Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70474
Needed to compile linux wheels for CUDA 11.x since we were OOM'ing with
16GB of RAM
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: atalman
Differential Revision: D33343322
Pulled By: seemethere
fbshipit-source-id: 9f62e07ce2ca229fa25285429c01dc074d63b388
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70332
Idea to avoid recompilations: what if we introduce a new macro REGISTER_ALL_CPU_DISPATCH that registers the same kernel across all CPU arch types? We'd call this from native/Convolution*.cpp and wouldn't need to move any logic underneath the native/cpu dir. That would simplify these PRs quite a bit and would also avoid the recompilation. Wdyt about this approach?
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D33301403
Pulled By: jbschlosser
fbshipit-source-id: d7cc163d4fe23c35c93e512d1f0a8af8c9897933
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70456
This job was still running on workflows despite ciflow not being enabled
This makes it so that test matrix generation only occurs before tests
are actually run.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: atalman
Differential Revision: D33338946
Pulled By: seemethere
fbshipit-source-id: 4b83d5fe6572771807708764609a72c4f1c5745d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70453
Removes the current xla config, downstream `pytorch/xla` is broken for
clang compilation so temporarily removing this config until the xla team
can fix this upstream CI.
Context: https://github.com/pytorch/xla/pull/3255/files#r775980035
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: zengk95
Differential Revision: D33338463
Pulled By: seemethere
fbshipit-source-id: 1ef332c685d5e2cc7e2eb038e93bd656847fd099
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70107
Histogram observer used floor division on tensors, which is a deprecated
behavior. There was a warning printed:
```
/Users/vasiliy/pytorch/torch/ao/quantization/observer.py:905: UserWarning: __floordiv__ is deprecated, and i
ts behavior will change in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' funct
ion NOT 'floor'). This results in incorrect rounding for negative values. To keep the current behavior, use
torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='flo
or').
```
This PR fixes the warning.
Test Plan:
```
python test/test_quantization.py TestHistogramObserver
```
Reviewed By: ejguan
Differential Revision: D33187926
Pulled By: vkuzo
fbshipit-source-id: 9c37de4c6d6193bee9047b6a28ff37ee1b019753
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70106
Some of quantization tests had log spew like
```
UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
```
This PR cleans up the root cause from the utils. Some other
tests may still hit this warning from other places
Test Plan:
```
python test/test_quantization.py TestFakeQuantizeOps
```
this particular warning no longer appears
Reviewed By: soulitzer
Differential Revision: D33187925
Pulled By: vkuzo
fbshipit-source-id: bd1acd77fd72a10dad0c254f9f9f32e513c8a89a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70336
broadcast_object_list casted the sum of all object lengths to int from long causing overflows.
Test Plan:
Increased size of Tensor used in object transfers to have >2GB storage requirement (in distributed_test.py)
Without fix the length will overflow and the program will request a negative sized Tensor:
```
RuntimeError: Trying to create tensor with negative dimension -2147482417: [-2147482417]
```
With fix it will pass the test.
Test used on server with GPUs:
buck test mode/dev-nosan //caffe2/test/distributed:distributed_nccl_spawn --local -- broadcast_object
Differential Revision: D33281300
fbshipit-source-id: 1bc83e8624edc14e747eeced7bc8a7a10e443ee4
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 52791a2fd2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70438
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: zertosh
Differential Revision: D33331758
fbshipit-source-id: 1e811ddc30e9afa440523c6cb5c4e893eb560978
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70339
When a python program is translated to TorchScript, the python exception type is dropped. This makes users's life hard when they need to categorize errors based more than only exception message.
Here we make the change so when we raise a python exception, we record the fully qualified class name for the exception. Later on when the TorchScript is interpreted, a special exception CustomJITException is thrown. User can get the python class name from CustomJITException::getPythonClassName .
Note that, this diff does not customize the mapping from C++ exception to Python exception. It's left to the users to do whatever mapping they want.
Code under scripts/shunting are just my own experimental code. I can split them out if requested.
ghstack-source-id: 146221879
Test Plan: buck test mode/opt //caffe2/test:jit
Reviewed By: gmagogsfm
Differential Revision: D33282878
fbshipit-source-id: 910f67a764519f1053a48589d1a34df69001525d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70370
Demo of Mobilenetv3 compiled with NNC in FB4A Playground app:
- Add compiled ModelConfig in FB4A app
- Enable Camera inputs for Mobilenet processor in the app and add ability to show live outputs
- Use downscaled inputs, which works for both original mobilenetv3 model and the compiled model
- Update nnc_aten_adaptive_avg_pool2d to use adaptive_avg_pool2d instead of adaptive_avg_pool2d_out as the latter is not included in the traced operators of mobilenetv3 model and hence not included in the app.
- Update app dependencies to include nnc_backend_lib and asm binary
Test Plan:
Run `arc playground pytorchscenario` from fbandroid to build and install the app on a connected device.
Live demo with compiled Mobilenetv3 model:
https://pxl.cl/1W1kb
Reviewed By: larryliu0820
Differential Revision: D33301477
fbshipit-source-id: 5d50a0e70a7f7d2157d311d6b1feef46e78e85b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69998
Fixes: https://github.com/pytorch/pytorch/issues/69855
The check for undefined grads for forward AD was not being run because `check_undefined_grads` was only passed as True by OpInfo for backward AD. This PR updates gradcheck to interpret `check_undefined_grads` as possibly for forward or backward AD.
This PR also updates codegen to 1) not use ZeroTensor for `self` when the op is inplace. 2) only create zeros (either through ZeroTensor or at::zeros) if the tensor itself is not undefined. Previously we would error in this case when we call `.options` on the undefined tensor.
~TODO: undo the skips that are due to the original issue~
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D33235973
Pulled By: soulitzer
fbshipit-source-id: 5769b6d6ca123b2bed31dc2bc6bc8e4701581891
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70365
We should only mark ops as unary if they should have a single fx.Node input. However, `cat` has a sequence of `tensors` input.
Reviewed By: alexbeloi
Differential Revision: D33299988
fbshipit-source-id: db3581eaee4ad9d2358eed01ec9027825f58f220
Summary:
The windows 1st shard was silently failing to run (more details here https://github.com/pytorch/pytorch/issues/70010) because the code to run them was never reached. It was silently failing because our CI still returned green for those workflow jobs, because the exit code from the batch script DID NOT PROPAGATE to the calling bash script.
The key here is that even though we have
```
if ERRORLEVEL 1 exit \b 1
```
The exit code 1 was NOT propagating back to the bash script, as the `exit \b 1` was within an `if` statement and the batch script was actually run in a cmd shell, so the bash script win-test.sh continued without erroring. Moving the `exit \b 1` to be standalone fixes it.
More details for this can be found in this stack overflow https://stackoverflow.com/a/55290133
Evidence that now a failure in the .bat would fail the whole job:
https://github.com/pytorch/pytorch/runs/4621483334?check_suite_focus=true
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70011
Reviewed By: malfet
Differential Revision: D33301254
Pulled By: janeyx99
fbshipit-source-id: 6861dbf0f0a34d5baed59f928e34eab15af6f461
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70341
Per title
ghstack-source-id: 146181936
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D33290099
fbshipit-source-id: e4415a42086d9b1b78b0b5f42d4b02f275131dfa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70340
Some wrap APIs support module.wrapper_config to specify the FSDP
arguments, though this feature is currently unused in all use cases and there
is no plan to support this API. enable_wrap() and wrap() along with FSDP
constructor wrapping should be enough for all use cases, so get rid of the
unnecessary code.
ghstack-source-id: 146181819
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D33290066
fbshipit-source-id: e7f3d8b2f2ff6bdf4a3e5021dbb53adf052ee8dc
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/64785 by introducing a `torch.LinAlgError` for reporting errors caused by bad values in linear algebra routines which should allow users to easily catch errors caused by numerical errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68571
Reviewed By: malfet
Differential Revision: D33254087
Pulled By: albanD
fbshipit-source-id: 94b59000fdb6a9765e397158e526d1f815f18f0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70210
Add a fast-path for `VarStack` nodes for when the inputs are scalars.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest -- VarStack`
Reviewed By: hlu1
Differential Revision: D33177498
fbshipit-source-id: 922ab76a6808fbfdb8eb6091163a380344e38de6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70235
address comments in https://github.com/pytorch/pytorch/pull/69282:
Have fixed a few corner cases for prefetching full parameters in post backward hook.
After benchmarking, prefetching full parameters in the pre-backward hook has the best performance and stable but at cost of increased memory; prefetching full parameters in the post-backward hook did not see expected performance, also failed in a few corner cases (fixed) although there is no memory increase. The main issue is that post backward hook fire order is not consistent with opposite of forward computation order, so incorrectly prefetched all gather could delay the really needed all gather in the single NCCL stream and cause some layer's computation delay.
So putting these two algorithms as two configurable experimental algorithms for now
prefetch full parameters at pre-backward hook:
It is observed from past traces that all gather ops are not triggered until current layer's backward pass starts to compute, also for some models previous layers' reduce scatter is scheduled before next layer's all gather ops, since all gather and reduce scatter are in the same nccl stream, this case could result in backward pass has no communication and computation overlap.
To explicitly make next layers' all gather scheduled while previous layers' backward computation is running, we can prefetch next layers' all gather full params. This can help 1) both all gather and reduce scatter are overlapped with computation deterministically 2) only prefetch one layer's all gather full parameters, to avoid increasing too much memories.
The implementation borrowed the idea from facebookresearch/fairscale#865, where forward graph order is recorded in the forward pass.
In the backward pass, this PR prefetches all gather full parameter in current layer's pre-backward hook, instead of prefetching in current layer's post backward hook in facebookresearch/fairscale#865. Also make sure all gather streams are synced properly.
Experiments showed 10% memory increase and 20% latency speed up for 1GB roberta model in a slow network environment.
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D33252795
fbshipit-source-id: 4e2f47225ba223e7429b0dcaa89df3634bb70050
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70150
This PR allows user to specify backend_config_dict for standalone modules, both in prepare and convert step
adding this now to allow prototype for some of our customer use cases, test for the codepath will be added in
a separate PR
Test Plan:
regression tests
```
python test/test_quantization.py TestQuantizeFx
```
test that specifies backend_config for some module will be added in a separate PR for the use case we have in mind
since it requires other features
Imported from OSS
**Static Docs Preview: classyvision**
|[Full Site](https://our.intern.facebook.com/intern/staticdocs/eph/D33205162/V9/classyvision/)|
|**Modified Pages**|
Reviewed By: vkuzo
Differential Revision: D33205162
fbshipit-source-id: a657cef8e49d99b6a43653141521dc87c33bfd89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70327
After D32678163 (7ea86dfdb1), test_rpc_profiler began failing. This was surprising, because it should have been a no-op refactor. However, one change is that a Kineto profiler is no longer also an autograd profiler; the RPC framework was assuming a legacy profiler but when a kineto profiler was active things still kind of worked due to that implementation detail. (But crashed after the class split.)
This diff tidys up a couple of things:
1) Move `getProfilerConfig` into `api.cpp`, since it is no longer correct to static_cast a `KinetoThreadLocalState` to a `ProfilerLegacyThreadLocalState`. (And really the class we want is `ProfilerThreadLocalStateBase` anyway.)
2) Add a mechanism for callers to check if the active profiler is a legacy or kineto profiler. (So callers like RPC can adjust or provide a nice error message.)
3) Fix the RPC test to create a legacy profiler.
Test Plan: `caffe2/torch/fb/training_toolkit/backend/tests:test_rpc_profiler` now passes, and before the fix to `test_rpc_profiler.py`, I verified that the test failed with the error message added to `utils.cpp` rather than just crashing.
Reviewed By: suphoff
Differential Revision: D33283314
fbshipit-source-id: e4fc5b5cfc9ca3b91b8f5e09adea36f38611f90d
Summary:
Github's checkout action sometimes leaves untracked files in the repo
Remedy it by running `git clean -fxd`, which should nuke them all
Tentative fix for https://github.com/pytorch/pytorch/issues/70097
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70337
Reviewed By: suo
Differential Revision: D33289189
Pulled By: malfet
fbshipit-source-id: 16e3ebe7a61fda1648189c78bdf1b1185247037a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69774
We recently ran into a nasty bug caused by incorrect schema annotations on an `aten::split` overload. `verify_and_correct_memory_overlap` is supposed to prevent crashes in this scenario, but it didn't because it did not handle `Tensor[]` outputs.
This change extends the memory correction mechanism to handle tensor lists.
ghstack-source-id: 146152478
Test Plan: `buck test caffe2/benchmarks/static_runtime/...`
Reviewed By: hlu1
Differential Revision: D33022494
fbshipit-source-id: 8d1d41ca1d4fd5dfb7c8a66028c391ba63551eb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70066
This commit upstreams utils to convert at::Tensors into LazyTensors and
vice versa.
Test Plan:
Covered by test_ptltc on the lazy_tensor_staging branch since TorchScript
Backend hasn't merged yet.
Reviewed By: desertfire
Differential Revision: D33171590
Pulled By: alanwaketan
fbshipit-source-id: b297ff5fc8ca1a02d30e16ad2249985310e836a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68948
The case where both the negative and conjugate bits are set
isn't tested currently despite being handled explicitly by `copy`.
In theory this shouldn't matter because neg_bit is only used for real
values, but it does mean the code in copy is untested. So, this just
runs it with a single sample as a sanity check.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33064371
Pulled By: anjali411
fbshipit-source-id: e90c65e311507c4fc618ff74fecc4929599c4fa3
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/70271
Test Plan:
Rebase on top of D32407544 and
buck run mode/opt -c fbcode.enable_gpu_sections=true pytext/fb/tools:benchmark_masked_softmax -- masked-softmax --batch-size=10
to see correct perf data ( PT time = ~2.5x PT native time )
Reviewed By: ngimel
Differential Revision: D33268055
fbshipit-source-id: f48b17852c19c2bc646f9ed8d9d5aac85caa8a05
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70306
USE_XNNPACK is the right one to enable lowering to prepacked xnnpack based ops
Test Plan: CI
Reviewed By: ZolotukhinM, priyaramani
Differential Revision: D33279375
fbshipit-source-id: d19ded5643f487f7b58c54a860ad39c8d484ed05
Summary:
Fixes https://github.com/pytorch/pytorch/issues/66725
This removes the ci_flow_should_run job and puts it in the build stage for the different job templates.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70204
Reviewed By: malfet
Differential Revision: D33282338
Pulled By: zengk95
fbshipit-source-id: 327ff2bca9720d2a69083594ada5c7788b65adbd
Summary:
Changes made to line 1073: The denominator of the formula was the EXP(SUM(x)) and changed it to SUM(EXP(x))
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70220
Reviewed By: davidberard98
Differential Revision: D33279050
Pulled By: jbschlosser
fbshipit-source-id: 3e13aff5879240770e0cf2e047e7ef077784eb9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70294
In order to inference shape for permute, the node target needs to get converted from torch.permute to acc_opts.permute.
Reviewed By: jfix71
Differential Revision: D33267469
fbshipit-source-id: b77eff1892211eac4a798a2f3e624140e287f4a2
Summary:
`linalg.inv` and `inverse` are aliases according to documentation, yet their implementation is somewhat diverged. This makes `inverse` call into `linalg_inv`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70276
Reviewed By: malfet
Differential Revision: D33271847
Pulled By: ngimel
fbshipit-source-id: cf018ddd2c1cee29026dd5f546f03f3a1d3cf362
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70198
This PR fixes composite compliance problems with:
- binary_cross_entropy's backward formula
- binary_cross_entropy_with_logits's backward formula
- binary_cross_entropy's double backward formula
It does so by adding checks for areAnyTensorSubclassLike.
Test Plan:
- I tested everything with functorch.
- We are going to do https://github.com/pytorch/pytorch/issues/69530 in
the future so we have a way of testing this in core. I need the
binary_cross_entropy ones for something right now and didn't want to
wait until we come up with a solution for #69530.
Reviewed By: Chillee
Differential Revision: D33246995
Pulled By: zou3519
fbshipit-source-id: 310ed3196b937d01b189870b86a6c5f77f9258b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70249
IMO, the `unbatch_level` argument is not needed here since users can simply can `.unbatch` before calling `.groupby` if needed. One small step closer to an unified API with other libraries.
Note that we may rename the functional name from `.groupby` to `.group` in the future. TBD.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33259104
Pulled By: NivekT
fbshipit-source-id: 490e3b6f5927f9ebe8772d5a5e4fbabe9665dfdf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70062
This commit upstreams LTCTensorImpl from the lazy_tensor_staging branch.
It inherits from c10::TensorImpl and thus manages the lifetime/storage
of LazyTensor.
Test Plan: ./build/bin/test_lazy --gtest_filter=LazyTensorImplTest.*
Reviewed By: desertfire
Differential Revision: D33171186
Pulled By: alanwaketan
fbshipit-source-id: 6af9f91cc7c7e997f120cb89a7bcd6785c03ace0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69479
This diff adds support for out-variant optimization for `TensorExprDynamicGroup` op, which will be used for TensorExpr based fusion in Static Runtime.
ghstack-source-id: 146107008
Test Plan:
```
buck run mode/opt //caffe2/caffe2/fb/predictor:pytorch_predictor_test
```
Completed accuracy test on inline_cvr model 294738512 v0. Results:
```
get 1012 prediction values
get 1012 prediction values
pyper_inference_e2e_local_replayer_test.out.132ea03c2 pyper_inference_e2e_local_replayer_test.out.1858bbeb0
max_error: 0 % total: 0
```
Reviewed By: d1jang, mikeiovine
Differential Revision: D32768463
fbshipit-source-id: a3e6c1ea9ff5f3b57eb89095aa79a6d426fbb52a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69478
This diff handles the case when output tensors are being passed in as
inputs to TensorExprDynamicGroup op.
This is in preparation to support out-variant optimizations in Static Runtime.
ghstack-source-id: 146107007
Test Plan: buck test mode/dev-nosan //caffe2/test/cpp/jit:jit
Reviewed By: eellison
Differential Revision: D32823889
fbshipit-source-id: ff18e17fcd09953e55c8da6b892e60756521c2fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69477
This diff adds a new run method to `TensorExprKernel` which takes in
output tensors as inputs and stores the output in those given tensors.
ghstack-source-id: 146107009
Test Plan: buck test mode/dev-nosan //caffe2/test/cpp/tensorexpr:tensorexpr -- --exact 'caffe2/test/cpp/tensorexpr:tensorexpr - Kernel.RunWithAllocatedOutputs'
Reviewed By: ZolotukhinM
Differential Revision: D32823890
fbshipit-source-id: edc1f4839785124048b034060feb71cb8c1be34f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69476
This diff adds a new op, `TensorExprDynamicGroup`, that composes all the logic behind running a dynamic shaped fused node. This includes a guard instruction that checks for conditions, a conditional that calls the fused node or the fallback graph depending on the guard.
ghstack-source-id: 146107006
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/cpp/jit:jit
```
Reviewed By: eellison
Differential Revision: D32320082
fbshipit-source-id: 2bd1a43391ca559837d78ddb892d931abe9ebb73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70225
Thanks for zhxchen17's suggestion. This pr move the operator initialization logic to `upgrader_mobile.cpp`, such that we can leverage the static variable to ensure the operator initialization only happens once.
ghstack-source-id: 146103229
Test Plan:
```
buck test mode/opt //papaya/integration/service/test/analytics/histogram:generic_histogram_system_test -- --exact 'papaya/integration/service/test/analytics/histogram:generic_histogram_system_test - SumHistogramSystemTest.test' --run-disabled
buck test mode/opt //caffe2/test/cpp/jit:jit
buck test mode/dev //papaya/integration/service/test/mnist:mnist_system_test -- --exact 'papaya/integration/service/test/mnist:mnist_system_test - MnistFederatedSystemTest.test'
```
Reviewed By: zhxchen17
Differential Revision: D33247543
fbshipit-source-id: 6c3a87fe909a1be01452fa79649065845b26d805
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67045
To run: `python benchmarks/functional_autograd_benchmark/functional_autograd_benchmark.py --gpu -1 --model-filter=ppl _robust_reg --num-iter 100`
```
Results for model ppl_robust_reg on task vjp: 0.0012262486852705479s (var: 2.2107682351446556e-10)
Results for model ppl_robust_reg on task vhp: 0.002099371049553156s (var: 6.906406557760647e-10)
Results for model ppl_robust_reg on task jvp: 0.001860950025729835s (var: 1.1251884146634694e-10)
Results for model ppl_robust_reg on task hvp: 0.003481731517240405s (var: 2.2713633751614282e-10)
Results for model ppl_robust_reg on task jacobian: 0.0012128615053370595s (var: 1.3687526667638394e-09)
Results for model ppl_robust_reg on task hessian: 0.009885427542030811s (var: 9.366265096844018e-09)
Results for model ppl_robust_reg on task hessian_fwdrev: 0.005268776323646307s (var: 2.4293791422991262e-09)
Results for model ppl_robust_reg on task hessian_revrev: 0.002561321249231696s (var: 7.557877101938004e-10)
Results for model ppl_robust_reg on task jacfwd: 0.002619938924908638s (var: 5.109343503839625e-10)
Results for model ppl_robust_reg on task jacrev: 0.0013469004770740867s (var: 3.1857563254078514e-09)
```
Notes:
- We go through batched fallback for both
- ppl_robust_reg takes 3 tensor inputs and returns a single scalar output
- this means that jacobian is equivalent to doing vjp and vmap would not help us
- we expect jacfwd to be slower than jacrev
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D33265947
Pulled By: soulitzer
fbshipit-source-id: 14f537a1376dea7e5afbe0c8e97f94731479b018
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70228
fix named_params_with_sharded_tensor impl, where `named_parameters` already loop the submodules recursively, so we shouldn't put it in the submodule loop.
ghstack-source-id: 146076471
Test Plan: Added more complicated test cases (that involves multiple submodules) to capture this issue.
Reviewed By: pritamdamania87
Differential Revision: D33251428
fbshipit-source-id: cf24ca7fbe4a5e485fedd2614d00cdea2898239e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70145
Added support for torch.equal to ShardedTensor. This is really
helpful in terms of comparing two ShardedTensors.
ghstack-source-id: 146066939
Test Plan: waitforbuildbot
Reviewed By: wanchaol
Differential Revision: D33201714
fbshipit-source-id: 56adfc36e345d512c9901c56c07759bf658c745b
Summary:
1. Split the test `test_save_load.py` to two files. Basically move the operator versioning related changes to `test_save_load_for_op_versions.py`.
2. Add mobile module related test to `test_save_load_for_op_versions.py`
How to run:
```
buck test mode/opt //caffe2/test:jit
or
python test/test_jit.py TestSaveLoadForOpVersion
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70090
ghstack-source-id: 146103547
Test Plan:
```
buck test mode/opt //caffe2/test:jit
python test/test_jit.py TestSaveLoadForOpVersion
```
Reviewed By: tugsbayasgalan
Differential Revision: D33180767
fbshipit-source-id: dd31e313c81e90b598ea9dd5ad04a853c017f994
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69475
This diff adds TensorExpr fusion with dynamic shapes in SR. This includes tracing the input graph with sample inputs, and then performing fusion with generalization to get fused graphs with dynamic shapes.
ghstack-source-id: 146059043
Test Plan:
```
buck run mode/opt //caffe2/caffe2/fb/predictor:pytorch_predictor_test
```
Reviewed By: d1jang
Differential Revision: D32320088
fbshipit-source-id: 397f498878ddfcee9dad7a839652f79f034fefe3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69474
This diff adds support for dynamic shape fusion in JIT. This is done
by performing fusion with the static shapes observed on the first run,
generalizing the fused subgraphs and generating code for the generalized fused
subgraphs with dynamic shapes.
ghstack-source-id: 146059044
Test Plan:
```
buck test mode/dev-nosan //caffe2/test/cpp/jit:jit
```
Reviewed By: eellison
Differential Revision: D32781307
fbshipit-source-id: f821d9f8c271bcb78babcb4783d66f2f0020b0ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69473
This diff refactors StaticModule and its uses to pass in sample inputs. These inputs need to be passed into the constructor because they are need to perform TensorExpr fusion before other optimizations are performed on the input graph.
ghstack-source-id: 146059041
Test Plan: buck run mode/opt //caffe2/caffe2/fb/predictor:pytorch_predictor_test
Reviewed By: donaldong
Differential Revision: D32320084
fbshipit-source-id: b8bd46d442be4cc90ca60f521e0416fdb88eea60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70165
Implements activation offload support in checkpoint_wrapper API via
save_on_cpu hooks. We avoid modifying the torch.utils.checkpoint implementation
and instead compose offload + checkpoint using the save_on_cpu hook for the
former.
ghstack-source-id: 146078900
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D33228820
fbshipit-source-id: 98b4da0828462c41c381689ee07360ad014e808a
Summary:
All for builds of the Android (arm32/64 and x86_32/64) are not migrated to the GHA, away from circleCI. Since this part of the workflow creates final binary with all architectures in it, it was not possible to do migration step by step.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68843
Reviewed By: malfet
Differential Revision: D33257480
Pulled By: b0noI
fbshipit-source-id: dd280c8268bdd31763754c36f38e4ea12b23cd2e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70032
Windows build of PyTorch doesn't produce the `c10::OperatorHandle::~OperatorHandle(void)` symbol in any of its `*.lib` files. This fix is to explicitly define it in Dispatcher.cpp, so downstream consumers wanting to dllimport can find it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70033
Reviewed By: jbschlosser
Differential Revision: D33240599
Pulled By: bdhirsh
fbshipit-source-id: 56cc5963043bd5caac30e42c3501a4f48d086b36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70128
Previous code disabled torch_function when dequantizing arguments
to an unquantizeable function. This PR blocklists the dequantize
method from the dequantize hook instead, so we can remove
the previous hack.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: ejguan
Differential Revision: D33194396
Pulled By: vkuzo
fbshipit-source-id: 6175c2da637c1d0c93b3fea0ef8218eaee6a2872
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70115
This PR turns off DBR quant __torch_function__ overrides on
tensor attribute getters such as `x.dtype`. This should help
with making the debug logs more readable, and reduce framework
overhead.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: ejguan
Differential Revision: D33189544
Pulled By: vkuzo
fbshipit-source-id: e0d664bb6b76ca9e71c8a439ae985a0849312862
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70114
This PR makes the debug logging for DBR quant be more useful
and easier to read.
New format looks like
```
DEBUG:auto_trace: fqn: _tf_ <function tanhshrink at 0x7fa4d02d4790> out torch.float32 end
```
This will be useful to speed up further work.
Test Plan:
```
// run this with logging enabled, logs easier to read
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D33189545
Pulled By: vkuzo
fbshipit-source-id: 20af7e066e710beac5a3871a9d6259ee5518f97d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70109
Adds a test case for DBR quant + qconfig_dict specifying methods
by object_type. Fixes a bug in the FX rewriter for scripting
to make the test pass.
Full coverage of methods will come in future PRs, this PR is
just to verify qconfig_dict is hooked up correctly.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_qconfig_dict_object_type_method
```
Reviewed By: jerryzh168
Differential Revision: D33188160
Pulled By: vkuzo
fbshipit-source-id: 47ab9dbca8cdb1cf22d6d673d9c15b3bc0d1ec81
Summary:
Just updated a few examples that were either failing or raising deprecated warnings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69816
Reviewed By: bdhirsh
Differential Revision: D33217585
Pulled By: albanD
fbshipit-source-id: c6804909be74585c8471b8166b69e6693ad62ca7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70022
Add support for fusing ConvTranpose{1,2,3}d with BatchNorm{1,2,3}d. This re-uses the existing fusion logic but adds a "transpose" flag to the fusing function which when enabled will use the appropriate reshape for ConTranspose's transposed weights.
Test Plan: `buck test mode/dev //caffe2/test:quantization -- -r quantization.eager.test_fusion.TestFusion`
Reviewed By: jerryzh168
Differential Revision: D33074405
fbshipit-source-id: 5e9eff1a06d8f98d117e7d18e80da8e842e973b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69999
This adds support for the split_with_sizes operator in static runtime by adding native operators. Those operators will have less overhead comparing to their JIT fallbacks (no dispatching, no stack constructing in runtime).
split_with_sizes can be called directly from cpp API, or in `torch.split` when `split_sizes` is a list. This diff adds support for both use cases.
Test Plan:
- Added unit tests. Made sure the operators are used
- Benchmark
```
./buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench \
--scripted_model=/data/users/dxd/305797439_0.predictor.precompute.remote_request_only \
--method_name=user.forward --pt_cleanup_activations=1 \
--pt_enable_out_variant=1 --pt_optimize_memory=1 --iters=1000 --warmup_iters=500 \
--num_threads=1 --pt_enable_static_runtime=1 --set_compatibility=1 \
--input_type="recordio" --pt_inputs=/data/users/dxd/305797439_0_user.inputs.recordio \
--recordio_use_ivalue_format=1 --do_profile=1 --do_benchmark=1
```
#### Before
```
Static runtime ms per iter: 3.62073. Iters per second: 276.187
0.0471904 ms. 1.31501%. aten::split_with_sizes (5 nodes)
```
#### After
```
Static runtime ms per iter: 3.44374. Iters per second: 290.382
0.0432057 ms. 1.34276%. aten::split_with_sizes (5 nodes, native)
```
Reviewed By: swolchok
Differential Revision: D33141006
fbshipit-source-id: feae34c4c873fc22d48a8ff3bf4d71c0e00bb365
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70207
In corner case when min == max, adjust_hist_to_include_zero() function used in L2 search will cause additional_nbins = -2147483648 and initialize bins_f with negative size.
Test Plan:
Before fix:
f315187213
After fix:
f315471862
Reviewed By: jspark1105
Differential Revision: D33227717
fbshipit-source-id: 7e8a455e51a0703a3a9c5eb7595d9b4d43966001
Summary:
Reduces the binary size of DistributionBernoulli.cu 12282600 -> 3946792
Tensor-tensor bernoulli kernels are rarely used, we limit dispatches to double probability type for double `self` tensor, and `float` probability type for everything else. This would be a minor perf hit if probability tensor is of the different dtype, but given how rarely these kernels are used (and how rarely the probability tensor is not float) this is not a problem.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70169
Reviewed By: jbschlosser
Differential Revision: D33237890
Pulled By: ngimel
fbshipit-source-id: 185c4b97aba0fb6ae159d572dd5bbb13cf676bb4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70164
Implement Alban's suggestion to make checkpoint_wrapper an nn.Module
instead of patching the forward pass, which is too hacky.
ghstack-source-id: 146011215
Test Plan: IC
Reviewed By: mrshenli
Differential Revision: D33214696
fbshipit-source-id: dc4b3e928d66fbde828ab60d90b314a8048ff7a2
Summary:
Try using Rockset as backend for data instead of RDS
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70136
Reviewed By: suo
Differential Revision: D33242148
Pulled By: janeyx99
fbshipit-source-id: 8935ceb43717fff4922b634165030cca7e934968
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69727
Still need to test the backward ones. We would need to update gradgradcheck to check forward over backward.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33031728
Pulled By: soulitzer
fbshipit-source-id: 86c59df5d2196b5c8dbbb1efed9321e02ab46d30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68750
There was some room for optimization in static runtime's `prim::VarStack`:
* Avoid refcount bumps - constructing the `std::vector<at::Tensor>` can be avoided by writing a custom version of `stack_out` that takes a `std::vector<at::Tensor*>`
* Skip the memory overlap check
* Avoid device dispatcher overhead in a few places (e.g. `tensor.unsqueeze -> at::native::unsqueeze`)
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest -- Stack`
Reviewed By: swolchok
Differential Revision: D32596934
fbshipit-source-id: e8f0ccea37c48924cb4fccbfdac4e1e11da95ee0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70142
Create lower code example in oss, and run benchmark agaist resnet101
Test Plan: CI
Reviewed By: 842974287
Differential Revision: D33117440
fbshipit-source-id: 359d0c9e65899ab94c8f3eb112db70db5d938504
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70072
Like (sparse COO tensors), sparse CSR tensors don't really have an actual storage() that can be accessed, so sparsetensor->storage() should throw.
cc nikitaved pearu cpuhrsch
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33181309
Pulled By: davidberard98
fbshipit-source-id: 8f1dc4da03073d807e5acee2ac47caeffb94b16c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70167
1. Change unit test dependency to open source base class, so that this unit test can run on git oss CI
2. Remove usage of typing.Protocol, so that lower can run with Python 3.6
Test Plan:
oss CI
passed with change included in commit:
https://github.com/pytorch/pytorch/actions/runs/1597530689
see test(fx2trt)
Reviewed By: yinghai
Differential Revision: D33228894
fbshipit-source-id: ffe3d40a02a642b3b857a0605101797037a580bb
Summary:
Upgrader should only be initialized once when runtime loads the first module. It no longer needs to initialized afterwards.
Previously, instead of using an atomic variable, the upgrader will be initialized depends on whether byteCodeFunctionWithOperator.function.get_code().operators_ is empty. If it's empty, it means the operator from the upgrader is not initialized yet. However, it's not thread safe. When multiple thread loads module together, it's possible that they all consider it's the first module. Use an atomic variable here to make sure it's thread safe.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70161
ghstack-source-id: 146012642
Test Plan:
```
buck test mode/opt //papaya/integration/service/test/analytics/histogram:generic_histogram_system_test -- --exact 'papaya/integration/service/test/analytics/histogram:generic_histogram_system_test - SumHistogramSystemTest.test' --run-disabled
buck test mode/opt //caffe2/test/cpp/jit:jit
```
Reviewed By: iseeyuan
Differential Revision: D33220320
fbshipit-source-id: 10f2397c3b358d5a1d39a2ce25457e3fdb640d2c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69459
This change breaks the dependency between the kineto and legacy profiler; instead of `profiler_kineto.h` including `profiler_legacy.h`, they both include `profiler/api.h`. As part of this refactor, I injected some intermediate classes to keep legacy behavior from leaking into the kineto profiler:
1) ProfilerThreadLocalState has become ProfilerThreadLocalStateBase which just handles config and callback handle. Legacy and Kineto profilers inherit this and implement their own very disjoint set of logic.
2) CUDAStubs is a pure virtual class to make the interface more readable, and the "always fail" behavior has been moved to a `DefaultCUDAStubs` class in `api.cpp`.
Test Plan: Ran the overhead ubenchmark.
Reviewed By: aaronenyeshi
Differential Revision: D32678163
fbshipit-source-id: 9b733283e4eae2614db68147de81b72f6094ce6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69406
Most files that include `interned_strings.h` don't actually depend on
anything generated from `FORALL_NS_SYMBOLS` yet because they're in a
single file you need to recompile whenever a new symbol is added. Here
I move the class definition into a separate file so this doesn't
happen.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D32923637
Pulled By: albanD
fbshipit-source-id: 6e488cbfcfe2c041a99d9ff22e167dbddf3f46d7
Summary:
This adds support for bfloat16 and fp16 types for jiterator by adding at::Half and at::BFloat16 classes to the jiterator code template. The only methods defined in those classes are construction from float and implicit conversion to float. Mathematical operations on them never need to be defined, because jiterator is written in a way to implicitly upcast the inputs to the functor, so all math has to be performed on float only (e.g. compute part of the kernel would always be written as
```
out[j] = i0<float>(arg0[j]);
```
It also adds support for casting to complex outputs, by adding a similar templated class c10::complex<T>. Originally I planned to only support float -> complex complex for it, but to compile fetch_and_cast function we also need complex -> float conversion. We can avoid it by compiling fetch_and_cast for a different subset of types, but I'm not doing it in this PR. Thus, technically, we can compile a kernel that would accept complex inputs and produce wrong results, but we are guarding against it by static asserting that none of the functor datatype are complex, and runtime-checking that none of the inputs are complex.
Adding bfloat16, half and complex support allows us to remove special handling for type promotion tests for gcd.
i0 (that supports half and bfloat16 inputs) is moved to use jiterator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70157
Reviewed By: mruberry
Differential Revision: D33221645
Pulled By: ngimel
fbshipit-source-id: 9cfe8aba3498a0604c4ea62c217292ea06c826b1
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/69846
Test Plan:
In pytorch main dir, execute
to run the added test
Reviewed By: jbschlosser
Differential Revision: D33152672
Pulled By: dzdang
fbshipit-source-id: 89951fcd23e7061d6c51e9422540b5f584f893aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69806
Minor modifications were made to support 4 bit embedding quantized module in eager mode quantization flow and to allow for testing of the changes
Test Plan:
In pytorch main dir, execute
```
python test_quantization.py TestPostTrainingStatic.test_quantized_embedding
```
to run the series of tests, including the newly added test_embedding_4bit
function
Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33152675
fbshipit-source-id: 5cdaac5aee9b8850e61c99e74033889bcfec5d9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69769
Added 4 bit support and the correpsonding test in the module api. Restructured the test_quantized_module for both 4 & 8 bit support.
Test Plan:
In pytorch main dir, execute
```
python test/test_quantization.py TestStaticQuantizedModule.test_embedding_api
```
Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33152674
fbshipit-source-id: 73e63383cf60994ab34cc7b4eedd8f32a806cf7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69768
Support for the 4 embedding operator has been added. The support is analogous to the preexisting support for byte/8bit embedding. A corresponding test case was added to test_quantized_embedding_op.py
Test Plan:
In pytorch main dir, execute
```
python test/test_quantization.py TestStaticQuantizedModule.test_embedding_api
```
to run the series of tests, including the newly added test_embedding_4bit
function
Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33152673
fbshipit-source-id: bdcc2eb2e37de38fda3461ff3ebf1d2fb5e58071
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69878
But we'll still verify that model.training is True when user call prepare_qat API.
Relaxing this condition might also mean that we change the api for methods in fuser_method_mapping,
with additional flag for qat (currently we just have different fusions for training/eval), I don't think
this is P0, we could revisit if there is a need in the future
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D33080988
fbshipit-source-id: b13715b91f10454948199323c5d81ef88bb3517f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69864
att, will have a follow up PR that removes QConfigDynamic in the api
Test Plan:
regression tests
```
python test/test_quantization.py TestPostTrainingStatic
python test/test_quantization.py TestPostTrainingDynamic
python test/test_quantization.py TestQuantizeFx
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D33073235
fbshipit-source-id: 6c1a1647032453803c55cdad7c04154502f085db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70144
It can be an integer and in this case we need to extend it.
Test Plan:
Added a unit test.
```
RemoteExecution session id: reSessionID-d97b46e3-20d1-4f5c-a166-4efcf1579352-tpx
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/8162774391775638
✓ ListingSuccess: caffe2/test/fx2trt/converters:test_adaptive_avgpool - main (9.454)
✓ Pass: caffe2/test/fx2trt/converters:test_adaptive_avgpool - test_adaptive_avgpool_with_dynamic_shape (caffe2.test.fx2trt.converters.acc_op.test_adaptive_avgpool.TestAdaptiveAvgPoolConverter) (16.083)
✓ Pass: caffe2/test/fx2trt/converters:test_adaptive_avgpool - test_adaptive_avgpool_1 (caffe2.test.fx2trt.converters.acc_op.test_adaptive_avgpool.TestAdaptiveAvgPoolConverter) (16.349)
✓ Pass: caffe2/test/fx2trt/converters:test_adaptive_avgpool - test_adaptive_avgpool_2 (caffe2.test.fx2trt.converters.acc_op.test_adaptive_avgpool.TestAdaptiveAvgPoolConverter) (16.543)
✓ Pass: caffe2/test/fx2trt/converters:test_adaptive_avgpool - test_adaptive_avgpool_0 (caffe2.test.fx2trt.converters.acc_op.test_adaptive_avgpool.TestAdaptiveAvgPoolConverter) (16.651)
Summary
Pass: 4
ListingSuccess: 1
```
Reviewed By: wushirong
Differential Revision: D33200773
fbshipit-source-id: 8c10d644982a4723a78f8615d8bcdbc3968790db
Summary:
Fixes a couple of bugs that surfaced during integration of graph opts into `AcceleratedGraphModule` (D31484770).
2. Fix bug in `graph_opt.transpose_to_reshape` implementation that causes it to incorrectly apply opt for `permute` op acting on shape `(B, N, N)` with `N > 1` and permutation `(0, 2, 1)`. Fixed the bug and added test case to cover this case.
3. Revert part of D31671833 (0e371e413d), where I made `acc_out_ty` into a required argument
4. Align `graph_opt.transpose_to_reshape` and `graph_opt.optimize_quantization` to not set `acc_out_ty` when adding a new node to graph and instead rely on tensor metadata
5. Run `acc_utils.copy_acc_out_ty_from_meta_to_acc_ops_kwargs()` in `GraphOptsTest.verify_numerics` before running graph on sample inputs.
Test Plan:
```
buck test mode/opt glow/fb/fx/graph_opts:
```
```
...
Summary
Pass: 85
ListingSuccess: 4
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/562950163929022
```
Reviewed By: jfix71
Differential Revision: D31851549
fbshipit-source-id: 602affe2a2a0831d2f17b87025107ca87ecb0e59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70052
As the title. Also refactored a bit to separate out the common part of adding a reduce operator.
This would make mnasnet lowerable without splitter.
Test Plan: Added unit tests.
Reviewed By: wushirong
Differential Revision: D33163950
fbshipit-source-id: 7eb8f8a852cd8e8d9937029c4b4602b036502b3a
Summary:
Removes the internal typeshed for PyTorch and replaces it with PyTorch's own type annotations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69926
Generated files are in P471601595, P471601643, P471601662
Based on an example in D26410012
Test Plan: Sandcastle
Reviewed By: malfet, pradeep90
Differential Revision: D32292834
fbshipit-source-id: 5223f514cbdccd02c08ef0a027a48d92cdebed2c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/35316
On master, bazel cuda build is disabled due to lack of a proper `cu_library` rule. This PR:
- Add `rules_cuda` to the WORKSPACE and forward `cu_library` to `rules_cuda`.
- Use a simple local cuda and cudnn repositories (adopted from TRTorch) for cuda 11.3.
- Fix current broken cuda build.
- Enable cuda build in CI, not just for `:torch` target but all the test binaries to catch undefined symbols.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66241
Reviewed By: ejguan
Differential Revision: D31544091
Pulled By: malfet
fbshipit-source-id: fd3c34d0e8f80fee06f015694a4c13a8e9e12206
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70071
This commit adds tanh_backward to aten_interned_strings.h as an AT symbol.
Test Plan: CI.
Reviewed By: mruberry
Differential Revision: D33173370
Pulled By: alanwaketan
fbshipit-source-id: e20ed2a807156ce772b7c1e3f434fa895116f4c3
Summary:
For Pytorch source build when using Ninja generator, it requires **CMake >=3.13**, Pytorch always checks **cmake3 >= 3.10** first, so when **3.13> cmake3 >= 3.10** and then PyTorch will use cmake3, there will report an error: ```Using the Ninja generator requires CMake version 3.13 or greater``` even the **CMake >=3.13** .
For example: for my centos machine, the system CMake3 is ```3.12```, and my conda env's CMake is ```3.19.6```, there will have a build error which PyTorch choose CMake 3, I can update CMake3 or create an alias or a symlink to solve this problem, but the more reasonable way is that ```_get_cmake_command ``` always return the newest CMake executable (unless explicitly overridden with a same CMAKE_PATH environment variable).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69355
Reviewed By: jbschlosser
Differential Revision: D33062274
Pulled By: malfet
fbshipit-source-id: c6c77ce1374e6090a498be227032af1e1a82d418
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68710
This PR adds support for block sparse (BSR) matrices for functions that
use Inspector-Executor MKL Sparse API. At the moment of this PR it's:
* torch.addmm
* torch.addmv
* torch.triangular_solve (once https://github.com/pytorch/pytorch/pull/62180 is merged)
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D33179486
Pulled By: cpuhrsch
fbshipit-source-id: e1dec0dccdbfed8b280be16b8c11fc9e770d50ae
Summary:
Currently, `cartesian_prod` calls `meshgrid` without passing an indexing parameter. This causes a warning to be shown when running the `cartesian_prod` example from the docs. This PR simply passes the default value for this indexing parameter instead.
Fixes https://github.com/pytorch/pytorch/issues/68741
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68753
Reviewed By: kimishpatel
Differential Revision: D33173011
Pulled By: mruberry
fbshipit-source-id: 667185ec85bd62bda177bc5768d36f56cfc8b9ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68692
ADInplaceOrViewType is a sharded file, so by only including specific
operator headers, we ensure that changing one (non-method) operator
only needs one shard to be re-compiled.
This also ports the generated code over to the `at::_ops` interface,
and the code generator itself to using `write_sharded` instead of
re-implementing its own version of sharding.
Test Plan: Imported from OSS
Reviewed By: jbschlosser, malfet
Differential Revision: D32596274
Pulled By: albanD
fbshipit-source-id: 400cad0237829720f94d60f9db7acd0e918e202e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68691
TraceType is a sharded file, so by only including specific operator
headers, we ensure that changing one (non-method) operator only needs
one shard to be re-compiled.
This also changes all the included autograd and jit headers from
including `ATen/ATen.h` to just including `ATen/core/Tensor.h`.
Test Plan: Imported from OSS
Reviewed By: jbschlosser, malfet
Differential Revision: D32596264
Pulled By: albanD
fbshipit-source-id: 2f28b62d7b9932f30fad7daacd8ac5bb7f63c621
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68476
We implemented all of the following `dict` methods for `ParameterDict`
- `get `
- `setdefault`
- `popitem`
- `fromkeys`
- `copy`
- `__or__`
- `__ior__`
- `__reversed__`
- `__ror__`
The behavior of these new methods matches the expected behavior of python `dict` as defined by the language itself: https://docs.python.org/3/library/stdtypes.html#typesmapping
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69403
Reviewed By: albanD
Differential Revision: D33187111
Pulled By: jbschlosser
fbshipit-source-id: ecaa493837dbc9d8566ddbb113b898997e2debcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69976
These are sample functions that already use generators internally, this just moves the `yield` into the sample function itself.
Re-submit of #69257
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33172953
Pulled By: mruberry
fbshipit-source-id: 7b8bae72df6a225df88a158b7ffa82a71d3c061b
Summary:
Use `c10::printQuotedString` to escape any characters that might render
string to be interpreted as more than one argument by shell script.
Please note, that this codepath is deprecated and is not accessible
by a typical PyTorch usage workflows.
This issue was discovered by Daniel Lawrence of the Amazon Alexa team.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70070
Reviewed By: suo
Differential Revision: D33172721
Pulled By: malfet
fbshipit-source-id: 9dbd17f6eb775aaa1a545da42cbc95864c1189ee
Summary:
Many users actually send things like `Fixes #{69696}` which then fails to properly close the corresponding issue.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70105
Reviewed By: ejguan
Differential Revision: D33187501
Pulled By: albanD
fbshipit-source-id: 2080ee42c30b9db45177f049627118a6c3b544b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69766
Follow-up on the previous PR, removes the requirement to have a parent
qconfig in order for the object type qconfig to be applied for a function.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D33020218
Pulled By: vkuzo
fbshipit-source-id: fa0e10f05ca5f88b48ef74b9d2043ea763506742
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69758
Extends DBR quant `qconfig_dict['object_type']` support to function types,
with the restriction that a parent module must have a qconfig.
A future PR will remove the restriction above (it is due to some technical
debt), to keep PR sizes small.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D33020217
Pulled By: vkuzo
fbshipit-source-id: ce8a8185f9c87d437e1319ff6f19e8f6adf41e02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69726
This is a cleanup, this variable was previously optional
but it always exists, because the only way an op hook
can run if there is a parent module with an `AutoQuantizationState`
object.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: albanD
Differential Revision: D33003472
Pulled By: vkuzo
fbshipit-source-id: de5769194808d42b025b848667815b4e3d73b6c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69720
This function is also useful for DBR quant, moving it from FX utils
to common utils.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D33003473
Pulled By: vkuzo
fbshipit-source-id: 20360682c69d614a645c14fc29d3ee023d6b2623
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69719
This PR changes the API signature of DBR quant to use `qconfig_dict`,
similar to FX graph mode quantization. In this first PR, only basic
functionality is implemented:
* qconfig=None or static quantization with quint8 only is tested
* non-default qconfig for modules only is tested
* targeting ops by order is not implemented
Expanding this support will be done in future PRs.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D33003475
Pulled By: vkuzo
fbshipit-source-id: f5af81e29c34ea57c2e23333650e44e1758102e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69636
Moves some of the qconfig_dict utilities away from the FX subdirectory
into the quantization subdirectory. These utilities can be reused with
other workflows.
A future PR will start using these utilities in DBR quant.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
```
Reviewed By: albanD
Differential Revision: D33003474
Pulled By: vkuzo
fbshipit-source-id: 34417b198681279469e6d7c43ea311180086d883
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69880
Making the test cases more standardized, in general we would like to have
```
TestQuantizeEager,
TestQuantizeEagerOps,
TestQuantizeEagerModels,
```
but currently since we have separate ptq static, ptq dynamic and qat static apis, we only partially cleaned
up the test cases, we can merge all of them later when we merge all the apis
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: supriyar
Differential Revision: D33081418
fbshipit-source-id: fcb96559b76bbc51eb1b0625e0d4b193dbb37532
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69946
This PR remove the implicit set_device for nccl pg according to the proposal of https://github.com/pytorch/pytorch/issues/69731
ghstack-source-id: 145847504
Test Plan: wait for ci
Reviewed By: pritamdamania87
Differential Revision: D33099095
fbshipit-source-id: 3fe9f6a0facf5ea513c267e9f32c6a7fd56cc8a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70007
This PR extends fusion pattern support from simple sequence of ops to a simple
subgraph like conv - add
```
x - conv ---\
y ---------add ---- ouptut
```
where input x, y and output are observed/quantized
Test Plan:
```
python test/fx2trt/test_quant_trt.py TestQuantizeFxTRTOps.test_conv_add
```
Imported from OSS
Imported from OSS
Reviewed By: supriyar
Differential Revision: D33144605
fbshipit-source-id: 331fda77bdc431a8cd9abe1caea8347a71776ec2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70006
reland: fixing some mypy errors that was missed before
This PR enables fuse handler for sequence of three ops, and merges all fuse handlers into one
TODO: we can also move this to backend_config_dict folder
Test Plan:
regression fusion test
```
python test/test_quantization.py TestFuseFx
```
Imported from OSS
Imported from OSS
Reviewed By: supriyar
Differential Revision: D33144606
fbshipit-source-id: ca34f282018a0fb4d04c7e35119eaf2d64258e78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68037
Right now mobile::Code doesn't outlive its enclosing Function, and all accesses to Code happens inside interpreter loop which doesn't outlive the module, so we don't need to use std::shared_ptr here. This also should saves us 1-2 KB for binary size, because shared_ptr seems to bloat on arm64 android.
ghstack-source-id: 145818696
Test Plan: eyes.
Reviewed By: qihqi, tugsbayasgalan
Differential Revision: D32264616
fbshipit-source-id: d83f538d6604cf75fd7728a25127b4849ce7ab2a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68036
In Edge cases we want to separately include class_type.h because in the future we want to stop depending on the rest of the JIT types declared inside jit_type.h
ghstack-source-id: 145818699
Test Plan: no behavior change.
Reviewed By: qihqi, gmagogsfm
Differential Revision: D32264618
fbshipit-source-id: 53dc187772e3dde88ff978b87252c31f3641860b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68709
This PR adds support for triangular solver with a block CSR matrix.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33066067
Pulled By: cpuhrsch
fbshipit-source-id: 9eaf1839071e9526be8d8c6d47732b24200f3557
Summary:
- ~optimizer isn't required for `SequentialLR` since it's already present in the schedulers. Trying to match the signature of it with `ChainedScheduler`.~
- ~`verbose` isn't really used anywhere so removed it.~
updated missing docs and added a small check
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69817
Reviewed By: ngimel
Differential Revision: D33069589
Pulled By: albanD
fbshipit-source-id: f015105a35a2ca39fe94c70acdfd55cdf5601419
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69874
We have a handful of ops supported for ShardedTensor via
``__torch_function__`` dispatch. However, we currently can't cover all torch
operators and having a way for users to extend this functionality will make
this functionality much more general.
In this PR, I've introduced a custom_sharded_op decorator which can be used to
register a custom sharded op implementation.
ghstack-source-id: 145841141
Test Plan: waitforbuildbot
Reviewed By: wanchaol
Differential Revision: D33078587
fbshipit-source-id: 5936b7ac25582e613653c19afa559219719ee54b
Summary:
I've noticed that the `HANDLE_TH_ERRORS` macros are actually very expensive in terms of compile time. Moving the bulk of the catch statements out of line using a lippincott function significantly improves compile times and object file binary sizes. For just the generated autograd bindings, this halves serial build time from 8 minutes to 4 and binary size is more than halved for most files with the biggest difference being `python_variable_methods.cpp` which went from 126 MB to 43 MB.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69974
Reviewed By: mruberry
Differential Revision: D33160899
Pulled By: albanD
fbshipit-source-id: fc35fa86f69ffe5a0752557be30b438c8564e998
Summary:
Move TH<C>GenerateByteType includes into torch/csrc (the only place they are used), and we can remove TH folder altogether!
The only thing left in THC are includes left for bc compatibility.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69929
Reviewed By: mruberry
Differential Revision: D33133013
Pulled By: ngimel
fbshipit-source-id: 78c87cf93d2d641631b0f71051ace318bf4ec3c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69255
One thing that I've found as I optimize profier is that there's a lot of intermingled code, where the kineto profiler relies on the legacy (autograd) profiler for generic operations. This made optimization hard because I had to manage too many complex dependencies. (Exaserbated by the USE_KINETO #ifdef's sprinkled around.) This PR is the first of several to restructure the profiler(s) so the later optimizations go in easier.
Test Plan: Unit tests
Reviewed By: aaronenyeshi
Differential Revision: D32671972
fbshipit-source-id: efa83b40dde4216f368f2a5fa707360031a85707
Summary:
From operator version map and upgrader torchscript, generate upgrader_mobile.cpp file. It also includes a unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69194
ghstack-source-id: 145819351
Test Plan:
```
buck test mode/opt //caffe2/test:upgrader_codegen
```
```
buck run mode/opt //caffe2/torch/fb/mobile/upgrader_codegen:upgrader_codegen
```
```
python /Users/chenlai/pytorch/tools/codegen/operator_versions/gen_mobile_upgraders.py
```
Reviewed By: iseeyuan
Differential Revision: D32748985
fbshipit-source-id: f8437766edaba459bfc5e7fc7a3ca0520c4edb9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69955
Implements a checkpoint_wrapper function, which wraps nn.Module with checkpointing so user won't have to call checkpoint() everytime they want to checkpoint the module.
Currently only support for reentrant-based checkpointing is added and only tested with FSDP to unblock a use case.
Future work is to add support for new checkpointing API, add more tests, upstream to torch.utils.checkpoint.
ghstack-source-id: 145811242
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D33107276
fbshipit-source-id: c4a1c68d71d65713a929994940a8750f73fbdbdb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68858
when executing with ir_eval, check for index out of bounds.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D32657881
Pulled By: davidberard98
fbshipit-source-id: 62dd0f85bb182b34e9c9f795ff761081290f6922
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69964
Things added in this PR that requires review:
1. cuLaunchCooperativeKernel driver API added
aten/src/ATen/cuda/detail/LazyNVRTC.cpp
aten/src/ATen/cuda/nvrtc_stub/ATenNVRTC.h
nvfuser code update:
1. perf turning on codegen scheduler that improves performance.
2. permutation support has been extended beyond contiguous/channels-last. (The improvements could be observed on PW benchmark)
Things reverted from local changes:
1. aten::gelu with approximation
2. local changes that is upstreamed in PR https://github.com/pytorch/pytorch/issues/68804
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69428
Reviewed By: ngimel
Differential Revision: D33073817
Pulled By: wconstab
fbshipit-source-id: e77d32e81d037d7370822b040456fd4c3bd68edb
Summary:
There was a declaration of function at::Tensor::print() in TensorBody.h, left there during the refactoring of Tensor and TensorBase (d701357d921ef167d42c125e65b6f7da6be3ad0f). Removing it from TensorBody.h resolve the issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69615
Test Plan:
code below now compile and works fine (print `[CPUFloatType [3, 4, 5, 5, 5]] `)
```
#include <torch/torch.h>
int main()
{
torch::Tensor tensor = torch::randn({3, 4, 5, 5, 5});
tensor.print();
}
```
Fixes https://github.com/pytorch/pytorch/issues/69515
Reviewed By: ngimel
Differential Revision: D33020361
Pulled By: albanD
fbshipit-source-id: 190f253fb4101a4205aede3574b6e8acd19e54a1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68261
This PR changes the number of test shard from 2-->3 for all Asan test, aiming to improve the run time for Asan tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69843
Reviewed By: janeyx99
Differential Revision: D33160771
Pulled By: xidachen
fbshipit-source-id: dba1d318cc49b923e18704839471d8753cc00eca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69923
Original commit changeset: fbaf2cc06ad4
Original Phabricator Diff: D32606547 (e61fc1c03b)
This is the same thing as the original diff but just using a normal std::mutex instead of std::shared_timed_mutex which is not available on OSX 10.11. The performance difference should be negligible and easy to change down the line if it does become a bottleneck.
Old failing build: https://github.com/pytorch/pytorch/runs/4495465412?check_suite_focus=true
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68783
Test Plan:
buck test //caffe2/test/cpp/monitor:monitor
will add ciflow tags to ensure mac builds are fine
Reviewed By: aivanou
Differential Revision: D33102715
fbshipit-source-id: 3816ff01c578d8e844d303d881a63cf5c3817bdb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69569
Since ShardedOptimizer is added in https://github.com/pytorch/pytorch/pull/68607. We now integrate it in our unit test for Sharded Linear.
ghstack-source-id: 145773749
Test Plan: CI + Unit test
Reviewed By: wanchaol
Differential Revision: D32777020
fbshipit-source-id: eb6b1bb0f6234976f024273833154cab274fed25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69725
We have added a `no_grad` cx manager in the tensor sharding to ensure that the local_shard is the root node. But it turns out for embedding and embedding_bag, when the `max_norm` is specified, it will complain for row-wise sharding. We use the original `max_norm` of the operators.
Error traces:
```
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/caffe2/test/distributed/_sharded_tensor/sharded_embedding#binary,link-tree/torch/overrides.py", line 1389, in handle_torch_function
result = torch_func_method(public_api, types, args, kwargs)
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/caffe2/test/distributed/_sharded_tensor/sharded_embedding#binary,link-tree/torch/distributed/_sharded_tensor/api.py", line 554, in __torch_function__
return sharded_embedding(types, args, kwargs, self._process_group)
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/caffe2/test/distributed/_sharded_tensor/sharded_embedding#binary,link-tree/torch/distributed/_sharded_tensor/ops/embedding.py", line 115, in sharded_embedding
return _handle_row_wise_sharding(
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/caffe2/test/distributed/_sharded_tensor/sharded_embedding#binary,link-tree/torch/distributed/_sharded_tensor/ops/embedding.py", line 309, in _handle_row_wise_sharding
gathered_input_embeddings = torch.nn.functional.embedding(
File "/data/sandcastle/boxes/fbsource/fbcode/buck-out/dev/gen/caffe2/test/distributed/_sharded_tensor/sharded_embedding#binary,link-tree/torch/nn/functional.py", line 2153, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: A view was created in no_grad mode and its base or another view of its base has been modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked).
exiting process 2 with exit code: 10
```
As a fix, we clone, detach the local shard from the narrow result without using the context manager.
ghstack-source-id: 145773748
Test Plan: CI + Unit test.
Reviewed By: pritamdamania87, wanchaol
Differential Revision: D33000927
fbshipit-source-id: 4d5a93120675e90d4d6d6225a51c4a481d18d159
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69895
sparse.Linear has an error message that doesn't tell the user how to resolve the issue. This adds more info.
ghstack-source-id: 145603212
Test Plan: Not needed -- string change only
Reviewed By: jerryzh168
Differential Revision: D33039278
fbshipit-source-id: b5f7f5d257142eb3e7ad73f7c005755253a329d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70002
callbacks are limited to 4. no reason for it to be `std::vector`
Test Plan: CI
Reviewed By: aaronenyeshi
Differential Revision: D32611294
fbshipit-source-id: 21823248abe40d461579b9b68d53c8c0de2a133d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70001
multiplying inversion of `kLowProb` instead of division which uses less expensive `mul` instead of `idv`
Test Plan:
Before
{F682076291}
After
{F682076323}
Reviewed By: robieta
Differential Revision: D32608440
fbshipit-source-id: 7851317a0f7e33813f2bd7a152e5e7f4b5c361b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69935
Didn't realize that `AT_DISPATCH_ALL_TYPES` should really be called `AT_DISPATCH_MOST_TYPES`.
ghstack-source-id: 145661358
Test Plan:
Added test for dtype bool.
Ran CMF local_ro net:
before:
```
I1215 12:33:49.300174 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.966491. Iters per second: 1034.67
I1215 12:33:49.825570 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.94867. Iters per second: 1054.11
I1215 12:33:50.349246 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.947926. Iters per second: 1054.93
I1215 12:33:50.870433 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.943779. Iters per second: 1059.57
I1215 12:33:51.393702 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.947185. Iters per second: 1055.76
I1215 12:33:51.915666 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.945672. Iters per second: 1057.45
I1215 12:33:52.438475 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.948407. Iters per second: 1054.4
I1215 12:33:52.965337 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.95472. Iters per second: 1047.43
I1215 12:33:53.494563 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.967083. Iters per second: 1034.04
I1215 12:33:54.017879 1606538 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.948945. Iters per second: 1053.8
I1215 12:33:54.017930 1606538 PyTorchPredictorBenchLib.cpp:290] Mean milliseconds per iter: 0.951888, standard deviation: 0.0083367
```
after:
```
I1215 12:32:35.820874 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.999845. Iters per second: 1000.15
I1215 12:32:36.343147 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.944363. Iters per second: 1058.91
I1215 12:32:36.863806 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.942542. Iters per second: 1060.96
I1215 12:32:37.385459 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.944677. Iters per second: 1058.56
I1215 12:32:37.905436 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.941135. Iters per second: 1062.55
I1215 12:32:38.424907 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.939748. Iters per second: 1064.11
I1215 12:32:38.944643 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.941764. Iters per second: 1061.84
I1215 12:32:39.463791 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.938946. Iters per second: 1065.02
I1215 12:32:39.987567 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.95437. Iters per second: 1047.81
I1215 12:32:40.511204 1594955 PyTorchPredictorBenchLib.cpp:279] PyTorch run finished. Milliseconds per iter: 0.959139. Iters per second: 1042.6
I1215 12:32:40.511242 1594955 PyTorchPredictorBenchLib.cpp:290] Mean milliseconds per iter: 0.950653, standard deviation: 0.0184761
```
Reviewed By: hlu1
Differential Revision: D33106675
fbshipit-source-id: 5bb581f8d0ed22ef08df1936dc8d67045e44e862
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68697
Currently, if you include `Tensor.h` but not `TensorOperators.h` then
using overloaded operators will compile but fail at link time.
Instead, this defines the member functions in `TensorBody.h` and
leaves `TensorOperators.h` as only the free functions.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596269
Pulled By: albanD
fbshipit-source-id: 5ce39334dc3d505865268f5049b1e25bb90af44a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68690
RegisterFunctionalization.cpp is a shared file, so only including the
required operators means a single operator change only requires 1
shard to be rebuilt instead of all of them.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596275
Pulled By: albanD
fbshipit-source-id: 8b56f48872156b96fbc0a16b542b8bab76b73fd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68689
Currently Register{DispatchKey}.cpp includes all of
`NativeFunctions.h`, so any operator signature change requires all
backend registration to be recompiled. However, most backends only
have registrations for a small fraction of operators so it makes sense
to only include the specific functions required.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596273
Pulled By: albanD
fbshipit-source-id: 11d511f47937fbd5ff9f677c9914277b5d015c25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68714
This splits the static dispatch headers (e.g. `CPUFunctions.h`)
into per operators headers (e.g. `ops/empty_cpu_dispatch.h`) which is
needed for when `Tensor.h` is compiled with static dispatch enabled.
There are also several places in ATen where the static dispatch
headers are used as an optimization even in dynamic dispatch builds.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596265
Pulled By: albanD
fbshipit-source-id: 287783ef4e35c7601e9d2714ddbc8d4a5b1fb9e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68688
This adds a new macro `TORCH_ASSERT_ONLY_METHOD_OPERATORS` which
allows `Tensor.h` to be included, but not headers which pull in all
other operators. So, a file that defines this macro needs to use the
fine-grained headers to include only the operators being used.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596267
Pulled By: albanD
fbshipit-source-id: 6fc2ce3d2b0f52ac6d81b3f063193ce26e0d75a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68687
This adds `NativeFunction.root_name` which is the canonical name
for the operator group. i.e. the BaseOperatorName without inplace or
double-underscores. In the previous PR I referred to this as
`base_name` but confusingly `BaseOperatorName` does potentially
include inplace or double-underscores.
I also add the property to `NativeFunctionsGroup` so that grouped
functions with type `Union[NativeFunction, NativeFunctionsGroup]`
can have the property queried without needing `isinstance` checks.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596271
Pulled By: albanD
fbshipit-source-id: 8b6dad806ec8d796dcd70fc664604670d668cae7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69734
Added support for `torch.equal` to ShardedTensor. This is really
helpful in terms of comparing two ShardedTensors.
Will implement `allclose` in a follow PR.
ghstack-source-id: 145301451
Test Plan: waitforbuildbot
Reviewed By: fduwjj, wanchaol
Differential Revision: D33004315
fbshipit-source-id: 786fe26baf82e1bb4fecfdbfc9ad4b64e704877f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69421
I've hit a lot of build issues in D32671972, and I've come to realize that a lot of it boils down to header hygene. `function.h` includes `profiler.h` *solely* to transitively include `record_function.h` which winds up leaking the profiler symbols. Moreover several files are relying on transitive includes to get access to `getTime`. As long as I have to touch all the places that use `getTime`, I may as well also move them to the new namespace.
Test Plan: Unit tests and CI.
Reviewed By: aaronenyeshi, albanD
Differential Revision: D32865907
fbshipit-source-id: f87d6fd5afb784dca2146436e72c69e34623020e
Summary:
`assertSignatureIsCorrect` is instantiated at minimum once per unique operator signature yet its core logic is independent of the type. So, it makes sense to have a light-weight template that does nothing but call into the non-templated function with the correct `CppSignature` object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67986
Reviewed By: jbschlosser
Differential Revision: D33108600
Pulled By: swolchok
fbshipit-source-id: 7594524d3156ff2422e6edcdffcb263dc67ea346
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68483
Doesn't need to be in the header.
ghstack-source-id: 145668417
Test Plan: CI
Reviewed By: chaekit
Differential Revision: D32477113
fbshipit-source-id: 30e7796413e3220e4051544559f9110ab745022d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69087
This diff includes a variety of improvements to `set_inputs` to unify behavior with `torch::jit::Module`:
1. Eliminate code duplication between rvalue/lvalue overloads
2. Add type checks
3. Make input length check a `TORCH_CHECK` instead of a debug check - we have to fail when the wrong number of inputs are passed.
4. `schema` now always includes `self`, even if we release `module_`. This is consistent with `torch::jit::Module`.|
ghstack-source-id: 145599837
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D32711705
fbshipit-source-id: fe97c10b4f03801ba59868b452e7d02b26b3106b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68412
These lists have the same size as CallbackHandles, so they should be the same container type.
ghstack-source-id: 145668416
Test Plan:
Run same command as previous diff.
Before: see previous diff, average about 0.46us
After: P467928077, average about 0.43us
Reviewed By: chaekit
Differential Revision: D32454856
fbshipit-source-id: 3a3ff4d381d99f51ef868d4dec4db7c411b5ea56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69860
Previously I made a mistake and checked in the aten::full.names for the upgrader of aten::full. So changed it back to just aten::full.
Test Plan: None
Reviewed By: gmagogsfm
Differential Revision: D33066985
fbshipit-source-id: a5598d60d1bff9b4455f807361388fac0689ba14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69412
TypePrinter does not need to take ownership of the Type.
This helps unblock the following diff to stop refcounting Type singletons.
ghstack-source-id: 145671619
Test Plan: CI
Reviewed By: suo
Differential Revision: D32858525
fbshipit-source-id: df58676938fd20c7bae4a366d70b2067a852282d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69778
This PR extends fusion pattern support from simple sequence of ops to a simple
subgraph like conv - add
```
x - conv ---\
y ---------add ---- ouptut
```
where input x, y and output are observed/quantized
Test Plan:
```
python test/fx2trt/test_quant_trt.py TestQuantizeFxTRTOps.test_conv_add
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D33024528
fbshipit-source-id: 5c770c82c8f693fabdac5c69343942a9dfda84ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69658
This PR enables fuse handler for sequence of three ops, and merges all fuse handlers into one
TODO: we can also move this to backend_config_dict folder
Test Plan:
regression fusion test
```
python test/test_quantization.py TestFuseFx
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32974907
fbshipit-source-id: ba205e74b566814145f776257c5f5bb3b24547c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69614
Previously sparse COO tensors were ignored during freezing, because
`tryInsertConstant` would fail during `freeze_module.cpp`, and because
hashes weren't implemented for COO tensor IValues.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32954620
Pulled By: davidberard98
fbshipit-source-id: a91f97fdfc2152b417f43a6948100c94970c0831
Summary:
Refactor torch.profiler.profile by separate it into one low level class and one high level wrapper.
The PR include the following change:
1. separate class torch.profiler.profile into two separated class: kineto_profiler and torch.profiler.profile.
2. The former class has the low-level functionality exposed in C++ level like: prepare_profiler, start_profiler, stop_profiler.
3. The original logics in torch.profiler.profile including export_chrome_trace, export_stacks, key_averages, events, add_metadata are all moved into kineto_profiler since they are all exposed by the torch.autograd.profiler.
4. The new torch.profiler.profile is fully back-compatible with original class since it inherit from torch.profiler.kineto_profiler. Its only responsibility in new implementation is the maintenance of the finite state machine of ProfilerAction.
With the refactoring, the responsibility boundary is clear and the new logic is simple to understand.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63302
Reviewed By: albanD
Differential Revision: D33006442
Pulled By: robieta
fbshipit-source-id: 30d7c9f5c101638703f1243fb2fcc6ced47fb690
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69381
Open source lowering workflow, related tools and tests.
Test Plan: CI
Reviewed By: 842974287
Differential Revision: D32815136
fbshipit-source-id: 3ace30833a2bc52e9b02513c5e223cb339fb74a3
Summary:
- PyTorch and ONNX has supported BFloat16, add this to unblock some mixed-precision training model.
- Support PyTorch TNLG model to use BFloat16 tensors for the inputs/outputs of the layers that run on the NPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66788
Reviewed By: jansel
Differential Revision: D32283510
Pulled By: malfet
fbshipit-source-id: 150d69b1465b2b917dd6554505eca58042c1262a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68607
This PR added ShardedOptimizer and a API to get module parameters along with ShardedTensor param, it allows user to use this Optimizer Wrapper to construct a optimizer that involves ShardedTensor
The state_dict support will be a follow up diff
ghstack-source-id: 145532834
Test Plan: python test_sharded_optim.py
Reviewed By: pritamdamania87
Differential Revision: D32539994
fbshipit-source-id: a3313c6870d1f1817fc3e08dc2fc27dc43bef743
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65993
This PR attempts to port `index_add` to structured kernels, but does more than that:
* Adds an `out=` variant to `index_add`
* Revises `native_functions.yaml` registrations, to not have multiple entries and instead pass default value to `alpha`.
* Changes in `derivatives.yaml` file for autograd functioning
* Revises error messages, please see: https://github.com/pytorch/pytorch/pull/65993#issuecomment-945441615
Follow-up PRs in near future will attempt to refactor the OpInfo test, and will give another look at tests in `test/test_torch.py` for this function. (hence the use of ghstack for this)
~This is WIP because there are tests failing for `Dimname` variant on mobile/android builds, and I'm working on fixing them.~
Issue tracker: https://github.com/pytorch/pytorch/issues/55070
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32646426
fbshipit-source-id: b035ecf843a9a27d4d1e18b202b035adc2a49ab5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68947
`_test_math_view` currently calls the operator with different values
than those specified in the `SampleInput`. This is undesirable as it
could break mathematical properties required by the operator. Instead,
this calls `math_op_view(math_op_physical(sample.input))` to get a
view that represents the same value as the original input.
`test_neg_view` already did this by returning `torch._neg_view(-x)`
from `math_op_view` but this moves the handling into `_test_math_view`
to make it apply to all view op tests.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33064327
Pulled By: anjali411
fbshipit-source-id: 4d87e0c04fc39b95f8dc30dcabda0d554d16a1d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69272
In transformer encoder and MHA, masked_softmax's mask is a 2D tensor (B, D), where input is a 4D tensor (B, H, D, D).
This mask could be simply broadcasted to a (B, H, D, D) like input, and then do a regular masked_softmax, however it will bring the problem of non-contiguous mask & consume more memory.
In this diff, we maintained mask's shape unchanged, while calc the corresponding mask for input in each cuda thread.
This new layout is not currently supported in CPU yet.
Test Plan: buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_masked_softmax
Reviewed By: ngimel
Differential Revision: D32605557
fbshipit-source-id: ef37f86981fdb2fb264d776f0e581841de5d68d2
Summary:
`torch.movedim` directly handle the case of a scalar tensor (0-dim) in input as a no-op by returning a view of the input tensor (after all the usual checks for the other parameters)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69537
Test Plan:
This code now works fine and res1 is a view of tensor
```
import torch
tensor = torch.rand(torch.Size([]))
res1 = torch.movedim(tensor, 0, 0)
```
Fixes https://github.com/pytorch/pytorch/issues/69432
Reviewed By: jbschlosser
Differential Revision: D33020014
Pulled By: albanD
fbshipit-source-id: b3b2d380d70158bd3b3d6b40c073377104e09007
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69819
We should skip ReplaceWithCopy if the inputs to the operator can be updated during inference. For a set of tensors that share data, ReplaceWithCopy should not happen to any of them if there exists updates to any of them.
Currently, the check in place has missed some cases (suppose there exists updates, and uses <= 1). This diff addresses the missing cases by querying AliasDB.
Test Plan:
- Added test cases, including a one that is problematic before this diff
- CI
Reviewed By: mikeiovine
Differential Revision: D33052562
fbshipit-source-id: 61f87e471805f41d071a28212f2f457e8c6785e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68247
This splits `Functions.h`, `Operators.h`, `NativeFunctions.h` and
`NativeMetaFunctions.h` into seperate headers per operator base name.
With `at::sum` as an example, we can include:
```cpp
<ATen/core/sum.h> // Like Functions.h
<ATen/core/sum_ops.h> // Like Operators.h
<ATen/core/sum_native.h> // Like NativeFunctions.h
<ATen/core/sum_meta.h> // Like NativeMetaFunctions.h
```
The umbrella headers are still being generated, but all they do is
include from the `ATen/ops' folder.
Further, `TensorBody.h` now only includes the operators that have
method variants. Which means files that only include `Tensor.h` don't
need to be rebuilt when you modify function-only operators. Currently
there are about 680 operators that don't have method variants, so this
is potentially a significant win for incremental builds.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32596272
Pulled By: albanD
fbshipit-source-id: 447671b2b6adc1364f66ed9717c896dae25fa272
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68631
This PR:
- Adds the check that the storage numel of the base and tangent tensors are the same. This is to support the case when as_strided reveals elements that aren't indexable by the input tensor.
- Skips the check when batched tensors are involved, because using as_strided to reveal elements that not indexable by the input tensor is already not allowed vmap.
- Adds tests for the above two cases, as well as an edge case regarding conj bit (what about neg bit?)
For functorch:
- we need to copy the batching rule implemented here
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32899678
Pulled By: soulitzer
fbshipit-source-id: 54db9550dd2c93bc66b8fb2d36ce40799ebba794
Summary:
Unfortunately there're two versions of removeProfilingNodes function and one of them is not cleaning up profile_ivalue nodes properly. This leads to a dangling profile_ivalue node, which ended up being profiled multiple times and could give us false assert failures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68804
Reviewed By: mrshenli
Differential Revision: D32980157
Pulled By: Krovatkin
fbshipit-source-id: cd57c58a941d10ccd01a6cd37aac5c16256aaea6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69487
Write customized plugin for trt requires extend IPluginV2IOExt. This diff extract functions that should share comon impl between plugins from IPluginV2IOExt into plugin_base, make writing customized plugin for oss user easier.
This diff also fix double creator issue, the root cause is about get_trt_plugin in converters.py look for plugin by name matching. Swith to use the util function from converters_utils.py resolve the issue.
Test Plan: CI
Reviewed By: 842974287
Differential Revision: D32747052
fbshipit-source-id: 7f2e8811c158230f66a0c389af4b84deaf7e2d1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69789
Add details on how to save and load quantized models without hitting errors
Test Plan:
CI autogenerated docs
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D33030991
fbshipit-source-id: 8ec4610ae6d5bcbdd3c5e3bb725f2b06af960d52
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68805
The bug is described in the linked issue. This PR is an attempt to make the functions `_recurse_update_dict` and `_recurse_update_module` more efficient in how they iterate over the submodules. The previous implementation was suboptimal, as it recursively called the update method on the submodules returned by `module.named_modules()`, while `module.named_modules()` already returned all submodules including nested ones.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68806
Reviewed By: pritamdamania87
Differential Revision: D33053940
Pulled By: wanchaol
fbshipit-source-id: 3e72822f65a641939fec40daef29c806af725df6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69041
`TH_CONCAT_{N}` is still being used by THP so I've moved that into
it's own header but all the compiled code is gone.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D32872477
Pulled By: ngimel
fbshipit-source-id: 06c82d8f96dbcee0715be407c61dfc7d7e8be47a
Summary:
Remove all hardcoded AMD gfx targets
PyTorch build and Magma build will use rocm_agent_enumerator as
backup if PYTORCH_ROCM_ARCH env var is not defined
PyTorch extensions will use same gfx targets as the PyTorch build,
unless PYTORCH_ROCM_ARCH env var is defined
torch.cuda.get_arch_list() now works for ROCm builds
PyTorch CI dockers will continue to be built for gfx900 and gfx906 for now.
PYTORCH_ROCM_ARCH env var can be a space or semicolon separated list of gfx archs eg. "gfx900 gfx906" or "gfx900;gfx906"
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61706
Reviewed By: seemethere
Differential Revision: D32735862
Pulled By: malfet
fbshipit-source-id: 3170e445e738e3ce373203e1e4ae99c84e645d7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69755
Per swolchok's suggestion on D32609915 (1c43b1602c). Hide the value offset indices behind accessors to provide more flexibility if we ever decide to change the layout of the values array.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D32838145
fbshipit-source-id: cf805c077672de4c2fded9b41da01eca6d84b388
Summary:
Solves the next most important use case in https://github.com/pytorch/pytorch/issues/68052.
I have kept the style as close to that in SGD as seemed reasonable, given the slight differences in their internal implementations.
All feedback welcome!
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68164
Reviewed By: VitalyFedyunin
Differential Revision: D32994129
Pulled By: albanD
fbshipit-source-id: 65c57c3f3dbbd3e3e5338d51def54482503e8850
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69809
SR options is only printed out once per model per net. Logging it is actually pretty helpful for debugging.
Test Plan: CI
Reviewed By: donaldong
Differential Revision: D33046814
fbshipit-source-id: 536b34e00fbc8a273c5eb4d8ae5caca0dc1f4c24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69592
Currently, forward AD function for`copy_` (in `VariableTypeManual`) does not handle the broadcasting case. ~EDIT: but that is not a design decision, not a bug. In this PR, we make that clear as a comment.~
Note: `broadcast_to` does not have a batching rule in core, so the ops that rely on `copy_` to broadcast will still fail batched forward grad computation.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33020603
Pulled By: soulitzer
fbshipit-source-id: 09cb702bffc74061964a9c05cfef5121f8164814
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69558
Currently we skip batched forward grad checks completely for certain views that also have inplace variants. This PR allow us to decouple the check.
Alternative: just skip the batched forward checks for inplace ops entirely. I'm okay with this because it was surprising to me these checks are being run in the first place.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33020599
Pulled By: soulitzer
fbshipit-source-id: f8012aadc0e775f80da0ab62b2c11f6645bb1f51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69644
This PR cleans up the init of ModuleReLUFuseHandler and moved all `module - relu`
fusion pattern to use this handler
also disabled additional_fuser_method argument temporarily, will enable
after we bring back the simple pattern format
Test Plan:
```
python test/test_quantize_fx.py TestFuseFx
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32974906
fbshipit-source-id: 23483ea4293d569cb3cec6dadfefd4d9f30921a7
Summary:
This adds a C++ event handler corresponding to the Python one mentioned in the RFC.
This changes the counters a bit to all be push driven instead of being polled. The two window types are "fixed count" and "interval". One is based off the number of logged events and the other is based off of time windows. There's currently no active ticker for interval so it needs a regular stream of events to ensure events are produced. A follow up diff can add support for things like HHWheel / simple ticker.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68783
Test Plan: buck test //caffe2/test/cpp/monitor:monitor
Reviewed By: kiukchung
Differential Revision: D32606547
fbshipit-source-id: a00d0364092d7d8a98e0b18e503c0ca8ede2bead
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68485
In OSS, the only change is that we make the predict_net field of PredictorExporterMeta nullable.
Test Plan: sandcastle, let CI run
Reviewed By: boryiingsu
Differential Revision: D32467138
fbshipit-source-id: 81bd5fca695462f6a186bcfa927073874cc9c26a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69737
We can use stack allocation instead.
ghstack-source-id: 145312454
Test Plan: Ran internal framework overhead benchmark with --stressTestKinto --kinetoAddFlops, but difference was minimal. Still good to fix.
Reviewed By: chowarfb
Differential Revision: D33007329
fbshipit-source-id: e096312fef5b729cf12580be152c9418683745b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69710
Namely no range-loop-analysis (that detect when loop variable can not be const reference
Test Plan: Imported from OSS
Reviewed By: r-barnes
Differential Revision: D32997003
Pulled By: malfet
fbshipit-source-id: dba0e7875e5b667e2cc394c70dd75e2403265918
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69110
I pasted the current LLVM code, reapplied the modifications listed in the code comments, caught a few more in the diff/build process. The trivially copyable detection is different now; if gcc builds fail, will try reverting to C10_IS_TRIVIALLY_COPYABLE or copying what LLVM is doing.
The motivation for this change is that, as noted in an existing comment, C10_IS_TRIVIALLY_COPYABLE did the wrong thing for std::unique_ptr, which caused problems with D32454856 / #68412.
ghstack-source-id: 145327773
Test Plan: CI
Reviewed By: bhosmer, mruberry
Differential Revision: D32733017
fbshipit-source-id: 9452ab90328e3fdf457aad23a26f2f6835b0bd3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66695
More extra reference counting in this path.
ghstack-source-id: 145125484
Test Plan: CI
Reviewed By: suo
Differential Revision: D31692197
fbshipit-source-id: 126b6c72efbef9410d4c2e61179b6b67459afc23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69493
When added `with_comms` decorator with arguments, we added an `with_comms_decorator` inner function, `with_comms()` will refer to a function object, the added parentheses was necessary to use in test cases.
This PR fixes the `with_comms` wrapper behavior, to allow we both specify with/without arguments in test cases:
```
with_comms
def test_case:
...
```
or
```
with_comms(backend="gloo")
def test_case:
...
```
ghstack-source-id: 145327066
Test Plan: test_sharded_tensor
Reviewed By: pritamdamania87
Differential Revision: D32897555
fbshipit-source-id: 2f3504630df4f6ad1ea73b8084fb781f21604110
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69096
Instead of storing profiling data in a map and then merginging at
the end, perform merging directly during profiling.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D32772626
Pulled By: davidberard98
fbshipit-source-id: 22622c916a61908b478dd09433815685ce43682a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69707
`const` modifier for `__m512` return value doesn't make much sense
Test Plan: Imported from OSS
Reviewed By: r-barnes
Differential Revision: D32997008
Pulled By: malfet
fbshipit-source-id: fb98659713fe2a23cc702252c0655106687f0dbf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69169
I checked `derivatives.yaml`, and it doesn't look like `logical_not/and/xor` are meant to work with autograd. Those 3 ops are currently set as `CompositeImplicitAutograd` though, implying that they do work with autograd. Updating them to be CompositeExplicitAutograd instead.
This came up because I'm trying to improve the error checking in external backend codegen, and these ops being improperly labeled incorrectly triggers my new error checks for XLA (see https://github.com/pytorch/pytorch/pull/67090)
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D32739976
Pulled By: bdhirsh
fbshipit-source-id: a756dd9e0b87276368063c8f4934be59dca371d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66746
Modified loops in files under fbsource/fbcode/caffe2/ from the format
`for(TYPE var=x0;var<x_max;x++)`
to the format
`for(const auto var: irange(xmax))`
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision: D31705361
fbshipit-source-id: 33fd22eb03086d114e2c98e56703e8ec84460268
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69268
This diff enabled native masked softmax on CUDA, also expanded our current warp_softmax to accept masking.
The mask in this masked softmax has to be the same shape as input, and has to be contiguous.
In a following diff I will submit later, I will have encoder mask layout included, where input is BHDD and mask is BD.
Test Plan: buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_masked_softmax
Reviewed By: ngimel
Differential Revision: D32338419
fbshipit-source-id: 48c3fde793ad4535725d9dae712db42e2bdb8a49
Summary:
Follow up to https://github.com/pytorch/pytorch/issues/68095
This also changes the files from the ATen folder to include c10's `Export.h` instead since they can't ever be exporting `TORCH_PYTHON_API`.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69585
Reviewed By: mrshenli
Differential Revision: D32958594
Pulled By: albanD
fbshipit-source-id: 1ec7ef63764573fa2b486928955e3a1172150061
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69568
Non-empty vectors should never be passed to `assignStorageToManagedTensors` and `assignStorageToManagedOutputTensors`. Presumably, this out-variant convention was adopted to avoid move-assigning the corresponding attribtues in `MemoryPlanner`. But the cost of a vector move-assign is not high, and this function type signature is safer.
Test Plan: `buck test caffe2/bechmarks/static_runtime:static_runtime_cpptest`
Reviewed By: donaldong
Differential Revision: D32729289
fbshipit-source-id: 88f19de8eb89d8a4f1dd8bbd4d9e7f686e41888b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69595
This changes encapsulates `function` object in `ProcessedFunction` objects instead of exposing it unnecessarily just for executing it.
Test Plan: Existing tests
Reviewed By: mikeiovine
Differential Revision: D32908341
fbshipit-source-id: 5ff4951cbe276c5c6292227124d9eec1dd16e364
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69534
Something is TensorSubclassLike if it is a Tensor subclass or if it has
the same problems as Tensor subclasses. Today that just includes Tensor
Subclasses and meta tensors but may include other things in the future.
Some of our backwards formulas are incompatible with TensorSubclassLike
objects. For example, calling .data_ptr() is a problem because many
TensorSubclassLike objects don't have storage. Another problem is
in-place operations: performing `regular_tensor.inplace_(tensor_subclass)`
is a problem.
This PR adds special cases to the backward formulas for torch.max and
torch.clamp to handle this. The backward formulas for torch.max and
torch.clamp are not dispatcher operations so they cannot be overridden
and we hesitate to make them dispatcher operations for FC/BC concerns
and performance overhead concerns.
Furthermore, the old concept of "is this inplace operation vmap
compatible?" can be subsumed by the general "is this inplace operation
tensor-subclass compatible" question, so I replaced all instances of
isInplaceVmapCompatible and replaced it with the isTensorSubclassLike
checks.
Test Plan
- I tested the changes using functorch.
- It's possible to write a test for these in core (one has to make
a custom tensor subclass and then send it through the operation and then
invoke autograd), but I wanted to push the work to doing some
generic testing for backward formulas
(https://github.com/pytorch/pytorch/issues/69530) instead of doing some
one-off things now.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32967727
Pulled By: zou3519
fbshipit-source-id: 30fda1a7581da4c55179b7a3ca05069150bbe2dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69718
canary is now pushing to fbsync so we should change our workflows to
reflect that.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet, janeyx99
Differential Revision: D32999967
Pulled By: seemethere
fbshipit-source-id: bc4bc9afd2d73c53f91d3af3b81aca1b31f665a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69559
We have a lot of special cases. Document them so they're easy to learn about.
ghstack-source-id: 145226542
Test Plan: Spell check? :)
Reviewed By: d1jang
Differential Revision: D32929416
fbshipit-source-id: 2362410f25a27cdb74a4939903446192cef61978
Summary:
This PR upgrades oneDNN to [v2.3.3](https://github.com/oneapi-src/oneDNN/releases/tag/v2.3.3) and includes [Graph API preview release](https://github.com/oneapi-src/oneDNN/releases/tag/graph-v0.2) in one package.
- oneDNN will be located at `pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN`
- The version of oneDNN will be [v2.3.3](https://github.com/oneapi-src/oneDNN/releases/tag/v2.3.3)
The main changes on CPU:
- v2.3
- Extended primitive cache to improve primitive descriptor creation performance.
- Improved primitive cache performance in multithreaded configurations.
- Introduced initial optimizations for bfloat16 compute functionality for future Intel Xeon Scalable processor (code name Sapphire Rapids).
- Improved performance of binary primitive and binary post-op for cases with broadcast and mixed source and destination formats.
- Improved performance of reduction primitive
- Improved performance of depthwise convolution primitive with NHWC activations for training cases
- v2.3.1
- Improved int8 GEMM performance for processors with Intel AVX2 and Intel DL Boost support
- Fixed integer overflow for inner product implementation on CPUs
- Fixed out of bounds access in GEMM implementation for Intel SSE 4.1
- v2.3.2
- Fixed performance regression in fp32 inner product primitive for processors with Intel AVX512 support
- v2.3.3
- Reverted check for memory descriptor stride validity for unit dimensions
- Fixed memory leak in CPU GEMM implementation
More changes can be found in https://github.com/oneapi-src/oneDNN/releases.
- The Graph API provides flexible API for aggressive fusion, and the preview2 supports fusion for FP32 inference. See the [Graph API release branch](https://github.com/oneapi-src/oneDNN/tree/dev-graph-preview2) and [spec](https://spec.oneapi.io/onednn-graph/latest/introduction.html) for more details. A separate PR will be submitted to integrate the oneDNN Graph API to Torchscript graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63748
Reviewed By: albanD
Differential Revision: D32153889
Pulled By: malfet
fbshipit-source-id: 536071168ffe312d452f75d54f34c336ca3778c1
Summary:
This fixes the case when `torch.inference_mode` is called with `mode=False` (disabled). When used as a decorator, it ignored the argument and enabled inference mode anyway.
`_DecoratorContextManager` is changed so that a new instance is a copy instead of a new instance with default parameters.
I also added more tests to cover this case.
Current behaviour:
```python
>>> import torch
>>> x = torch.ones(1, 2, 3, requires_grad=True)
>>> torch.inference_mode(mode=False)
... def func(x):
... return x * x
...
>>> out = func(x)
>>> out.requires_grad
False
```
New behaviour (fixed):
```python
>>> import torch
>>> x = torch.ones(1, 2, 3, requires_grad=True)
>>> torch.inference_mode(mode=False)
... def func(x):
... return x * x
...
>>> out = func(x)
>>> out.requires_grad
True
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68617
Reviewed By: mrshenli
Differential Revision: D32958434
Pulled By: albanD
fbshipit-source-id: 133c69970ef8bffb9fc9ab5142dedcffc4c32945
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69394
Modified loops in files under fbsource/fbcode/caffe2/ from the format
```
for(TYPE var=x0;var<x_max;x++)
```
to the format
```
for(const auto var: irange(xmax))
```
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision: D32837991
fbshipit-source-id: fc7c4f76d2f32a17a0faf329294b3fe7cb81df32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69257
These are sample functions that already use generators internally, this just moves the `yield` into the sample function itself.
Diff is best viewed ignoring whitespace changes https://github.com/pytorch/pytorch/pull/69257/files?diff=unified&w=1
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32942007
Pulled By: mruberry
fbshipit-source-id: bb5b253d6d87b3495b7059924bed35b09d2768a2
Summary:
This fixes the following error:
```python
Traceback (most recent call last):
File "/home/gaoxiang/pytorch-ucc2/test/distributed/test_distributed_spawn.py", line 40, in <module>
run_tests()
File "/home/gaoxiang/.local/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py", line 618, in run_tests
['--import-slow-tests'] if IMPORT_SLOW_TESTS else List[str]([]))
File "/usr/lib/python3.9/typing.py", line 680, in __call__
raise TypeError(f"Type {self._name} cannot be instantiated; "
TypeError: Type List cannot be instantiated; use list() instead
Traceback (most recent call last):
File "/home/gaoxiang/pytorch-ucc2/test/run_test.py", line 1058, in <module>
main()
File "/home/gaoxiang/pytorch-ucc2/test/run_test.py", line 1036, in main
raise RuntimeError(err_message)
RuntimeError: distributed/test_distributed_spawn failed!
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69578
Reviewed By: mrshenli
Differential Revision: D32963113
Pulled By: malfet
fbshipit-source-id: b064e230c5e572e890b4ac66ebdda2707b8c12d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66778
This removes the hack of the context manager that would communicate the zeros block shape to the quantization convert.
The conversion will assume that the converted modules have `sparse_params` (which is added by the sparsifier).
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D31835721
Pulled By: z-a-f
fbshipit-source-id: c5fd2da3b09a728a2296765c00ca69275dbca3b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69361
This PR introduces the new issue forms that replace issue templates.
(This is exactly the same as https://github.com/pytorch/pytorch/pull/65917 which was reverted due to an issue during the import)
This is similar to what was done in torchvision https://github.com/pytorch/vision/pull/4299 and torchaudio, you can see the end result here: https://github.com/pytorch/vision/issues/new/choose (click e.g. on the [bug report](https://github.com/pytorch/vision/issues/new?assignees=&labels=&template=bug-report.yml))
The main new thing is that we can enforce some of the fields to be filled, especially for bug reports. It's also a much cleaner GUI for users IMHO, and we can provide better examples and instructions.
There is still a "blank" template available.
I removed the "Questions" form: we say we close these issues anyway. I replaced it with a direct link to https://discuss.pytorch.org. Since we still have a "blank" template, I think this covers all previous use-cases properly.
Test Plan: Imported from OSS
Reviewed By: albanD, mrshenli
Differential Revision: D32947189
Pulled By: NicolasHug
fbshipit-source-id: f19abe3e7c9c479b0b227969a207916db5bdb6e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66777
Sometimes one might need to keep the sparsity parameters after the sparsifier is detached.
This saves the parameters in the `sparse_params`.
There are two ways of keeping the sparsifier params:
1. Tuple[str, ...]: A tuple of all the parameters that need to be stored.
2. Dict[str, Tuple[str, ...]]: A dict of layer keys and parameters. In this case only specified layers will have the parameters attached to.
For example:
```
>>> # This will keep params in every module
>>> sparsifier.squash_mask(keep_sparse_params=('sparse_block_shape',))
>>> print(model.submodule.linear1.sparse_params)
{'sparse_block_shape': (1, 4)}
>>> print(model.submodule.linear2.sparse_params)
{'sparse_block_shape': (1, 4)}
```
```
>>> # This will keep params only in specific modules
>>> sparsifier.squash_mask(keep_sparse_params={'submodule.linear1': ('sparse_block_shape',)})
>>> print(model.submodule.linear1.sparse_params)
{'sparse_block_shape': (1, 4)}
>>> print(model.submodule.linear2.sparse_params)
AttributeError: 'Linear' object has no attribute 'sparse_params'
```
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31835722
Pulled By: z-a-f
fbshipit-source-id: 20c2d80207eb7ce7291e7f5f655d3fb2a627190f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67730
This pr implement the register function for upgrader so it can be used at loading stage
ghstack-source-id: 145170986
Test Plan:
```
buck test //caffe2/test/cpp/jit:jit
```
Reviewed By: iseeyuan
Differential Revision: D32092518
fbshipit-source-id: 779b51eb12b8cb162a93a55c1e66fe0becc4cb36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69415
Adding the imports inside the torch/ao/__init__.py has a high chance of causing circular dependencies, especially if sparsity and quantization use each other's resources.
To avoid the dependency issues, we can just keep the __init__ empty.
Notes:
- This means that the user will have to explicitly import the `torch.ao.quantization` or `torch.ao.sparsity` instead of `from torch import ao; ao.quantization.???`.
- The issue of circular dependencies that are caused by the imports with binding submodules is [fixed in Python 3.7](https://docs.python.org/3/whatsnew/3.7.html#other-language-changes), which means this solution will become obsolete at the [3.6's EoL](https://www.python.org/dev/peps/pep-0494/#and-beyond-schedule), which comes [12/23/2022](https://devguide.python.org/#status-of-python-branches).
Future options to resolve the circular dependencies (subject to discussion):
1. Use interfaces for binding submodules. For example, have a torch/ao/_nn with all the source code, and an interface torch/ao/nn with only the __init__.py file. The __init__ files inside the torch/ao/_nn will be empty
2. Completely isolate the common code into a separate submodule, s.a. torch/ao/common. The other submodules will not be referencing each other.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32860168
Pulled By: z-a-f
fbshipit-source-id: e3fe77e285992d34c87d8742e1a5e449ce417c36
Summary:
Also fixes the documentation failing to appear and adds a test to validate that op works with multiple devices properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69640
Reviewed By: ngimel
Differential Revision: D32965391
Pulled By: mruberry
fbshipit-source-id: 4fe502809b353464da8edf62d92ca9863804f08e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69576
Vulkan backend for OSS is also thread-safe by default:
* Removed `MAKE_VULKAN_THREADSAFE` preprocessor and if-conditions
Test Plan:
Test build on Android:
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_perf_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_perf_test
adb shell "/data/local/tmp/vulkan_perf_test"
```
Test build on MacOS:
```
cd ~/fbsource
buck build //xplat/caffe2:pt_vulkan_perf_test_binAppleMac
./buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAppleMac\#macosx-x86_64
```
Test result on Google Pixel 5:
```
//xplat/caffe2:pt_vulkan_perf_test_binAndroid#android-arm64 buck-out/gen/fe3a39b8/xplat/caffe2/pt_vulkan_perf_test_binAndroid#android-arm64
buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAndroid#android-arm64: 1 file pushed, 0 skipped. 145.4 MB/s (826929592 bytes in 5.426s)
Running /data/local/tmp/vulkan_perf_test
Run on (8 X 1804.8 MHz CPU s)
***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead.
-------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 39.3 ms 10.1 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 27.1 ms 5.86 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 58.5 ms 11.8 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 5.98 ms 0.803 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 9.14 ms 0.857 ms 5000
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:3 32.1 ms 31.3 ms 3000
```
Test result on MacOS:
```
Running ./buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAppleMac#macosx-x86_64
Run on (16 X 2400 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x8)
L1 Instruction 32 KiB (x8)
L2 Unified 256 KiB (x8)
L3 Unified 16384 KiB (x1)
Load Average: 18.89, 29.61, 24.95
***WARNING*** Library was built as DEBUG. Timings may be affected.
-------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 53.3 ms 39.6 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 28.0 ms 20.7 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 51.8 ms 38.7 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 2.76 ms 1.31 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 2.29 ms 1.11 ms 5000
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:3 49.2 ms 41.8 ms 3000
```
Reviewed By: SS-JIA
Differential Revision: D32933891
fbshipit-source-id: d8ebd5394771e1d79230c1f3aa8fbec4472b3197
Summary:
This PR does several things
1) eliminates `where` instantiations for deprecated `byte` condition dtype, and casts `condition` to `bool` in this case. This is a perf penalty for people using deprecated calls
2) Makes `clamp_{min/max}.Tensor` overload reuse `clamp_{min/max}.Scalar` kernels if limit argument is cpu scalar, instead of instantiating `gpu_kernel_with_scalars`
3) Unifies all clamp_scalar kernels to use a single kernel with lambda picking the correct operation. I've verified that it doesn't degrade kernel performance.
4) Eliminates redundant TensorIterator construction that `clamp` structured kernel was doing when only `min` or `max` was specified
This reduces the cubin size for TensorCompare.cu on V100 from 15751920 bytes to 7691120 bytes, with corresponding reduction in compile time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68835
Reviewed By: mruberry
Differential Revision: D32839241
Pulled By: ngimel
fbshipit-source-id: 0acde5af10a767264afbdb24684b137c5544b8d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69551
Implemented `clone` operator in the Vulkan backend:
* Supports only <= 4D tensors.
* Internal name is `aten::clone`.
* Vulkan `clone` operator accepts only `c10::MemoryFormat::Preserve` and `c10::MemoryFormat::Contiguous` for the argument `c10::optional<c10::MemoryFormat> optional_memory_format`.
