1. Update "Package Reference" to "Python API"
2. Add in torchaudio and torchtext reference links so they show up across all docs not just the main page
3. Add "Other Languages" section and add in C++ docs
Changelog:
- When number of batches = 1, dispatch to trsm instead of trsm_batched in MAGMA
Test Plan:
- All triangular_solve tests should pass to ensure that the change is valid
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23376
This uses master version of sphinxcontrib-katex as it only
recently got prerender support.
Fixes#20984
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16582064
Pulled By: ezyang
fbshipit-source-id: 9ef24c5788c19572515ded2db2e8ebfb7a5ed44d
This is temporary, won't be needed with the new serialization format.
But for now, since the main module gets its name from the archive name,
we need this for safety, other wise something like
`torch.jit.save("torch.pt") will break things.
ghstack-source-id: f36febe1025ff04e7f79617e548819d4876dc7fa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23630
Now when initializing a ScriptModule during the torch.jit.load()
process, there is already a cpp module backing the thing. That means
that setting training will overwrite whatever the initialized
ScriptModule had.
This PR splits apart the common "set up internal state" part of the
Module __init__ and calls that from ScriptModule.__init__ and
Module.__init__, leaving the "nn.Module-specific" part (setting
`self.training`) for the nn.Module __init__
ghstack-source-id: 9b2ba8a15c43cf230363e4cd10ba4ad3ac4931f7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23680
* [jit] Support nn.GRU and Make nn.LSTM accept PackedPaddedSequence
Summary:
Test Plan:
Reviewers:
Subscribers:
Tasks:
Tags:
* fix
* add link to comments
In max_pool2d, max_pool3d, avg_pool2d, avg_pool3d.
There is only one substantive change: when stride.size() == 1,
we expand it to size 2. However, I also took the opportunity
to give a better error message.
Testing here is bare minimum, because I'm in a hurry. Just make
sure C++ API with all size 1 inputs works.
This is a squash of four commits.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Summary:
Simplifying https://github.com/pytorch/pytorch/issues/23793: The dependency relationship between
{INSTALL,BUILD}_TEST is already properly handled in CMakeLists.txt. All
we need to do is to pass down INSTALL_TEST.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23806
Differential Revision: D16691833
Pulled By: soumith
fbshipit-source-id: 7607492b2d82db3f79b174373a92e2810a854a61
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/23480.
I only verified that the schedule reaches the restart at the expected step as specified in the issue, it would be good to have someone else verify correctness here.
Script:
```
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(torch.optim.SGD([torch.randn(1, requires_grad=True)], lr=0.5), T_0=1, T_mult=2)
for i in range(9):
print(i)
print(scheduler.get_lr())
scheduler.step()
```
Output:
```
0
[0.5]
1
[0.5]
2
[0.25]
3
[0.5]
4
[0.42677669529663687]
5
[0.25]
6
[0.07322330470336313]
7
[0.5]
8
[0.4809698831278217]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23833
Differential Revision: D16657251
Pulled By: gchanan
fbshipit-source-id: 713973cb7cbfc85dc333641cbe9feaf917718eb9
Summary:
This allows `INSTALL_*` to pass through to cmake.
Additional fix is that if `INSTALL_TEST` is specified, it wont use `BUILD_TEST` as the default value for `INSTALL_TEST`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23793
Differential Revision: D16648668
Pulled By: soumith
fbshipit-source-id: 52c2a0d8033bc556355b87a6731a577940de9859
Summary:
Changelog:
- Add batching for det / logdet / slogdet operations
- Update derivative computation to support batched inputs (and consequently batched outputs)
- Update docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22909
Test Plan:
- Add a `test_det_logdet_slogdet_batched` method in `test_torch.py` to test `torch.det`, `torch.logdet` and `torch.slogdet` on batched inputs. This relies on the correctness of `torch.det` on single matrices (tested by `test_det_logdet_slogdet`). A port of this test is added to `test_cuda.py`
- Add autograd tests for batched inputs
Differential Revision: D16580988
Pulled By: ezyang
fbshipit-source-id: b76c87212fbe621f42a847e3b809b5e60cfcdb7a
* [jit] Recursive compilation error hot fixes
This is a combination of #23454 and #23682 which are needed for the
error reporting on recrusively compiled code
* #23682
Summary:
Changelog:
- Use narrow instead of narrow_copy while returning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23591
Test Plan:
- All tests should pass to ensure that the change is correct
Fixes https://github.com/pytorch/pytorch/issues/23580
Differential Revision: D16581174
Pulled By: ezyang
fbshipit-source-id: 1b6bf7d338ddd138ea4c6aa6901834dd202ec79c
Summary:
accidently calls clone, but what we want is creating an empty tensor and set storage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23452
ghstack-source-id: 87438096
Differential Revision: D16442756
fbshipit-source-id: 6d5663f82c9bd4e9de8fc846c52992477843af6a
Summary:
Changelog:
- Rename `gels` to `lstsq`
- Fix all callsites
- Rename all tests
- Create a tentative alias for `lstsq` under the name `gels` and add a deprecation warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23460
Test Plan: - All tests should pass to confirm that the patch is correct
Differential Revision: D16547834
Pulled By: colesbury
fbshipit-source-id: b3bdb8f4c5d14c7716c3d9528e40324cc544e496
Summary:
Only check for cmake dependencies we directly depend on (e.g., hipsparse but not rocsparse)
Use cmake targets for ROCm where possible.
While there, update the docker CI build infrastructure to only pull in packages by name we directly depend on (anticipating the demise of, e.g., miopengemm). I do not anticipate a docker rebuild to be necessary at this stage as the changes are somewhat cosmetic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23527
Differential Revision: D16561010
Pulled By: ezyang
fbshipit-source-id: 87cd9d8a15a74caf9baca85a3e840e9d19ad5d9f
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
LARGE: 66
MEDIUM: 649
XLARGE: 1
Updated actions:
From LARGE to MEDIUM: 18
From LARGE to XLARGE: 2
From MEDIUM to LARGE: 20
From XLARGE to LARGE: 1
Differential Revision: D16559356
fbshipit-source-id: a51ef034265649314661ab0e283089a069a20437
Summary:
When a user tries to change metadata of a tensor created from `.data` or `.detach()`, we currently shows an error message "<function_name> is not allowed on Tensor created from .data or .detach()". However, this error message doesn't suggest what the right fix should look like. This PR improves the error message.
Closes https://github.com/pytorch/pytorch/issues/23393.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23504
Differential Revision: D16547415
Pulled By: yf225
fbshipit-source-id: 37f4a0385442e2b0966386fb14d3d938ecf4230c
Summary:
Previously these were left out which would lead to confusing messages,
now it looks something like:
```
torch.jit.frontend.UnsupportedNodeError: import statements aren't
supported
:
at ../test.py:13:9
def bad_fn(self):
import pdb
~~~~~~ <--- HERE
'__torch__.X' is being compiled since it was called from 'fn'
at ../test.py:16:12
def fn(x):
return X(10)
~~~~ <--- HERE
```
Fixes#23453
](https://our.intern.facebook.com/intern/diff/16526027/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23454
Pulled By: driazati
Differential Revision: D16526027
fbshipit-source-id: 109f2968430dbf51ee91b1b3409badfd557d19a4
Summary:
Use the recursive script API in the existing docs
TODO:
* Migration guide for 1.1 -> 1.2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21612
Pulled By: driazati
Differential Revision: D16553734
fbshipit-source-id: fb6be81a950224390bd5d19b9b3de2d97b3dc515
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23521
non-fbgemm path should have the same arguments as fbgemm path.
Reviewed By: jianyuh
Differential Revision: D16547637
fbshipit-source-id: bb00d725fb968cbee32defb8facd2799a7e79bb4
Summary:
This resolves two issues in one shot:
- sub shouldn't be available for bool type.
- When sub is applied to an unsupported type, the current error messages
shows "add_cpu/add_cuda is not implemented for [type]". They should be
"sub_cpu/sub_cuda" instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23519
Differential Revision: D16548770
Pulled By: izdeby
fbshipit-source-id: fe404a2a97b8d11bd180ec41364bf8e68414fb15
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/23417
Test Plan:
cd docs; make html
Imported from OSS
Differential Revision: D16523781
Pulled By: ilia-cher
fbshipit-source-id: d6c09e8a85d39e6185bbdc4b312fea44fcdfff06
Summary:
No real change on the CI since currently the default latest is 0.4.0. houseroad bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23517
Differential Revision: D16550375
Pulled By: bddppq
fbshipit-source-id: a669b8af678c79c4d6909300b28458fe6b7cd30c
Summary:
There is an internal fbcode assert that fails if i do not add these checks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23511
Differential Revision: D16545606
Pulled By: eellison
fbshipit-source-id: cd3a799850bae8f052f9d81c1e4a2678fda19317
Summary:
PyTorch test sets a policy() method to assertLeaksNoCudaTensors.
Whenever a test is run, assertLeaksNoCudaTensors is called,
which in turn calls CudaMemoryLeakCheck, which in turn calls
initialize_cuda_context_rng, where it executes torch.randn
on each device, where a kernel is launched on each device.
Since the kernel may not finish on device 1, the assertion
self.assertTrue(s1.query()) fails.
The fix is to insert
torch.cuda.synchronize(d0)
torch.cuda.synchronize(d1)
at the beginning of the test so that previously launched kernels finish before the real
test begins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23520
Differential Revision: D16547701
Pulled By: soumith
fbshipit-source-id: 42ad369f909d534e15555493d08e9bb99dd64b6a
Summary:
Add a sorting policy to ChunkDataset.
This is considered an advanced parameter for developers who want to apply a 'sorting policy' to the chunk data before sampling into minibatch.
Different than the collate method, this policy is applied on the chunk level instead of minibatch level. When a chunk of data is loaded (multiple chunks if cross_chunk_shuffle_count_ is greater than 1), this policy is targeting to the full loaded data. It will be useful if developers want to perform some pre-processing (like bucketing) to the chunk data before example sampler samples the data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23053
Differential Revision: D16537692
Pulled By: colesbury
fbshipit-source-id: cd21ed40ab787a18b8c6dd304e5b806a7a45e6ba
Summary:
Thanks adefazio for the feedback, adding a note to the Contribution guide so that folks don't start working on code without checking with the maintainers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23513
Differential Revision: D16546685
Pulled By: soumith
fbshipit-source-id: 1ee8ade963703c88374aedecb8c9e5ed39d7722d
Summary:
This modernizes distributions code by replacing a few uses of `.contiguous().view()` with `.reshape()`, fixing a sample bug in the `Categorical` distribution.
The bug is exercised by the following test:
```py
batch_shape = (1, 2, 1, 3, 1)
sample_shape = (4,)
cardinality = 2
logits = torch.randn(batch_shape + (cardinality,))
dist.Categorical(logits=logits).sample(sample_shape)
# RuntimeError: invalid argument 2: view size is not compatible with
# input tensor's size and stride (at least one dimension spans across
# two contiguous subspaces). Call .contiguous() before .view().
# at ../aten/src/TH/generic/THTensor.cpp:203
```
I have verified this works locally, but I have not added this as a regression test because it is unlikely to regress (the code is now simpler).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23328
Differential Revision: D16510678
Pulled By: colesbury
fbshipit-source-id: c125c1a37d21d185132e8e8b65241c86ad8ad04b
Summary:
Currently there is no way to build MKLDNN more optimized than sse4. This commit let MKLDNN build respect USE_NATIVE_ARCH.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23445
Differential Revision: D16542275
Pulled By: ezyang
fbshipit-source-id: 550976531d6a52db9128c0e3d4589a33715feee2
Summary:
- MSVC_Z7_OVERRIDE has already handled in CMakeLists.txt. No need to process it for once more in the Python scripts.
- Option MSVC_Z7_OVERRIDE should be visible to the user only if MSVC is used.
- Move the setting of "/EHa" flag to CMakeLists.txt, where other MSVC-specific flags are processed. This also further prepares the removal of redundant cflags setup in Python build scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23455
Differential Revision: D16542274
Pulled By: ezyang
fbshipit-source-id: 4d3b8b07161478bbba8a21feb6ea24c9024e21ac
Summary:
Closes gh-16955.
Closes https://github.com/pytorch/vision/issues/977
On Linux both `lib64` and `lib` may be present (symlinked). The reports
seem to all be about macOS, but it seems like this is also possibly more
robust on Linux and can't hurt. So not treating platforms differently.
Note that Eigen has a similar check in its CMake:
```
if(CUDA_64_BIT_DEVICE_CODE AND (EXISTS "${CUDA_TOOLKIT_ROOT_DIR}/lib64"))
link_directories("${CUDA_TOOLKIT_ROOT_DIR}/lib64")
else()
link_directories("${CUDA_TOOLKIT_ROOT_DIR}/lib")
endif()
```
There may be other issues for building from source on macOS, can't test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23491
Differential Revision: D16538973
Pulled By: soumith
fbshipit-source-id: cc309347b7d16e718e06878d3824d0a6e40b1019
Summary:
Currently set_rng_state and get_rng_state do not accept string as their parameters. This commit let them accept strings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23448
Differential Revision: D16527172
Pulled By: soumith
fbshipit-source-id: 8f9a2129979706e16877cc110f104770fbbe952c
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
MEDIUM: 981
LARGE: 56
Updated actions:
From MEDIUM to LARGE: 10
From LARGE to MEDIUM: 3
From LARGE to XLARGE: 1
Differential Revision: D16532427
fbshipit-source-id: c58bf59e6c571627b3994f8cdfa79758fb85892b
Summary:
(1) Add `COMMON_MSVC_FLAGS` to the flags in the ninja codepath
(2) Add `/EHsc` to `COMMON_MSVC_FLAG`
(3) Remove `-fPIC` and `-std=c++11` from the flags in the windows codepath
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23472
Differential Revision: D16532993
Pulled By: soumith
fbshipit-source-id: bc2d983f5f8b4eae9c7385bf170f155679e92e87
Summary:
Add `sorted` keyword to JIT for lists and dicts. This desugars to a list copy and a call to `list.sort()`. Since we don't have interfaces yet I implement it in terms of `list.sort()`. When we do we can re-visit implementing this op in a different manner.
The test fails bc of a fix to specialized lists which is landing here: https://github.com/pytorch/pytorch/pull/23267
Ignore the first commit because it is formatting, plz use clang_format ppl :'(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23274
Differential Revision: D16527323
Pulled By: eellison
fbshipit-source-id: aed8faef23cb790b9af036cd6c1b9b1d7066345d
Summary:
Scatter is unnecessary if only using one device, and it breaks on some custom data structures like namedtuple, so would like to avoid :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22384
Differential Revision: D16428208
Pulled By: soumith
fbshipit-source-id: eaa3876b2b95c1006ccaaacdb62f54c5280e730c
Summary:
This is part of the effort to shrink OSS libtorch mobile build size.
We shouldn't need Module::save function on mobile - it depends on
csrc/jit/export.cpp which then depends on ONNX. By gating these two
methods we can avoid these dependencies for libtorch mobile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23415
ghstack-source-id: 87288228
Reviewed By: dreiss
Differential Revision: D16511143
fbshipit-source-id: fd031f91fcf9b7be54cbe1436506965af94ab537
Summary:
Add early returns to JIT with minimal changes to compiler.cpp and an IR->IR pass that will transform the graph so that there is only one return value.
In compiler.cpp, record when a block will exit so that in the following example will work:
```
if cond:
a = torch.zeros([2])
else:
return 2
a += 2
...
```
To match block outputs with values that will not be used, like in the above example with `a`, I add a Bottom Type that subtypes everything else. This allows shape propagation to continue to work, and makes it so that we don't need many extra nodes filling up the graph.
The IR transform currently doesn't work on Loops, I didn't add that to this PR to avoid too much complexity, but will add it as a stack (and it should be very little extra code). the IR transform is commented at the top of the file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19179
Differential Revision: D16519819
Pulled By: eellison
fbshipit-source-id: 322a27f69966d1fd074ebe723c3e948b458b0e68
Summary:
Adds qtensor specific fields to the proto file so that they get serialized into the model.json
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23356
ghstack-source-id: 87263428
Differential Revision: D16473237
fbshipit-source-id: bf5b51d0863d036d30a1644a3c3b74516468224b
Summary:
As pointed out by SsnL in https://github.com/pytorch/pytorch/issues/20910, when clone destination is different from the module's device,
`Cloneable` currently calls `clone()` and then `to()` on every parameter and buffer, where the first clone is unnecessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20995
Differential Revision: D15517353
Pulled By: mrshenli
fbshipit-source-id: 6b6dc01560540a63845663f863dea0a948021fa5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23442
Replace the argument name from `operator` to `operators` which can take a list of operators to test.
Reviewed By: hl475
Differential Revision: D16520779
fbshipit-source-id: 94284a87c64471793e319f5bd3143f89b9a192bb
Summary:
When an exception occurs in one of the modules passed to `parallel_apply()`, it is caught and re-raised in the main thread. This preserves the original exception type and message, but has the traceback point at the position where it's re-raised, rather than the original point of failure.
This PR saves the exception information required to generate the traceback, and includes the original traceback in the message of the exception raised in the main thread.
Before:
```
...
File ".../torch/nn/parallel/data_parallel.py", line 153, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File ".../torch/nn/parallel/parallel_apply.py", line 84, in parallel_apply
raise output
RuntimeError: expected type torch.FloatTensor but got torch.cuda.FloatTensor
```
After:
```
...
File ".../torch/nn/parallel/data_parallel.py", line 153, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File ".../torch/nn/parallel/parallel_apply.py", line 88, in parallel_apply
''.join(traceback.format_exception(*exc_info)))
RuntimeError: Caught exception in replica 0. Original traceback and message:
Traceback (most recent call last):
...
File "../models/foo.py", line 319, in bar
baz = asdf / ghij[:, np.newaxis]
RuntimeError: expected type torch.FloatTensor but got torch.cuda.FloatTensor
```
I took care to raise an exception of the original type (in case the main code checks for that), but replaced the message. It helped me find a bug that did not occur outside `data_parallel()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18055
Differential Revision: D16444972
Pulled By: zhangguanheng66
fbshipit-source-id: ec436c9d4677fad18106a8046cfa835a20a101ce
Summary:
Don't automatically unwrap top layer DataParalllel for users. Instead, we provide useful error information and tell users what action to take.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23365
Reviewed By: zrphercule
Differential Revision: D16514273
Pulled By: houseroad
fbshipit-source-id: f552de5c53fb44807e9d9ad62126c98873ed106e
Summary:
The conda compiler are gcc/c++ 7.3.0, but have custom version strings
for clarity:
x86_64-conda_cos6-linux-gnu-cc
x86_64-conda_cos6-linux-gnu-c++
Using these compilers to build a C++ or CUDA extension now gives this warning (unnecessarily):
```
!! WARNING !!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Your compiler (/home/rgommers/anaconda3/envs/pytorch-nightly/bin/x86_64-conda_cos6-linux-gnu-c++) is not compatible with the compiler Pytorch was
built with for this platform, which is g++ on linux.
...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23396
Differential Revision: D16500637
Pulled By: soumith
fbshipit-source-id: 5b2fc3593e22e9a7d07dc2c0456dbb4934ffddb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23104
ghstack-source-id: 87247148
As suggested in https://github.com/pytorch/pytorch/pull/22891, we will add an overload for ```torch.fbgemm_linear_int8_weight``` (dynamic quantized version of linear function) that takes PackedLinearWeight as input and is pretty much the same in signature as regular aten::linear.
Differential Revision: D16381552
fbshipit-source-id: 1ccc4174fd02c546eee328940ac4b0da48fc85e8
Summary:
adding qconv+relu and qlinear+relu modules in nn/_intrinsic/quantized
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23410
Test Plan:
Extended tests to test these new modules as well
buck test mode/dev caffe2/test:quantized -- 'test_linear_api' --print-passing-details
```
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/2251799820197379
✓ caffe2/test:quantized - test_linear_api (test_nn_quantized.ModuleAPITest) 4.055 1/1 (passed)
Test output:
> test_linear_api (test_nn_quantized.ModuleAPITest)
> test API functionality for nn.quantized.linear and nn._intrinsic.quantized.linear_relu ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 4.056s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/2251799820197379
Summary (total time 10.66s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
```
buck test mode/dev caffe2/test:quantized -- 'test_conv_api' --print-passing-details
```
Running 2 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/4785074607089664
✓ caffe2/test:quantized - test_conv_api (test_quantized_conv.QuantizedConvTest) 5.195 1/2 (passed)
Test output:
> test_conv_api (test_quantized_conv.QuantizedConvTest)
> Tests the correctness of the conv functional. ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 5.195s
>
> OK
✓ caffe2/test:quantized - test_conv_api (test_nn_quantized.ModuleAPITest) 10.616 2/2 (passed)
Test output:
> test_conv_api (test_nn_quantized.ModuleAPITest)
> Tests the correctness of the conv module. ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 10.616s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/4785074607089664
Summary (total time 17.31s):
PASS: 2
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
``
Differential Revision: D16505333
Pulled By: dskhudia
fbshipit-source-id: 04f45cd0e76dc55f4694d558b913ab2958b7d727
Summary:
This is still work in progress.
There are several more items to add to complete this doc, including
- [x] LHS indexing, index assignments.
- [x] Tensor List.
- [x] ~Shape/Type propagation.~
- [x] FAQs
Please review and share your thoughts, feel free to add anything that you think should be included as well. houseroad spandantiwari lara-hdr neginraoof
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23185
Differential Revision: D16459647
Pulled By: houseroad
fbshipit-source-id: b401c005f848d957541ba3b00e00c93ac2f4609b
Summary:
They should be forwarded by their actual type, not their rvalue reference.
This looked like perfect forwarding but actually wasn't.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23412
ghstack-source-id: 87214575
Reviewed By: dzhulgakov
Differential Revision: D16507872
fbshipit-source-id: 2b20a37df83067dd53e917fe87407ad687bb147c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21211
There are cases where the `init` method used to create inputs can exit with error. When this happens, that specific input should be skipped.
Reviewed By: zheng-xq
Differential Revision: D15466410
fbshipit-source-id: 55e86764b2ec56f7730349ff1df6e50efc0239d7
Summary:
Align the Argument's operator<< with parser,
additional support:
1) List size
2) real default value
3) Alias information
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23203
ghstack-source-id: 87118985
Reviewed By: zrphercule
Differential Revision: D16433188
fbshipit-source-id: aea5711f93feacd94d1732e2f0d61218a31a0c5c
Summary:
The builder pattern doesn't seem to work well with return-value-optimization.
This saves ~100 ns in the construction of TensorIterator::binary_op.
```
import torch
x = torch.rand(1)
y = torch.rand(1)
z = torch.rand(1)
%timeit torch.add(x, y, out=z) # ~1.76 us vs ~1.88 us on my machine
```
cc resistor zheng-xq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23329
Differential Revision: D16495070
Pulled By: VitalyFedyunin
fbshipit-source-id: 8ce116075fa4c7149dabfcdfa25885c1187c8e2f
Summary:
The legacy iOS build script (`build_ios.sh`) is still working, but the output is in caffe2, not Pytorch. To enable the Pytorch iOS build, we can set the value of `BUILD_CAFFE2_MOBILE` to `NO`, and turn on another cmake arg - `INTERN_BUILD_MOBILE` ljk53 has created for Android.
There is a trivial issue in `used_kernel.cpp` that will cause the compiling error when running `build_ios.sh`, as it uses a `system`API that has been deprecated since iOS 11. The fix below is to bypass this file since it's not needed by mobile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23293
Test Plan:
The `build_ios.sh` completed successfully, and all the generated static libraries can be compiled and linked successfully on iOS devices.
### Build script
```shell
./scripts/build_ios.sh \
-DBUILD_CAFFE2_MOBILE=OFF \
-DCMAKE_PREFIX_PATH=$(python -c 'from distutils.sysconfig import get_python_lib; print(get_python_lib())') \
-DPYTHON_EXECUTABLE=$(python -c 'import sys; print(sys.executable)')
```
Differential Revision: D16456100
Pulled By: xta0
fbshipit-source-id: 38c73e1e3a0c219a38ddc28b31acc181690f34e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22175
- Rename AliasAnalysisKind::DEFAULT to AliasAnalysisKind::CONSERVATIVE
- Introduce AliasAnalysisKind::FROM_SCHEMA that means the alias annotations of the schema should be honored
- Introduce AliasAnalysisKind::INTERNAL_SPECIAL_CASE to be able to run assertions that internal special cased ops are treated correctly
- aten:: and prim:: ops are not treated as special cases anymore, but just use AliasAnalysisKind::FROM_SCHEMA
- There's a set of assertions to ensure that aten:: and prim:: ops are all correctly set up to use AliasAnalysisKind::FROM_SCHEMA. Once this PR lands and passes all tests, we will remove those assertions and open up for the possibility of different AliasAnalysisKind settings for aten:: and prim:: ops
Differential Revision: D15929595
fbshipit-source-id: 7c6a9d4d29e13b8c9a856062cd6fb3f8a46a2e0d
Summary:
torch::List recently received some polishing that now also is done for Dict. This should be done before the PyTorch 1.2 release because of backwards compatibility.
- Dict is just a reference type, so "const Dict" should have the same capabilities as "Dict", constness is not guaranteed in any way.
- DictIterator gets comparison operators <, <=, >, >=
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23344
ghstack-source-id: 87170304
Differential Revision: D16468800
fbshipit-source-id: 2978c3b9cdcfb2cfb3f26516b15bd455d9a48ba9
Summary:
This check is not needed. Even if it were, the assignment is clobbered anyway.
Closes#23300.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23370
ghstack-source-id: 87157671
Differential Revision: D16485329
fbshipit-source-id: 8ccac79e81f5e0d0d20099d550411c161f58c233
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22808
- Use ```size_to_dim_```.
- ```mod``` is not in the scope. Should be ```module```.
Reviewed By: mingzhe09088
Differential Revision: D16225799
fbshipit-source-id: 9a263227d2d508eefdfddfee15fd0822819de946
Summary:
all cases should be prim ops, but let's support it. it will expect variadic return schema to be prim::PythonOp(...) -> ...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23199
ghstack-source-id: 87113845
Differential Revision: D16431635
fbshipit-source-id: 798b6957ce5d800f7fcf981c86fdcb009cd77a78
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/22833
grad_sum_to_size does not commute with AutogradAdd after all because it turns the broadcasting AutogradAdd into a broadcasting add.
Chillee did actually do most of the tracking down to the fusion of grad_sum_to_size and pinging me when he had found the cause. Thank you!
About the choice of removing the fusion completely instead of being more precise:
- We do have grad_sum_to_size elimination which works for cases where broadcasting does not actually happen in the forward, so the cases where the fusing of grad_sum_to_size is actually beneficial is much smaller than when initially proposed.
- There will be less fusion, in terms of the tests, IOU stops being fully fused. I vaguely think that it is a case we could handle with refined logic.
- Keeping it would add complexity in checking when to merge fusion groups to the complexities that this PR removes.
- The future of fusion probably lies more in more complete solutions including reductions (TVM or KeOps or our own or ...).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23372
Differential Revision: D16489930
Pulled By: soumith
fbshipit-source-id: bc0431b0d3eda264c401b634675872c4ce46f0f4
Summary:
Instead, defer its default value to CMakeLists.txt
NO_FBGEMM has already been handled in tools/setup_helpers/env.py
(although deprecated)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23314
Differential Revision: D16493580
Pulled By: ezyang
fbshipit-source-id: 7255eb1df5e8a6dd0362507d68da0986a9ed46e2
Summary:
This is a small fix on top of gh-23348, which fixed the libtorch
nightly build timeouts.
For the latest nighly build (25 July), see
https://circleci.com/workflow-run/33d0a24a-b77c-4a8f-9ecd-5646146ce684
The only failures are these uploads, which is because `aws s3 cp`
can only deal with one file at a time. The only way to make it do
multiple files at once is:
```
aws s3 cp . "$s3_dir" --exclude "*" --include "libtorch-*.zip" --recursive --acl public-read
```
which is much more verbose. executing one `cp` per file should be fine,
and this is also what's done in `binary_macos_upload.sh`
Closes gh-23039
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23368
Differential Revision: D16488853
Pulled By: soumith
fbshipit-source-id: 6dc04b4de2f6cd2de5ae9ad57a6e980f56896498
Summary:
With this change you can now list multiple interfaces separated by
comma. ProcessGroupGloo creates a single Gloo context for every device
in the list (a context represents a connection to every other
rank). For every collective that is called, it will select the context
in a round robin fashion. The number of worker threads responsible for
executing the collectives is set to be twice the number of devices.
If you have a single physical interface, and wish to employ increased
parallelism, you can also specify
`GLOO_SOCKET_IFNAME=eth0,eth0,eth0,eth0`. This makes ProcessGroupGloo
use 4 connections per rank, 4 I/O threads, and 8 worker threads
responsible for executing the collectives.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22978
ghstack-source-id: 87006270
Differential Revision: D16339962
fbshipit-source-id: 9aa1dc93d8e131c1714db349b0cbe57e9e7266f1
Summary:
Illegal instruction is encountered in pre-built package in MKL-DNN. https://github.com/pytorch/pytorch/issues/23231
To avoid such binary compatibility issue, the HostOpts option in MKL-DNN is disabled in order to build MKL-DNN for generic arch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23292
Differential Revision: D16488773
Pulled By: soumith
fbshipit-source-id: 9e13c76fb9cb9338103cb767d7463c10891d294a
Summary:
This is step 1 in trying to get rid of constants that are set prior to
executing the test runner. All setup logic should be concentrated in
the setupClass() function of the TestCase subclass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23223
ghstack-source-id: 87005260
Reviewed By: zhaojuanmao
Differential Revision: D16439147
fbshipit-source-id: 7a929ad4b1c8e368e33d1165becbd4d91220882c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23347
This diff replaces uint8 with int8 to match with the underlying kernel implementation. When we do int8 quantization, we are computing with uint8 (input activation) * int8 (weight) -> uint8 (output activation). The weight is quantized into int8.
Reviewed By: jianyuh
Differential Revision: D16469435
fbshipit-source-id: a697655b0e97833fc601e5980970aec4dba53c39
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23354
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16474254
Pulled By: ezyang
fbshipit-source-id: 0dd7ce02e1aa1a42a24d2af066ebd0ac5206c9a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23325Fixes#19990
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D16473826
Pulled By: ezyang
fbshipit-source-id: 466db2c22fabd7b574f0a08aec67a18318ddb431
Summary:
Proposed PR for
https://github.com/pytorch/pytorch/issues/23342
Disables execution of QNNpack tests if IS_PPC.
Basically this parallels the same skipping of tests for IS_WINDOWS as well, which is already present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23343
Differential Revision: D16469218
Pulled By: soumith
fbshipit-source-id: 80b651d00e5d413e359cf418f79e20d74cd9c8e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23317
Print out the kind type when fail to export
Reviewed By: zrphercule
Differential Revision: D16462641
fbshipit-source-id: 27157c0bd597362f90ac8cfb33e1808bac0ec48b
Summary:
fix https://github.com/pytorch/pytorch/issues/21044
Bicubic interpolation can cause overshoot.
Opencv keeps results dtype aligned with input dtype:
- If input is uint8, the result is clamped [0, 255]
- If input is float, the result is unclamped.
In Pytorch case, we only accept float input, so we'll keep the result unclamped, and add some notes so that users can explicitly call `torch.clamp()` when necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23321
Differential Revision: D16464796
Pulled By: ailzhang
fbshipit-source-id: 177915e525d1f54c2209e277cf73e40699ed1acd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23257
Overal context: open-source BlackBoxPredictor as the entry
point for inference in Caffe2 (thread safe abstraction for Caffe2
inference). This should be used in ThroughputBenchmark for the purpose
of framework comparison
This specific diff:
There should be no harm in moving transformation code to
OSS. On the advantages side we will be able to compare production
Caffe2 setup with PyTorch in the most fair way via
ThroughputBenchmark. This approach avoid any complicated
transformation regirstries. Building those proper would be significant
engineering effort as well as production risk. In the past we had SEVs
related to transforms being turned off due to various refactors. Given
that we don't plan to build any other significant investments into
transformation logic except existing ones (like TVM and Glow), and
those also relate to open-source technologies, I came up to the
conclusion of moving to OSS the whole thing.
Reviewed By: zrphercule
Differential Revision: D16428124
fbshipit-source-id: b35deada5c015cd97b91ae12a7ea4aac53bd14b8
Summary:
Covering fleet-wide profiling, api logging, etc.
It's my first time writing rst, so suggestions are definitely welcomed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23010
Differential Revision: D16456721
Pulled By: dzhulgakov
fbshipit-source-id: 3d3018f41499d04db0dca865bb3a9652d8cdf90a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23291
This diff implements LSTM with FP16 weights based on FBGEMM.
At a high level, here are the steps:
1. Quantize and pack weight in every layer of LSTM
2. Pass weights from step 1 to the ATen `quantized_lstm` function which does matrix multiplication with FP16 weight. The following code shows the dtype of each variable used in MM:
Y = X * W + B
(fp32, fp32, fp16, fp32)
Reviewed By: jianyuh
Differential Revision: D16389595
fbshipit-source-id: c26ae4e153c667a941f4af64e9d07fc251403cee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22733
This refactor changes the conv module to avoid the usage of the functional ops.
Reviewed By: jerryzh168
Differential Revision: D15835572
fbshipit-source-id: f2294cd708fbe8372eb3a15cc60d83777d4f7029
Summary:
It used to be run with comm_size=8, which causes flaky results in a
stress run. The flakiness was caused by too many listening sockets
being created by Gloo context initialization (8 processes times 7
sockets times 20-way concurrency, plus TIME_WAIT).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23221
ghstack-source-id: 86995596
Reviewed By: d4l3k
Differential Revision: D16437834
fbshipit-source-id: 998d0e2b087c0ab15eca64e308059c35e1b51e7b
Summary:
I manually went through all functions in `torch.*` and corrected any mismatch between the arguments mentioned in doc and the ones actually taken by the function. This fixes https://github.com/pytorch/pytorch/issues/8698.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22973
Differential Revision: D16419602
Pulled By: yf225
fbshipit-source-id: 5562c9b0b95a0759abee41f967c45efacf2267c2
Summary:
Currently the build type is decided by the environment variable DEBUG
and REL_WITH_DEB_INFO. This commit also lets CMAKE_BUILD_TYPE be
effective. This makes the interface more consistent with CMake. This
also prepares https://github.com/pytorch/pytorch/issues/22776.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22875
Differential Revision: D16281663
Pulled By: ezyang
fbshipit-source-id: 952f92aad85ff59f1c7abe8256eca8a4a0936026
Summary:
Rehash of https://github.com/pytorch/pytorch/issues/22322 .
Given that python 2.7 will be EOL'd on Jan 1, 2020 and we have models depending on python3.5+, we'd like to update the ROCm CI across the board to python3.6.
This PR adds the skip tests and some semantic changes for PyTorch.
Added pattern match skip for anything but the ROCm CI compared to #223222 for the python find step in the PyTorch build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23088
Differential Revision: D16448261
Pulled By: bddppq
fbshipit-source-id: 69ece1a213418d9abf1444c496dce1c190ee07c8
Summary:
there are a lot of formatting changes which makes other diffs to these PRs noisy & hard to read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23283
Differential Revision: D16453590
Pulled By: eellison
fbshipit-source-id: 97b4bf1dbbbfb09c44c57402f61ea27287060044
Summary:
In Python, `register_module` / `register_parameter` / `register_buffer` method in `nn.Module` is public. This PR makes those APIs public for C++ `nn::Module` as well. Closes https://github.com/pytorch/pytorch/issues/23140.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23196
Differential Revision: D16440239
Pulled By: yf225
fbshipit-source-id: e0eff6e1db592961fba891ec417dc74fa765e968
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23272
We see significant performance improvements by limiting concurrency
at caffe2 level on mobile. This diff enables setting the number of caffe2
workspaces used during rnn inference.
Reviewed By: akyrola
Differential Revision: D16448611
fbshipit-source-id: 28abaddb4ea60bacb084ceb28cb7a4d1e67ccc17
Summary:
Support exporting
* Standard tensor indexing like
```
x = torch.ones(4, 5)
ind = torch.tensor([0, 1])
return x[ind]
```
* [Advanced indexing](https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html#advanced-indexing) like
```
x = torch.ones(4,5,6,7,8)
ind1 = torch.tensor([0, 1])
ind2 = torch.tensor([[3], [2]])
ind3 = torch.tensor([[2, 2], [4, 5]])
return x[2:4, ind1, None, ind2, ind3, :]
```
It would be ideal if ONNX can natively support indexing in future opsets, but for opset <= 10 it will always need this kind of workarounds.
There are still various limitations, such as not supporting advanced indexing with negative indices, not supporting mask indices of rank > 1, etc. My feeling is that these are less common cases that requires great effort to support using current opset, and it's better to not make the index export more cumbersome than it already is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21716
Reviewed By: zrphercule
Differential Revision: D15902199
Pulled By: houseroad
fbshipit-source-id: 5f1cc687fc9f97da18732f6a2c9dfe8f6fdb34a6
Summary:
Previously we weren't specializing the list returned from `dict.keys()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23267
Differential Revision: D16448512
Pulled By: eellison
fbshipit-source-id: fcd2a37ac680bdf90219b099a94aa36a80f4067c
Summary:
Overal context: open-source BlackBoxPredictor as the entry
point for inference in Caffe2 (thread safe abstraction for Caffe2
inference). This should be used in ThroughputBenchmark for the purpose
of framework comparison
This specific diff:
There should be no harm in moving transformation code to
OSS. On the advantages side we will be able to compare production
Caffe2 setup with PyTorch in the most fair way via
ThroughputBenchmark. This approach avoid any complicated
transformation regirstries. Building those proper would be significant
engineering effort as well as production risk. In the past we had SEVs
related to transforms being turned off due to various refactors. Given
that we don't plan to build any other significant investments into
transformation logic except existing ones (like TVM and Glow), and
those also relate to open-source technologies, I came up to the
conclusion of moving to OSS the whole thing.
Reviewed By: bertmaher
Differential Revision: D16367134
fbshipit-source-id: fc6bacc1be3ff6336beb57cdad58168d3a2b8c28
Summary:
per https://github.com/pytorch/pytorch/issues/22260, default number of open mp threads are spawned to be the same of number of cores available, for multi processing data parallel cases, too many threads may be spawned and could overload the CPU, resulting in performance regression.
so set OMP_NUM_THREADS = number of CPU processors/number of processes in default to neither overload or waste CPU threads
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22501
Test Plan:
1. without and with this change, example codes result in same result
python ~/local/fbsource-fbcode/fbcode/caffe2/torch/distributed/launch.py --nproc_per_node=2 pytorch/examples/yanlizhao/distributed_launch_example.py
Setting OMP_NUM_THREADS environment variable for each process to be: 24, which
is max(1, num_cpus / num_processes), you can further tune the variable for optimal performance in your application if needed.
final loss = tensor(0.5211, device='cuda:0', grad_fn=<MseLossBackward>)
Differential Revision: D16092225
Pulled By: zhaojuanmao
fbshipit-source-id: b792a4c27a7ffae40e4a59e96669209c6a85e27f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23003
torch.quantization.fuse_module and torch.nn._intrinsic convRelu and LinearRelu
Fusion function to combine specific modules: (conv,bn) and (conv,bn,relu).
In all cases, replace modules in place. The first module is replaced with the _intrinsic fused module and the remaining modules are replaced by nn.Identity.
Support both training and eval. For training, the modules are "fused" with a sequential container. This is to allow for further module swaps for quantization aware training.
Also add: torch.nn._intrinsic for convRelu and LinearRelu.
TODO: Add tests for _intrinsic modules.
Conv BN fusion code is based on DsKhudia's implementation
Differential Revision: D16199720
fbshipit-source-id: 95fb9ffe72b361d280313b2ec57de2acd4f9dda2
Summary:
This adds a replace_module method to the C++ api. This is needed to be able to replace modules.
The primary use case I am aware of is to enable finetuning of models.
Given that finetuning is fairly popular these days, I think it would be good to facilitate this in the C++ api as well.
This has been reported by Jean-Christophe Lombardo on the [forums](https://discuss.pytorch.org/t/finetuning-a-model-on-multiple-gpu-in-c/49195).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22546
Differential Revision: D16440289
Pulled By: yf225
fbshipit-source-id: c136f914b8fc5c0f1975d877ea817fda5c851cda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23022
will be tested in later diffs.
Added LinearReLU module for qat, allows conversion from torch.nn._intrisic.LinearReLU to torch.nn._intrinsic.qat.LinearReLU
Reviewed By: zafartahirov
Differential Revision: D16286800
fbshipit-source-id: 84cce3551d46e649781b9b6107d4076e10e51018
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23181
We can't run dead code elimination after erasing number types because dce relies on graph invariants that erase_number_types breaks.
Reviewed By: houseroad
Differential Revision: D16427819
fbshipit-source-id: d1b98a74d2558b14d4be692219691149689a93d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23180
This pass needs to be run later because it breaks jit graph invariants and the lower_all_tuples pass still needs a valid jit graph.
Reviewed By: houseroad
Differential Revision: D16427680
fbshipit-source-id: 427c7e74c59a3d7d62f2855ed626cf6258107509
Summary:
Creating an untyped generic list is deprecated, we always want type information to be present.
This fixes test cases and removes one that used lists with ambigious types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23192
ghstack-source-id: 86972891
Differential Revision: D16431482
fbshipit-source-id: 4ca5cd142118a3f0a4dcb8cd77383127c54abb29
Summary:
---
How does the current code subsume all detections in the deleted `nccl.py`?
- The dependency of `USE_NCCL` on the OS and `USE_CUDA` is handled as dependency options in `CMakeLists.txt`.
- The main NCCL detection happens in [FindNCCL.cmake](8377d4b32c/cmake/Modules/FindNCCL.cmake), which is called by [nccl.cmake](8377d4b32c/cmake/External/nccl.cmake). When `USE_SYSTEM_NCCL` is false, the previous Python code defer the detection to `find_package(NCCL)`. The change in `nccl.cmake` retains this.
- `USE_STATIC_NCCL` in the previous Python code simply changes the name of the detected library. This is done in `IF (USE_STATIC_NCCL)`.
- Now we only need to look at how the lines below line 20 in `nccl.cmake` are subsumed. These lines list paths to header and library directories that NCCL headers and libraries may reside in and try to search these directories for the key header and library files in turn. These are done by `find_path` for headers and `find_library` for the library files in `FindNCCL.cmake`.
* The call of [find_path](https://cmake.org/cmake/help/v3.8/command/find_path.html) (Search for `NO_DEFAULT_PATH` in the link) by default searches for headers in `<prefix>/include` for each `<prefix>` in `CMAKE_PREFIX_PATH` and `CMAKE_SYSTEM_PREFIX_PATH`. Like the Python code, this commit sets `CMAKE_PREFIX_PATH` to search for `<prefix>` in `NCCL_ROOT_DIR` and home to CUDA. `CMAKE_SYSTEM_PREFIX_PATH` includes the standard directories such as `/usr/local` and `/usr`. `NCCL_INCLUDE_DIR` is also specifically handled.
* Similarly, the call of [find_library](https://cmake.org/cmake/help/v3.8/command/find_library.html) (Search for `NO_DEFAULT_PATH` in the link) by default searches for libraries in directories including `<prefix>/lib` for each `<prefix>` in `CMAKE_PREFIX_PATH` and `CMAKE_SYSTEM_PREFIX_PATH`. But it also handles the edge cases intended to be solved in the Python code more properly:
- It only searches for `<prefix>/lib64` (and `<prefix>/lib32`) if it is appropriate on the system.
- It only searches for `<prefix>/lib/<arch>` for the right `<arch>`, unlike the Python code searches for `lib/<arch>` in a generic way (e.g., the Python code searches for `/usr/lib/x86_64-linux-gnu` but in reality systems have `/usr/lib/x86_64-some-customized-name-linux-gnu`, see https://unix.stackexchange.com/a/226180/38242 ).
---
Regarding for relevant issues:
- https://github.com/pytorch/pytorch/issues/12063 and https://github.com/pytorch/pytorch/issues/2877: These are properly handled, as explained in the updated comment.
- https://github.com/pytorch/pytorch/issues/2941 does not changes NCCL detection specifically for Windows (it changed CUDA detection).
- b7e258f81ef61d19b884194cdbcd6c7089636d46 A versioned library detection is added, but the order is reversed: The unversioned library becomes preferred. This is because normally unversioned libraries are linked to versioned libraries and preferred by users, and local installation by users are often unversioned. Like the document of [find_library](https://cmake.org/cmake/help/v3.8/command/find_library.html) suggests:
> When using this to specify names with and without a version suffix, we recommend specifying the unversioned name first so that locally-built packages can be found before those provided by distributions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22930
Differential Revision: D16440275
Pulled By: ezyang
fbshipit-source-id: 11fe80743d4fe89b1ed6f96d5d996496e8ec01aa
Summary:
Some overlap with https://github.com/pytorch/pytorch/pull/21716 regarding caffe2 nonzero. Will rebase the other one accordingly whichever gets merged first.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22601
Reviewed By: zrphercule
Differential Revision: D16224660
Pulled By: houseroad
fbshipit-source-id: dbfd1b8776cb626601e0bf83b3fcca291806e653
Summary:
https://github.com/pytorch/pytorch/issues/20153
I believe you need 2 passes for this. Take this example
```python
torch.jit.script
def f():
x = torch.ones(10, 9, 8, 7, 6)
return x[..., None, None].shape
```
which results in `[10, 9, 8, 7, 6, 1, 1]`
vs
```
torch.jit.script
def f():
x = torch.ones(10, 9, 8, 7, 6)
return x[..., None, None, :].shape
```
which results in `[10, 9, 8, 7, 1, 1, 6]`
After only processing `x[..., None, None` we don't know whether we should be creating a new dimension at the end of the dimension list or somewhere in the middle. What we do depends on the elements to the right of it.
Thus, I do 2 passes - one to collect all the dimensions that the index operations operate on, and another that executes the index operations.
This still doesn't work for an ellipse index followed by a tensor index, but it wasn't working previously either.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22905
Differential Revision: D16433558
Pulled By: Chillee
fbshipit-source-id: c1b303cb97b1af8b6e405bad33495ef3b4c27c4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23182
This fixes the issue seen in D16390551
Changing the load op to take in shapes vector needs changes in lots of places (almost all usages of load op).
Instead this is a small and safe change where the behavior is unchanged if we are loading multiple blobs and when loading a single blob without shape information.
If you are loading just one blob and the shape information is provided, then this returns the right shape info back.
For all other cases, behavior is unchanged as before we introduced the issue.
This fixes the issue reported by Andrey in D16229465
Reviewed By: boryiingsu
Differential Revision: D16428140
fbshipit-source-id: 8ef6705ab2efb346819489e1f166e23269f7ef8a
Summary:
fbgemm requires a AVX512 which requires a more recent compiler, so this also switches all the nightlies from devtoolset3 to devtoolset7. Since CUDA 9.0 doesn't support devtoolset7, we also switch from CUDA 9.0 to CUDA 9.2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22784
Differential Revision: D16428165
Pulled By: pjh5
fbshipit-source-id: c1af3729d8edce88a96fa9069d4c5a1808c25f99
Summary:
We need a way to figure get a complete list fo features that are used in training a model. One way to do this is to make it possible to get the list of features used in each Model Layer. Then once the model is complete we can go through the layers and aggregate the features.
I've introduced a function to expose that information here, get_accessed_features, and implemented it in the FeatureSparseToDense layer to start with.
I've tried to include the minimum amount of information to make this useful, while making it easy to integrate into the variety of model layers. This is, for example, why AccessedFeatures does not contain feature_names which is not always present in a model layer. I debated whether or not to include feature_type, but I think that's useful enough, and easy enough to figure out in a model layer, that it's worth including.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23036
Test Plan:
Added a unit test to verify the behavior of get_accessed_features in FeatureSparseToDense.
aml_dper2-fblearner-flow-integration-tests failed due to a known issue D16355865
aml_dper3-fblearner-flow-integration-tests failed due to a known issue T47197113
I verified no tests in the integration tests failed to issues other than those known ones.
DPER2 canaries: https://fburl.com/fblearner/1217voga
Reviewed By: volkhin
Differential Revision: D16365380
Pulled By: kevinwilfong
fbshipit-source-id: 2dbb4d832628180336533f29f7d917cbad171950
Summary:
I ran into the following error when trying to pass a Python int as an arg to `torch::jit::createStackForSchema`, and I think it is due to the missing support for `NumberType` in [toIValue](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/pybind_utils.h#L448).
