This docs build won't actually be run until we open a new pull request,
after this one has been merged, "merging" v1.1.0 into master.
On that pull request, the docs build gets run.
It is safe to merge this PR in whenever, but the new docs build should
wait until after pytorch/pytorch.github.io#187 gets merged.
Summary:
As DDP in previous releases does not support unused params, turning off `find_unused_parameters` by default to derisk new reducer.
CC pietern soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19895
Reviewed By: pietern
Differential Revision: D15118563
Pulled By: mrshenli
fbshipit-source-id: 6215c486e1dae3387b36011d8e64a2721ac85f58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19901
The existing code used `expect_autograd_hooks_` as a proxy for the
situation where finalization of the previous iteration is needed. This
is not correct, however, since you may decide to completely ignore the
output of a DDP wrapped module. If this is the case, and no gradients
have been passed to the reducer, it is fine to keep going. This commit
adds a new variable `require_finalize_` that tracks whether the
finalization is really needed.
Reviewed By: mrshenli
Differential Revision: D15118871
fbshipit-source-id: 25938eaf1fe13e2940feae1312892b9d3da8a67d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19897
During validation, gradient reduction is not needed, and autograd is
never called. The model output will always be a detached tensor. After
the new reducer was merged, this meant that it would find all model
parameters unused, and kick off reduction for them. When #19799 and
output where no parameters are used and it tries to kick off reduction
of zeroed gradients. Test for `torch.is_grad_enabled()` and
`self.training` before calling into the reducer.
Reviewed By: mrshenli
Differential Revision: D15118726
fbshipit-source-id: b0208f632a61cbe8110fa626fa427937b7f05924
Summary:
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#19638 [jit] Serialize attribute module as torch.jit._pickle**
* use `torch.jit._pickle` as the module for globals in the pickle program. Pickle will try to resolve these to the actual functions in `torch.jit._pickle.py` automatically (I believe this can also be overridden to point to whatever functions you want). This means that `pickle.load("my_model/attributes.pkl")` will work instead of having to use a custom `pickle.Unpickler`
* use `REDUCE` opcodes instead of `BUILD` to make use of the last bullet
* use a union in the unpickler to support globals better (+ any future metadata we might need that can't be stored in an `IValue`), this makes some of the code around `IntList`s clearer and lets us get rid of any lookbehind for opcodes
* pickle things as a tuple instead of a list (an immutable result is more semantically correct)](https://our.intern.facebook.com/intern/diff/15111203/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19638
Pulled By: driazati
Differential Revision: D15111203
fbshipit-source-id: 526c6c2b63a48eb1cba1c658045a7809730070dd
Summary:
Trying to get this in before 1.1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19918
Reviewed By: driazati
Differential Revision: D15124430
Pulled By: eellison
fbshipit-source-id: 549cdcbaff91218657e94ce08c0f4e69b576d809
It is possible that not a single parameter is used during an
iteration. If this is the case, the prepare_for_backward function
marks all parameters as unused, kicks off reduction of all buckets,
and finalizes the reduction.
This is different from the prior implementation where we assumed that
autograd would produce a gradient for at least a single parameter.
We then used the autograd callback mechanism to queue a finalizer
callback. Now, this finalizer may be executed in line.
Summary:
When output blob names are specified while load_all=1, output blob names are ignored. However, this behavior is not documented. In this diff, we just disallow users to provide blob names when load_all=1.
See discussion at https://fb.workplace.com/groups/1405155842844877/permalink/2714909788536136/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19133
Reviewed By: dzhulgakov
Differential Revision: D14883698
Pulled By: chandlerzuo
fbshipit-source-id: 6e4171e36c4ccc4f857e79da98b858a06b7d8ad6
Summary:
Previously in type unification when we encountered an Optional[T] and a None, we would unify it to Optional[Optional[T]]. If you think about Optionals as a union of [T, None], then a union of [Optional[T], None] -> [T, None]. We should just be never create an Optional of an Optional.