* Throws an exception if the `optional_memory_format argument` is neither `MemoryFormat::Preserve` nor `MemoryFormat::Contiguous`
* CPU implementation: [/aten/src/ATen/native/TensorFactories.cpp::clone()](3e45739543/aten/src/ATen/native/TensorFactories.cpp (L1415))
* MKL-DNN implementation: [/aten/src/ATen/native/mkldnn/TensorShape.cpp::mkldnn_clone()](3e45739543/aten/src/ATen/native/mkldnn/TensorShape.cpp (L58))
* `self.copy_(src)` calls `copy_()` for Vulkan to Vulkan copy operation
```
vTensor::copy_()
vTensor::copy_() X -> Vulkan
vTensor::copy_() CPU -> Vulkan
vTensor::clone()
vTensor::clone() -> MemoryFormat::Preserve
vTensor::clone() -> MemoryFormat::Preserve -> self = at::empty_like(src)
vTensor::clone() self.copy_(src); -> BEFORE
vTensor::copy_()
vTensor::copy_() X -> Vulkan
vTensor::copy_() Vulkan -> Vulkan
vTensor::clone() self.copy_(src); -> AFTER
vTensor::copy_()
vTensor::copy_() Vulkan -> X
vTensor::copy_() Vulkan -> CPU
```
* References:
* Function `torch.clone` in PyTorch documentation: https://pytorch.org/docs/stable/generated/torch.clone.html
* Pytorch preferred way to copy a tensor: https://stackoverflow.com/questions/55266154/pytorch-preferred-way-to-copy-a-tensor
* `torch.memory_format`: https://pytorch.org/docs/stable/tensor_attributes.html?highlight=memory_format#torch.torch.memory_format
* `c10::MemoryFormat` definition in [/c10/core/MemoryFormat.h](3e45739543/c10/core/MemoryFormat.h (L28))
Test Plan:
Build & test on Android:
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_api_test
adb shell "/data/local/tmp/vulkan_api_test"
```
Build & test on MacOS:
```
cd ~/fbsource
buck build //xplat/caffe2:pt_vulkan_api_test_binAppleMac
./buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAppleMac\#macosx-x86_64
```
Test result on Android (Google Pixel 5):
```
[ RUN ] VulkanAPITest.clone_success
[ OK ] VulkanAPITest.clone_success (5 ms)
[ RUN ] VulkanAPITest.clone_invalidinputs_exceptions
[ OK ] VulkanAPITest.clone_invalidinputs_exceptions (1 ms)
```
Test result on MacOS:
```
[ RUN ] VulkanAPITest.clone_success
[ OK ] VulkanAPITest.clone_success (19 ms)
[ RUN ] VulkanAPITest.clone_invalidinputs_exceptions
[ OK ] VulkanAPITest.clone_invalidinputs_exceptions (2 ms)
```
Reviewed By: SS-JIA
Differential Revision: D32923535
fbshipit-source-id: ea29792e1b0080cbbc1c8c7e8bf2beffad9b5c0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69626
Sparse tensors are only supported by the TensorPipe RPC backend. As a
result, moving test_embedding_bag_with_no_grad_tensors to be a TensorPipe
specific test.
ghstack-source-id: 145134888
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D32959952
fbshipit-source-id: d65f2edbb6dad7705475690a8c6293a322299dde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68630
Constraints:
1) (functorch) if all the inputs to an op have requires_grad=False and don't have tangents, then their VariableType
kernel should be a no-op i.e., behave like a redispatch. This is due to functorch's DynamicLayerStack
having the autograd key by default (which is so that transformations like vmap) still work with autograd
2) (inference mode) inference tensors in inference mode will call straight into the kernel, we should still do something sensible
inside even if we normally wouldn't redispatch into it.
3) ~Should support potential application of interposition below autograd: `nn.Parameter` is a example of subclassing where the subclass
is not preserved when an operation is performed. There is an exception though: we want calling `make_dual` on a
`nn.Parameter` to preserve its parameterness.~
4) Should avoid calls to shallow_copy_and_detach to avoid spurious calls into `__python_dispatch__`.
This PR:
- does not redispatch to `make_dual` from its `ADInplaceOrView` kernel to satisfy (1)
- calls into `alias` from the kernel in the native namespace so that behavior is consistent with other views in inference mode to satisfy (2)
- discussion of (3). We still wouldn't be able to directly override `make_dual` below autograd. In this PR, instead of not redispatching at all, we choose to redispatch into `at::alias` so that one can override `make_dual`. The side effect is that one would not be able to distinguish calls between the two, which can be problematic (though a straightforward but hacky solution would be to create a new `at::alias_for_make_dual` that would allow users to distinguish) the two. This isn't ideal but seems to be the simplest way to satisfy (3). We don't pursue that hacky solution here.
- (4) is satisfied because we remove calls to `shallow_copy_and_detach`
<details>
<summary> A potentially less hacky but more involved solution? (WIP) </summary>
Realizing that make_dual is more like requires_grad, perhaps it shouldn't be autograd explicit? Make make_dual a composite or python-only construct. i.e., it would be a view on the primal followed by something to the effect of primal.set_fw_grad(tangent).
Additional constraints:
5) make_dual needs to be backward-differentiable (I can't think of any applications yet becuase
technically as a high-order function, jvp's input is the tangent only, "detach" is not applied on
the tangent, so one would still be able to propagate gradients through it).
6) set_fw_grad needs to raise an error if there is a layout mismatch and base is a forward-differnentiable view
Possible plan
- (6) implies that a plain view would not suffice. We need a `detach`-like operation to ensure that set_fw_grad
knows the view is not forward differentiable.
- (5) implies that is this (new) `detach` would need to be backward differentiable (API TBD).
- (3) is no longer relevant because make_dual is no longer autograd explicit, but perhaps this new detach should behave like the current one? There is a lot of logic to replicate for detach, so this may be hard.
- (1) is satisfied if we use current detach logic, i.e., , and (4) is trivial.
I'm not convinced that this is the right solution either, because in the end does (3) still work?
</details>
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32899679
Pulled By: soulitzer
fbshipit-source-id: 98e13ae954e14e1e68dbd03eb5ab3300d5ed2c5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68795
This change improves static runtime exception safety. Added a scope exit guard that invokes `MemoryPlanner::deallocate` in its destructor.
Caveat: we have to be really careful with the exception behavior of `MemoryPlanner::deallocate` and `MemoryPlanner`'s constructor, because they're now both potentially called in the destructor of the scope exit guard. Letting exceptions potentially escape destructors is playing with fire since 1) the destructor of `Deallocator` is (implicitly) `noexcept`, 2) even if it wasn't, `std::terminate` will be called if an exception escapes and the stack is already unwinding. To get around this, we wrap the deallocation stuff in a try/catch. If deallocation throws, then we simply reset all of the memory planner stuff and carry on.
There's a catch: the code path that we take when handling the deallocation exception can't throw. However, this code path is much simpler than memory planner construction/deallocation, so it's much easier to manually audit the correctness here.
Test Plan:
**New unit tests**
`buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D32609915
fbshipit-source-id: 71fbe6994fd573ca6b7dd859b2e6fbd7eeabcd9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67404
Port smooth_l1_loss to structured kernels.
Brian Hirsh authored the part of adding build_borrowing_binary_op_coerce_to_scalar to TensorIterator.
Test Plan: This commit shouldn't change the behavior. So, CI.
Reviewed By: bdhirsh, ngimel
Differential Revision: D31981147
Pulled By: alanwaketan
fbshipit-source-id: a779bb76c848eed8b725dc0e1d56b97a3bd9c158
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67256
To change what tests can be run in various cases, the check logic should be moved to functions and variables that can be changed.
One challenge here is that decorators don't have dynamic functionality. If something is read in when imported and then changed afterwards, it will not actually change. This means we need to separate out the variables that need to be changed for our use case.
Those are put into common_distributed.py and can be changed before importing the distributed_test.py code.
The use case is to add new backends to the tests and split it into tests that can be ran on demand as a separate instance. To do so, you would change DistTestSkipCases after importing it into a launcher or a setup script and then load distributed_test.
Test Plan: Check the signals
Reviewed By: mrshenli
Differential Revision: D31906947
fbshipit-source-id: 45e3258c55f4dc34e12a468bed65280f4c25748f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67729
1. operator version is needed to decide whether applying upgrader or not. This pr make it available at loading stage.
2. Swap the order of parsing instruction and operator, because instruction needs to know the operator first because deciding whether applying upgrader or not (change `OP` to `CALL` or not).
ghstack-source-id: 145082390
Test Plan:
```
buck test //caffe2/test/cpp/jit:jit
```
Reviewed By: iseeyuan
Differential Revision: D32092516
fbshipit-source-id: 853a68effaf95dca86ae46b7f7f4ee0d8e8767da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69104
Add nvidia-smi memory and utilization as native Python API
Test Plan:
testing the function returns the appropriate value.
Unit tests to come.
Reviewed By: malfet
Differential Revision: D32711562
fbshipit-source-id: 01e676203299f8fde4f3ed4065f68b497e62a789
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69496
tostring is expensive, and this is equivalent and faster
Test Plan: covered by lazy tensor unit tests
Reviewed By: desertfire, alanwaketan
Differential Revision: D32901050
fbshipit-source-id: 34080f415db5fd5d3817f7f2533f062a6ec07d21
Summary:
Earlier, we were only testing for inputs with the shape of `(5,)` for `nn.functional.dropout`, but since it's used a lot - I feel it's a good idea to test for a few more shapes including scalars. This PR:
1. Revises sample inputs for `nn.functional.dropout`
2. Adds an OpInfo for `nn.functional.dropout2d`.
A note regarding the documentation:
Looks like `nn.functional.dropout2d` also supports inputs of shape `(H, W)` apart from `(N, C, H, W) / (C, H, W)` but the [documentation](https://pytorch.org/docs/stable/generated/torch.nn.Dropout2d.html#torch.nn.Dropout2d) doesn't mention that (`H, W` case). Should that be revised or am I missing anything here? (Filed an issue here: https://github.com/pytorch/pytorch/issues/67892)
```python
# A 2D tensor is a valid input for Dropout2d
In [11]: tensor = torch.randn((3, 4), device='cpu', dtype=torch.float32)
In [12]: dropout2d = torch.nn.Dropout2d(p=0.5)
In [13]: dropout2d(tensor)
Out[13]:
tensor([[-0.1026, -0.0000, -0.0000, -0.0000],
[-1.5647, 0.0000, -0.0000, -0.5820],
[-0.0000, -3.2080, 0.1164, -3.6780]])
```
Issue Tracker: https://github.com/pytorch/pytorch/issues/54261
cc: mruberry zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67891
Reviewed By: mrshenli
Differential Revision: D32628527
Pulled By: mruberry
fbshipit-source-id: 4c9b89550f1d49526e294378ce107eba9f29cabb
Summary:
The error message was changed following a PR comment. And since the test doesn't run on CI, I forgot to update the test to catch the new error message.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69565
Reviewed By: mrshenli
Differential Revision: D32932982
Pulled By: albanD
fbshipit-source-id: a1da72b0ca735e72b481bc944039233094f1c422
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69489
This change avoids pulling out `Node*` out of `ProcessedNode*` to evaluate expressions related to `Node*` at op execution time.
Perf gain is expected to be there but not measurable and the purpose of this change is to make SR's code more self-contained (calling more code from SR not JIT) during execution time.
Test Plan: Existing tests
Reviewed By: mikeiovine
Differential Revision: D32893265
fbshipit-source-id: f0f397666b3556f985d45112af8fe0b08de22139
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69334
Original PR #68121 broke with incompatible qengine for Mac OS, this PR re-introduces changes with fix
Add FX support for QAT EmbeddingBag operator, previously only eager mode support.
Test Plan:
pytest test/quantization/fx/test_quantize_fx.py -v -k "test_qat_embeddingbag_linear"
Imported from OSS
Reviewed By: jingsh
Differential Revision: D32815153
fbshipit-source-id: 33654ce29de6e81920bf3277a75027fe403a1eb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69333
Original PR reverted due to break with incompatible qengine on Mac OS, this diff fixes that.
Support QAT workflow by using torch.fx QAT API. e.g. `prepare_qat_fx` and `convert_fx`.
Test Plan:
`pytest test/quantization/fx/test_quantize_fx.py -v -k "test_qat_embedding_linear"`
Imported from OSS
Reviewed By: jingsh
Differential Revision: D32814827
fbshipit-source-id: f7a69d2b596f1276dc5860b397c5d5d07e5b9e16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68520
Ref #56794
This changes the code from allocating 1 tensor per thread inside the
parallel region, to allocating one larger tensor outside the parallel
region and manually viewing each thread's slice of the histogram.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D32929365
Pulled By: ngimel
fbshipit-source-id: e28da2736e849a0282b70f34d11526d3355d5bd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69590
The variable `callbackRegisteredData_` was written to without
synchronization.
ghstack-source-id: 145066862
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D32938979
fbshipit-source-id: bc9a11a70680db45ece95880ae19ce2026e8a88e
Summary:
As per title.
While working on this I have discovered several issues with these methods related to grad instabilities. I will file them and link here later. These were quite painful to force to pass all the tests with these discovered issues, sorry for the delay, mruberry!
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69107
Reviewed By: zou3519
Differential Revision: D32920341
Pulled By: mruberry
fbshipit-source-id: 15b33e2b46acdcbff8a37d8e43e381eb55d1a296
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69335
This PR added support for configuring fusion with:
"pattern", "fuser_method"
This only works for simple sequence of 2 op patterns currently, will extend this in future PRs
Test Plan:
regresion test on linear-relu fusion:
```
python test/fx2trt/test_quant_trt.py TestQuantizeFxTRTOps
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32816164
fbshipit-source-id: f300b7b96b36908cb94a50a8a17e0e15032509eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69533
Modified loops in files under fbsource/fbcode/caffe2/ from the format
```
for(TYPE var=x0;var<x_max;x++)
```
to the format
```
for(const auto var: irange(xmax))
```
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision: D32837942
fbshipit-source-id: 8663037a38ade8f81bd5e983a614d197ea11f0d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69508
Original Phabricator Diff: D32704467 (e032dae329)
Reland, fix is to not test traditional checkpoint when input does not require grad as that is unsupported as documented.
Original PR body:
Resubmission of https://github.com/pytorch/pytorch/pull/62964 with the
suggestions and tests discussed in
https://github.com/pytorch/pytorch/issues/65537.
Adds a `use_reentrant=False` flag to `checkpoint` function. When
`use_reentrant=True` is specified, a checkpointing implementation that uses
SavedVariableHooks instead of re-entrant autograd is used. This makes it more
composable with things such as `autograd.grad` as well as DDP (still need to
add thorough distributed testing).
As discussed in https://github.com/pytorch/pytorch/issues/65537, the tests that we need to add are:
- [x] Gradient hooks are called once
- [x] works when input does require grads but Tensor that require grads are captures (like first layer in a nn)
- [x] works for functions with arbitrary input/output objects
- [x] distributed tests (next PR)
Note that this is only for `torch.utils.checkpoint`, if this approach overall looks good, we will do something similar for `checkpoint_sequential`.
ghstack-source-id: 144948501
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32902634
fbshipit-source-id: 2ee87006e5045e5471ff80c36a07fbecc2bea3fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69332
---
## Context
The `build_android.sh` script currently does not forward Vulkan configuration options, which makes it impossible to control them when running `build_pytorch_android.sh`.
## Changes
Slightly change the script to allow Vulkan configuration options to propagate from `build_pytorch_android.sh` to `build_android.sh`
Test Plan: Imported from OSS
Reviewed By: beback4u
Differential Revision: D32840908
Pulled By: SS-JIA
fbshipit-source-id: e55d89c93c996b92b743cf047f5a285bb516bbc4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69331
---
## Context
When the optimization flag is turned on, some SPIR-V modules produced from the Vulkan compute shaders were invalid. The Vulkan Validation layer raises the following error for these modules:
```
[ UNASSIGNED-CoreValidation-Shader-InconsistentSpirv ] Object: VK_NULL_HANDLE (Type = 0) | SPIR-V module not valid: Header block 52[%52] is contained in the loop construct headed by 44[%44], but it's merge block 47[%47] is not
%52 = OpLabel
```
Turning off the optimization flag, the SPIR-V modules produced no longer reports these errors in the Validation layer.
## Changes
Turns off optimization when generating SPIR-V modules to ensure correctness of the modules.
**Note that disabling SPIR-V optimization did not regress inference latency for the several models I tested**.
Test Plan: Imported from OSS
Reviewed By: beback4u
Differential Revision: D32840910
Pulled By: SS-JIA
fbshipit-source-id: 7ccb5691fd0e2d11b9c8c28ad7b83906e8163699
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68770
Previous fusion only works for a sequnce of ops, which is not general enough for fusion patterns
that is defined by a subgraph, this PR refactors that to make it more general
Test Plan:
```
python test/test_quantization.py TestFuseFx
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32602637
fbshipit-source-id: a7897c62081b9d71c67fb56e78484cf68deaacf6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66742
Modified loops in files under fbsource/fbcode/caffe2/ from the format
`for(TYPE var=x0;var<x_max;x++)`
to the format
`for(const auto var: irange(xmax))`
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision: D31705366
fbshipit-source-id: be58222426c192406a7f93c21582c3f6f2082401
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68246
Currently the codegen produces a list of output files at CMake
configuration time and the build system has no way of knowing if the
outputs change. So if that happens, you basically need to delete the
build folder and re-run from scratch.
Instead, this generates the output list every time the code generation
is run and changes the output to be a `.cmake` file that gets included
in the main cmake configuration step. That means the build system
knows to re-run cmake automatically if a new output is added. So, for
example you could change the number of shards that `Operators.cpp` is
split into and it all just works transparently to the user.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D32596268
Pulled By: albanD
fbshipit-source-id: 15e0896aeaead90aed64b9c8fda70cf28fef13a2
Summary:
This renames `WindowsTorchApiMacro.h` to `Export.h` to mirror the c10 header `c10/macros/Export.h` and also updates it to use `C10_EXPORT`/`C10_IMPORT`. This also removes the `THP_API` macro from `THP_export.h` which appears to serve the same purpose.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68095
Reviewed By: jbschlosser
Differential Revision: D32810881
Pulled By: albanD
fbshipit-source-id: d6949ccd0d80d6c3e5ec1264207611fcfe2503e3
Summary:
ORT Tensors are similar to XLA tensors which doesn't have storage. So extend the condition to ORT tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68705
Reviewed By: zou3519
Differential Revision: D32921378
Pulled By: albanD
fbshipit-source-id: 3bda9bba2ddd95cb561a4d1cff463de652256708
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68302
Implement the new memory re-use algorithm. It’s roughly based on the c2 one, but after going through many iterations it may not be a 1:1 port anymore. Also deleted the old liveness analysis.
Test Plan:
## **Re-use metrics**
`inline_cvr` (294738512_58)
**Before**
* `local`
```
Total number of managed tensors: 2660
Total number of managed output tensors: 0
Total number of unmanaged values: 3041
Total memory managed: 4601984 bytes
Total number of reused tensors: 1183
```
* `local_ro`
```
Total number of managed tensors: 1412
Total number of managed output tensors: 0
Total number of unmanaged values: 2677
Total memory managed: 29696 bytes
Total number of reused tensors: 959
```
**After**
* `local`
```
Total number of managed tensors: 2660
Total number of managed output tensors: 0
Total number of unmanaged values: 3041
Total memory managed: 4520000 bytes
Total number of reused tensors: 1198
```
* `local_ro`
```
Total number of managed tensors: 1412
Total number of managed output tensors: 0
Total number of unmanaged values: 2677
Total memory managed: 29120 bytes
Total number of reused tensors: 963
```
Reviewed By: hlu1
Differential Revision: D32370424
fbshipit-source-id: 06a8e0a295ed7a2b4d14071349c1f1e975f746bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68668
This updates run_frozen_optimizations so that it will run on additional methods other than forward
ghstack-source-id: 143871758
Test Plan:
Added test in test_freezing.py
```
python3 test/test_jit.py -- test_conv_bn_folding_not_forward
```
Reviewed By: eellison
Differential Revision: D32567857
fbshipit-source-id: 75e56efad576404dc8d6897861d249573f5ccd7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68788
In debug mode, this should throw errors for ops where the wrong number ops is returned (i.e. the number of values left on the stack is different from the number shown in the schema)
Test Plan:
Run this in debug mode and verify that it doesn't throw an assert
```
import torch
class Thing(torch.nn.Module):
torch.jit.export
def en(self, x: torch.Tensor):
return torch.add(x, 2.0)
def forward(self, x: torch.Tensor, y: torch.Tensor):
a = torch.mm(x, y)
b = torch.nn.functional.gelu(a)
c = self.en(b)
return c.std_mean()
if __name__ == '__main__':
unsc = Thing()
thing = torch.jit.script(unsc)
x = torch.randn(4, 4)
y = torch.randn(4, 4)
std, mean = thing.forward(x, y)
print(std, mean)
print(str(thing.forward.graph))
```
Reviewed By: gchanan
Differential Revision: D32625256
Pulled By: davidberard98
fbshipit-source-id: 61d5ec0c5a9f8b43706257119f4f524bb9dbe6f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69391
As part of the efforts to unify the APIs across different data backends (e.g. TorchData, TorchArrow), we are making changes to different DataPipes' APIs. In this PR, we are removing the input argument `nesting_level` from `FilterIterDataPipe`.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32849462
Pulled By: NivekT
fbshipit-source-id: 91cf1dc03dd3d3cbd7a9c6ccbd791ade91355f30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69390
As part of the efforts to unify the APIs across different data backends (e.g. TorchData, TorchArrow), we are making changes to different DataPipes' APIs. In this PR, we are removing the input argument `nesting_level` from `MapperIterDataPipe`.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32849465
Pulled By: NivekT
fbshipit-source-id: 963ce70b84a7658331d126e5ed9fdb12273c8e1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68769
att, since we want to use this type in fuser_method_mapping in later PRs
Test Plan:
no change to logic, just regression test on ci
```
python test/test_quantization.py
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32602636
fbshipit-source-id: 15b95241431dfca9b1088d0920bf75705b37aa9a
Summary:
Removed JSON uploading to S3 for Mac GHA workflows as the AWS credentials were not working.
This PR tries uploading them to GitHub instead, which works https://github.com/pytorch/pytorch/runs/4413940318?check_suite_focus=true
They should show up on the HUD page: hud.pytorch.org/pr/69387 with the name test-jsons after the CI is completed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69387
Reviewed By: seemethere
Differential Revision: D32885204
Pulled By: janeyx99
fbshipit-source-id: 3d25ead6d464144a228fdf8ead5172de3ed8430e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69400
Hopefully this makes naming more consistent. Without this change, some tests will fail for plugins since values can be set to upper case in some cases. This should prevent that and make lookup and comparison consistent.
Test Plan: Check the signals. There is no specific test for this, but all tests should pass.
Reviewed By: mrshenli
Differential Revision: D32836529
fbshipit-source-id: 1b7d2b64e04fe0391b710aa6ed6d1e47df9027a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69368
Before this PR, copying a node would lose the stack trace. This PR
ensures that the stack trace is preserved across copies.
This is useful because quantization passes would like to start
allowing the user to preserve stack traces, and we use the copy
behavior.
Test Plan:
```
python test/test_fx.py TestFX.test_stack_traces
```
Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D32835248
fbshipit-source-id: 91610fd8d05f5683cfa5e11fb6f9f3feacb8e241
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69249
This PR added default_replay_qconfig and default_replay_observer which is used
when we want to configure an operator to reuse the observer from input, if the input
Tensor for the operator is not observed, we will not observe the output of this operator either,
if the input Tensor is observed, we will observe the output of the operator with the same observer.
e.g.
```
x1 = x0.reshape()
```
if reshape is configured with default_replay_qconfig:
1. if x0 is observed with observer_0, we'll observe x1 with the same observer instance
2. if x0 is not observed, we won't observe x1 either
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_replay_qconfig
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32774723
fbshipit-source-id: 26862b2bc181d0433e2243daeb3b8f7ec3dd33b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68149
JIT optimization passes are part of the CPU-only build (i.e. necessary GPU flags are not passed in). This separates the implementation of frozen_conv_add_relu_fusion so that the GPU-enabled implementation is registered at runtime (if it is available)
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D32773666
Pulled By: davidberard98
fbshipit-source-id: c83dbb88804bdef23dc60a6299acbfa76d5c1495
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68229
This PR makes BinaryOpQuantizeHandler to always produce reference patterns, and we rely on
subgraph_rewriter to rewrite the reference qunatized patterns to quantized ops
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32537714
fbshipit-source-id: 456086b308c4446840d8d37997daa6f8f8068479
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69495
As the title. Separated from D30589161.
Test Plan: Tested in D30589161.
Reviewed By: maratsubkhankulov, wushirong
Differential Revision: D32898927
fbshipit-source-id: 89e18d2eb19b43fbab92b4988d0a21d21cff2d1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69486
As the title. Migrate from sign plugin to native trt layers. All the layers are fused into one single PWN kernel in TRT.
```
[TensorRT] VERBOSE: Engine Layer Information:
Layer(PointWiseV2): PWN(sign_1_sign_rhs + sign_1_sign_rhs_broadcast, PWN(PWN(sign_1_floor_div*2_rhs + sign_1_floor_div*2_rhs_broadcast, PWN(PWN(PWN([UNARY]-[acc_ops.sign]-[sign_1_prod_abs], [UNARY]-[acc_ops.sign]-[sign_1_prod_abs_exp]), PWN([UNARY]-[acc_ops.sign]-[sign_1_prod_exp], [ELEMENTWISE]-[acc_ops.sign]-[sign_1_exp_floor_div])), [ELEMENTWISE]-[acc_ops.sign]-[sign_1_floor_div*2])), [ELEMENTWISE]-[acc_ops.sign]-[sign_1_sign])), Tactic: 0, x[Float(2,2,3)] -> output0[Float(2,2,3)]
```
Test Plan: CI
Reviewed By: wushirong
Differential Revision: D32887537
fbshipit-source-id: ac250b5197e340319de29653a27f879a0e1ea9cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69458
1. Added type hints to acc ops converters.
2. Put some of the class/logic in fx2trt.py to some separated files. (input_tensor_spec.py, trt_module.py, converter_registry.py).
3. Added import in `__init__.py` so that user can just call `from torch.fx.experimental.fx2trt import xxx` instead of `experimental.fx2trt.fx2trt`.
Test Plan: CI
Reviewed By: wushirong
Differential Revision: D32884637
fbshipit-source-id: e3e1e597edb9a08b47b4595bd371f570f2f3c9b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69405
Add a helper function that will generate input tensor specs with dynamic batch size.
Note that the constraint currently on this function is that the batch dimension of all these tensors should be the first dimension.
Also add more doc strings.
Test Plan:
Added unit tests.
```
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/7881299413036896
✓ ListingSuccess: caffe2/test/fx2trt/core:test_input_tensor_spec - main (7.455)
✓ Pass: caffe2/test/fx2trt/core:test_input_tensor_spec - test_from_tensor (caffe2.test.fx2trt.core.test_input_tensor_spec.TestTRTModule) (7.047)
✓ Pass: caffe2/test/fx2trt/core:test_input_tensor_spec - test_from_tensors_with_dynamic_batch_size (caffe2.test.fx2trt.core.test_input_tensor_spec.TestTRTModule) (7.066)
✓ Pass: caffe2/test/fx2trt/core:test_input_tensor_spec - test_from_tensors (caffe2.test.fx2trt.core.test_input_tensor_spec.TestTRTModule) (7.181)
Summary
Pass: 3
ListingSuccess: 1
```
Wait for CI to verify if this unit test can run without RE.
Reviewed By: yinghai, kflu
Differential Revision: D32853947
fbshipit-source-id: 19713e8ad5478c945385c7013f7a1b9894151fea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69492
We already add empty, and this is another weird variation that sometimes pops up. Triggering it is unclear, so just adding it for now.
Test Plan: ran tracer
Differential Revision: D32896522
fbshipit-source-id: 38627d8efc48ef240100ccdbd94c0e7208b0b466
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68096
We replace all c10d APIs with the Auto-grad collection in the shareded linear op. So that we can enable the backward propagation (grad calculation for sharded linear).
ghstack-source-id: 144882914
Test Plan: Unit test + CI
Reviewed By: pritamdamania87
Differential Revision: D32177341
fbshipit-source-id: 1919e8ca877bdc79f4cdb0dc2a82ddaf6881b9f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68786
To enable the auto grad for the sharded linear, we find we need to make some changes to the current nn function api (c10d api with auto grad enabled). So we made the following several changes:
1. Add a new api `reduce_scatter` since we need it in the rowwise sharding.
2. Modify the `all_to_all` api to make sure it consistent with the ones in distributed_c10d.py.
3. Found the cpp input params of `reduce_scatter` is missing input param, added more unit test to cover these cases.
4. Sync the NN test from gloo to nccl.
ghstack-source-id: 144860208
Test Plan: CI + Unit Test
Reviewed By: pritamdamania87
Differential Revision: D32569674
fbshipit-source-id: 9bd613f91bbf7a39eede0af32a5a5db0f2ade43b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69027
Resubmission of https://github.com/pytorch/pytorch/pull/62964 withe
suggestions and tests discussed in
https://github.com/pytorch/pytorch/issues/65537.
Adds a `use_reentrant=False` flag to `checkpoint` function. When
`use_reentrant=True` is specified, a checkpointing implementation that uses
SavedVariableHooks instead of re-entrant autograd is used. This makes it more
composable with things such as `autograd.grad` as well as DDP (still need to
add thorough distributed testing).
As discussed in https://github.com/pytorch/pytorch/issues/65537, we have added
the following tests:
-[ ] Gradient hooks are called once
ghstack-source-id: 144644859
Test Plan: CI
Reviewed By: pbelevich
Differential Revision: D32704467
fbshipit-source-id: 6eea1cce6b935ef5a0f90b769e395120900e4412
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69472
Neglected the fact that the actual push for these variables is happening
inside of a docker container, this should help resolve that issue
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32889583
Pulled By: seemethere
fbshipit-source-id: d0ef213787694ab1a7e9fb508c58d2f53ff218c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69358
Enforces and raises error earlier if wrapper_cls is not provided as an
arg into enable_wrap() function. Also improves the documentation.
ghstack-source-id: 144807950
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32826963
fbshipit-source-id: d1b98df021e86d3d87a626e82facf6230b571a55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69357
Since we only want to support enable_wrap() and wrap() manual wrapping
APIs without them accepting auto_wrap_policy, remove all this unneeded code.
ghstack-source-id: 144807951
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32826318
fbshipit-source-id: 6526e700ebdf132cbb10439698f5c97ce083cd3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69356
Per title
ghstack-source-id: 144807949
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32816150
fbshipit-source-id: 6b4eacc63edd267bc1eb8a1c1d6c753bc581d63a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68776
Makes these APIs independent of ConfigAutoWrap so that they can be
used by FSDP ctor without it knowing about ConfigAutoWrap.
Also gets us one step closer to killing ConfigAutoWrap.recursive_wrap and
auto_wrap(), as we will only support enable_wrap() and wrap() moving forward.
Will test via unittests and FSDP benchmarks to ensure the wrapping still works.
ghstack-source-id: 144807948
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32604021
fbshipit-source-id: 54defc0cd90b16b5185a8c1294b39f75c06ffd21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69340
- An FX pass to fuse ops resulting from addmm(a, b.t())
- Used to enable structured sparsity using TRT
Reviewed By: 842974287
Differential Revision: D32456684
fbshipit-source-id: 601826af216cea314ee85ed522d5c54a5151d720
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69382
Implemented `slice` operator on the Vulkan backend:
* Supports only <= 4D tensors.
* `aten::slice.Tensor` will be executed internally by indexing Tensor.
* Slicing means selecting the elements present in the tensor by using `:` slice operator. We can slice the elements by using the index of that particular element.
* Indexing starts with 0. `end` is exclusive. In this example, we will be getting the elements from the very start to the end index 4(exclusive) of the tensor.
```
tensor = torch.tensor([2, 4, 1, 7, 0, 9])
print(tensor[ : 4])
# Outputs- tensor([2, 4, 1, 7])
```
* Generalized input tensors to 4D ones to simplify input/output texture handling. For example, {2, 3} is treated as {1,1,2,3} internally.
* Negative `start` and `end` inputs are allowed.
* CPU implementation: [/aten/src/ATen/native/TensorShape.cpp::slice()](3e45739543/aten/src/ATen/native/TensorShape.cpp (L1262))
* For **width** dimension, use `vkCmdCopyImage` API,
* input texture size = `{x,y,z}`
* if `step` is 1, copy a region from the input texture to the output texture once where
* source offset = `{start,0,0}`
* destination offset = `{0,0,0}`
* copy extents = `{end-start,y,z}`
* call `vkCmdCopyImage` API
* if `step` is not 1, do for-loop from x=`start` to `end-1` by `step` (also from x_new=`0` to `end-start-1`) where
* x_max = x
* copy extents = `{1,y,z}`
* if (x >= x_max) continue; // out of range
* source offset = `{x,0,0}`
* destination offset = `{x_new,0,0}`
* call `vkCmdCopyImage` API
* For **height** dimension, use `vkCmdCopyImage` API,
* input texture size = `{x,y,z}`
* if `step` is 1, copy a region from the input texture to the output texture once where
* source offset = `{0,start,0}`
* destination offset = `{0,0,0}`
* copy extents = `{x,end-start,z}`
* call `vkCmdCopyImage` API
* if `step` is not 1, do for-loop from y=`start` to `end-1` by `step` (also from y_new=`0` to `end-start-1`) where
* y_max = y
* copy extents = `{x,1,z}`
* if (y >= y_max) continue; // out of range
* source offset = `{0,y,0}`
* destination offset = `{0,y_new,0}`
* call `vkCmdCopyImage` API
* For **batch** and **feature**(channel) dimensions, we build up shader operations from the output texture point of view to avoid the nondeterministic order of GPU shader operations between texels. See [incoherent memory access](https://www.khronos.org/opengl/wiki/Memory_Model#Incoherent_memory_access)
* `b,c,h,w` = input tensor dims (NCHW)
* `b1,c1,h1,w1` = output tensor dims (NCHW)
* `posIn` = position (x,y,z) for input texture
* `posOut` = position (x,y,z) for output texture
* `inval` = input texel value
* `outval` = output texel value
* `max_dst_index` = batch size of output tensor * channel size of output tensor
* `n` = end - start
* `i` = index of input texel (0...3) and `j` = index of output texel (0..3)
* Pseudo code:
```
for (uint j = 0; j < 4; ++j) {
dst_index = posOut.z * 4 + j;
if (dst_index >= max_dst_index) {
save outval to output texture at posOut
break; // out of reange
}
b1 = int(dst_index / channel size of output tensor);
c1 = dst_index % channel size of output tensor;
h1 = posOut.y;
w1 = posOut.x;
b=b1
c=c1
h=h1
w=w1
if (dim==0) { // batch
b=start+step*b1;
} else { // feature(channel)
c=start+step*c1
}
src_index = b * channel size of input tensor + c;
posIn.x = int(w);
posIn.y = int(h);
posIn.z = int(src_index / 4);
i = (src_index % 4);
read inval from input texture at posIn
outval[j] = inval[i]
if (j == 3) {
save outval to output texture at posOut
}
}
```
* Error/edge cases:
* Vulkan backend doesn't support zero-sized slice. It throws an exception when allocating a Vulkan buffer if any dim size is zero.
* The slice step should be positive.
* Generalized test cases with different dim size tensors for batch, feature, height and width. For example, a 4D tensor slicing by dim=width:
```
tensor {2, 3, 40, 50} slicing with dim=3, start=10, end=30, step=1 <-> tensor indexing by [:,:,:,10:30:1]
tensor {2, 3, 40, 50} slicing with dim=3, start=10, end=30, step=7 <-> tensor indexing by [:,:,:,10:30:7]
tensor {2, 3, 40, 50} slicing with dim=3, start=10, end=50, step=2 <-> tensor indexing by [:,:,:,10:50:2] with end=out of range
tensor {2, 3, 40, 50} slicing with dim=3, start=-60, end=60, step=2 <-> tensor indexing by [:,:,:,-60:60:2] with start/end=out of range
tensor {2, 3, 40, 50} slicing with dim=3, start=-30, end=-10, step=2 <-> tensor indexing by [:,:,:,-30:-10:1] with negative start/end
tensor {2, 3, 40, 50} slicing with dim=3, start=0, end=INT64_MAX, step=2 <-> tensor indexing by [:,:,:,0:9223372036854775807:1] with end=INT64_MAX
tensor {2, 3, 40, 50} slicing with dim=3, start=-10, end=INT64_MAX, step=2 <-> tensor indexing by [:,:,:,-10:9223372036854775807:1] with negative start and end=INT64_MAX
tensor {2, 3, 40, 50} slicing with dim=3, start=INT64_MIN, end=INT64_MAX, step=2 <-> tensor indexing by [:,:,:,-9223372036854775808:9223372036854775807:1] with start=INT64_MIN and end=INT64_MAX
tensor {2, 3, 40, 50} slicing with dim=3, start=empty, end=empty, step=2 <-> tensor indexing by [:,:,:,::1] with empty start/end
```
* References:
* [Slicing PyTorch Datasets](https://lewtun.github.io/blog/til/nlp/pytorch/2021/01/24/til-slicing-torch-datasets.html)
* [How to Slice a 3D Tensor in Pytorch?](https://www.geeksforgeeks.org/how-to-slice-a-3d-tensor-in-pytorch/)
* [PyTorch Tensor Indexing API](https://pytorch.org/cppdocs/notes/tensor_indexing.html#translating-between-python-c-index-types)
* [PyTorch Tensor Indexing](https://deeplearninguniversity.com/pytorch/pytorch-tensor-indexing/)
* [Slicing and Striding](https://mlverse.github.io/torch/articles/indexing.html#slicing-and-striding)
* Vulkan `slice` operator tensor conversion:
{F684363708}
Test Plan:
Build & test on Android:
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_api_test
adb shell "/data/local/tmp/vulkan_api_test"
```
Build & test on MacOS:
```
cd ~/fbsource
buck build //xplat/caffe2:pt_vulkan_api_test_binAppleMac
./buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAppleMac\#macosx-x86_64
```
Test result on Android (Google Pixel 5):
```
[ RUN ] VulkanAPITest.slice_width_success
[ OK ] VulkanAPITest.slice_width_success (17 ms)
[ RUN ] VulkanAPITest.slice_height_success
[ OK ] VulkanAPITest.slice_height_success (13 ms)
[ RUN ] VulkanAPITest.slice_feature_success
[ OK ] VulkanAPITest.slice_feature_success (20 ms)
[ RUN ] VulkanAPITest.slice_batch_success
[ OK ] VulkanAPITest.slice_batch_success (9 ms)
[ RUN ] VulkanAPITest.slice_invalidinputs_exceptions
[ OK ] VulkanAPITest.slice_invalidinputs_exceptions (0 ms)
```
Test result on MacOS:
```
[ RUN ] VulkanAPITest.slice_width_success
[ OK ] VulkanAPITest.slice_width_success (81 ms)
[ RUN ] VulkanAPITest.slice_height_success
[ OK ] VulkanAPITest.slice_height_success (56 ms)
[ RUN ] VulkanAPITest.slice_feature_success
[ OK ] VulkanAPITest.slice_feature_success (132 ms)
[ RUN ] VulkanAPITest.slice_batch_success
[ OK ] VulkanAPITest.slice_batch_success (33 ms)
[ RUN ] VulkanAPITest.slice_invalidinputs_exceptions
[ OK ] VulkanAPITest.slice_invalidinputs_exceptions (1 ms)
```
Reviewed By: SS-JIA
Differential Revision: D32482638
fbshipit-source-id: 65841fb2d3489ee407f2b4f38619b700787d41b0
Summary:
Cleans up the CODEOWNERS file to reflect current team
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69395
Test Plan: yeah_sandcastle
Reviewed By: anjali411
Differential Revision: D32885237
Pulled By: seemethere
fbshipit-source-id: a465f2cd0e27d5e53f5af5769d1cad47ec5348e7
Summary:
ROCm and CUDA type promotion are slightly divergent and need to be updated.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69456
Reviewed By: anjali411, janeyx99
Differential Revision: D32883895
Pulled By: mruberry
fbshipit-source-id: 3b0ba8a9d092c2d7ff20d78da42d4a147b1db12d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69374
Enables existing native_dropout operator for use with lazy tensors. Also adds aten interned strings so lazy tensor codegen can refer to the symbols in generated IR classes.
Test Plan: CI for regressions of existing use cases, and manual tests of new Lazy Tensor functionality
Reviewed By: ngimel
Differential Revision: D32837301
fbshipit-source-id: a372a24ec65367fb84ad2e97c7e38cae4ec703a6
Summary:
This PR:
- creates the "jiterator" pattern, allowing elementwise unary and binary kernels that don't accept scalars to be jit compiled when called
- ports the gcd and i1 CUDA kernels to use the jiterator
- extends elementwise binary systemic testing to be comparable to elementwise unary systemic testing
- separates one test case from test_out in test_ops.py
- updates more OpInfos to use expected failures instead of skips
The jiterator currently does not support half, bfloat16 or complex dtypes. It also (as mentioned above) doesn't support scalar inputs. In the future we expect to add support for those datatypes and scalars.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69439
Reviewed By: ngimel
Differential Revision: D32874968
Pulled By: mruberry
fbshipit-source-id: d44bb9cde4f602703e75400ec5a0b209f085e9b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69438
We don't need to recompile the model if the OS version is not changed. This could save hundreds of ms when loading the model.
{F683788183}
ghstack-source-id: 144784720
ghstack-source-id: 144821734
Test Plan:
1. Test in the playground app
2. Test in the ig
Reviewed By: hanton
Differential Revision: D32866326
fbshipit-source-id: ae2174f68dda4d2ab89ee328cb710c08d45c4d9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69274
`impl.h` is the main header file that defines the interface of Static Runtime to its clients.
However, it is currently filled with implementation details that should not be leaked to our clients. 1) this can unnecessarily leak our internals to our clients which can make it hard to change them later 2) cause unnecessary merge conflicts when multiple people are touching this enormous impl.cpp file.
To alleviate the situation, this change moves the implementation details from impl.h into a new file, internal.h, that's internally kept without leaking the details to our clients.
This change will be followed by another change to rename `impl.h` into `runtime.h` or anything better since `impl.h` is currently not about implementation but SR's interface.
Note that this change is NOT complete since the remaining declarations in impl.h still contain a lot of implementation details. Therefore, we should keep working on minimizing the interface to prevent our API from being bloated unnecessarily. Also we need to work on modularizing our implementations into separate pieces organized by separate files in the near future.
Test Plan: Existing unittests
Reviewed By: donaldong
Differential Revision: D32780415
fbshipit-source-id: 119b7aedbf563b195641c5674572a9348732145f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69234
We don't need to recompile the model if the OS version is not changed. This could save hundreds of ms when loading the model.
{F683788183}
ghstack-source-id: 144784720
Test Plan:
1. Test in the playground app
2. Test in the ig
Reviewed By: hanton
Differential Revision: D32743881
fbshipit-source-id: 2e94c6035520de3eeaf0b61f7cf9082228c8a955
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69277
LazyView is the main class for tracking alias caused by view
ops. The corresponding IR classes for view ops are hand-written now, and
we can switch to code-gen them in future. For certain view ops, they
have a reverse IR class to perform inplace update in the backward
direction on a chain of alias ops.
As part of the future work, we will simplify the logic for LazyView once
the functionalization pass in core is ready to use.
Test Plan: Imported from OSS
Reviewed By: wconstab
Differential Revision: D32820014
Pulled By: desertfire
fbshipit-source-id: d9eb526cb23885f667e4815dc9dd291a7b7e4256
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69098
Add the following utils: helpers, ir_dump_util, and
tensor_util. Some of the util functions may be better organized by
grouping into different files, but we can leave that for later.
Test Plan: Imported from OSS
Reviewed By: alanwaketan
Differential Revision: D32758480
Pulled By: desertfire
fbshipit-source-id: 2a0707879f0c49573380b4c8227a3c916c99bf9a
Summary:
Per title.
This PR introduces a global flag that lets pytorch prefer one of the many backend implementations while calling linear algebra functions on GPU.
Usage:
```python
torch.backends.cuda.preferred_linalg_library('cusolver')
```
Available options (str): `'default'`, `'cusolver'`, `'magma'`.
Issue https://github.com/pytorch/pytorch/issues/63992 inspired me to write this PR. No heuristic is perfect on all devices, library versions, matrix shapes, workloads, etc. We can obtain better performance if we can conveniently switch linear algebra backends at runtime.
Performance of linear algebra operators after this PR should be no worse than before. The flag is set to **`'default'`** by default, which makes everything the same as before this PR.
The implementation of this PR is basically following that of https://github.com/pytorch/pytorch/pull/67790.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67980
Reviewed By: mruberry
Differential Revision: D32849457
Pulled By: ngimel
fbshipit-source-id: 679fee7744a03af057995aef06316306073010a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69219
This change fixes a bug that `aten::embedding_bag` implementation does not adjust the size of a managed output tensor according to a given input after memory planning starts.
Test Plan: Enhanced `StaticRuntime.EmbeddingBag` to trigger the existing bug that's fixed by this change.
Reviewed By: mikeiovine
Differential Revision: D32544399
fbshipit-source-id: 0a9f1d453e96f0cfa8443c8d0b28bbc520e38b29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66689
Let's not take an extra refcount bump to stringify types.
ghstack-source-id: 144374720
Test Plan: CI
Reviewed By: suo
Differential Revision: D31691526
fbshipit-source-id: 673d632a83e6179c063530fdbc346c22d5f47d7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69296
remove a commented block of code that was accidentally checked in
Test Plan: no testable changes
Reviewed By: alanwaketan
Differential Revision: D32799197
fbshipit-source-id: d3eb05cbafb0f5a4a3f41c17f66ca6d0c2fc60b7
Summary:
The `TORCH_CHECK` asserts for strictly-greater-than `kLargeBuffer`,
but the exception claims `>=`. Fix the error message to match the
code.
Happy to open an issue if it's helpful; I was hopeful the trivial fix doesn't need a separate issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69174
Reviewed By: zou3519
Differential Revision: D32760055
Pulled By: H-Huang
fbshipit-source-id: 1a8ab68f36b326ed62d78afdcb198f4d6572d017
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68884
This diff uses std::vector::reserve in GetLivenessMap to set container capacity for all local contains to avoid runtime resizing.
The changes should theoretically improves the performance by a little.
Test Plan:
- [x] `buck run //caffe2/benchmarks/static_runtime:static_runtime_cpptest -- -v 1`
- [x]
```
seq 1 10 | xargs -I{} ./buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench \
--scripted_model=/data/users/dxd/302008423_0.predictor.disagg.local \
--method_name=local_request_only.forward --pt_cleanup_activations=1 \
--pt_enable_out_variant=1 --pt_optimize_memory=1 --iters=0 --warmup_iters=0 \
--num_threads=1 --pt_enable_static_runtime=1 --set_compatibility=1 \
--input_type="recordio" --pt_inputs=/data/users/dxd/302008423_0.local_ro.inputs.recordio \
--recordio_use_ivalue_format=1
```
### Before
```
I1201 12:04:46.753311 2874563 PyTorchPredictorBenchLib.cpp:336] Took 10.9826 sec to initialize a predictor.
I1201 12:05:00.617139 2875780 PyTorchPredictorBenchLib.cpp:336] Took 11.1078 sec to initialize a predictor.
I1201 12:05:15.279667 2876813 PyTorchPredictorBenchLib.cpp:336] Took 11.7979 sec to initialize a predictor.
I1201 12:05:30.201207 2877554 PyTorchPredictorBenchLib.cpp:336] Took 11.8901 sec to initialize a predictor.
I1201 12:05:44.386926 2879713 PyTorchPredictorBenchLib.cpp:336] Took 11.2722 sec to initialize a predictor.
I1201 12:05:58.003582 2881426 PyTorchPredictorBenchLib.cpp:336] Took 10.8046 sec to initialize a predictor.
I1201 12:06:12.004778 2882604 PyTorchPredictorBenchLib.cpp:336] Took 11.2754 sec to initialize a predictor.
I1201 12:06:26.101241 2884888 PyTorchPredictorBenchLib.cpp:336] Took 11.3355 sec to initialize a predictor.
I1201 12:06:40.364817 2886572 PyTorchPredictorBenchLib.cpp:336] Took 11.401 sec to initialize a predictor.
I1201 12:06:54.483794 2888614 PyTorchPredictorBenchLib.cpp:336] Took 11.3498 sec to initialize a predictor.
```
### After
```
I1201 11:51:53.775239 2818391 PyTorchPredictorBenchLib.cpp:336] Took 10.9113 sec to initialize a predictor.
I1201 11:52:07.412720 2819530 PyTorchPredictorBenchLib.cpp:336] Took 10.8413 sec to initialize a predictor.
I1201 11:52:21.202816 2820359 PyTorchPredictorBenchLib.cpp:336] Took 11.0216 sec to initialize a predictor.
I1201 11:52:35.513288 2821029 PyTorchPredictorBenchLib.cpp:336] Took 11.4216 sec to initialize a predictor.
I1201 11:52:49.145979 2821930 PyTorchPredictorBenchLib.cpp:336] Took 10.8272 sec to initialize a predictor.
I1201 11:53:02.908790 2822859 PyTorchPredictorBenchLib.cpp:336] Took 11.0262 sec to initialize a predictor.
I1201 11:53:16.276015 2823657 PyTorchPredictorBenchLib.cpp:336] Took 10.6893 sec to initialize a predictor.
I1201 11:53:30.103283 2824382 PyTorchPredictorBenchLib.cpp:336] Took 11.1854 sec to initialize a predictor.
I1201 11:53:44.298514 2825365 PyTorchPredictorBenchLib.cpp:336] Took 11.4796 sec to initialize a predictor.
I1201 11:53:58.258708 2826128 PyTorchPredictorBenchLib.cpp:336] Took 11.2652 sec to initialize a predictor.
```
Reviewed By: swolchok
Differential Revision: D32649252
fbshipit-source-id: 5cd296d12b12e5b15e85e4f1a8a236e293f37f9c
Summary:
Fixes [issue#67](https://github.com/MLH-Fellowship/pyre-check/issues/67)
This PR fixes the type checking errors in Pytorch torch/fx/node.py .
The variable types in 363:20 and 364:20 were declared to have type `List[str]` but were assigned a value of `None`. This caused an incompatitble variable type error. I changed the type from `List[str]` to `Optional[List[str]` . This therefore fixed the incompatitble variable type error.
Signed-off-by: Onyemowo Agbo
onionymous
0xedward
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68124
Reviewed By: gmagogsfm
Differential Revision: D32322414
Pulled By: onionymous
fbshipit-source-id: be11bbbd463715ddf28a5ba78fb4adbf62878c80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69326
Looks like this really is slightly cheaper (see assembly diff screenshot in internal test plan). The problem is that `pop()` returns the value, so we have to spend instructions moving it out of the stack and then destroying it via a local.
ghstack-source-id: 144641680
Test Plan:
{F684148304}
CI
Reviewed By: zhxchen17
Differential Revision: D32812841
fbshipit-source-id: e9e43458d3364842f67edd43e43575a1f72e3cb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69324
This slightly shrinks runImpl.
Before:
- Move pointer out of IValue
- Clear the IValue to none
- Do our thing with the Object
- destroy the intrusive_ptr on the C stack
- destroy the IValue on the C stack (even though it was cleared to None, the destructor has to run anyway)
After:
- Grab the pointer out of IValue
- Do our thing with the Object
- Decref the pointer in the IValue on the JIT stack as we assign over it
We should be saving at least the memory traffic from clearing the IValue and possibly the dtor code as well.
ghstack-source-id: 144638920
Test Plan:
Inspected assembly to verify shorter runImpl
Tried to microbenchmark (D32809454) but can't show a difference.
Reviewed By: gchanan
Differential Revision: D32812252
fbshipit-source-id: a3689f061ee51ef01e4696bd4c6ffcbc41c30af5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68942
Currently, `at::native::is_metal_available()` is implemented, but it's not exposed in the header, so nobody can use it. It's a useful function and I want to use it, so exposing it in the header.
Test Plan: CI
Reviewed By: sodastsai, xta0
Differential Revision: D32675236
fbshipit-source-id: b4e692db7d171dfb872d5c2233cc808d7131f2e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69371
macOS jobs need credentials to upload their test stats
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32836893
Pulled By: seemethere
fbshipit-source-id: 0f5a8f1b35f4240d57b08a2120a97a13ba3b3de5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69164
We have lots of methods that take `std::unordered_map<std::string, c10::IValue>` now. That's kind of ugly and cumbersome to type, so add a `KWargs` typedef.
Also made the `operator()` default `kwargs` to empty. Note that we could have another overload that doesn't take `kwargs` at all, but the perf gain is so minuscule it's probably not worth it.
ghstack-source-id: 144691899
Test Plan: CI
Reviewed By: d1jang
Differential Revision: D32734677
fbshipit-source-id: 8d6496a6d1ec2dc71253151d2f6408f1387966cf
Summary:
This is partial revert of bb522c9d7a to revert addition of workflows for CUDA 11.5 windows that fails
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69365
Reviewed By: suo
Differential Revision: D32831418
Pulled By: atalman
fbshipit-source-id: 184346d22623f88594312a4ce2e4d29cc67e8338
Summary:
This fixes the `USE_PRECOMPILED_HEADERS` cmake version check which was accidentally inverted, so it was always disabled.
I've also made the precompiled header so it only includes headers used in 95% or more of code, weighted by compile time. This limits it to the standard library, `c10` and a limited subset of `ATen/core`. Crucially, the new pch doesn't depend on `native_functions.yaml` so won't cause as much unnecessary rebuilding.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67851
Reviewed By: zou3519
Differential Revision: D32290902
Pulled By: dagitses
fbshipit-source-id: dfc33330028c99b02ff40963926c1f1260d00d00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68295
There's no reason we can't figure out what tensors we need to manage at model load time. It's also useful to have the set of ranges available at load time for integrating the ranges algorithm introduced in the previous diff.
Test Plan: `buck test caffe2/benchmarks/static_runtime/...`
Reviewed By: hlu1
Differential Revision: D32400593
fbshipit-source-id: 0466b2641166ddc9c14f72774f4ba151407be400
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69328
Aten_metal_prepack is cpp based and can be safely included here.
Test Plan: "Traced" the xirp model with the script.
Reviewed By: xta0
Differential Revision: D32813686
fbshipit-source-id: 7a428151348dc9d3f576531701926d6b3413de3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69327
Original commit changeset: d44096d88265
Original Phabricator Diff: D32144240 (668574af4a)
Test Plan:
CI
original diff failed 175 builds in CI
Reviewed By: airboyang, anjali411
Differential Revision: D32809407
fbshipit-source-id: c7c8e69bcee0274992e2d5da901f035332e60071
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/67612 by creating a tensor first and then converting the dtype explicitly using `.to(dtype)` call.
Looking forward to your feedback and suggestions on this.
cc: kshitij12345 mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68113
Reviewed By: zou3519
Differential Revision: D32797329
Pulled By: saketh-are
fbshipit-source-id: 5c34709ab277c82cda316a3ea1cf01e853e4c38b
Summary:
See https://pytorch.slack.com/archives/G4Z791LL8/p1638229956006300
I grepped c10, aten, and torch for CUDA_VERSION and checked the usages I saw.
I can't guarantee I made a clean sweep. but this improves the status quo.
cc ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69092
Reviewed By: zou3519
Differential Revision: D32786919
Pulled By: ngimel
fbshipit-source-id: 1d29827dca246f33118d81e136252ddb5bf3830f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69298
I was exploring adding an invariant that we actually use properly-tracked pinned memory when doing non-blocking copies (to plug various correctness holes), and found this case where we allocate a tensor without pinned memory and then copy it with non_blocking=True.
Test Plan: Unit tests cover this code.
Reviewed By: rohan-varma
Differential Revision: D32786909
fbshipit-source-id: a53f96f57e6727238e4cd2164c1a0f04cf270413
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68528
Add operator converter div, torch.floor_div is announce to be deprecated by pytorch, consider remove after full deprecation done by pytorch.
Reviewed By: 842974287
Differential Revision: D32497573
fbshipit-source-id: d06c864077f745c295c33fb25639b7116f85ca20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69172
Migrates the docs push jobs to Github Actions by implementing a simple
WITH_PUSH switch to do the actual push.
Adds 2 new workflows for GHA:
* linux-docs (on trunk)
* linux-docs-push (on schedule)
linux-docs-push is the only workflow that actually gets access to
credentials so it should be relatively safe.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32767239
Pulled By: seemethere
fbshipit-source-id: 5b100f986cf4023c323f4f96f0fe7942fec49ad2
Summary:
Turn on layer_norm in autodiff
https://github.com/pytorch/pytorch/issues/67732 should have fixed the previously issue exposed by enabling layer_norm in autodiff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69007
Reviewed By: soulitzer
Differential Revision: D32699108
Pulled By: eellison
fbshipit-source-id: 6951668c0e74e056d3776294f4e1fd3123c763e5
Summary:
Preserves the .json files in the test folder for every test job as an artifact.
Going to hud.pytorch.org/pr/69258 and downloading/unzipping any of the `test-jsons-*.zip` shows that .pytorch-slow-tests.json and .pytorch-disabled-tests.json exist. (Though you won't see them in your file manager as they are hidden files.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69258
Reviewed By: seemethere
Differential Revision: D32807102
Pulled By: janeyx99
fbshipit-source-id: ed1b227cdd32160ed045dd79a7edc55216dcfe53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63570
There is a use of `at::triangular_solve_out` in the file
`torch/csrc/jit/tensorexpr/external_functions.cpp` that I have not dared
to move to `at::linalg_solve_triangular_out`.
**Deprecation note:**
This PR deprecates the `torch.triangular_solve` function in favor of
`torch.linalg.solve_triangular`. An upgrade guide is added to the
documentation for `torch.triangular_solve`.
Note that it DOES NOT remove `torch.triangular_solve`, but
`torch.triangular_solve` will be removed in a future PyTorch release.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32618035
Pulled By: anjali411
fbshipit-source-id: 0bfb48eeb6d96eff3e96e8a14818268cceb93c83
Summary:
Before:
`ValueError: InstanceNorm1d returns 0-filled tensor to 2D tensor.This is because InstanceNorm1d reshapes inputs to(1, N * C, ...) from (N, C,...) and this makesvariances 0.`
After:
`ValueError: InstanceNorm1d returns 0-filled tensor to 2D tensor. This is because InstanceNorm1d reshapes inputs to (1, N * C, ...) from (N, C,...) and this makes variances 0.`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69289
Reviewed By: jbschlosser
Differential Revision: D32796035
Pulled By: albanD
fbshipit-source-id: c8e7c5cf6e961ec5f7242b31c7808454104cde02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67701
I split this out to ease rebasing and review.
ghstack-source-id: 144507288
Test Plan: CI
Reviewed By: hlu1
Differential Revision: D32112523
fbshipit-source-id: dba14e6ada33df02dbcd7025b090a8a18cf438ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67220
Specifically we log AliasDb and same_storage_values, and are chattier about the aliasing logs in the liveness analysis.
ghstack-source-id: 144507289
Test Plan: Used to help develop D31776259
Reviewed By: hlu1
Differential Revision: D31847561
fbshipit-source-id: 8371455d060c17dace91cd90e4034b7618f820a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67219
I found that these specific test cases were causing different failures when developing D31776259. I also found that it was difficult to debug testStaticRuntime failures, so I added more verbose logs gated behind -v 2.
ghstack-source-id: 144507287
Test Plan: Used during development of D31776259
Reviewed By: hlu1
Differential Revision: D31847566
fbshipit-source-id: ea9147fb246c345d18bbc8d7f3bfba48d3a0fab3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69265
This is used in tab completion, we should not put warning here
Test Plan:
ci
Imported from OSS
Reviewed By: albanD
Differential Revision: D32778736
fbshipit-source-id: f1bec5e09a8238ab41329ac2b64e6f3267799f6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66743
Modified loops in files under fbsource/fbcode/caffe2/ from the format
`for(TYPE var=x0;var<x_max;x++)`
to the format
`for(const auto var: irange(xmax))`
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision: D31705359
fbshipit-source-id: c9ea2fbc0f9cd29e97a52dcb203addc5f2abb09b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67705
This PR rewrites ProcessGroupNCCLTest to be MultiProcessTestCase. It was originally written in a single process multi-GPU fashion, we change it to multi-process instead to align with other c10d tests.
ghstack-source-id: 144555092
Test Plan: wait for CI
Reviewed By: pritamdamania87, fduwjj
Differential Revision: D32113626
fbshipit-source-id: 613d36aeae36bf441de1c2c83aa4755f4d33df4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69238
The NS for FX graph matcher was not properly taking into account
seen_nodes, this allowed a node to be matched twice.
Test Plan:
FB-only testing on real model passes.
Ideally we would have a test case to capture this, but hopefully we can land this soon to unblock production work.
Imported from OSS
Reviewed By: HDCharles
Differential Revision: D32765761
fbshipit-source-id: ed3dff8fd981e399a649fcd406883b4d56cc712a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69181
functorch lives out-of-tree. However, it has some TLS that needs to be
propagated. The solution for that is we store a pointer to the TLS
inside pytorch/pytorch and extend FuncTorchTLSBase inside functorch to
include whatever functorch needs.
A previous solution used ThreadLocalDebugInfo. However, all
PyTorch-managed threads (e.g. spawned by Autograd) all receive a
shared_ptr that points to the same ThreadLocalDebugInfo. This leads to
race conditions if the multiple threads start modifying the TLS
stored within ThreadLocalDebugInfo without using mutexes.
Test Plan:
- tested with functorch
- The performance impact of this change when functorch is not used is
negligible because we end up manipulating nullptrs.
Reviewed By: albanD
Differential Revision: D32742312
Pulled By: zou3519
fbshipit-source-id: 1a8439a4af06b3d3e50b9a2dbca98a0ba612062a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69261
As this function is supposed to be called only once per type from
caching getCustomClassType template
Test Plan: Imported from OSS
Reviewed By: suo, lw
Differential Revision: D32776564
Pulled By: malfet
fbshipit-source-id: 218436657e6ad5ad0c87964857114d1e60c57140
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68852
When using a float zero_point in FakeQuant, such as for embeddings, it does not need to be between
quant_min and quant_max, as is enforced for integer zero_points.
This is because float zero_points are formulated as per:
```
xq = Round(Xf * inv_scale + zero_point),
Xq = Round((Xf - min) * inv_scale)
```
Test Plan:
pytest test/test_quantization.py -v -k "test_fake_quant_per_channel_qparam_range"
Imported from OSS
Reviewed By: supriyar
Differential Revision: D32645014
fbshipit-source-id: 96dc3ca6eef9cee60be6919fceef95c9f2759891
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69020
Merges the lazy tensor codegen infra which has already been used on lazy_tensor_staging.
Test Plan: Test via lazy_tensor_staging branch
Reviewed By: alanwaketan, bdhirsh
Differential Revision: D32570613
fbshipit-source-id: 2cd5698644398bda69669683f8de79fd3b6639b5
Summary:
As per title. This in particular allows to more easily override backward function for which the underlying backend returns `None`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67793
Reviewed By: zou3519
Differential Revision: D32242962
Pulled By: albanD
fbshipit-source-id: 6e114def90ee9499161e1303d301ba7fd003ff89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68639
Fix all problems related to `ProcessedNode:: verify_no_memory_overlap()`
- Only enable this check for native and fallback ops that are not inplace or view ops
- Enable ProcessedNode:: verify_no_memory_overlap() in debug mode and enforce it
- Add gflag --static_runtime_disable_debug_memory_overlap_check to test the runtime memory overlap fix for bad schemas
fb::expand_dims's schema was not correct after this check is re-enabled. It's fixed in D32556204 (39ab417107)
Reviewed By: mikeiovine
Differential Revision: D32553708
fbshipit-source-id: 88de63cdf1ee4f87b7726c8b65a11a5fb8a99d13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69226
This add back the previous init_from_local_shards API, but renamed it to init_from_local_shard_and_global_metadata. It's a partial revert of D32147888 (35712a8eb4). We now provide two APIs:
1. `init_from_local_shards`: user don't need to provide global metadata and we do all_gather under the hood, the other that
2. `init_from_local_shards_and_global_metadata`: user need to explicitly construct ShardedTensorMetadata to use this API, need to ensure correctness on all ranks, as there's no cross-rank communication/validations.
All of these two APIs stay private until it stablizes and proof of UX. The second one can only be called on `ShardedTensor` class directly, not included as a package API for now.
Test Plan:
test_init_from_local_shards_and_global_metadata
test_init_from_local_shards_and_global_metadata_invalid_shards
Reviewed By: dstaay-fb, pritamdamania87
Differential Revision: D32746882
fbshipit-source-id: bafd26ce16c02e2095907f9e59984a5d775c7df5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68417
1. since parameter attributes are lazily initialized at the beginning of forward, it makes more sense to init full_param_padded using parameters' data type during lazy_init, instead of using parameters' data type during construction, as parameters' data type may be changed after construction and before training loop
2.add checking whether parameter storage is changed outside FSDP and handle it properly
ghstack-source-id: 144479019
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D32458643
fbshipit-source-id: 0e07e5e08270f2e265e8f49124a6648641e42e7a
Summary:
Needed for NNC dynamic shape fusion. Previously, when creating a partially evaluated graph for symbolic shape compute, if the input wasn't used, we wouldn't compute it, which led to failures when NNC expected this value to be passed in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68281
Reviewed By: navahgar
Differential Revision: D32401365
Pulled By: eellison
fbshipit-source-id: 97a684e5f1faed5df77c8fd69f9623cdba0781f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68594
Based on my conversation with ejguan [here](https://github.com/pytorch/pytorch/pull/68197#pullrequestreview-809148827), we both believe that having the `unbatch_level` argument and functionality is making this DataPipe unnecessarily complicated, because users can call `.unbatch` before `.batch` if they would like to do so. That will likely be cleaner as well.
I also checked other libraries (for example, [TensorFlow](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#unbatch)), and I do not see them provide the ability the `unbatch` within the `batch` function either.
This PR simplifies the DataPipe by removing the argument.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D32532594
Pulled By: NivekT
fbshipit-source-id: 7276ce76ba2a3f207c9dfa58803a48e320adefed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69251
This adds some actual documentation for deploy, which is probably useful
since we told everyone it was experimentally available so they will
probably be looking at what the heck it is.
It also wires up various compoenents of the OSS build to actually work
when used from an external project.
Differential Revision:
D32783312
D32783312
Test Plan: Imported from OSS
Reviewed By: wconstab
Pulled By: suo
fbshipit-source-id: c5c0a1e3f80fa273b5a70c13ba81733cb8d2c8f8
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/68678
Test Plan: Ill update the unit test before land
Reviewed By: cccclai
Differential Revision: D32573603
fbshipit-source-id: 19271bcbb68b61d24d6943e61a943f4f75fddb5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67726
1. Check in one model with aten:div_tensor old op with unittest in both cpp and python. The following two lines are commented out and expected to work after using upgrader.
```
_helper(mobile_module_v2, div_tensor_0_3)
_helper(current_mobile_module, torch.div)
```
2. Update the commented code accordingly.
Currently there are 6 upgraders. The following old models with operators are added to cover these 6 upgraders:
```
// Tensor x Tensor
test_versioned_div_tensor_v3
// Tensor x Scalar
test_versioned_div_scalar_float_v3
test_versioned_div_scalar_reciprocal_int_v3
test_versioned_div_scalar_inplace_float_v3
// Scalar x Scalar
test_versioned_div_scalar_scalar_v3
// Tensor x Tensor with out kwarg
test_versioned_div_tensor_out_v3
// Tensor x Tensor inplace
test_versioned_div_tensor_inplace_v3
// Tensor x Scalar inplace
test_versioned_div_scalar_inplace_int_v3
```
Note:
In this pr, per model, it includes the following test:
1. Model (with old op) load/run test will be in both cpp and python
2. Model (with old op) + upgrader test will be in python
Other tests considered adding:
1. per upgrader bytecode test
2. app level integration test
ghstack-source-id: 144422418
Test Plan: CI and the added unittest
Reviewed By: iseeyuan
Differential Revision: D32069653
fbshipit-source-id: 96d9567088a1f709bc7795f78beed7a308e71ca9
Summary:
remove the line since line 10 has already included this header file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68983
Reviewed By: samdow
Differential Revision: D32706952
Pulled By: soulitzer
fbshipit-source-id: 98746e12d8d04d64ee2e0449e4aec5153ac723d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68603
FileStore is frequently used from the python lang, which has GC. This means, that users of FileStore from python do not have control over when FileStore destructor is invoked. If the directory for file store is created by some external logic, that has cleanup procedure, this procedure may have a race condition with the logic in the FileStore destructor.
The diff adds check for file access in destructor before actually invoking the cleanup. In long term, it makes sense to move out the cleanup logic out of the destructor to a separate method.
Test Plan:
CI
Stress tests: `buck test mode/dev-nosan //torchrec/examples/dlrm/tests:test_dlrm_main -- --exact 'torchrec/examples/dlrm/tests:test_dlrm_main - torchrec.examples.dlrm.tests.test_dlrm_main.MainTest: test_main_function' --run-disabled --jobs 18 --stress-runs 20 --record-results`
Reviewed By: colin2328
Differential Revision: D32535470
fbshipit-source-id: 6f421f2e7b0d9ac9c884a1db2f7e5a94fc59fc0e
Summary:
At https://github.com/pytorch/pytorch/issues/68873, jbschlosser states that maxunpool2d with the `output_size` argument only works for indices of the same size. This makes sense, but unfortunately it's not what's shown in the example! I've removed the wrong example and replaced it with one where specifying `output_size` is actually necessary -- the unpool call fails without it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68936
Reviewed By: H-Huang
Differential Revision: D32759207
Pulled By: jbschlosser
fbshipit-source-id: 658e1724150a95454a05a771ae7c6e2e736740a7
Summary:
Add test shard number and runner name to the test name suffix
Otherwise test report names for shard 1 and shard 2 will be identical
and override each other
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69188
Reviewed By: janeyx99
Differential Revision: D32747747
Pulled By: malfet
fbshipit-source-id: 149f921d8e420d3ed69ce812bdcd3c034799353a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63569
This PR also rewrites `lu_solve_backward` from scratch going from
solving 5 systems of equations to just 2.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32618014
Pulled By: anjali411
fbshipit-source-id: 0e915bcf7045a4db43ffd076d807beac816c8538
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68887Closes#46988, closes#46987, closes#46761
By "simple" I mean operators that map 0->0 so we can implement it by
just re-dispatching on the values tensor. That does mean we have `sin`
but not `cos` for example, but without fill value support this is the
best that can be done.
Most of these don't support autograd because the derivative formulas
use unsupported operators.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32734911
Pulled By: cpuhrsch
fbshipit-source-id: 203ab105799f3d2d682b01ca3d6b18e7c994776a
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: ed4bbe52b7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69089
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D32725534
fbshipit-source-id: 73b1e0f67c957ca0220cd47179dd4b350a98fd33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68825
Factoring out the elementwise ops in tensorexpr fuser and adding their corresponding shape functions, since we need shape functions to fuse them with dynamic shapes
Test Plan: Imported from OSS
Reviewed By: samdow
Differential Revision: D32732466
Pulled By: eellison
fbshipit-source-id: 69cacf6fbed8eb97e475f5d55b2eec0384fe8ec1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69167
Per title
ghstack-source-id: 144378083
Test Plan: Ci
Reviewed By: H-Huang
Differential Revision: D32736119
fbshipit-source-id: f37fd3e4ac393c07eb8bd1f9202841d33d0a8aad
Summary:
While implementing https://github.com/pytorch/pytorch/issues/68644,
during the testing of 'torch.distributions.constraint.positive_definite', I found an error in the code: [location](c7ecf1498d/torch/distributions/constraints.py (L465-L468))
```
class _PositiveDefinite(Constraint):
"""
Constrain to positive-definite matrices.
"""
event_dim = 2
def check(self, value):
# Assumes that the matrix or batch of matrices in value are symmetric
# info == 0 means no error, that is, it's SPD
return torch.linalg.cholesky_ex(value).info.eq(0).unsqueeze(0)
```
The error is caused when I check the positive definiteness of
`torch.cuda.DoubleTensor([[2., 0], [2., 2]])`
But it did not made a problem for
`torch.DoubleTensor([[2., 0], [2., 2]])`
You may easily reproduce the error by following code:
```
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> const = torch.distributions.constraints.positive_definite
>>> const.check(torch.cuda.DoubleTensor([[2., 0], [2., 2]]))
tensor([False], device='cuda:0')
>>> const.check(torch.DoubleTensor([[2., 0], [2., 2]]))
tensor([True])
```
The cause of error can be analyzed more if you give 'check_errors = True' as a additional argument for 'torch.linalg.cholesky_ex'.
It seem that it is caused by the recent changes in 'torch.linalg'.
And, I suggest to modify the '_PositiveDefinite' class by using 'torch.linalg.eig' function like the below:
```
class _PositiveDefinite(Constraint):
"""
Constrain to positive-definite matrices.
"""
event_dim = 2
def check(self, value):
return (torch.linalg.eig(value)[0].real > 0).all(dim=-1)
```
By using above implementation, I get following result:
```
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> const = torch.distributions.constraints.positive_definite
>>> const.check(torch.cuda.DoubleTensor([[2., 0.], [2., 2.]]))
tensor(True, device='cuda:0')
>>> const.check(torch.DoubleTensor([[2., 0.], [2., 2.]]))
tensor(True)
```
FYI, I do not know what algorithm is used in 'torch.linalg.eig' and 'torch.linalg.cholesky_ex'. As far as I know, they have same time complexity generally, O(n^3). It seems that in case you used special algorithms or finer parallelization, time complexity of Cholesky decomposition may be reduced to approximately O(n^2.5). If there is a reason 'torch.distributions.constraints.positive_definite' used 'torch.linalg.cholesky_ex' rather than 'torch.linalg.eig' previously, I hope to know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68720
Reviewed By: samdow
Differential Revision: D32724391
Pulled By: neerajprad
fbshipit-source-id: 32e2a04b2d5b5ddf57a3de50f995131d279ede49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68677
Using in compatibility apis. Luckily the stream reader kinda just does this already so mostly just create a wrapper in our compatibility files
Test Plan: ci
Reviewed By: cccclai
Differential Revision: D32573132
fbshipit-source-id: 86331c03a1eebcd86ed29b9c6cd8a8fd4fe79949
Summary:
This PR adds an OpInfo entry for tensorsolve function.
The keyword argument is different from NumPy so a lambda function is needed to be passed to `ref=`.
I had to change the dtypes for `test_reference_testing` because NumPy does computation internally using double for all linear algebra functions and maybe for some other functions. Using `torch.float64` and `torch.complex128` is more reliable for NumPy comparisons.
cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68810
Reviewed By: soulitzer
Differential Revision: D32696065
Pulled By: mruberry
fbshipit-source-id: a4305065d3e7d0097503dc05938b3c4784e14996
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67656
Currently, each cpu kernel file is copied into the build folder 3 times to give them different compilation flags. This changes it to instead generate 3 files that `#include` the original file. The biggest difference is that updating a copied file requires `cmake` to re-run, whereas include dependencies are natively handled by `ninja`.
A side benefit is that included files show up directly in the build dependency graph, whereas `cmake` file copies don't.
Test Plan: Imported from OSS
Reviewed By: dagitses
Differential Revision: D32566108
Pulled By: malfet
fbshipit-source-id: ae75368fede37e7ca03be6ade3d4e4a63479440d
Summary:
Unversioned python invocations should not be used, as it can be aliased to Python-2
Also invoke mypy as `python3 -mmypy` as binary aliases are not always available for user installation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69097
Reviewed By: janeyx99
Differential Revision: D32729367
Pulled By: malfet
fbshipit-source-id: 7539bd0af15f97eecddfb142dba7de7f3587083d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69165
We're hitting hard concurrency limits for built in github runners so
let's use our own runners and make them non-ephemeral so they'll have
basically constant uptime
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: atalman
Differential Revision: D32735494
Pulled By: seemethere
fbshipit-source-id: c042c6f0fb23fd50acef312d96b0c89d02c93270
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68411
Avoids heap-allocating a std::string instance in before() each time even if it's not going to be used.
ghstack-source-id: 144287655
Test Plan:
Run //caffe2/caffe2/fb/high_perf_models/pytorch/benchmark_framework_overheads:cpp_benchmark before/after this diff with arguemnts --stressTestRecordFunction --op empty
Before: P467922606
After: P467922626
Reviewed By: chaekit
Differential Revision: D32453846
fbshipit-source-id: 18e1b482dbf5217add14cbaacd447de47cb5877b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68410
First step toward not heap-allocating a string in RecordFunction::before() every time
ghstack-source-id: 144287654
Test Plan: CI
Reviewed By: chaekit
Differential Revision: D32453847
fbshipit-source-id: 080d95095fb568287b65fcc41a4ca6929b5f9a87
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69088
It was found that the Vulkan backend was consuming a huge (~287 MB) of graphics memory when executing a lightweight segmentation model. In fact the Vulkan backend tends to consume a huge amount of memory in general.
It was found that the reason for this is due to how the backend uses [VMA](https://gpuopen-librariesandsdks.github.io/VulkanMemoryAllocator/html/). When allocating memory, VMA will first allocate a large block of memory, then subdivide that block to use for individual textures and buffers. The pattern is used because Vulkan has a limit on the number of `vkDeviceMemory` allocations that can be active at one time.
It turns out that the Vulkan backend was using custom memory pools with a block size of 64 MiB, meaning that the minimum amount of memory used will be 64 MiB at minimum. Furthermore, usage of the [linear allocation algorithm](https://gpuopen-librariesandsdks.github.io/VulkanMemoryAllocator/html/custom_memory_pools.html#linear_algorithm) resulted in minimal reuse of memory, leading to the creation of much more blocks than were actually required and a huge amount of unused memory.
By avoiding the use of custom memory pools and instead simply using the default memory pool provided by VMA, the library seems to have a much easier time minimizing the amount of unused memory. This change reduces memory usage down to 20 MB when running the aforementioned segmentation model.
This diff also reduces the preferred block size to 32 MiB and removes the use of the linear allocation algorithm in case custom memory pools are needed in the future.
Test Plan:
Build and run vulkan_api_test:
```
cd ~/pytorch
BUILD_CUSTOM_PROTOBUF=OFF \
BUILD_TEST=ON \
USE_EIGEN_FOR_BLAS=OFF \
USE_FBGEMM=OFF \
USE_MKLDNN=OFF \
USE_NNPACK=OFF \
USE_NUMPY=OFF \
USE_OBSERVERS=OFF \
USE_PYTORCH_QNNPACK=OFF \
USE_QNNPACK=OFF \
USE_VULKAN=ON \
USE_VULKAN_API=ON \
USE_VULKAN_SHADERC_RUNTIME=ON \
USE_VULKAN_WRAPPER=OFF \
MACOSX_DEPLOYMENT_TARGET=10.9 CC=clang CXX=clang++ python3 setup.py develop --cmake && ./build/bin/vulkan_api_test
```
Reviewed By: beback4u
Differential Revision: D32653767
fbshipit-source-id: b063a8ea76d34b57d0e2e6972ca5f6f73f2fd7e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68827
Add a note about current checkpoint support with DDP. Note that this
does not include the features enabled with _set_static_graph yet, as it is an
undocumented private API. Once we support static graph as beta feature in OSS
we can add to the note here.
ghstack-source-id: 144285041
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D32624957
fbshipit-source-id: e21d156a1c4744b6e2a807b5b5289ed26701886f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68792
Refactor tests to be more clear what features are supported and
unsupported under certain DDP configs.
ghstack-source-id: 144285040
Test Plan: Ci
Reviewed By: pbelevich
Differential Revision: D32609498
fbshipit-source-id: 5231242054d4ff6cd8e7acc4a50b096771ef23d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68390
Observer zero_point's dtype can be float, in the specific case of `torch.per_channel_affine_float_qparams`.
This change sets FakeQuant's zero_point dtype accordingly.
Test Plan:
`pytest test/quantization/core/test_workflow_module.py -v -k "embedding"`
`pytest test/quantization/eager/test_quantize_eager_qat.py -v -k "embedding"`
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32446405
fbshipit-source-id: cca7aade68ff171887eeeae42801f77d934dad4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69032
I am removing it because, for packaging-related reasons, it's easier if
torch.fx is a pure Python module.
I don't think there is much reason to keep it: this functionality was
experimental, has no known users currently, and we didn't have a clear
path to turning it on by default due to regressions in tracing
performance. Also, it only was ever enabled for `rand` and friends.
Technically the removal of the `enable_cpatching` arguments on
`symbolic_trace` and `Tracer.__init__` are BC-breaking, but the
docstrings clearly state that the argument is experimental and BC is not
guaranteed, so I think it's fine.
Test Plan: Imported from OSS
Reviewed By: soulitzer
Differential Revision: D32706344
Pulled By: suo
fbshipit-source-id: 501648b5c3610ae71829b5e7db74e3b8c9e1a480
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69028
This change converts
```
if (..) {
...
} else {
...
}
# end of function
```
into
```
if(...) {
...
return;
}
...
```
in ops.cpp to remove the else branch to reduce the indentation depth by 1 for better readability.
Test Plan: N/A
Reviewed By: hlu1
Differential Revision: D32506235
fbshipit-source-id: a4fd5188bd680dba5dcad2b6e873735a54497664
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65819
Related to #61669.
Functions registered as CompositeImplicitAutograd MUST work for most, if
not all, backends. This includes Tensor subclasses.
To achieve this, we (PyTorch) impose a set of constraints on how a
CompositeImplicitAutograd function can be written.
Concretely, this PR adds tests for all OpInfos that checks for
compliance. The things that get tested in this PR apply to composite
ops and are that:
- the op does not change the metadata of a Tensor without performing
dispatches
- the op does not call set_ or resize_
- the op does not directly access the data ptr
The mechanism for the test is to create a new __torch_dispatch__
object, CompositeCompliantTensor. For each operator, we wrap all inputs
in CompositeCompliantTensor, turn on python mode for it,
and send it through the operator.
Non-CompositeImplicitAutograd operators will pass the test because they
perform a dispatch to backend code. Here's how CompositeCompliantTensor
catches problems:
- If it sees set_ or resize_ getting called, it will directly error
out
- After each operation, CompositeCompliantTensor checks to make sure
that its metadata is consistent with that of the thing it is wrapping.
If the CompositeImplicitAutograd op modifes the metadata directly
(through e.g. the TensorImpl API) then the metadata will go out of sync.
- If data_ptr gets called, that returns a nice error (because the
storage is meta).
CompositeCompliantTensor is written in an interesting way. First off,
if a view operation occurs (e.g. `B = A.view_op(...)`), then B.storage()
must alias A.storage() where B.storage() is CompositeCompliantTensor's
storage, NOT the storage of the tensor it is wrapping. This is an
invariant in autograd, see #62182 for details. To handle
this we replay the view on A's storage and set it as B's storage.
Secondly, there are cases where the metadata is allowed to go out of
sync. I believe this is only possible with in-place view functions, like
transpose_, t_, squeeze_, unsqueeze_. Those are special cased.
Finally, I added a new section to aten/src/ATen/native/README.md about
what it means to be CompositeImplicitAutograd Compliant
Test Plan: - run tests
Reviewed By: ezyang, bdhirsh
Differential Revision: D31268369
Pulled By: zou3519
fbshipit-source-id: 31634b1cbe1778ab30196013cfc376ef9bd2e8b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69012
Some changes to torch/csrc/lazy/core were done on the
lazy_tensor_staging branch (https://github.com/pytorch/pytorch/pull/68427).
Merge those back into the trunk.
Test Plan: Imported from OSS
Reviewed By: wconstab
Differential Revision: D32708696
Pulled By: desertfire
fbshipit-source-id: e54b978f2bdb9c7db27880f60246fdf1e8b41019
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68636
Same old alias problem
Reviewed By: mikeiovine
Differential Revision: D32556204
fbshipit-source-id: 4d380f0110ad1be83f705e6d6910a6aaf818ec08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68877
Saves whether an op type is a module during tracing, so we
can avoid recalculating this when validating the op during inference.
This leads to a small speedup.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
```
// MobileNetV2, 1x3x224x224, function level profiling
// before
validate_cur_op - 1.77%
// after
validate_cur_op - 1.41%
```
Reviewed By: jerryzh168
Differential Revision: D32646149
Pulled By: vkuzo
fbshipit-source-id: 03ebc4fedceb84bb885939dff8dec81d30ba6892
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68906
The existing PyTorch pinned memory allocator has been a challenge for scalability in multi-GPU inference workloads. The existing allocator is mostly designed in the context of training, where in the process-per-GPU setup we have natural sharding of the global locks and lower allocation rates (perhaps O(100 allocs/sec) per process. In this setup we might have globally on the order of O(200k allocs/sec) - e.g. 20k QPS and 10 allocs/query. This is a different domain.
In the existing allocator, we observe tail latencies of cudaEventCreate and cudaEventDestroy (while holding the lock) can also completely stall all allocations, which is undesirable.
The idea here is to retain a similar design to the existing PyTorch allocator - eager collection of used memory, no lock-free or deferred tricks, identical semantics around events, but to:
a) split up the locks around the various critical datastructures, and
b) do as little work as possible while holding any process-global mutexes (importantly, no CUDA runtime API calls)
c) pool CUDA events manually (as cuda event creation is a bottleneck at high rates from multiple threads).
This does require a bit of care, but I believe it's correct. In general the threading and state transitions are fairly simple.
With these improvements, microbenchmarks show significant improvements (1.5x-3x). Importantly, real workloads also show significant improvements, especially WRT tail latency and stalls.
Test Plan:
Unit tests all pass.
With a synthetic benchmark such as:
```
static void BM_copies_baseline(benchmark::State& state) {
auto N = state.range(0);
auto scale = state.range(1);
auto object_size_min = N;
auto object_size_max = scale * N;
auto device = at::Device(at::kCUDA, at::cuda::current_device());
uint64_t bytes_copied = 0;
uint64_t allocs = 0;
auto stream = at::cuda::getCurrentCUDAStream();
for (auto _ : state) {
auto object_size = static_cast<int64_t>(expf(folly::Random::randDouble(
logf(object_size_min), logf(object_size_max))));
auto tensor = at::empty(
{object_size},
at::TensorOptions().dtype(at::kByte).pinned_memory(true));
at::cuda::CachingHostAllocator_recordEvent(
tensor.storage().data_ptr().get_context(), stream);
bytes_copied += object_size;
allocs += 1;
}
state.counters["BW"] =
benchmark::Counter(bytes_copied, benchmark::Counter::kIsRate);
state.counters["Allocs"] =
benchmark::Counter(allocs, benchmark::Counter::kIsRate);
}
BENCHMARK(BM_copies_baseline)->Args({1000000, 20})->Threads(1)->UseRealTime();
BENCHMARK(BM_copies_baseline)->Args({1000000, 20})->Threads(4)->UseRealTime();
BENCHMARK(BM_copies_baseline)->Args({1000000, 20})->Threads(16)->UseRealTime();
BENCHMARK(BM_copies_baseline)->Args({1000000, 20})->Threads(64)->UseRealTime();
BENCHMARK(BM_copies_baseline)->Args({1000000, 20})->Threads(128)->UseRealTime();
BENCHMARK(BM_copies_baseline)->Args({1000000, 20})->Threads(256)->UseRealTime();
```
I observe roughly 1.5-3x improvements.
End to end application testing also sees significant improvements in the contended scenario.
Reviewed By: jianyuh, ngimel
Differential Revision: D32588784
fbshipit-source-id: ee86c3b7ed4da6412dd3c89362f989f4b5d91736
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68887Closes#46988, closes#46987, closes#46761
By "simple" I mean operators that map 0->0 so we can implement it by
just re-dispatching on the values tensor. That does mean we have `sin`
but not `cos` for example, but without fill value support this is the
best that can be done.
Most of these don't support autograd because the derivative formulas
use unsupported operators.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32706197
Pulled By: cpuhrsch
fbshipit-source-id: 65e1acb3645737ca7bdb7f2db739d8e118906f4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68751
Add option to get input dtype from user for AOT compilation
Test Plan:
BI model compiles and runs fine
```
(pytorch) ~/fbsource/fbcode/caffe2/fb/nnc
└─ $ buck run //caffe2/binaries:aot_model_compiler -- --model=bi.pt --model_name=pytorch_dev_bytedoc --model_version=v1 '--input_dims=1,115;1' --input_types='int64;int64'
Building... 8.3 sec (99%) 7673/7674 jobs, 0/7674 updated
WARNING: Logging before InitGoogleLogging() is written to STDERR
W1116 14:32:44.632536 1332111 TensorImpl.h:1418] Warning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (function operator())
E1116 14:32:44.673710 1332111 huge_pages_allocator.cc:287] Not using huge pages because not linked with jemalloc
The compiled llvm assembly code was saved to bi.compiled.ll
The compiled model was saved to bi.compiled.pt
```
> Error thrown when input dims and input types sizes don't match
```
(pytorch) ~/fbsource/fbcode/caffe2/fb/nnc
└─ $ buck run //caffe2/binaries:aot_model_compiler -- --model=bi.pt --model_name=pytorch_dev_bytedoc --model_version=v1 '--input_dims=1,115;1' --input_types='int64;int64;int64'
.
.
terminate called after throwing an instance of 'c10::Error'
what(): [enforce fail at aot_model_compiler.cc:208] split(';', FLAGS_input_dims).size() == split(';', FLAGS_input_types).size(). Number of input_dims and input_types should be the same
.
.
.
```
Reviewed By: ljk53
Differential Revision: D32477001
fbshipit-source-id: 8977b0b59cf78b3a2fec0c8428f83a16ad8685c5
Summary:
These seem to not be needed and cause ninja to rebuild the files at every build.
(There also is THCStorage.cu, but hopefully this will go away with https://github.com/pytorch/pytorch/issues/68556 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69024
Reviewed By: soulitzer
Differential Revision: D32705309
Pulled By: ngimel
fbshipit-source-id: 5255297f213fdcf36e7203de7460a71291f8c9a0
Summary:
`cpu_kernel_vec` does stride checks to determine whether to use the vectorized or scalar inner loop. Since it uses a 1d `for_each` loop, it re-does these stride checks after every loop over the inner dimension. For iterators with small inner dimensions, this means a significant proportion of the time may be spent just on stride checks.
This changes it to use a 2d loop so the stride checks are further amortized. With the below `copy_` benchmark, it saves 50% of the callgrind instruction count from 28.4 Million to 13.5 Million and 30% time speedup from 22.8 us to 16.4 us on my machine.
```
from torch.utils.benchmark import Timer
import timeit
timer = Timer(
stmt="b.copy_(a);",
setup="""
auto a = at::rand({10000, 8}, at::kComplexDouble).slice(0, 0, -1, 2);
auto b = at::empty_like(a);
""",
num_threads=1,
language='c++',
timer=timeit.default_timer
)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68962
Reviewed By: mrshenli
Differential Revision: D32684191
Pulled By: ngimel
fbshipit-source-id: 582af038314a0f999f43669e66edace38ff8d2dc
Summary:
This PR absolves `_TestParametrizer`s (e.g. `ops`, `modules`, `parametrize`) of the responsibility of adding device type (e.g. `'cpu'`, `'cuda'`, etc.) / dtype (e.g. 'float32') to generated test names. This fixes repeated instances of the device string being added to generated test names (e.g. `test_batch_norm_training_True_cuda_track_running_stats_True_cuda_affine_True_cuda`).
The responsibility for placing device / dtype suffixes is now handled by `instantiate_device_type_tests()` instead so it is added a single time. It will place `<device>_<dtype>` at the end of the test name unconditionally, maintaining the current naming convention.
As part of this work, I also tightened the semantics through some additional error case handling:
* Composing multiple decorators that each try to handle the same parameter will error out with a nice message. This includes the case to trying to compose `modules` + `ops`, as they each try to handle `dtype`. Similarly, `ops` + `dtypes` is forbidden when both try to handle `dtype`. This required changes in the following test files:
* `test/test_unary_ufuncs.py`
* `test/test_foreach.py`
* The `modules` / `ops` decorators will now error out with a nice message if used with `instantiate_parametrized_tests()` instead of `instantiate_device_type_tests()`, since they're not (currently) written to work outside of a device-specific context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65217
Reviewed By: mruberry
Differential Revision: D32627303
Pulled By: jbschlosser
fbshipit-source-id: c2957228353ed46a0b7da8fa1a34c67598779312
Summary:
These APIs are not yet officially released and are still under discussion. Hence, this commit removes those APIs from docs and will add them back when ready.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69011
Reviewed By: fduwjj
Differential Revision: D32703124
Pulled By: mrshenli
fbshipit-source-id: ea049fc7ab6b0015d38cc40c5b5daf47803b7ea0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67655
Some of the CPU operators already use the `namespace CPU_CAPABILITY` trick to avoid anonymous namespacing, like [`PowKernel.cpp`](cd51d2a3ec/aten/src/ATen/native/cpu/PowKernel.cpp (L14)). This extends that pattern to the `Vectorized` class, which avoids `Wsubobject-linage` warnings like I was getting in #67621.
For many functions, it was necessary to add `inline` because the functions are defined in a header. There were no link errors previously because the anonymous namespace ensured they were not exposed to linkage. Similarly, free functions defined in an anonymous namespace might need the `C10_UNUSED` attribute to silence warnings about the function not being called in the only translation unit that it's defined in. By removing the anonymous namespace, these decorators are no longer necessary.
Test Plan: Imported from OSS
Reviewed By: dagitses
Differential Revision: D32566109
Pulled By: malfet
fbshipit-source-id: 01d64003513b4946dec6b709bd73bbab05772134
Co-authored-by: Nikita Shulga <nshulga@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68397
Now that hot paths can avoid instantiating RecordFunction by using shouldRunRecordFunction, we can improve efficiency for profiling cases by avoiding a large heap allocation.
ghstack-source-id: 144235785
Test Plan:
1) Run //caffe2/caffe2/fb/high_perf_models/pytorch/benchmark_framework_overheads:cpp_benchmark before/after this diff with arguemnts --stressTestRecordFunction --op empty.
Before: P467891381
After: P467902339
2) Run without --stressTestRecordFunction to verify no regression in the regular dispatcher path.
Before: P467902381
After: P467902403
Reviewed By: chaekit
Differential Revision: D32448365
fbshipit-source-id: 2d32a3bd82c60d2bb11fc57bb88bf3f02aa3fa25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68841
Caches the current module's hook type as an attribute on the module.
This requires the assumption that the current module's hook type
does not change during inference, which is an assumption we can
commit to.
Test Plan:
correctness
```
python test/test_quantization.py TestQuantizeDBR
```
performance
```
// MobileNetV2, 1x3x224x224, function profiling
// before
get_module_hook_type -> 2.58%
// after
get_module_hook_type -> 0.73%
```
Reviewed By: jerryzh168
Differential Revision: D32630881
Pulled By: vkuzo
fbshipit-source-id: 667f2667ef9c5514e5d82e4e7e4c02b8238edc65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68840
Fixes the debugging FQN info for a converted model. Some of this
information was missing because eager mode convert performed
module swaps. This information is only used in debugging and is
not used for inference.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
turn `enable_logging` on in `auto_trace.py`, the FQN is now displayed
for a converted model
Reviewed By: jerryzh168
Differential Revision: D32630884
Pulled By: vkuzo
fbshipit-source-id: be8c43343abfdab9fe0af39499d908ed61a01b78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68839
We can assume that there are no overrides needed for the hook which
dequantizes the module outputs, so we can turn them off explicitly.
While this does not lead to a measurable perf win, it makes things
easier to debug by eliminating the no-op overrides.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32630886
Pulled By: vkuzo
fbshipit-source-id: 1719c168f5f21f3e59c80a3b6d0f32ebb1c77ef8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68838
Removes an unnecessary outputs hook on the top level
module. The same hook is already called inside the regular
hook flow.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: soulitzer
Differential Revision: D32630882
Pulled By: vkuzo
fbshipit-source-id: aa5f1b1cb866051013195d7311949333b08df4de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68837
The module convert hook dequantizes the module outputs if the user
requested the module to adhere to a certain dtype for outputs. This
is most commonly used for the assumption that a model's overall return
type if fp32.
This PR precalculates for each module whether this hook will do anything,
and returns early if it does not. This prevents the overhead of this
hook to influencing any module which does not need this hook.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
perf
```
MobileNetV2, 1x3x224x224, function level profiling
// before
outputs_convert_hook - 0.73%
// before
outputs_convert_hook - 0.45%
```
Reviewed By: jerryzh168
Differential Revision: D32630885
Pulled By: vkuzo
fbshipit-source-id: 7ee84de742fc0c752b66d20d097405a754c8b480
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68836
If we have a leaf module like a `torch.nn.Conv2d`, DBR quant handles
the input and output of the module and should treat the inside of
this module as invisible. Specifically, there is no need to override
the `F.conv2d` call if the parent module is already being overridden.
Before this PR, `__torch_function__` was still overridden for the insides
of leaf modules, and the override was a no-op. There was some overhead
in these overrides because they were checking the hook type.
This PR adds a fast global override so we can skip overridding the insides
of leaf modules. This has some performance benefits in the prepare model,
because we now skip overriding all of the inner functions in observers.
Test Plan:
testing
```
python test/test_quantization.py TestQuantizeDBR
```
perf
```
// MobileNetV2, 1x3x224x224, comparing fp32 with dbr quant, Mac OS laptop
// before
fp32: 0.017837 seconds avg
fx_prepared: 0.021963 seconds avg, 0.812143 speedup vs fp32
fx_quantized: 0.012632 seconds avg, 1.412056 speedup vs fp32
dt_prepared: 0.034052 seconds avg, 0.523820 speedup vs fp32
dt_quantized: 0.018316 seconds avg, 0.973829 speedup vs fp32
// after
fp32: 0.020395 seconds avg
fx_prepared: 0.026969 seconds avg, 0.756230 speedup vs fp32
fx_quantized: 0.013195 seconds avg, 1.545611 speedup vs fp32
dt_prepared: 0.033432 seconds avg, 0.610023 speedup vs fp32
dt_quantized: 0.018244 seconds avg, 1.117866 speedup vs fp32
```
Reviewed By: jerryzh168
Differential Revision: D32630883
Pulled By: vkuzo
fbshipit-source-id: 6365e1c514726d8b2a4b3a51f114f5fed3ebe887
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68007
This PR adds a new function to the sparse module.
`sampled_addmm` computes α*(A @ B) * spy(C) + β*C, where C is a sparse CSR matrix and A, B are dense (strided) matrices.
This function is currently restricted to single 2D matrices, it doesn't support batched input.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32435799
Pulled By: cpuhrsch
fbshipit-source-id: b1ffac795080aef3fa05eaeeded03402bc097392
Summary:
This PR is trying to fix the no device bug when user resets the `GLOO_SOCKET_IFNAME_ENV` with
```bash
export GLOO_SOCKET_IFNAME_ENV=
```
Thank you for your time on reviewing this PR :).
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68933
Reviewed By: soulitzer
Differential Revision: D32690633
Pulled By: mrshenli
fbshipit-source-id: f6df2b8b067d23cf1ec177c77cc592dc870bda72
Summary:
`default_collate`, `default_convert`, and `pin_memory` convert sequences into lists. I believe they should keep the original type when possible (e.g., I have a class that inherits from `list`, which comes from a 3rd party library that I can't change, and provides extra functionality).
Note it's easy to do when the type supports an iterable in its creation but it's not always the case (e.g., `range`).
Even though this can be accomplished if using a custom `default_collate`/`default_convert`, 1) this is behavior they should support out-of-the-box IMHO, and 2) `pin_memory` still does it.
cc VitalyFedyunin ejguan NivekT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68779
Reviewed By: wenleix
Differential Revision: D32651129
Pulled By: ejguan
fbshipit-source-id: 17c390934bacc0e4ead060469cf15dde815550b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68822
Per title, we switched over c10d_gloo and nccl and results look good
so far, so switch the rest of them as well. After the only dist tests that
won't run in subprocess are pipe and fsdp tests, which historically haven't had
much flakiness.
ghstack-source-id: 144213522
Test Plan: CI
Reviewed By: H-Huang
Differential Revision: D32624330
fbshipit-source-id: 469f613e5b0e4529e6b23ef259d948837d4af26b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68821
Continuing effort to move most distributed tests to run in subprocess
for better reproducibility + reduce flakiness.
ghstack-source-id: 144213520
Test Plan: CI
Reviewed By: H-Huang
Differential Revision: D32624199
fbshipit-source-id: 04448636320554d7a3ab29ae92bc1ca9fbe37da2
Summary:
Do not run distributed tests as part of separate shard, but keep it inside one of the two shards (to limit concurrency problems)
Fixes https://github.com/pytorch/pytorch/issues/68260
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68784
Reviewed By: seemethere, janeyx99
Differential Revision: D32653440
Pulled By: malfet
fbshipit-source-id: ebe5bbc30bdf67e930f2c766c920932700f3a4e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68707
This PR adds a path for block CSR matrices for `torch.addmm`. cuSPARSE interface is restricted to 32-bit indices and square blocks.
My plan is to make everything work and tests passing using an unsafe constructor first, keeping it all private. Then discuss & implement constructors with block information separately unlocking the functions for wider use. Documentation will come with the update to constructors.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D32650366
Pulled By: cpuhrsch
fbshipit-source-id: 430a9627901781ee3d2e2496097b71ec17727d98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68885
`torch.neg` should preserve the input dtype but for sparse tensors it
was promoting integers to floating point. This would have been picked
up by the OpInfo-based test, but `neg` wasn't marked with
`supports_sparse=True` so it was never run.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32680008
Pulled By: cpuhrsch
fbshipit-source-id: 502f8743c1c33ab802e3d9d097792887352cd220
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68314
Add a convenience to lazy::Shape for counting the number of elements (by multiplying out the dimensions). This is a method on Tensor, and in switching other lazy tensor shape utils to use aten shape inference, we need numel counts.
Test Plan: add unit tests
Reviewed By: alanwaketan
Differential Revision: D32409138
fbshipit-source-id: 3ae725300f8826d38e45412f46501d5e5f776fb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68817
Looks like these files are getting used by downstream xla so we need to
include them in our package_data
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32622241
Pulled By: seemethere
fbshipit-source-id: 7b64e5d4261999ee58bc61185bada6c60c2bb5cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68566
These are just auto-linear as pointed out by Jeffrey.
ghstack-source-id: 143814393
Test Plan: - Run OpInfo tests.
Reviewed By: albanD, soulitzer
Differential Revision: D32520239
Pulled By: zou3519
fbshipit-source-id: 807115157b131e6370f364f61db1b14700279789
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62146.
