
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88373
Approved by: https://github.com/ZainRizvi, https://github.com/huydhn
During build, users commonly see a message like
```
fatal: no tag exactly matches 'd8b4f33324b1eb6c1103874764116fb68e0d0af4'
```
which is usually ignored when builds succeed, but has confused users when build fails (due to a different issue). This PR removes the red herring, since this usually prints for local development when tags are not found.
We catch the exception anyway and handle it under the hood, so we don't need to print it and confuse the user.
Test plan:
Note that builds on trunk current have this line, cmd-F 'fatal: no tag exactly matches' in https://github.com/pytorch/pytorch/actions/runs/3379162092/jobs/5610355820.
Then check in the PR build to see that the line no longer appears.
I also tagged my commit locally and printed what tag would be--this code and the old code printed the same results for what tag would be.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88335
Approved by: https://github.com/seemethere
Syncing nvfuser devel branch to upstream master. https://github.com/csarofeen/pytorch/
Codegen changes include:
* codegen improvement:
i. allow non-root trivial reductions, allow empty/no-op fusion
ii. fixes vectorization checks and size calculation
iii. bank conflict handle improvement
iv. enables transpose scheduler
* misc:
i. CI tests failure fixes
ii. cpp tests file clean up
iii. trivial forwarding supports added in codegen runtime
iv. added factory methods support in codegen
Commits that's in this PR from the devel branch:
```
7117a7e37ebec372d9e802fdfb8abb7786960f4a patching nvfuser conv cudnn test numerics mismatch (#2048)
65af1a4e7013f070df1ba33701f2d524de79d096 Inserting sync for redundant parallel types is already done at the (#2023)
6ac74d181689c8f135f60bfc1ec139d88941c98c Fix sync map (#2047)
f5bca333355e2c0033523f3402de5b8aac602c00 Bank conflict checker improvements (#2032)
d2ca7e3fd203537946be3f7b435303c60fa7f51e Minor update on cp.async code generation. (#1901)
d36cf61f5570c9c992a748126287c4e7432228e0 Test file cleanup (#2040)
0b8e83f49c2ea9f04a4aad5061c1e7f4268474c6 Allow non-root trivial reductions (#2037)
a2dfe40b27cd3f5c04207596f0a1818fbd5e5439 Fix vectorize size calculation (#2035)
e040676a317fe34ea5875276270c7be88f6eaa56 Use withPredicate to replace setPredicate to maintain Exprs immutable (#2025)
197221b847ad5eb347d7ec1cf2706733aacbf97c removing ci workflow (#2034)
40e2703d00795526e7855860aa00b9ab7160755f Reduction rand like patch (#2031)
bc772661cbdb3b711d8e9854ae9b8b7052e3e4a3 Add utility for checking bank conflict of shared memory (#2029)
ddd1cf7695f3fb172a0e4bcb8e4004573617a037 Add back FusionReductionWithTrivialReduction_CUDA (#2030)
fbd97e5ef15fa0f7573800e6fbb5743463fd9e57 Revert "Cleanup trivial reduction workarounds (#2006)" (#2024)
bca20c1dfb8aa8d881fc7973e7579ce82bc6a894 Cleanup trivial reduction workarounds (#2006)
e4b65850eee1d70084105bb6e1f290651adde23e Trivial forwarding (#1995)
1a0e355b5027ed0df501989194ee8f2be3fdd37a Fix contiguity analysis of predicates to match updated contiguity. (#1991)
a4effa6a5f7066647519dc56e854f4c8a2efd2a7 Enable output allocation cache (#2010)
35440b7953ed8da164a5fb28f87d7fd760ac5e00 Patching bn inference (#2016)
0f9f0b4060dc8ca18dc65779cfd7e0776b6b38e8 Add matmul benchmark (#2007)
45045cd05ea268f510587321dbcc8d7c2977cdab Enable tests previously disabled due to an aliasing bug (#2005)
967aa77d2c8e360c7c01587522eec1c1d377c87e Contiguous indexing for View operations (#1990)
a43cb20f48943595894e345865bc1eabf58a5b48 Make inlining even more modular (#2004)
dc458358c0ac91dfaf4e6655a9b3fc206fc0c897 Test util cleanup (#2003)
3ca21ebe4d213f0070ffdfa4ae5d7f6cb0b8e870 More strict validation (#2000)
a7a7d573310c4707a9f381831d3114210461af01 Fix build problem (#1999)
fc235b064e27921fa9d6dbb9dc7055e5bae1c222 Just fixes comments (#1998)
482386c0509fee6edb2964c5ae72074791f3e43a cleanup (#1997)
4cbe0db6558a82c3097d281eec9c85ad2ea0893a Improve divisible split detection (#1970)
42ccc52bdc18bab0330f4b93ed1399164e2980c9 Minor build fix. (#1996)
fcf8c091f72d46f3055975a35afd06263324ede6 Cleanup of lower_utils.cpp: Isolate out GpuLower usage (#1989)
15f2f6dba8cbf408ec93c344767c1862c30f7ecc Move ConcretizedBroadcastDomains to shared_ptr in GpuLower. (#1988)
8f1c7f52679a3ad6acfd419d28a2f4be4a7d89e2 Minor cleanup lower_unroll.cpp (#1994)
1d9858c80319ca7f0037db7de5f04e47f540d76c Minor cleanup (#1992)
f262d9cab59f41c669f53799c6d4a6b9fc4267eb Add support for uniform RNG (#1986)
eb1dad10c73f855eb1ecb20a8b1f7b6edb0c9ea3 Remove non-const functions, remove GpuLower instance on build, pass in ca_map. (#1987)
634820c5e3586c0fe44132c51179b3155be18072 Add support for some empty fusion (#1981)
eabe8d844ad765ee4973faa4821d451ef71b83c3 Segment self mapping fusions (#1954)
e96aacfd9cf9b3c6d08f120282762489bdf540c8 Enable Transpose operation (#1882)
425dce2777420248e9f08893765b5402644f4161 Add a null scheduler that helps segmenting away no-op schedules (#1835)
306d4a68f127dd1b854b749855e48ba23444ba60 Fix canScheduleCompileTime check of transpose scheduler (#1969)
b1bd32cc1b2ae7bbd44701477bddbcfa6642a9be Minor fix (#1967)
bd93578143c1763c1e00ba613a017f8130a6b989 Enable transpose scheduler (#1927)
b7a206e93b4ac823c791c87f12859cf7af264a4c Move scheduler vectorize utilities into their own file (#1959)
d9420e4ca090489bf210e68e9912bb059b895baf View scheduling (#1928)
c668e13aea0cf21d40f95b48e0163b812712cdf2 Upstream push ci fixes (#1965)
c40202bb40ce955955bb97b12762ef3b6b612997 Fix dump effective bandwidth (#1962)
93505bcbb90a7849bd67090fe5708d867e8909e4 WAR on index mapping when exact and permissive maps differ (#1960)
45e95fd1d3c773ee9b2a21d79624c279d269da9f Allow splitting inner-most ID to create virtual innermost ID in transpose scheduler (#1930)
a3ecb339442131f87842eb56955e4f17c544e99f Improve the comments at the beginning of index_compute.h (#1946)
f7bc3417cc2923a635042cc6cc361b2f344248d6 Remove unused variables (#1955)
df3393adbb5cb0309d091f358cfa98706bd4d313 Some cleanup (#1957)
7d1d7c8724ab5a226fad0f5a80feeac04975a496 TVDomainGuard factory (#1953)
357ba224c0fb41ed3e4e8594d95599c973f4a0ca Fill allocation with nan on tests (#1956)
8eafc54685d406f5ac527bcbacc475fda4492d7a Fix detection of unmappable root domains (#1952)
90a51f282601ba8ebd4c84b9334efd7762a234bc Some indexing cleanups, Add eye support (#1940)
ddc01e4e16428aec92f9c84d698f959b6436a971 Exclude unsupported data types (#1951)
992e17c0688fe690c51b50e81a75803621b7e6aa test the groups the same order as they are merged (#1949)
208262b75d1fed0597a0329d61d57bc8bcd7ff14 Move detection of self mapping IDs to IterDomainGraph from (#1941)
ac4de38c6ee53b366e85fdfe408c3642d32b57df Merge pull request #1945 from csarofeen/master_merge_0828
631094891a96f715d8c9925fb73d41013ca7f2e3 Add full, full_like, zeros, zeros_like, ones, ones_like (#1943)
aab10bce4541204c46b91ff0f0ed9878aec1bfc4 Merge remote-tracking branch 'upstream/viable/strict' into HEAD
4c254c063bb55887b45677e3812357556a7aa80d Fix arange when step is negative (#1942)
89330aa23aa804340b2406ab58899d816e3dc3d2 Tensor factories must set the output shape as its input (#1939)
```
RUN_TORCHBENCH: nvfuser
Differential Revision: [D40869846](https://our.internmc.facebook.com/intern/diff/D40869846)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87779
Approved by: https://github.com/davidberard98
Summary:
Improved roundup_power2_divisions knob so it allows better control of rouding in the PyTorch CUDA Caching Allocator.
This new version allows setting the number of divisions per power of two interval starting from 1MB and ending at 64GB and above. An example use case is when rouding is desirable for small allocations but there are also very large allocations which are persistent, thus would not benefit from rounding and take up extra space.
Test Plan: Tested locally
Differential Revision: D40103909
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87290
Approved by: https://github.com/zdevito
The bug was that I was accidentally caching at the wrong key name, so
we were never actually hitting the cache. I've renamed the resolved
key to final_key to avoid shadowing in this way.
This reverts commit 410ce96a23a3496a45478e0b25ffac53aa3c116f.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88489
Approved by: https://github.com/albanD
Summary: When using torch deploy, if we do fx transformation and then try to pickle/unpickle a fx GraphModule, it's possible that the GraphModule's code depends on `builtins` but we didn't add it to extern module.
Reviewed By: PaliC
Differential Revision: D40958730
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88385
Approved by: https://github.com/PaliC
This improves the memory compression of resnet18 from .84 -> .94 on inductor no-cudagraphs. It does mean that any extern kernel which incorrectly computes strides will be a hard error at runtime, but that's an issue we are going to have to face with dynamic shapes anyway. CC @ezyang, @SherlockNoMad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88248
Approved by: https://github.com/ezyang
Summary:
User can't call `.unpack()` when they have a quantized Embedding layer because `&EmbeddingPackedParamsBase::unpack` was never exposed to Python through pybind.
This diff fixes that.
Test Plan: CI
Reviewed By: jerryzh168
Differential Revision: D40606585
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88362
Approved by: https://github.com/jerryzh168
Summary:
# Initialize Kineto Profiler for on-demand profiling
## TLDR
Overall this patch enables initializing the kineto profiling library on start-up. This is guarded by an env variable that is described a bit more later. The kineto profiler is otherwise initialized lazily when pytorch profiler is invoked.
## Background
We are enabling on-demand profiling capability for pytorch. As users run large distributed training flows this will enable one to capture a pytorch profiler/GPU trace remotely, from outside the process. The kineto library and a monitoring daemon - dynolog- interact to achieve this.
Dynolog will be open sourced by end of October, and has been dogfooded on Meta AI Research cluster.
https://github.com/facebookincubator/dynolog
### How it works
Kineto library registers itself with the dynolog daemon running on the host over inter process communication
```
| kineto | --> (ipcfabric) --> | dynolog |
* register()
* poll for on-demand tracing configs()
```
This feature is currently enabled by setting the env variable `KINETO_USE_DAEMON`. However, it only works if we initialize kineto, else the thread to talk to dynolog is not spun up.
Related PRs in kineto include
https://github.com/pytorch/kineto/pull/637https://github.com/pytorch/kineto/pull/653
## TestPlan:
Build pytorch from source (need to set USE_LITE_INTERPRETER_PROFILER=OFF)
Run a simple linear model [example](https://pytorch.org/tutorials/beginner/basics/tensorqs_tutorial.html).
### First run with the env variable set
```
export KINETO_CONFIG=/private/home/bcoutinho//libkineto.conf
export KINETO_USE_DAEMON=1
python3 /private/home/bcoutinho/linear_model.py
```
Output
```
INFO:2022-10-18 09:01:12 4169946:4169946 init.cpp:98] Registering daemon config loader
cuda:0
```
We can trigger a trace using the dynolog client tool
```
#> dyno gputrace --log-file /tmp/gpu_trace_test.json
response length = 147
response = {"activityProfilersBusy":0,"activityProfilersTriggered":[4116844],"eventProfilersBusy":0,"eventProfilersTriggered":[],"processesMatched":[4116844]}
Matched 1 processes
Trace output files will be written to:
/tmp/gpu_trace_test_4116844.json
```
### Run without env variable.
```
python3 ../../linear_model.py
cuda:0
99 1425.056884765625
10099 8.817168235778809
```
## Side effects to initialization
Currently the environment should guard users from picking this change up unless intended. The libkineto_init does setup CUPTI APIs and spins up a thread to read on-demand configurations. This should not be problematic, we can provide a more granular init in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87226
Reviewed By: chaekit
Differential Revision: D40558184
Pulled By: briancoutinho
fbshipit-source-id: afea7502b1d72201c00994c87fde63a35783f4d5
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88020
Approved by: https://github.com/chaekit
Summary:
https://www.internalfb.com/code/fbsource/[c0e4da0b5c7fff3b4e31e4611033c30cabdc6aef]/fbcode/caffe2/torch/csrc/jit/backends/backend_detail.cpp?lines=268-276
seems like the torchscript addition of
`$unpack, = self.__backend.execute( ... `
the comma after unpack forces the result of execute to have only one item. So for this fix now when the size of the outputs > 1, execute returns a List List of outputs (basically put the outputs in another list before putting it into the list we return)
```
[[output1, output2, output3, ...]]
```
instead of
```
[output1, output2, output3, ...]
```
Do we want to fix this in backend_detail? Or should we make the change in our delegate to accomadate the torchscript? Proposing this q here. Requesting cccclai, kimishpatel for approval here
Test Plan: unblocked models for chengxiangyin and models in pytorch playground all passing unit tests
Reviewed By: kimishpatel, cccclai
Differential Revision: D40328684
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88345
Approved by: https://github.com/jmdetloff, https://github.com/Skylion007
We would like to be able to parameterize kernels such that a parameterized
algorithm can be implemented via templates. We can then profile performance of
a kernel with different parameter values. This enables us to determine what
parameters may work the best for a given kernel or a given device.
In this diff one such kernel added in 1x1 conv which parameters across size of
the tile being produced by each invocation.
Few other options for parameters can be:
- One can imagine dtype can also be a parameter such that we can do compute in
fp16 or int8/int16.
- Register blocking for input channels
Differential Revision: [D40280336](https://our.internmc.facebook.com/intern/diff/D40280336/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D40280336/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88323
Approved by: https://github.com/jmdetloff
Summary:
See https://github.com/pytorch/torchdynamo/issues/1475
Not allowing any new mutations happen inside forward() function during
export.
Test Plan:
Run `python test/dynamo/test_export.py` and make sure it passes
Added new unit tests (3 positive tests and 4 negative tests)
Here's what the actual error looks like
```
File "/home/mnachin/local/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 322, in step
getattr(self, inst.opname)(inst)
File "/home/mnachin/local/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 835, in STORE_ATTR
assert not self.export, f"Mutating module attribute {inst.argval} during export."
AssertionError: Mutating module attribute a during export.
from user code:
File "/data/users/mnachin/pytorch/test/dynamo/test_export_mutations.py", line 25, in forward
self.a = self.a.to(torch.float64)
Set torch._dynamo.config.verbose=True for more information
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88354
Approved by: https://github.com/tugsbayasgalan, https://github.com/jansel
This reverts commit 1c8a0656d65412b83d3c00f2fc66ab958e991de8.
Reverted https://github.com/pytorch/pytorch/pull/88175 on behalf of https://github.com/huydhn due to Sorry for reverting your PR but it breaks cuda 11.6 in trunk. As the PR signal was green, this is probably a landrace
In cases where a tensor kwarg is actually "out=", the following error message would look nicer than this :
```
Traceback (most recent call last):
File "/fsx/users/binbao/pytorch/torch/_inductor/graph.py", line 241, in call_function
out = lowerings[target](*args, **kwargs)
File "/fsx/users/binbao/pytorch/torch/_inductor/lowering.py", line 168, in wrapped
assert not any(isinstance(x, TensorBox) for x in kwargs.values())
AssertionError
```
https://github.com/pytorch/torchdynamo/issues/1798
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88367
Approved by: https://github.com/desertfire
See strategy at PythonOpRegistrationTrampoline.cpp for the
big picture.
Along the way, I made OperatorHandle support == and hashing,
and slightly changed the low level python_dispatch impl API
to disallow empty strings for dispatch key, which had the knock
on effect of requiring us to explicitly make sure we pass in
CompositeImplicitAutograd if we would have passed in "" (I didn't apply
this to the rest of the file because I'm lazy.)
Test strategy is we delete the logic for preventing Python op
registrations in torch from being skipped in a torchdeploy context
and show CI still works.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87162
Approved by: https://github.com/anjali411, https://github.com/bdhirsh
The motivation is that I am going to add the ability to temporarily
install entries to the python dispatcher, and to do that, I need
an easier way to clear the cache. Putting the cache in a dict
centralizes cache clearing in one place. I then add some easy
cache clearing.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88329
Approved by: https://github.com/albanD
983c0e7f31/torch/optim/adam.py (L163)
The above line requires that a candidate optimizer state dict being loaded via `load_state_dict()` has non-empty state for its 0th parameter (via `state_values[0]`). This PR changes FSDP to only include non-empty mappings in the state returned by `_flatten_optim_state_dict()`, which is the subroutine for both `shard_full_optim_state_dict()` and `flatten_sharded_optim_state_dict()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88353
Approved by: https://github.com/fegin
After internal discussion, we are currently preferring `fully_shard()` as the name of the composable FSDP API.
- `FullyShardedDataParallel` (FSDP) has existing brand value, so the chosen name should try to preserve that. We think this takes precedence over the fact that composable FSDP may encompass than just the ZeRO-3 approach of _fully sharding_.
- Given the refactoring efforts, it would also not be challenging to create a new frontend API like `hybrid_shard()` that calls into the same underlying initialization and runtime except for a different `ShardingStrategy`. In other words, we do not have to coalesce all sharding strategies under `fully_shard()`.
- The other composable APIs are verbs (`replicate()`, `checkpoint()`), so the chosen name should be a verb.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88233
Approved by: https://github.com/mrshenli
As part of the ongoing LTC migration effort, PyTorch/XLA is updating its codegen to use `xla::Shape` instead of `torch::lazy::Shape`. To achieve this, this PR updates the codegen to make the `GenLazyNativeFuncDefinition` generator customizable.
The existing `GenLazyNativeFuncDefinition` is kept by using the initial default values, so this change should not introduce any new behaviors to the existing codegen in PyTorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87823
Approved by: https://github.com/alanwaketan, https://github.com/wconstab
Fixes https://github.com/pytorch/pytorch/issues/84365 and more
This PR addresses not only the issue above, but the entire family of issues related to `torch._C.Value.type()` parsing when `scalarType()` or `dtype()` is not available.
This issue exists before `JitScalarType` was introduced, but the new implementation refactored the bug in because the new api `from_name` and `from_dtype` requires parsing `torch._C.Value.type()` to get proper inputs, which is exactly the root cause for this family of bugs.
Therefore `from_name` and `from_dtype` must be called when the implementor knows the `name` and `dtype` without parsing a `torch._C.Value`. To handle the corner cases hidden within `torch._C.Value`, a new `from_value` API was introduced and it should be used in favor of the former ones for most cases. The new API is safer and doesn't require type parsing from user, triggering JIT asserts in the core of pytorch.
Although CI is passing for all tests, please review carefully all symbolics/helpers refactoring to make sure the meaning/intetion of the old call are not changed in the new call
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87245
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
I am one of the maintainers of pybind11, and a frequent PyTorch user. We added quite a lot of bugfixes and performance improvements in 2.10.1 (see the changelog for full details) and I wanted to upstream them to PyTorch.
Our releases is tested throughout Google's codebase including on their global builds of PyTorch so there should be no surprises.
The main new feature is optin in Eigen Tensor to Numpy casters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88332
Approved by: https://github.com/soumith
Summary:
Sometimes we want to extend an existing custom namespace library, instead of creating a new one,
but we don't have a namespace config right now, so we hardcode some custom libraries defined
in pytorch today, i.e. quantized and quantized_decomposed
Test Plan:
ci
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88229
Approved by: https://github.com/ezyang
Fixes: https://github.com/pytorch/pytorch/issues/88010
This PR does a couple things to stop slow gradcheck from timing out:
- Splits out test_ops_fwd_gradients from test_ops_gradients, and factors out TestFwdGradients and TestBwdGradients which both inherit from TestGradients, now situated in common_utils (maybe there is a better place?)
- Skips CompositeCompliance (and several other test files) for slow gradcheck CI since they do not use gradcheck
- because test times for test_ops_fwd_gradients and test_ops_gradients are either unknown or wrong, we hardcode them for now to prevent them from being put together. We can undo the hack after we see actual test times are updated. ("def calculate_shards" randomly divides tests with unknown test times in a round-robin fashion.)
- Updates references to test_ops_gradients and TestGradients
- Test files that are skipped for slow gradcheck CI are now centrally located in in run_tests.py, this reduces how fine-grained we can be with the skips, so for some skips (one so far) we still use the old skipping mechanism, e.g. for test_mps
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88216
Approved by: https://github.com/albanD
Fixes#83038
Currently _compare_ort_pytorch_outputs does not produce clearer error messages for differences in the zero point or scale of the two outputs. It also does not produce a clear error message for whether both are quantized.
This pull request adds assertions to output whether the scales and zero points have differences, and whether each individual output is quantized.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87242
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Summary: Fix the typing stub of `ProcessGroup` in "torch/distributed/__init__.py", so that it won't confuse pyre, and we can remove a lot of pyre suppression comments.
Test Plan: pyre check
Differential Revision: D40921667
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88281
Approved by: https://github.com/wanchaol
This PR updates the reviewers responsible for CPU related modules: "IDEEP", "oneDNN graph", "CPU ATen backend", "CPU frontend" and "Autocast". It also adds "NNC" and adds the corresponding reviewers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87591
Approved by: https://github.com/malfet
Previously the permute function was extended to behave like the `order`
function for first-class dimensions. However, unlike `permute`,
`order` doesn't have a keyword argment `dims`, and there is no way to add
it in a way that makes both permute an order to continue to have the same
behavior. So this change just removes the extra functionality of permute,
which wasn't documented anyway. Fixes#88187
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88226
Approved by: https://github.com/zou3519
Fixes: https://github.com/pytorch/pytorch/issues/88205
The `CreationMeta::NO_GRAD_MODE` path in handle_view_on_rebase wrongly assumes that the tensor would be a leaf, because tensors created in no_grad are always leaf tensors. However, due to creation_meta propagation, a view of a view created in no_grad also has `CreationMeta::NO_GRAD_MODE`, but DOES have grad_fn.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88243
Approved by: https://github.com/albanD
After conda, consolidating all macos pip dependencies to cache every dependencies that macos CI needs. Two small issues are found along the way in `_mac-test-mps` workflow:
* It didn't have `Install macOS homebrew dependencies` to install libomp like the regular `_mac-test` workflow
* It didn't install `scipy`, thus silently skipping some `signal.windows` tests
Both are fixed in this PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88071
Approved by: https://github.com/malfet
Fixes https://github.com/pytorch/torchdynamo/issues/1708
Our FX subgraph partitioner works by taking all of the original output nodes from a subgraph, and replacing it with a new `call_module` node in the graph.
If the original subgraph outputs had fake tensors and other metadata stored in their `.meta` attribute though, then this information was getting lost when we spliced in the subgraph.
Losing metadata on an FX graph also seems like an easy trap to fall into, so I'm wondering if there are any better guardrails that we can add. I ended up fixing in this PR by adding an optional kwarg to propagate meta info directly in the `fx.Node.replace_all_uses_with`, just because propagating metadata seems like a pretty core thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87255
Approved by: https://github.com/wconstab, https://github.com/SherlockNoMad
* Add support to use Linux kernel perf subsystem via the profiler.
* For now the perf configurability is quite limited to just event names. Threading etc. to come later.
* Given we want to support variety of different cpu types, number of events list (in addition to the standard set of events) is also limited.
* Rather than failing with unsupported feature for non-Linux platforms, it returns zeros for all the event counts.
* For now, max event counts is capped at 4, time multiplexing is not allowed.
* Threadpool recreate hack is restricted to mobile only - need to add better support for threading in general
Differential Revision: [D40238033](https://our.internmc.facebook.com/intern/diff/D40238033/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D40238033/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87866
Approved by: https://github.com/SS-JIA
**`_init_param_attributes()` -> `init_flat_param_attributes()`**
We move `_init_param_attributes()` to `FlatParamHandle.init_flat_param_attributes()` (as already marked as to-do during previous refactoring).
**`_reset_lazy_init()`**
We no longer delete `_local_shard` from each `FlatParameter` in `_reset_lazy_init()`.
**Analysis**
Thus, the two semantic differences are that we remove the initial `if hasattr(p, "_local_shard")` early return in `_init_param_attributes()` and the `delattr(p, "_local_shard")` in `_reset_lazy_init()`.
This is safe because
- If we never call `_reset_lazy_init()`, then `init_flat_param_attributes()` is only called once. There is no opportunity for an early return.
- If we call `_reset_lazy_init()`, then `init_flat_param_attributes()` will be called again in the next `_lazy_init()`. However, since we removed the early return, all of the attributes initialized in `init_flat_param_attributes()` simply get re-initialized and override any existing attributes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87938
Approved by: https://github.com/mrshenli
This PR refactors and fixes `_cast_buffers()`.
**Before**
Buffers were not correctly cast back to their original dtypes for submodules when using buffer mixed precision.
- `_cast_buffers(recurse=False)` incorrectly casts all buffers, including those in submodules. This is because of this outer loop over `self.modules()`:
c40033be16/torch/distributed/fsdp/fully_sharded_data_parallel.py (L700)
- There was a unit test that checked that buffers were cast as expected (`test_mixed_precision_e2e_full_shard()`). The unit test _coincidentally_ passed because all modules shared the same buffer name `"buffer"`. In `_cast_buffers()`, the `dict` mapping buffer name to original dtype is populated lazily (during `_lazy_init()`). However, the keys are unprefixed:
c40033be16/torch/distributed/fsdp/fully_sharded_data_parallel.py (L712-L717)
- Thus, even though (1) `_cast_buffers(recurse=False)` was only called on the root and (2) `self._buffer_name_to_orig_dtype` had unprefixed names as keys, the unit test still passed because (1) `_cast_buffers()` still looped over all buffers despite `recurse=False` and (2) all submodules' buffers were named `"buffer"` and had the same original and low-precision dtypes and hence were cast correctly.
If we change each submodule to have its own distinct buffer name, then the unit test fails. This PR makes such a change to showcase the progression granted by this PR.
**After**
This PR separates `_cast_buffers()` into three methods: `_get_buffers_and_dtypes_for_computation()`, `_get_buffers_and_dtypes_for_checkpoint()`, and `_cast_buffers_to_dtype_and_device()`. This is to separate the different use cases (casting for computation and casting for checkpointing) and the corresponding code paths. Plus, the signature for `_cast_buffers_to_dtype_and_device()` makes it clear exactly what buffers are being cast and to what dtype.
Both `_get_...()` functions assume that they are called on the root only for now. This coincides with the construction of `_buffer_name_to_orig_dtype` in the FSDP constructor, which loops over all submodules. (This means that for non-root modules, their `_buffer_name_to_orig_dtype` is populated but not used.) The `dict`'s keys are clean since the buffer cast to original dtype happens in a `summon_full_params()` context, which cleans the names.
**Follow-Ups**
- We can try to move `_get_buffers_and_dtypes_for_checkpoint()` into `_state_dict_utils.py` in a follow-up.
- We may want to move to per-module buffer casting (i.e. do not have the root module cast for all submodules).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87935
Approved by: https://github.com/mrshenli
This PR moves `_fsdp_root_pre_forward()` to `_runtime_utils.py`.