> RuntimeError: Missing cases in toIValue for type: Scalar! File a bug report. (toIValue at ../torch/csrc/jit/pybind_utils.h:449)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22817
Differential Revision: D16276006
Pulled By: mrshenli
fbshipit-source-id: 7f63519bb37219445e836ec1f51ca4f98bf52c44
Summary:
Bumping up the producer_version in exported ONNX models in view of the next release. Updating tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23120
Reviewed By: zrphercule
Differential Revision: D16420917
Pulled By: houseroad
fbshipit-source-id: 6686b10523c102e924ecaf96fd3231240b4219a9
Summary:
`pickle` supports this and a lot of the quantized use cases for get/set
state follow this pattern
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23119
Pulled By: driazati
Differential Revision: D16391234
fbshipit-source-id: 9f63e0a1679daa61b17aa64b5995e2be23b07b50
Summary:
Previously we looked at the stack frame of the function that called
`script` to resolve variables. This doesn't work if someone calls script
with a function defined somewhere else that references captured
variables. We already have a mechanism to look at the closed over
variables for a function, so this changes the `rcb` to use that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22270
Pulled By: driazati
Differential Revision: D16391346
fbshipit-source-id: ad9b314ae86c249251b106079e76a5d7cf6c04c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23166
Changing the load op to take in shapes vector needs changes in lots of places (almost all usages of load op).
Instead this is a small and safe change where the behavior is unchanged if we are loading multiple blobs and when loading a single blob without shape information.
If you are loading just one blob and the shape information is provided, then this returns the right shape info back.
For all other cases, behavior is unchanged as before we introduced the issue.
This fixes the issue reported by Andrey in D16229465
Reviewed By: boryiingsu
Differential Revision: D16390551
fbshipit-source-id: 1055b481a7a9e83021209e59f38a7cc0b49003cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23077
Although the difference between running from python and this is not much if we
have forward method's loop long enough (like 1000 in this case).
Reviewed By: mingzhe09088
Differential Revision: D16122343
fbshipit-source-id: 5c1d1b98ae82c996baf9d42bcd04995e2ba60c78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23076
Tracing based and non tracing based added
Reviewed By: mingzhe09088
Differential Revision: D16097280
fbshipit-source-id: 3a137092f7ccc3dd2d29d95e10178ec89d3ce892
Summary:
Update ScatterWeightedSum op when there exists only one weighted X to update slice of Y which is usually the case when the op is used for gradient update. The changes remove the copy overhead and seeing significant operator performance improvement
- 25 - 50% improvment on CUDA based on input configuration
- ~50% improvement on ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23087
Differential Revision: D16385194
Pulled By: bddppq
fbshipit-source-id: 3189e892940fb9c26305269eb0d47479b9b71af0
Summary:
This is a small patch to not overwrite unchanged files to help a bit with building.
It is not as incremental as one might like, given that one has to pass `--out-of-place-only` to not run into the patching and things.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23112
Differential Revision: D16402623
Pulled By: bddppq
fbshipit-source-id: 531ce0078bc716ae31bd92c5248080ef02a065b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22765
the pooling signature is the same as the non-quantized one. Adding it to the native_functions.yaml
Reviewed By: jerryzh168
Differential Revision: D16102608
fbshipit-source-id: 7627ad8f02a231f488b74d1a245b853f89d9c419
Summary:
USE_{C11,MSC,GCC}_ATOMICS are not used in PyTorch or submodules. Now we remove their underlying detection code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23089
Differential Revision: D16402750
Pulled By: ezyang
fbshipit-source-id: fde84b958eb0b5b4d3f0406acefa92ab30ea43be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21749
This is the first version without "requantization"
Reviewed By: jerryzh168
Differential Revision: D15807940
fbshipit-source-id: 19bb0482abed8ed9d1521a3fa1f15bda8e6a6a7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23096
nets can have states that depends on the rest of the state in the Workspace. Hence, they should be destructed first.
Reviewed By: ajyu
Differential Revision: D16382987
fbshipit-source-id: 3fd030ba206e2d0e897abb9e31c95bdaeb9482b7
Summary:
Add support for quantization aware training in eager mode
Modifications to Post training flow:
## Prepare
* Fusion: e.g. (Conv, Bn) → ConvBn (float)
* Swapping: To insert fake_quant to weight, we need to swap the float modules that has weight with different qat modules, e.g. Conv → torch.nn.qat.Conv , ConvBn → torch.nn._intrinsic.qat.ConvBn
```
* previously we were thinking about modify the weight in forward_pre hook and change it back in forward_hook:
* def forward_pre_hook(self, input):
self.float_weight = self.weight
self.weight = self.fake_quantize(self.float_weight)
def forward_hook(self, input):
self.weight = self.float_weight
```
* Assignments to self.weight are needed because we can’t change forward function and in forward function they are using self.weight.
* But we will need to keep two copies of weight in this case, so it’s probably better to just swap the module
* So we want to just swap Conv to torch.nn.qat.Conv and Linear to torch.nn.qat.Linear
* qat modules will have fake_quant for output and weights inserted in forward function
## Convert
* flow should be identical to ptq, but the swapping dictionary is slightly different since modules are changed in prepare step.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23082
ghstack-source-id: 86824650
Differential Revision: D16379374
fbshipit-source-id: 7d16d1acd87025065a24942ff92abf18e9fc8070
Summary:
Overal context: open-source BlackBoxPredictor as the entry
point for inference in Caffe2 (thread safe abstraction for Caffe2
inference). This should be used in ThroughputBenchmark for the purpose
of framework comparison
This specific diff:
There should be no harm in moving transformation code to
OSS. On the advantages side we will be able to compare production
Caffe2 setup with PyTorch in the most fair way via
ThroughputBenchmark. This approach avoid any complicated
transformation regirstries. Building those proper would be significant
engineering effort as well as production risk. In the past we had SEVs
related to transforms being turned off due to various refactors. Given
that we don't plan to build any other significant investments into
transformation logic except existing ones (like TVM and Glow), and
those also relate to open-source technologies, I came up to the
conclusion of moving to OSS the whole thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22877
Test Plan:
did a bunch of unit tests locally and now
waitforsandcaslte
AdFinder canary:
https://our.intern.facebook.com/intern/ads/canary/419623727275650390
adindexer:
https://our.intern.facebook.com/intern/ads/canary/419623750891549182
prospector:
https://our.intern.facebook.com/intern/ads/canary/419644899887610977https://our.intern.facebook.com/intern/ads/canary/419645123742738405
Differential Revision: D16267765
Pulled By: salexspb
fbshipit-source-id: 776a1cd5415e0695eae28254b3f155e7a9bd8c2b
Summary:
1. Fix out of range memory access for reduction on all dimensions for non-packed
tensor.
2. Enabling launch config that maps block width to reduction on fastest striding
dimension. This mapping was previously only active when reducing on fastest
striding dimension of packed tensor, which is not necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22827
Differential Revision: D16271897
Pulled By: zdevito
fbshipit-source-id: 20763f6cf9a58e44ffc0e7ec27724dfec8fe2c5d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/22389
In most cases we only import `PIL` methods when we need them, but we missed a spot.
cc lanpa natalialunova sanekmelnikov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23023
Reviewed By: sanekmelnikov
Differential Revision: D16373492
Pulled By: orionr
fbshipit-source-id: b08bf8a9b5a861390eadf62eda21ac055777180f
Summary:
This PR fixes the invalid None return when calling get_all_math_dtype(device='cuda').
Issue came from the __append__ method which doesn't have any return value used in `return dtypes.append(...)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23028
Differential Revision: D16362732
Pulled By: colesbury
fbshipit-source-id: 0bbc30a0c663749d768159f1bc37b99f7263297b
Summary:
This PR aims at improving BERT performance on CPU by using `mkldnn` inner product for `nn.Linear()`.
The current logic is to use `mkldnn` only when `input` tensor is of mkldnn layout. This PR loosens this condition, `mkldnn` will be used for `nn.Linear()` when `input` tensor is of dense layout. The aten tensor is viewed inplace in `mkldnn` without additional memory copy.
1. when `input.dim() >= 3` , it is viewed as 2d tensor. e.g. `[T, N, C]` is treated as `[TN, C]`;
2. when `input` is not contiguous, it is copied so as to be contiguous. `mkldnn` inner product can't handle non-contiguous memory.
With this PR, BERT on `glue/MRPC` inference (batch size = 1) on Xeon 6148 single socket (20 cores@2.5GHz) improves by `44%`:
1. before (unit: iterations/sec):
```bash
408/408 [00:24<00:00, 16.69it/s]
```
2. after (unit: iterations/sec):
```bash
408/408 [00:16<00:00, 24.06it/s]
```
The latency reduces from `59.92 ms` to `41.56ms` correspondingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21851
Differential Revision: D16056334
Pulled By: dzhulgakov
fbshipit-source-id: 9b70ed58323b5e2f3f4e3ebacc766a74a8b68a8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22732
Add support for quantization aware training in eager mode
Modifications to Post training flow:
## Prepare
* Fusion: e.g. (Conv, Bn) → ConvBn (float)
* Swapping: To insert fake_quant to weight, we need to swap the float modules that has weight with different qat modules, e.g. Conv → torch.nn.qat.Conv , ConvBn → torch.nn._intrinsic.qat.ConvBn
```
* previously we were thinking about modify the weight in forward_pre hook and change it back in forward_hook:
* def forward_pre_hook(self, input):
self.float_weight = self.weight
self.weight = self.fake_quantize(self.float_weight)
def forward_hook(self, input):
self.weight = self.float_weight
```
* Assignments to self.weight are needed because we can’t change forward function and in forward function they are using self.weight.
* But we will need to keep two copies of weight in this case, so it’s probably better to just swap the module
* So we want to just swap Conv to torch.nn.qat.Conv and Linear to torch.nn.qat.Linear
* qat modules will have fake_quant for output and weights inserted in forward function
## Convert
* flow should be identical to ptq, but the swapping dictionary is slightly different since modules are changed in prepare step.
Reviewed By: zafartahirov
Differential Revision: D16199356
fbshipit-source-id: 62aeaf47c12c62a87d9cac208f25f7592e245d6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22714
We need this module for add fake_quant for weight
Reviewed By: zafartahirov
Differential Revision: D16193585
fbshipit-source-id: ed6c04ecf574ca1fe1dcded22c225da05976f7a3
Summary:
When working on https://github.com/pytorch/pytorch/pull/22762, we discovered that we haven't actually deprecated legacy autograd function. This PR puts up the deprecation warning for 1.2, with the goal to remove legacy function support completely in the near future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22922
Differential Revision: D16363916
Pulled By: yf225
fbshipit-source-id: 4b554010a3d1f87a3fa45cc1aa29d019c8f1033c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22950
Print quantized tensor by first dequantizing it and then printing. Also print the scale, zero_point. size and type of tensor.
Reviewed By: jerryzh168
Differential Revision: D16286397
fbshipit-source-id: 2d6fb1796e5b329a77c022b18af0a39f6edde0d7
Summary:
We are planning to put up a deprecation warning for legacy autograd function in 1.2: https://github.com/pytorch/pytorch/pull/22922. This PR removes all usage of legacy function in PyTorch core and test suite, to prepare for the eventual removal of legacy function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22925
Differential Revision: D16344834
Pulled By: yf225
fbshipit-source-id: 8bf4cca740398835a08b7a290f3058c3e46781ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22316
Adding the quantized ReLU to the native_functions.yamp, as it has the same signature as non-quantized relu
Reviewed By: jerryzh168
Differential Revision: D16038441
fbshipit-source-id: 1cfbb594eb9bca1b7ec49ca486defcf1908b0d26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22966
We want to implement "trimmed lasso" for feature selection with learnable and regularizable weights. Trimmed lasso is a simple yet powerful improved version from traditional lasso. More reference can be found at https://arxiv.org/abs/1708.04527 and http://proceedings.mlr.press/v97/yun19a.html. For quick and necessary intro, please refer to P1-3 of the paper at https://arxiv.org/abs/1708.04527.
Given n weights, traditional lasso sums up all weights' l1 norms. The trimmed lasso takes an input integer k (how many weights you want to select from n) and only sums over the smallest n - k weights. Given lambda as the regularization constant, the penalty term is only on the smallest n - k weights, but not other larger weights. If lambda becomes larger than certain threshold, the smallest n - k weights are shrunk to zero. That means we have those weights "dropped". With this property, the number k is the number of weights left after lasso, which we can easily control.
Meanwhile, we further support all available regularization in a single interface. Current supported regularizers on weights include no reg, l1, l2, elastic, trimmed l1, elastic with trimmed l1, group l1, and logbarrier.
Differential Revision: D16326492
fbshipit-source-id: 6e1fd75606005d9bc09d6650435c96a7984ba69c
Summary:
Given that python 2.7 will be EOL'd on Jan 1, 2020 and we have models depending on python3.5+, we'd like to update the ROCm CI across the board to python3.6.
This PR adds the skip tests and some semantic changes for PyTorch.
Open tasks/questions:
* RoiAlignTest.CheckCPUGPUEqual fails in the Caffe2 unit tests. Is this something expects / can be skipped?
* for testing, I've used update-alternatives on CentOS/Ubuntu to select python == python 3.6. Is this the preferred way?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22322
Differential Revision: D16199862
Pulled By: ezyang
fbshipit-source-id: 46ca6029a232f7d23f3fdb5efc33ae39a379fca8
Summary:
Fixes https://github.com/pytorch/pytorch/issues/21935 by using the integer floor division that was introduced for convolution shapes in https://github.com/pytorch/pytorch/issues/9640. Without this fix, the pooling operators can produce a 1-element output in cases they shouldn't.
Disclaimer: I couldn't properly test it locally (it's not picking up the modified version for some reason). I'm marking this WIP until I checked what the CI tools say...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22304
Differential Revision: D16181955
Pulled By: ezyang
fbshipit-source-id: a2405372753572548b40616d1206848b527c8121
Summary:
This cleans up the `torch.utils.tensorboard` API to remove all kwargs usage (which isn't clear to the user) and removes the "experimental" warning in prep for our 1.2 release.
We also don't need the additional PyTorch version checks now that we are in the codebase itself.
cc ezyang lanpa natalialunova
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21786
Reviewed By: natalialunova
Differential Revision: D15854892
Pulled By: orionr
fbshipit-source-id: 06b8498826946e578824d4b15c910edb3c2c20c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22958
When we use `extension_loader.DlopenGuard()` to dyndep or import modules, it sets a `RTLD_GLOBAL` flag, and restores the original flags after the `yield`. However, if the modules is not there, yield will fail, and the flags won't be restored, creating all kinds of symbol conflict problems.
Reviewed By: bddppq
Differential Revision: D16311949
fbshipit-source-id: 7b9ec6d60423ec5e78cae694b66c2f17493840b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22830
Separating the tensor generation and the generation of the quantization parameters
- Introducing hypothesis filter `assume_not_overflowing`, which makes sure that the generated tensor and qparams play well with each other. **Note: This is an expensive filter!**
- `qtensor` -> Renameed to `tensor`
- `qtensor_conv` -> Renamed to `tensor_conv2d`
- The tensors don't return the quantization parameters anymore, use `qparams` for it
- The `dtypes` argument is just a quantized dtype now.
- The enforcement for zero_point is predefined as before. As before, if set to `None` the zero_point will be sampled. However, if `None`, you can override sampling with `zero_point_min` and `zero_point_max`
- Scale sampling can also be overriden using `scale_min` and `scale_max`
Reviewed By: jerryzh168
Differential Revision: D16234314
fbshipit-source-id: 5b538a5aa9772b7add4f2ce5eff6fd0decd48f8e
Summary:
ONNX uses virtualenv, and PyTorch doesn't. So --user flag is causing problems in ONNX ci...
Fixing it by moving it to pytorch only scripts. And will install ninja in onnx ci separately.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22946
Reviewed By: bddppq
Differential Revision: D16297781
Pulled By: houseroad
fbshipit-source-id: 52991abac61beaf3cfbcc99af5bb1cd27b790485
Summary:
…te argument in macro
Changelog:
- Update note about tensors on CPU for the following MAGMA functions
- magma_(d/s)getrf_gpu and magma_getrf_nopiv_gpu require tensors on CPU for pivots
- magma_(d/s)geqrf2_gpu requires tensors on CPU for elementary reflectors
- magma_(d/s)syevd_gpu requires tensors on CPU for eigenvalues
- Remove dummy tensor in ALLOCATE_ARRAY MACRO
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22618
Test Plan:
- All existing tests should pass to verify that the patch is correct
This PR has been proposed to eliminate confusion due to the previous comments, as indicated in https://github.com/pytorch/pytorch/issues/22573
Differential Revision: D16286198
Pulled By: zou3519
fbshipit-source-id: a5a6ec829084bdb752ca6006b8795227cbaf63b1
Summary:
This fixes up the test suite (mostly just adding `ignore` decorations
to tests that need to call Python function) so that it all passes with
recursive script enabled.
The main user-facing result of this change is that Python functions are
compiled without any decorators, so non-TorchScriptable code must be
decorated with `torch.jit.ignore` (or
`torch.jit.ignore(drop_on_export=True` to maintain the functionality of
the current `ignore`)
Details can be found in #20939
](https://our.intern.facebook.com/intern/diff/16277608/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22887
Pulled By: driazati
Differential Revision: D16277608
fbshipit-source-id: 0abd0dc4291cf40651a1719bff813abb2b559640
Summary:
Motivation:
The forward method of MultiheadAttention has a kwarg a key_padding_mask. This mask is of shape (N,S) where N is batch and S is sequence length. This mask is applied prior to attention softmax where True values in the mask are set to float('-inf'). This allows you to mask position j from attention for all position i in input sequence. It's typically used to mask padded inputs. So for a sample in a batch we will be able to make sure no encoder outputs depend on padding inputs. Currently the Transformer, TransformerEncoder, and TransformerEncoderLayer do not have this kwarg, and only have options for a (S,S), (T,T), and (S,T) masks which are applied equally across the batch for source input, target output, and target-source memory respectively. These masks can't be used for padding and are instead used for things like subsequent masking in language modeling, by masking the attention of position i to position j.
This diff exposes the key_padding_mask to Transformer, TransformerEncoder, and TransformerEncoderLayer forward methods which is ultimately passed to MultiheadAttention forward.
Open question: should we also allow a key_padding_mask for the decoder layer? As padding is usually at the end of each sentence in a batch and sentences are usually decoding from left to right, usually people deal with padding on decoded outputs by just masking those outputs at the loss layer. There might be some scenarios where it's needed though I don't think it would be common. People can also still just subclass and override the layers. We could also pass the input key_padding_mask to the memory <> decoder attention layer. Not sure if that's necessary though because the output of position i from each attention encoder layer won't depend on any masked positions in the input (even if position i is a masked position itself) so there's not really any point in masking position i again.
Adds the key_padding_mask kwarg to Transformer, TransformerEncoder, and TransformerEncoderLayer forward methods.
The standard TransformerEncoderLayer uses a MultiheadAttention layer as self_attn. MultiheadAttention forward method has a key_padding_mask kwarg that allows for masking of values such as padding per sequence in a batch, in contrast to the attn_mask kwarg which is usually of shape (S,S) and applied equally across the batch.
MultiheadAttention calls functional.multi_head_attention_forward, which has the same key_padding_mask kwarg of shape (N,S). Masked (True) values are set to float('-inf').
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22588
Test Plan:
buck test mode/dev caffe2/test:nn -- 'test_transformerencoderlayer \(test_nn\.TestNN\)'
buck test mode/dev caffe2/test:nn -- 'test_Transformer_cell \(test_nn\.TestNN\)'
buck test mode/dev caffe2/test:nn -- 'test_transformer_args_check \(test_nn\.TestNN\)'
Differential Revision: D16112263
Pulled By: lucasgadams
fbshipit-source-id: dc4147dd1f89b55a4c94e8c701f16f0ffdc1d1a2
Summary:
Asterisks start emphases in rst. We should either escape them or put them as interpreted text.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22896
Differential Revision: D16282869
Pulled By: zou3519
fbshipit-source-id: 15ec4286434db55fb8357b1a12e6f70ef54f8c66
Summary:
The sccache wrapping strategy causes problems for at-runtime kernel
compilation of MIOpen kernels. We therefore - after the builds of
caffe2/pytorch are complete - unwrap sccache again by moving the clang-9
actual binary back into its original place.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22743
Differential Revision: D16283329
Pulled By: bddppq
fbshipit-source-id: 4fcdc92be295d5ea9aba75c30e39af1a18a80c13
Summary:
This is achieved by using `cuDevicePrimaryCtxGetState` as a way to check whether a primary context exists on a device. It is not too slow, from this benchmark of a single call to it on CUDA 10.1, Titan Xp, driver 415.27:
```
---------------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------------
BM_cuDevicePrimaryCtxGetState 301 ns 301 ns 2319746
```
Commits:
1. Add `CUDAHooks::getDeviceWithPrimaryContext` which returns a device index with primary context (if exists).
Link `c10/cuda` against `libcuda` for device API calls.
2. Use `getDeviceWithPrimaryContext` to check primary context in `pin_memory`.
Fix `OptionalDeviceGuard` doc.
3. Refactor `test_cuda_primary_ctx.py` to support multiple tests.
Add test for this in that file.
Fixes https://github.com/pytorch/pytorch/issues/21081.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22229
Differential Revision: D16170194
Pulled By: zou3519
fbshipit-source-id: 485a45f211b7844c9e69c63f3b3b75194a796c5d
Summary:
…te argument in macro
Changelog:
- Update note about tensors on CPU for the following MAGMA functions
- magma_(d/s)getrf_gpu and magma_getrf_nopiv_gpu require tensors on CPU for pivots
- magma_(d/s)geqrf2_gpu requires tensors on CPU for elementary reflectors
- magma_(d/s)syevd_gpu requires tensors on CPU for eigenvalues
- Remove dummy tensor in ALLOCATE_ARRAY MACRO
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22618
Test Plan:
- All existing tests should pass to verify that the patch is correct
This PR has been proposed to eliminate confusion due to the previous comments, as indicated in https://github.com/pytorch/pytorch/issues/22573
Differential Revision: D16227440
Pulled By: zou3519
fbshipit-source-id: 97d5537c5da98c0ed3edc4668a09294794fc426b
Summary:
…rides
Changelog:
- Fix behavior of `torch.triu` / `torch.tril` on certain unsqueezed tensors that lead to uninitialized values on CPU
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22730
Test Plan:
- Add tests for these cases in test_triu_tril in test_torch
Fixes https://github.com/pytorch/pytorch/issues/22581
Differential Revision: D16222897
Pulled By: zou3519
fbshipit-source-id: b86b060187797e5cd2a7731421dff1ba2b5c9596
Summary:
Align the behavior of `torch.utils.cpp_extension.CUDA_HOME` with that of `tools.setup_helpers.cuda.CUDA_HOME`.
Typically, I swapped the position of guess 2 and guess 3 in `torch.utils.cpp_extension.CUDA_HOME` .
Fixing issue https://github.com/pytorch/pytorch/issues/22844
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22845
Differential Revision: D16276241
Pulled By: zou3519
fbshipit-source-id: 3b62b439b2f794a6f3637a5fee58991f430985fe
Summary:
We introduced RTTI in recent change: https://github.com/pytorch/pytorch/pull/21613
For internal mobile build we don't enable '-frtti' yet. This diff is trying to replace
RTTI with alternative approach.
According to dzhulgakov we could compare two tensors' type_id directly in most cases -
which is more strict than comparing TensorImpl subclass type as TensorImpl -> type_id
mapping is 1-to-n but it's more proper for this use case.
The only two cases where we can relax direct type comparison (for legacy reason) are:
1. CPUTensor <-> CUDATensor;
2. SparseCPUTensor <-> SparseCUDATensor;
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22773
Differential Revision: D16277696
Pulled By: ljk53
fbshipit-source-id: 043e264fbacc37b7a11af2046983c70ddb62a599
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22892
Think of num_runs as manually run the binary <num_runs> times. Each run runs the operator for many iterations.
Reviewed By: hl475
Differential Revision: D16271597
fbshipit-source-id: b6f509ee0332c70f85bec0d447b84940c5c0cecd
Summary:
Since recursive script creates a ScriptModule from an `nn.Module`,
there's no ties to the original module to pull a type name from, so we
have to explicitly pass it in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22873
Pulled By: driazati
Differential Revision: D16268547
fbshipit-source-id: 902a30e6e36427c6ba7033ded027a29d9dcbc1ee
Summary:
Changelog:
- Port SVD TH implementation to ATen/native/BatchLinearAlgebra.cpp
- Port SVD THC implementation to ATen/native/cuda/BatchLinearAlgebra.cu
- Allow batches of matrices as arguments to `torch.svd`
- Remove existing implementations in TH and THC
- Update doc string
- Update derivatives to support batching
- Modify nuclear norm implementation to use at::svd instead of _batch_svd
- Remove _batch_svd as it is redundant
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21588
Test Plan:
- Add new test suite for SVD in test_torch.py with port to test_cuda.py
- Add tests in common_methods_invocations.py for derivative testing
Differential Revision: D16266115
Pulled By: nairbv
fbshipit-source-id: e89bb0dbd8f2d58bd758b7830d2389c477aa61fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22517
Force anybody creating an untyped Dict to call c10::impl::deprecatedUntypedDict().
This should hopefully make it clear that this is not public API and prevent people from using it.
Reviewed By: dzhulgakov
Differential Revision: D16115214
fbshipit-source-id: 2c8d0e4e375339c699d583995f79c05c59693c3e
Summary:
Introduce Azure Pipelines for the linting checks. This is meant to be equivalent to the existing Travis linting phase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22839
Differential Revision: D16260376
Pulled By: ezyang
fbshipit-source-id: 1e535c3096358be67a0dad4cd920a92082b2d18e
Summary:
As part of the Variable/Tensor merge, `variable.tensor_data()` should be removed in favor of `variable.detach()`. This PR removes `tensor_data()` call sites in Python `Variable()` and `nn.Parameter()` constructor paths.
Note that this PR is BC-breaking in the following way:
- For Python `Variable()` constructor:
Previously, in-place updating a tensor after it's been used to create a Variable does not bump the Variable's version counter, which causes the following problem:
```python
t = torch.ones(2, 3)
v = torch.autograd.Variable(t).requires_grad_()
y = v * v
t.add_(1) # This bumps version counter of `t`
y.sum().backward() # This computes `v`'s gradient incorrectly before this patch, and throws error after this patch
```
After this patch, in-place updating a tensor after it's been used to create a Variable will also bump the Variable's version counter, thus preserving the correctness of the Variable's version counter.
- For Python `nn.Parameter()` constructor:
Previously, in-place updating a tensor after it's been used to create an nn.Parameter does not bump the nn.Parameter's version counter, which causes the following problem:
```python
t = torch.ones(2, 3)
v = torch.nn.Parameter(t)
y = v * v
t.add_(1) # This bumps version counter of `t`
y.sum().backward() # This computes `v`'s gradient incorrectly before this patch, and throws error after this patch
```
After this patch, in-place updating a tensor after it's been used to create an nn.Parameter will also bump the nn.Parameter's version counter, thus preserving the correctness of the nn.Parameter's version counter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22821
Differential Revision: D16258030
Pulled By: yf225
fbshipit-source-id: 9a6d68cea1864893193dbefbb6ef0c1d5ca12d78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22829
Sending out caffe2 load op changes separately since we want pick it to open source.
This change is needed because the shape information of the blobs is determined from the load operator and that shape information is needed in our download_group.
Reviewed By: boryiingsu
Differential Revision: D16229465
fbshipit-source-id: f78b2df9a7f26968d70eca68dde75cd11ab6f7a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22323
This diff adds an interface to use quantized Linear op in JIT.
Reviewed By: jamesr66a
Differential Revision: D16040724
fbshipit-source-id: 90e90aff9973c96ea076ed6a21ae02c349ee2bcf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22023
This diff implements Linear operation with fp16 weights based on FBGEMM. At a hight level, we want to perform the following operation:
Y = X * W + B with dtypes:
(fp32, fp32, fp16, fp32)
To do that, three steps are needed:
1. Quantize weights from fp32 to fp16, this is done using `PackedGemmMatrixFP16` in the `fbgemm_pack_gemm_matrix_fp16`
2. Conduct matrix multiplication with quantized weights using `cblas_gemm_compute` in `fbgemm_linear_fp16_weight`
3. Add bias to the result from step2 and return the final Y
Reviewed By: jianyuh
Differential Revision: D15921768
fbshipit-source-id: dc4e5b366f846ce9d58975876940a9b3372b8b8d
Summary:
Add support for breaks and continues in the jit. We do with a Graph transform pre-SSA.
A graph of the form
```
def test():
while i < 5:
if i == 3:
break
i += 1
print(i)
```
has the body of the loop transformed to
```
if i == 3:
did_break = True
else:
did_break = False
if did_break:
loop_exit = True
else:
i += 1
print(i)
loop_exit = i < 5
```
I am going to add more tests but I think it is ready for review now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21692
Differential Revision: D16215807
Pulled By: eellison
fbshipit-source-id: 365102f42de4861d9323caaeb39a96de7619a667
Summary:
This is an extension to the original PR https://github.com/pytorch/pytorch/pull/21765
1. Increase the coverage of different opsets support, comments, and blacklisting.
2. Adding backend tests for both caffe2 and onnxruntime on opset 7 and opset 8.
3. Reusing onnx model tests in caffe2 for onnxruntime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22421
Reviewed By: zrphercule
Differential Revision: D16225518
Pulled By: houseroad
fbshipit-source-id: 01ae3eed85111a83a0124e9e95512b80109d6aee
Summary:
Using PMCTest (https://www.agner.org/optimize/) to measure
TensorIterator construction, this results in ~600 fewer instructions
retired (~300 fewer cycles) for constructing TensorIterator on a 1D
tensor. (Should be roughly ~100 ns, but it's hard to measure that
precisely end-to-end).
```
Before:
Clock Core cyc Instruct Uops L1D Miss
5082 2768 5690 7644 3
After:
Clock Core cyc Instruct Uops L1D Miss
4518 2437 5109 6992 0
```
Note that Instruct is reliable, Core cyc is a little noisy, and Clock
is a little more noisy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22756
Differential Revision: D16207777
Pulled By: VitalyFedyunin
fbshipit-source-id: bcc453a90472d9951a1c123bcb1b7a243fde70ac
Summary:
Speeds up the common case where Tensor is a torch.Tensor (not a
subclass). This reduces the number of executed instructions for a
torch.add(tensor1, tensor2) by ~328 (should be ~65 ns faster).
Note that most of the PythonArgs accessors are too large to be inlined.
We should move most of them to the cpp file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22782
Differential Revision: D16223592
Pulled By: colesbury
fbshipit-source-id: cc20f8989944389d5a5e3fab033cdd70d581ffb1
Summary:
This PR aims at improving `topk()` performance on CPU. This is useful when computing **beam search** during `Transformer` and `BERT`.
Given a tensor x of size `[N, C]`, and we want to apply `x.topk(K)`, the current logic is **sequentially** loop on the dimension of `N` and do **quick select** on the dimension of `C` so as to find out top K elements.
Performance can be further improved from:
- On the dimension of `N`, it can be paralleled
- Maybe a faster sorting algorithm for `topk`. (After a bunch of experimenting, `std::partial_sort` seems to be the most promising)
So i compared 3 versions:
1. vanilla: sequential + quick select
2. reference PR https://github.com/pytorch/pytorch/issues/19737: parallel + quick select
3. this PR: parallel + partial sort
with the following benchmark, on `Xeon 8180, 2*28 cores@2.5 GHz`:
```python
import torch
from time import time
num_iters = 1000
def bench_topk(N=8, C=168560, k=10):
a = torch.randn(N, C)
# warm up
for i in range(100):
torch.topk(a, k)
t = 0
for i in range(num_iters):
a = torch.randn(N, C)
start = time()
value, indice = torch.topk(a, k)
t += time() - start
print("#[%d, %d] times: %f ms" % (N, C, t / num_iters * 1000))
Ns = [10, 20, 30]
Cs = [10000, 20000, 40000, 80000, 160000, 320000]
for n in Ns:
for c in Cs:
bench_topk(N=n, C=c)
```
### vanilla: sequential + quick select
```
#[10, 10000] times: 0.746740 ms
#[10, 20000] times: 1.437399 ms
#[10, 40000] times: 2.832455 ms
#[10, 80000] times: 5.649426 ms
#[10, 160000] times: 11.309466 ms
#[10, 320000] times: 22.798765 ms
#[20, 10000] times: 1.511303 ms
#[20, 20000] times: 2.822024 ms
#[20, 40000] times: 5.564770 ms
#[20, 80000] times: 11.443044 ms
#[20, 160000] times: 22.747731 ms
#[20, 320000] times: 46.234449 ms
#[30, 10000] times: 2.214045 ms
#[30, 20000] times: 4.236179 ms
#[30, 40000] times: 8.418577 ms
#[30, 80000] times: 17.067578 ms
#[30, 160000] times: 33.826214 ms
#[30, 320000] times: 68.109420 ms
```
### reference PR: parallel + quick select
```
#[10, 10000] times: 0.271649 ms
#[10, 20000] times: 0.593016 ms
#[10, 40000] times: 1.133518 ms
#[10, 80000] times: 2.082355 ms
#[10, 160000] times: 4.049928 ms
#[10, 320000] times: 7.321285 ms
#[20, 10000] times: 0.315255 ms
#[20, 20000] times: 0.539054 ms
#[20, 40000] times: 1.000675 ms
#[20, 80000] times: 1.914586 ms
#[20, 160000] times: 4.437122 ms
#[20, 320000] times: 8.822445 ms
#[30, 10000] times: 0.347209 ms
#[30, 20000] times: 0.589947 ms
#[30, 40000] times: 1.102814 ms
#[30, 80000] times: 2.112201 ms
#[30, 160000] times: 5.186837 ms
#[30, 320000] times: 10.523023 ms
```
### this PR: parallel + partial sort
```
#[10, 10000] times: 0.150284 ms
#[10, 20000] times: 0.220089 ms
#[10, 40000] times: 0.521875 ms
#[10, 80000] times: 0.965593 ms
#[10, 160000] times: 2.312356 ms
#[10, 320000] times: 4.759422 ms
#[20, 10000] times: 0.167630 ms
#[20, 20000] times: 0.265607 ms
#[20, 40000] times: 0.471477 ms
#[20, 80000] times: 0.974572 ms
#[20, 160000] times: 3.269645 ms
#[20, 320000] times: 6.538608 ms
#[30, 10000] times: 0.204976 ms
#[30, 20000] times: 0.342833 ms
#[30, 40000] times: 0.589381 ms
#[30, 80000] times: 1.398579 ms
#[30, 160000] times: 3.904077 ms
#[30, 320000] times: 9.681224 ms
```
In summary, `2` is **5x** faster than `vanilla` on average and `3` is **8.6x** faster than `vanilla`.
On `Fairseq Transformer`, the default parameter on dataset `wmt14` would have a `topk` size of `[8, 168560]`, and this operator gets `3x` faster with this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19736
Differential Revision: D16204820
Pulled By: VitalyFedyunin
fbshipit-source-id: ea70562c9149a0d832cf5872a891042ebd74fc63
Summary:
For three 1-D operands, compute_strides now takes 298 instructions instead
of 480. (Saves ~36 ns). We'll want to make Tensor::sizes(), strides(), and
element_size() trivially inlinable to speed this up more.
(Using PMCTest from https://www.agner.org/optimize/ to measure instructions retired)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22779
Differential Revision: D16223595
Pulled By: colesbury
fbshipit-source-id: e4730755f29a0aea9cbc82c2d376a8e6a0c7bce8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22781
The custom op is required to make the op benchmark work with JIT. Running this command `python setup.py install` in the pt_extension directory to install it. It is required.
Reviewed By: hl475
Differential Revision: D16214430
fbshipit-source-id: c9221c532011f9cf0d5453ac8535a6cde65e8376
Summary:
Currently ONNX constant folding (`do_constant_folding=True` arg in `torch.onnx.export` API) supports only opset 9 of ONNX. For opset 10, it is a no-op. This change enables ONNX constant folding for opset 10. Specifically there are three main changes:
1) Turn on constant folding ONNX pass for opset 10.
2) Update support for opset 10 version of `onnx::Slice` op for backend computation during constant folding.
3) Enable constant folding tests in `test/onnx/test_utility_funs.py` for multiple opsets (9 and 10).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22515
Reviewed By: zrphercule
Differential Revision: D16189336
Pulled By: houseroad
fbshipit-source-id: 3e2e748a06e4228b69a18c5458ca71491bd13875
Summary:
1. update on restricting block.z <= 64, compliant to CUDA maximum z-dimension of
a block;
2. clang-format
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22602
Differential Revision: D16203857
Pulled By: ezyang
fbshipit-source-id: 567719ae175681a48eb0f818ca0aba409dca2550
Summary:
Some other environment variables can be added to speed things up for development.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22736
Differential Revision: D16200904
Pulled By: soumith
fbshipit-source-id: 797ef91a863a244a6c96e0adf64d9f9b4c9a9582
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22706
Moved the models used for quantization test from the test_quantization.py file to common_quantization.py
Reviewed By: jerryzh168
Differential Revision: D16189865
fbshipit-source-id: 409b43454b6b3fe278ac16b1affb9085d6ed6835
Summary:
Previously in tracing when we called a script function we would inline the graph and set the graph inputs equal to the types the graph was invoked with.
This breaks for optional arguments invoked with None since we rely on None being set to Optional[T] in schema matching.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22686
Differential Revision: D16186372
Pulled By: eellison
fbshipit-source-id: e25c807c63527bf442eb8b31122d50689c7822f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22694
Move quantization and quantized utility functions for testing to common_quantized.py and common_quantization.py. Addditionally, add a quantized test case base class which contains common methods for checking the results of quantization on modules. As a consequence of the move, fixed the import at the top of test_quantized.py, and test_quantization to use the new utility
Reviewed By: jerryzh168
Differential Revision: D16172012
fbshipit-source-id: 329166af5555fc829f26bf1383d682c25c01a7d9
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/22631
Test Plan:
test suite
Imported from OSS
Differential Revision: D16185040
fbshipit-source-id: 9b83749f6c9cd05d13f54a3bb4801e263293252b
Summary:
After converting BN layers to SyncBN layers, the function will set all `requires_grad = True` regardless of the original requires_grad states. I think it is a bug and have fixed it in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22569
Differential Revision: D16151647
Pulled By: zou3519
fbshipit-source-id: e2ad1886c94d8882485e7fb8be51ad76469ecc67
Summary:
Addressing potential dependency issue by adding forward declaration for OutputArchive/InputArchive.
This change follows the same pattern in base.h in 'torch/csrc/api/include/torch/data/samplers/base.h'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22562
Differential Revision: D16161524
Pulled By: soumith
fbshipit-source-id: d03f8a2ece5629762f9fa8a27b15b0d037e8f07b
Summary:
Also revert the change of cmake.py in
c97829d7011bd59d662f6af9c3a0ec302e7e75fc . The comments are added to
prevent future similar incidents in the future (which has occurred a couple of times in the past).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22641
Differential Revision: D16171763
Pulled By: ezyang
fbshipit-source-id: 5a65f9fbb3c1c798ebd25521932bfde0ad3d16fc
Summary:
No need to `clone` if the expanded size matches original size.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22634
Differential Revision: D16171091
Pulled By: ezyang
fbshipit-source-id: 3d8f116398f02952488e321c0ee0ff2868768a0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21209
This diff introduces a new interface to add a list of operators. Here are the steps to add ops using this interface:
- create op_list:
```unary_ops_list = op_bench.op_list(
attr_names=["op_name", "op_function"],
attrs=[
["abs", torch.abs],
["abs_", torch.abs_],
],
)
```
- create a bench class:
```
class UnaryOpBenchmark(op_bench.TorchBenchmarkBase):
def init(self, M, N, op_function):
self.input_one = torch.rand(M, N)
self.op_func = op_function
def forward(self):
return self.op_func(self.input_one)
```
- 3. register those ops
``` op_bench.generate_pt_tests_from_list(unary_ops_list, unary_ops_configs, UnaryOpBenchmark)
```
Reviewed By: zheng-xq
Differential Revision: D15514188
fbshipit-source-id: f09b359cab8175eeb8d51b3ad7bbbcfbc9f6430f
Summary:
The error for `test_error_stack_module`:
```
Traceback (most recent call last):
File "../test.py", line 35, in <module>
scripted = torch.jit.script(M())
File "/home/davidriazati/other/pytorch/torch/jit/__init__.py", line 1119, in script
return _convert_to_script_module(obj)
File "/home/davidriazati/other/pytorch/torch/jit/__init__.py", line 1825, in _convert_to_script_module
raise e
RuntimeError:
d(int x) -> int:
Expected a value of type 'int' for argument 'x' but instead found type 'str'.
:
at ../test.py:11:12
def c(x):
return d("hello") + d(x)
~ <--- HERE
'c' is being compiled since it was called from 'b'
at ../test.py:14:12
def b(x):
return c(x)
~~~ <--- HERE
'b' is being compiled since it was called from 'forward'
at ../test.py:22:16
def forward(self, x):
return b(x)
~~~ <--- HERE
'forward' is being compiled since it was called from 'forward'
at ../test.py:31:20
def forward(self, x):
return x + self.submodule(x)
~~~~~~~~~~~~~~~~ <--- HERE
```
This also unifies our error reporting in the front end with `ErrorReport`
TODO
* Include module names in message, #22207 should make this easy
](https://our.intern.facebook.com/intern/diff/16060781/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22280
Pulled By: driazati
Differential Revision: D16060781
fbshipit-source-id: c42968b53aaddb774ac69d5abbf7e60c23df8eed
Summary:
Some of my qpth users have told me that updating to the latest version of PyTorch and replacing the btrifact/btrisolve calls with the LU ones wasn't working and I didn't believe them until I tried it myself :)
These updates have broken unpivoted LU factorizations/solves on CUDA. The LU factorization code used to return the identity permutation when pivoting wasn't used but now returns all zeros as the pivots. This PR reverts it back to return the identity permutation. I've not yet tested this code as I'm having some trouble compiling PyTorch with this and am hitting https://github.com/pytorch/pytorch/issues/21700 and am not sure how to disable that option.
Here's a MWE to reproduce the broken behavior, and my fix.
```python
torch.manual_seed(0)
n = 4
L = torch.randn(n,n)
A = L.mm(L.t()).unsqueeze(0)
b = torch.randn(1, n)
A_lu_cpu = torch.lu(A)
A_lu_cuda_nopivot = torch.lu(A.cuda(), pivot=False)
A_lu_cuda_pivot = torch.lu(A.cuda(), pivot=True)
print('A_lu_cuda_nopivot\n', A_lu_cuda_nopivot)
print('-----\nA_lu_cuda_pivot\n', A_lu_cuda_nopivot)
x_cpu = b.lu_solve(*A_lu_cpu)
x_cuda_nopivot = b.cuda().lu_solve(*A_lu_cuda_nopivot)
x_cuda_nopivot_fixed = b.cuda().lu_solve(
A_lu_cuda_nopivot[0], torch.arange(1, n+1, device='cuda:0').int())
x_cuda_pivot = b.cuda().lu_solve(*A_lu_cuda_pivot)
print(x_cpu, x_cuda_nopivot, x_cuda_nopivot_fixed, x_cuda_pivot)
```
Output:
```
A_lu_cuda_nopivot
(tensor([[[ 2.8465, -0.7560, 0.8716, -1.7337],
[-0.2656, 5.5724, -1.1316, 0.6678],
[ 0.3062, -0.2031, 1.4206, -0.5438],
[-0.6091, 0.1198, -0.3828, 1.5103]]], device='cuda:0'), tensor([[0, 0, 0, 0]], device='cuda:0', dtype=torch.int32))
-----
A_lu_cuda_pivot
(tensor([[[ 2.8465, -0.7560, 0.8716, -1.7337],
[-0.2656, 5.5724, -1.1316, 0.6678],
[ 0.3062, -0.2031, 1.4206, -0.5438],
[-0.6091, 0.1198, -0.3828, 1.5103]]], device='cuda:0'), tensor([[0, 0, 0, 0]], device='cuda:0', dtype=torch.int32))
(tensor([[-0.3121, -0.1673, -0.4450, -0.2483]]),
tensor([[-0.1661, -0.1875, -0.5694, -0.4772]], device='cuda:0'),
tensor([[-0.3121, -0.1673, -0.4450, -0.2483]], device='cuda:0'),
tensor([[-0.3121, -0.1673, -0.4450, -0.2483]], device='cuda:0'))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22242
Differential Revision: D16049334
Pulled By: ezyang
fbshipit-source-id: 7eacae810d87ffbdf8e07159bbbc03866dd9979d
Summary:
This PR activates faster depthwise convolution kernels for Volta and Turing GPUs using cudnn >= 7600.
The script to benchmark the current PyTorch master branch and this PR branch can be found [here](https://gist.github.com/ptrblck/4590cf20721d8f43296c9903abd4a774).
(50 warmup iterations, 1000 iterations for timing)
I've used https://github.com/pytorch/pytorch/issues/3265 to create a similar benchmark and added a few additional setups.
Since the results are quite long, I've uploaded them in a spreadsheet [here](https://docs.google.com/spreadsheets/d/13ByXcqg7LQUr3DVG3XpLwnJ-CXg3GUZJ3puyTMw9n2I/edit?usp=sharing).
Times are given in ms per iteration.
We've benchmarked this PR on a DGX1 using V100 GPUs.
The current workload check in `check_cudnn_depthwise_workload` is quite long and can be moved to another file, if wanted.
CC ngimel (Thanks for the support while benchmarking it ;) )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22302
Differential Revision: D16115057
Pulled By: ezyang
fbshipit-source-id: bad184658518e73b4d6b849d77e408f5a7a757de
Summary:
Having the NVRTC stub in ATen is necessary to call driver APIs in ATen. This is currently blocking https://github.com/pytorch/pytorch/pull/22229.
`DynamicLibrary` is also moved as it is used in the stub code, and seems general enough.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22362
Differential Revision: D16131787
Pulled By: ezyang
fbshipit-source-id: add2ee8a8865229578aa00001a00d5a6671e0e73
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
MEDIUM: 488
LARGE: 29
XXLARGE: 2
Updated actions:
From MEDIUM to LARGE: 227
From XLARGE to MEDIUM: 1
From XLARGE to LARGE: 1
From XLARGE to XXLARGE: 1
From LARGE to MEDIUM: 2
From LARGE to XLARGE: 2
Differential Revision: D16161669
fbshipit-source-id: 67a4e0d883ca3f1ca3185a8285903c0961537757
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22143
Like Conv DNNLOWP operator, allow FC to run the slow path to debug numerical issues caused by Intel's int8 instruction that does horizontal addition of 2 int8 multiplication results in 16 bit
Reviewed By: hx89
Differential Revision: D15966885
fbshipit-source-id: c6726376a3e39d341fd8aeb0e54e0450d2af8920
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22174
This is a preliminary change outlining the approach we plan to follow to integrate QNNPACK operators into the pytorch backend. The operators will not be made visible to the user in the python world, so ultimately we will have a function that calls qnnpack backend based on the environment being run on.
The goal of the project is to integrate QNNPACK library with PyTorch to achieve good performance for quantized mobile models.
Reviewed By: ljk53
Differential Revision: D15806325
fbshipit-source-id: c14e1d864ac94570333a7b14031ea231d095c2ae
Summary:
Some duplicated code is removed. It also becomes clear that there is only one special case `div_kernel_cuda` is handling.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22555
Differential Revision: D16152091
Pulled By: zou3519
fbshipit-source-id: bb875370077c1f84efe4b766b3e1acc461e73e6c
Summary:
Fix a grammatical error of the comment in line 233.
change from " Returns an `OrderedDict` of he submodules of this `Module`"
to " Returns an `OrderedDict` of the submodules of this `Module`"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22548
Differential Revision: D16134534
Pulled By: zou3519
fbshipit-source-id: 33b1dd0fbc3a24bef99b6e0192566e2839292842
Summary:
As part of the Variable/Tensor merge, we want to be able to pass Variables into Caffe2 without doing extra shallow copy, to improve performance and also allow for in-place mutations in Caffe2 ops. There are a few approaches outlined in https://github.com/pytorch/pytorch/pull/22418, and this PR is the chosen approach.
Specifically, we can have the assumption that we won't be connecting autograd to C2 gradients at any point (as it's too tricky and not that useful). Therefore, we can pass Variable into Caffe2 ops by requiring that all Variables in Caffe2 don't require grad. For code paths in Caffe2 that might potentially track gradients (e.g. `ScriptModuleOp` and `call_caffe2_op_from_c10`), we use the `torch::NoGradGuard` to make sure gradients are not tracked.
This supersedes https://github.com/pytorch/pytorch/pull/22418.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22473
Differential Revision: D16099042
Pulled By: yf225
fbshipit-source-id: 57efc3c7cfb3048d9abe90e63759acc14ebd2972
Summary:
Forgot to mirror the `nn/ __init__.py` semantics in the new `nn` type stub.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22411
Differential Revision: D16149798
Pulled By: ezyang
fbshipit-source-id: 0ffa256fbdc5e5383a7b9c9c3ae61acd11de1dba
Summary:
`addcmul_out` overwrote the samples, which led to constant values being output by `torch.normal`.