Modernizes and clarifies the documentation of torch.tensor and torch.as_tensor, highlighting the distinction in their copying behavior and preservation of autograd history.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63308
Reviewed By: albanD, ngimel
Differential Revision: D30338025
Pulled By: mruberry
fbshipit-source-id: 83a0c113e4f8fce2dfe086054562713fe3f866c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
This fixes custom class registration issue when `typeid` is not guaranteed to be unique across multiple libraries, which is the case for libc++ runtime on MacOS 11 in particular for M1
From [libcxx/include/typeinfo](78d6a7767e/include/typeinfo (L139)):
```
// -------------------------------------------------------------------------- //
// NonUniqueARMRTTIBit
// -------------------------------------------------------------------------- //
// This implementation of type_info does not assume always a unique copy of
// the RTTI for a given type inside a program. It packs the pointer to the
// type name into a uintptr_t and reserves the high bit of that pointer (which
// is assumed to be free for use under the ABI in use) to represent whether
// that specific copy of the RTTI can be assumed unique inside the program.
// To implement equality-comparison of type_infos, we check whether BOTH
// type_infos are guaranteed unique, and if so, we simply compare the addresses
// of their type names instead of doing a deep string comparison, which is
// faster. If at least one of the type_infos can't guarantee uniqueness, we
// have no choice but to fall back to a deep string comparison.
```
But `std::type_index` hash is computed always assuming that implementation is unique
By adding a slow path this problem can be fixed in those scenarios.
Fixes https://github.com/pytorch/pytorch/issues/68039
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68717
Reviewed By: seemethere
Differential Revision: D32605187
Pulled By: malfet
fbshipit-source-id: 8d50e56885b8c97dad3bc34a69c47ef879456dd1
Summary:
For some reason, the example for `torch.empty` showed the usage of `torch.empty_like` and the other way around. These are now swapped.
Fixes https://github.com/pytorch/pytorch/issues/68799
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68874
Reviewed By: wenleix
Differential Revision: D32646645
Pulled By: ejguan
fbshipit-source-id: c8298bcaca450aaa4abeef2239af2b14cadc05b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68749
The logic for asynchronous copies (either HtoD or DtoH) using cudaMemcpyAsync relies on recording an event with the caching host allocator to notify it that a given allocation has been used on a stream - and thus it should wait for that stream to proceed before reusing the host memory.
This tracking is based on the allocator maintaining a map from storage allocation pointers to some state.
If we try to record an event for a pointer we don't understand, we will silently drop the event and ignore it (9554ebe44e/aten/src/ATen/cuda/CachingHostAllocator.cpp (L171-L175)).
Thus, if we use the data_ptr of a Tensor instead of the storage allocation, then reasonable code can lead to incorrectness due to missed events.
One way this can occur is simply by slicing a tensor into sub-tensors - which have different values of `data_ptr()` but share the same storage, for example:
```
image_batch = torch.randn(M, B, C, H, W).pin_memory()
for m in range(M):
sub_batch = image_batch[m].cuda(non_blocking=True)
# sub_batch.data_ptr() != image_batch.data_ptr() except for m == 0.
# however, sub_batch.storage().data_ptr() == image_batch.storage().data_ptr() always.
```
Therefore, we instead use the storage context pointer when recording events, as this is the same state that is tracked by the caching allocator itself. This is a correctness fix, although it's hard to determine how widespread this issue is.
Using the storage context also allows us to use a more efficient structure internally to the caching allocator, which will be sent in future diffs.
Test Plan: Test added which demonstrates the issue, although it's hard to demonstrate the race explicitly.
Reviewed By: ngimel
Differential Revision: D32588785
fbshipit-source-id: d87cc5e49ff8cbf59052c3c97da5b48dd1fe75cc
Summary:
Implemented submodule for https://github.com/pytorch/pytorch/issues/68050
Opened cleaned, final version of PR for https://github.com/pytorch/pytorch/issues/68240
Explanation:
I am trying to contribute to PyTorch by implementing distributions for symmetric matrices like Wishart distribution and Inverse Wishart distribution. Although there is a LKJ distribution for the Cholesky decomposition of correlation matrices, it only represents equivalence to restricted form of Wishart distribution. [https://arxiv.org/abs/1809.04746](https://arxiv.org/abs/1809.04746) Thus, I started implementing Wishart distribution and Inverse Wishart distribution seperately.
I added a short code about the 'torch.distributions.constraints.symmetric', which was not included in 'torch.distributions.constraints' previously. i.e., 'torch.distributions.constraints' contains module like 'positive_definite' constraints, but it just assumes symmetricity of the input matrix. [Link](1adeeabdc0/torch/distributions/constraints.py (L466)) So, I think it will be better if we have constraint checking symmetricity of the tensors in PyTorch.
We may further utilize it like
`constraints.stack([constraints.symmetric, constraints.positive_definite])`
for the constraint of the covariance matrix in Multivariate Normal distribution, for example, to check if the random matrix is a symmetric positive definite matrix.
cc fritzo neerajprad alicanb nikitaved
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68644
Reviewed By: jbschlosser
Differential Revision: D32599540
Pulled By: neerajprad
fbshipit-source-id: 9227f7e9931834a548a88da69e4f2e9af7732cfe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68228
Forking this for now so that we can make changes as we need, the changes can be merged back to torch.fx
later
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32537713
fbshipit-source-id: 326598d13645fcc28ef2c66baaac6a077b80fd0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68707
This PR adds a path for block CSR matrices for `torch.addmm`. cuSPARSE interface is restricted to 32-bit indices and square blocks.
My plan is to make everything work and tests passing using an unsafe constructor first, keeping it all private. Then discuss & implement constructors with block information separately unlocking the functions for wider use. Documentation will come with the update to constructors.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D32633806
Pulled By: cpuhrsch
fbshipit-source-id: b98db0bd655cce651a5da457e78fca08619a5066
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68834
This diff uses std::vector::reserve for constructing constants in StaticModule. We can also avoid two extra iterations over all the graph nodes.
This diff should technically improve its performance by a tiny bit.
Test Plan: - [x] buck run //caffe2/benchmarks/static_runtime:static_runtime_cpptest -- -v 1
Reviewed By: mikeiovine
Differential Revision: D32628806
fbshipit-source-id: 99dd2a7a36e86899ca1fe5300f3aa90d30a43726
Summary:
**Summary**: FixedQParams operators do not need fake quantization
in the prepare step. This commit introduces FixedQParamsObserver
and makes FixedQParamsFakeQuantize a simple wrapper around this
observer. It also removes the fake quantize logic in forward.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68143
Test Plan:
Added two tests:
python3 test/test_quantization.py TestQuantizeFx.test_fixed_qparams_patterns
python3 test/test_quantization.py TestQuantizeFx.test_register_patterns
**Reviewers**: Jerry Zhang
**Subscribers**: Jerry Zhang, Supriya Rao
**Tasks**: T104942885
**Tags**: pytorch
Reviewed By: albanD
Differential Revision: D32484427
Pulled By: andrewor14
fbshipit-source-id: 5a048b90eb4da79074c5ceffa3c8153f8d8cd662
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68818
Operator Support was blocking all node with dtype int64 from lowering. This diff ease the condition, for input from get_attr node(which are known not gonna be used for trt compute) to have dtype int64.
Reviewed By: brad-mengchi, 842974287
Differential Revision: D32609457
fbshipit-source-id: ea255f3281349a4254cb6abdeed671ab2c0216ba
Summary:
Difference between `CUDA_VERSION` is magma package name is just a dot between major and minor
In process of refactoring, discovered that some docker images set `CUDA_VERSION` to contain minor revision, so modified pattern to strip it, i.e. `cuda-magma102` would be installed for `CUDA_VERSION=10.2.89` and `cuda-magma113` would be installed for `CUDA_VERSION=11.3.0`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68778
Reviewed By: seemethere
Differential Revision: D32605365
Pulled By: malfet
fbshipit-source-id: 43f8edeee5b55fdea6b4d9943874df8e97494ba1
Summary:
After 'maximize' flag was introduced in https://github.com/pytorch/pytorch/issues/46480 some jobs fail because they resume training from the checkpoints.
After we load old checkpoints we will get an error during optimizer.step() call during backward pass in [torch/optim/sgd.py", line 129] because there is no key 'maximize' in the parameter groups of the SGD.
To circumvent this I add a default value `group.setdefault('maximize', False)` when the optimizer state is restored.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68733
Reviewed By: albanD
Differential Revision: D32480963
Pulled By: asanakoy
fbshipit-source-id: 4e367fe955000a6cb95090541c143a7a1de640c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68782
These builds are no longer required for slow_gradcheck and should be
removed
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet, janeyx99
Differential Revision: D32606679
Pulled By: seemethere
fbshipit-source-id: e4827a6f217b91c34cfab6c2340e3272f3db1522
Summary:
An update to https://github.com/pytorch/pytorch/issues/67442 to make sure all of the inputs produced are independent
Updates group_norm and instance_norm (local_response_norm was already producing independent inputs)
Also updates instance_norm for a bug in one set of inputs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68526
Reviewed By: ngimel
Differential Revision: D32532076
Pulled By: samdow
fbshipit-source-id: 45b9320fd9aecead052b21f838f95887cfb71821
Summary:
There is a bug in CMake's Ninja generator where files considered inputs to the cmake command couldn't be generated by another build step. The fix was included in CMake 3.13, but 3.10.3 is still sufficient for other cmake generators e.g. makefiles.
For reference, the bug is here https://gitlab.kitware.com/cmake/cmake/-/issues/18584
This is necessary for https://github.com/pytorch/pytorch/issues/68246 but I'm isolating the change here to make testing easier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68731
Reviewed By: jbschlosser
Differential Revision: D32604545
Pulled By: malfet
fbshipit-source-id: 9bc0bd8641ba415dd63ce21a05c177e2f1dd9866
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68797
This change dist quantization op registration to each file instead, allow torch deploy test to pass
ghstack-source-id: 143994945
Test Plan: wait for sc
Reviewed By: jbschlosser
Differential Revision: D32610679
fbshipit-source-id: 3ade925286f1ed0f65017939f1ad3f5c539e1767
Summary:
Towards [convolution consolidation](https://fb.quip.com/tpDsAYtO15PO).
Introduces the general `convolution_backward` function that uses the factored-out backend routing logic from the forward function.
Some notes:
* `finput` is now recomputed in the backward pass for the slow 2d / 3d kernels instead of being saved from the forward pass. The logic for is based on the forward computation and is present in `compute_finput2d` / `compute_finput3d` functions in `ConvUtils.h`.
* Using structured kernels for `convolution_backward` requires extra copying since the backend-specific backward functions return tensors. Porting to structured is left as future work.
* The tests that check the routing logic have been renamed from `test_conv_backend_selection` -> `test_conv_backend` and now also include gradcheck validation using an `autograd.Function` hooking up `convolution` to `convolution_backward`. This was done to ensure that gradcheck passes for the same set of inputs / backends.
The forward pass routing is done as shown in this flowchart (probably need to download it for it to be readable since it's ridiculous):
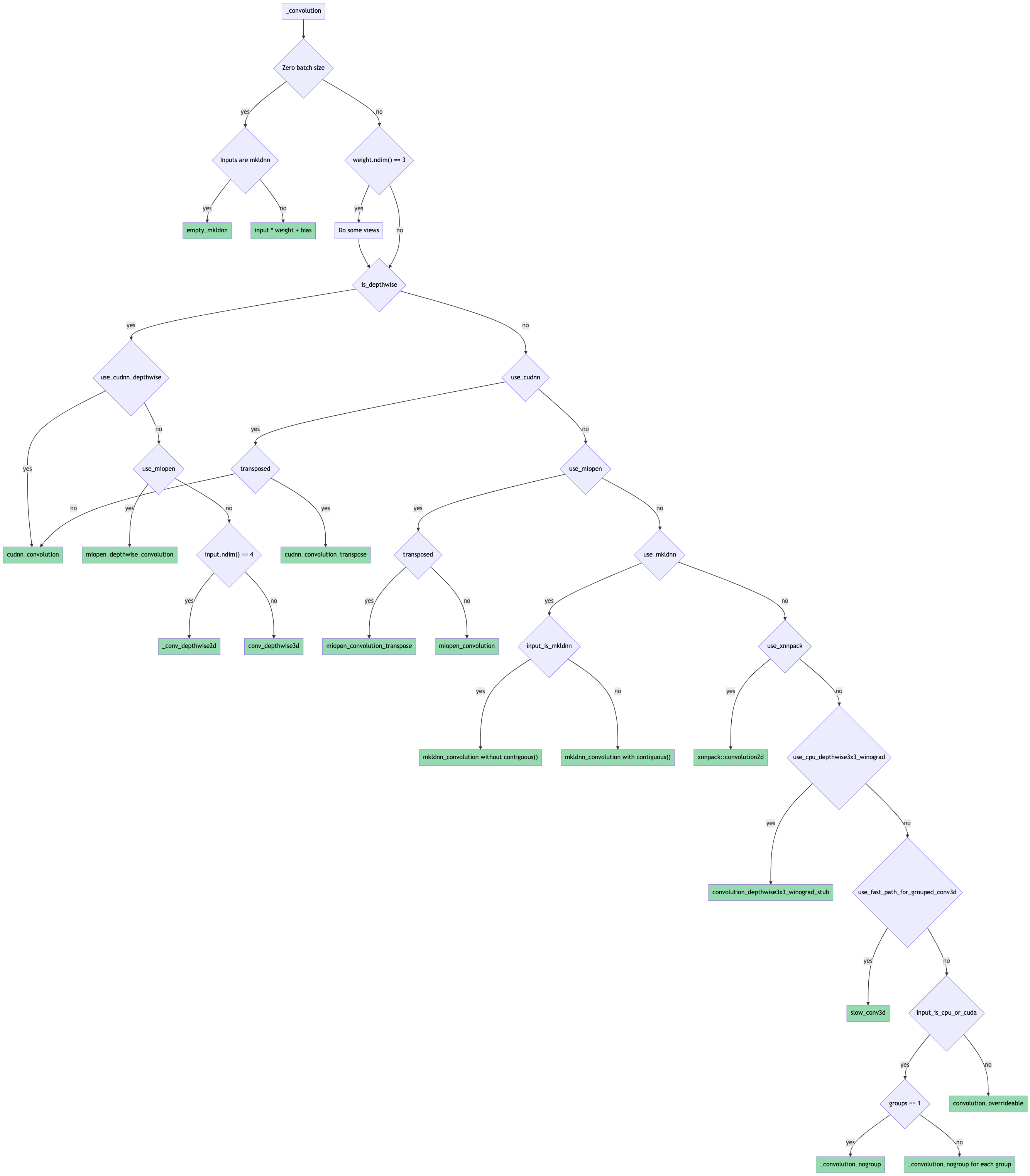
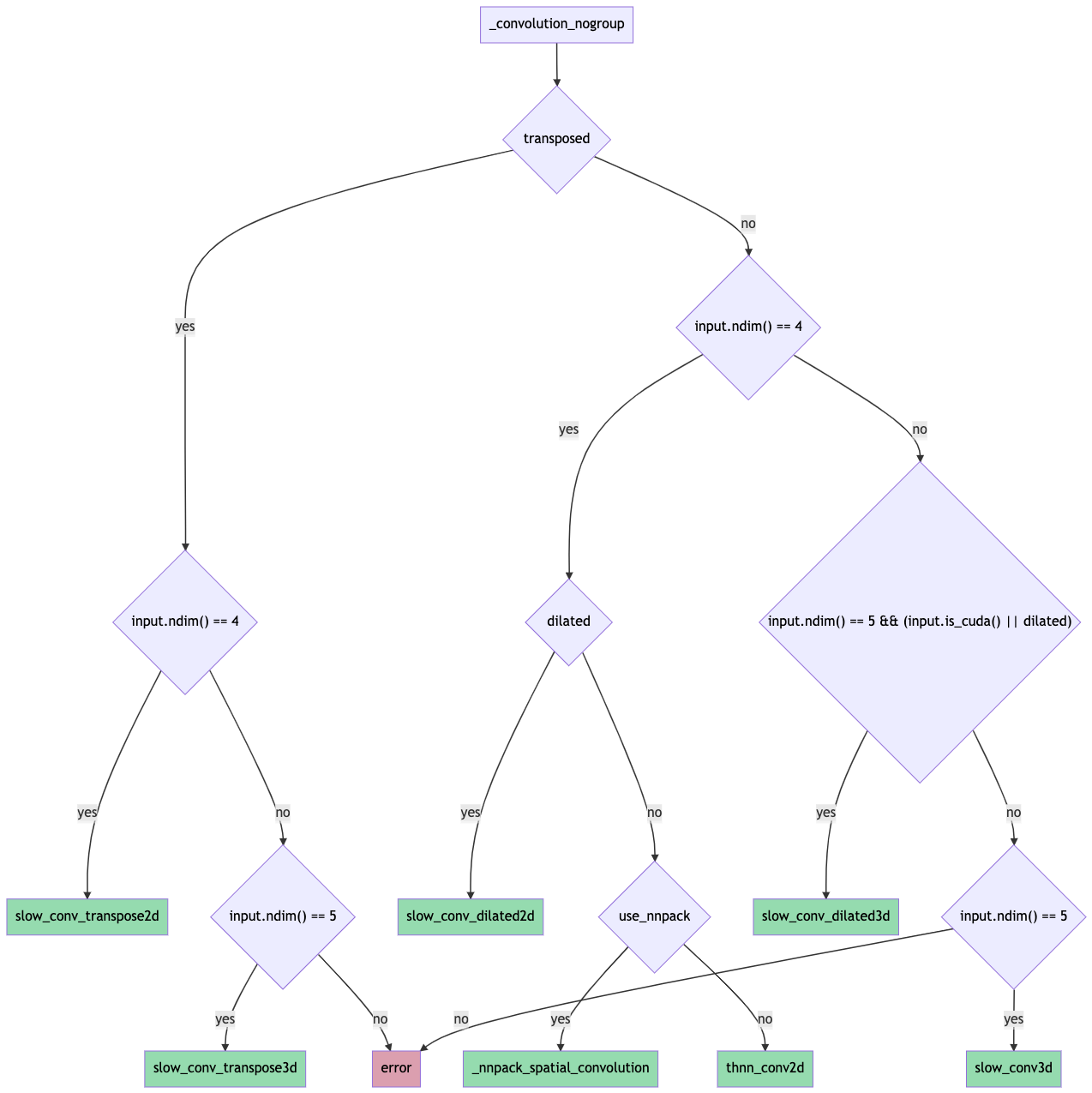
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65219
Reviewed By: mruberry
Differential Revision: D32611368
Pulled By: jbschlosser
fbshipit-source-id: 26d759b7c908ab8f19ecce627acea7bd3d5f59ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68227
This PR adds two keys to backend_config_dict:
"root_module": the root module for the pattern (since we may have patterns for fused ops)
"reference_quantized_module_for_root": the corresponding reference quantized module for the root
Test Plan:
```
python test/test_quant_trt.py TestQuantizeFxTRTOps
python test/test_quant_trt.py TestConvertFxDoNotUse
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32537711
fbshipit-source-id: 6b8f36a219db7bb6633dac53072b748ede8dfa78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68794
The pruner `test_constructor` fails because of a typo in the regular expression matching for the error that the pruner throws.
This fixes it.
Test Plan:
Separate test is not needed -- single letter change.
Previous test: `python test/test_ao_sparsity.py -- TestBasePruner
Reviewed By: ngimel
Differential Revision: D32609589
Pulled By: z-a-f
fbshipit-source-id: 800ef50c8cdbf206087bc6f945d1830e4af83c03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66412
The GPU training was not supported in the sparsifier.
The reason was that when the sparsifier was created the masks would default to the CPU.
Attaching a GPU model to the sparsifier would throw an error.
The solution is to create the masks on the same device as the weight.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31590675
Pulled By: z-a-f
fbshipit-source-id: 98c2c1cedc7c60aecea4076e5254ef6b3443139e
Summary:
Fixes https://github.com/pytorch/pytorch/issues/66119
Failure on ARM Neoverse N1 before this PR:
```
======================================================================
FAIL: test_bitwise_ops_cpu_int16 (__main__.TestBinaryUfuncsCPU)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/opt/pytorch/pytorch/torch/testing/_internal/common_device_type.py", line 373, in instantiated_test
result = test(self, **param_kwargs)
File "test_binary_ufuncs.py", line 315, in test_bitwise_ops
self.assertEqual(op(a, b), op(a_np, b_np))
File "/opt/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 1633, in assertEqual
self.assertEqual(
File "/opt/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 1611, in assertEqual
super().assertTrue(result, msg=self._get_assert_msg(msg, debug_msg=debug_msg))
AssertionError: False is not true : Tensors failed to compare as equal!Found 176 different element(s) (out of 225), with the greatest difference of 21850 (-21846 vs. 4) occuring at index (0, 2).
======================================================================
FAIL: test_bitwise_ops_cpu_int32 (__main__.TestBinaryUfuncsCPU)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/opt/pytorch/pytorch/torch/testing/_internal/common_device_type.py", line 373, in instantiated_test
result = test(self, **param_kwargs)
File "test_binary_ufuncs.py", line 315, in test_bitwise_ops
self.assertEqual(op(a, b), op(a_np, b_np))
File "/opt/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 1633, in assertEqual
self.assertEqual(
File "/opt/pytorch/pytorch/torch/testing/_internal/common_utils.py", line 1611, in assertEqual
super().assertTrue(result, msg=self._get_assert_msg(msg, debug_msg=debug_msg))
AssertionError: False is not true : Tensors failed to compare as equal!Found 188 different element(s) (out of 225), with the greatest difference of 1335341061 (-1335341056 vs. 5) occuring at index (14, 8).
----------------------------------------------------------------------
```
which passes now.
CC malfet ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66194
Reviewed By: dagitses, bdhirsh, ngimel
Differential Revision: D31430274
Pulled By: malfet
fbshipit-source-id: bcf1c9d584c02eff328dd5b1f7af064fac5942c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66411
The original tests were disabled, and had some bugs. This fixes those unittests.
Test Plan: Imported from OSS
Reviewed By: HDCharles
Differential Revision: D31590678
Pulled By: z-a-f
fbshipit-source-id: ddbed34cc01d5f15580cb8f0033416f2f9780068
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32588230
Pulled By: mruberry
fbshipit-source-id: 69e484849deb9ad7bb992cc97905df29c8915910
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68504
Per title
ghstack-source-id: 143928767
Test Plan: CI
Reviewed By: H-Huang
Differential Revision: D32485100
fbshipit-source-id: a55687aea4af69e3830aee6f0278550c72f142c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68503
Per title
ghstack-source-id: 143928768
Test Plan: CI
Reviewed By: H-Huang
Differential Revision: D32484990
fbshipit-source-id: 6682f46256af0da5153e5087a91a7044156dd17f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68647Fixes#68539
When all data from source datapipe depletes, there is no need to yield the biggest group in the buffer.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32562646
Pulled By: ejguan
fbshipit-source-id: ce91763656bc457e9c7d0af5861a5606c89965d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67401
some minor changes to dist quantization, mainly change the namespace and add some notes for future code dedup
ghstack-source-id: 143910067
ghstack-source-id: 143910067
Test Plan: wait for ci
Reviewed By: mrshenli
Differential Revision: D31979269
fbshipit-source-id: 85a2f395e6a3487dd0b9d1fde886eccab106e289
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67400
c10d/frontend.cpp was originally proposed to introduce pure C++ API and use TorcBind to share python level API with TorchScript. This is no longer needed, so delete this to reduce code redundancy.
ghstack-source-id: 143910066
ghstack-source-id: 143910066
Test Plan: wait for ci
Reviewed By: navahgar
Differential Revision: D31979270
fbshipit-source-id: 6ceb8b53d67ab8f9aef44b34da79346dfbb51225
Summary:
Replace usage of `dtypesIfCPU` with `dtypes` in OpInfo class and also make it a mandatory argument.
Also added DeprecationWarning on using `dtypesIfCPU`
This raises a question :
For an OpInfo entry, currently `dtypes` works for any external backend, `dtypesIfCPU` for CPU and `dtypesIfCUDA` and `dtypesIfROCM` for CUDA and ROCm respectively.
If we merge `dtypes` and `dtypesIfCPU`, then for cases where external backend `dtypes` don't match cpu `dtypes` then it will lead to failures.
Currently there are few issues (5 failures) due to this on XLA (we may add relevant skips for the same). If we agree that skip should be added, then should it be added via OpInfo using decorators mechanism or at the XLA end? I think XLA end makes more sense to me to have one source of skips.
<details>
<summary>XLA Fail Log</summary>
```
Nov 01 11:48:26 ======================================================================
Nov 01 11:48:26 ERROR [0.016s]: test_reference_eager_histogram_xla_float32 (__main__.TestOpInfoXLA)
Nov 01 11:48:26 ----------------------------------------------------------------------
Nov 01 11:48:26 Traceback (most recent call last):
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 371, in instantiated_test
Nov 01 11:48:26 result = test(self, **param_kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 737, in test_wrapper
Nov 01 11:48:26 return test(*args, **kwargs)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 411, in test_reference_eager
Nov 01 11:48:26 self.compare_with_eager_reference(op, sample_input)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 397, in compare_with_eager_reference
Nov 01 11:48:26 cpu_inp, cpu_args, cpu_kwargs = cpu(sample_input)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 393, in cpu
Nov 01 11:48:26 sample.args), to_cpu(sample.kwargs)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 386, in to_cpu
Nov 01 11:48:26 return {k: to_cpu(v) for k, v in x.items()}
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 386, in <dictcomp>
Nov 01 11:48:26 return {k: to_cpu(v) for k, v in x.items()}
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 390, in to_cpu
Nov 01 11:48:26 raise ValueError("Unknown type {0}!".format(type(x)))
Nov 01 11:48:26 ValueError: Unknown type <class 'NoneType'>!
Nov 01 11:48:26
Nov 01 11:48:26 ======================================================================
Nov 01 11:48:26 FAIL [0.575s]: test_reference_eager___rmatmul___xla_int64 (__main__.TestOpInfoXLA)
Nov 01 11:48:26 ----------------------------------------------------------------------
Nov 01 11:48:26 Traceback (most recent call last):
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 371, in instantiated_test
Nov 01 11:48:26 result = test(self, **param_kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 737, in test_wrapper
Nov 01 11:48:26 return test(*args, **kwargs)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 411, in test_reference_eager
Nov 01 11:48:26 self.compare_with_eager_reference(op, sample_input)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 402, in compare_with_eager_reference
Nov 01 11:48:26 self.assertEqual(actual, expected, exact_dtype=True, exact_device=False)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/pytorch_test_base.py", line 607, in assertEqual
Nov 01 11:48:26 return DeviceTypeTestBase.assertEqual(self, x, y, *args, **kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1903, in assertEqual
Nov 01 11:48:26 super().assertTrue(result, msg=self._get_assert_msg(msg, debug_msg=debug_msg))
Nov 01 11:48:26 AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0.001 and atol=0.001, found 44 element(s) (out of 50) whose difference(s) exceeded the margin of error (including 0 nan comparisons). The greatest difference was 9.187201950435738e+18 (-9.187201950435738e+18 vs. 34.0), which occurred at index (0, 4).
Nov 01 11:48:26
Nov 01 11:48:26 ======================================================================
Nov 01 11:48:26 FAIL [0.137s]: test_reference_eager_linalg_multi_dot_xla_int64 (__main__.TestOpInfoXLA)
Nov 01 11:48:26 ----------------------------------------------------------------------
Nov 01 11:48:26 Traceback (most recent call last):
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 371, in instantiated_test
Nov 01 11:48:26 result = test(self, **param_kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 737, in test_wrapper
Nov 01 11:48:26 return test(*args, **kwargs)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 411, in test_reference_eager
Nov 01 11:48:26 self.compare_with_eager_reference(op, sample_input)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 402, in compare_with_eager_reference
Nov 01 11:48:26 self.assertEqual(actual, expected, exact_dtype=True, exact_device=False)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/pytorch_test_base.py", line 607, in assertEqual
Nov 01 11:48:26 return DeviceTypeTestBase.assertEqual(self, x, y, *args, **kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1903, in assertEqual
Nov 01 11:48:26 super().assertTrue(result, msg=self._get_assert_msg(msg, debug_msg=debug_msg))
Nov 01 11:48:26 AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0.001 and atol=0.001, found 4 element(s) (out of 4) whose difference(s) exceeded the margin of error (including 0 nan comparisons). The greatest difference was 140230883884432.0 (0.0 vs. 140230883884432.0), which occurred at index (0, 0).
Nov 01 11:48:26
Nov 01 11:48:26 ======================================================================
Nov 01 11:48:26 FAIL [0.461s]: test_reference_eager_matmul_xla_int64 (__main__.TestOpInfoXLA)
Nov 01 11:48:26 ----------------------------------------------------------------------
Nov 01 11:48:26 Traceback (most recent call last):
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 371, in instantiated_test
Nov 01 11:48:26 result = test(self, **param_kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 737, in test_wrapper
Nov 01 11:48:26 return test(*args, **kwargs)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 411, in test_reference_eager
Nov 01 11:48:26 self.compare_with_eager_reference(op, sample_input)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 402, in compare_with_eager_reference
Nov 01 11:48:26 self.assertEqual(actual, expected, exact_dtype=True, exact_device=False)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/pytorch_test_base.py", line 607, in assertEqual
Nov 01 11:48:26 return DeviceTypeTestBase.assertEqual(self, x, y, *args, **kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1903, in assertEqual
Nov 01 11:48:26 super().assertTrue(result, msg=self._get_assert_msg(msg, debug_msg=debug_msg))
Nov 01 11:48:26 AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0.001 and atol=0.001, found 37 element(s) (out of 50) whose difference(s) exceeded the margin of error (including 0 nan comparisons). The greatest difference was 7.661375630332297e+18 (-7.66128151259864e+18 vs. 94117733658072.0), which occurred at index (4, 5).
Nov 01 11:48:26
Nov 01 11:48:26 ======================================================================
Nov 01 11:48:26 FAIL [0.050s]: test_reference_eager_remainder_autodiffed_xla_int64 (__main__.TestOpInfoXLA)
Nov 01 11:48:26 ----------------------------------------------------------------------
Nov 01 11:48:26 Traceback (most recent call last):
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 371, in instantiated_test
Nov 01 11:48:26 result = test(self, **param_kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 737, in test_wrapper
Nov 01 11:48:26 return test(*args, **kwargs)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 411, in test_reference_eager
Nov 01 11:48:26 self.compare_with_eager_reference(op, sample_input)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/test_ops.py", line 402, in compare_with_eager_reference
Nov 01 11:48:26 self.assertEqual(actual, expected, exact_dtype=True, exact_device=False)
Nov 01 11:48:26 File "/var/lib/jenkins/workspace/xla/test/pytorch_test_base.py", line 607, in assertEqual
Nov 01 11:48:26 return DeviceTypeTestBase.assertEqual(self, x, y, *args, **kwargs)
Nov 01 11:48:26 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1903, in assertEqual
Nov 01 11:48:26 super().assertTrue(result, msg=self._get_assert_msg(msg, debug_msg=debug_msg))
Nov 01 11:48:26 AssertionError: False is not true : Tensors failed to compare as equal!Attempted to compare equality of tensors with different dtypes. Got dtypes torch.int64 and torch.float32.
Nov 01 11:48:26
Nov 01 11:48:26 ----------------------------------------------------------------------
```
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67619
Reviewed By: ngimel
Differential Revision: D32541986
Pulled By: mruberry
fbshipit-source-id: 793d7d22c3ec9b4778784254ef6f9c980b4b0ce2
Summary:
Fixes failing tests for `householder_product` due to non-contiguous inputs as shown here: https://github.com/pytorch/pytorch/issues/67513.
The floating point error was set too high for the complex64 type, so this PR reduces the error threshold for that particular type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68231
Reviewed By: dagitses
Differential Revision: D32562774
Pulled By: mruberry
fbshipit-source-id: edae4447ee257076f53abf79f55c5ffa1a9b3cb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62180
This PR adds CPU dispatch for `triangular_solve` with sparse CSR matrix.
The implementation uses MKL Sparse library. If it's not available then a runtime error is thrown.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D32581395
Pulled By: cpuhrsch
fbshipit-source-id: 41c7133a0d2754ef60b5a7f1d14aa0bf7680a844
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68432
Speeds up `op_convert_after_hook` by precalculating when this hook is a no-op
based on informationg gathered while tracing, and skipping execution when
this flag is true.
```
MobileNetV2, function level profiling, 1x3x224x224
// before
op_convert_before_hook = 3.25%
// after
op_convert_before_hook = 1.35%
```
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463752
Pulled By: vkuzo
fbshipit-source-id: b0c3d37909ddc8c254fe53f90954f625ae874e3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68431
asserts have some overhead, removing the asserts used only to make
mypy happy from the path which is hit in every forward.
Test Plan: python test/test_quantization.py TestQuantizeDBR
Reviewed By: jerryzh168
Differential Revision: D32463767
Pulled By: vkuzo
fbshipit-source-id: 5f85f80144f35a725afe481bf027ea61ca6315bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68374
Cleans up the relatedness logic in DBR quant. For now, this is still
duplicated with NS. A future PR should unify these mappings.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463750
Pulled By: vkuzo
fbshipit-source-id: 90c2f5e79b86b1b595bd52650305bad88212ed49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68373
Removes redundant logic in `op_needs_quantization`, for a small speedup.
Test Plan:
```
// MobileNetV2, 1x3x224x224 input, % of time spent by function during DBR convert
// before
cur_op_needs_hooks - 0.76%
op_needs_quantizaion - 0.41%
// after
cur_op_needs_hooks - 0.70%
op_needs_quantization - 0.36%
```
Reviewed By: jerryzh168
Differential Revision: D32463762
Pulled By: vkuzo
fbshipit-source-id: 334591c514dfa5af6fabc1390005088e8c5ca952
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68372
Speeds up `AutoQuantizationState.reset_to_new_call` by going around
the getattr and setattr overhead in `torch.nn.Module`.
Test Plan:
```
// MobileNetV2, 1x3x224x224 input, % of time spent by function during DBR convert
// before
reset_to_new_call - 1.09%
// after
reset_to_new_call - 0.18%
```
Reviewed By: jerryzh168
Differential Revision: D32463759
Pulled By: vkuzo
fbshipit-source-id: f3faa464372b0703f7d246680d62acd2782453e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68371
`isinstance` has some overhead, changing the code in `op_convert_before_hook`
to use the information calculate during tracing instead which is cheaper.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
function level benchmarking
```
// MobileNetV2, 1x3x224x224 input, % of time spent by function during DBR convert
// before
op_convert_before_hook = 3.55%
isinstance = 1.62%
// after
op_convert_before_hook = 2.89%
```
Reviewed By: jerryzh168
Differential Revision: D32463757
Pulled By: vkuzo
fbshipit-source-id: 129efe9c279a41f55b8bfd09132e21c0066298a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68370
Removes asserts which are duplicate (the same condition is checked
when calculating the hook type, so there is no need to check it again).
For the assert in `validate_is_at_last_seen_idx`, rewrites it to
raise an Error instead to ensure it does not get stripped in
production environments.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463766
Pulled By: vkuzo
fbshipit-source-id: 8a7b7e0bf270bc327f49bd3e5bd156339e846381
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68369
`AutoQuantizationState` has various mappings keyed on IDs. Only
`tensor_id_to_observer` actually needs string keys because it is an
`torch.nn.ModuleDict`. This PR changes the other mappings to have
integer keys, for simplicity and performance.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463765
Pulled By: vkuzo
fbshipit-source-id: 5a9bf2a1102859097eedf1e536761084cd408856
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68351
Speeds up `get_module_hook_type` and `get_torch_function_hook_type` by
bypassing the expensive `torch.nn.Module` getters and setters and
fetching `_auto_quant_state` directly.
Test Plan:
Model level benchmarking is noisy. Individual `cProfile` results:
```
// MobileNetV2, 1x3x224x224 input, % of time spent by function during DBR convert
// before
get_module_hook_type - 5.96%
get_torch_function_hook_type - 2.24%
// after
get_module_hook_type - 2.10%
get_torch_function_hook_type - 0.57%
```
Reviewed By: jerryzh168
Differential Revision: D32463756
Pulled By: vkuzo
fbshipit-source-id: 6eb199052ddf8d78f1c123a427e7437fc7c4fe58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68350
`torch.nn.Module` has overhead for getting and setting attributes because
it does various type checks on the attribute.
This PR explicitly gets and sets the right thing for this particular
function, avoding the type checks. Model level benchmarks are too noisy,
but according to function level profiling this reduces the time spent in
this function in a quantized model from 2.60% to 0.53%, on MobileNetV2 with
input size 1x3x224x224.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: albanD
Differential Revision: D32463751
Pulled By: vkuzo
fbshipit-source-id: a29beed2a2b87ca4df675a30dd591f797c8a1dbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68347
Moves `op_convert_info` to be precalculated in the convert step
instead of calculated dynamically. This should help with framework
overhead.
Test Plan:
Noisy benchmark:
```
// before
fp32: 0.016103 seconds avg
fx_prepared: 0.019841 seconds avg, 0.811601 speedup vs fp32
fx_quantized: 0.011907 seconds avg, 1.352346 speedup vs fp32
dt_prepared: 0.035055 seconds avg, 0.459357 speedup vs fp32
dt_quantized: 0.018891 seconds avg, 0.852417 speedup vs fp32
// after
fp32: 0.020535 seconds avg
fx_prepared: 0.023071 seconds avg, 0.890070 speedup vs fp32
fx_quantized: 0.011693 seconds avg, 1.756206 speedup vs fp32
dt_prepared: 0.038691 seconds avg, 0.530734 speedup vs fp32
dt_quantized: 0.021109 seconds avg, 0.972793 speedup vs fp32
```
The benchmark is too noisy to rely on, but according to `cProfiler`
this removes about 5% of overhead.
Reviewed By: jerryzh168
Differential Revision: D32463761
Pulled By: vkuzo
fbshipit-source-id: e2ad0d7eeff7dbadf3aa379604bfe9bec0c228fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68346
Some utility functions for DBR quant need to be aware
of `AutoQuantizationState`. This PR moves them into their own file, so they
can use the type directly without circular imports, and removes the mypy
ignores which are no longer necessary after this change.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463763
Pulled By: vkuzo
fbshipit-source-id: e2c367de0d5887c61e6d2c3a73d82f7d76af3de1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68345
Removes a flag to unwrap scale and zp which was only needed by
the FX rewriter. Moves the logic to happen in the FX tracer instead.
This resolves a technical debt TODO.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463764
Pulled By: vkuzo
fbshipit-source-id: ba7c976664c95111174fb65488bdac62b4f4984d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68344
Makes `AutoQuantizationState._get_packed_param_name` use `seen_op_info`
instead of the current op. This will make future performance improvements
easier.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: albanD
Differential Revision: D32463758
Pulled By: vkuzo
fbshipit-source-id: 0c16fe4bc989cb66180ad674ec55060cd970e32e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68343
Refactors `AutoQuantizationState._get_input_args_quant_dequant_info` to
use less internal state, makes the function have no side effects by passing
the state in the arguments, and moves the function to utils file.
This will help with a future refactor to cache this info at runtime.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463760
Pulled By: vkuzo
fbshipit-source-id: bdd50b0772f128755f9b734b5eeb0a9f4bc4970b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68342
Before this PR, `get_quantized_op` required the current callable.
After this PR, `get_quantized_op` only requires `seen_op_info`.
The signature was changed slightly to return `None` if the original
callable does not need replacement for quantization.
This will make it easier to make performance improvements in a
future PR.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463768
Pulled By: vkuzo
fbshipit-source-id: 5db2c4199f6c0529817f4c058f81fd1d32b9fa9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68341
Before this PR, `get_func_output_obs_type` used information from the
incoming op and its arguments, which makes it hard to cache.
This PR refactors `get_func_output_obs_type` to only use information
collected during tracing. This will make it easier to make performance
improvements in a future PR.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D32463755
Pulled By: vkuzo
fbshipit-source-id: 25a220de652f0285685d43aedf7392082104b26c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68309
This is the first of a series of PRs to reduce overhead of DBR quantization
prototype. For now, the measurement of this work is not super scientific as
there are a lot of low hanging fruit. As we speed up the prototype, we
might need to invest in better benchmarking.
Current benchmarking setup:
* mac OS laptop with OMP_NUM_THREADS=1
* torchvision's mobilenet_v2
* input size 1x3x224x224
* we measure fp32 forward, prepared and quantized forward with FX quant vs DBR quant
Note that due to small input size, this benchmark is pretty noisy.
The goal here is to measure overhead of DBR quant logic (not the kernels),
so small input is good as we want the kernels to take as little % of overall
time as possible.
High level goal is for DBR quant convert forward to approach the FX time.
This first PR removes the expensive named_modules calls and resets the op
counter in the op instead. According to cProf, this should be a 2 to 3 pct win.
Test Plan:
```
benchmark: https://gist.github.com/vkuzo/1a4f98ca541161704ee3c305d7740d4a
// before
fp32: 0.020101 seconds avg
fx_prepared: 0.020915 seconds avg, 0.961083 speedup vs fp32
fx_quantized: 0.012037 seconds avg, 1.670005 speedup vs fp32
dt_prepared: 0.037506 seconds avg, 0.535953 speedup vs fp32
dt_quantized: 0.022688 seconds avg, 0.885988 speedup vs fp32
// after
fp32: 0.020722 seconds avg
fx_prepared: 0.023417 seconds avg, 0.884893 speedup vs fp32
fx_quantized: 0.014834 seconds avg, 1.396942 speedup vs fp32
dt_prepared: 0.039120 seconds avg, 0.529700 speedup vs fp32
dt_quantized: 0.020063 seconds avg, 1.032831 speedup vs fp32
```
Reviewed By: albanD
Differential Revision: D32463753
Pulled By: vkuzo
fbshipit-source-id: 1d7de7d9c4837e2b0ec815f0f67014c7600bb16c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68251
Before this PR, DBR quantization used to recalculate scale and zero_point
in the converted model every time it was needed, which is slow.
This PR creates a pass during the convert function to go through every
observer in the model and cache its scale and zero_point.
Note: only doing this for observers which correspond to int8 operations
is saved for a future PR.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: VitalyFedyunin
Differential Revision: D32463769
Pulled By: vkuzo
fbshipit-source-id: d1d2e598e2bccc1958e5023096b451d69dc34e29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67776
This adds a barebones `add_loggers` and `extract_logger_info` API
to analyze intermediate activations of models using quantization
with dynamic tracing. The API generally matches the NS for FX tool,
with some omissions. For now, this is moving fast to help us
debug real models, and the API will be 100% aligned before this is marketed to users,
in future PRs.
Note: the current approach couples Numeric Suite with the quantization
logic. This is not the best for composability, and may be changed
at a future time.
Test Plan:
```
python test/test_quantization.py TestAutoTracing.test_numeric_suite
```
```
python test/test_quantization.py TestAutoTracing.test_numeric_suite
```
Differential Revision:
D32231332
D32231332
Reviewed By: jerryzh168
Pulled By: vkuzo
fbshipit-source-id: 8adfb50cd8b7836c391669afe2e2ff6acae6d40a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68672
This PR adds `python_module: sparse` to `native_function.yaml`.
These functions would appear in `torch._C._sparse` namespace instead of
just `torch`.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32517813
fbshipit-source-id: 7c3d6df57a24d7c7354d0fefe1b628dc89be9431
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68637
Make AOT compiler compile BI bytedoc model also making the compiler generic enough for other models. Shape propagation pass replaced with the new JIT tracer as shape propagation doesn't yet support dynamic shapes.
Change to get and set input dtype to follow
Test Plan:
BI model changed to return a tuple of tensors instead of returning a tuple(list[tensor], list[string]). Modified BI model runs well with these changes
```
jf download GN91Hg9shoWzU1oPAGQ7X9SV8-5nbmQwAAAA --file bi.pt
└─ $ ./compile_model.sh -m pytorch_dev_bytedoc -p bi.pt -v v1 -i "1,115;1"
+ VERSION=v1
+ getopts m:p:v:i:h opt
+ case $opt in
+ MODEL=pytorch_dev_bytedoc
+ getopts m:p:v:i:h opt
+ case $opt in
+ MODEL_PATH=bi.pt
+ getopts m:p:v:i:h opt
+ case $opt in
+ VERSION=v1
+ getopts m:p:v:i:h opt
+ case $opt in
+ INPUT_DIMS='1,115;1'
+ getopts m:p:v:i:h opt
+ require_arg m pytorch_dev_bytedoc
+ '[' -n pytorch_dev_bytedoc ']'
+ require_arg p bi.pt
+ '[' -n bi.pt ']'
+ require_arg i '1,115;1'
+ '[' -n '1,115;1' ']'
+ '[' '!' -f bi.pt ']'
+++ dirname ./compile_model.sh
++ cd .
++ pwd -P
+ SRC_DIR=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc
+ FBCODE_DIR=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/../../..
+ FBSOURCE_DIR=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/../../../..
+ KERNEL_DIR=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/../../../../xplat/pytorch_models/build/pytorch_dev_bytedoc/v1/nnc
++ readlink -f bi.pt
++ sed 's/.pt.*//'
+ MODEL_PATH_PREFIX=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/bi
+ LLVM_CODE_PATH=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/bi.compiled.ll
+ ASSEMBLY_CODE_PATH=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/bi.compiled.s
+ COMPILED_MODEL_FILE_PATH=/data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/bi.compiled.pt
+ KERNEL_FUNC_NAME=nnc_pytorch_dev_bytedoc_v1_forward
+ buck run //caffe2/binaries:aot_model_compiler -- --model=bi.pt --model_name=pytorch_dev_bytedoc --model_version=v1 '--input_dims=1,115;1'
Restarting Buck daemon because Buck version has changed...
Buck daemon started.
Parsing buck files... 0.6 sec (0/unknown)
.
.
Parsing buck files: finished in 5.0 sec
Creating action graph: finished in 0.7 sec
Downloaded 3750/4917 artifacts, 16.09 Mbytes, 13.3% cache miss (for updated rules)
Building: finished in 01:22.3 min (100%) 4995/4995 jobs, 4995/4995 updated
Total time: 01:28.0 min
BUILD SUCCEEDED
Run with 56 threads
Run with 56 threads
Loading model...
Model loaded: /data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/bi.compiled.pt
Running forward ...
WARNING: Logging before InitGoogleLogging() is written to STDERR
W1115 11:42:18.170666 1597103 TensorImpl.h:1418] Warning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (function operator())
(Columns 1 to 10 0.5428 0.1651 0.0158 0.0055 0.0503 0.0749 0.0161 0.0204 0.0237 0.0095
Columns 11 to 12 0.0609 0.0148
[ CPUFloatType{1,12} ], Columns 1 to 10-1.3946 -0.0835 -1.1268 0.3325 -2.1884 4.6175 -0.1206 -1.5058 -1.5277 -2.1214
Columns 11 to 20 1.3726 -0.4573 -1.7583 -2.2275 1.9607 -5.3430 -4.4927 -3.2548 -5.3214 2.9002
Columns 21 to 30-1.3973 -0.8084 -1.8491 -1.6518 4.2531 -0.0321 -0.0282 -1.1180 -0.9800 2.9228
Columns 31 to 32 0.8228 2.2611
[ CPUFloatType{1,32} ])
Starting benchmark.
Running warmup runs.
Main runs.
Main run finished. Milliseconds per iter: 40.64. Iters per second: 24.6063
Memory usage before main runs: 71581696 bytes
Memory usage after main runs: 94347264 bytes
Peak memory usage after main runs: 94347264 bytes
Average memory increase per iter: 2.22495e+06 bytes
0 value means "not available" in above
```
Reviewed By: ljk53
Differential Revision: D32438852
fbshipit-source-id: 5defdc2593abda5da328f96248459d23b2c5e5c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66464
Dimension sizes are referred to as `size` in general in PyTorch and
hence rename shard_lengths to shard_sizes.
#Closes: https://github.com/pytorch/pytorch/issues/65794
ghstack-source-id: 143866449
Test Plan: waitforbuildbot
Reviewed By: fduwjj, wanchaol
Differential Revision: D31564153
fbshipit-source-id: 6273426c4b0e079358806070d0d9644740adb257
Summary:
CUDA's `at::nanmedian` creates a sorted copy of the array, then indexes into it to create a single element view. This view necessarily keeps the entire `sorted` tensor's storage alive which can be avoided by returning a copy, which is what `at::median` does indirectly via `at::where`.
This also changes the index variable `k` to be a simple `int64_t` instead of the CUDA tensor that was used before. This saves the additional host and device operations from calling `Tensor`'s `operator -` which helps balance out the cost of the `clone` added here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68591
Reviewed By: dagitses
Differential Revision: D32538538
Pulled By: ngimel
fbshipit-source-id: abe9888f80cf9d24d50a83da756e649af1f6ea3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68676
As the title, the helper functions handles setting layer name. We would want to use those helper functions whenever possible.
Test Plan: CI
Reviewed By: wushirong
Differential Revision: D32571061
fbshipit-source-id: 4a191f0085c0b3965dc02d99bb33de21973d565d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68624
Fix `caffe2.test.distributed.launcher.api_test` flaky tests for opt-tsan mode.
The diff changes the default `mp.Process` invocation to use spawn context. `mp.Process` will uses `fork` method that is not compatible with `*san`.
Test Plan: CI
Reviewed By: d4l3k
Differential Revision: D32550578
fbshipit-source-id: f4767987e8e10a6a2ece3f86e48278f2dbaebe7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68042
att
Also added test cases from TestQuantizeFx which tests all combinations of {fp32, int8} input and output override
Test Plan:
```
python test/fx2trt/test_quant_trt.py TestConvertFxDoNotUse
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32271511
fbshipit-source-id: 87ffc00069aaff7d1c455cdd97fac82b11aa4527
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68555
The outer namespace is already anonymous, so this is not necessary.
Test Plan: Imported from OSS
Reviewed By: dagitses
Differential Revision: D32565941
Pulled By: malfet
fbshipit-source-id: 4daf1c46b25ff68e748e6c834c63d759ec6fde4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67041
Original PR here: https://github.com/pytorch/pytorch/pull/62246 (The old PR does more things, but now that's split across this stack)
This PR:
- Adds "jacfwd" and "hessian_fwdrev"
- Modifies existing tests to also test the `forward_ad=True` case
Test Plan: Imported from OSS
Reviewed By: gchanan, zou3519
Differential Revision: D32314424
Pulled By: soulitzer
fbshipit-source-id: 785b0e39162b93dc3b3cb9413233447152eddd53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66294
In this PR:
- OpInfo for forward AD now checks batched forward grad when `op.check_batched_grad=True`
- Adds setting to disable the test for individual ops `check_batched_forward_grad` and disable for the ops here: https://github.com/pytorch/pytorch/issues/66357
Fixes some more failures:
- Make Forward AD metadata less strict by allowing stride to differ when size is 1
- Fix sum batching rule when logical tensor is a scalar and dim is unspecified
- Batching rule for `_reshape_alias`
- ~Batching rules now preserve storage offset for view operator that return non-zero storage offset~ (moved to previous PR)
Test Plan: Imported from OSS
Reviewed By: zou3519, albanD
Differential Revision: D31842020
Pulled By: soulitzer
fbshipit-source-id: 3517a8fb9d6291fccb53c0b1631eab5bbb24ebd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66293
This PR:
- Asserts that if the output is a view, then the `is_same_metadata` must return `true`. Otherwise, we are performing a copy.
- unless we are being called from `make_dual` which can allow the tangent and primal to have different layouts, because it is not forward differentiable.
- To make this possible, we add `is_make_dual` as a parameter. ~The alternative is to make `make_dual` non-composite, and then we can rely on its `view_info` for differentiability information. This also assumes that the only composite function that calls `set_fw_grad` is `make_dual`.~
- Batching rules now preserve storage offset for view operator that return non-zero storage offset
Test Plan: Imported from OSS
Reviewed By: zou3519, albanD
Differential Revision: D31842021
Pulled By: soulitzer
fbshipit-source-id: ed606f5a7b4770df1e9ebc6eb1d584b27dad5bae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66292
In this PR:
1. Fix the case when tangent has a different layout from the base when `set_fw_grad` by adding a native function and its batching rule.
For (1) we replace the following:
```
Tensor new_with_same_meta(const Variable& base) {
int64_t nelement_in_storage = base.storage().nbytes() / base.itemsize();
auto new_tensor = at::zeros({nelement_in_storage}, base.options());
auto res = new_tensor.as_strided(base.sizes(), base.strides(), base.storage_offset());
return res;
}
```
with a native function as to enable a batching rule to alter its behavior.
This new function will be similar to `new_zeros_strided` except we also require the `storage_offset` and `storage_numel` arguments.
Possible concerns:
- Why have redundant logic? Why not add new args `new_zeros_strided`? This is probably a niche use case, so it's better not to complicate the current API.
- Previously the created tensor inherits the TensorOptions of the primal. Now we inherit from the TensorOptions of the tangent.
- Probably fine. Likely, no one relies on this because the behavior is only triggered when tangent/base have different layouts.
- Why pass in exploded size, stride, and offset? It is possible in the non-batched case to pass in a tensor directly, but not possible when we'd like to have a batching rule. The size, stride, and offset we'd be passing won't belong to any live tensor.
Test Plan: Imported from OSS
Reviewed By: zou3519, albanD
Differential Revision: D31842019
Pulled By: soulitzer
fbshipit-source-id: a58433d814fd173bc43a2c550b395377dba40de2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67537
This PR adds support for quantizing torch.addmm to produce a reference quantized pattern,
and also adds support in the backend_config_dict api that allows people to specify the input, weight and bias input for each input:
```
addmm_config = {
"pattern": torch.addmm,
"observation_type": ObservationType.OUTPUT_USE_DIFFERENT_OBSERVER_AS_INPUT,
"dtype_configs": [
weighted_op_qint8_dtype_config,
],
# a map from input type to input index
"input_type_to_index": {
"bias": 0,
"input": 1,
"weight": 2,
}
}
```
This requires some changes in getting weight_dtype and bias_dtype in the type inference stage of prepare, which will be added in the previous PR
Test Plan:
```
pytho test/fx2trt/test_quant_trt.py TestQuantizeFxTRT.test_addmm
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32014998
fbshipit-source-id: 8d96c1e8b7ebb2ab385c08a5b1e43f2d5a2cbcbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68284
Add a new class `ManagedTensorRanges` that determines when manage tensors can be made available for re-use. This class provides a method `availableTensors(Node* node)` that returns a vector of `Value*` (corresponding to managed tensors) that are not used (either directly or through any alias) after `node`.
Test Plan: New unit tests: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: swolchok
Differential Revision: D32397207
fbshipit-source-id: fb0d9a23f13abf6f2207e3d7266384966f477fc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68602
This PR adds support for configuring weight/bias dtype in backend_config_dict
and refactor the current code that checks when to insert observers
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32537712
fbshipit-source-id: 28eb7c61a8dcad8c1f3f6622d490a34cff0c59e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68650
Allow fuse unsqueeze cat sum with >2 input, the impl in this diff is naive, just concat item with add. Not sure can have more perf gain with fuse multiple add into one operation.
Test Plan: unit test
Reviewed By: jfix71
Differential Revision: D32520135
fbshipit-source-id: 535b1c8c91e415d5f1af714378b9205c1ca02ffd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67794
This change is needed to conveniently use the same comparison mechanism for our internal testsuite (see #67796). The reworked version is on par with the previous version except for the ability to pass a custom message as callable. Before we converted everything to a tensor so it was fairly easy to provide consistent mismatch diagnostics to the callable. Now, with arbitrary `Pair`'s that are used for comparison that is no longer viable.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32532206
Pulled By: mruberry
fbshipit-source-id: dc847fba6a795c1766e01bc3e88b680a68287b1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68329
Pull Request resolved: https://github.com/pytorch/kineto/pull/466
1. Generalize ChromeTraceLogger::handleGenericActivity to enable it to handle Cuda runtime activities as well as the Roctracer generic activities.
This primarily involves enabling generic support for CPU -> GPU flows.
2. In the event of out-of-order GPU activities (an issue with Cuda11.0, likely fixed in later versions), no longer remove them but print warnings. Another diff will add these warnings to the metadata section.
Reviewed By: briancoutinho
Differential Revision: D31624496
fbshipit-source-id: dab04b3e3c0dd6799496ac87f837363de79eea25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65812
Multiple threads are recording events to a shared activity buffer and the buffer is at some point transferred to libkineto.
The access to and the transfer of the buffer needs to be done under lock.
Reviewed By: leitian, xw285cornell
Differential Revision: D31220061
fbshipit-source-id: f11c879df1b55aa9068187e600730bb0e5e5455f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66966
T* is convertible to const T*, so we don't need this overload.
ghstack-source-id: 143749559
Test Plan: builds
Reviewed By: hlu1
Differential Revision: D31809824
fbshipit-source-id: 70cca86c4a87dc09cd958953a08a801db3e4d047
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67075
Sharing storage if `mayAlias` is incorrect, as the old comment notes; sharing if `mustAlias` would be nice but, as the new comment notes, would not matter.
ghstack-source-id: 143749553
Test Plan: CI
Reviewed By: hlu1
Differential Revision: D31851893
fbshipit-source-id: 5bdc8de984d5919332c9010e8b0160211d96bc2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68074
This is the first step of many PRs towards implementing the `torch.monitor` RFC https://github.com/pytorch/rfcs/pull/30
This defines the aggregation types, the `Stat` class and provides some simple collection of the stats.
This doesn't match the RFC exactly as it incorporates some of the comments on the RFC as well as a few changes for performance.
Changes:
* added window_size to the stats. If specified it will always compute the stat using the `window_size` number of values. If there aren't enough values within that window it reports the previous stats.
* This doesn't include the push metrics yet (will be coming).
After more discussion it looks like the best way to handle this is to support a hybrid where the metric can set how frequently it'll be logged. For fixed window_size metrics it'll be logged each time it hits the window size. This will allow performant counters as well as lower frequency push counters (window_size=1).
Performance considerations:
* Updating the stats acquires a lock on that Stat object. This should be performant unless there's many-many threads writing to the same stat. Single thread will typically use futex so should be quite fast.
* Adding/removing/fetching all stats sets a global lock on the stat list -- this shouldn't be an issue since these events happen infrequently.
* Fetching stats accesses one stat at a time instead of a global lock. This means the exported values are linearizable but not serializable across multiple stats but I don't expect this to be an issue.
Next steps:
1. Add StatCollector interface for push style metrics
1. Add pybind interfaces to expose to Python
1. Add default metric providers
1. Integrate into Kineto trace view
Test Plan:
buck test //caffe2/test/cpp/monitor:monitor
CI
Reviewed By: kiukchung
Differential Revision: D32266032
fbshipit-source-id: dab8747b4712f5dba5644387817a3a0fda18b66a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68614
We need to copy modules over to the `split` graph during const folding. We were previously only doing so from the non-constant submod, but we need to do this for the constant one as well in case some `call_module` is const folded.
Test Plan: Added unit test
Reviewed By: wushirong, 842974287
Differential Revision: D32543289
fbshipit-source-id: 80d1d0ce2c18a665b00e1343d6c55d939390ab10
Summary:
Adds native_dropout to have a reasonable target for torchscript in auto diff. native_dropout has scale and train as arguments in its signature, this makes native_dropout more consistent with other operators and removes conditionals in the autodiff definition.
cc gmagogsfm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63937
Reviewed By: mruberry
Differential Revision: D32477657
Pulled By: ngimel
fbshipit-source-id: d37b137a37acafa50990f60c77f5cea2818454e4
Summary:
Previously I need to back out D32220626 and then apply D31841609 to run the textray unity demo. It's hard to have other people to take a look how this textray demo looks like.
I copied the textray demo (a single file) from pytext folder to unity folder and applied the changes needed. This way, other people can also run this textray demo. This also makes my dev environment cleaner.
Test Plan: buck run mode/opt :textray_demo
Reviewed By: mleshen
Differential Revision: D32537190
fbshipit-source-id: 5df6347c4bec583c225aea9f98fbc9f37b5d3153
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67367
- Adds check to make sure forward grad itself does not have forward grad at the same level
- Verify with `python test/test_ops.py -k test_forward_mode_AD_linalg_eigh_cpu_float64` that it fails the check before, but passes after the codegen update
Before:
```
if (_any_has_forward_grad_eigenvalues) {
auto self_t_raw = toNonOptFwGrad(self);
auto self_t = self_t_raw.defined() ? self_t_raw : at::zeros_like(toNonOptTensor(self));
auto eigenvalues_new_fw_grad = eigh_jvp_eigenvalues(self_t, eigenvalues, eigenvectors);
if (eigenvalues_new_fw_grad.defined()) {
// The hardcoded 0 here will need to be updated once we support multiple levels.
eigenvalues._set_fw_grad(eigenvalues_new_fw_grad, /* level */ 0, /* is_inplace_op */ false);
}
}
if (_any_has_forward_grad_eigenvectors) {
auto self_t_raw = toNonOptFwGrad(self);
auto self_t = self_t_raw.defined() ? self_t_raw : at::zeros_like(toNonOptTensor(self));
auto eigenvectors_new_fw_grad = eigh_jvp_eigenvectors(self_t, eigenvalues, eigenvectors);
if (eigenvectors_new_fw_grad.defined()) {
// The hardcoded 0 here will need to be updated once we support multiple levels.
eigenvectors._set_fw_grad(eigenvectors_new_fw_grad, /* level */ 0, /* is_inplace_op */ false);
}
}
```
After:
```
c10::optional<at::Tensor> eigenvalues_new_fw_grad_opt = c10::nullopt;
if (_any_has_forward_grad_eigenvalues) {
auto self_t_raw = toNonOptFwGrad(self);
auto self_t = self_t_raw.defined() ? self_t_raw : at::zeros_like(toNonOptTensor(self));
eigenvalues_new_fw_grad_opt = eigh_jvp_eigenvalues(self_t, eigenvalues, eigenvectors);
}
c10::optional<at::Tensor> eigenvectors_new_fw_grad_opt = c10::nullopt;
if (_any_has_forward_grad_eigenvectors) {
auto self_t_raw = toNonOptFwGrad(self);
auto self_t = self_t_raw.defined() ? self_t_raw : at::zeros_like(toNonOptTensor(self));
eigenvectors_new_fw_grad_opt = eigh_jvp_eigenvectors(self_t, eigenvalues, eigenvectors);
}
if (eigenvalues_new_fw_grad_opt.has_value() && eigenvalues_new_fw_grad_opt.value().defined()) {
// The hardcoded 0 here will need to be updated once we support multiple levels.
eigenvalues._set_fw_grad(eigenvalues_new_fw_grad_opt.value(), /* level */ 0, /* is_inplace_op */ false);
}
if (eigenvectors_new_fw_grad_opt.has_value() && eigenvectors_new_fw_grad_opt.value().defined()) {
// The hardcoded 0 here will need to be updated once we support multiple levels.
eigenvectors._set_fw_grad(eigenvectors_new_fw_grad_opt.value(), /* level */ 0, /* is_inplace_op */ false);
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68535
Reviewed By: ngimel
Differential Revision: D32536089
Pulled By: soulitzer
fbshipit-source-id: a3f288540e2d78a4a9ec4bd66d2c0f0e65dd72cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68609
The test is stale and tests non-existent method
Test Plan: ci
Reviewed By: kiukchung
Differential Revision: D32540127
fbshipit-source-id: c47b7aed3df6947819efb2f4ad1b7a059c252138
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: zou3519, JacobSzwejbka
Differential Revision: D32283178
Pulled By: mruberry
fbshipit-source-id: deb672e6e52f58b76536ab4158073927a35e43a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68303
Result of splitter is run on either accelerator or directly on gpu, rename gpu part graph to run_on_gpu
Test Plan: buck test mode/opt caffe2/test:trt_tools_test
Reviewed By: 842974287
Differential Revision: D32392492
fbshipit-source-id: b085376c00c1097752e856e22c631d74a0fbc38f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53647
With this if a test forgets to add `dtypes` while using `dtypesIf`, following error is raised
```
AssertionError: dtypes is mandatory when using dtypesIf however 'test_exponential_no_zero' didn't specify it
```
**Tested Locally**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68186
Reviewed By: VitalyFedyunin
Differential Revision: D32468581
Pulled By: mruberry
fbshipit-source-id: 805e0855f988b77a5d8d4cd52b31426c04c2200b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68268
Previously, `_make_wrapper_subclass` ignored the storage offset it was
passed. This PR fixes that by updating TensorMaker::computeStorageSize()
and TensorMaker::make_tensor() to take into account storage_offset.
Test Plan: - added test
Reviewed By: albanD, bdhirsh
Differential Revision: D32396330
Pulled By: zou3519
fbshipit-source-id: 2c85bc4066044fe6cb5ab0fc192de6c9069855fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68586
We updated the vmap warnings to be more descriptive in
https://github.com/pytorch/pytorch/pull/67347 . However, gradcheck does
some warning squashing that matches on the warning message and we didn't
update that. This PR updates the warning squashing in gradcheck.
Test Plan: - check logs
Reviewed By: albanD
Differential Revision: D32530259
Pulled By: zou3519
fbshipit-source-id: 9db380b57c38b3b72cbdb29574f71dbfe71e90d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68565
This makes it so that we can now vmap over nn.functional.pad (circular
variant). Previously we could not because we were effectively doing
`out.copy_(input)` where the out was created with empty.
This also has the added side effect of cleaning up the code.
Test Plan:
- I tested this using functorch.vmap and can confirm that vmap now
works.
- Unfortunately this doesn't work with the vmap in core so I cannot add
a test for this here.
Reviewed By: albanD
Differential Revision: D32520188
Pulled By: zou3519
fbshipit-source-id: 780a7e8207d7c45fcba645730a5803733ebfd7be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68532
Diff to better handle size 0 pinned memory allocation requests.
----
### Behavior before fix
The very first size 0 malloc comes in. It will create a block with `{key: 0, value: Block(0, 0, true)}`.
Another size 0 malloc comes in.
It will either 1) get a block with size > 0 (which is a waste of pinned memory) or 2) call `cudaHostAlloc()` with size 0 to eventually get *ptr=0.
Note that this block is *not registered* to the block pool because we have a duplicate entry (and that's why we will keep wasting size > 0 pinned memory block, if `available.empty() == false`).
----
### Behavior after fix
Let `malloc()` simply return a nullptr (0).
This avoids wasting valid size > 0 blocks as well as save the calls to `cudaHostAlloc()` which is expensive.
This is also safe since `free()` simply returns success for nullptrs.
-----
Test Plan: Unit tests.
Reviewed By: yinghai
Differential Revision: D32487522
fbshipit-source-id: 6140cab54ff5a34ace7d046f218fb32805c692c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67467
Unit tests for static runtime in the dper multi-env tests for cpu and scripted (including fx-traced + scripted) models. Only turn it on for single_operators_tests that are in the inline_cvr local/local_ro/remote_ro model for now.
Will have another diff that turns this on by default and explicitly disables for certain tests.
Test Plan: buck test dper3/dper3/modules/low_level_modules/tests:single_operators_test
Reviewed By: hlu1, houseroad
Differential Revision: D30870488
fbshipit-source-id: 382daec8dbcb95135cdd43e7b84a1d23b445d27c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68021
reland PR of https://github.com/pytorch/pytorch/pull/64481 as the previous one have some internal failures that didn't get captured when first landed.
This simplifies `init_from_local_shards` API in sharded tensor, to only require user pass in a list of `Shard` and `overall_size`, instead of ShardedTensorMetadata. We will do the all_gather inside to form a valid ShardedTensorMetadata instead.
TODO: add more test cases to improve coverage.
ghstack-source-id: 143661119
ghstack-source-id: 143661119
Test Plan: TestShardedTensorFromLocalShards
Reviewed By: pritamdamania87
Differential Revision: D32147888
fbshipit-source-id: 897128b75224f4b9644471a04a64079f51e0d5fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68499
TCP store is actually being accessed by multi-threading (NCCL watch dog thread), but no mutex protection while FileStore and HashStore have. As enabling desync root cause analysis makes store calls more often, the race condition of TCP store was always triggered when creating another process group like gloo. Adding mutex to TCP store, to be the same with FileStore and HashStore.
Test Plan:
DDP benchmark with desync debug enabled, no perf regression
https://www.internalfb.com/intern/fblearner/details/309398285?tab=Outputs
W/o this diff
https://www.internalfb.com/intern/fblearner/details/308379789?tab=Outputs
Reviewed By: mingzhe09088
Differential Revision: D32482254
fbshipit-source-id: e8f466e1c6fdcab6cfa170f44b9be70395935fb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68310
Enable desync root cause analysis by recording the last footprint of collective calls. When timeout we parse the store trace and figure out the root cause of the desync issue. This feature is built based on async error handling.
Test Plan:
Standalone test
* Typical desync - P467288969
* Mismatched collectives - P467288916
* Mismatched broadcast size - P467288873
DDP benchmark
* DDP benchmark desync - P467433483, P467520195
No perf regression:
* w/o this diff https://www.internalfb.com/intern/fblearner/details/308379789?tab=Outputs
* w/ this diff https://www.internalfb.com/intern/fblearner/details/308534088?tab=Outputs
Reviewed By: mingzhe09088
Differential Revision: D32348647
fbshipit-source-id: 43e7e96e3fa2be0ac66c1325bceb639b461a8b3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68395
At the time that I wrote the pass, I thought that `c10::TensorList` and `c10::List<Tensor>` were the same thing. But it looks like a `TensorList` is actually an `ArrayRef<Tensor>`. This led to a nasty bug when I tried to add conditional functionalization to `block_diag`, where in the boxed kernel, I would:
(1) unwrap the first `IValue` by calling `.toTensorList()` (this actually returns a `List<Tensor>`, not a `TensorList`).
(2) call `TensorList to_functional_tensor(List<Tensor>)` to get out a `TensorList` with the functionalized tensors
(3) wrap that back into an `IValue` and put in on the stack.
Somewhere in that sequence of operations, something bad happens and we segfault. Fixing up the signature of `to_functional_tensor` to be `List<Tensor> to_functional_tensor(List<Tensor>)` fixes the bug. I have a feeling that there's a latent TensorList-related bug in the boxing/unboxing logic that made this worse, but I'm okay to stick with my narrow fix for now.
Additionally tested by running `pytest test/test_ops.py test/test_vmap.py -v -k block_diag` on top of this PR: https://github.com/pytorch/functorch/pull/235
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D32448258
Pulled By: bdhirsh
fbshipit-source-id: 3b2b6c7cd5e4c29533d0502f24272d826bfe03c1
Summary:
To release constants computed and stored by `ConstantValueMap::SetValue(...)` during ONNX exporting, `ConstantValueMap::Clear()` needs to be called explicitly. Otherwise, it's a memory leak.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68210
Reviewed By: jansel
Differential Revision: D32465670
Pulled By: msaroufim
fbshipit-source-id: 521e474071b94c5d2cd4f353ee062cee78be1bd4
Summary:
1. is to convert Function -> mobile::Function
2. is to serialize mobile::Function
This also opens opportunity to create mobile::Module without saving/reloading
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66494
Reviewed By: zhxchen17
Differential Revision: D32293022
Pulled By: qihqi
fbshipit-source-id: 29b43d47ff86071d5e2f9d6ca4dba4445711ce3d
Summary:
After realizing that CUDA mem leaks were not rerun, I realized I forgot to pass the env var as a Docker variable.
What a noob mistake.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68486
Reviewed By: seemethere
Differential Revision: D32501718
Pulled By: janeyx99
fbshipit-source-id: 9918d626e90bea1562a3094c6eb12cb7d86dbf6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68317
We use the node_name_to_target_dtype to store the target dtype for output activations for each node, computed from qconfig for the node,
there are two problems with node_name_to_target_dtype that makes it hard to work with:
1. we mutate node_name_to_target_dtype when we insert observers, this makes the data structure confusing because it's typically unexpected
to change a data structure that store the "target" dtype
2. currently it only stores target dtype about output activations, while we also need target dtype for input activation, weight and bias
This PR fixes both problem by removing mutation from the node_name_to_target_dtype and expanding the target_dtype for node to include
the missing target dtype for input activation, weight and bias. We will have another refactor to simplify the observation for weight and bias dtype
in the future.
Please see comments for the updated structure of node_name_to_target_dtype
TODO: we may want to rename node_name_to_target_dtype to node_name_to_target_dtype_info in a separate PR.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D32411858
fbshipit-source-id: 3d76dd65056920ff8642899517bc1b95d43fc1de
Summary:
When porting `THAllocator` to ATen I changed `AT_ERROR` to `TORCH_INTERNAL_ASSERT` but the direct translation should have been `TORCH_CHECK`.
33e9a0b5f6/c10/util/Exception.h (L619-L623)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68424
Reviewed By: VitalyFedyunin
Differential Revision: D32465548
Pulled By: ngimel
fbshipit-source-id: 7fa9c1fe27e4849b76248badb681d7b6877ce9e8
Summary:
This PR simply updates the documentation following up on https://github.com/pytorch/pytorch/pull/64234, by adding `Union` as a supported type.
Any feedback is welcome!
cc ansley albanD gmagogsfm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68435
Reviewed By: davidberard98
Differential Revision: D32494271
Pulled By: ansley
fbshipit-source-id: c3e4806d8632e1513257f0295568a20f92dea297
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68279
While reworking the liveness analysis, I noticed that using `std::pair<size_t, std::vector<Tensor*>>` to represent storage groups made things quite unreadable.
Add a simple class to wrap a `std::vector<at::Tensor*>` and store a `size` attribute
Test Plan:
`buck test caffe2/benchmarks/static_runtime/...`
Also ran inline_cvr benchmarks, did not see any errors
Reviewed By: swolchok
Differential Revision: D32369447
fbshipit-source-id: e0b562aa7eefd738b1a34f1f37eb7bc95d71a257
Summary:
nvfuser code update:
1. Tuning heuristics on schedulers for reduction/normalization kernels;
2. bfloat16 on IO tensor support;
3. Refactored memory format support, now we can support dimension collapsing with non-coherent input tensors with different memory format. e.g. channels last tensor input to batch normalization. Note that we are currently limiting memory format to only Contiguous and Channels last;
4. Refactored nvfuser graph partitioning in `graph_fuser.cpp`, separated node merge and profile node API. Updated `profiling_record.cpp`.
Things that are reverted from our local branch:
1. changes on some entries in autodiff
2. aten::gelu with approximation
3. native_dropout(_backward)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67943
Reviewed By: ngimel
Differential Revision: D32288709
Pulled By: dzhulgakov
fbshipit-source-id: fc9491182ea7e0158bc112c66f096823c588eaf1
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/64075
Test Plan:
Before:
`I0826 17:17:54.165174 1064079 PyTorchPredictorBenchLib.cpp:313] PyTorch run finished. Milliseconds per iter: 6.66724. Iters per second: 149.987`
After:
`I0826 17:13:07.464485 1040300 PyTorchPredictorBenchLib.cpp:313] PyTorch run finished. Milliseconds per iter: 6.46362. Iters per second: 154.712`
Profile after: P453143683
Accuracy tested comparing with jit interpreter for no differences under 1e-3 (nnc ops turned on) https://www.internalfb.com/intern/diff/view-version/136824794/
======
With 100-request recordio inputs (211 inputs)
Before:
`I1101 12:43:13.558375 742187 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 11.7882. Iters per second: 84.8309`
After:
`I1101 13:50:41.087644 1126186 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 11.6763. Iters per second: 85.6438`
Profile after: P465977010
Constituent ops before (total is 0.5646):
```
0.187392 ms. 1.61737%. fb::clip_ranges_gather (309 nodes, out variant)
0.174101 ms. 1.50266%. fb::lengths_to_offsets (464 nodes, out variant)
0.203126 ms. 1.75317%. static_runtime::to_copy (805 nodes, out variant)
```
Constitutent ops after (total is 0.4985):
```
0.376559 ms. 3.25614%. fb::clip_ranges_to_gather_to_offsets (305 nodes, out variant)
0.0614349 ms. 0.531235%. fb::lengths_to_offsets (159 nodes, out variant)
0.0573315 ms. 0.495751%. static_runtime::to_copy (195 nodes, out variant)
0.00325543 ms. 0.0281501%. fb::gather_ranges (4 nodes, out variant)
```
Compare with jit interpreter inside benchmark:
`I1101 13:55:53.013602 1149446 PtVsBlackBoxPredictorBenchLib.cpp:175] Finished comparing PT static runtime and jit interpreter results`
======
Casting on the fly:
a. Static runtime off
```
Static runtime ms per iter: 11.4658. Iters per second: 87.2159
0.220367 ms. 1.94726%. static_runtime::to_copy (805 nodes, out variant)
0.172585 ms. 1.52504%. fb::clip_ranges_gather (309 nodes, out variant)
0.157836 ms. 1.39471%. fb::lengths_to_offsets (464 nodes, out variant)
```
b. Casting on the fly, using explicit allocation+to_copy (which has the fast pass for certain cases, but we'll always call empty):
```
I1115 09:08:35.711972 1925508 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 11.6732. Iters per second: 85.6662
0.599439 ms. 5.25098%. fb::clip_ranges_to_gather_to_offsets (305 nodes, out variant)
0.0552475 ms. 0.483958%. fb::lengths_to_offsets (159 nodes, out variant)
0.0576032 ms. 0.504593%. static_runtime::to_copy (195 nodes, out variant)
0.00299026 ms. 0.0261941%. fb::gather_ranges (4 nodes, out variant)
```
c. Casting on the fly with native::to (no explicit allocation, but no fast pass):
```
Static runtime ms per iter: 11.5627. Iters per second: 86.4849
0.454356 ms. 3.9652%. fb::clip_ranges_to_gather_to_offsets (305 nodes, out variant)
0.06315 ms. 0.551115%. static_runtime::to_copy (195 nodes, out variant)
0.0590741 ms. 0.515544%. fb::lengths_to_offsets (159 nodes, out variant)
0.00359182 ms. 0.031346%. fb::clip_ranges_gather (4 nodes, out variant)
```
d. Removal of the to() call in question from the fusion pattern:
```
Static runtime ms per iter: 11.3658. Iters per second: 87.9836
0.29591 ms. 2.6479%. fb::clip_ranges_to_gather_to_offsets (305 nodes, out variant)
0.154612 ms. 1.38352%. static_runtime::to_copy (500 nodes, out variant)
0.0567151 ms. 0.507505%. fb::lengths_to_offsets (159 nodes, out variant)
0.0051115 ms. 0.0457394%. fb::clip_ranges_gather (4 nodes, out variant)
```
Reviewed By: hlu1
Differential Revision: D30515441
fbshipit-source-id: 53acee10619ac2be7dc8982e929e3210c4bb6d21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68308
export CPUOffload in _fsdp package, as cpu_offload config in FSDP API needs to import this class
ghstack-source-id: 143560608
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D32408719
fbshipit-source-id: ee5c40ec91a423fbd58872fbdeb5f2dda8a3d89e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66819
This has a number of different advantages:
- For channels last tensors, DispatchStub overhead is only incurred once.
- For contiguous tensors, parallelization now happens over batch and
chanels, enabling better load balancing between threads.
- `q_scale()` and `q_zero_point()` are no longer called inside of a
parallel region, which is not allowed (see gh-56794)
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32445352
Pulled By: ngimel
fbshipit-source-id: cd938e886cd5696855eb56a649eaf3bccce35e54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67733
Vulkan backend is now thread-safe:
* `ThreadContext` class holds onto all per-thread Vulkan states such as Command, Descriptor and Resource objects.
* `ThreadContext::SingletonThreadLocalObject<T>` is a very light version of `folly::SingletonThreadLocal` (https://github.com/facebook/folly/blob/main/folly/SingletonThreadLocal.h). It holds a static object with `thread_local` modifier. It is tied with a `GPU` object which allows us to expand multi-threaded GPU backend and multi-GPU capability in the future. The lifetime of `SingletonThreadLocalObject<T>` object is from the first call (instantiation) to the termination of thread.
* `MAKE_VULKAN_THREADSAFE` preprocessor is used for BUCK and the implementation of thread-safe Vulkan backend. We can quickly exclude it from the BUCK if any unexpected issue gets uncovered in the future. Once we are confident it's stable, we can remove the preprocessor from the code.
* A new perf test is added with `{3,40,221,193}` with 3 threads.
* `vkQueueSubmit` is not thread-safe, only one thread can push the commands at a time (See https://vkguide.dev/docs/chapter-1/vulkan_command_flow/#vulkan-command-execution). The number of available queues depends on GPU. It could be 1 and we cannot assume we can create multiple queues. Thus, we need to avoid calling `vkQueueSubmit` from multiple threads at the same time. When running Vulkan backend in different threads without any locking mechanism, `vkQueueSubmit` will get the `VK_ERROR_INITIALIZATION_FAILED(-3)` error.
* In the `Context::~Context()`, we should not call `flush()` since all per-thread objects will be destroyed as each thread exits. From the following logs, you can verify all per-thread objects are getting destroyed as their threads are terminated. The logs captured all ctor/dtor calls when running Vulkan backend with 3 different threads:
```
ThreadContext::ThreadContext() -> thread[0x1207d5e00] this[0x0x7f9489981e28]
Context::Context() -> thread[0x1207d5e00] this[0x7f9489981800] device_[1]
Resource::Pool::Pool() -> thread[0x7000095ab000] this[0x7f9489965258] device_[0x7f94998cf218] allocator_[0x7f947980ee00]
Command::Pool::Pool() -> thread[0x7000095ab000] this[0x7f9489965068] device_[0x7f94998cf218] command_pool_[0xfa21a40000000003]
Resource::Pool::Pool() -> thread[0x70000962e000] this[0x7f947980d458] device_[0x7f94998cf218] allocator_[0x7f949b119c00]
Command::Pool::Pool() -> thread[0x70000962e000] this[0x7f947980d268] device_[0x7f94998cf218] command_pool_[0xead9370000000008]
Resource::Pool::Pool() -> thread[0x1207d5e00] this[0x7f949a0ee858] device_[0x7f94998cf218] allocator_[0x7f9499901c00]
Command::Pool::Pool() -> thread[0x1207d5e00] this[0x7f949a0ee668] device_[0x7f94998cf218] command_pool_[0xcad092000000000d]
Descriptor::Pool::Pool() -> thread[0x1207d5e00] this[0x7f949a0ee910] device_[0x7f94998cf218] descriptor_pool_[0xa43473000000002d]
Descriptor::Pool::Pool() -> thread[0x70000962e000] this[0x7f947980d510] device_[0x7f94998cf218] descriptor_pool_[0x980b0000000002e]
Descriptor::Pool::Pool() -> thread[0x7000095ab000] this[0x7f9489965310] device_[0x7f94998cf218] descriptor_pool_[0x4b7df1000000002f]
Descriptor::Pool::~Pool() -> thread[0x7000095ab000] this[0x7f9489965310] device_[0x7f94998cf218] descriptor_pool_[0x4b7df1000000002f] -> enter
Descriptor::Pool::~Pool() -> thread[0x7000095ab000] this[0x7f9489965310] device_[0x7f94998cf218] descriptor_pool_[0x4b7df1000000002f] -> leave
Command::Pool::~Pool() -> thread[0x7000095ab000] this[0x7f9489965068] device_[0x7f94998cf218] command_pool_[0xfa21a40000000003] -> enter
Command::Pool::~Pool() -> thread[0x7000095ab000] this[0x7f9489965068] device_[0x7f94998cf218] command_pool_[0xfa21a40000000003] -> leave
Resource::Pool::~Pool() -> thread[0x7000095ab000] this[0x7f9489965258] device_[0x7f94998cf218] allocator_[0x7f947980ee00] -> enter
Descriptor::Pool::~Pool() -> thread[0x70000962e000] this[0x7f947980d510] device_[0x7f94998cf218] descriptor_pool_[0x980b0000000002e] -> enter
Descriptor::Pool::~Pool() -> thread[0x70000962e000] this[0x7f947980d510] device_[0x7f94998cf218] descriptor_pool_[0x980b0000000002e] -> leave
Command::Pool::~Pool() -> thread[0x70000962e000] this[0x7f947980d268] device_[0x7f94998cf218] command_pool_[0xead9370000000008] -> enter
Command::Pool::~Pool() -> thread[0x70000962e000] this[0x7f947980d268] device_[0x7f94998cf218] command_pool_[0xead9370000000008] -> leave
Resource::Pool::~Pool() -> thread[0x70000962e000] this[0x7f947980d458] device_[0x7f94998cf218] allocator_[0x7f949b119c00] -> enter
Resource::Pool::~Pool() -> thread[0x7000095ab000] this[0x7f9489965258] device_[0x7f94998cf218] allocator_[0x7f947980ee00] -> leave
Resource::Pool::~Pool() -> thread[0x70000962e000] this[0x7f947980d458] device_[0x7f94998cf218] allocator_[0x7f949b119c00] -> leave
Descriptor::Pool::~Pool() -> thread[0x1207d5e00] this[0x7f949a0ee910] device_[0x7f94998cf218] descriptor_pool_[0xa43473000000002d] -> enter
Descriptor::Pool::~Pool() -> thread[0x1207d5e00] this[0x7f949a0ee910] device_[0x7f94998cf218] descriptor_pool_[0xa43473000000002d] -> leave
Command::Pool::~Pool() -> thread[0x1207d5e00] this[0x7f949a0ee668] device_[0x7f94998cf218] command_pool_[0xcad092000000000d] -> enter
Command::Pool::~Pool() -> thread[0x1207d5e00] this[0x7f949a0ee668] device_[0x7f94998cf218] command_pool_[0xcad092000000000d] -> leave
Resource::Pool::~Pool() -> thread[0x1207d5e00] this[0x7f949a0ee858] device_[0x7f94998cf218] allocator_[0x7f9499901c00] -> enter
Resource::Pool::~Pool() -> thread[0x1207d5e00] this[0x7f949a0ee858] device_[0x7f94998cf218] allocator_[0x7f9499901c00] -> leave
Context::~Context() -> thread[0x1207d5e00] this[0x7f9489981800] device_[1] -> enter
Context::~Context() -> thread[0x1207d5e00] this[0x7f9489981800] device_[1] -> leave
ThreadContext::~ThreadContext() -> thread[0x1207d5e00] this[0x0x7f9489981e28] -> enter
ThreadContext::~ThreadContext() -> thread[0x1207d5e00] this[0x0x7f9489981e28] -> leave
```
Some notes on unexpected behaviors by `VkQueue`:
* We need to make sure only one thread accesses `VkQueue` at a time if multi-threaded. Or we need to have a locking mechanism to protect `VkQueue` from multiple threads. This approach is used for this change.
* To avoid having lock overhead, we tried to have per-thread `VkQueue` (having separate object per thread) didn't fix `VK_ERROR_INITIALIZATION_FAILED` error by `vkQueueSubmit` call. This was not expected. Interestingly, MacOS doesn't crash with this per-thread approach but no wonder since its behavior has been not that reliable. Not sure it's an Android Vulkan driver issue or not.
* Making the entire `Context` as `thread_local` without any lock actually fixes the same error.
Test Plan:
**Test build on Android**
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_perf_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_perf_test
adb shell "/data/local/tmp/vulkan_perf_test"
```
**Test build on MacOS**
```
cd ~/fbsource
buck build //xplat/caffe2:pt_vulkan_perf_test_binAppleMac
./buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAppleMac\#macosx-x86_64
```
**Test result on Google Pixel 5**
```
//xplat/caffe2:pt_vulkan_perf_test_binAndroid#android-arm64 buck-out/gen/fe3a39b8/xplat/caffe2/pt_vulkan_perf_test_binAndroid#android-arm64
buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAndroid#android-arm64: 1 file pushed, 0 skipped. 145.4 MB/s (826929592 bytes in 5.426s)
Running /data/local/tmp/vulkan_perf_test
Run on (8 X 1804.8 MHz CPU s)
***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead.
=============================================================================================================
Thread-safe Vulkan backend on Google Pixel 5
-------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 55.8 ms 15.1 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 25.6 ms 4.08 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 60.6 ms 14.3 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 4.52 ms 0.757 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 7.16 ms 0.770 ms 5000
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:3 35.9 ms 38.8 ms 3000
=============================================================================================================
Non thread-safe Vulkan backend on Google Pixel 5
-------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 55.0 ms 14.5 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 25.8 ms 4.30 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 60.6 ms 14.5 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 4.52 ms 0.761 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 7.15 ms 0.765 ms 5000
```
For the single thread scenario of thread-safe and non thread-safe versions, the difference between them is less than 2% which is acceptable. In other words, there is no considerable performance degradation with the thread-safe Vulkan backend by using:
* singleton thread local objects for `Command`, `Descriptor` and `Resource` pools
* mutex lock for `VkQueueCommit` call
**Test result on MacOS**
```
Running ./buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAppleMac#macosx-x86_64
Run on (16 X 2400 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x8)
L1 Instruction 32 KiB (x8)
L2 Unified 256 KiB (x8)
L3 Unified 16384 KiB (x1)
Load Average: 11.96, 7.17, 5.45
***WARNING*** Library was built as DEBUG. Timings may be affected.
=============================================================================================================
Thread-safe Vulkan backend on MacOS
-------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 58.4 ms 42.8 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 12.3 ms 5.43 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 56.0 ms 41.2 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 3.00 ms 1.52 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 2.56 ms 1.34 ms 5000
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:3 42.8 ms 42.8 ms 3000
=============================================================================================================
Non thread-safe Vulkan backend on MacOS
-------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 58.6 ms 42.6 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 11.3 ms 4.67 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 57.6 ms 42.4 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 2.89 ms 1.45 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 2.47 ms 1.27 ms 5000
```
Non thread-safe version is slightly faster than the thread-safe one. This test result is only for reference since we cannot trust MacOS that has an extra layer [MoltenVk](https://github.com/KhronosGroup/MoltenVK) on top of `Metal`.
Reviewed By: SS-JIA
Differential Revision: D32093974
fbshipit-source-id: 9eab7f0db976eff717540a5b32f94ed17a00b662
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68198
This unearths some bugs in istft backward, so I've disabled
backward tests but it's fixed in the next PR in the stack.
cc mruberry peterbell10
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D32467044
Pulled By: mruberry
fbshipit-source-id: 5cf49560cbeb0263a66aafb48ed1bcc8884b75f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68226
**Note that this PR is unusually big due to the urgency of the changes. Please reach out to me in case you wish to have a "pair" review.**
This PR introduces a major refactoring of the socket implementation of the C10d library. A big portion of the logic is now contained in the `Socket` class and a follow-up PR will further consolidate the remaining parts. As of today the changes in this PR offer:
- significantly better error handling and much more verbose logging (see the example output below)
- explicit support for IPv6 and dual-stack sockets
- correct handling of signal interrupts
- better Windows support
A follow-up PR will consolidate `send`/`recv` logic into `Socket` and fully migrate to non-blocking sockets.
## Example Output
```
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[W logging.h:28] The server socket on [localhost]:29501 is not yet listening (Error: 111 - Connection refused), retrying...
[I logging.h:21] The server socket will attempt to listen on an IPv6 address.
[I logging.h:21] The server socket is attempting to listen on [::]:29501.
[I logging.h:21] The server socket has started to listen on [::]:29501.
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42650.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42650.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42722.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42722.
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42724.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42724.
[I logging.h:21] The client socket will attempt to connect to an IPv6 address on (127.0.0.1, 29501).
[I logging.h:21] The client socket is attempting to connect to [localhost]:29501.
[I logging.h:21] The client socket has connected to [localhost]:29501 on [localhost]:42726.
[I logging.h:21] The server socket on [::]:29501 has accepted a connection from [localhost]:42726.
```
ghstack-source-id: 143501987
Test Plan: Run existing unit and integration tests on devserver, Fedora, Ubuntu, macOS Big Sur, Windows 10.
Reviewed By: Babar, wilson100hong, mrshenli
Differential Revision: D32372333
fbshipit-source-id: 2204ffa28ed0d3683a9cb3ebe1ea8d92a831325a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68368
Currently, each instance of `StaticRuntime` has its own copy of `std::function` object wrapped in `ProcessedNode::Function` object, in order to invoke actual operation implementation.
However, all instances of `StaticRuntime` derived from same `StaticModule` objects invoke exactly same op implementation, and this is avoidable.
This change adds `StaticModule::functions_` member variable to keep a list of unique instance of `ProcessedFunction` objects. A newly constructed `StaticRuntime` takes `ProcessedFunction`'s pointers instead of the whole function object. This can save a substantial amount of memory per `StaticRuntime` instance.
This comes with a sacrifice in execution time. Now that a `ProcessedNode` instance keeps the function object's pointer, executing a node now involves an extra pointer dereference. However, this cost was proved to be negligible from local performance tests.
Thanks to hlu1 for proposing this non-intrusive improvement idea :D
Test Plan:
This change reduces the size of a StaticRuntime instance by 14.41% (459KB -> 393KB) (patched D32181666 to print the memory turnover from instantiating a StaticRuntime instance) for CMF/local ( & 8% for CMF/local_ro). No noticeable latency regression was observed.
==AFTER
* CMF/local
memory turnover: 393608
latency: PyTorch run finished. Milliseconds per iter: 15.6965. Iters per second: 63.7087
* CMF/local_ro
memory turnover:387288
latency: PyTorch run finished. Milliseconds per iter: 7.51308. Iters per second: 133.101
==BEFORE
* CMF/local
memory turnover: 459888
latency: PyTorch run finished. Milliseconds per iter: 15.8278. Iters per second: 63.18
* CMF/local_ro
memory turnover: 420832
latenfcy: PyTorch run finished. Milliseconds per iter: 7.43756. Iters per second: 134.453
==Confirmation that ptvsc2_predictor_bench reports the same memrmoy management stats for inline_cvr:
==AFTER
Total number of managed tensors: 2660
Total number of managed output tensors: 0
Total number of unmanaged values: 3041
Total memory managed: 1496896 bytes
Total number of reused tensors: 1183
Total number of 'out' variant nodes/total number of nodes: 2452/2469 (99.3115%)
Total number of managed tensors: 1412
Total number of managed output tensors: 0
Total number of unmanaged values: 2677
Total memory managed: 39040 bytes
Total number of reused tensors: 959
Total number of 'out' variant nodes/total number of nodes: 1928/1937 (99.5354%)
Total number of managed tensors: 1293
Total number of managed output tensors: 0
Total number of unmanaged values: 14
Total memory managed: 5293824 bytes
Total number of reused tensors: 771
Total number of 'out' variant nodes/total number of nodes: 1298/1298 (100%)
==BEFORE
Total number of managed tensors: 2660
Total number of managed output tensors: 0
Total number of unmanaged values: 3041
Total memory managed: 1496896 bytes
Total number of reused tensors: 1183
Total number of 'out' variant nodes/total number of nodes: 2452/2469 (99.3115%)
Total number of managed tensors: 1412
Total number of managed output tensors: 0
Total number of unmanaged values: 2677
Total memory managed: 39040 bytes
Total number of reused tensors: 959
Total number of 'out' variant nodes/total number of nodes: 1928/1937 (99.5354%)
Total number of managed tensors: 1293
Total number of managed output tensors: 0
Total number of unmanaged values: 14
Total memory managed: 5293824 bytes
Total number of reused tensors: 771
Total number of 'out' variant nodes/total number of nodes: 1298/1298 (100%)
Reviewed By: swolchok
Differential Revision: D32337548
fbshipit-source-id: e714e735399c93fde337b0f70e203a2de632057a
Summary:
After realizing that CUDA mem leaks were not rerun, I realized I forgot to pass the env var as a Docker variable.
What a noob mistake.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68486
Reviewed By: malfet, seemethere
Differential Revision: D32477989
Pulled By: janeyx99
fbshipit-source-id: e28d095773f50864ab49229e434187a9ecb004cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68316
Consider the following:
```
class Mod(nn.Module):
def __init__(self, val):
super().__init__()
self.param = nn.Parameter(val)
def forward(self, x):
# this method will change during freezing
return x + self.param
torch.jit.export
def make_prediction(self, x):
y = x + x
return self.forward(y)
param = torch.rand([2, 2])
unscripted_mod = Mod(param)
mod = torch.jit.script(unscripted_mod)
mod.eval()
mod = torch.jit.freeze(mod, preserved_attrs=["make_prediction"])`
```
During freezing the following will occur:
1. do some pre-freezing, including inlining; in particular, forward will be inlined into make_prediction. During inlining, forward.optimized_graph() is called, and the result is cached
2. freeze some methods. While freezing forward, the graph associated with the function will get updated. The cached optimized_graphs_ are not updated.
Previously, a call to `mod.forward(x)` would return an exectutor that would run on the old cached optimized_graph(). This would mean that the freezing optimizations would not apply, and potentially that the execution would fail because of parameters removed from the module.
This change clears the optimized_graphs_ cache after running freezing to prevent executing an old version of the graph.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D32410862
Pulled By: davidberard98
fbshipit-source-id: dd8bfe86ec2898b7c72813ab32c08f25c38e4cea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68477
We're printing a lot of unnecessary logs in prod. Change these from LOG(INFO) to VLOG(1) so you can easily flip them back for testing.
Test Plan: CI
Reviewed By: ajyu, d1jang
Differential Revision: D32439776
fbshipit-source-id: 40fa57f4eeb6ca0b610008062cc94aed62fb6981
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68415
remove e4["cpu_iter"] from short list as cpu may take some time to queue both compute and all-gather.
close#68391
ghstack-source-id: 143478769
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D32457334
fbshipit-source-id: baeedfb628ce4554a1ef365c3a2de27b8884f6d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67139
This diff enables setting breakpoint in the graph module's generated python code. See test plan for usage.
In order to support this functionality, and other similar functionalities to customize the generated code, a code transformer functionality is added to `fx.Graph`. This allows flexible customization of `fx.Graph`'s code gen behavior, in composable and functional ways. See test plan for its usage.
Test Plan:
### Use of `fx.experimental.debug.set_trace`
```
In [2]: from torch.fx.experimental.debug import set_trace
In [3]: set_trace(ttop)
Out[3]:
top(
(a): Sub()
)
In [4]: ttop(1)
> /data/users/kefeilu/fbsource33/fbcode/buck-out/dev/gen/caffe2/torch/fb/fx2trt/<eval_with_key>.10(6)forward()
(Pdb) l
1
2
3
4 def forward(self, x):
5 import pdb; pdb.set_trace()
6 -> a = self.a(x); x = None
7 getitem = a[0]
8 getitem_1 = a[0]; a = None
9 add = getitem + getitem_1; getitem = getitem_1 = None
10 return add
11
(Pdb)
```
### Use of `on_generate_code`
```
In [1]: def insert_pdb(body):
...: return ['import pdb; pdb.set_trace()\n', *body]
...:
In [8]: type(ttop)
Out[8]: torch.fx.graph_module.GraphModule.__new__.<locals>.GraphModuleImpl
In [10]: with ttop.graph.on_generate_code(lambda _: insert_pdb):
...: ttop.recompile()
...: print(f"== _on_generate_code should not be None: { ttop.graph._on_generate_code }")
...: print(ttop.code)
...:
== _on_generate_code should not be None: <function insert_pdb at 0x7fc9895ddd30>
def forward(self, x):
import pdb; pdb.set_trace()
a = self.a(x); x = None
getitem = a[0]
getitem_1 = a[0]; a = None
add = getitem + getitem_1; getitem = getitem_1 = None
return add
In [11]: ttop.graph._on_generate_code # restored to None
In [12]: ttop(1) # this should drop into pdb
> /data/users/kefeilu/fbsource33/fbcode/buck-out/dev/gen/caffe2/torch/fb/fx2trt/<eval_with_key>.6(6)forward()
(Pdb) l
1
2
3
4 def forward(self, x):
5 import pdb; pdb.set_trace()
6 -> a = self.a(x); x = None
7 getitem = a[0]
8 getitem_1 = a[0]; a = None
9 add = getitem + getitem_1; getitem = getitem_1 = None
10 return add
11
```
Reviewed By: jamesr66a
Differential Revision: D30736160
fbshipit-source-id: 9646867aae0461b5131dfd4ba9ee77a8c2ea9c93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68160
This generalizes the mechanism D32318674 added for letting native ops borrow their outputs and uses it in dict_unpack.
ghstack-source-id: 143424919
Test Plan:
4.5% in CMF local_ro compared to D32318674 (previous two diffs were necessary steps but didn't get the full win yet):
```
FastAliasingInSelectTensor, local_ro
========================================
I1110 22:06:37.549811 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08488. Iters per second: 921.76
I1110 22:06:38.147949 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08675. Iters per second: 920.171
I1110 22:06:38.766340 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08626. Iters per second: 920.592
I1110 22:06:39.366608 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08376. Iters per second: 922.717
I1110 22:06:39.964979 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08362. Iters per second: 922.833
I1110 22:06:40.565248 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08423. Iters per second: 922.312
I1110 22:06:41.167326 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.0945. Iters per second: 913.659
I1110 22:06:41.766187 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08373. Iters per second: 922.742
I1110 22:06:42.367816 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08995. Iters per second: 917.475
I1110 22:06:42.968391 119627 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.08854. Iters per second: 918.665
I1110 22:06:42.968446 119627 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.08662, standard deviation: 0.00351662
BorrowDictUnpackOutputs, local_ro
========================================
I1110 22:05:23.245435 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.03272. Iters per second: 968.313
I1110 22:05:23.822196 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.06478. Iters per second: 939.163
I1110 22:05:24.395256 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.035. Iters per second: 966.186
I1110 22:05:24.964169 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.02786. Iters per second: 972.898
I1110 22:05:25.536558 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.03205. Iters per second: 968.946
I1110 22:05:26.109027 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.04256. Iters per second: 959.174
I1110 22:05:26.679611 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.03245. Iters per second: 968.567
I1110 22:05:27.253048 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.04493. Iters per second: 957.005
I1110 22:05:27.822629 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.0299. Iters per second: 970.971
I1110 22:05:28.393326 113949 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.03039. Iters per second: 970.509
I1110 22:05:28.393368 113949 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.03726, standard deviation: 0.0111053
```
0.04936 (4.5%) usec/iter improvement
Reviewed By: hlu1
Differential Revision: D32347390
fbshipit-source-id: e636ddafacf30ed2a2d84a6e15fff97481342fdb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68159
These all look like they'll cause unnecessary refcount bumps to me.
ghstack-source-id: 143424917
Test Plan:
CI
TODO profile local_ro?