Note: This PR includes a (temporary) fix for `NO_SHARD` + `CPUOffload(offload_params=True)`, where we set `non_blocking=False` when copying the gradient from device to host. It is only included in this PR since the test was **flaky** (but not consistently failing) on this PR , so I needed to fix to unblock land.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87930
Approved by: https://github.com/mrshenli
triton master now does not require `d` or `f` suffix
to some libdevice function calls - it dispatches to right
library call based on argument type.
triton pin updated to
f16138d447
Also removed some xfails for some unrelated tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88242
Approved by: https://github.com/ngimel
This test by itself isn't the end goal, but it is a minimal test that exercises multi-gpu and the focus of the PR is the infra behind enabling that. I'll follow up with more tests using actual models etc.
and @malfet @desertfire for awareness/feedback on the infra side
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87996
Approved by: https://github.com/aazzolini
The flash attention code path requires sm80 or newer to run on
BFloat16, so any OpInfo tests running with BFloat16 would fail with
the error:
```
RuntimeError: Expected q_dtype == at::kHalf || (is_sm8x && q_dtype == at::kBFloat16) to be true, but got false.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86600
Approved by: https://github.com/ngimel
Re-submit of gh-72302
This still has a small performance hit, but it much smaller. On my
machine I see `_record_fucntion_exit._RecordFunction` takes 1.05 us
compared to the `Tensor` overload taking 0.79 us.
In an overall comparison, I see a 0.7 us slowdown from 6.0 us to
6.7 us for this timeit benchmark
```python
import torch
def foo():
with torch.profiler.record_function("foo"):
return torch.eye(3)
%timeit foo()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76420
Approved by: https://github.com/robieta
This line is added by autoCCBot, but is not really meaningful as commit
message
Test Plan:
```
>>> from trymerge import GitHubPR, RE_PR_CC_LINE
>>> import re
>>> pr=GitHubPR("pytorch", "pytorch", 87809)
>>> re.sub(RE_PR_CC_LINE, "", pr.get_body())
'Fixes #ISSUE_NUMBER\r\n\n\n'
>>> pr=GitHubPR("pytorch", "pytorch", 87913)
>>> re.sub(RE_PR_CC_LINE, "", pr.get_body())
'Parallel compilation warms the Threadpool when we call `torch._dynamo.optimize()`. In current benchmarks, we were setting up the TRITON_CACHE_DIR much later. Because of this parallel compilation artifacts were not used and compilation latency improvements were not visible in dashboard. This PR just prepones the setup of TRITON_CACHE_DIR.\n\n'
>>> pr=GitHubPR("pytorch", "pytorch", 85692)
>>> re.sub(RE_PR_CC_LINE, "", pr.get_body())
'This PR sets CUDA_MODULE_LOADING if it\'s not set by the user. By default, it sets it to "LAZY".\r\n\r\nIt was tested using the following commands:\r\n```\r\npython -c "import torch; tensor=torch.randn(20, 16, 50, 100).cuda(); free, total = torch.cuda.cudart().cudaMemGetInfo(0); print(total-free)"\r\n```\r\nwhich shows a memory usage of: 287,047,680 bytes\r\n\r\nvs\r\n\r\n```\r\nCUDA_MODULE_LOADING="DEFAULT" python -c "import torch; tensor=torch.randn(20, 16, 50, 100).cuda(); free, total = torch.cuda.cudart().cudaMemGetInfo(0); print(total-free)"\r\n```\r\nwhich shows 666,632,192 bytes. \r\n\r\nC++ implementation is needed for the libtorch users (otherwise it could have been a pure python functionality).\r\n\r\n'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88252
Approved by: https://github.com/xuzhao9, https://github.com/izaitsevfb
Summary:
att, this is experimental api so not marking it as bc-breaking.
The match will be accepted only if all the filters in the list passes.
Changing the filter arg to be list also allows us to pass in empty list that means no filter, which makes user code cleaner.
Test Plan:
python test/test_fx.py -k test_replace_pattern_with_filters
Reviewers:
Subscribers:
Tasks:
Tags:
Differential Revision: [D40810943](https://our.internmc.facebook.com/intern/diff/D40810943)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87998
Approved by: https://github.com/SherlockNoMad
This improves hf_Bert 1.139x->1.21x, currently lowmem dropout doesn't work for nn.Dropout module, and before this change we were recomputing all the dropout masks in a very inefficient kernel. This change pushes dropout masks to be saved in the dropout kernels where they are first computed.
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88046
Approved by: https://github.com/Chillee
- FSDP tests require nccl
- also run in inductor shard and skip inductor in distributed shard
- inductor shard has newer GPU and supports triton/inductor, but only runs on trunk
- distributed shard runs on PR, but inductor shard only runs on trunk/opt-in
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88133
Approved by: https://github.com/davidberard98
This PR introduces the composable FSDP API (with constructor semantics only) along with some further constructor refactoring. A notable contribution here is `_get_submodule_to_states()`, which performs auto wrapping without actually wrapping.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87924
Approved by: https://github.com/mrshenli
This PR makes a second pass over the constructor. The logic has been grouped into `_init_<...>` functions based on intent (e.g. `_init_prefetching_state()` or `_init_runtime_state()`). This makes the initialization code for composable FSDP much cleaner than having to re-write the same sequences of lower-level helper calls.
This PR also moves `_ExecOrderData` into its own file `_exec_order_utils.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87923
Approved by: https://github.com/mrshenli
Summary: `ReplaceWithMaybeCopy` is guarded by `FBCODE_CAFFE` in `OptimizeGraph`. Run the pass manually to ensure it does the replacement.
Test Plan: Existing tests
Differential Revision: D40858743
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88099
Approved by: https://github.com/huydhn
Fixes#87713
BMM for cpu supports non-contiguous nested tensor inputs, while BMM for Cuda does not support currently non-contiguous inputs.
The derivative for BMM:
```
- name: bmm(Tensor self, Tensor mat2) -> Tensor
self: grad.bmm(mat2.transpose(1, 2).conj())
mat2: self.transpose(1, 2).conj().bmm(grad)
result: self_t.bmm(mat2_p) + self_p.bmm(mat2_t)
```
When calling backward it was impossible for this function to succeed since the inputs were always discontiguous, regardless of the user input. This adds contiguous calls to BMM_cuda implementation for nested tensors.
This was not caught by tests because grad_check is currently only done on CPU in test_nestedtensors. This PR updates the autograd test to also be run on GPU.
As a result I found one more issue with the backward for to_padded_tensor erroring instead of calling the generic version.
cc @cpuhrsch @jbschlosser @bhosmer @mikaylagawarecki
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88108
Approved by: https://github.com/cpuhrsch
We introduced the serializer we created in the previous diff to our XNNGraph builder, the purpose of this is to serialize parts of the graph as we build this. At the end, we are able to finish and serialize the xnngraph into a std::string for use when we forward this along to on-device runtime.
The next diff will rebuild the xnngraph from the serialization we introduce here, so testing the serialization of the graph will be done in the next diff
Differential Revision: [D39335580](https://our.internmc.facebook.com/intern/diff/D39335580/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39335580/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87908
Approved by: https://github.com/digantdesai
This point we perform conversion for Torchscript IR to XNNPack graph. Currently we only support converting Add Nodes and fp32 tensor values.
As a caveat, we are not building this at runtime. So for testing we just run the xnn graph once ahead of time and with sample inputs and forward it to execute. This is only for testing, and will be changed in a later diff. This will allow us to check that graph creation is sound.
Differential Revision: [D39838851](https://our.internmc.facebook.com/intern/diff/D39838851/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87824
Approved by: https://github.com/digantdesai, https://github.com/salilsdesai
Avoid double exception in destructor if attempting to serialize to
python object that does not have `write` method
Use `Finalizer` class in `PyTorchStreamWriter::writeEndOfFile()` to a
always set `finailized_` property even if excretion occurs. (as there
isn't much one can do at this point)
Add expicit check for the attribue to `_open_zipfile_writer_buffer` and
add unitests
Modernize code a bit by using Python-3 `super()` method
Fixes https://github.com/pytorch/pytorch/issues/87997
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88128
Approved by: https://github.com/albanD
As per #87979, `custom_bwd` seems to forcefully use `torch.float16` for `torch.autograd.Function.backward` regardless of the `dtype` used in the forward.
Changes:
- store the `dtype` in `args[0]`
- update tests to confirm the dtype of intermediate result tensors that are outputs of autocast compatible `torch` functions
cc @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88029
Approved by: https://github.com/ngimel
Adds `/FS` option to `CMAKE_CXX_FLAGS` and `CMAKE_CUDA_FLAGS`.
So far I've encountered this kind of errors:
```
C:\Users\MyUser\AppData\Local\Temp\tmpxft_00004728_00000000-7_cuda.cudafe1.cpp: fatal error C1041: cannot open program database 'C:\Projects\pytorch\build\third_party\gloo\gloo\CMakeFiles\gloo_cuda.dir\vc140.pdb'; if multiple CL.EXE write to the same .PDB file, please use /FS
```
when building with VS 2022.
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
Related issues:
- https://github.com/pytorch/pytorch/issues/87691
- https://github.com/pytorch/pytorch/issues/39989
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88084
Approved by: https://github.com/ezyang
## Issues
Fixes https://github.com/pytorch/pytorch/issues/81129#issuecomment-1179435674
## Description
Passing a 2D attention mask `src_mask` into the fast path of `TransformerEncoderLayer` in CPU was causing an error and so was disabled in https://github.com/pytorch/pytorch/pull/81277. This PR unrolls this fix, enabling `src_mask` on the fast path:
- Either attention mask `src_mask` of shape `(L, L)` or padding mask `src_key_padding_mask` of shape `(B, L)` are now allowed on the CPU fast path. If softmax is applied along the last dimension (as in multi-head attention), these masks are processed without expanding them to 4D. Instead, when iterating through the input, `Softmax.cpp::host_softmax` converts the index to match the mask dimensions, depending on the type.
- If softmax is applied along the dimension other than the last, `Softmax.cpp::masked_softmax_cpu` expands masks to 4D, converting them to `mask_type=2`. Theoretically one could also add special optimized cases for `dim=0, 1, 2` and process them without mask expansion, but I don't know how often is that used
## Tests:
- `test_transformerencoderlayer_fast_path` is extended to cover both attention mask and padding mask
- `test_masked_softmax_mask_types_0_1` is added to ensure results from CPU softmax with attention and padding masks match the explicit slow calculation
- `test_masked_softmax_devices_parity` is added to ensure results from masked softmax on CPU and CUDA match
## Note
I had to replace `float` with `torch.get_default_dtype()` in a couple of tests for the following reason:
- `test_nn.py` [sets the default type to `torch.double`](https://github.com/pytorch/pytorch/blob/master/test/test_nn.py#L24-L26)
- If I execute `test_nn.py` and `test_transformers.py` in one `pytest` run, this default still holds for transformer tests
- Some tests in `test_transformers.py` which were previously following the slow path now switched to fast path, and hard-coded `float` started clashing with default `double`
Let me know if there is a better way around it - or maybe I'm not supposed to run tests with `pytest` like this
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87377
Approved by: https://github.com/mikekgfb, https://github.com/weiwangmeta, https://github.com/malfet
This reverts commit e3e84830aade59722d819bc5fa01922239494790.
Reverted https://github.com/pytorch/pytorch/pull/87292 on behalf of https://github.com/weiwangmeta due to breaking internal test relating to quantization eager tests, see test/quantization/eager/test_quantize_eager_ptq.py test_lower_graph_linear and test_lower_graph_conv2d
XPU would support channels last format for group norm operator, however, Pytorch converts all input tensor to contiguous format, which includes channels last tensor. Need Pytorch pass down this memory format hint to us.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87680
Approved by: https://github.com/albanD
Fixes https://github.com/pytorch/torchdynamo/issues/1802
There are a few problems,
1. torch.fused_moving_avg_obs_fake_quant doesn't have OpInfo test
2. self.empty_like() is not a valid call. it should be torch.empty_like(self)
3. python meta function has some unexplained behavior for arguments with default value of bool type?
In particular, problem 3 is the most concerning one.
**UPDATE: This is expected behavior, see discussion below for explanation.**
Without setting the default value for `per_row_fake_quant` and `symmetric_quant`, it gets the following error when running with meta tensor.
```
meta__fused_moving_avg_obs_fq_helper() missing 2 required positional arguments: 'per_row_fake_quant' and 'symmetric_quant'
```
I can fix this by adding the default values to these two args. However, I observer something strange when examining the actual value in meta function.
```
print("per_row_fake_quant", per_row_fake_quant)
print("symmetric_quant", symmetric_quant)
```
When default values are False, printed value correctly reflect the args value populated from call site.
When default values are True, printed value is ALWAYS True, regardless of the populated value from call site.
When default Values are None, printed value is `None` when call site set the value to 'False', printed value is 'True' when call site sets the value to 'True'.
I also verify that this bug also affect for other meta function with default args....
My speculation is that this is something about pybind value packing when called from c++ dispatcher to python meta function, and default value parsing for python meta function (and other python dispatch functions) ?
I tried to find the c++ call stack, but gdb is missing symbols and C++ stacktrace is not working properly... Appreciate anyone who can point me to the source file for pybind value packing.
cc @ezyang
cc @bdhirsh. I know you had a fix in the symbolic shape branch...
cc @yanboliang who reported this bug
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88058
Approved by: https://github.com/bdhirsh, https://github.com/yanboliang
unfold_backward has a dedicated kernel for `stride >= size` which uses temporary
tensors created by `at::arange` to perform the mapping from unfolded to folded.
This instead uses `unfold` to view the output, and does a direct copy from the
gradient into the view.
In benchmarks I see either no difference or a marginal speed benefit from
this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88061
Approved by: https://github.com/albanD
`unfold_backward` implements the same operation as `col2im` but without support
for 2d kernels or dilation. However, `istft` doesn't use any of those features
and `unfold_backward` actually has a faster `TensorIterator` based
implementation so we should use it here instead.
In the example from #87353 I see a 2x speedup on both CPU and CUDA.
On a wider variety of sizes and inputs I still see speedups across the board, especially
on CPU since `col2im` isn't parallelized but `unfold_backward` is:
| device | shape | hop_length | Master (us) | This PR (us) | Speedup |
|--------|-----------------|------------|-------------|--------------|---------|
| CUDA | (1, 129, 33) | 256 | 147 | 136 | 1.08 |
| | | 128 | 153 | 128 | 1.20 |
| | (100, 129, 20) | 256 | 181 | 147 | 1.23 |
| | | 128 | 171 | 137 | 1.25 |
| | (1000, 129, 10) | 256 | 681 | 443 | 1.55 |
| | | 128 | 632 | 446 | 1.42 |
| CPU | (1, 129, 33) | 256 | 106 | 104 | 1.02 |
| | | 128 | 103 | 81 | 1.27 |
| | (100, 129, 20) | 256 | 2400 | 399 | 6.02 |
| | | 128 | 2150 | 313 | 6.87 |
| | (1000, 129, 10) | 256 | 13800 | 3740 | 3.69 |
| | | 128 | 12700 | 2110 | 6.02 |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88060
Approved by: https://github.com/albanD
The goal of this PR is to make one pass over the FSDP constructor and refactor each helper method call to not be `self.<...>`. Subsequent PRs will make further passes over the FSDP constructor.
This PR looks like a lot of lines of code change, but it is only reorganization. Methods are moved to `_init_utils.py` and `_common_utils.py`. This also marks the beginning of moving methods from `_utils.py` to `_common_utils.py` -- they will be coalesced eventually. I am only using `_common_utils.py` as a staging ground to include the methods that have been affected by the refactoring.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87921
Approved by: https://github.com/mrshenli
- This PR defines a new `api.py` meant to hold the public API for FSDP (minus `FullyShardedDataParallel` itself). This is needed because several of the `_<...>_utils.py` files rely on the public API, and we cannot import from `torch.distributed.fsdp.fully_sharded_data_parallel` without a circular import. Calling the file `api.py` follows the convention used by `ShardedTensor`.
- This PR cleans up the wording in the `BackwardPrefetch`, `ShardingStrategy`, `MixedPrecision`, and `CPUOffload` docstrings.
- This PR adds the aforementioned classes to `fsdp.rst` to have them rendered in public docs.
- To abide by the public bindings contract (`test_public_bindings.py`), the aforementioned classes are removed from `fully_sharded_data_parallel.py`'s `__all__`. This is technically BC breaking if someone uses `from torch.distributed.fsdp.fully_sharded_data_parallel import *`; however, that does not happen in any of our own external or internal code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87917
Approved by: https://github.com/mrshenli
Fixes minor perf regression I saw in #85688 and replaced throughout the code base. `obj == Py_None` is directly equivalent to is_none(). Constructing a temporary py::none() object needlessly incref/decref the refcount of py::none, this method avoids that and therefore is more efficient.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88051
Approved by: https://github.com/albanD
Summary:
There is a memory leak because `torch.clear_autocast_cache()` clears
the autocast cache from the main thread, but autograd can write to
this cache from a background thread, so whatever autograd writes
will leak.
With some offline discussion we decided that a global cache is a
practical way to deal with this, and the performance impact of the
lock should be negligible.
Test Plan:
I don't have a local repro of the original issue, need to look into how to get
that.
A toy example
(https://gist.github.com/vkuzo/0d6318fe7f7cb1c505e370cd5c1a643b)
does cache clearing as expected on forward and backward pass.
local testing:
```
python test/test_cuda.py -k autocast
python test/test_autocast.py
```
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86492
Approved by: https://github.com/ezyang
# Summary
Use the private _scaled_dot_product_attention to support _native_multiheaded_attention. _SDP provides access to fused kernels when certain conditions are meant enabling a speed up for MHA.
cc @cpuhrsch @jbschlosser @bhosmer @mikaylagawarecki
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87312
Approved by: https://github.com/cpuhrsch
Add sequence number support for UCC, mostly following format of ProcressGroupNCCL.
Pass new test: `test_all_gather_object_subgroup`
Add skips for gather tests: `test_gather_object` and `test_gather_object_subgroup`
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85047
Approved by: https://github.com/kwen2501
Summary: Even "nvcc not found" should be commented out in minifier_launcher.py, cause there could be a case that PyTorch/minifier can find cuda path but nvcc is not explicitly included in env variable like PATH.
Differential Revision: D40790023
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87959
Approved by: https://github.com/anijain2305, https://github.com/jianyuh
Not sure, what I was thinking when writing something like:
```
auto foo = std::getenv("BAR");
if (!foo) {
foo = "baz";
}
```
as `std::getenv` return `char *` (i.e. mutable string), but string literals are immutable. (i.e. `const char *`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87949
Approved by: https://github.com/kit1980
# Motivation
- torchdynamo and torchxla uses different strategies to be a sound graph capture technique. The former relies on guards; the latter relies on retracing
- guard system is quite low overhead but torchxla tracing overhead is quite high
The main idea is to leverage guard system in torchdynamo to avoid retracing in torchxla so that
- we can integration torchdynamo with XLA
- we reduce or even completely avoid tracing overhead of torchxla
# Technique details
## XLA baseline
We found that different frameworks do not generate numerically identical results for the SAME model with the SAME input. By default, torchdynamo uses eager as baseline so the model will run with PyTorch. It would be tricky to compare a model running on XLA with this baseline: it's hard to check correctness. To make the comparison easier, we add a flag `--use-xla-baseline`. When it's enabled, the baseline will be run on XLA.
## New dynamo backends added
We add 2 new dynamo backends torchxla_trivial and trochxla_trace_once to control the optimization targets.
torchxla_trivial simply moves inputs/model parameters to XLA and run the model on XLA. There is tracing overhead for each run. We should expect that result to be mostly neutral compared to the XLA baseline.
torchxla_trace_once only traces once during AOT compiling time. Here are the steps:
1. dynamo capture guards and the subgraph
2. torchxla_trace_once backend trace the graph with torchxla, lowering the graph and record a hash of the graph for later lookup
3. at inference time, the hash is used directly to lookup the optimized graph and run it.
# Limitations
We can not handle LTC/torchxla fall back right now. If a op misses LTC kernel, we raise and exception and that will results in dynamo fallback (or try another compiler). People have brainstormed the idea of graph breaking and stitching the subgraphs together. But maybe it's easier to add those missing LTC kernels for those models.
# Results
The models we tested are those not causing LTC fallback. We run the tests on **GPU**. We see **1.38x** geomean speedup for trochxla_trace_once and torchxla_trivial is mostly neutral as expected.
```
| Model | XLA (trace once) | XLA (trace everytime) |
+=========================+====================+=========================+
| resnet18 | 1.346 | 1.045 |
+-------------------------+--------------------+-------------------------+
| resnet50 | 1.153 | 1.007 |
+-------------------------+--------------------+-------------------------+
| resnext50_32x4d | 1.381 | 1.039 |
+-------------------------+--------------------+-------------------------+
| alexnet | 1.045 | 1.018 |
+-------------------------+--------------------+-------------------------+
| mobilenet_v2 | 1.562 | 1.021 |
+-------------------------+--------------------+-------------------------+
| mnasnet1_0 | 1.303 | 1.069 |
+-------------------------+--------------------+-------------------------+
| squeezenet1_1 | 1.278 | 1.025 |
+-------------------------+--------------------+-------------------------+
| vgg16 | 1.076 | 1.008 |
+-------------------------+--------------------+-------------------------+
| BERT_pytorch | 2.224 | 0.978 |
+-------------------------+--------------------+-------------------------+
| timm_vision_transformer | 1.81 | 1.025 |
+-------------------------+--------------------+-------------------------+
| geomean | 1.38101 | 1.02324 |
+-------------------------+--------------------+-------------------------+
```
The speedup is similar to what we see from previous work for LTC's TorchScript backend (we see 1.40 geomean speedup there):
https://docs.google.com/presentation/d/1G09X8v41u_cLKLtSdf7v6R8G19-iZTPcW_VAdOnvYBI/edit#slide=id.g11bf989cb6b_1_5
# Next steps
- Use AOT autograd to enable training
- Share results on XLA devices
- Do more extensive tests on torchbench models
Example command
```
GPU_NUM_DEVICES=1 python benchmarks/dynamo/torchbench.py --randomize-input --performance --use-xla-baseline --only resnet18 --backend=torchxla_trace_once
```
Thanks @JackCaoG from torchxla team to help debugging various perf issues and merging the torchxla PR! That's super critical for us to get the results above. torchxla side PR: https://github.com/pytorch/xla/pull/4119
topic: not user facing
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @jansel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87741
Approved by: https://github.com/wconstab
This is exclusively used by macOS, ROCM (and any other future workflows) that don't have direct access to S3 to upload their artifacts
### Testing
Running the script locally with the personal GITHUB_TOKEN:
```
python3 -m tools.stats.upload_artifacts --workflow-run-id 3342375847 --workflow-run-attempt 1 --repo pytorch/pytorch
Using temporary directory: /var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb
Downloading sccache-stats-macos-12-py3-arm64-runattempt1-9155493770
Downloading sccache-stats-macos-12-py3-lite-interpreter-x86-64-runattempt1-9155493303
Downloading sccache-stats-macos-12-py3-x86-64-runattempt1-9155493627
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/sccache-stats-macos-12-py3-arm64-runattempt1-9155493770 to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/sccache-stats-macos-12-py3-arm64-9155493770
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/sccache-stats-macos-12-py3-lite-interpreter-x86-64-runattempt1-9155493303 to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/sccache-stats-macos-12-py3-lite-interpreter-x86-64-9155493303
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/sccache-stats-macos-12-py3-x86-64-runattempt1-9155493627 to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/sccache-stats-macos-12-py3-x86-64-9155493627
Downloading test-jsons-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip
Downloading test-jsons-runattempt1-test-default-1-2-macos-12_9155944815.zip
Downloading test-jsons-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip
Downloading test-jsons-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip
Downloading test-jsons-runattempt1-test-default-2-2-macos-12_9155944892.zip
Downloading test-jsons-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-1-2-linux.rocm.gpu_9155913429.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-1-2-macos-12_9155944815.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-1-2-macos-12_9155944815.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-1-2-macos-m1-12_9155888061.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-2-2-linux.rocm.gpu_9155913500.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-2-2-macos-12_9155944892.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-2-2-macos-12_9155944892.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-jsons-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-jsons-test-default-2-2-macos-m1-12_9155888182.zip
Downloading test-reports-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip
Downloading test-reports-runattempt1-test-default-1-2-macos-12_9155944815.zip
Downloading test-reports-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip
Downloading test-reports-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip
Downloading test-reports-runattempt1-test-default-2-2-macos-12_9155944892.zip
Downloading test-reports-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-1-2-linux.rocm.gpu_9155913429.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-1-2-macos-12_9155944815.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-1-2-macos-12_9155944815.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-1-2-macos-m1-12_9155888061.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-2-2-linux.rocm.gpu_9155913500.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-2-2-macos-12_9155944892.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-2-2-macos-12_9155944892.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/test-reports-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/test-reports-test-default-2-2-macos-m1-12_9155888182.zip
Downloading usage-log-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip
Downloading usage-log-runattempt1-test-default-1-2-macos-12_9155944815.zip
Downloading usage-log-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip
Downloading usage-log-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip
Downloading usage-log-runattempt1-test-default-2-2-macos-12_9155944892.zip
Downloading usage-log-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-1-2-linux.rocm.gpu_9155913429.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-1-2-linux.rocm.gpu_9155913429.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-1-2-macos-12_9155944815.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-1-2-macos-12_9155944815.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-1-2-macos-m1-12_9155888061.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-1-2-macos-m1-12_9155888061.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-2-2-linux.rocm.gpu_9155913500.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-2-2-linux.rocm.gpu_9155913500.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-2-2-macos-12_9155944892.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-2-2-macos-12_9155944892.zip
Upload /private/var/folders/x4/2kd9r0fn5b9bf_sbcw16fxsc0000gn/T/tmpxl6d7kcb/usage-log-runattempt1-test-default-2-2-macos-m1-12_9155888182.zip to s3://gha-artifacts/pytorch/pytorch/3342375847/1/artifact/usage-log-test-default-2-2-macos-m1-12_9155888182.zip
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87827
Approved by: https://github.com/clee2000
This is a composable activation checkpointing API. Unlike functional
activation checkpointing APIs, this one does not require changing
model source code. Unlike ``nn.Module`` wrapper activation checkpointing
APIs, this one does not modify model structure or fully-qualified names
either. Under the hood, it registers activation checkpointing logic as pre-
and post-forward hooks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87664
Approved by: https://github.com/zhaojuanmao
Currently CUDA UCC barrier is nonblocking with respect to CPU and there is no flag to change it. To make UCC PG barrier behaviour consistent with NCCL PG in this PR barrier has changed to be always blocking.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86961
Approved by: https://github.com/kwen2501
Meta tensor does a lot of work to make sure tensors "look" similar
to the original parts; e.g., if the original was a non-leaf, meta
converter ensures the meta tensor is a non-leaf too. Fake tensor
destroyed some of these properties when it wraps it in a FakeTensor.
This patch pushes the FakeTensor constructor into the meta converter
itself, so that we first create a fake tensor, and then we do various
convertibility bits to it to make it look right.
The two tricky bits:
- We need to have no_dispatch enabled when we allocate the initial meta
tensor, or fake tensor gets mad at us for making a meta fake tensor.
This necessitates the double-callback structure of the callback
arguments: the meta construction happens *inside* the function so
it is covered by no_dispatch
- I can't store tensors for the storages anymore, as that will result
in a leak. But we have untyped storage now, so I just store untyped
storages instead.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87943
Approved by: https://github.com/eellison, https://github.com/albanD
ONNX and PyTorch has different equation on pooling and different strategy on ceil_mode, which leads to discrepancy on corner case (#71549 ).
Specifically, PyTorch avereage pooling is not following [the equation on documentation](https://pytorch.org/docs/stable/generated/torch.nn.AvgPool2d.html), it allows sliding window to go off-bound instead, if they start within the left padding or the input (in NOTE section). More details can be found in #57178.
This PR changes avgpool in opset 10 and 11 back the way as opset 9, which it stops using ceil_mode and count_include_pad in onnx::AveragePool
A comprehensive test for all combinations of parameters can be found in the next PR. #87893
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87892
Approved by: https://github.com/BowenBao
The conda dependencies have all been installed for `_mac-test` in https://github.com/pytorch/pytorch/pull/87541. I missed the same step for `_mac-build` and `_mac-test-mps` workflows, so both are also updated here. Note that arm64 is cross-compiled from x86, so the env file needs to be set explicitly in that case
After this one, I have a WIP PR to consolidate macos pip dependencies next
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87816
Approved by: https://github.com/ZainRizvi
This PR actually has meaningful changes. We stratify `TrainingState` into two levels: one is per FSDP instance and one is per `FlatParamHandle`/`FlatParameter`.
- At the FSDP instance level, we only care about `IDLE`, FSDP computation (i.e. `FORWARD_BACKWARD`), or `SUMMON_FULL_PARAMS`. These dynamically modify behavior (e.g. `summon_full_params()` forces full precision).
- At the `FlatParamHandle` level, we care about the training state for invariants and debugging. Hence, we keep `IDLE`, `FORWARD`, `BACKWARD_PRE`, `BACKWARD_POST`, and `SUMMON_FULL_PARAMS`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87916
Approved by: https://github.com/mrshenli
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87643
1. Add a decorator function exception_handlers to c10d collectives.
2. Update test(torch/distributed/distributed_c10d.py) to include mp tests for exception_handler.
```
python3 test/distributed/test_c10d_error_logger.py
```
Test Plan: Test in OSS.