Changelog:
- Replace the `addcmul_out` calls with combo of inplace `mul` and `add` and justification for this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22533
Test Plan:
- Enable tests for test_normal on all devices
Fixes https://github.com/pytorch/pytorch/issues/22529
Differential Revision: D16141337
Pulled By: ezyang
fbshipit-source-id: 567a399042e0adcd154582f362318ce95a244c62
Summary:
Currently specifying different build options in respect to the "USE_"
series is in quite a disarray. There are a lot of build options that
accept three variants: USE_OPTION, WITH_OPTION, and NO_OPTION. Some
build options only accept USE_ and NO_ variant. Some accept only USE_.
This inconsistency is quite confusing and hard to maintain.
To resolve this inconsistency, we can either let all these build options
support all three variants, or we only support the USE_ variant.
This commit makes a step to the latter choice, i.e., deprecates and sets
a date for removing the NO_ and WITH_ variants and keeps only the
USE_ variant. This is likely better than the former solution because:
- NO_ and WITH_ variants are not documented.
- CMakeLists.txt only has the USE_ variants for relevant build options
defined. It would be a surprise that when user pass these variables to
CMake during rebuild and find them ineffective.
- Multiple variants are difficult to maintain.
- The behavior is confusing if more than one variant is passed. For
example, what to be expected if one sets "NO_CUDA=1 USE_CUDA=1"?
The downside is that this will break backward compatibility for existing
build scripts in the future (if they used the undocumented build
options).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22474
Differential Revision: D16149396
Pulled By: ezyang
fbshipit-source-id: 7145b88ad195db2051772b9665dd708dfcf50b7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22477
There is actually no use of uninitialized variable but some compilers are not smart enough to reason about two if branches are already taken together.
Reviewed By: hx89
Differential Revision: D16100211
fbshipit-source-id: 25f01d668063603d7aaa776451afe8a10415d2ea
Summary:
After the Variable/Tensor merge, code paths in ATen need to be able to check whether a tensor requires gradient, and throw errors in places where a `requires_grad=true` tensor is not allowed (such as https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/Utils.h#L76-L78 and https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/SparseTensorImpl.cpp#L86). Since the `GradMode` thread-local variable controls whether a tensor should accumulate gradients, we need to be able to check this variable from ATen when we determine whether a tensor requires gradient, hence the PR to move `GradMode` / `AutoGradMode` / `NoGradGuard` to ATen.
Note that we intentionally don't merge `at::GradMode` and `at::NonVariableTypeMode`, with the following reasoning:
Semantically, `at::GradMode` and `at::NonVariableTypeMode` actually mean different things: `at::GradMode` controls whether a tensor should accumulate gradients, and `at::NonVariableTypeMode` controls whether a Variable should be treated as a non-Variable tensor in type dispatches. There are places whether we *don't* want the tensor to accumulate gradients, but *still* want the Variable to be treated as a Variable. Here is one example:
```python
# torch/tensor.py
with torch.no_grad():
...
new_tensor = self.new() # `at::GradMode` is false at this point
...
```
```cpp
// tools/autograd/templates/python_variable_methods.cpp
static PyObject * THPVariable_new(PyObject* self, PyObject* args, PyObject* kwargs)
{
...
// if we merge `at::GradMode` and `at::NonVariableTypeMode`, since `at::GradMode` is false and `self_.type()` checks `at::GradMode` to decide whether to return non-Variable type, it will return a non-Variable type here, which is not what we want (and throws a "Tensor that was converted to Variable was not actually a Variable" error)
return THPVariable_Wrap(torch::utils::legacy_tensor_new(self_.type(), args, kwargs));
...
}
```
For the above reason, we cannot merge `at::GradMode` and `at::NonVariableTypeMode`, as they have different purposes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18573
Differential Revision: D16134413
Pulled By: yf225
fbshipit-source-id: 6140347e78bc54206506499c264818eb693cdb8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22479
In some cases, for example, when we training on CTR data, we would like to start training from old samples and finish on new recent samples.
This diff add the option to disable the shuffling in DistributedSampler to accommodate this use case.
Reviewed By: soumith
Differential Revision: D16100388
fbshipit-source-id: 35566581f5250040b2db5ec408a63037b47a9f5d
Summary:
Replaces https://github.com/pytorch/pytorch/pull/21501 because ghimport had errors when i tried to import the stack that i couldn't figure out :'(
has the two commits that were previously accepted and the merge commit
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22561
Differential Revision: D16135743
Pulled By: eellison
fbshipit-source-id: f0a98842ccb334c7ceab04d1437e09dc76be0eb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22516
Force anybody creating an untyped Dict to call c10::impl::deprecatedUntypedDict().
This should hopefully make it clear that this is not public API and prevent people from using it.
Differential Revision: D16115215
fbshipit-source-id: 2ef4cb443da1cdf4ebf5b99851f69de0be730b97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22005
When a Dict or List is created with type information, it will remember that.
If at any point later, this list is instantiated to a List<T> with a concrete type, it will assert that T is the correct type.
Differential Revision: D15914462
fbshipit-source-id: a8c3d91cb6d28d0c1ac0b57a4c4c6ac137153ff7
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/22551
Test Plan:
ran test locally
Imported from OSS
Differential Revision: D16132182
fbshipit-source-id: 5b9efbf883efa66c4d8b7c400bdb804ac668a631
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22510
Added a new function to implement clone operation on quantized tensors. Also added a test case which can be tested as shown in test plan.
This change is required to be able to call torch.jit.trace on quantized models.
Clone implementation calls copy_ on QTensor internally.
Differential Revision: D16059576
fbshipit-source-id: 226918cd475521b664ed72ee336a3da8212ddcdc
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/22397
Test Plan:
Added test for reentrant backwards with checkpoint and a test for a recursive backwards function (which should fail if we run all the reentrant tasks recursively in the same thread) and for testing priority of reentrant tasks.
~~Will add a test for priority of reentrant tasks in future pr.~~
Imported from OSS
Differential Revision: D16131955
fbshipit-source-id: 18301d45c1ec9fbeb566b1016dbaf7a84a09c7ac
Summary:
Currently, the **stream** parameter is not set when launching these two kernels: softmax_warp_forward() and softmax_warp_backward(), i.e. the kernels are always put on the default stream, which may fail to respect the stream that was set previously. Add **at::cuda::getCurrentCUDAStream()** as a launch argument to fix this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22470
Differential Revision: D16115051
Pulled By: izdeby
fbshipit-source-id: 38b27e768bb5fcecc1a06143ab5d63b0e68a279e
Summary:
re-apply changes reverted in:
https://github.com/pytorch/pytorch/pull/22412
Also change log_softmax to take positional arguments. Long-term we do want the kwarg-only interface, but seems to currently be incompatible with jit serialization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22456
Differential Revision: D16097159
Pulled By: nairbv
fbshipit-source-id: 8cb73e9ca18fc66b35b873cf4a574b167a578b3d
Summary:
* Deletes all weak script decorators / associated data structures / methods
* In order to keep supporting the standard library in script, this enables recursive script on any function defined in `torch.nn`
* Most changes in `torch/nn` are the result of `ag -Q "weak" torch/nn/ -l | xargs sed -i '/weak/d'`, only `rnn.py` needed manual editing to use the `ignore` and `export` to continue supporting the overloaded `forward` methods
* `Sequential`/`ModuleList` no longer need to be added to constants since they are compiled on demand
This should also fix https://github.com/pytorch/pytorch/issues/22212
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22212
Differential Revision: D15988346
Pulled By: driazati
fbshipit-source-id: af223e3ad0580be895377312949997a70e988e4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22309
This diff enables PT operators to run with JIT mode. Users can control eager and JIT mode using the `use_jit` flag.
In this diff, we are putting operators in a loop and passed it to JIT. One extra step which wraps the operator with the `_consume` op is introduced to avoid dead code elimination optimization in JIT. With that, the reported time includes the real operator execution time plus the `_consume` (directly return input, nothing else if happening inside) op.
Reviewed By: zheng-xq
Differential Revision: D16033082
fbshipit-source-id: e03be89fd5a505e44e81015dfc63db9cd76fb8a1
Summary:
- Fix typo in ```torch/onnx/utils.py``` when looking up registered custom ops.
- Add a simple test case
1. Register custom op with ```TorchScript``` using ```cpp_extension.load_inline```.
2. Register custom op with ```torch.onnx.symbolic``` using ```register_custom_op_symbolic```.
3. Export model with custom op, and verify with Caffe2 backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21321
Differential Revision: D16101097
Pulled By: houseroad
fbshipit-source-id: 084f8b55e230e1cb6e9bd7bd52d7946cefda8e33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21432
This diff introduce a new interface to generate tests based on the metadata of operators.
Reviewed By: ajauhri
Differential Revision: D15675542
fbshipit-source-id: ba60e803ea553d8b9eb6cb2bcdc6a0368ef62b1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22499
Another place where onnx export is running dead code elimination after making the jit graph invalid. Fixing it.
Reviewed By: houseroad
Differential Revision: D16111969
fbshipit-source-id: 5ba80340c06d091988858077f142ea4e3da0638c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22348
This is the last step of LRU hash eviction weight re-init. This diff checks if there's evicted values in sparse_lookup, if so call op created in D15709866 to re-init the values for indicies in evicted_values. Also created gradient op for the operator. The gradient op just passes the output gradient as input gradient.
Reviewed By: itomatik
Differential Revision: D16044736
fbshipit-source-id: 9afb85209b0de1038c5153bcb7dfc5f52e0b2abb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22476
Dead code elimination assumes a valid jit graph because it checks if operators have side effects.
The onnx export path destroys the jit graph right before calling dead code elimination, but it actually doesn't care about side effects.
We can just call dead code elimination and disable side effect lookup and things should work.
Reviewed By: houseroad
Differential Revision: D16100172
fbshipit-source-id: 8c790055e0d76c4227394cafa93b07d1310f2cea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22441
This include doesn't seem to be needed. Remove it to simplify mobile build dependency.
Reviewed By: dreiss
Differential Revision: D16088224
fbshipit-source-id: f6aec21655e259726412e26a006d785912436c2a
Summary:
This has been requested in https://github.com/pytorch/pytorch/issues/20323
(It is still not exactly the same as NumPy, which allows you to pass tensors at mean/std and broadcast them with size, but the present PR is extremely simple and does the main thing people are asking for)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20545
Differential Revision: D15358736
Pulled By: zhangguanheng66
fbshipit-source-id: 762ea5eab5b8667afbac2df0137df017ba6e413c
Summary:
The changes include:
1. Allow key/value to have different number of features with query. It supports the case when key and value have different feature dimensions.
2. Support three separate proj_weight, in addition to a single in_proj_weight. The proj_weight of key and value may have different dimension with that of query so three separate proj_weights are necessary. In case that key and value have same dimension as query, it is preferred to use a single large proj_weight for performance reason. However, it should be noted that using a single large weight or three separate weights is a size-dependent decision.
3. Give an option to use static k and v in the multihead_attn operator (see saved_k and saved_v). Those static key/value tensors can now be re-used when training the model.
4. Add more test cases to cover the arguments.
Note: current users should not be affected by the changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21288
Differential Revision: D15738808
Pulled By: zhangguanheng66
fbshipit-source-id: 288b995787ad55fba374184b3d15b5c6fe9abb5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21927
Add `OUTPUT_PROB` output to CTCBeamSearchDecoderOp to return a probability for each sequence.
Add argument to output top-k instead of top-1 decoded sequences.
Reviewed By: SuperIRabbit
Differential Revision: D15797371
fbshipit-source-id: 737ca5cc4f90a0bcc3660ac9f58519a175977b69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22461
We shouldn't call dead code elimination after EraseNumberTypes because dead code elimination assumes a valid jit graph which EraseNumberTypes just broke.
Let's have it clean up itself isntead.
Reviewed By: houseroad
Differential Revision: D16094656
fbshipit-source-id: f2752277d764e78ab276c57d56b2724b872b136f
Summary:
It's always set to equal USE_NCCL, we made Gloo depending on Caffe2 NCCL
build. See 30da84fbe1614138d6d9968c1475cb7dc459cd4b
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22467
Differential Revision: D16098581
Pulled By: ezyang
fbshipit-source-id: f706ec7cebc2e6315bafca013b669f5a72e04815
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22279
This new operator is used for embedding table weight re-init. After we get the evicted indices, they will be the rows need reseting in embedding table. Then we can create a 1d tensor with default values, and apply this operator to copy the tensor to all evicted rows in embedding table
Will add gradient op in next diff
Reviewed By: itomatik
Differential Revision: D15709866
fbshipit-source-id: 2297b70a7326591524d0be09c73a588da245cc08
Summary:
The sgemm in cuBLAS 9.0 has some issues with sizes above 2M on Maxwell and Pascal architectures. Warn in this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22034
Differential Revision: D15949930
Pulled By: zhangguanheng66
fbshipit-source-id: 0af977ec7900c76328d23898071de9c23778ff8b
Summary:
ROCm is already detected in cmake/public/LoadHIP.cmake. No need to
detect twice. Plus, the Python script read environment variable
ROCM_HOME, but what is really used in CMake scripts is ROCM_PATH -- A
user must specify both environment variables right. Since ROCM_HOME is
undocumented, this commit completely eradicates it.
---
ezyang A remake of https://github.com/pytorch/pytorch/issues/22228 because its dependency has been dismissed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22464
Differential Revision: D16096833
Pulled By: bddppq
fbshipit-source-id: fea461e80ee61ec77fa3a7b476f7aec4fc453d5d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22425
Currently, in bound_shape_inference.cc: InferBoundShapeAndType, we firstly infer ops in the order and then infer inputs of concat in reverse order. In ctr_instagram_model tiny version, concat is right before FC, so we can infer the inputs for concat. But in production version, we found there are some ops between concat and FC(or other ops we know the shape), so the shape of these ops cannot be inferred.
This diff is a tmp solution for this problem: infer shape in order and in reverse order repeatly until no more change.
Reviewed By: yinghai, ipiszy
Differential Revision: D16082521
fbshipit-source-id: d5066509368029c6736dce156030adf5c38653d7
Summary:
MKL-DNN is the main library for computation when we use ideep device. It can use kernels implemented by different algorithms (including JIT, CBLAS, etc.) for computation. We add the "USE_MKLDNN_CBLAS" (default OFF) build option so that users can decide whether to use CBLAS computation methods or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19014
Differential Revision: D16094090
Pulled By: ezyang
fbshipit-source-id: 3f0b1d1a59a327ea0d1456e2752f2edd78d96ccc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22004
In future, we want all dicts/lists to store information about the types they contain.
This is only possible if the creation API doesn't allow creating lists/dicts without type information.
This diff removes some call sites that don't specify type information and have it specify type information.
Reviewed By: dzhulgakov
Differential Revision: D15906387
fbshipit-source-id: 64766a2534b52c221e8a5501a85eaad13812e7bd
Summary:
Currently the build system accepts USE_NAMEDTENSOR from the environment
variable and turns it into NAMEDTENSOR_ENABLED when passing to CMake.
This discrepancy does not seem necessary and complicates the build
system. The naming of this build option is also semantically incorrect
("BUILD_" vis-a-vis "USE_"). This commit eradicate this issue before it
is made into a stable release.
The support of NO_NAMEDTENSOR is also removed, since PyTorch has been
quite inconsistent about "NO_*" build options.
---
Note: All environment variables with their names starting with `BUILD_` are currently automatically passed to CMake with no need of an additional wrapper.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22360
Differential Revision: D16074509
Pulled By: zou3519
fbshipit-source-id: dc316287e26192118f3c99b945454bc50535b2ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21389
As titled. To do weight re-init on evicted rows in embedding table, we need to pass the info of the evicted hashed values to SparseLookup, which is the layer model responsible for constructing the embedding table and do pooling.
To pass evicted values, we need to adjust the output record of lru_sparse_hash to include the evicted values, and add optional input to all processors that needs to take in sparse segment. For SparseLookup to get the evicted values, its input record needs to be adjusted. Now the input record can have type IdList/IdScoreList/or a struct of feature + evicted values
Reviewed By: itomatik
Differential Revision: D15590307
fbshipit-source-id: e493881909830d5ca5806a743a2a713198c100c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22241
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20387
glibc has a non-standard function, feenableexcept, that triggers floating-point exception handler . Compared to feclearexcept + fetestexcept , this approach allows us to see precisely where the exception is raised from the stack trace.
Reviewed By: jspark1105
Differential Revision: D15301095
fbshipit-source-id: 94f6e72456b2280f78d7d01c2ee069ae46d609bb
Summary:
empty_like uses the tensor options of `self`, rather than the passed in tensor options. This means it messes up variable/tensor types, and ignores specifications like different dtypes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21978
Differential Revision: D15903948
Pulled By: gchanan
fbshipit-source-id: f29946be01c543f888daef2e99fe928e7b7d9d74
Summary:
# What is this?
This is an implementation of the AdamW optimizer as implemented in [the fastai library](803894051b/fastai/callback.py) and as initially introduced in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101). It decouples the weight decay regularization step from the optimization step during training.
There have already been several abortive attempts to push this into pytorch in some form or fashion: https://github.com/pytorch/pytorch/pull/17468, https://github.com/pytorch/pytorch/pull/10866, https://github.com/pytorch/pytorch/pull/3740, https://github.com/pytorch/pytorch/pull/4429. Hopefully this one goes through.
# Why is this important?
Via a simple reparameterization, it can be shown that L2 regularization has a weight decay effect in the case of SGD optimization. Because of this, L2 regularization became synonymous with the concept of weight decay. However, it can be shown that the equivalence of L2 regularization and weight decay breaks down for more complex adaptive optimization schemes. It was shown in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101) that this is the reason why models trained with SGD achieve better generalization than those trained with Adam. Weight decay is a very effective regularizer. L2 regularization, in and of itself, is much less effective. By explicitly decaying the weights, we can achieve state-of-the-art results while also taking advantage of the quick convergence properties that adaptive optimization schemes have.
# How was this tested?
There were test cases added to `test_optim.py` and I also ran a [little experiment](https://gist.github.com/mjacar/0c9809b96513daff84fe3d9938f08638) to validate that this implementation is equivalent to the fastai implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21250
Differential Revision: D16060339
Pulled By: vincentqb
fbshipit-source-id: ded7cc9cfd3fde81f655b9ffb3e3d6b3543a4709
Summary:
Address the issue raised in https://github.com/pytorch/pytorch/issues/22377.
The PR https://github.com/pytorch/pytorch/issues/22016 introduces a temporary tensor of weights `grad_weight_per_segment` of the same dtype as the end result, which can be a problem when using `float16`.
In this PR, it now use a `float32` temporary tensor when the input is `float16`.
ngimel, can I get you to review? I think I have fixed the issues you have pointed out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22401
Differential Revision: D16077319
Pulled By: mrshenli
fbshipit-source-id: 7cfad7f40b4d41a244052baa2982ab51bbbd7309
Summary:
The CMake modifications include removal of some unnecessary paths
(e.g. find_package(CUDA) and friends) that are no longer used since
c10d is always part of the larger torch build. The macro
`C10D_USE_...` was ambiguous and is now removed in favor of only
having top level `USE_...`. The c10d test suite is changed to include
skip annotations for the tests that depend on Gloo as well.
Now, if you compile with `USE_DISTRIBUTED=1` and `USE_GLOO=0` you get
a functioning build for which the tests actually pass.
Closes https://github.com/pytorch/pytorch/issues/18851.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22257
Differential Revision: D16087993
Pulled By: pietern
fbshipit-source-id: 0cea66bd5cbd9736b06fa1d45ee13a18cab88adb
Summary:
The `assert False` lint error has been causing CI to fail:
./torch/utils/throughput_benchmark.py:14:13: B011 Do not call assert False since python -O removes these calls. Instead callers should raise AssertionError().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22424
Differential Revision: D16083464
Pulled By: bddppq
fbshipit-source-id: 6d96e36c8fcbb391d071b75fe79c22d526c1ba3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22429
Android NDK r20 removes the guard `(__ANDROID_API__ <= __ANDROID_API_O_MR1__)`, so we do it here also. There is insufficient reason to keep these decls undefined for earlier API levels. NDK r15 and earlier don't even define `__ANDROID_API_O_MR1__`, so the preprocessor defaults it to 0 and the guard evaluates as TRUE.
Reviewed By: smeenai, hlu1
Differential Revision: D16084105
fbshipit-source-id: f0857b3eb0573fe219f0d6c5e6583f89e2b5518f
Summary:
This change adds one advanced support for cross-chunk shuffling.
For training with static dataset, the default configuration is at user's disposal. However, in some user cases, over each epoch, new data is added to the current dataset, thus the dataset's size is dynamically changing/increasing. In order to mix the new data and the old data for better random sampling, one approach is to shuffle examples from more than 1 chunks. This feature is supported with this change. By specifying the `cross_chunk_shuffle_count_` on construction, advanced user can specify how many chunks to shuffle example from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22347
Differential Revision: D16081378
Pulled By: zhangguanheng66
fbshipit-source-id: fd001dfb9e66947839adecfb9893156fbbce80d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22413
_jit_pass_erase_number_types invalidates the jit graph but parts of _jit_pass_onnx rely on having a valid jit graph.
This splits _jit_pass_onnx into _jit_pass_onnx_remove_print and _jit_pass_onnx_preprocess_caffe2 (which rely on the valid jit graph), runs these before _jit_pass_erase_number_types,
and then runs the rest of _jit_pass_onnx after _jit_pass_erase_number_types
Reviewed By: houseroad
Differential Revision: D16079890
fbshipit-source-id: ae68b87dced077f76cbf1335ef3bf89984413224
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22334
Improve the function signatures of save_to_db and load_from_db in predictor_exporter.
Reviewed By: akyrola
Differential Revision: D16047208
fbshipit-source-id: a4e947f86e00ef3b3dd32c57efe58f76a38fcec7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22293
Just wrapping C class with nicer python interface which now
ust print dirrectly to get all the data. Later we can add various
visualizations there
Differential Revision: D16023999
fbshipit-source-id: 8436e37e36965821a690035617784dcdc352dcd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22292
as we do atomic fetch_add to validate if a thread should
finish, we should not take the last iteration into account. As a
result total number of iterations should be exactly the same as user
sets via config.num_iters
Now when running a unit test I see exact number of iterations reported
Differential Revision: D16023963
fbshipit-source-id: 3b12ee17276628ecd7b0979f28cd6deb777a1543
Summary:
As part of the Variable/Tensor merge, one invariant for tensor libraries such as ATen / Caffe2 / XLA is that they should only deal with Tensors, not Variables. However, currently in `variable_factories.h` we are potentially passing Variables into those tensor libraries without the `at::AutoNonVariableTypeMode` guard, which will cause those libraries to treat those Variables as Variables (i.e. their `is_variable()` is true), not Tensors.
Consider the following example for `full_like`:
```cpp
inline at::Tensor full_like(const at::Tensor & self, at::Scalar fill_value) {
...
// Both ATen and XLA rely on `at::full_like` to dispatch to library specific implementations.
//
// When `self` is a Variable, since we are not using `at::AutoNonVariableTypeMode`,
// `at::full_like` will also use `self` as a Variable (and it will see that `self.is_variable()` is true),
// which breaks the invariant that ATen / XLA should never deal with Variables.
at::Tensor tensor = at::full_like(self, fill_value, self.options().is_variable(false));
at::Tensor result =
autograd::make_variable_consuming(std::move(tensor), /*requires_grad=*/false);
...
return result;
}
```
Instead, the invariant-preserving implementation would be:
```cpp
inline at::Tensor full_like(const at::Tensor & self, at::Scalar fill_value) {
...
at::Tensor tensor = ([&]() {
at::AutoNonVariableTypeMode non_var_type_mode(true);
// Both ATen and XLA rely on `at::full_like` to dispatch to library specific implementations.
//
// When `self` is a Variable, since we have `at::AutoNonVariableTypeMode` in the scope,
// `at::full_like` will use `self` as a Tensor (and it will see that `self.is_variable()` is false),
// which preserves the invariant that ATen / XLA should only deal with Tensors.
return at::full_like(self, fill_value, self.options().is_variable(false));
})();
at::Tensor result =
autograd::make_variable_consuming(std::move(tensor), /*requires_grad=*/false);
...
return result;
}
```
This PR makes the suggested change for all variable factory functions.
cc. ailzhang This should allow us to remove all `tensor_data()` calls in the XLA codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22364
Differential Revision: D16074862
Pulled By: yf225
fbshipit-source-id: 3deba94b90bec92a757041ec05d604401a30c353
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22285
Previously forward hooks are expected to return None, this PR adds the support to overwrite input and output in `forward_pre_hook` and `forward_hook`, this is used to implement inserting quant/dequant function calls around forward functions.
Differential Revision: D16022491
fbshipit-source-id: 02340080745f22c8ea8a2f80c2c08e3a88e37253
Summary:
As per attached tasks, these are noops and are being deprecated/removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22113
Reviewed By: philipjameson
Differential Revision: D15901131
fbshipit-source-id: 3acf12208f692548afe4844be13717a49d74af32
Summary:
Saying `I` in an err msg is too subjective to be used in a framework.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22369
Differential Revision: D16067712
Pulled By: soumith
fbshipit-source-id: 2a390646bd5b15674c99f65e3c460a7272f508b6
Summary:
`setup.py` recommends setting `USE_QNNPACK=0` and `USE_NNPACK=0` to disable building QNNPACK and NNPACK respectively. However this wasn't reflected correctly because we were looking for `NO_QNNPACK` and `NO_NNPACK`. This PR fixes it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22367
Differential Revision: D16067393
Pulled By: soumith
fbshipit-source-id: 6491865ade9a6d41b7a79d68fd586a7854051f28
Summary:
Say the user inputs reduction=False. Of course, we can't add a bool and a string, so the ValueError itself will error -which is more confusing to the user. Instead, we should use string formatting. I would use `f"{reduction} is not..."` but unsure whether we are ok with using f"" strings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22160
Differential Revision: D15981826
Pulled By: soumith
fbshipit-source-id: 279f34bb64a72578c36bdbabe2da83d2fa4b93d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22319
The onnx pass replacing ints with Tensors produces an invalid JIT graph. It should only be called right before the onnx pass.
Also, it should only be called if we actually export to onnx.
Reviewed By: houseroad
Differential Revision: D16040374
fbshipit-source-id: e78849ee07850acd897fd9eba60b6401fdc4965b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22317
About to add an observer that is also statically initialized in a different
file, so we need to enforce initialization order.
Reviewed By: ilia-cher
Differential Revision: D16012275
fbshipit-source-id: f26e57149a5e326fd34cb51bde93ee99e65403c4
Summary:
Syncing worker requirement mismatches to improve remote build time.
Created actions:
MEDIUM: 445
LARGE: 354
Updated actions:
From MEDIUM to LARGE: 21
From LARGE to XLARGE: 34
From LARGE to MEDIUM: 9
From XLARGE to MEDIUM: 1
Differential Revision: D16047893
fbshipit-source-id: 7afab2ef879277f114d67fd1da9f5102ec04ed7f
Summary:
This does not occur in CUDA code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22271
Differential Revision: D16024605
Pulled By: bddppq
fbshipit-source-id: bb4f16bacbdc040faa59751fba97958f4c2d33cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22307
MSVC-specific pragma doesn't silence the warning about throwing constructor and therefore `clang-cl` fails to compile this file. This diff fixes the problem by adding additional check for `clang` compiler.
Reviewed By: smessmer
Differential Revision: D16032324
fbshipit-source-id: 6dbce0ebf0a533d3e42b476294720590b43a8448
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21921
Call FBGEMM kernels to implement quantized linear operator. This operator is used only for inference.
Differential Revision: D15375695
fbshipit-source-id: b9ca6c156fd60481fea83e55603b2897f7bfc3eb
Summary:
Reduction of gradients for unused parameters should happen as soon as
possible, because they potentially block reduction of gradients for
used parameters. This used to happen instantly when
`prepare_for_backward` was called and it found parameters that didn't
contribute. This meant that if you have a model with unused
parameters, and you want to discard the model output (i.e. not call
backward on some loss), reduction of the gradients of those unused
parameters would have been kicked off, and you'd see an error the next
time you called `forward`.
In this commit, this original approach is slightly changed to delay
reduction of the gradients of those unused parameters until the first
autograd hook is called. This means that you can now discard the model
output regardless of the model having unused parameters or not.
This is a prerequisite for making the `find_unused_parameters`
argument to DDP default to `True`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22219
Differential Revision: D16028698
Pulled By: pietern
fbshipit-source-id: c6aec2cd39c4a77746495d9cb1c9fb9c5ac61983
Summary:
This adds the rest of the `dict.???` methods that were missing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21979
Pulled By: driazati
Differential Revision: D16023573
fbshipit-source-id: 3ea9bd905090e2a176af654a8ca98c7d965ea679
Summary:
In talks with smessmer, we decided that it'd be better to put the logic in `list`, as optimal behavior requires knowing `.capacity()`
Results on my cpu (for the benchmark here: https://twitter.com/VahidK/status/1138674536679821312) now look like this:
```
Pytorch batch_gather took 0.018311 seconds.
Pytorch batch_gather jit took 0.013921 seconds.
Pytorch vectorized batch_gather took 0.001384 seconds.
```
Previously, `batch_gather jit` took 3x as long as `batch_gather`.
Some logic taken from https://github.com/pytorch/pytorch/pull/21690. Note that these two PR's are somewhat orthogonal. That PR handles this benchmark by looking at the alias analysis, while this PR specializes for `+=`.
Note that we can't jit the vectorized version as we think `torch.arange` returns a float tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21896
Differential Revision: D15998628
Pulled By: Chillee
fbshipit-source-id: b0085960da4613578b94deb98ac62c0a4532a8c3
Summary:
This is yet another step to disentangle Python build scripts and CMake
and improve their integration (Let CMake handle more build environment
detections, and less by our handcrafted Python scripts).
The processor detection logic also changed a bit: Instead of detecting
whether the system processor is PPC or ARM, this PR changes to detect
Intel CPUs, because this is more precise as MKL only supports Intel
CPUs. The build option `USE_MKLDNN` will also not be presented to
users on non-Intel processors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22215
Differential Revision: D16005953
Pulled By: ezyang
fbshipit-source-id: bf3f74d53609b3f835e280f63a872ff3c9352763
Summary:
When dealing with large scale dataset, it is handy if we can save the dataset status and resume later. Especially in cases where some unexpected crash happens, user don't need to start over the whole dataset from begining. Instead, they can reload it from the last checkpoint.
This change adds support for checkpoint save/load logic in ChunkDataset.
On ChunkDataset construction, user can specify a file name from which to load the checkpoint. If it is empty, default to start from fresh; otherwise the ChunkDataset will 'fast forward' the chunk sampler to the corresponding checkpoint.
The user can also call ChunkDataset::save() to serialize current status to a file, which can be used later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21889
Differential Revision: D16024582
Pulled By: ailzhang
fbshipit-source-id: 1862ab5116f94c9d29da174ce04a91041d06cad5
Summary:
`cmake/public/LoadHIP.cmake` calls `find_package(miopen)`, which uses the CMake module in MIOpen installation (It includes the line `set(miopen_DIR ${MIOPEN_PATH}/lib/cmake/miopen)`). `cmake/Modules/FindMIOpen.cmake` is not used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22244
Differential Revision: D16000771
Pulled By: bddppq
fbshipit-source-id: 07bb40fdf033521e8427fc351715d47e6e30ed34
Summary:
The original name `copy_tensor_data` could be confusing because users are not sure whether it deep-copies data in the tensor's storage or just copies the tensor's metadata. The renaming makes it more clear.
cc. ailzhang This might break XLA build, but I think the renaming makes it more clear why we use `copy_tensor_data` in XLATensorImpl's shallow-copy functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22266
Differential Revision: D16014724
Pulled By: yf225
fbshipit-source-id: f6ee966927d4d65d828b68264b3253b2f8fd768d
Summary:
This adds the rest of the `dict.???` methods that were missing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21979
Pulled By: driazati
Differential Revision: D15999938
fbshipit-source-id: 7bc2a55e3f791015a0ff2e3731703075cf0770ee
Summary:
I learned from https://github.com/pytorch/pytorch/pull/22058 that `worker_kill` is just flaky, regardless of `hold_iter_reference`. So let's disable it altogether for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22208
Differential Revision: D15990307
Pulled By: soumith
fbshipit-source-id: d7d3f4fe7eaac4987f240cb8fd032c73a84157d7
Summary:
As part of the Variable/Tensor merge, we want to gradually remove call sites of `tensor_data()` and the API itself, and instead uses `variable_data()`. This PR removes the `tensor_data()` call in the tensor_to_numpy conversion path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22214
Differential Revision: D15997397
Pulled By: yf225
fbshipit-source-id: 6fcab7b14e138824fc2adb5434512bcf868ca375
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22077
ghimport-source-id: 39cf0a2e66e7fa2b6866af72782a22a4bd025e4c
Test Plan:
- Compared the build/aten/src folder before and after this change
locally and verified they are identical (`diff -r`).
- Wait for CI + Also, [namedtensor ci]
Imported from OSS
Differential Revision: D15941967
Pulled By: zou3519
fbshipit-source-id: d8607df78f48325fba37e0d00fce0ecfbb78cb36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20729
Currently there is no way to specify what scalar types each nn function will support.
This change will allow to specify supported scalar types for each function/backward function and device. By default each function will support Float, Double, Half.
If you want to scpecify any extra supported scalar types, other then default, you will need to change nn.yalm:
- name: _some_func(Tensor self)
cname: SomeFunction
CPU:
forward_scalar_types: ['Float', 'Double', 'Long']
backward_scalar_types: ['Float', 'Double']
Differential Revision: D15423752
fbshipit-source-id: b3c157316d6e629bc39c1b377a3b23c71b1656cf
Summary:
In `torch/csrc/autograd/function.h` we define `torch::autograd::Function`, a (the?) central autograd record-holding class. `Function` is declared public API (`TORCH_API`).
We also define a custom deleter `deleteFunction` which we use throughout PyTorch's own use of `Function`. This trivial PR declares the deleter public API as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22236
Differential Revision: D16001335
Pulled By: yf225
fbshipit-source-id: 6ef0a3630e8f82f277a0e6e26cc64455ef7ee43e
Summary:
we used to not print device when it's on xla. It's sometimes confusing as it looks the same as cpu tensor...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22094
Differential Revision: D15975405
Pulled By: ailzhang
fbshipit-source-id: f19ceb9e26f5f2f6e7d659de12716f0dfe065f42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22084
For DictPtr/ListPtr, default construction was disallowed because it was ambigious if it's supposed to create an empty list or a nullptr.
But since we renamed them to Dict/List, we can now allow default construction without ambiguity.
Differential Revision: D15948098
fbshipit-source-id: 942a9235b51608d1870ee4a2f2f0a5d0d45ec6e6
Summary:
This cleans up the `checkScript` API and some old tests that were hardcoding outputs. It also now runs the Python function when a string is passed in to verify the outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22002
Differential Revision: D15924485
Pulled By: driazati
fbshipit-source-id: ee870c942d804596913601cb411adc31bd988558
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22157
This header uses `std::swap_ranges` function which is defined in `<algorithm>` header (https://en.cppreference.com/w/cpp/algorithm/swap_ranges). Therefore this file isn't guaranteed to compile on all platforms.
This diff fixes the problem by adding the missing header.
Reviewed By: smessmer
Differential Revision: D15971425
fbshipit-source-id: e3edcec131f72d729161f5644ee152f66489201a
Summary:
Changelog:
- Port `symeig` from TH/THC to ATen
- Enable batching of matrix inputs for `symeig`
- Modify derivative computation based on batching
- Update docs to reflect the change
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21858
Test Plan: - Added additional tests in `test_torch.py` (with a port to `test_cuda.py`) and `common_methods_invocations.py` to test if both the port and batching work.
Differential Revision: D15981789
Pulled By: soumith
fbshipit-source-id: ab9af8361f8608db42318aabc8421bd99a1ca7ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21885
If a kernel is defined as a stateful lambda
static auto registry = torch::RegisterOperators().op("my::op", [some_closure] (Tensor a) {...});
this can have very unexpected behavior when kernels are instantiated. There is no guarantee that the state is kept.
In the options based API, state is already disallowed:
// this is a compiler error
static auto registry = torch::RegisterOperators().op("my::op", torch::RegisterOperators::options().kernel([some_closure] (Tensor a) {...}));
but we can't disallow it in the non-options-based API for backwards compatibility reasons.
We can, however, show a deprecation warning. This is what this diff introduces.
Differential Revision: D15867089
fbshipit-source-id: 300fa4772fad8e7d177eb7cb910063d360537a4a
Summary:
Re-implementation of the `embedding_dense_backward_cuda()` and the `embedding_bag_backward_cuda_sum_avg()` functions.
#### Performance
Running a [Mortgage Workflow](https://github.com/EvenOldridge/MortgageWorkflowA) with a block size of 100K on a DXG-2 (single GPU), we see a 270% speedup:
```
Original version: 370,168 example/s
Optimized version: 1,034,228 example/s
```
The original version is bounded by the `EmbeddingBag_accGradParametersKernel_sum_avg`, which takes 70% of the CUDA execution time. In the optimized version, the optimized kernel now takes only 17% of the time.
#### Greater Numerical Stability
An added benefit is greater numerical stability. Instead of doing a flat sum where a single variable are used to accumulate the weights, this code uses two-steps where each GPU-thread computes a sub-result defined by `NROWS_PER_THREAD` before the final result are accumulated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22016
Differential Revision: D15944339
Pulled By: mrshenli
fbshipit-source-id: 398d5f48826a017fc4b31c24c3f8b56d01830bf0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22130
Optimize InstanceNormOp forward
For InstanceNormOp on CPU with order = NHWC, N = 128, C = 256, H = 56, W = 56: 183ms -> 115ms.
For InstanceNormOp on GPU with N = 256, C = 256, H = 112, W = 112:
NCHW: 1475ms -> 45ms
NHWC: 1597ms -> 79ms
Reviewed By: houseroad
Differential Revision: D15963711
fbshipit-source-id: 3fa03109326456b9f301514fecbefa7809438d3e
Summary:
In order to select more important features in dot product among a list of candidate sparse features, we can assign one learnable weight on each feature, reweight each feature by multiplying the weight onto its embedding before dot product. We finally select features based on the weight magnitude after training.
We can perform L1 and/or L2 regularization on the weights. To summarize, the weights tend to shrink their values (avoiding overfitting) due to L2 regularization, and some weights will vanish to zero as L1. To avoid sparse feature embedding being ignored due to early collapse of weights, a piece lr warm up policy is used in optimizing regularization term, such that regularization is weak at first stage and gets stronger afterwards (a small lr constant in iters less than threshold 1, a medium lr constant in stage 2, and a final reasonable large lr constant in all iters after threshold 2). The features with nonzero and relatively large weights (in absolute value) will be selected for the module.
We can also apply softmax on the original weights to make it sum to 1. We can even boosting the softmaxed weights by multiply the number of softmax components, which essentially make them sum to the number of softmax components and avergae to 1. In this idea, all the weights are positive and sum to a constant. Regularization is not a must since we can count on the competition between softmax weights themselves to achieve reasonable re-weighting. We expect those weights be more dense, comparing with sparse ones from L1 regularization and we can select features based on top K weights.
Overall, we aim to demonstrate the selected feature set outperform current v0 feature set in experiments. Special acknowledgement goes to Shouyuan Chen, who initiated the work of regularizable weighting.
---
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22176
The diff will export updates to Github repository, as stated below.
{F162787228}
Basically, the updates on the files are summarized as below:
- adding logger messages
`caffe2/python/layer_model_helper.py`
- add ElasticNet regularizer, which combines both L1 and L2 regularization
`caffe2/python/regularizer.py`
- implement piecewarmup, specifically warm up with three constant pieces
`caffe2/sgd/learning_rate_functors.h, caffe2/sgd/learning_rate_op.cc, caffe2/sgd/learning_rate_op.h`
Differential Revision: D15923430
fbshipit-source-id: ee18902cb88c23b1b7b367cc727d690a21e4cda9
Summary:
- PyCQA/flake8-bugbear#53 has been fixed (but not yet closed on their side) and a new version of flake8-bugbear has been released on Mar 28, 2019. Switch CI to use the latest stable version.
- Fix the new B011 errors that flake8-bugbear catches in the current codebase.
---
B011: Do not call assert False since python -O removes these calls. Instead callers should raise AssertionError().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21944
Differential Revision: D15974842
Pulled By: soumith
fbshipit-source-id: de5c2c07015f7f1c50cb3904c651914b8c83bf5c
Summary:
Returning the result of an inplace `squeeze_` in `einsum` (which itself is traced) interacts badly with `autograd.Function`.
I must admit that I'm not 100% certain whether it should be necessary to change this, but I consider this a good change overall.
Fixes: https://github.com/pytorch/pytorch/issues/22072
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22111
Differential Revision: D15974990
Pulled By: soumith
fbshipit-source-id: 477e7f23833f02999085f665c175d062e7d32acd
Summary:
The current error message displays as:
`RuntimeError: index koccurs twice in output`
A whitespace is missing between the index and 'occurs'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21904
Differential Revision: D15878941
Pulled By: colesbury
fbshipit-source-id: 163dda1829bf4956978cd01fd0e751673580722d
Summary:
The bug is that when target_length == 0, there is no preceding BLANK state and the original implementation will lead to out of bound pointer access.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21910
Differential Revision: D15960239
Pulled By: ezyang
fbshipit-source-id: 7bbbecb7bf91842735c14265612c7e5049c4d9b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22088
This diff is similar to D14163001. We need to handle the edge case when add_axis=1.
Reviewed By: jspark1105
Differential Revision: D15949003
fbshipit-source-id: 328d1e07b78b69bde81eee78c9ff5a8fb81f629b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22037
This adds support for sparse gradients to the reducer as well as to
the DistributedDataParallel wrapper. Note that an out of band signal
is needed whether or not a dense parameter (e.g. an embedding) is
expected to receive a sparse gradient or not. This information is
passed to the bucket assignment computation routine and the reducer as
a vector of booleans. Every parameter for which we expect a sparse
gradient is assigned its own bucket, as we cannot easily group
multiple unrelated sparse tensors.
Reviewed By: mrshenli
Differential Revision: D15926383
fbshipit-source-id: 39c0d5dbd95bf0534314fdf4d44b2385d5321aaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22036
Implemented only on ProcessGroupGloo, as an allgather of metadata
(sparse_dim, dense_dim, and nnz), followed by an allgather of indices,
followed by an allgather of values. Once these operations have
finished, all ranks locally compute a reduction over these sparse
tensors. Works for both CPU and CUDA tensors.
This surfaced a problem with the existing assumption of only modifying
tensors that are passed at the call site, because for sparse tensors
we don't know the dimensions of the output tensors before we run the
collective. To deal with this unknown, this commit adds a `result`
function to the `c10d::ProcessGroup::Work` class that returns a vector
of tensors.
It's a bit odd to have to retrieve the result through this function
only for operations on sparse tensors. To make this work irrespective
of tensor layout, we can create a follow-up commit to make all in
place operations make their results accessible through this function
as well. This doesn't break any existing contracts but does have the
potential to add interface ambiguity.
This is a resubmission of #19146.
Reviewed By: mrshenli
Differential Revision: D15926384
fbshipit-source-id: b6ee5d81606bfa8ed63c3d63a9e307613491e0ae
Summary:
This change is backwards incompatible in *C++ only* on mean(), sum(), and prod() interfaces that accepted either of:
```
Tensor sum(IntArrayRef dim, bool keepdim=false) const;
Tensor sum(IntArrayRef dim, ScalarType dtype) const;
```
but now to specify both the dim and dtype will require the keepdim parameter:
```
Tensor sum(IntArrayRef dim, bool keepdim=false, c10::optional<ScalarType> dtype=c10::nullopt) const;
```
[xla ci]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21088
Reviewed By: ailzhang
Differential Revision: D15944971
Pulled By: nairbv
fbshipit-source-id: 53473c370813d9470b190aa82764d0aea767ed74
Summary:
Currently many build options are explicitly passed from Python build scripts to CMake. But this is unecessary, at least for many of them. This commit removes the build options that have the same name in CMakeLists.txt and environment variables (e.g., `USE_REDIS`). Additionally, many build options that are not explicitly passed to CMake are lost.
For `ONNX_ML`, `ONNX_NAMESPACE`, and `BUILDING_WITH_TORCH_LIBS`, I changed their default values in CMake scripts (as consistent with what the `CMake.defines` call meant), to avoid their default values being redundantly set in the Python build scripts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21877
Differential Revision: D15964996
Pulled By: ezyang
fbshipit-source-id: 127a46af7e2964885ffddce24e1a62995e0c5007
Summary:
This PR tackles issue https://github.com/pytorch/pytorch/issues/18352 .
Progress:
- [x] conv_dilated2d CPU
- [x] conv_dilated3d CPU
- [x] conv_dilated2d CUDA
- [x] conv_dilated3d CUDA
- [x] RocM port
- [x] Port of CUDA gemm and gemv
- [x] Refactored 2d and 3d functions as well as output and gradient computations into a single C++ template function
- [x] Cleanup
+ [x] eliminate forward functions
+ [x] eliminate buffers `columns` and `ones` from functions API
+ [x] eliminate out functions
+ [x] eliminate using `ones`
Note that col2im, im2col, col2vol, vol2col implementations are exposed in `ATen/native/im2col.h` and `ATen/native/vol2col.h`. The corresponding operators (not ported in this PR) should use these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20983
Differential Revision: D15958088
Pulled By: ezyang
fbshipit-source-id: 1897f6e15abbf5710e9413cd1e443c2e1dc7d705
Summary:
This is useful for measuring inference performance of your
models. This is a very basic benchmark for now. We don't support
batching on the benchmark side, no inter and intra op parallelizm is
supported yet, just caller based parallelizm.
Main phylosophy here is that user should be able to provide inputs
from python and just stack them within the benchmark. API should be
exactly the same as passing inputs to module.forward.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20766
Test Plan: Added a new unit test
Differential Revision: D15435461
Pulled By: salexspb
fbshipit-source-id: db08829dc3f4398bb1d8aa16cc4a58b6c72f16c6
Summary:
Previously any assert failures would leave the updated setting, making
the test suite semantics dependent on the order in which the tests are run.
The diff is large only due to the indentation change (might be good to review without whitespace changes).
cc yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22115
Differential Revision: D15960875
Pulled By: soumith
fbshipit-source-id: 9313695277fc2d968786f13371719e03fff18519
Summary:
Apply launch bounds annotations for ROCm as the maximum threads per
block (1024) is higher than the ROCm internal default (256).
Reduce the minBlocksPerMultiprocessor for ROCm to 8 from 16 as this
improves performance in some microbenchmarks by (statistically
significant) 4%.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22081
Differential Revision: D15947426
Pulled By: bddppq
fbshipit-source-id: b4b7015417f99e14dfdedb62639e4d837c38e4fd
Summary:
We can't really test these until we get Python 3.8 in the CI, but these all work locally and won't be invoked at all for Python 3.7 and lower so this should be pretty safe.
Fixes#21710
](https://our.intern.facebook.com/intern/diff/15914735/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22007
Pulled By: driazati
Differential Revision: D15914735
fbshipit-source-id: 83833cebe7e38b162719a4f53cbe52c3fc638edd
Summary:
This was originally introduced between at::Half, which overloaded a number of operators; since this isn't necessary anymore, get rid of it.
Note in many cases, these files still need THCNumerics.cuh (which was included by THCHalfAutoNumerics); I was not careful about isolating these usages.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21878
Differential Revision: D15941236
Pulled By: gchanan
fbshipit-source-id: 65f30a20089fcd618e8f3e9646cf03147a15ccba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21753
- it accidentally didn't move non-IValue-based lists before. This is fixed now.
- it only needs to recreate a T() for IValue-based lists
Reviewed By: resistor
Differential Revision: D15809220
fbshipit-source-id: 944badf1920ee05f0969fff0d03284a641dae4a9
Summary:
Get benefit from the compile time vectorization and multi-threading.
Before:
```python
In [1]: import torch
In [2]: x = torch.randn(1000000)
In [3]: y = torch.randn(1000000)
In [4]: w = 0.7
In [5]: timeit torch.lerp(x, y, w)
2.29 ms ± 23.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
After:
```python
In [1]: import torch
In [2]: x = torch.randn(1000000)
In [3]: y = torch.randn(1000000)
In [4]: w = 0.7
In [5]: timeit torch.lerp(x, y, w)
452 µs ± 1.81 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After with multi-processing:
```python
In [1]: import torch
In [2]: x = torch.randn(1000000)
In [3]: y = torch.randn(1000000)
In [4]: w = 0.7
In [5]: timeit torch.lerp(x, y, w)
167 µs ± 48.8 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22038
Differential Revision: D15941468
Pulled By: VitalyFedyunin
fbshipit-source-id: fa8a5126187df4e6c849452e035b00b22be25739
Summary:
# Motivation
We allow to override JIT module serialization with `__getstate__/__setstate__` in order to cover cases where parameters are not serializable. Use cases include: MKLDNN integration: a388c78350/torch/utils/mkldnn.py (L18-L26)
and also fbgemm prepacked format integration for quantized tensors.
