Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30594
This testcase started breaking, clean up for the build.
ghstack-source-id: 94736837
Test Plan: Unittest disabling change
Differential Revision: D18758635
fbshipit-source-id: 05df1158ff0ccd75e401f352da529fb663b1cae0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30890
We've received way too many complaints about this functionality making tests flaky, and it's not providing value to us anyway. Let's cut the shit and kill deadline testing
Test Plan: Imported from OSS
Differential Revision: D18857597
Pulled By: jamesr66a
fbshipit-source-id: 67e3412795ef2fb7b7ee896169651084e434d2f6
* Fix interpolate
* add keypointrcnn test
* update ort versio for test
* pin tv version
* Update test.sh
* Get rid of onnxruntime test changes.
* [v1.4.0] Added torchvision tests as part of ORT tests (#31835)
Summary:
Added torchvision tests as part of ORT tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31835
Reviewed By: hl475
Differential Revision: D19278607
Pulled By: houseroad
fbshipit-source-id: 18a6a85ce3019bcc9aee9517af1378964b585afd
* Remove faster_rcnn and mask_rcnn tests.
Co-authored-by: Lara Haidar <haidar.lara@gmail.com>
Co-authored-by: Negin Raoof <neginmr@utexas.edu>
This PR restores the implementation of CUDA half linspace+logspace.
I added tests for the following:
- linspace+logspace have the same support for integral types on CPU/CUDA
- Precision tests for CUDA half, float, and double.
The precision for CUDA half seems bad, but I checked the numbers against
previous versions of pytorch. The output of CUDA Half linspace+logspace
are exactly the same when compared with 1.2.0.
Equivalent-ish PR on master:
https://github.com/pytorch/pytorch/pull/31962
This is going to be used by upsample (which currently uses magic values to represent optionals).
For now, we just introduce a fake function for testing (torch._test_optional_float(x)).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31517
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
* Dump operator names of a script module
Summary:
Introduce function jit.export_opnames(module), which returns a list of all operator names used in the module and its submodules. One usage is to have mobile custom build to link only operators in the returned list to save the mobile size.
Example:
import torch
m = torch.jit.load("example.pt")
print(torch.jit.export_opnames(m))
The outputs are in alphabetical order:
['aten::_convolution', 'aten::add.Tensor', 'aten::add_.Tensor', 'aten::addmm', 'aten::append.Tensor', 'aten::cat', 'aten::dropout', 'aten::embedding', 'aten::matmul', 'aten::max.dim', 'aten::mul.Tensor', 'aten::permute', 'aten::relu', 'aten::t', 'aten::tanh', 'prim::ListConstruct', 'prim::TupleConstruct', 'prim::TupleUnpack']
This is a simpler fix than https://github.com/pytorch/pytorch/pull/24947, which both fixed the bug and updated the protocol version.
This also adds a test (which the previous PR did not).
So the plan is that master (1.5) will have the new protocol version (and a test), 1.4 will have the old protocol version and the test.
Summary:
Fixes https://github.com/pytorch/pytorch/issues/31271
This fixes copy kernel speed regression introduced in https://github.com/pytorch/pytorch/issues/29631.
The previous implementation forces the compiler to instantiate `static_cast_with_inter_type` because it is passed as an argument of a function. This behavior makes it impossible for compilers to do optimizations like automatic vectorization, and, function call itself is expensive compared to a single casting instruction.
To check the change, run
```
readelf -Ws /home/xgao/anaconda3/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so | grep static_cast_with_inter_type
```
On nightly build, we have output
```
168217: 0000000001852bf0 5 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsdE5applyEd
168816: 0000000001852d30 33 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIfEaE5applyEa
168843: 00000000018531f0 7 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIblE5applyEl
168930: 0000000001852c20 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIslE5applyEl
168935: 00000000018528d0 124 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIfNS_4HalfEE5applyES1_
169023: 0000000001852f30 17 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdEhE5applyEh
169713: 00000000018525c0 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIahE5applyEh
170033: 0000000001852c10 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsiE5applyEi
170105: 0000000001852bd0 5 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIshE5applyEh
170980: 0000000001852fc0 27 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdES1_IfEE5applyES3_
171398: 0000000001852810 13 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIdbE5applyEb
171574: 00000000018532e0 35 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIbNS_8BFloat16EE5applyES1_
171734: 0000000001852b20 6 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIlSt7complexIdEE5applyES2_
172422: 0000000001853350 54 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_8BFloat16EaE5applyEa
172704: 00000000018533c0 38 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_8BFloat16EfE5applyEf
172976: 0000000001852890 10 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIflE5applyEl
173038: 0000000001852f80 9 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIdEfE5applyEf
173329: 00000000018531c0 20 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIbfE5applyEf
173779: 00000000018524d0 3 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIhiE5applyEi
174032: 0000000001852960 14 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIfNS_8BFloat16EE5applyES1_
174334: 0000000001852d60 29 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeISt7complexIfEdE5applyEd
174470: 0000000001852c60 124 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIsNS_4HalfEE5applyES1_
174770: 0000000001852bc0 15 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIlNS_8BFloat16EE5applyES1_
176408: 0000000001853980 144 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeINS_4HalfEbE5applyEb
176475: 0000000001852790 128 FUNC LOCAL DEFAULT 9 _ZN3c1027static_cast_with_inter_typeIdNS_4HalfEE5applyES1_
....
```
And after this PR, we get empty output
```
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31279
Differential Revision: D19075587
Pulled By: ngimel
fbshipit-source-id: c20088241f39fa40c1d055f0a46eb5b9ece52e71
* Make zeros argument of torch.where same dtype as other argument (#30661)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30661
Cherry-picked from https://github.com/pytorch/pytorch/pull/29080
Test Plan: Imported from OSS
Differential Revision: D18781870
Pulled By: nairbv
fbshipit-source-id: 9de85aa91bf7e0856f35c7c6238a8923315ed27f
Co-authored-by: ifedan
* Added check for torch.where on CPU that both arguments have same dtype (#30662)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30662
Cherry picked from: https://github.com/pytorch/pytorch/pull/29081
Test Plan: Imported from OSS
Differential Revision: D18782295
Pulled By: nairbv
fbshipit-source-id: 897ab25ddf8819ca34f5e86c5d3f41debb56cb04
Co-authored-by: ifedan
* added entires to quantization.rst per issue #27938
* more minor tweaks to quantization.rst to reflect the quantization support list (#27938)
* added discussion about setting backend engine to QNNPACK to quantization.rst (#29735)
* added docstrings to the fused functions in torch/nn/intrinsic/modules/fused.py (#26899)
* fixed the docstring for torch.nn.intrinsic.quantized.ConvReLU3d (#27451)
* fixed the formatting on fuse_modules() (#26305)
* fixed rendering issue on QConfig (#30283)
* resolved feedback on PR #30288. Thanks Raghu
Summary:
Currently, both `Conv{1,2,3}dOptions` and `ConvTranspose{1,2,3}dOptions` are aliases of the `ConvOptions<{1,2,3}>` class, which causes confusion because the `ConvOptions` class has parameters such as `transposed` that shouldn't be exposed to the end user. (This has caused issues such as https://github.com/pytorch/pytorch/issues/30931.) This PR makes the following improvements:
1. Rename the original `torch::nn::ConvOptions<N>` class to `torch::nn::detail::ConvNdOptions<N>` class, to signify that it's an implementation detail and should not be used publicly.
2. Create new classes `torch::nn::ConvOptions<N>` and `torch::nn::ConvTransposeOptions<N>`, which have parameters that exactly match the constructor of `torch.nn.Conv{1,2,3}d` and `torch.nn.ConvTranspose{1,2,3}d` in Python API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31005
Differential Revision: D18898048
Pulled By: yf225
fbshipit-source-id: 7663d646304c8cb004ca7f4aa4e70d3612c7bc75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30927
Classes that are used virtually (e.g. have virtual methods) must have a virtual destructor or bad things happen
ghstack-source-id: 95144736
Test Plan: waitforsandcastle
Differential Revision: D18870351
fbshipit-source-id: 333af4e95469fdd9103aa9ef17b40cbc4a343f82
This is already fixed in master as part of bc2e6d10fa.
Before this fix, compiling PyTorch with `-std=c++14` failed on clang 7 due to a compiler bug in the optimizer. With this fix, it works and people can compile PyTorch (or PyTorch extensions) with `-std=c++14`.
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30330
This is now possible due to previous changes made in `gloo` and `ProcessGroupGloo`. We `abort` the listener thread that is waiting for a message, and join all other threads. The API is changed so that the previous `wait_all_workers` does not destroy the agent, and this is now done in a new `shutdown` method. All callsites are updated appropriately.
ghstack-source-id: 94673884
ghstack-source-id: 94673884
Test Plan: Unit tests pass.
Reviewed By: mrshenli
Differential Revision: D18661775
fbshipit-source-id: 5aaa7c14603e18253394224994f6cd43234301c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30217
Before this commit, RRefContext throws an error if it detects any
RRef leak during shutdown. However, this requires applications to
make sure that is has freed all references to RRefs in application
code, which can be a bad debugging experience when for large
applications. Besides, this also relies on Python GC to free things
up in time, which might not always be true. After this commit,
RRefContext would ignore leaking RRefs during shutdown, as shutdown
is called when the application has finished training and no longer
care about local states. Hence, it should be OK to just ignore
those leaks and destroy OwnerRRefs. If application would like to
enforce no leaks, just set torch.distributed.rpc.api._ignore_rref_leak
to False.
Test Plan: Imported from OSS
Differential Revision: D18632546
Pulled By: mrshenli
fbshipit-source-id: 2744b2401dafdd16de0e0a76cf8e07777bed0f38
Summary:
This PR removes `namespace F = torch::nn::functional` from `torch/nn/modules/batchhnorm.h`, so that people don't have to define `torch::nn::functional` as `F` if they don't want to.
Fixes https://github.com/pytorch/pytorch/issues/30682.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30684
Differential Revision: D18795717
Pulled By: yf225
fbshipit-source-id: c9feffbeb632cc6b4ce3e6c22c0a78533bab69ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30208
Adds default arg for init_method so users don't have to pass this in,
and moves it to `RpcBackendOptions` struct. Removes `init_method` arg from rpc.init_rpc. Also fixes some docs.
ghstack-source-id: 94500475
Test Plan: Unit tests pass.
Reviewed By: mrshenli
Differential Revision: D18630074
fbshipit-source-id: 04b7dd7ec96f4c4da311b71d250233f1f262135a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30326
Note that this PR won't trigger the cocoapods build. We'll push the binary and release the cocoapods after the branch cut.
Test Plan: Imported from OSS
Differential Revision: D18660308
Pulled By: xta0
fbshipit-source-id: 95dd97b7b67e70ecee3a65d8bbc125791872b7ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30133
### Summary
Recently we've found that the master branch was constantly broken due to some unwanted change being landed on mobile. The problem is that our CI was not able to detect the runtime errors.
### Previous work
- Add an unit test target to the iOS TestApp ( #29962 )
- Update Fastlane to run tests ( #29963 )
### What's been changed in CI
1. XCode version has been updated to 11.2.1
2. For iOS simulator build, we'll run some unit tests( currently only one) after the build test.
Test Plan: Imported from OSS
Differential Revision: D18641413
Pulled By: xta0
fbshipit-source-id: 12942206f1dee045b2addba3ae618760e992752c
Summary:
Perf improvements to multi_head_attention_forward
- qkv_same and kv_same were not used outside of that branch. Further, kv_same was calculated even though it is not used if qkv_same
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30142
Differential Revision: D18610938
Pulled By: cpuhrsch
fbshipit-source-id: 19b7456f20aef90032b0f42d7da8c8a2d5563ee3
Summary:
Don't look into deep into the diff's implementation. The reason to send out this diff is to help sync on the design first. Once we agree on the design, I will update the implementation accordingly.
**Here is the basic design for achieving this functionality:**
**Q1: Do we need to tell apart case between the following:**
case 1: registry 1: PURE -> registry 2: CONSERVATIVE
case 2: registry 1: PURE -> registry 2: <not set>
A: should be yes though, right now both cases have same value(due to defaulting to CONSERVATIVE) in operators_ and operatorLookupTable_.
case 1 should be denied while case 2 should be legal case where registry 1 will be PURE at the end.
**How to tell apart both cases:**
Right now, AliasAnalysisKind::CONSERVATIVE is by default (code pointer: https://our.intern.facebook.com/intern/diffusion/FBS/browse/master/fbcode/caffe2/aten/src/ATen/core/dispatch/OperatorOptions.h?lines=22%2C52)
Current approach: Introducing a boolean flag in OperatorOptions called isDefault, defaulting to value true. When manually call setAliasAnalysis(AliasAnalysisKind), it will be set too false.
And then when findSchema() in Dispatcher.cpp, we will check response's option's isDefault value.
If isDefault = true, then with some sanity check and if all checks passed, we can update the option info in both operators_ and operatorLookupTable_
Other approaches:
1. Introducing a new AliasAnalaysisKind maybe called NOT_SPECIFIED. (I am not doing it this way since then I need to update other callosities related to AliasAnalaysisKind::CONSERVATIVE) Also, we will need to have additional logics to align between NOT_SPECIFIED and CONSERVATIVE
**What data to be updated:**
corresponding entry in std::list<OperatorDef> operators_ and LeftRight<ska::flat_hash_map<OperatorName, OperatorHandle>> operatorLookupTable_
(More things to be discussed here.)
**Do we need to trigger listeners if an entry get updated:**
I think no.
callOnOperatorRegistered(op) seems only to be using OperatorHandle.schema now from the only callsite from register_c10_ops.cpp
(code pointers: https://our.intern.facebook.com/intern/diffusion/FBS/browse/master/fbcode/caffe2/aten/src/ATen/core/dispatch/Dispatcher.cpp?commit=b4cefeaa98dca5b1ec5f7a0bca6028e368960244&lines=87-90
and https://our.intern.facebook.com/intern/diffusion/FBS/browse/master/fbcode/caffe2/torch/csrc/jit/register_c10_ops.cpp?lines=178&link_ref=biggrep)
However, things can be much more complicated if future extensions may use options when some listeners want to use options value to register operators.
**Future reading list + remaining questions:**
1. How options get consumed on the other side.
2. Usages for fields in OperatorEntry besides schema/options/kernals
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30187
Test Plan:
[xintchen@devvm6308.prn2 ~/fbsource/fbcode] buck test mode/dev //caffe2:ATen-core-test
All tests passed
Differential Revision: D18530964
Pulled By: charliechen0401
fbshipit-source-id: 60c0560a63a36e54f09f397667bb7122b61d6a8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30020
This is now possible due to previous changes made in `gloo` and `ProcessGroupGloo`. We `abort` the listener thread that is waiting for a message, and join all other threads. The destructor calls this same `localShutdown` method, but we ensure this is not called multiple times.
ghstack-source-id: 94415336
Test Plan: Unit tests pass.
Differential Revision: D5578006
fbshipit-source-id: 6258879fb44c9fca97fdfad64468c1488c16ac02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30239
Use unboxed registration per smessmer 's request. For some ops with optional arg or tensor list that unboxed registration are not supported, we still use boxed.
Test Plan: Imported from OSS
Differential Revision: D18653846
Pulled By: iseeyuan
fbshipit-source-id: c22ce8111dfff0ba63316a9bcfe2b712b2d31fc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30201
Provide a default constructor so that users don't have to construct
RPC agent options. Also rename this to RPCBackend Options as suggested.
ghstack-source-id: 94411768
Test Plan: Unit tests pass.
Differential Revision: D18628698
fbshipit-source-id: 81fb45f124ad1006e628f6045162308093c9d446
Summary:
Migrate index_add cpu from TH to ATen.
I couldn't find replacement for get1d and set1d, so doing pointer arithmetic inplace.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28421
Test Plan: existing tests
Differential Revision: D18060971
Pulled By: ggoossen
fbshipit-source-id: 413719990cdb2fe578964cde14e93577e48a4342
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30154
This doesn't seem to be used in thread_pool.cpp.
ghstack-source-id: 94264158
Test Plan: Let's see if this compiles.
Differential Revision: D18614141
fbshipit-source-id: c6ff3db56b55fcee7d8123d909ee275690163ece
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29118
It's never a good idea to throw from a destructor and per #28288 we
can't use `std::make_shared` on a class with a `noexcept(false)`
destructor.
To fix this, we `abort` instead of throw from the `NCCLComm` destructor.
Closes#28288.
ghstack-source-id: 93182910
Test Plan: ProcessGroupNCCLErrorsTest runs successfully.
Reviewed By: pritamdamania87
Differential Revision: D18298271
fbshipit-source-id: ccac37753fef64fb63cb304433f4f97dc5621379
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30298
This diff fixes test_tensorboard for python2:
- proto serialization is different in py2 vs py3 (e.g. for bytes) -> simple string comparison will fail for test_pytorch_graph. Modified to make graph comparison field by field
Reviewed By: J0Nreynolds
Differential Revision: D18654691
fbshipit-source-id: fdbca32e9a7fc2ea70a040bb825eab8a48d0dfe4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30285
PR #30144 introduced custom build script to tailor build to specific
models. It requires a list of all potentially used ops at build time.
Some JIT optimization passes can transform the IR by replacing
operators, e.g. decompose pass can replace aten::addmm with aten::mm if
coefficients are 1s.
Disabling optimization pass can ensure that the list of ops we dump from
the model is the list of ops that are needed.
Test Plan: - rerun the test on PR #30144 to verify the raw list without aten::mm works.
Differential Revision: D18652777
Pulled By: ljk53
fbshipit-source-id: 084751cb9a9ee16d8df7e743e9e5782ffd8bc4e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30292
We already have CI jobs to build Android/iOS libraries, but there are
two issues:
- It's no easy for people who are not regularly working on mobile to debug
these CI errors as they need setup Android/iOS build environment;
- It's hard to run cross-compiled mobile libraries as it requires
emulator. It happened a couple times recently that it can build but fail
to load and run a model with mobile build.
To address these problems, create this new CI job to build mobile
library with linux host toolchain so that we can build & test without
involving Android/iOS environment/simulator. Will add tests on top of it next.
Test Plan: - check the new CI job
Differential Revision: D18654074
Pulled By: ljk53
fbshipit-source-id: eb1baee97a7b52c44979dbf1719c3357e08f895e
Summary:
This adds support for gemm-style matrix multiplications with data and output in bf16 to PyTorch on ROCm to the backend (i.e., bgemm).
Enable operators depending on bgemm.
With this change, bf16 matrices on ROCm can be multiplied on the GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27719
Differential Revision: D18653514
Pulled By: bddppq
fbshipit-source-id: 805db923579bec6fc8fd1c51eeb5b1ef85a96758
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30286
add_hparams() in torch.utils.tensorboard.writer produced the following error
python3.7/site-packages/torch/utils/tensorboard/writer.py", line 294, in add_hparams
with SummaryWriter(log_dir=os.path.join(self.file_writer.get_logdir(), str(time.time()))) as w_hp:
AttributeError: 'NoneType' object has no attribute 'get_logdir'
Other methods such as add_scalar() and add_histogram() use self._get_file_writer() instead of self.file_writer directly.
Test Plan:
```
writer = summary_writer()
writer.add_hparams({"a": 0, "b": 0}, {"hparam/test_accuracy": 0.5}))
writer.flush()
writer.close()
```
Reviewed By: J0Nreynolds, sanekmelnikov
Differential Revision: D18650610
fbshipit-source-id: 1039dd2067d37913a8a131c8b372491a63154899
Summary:
Caches result of `scalar_type` call in TensorIterator and TensorOptions, because the call is expensive.
This removes 120 - 150 ns of overhead (from 1.25 us to 1.12 us for out-of-place case, from 0.86 us to 0.73 us for inplace case)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30065
Test Plan: Covered by existing tests
Differential Revision: D18576236
Pulled By: ngimel
fbshipit-source-id: 17f63851a911fc572c2146f8a520b7f0dadfd14a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30276
### Summary
When building PyTorch for iOS in BUCK, the compiler complains about the ivar shadowing
```
/Users/taox/fbsource/xplat/caffe2/aten/src/ATen/core/dispatch/Dispatcher.h:184:144: error: declaration shadows a field of 'c10::Dispatcher' [-Werror,-Wshadow]
inline Return Dispatcher::doCallUnboxed(const DispatchTable& dispatchTable, const LeftRight<ska::flat_hash_map<TensorTypeId, KernelFunction>>& backendFallbackKernels_, Args... args) const {
^
/Users/taox/fbsource/xplat/caffe2/aten/src/ATen/core/dispatch/Dispatcher.h:134:63: note: previous declaration is here
LeftRight<ska::flat_hash_map<TensorTypeId, KernelFunction>> backendFallbackKernels_;
```
This happens because the internal iOS compiler enforces the `[-Werror, -Wshadow]` on every source file when compiling. Say in `benchmark.mm` we import `<torch/script.h>`, then it'll leads all the way to `Dispatcher.h`
```
In file included from Apps/Internal/PyTorchPlayground/PyTorchPlayground/Application/Benchmark/Benchmark.mm:6:
In file included from /Users/taox/fbsource/xplat/caffe2/aten/src/ATen/ATen.h:5:
In file included from /Users/taox/fbsource/xplat/caffe2/aten/src/ATen/Context.h:4:
In file included from /Users/taox/fbsource/xplat/caffe2/aten/src/ATen/Tensor.h:12:
In file included from buck-out/cells/fbsource/gen/xplat/caffe2/TensorMethods.h/TensorMethods.h:10:
/Users/taox/fbsource/xplat/caffe2/aten/src/ATen/core/dispatch/Dispatcher.h
```
It'd be better to have a separate name for function parameters.
cc shoumikhin
Test Plan: Imported from OSS
Differential Revision: D18649116
Pulled By: xta0
fbshipit-source-id: 19f50b7a23c11dedcafc2ac2d85b45ae4999be2f
Summary:
When creating the onnx graph, we overwrite the output type with the output type of the PT graph.
In some special cases, when using scripting, the PT graph does not have type information. We want to avoid overwriting the input type is these cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25906
Reviewed By: hl475
Differential Revision: D18645903
Pulled By: houseroad
fbshipit-source-id: 56acc43e0c15c74ac8ebd689e04f7371054e362e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30207
This should work now that we're not using gold-specific linker flags.
Test Plan: CI
Differential Revision: D18653521
Pulled By: dreiss
fbshipit-source-id: 31c3cdbefc37b87bfb4140ffbac781131fe72ab3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30206
- --whole-archive isn't needed because we link libtorch as a dynamic
dependency, rather than static.
- --gc-sections isn't necessary because most (all?) of the code in our
JNI library is used (and we're not staticly linking libtorch).
Removing this one is useful because it's not supported by lld.
Test Plan:
Built on Linux. Library size was unchanged.
Upcoming diff enables Mac JNI build.
Differential Revision: D18653500
Pulled By: dreiss
fbshipit-source-id: 49ce46fb86a775186f803ada50445b4b2acb54a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30261
With #29827, the flakiness should disappear for test_call_method_on_rref
Test Plan: Imported from OSS
Differential Revision: D18645036
Pulled By: mrshenli
fbshipit-source-id: 44d759062fc78b1a797266096dbb4ddd104f07eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30221
PR #29881 moved Module::save() methods to a separate source file
and removed C10_MOBILE gating logic. Seems it should stay with
export_module.cpp (which is in "NOT INTERN_BUILD_MOBILE" section).
Otherwise it causes link error with build_mobile.sh.
Test:
- build locally
- check CI
Test Plan: Imported from OSS
Differential Revision: D18649234
Pulled By: ljk53
fbshipit-source-id: b6c90a532d191c41ce10c1047a869d8f73854c4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30244
This makes several small changes to the tensorboard graph parsing methods to address the recent changes to the PyTorch JIT trace/graph.
- Inline graph to get information for all nodes
- Assign and propagate scope names to GetAttr nodes
- Prune all useless GetAttr nodes (any with a ClassType output type - tensors and primitives are kept)
- Create output nodes so output tensor shape can be examined
Reviewed By: sanekmelnikov
Differential Revision: D18556323
fbshipit-source-id: b73a809bacfa554c3fe9c4ae3563525f57539874
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30243
Before this commit, rpc docs shows init_rpc as the following:
```
torch.distributed.rpc.init_rpc(
name,
backend=<BackendType.PROCESS_GROUP: BackendValue(
construct_rpc_agent_options_handler=<function _process_group_construct_rpc_agent_options_handler>,
init_backend_handler=<function _process_group_init_backend_handler>)>,
init_method=None,
rank=-1,
world_size=None,
rpc_agent_options=None
)
```
It unnecessarily leaks implementation details. This commit adds a
__repr__ function to BackendType Enum class to address this problem.
closes#29905
Test Plan: Imported from OSS
Differential Revision: D18641559
Pulled By: mrshenli
fbshipit-source-id: 19bf8a2d21c8207f026d097d8e3f077578d53106
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30240
Get rid of the following warning when build docs:
```
/Users/shenli/Project/pytorch/docs/source/notes/rref.rst:184: WARNING: Error in "code" directive:
maximum 1 argument(s) allowed, 6 supplied.
.. code::
import torch
import torch.distributed.rpc as rpc
# on worker A
rref = rpc.remote('B', torch.add, args=(torch.ones(2), 1))
# say the rref has RRefId 100 and ForkId 1
rref.to_here()
```
Test Plan: Imported from OSS
Differential Revision: D18640016
Pulled By: mrshenli
fbshipit-source-id: d527827f01183411d4b4c73e0a976bdd7fccbf49
Summary:
Given that pybind11 implements these gil functions, I don't think it makes sense for Pytorch to have its own bespoke versions.
Fixes https://github.com/pytorch/pytorch/issues/29065
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29095
Differential Revision: D18301806
Pulled By: ezyang
fbshipit-source-id: 03da6a26c41ee65aaadf7b67b9f0b14d2def2a5a
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28347
gchanan , I am generating a warning as follows:
```
(torch_new) prasun@prasun-xps:~/dev/explore-array-computing$ python arange_test.py
Trying 45...
Before arange shape is torch.Size([1, 45])
After arange shape is torch.Size([1, 45])
Trying 46...
Before arange shape is torch.Size([1, 46])
After arange shape is torch.Size([1, 46])
Trying 47...
Before arange shape is torch.Size([1, 47])
After arange shape is torch.Size([1, 47])
Trying 48...
Before arange shape is torch.Size([1, 48])
After arange shape is torch.Size([1, 48])
Trying 49...
Before arange shape is torch.Size([1, 49])
../aten/src/ATen/native/RangeFactories.cpp:163: UserWarning: Size of out Tensor does not match the result Tensor. The output Tensor will be resized!
After arange shape is torch.Size([50])
Traceback (most recent call last):
File "arange_test.py", line 10, in <module>
assert len(line.shape) == 2
AssertionError
```
Is this alright ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29195
Differential Revision: D18638184
Pulled By: ezyang
fbshipit-source-id: a93e4ce615b5a315570f9951021ef74fc1d895a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30168
Previous implementation of `clone` in `script::Module` copies both the module instance and the
class type, after we enabled type sharing https://github.com/pytorch/pytorch/pull/26666 we also
need to have a function to clone instance only and share the underlying class type.
Test Plan:
tbd
Imported from OSS
Differential Revision: D18631324
fbshipit-source-id: dbadcf19695faee0f755f45093b24618c047b9d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29731
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
Some subtleties about the patch:
- There were a few functions that crossed CPU-CUDA boundary without API macros. I just added them, easy enough. An inverse situation was aten/src/THC/THCTensorRandom.cu where we weren't supposed to put API macros directly in a cpp file.
- DispatchStub wasn't getting all of its symbols related to static members on DispatchStub exported properly. I tried a few fixes but in the end I just moved everyone off using DispatchStub to dispatch CUDA/HIP (so they just use normal dispatch for those cases.) Additionally, there were some mistakes where people incorrectly were failing to actually import the declaration of the dispatch stub, so added includes for those cases.
- torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
- The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
- In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/l
ibprotobuf.a(arena.cc.o) is referenced by DSO"
- A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly. This situation also happens with custom C++ extensions.
- There's a ROCm compiler bug where extern "C" on functions is not respected. There's a little workaround to handle this.
- Because I was too lazy to check if HIPify was converting TORCH_CUDA_API into TORCH_HIP_API, I just made it so HIP build also triggers the TORCH_CUDA_API macro. Eventually, we should translate and keep the nature of TORCH_CUDA_API constant in all cases.
Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18632773
Pulled By: ezyang
fbshipit-source-id: ea717c81e0d7554ede1dc404108603455a81da82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30223
I ran into find_package(OpenMP) failure in some linux environment when
USE_OPENMP=OFF. Figured this workaround to unblock - not sure how hard
to find & fix the root cause of find_package() failure.
Test:
- works in my case;
- will check CI;
Test Plan: Imported from OSS
Differential Revision: D18640309
Pulled By: ljk53
fbshipit-source-id: b5b30623f5da4edbe59574a8b35286b74c3225d3
Summary:
The PR tried to enable the per-channel(row-wise) dynamic quantization for linear operator. Given we have seen some accuracy drop due to the per-tensor quantization, we expect the per-channel could help improve the accuracy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30122
Differential Revision: D18630541
Pulled By: lly-zero-one
fbshipit-source-id: d52685deec5e7de46cd686ae649a8c8765b9cacf
Summary:
The original design of `torch::nn::utils::clip_grad_norm_` / `clip_grad_value_` takes input by non-const reference, which prevents users from passing rvalue reference as input into the functions. This PR changes the functions to take input by value, which matches the Python version's semantics, and also adheres to the C++ API convention that if a function modifies its input in-place, it should take that input by value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30216
Differential Revision: D18632543
Pulled By: yf225
fbshipit-source-id: 97a09d6467f982fe9c8120f483a9c07fcf13699e
Summary:
A prim::BailOut also needs to capture max trip counts as for some graphs they aren't constants and they are used in continuation graphs to figure out the remaining number of iterations to run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30097
Differential Revision: D18624446
Pulled By: Krovatkin
fbshipit-source-id: 085d25981c6669f65848996cd2d50066cc252048
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28287
This PR eliminates the static distinction between
Tensor and Variable. Every Variable is a Tensor, no need to static_cast
or call the Variable constructor.
To do this, I need Tensor to have API parity with Variable. I have already
moved most of the methods I don't want in Tensor off Variable.
These implementations are all placed in Tensor.cpp.
One API difference is that all Variable methods now have const, so we no longer
have faux const-correctness (see https://github.com/zdevito/ATen/issues/27 for
back story)
This diff is BC breaking in a few ways:
- Because torch::autograd::Variable is now just an alias of at::Tensor, ADL for
`torch::autograd` functions no longer works, you have to explicitly qualify
them with `torch::autograd` (examples: `torch/nn/parallel/data_parallel.h`)
- Because Variable and Tensor are now the same type, code which assumes that
they are different types (e.g., for the purposes of templating, or enable_if checks)
will not work until you delete the (now) redundant overload/specialization.
(examples: `torch/nn/modules/container/any.h`, `torch/csrc/utils/pybind.h`)
Some other notes:
- I'm not sure what was going with the old template implementation of `extract_vars`,
but I couldn't get the sfinae version to work. Replacing it with an overloading based version
made it work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18571426
Pulled By: ezyang
fbshipit-source-id: 2ea8151e5f1d8512cdebf1345399642e68b707b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29577
`torch.autograd.grad` can return none is one of the input is not in the
autograd graph or not requires_grad, this fix it so that it return a
list of optional tensor instead of list of tensor.
This might have BC issue unfortunately, but I think it's rare both
internal and external (only training use it, and most of the training
use backward, instead of autograd.grad), so whitelist it.
Test Plan: Imported from OSS
Differential Revision: D18491642
fbshipit-source-id: d32b2b3446cf9e8b9a98f6d203a21a75643d8991
Summary: Add a unit test for the Dynamic Quantized Linear operator (```torch.fbgemm_linear_quantize_weight```, ```torch.fbgemm_pack_quantized_matrix```, and ```torch.fbgemm_linear_int8_weight```) in ```test_quantized.py```.
Test Plan:
buck test mode/dev caffe2/test:quantized -- 'test_qlinear_legacy \(test_quantized\.TestDynamicQuantizedLinear\)' --print-passing-details
[jianyuhuang@devvm29567.prn1.facebook.com: ~/fbsource/fbcode/caffe2/test] $ buck test mode/dev caffe2/test:quantized -- 'test_dynamic_qlinear \(test_quantized\.TestQuantizedLinear\)' --print-passing-details
Parsing buck files: finished in 1.8 sec
Building: finished in 3.4 sec (100%) 6772/6772 jobs, 2 updated
Total time: 5.2 sec
Trace available for this run at /tmp/testpilot.20190714-220130.2698168.log
TestPilot test runner for Facebook. See https://fburl.com/testpilot for details.
Testpilot build revision 4f180136f799ab45ec2bf5d7644cb14955d4dd7a fbpkg
6c6253f255644ca3b8ce1bc5955b0f25 at Mon Jul 8 14:13:38 2019 by twsvcscm from /
usr/local/fbprojects/packages/testinfra.testpilot/651/t.par
Discovering tests
Running 1 tests
Started new test run: https://our.intern.facebook.com/intern/testinfra/testrun/1125900044862617
✓ caffe2/test:quantized - test_dynamic_qlinear (test_quantized.TestQuantizedLinear) 0.023 1/1
(passed)
Test output:
> test_dynamic_qlinear (test_quantized.TestQuantizedLinear) ... ok
>
> ----------------------------------------------------------------------
> Ran 1 test in 0.024s
>
> OK
Finished test run: https://our.intern.facebook.com/intern/testinfra/testrun/1125900044862617
Summary (total time 9.03s):
PASS: 1
FAIL: 0
SKIP: 0
FATAL: 0
TIMEOUT: 0
OMIT: 0
Differential Revision: D16404027
fbshipit-source-id: 4c85dd255637fd8b1eb4830e0464f48c22706f41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30143
We would like to integrate the int64 GEMM in FBGEMM into PyTorch. This brings ~4x speedup for the Linear op with LongTensor.
Benchmark code:
```
from __future__ import absolute_import, division, print_function, unicode_literals
import time
import torch
torch.set_num_threads(1)
print("M, N, K, GOPS/sec")
for M in range(128, 1025, 128):
N = M
K = M
x = torch.LongTensor(M, K)
w = torch.LongTensor(K, N)
NITER = 20
# Test torch.nn.functional.linear
s = time.time()
for _ in range(NITER):
torch.nn.functional.linear(x, w)
# Z = x @ w
elapsed_per_iter_linear = (time.time() - s) / NITER
print(
"{}, {}, {}, {:0.2f}".format(M, N, K, 2.0 * M * N * K / elapsed_per_iter_linear / 1e9)
)
```
Before this PR:
```
M, N, K, GOPS/sec
128, 128, 128, 2.31
256, 256, 256, 2.49
384, 384, 384, 2.54
512, 512, 512, 2.57
640, 640, 640, 2.46
768, 768, 768, 2.59
896, 896, 896, 2.59
1024, 1024, 1024, 2.61
```
After this PR:
```
(base) [root@rtptest10054.frc2 ~/jhuang_test/int64_gemm]# python torch_linear.py
M, N, K, GOPS/sec
128, 128, 128, 5.35
256, 256, 256, 8.34
384, 384, 384, 9.03
512, 512, 512, 9.22
640, 640, 640, 9.55
768, 768, 768, 9.73
896, 896, 896, 9.82
1024, 1024, 1024, 9.63
```
ghstack-source-id: 94308012
Test Plan: CI
Reviewed By: jspark1105
Differential Revision: D18610019
fbshipit-source-id: f830660927b2666db34427d9de51db011f80f766
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29928
Original author: Shihao Xu
- Add abort to `c10d::ProcessGroup::Work`.
- Change the return type of `c10d::ProcessGroup::Work::wait()` to boolean to indicate if the work is aborted after waiting.
- Add unit test for the correctness of abort.
ghstack-source-id: 94305515
ghstack-source-id: 94305515
Differential Revision: D5685727
fbshipit-source-id: 6e682bb563c2393a5c303c877331140417d3f607
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30180
Just applying `clang-format -i` to not mix it with other changes
Test Plan: Imported from OSS
Differential Revision: D18627473
Pulled By: IvanKobzarev
fbshipit-source-id: ed341e356fea31b8515de29d5ea2ede07e8b66a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30052
Some of the examples provided in `rpc/api.py` were not updated along
with the code changes, this PR updates them. Also removes the
`dist.ProcessGroup` information since `init_rpc` now initializes a default
process group.
ghstack-source-id: 94273004
Test Plan: Unit tests pass
Differential Revision: D18582596
fbshipit-source-id: a637683f0221f9600f7e50b74e9f7e5a1d331d8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30172
RRefContext is a conventional singleton, used by rref.cpp. At module teardown
time, it's not defined whether rref_context.cpp or rref.cpp will be destroyed first.
We were observing a SIGSEGV because RRefContext is destroyed before a dangling
~UserRRef() call is able to execute. Particularly, the underlying
ctx.agent()->getWorkerInfo(ownerId_) call failed.
This change just avoids the SIGSEGV by forcing an intentional leak, though we still
need to deal with why there's a dangling UserRref at module destruction time.
ghstack-source-id: 94287441
Test Plan:
existing test suite
test_elastic_averaging in context of D18511430, where the segfault reproed reliable.
Differential Revision: D18620786
fbshipit-source-id: 17b6ccc0eb1724b579a68615e4afb8e9672b0662
Summary:
This adds developer documentation for profiling PyTorch using py-spy. In my work on `__torch_function__` I found its ability to profile native code and dump flame graphs extremely useful. I'm not aware of another Python sampling profiler with similar functionality.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30166
Differential Revision: D18625133
Pulled By: ezyang
fbshipit-source-id: cf1b851564a07c9f12fcf1338ac4527f4a3c61c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30144
Create script to produce libtorch that only contains ops needed by specific
models. Developers can use this workflow to further optimize mobile build size.
Need keep a dummy stub for unused (stripped) ops because some JIT side
logic requires certain function schemas to be existed in the JIT op
registry.
Test Steps:
1. Build "dump_operator_names" binary and use it to dump root ops needed
by a specific model:
```
build/bin/dump_operator_names --model=mobilenetv2.pk --output=mobilenetv2.yaml
```
2. The MobileNetV2 model should use the following ops:
```
- aten::t
- aten::dropout
- aten::mean.dim
- aten::add.Tensor
- prim::ListConstruct
- aten::addmm
- aten::_convolution
- aten::batch_norm
- aten::hardtanh_
- aten::mm
```
NOTE that for some reason it outputs "aten::addmm" but actually uses "aten::mm".
You need fix it manually for now.
3. Run custom build script locally (use Android as an example):
```
SELECTED_OP_LIST=mobilenetv2.yaml scripts/build_pytorch_android.sh armeabi-v7a
```
4. Checkout demo app that uses locally built library instead of
downloading from jcenter repo:
```
git clone --single-branch --branch custom_build git@github.com:ljk53/android-demo-app.git
```
5. Copy locally built libraries to demo app folder:
```
find ${HOME}/src/pytorch/android -name '*.aar' -exec cp {} ${HOME}/src/android-demo-app/HelloWorldApp/app/libs/ \;
```
6. Build demo app with locally built libtorch:
```
cd ${HOME}/src/android-demo-app/HelloWorldApp
./gradlew clean && ./gradlew assembleDebug
```
7. Install and run the demo app.
In-APK arm-v7 libpytorch_jni.so build size reduced from 5.5M to 2.9M.
Test Plan: Imported from OSS
Differential Revision: D18612127
Pulled By: ljk53
fbshipit-source-id: fa8d5e1d3259143c7346abd1c862773be8c7e29a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30140
This seems more semantically correct to me, and makes it so we don't have to iterate over Uses of observed values
Test Plan: Imported from OSS
Differential Revision: D18610676
Pulled By: jamesr66a
fbshipit-source-id: f835266f148bd8198b05cd9df95276e1112dd250
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30066
This commit adds design reasoning and walks through four scenarios
for RRef.
Test Plan: Imported from OSS
Reviewed By: rohan-varma
Differential Revision: D18595094
Pulled By: mrshenli
fbshipit-source-id: 134102901ce515a44a2e7cd013b62143a6158120
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30050
Renames this API to wait_all_workers as discussed.
ghstack-source-id: 94273005
Test Plan: Unit tests pass
Differential Revision: D18581466
fbshipit-source-id: 4ff5d5fb2d528f17252d5b5f30c3047d2efb92bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30146
This PR fixes naming for kl_div and binary_cross_entropy functional options, to be more consistent with the naming scheme of other functional options.
Test Plan: Imported from OSS
Differential Revision: D18618971
Pulled By: yf225
fbshipit-source-id: 2af62c1a0ace2cd0c36c2f1071639bf131d8fe61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30160
The path torch.distributed.rpc.api is an implementation detail, which
should not be used by applications to import RPC APIs. Instead, all
RPC APIs are exposed directly as torch.distributed.rpc.*. This
commit makes the API doc consistent with the above expectation.
Test Plan: Imported from OSS
Differential Revision: D18616359
Pulled By: mrshenli
fbshipit-source-id: 8207f7d36c24cf55af737c03a27fd1896c231641
Summary:
This requires refactoring at::native::result_type to operate as a
state machine, processing the input types one at a time. There may
be other places in the code base that could benefit from adopting
this approach as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30018
Differential Revision: D18606427
Pulled By: resistor
fbshipit-source-id: f6b779326bdb746508690cf7ca6de777adc66244
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30047
Previously, we use dimType to represent dimension type for a tensor. Now, change it to vector<DimType> to record dim type for every dimension of the tensor.
Reviewed By: yinghai, ipiszy
Differential Revision: D18579363
fbshipit-source-id: 72d5a2a8a20a7653e73e64c8eb97f7eed953ea93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30043
This is already checked on in the GH actions linter, so this check is
redundant. And putting it in `setup` has the effect of blocking direct
changes to config.yml when I want to experiment, which is a bit
bothersome.
Test Plan: Imported from OSS
Differential Revision: D18611674
Pulled By: suo
fbshipit-source-id: f81670ae9f264408a3ea72c1ba5fcea208681311
Summary:
This PR adds all `torch::nn::functional` functions and updated their parity status in the C++/Python parity tracker.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29819
Differential Revision: D18617762
Pulled By: yf225
fbshipit-source-id: 75a4d770e2da28b626f785cab243465dbc51efd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29494
`calculate_qparams` of per channel quantization should return the axis, this
PR added this and also added corresponding support in graph mode
Test Plan:
python test/test_jit.py
Imported from OSS
Differential Revision: D18580905
fbshipit-source-id: f9691c1f043f8bca39f81716a4d0b10f60a65396
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29881
Breaking these into separate files allows us to have three different builds:
- Mobile inference-only.
- Mobile with module saving.
- Server with module saving and other export functions like ONNX.
And this can be accomplished just by selecting which cpp files to compile,
without setting any preprocessor flags.
Test Plan: CI. Local mobile+saving build.
Reviewed By: smessmer
Differential Revision: D18509296
fbshipit-source-id: 9438273bac4624df5c7f035b2bacb901cce43053
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30146
This PR fixes naming for kl_div and binary_cross_entropy functional options, to be more consistent with the naming scheme of other functional options.
Test Plan: Imported from OSS
Differential Revision: D18612158
Pulled By: yf225
fbshipit-source-id: 8c403fa1c2a0a65734a3ec2387cc0937c46cab24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29903
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18616888
Pulled By: ezyang
fbshipit-source-id: 360760a688dcc8ba117cd79d89db2afb2c35ab27
Summary:
Enabled basic support for bfloat16 on cuda
Tested via unit tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27259
Differential Revision: D17728661
Pulled By: izdeby
fbshipit-source-id: 99efb6bc4aec029fe6bbc8a68963dca9c9dc5810
Summary:
Fix order of recalculating numel and restriding as first one should always go first
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30025
Differential Revision: D18576446
Pulled By: VitalyFedyunin
fbshipit-source-id: fe9e18ec2bbb7b43d634e150f8979b8d6b7c5196
Summary:
VitalyFedyunin, This PR is about port sigmoid backward to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
for i in range(1000):
output = input.sigmoid().sum()
output.backward()
#get running time
for n in [100, 10000]:
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
for i in range(10000):
output = input.sigmoid().sum()
t1 = _time()
output.backward()
t2 = _time()
bwd_t = bwd_t + (t2 - t1)
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d), backwad avg time is %.2f (ms)." % (n, bwd_avg))
```
Test Device: CPU: skx-8280, GPU: Tesla P40
**Perfromance**:
Before:
```
GPU:
input size(128, 100), backwad avg time is 0.14 (ms).
input size(128, 10000), backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100), backwad avg time is 0.06 (ms).
input size(128, 10000), backwad avg time is 4.21 (ms).
OMP_NUM_THREADS=1
input size(128, 100), backwad avg time is 0.06 (ms).
input size(128, 10000), backwad avg time is 2.30 (ms).
```
After:
```
GPU:
input size(128, 100), backwad avg time is 0.14 (ms).
input size(128, 10000), backwad avg time is 0.17 (ms).
CPU:
OMP_NUM_THREADS=56
input size(128, 100), backwad avg time is 0.05 (ms).
input size(128, 10000), backwad avg time is 0.48 (ms).
OMP_NUM_THREADS=1
input size(128, 100), backwad avg time is 0.04 (ms).
input size(128, 10000), backwad avg time is 0.86 (ms).
```
How to set number thread? using following script:
```
num_threads=$1
script=$2
last_core=`expr $num_threads - 1`
echo "using $num_threads OMP threads"
echo "bind cores to 0~$last_core"
export OMP_NUM_THREADS=$num_threads
export KMP_AFFINITY=granularity=fine,compact,1,0
numactl --physcpubind=0-$last_core --membind=0 python $script
```
and run **./run.sh num_threads test.py**.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29185
Differential Revision: D18587352
Pulled By: VitalyFedyunin
fbshipit-source-id: 8167ca261960399f795d35a83fa8c4be365bc4da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29826
After save/load, we lose concrete type information. So if you tried to
script something that contained a loaded ScriptModule as a submodule,
the following sequence happened:
1. During ConcreteType inference, the loaded submodule got a new
inferred type.
2. But it already has a type! So there was a type mismatch.
To fix this, we should generate a ConcreteType directly from the loaded
submodule type (similar to what we do for interfaces). This makes sense
too--the ConcreteModuleType should be empty, since all the "sugaredness"
was stripped out during the save/load process.
Test Plan: Imported from OSS
Differential Revision: D18575009
Pulled By: suo
fbshipit-source-id: 4d329b7e9b7e7624f459e50092e35ab0ab813791
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29825
We made `ModuleInfo` a union initially to represent the idea that a
submodule could either be a regular module or a module interface.
This PR represents module interfaces as a ConcreteModuleType with no
info (e.g. no "sugaredness"), and with the interface type as the
underlying `jitType_`. This has the effect of reducing the special
casing around adding/maintaining module info.
Test Plan: Imported from OSS
Differential Revision: D18575011
Pulled By: suo
fbshipit-source-id: 53e297b39aa1a03bcdadd795ff225aa68fec9d70
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29824
We have two distinct phases/uses for ConcreteModuleType:
1. We are building it up and using it to check whether we can
reuse JIT types. (RawConcreteModuleType)
2. We are using it to satisfy ModuleValue::attr queries.
(ConcreteModuleType)
These types share an underlying `ConcreteModuleTypeData` which
actually stores the relevant info.
Previously they were the same type because I was lazy, but it's been the
source of a bug. So split them to formalize the differing invariants for
the two phases.
Test Plan: Imported from OSS
Differential Revision: D18575010
Pulled By: suo
fbshipit-source-id: 3e4ebcd36e78b947150d8f0dbb74ecccad23e7c4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30111
Add flag to strip C10 error message. To ensure there's no size regression, add the same flag to existing caffe2 and pytorch build
Test Plan: size bot check
Reviewed By: dreiss
Differential Revision: D18577969
fbshipit-source-id: 84ac57b11ec5c29e831d619260024a0a4a6fdcd0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29930
Right now, python call remote exception rethrown is coupled with deserializtiaon.
For owner ref, the setValue() and getValue() do not use serialization and deserialization, so when users create a ref to itself, and call ownerRef.to_here(), python call remote exception will not be rethrown.
This diff is to move remote exception rethrown out of deserialization, and exception can be handled for ownerRef.localValue() or ownerRef.to_here()
close#29924
ghstack-source-id: 94210894
Test Plan: unit tests
Differential Revision: D18541916
fbshipit-source-id: 7cda93f623d52c740b3c1b1fa9a442f866984340
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30093https://github.com/pytorch/pytorch/pull/28226 introduced `worker_to_id` arg to the `def init_rpc` function for other `RpcAgent`. While it's not really used by `ProcessGroupAgent`. Cleanup is wanted for this, as described in https://github.com/pytorch/pytorch/issues/29031.
To adapt to the difference of different `RpcAgent`, adding a `RpcAgentOptions` base classes, which allow leveraging inheritance to add extra fields.
ghstack-source-id: 94197295
Test Plan:
### OSS RPC + RRef tests
```
buck test mode/dev-nosan //caffe2/test:rpc_fork
```
```
buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcBackend/test:thrift_rpc_fork_test -- test_sync_rpc
```
### Prototype RRef tests
```
buck test mode/dev-nosan caffe2/torch/fb/distributed/pytorch/tests:test_rpc
```
```
buck test mode/dev-nosan //caffe2/torch/fb/distributed/pytorch/tests:test_rpc_thrift_rpc_agent
```
### Dist autograd
```
buck test mode/dev-nosan caffe2/test:dist_autograd_fork
```
```
buck test mode/dev-nosan caffe2/torch/fb/distributed/thriftRpcBackend/test:thrift_dist_autograd_fork_test
```
Differential Revision: D18595578
fbshipit-source-id: 616fca3b844c171ed5277bbc6a2b1693bc3a8065
Summary:
Overwrite `__setstate__` func in nn.MultiheadAttention func and add `self._qkv_same_embed_dim` attribute in the `dict`. Current users should not be affected by the change.
The changes have been tested to load a MultiheadAttention model trained by PyTorch 1.1. If users have an old MultiheadAttention model, please use `torch.load` func to load the old model for inference under v1.4.0 and above.
```
import torch
model = torch.load('old_v1.1.0_MultiheadAttention.pt') # model works for torch 1.4
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29001
Differential Revision: D18257671
Pulled By: zhangguanheng66
fbshipit-source-id: fa41b85f6d53034dc9f445af60f2ad9636e9abf7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30062
This allows to catch exceptions during optimizer creation.
ghstack-source-id: 94232436
Test Plan: new unit test.
Differential Revision: D18586108
fbshipit-source-id: 71cfdf337fe803dbea8787b4c68e5a52b70a1f68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30067
### Summary
The mobile build has been broken since last week due to a runtime error caused by a missing operator in JIT:
```shell
libc++abi.dylib: terminating with uncaught exception of type torch::jit::script::ErrorReport:
Unknown builtin op: aten::_adaptive_avg_pool2d_backward.
Could not find any similar ops to aten::_adaptive_avg_pool2d_backward. This op may not exist or may not be currently supported in TorchScript.
:
at <string>:9:28
grad_self = grad.expand(self.size()) / (self_size[-1] * self_size[-2])
else:
grad_self = torch._adaptive_avg_pool2d_backward(grad, self)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return grad_self
```
### How this happens
Since we've disabled the autograd for the opensourced version, the `backward` ops won't get registered by JIT.
When `forward` runs, a `GraphExecutor` will be created according to the value of `executor_mode`. In the mobile case , this one was set to true, which gives us the `ProfilingGraphExecutorImpl` object. Seems like this executor will eventually try to emit IR for autograd schemas? which causes the error.
### Fix
There are two ways to fix it.
1. Add a macro to disable `profiling_mode` as well as `executor_mode` on mobile. Like what `FBCODE_CAFFE2` does [here](https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/profiling_graph_executor_impl.cpp#L22).
2. Disable the two modes in runtime, by calling ` torch::jit::getExecutorMode() = false;` before calling forward.
(IMO, The second fix is sort of a workaround as it doesn't make sense from a user perspective (Why I need to do this). But the up side is that we don't have to introduce yet another macro )
Feel free to drop comments, if there is a better way to fix it.
### How this was not detected by our mobile CI
We're working on adding runtime tests to our mobile build to prevent similar issues like this.
### Test Plan
- The error above disappears
- Don't break CI
cc AshkanAliabadi
Test Plan: Imported from OSS
Differential Revision: D18605998
Pulled By: xta0
fbshipit-source-id: 11fa85c2b44d54bc28a9c45731af0f5d17d5804c
Summary:
This uses newly added InlinedCallStack to print the original call stack
even if the real call stack is shallower because of inlining.
This change also makes torchscript stacktraces look like python ones.
Example:
```
torch.jit.script
def baz(c, b):
return c + b
torch.jit.script
def foo(c, b):
return baz(c, b)
torch.jit.script
def bar(c, b):
return foo(c, b)
bar(torch.rand(10), torch.rand(9))
```
Output before:
```
Traceback (most recent call last):
File "fail.py", line 25, in <module>
bar(torch.rand(10), torch.rand(9))
RuntimeError: The size of tensor a (10) must match the size of tensor b (9) at non-singleton dimension 0
The above operation failed in interpreter, with the following stack trace:
at fail.py:15:11
torch.jit.script
def baz(c, b):
return c + b
~~~~~ <--- HERE
```
Output after:
```
Traceback (most recent call last):
File "fail.py", line 41, in <module>
bar(torch.rand(10), torch.rand(9))
RuntimeError: The size of tensor a (10) must match the size of tensor b (9) at non-singleton dimension 0
The above operation failed in interpreter.