Reviewed By: hlu1
Differential Revision: D32347392
fbshipit-source-id: d8ed91b5855b86765db00c61ad3650273302c7b6
Summary:
The `torch.histogramdd` operator is documented in `torch/functional.py` but does not appear in the generated docs because it is missing from `docs/source/torch.rst`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68273
Reviewed By: cpuhrsch
Differential Revision: D32470522
Pulled By: saketh-are
fbshipit-source-id: a23e73ba336415457a30bae568bda80afa4ae3ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68158
to() sometimes returns a reference; let's forward that through.
ghstack-source-id: 143424916
Test Plan: Combined with following diff, seeing a huge drop in dict_unpack self time in ctr_mobile_feed local_ro net. Following diff by itself didn't work.
Reviewed By: suo
Differential Revision: D32347391
fbshipit-source-id: da96295bf83ea30867a2e3fceedc9b4e0a33ffa3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68157
Does what it says on the tin. I don't have a use for `MaybeOwned<IValue>` itself right now, but following diffs will use `MaybeOwnedTraits<IValue>::{create,destroy}Borrow` and I thought it best to just provide the full thing.
ghstack-source-id: 143424915
Test Plan: Extended MaybeOwned tests to cover this.
Reviewed By: hlu1
Differential Revision: D32347393
fbshipit-source-id: 219658cb69b951d36dee80c2ae51387328224866
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67702
This isn't a particularly large optimization and it does
nothing before select_tensor is introduced (I'm surprised that no
operators have optimizable outputs!), but it seems like we should probably get the savings.
ghstack-source-id: 143424918
Test Plan: CI; checked `--do_profile=1` ouput with following diff and we save tracking hundreds of values, as expected.
Reviewed By: hlu1
Differential Revision: D32112522
fbshipit-source-id: 1804b77992a73670bfc1e36af608b852b8261bd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68367
- bmm_test.py was using syntax not allowed in 3.6
- Some suppressions were not placed on the correct line.
With this file,
```
lintrunner --paths-cmd='git grep -Il .'
```
passes successfully.
Test Plan: Imported from OSS
Reviewed By: janeyx99, mrshenli
Differential Revision: D32436644
Pulled By: suo
fbshipit-source-id: ae9300c6593d8564fb326822de157d00f4aaa3c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67935
Rationale should be documented in code comments. In short, we
can avoid heap-allocating arrays of input indexes for operators with 5
or fewer inputs, at the cost of a tag bit check on access.
ghstack-source-id: 143429112
Test Plan:
Patched d1jang's D32181666, which prints static runtime memory usage.
Previous diff, local:
```
I1105 12:17:36.459688 866763 PyTorchStaticRuntimePredictor.cpp:82] memory turnover after creating an instance of StaticRuntime: 354208
```
This diff, local:
```
I1105 12:48:35.820663 1066520 PyTorchStaticRuntimePredictor.cpp:82] memory turnover after creating an instance of StaticRuntime: 338064
```
4.5% savings (16144 bytes)
Ran 10 repetitions of CMF local_ro with core pinning: P467095603. This diff is perf neutral compared to the previous diff.
Reviewed By: hlu1
Differential Revision: D32216573
fbshipit-source-id: d18483db255f75f1d90e610ecded7727c6ffe65c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67934
This reduces the memory requirements of ProcessedNode: by allocating outputs sequentially into a shared array and supporting at most 2**16 - 1 values (current models seem to have 10-20x less than that), we only need to store the 2-byte offset into that array and 2-byte number of outputs in ProcessedNode.
ghstack-source-id: 143429113
Test Plan:
Patched d1jang's diff to measure memory turnover around SR startup.
Previous diff, CMF local:
```
I1104 12:19:39.900211 597593 PyTorchStaticRuntimePredictor.cpp:82] memory turnover after creating an instance of StaticRuntime: 427120
```
This diff, CMF local:
```
I1105 12:17:36.459688 866763 PyTorchStaticRuntimePredictor.cpp:82] memory turnover after creating an instance of StaticRuntime: 354208
72912 bytes (17%) savings
```
Perf looks neutral; see next diff (D32216573) test plan for details.
Reviewed By: hlu1
Differential Revision: D32190751
fbshipit-source-id: 30c1e2caa9460f0d83b2d9bb24c68ccfcef757cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67860
We don't need 8-byte sizes for inputs and outputs, and we only need op names if profiling isn't disabled.
ghstack-source-id: 143429111
Test Plan:
Ran CMF local & local_ro with recordio inputs. I'm calling
the result inconclusive/neutral because I saw some noise (as you'll
see below), but that's fine with me since this is a clear memory win.
```
Nov4Stable, local_ro
========================================
I1104 09:53:08.875444 505783 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.19925. Iters per second: 833.851
I1104 09:53:10.200443 505783 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.1996. Iters per second: 833.608
I1104 09:53:11.524045 505783 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.19746. Iters per second: 835.103
I1104 09:53:12.851861 505783 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.20479. Iters per second: 830.019
I1104 09:53:14.183387 505783 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.20487. Iters per second: 829.964
I1104 09:53:14.183427 505783 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.2012, standard deviation: 0.00341762
re-ran stable in light of baffling regression (see next entry), and sure enough we still have some significant run-to-run-variation:
I1104 09:56:15.244969 524012 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.24956. Iters per second: 800.28
I1104 09:56:16.621292 524012 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.24776. Iters per second: 801.437
I1104 09:56:18.018808 524012 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.25247. Iters per second: 798.42
I1104 09:56:19.399660 524012 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.25054. Iters per second: 799.656
I1104 09:56:20.781828 524012 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.25052. Iters per second: 799.664
I1104 09:56:20.781878 524012 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.25017, standard deviation: 0.00171396
Nov4SaveTwoWordsInProcessedNode, local_ro
========================================
I1104 09:53:42.070139 508309 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.2411. Iters per second: 805.736
I1104 09:53:43.438390 508309 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.24102. Iters per second: 805.788
I1104 09:53:44.773303 508309 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.20682. Iters per second: 828.621
I1104 09:53:46.110538 508309 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.21216. Iters per second: 824.973
I1104 09:53:47.448279 508309 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.21265. Iters per second: 824.639
I1104 09:53:47.448334 508309 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.22275, standard deviation: 0.0168698
early runs look like a glitch, rerunning
I1104 09:54:20.999117 511022 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.24558. Iters per second: 802.841
I1104 09:54:22.376780 511022 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.24436. Iters per second: 803.623
I1104 09:54:23.738584 511022 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.23176. Iters per second: 811.845
I1104 09:54:25.113063 511022 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.24938. Iters per second: 800.395
I1104 09:54:26.476349 511022 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.23552. Iters per second: 809.377
I1104 09:54:26.476395 511022 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.24132, standard deviation: 0.00737197
Nov4Stable, local
========================================
I1104 09:57:56.854537 533814 PyTorchPredictorBenchLib.cpp:346] memory turnover after getPredictor: 177885632
I1104 09:58:02.829813 533814 PrepareModelInputs.cpp:190] Loaded 696 records.
I1104 09:58:03.010681 533814 PyTorchPredictorBenchLib.cpp:353] memory turnover before benchmarking: 4590507056
I1104 09:58:03.010710 533814 PyTorchPredictorBenchLib.cpp:154] PyTorch predictor: number of prediction threads 1
I1104 09:58:58.839010 533814 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 20.0567. Iters per second: 49.8586
I1104 09:59:54.797755 533814 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 20.1007. Iters per second: 49.7494
I1104 10:00:50.696525 533814 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 20.0657. Iters per second: 49.8363
I1104 10:01:46.514736 533814 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 20.0696. Iters per second: 49.8265
I1104 10:02:42.378270 533814 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 20.0641. Iters per second: 49.8402
I1104 10:02:42.378316 533814 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 20.0714, standard deviation: 0.0170605
I1104 10:02:42.378325 533814 PyTorchPredictorBenchLib.cpp:366] memory turnover after benchmarking: 4591882400
Nov4SaveTwoWordsInProcessedNode, local
========================================
I1104 10:38:15.543320 733514 PyTorchPredictorBenchLib.cpp:346] memory turnover after getPredictor: 177721792
I1104 10:38:21.224673 733514 PrepareModelInputs.cpp:190] Loaded 696 records.
I1104 10:38:21.382973 733514 PyTorchPredictorBenchLib.cpp:353] memory turnover before benchmarking: 4590343216
I1104 10:38:21.382992 733514 PyTorchPredictorBenchLib.cpp:154] PyTorch predictor: number of prediction threads 1
I1104 10:39:17.005359 733514 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.9498. Iters per second: 50.1257
I1104 10:40:12.545269 733514 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.9279. Iters per second: 50.1808
I1104 10:41:08.138119 733514 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.999. Iters per second: 50.0026
I1104 10:42:03.686841 733514 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.9115. Iters per second: 50.2222
I1104 10:42:55.137498 733539 Proxy2Connection.cpp:343] Received NotRegisteredException from Configerator Proxy2.
I1104 10:42:55.138715 733539 ReadOnlyConnectionIf.h:91] Mark connection as healthy.
I1104 10:42:55.384534 733514 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.6297. Iters per second: 50.9433
I1104 10:42:55.384579 733514 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 19.8836, standard deviation: 0.14571
I1104 10:42:55.384588 733514 PyTorchPredictorBenchLib.cpp:366] memory turnover after benchmarking: 4591711760
```
Reviewed By: d1jang
Differential Revision: D32177531
fbshipit-source-id: 267e38a151d2dbab34fd648135d173cfbee1c22e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68028
Today, we demangle a typename before passing it to the TorchScript
compiler. This breaks compilation of torch classes in cases where we are
attempting to script the same class name from inside a package and out,
since we will return the same qualified name for both.
Differential Revision:
D32261907
D32261907
Test Plan: Imported from OSS
Reviewed By: saketh-are
Pulled By: suo
fbshipit-source-id: 921bc03ad385d94b9279fbc6f3b7dcd0ddbe5bc7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68311
prim::SetAttr is listed as an op with side effects, but in AliasDb, `analyzeSetAttr` already accounts for its behavior. By removing it from the list of ops with side effects, dead code elimination will work in a few other scenarios.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32409510
fbshipit-source-id: 52ed9e19f92afb95c669ad3c2440f72f9515ba4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68335
When discussing https://github.com/pytorch/pytorch/pull/63880, we
realised that the docs of `householder_product` were not correct. This
PR fixes this.
The new docs are slightly more difficult, but hopefully correct. Note
that this is a LAPACK function in disguise, so it is expected the
specification to be more difficult than normal.
cc brianjo mruberry jianyuh nikitaved pearu walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32429755
Pulled By: mruberry
fbshipit-source-id: 3ac866d30984adcd9f3b83d7fa9ae7b7ae5d4b53
Summary:
As per title.
It is planned to use these tests for fixing issues with the max_unpools' backward methods reported in https://github.com/pytorch/pytorch/issues/67658 and https://github.com/pytorch/pytorch/issues/67657.
max_unpool.backward methods are not tested and implemented with custom kernels. We can replace these kernels with advanced indexing operations (i.e. `gather`) which are efficient and well tested.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68075
Reviewed By: malfet
Differential Revision: D32308317
Pulled By: mruberry
fbshipit-source-id: 9f91c6e6a9d78c19230e93fc0a3164f4eb7b8ec5
Summary:
There were two issues with the original PR:
1) My assumption that bound C functions could be trusted to stay alive was not valid. I'm still not entirely sure what was dying, but I've just added a cache so that the first time I see a function I collect the repr just like I was already doing with Python functions.
2) `std::regex` is known to be badly broken and prone to segfaults. Because I'm just doing a very simple prefix prune it's fine to do it manually; see `trimPrefix`. Long term we should move all of PyTorch to `re2` as the internal lint suggests, but CMake is hard and I couldn't get it to work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68325
Reviewed By: chaekit
Differential Revision: D32432596
Pulled By: robieta
fbshipit-source-id: 06fb4bcdc6933a3e76f6021ca69dc77a467e4b2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68365
title. broadcast fastpath has been running fine for the enabled ops for a while now, so make it the default for these ops.
Test Plan: diff is a no-op, so sandcastle
Differential Revision: D32107847
fbshipit-source-id: b239b127b219985bf7df6a0eea2d879b8e9c79a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68266
* Use `if...endif` to adjust pyTorch internals towards XROS
Test Plan: CI
Reviewed By: kkosik20
Differential Revision: D32190771
fbshipit-source-id: cce073dea53c2b5681d913321101cd83c6472019
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67812
`UpdateShape` uses `.emplace(tensorName, shapeValue)`. This will not update `shapeValue` for `tensorName`, if such name already exist in the map. Hence our code is not able to correct the shape inference error, even if we inferred the shape correctly later.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32181300
Pulled By: malfet
fbshipit-source-id: 05c58ad3fdac683ad957996acde8f0ed6341781d
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68176
it should be noted that for the modules, reduce_range is set to
true by default in a similar fashion to linear_dynamic.
Test Plan:
python test/test_quantization.py TestDynamicQuantizedModule
python test/test_quantization.py TestDynamicQuantizedConv
python test/test_quantization.py TestQuantizedConv
Imported from OSS
Reviewed By: kimishpatel
Differential Revision: D32374003
fbshipit-source-id: 011562bd0f4d817387d53bb113df2600aa60a7a3
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28418
Related https://github.com/pytorch/pytorch/issues/32976 but has already been fixed before.
TorchScript handling of GRU and LSTM have been working, but not for RNN (Tanh and ReLU). The reason is that the ```Union[Tensor, PackedSequence]``` is not supported by TorchScript. Using ```torch._jit_internal._overload_method``` in ```RNNBase::Forward``` does not work, as it seems TorchScript does not correctly use them if the method gets inherited by ```RNN```. My solution is to move the ```RNNBase::forward``` to ```RNN``` and annotate using ```torch._jit_internal._overload_method```. LSTM and GRU anyway use their own ```forward``` methods, so there seems to be no problem related to this fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61274
Reviewed By: anjali411
Differential Revision: D32374452
Pulled By: malfet
fbshipit-source-id: 77bab2469c01c5dfa5eaab229429724a4172445d
Co-authored-by: Nikita Shulga <nshulga@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68091
Add record functions for recording perf stats on the entire network.
Note that this is backed by the same pre-sampling mechanism as the op record functions, so net level stats get logged relatively infrequently. (If this is not acceptable, we can not use pre-sampling at the cost of a little bit of perf, every inference will require an RNG call)
Reviewed By: hlu1
Differential Revision: D32296756
fbshipit-source-id: 09ff16c942f3bfc8f4435d6cca2be4a6b8dc6091
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68011
`qnnpack/operator.h` introduces a dependency on an external library fp16 via `qnnpack/requantization.h`.
Including `qnnpack/operator.h` in `pytorch_qnnpack.h` will make objects who really don't require fp16 depend on it indirectly because they include `pytorch_qnnpack.h`.
This was causing some test and bench targets to fail building for local and android/arm64 (only two tried) using cmake.
This diff moves `qnnpack/operator.h` from `pytorch_qnnpack.h` to `qnnpack_func.h`, and explicitly add `qnnpack/operator.h` in `src/conv-prepack.cc`.
Test Plan: Ran all the tests for local on my devserver, and arm64 on Pixel3a.
Reviewed By: salilsdesai
Differential Revision: D32250984
fbshipit-source-id: 21468d8ef79c90e9876dc00da95383180a1031b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68360
Added a helper function to do this. Only use `mod` to convert negative dim to positive. Do nothing when it's already positive.
Previously in `getitem` if we are slicing to the very end, we will get the dimension wrong.
Test Plan: Add a unit test
Reviewed By: yinghai, wushirong
Differential Revision: D32432893
fbshipit-source-id: 3c5d6a578d92a15207a5e52802750f9ea7f272a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68354
Lint rule: https://clang.llvm.org/extra/clang-tidy/checks/modernize-use-nodiscard.html
This check adds a ton of noise to our diffs. `[[nodiscard]]` is typically only useful when ignoring the return value of a function is a critical error, e.g. for `operator new`.
Test Plan: Verified that the lint does not get triggered
Reviewed By: hlu1
Differential Revision: D32429731
fbshipit-source-id: ca3d90686ec8d419d3f96167140dc406df6f4a53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67000
See the [related issue](https://github.com/pytorch/pytorch/issues/66654) for context.
This new JIT optimization transforms patterns like this:
```
%inputs.1 : Tensor[] = prim::ListConstruct(%a, %b, %c)
%concat.1 : Tensor = aten::cat(%inputs, %dim)
%inputs.2 : Tensor[] = prim::ListConstruct(%x, %concat.1, %y)
%concat.2 : Tensor = aten::cat(%inputs.2, %dim)
```
into this:
```
%inputs.2 : Tensor[] = prim::ListConstruct(%x, %a, %b, %c, %y)
%concat.2 : Tensor = aten::cat(%inputs.2, %dim)
```
(it can do this for chains of `aten::cat` longer than 2 as well)
A few conditions have to hold:
1. The `dim`s have to match.
2. `inputs.1` and `inputs.2` cannot be mutated
Test Plan: `buck test caffe2/test/cpp/jit:jit -- ConcatOpt`
Reviewed By: d1jang
Differential Revision: D31819491
fbshipit-source-id: 9f1a501d52099eb1a630b5dd906df4c38c3817ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68292
- noqa was typo-d to be the same as type: ignore
- generalize clang-tidy initialization and use it for clang_format as well
- Add a script that lets you update the binaries in s3 relatively easily
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32403934
Pulled By: suo
fbshipit-source-id: 4e21b22605216f013d87d636a205707ca8e0af36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67784
FX model generates quant/dequant layers for INT8 explicit mode support. However, if the inputs of quant/dequant layers are constant, the layer will be put into constant subgraph and optimized out. Hence TensorRT will fails to parse the left over graph. It is better to set up an optional function (skip_folding_node_fn) to skip folding nodes for split_const_subgraphs.
Reviewed By: jfix71
Differential Revision: D32076970
fbshipit-source-id: 7dcbb4f02386f8c831d09a2f0e40bcdba904471c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67783
Add `getstate_hook` to exclude primitive objects and callable when serialization when `exclude_primitive` is enabled for `traverse`.
For graph traversing, we don't have to handle the lambda and other stuff.
This is used by `OnDiskCacheHolder` to trace the DataPipe Graph.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D32146697
Pulled By: ejguan
fbshipit-source-id: 03b2ce981bb21066e807f57c167b77b2d0e0ce61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68318
Adding a `__iter__` binding so that when we do `tuple(Dims)` can construct the right iterator and knows where to stop instead of trial and error with exception catch. We should upstream this to https://github.com/NVIDIA/TensorRT. cc: wushirong
I did try a very similar `__iter__` fix previsouly but not sure why it wasn't effective...
Reviewed By: kflu, wushirong
Differential Revision: D32412430
fbshipit-source-id: 6390a1275dc34ef498acf933bb96f636c15baf41
Summary:
...because we don't like segfaults from Python (see test).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68253
Reviewed By: suo
Differential Revision: D32396747
Pulled By: gmagogsfm
fbshipit-source-id: a0925e8479702766e88176280985a63bc79e4f6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68223
DETAIL debug mode didn't work with object-based collectives for NCCL backend, because we'd only check if backend is NCCL and then move tensors to CUDA.
Instead, check if it is a wrapped PG, and then check the pg that is wrapped to see if its nccl.
ghstack-source-id: 143242023
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32366840
fbshipit-source-id: be0a2af6849f8f24446593f4a4fbea4a67586ee5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67347
This PR:
- changes the warning when torch.vmap gets called to suggest using
functorch.vmap
- changes the warning when a batching rule isn't implemented to suggest
using functorch.vmap
Test Plan: - test/test_vmap.py
Reviewed By: H-Huang
Differential Revision: D31966603
Pulled By: zou3519
fbshipit-source-id: b01dc1c2e298ce899b4a3a5fb333222a8d5bfb56
Summary:
This PR does NOT change how signal is displayed in CI but rather just reports stats of flaky tests to RDS. **None of the below will be enabled after landing this PR--it will be done in a separate PR with environment variables.**
We report flaky tests stats when a test first fails, and when we rerun it MAX_NUM_RETRIES times, we get at least one success.
For tests that fail all the reruns, we assume it is because it is a real test failure.
For tests that succeed the first time, we do not rerun the test, even if it was previously noted as flaky.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68150
Test Plan:
First, I modified:
test_async_python to always fail (will be our "failing test")
test_async_future_type_python to fail 40% of the time
test_async_script_capture to fail 60% of the time
Then, running `python test/test_jit.py -v -k test_async` while setting IN_CI to 1:
```
(pytorch) janeyx@janeyx-mbp pytorch % python test/test_jit.py -v -k test_async
...
Running tests...
----------------------------------------------------------------------
test_async_future_type_python (jit.test_async.TestAsync) ... ok (0.004s)
test_async_grad_guard_no_grad (jit.test_async.TestAsync) ... ok (0.020s)
test_async_grad_guard_with_grad (jit.test_async.TestAsync) ... ok (0.008s)
test_async_kwargs (jit.test_async.TestAsync) ... ok (0.045s)
test_async_parsing (jit.test_async.TestAsync) ... ok (0.010s)
test_async_python (jit.test_async.TestAsync) ... FAIL (0.003s)
test_async_python failed - num_retries_left: 3
test_async_python (jit.test_async.TestAsync) ... FAIL (0.003s)
test_async_python failed - num_retries_left: 2
test_async_python (jit.test_async.TestAsync) ... FAIL (0.003s)
test_async_python failed - num_retries_left: 1
test_async_python (jit.test_async.TestAsync) ... FAIL (0.003s)
test_async_python failed - num_retries_left: 0
test_async_script (jit.test_async.TestAsync) ... ok (0.008s)
test_async_script_capture (jit.test_async.TestAsync) ... FAIL (0.010s)
test_async_script_capture failed - num_retries_left: 3
test_async_script_capture (jit.test_async.TestAsync) ... FAIL (0.010s)
test_async_script_capture failed - num_retries_left: 2
test_async_script_capture (jit.test_async.TestAsync) ... ok (0.011s)
test_async_script_capture succeeded - num_retries_left: 1
test_async_script_capture (jit.test_async.TestAsync) ... FAIL (0.010s)
test_async_script_capture failed - num_retries_left: 0
test_async_script_error (jit.test_async.TestAsync) ... ok (0.040s)
test_async_script_multi_forks (jit.test_async.TestAsync) ... ok (0.025s)
test_async_script_multi_waits (jit.test_async.TestAsync) ... ok (0.009s)
...
======================================================================
FAIL [0.003s]: test_async_python (jit.test_async.TestAsync)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/janeyx/pytorch/test/jit/test_async.py", line 30, in test_async_python
self.assertTrue(False)
AssertionError: False is not true
======================================================================
FAIL [0.010s]: test_async_script_capture (jit.test_async.TestAsync)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/janeyx/pytorch/test/jit/test_async.py", line 123, in test_async_script_capture
self.assertTrue(False)
AssertionError: False is not true
----------------------------------------------------------------------
Ran 28 tests in 0.399s
FAILED (failures=2, expected failures=5, unexpected successes=1)
```
Yielding this as the test report (I changed the extension from xml to txt so it uploads here):
[TEST-jit.test_async.TestAsync-20211110222055.txt](https://github.com/pytorch/pytorch/files/7517532/TEST-jit.test_async.TestAsync-20211110222055.txt)
And then running print_test_stats correctly excludes the all failing test `test_async_python` and calculates red and green appropriately:
```
(pytorch) janeyx@janeyx-mbp pytorch % python tools/stats/print_test_stats.py test-reports/python-unittest/test.test_jit
[scribe] Not invoking RDS lambda outside GitHub Actions:
[{'create_table': {'table_name': 'flaky_tests', 'fields': {'name': 'string', 'suite': 'string', 'file': 'string', 'num_green': 'int', 'num_red': 'int', 'pr': 'string', 'ref': 'string', 'branch': 'string', 'workflow_id': 'string', 'build_environment': 'string'}}}]
[scribe] Writing for None
[scribe] Wrote stats for flaky_tests
[scribe] Not invoking RDS lambda outside GitHub Actions:
[{'write': {'table_name': 'flaky_tests', 'values': {'name': 'test_async_script_capture', 'suite': 'jit.test_async.TestAsync', 'file': 'test/test_jit', 'num_green': 1, 'num_red': 3, 'pr': None, 'ref': None, 'branch': None, 'workflow_id': None, 'build_environment': 'linux-xenial-gcc5.4-py3'}}}]
(pytorch) janeyx@janeyx-mbp pytorch %
```
-------------------
If you're curious, I also included the code for when we would like to override the report_only feature and also hide flaky signal in CI. The results for the same test command correctly still fail the test suite, but mark the flaky test_async_future_type_python as passed:
```
(pytorch) janeyx@janeyx-mbp pytorch % python test/test_jit.py -v -k test_async
...
Running tests...
----------------------------------------------------------------------
test_async_future_type_python (jit.test_async.TestAsync) ... FAIL (0.004s)
test_async_future_type_python failed - num_retries_left: 3
test_async_future_type_python (jit.test_async.TestAsync) ... ok (0.001s)
test_async_grad_guard_no_grad (jit.test_async.TestAsync) ... ok (0.017s)
test_async_grad_guard_with_grad (jit.test_async.TestAsync) ... ok (0.008s)
test_async_kwargs (jit.test_async.TestAsync) ... ok (0.091s)
test_async_parsing (jit.test_async.TestAsync) ... ok (0.010s)
test_async_python (jit.test_async.TestAsync) ... FAIL (0.003s)
test_async_python failed - num_retries_left: 3
test_async_python (jit.test_async.TestAsync) ... FAIL (0.003s)
test_async_python failed - num_retries_left: 2
test_async_python (jit.test_async.TestAsync) ... FAIL (0.004s)
test_async_python failed - num_retries_left: 1
test_async_python (jit.test_async.TestAsync) ... FAIL (0.003s)
test_async_python failed - num_retries_left: 0
test_async_script (jit.test_async.TestAsync) ... ok (0.008s)
test_async_script_capture (jit.test_async.TestAsync) ... ok (0.011s)
test_async_script_error (jit.test_async.TestAsync) ... ok (0.039s)
...
======================================================================
FAIL [0.003s]: test_async_python (jit.test_async.TestAsync)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/janeyx/pytorch/test/jit/test_async.py", line 30, in test_async_python
self.assertTrue(False)
AssertionError: False is not true
----------------------------------------------------------------------
Ran 26 tests in 0.390s
FAILED (failures=1, expected failures=4)
```
With test reports:
[TEST-jit.test_async.TestAsync-20211110224810.txt](https://github.com/pytorch/pytorch/files/7517663/TEST-jit.test_async.TestAsync-20211110224810.txt)
And running print_test_stats:
```
(pytorch) janeyx@janeyx-mbp pytorch % python tools/stats/print_test_stats.py test-reports/python-unittest/test.test_jit
[scribe] Not invoking RDS lambda outside GitHub Actions:
[{'create_table': {'table_name': 'flaky_tests', 'fields': {'name': 'string', 'suite': 'string', 'file': 'string', 'num_green': 'int', 'num_red': 'int', 'pr': 'string', 'ref': 'string', 'branch': 'string', 'workflow_id': 'string', 'build_environment': 'string'}}}]
[scribe] Writing for None
[scribe] Wrote stats for flaky_tests
[scribe] Not invoking RDS lambda outside GitHub Actions:
[{'write': {'table_name': 'flaky_tests', 'values': {'name': 'test_async_future_type_python', 'suite': 'jit.test_async.TestAsync', 'file': 'test/test_jit', 'num_green': 1, 'num_red': 1, 'pr': None, 'ref': None, 'branch': None, 'workflow_id': None, 'build_environment': 'linux-xenial-gcc5.4-py3'}}}]
```
Reviewed By: saketh-are
Differential Revision: D32393907
Pulled By: janeyx99
fbshipit-source-id: 37df890481ab84c62809c022dc6338b50972899c
Summary:
Cub routines are both expensive to compile and used in multiple
different operators throughout the cuda folder. So, it makes sense to
compile them in one centralized place where possible (i.e. when
custom operators aren't involved).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67650
Reviewed By: mruberry
Differential Revision: D32259660
Pulled By: ngimel
fbshipit-source-id: 5f7dbdb134297e1ffdc1c7fc5aefee70a2fa5422
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68067
Embedding QAT uses a NoopObserver class for activation,
and a FakeQuant for weight, make sure that qconfig comparison
functions properly for a mix of partial function and class in
qconfig.
Test Plan:
`pytest test/quantization/eager/test_quantize_eager_qat.py -v -k "test_embedding_qat_qconfig_equal"`
Imported from OSS
Reviewed By: HDCharles
Differential Revision: D32318434
fbshipit-source-id: c036eef9cbabe7c247745930501328e9c75a8cb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68255
Manually disabling these two tests because they can't be disabled via Probot.
See the issues #68222 and #68173 for details.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Test Plan: Imported from OSS
Reviewed By: malfet, saketh-are
Differential Revision: D32390899
Pulled By: NivekT
fbshipit-source-id: bd4996d73014337a9175b20ae67a3880ee994699
Summary:
This PR instruments the CPython interpreter and integrates the resulting trace into the PyTorch profiler.
The python tracing logic works by enabling `PyEval_SetProfile`, and then logging the minimal information to track every time python calls or returns from a function. A great deal of care has gone into keeping this process very lightweight; the `RawEvent` struct is only two words and doesn't do anything fancy. When a python function is called, we have to do extra work. If the call is to `nn.Module.__call__`, we simply incref to extend the life of the module. Otherwise we check if we have seen the function before, and if not go through the (somewhat expensive) task of saving the strings which we then cache.
To actually get a useful timeline, we have to replay the events to determine the state of the python stack at any given point. A second round of stack replay is needed to figure out what the last python function was for each torch op so we can reconstruct the correct python stack. All of this is done during post processing, so while we want to be reasonably performant it is no longer imperative to shave every last bit.
I still need to do a bit of refinement (particularly where the tracer interfaces with the profiler), but this should give a good sense of the general structure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67407
Test Plan:
```
import torch
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(2, 2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.linear(x)
return self.relu(x)
def call_module():
m = MyModule()
for _ in range(4):
m(torch.ones((2, 2)))
def top_level_fn():
with torch.profiler.profile(with_stack=True) as p:
call_module()
p.export_chrome_trace("test_trace.json")
top_level_fn()
```
<img width="1043" alt="Screen Shot 2021-10-27 at 6 43 18 PM" src="https://user-images.githubusercontent.com/13089297/139171803-f95e70f3-24aa-45e6-9d4b-6d437a3f108d.png">
PS: I've tried to comment liberally, particularly around some of the more magical parts. However I do plan on doing another linting and commenting pass. Hopefully it's not too bad right now.
Reviewed By: gdankel, chaekit
Differential Revision: D32178667
Pulled By: robieta
fbshipit-source-id: 118547104a7d887e830f17b94d3a29ee4f8c482f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68099
When an op in the graph cannot be matched to any known ops, alias_analysis.cpp throws an error.
Before:
```
RuntimeError: 0INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":612, please report a bug to PyTorch. We don't have an op for aten::add but it isn't a special case. Argument types: Tensor, float, Tensor,
```
After:
```
RuntimeError: 0INTERNAL ASSERT FAILED at "../torch/csrc/jit/ir/alias_analysis.cpp":612, please report a bug to PyTorch. We don't have an op for a
ten::add but it isn't a special case. Argument types: Tensor, float, Tensor,
Candidates:
aten::add.Tensor(Tensor self, Tensor other, *, Scalar alpha=1) -> (Tensor)
aten::add.Scalar(Tensor self, Scalar other, Scalar alpha=1) -> (Tensor)
aten::add.out(Tensor self, Tensor other, *, Scalar alpha=1, Tensor(a!) out) -> (Tensor(a!))
aten::add.t(t[] a, t[] b) -> (t[])
aten::add.str(str a, str b) -> (str)
aten::add.int(int a, int b) -> (int)
aten::add.complex(complex a, complex b) -> (complex)
aten::add.float(float a, float b) -> (float)
aten::add.int_complex(int a, complex b) -> (complex)
aten::add.complex_int(complex a, int b) -> (complex)
aten::add.float_complex(float a, complex b) -> (complex)
aten::add.complex_float(complex a, float b) -> (complex)
aten::add.int_float(int a, float b) -> (float)
aten::add.float_int(float a, int b) -> (float)
aten::add(Scalar a, Scalar b) -> (Scalar)
```
Test Plan:
Run
```
import torch
if __name__ == '__main__':
ir = """
graph(%x : Tensor,
%y : Tensor):
%2 : float = prim::Constant[value=1.2]()
%result : Tensor= aten::add(%x, %2, %y)
return (%result)
"""
x = torch.tensor([[1., 2.], [3., 4.]])
y = torch.tensor([[2., 1.], [2., 1.]])
graph = torch._C.parse_ir(ir)
print(graph)
graph.alias_db().analyze()
# print(script(x, y))
```
to get the results above
Imported from OSS
Reviewed By: anjali411
Differential Revision: D32339639
fbshipit-source-id: a79a3c2f157154b5fb1e3f33a23e43b7884e8e38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68201
Hash(c10::Scalar) made a bad assumption that it was valid to just hash over all the bytes of data of the c10::Scalar struct.
Becuase c10::Scalar stores a union of different (float/int/complex) types with different sizes, not all bytes are valid in all cases. Hash() should only read the bytes corresponding to the currently active type.
Test Plan: Added new unit tests. Verified HashTest.Scalar failed with the original Hash() impl and then fixed.
Reviewed By: alanwaketan
Differential Revision: D32367564
fbshipit-source-id: ac30dd4f6dd0513954986d3d23c0c11ba802c37b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68175
This slightly alters the way from_float works so it will work
with placeholder observers. It also fixes a but with ConvTranspose3d and
ConvTranspose1d where the parameters like kernel_size, stride...etc
weren't set properly. New tests were added to check for this type of
issue as well.
Test Plan:
python test/test_quantization.py TestQuantizedOps
python test/test_quantization.py TestStaticQuantizedModule
Imported from OSS
Reviewed By: z-a-f
Differential Revision: D32374004
fbshipit-source-id: caaa548d12d433d9c1fa0abc8597a7d31bb4e8af
Summary:
Adds a new class `ErrorOrWarningInput` that is a `SampleInput` with some additional metadata for validating that `SampleInput` throws the desired warning or error. The architecture to support these new tests is modeled after the existing reference tests and sample input functions.
Existing invalid input tests for neg and kthvalue are ported to the new scheme to validate it.
There may be a simpler/clearer naming scheme we can use here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67354
Reviewed By: jbschlosser
Differential Revision: D31989888
Pulled By: mruberry
fbshipit-source-id: 4fa816e1e8d0eef21b81c2f80813d42b2c26714e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67939
With `manage_output_tensor` enabled, a client of `StaticRuntime` requires to call it via `PyTorchPredictor::predict_managed_result`. If the client uses `PyTorchPredictor::operator()` the client will experience a crash (intended behavior not to leak memory of managed output tensors). This mistake can cause a catastrophic failure in production if that happens (by gatekeeper, config changes, etc).
Considering the complexity in how `PyTorchPredictor` is used in different settings, the chances that this bug can hit production is non-zero.
This change introduces `StaticRuntime::disableManageOutputTensor` to disable `manage_output_tensor` feature when a client mistakenly uses `PyTorchPredictor::operator()` instead of crashing. When `StaticRuntime` is invoked via `PyTorchPredictor::operator()`, it first calls `StaticRuntime::disableManageOutputTensor` to disable the feature, so that it can get non-managed output tensors to pass to the client safely.
A slight perf degradation is expected by forcefully disabling `manage_output_tensors`, but its robustness value outweighs a catastrophic failure of crashes at a high rate.
Test Plan: Added a unittest `StaticRuntime, DisableManageOutputTensors` to cover the newly added code.
Reviewed By: swolchok
Differential Revision: D32219731
fbshipit-source-id: caf5c910b34726c570e17435ede7d888443e90cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68180
Since we've open sourced the tracing-based selective build, we can deprecate the
op-dependency-graph-based selective build and the static analyzer tool that
produces the dependency graph.
ghstack-source-id: 143108377
Test Plan: CIs
Reviewed By: seemethere
Differential Revision: D32358467
fbshipit-source-id: c61523706b85a49361416da2230ec1b035b8b99c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67574
When adding the optional params for sharded embedding op. Found that we cannot get these params from `__torch_function__` override. The reason is that we don't pass them via keyword arguments. So maybe we want to change them to kwargs?
ghstack-source-id: 143029375
Test Plan: CI
Reviewed By: albanD
Differential Revision: D32039152
fbshipit-source-id: c7e598e49eddbabff6e11e3f8cb0818f57c839f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68192
- Run on exactly the same stuff as the existing linter checks.
- Exclude deploy interpreter headers from being reported.
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D32364023
Pulled By: suo
fbshipit-source-id: c27eca4a802534875d609d004fa9f6fca59ae6a5
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46741
pytorchbot
contributors: nickleus27, yanivsagy, and khanhthien123
SmrutiSikha this is mostly your work. We just did very minor clean up.
cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67664
Reviewed By: gchanan
Differential Revision: D32311838
Pulled By: mruberry
fbshipit-source-id: 0e5d4d888caeccb0fd7c80e6ff11b1b1fa8e00d6
Summary:
### Create `linalg.cross`
Fixes https://github.com/pytorch/pytorch/issues/62810
As discussed in the corresponding issue, this PR adds `cross` to the `linalg` namespace (**Note**: There is no method variant) which is slightly different in behaviour compared to `torch.cross`.
**Note**: this is NOT an alias as suggested in mruberry's [https://github.com/pytorch/pytorch/issues/62810 comment](https://github.com/pytorch/pytorch/issues/62810#issuecomment-897504372) below
> linalg.cross being consistent with the Python Array API (over NumPy) makes sense because NumPy has no linalg.cross. I also think we can implement linalg.cross without immediately deprecating torch.cross, although we should definitely refer users to linalg.cross. Deprecating torch.cross will require additional review. While it's not used often it is used, and it's unclear if users are relying on its unique behavior or not.
The current default implementation of `torch.cross` is extremely weird and confusing. This has also been reported multiple times previously. (See https://github.com/pytorch/pytorch/issues/17229, https://github.com/pytorch/pytorch/issues/39310, https://github.com/pytorch/pytorch/issues/41850, https://github.com/pytorch/pytorch/issues/50273)
- [x] Add `torch.linalg.cross` with default `dim=-1`
- [x] Add OpInfo and other tests for `torch.linalg.cross`
- [x] Add broadcasting support to `torch.cross` and `torch.linalg.cross`
- [x] Remove out skip from `torch.cross` OpInfo
- [x] Add docs for `torch.linalg.cross`. Improve docs for `torch.cross` mentioning `linalg.cross` and the difference between the two. Also adds a warning to `torch.cross`, that it may change in the future (we might want to deprecate it later)
---
### Additional Fixes to `torch.cross`
- [x] Fix Doc for Tensor.cross
- [x] Fix torch.cross in `torch/overridres.py`
While working on `linalg.cross` I noticed these small issues with `torch.cross` itself.
[Tensor.cross docs](https://pytorch.org/docs/stable/generated/torch.Tensor.cross.html) still mentions `dim=-1` default which is actually wrong. It should be `dim=None` after the behaviour was updated in PR https://github.com/pytorch/pytorch/issues/17582 but the documentation for the `method` or `function` variant wasn’t updated. Later PR https://github.com/pytorch/pytorch/issues/41850 updated the documentation for the `function` variant i.e `torch.cross` and also added the following warning about the weird behaviour.
> If `dim` is not given, it defaults to the first dimension found with the size 3. Note that this might be unexpected.
But still, the `Tensor.cross` docs were missed and remained outdated. I’m finally fixing that here. Also fixing `torch/overrides.py` for `torch.cross` as well now, with `dim=None`.
To verify according to the docs the default behaviour of `dim=-1` should raise, you can try the following.
```python
a = torch.randn(3, 4)
b = torch.randn(3, 4)
b.cross(a) # this works because the implementation finds 3 in the first dimension and the default behaviour as shown in documentation is actually not true.
>>> tensor([[ 0.7171, -1.1059, 0.4162, 1.3026],
[ 0.4320, -2.1591, -1.1423, 1.2314],
[-0.6034, -1.6592, -0.8016, 1.6467]])
b.cross(a, dim=-1) # this raises as expected since the last dimension doesn't have a 3
>>> RuntimeError: dimension -1 does not have size 3
```
Please take a closer look (particularly the autograd part, this is the first time I'm dealing with `derivatives.yaml`). If there is something missing, wrong or needs more explanation, please let me know. Looking forward to the feedback.
cc mruberry Lezcano IvanYashchuk rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63285
Reviewed By: gchanan
Differential Revision: D32313346
Pulled By: mruberry
fbshipit-source-id: e68c2687c57367274e8ddb7ef28ee92dcd4c9f2c
Summary:
use product instead of zip to cover all cases
cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67635
Reviewed By: malfet
Differential Revision: D32310956
Pulled By: mruberry
fbshipit-source-id: 806c3313e2db26d77199d3145b2d5283b6ca3617
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68128
Reland of D31762735 (0cbfd466d2).
This diff was originally reverted due to failure in test_send_export_type_through_rpc_with_custom_pickler.
I updated rpc_pickler_test.py to prevent a race condition where processes were not registering their pickler before handling their rpc_sync calls.
Test Plan:
rpc_pickler_test file:
buck test mode/dev-nosan -c 'cxx.coverage_only=caffe2' //caffe2/torch/fb/training_toolkit/backend/metrics/tests:rpc_pickler_test //caffe2/torch/fb/training_toolkit/backend/metrics/collectors/fbdata_aggregator/tests:batch_collector_test -- --run-disabled --collect-coverage '--code-coverage-session=test_session' --force-tpx
rpc_pickler stress test:
buck test mode/dev-nosan -c 'cxx.coverage_only=caffe2' //caffe2/torch/fb/training_toolkit/backend/metrics/tests:rpc_pickler_test -- --exact 'caffe2/torch/fb/training_toolkit/backend/metrics/tests:rpc_pickler_test - test_send_export_type_through_rpc_with_custom_pickler (caffe2.torch.fb.training_toolkit.backend.metrics.tests.rpc_pickler_test.CythonTypeRpcSpawnTest)' --run-disabled --collect-coverage '--code-coverage-session=test_session' --force-tpx --jobs 18 --stress-runs 10 --record-results
Reviewed By: mrshenli
Differential Revision: D32316077
fbshipit-source-id: e58de2335fbaa3ab46d46fe222c659197633a5e4
Summary:
**TLDR**: Makes torch.histc run 400x faster on large inputs. Should fix [a broken test on internal CI](https://www.internalfb.com/intern/test/281475013640093/).
HistogramKernel presently calls torch.Tensor.index_put_ once for each element of its input tensor. Obtaining a data pointer and manipulating it directly avoids the considerable dispatch overhead from calling index_put_. Behavior is unchanged because the tensor being operated on is known to be contiguous and in CPU memory.
Fixes performance regression introduced in https://github.com/pytorch/pytorch/pull/65318.
Benchmark: time taken to compute histc on a tensor with 10,000,000 elements
1. Before https://github.com/pytorch/pytorch/pull/65318: **0.003s**
2. After https://github.com/pytorch/pytorch/pull/65318: **2.154s**
3. After this change: **0.005s**
Benchmark code:
```
import torch as t
from timeit import default_timer as timer
x = t.randperm(10000000, dtype=t.float32)
start = timer()
t.histc(x)
end = timer()
print(end - start)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67815
Reviewed By: anjali411
Differential Revision: D32357663
Pulled By: saketh-are
fbshipit-source-id: f8fa59173ea4772c8ad1332548ef4d9ea8f01178
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66100
A backend should not directly dependent on ATen operators. The demo backend is changed to that way for testing purpose.
Test Plan: Imported from OSS
Reviewed By: pavithranrao
Differential Revision: D31384614
Pulled By: iseeyuan
fbshipit-source-id: c97f0c4aa12feb1d124f1d7a852e9955a7a2ce42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68134
Add the macros in preparation of making these selective. Should be a no-op in this diff.
ghstack-source-id: 143023844
Test Plan: CI
Reviewed By: dhruvbird
Differential Revision: D32326833
fbshipit-source-id: 7abc93102bff0aa0bc5e3383bdf3e95fb84ce5ba
Summary:
This adds apex-inspired fast layer norm forward kernel to pytorch (it is a significant rewrite though).
It's much faster than current implementation, for a typical transformer size (32*196, 1024) time goes down from ~180us to ~49 us on Volta. Compared to apex, it also produces bitwise accurate results between float inputs representable in fp16, and fp16 inputs. It produces slightly different results compared to current implementation though, because welford summation is implemented differently.
It is slower than lightSeq (~37 us), but lightseq uses inaccurate variance approximation, and doesn't guarantee float - fp16 bitwise accuracy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67977
Reviewed By: mruberry
Differential Revision: D32285331
Pulled By: ngimel
fbshipit-source-id: a8b876a9cf3133daacfe0ce3a37e3ad566f4b6a8
Summary:
This PR adds OpInfo for `nn.functional.conv1d`. There is a minor typo fix in the documentation as well.
Issue tracker: https://github.com/pytorch/pytorch/issues/54261
cc: mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67747
Reviewed By: malfet
Differential Revision: D32309258
Pulled By: mruberry
fbshipit-source-id: add21911b8ae44413e033e19398f398210737c6c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67904.
- Create a sparse tensor when the sparse layout is given even if the input tensor is not sparse.
cc nikitaved pearu cpuhrsch IvanYashchuk
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68108
Reviewed By: anjali411
Differential Revision: D32316269
Pulled By: cpuhrsch
fbshipit-source-id: 923dbd4dc7c74f51f7cdbafb2375a30271a6a886
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68148
Question raised regarding whether we should fuse pass a->b->c if node a has other consumer rather than node b. This diff is to ease the constrain in fuse path so that in case:
```
a
| |
b d
|
c
```
we still allow fuse path(a->b->c), after fuse, node b will be eliminated by dead_node_eliminator while node a keep in graph.
Reviewed By: yinghai, 842974287
Differential Revision: D32296266
fbshipit-source-id: 44ded07a97b5b708bdf37193a022fae21410b4bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67357
This PR adds OpInfos for:
- new_ones, new_zeros, new_full, new_empty
- rand_like, randint_like
I forgot to add the _like functions in a previous PR, so here they are.
Test Plan: - wait for tests
Reviewed By: mruberry
Differential Revision: D31969533
Pulled By: zou3519
fbshipit-source-id: 236d70d66e82f1d6f8e5254b55ca2a37b54c9494
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64676
We implement a working eager mode quantization flow which uses
tracing and `__torch_function__` and `torch.nn.Module.__call__` overrides to automate the model modifications needed for quantization. Partial program capture (instead of full program capture) is used, allowing this scheme to target a wide variety of user programs. Control flow over quantizeable ops is not supported, but general control flow is supported.
In particular:
* `auto_trace.py` contains the machinery to override `__torch_function__` and `torch.nn.Module.__call__` and call hooks before and after each quantizeable module or function
* `quantization_state.py` contains the state needed to use the hooks to implement quantization logic such as adding quants/dequants, observers, etc.
* please see `README.md` for more details
Test Plan:
```
python test/test_quantization.py TestAutoTracing
python test/test_quantization.py TestAutoTracingModels
```
```
python test/test_quantization.py TestAutoTracing
python test/test_quantization.py TestAutoTracingModels
```
Differential Revision:
D31992281
D31992281
Reviewed By: HDCharles
Pulled By: vkuzo
fbshipit-source-id: 6d40e855f3c96b9a4b637a0e677388a7b92f7967
Summary:
Context: https://github.com/pytorch/pytorch/issues/67061
Use `run_test.py`'s provided flag `"--subprocess"`, passed in like `extra_unittest_args=["--subprocess"]` when running test_distributed_spawn. This will ensure that each test is run separately in its own process. The goal is to more closely simulate how a developer would run a single test when reproducing a CI failure and make reproducibility easier in general.
Also, when a test fails, print out the exact command that was issued so developer knows how to reproduce it.
For example test fails, it will print out something like the following to logs -
```
Test exited with non-zero exitcode 1. Command to reproduce: BACKEND=gloo WORLD_SIZE=3 /fsx/users/rvarm1/conda/envs/pytorch/bin/python distributed/test_distributed_spawn.py -v TestDistBackendWithSpawn.test_Backend_enum_class
```
running test_distributed_spawn is still the same cmd as before:
`
python test/run_test.py --verbose -i distributed/test_distributed_spawn
`
as seen in [distributed contributing](https://github.com/pytorch/pytorch/blob/master/torch/distributed/CONTRIBUTING.md) guide.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67901
Reviewed By: cbalioglu, mruberry
Differential Revision: D32225172
Pulled By: rohan-varma
fbshipit-source-id: 7e8d4c7a41858044bd2a4e0d1f0bf8f1ac671d67
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/kineto](https://github.com/pytorch/kineto).
New submodule commit: f60ad2cb0f
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67445
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: robieta
Differential Revision: D31993939
fbshipit-source-id: 3d4aa2f900434d4bbe5134db8453deb227ef5685
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67750
Add more information about why exporting model fails.
Before: error message:
```
E1102 22:57:42.984015 3220949 ExceptionTracer.cpp:221] exception stack complete
terminate called after throwing an instance of 'c10::Error'
what(): __torch__ types other than torchbind (__torch__.torch.classes)are not supported in lite interpreter. Workaround: instead of using arbitrary class type (class Foo()), define a pytorch class (class Foo(torch.nn.Module)). The problematic type is: __torch__.dper3.core.schema_utils.IdListFeature
Exception raised from getFunctionTuple at caffe2/torch/csrc/jit/serialization/export_module.cpp:246 (most recent call first):
```
After
```
E1102 22:57:42.984015 3220949 ExceptionTracer.cpp:221] exception stack complete
terminate called after throwing an instance of 'c10::Error'
what(): __torch__ types other than torchbind (__torch__.torch.classes)are not supported in lite interpreter. Workaround: instead of using arbitrary class type (class Foo()), define a pytorch class (class Foo(torch.nn.Module)).
Exception raised from getFunctionTuple at caffe2/torch/csrc/jit/serialization/export_module.cpp:246 (most recent call first):
```
ghstack-source-id: 143009294
Test Plan: CI
Reviewed By: larryliu0820
Differential Revision: D32129397
fbshipit-source-id: 0594a98a59f727dc284acd1c9bebcd7589ee7cbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68135
Update the schema to reflect the changes in D31935573 (6b44e75f6b).
Test Plan:
`buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Confirmed native implementation is used.
Reviewed By: hlu1
Differential Revision: D32326865
fbshipit-source-id: 7f607f57ceb6690a2782d94d9ee736ba64e7d242
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67825
The comment explains how it works.
Test Plan:
A small regression to local and local_ro if we only enable it for fallback ops.
```
## local_ro
# before
I1103 21:25:05.250440 2636751 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.22213. Iters per second: 818.247
I1103 21:25:08.629221 2636751 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.22351. Iters per second: 817.319
I1103 21:25:12.005179 2636751 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.22285. Iters per second: 817.759
I1103 21:25:12.005236 2636751 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.22283, standard deviation: 0.000693619
# after
# # only enable for fall back ops: 0.7%
I1103 21:26:40.190436 2644597 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.22928. Iters per second: 813.481
I1103 21:26:43.590443 2644597 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.23265. Iters per second: 811.262
I1103 21:26:46.992928 2644597 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.23379. Iters per second: 810.51
I1103 21:26:46.992980 2644597 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.23191, standard deviation: 0.0023424
# enable for all (no clone): 4.7%
I1103 21:27:55.291216 2649780 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.28204. Iters per second: 780.005
I1103 21:27:58.822347 2649780 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.27854. Iters per second: 782.14
I1103 21:28:02.354184 2649780 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 1.27958. Iters per second: 781.506
I1103 21:28:02.354240 2649780 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 1.28006, standard deviation: 0.00179765
# local
# before
I1103 21:52:00.784718 2765168 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.676. Iters per second: 50.8233
I1103 21:52:28.985873 2765168 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.699. Iters per second: 50.7641
I1103 21:52:57.200223 2765168 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.6953. Iters per second: 50.7735
I1103 21:52:57.200273 2765168 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 19.6901, standard deviation: 0.0123206
# after
# # only enable for fall back ops: 0.1%
I1103 21:45:25.514535 2734440 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.7103. Iters per second: 50.7349
I1103 21:45:53.773594 2734440 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.7005. Iters per second: 50.7601
I1103 21:46:21.955680 2734440 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.7398. Iters per second: 50.659
I1103 21:46:21.955729 2734440 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 19.7169, standard deviation: 0.0204658
# enable for all (no clone): 0.9%
I1103 21:43:22.162272 2723868 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.8893. Iters per second: 50.2783
I1103 21:43:50.651847 2723868 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.8566. Iters per second: 50.3611
I1103 21:44:19.068519 2723868 PyTorchPredictorBenchLib.cpp:274] PyTorch run finished. Milliseconds per iter: 19.8793. Iters per second: 50.3037
I1103 21:44:19.068570 2723868 PyTorchPredictorBenchLib.cpp:285] Mean milliseconds per iter: 19.875, standard deviation: 0.0167498
```
Reviewed By: d1jang
Differential Revision: D32124812
fbshipit-source-id: 0f60c26f8fb338d347e4ca7a70b23e5a386fc9aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68103
The error message `'training' attribute not found.` in itself isn't particularly actionable. Anyone running into this tends to be clueless regarding why they are getting this message.
For example, see [this post](https://fb.workplace.com/groups/pytorch.edge.users/posts/965868874283406/) asking for help when seeing this specific error message.
The most common reason for this error is that users call `.eval()` in the model instance before saving it. This change tries to draw attention to that oversight and allows them to proactively investigate and correct that mis-action if necessary.
This saves valuable time for our users and effort from the team tp provide support. Overall, I believe this is a Developer Experience win.
ghstack-source-id: 143021300
Test Plan: Build/CI
Reviewed By: JacobSzwejbka
Differential Revision: D32304477
fbshipit-source-id: 474abe717a862347f16ad981834ddab6819cb4d3
Summary:
Only packages and tools (which are explicitly specified) are included in the wheel/conda files
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68139
Test Plan:
Run `python3 -c "from setuptools import find_packages; print([x for x in find_packages(exclude=('tools','tools.*')) if 'torch.fx' in x])"` before and after the change
Fixes https://github.com/pytorch/pytorch/issues/68059
Reviewed By: nrsatish, seemethere
Differential Revision: D32330483
Pulled By: malfet
fbshipit-source-id: a55443730999a83c615b3f943c327353c011bf7b
Summary: Torch.save use pickle, which cannot handle lambda function or local function directly without modify serialization.py. This diff fix the issue by extract lambda to a normal function.
Test Plan: buck test mode/dev-nosan //caffe2/test/fx2trt/core:test_trt_module
Reviewed By: 842974287
Differential Revision: D32320536
fbshipit-source-id: 497d2e64f94526f92e6d1a9909b6ad629dbca850
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67927
BackendData - represents 'tensor data' in opaque backend storage
LoweringContext - interface for performing backend-specific IR lowering
BackendImplInterface - interface for lazy tensors backends to implement
Reorgs backend-related files into lazy/backend subdir
includes a few small fixes, which were made on lazy_tensor_staging but need to be back-ported to master.
Test Plan: used by lazy_tensor_staging branch
Reviewed By: desertfire
Differential Revision: D32142032
fbshipit-source-id: 828c717bcd0d511876e64ad209b50f7bfb10cec5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68080Fixes#68002
After FaultyProcessGroupAgent was replaced with FaultyTensorpipeAgent there is now a dependency on Tensorpipe for rpc testing. However, if user does not have USE_TENSORPIPE enabled they will hit an issue such `undeclared identifier 'FaultyTensorPipeRpcBackendOptions'`. This is for testing the faulty agent method so it should not block compilation. Update to wrap the Tensorpipe specific code in a directive.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D32292861
Pulled By: H-Huang
fbshipit-source-id: 4ffb879860ced897674728200a1831f18fea0a4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68093
We don't want regular users without write access to be able to file an
actual issue with the `ci: sev` label since that issue will
automatically show up on hud.pytorch.org
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D32299553
Pulled By: seemethere
fbshipit-source-id: d46a96f16ae29120fff94288d3e0c06b103edf7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67476
Native ops are faster than falling back to the JIT interpreter, sometimes significantly (we've previously seen this with ops like TupleUnpack). We should improve op coverage where possible.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: d1jang
Differential Revision: D31994040
fbshipit-source-id: 9de57d8d7925ee46544478eae8229952ca5f248a
Summary:
This PR introduces a new function `_select_conv_backend` that returns a `ConvBackend` enum representing the selected backend for a given set of convolution inputs and params.
The function and enum are exposed to python for testing purposes through `torch/csrc/Module.cpp` (please let me know if there's a better place to do this).
A new set of tests validates that the correct backend is selected for several sets of inputs + params. Some backends aren't tested yet:
* nnpack (for mobile)
* xnnpack (for mobile)
* winograd 3x3 (for mobile)
Some flowcharts for reference:


Pull Request resolved: https://github.com/pytorch/pytorch/pull/67790
Reviewed By: zou3519
Differential Revision: D32280878
Pulled By: jbschlosser
fbshipit-source-id: 0ce55174f470f65c9b5345b9980cf12251f3abbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68027
This commit upstreams class BackendDevice to the master, which is a backend
specific representation of the actual hardware, for instances, CPU, GPU, or
TPU.
This concept is important for backend like XLA where it needs to tell the
actual hardware type from the c10::DeviceType::Lazy virtual device during
both IR constructions and lowerings.
Test Plan: ./build/bin/test_lazy --gtest_filter=BackendDeviceTest.*
Reviewed By: wconstab
Differential Revision: D32261838
Pulled By: alanwaketan
fbshipit-source-id: 579c3fc5f9da7847c887a383c6047e8ecb9cc5bc
Summary:
This fixed a few of the linalg checks that we disabled before!
This also seems to break sgn, abs and angle (sending on CI here to see if there are more). These two functions used to only ever get pure imaginary or real values.
This is very much likely that something is wrong with their formula.
But they are implemented as element-wise, so not sure where the error can come from. I tried to look at it but nothing obvious seems wrong there (especially because it is correct in backward mode).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68001
Reviewed By: soulitzer
Differential Revision: D32280475
Pulled By: albanD
fbshipit-source-id: e68b1ce0e2e97f8917c3d393141d649a7669aa9d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67601.
As simple a fix as I could make it. I even managed to delete some testing code!
I checked calling `super()` and, as I had feared, it doesn't work out the box, so perhaps that ought to be revisited later.
As it stands, https://github.com/pytorch/pytorch/issues/20124, still applies to the chained scheduler, but I think this change is still an improvement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68010
Reviewed By: zou3519
Differential Revision: D32278139
Pulled By: albanD
fbshipit-source-id: 4c6f9f1b2822affdf63a6d22ddfdbcb1c6afd579
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66064
The only place this is used seems to be in the dispatcher for `operatorLookupTable_`. Disarming `LeftRight` disarms it for this one use case.
This should make .so loading faster, and also reduce memory consumption since `LeftRight<T>` does 2 writes for every write. I'd like to get a thorough review from reviewers for this diff since I want to make sure that initialization of stuff that writes into the dispatcher isn't going to happen on multiple threads for on-device use.
Created a new class named `LeftRightNoOpWrapper<T>` for use in mobile builds.
### Why is LeftRight<T> slow?
It maintains 2 copies of each data structure `T` to be able to keep reads quick. Every write goes to both data structures, which means that writes that 2x and memory overhead is also 2x
### Why is this safe for mobile builds?
1. .so loading never happens concurrently with model execution
2. Custom ops are loaded during .so load - initializers are all run serially
3. I don't see any threads being spawned from the global schema and kernel initializers
After discussing with dreiss, it seems like there could be rare cases in OSS apps or internal Android/iOS apps where a `.so` or `dylib` is loaded after the PT runtime is loaded, and this load happens concurrently with an in-progress inference run, which is looking up the operator table in the dispatcher.
To avoid crashes there, it seems reasonable to use the RW lock, since I don't expect any contention 99.9% of the time.
When registering operators, everything is serial so only one thread will ever hold the lock. The next time it needs the lock, it will have already released it.
During inference runs, only one thread will ask for the shared lock unless multiple concurrent inferences are in progress. Even in that case, they will all be able to simultaneously get the Read lock.
Test Plan: Build and generate a local build of the iOS app to test.
Reviewed By: swolchok
Differential Revision: D31352346
fbshipit-source-id: c3f12454de3dbd7b421a6057d561e9373ef5bf98
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67787
First noticed in https://fb.workplace.com/groups/pytorch.edge.team/posts/952737705280969/ - basically one of the speech models has ~400 0 byte tensor files, so we're basically paying the cost of looking it up in the archive and reading nothing from it.
Turns out that there's a fairly simple fix to avoid reading a 0 byte tensor. Once we notice that it's 0 bytes, just use the default `DataPtr` instead to initializing it with 0 bytes read in from the input file stream.
ghstack-source-id: 142025211
Test Plan: CI and manually ran a couple production mobile models with bundled inputs. CI Will run all prod. mobile mobiles with bundled inputs.
Reviewed By: swolchok
Differential Revision: D32054983
fbshipit-source-id: 919b0cdbc44bccb8f6cfe0da10ff5474af37fd99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67788
Based on comments from supriyar in D31657430 (20aa417e38).
ghstack-source-id: 142924000
Test Plan: CI
Reviewed By: supriyar
Differential Revision: D32055028
fbshipit-source-id: 756d526585f8ded755ea42b52dbbf5c1687acde2
Summary:
https://github.com/pytorch/pytorch/issues/67578 disabled reduced precision reductions for FP16 GEMMs. After benchmarking, we've found that this has substantial performance impacts for common GEMM shapes (e.g., those found in popular instantiations of multiheaded-attention) on architectures such as Volta. As these performance regressions may come as a surprise to current users, this PR adds a toggle to disable reduced precision reductions
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = `
rather than making it the default behavior.
CC ngimel ptrblck
stas00 Note that the behavior after the previous PR can be replicated with
`torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = False`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67946
Reviewed By: zou3519
Differential Revision: D32289896
Pulled By: ngimel
fbshipit-source-id: a1ea2918b77e27a7d9b391e030417802a0174abe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68029
Temporarily disable quantization external functions with a new macro DISABLE_NNC_QUANTIZATION.
The ATen CPU library consists of two parts:
A. Common operator functions, e.g. "at::empty()", the list of sources can be found at "aten_cpu_source_list" in "tools/build_variables.bzl";
B. Implementations of these operators, e.g. "at::native::empty()", the list of sources is defined at "aten_native_source_list" in "tools/build_variables.bzl";
Note that A does not directly depend on B. A calls B via dispatch table. The dependency is injected into the dispatch table by B during its static initialization.
For internal mobile builds, B is built on a per-app basis. A is the public library for other libraries to depend on. Because these external functions call quantization functions that are not part of A, the NNC kernel library cannot resolve the missing symbols.
Use this PR to unblock the internal experiment until we figure out a better solution (e.g. move quantization API to A).
ghstack-source-id: 142868370
Test Plan: Make sure it can build with the stacked diff.
Reviewed By: IvanKobzarev
Differential Revision: D32239783
fbshipit-source-id: 3797b14104b0f54fb527bc3fc5be7f09cc93d9e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68094
Turns out sccache was not getting activated properly on master pushes so
this should help resolve that
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D32299636
Pulled By: seemethere
fbshipit-source-id: 5f1be98dffdb202d3c11b6ceb2b49af235e1f91b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67941
I just found out that due to the round up of the Tensor storage sizes to multiples of 64 bytes, resizing is not actually triggered for a lot of our unit tests (23 OSS, 16 internal). Now they should be all fixed. Also moved a bunch of tests to `test_static_module.cc` so that `test_static_runtime.cc` now only contains operator tests.
From now on, by default if `args2` is passed to `test_static_runtime`, at the end of the second iteration, it would check that the managed buffer's size is bigger than the previous size and enforce that. You can bypass the check for ops with constant output sizes, such as `aten::sum` without `dim` passed in.
Test Plan:
Facebook
```
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
buck test //caffe2/benchmarks/static_runtime/fb:test_fb_operators
```
Reviewed By: swolchok
Differential Revision: D32196204
fbshipit-source-id: 8425d9efe6b9a1c1e3807e576b1143efd7561c71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67817
Implementation of build features as a useable feature. Includes tracing support and selectivity support. Follow up of Dhruv's prototype in D30076214.
The general idea is to allow selectivity of arbitrary sections of the codebase through the 2 apis,
BUILD_FEATURE_REQUIRED(NAME), and
BUILD_FEATURE_AVAILABLE(NAME)
References
PyTorch Edge Team Workplace group post link: https://fb.workplace.com/groups/pytorch.edge.team/posts/905584476662959/
Quip talking about some early ideas related to build features: https://fb.quip.com/iur3ApU9q29v
Google Doc about most recent discussion and details: https://docs.google.com/document/d/1533zuN_9pwpQBa4RhtstUjT5B7guowblqJz35QYWPE0/edit
Will remove the copy kernel example after. Its just here as an example.
ghstack-source-id: 142850218
Test Plan: CI, dummy traced a model, and played around with its unit test if i removed the traced value from the yaml
Reviewed By: dhruvbird
Differential Revision: D32151856
fbshipit-source-id: 33764c1f6902a025e53807b784792a83c8385984
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66101
Updated description:
This PR tests the functionalization pass in python in two ways. For each of the test programs that I have in `test_functionalization.py`, it:
- runs the program with and without functionalization, and asserts the outputs and (potentially mutated) inputs are equal in both cases
- runs the program with `LoggingTensor`, and uses expecttests on the resulting graph. I manually confirm that the graphs look reasonable and only contain functional ops.
Mechanically, the changes include:
- factoring out `LoggingTensor` into a testing util so it can be re-used in multiple tests
- adding some private python api's in the `torch` namespace as hooks that I can use during testing
In the original version of this PR, I also added some fixes to the `_make_subclass()` function in python: allowing you to pass in strides and storage_offset. I kept them in mainly because the changes were already there.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D31942095
Pulled By: bdhirsh
fbshipit-source-id: 90ff4c88d461089704922e779571eee09c21d707
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67878
The functionalization pass doesn't work with `copy_()` which is a problem with functorch. Originally we were going to make a functional `copy()` operator to fix this problem, but zou3519 that we can get (most of) the existing functionality by mapping `self.copy_(src)` to `src.to(self).expand_as(self)`. This makes the codegen a bit uglier, but has the benefit of avoiding a totally unnecessary tensor allocation in functorch.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D32280588
Pulled By: bdhirsh
fbshipit-source-id: 2c6ee65f0929e0846566987183ba2498c88496c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67715
I had original made the `vector<ViewMeta>` and `Tensor`s stored on the `Update` struct references, but will pointed out a bug in the conditional-functionalization PR due to a use-after-free error. This happens because the queued-up updates might not be synced until later, and can out-live the original tensor that was used to create them.
It was kind of strange that this doesn't show up in the existing `test/test_functionalization.py` tests that I have in this stack, which technically also should have this bug (they call sync_() after the mutated tensors have gone out of scope). I looked at it with gdb, and I'm wondering if it's just because the stored values in the free'd `ViewMeta`/`Tensor` just happen to not get clobbered by the time the sync is called in the test.
Either way, copying the Tensor + vector<ViewMeta> is probably not ideal for performance, but I couldn't think of an easy work-around for now.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32136007
Pulled By: bdhirsh
fbshipit-source-id: 707c6392a31b967e8965b9b77f297fd10a0a095a
Summary:
When I run this part of the code on the document with PyTorch version 1.10.0, I found some differences between the output and the document, as follows:
```python
import torch
import torch.fx as fx
class M(torch.nn.Module):
def forward(self, x, y):
return x + y
# Create an instance of `M`
m = M()
traced = fx.symbolic_trace(m)
print(traced)
print(traced.graph)
traced.graph.print_tabular()
```
I get the result:
```shell
def forward(self, x, y):
add = x + y; x = y = None
return add
graph():
%x : [#users=1] = placeholder[target=x]
%y : [#users=1] = placeholder[target=y]
%add : [#users=1] = call_function[target=operator.add](args = (%x, %y), kwargs = {})
return add
opcode name target args kwargs
------------- ------ ----------------------- ------ --------
placeholder x x () {}
placeholder y y () {}
call_function add <built-in function add> (x, y) {}
output output output (add,) {}
```
This pr modified the document。
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68043
Reviewed By: driazati
Differential Revision: D32287178
Pulled By: jamesr66a
fbshipit-source-id: 48ebd0e6c09940be9950cd57ba0c03274a849be5
Summary:
Patch bfloat16 support in NCCL, PR https://github.com/pytorch/pytorch/issues/63260 adds bfloat16 support but is
still not complete to enable bfloat16 for allreduce in end-to-end training.
This patch does the followings:
* fix minimum NCCL version from 2.9.7 to 2.10, NCCL adds bf16 support in
v2.10.3-1 (commit 7e51592)
* update bfloat16 datatype flag in `csrc/cuda/nccl.cpp` so that NCCL
operations like all reduce can use it
* enable unit tests for bfloat16 datatype if possible
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67843
Reviewed By: H-Huang
Differential Revision: D32248132
Pulled By: mrshenli
fbshipit-source-id: 081e96e725af3b933dd65ec157c5ad11c6873525
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68061
Test had a typo that didn't compare test value against reference value, fixed typo.
Test Plan:
`pytest test/quantization/fx/test_quantize_fx.py -v -k "test_qat_functional_linear"`
Imported from OSS
Reviewed By: HDCharles
Differential Revision: D32280803
fbshipit-source-id: d57a25a0dcdd88df887a39b5117abafaf15125b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68012
Previous attempt to make qlinear threadsafe placed lock after weight ptr was already accessed via packB. Race condition occurs when thread1 acquires lock, packs weights but thread2 still uses old nullptr after acquiring the lock. This causes a null pointer dereference later.
ghstack-source-id: 142714894
Test Plan: Tested on repro diff
Reviewed By: kimishpatel
Differential Revision: D32252563
fbshipit-source-id: 429fcd3f76193f1c4c8081608b6f725b19562230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68069
- executable bit
- cub include
- raw CUDA API usage
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D32286559
Pulled By: suo
fbshipit-source-id: 21d58e259c951424f9c6cbf1dac6d79fe7236aa4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61536
This PR adds CPU dispatch for `addmv_out` with Sparse CSR matrix.
The implementation uses MKL Sparse library. If it's not available then a
runtime error is thrown.
Since structured_delegate is used we only need to implement the out variant, the in-place and normal variants are autogenerated.
MKL descriptor of sparse matrices is implemented in `at::mkl::sparse::MklSparseCsrDescriptor`.
MKL Sparse doesn't allow switching indices type in runtime, it's
predetermined in build time. Only 32-bit version of MKL was tested
locally, but I expect 64-bit version to work correctly as well.
When indices type of PyTorch CSR tensor doesn't match with MKL's,
indices tensor is converted to MKL compatible type (`int` vs `int64_t`).
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32141787
Pulled By: malfet
fbshipit-source-id: b818a0b186aa227982221c3862a594266a58a2a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67929
1. Write a node-hash based unit test for Cache
2. Replace CHECK with TORCH_CHECK in IrUtil
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D32246134
Pulled By: desertfire
fbshipit-source-id: c464bc300126d47e9ad4af3b3e8484a389757dc0
Summary:
Fixes [issue#64](https://github.com/MLH-Fellowship/pyre-check/issues/64)
This PR fixes the type checking errors in torch/distributed/rpc/options.py.
The variable types in 84:8 and 85:8 were declared to have type `List` but were sometimes assigned a value of `None`. This caused an incompatitble variable type error. Therefore, I changed the type from `List` to `Optional[List]` . Hence, this fixes the incompatitble variable type error.
Signed-off-by: Onyemowo Agbo
onionymous
0xedward
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68056
Reviewed By: zou3519
Differential Revision: D32282289
Pulled By: mrshenli
fbshipit-source-id: ee410165e623834b4f5f3da8d44bd5a29306daae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67981
To save on memory, various internal classes need to release all references to their `torch::jit::Module` after constructing their `StaticModule`. Unfortunately, many of these classes currently instantiate a `torch::jit::Method` attribute, which holds a reference to the `ivalue` backing its owning module.
To avoid this, I've introduced a new subclass of `IMethod` to represent scripted functions backed by static runtime.
Test Plan: CI
Reviewed By: swolchok
Differential Revision: D32232039
fbshipit-source-id: 434b3a1a4b893b2c4e6cacbee60fa48bd33b5722
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67911
If we can remove `self` from the graph inputs, there is no need for `StaticModule` to hold onto its `Module` reference anymore.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D32190755
fbshipit-source-id: 9c4649a63b6e68c7d2e47395a23572985d2babb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68035
RemoteModule is sometimes created using object.__new__ (ex:
init_from_module_rref), in this case the logging in the __init__ method would
not pick this up.
As a result, adding a `__new__` method to RemoteModule to log all usages
appropriately.
ghstack-source-id: 142762019
Test Plan: waitforbuildbot
Reviewed By: vipannalla
Differential Revision: D32263978
fbshipit-source-id: a95ab0bb5d0836da8fe6333c41593af164b008d9
Summary:
`.name()` has to call `__cxa_demangle` and allocate a new string, both of which can be avoided by just comparing the mangled names directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67987
Reviewed By: mruberry
Differential Revision: D32264560
Pulled By: H-Huang
fbshipit-source-id: 9dd4388ba4e2648c92e4062dafe6d8dc3ea6484e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67990
Duplicate of the following PR which was merged by mistake without ghimport
https://github.com/pytorch/pytorch/pull/67914
cc albanD NicolasHug
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D32247560
Pulled By: jdsgomes
fbshipit-source-id: 8ba5ba7d17fc3d0d2c377da467ea805822e21ec1
Summary:
TorchVision accidentally included model builders for quantized models without weights; this was an old bug. These builders were largely unusable and caused issues to the users. Commonly they were filtered out to avoid causing issues.
We've recently fixed that (https://github.com/pytorch/vision/pull/4854) by either removing those unnecessary builders or by providing quantized weights. This PR removes the no-longer necessary filtering of the methods.
**It should be merged after TorchVision is synced on FBCode.**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67836
Reviewed By: jerryzh168
Differential Revision: D32230658
Pulled By: datumbox
fbshipit-source-id: 01cd425b1bda3b4591a25840593b3b5dde3a0f12
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46480 -- for SGD.
## Notes:
- I have modified the existing tests to take a new `constructor_accepts_maximize` flag. When this is set to true, the ` _test_basic_cases_template` function will test both maximizing and minimizing the sample function.
- This was the clearest way I could think of testing the changes -- I would appreciate feedback on this strategy.
## Work to be done:
[] I need to update the docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67847
Reviewed By: H-Huang
Differential Revision: D32252631
Pulled By: albanD
fbshipit-source-id: 27915a3cc2d18b7e4d17bfc2d666fe7d2cfdf9a4
Summary:
Description:
- Follow up PR to https://github.com/pytorch/pytorch/issues/66790 to fix the tests on functorch, https://github.com/pytorch/functorch/issues/195
In functorch, a null tensor is added to the list of indices for the batch dimension in C++, but I can not find an equivalent of that in python without using `torch.jit.script`. If any other better solutions could be suggested, I'd be happy to replace the current way of testing.
cc ngimel zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67189
Reviewed By: suo
Differential Revision: D31966686
Pulled By: ngimel
fbshipit-source-id: a14b9e5d77d9f43cd728d474e2976d84a87a6ff4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68016
We would want to use oss test utils.
Also refactor both test utils so that the internal one is an enhancement over the oss test utils.
Test Plan: CI
Reviewed By: wushirong
Differential Revision: D32250266
fbshipit-source-id: 968b8f215ca2d294f7d0bd13cf9563be567954dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68015
Put all converter utils into a single file `converter_utils.py`.
Test Plan: CI
Reviewed By: wushirong
Differential Revision: D32250243
fbshipit-source-id: 93fb34bc9ca23f4c3cef3125e04871083dbd413d
Summary:
Magma's magma_queue was double allocating storage when creating
ptrArray for gemm operations. A fix has been upstreamed and the build
needs to pick this up going forward.
Fixes #{issue number}
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67225
Reviewed By: janeyx99
Differential Revision: D32252609
Pulled By: seemethere
fbshipit-source-id: e27ba1a54dc060fd1bfb4afad9079bf9b4705c8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67925
Previously, the following would always fail, because autocasting would not be enabled in the called method:
```
torch.jit.script
def fn(x, y):
with autocast():
# CallMethod() to some method
fn(x, y)
```
This allows the above, if autocasting is globally enabled, e.g.
```
torch.jit.script
def fn(x, y):
with autocast():
# CallMethod() to some method
with autocast():
fn(x, y) # now
```
ghstack-source-id: 142667351
Test Plan: added test in test_jit_autocast.py
Reviewed By: navahgar
Differential Revision: D32214439
fbshipit-source-id: bb7db054e25e18f5e3d2fdb449c35b5942ab303e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67808
torch.reciprocal implicitly casts the inputs to float, and ONNX
Reciprocal requires floating point inputs.
Also separate the reciprocal test from other tests, and test different
input types.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32181307
Pulled By: malfet
fbshipit-source-id: 3e1109b3c85a49c51dc713656a900b4ee78c8340
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67806
Previously new_full would fail with errors like:
`TypeError: only integer tensors of a single element can be converted to an index`
And full_like would trigger warnings like:
`DeprecationWarning: an integer is required (got type float). Implicit conversion to integers using __int__ is deprecated, and may be removed in a future version of Python.`
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32181301
Pulled By: malfet
fbshipit-source-id: 2cf262cfef36c18e7b2423efe1e1d4fa3438f0ba
Co-authored-by: Bowen Bao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67805
Also fix Reduce ops on binary_cross_entropy_with_logits
The graph says the output is a scalar but with `keepdims=1`
(the default), the output should be a tensor of rank 1. We set keep
`keepdims=0` to make it clear that we want a scalar output.
This previously went unnoticed because ONNX Runtime does not strictly
enforce shape inference mismatches if the model is not using the latest
opset version.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32181304
Pulled By: malfet
fbshipit-source-id: 1462d8a313daae782013097ebf6341a4d1632e2c
Co-authored-by: Bowen Bao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67960
For some reason, we are throwing py::index_error when converting a trt.Dims to tuple. This staying in the hot path of trt inference in not good, especially when we register a bunch of pybind11 exception translator where they repeatedly rethrow the exception. Since shape is static information, we save it once to avoid such repeated conversion.
Reviewed By: jianyuh, wushirong, 842974287
Differential Revision: D32232065
fbshipit-source-id: 11e49da9758ead0ff3aa647bbd3fce7735bf4a07
Summary:
**Summary:** This commit adds the `torch.nn.qat.dynamic.modules.Linear`
module, the dynamic counterpart to `torch.nn.qat.modules.Linear`.
Functionally these are very similar, except the dynamic version
expects a memoryless observer and is converted into a dynamically
quantized module before inference.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67325
Test Plan:
`python3 test/test_quantization.py TestQuantizationAwareTraining.test_dynamic_qat_linear`
**Reviewers:** Charles David Hernandez, Jerry Zhang
**Subscribers:** Charles David Hernandez, Supriya Rao, Yining Lu
**Tasks:** 99696812
**Tags:** pytorch
Reviewed By: malfet, jerryzh168
Differential Revision: D32178739
Pulled By: andrewor14
fbshipit-source-id: 5051bdd7e06071a011e4e7d9cc7769db8d38fd73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67942
- Change "name" to "code" for consistency with linttool and LintMessage
format.
- Change "args" and "init_args" to "command" and "init_command" for
consistency with internal representation.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D32250606
Pulled By: suo
fbshipit-source-id: 557fef731bab9adca7ab1e7cc41b996956076b05
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67932
Also various improvements to grep_linter.py, including the ability to
specify a replacement pattern.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D32250603
Pulled By: suo
fbshipit-source-id: e07eb182e9473a268e2b805a68a859b91228bfbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67936
- Add the strict config
- Make the patterns exactly match the current CI
- Add init_args
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D32250605
Pulled By: suo
fbshipit-source-id: a71d434bf6024db4462260a460a1bc2d9ac66a32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67894
As title. Confirmed that the code base passes by running:
```
lintrunner --paths-cmd='git grep -Il ""' --take NEWLINE
```
and seeing that it pases
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D32250604
Pulled By: suo
fbshipit-source-id: de9bcba635d21f8832bb25147b19b7b2e8802247
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67890
Adding another linter. I also added a generic initializer that installs
the right pip packages (you can invoke it by running `lintrunner init`).
Differential Revision:
D32197366
D32197366
Test Plan: Imported from OSS
Reviewed By: driazati
Pulled By: suo
fbshipit-source-id: 82844e78f1ee3047220d8444874eab41d7cc0e9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67872
As title. This demonstrates some of the nice features of lintrunner:
- Uniform error reporting means you get a nice diff of the changes for
free
- Can run with -a to just accept the changes (don't need to tell people
to run a special regenerate command since the linter adaper already knows how.)
Differential Revision:
D32187386
D32187386
Test Plan: Imported from OSS
Reviewed By: driazati
Pulled By: suo
fbshipit-source-id: 71de6b042730be80ff6794652039e9bc655a72b1
Summary:
Catches deprecation warnings when we call `scheduler.step(epoch)`
in tests.
Removes duplicate parameters to optimizers unless we are specifically
testing for that
Fixes https://github.com/pytorch/pytorch/issues/67696
There is one warning remaining when I run this locally -- however that is due to the implementation of the `SequentialLR` Scheduler. I will open a new issue relating to that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67954
Reviewed By: H-Huang
Differential Revision: D32244056
Pulled By: albanD
fbshipit-source-id: 2ab3086a58e10c8d29809ccbaab80606a1ec61d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67856
Returns a tensor constructed from scalar input
Test Plan:
```
buck test //caffe2/benchmarks/static_runtime:static_runtime_cpptest
```
Ran
```
buck run //caffe2/benchmarks/static_runtime:static_runtime_cpptest -- --gtest_filter=*NumToTensorScalar* --v=1
```
and the output contains `Switch to out variant for node: %2 : Tensor = prim::NumToTensor(%0)`.
Reviewed By: mikeiovine
Differential Revision: D32014194
fbshipit-source-id: e7df65ea1bf05d59c1fc99b721aee420e484f542
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67437
Certain ops do nothing on the forward pass and can be discarded after training: `aten::detach` and `fb::scale_gradient` are examples of this.
Test Plan: `buck test caffe2/test:jit -- test_freezing`
Reviewed By: hlu1
Differential Revision: D31980843
fbshipit-source-id: 0045b6babcfae786a2ce801b2f5997a078205bc0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67924
This diff reverts the changes made in D31762735 (0cbfd466d2)
Test Plan: Wait for CI
Reviewed By: derekmod-fb
Differential Revision: D32214744
fbshipit-source-id: e0a65b6a31a88216ae1243549fcbc901ef812374
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67882
I ran into a hard-to-interpret error message when trying to run the following script, which was missing an `init_rpc` call:
```
# $ torchrun --standalone --nnodes=1 --nproc_per_node=1 script.py
import os
rank = int(os.environ['LOCAL_RANK'])
world_size = int(os.environ['WORLD_SIZE'])
import torch.distributed
# !!!!!! Uncomment the following and the script succeeds
# torch.distributed.rpc.init_rpc('worker', rank=rank, world_size=world_size)
import torch.distributed as dist
dist.init_process_group(backend='gloo')
import torchvision.models as models
import torch
rn50 = models.resnet50()
rn50.train()
rn50 = torch.nn.parallel.DistributedDataParallel(rn50)
from torch.distributed.rpc import RRef
from torch.distributed.optim import DistributedOptimizer
params = []
for param in rn50.parameters():
params.append(RRef(param))
dist_optim = DistributedOptimizer(
torch.optim.SGD,
params,
lr=0.05)
loss_func = torch.nn.CrossEntropyLoss()
with torch.distributed.autograd.context() as context_id:
pred = rn50(torch.randn(50, 3, 224, 224))
target = torch.randn(50, 1000).softmax(dim=1)
loss = loss_func(pred, target)
dist.autograd.backward(context_id, [loss])
dist_optim.step(context_id)
```
Error:
```
Traceback (most recent call last):
File "/xxx/torchrun_exp/script.py", line 23, in <module>
params.append(RRef(param))
RuntimeError: agentINTERNAL ASSERT FAILED at "../torch/csrc/distributed/rpc/rpc_agent.cpp":237, please report a bug to PyTorch. Current RPC agent is not set!
```
Since this is a user-facing error, I've changed `TORCH_INTERNAL_ASSERT` to `TORCH_CHECK` and added a hint about how to resolve the issue. On the other hand, the fact that this was originally `TORCH_INTERNAL_ASSERT` may suggest that the author thought that this should be an internal-only error condition. If there is some other place that should be throwing an exception in this case that is failing, let me know and I can adapt the fix to change that location.
Question for reviewers:
* Is there a good test file where I can add a test for this error condition?
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D32190947
Pulled By: jamesr66a
fbshipit-source-id: 3621d755329fd524db68675c55b1daf20e716d43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67032
This PR adds meta backend support to the `range`, `arange`, `linspace`, and `logspace` operators.
Note that the original PR (#66630) was reverted due to two failing unit tests in the Bionic CI. This revision includes a fix for those tests; otherwise its content is identical to the previous PR.
Original commit changeset: 2f9d8d1acbb0
ghstack-source-id: 142487306
Test Plan: Extended the existing tensor creation tests to assert meta backend support.
Reviewed By: zhaojuanmao
Differential Revision: D31834403
fbshipit-source-id: a489858a2a8a38a03234b14408e14d2b208a8d34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67876
Previously we miss it when we call obj.convert and this argument would not impact the fusion.
This PR fixes it and adds a test for it
Test Plan:
python test/test_quantization.py TestFuseFx
Imported from OSS
Reviewed By: malfet
Differential Revision: D32191364
fbshipit-source-id: 566bd39461010d70a21de71f611bb929976fe01d
Summary:
PyTorch doesn't compile with the latest `main` branch of cub again. The root cause is, PyTorch defines a macro `NUM_THREADS`, and cub added some code like
```C++
template<...., int NUM_THREADS, ...>
```
and these two mess up with each other.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67258
Reviewed By: albanD
Differential Revision: D31932215
Pulled By: ngimel
fbshipit-source-id: ccdf11e249fbc0b6f654535067a0294037ee7b96
Summary:
This PR makes several changes:
- Changed function `bool cudnn_conv_use_channels_last(...)` to `at::MemoryFormat cudnn_conv_suggest_memory_format(...)`
- Removed `resize_` in cudnn convolution code. Added a new overloading method `TensorDescriptor::set` that also passes the desired memory format of the tensor.
- Disabled the usage of double + channels_last on cuDNN Conv-Relu and Conv-Bias-Relu. Call `.contiguous(memory_format)` before passing data to cuDNN functions.
- Disabled the usage of cuDNN fused Conv-Bias-Relu in cuDNN < 8.0 version due to a CUDNN_STATUS_NOT_SUPPORTED error. Instead, use the native fallback path.
- Let Conv-Bias-Relu code respect the global `allow_tf32` flag.
From cuDNN document, double + NHWC is genenrally not supported.
Close https://github.com/pytorch/pytorch/pull/66968
Fix https://github.com/pytorch/pytorch/issues/55301
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65594
Reviewed By: jbschlosser, malfet
Differential Revision: D32175766
Pulled By: ngimel
fbshipit-source-id: 7ba079c9f7c46fc56f8bfef05bad0854acf380d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67861
Previously submitted as https://github.com/pytorch/pytorch/pull/67197.
This got reverted because its failures were hidden by the failures of
another PR.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D32178196
Pulled By: navahgar
fbshipit-source-id: cc8a5c68aed360d06289e69645461cfa773e1300
Summary:
Fixes https://github.com/pytorch/pytorch/issues/66232
This should be the last immediate task. I anticipate test ownership will change overtime but this is the last big thing to close it out
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67859
Reviewed By: soulitzer
Differential Revision: D32210534
Pulled By: janeyx99
fbshipit-source-id: 7fd835d87d9d35d49ec49de1fcfa29b085133e99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67824
Testing backport of all prod models using model test framework
Ref:
[Create tests at run-time (google test)](https://stackoverflow.com/questions/19160244/create-tests-at-run-time-google-test)
breaking the list of models into 20 chunks based on a simple hash (sum of all char values)
ghstack-source-id: 142398833
Test Plan:
```
buck test //xplat/pytorch/mobile/test:test_read_all_mobile_model_configs
Starting new Buck daemon...
Parsing buck files: finished in 7.6 sec
Creating action graph: finished in 0.9 sec
[RE] Metadata: Session ID=[reSessionID-66f5adfe-50d1-4599-9828-3e8115181601]
[RE] Waiting on 0 remote actions. Completed 1008 actions remotely, action cache hit rate: 43.59%.
Downloaded 26/1523 artifacts, 252.60 Kbytes, 96.6% cache miss (for updated rules)
Building: finished in 01:18.6 min (100%) 5532/5532 jobs, 770/5532 updated
Total time: 01:27.3 min
Testing: finished in 11:21.6 min (41 PASS/0 FAIL)
BUILD SUCCEEDED
RESULTS FOR //xplat/pytorch/mobile/test:test_read_all_mobile_model_configs
PASS 673.8s 41 Passed 0 Skipped 0 Failed //xplat/pytorch/mobile/test:test_read_all_mobile_model_configs
TESTS PASSED
```
Reviewed By: dhruvbird
Differential Revision: D32068955
fbshipit-source-id: d06c2434a4a69572ab52df31a684e5973b9d551c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67803
* Addresses comments from #63589
[ONNX] remove torch::onnx::PRODUCER_VERSION (#67107)
Use constants from version.h instead.
This simplifies things since we no longer have to update
PRODUCER_VERSION for each release.
Also add TORCH_VERSION to version.h so that a string is available for
this purpose.
[ONNX] Set `ir_version` based on opset_version. (#67128)
This increases the odds that the exported ONNX model will be usable.
Before this change, we were setting the IR version to a value which may
be higher than what the model consumer supports.
Also some minor clean-up in the test code:
* Fix string replacement.
* Use a temporary file so as to not leave files around in the test
current working directory.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D32181306
Pulled By: malfet
fbshipit-source-id: 02f136d34ef8f664ade0bc1985a584f0e8c2b663
Co-authored-by: BowenBao <bowbao@microsoft.com>
Co-authored-by: Gary Miguel <garymiguel@microsoft.com>
Co-authored-by: Nikita Shulga <nshulga@fb.com>
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67800
Currently when the grad is the same layout as base, we try to assign the same tensor to the forward grad of both the base and the view. However, when the layout of the grad is different from the layout of the view, this triggers a copy to be created, and the tangent of the view (after the inplace) will not have a view relationship with the view of the base.
This PR just changes it so that we only do the above optimization when the layout also matches the layout of self
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67816
Reviewed By: malfet
Differential Revision: D32190021
Pulled By: soulitzer
fbshipit-source-id: b1b2c9b332e83f4df5695ee9686ea76447f9305b
Summary:
Many thanks to Forest Yang (meowmix) from the forum for reporting it with a minimal reproduction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67829
Reviewed By: malfet
Differential Revision: D32184786
Pulled By: albanD
fbshipit-source-id: b63dbd3148b5def2109deb2f4612c08f55f59dfb
Summary:
The final learning rate should be 0.05 like the lr used as the argument for the optimizer and not 0.005.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67840
Reviewed By: jbschlosser
Differential Revision: D32187091
Pulled By: albanD
fbshipit-source-id: 8aff691bba3896a847d7b9d9d669a65f67a6f066
Summary:
Fixes part of https://github.com/pytorch/pytorch/issues/67696 by adding calls to `optimizer.step()` in various places.
## Notes for reviewers:
- It is not entirely clear which is the right optimizer to step in each case. I have favoured the more explicit approach of creating a set of optimizers and calling step on each of them.
- At the time of writing, the only Scheduler without an `optimizer` instance variable is `ChainedScheduler` which I need to deal with once. I use `hasattr` to do this check. Let me know if this ought to be changed.
- I am opening this PR for review when it only solve part of the issue, as I'd rather get feedback sooner. I think it is fine to fix the issue in several PRs too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67756
Reviewed By: jbschlosser
Differential Revision: D32187864
Pulled By: albanD
fbshipit-source-id: fd0d133bcaa3a24588e5a997ad198fdf5879ff5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67554
This change adds a comment on clients taking ownership of managed output tensor to remind SR developers of how and why that matters.
Test Plan: N/A
Reviewed By: swolchok
Differential Revision: D32013468
fbshipit-source-id: bcc13055c329c61677bdcc76411fe8db44bb2cee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67814
There was a limitation on the xar file size we can embed into the binary previously. The payload (xar file here) is added to .data section by default using 'ld -b binary -r' command (which section the payload goes is hardcoded in ld BTW. Check code pointer [here](https://github.com/bminor/binutils-gdb/blob/binutils-2_32/bfd/binary.c#L80) ) . When we link the object file containing the payload to other parts of the executable, we will get relocation out of range error if the overall size of .test, .data, .bss etc sections exceed 2G. Some relocation entries uses 32 bit singed integer, thus the limit is 2G here.
To solve the issue and mitigate the risk, we designed a mechanism to put the payload in a customized payload section (.torch_deploy_payload.unity here). The payload section does not join the party of relocating and symbol resolution, thus in theory it can be as large as the disk space... Since we don't do relocation for the payload section, the start/end/size symbols are no longer available/valid, we have to parse the ELF file ourselves to figure out those.
The mechanism can be used to embed interprter.so as well. The interpreter.so is currently 0.5G. That will limit the other .test/.data/.bss sections of the executable to be at most 1.5G. Using this mechanim in this diff avoid the interpreter.so taking any budgets. We could also use this mechanism to ship python scripts with our binary rather than freeze them before hand. These use cases are not handled in this diff.
This diff also improves experience for those simple use cases that does not depends on extra shared libraries in the XAR file (except the shared libraries for python extensions themselves). This is mainly for fixing the stress test right now, but it also makes other simple cases easier.
ghstack-source-id: 142483327
Test Plan:
# Verify the relocation out of range issue is fixed
Add //caffe2:torch as a dependency to the macro build_unity(name="example", …) in torch/csrc/deploy/unity/TARGETS and run 'buck run mode/opt :unity_demo', it's expected to get the relocation errors like:
```
ld.lld: error:
caffe2/c10/util/intrusive_ptr.h:325:(.text._ZN11ska_ordered8detailv317sherwood_v3_tableISt4pairIN3c106IValueES4_ES4_NS3_6detail11DictKeyHashENS0_16KeyOrValueHasherIS4_S5_S7_EENS6_14DictKeyEqualToENS0_18KeyOrValueEqualityIS4_S5_SA_EESaIS5_ESaINS0_17sherwood_v3_entryIS5_EEEE15emplace_new_keyIS5_JEEES2_INSH_18templated_iteratorIS5_EEbEaPSF_OT_DpOT0_+0x4E9): relocation R_X86_64_32S out of range: 2345984168 is not in [-2147483648, 2147483647]; references c10::UndefinedTensorImpl::_singleton
>>> defined in /data/sandcastle/boxes/fbsource/fbcode/buck-out/opt/gen/caffe2/c10/c10#platform009-clang,static/libc10.a(../c10#compile-UndefinedTensorImpl.cpp.o44c44c4c,platform009-clang/core/UndefinedTensorImpl.cpp.o)
```
With the diff, the error above is resolved.
# Pass Stress Test
Also pass existing unit tests for unity.
buck test mode/opt //caffe2/torch/csrc/deploy/unity/tests:test_unity_sum -- --exact 'caffe2/torch/csrc/deploy/unity/tests:test_unity_sum - UnityTest.TestUnitySum' --run-disabled --jobs 18 --stress-runs 10 --record-results
buck test mode/opt //caffe2/torch/csrc/deploy/unity/tests:test_unity_simple_model -- --exact 'caffe2/torch/csrc/deploy/unity/tests:test_unity_simple_model - UnityTest.TestUnitySimpleModel' --run-disabled --jobs 18 --stress-runs 10 --record-results
# Verify debug sections are not messed up
Verified that debug sections are not messed up and GDB still works:
`gdb ~/fbcode/buck-out/gen/caffe2/torch/csrc/deploy/unity/unity_demo`
```
b main
run
l
c
```
Reviewed By: suo
Differential Revision: D32159644
fbshipit-source-id: a133513261b73551a71acc257f4019f7b5af34a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67768
We don't need to pass so many padding args after removing support for asymm padding from qnnpack
Test Plan: it builds
Reviewed By: jshen
Differential Revision: D32082204
fbshipit-source-id: 2bfe4c135ad613f0cc267e7e3ab6357731f29bc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67886
Similar to what we have in torch2trt tensorrt_converter, introduce version enablement for fx2trt converters. Upgrade to trt 8.2 will introduce new op converter as well as deprecate old op.
Test Plan: pass existing unit test
Reviewed By: 842974287
Differential Revision: D32183581
fbshipit-source-id: 6419acada296d24e882efa9fca25eca6349153e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66130
We're reusing backing storage for these tensors, which is only safe because they have non-overlapping lifetimes. Accordingly, it seems that they can also share their StorageImpl.
ghstack-source-id: 142427752
Test Plan:
benchmarked ctr_mobile_feed local and local_ro:
Using recordio inputs for model 302008423_0
```
swolchok@devbig032 ~/f/fbcode> env MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 > environment^C
swolchok@devbig032 ~/f/fbcode> sudo ~/fbsource2/fbcode/scripts/bertrand/noise/denoise-env.sh \
/tmp/ptvsc2_predictor_benchNov1ArenaAllocateStorageImpls \
--scripted_model=/data/users/swolchok/ctr_mobile_feed_q3_2021/302008423_0.predictor.disagg.local \
--method_name=local.forward --pt_cleanup_activations=1 \
--pt_enable_out_variant=1 --pt_optimize_memory=1 --iters=2 --warmup_iters=2 \
--num_threads=1 --pt_enable_static_runtime=1 --set_compatibility=1 --repetitions=5 --recordio_use_ivalue_format=1 --recordio_inputs=/data/users/swolchok/ctr_mobile_feed_q3_2021/302008423_0.local.inputs.recordio
Stable
========================================
I1101 14:19:16.473964 2748837 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 20.0131. Iters per second: 49.9673
I1101 14:20:12.193130 2748837 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 20.0155. Iters per second: 49.9612
I1101 14:21:07.761898 2748837 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.9751. Iters per second: 50.0624
I1101 14:22:03.218066 2748837 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.9104. Iters per second: 50.2249
I1101 14:22:58.723256 2748837 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.956. Iters per second: 50.1102
I1101 14:22:58.723306 2748837 PyTorchPredictorBenchLib.cpp:262] Mean milliseconds per iter: 19.974, standard deviation: 0.043643
ArenaAllocateStorageImpls
========================================
I1101 14:08:57.070914 2695478 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.9771. Iters per second: 50.0572
I1101 14:09:52.605121 2695478 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.924. Iters per second: 50.1907
I1101 14:10:48.098287 2695478 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.9353. Iters per second: 50.1624
I1101 14:11:43.645395 2695478 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.9723. Iters per second: 50.0694
I1101 14:12:39.171636 2695478 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 19.9673. Iters per second: 50.0819
I1101 14:12:39.171685 2695478 PyTorchPredictorBenchLib.cpp:262] Mean milliseconds per iter: 19.9552, standard deviation: 0.0239318
difference: 0.0188 (0.09%), which is less than 1 standard deviation
Stable, local_ro
========================================
I1101 14:26:10.796161 2787930 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.25991. Iters per second: 793.708
I1101 14:26:12.194727 2787930 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.26862. Iters per second: 788.26
I1101 14:26:13.591312 2787930 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.26549. Iters per second: 790.207
I1101 14:26:14.982439 2787930 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.25943. Iters per second: 794.01
I1101 14:26:16.377033 2787930 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.25995. Iters per second: 793.68
I1101 14:26:16.377094 2787930 PyTorchPredictorBenchLib.cpp:262] Mean milliseconds per iter: 1.26268, standard deviation: 0.00414788
ArenaAllocateStorageImpls, local_ro
========================================
I1101 14:26:45.875073 2790009 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.20987. Iters per second: 826.536
I1101 14:26:47.207271 2790009 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.20827. Iters per second: 827.633
I1101 14:26:48.533766 2790009 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.20023. Iters per second: 833.174
I1101 14:26:49.850610 2790009 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.19206. Iters per second: 838.884
I1101 14:26:51.172356 2790009 PyTorchPredictorBenchLib.cpp:251] PyTorch run finished. Milliseconds per iter: 1.19958. Iters per second: 833.622
I1101 14:26:51.172411 2790009 PyTorchPredictorBenchLib.cpp:262] Mean milliseconds per iter: 1.202, standard deviation: 0.00722754
Difference: 0.06 usec/iter (4.8%), which is much more than 1 standard deviation
```
we can see that this is a large relative improvement on local_ro, but no effect on local.
Reviewed By: hlu1
Differential Revision: D31357486
fbshipit-source-id: 229c003677da76e89c659d0e0639002accced76e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66638
See comments in code explaining what we're doing here.
ghstack-source-id: 142427750
Test Plan:
Ran ptvsc2_predictor_bench on ctr_mobile_feed local and local_ro net before/after this change on a devserver with turbo off.