However many Eager scripts use `torch.save(module.state_dict())` form of serialization. There are several ways to make it work:
* make packed_weight itself pickleable (e.g. by binding `__getstate__/__setstate__` on C++ UDT level)
* change: we’d need to allow module buffers to be of arbitrary, non-Tensor types
* pro: no change to state_dict behavior
* cons: might not be directly inspectable by user calling .state_dict(), especially if packed weights represent several tensors fused together
* make packed_weight being proper Tensor layout
* pro: no change to state_dict or buffers behavior
* cons: adding new tensor layouts is pretty costly today
* cons: doesn’t work if multiple tensors are packed in one interleaved representation
* *[this approach]* allow Modules to override state_dict and return regular tensors
* pro: most flexible and hackable
* pro: maintains semantic meaning of statedict as all data necessary to represent module’s state
* cons: complicates state_dict logic
* cons: potential code duplication between `__getstate__/__setstate__`
Based on discussions with zdevito and gchanan we decided to pick latter approach. Rationale: this behavior is fully opt-in and will impact only modules that need it. For those modules the requirement listed above won't be true. But we do preserve requirement that all elements of state_dict are tensors. (https://fburl.com/qgybrug4 for internal discussion)
In the future we might also implement one of the approaches above but those are more involved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21933
Differential Revision: D15937678
Pulled By: dzhulgakov
fbshipit-source-id: 3cb5d1a8304d04def7aabc0969d0a2e7be182367
Summary:
This pull request adds the necessary Windows DLL code to be able to support JIT fusion for CUDA. CPU JIT Fusion isn't supported. This also adds all the non-CPU JIT tests back in on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21861
Differential Revision: D15940939
Pulled By: soumith
fbshipit-source-id: e11f6af1ac258fcfd3a077e6e2f2e6fa38be4ef1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22015
Previous fusion logic only works for operators back-to-back in the linear order of protobuf file.
This diff generalizes to work for any predecessor-successor operators in the graph without any "interfering" use/def of the related blobs.
Reviewed By: csummersea
Differential Revision: D15916709
fbshipit-source-id: 82fe4911a8250845a8bea3427d1b77ce2442c495
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21709
Change the return type from Scalar to double/int64_t so we don't need to do conversion when we call other quantize related aten functions
Differential Revision: D15793003
fbshipit-source-id: 510936c69fa17a4d67340a31ebb03415647feb04
Summary:
This is a modified version of https://github.com/pytorch/pytorch/pull/14705 since commit structure for that PR is quite messy.
1. Add `IterableDataset`.
3. So we have 2 data loader mods: `Iterable` and `Map`.
1. `Iterable` if the `dataset` is an instance of `IterableDataset`
2. `Map` o.w.
3. Add better support for non-batch loading (i.e., `batch_size=None` and `batch_sampler=None`). This is useful in doing things like bulk loading.
3. Refactor `DataLoaderIter` into two classes, `_SingleProcessDataLoaderIter` and `_MultiProcessingDataLoaderIter`. Rename some methods to be more generic, e.g., `get_batch` -> `get_data`.
4. Add `torch.utils.data.get_worker_info` which returns worker information in a worker proc (e.g., worker id, dataset obj copy, etc.) and can be used in `IterableDataset.__iter__` and `worker_init_fn` to do per-worker configuration.
5. Add `ChainDataset`, which is the analog of `ConcatDataset` for `IterableDataset`.
7. Import torch.utils.data in `torch/__init__.py`
9. data loader examples and documentations
10. Use `get_worker_info` to detect whether we are in a worker process in `default_collate`
Closes https://github.com/pytorch/pytorch/issues/17909, https://github.com/pytorch/pytorch/issues/18096, https://github.com/pytorch/pytorch/issues/19946, and some of https://github.com/pytorch/pytorch/issues/13023
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19228
Reviewed By: bddppq
Differential Revision: D15058152
fbshipit-source-id: 9e081a901a071d7e4502b88054a34b450ab5ddde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20673
Add option to bucket-weighted pooling to hash the bucket so that any cardinality score can be used.
Reviewed By: huginhuangfb
Differential Revision: D15003509
fbshipit-source-id: 575a149de395f18fd7759f3edb485619f8aa5363
Summary:
The first attempt and more discussions are available in https://github.com/pytorch/pytorch/issues/19577
#### Goal
Allow toggling DDP gradient synchronization across iterations. With this feature, users may accumulate grads in module variables, and only kick off expensive grad synchronize every a few iterations.
#### Concerns
Our first attempt in https://github.com/pytorch/pytorch/issues/19577 tries to do it using a variable or a function. But apaszke made a good point that it will not be error prone, and favors a context manager instead.
#### Proposed Solution
Instead of providing a `accumulate_grads` variable/function/context, we provide a `DistributedDataParallel.no_sync()` context manager. And it does exactly what the name suggests, i.e., disable DDP grad synchronization within the context. Note that `accumulate_grads` means `no_sync` + no optimizer step, where the latter is not controlled by DDP.
It is true that users need to call another `model(input).backward()` after exiting the context, and this is indeed more verbose. But I think it is OK as one major concern in the previous discussion is to prevent users from running into errors without knowing it. This API should reaffirm the expected behavior, and does not mess up with other use cases if accumulating grads is not required..
The application would then look like:
```python
with ddp.no_sync():
for input in inputs:
ddp(input).backward()
ddp(one_more_input).backward()
optimizer.step()
```
chenyangyu1988 myleott
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21736
Differential Revision: D15805215
Pulled By: mrshenli
fbshipit-source-id: 73405797d1e39965c52016af5cf45b15525ce21c
Summary:
There aren't any substantive changes aside from some test renames (e.g. `TestScript.test_dict_membership` -> `TestDict.test_membership`) and the addition of `TestDict.dict()`.
Adding the rest of the dict ops was making the tests a mess and `TestScript` is already > 10000 lines by itself, so breaking them up should make things cleaner
](https://our.intern.facebook.com/intern/diff/15911383/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22000
Pulled By: driazati
Differential Revision: D15911383
fbshipit-source-id: 614428e03fbc14252f0e9cde74ab9a707169a860
Summary:
The cppdocs build job (originally run on Chronos as a cron job) was frequently broken because it was not run on every PR. This PR moves it to CircleCI and enables it on every PR, so that we can get the build failure signal much earlier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19768
Differential Revision: D15922289
Pulled By: yf225
fbshipit-source-id: e36ef59a2e42f78b7d759ee02f2d94dc90f88fff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19443
This adds support for sparse gradients to the reducer as well as to
the DistributedDataParallel wrapper. Note that an out of band signal
is needed whether or not a dense parameter (e.g. an embedding) is
expected to receive a sparse gradient or not. This information is
passed to the bucket assignment computation routine and the reducer as
a vector of booleans. Every parameter for which we expect a sparse
gradient is assigned its own bucket, as we cannot easily group
multiple unrelated sparse tensors.
Reviewed By: mrshenli
Differential Revision: D15007365
fbshipit-source-id: f298e83fd3ca828fae9e80739e1db89d045c99ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19146
Implemented only on ProcessGroupGloo, as an allgather of metadata
(sparse_dim, dense_dim, and nnz), followed by an allgather of indices,
followed by an allgather of values. Once these operations have
finished, all ranks locally compute a reduction over these sparse
tensors. Works for both CPU and CUDA tensors.
This surfaced a problem with the existing assumption of only modifying
tensors that are passed at the call site, because for sparse tensors
we don't know the dimensions of the output tensors before we run the
collective. To deal with this unknown, this commit adds a `result`
function to the `c10d::ProcessGroup::Work` class that returns a vector
of tensors.
It's a bit odd to have to retrieve the result through this function
only for operations on sparse tensors. To make this work irrespective
of tensor layout, we can create a follow-up commit to make all in
place operations make their results accessible through this function
as well. This doesn't break any existing contracts but does have the
potential to add interface ambiguity.
Reviewed By: mrshenli
Differential Revision: D14889547
fbshipit-source-id: 34f3de4d6a2e09c9eba368df47daad0dc11b333e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21938
After having changed all call sites, we can now remove the old naming scheme.
Reviewed By: zdevito
Differential Revision: D15892402
fbshipit-source-id: 1f5b53a12fa657f6307811e8657c2e14f6285d2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21937
This changes call sites to use the new naming scheme
Reviewed By: zdevito
Differential Revision: D15892404
fbshipit-source-id: 8d32aa90a0ead1066688166478f299fde9c2c133
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21936
This introduces torch::List and torch::Dict as aliases to ListPtr/DictPtr.
After this lands, we can step by step change the call sites to the new naming
and finally remove the old spellings.
Reviewed By: zdevito
Differential Revision: D15892405
fbshipit-source-id: 67b38a6253c42364ff349a0d4049f90f03ca0d44
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21806
Dispatcher::findSchema(op_name) now uses a lookup table instead of iterating through the list of operators to find it.
This speeds up op lookup (as in finding the operator handle from the name, not as in finding a kernel when you already have the operator handle)
and it also speeds up op registration since that needs to look if an op with the same name already eists.
Differential Revision: D15834256
fbshipit-source-id: c3639d7b567e4ed5e3627c3ebfd01b7d08b55ac1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21809
Many error messages show dispatch keys, for example when the dispatcher didn't find a kernel to dispatch to.
Previously, this was a string like "CPU" or "CUDA" for known backends and just an arbitrary number for other backends.
Now, tensor type id registration also registers a name for the dispatch key and shows that in the error messages.
There is no API change, just the error messages are better now.
Differential Revision: D15835809
fbshipit-source-id: 4f0c9d0925c6708b02d79c653a2fae75b6623bb9
Summary:
https://github.com/pytorch/pytorch/pull/17072 breaks `model.to(xla_device)`, because moving `model` to XLA device involves changing its parameters' TensorImpl type, and the current implementation of `nn.Module.to()` doesn't support changing module parameters' TensorImpl type:
```python
# 6dc445e1a8/torch/nn/modules/module.py (L192-L208)
def _apply(self, fn):
...
for param in self._parameters.values():
if param is not None:
# Tensors stored in modules are graph leaves, and we don't
# want to create copy nodes, so we have to unpack the data.
param.data = fn(param.data) # NOTE: this doesn't allow changing `param.data`'s TensorImpl type
if param._grad is not None:
param._grad.data = fn(param._grad.data) # NOTE: this doesn't allow changing `param._grad.data`'s TensorImpl type
...
```
yf225 TODO: fix the description here when we finish the implementation
To fix this problem, we introduce a new API `model.to_()` that always assign new tensors to the parameters (thus supporting changing the parameters to any TensorImpl type), and also bump the version counter of the original parameters correctly so that they are invalidated in any autograd graph they participate in.
We also add warning to the current `model.to()` API to inform users about the upcoming behavior change of `model.to()`: in future releases, it would create and return a new model instead of in-place updating the current model.
This unblocks adding XLA to our CI test suite, which also allows XLA to catch up with other changes in our codebase, notably the c10 dispatcher.
[xla ci]
cc. resistor ailzhang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21613
Differential Revision: D15895387
Pulled By: yf225
fbshipit-source-id: b79f230fb06019122a37fdf0711bf2130a016fe6
Summary:
When we pass `fn` to `nn.Module._apply()` and `fn` is an in-place operation, the correct behavior should also include bumping the parameters' and their gradients' version counters. This PR fixes the old incorrect behavior and makes sure the new behavior is right.
Note that this PR is BC-breaking in the following way:
Previously, passing an in-place operation to `nn.Module._apply()` does not bump the module's parameters' and their gradients' version counters. After this PR, the module's parameters' and their gradients' version counters will be correctly bumped by the in-place operation, which will invalidate them in any autograd graph they previously participate in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21865
Differential Revision: D15881952
Pulled By: yf225
fbshipit-source-id: 62f9244a4283a110147e9f20145ff232a5579fbd
Summary:
Added some extra tests for std_mean and var_mean for multiple dims.
Some refactoring of previously created tests based on PR comments: https://github.com/pytorch/pytorch/pull/18731
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20650
Differential Revision: D15396101
Pulled By: ifedan
fbshipit-source-id: d15c3c2c7084a24d6cfea4018173552fcc9c03a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21852
To enable change of q_scale and q_zero_point in `copy_`
Differential Revision: D15793427
fbshipit-source-id: a7040b5b956d161fd6af6176287f4a4aa877c9be
Summary:
The code in `python_sugared_value.cpp` to recursively compile methods
was not being tested, so this adds a test for it and fixes some errors
in it
It was necessary to disable any hooks set since (at least in our tests) they would try to export
a half-finished graph since they were being called on recursively
compiled methods
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21862
Differential Revision: D15860314
Pulled By: driazati
fbshipit-source-id: e8afe9d4c75c345b6e1471072d67c5e335b61337
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21914https://github.com/pytorch/pytorch/pull/21591 added a needed feature to clean up grad accumulator post hooks when the DistributedDataParallel model object is cleaned up. There's a minor typo that causes it to loop infinitely over the first element.
Differential Revision: D15878884
fbshipit-source-id: b7fd0bbd51eb187579d639b1709c6f7b62b85e7a
Summary:
This PR adds support for `in` checks like `key in my_dict`
For now it leaves lists as a follow up due to the changes around `IValue` lists and it needing an `IValue` equality op.
For objects it uses the magic method `__contains__(self, key)`
](https://our.intern.facebook.com/intern/diff/15811203/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21527
Pulled By: driazati
Differential Revision: D15811203
fbshipit-source-id: 95745060394f8a9450efaaf8ab09d9af83bea01e
Summary:
This adds support for inferred attributes (everything except empty lists, dicts, and tuples) as well as using the PEP 526 style annotations on a class, so this eliminates the need for `torch.jit.Attribute`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21379
Differential Revision: D15718537
Pulled By: driazati
fbshipit-source-id: b7481ae3d7ee421613e931b7dc3427ef2a99757f
Summary:
This is a fix for https://github.com/pytorch/pytorch/issues/21469
Currently there is no way to define if backward function released variables when variables were added to a vector. This change will set a flag if function has saved variables and they were released. So we will prevent if somebody will call this function again with already released variables.
Functions that do not have saved variables can be called multiple times for BC
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21533
Differential Revision: D15810481
Pulled By: ifedan
fbshipit-source-id: 5663e0c14f1b65727abc0d078aef348078d6a543
Summary:
This will need a conflict resolution once avg_pool2d() has been merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21732
Differential Revision: D15824923
Pulled By: ezyang
fbshipit-source-id: 83341e0209b660aecf788272079d8135d78b6ff1
Summary:
This was some code I added :^)
Time for me to remove it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21897
Differential Revision: D15873213
Pulled By: Chillee
fbshipit-source-id: 769c3bd71c542be4afddc02dc2f65aa5c751b10d
Summary:
What's the point of having warnings if we never fix them :^)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21898
Differential Revision: D15873280
Pulled By: Chillee
fbshipit-source-id: a8274bab2badd840d36a9d2e1354677a6114ae1d
Summary:
cosine_similarity has two non-tensor parameters, needs some special handling. Add the support for its export in this diff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21884
Reviewed By: zrphercule
Differential Revision: D15866807
Pulled By: houseroad
fbshipit-source-id: a165fbc00c65c44b276df89ae705ca8960349d48
Summary:
```
This replaces the kernel helpers in Loops.h/cuh with the following:
cpu_kernel
cpu_kernel_vec
gpu_kernel
gpu_kernel_with_scalars
These work with functions with any number of input arugments, with the
exception of 'gpu_kernel_with_scalars' which is limited to binary
operations. Previously, we only supported functions of 0, 1, or 2 input
arguments. Adding support for 3 or 4 input argument functions required
significant amount of additional code.
This makes a few other changes:
Remove 'ntensors' from the for_each/serial_for_each loop. Most loops
assume a fixed number of tensors, and the value is accessible from
TensorIterator::ntensors()
Only lift CPU scalars to parameters in 'gpu_kernel_with_scalars'.
Previously, we performed this recursively in gpu_unary_kernel and
gpu_binary_kernel, so something like `torch.add(3, 4, out=cuda_tensor)`
would specialize to a "nullary" kernel. Now, only the first
scalar input is lifted to a kernel parameter. Any additional scalar
inputs are copied to CUDA tensors. Note that operations like `x + 5`
and `5 + x` still work efficiently. This avoids generating an exponential
number of specializations in the number of input arguments.
```
**Performance measurements**
Timing numbers are unchanged for basic elementwise operations. Linked below is a script to measure torch.add perf on PR vs. master CPU+GPU (GCC 7.3):
[miniperf.py](https://gist.github.com/colesbury/4a61893a22809cb0931f08cd37127be4)
**Generated assembly**
cpu_kernel and cpu_kernel_vec still generate good vectorized code with
both GCC 7.3 and GCC 4.8.5. Below is the assembly for the "hot" inner loop of
torch.add as well as an auto-vectorized torch.mul implementation using cpu_kernel/
binary_kernel. (The real torch.mul uses cpu_kernel_vec but I wanted to check that
auto vectorization still works well):
[torch.add GCC 7.3](https://gist.github.com/colesbury/927ddbc71dc46899602589e85aef1331)
[torch.add GCC 4.8](https://gist.github.com/colesbury/f00e0aafd3d1c54e874e9718253dae16)
[torch.mul auto vectorized GCC 7.3](https://gist.github.com/colesbury/3077bfc65db9b4be4532c447bc0f8628)
[torch.mul auto vectorized GCC 4.8](https://gist.github.com/colesbury/1b38e158b3f0aaf8aad3a76963fcde86)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21475
Differential Revision: D15745116
Pulled By: colesbury
fbshipit-source-id: 914277d7930dc16e94f15bf87484a4ef82890f91
Summary:
PR https://github.com/pytorch/pytorch/issues/20685 incorrectly only enabled P2P access for non-contiguous copies.
This can make cudaMemcpy slow for inter-gpu copies, especially on ROCm
devices. I didn't notice a difference on CUDA 10, but ngimel says it's
important for CUDA too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21872
Differential Revision: D15863965
Pulled By: colesbury
fbshipit-source-id: 0a858f3c338fa2a5d05949d7f65fc05a70a9dfe1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21080
Add Huber loss as a new option for regression training (refer to TensorFlow implementation: https://fburl.com/9va71wwo)
# huber loss
def huber(true, pred, delta):
error = abs(true-pred)
loss = 0.5 * min(error, delta)^2 + delta * max(error - delta, 0)
return mean(loss)
As a combination of MSE loss (`x < delta`) and MAE loss (`x >= delta`), the advantage of Huber loss is to reduce the training dependence on outlier.
One thing worth to note is that Huber loss is not 2nd differential at `x = delta`. To further address this problem, one could consider adopt the loss of `LOG(cosh(x))`.
Reviewed By: chintak
Differential Revision: D15524377
fbshipit-source-id: 73acbe2728ce160c075f9acc65a1c21e3eb64e84
Summary:
After fixing https://github.com/pytorch/pytorch/issues/20774 the TRT build was broken
Because of missing annotations, pybind_state_gpu.so was missing symbols, but pybind_state.so did not. It caused a weird combination when trying to import pybind_state_gpu first left system in semi-initialized state and lead to sigsev.
Minimal repro:
```
>>> import ctypes
>>> ctypes.CDLL('/var/lib/jenkins/.local/lib/python2.7/site-packages/caffe2/python/caffe2_pybind11_state_gpu.so')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python2.7/ctypes/__init__.py", line 362, in __init__
self._handle = _dlopen(self._name, mode)
OSError: /var/lib/jenkins/.local/lib/python2.7/site-packages/caffe2/python/caffe2_pybind11_state_gpu.so: undefined symbol: _ZN6caffe219TensorRTTransformer9TransformEPNS_9WorkspaceEPNS_6NetDefERKSt13unordered_mapINSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEENS_11TensorShapeESt4hashISB_ESt8equal_toISB_ESaISt4pairIKSB_SC_EEE
>>> ctypes.CDLL('/var/lib/jenkins/.local/lib/python2.7/site-packages/caffe2/python/caffe2_pybind11_state.so')
Segmentation fault (core dumped)
```
Too lazy to repro locally, let's see if CI passes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21775
Differential Revision: D15829605
Pulled By: dzhulgakov
fbshipit-source-id: 1adb2bde56b0cd68f84cfca67bc050adcf787cd9
Summary:
Following up b811b6d5c03596d789a33d7891b606842e01f7d2
* Use property instead of __setattr__ in CMake.
* Add a comment clarifying when built_ext.run is called.
---
cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21792
Differential Revision: D15860606
Pulled By: umanwizard
fbshipit-source-id: ba1fa07f58d4eac81ac27fa9dc7115d1cdd3dec0
Summary:
https://github.com/pytorch/pytorch/issues/11866 has corrected this issue in function `host_softmax` (aten/src/ATen/native/SoftMax.cpp). But I tried the example proposed in https://github.com/pytorch/pytorch/issues/11752. `log_softmax` is still not working for big logits.
I have looked into the source code, found that example had called `vec_host_softmax_lastdim`, not `host_softmax`.
This code fixes the issue in `_vec_log_softmax_lastdim` and has a test for `log_softmax`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21672
Differential Revision: D15856327
Pulled By: VitalyFedyunin
fbshipit-source-id: 7a1fd3c0a03d366c99eb873e235361e4fcfa7567
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21735
ghimport-source-id: 4a4289693e372880e3d36e579c83d9e8745e70ed
Test Plan:
- I'm not sure how to test this other than making sure it compiles.
- [namedtensor ci]
gh-metadata: pytorch pytorch 21735 gh/zou3519/49/head
Imported from OSS
Differential Revision: D15833456
Pulled By: zou3519
fbshipit-source-id: ea2fa6d5c5f1eb2d7970d47189d6e4fcd947146d
Summary:
kuttas pointed out that the DDP Reducer only needs to remember `uintptr, Function` pairs, and hence does not need a nunordered map as added by https://github.com/pytorch/pytorch/issues/21591. Using a vector should speed it up a bit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21783
Differential Revision: D15854312
Pulled By: mrshenli
fbshipit-source-id: 153ba035b8d658c7878a613f16a42de977d89c43
Summary:
After https://github.com/pytorch/pytorch/pull/17072, we are allowed to pass Variables into ATen ops, thus there is no need to unwrap input variables in the c10 call path.
Note that since Caffe2 still expects inputs to be pure Tensors, we moved the unwrapping logic to the Caffe2 wrapper.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21620
Differential Revision: D15763560
Pulled By: yf225
fbshipit-source-id: 5375f0e51eb320f380ae599ebf98e6b259f0bff8
Summary:
This refactors pybind_utils so we can have all our type-inferring stuff in
1 place (e.g. for #21379)
There is some follow up work to make the error messages better, but I think that's fine to save for another PR.
](https://our.intern.facebook.com/intern/diff/15727002/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21550
Pulled By: driazati
Differential Revision: D15727002
fbshipit-source-id: a6974f2e1e5879f0503a18efc138da31cda7afa2
Summary:
Resolves https://github.com/pytorch/lockdown/issues/18
This implements NamedTuple by taking advantage of the existing `names` field in `TupleType`.
TODO: This currently doesn't retain the NamedTuple-ness through serialization. Discussed with suo offline, we can probably make a way to define an anonymous NamedTuple in script (e.g. `NamedTuple('Foo', [('a', int), ('b', float), ('c', List[float])])` and serialize that
TODO: implement support for calling the constructor with kwargs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21428
Differential Revision: D15741564
Pulled By: jamesr66a
fbshipit-source-id: c077cbcea1880675ca6deb340a9ec78f824a136c
Summary:
when enabling this flag, there were a lot of warnings, this pr focuses on the warnings where this comparison could be affecting array indices, which could be ones most prone to fail
the good news is that I didn't find anything obviously concerning
one degenerate case could be when the matrices we work with are too skinny could run into issues (dim1=1, dim2 needs to hold a big number)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18187
Differential Revision: D14527182
Pulled By: hyuen
fbshipit-source-id: b9f46b6f68ab912c55368961758a7a5af1805555
Summary:
We plan on generating python bindings for C++ ChunkDataset API using the current Pytorch Dataloader class, which must call get_batch() instead of get_batch(size)
This changes doesnt break the current API, just add one more method that will make future extensions easier (WIP)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21797
Differential Revision: D15830522
Pulled By: soumith
fbshipit-source-id: 7208f305b48bf65d2783eaff43ff57a05e62c255
Summary:
Originally, the tests for tensorboard writer are smoke tests only. This PR lets CI compare the output with expected results at low level. The randomness of the tensors in the test are also removed.
ps. I found that how protobuf serializes data differs between different python environment. One method to solve this is to write the data and then read it back instantly. (compare the data at a higher level)
For `add_custom_scalars`, the data to be written is a dictionary. and the serialized result might be different (not `ordereddict`). So only smoke test for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20987
Reviewed By: NarineK, lanpa
Differential Revision: D15804871
Pulled By: orionr
fbshipit-source-id: 69324c11ff823b19960d50def73adff36eb4a2ac
Summary:
Try to fix a sporadic failure on some CIs.
I've run this test hundreds of times on my machine (GeForce 1060, MAGMA) but I cannot reproduce this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21638
Differential Revision: D15827779
Pulled By: ezyang
fbshipit-source-id: 3586075e48907b3b84a101c560a34cc733514a02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21712
Warn when people use unordered_map or vector with IValues. These APIs are deprecated.
The unordered_map API is slow because it requires copying the whole map.
The vector API is slow for some types (e.g. std::string) because for them it also requires copying the whole map.
Also, the vector API would get slow for all types if we decide to switch to SmallVector.
Differential Revision: D15792428
fbshipit-source-id: 1b72406b3a8d56521c862858c9f0ed01e56f2757
Summary:
When kwargs are specified in a test defined via common_method_invocations, it doesn't work if there isn't also a positional argument (`{'foo':'foo'}` without a positional arg generates a python call like: `self.method(, foo=foo)`, erroring on the `,`). I wanted to test something in a different PR and noticed I couldn't.
Also fixed some flake8 warnings I was seeing locally.
I replaced `lambda x: x` with `ident` since it seems a bit cleaner to me, but happy to revert that if others don't agree?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21499
Differential Revision: D15826974
Pulled By: nairbv
fbshipit-source-id: a3f37c80ba2303c7d9ae06241df06c7475b64e36
Summary:
So far, we only have py2 ci for onnx. I think py3 support is important. And we have the plan to add onnxruntime backend tests, which only supports py3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21715
Reviewed By: bddppq
Differential Revision: D15796885
Pulled By: houseroad
fbshipit-source-id: 8554dbb75d13c57b67ca054446a13a016983326c
Summary:
Some data loader tests are flaky on py 2 with the following error
```
Jun 12 22:17:31 Traceback (most recent call last):
Jun 12 22:17:31 File "test_dataloader.py", line 798, in test_iterable_dataset
Jun 12 22:17:31 fetched = sorted([d.item() for d in dataloader_iter])
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 697, in __next__
Jun 12 22:17:31 idx, data = self._get_data()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 664, in _get_data
Jun 12 22:17:31 success, data = self._try_get_data()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 617, in _try_get_data
Jun 12 22:17:31 data = self.data_queue.get(timeout=timeout)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/multiprocessing/queues.py", line 135, in get
Jun 12 22:17:31 res = self._recv()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/multiprocessing/queue.py", line 22, in recv
Jun 12 22:17:31 return pickle.loads(buf)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/pickle.py", line 1382, in loads
Jun 12 22:17:31 return Unpickler(file).load()
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/pickle.py", line 858, in load
Jun 12 22:17:31 dispatch[key](self)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/pickle.py", line 1133, in load_reduce
Jun 12 22:17:31 value = func(*args)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/site-packages/torch/multiprocessing/reductions.py", line 274, in rebuild_storage_fd
Jun 12 22:17:31 fd = multiprocessing.reduction.rebuild_handle(df)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/multiprocessing/reduction.py", line 157, in rebuild_handle
Jun 12 22:17:31 new_handle = recv_handle(conn)
Jun 12 22:17:31 File "/opt/python/2.7.9/lib/python2.7/multiprocessing/reduction.py", line 83, in recv_handle
Jun 12 22:17:31 return _multiprocessing.recvfd(conn.fileno())
Jun 12 22:17:31 OSError: [Errno 4] Interrupted system call
```
Apparently, Python 2.7's `recvfd` calls `recvmsg` without EINTR retry: https://github.com/python/cpython/blob/2.7/Modules/_multiprocessing/multiprocessing.c#L174
So we should call it with an outer try-catch loop.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21723
Differential Revision: D15806247
Pulled By: ezyang
fbshipit-source-id: 16cb661cc0fb418fd37353a1fef7ceeb634f02b7
Summary:
Currently when building extensions, variables such as USE_CUDA, USE_CUDNN are used to determine what libraries should be linked. But we should use what CMake has detected, because:
1. If CMake found them unavailable but the variables say some libraries should be linked, the build would fail.
2. If the first build is made using a set of non-default build options, rebuild must have these option passed to setup.py again, otherwise the extension build process is inconsistent with CMake. For example,
```bash
# First build
USE_CUDA=0 python setup.py install
# Subsequent builds like this would fail, unless "build/" is deleted
python setup.py install
```
This commit addresses the above issues by using variables from CMakeCache.txt when building the extensions.
---
The changes in `setup.py` may look lengthy, but the biggest changed block is mostly moving them into a function `configure_extension_build` (along with some variable names changed to `cmake_cache_vars['variable name']` and other minor changes), because it must be called after CMake has been called (and thus the options used and system environment detected by CMake become available).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21653
Differential Revision: D15824506
Pulled By: ezyang
fbshipit-source-id: 1e1eb7eec7debba30738f65472ccad966ee74028
Summary:
This makes the error thrown in aten_to_numpy_dtype consistent with that in numpy_dtype_to_aten.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21608
Differential Revision: D15816035
Pulled By: gchanan
fbshipit-source-id: 392e8b9ea37003a859e7ed459911a1700fcbd695
Summary:
This PR is intended as a fix for https://github.com/pytorch/pytorch/issues/21644.
It allows the `with emit_nvtx` context manager to take an additional `record_shapes` argument. `record_shapes` is False by default, but if True, the nvtx ranges generated for each autograd op will append additional information about the sizes of Tensors received by that op.
The format of shape information is equivalent to what the CPU-side profiler spits out. For example,
```
M = torch.randn(2, 3)
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 3)
with torch.cuda.profiler.profile():
with torch.autograd.profiler.emit_nvtx(record_shapes=True):
torch.addmm(M, mat1, mat2)
```
produces the following nvtx range label for addmm:

(cf the "Input Shapes" shown in 864cfbc216 (diff-115b6d48fa8c0ff33fa94b8fce8877b6))
I also took the opportunity to do some minor docstring cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21691
Differential Revision: D15816226
Pulled By: gchanan
fbshipit-source-id: b2b01ea10fea61a6409a32b41e85b6c8b4851bed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20924
I found a python3 bug for deserializing caffe2 code. The exception thrown is Unicode related error instead of just decode error, and we need to catch that as well
Reviewed By: ipiszy
Differential Revision: D15293221
fbshipit-source-id: 29820800d1b4cbe5bf3f5a189fe2023e655d0508
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21763
Custom __getattr__ functions can only raise AttributeError. This code throwed NotImplementedError which caused upstream troubles when hasattr() was called.
Differential Revision: D15815176
fbshipit-source-id: 0982e2382de4578d3fc05c5d2a63f624d6b4765e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21446
this is used for easier tracing of iter id when looking at trace diagram
Reviewed By: ilia-cher
Differential Revision: D15628950
fbshipit-source-id: ee75b3bdb14a36abc18c7bddc49d8ec9789b724d
Summary:
```
The stride calculation using OffsetCalculator performs poorly with
MAX_DIMS=25. This reduces MAX_DIMS (after coalescing) to 16 on ROCm.
I think it's unlikely that anyone will exceed this limit. If they do,
we can add additional specializations for ROCm with more dimensions.
```
I'm not sure about the underlying cause. With MAX_DIM=25, the add kernel's params
is ~648 bytes vs. ~424 bytes with MAX_DIM=16. The kernel instruction footprint is
bigger too, but most of these instructions are never executed and most kernel parameters
are never loaded because the typical dimensionality is much smaller.
Mini benchmark here:
https://gist.github.com/colesbury/1e917ae6a0ca9d24712121b92fed4c8f
(broadcasting operations are much faster)
cc iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21754
Reviewed By: bddppq
Differential Revision: D15811906
Pulled By: colesbury
fbshipit-source-id: 063f92c083d26e2ef2edc98df7ff0400f9432b9d
Summary:
Currently multihead attention for half type is broken
```
File "/home/ngimel/pytorch/torch/nn/functional.py", line 3279, in multi_head_attention_forward
attn_output = torch.bmm(attn_output_weights, v)
RuntimeError: Expected object of scalar type Float but got scalar type Half for argument https://github.com/pytorch/pytorch/issues/2 'mat2'
```
because softmax converts half inputs into fp32 inputs. This is unnecessary - all the computations in softmax will be done in fp32 anyway, and the results need to be converted into fp16 for the subsequent batch matrix multiply, so nothing is gained by writing them out in fp32. This PR gets rid of type casting in softmax, so that half works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21658
Differential Revision: D15807487
Pulled By: zhangguanheng66
fbshipit-source-id: 4709ec71a36383d0d35a8f01021e12e22b94992d
Summary:
In this PR, we use `expect` to fill in the token for pytorchbot when doing `git push`, so that we don't need to save the token in the git remote URL.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20459
Differential Revision: D15811676
Pulled By: yf225
fbshipit-source-id: cd3b780da05d202305f76878e55c3435590f15a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21742
Add error message to NotImplementedError so we know which function it is about.
Reviewed By: bddppq
Differential Revision: D15806379
fbshipit-source-id: 14eab9d03aa5b44ab95c5caeadc0e01d51f22188
Summary:
When converting pixel_shuffle to reshape + transpose + reshape, the first reshape should
be:
[N, C * r^2, H, W] => [N, C, r, r, H, W]
in order to match pytorch's implementation (see ATen PixelShuffle.cpp).
This previously wasn't caught by the test case, since it uses C = r = 4. Updated test case to
have C = 2, r = 4.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21486
Reviewed By: houseroad
Differential Revision: D15700945
Pulled By: houseroad
fbshipit-source-id: 47019691fdc20e152e867c7f6fd57da104a12948
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21718
adding a detection method on whether the package is built for AMD.
Reviewed By: bddppq
Differential Revision: D15795893
fbshipit-source-id: 91a21ee76b2273b1032507bdebe57e016717181d
Summary:
**Closes:** Confusing documentation with distributions.Categorical about logits https://github.com/pytorch/pytorch/issues/16291
**Solution**: Changes documentation on the Categorical distribution from `log probabilities` to `event log-odds`. This makes should reduce confusion as raised by this issue, and is consistent with other distributions such as `torch.Binomial`.
More than happy to make any other changes if they fit :).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21707
Differential Revision: D15799181
Pulled By: soumith
fbshipit-source-id: f11acca7a5c130102a3ff6674640235ee5aa69bf
Summary:
- [x] Add tests after https://github.com/pytorch/pytorch/pull/20256 is merged
- Support exporting ScriptModule with inputs/outputs of arbitrarily constructed tuples.
- Moved the assigning of output shapes to after graph conversion to ONNX is completed. By then all tuples in the IR has already been lowered by the pass ```_jit_pass_lower_all_tuples```. If assigning output shapes is required to happen before that, we'll need to hand parse the tuple structures in the graph, and repeat the same logic in ```_jit_pass_lower_all_tuples```. Handling inputs is easier because all tuple information is encoded within the input tensor type.
- Swap the order of ```_jit_pass_lower_all_tuples``` and ```_jit_pass_erase_number_types```. Ops like ```prim::TupleIndex``` relies on index being a scalar. ```_jit_pass_erase_number_types``` will convert these kind of scalars to tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20784
Reviewed By: zrphercule
Differential Revision: D15484171
Pulled By: houseroad
fbshipit-source-id: 4767a84038244c929f5662758047af6cb92228d3
Summary:
This renames the CMake `caffe2` target to `torch`, as well as renaming `caffe2_gpu` to `torch_gpu` (and likewise for other gpu target variants). Many intermediate variables that don't manifest as artifacts of the build remain for now with the "caffe2" name; a complete purge of `caffe2` from CMake variable names is beyond the scope of this PR.
The shell `libtorch` library that had been introduced as a stopgap in https://github.com/pytorch/pytorch/issues/17783 is again flattened in this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20774
Differential Revision: D15769965
Pulled By: kostmo
fbshipit-source-id: b86e8c410099f90be0468e30176207d3ad40c821
Summary:
Class member annotations can be marked with `Final[T]` instead of adding them to `__constants__`. `Final` comes from the `typing_extensions` module (which will be used if it is present). If not, the polyfill from `_jit_internal` is exposed as `torch.jit.Final` for users that don't want to install `typing_extensions`.
This keeps around `__constants__` since a lot of code is still using it, but in documentation follow ups we should change the examples to all to use `Final`.
TODO: install typing_extensions on CI, move tests to a Python3 only file when #21489 lands
](https://our.intern.facebook.com/intern/diff/15746274/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21603
Pulled By: driazati
Differential Revision: D15746274
fbshipit-source-id: d2c9b5643b4abba069b130c26fd42714c906ffac
Summary:
This adds support for PEP 526 style annotations on assignments in place of
`torch.jit.annotate()`, so
```python
a = torch.jit.annotate(List[int], [])
```
turns into
```python
a : List[int] = []
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21390
Differential Revision: D15790937
Pulled By: driazati
fbshipit-source-id: 0cc204f7209a79839d330663cc6ba8320d3a4120
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21177
- Integrate c10::ListPtr into IValue and the c10 dispatcher.
- Streamline conversion to/from IValue. Before, we had IValue::to<> and kernel_functor.h had its own ivalue_to_arg_type and return_type_to_ivalue. They are now unified. Also, this means that nested types like Dicts of Lists of Optional of Dict of ... do work as expected now
Differential Revision: D15476433
fbshipit-source-id: bde9df80df20091aa8e6ae17ba7e90abd149b954
Summary:
Accidentally rebased the old PR and make it too messy. Find it here (https://github.com/pytorch/pytorch/pull/19274)
Create a PR for comments. The model is still WIP but I want to have some feedbacks before moving too far. The transformer model depends on several modules, like MultiheadAttention (landed).
Transformer is implemented based on the paper (https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf). Users have the flexibility to build a transformer with self-defined and/or built-in components (i.e encoder, decoder, encoder_layer, decoder_layer). Users could use Transformer class to build a standard transformer model and modify sub-layers as needed.
Add a few unit tests for the transformer module, as follow:
TestNN.test_Transformer_cell
TestNN.test_transformerencoderlayer
TestNN.test_transformerdecoderlayer
TestNN.test_transformer_args_check
TestScript.test_scriptmodule_transformer_cuda
There is another demonstration example for applying transformer module on the word language problem. https://github.com/pytorch/examples/pull/555
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20170
Differential Revision: D15417983
Pulled By: zhangguanheng66
fbshipit-source-id: 7ce771a7e27715acd9a23d60bf44917a90d1d572
Summary:
Currently we don't have any Linux libtorch binary build in the PR CI, which led to nightly build failure such as https://circleci.com/gh/pytorch/pytorch/1939687. This PR adds Linux libtorch CPU binary build to prevent such breakage from happening in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21671
Differential Revision: D15785003
Pulled By: yf225
fbshipit-source-id: d1f2e4235e48296ddecb3367f8e5a0df16f4ea49
Summary:
Fix https://github.com/pytorch/pytorch/issues/20421
`ProcessGroupGloo` only requires input/output tensors to be contiguous. Contiguous tensors might not start from the beginning of the underlying storage, e.g., `chunk(..., dim=0)[1]`. The current implementation passes `tensor.storage().data()` ptr to gloo buffer. This leads to wrong results if the tensor has a non-zero storage offset.
The proposed solution is to use `tensor.data_ptr()` instead. Let's see if this breaks any tests.
cc qijianan777
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21490
Differential Revision: D15768907
Pulled By: mrshenli
fbshipit-source-id: 9d7d1e9baf0461b31187c7d21a4a53b1fbb07397
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21592
We now support groupwise convolutions for qconv2d
Reviewed By: zafartahirov
Differential Revision: D15739239
fbshipit-source-id: 80b9b4fef5b9ee3d22ebecbaf205b970ab3d4250
Summary:
Closes https://github.com/pytorch/pytorch/issues/21344
DDP assigns the original module to the first module replica instead of creating a new one. Then, it creates a new Reducer to add post hooks to sync gradients. However, because every reconstructed DDP instance wraps the same original module, all their reducers will add hooks to the same set of variables. This PR deletes DDP hooks from variables when destructing Reducer, trying to make DDP failure recoverable.
pietern kuttas and I discussed the following solutions:
#### Solution 1
Keep `add_post_hook` API intact, and do a `dynamic_cast` in `del_post_hook` to check hook type. If the type matches Reducer's hook, delete it. As pietern mentioned, this will not work if we create multiple DDP instances from the same original model.
#### Solution 2
Use a counter to generate a unique key for every hook in `Function`, and keep them in a map. return the key to the caller of `add_post_hook`, and ask the caller to provide key if it needs to delete the hook.
Con: this would add extra overhead to `add_post_hook` and every `Function` object.
#### Solution 3 [Current implementation]
kuttas suggests that, instead of generating a unique key, directly using the address of the pointer would be better. In order to avoid messing up dereferencing, let `add_post_hook` to return a `uintptr_t`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21591
Differential Revision: D15745706
Pulled By: mrshenli
fbshipit-source-id: e56d2d48de0c65f6667790ab16337eac7f7d8b76
Summary:
This makes it so we can see the output of prim::Print in environments like iPython notebooks which override sys.stdout
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21625
Differential Revision: D15756793
Pulled By: jamesr66a
fbshipit-source-id: 7d9a14b2e229ed358e784318e9d862677db2c461
Summary:
Emit loop condition as a separate block in loops, then inline them before conversion to SSA. This is needed for breaks & continues where we will inline the condition block after the continue pass and before the break pass.
I also considered emitting a prim::For and a prim::While, but i think it's easier to just have one pathway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21611
Differential Revision: D15775820
Pulled By: eellison
fbshipit-source-id: de17c5e65f6e4a0256a660948b1eb630e41b04fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21606
StoreMatrixInMatrixMarketFormat was able to dump quantized tensors only but sometimes we want to dump float tensors.
Reviewed By: csummersea
Differential Revision: D15741611
fbshipit-source-id: 95b03c2fdf1bd8407f7d925171d9dc9f25677464
Summary:
Stream is not respected on range/linspace/logspace functions, which contributes to https://github.com/pytorch/pytorch/issues/21589 (this is not a complete solution for that issue).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21619
Differential Revision: D15769666
Pulled By: ezyang
fbshipit-source-id: 7c036f7aecb3119430c4d432775cad98a5028fa8
Summary:
Resolves issue https://github.com/pytorch/pytorch/issues/19003
The author of this issue also asked that `cycle_momentum` default to `False` if the optimizer does not have a momentum parameter, but I'm not sure what the best way to do this would be. Silently changing the value based on the optimizer may confuse the user in some cases (say the user explicitly set `cycle_momentum=True` but doesn't know that the Adam optimizer doesn't use momentum).
Maybe printing a warning when switching this argument's value would suffice?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20401
Differential Revision: D15765463
Pulled By: ezyang
fbshipit-source-id: 88ddabd9e960c46f3471f37ea46013e6b4137eaf
Summary:
This adds support for PEP 526 style annotations on assignments in place of
`torch.jit.annotate()`, so
```python
a = torch.jit.annotate(List[int], [])
```
turns into
```python
a : List[int] = []
```
](https://our.intern.facebook.com/intern/diff/15706021/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21390
Pulled By: driazati
Differential Revision: D15706021
fbshipit-source-id: 8bf1459f229d5fd0e16e59953b9656e85a2207fb
Summary:
Ops on a Process Group (pg) instance will hit an error when input/output tensors are created on a different process, because, pg calls `recordStream` on `CUDACachingAllocator` which only knows tensors created within the same process.
The proposed solution is to add a `suppressError` arg (suggestions for better names?) to `recordStream`. See comments in code for arguments.
CC pichuang1984
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21449
Differential Revision: D15689736
Pulled By: mrshenli
fbshipit-source-id: e7fc81b167868f8666536067eaa7ae2c8584d88e
Summary:
1. reduce the overhead of mkldnn-bridge itself
2. remove redundant code and useless APIs
3. provide new operators, including int8 inner_product, ND permute/transpose, elem_add/mul, and etc.
4. improve inner_product to support io format weights without implicit reorder
5. add SoftMax support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20569
Reviewed By: houseroad
Differential Revision: D15558663
Pulled By: bddppq
fbshipit-source-id: 79a63aa139037924e9ffb1069f7e7f1d334efe3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21207
This diff adds 80 PT pointwise unary ops to the benchmark suite. Most of the ops are added using the generate_pt_tests_from_list interface. The rest are handled separately.
Reviewed By: zheng-xq
Differential Revision: D15471597
fbshipit-source-id: 8ea36e292a38b1dc50f064a48c8cd07dbf78ae56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21210
This diff introduces a new path to run op with JIT. There are two steps involved here:
1. Users need to script the op. This should happen in the `init` method.
2. The generated graph from step1 is passed to `jit_forward` which will be executed by the benchmark backend
Reviewed By: zheng-xq
Differential Revision: D15460831
fbshipit-source-id: 48441d9cd4be5d0acebab901f45544616e6ed2ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20723
These classes already existed but only as c10::Dict and c10::OperatorKernel.
Since they're now part of torch::RegisterOperators(), they should also live in the torch namespace.
Differential Revision: D15421575
fbshipit-source-id: d64ebd8664fadc264bbbae7eca1faa182529a32b
Summary:
yf225 helped me discovered that our CI does not run multi-gpu tests in `test_c10d.py`. There are quite a few multi-gpu c10d tests. This PR tries to enable those tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21598
Differential Revision: D15744256
Pulled By: mrshenli
fbshipit-source-id: 0a1524a862946128321f66fc8b7f331eff10e52a
Summary:
Create an uninitialized ivalue. This will be needed for Breaks & Continues to match up if block outputs of values that are guaranteed not to be used but need to escape the block scope. It is not exposed to users.
Was previously part of final returns but I was asked to make a separate PR for it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21387
Differential Revision: D15745124
Pulled By: eellison
fbshipit-source-id: ae6a6f766b4a70a71b9033987a630cfbf044e296
Summary:
For consistency, derivatives.yaml now uses the same schema specification as native_functions.yaml.
Note that there are some small downsides, e.g. changing the default values or return parameter names in native_functions.yaml also now requires updating derivatives.yaml as well. But this has a few nice properties:
1) Able to copy-paste definitions from native_functions to derivatives.
2) Makes it impossible to write derivatives for operators without schemas (e.g. old TH operators).
3) Moves us closer to the ideal situation of co-locating forward and backwards declarations.
Note that this doesn't change any generated code; in particular, this has the same behavior of mapping in-place and out-of-place definitions together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20916
Differential Revision: D15497800
Pulled By: gchanan
fbshipit-source-id: baee5caf56b675ce78dda4aaf6ce6a34575a6432
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21599
We prevented this because c10 ops can't have a backwards yet and calling them with requires_grad=True would do the wrong thing
if the c10 op is not purely implemented by calling other autograd-able ops.
However, it is a valid use case to have c10 ops that just call other autograd-aware ops, and these ops should be callable with requires_grad=True.
This should fix https://github.com/pytorch/pytorch/issues/21584.
Differential Revision: D15744692
fbshipit-source-id: ba665365c850ef63fc9c51498fd69afe49e5d7ec
Summary:
An incorrect increment / decrement caused the samples to not be generated from a multinomial distribution
Changelog:
- Remove the incorrect increment / decrement operation
Fixes#21257, fixes#21508
cc: LeviViana neerajprad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21324
Differential Revision: D15717575
Pulled By: ezyang
fbshipit-source-id: b1154e226d426c0d412d360c15f7c64aec95d101
Summary:
test that wasn't on the CI, but is tested internally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21594
Differential Revision: D15742157
Pulled By: eellison
fbshipit-source-id: 11fc82d1fc0281ffedd674ed96100e0c783c0599
Summary:
This PR addresses some numerical issues of Sigmoid/StickBreakingTransform, where these transforms give +-inf when the unconstrained values move to +-20 areas.
For example, with
```
t = torch.distributions.SigmoidTransform()
x = torch.tensor(20.)
t.inv(t(x)), t.log_abs_det_jacobian(x, t(x))
```
current behaviour the inverse will return `inf` and logdet return `-inf` while this PR makes it to `15.9424` and `-15.9424`.