Traceback (most recent call last):
File "fail.py", line 33
torch.jit.script
def bar(c, b):
return foo(c, b)
~~~ <--- HERE
File "fail.py", line 29, in foo
torch.jit.script
def foo(c, b):
return baz(c, b)
~~~ <--- HERE
File "fail.py", line 25, in baz
torch.jit.script
def baz(c, b):
return c + b
~~~~~ <--- HERE
```
Output of non-scripted python code:
```
Traceback (most recent call last):
File "fail.py", line 36, in <module>
bar(torch.rand(10), torch.rand(9))
File "fail.py", line 21, in bar
return foo(c, b)
File "fail.py", line 18, in foo
return baz(c, b)
File "fail.py", line 15, in baz
return c + b
RuntimeError: The size of tensor a (10) must match the size of tensor b (9) at non-singleton dimension 0
```
Differential Revision: D18532812
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: e7e5ba5e4a8f1c7086406271d0f1685d9db8541a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27921
InlinedCallstack serves a similar purpose to Scope, but instead of storing
string names of the functions it stores pointer to Function objects
themselves. Currently, scopes are used in tracing and callstacks are
used in scripting - hopefully I would be able to merge them in future.
gh-metadata: pytorch pytorch 27921 gh/ZolotukhinM/139/head
Differential Revision: D17914132
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: b1daa6700199ee1a97a7f49a6fced9ac0dc13051
Summary:
Hi yf225,
I have a few doubts related to implementation:
1) What tests do I have to write?
2) What does _load_state_from_dict does?
3) Do I need to override reset() function as I can not see it's utility?
4) InstanceNormOptions could be removed with BatchNormOptions, but I find that
`track_running_status` is not defined instead `stateful` is defined.
InstanceNorm{1,2,3}d https://github.com/pytorch/pytorch/issues/25883
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28790
Differential Revision: D18588666
Pulled By: yf225
fbshipit-source-id: bb9b81f01f62c3fc8765fa0ba0716768087ee155
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29963
### Summary
To run unit tests via Fastlane, simply run `fastlane scan`. Under the hood, it uses `xcodebuild` to run the unit tests. The Scanfile serves as a config file for Fastlane where you can specify parameters you want to pass to `xcodebuild`. More about Scan - https://docs.fastlane.tools/actions/scan/
### Test Plan
- `fastlane scan` is able to run on CI machines.
Test Plan: Imported from OSS
Differential Revision: D18606098
Pulled By: xta0
fbshipit-source-id: b4727d964fa56076b2ff383b40d1b13607721394
Summary:
Since torchvision is not using input_channels / output_channels / with_bias in ConvOptions anymore (https://github.com/pytorch/vision/pull/1576), we can remove the bridges now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29838
Differential Revision: D18597943
Pulled By: yf225
fbshipit-source-id: 59101437f032f042574998eb90eaf0be09352364
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30092
There are duplicate code for component that rely on RpcAgent. Extract them into a re-usable test fixture class.
ghstack-source-id: 94196891
Test Plan:
### RPC + RRef
```
buck test mode/dev-nosan //caffe2/test:rpc_fork
buck test mode/dev-nosan //caffe2/test:rpc_spawn
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift
```
### Dist Autograd
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork
buck test mode/dev-nosan //caffe2/test:dist_autograd_spawn
```
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork_thrift
buck test mode/dev-nosan //caffe2/test:dist_autograd_spawn_thrift
```
### Dist Optimizer
```
buck test mode/dev-nosan //caffe2/test:dist_optimizer_fork
buck test mode/dev-nosan //caffe2/test:dist_optimizer_spawn
```
```
buck test mode/dev-nosan //caffe2/test:dist_optimizer_fork_thrift
buck test mode/dev-nosan //caffe2/test:dist_optimizer_spawn_thrift
```
Differential Revision: D18595408
fbshipit-source-id: 8360759c63e838fb19d4eb1aeacca0bf8eb4b55f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30112
Currently, we have torch::nn functionals that takes `input` as `Tensor&` in order to be able to in-place change `input`'s value. We likely shouldn't do this because it will prevent the following use case:
```cpp
F::elu(torch::tensor(1), F::ELUFuncOptions().inplace(true))
```
The solution is to change the type of `input` to `Tensor`, so that we can pass an rvalue into the functional.
Test Plan: Imported from OSS
Differential Revision: D18601580
Pulled By: yf225
fbshipit-source-id: 639a86eb62f6c986b0f20bf7e201983e83126e73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29770
We were passing around const and non-const references for
DistAutogradContext from DistAutogradContainer. This wasn't safe since the
context could be deleted from the container and a thread might still be using
the reference. This usually would happen when a backward pass fails on the node
driving the backward pass (resulting in delete context messages being sent to
all nodes) but other nodes are still executing code related to that autograd
context.
This was also the reason why `test_backward_autograd_engine_error` was flaky.
Using a std::shared_ptr everywhere ensures we're safe and never crash.
Closes#28928Closes#26922
ghstack-source-id: 94201446
Differential Revision: D18494814
fbshipit-source-id: 0c925fdbd5755f6d876dad56885e2cbaf41fc5f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30100
As after #29827 we only test RPC using spawn, the multi-thread/fork
error should disappear.
Test Plan: Imported from OSS
Differential Revision: D18597002
Pulled By: mrshenli
fbshipit-source-id: 64aa6a59248e5d1b7e1ad1aebffb6a25248388d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30099
As after #29827 we only test RPC using spawn, the multi-thread/fork
error should disappear.
Test Plan: Imported from OSS
Differential Revision: D18597003
Pulled By: mrshenli
fbshipit-source-id: ebfb1f6f3f961d98351e06ce4b951793a9b95398
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30098
As after #29827 we only test RPC using spawn, the multi-thread/fork
error should disappear.
Test Plan: Imported from OSS
Differential Revision: D18597001
Pulled By: mrshenli
fbshipit-source-id: 68256289085fac1a9ca76d5b4882e97e2f81d1f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29492
Previously graph mode quantization only works for per tensor quantization,
this PR added support for per channel quantization as well, changes include
- insert per channel quantization calls(insert_quant_dequant)
- add support of folding for prepacked per channel quantized weight (fold_prepack)
Test Plan:
test is not possible until we can script PerChannelObserver, which comes in https://github.com/pytorch/pytorch/pull/29416
we'll add test in a separate PR after that.
Imported from OSS
Differential Revision: D18580444
fbshipit-source-id: 347c07f201648ec49f070523642a9170278f8aa4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29901
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18594828
Pulled By: ezyang
fbshipit-source-id: cf4ade2da9bf8769cfb3149713941aa9e5e0d197
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29962
### Summary
Recently we've found that the master branch was constantly broken due to some unwanted change being landed on mobile. The problem is that our CI was not able to detect the runtime errors. Starting from this PR, we'll add some unit tests to the iOS Simulator build. As follows:
1. Add an unit test target to XCode (this PR)
2. Use Fastlane to run the tests on CI
3. Modify the CI scripts to trigger tests
### Test Plan
- Don't break the existing CI jobs unless they are flaky.
Test Plan: Imported from OSS
Differential Revision: D18582908
Pulled By: xta0
fbshipit-source-id: f960c47d3bbda79e754a0513e8711867fd3588d2
Summary:
Stacked PRs
* https://github.com/pytorch/pytorch/issues/29244 - Use custom CRC
* **https://github.com/pytorch/pytorch/issues/29232 - Add zipfile serialization**
This adds a serialization method that uses a zipfile (https://github.com/pytorch/pytorch/issues/26567). Right now it is
guarded behind a flag `_use_new_zipfile_serialization`. In release mode it seems to have performance about the same / slightly better than the current serialization in some simple benchmarks for large/small tensors.
Follow ups:
* Flip the `_use_new_zipfile_serialization` flag
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29232
Differential Revision: D18332036
Pulled By: driazati
fbshipit-source-id: 1bac0847c4d599612cba905f2cac8248783be2f4
Summary:
The main changes in this PR are:
- skip device dispatch for CPU scalars (number literals also fall into this). In most cases scalars should be on CPU for best perf, but if users explicitly put on other device, we will respect that setting and exit fast pass.
- directly manipulate Tensor data_ptr when filling scalar into a 1-element tensor.
Some perf benchmark numbers:
```
## Before
In [4]: def test(x):
...: x = x + 2
...: return x
...:
In [5]: with torch.no_grad():
...: x = torch.ones(100)
...: %timeit {test(x)}
...:
79.8 µs ± 127 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
## After
In [2]: def test(x):
...: x = x + 2
...: return x
...:
In [3]: with torch.no_grad():
...: x = torch.ones(100)
...: %timeit {test(x)}
...:
60.5 µs ± 334 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Before the patch `tensor_slow` took 15.74% of total time.
<img width="1186" alt="Screen Shot 2019-11-15 at 12 49 51 PM" src="https://user-images.githubusercontent.com/5248122/68976895-cc808c00-07ab-11ea-8f3c-7f15597d12cf.png">
After the patch `tensor_slow` takes 3.84% of total time.
<img width="1190" alt="Screen Shot 2019-11-15 at 1 13 03 PM" src="https://user-images.githubusercontent.com/5248122/68976925-e28e4c80-07ab-11ea-94c0-91172fc3bb53.png">
cc: roosephu who originally reported this issue to me.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29915
Differential Revision: D18584251
Pulled By: ailzhang
fbshipit-source-id: 2353c8012450a81872e1e09717b3b181362be401
Summary:
Fixes https://github.com/pytorch/pytorch/issues/29187
This introduces a new class `_NormBase` that `_InstanceNorm` and `_BatchNorm` inherit from separately. This means the `isinstance(module, _BatchNorm)` check won't falsely pass for `_InstanceNorm`.
The suggested fix of adding `and not isinstance(module, _InstanceNorm)` works as well, but requires introducing a cyclic dependency between `instancenorm.py` and `batchnorm.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29985
Differential Revision: D18588104
Pulled By: yf225
fbshipit-source-id: f599da3b902ad9c56836db4d429bfc462ed51338
Summary:
Support exporting left/right bitshifts to ONNX for all opset versions.
ONNX has a bitshift operator in opset 11, but it only supports unsigned ints, so it can't be used in PyTorch (since only uint8 is the only uint type).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28210
Reviewed By: hl475
Differential Revision: D18575512
Pulled By: houseroad
fbshipit-source-id: 74161db67f599996a0614981edcc171af6780d21
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex)
- [x] Replaced std:real(a) with a.real() in kernel level code.
- [x] Fixed Vec256_base implementation of complex ops so that it works correctly on Non-AVX devices.
- [x] Fix NumericUtils.h
cc: iotamudelta, ezyang, bddppq, zasdfgbnm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29840
Differential Revision: D18531274
Pulled By: ezyang
fbshipit-source-id: 0fa842c68e4bd55134fe0271880e2d15fe692b7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29827
There are known issues for "fork tests + OMP" in Pytorch, rpc and dist autograd tests use OMP thread pools, this caused rpc fork and dist autograd fork tests to be flaky. So remove these fork tests from PyTorch repo. rpc spawn and dist autograd spawn tests are still running.
Test Plan: unit tests
Differential Revision: D18507384
fbshipit-source-id: 9e239f13850832b4b84724828537f73512f3fca9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29601
Follow up from https://github.com/pytorch/pytorch/pull/28392. Adds a background thread to `ProcessGroupAgent` that polls for timed out RPCs at a pre-set interval, and marks them as completed with a timeout exception if they have timed out. Also deletes the futures from the corresponding maps `futures_` and `futureTimeouts`. Unit tests are added to ensure that timed out RPCs are appropriately cleaned up.
Also adds a `shutdown` variable to process group agent to control the shutting down of this background thread, which can eventually be extended to use for controlling a clean shutdown of process group agent.
ghstack-source-id: 94175131
Test Plan: Added unit tests
Differential Revision: D18434215
fbshipit-source-id: c48abdb8759fe1447200ec66bb9d4b1c50ec4535
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30072
Fix the test failure with mode/opt-lto by disabling openmp in both static and dynamic histograms. We will just use single thread in histogram processing as it's the common use case.
Test Plan:
```
buck run mode/opt caffe2/caffe2/fb/fbgemm/numerical_debugger/workflows:int8_static_quantization_exporter -- --model-dir /mnt/public/summerdeng/ads/ --model-name downsized_ins_97293388_0.predictor --run --iter 10 --dataset-path /mnt/public/summerdeng/ads/ctr_instagram_story_int8/dataset/train/dataset_115764229_10 --hive-path="hive://ad_delivery/ig_ad_prefiltered_training_data_orc_injected/ds=2019-09-09/pipeline=ctr_instagram_story_click_only_model_opt_out_df" --collect-histogram --activation-histogram-file=/mnt/public/summerdeng/ads/ctr_instagram_story_int8/activation_histograms/dummy_debug_OOM.txt
```
```
buck test mode/opt-lto caffe2/caffe2/quantization/server:dynamic_histogram_test -- --run-disabled
```
Reviewed By: hx89
Differential Revision: D18554614
fbshipit-source-id: cfff51174154e753b7123b4ec502b88ffc508917
Summary:
Fix for https://github.com/pytorch/pytorch/issues/29578
Shape check is moved up as much as possible, because backends by and large don't correctly handle empty inputs, so check needs to be done before backend selection. That also automatically takes care of backward, because forward for empty input is automatically differentiable, so no backend-specific backward routines are ever called.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30035
Test Plan: tests for empty inputs are added.
Differential Revision: D18584427
Pulled By: ngimel
fbshipit-source-id: a42918f50eb1f6995921aafa92879cd42dd5e9e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30060
Mobile forward() passed inputs by reference, which is different from JIT's script::module. To make it consistent, change it pass by value.
Test Plan: Imported from OSS
Differential Revision: D18587786
Pulled By: iseeyuan
fbshipit-source-id: fa398124fd0a5168f708733ff88f0ba327726f43
Summary:
This is a fix for batch norm 2D with affine=False.
Repro: https://github.com/pytorch/pytorch/issues/29271
Error is because the output of the unsqueeze op does not have scalar type information. So I moved the references to scalar type after the unsqueeze line.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29458
Reviewed By: hl475
Differential Revision: D18400975
Pulled By: houseroad
fbshipit-source-id: f5c5633857c584edcef3b9e9946861dcfccccd75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29958
DistributedOptimizer relies on hashing WorkerInfo in order to coalesce fan-out RPCs. This will likely be a very common use case (EASGD will do the same, for example).
ghstack-source-id: 94169198
Test Plan: unit test.
Differential Revision: D18548257
fbshipit-source-id: 7d67d4e1b9bc60403c372164982a75ae8c1d8389
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30040
The benchmark will run each test in a loop of 200 iters, then keep doubling the number of iters until the time is significant. For operators which have very large input shapes, the initial 200 iters will take too much time which is not really necessary. This diff changed that 200 to 100.
(Note: this ignores all push blocking failures!)
Test Plan:
```
Before
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : None
# Benchmarking PyTorch: ConvTranspose2d
# Mode: Eager
# Name: ConvTranspose2d_in_c512_out_c512_kernel3_stride2_N8_H64_W64_cpu
# Input: in_c: 512, out_c: 512, kernel: 3, stride: 2, N: 8, H: 64, W: 64, device: cpu
Forward Execution Time (us) : 729634.577
After
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : None
# Benchmarking PyTorch: ConvTranspose2d
# Mode: Eager
# Name: ConvTranspose2d_in_c512_out_c512_kernel3_stride2_N8_H64_W64_cpu
# Input: in_c: 512, out_c: 512, kernel: 3, stride: 2, N: 8, H: 64, W: 64, device: cpu
Forward Execution Time (us) : 718315.899
Reviewed By: hl475
Differential Revision: D18579588
fbshipit-source-id: ef52474cf77e7549bbab0a9ae7b1b0c04023d208
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29787
The initializedContextIds_ map was never cleaned up in DistEngine and
kept on growing as we continue to run backward passes. To fix this, in this PR
we ensure that the context id is cleaned up from this map once we are done with
the backward pass.
Closes#29083
ghstack-source-id: 94161770
Test Plan: waitforbuildbot
Differential Revision: D18498937
fbshipit-source-id: 8d31fc066f6994627766f2b6ca36efa1bef89840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30033
Removing this API for now since we don't have a concrete use-case for
this yet and as a result exposing this as a public API might result in users
depending on this API.
We can always add some variant of this API back if needed later.
ghstack-source-id: 94138302
Test Plan: waitforbuildbot
Differential Revision: D18578056
fbshipit-source-id: 078c62331725e03bd5702624afc16b1cdcdf26a4
Summary:
This is to help the bisecting for unstable convergence that https://github.com/pytorch/pytorch/issues/29997 targets, comparing to the other PR, this one is a smaller hammer (few lines of code change) and would facilitate our future repro/fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30031
Differential Revision: D18577624
Pulled By: VitalyFedyunin
fbshipit-source-id: 92a76cf5db24b25105395f80086d90d8e51dcc4b
Summary:
update the requirements on input dimensions for `torch.nn.SyncBatchNorm`:
1. 2D inputs is now permissible, https://github.com/pytorch/pytorch/issues/20204 ;
2. requires at least two element along normalization plane (BatchNorm behavior);
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29626
Differential Revision: D18492531
Pulled By: albanD
fbshipit-source-id: f008e46a2d520d73c3c2730890a7424eba2ede9e
Summary: We added caffe2 python wrapper and unit test for the SparseRAdam C++ operator.
Test Plan:
Unit test is constructed following the design pattern of [Wngrad optimizer](https://our.intern.facebook.com/intern/diff/D8655724/). Test passed smoothly.
buck test //caffe2/caffe2/python:optimizer_test -- TestSparseRAdam
Test result:
{F221144048}
Reviewed By: wx1988
Differential Revision: D18330650
fbshipit-source-id: e0f4724c2b616b665e2a0fe2e5c3430696cca7ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29747
There are duplicate code for component that rely on RpcAgent. Extract them into a re-usable test fixture class.
Test Plan:
### RPC + RRef
```
buck test mode/dev-nosan //caffe2/test:rpc_fork
buck test mode/dev-nosan //caffe2/test:rpc_spawn
```
```
buck test mode/dev-nosan //caffe2/test:rpc_fork_thrift
buck test mode/dev-nosan //caffe2/test:rpc_spawn_thrift
```
### Dist Autograd
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork
buck test mode/dev-nosan //caffe2/test:dist_autograd_spawn
```
```
buck test mode/dev-nosan //caffe2/test:dist_autograd_fork_thrift
buck test mode/dev-nosan //caffe2/test:dist_autograd_spawn_thrift
```
### Dist Optimizer
```
buck test mode/dev-nosan //caffe2/test:dist_optimizer_fork
buck test mode/dev-nosan //caffe2/test:dist_optimizer_spawn
```
```
buck test mode/dev-nosan //caffe2/test:dist_optimizer_fork_thrift
buck test mode/dev-nosan //caffe2/test:dist_optimizer_spawn_thrift
```
Differential Revision: D5689636
fbshipit-source-id: f35eea1359addaaac9bd8d00d0a5df228a236511
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29694
This PR adds preliminary support required to be able to run quantized pytorch models on a C2 backend.
For quantized ops we use a custom domain name 'caffe2' to register the ops if they are in the "quantized" namespace.
The change also adds JIT pass to unpack the quantized weights and insert the unpacked values into the graph.
The actual tensor values are looked up from the params dict.
Test Plan:
python test/onnx/test_pytorch_onnx_caffe2.py TestQuantizedOps
Imported from OSS
Reviewed By: houseroad
Differential Revision: D18467130
fbshipit-source-id: 53ebd8c43935f7d7e74305dad6c231a2247df176
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29469
The original approach is to save both fp16 and fp32 for all models, which increased the filesize and memory.
This diff is to save 'used' blobs into predictor file.
Test Plan:
fc clone workflow :
f149878151
ctr mbl feed test with fc fp16 quantization:
f149996395
No fp32 in local file
{F221750392}
QRT after the fix:
https://fburl.com/qrt/cp8r8263
Reviewed By: wx1988
Differential Revision: D18382503
fbshipit-source-id: 231c41668f25b1d35ca8d4358ce9b12ba60a4f91
Summary:
T53944549 aims to integrate [`RAdam`](https://arxiv.org/pdf/1908.03265.pdf) optimizer to `Adam`. In this diff, we first try to integrate `RAdam` to `SparseAdamOp` on CPU platform.
Note that `adam_op.cc` and `adam_op_gpu.cu` may be implemented in other diffs.
The implementation of `RAdam` follows the algorithm below:
{F220259279}
The algorithm of [`Adam`](https://arxiv.org/pdf/1412.6980.pdf) is attached:
{F220389971}
Test Plan: Run `buck build caffe2` successfully.
Reviewed By: wx1988
Differential Revision: D18239578
fbshipit-source-id: fdc028261ee20986cae1f30f1d26d8705587331a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29667
Some previous implementations are defined in native_functions.yaml.
In this case, I don't define them explicitly in Tensor; instead
they are placed in VariableTypeManual.cpp. When I did this, I would
have deleted documentation; instead, this documentation was moved
to native_functions.yaml
This also replaces `current_version` with just `_version`.
This is a carved out portion of #28287, rebased past Tensor-Variable
merge.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18504934
Pulled By: ezyang
fbshipit-source-id: be7adf45b637daffe2b0b1631eb31d967525fc31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29665
Our intention is to merge the static distinction between Tensor and
Variable. Ordinarily, this would entail merging the methods of Tensor
and Variable. But there are a lot of "private"-ish methods on Variable
that we don't actually want to dump onto the Tensor class. So, as prep
work, we move all of those methods off of Variable and into
the torch::autograd::impl namespace (impl as in, please don't use this
end users). This ends up being a fairly large patch because all of
the call sites have to play ball too.
While I was on the topic, I also moved any of the touched functions into
the C++ file, so that modifying them would not trigger a recompilation of
all of torch.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18496169
Pulled By: ezyang
fbshipit-source-id: afb203252620ec274be596b3e7b1d84d321bad3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29730
Back in the day, Caffe2 had a good idea: instead of spattering
target_compile_options all over the codebase, define a helper
function which sets all the options for a target. This is especially
helpful if I want to split libtorch.so into libtorch_cpu.so
and libtorch_cuda.so; I need a way to easily apply options
to multiple targets. A shared helper function is just the ticket.
I moved every target_compile_options call in caffe2/CMakeLists.txt
that didn't seem target dependent (exclusions included OpenMP flags,
API-related macros, ONNX related macros and HIP flags) into
torch_compile_options. I slavishly preserved the structure:
there's a nearly redundant WERROR if() in the output but I preserved
it.
There is one thing I don't like about this, which is that now
the compile options are off in a random directory that no one would
expect. But c'est la vie...
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18571166
Pulled By: ezyang
fbshipit-source-id: 21cd5f7663485077600782078fbb1787fab09035
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29729
It already errored when you built with CUDA/HIP support as no longer supported;
now I expunge it entirely. Along the way, I delete useless INTERFACE
libraries (which aren't used anywhere else in the cmake.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18571167
Pulled By: ezyang
fbshipit-source-id: f88c73a16fad3b61eaa7745a2d15514c68704bec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29762
Rename this API as discussed, since it's use cases extend beyond only
model parallelism.
ghstack-source-id: 94020627
Test Plan: Unit tests pass
Differential Revision: D18491743
fbshipit-source-id: d07676bb14f072c64da0ce99ee818bcc582efc57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27979
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980311
Pulled By: VitalyFedyunin
fbshipit-source-id: 12d013521091fcc9c045833577f6dc78d7b1e68f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29970
Add operators and JMP instruction used in PyText model in lite interpreter.
Test Plan: Imported from OSS
Differential Revision: D18555483
fbshipit-source-id: e5124d908762f78fb548505aecf33be8c8503275
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29960
Overload name is required in mobile operators with the same name but different schema. Since it's not used in JIT, it's safe to add overload names for JIT operators.
Test Plan: Imported from OSS
Differential Revision: D18555484
fbshipit-source-id: b451379af24e255d8b0c61b964ae32fd1a64ed34
Summary:
Hi yf225 , I have added **NLLLoss and CrossEntropyLoss.**
```
Also, while using log_softmax in cross_entropy_loss, I am getting an error
../caffe2/../torch/csrc/api/include/torch/nn/functional/loss.h:537:63: error: no matching function for call to log_softmax(const at::Tensor&)’
const Tensor& log_softmax_input = torch::log_softmax(input);
aten/src/ATen/Functions.h:5551:22: note: candidate: at::Tensor at::log_softmax(const at::Tensor&, int64_t, c10::optional<c10::ScalarType>)
static inline Tensor log_softmax(const Tensor & self, int64_t dim, c10::optional<ScalarType> dtype) {
^~~~~~~~~~~
aten/src/ATen/Functions.h:5551:22: note: candidate expects 3 arguments, 1 provided
```
I think the other two parameters should be optional as in python frontend(shown in documentation here at https://pytorch.org/docs/stable/nn.functional.html#torch.nn.functional.log_softmax ). Rest, there were no errors in build and tests have passed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29812
Differential Revision: D18548249
Pulled By: yf225
fbshipit-source-id: 2ab350abd2a6f498d4dba2345f51ad87471f3038
Summary:
Since torchvision is not using input_channels / output_channels / with_bias in ConvOptions anymore (https://github.com/pytorch/vision/pull/1576), we can remove the bridges now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29838
Differential Revision: D18531481
Pulled By: yf225
fbshipit-source-id: e48d9e8cf110095f83d9ed18b9fec020ec725f3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29773
Improve legacy QuantizedLinear functions to reduce overhead.
Separate from the stack of D18381988.
Test Plan: buck test mode/dev-nosan //caffe2/test:jit -- "quant"
Reviewed By: lly-zero-one
Differential Revision: D18494988
fbshipit-source-id: 5627d7e8b0b7a750852eead9e28c5a9b3fa70559
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29888
Extract some common functions out of class LoadOp.
Reviewed By: yinghai, ipiszy
Differential Revision: D18456785
fbshipit-source-id: d0b8e86ad5709c35f1dc3821376000db1114dc95
Summary:
Small fixes to rpc docs:
- mark as experimental and subject to change
- Reference the distributed autograd design document in pytorch notes page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29857
Differential Revision: D18526252
Pulled By: rohan-varma
fbshipit-source-id: e09757fa60a9f8fe9c76a868a418a1cd1c300eae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29927
With the docs page now up, we can update the links in the design doc
to point to the docs page.
ghstack-source-id: 94055423
Test Plan: waitforbuildbot
Differential Revision: D18541878
fbshipit-source-id: f44702d9a8296ccc0a5d58d56c3b6dc8a822b520
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29914
Currently we're visiting all submodules every time we're visiting a
method of a module.
Test Plan: Imported from OSS
Differential Revision: D18534602
Pulled By: ZolotukhinM
fbshipit-source-id: 38c5b0ab0bdd27599fd0a6af0eaa3603c68a97a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29885
### Summary
Currently, we have a deadlock issue on iOS when running Resnet50. The problem happens when the task being run in the ThreadPool wants to call `getNumThread()` who will try to acquire the same mutex. And thus cause the deadlock situation. The fix is just remove the guard for `_numThreads`, as it's not likely to change after initialization.
### Test Plan
1. Generate a Resnet50 model using trace_model.py
2. Run `ios/TestApp/bootstrap.sh` to do the benchmark
cc shoumikhin AshkanAliabadi
Test Plan: Imported from OSS
Differential Revision: D18533505
Pulled By: xta0
fbshipit-source-id: 2a069d20b59833ec8b02ff05515c3739a85a15de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29917
move test_module_interface to its own file, no code logic change
Test Plan: Imported from OSS
Differential Revision: D18543235
fbshipit-source-id: ab5e233061ba45cb0c05cafdd289b859036c207c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29926
add a macro to enable full error message for mobile
Test Plan: buck build -c project.ignore= //xplat/experimental/pytorch/predictor:predictorAndroid#android-armv7
Reviewed By: dreiss
Differential Revision: D18521937
fbshipit-source-id: 99673b60a03da249236dc916bab3dff88d24bc25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29873
Renorm requires at least 2-dimensions, so scalar_check could never succeed.
Test Plan: Imported from OSS
Differential Revision: D18521733
Pulled By: gchanan
fbshipit-source-id: 9701c750a14ce67e1bd63dd0753bd8863da42c17
Summary:
- Add a "BUILD_JNI" option that enables building PyTorch JNI bindings and
fbjni. This is off by default because it adds a dependency on jni.h.
- Update to the latest fbjni so we can inhibit building its tests,
because they depend on gtest.
- Set JAVA_HOME and BUILD_JNI in Linux binary build configurations if we
can find jni.h in Docker.
Test Plan:
- Built on dev server.
- Verified that libpytorch_jni links after libtorch when both are built
in a parallel build.
Differential Revision: D18536828
fbshipit-source-id: 19cb3be8298d3619352d02bb9446ab802c27ec66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29866
This is a no-op anyway, so no reason to output.
Test Plan: Imported from OSS
Differential Revision: D18521742
Pulled By: gchanan
fbshipit-source-id: f695e453beeee609dbdf23d26f9b5eaf519e16b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29768
The previous histogram observer saves all histograms for new data and merge the histograms in the end. It could cause OOM issue when we want to collect histograms on large amount of data. In this diff, we assume running the histogram observer with a single thread and remap the histogram after seeing new data.
Test Plan:
```
buck test mode/opt caffe2/caffe2/quantization/server:dynamic_histogram_test
```
```
buck run mode/opt caffe2/caffe2/fb/fbgemm/numerical_debugger/workflows:int8_static_quantization_exporter -- --model-dir /mnt/public/summerdeng/ads/ --model-name downsized_ins_97293388_0.predictor --run --iter 10 --dataset-path /mnt/public/summerdeng/ads/ctr_instagram_story_int8/dataset/train/dataset_115764229_10 --hive-path="hive://ad_delivery/ig_ad_prefiltered_training_data_orc_injected/ds=2019-09-09/pipeline=ctr_instagram_story_click_only_model_opt_out_df" --collect-histogram --activation-histogram-file=/mnt/public/summerdeng/ads/ctr_instagram_story_int8/activation_histograms/dummy_debug_OOM.txt
```
Reviewed By: jspark1105
Differential Revision: D18458764
fbshipit-source-id: c0e36fffe9bf021efd17d8494deef43727333da2
Summary:
This adds the HIP_VERSION cmake variable as hip_version.
This should help detecting ROCm, e.g. in https://github.com/pytorch/pytorch/issues/22091.
To parallel CUDA, hip_version is a string.
An alternative variant might be to split by '.' and only take the first two parts.
The method suffers a bit from ROCm not being as monolithic as CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29815
Differential Revision: D18532267
Pulled By: bddppq
fbshipit-source-id: 1bde4ad0cfacc47bfd1c0945e130921d8575a5bf
Summary:
Changelog:
- Expose is_signed for torch.dtype by modifying torch/csrc/Dtype.cpp
- Allow half, bfloat16 and bool to also been "known" by the isSignedType function
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29511
Test Plan:
- Add tests in test/test_torch.py
Closes https://github.com/pytorch/pytorch/issues/29475
Differential Revision: D18439030
Pulled By: albanD
fbshipit-source-id: 4b1f9da70c1c8dfd0a5bc028b6936acd1c64af47
Summary:
To avoid ABI issue
EDIT: After this PR, the example CMakeLists.txt will always use the `-D_GLIBCXX_USE_CXX11_ABI` value set in `share/cmake/Torch/TorchConfig.cmake`, regardless of the `-D_GLIBCXX_USE_CXX11_ABI` value passed to the `cmake` command by the user.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29890
Differential Revision: D18531391
Pulled By: yf225
fbshipit-source-id: 2db78ae7a33a4088b579e81c60b9a74861f1ccde
Summary:
Test type promotion was already running on CUDA with its own (tiny) version of a generic test framework. This PR makes it use the actual generic test framework.
In addition, the tests previously set the default dtype (and did not reset it). A new decorator replaces the previous style and resets the default dtype after each test. This is still not thread-safe, but at least there's a comment to that effect now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29417
Differential Revision: D18514545
Pulled By: mruberry
fbshipit-source-id: 5aad43481ae71124cba99fb2e4a946894f591d68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29839
std::to_string isn't reliably available on Android. Use c10::to_string
instead in some more files that we want to add to some Android builds.
Test Plan: CI
Reviewed By: linbinyu
Differential Revision: D18509295
fbshipit-source-id: 678af1abbea05777310499634ab01afbe21134d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29835
Using images from personal accounts restricts our ability to push
updates in a timely manner.
Test Plan: CI
Reviewed By: soumith
Differential Revision: D18524393
Pulled By: dreiss
fbshipit-source-id: f12dd3ce50c8362e152ed265e2d24bcb073dcfd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29781
Even though the request might not contain any requires_grad tensor,
the return value could. Therefore, we should always include the
autograd context id in the request.
closes#28819
Test Plan: Imported from OSS
Differential Revision: D18496709
Pulled By: mrshenli
fbshipit-source-id: 2f870c410291a1300952895b7488ea07e5574228
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28494
Allow a backend-level fallback kernel that is called whenever an operator doesn't have a concrete kernel for the backend.
This is needed for lazy.
ghstack-source-id: 93872571
Test Plan: unit tests
Differential Revision: D18081495
fbshipit-source-id: 5f4964249cc226a39fd6e929a5be88a771c401a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28314
Simplify the c10 dispatcher, making it more easy to understand.
Also, this moves the dispatch decision from the DispatchTable class into the Dispatcher class.
This is required because DispatchTable only knows things about one operator but the dispatch decision will (in future diffs) also need to look at backend-level fallbacks, for example for lazy.
ghstack-source-id: 93872575
Test Plan: unit tests
Differential Revision: D18018736
fbshipit-source-id: 375729d5e307e0622906f8cc9a0b087b94aea2b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29861
Follow https://github.com/pytorch/pytorch/issues/6570 to run ./run_host_tests.sh for Mac Build, we saw error below:
```error: cannot initialize a parameter of type 'const facebook::jni::JPrimitiveArray<_jlongArray *>::T *' (aka 'const long *') with an rvalue of type
'std::__1::vector<long long, std::__1::allocator<long long> >::value_type *' (aka 'long long *')
jTensorShape->setRegion(0, tensorShapeVec.size(), tensorShapeVec.data());```
ghstack-source-id: 93961091
Test Plan: Run ./run_host_tests.sh and verify build succeed.
Reviewed By: dreiss
Differential Revision: D18519087
fbshipit-source-id: 869be12c82e6e0f64c878911dc12459defebf40b
Summary:
This PR adds `reset_parameters` to the torch::nn modules whose Python version also has `reset_parameters` defined, so that there is better parity between Python and C++ version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29832
Differential Revision: D18515939
Pulled By: yf225
fbshipit-source-id: 5aa23e5c7ce1026787c04ffeb6c7f167620dd491
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29716
Move out the test project from PR #29550 into this separate PR.
It serves these purposes:
- Defines the ".yaml" format to describe inter-op dependency.
- Can be used as a small testbed for us to quickly experiment, evaluate
and test different dependency analysis techniques (llvm-pass, linker,
etc).
- Covers various different c10 operator APIs and builds a runnable binary.
I create a 'mobile' folder under 'test/' because I feel we can create a
few other similar projects here to test mobile specific yet platform
independent stuff, e.g.:
- use host tool chain + mobile build options to do continuous E2E test;
- test custom build workflow for mobile;
Test Plan:
- run build script and verify the binary is runnable:
```
scripts/build_mobile.sh
test/mobile/op_deps/build.sh
```
Differential Revision: D18474641
Pulled By: ljk53
fbshipit-source-id: 3fae9da5e0e3fe6cb17ada8783d5da2f144a6194
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29837
The current TorchConfig seems only handles shared libraries. When
building static libraries it doesn't provide the list of all needed
static libraries. This is especially a problem for mobile build as we
build static libraries first then link into shared library / binary to
do "gc-sections". Today we have to manually import these dependent
libraries on each callsite.
Test Plan:
- build_mobile.sh builds and runs;
- The baby test project in #29716 builds and runs;
- Will check CI for other platforms;
Differential Revision: D18513404
Pulled By: ljk53
fbshipit-source-id: c3dc2c01004c4c9c4574c71fd9a4253c9e19e1e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29715
Previous we hard code it to enable static dispatch when building mobile
library. Since we are exploring approaches to deprecate static dispatch
we should make it optional. This PR moved the setting from cmake to bash
build scripts which can be overridden.
Test Plan: - verified it's still using static dispatch when building with these scripts.
Differential Revision: D18474640
Pulled By: ljk53
fbshipit-source-id: 7591acc22009bfba36302e3b2a330b1428d8e3f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29865
For some operators, the number of tests (forward + backward) could easily go above 100. Many of them could be redundant so this diff tries to reduce the number of shapes.
Test Plan:
```
buck run //caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --iterations 1
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: add
# Mode: Eager
# Name: add_M64_N64_K64_cpu
# Input: M: 64, N: 64, K: 64, device: cpu
Forward Execution Time (us) : 28418.926
...
Reviewed By: hl475
Differential Revision: D18520946
fbshipit-source-id: 1056d6d5a9c46bc2d508ff133039aefeb9d11c27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29864
This diff make `all` as a reserved keyword for tag_filter. When `all` is passed from user, it will run all the supported shapes.
Test Plan:
```
buck run //caffe2/benchmarks/operator_benchmark/pt:add_test -- --iterations 1 --tag_filter all
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : all
# Benchmarking PyTorch: add
# Mode: Eager
# Name: add_M8_N32_K256_cpu
# Input: M: 8, N: 32, K: 256, device: cpu
Forward Execution Time (us) : 6798.688
...
Reviewed By: hl475
Differential Revision: D18520249
fbshipit-source-id: 4d55af9f46f89b2fe8842e1a00dfa8e5acaf4fa2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29830
as title
Test Plan: na
Reviewed By: hl475
Differential Revision: D18506023
fbshipit-source-id: 15693894c0aa736ab3e818bc740099f0d629cb84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29765
instead of wrapping this C++ function with python that causes
unnecessary overhead, we can move this to pybind and use the `DefaultRpcAgent`
to get the timeout.
ghstack-source-id: 93879236
Test Plan: unit tests pass
Differential Revision: D18493195
fbshipit-source-id: fd0f1f13ee15acb5ea1ae7c696925c9b54304f6d
Summary:
Fix for https://github.com/pytorch/pytorch/issues/21545
We we were silently giving wrong semantics previously:
Python behavior:
```
def test(x=[]):
x.append(1)
return len(x)
print(test()) # 1
print(test()) # 2
```
By checking at the python layer, we prevent any new models from serializing this behavior but do not break existing serialized models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29833
Differential Revision: D18513168
Pulled By: eellison
fbshipit-source-id: 6fe73f28e1f9d39dedeaf67a04718089d14401a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29696
The paths distributed/autograd/context/dist_autograd_context.h and
distributed/autograd/context/dist_autograd_container.h were repetitive.
Therefore renaming these to distributed/autograd/context/context.h and
distributed/autograd/context/container.h
ghstack-source-id: 93850266
Test Plan: waitforbuildbot
Differential Revision: D18467624
fbshipit-source-id: bbf3905396f553006851af296c880c1bd106ec47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29653
I didn't remove is_variable from Tensor for BC reasons, but I did
remove as many uses as I could from the codebase.
at::impl::variable_excluded_from_dispatch got moved to TensorBody.h
so that it's more widely accessible.
This diff is NOT semantics preserving. Here are the major differences:
- In a number of native operator implementations, we tested that arguments
are not variable. I replaced these with asserts that variable is
excluded from dispatch. I actually don't think these asserts are really
necessary now (they should certainly be true, but it's hard to get
it wrong), but I've kept them for old time's sake. At least, they'll detect
if you call these functions before you've processed variable (indicating
a bug in your kernel.)
- There are a number of places where we do a per-tensor test for being a
variable, for better error reporting when someone commits Tensor/Variable
confusion. Although these tests are substantively the same as the
tests above, in these cases I decided to *delete* the test entirely.
The reasoning is that in these cases, we didn't really care about
dispatch (also, see above; I'm not too sure we really need the dispatch
asserts), we cared about Tensor/Variable confusion. Since Tensor/Variable
confusion is impossible now, we don't need the tests. One of the key
factors which pushed me one way or another was whether or not a function
was doing per-tensor validation; if I kept the assert in such functions,
I'd repeatedly access the TLS. Even if we want to bring back the asserts,
they would have to go somewhere else.
Another similar idiom is the number of places we do !x.defined() ||
x.is_variable(); I treated this equivalently.
- nuclear_norm's computation of compute_uv is a bit weird, but I think
it's OK to just delete the is_variable case (I *suspect* that it is
always the case that self.is_variable(), but it doesn't really matter.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18496168
Pulled By: ezyang
fbshipit-source-id: 5a1ded931e0c10a6b758ba64a8380d34110e0c3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29818
When some of the test running on cuda, there is a runtime error because of missing data transfer from cpu to cuda. This diff fixes that issue.
Test Plan:
```
buck run mode/opt //caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --iterations 1
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: add
# Mode: Eager
# Name: add_M64_N64_K64_cpu
# Input: M: 64, N: 64, K: 64, device: cpu
Forward Execution Time (us) : 165.241
# Benchmarking PyTorch: add
# Mode: Eager
# Name: add_M64_N64_K64_cuda
# Input: M: 64, N: 64, K: 64, device: cuda
Forward Execution Time (us) : 56.546
...
Reviewed By: hl475
Differential Revision: D18506269
fbshipit-source-id: 87942d7a52bd398600766c0f5363d791b74a6ca6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29746
I don't know if this actually broke anything because I just discovered
the typo while reading the cmake.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18504546
Pulled By: ezyang
fbshipit-source-id: 6cb5fb1e71721e5cf8fc2f7b5552dc7c514f065f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29634
This implementation supports rpc.remote to self by doing the
following steps:
1. create an owner RRef
2. add the owner RRef to owners_ in RRefContext, and keep it alive
by using RRefId as the ForkId.
3. Go through serde and insert the message to the caller's thread-pool
4. When the response message gets processed, remove the itself from
RRef fork map.
Test Plan: Imported from OSS
Differential Revision: D18445812
Pulled By: mrshenli
fbshipit-source-id: e3b9aa98962c388acbc2ce294101a236d5cb2da6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29794
Before this diff, all tests of an operator are created at once before testing. Once an operator is benchmarked, the same process will move to the next operator and so on. The issue is that the number of tests of a single operator could be > 100 which can cause OOM issues. This diff avoids creating all the tests of an operator at once by using generators which creates/runs test one by one.
Test Plan:
```
buck run //caffe2/benchmarks/operator_benchmark:benchmark_all_quantized_test -- --iterations 1
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: relu
# Mode: Eager
# Name: relu_dims(3,4,5)_contigFalse_inplaceFalse_dtypetorch.quint8
# Input: dims: (3, 4, 5), contig: False, inplace: False, dtype: torch.quint8
Forward Execution Time (us) : 52.493
# Benchmarking PyTorch: relu
# Mode: Eager
# Name: relu_dims(3,4,5)_contigFalse_inplaceFalse_dtypetorch.qint8
# Input: dims: (3, 4, 5), contig: False, inplace: False, dtype: torch.qint8
Forward Execution Time (us) : 44.945
...
Reviewed By: hl475
Differential Revision: D18500103
fbshipit-source-id: 747c0ad0d302177da04da36e112c67f154115b6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29673
Following https://github.com/pytorch/pytorch/pull/29364 and https://github.com/pytorch/pytorch/pull/29404, this PR makes `F::EmbeddingFuncOptions` and `F::EmbeddingBagFuncOptions` separate classes from `torch::nn::EmbeddingOptions` and `torch::nn::EmbeddingBagOptions`, so that it's easier to enforce that arguments such as `num_embeddings` and `embedding_dim` are required for `torch::nn::EmbeddingOptions` and `torch::nn::EmbeddingBagOptions`.
Test Plan: Imported from OSS
Differential Revision: D18462540
Pulled By: yf225
fbshipit-source-id: f2abf431e48675b0a9d7f6f398cdb90ff9037c35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29707
In D17885977, Linearizable label (a multi-class classification) was implemented in MTML.
In this diff, we add several items for Linearizable label:
- Assigning different weights to each class through ```model_def.tasks[i].class_weights```.
- This option is a dictionary, the keys of which are indices of the classes and the values of which are weights for each class.
- For example, if a linearizable-label task has 4 classes and its ```class_weights = {"0": 1, "1": 0.1, "2": 0.1, "3": 0.01}```, it means that in the loss function of this task, we assign weight 1 to its first class, weight 0.1 to its second and third class, and weight 0.01 to its forth class. The index/order of classes follows the logic of linearizable label.
- Note that when you assign different weights to different classes, you need to correct the calibration by setting an appropriate ```model_def.tasks[i].calibration.linearizable_class_weight```. Basically, the class weights in calibration should be the reciprocals of the class weights in loss function. So the ```calibration.linearizable_class_weight = {"0": 1, "1": 10, "2": 10, "3": 100}``` for the example above.
- Example FBLearner job: f150763093
- We also support ```model_def.allow_missing_label_with_zero_weight``` for linearizable label, which will ignore those examples with first label missing, by assigning zero weights to them in loss function.
- We need to set ```allow_missing_label_with_zero_weight = true``` to enable it.
- Example FBLearner job: f150763093
- Last but not least, we update caffe2 operator ```SoftmaxWithLoss``` to support loss averaged by batch size.
- We need to set ```model_def.tasks[i].loss.softmaxLoss.average_by_batch_size = true``` to enable it.
- Previously, the loss was averaged by weight sum of examples in batch, which is still the default behavior now (when ```average_by_batch_size = null``` or ```average_by_batch_size = false```).
- Without this new feature, the calibration will be incorrect when applying non-equal-weight training among different classes to a linearizable task.
- Example FBLearner job with ```average_by_batch_size = true``` results in a correct calibration: f150763093
- Example FBLearner job with ```average_by_batch_size = null``` results in an incorrect calibration: f150762990
Test Plan:
buck test caffe2/caffe2/fb/dper/layer_models/tests:mtml_test_2 -- test_linearizable_label_task_with_class_weights
buck test caffe2/caffe2/fb/dper/layer_models/tests:mtml_test_2 -- test_linearizable_label_task_with_zero_weight
buck test caffe2/caffe2/fb/dper/layer_models/tests:mtml_test_2 -- test_linearizable_label_task_average_by_batch_size
All tests passed.
full canary: https://fburl.com/fblearner/troznfgh
Reviewed By: chenshouyuan
Differential Revision: D18461163
fbshipit-source-id: aaf3df031406ae94f74e2e365b57e47409ef0bfe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29670
This is the entry point to loading CUDA code, improve error message to prompt users to check that gpu code is included.
Test Plan: Build without gpu code. Run the binary. Check that the new error message exists.
Reviewed By: yfeldblum
Differential Revision: D18453798
fbshipit-source-id: 63d9ec50acdf57ef4baf3f7d99c836c56bc1435e
Summary:
Uses new overload mechanism for rnns, making it so that python & torchscript go through the same path and using an API that is in line with the one specified
in https://docs.python.org/3/library/typing.html#typing.overload
This brings the TorchScriptable rnns closer to the base implementation; unifying them should be done in a follow up PR but there are still a few limitations that make it difficult to do so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29614
Differential Revision: D18486982
Pulled By: eellison
fbshipit-source-id: aaaea66a4a7f12d2e46199ca254f9e8f7475500e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29632
This PR is BC-breaking in the following way:
Previously, C++ `torch::tensor` with a floating-point literal with no suffix (e.g. `torch::tensor(1.1)`) or a (nested) braced-init-list of
floating-point literals with no suffix (e.g. `torch::tensor({{1.1, 2.2}})` produces a tensor with dtype `at::kDouble`. After this PR, it produces a tensor with dtype `torch::get_default_dtype()`, matching Python `torch.tensor` behavior.
Test Plan: Imported from OSS
Differential Revision: D18465819
Pulled By: yf225
fbshipit-source-id: 6834fe50335c677bc3832f2a5e9cf8d1ede9f665
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29605
Adds a wrapper around the existing createException function that
allows passing of an error string, instead of a regular C++ exception. This
allows us to createExceptions for errors that aren't necessarilu c++
exceptions. This function is used by
https://github.com/pytorch/pytorch/pull/29601 and
https://github.com/pytorch/pytorch/pull/26336.
ghstack-source-id: 93819039
Test Plan: Unit tests pass
Differential Revision: D18439216
fbshipit-source-id: 70b6a2e4f107304e322cdd2630847ad0071bc0c1
Summary:
The issue with previous build was that after phabricators lint error about double quotes I changed:
`$GRADLE_PATH $GRADLE_PARAMS` -> `"$GRADLE_PATH" "$GRADLE_PARAMS"`
which ended in error:
```
Nov 13 17:16:38 + /opt/gradle/gradle-4.10.3/bin/gradle '-p android assembleRelease --debug --stacktrace --offline'
Nov 13 17:16:40 Starting a Gradle Daemon (subsequent builds will be faster)
Nov 13 17:16:41
Nov 13 17:16:41 FAILURE: Build failed with an exception.
Nov 13 17:16:41
Nov 13 17:16:41 * What went wrong:
Nov 13 17:16:41 The specified project directory '/var/lib/jenkins/workspace/ android assembleRelease --debug --stacktrace --offline' does not exist.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29738
Differential Revision: D18486605
Pulled By: IvanKobzarev
fbshipit-source-id: 2b06600feb9db35b49e097a6d44422f50e46bb20
Summary:
Is this description still true? I have never seen any `s_` ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29742
Differential Revision: D18485707
Pulled By: ezyang
fbshipit-source-id: c5ce2587bb499561706c3c2817571ee11f7eb63c
Summary:
This PR changes the implementation of C++ Conv{1,2,3}d layers to exactly match the Python version, and add F::conv{1,2,3}d functionals. For more thorough testing, I will rely on the parity test mechanism which uses values from `common_nn.py` to generate the inputs and options that we are interested in testing.
This PR is BC-breaking in the following way:
In `Conv{1,2,3}dOptions`:
- `with_bias` is renamed to `bias`.
- `input_channels` is renamed to `in_channels`.
- `output_channels` is renamed to `out_channels`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28917
Differential Revision: D18471526
Pulled By: yf225
fbshipit-source-id: 7a33f60654ad93cc2e043245e7ff9e0ef9da15b3
Summary:
We (me fnabulsi bmcdb) have a handful of fixes used locally to build and run with clang-cl. I am aware of https://github.com/pytorch/pytorch/issues/8784 but it has not been touched in almost a year.
It may be more practical to upstream the non-controversial fixes piecewise. For example, this one.
Here, the dummy version of `_cvtsh_ss` for MSVC is not required (and hence causes conflicts) when using clang-cl so can be #ifdef'd out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29726
Differential Revision: D18478120
Pulled By: ezyang
fbshipit-source-id: cdcd94251e68347446f2ad1ac5a0e71089f7d0ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29322
torch.equal checks if two tensors are equal in both size and values. For
named tensors, it also checks that the names are exactly equal. There is
an argument to be made for alternative semantics (check that the names
*match*), but for an API that is called "equal" I would expect it to
check equality on names as well.
Test Plan: - new tests
Differential Revision: D18453387
Pulled By: zou3519
fbshipit-source-id: d52bde4e3fdd7f331eef097a3b31d35c89c78049
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29307
In our name inference functions we currently create an extra TensorNames
every time we unify names. This isn't completely necessary.
To do this, I made the following changes:
- TensorName now has two states, initialized and uninitialized
- Renamed unifyFromRight to unifyFromRightInplace.
Test Plan: - `pytest test/test_namedtensor.py -v`
Differential Revision: D18453388
Pulled By: zou3519
fbshipit-source-id: 96c3c6fd9478d57e92e1cf770c864aeac6d29dd2
Summary:
Missing `__device__` and `__host__` annotations in the complex case. Make it less UB.
Note that this still rather unsavory code: `std::real` is only `constexpr` from C++14 on onwards ( https://en.cppreference.com/w/cpp/numeric/complex/real2 ) which is the requirement for `__device__`.
What I am trying to say is: this particular piece of code should not have passed review and not been merged, IMHO, as it tries to codify UB.
Also note that the benchmarks referenced in source were CPU and CUDA-only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29547
Differential Revision: D18428156
Pulled By: bddppq
fbshipit-source-id: 855ced903ef91bd7f82fcd3a2167ae59bdd30d8b
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex)
- [x] Replaced std:real(a) with a.real() in kernel level code.
- [x] Fixed Vec256_base implementation of complex ops so that it works correctly on Non-AVX devices.
- [ ] Clean up CopyKernel after https://github.com/pytorch/pytorch/issues/29612 is approved.
zasdfgbnm is fixing this issue in https://github.com/pytorch/pytorch/issues/29612. This should be added first.
cc: iotamudelta, ezyang, bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29607
Differential Revision: D18451046
Pulled By: ezyang
fbshipit-source-id: b9dcd8e25e91cab13bd131b070d027b090cdedc9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29213
A trivial use of make_variable is one where requires_grad=False. This
transformation is not technically semantics preserving, as make_variable
will create a shallow copy of the tensor in question; however, I
am guessing that we have the invariant that we don't actually make
use of this shallow copy in a nontrivial way.
There were some cases where the surrounding code expected a Variable proper
to be returned; I retained those sites.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18353503
Pulled By: ezyang
fbshipit-source-id: 57fe34d82e009c0cc852266fb0b79d6d9c62bb03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29204
Code review comments from #28620
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18353506
Pulled By: ezyang
fbshipit-source-id: 0432ce513eff257fd85cddff8bc3e41935127ed8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29203
There is no more Variable/Tensor distinction, so fix the misleading name.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18353505
Pulled By: ezyang
fbshipit-source-id: dadc394d533ab7746f70bc186c6645441a784518
Summary:
Per ailzhang's suggestion in https://github.com/pytorch/pytorch/pull/28162#discussion_r344361926, this PR changes the implementation of binary comparison and logical ops
to those of unary ops in UnaryOps.cpp. The reason is that the call should eventually go through
at::op_out (e.g., at::logical_xor_out).
The check for Boolean output tensor is also removed, because:
- This check should only apply to _out functions but not on other variants. However, other variants
must go through the _out variant eventually.
- It does not have a clear motivation and seems unnecessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29591
Differential Revision: D18460113
Pulled By: ailzhang
fbshipit-source-id: 58d501e59335186b3b8cc7d80ee9eed74efeeac8
Summary:
https://github.com/pytorch/pytorch/issues/29159
Introducing GRADLE_OFFLINE environment variable to use '--offline' gradle argument which will only use local gradle cache without network.
As it is cache and has some expiration logic - before every start of gradle 'touch' files to update last access time.