Results:
```
stable, local_ro:
========================================
I1014 16:13:52.713300 151733 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.68012. Iters per second: 373.118
I1014 16:14:00.961875 151733 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.66156. Iters per second: 375.719
I1014 16:14:09.163097 151733 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.6449. Iters per second: 378.086
I1014 16:14:17.425621 151733 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.66661. Iters per second: 375.008
I1014 16:14:25.711349 151733 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.67375. Iters per second: 374.006
I1014 16:14:25.711390 151733 PyTorchPredictorBenchLib.cpp:269] Mean milliseconds per iter: 2.66539, standard deviation: 0.0134423
stable, local:
========================================
I1014 15:08:28.547081 3979345 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.42772. Iters per second: 155.576
I1014 15:08:48.276582 3979345 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.3643. Iters per second: 157.127
I1014 15:09:07.978683 3979345 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.3566. Iters per second: 157.317
I1014 15:09:27.875543 3979345 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.42044. Iters per second: 155.752
I1014 15:09:47.558079 3979345 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.34902. Iters per second: 157.505
I1014 15:09:47.558120 3979345 PyTorchPredictorBenchLib.cpp:269] Mean milliseconds per iter: 6.38361, standard deviation: 0.037421
cache storages, local_ro:
========================================
I1014 16:15:42.292997 160496 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.66604. Iters per second: 375.088
I1014 16:15:50.622402 160496 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.68683. Iters per second: 372.186
I1014 16:15:58.901475 160496 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.67028. Iters per second: 374.493
I1014 16:16:07.156373 160496 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.66317. Iters per second: 375.492
I1014 16:16:15.474292 160496 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 2.68394. Iters per second: 372.587
I1014 16:16:15.474334 160496 PyTorchPredictorBenchLib.cpp:269] Mean milliseconds per iter: 2.67405, standard deviation: 0.0106982
cache storages, local:
========================================
I1014 20:53:43.113400 1657168 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.3811. Iters per second: 156.713
I1014 20:54:02.829102 1657168 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.36039. Iters per second: 157.223
I1014 20:54:22.885171 1657168 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.47333. Iters per second: 154.48
I1014 20:54:42.768963 1657168 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.41404. Iters per second: 155.908
I1014 20:55:02.624423 1657168 PyTorchPredictorBenchLib.cpp:252] PyTorch run finished. Milliseconds per iter: 6.4042. Iters per second: 156.147
I1014 20:55:02.624460 1657168 PyTorchPredictorBenchLib.cpp:269] Mean milliseconds per iter: 6.40661, standard deviation: 0.0427168
```
Looks like this diff is neutral or a slight regression, but it is a stepping stone on the way to the following diff.
Reviewed By: hlu1
Differential Revision: D31326711
fbshipit-source-id: a6e0185f24a6264b1af2a51b69243c310d0d48d5
Summary:
Combine `xla` and `builder` branch pinning steps and link them to a PR that does it correctly
Update example PR for version bump, as few files have changed
Deleted FaceHub step as it is no longer necessary after recent update
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65489
Reviewed By: zhouzhuojie, seemethere
Differential Revision: D31120498
Pulled By: malfet
fbshipit-source-id: e1a9db2b03243c8d28eeed9888c3653e4460ad07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66401
This PR fixes the case when result and input tensors have different
strides.
cuSPARSE from CUDA 11.3.1 has a bug: it doesn't use correct strides to
write the result. This is "fixed" in PyTorch code by copying the input
tensor to a tensor with same strides as result tensor has.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: davidberard98
Differential Revision: D32177966
Pulled By: cpuhrsch
fbshipit-source-id: 118437409df147f04dce02763aff9bfd33f87c63
Summary:
Follow up to https://github.com/pytorch/pytorch/issues/61935
This PR adds device to device transfer test into `ModuleInfo`.
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65488
Reviewed By: mruberry
Differential Revision: D32063662
Pulled By: jbschlosser
fbshipit-source-id: 0868235a0ae7e5b6a3e4057c23fe70753c0946d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67703
Had this script fail on me within CI without actually telling me what
was wrong so adding some more output here to showcase what the actual
vs. the expected result is
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D32112898
Pulled By: seemethere
fbshipit-source-id: dfc9a82c709d52e0dde02d1e99a19eecc63c5836
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67802
In RPC C++ code, we might sometimes call constValue() when the future actually has an exception, and in unittests we want to assert on the exception. What happens is that we get a message basically saying "!eptr_" which indicates there is some exception but we don't know what it is.
This diff simply adds logging for the exception and mentions that `value` over `constValue` should be used when the future can have an exception. The contract of `constValue` to throw when `eptr_` is set is still held, it is just enhanced with additional logging.
ghstack-source-id: 142375391
Test Plan: Added UT
Reviewed By: mrshenli
Differential Revision: D32156552
fbshipit-source-id: 4dd5e73b92173209074c104a4b75c2021e20de4b
Summary:
https://github.com/pytorch/pytorch/issues/65868 pointed out that the "long-form" versions of some binary ops like `mul`, `sub`, and `div` don't match their alias's behavior when it comes to handling scalar inputs. This PR adds the missing registration in `python_arg_parser.cpp` to resolve this.
CC ptrblck ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65937
Reviewed By: malfet
Differential Revision: D32156580
Pulled By: ngimel
fbshipit-source-id: b143cf7119a8bb51609e1b8734204edb750f0210
Summary:
Running one test in test_distributed_spawn is a bit confusing but possible. Add documentation to the CONTRIBUTING.md for this.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67801
Reviewed By: mrshenli
Differential Revision: D32157700
Pulled By: rohan-varma
fbshipit-source-id: a1d10f2fb5f169b46c6d15149bf949082d9bd200
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: d2aa3485e8
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67845
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D32170821
fbshipit-source-id: 1958e824a9f02c5178fa5d4a73a171dedefc540c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67363
ProcessGroup RPC backend is deprecated. In 1.10 it would throw an error to the user to be more user friendly. This PR now removes it completely.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D32138321
Pulled By: H-Huang
fbshipit-source-id: b4f700d8f1b1d46ada7b5062d3f754646571ea90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67443
Fixes https://github.com/pytorch/pytorch/issues/57459
After discussing the linked issue, we resolved that `F.kl_div` computes
the right thing as to be consistent with the rest of the losses in
PyTorch.
To avoid any confusion, these docs add a note discussing how the PyTorch
implementation differs from the mathematical definition and the reasons
for doing so.
These docs also add an example that may further help understanding the
intended use of this loss.
cc brianjo mruberry
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D32136888
Pulled By: jbschlosser
fbshipit-source-id: 1ad0a606948656b44ff7d2a701d995c75875e671
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: caa2ccb394
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67769
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D32138256
fbshipit-source-id: dfe4c73ae25c8f362f2917dd7594bdcd418c2a0d
Summary:
Some of the "no-ops" are not actually no-ops because they can change the dtype
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67688
Reviewed By: davidberard98
Differential Revision: D32104601
Pulled By: eellison
fbshipit-source-id: ccb99179a4b30fd20b5a9228374584f2cdc8ec21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67188
This diff/PR is trying to implement the ShardedEmbeddingBag using the ShardedTensor.
We support both row-wise and column-wise sharding of the embedding bag. The detailed logic can be found in the comment.
Several caveats:
1. Only the sharding of one weight is supported now.
1. We support limited input params for the op. To support more params are on the way.
2. We only support chuck sharding for now.
3. We only support a single local shard per rank for now.
Some other changes include:
1. Refactor the ShardedEmbedding code so that the common logic can be reused.
2. Fix tiny typos and corner cases in API `get_chunked_dim_size`. Where it will return -1 if the we set the dim_size = 5, split_size = 2, idx = 3. (This is a valid case because when chunks = 4, dim_size = 5, then the split_size = 2)
ghstack-source-id: 142325915
Test Plan: Unit test and CI
Reviewed By: pritamdamania87
Differential Revision: D31749458
fbshipit-source-id: ed77e05e4ec94ef1a01b1feda8bbf32dc5d5da1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67135
Add ability to use env var backend for quicker testing (and gloo2 in
the future)
ghstack-source-id: 142274304
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D31878285
fbshipit-source-id: 80ae7107cd631a1a15ebc23262b27d8192cfe4b6
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/66066
This PR:
- cleans up op-specific testing from test_autograd. test_autograd should be reserved for testing generic autograd functionality
- tests related to an operator are better colocated
- see the tracker for details
What to think about when moving tests to their correct test suite:
- naming, make sure its not too generic
- how the test is parametrized, sometimes we need to add/remove a device/dtype parameter
- can this be merged with existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67413
Reviewed By: jbschlosser, albanD
Differential Revision: D32031480
Pulled By: soulitzer
fbshipit-source-id: 8e13da1e58a38d5cecbfdfd4fe2b4fe6f816897f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67707https://github.com/pytorch/pytorch/pull/63939/files has added FP16 support to torchscript.
This is to add BF16 device type when doing full conversion.
Test Plan: Unit test. Also tested BF16 locally on A100 using MLP model.
Reviewed By: idning
Differential Revision: D32027152
fbshipit-source-id: b2a5ff2b22ea1e02306b0399f2b39b8493be4f45
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67779
Not all flaky failures from this test are URLErrors; I think we should
err on the side of being expansive with retries here.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D32145434
Pulled By: suo
fbshipit-source-id: 3c3274b2080681fcafb3ea6132e420605f65c429
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67497
This allows more of the code-generation to happen in parallel, whereas
previously all codegen was serialized.
Test Plan: Imported from OSS
Reviewed By: dagitses, mruberry
Differential Revision: D32027250
Pulled By: albanD
fbshipit-source-id: 6407c4c3e25ad15d542aa73da6ded6a309c8eb6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67496
gen_autograd.py doesn't use `Declarations.yaml` any more, and removing
the dependency allows it to run in parallel with
`tools/codegen/gen.py`.
Test Plan: Imported from OSS
Reviewed By: dagitses, ejguan
Differential Revision: D32027251
Pulled By: albanD
fbshipit-source-id: 2cc0bbe36478e6ec497f77a56ab8d01c76145703
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67484
Maps from `c10::Symbol -> c10::Symbol` can be hard to parse when `fromQualString` is scattered everywhere. I've been annoyed by this issue many times when rebasing, and have even messed up `FuseListUnpack` a few times.
Introduce a macro to make it easier to see what maps to what.
Test Plan: CI
Reviewed By: hlu1
Differential Revision: D32004451
fbshipit-source-id: 1086254c8403a0880d014512c439edbefa6fa015
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67166
This optimization is not really the same thing as `FuseListUnpack`, and mixing the logic in that pass is confusing and error-prone. It should really be its own pass.
It's slower since we have to do another pass over the graph, but this is not perf critical code; readability is more important.
Test Plan: Unit tests: `buck test caffe2/benchmarks/static_runtime/...`
Reviewed By: hlu1
Differential Revision: D31887458
fbshipit-source-id: 289e281d512435861fccfe19f017751ad015688c
Summary:
Use the main branch when TorchBench branch is not specified.
RUN_TORCHBENCH: soft_actor_critic
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67743
Reviewed By: seemethere
Differential Revision: D32142663
Pulled By: xuzhao9
fbshipit-source-id: 160227835543b8e55c970025073839bf0f03aa81
Summary:
stas00 uncovered an issue where certain half-precision GEMMs would produce outputs that looked like the result of strange rounding behavior (e.g., `10008.` in place of `10000.`). ptrblck suspected that this was due to the parameters being downcasted to the input types (which would reproduce the problematic output). Indeed, the GEMM and BGEMM cublas wrappers are currently converting the `alpha` and `beta` parameters to `scalar_t` (which potentially is reduced precision) before converting them back to `float`. This PR changes the "ARGTYPE" wrappers to use `acc_t` instead and adds a corresponding test.
CC ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67633
Reviewed By: mruberry
Differential Revision: D32076474
Pulled By: ngimel
fbshipit-source-id: 2540d9b9d0195c17d07d1161374fb6a5850779d5
Summary:
Partial fix for https://github.com/pytorch/pytorch/issues/66800. (Duplicate of https://github.com/pytorch/pytorch/issues/67725 against pytorch/pytorch so as to trigger TorchBench)
https://github.com/pytorch/pytorch/issues/61056 added a more verbose error message for distributions failing argument validation. However, it did not replace the earlier error check as was originally intended and was flagged by xuzhao9 as being the potential cause of a perf regression in `test_eval[soft_actor_critic-cuda-eager]`.
xuzhao9: Is there a way for me to check if this resolves the perf issue you mentioned?
cc VitalyFedyunin ngimel
Note that existing tests already check for the error message and should verify that the removed lines are redundant.
RUN_TORCHBENCH: soft_actor_critic
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67741
Reviewed By: neerajprad
Differential Revision: D32135675
Pulled By: xuzhao9
fbshipit-source-id: 37dfd3ff53b95017c763371979ab3a2c302a72b9
Summary:
in scope of: https://github.com/pytorch/pytorch/issues/67301. Main changes:
* generated-pytorch-linux-xenial-py3-clang5-android-ndk-r19c-gradle-custom-build-single-full-jit deleted from circle
* pytorch_android_gradle_custom_build_single removed since it is no longer used
* generated-pytorch-linux-xenial-py3-clang5-android-ndk-r19c-gradle-custom-build-single-full-jit added to GHA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67695
Reviewed By: malfet, seemethere, ejguan
Differential Revision: D32115620
Pulled By: b0noI
fbshipit-source-id: 113d48303c090303ae13512819bac2f069a2913f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67498
Add acc_ops.pad and a converter for it. We want to try padding convolution channel dimension to get better int8 performance.
This one only support padding the last two dimension though. Starting from 8.2, it's suggested to use Slice layer to do padding but this might be nice to have for old version support.
Test Plan: buck test mode/dev-nosan caffe2/test/fx2trt/converters:test_pad
Reviewed By: wushirong
Differential Revision: D32006072
fbshipit-source-id: 96c3aa2aec2d28345d044a88bee2f46aba5cca0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67734
The implementation of `aten::cat` op in NNC has to ignore tensors that have 0-size in any dimension.
Test Plan: `buck test mode/dev-nosan //caffe2/test/cpp/tensorexpr:tensorexpr -- --exact 'caffe2/test/cpp/tensorexpr:tensorexpr - Kernel.CatWithEmptyInputs'`
Reviewed By: ZolotukhinM
Differential Revision: D32122171
fbshipit-source-id: 90c697813bc504664673cdc262df6e7ce419c655
Summary:
Fix https://github.com/pytorch/pytorch/issues/67239
The CUDA kernels for `adaptive_max_pool2d` (forward and backward) were written for contiguous output. If outputs are non-contiguous, first create a contiguous copy and let the kernel write output to the contiguous memory space. Then copy the output from contiguous memory space to the original non-contiguous memory space.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67697
Reviewed By: ejguan
Differential Revision: D32112443
Pulled By: ngimel
fbshipit-source-id: 0e3bf06d042200c651a79d13b75484526fde11fe
Summary:
OpenBLAS recently added support for bfloat16 GEMM, so this change has PyTorch call out to OpenBLAS for that, like it does for single and double precision
Our goal is to try to enable PyTorch to make calls to "sbgemm" in OpenBLAS.
We are prepared (if it is your preference) to add fences to the code to limit this change to the Power architecture,
but our first instinct is that anyone on any architecture that enables access to sbgemm in their OpenBLAS library
should be able to use this code. (but again, we respect that as we are just starting to modify PyTorch, we respect
your guidance!)
(there is no issue number related to this)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58831
Reviewed By: albanD
Differential Revision: D29951900
Pulled By: malfet
fbshipit-source-id: 3d0a4a638ac95b2ff2e9f6d08827772e28d397c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67368
This PR adds an addition test variant for the tensor conversion
functions (bfloat16, char, long, ...) that tests channels_last. This is
because some backends (mostly just functorch right now) don't have
channels last handling and may want to test that separately from the
more general case of these operations.
Test Plan: - wait for tests
Reviewed By: mruberry
Differential Revision: D31972959
Pulled By: zou3519
fbshipit-source-id: 68fea46908b2cdfeb0607908898bb8f9ef25b264
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65740
fp32 hardsigmoid supports inplace. This PR adds the inplace support to the quantized
hardsigmoid function, to make the signatures match.
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_qhardsigmoid
```
Reviewed By: supriyar
Differential Revision: D31992282
Pulled By: vkuzo
fbshipit-source-id: f6be65d72954ab8926b36bb74a5e79d422fbac90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66859
`MTLCreateSystemDefaultDevice` can return `nil`. If that happens then inside `createDeviceInfo`, we'll crash trying to convert the `nullptr` from `device.name.UTF8String` into a `std::string`.
Let's fix it by returning early in setup if there's no Metal device. But also make `createDeviceInfo` safe if we do pass in `nil`.
Test Plan: * CircleCI
Reviewed By: xta0
Differential Revision: D31759690
fbshipit-source-id: 74e878ab5b8611250c4843260f1d2e4eab22cdaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66637
We can give more information when verify_no_memory_overlap would fail by separating the DCHECK.
ghstack-source-id: 142226105
Test Plan: fitsships
Reviewed By: d1jang
Differential Revision: D31517151
fbshipit-source-id: 8cbc324c27f6b4db4489d1bd469d37b1d8ae6ce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67249
Implements CPU offload for model parameters in FSDP.
- CPU offload class with only offload_params attribute is created
- If this is specified in FSDP ctor, model parameters are moved back to CPU after sharding in __init__
- In forward pass, during lazy init, p._local_shard gets set to p.data so it is on CPU. We pin_memory here.
- In forward pass, in _rebuild_full_params, we move p.data back to self.compute_device if necessary. Note that we don't use the device of p._full_param_padded because we don't always have this attr, but when we do its always the same as compute_device.
- The same logic as above applies to the beginning of backwards pass.
- At end of fwd and end of bwd, `_use_param_local_shard` takes care to ensure the parameters are offloaded to CPU again, by pointing it to p._local_shard, which is always on CPU.
Regarding tests:
- We tests 3 different types of init: 1) CUDA the model before wrapping with FSDP, 2) CUDA the model after wrapping with FSDP, 3) never CUDA the model.
- Case 1 is always supported. Case 2 is not supported with CPU offload and throws an error during fwd pass. Case 3 is only supported with CPU offload at the moment.
- Verifies all params are offloaded to CPU after init.
- Verifies all params are offloaded to CPU after forward and backward.
- Note that there is an issue with verifying exact parity when CPU offloading, but it appears to be related to transfering model back and forth cpu/CUDA. More details in https://github.com/pytorch/pytorch/pull/66961
ghstack-source-id: 141851903
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D31911085
fbshipit-source-id: 3ddf73c070b55ce383e62251868d609004fc30e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65598
This change adds `PyTorchPredictor::predict_managed_result` to enable Static Runtime to return managed output tensors, allocated and owned by Static Runtime to accelerate inference workloads.
- `PyTorchPredictor::predict_managed_result` does only meaningful work for the overridden `PyTorchStaticRuntimePredictor::predict_managed_result`. For other subclasses, it returns a simple object that just wraps the returned `Ivalue`.
- When `manage_output_tensors` is enabled, a `StaticRuntime` cannot be reentered until its return value gets deallocated by calling `StaticRuntime::deallocateOutputTensors`. Currently an instance of `StaticRuntime` gets immediately pushed back to `static_runtime_pool` to be reentered again, and this cannot be done when `manage_output_tensors` is enabled. `PyTorchStaticRuntimePredictorManagedResult` makes sure to delay pushing a `StaticRuntime` instance back to the pool only after `StaticRuntime::deallocateOutputTensors` is called on the runtime instance.
- When `manage_output_tensors` is enabled, `PyTorchStaticRuntimePredictor::predict_managed_result` returns the prediction result, whose backing memory is managed by an instance of `StaticRuntime`. The lifetime of any value reachable from `PyTorchStaticRuntimePredictorManagedResult.get()` is expected to end before `PyTorchStaticRuntimePredictorManagedResult` gets destructed. As explained above, `PyTorchPredictorManagedResult`'s destruction pushes the runtime instance that returned the result back to `static_runtime_pool` to be reused again.
- The current API design of adding `predict_managed_result` instead of forcing `operator()` to return `PyTorchPredictorManagedResult` was motivated by the fact that `manage_output_tensors` will be selectively enabled just for a few models. In case `manage_output_tensors` becomes a commonly used feature we should revisit this API design to merge them together.
Reviewed By: hlu1
Differential Revision: D31149323
fbshipit-source-id: 5ca026188077232d6a49a46759124a978439d7b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67639
Due to BC considerations, we cannot directly error out, as that
might break existing applications. Raise warnings first to improve
debuggability.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D32075151
Pulled By: mrshenli
fbshipit-source-id: 5680d420f5f6cd3f74a36616c03350e8a976b363
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67245
Add support for fused modules in the new convert path, including linear-relu, conv{1-3}d-relu and their qat versions,
also tested with trt (conv2d-relu and linear-relu)
Test Plan:
```
python test/fx2trt/test_quantize_fx.py TestQuantizeFxTRTOps.test_linear_relu_module
python test/fx2trt/test_quantize_fx.py TestQuantizeFxTRTOps.test_conv_relu_module
```
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31919724
fbshipit-source-id: 7e5c96eba30706f7989da680aa3443159847bdfd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67668
This adds an env var to enable NCCL health check, which when left unspecified, results in the check not being run. Unit tests that need to test this functionality have the env variable set. Please see internal diff for more details.
Test Plan: CI
Reviewed By: yuguo68, mrshenli
Differential Revision: D32089763
fbshipit-source-id: dff5664a5e607f711515cd1042089ca769914fbb
Summary:
Most of the failing tests are since the test doesn't work with python functions (only builtins like `torch.add`).
I added a check for that and ported the remaining skips into the `skips` field.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67520
Reviewed By: ZolotukhinM
Differential Revision: D32046856
Pulled By: Chillee
fbshipit-source-id: 05fa3e3c40fa6cc4f776e0c24f667629b14afd25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66620
This splits the Tensor-dependant code out into a cpp file.
A slight complicating factor is `scan_dim` using `copy_` to handle
non-contiguous out arguments. So, I've moved that code into the
caller which does introduce some duplication. Though it's only ~10
lines extra in total.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D31856106
Pulled By: dagitses
fbshipit-source-id: 91bb4ce5e7c6487e3ea0d5ec4d9f7a625d8ef978
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66220
- Pass pointers rather than tensors to ```quantize_tensor_arm``` to allow for using ```__restrict__``` and to make parallelization easier (as in the next diff on this stack D31205883)
- Replace ```auto``` with actual types
- Replace raw cast with reinterpret_cast<...>
- All of these changes make the code structure similar to that of Dequantize
ghstack-source-id: 142166376
Test Plan: same as D31066997 (all tests pass)
Reviewed By: kimishpatel
Differential Revision: D31444248
fbshipit-source-id: 6a31d090082047263403f415911c199519987595
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65844
When run on [Partially Quantized Mobile Vision Transformer Model](https://www.internalfb.com/diff/D30648171), with config from rebasing onto v4 of D31869106
Before:
[AIBench Run (128ms)](https://www.internalfb.com/intern/aibench/details/309792316534505)
[Perf Report](https://interncache-all.fbcdn.net/manifold/aibench/tree/mobile/pt/profiling_reports/model_perf_1635881079420.html)
After:
[AIBench Run (117ms)](https://www.internalfb.com/intern/aibench/details/20433505461364)
[Perf Report](https://interncache-all.fbcdn.net/manifold/aibench/tree/mobile/pt/profiling_reports/model_perf_1635881527831.html)
Total events spent on at::native::dequantize_quantized reduced from 1.97 Billion to 0.97 Billion (~50% Reduction)
ghstack-source-id: 142166373
Test Plan:
To run quantized_test
- Clone open source repo
- Set ANDROID_NDK and ANDROID_SDK
- Build with ```BUILD_MOBILE_BENCHMARK=1 BUILD_MOBILE_TEST=1 ANDROID_DEBUG_SYMBOLS=1 BUILD_LITE_INTERPRETER=0 ANDROID_ABI=arm64-v8a ./scripts/build_android.sh -DANDROID_CCACHE=$(which ccache) -DBUILD_BINARY=ON```
- Move ```build_android/bin/quantized_test``` to devserver
- Use one world to connect to android device (ex. ```one_world android device pixel-3a```)
- In another terminal: Make quantized_test executable (```chmod +x quantized_test```), copy it to android device (```adb push quantized_test /data/local/tmp```), and run it (```adb shell /data/local/tmp/quantized_test```)
Results:
{F676102702}
Also ```buck test mode/dev //caffe2/aten:quantized_test``` passes
To test performance on [Partially Quantized Mobile Vision Transformer Model](https://www.internalfb.com/diff/D30648171) with AI Bench:
- Save this config file: P466124028 (for example: D31869106)
- Before or after the changes in this diff, run ```buck run aibench:run_bench -- -b benchmark_mobile_vision_transformer_model_config.json --platform android/arm64 --framework pytorch --remote --devices Pixel-3a-11-30 --force_profile```
Reviewed By: kimishpatel
Differential Revision: D31066997
fbshipit-source-id: 9067e683e0181aa13a2b636b68ac4fe5a4b2e618
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67636
Modify decorator to denote whether a acc op converter is able to support explicit/implicit batch dim. This info will be used by trt_splitter when determine whether a node can be split into acc graph.
This is can prevent us from split node to acc module and later found no proper converter exist for the node and fail the lower process.
Test Plan: unit test
Reviewed By: 842974287
Differential Revision: D31998477
fbshipit-source-id: 6789ebef4a76f9a0c1ab3edf8e846a5b6143326b
Summary:
It became a mandatory argument since PyYaml-6, but has been present since PyYaml-3
Unblock migration to newer runtime
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67694
Reviewed By: seemethere
Differential Revision: D32106043
Pulled By: malfet
fbshipit-source-id: 35246b97a974b168c066396ea31987b267534c7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67165
We previously skipped the optimization if `value_out->uses().size() > 1`. But it's possible that the number of uses is 0. In that case, it's not safe to access `value_out->uses()[0]`.
This is not causing any problems in production right now since we don't have any dead code before running this pass. But we should handle this case correctly to make the pass more robust.
Test Plan: CI
Reviewed By: hlu1
Differential Revision: D31887416
fbshipit-source-id: d30a5824e8bd1cda1debdc16524db3fb0da312f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65951
Profiling shows that we do a bunch of heap allocations to copy Argument structs in append_operator. Capturing by reference here should be safe as long as the schema objects args is from outlive the operator function.
IMPORTANT: Reviewers (or automated tests if we're lucky) need to
confirm that the above is true or we're going to have fun
use-after-free bugs.
ghstack-source-id: 142065422
Test Plan:
AIBench run for speech model on MilanBoard
control: https://www.internalfb.com/intern/aibench/details/485570882988661 (mean 906 ms)
test: https://our.intern.facebook.com/intern/aibench/details/620835625995669 (mean 818 ms)
So almost a 10% improvement in the wall time metric?
Reviewed By: iseeyuan
Differential Revision: D31319988
fbshipit-source-id: 7da56357420df500df344f49007e070ebb1bc581
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66134
No reason to do the comparison the old way when we could do it this way and avoid copying into std::string.
ghstack-source-id: 142065423
Test Plan: AIBench Milan run shows neutral to slight regression, but I think we should probably just make this change anyway.
Reviewed By: dhruvbird
Differential Revision: D31319669
fbshipit-source-id: dde329a4f2c4054f275eb98fb6556f5341e7533a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67164
Migrated both the variadic and non-variadic versions.
This diff is part of the effort to migrate all ops used in `FuseListUnpack` to `FuseListUnpackV2`. The original version of `FuseListUnpack` is problematic for a few reasons:
* You have to complicate the op implementation with an `is_fused` check, resulting in messier code. It is easier to reason about two ops, fused (out variant) and unfused (native).
* The original version of `FuseListUnpack` is buggy. It assumes that the `ListUnpack` node occurs immediately after the fusion candidate, which is not necessarily true.
This diff finishes the migration, so the original version of `FuseListUnpack` is removed
Test Plan:
Unit tests: `buck test caffe2/benchmarks/static_runtime/...`
**Accuracy Test**
Done at the top of this diff stack.
Reviewed By: hlu1
Differential Revision: D31887386
fbshipit-source-id: 9d44c813667a75bce13dce62bf98e6109edea6ba
Summary:
in scope of: https://github.com/pytorch/pytorch/issues/67301. Main changes:
* pytorch_android_gradle_custom_build_single removed from the circle (however template is still there since it is used by another similar workflow: pytorch-linux-xenial-py3-clang5-android-ndk-r19c-gradle-custom-build-single-full-jit, which will be migrated next)
* new GHA workflow added: pytorch_android_gradle_custom_build_single
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67577
Reviewed By: malfet, mruberry
Differential Revision: D32087709
Pulled By: b0noI
fbshipit-source-id: f9581558ddc1453b63264bf19fe5a4c245b7c007
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65504
We should be able to borrow a Tuple from an IValue without incurring refcount bumps.
ghstack-source-id: 142065833
Test Plan:
Added test coverage.
Profiled static runtime on the local_ro net for ctr_mobile_feed. Inclusive time spent in VarTupleUnpack decreased about 0.3%, which roughly matches with the 0.36% of runtime that was previously spent in IValue::toTuple().
Reviewed By: hlu1
Differential Revision: D31130570
fbshipit-source-id: afa14f46445539e449068fd908d547b8da7f402c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65381
The previous diff adds a way to make Tuples of size 3 or less
more efficiently. This diff makes it easier to hit that path and
updates a bunch of callsites to hit it.
ghstack-source-id: 142065832
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D31069538
fbshipit-source-id: d04da3709594ed68ab1c0a1471f8cffd8d001628
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67281
`qnnpack/operator.h` introduces a dependency on an external library fp16 via `qnnpack/requantization.h`.
Including `qnnpack/operator.h` in `pytorch_qnnpack.h` will make objects who really don't require fp16 depend on it indirectly because they include `pytorch_qnnpack.h`.
This was causing some test and bench targets to fail building for local and android/arm64 (only two tried) using cmake.
This diff moves `qnnpack/operator.h` from `pytorch_qnnpack.h` to `qnnpack_func.h`, and explicitly add `qnnpack/operator.h` in `src/conv-prepack.cc`.
Test Plan: Ran all the tests for local on my devserver, and arm64 on Pixel3a.
Reviewed By: kimishpatel
Differential Revision: D31861962
fbshipit-source-id: e1425c7dc3e6700cbe3e46b64898187792555bb7
Summary:
This PR addresses https://github.com/pytorch/pytorch/issues/54261.
This adds OpInfos for binary logical element wise operators. This is my first PR in OpInfos to PyTorch, looking forward to suggestions and any feedback.
cc: mruberry krshrimali
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67178
Reviewed By: jbschlosser
Differential Revision: D32057889
Pulled By: mruberry
fbshipit-source-id: 7e670260af6b478dba9d6e8d77de4df1b6d0b5d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67134
This diff demos torch::deploy unity which builds the model, the dependencies and the runtime as a unity!
The end user only need to use the build_unity rule to replace the python_binary rule to define the python application. Under the hood, we build the python application (an xar file), build the torch deploy runtime, and then embed the python application (the xar file) into the torch deploy runtime.
When starting the torch::deploy runtime, the xar will be written to the filesystem and extracted. We put the extracted path to python sys.path so all the model files and all the python dependencies can be found!
As a demo, the model here is just a simple python program using numpy and scipy. But theoretically, it can be as complex as we want.
I'll check how bento_kernel works. Maybe we can learn from bento_kernel to simplify things a bit.
ghstack-source-id: 142085742
Test Plan:
```
#build
buck build mode/opt unity:unity
# make sure the path exists before we start torch::deploy runtime
# Otherwise the dynamic loader will just skip this non-existing path
# even though we create it after the runtime starts.
mkdir -p /tmp/torch_deploy_python_app/python_app_root
#run
LD_LIBRARY_PATH=/tmp/torch_deploy_python_app/python_app_root ~/fbcode/buck-out/gen/caffe2/torch/csrc/deploy/unity/unity
```
Reviewed By: suo
Differential Revision: D31816526
fbshipit-source-id: 8eba97952aad10dcf1c86779fb3f7e500773d7ee
Summary:
Inserted check for the return of PyObject_IsInstance to capture the case in which it raises an exception and return -1. When this happen THPVariable_Check now throws a python_error to signal the exception.
Fixes https://github.com/pytorch/pytorch/issues/65084
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67588
Reviewed By: mruberry
Differential Revision: D32064776
Pulled By: albanD
fbshipit-source-id: 895c7682e0991ca257e27f9638a7462d83707320
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67397
Expand selectivity coverage to classes created outside of TORCH_LIBRARY.
ghstack-source-id: 142076940
Test Plan: Model unit tests, manually run some models on prod apps.
Reviewed By: dhruvbird, bdhirsh
Differential Revision: D31978965
fbshipit-source-id: 708901b47a9838ac54c78788028d0e18c1e378c0
Summary:
Summary : Inserted a check for the momentum and print "None" in case is not defined. See https://github.com/pytorch/pytorch/issues/65143
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67335
Test Plan:
The code below now prints `torch::nn::BatchNorm2d(128, eps=1e-05, momentum=None, affine=true, track_running_stats=true)` without generating errors.
```
torch::nn::BatchNorm2d m(torch::nn::BatchNormOptions(128).momentum(c10::nullopt));
std::cerr << *m << "\n";
```
Fixes https://github.com/pytorch/pytorch/issues/65143
Reviewed By: mruberry
Differential Revision: D32067820
Pulled By: ngimel
fbshipit-source-id: f40f9bbe090aa78e00f6c3a57deae393d946b88d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66879
This adds a quantized implementation for bilinear gridsample. Bicubic interpolation cannot be supported as easily since we rely on the linearity of quantization to operate on the raw values, i.e.
f(q(a), q(b)) = q(f(a, b)) where f is the linear interpolation function.
ghstack-source-id: 141321116
Test Plan: test_quantization
Reviewed By: kimishpatel
Differential Revision: D31656893
fbshipit-source-id: d0bc31da8ce93daf031a142decebf4a155943f0f
Summary:
She no longer works on the ONNX exporter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67631
Reviewed By: malfet
Differential Revision: D32070435
Pulled By: msaroufim
fbshipit-source-id: d741a15bd7a916745aa7f2f3d9bb1dc699553900
Summary:
It turns out my lint doesn't work on CI all the time because of shell differences. I'm working on a new more comprehensive lint in https://github.com/pytorch/pytorch/pull/66826 and it'd be nice if these could be cleared first.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67583
Reviewed By: H-Huang, mruberry
Differential Revision: D32045155
Pulled By: janeyx99
fbshipit-source-id: ecfe9f008310c28e3b731e246c2b2ed0106d03b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66564
Mobile thinks that we are segfaulting in _convolution, and this
is the most recent substantive change to this function. I think
it's pretty unlikely to have caused the crash, but if we don't have
any better ideas we should try this.
ghstack-source-id: 141972758
Test Plan: ship it and see if it resolves the error report
Reviewed By: kimishpatel
Differential Revision: D31598633
fbshipit-source-id: c34f4b0b7b8529e21fd019c886ad8d68ffe286b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67441
Native ops are faster than falling back to the JIT interpreter, sometimes significantly (we've previously seen this with ops like TupleUnpack). We should improve op coverage where possible.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D31992093
fbshipit-source-id: 88191c13d229ffeac4e5b17b78e25f51d3f7f23e
Summary:
Add check to make sure we do not add new submodules without documenting them in an rst file.
This is especially important because our doc coverage only runs for modules that are properly listed.
temporarily removed "torch" from the list to make sure the failure in CI looks as expected. EDIT: fixed now
This is what a CI failure looks like for the top level torch module as an example:

Pull Request resolved: https://github.com/pytorch/pytorch/pull/67440
Reviewed By: jbschlosser
Differential Revision: D32005310
Pulled By: albanD
fbshipit-source-id: 05cb2abc2472ea4f71f7dc5c55d021db32146928
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67550
`aten::__is__` and `aten::__isnot__` are extremely problematic for a large number of SR graph optimizations.
Some examples:
- Removing ops that are no-ops in the forward pass like `aten::detach`. This would normally be trivial, but `is` introduces corner cases like this:
```
def forward(x):
y = x.detach()
return x is y
```
We get `False` before optimizations. But after optimizations, the test becomes `x is x`, and we get `True`.
- `ReplaceWithCopy`: the pass that replaces ops like `aten::to` with an out variant that copies its input. The following graph returns `True` before optimizations, but `False` afterwards
```
def forward(x):
y = x.to(x.dtype)
return x is y
```
- And many more, `FuseListUnpack` can break too
Since the ops are not used by 99.99% of users, rejecting them so we don't have to think about this is not a big deal.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: d1jang
Differential Revision: D32022584
fbshipit-source-id: d135938edb2299c9b8f9511afac2bf568578879e
Summary:
This test is narrowly failing intermittently. See https://ci.pytorch.org/jenkins/job/pytorch-builds/job/pytorch-linux-bionic-rocm4.3.1-py3.6-test1/7736//console for an example. Relevant snippet:
```
12:28:43 ======================================================================
12:28:43 FAIL [0.104s]: test_noncontiguous_samples_matmul_cuda_float32 (__main__.TestCommonCUDA)
12:28:43 ----------------------------------------------------------------------
12:28:43 Traceback (most recent call last):
12:28:43 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1422, in wrapper
12:28:43 method(*args, **kwargs)
12:28:43 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1422, in wrapper
12:28:43 method(*args, **kwargs)
12:28:43 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 371, in instantiated_test
12:28:43 result = test(self, **param_kwargs)
12:28:43 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 737, in test_wrapper
12:28:43 return test(*args, **kwargs)
12:28:43 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_device_type.py", line 920, in only_fn
12:28:43 return fn(self, *args, **kwargs)
12:28:43 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1041, in wrapper
12:28:43 fn(*args, **kwargs)
12:28:43 File "test_ops.py", line 262, in test_noncontiguous_samples
12:28:43 self.assertEqual(actual_grad, expected_grad)
12:28:43 File "/opt/conda/lib/python3.6/site-packages/torch/testing/_internal/common_utils.py", line 1903, in assertEqual
12:28:43 super().assertTrue(result, msg=self._get_assert_msg(msg, debug_msg=debug_msg))
12:28:43 AssertionError: False is not true : Tensors failed to compare as equal!With rtol=1.3e-06 and atol=1e-05, found 1 element(s) (out of 10) whose difference(s) exceeded the margin of error (including 0 nan comparisons). The greatest difference was 1.2278556823730469e-05 (-1.458460807800293 vs. -1.4584730863571167), which occurred at index 7.
```
Setting an absolute tolerance of 1e-4, which is what this PR does, should make the test pass consistently.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67593
Reviewed By: ngimel
Differential Revision: D32050986
Pulled By: mruberry
fbshipit-source-id: f15bc8c4516be0a859afcfa76d52334c0b2c58a5
Summary:
It appears that most NVIDIA architectures (well, at least there haven't been many reports of this issue) don't do reduced precision reductions (e.g., reducing in fp16 given fp16 inputs), but this change attempts to ensure that a reduced precision reduction is never done. The included test case currently fails on Volta but passes on Pascal and Ampere; setting this flag causes the test to pass on all three.
CC stas00 ngimel ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67578
Reviewed By: mruberry
Differential Revision: D32046030
Pulled By: ngimel
fbshipit-source-id: ac9aa8489ad6835f34bd0300c5d6f4ea76f333d1
Summary:
Adds `torch.argwhere` as an alias to `torch.nonzero`
Currently, `torch.nonzero` is actually provides equivalent functionality to `np.argwhere`.
From NumPy docs,
> np.argwhere(a) is almost the same as np.transpose(np.nonzero(a)), but produces a result of the correct shape for a 0D array.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64257
Reviewed By: qihqi
Differential Revision: D32049884
Pulled By: saketh-are
fbshipit-source-id: 016e49884698daa53b83e384435c3f8f6b5bf6bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67567
- Fix an issue to allow it to work against modules that contains ScriptModule submodules.
- Fix a bug where `getattr(base_class, method_name)` could raise KeyError
Test Plan: linter; CI;
Reviewed By: 842974287
Differential Revision: D31956070
fbshipit-source-id: 1114937f380af437fd6d36cd811ef609d7faefe7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67564
moves the functionalize fallback out of aten/core and into aten, which should fix the issue described at https://fb.workplace.com/groups/163556484490704/permalink/1029416141238063/. I'm still not clear on why this didn't fail anything in CI / sandcastle on the initial diff: D31942093 (0032fa7725)
ghstack-source-id: 141959891
Test Plan: Locally, running `buck build mode/opt //sigrid/feed/prediction_replayer:fully_remote_replayer_main`
Reviewed By: zou3519
Differential Revision: D32027585
fbshipit-source-id: 2d86c4a6b3a73b00ee0ccee2f89a54704ed83e00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67569
Splitter_base has assumption that the first subgraph after split must be cpu subgraph if there exists cpu node. This is wrong, start subgraph should be determined by which subgraph has 0-dep node.
Also add unit test for splitter.
Reviewed By: yinghai
Differential Revision: D32012549
fbshipit-source-id: e2639ccd7774b4295ca05c2ddbefff9726702b3f
Summary:
Make `TORCH_CUDABLAS_CHECK` and `TORCH_CUSOLVER_CHECK` available in custom extensions by exporting the internal functions called by the both macros.
Rel: https://github.com/pytorch/pytorch/issues/67073
cc xwang233 ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67161
Reviewed By: jbschlosser
Differential Revision: D31984694
Pulled By: ngimel
fbshipit-source-id: 0035ecd1398078cf7d3abc23aaefda57aaa31106
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67530
Currently `ptvsc2_predictor_bench` only uses the first input of a given recordio file even when the record io file contains many inputs.
This change extends `StaticRuntime::benchmark` to accept multiple input entries so that we can benchmark more extensibly and realistically using all the inputs in the recordio file.
Test Plan:
Tested `ptvsc2_predictor_bench` with / without this change executing the following command:
```
MKL_NUM_THREADS=1 OMP_NUM_THREADS=1 numactl -m 0 -C 3 ./buck-out/opt/gen/caffe2/caffe2/fb/predictor/ptvsc2_predictor_bench --scripted_model=/home/djang/ads/adfinder/ctr_mobilefeed/302008423/302008423_0.predictor.disagg.local --recordio_inputs=/home/djang/ads/adfinder/ctr_mobilefeed/302008423/302008423.local.inputs.recordio --pt_enable_static_runtime=1 --compare_results=0 --iters=1 --warmup_iters=1 --num_threads=1 --do_profile=1 --method_name=local.forward --set_compatibility --do_benchmark=1 --recordio_use_ivalue_format=1
```
Reviewed By: hlu1
Differential Revision: D31947382
fbshipit-source-id: 4188271613aad201f8cad5f566e0dfed26680968
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67163
Migrated both the variadic and non-variadic versions.
This diff is part of the effort to migrate all ops used in `FuseListUnpack` to `FuseListUnpackV2`. The original version of `FuseListUnpack` is problematic for a few reasons:
* You have to complicate the op implementation with an `is_fused` check, resulting in messier code. It is easier to reason about two ops, fused (out variant) and unfused (native).
* The original version of `FuseListUnpack` is buggy. It assumes that the `ListUnpack` node occurs immediately after the fusion candidate, which is not necessarily true.
Test Plan:
Unit tests: `buck test caffe2/benchmarks/static_runtime/...`
**Accuracy Test**
Done at the top of this diff stack.
**Performance**
Everything seems to be about the same plus or minus some noise.
* Baseline (D31947382 with some errors correct locally, the version of the op here is fused and variadic): P464964343
* This diff, fused_variadic: P464960645
* Variadic transformation disabled, fused (caught and fixed a schema error here): P464961561
* List unpack fusion disabled, variadic: P464962661
* Both variadic and fusion passes disabled: P464963342
The predictions match with the JIT interpreter for all ops.
Reviewed By: hlu1
Differential Revision: D31887300
fbshipit-source-id: 25a7b4e35eed21ca8b2c98297513425cf17f461a
Summary: Original commit changeset: 6e97d95ffafd
Test Plan: unit test
Reviewed By: wanchaol
Differential Revision: D32023341
fbshipit-source-id: 2a9f7b637c0ff18700bcc3e44466fffcff861698
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67385
As part of the expanded operator versioning effort we are going to start looking at this variable and whats stored locally in the model file.
ghstack-source-id: 141782717
Test Plan: unit test
Reviewed By: cccclai
Differential Revision: D31976654
fbshipit-source-id: 255a23cff7c4f4039089de23b4da95772be48324
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65971
ghstack-source-id: 141842335
We should be able to load methods into their ClassTypes. Right now mobile runtime only loads data member to ClassTypes but not for methods. To support interface call, we inject methods into ClassTypes when the methods are loaded.
Test Plan: existing tests should all pass.
Reviewed By: qihqi
Differential Revision: D31326146
fbshipit-source-id: fb1dbea619910ef1f8fa26146da3ebab348fe902
Summary:
Action following https://github.com/pytorch/pytorch/issues/66232
This change does require some context: there were several suggestions regarding what to do about this group of tests: tests that are core and crucial to all of PyTorch and are too broad to be owned by one team.
1. Let's add a "module: core" and put people behind it! This idea sounds appealing unless you are one of the people backing the label. From talking to albanD among others, this idea of putting all these core tests on the shoulder of a few people or one team isn't super fair and I have not yet found anyone willing to take on this job.
2. Taking advantage of the fact that we already have a triaging oncall that takes turns triaging issues, we can leave these tests essentially unlabeled and allow the oncall to triage these tests. Since these tests are crucial to PyTorch, we'll add the "high priority" label to mark them different from other unowned tests (see https://github.com/pytorch/pytorch/issues/67552).
3. I _could_ still create an unbacked label "module: core" and attribute these tests there, but I don't like the idea of creating a facade that the tests are "triaged" to a label when no one is actually taking a look.
Now we could potentially break these tests down into smaller files so that each piece _could_ be owned by a team, but 1. I don't know if this is currently feasible and 2. This approach does not prevent that from happening in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67553
Reviewed By: albanD
Differential Revision: D32025004
Pulled By: janeyx99
fbshipit-source-id: 1fb1aa4c27e305695ab6e80ae3d02f90519939c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63948
This PR adds `torch.add(a, b, alpha=None, out=out)` variant with `a, b,
out` all being sparse CSR tensors.
The underlying cuSPARSE function works only with 32-bit indices, and in
the current implementation, the result tensor has 32-bit indices. Input
tensors can have both 64-bit and 32-bit indices tensors.
Fixes https://github.com/pytorch/pytorch/issues/59060
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D31909731
Pulled By: cpuhrsch
fbshipit-source-id: 656f523e3947fec56b2f93c474fb6fd49f0360ca
Summary:
Fixes https://github.com/pytorch/pytorch/issues/63341.
This PR adds a new test, `test_noncontigous_samples`, that runs ops forward and backward and compares their outputs and grads between "normal" contiguous SampleInputs and noncontiguous SampleInputs. This test should preclude the need for noncontiguous SampleInputs going forward.
The test was added by generalizing the `.numpy()` transform on SampleInputs to support a new `.noncontiguous()` transform and copying forward/backward patterns from other tests in test_ops.py. It also discovered that many SampleInputs were incorrectly reusing tensors, so those have been revised. SampleInputs creating noncontiguous tensors for testing have also been altered to no longer do so.
In addition, this test discovered the following high priority silent correctness issues:
- https://github.com/pytorch/pytorch/issues/67432
- https://github.com/pytorch/pytorch/issues/67517
- https://github.com/pytorch/pytorch/issues/67513
- https://github.com/pytorch/pytorch/issues/67512
- https://github.com/pytorch/pytorch/issues/67470
It also identified the following issues:
- https://github.com/pytorch/pytorch/issues/67539
The pow OpInfo also incorrectly specified that pow supported the bool datatype, and this has been fixed. Its SampleInputs were written in a way that made requests for boolean SampleInputs return type promoting inputs that never actually tried to compute pow in bool.
This PR suggests we should add the following guidance for writing SampleInputs:
- ensure that all SampleInputs are independent of each other (don't reuse tensors)
- ensure that all SampleInput tensors have no grad or backward functions (no autograd history) -- they should be leaves
- prefer keeping sample inputs simple where possible, a good set of handwritten samples that test interesting cases may be better than an exhaustive but hard to read and maintain programmatic enumeration
- keep code readable by using functools.partial and writing simple inline helpers; break up large statements into a more readable series of smaller statements; especially don't write complicated generator expressions with a `for` at the end!
fyi kshitij12345 krshrimali pmeier anjali411 saketh-are zou3519 dagitses
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67434
Reviewed By: ngimel
Differential Revision: D32014557
Pulled By: mruberry
fbshipit-source-id: b17e19adc1d41e24441f0765af13d381fef5e3c1
Summary:
Removes the 3D special case logic in `_convolution_double_backward()` that never worked.
The logic was never called previously since `convolution()` expands input / weight from 3D -> 4D before passing them to backends; backend-specific backward calls thus save the 4D version to pass to `_convolution_double_backward()`.
The new general `convolution_backward()` saves the original 3D input / weight, uncovering the bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67283
Reviewed By: anjali411
Differential Revision: D32021100
Pulled By: jbschlosser
fbshipit-source-id: 0916bcaa77ef49545848b344d6385b33bacf473d
Summary:
This ensures deterministic output, allowing systems like ccache to be
more effective.
cc ezyang bhosmer bdhirsh
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67046
Reviewed By: VitalyFedyunin
Differential Revision: D31896114
Pulled By: bdhirsh
fbshipit-source-id: d29ef0cf6c7e3408b104c5239b620eaa24327088
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67234
Extends the dequantize fp16 function to also work on CUDA,
and adds a test.
Test Plan:
```
python test/test_quantization.py TestQuantizedTensor.test_dequantize_fp16_cuda
python test/test_quantization.py TestQuantizedTensor.test_dequantize_fp16_cpu
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D31915330
fbshipit-source-id: 622d47464fae26bf02f295ff56df63a3bf80b786
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67449
Adds a description of what the current custom module API does
and API examples for Eager mode and FX graph mode to the main
PyTorch quantization documentation page.
Test Plan:
```
cd docs
make html
python -m http.server
// check the docs page, it renders correctly
```
Reviewed By: jbschlosser
Differential Revision: D31994641
Pulled By: vkuzo
fbshipit-source-id: d35a62947dd06e71276eb6a0e37950d3cc5abfc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67210
`OUTPUT_SHARE_OBSERVE_WITH_INPUT` is an observation type for operators that would have the same observer/fake_quant instance
as output, when quantized, these ops can take quantized Tensor as input and output a quantized Tensor with the same quantization parameters (scale/zero_point etc.) as input
Using cat as an example in this PR. Other ops can be added later gradually (together with tests).
Test Plan:
python test/fx2trt/test_quantize_fx.py TestQuantizeFxTRTOps.test_cat
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31907243
fbshipit-source-id: 2c7af4a456deb5e6597b0b9cd4e32c5fcdec580b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67129
Since the tests depends on experimental feature (fx2trt), we'll move them to fx2trt foler
Test Plan:
python test/fx2trt/test_quantize_fx.py
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31877123
fbshipit-source-id: 5a98a257c4806c1911cfc2616d5ad98d715234c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67524
We have some loose ends to tie to make timing cache really work. This diff fixes them.
Reviewed By: wushirong
Differential Revision: D32012021
fbshipit-source-id: 1e93c76d48a3740a02613e1f19222ed92cca9deb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67499
Since https://github.com/pytorch/pytorch/pull/62030 was landed, storages being produced when loading from a pickle are of type TypedStorage. We weren't catching this in our deploy serialization, leading tensors to actually get pickled instead of the storages getting shared across interpreters.
Since this is technically correct still, it wasn't caught by any of our tests, until someone tried to pass a really big tensor and started ooming.
ghstack-source-id: 141869521
Test Plan: added unit test
Reviewed By: shunting314
Differential Revision: D32004075
fbshipit-source-id: ef5a80cd3cb1dff0b6b4c1b6c95923e4faab7d50
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67275
Specifically targets the symbolic functions that directly returns input as output. The old logic will override the value name with output value name. But since the input is unmodified and unchanged, it is more logically to keep its original input name. Especially for cases where inputs are directly from model parameters.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D31962517
Pulled By: malfet
fbshipit-source-id: 9cb4a2bb55aa08dd1ce8fdec24e7cfb11d7ea97c
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67327
At cerntain condition, TRT will create extra outputs, which seems more like a bug. If we don't capture those hidden outputs, we won't allocate memory to host those outputs and trt will end up writing to illegal memory. This diff address the issue but capturing the hidden outputs and allocate proper memory for them.
Reviewed By: jianyuh, wushirong, 842974287
Differential Revision: D31955379
fbshipit-source-id: c9faaf91ed45bec8e0bc4e0bea812a0a3f2abad0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67455
Migrates docker builds that don't have dependent jobs within the pytorch
repository to our new GHA docker build job
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet, janeyx99
Differential Revision: D31997671
Pulled By: seemethere
fbshipit-source-id: 9d6f58fa8ea8731cf12457fe64dc65e70f3d9f25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67346
Native ops are faster than falling back to the JIT interpreter, sometimes significantly (we've previously seen this with ops like TupleUnpack). We should improve op coverage where possible.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: d1jang
Differential Revision: D31965159
fbshipit-source-id: 86a69c395f401c4a4c55daa4c5fe80764383c8e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67341
Native ops are faster than falling back to the JIT interpreter, sometimes significantly (we've previously seen this with ops like `TupleUnpack`). We should improve op coverage where possible.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D31962589
fbshipit-source-id: 3107fb169c1b02fb2bafbb355c005669b5fa8435
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65970
ghstack-source-id: 141842338
mobile::Function should inherit from jit::Function, because for interface call support, we need an abstract jit::Function type stored in corresponding ClassTypes, so that we can look up methods in there. Previously mobile::Function is implemented separately which prevents this. Since we get rid of all the unneeded virtual methods from jit::Function, we can inherit from torch::jit::Function without too much cost.
NOTE that torch::jit::Function is already in dependency because we need it to support custom class call. We should be able to use Function uniformly without looking into whether it's a builtin function or mobile::Function.
Test Plan: no behavior change.
Reviewed By: iseeyuan, mrshenli
Differential Revision: D31326148
fbshipit-source-id: 36caeaf3c8c5f54c23a1a7c8c9e2fd6e78b19622
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67436
This information is useful for comparing static runtime to c2
Reviewed By: d1jang
Differential Revision: D31991571
fbshipit-source-id: eb83bc4564b05d56fb9a550863eea3f6312f3f6c
Summary:
The frexp function has been enabled in ROCm code. Updating PyTorch
to enable this functionality.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67226
Reviewed By: jbschlosser
Differential Revision: D31984606
Pulled By: ngimel
fbshipit-source-id: b58eb7f226f6eb3e17d8b1e2517a4ea7297dc1d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65968
tryToGraphFunction() should cover all cases and more composable than
adhoc virtual methods.
ghstack-source-id: 141759214
Test Plan: no behavior change.
Reviewed By: gmagogsfm
Differential Revision: D31326154
fbshipit-source-id: 692a35df424f7d4f777a96489c4cbb24b3ae7807
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67373
From the implementation of mv, it's decomposed into addmv. So it should
be a CompositeExplicitAutograd op.
Test Plan: It shouldn't change any behaviors. So, CI.
Reviewed By: bdhirsh
Differential Revision: D31973265
Pulled By: alanwaketan
fbshipit-source-id: 3b6850f08e6f671b908a177f148cc6194baa8a13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67102
Getting rid of top/bottom and left/right distinction, replacing with height and width. These parameters are widely used in qnnpack and always passed together but never different. Pytorch doesn't support asymmetrical paddings either so I see no potential use for this.
ghstack-source-id: 141334544
Test Plan: qnnpack unit tests
Reviewed By: kimishpatel
Differential Revision: D31863370
fbshipit-source-id: aa57490399e23d6139b2ad7b745139752acd7848
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66257
Used `clang-format -i` for these two files.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D31762737
Pulled By: H-Huang
fbshipit-source-id: e94e301d0b013dbb8f2cef19ff140bac5811738f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64432
Original PR description + feedback here: https://github.com/pytorch/pytorch/pull/63048
I've addressed all of the feedback in the original PR and made some pretty large changes, listed below.
**Table of Contents**
- Starting points
- List of the main changes from the original PR
- Next Steps
- Example codegen output (for a view, mutation, and view+mutation op)
**Starting Points**
A good place to start when looking through the PR:
* Alban mentioned that this is a useful mental model (thanks Ed for originally making this clear to me). Semantically, the pass currently does THREE things, which are all needed by functorch - all fused together into one big pass.
* (a) alias removal, which replaces {view} calls with {view}_copy calls, and manually tracks aliasing information, so that when one tensor is mutated, we re-apply the same mutation to all of the aliases. This is the bulk of the work - once this is done, the next 2 things are trivial to implement.
* (b) mutation removal, which is easy to do once we know that there are no aliases. Every mutation `a.add_(b)` becomes `a.replace_(a.add(b))`
* (c) reapplying views: all of the `{view}_copy` calls are replaced with `{view}` calls again. This is an optimization that we can make specifically for functorch (and strided backends), that only care about mutation removal and not alias removal
* XLA and Vulkan only want (a), or (a) + (b). Later, we'll want to split this out so that you can actually opt into different versions of this logic.
* There is currently no {view}_copy replacement, because the pass just <replace views with copies> and <replace copies with views> steps have been combined. Later, we'll want to actually implement {view}_copy variants of each view operator, probably with codegen.
* documentation breadcrumb 1, in `FunctionalTensorWrapper.cpp`: https://github.com/pytorch/pytorch/pull/64432/files#diff-a0bac99bf205dba5b94cb64fc2466d3d55d991887572f9cd6a02e27b3a91dd60R59 (you might have to expand the `FunctionalTensorWrapper.cpp` file, which GitHub closes by default because it's large)
* documentation breadcrumb 2, in `FunctionalTensorWrapper.h`: https://github.com/pytorch/pytorch/pull/64432/files#diff-c945c71a4ccac65871f24a912e8904f9a5088b24a32e636727ea9c8fe920708aR12
* Reading through the codegen output at the bottom of this description.
**Main changes from the original PR**
(1) I use lambdas instead of a giant enum to handle all of the different views.
This results in less boilerplate per view op (and more stuff that can be codegen'd). Every `ViewMeta` object now contains a `forward` and `reverse` lambda, that knows how to replay the view and its inverse. This makes the actual code that executes the replaying logic a lot less boilerplate-y (see `Alias::sync_update_operations` and `FunctionalTensorWrapper::sync_`)
(2) Every tensor during the functionalization pass is always wrapped in a `FunctionalTensorWrapper`.
This is potentially unnecessary for Vulkan/XLA, and will have a mild perf impact, but for now this PR just targets the functorch use case. I previously had a complicated design a (`FunctionalTensorImplBase` class) to avoid needing the wrapper for XLA, but it had some subtleties that are gonna require more thought to fix, so I'm pushing that off for now.
(3) `FunctionalTensorWrapper` objects accurately report stride information.
It's a little annoying to do this though, because the logic that calculates stride info for each view isn't easily separated from the actual view kernels in core, `at::native::{view}`. I do this by adding logic in each `at::functionalization::{view}` kernel to call the reference implementation `at::native::{view}`. I don't do anything with the output aside from taking it's size/stride/storage_offset to set the actual output tensor's size/stride/storage_offset correctly. There's another annoying part to this: I'm pretty sure that we want to pass in the actual *wrapper* tensors directly into the native kernels, not their inner unwrapped values. But there are some `at::native::{view}` kernels that call other tensor methods, which re-invokes the dispatcher, calling functionalization/functorch kernels that try do the unwrapping.
To do this, right now I have an `AutoDispatchDirectlyToNative` guard that basically ensures that any tensor methods called inside of the at::native::{view} op always redispatch straight to the CPU kernel (which will be another at::native:: kernel). This feels kind of heavy handed, but I'm not sure of a better way to do it.
(4) `FunctionalTensorWrapper` objects accurately report aliasing information.
There's a new `FunctionalStorageImpl` class (subclass of `StorageImpl`) that allows tensors in the functionalization pass to accurately alias storage. If two tensors `a` and `b` in a functionalized program are views of one another, then `a.storage.is_alias_of(b.storage)` should return true. I added this in a pretty similar way to how meta tensors allocate storage, although I don't pass in an actual allocator (I think this is fine because you should never resize a functional tensor's storage).
One thing I'm not sure about - should `FunctionalTensorWrapper` set `storage_access_should_throw_`: (a) always, (b) never, (c) only if its wrapped tensor has it set.
Right now I have it not set, mostly because calling the reference view functions (`at::native::{view}`) requires looking at the storage. But that means that if you try to access storage from python in a functionalized program, you'll get silent garbage instead of an error. Related question: are we planning on exposing meta tensor storage to python in the future (even though it contains garbage)?
(5) better docs :)
**View operator coverage**
(6) The functionalization pass now gets math-composite view ops for free.
I didn't add the `Functionalize` dispatch key to the composite set, because I don't want composite ops like `torch.ones` to get decomposed before hitting the functionalization pass. Instead, I added codegen to manually register the `at::native::` kernels of composite view ops. This is a little hairy, because the names of the `at::native::` kernels aren't easily accessible. They're stored in a `Dict[DispatchKey, BackendIndex]`. I made a best-effort attempt to get each view kernel's name, basically by assuming that every view op has either a composite or cpu implementation.
There's also a hardcoded list of composite view ops in `gen_inplace_or_view_type.py`, but it looks like it's wrong. This is probably worth rationalizing later, but instead I created a new list of the "complete" set of composite view ops, and preserved the old set by hardcoding the delta between the two sets.
(7) I've added codegen for ops that are both views AND mutations, like `transpose_()` (why do we even have these {emoji:1f622}).
From some light testing, it looks like they work correctly with one caveat: I had a hard time ensuring that functorch programs that mutate their inputs using ops like `transpose_()` preserve the input mutations after the program finishes running. For (in my corresponding functorch branch) I emit a warning when this happens, and just don't preserve the mutation
(8) I added `{view}_inverse` implementations for every view op, in `FunctionalInverses.cpp`.
These are needed to take mutations made to views and replay them back onto the base. To reduce boilerplate, the codegen generates function declarations for each `{view}_inverse` function, so you get a nice compiler error when someone eventually adds a new view op.
The only view ops currently not supported are (a) as_strided, and (b) the sparse view ops (values()/indices()).
I can add support for as_strided, but it needs an `as_strided_inverse()` function. That will look really similar to the `as_strided_backward()` function in FunctionsManual.cpp, but it has some noticeable differences: we basically want an `as_strided_embed` for autograd and `as_strided_scatter` for functionalization. We also will probably need them to be primitives w.r.t to autograd, since the currently implementation for autograd uses view().copy_() calls that XLA won't be able to handle. I'm wondering if anyone has any objections, but otherwise I can make those change (which will require writing backward formulas for `as_strided_embed` and `as_strided_scatter`).
I did a bunch of manual testing that all looks pretty good, but it's definitely not fully tested. Ed pointed out that once XLA uses this pass (or at least once there's a POC), we can just run the existing xla view test suite. Hopefully that delay is okay - if it's not, maybe we can think about using OpInfos similar to how functorch uses them for testing.
Note: there's some duplication with autograd's view code. Every `{view}_inverse` implementation is really similar to the implementation for that view listed in `derivatives.yaml`. There are some major differences though:
* the autograd implementations over those backwards functions (like `permute_backwards()`, in `FunctionsManual.cpp`) internally call other view ops. For functoinalization, we want them to (eventually call `{view}_copy` operators).
* For view ops that take a subset of the original storage, like `slice/select/diagonal/as_strided()`, the autograd backward functions fill the "spaces" in the inverse call with zeroes. For functionalizations, we want to fill them with the value of `base` at those positions. It looks like this currently applies to 6 total ops (since we can ignore composites):
* select
* slice
* diagonal
* as_stridied
* split
* split_with_sizes
A nice end state would probably be for the autograd + functoinalization codegen to both look at the same yaml (either `derivatives.yaml`, or something else), and automatically generate the right thing. I didn't leave that in scope for this PR though.
**Current State + Next Steps**
There are a bunch of followups after this PR eventually lands. Roughly in order:
* Use the current pass to register problematic composite ops in functorch. Also, nested `functionalize()` calls aren't supported yet (I mostly just need to remove some debug asserts and test it).
* Work on freeing up dispatch key space in the by deduplicating the `{backend}`/`Autograd{backend}`/`Sparse{backend}`/`Quantized{backend}` keys
* Once we have more dispatch keys, split up this pass into 3 pieces - it's currently fused, and doesn't do the right thing for vulkan/XLA. Specifically, all of the `{view}` calls in the current pass's view-replay logic should turn into `{view}_copy` calls that vulkan/XLA know how to implement, and there will be separate passes for (a) removing mutations, and (b) turning `{view}_copy` calls back into `{view}` calls. For Vulkan, we eventually want a pass that ONLY removes aliasing and view calls, and doesn't remove mutations. We can also probably make the 2 new passes user dispatch keys to save dispatch key space, if they'll only be used by functorch anyway.
* Do more of a dive on perf for the vulkan/xla use cases. There are several areas to improve perf with varying levels of effort required. The simplest one that I'll probably do regardless is to codegen the out-of-place kernels instead of using a boxed fallback. Getting a POC working for xla will also be useful to test the view operator coverage.
**Example Codegen Output**
View Op:
```
::std::vector<at::Tensor> split_Tensor(c10::DispatchKeySet ks, const at::Tensor & self, int64_t split_size, int64_t dim) {
auto self_ = at::functionalization::impl::unwrapFunctionalTensor(self);
::std::vector<at::Tensor> out;
{
at::AutoDispatchBelowFunctionalize guard;
auto tmp_output = at::redispatch::split(ks & c10::after_func_keyset, self_, split_size, dim);
out = at::functionalization::impl::wrapFunctionalTensor(tmp_output);
// I'm fusing the [alias removal], [mutation removal], [add views back] passes together.
// Later, we'll want to turn them into separate passes (since e.g. vulkan only cares about alias removal).
}
at::functionalization::ViewMeta view_meta = at::functionalization::ViewMeta(
[split_size, dim](const at::Tensor& base, int64_t mutated_view_idx) -> at::Tensor {
return base.split(split_size, dim)[mutated_view_idx];
},
[split_size, dim](const at::Tensor& base, const at::Tensor& mutated_view, int64_t mutated_view_idx) -> at::Tensor {
return at::functionalization::impl::split_inverse(base, mutated_view, mutated_view_idx, split_size, dim);
}
);
at::functionalization::impl::set_view_meta(out, self, view_meta);
at::AutoDispatchDirectlyToNative native_guard;
::std::vector<at::Tensor> reference_tensor_output = at::native::split(self, split_size, dim);
at::functionalization::impl::set_strides(out, reference_tensor_output);
return out;
}
```
Mutation Op:
```
at::Tensor & add__Tensor(c10::DispatchKeySet ks, at::Tensor & self, const at::Tensor & other, const at::Scalar & alpha) {
at::functionalization::impl::sync(self);
at::functionalization::impl::sync(other);
auto self_ = at::functionalization::impl::unwrapFunctionalTensor(self);
auto other_ = at::functionalization::impl::unwrapFunctionalTensor(other);
at::Tensor tmp_output;
{
at::AutoDispatchBelowFunctionalize guard;
// The functionalization pass explicitly doesn't pass out= parameters to the redispatch
tmp_output = at::redispatch::add(
ks & c10::after_func_keyset, self_, other_, alpha);
}
self.replace_(tmp_output);
at::functionalization::impl::maybe_add_update(self);
return self;
}
```
View + Mutation Op:
```
at::Tensor & transpose_(c10::DispatchKeySet ks, at::Tensor & self, int64_t dim0, int64_t dim1) {
at::functionalization::ViewMeta view_meta = at::functionalization::ViewMeta(
[dim0, dim1](const at::Tensor& base, int64_t mutated_view_idx) -> at::Tensor {
return base.transpose(dim0, dim1);
},
[dim0, dim1](const at::Tensor& base, const at::Tensor& mutated_view, int64_t mutated_view_idx) -> at::Tensor {
return at::functionalization::impl::transpose_inverse(base, mutated_view, dim0, dim1);
}
);
at::functionalization::impl::mutate_view_meta(self, view_meta);
// See Note [Propagating strides in the functionalization pass]
// Directly update the sizes/strides/storage_offset fields on self using the inplace call.
// I need the guard because I don't want the at::native kernel to end up calling more functionalization/functorch kernels.
// Its only job is to directly compute the output size/stride/storage_offset metadata.
at::AutoDispatchDirectlyToNative native_guard;
at::native::transpose_(self, dim0, dim1);
return self;
}
```
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31942093
Pulled By: bdhirsh
fbshipit-source-id: b95598dae35dd1842fa8b1d8d1448332f3afaadf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64430
The functionalization pass needs `{view}_scatter` versions of the slice/select/diagonal ops in order to correctly propagate mutations from a view to its base. On top of that, the implementations need to be primitive w.r.t. autograd, because they look something like `...slice().copy_()`, and the functionalization pass can't use views + mutations inside of it's own alias-removal machinery!
I added some basic tests that I tried to base off of existing tests for views (particularly around testing the derivative formulas), but I'm wondering if I should add something more comprehensive.
Also, as_strided fits into this category - the functionalization pass will need an `as_strided_scatter` op that's primitive w.r.t. autograd. I didn't add it for now, because it'll involve duplicating a bunch of logic from the current `as_strided_backward()` function, and also writing a derivative formula that I wasn't sure how to write :)
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31942092
Pulled By: bdhirsh
fbshipit-source-id: c702a57c2748a7c771c14e4bcc3e996b48fcc4c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63094
This PR:
- Moves `FileManager` and its dependencies (`assert_never` and other imports) to `utils.py`, and updates all of the call-sites with the fresh imports
- Passes the list of NativeFunction objects into `gen_trace_type` directly, instead of requiring the function to regenerate it (we already have it)
The purpose of the reshuffling is to avoid circular dependencies in the next PR, where I add codegen for the functionalization pass, which gets called from `gen.py` (but depends on some stuff from the autograd codegen - in partulcar, the list of view ops).
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31942096
Pulled By: bdhirsh
fbshipit-source-id: 36118facae61f25f8922bb43ad2818c80b53504e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67456
There are some compatibility issues, we need to back-out before it gets to prod feed models
Test Plan: CI
Reviewed By: pgarbacki
Differential Revision: D31997684
fbshipit-source-id: 8b2584cb5d43e487719c6530d4178988fd03c455
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65946
Add new function in agent_utils to perform a synchronization of active call counts using store. This is intended to replace the barrier and all_reduce used by the process group in RPC shutdown.
`test_ddp_comparison` and `test_ddp_comparison_uneven_inputs` test fail with these changes. It seems like the RPC agents are not accessing the same store, so the total count of processes never reaches the world size to exit the barrier, still ened to investigate why it is like this only for these test cases. Setting clean_shutdown to false ignores this code path which allows the test to pass.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D31762736
Pulled By: H-Huang
fbshipit-source-id: cb5d0efe196f72726c63393c4293e97ec4f18548
Summary:
linux-xenial-cuda10.2 and linux-bionic-cuda10.2 are very similar, no
need to run both configs
Moved all auxiliary builds from xenial to bionic
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67344
Reviewed By: seemethere, janeyx99
Differential Revision: D31964850
Pulled By: malfet
fbshipit-source-id: d07ce266c843c7fd69b281e678c4247b0bf6da20
Summary:
Action following discussion with distributed and r2p team--the tests under elastic in distributed should be owned by oncall: r2p and not distributed.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67293
Reviewed By: jbschlosser
Differential Revision: D31973779
Pulled By: janeyx99
fbshipit-source-id: 05875a7600c6eb1da1310a48e1e32a1a69461c55
Summary:
This reduces the chance of a newly added functions to be ignored by mistake.
The only test that this impacts is the coverage test that runs as part of the python doc build. So if that one works, it means that the update to the list here is correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67395
Reviewed By: jbschlosser
Differential Revision: D31991936
Pulled By: albanD
fbshipit-source-id: 5b4ce7764336720827501641311cc36f52d2e516
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67271
* [ONNX] Use Reciprocal operator instead of Div(1, x).
This is a more readable and perhaps more performant way to export
torch.reciprocal.
* Use Reciprocal in caffe to operator to import onnx
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D31962519
Pulled By: malfet
fbshipit-source-id: d926e75b1c8312b9a980c9a1207a1a93ba0c71e0
Co-authored-by: take-cheeze <takechi101010@gmail.com>
Summary:
Fixes [Issue#70](https://github.com/MLH-Fellowship/pyre-check/issues/70)
This PR fixes the type checking error that was found in fuse.py as follows:
torch/quantization/fx/fuse.py:34:13 Incompatible variable type [9]: fuse_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
Signed-off-by: Onyemowo Agbo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66799
Reviewed By: 0xedward
Differential Revision: D31961462
Pulled By: onionymous
fbshipit-source-id: 7481afc07152ba13f3224e4ad198fd8e2c34c880
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67255
Add an out variant for `aten::where`.
Since this op can be implemented quite trivially in NNC with `ifThenElse`, I added an NNC kernel as well.
Test Plan: Unit tests: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: navahgar
Differential Revision: D31923886
fbshipit-source-id: b4379ee3aaf31a000e626b4caeafd3e3f3d60837
Summary:
This PR introduces the new issue forms that replace issue templates.
This is similar to what was done in torchvision https://github.com/pytorch/vision/pull/4299 and torchaudio, you can see the end result here: https://github.com/pytorch/vision/issues/new/choose (click e.g. on the [bug report](https://github.com/pytorch/vision/issues/new?assignees=&labels=&template=bug-report.yml))
The main new thing is that we can enforce some of the fields to be filled, especially for bug reports. It's also a much cleaner GUI for users IMHO, and we can provide better examples and instructions.
There is still a "blank" template available.
I removed the "Questions" form: we say we close these issues anyway. I replaced it with a direct link to https://discuss.pytorch.org. Since we still have a "blank" template, I think this covers all previous use-cases properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65917
Reviewed By: VitalyFedyunin
Differential Revision: D31894777
Pulled By: NicolasHug
fbshipit-source-id: fbd39f7ed4cadab732d106d3166c04c451c31f94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66585
Add a new op `static_runtime::fused_variadic_grouped_accessor_op` that outputs many tensors rather than a single tensor list. Incorporated this new op into `FuseListUnpack`. This eliminates `ListUnpack` overhead and tensor refcount bumps.
Test Plan:
**Accuracy Test**
Model 294738512_40 (manually confirmed that fusion happens)
```
get 2861 prediction values
get 2861 prediction values
max_error: 0 total: 0
```
Accuracy test with model 296213501_65 (has V2 op): passes with 0 errors.
**Performance**
TW replayer test w/ 800 QPS (stacked with D31482816 (72e25c9f4e)) shows 5% CPU decrease for storage tier.
Results:
{F673610679}
Reviewed By: hlu1
Differential Revision: D31620408
fbshipit-source-id: f05c298bcbce61a491b63d575af4aca746881696
Summary:
simply propagate profile_none_ value through profile_ivalue nodes inserted by nvfuser.
Without the propagation, profile_ivalue inserted by other passes would block the optimization on no-op sum_to_size.
cc gmagogsfm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63941
Reviewed By: shunting314, cpuhrsch
Differential Revision: D31972765
Pulled By: Krovatkin
fbshipit-source-id: 4fa571a758e269b486c584f47c2a933de82d463b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66351
This add the ability for use to just provide shard_offsets and optionally rank, to construct a local shard, instead of knowing there's a ShardedMetadata. Under the hood, we will construct the ShardedMetadata by inferring shard_lengths and device from the local tensor.
ghstack-source-id: 141742410
Test Plan: test_local_shards
Reviewed By: pritamdamania87
Differential Revision: D31519919
fbshipit-source-id: 8f3b4682ffc74b79b41076f3f4b832f4cacda49d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64481
This simplifies `init_from_local_shards` API in sharded tensor, to only require user pass in a list of `Shard` and `overall_size`, instead of ShardedTensorMetadata. We will do the all_gather inside to form a valid ShardedTensorMetadata instead.
TODO: add more test cases to improve coverage.
ghstack-source-id: 141742350
Test Plan: TestShardedTensorFromLocalShards
Reviewed By: pritamdamania87
Differential Revision: D30748504
fbshipit-source-id: 6e97d95ffafde6b5f3970e2c2ba33b76cabd8d8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67067
Plan to gradually adding features to backend_config_dict, this PR adds support
for specifying the dtype for input and output of a given pattern
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31849074
fbshipit-source-id: ca2fbb873176fe72e08ea79ed1bc659bf27cbd8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67412
For inputs, we'll be using the shape from PyTorch tensors. For outputs, we'll be using the shape from MLMultiArray. Thus, we can decouple from the symbolic shapes defined in the compile spec.
ghstack-source-id: 141746346
Test Plan:
- Sandcastle
- buck test pp-ios
Reviewed By: hanton
Differential Revision: D31299408
fbshipit-source-id: 337d5bb9efc2ff51409586c288d607399b937212
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66724
Forwarding fix from previous diff through the ClassType getters & moving Types in where possible.
ghstack-source-id: 141594741
Test Plan: CI
Reviewed By: suo
Differential Revision: D31697995
fbshipit-source-id: 05d6af7c23e3b7a94db75b20d06338bc9ade3e20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66723
Missing move in constructor and forced copy in getter.
ghstack-source-id: 141594742
Test Plan: CI
Reviewed By: suo
Differential Revision: D31697702
fbshipit-source-id: c2018531e7ec4a4853cd003ea3753273a5fae7fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67118
Fixes a bug in the reference pattern support for nn.Linear when the same quantized input is shared across multiple Linear nodes.
This PR adds a pass to duplicate the dequant nodes for each use so that for a case like
```
x -> quant -> dequant -> linear1 - quant1
|
linear2 - quant2
```
We duplicate the dequant nodes
```
x -> quant -> dequant1 -> linear1 - quant1
|
dequant2-> linear2 - quant2
```
So that we can match each pattern in the loweing step
We also add a pass to remove the extra/duplicate dequant nodes that may be leftover from the above pass if we don't lower them based on pattern match
Test Plan:
python test/test_quantization.py test_ref_pattern_multi_use
Imported from OSS
Reviewed By: mrshenli
Differential Revision: D31873511
fbshipit-source-id: aea0819222f084635157426743a50e065e6503c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67396
frozen_numpy did not work on GPU since we didn't added register_frozennumpy to the :builtin_registry_cuda target.
This was not found earlier since the unit test we added to test_deploy.cpp is only run on CPU. On GPU, we run test_deploy_gpu.cpp which does not contains the added unit tests for numpy.
In this diff, I just duplidate the unit tests for numpy (and pyyaml) across test_deploy.cpp and test_deploy_gpu.cpp.
I think ideally we should consolidate there 2 files to a single one. So we can add unit test in a single place while run them in both hardward platforms.
Tracking task: T104399180
ghstack-source-id: 141750276
Test Plan: buck test mode/opt :test_deploy_gpu
Reviewed By: suo
Differential Revision: D31978156
fbshipit-source-id: 2f5cd55ca33107cc7d230b72f1353df81f0a3bda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67340
Currently Torchbind classes arent selective. This makes is a rough granularity pass that will remove entire classes if they arent selected. If we need finer granularity in the future we can make individual methods within classes Selective though instrumenting that will be significantly more involved I think. On a linux build only __torch__.torch.classes._nnapi.Compilation remains unselective. I cant find where its registered :P (theres a couple Android only ones and presumably some metal only ones as well)
Many of the classes registered in functions returned a reference to the class that was created. I talked with dreiss about it and we decided that this seemingly didnt serve any purpose, and leaving it like that would make the return value difficult (but possible) to create with selectivity. Since it seems useless anyway I just changed them to return an int so that they can still be called from a global scope, but not have any issues with the return type.
ghstack-source-id: 141690776
Test Plan: CI, model unit tests, test models in prod apps
Reviewed By: dhruvbird
Differential Revision: D31092564
fbshipit-source-id: 657f7eb83490292436c15cf134ceca9b72fb9e1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67323
Applied patch proposed by Jeff https://github.com/pytorch/pytorch/pull/63948#issuecomment-952166982.
In PyTorch, we map cuBLAS->rocBLAS and cuSPARSE->hipSPARSE. Note the prefix, roc versus hip.
The 'hip' APIs offer a more direct CUDA-friendly mapping, but calling rocBLAS directly has better performance.
Unfortunately, the `roc*` types and `hip*` types differ, i.e., `rocblas_float_complex` versus `hipComplex`.
In the case of SPARSE, we must use the hip types for complex instead of the roc types,
but the pytorch mappings assume roc. Therefore, we create a new SPARSE mapping that has a higher priority.
Its mappings will trigger first, and only when a miss occurs will the lower-priority pytorch mapping take place.
When a file contains "sparse" in the filename, a mapping marked with API_SPARSE is preferred over other choices.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D31969246
Pulled By: cpuhrsch
fbshipit-source-id: 4ce1b35eaf9ef0d146a0955ce70c354ddd8f4669
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67270
* Add dim argument to all symbolic
* All symbolic depends on any symbolic
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D31962518
Pulled By: malfet
fbshipit-source-id: f7ee05cf4eff5880fc508154267e060952b5b42d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66753
Fixes these Wextra compilation errors:
```
stderr: caffe2/aten/src/ATen/native/cuda/UnarySignKernels.cu: In lambda function:
caffe2/aten/src/ATen/native/cuda/UnarySignKernels.cu:49:72: error: comparison is always false due to limited range of data type [-Werror=type-limits]
49 | AT_DISPATCH_ALL_TYPES_AND2 (44fd312604)(kBFloat16, ScalarType::Half, iter.input_dtype(), "signbit_cuda", [&]() {
| ~~^~~
stderr: caffe2/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu: In lambda function:
caffe2/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu:99:86: error: comparison is always false due to limited range of data type [-Werror=type-limits]
99 | AT_DISPATCH_INTEGRAL_TYPES(dtype, "div_floor_cuda", [&]() {
| ^
caffe2/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu:99:97: error: comparison is always false due to limited range of data type [-Werror=type-limits]
99 | AT_DISPATCH_INTEGRAL_TYPES(dtype, "div_floor_cuda", [&]() {
| ^
stderr: caffe2/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu: In lambda function:
caffe2/aten/src/ATen/native/cuda/BinaryMulDivKernel.cu:99:86: error: comparison is always false due to limited range of data type [-Werror=type-limits]
99 | AT_DISPATCH_INTEGRAL_TYPES(dtype, "div_floor_cuda", [&]() {
| ^
```
And also these warnings:
```
caffe2/c10/util/Half.h(461): warning: pointless comparison of unsigned integer with zero
detected during instantiation of "std::enable_if<<expression>, __nv_bool>::type c10::overflows<To,From>(From) [with To=size_t, From=unsigned long]"
caffe2/aten/src/ATen/native/Resize.h(45): here
caffe2/c10/util/Half.h(459): warning: pointless comparison of unsigned integer with zero
detected during instantiation of "std::enable_if<<expression>, __nv_bool>::type c10::overflows<To,From>(From) [with To=size_t, From=unsigned long]"
caffe2/aten/src/ATen/native/Resize.h(45): here
```
I thought I'd fixed this previously using `std::is_unsigned` in D25256251 (cff1ff7fb6), but apparently that was insufficient.
Test Plan: Sandcastle
Reviewed By: malfet, ngimel
Differential Revision: D31708173
fbshipit-source-id: 7714f6bbf109d2f2164630d3fc46bad18046c06c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67307
Wrap TRTInterpreter result so that any future change to output params is less likely to break existing use cases.
Test Plan: Run test with all touched file
Reviewed By: 842974287
Differential Revision: D31945634
fbshipit-source-id: 7cf73a1ef0098bff2013815f2f1692233ef7ec14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67229
Right now, assembly code generated for the a given method from the model is named wrapper or func by default. The function name is then replaced with a proper kernel_func_name after target specific assembly is generated.
This PR propagates a desired kernel_func_name right from aotCompiler API so that the generated function has the needed name that doesn't need to be replaced later.
Note: Most of this change was landed in https://github.com/pytorch/pytorch/pull/66337 which had to be reverted as it was breaking `test_profiler` in `test_jit_fuser_te` as it replaced the name generated for graph with the default kernel_func_name value. This PR fixes that as well.
```
(pytorch) ~/local/pytorch kname
└─ $ python3 test/test_jit_fuser_te.py
CUDA not available, skipping tests
monkeytype is not installed. Skipping tests for Profile-Directed Typing
........................................<string>:3: UserWarning: torch.cholesky is deprecated in favor of torch.linalg.cholesky and will be removed in a future PyTorch release.
L = torch.cholesky(A)
should be replaced with
L = torch.linalg.cholesky(A)
and
.
.
.
......................<string>:3: UserWarning: torch.symeig is deprecated in favor of torch.linalg.eigh and will be removed in a future PyTorch release.
The default behavior has changed from using the upper triangular portion of the matrix by default to using the lower triangular portion.
L, _ = torch.symeig(A, upper=upper)
should be replaced with
L = torch.linalg.eigvalsh(A, UPLO='U' if upper else 'L')
and
L, V = torch.symeig(A, eigenvectors=True)
should be replaced with
L, V = torch.linalg.eigh(A, UPLO='U' if upper else 'L') (Triggered internally at ../aten/src/ATen/native/BatchLinearAlgebra.cpp:2492.)
......[W pybind_utils.cpp:35] Warning: Using sparse tensors in TorchScript is experimental. Many optimization pathways have not been thoroughly tested with sparse tensors. Please include the fact that the network is running sparse tensors in any bug reports submitted. (function operator())
/data/users/priyaramani/pytorch/torch/testing/_internal/common_utils.py:403: UserWarning: Using sparse tensors in TorchScript is experimental. Many optimization pathways have not been thoroughly tested with sparse tensors. Please include the fact that the network is running sparse tensors in any bug reports submitted. (Triggered internally at ../torch/csrc/jit/python/pybind_utils.h:691.)
return callable(*args, **kwargs)
.....................................................................[W Resize.cpp:23] Warning: An output with one or more elements was resized since it had shape [1], which does not match the required output shape [].This behavior is deprecated, and in a future PyTorch release outputs will not be resized unless they have zero elements. You can explicitly reuse an out tensor t by resizing it, inplace, to zero elements with t.resize_(0). (function resize_output_check)
[W Resize.cpp:23] Warning: An output with one or more elements was resized since it had shape [1, 5], which does not match the required output shape [5].This behavior is deprecated, and in a future PyTorch release outputs will not be resized unless they have zero elements. You can explicitly reuse an out tensor t by resizing it, inplace, to zero elements with t.resize_(0). (function resize_output_check)
........................................................................s.......s...s.s....s......s..sss............................
----------------------------------------------------------------------
Ran 503 tests in 37.536s
OK (skipped=10)
```
Test Plan: Imported from OSS
Reviewed By: navahgar, pbelevich
Differential Revision: D31945713
Pulled By: priyaramani
fbshipit-source-id: f2246946f0fd51afba5cb6186d9743051e3b096b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66289
Add a variadic version of `grouped_accessor_op` to eliminate list construction overhead and associated refcount bumps in static runtime.
Test Plan:
Accuracy test with model 294738512_40: passes with 0 errors.
Accuracy test with model 296213501_65 (has V2 op): passes with 0 errors.
**Perf impact**
TW replayer test w/ 800 QPS (stacked with D31620408) shows ~5% CPU decrease for storage tier.
Results:
{F673610665}
Reviewed By: hlu1
Differential Revision: D31482816
fbshipit-source-id: 14393da122cefd094c3e4f423beb897c1d17b32c
Summary:
Adds mixed precision autocasting support between fp32/fp16 to torchscript/JIT. More in depth descriptoin can be found at [torch/csrc/jit/JIT-AUTOCAST.md](https://github.com/pytorch/pytorch/pull/63939/files#diff-1f1772aaa508841c5bb58b74ab98f49a1e577612cd9ea5c386c8714a75db830b)
This PR implemented an autocast optimization pass that inserts casting ops per AMP rule (torch/csrc/jit/passes/autocast.cpp), that mimics the behavior of eager autocast. The pass also takes into consideration the context of `torch.cuda.amp.autocast` and only inserts casting ops within the enabled context manager, giving feature parity as with eager amp autocast.
We currently provide JIT AMP autocast as a prototyping feature, so it is default off and could be turned on via `torch._C._jit_set_autocast_mode(True)`
The JIT support for autocast is subject to different constraints compared to the eager mode implementation (mostly related to the fact that TorchScript is statically typed), restriction on the user facing python code is described in doc torch/csrc/jit/JIT-AUTOCAST.md
This is a prototype, there are also implementation limitation that's necessary to keep this PR small and get something functioning quickly on upstream, so we can iterate on designs.
Few limitation/challenge that is not properly resolved in this PR:
1. Autocast inserts cast operation, which would have impact on scalar type of output tensor feeding downstream operations. We are not currently propagating the updated scalar types, this would give issues/wrong results on operations in promotion rules.
2. Backward for autodiff in JIT misses the casting of dgrad to input scalar type, as what autograd does in eager. This forces us to explicitly mark the casting operation for certain operations (e.g. binary ops), otherwise, we might be feeding dgrad with mismatch scalar type to input. This could potentially break gradient function consuming dgrad. (e.g. gemm backwards, which assumes grad_output to be of same scalar type as input')
3. `torch.autocast` api has an optional argument `dtype` which is not currently supported in the JIT autocast and we require a static value.
Credit goes mostly to:
tlemo
kevinstephano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63939
Reviewed By: navahgar
Differential Revision: D31093381
Pulled By: eellison
fbshipit-source-id: da6e26c668c38b01e296f304507048d6c1794314
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67345
Was hitting capacity issues, setting these to non-ephemeral would mean
keeping the current capacity at the expense of "unclean" nodes
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31965477
Pulled By: seemethere
fbshipit-source-id: 6d45fb34d07d55c5112db065af2aa0a8b1fd8d1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65967
Graph is an implementation detail. If user wants to get access to the
underlying graph, they should be able to explicitly dynamic cast instead.
ghstack-source-id: 141659819
Test Plan: no behavior change.
Reviewed By: gmagogsfm
Differential Revision: D31326153
fbshipit-source-id: a0e984f57c6013494b92a7095bf5bb660035eb84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61858
This PR adds `triangular_solve_out_sparse_csr_cuda`. The operation is
used to comput the solution to the linear system where coefficient
matrix is triangular.
Structured kernels are used and the meta function needed some changes to
support sparse csr layout. With sparse matrix input the `cloned_coefficient`
tensor is 0-sized tensor.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D31948435
Pulled By: cpuhrsch
fbshipit-source-id: 7775fece83ca705a26d75f82aead10b956b14bfd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67068
Prepending a node to itself will result in the node gets removed from the graph.
Usually people won't prepend a node with itself. But people would accidentally try to append a node that's already next to `self` node, which will be prepending `self` to `self`.
Test Plan: Added a unit test
Reviewed By: jamesr66a
Differential Revision: D31849030
fbshipit-source-id: b0fdfbb893f785f268595acd823b426d57c15e61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66291
In this PR:
- Trivial batching rules for `make_dual` and `is_same_size` that enable forward ad + vmap functionality
- Adds a check in gradcheck that is performed when both `check_batched_grad` and `check_forward_ad` are `True` (an OpInfo using this is added later in the stack).
- Tests for the gradcheck functionality
- Tests that basic out-of-place op works
Test Plan: Imported from OSS
Reviewed By: albanD, saketh-are
Differential Revision: D31842018
Pulled By: soulitzer
fbshipit-source-id: 84b18d9a77eeb19897757e37555581f2a9dc43d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66738
added a field `max_batch_size` to TRTModule, which would be later used to determine how big the engine holder would need to pad the input to
Reviewed By: 842974287
Differential Revision: D31286509
fbshipit-source-id: be5c6d4ad9c87ca0842679dc507b187275d4e8dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67230
Added a new test `vulkan_perf_test` for measuring performance with google benchmark.
**Summay:**
* `vulkan_perf_test` can be used to perform a quick benchmark test for Vulkan features to compare before and after performance when applying a new method and/or optimizing the existing implementation on your local machine.
* The **google benchmark** 3rd party library (https://github.com/google/benchmark) is already in the repo (`fbsource/third-party/benchmark`).
* The number of threads is set to 1 since Vulkan backend is not thread-safe.
* Added a new API `Context::wait()` to allow benchmark tests to wait for all GPU operations to be done before calling `Context::flush()`
* Call `Context::wait()` for each output Vulkan tensor and then `Context::flush()` to avoid out-of-memory issues while running a number of iterations in the benchmark test code
* Use `Time` column (wall clock) as a total execution time for each iteration (instead of `CPU` column = CPU execution time only) from the benchmark result table
* The more iterations, the more reliable data. But, it will take much longer. 100-1,000 iterations for bigger tensors and 5,000-10,000 iterations for smaller ones would be sufficient.
* The benchmark data on MacOS is not reliable since there is an extra layer [MoltenVk](https://github.com/KhronosGroup/MoltenVK) that is running on top of `Metal`. And also running Vulkan models on MacOS instead of Metal ones is generally not a good idea.
**Next steps:**
* Add more benchmark tests as we optimize more Vulkan operators
* Consider using Vulkan own performance counter such as [uVkCompute](https://github.com/google/uVkCompute) in the near future. Each iteration time can be manually set by `benchmark::State::SetIterationTime()` and `Benchmark::UseManualTime()` APIs (see [UseManualTime API](365670e432/include/benchmark/benchmark.h (L1013)))
* Consider this `vulkan_perf_test` as a performance BAT (Build Acceptance Test) on the CI pipeline. `gtest` and `google benchmark` can be written in the same place ([see](https://stackoverflow.com/questions/8565666/benchmarking-with-googletest)). And [swiftshader](https://github.com/google/swiftshader) can be used for Sandcastle devservers that don't support Vulkan. We may come up with a reasonable performance criteria for each test and it will fail if any significant performance degradation.
Test Plan:
**Test build on Android**
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_perf_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_perf_test
adb shell "/data/local/tmp/vulkan_perf_test"
```
**Test build on MacOS**
```
cd ~/fbsource
buck build //xplat/caffe2:pt_vulkan_perf_test_binAppleMac
./buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAppleMac\#macosx-x86_64
```
**Test result on Google Pixel 5**
```
Running /data/local/tmp/vulkan_perf_test
Run on (8 X 1804.8 MHz CPU s)
***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead.
-------------------------------------------------------------------------------------------------------------
Benchmark (Without optimization for 4x channels) Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 60.4 ms 14.1 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 24.1 ms 0.947 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 59.6 ms 14.0 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 5.98 ms 0.844 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 6.02 ms 0.845 ms 5000
-------------------------------------------------------------------------------------------------------------
Benchmark (With optimization for 4x channels) Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 39.3 ms 13.3 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 16.4 ms 3.49 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 59.7 ms 14.1 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 3.93 ms 0.855 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 6.14 ms 0.852 ms 5000
```
Note that the smaller tensors (`3.93 ms` vs `6.14 ms` when comparing `{3,4,221,193}` with `{3,3,221,193}`) receive significant improvement on the Android builds. Because `vkCmdCopyImage` API is used for the bigger tensor `{3,4,22,193}` instead of shader operations.
* `{3,40,221,193}`: 60.4 ms -> 39.3 ms (34.93% faster)
* `{3,20,221,193}`: 24.1 ms -> 16.4 ms (31.95% faster)
* `{3,4,221,193}`: 5.98 ms -> 3.93 ms (34.28% faster)
{F674052834}
**Test result on MacOS**
```
Running ./buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAppleMac#macosx-x86_64
Run on (16 X 2400 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x8)
L1 Instruction 32 KiB (x8)
L2 Unified 256 KiB (x8)
L3 Unified 16384 KiB (x1)
Load Average: 5.95, 5.02, 5.15
***WARNING*** Library was built as DEBUG. Timings may be affected.
-------------------------------------------------------------------------------------------------------------
Benchmark (Without optimization for 4x channels) Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 51.2 ms 35.5 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 11.4 ms 4.76 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 51.9 ms 35.0 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 2.84 ms 1.36 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 2.30 ms 1.13 ms 5000
-------------------------------------------------------------------------------------------------------------
Benchmark (With optimization for 4x channels) Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 70.1 ms 36.9 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 11.8 ms 5.00 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 69.3 ms 36.8 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 4.60 ms 1.48 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 3.65 ms 1.41 ms 5000
```
Note that `{3,40,221,193}` input tensors don't receive any performance improvement when we use `vkCmdCopyImage` API to directly copy textures when the number of channel is a multiple of 4 on MacOS. This is maybe due to an extra layer [MoltenVk](https://github.com/KhronosGroup/MoltenVK) that is running on top of `Metal`.
Reviewed By: SS-JIA
Differential Revision: D31906379
fbshipit-source-id: 0addc766502dba1a915b08840b3a4dc786a9cd9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67207
Improved performance for `cat` operator for channel dimension:
* Improved when the input tensor's channel size is a multiple of 4.
* Add new test cases to cover this scenario
* Limitation: We can't mix up using shader and `vkCmdCopyImage` at the same time. The way we create the output texture is different between two so we can't cross unless we create the output texture every time. We consider using `vkCmdCopyImage` only if all input tensors' channel is a multiple of 4.
{F673815905}
Test Plan:
**Test Conditions**
* 3 input tensors with size `{3, 40, 221, 193}`
* Number of iteration: `1,000`
* Compare `Time` column (`CPU` column is only for CPU execution time)
* Flushes resources every 1 iteration since the input tensor size is big
* running vulkan_perf_test requires a separate diff (D31906379)
**Test build on Android**
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_perf_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_perf_test
adb shell "/data/local/tmp/vulkan_perf_test"
```
**Test build on Mac**
```
cd ~/fbsource
buck build //xplat/caffe2:pt_vulkan_perf_test_binAppleMac
./buck-out/gen/xplat/caffe2/pt_vulkan_perf_test_binAppleMac\#macosx-x86_64
```
**Test result on Google Pixel 5**
a) Without using `vkCmdCopyImage` for multiples of 4 in channel dimension
```
Run on (8 X 1804.8 MHz CPU s)
***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead.
-------------------------------------------------------------------------------------------------------------
Benchmark (Without optimization for 4x channels) Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 60.4 ms 14.1 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 24.1 ms 0.947 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 59.6 ms 14.0 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 5.98 ms 0.844 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 6.02 ms 0.845 ms 5000
```
b) With using `vkCmdCopyImage` for multiples of 4 in channel dimension
```
Run on (8 X 1804.8 MHz CPU s)
***WARNING*** CPU scaling is enabled, the benchmark real time measurements may be noisy and will incur extra overhead.
-------------------------------------------------------------------------------------------------------------
Benchmark (With optimization for 4x channels) Time CPU Iterations
-------------------------------------------------------------------------------------------------------------
cat_op_channel_perf/N:3/C:40/H:221/W:193/iterations:1000/threads:1 39.3 ms 13.3 ms 1000
cat_op_channel_perf/N:3/C:20/H:221/W:193/iterations:1000/threads:1 16.4 ms 3.49 ms 1000
cat_op_channel_perf/N:3/C:39/H:221/W:193/iterations:1000/threads:1 59.7 ms 14.1 ms 1000
cat_op_channel_perf/N:3/C:4/H:221/W:193/iterations:5000/threads:1 3.93 ms 0.855 ms 5000
cat_op_channel_perf/N:3/C:3/H:221/W:193/iterations:5000/threads:1 6.14 ms 0.852 ms 5000
```
* `{3,40,221,193}`: 60.4 ms -> 39.3 ms (34.93% faster)
* `{3,20,221,193}`: 24.1 ms -> 16.4 ms (31.95% faster)
* `{3,4,221,193}`: 5.98 ms -> 3.93 ms (34.28% faster)
{F674052795}
Reviewed By: SS-JIA
Differential Revision: D31781390
fbshipit-source-id: 42179d28ae461a9e247053bc9718f6b8c6c819e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66587
Made some changes in the step function of the non-vectorized Adadelta optimizer to handle complex numbers as two real numbers as per 65711 on github
ghstack-source-id: 141484731
Test Plan:
buck test mode/dev caffe2/test:optim -- 'test_adadelta_complex'
https://pxl.cl/1R7kJ
Reviewed By: albanD
Differential Revision: D31630069
fbshipit-source-id: 2741177b837960538ce39772897af36bbce7b7d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67299
Switches the linux.8xlarge.nvidia.gpu to the 4xlarge instance type to
help with queueing / capacity issues. This change is only meant to be a
bridge until everyone updates their PRs to use the new
linux.4xlarge.nvidia.gpu node type
NOTE: This node type will be removed so do not depend on it for any new
workflows.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31945507
Pulled By: seemethere
fbshipit-source-id: fb8587de7f31da72e968d46eeecc573d3f5b440f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66584
This will help avoid "-1"s in different places in our and backend codebase when
debug handle is not known.
Test Plan: CI
Reviewed By: sxu
Differential Revision: D31614478
fbshipit-source-id: 97fceb04e3e78f52feda7b1ba1da08fa4480dd77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65966
ghstack-source-id: 141594521
Support exportation of "interface methods" from submodule to a mobile module. "Interface methods" are defined as methods which might be dynamically called in a module therefore need to be exported anyway, like virtual functions in C++.
Before this change the algorithm of exportation is a simple iteration through all toplevel methods. Now since we have indirect calls, we need to recursively walkthrough the call graph to find all potentially used methods, which means the order we export methods might break in old runtimes, to guarantee forward compatibility we need to export toplevel methods first, then extra methods, in this order toplevel methods will always be found first.
NOTE that interface methods exportations are disabled by default in this diff. We need to call torch._C._enable_mobile_interface_call_export to actaully enable it.