The other fix is to change unify_types directly, but I think this is the more general fix, and would play more nicely with our optional type refinement, which also assumes we never encounter an Optional[Optional[T]].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19813
Reviewed By: suo
Differential Revision: D15103083
Pulled By: eellison
fbshipit-source-id: db803db10d6934eaa5458e7c1746546b0d0c0a6c
Summary:
It's been hard to understand how workers are launched and what code runs in the worker vs. main process, especially on Windows, which leads to many of our samples failing. This explains when workers run an how to make code work on Windows as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18091
Differential Revision: D15083766
Pulled By: soumith
fbshipit-source-id: 8a7e60defc8a72ec63874f657d7d5267d951dccf
Summary:
One more fix for https://github.com/pytorch/pytorch/pull/19810
We now know that we are running with python3, so no need to check python version. The quotes were probably causing problems here.
cc ezyang soumith zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19814
Differential Revision: D15106459
Pulled By: orionr
fbshipit-source-id: 0443b9b54d17fead9c8c2c9d8d2f373e1f95a28b
Summary:
This is a follow up PR for #19547.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19748
Differential Revision: D15103230
Pulled By: ezyang
fbshipit-source-id: e7ce925faeadea502f77ed42d52e247c8c6571d8
Summary:
This is a follow up PR for #19409.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19738
Differential Revision: D15103231
Pulled By: ezyang
fbshipit-source-id: 11c9fec641b389906b8accd22504a683331fa6ec
Summary:
Eigen was updated with the commit needed to get rid of this warning that plagued the CI. This PR bumps third_party/eigen to that commit head.
```
warning: #warning "host_defines.h is an internal header file and must not be used directly. This file will be removed in a future CUDA release. Please use cuda_runtime_api.h or cuda_runtime.h instead." [-Wcpp]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19789
Differential Revision: D15103223
Pulled By: ezyang
fbshipit-source-id: 5b56c4dd9cc41ff1794570ba2f6abfbe23f6ab68
Summary:
Tested locally this fix#19039, did not add a test since there's no way to create a script module in the cpp world.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19700
Differential Revision: D15094195
Pulled By: wanchaol
fbshipit-source-id: fcc2c1e5efbc160d976ae485ba2457442f62f065
Summary:
Currently, the Python API doesn't serialize layers that don't have weights (such as `nn.ReLU` and `nn.MaxPool2d`e.g. in https://github.com/pytorch/vision/blob/master/torchvision/models/densenet.py#L80-L81). If one saves a model that contains weight-less layers in Python and tries to load it into C++, the C++ module loading code (`torch::load(...)`) will throw an error complaining that the expected layers are not found in the serialized file (e.g. https://github.com/pytorch/vision/pull/728#issuecomment-480974175). This PR solves the problem by ignoring layers that are not serializable (which currently only include `nn::Functional`) in the C++ module serialization code (`torch::save(...)` and `torch::load(...)`), and the user is expected to use `nn::Functional` to wrap the weight-less layers so that they can be ignored when serializing / deserializing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19740
Differential Revision: D15100575
Pulled By: yf225
fbshipit-source-id: 956481a2355d1de45341585abedda05e35d2ee8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18820
ghimport-source-id: 220b2a3dd9d4d6d2e557e1802851f082c2dc6452
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18820 Refactor ProcessGroupNCCL collective primitives**
Planning to add reduce-scatter, but no room in my stomach for more
copypasta.
Also rewrote the tensor list validation logic. The existing validation
was ill-suited for all the cases it was being used for; it took a vector
of input tensors and a vector of output tensors, but only ever received
either two references to the same vector, or a bespoke singleton vector
and a vector of outputs (for which it would ignore all but the first
output). In the first case, it performed unnecessary checks, and in the
second, it skipped necessary ones.
Reviewed By: mrshenli
Differential Revision: D14762369
fbshipit-source-id: dcf882ce1c5854333a9eb4424bfc18d9f4648ddf
Summary:
In order to have `torch.utils.tensorboard.SummaryWriter` rendered in the documentation at the bottom of https://pytorch.org/docs/master/tensorboard.html we need to have TensorBoard installed.