And for
```
t = torch.distributions.StickBreakingTransform()
x = torch.tensor([20., 20.])
t.inv(t(x)), t.log_abs_det_jacobian(x, t(x))
```
current value is `(inf, nan)` and `-inf` for logdet, while this PR makes it `[16.6355, 71.3942]` and `-47.8272` for logdet.
Although these finite values are wrong and seems unavoidable, it is better than returning `inf` or `nan` in my opinion. This is useful in HMC where despite that the grad will be zero when the unconstrained parameter moves to unstable area (due to clipping), velocity variable will force the parameter move to another area which by chance can move the parameter out of unstable area. But inf/nan can be useful to stop doing inference early. So the changes in this PR might be inappropriate.
I also fix some small issues of `_Simplex` and `_RealVector` constraints where batch shape of the input is not respected when checking validation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20288
Differential Revision: D15742047
Pulled By: ezyang
fbshipit-source-id: b427ed1752c41327abb3957f98d4b289307a7d17
Summary:
This changes our compiler so it first emits Loads & Stores, and then transforms the graph to SSA in a follow up pass. When a variable is set, we emit a prim::Store, and when a variable is referenced, we emit a prim::Load.
```
a = 1
print(a)
```
becomes:
```
%a.1 : int = prim::Constant[value=1]()
prim::Store[name="a"](%a.1)
%a : int = prim::Load[name="a"]()
prim::Print(%a)
```
In the follow up pass, convertToSSA, the values are turned into SSA form with the Loads & Stores removed. This change will enable breaks and continues because you can transform the graph with the variable naming information still intact.
There are still some remaining jitter and edge cases issues that I have to look through, but I think is still ready for eview.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21101
Differential Revision: D15723353
Pulled By: eellison
fbshipit-source-id: 3269934d4bc24ddaf3a87fdd20620b0f954d83d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21382
Concat tensor inference function was not handling correctly the case where axis argument points to the last dimension so input tensors don't need to have the same number of dimensions.
Split tensor inference function was not handling correctly the case where split information is provided as the second input tensor rather than as an argument.
Reviewed By: mdschatz
Differential Revision: D15633148
fbshipit-source-id: d566af44dc882457ee9efe83d2461b28408c2c5d
Summary:
Should be self-explanatory. This `int` variable is overflowing.
Reported in #21526
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21530
Differential Revision: D15719275
Pulled By: umanwizard
fbshipit-source-id: 24e917a00a5b78bc3af29ef3b8b72eea7e89d5d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21556
Optimize batch mm op when broadcast the second input
Reviewed By: houseroad
Differential Revision: D15728914
fbshipit-source-id: c60441d69d4997dd32a3566780496c7ccda5e67a
Summary:
This was looking at the number of elements in the memo table, not the total capacity, and was thus calling reserve() a lot more than it should have
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21542
Reviewed By: driazati
Differential Revision: D15723132
Pulled By: jamesr66a
fbshipit-source-id: 20e1f9099b6a51a33994ea9dbc3f22eb3bc0c8f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21195
The motivation is that, while we shouldn't break USER code for using
deprecated declarations, we should keep our internal code base
deprecation clean.
Differential Revision: D15576968
fbshipit-source-id: fb73a8986a5b60bf49ee18260653100319bb1030
Summary:
namedtensor build + test should run on PRs only if the commit message
includes [namedtensor ci].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21520
Differential Revision: D15718404
Pulled By: zou3519
fbshipit-source-id: ce8b5df2682e795e64958a9d49e2e3c091599b33
Summary:
This should further reduce noise by only clang-formatting the lines you actually touched in the precommit hook.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15657
Differential Revision: D15717337
Pulled By: suo
fbshipit-source-id: 57e65a679a8fdee5c3ff28e241c74ced9398eb0c
Summary:
The new implementation of tracing supports more module. So many error-handling code can be removed by placing the old one (LegacyTracedModule).
cc orionr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21339
Reviewed By: natalialunova
Differential Revision: D15695154
Pulled By: orionr
fbshipit-source-id: af7d35754e9f34bd1a0ad7b72a9ebe276ff8ab98
Summary:
Fixes#12259, needs to make sure tests (see #13766) don't break due to numerical precision issues. Not sure what would need to be adjusted here...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13774
Differential Revision: D15715021
Pulled By: ezyang
fbshipit-source-id: 20ce2beee1b39ebe9f023c5f2b25be53acccb5f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21492
If one async operator failed, async_scheduling net currently only marks all scheduled async operators as finished without cancelling the callbacks.
The new behavior is to cancel the callbacks first, then set event status to finished.
Reviewed By: ilia-cher
Differential Revision: D15702475
fbshipit-source-id: 55a1774d768b2e238bab859b83332f1877a001ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21502
In BenchResult, we keep name, avg_fwd, std_fwd, avg_bwd, and std_bwd. There is no information about the number of each iteration. In this diff, I am adding more info to BenchResult to include the number reported from each iteration.
Reviewed By: wanchaol
Differential Revision: D15706306
fbshipit-source-id: 3f14be4ba91f1f6da473995783bd7af1d067938d
Summary:
This moves `JitTestCase` to its own file so that we can have other jit
test files (ex. `test_jit_py3.py`)
There aren't any code changes, just a move and cleaning up the imports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21491
Pulled By: driazati
Differential Revision: D15703060
fbshipit-source-id: 6082e8b482100bb7b0cd9ae69738f1273e626171
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21230
tsia; we support empty tensor with this diff for reshape operator
Reviewed By: jerryzh168
Differential Revision: D15583356
fbshipit-source-id: 6d44c04e95ca3546509bfb12102e29c878f9a7c7
Summary:
Modify MKLDNN pooling operation to support ceil mode by adjusting the right/bottom padding accordingly. This is done similarly as in Caffe (see discussion https://github.com/pytorch/pytorch/pull/19205#discussion_r276903751).
To make this possible, I split the padding to left and right (top / bottom). This naming is confusing but actually follows mkldnn's own naming for pooling::compute(). We increase the r paddings so that it matches the ceiling mode expected output size.
Strengthened the test case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21310
Reviewed By: bddppq
Differential Revision: D15611664
Pulled By: akyrola
fbshipit-source-id: 46b40015dafef69a8fd5e7b2c261d8dbf448cd20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21393
Result of splitting the base diff. We moved a header from src/* to include/fbgemm/*
Reviewed By: jianyuh
Differential Revision: D15635188
fbshipit-source-id: ad7d0ddba964ff1cb8b2e33f5f98e457a4d2eac9
Summary:
changed `UpsampleBilinearKernel` s.t. the throughput increased 40~50%.
I tested locally with my local test code -- **not pytorch's provided test code** -- because I am having a build problem ( which I made an issue about [here](https://github.com/pytorch/pytorch/issues/19184)). I tested with various tensor sizes and across all the sizes, it should a significant increase in throughput.
1. added `__restrict__`
2. instead of launch as many threads as there are output elements, I launched only `output_height * output_width` may threads and had each thread iterate through the channel and batch dimension.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19306
Differential Revision: D15701840
Pulled By: ezyang
fbshipit-source-id: 53c54d4f4e4a28b58ecc7d7ae6b864cbfc760e27
Summary:
Currently, when the input of MVN is precision matrix, we take inverse to convert the result to covariance matrix. This, however, will easily make the covariance matrix not positive definite, hence will trigger a cholesky error.
For example,
```
import torch
torch.manual_seed(0)
x = torch.randn(10)
P = torch.exp(-(x - x.unsqueeze(-1)) ** 2)
torch.distributions.MultivariateNormal(loc=torch.ones(10), precision_matrix=P)
```
will trigger `RuntimeError: cholesky_cpu: U(8,8) is zero, singular U.`
This PR uses some math tricks ([ref](https://nbviewer.jupyter.org/gist/fehiepsi/5ef8e09e61604f10607380467eb82006#Precision-to-scale_tril)) to only take inverse of a triangular matrix, hence increase the stability.
cc fritzo, neerajprad , SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21366
Differential Revision: D15696972
Pulled By: ezyang
fbshipit-source-id: cec13f7dfdbd06dee94b8bed8ff0b3e720c7a188
Summary:
This PR addresses the problem described in the comment: https://github.com/pytorch/pytorch/pull/20203#issuecomment-499231276
and previously coded bad behaviour:
- a warning was raised all the times when lr schedulling is initialized
Now the code checks that:
- on the second call of `lr_scheduler.step`, ensure that `optimizer.step` has been already called, otherwise raise a warning (as it was done in #20203 )
- if optimizer's step is overridden -> raise once another warning to aware user about the new pattern:
`opt.step()` -> `lrs.step()` as we can not check this .
Now tests check that
- at initialization (`lrs = StepLR(...)`)there is no warnings
- if we replace `optimizer.step` by something else (similarly to the [code of nvidia/apex](https://github.com/NVIDIA/apex/blob/master/apex/amp/_process_optimizer.py#L287)) there is another warning raised.
cc ezyang
PS. honestly I would say that there is a lot of overhead introduced for simple warnings. I hope all these checks will be removed in future `1.2.0` or other versions...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21460
Differential Revision: D15701776
Pulled By: ezyang
fbshipit-source-id: eac5712b9146d9d3392a30f6339cd33d90c497c7
Summary:
Fixes#21026.
1. Improve build docs for Windows
2. Change `BUILD_SHARED_LIBS=ON` for Caffe2 local builds
3. Change to out-source builds for LibTorch and Caffe2 (transferred to #21452)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21190
Differential Revision: D15695223
Pulled By: ezyang
fbshipit-source-id: 0ad69d7553a40fe627582c8e0dcf655f6f63bfdf
Summary:
Another simple bit of syntax that NumPy supports and we don't.
Support int, float, and bool.
```python
>>> torch.randn((2,3), dtype=float)
tensor([[-0.1752, -0.3240, -0.6148],
[ 0.1861, 1.6472, 0.1687]], dtype=torch.float64)
```
A bit confusingly, Python's "float" actually means double, but nothing we can do about that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21215
Differential Revision: D15697012
Pulled By: umanwizard
fbshipit-source-id: 9a38d960a610b8e67023486b0c9265edd3c22246
Summary:
Adds support for recursively compiling `nn.Sequential` and
`nn.ModuleList`. When either is used, it is converted to a
`jit._ConstModuleList` or `jit._ConstSequential` as necessary. Due to
this, we don't need to add it to `__constants__` since it's made
constant on demand.
This PR also moves the recursive script tests out to their own class
`TestRecursiveScript` (the added test is called `test_iterable_modules`)
](https://our.intern.facebook.com/intern/diff/15611738/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21306
Pulled By: driazati
Differential Revision: D15611738
fbshipit-source-id: fac52993990bd2dfad71d044c463a58a3759932a
Summary:
Enable bool tensors for these index methods:
- index_select
- index_copy
- put
- take
- index_fill
Tested via unit tests
TODO:
Enable index_add in a separate PR as it requires more "side" changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21435
Differential Revision: D15684964
Pulled By: izdeby
fbshipit-source-id: 48440e4d44873d70c4577e017dd0d8977e0fa15a
Summary:
`torch.tensor([True, False, True], dtype=torch.bool).sum()` should return **2** instead of **True** as it does now.
Tested via unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21421
Differential Revision: D15674203
Pulled By: izdeby
fbshipit-source-id: b00e3d0ca809c9b92b750adc05632522dad50c74
Summary:
Fixes#19540
CC nmerrill67
C++ data parallel was using Module.clone() to create module replicas on every destination device. However, clone() does not set up gradient edges to point from replicas to the original module. As a result, the gradient will not be aggregated into the original module. This commit fixes the the problem by manually setting gradient edges from every parameter X in every replica to the same parameter X in the original module.
## Failed Attempt
Initially I tried implementing what we did in `replicate.py`, which
1. create module replicas
2. use Python `Broadcast` autograd function to broadcast every parameter in the original module to all destination devices.
3. assign the broadcast result params to module replicas' `_parameters` dict.
This works in Python because derived module member field params (e.g., `Linear.weight`) and base module `_parameters` (e.g., `Linear._parameters['weight']`) are referencing the same parameter instance. Assigning one of them will apply to both. However, in C++, even though I can modify Module's `parameters_ `values and gradient edges to point to the broadcast source, I cannot touch the weight and bias member fields in Linear, because replicate cannot (and should not) add special-case handlers to every different module. (See `Linear` [.h](https://github.com/pytorch/pytorch/blob/master/torch/csrc/api/include/torch/nn/modules/linear.h), [.cpp](https://github.com/pytorch/pytorch/blob/master/torch/csrc/api/src/nn/modules/linear.cpp)) Although they initially point to the same `TensorImpl` instance, after assigning to `Module.parameters_['weight']`, it will be different from `Linear.weight`.
## Solution Options
gchanan and I had several discussions on this issue and figured two solutions to this problem.
### Option One [implemented in this PR]
Replicate the module in two steps:
1. call `Module.clone()` to create a module replica on every destination device.
2. manually setting gradient edges from every parameter in every replica to the same parameter in the original module.
* Pro: Does not need to change any existing module, and relatively easier to implement
* Con: It is a little hackish.
### Options Two
Implement a `Replicatable` class (similar to `Cloneable`), and make it a friend class of `Module`. For more details see `Note [Replicating Modules]` in the code change.
* Pro: Maybe this aligns more with our existing approach implemented in `Cloneable`?
* Con: Require changes to every existing module.
I am inclined to go with option one, because `replicate` will only be used on data parallel. I feel it is too big an overkill if we have to change all existing module implementations due to a data parallel requirement.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20910
Differential Revision: D15556426
Pulled By: mrshenli
fbshipit-source-id: aa836290ec657b32742e2bea80bd0ac2404ef3b0
Summary:
Fixed an issue where models can not be loaded in a 32-bit environment like Raspbian.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20900
Differential Revision: D15696709
Pulled By: ezyang
fbshipit-source-id: 37a81f05f235d3b9fc6244e12d3320ced3d1465e
Summary:
Current versions of NVRTC incorrectly map error code 7 to the error string "NVRTC unknown error." This update maps error code 7 to the correct string explicitly in PyTorch. See the documentation at: https://docs.nvidia.com/cuda/nvrtc/index.html#group__error.
This may give us a better idea of the source of NVRTC errors that some community members, like Uber, have reported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21174
Differential Revision: D15696593
Pulled By: ezyang
fbshipit-source-id: f5c7b5876c07b311ab5f2d7c8e375e93273912c6
Summary:
Fixed#21269 by removed the the expected `ValueError` when converting a tensor to a Numpy `int8` array in the Numba interoperability test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21458
Differential Revision: D15696363
Pulled By: ezyang
fbshipit-source-id: f4ee9910173aab0b90a757e75c35925b026d1cc4
Summary:
I inserted default weight and reduction params in binary_cross_entropy_with_logits function . These default params exist in python and binary_cross_entropy function in cpp.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21336
Differential Revision: D15628917
Pulled By: ezyang
fbshipit-source-id: 38e5f53851125238842df1bd71cb6149c8603be1
Summary:
This could serve as a alternative solution to export ```torch.gather``` before something similar goes into ONNX spec. The exported model is verified to be correct against onnxruntime backend. We weren't able to test against Caffe2 backend because it doesn't seem to support OneHot opset9.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21235
Differential Revision: D15613039
Pulled By: houseroad
fbshipit-source-id: 7fc097f85235c071474730233ede7d83074c347f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21440
This diff modifies the output format when ai_pep_format is enabled.
Reviewed By: hl475
Differential Revision: D15681042
fbshipit-source-id: df5f2dbb38d1bd866ca7f74ef4e63459d480be6e
Summary:
We have encountered `std::bad_cast` error when running PyTorch binary built with cxx11 abi on CentOS7, stack trace:
```
#0 0x00007fec10160207 in raise () from /lib64/libc.so.6
#1 0x00007fec101618f8 in abort () from /lib64/libc.so.6
#2 0x00007fec015767d5 in __gnu_cxx::__verbose_terminate_handler() () from /lib64/libstdc++.so.6
#3 0x00007fec01574746 in ?? () from /lib64/libstdc++.so.6
#4 0x00007fec01574773 in std::terminate() () from /lib64/libstdc++.so.6
#5 0x00007fec01574993 in __cxa_throw () from /lib64/libstdc++.so.6
#6 0x00007fec015c94d2 in std::__throw_bad_cast() () from /lib64/libstdc++.so.6
#7 0x00007feb2ab3c2d7 in std::__cxx11::numpunct<char> const& std::use_facet<std::__cxx11::numpunct<char> >(std::locale const&) ()
from /root/.local/lib/python2.7/site-packages/torch/lib/libcaffe2.so
#8 0x00007feb28643d62 in torch::jit::script::strtod_c(char const*, char**) () from /root/.local/lib/python2.7/site-packages/torch/lib/libcaffe2.so
```
We are suspecting this line will get compiled to gcc abi dependent symbol:
```
char decimal_point = std::use_facet<std::numpunct<char>>(std::locale()).decimal_point();
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21293
Differential Revision: D15609910
Pulled By: bddppq
fbshipit-source-id: e247059729863868e4b36d6fec4fcbc36fbc4bb1
Summary:
Fixing an incorrect implementation of the CELU activation function. The existing implementation works by a chance combination of errors that seem to cancel each other out. This change makes the code more readable, aligns the parameter names correctly, and is consistent with the cuda implementation.
I came across this issue while working on version counters... I attempted to specify a gradient in derivatives.yaml for CELU due to a failed test, but the derivative couldn't be specified correctly without fixing the celu implementation.
https://github.com/pytorch/pytorch/pull/20612
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21213
Differential Revision: D15678823
Pulled By: nairbv
fbshipit-source-id: 29fa76b173a66c2c44ed2e0b7959e77f95d19c43
Summary:
This PR is a continuation of #15310, which itself is a continuation of #14845, #14941, & #15293. It should be synced up with the pytorch/master branch as of yesterday.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19465
Differential Revision: D15632268
Pulled By: ezyang
fbshipit-source-id: 8e337e8dc17ac31439935ccb530a7caf77f960e6
Summary:
We want to be able to call stft from a torchscript which requires that stft have a type annotation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21302
Differential Revision: D15607973
Pulled By: cpuhrsch
fbshipit-source-id: c4a5c09cdaafe7e81cf487a3ad216d1b03464a21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21392
as discussed at https://github.com/pytorch/pytorch/pull/21244, we
found some values in log_beta are not properly initialized. This diff will 1)
initialize all log_beta to -inf; 2) fix a tricky compare condition; 3) zero all
the gradient elements corresponding to padding to zero.
Offline experiments show that this diff can fix previous seen NaN loss.
Differential Revision: D15637977
fbshipit-source-id: 477008a5e11aae946bd2aa401ab7e0c513421af0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21398
Module::forward method calls find_method() function potentially in multiple threads.
Internally it calls find_offset() method and reads dict_ object.
If the correspondent name is not in a dictionary thread call insert() method and modifies dict_ object.
At the same time when first thread modifies dict_ object another thread can enter forward()->find_method()->find_offset() path
and access dict_ object for reading while it have been modified -> crash.
Moved mutex protection up to protect both calls find_offset() and insert().
Consider to use C++ 17 shared_mutex locking object instead of recursive_mutex object.
Reviewed By: bddppq
Differential Revision: D15638942
fbshipit-source-id: ca6a453448302a0b3666c87724755fa4e9ce242f
Summary:
Something flaky is going on with `test_inplace_view_saved_output` on Windows.
With my PR #20598 applied, the test fails, even though there is no obvious reason it should be related, so the PR was reverted.
Based on commenting out various parts of my change and re-building, I think the problem is with the name -- renaming everything from `T` to `asdf` seems to make the test stop failing. I can't be sure that this is actually the case though, since I could just be seeing patterns in non-deterministic build output...
I spoke with colesbury offline and we agreed that it is okay to just disable this test on Windows for now and not block landing the main change. He will look into why it is failing.
**Test Plan:** I will wait to make sure the Windows CI suite passes before landing this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21175
Differential Revision: D15566970
Pulled By: umanwizard
fbshipit-source-id: edf223375d41faaab0a3a14dca50841f08030da3
Summary:
Currently tools/build_pytorch_libs.py looks quite convoluted. This commit reorgnizes cmake related functions to a separate file to make the code clearer.
---
This is hopefully helpful for further contribution for better integration with cmake.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21367
Differential Revision: D15636991
Pulled By: soumith
fbshipit-source-id: 44d76e4e77aec0ce33cb32962b6a79a7f82785da
Summary:
This default was incorrect and made printing in python not print file:line:col
This wasn't caught because FileCheck internally uses operator<< to print the graph, which has `true` hardcoded as the value. I've added more comprehensive tests to catch this
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21370
Differential Revision: D15631135
Pulled By: jamesr66a
fbshipit-source-id: c809e06fff4f0174eefeb89062024384b4944ef7
Summary:
I found this significantly speeds up incremental builds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21334
Differential Revision: D15632994
Pulled By: suo
fbshipit-source-id: bb4af90f4400bffa90d168d82ff30fece5e3835c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21365
This diff adds new operators to benchmark_all_test so all the supported ops can be built as one binary
Reviewed By: hl475
Differential Revision: D15627328
fbshipit-source-id: b7ca550a279f485102a6a6bd47e4032c7beb9940
Summary:
The original PR (#16071) is not working anymore after `caffe2` and `torch` is unified. What's more, It is making the binary big since the optimizing flag is disabled on a very big project(the `torch` library used to be small, but it now applies on the whole `caffe2` and `caffe2_gpu` library). We need to get it reverted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21335
Differential Revision: D15622163
Pulled By: soumith
fbshipit-source-id: 900bd400106d27a1512eed1e9f2288114f5f41bb
Summary:
This adds a regression test for the bug fix in #21236. Operations
involving CUDA tensors an CPU scalars should not copy the CPU scalar to
the device (because that is slow). They should instead "lift" the scalar
to a kernel parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21253
Reviewed By: bddppq
Differential Revision: D15604080
Pulled By: colesbury
fbshipit-source-id: c14ded5d584499eaa5ea83337ffc50278205f3d6
Summary:
This solves the situation where, for example, someone instantiates LSTM with `dropout=0`, a Python integer. This works fine in Python, but JIT throws a type error because it expected float but got int
Resolves https://github.com/pytorch/lockdown/issues/65
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21304
Differential Revision: D15613153
Pulled By: jamesr66a
fbshipit-source-id: eabff76e3af3de0612583b37dbc5f7eab7e248a4
Summary:
This PR adds support for torch.rand export in the PyTorch ONNX exporter. There are other generator ops that need to be supported for export and they will added in subsequent PRs. This op is needed with priority for a model on our end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20559
Differential Revision: D15379653
Pulled By: houseroad
fbshipit-source-id: d590db04a4cbb256c966f4010a9361ab8eb3ade3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20915
Clean the unary processor code. Some question are added into the comments to seek suggestions.
Reviewed By: pjh5
Differential Revision: D15448502
fbshipit-source-id: ef0c45718c1a06187e3fe2e4e59b7f20c641d9c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21206
This diff change the default test_name to be a globally unique value across tests. With that, users can list all the tests and choose to run a specific test.
Reviewed By: zheng-xq
Differential Revision: D15543508
fbshipit-source-id: 0814ef6a60d41637fed5245e30c282497cf21bb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21149
The diff modifies the interface for PyTorch operators in the benchmark suite
Reviewed By: zheng-xq
Differential Revision: D15433897
fbshipit-source-id: e858183431eb37d90313356716c2de8709372b58
Summary:
This doesn't affect anything because we run constant pooling, and in the case of Closures and Forks creates unnecessary closures over constants.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21229
Differential Revision: D15587764
Pulled By: eellison
fbshipit-source-id: d5609b0a5697071fab5050eb9e03876ab9ebb27a
Summary:
~~This is work in progress due to its dependency on multiple pending PRs.~~
- [x] ONNX: Relax constraint on subgraph input/output type & shape check. https://github.com/onnx/onnx/pull/2009
- [x] PyTorch: Add infra to test_pytorch_onnx_caffe2.py to test ScriptModule models. https://github.com/pytorch/pytorch/pull/20256
This PR should partially resolve https://github.com/pytorch/pytorch/issues/17531. However, ideally we shouldn't need to put cast(and reshape) node to help the conversion for loop condition.
- Added cast node for condition values before entering loop node. The ONNX spec only accepts Bool type, while in PyTorch if the condition value is an output from other node it could potentially have any integral type.
- Tidying up the exported ONNX loop subgraph input type & shape. According to ONNX spec, input "M" is exported as 0-d scalar tensor with type int64. input "Cond" is exported as incomplete tensor of type Bool without shape information. This is because through out the iteration, the rank of condition value is dynamic, either 0-d or 1-d, as long as it holds a single value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20445
Differential Revision: D15534188
Pulled By: houseroad
fbshipit-source-id: d174e778529def05ee666afeee4b8fb27786e320
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21267
Replace AT_ASSERTM with TORCH_CHECK: AT_ASSERTM is deprecated.
Not sure when ```AT_ASSERT``` is dprecated with some new TORCH ASSERT function.
Reviewed By: zafartahirov
Differential Revision: D15599242
fbshipit-source-id: 23f21a9a23dc3c147dc817e6d278066d0832e08d
Summary:
This PR improves performance of advanced indexing backward, partially solving #15245 (performance is still worse than gather, but not by such outrageous margins). Before, using benchmarking harness from #15245, cuda 10/V100:
```
Indexing is faster by at most -270.61607820767887 us on N: 16 D: 256 K: 1
Indexing is slower by at most 11127.466280784833 us on N: 16 D: 4096 K: 4096
```
after:
```
Indexing is faster by at most 23.524456737696028 us on N: 512 D: 4096 K: 4096
Indexing is slower by at most 186.24056029472553 us on N: 16 D: 1024 K: 4096
```
Strategy is to reuse embedding backward kernel, adapting it to handle unindexed dimensions in the beginning by launching additional threadblocks, and also allowing it to handle slices that are bigger than `65K*128`, that is hardly ever a problem for embedding. Still, integer indexing is baked in the kernel, and is important for performance, so for now bigger than 2G element tensors are not supported.
The main savings come from not having to expand index to all unindexed dimensions, and not sorting expanded index with incoming gradient values, but rather only sorting unexpanded index.
There are ways to make sorting overhead smaller (thanks mcarilli for suggestions) but I'll get to it when it becomes a real problem, or rather, when cuda graphs will force us to get rid of thrust::sort calls.
I've also added tests for indexing backward, before tests for index_put_ and indexing backward were non-existent.
This PR also fixes#20457 by casting indices to `self` backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20557
Differential Revision: D15582434
Pulled By: ezyang
fbshipit-source-id: 91e8f2769580588ec7d18823d99a26f1c0da8e2a
Summary:
Stacked on https://github.com/pytorch/pytorch/pull/21217
This adds support for recording file and line information during tracing, by extracting the top Python interpreter frame
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21247
Reviewed By: suo, driazati
Differential Revision: D15594553
Pulled By: jamesr66a
fbshipit-source-id: 72e1b3a46f1dabe3e83a608ec1a7d083bd1720f9
Summary:
Remove Dropout from the opset 10 blacklist.
ONNX Dropout was modified in opset 10, but only the output "mask" was modified, which is not exported in pytorch opset 9. So we can still fallback on the opset 9 op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20710
Differential Revision: D15571248
Pulled By: houseroad
fbshipit-source-id: 15267eb63308a29a435261034b2f07324db1dea6
Summary:
We're not getting much from checking the export strings, and they are noisy and slow development. DIdn't realize they existed until now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21238
Differential Revision: D15604256
Pulled By: eellison
fbshipit-source-id: 488e9401231228cffe132dab99d519563fa63afc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21100
Added multifile flag to write scalar data into separate files. This can slow down dashboard loading.
Reviewed By: orionr
Differential Revision: D15548913
fbshipit-source-id: dd39a7f76f93025d28f14babbf933e39860e6910
Summary:
Loops.h has contains specializations for cases where all the inputs are
contiguous as well as cases where one input is a scalar and all other
inputs are contiguous.
Previously, there were separate checks for each functions that take
zero, one, or two input arguments. This is getting unwieldy, especially
once we add support for functions that take three inputs (#21025).
This requires the use of recursive templates (which have their own
downsides), but this seems better than the alternative.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21106
Differential Revision: D15562430
Pulled By: colesbury
fbshipit-source-id: 5f19ab2212e16e29552887f4585c2b4a70309772
Summary:
Instead of attempting to hardcode calls to "ninja" or "make", we should always let cmake do it. This better integrates build configurations (DEBUG or REL_WITH_DEB_INFO) and better handles the case in which the native build tool is not in PATH (cmake has some capacity to find them and has options for users to specify their locations).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21105
Differential Revision: D15602883
Pulled By: soumith
fbshipit-source-id: 32ac46d438af00e791defde6ae5ac21c437d0bb0
Summary:
Retry #21197
The previous one failed because it uses some Python3 only syntax.
ezyang Do we still have multi-GPU py2 tests? I am curious why the CI tests did not catch this error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21262
Differential Revision: D15598941
Pulled By: mrshenli
fbshipit-source-id: 95f416589448c443685d6d236d205b011998a715
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20883
Add autograd for layer_norm on CPU, after this diff, both PyTorch and jit model can automatically benefit from performance improvement of nn.functional.layer_norm
Reviewed By: zheng-xq
Differential Revision: D15483790
fbshipit-source-id: 94ed3b16ab6d83ca6c254dbcfb224ff7d88837f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20665
Add gelu activation forward on CPU in pytorch
Compare to current python implemented version of gelu in BERT model like
def gelu(self, x):
x * 0.5 * (1.0 + torch.erf(x / self.sqrt_two))
The torch.nn.functional.gelu function can reduce the forward time from 333ms to 109ms (with MKL) / 112ms (without MKL) for input size = [64, 128, 56, 56] on a devvm.
Reviewed By: zheng-xq
Differential Revision: D15400974
fbshipit-source-id: f606b43d1dd64e3c42a12c4991411d47551a8121
Summary:
cc ezyang this is meant to fix the fuser failures on master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21252
Differential Revision: D15594283
Pulled By: jamesr66a
fbshipit-source-id: 85f37e78b2de051c92ade3fe4c44c7530b4542e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21233
It is possible that OnnxifiOp is created in a thread where weights have been cleaned from the workspace, which is legit use case as we can create the backend once and lower all the weights. So we need to extract the weight shape info the first time we create the backend and save it.
Reviewed By: bertmaher, rdzhabarov
Differential Revision: D15587237
fbshipit-source-id: 1f264dc32c0398c42b618e9c41c119eb13e1c9f1
Summary:
Fixes#21108
When grad is disabled, Python autograd function outputs are [wrapped as detached aliases](8cde4c4d22/torch/csrc/autograd/python_function.cpp (L395-L399)), which prevents calling `Tensor.set_()` on them after recent changes in Tensors and Variables. This will hit a problem when users would like to call `rnn.flatten_parameters()` in the forward pass, as the function [calls `set_()`](9d09f5df6c/aten/src/ATen/native/cudnn/RNN.cpp (L669)).
The proposed solution is to avoid using an autograd Broadcast if in no_grad mode.
apsdehal
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21197
Differential Revision: D15577342
Pulled By: mrshenli
fbshipit-source-id: 1a024c572171a3f2daca9454fd3ee6450d112f7c
Summary:
I think there was a typo in #20690 here https://github.com/pytorch/pytorch/pull/20690/files#diff-b47a50873394e38a005b4c1acd151957R130.
Original conditional was ` common_backend == Backend::CUDA && op.tensor.type().backend() == Backend::CPU)`, now it is `op.device.is_cuda() && op.tensor.device().is_cpu()`. It seems that `op.device` and `op.tensor.device()` should be the same, so this conditional is never true. This leads to spurious h2d copies for operations between cuda tensors and cpu scalars, because cpu scalars are now sent to gpu, instead of being passed to lambdas directly.
Unfortunately, I don't know how to test this change, because functionally everything was fine after #20690, it was just a performance regression.
cc colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21236
Differential Revision: D15592754
Pulled By: soumith
fbshipit-source-id: 105bfecc61c222cfdb7294a03c9ecae3cc7f5817
Summary:
`Tensor.is_cuda` and `is_leaf` is not a predicate function but a `bool` attribute. This patch fixes the type hints in `torch/__init__.pyi` for those attributes.
```diff
- def is_cuda(self) -> bool: ...
+ is_cuda: bool
- def is_leaf(self) -> bool: ...
+ is_leaf: bool
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21192
Differential Revision: D15592766
Pulled By: soumith
fbshipit-source-id: 8c4ecd6939df8b8a8a19e1c9db6d40193bca7e4a
Summary:
This makes file-line reporting also work for things loaded using `torch.jit.load()` as well as the string frontend (via `CompilationUnit`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21217
Differential Revision: D15590838
Pulled By: jamesr66a
fbshipit-source-id: 6b6a12574bf9eca0b83f24f0b50535fda5863243
Summary:
Studied why sparse tensor coalesce was slow: issue #10757.
Using nv-prof, and writing a simple benchmark, I determined bulk of the time was used ``kernelTransformReduceInnermostDimIndex``, which is called when sparse tensor is constructed with sparse_coo_tensor when it does sanity check on the minimum and maximum indices. However, we do not need this sanity check because after coalescing the tensor, these min/maxs won't change.
On my benchmark with 1 million non-zeros, the runtime of coalesce. was about 10x from 0.52s to 0.005 sec.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21214
Reviewed By: bddppq
Differential Revision: D15584338
Pulled By: akyrola
fbshipit-source-id: a08378baa018dbd0b45d7aba661fc9aefd3791e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21163
These two backend transformation share some common traits. Therefore we want to reuse the data struct/code as much as possible.
Reviewed By: hlu1
Differential Revision: D15561177
fbshipit-source-id: 35f5d63b2b5b3657f4ba099634fd27c3af545f1b
Summary:
Some of the functions are only used in this file - mark them `static`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21140
Differential Revision: D15578076
Pulled By: Krovatkin
fbshipit-source-id: 71ae67baabebd40c38ecb9292b5b8202ad2b9fc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21152
Migrate existing add benchmark to use the new op front-end
Reviewed By: zheng-xq
Differential Revision: D15325524
fbshipit-source-id: 34e969e1bd289913d881c476711bce9f8ac18a29
Summary:
i will do loops in a follow up after some other changes I am working on have landed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20911
Differential Revision: D15497205
Pulled By: eellison
fbshipit-source-id: 8cac197c6a6045b27b552cbb39e6fc86ca747b18
Summary:
Following on #19747, this implements most of the `torch.jit.script()` changes laid out in #20939.
Still to do:
* Accessing a method from Python does not add it as a `ScriptMethod` (so only `export`ed methods and `forward` are compiled)
* Calling a method other than `forward` on a submodule doesn't work
](https://our.intern.facebook.com/intern/diff/15560490/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20708
Pulled By: driazati
Differential Revision: D15560490
fbshipit-source-id: cc7ef3a1c2772eff9beba5f3e66546d2b7d7198a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21085
Now that torch::jit::RegisterOperators() always passes through to torch::RegisterOperators() (see diffs stacked below this), we can remove the old custom op implementation.
Reviewed By: dzhulgakov
Differential Revision: D15542261
fbshipit-source-id: ef437e6c71950e58fdd237d6abd035826753c2e4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21084
- Now AliasAnalysisKind can be set using the torch::RegisterOperators() API
- This also allows us to remove the last place in torch::jit::RegisterOperators that didn't use c10 yet.
Reviewed By: dzhulgakov
Differential Revision: D15542097
fbshipit-source-id: ea127ecf051a5c1e567e035692deed44e04faa9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21181
Implement c10::OperatorOptions as a class to store metadata about operators.
This is meant to replace torch::jit::OperatorOptions.
Reviewed By: dzhulgakov
Differential Revision: D15569897
fbshipit-source-id: 95bf0bf917c1ef2bdf32702405844e1a116d9a64
Summary:
This reduces DenseNet load time by about 25% (down to 5.3s on my laptop) and gets AliasAnalysis out of the profile top hits entirely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21203
Differential Revision: D15578155
fbshipit-source-id: ddbb1ad25c9540b5214702830084aa51cc6fd3cb
Summary:
Adds persistent cuda kernels that speed up SoftMax applied over the fast dimension, i.e. torch.nn.Softmax(dim=-1) and torch.nn.LogSoftmax(dim=-1). When the size is <= 1024, this code is 2-10x faster than the current code, speedup is higher for smaller sizes. This code works for half, float and double tensors with 1024 or fewer elements in the fast dimension. Numerical accuracy is on par with the current code, i.e. relative error is ~1e-8 for float tensors and ~1e-17 for double tensors. Relative error was computed against the CPU code.
The attached image shows kernel time in us for torch.nn.Softmax(dim=-1) applied to a half precision tensor of shape [16384,n], n is plotted along the horizontal axis. Similar uplifts can be seen for the backward pass and for LogSoftmax.
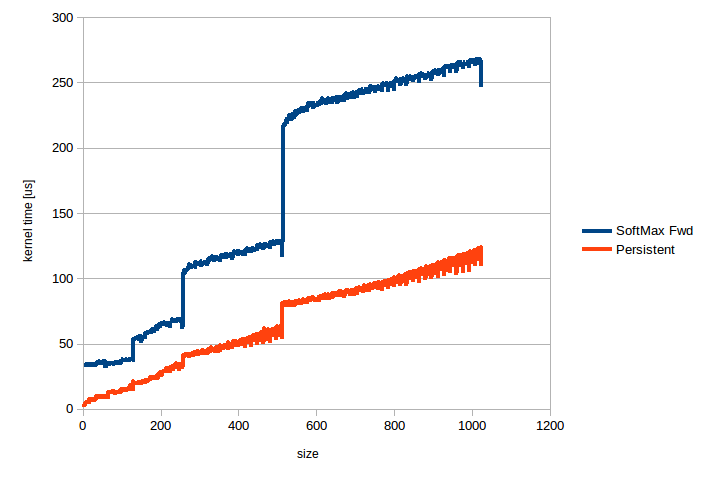
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20827
Differential Revision: D15582509
Pulled By: ezyang
fbshipit-source-id: 65805db37487cebbc4ceefb1a1bd486d24745f80
Summary:
This is a follow up on Jame's PR: https://github.com/pytorch/pytorch/pull/19041. The idea is to replace the legacy `sinh` / `cosh` ops that are being dispatched to TH with the operations defined in `Vec256` for better performance.
benchmark(from Jame's script):
```python
import torch, time
ops = ['sinh', 'cosh']
x = torch.rand(1024, 1024)
NITER = 10000
print('op', 'time per iter (ms)', 'gops/s', 'GB/s', sep='\t')
for op in ops:
s = time.time()
for i in range(NITER):
getattr(x, op)()
elapsed_sec = ((time.time() - s) / NITER)
print(op, elapsed_sec * 1000, (1024*1024/elapsed_sec)/1e9, (1024*1024*4*2) / elapsed_sec / 1e9, sep='\t')
```
code on master:
```
op time per iter (ms) gops/s GB/s
sinh 3.37614369392395 0.3105839369002935 2.484671495202348
cosh 3.480502033233643 0.3012714803748572 2.4101718429988574
```
after change (on Macbook pro 2018):
```
op time per iter (ms) gops/s GB/s
sinh 0.8956503868103027 1.1707425301677301 9.365940241341841
cosh 0.9392147302627564 1.1164390487217428 8.931512389773943
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21115
Reviewed By: ljk53
Differential Revision: D15574580
Pulled By: xta0
fbshipit-source-id: 392546a0df11ed4f0945f2bc84bf5dea2750b60e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21196
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15577123
fbshipit-source-id: d0abeea488418fa9ab212f84b0b97ee237124240
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21169
We should minimize dependency from perfkernels (we were including eigen header files only in cc files not compiled with avx or avx2 options but better to be very strict because it's easy to introduce illegal instruction errors in perfkernels)
Reviewed By: salexspb
Differential Revision: D15563839
fbshipit-source-id: d4b1bca22d7f2e6f20f23664d4b99498e5984586
Summary:
Most important fix: Correct "tensor.rst" to "tensors.rst"
Secondary fix: some minor English spelling/grammar fixes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21029
Differential Revision: D15523230
Pulled By: umanwizard
fbshipit-source-id: 6052d8609c86efa41a4289cd3a099b2f1037c810
Summary:
Dynamically creating a type at runtime was messing up the MRO and has been causing many other problems. I think it's best to delete it, this causes a regression since
```python
self.linear = nn.Linear(10, 10)
isinstance(self.linear, nn.Linear)
```
will now be `False` again, but this will be fixed once recursive script mode is the default (#20939)
](https://our.intern.facebook.com/intern/diff/15560549/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21107
Pulled By: driazati
Differential Revision: D15560549
fbshipit-source-id: 7bd6b958acb4f353d427d66196bb4ee577ecb1a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21148
The diff modifies the interface for Caffe2 operators in the benchmark suite
Reviewed By: zheng-xq
Differential Revision: D15433888
fbshipit-source-id: c264a95906422d7a26c10b1f9836ba8b35e36b53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21147
This diff introduces a new interface to add PT/C2 operators to the benchmark suite.
The following steps are needed to add a new operator:
1. Specify the input shapes, args to an operator in configs
2. Create a PT/C2 benchmark class which includes ```init``` (create tensors), ```forward``` (specify the operator to be tested.), and ```backward```(gradient of an op.) methods
3. call generate_pt_test/generate_c2_test to create test cases based on configs
Reviewed By: zheng-xq
Differential Revision: D15250380
fbshipit-source-id: 1025a7cf60d2427baa0f3f716455946d3d3e6a27
Summary:
This should pass once https://github.com/pytorch/vision/pull/971 is merged.
To remove torchvision as baseline, we just compare to sum of all param.sum() in pretrained resnet18 model, which means we need to manually update the number only when that pretrained weights are changed, which is generally rare.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21132
Differential Revision: D15563078
Pulled By: ailzhang
fbshipit-source-id: f28c6874149a1e6bd9894402f6847fd18f38b2b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21164
Write a List type to be used in operator kernels. This abstracts away from the concrete list type used (e.g. std::vector vs SmallVector)
and allows us to change these implementation details without breaking the kernel API.
Also, this class allows for handling List<bool>, which would not work with ArrayRef because vector<bool> is a bitset and can't be converted to ArrayRef<bool>.
Reviewed By: ezyang
Differential Revision: D15476434
fbshipit-source-id: 5855ae36b45b70437f996c81580f34a4c91ed18c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21156
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15558784
fbshipit-source-id: 0b194750c423f51ad1ad5e9387a12b4d58d969a9
Summary:
In the previous implementation of triu / tril, we passed the batch size in the 2nd dimension of a grid. This is limited to 65535, which means that performing triu / tril on a tensor with batch size > 65535 will throw an error. This PR removes the dependence on the 2nd dimension, and corresponding non-contiguity constraints.
Changelog:
- Compute offset, row and col in the kernel
- Use 1st dimension of grid alone
- Remove unnecessary contiguity checks on tensors as a result of this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21067
Differential Revision: D15572501
Pulled By: ezyang
fbshipit-source-id: 93851cb661918ce794d43eeb12c8a38762e1358c
Summary:
Resolves https://github.com/pytorch/lockdown/issues/51
This adds support for converting simple f-string literals to calls to `string.format()`. It does not support conversion specifiers or format strings.
This also does not support the string parser frontend, since that implementation would be more involved and likely would require modifying our TorchScript AST
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21037
Reviewed By: zdevito
Differential Revision: D15541183
Pulled By: jamesr66a
fbshipit-source-id: ae9df85e73f646d7219c1349f5b7683becbcef20
Summary:
# Overall Improvements
1. Switched from using `unordered_set` to sparse bitset.
1. Prevent some excessive memory allocations (thanks to resistor )
1. Take advantage of the sparse bitset operations
1. Switch to `flat_hash_map` instead of `unordered_map` in some places.
# Benchmarks (somewhat approximate, best of a couple runs)
1. InceptionNet (load + one forward pass): 19.8->13.3
1. GoogleNet(load + one forward pass): 10.0 -> 7.24
1. DenseNet (only load): 7.3 -> 5.3
I use the `sparse bitset` taken from https://llvm.org/doxygen/SparseBitVector_8h_source.html. I had to make some modifications to use `__builtin_popcountl` and instructions like that instead of other transitive clang dependencies.
## Some notes on our graph topologies
In general, our graphs are very sparse, and most of the components aren't connected. For GoogleNet, we have 200k nodes, we do 2k `mayAlias` queries, and the sum of magnitudes of sets at each node is 500k (ie: every node, on average, reaches 2.5 leaves).
PS: Holy crap macbooks throttle an insane amount with the default fan settings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20899
Differential Revision: D15564612
Pulled By: Chillee
fbshipit-source-id: 2a293a21a9be25f942ca888c8f225cab32bbfcd0
Summary:
Now you can run `python test/run_tests --jit` to run all jit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21161
Differential Revision: D15563912
Pulled By: eellison
fbshipit-source-id: 4bb0285cda4168b72a3dc4bba471485566a59873
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21051
In net transforms, we perform an SSARewrite where we update the 'net_pos' for all the ops in the net. The transform function also takes a unordered set of net positions for blacklisting. It's possible that SSARewrite will change the indexes of the ops so the blacklist is applied to the wrong ops. We fix this issue by having SSARewrite only assign new net_pos if the op doesn't already have one.
Reviewed By: yinghai
Differential Revision: D15532795
fbshipit-source-id: e020492a7b5196a91cdc39d0eda761b1ca612cdb
Summary:
These do not work. We'll save time and cpu until someone has the time to fix these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21153
Differential Revision: D15558601
Pulled By: pjh5
fbshipit-source-id: f9bfe580aa7962a88506f9af0032647f553637a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21027
Previously, we are only able to adjust batch size when output shape has batch size conditioned at its first dim. Although not common, there are cases where we want to slice back the output whose batch size is conditioned on non-first dim, or whose output shape doesn't really has batch size in it but rather is an expression of it. Examples are shapes at the output of `Transpose` or `Tile`. This diff redesigns how we handle the output size. The key is when we run OnnxifiOp, the input shapes are given, and we can actually do a shape inference to derive the real output shapes, no matter how they got transformed. And then we compare the real output shape with max batch sized output shape, dim by dim and use a `Slice` op to cut the max output back to real output shape.
Notice that general `Slice` op is slow and in most of the cases, we still prefer adjusting batch size by shrinking its first dim, which is just an operation on meta info without data allocation/manipulation. Therefore, we add a flag `fast_path` to detect this situation and operate accordingly.
Reviewed By: tracelogfb
Differential Revision: D15515189
fbshipit-source-id: 9c1fff161f82d0bc20eeac07ca4a2756e964e9fd
Summary:
Resolves https://github.com/pytorch/lockdown/issues/29
Examples:
```
import torch
torch.jit.script
def foobar(x):
return torch.blargh(xyz)
==
RuntimeError:
object has no attribute blargh:
at compile.py:5:12
torch.jit.script
def foo(x):
return torch.blargh(x)
~~~~~~~~~~~~ <--- HERE
```
It also gets the correct column number in the case where the original source file has common leading whitespace in front of the callable:
```
import torch
with torch.no_grad():
torch.jit.script
def foo(x):
return torch.blargh(x)
==
RuntimeError:
object has no attribute blargh:
at compile_leading.py:6:24
torch.jit.script
def foo(x):
return torch.blargh(x)
~~~~~~~~~~~~ <--- HERE
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20898
Differential Revision: D15552424
Pulled By: jamesr66a
fbshipit-source-id: 78d0f0de03f7ccbf3e7ea193a1b4eced57ea5d69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20874
A criteria for what should go in Tensor method is whether numpy has it, for this one it does not
so we are removing it as a Tensor method, we can still call it as function.
Python
```
torch.quantize_linear(t, ...), torch.dequantize(t)
```
C++
```
at::quantize_linear(t, ...), at::dequantize(t)
```
Reviewed By: dzhulgakov
Differential Revision: D15477933
fbshipit-source-id: c8aa81f681e02f038d72e44f0c700632f1af8437
Summary:
Following on #19747, this implements most of the `torch.jit.script()` changes laid out in #20939.
Still to do:
* Accessing a method from Python does not add it as a `ScriptMethod` (so only `export`ed methods and `forward` are compiled)
* Calling a method other than `forward` on a submodule doesn't work
](https://our.intern.facebook.com/intern/diff/15546045/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20708
Pulled By: driazati
Differential Revision: D15546045
fbshipit-source-id: c2c8fe179088ffbdad47198e799a456560655b86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20869
Adding support for the functions listed in the title, by implementing the copy kernel.
Differential Revision: D15474060
fbshipit-source-id: 9264df6e442cca1cc5d952e3e5dcc9f4a426f317
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20876
Tell the compiler that assertions are likely to succeed.
This allows the compiler to generate betterr code and optimize for the success case.
Differential Revision: D15480066
fbshipit-source-id: 4485154d66b2ee0ef8a401718712dbd61d811aee
Summary:
Thanks Jonas1312 for validating this workground.
Fixes#20635.
However, I don't know exactly why this one is needed.