Reviewed By: H-Huang
Differential Revision: D40281632
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87988
Approved by: https://github.com/H-Huang
Summary: The Mac contbuild builds under the `fbcode/mode/mac` which caffe2 fails to build under. This is due to that build mode enforcing protobuf v3. The caffe2 targets already account for this issue under `arvr` build modes by swapping out protobuf dependencies. They don't account for the same issue under `fbcode/mode/mac`. This diff fixes that by checking for `is_fbcode_mac` in these situations (in addition to `arvr`).
Test Plan:
```
buck build --flagfile fbsource//fbcode/mode/mac fbsource//xplat/caffe2/...
```
Reviewed By: kimishpatel
Differential Revision: D39552724
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87293
Approved by: https://github.com/kimishpatel
These PR fixes a number of bugs found by Svace static analyzer:
1. DEREF_AFTER_FREE at qnnpack_utils.h:
Pointer '&convolution->zero_buffer' is dereferenced at qnnpack_utils.h:258 after the referenced memory was deallocated at operator-delete.c:25 by passing as 1st parameter to function 'pytorch_qnnp_delete_operator' at qnnpack_utils.h:251.
2. DEREF_AFTER_NULL at impl.cpp:
After having been compared to NULL value at impl.cpp:1892, pointer 'schema' is passed as 2nd parameter in call to function 'c10::operator<<' at impl.cpp:1921, where it is dereferenced at function_schema_inl.h:13.
3. DEREF_OF_NULL at stmt.h:
After having been compared to NULL value at stmt.h:744, pointer 'body->_M_ptr' is passed in call to function 'torch::jit::tensorexpr::malformed_input::malformed_input' at stmt.h:745, where it is dereferenced at exceptions.h:67.
4. DEREF_OF_NULL at loopnest.h:
Pointer 'f->ptr' that can have only NULL value (checked at loopnest.cpp:1482), is passed in call to function 'torch::jit::tensorexpr::malformed_input::malformed_input' at loopnest.cpp:1483, where it is dereferenced at exceptions.h:67.
This is the same error as 3: forwarding a nullptr to malformed_input().
4. TAINTED_INT.LOOP in python_arg_parser:
Integer value 'this->size' obtained from untrusted source at python_arg_parser.cpp:118 without checking its bounds is used as a loop bound at python_arg_parser.cpp:698 by calling function 'torch::FunctionParameter::set_default_str' at python_arg_parser.cpp:133.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85705
Approved by: https://github.com/kit1980
Avoid passing raw pointer of 'torch::jit::Graph' to python. Otherwise, it will corrupt the
`internals::registered_instance` of pybind11, caching a holder for python w.r.t the raw
pointer of 'torch::jit::Graph', while not increasing the use count of the existing shared_ptr.
The behavior afterwards is random and probably undefined.
Most of the time it works, if the holder is deallocated timely on python side, and the
cache then cleared from `internals::registered_instance`. Things are back to normal.
Otherwise, it fails with either segfault or a runtime error of message "Unable to cast
from non-held to held instance". One of such scenarios is normally and correctly
returning a shared_ptr of that 'torch::jit::Graph' to python. Pybind finds the holder via
cache. Due to this, the shared_ptr use_count will not increase. If there is no other use
on C++ side, the graph will be freed, while python still has access, via the holder created
previously.
@t-vi had a great analysis and solution to this exact problem at #51833 which I hope
I had seen before debugging this issue... ~~I'm building the PR based on the original
commit. @t-vi please let me know if you'd prefer otherwise.~~ Sending the PR separately
due to CLA issues.
Need to check in CI if adding `enable_shared_from_this` breaks other stuff.
Fixes#51833, and CI issues in #87258, #86182.
cc @malfet, @kit1980 for changes on JIT IR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87343
Approved by: https://github.com/justinchuby, https://github.com/AllenTiTaiWang, https://github.com/malfet
Summary:
Previously we hardcoded the supported observers for fixedqparam ops, this PR changes that to take the information from BackendConfig,
this allows users to customize the support for fixed qparam ops
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_change_backend_config_for_fixed_qparam_ops
Reviewers:
Subscribers:
Tasks:
Tags:
unlinked from diff since it's too hard to land
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87425
Approved by: https://github.com/andrewor14
This is for consistency with FSDP.
- `_FSDP_WRAPPED_MODULE` and `_CHECKPOINT_WRAPPED_MODULE` are exactly the wrapped module variable name, meaning you can call `getattr(module, _FSDP_WRAPPED_MODULE)` or `getattr(module, _CHECKPOINT_WRAPPED_MODULE)`.
- `_FSDP_PREFIX` and `_CHECKPOINT_PREFIX` include the trailing `"."` and are only used for FQNs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87951
Approved by: https://github.com/zhaojuanmao
We change `.module` to pass through `ActivationWrapper` directly to the inner wrapped module. This should fix the state dict issues.
Given the invariant that `.module` always returns the inner wrapped module, FSDP always registers the `FlatParameter` on the inner wrapped module, regardless of if there is an intermediate `ActivationWrapper` or not. This avoids casing on whether `ActivationWrapper` is added before or after FSDP construction.
This PR removes the added unit test in `test_fsdp_misc.py` for changing the wrapped module because I would rather not complicated `_lazy_init()` logic just to support that kind of adversarial behavior. The user should not be swapping out the wrapped module arbitrarily or deleting the `FlatParameter`. I mainly had those tests to make sure that all branches of the code I added was correct.
Differential Revision: [D40799961](https://our.internmc.facebook.com/intern/diff/D40799961)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87950
Approved by: https://github.com/zhaojuanmao
The logic for determine conv backend and therefore output striding is very complex. It depends on build settings, input striding/contiguity, sizes, etc. Eventually we should port that logic to the meta impl for dynamic shapes but that will require a lot more work and keeping the implementations in sync. See https://github.com/pytorch/torchdynamo/issues/1701
This is a prerequisite to removing the inductor conv stride propagation and more general fake tensor for inductor propagation. In that PR, the meta impls for cpu conv give incorrect striding which led to test failures (https://github.com/pytorch/pytorch/pull/87083).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87305
Approved by: https://github.com/ezyang
Workaround for https://github.com/pytorch/torchdynamo/issues/1775, and calling sqrt is better in any case, but `libdevice.pow` still for some reason doesn't work if both arguments are scalars
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @mreso, can you please check if that takes you further with diffusers
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87912
Approved by: https://github.com/desertfire
# Summary
Add in a torch.backends.cuda flag and update context manager to pic between the three implementations of the scaled_dot_product_attention.
cc @cpuhrsch @jbschlosser @bhosmer @mikaylagawarecki
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87946
Approved by: https://github.com/cpuhrsch
**Description**
Replace pooling algorithm `pooling_avg` with `pooling_avg_exclude_padding` in implementation of mkldnn pooling. It's only a change of names, not algorithm. The former is an alias of the latter and it will be removed in future oneDNN library upgrades.
This change has no effect on functionality or performance.
**Validation**
Covered by UT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87851
Approved by: https://github.com/jgong5, https://github.com/XiaobingSuper
Fix Caffe2_CPU_INCLUDE with Caffe2_GPU_INCLUDE. The expanding parent scope should be with the same variable name. The compilation in certain build configurations is corrected with this fix.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87030
Approved by: https://github.com/kit1980
### Bug description
When `__SYCL_DEVICE_ONLY__` is defined, while building PyTorch, the output of the preprocessing step would not have the closing curly brace of the `extern "C"` block, as it has been incorrectly placed. Compilers don't seem to report an error or a warning for a missing closing brace of an `extern "C"` block.
### Impact of the bug
If `c10/macros/Macros.h` would be included in a C++ file, and after the preprocessing stage, if the preprocessed source file would have some templated code after `extern "C" {`, then, after compilation, linking might fail with the error `templates must have c++ linkage`). eg. https://stackoverflow.com/questions/61717819/template-with-c-linkage-error-when-using-template-keyword-in-main-cpp/61717908#61717908 (its answer also has a small snippet of code to reproduce such an issue).
### Solution in this PR
one-liner bug fix that rectifies the placement of closing curly brace (`}`), so that the `extern "C"` block ends properly when `__SYCL_DEVICE_ONLY__` is defined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87853
Approved by: https://github.com/jgong5, https://github.com/kit1980, https://github.com/malfet
Parallel compilation warms the Threadpool when we call `torch._dynamo.optimize()`. In current benchmarks, we were setting up the TRITON_CACHE_DIR much later. Because of this parallel compilation artifacts were not used and compilation latency improvements were not visible in dashboard. This PR just prepones the setup of TRITON_CACHE_DIR.
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87913
Approved by: https://github.com/wconstab
`_recursive_wrap()` returns `Tuple[nn.Module, int]`, where the `nn.Module` is the in-place modified module and the `int` is the numel wrapped. In that sense, the return value is not meant to be publicly used. The `apply_activation_checkpointing()` docs already suggest that the function returns `None`, so this PR simply follows that.
**Test Plan**
CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87871
Approved by: https://github.com/zhaojuanmao
Summary:
The pass introduces an `fb::` operator and thus cannot be used in OSS.
The test failure was not exposed because the Static Runtime tests have been disabled in OSS for a while. The Dev Infra folks encountered this failure when re-enabling the tests.
Test Plan: Existing tests
Differential Revision: D40724547
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87799
Approved by: https://github.com/huydhn
Recently, I retired `FlattenParamsWrapper`, which meant that FSDP registers its `FlatParameter` on the wrapped module instead of the `FlattenParamsWrapper` instance. This is only relevant for `use_orig_params=False`.
If the user changes an FSDP instance's wrapped module after the FSDP constructor, then the `FlatParameter` is no longer registered on the wrapped module. This can cause issues for full state dict, which checks if the `FlatParameter` is currently registered as an early return condition for `rank0_only=True`.
The solution in this PR is to re-establish the wrapped module in `_lazy_init()`, de-registering from the old wrapped module and re-registering to the new wrapped module, where the assumption is that the user should not modify the module structure upon `_lazy_init()`.
The direct access to the private attribute `_parameters` from `nn.Module` is not ideal, but we already rely on it for the dynamic `FlatParameter` registration. The tradeoff is whether we want an additional `nn.Module` wrapper (`FlattenParamsWrapper`) and use `delattr` plus a singleton list to do the dynamic registration or we want to access `_parameters`. If this becomes a problem, we can work with Core team on a solution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87837
Approved by: https://github.com/zhaojuanmao
This refactor was prompted by challenges handling mixed int/float
operations in C++. A previous version of this patch
added overloads for each permutation of int/float and was unwieldy
https://github.com/pytorch/pytorch/pull/87722/ This PR takes a different
approach.
The general outline of the patch is to combine the C++ types SymIntNode
and SymFloatNode into a single type, SymNode. This is type erased; we
no longer know statically at C++ if we have an int/float and have to test
it with the is_int()/is_float() virtual methods. This has a number of
knock on effects.
- We no longer have C++ classes to bind to Python. Instead, we take an
entirely new approach to our Python API, where we have a SymInt/SymFloat
class defined entirely in Python, which hold a SymNode (which corresponds
to the C++ SymNode). However, SymNode is not pybind11-bound; instead,
it lives as-is in Python, and is wrapped into C++ SymNode using PythonSymNode
when it goes into C++. This implies a userland rename.
In principle, it is also possible for the canonical implementation of SymNode
to be written in C++, and then bound to Python with pybind11 (we have
this code, although it is commented out.) However, I did not implement
this as we currently have no C++ implementations of SymNode.
Because we do return SymInt/SymFloat from C++ bindings, the C++ binding
code needs to know how to find these classes. Currently, this is done
just by manually importing torch and getting the attributes.
- Because SymInt/SymFloat are easy Python wrappers, __sym_dispatch__ now
takes SymInt/SymFloat, rather than SymNode, bringing it in line with how
__torch_dispatch__ works.
Some miscellaneous improvements:
- SymInt now has a constructor that takes SymNode. Note that this
constructor is ambiguous if you pass in a subclass of SymNode,
so an explicit downcast is necessary. This means toSymFloat/toSymInt
are no more. This is a mild optimization as it means rvalue reference
works automatically.
- We uniformly use the caster for c10::SymInt/SymFloat, rather than
going the long way via the SymIntNode/SymFloatNode.
- Removed some unnecessary toSymInt/toSymFloat calls in normalize_*
functions, pretty sure this doesn't do anything.
- guard_int is now a free function, since to guard on an int you cannot
assume the method exists. A function can handle both int and SymInt
inputs.
- We clean up the magic method definition code for SymInt/SymFloat/SymNode.
ONLY the user classes (SymInt/SymFloat) get magic methods; SymNode gets
plain methods; this is to help avoid confusion between the two types.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87817
Approved by: https://github.com/albanD, https://github.com/anjali411
`.detach()` worked in basic cases previously, but didn't properly preserve view relationships between the base and the output. This wasn't heavily tested, because autograd doesn't normally encounter `FunctionalTensorWrapper` directly, but could become more common if we fuse functionalization and autograd into a single tracing pass.
This will also be a bug fix for LTC (and XLA when they use functionalization)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87750
Approved by: https://github.com/ezyang
Summary:
Python's function parsing from the `ast` module records the line number of the function definition, not the first decorator. So this diff fixes crashes like this:
```
IndexError: vector::_M_range_check: __n (which is 10) >= this->size() (which is 8)
```
Test Plan: New unit test
Differential Revision: D40726352
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87804
Approved by: https://github.com/tugsbayasgalan, https://github.com/davidberard98
A recurring problem with assigning Tensor IDs is that we want to preserve identity when storage changes but we don't observe TensorImpl destruction so identity assignment is not robust to the ABA problem with respect to TensorImpl*. ~TensorImpl is far too hot to instrument; even adding a call to a no-op function in a different compilation unit increases overhead by tens of percent. (OSS builds do not have any sort of LTO.)
Fortunately there is a solution. A PyTorch Tensor is a `c10::intrusive_ptr<c10::TensorImpl>`, which in turn holds a storage. (Which is a `c10::intrusive_ptr<c10::StorageImpl>`) `c10::intrusive_ptr` has a `c10::weak_intrusive_ptr` class for taking non-owning references to the underlying object. The implementation involves both a strong refcount and weak refcount in `c10::intrusive_ptr`. If the strong refcount of an intrusive_ptr goes to zero and there are no weak references then everything is deleted. However if there is a weak reference then the intrusive_ptr calls `release_resources()` but not delete.
This has the effect of freeing the underlying resources (ensuring that program semantics are unchanged) but leaves behind an empty shell of an `intrusive_ptr` that the `weak_intrusive_ptr`s use to check status. And herein lies the solution: as long as we hold a weak reference to a TensorImpl we will block deletion and prevent the `TensorImpl*` from being reused.
This PR uses a `c10::weak_intrusive_ptr<c10::TensorImpl>` to store the address of profiled TensorImpls and then converts it to a raw pointer (or rather, a `TensorImplAddress`) during post processing when we no longer care about blocking address reuse.
Differential Revision: [D40492848](https://our.internmc.facebook.com/intern/diff/D40492848/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87244
Approved by: https://github.com/slgong-fb, https://github.com/albanD
Summary: Duplicating fbcode target `fbcode//caffe2:torch-cpp-cpu` target in xplat. In D40460749 our user wants to use `torch::kNearest` enum which is defined in `torch/csrc/api/src/enum.cpp`. Adding this target to support it.
Test Plan: Rely on CI
Differential Revision: D40532087
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87327
Approved by: https://github.com/ezyang
Summary:
att, this is experimental api so not marking it as bc-breaking.
The match will be accepted only if all the filters in the list passes.
Changing the filter arg to be list also allows us to pass in empty list that means no filter, which makes user code cleaner.
Test Plan:
python test/test_fx.py -k test_replace_pattern_with_filters
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87257
Approved by: https://github.com/SherlockNoMad
Summary:
_convert_to_reference_decomposed is a private convert function in fx graph mode quantization flow to convert
a calibrated/trained model to a reference quantized model with decomposed quantized tensor representations.
Test Plan:
python test/test_quantization.py TestQuantizeFx.test__convert_to_reference_decomposed_fx
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87094
Approved by: https://github.com/andrewor14
Simplification of one of the installation instructions in CONTRIBUTING.md that I found tricky to parse at first.
Also adds a link to the "Make no-op build fast" section to make it easier to navigate to.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87460
Approved by: https://github.com/ngimel
In this PR:
- graph_task stores graph roots on construction so that we can later traverse through the graph
- before the nodes are returned, they needed to be converted from raw_ptr to shared_ptr, and this should be OK because the graph is guaranteed to be alive
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87507
Approved by: https://github.com/albanD
The current unittests were only checking the tensors whose shapes were already multiples of the block size. That caused some hidden bugs to creep in. Specifically, for the shapes that would require padding for the mask/data, the sparsifier would try to apply shape-mismatching tensors onto each other. This caused segfaults as well as silent failures.
This makes minor adjustments to the code to make sure the masks and data shapes are aligned, as well as fixing the tests to catch this.
Test Plan:
```python
python test/test_ao_sparsity.py
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87326
Approved by: https://github.com/jcaip
I missed the fine print in https://github.com/actions/setup-python/blob/main/README.md#caching-packages-dependencies when setting up the cache using setup-python GHA
> Restored cache will not be used if the requirements.txt file is not updated for a long time and a newer version of the dependency is available which can lead to an increase in total build time.
The latter part is important because it implies that even with the cache, pip will still try to check if a newer version exists and that part can be flaky, i.e. https://github.com/pytorch/pytorch/actions/runs/3313764038/jobs/5472180293
This undesired behavior can be turned off by setting the advance option `check-latest` to false https://github.com/actions/setup-python/blob/main/docs/advanced-usage.md#check-latest-version. Per my understanding, this should tell pip install in these workflows to use the local cached copy of the package avoiding the need to query pypi every single time.
`check-latest` was added quite recently https://github.com/actions/setup-python/pull/406, so `actionlint-1.6.15` fails to recognize it. Thus, this PR also upgrades `actionlint` to the latest 1.6.21 to pass the linter check. Here is an example error from 1.6.15 from https://github.com/pytorch/pytorch/actions/runs/3315388073/jobs/5475918454:
```
>>> Lint for .github/workflows/lint.yml:
Error (ACTIONLINT) [action]
input "check-latest" is not defined in action "actions/setup-python@v4".
available inputs are "architecture", "cache", "cache-dependency-path",
"python-version", "python-version-file", "token"
25 | with:
26 | python-version: 3.8
27 | architecture: x64
>>> 28 | check-latest: false
29 | cache: pip
30 | cache-dependency-path: |
31 | **/.github/requirements-gha-cache.txt
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87621
Approved by: https://github.com/ZainRizvi
This reverts commit 4080b1db284fd531654bcb2984a7fe0ff3b310cd.
Reverted https://github.com/pytorch/pytorch/pull/87621 on behalf of https://github.com/huydhn due to Somehow setup-python treats Python 3.10 as Python 3.1 in pr-label.yml. I missed this signal because this is only run at push
I missed the fine print in https://github.com/actions/setup-python/blob/main/README.md#caching-packages-dependencies when setting up the cache using setup-python GHA
> Restored cache will not be used if the requirements.txt file is not updated for a long time and a newer version of the dependency is available which can lead to an increase in total build time.
The latter part is important because it implies that even with the cache, pip will still try to check if a newer version exists and that part can be flaky, i.e. https://github.com/pytorch/pytorch/actions/runs/3313764038/jobs/5472180293
This undesired behavior can be turned off by setting the advance option `check-latest` to false https://github.com/actions/setup-python/blob/main/docs/advanced-usage.md#check-latest-version. Per my understanding, this should tell pip install in these workflows to use the local cached copy of the package avoiding the need to query pypi every single time.
`check-latest` was added quite recently https://github.com/actions/setup-python/pull/406, so `actionlint-1.6.15` fails to recognize it. Thus, this PR also upgrades `actionlint` to the latest 1.6.21 to pass the linter check. Here is an example error from 1.6.15 from https://github.com/pytorch/pytorch/actions/runs/3315388073/jobs/5475918454:
```
>>> Lint for .github/workflows/lint.yml:
Error (ACTIONLINT) [action]
input "check-latest" is not defined in action "actions/setup-python@v4".
available inputs are "architecture", "cache", "cache-dependency-path",
"python-version", "python-version-file", "token"
25 | with:
26 | python-version: 3.8
27 | architecture: x64
>>> 28 | check-latest: false
29 | cache: pip
30 | cache-dependency-path: |
31 | **/.github/requirements-gha-cache.txt
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87621
Approved by: https://github.com/ZainRizvi
Summary: Added QConfigMultiMapping which is essentially a
List[QConfigMapping] with set methods and dedicated handling to
avoid unwanted matches and improve UX.
note: the from __future__ import annotations line caused weird errors when the
QConfigMultiMapping class was put in _numeric_suite_fx.py so it was moved.
Test Plan: python test/test_quantization.py TestFxNumericSuiteNShadows
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86922
Approved by: https://github.com/vkuzo
Fixes#86744
- Implementing the new `expm1_out_mps` function in `aten/src/ATen/native/mps/operations/UnaryOps.mm`
- Adding it to `aten/src/ATen/native/native_functions.yaml`
- Adding it to existing `test.test_mps.TestNLLLoss.test_unary_ops`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87147
Approved by: https://github.com/kulinseth
[Alban]: the other changes that used to be in this PR (neg and fix for true div) are moved to other places where they already exist. Namely neg is already in master and true div will be in the next PR on the stack where all other functions are fixed at the same time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87294
Approved by: https://github.com/ezyang
This PR allows transposes to be fused with other operations. If a fusion group is formed only from operations that just manipulate metadata in PyTorch (transpose, view, etc.) then this group is not sent to nvFuser.
On top of that if we have converted to `nvprims` but then decided to not form a fusion group we modify the graph use `prim.impl_aten` attribute instead of calling `prim(*args, **kwargs)` that has a higher overhead.
cc @kevinstephano @jjsjann123
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86967
Approved by: https://github.com/jjsjann123, https://github.com/SherlockNoMad
Summary: This diff implements copy_ in order to allow pinned memory transfers for nested tensors, as well as fill_ and ones_like, to test whether nested tensors can be created with other factory functions.
Test Plan: Pass all CI and sandcastle jobs.
Reviewed By: mikekgfb
Differential Revision: D40689594
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87728
Approved by: https://github.com/cpuhrsch
Summary:
Someone was running into problems where
1) Static Runtime enablement would fail
2) We would try to fall back to the JIT interpreter *after trying to create `StaticModule`*
3) The fallback fails because Static Runtime mangled the graph.
We don't want to prevent Static Runtime from mutating its input due to memory concerns. The intent of `canEnableStaticRuntime` is to catch issues in the module before Static Runtime messes with it.
With this diff, `StaticModule` instantiation can be avoided by querying `canEnableStaticRuntime` and the issue is fixed.
Test Plan: New unit test
Differential Revision: D40564452
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87396
Approved by: https://github.com/tenpercent
If python was launched with 'spawn' it will not use the standard
shutdown methods that concurrent.futures requires. So we register a
shutdown with the method it does uses. Without this, shutdown hangs
since the workers will not exit.
cc @jansel @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87725
Approved by: https://github.com/wconstab
The `_cast_` family of symbolic functions has been created from a template function. Even though it saved some lines, it very much obscured the intention of the code. Since the list doesn't really change and the `_cast_` family are IIRC deprecated, it is safe for us to expand the templates and make the code more readable.
This PR also removes any direct calls to `_cast_` functions to maintain a consistent pattern of directly creating `Cast` nodes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87666
Approved by: https://github.com/BowenBao
Summary:
Added q/dq implementation for out of core (decomposed) quantized Tensor representation, meaning that
instead of storing quantization parameters (e.g. scale/zero_point) in a separate quantized Tensor object, we will store
quantization parameters in the argument of operators.
```
quantize(float32_tensor, scale, zero_point, dtype) -> int8_tensor
dequantize(int8_tensor, scale, zero_point, dtype) -> float32_tensor
```
Test Plan:
python test/test_quantization.py TestQuantizedTensor.test_decomposed_quantize
python test/test_quantization.py TestQuantizedTensor.test_decomposed_dequantize
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87093
Approved by: https://github.com/dzdang, https://github.com/z-a-f
Fixes some failures we observed in `functorch` tests which seemed to stem from benchmark cache collisions on the same memory format. Changing the memory format to be dependent on both input and weight seems to resolve them.
CC @crcrpar @ptrblck
cc @csarofeen @ptrblck @xwang233
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87617
Approved by: https://github.com/ngimel
Summary:
When building 3d photo sdk generator package in arvr/mode/mac and arvr/mode/mac-arm modes, we got several issues with aten cpu and xnnpack libraries.
The reason is that those packages are using platform-* properties (platform-deps, platform-srcs...) which are not compatible with arvr modes.
This diff fixes those issues by using `select` for non-platform properties when is_arvr_mode() is true, while keeping those platform ones for non-arvr modes.
Test Plan:
```
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac-arm/dev
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac-arm/opt
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac/dev
buck build //arvr/projects/compphoto/photo3d_sdk/unity/plugin:generator_plugin_shared arvr/mode/mac/opt
```
and sandcastle builds
Differential Revision: D40028669
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87125
Approved by: https://github.com/kimishpatel
Beginning of building the xnnpack graph from the torchscript IR. We first massage the torchscript graph using a few graph passes that perform things such as unused self argument removal and constant propagation.
This also performs tracing for us so that the model does not have to be prepped by tracing before being lowered by us.
The other check we perform is through the torchscript IR to identify any nodes that are not lowerable/supported, and throwing an error to spit out the specific nodes that are not lowerable.
Differential Revision: [D39838338](https://our.internmc.facebook.com/intern/diff/D39838338/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39838338/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87128
Approved by: https://github.com/salilsdesai
**Introduces symbolic shape guards into dynamo.**
In this PR, we take the existing fake tensor infra and plumbing in dynamo and we start passing a shape_env around. This shape_env does not get plumbed down to middle layers / backend yet - it only collects expressions from frontend invocations at the moment. We then translate these expressions into guards at the point where we take other guards installed throughout dynamo - and add them to check_fn.
Part 1 of https://docs.google.com/document/d/1QJ-M4zfMkD-fjHIqW089RptjLl9EgozZGCceUbvmgfY/edit#
cc @jansel @lezcano @fdrocha @mlazos @soumith @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87570
Approved by: https://github.com/ezyang
We witnessed slow compilation times last week. Earlier, I thought it was due to parallel compilation. But, after git bisect, I found the source of extra time to be my PR - https://github.com/pytorch/pytorch/pull/87049
For 1x1 kernel, the current striding check incorrectly declares channels-first 1x1 convs to channels last. I am not sure why it caused so much compilation time jump. Or why it did not fail? There was no change in performance speedup. cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang @penguinwu to identify what could be source of this compilation time increase, so that we can manually check that part of the stack.
With this `res2next50` compilation time went back to 96 seconds (which was raised to 900 seconds with my earlier PR) for single thread. And parallel-compilation brings it down to ~30 seconds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87588
Approved by: https://github.com/soumith, https://github.com/jansel, https://github.com/ngimel
According to #38248, quantized::conv1d_relu shares packing parameters with Conv2D (kspatialDim is also 2), and needs a different unpacking way. Therefore, a new `QuantizedParamsType=Conv1D` is used to differentiate the two, and has to extract 1D information from 2D packed parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85997
Approved by: https://github.com/BowenBao
Why we want to graph-break FSDP
- FSDP has communication ops during forward and backward which we currently can't trace into the graph but also want to ensure are overlapped with compute
- dynamo has issues tracing into or capturing a call to fsdp module without a break (see below)
How we graph-break on FSDP
- marking FSDP.forward code as skip means the code frames will graph-break; but in this case all of torch.* is listed in skipfiles.py anyway, so this is taken care of
- disallowing the FSDP module prevents dynamo trying to record a 'call_module(FSDPmodule)' node into a graph, which happens earlier than the graphbreak that would be caused by skip, and causes additional issues: dynamo deepcopies modules before call-module handling, and FSDP module isn't trivially deep-copyable
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87420
Approved by: https://github.com/aazzolini
This is a policy update for meta registration. **We now prefer python meta implementation over C++ meta function.** This is a flip of the previous policy, where we prefer C++ meta function over python meta function if they both exist.
Here's the meta registration process:
1. register_meta and register_decomposition will place the python meta/decomp functions into the `global_decomp_table`. However, they will NOT register them into dispatcher.
2. After global_decomp_table is populated, we will compile an `active_meta_table`. For a given op, we pick the most specific decomp function from `global_decomp_table` in the preference order of Meta > PostAutograd > PreAutograd.