Test Plan: buck test mode/dev //caffe2/test:jit -- --exact 'caffe2/test:jit - test_export_opnames_interface (jit.test_misc.TestMisc)'
Reviewed By: qihqi, iseeyuan
Differential Revision: D31326155
fbshipit-source-id: 5be7234cca07691f62648a85133b6db65e427b53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67264
Downgrades linux gpu instances from 4xlarge -> 8xlarge
We were seeing capacity issues in terms of scaling 8xlarge instances,
downgrading this to 4xlarge (which only have a single gpu) to see if
that helps resolve some of the capacity issues we were seeing
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D31933488
Pulled By: seemethere
fbshipit-source-id: b41922ebb675e663cb035cd3795bc9bae94dcac7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66996
We do this conversion a few times, and further diffs (which I'm trying to keep as small as possible) will do it more.
ghstack-source-id: 141496817
Test Plan: CI
Reviewed By: mikeiovine
Differential Revision: D31821037
fbshipit-source-id: 1d3b54cadaedd53189aec6a35ed1a126c6fe4824
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66965
external aliases aren't defined to be outputs (though output aliases may end up in there as the following sentence clarifies).
ghstack-source-id: 141473794
Test Plan: review
Reviewed By: mikeiovine
Differential Revision: D31809715
fbshipit-source-id: 82d1391b04e22559932f82270669a7ff94a1c90f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67204Fixes#66422Fixes#66423
In the original test, all collectives are dummy local ones. As a
result, rank 0 could exit earlier than other ranks. However, the
`TCPStore` lives on rank 0, and other ranks might need to talk to
that store after rank 0 exits. This commit explicitly makes rank 0
wait for all other ranks to finish.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31906802
Pulled By: mrshenli
fbshipit-source-id: 82745f5497d784ea3cea9df6bda537ec71380867
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67059
Debugging some workflows, and sometimes the training does not finish
but I want to know whether the graph was not static. Also, log 0 for unused
parameter size if no unused params were found.
ghstack-source-id: 141428950
Test Plan: Ci
Reviewed By: mrshenli
Differential Revision: D31846669
fbshipit-source-id: 21763fcdc1b244ba829117da1f15b2271d966983
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67123
Makes `sigrid_hash_compute_multipler_shift` return a tuple instead of a tensor and modifies functions that depends on it.
Test Plan:
```
buck test //caffe2/benchmarks/static_runtime/fb:test_fb_operators
```
Benchmarks:
`local`:
```
I1022 13:56:34.529495 2866038 PyTorchPredictorBenchLib.cpp:266] Mean milliseconds per iter: 5.67114, standard deviation: 0.336918
I1022 15:29:45.248790 3292725 PyTorchPredictorBenchLib.cpp:266] Mean milliseconds per iter: 5.66678, standard deviation: 0.403032
```
`local_ro`:
```
I1022 13:59:24.262511 2882599 PyTorchPredictorBenchLib.cpp:266] Mean milliseconds per iter: 1.56012, standard deviation: 0.0537101
I1022 15:34:53.941890 3328358 PyTorchPredictorBenchLib.cpp:266] Mean milliseconds per iter: 1.5525, standard deviation: 0.0280267
```
FB: local - P463676888, local_ro - P463676984, master local - P463686094, master local_ro - P463686470
Reviewed By: mikeiovine
Differential Revision: D31867186
fbshipit-source-id: 0f640487b74d1cd0d5f714f2258e056a2f0c2c07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67195
Now that `is_nonzero` is part of `at::native` refer https://github.com/pytorch/pytorch/pull/66663, replacing `TensorCompare::is_nonzero` to `at::native::is_nonzero`
ghstack-source-id: 141514416
Test Plan: CI
Reviewed By: larryliu0820
Differential Revision: D31704041
fbshipit-source-id: 36813e5411d0aa2eb2d0442e2a195bbed417b33d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67004
New version because the other one was impossible to rebase
Trace custom classes
Test Plan: CI.
Reviewed By: dhruvbird
Differential Revision: D31818978
fbshipit-source-id: daa22ccb153e32685bcca43a303ba9e21042d052
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67215
We were regularly seeing gaps in our docker image builds due to specific
workflows not being run when docker builds occurred on PRs, this should
remove that ambiguity and ensure that all docker builds be re-built if a
rebuild is deemed necessary
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31910422
Pulled By: seemethere
fbshipit-source-id: f346e64f1857e35a995c49bf30521a3acd8af0b1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67027
`torch.Tensor` is considered a Mapping, but not a Sequence in Python
because it uses `tp_as_mapping` instead of defining `__getitem__` in
Python. However, If you try to overwrite `__getitem__` from Python
it is considered a `Sequence` and so the tensor is treated like a
tuple for indexing purposes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67202
Reviewed By: VitalyFedyunin
Differential Revision: D31908515
Pulled By: albanD
fbshipit-source-id: 0ca55a36be3421f96428a8eacf5d195646252b38
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/67106
Test Plan: Recloned cpuinfo, rebuilt, and ran all the tests locally
Reviewed By: kimishpatel
Differential Revision: D31782317
fbshipit-source-id: 4a71be91f02bb6278db7e0124366d8009e7c7a60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67203
This commit uses `dist` for `torch.distributed` and `c10d` for
`torch.distributed.distributed_c10d`. The former is for public APIs
and the latter is for private ones.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D31906801
Pulled By: mrshenli
fbshipit-source-id: c3a01f33962b01a03dbd565ed119dcdac594bcf2
Summary:
Some minor changes are needed to the .circleci docker scripts to support ubuntu 20.04. One edit updates the packages needed for all images (.circleci/docker/common/install_base.sh), while the other edit is specific to ROCm support.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH seemethere malfet pytorch/pytorch-dev-infra
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66942
Reviewed By: albanD
Differential Revision: D31899271
Pulled By: janeyx99
fbshipit-source-id: f7677ddc063a4504da9f39a756dc181ac55f200a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67162
It's a bit annoying/ugly to type `c10::Symbol::fromQualString` everywhere, and we can't do `using c10::Symbol::fromQualString` since it's a static class function.
Test Plan: CI
Reviewed By: d1jang
Differential Revision: D31887042
fbshipit-source-id: 073a56c72281c20284a9feef741aed96b58a921d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67206
The memory overlap check still checks the memory overlap for alias ops. It only skips the check for inplace ops. This needs to be fixed if we want to use the memory overlap check in prod.
This diff only adds more debug info. It doesn't fix the aforementioned problem.
Reviewed By: d1jang
Differential Revision: D31889866
fbshipit-source-id: 05a80ace3d404f66f21a8bbdc9678485ff76c8d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67199
This PR refactors _sharded_tensor package so that it splits from api.py, and add different components to make it more modularized, this will also help us resolve circular dependency due to increasing code size and better organize the package:
* api.py: sharded tensor APIs
* metadata.py: Metadata definition for ShardedTensors
* shard.py: Shard definition for ShardedTensor
* utils.py: utility functions for validation, etc.
ghstack-source-id: 141533618
Test Plan: test_sharded_tensor.py
Reviewed By: pritamdamania87
Differential Revision: D31904249
fbshipit-source-id: c747d96e131a1d4731991ec4ac090f639dcb369b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67228
We added `AccOpProperty` for easy enablement of graph opts for new acc ops based on general properties. This diff adds
1. `AccOpProperty.unary`
2. Automated testing for acc ops with both `AccOpProperty.unary` and `AccOpProperty.pointwise` with `sink_reshape_ops` graph opt. [Adds coverage for 30 more acc_ops]
3. Refactors `graph_opts/TARGETS` to collect all graph optimizations into a common library
4. replaces `def foo(*, input, acc_out_ty=None): assert acc_out_ty is not None` with just `def foo(*, input, acc_out_ty)`. Let me know if there is some hidden purpose to the other implementation.
5. adds `AccOpProperty.*` flags to appropriate ops.
Test Plan:
`buck test mode/dev glow/fb/fx/graph_opts:test_fx_sink`
```
...
Summary
Pass: 31
ListingSuccess: 1
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/4222124724581304
```
Also ran
```
`buck test mode/dev glow/fb/fx/acc_tracer:`
```
```
...
Summary
Pass: 136
ListingSuccess: 4
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/5910974582823618
```
Reviewed By: jfix71
Differential Revision: D31671833
fbshipit-source-id: aa16d1008f18f7c8626058361efff33843de3505
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch-canary/pull/4
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67211
Record the algorithm selection, dump it in json format and replay it. This has potential to
1. consistently repro the issue (algo selection could be sensitive to local benchmark timing)
2. manual edit the dumped json file to control algorithm selection.
Reviewed By: wushirong, 842974287
Differential Revision: D31888836
fbshipit-source-id: 4611fda548f7391776f1ad61572b1f59fa4665b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67209
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67198
Fixing a couple instances where parameters were named method_compile_spec when they were actually compile_specs that could have multiple method_compile_specs inside.
Also use output dtype from buffer.
Test Plan:
Mobilenetv3 compiles and runs fine
```
(pytorch) ~/fbsource/fbcode/caffe2/fb/nnc
└─ $ PYTORCH_JIT_LOG_LEVEL="aot_compiler" buck run //caffe2/binaries:aot_model_compiler -- --model mobilenetv3.pt --model_name=pytorch_dev_mobilenetv3 --model_version=v1 --input_dims="1,3,224,224
"
Downloaded 4501/6195 artifacts, 433.89 Mbytes, 14.3% cache miss (for updated rules)
Building: finished in 06:34.6 min (100%) 20233/20233 jobs, 5467/20233 updated
Total time: 06:35.0 min
BUILD SUCCEEDED
The compiled llvm assembly code was saved to mobilenetv3.compiled.ll
The compiled model was saved to mobilenetv3.compiled.pt
└─ $ ./compile_model.sh -m pytorch_dev_mobilenetv3 -p /data/users/priyaramani/fbsource/fbcode/caffe2/fb/nnc/mobilenetv3.pt -v v1 -i "1,3,224,224"
+ VERSION=v1
+ getopts m:p:v:i:h opt
+ case $opt in
+ MODEL=pytorch_dev_mobilenetv3
.
.
Columns 961 to 9701e-11 *
-4.2304 -3.9674 2.4473 -0.8664 -0.7513 1.2140 0.0010 3.8675 1.2714 2.2989
Columns 971 to 9801e-11 *
-2.7203 1.6772 -0.7460 -0.6936 4.4421 -0.9865 -0.5186 -1.4441 1.3047 -1.6112
Columns 981 to 9901e-11 *
0.1275 -1.8815 2.5105 -0.4871 -2.2342 0.8520 0.8658 1.6180 3.8901 -0.2454
Columns 991 to 10001e-11 *
-1.4896 4.1337 -2.6640 0.8226 0.2441 -1.4830 -1.7430 1.8758 0.5481 0.5093
[ CPUFloatType{1,1000} ]
Starting benchmark.
Running warmup runs.
Main runs.
Main run finished. Milliseconds per iter: 276.255. Iters per second: 3.61984
Memory usage before main runs: 104366080 bytes
Memory usage after main runs: 343441408 bytes
Average memory increase per iter: 2.39075e+07 bytes
0 value means "not available" in above
```
Reviewed By: ljk53
Differential Revision: D31698338
fbshipit-source-id: da6c74c1321ec02e0652f3afe6f97bf789d3361b
Summary:
Add type support for namedtule custom class. For the namedtuple type, it will deserailize to the following format in string
```
"qualified_named[
NamedTuple, [
[filed_name_1, field_type_1],
[filed_name_2, field_type_2]
]
]"
```
If it's nested, it will be
```
"__torch__.A[
NamedTuple, [
[field_name_a, __torch__.B [
NamedTuple, [
[field_name_b, __torch__.C [
NamedTuple, [
[field_name_c_1, Tensor],
[field_name_c_2, Tuple[Tensor, Tensor]],
]
]
]
]
]
]
]
]
"
```
The nametuple type includes both `collection` and `typing`.
```
from typing import NamedTuple
from collections import namedtuple
```
It will be a forward incompatible change. However this type is never supported and exported before and we don't have a proper way to backport it. The optimum solution to ship this change is probably
1. Update the change for import without the change to export. So the runtime can read the new format, but no new format will be exported.
2. Update the change to export the new type. So runtime can export new format.
For the following example:
```
class Foo(NamedTuple):
id: torch.Tensor
class Bar(torch.nn.Module):
def __init__(self):
super(Bar, self).__init__()
self.foo = Foo(torch.tensor(1))
def forward(self, a: torch.Tensor):
self.foo = Foo(a)
return self.foo
```
The new bytecode.pkl will be
```
(6,
('__torch__.mobile.test_lite_script_type.MyTestModule.forward',
(('instructions',
(('STOREN', 1, 2),
('DROPR', 1, 0),
('MOVE', 2, 0),
('LIST_CONSTRUCT', 0, 1),
('NAMED_TUPLE_CONSTRUCT', 1, 1),
('RET', 0, 0))),
('operators', ()),
('constants', ()),
('types',
('List[Tensor]',
'__torch__.mobile.test_lite_script_type.myNamedTuple[NamedTuple, [[a, '
'List[Tensor]]]]')),
('register_size', 2)),
(('arguments',
((('name', 'self'),
('type', '__torch__.mobile.test_lite_script_type.MyTestModule'),
('default_value', None)),
(('name', 'a'), ('type', 'Tensor'), ('default_value', None)))),
('returns',
((('name', ''),
('type', '__torch__.mobile.test_lite_script_type.myNamedTuple'),
('default_value', None)),)))))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62612
ghstack-source-id: 141485500
Test Plan:
fb:
1. Add a simple unittest to test NamedTuple custom class
2. Use following cpp code (D30271153)
```
TEST(LiteTrainerTest, CustomOp) {
std::string jit_model =
"/home/chenlai/local/notebooks/ads_dper_fl_model_282250609.pt";
Module jit_m = load(jit_model);
jit_m.eval();
torch::jit::Module module_freeze = freeze(jit_m);
IValue tuple =
c10::ivalue::Tuple::create({1 * torch::ones({10, 1034}), 3 * torch::ones({10, 1034})});
std::vector<IValue> inputs_1{tuple};
auto jit_output = jit_m.forward(inputs_1);
jit_output.dump();
std::stringstream ss;
jit_m._save_for_mobile(ss);
jit_m._save_for_mobile("/home/chenlai/local/notebooks/tmp/tmp.ptl");
torch::jit::mobile::Module mobile_m = _load_for_mobile(ss);
auto mobile_output = mobile_m.forward(inputs_1);
std::cout << "mobile output: " << std::endl;
mobile_output.dump();
}
```
And output from both mobile and jit are
```
{prediction: ([ CPUFloatType{0} ], [ CPUFloatType{0} ])}
```
3. N1033894 with model inspection, also compare the result between jit and mobile with the dper model.
Reviewed By: iseeyuan
Differential Revision: D30004716
fbshipit-source-id: cfd30955e66a604af8f9633b1b608feddc13d7d7
Summary:
**Summary**: This commit solves the first part of https://github.com/pytorch/pytorch/issues/52306, which disallows type annotations on instance attributes inside any method other than the constructor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67051
Test Plan:
Added test to test_types.py.
**Reviewers**: Zhengxu Chen
**Subscribers**: Zhengxu Chen, Yanan Cao, Peng Wu, Yining Lu
**Tasks**: T103941984
**Tags**: pytorch
**Fixes** https://github.com/pytorch/pytorch/issues/52306
Reviewed By: zhxchen17
Differential Revision: D31843527
Pulled By: andrewor14
fbshipit-source-id: 624879ae801621e367c59228be8b0581ecd30ef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67200
We want to put more information on the tensorrt layer name. Mainly we want to be able to tell the original op that a TensorRT layer is mapped from.
The layer format is `[TensorRT Layer Type]-[Original Op Code]-[FX Node Name]`
```
Reformatting CopyNode for Input Tensor 0 to [FULLY_CONNECTED]-[acc_ops.linear]-[linear_1]: 0.0328ms
[FULLY_CONNECTED]-[acc_ops.linear]-[linear_1]: 0.027712ms
PWN([RELU]-[acc_ops.relu]-[relu_1]): 0.008672ms
```
Test Plan:
CI
```
buck run mode/dev-nosan -c python.package_style=inplace caffe2:fx2trt_example
```
Reviewed By: wushirong
Differential Revision: D31627274
fbshipit-source-id: 3dbb576caa63b922274541d2a306b4bd37e707c5
Summary:
This PR is to update PyTorch with the following cub changes:
- Starting cub 1.13.1, cub requires users to define `CUB_NS_QUALIFIER` if `CUB_NS_PREFIX` is also defined. Besides that, a new mechanism `CUB_WRAPPED_NAMESPACE` is added.
And I do the following change to PyTorch:
- Starting CUDA 11.5, define `CUB_WRAPPED_NAMESPACE` globally as an nvcc flag.
- Fix caffe2 failures caused by the above change.
- Add a `aten/src/ATen/cuda/cub_definitions.cuh` that defines helper macros about feature availability.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66219
Reviewed By: bdhirsh
Differential Revision: D31626931
Pulled By: ngimel
fbshipit-source-id: 97ebf5ef671ade8bf46d0860edc317f22660f26d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63511
This PR adds `torch.addmm(c, a, b)` variant with `c, a, b` all being CSR tensors.
The underlying cuSPARSE function works only with 32-bit indices, and in
the current implementation the result tensor has 32-bit indices. Input
tensors can have both 64-bit and 32-bit indices tensors.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D31809838
Pulled By: cpuhrsch
fbshipit-source-id: 97005dba27d8adcae445eb756bcbd7271061e9b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66972
Add api to view how many custom classes we have and what their names are
Test Plan: unit test
Reviewed By: cccclai
Differential Revision: D31811337
fbshipit-source-id: 9f8ca1fc578a0a5360c9cd8f95475acc33f250e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62734
Following https://github.com/pytorch/pytorch/pull/62715#discussion_r682610788
- squareCheckInputs takes a string with the name of the function
- We reuse more functions when checking the inputs
The state of the errors in torch.linalg is far from great though. We
leave a more comprehensive clean-up for the future.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D31823230
Pulled By: mruberry
fbshipit-source-id: eccd531f10d590eb5f9d04a957b7cdcb31c72ea4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67085
leverages BuiltinRegistry to register the CPython standard C modules. The standard C modules moved are in the FOR_EACH macro
Test Plan:
buck test mode/opt //caffe2/torch/csrc/deploy/interpreter:test_builtin_registry
buck test mode/opt //caffe2/torch/csrc/deploy:test_deploy
Reviewed By: shunting314
Differential Revision: D31848547
fbshipit-source-id: 7eb49d222eaaccb2b8ca5c984b05bf54cc233f25
Summary:
Followup after https://github.com/pytorch/pytorch/issues/58653
It does not matter whether one compiles locally or cross-compiles -
attempts to use SVE on M1 results in compiler crash as SVE ABI is not
defined on MacOS
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67114
Reviewed By: VitalyFedyunin
Differential Revision: D31869356
Pulled By: malfet
fbshipit-source-id: 184e26ae40edc7ef7b703200b53ea7a15da74818
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66659
Original message: We added and registered a new operator, static_runtime::fused_sigrid_transforms, and modified the original sigrid_transforms to handle non-fused case only
Note: this diff was commandeered from a bootcamper. Some final touches were needed.
Test Plan: `buck test caffe2/benchmarks/static_runtime/...`
Reviewed By: swolchok
Differential Revision: D31550307
fbshipit-source-id: 287380be0cca20ee6e145bcc7217547bd58cf6d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67097
all delegated models have `is_nonzero` ops by default, by making the op native and consumable without dispatch eases the portability of such models
ghstack-source-id: 141375082
Test Plan:
`buck test caffe2/test/cpp/jit:jit -- BackendTest.TestComposite`
```
~/fbsource/fbcode] cd ~/fbsource/fbcode/ && buck test caffe2/test:jit -- test_trace_arange
Parsing buck files: finished in 0.5 sec
Building: finished in 9.4 sec (100%) 16035/16035 jobs, 0/16035 updated
Total time: 10.0 sec
More details at https://www.internalfb.com/intern/buck/build/1e55eea5-2adb-41d1-96ae-cbf4b446d6c6
BUILD SUCCEEDED
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 46eedba2-ae17-4e88-b205-93bd1332665d
Trace available for this run at /tmp/tpx-20211015-113905.235421/trace.log
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/1970324912349177
✓ ListingSuccess: caffe2/test:jit - main (12.372)
✓ Pass: caffe2/test:jit - test_trace_arange (jit.test_tracer.TestTracer) (13.748)
✓ Pass: caffe2/test:jit - test_trace_arange_with_grad (jit.test_tracer.TestTracer) (13.892)
Summary
Pass: 2
ListingSuccess: 1
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/1970324912349177
```
Reviewed By: iseeyuan
Differential Revision: D31656842
fbshipit-source-id: c0e6c798478a2783c0e17e6e9100ba5ce044da78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66671
Made changes in the step function of the vectorized and non-vectorized adagrad optimizers to handle complex numbers as two real numbers as per 65711 on github
ghstack-source-id: 141442350
Test Plan:
buck test mode/dev caffe2/test:optim -- 'test_adagrad_complex'
https://pxl.cl/1Rd44
Reviewed By: albanD
Differential Revision: D31673503
fbshipit-source-id: 90a0d0c69b556716e2d17c59ce80f09c750fc464
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67001
The overload of `operator()` taking `std::vector<at::Tensor>` was only used for testing. In a diff following this one, I will add a new overload that takes `std::vector<c10::IValue> args` and no `kwargs` so we can avoid default-constructing `kwargs` everywhere.
This new overload will probably take a forwarding reference, so to avoid problems with overloading on forwarding reference and simplify the interface, it's best to remove this unused one.
Test Plan:
`buck test caffe2/benchmarks/static_runtime/...`
`buck test caffe2/test:static_runtime`
Reviewed By: hlu1
Differential Revision: D31821990
fbshipit-source-id: 6d2e4a75ca4abe6e262651532eb96c3b274c6f4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67125
Using explicit template instantiations in D31659973 (f2582a59d0) was a bad idea. The problem is that the lvalue instantiation was for a `const` vector of `IValue`, meaning that if you tried to pass SR a non-const vector of arguments, the linker would fail to find the symbol.
The reason we didn't catch this in D31659973 (f2582a59d0) was because predictor always passes a `const` reference anyways. But we should fix this to prevent unexpected problems in the future.
Test Plan: `buck test caffe2/benchmarks/static_runtime/...`
Reviewed By: hlu1
Differential Revision: D31873406
fbshipit-source-id: 5ab5a03334bed925cec11facadcedf9bec9b90ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67169
Looks like the doc error only appears after it's landed
Test Plan: Imported from OSS
Reviewed By: seemethere
Differential Revision: D31890431
fbshipit-source-id: d40cba082712c4b35704ea15d82fbc4749f85aec
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/67152
Test Plan:
```
cd docs
make html
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D31884570
fbshipit-source-id: 2b521f617c93f6fa08da3387df2d25497293eee6
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/kineto](https://github.com/pytorch/kineto).
New submodule commit: 879a203d9b
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67133
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: mrshenli
Differential Revision: D31877172
fbshipit-source-id: 224a499607d1f3bf7c00d8d8dd1fdac47cd33a3b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66957
chunk appears to return a tuple which is enough given that we just
index to the right chunk and discard the rest.
ghstack-source-id: 141391149
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D31780799
fbshipit-source-id: fdb1b77fffa916328e14a4cd692b5241ae46a514
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66956
Adds some comments I found helpful while ramping up on FSDP code.
ghstack-source-id: 141391150
Test Plan: n/a
Reviewed By: mrshenli
Differential Revision: D31780798
fbshipit-source-id: e2d38a9801b4548b202a73615774d5f0f7f5e3ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66337
Right now, assembly code generated for the a given method from the model is named wrapper or func by default. The function name is then replaced with a proper kernel_func_name after target specific assembly is generated.
This PR propagates a desired kernel_func_name right from aotCompiler API so that the generated function has the needed name that doesn't need to be replaced later.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31514095
Pulled By: priyaramani
fbshipit-source-id: b70c8e2c733600a435cd4e8b32092d37b7bf7de5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67066
We'll add it later when the api is ready
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31849079
fbshipit-source-id: 0c00d08510166b2d897cf1562c7276527319b05c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66878
Currently convert_fx quantizes all layers that have been prepared, depending on the prepare qconfig_dict
This PR adds support to accept a variation of qconfig_dict in convert_fx that can be used to specify skip quantizing certain layers
This can help with prepare/observe all operators, quantize a subset of them (based on quantization error), to avoid preparing multiple times.
The qconfig_dict passed to convert_fx can only have the values set to `None`, with the keys being the same as what is allowed in the prepare qconfig_dict
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_convert_qconfig_dict
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D31808247
fbshipit-source-id: a4f5dca1090f0083fc3fea14aff56924033eb24f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66767
Make observer fqn in prepare step independent of input_node/observed_node name.
This change names the observers as `{input/output}_activation_post_process_{idx}` where idx will be incremented for each new observer instance and is guaranteed to be unique.
Test Plan:
python test/test_quantization.py test_observer_fqn
Imported from OSS
Reviewed By: anjali411
Differential Revision: D31752052
fbshipit-source-id: e0995b1ef33a99d5b012133fe92d303d55a73b7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66245Fixes#66053
This PR splits `declare_static_dtype_and_device` into two new methods for
`TensorIteratorBase`: `declare_static_dtype` and `declare_static_device`.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D31503849
Pulled By: ngimel
fbshipit-source-id: 4b131b691d29ceb5f3709f5d6503997ea0875c54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67065
Switching to use _convert_fx_do_not_use in the tests
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31849077
fbshipit-source-id: 3688fc09ac538b6abc16ce87c600b8ee04acfcd1
Summary:
There are multiple improvement of depthwise convolution speed in cudnn between 7.6 and 8.2, since https://github.com/pytorch/pytorch/pull/22302.
This PR aim to harvest all the new improvement by enable more cudnn kernel. The workload checking logic can also be simplified now.
To keep the change simple, I kept things before cudnn 8.2 unchanged.
Similar to https://github.com/pytorch/pytorch/pull/22302, I used a script [here](https://gist.github.com/FDecaYed/e8ba98a95cd33697df2ace86fdb44897) to benchmark. Both run are using cudnn 8.2
One enhancement I did to the script is switch to event based timing. With warmup kernels to fill the launch queue ahead, this should give us accurate kernel timing even in CPU launch bound cases.
Here is A100 and V100 result sorted by speedup.
[Book1.xlsx](https://github.com/pytorch/pytorch/files/6530371/Book1.xlsx)
Result highlights:
Newly turned on 5x5 cudnn kernel show up to 6x speedup.
Close to half of test sizes show >10% speedup.
Fixed some corner cases that previously caused 15-20x slowdown.
Only slowdown a handful of cases(~10 out of >1000)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58749
Reviewed By: bdhirsh
Differential Revision: D31613199
Pulled By: ngimel
fbshipit-source-id: 883b58facad67ccd51dc9ab539368b4738d40398
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67050
This PR moves init_multi_gpu_helper to common_distributed so that it could be shared by different distributed tests.
ghstack-source-id: 141370119
Test Plan: wait for ci.
Reviewed By: mrshenli
Differential Revision: D31842644
fbshipit-source-id: c7bad25d6cef9bdce7ad1fb6c60c1cad4b765702
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66904
Add more FSDP unit tests to cover core logic, freezing weights and flatten parameter wrappe, these unit tests are refactored to be aligned with PyTorch commonly used test classes
ghstack-source-id: 141335614
Test Plan: unit tests
Reviewed By: mrshenli
Differential Revision: D31779565
fbshipit-source-id: c727110d1d7570c0ec49e42cadfc9e9a5e440073
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66649
some minor changes to dist quantization, mainly change the namespace and add some notes for future code dedup
ghstack-source-id: 141336191
Test Plan: wait for ci
Reviewed By: cbalioglu
Differential Revision: D31663043
fbshipit-source-id: 2f96b7346e9c90df5ab2536767f8301eb86a9c79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66149
Updated logic will be able to infer rank of slice output, when only rank is known for slice input. Enables cases where `ConstantValueMap::HasRank(input)` is `True`, while `ConstantValueMap::HasShape(input)` is `False`.
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D31423840
Pulled By: malfet
fbshipit-source-id: 17b2b24aa63435d5212ebe6bdf66ae3c348c4e3b
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66143
Delete test_list_remove. There's no point in testing conversion of
this model since TorchScript doesn't support it.
Add a link to an issue tracking test_embedding_bag_dynamic_input.
[ONNX] fix docs (#65379)
Mainly fix the sphinx build by inserting empty before
bulleted lists.
Also some minor improvements:
Remove superfluous descriptions of deprecated and ignored args.
The user doesn't need to know anything other than that they are
deprecated and ignored.
Fix custom_opsets description.
Make indentation of Raises section consistent with Args section.
[ONNX] publicize func for discovering unconvertible ops (#65285)
* [ONNX] Provide public function to discover all unconvertible ATen ops
This can be more productive than finding and fixing a single issue at a
time.
* [ONNX] Reorganize test_utility_funs
Move common functionality into a base class that doesn't define any
tests.
Add a new test for opset-independent tests. This lets us avoid running
the tests repeatedly for each opset.
Use simple inheritance rather than the `type()` built-in. It's more
readable.
* [ONNX] Use TestCase assertions rather than `assert`
This provides better error messages.
* [ONNX] Use double quotes consistently.
[ONNX] Fix code block formatting in doc (#65421)
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D31424093
fbshipit-source-id: 4ced841cc546db8548dede60b54b07df9bb4e36e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66140
* Add new argument to export api to enable users specifying `nn.Module` classes that they wish to be exported as local function in ONNX model.
* Refactor `torch/csrc/jit/serialization/export.cpp`, and remove redundant `EncoderBase` class.
* ~~Contains changes from #63268~~
* Depends on #63716 to update onnx submodule.
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D31424098
fbshipit-source-id: c949d0b01c206c30b4182c2dd1a5b90e32b7a0d3
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66581
c10d/frontend.cpp was originally proposed to introduce pure C++ API and use TorcBind to share python level API with TorchScript. This is no longer needed, so delete this to reduce code redundancy.
ghstack-source-id: 141336190
Test Plan: wait for ci
Reviewed By: rohan-varma
Differential Revision: D31627107
fbshipit-source-id: 07d30d280c25502a222a74c2c65dfa4069ed8713
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66648
Currently, SR shallow-copies its `IValue` inputs when running inferences. We can avoid refcount bumps by `std::move`-ing the inputs into their slots. To achieve this, I've made the following changes:
1. Add an overload for `set_inputs` that takes a `std::vector<IValue>&&`.
2. Change the signatures of `StaticModule::operator()` and `StaticRuntime::operator()`.
Old:
```
operator()(const std::vector<IValue>& args, const std::unordered_map<std::string, IValue>& kwargs)
```
New:
```
template <class IValueList>
operator()(IValueList&& args, const std::unordered_map<std::string, IValue>& kwargs)
```
The implementations use perfect forwarding to invoke the correct overload of `set_inputs`.
Test Plan: Added a short new unit test to exercise the new code path. All other unit tests still pass.
Reviewed By: hlu1
Differential Revision: D31659973
fbshipit-source-id: b8c194405b54a5af1b418f8edaa1dd29a061deed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66288
This change makes it so `UseVariadicOp` can transform ops with many Tensor list inputs.
Input pattern:
```
%output : Type = op(%list_1, %arg_1, %list_2, %list_3)
```
Output pattern:
```
%output : Type = variadic_op(%list_11, ..., %list_1N, %arg_1, %list_21, ..., %list_2M, %list_31, ..., %list_3K, N, M, K)
```
The length of each list is passed at the end of the variadic op so that the op implementation can process the inputs appropriately. This also frees us from needing to update `hasVarArgs` in static runtime each time we add a variadic op.
This diff also makes `UseVariadicOp` more robust. Before, `list_idx` was passed as an argument. Now, `VariadicUpdater` determines `list_idx` from the node's schema.
Test Plan:
Existing variadic ops do not break:
`buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: d1jang
Differential Revision: D31450811
fbshipit-source-id: 808fcc3ae8940b9e602586f38f8cf9154c9a6462
Summary:
Similar to pytorch/text#1416
malfet, brianjo
The previous code failed when tags changed from `v0.9.0` to `v0.10.0`. I tested this offline, it would be nice to somehow be actually tag the repo and see that this adds the correct documentation directory to the pytorch/pytorch.github.io repo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67026
Reviewed By: saketh-are
Differential Revision: D31843381
Pulled By: malfet
fbshipit-source-id: 21526ad9ed4c1751c2d7f6d621da305f166a7f55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65860
Re-enable peepholes like `x + 0 == x`. These were at one point enabled, and then disabled because they did not properly account for aliasing, and then re-enabled with reconstructing the alias db everytime which is slow - O(n^2). I've added correctness conditions, and I've also made it so that we avoid using stale aliasing properties for either the input or output of nodes we optimize.
Some of the other code that we have written to avoid re-instantiating the alias db involves internally mutating it, however this is tricky to reason about and we probably have to add some extra invariants...
cc navahgar relevant to graph opts and d1jang alias analysis relevant here
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D31352382
Pulled By: eellison
fbshipit-source-id: 441a27f17dc623d6c24538d1d43cba0412c3c482
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66974
`D31591785 (67e003f09b)` started carrying a function object to be executed and `FunctionKind` for the type of the function *separately*, and this caused a bug fixed by D31783028 (79803b199f).
This change bundles them as it was before done by swolchok to reduce the chances of such a mistake in the future. They need to be carried altogether always since `FunctionKind` identifies the type of the function object.
Note that `struct Function` is a POD type, so accessing its field (first, second) shouldn't cause an extra overhead in `ProcessedNode::run()`.
Test Plan:
Confirmed that the managed memory metics remain the same before/after this diff on inline_cvr:
```
#AFTER
# inline_cvr/local
Total number of managed tensors: 2660
Total number of managed output tensors: 0
Total number of unmanaged values: 3041
Total memory managed: 1496896 bytes
Total number of reused tensors: 1183
Total number of 'out' variant nodes/total number of nodes: 2452/2469 (99.3115%)
# inline_cvr/local_ro
Total number of managed tensors: 1412
Total number of managed output tensors: 0
Total number of unmanaged values: 2679
Total memory managed: 39040 bytes
Total number of reused tensors: 959
Total number of 'out' variant nodes/total number of nodes: 1928/1939 (99.4327%)
# inline_cvr/remote_ro
First iter time: 12.0344 ms
Total number of managed tensors: 1293
Total number of managed output tensors: 0
Total number of unmanaged values: 14
Total memory managed: 5293824 bytes
Total number of reused tensors: 771
Total number of 'out' variant nodes/total number of nodes: 1298/1298 (100%)
```
```
#BEFORE
# inline_cvr/local
Total number of managed tensors: 2660
Total number of managed output tensors: 0
Total number of unmanaged values: 3041
Total memory managed: 1496896 bytes
Total number of reused tensors: 1183
Total number of 'out' variant nodes/total number of nodes: 2452/2469 (99.3115%)
#inline_cvr/local_ro
Total number of managed tensors: 1412
Total number of managed output tensors: 0
Total number of unmanaged values: 2679
Total memory managed: 39040 bytes
Total number of reused tensors: 959
Total number of 'out' variant nodes/total number of nodes: 1928/1939 (99.4327%)
#inline_cvr_remote_ro
Total number of managed tensors: 1293
Total number of managed output tensors: 0
Total number of unmanaged values: 14
Total memory managed: 5293824 bytes
Total number of reused tensors: 771
Total number of 'out' variant nodes/total number of nodes: 1298/1298 (100%)
```
Reviewed By: mikeiovine
Differential Revision: D31798419
fbshipit-source-id: fd4301b6731e402be0820729654735c791511aba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66854
diff tool and script to test correctness of flatbuffer format
Test Plan:
`./verify_flatbuffer.sh | pastry`
P463163180
Reviewed By: zhxchen17
Differential Revision: D31752696
fbshipit-source-id: bea00102b21e62c02367853c8bec2742b483fbda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66955
The new convert function are not meant to be used by users, it's a temporary function that
we use to build up the new convert path, we will bring feature parity with the old path
and deprecate the old path after that
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D31810488
fbshipit-source-id: 2f65a110506683123350e619c48df090a15570fc
Summary:
CAFFE2 has been deprecated for a while, but still included in every PyTorch build.
We should stop building it by default, although CI should still validate that caffe2 code is buildable.
Build even fewer dependencies when compiling mobile builds without Caffe2
Introduce `TEST_CAFFE2` in torch.common.utils
Skip `TestQuantizedEmbeddingOps` and `TestJit.test_old_models_bc` is code is compiled without Caffe2
Should be landed after https://github.com/pytorch/builder/pull/864
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66658
Reviewed By: driazati, seemethere, janeyx99
Differential Revision: D31669156
Pulled By: malfet
fbshipit-source-id: 1cc45e2d402daf913a4685eb9f841cc3863e458d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67062
For cc and potential reviews
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D31849050
fbshipit-source-id: d3899c2ca857b8f22bdc88b4e83cdd20bbf0b1d6
Summary:
### BUG
If a PyTorch binary is built with a compiler that doesn't support all the AVX512 intrinsics in the codebase, then it won't have ATen AVX512 kernels, but at runtime, CPU capability would still be incorrectly returned as AVX512 on a machine that supports AVX512. It seems that PyTorch Linux releases are done on CentOS with `gcc 7.3`, so this bug would manifest in the 1.10 release, unless a fix such as this one is added. gcc versions below 9.0 don't support all the AVX512 intrinsics in the codebase, such as `_mm512_set_epi16`.
### FIX
CPU Capability would be returned as AVX512 at runtime only if the binary was built with a compiler that supports all the AVX512 intrinsics in the codebase, and if the hardware the binary is being run on supports all the required AVX512 instruction sets.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66703
Reviewed By: gchanan
Differential Revision: D31732625
Pulled By: malfet
fbshipit-source-id: e52d06b87fbe2af9b303a2e9c264189c8512d5ec
Summary:
Adds `torch.argwhere` as an alias to `torch.nonzero`
Currently, `torch.nonzero` is actually provides equivalent functionality to `np.argwhere`.
From NumPy docs,
> np.argwhere(a) is almost the same as np.transpose(np.nonzero(a)), but produces a result of the correct shape for a 0D array.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64257
Reviewed By: dagitses
Differential Revision: D31474901
Pulled By: saketh-are
fbshipit-source-id: 335327a4986fa327da74e1fb8624cc1e56959c70
Summary:
Fixes https://github.com/pytorch/pytorch/issues/61926
1. update the `if` to just use requires_derivative since that should reflect when function is not differentiable
2. if `requires_derivative=True` but no outputs have forward derivatives, we should error as usual
3. ~In the future we may also want to handle the case~ when `len(fw_derivatives) > 0 and len(fw_derivatives) < num_diff_outputs` we should add assert in codegen that this does not happen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66926
Reviewed By: anjali411
Differential Revision: D31810736
Pulled By: soulitzer
fbshipit-source-id: 11a14477cc7554f576cff2ed1711a448a8c6a66a
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: 183172ba8c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65353
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D31059779
fbshipit-source-id: 7bddff5139f8168750e22e1cc8c0d49931db542e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66991
Currently, c10d extensions uses Backend.NAME to store the creator
function. However, builtin ones use that same field to store the
name. This commit makes c10d extensions comply with builtin ones,
and uses a dedicated `_plugins` field to store creator functions.
Thanks bryanmr for pointing this out.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D31820307
Pulled By: mrshenli
fbshipit-source-id: 259769ebfc80c0c9fc44d25498c8d19a3a09d1bc
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45255
Mostly straightforward. Only downside in this PR is the lack of more scalable way to check for all newly-created nodes in `callPySymbolicFunction`. The other options were:
* Create a scope within the node's scope and loop through all nodes that correspond to the scope. The code would still need to loop through all nodes.
* Add extra state to the graph (no good reason to do so).
* Add extra state to the ONNX exporter, since python calls go back to `g.op(...)` (no good reason to do so, also not very pythonic).
cc BowenBao neginraoof
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45256
Reviewed By: malfet, houseroad
Differential Revision: D31744281
Pulled By: msaroufim
fbshipit-source-id: 1b63f6e7f02ed61b3a9b7ac3d0be0a3a203c8ff6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67021
When applying the equally split optimization, we still need to delete the list unpack node.
I did an accuracy test yesterday but didn't catch this issue because my diffs were not properly synced between devservers (I use hlu1's devbig for testing and it had an old version of "Add FuseListUnpackV2"). But I did another test this morning and realized that there was an issue.
This is not affecting anything in prod right now since D31742293 has not landed.
Reviewed By: hlu1
Differential Revision: D31827278
fbshipit-source-id: c7b05e3d8ec942632adcff4bdfebb8c27c1a7a39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66952
Added splitter to lower parts of the transformer model
Program now supports arg input
Test Plan:
Performance on non-lowered model:
0.19662559509277344
Performance on semi-lowered model:
0.19131642150878905
Reviewed By: 842974287
Differential Revision: D31541325
fbshipit-source-id: 194aba97afc794dbeada4bbc4777d0a7b02e3635
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66889
Added support for negative dims and modified unit test.
Test Plan: buck test mode/dev-nosan caffe2/test/fx2trt/converters:test_unsqueeze
Reviewed By: 842974287
Differential Revision: D31769393
fbshipit-source-id: 854335ead2ffad5f466ad66b9be36ba20a0fea67
Summary:
This completes the removal of conv_utils and redistributes its dependencies
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66605
ghstack-source-id: 140565820
Test Plan: ci tests
Reviewed By: kimishpatel
Differential Revision: D31637731
fbshipit-source-id: 48d3a423e4ff0eb6ab21bb13bda44da16996423b
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62533.
In very rare cases, the decorator for detecting memory leak is throwing assertion, even when the test is passing, and the memory is being freed with a tiny delay. The issue is not being reproduced in internal testing, but shows up sometimes in CI environment.
Reducing the severity of such detection to warning, so as not to fail the CI tests, as the actual test is not failing, rather only the check inside the decorator is failing.
Limiting the change to ROCM only for now.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65973
Reviewed By: anjali411
Differential Revision: D31776154
Pulled By: malfet
fbshipit-source-id: 432199fca17669648463c4177c62adb553cacefd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63997
Use torch_function to extend torch.nn.init.uniform_
The Init is done in SPMD fashion. Note that ideally we want to aggregate sharded tensors into a global tensor, init it and reshard. It's fine to run it SPMD since uniform is I.I.D indepenent and identifically distributed.
Also enable unit test for test_linear.py for OSS test
Test Plan:
a) Unit Test
(pytorch) ... $ python test/distributed/_sharded_tensor/ops/test_init.py TestShardedTensorNNInit --v
(pytorch) ... $ python test/distributed/_sharded_tensor/ops/test_linear.py --v (before runs this command is no-op)
or b) Manual run: Instruction here: https://docs.google.com/document/d/1_m1Hdo5w51-hhPlZ_F8Y6PIWrN7UgJZqiSpARYvhsaE/edit#
Imported from OSS
Reviewed By: pritamdamania87, anjali411
Differential Revision: D30563017
fbshipit-source-id: d1859f7682235bcb44515efc69ca92bc5e34fce1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66990
NNC fusion groups currently show up as "TensorExpr" in the profiler,
which is true but not super useful since it obscures what's actually happening
in the fusion group. This change will log them as `fused_XXX` where XXX is a
(length-limited) series of ops describing the subgraph, for instance
`fused_mul_add` to represent a group containing `aten::mul`, `aten::add`.
Test Plan: New unit test to check the output of autograd profiler.
Reviewed By: dzhulgakov
Differential Revision: D31762087
fbshipit-source-id: 3fadbdc67b054faa01aa42e5b6ea2c4a6bc3481f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66950
Just to show that it works for weighted operations as well, qat/fused op not supported yet
We can start developing the backend_config_dict and work towards making the support more complete afterwards
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31801782
fbshipit-source-id: 8491bab7939a7a1c23ffa87c351844b82e390027
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66925
Current convert_fx implementation is using "The Interpreter Pattern" in https://pytorch.org/docs/stable/fx.html
There are two things that's changed which make the approach in this PR possible and needed:
1). original convert implementation is developed at the initial prototype where fx does not allow mutations, now fx
supports mutations
2). original convert needs to work for a lot of fbgemm/qnnpack specific logic, which is not needed for reference patterns
Therefore it makes sense for us to write a new convert function just for reference patterns, the implementation
is significantly easier to understand than the original convert implementation
Current support:
* we should be able to support all non-weighted ops like relu, add etc.
Missing:
* linear and conv
* some advanced features like standalone modules, input_quantized_idxs etc.
will add linear and conv support and start defining the backend_config_dict based on this version of convert
Test Plan:
python test/test_quantization.py TestQuantizeFxOpsNew
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31786241
fbshipit-source-id: 2a32156eb6d3c5271cb44906cd863055785fb5d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66509
Like `FuseListUnpack`, but instead of adding arguments to the fused node's outputs, inserts a new fused op.
By using a new fused op, we can avoid runtime `is_fused` checks. This will make the op implementations significantly cleaner. Eventually, we will migrate all ops to `V2` and delete to old pass.
`FuseListUnpackV2` also fixes the bug described in T103159043.
Test Plan: I've made some changes to D31550307 locally and verified that everything works.
Reviewed By: hlu1
Differential Revision: D31492017
fbshipit-source-id: 4f90fcbc17e4c70a3d65985bee836fabf868a22c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66098
`cat` is somewhat special-cased right now because currently we only have list of Tensor inputs where the list is constructed in the JIT IR graph. While that is generally true for Fusion (e.g. why we have ConstantChunk) that may not be true for shape analysis generally, so I'm waiting a bit to generalize.
Test Plan: Imported from OSS
Reviewed By: navahgar, anjali411
Differential Revision: D31797467
Pulled By: eellison
fbshipit-source-id: ca761e214dfd7f3bba8d189f3b3f42ffec064f63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66097
Adding logic to generate runtime shapes for nodes with multi-outputs. It is generalizing existing flow of looking at a node, getting its shape graph, inlining it, and adding a mapping from the output to the new value in the stitched shape compute graph to loop over multiple outputs.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31797468
Pulled By: eellison
fbshipit-source-id: 2c182b71a46b36d33f23ad35b89790a4a5d4471c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65575
This is needed for lowering an NNC model to mobile. It is also the last class of unhandled ops which NNC fuses, and we need integration this for computing output symbolic shapes.
The graph of with two dynamic shape inputs produces:
```
graph(%x.1 : Tensor(SS(-2), 2, 3),
%y.1 : Tensor(SS(-3), 2, 3)):
%5 : int = prim::Constant[value=0]()
%4 : Tensor[] = prim::ListConstruct(%x.1, %y.1)
%6 : Tensor(SS(-4), 2, 3) = aten::cat(%4, %5) # /private/home/eellison/pytorch/test/jit/test_symbolic_shape_analysis.py:290:19
return (%6)
```
With a partial eval graph of
```
Done with partial evaluation
graph(%129 : int[],
%130 : int[],
%dim.14 : int):
%738 : int = prim::Constant[value=3]()
%737 : int = prim::Constant[value=2]()
%132 : int = prim::Constant[value=0]()
%392 : int = aten::__getitem__(%129, %132) # <string>:339:44
%417 : int = aten::__getitem__(%130, %132) # <string>:339:44
%cat_dim_size.48 : int = aten::add(%392, %417) # <string>:339:29
%result_size.5 : int[] = prim::ListConstruct(%cat_dim_size.48, %737, %738)
return (%result_size.5)
```
To handle cat, I essentially make the cat shape op variadic,
replacing
```
torch.cat([x, y]
...
def cat_shape_op(tensors: List[List[int]], dim: int):
...
op(tensors)
```
with
```
def cat_shape_op(x: List[int], y: List[int], dim: int):
tensors = [x, y]
op(tensors)
```
This reuses the existing input Tensor properties partial evaluation path and avoids having to add special handling to optimize out `len(tensors)` calls in the IR.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31797471
Pulled By: eellison
fbshipit-source-id: 62c794533d5fabfd3fad056d7e5fe3e8781b22c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65573
When we remove mutation on
```
x = [0, 1, 3, 4]
x[-2] = 4
```
we have a safety check that the new index will be in bounds of the old index. in practice, this should always be the case otherwise you would have a runtime error. Within that check (not within the actual adjustment) we were using the wrong length of inputs preventing the optimization from firing.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31797469
Pulled By: eellison
fbshipit-source-id: 02a1686b9f6016eb5aeb87ed342c043c203dcd0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65148
No functional changes, factoring out optimizations and renaming the `graph` in symbolic shape analysis to `shape_compute_graph` as ZolotukhinM suggested
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31797447
Pulled By: eellison
fbshipit-source-id: 60d322da040245dd7b47ee7c8996239572fd11c2
Summary:
**Summary:** Move the error reporting part to the cpp file to avoid callers inlining it, which inflates the generated code size. See https://github.com/pytorch/pytorch/issues/65830.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66721
Test Plan:
Compiling the simple program below now generates ~150 lines of assembly, compared to 700+ lines before.
```
#include <c10/core/Scalar.h>
void g(float) {}
void f(const c10::Scalar& scalar) {
auto x = scalar.to<float>();
g(x);
}
```
**Reviewers:** Brian Hirsh
**Subscribers:** Brian Hirsh, Edward Yang, Yining Lu
**Tasks:** T103384490
**Tags:** pytorch
Fixes https://github.com/pytorch/pytorch/issues/65830
Reviewed By: zou3519, bdhirsh
Differential Revision: D31737607
Pulled By: andrewor14
fbshipit-source-id: 3d493c4d8e51d8f8a19d00f59b8ea28176c8a9e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66940
`aten::index`'s schema is as follows:
```
"aten::index.Tensor(Tensor self, Tensor?[] indices) -> Tensor
```
The current implementation assumes `indices`' elements are all tensors by doing `elem.toTensor`, which is incorrectly. This change creates an empty optional value if an element from `indices` is not a tensor.
Test Plan: Fixed `StaticRuntime, IndividualOps_Index` to correctly test `aten::index` with `indices` that contains `None`.
Reviewed By: hlu1
Differential Revision: D31712145
fbshipit-source-id: be1c29674bcd55b67b0dcc2a988bc37fd43745f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66604
This diff/PR is trying to implement the ShardedEmbedding and ShardedEmbedding using the ShardedTensor.
Several caveats:
1. We support limited input params for the op. To support more params are on the way.
2. We only support chuck sharding for now.
3. We only support a single local shard per rank for now.
ghstack-source-id: 141056130
Test Plan: Unit test and CI
Reviewed By: pritamdamania87
Differential Revision: D31544556
fbshipit-source-id: cc867dcba8c11e6f4c7c3722488908f5108cc67f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63510
Sparse CSR matrix resizing behavior:
If we _increase the number of rows_ the number of specified elements in the matrix remains the same -> the size of col_indices, values doesn't change, the size of crow_indices becomes `rows+1`.
If we _decrease the number of rows_ the number of specified elements will be `min(nnz, rows*cols)` -> need to resize `crow_indices` to `rows+1` and set the last element to `min(nnz, rows*cols)`; decrease the size of col_indices and values to `min(nnz, rows*cols)`.
If we _increase the number of columns_ the number of specified elements in the matrix remains the same, the number of rows remains the same -> no need to resize anything, just set new sizes.
We _cannot decrease the number of columns_ because it would require recomputing `crow_indices`.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D31796680
Pulled By: cpuhrsch
fbshipit-source-id: 7d8a9701ce06d30a1841f94bba0a057cacea9401
Summary:
Fixes https://github.com/pytorch/pytorch/issues/65154, tests for backwards compatibility of torch.package by checking if packages that were created before can still be loaded.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66739
Reviewed By: suo
Differential Revision: D31771526
Pulled By: PaliC
fbshipit-source-id: ba8c652c647b94114a058e4c7d7f1c7ce6033d84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66554
In native_functions.yaml, the schemas for batch_norm and instance_norm
are incorrect: the inputs `running_mean` and `running_var` are mutated,
but are not marked as such in the function schema. Since `(a!)?`
annotations are currently not working (see #65760), this instead adds a
special case to `alias_anaysis.cpp`. If the value of `training` or
`use_input_stats` is known to be `false`, then `alias_analysis` will
mark the input as _not_ being written to.
Test Plan:
Removed the `skip` annotation on the following test, and added a special
exception in `check_alias_annotations`:
```
python test/test_ops.py -k test_variant_consistency_jit_nn_functional_batch_norm
```
Also:
```
./build/bin/test_jit --gtest_filter="*BatchAndInstanceNormFixture*"
```
Imported from OSS
Reviewed By: eellison
Differential Revision: D31612339
fbshipit-source-id: 12ca61b782b9e41e06883ba080a276209dc435bb
Summary:
On the HUD, the test tools job is failing as the runners now install Python 3.10, which is not compatible with numpy 1.20
See https://github.com/pytorch/pytorch/runs/3952169950?check_suite_focus=true Install dependencies step:
```
ERROR: Command errored out with exit status 1:
command: /opt/hostedtoolcache/Python/3.10.0/x64/bin/python /opt/hostedtoolcache/Python/3.10.0/x64/lib/python3.10/site-packages/pip/_vendor/pep517/in_process/_in_process.py build_wheel /tmp/tmptq8aay7m
cwd: /tmp/pip-install-dk_6t98q/numpy_e9431bf106b746148c0e7c36e46551b4
Complete output (1169 lines):
setup.py:66: RuntimeWarning: NumPy 1.20.0 may not yet support Python 3.10.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66947
Reviewed By: suo, malfet
Differential Revision: D31799205
Pulled By: janeyx99
fbshipit-source-id: 64bf10c37c0aa4f5837c48e92d56e81d920722bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66917
The total number of 'out' variant nodes/total number of nodes is now 100% for all the models, which isn't true obviously.
Reviewed By: swolchok, mikeiovine
Differential Revision: D31783028
fbshipit-source-id: e0bc2c6614aa3c3a235283c9125de1b339f42585
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66603
Found the issue here: https://github.com/pytorch/pytorch/issues/66281 by make the test cases more complicated.
By closely reading the code again, it turns out my original understanding is also wrong. Let's use the example mentioned in the issue to explain:
If the placement is like:
```
"rank:3/cuda:3",
"rank:0/cuda:0",
"rank:1/cuda:1",
"rank:2/cuda:2",
```
First, we split the column or row by the order of [3, 0, 1, 2].
In the case of column-wise sharding:
We get to reaggrage the result from rank0-4.
Step 1: we split the output based on the original sharding strategy, aka, rank3 gets the 1st shard, rank0 get the 2nd shard, etc.
Step 2: we need to rearrange the result from rank0-4 by ordering them following the order of [3, 0, 1, 2], aka, the result from rank3 needs to be put in the front, and so forth.
In the case of row-wise sharding:
We need to rearrange the input being sent to rank0-4.
Step 1: we reorder the input and follow the map of [3, 0, 1, 2]. For example, the first shard goes to rank 3 so we need to put in the 3rd part, the second shard goes to rank 0, so we put it in the 2nd part, and so on.
Step 2: the size of the sharding for each rank is decided by the original placement: [3, 0, 1, 2], aka, rank 3 gets the first shard and its size, etc.
Update the unit test to reflect this change.
Also, correct some format and comments in the sharded linear.
ghstack-source-id: 141055689
Test Plan: unit test and wait for CI.
Reviewed By: pritamdamania87, bowangbj
Differential Revision: D31634590
fbshipit-source-id: 677a9c2b42da1e2c63220523ed2c004565bbecc7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66098
`cat` is somewhat special-cased right now because currently we only have list of Tensor inputs where the list is constructed in the JIT IR graph. While that is generally true for Fusion (e.g. why we have ConstantChunk) that may not be true for shape analysis generally, so I'm waiting a bit to generalize.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31732415
Pulled By: eellison
fbshipit-source-id: 7f513cea355f1e4c1d2ca7c32c06690a9bdcb050
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66097
Adding logic to generate runtime shapes for nodes with multi-outputs. It is generalizing existing flow of looking at a node, getting its shape graph, inlining it, and adding a mapping from the output to the new value in the stitched shape compute graph to loop over multiple outputs.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31732418
Pulled By: eellison
fbshipit-source-id: 767698d031b1daf002678a025b270e0ede429061
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65575
This is needed for lowering an NNC model to mobile. It is also the last class of unhandled ops which NNC fuses, and we need integration this for computing output symbolic shapes.
The graph of with two dynamic shape inputs produces:
```
graph(%x.1 : Tensor(SS(-2), 2, 3),
%y.1 : Tensor(SS(-3), 2, 3)):
%5 : int = prim::Constant[value=0]()
%4 : Tensor[] = prim::ListConstruct(%x.1, %y.1)
%6 : Tensor(SS(-4), 2, 3) = aten::cat(%4, %5) # /private/home/eellison/pytorch/test/jit/test_symbolic_shape_analysis.py:290:19
return (%6)
```
With a partial eval graph of
```
Done with partial evaluation
graph(%129 : int[],
%130 : int[],
%dim.14 : int):
%738 : int = prim::Constant[value=3]()
%737 : int = prim::Constant[value=2]()
%132 : int = prim::Constant[value=0]()
%392 : int = aten::__getitem__(%129, %132) # <string>:339:44
%417 : int = aten::__getitem__(%130, %132) # <string>:339:44
%cat_dim_size.48 : int = aten::add(%392, %417) # <string>:339:29
%result_size.5 : int[] = prim::ListConstruct(%cat_dim_size.48, %737, %738)
return (%result_size.5)
```
To handle cat, I essentially make the cat shape op variadic,
replacing
```
torch.cat([x, y]
...
def cat_shape_op(tensors: List[List[int]], dim: int):
...
op(tensors)
```
with
```
def cat_shape_op(x: List[int], y: List[int], dim: int):
tensors = [x, y]
op(tensors)
```
This reuses the existing input Tensor properties partial evaluation path and avoids having to add special handling to optimize out `len(tensors)` calls in the IR.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31732416
Pulled By: eellison
fbshipit-source-id: 6d93ddf62c34846ec238159f75229632515530b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65573
When we remove mutation on
```
x = [0, 1, 3, 4]
x[-2] = 4
```
we have a safety check that the new index will be in bounds of the old index. in practice, this should always be the case otherwise you would have a runtime error. Within that check (not within the actual adjustment) we were using the wrong length of inputs preventing the optimization from firing.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31732417
Pulled By: eellison
fbshipit-source-id: dd734254c0212ca459c1c135da262974de5299be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65148
No functional changes, factoring out optimizations and renaming the `graph` in symbolic shape analysis to `shape_compute_graph` as ZolotukhinM suggested
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31732421
Pulled By: eellison
fbshipit-source-id: e934507d1795e0bc4d98a3bfe6cb792e2f08b119
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63509
The primary use of `torch.empty` is to reserve memory for tensor and set the type, device, size information. The same is done here for SparseCSR.
`crow_indices` is initialized as an empty tensor of size `num_rows + 1`. `col_indices` and `values` are initialized as empty tensors of size 0.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D31770359
Pulled By: cpuhrsch
fbshipit-source-id: c83f2a2e0d7514ba24780add1086e1bccf541dd9
Summary:
This changes the link for installing binaries to the page on pytorch.org that is entirely the download command selector (which isn't visible on a normal aspect ratio screen when the main website page first loads anymore).
This also includes some other random fixes:
* Update HUD link
* Clean ups
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66828
Reviewed By: malfet
Differential Revision: D31750654
Pulled By: driazati
fbshipit-source-id: aef9ceba71418f6f7648eab9a8c8a78d6c60518b
Summary:
`linux-xenial-py3-clang5-mobile-build`, `linux-xenial-py3-clang5-mobile-custom-build-dynamic`, `linux-xenial-py3-clang5-mobile-custom-build-dynamic` and `linux-xenial-py3-clang5-mobile-code-analysis` are just the flavors of regular linux build job with no tests.
`linux-xenial-py3-clang5-mobile-code-analysis` is the master only job
`code-analysis` job is dispatch to `.jenkins/pytorch/build-mobile-code-analysis.sh` in
583217fe37/.jenkins/pytorch/build.sh (L23-L25)
and all `mobile-build` jobs are dispatched to `.jenkins/pytorch/build-mobile.sh` in
583217fe37/.jenkins/pytorch/build.sh (L19-L21)
Rename `is_libtorch` `CIWorkflow` property into `build_generates_artifacts` and change defaults from False to True
Both libtorch and mobile build jobs do not generate build artifacts
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66673
Reviewed By: janeyx99
Differential Revision: D31674434
Pulled By: malfet
fbshipit-source-id: 24d05d55366202cd4d9c25ecab429cb8f670ded0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66877
Fixes (hopefully):
```
program_source:516:27: error: use of undeclared identifier 'c10'
for (const auto idx : c10::irange(4)) {
^
program_source:590:27: error: use of undeclared identifier 'c10'
for (const auto idx : c10::irange(4)) {
^
program_source:810:26: error: use of undeclared identifier 'c10'
for (const auto iy : c10::irange(roi_bin_grid_h)) {
^
program_source:811:30: error: use of undeclared identifier 'c10'
for (const auto ix : c10::irange(roi_bin_grid_w)) {
^
DeviceName: AMD Radeon Pro 5500M, LanguageVersion: 131075
Exception raised from -[MetalContext available] at xplat/caffe2/aten/src/ATen/native/metal/MetalContext.mm:66 (most recent call first):
(no backtrace available)
```
Test Plan: Sandcastle
Reviewed By: benb, xta0
Differential Revision: D31763270
fbshipit-source-id: cfe4364b14c5fe6dbd39893788919769c9a9eb00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66717
No need to require a refcount bump for this function.
ghstack-source-id: 140921170
Test Plan: CI
Reviewed By: suo
Differential Revision: D31696898
fbshipit-source-id: a3732a04ccbddc32207ce90836030f3020154a77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66352
Add cmake rules for interactive_embedded_interpreter.cpp .
The builtin_registry.cpp has already been handled in https://github.com/pytorch/pytorch/pull/66347 . I'll remove the change in this PR once that one is merged.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D31521249
Pulled By: shunting314
fbshipit-source-id: bb9d340e5a6aad7d76078ca03a82b5ae7494a124
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66485
The errors for incorrectly sized inputs should match the dense variants
of functions.
Moved addmm_out_sparse_csr_dense_cuda from SparseCsrTensorMath.cu and
removed unnecessary device check.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D31764036
Pulled By: cpuhrsch
fbshipit-source-id: 76900fe9e4a49474695a01f34bad41cb3422321c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66697
We own this vector, so we can move from it.
ghstack-source-id: 140742640
Test Plan: CI
Reviewed By: suo
Differential Revision: D31693230
fbshipit-source-id: 3f33ca6e47e29b0e3d6c8fad59c234c55e1e159f
Summary:
- [x] Fix the Pyre type checking errors in `torch/ao/quantization/quantize_fx.py`
```
torch/quantization/quantize_fx.py:41:8 Incompatible variable type [9]: fuse_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:143:16 Incompatible variable type [9]: prepare_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:144:16 Incompatible variable type [9]: equalization_qconfig_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:206:8 Incompatible variable type [9]: prepare_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:230:12 Incompatible variable type [9]: fuse_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:268:8 Incompatible variable type [9]: prepare_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:269:8 Incompatible variable type [9]: equalization_qconfig_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:427:8 Incompatible variable type [9]: prepare_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:464:8 Incompatible variable type [9]: convert_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:486:8 Incompatible variable type [9]: convert_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/quantize_fx.py:547:8 Incompatible variable type [9]: convert_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
```
Fixes the issue: [MLH-Fellowship/pyre-check/issues/76](https://github.com/MLH-Fellowship/pyre-check/issues/76)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66804
Reviewed By: onionymous
Differential Revision: D31738171
Pulled By: 0xedward
fbshipit-source-id: 00d4c5749c469aff39a1531365461ced747e52fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66733
Fix the test for BatchMatMul to compare glow/caffe2 outputs and fix its shape inference function since it made simplifying assumptions for broadcasting and failed on some of the shapes in the test. The previous inference was failing for any cases where the first n - 2 output dimensions of A x B was not simply that of whichever one of A or B had higher rank (ex. A: [2, 2, 2, 3, 4], B: [3, 1, 2, 2, 4, 5] we expect output dimensions [3, 2, 2, 2, 3, 5] rather than [3, 1, 2, 2, 3, 5].
Test Plan:
```
buck test glow/fb/test/numerics:test_operator_onnxifinnpi -- -r .*test_batch_matmul_manydims.* --env USE_INF_API=1
```
Reviewed By: khabinov
Differential Revision: D31701184
fbshipit-source-id: 31d0fb17409a399b90fb8042385e000ed81c3581
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66741
Modified loops in files under fbsource/fbcode/caffe2/ from the format
`for(TYPE var=x0;var<x_max;x++)`
to the format
`for(const auto var: irange(xmax))`
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D31705360
fbshipit-source-id: 7115f76e381ad2d98584eb534961c3cbb957ebaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66757
`InterpreterStateImpl::run()` gets the number of outputs from the current frame, but by the time the continuation completes, the frame is gone, so we're calling `front()` on an empty vector. This works out in practice (data is still there) but it is technically undefined behavior and could break in the future.
Also, `std::polar()` expects its argument to be non-negative, but `c10::polar()` does not, so implement it explicitly (implementation is the same as libstdc++).
Test Plan: JIT tests pass.
Reviewed By: zhxchen17
Differential Revision: D31715587
fbshipit-source-id: 98abcc10c2742887af866d8e70169a0187c41d33
Summary:
This would save the cost copying text from stack to heap in some cases (like
parsing function schema during loading phase of libtorch.so)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65309
Reviewed By: swolchok
Differential Revision: D31060315
Pulled By: gmagogsfm
fbshipit-source-id: 0caf7a688b40df52bb4388c5191d1a42351d6f1a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66680
Closes https://github.com/pytorch/pytorch/issues/66215. Tracks models
with sync BN so we can find workflows that use them and target for perf
optimization.
ghstack-source-id: 140875182
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D31679477
fbshipit-source-id: 0e68cd1a7aabbc5b26227895c53d33b8e98bfb8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66744
Modified loops in files under fbsource/fbcode/caffe2/ from the format
`for(TYPE var=x0;var<x_max;x++)`
to the format
`for(const auto var: irange(xmax))`
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D31705358
fbshipit-source-id: d6ea350cbaa8f452fc78f238160e5374be637a48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66747
Modified loops in files under fbsource/fbcode/caffe2/ from the format
`for(TYPE var=x0;var<x_max;x++)`
to the format
`for(const auto var: irange(xmax))`
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D31705365
fbshipit-source-id: 5c3af2184766b063eed2f4e8feb69f1fedd3503e
Summary:
Skip failing tests when LAPACK and MAGMA are not available for ` test_linalg.py` and ` test_ops.py`.
Note that there's no CI without LAPACK or MAGMA. I verified locally that now it works as expected, but in the future we have no guards against tests failing again for this situation.
<details>
<summary> test_ops.py failures that are fixed</summary>
```
FAILED test/test_ops.py::TestCommonCPU::test_out_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
<details>
<summary> test_linalg.py failures that are fixed</summary>
```
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_dtype_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_nuclear_norm_axes_small_brute_force_old_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_complex128 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_float64 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_lowrank_cuda_float64 - RuntimeError: Calling torch.lu on a CUDA tensor requires compiling PyTorch with MAGMA. lease rebuild with MAGMA.
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
Fixes https://github.com/pytorch/pytorch/issues/59662
cc mruberry jianyuh nikitaved pearu walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64930
Reviewed By: zou3519
Differential Revision: D31739416
Pulled By: mruberry
fbshipit-source-id: 153c40d8eeeb094b06816882a7cbb28c681509a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66698
this type should fit in a register; no need to pass by reference.
ghstack-source-id: 140742830
Test Plan: CI
Reviewed By: suo
Differential Revision: D31693291
fbshipit-source-id: 299fb3d1830a059b59268487c22e030446c3496e
Summary:
- Adds Node base class and unit tests
- Also adds metadata utils to enable source code annotation and scope tracking
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66601
Test Plan: Add new unit tests
Reviewed By: desertfire
Differential Revision: D31634044
fbshipit-source-id: a042d54f06fbc480acfc63c18d43cb6fceb6fea5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66691
Does what it says on the tin.
ghstack-source-id: 140736047
Test Plan: CI
Reviewed By: suo
Differential Revision: D31691627
fbshipit-source-id: 21a5d0248bf3412f5af36260597a5f663ab34361
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66701
We own the argument vector.
ghstack-source-id: 140760983
Test Plan: CI
Reviewed By: suo
Differential Revision: D31693645
fbshipit-source-id: 02829bc3c728f6d1d07be08b0d977eee1efee38f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66699
std::string::operator+ will copy the string an extra time even if the argument is `""`. See https://godbolt.org/z/3sM5h1qTo
ghstack-source-id: 140743822
Test Plan: CI
Reviewed By: suo
Differential Revision: D31693522
fbshipit-source-id: 6a8033c90366904b9aff44214b600cfb255a0809
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66693
Passing a `TypePtr` by value causes an unnececssary refcount
bump. We don't need to take ownership, so `const Type&` is all we
need.
I considered providing a compatibility shim that takes `const
TypePtr&`, but doing so is dangerous because a
copy is required to convert from a more specific pointer like
`NoneTypePtr`.
ghstack-source-id: 140737081
Test Plan: CI
Reviewed By: suo
Differential Revision: D31691869
fbshipit-source-id: f766ce3234a28771c2a9ca4c284eb3f96993a3d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66798
get_cycles_per_ms is copied and used in a few places, move it to common_utils so that it can be used as a shared util function
ghstack-source-id: 140790599
Test Plan: unit tests
Reviewed By: pritamdamania87
Differential Revision: D31706870
fbshipit-source-id: e8dccecb13862646a19aaadd7bad7c8f414fd4ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66815
Was seeing 403's when attempting to wget from github, re-hosting the
binary on s3 so we shouldn't see those issues anymore
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D31740656
Pulled By: seemethere
fbshipit-source-id: 4462678d51a52b63020f8da18d7cdc80fb8dbc5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65723
Example lowering reference linear module to fbgemm/qnnpack quantized linear module
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31567461
fbshipit-source-id: 0b8fffaf8e742ec15cb07bf6a4672cf3e856db2d
Summary:
The documentation of torch.nn.Upsample stated that `align_corners` only affects `linear`, `bilinear` and `trilinear`.
This PR updates the documentation for the Python `Upsample` module and the C++ `UpsampleOptions` struct to reflect that `bicubic` is also affected by `align_corners`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66756
Reviewed By: zou3519
Differential Revision: D31731148
Pulled By: jbschlosser
fbshipit-source-id: 3ec277fc3fbdf8414d0de327d8c57ba07342a5b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64181
This PR replaces all the calls to:
- `transpose(-2, -1)` or `transpose(-1, -2)` by `mT()` in C++ and `mT` in Python
- `conj().transpose(-2, -1)` or `transpose(-2, -1).conj()` or `conj().transpose(-1, -2)` or `transpose(-1, -2).conj()` by `mH()` in C++ and `mH` in Python.
It also simplifies two pieces of code, and fixes one bug where a pair
of parentheses were missing in the function `make_symmetric_matrices`.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D31692896
Pulled By: anjali411
fbshipit-source-id: e9112c42343663d442dc5bd53ff2b492094b434a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65618
This saves 8 bytes per KernelFunction, which should help in resource-constrained environments.
ghstack-source-id: 140731069
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25405736
fbshipit-source-id: 757c0f1387da9147e46ac69af2aa9fffd2998e35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66716
No need to require a refcount bump for this function.
ghstack-source-id: 140754065
Test Plan: CI
Reviewed By: suo
Differential Revision: D31696639
fbshipit-source-id: bf8aa3f542d52e82e0f6a444b8898330f3d16a31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66728
Two extra refcount bumps.
ghstack-source-id: 140760872
Test Plan: CI
Reviewed By: suo
Differential Revision: D31698577
fbshipit-source-id: 1f50195a99f98f857abc9b03b4254519c316fefe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66765
This guts `THCState` to simply be an empty struct, as well as:
- moving `THCState_getPeerToPeerAccess` and its cache into `ATen`.
- cleaning up dead code in `THCGeneral.cpp`
- moving `THCudaInit` and `THCMagma_init` into `CUDAHooks::initCUDA`
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D31721648
Pulled By: ngimel
fbshipit-source-id: 772b24787656a95f9e3fcb287d912b1c3400f32d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66722
Missing move, s/cast/castRaw/, and take TypePtr arg by const ref because we only sometimes need to take ownership.
ghstack-source-id: 140757141
Test Plan: CI
Reviewed By: suo
Differential Revision: D31697631
fbshipit-source-id: 04afe13688c6e2aaf79157400c0a44021cb8179d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66706
Missing moves in the construction path.
ghstack-source-id: 140746585
Test Plan: CI
Reviewed By: suo
Differential Revision: D31694356
fbshipit-source-id: 8e2bf2dd41f3f65fc06e30ffd5fddd487d01aaa8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66714
Forced copy in getValueType and unnecessary use of cast over castRaw.
ghstack-source-id: 140752791
Test Plan: CI
Reviewed By: suo
Differential Revision: D31696164
fbshipit-source-id: fc2316617a61ca32f1fb952fb0af18b8784a606b
Summary:
Apex O2 hook state_dict to return fp16 weights as fp32. Exporter cannot identify them as same tensors.
Since this hook is only used by optimizer, it is safe to remove this hook while exporting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66700
Reviewed By: zou3519
Differential Revision: D31695132
Pulled By: malfet
fbshipit-source-id: 977bdf57240002498f3ad0f1a8046c352e9860e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66719
Some cast that could be castRaw. Parameters did not need to force a refcount bump.
ghstack-source-id: 140756356
Test Plan: CI
Reviewed By: suo
Differential Revision: D31697455
fbshipit-source-id: 87a8cba221a7ae53f2a485acafd31622e9328ff0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66718
Some missing moves and use of cast instead of castRaw (due to a previous automated fixup only being a partial fix).
ghstack-source-id: 140755229
Test Plan: CI
Reviewed By: suo
Differential Revision: D31697115
fbshipit-source-id: 86743f8982951a58638ba244b3a92d3737dde58b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66647
Missed in the last round ,
This adds reference patterns for general shape ops like view when is_reference is True
bc-breaking:
basically disabled getitem from supporting quantized ops here, we may support it later in fbgemm
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
python test/test_quantization.py TestQuantizeFxModels
Imported from OSS
Reviewed By: H-Huang
Differential Revision: D31680379
fbshipit-source-id: 6a3a7128514baf6d92b1607308c40339469d0066
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66702
Missing moves in the construction path and forced copies of the key & value type on access.
ghstack-source-id: 140744707
Test Plan: CI
Reviewed By: suo
Differential Revision: D31693818
fbshipit-source-id: 4c5d2359f58148744621abe81429e56e7889f754
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66704
Missing moves in the construction path.
ghstack-source-id: 140746391
Test Plan: CI
Reviewed By: suo
Differential Revision: D31694296
fbshipit-source-id: 3bed477c811069248611efdb57ad27c6ca233442
Summary:
This PR fixes a typo in the `torch/autograd/function.py` doc
-----------------------
Additionally, the example at https://pytorch.org/docs/master/autograd.html#torch.autograd.Function doesn't quite compile:
```
'builtin_function_or_method' object has no attribute 'exp'
```
even though `i.exp()` is a valid function if `i` is a tensor.
I changed it to:
```
result = torch.exp(i)
```
but python doesn't like it either:
```
TypeError: exp(): argument 'input' (position 1) must be Tensor, not builtin_function_or_method
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66754
Reviewed By: albanD
Differential Revision: D31729400
Pulled By: soulitzer
fbshipit-source-id: eef783bcdc8d4693a8b7f1ab581e948abc0f9b94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65855
This adjusted our test base to support non-nccl backend like gloo/mpi, so that we could test sharding on CPU with gloo/mpi backend.
ghstack-source-id: 140840866
Test Plan: wait for the CI for existing tests, also adding tests in the stacked diff above.
Reviewed By: pritamdamania87, bowangbj
Differential Revision: D31287162
fbshipit-source-id: d48dfc8ef886a4d34b1de42f3ce6b600b5c9a617
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66484https://github.com/pytorch/pytorch/pull/50748 added linear - bn1d fusion
in Eager mode, for PTQ only. This PR also enables this in FX graph mode.
We reuse the existing conv-bn-relu fusion handler, renaming `conv` to
`conv_or_linear` for readability.
The QAT version is saved for a future PR, for both eager and FX graph.
Test Plan:
```
python test/test_quantization.py TestFuseFx.test_fuse_linear_bn_eval
```
Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D31575392
fbshipit-source-id: f69d80ef37c98cbc070099170e335e250bcdf913
Summary:
There were 2 versions of the same code which were slightly different although functionally equivalent.
When adding support for another CUDA / device version both would need to be changed and kept in sync. So it is better to have only 1 version of it as the unique source of truth.
I chose the implementation which looks cleaner and easier to read and added some minor enhancements and comments to further increase readability.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55901
Reviewed By: H-Huang
Differential Revision: D31636917
Pulled By: bertmaher
fbshipit-source-id: 622e1fabc39de4f3f1b1aa9a1544cfbd35a5cfd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66715
Adding StreamWrapper to streams produced by DataPipes within PyTorch Core and TorchData
Test Plan: OSS CI and Internal Tests
Reviewed By: ejguan
Differential Revision: D31695248
fbshipit-source-id: c26fa1bc1688d5597851ad265f667fafdcd64c59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66540
Currently the macro `HAS_DEMANGLE` is determined by compiler predefined macros. Here I'm adding an option to allow `HAS_DEMANGLE` to be defined in build files.
Test Plan: Rely on CI
Reviewed By: poweic
Differential Revision: D31600007
fbshipit-source-id: 76cf088b0f5ee940e977d3b213f1446ea64be036
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66297
Link register_numpy.cpp with the embedded interpreter will register numpy as a builtin library.
Test Plan: Add unit test to test basic numpy functionality in torch::deploy like creating random matrices, matric multiplication.
Reviewed By: suo
Differential Revision: D31490434
fbshipit-source-id: b052ce01fc64fb0efee846feb0acc1f107ba13e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66694
`lhs.equal(rhs)` would throw if the device doesn't match. To avoid that we return early if the device doesn't match.
Test Plan: CI
Reviewed By: houseroad
Differential Revision: D31691608
fbshipit-source-id: 513c3e0743a65d9778c7ef9b79ececfeaccc0017
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66480
This guts `THCState` to simply be an empty struct, as well as:
- moving `THCState_getPeerToPeerAccess` and its cache into `ATen`.
- cleaning up dead code in `THCGeneral.cpp`
- moving `THCudaInit` and `THCMagma_init` into `CUDAHooks::initCUDA`
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D31577488
Pulled By: ngimel
fbshipit-source-id: 90604f30854fe766675baa3863707ac09995bc9e
Summary:
These stable sorts currently use a combination of `at::arange`, view ops and `tensor.copy_` to fill in the initial values for the indices before calling into `CUB` to do the actual sort. This is somewhat inefficient because it requires 2 to 4 kernel launches, and the copies all use strided kernels instead of the more efficient contiguous kernels. Instead, a fairly straight-forward custom kernel is more efficient in terms of both CUDA and CPU runtime.
In a simple benchmark I profiled `a.sort(stable=True, dim=1)` for different shapes and single out the kernel invocations for intitializing the index tensors (i.e. the non-`cub` kernels). Note that when the batch dim is `<128` we call `segmented_sort_pairs_by_full_sort` instead of `segmented_sort_pairs`:
| shape | Master (us) | This PR (us) |
|--------------|:-----------:|:------------:|
| (100, 1000) | 5.000 | 2.300 |
| (1000, 100) | 2.070 | 1.090 |
| (100, 10000) | 87.34 | 26.47 |
| (1000, 1000) | 28.63 | 20.27 |
Of course for sufficiently large inputs, the overall runtime is dominated by the actual sort. But I have another motive of wanting to remove operator the calls from the middle of this kernel launch code. This change makes it easier to split the kernel code that needs to be compiled with `nvcc` into it's own file that doesn't include `Tensor.h`, similar to what I'm doing in https://github.com/pytorch/pytorch/issues/66620.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66668
Reviewed By: H-Huang
Differential Revision: D31693722
Pulled By: ngimel
fbshipit-source-id: 5765926e4dbbc7a20d2940c098ed093b3de2204e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65508
This has some misc cleanups for the code that happens before `run_test.py`:
* remove hardcoding of 2 shards
* add `set -eux` in some places
Test Plan: Imported from OSS
Reviewed By: seemethere
Differential Revision: D31296509
Pulled By: driazati
fbshipit-source-id: 2df1463432846d8a4d8a579812a4e9c3b7c2b957
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66669
Implemented `cat` operator for channel dimension
**Facts:**
* texture coordinate: x(width), y(height), z(depth)
* input x, y, z -> no change
* out x, y -> no change
* out z and index i, j only matter
**Equations:**
batch_size = bt0 (or bt1 or bt2 or ...) = # of batch for tensor i
ch_size = ch0 (or ch1 or ch2 or ...) = # of channels for tensor i
ch_interval = ch0 + ch1 + ch2 + ... = total # of channels for all tensors
ch_size_allprior = ch0 (or ch0+ch1 or ch0+ch1+ch2 or ...) = # of channels for tensor 0 to i-1 where pos.z = d (input)
i = index of input texel = vec4[i] of texel at posIn(x,y,z) on input texture
j = index of output texel = vec4[j] of texel at posOut(x',y',z') on input texture
posIn[i] = {x,y,z} at ith index of vec4
src_index = posIn.z * 4 + i
dst_index = int(src_index / ch_size) * ch_interval + (src_index % ch_size) + ch_size_allprior
d = posOut.z = int(dst_index / 4)
j = (dst_index % 4)
posOut[j] = {posIn.x, posIn.y, d} at jth index of vec4
**Shader pseudo code:**
posOut = posIn;
for (i = 0; i < 4; ++i) {
src_index = posIn.z * 4 + i;
if (src_index >= ch_size * batch_size) break; // out of range
dst_index = int(src_index / ch_size) * ch_interval + (src_index % ch_size) + ch_size_allprior;
posOut.z = int(dst_index / 4);
j = (dst_index % 4);
uOutput[j] = uInput[i]
}
Test Plan:
Test build on Android:
```
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_api_test
adb shell "/data/local/tmp/vulkan_api_test"
```
Test result:
```
[ RUN ] VulkanAPITest.cat_dim1_samefeature_success
[ OK ] VulkanAPITest.cat_dim1_samefeature_success (101 ms)
[ RUN ] VulkanAPITest.cat_dim1_difffeature_success
[ OK ] VulkanAPITest.cat_dim1_difffeature_success (81 ms)
[ RUN ] VulkanAPITest.cat_dim1_texture2d_success
[ OK ] VulkanAPITest.cat_dim1_texture2d_success (2 ms)
[ RUN ] VulkanAPITest.cat_dim1_singledepth_success
[ OK ] VulkanAPITest.cat_dim1_singledepth_success (6 ms)
[ RUN ] VulkanAPITest.cat_dim1_singletensor_success
[ OK ] VulkanAPITest.cat_dim1_singletensor_success (21 ms)
[ RUN ] VulkanAPITest.cat_dim1_twotensors_success
[ OK ] VulkanAPITest.cat_dim1_twotensors_success (53 ms)
[ RUN ] VulkanAPITest.cat_dim1_bat1_ch4multiple_success
[ OK ] VulkanAPITest.cat_dim1_bat1_ch4multiple_success (17 ms)
[ RUN ] VulkanAPITest.cat_dim2_sameheight_success
[ OK ] VulkanAPITest.cat_dim2_sameheight_success (83 ms)
[ RUN ] VulkanAPITest.cat_dim2_diffheight_success
[ OK ] VulkanAPITest.cat_dim2_diffheight_success (86 ms)
[ RUN ] VulkanAPITest.cat_dim2_singledepth_success
[ OK ] VulkanAPITest.cat_dim2_singledepth_success (5 ms)
[ RUN ] VulkanAPITest.cat_dim2_invalidinputs_exceptions
[ OK ] VulkanAPITest.cat_dim2_invalidinputs_exceptions (82 ms)
```
Reviewed By: SS-JIA
Differential Revision: D31593623
fbshipit-source-id: e52dc57985e3f0bb9b20313d4fcc7248a436e863
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66692
Currently `ProcessedNode::run()` performs 2 dynamic dispatches to decide which function implementation to execute depending on if the function is an out variant / native / or interpreter fallback. Note that this is happening every time an operation is executed by Static Runtime dynamically.
This change makes *that* same decision during module loading time once so that we can remove 1 dynamic dispatch cost at runtime.
**size reduction**
Saving 4 bytes per `ProcessedNode`.
- Before: sizeof(c10::variant<OutVariant, NativeFunction, Operation>):40
- After: sizeof(std::function<void(ProcessedNode*)>): 32 + sizeof(FunctionKind):4 = 36
**latency optimization**
Expected to remove 2 memory loads & 1 conditional jump per `ProcessedNode::run()` execution (needs to be confirmed from compiled binary code).
Ran `ptvsc2_predictor_bench` with `inline_cvr` with 1000 iterations:
- local : 7.56026 -> 7.24794
- local_ro: 1.5799. -> 1.55504.
- remote_ro: 10.6464 -> 10.3017
Test Plan: Ran existing unittests
Reviewed By: swolchok
Differential Revision: D31591785
fbshipit-source-id: 5de83ca386af509381e08ecedf071ee4e9f0f0b0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/64883
Adds a `warn_only` kwarg to `use_deterministic_algorithms`. When enabled, calling an operation that does not have a deterministic implementation will raise a warning, rather than an error.
`torch.testing._internal.common_device_type.expectedAlertNondeterministic` is also refactored and documented in this PR to make it easier to use and understand.
cc mruberry kurtamohler
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66233
Reviewed By: bdhirsh
Differential Revision: D31616481
Pulled By: mruberry
fbshipit-source-id: 059634a82d54407492b1d8df08f059c758d0a420
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66234
Modified loops in files under fbsource/fbcode/caffe2/ from the format
`for(TYPE var=x0;var<x_max;x++)`
to the format
`for(const auto var: irange(xmax))`
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
bypass_size_limit
allow-large-files
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D30652629
fbshipit-source-id: 0ae6c4bbbb554bad42e372792a6430e1acf15e3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66645
Fixes:
```
test_cholesky_solve_batched_broadcasting_cpu_complex128 (__main__.TestLinalgCPU) ... test_linalg.py:3099: UserWarning: torch.cholesky is deprecated in favor of torch.linalg.cholesky and will be removed in a future PyTorch release.
```
Test Plan: Sandcastle
Reviewed By: mruberry
Differential Revision: D31635851
fbshipit-source-id: c377eb88d753fb573b3947f0c6ff5df055cb13d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66696
D31511082 (9918fd8305) moved unit test but didn't add proper target in build file, fix it in this diff.
Test Plan: buck test mode/opt caffe2/test/fx2trt/converters/...
Reviewed By: 842974287
Differential Revision: D31667697
fbshipit-source-id: 49e04afa323b27a1408c9bc2b5061b6529ced985
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64066
I noticed a bunch of time being spent heap-allocating Tuples
in the unpickler. 1-, 2-, and 3-element Tuples are apparently common
enough that they get their own bytecode instructions, so I decided to
try also giving them their own representation. We store up to 3
IValues inline in `Tuple` rather than doing a second heap allocation
for a `std::vector<IValue>`.
ghstack-source-id: 140695395
Test Plan:
Added automated tests for TupleElements.
Pixel 3 before: https://www.internalfb.com/intern/aibench/details/761596366576284
Pixel 3 after: https://www.internalfb.com/intern/aibench/details/591414145082422
We went from 347 ms to 302 ms.
Reviewed By: dhruvbird
Differential Revision: D30592622
fbshipit-source-id: 93625c54c9dca5f765ef6d5c191944179cb281a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66630
This PR adds meta backend support to the `range`, `arange`, `linspace`, and `logspace` operators.
ghstack-source-id: 140618055
Test Plan: Extended the existing tensor creation tests to assert meta backend support.
Reviewed By: ezyang
Differential Revision: D31656999
fbshipit-source-id: 06e7f3655b94c0d85a28bcd0ca61d9f9ce707f1d
Summary:
This moves it to where the user would expect it to be based on the
documentation and all the other public classes in the torch.onnx module.
Also rename it from ONNXCheckerError, since the qualified name
torch.onnx.ONNXCheckerError is otherwise redundant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66644
Reviewed By: malfet
Differential Revision: D31662559
Pulled By: msaroufim
fbshipit-source-id: bc8a57b99c2980490ede3974279d1124228a7406
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66578
flatten parameters for performance optimization and handle the case when grad ready order is different or there are unused parameters among ranks. when there is no param to be sharded in the FSDP instance (usually root), the flatten wrapper module's flat_param is None.
ghstack-source-id: 140696745
Test Plan: unit test
Reviewed By: mrshenli
Differential Revision: D31625194
fbshipit-source-id: c40e84f9154f5703e5bacb02c37c59d6c4e055c7
Summary:
As title, introduce the file `TracerRunner` shared by internal/external tracer and the main function is
```
TracerResult trace_run(const std::string& input_module_path);
```
which basically takes the path to model file and generate the trace result. The main difference between external tracer and internal tracer is
1. the dependency on `<yaml-cpp/yaml.h>`.
2. the output yaml file from internal tracer includes `model_version` and `model_asset`. These are only needed for internal.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64152
ghstack-source-id: 140692467
Test Plan:
```
./build/bin/model_tracer --model_input_path "/Users/chenlai/Documents/pytorch/tracing/deeplabv3_scripted_with_bundled_input.ptl" --build_yaml_path "/Users/chenlai/Documents/pytorch/tracing/tmp.yaml"
```
```
./fbcode/caffe2/fb/model_tracer/run_model_with_bundled_inputs.sh ~/local/notebooks/prod_models/deeplabv3_scripted_with_bundled_input.ptl
```
have the same operator output
selected_operators.yaml (P460296279)
selected_mobile_ops.h (P460296258)
Reviewed By: dhruvbird
Differential Revision: D30632224
fbshipit-source-id: eb0321dbc0f1fcf6d2e05384695eebb59ac04f8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65772
Looking at some workloads and it would be useful to have this info.
ghstack-source-id: 140555200
Test Plan: CI
Reviewed By: zhaojuanmao, wayi1
Differential Revision: D31224417
fbshipit-source-id: 14eeb053aced87c7ca43b6879f81f54bd0a42b76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65771
Fixes some logging around monitored_barrier to make it cleaner.
ghstack-source-id: 140555204
Test Plan: CI
Reviewed By: zhaojuanmao, wayi1
Differential Revision: D31222881
fbshipit-source-id: 77d6f072ce98a9b31192e0d48ea0f8cbd8f216fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66393
Third try!
Fixes:
- test_nccl_timeout can be flaky because of 1s timeout, bump up the timeout to resolve the flakiness. But in general we should not have been relying on time.sleep for this test, filed https://github.com/pytorch/pytorch/issues/66354 to track that.
- ciflow/all did not actually run tests due to a bug causing multigpu tests to not be run. This has since been fixed.
ghstack-source-id: 140560113
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D31534735
fbshipit-source-id: 8b7e0f4fed3972b7a77cbcda28876c9eefb0c7e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66612
For op authoring project, we want to expose the python bindings
to create Expr. These are the missing bindings.
Test Plan: Imported from OSS
Reviewed By: soulitzer
Differential Revision: D31667852
fbshipit-source-id: 6d3ff83a7676cfea391ab3ea60dde6874a64047a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66244
Make sure the bn statistics are the same in the unit test.
* The fused model in the existing code will have different bn statistics compared to the model without fusion. They will produce the same result when the model is in training mode, but different result in eval mode.
Test Plan: buck run mode/dev-nosan //caffe2/test:quantization -- -r quantization.eager.test_fusion.TestFusion
Reviewed By: jerryzh168
Differential Revision: D29504500
fbshipit-source-id: 41e3bfd7c652c27619baa7cbbe98d8d06a485781
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66590
Updated fx2trt example to run all submodules
Added assertion to make sure outputs from lowered and regular models matches
Test Plan: buck run mode/dev-nosan caffe2:fx2trt_example
Reviewed By: 842974287
Differential Revision: D31592985
fbshipit-source-id: 45ce0b33e957f16b3729d3ecde706331c29d7214
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66631
writing to the current directory is causing issues in CI. we might also consider writing the ".dot" files to some temporary location.
Test Plan: CI
Reviewed By: 842974287
Differential Revision: D31657078
fbshipit-source-id: 9876327c7f172cd354f1b8e8076597c6a26e2850
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66628
Ensure BroadcastMKLDNNTensors do not break the stack invariant by pushing more than 2 tensors into the stack.
Reviewed By: eellison
Differential Revision: D31638565
fbshipit-source-id: 4526c0cf7ba8d87dc8a9c213c66c711e83adfc66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66577
There was a rebase artifact erroneously landed to quantization docs,
this PR removes it.
Test Plan:
CI
Imported from OSS
Reviewed By: soulitzer
Differential Revision: D31651350
fbshipit-source-id: bc254cbb20724e49e1a0ec6eb6d89b28491f9f78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66600
Sparse RPC functionality added in
https://github.com/pytorch/pytorch/pull/62794 works only for TensorPipe and is
broken for other agent types.
Moving these tests to a TensorPipe only class.
ghstack-source-id: 140553147
Test Plan: waitforbuildbot
Reviewed By: rohan-varma
Differential Revision: D31633305
fbshipit-source-id: 37d94cb9ed5565a72a6d512c2a9db75a497d5b95
Summary:
All of the pooling modules except MaxUnpool and LPPool return either a
Tensor or [Tensor, Tensor]. The current type annotations are inaccurate,
and prevent scripting the module if return_indices is set as True in the
module.
There's not a great way to make this agree with mypy because the
overload is dependent on the value of return_indices, an attribute.
I tried changing the annotations from `Tensor` to
`Union[Tensor, Tuple[Tensor, Tensor]]`, but that breaks a bunch of uses
that have return_indices=False.
For example, this breaks:
4e94e84f65/torch/nn/modules/container.py (L139)
Also clean up how test names were being constructed in test_jit, since
otherwise we were getting name collisions when there were two tests on
the same nn.Module.
Fixes https://github.com/pytorch/pytorch/issues/45904
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65847
Reviewed By: ZolotukhinM
Differential Revision: D31462517
Pulled By: eellison
fbshipit-source-id: 6f9e8df1be6c75e5e1e9bae07cf3ad3603ba59bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66274
Removed outdated context manager in unit test.
* The linked issue (https://github.com/pytorch/pytorch/issues/23825) seemed have been be fixed in 2020.
Test Plan: buck run mode/dev-nosan //caffe2/test:quantization -- -r quantization.eager.test_quantize_eager_qat
Reviewed By: vkuzo
Differential Revision: D29507087
fbshipit-source-id: e8fa04c9527023a5adaf1a012b2c393ce0c5cd97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64282
OpInfos for:
- Tensor.bfloat16, Tensor.bool, Tensor.bypte, Tensor.char
- Tensor.double, Tensor.float, Tensor.half, Tensor.int
- Tensor.short, Tensor.long
None of these are supported by TorchScript. Also, the OpInfo autograd
test runner assumes that the operation is not allowed to change the
dtype of the argument, so only Tensor.double has
`supports_autograd=True` (in theory Tensor.bfloat16, Tensor.float,
Tensor.half should be differentiable).
Test Plan: - run tests
Reviewed By: dagitses
Differential Revision: D31452627
Pulled By: zou3519
fbshipit-source-id: b7f272e558558412c47aefe947af7f060dfb45c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66238
The codegen should error if it sees two yaml entries with the same key. The default behavior of python's yaml loader is to overwrite duplicate keys with the new value.
This would have caught a nasty bug that showed up in https://github.com/pytorch/pytorch/pull/66225/files#r723796194.
I tested it on that linked PR, to confirm that it errors correctly (and gives the line number containing the duplicate).
Test Plan: Imported from OSS
Reviewed By: dagitses, albanD, sean-ngo
Differential Revision: D31464585
Pulled By: bdhirsh
fbshipit-source-id: 5b35157ffa9a933bf4b344c4b9fe2878698370a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64180
**BC-breaking note:**
This PR deprecates the `Tensor.T` are not matrices. An upgrade guide is added to the
documentation for `Tensor.T`.
This PR DOES NOT make this attribute to throw an error when called on a tensor of `dim != 2`,
but this will be its behavior in a future PyTorch release.
cc mruberry rgommers pmeier asmeurer leofang AnirudhDagar asi1024 emcastillo kmaehashi heitorschueroff
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D31610611
Pulled By: anjali411
fbshipit-source-id: af8ff7e862790dda9f06921de005b3f6fd0803c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66525
This should solve https://github.com/pytorch/pytorch/issues/60015
There were two `q_zero_point()` accesses inside a for loop which was
expensive. Moving them to before the loop sped things up 10x for a
microbenchmark.
Test Plan:
```
// comment out benchmarks unrelated to original issue, for simplicity
cd benchmarks/operator_benchmark
python -m pt.qinterpolate_test
// before: 2994 us
// after: 324 us
// full results: https://gist.github.com/vkuzo/cc5ef9526dc0cda170d6d63498c16453
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D31592422
fbshipit-source-id: b6078ac1039573bbe545275f7aedfd580910b459
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66606
- Remove dead code (see comment for where)
- Add debug prints
- Small reorganization of the code to improve readability
Reviewed By: d1jang
Differential Revision: D31568219
fbshipit-source-id: 50240c325bf4fd012e1947ac931bb67c6f5dfafb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66579
Didn't commit this file in the PR that open sources fx2trt tests
Test Plan: ci
Reviewed By: 842974287
Differential Revision: D31623354
fbshipit-source-id: 6cedbe0f229da40499b83e6df28e16caca392d9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66562
Adding shape inference for `acc_ops.quantize_per_channel`, and fixing some bugs.
Bugs were related to the fact that `quantize_per_channel` arguments `scales` and `zero_points` take tensors, so when we fetch the values (which needs to be done using `.tolist()` instead of `.item()`) we may get either a list or a scalar value.
Test Plan:
# Test Quantized Resnet
From sandbox with GPU that supports quantized types (tested with V100)
`buck run mode/opt -c python.package_style=inplace caffe2:fx2trt_quantized_resnet_test`
Output
```
...
[TensorRT] INFO: [MemUsageSnapshot] Builder end: CPU 0 MiB, GPU 1548 MiB
[TensorRT] INFO: [MemUsageSnapshot] ExecutionContext creation begin: CPU 0 MiB, GPU 1548 MiB
[TensorRT] VERBOSE: Using cublasLt a tactic source
[TensorRT] WARNING: TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.1.0
[TensorRT] INFO: [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 0, GPU 1556 (MiB)
[TensorRT] VERBOSE: Using cuDNN as a tactic source
[TensorRT] INFO: [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 0, GPU 1564 (MiB)
[TensorRT] WARNING: TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.0.5
[TensorRT] VERBOSE: Total per-runner device memory is 23405056
[TensorRT] VERBOSE: Total per-runner host memory is 73760
[TensorRT] VERBOSE: Allocated activation device memory of size 154140672
[TensorRT] INFO: [MemUsageSnapshot] ExecutionContext creation end: CPU 0 MiB, GPU 1736 MiB
trt fp16 time (ms/iter) 1.252899169921875
trt int8 time (ms/iter) 1.3774776458740234
trt implicit int8 time (ms/iter) 1.3835883140563965
PyTorch time (CUDA) (ms/iter) 4.34483528137207
PyTorch time (CPU) (ms/iter) 55.687150955200195
[TensorRT] INFO: [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 0, GPU 1918 (MiB)
[TensorRT] INFO: [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 0, GPU 1866 (MiB)
[TensorRT] INFO: [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 0, GPU 1738 (MiB)
WARNING: Logging before InitGoogleLogging() is written to STDERR
W1012 12:07:23.556475 711816 DynoConfigLoader.cpp:32] Failed to read config: No dyno config client
```
# Test shape inference
`buck test mode/opt glow/fb/fx/acc_tracer:test_acc_shape_inference`
Output
```
...
Summary
Pass: 95
ListingSuccess: 1
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/1407375092088240
```
Reviewed By: jfix71, jerryzh168
Differential Revision: D31457323
fbshipit-source-id: 8ccc4a9b0ca655fb30838e88575aff2bf3a387a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65429
The sizes of these arrays can't change, so there's no need to waste an extra pointer on them.
ghstack-source-id: 140532722
Test Plan:
CI
I profiled this diff and the previous diff together. Comparing time spent in the operator functor handler for to_copy, I see the load instruction fetching the inputs pointer from p_node on https://www.internalfb.com/code/fbsource/[4c98a83b2451fa6750f38796c91ebb0eb0afd800]/fbcode/caffe2/torch/csrc/jit/runtime/static/ops.cpp?lines=947 (`p_node->Input(0).toTensor()`) improved a tiny bit, and the overall time spent in that wrapper decreased from 0.8% to 0.7%.
Reviewed By: hlu1
Differential Revision: D31096042
fbshipit-source-id: 35c30462d6a9f9bd555d6b23361f27962e24b395
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66376
Added converter for cumsum and unit test
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_cumsum
Reviewed By: wushirong, 842974287
Differential Revision: D31423701
fbshipit-source-id: ee3aa625d6875ba8e6bad27044d22638e99b5c03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66486
The newly-introduced Python dispatcher mode (`__torch_dispatch__`) does not have support for `torch.tensor()` (see #64360) and this causes friction in the user experience if some `nn.Modules` use `torch.tensor()` either implicitly or explicitly.
This PR replaces calls to `torch.tensor()` in `Parameter`, `UninitializedParameter`, and `UninitializedBuffer` with an equivalent call to `torch.empty()` which serves the same purpose and is syntactically more readable.
ghstack-source-id: 140520931
Test Plan: Since no behavioral change, run the existing unit and integration tests.
Reviewed By: pbelevich
Differential Revision: D31575587
fbshipit-source-id: bd7bdeea54370f3e53dc13bd182b97d0f67146f5
Summary:
Fixes https://github.com/pytorch/pytorch/issues/20972
log_sigmoid calculates something like `log(1 + x)` where x is always a
positive number less than one. This wastes floating point precision
because the exponent always becomes zero. Instead, using
`log1p(x)` gives the full mantissa precision around `x=0`.
This also fixes infinity propagation because the old code does,
`exp(in - in)` when `in` is negative. Which for infinity, results in a
NaN instead of 0.
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66441
Reviewed By: bdhirsh
Differential Revision: D31619630
Pulled By: albanD
fbshipit-source-id: e7867f3459a91e944b92f8ca42b6e0697b13f89b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64499
This moves the native functions into a separate Activation.cpp file,
which calls into `launch_..._kernel` functions defined in `Activation.cu`.