Deploying new docker images that includes prefetching to gradle cache all android dependencies, commit with update of docker images: df07dd5681
Reenable android gradle jobs on CI (revert of 54e6a7eede)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29262
Differential Revision: D18455666
Pulled By: IvanKobzarev
fbshipit-source-id: 8fb0b54fd94e13b3144af2e345c6b00b258dcc0f
Summary:
Example
```python
import torch
x = torch.randn(1)
with torch.autograd.profiler.profile(use_cuda=False) as prof:
x + x
print(prof.key_averages().table(sort_by='cpu_time_total'))
```
Before:
```
------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls
------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
add 100.00% 25.781ms 100.00% 25.781ms 25.781ms NaN 0.000us 0.000us 1
------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 25.781ms
CUDA time total: 0.000us
```
After:
```
------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls
------- --------------- --------------- --------------- --------------- --------------- ---------------
add 100.00% 25.037ms 100.00% 25.037ms 25.037ms 1
------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 25.037ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29666
Differential Revision: D18458828
Pulled By: bddppq
fbshipit-source-id: d96ef4cec8b1e85b77c211292a3099048882734d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29603
Previously, named tensors were off for the internal caffe2 xplat builds.
However, we have since excised the caffe2 xplat build's dependencies on
PyTorch. This makes it so that we can turn on named tensors for all
builds.
Test Plan: - Wait for CI
Differential Revision: D18439084
Pulled By: zou3519
fbshipit-source-id: f1cc405d0ce9ffe991eff1bbb80575ce87c02d4a
Summary:
When installing the 4.4.0-168 version, the following error is thrown (e.g. in https://app.circleci.com/jobs/github/pytorch/pytorch/3577840):
```
Some packages could not be installed. This may mean that you have
requested an impossible situation or if you are using the unstable
distribution that some required packages have not yet been created
or been moved out of Incoming.
The following information may help to resolve the situation:
The following packages have unmet dependencies:
linux-image-generic : Depends: linux-image-4.4.0-168-generic but it is not going to be installed or
linux-image-unsigned-4.4.0-168-generic but it is not installable
Depends: linux-modules-extra-4.4.0-168-generic but it is not installable
Recommends: thermald but it is not going to be installed
E: Unable to correct problems, you have held broken packages.
```
The (temporary) solution is to pin the Linux image and modules version to 4.4.0-166.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29690
Differential Revision: D18466043
Pulled By: yf225
fbshipit-source-id: d3c69c9ab3bf505c6eb3a2edd138e9789b62b6d6
Summary:
Uses new overload mechanism for rnns, making it so that python & torchscript go through the same path and using an API that is in line with the one specified
in https://docs.python.org/3/library/typing.html#typing.overload
This brings the TorchScriptable rnns closer to the base implementation; unifying them should be done in a follow up PR but there are still a few limitations that make it difficult to do so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29614
Differential Revision: D18458751
Pulled By: eellison
fbshipit-source-id: 07c71838f21cb5425e8d6dbd4a512f774c8c2970
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29584
In Python, `float` dtype is always 64-bit (https://stackoverflow.com/a/8216110), and the C++ equivalent APIs should take `double` dtype to match the bit length.
Test Plan: Imported from OSS
Differential Revision: D18436616
Pulled By: yf225
fbshipit-source-id: ece510bba6f089ccada03af216f4805bbd03f5f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29404
This PR makes all non-input arguments to functionals part of its options parameters, so that we won't break backward compatibility even if we add or reorder some of the non-input arguments to functionals in the future.
Test Plan: Imported from OSS
Differential Revision: D18378526
Pulled By: yf225
fbshipit-source-id: f5cf6bdfb844e75bf94fdee58c121e0955631b6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29175
Updates our docs to include a design doc for distributed autograd.
Currently, this doc only covers the FAST mode algorithm. The Smart mode
algorithm section just refers to the original RFC.
There is a section for Distributed Optimizer that we can complete once we've
finalized the API for the same.
ghstack-source-id: 93701129
Test Plan: look at docs.
Differential Revision: D18318949
fbshipit-source-id: 670ea1b6bb84692f07facee26946bbc6ce8c650c
Summary:
Also move the logic that installs the pybind11 headers from setup.py to cmake (to align with other headers).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29659
Differential Revision: D18458208
Pulled By: bddppq
fbshipit-source-id: cfd1e74b892d4a65591626ab321780c8c87b810d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28988
Make ModuleList, Sequential, ModuleDict go through the same pathway as other modules, cleaning up a bunch of code and allowing them to define custom forwards and other methods.
EDIT: Previously, we would ignore an nn.Sequential attribute if it was not in `__constants__` ("did you forget to add it to Constants"). This PR scripts it even if it is not in `__constants__`. Is that what we want?
Test Plan: Imported from OSS
Differential Revision: D18402821
Pulled By: eellison
fbshipit-source-id: dd4f28fb0df0d1ba4ad1b3bc34ba141959a433f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28987
We have `__iter__` defined on nn.ModuleList. Chainer's `Sequential` defines `__iter__`. This will also be helpful in modules which extend `nn.Sequential` and define a custom forward, because they can use the `for x in self` syntax that is supported in both python & TorchScript.
Test Plan: Imported from OSS
Differential Revision: D18402822
Pulled By: eellison
fbshipit-source-id: 1ece0f891a9d37f401e232320f58b056d5481856
Summary:
cumsum/cumprod perform their own respective operations over a desired dimension, but there is no reduction in dimensions in the process, i.e. they are not reduction operations and hence just keep the input names of the tensor on which the operation is performed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29453
Differential Revision: D18455683
Pulled By: anjali411
fbshipit-source-id: 9e250d3077ff3d8f3405d20331f4b6ff05151a28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29617
As for internal build, we will use mobile interpreter instead of full jit, so we will need to separate the existing pytorch_jni.cpp into pytorch_jni_jit.cpp and pytorch_jni_common.cpp. pytorch_jni_common.cpp will be used both from pytorch_jni_jit.cpp(open_source) and future pytorch_jni_lite.cpp(internal).
ghstack-source-id: 93691214
Test Plan: buck build xplat/caffe2/android:pytorch
Reviewed By: dreiss
Differential Revision: D18387579
fbshipit-source-id: 26ab845c58a0959bc0fdf1a2b9a99f6ad6f2fc9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29625
This PR also adds a template for benchmarking methods that require no input.
Test Plan: Imported from OSS
Differential Revision: D18443485
Pulled By: z-a-f
fbshipit-source-id: 6f25c3a7cd94e396c112b5f7c33307b71f78ecd3
Summary:
```
c10/util/Half.h:467:37: warning: implicit conversion from 'long' to 'double' changes value from 9223372036854775807 to 9223372036854775808 [-Wimplicit-int-float-conversion]
return f < limit::lowest() || f > limit::max();
~ ^~~~~~~~~~~~
c10/util/Half.h:497:41: note: in instantiation of function template specialization 'c10::overflows<long, double>' requested here
if (!std::is_same<To, bool>::value && overflows<To, From>(f)) {
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29604
Differential Revision: D18440713
Pulled By: bddppq
fbshipit-source-id: f059b4e37e90fa84308be52ff5e1070ffd04031e
Summary:
Currently, the dynamic casting mechanism is implemented assuming no support of complex on GPU. This will no longer be true in the soon future.
https://github.com/pytorch/pytorch/pull/29547 could clear some clang warning but the complex support on GPU is still not complete:
- fetch is not supported
- casting between complex64 and complex128 is not supported
- complex scalar types are not tested
This PR is what should be done for type promotion in order to add support to complex dtype on GPU, as suggested in https://github.com/pytorch/pytorch/issues/755#issuecomment-552631381
Note that what is newly added here in this PR is not tested due to the lack of basic support of complex dtypes (I can not construct a complex tensor). But his PR shouldn't break any existing part of PyTorch.
For the merge this PR, consider two options:
- We could merge this PR now so that dylanbespalko could conveniently work based on master, if there is something wrong here not found by code review, dylanbespalko would find when adding complex integration.
- Or, we could just leave this PR open, don't merge it. But then dylanbespalko might need to manually apply this to his branch in order to support type promotion of complex.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29612
Differential Revision: D18451061
Pulled By: ezyang
fbshipit-source-id: 6d4817e87f0cc2e844dc28c0355a7e53220933a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29610
`DeprecationWarning` is intended for developers (and so is ignored in
certain circumstances). `FutureWarning` is the user-facing deprecation
warning. This fixes fbcode failures.
Test Plan: Imported from OSS
Differential Revision: D18446393
Pulled By: suo
fbshipit-source-id: ded11a007f0a62132a9839b733157a97cf9006e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29529
Pull Request resolved: https://github.com/pytorch/glow/pull/3771
We would like to replace `conv_prepack` with `conv2d_prepack` and `conv_unpack` with `conv2d_unpack`.
This makes the naming consistent between 2D and 3D conv:
```
torch.ops.quantized.conv2d_prepack
torch.ops.quantized.conv2d_unpack
torch.ops.quantized.conv2d
torch.ops.quantized.conv3d_prepack
torch.ops.quantized.conv3d_unpack
torch.ops.quantized.conv3d
```
We should do this earlier rather than later when we have more users for the quantized conv2d ops, for better engineering.
The replacement bash command is as the follows:
```
find ./ -type f -exec sed -i -e 's/quantized::conv_prepack/quantized::conv2d_prepack/g' {} \;
find ./ -type f -exec sed -i -e 's/quantized::conv_unpack/quantized::conv2d_unpack/g' {} \;
find ./ -type f -exec sed -i -e 's/torch.ops.quantized.conv_prepack/torch.ops.quantized.conv2d_prepack/g' {} \;
find ./ -type f -exec sed -i -e 's/torch.ops.quantized.conv_unpack/torch.ops.quantized.conv2d_unpack/g' {} \;
```
ghstack-source-id: 93661879
Test Plan: CI
Reviewed By: jackm321
Differential Revision: D18421079
fbshipit-source-id: 17ae8b1ee79223bd2c5d4bbccd57af6580c4ab12
Summary:
- Add support for missing case where interpolate is exported with missing shape information in scripting
- Add warnings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29489
Reviewed By: hl475
Differential Revision: D18438872
Pulled By: houseroad
fbshipit-source-id: d01f833bec0cc4e881ddc18e7054d22f54e9886b
Summary:
Support exporting torch.scalar_tensor() to ONNX.
This will allow making operations on dynamic scalars (like x.size(dim) where x is a tensor of dynamic shape) and exporting them to ONNX.
This is a dummy example of operations that could not be exported dynamically before this PR:
```
size_x = x.size(0)
size_y = y.size(0)
size_x_y_static = torch.tensor([size_x , size_y]) # size_x_y_static is traced as constant
size_x = torch.scalar_tensor(size_x).unsqueeze(0)
size_y = torch.scalar_tensor(size_y).unsqueeze(0)
size_x_y_dynamic = torch.cat((size_x , size_y)) # size_x_y_dynamic is dynamic and depends on x and y's size
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28713
Reviewed By: hl475
Differential Revision: D18438880
Pulled By: houseroad
fbshipit-source-id: c1651e480a41602c7c7452ffc4acba40a2b3827c
Summary:
Currently clone() has parameter memory_format with default value as Contiguous.
In the future it will be changed to different default memory format - Preserve.
To avoid any potencial issues, specify memory_format explicitly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29593
Differential Revision: D18439783
Pulled By: ifedan
fbshipit-source-id: e7ed6c19ee227990214d44c562c26a7250981324
Summary:
The old implementation assumed `is_channels_last_contiguous_` to be mutually
exclusive to `is_contiguous_`, which is not true.
Properly set the flag by checking strides.
Original Pull Request resolved: https://github.com/pytorch/pytorch/pull/24113
Original GitHub Author: jjsjann123 <jiej@nvidia.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28466
Differential Revision: D16860715
Pulled By: VitalyFedyunin
fbshipit-source-id: facd19d3501b6566d77c46199567e0cd051a6b49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29616
1. Reduce the predefined_min_time which is the minimum time each test needs to run. Based on the test result, the average time across different epoch are pretty stable before exiting. So we can safely reduce the predefined time here.
2. Chang the input shapes of several ops
Test Plan:
```
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: add
200 256.044864655
400 165.850520134
800 163.579881191
1600 162.871927023
3200 160.3128016
# Mode: Eager
# Name: add_cpu_M64_K64_bwd1_N64
# Input: device: cpu, K: 64, M: 64, N: 64
Backward Execution Time (us) : 164.715
# Benchmarking PyTorch: add
200 170.650482178
400 168.895125389
800 169.867575169
1600 163.400024176
3200 168.658420444
# Mode: Eager
# Name: add_cpu_M64_K64_bwd2_N64
# Input: device: cpu, K: 64, M: 64, N: 64
Backward Execution Time (us) : 168.777
Reviewed By: hl475
Differential Revision: D18438540
fbshipit-source-id: 1fd27cf4bbc34e46e74393af912ee2fcb75c33b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29615
Remove that flag as it's not needed any more.
Test Plan: na
Reviewed By: hl475
Differential Revision: D18440271
fbshipit-source-id: 41b0659c72ef746a1cc268174fd1e7dc2beb1ae2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29147
Previously we use a vector of weight and bias to record the values of weight/bias and we
assume we'll get them by GetAttr nodes, then we propagate these values through the function calls
However, it doesn't work if we also do some transformations on these values right now, we'll need
to mark all the values that's produced by weight/bias as weight/bias, e.g.
```
%w = GetAttr[name="weight"](%conv)
%wt = aten::transpose(%w)
%r = aten::conv2d(..., %wt, ...)
```
we'll mark both %w and %wt as weight. This is a bit over compilicated to support this.
Alternatively, we can identify weights by argument positions, e.g.
for call %r = aten::conv2d(..., %w, ...), we know the argument 1 is weight, argument 2 is bias.
Test Plan:
test_jit.py
Imported from OSS
Differential Revision: D18362839
fbshipit-source-id: afbf07f48bab8d01c5be1c882561a0255730a6b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28985
Remove the observer module in the quantized model
Test Plan:
python test/test_jit.py 'TestJit.test_insert_quant_dequant'
Imported from OSS
Differential Revision: D18253777
fbshipit-source-id: 26081c4c3fd3dc049cafa8c0383219bc4c233589
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29596
as title
Test Plan: na
Reviewed By: hl475
Differential Revision: D18437811
fbshipit-source-id: 7996d1689d8a46849b62b2b3875c67cf8dc5861c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29583
The normal flow for type sharing assumes that we will construct the
`ConcreteModuleType`, then use `operator==` to decide whether or not to
reuse an existing JIT type. In this case, `jitType_` is not populated,
so it doesn't make sense to compare it.
However, there is one exception to this flow: for traced modules, we
pre-compute the JIT type and poke it into the `ConcreteModuleType`
manually. To handle this case, we should compare the `jitType_`s in
`operator==` like everything else.
Test Plan: Imported from OSS
Differential Revision: D18435949
Pulled By: suo
fbshipit-source-id: 44b7672a686015aaf02f6664c6aff00e165fde65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29582
Give it more info, fix a segfault
Test Plan: Imported from OSS
Differential Revision: D18435950
Pulled By: suo
fbshipit-source-id: 43c695ffe1f13f33df69c6e51caa531f8b993208
Summary:
- Building `BinaryOpsKernel.cu` takes extremely long. Split the original file into 3 pieces, and copy-paste code into these files.
- Remove some useless logic
- change some wrong ops name `*_cpu` -> `*_cuda`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29428
Differential Revision: D18408858
Pulled By: VitalyFedyunin
fbshipit-source-id: 29323b0bc40a928ae698345ad1ffe46c5851b012
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29499
This changes how DataParallel and trace module creation works so that
we no longer need to mutate Module class after it has been created.
The only remaining usage of register_* functions are now inside C++
tests.
Test Plan: Imported from OSS
Differential Revision: D18413652
Pulled By: zdevito
fbshipit-source-id: f039e5400cd016632768be4547892f6a69645c20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29432
This removes a lot of the private methods on torch._C.ScriptModule,
and instead implements functionality in terms of slot_dict_impl views
to implement _parameter, _buffers, and _modules in nn.Module.
A followup PR should also remove the _register_attribute,
_register_module, and _register_parameter methods, but this requires
more refactoring of the way tracing creates modules and replication
for data parallel works.
Test Plan: Imported from OSS
Differential Revision: D18387963
Pulled By: zdevito
fbshipit-source-id: f10d47afeb30c1e05d704ae5ac4166830933125c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29407
Fixes https://github.com/pytorch/pytorch/issues/27753.
The bug was that random tensors print subtly differently. This causes
the "names=" tag to appear in slightly different places; sometimes it is
on the same line as the data, sometimes it is on different lines.
For this test, we wanted to know the following:
- printing a big named tensor's repr doesn't crash
- a big named tensor's repr shows the names
This PR changes the test to check those two things.
Test Plan: - run existing tests
Differential Revision: D18428657
Pulled By: zou3519
fbshipit-source-id: 6bcf247ffba010520878a175e766a496028f87d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28948
Add the constructor RRef(value) in python. This allows to wrap a local object with RRef an pass or return this RRef to users.
This enables returning, for example, a list of RRefs containing the parameters of a module to the user of the module.
ghstack-source-id: 93565010
Test Plan: unit test.
Differential Revision: D18241227
fbshipit-source-id: b9e9b958f40623348d62ee6fc9e7f0414b4215b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28926
The get_gradients method was a pybind only method without any
documentation for this method for users.
I've moved this method to our python distributed autograd API and ensured that
we have appropriate docs for this method.
ghstack-source-id: 93558845
Test Plan: waitforbuildbot
Differential Revision: D18234443
fbshipit-source-id: 317267d8c2416da75afd3f9d900a3cd74bb78dfb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29304
Implements a simple python distributed optimizer that takes rrefs to parameters that will be optimized.
It keeps instances of optimizers remotely and calling step on distributed optimizer will call step on each of the remote optimizers in parallel.
ghstack-source-id: 93564364
Test Plan: unit tests.
Differential Revision: D18354586
fbshipit-source-id: 85d4c8bfec4aa38d2863cda704d024692511cff5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29148
We would skip rpc.join_rpc() in the case of `clean_shutdown=False`.
This would exit the process without properly cleaning up the local RPCAgent
resulting in a crash.
As a result, to fix this we still call rpc.join_rpc() even in an unclean
shutdown. Note that, rpc.join_rpc() needs to be replaced with a local
`shutdown` call eventually since we need a way to shutdown the local RPC agent
properly.
Test Plan: waitforbuildbot
Reviewed By: xush6528
Differential Revision: D18306941
fbshipit-source-id: 2685db3924f7aa4516f3b28f58d6c127bcd55ba9
Summary:
Fixes https://github.com/pytorch/pytorch/issues/17662
I'm not sure if `arange` needs to be in python_arg_parser at all, given the schemas in native_functions.yaml. In any case this at least fixes the dytpe mismatch.
In follow up PRs I will try to handle some of the other ops that do type inference at the python level, like randint.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27629
Differential Revision: D17885939
Pulled By: eellison
fbshipit-source-id: f97a8bc722b7ab77de1c42a992e49a4a3175ad60
Summary:
Fixes https://github.com/pytorch/pytorch/issues/27627
The variable being declared in a header as `static` meant that the global variable is initialized in every source file that includes it. This is particularly problematic when included in AVX source files as it generates SIGILL on older hardware.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29384
Differential Revision: D18380379
Pulled By: zou3519
fbshipit-source-id: 0dcd87db01c468a5c9ddb2c695528b85ed2e1504
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29483
Somehow, these macros were not necessary!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18427851
Pulled By: ezyang
fbshipit-source-id: 86e1d75d98342461c9a5afa1c30c14346188f7cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29409Fixes#27875
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18396828
Pulled By: ezyang
fbshipit-source-id: 3f53cbbe620cd3445852273be90ff5744aa7a8cb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/23401
We cannot rely on `multiprocessing.util.register_after_fork` since it is only
called for processes created by the `multiprocessing` module and not `os.fork()`.
Moving to `pthread_atfork` does always get called. However, I don't think it's safe to call python functions inside of the `atfork` handler so the python code has to be a bit more careful when checking `_initialized`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29101
Differential Revision: D18355451
Pulled By: ezyang
fbshipit-source-id: 4d4253a3669796212c099dad4e5bdfdb0df40469
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29167
As titled.
This fix is crucial as multi_channel splitting would create history that has no items (i.e., D == 0), which leads to flow failure.
Test Plan:
Unittest
flow test:
before fix: f148783160
after fix: f149082299
buck test mode/dev-nosan caffe2/caffe2/python/operator_test:softmax_ops_test
Reviewed By: xianjiec
Differential Revision: D18296081
fbshipit-source-id: e0bb2dc2c4e5b465e213f31e5c5ced3a7e1fd574
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29485
The flakiness is likely due to the problem with OMP and fork. We
should disable fork tests for good, but that would have negative
impact on internal test coverage. This commit disables the most
buggy nested tests for now, until we find a way to turn fork test
off.
Test Plan: Imported from OSS
Differential Revision: D18407529
Pulled By: mrshenli
fbshipit-source-id: dcbe49a9d104fcf1eaf83107d58904d49dc18aff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29481
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18422265
Pulled By: ezyang
fbshipit-source-id: b483cd5f688676444c83174a38c99cb1777a60b0
Summary:
Replace the custom thread-safe invalid index checking and instead rely on the internal exception propagation of parallel_for. Use the `TORCH_CHECK_INDEX` macro when checking indices.
Align index check in `nll_loss` implementation with `nll_loss2d`, see https://github.com/pytorch/pytorch/issues/28304.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29454
Differential Revision: D18418169
Pulled By: ezyang
fbshipit-source-id: 273da5230dd4b66a51bf02386718b31d2dd41e66
Summary:
Added check for indicies in Reduction::None case.
### Benchmark results
Note: Due to the size of the input tensors this time the random number generation is responsible for a significant portion of the total time. It is better to look at the individual net time-outputs (which do not include the input preparation).
Script used for benchmark.: [nnl_loss2d_benchmark.py](https://gist.github.com/andreaskoepf/5864aa91e243317cb282c1e7fe576e1b)
#### WITH PR applied
```
using reduction: none
CPU forward 1000 took 7.916500908322632e-05
CPU forward 10000 took 0.0002642290201038122
CPU forward 100000 took 0.003828087996225804
CPU forward 1000000 took 0.037140720000024885
CPU forward 10000000 took 0.33387596398824826
CPU forward TOTAL time 7.218988707987592
using reduction: mean
CPU forward 1000 took 9.165197843685746e-05
CPU forward 10000 took 0.0005258890159893781
CPU forward 100000 took 0.0050761590246111155
CPU forward 1000000 took 0.047345594997750595
CPU forward 10000000 took 0.4790863030066248
CPU forward TOTAL time 7.9106070210109465
CPU for- & backward 1000 took 0.0005489500181283802
CPU for- & backward 10000 took 0.0015284279943443835
CPU for- & backward 100000 took 0.015138130984269083
CPU for- & backward 1000000 took 0.15741890601930209
CPU for- & backward 10000000 took 1.6703072849777527
CPU for- & backward TOTAL time 9.555764263990568
using reduction: sum
CPU forward 1000 took 8.789298590272665e-05
CPU forward 10000 took 0.000514078012201935
CPU forward 100000 took 0.005135576997417957
CPU forward 1000000 took 0.04715992201818153
CPU forward 10000000 took 0.4821214270195924
CPU forward TOTAL time 7.9119505700073205
CPU for- & backward 1000 took 0.00047759301378391683
CPU for- & backward 10000 took 0.0015945070190355182
CPU for- & backward 100000 took 0.018208994006272405
CPU for- & backward 1000000 took 0.15904426100314595
CPU for- & backward 10000000 took 1.5679037219961174
CPU for- & backward TOTAL time 9.495157692988869
```
#### WITHOUT original TH impl
```
using reduction: none
CPU forward 1000 took 0.0003981560003012419
CPU forward 10000 took 0.0035912430030293763
CPU forward 100000 took 0.035353766987100244
CPU forward 1000000 took 0.3428319719969295
CPU forward 10000000 took 3.364342701010173
CPU forward TOTAL time 11.166179805004504
using reduction: mean
CPU forward 1000 took 8.63690220285207e-05
CPU forward 10000 took 0.0004704220045823604
CPU forward 100000 took 0.0045734510058537126
CPU forward 1000000 took 0.046232511987909675
CPU forward 10000000 took 0.4191019559802953
CPU forward TOTAL time 7.846049971994944
CPU for- & backward 1000 took 0.0005974550149403512
CPU for- & backward 10000 took 0.0014057719963602722
CPU for- & backward 100000 took 0.013776941981632262
CPU for- & backward 1000000 took 0.13876214998890646
CPU for- & backward 10000000 took 1.3666698939923663
CPU for- & backward TOTAL time 9.10526105100871
using reduction: sum
CPU forward 1000 took 7.598899537697434e-05
CPU forward 10000 took 0.00046885499614290893
CPU forward 100000 took 0.0044489419960882515
CPU forward 1000000 took 0.04495517900795676
CPU forward 10000000 took 0.418376043002354
CPU forward TOTAL time 7.789334400993539
CPU for- & backward 1000 took 0.0004464260127861053
CPU for- & backward 10000 took 0.0017732900159899145
CPU for- & backward 100000 took 0.01626713399309665
CPU for- & backward 1000000 took 0.11790941300569102
CPU for- & backward 10000000 took 1.4346664609911386
CPU for- & backward TOTAL time 9.294745502003934
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28304
Differential Revision: D18350157
Pulled By: ezyang
fbshipit-source-id: e9437debe51386a483f4265193c475cdc90b28e4
Summary:
It is reported this test is flaky due to the time expiration. This pr flags it as no_deadline test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29502
Differential Revision: D18416632
Pulled By: lly-zero-one
fbshipit-source-id: 27cd7b28139f3f16ee0cf5802a0709385719d487
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29364
Currently, we use `torch::nn::*Options` both as module options and functional options. However, this makes it very hard to manage the parameters in `torch::nn::*Options`, because a module's constructor can take a different set of arguments than the module's equivalent functional (e.g. `torch.nn.BatchNorm1d` takes `num_features, eps=1e-5, momentum=0.1, affine=True,
track_running_stats=True`, while `F::batch_norm` takes `running_mean, running_var, weight=None, bias=None, training=False, momentum=0.1, eps=1e-5`).
This PR resolves the above problem by making `F::*FuncOptions` a different class from `torch::nn::*Options` when necessary (i.e. when a module's constructor takes a different set of arguments than the module's equivalent functional). In the rest of the cases where the module constructor takes the same set of arguments as the module's equivalent functional, `F::*FuncOptions` is an alias of `torch::nn::*Options`.
Also as part of this PR, we change all functional options to pass-by-value, to make the semantics consistent across all functionals.
Test Plan: Imported from OSS
Differential Revision: D18376977
Pulled By: yf225
fbshipit-source-id: 8d9c240d93bfd5af0165b6884fdc912476b1d06b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29491
Setting DEBUG=1 causes tests to run super slow. There are two reasons
why you might do it:
1. Testing `#NDEBUG` stuff. We don't really use this macro.
2. https://github.com/pytorch/pytorch/issues/4119. This is valid,
but I would prefer to allow internal contbuilds to test this, as the
infra is better there.
Test Plan: Imported from OSS
Differential Revision: D18411635
Pulled By: suo
fbshipit-source-id: 54e1d0f9cddaa448cd2dd11fe263d5001845bdd8
Summary:
For the same reason we don't allow iteration over heterogenous types (modulelists/tuples) with types that don't have a static length, we also can't break/continue within them - we need to statically know all types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29474
Differential Revision: D18406097
Pulled By: eellison
fbshipit-source-id: 70ed3fc4947b6237cdd6703135a988a5c13ce786
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29360
This PR adds functional overloads that take the full set of arguments (instead of just Options) for the following functionals:
- fold
- linear
- loss
- normalization
- padding
These new functionals lives in the `torch::nn::functional::detail` namespace and they are only meant to be called from the module forward methods (i.e. they are not public API). This is in preparation for the future change where we make module Options and functional Options two different classes, because if the module forward method has to construct a new functional Options object every time it runs it will be pretty silly and bad performance.
Test Plan: Imported from OSS
Differential Revision: D18376975
Pulled By: yf225
fbshipit-source-id: 233cd940834dc9d0b5d4b89339ab7082ec042c3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29425
This change saves roughly 5-6% in the TorchSaveSmallTensor benchmark
(torch::save() on a tensor with 64 random floats) by reusing the
padding string across records.
ghstack-source-id: 93517961
Test Plan:
Correctness: buck test mode/dev-nosan caffe2/test/...
Benchmark buck build mode/opt experimental/jeremyl/c2/...
buck-out/opt/gen/experimental/jeremy/c2/SerializationBench
Differential Revision: D18385731
fbshipit-source-id: 20bcbe1efd2fb7e3012dd68080542f2a74a7d4f2
Summary:
We dont have ATen/native/quantized/cpu/*.h in torch target before, and we would like it to be exposed for external use.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29418
Differential Revision: D18383534
Pulled By: zrphercule
fbshipit-source-id: 72c06ae2c10e8cc49e7256c9e9b89288263bbfde
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29412
Originally, this was going to be Android-only, so the name wasn't too
important. But now that we're planning to distribute it with libtorch,
we should give it a more distinctive name.
Test Plan:
Ran tests according to
https://github.com/pytorch/pytorch/issues/6570#issuecomment-548537834
Reviewed By: IvanKobzarev
Differential Revision: D18405207
fbshipit-source-id: 0e6651cb34fb576438f24b8a9369e10adf9fecf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29455
- Don't need to load native library.
- Shape is now private.
Test Plan: Ran test.
Reviewed By: IvanKobzarev
Differential Revision: D18405213
fbshipit-source-id: e1d1abcf2122332317693ce391e840904b69e135
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29351
When torch::save()ing a smallish tensor, we spend ~5% of the time
still in std::stringstream constructors.
This removes the last couple of cases. Benchmark shows ~5% improvement:
TorchSaveSmallTensor Pre: 13.12us
TorchSaveSmallTensor Post: 12.48us
ghstack-source-id: 93517928
Test Plan:
buck build mode/opt experimental/jeremyl/c2:
buck-out/opt/gen/experimental/jeremyl/c2/SerializationBench --bm_regex=TorchSaveSmallTensor
Differential Revision: D18365066
fbshipit-source-id: a3284bec004751cedae1cdadf27f969422faff8e
Summary:
Reason:
To have one-step build for test android application based on the current code state that is ready for profiling with simpleperf, systrace etc. to profile performance inside the application.
## Parameters to control debug symbols stripping
Introducing /CMakeLists parameter `ANDROID_DEBUG_SYMBOLS` to be able not to strip symbols for pytorch (not add linker flag `-s`)
which is checked in `scripts/build_android.sh`
On gradle side stripping happens by default, and to prevent it we have to specify
```
android {
packagingOptions {
doNotStrip "**/*.so"
}
}
```
which is now controlled by new gradle property `nativeLibsDoNotStrip `
## Test_App
`android/test_app` - android app with one MainActivity that does inference in cycle
`android/build_test_app.sh` - script to build libtorch with debug symbols for specified android abis and adds `NDK_DEBUG=1` and `-PnativeLibsDoNotStrip=true` to keep all debug symbols for profiling.
Script assembles all debug flavors:
```
└─ $ find . -type f -name *apk
./test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
./test_app/app/build/outputs/apk/resnet/debug/test_app-resnet-debug.apk
```
## Different build configurations
Module for inference can be set in `android/test_app/app/build.gradle` as a BuildConfig parameters:
```
productFlavors {
mobilenetQuant {
dimension "model"
applicationIdSuffix ".mobilenetQuant"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_MOBILENET_QUANT'))
addManifestPlaceholders([APP_NAME: "PyMobileNetQuant"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-mobilenet\"")
}
resnet {
dimension "model"
applicationIdSuffix ".resnet"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_RESNET18'))
addManifestPlaceholders([APP_NAME: "PyResnet"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-resnet\"")
}
```
In that case we can setup several apps on the same device for comparison, to separate packages `applicationIdSuffix`: 'org.pytorch.testapp.mobilenetQuant' and different application names and logcat tags as `manifestPlaceholder` and another BuildConfig parameter:
```
─ $ adb shell pm list packages | grep pytorch
package:org.pytorch.testapp.mobilenetQuant
package:org.pytorch.testapp.resnet
```
In future we can add another BuildConfig params e.g. single/multi threads and other configuration for profiling.
At the moment 2 flavors - for resnet18 and for mobilenetQuantized
which can be installed on connected device:
```
cd android
```
```
gradle test_app:installMobilenetQuantDebug
```
```
gradle test_app:installResnetDebug
```
## Testing:
```
cd android
sh build_test_app.sh
adb install -r test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
```
```
cd $ANDROID_NDK
python simpleperf/run_simpleperf_on_device.py record --app org.pytorch.testapp.mobilenetQuant -g --duration 10 -o /data/local/tmp/perf.data
adb pull /data/local/tmp/perf.data
python simpleperf/report_html.py
```
Simpleperf report has all symbols:
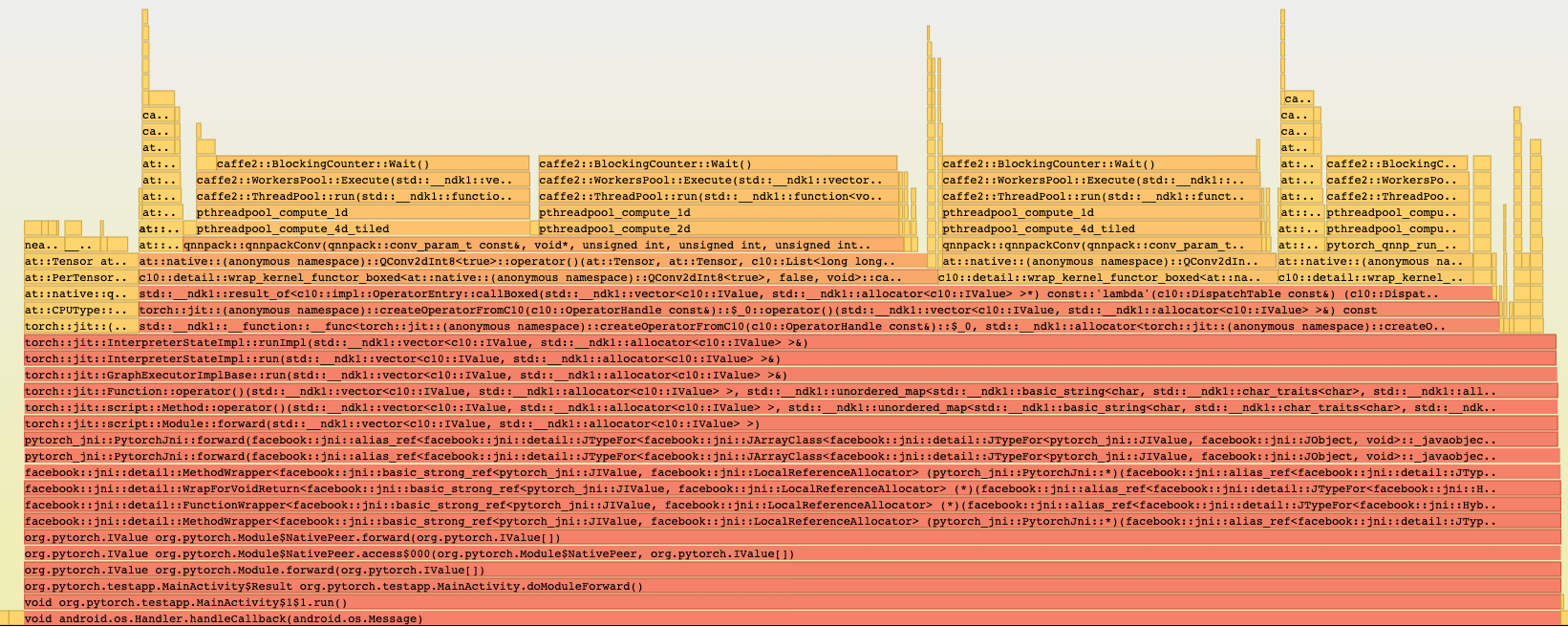
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28406
Differential Revision: D18386622
Pulled By: IvanKobzarev
fbshipit-source-id: 3a751192bbc4bc3c6d7f126b0b55086b4d586e7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29332
Even though we're statically typed, this can be useful, e.g. as
shorthand when iterating through a module list.
Test Plan: Imported from OSS
Differential Revision: D18393097
Pulled By: suo
fbshipit-source-id: aa42e955f88d1b8a876d0727055eb596453b9839
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29478
caffe2 is still tested internally, but removing the OSS configurations.
ONNX remains, however. I will look at migrating them to the pytorch
docker images so we can kill the entire caffe2 part of the config
Test Plan: Imported from OSS
Differential Revision: D18406233
Pulled By: suo
fbshipit-source-id: c3a7d1c58a2828f04778497faa1b5d13b67acbbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29359
This PR adds functional overloads that take the full set of arguments (instead of just Options) for the following functionals:
- pixelshuffle
- pooling
- upsampling
- vision
These new functionals lives in the `torch::nn::functional::detail` namespace and they are only meant to be called from the module forward methods (i.e. they are not public API). This is in preparation for the future change where we make module Options and functional Options two different classes, because if the module forward method has to construct a new functional Options object every time it runs it will be pretty silly and bad performance.
Test Plan: Imported from OSS
Differential Revision: D18376978
Pulled By: yf225
fbshipit-source-id: 4ea8d359e7efde0d741eff79faad6b24b2a5d804
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29405
We never actually used this (function attributes are a separate pathway
in ConcreteModuleType).
Test Plan: Imported from OSS
Differential Revision: D18378392
Pulled By: suo
fbshipit-source-id: b06c4b6d70f0b2534be78a215125cffd22ab44f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29421
Inline graph before writing the bytecode file, so that all the instructions are emitted from the top-level methods.
Test Plan: Imported from OSS
Differential Revision: D18404180
fbshipit-source-id: 4759474a8dba3813616ebce8253bea09941f6bbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29440
as titled. same as diff: D18195868.
We fix the windows compiling issue by changing the marco, inspired from: D15511736
Test Plan:
buck test -v 2 caffe2/caffe2/fb/dper/layer_models/tests/split_1:sparse_nn_test -- test_composite_cosine_lr_policy
canary: https://fburl.com/fblearner/ky7wh3vg
Differential Revision: D18392276
fbshipit-source-id: 83c84c985cd23b1cc43efedfef176ff3c67acb6e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29253
Some operations can be simpler if a worker can send an rpc to itself.
The main reason for not doing previous was that Gloo doesn't support
self-sending.
That said, this changes the process_group_agent to skip the assert
check, and simply enqueue the rpc message in its receiving queue.
ghstack-source-id: 93518076
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18339715
fbshipit-source-id: 08ade40e81da378b003a550c898a726e99d50e34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29069
Distributed autograd was initialized after RPC and this would cause a
race in some scenarios where one node might have initialized distributed
autograd, calls backward() but other nodes have not initialized distributed
autograd yet.
Moving this before `_init_rpc` fixes the problem since `_init_rpc` implicitly
has a sync between processes via the store.
ghstack-source-id: 93535922
Test Plan: waitforbuildbot
Differential Revision: D18280875
fbshipit-source-id: 739a1c22dec21df859738d074e6e497fa43257fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28900
Decouple the JIT and autograd codes (and their dependencies). After this decoupling, the compressed torch mobile size is 548 KB total (comparing to 2.98 MB with full JIT).
ghstack-source-id: 93447313
Test Plan: buck build fbandroid/mode/dev_clang_libcxx //xplat/experimental/pytorch/mobile:lite_predictorAndroid#android-armv7 -c project.ignore= -c user.ndk_cxxflags=-g0 --show-output
Differential Revision: D18226237
fbshipit-source-id: a188329274b450f63eb6448f42adec28517e14fd
Summary:
as part of https://github.com/pytorch/hub/issues/62 I found that the stack-trace of a failed kernel launch was being recorded elsewhere, even with CUDA_LAUNCH_BLOCKING=1.
So, I started debugging, and found that magma launches don't do error checking.
I eventually found the issue to be that I didn't compile-in sm37 SASS into the magma binary and the failure was on `x.inverse()`, and that's somehow a problem for magma 2.5.1 (but not 2.5.0).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29003
Differential Revision: D18397358
Pulled By: soumith
fbshipit-source-id: 04baca68eac209d7af773daddd0193697d4ab0d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29358
This PR adds functional overloads that take the full set of arguments (instead of just Options) for the following functionals:
- activation
- batchnorm
- distance
- embedding
These new functionals lives in the `torch::nn::functional::detail` namespace and they are only meant to be called from the module forward methods (i.e. they are not public API). This is in preparation for the future change where we make module Options and functional Options two different classes, because if the module forward method has to construct a new functional Options object every time it runs it will be pretty silly and bad performance.
Test Plan: Imported from OSS
Differential Revision: D18376976
Pulled By: yf225
fbshipit-source-id: 0b254dc6340b6d6ac08c9f95d2b1c02b791b2f38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29396
The return types of RRef.to_here()/local_value() were recently
changed to Future, which triggers flakiness as the RRef could be
deleted before the future.wait() finishes. While we are still
discussing how we'd like to solve it, this commit reverts the
return type to stop bleeding in tests.
closes#28885
Test Plan: Imported from OSS
Differential Revision: D18375571
Pulled By: mrshenli
fbshipit-source-id: 354dbf38b15ab804e44fc9968dd30888415c1fab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29342
This is not necessary, as we use `lazy_bind` to retrieve those methods
from the class anyway.
Test Plan: Imported from OSS
Differential Revision: D18383381
Pulled By: suo
fbshipit-source-id: e8b7c9e696087cc1e707ac38f7ae85f569f08371
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29341
So that other RpcAgent could use this timeout setting as well.
ghstack-source-id: 93481902
Differential Revision: D5681951
fbshipit-source-id: 569c768dc342e8a2d9faf142ceccf696e12e41dc
Summary:
Export _weight_norm
Caffe2 tests are inplace
Looks like there is a conflicting behavior in torch.nn.utils.weight_norm regarding None dim.
Where dim could be negative for backwards axes, but when dim = None, it's overwitten to -1
0c48092b22/torch/nn/utils/weight_norm.py (L10)
For now, this symbolic to matches the current behavior. But this might need to be changed in the torch module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28618
Reviewed By: hl475
Differential Revision: D18354270
Pulled By: houseroad
fbshipit-source-id: 0d64ee9ee1156bb96d36ed0a25b2e8cc5058ce90
Summary:
As title. Also, replaces output allocation by `empty` instead of `empty_strided` in the regular path when possible, thus avoiding resizing of outputs and taking additional DeviceGuard for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29180
Test Plan: covered by existing tests
Differential Revision: D18327836
Pulled By: ngimel
fbshipit-source-id: e8d925f0fe915f327ec41aba83fd6857b09772b5
Summary:
The code checking `if dimensions == 2` is not needed
because the case of a 2D tensor (Linear) is already handled
by the statement:
`receptive_field_size = 1`
and this conditional:
`if tensor.dim() > 2:`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29370
Differential Revision: D18372987
Pulled By: albanD
fbshipit-source-id: fcb4dddbc76b9f4414c6d88c0aa2fb4435bf3385
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29269
Hit this bug when I have an attribute of type `Optional[Tensor]` which
is initialized to None and reassigned later to some tensor.
Test Plan:
.
Imported from OSS
Differential Revision: D18364338
fbshipit-source-id: d8e1277a84ab7d80331cba83f5639469d398632e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29331Closes#27954
This fixes the hard-coding of packed parameter values for the dynamic quantized LSTM by orchestrating the following dance:
1) Each variadic parameter on the module has its own Module. That Module defines the `__getstate__` and __setstate__` method s.t. packed weights are properly re-done on model load.
2) Each of these modules is wrapped into a `torch.nn.ModuleList`, s.t. the parameters appear as attributes in the hierarchy. Then, `gatherParametersAndBuffers` (9c43b16df9/torch/csrc/jit/tracer.cpp (L285)) can see these parameters and create a `Value*` for them in the traced graph.
3) In forward, we need to convert from ModuleList -> Module -> Parameter to a simple TensorList of the parameters. We just use a loop here. In tracing, we simply record a `ListConstruct` with each of the proper parameter values. In scripting, the `ModuleList` is const, so it can be unrolled into the graph and a subsequent `ListConstruct` does its business.
The `forward` of the traced LSTM before and after this change are as follows:
Before
```
def forward(self,
input: Tensor,
argument_2: Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]:
hx, hx0, = argument_2
_0, _1, _2 = torch.quantized_lstm(input, [hx, hx0], [CONSTANTS.c0, CONSTANTS.c1], True, 1, 0., True, False, False, dtype=12, use_dynamic=True)
return (_0, (_1, _2))
```
After
```
def forward(self,
input: Tensor,
argument_2: Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]:
_0 = self.cell._all_weight_values
_1 = getattr(_0, "0").param
_2 = getattr(_0, "1").param
hx, hx0, = argument_2
_3, _4, _5 = torch.quantized_lstm(input, [hx, hx0], [_1, _2], True, 1, 0., True, False, False, dtype=12, use_dynamic=True)
return (_3, (_4, _5))
```
Test Plan: Imported from OSS
Differential Revision: D18374904
Pulled By: jamesr66a
fbshipit-source-id: f1a9b58998bc365b9baad38c21fd4bb510dd639c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/6962
The PR implements the handle pool mechanism for cublas as suggested by mcarilli in https://github.com/pytorch/pytorch/issues/6962#issuecomment-530563872.
~~I didn't add any unit test here yet because as mcarilli mentioned:~~
> ~~On my local machine, out of curiosity I also rewrote that test to use gemms instead of convolutions. The race condition seemed rarer, but the test did show that cublas use is not thread safe. I can share the script if you want.~~
~~Please share your script with me mcarilli. And if the race condition is rare, would it still be possible for the CI to detect it?~~
cc: colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29233
Differential Revision: D18372007
Pulled By: ezyang
fbshipit-source-id: 3492bf13410598e8452e89cf4e3e63e8df9c8c3d
Summary:
This reverts the 9a9bb448ee49a1493f22bbbeed4af92b1364fce9
Fixing the broken case which reverts the previous commit.
details about fix:
modified: aten/src/ATen/native/Convolution.cpp
called contiguous on 3D input tensor. This avoids the code path to accidentally
recognize the input as channel_last stride, due to unsqueezing of permuted 3d
tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29361
Differential Revision: D18371964
Pulled By: VitalyFedyunin
fbshipit-source-id: a5985f4687b37e183649fa35b8ccdb50368ebfdf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29048
In order to support remove_attribute in module, we need to support
remove slot in ivalue::Object, it's caller's responsiblity to gaurantee
the safety of the remove operation
Test Plan:
build/bin/test_jit
Imported from OSS
Differential Revision: D18343464
fbshipit-source-id: c1ba3a06afc40d928e59500b7b35c9e6c8720028
Summary:
Re-submit of https://github.com/pytorch/pytorch/issues/29133
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex)
Changes
- [x] Fixed Vec256 Permute operations for Complex Float
- [x] Fixed copy_kernel_cast between complex data types
- copy_kernel_cast should not call std::real during inter-complex dtype conversion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29294
Differential Revision: D18371928
Pulled By: ezyang
fbshipit-source-id: a80a894eeaeb68540054ccfe405c4d0338fa4350
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29200
Before, the dispatch key for unboxed operators from native_functions.yaml was generated in codegen and passed to the c10 dispatcher.
Now, we generate it inside of the dispatcher, right next to where the same thing happens for boxed calls.
ghstack-source-id: 93371022
Test Plan: unit tests
Differential Revision: D18282747
fbshipit-source-id: 96a97fe83778d0a9e61b4441d6e2aed10d73209c
Summary:
This diff adds the following:
- An AsyncIf to support conditional async execution. This op assumes that then_net and else_net are async scheduling nets. This op itself completes when every async op in the active net completes. Cancellation cancels the inner nets and the async ops.
- Unit tests targeting asynchronicity and error/cancellation handling.
Test Plan:
New unit tests
With --stress-runs=2000:
https://our.intern.facebook.com/intern/testinfra/testrun/4785074616784325
Reviewed By: ilia-cher
Differential Revision: D18051357
fbshipit-source-id: 1399a437b3ca63fd4ea0cf08d173f85b9242cc1f
Summary:
When NHWC Tensor has height or width larger then max CUDA grid size, max_pool fails with error code 0
The example is: https://github.com/pytorch/pytorch/issues/28714
This change should limit grid size to the CUDA max possible size and chunk the input to be able to process it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28931
Differential Revision: D18358892
Pulled By: ifedan
fbshipit-source-id: 2fd65448bd644f1588a0e208edaaea5bcb6a7d52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28395
Currently property methods are broken in TorchScript because we
basically treat it as an attribute in the existing path: we'll evaluate
the method once and store that as the value forever.
Since lack of property support is easily worked around (just make it
a method), I've opted to just explicitly error to avoid confusion. If
people want it, they can file an issue and we can look at their use
case.
This also helps us nicely clean up some parts of the ScriptModule conversion
path.
Test Plan: Imported from OSS
Reviewed By: shannonzhu
Differential Revision: D18054946
Pulled By: suo
fbshipit-source-id: 7e927836ae687cd2f13a94b9f0af399437fae422
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28828
This updates torch::script::Module to more closely match the behavior
of nn.Module. In particular, it implements the (optionally recurisive)
iterators that retrieve submodules, parameters, and buffers and makes
their names match the python versions.
This also removes the individual accessors for Parameter, Module, Buffer, etc.
and replaces them with a single `attr` function which is equivalent to
writing `a.foo` in Python (`setattr` emulates `a.foo = v`).
As we build out the user-facing API for TorchScript values this will end
up matching how an attribute is accessed on general objects.
This PR preservers the python bindings for script::Module by emulating the
old API at the binding level. A followup will clean up the usage to more
directly match the C++ API.
Test Plan: Imported from OSS
Differential Revision: D18197611
Pulled By: zdevito
fbshipit-source-id: 7ee4dcbb258605d1c988314b05d938423f1ccee5
Summary:
Currently, `keep_initializers_as_input` argument in `torch.onnx.export` API can be used to choose whether to export an ONNX model with IR v3 or v4 semantics. Currently, the implementation does not check for which opset is being used for export. This is an issue because ONNX IR v4 is valid only for opset 9 and above (as listed [here](https://github.com/onnx/onnx/releases/tag/v1.4.0)), and opset 8 or lower export with `keep_initializers_as_input=False` will create a illegal ONNX graph.
This change fixes this by introducing a check on opset version when deciding whether to export ONNX IR v3 or v4.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28990
Reviewed By: hl475
Differential Revision: D18352523
Pulled By: houseroad
fbshipit-source-id: 7e9055d405c3faf52b80a8de0d04186d4c350c15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29328
Tests are flaky as seen in issue #29326.
Disable until we fix the kernels.
Test Plan:
python test/test_quantized.py TestQNNPackOps
Imported from OSS
Differential Revision: D18358200
fbshipit-source-id: 58f1981799fe8253234fcc7b0540e1c0b6babc15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29208
A binary to dump operator names from a script model and its sub models.
Usage:
dump_operator_names path/to/script_model.pt path/to/output.yaml
Test Plan: Imported from OSS
Differential Revision: D18350353
fbshipit-source-id: 2026c8ab765069ad059ab2ca44fc27b79315b973
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29146
getFuncName takes the Value that represents the function for argument
e.g.
for CallFunction(%1, %a, %b, %c), it takes %1 for argument
Test Plan:
test_jit.py
Imported from OSS
Differential Revision: D18362840
fbshipit-source-id: fc90ebe7db702aec9b50cec6db454d0eb8ee5612
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29331Closes#27954
This fixes the hard-coding of packed parameter values for the dynamic quantized LSTM by orchestrating the following dance:
1) Each variadic parameter on the module has its own Module. That Module defines the `__getstate__` and __setstate__` method s.t. packed weights are properly re-done on model load.
2) Each of these modules is wrapped into a `torch.nn.ModuleList`, s.t. the parameters appear as attributes in the hierarchy. Then, `gatherParametersAndBuffers` (9c43b16df9/torch/csrc/jit/tracer.cpp (L285)) can see these parameters and create a `Value*` for them in the traced graph.
3) In forward, we need to convert from ModuleList -> Module -> Parameter to a simple TensorList of the parameters. We just use a loop here. In tracing, we simply record a `ListConstruct` with each of the proper parameter values. In scripting, the `ModuleList` is const, so it can be unrolled into the graph and a subsequent `ListConstruct` does its business.
The `forward` of the traced LSTM before and after this change are as follows:
Before
```
def forward(self,
input: Tensor,
argument_2: Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]:
hx, hx0, = argument_2
_0, _1, _2 = torch.quantized_lstm(input, [hx, hx0], [CONSTANTS.c0, CONSTANTS.c1], True, 1, 0., True, False, False, dtype=12, use_dynamic=True)
return (_0, (_1, _2))
```
After
```
def forward(self,
input: Tensor,
argument_2: Tuple[Tensor, Tensor]) -> Tuple[Tensor, Tuple[Tensor, Tensor]]:
_0 = self.cell._all_weight_values
_1 = getattr(_0, "0").param
_2 = getattr(_0, "1").param
hx, hx0, = argument_2
_3, _4, _5 = torch.quantized_lstm(input, [hx, hx0], [_1, _2], True, 1, 0., True, False, False, dtype=12, use_dynamic=True)
return (_3, (_4, _5))
```
Test Plan: Imported from OSS
Differential Revision: D18359880
Pulled By: jamesr66a
fbshipit-source-id: 0ff2cad294a1871123015dfc704eaf73a7ac1d9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29158
My plan is to split out libtorch_cuda.so from libtorch.so. To do this,
I need accurate _API annotations for files in these directories.
I determined the correct set of annotations by looking at
tools/build_variables.py and making sure every file that was a member
of the libtorch_cuda/ATen-cu targets had these annotations. (torch-cpp-cuda
doesn't count since that's going to be where the stuff that has explicit
USE_CUDA lives, so it's going to be in a separate dynamic library).