3. We will unconditionally register all of them into python dispatcher. And register them into C++ dispatcher, unless it one of the following 3 cases
- 1. the op is a CompositeImplicitAutograd, and should rely on decomposed op's meta
- 2. the op is a view op, as the MetaTensor doesn't support aliased storage
- 3. the op is in the blocklist (due to UT failures, and we will burn down this list op by op)
Over the long run, we wish to implement all meta functions in python. With this PR, 321 op_overloads will have cpp meta overridden by python meta. There are still 400 op_overloads is using cpp meta. The exact list can be found here https://gist.github.com/SherlockNoMad/d20bb736178df8eebd3b054c8bb7cdc5
cc @ngimel @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87426
Approved by: https://github.com/ezyang, https://github.com/jansel
I am not sure if this will break things ...
Although 0d tensor is an undefined behavior in ONNX spec, I did some experiments and found that ONNX shape inference actually provides 0d as inference from 0d and 1d Op calculations, and the bug happened in Broadcast function. But still, if this breaks things really bad, I think we can put 0d tensor handling on hold, as it's not very common usage on models?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87211
Approved by: https://github.com/jcwchen, https://github.com/BowenBao
Threads within a thread block would be synchronize inside the function BlockReduceSum when intra-warp reduce finishes. It's unnessary to synchronize threads before invoking function BlockReduceSum.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84854
Approved by: https://github.com/ngimel
Fixes#87359, which identifies use after free for reverse device maps. This is only in the dynamic RPC feature and not effecting stable RPC code path.
Unfortunately the test `TensorPipeRpcTest.test_dynamic_rpc_existing_rank_can_communicate_with_new_rank_cuda` that is failing is also running into separate issue. I've temporarily disabled some of the test code to investigate the error in asychronously.
Testing plan:
- tested all the dynamic RPC tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87627
Approved by: https://github.com/rohan-varma
Sometimes you want to query the small element of a set of elements and use `sorted(elements)[0]` without a second thought. However, this is not optimal, since the entire list must be sorted first `O(n log n)`. It would be better to use the `min(elements)` method provided for this purpose `O(n)`.
Furthermore `sorted(elements)[::-1]` is not very efficient, because it would be better to use `sorted(elements, reverse=True)` to save the slice operation.
**TLDR: using `sorted(elements)[0]` is slow and can be replaced with `min(elements)`.**
I stumbled across these code snippets while playing around with CodeQL (see https://lgtm.com/query/4148064474379348546/).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86995
Approved by: https://github.com/jansel
So far, we only cache macos conda dependency for build workflow. All the test dependencies are still not cached and installed by the CI. This PR introduces a new `.github/requirements` directory which I plan to explicitly include all the conda and pip build and test dependencies across all platforms. This allows pip and conda installation to be consolidated in one place (and properly cached)
Those conda dependencies come from https://github.com/pytorch/pytorch/blob/master/.jenkins/pytorch/macos-common.sh. Once this PR is merged, I will follow up with another one to clean up all conda installation from that file (to make sure that nothing break along the way)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87541
Approved by: https://github.com/ZainRizvi
This is temporary fix for internal SEV. We have run three different workflows to validate this fix would unblock internal SEV.
And, those are a few following-up tasks:
- [ ] Create reproducible test for multithreading with generator
- [ ] Figure out how to make fullsynciterator is working properly with generator
- [ ] Move Wrapper back to generator if needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87459
Approved by: https://github.com/NivekT
Summary: Rather than using the full name Profiler Event Index, use a shorten name Ev Idx. In the future, we should address this by adding a lookup table of short name to long name.
Test Plan: CI
Reviewed By: robieta, slgong-fb
Differential Revision: D40328758
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87477
Approved by: https://github.com/chaekit
I always need to install these 2 tools whenever I use Docker manually to debug build and test issues:
* unzip is to extracted the zipped artifacts from PyTorch CI
* gdb is to do you know what :)
IMO, it makes sense to have them as part of the container image
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86993
Approved by: https://github.com/ZainRizvi
Fixes https://github.com/pytorch/torchdynamo/issues/1599
Inductor performs aggressive fusion of ops during the lowering of Fx graph into IR nodes. Note that this fusion is different from the fusion that we typically discuss in the context of Inductor, which refers to the fusion of SchedulerNodes (way after lowering). This PR, instead, ensures that we don't accumulate too many ops in the IR node to begin with.
In the case of hf_t5_large backward graph, earlier we would generate a kernel with 100s of operators, causing that kernel to take ~350 seconds of compilation time. With this PR, we get it down from 350 seconds to 50 seconds.
Note that this could affect performance. I doubt that it will lead to really large dip though. In my toy examples, even if the lowering creates multiple IR nodes, if its a simple fusion, later fusion still creates one node.
I would like (1) test_torchinductor.py, (2) test_torchinductor_info.py, and (3) atleast HF models to be enabled in CI before merging this one.
@ngimel @jansel @Chillee
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang @penguinwu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87447
Approved by: https://github.com/jansel
currently failing with
```
To https://github.com/pytorch/cppdocs
+ 2825b2745bb...80ec4daa657 HEAD -> pytorchbot/temp-branch-cpp (forced update)
Branch 'master' set up to track remote branch 'pytorchbot/temp-branch-cpp' from 'origin'.
++ sleep 30
++ git push -u origin
fatal: The upstream branch of your current branch does not match
the name of your current branch. To push to the upstream branch
on the remote, use
git push origin HEAD:pytorchbot/temp-branch-cpp
To push to the branch of the same name on the remote, use
git push origin HEAD
```
just checked the settings, master of pytorch/cppdocs does not have easy cla as a required check, so we don't need the temp branch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87614
Approved by: https://github.com/huydhn
The list is for people who want to be notified on changes to the files
in there. Review is not required from the list of names; I just want to be
notified to keep track of what is going on.
Let me know if you want your names added too in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86213
Approved by: https://github.com/Chillee
Introduced RECORD_OUTPUTS() macro that goes with RECORD_FUNCTION(). It is used to capture the output tensors from a kernel launch. The tensors automatically get passed to the profiler using record_function methods. This allows the profiler to track the tensors that flow into and out of each op.
Fixes#85575
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86514
Approved by: https://github.com/robieta
Without this change, the post-backward hooks do not run when using reentrant activation checkpointing.
**Explanation**
FSDP registers the original parameters as plain `Tensor`s in the forward pass so that their ops are tracked by autograd to ensure proper gradient propagation into the `FlatParameter`s. FSDP registers the post-backward hooks in its pre-forward.
For `use_orig_params=True`, FSDP replaces the plain `Tensor`s with the sharded `nn.Parameter`s in the post-forward when resharding. This differs from `use_orig_params=False`, which keeps the plain `Tensor`s registered as attributes, except their data are freed, meaning that accessing them between forward and backward errors. Before this PR, for `use_orig_params=True`, FSDP simply restores the unsharded original parameter data in the pre-backward to enable correct gradient computation. However, this does not suffice for reentrant activation checkpointing (AC), where the recomputed forward happens after FSDP's pre-backward and the ops in the recomputed forward must be tracked by autograd.
My initial solution was to simply have FSDP restore the original parameters as plain `Tensor`s again in the pre-backward so that they would be tracked by autograd exactly like the normal forward. However, this seems to not suffice in general. The `FlatParameter`'s `AccumulateGrad` object may change after the original pre-forward when performing a recomputed forward.
The new approach in this PR is to follow the `use_orig_params=False` way -- namely, to preserve the plain `Tensor` variables across forward and backward. I achieved this by saving the variables explicitly in the forward and restoring them in the pre-backward. I clear them in the post-backward to avoid the dangling references (though, I do not think this is strictly necessary).
An alternative approach I considered is using forward hooks. However, this does not change the order of operations across FSDP, checkpoint, and the wrapped module, so it does not work. (As long as the order is FSDP(checkpoint(module)), then registered hooks still happen either before or after the checkpoint recomputation -- we cannot insert logic to run inside the checkpoint recomputation.)
**Test Plan**
I augmented the existing reentrant checkpointing unit tests to also test `use_orig_params=True`. I also verified that the pycls model does not error (even with the new approach).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87413
Approved by: https://github.com/rohan-varma
Util for convenient local benchmarking/debugging of distributed models. Not to be confused with the 'real' distributed benchmark script we use for torchbench experiments on slurm. Tries to be simple/hackable and let you use different combinations of DDP/FSDP with models and dynamo backends.
Example usage
`python benchmarks/dynamo/distributed.py --toy_model --dynamo inductor --ddp`
`--dynamo` flag accepts normal dynamo backends (plus 'print' which literally prints graphs to screen)
`--torchbench_model <model_name>` works in place of `--toy_model`
`--fsdp` is WIP
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87419
Approved by: https://github.com/jansel
Fixes#84053
As described in the issue, the AveragedModel will deep copy the model during initialization, which means that the buffers in the averaged model cannot be updated together with the model.
One solution is to make the buffers equal to the source model every time when calling `update_parameters`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84054
Approved by: https://github.com/samdow
This should help with memory usage. In particular, this allows FSDP to use caching allocator blocks from the computation stream for the `summon_full_params()` all-gathers, which should help avoid over-allocating blocks to the unshard stream.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86836
Approved by: https://github.com/rohan-varma
Summary: This adds a README for `torch.ao.quantization.backend_config`
that describes both the high level motivation and the specifications
of the BackendConfig API.
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86523
Approved by: https://github.com/jerryzh168
This PR removes the property `params_with_grad` from `FullyShardedDataParallel`. It was introduced when implementing `clip_grad_norm_()` but was not consistently used. Personally, I do not think it makes sense for `FullyShardedDataParallel` to expose this helper because it is not a common paradigm.
This PR is technically BC-breaking. However, I checked that no one internally is using this API.
cc @ezyang @gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87480
Approved by: https://github.com/rohan-varma
This PR reworks FSDP's `clip_grad_norm_()` and its unit tests. The unit tests in `test_fsdp_core.py` still need to be revisited and will be done in follow-up work.
Some details in arbitrary order:
- This renames `_calc_grad_norm()` to `_get_grad_norm()`. This is to simplify our verb usage in method names. Otherwise, we may diverge to different verbs like "compute", "calculate", "get", "find" etc. I am open to discussion here.
- Because we call `torch.linalg.vector_norm()` as the underlying norm calculation subroutine, which can take infinity as input for the norm type, there is no reason to have a separate conditional branch for the infinity norm.
- This removes a host-device synchronization point from `clip_grad_norm_()` by using the same trick from `torch.nn.utils.clip_grad_norm_()`. This may improve throughput for workloads like metaseq, which computes gradient norms regularly.
- This returns the total norm from `clip_grad_norm_()` as mentioned in the docstring. Before nothing was returned.
- This rewrites the unit tests, which were slightly problematic. Much of the logic to verify gradient norms were computed correctly were exactly the same as the logic used to compute them in FSDP (i.e. `^p`, sum via all-reduce, `^(1/p)`). This defeats the purpose of unit testing. There were some other oddities like `input = torch.rand(14, 2, device=self.rank); in_data = torch.tensor(input[self.rank], device=self.rank)`, where we materialize a full `(14, 2)` shape but only ever use the first two rows (assuming world size 2).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87479
Approved by: https://github.com/rohan-varma
This time around, I decided to rename the "all_gather" stream to the "unshard" stream to emphasize that it includes both the actual all-gather op but also the corresponding memory allocations (and also now the unflattening as well). (A similar reasoning applies for the "pre-all-gather" stream becoming the "pre-unshard" stream.)
This PR is definitely safe.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86833
Approved by: https://github.com/rohan-varma
`diag` was unnecessarily implemented as a kernel rather than as a composite
function, which made it unnecessarily difficult (explicit backward + all it entails).
We also change a few uses of `diag` on 2D tensors for `diagonal()`. The
latter returns a view rather than creating a new tensor.
We also upgrade its meta implementation to a fully-fledged
decomposition
I tried implementing the backwards of `diagonal()` via `diag_scatter` (or better `diag_scatter_` to keep the perf) but functionalisation was failing and I was not sure how to fix this, so I moved on. It may be possible to simplify that one as well if @soulitzer or someone knows how to do this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87180
Approved by: https://github.com/ngimel, https://github.com/albanD, https://github.com/mruberry
- adds support for 'first_bucket_cap' arg, to align bucketing more precisely
with DDP, which may start a smaller first bucket
- refactors the bucket splitting logic to be cleaner
- adds pretty-print for bucket info, and a way to access bucket info
from the DDPOptimizer class from a test case or benchmark
- dumps debug logs to stdout
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87549
Approved by: https://github.com/soumith
Summary:
1) Adding MKL/AVX2 based implementation into perfkernels. This implementation is similar to caffe2/operators/batch_box_cox_op.cc
2) Migrating batch_box_cox_op of caffe2 use this implementation
Test Plan: CI
Differential Revision: D40208074
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86569
Approved by: https://github.com/hyuen
While optimizer can store state however it likes, in practice most optimizer state corresponds to a particular parameter. (This is the case for all `torch.optim` optimizers.) Thus, it turns out to be ergonomic to collect using that structure. Note that this doesn't lock us into anything; we can always collect state with non Tensor keys if the use case arises.
One simplification that arises is that Module and Optimizer collection has very similar structure. So similar, in fact, that it is possible to use a common template for config. I also found that a lot of the `check_and_store` logic could be simplified and inlined by this joining of collected optimizer state.
Differential Revision: [D40210703](https://our.internmc.facebook.com/intern/diff/D40210703/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86753
Approved by: https://github.com/slgong-fb, https://github.com/aaronenyeshi
As we are linking with cuDNN and cuBLAS dynamically for all configs anyway, as statically linked cuDNN is different library than dynamically linked one, increases default memory footprint, etc, and libtorch_cuda even if compiled for all GPU architectures is no longer approaching 2Gb binary size limit, so BUILD_SPLIT_CUDA can go away.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87502
Approved by: https://github.com/atalman
- adds support for 'first_bucket_cap' arg, to align bucketing more precisely
with DDP, which may start a smaller first bucket
- refactors the bucket splitting logic to be cleaner
- adds pretty-print for bucket info, and a way to access bucket info
from the DDPOptimizer class from a test case or benchmark
- dumps debug logs to stdout
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87525
Approved by: https://github.com/davidberard98
- this `--cold_start` experiment didn't end up being used
- there is a new `--cold_start_latency` flag that is used
- this experiment was only hooked up for nvfuser anyway
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87470
Approved by: https://github.com/anijain2305
Enable a test that would have caught https://github.com/pytorch/pytorch/issues/86239
Prior to the fix for that bug, this test fails with
```
_____________________________ TestCommonMPS.test_numpy_ref_mps_where_mps_float32 _____________________________
Traceback (most recent call last):
File "/Users/alex/git/pytorch/test/test_ops.py", line 197, in test_numpy_ref_mps
self.compare_with_reference(
File "/Users/alex/git/pytorch/torch/testing/_internal/common_utils.py", line 2366, in compare_with_reference
actual = torch_fn(t_inp, *t_args, **t_kwargs)
File "/Users/alex/git/pytorch/torch/testing/_internal/opinfo/core.py", line 1068, in __call__
return self.op(*args, **kwargs)
File "/Users/alex/git/pytorch/torch/testing/_internal/common_methods_invocations.py", line 15167, in <lambda>
op=lambda self, condition, other: torch.where(condition, self, other),
RuntimeError: 0'th index 3 of x tensor does not match the other tensors
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87342
Approved by: https://github.com/albanD
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86699
This diff does the following:
1. **c10d_error_logger.py**: Add an API to create a logger with a specific logging handler based on the destination.
2. The API from above would get a logging handler based on the destination provided.
- **caffe2/torch/distributed/logging_handlers.py**: For OSS, we simply use a NullHandler() for now.
3. Add associated test files for 1 and 2.
Test Plan:
## Unit Test
```
buck test @//mode/dev-nosan //caffe2/test/distributed:test_c10d_error_logger -- --print-passing-details
```
```
File changed: fbcode//caffe2/test/distributed/test_c10d_error_logger.py
File changed: fbsource//xplat/caffe2/test/distributed/TARGETS
9 additional file changes
waiting for all tests to finish...
✓ Listing success: caffe2/test/distributed:test_c10d_error_logger (0.2s)
Found 1 tests
✓ Pass: caffe2/test/distributed:test_c10d_error_logger - test_get_or_create_logger (caffe2.test.distributed.test_c10d_error_logger.C10dErrorLoggerTest) (0.2s)
stdout:
stderr:
Buck UI: https://www.internalfb.com/buck2/b975f6b0-77e9-4287-8722-f95b48036181
Test Session: https://www.internalfb.com/intern/testinfra/testrun/1407375150206593
RE: reSessionID-4d7ab8ca-1051-48e9-a5a8-6edbe15d1fe4 Up: 124 B Down: 0 B
Jobs completed: 5. Time elapsed: 3.5s.
Tests finished: Pass 1. Fail 0. Fatal 0. Skip 0. 0 builds failed
```
Differential Revision: D39920391
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87123
Approved by: https://github.com/fduwjj, https://github.com/H-Huang
When a commit is triggered via any mechanism other than a pull request, there will not be a PR to check labels for.
The job will fail with the error:
```
2022-10-21T17:50:53.2938592Z + python3 .github/scripts/check_labels.py ''
2022-10-21T17:50:53.4758863Z usage: Check PR labels [-h] pr_num
2022-10-21T17:50:53.4759337Z Check PR labels: error: argument pr_num: invalid int value: ''
```
Instead, we should limit the workflow to only run on pull requests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87488
Approved by: https://github.com/huydhn
dynamo tests call a helper function in torch/_dynamo/test_case.py which then calls run_tests in common_utils.py so the test report path looked something like /opt/conda/lib/python3/10/site-packages/torch/_dynamo/test_case
* instead of using frame, use argv[0] which should be the invoking file
* got rid of sanitize functorch test name because theyve been moved into the test folder
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87378
Approved by: https://github.com/huydhn
This fixes an issue with mobile: The output of view_copy ops should always be contiguous.
Later, we can consider adding optional arguments to the `view_copy()` functions to let you explicitly say what the contiguity of the output can be (e.g. channels_last)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85747
Approved by: https://github.com/ezyang
### Context
When a dev submits a PR against the repo, we want to validate that they applied two labels to the PR corresponding the module they edited and the kind of change they're making.
### Change
Extended the open source workflow CI to add a validation to ensure that the PR being checked has the required labels on it. If it doesn't, the check fails and a bot will post a message on the PR with instructions on what labels the developer needs to add (https://github.com/pytorch/pytorch/wiki/PyTorch-AutoLabel-Bot#why-categorize-for-release-notes-and-how-does-it-work).
### Impact
Every time a new version of PyTorch is released, we want to compile all the changes made to each module. However, when devs forget to tag their PR, compiling the changes to write the release notes becomes a burdensome process (only ~20% of PRs are currently labeled appropriately, which means it can take up to 40 hours to compile release notes). With this new validation, the hope is that most PRs are labeled accordingly for more timely release notes compilation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86829
Approved by: https://github.com/ZainRizvi
All of the kernels already either start by zeroing the output, or are
careful in their implementation to write values to every output
location. So, these `zero_` calls should be redundant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87375
Approved by: https://github.com/albanD
To cooperate with other multithreading methods, this
forces the process pool to use 'fork' even if others have set it
diferently. We require fork because otherwise `if __name__ == __main__`
needs to be set which we do not control as a library.
Furthermore this adds code to cleanup worker processes if
the parent exits abnormally (e.g. segfault). Previously we would leave
live but inactive workers around.
cc @jansel @lezcano @fdrocha
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87411
Approved by: https://github.com/soumith, https://github.com/anijain2305
I noticed that a lot of bugs are being suppressed by torchdynamo's default
error suppression, and worse yet, there's no way to unsuppress them. After
discussion with voz and soumith, we decided that we will unify error suppression
into a single option (suppress_errors) and default suppression to False.
If your model used to work and no longer works, try TORCHDYNAMO_SUPPRESS_ERRORS=1
to bring back the old suppression behavior.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87440
Approved by: https://github.com/voznesenskym, https://github.com/albanD
Some original parameters corresponding to one `FlatParameter` may have `None` gradient while others do not. In that case, the `flat_param.grad` must be non-`None`. However, FSDP should take care to expose the original parameters' gradients regardless. To achieve this, we track a `_is_grad_none` mask over the parameters' gradients.
- `_is_grad_none` is initialized to `False` for all.
- `_is_grad_none[i]` is set to `True` when writing zeros in place of `None` when writing back the `i`th gradient.
- `_is_grad_none[i]` is set to `False` via `_reset_is_grad_none()`, which should be called in the post-backward. See the docstring for details.
- `_is_grad_none[i]` must be `False` in order to set `param.grad` to be a view into `flat_param.grad`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87308
Approved by: https://github.com/zhaojuanmao
This PR changes `summon_full_params(with_grads=True)`'s behavior to be such that if all ranks have `flat_param.grad = None`, then the original parameters will correctly have `orig_param.grad = None`. This is achieved with a preliminary all-reduce. Note that if a particular original parameter's gradient is `None` on all of the containing ranks, but not all ranks' `flat_param.grad = None`, then that particular gradient is still going to be set to zeros. This can be handled if desired in follow-up work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87314
Approved by: https://github.com/zhaojuanmao
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86259
Add assertion to make sure backend is one of "fbgemm", "x86", "qnnpack" and "onednn"
for get_default_qconfig, get_default_qat_qconfig, get_default_qconfig_mapping and get_default_qat_qconfig_mapping
Test Plan:
python test/test_quantization.py -k test_get_default_qconfig_mapping
Imported from OSS
Reviewed By: jcaip
Differential Revision: D40236474
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87331
Approved by: https://github.com/andrewor14
This PR resolves a TODO left in `FlatParamHandle` that was conditional on deprecating `FlattenParamsWrapper`. We simply pass in the process group into the `FlatParamHandle` constructor instead of later in `shard()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87113
Approved by: https://github.com/zhaojuanmao
Testing coverage is pretty much preserved except that we do not test on CPU, which is not a tangible loss for FSDP anyway.
I renamed a few tests slightly, and I moved some helpers to be immediately below the corresponding test method. This makes it a bit easier to read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87112
Approved by: https://github.com/zhaojuanmao
This PR registers each `FlatParameter` to the wrapped module, eliminating `FlattenParamsWrapper` usage completely from FSDP.
Registering each `FlatParameter` to the wrapped module is preferred over registering to the `FullyShardedDataParallel` instance for both functional-like and non-recursive wrapping. It simplifies the `FlatParameter` naming to be a function of the number of `FlatParameter`s per wrapped module instead of the number of `FlatParameter`s per FSDP instance. For now, we assume 1 `FlatParameter` per wrapped module, so we can simply use a single name `FLAT_PARAM = _flat_param`.
From an implementation perspective, we raise some methods from `FlattenParamsWrapper` directly up to `FullyShardedDataParallel`. There will need to be further refactoring for functional-like and non-recursive wrapping. For example, the property `self._has_params -> bool` may need to change to a method `self._has_params(wrapped_module) -> bool`. Such changes are out of scope for this PR and will be done in follow-ups.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87086
Approved by: https://github.com/zhaojuanmao
This removes **direct** usages of `_fsdp_wrapped_module.flat_param` with `_handles[0].flat_param`. The preferred way to access the `flat_param` will be through the handle. We may converge to only storing `self._handles` and no longer `self.params` in the future. Right now, `self.params` is always exactly `[handle.flat_param for handle in self._handles]`.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86122
Approved by: https://github.com/zhaojuanmao
We recently fixed a bug on symbolic-shapes branch where
an isinstance(x, int) test failed when passed a SymIntNode.
To prevent this, I've added a lint for all the codepaths
where we may pass SymInt/SymFloat directly to reject
direct isinstance int/float tests, and instead use one of
the aliases. The lint rule explains the options. I then
go and fix all of them.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87345
Approved by: https://github.com/bdhirsh, https://github.com/albanD
Tensor's view in linear storage is represented by the following parameters: `.shape`, `.stride()` and `.storage_offset()`.
Only tensors that are representable as 1d-views can be copied from host to device (and vice versa) using single [`copy(from:sourceOffset:to:destinationOffset:size:)`](https://developer.apple.com/documentation/metal/mtlblitcommandencoder/1400767-copyfrombuffer?language=objc) call.
Modify `copy_to_mps_` function to do the following steps:
- Cast `src` tensor to dst data type if needed
- Expand `src` tensor to `dst` tensor shape
- Clone `src` tensor if it is not stride contiguous (i.e. can not be represented by `src.view(src.numel())`)
- Create an empty tensor if `dst` is not stride-contiguous or if its strides are different then potentially cloned `src` strides
- Do 1d copy for `src` to (potentiall temp) `dst`
- Finally do re-striding/copy on MPS if needed
Add test to cover cases where stide-contiguous permuted tensor is copied to MPS, non-stride-contiguous tensor is copied to MPS and if permuted CPU tensor is copied to differently permuted MPS tensor
Fixes https://github.com/pytorch/pytorch/issues/86954
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86956
Approved by: https://github.com/kulinseth
There is a bug in the implementation of the registration hooks introduced in https://github.com/pytorch/pytorch/pull/86148 whereby if the hook returns a tensor, then the short circuiting logic:
```
value = hook(self, name, value) or value
```
Raises an exception
```
RuntimeError: Boolean value of Tensor with more than one value is ambiguous
```
Fixing the logic so that it only checks to see if the value is `None` before overriding
Fixes#85837
CC: @albanD @jbschlosser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87369
Approved by: https://github.com/albanD
This addresses the security issue in default Python's `unpickler` that allows arbitrary code execution while unpickling.
Restrict classes allowed to be unpicked to in `None`, `int`, `bool`, `str`, `float`, `list`, `tuple`, `dict`/`OrderedDict` as well as `torch.Size`, `torch.nn.Param` as well as `torch.Tensor` and `torch.Storage` variants.
Defaults `weights_only` is set to `False`, but allows global override to safe only load via `TORCH_FORCE_WEIGHTS_ONLY_LOAD` environment variable.
To some extent, addresses https://github.com/pytorch/pytorch/issues/52596
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86812
Approved by: https://github.com/ezyang
Summary:
reland after fixing windows build failure for OVR.
Notable change:
```
#if defined(FBCODE_CAFFE2) or defined(FB_XPLAT_BUILD)
```
changed to
```#if defined(FBCODE_CAFFE2) || defined(FB_XPLAT_BUILD)
```
Appearently `-DFB_XPLAT_BUILD` wasn't getting picked up in windows if using `or `to connect
Original commit changeset: 7a31fc4b455f
Original Phabricator Diff: D40198461
Test Plan: waitforsandcastle
Reviewed By: davidberard98, cccclai
Differential Revision: D40290932
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87124
Approved by: https://github.com/gmagogsfm
This reverts commit 703c19008df4700b6a522b0ae5c4b6d5ffc0906f.
Reverted https://github.com/pytorch/pytorch/pull/87311 on behalf of https://github.com/anijain2305 due to Bin (desertfire) is trying to get torchbench models in CI, and this PR prevents that. I will bring this back after models are in CI.
Previously we claimed that "forward-mode AD coverage is not that good".
We've since improved it so I clarified the statement in our docs and
downgraded the warning to a note.
Test Plan:
- view docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87383
Approved by: https://github.com/samdow
The bug was discovered in https://github.com/pytorch/pytorch/pull/86842.
torch.cat has an edge case where it ignores all tensors of shape [0]. So
if any of the BatchedTensors have logical shape [0] but physical shape
[B, 0], then we coerce them to shape [0] by slicing them.
Why don't we just ignore those Tensors? We need to propagate
requires_grad-ness somehow (e.g. if the BatchedTensor wraps a Tensor of
shape [B, 0] that requires grad, then the output must require grad).
Test Plan:
- new tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86932
Approved by: https://github.com/Chillee
It seems like when popen.communicate() is used it waits for all the
desendents of popen to close the stdin/stderr. However, if we have
have worker processes running in the child, and the child segfaults,
those processes will stay alive until someone waitpid's the child.
Since those children have open handles to the stdin/stderr pipe,
communicate never returns.
This change just writes the output to temp files and directly calls
wait() on the child, which returns as soon as it dies.
cc @jansel @lezcano @fdrocha
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87335
Approved by: https://github.com/anijain2305, https://github.com/voznesenskym
Summary: This commit adds support for moving NestedTensors from CPU to GPU and back. The implementation includes requires implementing empty_like(), which is based on PR#83140.
Test Plan: Added a new unit test based on the unit test for the main .to() implementation. All unit tests must pass, as well as every sandcastle job.
Differential Revision: D40437585
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87146
Approved by: https://github.com/drisspg
Summary: Today, in order to get XNNPACK quantized ops to work,
the user must write some code that refers to private data
structures (`_FIXED_QPARAMS_OP_TO_OBSERVER`) to create a
QConfigMapping that is compatible with the symmetric constraints
in the QNNPACK BackendConfig. This is because
`get_default_qconfig("qnnpack")` produces a QConfig that does
not satisfy these constraints, and the default QConfigMapping
for QNNPACK uses this Qconfig.