This change makes it so our pinned version of `tb-nightly` is used for doc generation same as it is used for running tests at https://github.com/pytorch/pytorch/blob/master/.jenkins/pytorch/test.sh#L45-L52
Eventually we'll use a pinned version of `pip install tensorboard`, but it's not on the release channel yet.
cc kostmo soumith ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19810
Differential Revision: D15101730
Pulled By: orionr
fbshipit-source-id: c41678c4f9ef3d56a168f2b96a1ab05f351bdc56
Summary:
Input argument `f` in `_model_to_graph()` method in `torch/onnx/utils.py` is unused. This PR removes it. If there's a reason to keep it around, please let me know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19647
Reviewed By: dzhulgakov
Differential Revision: D15071720
Pulled By: houseroad
fbshipit-source-id: 59e0dd7a4d5ebd64d0e30f274b3892a4d218c496
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19799
A module that returns multiple outputs and where the called may end up
doing multiple calls to torch.autograd.backward did not work with
DistributedDataParallel. It expected the first call to
torch.autograd.backward to provide gradients for ALL parameters that
expect gradients and were used in computing the module output. If you
have outputs with disjoint autograd graphs it is fine to call
torch.autograd.backward on both and fill in the module's parameter
gradients in separate chunks.
With this change we delay queuing the finalizer callback until we have
marked all buckets as ready, instead of queueing it the first time we
receive an autograd hook. This returns the current implementation to
be functionally equivalent to the DistributedDataParallel
implementation before #18953 was merged.
Reviewed By: mrshenli
Differential Revision: D15097045
fbshipit-source-id: 2df023319713bc31e29a8b45108c78e6593fccd4
Summary:
* adds TORCH_API and AT_CUDA_API in places
* refactor code generation Python logic to separate
caffe2/torch outputs
* fix hip and asan
* remove profiler_cuda from hip
* fix gcc warnings for enums
* Fix PythonOp::Kind
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19554
Differential Revision: D15082727
Pulled By: kostmo
fbshipit-source-id: 83a8a99717f025ab44b29608848928d76b3147a4
Summary:
This PR adds TensorBoard logging support natively within PyTorch. It is based on the tensorboardX code developed by lanpa and relies on changes inside the tensorflow/tensorboard repo landing at https://github.com/tensorflow/tensorboard/pull/2065.
With these changes users can simply `pip install tensorboard; pip install torch` and then log PyTorch data directly to the TensorBoard protobuf format using
```
import torch
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
s1 = torch.rand(1)
writer.add_scalar('data/scalar1', s1[0], 0)
writer.close()
```
Design:
- `EventFileWriter` and `RecordWriter` from tensorboardX now live in tensorflow/tensorboard
- `SummaryWriter` and PyTorch-specific conversion from tensors, nn modules, etc. now live in pytorch/pytorch. We also support Caffe2 blobs and nets.
Action items:
- [x] `from torch.utils.tensorboard import SummaryWriter`
- [x] rename functions
- [x] unittests
- [x] move actual writing function to tensorflow/tensorboard in https://github.com/tensorflow/tensorboard/pull/2065
Review:
- Please review for PyTorch standard formatting, code usage, etc.
- Please verify unittest usage is correct and executing in CI
Any significant changes made here will likely be synced back to github.com/lanpa/tensorboardX/ in the future.
cc orionr, ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16196
Differential Revision: D15062901
Pulled By: orionr
fbshipit-source-id: 3812eb6aa07a2811979c5c7b70810261f9ea169e
Summary:
disable_autodiff_subgraph_inlining should be always on to check AD regression.
Thanks eellison for spotting the test regression!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19787
Differential Revision: D15093104
Pulled By: ailzhang
fbshipit-source-id: 82a75a7dd7097d5f93a2e4074023da2105341c1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19378
Function profile events are typically nested. In this diff I
add parent child relationship to the intervals. This way we can
attribute self time easily. As a result, user printing a table from a
profiler trace gets self cpu time.
This diff doesn't try to address CUDA self time as CUDA kernels are
already getting special care in the profiler.
There are also some other minor improvements. Like reporting total CPU
time spent, reversed sorting, aggregated data after the table,
etc.
There is a new unit test added which tests more functionality than
previous profiler test
Reviewed By: zheng-xq
Differential Revision: D14988612
fbshipit-source-id: 2ee6f64f0a4d0b659c6b23c0510bf13aa46f07dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19319
Quantized SUM + ReLU (Fused). The implementation is the same as the one in the DNNLOWP.