As future work, it would be good to setup a lint rule to help people
understand what the correct _API annotation to use in a file is; it
would also be good to reorganize folder structure so that the library
structure is clearer.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18309593
Pulled By: ezyang
fbshipit-source-id: de710e721b6013a09dad17b35f9a358c95a91030
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29143
THP_CORE macro is a very old macro that appeared to have served
two purposes:
1. The torch-python equivalent of CAFFE2_BUILD_MAIN_LIB, to toggle
symbol visibility headers
2. Some sort of ad hoc way of hiding certain definitions from headers
so external clients can't get at them.
It did (2) in a very confusing manner, because we set THP_CORE in both
torch and torch-python (it shouldn't do anything in torch). In this
PR I just get rid of use case (2) entirely (so everything shows up in
headers all the time), and then redo (1) using a new THP_BUILD_MAIN_LIB
macro. This cleans up some of the macro definitions and makes my life
easier for working on #27215.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18309594
Pulled By: ezyang
fbshipit-source-id: adcb6d7cb387cd818480137e2b94e5e761dbfefc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29239
There were a few main changes, summarized below.
Rename `propagate_names`
----------------------------------------------
There are two main APIs now, `propagate_names_if_nonempty(Tensor&,
ArrayRef<Dimname>)` and `propagate_names(Tensor&, ArrayRef<Dimname>)`
The former propagates names if they are not empty and the latter
unconditionally tries to propagate names.
`names` can be empty if name inference did not occur (see the next
section).
Removed usages of `optional` in name inference
----------------------------------------------
Previously, we used `optional<ArrayRef<Dimname>>` and
`optional<vector<Dimname>>`. `nullopt` represens that no name inference
happened.
The problem with this is that these types are not implicitly convertible
to each other and dealing with them is painful as a result (users have
to manually unwrap `optional<vector>` and convert to
`optional<arrayref>`.
To fix this, I rewrote most named inference functions to use an empty array as an
indicator value:
- If an array is empty, then no name inference occured
- If an array is not empty, then name inference occured.
Removed `vector<Dimname>&&` overloads
----------------------------------------------
These were originally meant for efficiency: instead of copying a vector
of names we could move it directly inside the tensor and replace the old
names. However, looking around the code base, we do copies for
`IntArrayRef` for sizes and strides instead of optimizing them, so the
perf gain is probably not critical. I removed `vector<Dimname>&&` overloads
to stop optimizing prematurely.
Furthermore, one potential design for a faster named inference api is
to construct names directly on a tensor's names object; in this design
there is also no `vector<Dimname>&&` overload.
Plans
----------------------------------------------
After this PR I'll keep attempting to cleaning up `propagate_names`
functions. There are a lot of `propagate_names_for_{blah}` functions
that exist that probably don't need to.
Test Plan: - `python test/test_namedtensor.py -v`
Differential Revision: D18350090
Pulled By: zou3519
fbshipit-source-id: eb5dd6cbd2d4f1838431db5edbdb207204c5791d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29334
As title
Test Plan: Imported from OSS
Differential Revision: D18358592
Pulled By: suo
fbshipit-source-id: d7afbce52ddd008ae9c42aeda6be24e35086ef01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29289
as title
Test Plan: na
Reviewed By: hl475
Differential Revision: D18350580
fbshipit-source-id: 80f41cbbfda9cbcd8988b451cdfb199f2b89e49b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29249
This splits out all the tests that are "easy", leaving `TestJit`,
`TestScript`, the autogenerated tests, and a small docs test.
Splitting those into reasonable chunks is more effort which is less
mechanical.
Differential Revision: D18339007
Test Plan: Imported from OSS
Pulled By: suo
fbshipit-source-id: 69164b9f9a2c379fe8923a846c98dd3c37ccb70e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28984
Support removing an attribute in `ClassType`, `ClassType` is
considered as a low level API and user of this function
need to guarantee the safety of calling this method.
Test Plan:
tbd
Imported from OSS
Differential Revision: D18253776
fbshipit-source-id: 5814baa3fdf6de6c71d3cc1be225ded9116c961a
Summary:
Update gloo submodule to use the new APIs introduced in https://github.com/facebookincubator/gloo/pull/232. Done by `cd third_party/gloo && git checkout 7c54124` which is gloo's latest commit.
Next step would be to consume the introduced APIs in `ProcessGroup::Work`. Then we can use this layer to be able to interrupt `ProcessGroupAgent` (only for the gloo backend).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29248
Reviewed By: xush6528
Differential Revision: D18350654
Pulled By: rohan-varma
fbshipit-source-id: e41f7446bbb500087a0ca3919173b2e8379c7ce7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29242
I don't really know why this is crashing, but it is crashing on ios with a EXC_BAD_ACCESS / KERN_INVALID_ADDRESS.
(see attached task).
Removing it.
ghstack-source-id: 93304255
Test Plan: waitforsandcastle
Differential Revision: D18333464
fbshipit-source-id: 166012fabe1e1b1d84c10f3d3dcc2c1e24bff3aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29199
Previously, we called `native::mean_cpu_gpu` inside `mean(Tensor, Dimname)`;
`native::mean_cpu_gpu` is not supported by autograd. This PR replaces
`native::mean_cpu_gpu` with `at::mean(Tensor, int)` so that the dimname
overload can piggyback off of autograd support for `at::mean(Tensor,
int)`.
Also added tests (those didn't exist before) for autograd support for
named tensor reduction functions.
Test Plan: - `python test/test_namedtensor.py -v`
Differential Revision: D18334617
Pulled By: zou3519
fbshipit-source-id: 1714eb3fd93714fe860f208831e8d910f01c1c78
Summary:
Except for the Windows default path, everything it does has been done in
FindCUDA.cmake. Search for nvcc in path has been added to FindCUDA.cmake (https://github.com/pytorch/pytorch/issues/29160). The Windows default path part is moved to
build_pytorch_libs.py. CUDA_HOME is kept for now because other parts of
the build system is still using it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28617
Differential Revision: D18347814
Pulled By: ezyang
fbshipit-source-id: 22bb7eccc17b559ce3efc1ca964e3fbb270b5b0f
Summary:
Currently ONNX constant folding (`do_constant_folding=True` arg in `torch.onnx.export` API) supports only opset 9 and 10 of ONNX. Opset 11 support was recently introduced in the ONNX exporter. For opset 11, it is currently a no-op. This change enables ONNX constant folding for opset 11. Specifically there are three main changes:
1) Turn on constant folding ONNX pass for opset 11.
2) Enable constant folding tests in `test/onnx/test_utility_funs.py` and `test/onnx/test_pytorch_onnx_onnxruntime.py` for opset 11.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29011
Reviewed By: hl475
Differential Revision: D18306998
Pulled By: houseroad
fbshipit-source-id: afeed21ca29e01c278612e51dacd93397dd6e2d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29247
### Summary
If you run the TestApp using Cocoapods, you'll likely run into an error due to the lack of `config.json` in the main bundle. This PR fixes this crash and updates the README as well.
### Test Plan
- Don't break CIs
Test Plan: Imported from OSS
Differential Revision: D18339047
Pulled By: xta0
fbshipit-source-id: 244cf1ca8729c7ac918258d4eff14d34363e8389
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29157
As reported, these tests are flaky and time out. Skip them
while we investigate further.
ghstack-source-id: 93287663
Test Plan: CI
Differential Revision: D18309204
fbshipit-source-id: 95f0ea5e0c1162b78da412a34db446a01dfc33bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28464
We would like to enable the intra-op parallelism for layer norm. This will be mapped to the parallel performance win for the BERT/RoBERTa model.
Test Plan: buck test mode/dev-nosan //caffe2/test:nn -- "LayerNorm"
Reviewed By: BIT-silence
Differential Revision: D18063407
fbshipit-source-id: c116e744d78ea50b3aadf2e9a819e5b876a944bf
Summary:
Type objects in python have an attribute `__abstractmethods__` that throws when it is accessed, so we were failing with an AttributeError whenever a type was used in TorchScript.
This pr prevents that error from happening. We can't just throw when a type is used because it could be used to access a static method: https://github.com/pytorch/pytorch/pull/27163
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28053
Differential Revision: D18332347
Pulled By: eellison
fbshipit-source-id: 9c7f2220f92674ad4d903621d9762cecc566ab0d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29139
Each test has 100 sec timeout.
Current this test takes 90~110 secs to finish, causing flakiness.
Half the load to make it not on the edge of timeout.
ghstack-source-id: 93203670
Differential Revision: D5644012
fbshipit-source-id: 2a85999cf1ae6d18e9a871cd76ce194e1ce7b3e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29240
### Summary
The 1.3.1 binary has been uploaded to AWS - https://ossci-ios.s3.amazonaws.com/libtorch_ios_1.3.1.zip. This PR updates the cocoapods version to 1.3.1
### Test Plan
- The 1.3.1 binary works well
Test Plan: Imported from OSS
Differential Revision: D18333750
Pulled By: xta0
fbshipit-source-id: fe6e42c51f3902ad42cab33f473dffb0f6f33333
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28409
This PR enables submodule swapping via module interface. User could
declare a submodule as an module interface type in the ScriptModule,
during compilation we will record the module interface type in
ModuleInfo of ConcreteModuleType, the JIT type associated will have the
correct ModuleInterfaceType, and CppModule will get the correct module list
Given that we still keep the module interface type in the type system,
the graph is not inlined when we call Module::Attr and it will use
prim::CallMethod to call the method, this allow us to do module swapping
for the ScriptModule that also meet the same module interface type, and
we only allow the module swapping through the module interface
approach.
Test Plan: Imported from OSS
Reviewed By: driazati
Differential Revision: D18284309
fbshipit-source-id: 2cb843e4b75fa3fcd8c6020832a81014dbff4f03
Summary:
Copy of android.md from the site + information about Nightly builds
It's a bit of duplication with separate repo pytorch.github.io , but I think more people will find it and we can faster iterate on it and keep in sync with the code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28533
Reviewed By: dreiss
Differential Revision: D18153638
Pulled By: IvanKobzarev
fbshipit-source-id: 288ef3f153d8e239795a85e3b8992e99f072f3b7
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28658
I have added the link to the docs for `flatten_parameters`.
RNNBase is a superclass of RNN, LSTM and GRM classes. Should I add a link to `flatten_parameters()` in those sections as well ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29196
Differential Revision: D18326815
Pulled By: ezyang
fbshipit-source-id: 4239019112e77753a0820aea95c981a2c868f5b0
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex)
Changes
- [x] Fixed Vec256 Permute operations for Complex Float
- [x] Fixed copy_kernel_cast between complex data types
- copy_kernel_cast should not call std::real during inter-complex dtype conversion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29133
Differential Revision: D18309297
Pulled By: ezyang
fbshipit-source-id: adf4bc3a45ba2918c8998d59fa94a52f89663e94
Summary:
I don't see `_frames_up` being used anywhere. Just to clean up the code thought it should be removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29179
Differential Revision: D18319876
Pulled By: suo
fbshipit-source-id: 5e612ff94ccc88fc85288ffc26213e1d11580c36
Summary:
# Description
I'm new to this project just wanted to start with small bug fixes. I found some unused local variables and I've removed them in this pr.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29181
Differential Revision: D18319893
Pulled By: suo
fbshipit-source-id: e4f9f13b6db2ca213015569deb12d3fd9beb74a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29129
cdist(x1, x2) does the following:
- assume x1, x2 are 2-dimensional. Then x1, x2 are each considered to be
a list of vectors.
- The operation returns a matrix that is the pairwise distance between
each vector in x1 and each vector in x2. The matrix has first dimension
size equal to the number of vectors in x1 and second dimension size equal
to the number of vectors in x2.
- cdist also supports arbitrary left-hand broadcastable batch
dimensions. In this case, x1 and x2 are each considered to be a batch
of a list of vectors.
The above leads to the following name inference rule for cdist:
- In the 2D case, propagate x1.names[-2] and x2.names[-1] (because
the final result has size (x1.size[-2], x2.size[-2]).
- in the ND case, unify all the batch dimensions together to produce the
output batch dimensions and then apply the rule for the 2D case.
Furthermore, I moved all of the name checking in the implementation to
occur before name inference because name inference assumes that the
shapes are valid.
Test Plan: - new test: `pytest test/test_namedtensor.py -v -k "cdist"`
Differential Revision: D18311867
Pulled By: zou3519
fbshipit-source-id: 713d7cdda93c8fe92e7f1bd7f7c5c6e20a8138e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29124
TensorNames::checkUnique gives a nice error message if there are
duplicate names.
Adding operator<< on TensorName cleans up some code. A TensorName gets
printed out as: "'H' (index 2 of ['N', 'C', 'H', 'W'])" for example.
Test Plan: - New c++ tests. test with `build/bin/NamedTensor_test`.
Differential Revision: D18311868
Pulled By: zou3519
fbshipit-source-id: 5be197dba227f0328b40d7f66e78fffefe4dbd00
Summary:
This fixes https://github.com/pytorch/pytorch/issues/28575.
It seems `poisson_nll_loss` was implemented with the incorrect assumption about `masked_select`, which actually doesn't return tensor with the same storage, so in-place operation used there didn't work as intended.
Here I used `masked_fill` instead.
Also, the existing test didn't have `reference_fn`, so I added it (although it's not fundamentally useful since current cpp `poisson_nll_loss` itself does exactly same algorithm as `reference_fn`).
Thanks in advance for reviewing this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28637
Differential Revision: D18299724
Pulled By: albanD
fbshipit-source-id: 1aac5b20e77bf54874b79018207ba8f743766232
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27530
Per discussion in #27286, the `UDF` part is superfluous.
This makes the naming consistent with the `MessageType` enum.
Test Plan: Imported from OSS
Differential Revision: D17808211
Pulled By: pietern
fbshipit-source-id: 0ff925de26d027951ce285750ad276ed17fee4c6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29085
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/159
Change DNNLOWP operators to use fbgemm's new 3D groupwise convolution (D18192339)
This diff also fixes an issue when column offsets are fused into bias.
In this case, we construct ReQuantizeOutput with col_offsets == 0 and A_zero_point == 0 even if real A_zero_point is 0.
In fbgemmGroupwiseConv, when we call dispatchOutputProcessing, we shouldn't pass the original A_zero_point .
Test Plan: https://github.com/pytorch/pytorch/pull/29134
Reviewed By: dskhudia
Differential Revision: D18282373
fbshipit-source-id: 993d584e7fa8e07c74597304c0fd9386f7ed0e41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28965
Fixed the reference to correct object
Test Plan:
Added new unit test test_serialization_save_warnings in test_torch
Verified by running the test_torch tests
Imported from OSS
Differential Revision: D18306797
fbshipit-source-id: bbdc7a1aa59a395fcbb736bcc7c3f96db45454d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29066
This PR is BC-breaking in the following way:
Previously, C++ `torch::tensor` with an integer literal or a braced-init-list of
integer literals produces a tensor with dtype being the type of the integer literal(s). After this PR, it always produces a tensor of dtype `at::kLong` (aka. int64_t), matching Python `torch.tensor` behavior.
Test Plan: Imported from OSS
Differential Revision: D18307248
Pulled By: yf225
fbshipit-source-id: 7a8a2eefa113cbb238f23264843bdb3b77fec668
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29152
Bootstrapping uncertainty approach: bootstrap the last layer before the last fully-connected layer. FCWithBootstrap is a new layer to handle the logic for the bootstrapping process.
Goal:
- return a struct with the bootstrapped indices and bootstrapped predictions from this layer
- separate the functionality in the train_net and eval_net
- save the bootstrapped FC in this object so that the eval_net can use them during prediction time
Reviewed By: wx1988
Differential Revision: D17822429
fbshipit-source-id: 15dec501503d581aeb69cb9ae9e8c3a3fbc7e7b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29155
Update the L0 norm regularizer with a budget feature to penalize features over this limit
Formula and summary:
{F212248495}
Test Plan: * Unit test located in: ~/fbsource/fbcode/caffe2/caffe2/fb/dper/layer_models/tests/split_1/fsparse_nn_test.py
Reviewed By: un-disclosed, wx1988
Differential Revision: D17458138
fbshipit-source-id: 2ed9ce6f55573b0bfc0fefbfd392f90c7542a0fd
Summary:
When building with Android NDK platforms prior to android-21,
and when building for Android with libstdc++, there are some
gaps in the C and C++ standard libraries. We use both for our
internal 32-bit builds, so we need PyTorch to support this platform.
All of the gaps are filled with this math_compat.h header, which
needs to be included in any file that uses one of the functions
that are not properly defined on Android. The file is a bit
hack-tastic, but it is only used on a platform that is not receiving
updates, so there shouldn't be a risk of breakage in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28567
Test Plan: Internal android build.
Differential Revision: D18099513
Pulled By: dreiss
fbshipit-source-id: 020aab19c6fa083206310b018925d92275d4a548
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29131
caffe2_pb2.CUDA --> workspace.GpuDeviceType
workspace.NumCudaDevices() --> workspace.NumGpuDevices()
Also added the totalGlobalMem into get_device_properties(), which is needed by multi_gpu_utils.py
Test Plan:
sandcastle
f148921769
Reviewed By: bddppq
Differential Revision: D18290090
fbshipit-source-id: bde7c175d1fb6ff59a062266c1b17de39d113b24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29126
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18300420
Pulled By: ezyang
fbshipit-source-id: d9b3ec75098cdb54624e4f98d4c66db1f4ff62bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29030
Might fix#27648
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18300252
Pulled By: ezyang
fbshipit-source-id: 542c16b6c1e78c2f9cc45e567f2e0cd1d4272ee3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28620
All Tensors are Variables now, they just happen to have requires_grad=False. Tensors ALWAYS have `VariableTensorId` in their type set.
When constructing this patch, I had to make decisions about what I would fix in this patch, and what I would leave for follow up PRs. Here is the cleanup that happens in this patch:
- The `is_variable` property is removed from TensorOptions. I removed this immediately because unlike Tensor::is_variable, TensorOptions::is_variable doesn't respect our VariableTensorId thread-local state. This means that there were a bunch of places where TensorOptions::is_variable was false, which is obviously bogus in the world when tensor and variable are merged. Instead of keeping the method as a function that always returns true, I just opted to remove it entirely (it's not public API.) All places we set `is_variable` are deleted.
- Knock on effect: there is no longer a separate DeprecatedTypeProperties for the variable and non-variable versions of type.
- Knock on effect: instead of asserting on TensorOptions::is_variable, instead we just test `at::impl::variable_is_excluded()`
- There is now only one copy of the cuDNN RNN dropout cache, not two (I'm not sure why we had two to begin with)
Some cleanup that doesn't happen in this patch:
- Eliminating unnecessary uses of `make_variable`
- Eliminating `Tensor::is_variable`
The most subtle part of this patch is retaining tracing behavior: the fact that everything is a Variable means that more code gets routed to VariableType than before; this can change traces. I identified two places where we didn't appropriately turn off VariableType, mostly factory functions:
- `torch.tensor` must turn off VariableType before invoking `at::empty` to construct the tensor, as it subsequently does direct data access
- `tensor_slow` (invoked when you pass a Python scalar to a tensor argument) must turn off VariableType before calling `scalar_to_tensor` so the scalar gets traced as constant, rather than as a call to `scalar_to_tensor`.
Honestly, these are all giant hacks, and should be replaced with a more specialized guard that just toggles tracing.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: dreiss
Differential Revision: D18171156
Pulled By: ezyang
fbshipit-source-id: 5b6a045beba37492647e350190f495114e86504d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29047
When a tuple is returned, it is helpful to know specifically
which output was the culprit.
Actually, it was somewhat /more/ helpful to actually see the
contents of the tensor which didn't have dependence (or, e.g.,
the backtrace of the code that populated it), but that seemed
a step too far.
ghstack-source-id: 93091993
Test Plan:
manually tested because I was debugging an incorrect
trace and looked to see that the output number was indeed identifying
the correct tensor.
Reviewed By: dreiss
Differential Revision: D18274323
fbshipit-source-id: f1551bb03a3cdfa58b9e7f95736d53f317f53d5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28392
Per #25531, we want to clean up futures when we detect that there are
failures/timeouts. As a first step, this diff adds timers to the future object,
provides functionality to check if a future is timed out, and allows
specification of the timeout when initializing rpc. A future diff will check for these timeouts and mark the future completed with an exception indicating that it has timed out.
ghstack-source-id: 93192622
Test Plan: Added unit tests.
Differential Revision: D18025163
fbshipit-source-id: 195fb50c736caf5c7b2bada9a5f6116bb106ed33
Summary:
This is a minor update to the test point `TestUtilityFuns.test_constant_fold_concat` in `test/onnx/test_utility_fun.py` for clarity. Unlike before, the test model forward() method now uses the input `x`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28861
Differential Revision: D18306881
Pulled By: houseroad
fbshipit-source-id: dda8b4123e7646c2e416ce914a4698f9b96e2a6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29061
It looks like we are too close to the maximum library size on
Windows. Kill Caffe2 operators to get us lower again.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D18281083
Pulled By: ezyang
fbshipit-source-id: 8a11f9059dbf330f659bd96cc0cc2abc947723a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29086
For Int8ConvPackWeight to decide which convolution implementation should be used, we need to pass more arguments.
Test Plan: CI
Reviewed By: dskhudia
Differential Revision: D18286931
fbshipit-source-id: d178cc6d696d0e83aad18bb34eb071f44b0c2015
Summary:
Updated PR instead of https://github.com/pytorch/pytorch/issues/29114
Running mypy on the following code is throwing an error, Module has no attribute Identity:
```
import torch.nn as nn
layer = nn.Identity()
```
Using the following instead does not give an error:
```
import torch
layer = torch.nn.Identity()
```
CC: ezyang soumith (Sorry for causing the revert previously! Hope this one works fine!)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29135
Differential Revision: D18306331
Pulled By: ezyang
fbshipit-source-id: f10be8a0cccecef423184d009bad8be6d54098a5
Summary:
VitalyFedyunin, This PR is about port L1 lose to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
loss = nn.L1Loss(reduction = 'sum')
if torch.cuda.is_available():
device = "cuda"
loss = loss.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
target = torch.randn(128, n, device=device)
for i in range(1000):
output = loss(input, target)
output.backward()
#get running time
for n in [100, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
target = torch.randn(128, n, device=device)
for i in range(10000):
t1 = _time()
output = loss(input, target)
t2 = _time()
output.backward()
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
Test Device: CPU: skx-8180, GPU: Tesla P100.
**Perfromance:**
Before:
```
GPU:
reduction=’mean’
nput size(128, 100) forward time is 0.31 (ms); backwad avg time is 0.09 (ms).
input size(128, 10000) forward time is 0.33 (ms); backwad avg time is 0.14 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.31 (ms); backwad avg time is 0.10 (ms).
input size(128, 10000) forward time is 0.34 (ms); backwad avg time is 0.14 (ms).
CPU:
reduction=’mean’
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.10 (ms).
input size(128, 10000) forward time is 1.92 (ms); backwad avg time is 2.96 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.09 (ms).
input size(128, 10000) forward time is 1.96 (ms); backwad avg time is 2.79 (ms).
nume_thread = 1:
reduction=’mean’
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 1.67 (ms); backwad avg time is 2.50 (ms).
reduction=’sum’:
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 1.67 (ms); backwad avg time is 2.51 (ms).
```
After:
```
GPU:
reduction=’mean’
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.10 (ms).
input size(128, 10000) forward time is 0.11 (ms); backwad avg time is 0.17 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.05 (ms); backwad avg time is 0.08 (ms).
input size(128, 10000) forward time is 0.11 (ms); backwad avg time is 0.16 (ms).
CPU:
reduction=’mean’
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 0.14 (ms); backwad avg time is 0.18 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 0.15 (ms); backwad avg time is 0.17 (ms).
nume_thread = 1:
reduction=’mean’:
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.06 (ms).
input size(128, 10000) forward time is 1.05 (ms); backwad avg time is 1.72 (ms).
reduction=’sum’:
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 1.03 (ms); backwad avg time is 1.71 (ms).
```
How to set number thread? using following script:
```
num_threads=$1
script=$2
last_core=`expr $num_threads - 1`
echo "using $num_threads OMP threads"
echo "bind cores to 0~$last_core"
export OMP_NUM_THREADS=$num_threads
export KMP_AFFINITY=granularity=fine,compact,1,0
numactl --physcpubind=0-$last_core --membind=0 python $script
```
and run `./run.sh 1 L1loss.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26795
Differential Revision: D18140434
Pulled By: VitalyFedyunin
fbshipit-source-id: d0b976ec36797f2e6b4e58fbbac89688d29e736f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29052
Make sure we handle the case of multiple, async, terminal (no children)
and failing cpu ops.
Test Plan: AsyncIf tests
Reviewed By: yyetim
Differential Revision: D18276401
Pulled By: ilia-cher
fbshipit-source-id: 35b175dd025bc7e392056ac1331b159376a29e60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28696
They are not used anywhere.
Test Plan: Imported from OSS
Differential Revision: D18302769
Pulled By: VitalyFedyunin
fbshipit-source-id: 8680951cbceb607ef545f92cbfa9204ce8f7ac4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29056
There are a couple of recent published diffs break the internal pytorch build, so fix it here.
ghstack-source-id: 93101569
Test Plan:
buck install -r aidemos-android
buck install -r fb4a
Reviewed By: iseeyuan
Differential Revision: D18236331
fbshipit-source-id: e1cecae8c30fd9b23b6bf379f652b4926542618d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28255
Add support for treating Sequentials, ModuleLists, and ModuleDicts as iterables.
As previously, when emitting a for loop over a Module Container we unroll the for loop over all elements. We require that any Sugared Value in an iterable with a Module Container have a statically - determinable length.
Otherwise, if you zipped over a list of varying length and an nn.Sequential that alternated between returning a Tensor and a Dictionary, the output type would change based on the length of the list.
Fix for #17179
And https://github.com/pytorch/pytorch/issues/27401
and https://github.com/pytorch/pytorch/issues/27506
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D18278124
Pulled By: eellison
fbshipit-source-id: aca336a5b8da89c756b1f0884883649510cbde3c
Summary:
Added nhwc support for:
1. cudnn_batch_norm & cudnn_batch_norm_backward
2. cudnn_convolution_forward & cudnn_convolution_backward
3. cudnn_convolution_transpose & cudnn_convolution_transpose_backward
patching suggest_memory_format for convolution
suggest_memory_format has ambiguous meaning for two cases:
1. tensor with NCHW where C = 1.
we could use stride of C as a hint to tell the intended memory format.
2. tensor with NCHW where H == W == 1.
there's no way to identify the intended memory format from strides.
Currently we fallback to NCHW whenever we see contiguous tensor. Hence avoiding
ambiguity for some of the special cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23861
Differential Revision: D18263434
Pulled By: VitalyFedyunin
fbshipit-source-id: dd9f69576ec12fec879cd87a3d446931371360d9
Summary:
At the encouragement of Pyro developers and https://github.com/pytorch/pytorch/issues/13811, I have opened this PR to move the (2D) von Mises distribution upstream.
CC: fritzo neerajprad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17168
Differential Revision: D18249048
Pulled By: ezyang
fbshipit-source-id: 3e6df9006c7b85da7c4f55307c5bfd54c2e254e6
Summary:
Handling of empty example was giving a cuda error.
Adding getLastError check to make sure cuda errors are attributed to the
correct function (instead of currently it was attributing the error to the next
cuda operator).
Added special case for batch-size zero, also added to cpu to keep things
consistent.
Resubmit of D18085429 without stacked commits
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28614
Test Plan: test included
Differential Revision: D18122212
Pulled By: ggoossen
fbshipit-source-id: 8c6741a157a9fbbc82685d81a6f8021452b650d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29059
This is a resubmit of reverted diff D18209289 ( PR #28857 ).
Test Plan:
buck test caffe2/test:c10d
buck test caffe2/test:distributed_gloo
Reviewed By: pietern
Differential Revision: D18277097
fbshipit-source-id: aecfd7206d70829f0cac66182bf02fccee410fed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28994
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18273476
Pulled By: ezyang
fbshipit-source-id: de59faa49c13198c18e61fdb05ab1d3d7cc16e08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28979Fixes#28969
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18273477
Pulled By: ezyang
fbshipit-source-id: 9bcc10034a4ad7d55709dd54735d60500043da65
Summary:
VitalyFedyunin, this PR port cuda sigmoid to Aten: https://github.com/pytorch/pytorch/issues/24624; TH/THC sigmoid code can 't be removed because the sigmoid_backward in THNN/THCUNN rely on it. I will port sigmoid_backward to Aten next step, incuding CPU and CUDA, which will remove the sigmoid code in TH/THC .
Test script:
```
import timeit
device = "cuda"
for n, t in [(10, 100000),(1000, 10000)]:
print('a.sigmoid() (a.numel() == {}) for {} times'.format(n, t))
for dtype in ('torch.float', 'torch.double', 'torch.half'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a.sigmoid()\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.ones({n}, device="{device}", dtype={dtype})', number=t))
```
Device: **Tesla P40**
Before:
```
a.sigmoid() (a.numel() == 10) for 100000 times
device: cuda, dtype: torch.float, 100000 times 1.2853778750286438
device: cuda, dtype: torch.double, 100000 times 1.2787265420192853
device: cuda, dtype: torch.half, 100000 times 1.2610833930084482
a.sigmoid() (a.numel() == 1000) for 10000 times
device: cuda, dtype: torch.float, 10000 times 0.1274153349804692
device: cuda, dtype: torch.double, 10000 times 0.13953313598176464
device: cuda, dtype: torch.half, 10000 times 0.1265286349807866
```
After:
```
a.sigmoid() (a.numel() == 10) for 100000 times
device: cuda, dtype: torch.float, 100000 times 1.275270765996538
device: cuda, dtype: torch.double, 100000 times 1.285128042974975
device: cuda, dtype: torch.half, 100000 times 1.2761492819990963
a.sigmoid() (a.numel() == 1000) for 10000 times
device: cuda, dtype: torch.float, 10000 times 0.12851508799940348
device: cuda, dtype: torch.double, 10000 times 0.13738596899202093
device: cuda, dtype: torch.half, 10000 times 0.12715664599090815
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26643
Differential Revision: D17666550
Pulled By: VitalyFedyunin
fbshipit-source-id: 376479d94d0649c171fd0b2557699bbdd050fec3
Summary:
Running mypy on the following code is throwing an error, `Module has no attribute Identity`:
```
import torch.nn as nn
layer = nn.Identity()
```
Using the following instead does not give an error:
```
import torch
layer = torch.nn.Identity()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29114
Differential Revision: D18298225
Pulled By: soumith
fbshipit-source-id: b271bf00086876cca8d63ae0cde6cebf69a7051e
Summary:
Was just trying to build pytorch from source and had a small hiccup because the instructions say to `conda install typing`. Because `typing` is a built-in module in recent Python 3 versions, conda interpreted that to mean that I want Python 2. So I added a note to the docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29103
Differential Revision: D18294139
Pulled By: soumith
fbshipit-source-id: 621a2f62ebe870520197baec8f8bcdc1a0c57de9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28408
This enable interface to defined on a nn.Module, and the InterfaceType
now have a field of is_module_ to distinguish if it's a module interface
or a normal interface (This is similar to what ClassType distinguish on
module and torchscript classes).
The module interface can be assigned with any ScriptModule that has the
compatible signatures on schemas. A normal object that is not a
ScriptModule will not be able to assigned to an module interface and
will error out when user explicitly doing so. Assigning a ScriptModule
to class interface will make it only available in attribute_list, not
module_list. More details on subtyping relationship documented in the
jit_type.h
If you declare an module interface inside an nn.Module that is being
compiled to a ScriptModule, behavior to our internal compilation will
be:
1. ConcreteModuleType will record it as an module attribute and add to
the attributes_ list.
2. JitType that is created from the ConcreteModuleType will record it as
an attribute and pre-genenerate the slot. The slot will be marked as
EntityType::MODULE still to make sure JitType record it as a Module
slot
3. cpp_module will also register it as a Module as the Slot type is the
source of truth
Since JitType will record it as attribute as store its type, it will
behave normally as the class interface attribute behave now. This means
the submodule assigned to this module interface is not getting inlined
into the graph as the normal `Module::attr` behave, it will generate
interface callMethod and allow us to later swap this with another
ScriptModule that implicitly implements this module interface.
Test Plan: Imported from OSS
Differential Revision: D18284311
fbshipit-source-id: e0b8f6e8c34b2087fab337a969e5ea3fb37ec209
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28407
Given that we do not have support for inheitance or any polymorphism
strategy yet, we should guard against user from using it until we get
the full support so that user won't confuse by the weird behaviors.
Test Plan: Imported from OSS
Differential Revision: D18284310
fbshipit-source-id: f55a224f4190d57926d91ed98f6168d787387eb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28996
### Summary
It'd be frustrated to realize the device is not connected after waiting for the build finishes. This PR checks the device connection status before xcodebuild.
### Test Plan
- Don't break `bootstrap.sh`
Test Plan: Imported from OSS
Differential Revision: D18258348
Pulled By: xta0
fbshipit-source-id: dda90e7194114e99b2774a3b64ed41f78221f827
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29041
1) Enhanced autograd unit tests to test the
torch.distributed.autograd.backward() API more thoroughly on Python UDFs.
2) Enhanced `python_error` to override `what` such that it returns an
appropriate error string if we call `what()` on this error. This ensures we can
propagate exceptions over the wire during RPCs (since we get the error string
by calling what() on the exception)
ghstack-source-id: 93098679
ghstack-source-id: 93098679
Test Plan: waitforbuildbot
Reviewed By: mrshenli
Differential Revision: D18273041
fbshipit-source-id: 85d3932fed6337668a812367fdfce233c1b3ff8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29045
Addressing an issue seen in GitHub https://github.com/pytorch/pytorch/issues/28958
It seems sometimes the workers in this test don't stop cleanly. The purpose of this test is to check that the init_fun in init_workers works as expected, which is captured by the assertEqual in the for loop in the test. The behavior of stop() is not really important here.
The fact it's returning false is probably indicative that a worker is getting blocked but that doesn't affect the correctness of the test.
Test Plan: Ran the test 100 times, it consistently succeeds.
Reviewed By: akyrola
Differential Revision: D18273064
fbshipit-source-id: 5fdff8cf80ec7ba04acf4666a3116e081d96ffec
Summary:
Thanks to AddyLaddy ptrblck for tracking this fix down.
In torch/csrc/cuda/nccl.cpp and torch/csrc/cuda/python_nccl.cpp, construction of the `AutoNcclGroup` guard (which calls `ncclGroupStart()`) [precedes](https://github.com/pytorch/pytorch/pull/29014/files#diff-3b6a42619dd44000cf58c0328b679a1cL239-L241) a possible call to `get_communicators`, which may call `ncclCommInitAll()`. Calling `ncclCommInitAll()` within a `ncclGroupStart()/End()` is incorrect according to our Nccl people.
It seemed ok (relevant tests were silently passing) as long as Pytorch was compiled/linked against Nccl 2.4.x (which is currently what's locked into your third_party/nccl subrepo). However, when we tried to compile and link against Nccl 2.5.x in internal builds, we began to see test hangs (TestAutogradDeviceTypeCUDA.test_unused_output_device_cuda was what initially brought it to our attention).
The present PR fixes those hangs, as far as we know, and will prevent a nasty future surprise when you start building against nccl 2.5.
The backend affected by this PR is exposed via https://github.com/pytorch/pytorch/blob/master/torch/cuda/nccl.py. I'm not sure if the exposure is actually used anywhere (I think the distributed frontend is now backed by ProcessGroupNCCL in torch/lib/c10d). So this PR may affect code that is already dead or dying, but still tested, it seems.
I skimmed ProcessGroupNCCL.cpp for potential similar vulnerabilities and didn't spot anything obvious.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29014
Differential Revision: D18274799
Pulled By: ezyang
fbshipit-source-id: c5f88cf187960d61736be14458be01e3675c6702
Summary:
This fixes https://github.com/pytorch/pytorch/issues/28789
Only the first two elements of `smem` are used in this function but at the beginning, it resets all the `C10_WARP_SIZE` to 0. When the `scalar_t` is 64bit, it goes out of the total shared memory size which is `sizeof(int) * C10_WARP_SIZE`, although this does not lead to any failure in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28989
Differential Revision: D18271598
Pulled By: ngimel
fbshipit-source-id: 38cc863722509892646f719efb05e2730a7d9ae1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27403
In fold_convbn pass, we need to recompute the parameter(weight, bias) for
conv, update the attribute of conv and update the access of bias in conv
because if the original conv have no bias, the `self.bias` access will be
inline and replaced by Constant node `None = prim::Constant()`, we need to
update this to use `GetAttr[name="bias"]` to make this work. But there is
also some work going on the handle constants, so we'll fix this pass after
that is done.
Test Plan:
.
Imported from OSS
Differential Revision: D18182918
fbshipit-source-id: bba510bc41ab58e0eb76f7b77335b6e3ffe2862d
Summary:
Currently when ROCM is used, CUDA libraries are still linked. There has
been no error because USE_CUDA is set to OFF upon a preliminary check in
tools/setup_helper/cuda.py, and no CUDA variable is set. Hence, these
lines can pass simply because those variables are always undefined, and thus expanded to empty strings. But this
cannot be safely relied on, and is causing https://github.com/pytorch/pytorch/issues/28617 to fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29009
Differential Revision: D18273472
Pulled By: ezyang
fbshipit-source-id: b8b6580e8a44d874ac678ed9073412d4d2e393ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28981
This PR adds support for calling those functions on named tensors. The
implementation is not the nicest: in the future we have plans to merge
names into TensorOptions, at which point we don't need the extra
branches that check if the tensor has names. Right now, however, these
functions are very useful to have (in particular, ones_like is used by
autograd to generate gradients).
Test Plan: - Added tests for each of these
Differential Revision: D18270937
Pulled By: zou3519
fbshipit-source-id: 720739ff0474449a960b81728345a4250becbfc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28904
Motivation
============
Before this PR, a core problem with writing name inference rules was
that each rule needed to handle misalignment by themselves. A misaligned
name occurs when we are matching None with a non-None name, but the
non-None name already exists in the first tensor.
For example, `A` is misaligned in `Tensor[A, None] + Tensor[None, A]`.
Each op handled this in a custom way
- align_from_right (used by broadcasting) handles misalignment
- compute_matmul_outnames checks for misalignment across batch and
feature dimensions.
We can actually codify "misalignment" into something more rigorous by
folding it into the definition of `match` and eliminate special handling
of "misalignment". That is what this PR attempts to do.
Approach
============
Definition: Two names in two tensors *match* if they are equal, or if at
least one of them is a wildcard that can be *refined* to the other name.
With this new definition, to check if two names match, we need to know
about the names list that each name came from to determine if a wildcard
can successfully be *refined* to the other name.
For example, consider the following:
```
tensor: Tensor[A, None]
other: Tensor[None, A]`
```
when unifying `tensor.names[-1]` with `other.names[-1]`, we see that
`tensor.names[-1]` is None and `other.names[-1]` is A. Then we check to
see if `tensor.names[-1]` can be refined to `A`; it can't be refined if
there is already an `A` in `tensor.names`.
Enter `TensorNames`.
A TensorName represents a Dimname associated with some DimnameList
(that came from a Tensor).
`TensorNames` is a list of such TensorName objects with some helper
functions attached.
One can perform the following operations:
- unify two `TensorName` objects
- unify two `TensorNames` objects with right alignment.
Plan
============
This PR changes `compute_matmul_outnames` to use `TensorNames` to
demonstrate how they make writing name inference rules easier. In the
future I'll convert other name inference rules to use `TensorNames` as
well.
Test Plan
- run all tests
Test Plan: Imported from OSS
Differential Revision: D18270666
Pulled By: zou3519
fbshipit-source-id: 3ec96cc957747eb4cfe4ea17fd02ef3d8828a20c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28251
Before, the dispatch key for unboxed operators from native_functions.yaml was generated in codegen and passed to the c10 dispatcher.
Now, we generate it inside of the dispatcher, right next to where the same thing happens for boxed calls.
ghstack-source-id: 93085152
Test Plan: unit tests
Differential Revision: D17989951
fbshipit-source-id: b343d9650debc62bfcff84cf4d6bdaf9dacc9d16
Summary:
This is a port of the SpatialConvolutionMM TH (CPU) implementation to ATen as `slow_conv2d`. In practice it is invoked for ungrouped, non-dilated, non-float32 convolutions (e.g. float64, long, bfloat16).
- [x] unfolded_copy & unfolded_acc
- [x] forward
- [x] backward
- [x] basic sanity cross check with 1.3 impl
- [x] systematic testing
- [x] performance comparison & optimization
File used for performance testing: [benchmark_conv2d.py](https://gist.github.com/andreaskoepf/c2777b2e5e9d11610f9fc74372930527)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28793
Differential Revision: D18256451
Pulled By: ezyang
fbshipit-source-id: d09e84eef11ccf8a6178dfad485fe6fd0ddf0c86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28975
TensorIterator supports propagating names so we just needed to enable
them with support_named_tensor: True
Test Plan:
- really basic tests to test that each variant (outplace, inplace, out=)
supports named tensors.
Differential Revision: D18252421
Pulled By: zou3519
fbshipit-source-id: ea7fb59dcf8c708b6e45d03b9c2ba27fa6b6ce98
Summary:
Adds C++ API clip_grad_value_ for torch::nn:utils module.
Also, fix the for indent level error in the original test/test_nn.py.
Issue: https://github.com/pytorch/pytorch/issues/25883
Reviewer: yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28736
Differential Revision: D18263807
Pulled By: yf225
fbshipit-source-id: 29282450bd2099df16925e1d0edd3d933f6eeb9b
Summary:
This is a small fix, but the runtime improvement does seem consistent (a bit less than 10%):
Benchmark (no turbo, Release build, gcc 8.3, RHEL 7.7, Intel(R) Core(TM) i7-8850H):
```python
import timeit
for dtype in ('torch.double', 'torch.float', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'dtype={dtype}')
for n, t in [(70_000, 200000),
(700_000, 20000)]:
print(f'torch.nn.Threshold(0.1, 20)(a), numel() == {n} for {t} times')
print(timeit.timeit(f'm(a)', setup=f'import torch; m=torch.nn.Threshold(0.1, 20); a = torch.arange({n}, dtype={dtype})', number=t))
```
Before:
```
dtype=torch.double
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
8.88117562699972
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
9.525143070000013
dtype=torch.float
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
5.673380930000349
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
3.677610996000112
dtype=torch.int16
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
3.957677209999929
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
1.8512293700005102
dtype=torch.int32
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
5.624350482999944
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
3.670380037000541
dtype=torch.int64
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
8.86375758200029
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
9.468234717999621
```
After:
```
dtype=torch.double
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
8.64173036200009
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
9.456986365000375
dtype=torch.float
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
5.431988049000211
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
3.446968590000324
dtype=torch.int16
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
3.743787463999979
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
1.823233144000369
dtype=torch.int32
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
5.42801834400052
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
3.4600211680008215
dtype=torch.int64
torch.nn.Threshold(0.1, 20)(a), numel() == 70000 for 200000 times
8.562551314000302
torch.nn.Threshold(0.1, 20)(a), numel() == 700000 for 20000 times
9.37924196699987
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27155
Differential Revision: D17790768
Pulled By: VitalyFedyunin
fbshipit-source-id: 3281eaff77ddddd658048c9e73824dd68c548591
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28909
This allows to chain calls on RRef as exemplified in the new test case added.
ghstack-source-id: 92996018
Test Plan: unit test.
Differential Revision: D18231081
fbshipit-source-id: deeac044ef6d63f18ea241760ac17a3e644cb3d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27347
it's already done in the op, we don't need to permute again
Test Plan:
test_jit.py
we'll test in e2e tests
Imported from OSS
Differential Revision: D18182919
fbshipit-source-id: 04dd2a19a719828fbc7b62e451b81752187e0fcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28824
1) Enhanced autograd unit tests to test the
torch.distributed.autograd.backward() API more thoroughly on Python UDFs.
2) Enhanced `python_error` to override `what` such that it returns an
appropriate error string if we call `what()` on this error. This ensures we can
propagate exceptions over the wire during RPCs (since we get the error string
by calling what() on the exception)
ghstack-source-id: 92972494
Test Plan: waitforbuildbot
Differential Revision: D18195584
fbshipit-source-id: b795daf644ba1816fdec484545192ab55a2f71e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28921
This implementation is quite similar to the HashStore in gloo -
an ephemeral in-process store with a lock and unordered_map<>.
There are a few tweaks/differences based on c10d vs gloo:
- c10d expects add/check methods
- c10d get() use cases expect to wait up to super::timeout_ if the value isn't present
- c10d set() isn't expected to throw if the value is present.
- c10d uses uint8_t vs char
It's potentially a better choice for some cases than FileStore when we
don't need cross-process access, or care about the backing file.
ghstack-source-id: 92992341
Test Plan:
buck build mode/dev-nosan caffe2/torch/lib/c10d/...
buck-out/dev/gen/caffe2/torch/lib/c10d/HashStoreTest
Differential Revision: D18233713
fbshipit-source-id: ab23f3f93d3148c1337f2cc6a8f2aff4aa6549f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26706
This has been ready for some time, just waiting on services to push with
the new code.
#forceTDhashing
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D17543304
fbshipit-source-id: baad22f4abc5af724ebde8507e948bee3e8bf6d4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28523
New features:
1. Previously, `torch::tensor({true, false, true})` throws `"tensor_cpu" not implemented for 'Bool'`. After this PR, it produces the correct bool tensor, matching the Python API behavior.
2. Tensors with zero-size dimensions are now supported, e.g. `torch::tensor({{}, {}})` produces a tensor with sizes `{2, 0}`, matching the Python API behavior.
BC-breaking bug fixes:
1. Previously, `torch::tensor({{1}, {2}})` produces a tensor of sizes `{2}`. After this PR, it produces a tensor of sizes `{2, 1}`, matching the Python API behavior.
2. Fixed semantics of `torch::tensor(1.1)`: it now returns a 0-dim tensor instead of a 1-dim tensor, matching the Python API behavior.
3. Previously, when passed a non-dtype `TensorOptions` to the `torch::tensor` constructor, it always produces a tensor of dtype `float`. After this PR, it produces tensor of different dtypes based on the dtype of the braced-init-list, matching the behavior of the no-options case.
```cpp
// Previously:
torch::tensor({1, 2, 3}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> float
torch::tensor({{1, 2, 3}}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> float
torch::tensor({1., 2., 3.}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> float
torch::tensor({{1., 2., 3.}}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> float
// Now:
torch::tensor({1, 2, 3}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> int
torch::tensor({{1, 2, 3}}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> int
torch::tensor({1., 2., 3.}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> double
torch::tensor({{1., 2., 3.}}, torch::TensorOptions(/*non-dtype-options*/)).dtype() -> double
// As comparison, currently:
torch::tensor({1, 2, 3}).dtype() -> int
torch::tensor({{1, 2, 3}}).dtype() -> int
torch::tensor({1., 2., 3.}).dtype() -> double
torch::tensor({{1., 2., 3.}}).dtype() -> double
```
Notes:
1. From now on, the behavior of `at::tensor(scalar_value)` (which produces a 1-dim tensor) would be different from `torch::tensor(scalar_value)` (which produces a 0-dim tensor). I will fix the behavior of `at::tensor(scalar_value)` in a follow-up PR.
2. From now on, the behavior of `at::tensor({1, 2, 3}, torch::TensorOptions(/*non-dtype-options*/))` (which produces a `float` tensor) would be different from `torch::tensor({1, 2, 3}, torch::TensorOptions(/*non-dtype-options*/))` (which produces a an `int` tensor). I will fix this behavior of `at::tensor` constructor in a follow-up PR.
Context for the changes in this PR:
The motivation comes from fixing the "`torch::tensor({{1}, {2}})` gives tensor of wrong sizes" bug - in order to fix it, I have to move the handling of `at::ArrayRef` and `std::vector` into `InitListTensor` (see below on why we need to do this) and renamed `InitListTensor` to `TensorDataContainer`. After such changes, support for bool values comes out of the box without extra effort, and support for tensors with zero-size dimensions only requires adding a default constructor for `TensorDataContainer`, so I added those two in this PR.
For the semantic change of `torch::tensor(1.1)`, it's actually more effort to preserve the original wrong behavior (i.e. we need to check the sizes of the tensor converted from `TensorDataContainer` and reshape any scalar tensor to a 1-D tensor). I think preserving the original wrong behavior doesn't give us much value, and since the above changes naturally fix the problem, we should just start using the right behavior instead.
For the "constructor with non-dtype options behavior" fix, the code looks simpler and easier to reason about with the fix, so I included it in this PR.
--------
Why we need to move the handling of `at::ArrayRef` and `std::vector` into `TensorDataContainer`:
`torch::tensor({{1}, {2}})` can match this function overload:
`torch::tensor(at::ArrayRef<int> values)`, because `{1}` and `{2}` can be treated as
a list-initialization of an `int` value. However, this will produce a Tensor with sizes `{2}`,
but we actually want a Tensor with sizes `{2, 1}`. In order to avoid matching this function overload,
we removed the function overload and moved the ability to convert `at::ArrayRef<T>`
(and similarly `std::vector<T>`) into `TensorDataContainer`, and since for braced-init-list the
`TensorDataContainer(std::initializer_list<TensorDataContainer>)` constructor is always preferred over all other constructors, it will take the `std::initializer_list` path, and all is good.
Test Plan: Imported from OSS
Differential Revision: D18234625
Pulled By: yf225
fbshipit-source-id: 0f3f6912e82e2117d2103e31b74e7e97baaa8693
Summary:
VitalyFedyunin, This PR is about port mse lose to Aten:
**Test script:**
```
import torch
import torch.nn as nn
import time
def _time():
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
device = "cpu"
loss = nn.MSELoss(reduction = 'sum')
if torch.cuda.is_available():
device = "cuda"
loss = loss.cuda()
#warm up
for n in [100, 10000]:
input = torch.randn(128, n, requires_grad=True, device=device)
target = torch.randn(128, n, device=device)
for i in range(1000):
output = loss(input, target)
output.backward()
#get running time
for n in [100, 10000]:
fwd_t = 0
bwd_t = 0
input = torch.randn(128, n, requires_grad=True, device=device)
target = torch.randn(128, n, device=device)
for i in range(10000):
t1 = _time()
output = loss(input, target)
t2 = _time()
output.backward()
t3 = _time()
fwd_t = fwd_t + (t2 -t1)
bwd_t = bwd_t + (t3 - t2)
fwd_avg = fwd_t / 10000 * 1000
bwd_avg = bwd_t / 10000 * 1000
print("input size(128, %d) forward time is %.2f (ms); backwad avg time is %.2f (ms)."
% (n, fwd_avg, bwd_avg))
```
**Test Device:** CPU: skx-8180, GPU: Tesla P40.
### Perfromance:
**Before:**
```
GPU:
reduction=’mean’
input size(128, 100) forward time is 0.08 (ms); backwad avg time is 0.14 (ms).
input size(128, 10000) forward time is 0.12 (ms); backwad avg time is 0.21 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.09 (ms); backwad avg time is 0.15 (ms).
input size(128, 10000) forward time is 0.11 (ms); backwad avg time is 0.20 (ms).
CPU:
OMP_NUM_THREADS=56
reduction=’mean’
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.09 (ms).
input size(128, 10000) forward time is 3.49 (ms); backwad avg time is 3.23 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.06 (ms); backwad avg time is 0.09 (ms).
input size(128, 10000) forward time is 3.49 (ms); backwad avg time is 3.23 (ms).
OMP_NUM_THREADS=1
reduction=’mean’
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.04 (ms).
input size(128, 10000) forward time is 1.41 (ms); backwad avg time is 1.66 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.04 (ms).
input size(128, 10000) forward time is 1.44 (ms); backwad avg time is 1.68 (ms).
```
**After:**
```
GPU:
reduction=’mean’
input size(128, 100) forward time is 0.07 (ms); backwad avg time is 0.13 (ms).
input size(128, 10000) forward time is 0.13 (ms); backwad avg time is 0.20 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.07 (ms); backwad avg time is 0.14 (ms).
input size(128, 10000) forward time is 0.13 (ms); backwad avg time is 0.20 (ms).
CPU:
OMP_NUM_THREADS=56
reduction=’mean’
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.06 (ms).
input size(128, 10000) forward time is 0.14 (ms); backwad avg time is 0.30 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.06 (ms).
input size(128, 10000) forward time :qis 0.13 (ms); backwad avg time is 0.30 (ms).
OMP_NUM_THREADS=1
reduction=’mean’
input size(128, 100) forward time is 0.04 (ms); backwad avg time is 0.05 (ms).
input size(128, 10000) forward time is 0.85 (ms); backwad avg time is 1.27 (ms).
reduction=’sum’
input size(128, 100) forward time is 0.03 (ms); backwad avg time is 0.04 (ms).
input size(128, 10000) forward time is 0.83 (ms); backwad avg time is 1.27 (ms).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26529
Differential Revision: D18225144
Pulled By: VitalyFedyunin
fbshipit-source-id: ce837a297c70398a3ffa22f26ee9e812cf60d128
Summary:
The central fbjni repository is now public, so point to it and
take the latest version, which includes support for host builds
and some condensed syntax.
Test Plan: CI
Differential Revision: D18217840
fbshipit-source-id: 454e3e081f7e3155704fed692506251c4018b2a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28610
The basic idea is, in some cases where we stored a pointer to a full AutogradMeta object, instead store a nullptr. We let a nullptr represent a default-constructed AutogradMeta object, and simply populate it with a real AutogradMeta if there is ever a situation where we need to modify it.
The primary technical contrivance in this diff is I have to use AutogradMetaFactory to lazily initialize the AutogradMeta, as it is not available in the dynamic library that TensorImpl is in. (I spent a while trying to put them in the same compilation unit, but gave up in the end as it pushed us over the Windows linking binary size limit. Eep.)
Some other notes:
- `set_autograd_meta` now unconditionally turns a tensor into a variable. I audited all call sites and observed there are no occurrences where nullptr is passed (after this patch, there are now!)
- `copy_tensor_metadata` is updated to unconditionally preserve the VariableTensorId-ness of the destination tensor. I think this is the more correct semantics; we can't do the old semantics anymore.