Instead, we simply put this code into a helper function to make
it easier for the user to run XNNPACK quantized ops. In the
future, once there is feature parity between the set of ops
supported by QNNPACK and XNNPACK, we should revisit whether
to simply change `get_default_qconfig("qnnpack")` to return
an XNNPACK-compatible QConfig.
Test Plan:
python test/test_quantization.py
TestQuantizeFx.test_symmetric_qnnpack_qconfig_mapping
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87002
Approved by: https://github.com/vkuzo
This is parts of the effort to consolidate pip and conda installation in the CI to improve our CI reliability. This moves conda cmake installation to Docker in those use cases that require it:
* Ubuntu bionic and focal
On the other hand:
* XLA doesn't seem to need conda cmake anymore (Build and test successfully)
* Centos is not in used anywhere in the CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87309
Approved by: https://github.com/ZainRizvi, https://github.com/malfet
This replaces the manual function pointers, making it easier to write
new drop-in allocators.
Note that most allocation goes through the Allocator interface, which
CUDAAllocator inherits from, and this arrangement avoids adding and
additional layer of dispatch along this pathway compared to what existed before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87251
Approved by: https://github.com/wconstab
The syntax is invalid for pip. I missed this a while back:
```
Run pip install -r .github/requirements-gha-cache.txt
ERROR: Invalid requirement: 'lintrunner=0.9.2' (from line 11 of .github/requirements-gha-cache.txt)
Hint: = is not a valid operator. Did you mean == ?
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87295
Approved by: https://github.com/ZainRizvi
Fixes https://github.com/pytorch/functorch/issues/1052
I got here after some discussion with Alban. Today, if you aot_function() trace a program where some of its inputs have `requires_grad=True`, but some outputs are expected to have `requires_grad=False`, we will incorrectly set all outputs to have `requires_grad=True`.
A simple solution is to use autograd.function's API for marking outputs as non-differentiable, based on what we witnessed when we traced the forward.
This will make the `autograd.Function` that we return **wrong**, if you created it using inputs that required grad, and tried to re-use it with inputs that have different `requires_grad` field. But as long as we're hiding behind dynamo, which should guard on requires_grad, then we'll re-run `aot_function()` and get out a new compiled function that does the right thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86838
Approved by: https://github.com/ezyang
We initially left it there for BC concerns.
- It has been more than a month since then,
- I have migrated folks who used the previous install command (pip
install ...pytorch.git@subdir=functorch) off of it
so it's time to get rid of it
Test Plan:
- code reading
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87235
Approved by: https://github.com/Chillee
This API adds some improvements to external backends who are building C++ backends out of tree using the `PrivateUse1` dispatch key.
The docs and linked examples go over the API in more detail, but you should be able to use it like:
```
# This should probably be in the __init__.py file of a external backend's python package
> torch.register_privateuse1_backend("foo")`
# And it will allow the user to do this:
> a = torch.ones(2, device="foo")
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86992
Approved by: https://github.com/albanD
The context is that historically, XLA/LTC tensors haven't had accurate stride information, and functionalization would run "reference" meta kernels for view ops on the side to properly compute strides.
This is more complicated in symint tracing world - we have a `FunctionalTensorWrapper()` that wraps the underlying tensor and has its own set of sizes/strides metadata, but we never create proxy objects for the sizes/strides of the wrapper.
In symint tracing world with aot autograd, we're guaranteed that our underlying strides are accurate anyway, since aot autograd uses fake tensors to perform tracing. We encountered a few bugs with symint's from the `FunctionalTensorWrapper` making their way into `__torch_dispatch__`. To side-step that area of bugs completely (and marginally improve perf), this PR disables the meta tensor tracing for non XLA/LTC use cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87108
Approved by: https://github.com/ezyang, https://github.com/wconstab
This reverts commit bbd7b38d5580c44ffb4404d431e07bc2316e59d5.
Reland https://github.com/pytorch/pytorch/pull/86915 with a fix for python arg parser handing for SymInt and SymIntList.
This was uncovered because we are calling directly into python bindings code through test_autocast.py (`torch._C._nn.nll_loss`) without providing a value for the optional symint arg (`ignore_index`). The arg parser constructs the SymInt and SymIntList using the recorded "default_int" or "default_int_list" (schema string parsing) in case a value is not received for an optional argument. Since we weren't handling the symint case properly, the default_int just had a garbage value which was later being used to construct SymInt.
Follow up issue for other unhandled parameter types: https://github.com/pytorch/pytorch/issues/87283
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87095
Approved by: https://github.com/ezyang, https://github.com/albanD
Also, add `torchtriton` and `jinja2` as extra `dynamo` dependency to PyTorch wheels,
Version packages as first 10 characters of pinned repo hash and make `torch[dynamo]` wheel depend on the exact version it was build against.
TODO: Automate uploading to nightly wheels storage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87234
Approved by: https://github.com/msaroufim
Summary:
The current behavior of owning_module setter is difficult to understand: it changes the owning_module to None if owners is not 0 but increments the owners count. If the owning_module is None, the owners count should be 0 as none of them is accessible. On the other hand, if the owners count increases, the owning_module should be a collection (e.g. a list).
This diff changes owning_module to be a normal attribute. The semantic is that graph can have **at most one** owning module and can be assigned to new module.
The alternative is to use a list to represent the owning_modules of a graph but it breaks backward compatibility and the exact use cases of having multiple owning_modules are not clear.
Test Plan: Test with CI.
Differential Revision: D40200624
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86822
Approved by: https://github.com/tugsbayasgalan
Fixes#87010.
It turns out that squeeze is much faster than sum, and view is faster than squeeze, so we should default to that whenever possible.
Benchmarking results show that, on MPS, we would be going from the following code taking **29.89ms instead of the current 1466ms, almost a 50x speedup**.
```
q = torch.rand(16, 4096, 40, device='mps', dtype=torch.float)
k = torch.rand(16, 4096, 40, device='mps', dtype=torch.float)
torch.einsum('b i d, b j d -> b i j', q, k).max().item()
```
And a regular einsum will now take **.506ms instead of 2.76ms.**
```
q = torch.rand(16, 4096, 40, device='mps', dtype=torch.float)
k = torch.rand(16, 4096, 40, device='mps', dtype=torch.float)
torch.einsum('b i d, b j d -> b i j', q, k)
```
Special thanks to @soulitzer for helping me experiment + figure out how to squash the remaining 5x regression due to squeeze being slower than view!!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87135
Approved by: https://github.com/soulitzer, https://github.com/malfet, https://github.com/albanD
We promise that if path is not defined, we would go left to right. The previous code did not keep that promise as we push'd combined ops to the back of the list. For most use cases this is fine (einsum with 3 or fewer inputs), but we should do what we say.
Test plan:
Added a print statement to print the sizes of ops we're contracting to see if the order is fixed. Code run:
```
import torch
a = torch.rand(1)
b = torch.rand(2)
c = torch.rand(3)
d = torch.rand(4)
torch.einsum('a,b,c,d->abcd', a,b,c,d)
```
BEFORE--it does a+b, then c+d, then a+b+c+d, which...is right, but it's not the order specified by the user.
```
/Users/janeyx/pytorch/torch/functional.py:378: UserWarning: Contracting a: [1, 1, 1, 1]and b: [1, 2, 1, 1] (Triggered internally at /Users/janeyx/pytorch/aten/src/ATen/native/Linear.cpp:507.)
return _VF.einsum(equation, operands) # type: ignore[attr-defined]
/Users/janeyx/pytorch/torch/functional.py:378: UserWarning: Contracting a: [1, 1, 3, 1]and b: [1, 1, 1, 4] (Triggered internally at /Users/janeyx/pytorch/aten/src/ATen/native/Linear.cpp:507.)
return _VF.einsum(equation, operands) # type: ignore[attr-defined]
/Users/janeyx/pytorch/torch/functional.py:378: UserWarning: Contracting a: [1, 2, 1, 1]and b: [1, 1, 3, 4] (Triggered internally at /Users/janeyx/pytorch/aten/src/ATen/native/Linear.cpp:507.)
return _VF.einsum(equation, operands) # type: ignore[attr-defined]
```
WITH THIS CHANGE--it actually goes left to right: a+b, a+b+c, a+b+c+d
```
/Users/janeyx/pytorch/torch/functional.py:378: UserWarning: Contracting a: [1, 1, 1, 1]and b: [1, 2, 1, 1] (Triggered internally at /Users/janeyx/pytorch/aten/src/ATen/native/Linear.cpp:507.)
return _VF.einsum(equation, operands) # type: ignore[attr-defined]
/Users/janeyx/pytorch/torch/functional.py:378: UserWarning: Contracting a: [1, 2, 1, 1]and b: [1, 1, 3, 1] (Triggered internally at /Users/janeyx/pytorch/aten/src/ATen/native/Linear.cpp:507.)
return _VF.einsum(equation, operands) # type: ignore[attr-defined]
/Users/janeyx/pytorch/torch/functional.py:378: UserWarning: Contracting a: [1, 2, 3, 1]and b: [1, 1, 1, 4] (Triggered internally at /Users/janeyx/pytorch/aten/src/ATen/native/Linear.cpp:507.)
return _VF.einsum(equation, operands) # type: ignore[attr-defined]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87199
Approved by: https://github.com/soulitzer
Summary: For Python Tracing enabled trace files, this field "python thread": 0 is repeated for every python_function event. This bloats the trace json size for large number of events or deep call stacks. Instead make this metadata guarded by the verbose flag.
Test Plan: CI
Reviewed By: robieta, slgong-fb
Differential Revision: D40325815
Pulled By: aaronenyeshi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87096
Approved by: https://github.com/slgong-fb, https://github.com/robieta
Porting over [torchdynamo/#1633](https://github.com/pytorch/torchdynamo/pull/1633)
`torch/_inductor/codegen/triton.py` now defines `libdevice_<function>` variants
of some functions. You can request dispatch to those for
float64 dtypes when using `register_pointwise` by setting
`use_libdevice_for_f64=True`.
Other minor changes:
- In triton, sigmoid now codegens tl.sigmoid
- silu now comes from decomp, not lowering
- Some test skips no longer necessary, removed or made xfails
Switching to `tl.sigmoid` has exactly same performance.
Moving `silu` to decomp does not change anything, same triton code is generated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87189
Approved by: https://github.com/ngimel
At the moment, they were casted to `int64`, which breaks quite a few
casting rules for example in `ops.aten`.
Quite a vintage bug, circa 2020.
With this fix, the following code prints `torch.bool`, rather than `torch.int64`.
```python
import torch
msk = torch.tensor([False])
b = torch.tensor([False])
print(torch.ops.aten.where.ScalarSelf(msk, True, b).dtype)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87179
Approved by: https://github.com/albanD
1. Made TreeSpec into a dataclass.
2. In `__repr__`, recursively transformed TreeSpec into dictionaries and then pretty-printed it.
Fixes#46538. Hi, @ezyang. this PR is for the TreeSpec `__repr__` refactor we discussed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86546
Approved by: https://github.com/ezyang
Fixes https://github.com/pytorch/torchdynamo/issues/1690
This fixes the error seen in the minifiers. But does not repro the original issue that prompted the above issue.
Fx minifiers work at the level of Fx-graphs, and the original issue lies outside of the Fx graph and is only visible on the second iteration. Therefore, the original issue escapes the abstraction of our existing Fx-based minifiers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87062
Approved by: https://github.com/eellison
Without this, I was running into obvious `KeyError`s that were assuming that the device was an integer when running `examples/imagenet`.
```python
(pytorch) soumith@bluebox:~/code/examples/imagenet$ python main.py --gpu 0 /home/soumith/dataset/imagenet
/home/soumith/code/vision/torchvision/io/image.py:13: UserWarning: Failed to load image Python extension:
warn(f"Failed to load image Python extension: {e}")
/home/soumith/code/examples/imagenet/main.py💯 UserWarning: You have chosen a specific GPU. This will completely disable data parallelism.
warnings.warn('You have chosen a specific GPU. This will completely '
Use GPU: 0 for training
=> creating model 'resnet18'
make_fallback(aten.unfold): a decomposition exists, we should switch to it
make_fallback(aten.unfold_backward): a decomposition exists, we should switch to it
Traceback (most recent call last):
File "/home/soumith/code/pytorch/torch/_inductor/graph.py", line 254, in call_function
return lowerings[target](*args, **kwargs)
File "/home/soumith/code/pytorch/torch/_inductor/lowering.py", line 202, in wrapped
return decomp_fn(*args, **kwargs)
File "/home/soumith/code/pytorch/torch/_inductor/lowering.py", line 2994, in var_
diffs = square(sub(x, mean(x, axis, keepdim=True)))
File "/home/soumith/code/pytorch/torch/_inductor/lowering.py", line 202, in wrapped
return decomp_fn(*args, **kwargs)
File "/home/soumith/code/pytorch/torch/_inductor/lowering.py", line 2983, in mean
sum_result = sum_(x, axis, keepdim)
File "/home/soumith/code/pytorch/torch/_inductor/lowering.py", line 202, in wrapped
return decomp_fn(*args, **kwargs)
File "/home/soumith/code/pytorch/torch/_inductor/lowering.py", line 3211, in sum_
return fn(x, axis, keepdims, dtype=dtype)
File "/home/soumith/code/pytorch/torch/_inductor/lowering.py", line 2953, in inner
result = Reduction.create(
File "/home/soumith/code/pytorch/torch/_inductor/ir.py", line 714, in create
hint, split = cls.num_splits(
File "/home/soumith/code/pytorch/torch/_inductor/ir.py", line 454, in num_splits
num_sm = get_device_properties(device).multi_processor_count
File "/home/soumith/code/pytorch/torch/_inductor/cuda_properties.py", line 43, in get_device_properties
return _properties()[_device(device)]
KeyError: device(type='cuda', index=0)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87174
Approved by: https://github.com/yf225
Real dtype input to `torch.istft` has been deprecated since PyTorch
1.8, so it is more than passed its due date to be removed.
BC-breaking message:
`torch.istft` no longer supports input in the form of real tensors
with shape `(..., 2)` to mimic complex tensors. Instead, convert
inputs to a complex tensor first before calling `torch.istft`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86628
Approved by: https://github.com/mruberry
Fixes https://github.com/pytorch/pytorch/pull/87048 by saving the needed properties before fork.
Actually attempting to get CUDA to load in the workers is probably not desired: cuda initialization takes O(seconds). Having multiple processes using the same device will slow things down.
This just moves the needed properties from the main trainer process to the workers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87101
Approved by: https://github.com/soumith
Mitigate https://github.com/pytorch/pytorch/issues/87148
### Testing
On AWS (m1, linux)
* Run `conda install blas:openblas`, it should failed with `ChecksumMismatchError`:
```
ChecksumMismatchError: Conda detected a mismatch between the expected content and downloaded content
for url 'https://repo.anaconda.com/pkgs/main/linux-64/blas-1.0-openblas.conda'.
download saved to: /tmp/debug/pkgs/blas-1.0-openblas.conda
expected sha256: c85b5d0a336b5be0f415c71fd7fe2eca59e09f42221bfa684aafef5510ba5487
actual sha256: 5dc5483db0d9785b19e021cee418a8ee03e0ff0e5ebd0b75af4927746604e187
```
* Run ` conda install -c conda-forge blas:openblas` works
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87150
Approved by: https://github.com/kit1980
Previously a check would only apply DDP optimizer on frames named "forward".
But on hf_T5_large, a graph break causes some frames like:
```
<graph break in _shift_right>
<graph break in forward>
```
So instead, apply DDP optimizer on all frames.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87097
Approved by: https://github.com/wconstab
Right now, example_value is doing two jobs:
- We use it to propagate metadata (e.g. return type, shapes, etc.)
throughout the graph
- We use it to satisfy queries for the actual value (e.g. torch.cond,
`assume_constant_result`)
This is further complicated by the fact that we have two modes, one
where `example_value` is a fake tensor, and one where it is a real
tensor (this is the `fake_tensor_propagation` config flag).
This leads to scenarios where we don't support every combination of
job + mode,
e.g. if `fake_tensor_propagation=False`, `assume_constant_result` is
broken.
This is made worse by the fact that "fake tensor mode" is the default
and is required if you want dynamic shapes to work.
So, this PR introduces a `get_real_value` API that just runs the graph
up to `node` in order to get a concrete value. This API is orthogonal
to
`example_value`, so it doesn't care about `fake_tensor_propagation`.
When `fake_tensor_propagation=True`: `example_value` is a fake tensor,
you must use the `get_real_value` API to get a concrete value. This
will
be the only configuration in the future.
When `fake_tensor_propagation=False`: `example_value` and
`get_real_value` will produce the same value. This is redundant but we
will be removing this config soon.
To support this, I introduce a cache for computed real values, to
memoize the work involved if we're asking for real values a lot.
I attached this state to `OutputGraph` because it seems to be what
historically managed `example_value` lifetimes, but idk.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87091
Approved by: https://github.com/wconstab
This PR adds workarounds to support AOT Autograd's graphs containing `aten.cudnn_batch_norm` and `aten.cudnn_batch_norm_backward` with `TorchRefsNvfuserCapabilityMode`.
The problem with the decomposition of `aten.cudnn_batch_norm` is that it uses a `new_empty` call that is not supported by nvFuser and we are conservative with lowering functions to nvprims by default.
The problem with the decomposition of `aten.cudnn_batch_norm_backward` is described here https://github.com/pytorch/pytorch/pull/86115#issue-1394883782, but changing the decomposition directly in that PR makes many tests fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86796
Approved by: https://github.com/mruberry
Using runner label like `linux.12xlarge` results in linter failure from actionlint, i.e. https://github.com/pytorch/pytorch/actions/runs/3253740221/jobs/5341281952
```
Error (ACTIONLINT) [runner-label]
label "linux.12xlarge" is unknown. available labels are "windows-
latest", "windows-2022", "windows-2019", "windows-2016", "ubuntu-
latest", "ubuntu-22.04", "ubuntu-20.04", "ubuntu-[18](https://github.com/pytorch/pytorch/actions/runs/3253740221/jobs/5341281952#step:7:19).04", "macos-latest",
"macos-12", "macos-12.0", "macos-11", "macos-11.0", "macos-10.15",
"self-hosted", "x64", "arm", "arm64", "linux", "macos", "windows",
"linux.[20](https://github.com/pytorch/pytorch/actions/runs/3253740221/jobs/5341281952#step:7:21)_04.4x", "linux.20_04.16x", "linux.large", "linux.2xlarge",
"linux.4xlarge", "linux.4xlarge.nvidia.gpu", "linux.8xlarge.nvidia.gpu",
"linux.16xlarge.nvidia.gpu", "windows.4xlarge",
"windows.8xlarge.nvidia.gpu", "bm-runner", "linux.rocm.gpu", "macos-m1-
12", "macos-12-xl", "macos-12", "macos12.3-m1". if it is a custom label
for self-hosted runner, set list of labels in actionlint.yaml config file
47 | # an OOM issue when running the job, so this upgrades the runner from 4xlarge
48 | # to the next available tier of 12xlarge. So much memory just to generate cpp
49 | # doc
>>> 50 | runner: linux.12xlarge
51 | # Nightly cpp docs take about 150m to finish, and the number is stable
52 | timeout-minutes: 180
53 | - docs_type: python
```
`linux.12xlarge` is a valid runner label from https://github.com/pytorch/test-infra/blob/main/.github/scale-config.yml. This also adds `linux.24xlarge` and `linux.g5.4xlarge.nvidia.gpu`, which are also not added yet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87009
Approved by: https://github.com/ZainRizvi
Fixes#83936#83907
In #83936, I noticed that after I wrote cross, it's silently incorrect because I misunderstood what the fix to linalg was going to be. This fixes functorch to not be silently incorrect with `linalg.cross`. Since it's a silent correctness issue that I missed, I'm hoping to cherry pick it too
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86926
Approved by: https://github.com/zou3519
https://github.com/pytorch/pytorch/pull/87032 seems to have an issue that breaks our benchmark script, it might have to do with the benchmark script also using subprocess.
Before this PR:
```
$ ./benchmarks/dynamo/torchbench.py --performance --inductor --raise --training --float16
...
Traceback (most recent call last):
File "/home/jansel/conda/envs/pytorch/lib/python3.9/concurrent/futures/process.py", line 246, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/home/jansel/pytorch/torch/_inductor/codecache.py", line 239, in _worker_compile
kernel = TritonCodeCache.load(source_code)
File "/home/jansel/pytorch/torch/_inductor/codecache.py", line 234, in load
mod = PyCodeCache.load(source_code)
File "/home/jansel/pytorch/torch/_inductor/codecache.py", line 212, in load
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_jansel/ij/cij7smji4sw2a56i4yz45bjkrosd2sb2raqnxzsxxpg4kwzuo2ta.py", line 5, in <module>
from torch._inductor.triton_ops.autotune import reduction
File "/home/jansel/pytorch/torch/_inductor/triton_ops/__init__.py", line 3, in <module>
if has_triton():
File "/home/jansel/pytorch/torch/_inductor/utils.py", line 38, in has_triton
return triton is not None and torch.cuda.get_device_capability() >= (7, 0)
File "/home/jansel/pytorch/torch/cuda/__init__.py", line 368, in get_device_capability
prop = get_device_properties(device)
File "/home/jansel/pytorch/torch/cuda/__init__.py", line 382, in get_device_properties
_lazy_init() # will define _get_device_properties
File "/home/jansel/pytorch/torch/cuda/__init__.py", line 228, in _lazy_init
raise RuntimeError(
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method
```
cc @zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87048
Approved by: https://github.com/soumith
This behavior has been deprecated since PyTorch 1.8 but this step of
the deprecation cycle was put on hold in #50102 waiting for JIT
upgraders functionality which doesn't seem to have panned out. I'd say
there has been more than enough of a deprecation period, so we should
just continue.
BC-breaking message:
`torch.stft` takes an optional `return_complex` parameter that
indicates whether the output should be a floating point tensor or a
complex tensor. `return_complex` previously defaulted to `False` for
real input tensors. This PR removes the default and makes
`return_complex` a required argument for real inputs. However, complex
inputs will continue to default to `return_complex=True`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86724
Approved by: https://github.com/mruberry, https://github.com/albanD
This patch significantly improves the parallel compilation performance for cThis patch significantly improves the parallel compilation performance for compiling triton kernels
by using ProcessPoolExecutor to create persistent pool of compilation
workers.
Previously os.fork overhead and GIL contention limited the achieved
parallelism. This patch replaces
the worker threads with a pool of processes to do the raw compilation,
and does serial work on the main thread
for everything else. This other work couldn't be parallelized anyway
since it is mostly in python.
In cold start situations, the time to get the worker threads started can
be significant portion of the time.
This patch starts the workers earlier so they are ready to perform
compilation (see code comments) when dynamo
gets to that point.
Just tested this on one example benchmark (tf_efficientnet_b0), but the
results are significant, almost eliminating the difference between a
warm and cold compilation.
```
39.613s - warm
41.290s - cold, this patch
2m53.197s - cold, single threaded:
1m7.092s - cold, old setup n = 8 (its best config)
```
(cold compilation is done after running `rm -rf
/tmp/torchinductor_$USER`).ompiling triton kernels
by using ProcessPoolExecutor to create persistent pool of compilation workers.
Previously os.fork overhead and GIL contention limited the achieved parallelism. This patch replaces
the worker threads with a pool of processes to do the raw compilation, and does serial work on the main thread
for everything else. This other work couldn't be parallelized anyway since it is mostly in python.
In cold start situations, the time to get the worker threads started can be significant portion of the time.
This patch starts the workers earlier so they are ready to perform compilation (see code comments) when dynamo
gets to that point.
Just tested this on one example benchmark (tf_efficientnet_b0), but the results are significant, almost eliminating the difference between a warm and cold compilation.
```
39.613s - warm
41.290s - cold, this patch
2m53.197s - cold, single threaded:
1m7.092s - cold, old setup n = 8 (its best config)
```
(cold compilation is done after running `rm -rf /tmp/torchinductor_$USER`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87032
Approved by: https://github.com/soumith, https://github.com/jansel
Inductor internally models any `size=1` dimension as having `stride=0` to simplify indexing formulas (sympy will remove these terms from the expression).
This caused a bug in our generate stride assert in detectron2_maskrcnn_r_50_fpn, where we asserted the wrong stride of a size==1 dimension.
This fixes that bug, and moves size/stride assert logic to C++ which should be a small perf gain.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87028
Approved by: https://github.com/anijain2305
Fixes the confusing situation mentioned here https://github.com/pytorch/pytorch/issues/85224#issuecomment-1278628262 by
- setting better OG defaults
- changing warnings to errors now that we have better defaults
Test plan:
- Ran einsum tests locally + CI
- Uninstalled opt-einsum and ran through setting
- `enabled` to False (doesn't throw error)
- `strategy` to anything that's not None (errors)
- `strategy` to None (noops)
- Installed opt-einsum and ran through setting
- `enabled` to False (doesn't throw error)
- `enabled` to True (doesn't throw error, no ops + defaults to 'auto')
- `strategy` to random string (errors)
- `strategy` to None (noops, still is 'auto')
- `strategy` to 'greedy' (is set to 'greedy')
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86985
Approved by: https://github.com/soulitzer
# Support unpacking python dictionary in **torch.jit.trace()**
## Problem statement & Motivation
### Problem 1(usability):
Say, if you have a model and its forward method defined as follows:
**`def forward(self, key1=value1, key2=value2, key3=value3)`**
And you have a dataset and each data point in the dataset is a python dict as follows:
**`data = {key1:value1, key3:value3, key2:value2}`**
The problem is that if you want to trace the model using the dict data by the giving dataset, you need unpack the dictionary and reorder its value manually and make up a tuple as **`data_tuple = (value1, value2, value3)`** as the **`example_inputs`** parameter of **`torch.jit.trace()`**. This marshalling process is not user friendly.
### Problem 2 (feasibility):
Say, if you have a model and its forward method defined as follows:
**`def forward(self, key1=None, key2=None, key3=None)`** -> The default value is **None**
And you have a dataset and each data point in the dataset is a python dict as follows:
**`data = {key1:value1, key3:value3}`** -> Only **part of** the required value by forward was given, the rest use the default value.
The problem is that if you want to trace the model using the dict data by the giving dataset, it's not feasible at all. Cause neither you can pass a tuple like **`T1 = (value1, value3)`** nor **`T2 = (value1, None, value3)`**. T1 will mismatch value3 with key2 and T2 include **None** type which will be blocked by tracer's type checking. (Of course you can pass **`T3 = (value1,)`** to make the trace function finish without exception, but the traced model you get probably is not what you expect cause the different input may result in different traced result.).
These problems come from the HuggingFace's PT model, especially in text-classification tasks with datasets such as [MRPC,](https://paperswithcode.com/dataset/mrpc) [MNLI](https://paperswithcode.com/dataset/multinli) etc.
## Solution
To address these two issues, we propose to support a new type, that is, python dict as example_inputs parameter for torch.jit.trace(). We can base on the runtime type information of the example_inputs object to determine if we fall back to the original tuple path or go into the new dictionary path. Both problem 1 and problem 2 can be solved by utilizing the "**`**`**"
operator.
## Limitation & Mitigation
1. If we use dict as example_inputs to trace the model, then we have to pass a dictionary to the traced model too. (Cause probably we will change the order of debug name of the input parameter in torchscript IR, thus we can't assume the traced model's input parameters order are the same with the original model.). We need highlight this too in the document to mitigate this problem.
For example:
```
# fetch a data from dataloader, and the data is a dictionary
# and the example_inputs_dict is like: {key1:value1, key3:value3, key2:value2}
# the forward() is like: def forward(self, key1=value1, key2=value2, key3=value3)
example_inputs_dict = next(iter(dataloader))
jit_model = model.eval()
# use the dictionary to trace the model
jit_model = torch.jit.trace(jit_model, example_inputs_dict, strict=False) # Now the IR will be graph(%self : __torch__.module.___torch_mangle_n.Mymodule, %key1 : type1, %key3 : type3, %key2 : type2)
jit_model = torch.jit.freeze(jit_model)
# It's OK to use dict as the parameter for traced model
jit_model(**example_inputs_dict)
example_inputs_tuple = (value1, value3, value2)
# It's wrong to rely on the original args order.
jit_model(*example_inputs_tuple)
```
## Note
1. This PR will make some UT introduced in [39601](https://github.com/pytorch/pytorch/pull/39601) fail, which I think should be classified as unpacking a tuple containing a single dictionary element in our solution.
4. I think there is ambiguity since currently we only specify passing a tuple or a single Tensor as our example_inputs parameter in **torch.jit.trace()**'s documentation, but it seems we can still passing a dictionary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81623
Approved by: https://github.com/davidberard98
Passing in `offload_to_cpu=True` to checkpoint_wrapper is a bit confusing, because this causes the activation checkpoint args to be ignored and we do CPU offloading. This isn't ideal from API design perspective, so proposing to make `offload_wrapper` its own concept.