Reviewed By: jianyuh
Differential Revision: D14866442
fbshipit-source-id: c8c737a37e35b6ce3c1c2077c07546aba16e0612
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19312
Replaces the tuple hack with the QTensor. Please, note this can be landed ONLY after #18960 (D14810261) is landed.
Reviewed By: raghuramank100
Differential Revision: D14819460
fbshipit-source-id: 75ca649304b1619cb3cfe845962c9f226b8f884a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19714
We had rounding in the quantizer set as `round(x/scale) + zp`. To make it consistent, converting it to `round(x/scale + zp)`.
Reviewed By: raghuramank100
Differential Revision: D15077095
fbshipit-source-id: 5d20a90391fe8c2e11b338c05631fcf7770320c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19751
This has probably never been tested on Windows but destruction of WorkersPool crashes because it uses _aligned_malloc to allocate and 'free' to deallocate, which is not symmetric. Fix is to use _aligned_free in deallocation
Reviewed By: hlu1
Differential Revision: D15083472
fbshipit-source-id: 42243fce8f2dfea7554b52e6b289d9fea81d7681
Summary:
New pip package becomes more restricted. We need to add extra flag to make the installation work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19725
Differential Revision: D15078698
Pulled By: houseroad
fbshipit-source-id: bbd782a0c913b5a1db3e9333de1ca7d88dc312f1
Summary:
Fixes#19650
When driazati started bicubic implementation we used TF result as ground truth. It turns out opencv version bicubic resize is used more commonly.
This PR does two things:
- Fix a bug where we didn't use area mode to compute source index
- Follow the Opencv logic to handle computed negative source indices(we used to bound them by 0).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19703
Differential Revision: D15078159
Pulled By: ailzhang
fbshipit-source-id: 06a32baf2fbc93b90a156b863b4f9fab326d3242
Summary:
I want to use libtorch in a C++/CUDA project but as soon as I include `<torch/torch.h>`, ".cu" files fail to compile:
`torch/csrc/jit/script/tree.h(64): error C3520: 'args': parameter pack must be expanded in this context`
This PR makes it build on my machine (don't know if it breaks anything though).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19615
Differential Revision: D15063712
Pulled By: ezyang
fbshipit-source-id: 7561e705f8f5b42b8e6a23430710b36508fee1ee
Summary:
Because of merge error with master in #15042, open a new PR for ezyang.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17226
Differential Revision: D14418145
Pulled By: mrshenli
fbshipit-source-id: 099ba225b28e6aba71760b81b2153ad1c40fbaae
Summary:
Replace cpu_apply functions with the TensorIterator.
Vectorize copy and clone functions.
Move big pieces of the code to cpu kernels folder to be able to use AVX2.
Add fast path for copy_ function if tensor types matches.
Slow down observed on smaller tensors (up to 10% or about 1us per op.) which might be explained by the bigger CPU footprint of TensorInterator in compare to simpler cpu_apply. COntrary on bigger tensors we can see 2x-3x performance improvement (single threaded, multithreading giving even better performance boost).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18618
Differential Revision: D14954118
Pulled By: VitalyFedyunin
fbshipit-source-id: 9d9bdf3fd9d5e539a03071cced50d0a47bac1615
Summary:
Sometimes at::cat gets transposed inputs and goes on a slow path. Also, make jit_premul lstm benchmark add bias to the whole input tensor to avoid separate reduction kernels in the backward pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18816
Differential Revision: D15013576
Pulled By: wanchaol
fbshipit-source-id: bcfa1cf44180b11b05b0f55f034707012f66281a
Summary:
move the insert_guard all the way up to the beginning of the decomposation, this will fix the case that we lose insert_point context after decomposeCommonNormalization and we still need to modify the graph.
fixes#19502
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19646
Differential Revision: D15058040
Pulled By: wanchaol
fbshipit-source-id: ebdbf8623ebfe4556c461e1b650e94b905791adb
Summary:
We had a few hard to repro cases where very occasionally libthnvrtc failed to be loaded due to what looked like garbled dladdr return in `info.dli_fname` field. We could not root cause why this is happening, but this workaround avoids the problem altogether. $ORIGIN is already added to RPATH as the first search location, so dlopen("libthnnvrtc.so") will look for libthnvrtc in the caller (`libtorch.so.1`) directory, which was the purpose of the previous code that was getting `libtorch.so.1` directory using dladdr.