- There's a bunch of places in the API where we return const references to objects. This is pretty weird to me, but I didn't feel like cleaning it up. But sometimes I don't conveniently have something that's the right lifetime, so I introduced a number of singletons to handle this correctly.
You might wonder why I'm doing the optimization before the variable-tensor dynamic merge. The reason is simple: this change is semantics preserving, while variable-tensor dynamic merge is not. So it is easier to get right, and prevents us from regressing performance if we do it the other way.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18171162
Pulled By: ezyang
fbshipit-source-id: 580df729e4d04881b2b9caa0f0c00785b3afbb92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28609
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18171159
Pulled By: ezyang
fbshipit-source-id: 509061ca56186c7762da9634abecbafad0277d94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28602
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18171163
Pulled By: ezyang
fbshipit-source-id: 3f3d4cf0bd05c302f502795a04ecace0fc064255
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28593
When I turn on Variable everywhere, I will need to be able to construct
AutogradMetas from TensorImpl. But I cannot call the constructor directly
as it lives in another dynamic library. So I need another virtual factory interface
to be able to do this.
I also adjust the AutogradMeta constructor so that the TensorImpl argument is
optional. This argument is only needed if `requires_grad == True`, as we use it
to test if the variable is valid (only floating point tensors can have requires grad true).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18171161
Pulled By: ezyang
fbshipit-source-id: 3f2e86720899b3bda36ddd90244c2624645cc519
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28601
In the process, I moved AutogradMeta out of the Variable class. The
intent here is that I'm going to delete Variable class entirely,
so I had better not be putting stuff in it!
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18171160
Pulled By: ezyang
fbshipit-source-id: 9c0bcdc82797eca0577d1b0745b4a2ae962f3010
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28592
These aren't perf critical, and putting them in a cpp file makes it easier to
work on them.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18171158
Pulled By: ezyang
fbshipit-source-id: 4aad434ad4aecba7ed46761f676df6bbec37733e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28543
By the current autograd_meta_ <=> type_set_ invariant (now explicitly documented
in the right place!), these are equivalent. But when I introduce null
autograd_meta_ optimization, they won't be equivalent anymore: TensorTypeSet is
going to give me the right information no matter what.
In the long run, this patch will be a wash, because everything will "be a variable"
in the long term. But I am making this change now to make sure that the invariant
actually holds.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18171157
Pulled By: ezyang
fbshipit-source-id: cbba8fd5df9e6873a8757925db5f578fecbd2486
Summary:
The Java and Python code were updated, but the test currently fails
because the model was not regenerated.
Test Plan: Ran test.
Reviewed By: xcheng16
Differential Revision: D18217841
fbshipit-source-id: 002eb2d3ed0eaa14b3d7b087b621a6970acf1378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28934
These tests are flaky, skip them as we investigate for a root cause
ghstack-source-id: 92945898
Test Plan: tests pass
Differential Revision: D18235766
fbshipit-source-id: 9bff65653954b767e32bcc1d25c65b0cea2c4331
Summary:
Fixes https://github.com/pytorch/pytorch/issues/28198 in my tests on a 24 core AMD threadripper.
Profiling the benchmark showed that most of the slowdown in https://github.com/pytorch/pytorch/issues/28198 was from `THFloatTensor_fill` not being distributed across threads. It internally uses `TH_TENSOR_APPLY_CONTIG` which is a thin wrapper around `at::parallel_for` and uses `TH_OMP_OVERHEAD_THRESHOLD` or 100,000 as the grain size.
Here I've changed it to use `at::internal::GRAIN_SIZE` which is 32,768 so ~1/3 of the old value. I think it makes sense to unify these two values so any future tuning in `ATen` will apply to `TH` as well. It's not entirely clear to me what the "uncertain", "ordin" and "hyper" variants are meant to represent but I've kept them at roughly the same ratio to `TH_OMP_OVERHEAD_THRESHOLD` as before.
Here are the timing results I get:
| Version | Full iteration time | `index_select` | `mm` | `addmm` |
|:----------:|---------------:|-------------:|---------:|---------:|
| master | 3505.85 ms/it | 184.302 ms | 9.520 ms | 8.494 ms |
| no scaling | 3453.18 ms/it | 184.456 ms | 5.810 ms | 5.069 ms |
| this PR | 3453.23 ms/it | 184.526 ms | 5.824 ms | 5.202 ms |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28770
Differential Revision: D18202646
Pulled By: ezyang
fbshipit-source-id: ab30e5ef24e62213f9bd3abace5c6442c75c9854
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28903
Use of predefined and less compute intensive functions instead of pow() for predefined scalar exponent values.
Test Plan: automated tests
Reviewed By: jspark1105
Differential Revision: D18227280
fbshipit-source-id: 0a443832c3ff8372e64dbe04de4f7fb4ce7c0740
Summary:
This is to fix https://github.com/pytorch/pytorch/issues/22526
Adding limitation on launch config for grid sizes as well, previous code is asking to launch blocks more than what's supported by the hardware;
Test added in test_cuda;
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28927
Differential Revision: D18241759
Pulled By: soumith
fbshipit-source-id: 8f2535bb0bc4ea7998024b137576a38067668999
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28933
Merge all the things that don't add annotations into a single
`quick-checks` job. This helps reduce concurrency and clutter
at the top of the status check page.
This doesn't touch the actually important items (flake8 + clang-tidy),
but those are a little trickier to handle because of how annotations are
added.
Test Plan: Imported from OSS
Differential Revision: D18235396
Pulled By: suo
fbshipit-source-id: 8fba44f3f5d398b1dce0f39f51d6652f3e0c1bf7
Summary:
Currently, `reshape` does an `as_strided` when the geometry is viewable. However, `as_strided` backward is not very optimized, and can not always detect such cases. Improvements are planned at https://github.com/pytorch/pytorch/pull/8965, and I will finish it some day. But the current situation is that in these cases backward through `reshape` will copy gradient while a simple `view` will not. This is unnecessary.
Notably this affects `flatten` and a whole bunch of other ops implemented on top of `reshape`.
```py
In [15]: x = torch.randn(3, 4, requires_grad=True)
In [16]: y = x.reshape(x.shape)
In [17]: assert y._base is not None
In [18]: gy = torch.randn_like(y)
In [20]: gx = torch.autograd.grad(y, x, gy)[0]
In [21]: gx
Out[21]:
tensor([[ 0.2189, 0.3396, -0.1108, 1.7703],
[ 1.0737, -0.1222, 1.0765, -1.3363],
[-1.3798, -0.2950, 0.0800, 0.2501]])
In [22]: gx._base # not gy
Out[22]:
tensor([ 0.2189, 0.3396, -0.1108, 1.7703, 1.0737, -0.1222, 1.0765, -1.3363,
-1.3798, -0.2950, 0.0800, 0.2501])
In [23]: gy.zero_()
Out[23]:
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
In [24]: gx # not sharing storage with gy
Out[24]:
tensor([[ 0.2189, 0.3396, -0.1108, 1.7703],
[ 1.0737, -0.1222, 1.0765, -1.3363],
[-1.3798, -0.2950, 0.0800, 0.2501]])
# but everything is optimized with view, which should be equivalent with reshape in this case
In [25]: y = x.view(x.shape)
In [26]: assert y._base is not None
In [27]: gy = torch.randn_like(y)
In [28]: gx = torch.autograd.grad(y, x, gy)[0]
In [29]: gx
Out[29]:
tensor([[-2.4463, 1.1446, 0.1501, 0.1212],
[-1.1125, 1.4661, 0.9092, -0.2153],
[-0.1937, -0.3381, -1.3883, -0.7329]])
In [30]: gy.zero_()
Out[30]:
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
In [31]: gx # sharing storage with gy
Out[31]:
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28901
Differential Revision: D18240868
Pulled By: ezyang
fbshipit-source-id: 28fdaa0c7014a9dae6731dfe8b67784d38fc27f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28916
The previous regex caused a `std::regex_error` under clang8 complaining about `error_brack`, which is strange because the square brackets are balanced. Seems like a stdlib bug to me. So to workaround this, I've switched to the older regex with a non-greedy match in the inner atom
Test Plan: Imported from OSS
Differential Revision: D18232654
Pulled By: jamesr66a
fbshipit-source-id: f82a9a24acf090010b03f23454d2b0f7a1e3589e
Summary:
This is a port of the negative log likelihood TH loss implementation to ATen which is used by `torch.nn.functional.nll_loss()` for 2d inputs (N, C).
## Performance Impact
I measured no significant performance-difference of the port compared to the original implementation when using this [benchmark test script](https://gist.github.com/andreaskoepf/3c8e3698607773db2788dfd8885a9ed9).
### WITH PR applied:
```
CPU forward 1000 took 2.5290995836257935e-05
CPU forward 10000 took 5.757302278652787e-05
CPU forward 100000 took 0.0004873779835179448
CPU forward 1000000 took 0.0051894880016334355
CPU forward 10000000 took 0.026263039995683357
CPU forward TOTAL time 0.8068871730065439
CPU for- & backward 1000 took 0.00018794499919749796
CPU for- & backward 10000 took 0.0002642899926286191
CPU for- & backward 100000 took 0.0011828370043076575
CPU for- & backward 1000000 took 0.01250307000009343
CPU for- & backward 10000000 took 0.11453165800776333
CPU for- & backward TOTAL time 0.824805997981457
```
### Original TH version:
```
CPU forward 1000 took 2.1958985598757863e-05
CPU forward 10000 took 6.608400144614279e-05
CPU forward 100000 took 0.0004632119962479919
CPU forward 1000000 took 0.005477247992530465
CPU forward 10000000 took 0.02681165697867982
CPU forward TOTAL time 0.8073387439944781
CPU for- & backward 1000 took 0.00020634100656025112
CPU for- & backward 10000 took 0.00031720998231321573
CPU for- & backward 100000 took 0.0011843869870062917
CPU for- & backward 1000000 took 0.010876987013034523
CPU for- & backward 10000000 took 0.09893897600704804
CPU for- & backward TOTAL time 0.8271351839939598
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28270
Differential Revision: D18009584
Pulled By: ezyang
fbshipit-source-id: 77daf47c61a9dd9bb3b5a8d3e48585bbb665e979
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28879
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18231741
Pulled By: ezyang
fbshipit-source-id: d49711ad41d7ff7e527326c68fd8db86da10a818
Summary:
Adds `torch::nn::functional::fold` support and updates `Fold::pretty_print` in the C++ API for more thorough Python parity.
Note: Small updates in source files to maintain consistency elsewhere.
Reviewer: yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28732
Differential Revision: D18219955
Pulled By: yf225
fbshipit-source-id: fd2e9be8f17db77c1b1f384c0d2e16cc34858c0c
Summary:
Current reges also matches strings with '{}' so warning is always given.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28616
Test Plan: Previous code was giving a warning about unspported options, these disappeared. When adding something inside '{}' the warning came back.
Differential Revision: D18039443
Pulled By: ggoossen
fbshipit-source-id: bb3a2892d5707a32030d43250c40f3058aa1d18b
Summary:
This problem is from issue [https://github.com/pytorch/pytorch/issues/28753](https://github.com/pytorch/pytorch/issues/28753)
The header files on directories`math` and `threadpool` should be included on the built package because they are included on the other header files, such as on file `torch/include/caffe2/utils/math.h`
```
#include "caffe2/core/common.h"
#include "caffe2/core/types.h"
#include "caffe2/utils/math/broadcast.h"
#include "caffe2/utils/math/elementwise.h"
#include "caffe2/utils/math/reduce.h"
#include "caffe2/utils/math/transpose.h"
#include "caffe2/utils/math/utils.h"
```
But the `setup.py` doesn't include the header files on `master` branch. The header files on `utils` directory of a built `torch` package are the following:
```
> ls include/caffe2/utils
bench_utils.h conversions.h eigen_utils.h map_utils.h murmur_hash3.h proto_wrap.h smart_tensor_printer.h
cast.h cpuid.h filler.h math-detail.h proto_convert.h signal_handler.h string_utils.h
cblas.h cpu_neon.h fixed_divisor.h math.h proto_utils.h simple_queue.h zmq_helper.h
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28869
Differential Revision: D18226319
Pulled By: soumith
fbshipit-source-id: 51575ddc559181c069b3324aa9b2d1669310ba25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28812
FileStore isn't thread-safe. We've observed a few FB unittests
already using this class in an unsafe manner.
This change enforces at most a single concurrent use of
the various file options, from this specific Store instance.
This protects the cache_, pos_, and the relative integrity
of the operations.
An alternative would be simply to explicitly document this
class as non-thread-safe, though perhaps not everybody will
read the warning.
ghstack-source-id: 92874098
Test Plan:
buck test mode/dev-nosan caffe2/...
Actual observed failures were in ThreadRpcAgentTest
Differential Revision: D18187821
fbshipit-source-id: 67c765da74c836a9ac9f887cdf1a28a75247e04b
Summary:
Before, we would only give the key we are looking for (i.e. typically
just "No such serialized tensor 'weight'", no matter for which submodule
we were looking for a weight.
Now we error with "No such serialized tensor '0.conv1.weight'" or
similar.
The analogous information is added to missing module error messages.
I threw in a test, and it saved me already...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28499
Differential Revision: D18122442
Pulled By: yf225
fbshipit-source-id: a134b6d06ca33de984a11d6fea923244bcd9fb95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28799
When the verbosity is quiet, hypothesis no longer prints the real
error when it finds multiple falsifying examples: it just says
that there are two failures. This is supremely unuseful. Make
it print more.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18206936
Pulled By: ezyang
fbshipit-source-id: 03bb60ba24cee28706bb3d1f0858c32b6743a109
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28866
When we are working on the fix for int32 instead of int64, we also need to take care of the ClipRangesGatherSigridHash since this is the operator that actually gets used during inference.
Test Plan: Added unittest to cover for the new case
Reviewed By: ipiszy
Differential Revision: D17147237
fbshipit-source-id: 2b562b72a6ae8f7282e54d822467b8204fb1055e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28855
Resubmit:
OfflineTensor will be a shell to just carry the shape and dtype. No data will be stored. This should help us plumb through the onnxifi process.
Test Plan:
```
buck test caffe2/caffe2/fb/opt:onnxifi_with_offline_tensor_test
```
Reviewed By: ipiszy, ChunliF
Differential Revision: D18212824
fbshipit-source-id: 5c8aaed2ef11d719dfa2a2901875efd66806ea56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28630
This includes:
1. Respect autograd context in rpc.remote for builtin ops
2. Force setting autograd context in RRef.to_here() even if the
message for to_here() does not contain any tensor.
Test Plan: Imported from OSS
Differential Revision: D18138562
Pulled By: mrshenli
fbshipit-source-id: a39ec83e556d19130f22eb317927241a017000ba
Summary:
Having them in BatchLinearAlgebra.cpp/.cu seemed out of place, since they are more general purpose and this code was interspersed between LAPACK and MAGMA wrappers as well.
Changelog:
- Move tril* / triu* to TriangularOps.cpp/.cu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28750
Test Plan:
- Builds should complete successfully to ensure that the migration is error-free
- Tests should pass to ensure the methods that the front-end is unaffected.
Differential Revision: D18205456
Pulled By: soumith
fbshipit-source-id: 41966b9ddfe9f196f4d7c6a5e466782c1985d3d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27269
Remove `test_quantizer.py`, add and rewrite one of the tests in `test_quantizer`
in `test_quantization.py`
The conv test is removed for now since conv pattern is still broken, we'll add another test
later
ghstack-source-id: 92869823
Test Plan:
python test/test_quantization.py
Imported from OSS
Differential Revision: D18182916
fbshipit-source-id: 325b5d8e877228d6a513e3ddf52c974479250d42
Summary:
Add torch::nn::BatchNorm1d function/module support for the C++ API.
torch::nn::BatchNorm{2,3}d will be added after this PR is merged.
Related Issue: https://github.com/pytorch/pytorch/issues/25883
Reviewer: yf225
I would like to discuss about below items.
* Necessity of `num_batches_tracked` in `BatchNormImplBase`
* `num_batches_tracked` is needed to calculate `momentum` when we do not feed `momentum` argument in Python API. But in C++ API, `momentum` argument has a default value.
* `num_batches_tracked` is only used for counting up `BatchNorm1d::foward()` call. I think it is no necessary for user anymore.
* The design of `BatchNorm{1,2,3}dOptions`
* We have already `BatchNormOptions` used for deprecated `BatchNorm` module. However, it is hard to use it for `BatchNorm{1,2,3}dOptions` because of the arguments disagreement of each modules.
* In this PR, I introduce `BatchNormOptionsv2` template class for the `BatchNorm{1,2,3}dOptions`. But I'm not sure this design is good or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28176
Differential Revision: D18196843
Pulled By: yf225
fbshipit-source-id: 667e2b5de4150d5776c41b9088c9e6c2ead24cd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28767
The scale and zero_point are for the output activation tensor, not for the weight tensor. We removed them here because we don't need the zero points and scales for the output tensors in dynamic quantization.
ghstack-source-id: 92807318
Test Plan: CI
Differential Revision: D18164949
fbshipit-source-id: 0f9172bfef615c30dc28e1dd4448a9f3cc897c2e
Summary:
prim::AutogradAnyNonZero is optimized away under normal circumstances (a graph executor specializes tensor arguments and runs `specializeAutogradZero`), so the change should be backward compatible for as long as we are running the original executor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28852
Differential Revision: D18213118
Pulled By: Krovatkin
fbshipit-source-id: 223f172c59e5f2b05460db7de98edbadc45dd73d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27664
When ANDROID_ABI is not set, find libtorch headers and libraries from
the LIBTORCH_HOME build variable (which must be set by hand), place
output under a "host" directory, and use dynamic linking instead of
static.
This doesn't actually work without some local changes to fbjni, but I
want to get the changes landed to avoid unnecessary merge conflicts.
Test Plan: Imported from OSS
Differential Revision: D18210315
Pulled By: dreiss
fbshipit-source-id: 685a62de3c2a0a52bec7fd6fb95113058456bac8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27663
CMake sets CMAKE_BINARY_DIR and creates it automatically. Using this
allows us to use the -B command-line flag to CMake to specify an
alternate output directory.
Test Plan: Imported from OSS
Differential Revision: D18210316
Pulled By: dreiss
fbshipit-source-id: ba2f6bd4b881ddd00de73fe9c33d82645ad5495d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27662
This adds a new gradle subproject at pytorch_android/host and tweaks
the top-level build.gradle to only run some Android bits on the other
projects.
Referencing Java sources from inside the host directory feels a bit
hacky, but getting host and Android Gradle builds to coexist in the same
directory hit several roadblocks. We can try a bigger refactor to
separate the Android-specific and non-Android-specific parts of the
code, but that seems overkill at this point for 4 Java files.
This doesn't actually run without some local changes to fbjni, but I
want to get the files landed to avoid unnecessary merge conflicts.
Test Plan: Imported from OSS
Differential Revision: D18210317
Pulled By: dreiss
fbshipit-source-id: dafb54dde06a5a9a48fc7b7065d9359c5c480795
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex)
These changes optimize complex Vec256 math kernels so that are within 2X real number performance on average. [Benchmarks are here](https://docs.google.com/spreadsheets/d/17pObcrSTpV4BOOX9FYf1vIX3QUlEgQhLvL1IBEyJyzs/edit#gid=0)
Changes so far:
- [x] Added complex support for eq, neq, max, and min ops.
- max/min ops need to compare the absolute value for complex numbers (using zabs).
- [x] Added complex support for is_nonzero and where.
- where op compares the absolute value for complex numbers (using zabs).
- [x] Added complex support for linear interp and and pointwise ops.
- [x] Added complex support for check_convert and Linspace/Logspace.
- std::complex does not support ++operator.
- All compilers from clang, g++, c++ on aarch64, x86 produce the same assembly code when using `+=1' instead of `++`. [example for loop](https://godbolt.org/z/O6NW_p)
- [x] Added complex support for log, log2, log10.
- [x] Optimized Vec256 operators using various logarithmic identities.
- `asin()`, `acos()`, `atan()` is optimized using a `ln()` identity.
- `sqrt()` is optimized by splitting the computation into real and imag parts.
- several `_mm256_mul_pd` are avoided by using `_mm256_xor_pd` ops instead.
- [x] Added complex support for pow.
- exp is cast to `std::complex<double>`.
- no special optimization is added when the `exp` is real because the `std::pow()` operator expects a std::complex number.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28735
Differential Revision: D18170691
Pulled By: ezyang
fbshipit-source-id: 6f167398e112cdeab02fcfde8b543cb6629c865a
Summary: OfflineTensor will be a shell to just carry the shape and dtype. No data will be stored. This should help us plumb through the onnxifi process.
Test Plan:
```
buck test caffe2/caffe2/fb/opt:onnxifi_with_offline_tensor_test
```
Reviewed By: ChunliF, zrphercule
Differential Revision: D18187208
fbshipit-source-id: 57c70f6f9897a5fc66580c81295db108acd03862
Summary:
Remove autograd copy_ specific isFloatingPoint and use
c10's isFloatingType (and isComplexType).
Before this, .to or .copy_ would drop requires_grad for bfloat16
as the floating types were only considered to be double, float,
and half.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28279
Differential Revision: D18176084
Pulled By: izdeby
fbshipit-source-id: 8a005a6105e4a827be5c8163135e693a7daae4f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28842
We don't care which python version, and github actions has changed the
versions available, breaking our CI. So just pin it to 3-something to
make it more future proof
Test Plan: Imported from OSS
Differential Revision: D18205349
Pulled By: suo
fbshipit-source-id: bf260dc29a138dd8bf8c85081a182aae298fe86d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28837
The JIT code used in op bench is not compatibility with latest JIT code path. This diff aims to resolve that issue.
Test Plan:
```buck run mode/opt //caffe2/benchmarks/operator_benchmark/pt:add_test -- --use_jit
Building: finished in 02:29.8 min (100%) 7055/7055 jobs, 1 updated
Total time: 02:30.3 min
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: add
# Mode: JIT
# Name: add_M64_N64_K64_cpu
# Input: M: 64, N: 64, K: 64, device: cpu
Forward Execution Time (us) : 118.052
Reviewed By: hl475
Differential Revision: D18197057
fbshipit-source-id: 92edae8a48abc4115a558a91ba46cc9c3edb2eb8
Summary: as title
Test Plan: test in stacked diff
Reviewed By: csummersea
Differential Revision: D18123726
fbshipit-source-id: ce75db1e6f314a822a94ebdfc11988fab50ee836
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28836
as title
Test Plan:
```
buck run mode/opt //caffe2/benchmarks/operator_benchmark/pt:softmax_test
Invalidating internal cached state: Buck configuration options changed between invocations. This may cause slower builds.
Changed value project.buck_out='buck-out/opt' (was 'buck-out/dev')
... and 56 more. See logs for all changes
Parsing buck files: finished in 6.2 sec
Creating action graph: finished in 8.8 sec
Building: finished in 05:42.6 min (100%) 28336/28336 jobs, 23707 updated
Total time: 05:57.7 min
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: Softmax
/proc/self/fd/4/softmax_test.py:57: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
"""
# Mode: Eager
# Name: Softmax_N4_C3_H256_W256
# Input: N: 4, C: 3, H: 256, W: 256
Forward Execution Time (us) : 18422.487
Reviewed By: hl475
Differential Revision: D18202335
fbshipit-source-id: 0bb376cb465d998a49196e148d48d436126ae334
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28809
### Summary
This PR adds the interactive mode to `bootstrap.sh`. Instead of passing the credential information from command parameters(`-t`,`-p`), we're going to ask the user enter that information and save it to a config file, such that next time you don't have to enter again. So all you need now, is one line command
```shell
./bootstrap
```
### Test Plan
- TestApp.ipa can be installed on any devices
- Don't break CI jobs
Test Plan: Imported from OSS
Differential Revision: D18194032
Pulled By: xta0
fbshipit-source-id: a416ef7f13fa565e2c10bb55f94a8ce994b4e869
Summary:
build error in internal pt mobile build
```
xplat/caffe2/torch/csrc/autograd/VariableTypeManual.cpp:118:49: error: address of function 'requires_grad' will always evaluate to 'true' [-Werror,-Wpointer-bool-conversion]
autograd::utils::requires_grad_leaf_error(requires_grad)
~~~~~~~~ ^~~~~~~~~~~~~
xplat/caffe2/torch/csrc/autograd/VariableTypeManual.cpp:118:49: note: prefix with the address-of operator to silence this warning
```
I think the variable name in requires_grad_leaf_error is wrong.
Test Plan: mobile build works
Reviewed By: pbelevich
Differential Revision: D18192663
fbshipit-source-id: a3d3ebb9039022eb228c1d183a1076f65f9e84e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28800
Fix up namespaces and make friendly error message when registered class doesn't inherit from the right base
Test Plan: Imported from OSS
Differential Revision: D18175067
Pulled By: jamesr66a
fbshipit-source-id: 5c7cf3a49fb45db502d84eb3f9a69be126ee59fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28428
Using the new type promotion and dynamic casting added to
`TensorIterator`, the copy kernels could be greatly simplified.
Benchmark on CUDA:
```python
import torch
import timeit
import pandas
import itertools
from tqdm.notebook import tqdm
import math
print(torch.__version__)
print()
_10M = 10 * 1024 ** 2
d = {}
for from_, to in tqdm(itertools.product(torch.testing.get_all_dtypes(), repeat=2)):
if from_ not in d:
d[from_] = {}
a = torch.empty(_10M, dtype=from_, device='cuda')
min_ = math.inf
for i in range(100):
torch.cuda.synchronize()
start = timeit.default_timer()
a.to(to)
torch.cuda.synchronize()
end = timeit.default_timer()
elapsed = end - start
if elapsed < min_:
min_ = elapsed
d[from_][to] = int(min_ * 1000 * 1000)
pandas.DataFrame(d)
```
original:

new:

Test Plan: Imported from OSS
Differential Revision: D18170995
Pulled By: ezyang
fbshipit-source-id: 461b53641813dc6cfa872a094ae917e750c60759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28427
Fixes: https://github.com/pytorch/pytorch/issues/26401
This PR fixes the issue by using the newly added dynamic cast inside
`TensorIterator` so that instead of converting the type at the beginning
(which generates extra kernel launches), the `TensorIterator` do a
load-cast-compute-store for each element while looping. So there is only
one read and one write of memory.
**nvprof:**
```python
import torch
_100M = 100 * 1024 ** 2
r = torch.randn(_100M, dtype=torch.float32, device='cuda')
d = torch.randn(_100M, dtype=torch.float64, device='cuda')
torch.cuda.synchronize()
torch.cuda.profiler.start()
r.add_(d)
torch.cuda.profiler.stop()
torch.cuda.synchronize()
```
```
==11407== NVPROF is profiling process 11407, command:
/home/xgao/anaconda3/bin/python simple.py
==11407== Profiling application: /home/xgao/anaconda3/bin/python
simple.py
==11407== Profiling result:
Type Time(%) Time Calls Avg Min
Max Name
GPU activities: 100.00% 2.0611ms 1 2.0611ms 2.0611ms
2.0611ms
_ZN2at6native18elementwise_kernelILi512ELi1EZNS0_15gpu_kernel_implIZZZNS0_15add_kernel_cudaERNS_14TensorIteratorEN3c106ScalarEENKUlvE_clEvENKUlvE1_clEvEUlddE_EEvS4_RKT_EUliE_EEviT1_
API calls: 100.00% 1.05006s 1 1.05006s 1.05006s
1.05006s cudaLaunchKernel
0.00% 2.7740us 2 1.3870us 673ns
2.1010us cudaGetDevice
0.00% 2.3730us 1 2.3730us 2.3730us
2.3730us cudaSetDevice
0.00% 830ns 1 830ns 830ns
830ns cudaGetLastError
```
**benchmark**
```python
import torch
print(torch.__version__)
print(torch.version.git_version)
_100M = 100 * 1024 ** 2
r = torch.randn(_100M, dtype=torch.float32, device='cuda')
d = torch.randn(_100M, dtype=torch.float64, device='cuda')
torch.cuda.synchronize()
%timeit r.add_(d); torch.cuda.synchronize()
```
original
```
1.4.0a0+7d277b0
7d277b0670eb1f9098a7e098e93b20453e8b5c9f
6.83 ms ± 1.12 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
after
```
1.4.0a0+f0f2f65
f0f2f654cba9b8c569f0bcd583732bbc891f80b2
2.08 ms ± 139 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
For more benchmark, see: https://github.com/pytorch/pytorch/pull/28344
Test Plan: Imported from OSS
Differential Revision: D18170997
Pulled By: ezyang
fbshipit-source-id: 9c82c1c89583f3e6202c5d790b9b73ad9f960fad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28426
Type casting is used in copy, and will be used also in tensor iterator
in the next stacked diff. I move it to c10 to make it serve as an common
util for different things.
I also add two dynamic casting functions
- fetch_and_cast
- cast_and_store
fetch_and_cast fetch a value with dynamic type specified by a ScalarType
from a void pointer and cast it to a static type.
cast_and_store casts a static typed value into dynamic type specified
by a ScalarType, and store it into a void pointer.
Test Plan: Imported from OSS
Differential Revision: D18170996
Pulled By: ezyang
fbshipit-source-id: 41658afd5c0ab58c6b6c510424893d9a2a0c059e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28766
Add the warning message to explicitly ask the users to upgrade the deprecated `torch.jit.quantized` API to the new `torch.quantization.quantize_dynamic` API.
ghstack-source-id: 92711620
Test Plan: CI
Differential Revision: D18164903
fbshipit-source-id: e6aff2527f335c2d9f362e6856ce8597edb52aaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28807
`FAIL: test_numerical_consistency_per_channel (_main_.TestFakeQuantizePerChannel)`
This test is failing consistently on master, we can't find a clean blame.
ghstack-source-id: 92763176
Test Plan: CI
Differential Revision: D18181496
fbshipit-source-id: 5948af06c4cb7dea9a8db1366deb7c12f6ec1c72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28788
Okay, my last fix was wrong because it turns out that the base SHA is
computed at PR time using the actual repo's view of the base ref, not
the user's. So if the user doesn't rebase on top of the latest master
before putting up the PR, the diff thing is wrong anyway.
This PR fixes the issue by not relying on any of these API details and
just getting the merge-base of the base and head refs, which should
guarantee we are diffing against the right thing.
This solution taken from https://github.com/github/VisualStudio/pull/1008
Test Plan: Imported from OSS
Differential Revision: D18172391
Pulled By: suo
fbshipit-source-id: 491a50119194508b2eefa5bd39fe813ca85f27b1
Summary:
I finally found a way to get the following API to work for constructing a list of named submodules for `Sequential`:
```cpp
Sequential sequential({
{"m1", MyModule(1)},
{"m2", MyModule(2)}
})`
```
which was actually our original proposed design and much simpler than our current API:
```cpp
Sequential sequential(modules_ordered_dict({
{"m1", MyModule(1)},
{"m2", MyModule(2)}
}));
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28774
Differential Revision: D18174013
Pulled By: yf225
fbshipit-source-id: 3a18c2d36b6a65a07bee7346a7516780567c7774
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28731
as title
Test Plan:
```
Before:
buck run mode/opt caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --operator sigmoid
Invalidating internal cached state: Buck configuration options changed between invocations. This may cause slower builds.
Changed value project.buck_out='buck-out/opt' (was 'buck-out/dev')
... and 69 more. See logs for all changes
Parsing buck files: finished in 7.2 sec
Creating action graph: finished in 10.0 sec
Building: finished in 06:38.4 min (100%) 29890/29890 jobs, 29890 updated
Total time: 06:55.7 min
# ----------------------------------------
# PyTorch/Caffe2 Operator Micro-benchmarks
# ----------------------------------------
# Tag : short
# Benchmarking PyTorch: sigmoid
With this diff
buck run mode/opt caffe2/benchmarks/operator_benchmark:benchmark_all_test -- --operator sigmoid
Parsing buck files: finished in 6.4 sec
Creating action graph: finished in 9.8 sec
Building: finished in 06:35.9 min (100%) 29892/29892 jobs, 29892 updated
Total time: 06:52.1 min
Reviewed By: hl475
Differential Revision: D18152071
fbshipit-source-id: 80c29570581bbd2f0e78e2df32734c17a2b036ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28547
Pull Request resolved: https://github.com/pytorch/glow/pull/3672
See D18090864 for more background. The issue i addressed there is more widespread, so i'm fixing all the other `.clang-tidy` files clearly not working as intended.
Perhaps this means it's time to lint the linter config :-)
Test Plan:
Here's the resulting output for `~/fbsource/fbcode/third-party-buck/platform007/build/llvm-fb/bin/clang-tidy` related to each file touched:
`fbcode/admarket/intent/.clang-tidy`: P119723794
`fbcode/caffe2/.clang-tidy`: P119723978
`fbcode/glow/glow/.clang-tidy`: P119724081
`fbcode/ice_palace/.clang-tidy`: P119724774
`fbcode/unified_graph/aggregator/.clang-tidy`: P119724375
`xplat/caffe2/.clang-tidy`: P119724464
`xplat/mcfcpp/.clang-tidy`:
```
[billfarner@devvm2187.ftw3 ~/fbsource/xplat/mcfcpp] ~/fbsource/fbcode/third-party-buck/platform007/build/llvm-fb/bin/clang-tidy -explain-config
'readability-identifier-naming' is enabled in the /home/billfarner/fbsource/xplat/mcfcpp/.clang-tidy.
```
`xplat/wa-msys/mcfcpp/.clang-tidy`:
```
[billfarner@devvm2187.ftw3 ~/fbsource/xplat/wa-msys/mcfcpp] ~/fbsource/fbcode/third-party-buck/platform007/build/llvm-fb/bin/clang-tidy -explain-config
'readability-identifier-naming' is enabled in the /home/billfarner/fbsource/xplat/wa-msys/mcfcpp/.clang-tidy.
```
Reviewed By: soumith
Differential Revision: D18092684
fbshipit-source-id: 951307d125c0346322cb2c636c0300004a48d7a9
Summary:
reorder_dimensions() currently iterate all the operands when determining the dimension order in the TensorIterator. It tries to move a dimension to front if any operand has a dimension whose stride is bigger than this dimension.
reorder_dimensions() do respect the case that stride has zero value. I did not see a reason why reorder_dimensions() need to keep probing each operand under regular cases.
Changed behavior a little bit.
Since operands is ordered by outputs tensor first followed by input tensor. I would favor the writing of outputs is as sequential as possible. This could make the copy between tensors with different memory format faster.
Pls correct me if this change is wrong, thanks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28615
Reviewed By: VitalyFedyunin
Differential Revision: D18122474
Pulled By: glaringlee
fbshipit-source-id: f36467489fe6c6514b14ce9dcc439628d5d5ad0e
Summary:
Hi, I notice that the pytorch faced the the issue as HIPS/autograd#541 .
I try to solve it, hope it can help.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28651
Reviewed By: gchanan
Differential Revision: D18137163
Pulled By: albanD
fbshipit-source-id: 888bef65c72c4c15c2acdd4b13d5041008b1354e
Summary:
provide memory format explicitly when calling to clone():
```
clone(MemoryFormat::Contiguous); \\instead of clone()
```
This change is based on https://github.com/pytorch/pytorch/pull/27106
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28029
Differential Revision: D17937468
Pulled By: ifedan
fbshipit-source-id: 0a6a600af76fc616f88893e5db16aabd7981ce14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28634
caveat 1: this only works in sync mode.
caveat 2: this is going to go away and be replaced by c++ implementation
Test Plan: buck test caffe2/test:distributed_gloo -- test_all_gather_coalesced
Reviewed By: mrshenli
Differential Revision: D18123422
fbshipit-source-id: cfb9950d5d54c6181a5240e7cc9fed88ed47f5d9
Summary:
Changelog:
- Guard inclusion of certain files in torch/csrc/distributed included in caffe2/CMakeLists.txt when USE_DISTRIBUTED=0
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28621
Test Plan:
- Builds should be successful
- Tests should pass
Differential Revision: D18145330
Pulled By: ezyang
fbshipit-source-id: 7167a356b03ae783e6b0120f2ad3552db2b3ed86
Summary:
Fixes https://github.com/pytorch/pytorch/issues/24334.
I'm still kind of confused why `FindMKL.cmake` was unable to locate my MKL libraries. They are in the standard `/opt/intel/mkl` installation prefix on macOS. But at least with this more detailed error message, it will be easier for people to figure out how to fix the problem.
zhangguanheng66 xkszltl soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28779
Differential Revision: D18170998
Pulled By: soumith
fbshipit-source-id: 47e61baadd84c758267dca566eb1fb8a081de92f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28613
addmm: Fix handling of case with empty tensor.
Currently these cause an error
Recreation of D18085389 without stacked diffs
Test Plan: test included
Differential Revision: D18122004
fbshipit-source-id: 71513c02ace691902553bea5ce9dc2538cca4c99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28717
Make HasElements support multiple inputs. Any input has element, then return true.
Test Plan: to be added
Reviewed By: BIT-silence
Differential Revision: D17972759
fbshipit-source-id: 3ecdea74a30fcfaaa6490fef1debc6cde68db922
Summary:
Based on the discussion in https://github.com/pytorch/pytorch/pull/28413#discussion_r338839489, putting anything that's not tagged as `public:` under a `TORCH_ARG` line would hide it under `private:`. To get around this problem, we should move the `mode_t` declaration at the top of the PadOptions declaration.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28760
Differential Revision: D18165117
Pulled By: yf225
fbshipit-source-id: cf39c0a893822264cd6a64cd887729afcd84dbd0
Summary:
I've typed some attributes from ee920b92c4/torch/csrc/autograd/python_variable.cpp (L490) that were not included in the stubs so that MyPy will be aware of them. I made sure to only add those attributes that are mentioned somewhere in the documentation. If there are attributes mentioned in the documentation that are not meant to be part of the public API (or the opposite), please let me know. I've also made sure that attributes that can't be set are typed as read-only properties. If setting `dtype`, `shape`, `device` or `names` directly is not part of the public API, let me know and I'll make them properties as well.
I've also added `__len__`, `__iter__` and `__contains__`, which means MyPy will no longer complain about `len(t)`, `t1 in t2` and `for t1 in t2`.
Shameless plug: I have another typing-related PR here that needs review: https://github.com/pytorch/pytorch/pull/27445
Fixes https://github.com/pytorch/pytorch/issues/28457
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28578
Reviewed By: lerks
Differential Revision: D18113954
Pulled By: fmassa
fbshipit-source-id: 0b69a2966d22054d8d87392f19ec5aa3918773bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28748
Found D17980313 to break unit tests, backed out descendants too to avoid conflicts.
Test Plan:
Failed on master:
buck test mode/dev-nosan language_technology/neural_mt/fb/pytorch_translate/test:test_onnx
Passes with this diff.
Differential Revision: D18157588
fbshipit-source-id: e2b56eac8c5bfccf3ce9a3a2993f6332ab1471e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28622
### Summary
As discussed in #28405 , this is the third PR. The`bootstrap.sh` script is mainly for those who want to do perf on iOS but don't want to touch XCode or any iOS code. But it does require you have valid iOS dev credentials installed on your machine. (You can easily acquire those stuff from any experienced iOS developers. Takes only 5 mins to setup )
All you need to do is run
```shell
./bootstrap -t ${TEAM_ID} -p ${PROFILE}
```
The testing app will be automatically installed on your device. The log of the benchmark function will be displayed on the screen.
### Test plan
Don't break any CI jobs unless they're flaky.
Test Plan: Imported from OSS
Differential Revision: D18156178
Pulled By: xta0
fbshipit-source-id: cd7ba8d87bf26db885262888b9d6a5fd072309d1
Summary:
This makes MultiheadedAttention TorchScript compatible
It also breaks BC-compatibility for old models that do not have `_qkv_same_embed_dim` as an attribute.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28555
Pulled By: driazati
Differential Revision: D18124746
fbshipit-source-id: 5c5042fc6fc0e557db859a8ae05174cba5fce6a9
Summary:
Currently when _apply() is called on RNNBase (or one of its children, like LSTM), the _flat_weights attribute may or may not be updated. In particular, when using .to() and sending a module like LSTM to XLA, a third party device type, the tensors in _flat_weights will not be updated and will remain on CPU. This causes the LSTM forward to fail since the forward call receives a mix of XLA and CPU tensors.
This occurs because third party device types, like XLA, may not be a compatible shallow copy type to native tensors. When this is the case and _apply is called Module parameters are replaced, not updated. RNNBase would not sync _flat_tensors with its params in this case, and that caused the references in _flat_tensors to not reflect the module's current params.
This small change forces a resync of the _flat_tensors and the actual params on each _apply. This lets .to('xla') work for LSTMs, for example. A test will be added to PyTorch/XLA (which runs in our CI) to validate this behavior after the change appears in PyTorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28562
Differential Revision: D18138863
Pulled By: mruberry
fbshipit-source-id: 284092cbe4ecff9dd334a9413c330cacdd5e04fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28514
Verified that there are no generated code changes after applying the diff.
Test Plan: Imported from OSS
Differential Revision: D18086966
Pulled By: gchanan
fbshipit-source-id: 86c660ca78dfeeda2c888947d557cee2c4df08aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28513
This just ensures that (since we only have a Scalar implementation), if you pass in a Tensor that's not zero-dim you get a nice error message.
Instead of doing this with codegen, we do this in code at the ATen level.
Test Plan: Imported from OSS
Differential Revision: D18086969
Pulled By: gchanan
fbshipit-source-id: 83fe2c16046e243d573e033d033aa3844b03930a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28512
This just ensures that (since we only have a Scalar implementation), if you pass in a Tensor that's not zero-dim you get a nice error message.
Instead, of doing this with codegen, we do this in code at the ATen level.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D18086965
Pulled By: gchanan
fbshipit-source-id: f3853bbbb0cf5816803a00877a2e94aa89e32c3b
Summary:
This PR makes Caffe2 compatible with TensorRT 6. To make sure it works well, new unit test is added. This test checks PyTorch->ONNX->TRT6 inference flow for all classification models from TorhchVision Zoo.
Note on CMake changes: it has to be done in order to import onnx-tensorrt project. See https://github.com/pytorch/pytorch/issues/18524 for details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26426
Reviewed By: hl475
Differential Revision: D17495965
Pulled By: houseroad
fbshipit-source-id: 3e8dbe8943f5a28a51368fd5686c8d6e86e7f693
Summary:
All USE_ROCM logics have been moved to cmake now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28641
Differential Revision: D18139209
Pulled By: bddppq
fbshipit-source-id: bbf0931aa6a3be963b7e0d09b6f99f088c92c94d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27940
1) If we receive an error for outstanding rpcs, we enqueue an appropriate error
on the local autograd engine.
2) Add an `exit_on_error` mode for the local autograd engine, where the
computation stops if we see an error.
ghstack-source-id: 92603377
Test Plan: Added unit tests to test failures.
Differential Revision: D17916844
fbshipit-source-id: 199a7832f1033c36a9bbcc1e80d86576c04965d0
Summary:
This is a port of the CPU version of the TH MultiLabelMarginCriterion to ATen.
This reverts the revert of previous PR https://github.com/pytorch/pytorch/issues/28205 which caused a Windows Build to fail, please see comments in the original PR. I refactored the code so that the lambda-bodies of forward & backward of the AT_DISPATCH macro were extracted into separate functions. Similar code can be found at several cases in the ATen code base. Since I was not yet able to successfully compile PyTorch on Windows (due to other compile error) it would be great if somebody could launch a Windows test build for this PR to see if it now can be compiled successfully. Thanks in advance!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28504
Differential Revision: D18115598
Pulled By: ezyang
fbshipit-source-id: b62b6367966e0f6786794213b94eb0820092e572
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28581Fixes#28305
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18124450
Pulled By: ezyang
fbshipit-source-id: 0d4bb99a6bdff9ddbfb4d25cc0f67cc261ed26ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28485
This diff adds a test to ensure that when we have multiple nested RPCs
inside a dist autograd context, the context that is created as a result of a
nested rpc is cleaned up after the node creating the context exits the context
manager. For example, worker 0 might send an rpc to worker 1 that results in an
rpc to worker 2, so worker 2 will have 0's context, even though worker 0 never
directly talked to 2. This test ensures that the context on 2 would also be
cleaned up.
ghstack-source-id: 92611018
Test Plan: Ran the unit test.
Differential Revision: D18079212
fbshipit-source-id: d49f0cda0bf2908747546e5c8a967256c848c685
Summary:
Fixes MSVC error message
```
15>d:\pytorch-scripts\caffe2_builders\v141\pytorch\torch\csrc\jit\register_string_ops.cpp(173): error C4805: '|=': unsafe mix of type 'bool' and type 'int' in operation
15>d:\pytorch-scripts\caffe2_builders\v141\pytorch\torch\csrc\jit\register_string_ops.cpp(173): error C4805: '|': unsafe mix of type 'bool' and type 'int' in operation
15>d:\pytorch-scripts\caffe2_builders\v141\pytorch\torch\csrc\jit\register_string_ops.cpp(186): error C4805: '|=': unsafe mix of type 'bool' and type 'int' in operation
15>d:\pytorch-scripts\caffe2_builders\v141\pytorch\torch\csrc\jit\register_string_ops.cpp(186): error C4805: '|': unsafe mix of type 'bool' and type 'int' in operation
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28156
Differential Revision: D18115151
Pulled By: ezyang
fbshipit-source-id: ed67a2b1330dfd4c12858ae9ca181163c0c72e51
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28553
This change improves double pickling in 1M double list
microbenchmark by roughly 40% (33msec -> 20msec).
The main benefit is avoiding per-byte bounds checks, so
we only bounds-check 2 times rather than 9 times.
Unpickle is already doing something reasonable, so no need to change.
fwiw, putting the swapping logic in a separate func/lambda provided
roughly 20% better results, consistently when microbenchmarking.
Looking at the objdump disassembly, gcc somehow generates better code
when it's separated.
ghstack-source-id: 92585739
Test Plan:
Benchmarks: buck build mode/opt experimental/jeremyl/c2:SerializationBench
buck-out/opt/gen/experimental/jeremyl/c2/SerializationBench --bm_regex=.*Float.*
Correctness: buck build mode/dev-nosan caffe2/test/...
Differential Revision: D18089481
fbshipit-source-id: a5f39e5d38c432893844241a7cce244831037e1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27890
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980314
Pulled By: VitalyFedyunin
fbshipit-source-id: a2cf3b1b2df1a4956da971fd47ce69487b2c09e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27889
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980307
Pulled By: VitalyFedyunin
fbshipit-source-id: f1766c2bcb015ef870bfb92c16b4cd363b3cbc14
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27562
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980313
Pulled By: VitalyFedyunin
fbshipit-source-id: 9ca8453dc1a554ceea93c6949e01263cc576384b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27561
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980316
Pulled By: VitalyFedyunin
fbshipit-source-id: 2a1d47571268673de0c6f5ae1b6d4f9110962ab0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27270
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980312
Pulled By: VitalyFedyunin
fbshipit-source-id: 5da9530f6b239306dbb66d1dfeefe88237f13bbd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27262
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980309
Pulled By: VitalyFedyunin
fbshipit-source-id: 1761a9939aa7c5ab23e927b897e25e225089a8e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27244
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D17980310
Pulled By: VitalyFedyunin
fbshipit-source-id: 00a39b40daa4b8ee63c32e60d920222f8be2d6a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28511
We still keep the function in TH, since it's called from within TH.
Test Plan: Imported from OSS
Differential Revision: D18086967
Pulled By: gchanan
fbshipit-source-id: de026fbb076c8bf9d054ed4cf93eba9c7bcfb161
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28510
It was off in TH, it can be off in ATen.
Test Plan: Imported from OSS
Differential Revision: D18086968
Pulled By: gchanan
fbshipit-source-id: 9be9a61da1dc82224f04a22008629db982f65230
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28462
Unfold is implemented in TH (as _th_unfold), and uses the standard scalar checks. That means, even though torch.tensor(5).unfold(dim=0, size=1, step=1) should produce:
torch.tensor([5]), it actually produces torch.tensor(5) because the scalar_check infers it's a scalar.
We can fix this by just turning off the scalar_check.
Test Plan: Imported from OSS
Differential Revision: D18074671
Pulled By: gchanan
fbshipit-source-id: 5db09d614692830d66d6e6d8aba799ebe8144cf5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28569
Previously, the inclusion of function attributes would "poison" a
ConcreteModuleType, because we did not have a way of checking whether
they are actually the same function. This PR uses the Python function
object to perform that check. This improves our ability to reuse JIT
types between modules.
Also this PR fixes a bug where we weren't properly adding modules as
attributes when converting from ConcreteType -> JIT type (we were adding
them after the fact--another reason to switch from using `register_x` to
`set_x` during module construction, which is on my to-do list after
this).
Fixes https://github.com/pytorch/pytorch/issues/28559
Test Plan: Imported from OSS
Differential Revision: D18111331
Pulled By: suo
fbshipit-source-id: ec2cccf832d3ddd4cd4d28fe19cb265f1275325a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28468
We don't need this anymore.
ghstack-source-id: 92595388
Test Plan: unit tests
Differential Revision: D18073339
fbshipit-source-id: d0ef1332c83e47117fe0a5eadc8faedb259cfba0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28186
Since now all ops are on c10, we don't need to forward any registrations to globalATenDispatch anymore.
ghstack-source-id: 92586962
Test Plan: waitforsandcastle
Differential Revision: D17969011
fbshipit-source-id: 30e6cb072c934b3d24089055754ed3695f8ea693
Summary:
This PR is BC-breaking in the following way:
Previous, we require the use of `std::string` to specify the mode for `EmbeddingBag`. After this PR, we use variant-based enums such as `torch::kSum` / `torch::kMean` / `torch::kMax` to specify the mode for `EmbeddingBag`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28330
Differential Revision: D18127116
Pulled By: yf225
fbshipit-source-id: 15cd86c764777f4d399587be92cda15b6ce8524b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28603
This symbol isn't availble in older Android configs, so import it
from the global namespace in the same file as the rest of our
Android string compatibility hacks.
Test Plan: Internal android build.
Reviewed By: jerryzh168
Differential Revision: D18099515
fbshipit-source-id: f8b0c80ea7344e05975a695afb359b339b6d9404
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28605
This was added because std::to_string isn't available in libstc++
on Android. Use it in more places to get the PyTorch Android
build working with libstdc++.
Test Plan: Internal android build.
Reviewed By: jerryzh168
Differential Revision: D18099520
fbshipit-source-id: 17a2b617c2d21deadd0fdac1db849823637981fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28604
This isn't used anywhere, and it doesn't work with older libstdc++
because std::ostringstream is not copyable or movable.
Test Plan: Internal android build.
Reviewed By: jamesr66a
Differential Revision: D18099511
fbshipit-source-id: 1ffb49303aa5d7890ca7f057b21886f88c04ce20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28606
Without passing setup_model_parallel=True to dist_init, it the
decorator actually takes function object as the value for the
flag.
Test Plan: Imported from OSS
Differential Revision: D18120507
Pulled By: mrshenli
fbshipit-source-id: afbaa381647e8f284e28fa9dbdd2a7c411073b3f
Summary:
https://github.com/pytorch/pytorch/issues/25883
I put grid_sample in vision.h with affine grid.
I have a question in string argument(interpolation mode, padding mode)
I reuse torch::native::detail::GridSamplerInterpolation in GridSampler.h instead of using string.
It follows the way that uses reduction enum in loss functions.
I am not sure this is right.
yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28354
Differential Revision: D18109333
Pulled By: yf225
fbshipit-source-id: 1bf972b671b107464f73b937bbe0de76fb259fbf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28393
We should skip this test if CUDA is not available and alert the user.
Previously, if this test was ran on cpu it would fail with:
```
terminate called after throwing an instance of 'std::runtime_error'
what(): cuda runtime error (3) : This binary is linked with CUDA lazy stubs and underlying .so files were not loaded. CUDA functionality is disabled. Set env variable CUDA_LAZY_DEBUG to get messages during startup
```
Test Plan:
Build on CPU and verify that that are no errors when running, we should get the message:
`CUDA not available, skipping test`. Previously, we would get an error:
```
terminate called after throwing an instance of 'std::runtime_error'
what(): cuda runtime error (3) : This binary is linked with CUDA lazy stubs and underlying .so files were not loaded. CUDA functionality is disabled. Set env variable CUDA_LAZY_DEBUG to get messages during startup. at caffe2/aten/src/THC/THCGeneral.cpp:54
```
Differential Revision: D18054369
fbshipit-source-id: f1d06af88b780a24ca3373a7a133047a2cfe366e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28300
- Remove trivial stringstream from ScriptModuleSerializer::writeCode;
I didn't include this in earlier changes to avoid a merge conflict
with an earlier change.
- Remove underscore from QualifiedName var ref; no difference in
current use, but more correct.
ghstack-source-id: 92206909
Test Plan:
Benchmark: buck build mode/opt experimental/jeremyl/c2:
Correctness: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18012511
fbshipit-source-id: 7db057d77741cf69c4f2fed560771c3201da19ed
Summary:
Initial kernel support added for optimized NHWC tensor.
TODO: currently backwards kernel spits out tensor with NHWC stride.
Unfortunately autograd restores grad to contiguous (in either copy or add). This
makes real perf tuning annoying to do. (since I cannot easily measure end-to-end
time in my python script)
My current kernel is blazing fast comparing to the original NCHW kernel in fp16,
since I avoided atomicAdd. I'll finish perf tuning after we merged some future
PR expanding NHWC support in the core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24396
Differential Revision: D18115941
Pulled By: VitalyFedyunin
fbshipit-source-id: 57b4922b7bf308430ffe1406681f68629baf8834
Summary:
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: [pytorch-cpu-strided-complex extension](https://gitlab.com/pytorch-complex/pytorch-cpu-strided-complex)
Changes so far:
- [x] Renamed references to variable "I" that may be confused for "I" defined in complex.h. I did this to avoid crazy CI failures messages as complex.h is included by more source files.
- aten/src/ATen/native/cpu/Loops.h (Renamed I to INDEX)
- aten/src/ATen/native/cuda/Loops.cuh (Renamed I to INDEX)
- aten/src/ATen/core/ivalue_inl.h (Renamed I to INDEX)
- c10/util/Array.h (Renamed I to INDEX)
- c10/util/C++17.h (Renamed I to INDEX)
- c10/util/Metaprogramming.h (Renamed I to INDEX)
- c10/util/SmallVector.h (custom renaming)
- [x] Added complex support of Linear Algebra Ops.