Now, offload to CPU + checkpoint can be composed together, such as
```
# apply AC to transformer layers
apply_ac_wrapper(model, checkpoint_wrapper, check_fn=lambda mod: isinstance(mod, TransformerLayer))
# offload the rest of activations to CPU
model = offload_wrapper(model)
```
Will polish / add tests if this proposal sounds good.
Differential Revision: [D39719854](https://our.internmc.facebook.com/intern/diff/D39719854/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85459
Approved by: https://github.com/awgu
Summary:
att, with the introduction of QConfigMapping, this name is now very confusing, so renamed
it to something clearer
Test Plan:
python test/test_quantization.py TestQuantizeFx
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86861
Approved by: https://github.com/vkuzo
- `vector<T>({0})` would give you the vector(size, ...) ctor and produce an empty vector of T, along with the scalar-init warning
- `vector<T>({T(0)})` would give you the vector of a single T(0) as you might have intended, and bypasses the warning/error
- the warning can easily be missed but can have serious consequences, so make it an error
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86911
Approved by: https://github.com/albanD
Big-bang PR to symintify **all** .sizes() calls in derivatives.yaml, which will be needed for symbolic tracing.
* with the exception of `split()`, which is tougher to land because it requires internal changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86610
Approved by: https://github.com/albanD
This PR shouldn't matter too much, but I figured I'd land it instead of deleting. `PySymInt.min/max` are technically broken today, and this fixes them - but it doesn't matter (yet) because nobody is calling `min()` / `max()` on symints from python (they all happen using `std::min/max` in C++, which desugar to lt / gt calls).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86609
Approved by: https://github.com/albanD
`min_cut_rematerialization_partition` has a default set of hard-coded operations that are allowed to be recomputed in the backward pass.
This PR adds customization ability to this function allowing users to control the behavior by passing `recomputable_ops` instead of relying on the default setting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86686
Approved by: https://github.com/Chillee
The legacy profiler is an eyesore in the autograd folder. At this point the implementation is almost completely decoupled from the rest of profiler, and it is in maintaince mode pending deprecation.
As a result, I'm moving it to `torch/csrc/profiler/standalone`. Unfortuantely BC requires that the symbols remain in `torch::autograd::profiler`, so I've put some basic forwarding logic in `torch/csrc/autograd/profiler.h`.
One strange bit is that `profiler_legacy.h` forward declares `torch::autograd::Node`, but doesn't seem to do anything with it. I think we can delete it, but I want to test to make sure.
(Note: this should not land until https://github.com/pytorch/torchrec/pull/595 is landed.)
Differential Revision: [D39108648](https://our.internmc.facebook.com/intern/diff/D39108648/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85512
Approved by: https://github.com/aaronenyeshi
There are a number of instrumentation utils which have been added to the profiler toolkit. They are generally small and self contained, often wrapping vendor APIs. (NVTX, ITT)
They don't really interact with the much more expansive machinery of the PyTorch profiler beyond registration / unregistration, minor util sharing, and reusing the profiler base class. Just as in the case of stubs, it makes sense to group them in a dedicated subfolder.
Differential Revision: [D39108649](https://our.internmc.facebook.com/intern/diff/D39108649/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39108649/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85511
Approved by: https://github.com/albanD
There is a concept in profiler of a stub that wraps a profiling API. It was introduced for CUDA profiling before Kineto, and ITT has adopted it to call into VTune APIs. However for the most part we don't really interact with them when developing the PyTorch profiler.
Thus it makes sense to unify the fallback registration mechanism and create a subfolder to free up real estate in the top level `torch/csrc/profiler` directory.
Differential Revision: [D39108647](https://our.internmc.facebook.com/intern/diff/D39108647/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85510
Approved by: https://github.com/aaronenyeshi
Move a bunch of globals to instance methods and replace all use to them.
We move all PG related globals under World and use a singleton instance under _world.
This creates an undocumented extension point to inject full control of how how c10d
state behaves.
One simple hack is to change _world to an implementation that uses a threadlocal
and enable per-thread PGs.
It almost get DDP working and the PG is missing an implementation of all_reduce.
This enables notebook usage of PTD, which is a big deal for learning it:
https://gist.github.com/kumpera/32cb051fa26b8cad8bdf671f968dcd68
This change ensures BC by keeping the global variables around and have the default _World wrap it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86348
Approved by: https://github.com/rohan-varma
The complex lerp kernel uses `std::abs(z) < 0.5` which involves
computing a sqrt. Instead compare the square against 0.25 has much
lower latency and so performs much better overall.
In a simple timeit benchmark I see more than 10x speedup on CPU for a 4096
element complex lerp, from 84 us to 6.7 us.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84844
Approved by: https://github.com/ngimel
## BFloat16 dtype support for faster inference with TorchScript using oneDNN Graph
Intel Xeon Cooper Lake platform & beyond support the `AVX512_BF16` ISA, which is essentially native BFloat16 support.
oneDNN Graph delivers high inference performance with BFloat16 on such machines.
While oneDNN Graph can still be used with BFloat16 on older machines that lack `avx512_bf16` ISA but support `avx512bw`, `avx512vl` & `avx512dq` ISAs, the BF16 performance on these older machines will be significantly poorer (probably even poorer than Float32), as they lack native BF16 support.
Currently, [AMP support for eager mode & JIT mode is divergent in PyTorch](https://github.com/pytorch/pytorch/issues/75956).
So, for using oneDNN Graph with BFloat16, eager-mode AMP should be leveraged by turning off AMP for JIT mode, using `torch._C._jit_set_autocast_mode(False)` in python code, so as to avoid conflicts.
Please use the following environment variable to view JIT logs -
`PYTORCH_JIT_LOG_LEVEL=">>graph_helper:>>graph_fuser:>>kernel:>>interface"`
## Changes being made in this PR
1. This PR does NOT change the `oneDNN` commit or the `ideep` files. While the `ideep` commit is being updated, only files pertaining to oneDNN Graph are being updated. oneDNN Graph is being upgraded to version 0.5.2 (alpha patch release 2).
To put things into perspective, `ideep` is a git submodule of PyTorch. `oneDNN Graph` is a git submodule of `ideep` (`ideep/mkl-dnn`), and oneDNN is a git submodule of oneDNN Graph (`ideep/mkl-dnn/third_party/oneDNN`).
2. Unit-tests are being updated. We now use the [existing dtypes decorator](https://github.com/pytorch/pytorch/blob/master/torch/testing/_internal/common_device_type.py#L123-L131).
3. Suggestions made by @eellison in the [FP32 PR](https://github.com/pytorch/pytorch/pull/68111#pullrequestreview-896719477) are being incorporated/addressed -
| Action-item | Status |
| :--- | ---: |
|checkInputCompatibility follow up | Fixed |
|the mayConvertScalarInputToTensor logic we can consider | Added type promotion code |
|fix up fixConvOptionalBias| The current approach seems correct |
|Use opinfo tests| using dtypes decorator. Will use `OpInfo` in a subsequent PR, if that'd be possible. Should we create a list of ops from opDB that are supported by oneDNN Graph, and add it to `common_methods_invocations.py`? |
|inferDevice torch_check call | not necessary now, perhaps, as only CPU is supported, for now? We'd add it by the beta release of oneDNN Graph, though, so that by then, users might be able to use other fusers with oneDNN Graph (NNC/TensorExpr are already compatible with the oneDNN Graph fuser). We can still add it, if you'd insist. |
|not checking shapes of input mkldnn tensor to llga guard | Those checks should not be present because oneDNN Graph may use blocked or channels-last layout, so those strides would be different. They're only skipped if an LLGA subgraph's output is input to another LLGA subgraph, which enables LLGA to choose an optimal layout between them. |
|fix test failures with respect to unsupported inputs | We'll address them with the upcoming release of oneDNN Graph beta version|
4. More PyTorch ops are being been mapped to oneDNN Graph
## Example of using oneDNN Graph with BFloat16
```python
# Assuming we have a model of the name 'model'
example_input = torch.rand(1, 3, 224, 224)
# enable oneDNN Graph
torch.jit.enable_onednn_fusion(True)
# Disable AMP for JIT
torch._C._jit_set_autocast_mode(False)
with torch.no_grad(), torch.cpu.amp.autocast():
model = torch.jit.trace(model, (example_input))
model = torch.jit.freeze(model)
# 2 warm-ups (2 for tracing/scripting with an example, 3 without an example)
model(example_input)
model(example_input)
# speedup would be observed in subsequent runs.
model(example_input)
```
## TorchBench based Benchmarks
**URL:** https://github.com/sanchitintel/benchmark/tree/onednn_graph_benchmark (instructions present at URL).
**Batch-size(s):** TorchBench-default for each model
**Baseline :** PyTorch JIT OFI FP32
**Machine:** Intel(R) Xeon(R) Platinum 8371HC (Cooper Lake)
**Sockets used**: 1
**Number of cores on one socket**: 26
Intel OpenMP & tcmalloc were preloaded
#### Benchmark results with single thread
| name | latency of PyTorch JIT OFI FP32 (s) | Latency of oneDNN Graph BF16 (s) | % change |
| :--- | ---: | ---: | ---: |
| test_eval[alexnet-cpu-jit] | 1.063851 | 0.509820 | -52.1% |
| test_eval[mnasnet1_0-cpu-jit] | 0.218435 | 0.107100 | -51.0% |
| test_eval[mobilenet_v2-cpu-jit] | 0.114467 | 0.058359 | -49.0% |
| test_eval[mobilenet_v3_large-cpu-jit] | 0.233873 | 0.117614 | -49.7% |
| test_eval[resnet18-cpu-jit] | 0.160584 | 0.075854 | -52.8% |
| test_eval[resnet50-cpu-jit] | 1.652846 | 0.713373 | -56.8% |
| test_eval[resnext50_32x4d-cpu-jit] | 0.471174 | 0.209431 | -55.6% |
|test_eval[shufflenet_v2_x1_0-cpu-jit] | 0.310306 | 0.167090 | -46.2% |
| test_eval[squeezenet1_1-cpu-jit] | 0.161247 | 0.045684 | -71.7% |
| test_eval[timm_efficientnet-cpu-jit] | 1.643772 | 0.800099 | -51.3% |
| test_eval[timm_regnet-cpu-jit] | 5.732272 | 2.333417 | -59.3% |
| test_eval[timm_resnest-cpu-jit] | 1.366464 | 0.715252 | -47.7% |
| test_eval[timm_vision_transformer-cpu-jit] | 0.508521 | 0.271598 | -46.6% |
| test_eval[timm_vovnet-cpu-jit] | 2.756692 | 1.125033 | -59.2% |
| test_eval[vgg16-cpu-jit] | 0.711533 | 0.312344 | -56.1% |
#### Benchmark results with 26 threads:
| name | latency of PyTorch JIT OFI FP32 (s) | Latency of oneDNN Graph BF16 (s) | % change |
| :--- | ---: | ---: | ---: |
| test_eval[alexnet-cpu-jit] | 0.062871 | 0.034198 | -45.6% |
| test_eval[mnasnet1_0-cpu-jit] | 0.022490 | 0.008172 | -63.7% |
| test_eval[mobilenet_v2-cpu-jit] | 0.012730 | 0.005866 | -53.9% |
| test_eval[mobilenet_v3_large-cpu-jit] | 0.025948 | 0.010346 | -60.1% |
| test_eval[resnet18-cpu-jit] | 0.011194 | 0.005726 | -48.9% |
| test_eval[resnet50-cpu-jit] | 0.124662 | 0.045599 | -63.4% |
| test_eval[resnext50_32x4d-cpu-jit] | 0.034737 | 0.015214 | -56.2% |
|test_eval[shufflenet_v2_x1_0-cpu-jit] | 0.028820 | 0.012517 | -56.6% |
| test_eval[squeezenet1_1-cpu-jit] | 0.012557 | 0.003876 | -69.1% |
| test_eval[timm_efficientnet-cpu-jit] | 0.203177 | 0.051879 | -74.5% |
| test_eval[timm_regnet-cpu-jit] | 0.452050 | 0.151113 | -66.6% |
| test_eval[timm_resnest-cpu-jit] | 0.117072 | 0.052848 | -54.9% |
| test_eval[timm_vision_transformer-cpu-jit] | 0.046048 | 0.023275 | -49.5% |
| test_eval[timm_vovnet-cpu-jit] | 0.213187 | 0.077482 | -63.7% |
| test_eval[vgg16-cpu-jit] | 0.044726 | 0.021998 | -50.8% |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85591
Approved by: https://github.com/jgong5, https://github.com/frank-wei, https://github.com/chunyuan-w
Added some details about:
- `pip uninstall functorch` being helpful if there are problems
- `pip install functorch` still working for BC reasons.
Test Plan:
- wait for docs preview
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86823
Approved by: https://github.com/samdow
This rewrites various sample and error input functions to:
- use the convention of `make_arg = functools.partial(make_tensor, ...)`
- use the new natural syntax for `SampleInput` construction
- yield instead of returning a lists, to reduce memory consumption
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86231
Approved by: https://github.com/mruberry
Fixes https://github.com/pytorch/pytorch/issues/82235
cc @albanD - `at::pixel_shuffle` and `at::pixel_unshuffle` advertise as being non-aliasing, but they have a C++ decomposition that internally uses reshape(), which means that it might return an alias.
I happened to notice this because a bunch of tests in `test/test_ops.py` failed when I ran locally with a `DEBUG=1` build.
(P.S.: when are we finally gonna get a debug build test in CI? 😃)
I fixed by adding an extra clone, which... is going to be an unnecessary perf hit in the case where the `reshape()` already properly cloned the input. My hope is that this is fine, because this only impacts the composite kernel- we already have a "fast" CPU kernel that does the right thing. Is `pixel_shuffle/unshuffle` commonly used with cuda? Maybe we should just add a fast cuda kernel for it if that's the case.
Alternatively, it seems like it would be nice if `reshape()` accepted an optional argument to unconditionally return a copy. That seems like a rabbit hole that isn't worth going down for now though - I remember a discussion a while ago about making `reshape()` copy-on-write
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86608
Approved by: https://github.com/albanD
python decomp for `native_group_norm` is correct in more cases than the C++ composite. Updating the tests to fail properly in this case was more annoying than just fixing the C++ decomp, so I fixed it here.
When the input tensor had a dtype with less precision than float32, the C++ decomp would unconditionally set the mean/variance to float32, which was wrong.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86607
Approved by: https://github.com/albanD
This PR adds vmap support for slogdet -- slogdet just decomposes into
linalg.slogdet.
This fixes a regression from functorch 0.2.1 (slogdet had a batching
rule then, and doesn't anymore). We didn't catch the regression because
it seems like slogdet doesn't have an OpInfo (I'm not sure if it had one
before).
Test Plan:
- new one-off test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86815
Approved by: https://github.com/samdow
This PR sets CUDA_MODULE_LOADING if it's not set by the user. By default, it sets it to "LAZY".
It was tested using the following commands:
```
python -c "import torch; tensor=torch.randn(20, 16, 50, 100).cuda(); free, total = torch.cuda.cudart().cudaMemGetInfo(0); print(total-free)"
```
which shows a memory usage of: 287,047,680 bytes
vs
```
CUDA_MODULE_LOADING="DEFAULT" python -c "import torch; tensor=torch.randn(20, 16, 50, 100).cuda(); free, total = torch.cuda.cudart().cudaMemGetInfo(0); print(total-free)"
```
which shows 666,632,192 bytes.
C++ implementation is needed for the libtorch users (otherwise it could have been a pure python functionality).
cc: @ptrblck @ngimel @malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85692
Approved by: https://github.com/malfet
TLDR: see D39003528 to see the actual changes in this diff more clearly, which will make reviewing easier
___
The 32bit versions were changed to be created with a macros which are also used to create 16bit and 8bit versions
This diff shows that almost all of the lines in the .s files were modified, but most changes are just adding spaces to the front and ;/ to the end so they can be contained in the macro. To generate these changes, I first wrote the macros without the spaces and ;/, and then I ran a script (see the python file in D39003528) to get the final version.
To review this diff more easily, if you want to see the code changes before I ran the script, which makes it much easier to see which lines were changed, see D39003528.
Each version of this diff is synched with the same number version of that diff (so if I change this diff I will mirror the changes to the same version on that diff)
Differential Revision: [D39003527](https://our.internmc.facebook.com/intern/diff/D39003527/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85245
Approved by: https://github.com/kimishpatel
Summary: this file doesn't actually exist anymore so its just a case of
removing the exception for it
Test Plan: python test/test_public_bindings.py
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86036
Approved by: https://github.com/jerryzh168
The model TTS will crash due to the issue:: when input of BN is not contiguous and the data type of input is different with that of parameters, BN will raise error `RuntimeError: !needs_dynamic_casting<func_t>::check(iter) INTERNAL ASSERT FAILED at "xxx/pytorch/aten/src/ATen/native/cpu/Loops.h":311, please report a bug to PyTorch`.
Make the data types of output and input consistenst for batchnorm to fix the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84410
Approved by: https://github.com/mingfeima, https://github.com/jgong5, https://github.com/malfet
Allow `viable/strict` promotion even if `periodic` or `docker-release-builds` jobs are failing
**Why?** Those jobs only run occasionally and for all we know the current viable/strict commit may already include the errors that the above cron based workflows may have later detected. Blocking the viable/strict upgrade because of these scheduled jobs doesn't really offer any value, it just leads to people getting older PRs when they try to fork off of viable/strict without guaranteeing an improvement in test quality
Though frankly, the current situation is worse than that.
Assume the branch history looks like A -> B
A is the current `viable/strict` commit
B is a commit that failed some `periodic` test, so `viable/strict` wasn't upgraded to B
Now lets say there's a commit C that gets merged. C neither contains a fix for the failing periodic build, nor does a scheduled periodic workflow run against C. The branch becomes A -> B -> C
In the above scenario, today we will promote `viable/strict` to C since there was no failing workflow there!!! Even though it didn't actually fix what was broken with B!
In short, avoiding the upgrade to B really doesn't make any sense today and we shouldn't do it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86827
Approved by: https://github.com/janeyx99
As described in the issue, this PR adds hooks to be run when `register_parameter`, `register_buffer` and `register_module` are called.
Fixes#85837
cc @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86148
Approved by: https://github.com/albanD
Summary:
This PR adds checks for the existence of "weight_dtype" and "bias_dtype" in the node_name_to_dtype dictionary before accessing it,
the corner case is hit when we check the compatibility of qconfig and backend_config for weight and bias that appears before activation (e.g. torch.addmm)
Test Plan:
python test/test_quantization.py -k test_backend_config_check_for_weight_and_bias
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86719
Approved by: https://github.com/andrewor14
Summary: added __all__, one issue with QuantizeHandler is that since its
defined as 'Any' it can't be set as a public module although it should
be, i've set it to private here but when the circular dependency gets
fixed, it will probably be removed.
Test Plan: python test/test_public_bindings.py
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86033
Approved by: https://github.com/jerryzh168
Summary: the main problem with this was that the different objects
defined simply as 'Any' should theoretically be public but making them
public either A) results in an error about the module being 'typing'
rather than whatever module it should be or B) you set the module
manually, thereby changing the module for the original 'Any' class.
note: QuantizeHandler has a similar issue where its simply defined as
'Any'
Pattern was defined in multiple places which was causing issues so i just moved it to a single
place given the note at the top of quantization_types.py indicating
these definitions should be moved to utils at some point anyway.
Finally i changed any references to these objects to point at the
correct locations. Note: i didn't see any fb internal references to
NodePattern or QuantizerCls that would cause issues.
Test Plan: python test/test_public_bindings.py
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86031
Approved by: https://github.com/jerryzh168
Currently `test_dtypes` swallows all exceptions which can make debugging failures more tricky.
This changes the test to save the exceptions and print only the unexpected ones at the end e.g.
```
AssertionError: The supported dtypes for nn.functional._scaled_dot_product_attention on device type cuda are incorrect!
The following dtypes did not work in backward but are listed by the OpInfo: {torch.bfloat16}.
Unexpected failures raised the following errors:
torch.bfloat16 - CUDA error: CUBLAS_STATUS_NOT_SUPPORTED when calling [...]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86599
Approved by: https://github.com/mruberry
This PR applies a large hammer and disables TF32 in specific functorch transform tests. TF32 isn't precise enough to test correctness.
We could have applied a smaller hammer by disabling TF32 per-OpInfo, but that doesn't seem to have too much additional benefit (e.g. if a convolution batching rule is correct on fp32 then I would expect it to be correct under TF32 modulo precision issues because the actual sequence of PyTorch operators we invoke has not changed, only the backend did).
Test Plan:
- I tested this locally on a machine with A100 GPUs.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86799
Approved by: https://github.com/malfet
Fixes#83973 (This is a substitute PR for https://github.com/pytorch/pytorch/pull/85024)
First of all, thanks for your invaluable contributions to PyTorch everyone!
Given how extensively `torch.cuda.is_available` is used in the PyTorch ecosystem, IMHO it's worthwhile to provide downstream libraries/frameworks/users the ability to alter the default behavior of `torch.cuda.is_available` in the context of their PyTorch usage.
I'm confident there are many current and future such use cases which could benefit from leveraging a weakened, NVML-based `torch.cuda.is_available` assessment at a downstream framework's explicit direction (thanks @malfet 81da50a972 !). Though one could always patch out the `torch.cuda.is_available` function with another implementation in a downstream library, I think this environmental variable based configuration option is more convenient and the cost to including the option is quite low.
As discussed in https://github.com/pytorch/pytorch/pull/85024#issuecomment-1261542045, this PR gates new non-default NVML-based CUDA behavior with an environmental variable (PYTORCH_NVML_BASED_CUDA_CHK) that allows a user/framework to invoke non-default, NVML-based `is_available()` assessments if desired.
Thanks again for your work everyone!
@ngimel @malfet @awaelchli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85951
Approved by: https://github.com/ngimel
This enables testing on lots of modern CUDA features on sm_86 capable GPU
While migrating to that platform, discovered that `functorch` tests for `nn.functional.conv.transpose3d` produce garbage on sm_80+ as well as 2 `nvfuser` tests unexpectedly pass and one unexpectedly fails.
TODO:
- Investigate unexpected success for `test_vmapvjp_linalg_householder_product_cuda_float32` and add `functorch` shard
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85524
Approved by: https://github.com/ngimel
Fix for https://github.com/pytorch/torchdynamo/issues/1368
From comment:
> When we invoke a Composite Implicit autograd operator that has an autocast rule, such as Einsum,
autocast is disabled during its invocation. When we trace out the operators in an implicit op,
re-applying on autocast rules on those operators might yield divergence from what was executed at runtime.
This pass checks for divergence. If divergence is found, we will disable autocast.
We would like to avoid disabling autocast if possible because accessing TLS is slow.
Concretely, the problem found was when invoked `sum` in `einsum`:
As seen by the following divergence:
```
>>> with torch.cuda.amp.autocast(enabled=True):
... print(torch.ops.aten.sum.dim_IntList(torch.rand([2, 2, 2], device="cuda", dtype=torch.half), [1, 2]).dtype)
...
torch.float32
>>> print(torch.ops.aten.sum.dim_IntList(torch.rand([2, 2, 2], device="cuda", dtype=torch.half), [1, 2]).dtype)
torch.float16
```
Edit: we've decided to accept the overhead of universally disabling autocast instead
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86515
Approved by: https://github.com/bdhirsh, https://github.com/Chillee
Backport currently dont work with some models if:
* model is originally exported with interface call enabled (backport would disable it)
* model is flatbuffer (flatbuffer support is soft enabled via link time registry), so we manually trigger it
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86510
Approved by: https://github.com/cccclai
This reverts commit 978b46d7c96627e3b3553ad70ad21cb161d05f90.
Reverted https://github.com/pytorch/pytorch/pull/86488 on behalf of https://github.com/osalpekar due to Broke executorch builds internally with the following message: RuntimeError: Missing out variant for functional op: aten::split.Tensor(Tensor(a -> *) self, SymInt split_size, int dim=0) -> Tensor(a)[] . Make sure you have loaded your custom_ops_generated_lib
If an invalid platform is specified when disabling a test with flaky test bot, the CI crashes, skipping all tests that come after it.
This turns it into a console message instead. Not erroring out here since it'll affect random PRs. Actual error message should go into the bot that parses the original issue so that it can respond on that issue directly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86632
Approved by: https://github.com/huydhn
Bug fix. nvfuser is functional for ROCm on gfx906, but some tests are failing for other gfx targets. Disable nvfuser until all features are verified. Users may still opt-in by setting the known env var PYTORCH_JIT_ENABLE_NVFUSER=1. This PR sets this env var for the github actions workflow for ROCm since all current CI hosts are gfx906.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86369
Approved by: https://github.com/huydhn
Summary: D40151818 (82ed5ca340) replaces the `TORCH_CHECK` with a `TORCH_WARN` but since it does not check if the context is valid the message gets printed every time. This diff fixes that.
Test Plan:
Referring to [Pytorch Vulkan Testing Procedures](https://fb.quip.com/fZALAc9zhlcU)
On Mac:
1. `vulkan_api_test` on Mac
2. model comparison binary on Mac
On Android:
1. `vulkan_api_test` on Android
2. benchmark binary on Android
Reviewed By: salilsdesai
Differential Revision: D40266820
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86697
Approved by: https://github.com/kirklandsign
This can be critical when processing a large number of tensors
```bash
python -m timeit --setup 'import torch; t = torch.empty(1000, device="cuda")' 't.__dlpack_device__()'
```
based on 1.12.1:
before:
100000 loops, best of 5: 2.32 usec per loop
after:
500000 loops, best of 5: 844 nsec per loop
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86665
Approved by: https://github.com/SunDoge, https://github.com/soulitzer
It seems like the [torch.fx.Node docs](https://pytorch.org/docs/stable/fx.html#torch.fx.Node) are incorrect regarding the inclusion of the self argument for module call nodes.
While the docs state that self (the module) is included in `args`, it is in fact not, as demonstrated by this code:
```python
import torch
from torch import fx, nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.submod = nn.Linear(10, 10)
def forward(self, x):
x = x.flatten()
return self.submod(x)
graph_module = fx.symbolic_trace(Net())
print(graph_module.graph) # doesn't show self for the submodule call
submod_node = list(graph_module.graph.nodes)[2]
print(submod_node.op) # call_module
print(submod_node.args) # (flatten,) => would need to have len 2 if self was included
flatten_node = list(graph_module.graph.nodes)[1]
print(flatten_node.op) # call_method
print(flatten_node.args) # (x,) => here self is included (and docs are correct)
```
Since [torch.fx.Interpreter also uses `args` as if self was is not included](2fe5808590/torch/fx/interpreter.py (L288)), I assume the docs are incorrect.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86685
Approved by: https://github.com/soulitzer
- supports saving symint (and symfloat..) values between fw/bwd, using sketchy logic that probably needs to be improved but seems to work so far
- sets a correct weight=1 for sym nodes for cost purposes
- lets user functions return symints/floats (but if the same symfloat is saved for backward, that gets duplicated annoyingly)
- makes partitioning decisions based on observed trace-time sizes without guarding! (this is sketchy, but it isn't clear that it will lead to bad partitioning choices either)
- improves infra for tracking symint-family of types: is_sym_node() and _py_sym_types
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86425
Approved by: https://github.com/ezyang
Summary:
As titled, HistogramObserver may fail in a certain scenario.
Specifically, we originally compute `hist_bin_width` as `(self.max_val - self.min_val) / (self.bins * upsample_rate)`. It's possible that the numerator part is close the the FP32 threshold (1.4e-45) and conducting the division will cause overflow.
Bring some redundent computations to avoid such scenario.
Test Plan: https://pxl.cl/2ggD4 (04490e90ea)
Differential Revision: D40149594
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86522
Approved by: https://github.com/jerryzh168
since the default qengine is the last element of the engine in supported_engines list, adding x86 qengine in the end of the list changes the default quantized engine as well. this PR will be a short term fix to revert the changes. We have an issue here to track the proper fix: https://github.com/pytorch/pytorch/issues/86404
Motivation:
a meta internal team found that the inference failed in onednn prepacking with error: "could not create a primitive descriptor for a reorder primitive." in a COPPER_LAKE machine, we are working with intel to repro and fix the problem. in the mean time, we'll revert the changes of default option back to fbgemm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86631
Approved by: https://github.com/vkuzo
Fixes#86159 and #86108
Refactored graph partition to check for cyclic dependency on each partition merge, instead of relying on a pre-baked dependency map.
The previous implementation suffers from not updating dependency on existing partition. When a fusion happens, the updated dependency map needs to be propagated to all nodes in the graph, so each node in a partition shares an identical dependency set. Previous implementation suffers from the not identifying cyclic dependency in issue #86159.