The following are my guesses:
1. It is a CUDA bug. Static linking against `cudart` is the default now, so they didn't run enough tests for dynamic ones.
2. It is related to UCRT. But (1)according to msdn, shared DLLs should share the same CRT. (2) The CUDA related objects like `CUDevice` passing to `cudart` are stored on the stack, not the heap. (3) If this is the case, it should always fail, not sometimes. https://docs.microsoft.com/en-us/cpp/c-runtime-library/potential-errors-passing-crt-objects-across-dll-boundaries?view=vs-2019
3. It is a bug of our side. However, I was unable to find it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21062
Differential Revision: D15543557
Pulled By: ezyang
fbshipit-source-id: c23af45ebf582fad93ce5f029af6e1f06cf1d49d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20887
Switch AT_xxx assertion macros to the TORCH_ variants and make sure the separation between TORCH_CHECK and TORCH_INTERNAL_ASSERT makes sense.
Differential Revision: D15484658
fbshipit-source-id: 490ae64cc36946756c30971f1b685048bc5f77da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20940
- `torch.nn._intrinsic` will contain normal(unquantized) fused modules like Conv2DRelu, Conv2DBnRelu, FakeQuantize ops etc.
- `torch.nn._intrinsic` will contain fused and quantized modules like Quantized Conv2DRelu, Quantized LinearRelu etc.
Right now I only added FakeQuantize op in `torch.nn._intrinsic` namespace, we'll have more later
Differential Revision: D15505228
fbshipit-source-id: d380929e38af7a5bcfbea27474d5b80f95d43b03
Summary:
A bunch of modules were missing entries for `__constants__` which was making their `__repr__`s not work. Others had `__constants__` that were not necessary since it was provided by some parent class instead.
Fixes#20978
](https://our.intern.facebook.com/intern/diff/15539518/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21071
Pulled By: driazati
Differential Revision: D15539518
fbshipit-source-id: 24bdd1ef41ef636eefd5d2bad4ab2d79646ed4f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17946
Some of these are probably implementable for exported operators,
but aren't implemented yet and for now it's better to assert than to just return wrong results.
Reviewed By: ezyang
Differential Revision: D14430749
fbshipit-source-id: 2b0037a9ed227a22aa7376a90e6d3d09d3e04707
Summary:
Fixes#18440
I calculate a derived index from `start,stop,step` as `start + step*index`. When `start=0` and `step=1` (the defaults/`range(n)`), this is the same behavior as before.
Unluckily, it seems that we do not optimize out operations like `x*1` or `x+0`. That means that we're doing lots of redundant operations when we don't need to. EDIT: More specifically, it seems like we only do this optimization for (tensor, scalar): https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/passes/peephole.cpp#L128
The most annoying part of this code is calculating the number of iterations, given `start, stop, step`. I ended up going with the formula `(abs(stop-start) + abs(step)-1)//abs(step)`. Other intuitively appealing formulas like `(stop-start + step -1)//step` don't work for negative numbers.
I tried using `SymbolicVariable` for the calculations, but it seems that `symbolicvariable` only outputs ops for `tensors`, not the integers we have.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20795
Differential Revision: D15446869
Pulled By: Chillee
fbshipit-source-id: 6085545ace04e25985c6ac870226f7a651f670d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21035
Fix the dtype error in `dequantize_linear`, it should accept the same dtype argument as `quantize_linear`
Differential Revision: D15521931
fbshipit-source-id: 0114c046a3f1046e42fca49c74c85e487fee8616
Summary:
This PR adds a check that prints a warning if a type annotation prefix isn't what mypy expects.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20884
Differential Revision: D15511043
Pulled By: Krovatkin
fbshipit-source-id: 9038e074807832931faaa5f4e69628f94f51fd72
Summary:
I accidentally added a TF dependency in #20413 by using the from tensorboard.plugins.mesh.summary import _get_json_config import.
I'm removing it at the cost of code duplication.
orionr, Please review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21066
Reviewed By: natalialunova
Differential Revision: D15538746
Pulled By: orionr
fbshipit-source-id: 8a822719a4a9f5d67f1badb474e3a73cefce507f
Summary:
In larger system environment, there's usually a need to store some information about how the model was created (e.g. from which process, workflow, by which user, etc). It's almost like JPEG metadata written by camera.
This PR adds a low-level c++ hook to allow population of additional files in zip container based on environment. The reason to have it a low-level hook instead of top-level API wrapper (e.g. `m.save_with_metadata`) is to capture all usages of the saving API transparently for user.
Let me know if there are concerns.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20863
Differential Revision: D15487941
Pulled By: dzhulgakov
fbshipit-source-id: 120c5a4c9758aa82846bb51a1207f923e3da1333
Summary:
This doesn't have `strace` yet. But still have `faulthandler` to print stack traces at hanging. Also part of an attempt to isolate changes from #19228 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20166
Differential Revision: D15536504
Pulled By: ezyang
fbshipit-source-id: fe6e6e2e9899f30d8167436d7bc62b42883a3356
Summary:
Previously, we didn't work when 2d target tensors had extra columns at the end. Now we just ignore those.
Also fix the confusion in the doc example regarding the number of classes.
Thank you, ypw-rich for the report with reproducing example.
Fixes: #20522
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20971
Differential Revision: D15535481
Pulled By: ezyang
fbshipit-source-id: 397e44e20165fc4fa2547bee9390d4c0b688df93
Summary:
https://github.com/pytorch/pytorch/pull/17783 has made ninja and makefile builds to print out build commands unconditionally, this has made the build log very verbose, e.g. ROCm CI build log becomes >13mb. Large build log make searching for real error hard.
https://github.com/pytorch/pytorch/pull/20508 has reverted the ninja change, and this one reverts the makefile change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21053
Differential Revision: D15533412
Pulled By: bddppq
fbshipit-source-id: ad89b617d06acc670d75d4cf25111a4081e9c95e
Summary:
I've reported inconsistency between `checkpoint_sequential` and `nn.Sequential` at https://github.com/pytorch/pytorch/issues/19260. Both should provide the same input signature but they don't. I think the consistency is important and I agree with apaszke that `nn.Sequential`'s semantics should be kept instead of `checkpoint_sequential`.
I hope `checkpoint_sequential` raises `TypeError` on variadic arguments since PyTorch 1.2.0. But for now, it's okay just to warn as `DeprecationWarning`. I've talked about this approach with soumith.
Please review this pull request. Any comment will be my pleasure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21006
Differential Revision: D15530801
Pulled By: soumith
fbshipit-source-id: 0ceb2cc6a17dcc547d0d00ebaf9df8603be53183
Summary:
gradcheck currently includes a determinism check (although only trying twice and seeing if results match).
This can lead to flaky tests, e.g. in #20971, but also #13818.
This adds nondet_tol for both gradcheck and gradgradcheck. It does not change / reenable any tests yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20980
Differential Revision: D15530129
Pulled By: soumith
fbshipit-source-id: 04d7f85b5b59cd62867820c74b064ba14f4fa7f8
Summary:
Fixes a typo in the CyclicLR docs by adding the lr_scheduler directory and puts in other required arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21021
Differential Revision: D15530109
Pulled By: soumith
fbshipit-source-id: 98781bdab8d82465257229e50fa3bd0015da1286
Summary:
Just an annoying warning that's been popping up a lot.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20964
Differential Revision: D15531064
Pulled By: Chillee
fbshipit-source-id: 9580115676c5e246481054bbfc749a551a3cca5e
Summary:
This PR covers two important points with respect to the QR decomposition:
- batching of input matrices (#7500)
- adding `some` as an option in `torch.qr` akin to NumPy's `mode` option (#10538)
Changelog:
- Enable batching for inputs to `torch.qr`
- Move QR decomposition implementation to ATen (CPU and CUDA)
- Remove existing implementations in TH/THC
- Add a `some` option to `torch.qr` that will enable users to switch between complete and reduced decomposition
- Modify doc strings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20689
Differential Revision: D15529230
Pulled By: soumith
fbshipit-source-id: 16af82b1d2db8a3a758fa8a5f798d83f5f950efb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20603
When we use intra_op_parallel operators, Caffe2 tracing was generating trace only for the master task giving a false impression that a lot of threads are underutilized.
This diff also traces child tasks.
Reviewed By: ilia-cher
Differential Revision: D14820008
fbshipit-source-id: ff4ed203804d86d9231c21c99d869f1ddf1d1ef9
Summary:
Add an option to setup.py to stop the build process once cmake terminates. This leaves users a chance to fine adjust build options. Also update README accordingly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21034
Differential Revision: D15530096
Pulled By: soumith
fbshipit-source-id: 71ac6ff8483c3ee77c38d88f0d059db53a7d3901
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20647
The initial assumption was that `qint8` would be unsigned. After introduction of `quint8` and `qint8`, some tests break.
Reviewed By: jerryzh168
Differential Revision: D15332106
fbshipit-source-id: 6ed18da428915aea918a363c5f38754a3c75d06b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20493
This helps distinguish if the op was a quantized op or not.
Reviewed By: salexspb
Differential Revision: D15337854
fbshipit-source-id: 43c7aef143085cfaeb4ec2102a7f36cc454e0e94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20173
Enabled op profiling even when net type is not dag or prof dag. Also added
engine type info to summary.
Reviewed By: salexspb, ilia-cher
Differential Revision: D15177813
fbshipit-source-id: 5be0efeaabc9a961cf1d73b0703749c08bb1adbb
Summary:
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#19587 [jit] Make ScriptModule.training an attribute instead of a parameter**
Remove the hack we had previously where `training` was a buffer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19587
Differential Revision: D15502768
Pulled By: driazati
fbshipit-source-id: 3022f2d57ec6849868f9225d9bc2bfb7828cb318
Summary:
Before we look into supporting `deepcopy` we could at least improve an error msg.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20885
Differential Revision: D15511023
Pulled By: Krovatkin
fbshipit-source-id: 93b8730a2cc663eee0147f14d3341d0606748eaf
Summary:
This #20919 without the changes to aten/src/THC/THCIntegerDivider.cuh
that broke the ROCm build.
cc bddppq
Original summary:
This fixes advanced indexing in cases where there's more than 2^31-1
bytes in the output. The `gpu_index_kernel` was missing the
`can_use_32bit_indexing`/`with_32bit_indexing` check.
This also adds a number of TORCH_INTERNAL_ASSERTS in Loops.cuh,
OffsetCalculator, and IntDivider that sizes are fit in a signed 32-bit
integer.
More comprehensive tests that require a 32 GB GPU are here:
https://gist.github.com/colesbury/e29387f5851521256dff562be07b981e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21019
Differential Revision: D15518477
Pulled By: colesbury
fbshipit-source-id: 4db5626fda76eb58250793e8aa7d4f2832db3a34
Summary:
Fixes#20495 .
Now for
```python
class A(torch.jit.ScriptModule):
def __init__(self):
super(A, self).__init__()
torch.jit.script_method
def forward(self, x):
return x + self.whatisgoingon
class B(A):
def __init__(self):
super(B, self).__init__()
torch.jit.script_method
def bar(self, x):
return x * x
A()
```
it does
```
RuntimeError:
attribute 'whatisgoingon' does not exist:
torch.jit.script_method
def forward(self, x):
return x + self.whatisgoingon
~~~~~~~~~~~~~~~~~~ <--- HERE
```
I added a test in `test_jit.py` as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20779
Differential Revision: D15441138
Pulled By: Chillee
fbshipit-source-id: 88f458c36b5e32a1ffc467b27bbc28a3c5c07321
Summary:
As a part of https://github.com/pytorch/pytorch/pull/20580 I noticed that we had some unusual variable naming in `summary.py`. This cleans it up and also removes some variables that weren't being used.
I'll wait until we have an `add_custom_scalars` test to land this.
cc lanpa natalialunova
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20861
Differential Revision: D15503420
Pulled By: orionr
fbshipit-source-id: 86d105a346198a1ca543d1c5d297804402ab5a0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20880
This clarifies how the momentum parameters should be used.
Reviewed By: soumith
Differential Revision: D15482450
fbshipit-source-id: e3649a38876c5912cb101d8e404abca7c3431766
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20610
Change InferLengthsRangeFill
Add InferGatherRanges
add tests from ClipRangesGatherSigridHash all the way to SparseLengthsWeightedSum
add tests from SigridTransforms all the way to SparseLengthsWeightedSum
e2e test will be added in the following diff
Reviewed By: ipiszy
Differential Revision: D15382730
fbshipit-source-id: a611cd129007a273dfc43955cd99af1c4ed04efd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20938
Dequantize_linear need not be exposed to the front end users.
It will only be used for the jit passes for q-dq insertion and op
substitution.
Differential Revision: D15446097
fbshipit-source-id: a5fbcf2bb72115122c9653e5089d014e2a2e891d
Summary:
Remove the internal functions in multi_head_attention_forward. Those internal functions cause 10-15% performance regression and there is possibly a JIT issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20653
Differential Revision: D15398888
Pulled By: cpuhrsch
fbshipit-source-id: 0a3f053a4ade5009e73d3974fa6733c2bff9d929
Summary:
Changes:
- protobuf has been moved to protocolbuffers/protobuf a while ago.
- cpuinfo has been moved to pytorch/cpuinfo and updated in FBGEMM recently.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20973
Differential Revision: D15511926
Pulled By: soumith
fbshipit-source-id: 2c50373c9b245524f839bd1059870dd2b84e3b81
Summary:
Sometimes users forget using the "--recursive" option when they update submodules. This added check should help expose this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20937
Differential Revision: D15502846
Pulled By: mrshenli
fbshipit-source-id: 34c28a2c71ee6442d16b8b741ea44a18733b1536
Summary:
This changes the progress bars in `_download_url_to_file` from saying things like `49773343.40it/s` to `47.5MB/s`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20908
Differential Revision: D15511223
Pulled By: soumith
fbshipit-source-id: 2422eb5fb486f9ef4bd69c556c4ed1775b8b2860
Summary:
I believe the `True` and `False` in the doc are reversed :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20961
Differential Revision: D15510806
Pulled By: soumith
fbshipit-source-id: 62566bb595e187506b23dedc24892e48f35b1147
Summary:
Fixes#20630
Haven't tested it yet. Let's see if it passes all CI tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20882
Reviewed By: pietern
Differential Revision: D15483561
Pulled By: mrshenli
fbshipit-source-id: 5f0730a04d92906af077b2fe2170b674ca371e6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20868
When `input_boxes_include_bg_cls` is false (which means `input_scores_fg_cls_starting_id` is 0), It doesn't map the class index of score currectly when sorting and limiting the detections over all classes after nms.
Reviewed By: newstzpz
Differential Revision: D15472706
fbshipit-source-id: dc1e808b63ad09fb4bd95acf866771bb3fa92d69
Summary:
This fixes advanced indexing in cases where there's more than 2^31-1
bytes in the output. The `gpu_index_kernel` was missing the
`can_use_32bit_indexing`/`with_32bit_indexing` check.
This also adds a number of TORCH_INTERNAL_ASSERTS in Loops.cuh,
OffsetCalculator, and IntDivider that sizes are fit in a signed 32-bit
integer.
More comprehensive tests that require a 32 GB GPU are here:
https://gist.github.com/colesbury/e29387f5851521256dff562be07b981eFixes#20888
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20919
Differential Revision: D15501945
Pulled By: colesbury
fbshipit-source-id: e876e678e866d2efda8ee92c47a1d2d1310671f0
Summary:
Previously, this used `crepr` afer the decref of `repr`. This is not
allowed because `repr` owns the cached copy of `crepr`.
Let's see if this fixes the contbuild.
See #20926
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20931
Differential Revision: D15501929
Pulled By: colesbury
fbshipit-source-id: 24141ba62df8758d2a3998cf7c2054be09088b6a
Summary:
Bug reported internally at FB:
```python
>>> t=torch.from_numpy(np.empty((0,4)))
>>> t[:,1::2]*=1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Trying to resize storage that is not resizable at ../aten/src/TH/THStorageFunctions.cpp:76
```
This happens because the storage offset of `t[:, 1::2]` is 1, and it has 0 elements. We can fix this by avoiding resizing the storage for no-element arrays.
(We could *also* have avoided it by not modifying the storage index in this case, but I felt this way was more semantically correct -- in general, we should not be assuming it's okay to do anything to the storage when it has zero elements).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20914
Differential Revision: D15497860
Pulled By: umanwizard
fbshipit-source-id: 6af61d73a05edfc5c07ce8be9e530f15bf72e6a9
Summary:
I started adding support for the new **[mesh/point cloud](https://github.com/tensorflow/graphics/blob/master/tensorflow_graphics/g3doc/tensorboard.md)** data type introduced to TensorBoard recently.
I created the functions to add the data, created the appropriate summaries.
This new data type however requires a **Merged** summary containing the data for the vertices, colors and faces.
I got stuck at this stage. Maybe someone can help. lanpa?
I converted the example code by Google to PyTorch:
```python
import numpy as np
import trimesh
import torch
from torch.utils.tensorboard import SummaryWriter
sample_mesh = 'https://storage.googleapis.com/tensorflow-graphics/tensorboard/test_data/ShortDance07_a175_00001.ply'
log_dir = 'runs/torch'
batch_size = 1
# Camera and scene configuration.
config_dict = {
'camera': {'cls': 'PerspectiveCamera', 'fov': 75},
'lights': [
{
'cls': 'AmbientLight',
'color': '#ffffff',
'intensity': 0.75,
}, {
'cls': 'DirectionalLight',
'color': '#ffffff',
'intensity': 0.75,
'position': [0, -1, 2],
}],
'material': {
'cls': 'MeshStandardMaterial',
'roughness': 1,
'metalness': 0
}
}
# Read all sample PLY files.
mesh = trimesh.load_remote(sample_mesh)
vertices = np.array(mesh.vertices)
# Currently only supports RGB colors.
colors = np.array(mesh.visual.vertex_colors[:, :3])
faces = np.array(mesh.faces)
# Add batch dimension, so our data will be of shape BxNxC.
vertices = np.expand_dims(vertices, 0)
colors = np.expand_dims(colors, 0)
faces = np.expand_dims(faces, 0)
# Create data placeholders of the same shape as data itself.
vertices_tensor = torch.as_tensor(vertices)
faces_tensor = torch.as_tensor(faces)
colors_tensor = torch.as_tensor(colors)
writer = SummaryWriter(log_dir)
writer.add_mesh('mesh_color_tensor', vertices=vertices_tensor, faces=faces_tensor,
colors=colors_tensor, config_dict=config_dict)
writer.close()
```
I tried adding only the vertex summary, hence the others are supposed to be optional.
I got the following error from TensorBoard and it also didn't display the points:
```
Traceback (most recent call last):
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/serving.py", line 302, in run_wsgi
execute(self.server.app)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/serving.py", line 290, in execute
application_iter = app(environ, start_response)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/application.py", line 309, in __call__
return self.data_applications[clean_path](environ, start_response)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/wrappers/base_request.py", line 235, in application
resp = f(*args[:-2] + (request,))
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/plugins/mesh/mesh_plugin.py", line 252, in _serve_mesh_metadata
tensor_events = self._collect_tensor_events(request)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/plugins/mesh/mesh_plugin.py", line 188, in _collect_tensor_events
tensors = self._multiplexer.Tensors(run, instance_tag)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/event_processing/plugin_event_multiplexer.py", line 400, in Tensors
return accumulator.Tensors(tag)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/event_processing/plugin_event_accumulator.py", line 437, in Tensors
return self.tensors_by_tag[tag].Items(_TENSOR_RESERVOIR_KEY)
KeyError: 'mesh_color_tensor_COLOR'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20413
Differential Revision: D15500737
Pulled By: orionr
fbshipit-source-id: 426e8b966037d08c065bce5198fd485fd80a2b67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20821
Change registration API. Instead of
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel>()
.dispatchKey(CPUTensorId()));
it is now
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel>(CPUTensorId()));
This binds kernel and dispatch key together, allowing them to be separate from other future configuration options like alias analysis or autograd wrappers.
The semantic problem behind this is that the dispatch key is a *kernel config parameter* and not an *operator config parameter* while things like autograd wrappers, alias info, and actually the kernel itself are *operator config parameters*. And while previously, the different kind of config parameters have been mixed, this diff now separates them.
Before this change, it wouldn't have been well defined if you specified a dispatchKey together with an autogradWrapper or aliasInfo for example.
// what is this supposed to do?
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.aliasInfo(DEFAULT)
.dispatchKey(CPUTensorId()));
If we get more kernel config parameters in the future, we could introduce something like this
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel>(torch::RegisterOperators::kernelOptions()
.dispatchKey(CPUTensorId())
.otherConfig());
but that's overkill as long as dispatch keys are the only kernel config parameter, and we can introduce that later without breaking backwards compatibility.
A nice side effect of this is that people can register multiple kernels to the same operator in the same `.op()` call:
static auto registry = torch::RegisterOperators()
.op("my::op", torch::RegisterOperators::options()
.kernel<Kernel1>(CPUTensorId())
.kernel<Kernel2>(CUDATensorId()));
Reviewed By: dzhulgakov
Differential Revision: D15455790
fbshipit-source-id: 1c46bfe676dcacf74cf36bd3f5df3d2c32b8fb11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17818
Some of these are probably implementable for exported operators,
but aren't implemented yet and for now it's better to assert than to just return wrong results.
Reviewed By: ezyang
Differential Revision: D14392459
fbshipit-source-id: bf86e6cb0a7cfefd112a65dc85cc243e57a5ad52
Summary:
This PR also moves Device::validate into the header file, which makes
statements like `Device d = kCPU` effectively free.
Device includes the device's index, so TensorIterator::compute_types
now implicitly checks that all CUDA inputs are on the same GPU.
Previously, this was done ad-hoc in places like TensorIterator::binary_op.
Note that zero-dim Tensor (scalars) are NOT required to be on the
same device as other inputs because they behave almost like Python numbers.
TensorIterator handles copying zero-dim Tensors to the common device.
Prior to this PR, TensorIterator would copy zero-dim Tensors between CPU
and GPU, but not between different GPUs (because Backend didn't encode
the GPU index). This removes that restriction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20690
Differential Revision: D15414826
Pulled By: colesbury
fbshipit-source-id: 1d0ad1f7d663252af36dd4590bcda418c2f7a09f
Summary:
This PR is a eliminates unneeded grad_sum_to_size and in particular speeds up the LSTM backward by allowing better fusion.
It consists of two parts:
- In AutoDiff, record broadcasting sizes only if the broadcast output size is different from the input size, otherwise record None.
- The specialization of Optional arguments (#18407) allows us to then eliminate ` _grad_sum_to_size(t, None)` in the peephole optimization step.
Thus, in the LSTM case, no SumToSize remain in the crucial fusion group. The trick here is that we can specialize on the runtime information from the forward.
I'm testing that different broadcasting situations lead to different graphs.
I didn't move all symbolic_script _grad_sum_to_size to the new logic, but it might be better to do this incrementally, anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18697
Differential Revision: D15482076
Pulled By: wanchaol
fbshipit-source-id: 7f89367e35b8729910077c95c02bccefc8678afb
Summary:
To say that we don't do refinement on module attributes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20912
Differential Revision: D15496453
Pulled By: eellison
fbshipit-source-id: a1ab9fb0157a30fa1bb71d0793fcc9b1670c4926
Summary:
Earlier, the workspace size query and allocation was placed inside the loop.
However, since we have batches of matrices with the same number of rows and columns, the workspace size query and allocation for every matrix in the batch is redundant.
This PR moves the workspace size query and allocation outside the loop, effectively saving (batch_size - 1) number of queries and allocation (and consequently the deallocation).
There is a tremendous speedup in inverse computation as a result of this change.
Changelog:
- Move workspace query and allocation outside the batch loop
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20904
Differential Revision: D15495505
Pulled By: ezyang
fbshipit-source-id: 226729734465fcaf896f86e1b1a548a81440e082
Summary:
- Do not install unecessary packages in the Docker image.
- In the Docker image, use conda to install ninja (saving one layer)
- When workdir is set, use "." to refer to it to reduce redundancy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20881
Differential Revision: D15495769
Pulled By: ezyang
fbshipit-source-id: dab7df71ac107c85fb1447697e25978daffc7e0b
Summary:
Currently PyTorch forces color output due to #20662. But users should be left an option to turn it off because redirection of the output to a file would be messed if color output is forced.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20771
Differential Revision: D15495677
Pulled By: ezyang
fbshipit-source-id: 9d89bbed40d0b67368554305394763a54c5ff6f5
Summary:
Currently when the argument to isinf and isfinite is not tensor, a ValueError is raised. This, however, should be a TypeError, because the error is a type mismatch.
In the error message, "str(tensor)" is replaced by "repr(tensor)" because, when an error occurs, a printable representation of the object is likely more useful than the "informal" string version of the object.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20817
Differential Revision: D15495624
Pulled By: ezyang
fbshipit-source-id: 514198dcd723a7031818e50a87e187b22d51af73
Summary:
Attention mask should be of shape `(L, S)` since it is added to `attn_output_weights`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20850
Differential Revision: D15495587
Pulled By: ezyang
fbshipit-source-id: 61d6801da5291df960daab273e874df28aedbf6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20892
FBGEMM uses 64 bit values. Need to change our implementation to match
Reviewed By: jerryzh168
Differential Revision: D15487664
fbshipit-source-id: 29cba26093c6f9aeafce14982c1ae12149e63562
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20773
This removes the feature to register fallback kernels that are called when no other kernel matches.
Instead, we introduce the concept of catchall kernels that are always called independent of inputs.
If you only have a fallback/catchall kernel and no kernels with concrete dispatch keys, then both concepts behave in the same way.
The difference is that we now disallow operators to have both, a catchall kernel and kernels with concrete dispatch keys.
This was possible before when they have been fallback kernels.
The reason for this change is that we anticipate needing a method_missing feature in backends, i.e. a backend-wide fallback to call when the backend doesn't specify a kernel for an operator.
We are not clear on precendence between this backend-wide fallback and an operator level fallback. Disallow fallbacks for now so we are free to choose later without breaking backwards compatibility.
Reviewed By: dzhulgakov
Differential Revision: D15438977
fbshipit-source-id: cb3aa764a1659d909ee21a7bd8ec3d32438aafaa
Summary:
Resubmit #20698 which got messed up.
Idea is that when PyTorch is used in a custom build environment (e.g. Facebook), it's useful to track usage of various APIs centrally. This PR introduces a simple very lightweight mechanism to do so - only first invocation of a trigger point would be logged. This is significantly more lightweight than #18235 and thus we can allow to put logging in e.g. TensorImpl.
Also adds an initial list of trigger points. Trigger points are added in such a way that no static initialization triggers them, i.e. just linking with libtorch.so will not cause any logging. Further suggestions of what to log are welcomed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20745
Differential Revision: D15429196
Pulled By: dzhulgakov
fbshipit-source-id: a5e41a709a65b7ebccc6b95f93854e583cf20aca
Summary:
As part of the Variable/Tensor merge work: https://github.com/pytorch/pytorch/issues/13638, we make the following changes in this PR:
1. Remove the `Variable::Impl` class and the `DifferentiableViewImpl` class
2. Change all `Variable.data()` call sites to either use `Variable` directly, or use `Variable.tensor_data()`
3. Remove `Variable.data()` API
3. Add `Variable.variable_data()` that matches `tensor.data` in Python API, which creates a new `Variable` that shares the same storage and tensor metadata with the original `Variable`, but with a completely new autograd history.
After this PR, Variable doesn't wrap a Tensor internally anymore, and both Variable and Tensor use the same TensorImpl class as its `impl_`. The only difference is that Variable always has AutogradMeta in its TensorImpl, but Tensor doesn't.
**Note that this PR is BC-breaking in the following use cases:**
**Use Case 1:**
Previously, `x.data = y` works even if `x` and `y` are of different TensorImpl type (e.g. `x` is a CPU dense tensor whose impl is of type TensorImpl, while `y` is a CPU sparse tensor whose impl is of type SparseTensorImpl). However, after this PR, `x.data = y` doesn't work anymore if `x` and `y` are of different TensorImpl type, because the underlying implementation `variable.set_data(tensor)` no longer works if `variable` and `tensor` have different TensorImpl type.
**Use Case 2:**
If a tensor `x`'s `grad` is sparse, accumulating dense gradients to `x` will change the tensor that `x.grad` is pointing to. This is better illustrated with the following example:
```python
params = torch.tensor([1.5, 1.5]).requires_grad_()
with torch.no_grad():
# Change gradient to a sparse tensor
params.grad = torch.sparse_coo_tensor(torch.tensor([[1, 1]]).long(), torch.tensor([1., 1.]))
grad_saved = params.grad
params.backward(torch.tensor([1.5, 1.5]))
assert id(grad_saved) == id(params.grad) # This will fail after this PR
```
The assertion in the last line will fail after this PR, because adding dense gradients to sparse gradients will change the `params.grad` tensor reference.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17072
Differential Revision: D14075257
Pulled By: yf225
fbshipit-source-id: 0e681df641270dea586042dd26db59f2e76b5957
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20669
Before, Dict was a value type, i.e. copying it did a deep copy.
Unfortunately, this doesn't work well with storing and passing Dicts around in IValues because IValues are reference types.
This diff changes Dict to be a reference type.
Reviewed By: dzhulgakov
Differential Revision: D15404911
fbshipit-source-id: dc990d3eb7cae044b74dd0253f8b704dde6a6c86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20833
Att. The algorithm is still "horrendously inefficient". But since we are sunsetting Nomnigraph, I just did the minimal fix here.
Reviewed By: tracelogfb
Differential Revision: D15463880
fbshipit-source-id: 413a1280a92c1923ba49031177816a2d5f888575
Summary:
This tries to fix the following error on current master:
```
May 23 16:18:47 Traceback (most recent call last):
May 23 16:18:47 File "main.py", line 7, in <module>
May 23 16:18:47 from torchvision import datasets, transforms
May 23 16:18:47 File "/opt/conda/lib/python3.6/site-packages/torchvision/__init__.py", line 1, in <module>
May 23 16:18:47 from torchvision import models
May 23 16:18:47 File "/opt/conda/lib/python3.6/site-packages/torchvision/models/__init__.py", line 11, in <module>
May 23 16:18:47 from . import detection
May 23 16:18:47 File "/opt/conda/lib/python3.6/site-packages/torchvision/models/detection/__init__.py", line 1, in <module>
May 23 16:18:47 from .faster_rcnn import *
May 23 16:18:47 File "/opt/conda/lib/python3.6/site-packages/torchvision/models/detection/faster_rcnn.py", line 7, in <module>
May 23 16:18:47 from torchvision.ops import misc as misc_nn_ops
May 23 16:18:47 File "/opt/conda/lib/python3.6/site-packages/torchvision/ops/__init__.py", line 1, in <module>
May 23 16:18:47 from .boxes import nms, box_iou
May 23 16:18:47 File "/opt/conda/lib/python3.6/site-packages/torchvision/ops/boxes.py", line 2, in <module>
May 23 16:18:47 from torchvision import _C
May 23 16:18:47 ImportError: /opt/conda/lib/python3.6/site-packages/torchvision/_C.cpython-36m-x86_64-linux-gnu.so: undefined symbol: _ZN2at19NonVariableTypeMode10is_enabledEv
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20865
Differential Revision: D15481736
Pulled By: yf225
fbshipit-source-id: 67d4fd70652ccc709b44cb15392d6e44a8fe9235
Summary:
This PR changes CPU implementation of `AdaptiveAveragePool2D` by
- move dispatch to outside the OpenMP loop
- support fp16
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20366
Differential Revision: D15456069
Pulled By: ezyang
fbshipit-source-id: 00fa2916f8b136af9f5c8b5db0eca4619f9f5bac
Summary:
When adding custom scalars like this
```python
from torch.utils.tensorboard import SummaryWriter
with SummaryWriter() as writer:
writer.add_custom_scalars({'Stuff': {
'Losses': ['MultiLine', ['loss/(one|two)']],
'Metrics': ['MultiLine', ['metric/(three|four)']],
}})
```
This error is raised:
```
TypeError: Parameter to MergeFrom() must be instance of same class: expected tensorboard.SummaryMetadata.PluginData got list.
```
Removing the square brackets around `SummaryMetadata.PluginData(plugin_name='custom_scalars')` should be enough to fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20580
Differential Revision: D15469700
Pulled By: orionr
fbshipit-source-id: 7ce58034bc2a74ab149fee6419319db68d8abafe
Summary:
fix#20781#20757
hmm I don't know an easy way to add a test to make sure it runs against a package installed as .egg. But i tested it locally with torchvision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20782
Differential Revision: D15443600
Pulled By: ailzhang
fbshipit-source-id: 285eb0d9a44d6edb8e93618fa293f4feb431d2ae
Summary:
XLA needs a way to override CPUTensor.copy_(XLATensor), but we only
dispatch on the "self" argument. This inverts the dispatch order when
"src" is an unhandled type.
Note that things like XLATensor.copy_(CPUTensor) never enter this
implementation.
cc dlibenzi
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20783
Differential Revision: D15443187
Pulled By: colesbury
fbshipit-source-id: 4ee93ba598ef0fed2a99c0683aae30cb50a1f99c
Summary:
was reading the README on github and came across a couple of typos.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20819
Differential Revision: D15469603
Pulled By: nairbv
fbshipit-source-id: 0ed7868de2d4e6d82557a8c170783966f8a1afd7
Summary:
The duplicated code of `_optimize_trace` in _pytorch_graph.py is used to bypass some optimization step which causes missing scope.
It seems that most of the problematic steps have been fixed recently. Standard models implemented in torchvision are visually inspected before the commit. However, the `+=` in 50d54a82d1/torchvision/models/resnet.py (L63) will let f4d9bfaa4d/torch/onnx/utils.py (L159) produce a bad result. It can be fixed by replacing it with `out += identity`. This also implies that `+=` has non-intuitive behavior.
cc orionr ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20394
Reviewed By: NarineK
Differential Revision: D15452204
Pulled By: orionr
fbshipit-source-id: eaa4c13f16551c78dc6419f1e22eb2c560af4cc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20772
Copy of D15178352
A conflicting commit landed at the same time as D15178352 that removed registering kernels using IntArrayRef, Hence, D15178352 was revered. Using std::vector instead.
Reviewed By: zafartahirov
Differential Revision: D15437237
fbshipit-source-id: cd2f1caebcc720352b48ce25d716cb1ca49a5197
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20816
Previously, the c10 dispatcher expected ops to be called with Variables and unwrapped them to Tensors before calling into the kernel.
The kernel was expected to return Tensors that were re-wrapped into Variables before passing them on into the system.
However, that doesn't work with kernels that call other operators. One recent example was a kernel that returned the result of `torch::ones()` as output.
Now, with this diff, the c10 dispatcher still passes Tensors to the kernel and Variables back into the system, but it accepts ops to be called with both Tensors or Variables
and kernels are also allowed to return either.
After https://github.com/pytorch/pytorch/pull/17072 , we should be able to get rid of the whole wrapping/unwrapping logic.
Reviewed By: hl475
Differential Revision: D15453963
fbshipit-source-id: 7602b7f2bc43e8ceb8a8c0e97aafcc53d4c47b6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20740
Provide a way to assemble quantized Tensor from int8 Tensor, scale and zero point.
Differential Revision: D15232416
fbshipit-source-id: c3a3d9d7214b1dc569214c019440c2779fbd063b
Summary:
This is the first part of the planned changes to change the comparison operations result tensor dtype from Byte to Bool. You can see the whole list of changes (not cleaned up) [here](https://github.com/pytorch/pytorch/pull/19332). As the PR is too big for a single review im breaking it into pieces.
**Changes in this PR:**
1. Enable these methods for bool tensors:
- maskedSelect
- maskedSelectBool
- bitand
- cbitand
- bitor
- cbitor
- bitxor
- cbitxor
- sign
- equal
- neg
2. Add bool clause for the TH version of sign method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20767
Differential Revision: D15436446
Pulled By: izdeby
fbshipit-source-id: 8d2494b5f4873cd79c7f1a40d2cb045cadfad51a
Summary:
I didn't update the Windows references because I wasn't sure if they apply to CUDA 9. peterjc123 what should the Windows section say?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20718
Differential Revision: D15459276
Pulled By: colesbury
fbshipit-source-id: 917e22f8ac75378d88c962c226b5a42b6799c79a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20802
Need this for sequence model
Reviewed By: dzhulgakov
Differential Revision: D15448529
fbshipit-source-id: cd5abe3b689fc0e02feff10faf8cd61c99369f4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20786
Add a method to LayerModelHelper to filter metrics_schema. A general model builder may add metric schema that is not needed in some situations. This change add the ability to skip those unneeded.
Reviewed By: alex1o1o7cloud
Differential Revision: D15418140
fbshipit-source-id: 520f5dffd9938cf206cb1352e2953a4d4d2b6ab1
Summary:
When detecting the presence of NumPy using import, move numpy-related variable assignments outside the try block (i.e., to an else block) to improve readability.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20739
Differential Revision: D15453916
Pulled By: ezyang
fbshipit-source-id: d3c37f2b290846be3c6a1462251cbb3e95d493be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20787
Set requires_grad=False for bias: this will block the jit tracing.
The as_type fix: The input tensor shape and output tensor shape will be different, which will trigger the assertion failure at https://fburl.com/0m8xy7tc.
Reviewed By: jamesr66a
Differential Revision: D15445092
fbshipit-source-id: 22da41a56ecb9ac092585d0cc1ff0658fb9d631b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20045
This pass adds quant-dequant nodes for bias. This pass requires
quant-dequant pass for activations and weights to be done as it is required
to compute the qparams for bias
Differential Revision: D15179141
fbshipit-source-id: 3aab9fceefcadc3fa42a4e802d9b1e18addad78a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20770
Add dict type since it's part of the pytorch built-in system, and sparse features and text features will be converted to Dict
Reviewed By: pritamdamania87
Differential Revision: D15436255
fbshipit-source-id: 239adbd6a8f68be29020fe656d790f6872f1f0e9
Summary:
as title. We were using AT_ASSERT, which is newly deprecated. In this case, we do in fact want an internal assertion since this is used in testing code to describe expected behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20555
Differential Revision: D15362964
Pulled By: suo
fbshipit-source-id: 984bfe71a774571611f3bbd81767d3cdb878a6fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20345
Seperate from D15194600
Optimize pytorch layer_norm op part 1:
optimize layer_norm_forward_cpu
import Eigen Maps for the performance of reduction
Reviewed By: zheng-xq
Differential Revision: D15290608
fbshipit-source-id: cf2c208dfd6fbcbc4c69db3ed60278d9bee156b5
Summary:
Previous implementation of magic methods extended from BuiltinOperators, but it should be able to work with other sugared values, such as casts.
I was also considering making CastValue's and BuiltinOperators's extend from a MagicMethod super class, and having them try to call into the super's before their own call. However, not all Builtin Operators have corresponding magic methods so i did it this way instead (although there are workarounds for that).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20654
Differential Revision: D15434469
Pulled By: eellison
fbshipit-source-id: 813fa00bf8b5b9ada46505075ebf984d8eee6aef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20711
For uint8_t, ```std::numeric_limits::digits``` returns 8;
For int8_t, ```std::numeric_limits::digits``` returns 7.
FBGEMM wants to get the ```qparams.precision``` to be always 8 for both int8_t and uint8_t.
Reviewed By: jerryzh168
Differential Revision: D15410695
fbshipit-source-id: 17dc3842d7c426947454c201bcb167b87b7301ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20726
Edward says it doesn't actually provide compilers,
but it does provide dependencies, so let's mention that instead.
Reviewed By: ezyang
Differential Revision: D15423316
fbshipit-source-id: 9b384f88e5bf7a3d2c132508620c276b49e1569f
Summary:
This PR implements auto-conversion of GPU arrays that support the `__cuda_array_interface__` protocol (fixes#15601).
If an object exposes the `__cuda_array_interface__` attribute, `touch.as_tensor()` and `touch.tensor()` will use the exposed device memory.
#### Zero-copy
When using `touch.as_tensor(...,device=D)` where `D` is the same device as the one used in `__cuda_array_interface__`.
#### Implicit copy
When using `touch.as_tensor(...,device=D)` where `D` is the CPU or another non-CUDA device.
#### Explicit copy
When using `torch.tensor()`.
#### Exception
When using `touch.as_tensor(...,device=D)` where `D` is a CUDA device not used in `__cuda_array_interface__`.
#### Lifetime
`torch.as_tensor(obj)` tensor grabs a reference to `obj` so that the lifetime of `obj` exceeds the tensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20584
Differential Revision: D15435610
Pulled By: ezyang
fbshipit-source-id: c423776ba2f2c073b902e0a0ce272d54e9005286
Summary:
Appending `arch` to the generator name is not supported for VS starting from VS 2019.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20752
Differential Revision: D15436740
Pulled By: ezyang
fbshipit-source-id: 20057aae8f708d82619927bf2cb87dd1bc2df312
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20737
If someone tries to register multiple kernels in the same .op() call, we're now throwing an error.
Differential Revision: D15425660
fbshipit-source-id: 6d2f1444da3e16a6a98863d847965c2aa211e046
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20674
A few targets in caffe2/caffe2/distribute needs to be split too, otherwise won't compile. Also some clean ups and make select_gpu_type to gpu_library_selector
Differential Revision: D15406019
fbshipit-source-id: 6455ab885b248502b48d4c7565597e00fecfd547
Summary:
Let there be color!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20662
Differential Revision: D15434110
Pulled By: suo
fbshipit-source-id: a317ae72ad72e0b8249f55c9c8d31f420c78c040
Summary:
building with cuda and gcc 4.8.5-28, we see many warnings like:
[893/1645] Building NVCC (Device) object caffe2/CMakeFiles/caffe2_gpu.dir/__/aten/src/THCUNN/caffe2_gpu_generated_ELU.cu.o
/home/bvaughan/repos/pytorch/c10/util/ArrayRef.h:277:48: warning: ‘deprecated’ attribute directive ignored [-Wattributes]
using IntList C10_DEPRECATED_USING = ArrayRef<int64_t>;
This change prevents those warnings on the older compiler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20587
Differential Revision: D15432749
Pulled By: nairbv
fbshipit-source-id: fd707afcbd6564f96617378d7cd6d62d941a052b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20468
ScalarType node is mandatory for activations and parameters now.
This change inserts ScalarType node for all the quant-dequant nodes. For the activations, currently the default value is at::ScalarType::Undefined. Remove this and explicitly pass the at::ScalarType::QUint8 dtype
Differential Revision: D15331600
fbshipit-source-id: 5b51e0b42e694bf409026af4783a12da6d7e234b
Summary:
Copy.cu goes from 308 to 190 lines of code. In general it uses, the same
copy strategy, using cudaMempcyAsync, a pointwise kernel, or a copy
using temporary buffers. The pointwise kernel has slightly improved
performance when broadcasting due to faster index calculation.
This deletes "`s_copy_`", "`_s_copy_from`", and "`_copy_same_type_`". The only
entry-point now is "`copy_`".
A mini-benchmark is here:
https://gist.github.com/colesbury/706de1d4e8260afe046020988410b992
Before:
https://gist.github.com/colesbury/ab454b6fe3791bff420d7bcf8c041f18
After:
https://gist.github.com/colesbury/9024d242b56ab09a9ec985fa6d1620bc
Results were measured on 2.2 GHz Broadwell; no-turbo; one thread;
compiled with GCC 7.3.0. (Results are slower than typical usage due to
turbo being off.)
The only significant differences is in the CUDA [1024] -> [1024, 1024]
broadcasting copy which is ~25% faster. I don't expect a noticeable
difference in real programs.
CPU copy overhead is a tiny bit (~200 ns) faster, but I don't expect
anyone to notice that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20685
Differential Revision: D15414819
Pulled By: colesbury
fbshipit-source-id: d3c6e04a5020470e3bef15b1fc09503cae5df440
Summary:
Symbols are given hidden visibility by default on Linux to emulate the behavior on Windows. This helps developers catch visibility issues in their streamlined Linux dev environment before being surprised, late in the process, by Windows errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20461
Reviewed By: kostmo
Differential Revision: D15410410
Pulled By: dzhulgakov
fbshipit-source-id: 1d684b5a9a80b692966a775c3f1c56b7c72ffc95
Summary:
Fixes#20017
This wraps the `torch._C.Function` currently returned from `torch.jit.script` and `torch.jit.trace` in a `ScriptFunction` and `TracedFunction` respectively, both of which are just wrappers to hold the function.
](https://our.intern.facebook.com/intern/diff/15403161/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20386
Pulled By: driazati
Differential Revision: D15403161
fbshipit-source-id: 94fb9f32929e62a00be6cf7512ea144ec9b91e0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20677
With new changes in IR, it is possible to insert nodes after param
nodes in graph. Thus we do not need to have two methods for inserting q-dq
nodes to input or output to quantizable nodes.
Differential Revision: D15406354
fbshipit-source-id: 1963762f434fd82877fa76a272e8520c342b6069
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20709
- Remove ArrayRef based API. This is neither the old nor the planned new API.
- De-deprecate kernels based on std::vector and std::unordered_map. We don't have the Dict/List based API figured out entirely yet, so we shouldn't push people towards using them.
std::vector and std::unordered_map will get deprecated again once we figured out List/Dict.
Reviewed By: dzhulgakov
Differential Revision: D15417025
fbshipit-source-id: bfbb33c762e43487bb499bc8cc36d515e678f8fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20667
Compilation errors:
```
xplat/caffe2/caffe2/utils/signal_handler.h:31:10: error: private field 'SIGINT_action_' is not used [-Werror,-Wunused-private-field]
Action SIGINT_action_;
^
xplat/caffe2/caffe2/utils/signal_handler.h:32:10: error: private field 'SIGHUP_action_' is not used [-Werror,-Wunused-private-field]
Action SIGHUP_action_;
^
xplat/caffe2/caffe2/utils/signal_handler.h:33:17: error: private field 'my_sigint_count_' is not used [-Werror,-Wunused-private-field]
unsigned long my_sigint_count_;
^
xplat/caffe2/caffe2/utils/signal_handler.h:34:17: error: private field 'my_sighup_count_' is not used [-Werror,-Wunused-private-field]
unsigned long my_sighup_count_;
^
4 errors generated.
xplat/caffe2/caffe2/share/fb/stylizer/median_blur_ops.cc:593:14: error: private field 'ws_' is not used [-Werror,-Wunused-private-field]
Workspace* ws_;
^
1 error generated.
```
Reviewed By: bwasti
Differential Revision: D15402928
fbshipit-source-id: 5b98499850aa659fd37ab8e7f2e75166787b8129
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20040
Add the support of feature store example in fblearner pytorch predictor, end to end
Reviewed By: dzhulgakov
Differential Revision: D15177897
fbshipit-source-id: 0f6df8b064eb9844fc9ddae61e978d6574c22916
Summary:
load_state_dict includes a recursive inner function `load` that captures
Tensors through the close-over variable `state_dict`. Because it's
recursive, it also captures itself leading to a reference cycle.
This breaks the reference cycle so that any Tensors in state_dict can be
collected immediately instead of waiting until the next GC cycle.
Alternatively, we could have passed `state_dict` and `metadata` as
arguments to load to prevent capture of Tensors. (That would still
result in cyclic garbage, but not any cyclic garbage of Tensors).
See:
https://github.com/pytorch/pytorch/issues/20199#issuecomment-491089004
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20397
Differential Revision: D15414834
Pulled By: colesbury
fbshipit-source-id: 4c2275a08b2d8043deb3779db28be03bda15872d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20607
Add a new method SummaryWriter.flush() that iterates through all of the FileWriters and flushes them
Reviewed By: orionr
Differential Revision: D15380124
fbshipit-source-id: 1975f3f61c5ae3754552bfdb23f2cd78f687d19f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20649
I went through every occurrence of AT_ASSERT in this file and
thought about whether or not it should be TORCH_INTERNAL_ASSERT
or TORCH_CHECK. I think I did a good job at it. Some thoughts:
- In order to decide if a check is "internal" or not, we must
think about where the separation between userspace and our internals
are. I think any code that utilizes the PyTorch or Caffe2 C++ frontends
count as userspace. An important collorary is that the majority of operator
code "counts" as userspace, even though it lives in our repository. This
is inline with TCB (trusted computing base) thinking: you want the TCB to
be as small as possible, and because we have a *lot* of operator
implementations, they should not count as TCB.
- The primary test I applied when considering an AT_ASSERT was whether or
not I could trigger this error by just making method calls on caffe2::Tensor
or at::Tensor. If I could, that made it a TORCH_CHECK. This covers most
of the misapplications of TORCH_INTERNAL_ASSERT. One place I didn't
do this was the "is variable" checks; I think you have to work a bit
harder to trigger this case, and userspace code is not mixing up
Variables and Tensros.
- I updated the docs for device_opt_, explaining when it could be nullopt.
(The nullopt checks here are TORCH_CHECK, because you can trigger them
by taking an undefined tensor and poking the methods.)