```
root@4ec0aab027a0:/opt/conda/lib/python3.6/site-packages/torch/lib# readelf -d ./libtorch.so.1 | grep RPATH
0x000000000000000f (RPATH) Library rpath: [$ORIGIN:/usr/local/cuda/lib64:/opt/conda/lib]
```
Hopefully, same should be happening on Mac.
cc zdevito ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19690
Differential Revision: D15076990
Pulled By: soumith
fbshipit-source-id: a4d2992ccf26953f1fc73f17c4e752d69c58e2fc
Summary:
In the distributed training development work, we need to be able to serialize a `std::vector` of `torch::Tensor`s. This PR adds support for serializing `std::vector<torch::Tensor>`.
cc. mrshenli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19677
Differential Revision: D15069860
Pulled By: yf225
fbshipit-source-id: 505147e5f5fea78be1bf60fb8418bc187dbc2a98
Summary:
Print out the tensor value when throwing the cannot insert tensor with grad error
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19645
Differential Revision: D15057809
Pulled By: eellison
fbshipit-source-id: 3f622ef1322a75c965e780275f1fb447e9acf38d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19676
Make copy work with QTensor, enable assignment of QTensor in pytorch frontend.
Differential Revision: D15064710
fbshipit-source-id: 04f2dc02a825695d41fa1114bfca49e92108fef3
Summary:
The input shape checkers in conv/int8_conv operator is aims to avoid the issue when running with mkldnn winograd, the weigths has to be reordered each time if input shape changed.
However, the checkers result to big performance regression due to frequent reorder.
Meanwhile, in mkldnn-bridge, such case has been already fixed by correcting the prop_kind.
Therefore, we have to remove the useless checker to fix the performance regression.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19608
Differential Revision: D15061169
Pulled By: yinghai
fbshipit-source-id: 649a43ae6fce989e84939210f6dffb143ec3d350
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19585
Originally we will unroll all If op to many different subnets;
Now we will not unroll it anymore, but just add all external input of its subnet to the If op, and ssa-rewrite all external input/outputs. That would be enough.
Reviewed By: yinghai
Differential Revision: D15038139
fbshipit-source-id: 8532216d8749068acd5558ad0d8cb1d98463a063
Summary:
Also
1. Bump multiprocessing test timeout following python core tests
2. Fix one type of flakiness in `test_proper_exit`.
3. Add trace reporting when loader process hangs in `test_proper_exit` using `faulthandler`.
3. Give `test_proper_exit` another try.
I'll heavily retest this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19421
Differential Revision: D15063728
Pulled By: ezyang
fbshipit-source-id: 4e0d992622e11053c44a9ec237b88b9a28a4472c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19530
Make copy work with QTensor, enable assignment of QTensor in pytorch frontend.
Differential Revision: D15008160
fbshipit-source-id: 5f1166246d768b23f009cde1fa03e8952368a332
Summary:
We can't introduce aliasing to a graph output, since they may be mutated after.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19576
Differential Revision: D15057734
Pulled By: eellison
fbshipit-source-id: 33594c05d985a0c58edebd6252e1ee2c0efb6f0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19607
Explicit is better than implicit - it's pretty hard to debug where particular file is if it's not greppable.
As a follow up step - we should look whether we can just include build_variables.py in CMake directly to share setups of two build systems
Reviewed By: ezyang
Differential Revision: D15023348
fbshipit-source-id: 600ef2d1871bc28530c6a02681b284f7499904df
Summary:
We would previously have statements like
```
set_history(flatten_tensor_args( result ), grad_fn);
```
Internally, {set,rebase}_history would check grad_fn and short circuit if it is nullptr. However, this means that we are executing the expression `flatten_tensor_args( result )` and immediately throwing away the results. This was causing unnecessary allocations + overhead.