The exception is `rrelu_with_noise` which is compilcated by the
random number generation code, so I've moved it into its own file.
Test Plan: Imported from OSS
Reviewed By: jbschlosser, ezyang
Differential Revision: D30867323
Pulled By: dagitses
fbshipit-source-id: a4cd6f1fb1b1fed4cc356bf8b3778991ae2278ba
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50209
This adds a new warning handler that stores all warnings in a shared
queue, which can be "replayed" at a later time and, crucially, on
another thread. Then, I use this inside the autograd engine to ensure
that warnings are processed by the handler registered on the main
thread.
For testing, I also add an operator that always warns in the backward
pass and test that the warning is a normal Python warning.
cc ezyang albanD zou3519 gqchen pearu nikitaved soulitzer Lezcano Varal7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66235
Reviewed By: ejguan
Differential Revision: D31505413
Pulled By: albanD
fbshipit-source-id: 1a7f60b038f55c20591c0748b9e86735b3fec2f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66295
Tidying up the top sources of reference count decrements seen during static runtime startup in alias_analysis.cpp specifically.
ghstack-source-id: 140484160
Test Plan:
CI
perf now shows under 2% time spend in ~__shared_count instead of about 5%.
Reviewed By: suo
Differential Revision: D31490761
fbshipit-source-id: bbdcb7f9065c3aafa7fff7bfea9cea6dbc41f9d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65344
Callsites that know they are using a cache can borrow AliasTypeSets from the cache instead of copying them.
ghstack-source-id: 140484162
Test Plan: Running perf on static runtime startup seems to show less inclusive time spent in AliasDb::getElements
Reviewed By: ejguan
Differential Revision: D31027363
fbshipit-source-id: b7a1473f4f9e9f14566f56f4b3b4e6317076beeb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65178
There is no need to copy the MemoryLocations in this case.
ghstack-source-id: 140484161
Test Plan:
CI
static runtime startup for ctr_mobile_feed decreased from 7.0s to 6.3s
Reviewed By: suo
Differential Revision: D30984442
fbshipit-source-id: 61bb678c4480cd030aaab2bbc8a04cbd9b7c7f4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66496
As the title. No changes on the code logic.
Test Plan: CI
Reviewed By: wushirong
Differential Revision: D31576303
fbshipit-source-id: f2132309023b3c9e09810e32af91eb42eefd3f32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66557
The test was previously using `at::empty_strided` to initialize one of its inputs. The contents of the tensor returned by this function are random, uninitialized memory. If we happened to get a NaN, this test would fail since `use_equalnan` was not set.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D31611961
fbshipit-source-id: 79a9476d0d6ce7a9f1412eefcef19bc2618c54b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66465
conv_param_t is being removed as it stores redundant information. This removes the last usage of it in qnnpack so we can begin removing the dependency.
ghstack-source-id: 140475374
Test Plan: github tests
Reviewed By: kimishpatel
Differential Revision: D31564679
fbshipit-source-id: 049a28fac0235b2e739fb2e048484d7e8e7189fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63602
This PR fixes the case when a read and write is performed on a memory shared between mutable and (or) non-mutable arguments. Example:
```
a=torch.tensor([1+1j])
b=a.conj()
b.add_(a) # should return tensor([2]) but returns tensor ([2-2j])
```
The issue here is that in the conjugate fallback, we resolve the conjugation in-place for mutable arguments which can be a problem as shown above in the case when other input arguments share memory with the mutable argument(s).
This PR fixes this issue by:
1. first scanning through the operator input arguments and creating a vector of mutable arguments that have the conj bit set to `True` (and accordingly setting the flag `check_for_alias_with_mut_arg ` to `True` or `False`).
2. Iterating through all the arguments. At this time we only look at the non-mutable arguments. If `check_for_alias_with_mut_arg` is set to `True`, then we iterate through `mutable_inputs` to check if the current arg tensor in question doesn't alias any of the entries in `mutable_inputs`. If yes, then we clone the non-mutable tensor arg, else we resolve the conjugation as before.
3. Now we look through the mutable_inputs vector (which contains only mutable input tensors with conj bit set to `True`). We in-place conjugate each of the entries in the vector.
4. Do the computation.
5. Re-conjugate the mutable argument tensors.
NOTE: `TensorLists` are not fully handled in ConjugateFallback. Please see the in-line comment for more details.
Fixes https://github.com/pytorch/pytorch/issues/59943
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D30466905
Pulled By: anjali411
fbshipit-source-id: 58058e5e6481da04a12d03f743c1491942a6cc9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66513
These were missed in the migration of onnx to github actions.
Adds ort tests with 2 shards for the onnx workflow
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31599433
Pulled By: seemethere
fbshipit-source-id: 73dce0d3017c4280e64f0c8578e2be7ef6a168d6
Summary:
- this change should not impact existing use cases, but allows for
additional use cases where the container holds const types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66497
Reviewed By: alanwaketan
Differential Revision: D31582242
Pulled By: wconstab
fbshipit-source-id: 3a0e18b4afaf3c7ff93a0e3d09067ed066402b44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66512
TLDR, we are able to use the interactive_embedded_interpreter (basically just torch::deploy interpreter with an interactive shell) to dynamicly load various third party libraries. We use the popular libraries numpy, scipy, regex, pandas for illustration purpose.
A couple of changes need to be done for the interactive_embedded_interpreter:
1, we need link with :embedded_interpreter_all rather than :embedded_interpreter so we can enable DEEPBIND and use our custom loader
2, we provide a pylibRoot path to construct the InterpreterManager. The path will be added to the embedded interpreter's sys.path. Typically we can pass in the python library root path in a conda environment so torch::deploy interpreter can find all installed packages.
3, we allow interactive_embedded_interpreter execute a script to ease recording the exploration of various python libraries.
ghstack-source-id: 140453213
Test Plan:
Install numpy, scipy, regex, pandas in the conda environment or on the machine directly. Suppose /home/shunting/.local/lib/python3.8/site-packages/ is the root path for the installed libraries.
- buck run mode/opt :interactive_embedded_interpreter -- --pylib_root=/home/shunting/.local/lib/python3.8/site-packages/ --pyscript=~/p7/iei_examples/try_regex.py
content of try_regex.py:
```
import regex
print(regex)
pat = r'(.+)\1'
print(regex.match(pat, "abcabc"))
print(regex.match(pat, "abcba"))
print("bye")
```
- buck run mode/opt :interactive_embedded_interpreter -- --pylib_root=/home/shunting/.local/lib/python3.8/site-packages/ --pyscript=~/p7/iei_examples/try_numpy.py
content of try_numpy.py:
```
import numpy as np
print(f"numpy at {np}")
a = np.random.rand(2, 3)
b = np.random.rand(3, 2)
print(np.matmul(a, b))
```
- buck run mode/opt :interactive_embedded_interpreter -- --pylib_root=/home/shunting/.local/lib/python3.8/site-packages/ --pyscript=~/p7/iei_examples/try_scipy.py
content of try_scipy.py:
```
import numpy as np
from scipy import linalg
mat_a = np.array([[1, 0, 0, 0], [1, 1, 0, 0], [1, 2, 1, 0], [1, 3, 3, 1]])
mat_b = linalg.inv(mat_a)
print(mat_b)
```
- buck run mode/opt :interactive_embedded_interpreter -- --pylib_root=/home/shunting/.local/lib/python3.8/site-packages/ --pyscript=~/p7/iei_examples/try_pandas.py
content of try_pandas.py:
```
import pandas as pd
print(f"pandas at {pd}")
df = pd.DataFrame({
"col1": [1, 2, 3, 4],
"col2": [2, 4, 8, 16],
})
print(df)
```
Reviewed By: suo
Differential Revision: D31587278
fbshipit-source-id: c0b031c1fa71a77cdfeba1d04514f83127f79012
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66478
A persistent resource pool was needed to store prepacked tensors since the main resource pool tied to the global Vulkan context would be flushed at the end of each inference run. However, prepacked tensors needed to alive between inference runs, so an additional persistent resource pool was introduced that would only be flushed when the Vulkan context was destroyed.
However, with [this change](https://github.com/pytorch/pytorch/pull/66477) the resource pool no longer indiscrimately flushes allocated resources at the end of an inference run. Tensors will have to call `release_resources()` before they become eligible to be destroyed. Since prepacked tensors are tied to an `OpContext` object they will stay alive between inference runs.
Therefore, the persistent resource pool is no longer needed.
Test Plan: Build and run `vulkan_api_test`.
Reviewed By: beback4u
Differential Revision: D31490076
fbshipit-source-id: 3741a2333c834796d589774e819eaaf52bb9f0fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66477
Currently, Vulkan tensor memory is allocated and deallocated through the following mechanism:
1. During inference, ops will request buffer and/or texture memory for tensors from the [Resource Pool](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/vulkan/api/Resource.h#L324-L327)
2. The resource pool allocates the memory and [adds it to a vector](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/vulkan/api/Resource.cpp#L609-L622) containing all the memory allocations it has made this inference, then returns the most recently allocated block of memory
3. At the end of inference, results are transferred back to the CPU and the [context is flushed](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/vulkan/ops/Copy.cpp#L150)
4. As part of the context flush the [resource pool is purged](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/vulkan/api/Context.cpp#L143) which [deallocates all buffer and texture memory](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/vulkan/api/Resource.cpp#L683-L684) allocated by the resource pool
This pattern makes it impossible to have models with multiple outputs. When the first output tensor is transferred back to the CPU, the memory of the other output tensors will be deallocated when the context is flushed.
Instead, an alternative is to tie resource destruction to the destructor of the [vTensor::View](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/vulkan/ops/Tensor.h#L243) class, which holds the actual implementation and storage of Vulkan tensors. This will ensure that memory associated with a tensor will be cleaned up whenever it is no longer used.
The new deallocation mechanism proposed is:
1. During inference, `vTensor` objects will request GPU memory from the resource pool, same as before.
2. The resource pool allocates buffer or texture memory and returns it directly to the `vTensor`
3. Throughout inference, intermediate tensors' reference counts will go to 0 and the destructor of the `View` class will be called
4. The destructor will any texture and buffer memory it's holding to the resource pool's list of GPU memory allocations to be cleaned
5. At the end of inference `purge()` will be called which will destroy all allocations in the list of allocations to be cleaned
6. GPU memory for output tensors will not be destroyed, since their reference counts will be greater than 0, thus they have not yet been added to the list of allocations to be destroyed
Note that it is not correct to have the destructor directly deallocate GPU memory. This is due to the fact that Vulkan ops simply submit work to the GPU but does not guarantee that work has completed when the op returns. Therefore we must keep all allocated GPU memory until the end of inference, when we wait for the GPU to complete work.
Test Plan:
build and run `vulkan_api_test` to make sure existing functionality is not impacted.
Also test in a later diff that checks that output tensors stay alive after inference completes.
Reviewed By: dreiss
Differential Revision: D31510899
fbshipit-source-id: 99250c2800a68f07b1b91dbf5d3b293184da5bd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66472
A follow up of https://github.com/pytorch/pytorch/pull/66362. Same fix.
Test Plan:
```
buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_fuse_permute_matmul_trt
buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_fuse_permute_linear_trt
```
Reviewed By: wushirong, 842974287
Differential Revision: D31567662
fbshipit-source-id: 2c9e6a138fc31996d790fd4d79e0bf931507fc99
Summary:
- [x] Fixed the Pyre type checking errors in `torch/utils/hipify/hipify_python.py`:
```
torch/utils/hipify/hipify_python.py:196:8 Incompatible variable type [9]: clean_ctx is declared to have type `GeneratedFileCleaner` but is used as type `None`.
torch/utils/hipify/hipify_python.py:944:4 Incompatible variable type [9]: clean_ctx is declared to have type `GeneratedFileCleaner` but is used as type `None`.
```
Fixing the issue: https://github.com/MLH-Fellowship/pyre-check/issues/78
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66164
Reviewed By: onionymous
Differential Revision: D31411443
Pulled By: 0xedward
fbshipit-source-id: c69f8fb839ad1d5ba5e4a223e1322ae7207e1574
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66501
Add testing for the Adagrad optimizer to ensure that it behaves as if complex numbers are two real numbers in R^2 as per issue 65711 on github
ghstack-source-id: 140414042
Test Plan:
buck test mode/dev caffe2/test:optim -- 'test_adagrad_complex'
https://pxl.cl/1R27M
Reviewed By: albanD
Differential Revision: D31584240
fbshipit-source-id: 5c9938084566b8ea49cc8ff002789731f62fe87e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65736
We ran into some limitations to extract PyTorch operator parameters through hooks or the execution graph. Some of these limitations are not due to the operator not exposing them, rather the inputs for these operators are already fused/processed in some cases (like embedding table). We want to be able to attach some metadata to the user scope record functions allowing the profilers to later extract these information.
The record function C++ API already supports taking inputs and outputs information. The corresponding Python interface does not support them and only allows a string name as record function parameter.
This diff adds support for user to optionally to add additional arguments to the record function in two ways.
1. to remain backward compatible with `record_function_op`, we have added an optional string arg to the interface: `with record_function(name, arg_str)`.
2. to support data dependency graph, we also have the new `torch.autograd._record_function_with_args_enter` and `torch.autograd._record_function_with_args_exit` functions to provide an interface where we can give additional tensor arguments. For now we imagine this can be used for debugging or analysis purpose. In this form, we currently support some basic data types as inputs: scalars, string, list, and tensor.
Example usage:
```
# record_function operator with a name and optionally, a string for arguments.
with record_function("## TEST 1 ##", "[1, 2, 3]"):
<actual module or operator>
# more general form of record_function
a = _record_function_with_args_enter("## TEST 2 ##", 1, False, 2.5, [u, u], "hello", u)
<actual module or operator>
_record_function_with_args_exit(a)
```
Corresponding outputs in execution graph:
```
{
"name": "## TEST 2 ##", "id": 7, "parent": 3, "fw_parent": 0, "scope": 5, "tid": 1, "fw_tid": 0,
"inputs": [1,false,2.5,[6,6],"hello",6], "input_shapes": [[],[],[],[[3,4,5],[3,4,5]],[],[3,4,5]], "input_types": ["Int","Bool","Double","GenericList[Tensor(float),Tensor(float)]","String","Tensor(float)"],
"outputs": [], "output_shapes": [], "output_types": []
},
{
"name": "## TEST 1 ##", "id": 3, "parent": 2, "fw_parent": 0, "scope": 5, "tid": 1, "fw_tid": 0,
"inputs": ["1, 2, 3"], "input_shapes": [[]], "input_types": ["String"],
"outputs": [], "output_shapes": [], "output_types": []
},
```
Test Plan:
```
=> buck build caffe2/test:profiler --show-output
=> buck-out/gen/caffe2/test/profiler#binary.par test_profiler.TestRecordFunction
test_record_function (test_profiler.TestRecordFunction) ... Log file: /tmp/libkineto_activities_1651304.json
Net filter:
Target net for iteration count:
Net Iterations: 3
INFO:2021-09-27 01:10:15 1651304:1651304 Config.cpp:424] Trace start time: 2021-09-27 01:10:30
Trace duration: 500ms
Warmup duration: 5s
Net size threshold: 0
GPU op count threshold: 0
Max GPU buffer size: 128MB
Enabled activities: cpu_op,user_annotation,external_correlation,cuda_runtime,cpu_instant_event
Manifold bucket: gpu_traces
Manifold object: tree/traces/clientAPI/0/1632730215/devvm2060.ftw0/libkineto_activities_1651304.json
Trace compression enabled: 1
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:536] Tracing starting in 14s
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:48] Target net for iterations not specified - picking first encountered that passes net filter
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:57] Tracking net PyTorch Profiler for 3 iterations
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:126] Processing 1 CPU buffers
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:686] Recorded nets:
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:689] PyTorch Profiler: 1 iterations
ok
----------------------------------------------------------------------
Ran 1 test in 0.021s
OK
```
Reviewed By: gdankel
Differential Revision: D31165259
fbshipit-source-id: 15920aaef7138c666e5eca2a71c3bf33073eadc4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66361
ossci will be setup later, fbonly ci is ready
Test Plan:
buck run caffe2/test:fx2trt_test_linear
testinprod
Reviewed By: 842974287
Differential Revision: D31511082
fbshipit-source-id: 9e2c50c83fdba822cd2488eb17b5787d8a57f087
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61407
This PR adds `addmv_out_sparse_csr_cuda`. The operation is used to
compute matrix-vector multiplication. Since structured_delegate is used
we only need to implement the out variant, the in-place and normal
variants are autogenerated.
Working on this PR revealed that float16 (and probably bfloat16) inputs
do not work correctly in cusparse, therefore for this case `addmm` is
used with squeezes and unsqueezes.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31584499
Pulled By: ngimel
fbshipit-source-id: 4c507791471ada88969116b88eeaaba7a7536431
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66513
These were missed in the migration of onnx to github actions.
Adds ort tests with 2 shards for the onnx workflow
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31591512
Pulled By: seemethere
fbshipit-source-id: 4a8bb3f0e62ff98ee77d3d8afc905f4e02db6f24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63878
See https://github.com/pytorch/pytorch/issues/64407, https://github.com/pytorch/pytorch/issues/62032 for context:
In this PR:
- Add boxed kernel by replicating `gen_inplace_or_view`'s logic that is ONLY for use with the Autograd not-implemented kernel
- Unlike `gen_inplace_or_view` we always pass a view_func to as_view in order to ensure that an "derivative is not implemented" error is raised even if an in-place update is performed on the view. Without the `view_func`, the CopySlice + AsStridedBackward nodes would replace the NotImplemented node.
- This limitation makes it impossible to use this node for general use
- view relationship must be between first input (must be tensor) and first output (may be tensor or vec of tensor)
- do not support non-differentiable views (_values, _indices, view.dtype) - view relationship is always fw and bw differentiable
- Adds the macro `#define REGISTER_AUTOGRAD_NOT_IMPLEMENTED_FALLBACK(ns, op)` to be the interface for this feature:
- static initialization can be slowed down(? not measured) if there are many registrations, because each line translates to 2 library calls but the workaround is just to manually use the two functions `AutogradNotImplementedFallback` and `ADInplaceOrViewFallback` and call `m.impl`.
- Adds testing:
- for views: view relationship created
- performing in-place operation on the view, raises properly
- trying to create two view relationships is not allowed,
- single view relationship but not first input/first output should error
- view relation created properly for tensor vector output
- for in-place:
- version count bump
- triggers rebase_history
- multiple mutations is okay and also updates version counter
- TODO (follow up): Update tutorials for adding third-party operators (and document the above limitations)
- TODO (follow up): Look at torch-audio/torch-vision and identify places where this can simplify existing code
EDIT: Made it more clear what is introduced in this PR and moved some more contextual stuff into the issue itself
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D30901714
Pulled By: soulitzer
fbshipit-source-id: 48de14c28be023ff4bd31b7ea5e7cba88aeee04c
Summary:
`_mkdir_p` feels like a remnant of Python-2 era, add `exist_ok` argument and re-raise OSError to make it more human readable.
After the change attempt to build PyTorch in a folder that does not have write permissions will result in:
```
% python3.6 setup.py develop
Building wheel torch-1.10.0a0+git9509e8a
-- Building version 1.10.0a0+git9509e8a
Traceback (most recent call last):
File "/Users/nshulga/git/pytorch-worktree/tools/setup_helpers/cmake.py", line 21, in _mkdir_p
os.makedirs(d, exist_ok=True)
File "/opt/homebrew/Cellar/python36/3.6.2+_254.20170915/Frameworks/Python.framework/Versions/3.6/lib/python3.6/os.py", line 220, in makedirs
mkdir(name, mode)
PermissionError: [Errno 13] Permission denied: 'build'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "setup.py", line 895, in <module>
build_deps()
File "setup.py", line 370, in build_deps
cmake=cmake)
File "/Users/nshulga/git/pytorch-worktree/tools/build_pytorch_libs.py", line 63, in build_caffe2
rerun_cmake)
File "/Users/nshulga/git/pytorch-worktree/tools/setup_helpers/cmake.py", line 225, in generate
_mkdir_p(self.build_dir)
File "/Users/nshulga/git/pytorch-worktree/tools/setup_helpers/cmake.py", line 23, in _mkdir_p
raise RuntimeError(f"Failed to create folder {os.path.abspath(d)}: {e.strerror}") from e
RuntimeError: Failed to create folder /Users/nshulga/git/pytorch-worktree/build: Permission denied
```
Fixes https://github.com/pytorch/pytorch/issues/65920
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66492
Reviewed By: seemethere
Differential Revision: D31578820
Pulled By: malfet
fbshipit-source-id: afe8240983100ac0a26cc540376b9dd71b1b53af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64173
This one also required restructuring the code a bit to move the kernel
code into seperate files. So, I've mainly focused on CUDA which is
where the real build-time issues are.
Test Plan: Imported from OSS
Reviewed By: jbschlosser, ezyang
Differential Revision: D30728581
Pulled By: dagitses
fbshipit-source-id: a69eea5b4100d16165a02660dde200c8f648683d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65401
Per https://github.com/pytorch/pytorch/issues/57744 statically linked CUPTI
causes exception handling to break on certain compiler configurations, likely
because CUPTI comes with incompatible libstdc++ symbols. Rather than pray that
something reasonable happens, use the safer configuration (dynamic linking) by
default and give a warning if the user inverts the setting.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: gdankel
Differential Revision: D31082208
Pulled By: ezyang
fbshipit-source-id: 14f66af920847e158436b5801c43f3124b109b34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66421
Original commit changeset: ab6bb8fe4e83
Plus this incldes BUILD.bazel changes, the reason for the revert.
Test Plan: See original diff
Reviewed By: gdankel
Differential Revision: D31542513
fbshipit-source-id: ee30aca2d6705638f97e04b77a9ae31fe5cc4ebb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65348
Previously, this took several percent of model loading time. Now it is well under 1%.
We get this savings by avoiding allocating a vector and avoiding reference count bumps on contained types within each type.
ghstack-source-id: 140148562
Reviewed By: suo
Differential Revision: D31057278
fbshipit-source-id: 55a02cbfefb8602e41baddc2661d15385fb2da55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65347
This check is much cheaper than anything involving actually inspecting object fields (i.e., the cost is low), and if it succeeds we can skip the expensive (e.g., it involves locking a weak_ptr and then destroying the resulting shared_ptr) function body. It almost entirely eliminates time spent in this function during model loading according to perf.
ghstack-source-id: 140148561
Test Plan: Specifically I profiled static runtime startup for the ctr_mobile_feed model and saw self time in this function go from 2-3% to 0.36%.
Reviewed By: ejguan
Differential Revision: D31057279
fbshipit-source-id: efb6bdc0957b680112ac282e85dc1b06b1b6c0bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66302
Just move files, ossci can be setup later
Test Plan:
buck run //caffe2/test:test_fx_acc_tracer
testinprod
Reviewed By: 842974287
Differential Revision: D31495087
fbshipit-source-id: f182c7438e3e80ba98924990682cb45a99b9967c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66362
In general we cannot rely on Permute021Linear being kept as is before lowering phase before our transformation could have traced through this module. A acc based fx pass is more reliable to recover the perf.
Test Plan:
```
buck run mode/opt -c python.package_style=inplace -c fbcode.nvcc_arch=a100 //hpc/new/models/ads/benchmarks:ads_dense_benchmark -- over-arch --model-version=23x_3tb --batch-size=2048
OverArch, PyTorch, FP16, BS: 2048, TFLOP/s: 53.22, Time per iter: 14.46ms, QPS: 141629.45
OverArch, TensorRT, FP16, BS: 2048, TFLOP/s: 92.20, Time per iter: 8.35ms, QPS: 245354.15
```
Unittest:
```
buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_fuse_permute_linear_trt
```
Reviewed By: jianyuh, wushirong, 842974287
Differential Revision: D31525307
fbshipit-source-id: b472a8c277aa4d156d933d6a5abec091133f22c5
Summary:
I updated `sample_inputs_linalg_lstsq` and `test_nondifferentiable`
now correctly reveals the failure. The internal assert error was thrown
because autograd attempts to mark integer tensor as differentiable.
Fixes https://github.com/pytorch/pytorch/issues/66420.
cc ezyang albanD zou3519 gqchen pearu nikitaved soulitzer Lezcano Varal7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66426
Reviewed By: ejguan
Differential Revision: D31550942
Pulled By: albanD
fbshipit-source-id: 4a0ca60e62c5e9bb96af5020541da2d09ea3e405
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65554
We're relying on JIT based shape inference and not using the TE
implementation.
Question to the audience: we set `hasBroadcasts_` in that function, but
this function was almost never invoked. Do we behave correctly in the
presence of rand-calls and broadcasts?
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D31148925
Pulled By: ZolotukhinM
fbshipit-source-id: 2898a57e389ea0950163122089d0fec3d92701c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65856
Occasionally functions dont have this __name__ variable set and have name set instead? Not sure why this happens, but this should catch it.
Test Plan: ci
Reviewed By: iseeyuan
Differential Revision: D31286787
fbshipit-source-id: 8a339541215329b6e9ff43ef77363be41f19c5ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66445
`Type.cpp` implements `demangle()` function based on the macro `HAS_DEMANGLE`. This diff splits it into two `.cpps` so that we can add either one into the build target. This change follows the patternof `flags_use_no_gflags.cpp` and `flags_use_gflags.cpp`.
Test Plan: Rely on CI
Reviewed By: iseeyuan
Differential Revision: D31551432
fbshipit-source-id: f8b11783e513fa812228ec873459ad3043ff9147
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66347
It turns out that our hard-coded build flavor that we were running
deploy tests on in CI no longer exists lol. This PR fixes the OSS build
and also updates the build flavor.
Differential Revision:
D31517679
D31517679
Test Plan: Imported from OSS
Reviewed By: malfet, shunting314
Pulled By: suo
fbshipit-source-id: 763f126a3304f82e6dff7cff8c56414d82c54de3
Summary:
- `batch_isend_irecv` returns a list of requests instead of a single request
- remove some unused variables
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63112
Reviewed By: pbelevich, wayi1, fduwjj
Differential Revision: D30921265
fbshipit-source-id: e2075925172805d33974ef0de6fb631bdf33b5ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66430
On the whole, I'm not totally satisfied with this approach. I think we should be building a prefix tree data structure during initial iteration over the submodules and querying that when deleting submodules. But I think this approach works and I want to see if we can get it in before 1.10
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision: D31546137
Pulled By: jamesr66a
fbshipit-source-id: f08b8409a3cf511277017ccccb916097b7c4c4fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65948
This guts `THCState` to simply be an empty struct, as well as:
- moving `THCState_getPeerToPeerAccess` and its cache into `ATen`.
- cleaning up dead code in `THCGeneral.cpp`
- moving `THCudaInit` and `THCMagma_init` into `CUDAHooks::initCUDA`
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31386275
Pulled By: ngimel
fbshipit-source-id: 5c1f1bbe8c3d2d9f5b99996e0588fb7f07fa6a77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66380
Description:
1. creates doc pages for Eager and FX numeric suites
2. adds a link from main quantization doc to (1)
3. formats docblocks in Eager NS to render well
4. adds example code and docblocks to FX numeric suite
Test Plan:
```
cd docs
make html
python -m http.server
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31543173
Pulled By: vkuzo
fbshipit-source-id: feb291bcbe92747495f45165f738631fa5cbffbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66379
Description:
Creates a quantization API reference and fixes all the docblock errors.
This is #66122 to #66210 squashed together
Test Plan:
```
cd docs
make html
python -m http.server
// open webpage, inspect it, looks good
```
Reviewed By: ejguan
Differential Revision: D31543172
Pulled By: vkuzo
fbshipit-source-id: 9131363d6528337e9f100759654d3f34f02142a9
Summary:
- [x] Fix the Pyre type checking errors in `torch/quantization/fx/qconfig_utils.py`
```
torch/quantization/fx/qconfig_utils.py:241:46 Incompatible variable type [9]: prepare_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/fx/qconfig_utils.py:267:46 Incompatible variable type [9]: convert_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
torch/quantization/fx/qconfig_utils.py:284:43 Incompatible variable type [9]: fuse_custom_config_dict is declared to have type `Dict[str, typing.Any]` but is used as type `None`.
```
Fixes the issue: [MLH-Fellowship/pyre-check/issues/73](https://github.com/MLH-Fellowship/pyre-check/issues/73)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66428
Reviewed By: grievejia
Differential Revision: D31545215
Pulled By: 0xedward
fbshipit-source-id: 767ae7888854c2eec2ecf14855a5b011110b9271
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66028
Added converter and unit test for torch.chunk function
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_gelu
Reviewed By: 842974287
Differential Revision: D31345180
fbshipit-source-id: 9425685671b474449e825aa2a8e7e867a329eb6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66242
While working on random test generation, I observed that many simple transformations were upsetting vectorization. Digging deeper, I found that it calls SplitWithTail which incorrectly splits the loop when the loop start is not zero. This path normalizes the loop before we start splitting it.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D31506853
Pulled By: anijain2305
fbshipit-source-id: 5c5f2568ce0a239bfaa515458be52541eafd23b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66443
For some reason, this logging is adding noise to a lot of flow jobs. I am not sure if this is actually needed.
This is called from the __init__ so it's logged all the time and logs all key:values the current local symbol.
Test Plan: N/A
Reviewed By: chowarfb
Differential Revision: D31534372
fbshipit-source-id: bed032b66fed548c97a6f66b1b9e905fd2738851
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66440
* Set correct name for test worker executable
* Remove `test_get_override_executable` from oss, there already test that tests the functionality
Test Plan: buck test mode/dev-nosan //caffe2/test/distributed/launcher/fb:launch_test
Reviewed By: d4l3k
Differential Revision: D31544853
fbshipit-source-id: e1e009b4b38830d3a78981f8f93c2314ed851695
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66342
`decltype(auto)` in D31486117 (fb5a80ffd8) wasn't the right choice in these specializations, because it will *still* deduce a copy.
See https://godbolt.org/z/GjbcPE1c4 for example.
ghstack-source-id: 140144199
Test Plan: CI, added new static_assert to make sure we got it right for std::tuple in particular
Reviewed By: hlu1, JasonHanwen
Differential Revision: D31514960
fbshipit-source-id: cae722aa34345b590c46eae478229cb5f4b0d7dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66340
For functions that take `std::vector`s with `std::tuple`s in them, `getTypePtr` can get hit on every call, in which case creating a new `TupleType` object every time is expensive.
ghstack-source-id: 140143104
Test Plan: CI
Reviewed By: hlu1, JasonHanwen
Differential Revision: D31514792
fbshipit-source-id: 23652ca90ba1259afc05e953b99ce1fe1bebcc2b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66290
Add full specialization for std::string type index
It slightly speeds up compilation as well as solves the ambiguity how template instantiations implemented in inline namespaces are rendered during `__PRETTY_FUNCTION__` computation.
Not sure what `#pragma` controls this behaviour, but when code is compiled by clang-12+ using libstdc++, `__PRETTY_PRINT__`, sometimes resolve `std::string` to `std::basic_string<char>` and sometimes to `std::__cxx11::basic_string<char>`, even though in the object file symbol is always inside `std::__cxx11::` namespace, which might break caffe2 serialization code that depends on dynamic hash generation
Template name resolution were debugged using https://gist.github.com/malfet/c83b9ebd35730ebf8bac7af42682ea37
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: r-barnes
Differential Revision: D31490050
fbshipit-source-id: 127091574cf6b92c7ec3f972821e4e76f5f626a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66394
Skips this test as it currently does not seem to pass after several
internal local runs.
ghstack-source-id: 140210583
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D31534806
fbshipit-source-id: 799849a6a715506a85c9697b46f7098d9b71b32e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65515
This change enables `StaticRuntime` to manage output tensors (returned from a graph) as follows:
- At the creation of `StaticModule`, it gathers a set of candidates for output tensors (& their aliases) for managing. This is done by `ValueGroup` introduced by the previous diff.
- At the end of the 1st iteration, `MemoryPlanner` creates a set of output `at::Tensor*` to manage. This set consists of tensors objects from the aforementioned candidates, excluding the direct output value of the graph to simplify ivalue ownership passing (`std::move(ivalue)` to return from SR). Note that this exclusion has no perf implication for inline_cvr & ctr_mobilefeed since they only return a container object (e.g., tuple).
- The 2nd+ iterations preallocates a slab memory and all identified output tensors during the 1st iteration. Note that these preallocated tensors are *NOT* deallocated when returned from SR. The client receives the output tensors, and completes using them, and is responsible to call `StaticRuntime::deallocateOutputTensors()` to deallocate them. This mandates that SR cannot be reentered until `deallocateOutputTensors` is called by the client.
- In case of a buggy client missing a call to `StaticRuntime::deallocateOutputTensors()`, SR throws an exception when reentered instead of leaking memory.
- Nit: I plan to use camlcase for function names, and so all newly introduced functions use camlcase despite inconsistencies with snakecase. We can gradually fix the inconsistencies.
This change will be followed by another one to enable `manage_output_tensors` from `PyTorchScriptPredictor`, starting with `ptvsc2_prediction_bench` as a testbed.
Test Plan:
- Added `StaticRuntime.ManageOutputTensors*` to cover the newly added code paths.
- Enhanced `testStaticRuntime` to exercise each unittest test case with `manage_output_tensors` on. Confirmed that SR actually managed output tensors successfully for a few existing testcases (e.g., StaticRuntime.EmbeddingBag`).
Reviewed By: hlu1
Differential Revision: D31049221
fbshipit-source-id: 4ad1599179cc7f00d29e0ce41b33f776226d4383
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66260
Every workflow has ciflow enabled so this is not needed anymore
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: dagitses, janeyx99
Differential Revision: D31493340
Pulled By: seemethere
fbshipit-source-id: 8718fe5d22f4be6e0900962576782a9f23162a39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62550
I noticed that running the build twice in a row resulted in ~80 CUDA files being
rebuilt. Running `ninja -d explain` shows
```
ninja explain: TH/generic/THStorage.h is dirty
ninja explain: TH/generic/THStorageCopy.h is dirty
ninja explain: THC/generic/THCStorage.h is dirty
ninja explain: THC/generic/THCStorageCopy.h is dirty
ninja explain: TH/generic/THTensor.h is dirty
ninja explain: THC/generic/THCTensor.h is dirty
ninja explain: THC/generic/THCTensorCopy.h is dirty
ninja explain: THC/generic/THCTensorMath.h is dirty
ninja explain: THC/generic/THCTensorMathMagma.h is dirty
ninja explain: THC/generic/THCTensorMathPairwise.h is dirty
ninja explain: THC/generic/THCTensorScatterGather.h is dirty
```
considering `ninja` is working relative to the `build` folder, these files don't
actually exist. I traced this back to the output of `nvcc -MD` containing
paths relative to the include directory, instead of being absolute.
This adds a little script to launch the compiler then resolve any relative paths
in the `.d` file before `ninja` looks at it. To use it, I run the build with
```
export CMAKE_CUDA_COMPILER_LAUNCHER="python;`pwd`/tools/nvcc_fix_deps.py;ccache"
```
There are some possible pit-falls here. The same relative path might work for
two include directories, and the compiler could pick a different one. Or,
the compiler might have additional implicit include directories that are needed
to resolve the path. However, this has worked perfectly in my testing and it's
completely opt-in so should be fine.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D31503351
Pulled By: malfet
fbshipit-source-id: b184c4526679d976b93829b5715cafcb1c7db2ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62445
PyTorch currently uses the old style of compiling CUDA in CMake which is just a
bunch of scripts in `FindCUDA.cmake`. Newer versions support CUDA natively as
a language just like C++ or C.
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D31503350
fbshipit-source-id: 2ee817edc9698531ae1b87eda3ad271ee459fd55
Summary:
Also use range loop instead of regular one
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66315
Reviewed By: albanD
Differential Revision: D31503730
Pulled By: malfet
fbshipit-source-id: f5568f7f28e15a9becd27986dd061a6fcae34651
Summary:
There has an issue when calling **torch.get_autocast_cpu_dtype** and **torch.get_autocast_gpu_dtype**:
```
>>> torch.get_autocast_gpu_dtype()==torch.half
False
>>> torch.get_autocast_cpu_dtype()==torch.bfloat16
False
```
but the expected results should be :
```
>>> torch.get_autocast_gpu_dtype()==torch.half
True
>>> torch.get_autocast_cpu_dtype()==torch.bfloat16
True
```
This PR is about fixing this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66396
Reviewed By: ejguan
Differential Revision: D31541727
Pulled By: albanD
fbshipit-source-id: 1a0fe070a82590ef2926a517bf48046c2633d168
Summary:
Addresses this network risk mitigation mentioned in https://github.com/pytorch/pytorch/issues/65439#issuecomment-924627239.
I didn't include any mobile app/benchmarking changes because I think the pretrained matters there.
I ended up removing the changes in test_utils because those were sensitive to the pretrained variable.
I am saving the quantization test changes for another PR because they are currently disabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66312
Reviewed By: ejguan
Differential Revision: D31542992
Pulled By: janeyx99
fbshipit-source-id: 57b4f70247af25cc96c57abd9e689c34641672ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65538
Adds a test which verifies that `prepare_fx` and `convert_fx` work
on models created by `torch.package` in the past. In detail:
1. (one time) create a model and save it with torch.package. Also save input,
expected output, and names of quantization related get_attrs added by
our passes.
2. (every time) load the model from (1), and verify that expected output
matches current output, and that get_attr targets did not change.
Test Plan:
```
python test/test_quantization.py TestSerialization.test_linear_relu_package_quantization_transforms
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D31512939
fbshipit-source-id: 718ad5fb66e09b6b31796ebe0dc698186e9a659f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66338
This commit exposes c10d extension API to Python land. Users can
now override c10d communication behaviors in pure Python, and no
longer needs to go through the cpp extension steps.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D31514351
Pulled By: mrshenli
fbshipit-source-id: a8b94af0af7960c078e1006c29b25f7f3bd86c81
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66350
Implements conv3d for QNNPACK by writing another kernel for the indirection buffer in 3 dimensions. Modifies all structs to take depth, with depth = 1 indicating 2d operation. gemm and conv (non transpose) work, next up is depthwise and tranpose.
ghstack-source-id: 140152440
Test Plan: test/quantization
Reviewed By: kimishpatel
Differential Revision: D30858693
fbshipit-source-id: 883cca8ec53b9e15ab4b9473c6cc042e3d049d9c
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/kineto](https://github.com/pytorch/kineto).
New submodule commit: 6f9c0eeff5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59674
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: larryliu0820
Differential Revision: D28977762
fbshipit-source-id: d441d4d46a7044cc05eb8b21e59471deee312e02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66222
Description:
1. creates doc pages for Eager and FX numeric suites
2. adds a link from main quantization doc to (1)
3. formats docblocks in Eager NS to render well
4. adds example code and docblocks to FX numeric suite
Test Plan:
```
cd docs
make html
python -m http.server
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31447610
Pulled By: vkuzo
fbshipit-source-id: 441170c4a6c3ddea1e7c7c5cc2f1e1cd5aa65f2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66210
Description:
Moves the backend section of the quantization page further down,
to ensure that the API description and reference sections are closer
to the top.
Test Plan:
```
cd docs
make html
python -m server.http
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31447611
Pulled By: vkuzo
fbshipit-source-id: 537b146559bce484588b3c78e6b0cdb4c274e8dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66201
Description:
This PR switches the quantization API reference to use `autosummary`
for each section. We define the sections and manually write a list
of modules/functions/methods to include, and sphinx does the rest.
A result is a single page where we have every quantization function
and module with a quick autogenerated blurb, and user can click
through to each of them for a full documentation page.
This mimics how the `torch.nn` and `torch.nn.functional` doc
pages are set up.
In detail, for each section before this PR:
* creates a new section using `autosummary`
* adds all modules/functions/methods which were previously in the manual section
* adds any additional modules/functions/methods which are public facing but not previously documented
* deletes the old manual summary and all links to it
Test Plan:
```
cd docs
make html
python -m http.server
// renders well, links work
```
Reviewed By: jerryzh168
Differential Revision: D31447615
Pulled By: vkuzo
fbshipit-source-id: 09874ad9629f9c00eeab79c406579c6abd974901
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66198
Consolidates all API reference material for quantization on a single
page, to reduce duplication of information.
Future PRs will improve the API reference page itself.
Test Plan:
```
cd docs
make html
python -m http.server
// renders well
```
Reviewed By: jerryzh168
Differential Revision: D31447616
Pulled By: vkuzo
fbshipit-source-id: 2f9c4dac2b2fb377568332aef79531d1f784444a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66129
Adds a documentation page for `torch.ao.quantization.QConfig`. It is useful
for this to have a separate page since it shared between Eager and FX graph
mode quantization.
Also, ensures that all important functions and module attributes in this
module have docstrings, so users can discover these without reading the
source code.
Test Plan:
```
cd docs
make html
python -m http.server
// open webpage, inspect it, renders correctly
```
Reviewed By: jerryzh168
Differential Revision: D31447614
Pulled By: vkuzo
fbshipit-source-id: 5d9dd2a4e8647fa17b96cefbaae5299adede619c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66125
Before this PR, the documentation for observers and fake_quants was inlined in the
Eager mode quantization page. This was hard to discover, especially
since that page is really long, and we now have FX graph mode quantization reusing
all of this code.
This PR moves observers and fake_quants into their own documentation pages. It also
adds docstrings to all user facing module attributes such as the default observers
and fake_quants, so people can discover them from documentation without having
to inspect the source code.
For now, enables autoformatting (which means all public classes, functions, members
with docstrings will get docs). If we need to exclude something in these files from
docs in the future, we can go back to manual docs.
Test Plan:
```
cd docs
make html
python -m server.http
// inspect docs on localhost, renders correctly
```
Reviewed By: dagitses
Differential Revision: D31447613
Pulled By: vkuzo
fbshipit-source-id: 63b4cf518badfb29ede583a5c2ca823f572c8599
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66122
Description:
Adds a documentation page for FX graph mode quantization APIs which
reads from the docstrings in `quantize_fx`, and links it from the main
quantization documentation page.
Also, updates the docstrings in `quantize_fx` to render well with reStructuredText.
Test Plan:
```
cd docs
make html
python -m http.server
// open webpage, inspect it, looks good
```
Reviewed By: dagitses
Differential Revision: D31447612
Pulled By: vkuzo
fbshipit-source-id: 07d0a6137f1537af82dce0a729f9617efaa714a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66279
This error appears when compiling with "-Wextra" and cannot be resolved by fixing the code since the return type of the instrinic being passed to `map` is fixed.
Fixes:
```
caffe2/aten/src/ATen/cpu/vec/vec256/vec256_bfloat16.h:204:28: error: 'const' type qualifier on return type has no effect [-Werror,-Wignored-qualifiers]
Vectorized<BFloat16> map(const __m256 (*const vop)(__m256)) const {
^~~~~~
caffe2/aten/src/ATen/cpu/vec/vec256/vec256_bfloat16.h:204:28: error: 'const' type qualifier on return type has no effect [-Werror,-Wignored-qualifiers]
Vectorized<BFloat16> map(const __m256 (*const vop)(__m256)) const {
^~~~~~
```
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D31480888
fbshipit-source-id: 919c0d48c8ce13ce1106a9df124a077945e36707
Summary:
Previously https://github.com/pytorch/pytorch/pull/64087 broke the test `binary_macos_wheel_3_7_cpu_build`, because wheel build is not happy with `model_tracer`. Considering it's prototype and there is no need to ship model_tracer via wheel at the moment, using the option `TRACING_BASED` for building tracer. When tracing-based is mature enough, we can ship the tracer binary via wheel eventually.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66267
Original commit changeset: 8ac3d75a52d0
ghstack-source-id: 140122106
Test Plan:
binary_macos_wheel_3_7_cpu_build passes
{F668643831}
Reviewed By: dhruvbird
Differential Revision: D31478593
fbshipit-source-id: 726cab1b31c4596f6268b7824eecb20e2e59d161
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66286
No need to take refcount bumps on each comparator call.
Test Plan: CI, review
Reviewed By: hlu1, JasonHanwen
Differential Revision: D31487058
fbshipit-source-id: 98d2447ac27a12695cb0ebe1e279a6b50744ff4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66282
Now that a bunch of the `FooType::get()` functions return a const reference, we can forward that behavior through `getTypePtr()` using return type deduction.
Test Plan: Inspect assembly for List_test.cpp before/after the rest of the change; reference counting is no longer in the happy path.
Reviewed By: hlu1, JasonHanwen
Differential Revision: D31486117
fbshipit-source-id: 863b677bb6685452a5b325d327bdc2a0a09627bf
Summary:
- [x] Fix the Pyre type checking errors in `torch/quantization/fx/utils.py`
```
torch/quantization/fx/utils.py:490:4 Incompatible variable type [9]: target_module_type is declared to have type `Type[nn.modules.module.Module]` but is used as type `None`.
```
Fixes the issue: [MLH-Fellowship/pyre-check/issues/75](https://github.com/MLH-Fellowship/pyre-check/issues/75)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66311
Reviewed By: pradeep90
Differential Revision: D31506399
Pulled By: 0xedward
fbshipit-source-id: 3d866fba6005452378d4a2613b8689fa2d7a8b67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66253
This was initially broken in #65829 and unbroken in #66003, this PR cleans
it up by removing the mypy ignore line.
Test Plan:
```
mypy torch/jit/_recursive.py --no-incremental
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D31475100
fbshipit-source-id: 46ab2ede72c08b926f4f9a6b03b1a1375b884c8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65903
This changes the imports in the `caffe2/torch/nn/intrinsic` to include the new import locations.
```
codemod -d torch/nn/intrinsic --extensions py 'torch.quantization' 'torch.ao.quantization'
```
Test Plan: `python test/run_test.py`
Reviewed By: albanD
Differential Revision: D31301195
fbshipit-source-id: a5a9d84cb1ac33df6c90ee03cda3e2f1c5d5ff51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65902
This changes the imports in the `caffe2/torch/nn/qat` to include the new import locations.
```
codemod -d torch/nn/qat --extensions py 'torch.quantization' 'torch.ao.quantization'
```
Test Plan: `python test/run_test.py`
Reviewed By: jerryzh168
Differential Revision: D31301196
fbshipit-source-id: ff237790d74cd3b3b5be642a997810f4f439a1d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65901
This changes the imports in the `caffe2/torch/nn/quantizable` to include the new import locations.
```
codemod -d torch/nn/quantizable --extensions py 'torch.quantization' 'torch.ao.quantization'
```
Test Plan: `python test/run_test.py`
Reviewed By: jerryzh168
Differential Revision: D31301194
fbshipit-source-id: 8ce8a3015ea61da62d7658846d1ca64fbdabaf7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65900
This changes the imports in the `caffe2/torch/nn/quantized` to include the new import locations.
```
codemod -d torch/nn/quantized --extensions py 'torch.quantization' 'torch.ao.quantization'
```
Test Plan: `python test/run_test.py`
Reviewed By: jerryzh168
Differential Revision: D31301193
fbshipit-source-id: 58efb1ad51a8b441e2a3bd5b91af11eab6b9331f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64397
This diff exposes a way to add events to kineto profiler from external
source.
This can be a backend that executes a subgraph and wants to record this
execution in kineto profiler.
This diff also adds "backend" metadata to identify the backend an event
would have executed on.
Test Plan:
test_lite_interpreter
Imported from OSS
Reviewed By: raziel
Differential Revision: D30710710
fbshipit-source-id: 51399f9b0b647bc2d0076074ad4ea9286d0ef3e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63198
Linear layers using the same input tensor can be concatted together
as long as the weights and biases are compatible.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31240642
fbshipit-source-id: 1e78daa6b89822412ba2513d326ee0e072ceff1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65177
There is no need to heap-allocate any vectors in this case.
ghstack-source-id: 140052520
Test Plan:
CI
Startup for static runtime on ctr_mobile_feed local net decreased from 7.8s to about 7.0s
Reviewed By: malfet
Differential Revision: D30984194
fbshipit-source-id: 85091e55445f653ec728b27da4b459a2f1873013
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65122
Failure to cache this seems to contribute to quadratic startup time for the static runtime.
Disclaimer: I am entirely un-versed in the performance considerations for the JIT and have no idea what the other impacts of this change may be. Let the reviewer beware.
ghstack-source-id: 140052522
Reviewed By: suo
Differential Revision: D30983268
fbshipit-source-id: 4329aee6b5781f5c2e2d2334c396fab8528d4b7b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65343
No reason not to save a bit on re-hashing.
ghstack-source-id: 140052518
Test Plan:
CI
Static runtime startup seems to go from 5.9-6.0s to 5.8s-6.0s, perf shows less time spent rehashing
Reviewed By: mikeiovine
Differential Revision: D31027362
fbshipit-source-id: 39dd53ecd462693b518535856ddd92df78a4977b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64964
log API usage for fsdp API in PyTorch
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D30915734
fbshipit-source-id: 5e3b335327f4a3ff59b025e8e17a0fa0b7f6597d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66167
Sometimes due to desync we see PG wrapper monitored barrier fail. In
this case it would be useful to print the info about the collective that was
trying to run along with the actual error.
ghstack-source-id: 140037653
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D31353021
fbshipit-source-id: e2a515326c9314c98119978d5566eb5431cca96c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66166
These methods should be private.
ghstack-source-id: 139782587
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D31353020
fbshipit-source-id: 583fb315cc2cacc37df3d29cd5793b42558930b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65345
FooType::get() can return a const reference. Inconveniently, converting shared_ptr<FooType> to shared_ptr<Type> requires a copy & refcount bump, so to properly take advantage of this in unshapedType() we need to take a const Type& in isSubtypeOf(), which is good practice anyway -- don't require a shared_ptr if you don't need to take ownership.
ghstack-source-id: 140044165
Test Plan:
CI
perf says c10::unshapedType time decreased from 2.8% to 2.2% during static runtime startup, though I expect this to be generally beneficial.
Reviewed By: hlu1
Differential Revision: D31027361
fbshipit-source-id: 676feb81db9f74ad7b8651d8774f4ecb4cfa6ab8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65346
Tidying up the top sources of reference count decrements seen during static runtime startup.
ghstack-source-id: 140027349
Test Plan:
CI
perf now shows under 2% time spend in ~__shared_count instead of about 5%.
Reviewed By: suo
Differential Revision: D31057277
fbshipit-source-id: 9a16daf2e655fda80d4ec21290b30f02ba63d8da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66277
Previously, it is grouped together with tests related to `MapDataPipe`, but it should be with `IterDataPipe`.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D31485823
Pulled By: NivekT
fbshipit-source-id: d13d8c28cbfc305da0e3033d4109a0f971281a02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66275
Once this is added to Core, TorchData's PR will not need a custom class and can use this wrapper instead.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D31485822
Pulled By: NivekT
fbshipit-source-id: 790de27629c89c0ca7163a8ee5a09ee8b8233340
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66051
Make the error message clearer when quantized embedding is converted
with an unsupported dtype. This is helpful when debugging quantization
errors on new models.
Test Plan:
```
class M(nn.Module):
def __init__(self):
super().__init__()
self.embedding = nn.Embedding(1, 1)
m = M().eval()
m.qconfig = torch.quantization.QConfig(
activation=torch.quantization.MinMaxObserver.with_args(dtype=torch.qint8),
weight=torch.quantization.MinMaxObserver.with_args(dtype=torch.qint8))
m.embedding.qconfig = m.qconfig
mp = torch.quantization.prepare(m)
mq = torch.quantization.convert(m)
// error message now includes the incorrect dtype
```
Imported from OSS
Reviewed By: dagitses
Differential Revision: D31472848
fbshipit-source-id: 86f6d90bc0ad611aa9d1bdae24497bc6f3d2acaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66050
Adds the dtype to an error message when trying to quantize something
other than a float. This is useful for debugging quantization tools on
new models.
Test Plan:
```
x = torch.randn(1, 1, 1, 1, dtype=torch.double)
xq = torch.quantize_per_tensor(x, 0.01, 0, torch.quint8)
// error message now includes Double
```
Imported from OSS
Reviewed By: dagitses
Differential Revision: D31472849
fbshipit-source-id: 2331ffacefcbc6f8eca79694757d740de74a0f1d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66049
Enables quantized add with broadcasting. As pointed out by jamesr66a,
this was disabled but TensorIterator already supports it. Added a test
case to verify.
Test Plan:
```
python test/test_quantization.py TestQuantizedOps.test_qadd_broadcast
```
Imported from OSS
Reviewed By: dagitses
Differential Revision: D31472850
fbshipit-source-id: a3b16d9000487918db743525d22db6864330762b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66108
BC-breaking change: intT is now longT (which aligns it more accurately with how
the types are referred to in C++). The benefit for this is we can idiomatically
express all C++ dtypes (with intT now mapping to int32_t). These types are needed
for ufunc codegen in a latter patch.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31385761
Pulled By: ezyang
fbshipit-source-id: ec6f3a0953794313470dbe14911f23ac116be425
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66149
Updated logic will be able to infer rank of slice output, when only rank is known for slice input. Enables cases where `ConstantValueMap::HasRank(input)` is `True`, while `ConstantValueMap::HasShape(input)` is `False`.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31423232
Pulled By: ezyang
fbshipit-source-id: 516e3916aa71afda2b10e44620636e42ed837236
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Hi, I'm looking forward to contributing to PyTorch, so starting with a minor fix in the documentation for `index_add`.
Currently, in the documentation for `index_add_` (please see https://pytorch.org/docs/master/generated/torch.Tensor.index_add_.html#torch.Tensor.index_add_):
1. `tensor` attribute was pointing to `torch.tensor` class, which IMO - is (thought may not be a big deal) unintentional.
2. `dim` attribute is pointing to `torch.Tensor.dim`, which again IMO - is unintentional.
This PR suggests a correction for the first point above, to rename `tensor` attribute to `input` so that it doesn't point to `torch.tensor` class. (I've verified that others ops like `scatter` use `input`, so this should not break the consistency in the documentation). I couldn't find an appropriate fix for the second point above, since renaming `dim` to something else will break the consistency (as almost all others op in PyTorch use `dim` as the attribute name).
I may be wrong here, so please let me know if there is any feedback or an alternate fix for this.
_Note:_ I plan to fix this behavior for `index_copy_` (https://pytorch.org/docs/master/generated/torch.Tensor.index_copy_.html#torch.Tensor.index_copy_) once and if this PR is approved.
To the reviewers, please help me tag the correct person who could help review this PR.
cc: krshrimali mruberry zou3519
cc brianjo mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65806
Reviewed By: dagitses, mruberry
Differential Revision: D31431182
Pulled By: zou3519
fbshipit-source-id: 66ced9677ac3bc71d672d13366f9f567ecea0a2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65958
zhxchen17 added `pickle` pybind for trt engine which allows us to save and load a nn.Module with trt engine in fbcode. This diff though is explicitly ser/des engine in __set_state__` and `__get_state__` so that in OSS people can also save and load TRTModule directly.
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_fx2trt
Reviewed By: wushirong
Differential Revision: D31309429
fbshipit-source-id: 9068e2ae6375ed0e1bb55b0e9d582b8d9c049dbf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65959
Give some more controls over the output dtype of a trt engine. Previously it would be fp16 if we turn on fp16_mode. This diff allows the engine to generate fp32 output with fp16_mode=True.
Test Plan: CI
Reviewed By: kflu, wushirong
Differential Revision: D31243929
fbshipit-source-id: 09c752e6f382d6ad169da66878d9a9277c134869
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66131
Turns out that a model with 72k instructions causes about 0.5MiB of additional memory overhead (if there's an 8 byte memory overhead per instruction). This is not necessary if we're building w/o eager symbolication support. This change eliminates the 8 byte `debug_handle` if the build is w/o eager symbolication support.
ghstack-source-id: 140045478
(Note: this ignores all push blocking failures!)
Test Plan:
```
buck build -c "pt.enable_eager_symbolication"=1 //xplat/caffe2/fb/lite_predictor:lite_predictor
buck build //xplat/caffe2/fb/lite_predictor:lite_predictor
```
Reviewed By: kimishpatel
Differential Revision: D31387784
fbshipit-source-id: af56787ad833b990a46b79ab021e512edaa22143
Summary:
Noticed that `periodic-pytorch-linux-xenial-cuda10.2-cudnn7-py3-gcc7-slow-gradcheck` job has a `ciflow/default`, but does not have a `ciflow/scheduled` label
Added asserts to enforce that jobs with non-trival is_scheduled property do not have default and do have scheduled labesl
Rename `periodic-pytorch-linux-xenial-cuda10.2-cudnn7-py3-gcc7-slow-gradcheck` to `periodic-linux-xenial-cuda10.2-py3-gcc7-slow-gradcheck`
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66300
Reviewed By: seemethere
Differential Revision: D31493323
Pulled By: malfet
fbshipit-source-id: 194c1d7a4e659847d94a547b87a0d7d08e66406d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65326
parallel_for and parallel_reduce currently share some common code in
all backends, specifically for detecting if it should run in parallel
or not. This moves all the backend-specific code into a single
`internal::invoke_parallel` function and makes the `parallel_`
functions common to all backends.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D31124495
fbshipit-source-id: 65c3d2af42a8860cc4d6349566085c9fa8d8c6f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66258
Installing libgnutls30 has shown to be good when confronted with the
CERT issue related to deb.nodesource.com
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: dagitses
Differential Revision: D31477789
Pulled By: seemethere
fbshipit-source-id: f87ae4c098771acc505db14e3982d8858cf7326f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66015
Fixes https://github.com/pytorch/pytorch/issues/61982 by clone of
tensors in DDPSink. Only applies once for static_graph and generally for unused
params which already has overhead, so perf hit should not be an issue. Will
verify with benchmark.
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D31346633
fbshipit-source-id: 5b9245ade628565cffe01731f6a0dcbb6126029b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65517
This change retrofits `GetAlwaysAliveValues` into `ValueGroup` to group the values used by a graph into three groups as follows:
- input_aliases: values that are either inputs or contain aliases of inputs or constants.
- output_aliases: values that are either outputs or contain aliases of outputs and are not in input_aliases.
- Values that dont't show up in input_aliases and output_aliases are internally created consumed within the graph.
`output_aliases` is the only new group introduced by this change, and a following diff will use this to preallocate output Tensors to accelerate Static Runtime's performance.
Test Plan: Added `ValueGroup.Init` to cover the updated code path. Note that there was no test for `GetAlwaysAliveValues` before.
Reviewed By: hlu1
Differential Revision: D30940955
fbshipit-source-id: 2cb065ecda0f447a61e64a7cf70cc7c6947f7dfc
Summary: Adding test to ensure non-Vanilla SGD behaves as if complex numbers are two real numbers in R^2 as per issue 65711 on github
Test Plan:
```buck test mode/dev caffe2/test:optim -- 'test_sgd_complex'```
https://pxl.cl/1QLxw
Reviewed By: albanD
Differential Revision: D31477212
fbshipit-source-id: 500678e561a05ac96759223b4c87a37cab26c6a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66021
A builtin library consists of a list of frozen modules and a list of builtin modules. For tensorrt, it's quite simple since we only have a single builtin module tensorrt.tensorrt. But it can be complex for libraries like numpy which contains multiple builtin modules (np.core._multiarray_umath, np.random.mtrand etc.) if we want to add it as a torch::deploy builtin. We enhance the macro that registers builtin libraries to accept a variable length of builtin modules. We can use this macro to register frozentorch, frozenpython, tensorrt for now and can also use it to register libraries like numpy later on.
The enhanced macro now looks as follows. Although we don't need to worry about back-compatibility for now, but this enhanced version is fully compatible with the previous version. The previous version is just a special case when the library contains no builtin modules.
```
REGISTER_TORCH_DEPLOY_BUILTIN(library_name_without_quote, frozen_modules_list,
builtin_module_name_1, builtin_module_init_function_1, ...,
builtin_module_name_N, builtin_module_init_function_N)
```
ghstack-source-id: 140007970
Test Plan:
1. Play around with interactive_embedded_interpreter.cpp to import torch._C, tensorrt.tensorrt etc inside the embedded interpreter.
2. Enhance test_builtin_registry.cpp
3. Run test_deploy.cpp and test_deploy_gpu.cpp
Reviewed By: suo
Differential Revision: D31349390
fbshipit-source-id: 70a1fcf660341180fc4d5195aed15ceb07c2bef7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66218
This stack of diffs reduces the memory used by LLVMCodeGen object.
Here are the numbers on model `294738512`: (this is the number reported as `Memory turnover after freeze_module:` in the output)
```
Before: 123343496
After : 121566008
```
So, there is a reduction of about `~1.77MB` with this change of making `PytorchLLVMJIT` a singleton.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM, hlu1
Differential Revision: D31445798
Pulled By: navahgar
fbshipit-source-id: c860d36456b2c5d3e21010c1217e2948326f666d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65671
Tentative implementation to use dist.gather_object to collect shards from all ranks and then "merge" them. The merge is done on dst_rank though padding the sharded tensors into the size of full tensor based on their metadata (offsets, lengths) first, and then summing these padded tensors together.
Also considered concatenating sharded tensor without padding to minimize memory footprint (assuming padding will increase memory). But it may not be flexible enough for arbitrary sharing (e.g. shard on multiple directions)
Another way can be constructing the padded tensor on each rank and reduce to rank0. I feel this is the most easy implementation. But it will invoke higher memory usage and comm payload. Please let me know if this alternative is preferred.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang gcramer23
Test Plan:
Imported from OSS
python test/distributed/_sharded_tensor/test_sharded_tensor.py -v -k test_gather
did not manage to test on oss, but tested in fbcode by reserving on demand gpu
arc patch D31197611
modify the test with 2 gpus as on-demand gpu only has 2 cores (D31227986)
buck test -c fbcode.enable_gpu_sections=true mode/dev-nosan caffe2/test/distributed/_sharded_tensor:sharded_tensor -- test_gather
buck-out/gen/caffe2/test/distributed/_sharded_tensor/sharded_tensor#binary.par test_sharded_tensor.TestShardedTensorChunked.test_gather
{F667213605}
Reviewed By: dagitses, pritamdamania87
Differential Revision: D31197611
Pulled By: dracifer
fbshipit-source-id: cf98b4a2d7838b11b9582eb23f826bb0fa38a7f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65758
The same change has been made in conv2d, the proper algorithm is both
faster and gives more precision.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31257872
Pulled By: ngimel
fbshipit-source-id: 6ff3a7a00a05b66f83d45cc820bd0c230cb8de6d
Summary:
Enable testing of `torch.Tensor.resize_`.
The negative view test is skipped as the test doesn't work with resize_ see
https://github.com/pytorch/pytorch/issues/65945.
cc mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66135
Reviewed By: dagitses
Differential Revision: D31444263
Pulled By: mruberry
fbshipit-source-id: 00c7fe05df28fba01508b31adb3ed4fdcf4d0326
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65542
Add docstring for torch.fx.passes.split_module that conforms to Google Python Style conventions.
Changed original example to the example from this diff:
https://www.internalfb.com/diff/D24925283 (9734c042b8)
Test Plan:
Ran buck test //caffe2/test:fx. No errors detected
https://pxl.cl/1QCch
Reviewed By: jamesr66a
Differential Revision: D31145694
fbshipit-source-id: 8e54f3b1be3dca1c4d414fdeeab71b9f2b5d9f3e
Summary:
These utils are prerequisites for Lazy Node base class.
- set up new torch/csrc/lazy, test/cpp/lazy dirs
- add source files to build_variables.bzl in new lazy_core_sources var
- create new test_lazy binary
Fixes https://github.com/pytorch/pytorch/issues/65636
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66181
Original commit changeset: 3d0d5377d71e
Test Plan:
Run PyTorch XLA corresponding PR in XLA CI:
https://github.com/pytorch/xla/pull/3148/files
Reviewed By: suo
Differential Revision: D31416438
fbshipit-source-id: 58a6a49c5bc30134bc6bae2e42778f359b9a8f40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63881
This PR includes the minimal sets of features to make FSDP work, like sharding, core data flow and hooks. More tests will be added in the follow up PRs. Tests are refactored to utilize common PyTorch utils. Codes are also refactored a little bit. Alternative ways to replace ".data" usage in this PR are still being discussed offline.
Test Plan: unit tests
Reviewed By: mrshenli
Differential Revision: D30521673
fbshipit-source-id: 9a23390dd7c925749604c6860e08fbe39ddc5500
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66113
For a benchmark compiled in opt-mode in which the lookup items were shuffled and then the items were looked up round-robin fashion 10M times (for a total of 140M lookups) compiled in opt-mode we see:
```
Function Container Time (ms) Multiplier
TypeMetaToDataType if-chain 233 1x
TypeMetaToDataType std::vector 795 3.41x
TypeMetaToDataType std::map 1566 6.72x
TypeMetaToDataType std::unordered_map 2136 9.17x
DataTypeToTypeMeta switch 102 1x
DataTypeToTypeMeta std::vector 666 6.53x
DataTypeToTypeMeta std::map 1212 11.9x
DataTypeToTypeMeta std::unordered_map 1539 15.1x
DataTypeToTypeMeta folly::F14FastMap 1789 17.5x
```
From this, we draw two conclusions:
1. Using a complex container like `std::map` is worse than using a simple vector lookup here (there aren't enough items for the Big-O to assert itself).
2. Using any container at all is a mistake. (Unless we pull in more exotic reasoning like invalidating the code cache or preventing inlining.)
Test Plan: Sandcastle
Reviewed By: dzhulgakov
Differential Revision: D31375117
fbshipit-source-id: 0b310c6c2e94080d125c82fb7c2b43ab869adbcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66230
Adding test to ensure Vanilla SGD behaves as if complex numbers are two real numbers in R^2 as per issue 65711 on github
https://github.com/pytorch/pytorch/issues/65711
ghstack-source-id: 139918862
Test Plan:
```buck test mode/dev caffe2/test:optim -- 'test_sgd_complex'```
https://pxl.cl/1QHvX
Reviewed By: albanD
Differential Revision: D31449289
fbshipit-source-id: da8b00421085796a23b643e73f96b19b5b560a32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66221
JIT doesn't have an implementation for this op, so we can only use it when out variants are enabled.
Reviewed By: hlu1
Differential Revision: D31445887
fbshipit-source-id: 4565ac4df751d8ee4052647574c43efa05ea1452
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66182
closes https://github.com/pytorch/pytorch/issues/63174
Does a few things:
1. adds hostname to the error report
2. moves the "root cause" section to the end (presumably since the logs are being "tailed" we want the root cause to appear at the end)
3. moves redundant error info logging to debug
4. makes the border max 60 char in length and justifies left for the header
NOTE: YOU HAVE TO annotate your main function with torch.distributed.elastic.multiprocessing.errors.record, otherwise no traceback is printed (this is because python exception propagation does NOT work out of the both for IPC - hence the extra record annotation).
Test Plan:
Sample
```
============================================================
run_script_path FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2021-10-05_17:37:22
host : devvm4955.prn0.facebook.com
rank : 0 (local_rank: 0)
exitcode : 1 (pid: 3296201)
error_file: /home/kiuk/tmp/elastic/none_3_lsytqe/attempt_0/0/error.json
traceback :
Traceback (most recent call last):
File "/tmp/jetter.xr3_x6qq/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 372, in wrapper
return f(*args, **kwargs)
File "main.py", line 28, in main
raise RuntimeError(args.throws)
RuntimeError: foobar
============================================================
```
Reviewed By: cbalioglu, aivanou
Differential Revision: D31416492
fbshipit-source-id: 0aeaf6e634e23ce0ea7f6a03b12c8a9ac57246e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65674
Before this PR user had to use the eager mode static quantization APIs to quantize Embedding/EmbeddingBag modules.
With this PR they can use either the static or dynamic quantization APIs for Embedding quantization
The only qconfig supported for embedding quantization is float_qparams_weight_only_qconfig whcih is currently enforced in the from_float
method of the quantized Embedding/Embedding modules.
To combine embedding quantization with Linear dynamic quantization, user can use the qconfig_dict to specify different qconfig for each module type.
The prepare/convert APIs can still be used to quantize Embeddings, with the caveat that user need to ensure input to Embedding ops are FP32.
Addresses Issue #65185
ghstack-source-id: 139935419
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: gchanan
Differential Revision: D31211199
fbshipit-source-id: 8c747881caee5ccbf8b93c6704b08d132049dea4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66008
Added GELU converter and updated TARGET file of deeplearning/trt/fx2trt to load the plugins onto the converters
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_gelu
Reviewed By: 842974287
Differential Revision: D31284144
fbshipit-source-id: 0e938a47a99d289aefc3308aec3937c7334e9b8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66052
`aten::__getitem__.Dict_str` and `prim::unchecked_cast` are used in delegate API.
ghstack-source-id: 139860350
Test Plan: CI
Reviewed By: pavithranrao
Differential Revision: D31364720
fbshipit-source-id: dfca5e3ded4cdd3329c9b9d80a13f0fb1f5f2a51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65942
This one is a bit weird. The class is called `THCIpcDeleter` but it
actually has nothing IPC-specific. It just converts
`std::shared_ptr` + `void*` into a `c10::DataPtr`. Instead, moving
the `DataPtr` conversion into the actual IPC code allows 2 memory
allocations to be elided by merging 3 separate deletion contexts
into one.
Test Plan: Imported from OSS
Reviewed By: dagitses
Differential Revision: D31386278
Pulled By: ngimel
fbshipit-source-id: 5722beed9dcf680f0eb6bbff30405cff47b21962
Summary:
1. Introduce
```
MobileModelRunner.h
MobileModelRunner.cpp
TensorUtils.h
TensorUtils.cpp
```
in external. They are pretty much the same as internal, except namespace and the dependency in folly. In next prs, TensorUtils and MobileModelRunner are unified between external and internal.
2. Introduce
```
tracer.cpp
```
for external. Majority is the same as internal one, with some cleanup on unnecessary dependency. It's unified between internal and external in next change.
3. Add an executable to build the tracer. It will be built for desktop only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64087
ghstack-source-id: 139900300
Test Plan:
Given the model
```
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.lin = nn.Linear(10, 1)
def forward(self, x):
return self.lin(x)
model = Net()
scripted_module = torch.jit.script(model)
example_dict = {'a' : 1, 'b' : 2}
sample_input = {
scripted_module.forward : [(torch.zeros(1,10),)],
}
bundled_model = torch.utils.bundled_inputs.bundle_inputs(scripted_module, sample_input)
bundled_model._save_for_lite_interpreter("dummy_model_with_bundled_input.ptl")
```
External tracer
```
./build/bin/model_tracer --model_input_path "/Users/chenlai/Documents/pytorch/tracing/dummy_model_with_bundled_input.ptl" --build_yaml_path "/Users/chenlai/Documents/pytorch/tracing/tmp.yaml"
```
and compare `tmp.yaml` with the operator list generated from
Internal tracer
```
./fbcode/caffe2/fb/model_tracer/run_model_with_bundled_inputs.sh ~/local/notebooks/prod_models/dummy_model_with_bundled_input.ptl
```
QNNPACK only:
Example yaml from internal tracer: P460742166 [devserver]
Example yaml from external tracer: P460759099 [mac], P460742166 [devserver]
Comparison ops between internal and external on devserver:
{F666923807}
{F666924048}
Note: The operators generated on mac and devservers are different, the one on deserver includes two extra ops: `aten::addmm_, aten::slow_conv_dilated2d"`. Based on the traced list, when calling `aten::_convolution`, one calls `aten::mkldnn_convolution`, and the other calls `aten::_convolution_nogroup`, causing the divergence.
Thanks for Martin for pointing out:
> mkldnn is another backend from Intel
Reviewed By: dhruvbird
Differential Revision: D30599136
fbshipit-source-id: 102f23fb652c728a9ee4379f9acc43ae300d8e8a
Summary:
1. move 4 files to :
```
KernelDTypeTracer.h
KernelDTypeTracer.h
OperatorCallTracer.h
OperatorCallTracer.h
```
so it's visible in OSS.
2. Update the namespace to `torch::jit::mobile`
3. Add a `fb_xplat_cxx_library` `torch_model_tracer` with the source file list above.
4. update the `fb_xplat_cxx_library` `model_tracer_lib` dependency on the new `torch_model_tracer` library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63421
ghstack-source-id: 139900299
Reviewed By: dhruvbird
Differential Revision: D30378069
fbshipit-source-id: d56c6140e951bc13113a76d6b63767a93843c842
Summary:
Currently, if the same tensor constant is reused multiple times, we'll store a tensor constant for each time we use it.
For example
```
val = torch.randn(5)
for _ in range(10):
x = x + val
```
ends up storing 10 tensor constants.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66211
Reviewed By: jamesr66a
Differential Revision: D31437089
Pulled By: Chillee
fbshipit-source-id: 401169c8d58ce0afb7025ae11060680ef544419f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65953
Previously if people want to add a torch::deploy builtin, they need to change torch::deploy internal code (interpreter_impl.cpp) to register the python part as frozen modules and C++ part as builtin modules. This is not convenient and error prone. We want to add open registration support for torch::deploy builtins so that people only need to add one effective line of code in there *library code* to complete the registration.
Here is an example to registry numpy as torch::deploy builtins:
REGISTER_TORCH_DEPLOY_BUILTIN(numpy, numpy_frozen_modules, <list of name, PyInit function pairs>)
This diff supports open registration of frozen modules. It's the first step to achieve the plan above.
ghstack-source-id: 139888306
Test Plan: Run tests in test_deploy.cpp and test_builtin_registry.cpp
Reviewed By: suo
Differential Revision: D31321562
fbshipit-source-id: 6445bd8869f1bb7126b4c96cf06c31145f0e9445
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66179
The diff adds check for `PYTHON_EXEC` environment variable. If the variable is set, it will override `sys.executable` for `torch.distibuted.run`.
This means that if `PYTHON_EXEC` is set, user scripts executed via `torch.distributed.run` will start via value of `os.environ["PYTHON_EXEC"]`
Test Plan: unittest
Reviewed By: kiukchung
Differential Revision: D31329003
fbshipit-source-id: b9d0167d99bbf463a6390f508324883ca4a1e439
Summary:
This PR adds forward AD for `*_solve` methods.
Additionally, `cholesky_solve` gets OpInfo + a bug fix when wrong leading dimensions could be passed to LAPACK,
and `lu_solve` gets forward AD with 2x`lu_solve` instead of 1x`lu_solve` + 2x`triangular_solve`.
cc ezyang albanD zou3519 gqchen pearu nikitaved soulitzer Lezcano Varal7 jianyuh mruberry walterddr IvanYashchuk xwang233
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65546
Reviewed By: dagitses
Differential Revision: D31431847
Pulled By: albanD
fbshipit-source-id: 0e343e0d9da3c3d2051fca215fad289d77275251
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65176
getElements returns a reference.
ghstack-source-id: 139745230
Test Plan:
CI
Static runtime startup for ctr_mobile_feed local net reduced from 8.35s to 7.8s
Reviewed By: malfet
Differential Revision: D30983898
fbshipit-source-id: 884bff40f12322633c0fffd45aed5b8bc7498352
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66081
Two fixes:
1. Since the operators are always registered with both name and overload name, the overloaded name need to be included when looking for an operator.
2. Don't promote operators with alias, because the new registry does not support schema with alias.
ghstack-source-id: 139732099
Test Plan: CI
Reviewed By: pavithranrao
Differential Revision: D31382262
fbshipit-source-id: 43c6e6e0c13950a9ce8cf3a70debe0421372d053
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65757
See gh-56794
Avoid dispatch inside of parallel_for by:
- Replacing Tensor slicing with TensorAccessor
- Replaces `bmm` and `mm` with direct calls to gemm.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31257878
Pulled By: ngimel
fbshipit-source-id: e6aad2d5ae7fa432bd27af2b1a8b0dcef1fc6653
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65770
This logging info is printed out in debug mode, make it log the
iteration as well for clarity.
ghstack-source-id: 139838595
Test Plan: CI
Reviewed By: zhaojuanmao, wayi1
Differential Revision: D31222132
fbshipit-source-id: 14519aae1ba0b2a35b4b962e7d1a957c9142c8f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65769
Seeing some bottlenecks when copying bucket to grad, help make it more
clear here.
ghstack-source-id: 139838597
Test Plan: Ci
Reviewed By: zhaojuanmao, wayi1
Differential Revision: D31217340
fbshipit-source-id: 762a254a3538eb5292b3a53bb5d1211057ecbdbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65730
This should close out the door on migrating all scheduled workflows we have for CircleCI
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
cc ezyang seemethere malfet pytorch/pytorch-dev-infra
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31225188
Pulled By: seemethere
fbshipit-source-id: 4c49e88ec017edc30e07325dbc613ff54dd164d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65545
Introduce 2bit qtensor. The new dtype added for this is c10::quint2x4
The underlying storage for this is still uint8_t, so we pack 4 2-bit values in a byte while quantizing it.
Kernels that use this dtype should be aware of the packing format. (4 2-bit values in one byte)
Test Plan: `buck test mode/dev-asan caffe2/test/:quantization -- test_qtensor`
Reviewed By: supriyar
Differential Revision: D31148141
fbshipit-source-id: 1dc1de719e097adaf93fee47c6d1b8010a3eae6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65712
No reason for this to be here.
ghstack-source-id: 139743362
Test Plan: fitsships
Reviewed By: dhruvbird
Differential Revision: D31215696
fbshipit-source-id: 238ea6633629831e54847ce82de23571cf476740
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66161
`aten::add` is not guaranteed to be bit exact with the JIT interpreter. This was causing non-deterministic test failures on master.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D31406764
fbshipit-source-id: d968cb1bdb8f33934682ef3712a1341a3aacf18e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66189
Added acc_ops for cumsum and unit test
Test Plan: buck test glow/fb/fx/oss_acc_tracer:test_acc_tracer
Reviewed By: 842974287
Differential Revision: D31355244
fbshipit-source-id: 41490d300553b0a5d52cbc4e681bdd0cf990eb42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65737
See gh-56794
Avoid dispatch inside of parallel_for by:
- Replacing Tensor slicing with TensorAccessor
- Copy bias into output only once, outside of the parallel region
- Replaces `addmm_` and `baddbmm_` with direct calls to gemm.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31257874
Pulled By: ngimel
fbshipit-source-id: 20b94daa13082fb1e39eaa8144bfa4c611b61bab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66158
qtopk used hypothesis which created flaky tests. In addition to that the tests generated were not representative, and would not catch the cases that we are interested in.
This diff removes the hypothesis from the qtopk and merges the qtopk and qtopk_nhwc tests. We now use specific testcases.
ghstack-source-id: 139768865
Test Plan: `buck test mode/dev //caffe2/test:quantization -- test_qtopk`
Reviewed By: jerryzh168
Differential Revision: D31401341
fbshipit-source-id: a8fb37a7221fc43c159f34e28aa4a91ed3506944
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65222
When compiling against the Android SDK with `--D_FORTIFY_SOURCE=2`, the compiler will complain that the `dst` size is a larger size than the `src` size due to the function templating using two differently sized objects. There is a `TORCH_CHECK` to ensure we don't go through with these `memcpy`'s, but in the interest of making the compiler happy, lets switch the `memcpy` to take `sizeof(src)`.
Test Plan: CI
Reviewed By: bertmaher, lanza
Differential Revision: D30992678
fbshipit-source-id: b3e7aa992a3650e1051abad05be800b684e6332b
Summary:
Network communications are flaky by nature, test should be marked as
skipped if network ops can not be completed for some reason
Fixes https://github.com/pytorch/pytorch/issues/66184
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66185
Reviewed By: seemethere
Differential Revision: D31423193
Pulled By: malfet
fbshipit-source-id: 96c3a123c65913f44ea78b30a03e8e7eda164afe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65850
This step was never added
ghstack-source-id: 139753673
Test Plan: Run optimize_for_mobile on model with conv1d and see that it transforms to conv2d
Reviewed By: kimishpatel
Differential Revision: D31093503
fbshipit-source-id: 11a19f073789c01a9de80f33abbe628005996b66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61647
`prepare_fx` currently assumes that bias is always a positional argument to
convolutions, and only a keyword argument to other functions. This happens to work
today due to a quirk in how `__torch_function__` is handled for python
functions but shouldn't be considered stable.
Instead, we should support `bias` for both positional and keyword forms.
cc jerryzh168 jianyuh raghuramank100 jamesr66a vkuzo
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D31401360
Pulled By: albanD
fbshipit-source-id: 1e2f53d80e2176b870f326dc498e251e2386136e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65865
`operator_str` is not used in `import.cpp` and it is also defined in `parse_operators.cpp` so removing it from `import.cpp`.
Test Plan: CI passing
Reviewed By: iseeyuan
Differential Revision: D31293008
fbshipit-source-id: 1c857cbd63c57b8f79c1a068789fc8605605b642
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63129
1. Add an api to get `supported_types` from runtime, expose in c++ only.
2. Add an api to get `contained_types` from model, expose in both c++ and PyThon.
3. Add a field `contained_types_` in `type_parser.cpp` to track the contained types when parsing python string.
4. Expand `is_compatible` api to check type. When checking type, it will check the contained type list from the model with the support type list from runtime.
5. Expand the unittest for compatibility to cover type
6. Add unit test in python to check type list
ghstack-source-id: 139826944
Test Plan:
```
buck test mode/dev //caffe2/test/cpp/jit:jit -- --exact 'caffe2/test/cpp/jit:jit - LiteInterpreterTest.GetContainTypes'
buck test mode/dev //caffe2/test/cpp/jit:jit -- --exact 'caffe2/test/cpp/jit:jit - LiteInterpreterTest.isCompatibleSuccess'
buck test mode/dev //caffe2/test/cpp/jit:jit -- --exact 'caffe2/test/cpp/jit:jit - LiteInterpreterTest.isCompatibleFail'
buck test //caffe2/test:mobile
```
Reviewed By: iseeyuan
Differential Revision: D30231419
fbshipit-source-id: 8427f423ec28cc5de56411f15fd960d8595d6947
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65976
More TypeParser class to header file so it can be called from somewhere else. For example, the getContainedTypes() api in this stack can be moved to other files.
ghstack-source-id: 139826943
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D31294254
fbshipit-source-id: 1c532fd69c7f6b44ad2332055d24c95a0fac1846
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66054
I need this function in functorch to support the ability of custom
jitted kernels to invoke torch_function when applicable.
Test Plan: functorch unit tests
Reviewed By: qihqi, ngimel
Differential Revision: D31416599
Pulled By: bertmaher
fbshipit-source-id: 90b57badd6a6b9d505ebfc436869b962b55c66d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66169
Original change: D30368834 (57e5ae5306)
Switching to Push Constants from Uniform Buffers caused some unforseen memory errors when running Mac unit tests.
We'll switch back for now until we can pinpoint and resolve the issue.
Test Plan:
Build and run `vulkan_api_test`
```
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_api_test
adb shell "/data/local/tmp/vulkan_api_test"
```
Reviewed By: beback4u
Differential Revision: D31409130
fbshipit-source-id: cab1a3330945b50522235db6738406b6037f9c68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65955
This diff makes sure to give clear error message when user tries to create obj from obj that lives in different session
Test Plan: buck test //caffe2/torch/csrc/deploy:test_deploy
Reviewed By: suo
Differential Revision: D31323045
fbshipit-source-id: e7bd6f76afeb0285847bc11881185a164f80e3f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66038
Will help track workflows for DP deprecation. Tested via standalone DP
script.
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D31356975
fbshipit-source-id: c0a3ac3a1faed794e3362f3f3a19a6fb800587a7
Summary:
```python
class Foo(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, a=None, b=None):
res = a
if b is not None:
res = res + b
return res
concrete_args = {'b': torch.tensor(5)}
traced = fx.symbolic_trace(Foo(), concrete_args=concrete_args)
```
Gives the following error:
```
File "<eval_with_key_9>", line 2
def forward(self, a = None, b_1):
^
SyntaxError: non-default argument follows default argument
```
Since https://github.com/pytorch/pytorch/issues/55888, placeholders are also created for concrete arguments. But these placeholders do not have default values even when it was provided for the argument in question, causing the error above.
To solve this, I add a default value when it is available during placeholder creation for concrete arguments.
I also tried to set the default value to the value specified in concrete_args (since it many cases it will actually use this value anyway), but ran into an error because the default value is never defined:
```
def forward(self, a = None, b_1 = _tensor_constant0):
_tensor_constant0 = self._tensor_constant0
_tensor_constant1 = self._tensor_constant1
add = a + _tensor_constant1; a = _tensor_constant1 = None
NameError: name '_tensor_constant0' is not defined
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59569
Reviewed By: albanD
Differential Revision: D31385607
Pulled By: Chillee
fbshipit-source-id: 44a8ce28b5eabdb9b4c773e73a68ff0bb9c464cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66174
These configs have already been migrated so going to go ahead and remove
them
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31413579
Pulled By: seemethere
fbshipit-source-id: 8923736d347eb8c8470884be413122c198d1bf20
Summary:
These utils are prerequisites for Lazy Node base class.
- set up new torch/csrc/lazy, test/cpp/lazy dirs
- add source files to build_variables.bzl in new lazy_core_sources var
- create new test_lazy binary
Fixes https://github.com/pytorch/pytorch/issues/65636
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65635
Reviewed By: alanwaketan
Differential Revision: D31260343
Pulled By: wconstab
fbshipit-source-id: 8bb1194188e3e77fc42e08a14ba37faed37a9c2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65064
The problem appears when nvfuser is triggered from LazyTensor.
Because LT maintains its own thread pool, the thread used for the first-time
compilation does CUDA context initialization properly, but later
cached execution may use a different thread which does not have
a proper CUDA context.
Test Plan: Imported from OSS
Reviewed By: saketh-are
Differential Revision: D31269691
Pulled By: desertfire
fbshipit-source-id: 384362025c087d61e8b625ff938379df283ef8b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62030
Remove dtype tracking from Python Storage interface, remove all the different `<type>Storage` classes except for `ByteStorage`, and update serialization accordingly, while maintaining as much FC/BC as possible
Fixes https://github.com/pytorch/pytorch/issues/47442
* **THE SERIALIZATION FORMAT IS FULLY FC/BC.** We worked very hard to make sure this is the case. We will probably want to break FC at some point to make the serialization structure of tensors make more sense, but not today.
* There is now only a single torch.ByteStorage class. Methods like `Tensor.set_` no longer check that the dtype of storage is appropriate.
* As we no longer know what dtype of a storage is, we've **removed** the size method from Storage, replacing it with nbytes. This is to help catch otherwise silent errors where you confuse number of elements with number of bytes.
* `Storage._new_shared` takes a `nbytes` kwarg and will reject previous positional only calls. `Storage._new_with_file` and `_set_from_file` require explicit element size arguments.
* It's no longer possible to convert storages to different types using the float/double/etc methods. Instead, do the conversion using a tensor.
* It's no longer possible to allocate a typed storage directly using FloatStorage/DoubleStorage/etc constructors. Instead, construct a tensor and extract its storage. The classes still exist but they are used purely for unpickling.
* The preexisting serialization format stores dtype with storage, and in fact this dtype is used to determine the dtype of the tensor overall.
To accommodate this case, we introduce a new TypedStorage concept that exists only during unpickling time which is used to temporarily store the dtype so we can construct a tensor. **If you overrode the handling of pickling/unpickling, you MUST add handling for TypedStorage** or your serialization code will degrade to standard file-based serialization.
Original pull request: https://github.com/pytorch/pytorch/pull/59671
Reviewed By: soulitzer, ngimel
Differential Revision: D29466819
Pulled By: ezyang
fbshipit-source-id: 4a14e5d3c2b08e06e558683d97f7378a3180b00e
Summary:
Updating `computeStrideProps` logic to break ties on stride_indices.
For two dimension with identical stride, the dimension with size-1 should be considered as the faster dimension. Otherwise, its stride should be the product of existing stride and the size of the other dimension.
Note that there's still inconsistency between eager memory_format and stride_properties in JIT, this is a design issue due to the ambiguity on size-1 stride. One example showing this failing test has been disabled in the added cpp test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63940
Reviewed By: albanD
Differential Revision: D31227448
Pulled By: dzhulgakov
fbshipit-source-id: 51e3cd903757bef55d3158c057f9444d0cff7d2a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66058
After the initial migration from `torch.quantization` to `torch.ao.quantization`, some of the files did not change.
This happened because the migration was done in parallel, and some of the files were landed while the others were still in the original location.
This is the last fix in the AO migration phase 1, which completely enables the ao.quantization namespace.
Test Plan: `python test/test_quantization.py`
Reviewed By: vkuzo
Differential Revision: D31366066
Pulled By: z-a-f
fbshipit-source-id: bf4a74885be89d098df2d87e685795a2a64026c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66057
The current test is creating the sets that are too slow.
This will cause either "Filtering too much" or "Timeout" errors in the future versions of hypothesis.
This PR preemptively fixes the issue.
Test Plan: `python test/test_quantization.py`
Reviewed By: vkuzo
Differential Revision: D31366065
Pulled By: z-a-f
fbshipit-source-id: deaab4da8ee02a5dee8943cabdd30fc53d894a34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65783
convolution_op makes conv_param struct redundant, since it contains all the params of conv_param and more. We don't need to pass both structs to qnnpack or hold both in the packed weights, let's just hold convolution_op.
This makes it easier to implement 3dconv since we won't have to template two structs. The conv_param struct is left in existence since tests rely on it to set up the convolution.
ghstack-source-id: 139479651
(Note: this ignores all push blocking failures!)
Test Plan: ci
Reviewed By: kimishpatel
Differential Revision: D30738727
fbshipit-source-id: e6d39644357b99d3b7491ae8a7066bf107eb8b9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65726
This PR isn't strictly necessary since grad_weight doesn't use
parallel_for. However, this does reduce the function overhead and will
make it easier to parallelize in the future.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31257877
Pulled By: ngimel
fbshipit-source-id: d8ea97cc1f43d8d9dfff355ae27c9d982838b57e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66123
Some models may take in a list of tensors as inputs, thus the bundled inputs will contain `IValues` that are of the type `c10::List`. For Vulkan models, every tensor in the `IValue` list has to be converted to a vulkan tensor first, and this case is not currently handled by the Vulkan model wrapper in the benchmark binary.
This diff introduces `IValue` type checking to the input processor of the Vulkan model wrapper, and adds support for Tensor and List types.
Test Plan:
```
# Build the binary
cd ~/fbsource
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:ptmobile_compareAndroid\#android-arm64 --show-output
# Push it to the device
adb push buck-out/gen/xplat/caffe2/ptmobile_compareAndroid\#android-arm64 /data/local/tmp/compare_models
# Run the benchmark binary
BENCH_CMD="/data/local/tmp/compare_models"
BENCH_CMD+=" --model=$PATH_TO_MODEL"
BENCH_CMD+=" --refmodel=$PATH_TO_REFERENCE_MODEL"
BENCH_CMD+=" --input_type=float --input_dims=$MODEL_INPUT_SIZE"
BENCH_CMD+=" --iter=100"
BENCH_CMD+=" --tolerance 1e-5"
```
Reviewed By: beback4u
Differential Revision: D31276862
fbshipit-source-id: 1d9abf958963da6ecad641202f0458402bee5ced
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65849
Add tests for some of `StaticModule`'s exposed methods. Both of these are used by the memory planner, so it would be helpful to have some unit tests that ensure our basic invariants don't break.
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D31282901
fbshipit-source-id: e390329f4794e034170507e3a0de0abcfe0ab7b9
Summary:
Delete `-Wno-unused-variable` from top level `CMakeLists.txt`
Still suppress those warnings for tests and `torch_python`
Delete number of unused variables from caffe2 code
Use `(void)var;` to suppress unused variable in range loops
Use `C10_UNUSED` for global constructors and use `constexpr` instead of `static` for global constants
Do not delete `caffe2::OperatorBase::Output` calls as they have side effects
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66041
Reviewed By: ngimel
Differential Revision: D31360142
Pulled By: malfet
fbshipit-source-id: 6fdfb9f91efdc49ca984a2f2a17ee377d28210c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66048
Previously, create_arg would fail if it encountered a not `None` layout argument. Adding it to `BaseArgumentTypes` list should be enough to fix that.
Test Plan: Added unittest
Reviewed By: jamesr66a
Differential Revision: D31362662
fbshipit-source-id: 20049971e18c17e9c75e50540500c567266daa55
Summary:
Reland of https://github.com/pytorch/pytorch/pull/65242
The last attempt of the reland automatically rebased onto stable, which did not yet have the revert commit
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66018
Reviewed By: albanD
Differential Revision: D31348822
Pulled By: soulitzer
fbshipit-source-id: 881d701b404530c1352ac9245bd67264e1652b8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65566
This doesn't simplify vectorized jacobian computation, but is good to consolidate logic and helps us to test the logic
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31236257
Pulled By: soulitzer
fbshipit-source-id: 00ca0aa6519bed5f9ee2c7be4daa8872af5e92cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65564
- wrap the call into engine with vmap if `batched_grad` is `True`
- improves the comment on the call to engine (somewhat addressing https://github.com/pytorch/pytorch/issues/41659)
- borrows the message from functional.jacobian's vectorized argument concerning usage of the vmap feature
- adds basic test (further testing is done when we replace the usage in vectorized jacobian computation)
TODO:
- create an issue tracking this
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31236259
Pulled By: soulitzer
fbshipit-source-id: b33e6b26ea98fa9f70c44da08458fc54ba4df0f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65516
This change fixes a bug that Static Runtime's `aten::embedding_bag` out variant implementation creates aliases in its managed output tensors.
Managed output tensors should never be an alias with each other since writing to them can illegally overwrite others' contents unintentionally, and this exact problem was causing the bug at T97393697, causing SR to return wrong return values.
This bug is detected in inline_cvr/remote_ro by a DCHECK, `verify_no_memory_overlap` (introduced by D30211705 (3fb33b38b9)), but wasn't found so far since our testing didn't include running the model in the debug mode. Fortunately this bug is not hitting production since the aliases outputs are not used in production.
This change fixes the root cause from `_embedding_bag_cpu_impl_out` by replacing alias creation with copying.
Note that this change also includes a fundamental change in Static Runtime's unit testing: `testStaticRuntime` exercises the given graph 3 times:
1. profile run
2. run using the profile to allocate managed tensors
3. reuse the managed tensors -- newly added
Adding 3 reveals this bug with a new unittest `EmbeddingBagWithManagedOutput`.
Test Plan:
- Confirmed that the crash experienced by `StaticRuntime.EmbeddingBagWithManagedOutput` disappears with this change (crash paste: P459807248).
- Added `StaticRuntime.EmbeddingBagWithManagedOutput` to detect the same problem in the future.
Reviewed By: hlu1
Differential Revision: D31104345
fbshipit-source-id: 7bddf9cd82b400d18d8ce1bf15e29b815ef9ba8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66056
keep running into this unrelated failure when landing diffs regarding the gpu inference project,
disabling this operator unit test in gpu because it doesn't exist
RuntimeError: [enforce fail at operator.cc:277] op. Cannot create operator of type 'SmartDecaySparseAdam' on the device 'CUDA'. Verify that implementation for the corresponding device exist. It might also happen if the binary is not linked with the operator implementation code. If Python frontend is used it might happen if dyndep.InitOpsLibrary call is missing. Operator def: input: "param" input: "mom1" input: "mom2" input: "last_seen" input: "indices" input: "grad" input: "lr" input: "iter" output: "param" output: "mom1" output: "mom2" output: "last_seen" name: "" type: "SmartDecaySparseAdam" arg { name: "beta1" f: 0 } arg { name: "beta2" f: 0.9 } arg { name: "epsilon" f: 1e-05 } device_option { device_type: 1 }
https://www.internalfb.com/intern/testinfra/diagnostics/5910974579962988.562949996565057.1633122845/
Test Plan: sandcastle
Reviewed By: jianyuh
Differential Revision: D31364731
fbshipit-source-id: 7fbd994cbe7f6ca116f5f34506a1ed7f14759bdf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65842
During backport, only parts of the model (like bytecode.pkl) needs to be re-written, while the rest of the model is the same. However, `version` will always be re-written when `PyTorchStreamWriter` is destrcuted.
Change version to optional and add an api to allow skipping writing version when closing the writer.
ghstack-source-id: 139580386
Test Plan: buck run papaya/scripts/repro:save_load
Reviewed By: iseeyuan, tugsbayasgalan
Differential Revision: D31262904
fbshipit-source-id: 3b8a5e1aaa610ffb0fe8a616d9ad9d0987c03f23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66025
This change adds an option to selectively enable precise alias analysis for `prim::`TupleConstruct` (introduced by D30437737 (cd458fe092)) to minimize its exposure only to `StaticRuntime` as of now.
Test Plan: Modified existing unit tests whose behavior depends on D30437737 (cd458fe092).
Reviewed By: eellison
Differential Revision: D31350285
fbshipit-source-id: 3ce777f07f99650d74634481ad0805192dce55c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64572
Fixes https://github.com/pytorch/pytorch/issues/64256
It also fixes an inconsistent treatment of the case `reduction = "mean"`
when the whole target is equal to `ignore_index`. It now returns `NaN`
in this case, consistently with what it returns when computing the mean
over an empty tensor.
We add tests for all these cases.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D31116297
Pulled By: albanD
fbshipit-source-id: cc44e79205f5eeabf1efd7d32fe61e26ba701b52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65245
Building and running c10 and qnnpack tests on XROS.
Notable changes:
- Adding #if define(_XROS_) in few places not supported by XROS
- Changing Threadpool to abstract class
ghstack-source-id: 139513579
Test Plan: Run c10 and qnnpack tests on XROS.
Reviewed By: veselinp, iseeyuan
Differential Revision: D30137333
fbshipit-source-id: bb6239b935187fac712834341fe5a8d3377762b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65957
added accelerator ops and unit test for GELU.
Test Plan: buck test glow/fb/fx/oss_acc_tracer:test_acc_tracer
Reviewed By: 842974287
Differential Revision: D31277083
fbshipit-source-id: f66dd05ef574db58cfa599e3575f95f1ebe82e93
Summary:
Delete `-Wno-unused-variable` from top level `CMakeLists.txt`
Still suppress those warnings for tests and `torch_python`
Delete number of unused variables from caffe2 code
Use `(void)var;` to suppress unused variable in range loops
Use `C10_UNUSED` for global constructors and use `constexpr` instead of `static` for global constants
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65954
Reviewed By: ngimel
Differential Revision: D31326599
Pulled By: malfet
fbshipit-source-id: 924155f1257a2ba1896c50512f615e45ca1f61f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66006
Previously, this was resulting in a key collision and a crash.
ghstack-source-id: 139342089
Test Plan: Ran webdriver test locally.
Reviewed By: dhruvbird
Differential Revision: D31281092
fbshipit-source-id: f31311726c681d6d7e0504ff8e84c888af9054f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66005
ghstack-source-id: 139342091
Test Plan: Unit test, and used in a notebook.
Reviewed By: dhruvbird
Differential Revision: D31281091
fbshipit-source-id: 1e4d0713b9796a3d182de9e676c3b3c3b1610d6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66016
Add acc_ops.tile and converter for it.
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_tile
Reviewed By: wushirong
Differential Revision: D30587939
fbshipit-source-id: 1e2613cfca486fe54fcc0d38e5c7cdeb7d0ed4a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65928
This diff adds a decorator for adding flags to acc_ops. These flags inform graph optimizations that the op is eligible for optimization by some general criteria (e.g. op acts elementwise, op does quantization).
This makes it simpler to expand acc_ops. The user can add an op and add flags to enable optimization without going through all graph opts and trying to determine if new acc_op is eligible for the graph optimization.
Even though our list of graph opts is small now we already see that for `sink_reshape_ops` we had hardcoded 11 pointwise acc_ops, now there are 24 pointwise acc_ops.
Test Plan:
```
buck test mode/opt glow/fb/fx/graph_opts:test_fx_sink
```
```
Parsing buck files: finished in 0.5 sec
Downloaded 0/3 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 37.1 sec (100%) 10279/10279 jobs, 3/10279 updated
Total time: 37.7 sec
More details at https://www.internalfb.com/intern/buck/build/e13521bb-6142-4960-8cdd-6b5e4780da96
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 16260a2a-d364-4605-9111-6f2a19317036
Trace available for this run at /tmp/tpx-20210922-124332.623880/trace.log
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/4222124720425564
✓ ListingSuccess: glow/fb/fx/graph_opts:test_fx_sink - main (6.038)
✓ Pass: glow/fb/fx/graph_opts:test_fx_sink - test_no_sink_concat_below_quantize (glow.fb.fx.graph_opts.tests.test_fx_sink.TestSink) (0.036)
✓ Pass: glow/fb/fx/graph_opts:test_fx_sink - test_sink_concat_below_quantize (glow.fb.fx.graph_opts.tests.test_fx_sink.TestSink) (0.048)
✓ Pass: glow/fb/fx/graph_opts:test_fx_sink - test_sink_reshape_nodes (glow.fb.fx.graph_opts.tests.test_fx_sink.TestSink) (0.058)
✓ Pass: glow/fb/fx/graph_opts:test_fx_sink - test_no_sink (glow.fb.fx.graph_opts.tests.test_fx_sink.TestSink) (0.057)
Summary
Pass: 4
ListingSuccess: 1
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/4222124720425564
```
Reviewed By: jfix71
Differential Revision: D31121321
fbshipit-source-id: 6f6e3b8e2d57ea30766fa6bee34ca207cec86f0f
Summary:
The docs stuff is unnecessary since they are hosted in S3 anyways, and the reports are mirrored in S3 which has better upload/download speed and is available as soon as the upload is done rather than once the workflow is complete.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65875
Reviewed By: seemethere
Differential Revision: D31296500
Pulled By: driazati
fbshipit-source-id: 8c371230d0c8c0eb785702df9ae495de85f60afa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66000
Saw this in nvprof and I'm just a little too nitpicky to let it slide!
ghstack-source-id: 139547271
Test Plan: CI
Reviewed By: xiaomengy
Differential Revision: D31340262
fbshipit-source-id: ab48dc99c34a74585e66800b4bbcccc6aabbaff2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65499
When the tensors in question are contiguous, there is no need to go through dispatch, use TensorIterator, etc.
ghstack-source-id: 139549027
Test Plan:
Ran ptvsc2_predictor_bench for ctr_mobile_feed local net following https://fb.quip.com/q8hBAFGMeaOU (but without the profile and compare_results options).