Differential Revision: D15395576
fbshipit-source-id: 1c51b396012e7d949fbb4258092cf80e5e6f851b
Summary:
Fixes#20651
Communication collectives in `torch.distributed` call `CUDACachingAllocator::recordStream()` on input and output tensors to prevent their memory blocks being freed too early. `CUDACachingAllocator` uses tensor's data pointer to track memory blocks, which does not accept null pointers. However, empty tensor's `storage().data()` might be null. In this case, as there is no associated memory block for the empty tensor, it should be fine to make `recordStream()` a no-op.
Tests only cover `broadcast` empty tensors for GLOO backend, because GLOO does not support empty inputs (facebookincubator/gloo/issues/179). It can be addressed in either `ProcessGroupGloo` or GLOO itself. Will add more tests when that gap is filled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20658
Differential Revision: D15399371
Pulled By: mrshenli
fbshipit-source-id: d29ebd1c72fddae49531f32695f81b89e42e5a4d
Summary:
According to https://pytorch.org/docs/stable/notes/broadcasting.html, in-place operations do not allow the in-place tensor to change shape as a result of the broadcast. Therefore our shape analysis could keep the shape information on inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20661
Differential Revision: D15406477
Pulled By: wanchaol
fbshipit-source-id: 8ab60e783292f2fe26e5fdecfb64bec43bca6826
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20561
We previously planned to deprecate the direct passing of a kernel function or lambda to the op() call, e.g.
static auto registry = RegisterOperators().op("my::op", &func);
and push users towards the options based API:
static auto registry = RegisterOperators().op("my::op", RegisterOperators::options().kernel<decltype(func), &func>());
because that has a slightly lower performance overhead when calling the kernel.
However, that overhead is negligible for all but exotic use cases, so there's no reason to push users towards a more verbose API.
This diff removes the deprecation warning from that API.
However, if you use the API together with deprecated types like std::unordered_map, you will now get a deprecation warning there.
Reviewed By: zdevito
Differential Revision: D15364271
fbshipit-source-id: 56dae0c5870bbab16ad19ba5178f4bea9eafed9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20514
Change API from
static auto registry = c10::RegisterOperators()
.op("my::op",
c10::kernel(...),
c10::dispatchKey(...)
);
to
static auto registry = c10::RegisterOperators()
.op("my::op", c10::RegisterOperators::options()
.kernel(...)
.dispatchKey(...)
);
because this allows better discoverability. People looking for which options are available will easier find it and IDE autocompletion will work better.
Reviewed By: zdevito
Differential Revision: D15346348
fbshipit-source-id: 4b74a33b75c2b9cda4a903639fb7abd2c7cff167
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20672
Current test case looks for q->int_repr->dq pattern and constant nodes also.
The prim::Constant nodes are not guaranteed to be present at same point in graph.
So we modify the test case to only look for the q->int_repr->dq nodes.
Differential Revision: D15405606
fbshipit-source-id: 2086ffb5bbd328d2a9a55f4c2a2de342575194d3
Summary:
Otherwise users see something like (Tensor, Tensor)? and don't know what the ? means.
First commit is formatting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20657
Differential Revision: D15400225
Pulled By: eellison
fbshipit-source-id: cf826790bf2ddafd34f6d5c144526cad9904770b
Summary:
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#19578 [jit] Try to script all Python functions**
This adds the `torch.jit._enable_recursive_script` context manager, which will try to compile any Python functions it sees. It's hidden behind an internal context manager for now since it's incomplete (doesn't work for script_methods/Python submodules). If it can't compile the Python function it outputs an error.
](https://our.intern.facebook.com/intern/diff/15386727/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19578
Pulled By: driazati
Differential Revision: D15386727
fbshipit-source-id: 4e308f67677b8e9fccfc525a91bb2f4585062048
Summary:
Adds support for `__getstate__` and `__setstate__` on modules that are called as part of export (`torch.save()`) and import (`torch.jit.load`).
* `__getstate__` and `__setstate__` must be TorchScript functions with the signatures `() -> T` and `(T) -> None` respectively
* The results of `__getstate__` are stored using the pickler in `states.pkl` with one for each module in definition order (`__getstate__` returns `None` by default if an imlpementation is not provided)
* This prevents sharing between `__getstate__` and attributes, but this should be fine since their use is mostly unrelated (attributes are for storing values to be used in script methods, `__getstate__` for running arbitrary computations during import)
Follow up
* Somehow replacing `__getstate__`/`__setstate__` with a `ScriptMethodStub` makes `MyScriptModule().__getstate__()` call `ScriptModule.__getstate__()` when used in Python. This should be fixed so semantics in Python are preserved, but it doesn't affect the typical usage.
](https://our.intern.facebook.com/intern/diff/15287161/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20242
Pulled By: driazati
Differential Revision: D15287161
fbshipit-source-id: b3f5f33ab74a21a89e6d15460af63aff75cab2d8
Summary:
- Earlier, we had to use the legacy implementation of `getri` for single matrix inverse from TH and THC
- Now, this has been moved to ATen
Changelog:
- Move single matrix inverse implementation to ATen
- Remove unused code in TH and THC resulting from the change
- Minor modifications made to single matrix CPU function implementations in ATen to avoid redundancy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20534
Differential Revision: D15393383
Pulled By: ezyang
fbshipit-source-id: 81972111cd9757d15f1d634f294c93fd0f35636c
Summary:
Recent versions of GCC split unaligned load and store intrinsics into
two 128-bit instructions. On old processors (Sandy Bridge) this was a
bit faster for unaligned data, but bit slower for aligned data. On new
processors (Intel Haswell+, recent AMD) splitting loads is slower on
both aligned and unaligned data.
Clang, MSVC, and ICC do not split unaligned load and store intrinsics.
There's a good explanation here:
https://stackoverflow.com/questions/52626726/why-doesnt-gcc-resolve-mm256-loadu-pd-as-single-vmovupd#tab-top
Splitting load and store intrinsics makes no sense in our AVX2
configuration because the CPUs that support AVX2 instructions are the
same CPUs where splitting is disadvantageous on all data alignemnt.
Note that this doesn't change the AVX configuration (used by CPUs that
support AVX but not AVX2). It's possible this would be benficial for
that configuration too (our data is usually 32-byte aligned), but I'd
prefer the conservative change for now.
torch.add generated assembly (hot loop) (GCC 7.3.0)
before:
https://gist.github.com/colesbury/066376537bccd514daf8fe4ab54d8295
after:
https://gist.github.com/colesbury/8b4b948145001d44b225c51d2428bb91
Timing of `torch.add(x, y, out=z)` for size 10240 (1 thread, Broadwell,
no turbo):
before: 7.35 us after: 6.39 us
(Take the torch.add timings with a grain of salt. The difference in timings
is much larger than I would expect.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20609
Differential Revision: D15385800
Pulled By: colesbury
fbshipit-source-id: 66415b148a3b19360b9de9881af594ab46547b6f
Summary:
Change `Inputs` to `Shape` to unify the format of CTCLoss `class`, and add the type of `Output` in `Shape`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20422
Differential Revision: D15393484
Pulled By: ezyang
fbshipit-source-id: 5b49647f9740de77db49a566fa2de74fcecd9110
Summary:
CUDA 8 is no longer supported and removed from CI, so these checks are irrelevant
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20482
Differential Revision: D15393438
Pulled By: ezyang
fbshipit-source-id: ac0979bf660b3314eec502c745e34ce4940bda0e
Summary:
Fixes#20568.
Looks like CMake is passing `/MD` when we call `add_library`. We need to fix these with C source files too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20574
Differential Revision: D15392682
Pulled By: ezyang
fbshipit-source-id: c92034d8725fcec48fd7db6cf5322868e956dc6b
Summary:
Fixes#20523 .
nn.Upsample was unable to accept tuple inputs for the scale_factor argument due to direct casting to float, which was done in #17732.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20581
Differential Revision: D15392622
Pulled By: ezyang
fbshipit-source-id: b56ba8197a5bbf8891bc7e1bebf5cad63dcab04d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20441
This op is fairly complex and the fact that it isn't formatted
correctly makes things that much harder to reason about. Clean it up.
Reviewed By: dreiss
Differential Revision: D15220006
fbshipit-source-id: 30632d8bdbf15f96e73d8b6c96c5f29c052e6e7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20502
Following D15307410 removing more floating point exceptions in unit tests
Reviewed By: hx89
Differential Revision: D15340930
fbshipit-source-id: 269fc75e0800bc9d39126767a0f3ca15cd8b0cad
Summary:
(Reopens https://github.com/pytorch/pytorch/pull/20330 and fixes test error.)
After the Variable/Tensor merge, there is no guarantee that `indices` and `values` passed into the sparse tensor constructor don't contain AutogradMeta. However, we want to maintain the existing invariant that `indices_` and `values_` of a sparse tensor don't contain AutogradMeta, and to achieve this we need do shallow-copy in the sparse tensor constructor.
Note that this is BC-breaking for code that changes the sizes / strides of the indices or values tensor after it's used to create a sparse tensor. In current master, such changes will be reflected in the sparse tensor and break sparse tensor invariants. After this PR, those changes will not be reflected in the sparse tensor, and thus the sparse tensor invariants are always preserved. Specifically, running in-place size/stride-changing ops such as `resize_` / `resize_as_` / `as_strided_` / `set_` / `transpose_` on the original values tensor will not update the sparse tensor's `values_`. For example:
```python
# Calling resize_ on non-requires-grad value tensor
i2 = torch.zeros([1, 1])
v2 = torch.ones([1, 2, 3])
t2 = torch.sparse_coo_tensor(i2, v2, torch.Size([2, 2, 3]))
v2.resize_(4, 5)
t2.coalesce().values().size()
# On current master, this throws "indices and values must have same nnz, but got nnz from indices: 1, nnz from values: 4", because resizing the original value tensor affects `values_` of the sparse tensor.
# After this PR, this prints "torch.Size([1, 2, 3])", which means resizing the original value tensor doesn't affect `values_` of the sparse tensor.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20614
Differential Revision: D15385811
Pulled By: yf225
fbshipit-source-id: e963fcf5e4097f8c881b56145f408565d97cf5c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19932
In preparation to add int8_t data type for QTensor
Reviewed By: zafartahirov
Differential Revision: D15137838
fbshipit-source-id: 59462c36d6fc5982986d4196bf3f32f49bb294d7
Summary:
After the Variable/Tensor merge, there is no guarantee that `indices` and `values` passed into the sparse tensor constructor don't contain AutogradMeta. However, we want to maintain the existing invariant that `indices_` and `values_` of a sparse tensor don't contain AutogradMeta, and to achieve this we need do shallow-copy in the sparse tensor constructor.
Note that this is BC-breaking for code that changes the sizes / strides of the indices or values tensor after it's used to create a sparse tensor. In current master, such changes will be reflected in the sparse tensor and break sparse tensor invariants. After this PR, those changes will not be reflected in the sparse tensor, and thus the sparse tensor invariants are always preserved. Specifically, running in-place size/stride-changing ops such as `resize_` / `resize_as_` / `as_strided_` / `set_` / `transpose_` on the original values tensor will not update the sparse tensor's `values_`. For example:
```python
# Calling resize_ on non-requires-grad value tensor
i2 = torch.zeros([1, 1])
v2 = torch.ones([1, 2, 3])
t2 = torch.sparse_coo_tensor(i2, v2, torch.Size([2, 2, 3]))
v2.resize_(4, 5)
t2.coalesce().values().size()
# On current master, this throws "indices and values must have same nnz, but got nnz from indices: 1, nnz from values: 4", because resizing the original value tensor affects `values_` of the sparse tensor.
# After this PR, this prints "torch.Size([1, 2, 3])", which means resizing the original value tensor doesn't affect `values_` of the sparse tensor.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20330
Differential Revision: D15373683
Pulled By: yf225
fbshipit-source-id: 32e7275d7121e17937c7cc258e8a60bb0848ff25
Summary:
Currently `bmm()` has very heavy performance overhead on CPU due to construction/deconstruction of `TensorImpl`. Applying `TensorAccessor` when indexing tensor data can greatly improve the performance.
I tested this on `fairseq` Transformer model. Results on Xeon 6148 (20*2 cores 2.5GHz) indicate this PR improves Transformer training performance by approximately **10%** (seconds per iteration reduced from **3.60** to **3.21**). Considering the fact that `bmm()` takes only **14%** of the total time, 10% overall improvement indicates `bmm()` itself improves by roughly **3x**.
Before:
```
| epoch 001: 0%| | 43/25337 [02:34<25:17:11, 3.60s/it, loss=16.179, nll_loss=16.137, ppl=72045.59, wps=1320, ups=0, wpb=4758.767, bsz=136.558, num_updates=43, lr=6.45e-06, gnorm=6.88
```
After:
```
| epoch 001: 0%| | 23/25337 [01:13<22:32:48, 3.21s/it, loss=17.072, nll_loss=17.068, ppl=137419.42, wps=1478, ups=0, wpb=4746.870, bsz=128.348, num_updates=23, lr=3.45e-06, gnorm=10.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20266
Differential Revision: D15262201
Pulled By: cpuhrsch
fbshipit-source-id: c2e4e406c06714b04cc7534f3da71e986eddca35
Summary:
In onnx spec, the supported input/output type for `And` and `Or` is `Bool` only.
Thus in exporting, cast to/from `Bool` is inserted for input/output.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17894
Reviewed By: zrphercule
Differential Revision: D15103148
Pulled By: houseroad
fbshipit-source-id: 3e1068ea236c743260d42882fb11f0e3a21707e6
Summary:
First time this was merged it broke master and was reverted. This time I do not add ```set -u``` to the .circleci/scripts/setup* scripts. There's still a chance that ```set -u``` breaks the binary builds on master, but at least those can be fixed in parallel and don't completely eliminate signal from all merges.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20540
Differential Revision: D15373444
Pulled By: pjh5
fbshipit-source-id: 0203c20865827366ecd8fa07b2db74d255549ed1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20501
Fixing unit tests related to optimizer related operators and tests
Reviewed By: hx89
Differential Revision: D15307410
fbshipit-source-id: e5400c26e08f26191ee542fe6b02e0a69bc4e1ae
Summary:
#19975 was separated by 2 PRs.
This one:
Introduce MemoryFormat argument to the `x.is_contiguous(memory_format=torch.channels_last)` and to the `y = x.contiguous(memory_format=torch.channels_last)` functions.
At this moment both functions just operate with strides and doesn't store any tensor state.
(Original RFC #19092)
-----
Expands functionality of two tensor functions `.is_contiguous` and `.contiguous` (both python and c++ api).
Note: We had several complaints about `.to(memory_format)` function, and decided not to support it.
1. `.contiguous` now support optional keyword-only argument - `memory_format`, which can be either `torch.contiguous_format` or `torch.channels_last`.
- Using `torch.contiguous_format` will preserve existing `.contiguous()` behavior.
- Calling `x.contiguous(memory_format=torch.channels_last)` returns new tensor which maintain same semantical layout (NCHW), but have different memory allocation pattern.
`x.contiguous(memory_format=torch.channels_last)` expects input tensor to be 3d, 4d or 5d; and fails otherwise.
2. `.is_contiguous` now support optional keyword-only argument - `memory_format`, which can be either `torch.contiguous_format` or `torch.channels_last`.
- `x.is_contiguous(memory_format=torch.contiguous_format)` preserves same functionality as `x.is_contiguous()` and remains unchanged.
- `x.is_contiguous(memory_format=torch.channels_last)` returns true if A) input tensor is contiguous in memory AND B) allocated in the memory in NWHC (or similar for 3d,5d) format.
Note: By the end of the phase one `x.is_contiguous(memory_format=torch.channels_last)` will calculate state of the Tensor on every call. This functionality going to be updated later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20455
Differential Revision: D15341577
Pulled By: VitalyFedyunin
fbshipit-source-id: bbb6b4159a8a49149110ad321109a3742383185d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20513
They've been using an old API, switch them to the new one instead.
Reviewed By: li-roy
Differential Revision: D15346349
fbshipit-source-id: 538eb460897ec6addebeebf88b316eb0d6b1dd6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20379
The legacy custom op API allowed nesting of std::unordered_map and std::vector. While we haven't figured out yet how to do that with the new API,
we at least have to keep backwards compatibility. This diff adds the feature so we can switch to the new API without breaking third party code.
Reviewed By: li-roy
Differential Revision: D15287693
fbshipit-source-id: bb5b8429fddf6298719cbf567b584ed371f8fc81
Summary:
Previously, the caller of `shallow_copy_and_detach()` is responsible for deciding whether the shallow-copy should share the source TensorImpl's version counter, or have its own new version counter. However, since this decision is crucial for ensuring the correctness of the shallow-copy's version counter, we want to enforce users of `shallow_copy_and_detach()` to pass a version counter to the function call, so that they are required to make the decision at the time of API usage, not as an afterthought.
For similar reasons, we want to enforce users of `shallow_copy_and_detach()` to pass `allow_tensor_metadata_change` to the function call, so that they are required to decide "whether the TensorImpl shallow-copy should allow tensor metadata change" at the time of API usage, not as an afterthought.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20496
Differential Revision: D15363620
Pulled By: yf225
fbshipit-source-id: a65e74738b10452668d6dc644b43aad5b3d8c9e6
Summary:
Remove weak_script. After recently splitting the forward() function in MultiheadAttention module, we notice a memory leak on GPU. Fix the problem by removing those "weak_script" decorator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20563
Differential Revision: D15368262
Pulled By: zhangguanheng66
fbshipit-source-id: 475db93c9ee0dbaea8fb914c004e7d1e0d419bc2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20543
All of that code for concatenating strings together adds up. Just discard it all for mobile builds.
Reviewed By: ljk53
Differential Revision: D15353447
fbshipit-source-id: a82dd0b884335d662605aabf7dd3d09dfcc1478b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20439
This is the QTensorProto workflow for multi group quantization in C2 side.
No DNNLOWP Tensor related thing is included in this pr, so once we finished glow side, we should be able to test this pr using resnet50.
Reviewed By: yinghai
Differential Revision: D15096919
fbshipit-source-id: 741eecd59eb79d24d9fe2b035f6246d42422d25c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19816
We need this for quantization for bias
add third argument of ScalarType to `quantize_linear`
Differential Revision: D15094174
fbshipit-source-id: f19ec8f4716cf5fe0aa21b38d45af6d27c9ab377
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20512
Fixing typos in the description of schema for one of the inputs for BatchMatMul operator.
Reviewed By: jianyuh, BIT-silence
Differential Revision: D15343879
fbshipit-source-id: 06354e8e6b0d79fea937ed2703bb457b2d04f859
Summary:
Fix a typo in the doc.
Add an AssertError check back to MultiheadAttention module
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20492
Differential Revision: D15349008
Pulled By: cpuhrsch
fbshipit-source-id: 2d898345f03787c713e537673613a748ad826b34
Summary:
The current variance kernels compute mean at the same time. Many times we want both statistics together, so it seems reasonable to have a kwarg/function that allows us to get both values without launching an extra kernel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18731
Differential Revision: D14726082
Pulled By: ifedan
fbshipit-source-id: 473cba0227b69eb2240dca5e61a8f4366df0e029
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20374
This test case now also tests that the argument type works correctly in kernels that
- don't return outputs
- return multiple outputs
Reviewed By: li-roy
Differential Revision: D15298233
fbshipit-source-id: 82ab9d81b55b4f9fb34d66a155cc426af8592e25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20373
- Add support for Dict<Key, Value> arguments and returns to c10 operators
- Add support for std::unordered_map<Key, Value> to the legacy API (but not to c10 kernels)
Reviewed By: li-roy
Differential Revision: D15298235
fbshipit-source-id: 6d9793db1f12bea377f508a9b33a495ebe0bec18
Summary:
Add automatic translations for a few argument names that commonly differ between PyTorch and NumPy.
For now, they are as follows:
* `keepdim` -> `keepdims`
* `dim` -> `axis`
* `input` -> (any of `a`, `x`, `x1`)
* `other` -> `x2`
Basic examples:
```python
>>> t=torch.randn(10,10)
>>> torch.sum(x=t, axis=1)
tensor([ 0.5199, -0.3768, 4.3619, -0.9105, 1.1804, 1.0837, -0.9036, 0.2365,
1.1171, -0.0999])
```
```python
>>> torch.add(x1=5, x2=6)
tensor(11)
```
The additional overhead is zero when using traditional PyTorch argument names, and a few (usually 1) extra PyDict lookups when using NumPy argument names.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20451
Differential Revision: D15337521
Pulled By: umanwizard
fbshipit-source-id: 7a7d389786f4ccf5c86a14ecb2002c61730c51b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20020
Add shape inference for LearningRate op. The output (lr) should have similar shape with input (iteration), but not the same type (float vs int).
Reviewed By: un-disclosed
Differential Revision: D15112300
fbshipit-source-id: 09969aefa15172a6f3c70cd9b2548e3020da5d7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20372
Implement a Dict type that allows us to abstract away from the concrete implementation used.
The API is similar to std::unordered_map, but behind the scenes we can switch to any map implementation we like. ska::flat_hash_map, google dense map, or any future map implementation with better performance.
Switching such an implementation choice does not have to break backwards compatibility of kernel code using the Dict type.
Reviewed By: zdevito
Differential Revision: D15298234
fbshipit-source-id: b5ad368a9e9516030805cd8f5f1b02e3986933c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20463
Source file changes mostly involve ifdef'ing-out references to JIT code
from files that are part of Caffe2Go. Update Internal build scripts to
remove those files from our globs.
After this, changes to most of the JIT files should not trigger mobile CI.
Reviewed By: dzhulgakov
Differential Revision: D15329407
fbshipit-source-id: 48f614c6b028eef0a03ce5161d083a3e078b0412
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20021
Add shape inference for AtomicIter operator. The operator takes two blobs iteration and iter_mutex as input and outputs iteration, which should have the same type and shape as the input.
Reviewed By: un-disclosed
Differential Revision: D15111643
fbshipit-source-id: 0d06413305cc4c6257c0cfabf62fb874970803bc
Summary:
Moving functions from torch/nn/modules/activation.py to torch/nn/functional.py. For functions not implemented (_get_input_buffer and _set_input_buffer), a TODO is added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20415
Differential Revision: D15318078
Pulled By: jamarshon
fbshipit-source-id: 5ca698e2913821442cf8609cc61ac8190496a3c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20390
duc0 Ngo implemented observing floating point exceptions but there were a couple of places where we have "benign" floating point exceptions leading to false positives. This diff eliminates one source of such false positives, namely using _mm256_cvtph_ps and _mm256_cvtps_ph for partially uninitialized array for the remainder loop.
Reviewed By: hx89
Differential Revision: D15307358
fbshipit-source-id: 38f57dfdd90c70bc693292d2f9c33c7ba558e2c9
Summary:
Tagging along to changes in #20191 which added more support for types in the pickler
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20444
Pulled By: driazati
Differential Revision: D15321463
fbshipit-source-id: 985061bf5070a7d7bad58ea8db11d531f3d13e74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20108
Add cpp runs for c2, hooked up via pybinds. Print output to terminal. This is not hooked up with the pep output yet because I'd like to verify the numbers first.
Note that this isn't quite the same mechanism as the pytorch cpp hookup, which uses cpp_python_extensions. If I can use the same mechanism to pull all the inputs for c2 through cpp and do FeedBlobs in cpp, then I'll switch to that.
Reviewed By: zheng-xq
Differential Revision: D15155976
fbshipit-source-id: 708079dacd3e19aacfe43d70c5e5bc54da2cf9e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20321
First part of https://github.com/pytorch/pytorch/issues/20287
- Rename `AT_ASSERT` to `TORCH_INTERNAL_ASSERT`
- Make `TORCH_INTERNAL_ASSERT` work with variadic inputs
- Deprecated `AT_ASSERT` and `AT_ASSERTM`
- Rename `AT_CHECK` to `TORCH_CHECK`
- Make `TORCH_CHECK` give a better error message when no arguments are
provided
- Deprecate `AT_ERROR` in favor of `TORCH_CHECK(false, ...)`
- Deprecate `AT_INDEX_ERROR` in favor of `TORCH_CHECK_INDEX(false, ...)`
- Rename `AT_WARN` to `TORCH_WARN`
No use sites are changed; I'll work on that in follow up patches
(or disable the deprecation, if necessary.)
Differential Revision: D15278439
fbshipit-source-id: 7e0ed489d4e89e5f56b8ad7eafa72cb9a06065ee
Summary:
In https://github.com/pytorch/pytorch/pull/18223/files#diff-77a6f3462f2233b921d3042412fed6d3R178, we used `auto saved_version_ = data_.unsafeGetTensorImpl()->version_counter().current_version()` and then `new_data_impl_copy->set_version_counter(saved_version_)`, which actually doesn't preserve the original semantics that `var.set_data(tensor)` should keep `var`'s version counter object intact. This PR fixes the bug and adds test to make sure it doesn't happen again.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20391
Differential Revision: D15323430
Pulled By: yf225
fbshipit-source-id: e3ba49b51ec8ccecd51c80cb182387f74cfd2b2b
Summary:
As part of the Variable/Tensor merge, we allow passing Tensor with AutogradMeta into ATen ops, but we want to make sure they are not treated as Variables (i.e. their `is_variable()` is false). This PR makes the necessary change to make this work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20392
Differential Revision: D15321899
Pulled By: yf225
fbshipit-source-id: c2ab09db73c63bd71ba2d8391095f4d6b4240a9a
Summary:
"then the output would also has k tensors" -> "then the output would also have k tensors"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20425
Differential Revision: D15320152
Pulled By: zou3519
fbshipit-source-id: b04e2ccd29c6a3e33ad1040d0ea975a01a7bd9b5
Summary:
As a first step for this plan: https://github.com/pytorch/pytorch/issues/19508#issuecomment-485178192, this PR moves `THCTensor_(uniform)` to ATen. Major changes are:
- `uniform_` cuda kernel now utilizes a philox generator.
- the kernel also utilizes TensorIterator
- the kernel uses a grid-stride loop to achieve peak effective bandwidth
- Since the engine has changed from `curandStateMTGP32` to `curandStatePhilox4_32_10`, the randoms generated now will be different.
- Here is the diff showing codegen changes: https://gist.github.com/syed-ahmed/4af9ae0d42b6c7dbaa13b9dd0d1dd1e8 (BC breaking change if any)
- Philox4_32_10 is known to pass the standard TestU01 Big Crush test (https://www.thesalmons.org/john/random123/papers/random123sc11.pdf) and hence the quality of random numbers generated isn't an issue when compared to the previously used `curandStateMTGP32`.
- I have added a test case in `aten/src/ATen/test/cuda_distributions_test.cu` which verifies that philox offset is incremented properly
The benchmark was done on a DGX station with 4 V100s.
I modified the script from jcjohnson 's [multinomial benchmark](https://github.com/jcjohnson/pytorch-multinomial-benchmark) to produce this notebook which shows that there is a general speedup with this PR and a regression hasn't been introduced: https://gist.github.com/syed-ahmed/9d26d4e96308aed274d0f2c7be5218ef
To reproduce the notebook:
- Run https://gist.github.com/syed-ahmed/4208c22c541f1d30ad6a9b1efc1d728f in a container with the current pytorch top of tree with the command: `python uniform_benchmark.py --stats_json before.json`
- Apply this diff to the current pytorch top of tree and run the same script in a container with the command: `python uniform_benchmark.py --stats_json after.json`
- Run the notebook attached above with the `after.json` and `before.json` in the same directory
The effected bandwidth was calculated using the script (thanks to ngimel ): https://gist.github.com/syed-ahmed/f8b7384d642f4bce484228b508b4bc68
Following are the numbers before and after.
```
uniform, size, elements 65536 forward 5.168914794921875e-06 bandwidth (GB/s) 50.71548098597786
uniform, size, elements 131072 forward 5.056858062744141e-06 bandwidth (GB/s) 103.67860705101367
uniform, size, elements 262144 forward 7.164478302001953e-06 bandwidth (GB/s) 146.357621001797
uniform, size, elements 524288 forward 1.1217594146728515e-05 bandwidth (GB/s) 186.9520302275877
uniform, size, elements 1048576 forward 1.923084259033203e-05 bandwidth (GB/s) 218.10297600317384
uniform, size, elements 2097152 forward 3.640890121459961e-05 bandwidth (GB/s) 230.39992200138826
uniform, size, elements 4194304 forward 6.778717041015625e-05 bandwidth (GB/s) 247.49839679819922
uniform, size, elements 8388608 forward 0.00012810707092285157 bandwidth (GB/s) 261.92490202361347
uniform, size, elements 16777216 forward 0.00025241613388061524 bandwidth (GB/s) 265.86598474620627
uniform, size, elements 33554432 forward 0.000497891902923584 bandwidth (GB/s) 269.5720239913193
```
```
uniform, size, elements 65536 forward 5.550384521484375e-06 bandwidth (GB/s) 47.22988091821306
uniform, size, elements 131072 forward 5.581378936767578e-06 bandwidth (GB/s) 93.93520954942333
uniform, size, elements 262144 forward 6.165504455566406e-06 bandwidth (GB/s) 170.071404141686
uniform, size, elements 524288 forward 6.3276290893554685e-06 bandwidth (GB/s) 331.4277702414469
uniform, size, elements 1048576 forward 8.509159088134765e-06 bandwidth (GB/s) 492.91639239047356
uniform, size, elements 2097152 forward 1.2989044189453124e-05 bandwidth (GB/s) 645.8218077979443
uniform, size, elements 4194304 forward 2.347707748413086e-05 bandwidth (GB/s) 714.6211452997259
uniform, size, elements 8388608 forward 4.4286251068115234e-05 bandwidth (GB/s) 757.6715389250498
uniform, size, elements 16777216 forward 8.672237396240235e-05 bandwidth (GB/s) 773.8356427961071
uniform, size, elements 33554432 forward 0.00016920566558837892 bandwidth (GB/s) 793.2224227438523
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20292
Differential Revision: D15277761
Pulled By: ezyang
fbshipit-source-id: 8bfe31a01eeed77f0ed6e7ec4d2dda4c6472ecaa
Summary:
To fully support incremental_state function, it requires several additional utils available in fairseq. However, we lack a problem for the unit test. Therefore, the incremental_state function will be disable for now. If it is needed in the future, a feature request could be created. Fixed#20132
Add some unit tests to cover the arguments of MultiheadAttention module, including bias, add_bias_kv, add_zero_attn, key_padding_mask, need_weights, attn_mask.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20177
Differential Revision: D15304575
Pulled By: cpuhrsch
fbshipit-source-id: ebd8cc0f11a4da0c0998bf0c7e4e341585e5685a
Summary:
We don't need to overlay vc env when not using ninja. CMake will deal with it automatically. Overlaying is a no-op when the env is the same with the generator specified but will generate the error "Cannot find CMAKE_CXX_COMPILER" when they are different.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20417
Differential Revision: D15317081
Pulled By: ezyang
fbshipit-source-id: 5d9100321ecd593e810c31158f22c67d3e34973b
Summary:
This is an attempt to isolate unrelated changes from #19228 for easier review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20150
Differential Revision: D15314891
Pulled By: ezyang
fbshipit-source-id: 8c429747ba83ad5aca4cdd8f8086bcf65a326921
Summary:
* Constructs a new type at runtime so that `isinstance` checks work for
weak modules assigned to `ScriptModule`s
* Fix some extraneous names in `__constants__`
* Add `in_features` and `out_features` to `nn.Linear` `__constants__`
Fixes#19363
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20190
Pulled By: driazati
Differential Revision: D15302350
fbshipit-source-id: 1d4d21ed44ab9578a4bc2a72396a82e9bbcd387c
Summary:
TensorList, DoubleList, and BoolList were missing from the pickler, so
this adds them.
As a follow up a lot of the code for these could be templated and cut
down
](https://our.intern.facebook.com/intern/diff/15299106/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20191
Pulled By: driazati
Differential Revision: D15299106
fbshipit-source-id: f10c0c9af9d60a6b7fb8d93cea9f550b1a7e2415
Summary:
Given that tensorboardX and our PyTorch 1.1 release had `log_dir` as the argument for SummaryWriter initialization and member variable (which some users access), we need to preserve this name. However, we might deprecate this in the future and I've added a `get_logdir` method that can be used in the future.
cc natalialunova, lanpa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20382
Reviewed By: NarineK
Differential Revision: D15300941
Pulled By: orionr
fbshipit-source-id: a29a70fcbc614a32ebfa6c655962fdff081af1af
Summary:
This code is unused and has been superseded by TensorIterators.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20207
Differential Revision: D15240832
Pulled By: cpuhrsch
fbshipit-source-id: 4f600bb8645f9b28a137e2cefb099978f5152d05
Summary:
This PR add Poisson NLL loss to aten and substitute the python implementation with a call to the c++.
Fixes#19186.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19316
Differential Revision: D15012957
Pulled By: ezyang
fbshipit-source-id: 0a3f56e8307969c2f9cc321b5357a496c3d1784e
Summary:
This PR is an intermediate step toward the ultimate goal of eliminating "caffe2" in favor of "torch". This PR moves all of the files that had constituted "libtorch.so" into the "libcaffe2.so" library, and wraps "libcaffe2.so" with a shell library named "libtorch.so". This means that, for now, `caffe2/CMakeLists.txt` becomes a lot bigger, and `torch/CMakeLists.txt` becomes smaller.
The torch Python bindings (`torch_python.so`) still remain in `torch/CMakeLists.txt`.
The follow-up to this PR will rename references to `caffe2` to `torch`, and flatten the shell into one library.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17783
Differential Revision: D15284178
Pulled By: kostmo
fbshipit-source-id: a08387d735ae20652527ced4e69fd75b8ff88b05
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19803
There is no reason to set a specific logging level for this module. Removing it to just use the default logging level.
Differential Revision: D15098834
fbshipit-source-id: 1654c04500c19690ddde03343f2e84b04bb0f1ef
Summary:
Fixed#20250
Not sure if there's any specific design reason to `add_dependecy()` and manually add a few include dir, instead of linking the target.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20319
Differential Revision: D15294584
Pulled By: ezyang
fbshipit-source-id: 97f813a6b1829dad49958e0f880b33eb95747607
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20351
This was broken because of a merge race between #20282 and the stack in #20236.
Cleaned up the test and comments a bit as well.
Differential Revision: D15292786
fbshipit-source-id: a4379ea700cad959d3a6921fc5ddf9384fb8f228
Summary:
The trick here is that creating a mapping from const values to
const values means that downstream clients that want to mutate
the output of the mapping are stuck. However, a mapping from
const values to non-const values is just fine and doesn't put
constraints on downstream clients.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20303
Differential Revision: D15284076
fbshipit-source-id: 16206fd910dd5f83218525ca301b1889df0586cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20236
Use the new version of broadcast_coalesced that deals with both CPU
and CUDA models. Add tests that evaluate correctness of
DistributedDataParallel for CPU models.
Closes#17757.
Reviewed By: mrshenli
Differential Revision: D15245428
fbshipit-source-id: d2fa09f68593b3cd1b72efeb13f5af23ebd5c80a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20235
The tests expected to only run for CUDA models. In a future commit we
need to update this to work for CPU models as well. Therefore, we can
no longer rely on only integers being passed for device identifiers.
With this change we pass both the materialized list of devices to use
(as `torch.Device` objects), as well as an optional list of integers.
The latter is specified to exercise the code in the
DistributedDataParallel constructor that turns a list of integers into
CUDA devices, IFF it is used to wrap a single-device CUDA module.
This commit also groups together the 'str' and non-'str' tests. These
used to test passing the list of devices as integers or as
`torch.Device` instances. These are now executed from the same test.
Reviewed By: mrshenli
Differential Revision: D15245429
fbshipit-source-id: 5797ba9db33d2c26db8e7493c91bb52f694285ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20234
The differences with the existing function _dist_broadcast_coalesced
is that this one works for both CPU and CUDA tensors and that it has a
maximum number of in flight operations.
This should be the final change needed to have only a single version
of DistributedDataParallel that both supports CPU and CUDA models, or
even a mix of both.
See #17757 for more information.
Reviewed By: mrshenli
Differential Revision: D15228099
fbshipit-source-id: a2113ba6b09b68cb5328f49f4c1960031eb43c93
Summary:
The isConvFusion(...) is only for Conv op.
If non-Conv op, the crash takes place.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20139
Differential Revision: D15280604
Pulled By: yinghai
fbshipit-source-id: eb45be11990b3bf7c5b45f02ebb6018444ab5357
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20281
This is how it looks like now:
```
<FunctionEventAvg key=mm self_cpu_time=11.404s cpu_time=2.895ms
cuda_time=0.000us input_shapes=[[26, 4096], [4096, 1024]]>
```
Before I forgot to update the repr for these when updated it for not
averaged events
Differential Revision: D15262862
fbshipit-source-id: a9e5b32c347b31118f98b4b5bf2bf46c1cc6d0d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20185
This test case now also tests that the argument type works correctly in kernels that
- don't return outputs
- return multiple outputs
Reviewed By: li-roy
Differential Revision: D15227621
fbshipit-source-id: 83db7536e9065e0f8c5032d6b96e970bbaf718b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20184
- Add support for Dict<Key, Value> arguments and returns to c10 operators
- Add support for std::unordered_map<Key, Value> to the legacy API (but not to c10 kernels)
Reviewed By: li-roy
Differential Revision: D15227620
fbshipit-source-id: c1ea6c12165e07b74272cb48c6021bdb5c2d7922
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19976
Implement a Dict type that allows us to abstract away from the concrete implementation used.
The API is similar to std::unordered_map, but behind the scenes we can switch to any map implementation we like. ska::flat_hash_map, google dense map, or any future map implementation with better performance.
Switching such an implementation choice does not have to break backwards compatibility of kernel code using the Dict type.
Reviewed By: li-roy
Differential Revision: D15156384
fbshipit-source-id: b9313ec4dd9acb3b6a0035345b6ba4f2a437d1e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20282
Add unit test to ensure no gradients sync when calling ddp.module(input), e.g not invoking prepare_for_backward
PyText is depending on DDP for data parallel distributed training. To support accumulate gradients locally before gradients sync, we are calling orig_model.forward instead of ddp_model.forward. Add a unit test to avoid changes break the assumption.
Reviewed By: pietern, mrshenli
Differential Revision: D15263155
fbshipit-source-id: 7734e174f507690fb23ea6c52dffff4a93f9b151
Summary:
fixes#20215
The confusing behavior was caused by typos in type annotation :(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20306
Differential Revision: D15276216
Pulled By: ailzhang
fbshipit-source-id: 1b0c9635a72a05c9b537f80d85b117b5077fbec7
Summary:
This addresses #18436
The logic replicates the essence of closing file descriptors in numpy:
bf20e30340/numpy/core/include/numpy/npy_3kcompat.h (L278)
This stores the position of the file descriptor before resetting it to the Python handle offset, then resets to the original position before exit. The Python-side handle is then updated to reflect the new position. Also added somewhat more demanding tests to cover this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20270
Differential Revision: D15275902
Pulled By: soumith
fbshipit-source-id: 5ca8a52b61c7718d2e69571f72f80b1350b0acdb
Summary:
See Issue #20301
Specifying dim in docstring example to prevent UserWarning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20310
Differential Revision: D15277734
Pulled By: ezyang
fbshipit-source-id: 2e8b748dbe743675a5a538ccbe97713aad02e8ac
Summary:
Schema matching for sort is a little tricky because you have to check whether the class defines the __lt__ method correctly, and you have to mark whatever effects happen in __lt__ to the sorting op as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19706
Differential Revision: D15244366
Pulled By: eellison
fbshipit-source-id: 73b3e36462c6cc40f9d8cb235b44499a67d3149e
Summary:
This PR restricts the BatchType template argument of ChunkDataReader to STL
vectors only. Internally, ChunkDataReader was assuming BatchType was a
vector, but the user could pass any type to the template argument,
leading to compiling issues during CPP extensions.
Additionally to the proposed API change, this PR adds missing include
headers to chunk.h. Currently the current implementation works but if
users try to create C++ extensions that implements new ChunkDataReaders
to be along with the existing ChunkDataset, the build will fail due to
the missing headers.
In terms of functionality, nothing has changed. This PR simply makes the
implementation slightly more robust for future extensions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19485
Differential Revision: D15261725
Pulled By: soumith
fbshipit-source-id: 38c9465d665392ae6a2d12c5a520a4f501e1a6ca
Summary:
C++ `Scatter` and `Gather` always set autograd history for input data tensors regardless whether they require grad. This hits assertion failure in `set_history(Tensor, shared_ptr<Function> grad_fn)`
where `grad_fn` cannot be nullptr. After this PR, C++ `Scatter` and `Gather` only record `grad_fn` when required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20286
Differential Revision: D15266610
Pulled By: mrshenli
fbshipit-source-id: 641df0ea36e7c922b5820c8dc3f83e2a050412b5
Summary:
Previously we only had a Python wrapper for `torch.quantized_lstm_cell`. We had the op `torch.quantized_lstm`, but it didn't have a wrapper. This makes the wrapper
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20249
Reviewed By: driazati
Differential Revision: D15250023
Pulled By: jamesr66a
fbshipit-source-id: f05ad784d903e0ef3a62633c8bf80bad79de48ae
Summary:
This is a step towards enabling the ONNX constant folding pass by default in the PT->ONNX export. In this change we have enabled test points in `test/onnx/test_pytorch_onnx_caffe2.py` to run with constant folding pass enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20290
Reviewed By: zrphercule
Differential Revision: D15271674
Pulled By: houseroad
fbshipit-source-id: 9e59ab46ae74b4ad8dea1a2200ecc1f3eb8aad75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19660
Implementation of aggregated Scale operator.
The operator takes a list of tensors as an input and scales all of them them with the argument float value.
The tensor sizes can be different, therefore bookkeeping of the sizes and pointers to the tensors are
necessary for the GPU version of the kernel.
Reviewed By: BIT-silence
Differential Revision: D14984233
fbshipit-source-id: 37cc97159a4f2c38cd6fff4f5710ab7d3a773611
Summary:
Don't make an alias value for a value that is known to be None. This was preventing constant propagation from running the `out is None` check in nn.functional.normalize, and thus preventing the if statement from being inlined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20112
Differential Revision: D15267328
Pulled By: eellison
fbshipit-source-id: 5b878b0dc50944c2e7a2f583ea483dad9d6bbec3
Summary:
This PR makes `torch.save` call out to the pickler which saves a tensor in the same format that `torch.save()` does, the file looks like `| pickle archive 1 (includes sizes, strides, requires_grad, etc...) | pickle archive 2 (list of tensor keys) | tensor binary data |` and can be read back in with `torch.load(my_file, pickle_module=torch.jit._pickle)`
Fixes#18003
Unpickling in the JIT for things such as model parallelism will be a follow up PR
](https://our.intern.facebook.com/intern/diff/15015160/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18154
Pulled By: driazati
Differential Revision: D15015160
fbshipit-source-id: ef76a44b8c243f4794cd7e245ec8305e965bc59f
Summary:
Also, current mkldnn primitive code recreate the computation everytime, causes tiny Convolutions spending significant portion of its time on the repeated codegen. ideep has implemented an lru cache to save the computation and so this change will help us improving perfs for tiny Convolutions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19963
Differential Revision: D15156527
Pulled By: bddppq
fbshipit-source-id: 6a8fbd10a213ec22cdeaff1a2bdb0d09905d1fcd
Summary:
Canonicalize the ordering of outputs of if and loop nodes based on their first usage. Previously we were able to canonicalize output order by sorting on variable name, but this breaks down with outputs added in an early return pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20015
Differential Revision: D15266066
Pulled By: eellison
fbshipit-source-id: ba5340c068a68b1ffc73f056db194b92d3274dc4
Summary:
cc nairbv
All failures I have seen are of this combination. So let's just disable it for all cases. After #20063 I find it failing for py3 once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20172
Differential Revision: D15266527
Pulled By: nairbv
fbshipit-source-id: afb9389dfc54a0878d52975ffa37a0fd2aa3a735
Summary:
As a part of supporting writing data into TensorBoard readable format, we show more example on how to use the function in addition to the API docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20008
Reviewed By: natalialunova
Differential Revision: D15261502
Pulled By: orionr
fbshipit-source-id: 16611695a27e74bfcdf311e7cad40196e0947038
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19541
For the quantized FC operator, replace the tuple (Tensor, scale, zero_point) with QTensor.
Differential Revision: D14900407
fbshipit-source-id: 164df38f3564e0a68af21b9fedaba98a44ca1453
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19497
Implements a basic quantized FC (uint8 * int8 -> uint8) with FBGEMM APIs.
Related document:
https://fb.quip.com/rP5tAx56ApMMhttps://fb.quip.com/MU7aAbzGDesu
Work Item List:
1. [DONE] currently we use prepack routines inside Quantized FC operator. Will separate it as a standalone operator soon.
2. [DONE] rebase to D14817809 and D14994781 (cpp custom types).
3. [DONE] correctness unit test.
4. [To Do] rebase to QTensor. Similar to D14565413, this will be implemented in the next Diff.
Differential Revision: D14761865
fbshipit-source-id: 031a39915fecd947afb4dd2719112b4ddc1082d3
Summary:
Fixes https://github.com/pyro-ppl/pyro/issues/1853
This fixes a memory leak in `torch._dirichlet_grad()`. This function is used for reparametrized gradients for the `Dirichlet` and `Beta` distributions.
- [x] Could a reviewer please confirm that `freeCopyTo()` is being used correctly and doesn't need an additional `decref()`? The author is unfamiliar with PyTorch C++ memory utilities. Help appreciated.
- ran locally and confirmed leak is fixed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20244
Differential Revision: D15259008
Pulled By: ezyang
fbshipit-source-id: 222ec7d80ddd97bcdd7d54549f3e756575e8402e
Summary:
This just updates the `JIT` comments with the issue number #20215. Hopefully this will stop the proliferation of the workaround. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20222
Differential Revision: D15259007
Pulled By: ezyang
fbshipit-source-id: 5060a351aa618c6dae49d0b7a6ac9b0f57f2490a
Summary:
The earlier fix to extract scripts missed an attach_workspace which was used to make the built binaries available to the nightly build upload jobs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20265
Differential Revision: D15259080
Pulled By: soumith
fbshipit-source-id: bf835c2cd76976b4563798ee348f7db83c7a79c1
Summary:
The current pytorch config.yml is causing some backend performance
problems on CircleCI, due to the size of the file when all of the YAML
anchors have been expanded. You can view the "processed" config as our
internal system deal with it by running `circleci config process`.
circleci config process .circleci/config.yml | wc -c
Before: 2833769 bytes
After: 558252 bytes (~80% less)
Add create a new job, `setup`, that has 2 functions:
- Assert that config.yml is up to date
- Put the .circleci/scripts directory into a workspace, so that
downstream jobs can easily access it.
The `setup` job becomes the parent of all jobs in the workflow. This
allows us to fail fast if config is invalid. It might be a good place to
add other, quick, lint checks to help fail the build faster.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19674
Differential Revision: D15252864
Pulled By: pjh5
fbshipit-source-id: 0778c7b8f95e7f3f33ac92fbb8862377fc9fb0ac
Summary:
This ensures that custom operators registered through c10::RegisterOperators are recorded in autograd profile traces.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20175
Differential Revision: D15221311
Pulled By: jamesr66a
fbshipit-source-id: 9452b24272c2399c20a49af85b62d34cabe6e27a
Summary:
Do tests with common models from torchvision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20007
Differential Revision: D15251754
Pulled By: orionr
fbshipit-source-id: 9dc09bd407b3ccaaa310d2f4a8d53d5a7d12469d
Summary:
We now can build libtorch for Android.
This patch aims to provide two improvements to the build
- Make the architecture overridable by providing an environment variable `ANDROID_ABI`.
- Use `--target install` when calling cmake to actually get the header files nicely in one place.
I ran the script without options to see if the caffe2 builds are affected (in particularly by the install), but they seem to run OK and probably only produce a few files in build_android/install.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20152
Differential Revision: D15249020
Pulled By: pjh5
fbshipit-source-id: bc89f1dcadce36f63dc93f9249cba90a7fc9e93d
Summary:
Support operator overloading for User Defined Types, which includes desugaring `a + b` and python builtin functions which call into a method if it is defined like `len(x)`.
See https://rszalski.github.io/magicmethods/ for list of magic methods.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20033
Reviewed By: driazati
Differential Revision: D15246573
Pulled By: eellison
fbshipit-source-id: 03d45dd524ea2a3b40db36843d6067bede27b30d
Summary:
similar to too few blank lines, I feel like this is not important enough to warrant breaking signal for all linters when it's violated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20225
Differential Revision: D15243480
Pulled By: suo
fbshipit-source-id: 37cdc18daf09e07081e42b69c72d331d81660217
Summary:
This is useful when you would like to understand performance
bottlenecks of your model. One can use the shape analysis in order to
fit model to a roofline model of their hardware.
Please note that this feature can potentially skew profiling
results. Also timing for not nested events will become wrong. One
should only use timing for the bottom most events when shape analysis
is used. Also for the case where people don't need shapes, profiling
should not be affected. As in this case we don't collect shapes, which
is the default behavior and this diff doesn't change it.