- SVD needed to be modified to support mixed data types
- Example U(std::complex<double)), S(double), V(std::complex<double>)
- See before and after benchmark below (No observable change in performance).
- [x] Added complex support of Reduce Ops.
- var/std computations could have been faster if it was possible to interpret std::complex<double> Tensor as a double Tensor.
- [x] Added complex derivative support for autograd functionality.
- derivatives are the same as defined by numpy autograd library for real(), imag(), conj(), angle(). These functions only affect complex numbers.
- derivative of abs() has not been modified to not interfere with existing code.
- Autograd defines abs() for complex numbers and fabs() for real numbers. I will look into this further down the road.
----------------------------------------
PyTorch/Caffe2 Operator Micro-benchmarks Before Changes
----------------------------------------
Tag : short
Benchmarking PyTorch: svd
Mode: Eager
Name: svd_M512_N512
Input: M: 512, N: 512
Forward Execution Time (us) : 162339.425
Forward Execution Time (us) : 162517.479
Forward Execution Time (us) : 162847.775
----------------------------------------
PyTorch/Caffe2 Operator Micro-benchmarks After Changes
----------------------------------------
Tag : short
Benchmarking PyTorch: svd
Mode: Eager
Name: svd_M512_N512
Input: M: 512, N: 512
Forward Execution Time (us) : 162032.117
Forward Execution Time (us) : 161943.484
Forward Execution Time (us) : 162513.786
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27653
Differential Revision: D17907886
Pulled By: ezyang
fbshipit-source-id: a88b6d0427591ec1fba09e97c880f535c5d0e513
Summary:
Following from https://github.com/pytorch/pytorch/issues/28479 let's remove the type information from the docstrings of these functions as well, making them valid python signatures matching the other signatures in the docstrings for the torch API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28556
Differential Revision: D18115641
Pulled By: ezyang
fbshipit-source-id: e4c3d56981b16f5acabe8be7bfbe6ae506972d7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28226
# Goal
Rendezvous step should be the first step not only for `init_process_group` but also for `init_model_parallel`.
The road block is that there is special step in `init_process_group` where arguments `rank`, `world_size` passed to `init_process_group(..)` are appended to `init_method` url string.
We need to make this argument appending step common and re-usable for both `init_process_group` and `init_model_parallel`.
# Solution
- Put argument appending inside of `rendezvous` function.
- Remove manual `init_method` url construction. Delegate the responsibility to the `rendezvous` function.
- Use the `rendezvous` function for any `RpcAgent`.
Test Plan:
```
buck test mode/dev-nosan caffe2/test:c10d
```
```
buck test mode/dev-nosan caffe2/test:rpc_fork -- test_invalid_names
buck-out/gen/caffe2/test/rpc_fork\#binary.par -r test_worker_id
```
```
buck test mode/dev-nosan caffe2/torch/fb/distributed/pytorch/tests:test_rpc -- test_sync_rpc
```
```
buck test mode/dev-nosan caffe2/torch/fb/rendezvous:zeus_test
```
```
buck test mode/dev-nosan //caffe2/torch/fb/distributed/modules/tests:test_sharded_pairwise_attention_pooling -- test_single_trainer_multiple_pss
```
Differential Revision: D5524494
fbshipit-source-id: 50be58ec3c928621b0874b044ef4a1640534d8ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28025
Add a PyFuture type which is wrapper of either an OwnerRRef or a
jit::Future. The difference between PyFuture and jit::Future is that
PyFuture can return an custom py::object type.
Test Plan: Imported from OSS
Differential Revision: D17936746
Pulled By: mrshenli
fbshipit-source-id: a7451af3993d98aeab462ffd5318fc6d28f915c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27943
This is step 1 to make PyRRef::toHere() non-blocking on caller.
Test Plan: Imported from OSS
Differential Revision: D17936747
Pulled By: mrshenli
fbshipit-source-id: 7cf60e5804e72bdc28f0135fed4d7fdce05ea38a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28243
When building static libs version of pytorch 1.3 on windows (msvc v141), program crashes with bad memory reference because `fusion_backends_lock_` has not been initialized yet.
Test Plan:
sandcastle green,
tested locally on MSVC static builds that this fixes initialization.
Differential Revision: D17985919
fbshipit-source-id: ebd6178dedf5147d01c2c1754a0942a1bbbc7e34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28469
### Summary
As described [here](https://github.com/pytorch/pytorch/pull/28405), This PR is the second one that contains scripts for setting up the benchmark projects.
### Test Plan
Don't break CI jobs unless they are flaky.
Test Plan: Imported from OSS
Differential Revision: D18097248
Pulled By: xta0
fbshipit-source-id: 6f9d1275a07aecae21afd81d5e90a89a75d0270f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28422
The TH implementation had two differences:
1) It explicitly checked for null storages; this isn't supported anymore so can be removed.
2) It collapsed all empty tensors to the same shape for the purpose of checking. This was introduced to keep BC when we introduced N-dimensional empty tensors,
but since it's been quite a long time since we've had N-dimensional empty tensors and the CUDA implementation didn't support this, we should get rid of it.
Test Plan: Imported from OSS
Differential Revision: D18061916
Pulled By: gchanan
fbshipit-source-id: 1a54cf9ea4fcb35b358a9ab57f84eff059ff1e7b
Summary:
Sequential does not like modules added to it to take Tensor&
(const Tensor& and Tensor are both OK).
Functional and others use Tensor when they want to potentially
change things in-place.
This changes ReLU and friends to also do that.
Unfortunately, this seems to be BC breaking on the ABI level.
On the other hand, use of the module ReLU seems rare enough outside
Sequential (in particular in C++ models, the standard seems to be
to use torch::relu instead).
is the BC breaking OK here? (yf225 or anyone else)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28501
Differential Revision: D18089978
Pulled By: yf225
fbshipit-source-id: ac9aba6dc2081117dece57cd8a15bafe14ec8f51
Summary:
Changelog:
- Changes the behavior of returning a zero tensor when eigenvectors=False, matching behavior of torch.eig
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28338
Test Plan: - test_symeig has been modified appropriately for this change
Differential Revision: D18085280
Pulled By: ezyang
fbshipit-source-id: 43129a96dd01743997157974100e5a7270742b46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27254
`MultiplicativeLR` consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
Test Plan: Imported from OSS
Differential Revision: D17728088
Pulled By: vincentqb
fbshipit-source-id: 1c4a8e19a4f24c87b5efccda01630c8a970dc5c9
Summary:
The types don't appear in the docstrings for other functions in the `torch` namespace so I think this was included here because of a copy/paste error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28479
Differential Revision: D18086150
Pulled By: ezyang
fbshipit-source-id: 2481bccba6df36b12779a330f8c43d4aea68495f
Summary:
This is a port of the TH `SmoothL1Criterion` to ATen using TensorIterator. The forward implementation has been placed in BinaryOpsKernel.cpp/.cu while the backward version was added to PointwiseOpsKernel.cpp/.cu. CPU performance has improved for both forward & backward path. With CUDA the performance of the forward pass has slightly degraded compared to the TH
implementation (see benchmark results).
### Questions:
1. Is the storage location of the implementation ok (I followed https://github.com/pytorch/pytorch/pull/26529) or should we create a separate .cpp/.h file pair for each operator implementation (e.g. to keep things together)?
2. The GPU forward-pass now seems to take consistently longer than the old version. Any ideas what we could try to bring it on par with the old impl?
## WITH patch benchmark result:
```
CPU warmup 1000 took 0.00018124299822375178
CPU warmup 10000 took 0.00021713999740313739
CPU warmup 100000 took 0.0016273759974865243
CPU warmup TOTAL time 0.0020758909959113225
CPU forward 1000 took 6.229899736354128e-05
CPU forward 10000 took 0.00013340599980438128
CPU forward 100000 took 0.0008730469999136403
CPU forward 1000000 took 0.011010036003426649
CPU forward 10000000 took 0.11133221499767387
CPU forward 100000000 took 1.0425375220002024
CPU forward TOTAL time 1.1660894790038583
CPU for- & backward 1000 took 0.0002662249971763231
CPU for- & backward 10000 took 0.00023712700203759596
CPU for- & backward 100000 took 0.002531945996452123
CPU for- & backward 1000000 took 0.010394354998425115
CPU for- & backward 10000000 took 0.23814761800167616
CPU for- & backward 100000000 took 1.2651235049997922
CPU for- & backward TOTAL time 1.516897434994462
GPU warmup 1000 took 0.00020941899856552482
GPU warmup 10000 took 8.128300396492705e-05
GPU warmup 100000 took 8.551499922759831e-05
GPU warmup TOTAL time 0.0004199420000077225
GPU forward 1000 took 7.060499774524942e-05
GPU forward 10000 took 7.116600318113342e-05
GPU forward 100000 took 9.825800225371495e-05
GPU forward 1000000 took 0.000499356996442657
GPU forward 10000000 took 0.002032470001722686
GPU forward 100000000 took 0.018638986002770253
GPU forward TOTAL time 0.02148268099699635
GPU for- & backward 1000 took 0.00035967300209449604
GPU for- & backward 10000 took 0.00032710300001781434
GPU for- & backward 100000 took 0.0003689270015456714
GPU for- & backward 1000000 took 0.0007732619997113943
GPU for- & backward 10000000 took 0.02127284000016516
GPU for- & backward 100000000 took 0.2022330649997457
GPU for- & backward TOTAL time 0.2254496300010942
```
## WITHOUT patch benchmark result:
```
CPU warmup 1000 took 0.00011545199959073216
CPU warmup 10000 took 0.00016227000014623627
CPU warmup 100000 took 0.0013456509987008758
CPU warmup TOTAL time 0.001648657998885028
CPU forward 1000 took 2.627600042615086e-05
CPU forward 10000 took 0.00015939700097078457
CPU forward 100000 took 0.001139313004387077
CPU forward 1000000 took 0.013769682998827193
CPU forward 10000000 took 0.13163026500114938
CPU forward 100000000 took 1.321879123999679
CPU forward TOTAL time 1.4687001089987461
CPU for- & backward 1000 took 0.0002569290008977987
CPU for- & backward 10000 took 0.00033315900509478524
CPU for- & backward 100000 took 0.0016096779945655726
CPU for- & backward 1000000 took 0.014474845003860537
CPU for- & backward 10000000 took 0.1564881520025665
CPU for- & backward 100000000 took 1.5787935900007142
CPU for- & backward TOTAL time 1.7521004869995522
GPU warmup 1000 took 0.00025611399905756116
GPU warmup 10000 took 0.00014123699656920508
GPU warmup 100000 took 0.00012580600014189258
GPU warmup TOTAL time 0.0005591579974861816
GPU forward 1000 took 0.00031183200189843774
GPU forward 10000 took 0.00011483799607958645
GPU forward 100000 took 0.00010807999933604151
GPU forward 1000000 took 0.0007842139966669492
GPU forward 10000000 took 0.0017624700049054809
GPU forward 100000000 took 0.01519905700115487
GPU forward TOTAL time 0.018341148999752477
GPU for- & backward 1000 took 0.00047569099842803553
GPU for- & backward 10000 took 0.0003539700046530925
GPU for- & backward 100000 took 0.000808880002296064
GPU for- & backward 1000000 took 0.001639469999645371
GPU for- & backward 10000000 took 0.021154599002329633
GPU for- & backward 100000000 took 0.19268552300491137
GPU for- & backward TOTAL time 0.2172460189976846
```
### Code used for perforrmance testing
```
import torch
import torch.nn.functional as F
import torch.nn as nn
from timeit import default_timer
torch.manual_seed(0)
cpu = torch.device('cpu')
gpu = torch.device('cuda')
loss_fn = F.smooth_l1_loss
def run_benchmark(name, depth, require_grad, device, fn):
total_start = default_timer()
y = None
a = None
for i in range(3, 3 + depth):
start = default_timer()
n = 10 ** i
a = torch.rand(n, requires_grad=require_grad, device=device)
b = torch.rand(n, device=device)
y = fn(a, b)
y.cpu() # get result (potentially wait for gpu)
if a.grad is not None:
a.grad.cpu()
end = default_timer()
print('{} {} took {}'.format(name, n, end-start))
total_end = default_timer()
print('{} TOTAL time {}'.format(name, total_end-total_start))
def fwd_only(a, b):
out = loss_fn(a, b)
return out
def fwd_bck(a, b):
out = loss_fn(a, b)
out.backward()
return out
def sanity_check(name, device):
print('{} Operator sanity check:'.format(name))
a = torch.randn(16, requires_grad=True, device=device)
b = torch.randn(16, device=device) * 2
out = loss_fn(a, b)
print('out', out)
out.backward()
print(a.grad)
print('double backward')
loss = loss_fn(a, b)
loss2 = torch.autograd.grad(loss, a, create_graph=True)
z = loss2[0].sum()
print(z)
z.backward()
print('ok')
print()
print('PyTorch version:', torch.__version__)
sanity_check('CPU', cpu)
if torch.cuda.is_available():
sanity_check('GPU', gpu)
print()
run_benchmark('CPU warmup', 3, False, cpu, fwd_only)
run_benchmark('CPU forward', 6, False, cpu, fwd_only)
run_benchmark('CPU for- & backward', 6, True, cpu, fwd_bck)
print()
if torch.cuda.is_available():
run_benchmark('GPU warmup', 3, False, gpu, fwd_only)
run_benchmark('GPU forward', 6, False, gpu, fwd_only)
run_benchmark('GPU for- & backward', 6, True, gpu, fwd_bck)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27962
Differential Revision: D18061942
Pulled By: ezyang
fbshipit-source-id: 0d1fc528b59d47d4773b03240c3368db021cb9db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28208
Backend extensions should call torch::RegisterOperators, not globalATenDispatch().
If the op is still on globalATenDispatch, then torch::RegisterOperators will do the right thing and forward it to globalATenDispatch.
ghstack-source-id: 92436988
Test Plan: waitforsandcastle
Differential Revision: D17975369
fbshipit-source-id: 0d4bd5e4e5b86e6dcfba527a7d11c25508896ac1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28184
Out overloads of operators have a different `name` and `operator_name`. Fix the codegen for them.
ghstack-source-id: 92436987
Test Plan: A diff stacked on top enables `use_c10_dispatcher` for out operators. Doesn't work without but works with this diff.
Differential Revision: D17969013
fbshipit-source-id: 7b1118c9a4a36997e7375fac8d870ff08e7ff453
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28181
These types are needed to parse the schemas from native_functions.yaml.
Note: This doesn't actually add the functionality to JIT, it only makes the parser pass.
ghstack-source-id: 92436989
Test Plan: waitforsandcastle
Differential Revision: D17969014
fbshipit-source-id: 41ebe256baec81ed8fb165e7b7cffa5160d285c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28207
Enabling c++14 causes these lines to fail with the error "error: the last argument must be an 8-bit immediate".
So let's make them an 8 bit immediate before we enable C++14.
ghstack-source-id: 92419812
Test Plan: Enabling C++14 before this PR shows the error, after this PR does not.
Differential Revision: D17975236
fbshipit-source-id: aa53cdb2d38d89ede2212ed7374fedeb5896f254
Summary:
Fix Slice/Select trace arguments. This PR stashes arguments to functions in order to avoid tracing them as constants.
This PR depends on a fix for select op in PR:
https://github.com/pytorch/pytorch/pull/25273
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26549
Reviewed By: hl475
Differential Revision: D17623851
Pulled By: houseroad
fbshipit-source-id: ae314004266688d2c25c5bada2dcedbfc4f39c5b
Summary:
Codemod to remove all thread.isAlive() since it throws a warning that is breaking some tests that monitor the output of their cli's
is_alive() was added in python 2.6 this is super safe
This is a codemod I don't care if the code supports python3, just that its python code
Test Plan: unittests
Reviewed By: cooperlees
Differential Revision: D18069520
fbshipit-source-id: 4ca4dcb541c0b0debeb194aba5d060152ad0ef0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28295
Previous PR was landed in a broken state
Test Plan: Imported from OSS
Differential Revision: D18066217
Pulled By: bwasti
fbshipit-source-id: 665de7b28145885d6b01f5f212897ac3f8f6270f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28402
Revert PR #27274 as it's absorbed by PR #28398.
Test Plan: - make sure all mobile models can load and run
Differential Revision: D18055993
Pulled By: ljk53
fbshipit-source-id: 0d0ffdf2cfae18577189d3b69de15fa892210916
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28400
This is yet-another fix to issue #26764.
Some mobile models call tensor.detach() which won't work with
static-dispatch mode. We disable autograd for static-dispatch / mobile
build anyway so it seems fine to make these op-ops.
Test Plan: - With stacked PRs, confirmed it can run failed models now.
Differential Revision: D18055852
Pulled By: ljk53
fbshipit-source-id: bff3a55fee2ca68ac5333fb4978c11fd18dfcc91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28399
This is also to address issue #26764
Turns out it's incorrect to wrap the entire forward() call with
NonVariableTypeMode guard as some JIT passes has is_variable() check and
can be triggered within forward() call, e.g.:
jit/passes/constant_propagation.cpp
Since now we are toggling NonVariableTypeMode per method/op call, we can
remove the guard around forward() now.
Test Plan: - With stacked PRs, verified it can load and run previously failed models.
Differential Revision: D18055850
Pulled By: ljk53
fbshipit-source-id: 3074d0ed3c6e05dbfceef6959874e5916aea316c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28405
### Summary
As discussed with AshkanAliabadi and ljk53, the iOS TestApp will share the same benchmark code with Android's speed_benchmark_torch.cpp. This PR is the first part which contains the Objective-C++ code.
The second PR will include the scripts to setup and run the benchmark project. The third PR will include scripts that can automate the whole "build - test - install" process.
There are many ways to run the benchmark project. The easiest way is to use cocoapods. Simply run `pod install`. However, that will pull the 1.3 binary which is not what we want, but we can still use this approach to test the benchmark code. The second PR will contain scripts to run custom builds that we can tweak.
### Test Plan
- Don't break any existing CI jobs (except for those flaky ones)
Test Plan: Imported from OSS
Differential Revision: D18064187
Pulled By: xta0
fbshipit-source-id: 4cfbb83c045803d8b24bf6d2c110a55871d22962
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28231
Fix: https://github.com/pytorch/pytorch/issues/28010
A mixed-type index assignment that would have been an error in 1.2 was unintentionally made possible (with incorrect results) in 1.3. This PR restores the original behavior.
This is BC-breaking because:
```
a = torch.ones(5, 2, dtype=torch.double)
b = torch.zeros(5, dtype=torch.int)
a[:, [1]] = b.unsqueeze(-1)
```
now raises an error (as in 1.2) whereas it did not in 1.3.
Test Plan: Imported from OSS
Differential Revision: D18049637
Pulled By: nairbv
fbshipit-source-id: 11a37dc98364ae70aac0e9dbc090d2a500aa7ccc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28189
This makes it a separate createNamed function. The existing API resulted
in poor usage in fbcode, which in turn caused bugs in TorchScript programs.
Test Plan: Imported from OSS
Differential Revision: D17970220
Pulled By: zdevito
fbshipit-source-id: 59b082a726f56bec1c8d10d410db829f4aa271ea
Summary:
This is a port of the CPU version of TH MultiLabelMarginCriterion to ATen.
Benchmark results ([source of script used](https://gist.github.com/andreaskoepf/ce96eedb09e9480ae2263d31822ef26e)):
Slightly slower forward (probably acceptable), slightly faster forward & backward combination.
### WITH patch:
```
CPU forward 1000 took 0.0002544010058045387
CPU forward 10000 took 0.0022866200015414506
CPU forward 100000 took 0.02240650000749156
CPU forward 1000000 took 0.22985397902084514
CPU forward 10000000 took 2.227811124001164
CPU forward TOTAL time 4.282580643019173
CPU for- & backward 1000 took 0.0006969539972487837
CPU for- & backward 10000 took 0.004804529016837478
CPU for- & backward 100000 took 0.07736711099278182
CPU for- & backward 1000000 took 0.5985556179948617
CPU for- & backward 10000000 took 4.761040163983125
CPU for- & backward TOTAL time 7.318476865999401
```
### WITHOUT patch:
```
CPU forward 1000 took 0.00026982801500707865
CPU forward 10000 took 0.002569925010902807
CPU forward 100000 took 0.024335263995453715
CPU forward 1000000 took 0.2151200629887171
CPU forward 10000000 took 2.114590842014877
CPU forward TOTAL time 4.184845258976566
CPU for- & backward 1000 took 0.0007158009975682944
CPU for- & backward 10000 took 0.005468863993883133
CPU for- & backward 100000 took 0.05931608600076288
CPU for- & backward 1000000 took 0.5732014369859826
CPU for- & backward 10000000 took 5.2500802429858595
CPU for- & backward TOTAL time 7.7646528169861995
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28205
Differential Revision: D18001407
Pulled By: ezyang
fbshipit-source-id: 68cbd9ce0aacf99dd8c44fb4da9c09b3ffc1e59a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27716
This uses the gfile filesystem abstraction that allows for writing to any filesystem that satisfies the interface (including S3).
Test Plan: Tested with local files and using internal S3 equivalent.
Reviewed By: natalialunova
Differential Revision: D17530694
fbshipit-source-id: c1f88c035fc03d91186b39092e42489f1c03d2cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28356
### Summary
I'm working on setting up a benchmark test project for iOS, which will reuse this Fastlane file. This PR removes the "cert install" code from "before_all" to a standalone lane target.
### Test Plan
- don't break any existing CI jobs
Test Plan: Imported from OSS
Differential Revision: D18053675
Pulled By: xta0
fbshipit-source-id: e4760a8494916c410af19ca43f040fc463551d11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27791
This is the first part of the change. The next ones will amend more :)
Test Plan: Imported from OSS
Differential Revision: D17889913
Pulled By: z-a-f
fbshipit-source-id: ff74007903dd789d4c68684e83b50c0c86a25149
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28295
Previous PR was landed in a broken state
Test Plan: Imported from OSS
Differential Revision: D18012804
Pulled By: bwasti
fbshipit-source-id: 9b6acdeb0656d2d7911b0ed63f4d47ecca5473b9
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/28327
Test Plan:
Failed as expected and the full protobuf is logged
f145060005
Reviewed By: ffjiang, wx1988
Differential Revision: D17975560
fbshipit-source-id: 5375acffc1f9dede16622b06eb58b6c3a26ebe5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28388
The clang-tidy script diffs the PR head ref against the base ref so that
it works only on changed lines. If the base ref is a stale `master`,
then the script will fetch upstream `master` and potentially report
unrelated changes in the diff
Use the base sha instead of ref so that the revision that the script
diffs against is stable.
Test Plan: Imported from OSS
Differential Revision: D18051363
Pulled By: suo
fbshipit-source-id: 80ead2f837e2d6244245ed7b576e84a99f0ea035
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26616
Implement C++17 std::string_view for C++11.
This is useful for compile time type name retrievaly which I'm going to stack on top of this.
It is also useful to replace `const std::string&` with throughout our codebase.
ghstack-source-id: 92100314
Test Plan: unit tests
Differential Revision: D17518992
fbshipit-source-id: 48e31c677d51b0041f4b37e89a92bd176d4a0b08
Summary:
This is actually a bug in both testing and the average pool implementation.
In testing, we used the quantized value as float input and failed to padding the value with zero_point.
In op implementation, the size for averaging is not correct for padding case when count_include_pad is true.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28260
Differential Revision: D18039960
Pulled By: lly-zero-one
fbshipit-source-id: 7b5d34498b60f5d574a276a22798c9f576944734
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27951
we want to clean up the distributed autograd context across the other nodes when a single node is done (here done means exited the context manager `with dist_autograd.context() as context_id: ...`).
This PR does a few things to implement the above:
1) Add classes to encapsulate messages for requesting this context release and the response
2) Handling of this request in `request_callback_impl.cpp`. When we receive this request, we get the context from a given context_id and release it.
3) RPC call in `DistAutogradContainer::releaseContext` to send this command. This currently does not wait for an ack or implement any sort of retrying. We send the RPC to all the workerIds we have come into contact with (implemented in https://github.com/pytorch/pytorch/pull/26324)
4) Relevant unit tests
In follow up PRs, we will add error checking + retries for this call.
ghstack-source-id: 92269279
Test Plan: Added/modified unit tests in `test/dist_autograd_test.py`
Differential Revision: D17920137
fbshipit-source-id: 7403512ab5fcbc28d21c548b2e45319dd472e26a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27675
This leverages QNNPACK global average pooling to perform torch.mean on input feature maps
Currently can only support mean along HxW plane in NCHW tensor.
Test Plan:
python test/test_quantized.py TestQuantizedOps.test_mean
Imported from OSS
Differential Revision: D17989336
fbshipit-source-id: 8d4cbcbed5f146290b1580d26e5b45359d293761
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28312
1. currently if autograd context is valid, even tensors do not require grads and grads function are not attached.
it still send rpc with autograd meta. This is not ideal.
This diff makes some change to make sure rpc with autograd meta is sent only if autograd context is valid and tensors require grads
2. meanwhile create a utiliy to attach autograd info and functions as needed
3. add autograd send/recv functions for python rpc call
4. make changes to support nested python rpc calls
5. disallow nested dist autograd context (was landed in #27022)
ghstack-source-id: 92240367
Test Plan: unit tests
Differential Revision: D18017554
fbshipit-source-id: dbe79a5171063901a78a9b3322b9b31c159d098d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28326
- Message::type() should return a MessageType, not const MessageType&,
since MessageType is just an enum.
- Add moveTensors() method for parallelism with movePayload().
ghstack-source-id: 92236443
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D18021692
fbshipit-source-id: 5b2f5806f104a221de8df0282f3e395d15e5bfe4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28297
Splitting data parallel tests out of test_nn.py since its easier to
manage and track these tests separately and failures can be routed to
appropriate POCs.
Test Plan: waitforbuildbot
Differential Revision: D18011663
fbshipit-source-id: 17ebf7c04e7dc7ff4c8d38458daab5b911bed75d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28242
There is no reason to have it in a general API of Module/Method - it's
just another graph pass. It was there because some time ago modules were
not first class and all graphs were lowered. After that changed, this
API was added for easier transition, but now we don't need it anymore.
Test Plan: Imported from OSS
Differential Revision: D17986724
Pulled By: ZolotukhinM
fbshipit-source-id: 279a1ec450cd8fac8164ee581515b09f1d755630
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28229
We have `torch::RegisterOperators` for custom ops. `torch::jit::RegisterOperators` had a dual state of being able to register custom ops if called one way and being able to register pure JIT ops if called another way.
This is confusing because you end up in different operator libraries depending on which API exactly you're using.
This PR removes the ability for torch::jit::RegisterOperators to register custom ops and forces people to use the new torch::RegisterOperators.
This was already deprecated before but we now remove it.
ghstack-source-id: 92137305
Test Plan: unit tests
Differential Revision: D17981895
fbshipit-source-id: 0af267dfdc3c6a2736740091cf841bac40deff40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28285
1. Add generate-wrapper.py to route different code path base on different platform.
2. Append all the generated wrapper files by running generate-wrapper.py, and they will be used in the next diff for buck build targets.
ghstack-source-id: 92071247
Test Plan: Will be tested in the next diff when these files are linked.
Reviewed By: dreiss
Differential Revision: D17967339
fbshipit-source-id: 8af88af9e8d2e4640bcf9d29c4daf10666aa88dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27576
1. currently if autograd context is valid, even tensors do not require grads and grads function are not attached.
it still send rpc with autograd meta. This is not ideal.
This diff makes some change to make sure rpc with autograd meta is sent only if autograd context is valid and tensors require grads
2. meanwhile create a utiliy to attach autograd info and functions as needed
3. add autograd send/recv functions for python rpc call
4. make changes to support nested python rpc calls
5. disallow nested dist autograd context (was landed in #27022)
ghstack-source-id: 92154535
Test Plan: unit tests
Differential Revision: D17819153
fbshipit-source-id: 37d8a85855bf591f2f2da48d475a06e870a30ea1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28265
Fix the difference in dper3 and dper2 when regressionLoss is used.
Test Plan:
test using dper2 model id f134632386
Comparison tool output before change:
```
FOUND OP DIFFERENT WITH DPER2!!!
OP is of type ExpandDims
OP inputs ['supervision:label']
OP outputs ['sparse_nn/regression_loss/mean_squared_error_loss/ExpandDims:0']
===============================
Finished all dper3 ops, number of good ops 11, bad ops 1, skipped 26
run_comparison for dper2 / dper3 nets running time: 0.0020143985748291016
result type: <class 'NoneType'> result: None
```
After change:
```
FOUND OP DIFFERENT WITH DPER2!!!
OP is of type ExpandDims
OP inputs ['sparse_nn_2/regression_loss_2/mean_squared_error_loss_8/Squeeze:0_grad']
OP outputs ['sparse_nn_2/over_arch_2/linear_2/FC_grad']
===============================
Finished all dper3 ops, number of good ops 19, bad ops 1, skipped 16
run_comparison for dper2 / dper3 nets running time: 0.0017991065979003906
result type: <class 'NoneType'> result: None
```
dper2 label part of net P111794577
dper3 label part of net after change P116817194
Reviewed By: kennyhorror
Differential Revision: D17795740
fbshipit-source-id: 9faf96f5140f5a1efdf2985820bda3ca400f61fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28246
Updated the reference fp32 implementation to use the dequantized input tensor to correctly take padded values into account
Test Plan:
python test/test_quantized.py TestQNNPackOps.test_avg_pool2d
Imported from OSS
Differential Revision: D17989334
fbshipit-source-id: 848ce78713280f529f71ff48e930db8de18abc62
Summary:
I know this is really a minor one and the list of people to mention will be significantly larger in the future. Nevertheless I would love to see my name written in correct international spelling (the strange German o-umlaut in my name becomes oe).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28281
Differential Revision: D18007518
Pulled By: ezyang
fbshipit-source-id: 1d03065636d7f65ac6b376690256c0d021482958
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28230
This change improves the pickling small data benchmark by roughly 30%.
(25.8usec -> 18.05usec).
One of the main issues was that we were spending 25%+ of the cpu profile
time in std::[o]stringstream constructors alone.
Two main parts
- Change some std::stringstream to std::ostringstream, when they
showed up on hot-ish paths, and it was trivial to convert them.
Roughly 27% of the std::stringstream constructor time is spent
building the constituent std::basic_istream. If the istream isn't
needed, don't construct it.
- For a couple of very hot paths (e.g. Pickler::pushGlobal), just
convert to traditional string::append(). std::ostringstream is
convenient, but not particularly efficient.
ghstack-source-id: 92153103
Test Plan:
Benchmarking: buck build mode/opt experimental/jeremyl/c2:SerializationBench
Correctness: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D17982181
fbshipit-source-id: 7fd4d267293231244c10c1e5b8f4951a7a3d852f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28263
When looking at profiles of deserializing small data from torch::load(),
we found some straightforward string-related changes that in aggregate
improve the base time by 25%.
One of the main problems was over-use of std::stringstream - the
constructors alone were 18%+ of the time spent. This change improves
unpickling/deserializing by converting a handful of the hottest
usecases from the profiles:
- unpickler's readString() goes from 10.3% of time to mostly out of the picture
- QualifiedHame constructor (particularly Join call) was 8.9% of time,
but afterwards disappears from the profiles.
- getRecordID/hasRecord were ~5% each, but also get somewhat smaller.
ghstack-source-id: 92158727
Test Plan:
Benchmark in buck build mode/opt experimental/jeremyl/c2:SerializationBench
Correctness in buck test mode/dev-nosan caffe2/test/...
Differential Revision: D17997056
fbshipit-source-id: fc6d6c7da7557ff23c8e8c7dbe4c060abf860018
Summary:
Closes https://github.com/pytorch/pytorch/issues/22444.
It seemed low priority, but the necessary change seems trivial, so I made this PR anyway.
Thanks in advance for reviewing this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28219
Differential Revision: D17989123
Pulled By: ezyang
fbshipit-source-id: d122b50e90b63dc5d2eeb7689b5ea29d973424ed
Summary:
This PR adds ```MSELoss```, ```KLDivLoss``` and ```BCELoss```. The tests for ```BCELoss``` fail with the following error:
```
unknown file: Failure
C++ exception with description "autograd_meta() INTERNAL ASSERT FAILED at /home/shahriar/Contrib/pytorch/c10/core/TensorImpl.h:533, please report a bug to PyTorch. set_requires_grad is not implemented for Tensor (set_requires_grad at /home/shahriar/Contrib/pytorch/c10/core/TensorImpl.h:533)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27156
Differential Revision: D17960323
Pulled By: yf225
fbshipit-source-id: 84b8431064f2f573679c03a8d7994e3e2f81a4d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28114
This is followup on the pickler buffering change.
ghstack-source-id: 92019521
Test Plan: This just adds an static assert, hence if it builds, we're good.
Differential Revision: D17955006
fbshipit-source-id: d7fd69935d23f39db18029703f63c8f18d23047a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28180
ScriptModuleSerializer::writeCode() is the only place during torch::save()
serialization where we attempt to zip compress records.
This change avoids compressing these string records if they are
sufficiently small - e.g. in the example I looked at:
- the strings were 123 and 28 bytes, respectively.
- the cost in the compression routines was 16.5% of the torch::save() cost.
(we're building a huffman table for a 28 byte string).
We'd save time and not significantly affect the space if we add these
1-line conditional compressions, rather than making it unconditional.
ghstack-source-id: 92104517
Test Plan:
Benchmark: experimental/jeremyl/c2:SerializationBench
Correctness: normal buck mode/dev-nosan caffe2/test/...
Differential Revision: D17967995
fbshipit-source-id: 7ff934388533645dc987e105c814ffe6324f4596
Summary:
This was referenced in the `RNN` docs but wasn't actually assigned
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28058
Pulled By: driazati
Differential Revision: D17945867
fbshipit-source-id: 0f0dc2633183a7e67a12352a2a7ac0545284666a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28250
We've been running canaries with this setting for a while
Test Plan: build, sanity canary
Reviewed By: yinghai
Differential Revision: D17872108
fbshipit-source-id: fb7f0373eac1c8aaae007a17f6ffb91482952813
Summary:
This is a port of the existing TH CPU C MultiMarginCriterion to function multi_margin_loss for ATen. ~~The ATen/C++ version is unfortunately significantly slower than the original. It is currently unclear to me what causes the performance degradation since the Tensor access is raw-pointer based similar to the original C implementation. (A first implementation I had created using TensorAccessor was even about 2x slower than the one in this PR).~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28062
Differential Revision: D17980636
Pulled By: ezyang
fbshipit-source-id: bba27a13436adff5e687d95cc984ec2386ce7a73
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27977
The only remaining reason why we couldn't move some ops from globalATenDispatch to the c10 dispatcher was that schema inference didn't support some use cases.
But actually, we don't need schema inference for these ops. By disabling it, we can move the remaining ops from globalATenDispatch to the c10 dispatcher.
ghstack-source-id: 92104807
Test Plan: waitforsandcastle
Differential Revision: D17929696
fbshipit-source-id: 05ec65b615487fde784293e3b533fa3ec09cf234
Summary:
Per title. Several stream fixes have gone in that may make this pass in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28192
Differential Revision: D17974219
Pulled By: mruberry
fbshipit-source-id: 543d000789c83711a8b4bef169a87635fda7508b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27228
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980315
Pulled By: VitalyFedyunin
fbshipit-source-id: fd5615621bc4968aa4ef2a26430c492c552ed671
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27228
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17980128
Pulled By: VitalyFedyunin
fbshipit-source-id: b2646bab72c4475b7a82bb271d204a9d96d28bd4
Summary:
This clears a lot of dead code that isn't reachable due to `AT_DISPATCH`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28133
Test Plan: - All existing tests should pass to ensure that the change is valid.
Differential Revision: D17978803
Pulled By: ezyang
fbshipit-source-id: 8fdaa74f9addb1d7987c5d625557b8a463a25500
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28063
Avoid using the iostream versions of torch::load()/torch::save(), which
incur at least one additional full data copy.
ghstack-source-id: 92059608
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D17945206
fbshipit-source-id: ba24376c13762a28e569530e3b1a939ac6f72f43
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28024
We preallocated type ids to align them with ScalarType. At that point, the maximum type id was 10 and we used 11 to specify undefined type id.
However, since then, ScalarType got more additions, 11 isn't undefined anymore, and numbers 11-15 have meaning.
caffe2::TypeIdentifier also got its separate additions, 12 and upwards have meaning that differs from ScalarType.
I'm going with the (CI-tested) assumption that caffe2::TypeIdentifier and ScalarType actually don't need to be aligned
and remove the functionality for preallocated type ids. This simplifies our type ids.
ghstack-source-id: 92051872
Test Plan: unit tests
Differential Revision: D17936165
fbshipit-source-id: 2c9df2b9b3f35b3e319641c96638321ac3433d5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28129
The previous PR in the stack removed the need to order classes/functions
or have correct import statements. This resolved circular depedency issues
that can arise when class constructors like ModuleList put new instances
of themselves in a common namespace.
This PR changes our export format to no longer produce this information.
By doing so we can make the logic signficantly simpler, since we just
keep track of an individual PythonPrint object per file.
Notes:
* PythonPrint was changed to manage its own stream/list of ranges. It
was doing this anyway internally, this just makes the API more clear.
* Since we are changing the serialization format, I also removed op_version_set.
It is now replaced with the VERSION number that written in the zip archive.
This further simplifies the code emission process.
* A test of op_version_set was removed since there is no longer any behavior
to test.
Test Plan: Imported from OSS
Differential Revision: D17961610
Pulled By: zdevito
fbshipit-source-id: ada362c4ca34d05393a1a7e799c94785ab9d9825
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27631
Add support to perform avg_pool2d on mobile. Tested using existing avg_pool2d python tests
Uses qnnpack backend, which currently only support 4 dim inputs.
Test Plan:
python test/test_quantized.py TestQNNPackOps.test_avg_pool2d
Imported from OSS
Differential Revision: D17973792
fbshipit-source-id: 95ffffb2da656ed911a618b9cb68d6b728c16c74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27925
Add extra CI builds for TBB and native builds
Test Plan: check CI
Differential Revision: D17914952
Pulled By: ilia-cher
fbshipit-source-id: 16995038909d17eb6f9c69b9bddd8f12981ad36b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27947
Don't throw exception if the requested size is the same as the currently
used one
Test Plan:
ATEN_THREADING=NATIVE python setup.py develop --cmake
Imported from OSS
Differential Revision: D17919416
fbshipit-source-id: 411f7c9bd6a46e7a003b43a200c2ce3b76453a2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27260
This PR has the following changes:
- Slot class is removed. In all use cases except `lower_graph` we really
just needed the attribute name and thus having an extra layer of
abstraction through Slot only made the code harder to understand.
- get_parameters, get_attributes, get_modules, and get_slots now return
a list of <name, item> pairs instead of a list of Slots.
Differential Revision: D17728910
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: 94781611752dd88e7fddfe8b8e0252d6ec32ba68
Summary:
Adds the overridePrecision decorator, which allows device generic tests to specify per-dtype precision overrides.
Precision is overridden on the test class instance itself, and so is thread-local (so that running multiple tests in parallel will not conflict). It can be accessed directly from a test with self.precision, as before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28131
Differential Revision: D17969774
Pulled By: mruberry
fbshipit-source-id: c4e0b71afac6bdc7cbf4e799f3054922de764820
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28057
For pushLong() in Pickler, it looks like we only use for a single use case, with a 10-byte value.
We were handling > 256 bytes incorrectly, by using a LONG4 opcode (expecting 4-byte length), but pushing 8 bytes. We could harden this handling, but rather than improve codepaths that we never expect to use, this change simply removes the incorrect codepath and adds and assert.
ghstack-source-id: 92048325
Test Plan: buck test mode/dev-nosan caffe2/test/...
Differential Revision: D17934174
fbshipit-source-id: ecc1ca37dbcc87151fc5bf2ffb6b05dff91d3667
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27251
Explicitly clean up py::objects to avoid segment faults when py::objects with CPython are cleaned up later at program exit.
See similar issues reported https://github.com/pybind/pybind11/issues/1598
and https://github.com/pybind/pybind11/issues/1493.
Our local tests also caught this segment faults if py::objects are cleaned
up at program exit. The explaination is: CPython cleans up most critical
utitlies before cleaning up PythonRpcHandler singleton, so when
PythonRpcHandler signleton cleans up py::objects and call dec_ref(), it
will crash.
The solution is to clean up py::objects earlier when Rpc agent join().
Be note that py::objects can not be cleaned up when Rpc agent is destroyed
as well, as Rpc agent is global variable and it will have same issue as
PythonRpcHandler.
close#27182
ghstack-source-id: 92035069
Test Plan: unit tests on python 3.6 and python 3.5
Differential Revision: D17727362
fbshipit-source-id: c254023f6a85acce35528ba756a4efabba9a519f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27776
I think it’s not worth it to equip other `RPCAgent` with collective communication capability, i.e. 1) have GLOO contained in `RPCAgent`, or 2) Implemented ::barrier() and ::drain() based on RPC messaging.
The only use case that does not have a master is the OSS unit test suite, caffe2/test/rpc_test.py.
I think having those unit tests to have a master is simpler than equipping `RPCAgent` with collective communication capability.
Differential Revision: D5445858
fbshipit-source-id: 56ee24703abd8c5b366829430bef657e0f1dfeba
Summary:
1) Short-circuits computing common type and type promotion logic for the common case of operands and result of the same type
2) Improves performance of checking memory overlap by returning MemoryOverlap::FULL if tensors are the same, skips the call
from TensorIterator when tensors are the same
3) Changes the default size of DimVector from 5 to 6, thus allowing it not to be resized for a common case of binary operation. `strides`
DimVector is forced to have at least 2*num_tensors elements, which for an operation with 2 inputs and one output is 6
4) If `offset` is 0 (common non-broadcasting case), don't fill `strides` vector with 0-s, because all the values will be subsequently written to.
These changes combined improve the overhead from 1.02 us to .74 us for a simple in-place operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27457
Test Plan: should be covered by existing tests
Differential Revision: D17784532
Pulled By: ngimel
fbshipit-source-id: e6a8ee58be5de14461bdbc2e2b0b6d16a96c309f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28098
Make sure that we're building with GCC 5 everywhere
ghstack-source-id: 92013998
Test Plan: waitforsandcastle
Differential Revision: D17953640
fbshipit-source-id: 26d978c60fc973c787383297d730b45d40fa300b
Summary:
This PR updates `test/cpp_api_parity/parity-tracker.md` to reflect our progress on C++ `torch::nn` parity. It also disables the C++ API parity test temporarily, and as the next step I will refactor the parity test to make it simpler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28117
Differential Revision: D17957948
Pulled By: yf225
fbshipit-source-id: 1dd836c25665f57ba8efc6d1abf671a95c03eff7
Summary:
We currently support exporting traced interpolate ops to ONNX.
Scripting interpolate op invokes aten::__interpolate in the Torch IR (instead of aten::upsample_[mode][dim]d), which we do not support yet.
This PR implements the ONNX symbolic for __interpolate() to support exporting interpolate in scripting scenarios.
Related open issue: https://github.com/pytorch/pytorch/issues/25807
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27566
Reviewed By: hl475
Differential Revision: D17817731
Pulled By: houseroad
fbshipit-source-id: e091793df503e2497f24821cf2954ff157492c75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26767
Now that we have tagged ivalues, we can accurately recover the type with
`ivalue.type()`. This reomoves the other half-implemented pathways that
were created because we didn't have tags.
Test Plan: Imported from OSS
Differential Revision: D17561191
Pulled By: zdevito
fbshipit-source-id: 26aaa134099e75659a230d8a5a34a86dc39a3c5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26572
Combined with isinstance specialization this allows a degree of polymorphic
functions to work without needing to use our weirder overload hacks.
We do not define any operators on Any, so the only thing you can do with it
is to put it in containers or type refine it using an isinstance check.
Any is restricted from appearing in non-argument position because we
cannot restore type tags if it ends up as a field in a class.
Test Plan: Imported from OSS
Differential Revision: D17530643
Pulled By: zdevito
fbshipit-source-id: f06f78ce84819f7773953a492f3d4c49219ee94c
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/25801 (see there for my verbose analysis).
As an example, for the following code:
```
import torch
torch.jit.script
def f1(x):
# type: (int, int) -> None
pass
```
this PR will change error message from this:
```
RuntimeError:
Number of type annotations (2) did not match the number of function parameters (1):
# type: (int, int) -> None
```
to this:
```
RuntimeError:
Number of type annotations (2) did not match the number of function parameters (1):
at __scratch__/example.py:4:0
torch.jit.script
def f1(x):
~~~~~~~~ <--- HERE
# type: (int, int) -> None
pass
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27195
Differential Revision: D17910902
Pulled By: driazati
fbshipit-source-id: af5c6353069d005752d6c7f0bd6a0c6db8437e55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27667
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17886548
Pulled By: ezyang
fbshipit-source-id: b99db2e163e5621920f12b150709f0defbce13da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27666
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17886544
Pulled By: ezyang
fbshipit-source-id: b9ff845cb1e5ec6f7cb4f2fa171403d555014248
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27654
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17886547
Pulled By: ezyang
fbshipit-source-id: ea0c5b40a5f34bc37657ed5d3bce9140063ddcbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27651
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17886546
Pulled By: ezyang
fbshipit-source-id: b8f7c74b1004d35690a815b0c7671a07ca612e94
Summary:
Adds support for the Bilinear layer to the C++ frontend
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26082
Differential Revision: D17954148
Pulled By: yf225
fbshipit-source-id: 5e746bdea29b00e25969cd7a22044b8059b53687
Summary:
This change adds a small fixed-size buffer to Pickler to
avoid calling writer_() and the associated downstream checks
on a per-opcode/per-byte basis.
We end up still doing a bounds check in the common case,
but the memcpy() is a fixed size. And we reduce the number
of backend calls.
In practice, this change speeds up the Pickle1MInts benchmark
for me locally from roughly 56msec to 22msec.
Additionally, in this change we convert a few pushIValue() on
typed lists, where we know the type to be double/int/boot to be
pushInt() to bypass a bit of logic.
We should additionally change the Unpickler, though keeping
this separate, since the std::function<> prototype needs to be
changed for this to work (i.e. return size_t rather than bool).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27720
Test Plan:
buck test mode/dev-nosan caffe2/test:...
Benchmark in experimental/jeremyl/c2/SerializationBench.cpp (run in mode/opt)
Differential Revision: D17847174
Pulled By: jjlilley
fbshipit-source-id: 22e5e5fd33f1a369c124ea5aac7880538e2bf6a0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/15476, supersedes https://github.com/pytorch/pytorch/issues/23496, supersedes and closes https://github.com/pytorch/pytorch/issues/27607
As explained by rgommers in https://github.com/pytorch/pytorch/issues/23496, linking against the expanded library path for `libculibos` in `cmake/Dependencies.cmake` hard codes the path into the distributed cmake files.
Instead, I only link against the targets (e.g. `caffe2::cudnn`) and move the dependency on `libculibos` into the cuda import targets declared in `cmake/public/cuda.cmake`. That file is distributed with the other cmake files and so the variable is expanded on the user's machine. I am now also using `CMAKE_STATIC_LIBRARY_SUFFIX` instead of `.a` to fix the windows issue from https://github.com/pytorch/pytorch/issues/15828. I don't have a windows setup to confirm though.
Finally, to get pytorch to compile with the extra libraries enabled, I also had to link `__caffe2_nccl` to `torch_python`; otherwise I was getting include errors as the hard coded include directory was wrong. `nccl` is built into `build` not `third_party/build`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27887
Differential Revision: D17929440
Pulled By: ezyang
fbshipit-source-id: 3db6bd94d758fca2e1d6a64f4f5eea03cc07cf64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28039
Right now, torch::save() uses std::ostream, which results in unnecessary
data copies in practice. Similar for torch::load().
Adding a std::function<size_t(const void*, size_t)> as an output option,
parallel to the existing filename and std::ostream apis, gives users the
flexibility to emit directly to a backing store.
For a simple case of appending the output to a std::string, we observe
significant benchmark savings (on order of -50%), even with the
minor std::function<> dispatch overhead. The main reason is that
std::ostringstream effectively requires 2 extra copies of the data
beyond a simple string.append lambda.
We also provide a parallel api for the load(), though this one is
slightly more complex due to the need to do arbitrary position reads.
Test Plan:
buck test mode/dev-nosan caffe2/test/...
(Basic serialization test in caffe2/test/cpp/api/serialize.cpp)
Benchmark in experimental/jeremyl/c2/SerializationBench.cpp, with D17823443
(1M time goes from 90ms -> 40ms, albeit with crc patch applied)
Differential Revision: D17939034
fbshipit-source-id: 344cce46f74b6438cb638a8cfbeccf4e1aa882d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28013
ProcessGroupAgent currently kicks off the listener thread in its
constructor. However, serving requests requires contexts to be
initialized, e.g., RRefContext and agent_ global var in api.py,
which might not be done yet when the first request arrives.
ProcessGroupAgent does not know what would be the appropriate time
to start the listener thread, hence exposing an API for higher
layer code to explicitly start listeners.
Test Plan: Imported from OSS
Differential Revision: D17932271
Pulled By: mrshenli
fbshipit-source-id: 3b408477594d4d19319e7cd08dd6f383a7ed7670
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27883
Returns early if NCCL version code returned to us is < 100, to prevent
division errors. This shouldn't actually happen since the nvidia nccl version is way past 0.1.0 but nice to have this safeguard.
ghstack-source-id: 91861083
Test Plan: Follow same process as https://github.com/pytorch/pytorch/pull/27068. Also force version to be < 100 and ensure that "Unknown NCCL Version" is returned.
Differential Revision: D17903234
fbshipit-source-id: c4df63bb1c18f1b2ef9e4cd434d4ca6c5ac556df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27761
# Problem
`rpc_test` currently only has test cases that put equal amount of work on every worker node.
The problem is that even if the `RpcAgent::sync` is implemented as an empty method. There is no termination misbehavior detected.
# Solution
At least add one imbalanced-loaded test.
ghstack-source-id: 91785984
Differential Revision: D5361435
fbshipit-source-id: 92d1f7cad61b27cdeadc2825ceab6e88d5e4b459
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28018
We need a newer GCC, GCC 4 is discontinued.
ghstack-source-id: 91953133
Test Plan: waitforsandcastle
Differential Revision: D17935286
fbshipit-source-id: 12f584d4a240453c62a854438b8579c1cbfd1e94
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27772
This replaces unchecked_unwrap_optional with unchecked_cast. This
enables the generalization of type refinement so that it works for
isinstance checks as well. This also removes unchecked_unwrap_optional from
code we generate, which is good because it is a hard op to serialize well
since it doesn't directly encode the Optional[T] being unwrapped. In contrast,
unchecked_cast always explicitly lists the type.
Test Plan: Imported from OSS
Differential Revision: D17885424
Pulled By: zdevito
fbshipit-source-id: ce81077d6fbeaf2a802a2e0b17349aca85670466
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26787
A follow up PR will remove the need to issue import statements,
or write classes in order since they are no longer needed.
This change allows the same PythonPrint class
to be used for an entire file which will be needed in that patch.
Test Plan: Imported from OSS
Differential Revision: D17566440
Pulled By: zdevito
fbshipit-source-id: 1ee896da0cdfe6a003298e1d4b0238403b9ed6dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27107
Adds memory_format keyword argument (positional for cpp).
'Preserve' behavior now follows next rules:
1) If tensor is non-overlapping and dense - output tensor will have the same strides as input tensor.
2) If not (1) and tensor is stored in the channels last format, output tensor going to have channels last format.
3) Output tensor is going to be contiguous in all other cases.
---
Dense tensor is the tensor that store values in a contiguous block of memory.
Non-overlapping tensor is the tensor in which elements occupy individual non-repetitive memory.
Test Plan: Imported from OSS
Differential Revision: D17931062
Pulled By: VitalyFedyunin
fbshipit-source-id: 2c5dd3dd05bf58a9a29f25562cd45190b009c3f9
Summary:
Right now, torch::save() uses std::ostream, which results in unnecessary
data copies in practice. Similar for torch::load().
Adding a std::function<size_t(const void*, size_t)> as an output option,
parallel to the existing filename and std::ostream apis, gives users the
flexibility to emit directly to a backing store.
For a simple case of appending the output to a std::string, we observe
significant benchmark savings (on order of -50%), even with the
minor std::function<> dispatch overhead. The main reason is that
std::ostringstream effectively requires 2 extra copies of the data
beyond a simple string.append lambda.
We also provide a parallel api for the load(), though this one is
slightly more complex due to the need to do arbitrary position reads.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27586
Test Plan:
buck test mode/dev-nosan caffe2/test/...
(Basic serialization test in caffe2/test/cpp/api/serialize.cpp)
Benchmark in experimental/jeremyl/c2/SerializationBench.cpp, with D17823443
(1M time goes from 90ms -> 40ms, albeit with crc patch applied)
Differential Revision: D17822962
Pulled By: jjlilley
fbshipit-source-id: d344a7e59707f3b30d42280fbab78f87399e4d10
Summary:
Using grad_out for CuDNN CTC loss fixes: https://github.com/pytorch/pytorch/issues/26797, https://github.com/pytorch/pytorch/issues/25833.
We also fix a cudnn incompatible change that surfaced during the testing: As of CuDNN 7.6 the semantics of the CTC loss gradients are different.
This leads us to disable CuDNN CTC for CuDNN < 7.6. To mitigate the impact on users, we convert the parameters for the native implementation if CuDNN isn't applicable (previously this would give an error.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27039
Differential Revision: D17910815
Pulled By: ngimel
fbshipit-source-id: 465b33612d3402f10c355aa7026a7e1ffaef3073
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27727
This change uses a small buffer in the Unpickler to avoid
calling reader_() byte-by-byte. Particularly, the unpickler has a
tight loop reading 1-byte opcodes.
This can be more efficient because we avoid the variable-sized
memcpy (due to templating) and std::function indirection for the
common fast path.
This improves the unpickle-1m-ints benchmark by ~20%.