Before:
I0922 14:00:32.261942 3132627 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 7.18124. Iters per second: 139.252
I0922 14:01:44.865965 3132627 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 7.25314. Iters per second: 137.871
I0922 14:02:56.929602 3132627 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 7.1986. Iters per second: 138.916
I0922 14:04:05.923025 3132627 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 6.89211. Iters per second: 145.093
I0922 14:05:17.953056 3132627 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 7.19577. Iters per second: 138.971
mean: 7.144172, stddev: 0.1283
After:
I0922 13:51:55.233937 3086245 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 6.79709. Iters per second: 147.122
I0922 13:53:03.062682 3086245 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 6.77605. Iters per second: 147.579
I0922 13:54:10.230386 3086245 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 6.70993. Iters per second: 149.033
I0922 13:55:18.403434 3086245 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 6.81044. Iters per second: 146.833
I0922 13:56:26.568646 3086245 PyTorchPredictorBenchLib.cpp:312] PyTorch run finished. Milliseconds per iter: 6.80965. Iters per second: 146.85
mean: 6.800632, stddev: 0.013227
Looks like about a 5.3% improvement.
Reviewed By: hlu1
Differential Revision: D31125492
fbshipit-source-id: 92ab5af242d0a84dcf865323a57b48e8374eb823
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65713
This may not be needed anymore.
ghstack-source-id: 139114284
Test Plan: see if it builds
Reviewed By: dhruvbird
Differential Revision: D31216245
fbshipit-source-id: 29c9c013f94070c7713e46027881cb693b144d36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64065
It is only safe to mutate Tuple elements if you are the sole owner
of the tuple. The most efficient way to do this, then, is
`std::move(*std::move(tupleIValue).toTuple()).elements()` (the
innermost move allows `IValue::toTuple()` to avoid a refcount bump and
the outermost move allows the element vector to be moved out of the
tuple), but many callsites write simply
`tupleIValue.toTuple().elements()`, which incurs many extra refcount
bumps.
ghstack-source-id: 139468088
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D30592621
fbshipit-source-id: e8312de866de09b9ea2a62e5128cbf403ee16f09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65960
Fix a bug in the converter and add support for negative dim.
Test Plan: buck test mode/dev-nosan caffe2/torch/fb/fx2trt:test_narrow
Reviewed By: wushirong
Differential Revision: D31310232
fbshipit-source-id: 62887369d830202cae6d63b41747225b12dcf754
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65826
Should be marginally more efficient.
ghstack-source-id: 139315050
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D31272489
fbshipit-source-id: 7c309d67a0ec0ada35a5b62497bac374538394a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65933
We use `split_module` to split the input model that we want to const fold into const and non-const subgraphs. Previously we were taking the non-const graph and trying to hack it back into the same signature as the input model. However this was complex/buggy.
Instead, refactor to just keep using the base split module that contains both const and non-const graphs. This means we:
- Inline the non-const graph into the split module
- Remove the const graph from the module and replace it with a getattr that will be run to insert that attr when we `run_folding`
Test Plan: Added test coverage to cover newly supported folding, and updated other tests for new strategy.
Reviewed By: yinghai
Differential Revision: D31293307
fbshipit-source-id: 6e283a8c7222cf07b14e30e74dffc8ae5ee8b55f
Summary:
Fixes https://github.com/pytorch/pytorch/issues/64000
- updates double backward formula to compute grad wrt output instead of self
- ~~In some of the error messages, we still refer to the dtype of the input, even though we are now checking the dtype of the output~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65242
Reviewed By: malfet
Differential Revision: D31317680
Pulled By: soulitzer
fbshipit-source-id: b3b921e06775cfc12e5a97a9ee8d73aec3aac7c3
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/58547.
I added an OpInfo-based test that fails on master and passes with the
proposed changes.
cc ezyang albanD zou3519 gqchen pearu nikitaved soulitzer Lezcano Varal7 mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65714
Reviewed By: saketh-are, mruberry
Differential Revision: D31248307
Pulled By: albanD
fbshipit-source-id: 041eaa9b744c3043f78dd8ae5f457f67c311df4f
Summary:
This PR adds raising an error when `len(output_differentiability) != len(outputs)`
Notes in derivatives.yml tell that
> 'output_differentiability' and value a list of the same length as the number of outputs from the forward function.
but it was not enforced in codegen leading to confusion and unexpected bugs https://github.com/pytorch/pytorch/issues/65061#issuecomment-930271126.
cc ezyang albanD zou3519 gqchen pearu nikitaved soulitzer Lezcano Varal7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65823
Reviewed By: mrshenli
Differential Revision: D31307312
Pulled By: albanD
fbshipit-source-id: caeb949e9249310dffd237e77871e6d0d784e298
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65878
If we attempt to compute an offset into an empty tensor we trigger UB, since
we'd be adding an offset to a nullptr, which is UB
(https://reviews.llvm.org/D67122) even if we never use the pointer.
Since indexing into an empty tensor yields an empty tensor anyways, let's just
return the underlying (null) data ptr in this case.
ghstack-source-id: 139448496
Test Plan:
r-barnes originally pointed this out to me in a failing TE fuser test:
https://www.internalfb.com/intern/testinfra/diagnostics/5910974579561425.281475022329152.1632898053/
```
buck test mode/dev //caffe2/test:jit -- --exact 'caffe2/test:jit - test_unsupported_nn_functional_pad_circular_cpu_float32 (test_jit_fuser_te.TestNNCOpInfoCPU)'
```
But it turns out it's easily triggered by anything that tries to operate on a
slice of a size-0 tensor:
```
def test_pad(self):
F.pad(torch.ones(0, 3, 3), (1, 2), 'circular')
def test_index(self):
input = torch.zeros(0, 3, 3)
out = torch.zeros(0, 3, 6)
out[..., 1:4] = input[..., 0:3]
def test_add(self):
torch.ones(0, 2)[:, 1] + torch.ones(0, 1)
```
What's the right place for these sort of operator corner-case tests? Should
they be/are they part of OpInfo?
Reviewed By: jamesr66a
Differential Revision: D31296914
fbshipit-source-id: 0ef52ad311dceeed985498f8d9390bc6fbaefbfc
Summary:
This is to fix Pyre errors in our applications:
* calling `tensor.cos()` etc.
* creating a data loader with batch sampler that is `List[List[int]]`.
Test Plan: TODO: rebase the diffs and run Pyre.
Reviewed By: ejguan
Differential Revision: D31309564
fbshipit-source-id: 1c6f3070d7570260de170e2fe2153d277b246745
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65295
The m-out-of-n is implemented as follows:
1. Compute the blocks that need to be sparsified using the weight-norm criterion
2. Within each block below the threshold find the smallest absolute value elements
3. Zero out only the smallest values within each block
m-out-of-n describes sparsification scheme where in a block with "n" elements, only "m" of them would be zeroed-out.
Block sparsity, with the whole block being all zeros, is a special case of m-out-n: If m==n, the whole block is reset.
This echoes the implementation described in the https://github.com/pytorch/pytorch/issues/59835,
as well as meets the support of the nVidia cusparselt requirements.
To support the CUDA sparsity (2/4), one would need to set the sparsity_level to 1.0.
That translates to all blocks of shape 1x4 within a tensor will sprasify with 2-out-4 scheme.
Test Plan: Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31186828
Pulled By: z-a-f
fbshipit-source-id: 7bd3e2707915b90f4831859781fc6e25f716c618
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65296
The original API described in the https://github.com/pytorch/pytorch/issues/59835
assumed that the per-layer configuration would take a module/layer
reference. However, a more useful approach is to refer to the layers
by their fully qualified names (FQN). That allows us to store the
configuration in a file without serializing the models.
We define a layer's FQN as it's "path" within a model. For example,
if one can refer to a model using `model.layer0.sublayerX`, the FQN
of the sublayerX is `'layer0.sublayerX'`.
Test Plan:
```
python test/test_ao_sparsity.py -- TestBaseSparsifier
buck test mode/opt //caffe2:test -- TestBaseSparsifier
```
Reviewed By: gchanan
Differential Revision: D31186830
Pulled By: z-a-f
fbshipit-source-id: d8d87f1c054e5c10d470e67837476a11e0a9b1d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65939
This change includes 2 separate optimizations.
1. Provide an overload of `debugString(const char*, ...)` in addition to `debugString(std::string, ...)` for cases where `const char*` is passed in to avoid `std::string` construction in cases where `STRIP_ERROR_MESSAGES` is also defined and the caller is passing in a `const char*`
2. Return `std::string("", 0)` instead of `""` since the former triggers no call to `std::basic_string`'s constructor whereas the latter does. [Godbolt Link](https://godbolt.org/z/oTExed5h8). However, I'm surprosed by this since the man page for [std::basic_string](https://en.cppreference.com/w/cpp/string/basic_string/basic_string) clearly states that the constexpr overload is since C++20, and I am building using `-Os -std=c++17`
Godbolt Screenshot:
{F667311023}
ghstack-source-id: 139507542
Test Plan:
CI and local build via:
```
buck build //xplat/caffe2/fb/lite_predictor:lite_predictor
```
Reviewed By: swolchok
Differential Revision: D31312942
fbshipit-source-id: aa24abbfe1c16419f235d037595321982614c5ea
Summary:
Description:
- Have only added `stdout` and `stderr` as possible options from python
API for now. We can do file path passing later maybe.
- Put the class `JitLoggingConfig` in the cpp file as none of its methods were being used outside of this file.
Python API:
`torch._C._jit_set_logging_stream('stdout|stderr')`
C++ API:
`::torch::jit::set_jit_logging_output_stream(ostream);`
Testing:
- Tested python API locally.
- Unit test for the C++ API is written
Fixes https://github.com/pytorch/pytorch/issues/54182
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65768
Reviewed By: mrshenli
Differential Revision: D31291739
Pulled By: ZolotukhinM
fbshipit-source-id: eee72edc20488efad78a01c5b0ed8a132886a08d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65861
First in a series. This PR changes the code in deploy.h/cpp and
interpreter_impl.h/cpp to be camel case instead of snake case. Starting
with this as it has the most impact on downstream users.
Test Plan: Imported from OSS
Reviewed By: shannonzhu
Differential Revision: D31291183
Pulled By: suo
fbshipit-source-id: ba6f74042947c9a08fb9cb3ad7276d8dbb5b2934
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65552
This PR is mostly a verbatim move of several functions to different
files. The goal is to have more consistency in what resides where.
With this PR:
* All `compute*` functions defining how a given operator needs to be
lowered to TE IR will reside in `operators/*.{cpp,h}`.
* Auxiliary functions for these functions will reside in
`operators/misc.cpp`. `compute*` functions for ops not belonging
anywhere else can also go to that file.
* `operators/unary.*` is renamed to `operators/pointwise.*` and now
includes functions like `computeTwoOperands`.
* `kernel.*` now contains *only JIT-related* logic and implementations of
`TensorExprKernel` methods.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31148923
Pulled By: ZolotukhinM
fbshipit-source-id: e36ad8e779b8d30a33b49ea4ebf6d6a7438989f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65551
Previously we had a big switch on Op kind to decide how to lower a given
JIT operator to NNC. This PR changes this switch to a hash table lookup.
Why? This helps us with at least two things:
1) With this approach we can easily check if we know how to handle a
given node in advance - i.e. we can inspect the entire graph and tell
whether it's possible to compile it or not without actually trying to do
that and dying in the middle. This would allow us to, say, provide
user-friendly error messages in AOT workflow.
2) We can switch to use schema instead of op kind to determine correct
lowering. Unlike op schema, op kind might be ambigous (see e.g. #64963)
and using it instead of schema can lead to bugs.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31148926
Pulled By: ZolotukhinM
fbshipit-source-id: ac12684e2126c899426ef5e4cc1e3f70fa01f704
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65550
This PR adds the source files and the class for the registry, subsequent
PRs actually port existing lowerings to this mechanism.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31148922
Pulled By: ZolotukhinM
fbshipit-source-id: 4c087b22ee898d5a5a18a5d2a4bb795aa2ffd655
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65549
Previously it had a special handling, with this change it follows the
same mechanism as other ops.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31148924
Pulled By: ZolotukhinM
fbshipit-source-id: 572d8ae5e123e7a0e2a656154d7bd0f73c785a06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65882
`torch::jit::Module` is refcounted. There is no need to wrap it in a `shared_ptr`.
Test Plan:
```
buck run //caffe2/benchmarks/static_runtime:static_runtime_cpptest
```
Reviewed By: mikeiovine
Differential Revision: D31012222
fbshipit-source-id: 74d234bd85423e5ba0e396f24899631354a2c74b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65725
See gh-56794
Avoid dispatch inside of parallel_for by:
1. Replacing Tensor slicing with TensorAccessor
2. Call `grad_input.zero_()` only once, outside of the parallel region
3. Replace `at::mm` with a `gemm` call
Test Plan: Imported from OSS
Reviewed By: saketh-are
Differential Revision: D31257876
Pulled By: ngimel
fbshipit-source-id: f2902edeccd161431c1dfb1ab3e165d039ec259d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65493
Added a last resolve to use whatever ATen operator that has Tensor outputs in the graph as the operator node to check alias annotation.
Test Plan: python test/test_ops.py -k test_variant_consistency_jit
Reviewed By: mrshenli
Differential Revision: D31321221
Pulled By: alanwaketan
fbshipit-source-id: f4a5cbfd36bd0867d8c1bf9de9a65365ee7c35d6
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/65506
Test Plan: run a adfinder canary and verify this error is fixed.
Reviewed By: swolchok
Differential Revision: D31130083
fbshipit-source-id: c31f179f8a7de75ed6f6e7ee68b197f2970ddd3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65746
This also removes the cudaHostAllocator field on THCState, since there
doesn't seem to be an API anywhere for customizing it.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D31236630
Pulled By: ngimel
fbshipit-source-id: 2a8e756222ae70565e77f8e7139d60ec5be32276
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64578
* Fix remainder export for edge case when input is negative. New export relies on true_divide export.
* Simplified true_divide export. Cleaned up redundant code which is handled by scalar type analysis pass. Removed dependency on `onnx::Where`, thus supports opset 7 & 8.
Fixes#60179
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D30919601
Pulled By: malfet
fbshipit-source-id: 0f78621c0ac3bdb6bf4225e049ba5f470dc8ab12
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64381
* Added new ONNX test for batched_nms
* Update test according to PR in torchvision
* Update test/onnx/test_pytorch_onnx_onnxruntime.py
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D30919602
Pulled By: malfet
fbshipit-source-id: edfb5b9f75077429f7f242fd6ac06d962968dfba
Co-authored-by: Bowen Bao <imbowenbao@outlook.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64787
This PR added support for lowering per channel quantization and dequantization operators
in fx2trt, this also extends TensorMeta with extra arguments corresponding to per channel quantized Tensors,
initially I was thinking of adding a qpram that can capture everything, but currently we still have some lowering support
for fbgemm ops (which has scale and zero_point in operator interface). I think we can move everything to qprams
after we deprecate lowering support for fbgemm ops in the future.
Test Plan:
Test for per channel weight:
```
python torch/fx/experimental/fx2trt/example/quantized_resnet_test.py
```
change BC compatibility test expect for TensorMeta
```
python test/test_fx.py TestFXAPIBackwardCompatibility.test_class_member_back_compat --accept
```
Imported from OSS
Reviewed By: jfix71, mrshenli, 842974287
Differential Revision: D30879848
fbshipit-source-id: 76c3804bb1d9343183ae53d9f02c1a3bf6c79e1c
Summary:
torch.dtype.__reduce__ returns a string, which causes Pickle to look
up the object by module and name. In order to find the right module,
Pickle looks for __module__ on the object; if it doesn't find that, it
falls back to searching sys.modules.
Previously, torch.dtype instances did not have a `__module__`
attribute, so pickling dtypes would fall back to a search of
sys.module.
Instances of normal Python objects have a `__module__` attribute
because normal Python classes have a `__module__` key in their
`__dict__`. Imitate that by populating one in `torch.dtype`.
We set the field in `tp_dict` before calling `PyType_Ready` (instead
of afterwards) because of the doc warning against mutating a type's
dictionary once initialized:
https://docs.python.org/3/c-api/typeobj.html#c.PyTypeObject.tp_dict
fixes https://github.com/pytorch/pytorch/issues/65077
---
I didn't add any tests because I didn't see any obvious places with similar tests for pickling or dtype objects. Let me know if I missed the right place, or should start one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65182
Reviewed By: mrshenli
Differential Revision: D31310530
Pulled By: ezyang
fbshipit-source-id: 20cd713ce175a709d6ce47459c3891162ce29d77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65710
No need to incur extra refcount bumps, and no need to use a stringstream for what are presumably string keys anyway.
ghstack-source-id: 139325445
Test Plan: CI, reviewers to confirm the keys are supposed to be strings
Reviewed By: dhruvbird
Differential Revision: D31215347
fbshipit-source-id: 82be93cb2e57aefe94edf74d149115cb734112be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65848
This diff includes:
* [fix]: The initialization of `OperatorSupport._support_dict` makes it a class variable, so we need to move its initialization into constructor.
* Add abstract class (more of an interface) `OperatorSupportBase`, since `OperatorSupport`'s purpose is too specific.
* [refactor]: what `TRToperatorSupport` really does is to populate a `OperatorSupport._support_dict`, so there really is no reason for subclassing. So removing it, and changing it to instantiating a `OperatorSupport` with properly populated `_support_dict`.
* Add a framework for defining simple and basic op support logic, and composing them into more complex ones:
1. `create_op_support` wraps a function into a `OperatorSupportBase` instance
2. `chain` can combine several simple `OperatorSupportBase` into more complex ones
3. `OpSupports` provides a set of pre-defined, simple `OperatorSupportBase` that can be composed together using `chain`.
1. Currently the only pre-defined one is `decline_if_input_dtype(..)`, which declares a node non-supported, if its args are of user specified dtype
* Fix `TRTOperatorSupport` so that it not only looks for registered converters, but also decline a node if its arg is of int64
Test Plan: linter and CI
Reviewed By: 842974287
Differential Revision: D31275525
fbshipit-source-id: bbc02f7ccf4902a7912bb98ba5be2c2fbd53b606
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60838
Rewrote `addmm_out_sparse_csr_dense_cuda` implementation using new cusparse descriptors.
`addmm` now works without conversions with both 32-bit and 64-bit indices.
The dense tensors can have a row- or column-major layout. If the dense tensors are a contiguous slice of a larger tensor, the storage is used directly without temporary copies.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D30643191
Pulled By: cpuhrsch
fbshipit-source-id: 5555f5b59b288daa3a3987d322a93dada63b46c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65923
Still noticing that queues are long particularly for windows GPU
machines, bumping this to compensate
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31308728
Pulled By: seemethere
fbshipit-source-id: b68c3a76335960def23e1f425ba5b0a219f07e73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65672
`ATen/ATen.h` has a list of all headers but vararg_functions.cpp only uses two of them. Change to include less for min_runtime.
ghstack-source-id: 139389772
Test Plan: CI
Reviewed By: larryliu0820
Differential Revision: D31198293
fbshipit-source-id: 9794a2696a1b124be7fced2836c633ae899aa5c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65621
Add a new attribute to the FusedMovingAvgObsFakeQuantize that controls if the Fake Quant operation should be applied at the output of a particular layer. The motivation is to give the users additional control to control the numerics of the fake_quant operators during training. It defaults to always fake quant the output (True).
Note: We will still observer the tensors as before (only the fake_quant operation is controlled using this flag)
For example
```
input model
x -> fc1 -> fc2 -> non_quantizable_op -> fc3
After fake_quant
x -> fake_quant(x) -> fc1 -> fake_quant(fc1) -> fc2 -> fake_quant(fc2) -> non_quantizable_op -> fake_quant() -> fc3 -> fake_quantize(fc3)
With output_fake_quant disabled at the output of fc2 and fc3 (since their outputs are non-quantizable)
x -> fake_quant(x) -> fc1 -> fake_quant(fc1) -> fc2 -> non_quantizable_op -> fake_quant() -> fc3
```
Test Plan: ./buck-out/gen/caffe2/test/quantization_fx\#binary.par -r test_disable_output_fake_quant
Reviewed By: jerryzh168
Differential Revision: D31174526
fbshipit-source-id: bffe776216d041fb09133a6fb09bfc2c0bb46b89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65699
related to: https://github.com/pytorch/pytorch/pull/65443#discussion_r715132425
The QAT and PAT (pruning aware training) support for embedding bags needs a memoryless observer to work properly. This is necessitated by the changing pruned/non-pruned weights during training which can significantly change the quantization parameters.
This PR adds a memoryless flag to the simpler observer classes (not moving average since those explicitly have memory)
In addition to the above, I altered the reset_min_max_vals
function for MinMaxObserver so that it would preserve the device of the
existing self.min_val and self.max_val which was not preserved
previously compared to how it is initialized (using factory_kwargs)
Test Plan:
python test/test_quantization.py TestObserver
(added test_memoryless_minmaxobserver, test_memoryless_per_channel_minmaxobserver, test_memoryless_histogramobserver)
Imported from OSS
Reviewed By: supriyar
Differential Revision: D31209773
fbshipit-source-id: 44a63298e44880fbd3576f49ac568e781f3fd79a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64879
This change makes the output of `prim::TupleConstruct` alias only with its inputs *when* the created tuple is directly returned from the graph.
The same treatment could be made to any tuples newly constructed by `prim::TupleConstruct` if they do not let their elements escape. However, this change only focuses on only one simplest, but frequently used usecase: tuples constructed only to be returned from a graph. This usecase turns out to be very often used.
Test Plan:
Added
- `AliasMoveForTupleConstructWithSingleUseAsGraphOutput`
- `WildcardAliasForTupleConstructWithUses`
to cover the newly added code.
Reviewed By: eellison
Differential Revision: D30437737
fbshipit-source-id: 417fbc6bc348062e60e7acdddd340d4754d090eb
Summary:
Skip failing tests when LAPACK and MAGMA are not available for ` test_linalg.py` and ` test_ops.py`.
Note that there's no CI without LAPACK or MAGMA. I verified locally that now it works as expected, but in the future we have no guards against tests failing again for this situation.
<details>
<summary> test_ops.py failures that are fixed</summary>
```
FAILED test/test_ops.py::TestCommonCPU::test_out_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_reference_testing_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_linalg_tensorinv_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestCommonCPU::test_variant_consistency_eager_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_grad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_fn_gradgrad_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestGradientsCPU::test_forward_mode_AD_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestJitCPU::test_variant_consistency_jit_triangular_solve_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_linalg_tensorinv_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_conj_view_triangular_solve_cpu_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_linalg_tensorinv_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_ops.py::TestMathBitsCPU::test_neg_view_triangular_solve_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
<details>
<summary> test_linalg.py failures that are fixed</summary>
```
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_dtype_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_norm_matrix_cpu_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCPU::test_nuclear_norm_axes_small_brute_force_old_cpu - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_complex128 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_eigh_hermitian_grad_meta_float64 - RuntimeError: Calling torch.linalg.eigh or eigvalsh on a CPU tensor requires compiling PyTorch with LAPACK. Please use PyTorch built with LAPACK support.
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_inverse_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_lu_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_broadcasting_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_old_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_batched_non_contiguous_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_solve_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_square_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_all_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_col_maj_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgMETA::test_svd_tall_some_meta_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_inverse_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_lowrank_cuda_float64 - RuntimeError: Calling torch.lu on a CUDA tensor requires compiling PyTorch with MAGMA. lease rebuild with MAGMA.
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex128 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_complex64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_square_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_all_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_col_maj_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float32 - RuntimeError: svd: LAPACK library not found in compilation
FAILED test/test_linalg.py::TestLinalgCUDA::test_svd_tall_some_cuda_float64 - RuntimeError: svd: LAPACK library not found in compilation
```
</details>
Fixes https://github.com/pytorch/pytorch/issues/59662
cc mruberry jianyuh nikitaved pearu walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64930
Reviewed By: H-Huang
Differential Revision: D31137652
Pulled By: mruberry
fbshipit-source-id: c969f75d7cf185765211004a0878e7c8a5d3cbf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65838
closes https://github.com/pytorch/pytorch/pull/65675
The default `--max_restarts` for `torch.distributed.run` was changed to `0` from `3` to make things backwards compatible with `torch.distributed.launch`. Since the default `--max_restarts` used to be greater than `0` we never documented passing `--max_restarts` explicitly in any of our example code.
Test Plan: N/A doc change only
Reviewed By: d4l3k
Differential Revision: D31279544
fbshipit-source-id: 98b31e6a158371bc56907552c5c13958446716f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64911
The import statements that involve the `quantize.py` were not added to the module level __init__ file. Those imports are necessary to mimic the behavior of the old import locations. Otherwise, the user would need to change their import statements to `from torch.ao.quantization.quantize import quantize` (instead of `from torch.ao.quantization import quantize`.
Another change in this diff is that we don't use `__all__` anymore. The all dunder was never used in quantization anyway, and just creates a potential bug when using `from ... import *`.
ghstack-source-id: 139342483
Test Plan: `buck test mode/dev //caffe2/test:quantization`
Reviewed By: vkuzo
Differential Revision: D30897663
fbshipit-source-id: a7b4919a191755e3ba690a79ce3362889f416689
Summary:
Fixes https://github.com/pytorch/pytorch/issues/64000
- updates double backward formula to compute grad wrt output instead of self
- ~~In some of the error messages, we still refer to the dtype of the input, even though we are now checking the dtype of the output~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65242
Reviewed By: albanD
Differential Revision: D31238123
Pulled By: soulitzer
fbshipit-source-id: afd319d3676d9ef8d81607e0e8c2a3e6d09f68e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65493
Added a last resolve to use whatever ATen operator that has Tensor outputs in the graph as the operator node to check alias annotation.
Test Plan:
python test/test_ops.py -k test_variant_consistency_jit_linalg_tensorinv
python test/test_ops.py -k test_variant_consistency_jit_nn_functional_normalize
Reviewed By: eellison
Differential Revision: D31132861
Pulled By: alanwaketan
fbshipit-source-id: 26fc2e6bc77be3a296967cf29a3f6ded231302fa
Summary:
Fixes https://github.com/pytorch/pytorch/issues/64999
- Adds a flag to gradcheck `check_backward_ad` that can be used to disable gradcheck for backward ad
- This is a bit bc-breaking in terms of positional args, but I prefer this ordering
- In OpInfo tests for forward ad:
- set `check_backward_ad` False
- In test_ops treat `supports_autograd` as if it is `supports_backward_ad` (it basically already is)
- the only modification needed is to no longer skip forward ad tests if `supports_autograd` is false
- test_dtype, test_variant_consistency, etc behave correctly as-is
- In a follow-up PR, we can rename it to actually be `supports_backward_ad`
- Testing
- https://github.com/pytorch/pytorch/pull/65060
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65040
Reviewed By: albanD
Differential Revision: D31238177
Pulled By: soulitzer
fbshipit-source-id: f068d4cbe7ffb094930b16cddb210583b9b7b2c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65173
Initializes dummy NCCL communicators in constructor for a basic health
check that communicators can be initialized prior to launching the first
collective.
After successful init, we immediately use `ncclCommAbort` to destroy these
communicators to ensure they don't interfere with regular communicator creation
during collectives.
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D31005792
fbshipit-source-id: c2c582dee25a098361ead6ef03f541e7833c606b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65744
This is just dead code.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D31257940
fbshipit-source-id: 6c02264106c2dcbadd332f24b95bc9351a04fd9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65724
See gh-56794
Avoid dispatch inside of parallel_for by:
1. Replacing Tensor slicing with TensorAccessor
2. Copy bias into output only once, outside of the parallel region
3. Replaces `addmm`_ with a direct call to gemm.
Technically this also adds a new requirement that the output always be
contiguous, but the out argument version isn't exposed or used
anywhere in the `torch.nn` API. So that should be fine.
Test Plan: Imported from OSS
Reviewed By: saketh-are
Differential Revision: D31257875
Pulled By: ngimel
fbshipit-source-id: 84d2b39e7f65334bdfcc2c4719f93ee3c514ca32
Summary:
In Python 3, we can call `super()` without any arguments.
If I understand correctly, Python 2 is no longer supported by PyTorch, so we can change the documentation to be Python-3 only :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65748
Reviewed By: saketh-are
Differential Revision: D31246055
Pulled By: albanD
fbshipit-source-id: 3980def1a556d4bdfa391ea61cb2a65efa20df79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65593
Adds test cases that the three Numeric Suite Core APIs work
when the models are on cuda. In particular:
1. create models and move them to cuda
2. add loggers (if applicable)
3. run data through (if applicable)
4. extract results
It works without code changes because a `Logger` object is
created without any device specific objects (they only get
added if a data is passed through). It's good to have this tested.
Test Plan:
```
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_extract_weights_cuda
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_add_loggers_cuda
python test/test_quantization.py TestFXNumericSuiteCoreAPIs.test_add_shadow_loggers_cuda
```
Imported from OSS
Reviewed By: raghuramank100
Differential Revision: D31160897
fbshipit-source-id: 8eacf164d0496baf2830491200ea721c0f32ac92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65732
For certain on-device uses, runtime memory comes at a premium. On-device deployments won't use all the available dispatch keys, so it makes sense to keep only the on-device specific ones around for such uses to reduce runtime heap memory allocated.
This change keeps just 10 dispatch keys (the ones that used on-device), guarded under the `C10_MOBILE_TRIM_DISPATCH_KEYS` macro. it tries to keep the other code-paths unaffected and uses `constexpr` for use in the `array` declaration, and simple inline functions to ensure that the compiler is able to optimize these for server builds.
Test Plan:
Build and check mobile models end to end.
```
buck build -c "pt.enable_milan_dispatch_keys_trimming"=1 //xplat/caffe2/fb/lite_predictor:lite_predictor
```
Reviewed By: ezyang
Differential Revision: D31185407
fbshipit-source-id: e954765606373dea6ee9466a851dca7684167b0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65831
Was noticing scaling issues last night due to the lack of
linux.8xlarge.nvidia.gpu machines, seems as though that even at max
capacity we were still about ~50 queued workflows behind, this should
close that gap.
Also since these run the longest types of tests these are the most
likely to overlap with scale messages being processed while available
runners are still maxed out
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31275892
Pulled By: seemethere
fbshipit-source-id: b22ceda115b70d7bdd9c4bc207b55ffab50381ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65384
The following pattern appears frequently in `ops.cpp`:
```
if (!n->matches(schema_1) && !n->matches(schema_2) && ... && !n->matches(schema_n)) {
LogAndDumpSchema(n);
return nullptr;
}
return [](ProcessedNode* p_node) {
if (p_node->Output(0).isNone()) {
if (p_node->Input(i).isSomeType()) {
// special logic for schema 1
} else if (p_node->Input(i).isSomeOtherType()) {
// special logic for schema 2
} else if (...) {
// special logic for schema3
}
// and so on
} else {
// another complicated type checking chain
}
};
```
A much cleaner way to implement operator overloads is like this:
```
if (n->matches(schema_1)) {
return schema_1_impl;
} else if (n->matches(schema_2)) {
return schema_2_impl;
}
// and so on
```
This has a few advantages:
* Significantly reduces complexity of the out variant implementations, especially for ops with more than 2 overloads. One implementation corresponds to one schema. This makes the implementation more readable/maintainable.
* Adhering to this convention makes it easier to add a new overload. Just add a new `n->matches(...)` case instead of working the schema into existing complicated logic.
* Ops are marginally faster since we don't have to check types at runtime.
Note: there are a few cases where this actually made the code less concise (`aten::div`), so I left those ops untouched.
Thanks for pointing this out in another diff d1jang
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D31072328
fbshipit-source-id: c40a4f7e6a79881e94c9ec49e9008ed75cfc8688
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65731
It originally had purpose but after ciflow was introduced every PR had
on_pull_request set so it's not really as useful as it once was
Also removes the equally as confusing only_build_on_pull_request
variable as well
This change should produce no functional changes in our generated workflows
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
cc ezyang seemethere malfet pytorch/pytorch-dev-infra
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D31225398
Pulled By: seemethere
fbshipit-source-id: 7bd8e8175794ab7d09b0632321bf52538435e858
Summary:
Could be useful for the future.
Next steps: document it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65791
Reviewed By: suo
Differential Revision: D31254115
Pulled By: janeyx99
fbshipit-source-id: 715c18b4505f2be6328aa0be25976116d6956b25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65136
Opportunistically add type annotation for operator_support.py
Test Plan: run linter, CI
Reviewed By: yinghai
Differential Revision: D30928464
fbshipit-source-id: 615c75152b9938792f03cdceb2a113bda6ab28c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65610
- Replace HIP_PLATFORM_HCC with USE_ROCM
- Dont rely on CUDA_VERSION or HIP_VERSION and use USE_ROCM and ROCM_VERSION.
- In the next PR
- Will be removing the mapping from CUDA_VERSION to HIP_VERSION and CUDA to HIP in hipify.
- HIP_PLATFORM_HCC is deprecated, so will add HIP_PLATFORM_AMD to support HIP host code compilation on gcc.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport amathews-amd
Reviewed By: jbschlosser
Differential Revision: D30909053
Pulled By: ezyang
fbshipit-source-id: 224a966ebf1aaec79beccbbd686fdf3d49267e06
Summary:
`include_directories` is old-style CMake which adds the include path to every file being compiled. This instead makes python, numpy and pybind11 into targets that only torch_python and caffe2_pybind_state are linked to. So, python libraries can't be accidentally included elsewhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65654
Reviewed By: gchanan
Differential Revision: D31193205
Pulled By: malfet
fbshipit-source-id: 5c1b554a59d0e441a701a04ebb62f0032d38b208
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65741
This op previously assumed `axis == 1`, causing graphs that would otherwise be valid to return incorrect results after fusing.
Reviewed By: hlu1
Differential Revision: D31234944
fbshipit-source-id: 89885a3b119357698ebd9fd429b009813260a2f4
Summary:
The fact that these functions are only used in a single test might be a good enough reason to move them to that module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60862
Reviewed By: H-Huang
Differential Revision: D31141354
Pulled By: mruberry
fbshipit-source-id: 6ce1f721b88620c5f46222ad1b942bc689f0a3e0
Summary:
In case the inputs have a different layout, `assert_close(..., check_layout=False)` converts them to strided before comparison. This is helpful if you just want to compare the values of sparse COO / CSR tensor against a strided reference.
This keeps BC, since the default `check_layout=True` was the old, hard-coded behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65419
Reviewed By: H-Huang
Differential Revision: D31133629
Pulled By: mruberry
fbshipit-source-id: ca8918af81fb0e0ba263104836a4c2eeacdfc7e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65781
Fixes
```
stderr: In file included from caffe2/caffe2/contrib/shm_mutex/shm_mutex.cc:1:
caffe2/caffe2/contrib/shm_mutex/shm_mutex.h:334:28: error: anonymous non-C-compatible type given name for linkage purposes by alias declaration; add a tag name here [-Werror,-Wnon-c-typedef-for-linkage]
using TicketStruct = struct : ShmBaseHeader {
^
TicketStruct
caffe2/caffe2/contrib/shm_mutex/shm_mutex.h:334:31: note: type is not C-compatible due to this base class
using TicketStruct = struct : ShmBaseHeader {
^~~~~~~~~~~~~
caffe2/caffe2/contrib/shm_mutex/shm_mutex.h:334:7: note: type is given name 'TicketStruct' for linkage purposes by this alias declaration
using TicketStruct = struct : ShmBaseHeader {
^
1 error generated.
Cannot execute a rule out of process. On RE worker. Thread: Thread[main,5,main]
Command failed with exit code 1.
```
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D31248938
fbshipit-source-id: 47342fecc72ada9397a1b7bd6fcabfccf988dd3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64962
Moves windows builds / tests back to the default directory. Previously
we had moved them because checkout would sometimes fail due to file
handlers still being open on the working directory.
Moving back to the default directory also has the added bonus of sccache
working again so here's to hoping that this doesn't have any adverse
affects
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
cc peterjc123 mszhanyi skyline75489 nbcsm ezyang seemethere malfet lg20987 pytorch/pytorch-dev-infra
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31250072
Pulled By: seemethere
fbshipit-source-id: a803bf0e00e1b2b0d63f78600588281622ee0652
Summary:
The variable `%errorlevel%` is evaluated before the whole line of command starts, so it is useless when used in a if-block. Also, let's prevent using `%errorlevel%` because it may be set by the users accidentally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57331
Reviewed By: anjali411
Differential Revision: D28140182
Pulled By: malfet
fbshipit-source-id: a3f21d65623bb25f039805c175e9f3b468bcb548
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65715
Here is how we freeze a python module:
- we call python builtin compile method with the source code of the modules and the path. This method returns a python code object
- we call marshal.dumps to serialize the code object to bytes.
The code_object.co_filename actually matches the one passed in to the compile method. We can simply replace that with a marker
to avoid leak build time path to runtime.
This works on nested code objects as well:
```
#!/bin/env python3.8
import marshal
code_str = """
print("hello")
class MyCls:
def __init__(self):
pass
"""
co = compile(code_str, "<Generated by torch::deploy>", "exec")
cobytes = marshal.dumps(co)
import pdb; pdb.set_trace()
```
Checking `co`:
```
(Pdb) co.co_filename
'<Generated by torch::deploy>'
(Pdb) co.co_consts
('hello', <code object MyCls at 0x7f0e8670bbe0, file "<Generated by torch::deploy>", line 4>, 'MyCls', None)
(Pdb) co.co_consts[1].co_filename
'<Generated by torch::deploy>'
```
Test Plan:
Find the serialized frozenmodule for torch.nn.modules.linear module in the generated bytecode_x.c file. Put the content to /tmp/linear.bytecode
Run the testing script:
```
import marshal
co_bytes = bytes(eval("[{}]".format("".join(open('/tmp/linear.bytecode').readlines()).replace('\n', '').replace('\t', ''))))
co = marshal.loads(co_bytes)
print(co)
```
The output for the paste without the change:
```
<code object <module> at 0x7f39ca7f07c0, file "/data/users/shunting/fbsource/fbcode/buck-out/opt/gen/caffe2/gen_frozen_torchpython_src__srcs/torch/nn/modules/linear.py", line 1>
```
The output for the paste with the change:
```
<code object <module> at 0x7f05a765d710, file "<Generated by torch::deploy>", line 1>
````
Note that the file part is changed as expected.
Reviewed By: suo
Differential Revision: D31214555
fbshipit-source-id: 56958e0a7352f8c30a3377f83209efe7db61f0fb
Summary:
CIFLow workflows should always run on push event
On pull-request workflow should run if label conditions are met or if
no `ciflow/` labels are associated with it, workflow is enabled by
default
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65733
Reviewed By: zhouzhuojie
Differential Revision: D31251278
Pulled By: malfet
fbshipit-source-id: 31ce745cb224df7c6fec1682ec4180513e3dadf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65789
These common types of jobs can be moved into build since it's typically
a no-op, could be annoying in the future to debug docker builds but
dedicating an entire ephemeral node to a noop seems like a waste to me
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet, janeyx99
Differential Revision: D31253017
Pulled By: seemethere
fbshipit-source-id: c7b5ea35a57fb1576122df219d387c86e420fd1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65294
This adds the docstring documentation to the WeightNormSparsifier and adds the typehints for the constructor args.
Note, this does not require testing as only the doc is changed.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D31186827
Pulled By: z-a-f
fbshipit-source-id: c5010c9bba25b074c4cc6c88f251474b758f950d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65293
This fixes a bug in the WeightNormSparsifier, where the mask is being multiplied by the newly computed mask.
Because the mask elements are binary 0/1, this accumulates the mask over every iteration, eventually collapsing the mask to zero.
This bug accidentally bled through from old versions.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D31186829
Pulled By: z-a-f
fbshipit-source-id: 3f5b2c833148ab0bd8084e7410ce398f1252e65e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65292
That was the original design, that we decided to simplify by removing the packing in the sparsifier.
The state of the sparsifier is saved directly, and the old behavior accidentally bled through to the current version.
This change removes the `_pack_params` method, and changes the state_dict to include the state directly.
We don't have to change the load_state_dict, as it will work with either the old or the new format.
The main reason for this PR is the simplification. The original design didn't achieve anything useful by packing the sparsification parameters.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D31186826
Pulled By: z-a-f
fbshipit-source-id: 4ad72a7e669f048d2f2d269269ee11b63fa169db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65686Fixes: #57827
This PR introduces `check_inplace` function. It contains some common checks for all
structured in-place operators (e.g. dtype, device, and sizes). `set_output` method calls
`check_inplace` on in-place specializations of structured kernels.
Besides that, it also:
- adds overlap assertions for both in-place and out-of-place overloads
- remove in-place operator specific `TORCH_CHECK` around the code base
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31234063
Pulled By: ezyang
fbshipit-source-id: fa3b45775af7812e07a282e7cae00b68caf0fdb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65570
Although this is not an issue that could pop-up in practice, LLVM-12 throws an error about this issue if not checked.
Test Plan: `buck test mode/dev //caffe2/test:quantization -- --exact 'caffe2/test:quantization - test_empty_batch (quantization.core.test_quantized_op.TestQuantizedOps)'`
Reviewed By: r-barnes
Differential Revision: D31151681
fbshipit-source-id: e039c6aa1687a61ef6774f045744dc9d768d5c80
Summary:
This PR attempts to port `baddbmm` and `bmm` to structured kernels. The reason it's in the same PR: because a lot of it is common for both the ops, including the checks and implementation.
Issue tracker: https://github.com/pytorch/pytorch/issues/55070
cc: ysiraichi ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64805
Reviewed By: gchanan
Differential Revision: D31134454
Pulled By: ezyang
fbshipit-source-id: 3294619834a8cc6a0407aea660c556d3a42b6261
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65728
Changes the docker image generation script to only include image build
jobs for images that we actually use within CircleCI
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
cc ezyang seemethere malfet pytorch/pytorch-dev-infra
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D31224674
Pulled By: seemethere
fbshipit-source-id: 64b14e1a4ef82d345ec7b898c4c89d9a9419e4de
Summary:
This test occasionally deadlocks while waiting for the child process to report result.
But as the test is small, entire test should never take more than 1-2 sec, but to be on the safe side set timeout to 5 sec
Somewhat mitigates https://github.com/pytorch/pytorch/issues/65727
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65742
Reviewed By: janeyx99, ejguan
Differential Revision: D31235116
Pulled By: malfet
fbshipit-source-id: 0cdd2f7295f6f9fcefee954a14352e18fae20696
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65476
As suggested by `-Winconsistent-missing-destructor-override`.
Test Plan: CI
Reviewed By: pritamdamania87
Differential Revision: D31115128
fbshipit-source-id: a4e2441c13704c0c46e3e86f7886fca76c40ca39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65716
Currently, we send arguments to shaders by creating and filling a SSBO (Shader Storage Buffer Object). However, we can instead use [push constants](https://www.khronos.org/registry/vulkan/specs/1.2-extensions/man/html/vkCmdPushConstants.html) to send a small amount of uniform data to shaders.
Push constants are slightly more performant than using a SSBO and also have the added benefit of not needing to allocate and manage memory for a buffer object since they update the pipeline data directly.
The downside of using push constants is that there is a maximum size for a push constant block, described by `maxPushConstantsSize` in [VkPhysicalDeviceLimits](https://www.khronos.org/registry/vulkan/specs/1.1/html/vkspec.html#VkPhysicalDeviceLimits). The minimum size guaranteed by the spec is 128 bytes, which is enough for 32 `float`/`int` variables, or 8 `vec4` variables. This should be enough for our purposes.
Currently, the Convolution shaders use the largest uniform block which only uses 22 bytes.
Test Plan:
Run `vulkan_api_test`:
```
buck build -c ndk.custom_libcxx=false -c pt.enable_qpl=0 //xplat/caffe2:pt_vulkan_api_test_binAndroid\#android-arm64 --show-output
adb push buck-out/gen/xplat/caffe2/pt_vulkan_api_test_binAndroid\#android-arm64 /data/local/tmp/vulkan_api_test
adb shell "/data/local/tmp/vulkan_api_test"
```
Reviewed By: beback4u
Differential Revision: D30368834
fbshipit-source-id: 65a42b9da1a9084ba2337b41eaab9b612583c408
Summary:
Use `c10::optional` + thread_fence instead of `#pragma omp critical` inside max_unpooling kernels
Using any OpenMP pragma in `at::parallel_for` body is wrong, as it can
be implemented using native treading algorithms such as ptrheads
`c10::optional` sounds like a much better approach to pair of
`has_error` and `error_index` variables. Use `std::atomic_thread_fence` to ensure error_index value is synchronized.
It also fixes ICE reported in https://github.com/pytorch/pytorch/issues/65578
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65655
Reviewed By: ngimel
Differential Revision: D31206501
Pulled By: malfet
fbshipit-source-id: 93df34530e721777b69509cd6c68f5d713fb2b2a
Summary:
This PR adds forward AD for `*_solve` methods.
Additionally, `cholesky_solve` gets OpInfo + a bug fix when wrong leading dimensions could be passed to LAPACK,
and `lu_solve` gets forward AD with 2x`lu_solve` instead of 1x`lu_solve` + 2x`triangular_solve`.
cc ezyang albanD zou3519 gqchen pearu nikitaved soulitzer Lezcano Varal7 jianyuh mruberry walterddr IvanYashchuk xwang233
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65546
Reviewed By: gchanan
Differential Revision: D31206837
Pulled By: albanD
fbshipit-source-id: 040beda97442e7a88a9df9abc7bb18313ce55bc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65491
The only user of any of this code is THCStorage_copy, so I've
migrated that to call `Tensor.copy_` directly.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D31148183
Pulled By: ngimel
fbshipit-source-id: 92bab71306c84bc481c47a0615ebb811af2c2875
Summary:
- Only ported copy for sparse tensor to dispatcher. Everything else is the same
- Duplicated code for named tensor handling in sparse tensor copy
- Might change it later to handle named tensors using dispatcher
Issue https://github.com/pytorch/pytorch/issues/61122
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65304
Reviewed By: gchanan
Differential Revision: D31176720
Pulled By: ezyang
fbshipit-source-id: 56757a3b0fb56c3d05c16dd935428a0cd91ea766
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64750
conv2d bias is optional. It will be ArgNone in processing of the graph.
This bias is prim::constant NoneType, so we do not know shape at the moment of constant binding.
This adding it as a constant zeros Tensor at the moment of graph processing => for that adding `std::vector<TensorExprKernel::ConstantDescr>& constants and std::vector<at::Tensor>& constant_tensors` to `computeOperandValue` as it is not in `TensorExprKernel`
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D30842101
Pulled By: IvanKobzarev
fbshipit-source-id: 88020f6934e43fe606f8eae928b7e21b7c3f15f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65708
att
Test Plan: added unit test
Reviewed By: khabinov
Differential Revision: D31209992
fbshipit-source-id: c1b4e70bd9705dcfdf3039cb8791149c8646f1d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65707
Refactoring aotCompile to return a pair of compiled function and the LLVM assembly instead of updating an incoming string with assembly code
Testing: Gives expected results when compiled and run
```
(pytorch) ~/local/pytorch refactor_aot
└─ $ build/bin/aot_model_compiler --model mobilenetv3.pt --model_name=pytorch_dev_mobilenetv3 --model_version=v1 --input_dims="2,2,2"
The compiled model was saved to mobilenetv3.compiled.pt
```
Test Plan: Imported from OSS
Reviewed By: qihqi
Differential Revision: D31220452
Pulled By: priyaramani
fbshipit-source-id: f957c53ba83f876a2e7dbdd4b4571a760b3b6a9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65639
This op is used by mobilenet v2.
Test Plan:
buck test glow/fb/fx/oss_acc_tracer:test_acc_tracer -- test_hardtanh
buck test glow/fb/fx/acc_tracer:test_acc_shape_inference -- hardtanh
buck test glow/fb/fx/oss_acc_tracer:test_acc_tracer -- test_hardtanh
Reviewed By: yinghai
Differential Revision: D31184297
fbshipit-source-id: 5a04319f6d16fb930372442616e27211107ecc67
Summary:
Happy to get any feedback on how to make this code cleaner!
This:
- Fix Tensor attribute deepcopy BC-breaking?
- Add a test for Tensor attribute deepcopy
- Fix subclass deepcopy
- Moves the subclass serialization tests into their own class not to interfere with other serialization test logic
- Add a test for subclass deepcopy
cc ezyang gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65584
Reviewed By: gchanan
Differential Revision: D31206590
Pulled By: albanD
fbshipit-source-id: 74a8f0767f4933b9c941fbea880a8fd1b893ea2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65539
This function doesn't directly use thrust so these are simply unused variables.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D31193191
Pulled By: malfet
fbshipit-source-id: 231b6a197c9f1bd5a61e46cb858e8eedc85b2818
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65459
Just run linter on the change and apply all suggestions
Test Plan: N/A
Reviewed By: seemethere
Differential Revision: D31102960
fbshipit-source-id: 04e1d07935690f2ddbc64533661b3e55379d13b5
Summary:
The SHARD_NUMBER reset was to figure out a way to differentiate whether we had just one shard vs multiple.
We shouldn't reset SHARD_NUMBER but instead should just pass and use NUM_TEST_SHARDS for clarity and ease of scaling up to more shards.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65701
Reviewed By: driazati
Differential Revision: D31209306
Pulled By: janeyx99
fbshipit-source-id: 3a3504bd47e655d62aa0d9ed2f4657ca34c71c0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64943
Most ProcessGroup Collective APIs are pure virtual. As a result, c10d extensions need to override all of them and throw an error if they don't need certain APIs. This is too verbose for users. This commit changes those collective APIs to virtual and throws an error by default. Note that ProcessGroup is still an abstract class as `getBackendName` is a pure virtual function that all subclasses have to override.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang cbalioglu gcramer23
Test Plan: Imported from OSS
Reviewed By: cbalioglu
Differential Revision: D30906866
Pulled By: mrshenli
fbshipit-source-id: c4df8962d60350a44d2df72fd04f9dd6eadb9fa6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65519
Adds buck target so we can run this internally.
ghstack-source-id: 139009957
Test Plan: CI
Reviewed By: SciPioneer
Differential Revision: D31072784
fbshipit-source-id: 7185cc1e6f9df3d79251eb017270471942a9d7dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65385
Enables the ZeRO tests to run on windows. Closes
https://github.com/pytorch/pytorch/issues/63086.
Backend == NCCL was used as a proxy to see if we were running under CUDA, but Windows GPU tests uses Gloo. In this case use Gloo on GPU.
For some reason these tests don't seem to test Gloo on GPU with ZeRO in general (picks NCCL backend when GPU is available), so kept that behavior for now.
ghstack-source-id: 139003920
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D31071181
fbshipit-source-id: 45a76309ac5e882f5aa6c4b130118a68800754bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65590
hardswish is used by mobile net v3 oss model.
This diff added hardswish support in acc_tracer
Test Plan:
buck test glow/fb/fx/acc_tracer:test_acc_shape_inference
buck test glow/fb/fx/oss_acc_tracer:test_acc_tracer -- test_hardswish
Reviewed By: 842974287
Differential Revision: D30950061
fbshipit-source-id: cab57b8de5bea3a4d9d2b7d2a410d9afe787d66f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64824
See comment in function_schema.h for explanation. I claim that this is a good tradeoff because the aliasing information seems to be used only in compiler-ish code paths, where performance isn't as critical as actual execution. If performance is important there too, perhaps we should hoist isWrite into the Argument itself since there are several paths that only care about isWrite.
ghstack-source-id: 138958896
Test Plan: CI, profile schema parsing on startup and see much fewer page faults in createArgumentVector.
Reviewed By: suo
Differential Revision: D30860719
fbshipit-source-id: 1d4d2328f2b8e34f5ddf9d82083fd4dd7b7f738f
Summary:
Follow up to https://github.com/pytorch/pytorch/issues/61935
This PR:
1. Adds test for non-contiguous tensors
2. Fixes bug in `NLLLoss` that was catch by the test.
The reason this was not catch in `common_nn` is because `CriterionTest` overrides `test_cuda` but does not call `test_nonconfig`.
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64954
Reviewed By: zou3519
Differential Revision: D31174149
Pulled By: jbschlosser
fbshipit-source-id: a16073e59b40ccc01c82ede016b63a8db2e810f5
Summary:
This should help alleviate workflows failing due to docker pull timing out, which doesn't happen often, but did happen once in the past day.
Was also reported in https://github.com/pytorch/pytorch/issues/65439
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65103
Reviewed By: driazati
Differential Revision: D31157772
Pulled By: janeyx99
fbshipit-source-id: 7bf556f849b41eeb6dea69d73e5a8e1a40dec514
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65620
This was bothering me for a while.
ghstack-source-id: 138914860
Test Plan: Sandcastle
Reviewed By: beback4u
Differential Revision: D31162648
fbshipit-source-id: 72c47ea34d40c772bb53da721fcb36365b5dbaf3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65589
Without this prefix, the include guards interfere with attempts to indirectly include both c10::variant and the original mpark variant in the same translation unit.
ghstack-source-id: 138901838
Test Plan: Temporarily `#include <c10/util/variant.h>` in ivalue.h and buck build //data_preproc/preproc:preproc_adapter_utils mode/no-gpu -- this delayed D31101962 (01720d6a23) from fixing S244170
Reviewed By: bhosmer
Differential Revision: D31159414
fbshipit-source-id: 234c5ed37ca853702bcdf3263e4f185b95ac1d08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65592
IExecutionContext might not be safe to be serialized, therefore the simplest way to support save/load of TRTModule is to re-populate the execution context upon every load.
ghstack-source-id: 138904770
Test Plan: buck run mode/dev-nosan -c python.package_style=inplace -j 40 deeplearning/trt/fx2trt:acc2trt_test
Reviewed By: zrphercule
Differential Revision: D31070427
fbshipit-source-id: 88c58c6ce50e6dc9383d7f9419b5447cb89a4a3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65600
Previously AccessInfo owned two maps: dependencies_ and dependents_,
which represented an edge in dependency graph. These two maps were
holding shared pointers and thus each edge immediately became a cycle,
which resulted in memory leaks. This PR makes one of the ends of these
edges weak pointer thus breaking the loop.
Test Plan: buck test mode/dbgo-asan-ubsan //search/lib/query_expansion/candidate_generator/test:transliteration_expander_test -- --exact 'search/lib/query_expansion/candidate_generator/test:transliteration_expander_test - TransliterationExpander.romanizationByLocaleTest'
Reviewed By: bertmaher
Differential Revision: D31163441
Pulled By: ZolotukhinM
fbshipit-source-id: 9cef921f5c9293f1237144d1ee92e31f3e44c00a
Summary:
// A non owning pointer to a type. When a class get inserted as a constant
// into a graph, if we used a strong pointer we would have a circular reference
// from Object -> CompilationUnit and CompilationUnit -> Graph (which owns the
// Constant Object)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65442
Reviewed By: ezyang
Differential Revision: D31101962
Pulled By: eellison
fbshipit-source-id: f1c1cfbe5a8d16a832cad7ba46e2a57a98670083
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64382
* This `use_external_data_format` parameter is used for large models cannot be exported because of the 2GB protobuf limit.
* When `use_external_data_format` set to True, the model is exported in ONNX external data format, in which case some of the model parameters are stored in external binary files and not in the ONNX model file itself.
* This PR will set this paramter to DEPRECATED and check the model proto sizes by code instead of by user, if the sizes lager than 2GB, then `use_external_data_format = True` automatically.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905265
Pulled By: malfet
fbshipit-source-id: 82b4e17bfa6a8de2bfd700a5282c12f6835603cb
Co-authored-by: hwangdeyu <dejack953@outlook.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64380
* `example_outputs` used to determine the type and shape of the outputs without tracing the execution of the model. And it must be provided when exporting a ScriptModule or ScriptFunction when using export() function.
* Since we can work out `example_outputs` in internal function instead of being provided by user, so we deprecated this argument in the export() function to increase user experience of calling this function.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905266
Pulled By: malfet
fbshipit-source-id: d00b00d7d02b365d165028288ad915678caa51f2
Co-authored-by: hwangdeyu <dejack953@outlook.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64373
* Fix some bad formatting and clarify things in onnx.rst.
* In `export_to_pretty_string`:
* Add documentation for previously undocumented args.
* Document that `f` arg is ignored and mark it deprecated.
* Update tests to stop setting `f`.
* Warn if `_retain_param_name` is set.
* Use double quotes for string literals in test_operators.py.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905271
Pulled By: malfet
fbshipit-source-id: 3627eeabf40b9516c4a83cfab424ce537b36e4b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64372
custom_opsets arg from torch.onnx.export() is no needed to be removed.
Add some supplementary description and tests for easier understanding.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905269
Pulled By: malfet
fbshipit-source-id: 489fbee0e2c1d6c5405c9bf7dfd85223ed981a44
Co-authored-by: hwangdeyu <dejack953@outlook.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64371
As of now, the "strip_doc_string" parameter was described as below:
strip_doc_string (bool, default True): do not include the field
doc_string``` from the exported model. Otherwise the field will mention the source code locations for model``.
This is usually useless to users who want to transform a PyTorch model to ONNX one. Only when the user wants to debug the export process, these source code locations could provide benefits.
To make the export() function more friendly by providing less parameters, we combined "strip_doc_string" into "verbose" parameter. If a user set verbose to True, it means the users need some log information for debugging the export process and this is similar with the purpose of strip_doc_string parameter.
But the usage of these 2 arguments are opposite: setting verbose to True means we want to print log information to help debug, which means strip_doc_string should be False. And this is how we replace strip_doc_string with verbose argument in this PR.
This PR will still keep it in torch.onnx.export() function for backward support while the usage of it has been combined with verbose argument.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905268
Pulled By: malfet
fbshipit-source-id: 2f06eb805c01fe15ff7a1b4f6595c937ba716d60
Co-authored-by: fatcat-z <zhang-ji@outlook.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64370
As of now, the "_retain_param_name" parameter has no description in PyTorch docs website. According to code, this argument determines if we keep the original parameter names of PyTorch model in the final ONNX graph. If this is False, those original parameter names will be replaced with a series of integers starting from 1.
Since setting numbers as parameter names make no sense to users, we remove this argument from the torch.onnx.export() function to increase user experience of calling this function.
This PR will still keep it in torch.onnx.export() function for backward support while all backend logic has been changed to work as _retain_param_name is set to True.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D30905270
Pulled By: malfet
fbshipit-source-id: ca60757ca17daaff937e9f08da42596086795f4a
Co-authored-by: fatcat-z <zhang-ji@outlook.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65513
The error in #65231 means some child threads were destructed before
joined. I added some trace and prints and found that, in the failed
tests, all `assertEqual` are passed, but the `ProcessGroupGloo`
destructor wasn't called in one of the process. It could be due to
the only guarantee that Python makes is that garbage collection MAY
happen before the program exits. This commit adds an explicit
`destroy_process_group()` to alleviate the problem.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang gcramer23
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D31134174
Pulled By: mrshenli
fbshipit-source-id: 2e42fe93d3f16ce34681b591afc15a6ac0b9fab6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65484
This PR makes sure we only use FixedQParamFakeQuantize for quint8 dtype and allows user
to use other dtypes for ops like sigmoid, this is useful for producing reference pattern for
these ops that can be used in other backends like TensorRT
Test Plan:
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D31120377
fbshipit-source-id: 3b529d588e2b6ff0377a89c181f6237f8f0cc2f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64515
For performance reasons, we would like to ensure that we can await
user collectives as part of custom buffer reduction in parallel to other work.
As a result, add support to return futures from custom buffer hooks and await
those futures at end of backwards pass.
Also added some docs to clarify how to use these APIs.
ghstack-source-id: 138793803
Test Plan: I
Reviewed By: zhaojuanmao
Differential Revision: D30757761
fbshipit-source-id: e1a2ead9ca850cb345fbee079cf0614e91bece44
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 0108d4f552
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65360
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D31061552
fbshipit-source-id: 8bce5157a281e38cad5d5d0e9dcd123beda39735
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65503
There are two reasons for this change:
- I don't think trunk jobs should have different behavior than their PR equivalents.
- Continuing through error makes it challenging to figure out what is
actually failing, especially given the poor UX of GitHub Actions when it
comes to reading logs
Example: https://github.com/pytorch/pytorch/runs/3680114581. Here, there
is a failure but the rendered test results tell me everything is
successful. I have no idea how to quickly tell what failed; the log is so long
and terms like "error", "failure", etc. are common enough that searching
it is very difficult.
Differential Revision:
D31130478
D31130478
Test Plan: Imported from OSS
Reviewed By: ezyang
Pulled By: suo
fbshipit-source-id: 15a80475ca4c49644c0f7b779f5c6c2ffeb946a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65558
This will temporarily be replaced by an FB-internal workflow that does
the exact same thing, pending a migration of this workflow to probot.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport
Test Plan: Imported from OSS
Reviewed By: zhouzhuojie, driazati
Differential Revision: D31149105
Pulled By: suo
fbshipit-source-id: 2aa122820ae3b5286774501f5ecfe052bc949dea
Summary:
Refactor:
```
TORCH_CHECK ( key == a ||
key == b ||
key == c,
"expected key to be in ", a, " or ", b , " or ", c,
" but got ", key);
```
into
```
TORCH_CHECK( key_set.has(key),
"expected key to be in ", key_set,
" but got ", key );
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65535
Reviewed By: wconstab
Differential Revision: D31144239
Pulled By: malfet
fbshipit-source-id: 68a053041a38f043e688e491889dd7ee258f3db3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64823
We seem to spend noticable time in vfprintf for this, and the number of arguments is almost always small enough to do this in just a few instructions.
ghstack-source-id: 138623354
Test Plan: Profile schema parsing, saw less time in vfprintf
Reviewed By: ezyang, dhruvbird
Differential Revision: D30860716
fbshipit-source-id: 09ef085cd6f93dc1eaa78790dde918ac60e67450
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64839
Resulted in some extra shared_ptr refcount bumps.
ghstack-source-id: 138623356
Test Plan: CI
Reviewed By: smessmer
Differential Revision: D30875749
fbshipit-source-id: 531f04c453f7410ed3d4ff054217f21a250be8e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65509
With this change, we can get dumps of the model graphs by setting the env variable `PYTORCH_JIT_LOG_LEVEL=">>impl"` while running the model.
Test Plan: buck test mode/opt-clang //caffe2/benchmarks/static_runtime:static_runtime_cpptest
Reviewed By: mikeiovine
Differential Revision: D31125797
fbshipit-source-id: d8979a4e138047518140e0eaecb46e012891b17c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65420
Context: In some FB use cases we have a need to map observer stats from train model checkpoint to inference model. We observerd that some buffer names are different becuase the intermediate activation tensors
are generated differently across train and inference model. More details in https://fb.quip.com/PtGcAR0S5CQP
Currently, for each observer (activation_post_process), the FQN of the module inserted is determined based on the FQN of the input tensor it is observing.
In this change we change the observer FQN to include the FQN of the op/module it is observing rather than tensor/intermediate op names along with the “input”/“output” detail.
Before
```
def forward(self, x):
x_activation_post_process_0 = self.x_activation_post_process_0(x); x = None
mods1_w = self.mods1.w
mods1_w_activation_post_process_0 = self.mods1_w_activation_post_process_0(mods1_w); mods1_w = None
mods1_b = self.mods1.b
linear = torch.nn.functional.linear(x_activation_post_process_0, mods1_w_activation_post_process_0, bias = mods1_b); x_activation_post_process_0 = mods1_w_activation_post_process_0 = mods1_b = None
linear_activation_post_process_0 = self.linear_activation_post_process_0(linear); linear = None
return linear_activation_post_process_0
```
After
```
def forward(self, x):
mods1_input_activation_post_process_0 = self.mods1_input_activation_post_process_0(x); x = None
mods1_w = self.mods1.w
mods1_w_activation_post_process_0 = self.mods1_w_activation_post_process_0(mods1_w); mods1_w = None
mods1_b = self.mods1.b
linear = torch.nn.functional.linear(mods1_input_activation_post_process_0, mods1_w_activation_post_process_0, bias = mods1_b); x_activation_post_process_0 = mods1_w_activation_post_process_0 = mods1_b = None
mods1_output_activation_post_process_0 = self.mods1_output_activation_post_process_0(linear); linear = None
return mods1_output_activation_post_process_0
```
Test Plan:
python test/test_quantization.py test_observer_fqn
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D31088652
fbshipit-source-id: 2f1526f578a13000b34cfd30d11f16f402fd3447
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65422
hardsigmoid is used by mobile net v3 oss model.
This diff added hardsigmoid support in acc_tracer
Test Plan:
buck test glow/fb/fx/acc_tracer:test_acc_shape_inference
buck test glow/fb/fx/oss_acc_tracer:test_acc_tracer -- test_hardsigmoid
Reviewed By: jfix71
Differential Revision: D30950304
fbshipit-source-id: 8fe4b4c6df29c06a73850d32f59321a9311f94f5
Summary:
The source is shared across all threads running the torchscript
interpreter, so if several threads encounter errors at once, they will all race
to unpickle the source, leading to memory corruption.
Test Plan:
Model 217993215_0 is the problematic model; I wasn't able to repro
the crash with requests stored in Hive, but I could easily by adding my
devserver (SMC tier predictor.bertrand) as a shadow tier to the model's tier
(inference_platform.predictor_model.prod.bi.217993215_latest). (i.e., set
shadow_tier property to predictor.bertrand=1 to proxy 1% of traffic).
With this diff, the ASAN/TSAN errors go away.
Reviewed By: suo
Differential Revision: D31044009
fbshipit-source-id: 56f9ef3880e7cf09f334db71b4256e362b4de965
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65186
FBGEMM JIT'ed EmbeddingSpMDM kernel just returns false when there's an error delegating detailed error handling to the caller (since each framework like PyTorch and Caffe2 wants to do error handling differently). Many of PyTorch code was simply reporting there was "an" error without pinpointing exactly why error happened. This diff introduces more informative error msg following what Caffe2 was doing.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D31008300
fbshipit-source-id: b8d069af0692dc86dc642b18a9c68f22deaffea3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65482
Currently we hardcoded permute + bmm in a module and tagged it as a leaf module during tracing. This diff introduces a pass to fuse permute + matmul to a single node.
TODO:
For fusion transformation like this kind, they would actually share many similar code like finding the fusion pattern, replacing original nodes with fused node. Current fx subgraph rewriter allows us to specify patterns that we want to replace but we would need to extend it to allow specify constraint on nodes' kwargs.
Reviewed By: yinghai
Differential Revision: D31022055
fbshipit-source-id: 13d1f18d79b09d371897ecde840f582ccaf5713a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65481
Previous we have `acc_ops.transpose` but after a recent diff `torch.transpose` is mapped to `acc_ops.permute`. Here we clean up the fx2trt unittest for transpose and add support for negative indices in permute.
Reviewed By: wushirong
Differential Revision: D31115280
fbshipit-source-id: 58e689e6dd14181aea5186f3bb5b8745a07d0e51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65181
This PR changes `state_dict()` during sync to `named_parameters` and `named_buffers` explicitly. the underlying motivation is that, `state_dict()` doesn't necessarily equals to "params + buffers" for all cases, state_dict is used for checkpoint purpose mainly, and params/buffers are used for training, we might have cases that params/buffers be in different forms with state_dict (i.e. state_dict we might want to save in small pieces of tensors while in training we want to concat the tensors together for performance reasons).
ghstack-source-id: 138701159
Test Plan: wait for ci
Reviewed By: divchenko, rohan-varma
Differential Revision: D31007085
fbshipit-source-id: 4e1c4fbc07110163fb9b09b043ef7b4b75150f18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65014
ghstack-source-id: 138656948
Test Plan:
```
(pytorch) [maxren@devvm3115.atn0 ~/pytorch] python3 test/test_jit.py TestPeephole
CUDA not available, skipping tests
monkeytype is not installed. Skipping tests for Profile-Directed Typing
........s......................
----------------------------------------------------------------------
Ran 31 tests in 0.393s
OK (skipped=1)
(pytorch) [maxren@devvm3115.atn0 ~/pytorch] python3 test/test_jit.py TestPeephole.test_normalized_rsub
CUDA not available, skipping tests
monkeytype is not installed. Skipping tests for Profile-Directed Typing
.
----------------------------------------------------------------------
Ran 1 test in 0.015s
OK
```
Reviewed By: eellison
Differential Revision: D30941389
fbshipit-source-id: 03f0416d99090845c9bfb1e5fcf771d5f1d7a050
Summary:
## {emoji:1f41b} Bug
'CosineAnnealingWarmRestarts' object has no attribute 'T_cur'.
In the Constructor of the CosineAnnealingWarmRestarts, we're calling the constructor of the Parent class (_LRScheduler) which inturn calls the step method of the CosineAnnealingWarmRestarts.
The called method tries to update the object's attribute 'T_cur' which is not defined yet. So it raises the error.
This only holds, when we give the value for last_epoch argument as 0 or greater than 0 to the 'CosineAnnealingWarmRestarts', while initializing the object.

## To Reproduce
Steps to reproduce the behavior:
1. Give the value for the last_epoch argument as zero OR
1. Give the value for the last_epoch argument as a Positive integer.
## Expected behavior
I only expected the 'CosineAnnealingWarmRestarts' object to be initialized.
## Environment
PyTorch version: 1.9.0+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (x86_64)
GCC version: (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Clang version: Could not collect
CMake version: version 3.21.2
Libc version: glibc-2.31
Python version: 3.8.10 [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.8.0-59-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
## Additional context
We can able to solve this bug by moving the line 'self.T_cur = self.last_epoch' above the 'super(CosineAnnealingWarmRestarts,self).__init__()' line. Since we've initialized the "self.T_cur" to the object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64758
Reviewed By: ezyang
Differential Revision: D31113694
Pulled By: jbschlosser
fbshipit-source-id: 98c0e292291775895dc3566fda011f2d6696f721
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65387
Added a customized NNC implementation for signed log1p kernel and enabled the fusion pass that adds the fused signed log1p op.
Also, added a SR microbenchmark for this kernel which shows the performance improvement.
Without fusion:
```
--------------------------------------------------------------------------------
Benchmark Time CPU Iterations
--------------------------------------------------------------------------------
BM_signed_log1p/16 1953 ns 1953 ns 358746
BM_signed_log1p/64 2049 ns 2049 ns 342145
BM_signed_log1p/512 3291 ns 3291 ns 214342
BM_signed_log1p/4096 15559 ns 15559 ns 44420
BM_signed_log1p/32768 101936 ns 101935 ns 6843
BM_signed_log1p/65536 194792 ns 194789 ns 3615
```
With NNC fusion:
```
--------------------------------------------------------------------------------
Benchmark Time CPU Iterations
--------------------------------------------------------------------------------
BM_signed_log1p/16 369 ns 369 ns 1896179
BM_signed_log1p/64 497 ns 497 ns 1406995
BM_signed_log1p/512 1618 ns 1618 ns 430209
BM_signed_log1p/4096 11327 ns 11326 ns 61463
BM_signed_log1p/32768 84099 ns 84086 ns 8325
BM_signed_log1p/65536 166531 ns 166510 ns 4186
```
This clearly shows >15% improvement in performance of this kernel with NNC fusion.
On inline_cvr local model, there is a small improvement in terms of profiled time spent on ops:
without fusion: `0.9%` (computed by adding the % spent on all the 4 ops involved)
with NNC fusion: `0.55%`
Test Plan:
`buck test mode/opt-clang //caffe2/benchmarks/static_runtime:static_runtime_cpptest -- SignedLog1p`
Also, did the accuracy test with inline_cvr as described here, https://fb.quip.com/qmdDAJzEmPtf, on the full size model (285298536_1)
```
get 57220 prediction values
get 57220 prediction values
max_error: 0 total: 0
```
Reviewed By: hlu1
Differential Revision: D30609492
fbshipit-source-id: d2e68df580569a30ee61abb0ef18d2c4c56827bd
Summary:
- Replace THCNumerics with `at::_isnan`
- Replace `contiguous` with `expect_contiguous`
- Don't use `contiguous` on output tensors. Instead skip the copy and
just create a new empty tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65350
Reviewed By: ezyang
Differential Revision: D31103501
Pulled By: ngimel
fbshipit-source-id: 9030869e28d6c570fad074fd0502076de8e2ab09
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64514
sync_params is a misnomer since we don't actually synchroniz
parameters. While removing this I realized
`self._check_and_sync_module_buffers` does almost everything we need it to, so
just refactored that and made DDP forward call into it.
ghstack-source-id: 138684982
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D30751231
fbshipit-source-id: add7c684f5c6c71dad9e9597c7759849fa74f47a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65486
Adding this after observing jobs running for 6+ hours on `pytorch/pytorch-canary`, still trying to debug why they happen there but this should resovle jobs running forever
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
cc ezyang seemethere malfet pytorch/pytorch-dev-infra
Test Plan: Imported from OSS
Reviewed By: ezyang, malfet, janeyx99
Differential Revision: D31117497
Pulled By: seemethere
fbshipit-source-id: 126a10e844bdef77c2852cc5c392e5f37f130f7e
Summary:
Currently, the description of torch.any would be parsed like
```
param input
the input tensor.
```
However, it should be
```
Tests if any element in input evaluates to True.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65310
Reviewed By: ezyang
Differential Revision: D31102918
Pulled By: soulitzer
fbshipit-source-id: 678ade20ba16ad2643639fbd2420c8b36fcd8bd7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65340
I thought about a few possible ways of doing this. The main hazard is
that if I create a CPU tensor that doesn't have any real storage, the
moment I actually try to access the data on the tensor I will segfault.
So I don't want to use _make_subclass on a "cpu meta tensor" because
the CPU meta tensor (with no subclass) is radioactive: printing it
will immediately cause a segfault. So instead, I have to create
the CPU meta tensor AND subclass all in one go, and that means I need
another function for it. One downside to doing it this way is
I need another overload for explicit strides, and in general it is
difficult to get the view relationships to all work out properly;
tracked at https://github.com/pytorch/pytorch/issues/65339
Fixes https://github.com/pytorch/pytorch/issues/62972
Fixes https://github.com/pytorch/pytorch/issues/62730
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31057231
Pulled By: ezyang
fbshipit-source-id: 73522769e093ae8a1bf0c7f7e594659bfb827b28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65235
1. Updated the legacy type checks in `torch/csrc/autograd/engine.cpp` to individually validate the dtype, device, and layout equality for grad and tensor.
2. Removed device field from `InputMetadata` since it's already stored via storing options. Also, added `dtype()` and `layout()` methods to `InputMetadata`. To make this change, some calls had to be updated due to the change in constructor.
3. To fix https://github.com/pytorch/pytorch/issues/65016:
a. Added a `is_tensor_subclass` field in `InputMetadata` to skip device checks for grad and tensor when the tensor has
python key set on it (tensor subclass).
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D31117318
Pulled By: anjali411
fbshipit-source-id: 825401df98695c48bf9b320be54585f6aff500bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65033
1. Move the file:
```
hg mv caffe2/torch/quantization/fx caffe2/torch/ao/quantization/fx
hg mv caffe2/torch/quantization/quantize_fx.py caffe2/torch/ao/quantization/quantize_fx.py
```
2. Create new files
```
touch caffe2/torch/quantization/quantize_fx.py
touch caffe2/torch/quantization/fx/__init__.py
```
3. import things in the new files
4. add tests to test/quantization/ao_migration/test_quantization_fx.py
this is because we have some fx import in quantize_fx and fx/*.py
Test Plan: buck test mode/dev //caffe2/test:quantization
Reviewed By: vkuzo, z-a-f
Differential Revision: D30949749
fbshipit-source-id: 9e5d4d039c8a0a0820bc9040e224f0d2c26886d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65235
1. Updated the legacy type checks in `torch/csrc/autograd/engine.cpp` to individually validate the dtype, device, and layout equality for grad and tensor.
2. Removed device field from `InputMetadata` since it's already stored via storing options. Also, added `dtype()` and `layout()` methods to `InputMetadata`. To make this change, some calls had to be updated due to the change in constructor.
3. To fix https://github.com/pytorch/pytorch/issues/65016:
a. Added a `is_tensor_subclass` field in `InputMetadata` to skip device checks for grad and tensor when the tensor has
python key set on it (tensor subclass).
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D31082693
Pulled By: anjali411
fbshipit-source-id: cb551cd438c6ca40b0f18a4d0009e0861cf0fd4e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63010
This changes `test_neg_view` to call the operator with the same numeric values as the original sample input.
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D31082824
Pulled By: anjali411
fbshipit-source-id: 7d50f99dc0d1343247e366cbe9b0ca081bd0a9b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65376
Let's suppose there's a bug in PyTorch and python_error gets thrown
and never gets caught. Typically, you'll get a very useless error
message like this:
```
terminate called after throwing an instance of 'python_error'
what():
Aborted (core dumped)
```
Now, you'll get:
```
what(): unknown Python error (for more information, try rerunning with TORCH_SHOW_CPP_STACKTRACES=1)
```
and with TORCH_SHOW_CPP_STACKTRACES=1 you'll get:
```
what(): error message from Python object
```
If we're OK with making Python exceptions go even slower, we could
eagerly populate unconditionally. I'm also not so happy we don't get
a Python backtrace or the Python error name, that's worth improving
(this is a minimal diff to get the discussion going.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31067632
Pulled By: ezyang
fbshipit-source-id: 9cfda47cafb349ee3d6853cdfb0f319073b87bff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65427
Previously we added a input_tensor_meta for dequantize function, this is a bit hacky since this creates a dependency between
the arguments of dequantize and if there are passes that changes the input then we would need to update tensor meta as well
Test Plan:
python torch/fx/experimental/fx2trt/example/quantized_resnet_test.py
Imported from OSS
Reviewed By: soulitzer
Differential Revision: D31094274
fbshipit-source-id: 5e40648d3081e2363f3a70bcc9745df4a8190ad3
Summary:
Resubmit of https://github.com/pytorch/pytorch/pull/62303.
Reverts the revert, and restores some diffs that were mysteriously missing from the reverted revert. I think some of the diffs I pushed to the original PR raced with its import or landing, such that the original PR's merge didn't pick up all the diffs I wanted. I don't know enough about the landing process to do more than speculate wildly, but hopefully this resubmit sorts things out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62835
Reviewed By: zhouzhuojie, seemethere, janeyx99, heitorschueroff
Differential Revision: D30999982
Pulled By: malfet
fbshipit-source-id: 1f70ab4055208f1c6a80c9fc9fbe292ce68ecaa9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65119
Pytorch Quantization: allow prepare_qat to include custom module by passing allow_list into the prepare_qat.
When we are implementing custom module and custom mapping for Quantization Aware Training (QAT), we need to add the custom module to the mappings and to the allow_list during prepare_qat. The allow_list needs to be surfaced to the propagate_qconfig_.
Test Plan: relying on general unit test
Reviewed By: supriyar
Differential Revision: D30982060
fbshipit-source-id: 1114115b6a3b853238d33d72b5cbaafc60f463e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64113
Since there is only one model replica per process, `replicas`
can be simplified from `std::vector<std::vector<at::Tensor>>` to
`std::vector<at::Tensor>` in the Reducer class.
Test Plan:
All tests are passing
`pytest test/distributed/test_c10d_gloo.py -vs`
Imported from OSS
Reviewed By: mrshenli
Differential Revision: D30615965
fbshipit-source-id: d2ec809d99b788c200b01411333e7dbad1269b51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65220Fixes#65221
- Remove deepcopy from Mapper to support file handles
- Convert `IterableWrapper` to deepcopy iterable instance within each iterator to prevent in-place modification (different data per epoch)
- Convert `IDP` to `IterableWrapper` in test_datapipe.py
- Refine the variable names (prevent using `dp` that is module reference)
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D31021886
Pulled By: ejguan
fbshipit-source-id: 72a9eee66c758e2717d591cd0942892bddedc223
Summary:
This PR enables Half, BFloat16, ComplexFloat, and ComplexDouble support for matrix-matrix multiplication of COO sparse matrices.
The change is applied only to CUDA 11+ builds.
`cusparseSpGEMM` also supports `CUDA_C_16F` (complex float16) and `CUDA_C_16BF` (complex bfloat16). PyTorch also supports the complex float16 dtype (`ScalarType::ComplexHalf`), but there is no convenient dispatch, so this dtype is omitted in this PR.
cc nikitaved pearu cpuhrsch IvanYashchuk ezyang anjali411 dylanbespalko mruberry Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59980
Reviewed By: ngimel
Differential Revision: D30994115
Pulled By: cpuhrsch
fbshipit-source-id: 4f55b99e8e25079d6273b4edf95ad6fa85aeaf24
Summary:
Fixes https://github.com/pytorch/pytorch/issues/58839
After discussing with albanD he proposed this simple design.
Let's iterate over the idea here :).
Thanks.
The main point that this PR does is to use reparametrization to be reverted at the end of the functional call.
This allows us to have the original model with its status unchanged, also in this scenario the module is created without parameters so this will hard error if not all parameters are specified when the forward pass is done.
``` python
import torch
import torch.nn.utils._stateless
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.l1 = torch.nn.Linear(1, 1)
def forward(self, x):
return self.l1(x)
mod = MyModule()
print('weight before', mod.l1.weight)
x = torch.rand((1, 1))
parameters = {"l1.weight": torch.nn.Parameter(torch.tensor([[1.0]])),
"l1.bias": torch.nn.Parameter(torch.tensor([0.0]))}
res = torch.nn.utils._stateless.functional_call(mod, parameters, x)
print('Functional call input ', x, ' and result ', res)
print('weight after', mod.l1.weight)
```
Output
```
weight before Parameter containing:
tensor([[-0.4419]], requires_grad=True)
Functional call input tensor([[0.3531]]) and result tensor([[0.3531]], grad_fn=<AddmmBackward>)
weight after Parameter containing:
tensor([[-0.4419]], requires_grad=True)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61447
Reviewed By: soulitzer
Differential Revision: D31082765
Pulled By: albanD
fbshipit-source-id: ba814d0f9162fb39c59989ca9a8efe160405ba76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65391
TSAN tests are much slower than the usual dev/opt mode, about 5-10x
slower.
As a result, for TSAN build mode we use a much higher timeout for distributed
tests.
ghstack-source-id: 138584613
Test Plan: waitforbuildbot
Reviewed By: cbalioglu
Differential Revision: D31076575
fbshipit-source-id: 44a485f07101deac536470ceeff2a52cac4f9e0b
Summary:
Addresses https://github.com/facebookresearch/functorch/issues/78 and https://github.com/pytorch/pytorch/issues/54261.
* There exists `torch.batch_norm` but it takes an extra arg: `cudnn_enabled` (not there in functional variant). This is passed from the functional variant to `torch.batch_norm` here: https://github.com/pytorch/pytorch/blob/master/torch/nn/functional.py#L2282. `test_variant_consistency_jit` fails with an error: (when passed an alias)
```python
File "/home/krshrimali/Documents/Projects/Quansight/pytorch/test/test_ops.py", line 457, in _test_consistency_helper
variant_forward = variant(cloned,
TypeError: batch_norm() missing 1 required positional arguments: "cudnn_enabled"
```
* I'm not sure of a solution to this, as AFIK - there is no way to pass a lambda wrapper for an alias. Hence, I've skipped adding this as an alias there.
* On second thought, is this even an alias?
cc: mruberry zou3519 kshitij12345
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63218
Reviewed By: bdhirsh
Differential Revision: D31019785
Pulled By: zou3519
fbshipit-source-id: 2a834d05835da975289efc544a7ad7e98c99438f
Summary:
Part of migrating from Circle.
Once we get a successful force_on_cpu test, we can move it to trunk only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65094
Reviewed By: seemethere
Differential Revision: D31086289
Pulled By: janeyx99
fbshipit-source-id: e1d135cc844d51f0b243b40efb49edca277d9de8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65175
More efficient use of map API, more efficient way to insert all pairs of inputs/outputs in liveness map
ghstack-source-id: 138547815
Test Plan: Time to enable static runtime down from ~8.7s to ~8.4s
Reviewed By: mikeiovine
Differential Revision: D30983897
fbshipit-source-id: fa6000bfd0fa0adfcd7c5922199ee32ada8c430e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65169
Previously these composite functions created a new tensor
using at::empty (or some other factory function) using TensorOptions
which doesn't preserve Python subclass. Making new_empty a
non-composite op and then routing everyone through it makes it
respect subclass. We could also make all of these non-composite
but this reduces the number of derivatives.yaml entries I have to
make and allows you to trace the fill calls.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D31003713
Pulled By: ezyang
fbshipit-source-id: 19f906f1404a6b724769c49f48d123f407a561ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65352
This can be a big win if it saves the virtual call to operator== and the cost is tiny.
ghstack-source-id: 138497657
Test Plan: Profiled ptvsc2_predictor_bench startup, inclusive time spent in EqualNode::operator() dropped from 0.8% to negligible
Reviewed By: hlu1
Differential Revision: D30974969
fbshipit-source-id: 9c3af36cffe709dfce477dcc49722536470264a0
description:Create a report to help us reproduce and fix the bug
body:
- type:markdown
attributes:
value:>
#### Before submitting a bug, please make sure the issue hasn't been already addressed by searching through [the existing and past issues](https://github.com/pytorch/pytorch/issues?q=is%3Aissue+sort%3Acreated-desc+).
- type:textarea
attributes:
label:🐛 Describe the bug
description:|
Please provide a clear and concise description of what the bug is.
If relevant, add a minimal example so that we can reproduce the error by running the code. It is very important for the snippet to be as succinct (minimal) as possible, so please take time to trim down any irrelevant code to help us debug efficiently. We are going to copy-paste your code and we expect to get the same result as you did: avoid any external data, and include the relevant imports, etc. For example:
```python
# All necessary imports at the beginning
import torch
# A succinct reproducing example trimmed down to the essential parts:
t = torch.rand(5, 10) # Note: the bug is here, we should pass requires_grad=True
t.sum().backward()
```
If the code is too long (hopefully, it isn't), feel free to put it in a public gist and link it in the issue: https://gist.github.com.
Please also paste or describe the results you observe instead of the expected results. If you observe an error, please paste the error message including the **full** traceback of the exception. It may be relevant to wrap error messages in ```` ```triple quotes blocks``` ````.
placeholder:|
A clear and concise description of what the bug is.
```python
# Sample code to reproduce the problem
```
```
The error message you got, with the full traceback.
```
validations:
required:true
- type:textarea
attributes:
label:Versions
description:|
Please run the following and paste the output below.
about: Report an issue related to https://pytorch.org/docs
---
## 📚 Documentation
<!-- A clear and concise description of what content in https://pytorch.org/docs is an issue. If this has to do with the general https://pytorch.org website, please file an issue at https://github.com/pytorch/pytorch.github.io/issues/new/choose instead. If this has to do with https://pytorch.org/tutorials, please file an issue at https://github.com/pytorch/tutorials/issues/new -->
description:Report an issue related to https://pytorch.org/docs/stable/index.html
body:
- type:textarea
attributes:
label:📚 The doc issue
description:>
A clear and concise description of what content in https://pytorch.org/docs/stable/index.html is an issue. If this has to do with the general https://pytorch.org website, please file an issue at https://github.com/pytorch/pytorch.github.io/issues/new/choose instead. If this has to do with https://pytorch.org/tutorials, please file an issue at https://github.com/pytorch/tutorials/issues/new.
validations:
required:true
- type:textarea
attributes:
label:Suggest a potential alternative/fix
description:>
Tell us how we could improve the documentation in this regard.
about: Submit a proposal/request for a new PyTorch feature
---
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
## Pitch
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
description:Submit a proposal/request for a new pytorch feature
body:
- type:textarea
attributes:
label:🚀 The feature, motivation and pitch
description:>
A clear and concise description of the feature proposal. Please outline the motivation for the proposal. Is your feature request related to a specific problem? e.g., *"I'm working on X and would like Y to be possible"*. If this is related to another GitHub issue, please link here too.
validations:
required:true
- type:textarea
attributes:
label:Alternatives
description:>
A description of any alternative solutions or features you've considered, if any.
- type:textarea
attributes:
label:Additional context
description:>
Add any other context or screenshots about the feature request.
{%- set squid_proxy = "http://internal-tf-lb-20210727220640487900000002-835786077.us-east-1.elb.amazonaws.com:3128" -%}
{# squid_no_proxy is a list of common set of fixed domains or IPs that we don't need to proxy. See https://docs.aws.amazon.com/AmazonECS/latest/developerguide/http_proxy_config.html#windows-proxy #}
{%- set squid_no_proxy = "localhost,127.0.0.1,github.com,amazonaws.com,s3.amazonaws.com,169.254.169.254,169.254.170.2,/var/run/docker.sock" -%}
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
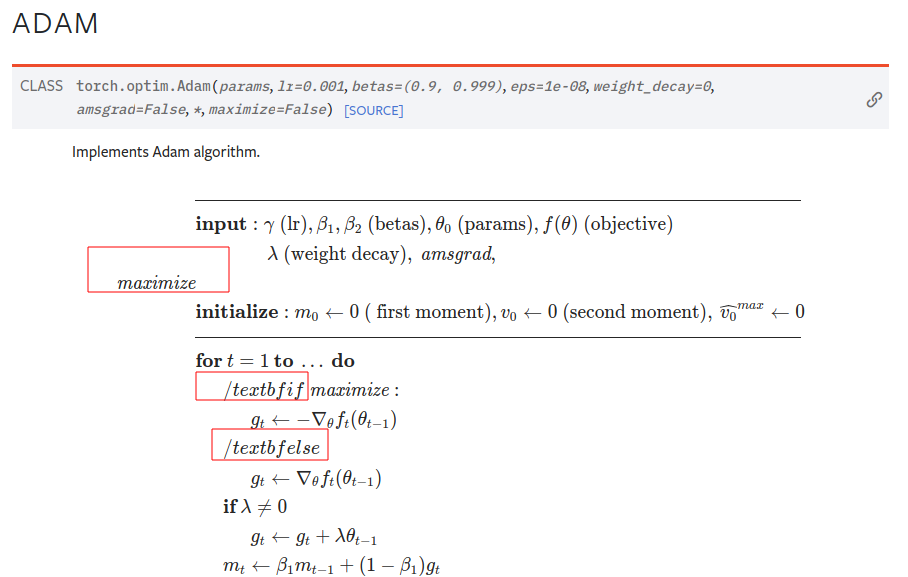{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
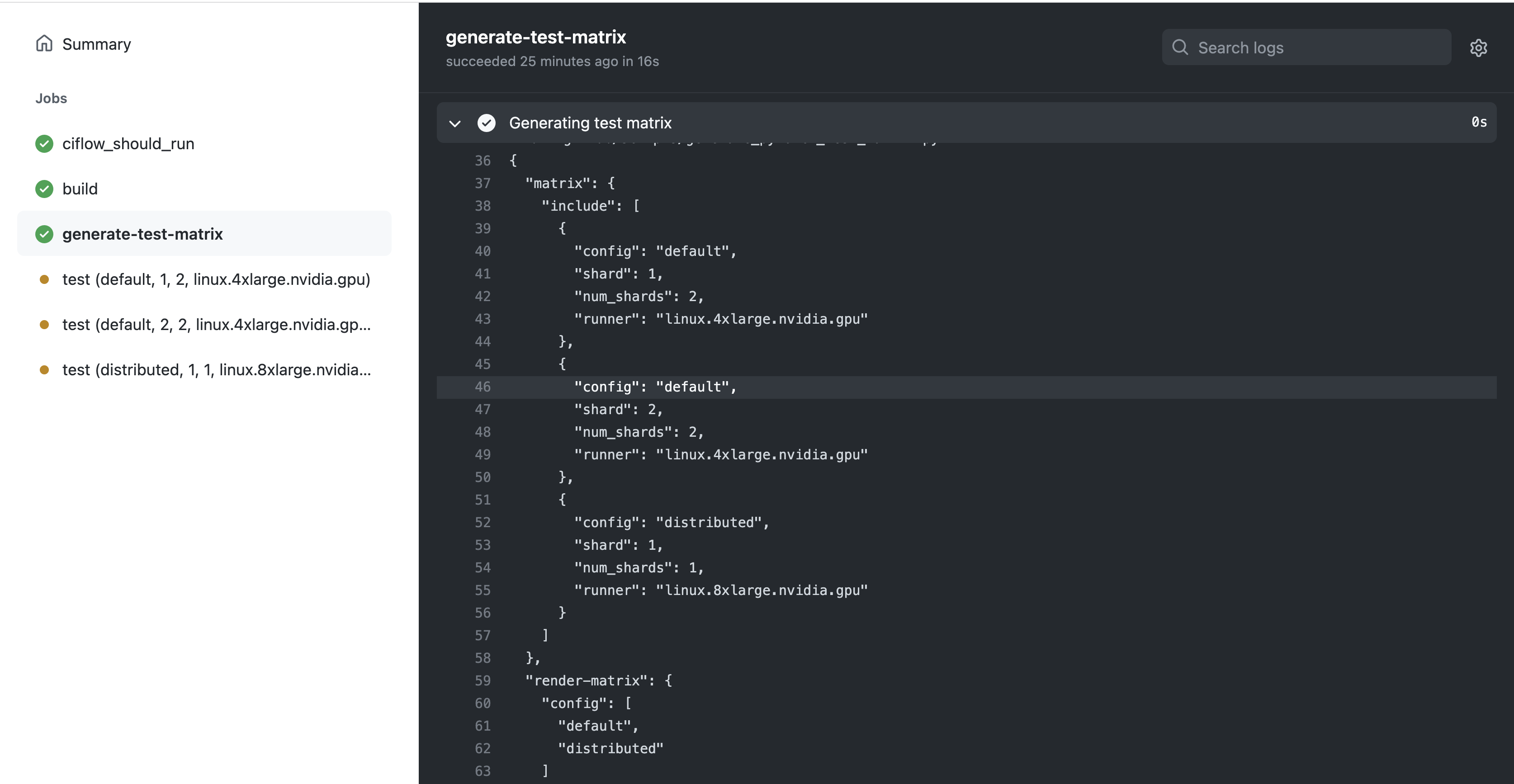{kind=link}
{kind=link}
{kind=link}
{kind=link}
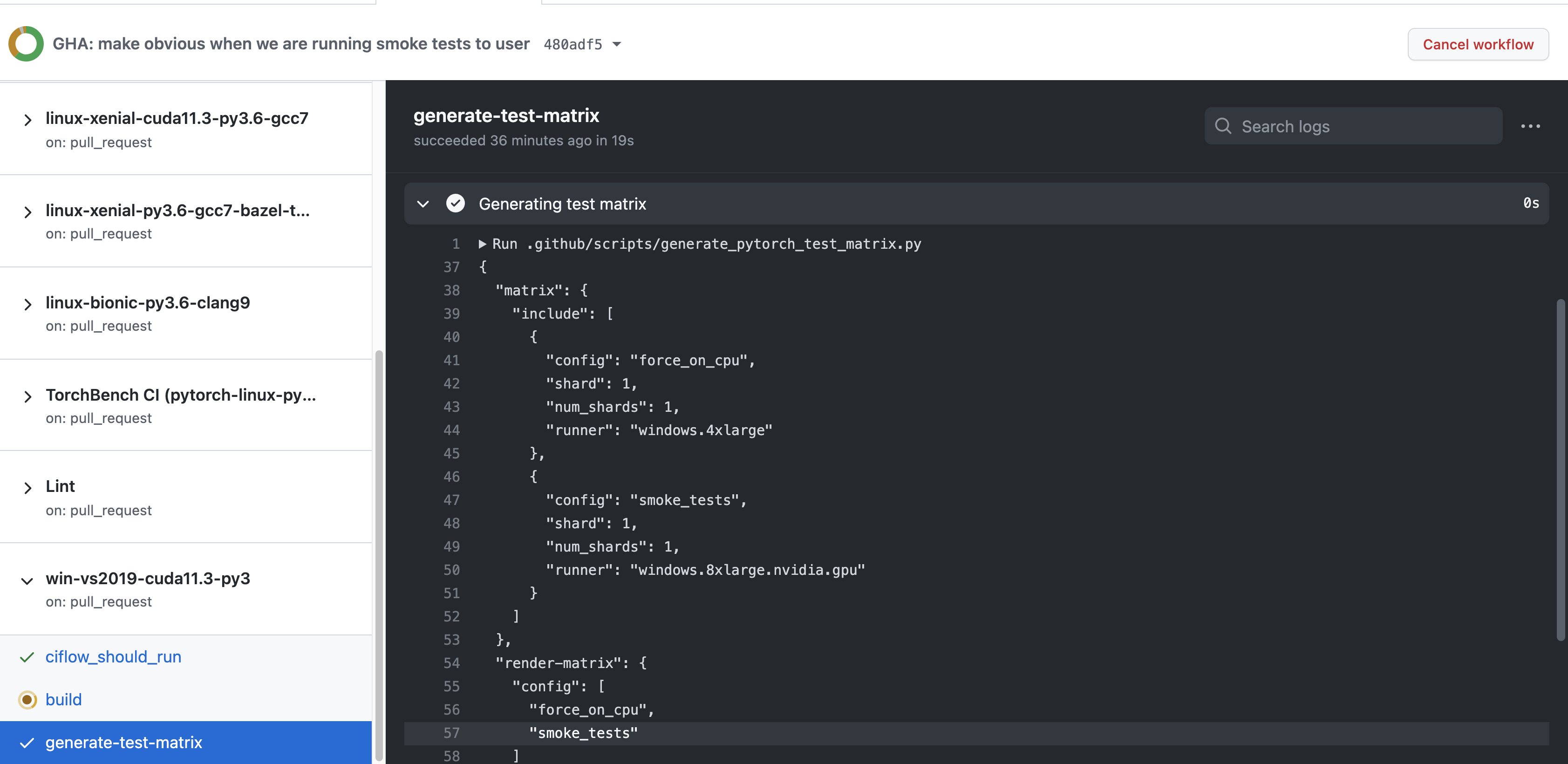{kind=link}
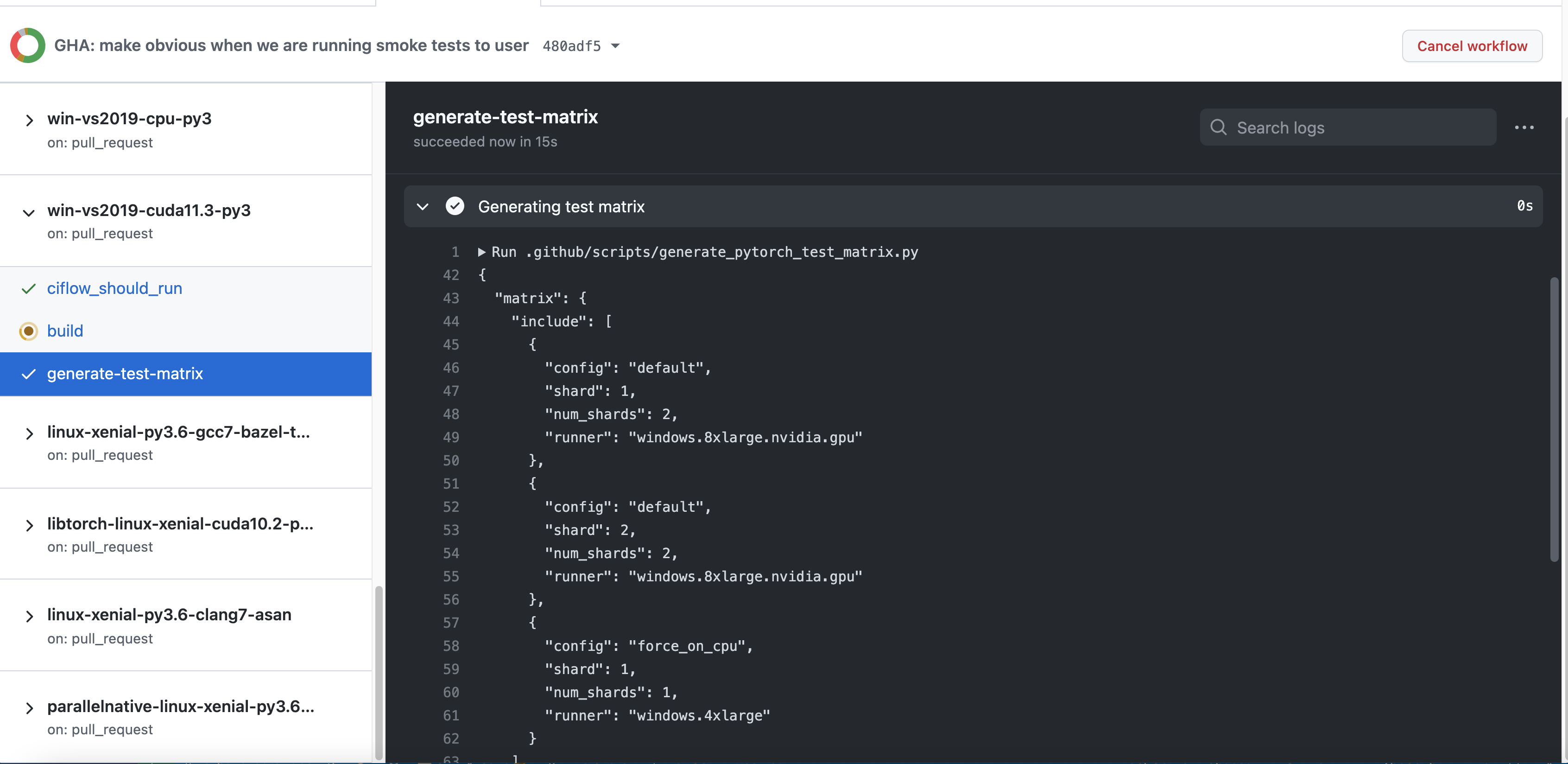{kind=link}
{kind=link}
{kind=link}
{kind=link}