One of the next steps
could be, for example, choosing best candidates for quantization. In
the scope of this diff I am just adding optional shapes collection
into the Even class. After that in python there is minor functionality
for providing groupping by shapes.
In the output tables shapes are being truncated but in groupping full
shape string is used as a key.
Here is an example output:
test_profiler_shapes (test_autograd.TestAutograd) ...
```
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
unsigned short 2.30% 305.031us 2.30% 305.031us 305.031us NaN 0.000us 0.000us 1 [[30, 20]]
addmm 69.40% 9.199ms 69.40% 9.199ms 9.199ms NaN 0.000us 0.000us 1 [[30], [128, 20], [20, 30], [], []]
unsigned short 0.98% 129.326us 0.98% 129.326us 129.326us NaN 0.000us 0.000us 1 [[40, 30]]
addmm 27.32% 3.621ms 27.32% 3.621ms 3.621ms NaN 0.000us 0.000us 1 [[40], [128, 30], [30, 40], [], []]
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 13.255ms
CUDA time total: 0.000us
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
unsigned short 2.30% 305.031us 2.30% 305.031us 305.031us NaN 0.000us 0.000us 1 [[30, 20]]
addmm 69.40% 9.199ms 69.40% 9.199ms 9.199ms NaN 0.000us 0.000us 1 [[30], [128, 20], [20, 30], [], []]
unsigned short 0.98% 129.326us 0.98% 129.326us 129.326us NaN 0.000us 0.000us 1 [[40, 30]]
addmm 27.32% 3.621ms 27.32% 3.621ms 3.621ms NaN 0.000us 0.000us 1 [[40], [128, 30], [30, 40], [], []]
------------------ --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 13.255ms
CUDA time total: 0.000us
```
Also added this for older aggregation test:
```
test_profiler_aggregation_lstm (test_autograd.TestAutograd) ...
======================================================================================================================================================================================================
TEST
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
lstm 0.69% 4.606ms 5.30% 35.507ms 35.507ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.67% 4.521ms 5.27% 35.340ms 35.340ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.66% 4.399ms 5.02% 33.638ms 33.638ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.65% 4.354ms 4.92% 32.958ms 32.958ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.65% 4.351ms 4.96% 33.241ms 33.241ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.65% 4.323ms 5.10% 34.163ms 34.163ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.304ms 4.92% 32.938ms 32.938ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.300ms 5.10% 34.172ms 34.172ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.292ms 5.05% 33.828ms 33.828ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
lstm 0.64% 4.263ms 4.98% 33.357ms 33.357ms NaN 0.000us 0.000us 1 [[5, 3, 10]]
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 670.120ms
CUDA time total: 0.000us
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
sigmoid 15.32% 102.647ms 15.32% 102.647ms 171.078us NaN 0.000us 0.000us 600 [[3, 20]]
mul 15.20% 101.854ms 15.20% 101.854ms 169.757us NaN 0.000us 0.000us 600 [[3, 20], [3, 20]]
lstm 12.74% 85.355ms 100.00% 670.120ms 33.506ms NaN 0.000us 0.000us 20 [[5, 3, 10]]
addmm 11.16% 74.808ms 11.16% 74.808ms 249.361us NaN 0.000us 0.000us 300 [[80], [3, 20], [20, 80], [], []]
tanh 9.89% 66.247ms 9.89% 66.247ms 165.617us NaN 0.000us 0.000us 400 [[3, 20]]
split 6.42% 43.019ms 6.42% 43.019ms 215.095us NaN 0.000us 0.000us 200 [[3, 80]]
add 5.67% 38.020ms 5.67% 38.020ms 190.101us NaN 0.000us 0.000us 200 [[3, 80], [3, 80], []]
add 4.81% 32.225ms 4.81% 32.225ms 161.124us NaN 0.000us 0.000us 200 [[3, 20], [3, 20], []]
addmm 3.79% 25.380ms 3.79% 25.380ms 253.796us NaN 0.000us 0.000us 100 [[80], [3, 10], [10, 80], [], []]
unsigned short 3.72% 24.925ms 3.72% 24.925ms 83.083us NaN 0.000us 0.000us 300 [[80, 20]]
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- -----------------------------------
Self CPU time total: 670.120ms
CUDA time total: 0.000us
Total time based on python measurements: 691.366ms
CPU time measurement python side overhead: 3.17%
ok
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20035
Differential Revision: D15174987
Pulled By: salexspb
fbshipit-source-id: 9600c5d1d1a4c2cba08b320fed9da155d8284ab9
Summary:
In line 508.
convert_sync_batchnorm is called recursively to convert the bn to syncbn, thus the process_group also should be passed in the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19240
Differential Revision: D15240318
Pulled By: ezyang
fbshipit-source-id: 0fc9e856392824814991e5e9e8f9513d57f311af
Summary: This can be used for problems where the action vector must sum to 1
Reviewed By: kittipatv
Differential Revision: D15206348
fbshipit-source-id: 665fbed893d8c52d451a12d3bb2e73b2638b7963
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20186
We're missing two USE_CUDA macro for GPU-related code in THD's DataChannelGloo.
Also adding GlooCache back to compilation.
Differential Revision: D15227502
fbshipit-source-id: f260e1cb294d662ba0c170931913b64287d62344
Summary:
Currently, constant folding pass during ONNX conversion removes all onnx::Constant nodes that are parents of nodes that are folded. In situations where the parent onnx::Constant node is other subscribers downstream this could be a problem. This change updates the removal logic to remove to only those onnx::Constant nodes that do not have other subscribers downstream
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20109
Reviewed By: zrphercule
Differential Revision: D15220392
Pulled By: houseroad
fbshipit-source-id: 150788654ea1c84262becaffd6de152114bf76c0
Summary:
Add logging import and a failed MLP model that confirms that we don't fail `add_graph` when graph optimization fails.
This addresses part of https://github.com/pytorch/pytorch/issues/18903
cc lanpa ezyang natalialunova
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20115
Reviewed By: natalialunova
Differential Revision: D15206765
Pulled By: orionr
fbshipit-source-id: c40b7e2671ef845a1529a2910ba030159f53f393
Summary:
This patch specializes `Optional[Tensor]` graph inputs to either a `DimensionedTensorType` (if a Tensor is passed) or `NoneType`. Other `Optional[T]` are specialized to `T` or `None`.
- For unwrapping (checked and unchecked) we need to keep the output type, as IR code that follows unwrapping may not work with NoneType (just as it doesn't deal with Optional). While it would not be hit during execution, it will run against the (legitimate) assumptions of the analysis passes.
- Function lookup currently will not match NoneType when it expects optional (I'm not entirely sure why this doesn't lead to unhappyness currently, but hey), I amend this at the level of the function matching code (`operator.cpp`), but see Adam's comments. We would run into trouble if we needed to select between functions whose signature only differs in Optional types with different subtypes, but we would have the same problem when calling them directly, so I would think this is OK.
- It would enable throwing away branches we can't hit. This also reduces the "blockyness" of the graph, so it may be easier to apply optimizations (e.g. fuse things in `if t is None: ...` and outside the `if`.
- Arguments passed into `Optional[Tensor]` arguments will get shape information, which is very handy.
- It get's rid of the problem that tensors passed into Optional arguments get requires_grad set erroneously #18270 (though that also affects lists, which aren't fixed here).
- `Optional[List[int]]` is needed for #18697.
- We're changing typing in a more subtle way than the `TensorType`->`DimensionedTensorType`.
- In particular, specializing to NoneType loses the Type information captured in the `OptionalType` element type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18407
Reviewed By: zdevito
Differential Revision: D15216808
Pulled By: eellison
fbshipit-source-id: 01f1a7643deaf4962c3f55eff2070d54b0e54b69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20062
Previously, the batch counter is incremented even if none of the readers has data. In this diff,
1) Limiter is applied to the last reader so that the batch counter is not incremented unless the first N-1 readers have data
2) The stop blob of the last reader as the stop blob of the task so that it's checked before the counter is incremented
Reviewed By: xianjiec
Differential Revision: D15099761
fbshipit-source-id: 47ed6c728118fe453cf57ac3457085867939485b
Summary:
As a work around for dynamic shape case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20093
Reviewed By: zrphercule
Differential Revision: D15220661
Pulled By: houseroad
fbshipit-source-id: de271fce542be380bd49a3c74032c61f9aed3b67
Summary:
Fix for https://github.com/pytorch/pytorch/issues/16962
This needs fixing because we turn lists into tuples when constantify a module, so indexing into a Tuple of one type with a non-constant integer is quite common.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20081
Differential Revision: D15205893
Pulled By: eellison
fbshipit-source-id: 61d74ee071ad0aad98e46fe807d6f6cc5f6abd2f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19513
Add support for printing a QTensor in python frontend
Differential Revision: D15017168
fbshipit-source-id: 312d1f18e6ca3c9eb4a5b8bb1c64f7cc8bc1dcf5
Summary:
Eigen was updated with the commit needed to get rid of this warning that plagued the CI. This PR bumps third_party/eigen to that commit head.
```
warning: #warning "host_defines.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead." [-Wcpp]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19917
Differential Revision: D15218183
Pulled By: ezyang
fbshipit-source-id: 653c7d61ea401a7d4469c2009612dc43cc70122d
Summary:
pytorch failed to build with the following error, complaining about the first regex match
It may be caused by a bug in python 2.7.5
This change proposed is a workaround for building pytorch with python 2.7.5
Since the '*' star notation is greedy in python regex, the new expression shall produce the identical result with the old one.
```
Traceback (most recent call last):
File "/data2/nihuini/pytorch/cmake/../aten/src/ATen/gen.py", line 14, in <module>
import preprocess_declarations
File "/data2/nihuini/pytorch/aten/src/ATen/preprocess_declarations.py", line 3, in <module>
from function_wrapper import TYPE_FORMAL_GENERIC
File "/data2/nihuini/pytorch/aten/src/ATen/function_wrapper.py", line 5, in <module>
from code_template import CodeTemplate
File "/data2/nihuini/pytorch/aten/src/ATen/code_template.py", line 13, in <module>
class CodeTemplate(object):
File "/data2/nihuini/pytorch/aten/src/ATen/code_template.py", line 23, in CodeTemplate
subtitution = re.compile(substitution_str, re.MULTILINE)
File "/usr/lib64/python2.7/re.py", line 190, in compile
return _compile(pattern, flags)
File "/usr/lib64/python2.7/re.py", line 242, in _compile
raise error, v # invalid expression
sre_constants.error: nothing to repeat
--
CMake Error at cmake/Codegen.cmake:162 (message):
Failed to get generated_cpp list
Call Stack (most recent call first):
caffe2/CMakeLists.txt:2 (include)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20137
Differential Revision: D15218122
Pulled By: ezyang
fbshipit-source-id: 10b618ff92a04e9074f5d83e31411fc2341e0cf8
Summary:
Some functions were not decorated with `CAFFE2_API`, makes them unusable when creating unit tests for custom ops outside Caffe2 repo.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20114
Differential Revision: D15217490
Pulled By: ezyang
fbshipit-source-id: dda3910ad24e566567607deaac705a34ec8e7b8d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20044
We do not have a gating functor. This diff adds it. I'm leveraging existing learning rate op because there are other policies I'll need to use as a union together.
* Since there are other policy in LearningRateOp which will be used as a union, I chose to add it as a LearningRateOp.
* constantwarmup cannot do step function of nonzero first and zero later
* There are multiple uses for it,
* e.g. as a gating blob generator that is useful for turning off.
* e.g. as a learning rate switcher at certain iteration.
* For generalizability, no regulation or constraint is applied on the range of the values
* see figure below for illustration
{F157366621}
Reviewed By: ccheng16
Differential Revision: D15178229
fbshipit-source-id: 1e66e9a4bc1bfb946a57f8aefc97d8170f6be731
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19777
When used from iPython/Jupyter/Bento, the cell doing kernel registration might be executed multiple times.
Also, there might be a kernel library that wants to overwrite one of the existing kernels.
Let's allow this.
Reviewed By: dzhulgakov
Differential Revision: D15090318
fbshipit-source-id: 09f842e8fd36646053c5c2f11325de4d31105b0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19776
The diff stacked on top of this enables overwriting of kernels, but before that, we need to do some refactorings.
This diff:
- hides deregistration logic behind a RAII class so we can keep more information about what exactly to deregister without the API user knowing about it.
- Split KernelRegistration from SchemaRegistration by taking Dispatcher::OperatorDef and moving it to a different file. This is better readable, especially since kernel registration will become more complex in the next diff.
- Move LeftRight synchronization out of DispatchTable to Operator because there will be a mutex added to Operator in the next diff and related synchronization primitives shouldn't live on different abstraction levels.
Reviewed By: dzhulgakov
Differential Revision: D15090322
fbshipit-source-id: 2e51a192075163f0d496956d9e54b9aaf26b2369
Summary:
This PR adds a new trace API `trace_module` that will allow us to trace multiple methods as a part of a single `ScriptModule`
See the example below.
```python
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Conv2d(1, 1, 3)
def forward(self, x):
return self.conv(x)
def weighted_kernel_sum(self, weight):
return weight * self.conv.weight
example_weight = torch.rand(1, 1, 3, 3)
example_forward_input = torch.rand(1, 1, 3, 3)
n = Net()
inputs = {'forward' : example_forward_input, 'weighted_kernel_sum' : example_weight}
module = torch.jit.trace_module(n, inputs)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19905
Differential Revision: D15200007
Pulled By: Krovatkin
fbshipit-source-id: 0354d973fe40cb6e58b395bd866df14e0fc29d5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19784
For backwards compatibility, we allow vector arguments if a kernel is registered with the deprecated API.
Reviewed By: dzhulgakov
Differential Revision: D15091972
fbshipit-source-id: 4db3e3a262e605504b05c42d40046011408501d2
Summary:
Class attributes preferably be explicitly initiated within
the __init__() call. Otherwise, overriding step() is
prone to bugs.
This patch partially reverts #7889
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20059
Differential Revision: D15195747
Pulled By: soumith
fbshipit-source-id: 3d1a51d8c725d6f14e3e91ee94c7bc7a7d6c1713
Summary:
This takes care of some outstanding review comments for https://github.com/pytorch/pytorch/pull/16196/
Specifically:
1. Add comment about kind
2. Add comment about GraphPy
3. Remove ONNX version comment
4. Remove scalar_dict from SummaryWriter and all history functions
cc lanpa ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20038
Reviewed By: natalialunova
Differential Revision: D15177257
Pulled By: orionr
fbshipit-source-id: 218aa799d8b7dbb58f422a331236bba4959347de
Summary:
Sometimes people need to checkout an older version and build PyTorch. In that case, they need to do `git submodule sync` and maybe `git submodule update --init` as mentioned [here](https://github.com/pytorch/pytorch/issues/20074).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20088
Differential Revision: D15195729
Pulled By: soumith
fbshipit-source-id: 73232b801e5524cdba462dd504fb973d95d0498c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20027
Before this change, any pointer was converted to bool, i.e.
IValue("string") == IValue(true)
After this change, it does the right thing and creates a string.
Reviewed By: dzhulgakov
Differential Revision: D15172409
fbshipit-source-id: 8167dd780005f9bceef4fe3c751f752e42ceeb20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19910
This change modifies the quant-dequant node pattern from
qparam->q->dq to qparam->q->int_repr->qparam->dq. The motivation for
this change is to make the qparams required for op substition one level
up at dequant node instead of multiple levels up.
Differential Revision: D15120146
fbshipit-source-id: 74b0fd5cb50a338f562740a9cc727a7791c718c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19680
This was broken for quite some time because of an operator schema
check that went into effect at some point in time.
Reviewed By: manojkris
Differential Revision: D15055082
fbshipit-source-id: 7f730f9b810bdaffd69bab7ac4d02c5b2e40645b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19402
This pass propagate the qparams calculated after calibration to the
quant nodes which will be used later for quantization
Differential Revision: D14995230
fbshipit-source-id: 5709153ea1c039c4ab4470ddb689a303b0bcc6fd
Summary:
From the comment: "don't use TYPE again in case it is an expensive or side-effect op"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19968
Differential Revision: D15151567
Pulled By: gchanan
fbshipit-source-id: 4d42c081ac1472b71f1cea5172cb42a7c83a7043
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19232
Add observer nodes to collect stats for input data nodes excluding params
which are constant at inference and need not be observed. This information
is required to compute quantization params.
Differential Revision: D14885485
fbshipit-source-id: 8762cc2a4e510e1553b3dbd1d1aecd55b4bdb89f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19783
Previously, the IValues were copied into the kernel arguments, which caused a refcount bump if Tensor was taken by value.
Now, a kernel can take Tensor by value without any refcount bump because it is moved in.
Reviewed By: dzhulgakov
Differential Revision: D15091973
fbshipit-source-id: 4c5ff2e3ee86f5934cc84191697f7dbc9c3ee345
Summary:
The second commit will be removed before landing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19965
Differential Revision: D15153243
Pulled By: pjh5
fbshipit-source-id: 70eae38d0cb07dc732c0cf044d36ec36d0a4472d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19945
this logging was removed in D6888977, but i think it could be useful to debug upstream data issue to check the violating index
Reviewed By: xianjiec
Differential Revision: D15127887
fbshipit-source-id: 4ad7eceefcd063bf45bc190a4c0d458a089c918a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19681
For accelerator, we need to lower just the quantized weights data without layout transformation. This diff attempts to provide this option.
Reviewed By: jerryzh168, zrphercule
Differential Revision: D15066568
fbshipit-source-id: 133d749e087c2ad4a899bee5e96f597f70b2443c
Summary:
log_normal_ and geometric_ were disabled for CPU by mistake in [this PR](bc53805f2e), this PR fixes it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19938
Differential Revision: D15143404
Pulled By: izdeby
fbshipit-source-id: 41c7bd29f046b5a3ac6d601de8c64ab553771d19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19811
This does not immediately take effect for the custom op API but will break backwards compatibility once we switch to the new operator registration.
Reviewed By: dzhulgakov
Differential Revision: D15101924
fbshipit-source-id: 8890a5a3e163d3263dc1837be0b4851984771917
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19779
This macro wasn't set correctly because the target macros weren't included from Apple's header.
Reviewed By: dzhulgakov
Differential Revision: D15090427
fbshipit-source-id: 43ca44f0f409e11718b7f60c3fdcd2aa02d7018e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19773
const members can't be moved, so whenever somebody moved a function schema, it was copied instead.
This diff fixes this.
Reviewed By: dzhulgakov
Differential Revision: D15090323
fbshipit-source-id: 123a1d6b96ac46cb237966c0b072edebcdafe54c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19817
A lot of files were depending on the JIT's typesystem
because operator.h depends on function_schema.h. However,
this isn't fundamental to the design. This diff tries to
remove the direct depenency and only includes the c10
wrapper helpers in files where it is required.
Reviewed By: smessmer
Differential Revision: D15112247
fbshipit-source-id: 2c53d83e542c32d9a398c8b60dbf40ab7a1cb0f6
Summary:
This adds method details and corrects example on the page that didn't run properly. I've now confirmed that it runs in colab with nightly.
For those with internal access the rendered result can be seen at https://home.fburl.com/~orionr/pytorch-docs/tensorboard.html
cc lanpa, soumith, ezyang, brianjo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19915
Differential Revision: D15137430
Pulled By: orionr
fbshipit-source-id: 833368fb90f9d75231b8243b43de594b475b2cb1
Summary:
Trying to get this in before 1.1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19918
Reviewed By: driazati
Differential Revision: D15124430
Pulled By: eellison
fbshipit-source-id: 549cdcbaff91218657e94ce08c0f4e69b576d809
Summary:
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#19638 [jit] Serialize attribute module as torch.jit._pickle**
* use `torch.jit._pickle` as the module for globals in the pickle program. Pickle will try to resolve these to the actual functions in `torch.jit._pickle.py` automatically (I believe this can also be overridden to point to whatever functions you want). This means that `pickle.load("my_model/attributes.pkl")` will work instead of having to use a custom `pickle.Unpickler`
* use `REDUCE` opcodes instead of `BUILD` to make use of the last bullet
* use a union in the unpickler to support globals better (+ any future metadata we might need that can't be stored in an `IValue`), this makes some of the code around `IntList`s clearer and lets us get rid of any lookbehind for opcodes
* pickle things as a tuple instead of a list (an immutable result is more semantically correct)](https://our.intern.facebook.com/intern/diff/15111203/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19638
Pulled By: driazati
Differential Revision: D15111203
fbshipit-source-id: 526c6c2b63a48eb1cba1c658045a7809730070dd
Summary:
Added deprecation warnings for the masked methods and enabled them for a bool tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19140
Differential Revision: D14888021
Pulled By: izdeby
fbshipit-source-id: 0e42daf8f3732ca29f36d10485402bfc502716ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19688
Minor changes to hipify script to take extra folders.
Reviewed By: bddppq
Differential Revision: D15068427
fbshipit-source-id: e2e792c8227cbd0e15fd2564f87d740a62c477da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19901
The existing code used `expect_autograd_hooks_` as a proxy for the
situation where finalization of the previous iteration is needed. This
is not correct, however, since you may decide to completely ignore the
output of a DDP wrapped module. If this is the case, and no gradients
have been passed to the reducer, it is fine to keep going. This commit
adds a new variable `require_finalize_` that tracks whether the
finalization is really needed.
Reviewed By: mrshenli
Differential Revision: D15118871
fbshipit-source-id: 25938eaf1fe13e2940feae1312892b9d3da8a67d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19897
During validation, gradient reduction is not needed, and autograd is
never called. The model output will always be a detached tensor. After
the new reducer was merged, this meant that it would find all model
parameters unused, and kick off reduction for them. When #19799 and
output where no parameters are used and it tries to kick off reduction
of zeroed gradients. Test for `torch.is_grad_enabled()` and
`self.training` before calling into the reducer.
Reviewed By: mrshenli
Differential Revision: D15118726
fbshipit-source-id: b0208f632a61cbe8110fa626fa427937b7f05924
Summary:
As DDP in previous releases does not support unused params, turning off `find_unused_parameters` by default to derisk new reducer.
CC pietern soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19895
Reviewed By: pietern
Differential Revision: D15118563
Pulled By: mrshenli
fbshipit-source-id: 6215c486e1dae3387b36011d8e64a2721ac85f58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19821
It is possible that not a single parameter is used during an
iteration. If this is the case, the `prepare_for_backward` function
marks all parameters as unused, kicks off reduction of all buckets,
*and* finalizes the reduction.
This is different from the prior implementation where we assumed that
autograd would produce a gradient for at least a single parameter.
We then used the autograd callback mechanism to queue a finalizer
callback. Now, this finalizer may be executed in line.
Reviewed By: mrshenli
Differential Revision: D15113272
fbshipit-source-id: dc91458b569cd8c106ddaeea558464b515683550
2. Persists CircleCI scripts (everything in `.circleci`) into a workspace. Why?
We don't always do a Git checkout on all subjobs, but we usually
still want to be able to call scripts one way or another in a subjob.
Persisting files this way lets us have access to them without doing a
checkout. This workspace is conventionally mounted on `~/workspace`
(this is distinguished from `~/project`, which is the conventional
working directory that CircleCI will default to starting your jobs
in.)
3. Write out the commit message to `.circleci/COMMIT_MSG`. This is so
we can determine in subjobs if we should actually run the jobs or
not, even if there isn't a Git checkout.
CircleCI configuration generator
================================
@ -35,4 +55,422 @@ Future direction
See comment [here](https://github.com/pytorch/pytorch/pull/17323#pullrequestreview-206945747):
In contrast with a full recursive tree traversal of configuration dimensions,
> in the future future I think we actually want to decrease our matrix somewhat and have only a few mostly-orthogonal builds that taste as many different features as possible on PRs, plus a more complete suite on every PR and maybe an almost full suite nightly/weekly (we don't have this yet). Specifying PR jobs in the future might be easier to read with an explicit list when we come to this.
> in the future future I think we actually want to decrease our matrix somewhat and have only a few mostly-orthogonal builds that taste as many different features as possible on PRs, plus a more complete suite on every PR and maybe an almost full suite nightly/weekly (we don't have this yet). Specifying PR jobs in the future might be easier to read with an explicit list when we come to this.
----------------
----------------
# How do the binaries / nightlies / releases work?
### What is a binary?
A binary or package (used interchangeably) is a pre-built collection of c++ libraries, header files, python bits, and other files. We build these and distribute them so that users do not need to install from source.
A **binary configuration** is a collection of
* release or nightly
* releases are stable, nightlies are beta and built every night
* python version
* linux: 2.7m, 2.7mu, 3.5m, 3.6m 3.7m (mu is wide unicode or something like that. It usually doesn't matter but you should know that it exists)
* macos and windows: 2.7, 3.5, 3.6, 3.7
* cpu version
* cpu, cuda 9.0, cuda 10.0
* The supported cuda versions occasionally change
* operating system
* Linux - these are all built on CentOS. There haven't been any problems in the past building on CentOS and using on Ubuntu
* MacOS
* Windows - these are built on Azure pipelines
* devtoolset version (gcc compiler version)
* This only matters on Linux cause only Linux uses gcc. tldr is gcc made a backwards incompatible change from gcc 4.8 to gcc 5, because it had to change how it implemented std::vector and std::string
### Where are the binaries?
The binaries are built in CircleCI. There are nightly binaries built every night at 9pm PST (midnight EST) and release binaries corresponding to Pytorch releases, usually every few months.
We have 3 types of binary packages
* pip packages - nightlies are stored on s3 (pip install -f <as3url>). releases are stored in a pip repo (pip install torch) (ask Soumith about this)
* conda packages - nightlies and releases are both stored in a conda repo. Nighty packages have a '_nightly' suffix
* libtorch packages - these are zips of all the c++ libraries, header files, and sometimes dependencies. These are c++ only
* shared with dependencies
* static with dependencies
* shared without dependencies
* static without dependencies
All binaries are built in CircleCI workflows. There are checked-in workflows (committed into the .circleci/config.yml) to build the nightlies every night. Releases are built by manually pushing a PR that builds the suite of release binaries (overwrite the config.yml to build the release)
# CircleCI structure of the binaries
Some quick vocab:
* A\**workflow** is a CircleCI concept; it is a DAG of '**jobs**'. ctrl-f 'workflows' on\https://github.com/pytorch/pytorch/blob/master/.circleci/config.yml to see the workflows.
* **jobs** are a sequence of '**steps**'
* **steps** are usually just a bash script or a builtin CircleCI command.* All steps run in new environments, environment variables declared in one script DO NOT persist to following steps*
* CircleCI has a **workspace**, which is essentially a cache between steps of the *same job* in which you can store artifacts between steps.
## How are the workflows structured?
The nightly binaries have 3 workflows. We have one job (actually 3 jobs: build, test, and upload) per binary configuration
3. For each binary configuration, e.g. linux_conda_3.7_cpu there is a
1. smoke_linux_conda_3.7_cpu
1. Downloads the package from the cloud, e.g. using the official pip or conda instructions
2. Runs the smoke tests
## How are the jobs structured?
The jobs are in https://github.com/pytorch/pytorch/tree/master/.circleci/verbatim-sources . Jobs are made of multiple steps. There are some shared steps used by all the binaries/smokes. Steps of these jobs are all delegated to scripts in https://github.com/pytorch/pytorch/tree/master/.circleci/scripts .
* Linux jobs: https://github.com/pytorch/pytorch/blob/master/.circleci/verbatim-sources/linux-binary-build-defaults.yml
* Common shared code (shared across linux and macos): https://github.com/pytorch/pytorch/blob/master/.circleci/verbatim-sources/nightly-binary-build-defaults.yml
* binary_checkout.sh - checks out pytorch/builder repo. Right now this also checks out pytorch/pytorch, but it shouldn't. pytorch/pytorch should just be shared through the workspace. This can handle being run before binary_populate_env.sh
* binary_populate_env.sh - parses BUILD_ENVIRONMENT into the separate env variables that make up a binary configuration. Also sets lots of default values, the date, the version strings, the location of folders in s3, all sorts of things. This generally has to be run before other steps.
* binary_install_miniconda.sh - Installs miniconda, cross platform. Also hacks this for the update_binary_sizes job that doesn't have the right env variables
* binary_run_in_docker.sh - Takes a bash script file (the actual test code) from a hardcoded location, spins up a docker image, and runs the script inside the docker image
### **Why do the steps all refer to scripts?**
CircleCI creates a final yaml file by inlining every <<* segment, so if we were to keep all the code in the config.yml itself then the config size would go over 4 MB and cause infra problems.
### **What is binary_run_in_docker for?**
So, CircleCI has several executor types: macos, machine, and docker are the ones we use. The 'machine' executor gives you two cores on some linux vm. The 'docker' executor gives you considerably more cores (nproc was 32 instead of 2 back when I tried in February). Since the dockers are faster, we try to run everything that we can in dockers. Thus
* linux build jobs use the docker executor. Running them on the docker executor was at least 2x faster than running them on the machine executor
* linux test jobs use the machine executor and spin up their own docker. Why this nonsense? It's cause we run nvidia-docker for our GPU tests; any code that calls into the CUDA runtime needs to be run on nvidia-docker. To run a nvidia-docker you need to install some nvidia packages on the host machine and then call docker with the '—runtime nvidia' argument. CircleCI doesn't support this, so we have to do it ourself.
* This is not just a mere inconvenience. **This blocks all of our linux tests from using more than 2 cores.** But there is nothing that we can do about it, but wait for a fix on circleci's side. Right now, we only run some smoke tests (some simple imports) on the binaries, but this also affects non-binary test jobs.
* linux upload jobs use the machine executor. The upload jobs are so short that it doesn't really matter what they use
* linux smoke test jobs use the machine executor for the same reason as the linux test jobs
binary_run_in_docker.sh is a way to share the docker start-up code between the binary test jobs and the binary smoke test jobs
### **Why does binary_checkout also checkout pytorch? Why shouldn't it?**
We want all the nightly binary jobs to run on the exact same git commit, so we wrote our own checkout logic to ensure that the same commit was always picked. Later circleci changed that to use a single pytorch checkout and persist it through the workspace (they did this because our config file was too big, so they wanted to take a lot of the setup code into scripts, but the scripts needed the code repo to exist to be called, so they added a prereq step called 'setup' to checkout the code and persist the needed scripts to the workspace). The changes to the binary jobs were not properly tested, so they all broke from missing pytorch code no longer existing. We hotfixed the problem by adding the pytorch checkout back to binary_checkout, so now there's two checkouts of pytorch on the binary jobs. This problem still needs to be fixed, but it takes careful tracing of which code is being called where.
# Code structure of the binaries (circleci agnostic)
## Overview
The code that runs the binaries lives in two places, in the normal [github.com/pytorch/pytorch](http://github.com/pytorch/pytorch), but also in [github.com/pytorch/builder](http://github.com/pytorch/builder) , which is a repo that defines how all the binaries are built. The relevant code is
```
# All code needed to set-up environments for build code to run in,
# but only code that is specific to the current CI system
pytorch/pytorch
- .circleci/ # Folder that holds all circleci related stuff
- config.yml # GENERATED file that actually controls all circleci behavior
- verbatim-sources # Used to generate job/workflow sections in ^
- scripts/ # Code needed to prepare circleci environments for binary build scripts
- setup.py # Builds pytorch. This is wrapped in pytorch/builder
- cmake files # used in normal building of pytorch
# All code needed to prepare a binary build, given an environment
# with all the right variables/packages/paths.
pytorch/builder
# Given an installed binary and a proper python env, runs some checks
# to make sure the binary was built the proper way. Checks things like
# the library dependencies, symbols present, etc.
- check_binary.sh
# Given an installed binary, runs python tests to make sure everything
# is in order. These should be de-duped. Right now they both run smoke
# tests, but are called from different places. Usually just call some
# import statements, but also has overlap with check_binary.sh above
- run_tests.sh
- smoke_test.sh
# Folders that govern how packages are built. See paragraphs below
- conda/
- build_pytorch.sh # Entrypoint. Delegates to proper conda build folder
- switch_cuda_version.sh # Switches activate CUDA installation in Docker
- pytorch-nightly/ # Build-folder
- manywheel/
- build_cpu.sh # Entrypoint for cpu builds
- build.sh # Entrypoint for CUDA builds
- build_common.sh # Actual build script that ^^ call into
- wheel/
- build_wheel.sh # Entrypoint for wheel builds
```
Every type of package has an entrypoint build script that handles the all the important logic.
## Conda
Both Linux and MacOS use the same code flow for the conda builds.
Conda packages are built with conda-build, see https://conda.io/projects/conda-build/en/latest/resources/commands/conda-build.html
Basically, you pass `conda build` a build folder (pytorch-nightly/ above) that contains a build script and a meta.yaml. The meta.yaml specifies in what python environment to build the package in, and what dependencies the resulting package should have, and the build script gets called in the env to build the thing.
tldr; on conda-build is
1. Creates a brand new conda environment, based off of deps in the meta.yaml
1. Note that environment variables do not get passed into this build env unless they are specified in the meta.yaml
2. If the build fails this environment will stick around. You can activate it for much easier debugging. The “General Python” section below explains what exactly a python “environment” is.
2. Calls build.sh in the environment
3. Copies the finished package to a new conda env, also specified by the meta.yaml
4. Runs some simple import tests (if specified in the meta.yaml)
5. Saves the finished package as a tarball
The build.sh we use is essentially a wrapper around ```python setup.py build``` , but it also manually copies in some of our dependent libraries into the resulting tarball and messes with some rpaths.
The entrypoint file `builder/conda/build_conda.sh` is complicated because
* It works for both Linux and MacOS
* The mac builds used to create their own environments, since they all used to be on the same machine. There’s now a lot of extra logic to handle conda envs. This extra machinery could be removed
* It used to handle testing too, which adds more logic messing with python environments too. This extra machinery could be removed.
## Manywheels (linux pip and libtorch packages)
Manywheels are pip packages for linux distros. Note that these manywheels are not actually manylinux compliant.
`builder/manywheel/build_cpu.sh` and `builder/manywheel/build.sh` (for CUDA builds) just set different env vars and then call into `builder/manywheel/build_common.sh`
The entrypoint file `builder/manywheel/build_common.sh` is really really complicated because
* This used to handle building for several different python versions at the same time. The loops have been removed, but there's still unneccessary folders and movements here and there.
* The script is never used this way anymore. This extra machinery could be removed.
* This used to handle testing the pip packages too. This is why there’s testing code at the end that messes with python installations and stuff
* The script is never used this way anymore. This extra machinery could be removed.
* This also builds libtorch packages
* This should really be separate. libtorch packages are c++ only and have no python. They should not share infra with all the python specific stuff in this file.
* There is a lot of messing with rpaths. This is necessary, but could be made much much simpler if the above issues were fixed.
## Wheels (MacOS pip and libtorch packages)
The entrypoint file `builder/wheel/build_wheel.sh` is complicated because
* The mac builds used to all run on one machine (we didn’t have autoscaling mac machines till circleci). So this script handled siloing itself by setting-up and tearing-down its build env and siloing itself into its own build directory.
* The script is never used this way anymore. This extra machinery could be removed.
* This also builds libtorch packages
* Ditto the comment above. This should definitely be separated out.
Note that the MacOS Python wheels are still built in conda environments. Some of the dependencies present during build also come from conda.
## General notes
### Note on run_tests.sh, smoke_test.sh, and check_binary.sh
* These should all be consolidated
* These must run on all OS types: MacOS, Linux, and Windows
* These all run smoke tests at the moment. They inspect the packages some, maybe run a few import statements. They DO NOT run the python tests nor the cpp tests. The idea is that python tests on master and PR merges will catch all breakages. All these tests have to do is make sure the special binary machinery didn’t mess anything up.
* There are separate run_tests.sh and smoke_test.sh because one used to be called by the smoke jobs and one used to be called by the binary test jobs (see circleci structure section above). This is still true actually, but these could be united into a single script that runs these checks, given an installed pytorch package.
### Note on libtorch
Libtorch packages are built in the wheel build scripts: manywheel/build_*.sh for linux and build_wheel.sh for mac. There are several things wrong with this
* It’s confusinig. Most of those scripts deal with python specifics.
* The extra conditionals everywhere severely complicate the wheel build scripts
* The process for building libtorch is different from the official instructions (a plain call to cmake, or a call to a script)
### Note on docker images / Dockerfiles
All linux builds occur in docker images. The docker images are
* soumith/conda-cuda
* Has ALL CUDA versions installed. The script pytorch/builder/conda/switch_cuda_version.sh sets /usr/local/cuda to a symlink to e.g. /usr/local/cuda-10.0 to enable different CUDA builds
* Also used for cpu builds
* soumith/manylinux-cuda90
* soumith/manylinux-cuda92
* soumith/manylinux-cuda100
* Also used for cpu builds
The Dockerfiles are available in pytorch/builder, but there is no circleci job or script to build these docker images, and they cannot be run locally (unless you have the correct local packages/paths). Only Soumith can build them right now.
### General Python
* This is still a good explanation of python installations https://caffe2.ai/docs/faq.html#why-do-i-get-import-errors-in-python-when-i-try-to-use-caffe2
# How to manually rebuild the binaries
tldr; make a PR that looks like https://github.com/pytorch/pytorch/pull/21159
Sometimes we want to push a change to master and then rebuild all of today's binaries after that change. As of May 30, 2019 there isn't a way to manually run a workflow in the UI. You can manually re-run a workflow, but it will use the exact same git commits as the first run and will not include any changes. So we have to make a PR and then force circleci to run the binary workflow instead of the normal tests. The above PR is an example of how to do this; essentially you copy-paste the binarybuilds workflow steps into the default workflow steps. If you need to point the builder repo to a different commit then you'd need to change https://github.com/pytorch/pytorch/blob/master/.circleci/scripts/binary_checkout.sh#L42-L45 to checkout what you want.
## How to test changes to the binaries via .circleci
Writing PRs that test the binaries is annoying, since the default circleci jobs that run on PRs are not the jobs that you want to run. Likely, changes to the binaries will touch something under .circleci/ and require that .circleci/config.yml be regenerated (.circleci/config.yml controls all .circleci behavior, and is generated using ```.circleci/regenerate.sh``` in python 3.7). But you also need to manually hardcode the binary jobs that you want to test into the .circleci/config.yml workflow, so you should actually make at least two commits, one for your changes and one to temporarily hardcode jobs. See https://github.com/pytorch/pytorch/pull/22928 as an example of how to do this.
# Update the PR, need to force since the commits are different now
git push origin my_branch --force
```
The advantage of this flow is that you can make new changes to the base commit and regenerate the .circleci without having to re-write which binary jobs you want to test on. The downside is that all updates will be force pushes.
## How to build a binary locally
### Linux
You can build Linux binaries locally easily using docker.
```
# Run the docker
# Use the correct docker image, soumith/conda-cuda used here as an example
#
# -v path/to/foo:path/to/bar makes path/to/foo on your local machine (the
# machine that you're running the command on) accessible to the docker
# container at path/to/bar. So if you then run `touch path/to/bar/baz`
# in the docker container then you will see path/to/foo/baz on your local
# machine. You could also clone the pytorch and builder repos in the docker.
#
# If you're building a CUDA binary then use `nvidia-docker run` instead, see below.
#
# If you know how, add ccache as a volume too and speed up everything
# Export whatever variables are important to you. All variables that you'd
# possibly need are in .circleci/scripts/binary_populate_env.sh
# You should probably always export at least these 3 variables
export PACKAGE_TYPE=conda
export DESIRED_PYTHON=3.6
export DESIRED_CUDA=cpu
# Call the entrypoint
# `|& tee foo.log` just copies all stdout and stderr output to foo.log
# The builds generate lots of output so you probably need this when
# building locally.
/builder/conda/build_pytorch.sh |& tee build_output.log
```
**Building CUDA binaries on docker**
To build a CUDA binary you need to use `nvidia-docker run` instead of just `docker run` (or you can manually pass `--runtime=nvidia`). This adds some needed libraries and things to build CUDA stuff.
You can build CUDA binaries on CPU only machines, but you can only run CUDA binaries on CUDA machines. This means that you can build a CUDA binary on a docker on your laptop if you so choose (though it’s gonna take a loong time).
For Facebook employees, ask about beefy machines that have docker support and use those instead of your laptop; it will be 5x as fast.
### MacOS
There’s no easy way to generate reproducible hermetic MacOS environments. If you have a Mac laptop then you can try emulating the .circleci environments as much as possible, but you probably have packages in /usr/local/, possibly installed by brew, that will probably interfere with the build. If you’re trying to repro an error on a Mac build in .circleci and you can’t seem to repro locally, then my best advice is actually to iterate on .circleci :/
But if you want to try, then I’d recommend
```
# Create a new terminal
# Clear your LD_LIBRARY_PATH and trim as much out of your PATH as you
# know how to do
# Install a new miniconda
# First remove any other python or conda installation from your PATH
# Always install miniconda 3, even if building for Python <3
# All MacOS builds use conda to manage the python env and dependencies
# that are built with, even the pip packages
conda create -yn binary python=2.7
conda activate binary
# Export whatever variables are important to you. All variables that you'd
# possibly need are in .circleci/scripts/binary_populate_env.sh
# You should probably always export at least these 3 variables
export PACKAGE_TYPE=conda
export DESIRED_PYTHON=3.6
export DESIRED_CUDA=cpu
# Call the entrypoint you want
path/to/builder/wheel/build_wheel.sh
```
N.B. installing a brand new miniconda is important. This has to do with how conda installations work. See the “General Python” section above, but tldr; is that
1. You make the ‘conda’ command accessible by prepending `path/to/conda_root/bin` to your PATH.
2. You make a new env and activate it, which then also gets prepended to your PATH. Now you have `path/to/conda_root/envs/new_env/bin:path/to/conda_root/bin:$PATH`
3. Now say you (or some code that you ran) call python executable `foo`
1. if you installed `foo` in `new_env`, then `path/to/conda_root/envs/new_env/bin/foo` will get called, as expected.
2. But if you forgot to installed `foo` in `new_env` but happened to previously install it in your root conda env (called ‘base’), then unix/linux will still find `path/to/conda_root/bin/foo` . This is dangerous, since `foo` can be a different version than you want; `foo` can even be for an incompatible python version!
Newer conda versions and proper python hygeine can prevent this, but just install a new miniconda to be safe.
echo NOTE: To run `import torch`, please make sure to activate the conda environment by running `call %CONDA_PARENT_DIR%\Miniconda3\Scripts\activate.bat %CONDA_PARENT_DIR%\Miniconda3` in Command Prompt before running Git Bash.
author={Paszke, Adam and Gross, Sam and Chintala, Soumith and Chanan, Gregory and Yang, Edward and DeVito, Zachary and Lin, Zeming and Desmaison, Alban and Antiga, Luca and Lerer, Adam},
USE_MKLDNN"Use MKLDNN. Only available on x86 and x86_64."ON
"CPU_INTEL"OFF)
set(MKLDNN_ENABLE_CONCURRENT_EXEC${USE_MKLDNN})
cmake_dependent_option(
USE_MKLDNN_CBLAS"Use CBLAS in MKLDNN"OFF
"USE_MKLDNN"OFF)
option(USE_DISTRIBUTED"Use distributed"ON)
cmake_dependent_option(
USE_MPI"Use MPI for Caffe2. Only available if USE_DISTRIBUTED is on."ON
@ -131,22 +157,27 @@ cmake_dependent_option(
cmake_dependent_option(
USE_GLOO_IBVERBS"Use Gloo IB verbs for distributed. Only available if USE_GLOO is on."OFF
"USE_GLOO"OFF)
option(USE_TBB"Use TBB"OFF)
# Used when building Caffe2 through setup.py
option(BUILDING_WITH_TORCH_LIBS"Tell cmake if Caffe2 is being built alongside torch libs"OFF)
option(BUILDING_WITH_TORCH_LIBS"Tell cmake if Caffe2 is being built alongside torch libs"ON)
# /Z7 override option
# When generating debug symbols, CMake default to use the flag /Zi.
# However, it is not compatible with sccache. So we rewrite it off.
# But some users don't use sccache; this override is for them.
option(MSVC_Z7_OVERRIDE"Work around sccache bug by replacing /Zi and /ZI with /Z7 when using MSVC (if you are not using sccache, you can turn this OFF)"ON)
cmake_dependent_option(
MSVC_Z7_OVERRIDE"Work around sccache bug by replacing /Zi and /ZI with /Z7 when using MSVC (if you are not using sccache, you can turn this OFF)"ON
PyTorch provides Tensors that can live either on the CPU or the GPU, and accelerates the
computation by a huge amount.
@ -151,15 +151,15 @@ They requires JetPack 4.2 and above and are maintained by @dusty-nv
### From Source
If you are installing from source, we highly recommend installing an [Anaconda](https://www.anaconda.com/distribution/#download-section) environment.
You will get a high-quality BLAS library (MKL) and you get a controlled compiler version regardless of your Linux distro.
You will get a high-quality BLAS library (MKL) and you get controlled dependency versions regardless of your Linux distro.
Once you have [Anaconda](https://www.anaconda.com/distribution/#download-section) installed, here are the instructions.
If you want to compile with CUDA support, install
- [NVIDIA CUDA](https://developer.nvidia.com/cuda-downloads) 7.5 or above
- [NVIDIA cuDNN](https://developer.nvidia.com/cudnn) v6.x or above
- [NVIDIA CUDA](https://developer.nvidia.com/cuda-downloads) 9 or above
- [NVIDIA cuDNN](https://developer.nvidia.com/cudnn) v7 or above
If you want to disable CUDA support, export environment variable `NO_CUDA=1`.
If you want to disable CUDA support, export environment variable `USE_CUDA=0`.
Other potentially useful environment variables may be found in `setup.py`.
If you are building for NVIDIA's Jetson platforms (Jetson Nano, TX1, TX2, AGX Xavier), Instructions to [are available here](https://devtalk.nvidia.com/default/topic/1049071/jetson-nano/pytorch-for-jetson-nano/)
@ -169,19 +169,22 @@ If you are building for NVIDIA's Jetson platforms (Jetson Nano, TX1, TX2, AGX Xa
@ -206,31 +209,67 @@ If the version of Visual Studio 2017 is higher than 15.4.5, installing of "VC++
<br/> There is no guarantee of the correct building with VC++ 2017 toolsets, others than version 15.4 v14.11.
<br/> "VC++ 2017 version 15.4 v14.11 toolset" might be installed onto already installed Visual Studio 2017 by running its installation once again and checking the corresponding checkbox under "Individual components"/"Compilers, build tools, and runtimes".
For building against CUDA 8.0 Visual Studio 2015 Update 3 (version 14.0), and the [patch](https://download.microsoft.com/download/8/1/d/81dbe6bb-ed92-411a-bef5-3a75ff972c6a/vc14-kb4020481.exe) are needed to be installed too.
The details of the patch can be found [here](https://support.microsoft.com/en-gb/help/4020481/fix-link-exe-crashes-with-a-fatal-lnk1000-error-when-you-use-wholearch).
NVTX is a part of CUDA distributive, where it is called "Nsight Compute". For installing it onto already installed CUDA run CUDA installation once again and check the corresponding checkbox.
Be sure that CUDA with Nsight Compute is installed after Visual Studio 2017.
Currently VS 2017, VS 2019 and Ninja are supported as the generator of CMake. If `ninja.exe` is detected in `PATH`, then Ninja will be used as the default generator, otherwise it will use VS 2017.
<br/> If Ninja is selected as the generator, the latest MSVC which is newer than VS 2015 (14.0) will get selected as the underlying toolchain if you have Python > 3.5, otherwise VS 2015 will be selected so you'll have to activate the environment. If you use CMake <= 3.14.2 and has VS 2019 installed, then even if you specify VS 2017 as the generator, VS 2019 will get selected as the generator.
CUDA and MSVC has strong version dependencies, so even if you use VS 2017 / 2019, you will get build errors like `nvcc fatal : Host compiler targets unsupported OS`. For this kind of problem, please install the corresponding VS toolchain in the table below and then you can either specify the toolset during activation (recommended) or set `CUDAHOSTCXX` to override the cuda host compiler (not recommended if there are big version differences).
"unsupported operation: more than one element of the written-to tensor "
"refers to a single memory location. Please clone() the tensor before"
"performing the operation.");
}
}
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
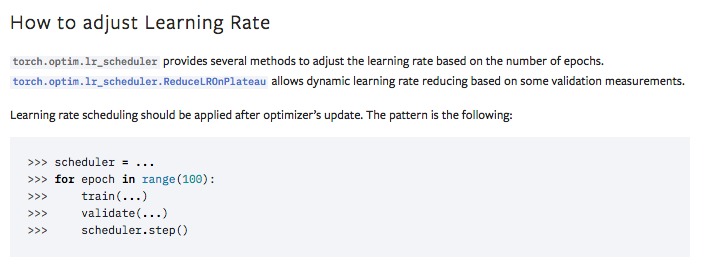{kind=link}