This change requires changing the std::function<> interface
to Unpickler to return size_t rather than bool, but there are
only a few uses of this api.
Test Plan:
buck test caffe2/test/...
benchmark in experimental/jeremyl/c2/SerializationBench
Differential Revision: D17869980
fbshipit-source-id: 37e752744d19e12b7282252c8963355970bd4feb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27762
These are now unnecessary because all of the named tensor tests run on
regular CI.
Test Plan: - verify that there are no named tensor builds on this PR.
Differential Revision: D17915432
Pulled By: zou3519
fbshipit-source-id: 64b0c0bc41af65762fa953b273c64f1b338b80ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27458
Same as the previous diff - improve error message by passing back the
size discrepancy.
ghstack-source-id: 91864213
Test Plan: `python test/test_c10d.py`
Differential Revision: D17785296
fbshipit-source-id: f939b8091aede768ea215f69df2c83e438c430cf
Summary:
f362a5a04b3708355b08e5c1285e46ca1b537ad6 reverted
5ca612b55ec1205f98e6bc5d5e64b1bf35f3b3cd due to build time conerns (also
see https://github.com/pytorch/pytorch/issues/25254). Now we come back to this by reusing the underlying code in
comparison operators: Logical operators on non-bool variables are
essentially comparison operators that semantically output bool
values. Compared with the previous implementation, we compromise by
always applying XOR on the same input type, while output can be either
the input type or the bool type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27248
Differential Revision: D17929356
Pulled By: ezyang
fbshipit-source-id: dbac08c7614b36f05d24c69104fee9df9ca523d5
Summary: previously loss_weight is not used correctly for self-supervision branch
Test Plan: buck test mode/dev-nosan //caffe2/caffe2/fb/dper/layer_models/models/experimental/tests:tum_test
Reviewed By: xianjiec
Differential Revision: D17862312
fbshipit-source-id: 554b793a5caa3886946c54333c81a0d8a10230d9
Summary:
Fixes a few small typos in the documentation, changing "endocder" to "encoder" and "sequnce" to "sequence"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26230
Differential Revision: D17910820
Pulled By: vincentqb
fbshipit-source-id: 58c63f8dbbd8e2079201d4485a0d4ef323ecfb49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26509
We preallocated type ids to align them with ScalarType. At that point, the maximum type id was 10 and we used 11 to specify undefined type id, see https://github.com/pytorch/pytorch/pull/10139.
However, since then, ScalarType got more additions, 11 isn't undefined anymore, and numbers 11-15 have meaning.
caffe2::TypeIdentifier also got its separate additions, 12 and upwards have meaning that differs from ScalarType.
I'm going with the (CI-tested) assumption that caffe2::TypeIdentifier and ScalarType actually don't need to be aligned
and remove the functionality for preallocated type ids. This simplifies our type ids.
ghstack-source-id: 91896918
Test Plan: unit tests
Differential Revision: D17490109
fbshipit-source-id: 800c340d9d3556a99f6e3ffc33af14ad68d7cc59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26502
Create type ids at compile time instead of incrementing a counter at runtime. This is done by computing a compile time crc64 on the type name. We couldn't do this before, because we still used GCC4 and that compiler didn't support the use of `__PRETTY_FUNCTION__` in a constexpr context. However, since GCC5 this is possible and we can use this trick.
This does not change the semantics of preallocated type ids. I actually think we don't need to preallocate anymore, but I split the removal of preallocation into a separate diff to be able to test it separately.
ghstack-source-id: 91896920
Test Plan: unit tests
Differential Revision: D17488861
fbshipit-source-id: ce7b059d7c8686b69cb091a4a8beaf4b96391343
Summary:
Replaces fused TH kernels with a 2-liner of regular Tensor functions.
Benchmarking revealed that performance improves compared to PyTorch 1.2.
Refs: https://github.com/pytorch/pytorch/issues/24631, https://github.com/pytorch/pytorch/issues/24632, https://github.com/pytorch/pytorch/issues/24764, https://github.com/pytorch/pytorch/issues/24765
VitalyFedyunin
### Benchmarking results on my laptop:
## 1.4.0a0+f63c9e8 output
```
PyTorch version: 1.4.0a0+f63c9e8
CPU Operator sanity check:
tensor(0.5926, grad_fn=<MeanBackward0>)
tensor([-0.0159, -0.0170, -0.0011, -0.0083, -0.0140, -0.0217, -0.0290, -0.0262,
-0.0078, -0.0129])
double backward
tensor(-0.1540, grad_fn=<SumBackward0>)
ok
GPU Operator sanity check:
tensor(0.5601, device='cuda:0', grad_fn=<MeanBackward0>)
tensor([-0.0393, -0.0316, -0.0233, -0.0140, -0.0141, -0.0161, -0.0322, -0.0238,
-0.0054, -0.0151], device='cuda:0')
double backward
tensor(-0.2148, device='cuda:0', grad_fn=<SumBackward0>)
ok
CPU warmup 1000 took 9.025700273923576e-05
CPU warmup 10000 took 0.0009383050055475906
CPU warmup 100000 took 0.0015631120040779933
CPU warmup TOTAL time 0.0026368020044174045
CPU forward 1000 took 6.919399311300367e-05
CPU forward 10000 took 0.00014462800754699856
CPU forward 100000 took 0.0011234670091653243
CPU forward 1000000 took 0.014555767003912479
CPU forward 10000000 took 0.13409724000666756
CPU forward 100000000 took 1.246048310000333
CPU forward TOTAL time 1.3961777170043206
CPU for- & backward 1000 took 0.0003219560021534562
CPU for- & backward 10000 took 0.00037290599721018225
CPU for- & backward 100000 took 0.001975035003852099
CPU for- & backward 1000000 took 0.02621342398924753
CPU for- & backward 10000000 took 0.2944270490115741
CPU for- & backward 100000000 took 1.6856628700043075
CPU for- & backward TOTAL time 2.0091958299890393
GPU warmup 1000 took 0.0002462909906171262
GPU warmup 10000 took 9.991199476644397e-05
GPU warmup 100000 took 0.00034347400651313365
GPU warmup TOTAL time 0.0007382350013358518
GPU forward 1000 took 9.67290106927976e-05
GPU forward 10000 took 9.349700121674687e-05
GPU forward 100000 took 9.384499571751803e-05
GPU forward 1000000 took 0.0004975290066795424
GPU forward 10000000 took 0.0017606960027478635
GPU forward 100000000 took 0.003572814996005036
GPU forward TOTAL time 0.006185991995153017
GPU for- & backward 1000 took 0.00035818999458570033
GPU for- & backward 10000 took 0.0003240450023440644
GPU for- & backward 100000 took 0.0003223370003979653
GPU for- & backward 1000000 took 0.00036740700306836516
GPU for- & backward 10000000 took 0.0003690610028570518
GPU for- & backward 100000000 took 0.0003672500024549663
GPU for- & backward TOTAL time 0.002197896988946013
```
## 1.2 output
```
PyTorch version: 1.2.0
CPU Operator sanity check:
tensor(0.5926, grad_fn=<SoftMarginLossBackward>)
tensor([-0.0159, -0.0170, -0.0011, -0.0083, -0.0140, -0.0217, -0.0290, -0.0262,
-0.0078, -0.0129])
double backward
tensor(-0.1540, grad_fn=<SumBackward0>)
ok
GPU Operator sanity check:
tensor(0.5601, device='cuda:0', grad_fn=<SoftMarginLossBackward>)
tensor([-0.0393, -0.0316, -0.0233, -0.0140, -0.0141, -0.0161, -0.0322, -0.0238,
-0.0054, -0.0151], device='cuda:0')
double backward
tensor(-0.2148, device='cuda:0', grad_fn=<SumBackward0>)
ok
CPU warmup 1000 took 8.422900282312185e-05
CPU warmup 10000 took 0.00036992700188420713
CPU warmup 100000 took 0.003682684007799253
CPU warmup TOTAL time 0.004169487991021015
CPU forward 1000 took 5.521099956240505e-05
CPU forward 10000 took 0.00036948200431652367
CPU forward 100000 took 0.003762389998883009
CPU forward 1000000 took 0.03725024699815549
CPU forward 10000000 took 0.3614480490068672
CPU forward 100000000 took 3.6139175269927364
CPU forward TOTAL time 4.016912263003178
CPU for- & backward 1000 took 0.0002734809968387708
CPU for- & backward 10000 took 0.0006605249946005642
CPU for- & backward 100000 took 0.005437346000690013
CPU for- & backward 1000000 took 0.051245586000732146
CPU for- & backward 10000000 took 0.5291594529990107
CPU for- & backward 100000000 took 5.23841712900321
CPU for- & backward TOTAL time 5.8253340990049765
GPU warmup 1000 took 0.0005757809994975105
GPU warmup 10000 took 0.0004058420017827302
GPU warmup 100000 took 0.0003764610009966418
GPU warmup TOTAL time 0.0013992580061312765
GPU forward 1000 took 0.0003543390048434958
GPU forward 10000 took 0.0003633670130511746
GPU forward 100000 took 0.0004807310033356771
GPU forward 1000000 took 0.0005875999922864139
GPU forward 10000000 took 0.0016903509967960417
GPU forward 100000000 took 0.014400018990272656
GPU forward TOTAL time 0.0179396449966589
GPU for- & backward 1000 took 0.0006167769897729158
GPU for- & backward 10000 took 0.0006845899915788323
GPU for- & backward 100000 took 0.000631830989732407
GPU for- & backward 1000000 took 0.0010741150035755709
GPU for- & backward 10000000 took 0.0017265130009036511
GPU for- & backward 100000000 took 0.014847910992102697
GPU for- & backward TOTAL time 0.01965981800458394
```
### Code used for performance test
```
import torch
import torch.nn.functional as F
import torch.nn as nn
from timeit import default_timer
torch.manual_seed(0)
cpu = torch.device('cpu')
gpu = torch.device('cuda')
loss_fn = F.soft_margin_loss
def run_benchmark(name, depth, require_grad, device, fn):
total_start = default_timer()
for i in range(3, 3 + depth):
start = default_timer()
n = 10 ** i
a = torch.rand(n, requires_grad=require_grad, device=device)
b = torch.rand(n, device=device)
fn(a, b)
end = default_timer()
print('{} {} took {}'.format(name, n, end-start))
total_end = default_timer()
print('{} TOTAL time {}'.format(name, total_end-total_start))
def fwd_only(a, b):
out = loss_fn(a, b)
def fwd_bck(a, b):
out = loss_fn(a, b)
out.backward()
def sanity_check(name, device):
print('{} Operator sanity check:'.format(name))
a = torch.rand(10, requires_grad=True, device=device)
b = torch.rand(10, device=device)
out = loss_fn(a,b)
print(out)
out.backward()
print(a.grad)
print('double backward')
loss = loss_fn(a, b)
loss2 = torch.autograd.grad(loss, a, create_graph=True)
z = loss2[0].sum()
print(z)
z.backward()
print('ok')
print()
print('PyTorch version:', torch.__version__)
sanity_check('CPU', cpu)
sanity_check('GPU', gpu)
print()
run_benchmark('CPU warmup', 3, False, cpu, fwd_only)
run_benchmark('CPU forward', 6, False, cpu, fwd_only)
run_benchmark('CPU for- & backward', 6, True, cpu, fwd_bck)
print()
run_benchmark('GPU warmup', 3, False, gpu, fwd_only)
run_benchmark('GPU forward', 6, False, gpu, fwd_only)
run_benchmark('GPU for- & backward', 6, True, gpu, fwd_bck)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27673
Differential Revision: D17889288
Pulled By: ezyang
fbshipit-source-id: 9ddffe4dbbfab6180847a8fec32443910f18f0a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26720
I'm trying to get rid of the need for CI jobs to have write access to ECR. Right now, they require write access because they push intermediate build results, which then get sucked down by downstream jobs. Instead of pushing back to ECR, we could just save them to CircleCI workspace. (There are some downsides to this approach: in particular, we save ALL layers to the workspace, not the new layers.) My original idea was to save to `~/built_image.tgz` and then load it.
Unfortunately, the Android tests have a substantially more complicated Docker structure which means my simple idea doesn't work. The current structure is that there are instantiations of `pytorch_linux_build` per configuration (e.g., `x86_32`, `x86_64`, ...). Then `gradle_build` collates these Docker images together and combines them to publish. To handle this case, the upstream jobs have to save Docker images to distinct filenames in the workspace for the load to work correctly. This is achieved by adding a new parameter to `pytorch_linux_build`, `saved_docker_filename`, which specifies where to put the image. Additionally, to pass this parameter to the jobs, I stopped using configuration generation for this case, as I couldn't figure out how to get the generator to conditionally add another line to the YAML for this case.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17843468
Pulled By: ezyang
fbshipit-source-id: c3f549e562c691b8f3f447705d4717c1fbb64040
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27927
This fixes
`WARNING: html_static_path entry '_images' does not exist`
by removing '_images' from conf.py. As far as I can tell, '_images' in
`html_static_path` is only necessary if images already exist in the
`_images` folder; otherwise, sphinx is able to auto-generate _images
into the build directory and populate it correctly.
Test Plan: - build and view the docs locally.
Differential Revision: D17915109
Pulled By: zou3519
fbshipit-source-id: ebcc1f331475f52c0ceadd3e97c3a4a0d606e14b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27850
Many of these are real problems in the documentation (i.e., link or
bullet point doesn't display correctly).
Test Plan: - built and viewed the documentation for each change locally.
Differential Revision: D17908123
Pulled By: zou3519
fbshipit-source-id: 65c92a352c89b90fb6b508c388b0874233a3817a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27773
We've changed how these functions are used over time, so I cleaned up
the header file API to match. In particular:
* tryMatchSchemas was added since the overload logic got copy/pasted
into three separate locations.
* With this change, tryMatchSchema is no longer public, as it is not needed
outside of tryMatchSchemas
* emitBuiltinFunction no longer needs a requires argument (it was always true)
* Argument order for all the schema matching stuff now puts the 'self'
builtin override last. This is only rarely used and was inconsistent with
matchSchema
Test Plan: Imported from OSS
Differential Revision: D17885425
Pulled By: zdevito
fbshipit-source-id: 064bc9fa4bd57b2e5366fff9f3c6ab9b9945e08b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27805
The expressions syntax for actions is pretty cool! Using it to clean up
some of my convoluted checks from before
Test Plan: Imported from OSS
Differential Revision: D17909353
Pulled By: suo
fbshipit-source-id: 8b9a85476ba19452f48c532a2daed830f074088a
Summary:
`at::ArrayRef` / `torch::IntArrayRef` should be discouraged in user code, because users might not be aware of the fact that it doesn't own the underlying data, which already leads to memory access bugs when they try to write the following:
```cpp
auto expected_sizes = torch::IntArrayRef({2, 16, 6}); // The memory that represents `{2, 16, 6}` is released after this line
ASSERT_EQ(output.sizes(), expected_sizes); // `expected_sizes` is pointing to invalid memory region
```
This PR changes all usage of `at::ArrayRef` and `torch::IntArrayRef` to the corresponding `std::vector` version, so that users won't pick up the habit of using `ArrayRef` by looking at the test code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27884
Differential Revision: D17921646
Pulled By: yf225
fbshipit-source-id: 461e79fc22b598aac230d36cc028085ce6cbe937
Summary:
Removing in-place operator for num_batches_tracked increment. The in-place
operator used here turns out to block many optimization opportunities due to
alias assumption for inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27299
Differential Revision: D17909341
Pulled By: ngimel
fbshipit-source-id: 7d635be94dfd2002af435acf6ea71995adaa40f6
Summary:
We are seeing error "[enforce fail at BlackBoxPredictor.cpp:134] ! !parameter_workspace->HasBlob(out). Net REMOTE of type predict_net writes to blob cat/NGRAM_QRT_VERSIONS_x_EVENT_TYPE_AUTO_FIRST_X/Pool_Option_0/Repeat_0/sparse_lookup/w which exists in the parameter workspace" in online testing for calibration models.
I'm suspecting it's due to the op CopyRowsToTensorOp are being used in prediction
Test Plan:
f143080108 offline predict net does not contain CopyRowsToTensorNet, which looks right.
Waiting for Olga to test online behavior
dper2 canary:
https://fburl.com/fblearner/sv3o3yj1
Differential Revision: D17741823
fbshipit-source-id: 19721b632b5ea9ebfa1ef9ae0e99d3a10c926287
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27819
The idea here is to preserve the fact that `test_jit.py` contains all the JIT tests. So we import `JitTestCase`s from `jit/` into `test_jit.py` so that the test loader will find and run them when you do `python test_jit.py`. This also means that things like `-k` will work as expected.
The individual test files in `jit/` will throw if run directly, to prevent cases where the CI accidentally runs multiple versions of the same test.
Differential Revision: D17898105
Test Plan: Imported from OSS
Pulled By: suo
fbshipit-source-id: 0cd6f8421c86c90a6e1bae33a3fdbe998f570e07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26722
Put them in a directory under jit/ to prep for test splitting
Test Plan: Imported from OSS
Differential Revision: D17550582
Pulled By: suo
fbshipit-source-id: a592b671ffe808f02d0a597d441bd98a18c9109e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27787
This makes it possible to directly run gdb after 'docker exec'ing into a
Docker image run from CircleCI (useful if you're doing the rerun with
SSH workflow).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17889312
Pulled By: ezyang
fbshipit-source-id: 522a75be18be69ff6ad83d47185ae3068bf725d4
Summary:
In accordance with https://github.com/pytorch/pytorch/issues/25883, I added the `MultiLabelSoftMarginLoss` module and `multilabel_soft_margin_loss` functional.
It looks like there isn't a C++ ATen implementation of `multilabel_soft_margin_loss`, so I translated the python version, which does not rely on a C/C++ backend either.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27669
Differential Revision: D17907608
Pulled By: yf225
fbshipit-source-id: ccb02951e009973c2adbe604593ce929f10c39eb
Summary:
People get confused with partial support otherwise: https://github.com/pytorch/pytorch/issues/27811#27729
Suggestions on where else put warnings are welcomed (probably in tutorials - cc SethHWeidman )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27829
Differential Revision: D17910931
Pulled By: dzhulgakov
fbshipit-source-id: 37a169a4bef01b94be59fe62a8f641c3ec5e9b7c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27818
This has been turned off since january. Might as well clean it up. I want to do a bit of refactoring in this area.
ghstack-source-id: 91827750
Test Plan: sandcastle
Differential Revision: D17898077
fbshipit-source-id: e70bf8ee72b4703767d4e38f8c346a7849a866f5
Summary: Currently accelerators does not have the concept for fp32, it only has understandings of fp16 and int8 in terms of data input. In order to fixe the issue here, we want to make sure unaries are turned into fp16 when we have the int8 exporter turned on.
Reviewed By: kennyhorror
Differential Revision: D17743791
fbshipit-source-id: 7322d23eb12ac3f813b525fc0ddd066f95c8ca85
Summary:
Per https://github.com/pytorch/pytorch/issues/25525 we want to clean up distributed autograd context on all nodes, in addition to the local one. To do this, we want to send async RPCs to the other nodes telling them to clean up the context.
The first step for this is for a node's context to know about the other workers. This PR does two things:
1) Adds the necessary data structures and getter functions to `DistAutogradContext`
2) Refactors calls to `addSendRpcBackward` to take in the `worker_id` as an additional argument
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26324
Differential Revision: D17769411
Pulled By: rohan-varma
fbshipit-source-id: b7327d1209a574e2e88cb197edff3103024d51ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26522
Our binaries are already built using GCC5, so there is no reason to test for GCC4 anymore.
This is an important prerequisite for switching to C++14, but even without the C++14 switch, this enables a gcc feature that I need for constexpr type ids.
ghstack-source-id: 91851144
Test Plan: unit tests
Differential Revision: D17494507
fbshipit-source-id: 7c0beb5e532ad9caa5cb02c1af26341c1017ff57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26971
I believe this is currently exhaustive of the unused operators in THCUNN:
LookupTable, SpatialSubSampling, Sqrt, Square, TemporalConvolution, TemporalMaxPooling.
Test Plan: Imported from OSS
Differential Revision: D17628380
Pulled By: gchanan
fbshipit-source-id: a3ebd24765d00073e60212f6f664ec4a6d8c1d1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26970
I believe these were only being (self)-referenced by direct THCUNN bindings, which were killed in the https://github.com/pytorch/pytorch/pull/25358 stack.
This list is NOT exhaustive of what can be removed, and notably doesn't include THNN:
Abs, DistKLDivCriterion, FeatureLPPooling, IndexLinear, L1Cost, LookupTableBag, MarginCriterion, SpatialConvolutionLocal, SpatialCrossMapLRn.
Test Plan: Imported from OSS
Differential Revision: D17628216
Pulled By: gchanan
fbshipit-source-id: 0a0b17b446cf8ec9adef631f6f5c515182b560bb
Summary:
Addresses https://github.com/pytorch/pytorch/issues/27048
PR Summary:
Files Added:
_torch/csrc/api/include/torch/nn/options/normalization.h
torch/csrc/api/include/torch/nn/functional/normalization.h_
Files Modified:
_test/cpp/api/functional.cpp
torch/csrc/api/include/torch/nn/functional.h_
---
yf225 : I couldn't find a C++ equivalent of gradcheck(), is there such a function or is it sufficient to call .backward() in the test body? I don't think any solutions are checked for the Python tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27280
Differential Revision: D17902109
Pulled By: yf225
fbshipit-source-id: 1bce1a88103d0f1848633fec90fde95ea8f3d1ed
Summary:
Technically, we don't need a C++14 compiler yet, but we will soon stop support for GCC 4. Requiring a "C++14" compiler excludes GCC 4, so it is a defensive statement. Some time later, we will actually require a C++14 compiler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26670
Differential Revision: D17907257
Pulled By: smessmer
fbshipit-source-id: 5363d714f8d93597db008135f681b2e14d052fa0
Test Plan:
The notebook showed no diff for id score list
https://our.intern.facebook.com/intern/anp/view/?id=154764
Reviewed By: alyssawangqq
Differential Revision: D17649974
fbshipit-source-id: 84cb4ae372fc215295c2d0b139d65f4eacafae4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27760
There's nothing special about the named tensor tests that requires that
they be run in their own CI job. In this PR we delete the
TEST_NAMEDTENSOR flag that hides named tensor tests from regular jobs.
In the future, we'll delete the named tensor CI job so that we do not
duplicate signals.
Test Plan: - wait for CI
Differential Revision: D17882262
Pulled By: zou3519
fbshipit-source-id: f90c71cb939e53b8ea23f7e2ab95a5c41b8be0e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27751
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17886488
Pulled By: ezyang
fbshipit-source-id: 1c8d98b6f7ee3127ebec9a0b03132c38c97523c3
Summary:
Changelog:
- DataLoader argument `sampler` is now of type `Optional[Sampler[int]]`instead of `Sampler[int]`
- DataLoader argument `batch_sampler` is now of type `Optional[Sampler[Sequence[int]]]` instead of `Sampler[Sequence[int]]`
Fixes https://github.com/pytorch/pytorch/issues/27737
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27821
Differential Revision: D17906623
Pulled By: ezyang
fbshipit-source-id: 088cacbb7e9f7988995f40b71adc3e719815f5ad
Summary:
The current embedding backwards CUDA kernel is somewhat broken. It effectively ignores padding_idx and also incorrectly drops an index from the input.
This commit fixes that bug and fixes the unit test so that this behavior won't break in the future.
This fixes https://github.com/pytorch/pytorch/issues/26302.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27731
Differential Revision: D17893803
Pulled By: ngimel
fbshipit-source-id: 4ba02a17ec0e29a7016d65480d4ff0c276550616
Summary:
Grammar edits to the Readme file to make it read better in English
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27808
Differential Revision: D17901414
Pulled By: soumith
fbshipit-source-id: 02e67289dafaf9280cb1c3bb2f37087cd134cc23
Summary:
Hi yf225 , I had to create a new branch to tackle merge conflict since I am using cloud due to some limitations on my PC. Therefore, I don't have enough command there.
Also, I have incorporated the changes you have put before here
https://github.com/pytorch/pytorch/pull/27613
Also, it would be great if you could recommend me some resources to work smmothly on GCP..:-D
Thank you
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27713
Differential Revision: D17899695
Pulled By: yf225
fbshipit-source-id: eb6643223148774a5cbbd093bdcc5623872e5bba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27782
Warnings show up when running `make html` to build documentation. All of
the warnings are very reasonable and point to bugs in our docs. This PR
attempts to fix most of those warnings.
In the future we will add something to the CI that asserts that there
are no warnings in our docs.
Test Plan: - build and view changes locally
Differential Revision: D17887067
Pulled By: zou3519
fbshipit-source-id: 6bf4d08764759133b20983d6cd7f5d27e5ee3166
Summary:
The impl class of `torch::nn` layers must always subclass from `torch::nn::Cloneable`, otherwise `module->clone()` doesn't work on them. This PR fixes layers that don't conform to this rule.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27770
Differential Revision: D17893051
Pulled By: yf225
fbshipit-source-id: 37cdf8c09e22f0f164cbd0e8700965a1778ec4c1
Summary:
The `pytorch_short_perf_test_gpu` CI job hasn't been giving useful signal compared to https://apaszke.github.io/pytorch-perf-hud/ or the FAI-PEP effort. This PR disables it to reduce maintenance workload for CI admins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27797
Differential Revision: D17897180
Pulled By: yf225
fbshipit-source-id: 91a66ebac3d15a44094a669da38c43e3ea9c20d2
Summary:
One fewer legacy decorator cluttering the test suite.
Functions relying on this decorator were updated or, in the case of test_sparse, the test suite was put back on double by default.
Note: this PR is blocked on https://github.com/pytorch/pytorch/issues/27599.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27628
Differential Revision: D17896254
Pulled By: mruberry
fbshipit-source-id: 13d460301f50ef4af7a660372432108164c0de1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26666
Changes:
- Introduce a `ConcreteModuleType` concept. This acts both as the key into the type
cache, and as the source of truth for `ModuleValue::attr` queries. It needs
to do both jobs because that's how we ensure correctness (if the types are
different, it's because `ModuleValue::attr` would return different things).
- Now `recursive_script` will first construct a `ConcreteModuleType` and search for a
pre-existing type before starting compilation.
- All previous paths to creating a `ScriptModule` (including inheriting from
`ScriptModule`) are now rewritten to go through `create_script_module`, so
that we have only a single place where construction happens.
Behavioral changes:
- Big change to `torch.jit.ScriptModule` inheritance: all attributes are now
recursively scripted if possible, matching recursive scripting semantics.
This makes it hard to keep something from being scripted (for example, a
Python submodule). Possibly we'll need an `ignore()` type thing for
attributes. In particular, this adds `self.training` to *every* ScriptModule, since
it's present on every `nn.Module`.
- I believe this change to be transparent to existing users of the inheritance API, since if you had an attribute that is unscriptable that you never used, there is no error. In some cases, we will create new attributes (even if they are unused), which will increase serialized model size from before.
Test Plan: Imported from OSS
Differential Revision: D17551196
Pulled By: suo
fbshipit-source-id: b476d1c9feb3ddfd63406d90989aaf9dfe890591
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27399
This was devised in a time when we didn't have module attributes. They
are essentially just tensor lists, so represent them that way. This has
the additional benefit of making the RNN forward pass faster because we
effectively cache the flattened weights.
The only complication part is that someone may come along and do:
```
my_rnn_mod.w_ih_l0 = torch.nn.Parameter(...)
```
This means we need to override setattr to keep the flattened weights
cache up to date.
Test Plan: Imported from OSS
Differential Revision: D17785658
Pulled By: suo
fbshipit-source-id: 7789cd1d0d4922bfd5eba1716976442fbf150766
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26665
This is actually useful. For example: in batchnorm.py, all the tracked
stats are either `nn.Parameter` or `None`. We should register them as
params if they are set, or attributes with type NoneType if they are
not.
Test Plan: Imported from OSS
Reviewed By: shannonzhu
Differential Revision: D17551197
Pulled By: suo
fbshipit-source-id: 8d6f6d76d4dab0d524c4ffdfe0c1dd465771cd00
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27022
This change implements the "FAST" mode distributed autograd backward
pass as described in https://github.com/pytorch/pytorch/issues/23110.
At a high level the backward pass works as follows:
1. We start by computing dependencies on the node that calls
`torch.distributed.backward`.
2. This node computes the dependencies starting from the root nodes provided in
the backward call and all the 'send' functions present in the current autograd
context. The "FAST" mode assumes all 'send' functions are part of the autograd
computation.
3. Once the dependency computation is done, the distributed autograd engine
calls the local autograd engine to execute the autograd graph. Note that the
autograd graph on a single node is not necessarily connected because of
inter-node communication. As a result, we have special handling to ensure the
local autograd engine ensures we execute the entire graph starting from the
provided roots and all 'send' functions on the node.
4. When the local autograd engine hits a 'recv' function, it performs an async
RPC to send the gradients over to the appropriate node and stores a future in
the autograd context to keep track of this RPC.
5. On the destination node, the appropriate 'send' function is looked up and
enqueued on the local autograd engine. If this is the first time the node is
hearing about this autograd context id on the backward pass, then the node
computes dependencies for the local autograd engine.
6. As part of compute dependencies, the distributed autograd engine discovers
all leaf nodes and ensures those are passed as 'outputs' to the local autograd
engine. This avoids running the 'AccumulateGrad' function.
7. The gradients computed for the leaf nodes are then actually accumulated in
`DistAutogradContext` for the appropriate autograd context id.
8. The distributed autograd engine waits for the local autograd engine
to complete and also waits for all the 'Futures' (stored in 4.) for respective
RPCs to finish.
We have made the following changes to the local autograd engine for this
purpose:
1. Expose GraphTask and NodeTask so that the distributed autograd engine can
use them.
2. Expose a `execute_with_graph_task` API which gives the distributed engine
to build a GraphTask and pass it to the local autograd engine.
3. Expose a `enqueue_on_cpu` API, which allows the distributed engine to build
a `NodeTask` for a 'send' function and enqueue it on the local autograd engine.
In addition to this a few general improvements:
1. Added a `PropagateGradients` RPC call for the 'recv' function to pass
gradients to the appropriate node during the backward pass.
2. Use IValues as much as possible in serialization for RpcWithAutograd.
3. If Future.wait(), contains a message type EXCEPTION, we throw an appropriate
exception instead of just returning the message. This is inline with what most
Future.wait() APIs do.
4. Added a `get_gradients(context_id)` API which allows users to retrieve a map
from Tensor to respective gradient for the provided context_id on the local
node.
ghstack-source-id: 91794926
Test Plan: unit tests.
Differential Revision: D17652615
fbshipit-source-id: 96f65c52adb2706ee29f4b49e1655afaa0a3bec3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27784
## Summary
Since the nightly jobs are running without any testing code, we don't really have a way to verify the binary before uploading it to AWS. To make the work more solid, I came up with an approach to test our builds.
## How it works
The XCode tool chain offers a way to build your app without XCode app, which is the [xcodebuild](https://developer.apple.com/library/archive/technotes/tn2339/_index.html) command. So the approach is link our binaries to a testing app and run `xcodebuild` to see if there is any linking error. The PRs below have already done some of the preparation jobs
- [#26261](https://github.com/pytorch/pytorch/pull/26261) adds a dummy testing app
- [#26632](https://github.com/pytorch/pytorch/pull/26632) adds a ruby script that does all the XCode configuration.
The challenge comes when testing the arm64 build as we don't have a way to code-sign our TestApp. Circle CI has a [tutorial](https://circleci.com/docs/2.0/ios-codesigning/) but is too complicated to implement. Anyway, I figured out an easier way to do it
1. Disable automatically code sign in XCode (done #27591 )
2. Export the encoded developer certificate and provisioning profile to org-context in Circle CI (done)
3. Install the developer certificate to the key chain store on CI machines via Fastlane. (done #27593 )
4. Add the testing code to PR jobs and verify the result. (done #27594 )
5. Add the testing code to nightly jobs and verify the result.
## Test Plan
- Both PR jobs and nightly jobs can finish successfully.
- `xcodebuild` can finish successfully
Test Plan: Imported from OSS
Differential Revision: D17893271
Pulled By: xta0
fbshipit-source-id: cb7679224e062a4884615f625a2933cad8bd4c11
Summary:
whoops, this got left in by accident
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27796
Differential Revision: D17892482
Pulled By: suo
fbshipit-source-id: f92255d78fe70d3c22c4422b6333ac288cb330d6
Summary:
katex is a deprecated package in Ubuntu and has been removed in recent
releases of Debian. Use npm instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27758
Differential Revision: D17891039
Pulled By: ezyang
fbshipit-source-id: 53de6e14b2638298e5b61996dcd7ba8de02420a3
Summary:
Per title. Also testing putting test_advancedindex back on the default stream.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27688
Differential Revision: D17888351
Pulled By: mruberry
fbshipit-source-id: af8adeca89f575fc276921b39049b07135ed9776
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27767
Note that this kills flake8 for py2.7. I think it's reasonable given the
impending removal of py2 support entirely, but someone sanity check me
on this
Test Plan: Imported from OSS
Differential Revision: D17888975
Pulled By: suo
fbshipit-source-id: 87559f9e18d39e035e0c781c67025b194a593bc6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27755
This gives us nice annotations. See
https://github.com/suo/pytorch/pull/22/files for an approximation of
what it will look like (ignore the warnings on the lint.yml file).
I deleted the old azure pipelines one since making the code work for
both was annoying, and unlike flake8 this one does not affect master
Test Plan: Imported from OSS
Differential Revision: D17888974
Pulled By: suo
fbshipit-source-id: d8928a1451b6ef500dc1889284cab2845ecdeeea
Summary:
Currently when an integral tensor is divided by zero, it emits a
"floating point exception" (which can be different from system to
system). Clarify in the document that nothing would be guaranteed under
this circumstance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25968
Differential Revision: D17888097
Pulled By: ezyang
fbshipit-source-id: 7c3ce3ac4080479d637cc2710b6aa3ae7e42431d
Summary:
Per title.
test_autograd.py no longer needs to import common_cuda as a result of this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27709
Differential Revision: D17881298
Pulled By: mruberry
fbshipit-source-id: 8b0351b65a49a072ce5ed7e7099b712847983877
Summary:
Some models many contain thousands constants (like list of ints) and Constant Pooling and CSE pass will move the constant around and update the constant pooling.
However our existing hash function only consider the node type + input type + output node (https://bddppq.github.io/codebrowser/pytorch/pytorch/torch/csrc/jit/node_hashing.cpp.html#_ZNK5torch3jit8HashNodeclEPKNS0_4NodeE), which will have a lot of conflicts... I have profiled, one insert may take as long as about 0.2 second... And loading the model will take 200 second, which is insane.
So we should fix this performance issue by considering the constant value as well to avoid the conflict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27733
Reviewed By: bddppq
Differential Revision: D17873733
Pulled By: houseroad
fbshipit-source-id: 2338d7bf67174a8e56caa19a30401199f68b592a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27357
Add extra CI builds for TBB and native builds
Test Plan: check CI
Differential Revision: D17757197
Pulled By: ilia-cher
fbshipit-source-id: e0522e15938710fbf6404478725620282d1287ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27748
There's TSAN test failure. From stack it's likely related to mkldnn (https://github.com/pytorch/pytorch/issues/27497). Before the issue is resolved, disable TSAN test.
ghstack-source-id: 91761706
Test Plan: buck test mode/dev-tsan caffe2/test/cpp/jit:jit -- 'JitTest\.LiteInterpreterConv' --run-disabled
Reviewed By: bddppq
Differential Revision: D17880082
fbshipit-source-id: 251d9b9577838146231c8e122f755936edd1c281
Summary:
resolves issues:
https://github.com/pytorch/pytorch/issues/27703
Updates to index for v1.3.0
* add javasphinx to the required sphinx plugins
* Update "Package Reference" to "Python API"
* Add in torchaudio and torchtext reference links so they show up across all docs not just the main page
* Add "Other Languages" section, add in C++ docs, add in Javadocs
* Add link to XLA docs under Notes: http://pytorch.org/xla/
this includes changes to:
docs/source/conf.py
docs/source/index.rst
docs/source/nn.rst
docs/requirements.txt
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27721
Differential Revision: D17881973
Pulled By: jlin27
fbshipit-source-id: ccc1e9e4da17837ad99d25df997772613f76aea8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27756
Implement approximate L0 norm for use in the dense feature regularizer that will be used for feature importance. The formula is as follows:
{F212246801}
Reviewed By: wx1988
Differential Revision: D17432708
fbshipit-source-id: 57d6c9c3dd1b4e210b9f10264075c57dbc9c8cb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27612
The file imports from torch.distributed.rpc, which won't be
initialized when running on Python 2.
Test Plan: Imported from OSS
Differential Revision: D17855033
Pulled By: pietern
fbshipit-source-id: 6e6b0ca248d0512dac5a44e10e153c710cefe02c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27439
When users call dist.gather, they have to pass in a `gather_list` to
the function on the destination worker, and this list needs to have the same
size as the number of processes in the group. When the user initializes this
list incorrectly, the current error message is not very helpful:
This changes the error message so that the incorrect gather_list size is
pointed out and the correct one is given.
ghstack-source-id: 91413442
Test Plan: Added a unit test and tested with an incorrect gather_list size.
Differential Revision: D17781370
fbshipit-source-id: b49aad1b1197daf77daa10911296664e6340e2fa
Summary:
We add an #ifdef check for USE_EXTERNAL_MZCRC, in which case miniz
will look for an external mz_crc32 definition. The default behavior
is unchanged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27558
Test Plan: Unchanged default behavior, but buck test caffe2/test/...
Differential Revision: D17814440
Pulled By: jjlilley
fbshipit-source-id: e4ecbe37ee2f9eec176093372f21b3b8e52a5f81
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27594
## Summary
Since the nightly jobs are lack of testing phases, we don't really have a way to test the binary before uploading it to AWS. To make the work more solid, we need to figure out a way to verify the binary.
Fortunately, the XCode tool chain offers a way to build your app without XCode app, which is the [xcodebuild](https://developer.apple.com/library/archive/technotes/tn2339/_index.html) command. Now we can link our binary to a testing app and run `xcodebuild` to to see if there is any linking error. The PRs below have already done some of the preparation jobs
- [#26261](https://github.com/pytorch/pytorch/pull/26261)
- [#26632](https://github.com/pytorch/pytorch/pull/26632)
The challenge comes when testing the arm64 build as we don't have a way to code-sign our TestApp. Circle CI has a [tutorial](https://circleci.com/docs/2.0/ios-codesigning/) but is too complicated to implement. Anyway, I figured out an easier way to do it
1. Disable automatically code sign in XCode
2. Export the encoded developer certificate and provisioning profile to org-context in Circle CI (done)
3. Install the developer certificate to the key chain store on CI machines via Fastlane.
4. Add the testing code to PR jobs and verify the result.
5. Add the testing code to nightly jobs and verify the result.
## Test Plan
- Both PR jobs and nightly jobs can finish successfully.
- `xcodebuild` can finish successfully
Test Plan: Imported from OSS
Differential Revision: D17850703
Pulled By: xta0
fbshipit-source-id: ab220061c6e2ec75cae23684ad999c4f9c276820
Summary:
Fixes https://github.com/pytorch/pytorch/issues/27605: The C++ L-BFGS Optimizer will not work properly if there are one or more registered tensors with no grad in the model:
```
terminate called after throwing an instance of 'c10::Error'
what(): There were no tensor arguments to this function (e.g., you passed an empty list of Tensors), but no fallback function is registered for schema aten::view. This usually means that this function requires a non-empty list of Tensors. Available functions are [CUDATensorId, QuantizedCPUTensorId, VariableTensorId, CPUTensorId, MkldnnCPUTensorId] (lookup_ at /pytorch/aten/src/ATen/core/dispatch/DispatchTable.h:245)
```
Add some `if (!parameter.grad().defined()) {...}` in the ` torch/csrc/api/src/optim/lbfgs.cpp`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27606
Differential Revision: D17866550
Pulled By: yf225
fbshipit-source-id: bcaf0bf75b93c57304856b03d8984c1617ebbfef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27592
The caffe2 data reader test `test_time_limit_reader_with_short_limit` is flaky as-written because it places an upper bound on how much can be read, but under stress it is possible for fewer records to be read. The fix is to make the assertion check a fuzzy/range check rather than exact equality, since there's not a straightforward way to precisely test a timer-based feature.
ghstack-source-id: 91543898
Test Plan:
`buck test mode/dev-tsan //caffe2/caffe2/python:dataio_test-2.7 -- --stress-runs 20` -> P117156924 (with fix, 100% pass)
P117158750 - without fix, lots of failures in this test
Reviewed By: boryiingsu
Differential Revision: D17816775
fbshipit-source-id: 2ab0d3304fbd9c9806d37a4fe2912c840616db61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27635
PyTorch uses `offsets` instead of `lengths` for embedding table lookup. Adding support to that for fused quantized version.
AVX2 version is generated with
```
python caffe2/caffe2/perfkernels/hp_emblookup_codegen.py --fused --use-offsets
```
Test Plan:
```
buck test caffe2/torch/fb/sparsenn:test
```
Reviewed By: jianyuh
Differential Revision: D17826873
fbshipit-source-id: 23c4a96d92521deaebc02b688ad735d76a4476df
Summary:
One of the purposes of the C++ API tests in `test/cpp/api/` should be to check that including `torch/torch.h` is a sufficient prerequisite for using all C++ frontend features. This PR change ensures that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27067
Differential Revision: D17856815
Pulled By: yf225
fbshipit-source-id: 49c057bd807b003e4a00f6ba73131d763a0f277a
Summary: There's TSAN test failure. From stack it's likely related to mkldnn (https://github.com/pytorch/pytorch/issues/27497). Before the issue is resolved, disable TSAN test.
Test Plan: buck test mode/dev-tsan caffe2/test/cpp/jit:jit -- 'JitTest\.LiteInterpreterConv' --run-disabled
Reviewed By: bddppq
Differential Revision: D17846079
fbshipit-source-id: 669d6385690223d83996fb14051c39df0c521dfa
Summary:
- Update torch.rst to remove certain autofunction calls
- Add reference to Quantization Functions section in nn.rst
- Update javadocs for v1.3.0
- Update index.rst:
- Update "Package Reference" to "Python API"
- Add in torchaudio and torchtext reference links so they show up across all docs not just the main page
- Add "Other Languages" section, add in C++ docs, add in Javadocs
- Add link to XLA docs under Notes: http://pytorch.org/xla/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27676
Differential Revision: D17850696
Pulled By: brianjo
fbshipit-source-id: 3de146f065222d1acd9a33aae3b543927a63532a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26499
We've changed how these functions are used over time, so I cleaned up
the header file API to match. In particular:
* tryMatchSchemas was added since the overload logic got copy/pasted
into three separate locations.
* With this change, tryMatchSchema is no longer public, as it is not needed
outside of tryMatchSchemas
* emitBuiltinFunction no longer needs a requires argument (it was always true)
* Argument order for all the schema matching stuff now puts the 'self'
builtin override last. This is only rarely used and was inconsistent with
matchSchema
Test Plan: Imported from OSS
Differential Revision: D17488297
Pulled By: zdevito
fbshipit-source-id: a32d838ce35544972fa8767557acc22149081b55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26271
This replaces unchecked_unwrap_optional with unchecked_cast. This
enables the generalization of type refinement so that it works for
isinstance checks as well. This also removes unchecked_unwrap_optional from
code we generate, which is good because it is a hard op to serialize well
since it doesn't directly encode the Optional[T] being unwrapped. In contrast,
unchecked_cast always explicitly lists the type.
Test Plan: Imported from OSS
Differential Revision: D17412856
Pulled By: zdevito
fbshipit-source-id: ded47eb086c4610998ad92bb1174225af00220f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27593
## Summary
Since the nightly jobs are lack of testing phases, we don't really have a way to test the binary before uploading it to AWS. To make the work more solid, we need to figure out a way to verify the binary.
Fortunately, the XCode tool chain offers a way to build your app without XCode app, which is the [xcodebuild](https://developer.apple.com/library/archive/technotes/tn2339/_index.html) command. Now we can link our binary to a testing app and run `xcodebuild` to to see if there is any linking error. The PRs below have already done some of the preparation jobs
- [#26261](https://github.com/pytorch/pytorch/pull/26261)
- [#26632](https://github.com/pytorch/pytorch/pull/26632)
The challenge comes when testing the arm64 build as we don't have a way to code-sign our TestApp. Circle CI has a [tutorial](https://circleci.com/docs/2.0/ios-codesigning/) but is too complicated to implement. Anyway, I figured out an easier way to do it
1. Disable automatically code sign in XCode
2. Export the encoded developer certificate and provisioning profile to org-context in Circle CI (done)
3. Install the developer certificate to the key chain store on CI machines via Fastlane.
4. Add the testing code to PR jobs and verify the result.
5. Add the testing code to nightly jobs and verify the result.
## Test Plan
- Both PR jobs and nightly jobs can finish successfully.
- `xcodebuild` can finish successfully
Test Plan: Imported from OSS
Differential Revision: D17848814
Pulled By: xta0
fbshipit-source-id: 48353f001c38e61eed13a43943253cae30d8831a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27609
It's a fix to PR27379, where it failed in Windows CI.
Currently the operators need to be registered manually through c10 registration.
Test Plan:
The operators should be covered by tests on operators.
A few ops (add, conv) are covered in test_lite_interpreter.cpp for demonstration.
CV models may be too large to include in unittests.
Simple local loaders can be built. Follow similar pattern as in test_lite_interpreter to
load the torch script model
run the model to get reference results
save and load the mobile module using torch::jit::module._save_for_mobile() and torch::jit::_load_for_mobile().
run the mobile module by run_method() and compare the results to reference results.
Tested models:
Lenet
XrayMobileV3
Differential Revision: D17832709
fbshipit-source-id: 51e44fa95240b241da85cb67dc2302878742903c
Summary:
Exporting a scripted module to ONNX, with ops like torch.zeros(), fails when the dtype is not specified.
This PR adds support to exporting scripted torch.zeros() ops (and similar ops) without specifying the dtype (dtype will default to float).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27577
Reviewed By: hl475
Differential Revision: D17822318
Pulled By: houseroad
fbshipit-source-id: b2d4300b869e782a9b72534fea1263eb83744953
Summary:
This was written by Raghu, Jessica, Dmytro and myself.
This PR will accumulate additional changes (there are a few more things we need to add to this actual rst file). I'll probably add the related image files to this PR as well.
I'm breaking draft PR https://github.com/pytorch/pytorch/pull/27553 into more easily digestible pieces.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27559
Differential Revision: D17843414
Pulled By: gottbrath
fbshipit-source-id: 434689f255ac1449884acf81f10e0148d0d8d302
Summary:
Fixes https://github.com/pytorch/pytorch/issues/20046
While installing, `aten/src/ATen` is shortened to just `ATen` so these relative paths become `/usr/local/include/ATen/core/../../../../torch` or simply `/usr/torch`.
Note that in cmake, `Caffe2` is the name for the root `pytorch` project so `Caffe2_SOURCE_DIR` gives the `pytorch` directory; *not* the `caffe2` directory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27449
Differential Revision: D17844763
Pulled By: ezyang
fbshipit-source-id: fcd964ef1b891972f18155eb72732e90f0d50b8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27308
Currently, `tensor.align_to(*names)` has the restriction that the
`tensor` must be fully named. This doesn't need to be the case, when
using Ellipsis, we "expand the ellipsis to all unmentioned dimensions,
in the order which they appear in the original tensor".
For example, consider `tensor: Tensor[None, None, C]`.
`tensor.align_to(C, None, None)` is ambiguous because the user might
have wanted to switch the order of the None dimensions and there is no
way to specify that using this API. However, `tensor.align_to('C', ...)`
isn't ambiguous: we can select the two unnamed dimensions in the order
in which they appear.
To actually implement this, we write a brand-new `align_to(names,
ellipsis_idx)` function in c++ that is separate from the regular
`align_to(names)` implementation. Ideally we would support "..." as a
special name in c++ and combine the two implementations; we'll need to
support "..." in c++ in the future but that requires a bit of extra work.
In this PR, Python processees the ellipsis and then calls the correct
overload.
Test Plan: - run tests
Differential Revision: D17745179
Pulled By: zou3519
fbshipit-source-id: 9fed06d224215cfb7efecd8c002604baab3c45e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27591
## Summary
Since the nightly jobs are lack of testing phases, we don't really have a way to test the binary before uploading it to AWS. To make the work more solid, we need to figure out a way to verify the binary.
Fortunately, the XCode tool chain offers a way to build your app without XCode app, which is the [xcodebuild](https://developer.apple.com/library/archive/technotes/tn2339/_index.html) command. Now we can link our binary to a testing app and run `xcodebuild` to to see if there is any linking error. The PRs below have already done some of the preparation jobs
- [#26261](https://github.com/pytorch/pytorch/pull/26261)
- [#26632](https://github.com/pytorch/pytorch/pull/26632)
The challenge comes when testing the arm64 build as we don't have a way to code-sign our TestApp. Circle CI has a [tutorial](https://circleci.com/docs/2.0/ios-codesigning/) but is too complicated to implement. Anyway, I figured out an easier way to do it
1. Disable automatically code sign in XCode
2. Export the encoded developer certificate and provisioning profile to org-context in Circle CI (done)
3. Install the developer certificate to the key chain store on CI machines via Fastlane.
4. Add the testing code to PR jobs and verify the result.
5. Add the testing code to nightly jobs and verify the result.
## Test Plan
- Both PR jobs and nightly jobs can finish successfully.
- `xcodebuild` can finish successfully
Test Plan: Imported from OSS
Differential Revision: D17844036
Pulled By: xta0
fbshipit-source-id: 741f0442a718c9bda706107a2c4c3baed4c37137
Summary:
Per title. Also makes a few test_torch tests generic.
This PR removes ~half the floating_dtype decorators. Follow-up will remove the rest.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27599
Differential Revision: D17840056
Pulled By: mruberry
fbshipit-source-id: 428bb5498c452083e3608325e0b548b1d75baf2d
Summary:
Hi yf225 , here is the C++ frontend API MultiMarginLoss implementation and tests https://github.com/pytorch/pytorch/issues/27198. Could you review it and tell me if it is okay?
I am not entirely sure I used `c10::optional` correctly, but `options.weight()` resulted in a compilation error, so I went with `options.weight().value()` instead of `value_or()` to follow the logic in `torch.nn._WeightedLoss.register_buffer` (where one can pass a `None` value).
Oh, and are the tests supposed to be skipped or did I do something wrong? I ran `pytest test/test_cpp_api_parity.py -k Loss -v` , and the `L1Loss` test passed but the others were skipped...
Thank you for the review in any case!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27424
Differential Revision: D17839963
Pulled By: yf225
fbshipit-source-id: f4b6012590cf22d56d42751c214df80cce717cb8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27616
Fix a problem in reference implementation of equal
Test Plan:
pytho test/test_quantized.py
Imported from OSS
Differential Revision: D17837055
fbshipit-source-id: 1e4bc32f4334c0352468a61fa4316a1c0ff76485
Summary:
Added Complex support with AVX to unary ops and binary ops.
I need to add nan propagation to minimum() and maximum() in the future.
In-tree changes to pytorch to support complex numbers are being submitted here.
Out-of-tree support for complex numbers is here: pytorch-cpu-strided-complex extension
Preliminary Benchmarks are here.
I tried rrii and riri and found that riri is better in most situations.
Divide is very slow because you can't reduce 1/(x+y)
Sqrt is also very slow.
Reciprocal could be sped up after I add conj()
Everything else is typically within 20% of the real number performance.
Questions:
Why does macOS not support mil? #if AT_MKL_ENABLED() && !defined(__APPLE__) in vml.h. MKL does support some complex operations like Abs, so I was curious about trying it.
Is MKL just calling AVX?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26500
Differential Revision: D17835431
Pulled By: ezyang
fbshipit-source-id: 6746209168fbeb567af340c22bf34af28286bd54
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26719
This PR adds a pair of tests for fallback boxed dispatch, exercising two different ways you might use it: (1) to implement a "wrapper" tensor type (e.g., LazyTensor, NestedTensor), and (2) to implement a toggleable "mode" (e.g., Profiling, Tracing). Both implement the most trivial possible implementations of their type: they "wrap" a real tensor simply forward along to the real implementation. This PR also adds the necessary feature support for toggleable mode, which is in the original generic dispatch abstraction design, but was not previously implemented. I had not originally intended to add this, but it turns out writing a new "mode" is a lot simpler than writing a "wrapper" type, so I ended up writing the mode version first.
General structure of the PR:
* Add two new testing tensor type ids, `TESTING_ONLY_GenericWrapperTensorId` and `TESTING_ONLY_GenericModeTensorId`, which our tests use. They might find other use in other tests if necessary.
* Add support for toggling the availability of `TESTING_ONLY_GenericModeTensorId`. Introduces a new thread local variable accessible by `tls_local_tensor_type_set()` which is considered as part of dispatch.
* The mode fallback is very simple: it increments a counter and then passes on the call to the underlying kernel by invoking the JIT.
* The wrapper fallback is more complex: it parses the arguments, unwrapping any wrapped tensor arguments, then invokes the JIT, and then rewraps the outputs.
The examples here are somewhat simplistic; there are a number of engineering improvements that could be applied. We could save these for later (landing this patch to get immediate testing), or incorporate them into this patch:
* `getOperator` is horrible. Bram Wasti and I discussed a plan for how to make this easier, by simply refactoring the JIT interface.
* `GenericWrapperTensorImpl` doesn't populate all of its fields accurately. Most notably, size is not setup correctly.
* `generic_wrapper_fallback` should handle tensor lists in arguments and returns properly.
One pitfall: fallback dispatch only works with non-c10 code. That's why I test using `batch_norm`.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D17549624
Test Plan: Imported from OSS
Pulled By: ezyang
fbshipit-source-id: 57dbdd8d6812a66082aa6db2934c8edcda340ea6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27515
Resoving variable names using the local activation frames does not work
when using recursive scripting, but our current code tries to do it
(incorrectly) anyway. The reason it works is only because the script
call is in the same local frame as the definition. This will not be
true in practice and makes it seem like the API works in more cases
than it really does. This forces us to always use closure-based annotations,
documents it, and it fixes the tests so that they still pass.