Updated implementation does a cyclic check on partitioned graph before attempting a merge of two partitions.
- [x] python repro added with cyclic dependency after partition `TestFXGraphPasses.forward12`
- [x] fix dependency map with updated implementation using cyclic check
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86511
Approved by: https://github.com/SherlockNoMad
Before this PR, if a user runs DDP with `device_ids` specified and with a `PackedSequence` input, then the execution will error with something like:
```
raise ValueError(
ValueError: batch_sizes should always be on CPU. Instances of PackedSequence should never be created manually. They should be instantiated by
functions like pack_sequence and pack_padded_sequences in nn.utils.rnn. https://pytorch.org/docs/stable/nn.html...
```
This is because the DDP forward calls `_to_kwargs()`, which calls `_recursive_to()`, which moves the inputs to GPU. However, `_is_namedtuple(packed_sequence)` returns `True`, leading to the branch `return [type(obj)(*args) for args in zip(*map(to_map, obj))]`, which tries to construct a `PackedSequence` directly via `type(obj)(*args)`, leading to the error.
Repro for `_is_namedtuple(packed_sequence)` returning `True`:
```
import random
import torch
import torch.nn.utils.rnn as rnn_utils
from torch.nn.parallel.scatter_gather import _is_namedtuple
def _ordered_sequence(tensor_type):
seqs = [tensor_type(random.randint(1, 256))
for _ in range(32)]
seqs = [s.random_(-128, 128) for s in seqs]
ordered = sorted(seqs, key=len, reverse=True)
return ordered
def _padded_sequence(tensor_type):
ordered = _ordered_sequence(tensor_type)
lengths = [len(i) for i in ordered]
padded_tensor = rnn_utils.pad_sequence(ordered)
return padded_tensor, lengths
padded, lengths = _padded_sequence(torch.Tensor)
packed = rnn_utils.pack_padded_sequence(
padded, lengths, enforce_sorted=False)
print(type(packed), packed.data.device)
print(_is_namedtuple(packed))
```
Test Plan:
```
python test/distributed/test_c10d_nccl.py -k test_ddp_packed_sequence
```
Without the fix, the added unit test fails with the expected error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86614
Approved by: https://github.com/rohan-varma
Summary:
This header is being included from both aten/native and torch/csrc, but
some of our build configurations don't allow direct dependencies from
torch/csrc to atent/native, so put the header in aten where it's always
accessible.
Resolves https://github.com/pytorch/pytorch/issues/81198
Test Plan:
CI.
```
./scripts/build_android.sh
env ANDROID_ABI="x86_64" ANDROID_NDK=".../ndk-bundle" CMAKE_CXX_COMPILER_LAUNCHER=ccache CMAKE_C_COMPILER_LAUNCHER=ccache USE_VULKAN=0 ./scripts/build_android.sh
echo '#include <torch/torch.h>' > test.cpp
g++ -E -I $PWD/build_android/install/include/ -I $PWD/build_android/install/include/torch/csrc/api/include test.cpp >/dev/null
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82379
Approved by: https://github.com/ezyang, https://github.com/malfet
Summary:
previously the call failed because there was an infinite loop in _get_share_qparams_ops_configs
Test Plan:
python test/test_quantization.py -k test_get_executorch_backend_config
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86338
Approved by: https://github.com/andrewor14
# Summary
Many NestedTensor ops are implemented using a connivence function named get_buffer. This returns a dense, contiguous tensor that is a view of the underlying storage of the NestedTensor. This function allows NestedTensor ops to piggy back off of the implementations for dense tensor under certain scenarios. This PR adds a TORCH_CHECK() to get buffer to insure that the calling NT is in fact contiguous. It also adds an "unsafe" version for a few ops that are designed to handle contiguity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86496
Approved by: https://github.com/albanD, https://github.com/cpuhrsch
In the documentation of `nn.MaxPool2d` and `nn.MaxPool3d`, the argument description of `padding` incorrectly states that zero padding is applied. The remainder of the documentation correctly states that negative infinity padding is applied.
The documentation of `padding` in `nn.MaxPool1d`, `nn.functional.max_pool1d/2d/3d` is correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86559
Approved by: https://github.com/albanD
symintify split_with_sizes, dropout, fused_fake_obs_quant. meta for padding_2d ops
add meta_bernoulli_
meta kernel for at::gather
get pytorch_struct to pass: meta for scatter_add, fix backward
symintify split ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86488
Approved by: https://github.com/ezyang
This deprecates `FlattenParamsWrapper`'s usage for "unflattening" the original parameters. After this PR, FPW only serves to register and de-register its `FlatParameter` for the parent `FullyShardedDataParallel` instance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86117
Approved by: https://github.com/zhaojuanmao
This PR renames `param_dtype` and `reduce_dtype` in `HandleConfig` to `low_prec_param_dtype` and `low_prec_reduce_dtype` to emphasize that they are meant to be of the low precision (if not `None`).
(In my mind, mixed precision refers to the paradigm of using both full and low precision together during training. "Reduced" and "low precision" mean the same thing, but I prefer the term "low precision" in the code since it is shorter. A particular dtype can be a low precision dtype or a full precision dtype.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86512
Approved by: https://github.com/zhaojuanmao
`gemm_transab_` accumulates the sum in the output, despite the inner
loop being over a single output element. This changes it to accumulate
in a register, which also avoids early truncation for bfloat16.
I've also factored out a generic `sum` function that can be shared
with `gemm_transa_` to handle unrolling and multiple accumulators.
I have benchmarked addmm for bfloat16 with shapes
(320,600) X (600,320) and for both layouts I see a significant
speedup.
| layout | Before (ms) | After (ms) |
|----------|-------------|------------|
| transa | 71.5 | 31 |
| transab | 249 | 35 |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80977
Approved by: https://github.com/ngimel
Summary: using the tool from D39559248 i was able to make g2p faster on mobile by taking a look at profiles on stella frames. It turned out that the pytorch interpreter code does some logging that ends up being a pretty big bottleneck.
Differential Revision: D39901455
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85907
Approved by: https://github.com/dzdang
This PR allows freezing modules like the one below:
```python
# Ex. 1
@torch.jit.interface
class ModuleInterface(torch.nn.Module):
def forward(self, inp: torch.Tensor) -> torch.Tensor:
pass
class ImplementsInterface(torch.nn.Module):
def __init__(self):
super(ImplementsInterface, self).__init__()
self.sum = torch.zeros((2, 2))
def forward(self, inp: torch.Tensor) -> torch.Tensor:
self.sum += inp.relu() # this makes the interface-implementing module mutable
# and previously this would prevent freezing
return self.sum
class WrapperModule(torch.nn.Module):
impl: ModuleInterface
def __init__(self):
super().__init__()
self.impl = ImplementsInterface()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.impl.forward(x)
```
Previously during freezing, we handle interfaces as shown below:
1. we inline interfaces in any preserved method graphs
2. during `cleanupFrozenModule`, we try to simplify the module data structure (<- this part is unrelated to freezing so far). During this step, if we found that a interface type was mutable, we'd error out; because of the possibility of a module that _swaps out the value of an interface-typed attribute at runtime_.
Below is an example of a module that swaps out the value of an interface-typed attribute at runtime:
```python
# Ex. 2
class MyBadModule(torch.nn.Module):
impl: MyInterface
option1: IfaceImpl1
option2: IfaceImpl2
....
def forward(self, x):
if x > 0:
self.impl = self.option1
else:
self.impl = self.option2
....
```
^ this type of situation cannot be supported by freezing (or at least would be difficult to do correctly) because it greatly complicates the details of handling types and simplifying the module data structure.
But we can still support the first example without _too_ much work:
1. inline the interface code as before
2. check to see if we have any setattrs on interface types; if so, error out
3. otherwise, replace the type of the interface types with the concrete type implementation
4. continue simplifying the module data structure as if we never had any interfaces.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86039
Approved by: https://github.com/eellison
Summary:
A user had a problem with fx-scripting and the error message can be improved.
Error was shown as:
RuntimeError: Keys for dictionaries used as an argument cannot contain a Node. Got key: {k}
which is obvious not quite helpful.
Test Plan:
Test in a notebook:
{F778667593}
Reviewed By: xunnanxu, SherlockNoMad
Differential Revision: D40157518
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86422
Approved by: https://github.com/SherlockNoMad
We currently can take snapshots of the state of the allocated cuda memory, but we do not have a way to correlate these snapshots with the actions the allocator that were taken between snapshots. This PR adds a simple fixed-sized buffer that records the major actions that the allocator takes (ALLOC, FREE, SEGMENT_ALLOC, SEGMENT_FREE, OOM, SNAPSHOT) and includes these with the snapshot information. Capturing period snapshots with a big enough trace buffer makes it possible to see how the allocator state changes over time.
We plan to use this functionality to guide how settings in the allocator can be adjusted and eventually have a more robust overall algorithm.
As a component of this functionality, we also add the ability to get a callback when the allocator will throw an OOM, primarily so that snapshots can be taken immediately to see why the program ran out of memory (most programs have some C++ state that would free tensors before the OutOfMemory exception can be caught).
This PR also updates the _memory_viz.py script to pretty-print the trace information and provide a better textual summary of snapshots distinguishing between internal and external fragmentation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86241
Approved by: https://github.com/ngimel
For decomposing index_select with 0-dim tensor, we cannot write `x.unsqueeze(0)[index].squeeze(0).clone()` , as tensor[index] will trigger index.item() if index is a 0-dim tensor, and .item() cannot be symbolically traced with FakeTensor.
We use `torch.ops.aten.index(x.unsqueeze(0), [index]).squeeze(0).clone()` as a workaround.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86469
Approved by: https://github.com/ngimel
This adds `summon_full_params(with_grads=True)` for `use_orig_params=True` and `offload_to_cpu=False`. Filling in the `use_orig_params=False` case requires some already-planned refactoring, and the `offload_to_cpu=True` case needs some additional work as well.
Adding this is helpful for debugging `use_orig_params=True` to make sure gradients are being updated correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85738
Approved by: https://github.com/rohan-varma
**Overview**
This PR adds the option to use the original parameters via `use_orig_params=True` in the FSDP constructor.
- This exposes the original parameters rather than the `FlatParameter`s from `named_parameters()`, which means that the optimizer runs on the original parameters. Hence, users may assign original parameters from the same `FlatParameter` to different parameter groups.
- This enables decoupling the original parameter variables from their storage without changing the variables themselves, which is critical for our upcoming execution-order-based non-recursive wrapping policy.
For more detailed design explanation, refer to the Quip shared internally.
**Follow-Ups**
See 85831 (removing link to avoid spamming the issue whenever I update this PR).
`test_fsdp_use_orig_params.py` adds ~4 min 46 seconds to the TTS on the AWS cluster.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84911
Approved by: https://github.com/rohan-varma
This PR cleans up m.impl(...) calls to use the new KERNEL / KERNEL_CPU
macros. That saves us the trouble of writing out the signatures.
Test Plan:
- code reading
- wait for tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86403
Approved by: https://github.com/ezyang
On the way to resolving https://github.com/pytorch/pytorch/issues/86294
Previously, there were three macros used to register autocast rules:
- KERNEL
- KERNEL_DIFFERENT_REDISPATCH_SIGNATURE
- KERNEL_CPU
This PR makes the KERNEL and KERNEL_CPU macros less redundant for users.
KERNEL_DIFFERENT_REDISPATCH_SIGNATURE is weird and only used three
times, so I didn't change them.
Concretely, KERNEL(OP, OP_NAME, SIGNATURE, POLICY) is redundant:
- op/op_name are similar, and the signature can be decltype'd.
PR changes it so that instead, one uses either:
- KERNEL(OP, POLICY)
- KERNEL2(OP, OVERLOAD, POLICY)
depending on whether the operator name has an overload.
This PR also gives the same treatment to the KERNEL_CPU macro, which is
used for registering autocast cpu rules: it splits KERNEL_CPU into
KERNEL_CPU(OP, POLICY) AND KERNEL_CPU2(OP, OVERLOAD, POLICY).
I will do some more cleanup of things that are implemented via
`m.impl(...)` in a follow-up PR so that I don't get confused when I need
to rebase.
Test Plan:
- wait for tests (how good are our autocast tests?)
- code reading
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86402
Approved by: https://github.com/ezyang
Summary:
- catch .grad tensor info
- update data type and `check_and_store`, etc
- update unit test case
Test Plan: buck run mode/opt //caffe2/test:profiler
Reviewed By: chaekit
Differential Revision: D39711295
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86355
Approved by: https://github.com/chaekit
This bug was in the native cuDNN V8 API integration and was fixed a while ago, but the change was never ported here.
Previously the returned alignment could be twice the actual alignment of the data if the alignment was smaller than 16.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86253
Approved by: https://github.com/dzdang
This PR introduces an interface for user defined function that filters the matches in SubgraphRewriter. The function will have the following signature.
callable(match: InternalMatch, original_graph: Graph, pattern_graph: Graph) -> bool
This filter is applied after SubgraphMatcher returns the matches, and before replacement takes place.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86430
Approved by: https://github.com/jerryzh168
`Sparsity` as a term doesn't reflect the tools that are developed by the AO. The `torch/ao/sparsity` also has utilities for structured pruning, which internally we always referred to as just "pruning". To avoid any confusion, we renamed `Sparsity` to `Prune`. We will not be introducing the backwards compatibility, as so far this toolset was kept under silent development.
This change will reflect the changes in the documentation as well.
**TODO:**
- [ ] Change the tutorials
- [ ] Confirm no bc-breakages
- [ ] Reflect the changes in the trackers and RFC docs
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84867
Approved by: https://github.com/supriyar
Summary:
The flow logic around torch.dist imports results in large number of pyre errors (100's); would be preferable to just raise on importing as opposed to silently fail.
Con: Some percentage (MacOS?) of users may have notebooks that imports PT-D, although would think small, since any attempt to call parts of the library would just fail...
TODO: assuming ok, will remove the 10's-100's of unused pyre ignores no longer required.
Test Plan: existing unit tests
Differential Revision: D39842273
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85781
Approved by: https://github.com/mrshenli
symintify split_with_sizes, dropout, fused_fake_obs_quant. meta for padding_2d ops
add meta_bernoulli_
meta kernel for at::gather
get pytorch_struct to pass: meta for scatter_add, fix backward
symintify split ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86334
Approved by: https://github.com/ezyang
Summary: no changes, just removed the exception for this file, someone
had already fixed the actual file
Test Plan: python test/test_public_bindings.py
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86026
Approved by: https://github.com/jerryzh168
Summary:
looks like Sandcastle CI didn't cover any of concrete mobile CI(cc: kimishpatel i'd assume we have ton of mobile tests in Github?). This is failing on Oculus with the similar failure as Mac(not sure if this is an ARM thing). either way on demand tracing should not be enabled on these platforms so disable them completely
in the future, we should have runtime check on this for even safer guarding
Test Plan:
Set up Hollywood via P536072492
## Before
crash on mutex. likely SIOF
```
FORTIFY: pthread_mutex_lock called on a destroyed mutex (0x5d7e298b08)
*** Aborted at 1665017107 (Unix time, try 'date -d 1665017107') ***
*** Signal 6 (SIGABRT) (0xeca) received by PID 3786 (pthread TID 0x785bd1eed0) (linux TID 3786) (maybe from PID 3786, UID 0) (code: -1), stack trace: ***
(error retrieving stack trace)
```
## After
Redacted in the top but the test passes without the crash
P536101962
Differential Revision: D40129840
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86347
Approved by: https://github.com/aaronenyeshi
Summary: include `torch.qint32` to `activation_is_statically_quantized` and `get_quant_type` so that fakequantize with `dtype=torch.qint32` won't be skipped
Test Plan: updated `test_custom_module_class`
Differential Revision: D40128178
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86345
Approved by: https://github.com/jerryzh168
The reason for enabling sparse/dense_dim() for strided tensors is to have more meaningful error messages:
For instance, compare
```
NotImplementedError: Could not run 'aten::sparse_dim' with arguments from the 'CPU' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::sparse_dim' is only available for these backends: [SparseCPU, SparseCUDA, SparseMeta, SparseCsrCPU, SparseCsrCUDA, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradHIP, AutogradXLA, AutogradMPS, AutogradIPU, AutogradXPU, AutogradHPU, AutogradVE, AutogradLazy, AutogradMeta, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, AutogradNestedTensor, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
```
[master] vs
```
RuntimeError: addmm: matrices expected, got 0D tensor
```
[this PR] where the latter message gives a hint of which function is to blame for dealing with unexpected inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86203
Approved by: https://github.com/cpuhrsch
This does 2 things:
* Ensure that `nvidia-driver-latest-dkms` package is removed if it's installed. This allows the installation to go forward without the below error when using the standard installation script from S3:
```
(Answer: Abort installation)
ERROR: The installation was canceled due to the availability or presence of an alternate driver installation. Please see /var/log/nvidia-installer.log for more details.
```
* Not skipping the installation if a driver different than `515.57` exists to avoid any unexpected behavior when using a different driver version. This partly addresses the recent issue in https://github.com/pytorch/pytorch/issues/85778 in which `510.60.02` is there instead (not sure from where) and fails CUDA 11.7 test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86344
Approved by: https://github.com/atalman, https://github.com/malfet
Summary: Weight dtypes should be specified only for weighted
ops like conv and linear. This commit removes weight dtypes
from the DTypeConfigs used in binary ops and fixed qparams ops.
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Reviewers: jerryzh168, vkuzo
Subscribers: jerryzh168, vkuzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86335
Approved by: https://github.com/vkuzo
Summary: In order to make the layer normalization implementation for nested tensors public, it needs to be generalized to accept a normalized_shape argument instead of assuming it to be the last dimension of the nested_tensor. This commit does that, as well as adding extra unit tests to ensure the implementation is correct.
Test Plan:
All unit tests designed to test different ways of using the function work:
`buck test //caffe2/test:nested -- test_layer_norm`
Differential Revision: D40105207
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86295
Approved by: https://github.com/drisspg
The TestApp benchmark was recently re-added, however it seems it only builds when pytorch is built with the lite interpreter. This diff adds a macro to compile out the benchmark when pytorch is built as full jit. This should fix our full jit simulator nightly builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86314
Approved by: https://github.com/malfet
Summary:
- Added config option to remove 'Call stack' field from trace file (#84982)
- Change default value to `false`
Test Plan:
- `experimental_config=_ExperimentalConfig(verbose=true),` will add 'Call stack' field back in the trace file.
- CI tests
Differential Revision: D40092377
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86263
Approved by: https://github.com/aaronenyeshi
Our prevailing strategy for symbolic shapes in C++ is to only
write the SymInt version of the code, and pay a slight performance
tax from not knowing if it is symbolic or not. However, there are
some fastpath functions where this tax is unacceptable, and we want
to specialize for the int case. Sometimes, it is easy to template
the function; but when the function involves Tensors, it is not,
because the functions you may want to call are not templated,
e.g., t.view vs t.view_symint
This PR adds an at::symint:: namespace which contains templated
functions for all functions in PyTorch which you can use in this
way. To show this works, I refactored sum_to to stop incorrectly
reinterpret casting and instead use a template. Instead of
t.sizes(), we call at::symint::sizes<T>(t), and so forth.
The template functions are SFINAE'd using a template argument that
is not otherwise used. As such, deduction is impossible. Typically, deduction
is hard anyway, because many of the constructors are ambiguous (this
is why we split foo and foo_symint in the first place). So you must pass
a template argument to these functions.
These functions are codegened into Functions.h so they are subject
to per-operator headers. This matters most for methods, which likely
didn't include the per-operator header, so you will have to add an
include in that case. We never generate method variants for these.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86329
Approved by: https://github.com/bdhirsh, https://github.com/voznesenskym
Summary:
This PR is an early prototype of a tool to quantize each layer of a model
N times, with N qconfigs each. We follow the design agreed upon in
https://fburl.com/gdoc/e1gaq3ih .
Current API:
```
m = M().eval()
example_input = (torch.randn(2, 2),)
qconfig_mappings = [
QConfigMapping().set_global(torch.quantization.default_qconfig),
QConfigMapping().set_global(torch.quantization.default_dynamic_qconfig),
]
backend_config = get_native_backend_config()
msp = prepare_n_shadows_model(
m, example_input, qconfig_mappings, backend_config)
for _ in range(2):
msp(*example_input)
msq = convert_n_shadows_model(msp)
msq(*example_input)
results = extract_results_n_shadows_model(msq)
print_comparisons_n_shadows_model(results)
// example output
subgraph_idx ref_node_name best_idx 1 2
-------------- --------------- ---------- ------- -------
subgraph_0 fc1 2 42.0834 42.6279
subgraph_1 fc2 2 43.7259 50.0593
```
Test plan:
```
python test/test_quantization.py -k test_n_shadows
```
Differential Revision: [D37650332](https://our.internmc.facebook.com/intern/diff/D37650332)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80521
Approved by: https://github.com/jerryzh168, https://github.com/andrewor14
Summary:
The test is causing issues:
```
terminate called after throwing an instance of 'std::runtime_error'
what(): The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
graph(%A: Tensor, %driver: str?):
%bias: None = prim::Constant()
%ret = aten::linalg_svdvals(%A, %driver)
~~~~ <--- HERE
%cloned = aten::clone(%ret, %bias)
return (%cloned)
RuntimeError: torch.linalg.svd: keyword argument `driver=` is only supported on CUDA inputs with cuSOLVER backend.
```
Just block the op and re-run the codegen script to remove everything and update the generated ops.
Test Plan: Existing tests
Differential Revision: D39973860
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85983
Approved by: https://github.com/xuzhao9, https://github.com/tenpercent
Currently index_select/index_add decompositions decompose to `index` or `index_put` ops. The problem with this is that `index_select` and `index_add` accept int32 indices while `index` doesn't. That leads to error in meta func for those decompositions. This PR adds non-performant support for int32 indices to `index` operations, to allow decompositions go through.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86309
Approved by: https://github.com/lezcano
https://github.com/pytorch/pytorch/pull/85780 updated all c10d headers in pytorch to use absolute path following the other distributed components. However, the headers were still copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch`, thus external extentions still have to reference the c10d headers as `<c10d/*.h>`, making the usage inconsistent (the only exception was c10d/exception.h, which was copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`).
This patch fixes the installation step to copy all c10d headers to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`, thus external extensions can consistently reference c10d headers with the absolute path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86257
Approved by: https://github.com/kumpera
Summary: biggest issue was that the constructors for the fake_quantize
classes use custom partials that live in the observer module and so
the module for these needed to be set correctly in the constructor class
method
Test Plan: python test/test_public_bindings.py
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86022
Approved by: https://github.com/jerryzh168
Our SymInt rep can be represented more efficiently as just a greater than test, but the compiler doesn't seem to figure it out. Help it out.
There is also some refactoring to simplify the code and add more debugging.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86230
Approved by: https://github.com/albanD
Summary: The "kill worker process" event was logged to Scuba only when the worker process was really reaped. We want to add a new event "timer expired", no matter the worker process will be reaped or not. This will help collect data before we enable the JustKnob to kill the worker process on timeout.
Test Plan:
### Unit Test
```
buck test mode/dev-nosan //caffe2/test/distributed/elastic/agent/server/test:local_agent_test
```
```
Test Session: https://www.internalfb.com/intern/testinfra/testrun/7318349508929624
RE: reSessionID-ea464c43-54e7-44f2-942b-14ea8aa98c74 Up: 10.5 KiB Down: 1.1 MiB
Jobs completed: 100. Time elapsed: 3206.9s. Cache hits: 91%. Commands: 11 (cached: 10, remote: 1, local: 0)
Tests finished: Pass 55. Fail 0. Fatal 0. Skip 0. 0 builds failed
```
--------
```
buck test mode/dev-nosan //caffe2/test/distributed/elastic/agent/server/test/fb:local_agent_fb_internal_test
```
```
Test Session: https://www.internalfb.com/intern/testinfra/testrun/6473924579130483
RE: reSessionID-231a47b7-a43d-4c0f-9f73-64713ffcbbd3 Up: 5.7 MiB Down: 1.9 GiB
Jobs completed: 182156. Time elapsed: 282.4s. Cache hits: 99%. Commands: 72112 (cached: 72107, remote: 1, local: 4)
Tests finished: Pass 2. Fail 0. Fatal 0. Skip 0. 0 builds failed
```
Differential Revision: D39903376
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85861
Approved by: https://github.com/d4l3k
Also, make sure it raises catcheable errors if invoked with integral types
Otherwise, it used to fail with following fatal error invoked for `torch.half` and with similar signatures if invoked for integral types
```
loc("mps_multiply"("(mpsFileLoc): /AppleInternal/Library/BuildRoots/4883e71d-37bd-11ed-b0ef-b25c5e9b9057/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShadersGraph/mpsgraph/MetalPerformanceShadersGraph/Core/Files/MPSGraphUtilities.mm":228:0)): error: input types 'tensor<2xf16>' and 'tensor<1xf32>' are not broadcast compatible
LLVM ERROR: Failed to infer result type(s).
```
Modified `test_gelu_simple` to check both fwd and backward gradients for gelu
It's not clear to me what's the difference between `unfold` and `unfold_copy`, as this latter one is codegen'd
I also took this chance to clean the implementation of unfold and its reference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85629
Approved by: https://github.com/mruberry
2022-10-05 12:15:49 +00:00
5067 changed files with 485375 additions and 190307 deletions
where ``$BUILD_ENVIRONMENT`` is one of the build environments
where ``$BUILD_ENVIRONMENT`` is one of the build environments
enumerated in
enumerated in
[pytorch-dockerfiles](https://github.com/pytorch/pytorch/blob/master/.circleci/docker/build.sh). The dockerfile used by jenkins can be found under the `.circle` [directory](https://github.com/pytorch/pytorch/blob/master/.circleci/docker)
[pytorch-dockerfiles](https://github.com/pytorch/pytorch/blob/master/.ci/docker/build.sh). The dockerfile used by jenkins can be found under the `.ci` [directory](https://github.com/pytorch/pytorch/blob/master/.ci/docker)
2. Run ``docker run -it -u jenkins $DOCKER_IMAGE``, clone PyTorch and
2. Run ``docker run -it -u jenkins $DOCKER_IMAGE``, clone PyTorch and
if ! python perf-tests/modules/test_cpu_torch.py "${ARGS[@]}";then
if ! python perf-tests/modules/test_cpu_torch.py "${ARGS[@]}";then
echo"To reproduce this regression, run \`cd .jenkins/pytorch/perf_test/ && bash ${FUNCNAME[0]}.sh\` on your local machine and compare the runtime before/after your code change."
echo"To reproduce this regression, run \`cd .ci/pytorch/perf_test/ && bash ${FUNCNAME[0]}.sh\` on your local machine and compare the runtime before/after your code change."
if ! python perf-tests/modules/test_cpu_torch_tensor.py "${ARGS[@]}";then
if ! python perf-tests/modules/test_cpu_torch_tensor.py "${ARGS[@]}";then
echo"To reproduce this regression, run \`cd .jenkins/pytorch/perf_test/ && bash ${FUNCNAME[0]}.sh\` on your local machine and compare the runtime before/after your code change."
echo"To reproduce this regression, run \`cd .ci/pytorch/perf_test/ && bash ${FUNCNAME[0]}.sh\` on your local machine and compare the runtime before/after your code change."
echo NOTE: To run `import torch`, please make sure to activate the conda environment by running `call %CONDA_PARENT_DIR%\Miniconda3\Scripts\activate.bat %CONDA_PARENT_DIR%\Miniconda3` in Command Prompt before running Git Bash.
echo NOTE: To run `import torch`, please make sure to activate the conda environment by running `call %CONDA_PARENT_DIR%\Miniconda3\Scripts\activate.bat %CONDA_PARENT_DIR%\Miniconda3` in Command Prompt before running Git Bash.