Test Plan: Imported from OSS
Differential Revision: D17803403
Pulled By: zdevito
fbshipit-source-id: e172559c655b05f0acf96c34f5bdc849f4e09ce2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27294Fixes#27291
I'm a little annoyed that I have to reintroduce manual binding code. But it's
probably not a good idea to teach the codegen how to do fastpath functions
(is it?)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17763486
Pulled By: ezyang
fbshipit-source-id: 5793b53e2db80b044e57faae325a95c649d9d459
Summary:
According to https://github.com/pytorch/pytorch/issues/27285 , seems we do not intend to use shebang as an indication of Python version, thus
we enable EXE001 flake8 check.
For violations, we either remove shebang from non-executable Python scripts or grant them executable permission.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27560
Differential Revision: D17831782
Pulled By: ezyang
fbshipit-source-id: 6282fd3617b25676a6d959af0d318faf05c09b26
Summary:
I was unable to use the existing instructions since I don't have sudo privileges on my GPU development machine and couldn't easily install `ccache` or the build dependencies for `ccache`.
However, I was able to get it working by installing `ccache` with `conda` and then creating symlinks to shadow my compilers as in the build-from-source installation instructions. I figure this might be generally useful as others might not have sudo privileges on their pytorch development machine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27481
Differential Revision: D17831556
Pulled By: ezyang
fbshipit-source-id: c5373d8739ad910015e677e7ad48bd91b770f842
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27173
`docs/source/named_tensor.rst` is the entry point; most users will land
either here or the named tensor tutorial when looking to use named
tensors. We should strive to make this as readable, concise, and understandable
as possible.
`docs/source/name_inference.rst` lists all of the name inference rules.
It should be clear but it's hard to make it concise.
Please let me know if anything doesn't make sense and please propose
alternative wordings and/or restructuring to improve the documentation.
This should ultimately get cherry-picked into the 1.3 branch as one
monolithic commit so it would be good to get all necessary changes made
in this PR and not have any follow ups.
Test Plan: - built and reviewed locally with `cd docs/ && make html`.
Differential Revision: D17763046
Pulled By: zou3519
fbshipit-source-id: c7872184fc4b189d405b18dad77cad6899ae1522
Summary:
added more variables to EmbeddingOptions and updated EmbeddingImpl reset, forward functions. Also added EmbeddingBag.
-----
This PR is BC-breaking in the following way:
Previously, `EmbeddingOptions` supports `count` and `dimension` as options arguments. After this PR, they are renamed to `num_embeddings` and `embedding_dim` respectively.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26358
Differential Revision: D17714337
Pulled By: yf225
fbshipit-source-id: f9f969c68e4bece106b92f8e2e02ac39c8455fb7
Summary: This test was failing in 3.7, turns out it was ommitted by test director in 3.6 so I added a skip for both versions
Test Plan: unittests is skipped in 3.7 and 3.6 all other tests pass.
Reviewed By: tomdz
Differential Revision: D17820967
fbshipit-source-id: 571f0ec7fe1b0cb50ead4e0d18c00151a701f36a
Summary:
Support attention weights input to SparseLookup. In attention sum pooling, if attention weights can be pre-calculated before embedding lookup, they can be passed to SparseLookup and processed by SparseLengthsWeightedSum op. One example is id_score attention sum pooling.
Essentially the net is converted from:
LengthsSum(Mul(Gather(keys, w), att_weight))
to:
SpaseLenghtsWeightedSum(keys, w, att_weight)
It unblocks potential efficiency gain with distributed training.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26748
Test Plan: unit test
Reviewed By: chocjy
Differential Revision: D17553345
Pulled By: wheatkit
fbshipit-source-id: 60cc3c4b0bc1eade5459ac598e85286f3849a412
Summary:
At the current moment of time nn.Linear (an it's interal functional code), will
fail in THBlas:
RuntimeError: invalid argument 8: lda should be at least max(1, 0), but have 0 at caffe2/aten/src/TH/generic/THBlas.cpp:363
This diff is trying to fix this bug.
As of now I was able to identify 2 possible places where changes needs to be done based on current dispatcher logic:
1. The file touched in this diff
2. caffe2/aten/src/THC/generic/THCTensorMathBlas.cu
At the moment I didn't find a better places comparing to injecting logic to those files:
the only non-generated function for forward pass, this + mm_mat2_backward function family on a backward pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27211
Test Plan: New unit-tests are passing. Code that was failing earlier works. Need to test other backends.
Differential Revision: D17599915
Pulled By: kennyhorror
fbshipit-source-id: 78894ce602d96aac2d6bf8c16a3fab43973e2d53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27555
It is already under '_c' anyway.
Test Plan: Imported from OSS
Differential Revision: D17814333
Pulled By: ZolotukhinM
fbshipit-source-id: ca21649d553f6601be12828958a8077867d0e30e
Summary:
Adds comprehensive memory instrumentation to the CUDA caching memory allocator.
# Counters
Added comprehensive instrumentation for the following stats:
- Allocation requests (`allocation`)
- Allocated memory (`allocated_bytes`)
- Reserved segments from cudaMalloc (`segment`)
- Reserved memory (`reserved_bytes`)
- Active memory blocks (`active`)
- Active memory (`active_bytes`)
- Inactive, non-releasable blocks (`inactive_split`)
- Inactive, non-releasable memory (`inactive_split_bytes`)
- Number of failed cudaMalloc calls that result in a cache flush and retry (`cuda_malloc_retries`)
- Number of OOMs (`num_ooms`)
Except for the last two, these stats are segmented between all memory, large blocks, and small blocks. Along with the current value of each stat, historical counts of allocs/frees as well as peak usage are tracked by the allocator.
# Snapshots
Added the capability to get a "memory snapshot" – that is, to generate a complete dump of the allocator block/segment state.
# Implementation: major changes
- Added `torch.cuda.memory_stats()` (and associated C++ changes) which returns all instrumented stats as a dictionary.
- Added `torch.cuda.snapshot()` (and associated C++ changes) which returns a complete dump of the allocator block/segment state as a list of segments.
- Added memory summary generator in `torch.cuda.memory_summary()` for ease of client access to the instrumentation stats. Potentially useful to dump when catching OOMs. Sample output here: https://pastebin.com/uKZjtupq
# Implementation: minor changes
- Add error-checking helper functions for Python dicts and lists in `torch/csrc/utils/`.
- Existing memory management functions in `torch.cuda` moved from `__init__.py` to `memory.py` and star-imported to the main CUDA module.
- Add various helper functions to `torch.cuda` to return individual items from `torch.cuda.memory_stats()`.
- `torch.cuda.reset_max_memory_cached()` and `torch.cuda.reset_max_memory_allocated()` are deprecated in favor of `reset_peak_stats`. It's a bit difficult to think of a case where only one of those stats should be reset, and IMO this makes the peak stats collectively more consistent.
- `torch.cuda.memory_cached()` and `torch.cuda.max_memory_cached()` are deprecated in favor of `*memory_reserved()`.
- Style (add access modifiers in the allocator class, random nit fixes, etc.)
# Testing
- Added consistency check for stats in `test_cuda.py`. This verifies that the data from `memory_stats()` is faithful to the data from `snapshot()`.
- Ran on various basic workflows (toy example, CIFAR)
# Performance
Running the following speed benchmark: https://pastebin.com/UNndQg50
- Before this PR: 45.98 microseconds per tensor creation
- After this PR: 46.65 microseconds per tensor creation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27361
Differential Revision: D17758747
Pulled By: jma127
fbshipit-source-id: 5a84e82d696c40c505646b9a1b4e0c3bba38aeb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27546
Add files in csrc/jit/mobile folder to torch_core, as a first step to have light interpreter built in BUCK. Next the files will be independent of torch_core (T54912812)
ghstack-source-id: 91523987
Test Plan:
buck build -c pytorch.enable_rtti=1 -c project.ignore= -c ndk.app_platform=android-23 -c user.libcxx_cflags=-DFOLLY_USE_LIBCPP=1 -c user.libcxx_cxxflags=-DFOLLY_USE_LIBCPP=1 -c ndk.cxx_runtime=libcxx -c user.ndk_cxxflags=-g0 //xplat/experimental/pytorch/mobile:lite_predictorAndroid#android-armv7 && adb push buck-out/gen/xplat/experimental/pytorch/mobile/lite_predictorAndroid#android-armv7 /data/local/tmp/
In adb shell:
data/local/tmp/lite_predictorAndroid\#android-armv7 add_it.bc
buck build -c project.ignore= @//fbcode/mode/dev-asan //xplat/experimental/pytorch/mobile:lite_predictor
Reviewed By: ljk53
Differential Revision: D17717547
fbshipit-source-id: 4c00a35eb231968d05d0d7b56bcfd5dc0258d4bb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27379
Currently the operators need to be registered manually through c10 registration.
Test Plan:
The operators should be covered by tests on operators.
A few ops (add, conv) are covered in test_lite_interpreter.cpp for demonstration.
CV models may be too large to include in unittests.
Simple local loaders can be built. Follow similar pattern as in test_lite_interpreter to
1. load the torch script model
2. run the model to get reference results
3. save and load the mobile module using torch::jit::module._save_for_mobile() and torch::jit::_load_for_mobile().
4. run the mobile module by run_method() and compare the results to reference results.
Tested models:
* Lenet
* XrayMobileV3
Differential Revision: D17810912
fbshipit-source-id: 2cc25dbe81a3c9a85108b3efe6a8e957028fc622
Summary:
CUDA_tensor_apply1 is unused, so it will be removed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27313
Differential Revision: D17746076
Pulled By: ifedan
fbshipit-source-id: 99120a5f1f0f716b4dc19b6ffe931071cbcdaea2
Summary:
std::atan2 is not used because it does not work with HIP.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26178
Differential Revision: D17747897
Pulled By: VitalyFedyunin
fbshipit-source-id: b300f0573c431e1425644c9c1899d0b024c6a57c
Summary:
Issue: https://github.com/pytorch/pytorch/issues/27366
The address of a view tensor might be shifted from the head of the storage.
```python
>>> x = torch.rand(10, 10, device=0, requires_grad=True)
>>> y = x[2:]
>>> hex(x.data_ptr())
'0x7f1b15c00000'
>>> hex(y.data_ptr())
'0x7f1b15c00050'
```
Currently, `Tensor.record_stream()` silently ignores shifted view tensors, because `CUDACachingAllocator` cannot find the block from the shifted address.
```c++
void recordStream(void* ptr, cuda::CUDAStream stream)
{
if (ptr) {
std::lock_guard<std::recursive_mutex> lock(mutex);
Block* block = find_allocated_block(ptr);
if (block) {
...
}
// 'block' is nullptr if 'ptr' is shifted.
}
}
```
So we cannot protect shifted view tensor which is used to compute or copy in an arbitrary stream against unexpected reallocation. Once we call `record_stream()` on a tensor, our intention is to protect the storage behind the tensor against reallocation until all works in the stream finish. This rule should be consistent regardless of the type of tensors including the view.
We can retrieve the head of the address from any types of tensors by `tensor.storage().data_ptr()`. Hence, I've thought it's better to pass to `recordStream()` rather than `tensor.data_ptr()` for consistent behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27371
Reviewed By: ezyang
Differential Revision: D17768558
Pulled By: albanD
fbshipit-source-id: 7705f52b0177625168edb6f71c07a029df471bc5
Summary:
Fix issue https://github.com/pytorch/pytorch/issues/26698.
With different query/keys/value dimensions, `nn.MultiheadAttention` has DDP incompatibility issue because in that case `in_proj_weight` attribute is created but not used. Fix it and add a distributed unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26826
Differential Revision: D17583807
Pulled By: zhangguanheng66
fbshipit-source-id: c393584c331ed4f57ebaf2d4015ef04589c973f6
Summary:
Back in April, malmaud added type annotations for `dataloader.py`. However, at about the same time, SsnL in https://github.com/pytorch/pytorch/issues/19228 replaced `_DataLoaderIter` with `_BaseDataLoaderIter` and two subclasses, `_SingleProcessDataLoaderIter`, and `_MultiProcessingDataLoaderIter`. However - probably because these changes happened in parallel at roughly the same time, the type stubs and several other references in the codebase were never updated to match this refactoring.
I've gone ahead and done the updates to reflect the refactoring in https://github.com/pytorch/pytorch/issues/19228, which fixes the specific type stub/impelementation mismatch pointed out in https://github.com/pytorch/pytorch/issues/26673, although not the broader problem that pytorch doesn't have a test to make sure that the `.pyi` type stub files match the real API defined in `.py` files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27105
Differential Revision: D17813641
Pulled By: ezyang
fbshipit-source-id: ed7ac025c8d6ad3f298dd073347ec83bb4b6600c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/10127.
This ensures that aten_op.h is regenerated whenever a new native kernel
is removed. Previously it was only being regenerated when new native
kernels were added because this generated new source files, which this
cmake target depended on. However if a native kernel is removed then
there is no dependent target and the header is never regenerated.
Explicitly depending on native_functions.yaml ensures that the header
is regenerated even if a kernel is removed.
I'm no cmake expert so alternative approaches or reasons why this is
obviously incorrect are very appreciated!
EDIT: reflecting comments below we now depend on `Dependencies.yaml` instead of `native_functions.yaml`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27253
Differential Revision: D17813659
Pulled By: ezyang
fbshipit-source-id: 2c754a88ba62495c14de8a9649f6675d2dad0b7d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27287
This is replaced by calls to `dist.rpc_sync` and `dist.rpc_async`.
Test Plan: Imported from OSS
Differential Revision: D17808210
Pulled By: pietern
fbshipit-source-id: 3103a615fa8b08224780387a3ea4ac6b1c73badb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27286
The name `runUDFFunction` stutters because the F in UDF also stands
for function. Renamed these variables to be identical to their Python
equivalents. Renamed those to share a prefix and drop `internal`,
because internal functions can use an underscore prefix.
Test Plan: Imported from OSS
Differential Revision: D17808208
Pulled By: pietern
fbshipit-source-id: 7619f07fc8215203dfb1da1eb281845edcd2bb99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27284
The warnings related to usage of the deprecated != operator. Instead
of checking the member field on every function call, we can check it
once, on construction of PythonRpcHandler.
Test Plan: Imported from OSS
Differential Revision: D17808213
Pulled By: pietern
fbshipit-source-id: 022c8f77f266942c49c55b1729e62dbb06262d77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26859
CUDA builds are intermittently taking greater than five hours,
hitting CircleCI's timeout limit, and also all around making
developers unhappy. Part of the reason for this is because
they build PyTorch twice: once as normal, and once as libtorch.
This diff splits libtorch into a new job to parallelize this
and get us below the patch. It's an emergency diff because
I did the minimum possible work to make this work, including
grody hacks to make sure macos libtorch builds still work
(without adding a separate job there).
- Add a new libtorch config, to cuda9 (same as before). Disable
generation of the other test variants.
- Adjust common.sh to NO LONGER set BUILD_TEST_LIBTORCH for
pytorch-linux-trusty-py3.6-gcc7; we will test for *libtorch*
in the job name for this case. (I noticed a bug while
looking at this.)
- Adjust build.sh and test.sh. The eventual logic is that if you are a
*libtorch* build, ONLY build libtorch; otherwise do the same
thing you used to do (including respecting BUILD_TEST_LIBTORCH)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17810592
Pulled By: ezyang
fbshipit-source-id: 8dcdb8f7424ddda293500d9fc90097a54dca28b9
Summary:
This PR stop common_utils.py from setting the default tensor type when it's imported. See issue https://github.com/pytorch/pytorch/issues/27355. This is a frequent source of confusion for test writers.
Many tests relied on this setting (whether they knew it or not), and this PR also updates the test suite to pass without common_utils.py setting the default tensor type. Some larger test files now set the default floating dtype themselves, however. These test files are:
- test_autograd.py
- test_distributions.py
- test_jit.py
- test_nn.py
This is still a significant improvement from today, however. First, these files set the default floating dtype much more clearly than importing it from common_utils. Second, the rest of the test suite no longer sets this globally. Third, this PR is a springboard to updating those tests, too. In particular, as tests are made generic they can be moved aways from relying on this global setting.
Notable technical changes in this PR are:
- Significant updates to test_torch.py to make it pass without setting the default floating dtype globally.
- The default_floating_dtype decorator is now defined in common_utils, a couple versions of this operator were defined in test files previously.
- test_torch-specific parts of common_utils were refactored into test_torch.
- tensor creation methods in common_utils were updated to accept an optional dtype and device.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27444
Differential Revision: D17795235
Pulled By: mruberry
fbshipit-source-id: 7f77271c0c836e69f183ad9057a2c4b29f09d2e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27508
Implemented a simple exponential decay of the weight of lr loss function, with a lower bound.
Test Plan:
buck test //caffe2/caffe2/fb/dper/layer_models/tests:mtml_test -- test_task_weight_decay
https://our.intern.facebook.com/intern/testinfra/testrun/3377699729136308
canary: f140103452
Reviewed By: chenshouyuan
Differential Revision: D17524101
fbshipit-source-id: 9a653e21a4ecb74dfc4ac949c9e3388f36ef3a20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27374
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17809770
Pulled By: ezyang
fbshipit-source-id: 75bd97426494a7bbbf08f9bce7563d35871443d8
Summary:
Fixing https://github.com/pytorch/pytorch/issues/27266
In general we should not rely on transitively included headers, we should implicitly include all headers if their members are used in the source file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27478
Differential Revision: D17799522
Pulled By: pbelevich
fbshipit-source-id: 5818394a212c947cfac3a6cf042af9ebb8b9d9a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27124
ncclCommAbort() and ncclGetAsyncError() were two APIs added in NCCL
2.4 to detect errors in NCCL communicators. These were used as part of
ProcesGroupNCCL and we also enforced that only NCCL versions 2.4+ were
supported. Although, there is still legitimate use for older NCCL versions and
hence we should still support those.
For that purpose, in this change I've ensured we disable NCCL error checking
for versions < 2.4.
ghstack-source-id: 91452959
Test Plan:
1) Test with 2.4.8
2) Test with 2.2.13
3) unit tests.
Differential Revision: D17178988
fbshipit-source-id: 5dc44b5f7b4b00466c67fd452315f1d4f5c47698
Summary:
All of the test cases move into a base class that is extended by the
intrumentation test and a new "HostTests" class that can be run in
normal Java. (Some changes to the build script and dependencies are
required before the host test can actually run.)
ghstack-source-id: fe1165b513241b92c5f4a81447f5e184b3bfc75e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27453
Test Plan: Imported from OSS
Reviewed By: IvanKobzarev
Differential Revision: D17800410
fbshipit-source-id: 1184f0caebdfa219f4ccd1464c67826ac0220181
Summary:
Exporting torch.select when index = negative one (x[:,-1]) was broken. This PR has the fix in symbolic function for select.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25273
Reviewed By: hl475
Differential Revision: D17159707
Pulled By: houseroad
fbshipit-source-id: 2c3b275421082758f1b63c1c9b6e578f03ca9f76
Summary:
Most of this was old cruft left over from special handling of `training` before we had a `bool` type. This makes all modules have a `training` attribute that is true by default and removes all other special handling.
Fixes#26884
](https://our.intern.facebook.com/intern/diff/17728129/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27109
Pulled By: driazati
Differential Revision: D17728129
fbshipit-source-id: 8ddc9fbb07a953dd05529538bfdd01ed88b5cb57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27410
Similar to https://github.com/pytorch/pytorch/pull/25005, TSAN is not
safe to use in a multi-threaded program with fork and can cause deadlocks. As a
result, disabling this test for TSAN.
ghstack-source-id: 91393545
Test Plan: buildbot
Differential Revision: D17775141
fbshipit-source-id: 109b8095240ad43ee4a6380f70b9efca863c0a4a
Summary:
We do support inputs with dim > 2 in _out variants
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26989
Differential Revision: D17785632
Pulled By: soumith
fbshipit-source-id: d42ba7ca9c225ad1a26ff3b410d0c5c08eaed001
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27086
This is a major source of merge conflicts, and AFAICT isn't necessary anymore (it may have been necessary for some mobile build stuff in the past).
This is a commandeer of #25031
Test Plan: Imported from OSS
Reviewed By: ljk53
Differential Revision: D17687345
Pulled By: ezyang
fbshipit-source-id: bf6131af835ed1f9e3c10699c81d4454a240445f
Summary:
ROCm 2.9 brings support for the rocTX API through rocTracer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27416
Differential Revision: D17777480
Pulled By: bddppq
fbshipit-source-id: 6bce9b54c94e5b4c5787570d2b85736882bd23a7
Summary:
Running models with inplace operators will change values of input tensors.
Deepcopy input tensors each time to keep the original input tensors intact.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27186
Differential Revision: D17776598
Pulled By: jerryzh168
fbshipit-source-id: d4808a11185a9ab0d782a62d7d708dfe7e94559c
Summary: Add helper function randomFill to test_utils.h so we can use it in benchmark scrips as well tests.
Test Plan:
```
buck run mode/opt //tvm/sparse:cblas_bench
```
Reviewed By: yinghai
Differential Revision: D17759193
fbshipit-source-id: e4909b04e83ca9382ab4718855fb63743d028de1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26770
This PR added the interface/object serialization as module attribute, to
allow initializing object as a interface type during python
initialization. Because interface type can be backed by any class object
that implements that interface, if we declare it in
python/module.__init__, we will need to collect the run time types of the
value and serialize them to ensure complete code information
Test Plan: Imported from OSS
Differential Revision: D17742707
fbshipit-source-id: 7f614ad4f982996d320a0e2dd3515bf47370e730
Summary:
Print warning when using DNNLOWP dynamic int8 quant for FC and activation_quantization_kind != min_max.
Warning will display in console but not in Bento. Would have to use CAFFE_ENFORCE to alert in Bento.
Test Plan: buck run unit test forcing DNNLOWP FC with activation_quantization_kind = "l2" and saw warning printed in console.
Reviewed By: csummersea
Differential Revision: D17770921
fbshipit-source-id: b6532e4c9a86d74e3db4cb432735505d378a366e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27359
Adding methods to TensorImageUtils:
```
bitmapToFloatBuffer(..., FloatBuffer outBuffer, int outBufferOffset)
imageYUV420CenterCropToFloat32Tensor(..., FloatBuffer outBuffer, int outBufferOffset)
```
To be able to
- reuse FloatBuffer for inference
- to create batch-Tensor (contains several images/bitmaps)
As we reuse FloatBuffer for example demo app - image classification,
profiler shows less memory allocations (before that for every run we created new input tensor with newly allocated FloatBuffer) and ~-20ms on my PixelXL
Known open question:
At the moment every tensor element is written separatly calling `outBuffer.put()`, which is native call crossing lang boundaries
As an alternative - to allocation `float[]` on java side and fill it and put it in `outBuffer` with one call, reducing native calls, but increasing memory allocation on java side.
Tested locally just eyeballing durations - have not noticed big difference - decided to go with less memory allocations.
Will be good to merge into 1.3.0, but if not - demo app can use snapshot dependencies with this change.
PR with integration to demo app:
https://github.com/pytorch/android-demo-app/pull/6
Test Plan: Imported from OSS
Differential Revision: D17758621
Pulled By: IvanKobzarev
fbshipit-source-id: b4f1a068789279002d7ecc0bc680111f781bf980
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27396
Observer that estimates moving averages of min and max values per batch, more suited for quantization aware training instead of minmax observers that track extremal values across batches
ghstack-source-id: 91369018
Test Plan:
buck test caffe2/test:quantization -- 'test_per_tensor_observers \(test_quantization\.ObserverTest\)' --print-passing-details
buck test caffe2/test:quantization -- 'test_per_channel_observers \(test_quantization\.ObserverTest\)' --print-passing-details
Differential Revision: D17727213
fbshipit-source-id: 024a890bf3dd0bf269d8bfe61f19871d027326f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27381
Changing android nightly builds from master to version 1.4.0-SNAPSHOT, as we also have 1.3.0-SNAPSHOT from the branch v1.3.0
Test Plan: Imported from OSS
Differential Revision: D17773620
Pulled By: IvanKobzarev
fbshipit-source-id: c39a1dbf5e06f79c25367c3bc602cc8ce42cd939
Summary:
Unfortunately, the HIP function takes uint32_t* instead of int*, so we still need to ifdef for the time being.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27390
Differential Revision: D17768832
Pulled By: bddppq
fbshipit-source-id: c65176660cb0783a04f0a4a064f686818d759589
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26140
Per https://github.com/pytorch/pytorch/issues/25883, we want to work
towards C++/Python API parity. This diff adds clip_grad_norm_ to the c++ API to
improve parity.
ghstack-source-id: 91334333
ghstack-source-id: 91334333
Test Plan: Added a unit test
Differential Revision: D17312367
fbshipit-source-id: 753ba3a4d084d01f3cc8919da3108e67c809ad65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27224
As part of adding error handling to NCCL, we are now able to specify a
timeout for operations using ProcessGroupNCCL. Although, this timeout had a
default of 10 seconds and didn't respect the timeout specified in
init_process_group.
In this change, I've ensured we pass the appropriate timeout to
ProcessGroupNCCL.
ghstack-source-id: 91283548
Test Plan:
Added unit test to verify timeout passed in to init_process_group is
respected.
Differential Revision: D17717992
fbshipit-source-id: c73320187f1f3b2693ba1e177d80646e282d01a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27068
Adds a function that uses ncclGetVersion from the NCCL API to retrieve the NCCL version. Converts it into a readable string, and is called in NCCL-related error messages to log the NCCL version. Hopefully this will help with debugging NCCL errors.
Test Plan:
Modify C10D_NCCL_CHECK in NCCLUtils.hpp to always error by setting ncclResult_t error = ncclSystemError
force an NCCL error with script test/simulate_nccl_errors.py:
Start master node: python test/simulate_nccl_errors.py localhost 9124 0 2
Start other node: python test/simulate_nccl_errors.py localhost 9124 1 2
On the master node, should see the following error message w/NCCL version:
```
Traceback (most recent call last):
File "simulate_nccl_errors.py", line 29, in <module>
process_group.allreduce(torch.rand(10).cuda(rank)).wait()
RuntimeError: NCCL error in: ../torch/lib/c10d/ProcessGroupNCCL.cpp:375, unhandled system error, NCCL version 2.4.8
```
Differential Revision: D17639476
fbshipit-source-id: a2f558ad9e883b6be173cfe758ec56cf140bc1ee
Summary:
10 lines of error context (on both sides) is overkill, especially now
that we have line numbers. With a compilation stack of a couple
functions, it becomes a pain to scroll to the top of the stack to see
the real error every time.
This also fixes class names in the compilation stack to a format of
`ClassName.method_name` instead of the the full qualified name
Old output
```
clip_boxes_to_image(Tensor boxes, (int, int) size) -> (Tensor):
Expected a value of type 'Tuple[int, int]' for argument 'size' but instead found type 'Tuple[int, int, int]'.
:
at /home/davidriazati/dev/vision/torchvision/models/detection/rpn.py:365:20
top_n_idx = self._get_top_n_idx(objectness, num_anchors_per_level)
batch_idx = torch.arange(num_images, device=device)[:, None]
objectness = objectness[batch_idx, top_n_idx]
levels = levels[batch_idx, top_n_idx]
proposals = proposals[batch_idx, top_n_idx]
final_boxes = []
final_scores = []
for boxes, scores, lvl, img_shape in zip(proposals, objectness, levels, image_shapes):
boxes = box_ops.clip_boxes_to_image(boxes, img_shape)
~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
keep = box_ops.remove_small_boxes(boxes, self.min_size)
boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep]
# non-maximum suppression, independently done per level
keep = box_ops.batched_nms(boxes, scores, lvl, self.nms_thresh)
# keep only topk scoring predictions
keep = keep[:self.post_nms_top_n]
boxes, scores = boxes[keep], scores[keep]
final_boxes.append(boxes)
final_scores.append(scores)
'RegionProposalNetwork.filter_proposals' is being compiled since it was called from 'RegionProposalNetwork.forward'
at /home/davidriazati/dev/vision/torchvision/models/detection/rpn.py:446:8
num_images = len(anchors)
num_anchors_per_level = [o[0].numel() for o in objectness]
objectness, pred_bbox_deltas = \
concat_box_prediction_layers(objectness, pred_bbox_deltas)
# apply pred_bbox_deltas to anchors to obtain the decoded proposals
# note that we detach the deltas because Faster R-CNN do not backprop through
# the proposals
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
proposals = proposals.view(num_images, -1, 4)
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
losses = {}
if self.training:
assert targets is not None
labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets)
regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)
loss_objectness, loss_rpn_box_reg = self.compute_loss(
objectness, pred_bbox_deltas, labels, regression_targets)
losses = {
'RegionProposalNetwork.forward' is being compiled since it was called from 'MaskRCNN.forward'
at /home/davidriazati/dev/vision/torchvision/models/detection/generalized_rcnn.py:53:8
"""
if self.training and targets is None:
raise ValueError("In training mode, targets should be passed")
original_image_sizes = [(img.shape[-2], img.shape[-3]) for img in images]
images, targets = self.transform(images, targets)
features = self.backbone(images.tensors)
if isinstance(features, torch.Tensor):
features = OrderedDict([(0, features)])
proposals, proposal_losses = self.rpn(images, features, targets)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
losses = {}
losses.update(detector_losses)
losses.update(proposal_losses)
# TODO: multiple return types??
# if self.training:
```
New output
```
RuntimeError:
clip_boxes_to_image(Tensor boxes, (int, int) size) -> (Tensor):
Expected a value of type 'Tuple[int, int]' for argument 'size' but instead found type 'Tuple[int, int, int]'.
:
at /home/davidriazati/dev/vision/torchvision/models/detection/rpn.py:365:20
final_scores = []
for boxes, scores, lvl, img_shape in zip(proposals, objectness, levels, image_shapes):
boxes = box_ops.clip_boxes_to_image(boxes, img_shape)
~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
keep = box_ops.remove_small_boxes(boxes, self.min_size)
boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep]
'RegionProposalNetwork.filter_proposals' is being compiled since it was called from 'RegionProposalNetwork.forward'
at /home/davidriazati/dev/vision/torchvision/models/detection/rpn.py:446:8
proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
proposals = proposals.view(num_images, -1, 4)
boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
losses = {}
'RegionProposalNetwork.forward' is being compiled since it was called from 'MaskRCNN.forward'
at /home/davidriazati/dev/vision/torchvision/models/detection/generalized_rcnn.py:53:8
if isinstance(features, torch.Tensor):
features = OrderedDict([(0, features)])
proposals, proposal_losses = self.rpn(images, features, targets)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
detections = self.transform.postprocess
```
](https://our.intern.facebook.com/intern/diff/17560963/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26765
Pulled By: driazati
Differential Revision: D17560963
fbshipit-source-id: e463548744b505ca17f0158079b80e08fda47d49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27104
* The use case here is to replace prim::ListConstruct, which requires Node, but Node is not available in mobile lite interpreter.
* (OPN, X, N), X is the index to the vararg operator-name and operator tables. N is number of inputs. For ListConstruct example, operator name can be "aten::listconstruct" and the overloaded name is the output type ("int", "float", "bool", "tensor" and "generic").
* A vararg operator table is built with void(int input_size, Stack& stack) functions.
## Unit test
LiteInterpreterConv covers OPN instruction and conv operator.
Test Plan: Imported from OSS
Differential Revision: D17762853
fbshipit-source-id: 475aa0c6678e3760cec805862a78510913a89c83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26423
Enable chainable schedulers as requested in #13022 by implementing the changes mentioned below from [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513370208).
* Changing the behavior of schedulers to the chainable formula when available
* Using the closed form whenever epoch is different from None until the next release with a deprecation warning
* Making `get_computed_values` the supported way of obtaining the last computed learning rate by the scheduler (see [comment](https://github.com/pytorch/pytorch/pull/21800#issuecomment-513940729) for new syntax)
* Returning a deprecation warning when invoking the undocumented get_lr function (see [comment](https://github.com/pytorch/pytorch/pull/21800#discussion_r294305485)) referring to `get_computed_values`, and deprecating it in the next release.
* `CosineAnnealingWarmRestart` still takes an epoch parameter as it is the only one with a mechanic relying on fractional epoch
* `MultiplicativeLR` is consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
# #20527
### Before
The user calls scheduler with a constant epoch either across loops or in the same loop.
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
# Scheduler with sometimes-constant epoch number
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
lr_scheduler.step(epoch)
print(optimizer.param_groups[0]['lr'])
```
### After
If the user wants to step
```
import torch.optim as optim
from torch import nn
conv = nn.Conv2d(3,3,3)
optimizer = optim.Adam(conv.parameters())
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, 2)
last_epoch = -1
for epoch in [0, 0, 1, 1, 2, 2, 3, 3]:
# Check if epoch number has changed manually
if epoch-last_epoch > 0:
lr_scheduler.step()
last_epoch = epoch
print(epoch, scheduler.get_computed_values())
```
# #22107
### Before
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Scheduler computes and returns new learning rate, leading to unexpected behavior
print(i, scheduler.get_lr())
scheduler.step()
```
### After
```
import torch
from torchvision.models import resnet18
net = resnet18()
optimizer = torch.optim.SGD(net.parameters(), 0.1)
lr_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 9], gamma=0.1)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 3, gamma=0.1)
for i in range(10):
# Returns last computed learning rate by scheduler
print(i, lr_scheduler.get_computed_values())
lr_scheduler.step()
```
# ghstack
This contains the changes from #24352. Opening again since they were reverted.
This reverts commit 1c477b7e1f378e9c1f8efed296241f68a8a4372b.
Test Plan: Imported from OSS
Differential Revision: D17460427
Pulled By: vincentqb
fbshipit-source-id: 8c10f4e7246d6756ac91df734e8bed65bdef63c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27304
The ellipsis version of `align_to` only works if it is called as a
method. To prevent any confusion, this PR disables `torch.align_to` (but
keeps `Tensor.align_to`.
Test Plan: - [namedtensor ci]
Differential Revision: D17743809
Pulled By: zou3519
fbshipit-source-id: cf5c53dcf45ba244f61bb1e00e4853de5db6c241
Summary:
- The tensor op tests generated in test_cuda.py are now generic and appear in test_torch,py
- Data previously held in auxiliary data structures and files, like test_cuda_ignores.txt, is inlined
Previously the tensor op tests used several auxiliary data structures, a file, and exception handling to filter the test suite. If a function wasn't implemented, for example, that exception would be caught. This let functions like trigamma, which isn't callable, appear to be tested. See https://github.com/pytorch/pytorch/issues/27230. Filtering from additional data stores is error prone, too. It requires developers understand what data stores are used and how they're used. The existing sources are also sometimes incorrect. The txt file claims that dist_ doesn't work on half tensors, for example, but the updated tests verify it does.
In addition to making these tests generic, this PR removes those auxiliary data structures and does not catch any exceptions. Exceptions are errors. (This also means that if something implemented breaks it will now report as an error. Previously the test suite would have reported a pass.) The test infrastructure was also simplified to not perform computations with CPU half tensors since they do not support many operations. This introduces a float<->half conversion quirk but eliminates awkward functions that would first convert cpu tensors to float, perform an operation, and convert them back.
With this change test_cuda.py is almost entirely CUDA-specific.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27210
Differential Revision: D17757907
Pulled By: mruberry
fbshipit-source-id: b3c191c379667b1a7d5361087bdf82f397f77f65
Summary:
PackedSequence.to(device) incorrectly places one of three tensors on the device and leaves the other two tensors where they are. If these devices are distinct then further operations on PackedSequence will fail. This behavior is inconsistent with Tensor.to and PackedSequence's behavior when .cuda() is called.
Additionally, PackedSequence defines multiple other conversion functions that were independently and inconsistently implemented.
This PR unifies all implementations and makes the PackedSequence.to behavior more consistent with Tensor.to. It is not completely consistent per comments. test_device_mask in test_nn.py is updated to validate the new functionality.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27245
Differential Revision: D17757850
Pulled By: mruberry
fbshipit-source-id: 58f0bd40f1aa300fb0a91ee743483d645f977dc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26270
We've accumulated a lot of sugared values whose only purpose is
to be instanced-checked against in emitApplyExpr. I need to add
another one to insert an unchecked_cast, and do not want to continue
the pattern. This creates an abstraction for this concept (SpecialFormValue),
and removes all the unneeded sugared values. There is no functionality
change here just a bunch of code movement in compiler.cpp
Test Plan: Imported from OSS
Differential Revision: D17412854
Pulled By: zdevito
fbshipit-source-id: 15877c91decaea5a00d1fe737ed2d0f0f8a79a28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27110
Previously missing methods on some types like tensors would talk about
'builtins' which are only a thing inside of the compiler. Furthermore,
the error would only occur when the builtin was applied and it was discovered
that no builtin existed. This changes the error message so that it
discovers that method on our builtin types does not exist on attribute lookup.
Test Plan: Imported from OSS
Differential Revision: D17677616
Pulled By: zdevito
fbshipit-source-id: 2f7cf6c6093a9c832569c44f4b1044a2e56fe205
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27339
This PR just shows a warning message.
Eventually we will show a correct __dir__
Test Plan: Imported from OSS
Differential Revision: D17751333
Pulled By: zafartahirov
fbshipit-source-id: e9bc62fd8dd0147979291d0aac3f1afe5b8c7a9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27322
# Problem
Existing test cases are too symmetric, so that didn't detect this error, request sent to the wrong worker.
Because of wrong `worker_names` setup, worker0 sends request to itself, while it should had sent to worker1.
# Solution
Add a test case, letting the dst side to check if it's an request from the expected src.
ghstack-source-id: 91299312
Reviewed By: satgera
Differential Revision: D17069062
fbshipit-source-id: ef7a532dd497bfc0f0ee8446fcd5d29656aaf175
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27268
For small pickle/unpickle, we spend a disproportionate amount of time in
time functions - roughly 23% in __tzset() for unpickle case.
We're currently not using the .m_time currently, though we can add this feature
back if it's ever needed.
An alternative would be to -DMINIZ_NO_TIME in compiler_flags, but we would
need to also consistently # define MINIZ_NO_TIME in any .cpp including this .h,
since this # define modifies the struct length in an unfortunate manner.
Test Plan:
buck test mode/dev-nosan caffe2/test/...
Run benchmark:
buck-out/opt/gen/caffe2/torch/fb/distributed/thriftRpcBackend/test/ThriftRpcAgentBench
Differential Revision: D17724198
fbshipit-source-id: b44a0217b1d9f8ce6c0f24297f59045c7cadf4b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25499
See #23110 for model parallel design details, and #26759 for the RRef
protocol. This commit add support for using RRef as Python UDF arguments
and return value. RRefs can now be shared from owner to user, from user to
owner, or from user to user.
Limitations:
1. No implicit type conversion yet. (#27099)
2. No failure handling and retry. (#26116)
3. UDF is not yet blocked until all RRefs are confirmed. (#27098)
4. Internal RRef control messages are not idempotent yet. (#26116)
5. Cannot delete RRefs correctly when there are circular dependencies. (#27096)
Main changes:
1. Added `SCRIPT_REMOTE_CALL` and `PYTHON_REMOTE_CALL` to `Message.h` to represent `dist.remote` invocations.
2. Added `SCRIPT_RREF_FETCH_CALL`, `PYTHON_RREF_FETCH_CALL`, `RREF_USER_ACCEPT`, `RREF_USER_DELETE`, `RREF_CHILD_ACCEPT`, and `RREF_FORK_REQUEST` to `Message.h` as internal RRef control messages.
3. New message request handling code is added to `functions.cpp`, and message format is added in `script_remote_call.h`, `python_remote_call.h`, and `rref_proto.h`.
4. Added a `PyRRef` type in `py_rref.h` and `py_rref.cpp` which holds a shared pointer to C++ `RRef` type. `PyRRef` wraps the C++ API and also implements RRef pickling and unpickling. RRef fork related control messages will be sent during RRef pickling/unpickling procedure.
5. Update `RRef.h` and `RRef.cpp` accordingly to support `py::object` RRefs.
6. RRef context (reference count, etc.) are tracked in `rref_context.h` and `rref_context.cpp`.
Test Plan:
Imported from OSS
buck test mode/dev-nosan //caffe2/test:rpc_fork
Differential Revision: D17184146
Pulled By: mrshenli
fbshipit-source-id: a3a268efc087ac1ef489136ab957080382629265
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26734
This PR added the python assignment for interface as an attribute in the
module, it enables any object that implicitly inheriting the specific
interface to be able to be assigned to the interface type in python.
Serialization support for interface/class assignment will be done in the
follow up PR
Test Plan: Imported from OSS
Differential Revision: D17742708
Pulled By: wanchaol
fbshipit-source-id: a0a2d8c74b60ed3fa6c05e1b0d49b7ad1abc670b
Summary:
Adds the method `add_hparams` to `torch.utils.tensorboard` API docs. Will want to have this in PyTorch 1.3 release.
cc sanekmelnikov lanpa natalialunova
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27344
Differential Revision: D17753689
Pulled By: orionr
fbshipit-source-id: cc8636e0bdcf3f434444cd29471c62105491039d
Summary: As title. Fix the build failures in unicorn-build-restrictions as discussed in D17330625
Test Plan:
buck test mode/opt caffe2/caffe2/quantization/server:resize_nearest_3d_dnnlowp_op_test
In vision libs, no need to explicitly add dep to resize 3d op as the caffe2_cpu dep is added by default.
Reviewed By: stephenyan1231
Differential Revision: D17676082
fbshipit-source-id: c034ab67a9078f72077b396991ffb9e54e6ab40b
Summary:
There is a magma package for the newest CUDA verson (10.1), mention it here lest someone try to mistakenly use the version for CUDA 10.0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27325
Differential Revision: D17749535
Pulled By: soumith
fbshipit-source-id: 2d34a7af1218e6157935bfd5e03f4d2c0f00f200
2019-10-03 15:21:53 -07:00
1769 changed files with 117202 additions and 57098 deletions
@ -340,12 +340,12 @@ Libtorch packages are built in the wheel build scripts: manywheel/build_*.sh for
All linux builds occur in docker images. The docker images are
* soumith/conda-cuda
* pytorch/conda-cuda
* Has ALL CUDA versions installed. The script pytorch/builder/conda/switch_cuda_version.sh sets /usr/local/cuda to a symlink to e.g. /usr/local/cuda-10.0 to enable different CUDA builds
* Also used for cpu builds
* soumith/manylinux-cuda90
* soumith/manylinux-cuda92
* soumith/manylinux-cuda100
* pytorch/manylinux-cuda90
* pytorch/manylinux-cuda92
* pytorch/manylinux-cuda100
* Also used for cpu builds
The Dockerfiles are available in pytorch/builder, but there is no circleci job or script to build these docker images, and they cannot be run locally (unless you have the correct local packages/paths). Only Soumith can build them right now.
@ -411,7 +411,7 @@ You can build Linux binaries locally easily using docker.
```
# Run the docker
# Use the correct docker image, soumith/conda-cuda used here as an example
# Use the correct docker image, pytorch/conda-cuda used here as an example
#
# -v path/to/foo:path/to/bar makes path/to/foo on your local machine (the
# machine that you're running the command on) accessible to the docker
@ -44,7 +44,7 @@ At a granular level, PyTorch is a library that consists of the following compone
| [**torch.multiprocessing**](https://pytorch.org/docs/stable/multiprocessing.html) | Python multiprocessing, but with magical memory sharing of torch Tensors across processes. Useful for data loading and Hogwild training |
| [**torch.utils**](https://pytorch.org/docs/stable/data.html) | DataLoader and other utility functions for convenience |
Usually one uses PyTorch either as:
Usually PyTorch is used either as:
- a replacement for NumPy to use the power of GPUs.
- a deep learning research platform that provides maximum flexibility and speed.
@ -88,7 +88,7 @@ You get the best of speed and flexibility for your crazy research.
PyTorch is not a Python binding into a monolithic C++ framework.
It is built to be deeply integrated into Python.
You can use it naturally like you would use [NumPy](http://www.numpy.org/) / [SciPy](https://www.scipy.org/) / [scikit-learn](http://scikit-learn.org) etc.
You can use it naturally like you would use [NumPy](https://www.numpy.org/) / [SciPy](https://www.scipy.org/) / [scikit-learn](https://scikit-learn.org) etc.
You can write your new neural network layers in Python itself, using your favorite libraries
and use packages such as Cython and Numba.
Our goal is to not reinvent the wheel where appropriate.
@ -124,7 +124,7 @@ You can write new neural network layers in Python using the torch API
[or your favorite NumPy-based libraries such as SciPy](https://pytorch.org/tutorials/advanced/numpy_extensions_tutorial.html).
If you want to write your layers in C/C++, we provide a convenient extension API that is efficient and with minimal boilerplate.
There is no wrapper code that needs to be written. You can see [a tutorial here](https://pytorch.org/tutorials/advanced/cpp_extension.html) and [an example here](https://github.com/pytorch/extension-cpp).
No wrapper code needs to be written. You can see [a tutorial here](https://pytorch.org/tutorials/advanced/cpp_extension.html) and [an example here](https://github.com/pytorch/extension-cpp).
## Installation
@ -145,12 +145,12 @@ Python wheels for NVIDIA's Jetson Nano, Jetson TX2, and Jetson AGX Xavier are av
They requires JetPack 4.2 and above and are maintained by @dusty-nv
They require JetPack 4.2 and above, and @dusty-nv maintains them
### From Source
If you are installing from source, we highly recommend installing an [Anaconda](https://www.anaconda.com/distribution/#download-section) environment.
If you are installing from source, you will need a C++14 compiler. Also, we highly recommend installing an [Anaconda](https://www.anaconda.com/distribution/#download-section) environment.
You will get a high-quality BLAS library (MKL) and you get controlled dependency versions regardless of your Linux distro.
Once you have [Anaconda](https://www.anaconda.com/distribution/#download-section) installed, here are the instructions.
@ -167,7 +167,7 @@ If you are building for NVIDIA's Jetson platforms (Jetson Nano, TX1, TX2, AGX Xa
conda install -c pytorch magma-cuda90 # or [magma-cuda92 | magma-cuda100 ] depending on your cuda version
conda install -c pytorch magma-cuda90 # or [magma-cuda92 | magma-cuda100 | magma-cuda101 ] depending on your cuda version
```
#### Get the PyTorch Source
@ -209,13 +209,13 @@ If the version of Visual Studio 2017 is higher than 15.4.5, installing of "VC++
<br/> There is no guarantee of the correct building with VC++ 2017 toolsets, others than version 15.4 v14.11.
<br/> "VC++ 2017 version 15.4 v14.11 toolset" might be installed onto already installed Visual Studio 2017 by running its installation once again and checking the corresponding checkbox under "Individual components"/"Compilers, build tools, and runtimes".
NVTX is a part of CUDA distributive, where it is called "Nsight Compute". For installing it onto already installed CUDA run CUDA installation once again and check the corresponding checkbox.
NVTX is a part of CUDA distributive, where it is called "Nsight Compute". To install it onto already installed CUDA run CUDA installation once again and check the corresponding checkbox.
Be sure that CUDA with Nsight Compute is installed after Visual Studio 2017.
Currently VS 2017, VS 2019 and Ninja are supported as the generator of CMake. If `ninja.exe` is detected in `PATH`, then Ninja will be used as the default generator, otherwise it will use VS 2017.
<br/> If Ninja is selected as the generator, the latest MSVC which is newer than VS 2015 (14.0) will get selected as the underlying toolchain if you have Python > 3.5, otherwise VS 2015 will be selected so you'll have to activate the environment. If you use CMake <= 3.14.2 and has VS 2019 installed, then even if you specify VS 2017 as the generator, VS 2019 will get selected as the generator.
CUDA and MSVC has strong version dependencies, so even if you use VS 2017 / 2019, you will get build errors like `nvcc fatal : Host compiler targets unsupported OS`. For this kind of problem, please install the corresponding VS toolchain in the table below and then you can either specify the toolset during activation (recommended) or set `CUDAHOSTCXX` to override the cuda host compiler (not recommended if there are big version differences).
CUDA and MSVC have strong version dependencies, so even if you use VS 2017 / 2019, you will get build errors like `nvcc fatal : Host compiler targets unsupported OS`. For this kind of problem, please install the corresponding VS toolchain in the table below and then you can either specify the toolset during activation (recommended) or set `CUDAHOSTCXX` to override the cuda host compiler (not recommended if there are big version differences).
Nightly(snapshots) builds are published every night from `master` branch to [nexus sonatype snapshots repository](https://oss.sonatype.org/#nexus-search;quick~pytorch_android)
To use them repository must be specified explicitly:
The current nightly(snapshots) version is the value of `VERSION_NAME` in `gradle.properties` in current folder, at this moment it is `1.4.0-SNAPSHOT`.
## Building PyTorch Android from Source
In some cases you might want to use a local build of pytorch android, for example you may build custom libtorch binary with another set of operators or to make local changes.
For this you can use `./scripts/build_pytorch_android.sh` script.
```
git clone https://github.com/pytorch/pytorch.git
cd pytorch
sh ./scripts/build_pytorch_android.sh
```
The workflow contains several steps:
1\. Build libtorch for android for all 4 android abis (armeabi-v7a, arm64-v8a, x86, x86_64)
2\. Create symbolic links to the results of those builds:
`android/pytorch_android/src/main/jniLibs/${abi}` to the directory with output libraries
`android/pytorch_android/src/main/cpp/libtorch_include/${abi}` to the directory with headers. These directories are used to build `libpytorch.so` library that will be loaded on android device.
3\. And finally run `gradle` in `android/pytorch_android` directory with task `assembleRelease`
Script requires that Android SDK, Android NDK and gradle are installed.
They are specified as environment variables:
`ANDROID_HOME` - path to [Android SDK](https://developer.android.com/studio/command-line/sdkmanager.html)
`ANDROID_NDK` - path to [Android NDK](https://developer.android.com/studio/projects/install-ndk)
`GRADLE_HOME` - path to [gradle](https://gradle.org/releases/)
After successful build you should see the result as aar file:
At the moment for the case of using aar files directly we need additional configuration due to packaging specific (`libfbjni.so` is packaged in both `pytorch_android_fbjni.aar` and `pytorch_android.aar`).
```
packagingOptions {
pickFirst "**/libfbjni.so"
}
```
## More Details
You can find more details about the PyTorch Android API in the [Javadoc](https://pytorch.org/docs/stable/packages.html).
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
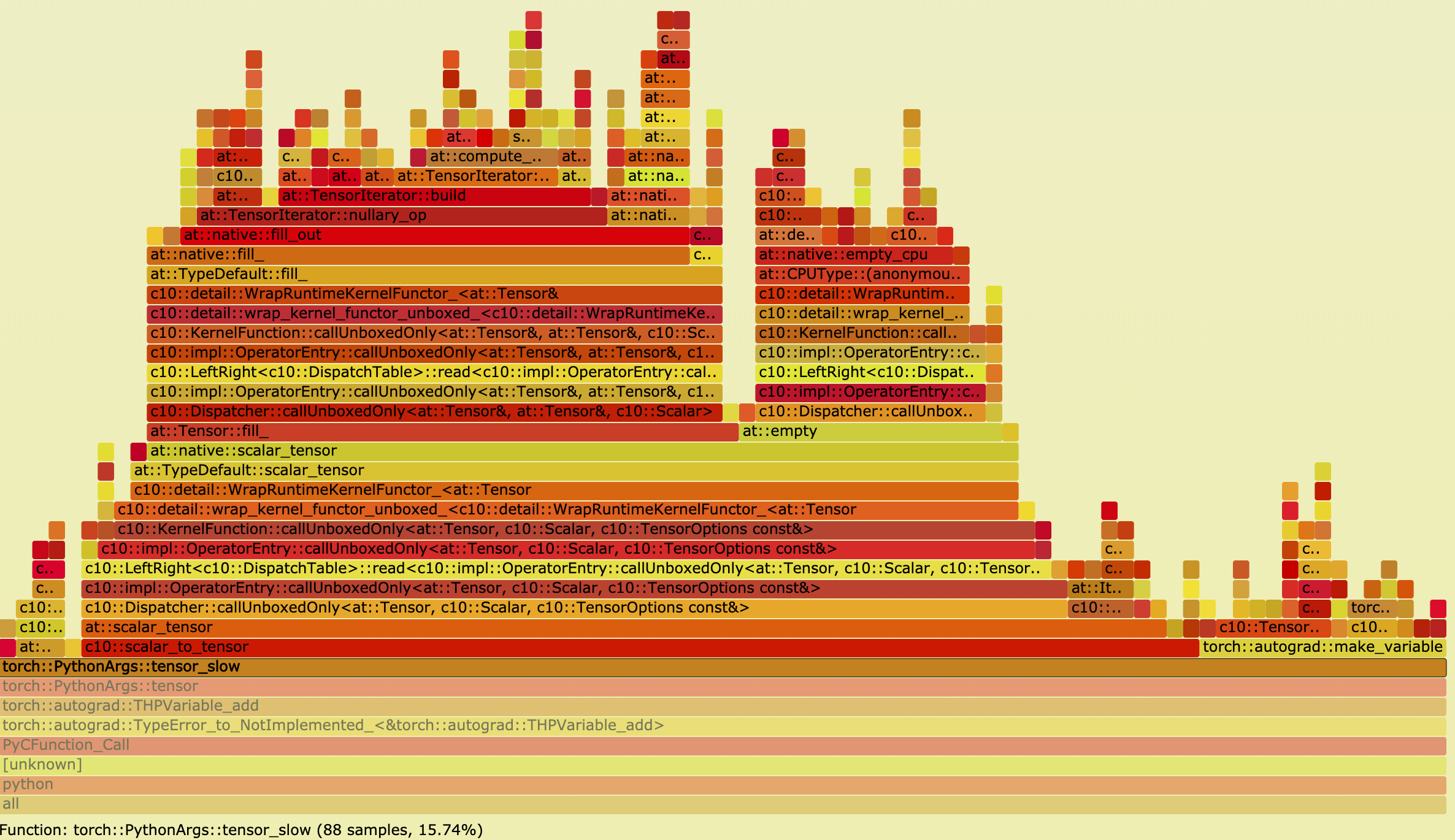{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}