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
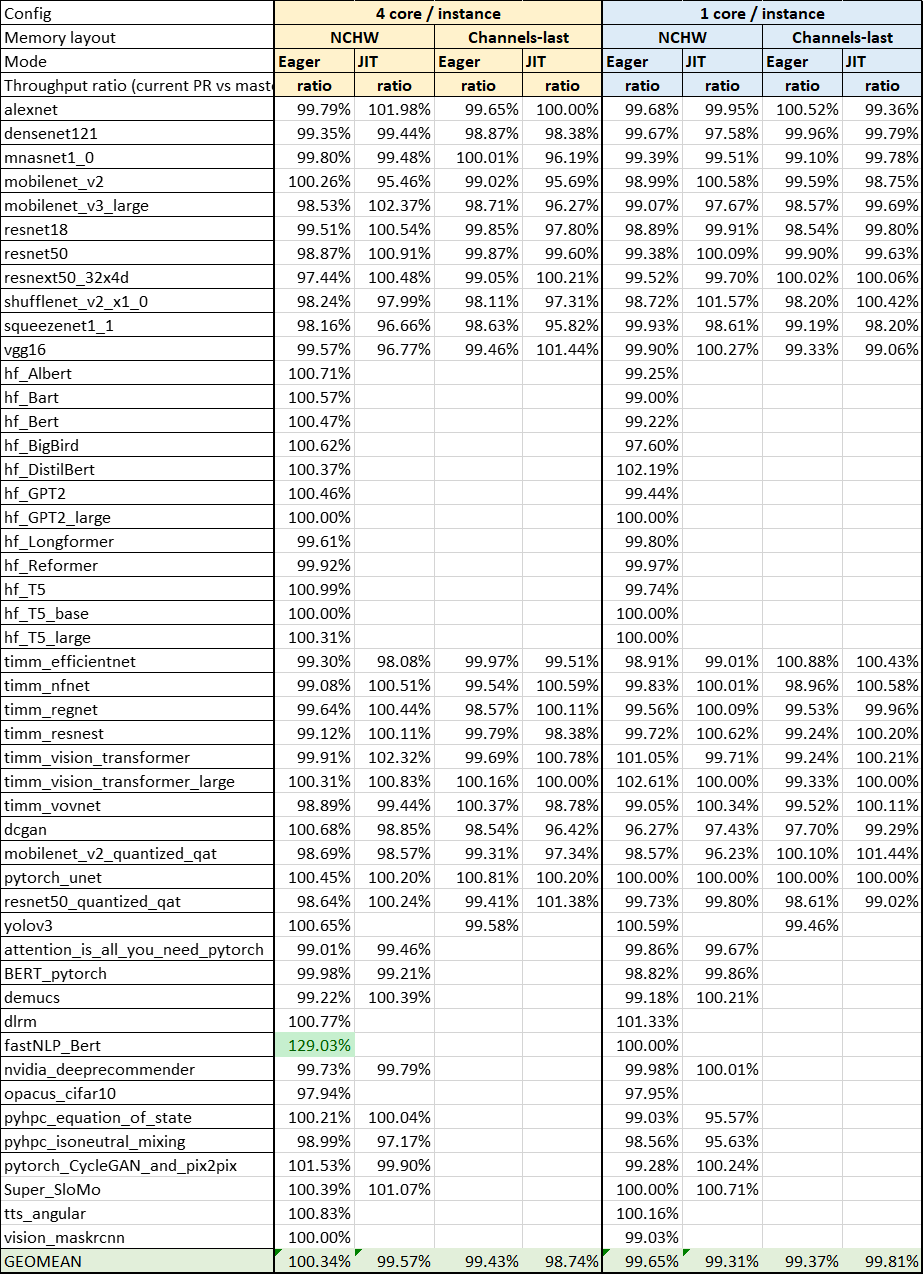{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
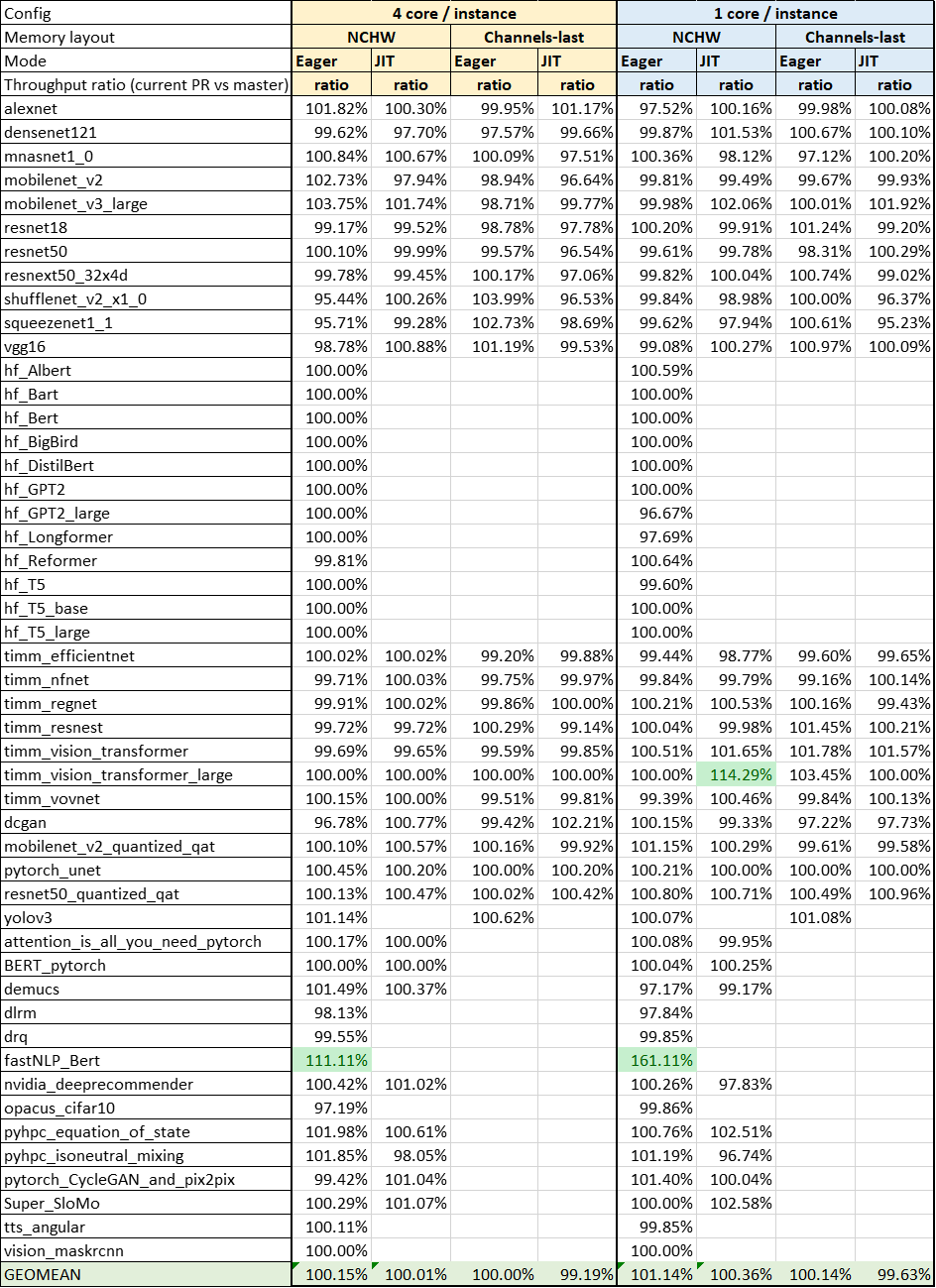{kind=link}
{kind=link}
{kind=link}
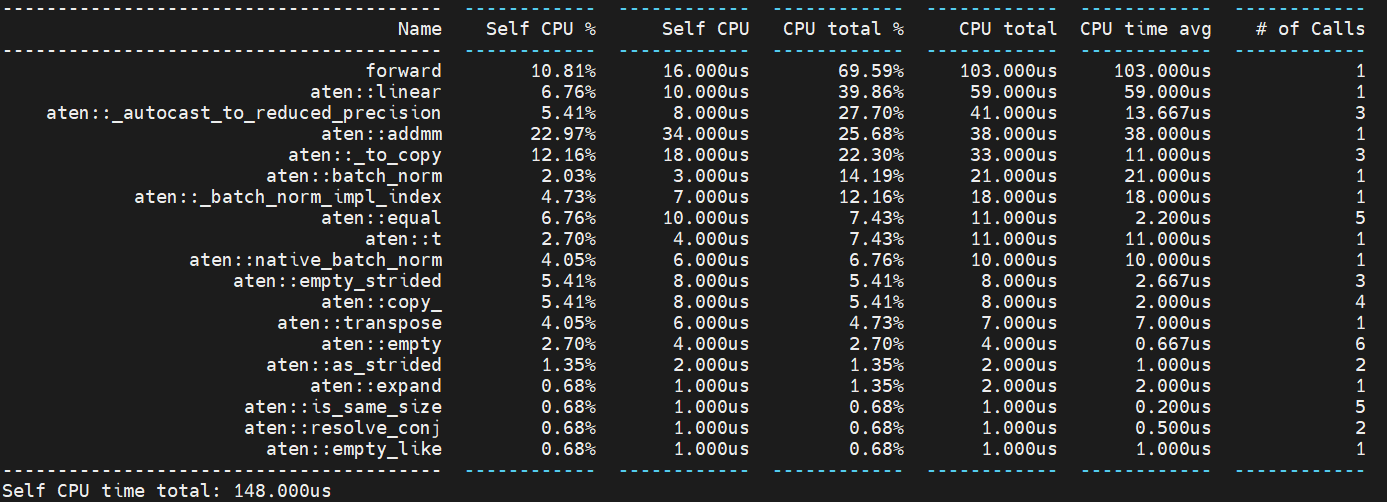{kind=link}
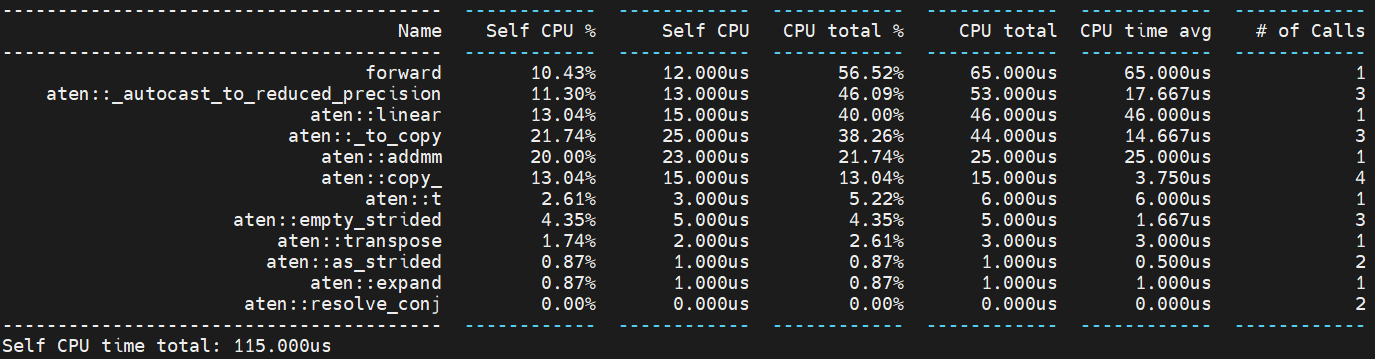{kind=link}
{kind=link}
{kind=link}
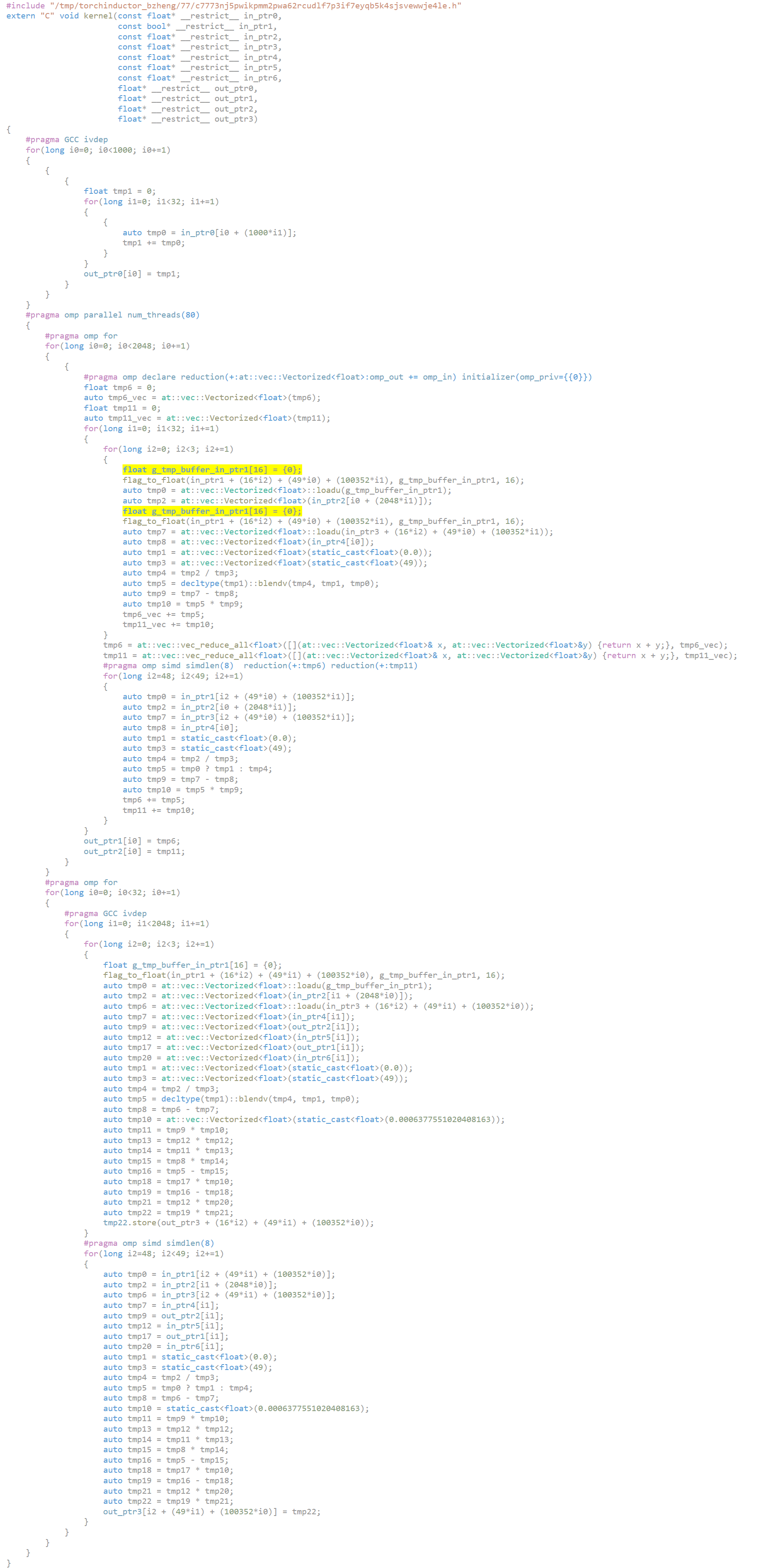{kind=link}
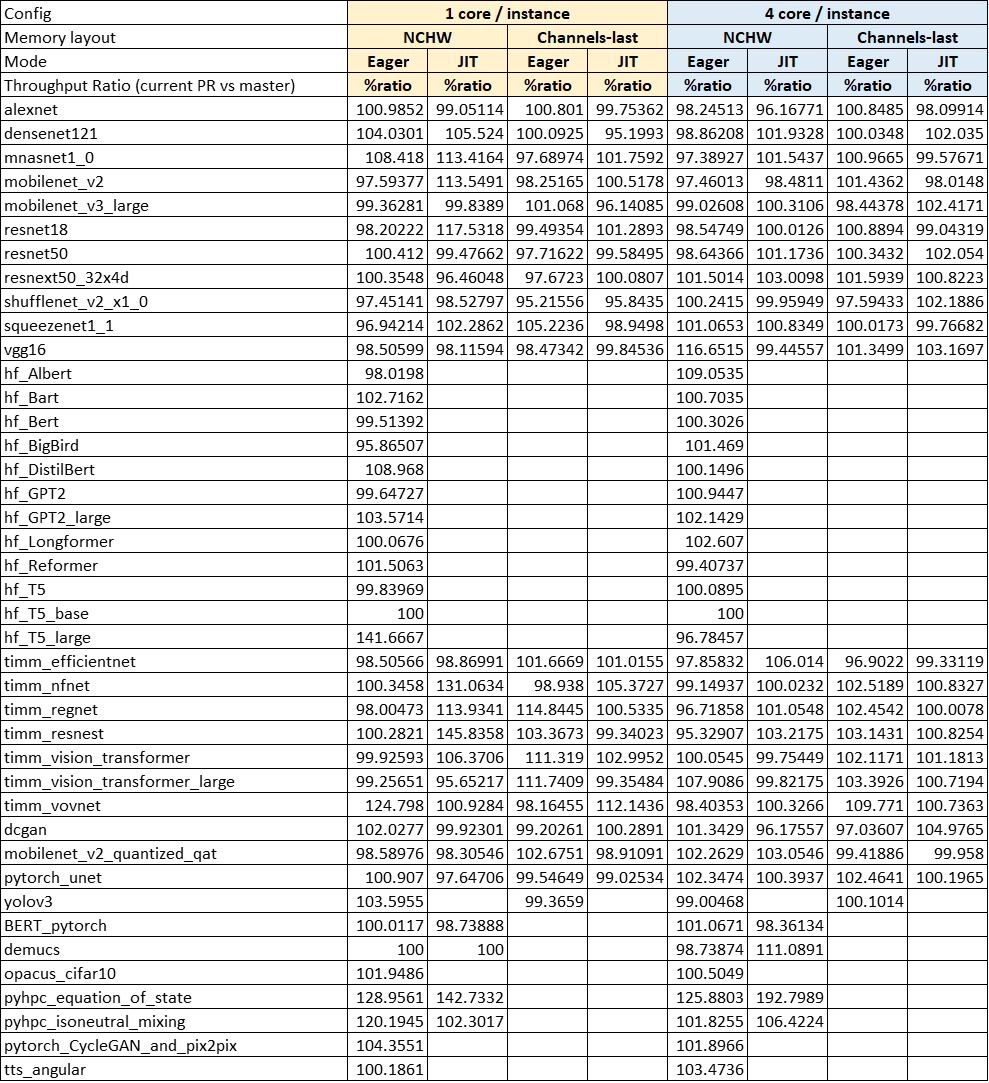{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
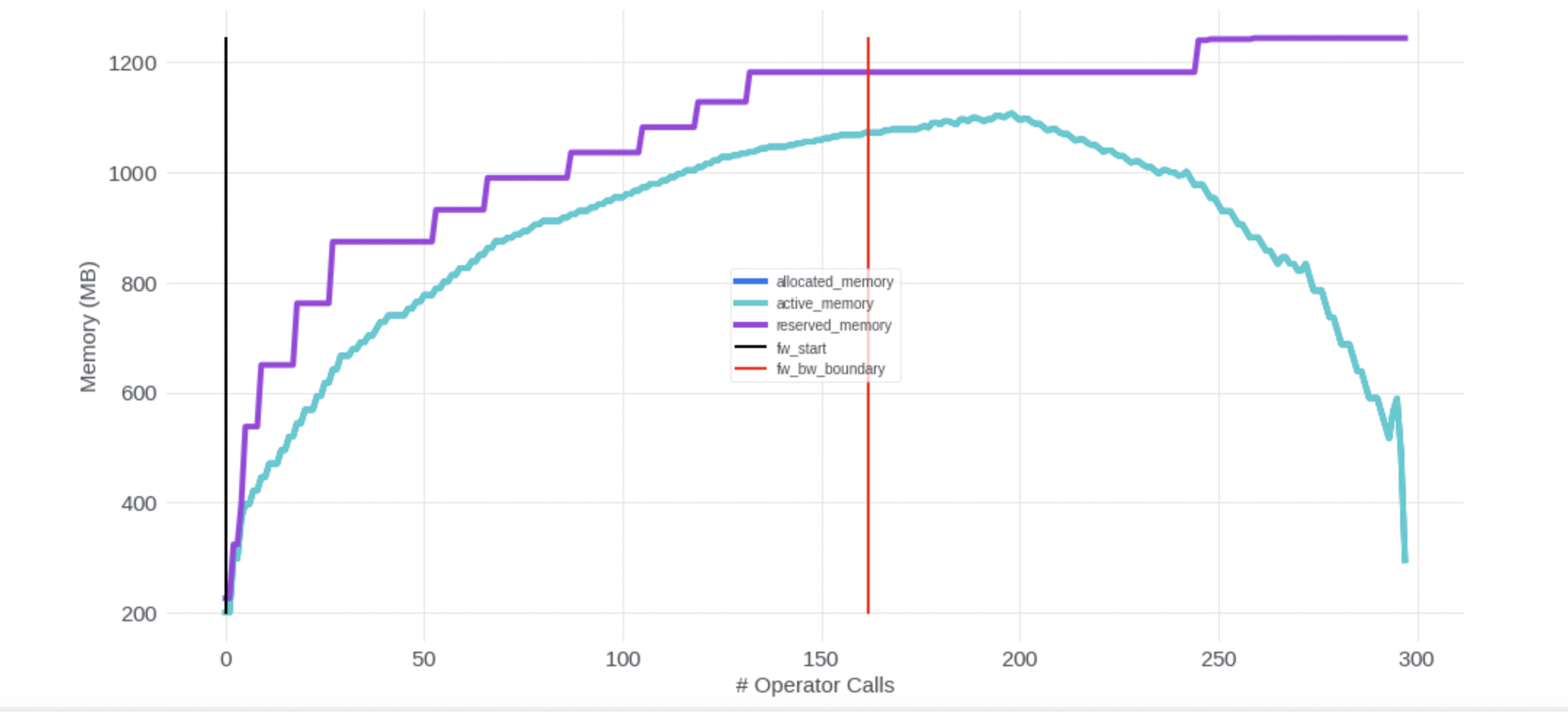{kind=link}
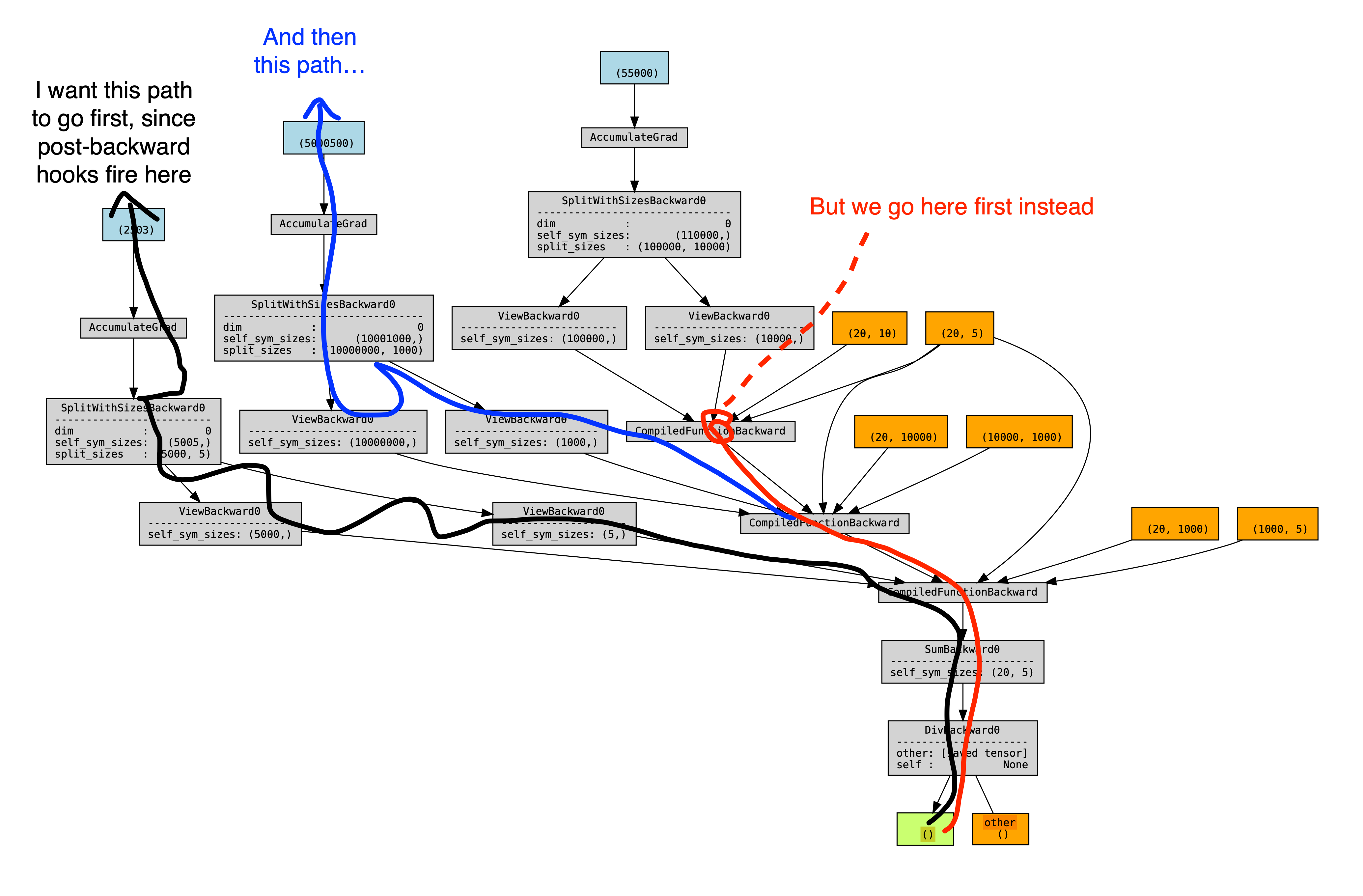{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
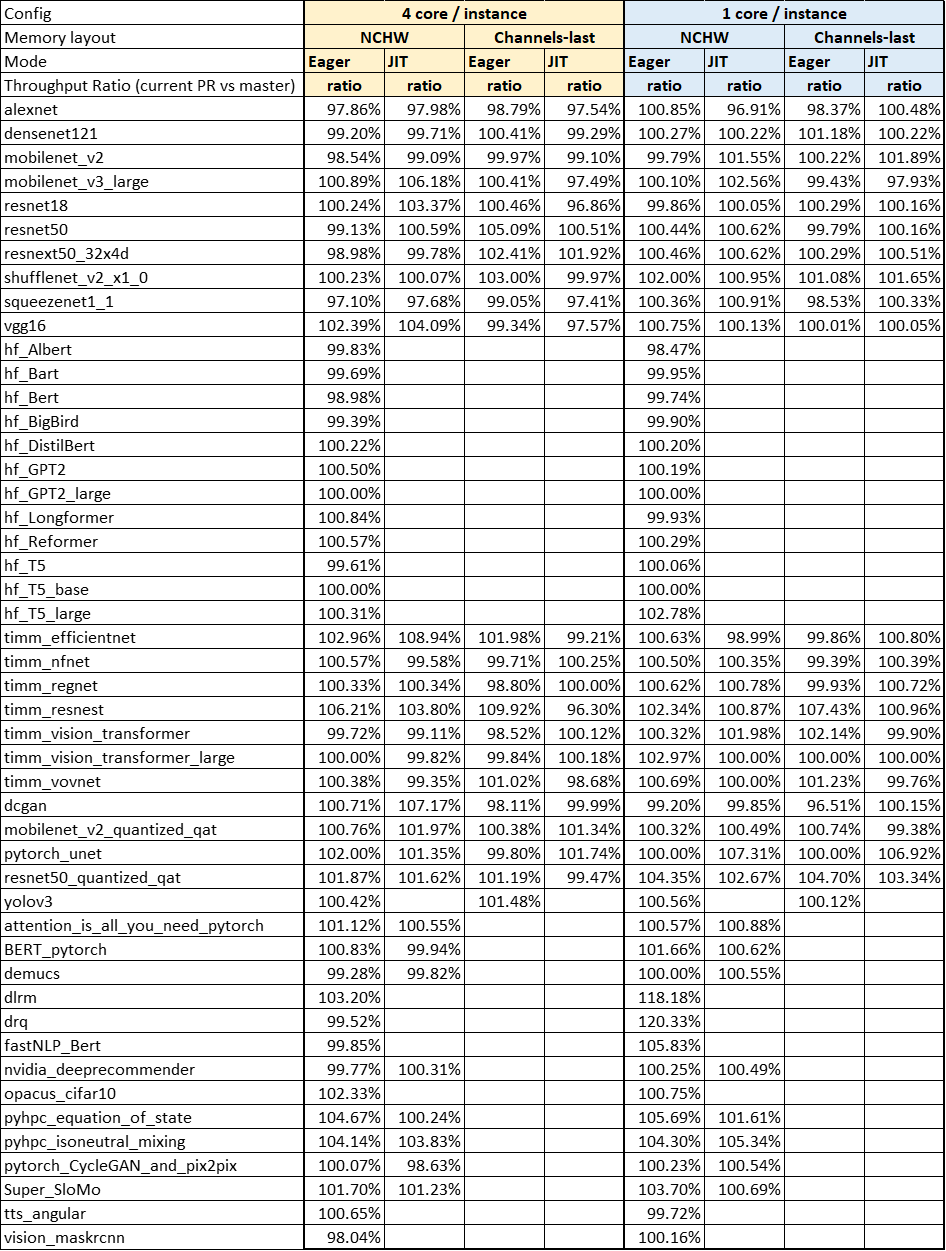{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}