My JIT overhead benchmark script (with custom benchmark method):
```
import torch, time
torch.jit.script
def add(x, y):
return x + y
a = torch.rand([])
b = torch.rand([])
niter = 1000000
with torch.no_grad():
s = time.time()
add.__getattr__('forward').benchmark(niter, a, b)
e = time.time() - s
print('overhead per call (us)', e / niter * 1e6)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19623
Differential Revision: D15053399
Pulled By: jamesr66a
fbshipit-source-id: 8777e1a2b5c5a5bbd3a035b7247c8154c5fc4aa6
Summary:
Add base support for torch.logspace. See #19220 for details.
SsnL can you feedback? Thanks a lot.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19542
Differential Revision: D15028484
Pulled By: soumith
fbshipit-source-id: fe5a58a203b279103abbc192c754c25d5031498e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19621
Comments for group_norm_op is not accurate (i.e., the math part), this diff will fix it.
Reviewed By: BIT-silence
Differential Revision: D15048695
fbshipit-source-id: 27d41d3ae21054257967815254134849944d56ca
Summary:
This is the second part of #18064.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19547
Differential Revision: D15046630
Pulled By: ezyang
fbshipit-source-id: 03f80602b94d47bca66bfd0dcab1b7bb99e5b7f1
Summary:
Add setting requires_grad = True within torchscript to torch.Tensor
Within constant propagation, we can't insert any constants that require grad.
Also added shape analysis and requires grad analysis to torch.tensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19445
Differential Revision: D15046211
Pulled By: eellison
fbshipit-source-id: b4ef7a6b4b6b8dc03e1fa49f87dc415874cd1998
Summary:
The current code initialize the `state` in `__init__` method, but the initialization process is not invoked in `add_parameter_group`.
I followed the same approach in other Optimizers to init the `state`.
```python
import torch
emb = torch.nn.Embedding(10,10)
emb2 = torch.nn.Embedding(10,10)
optim = torch.optim.Adagrad(emb.parameters())
print(optim.state[emb.weight]) # already initialized
optim.add_param_group({'params': emb2.parameters()})
print(optim.state[emb2.weight]) # empty dict
loss = emb2.weight.sum() + emb.weight.sum()
loss.backward()
optim.step() # raised KeyError
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17679
Differential Revision: D14577575
Pulled By: ezyang
fbshipit-source-id: 12440079ac964b9eedad48e393d47f558babe300
Summary:
Often times, we want to experiment with loss per element (image etc.). This changeset allows getting per element loss as well. This output is optional.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19579
Reviewed By: jerryzh168
Differential Revision: D15035797
Pulled By: prigoyal
fbshipit-source-id: 562dea514f49c1f2f1cbbc083a1938dc019a75c4
Summary:
in functional interfaces we do boolean dispatch, but all to max_pool\*d_with_indices. This change it to emit max_pool\*d op instead when it's not necessary to expose with_indices ops to different backends (for jit).
It also bind max_pool\*d to the torch namespace, which is the same behavior with avg_pool\*d
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19449
Differential Revision: D15016839
Pulled By: wanchaol
fbshipit-source-id: f77cd5f0bcd6d8534c1296d89b061023a8288a2c
Summary:
Adding fakequant op so that we can use it in pytorch models, the exact implementation might change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19387
Differential Revision: D13739657
fbshipit-source-id: d5cb084e843d236bb1da9827ac1ba3900ed99786
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18499
If the init op is not fp16 compatible, it should throw.
However, in the special case where the original init op is UniformFill,
we replace it with Float16UniformFill
Reviewed By: kennyhorror
Differential Revision: D14627209
fbshipit-source-id: eb427772874a732ca8b3a25d06670d119ce8ac14
Summary:
Added the formula for the corner case. Updated unit tests.
Fixes#17913
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19180
Differential Revision: D14942023
Pulled By: ezyang
fbshipit-source-id: 167c109b97a7830d5b24541dc91e4788d531feec
Summary:
I fixed a mistake in the explanation of `pos_weight` argument in `BCEWithLogitsLoss` and added an example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19212
Differential Revision: D14923431
Pulled By: ezyang
fbshipit-source-id: 15696c67d56789102ac72afbe9bdd7b667eae5a0
Summary:
fix
- the order of `Arguments` in `RandomSampler` doc
- the meaningless check of `replacement`'s type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19113
Differential Revision: D15013081
Pulled By: ezyang
fbshipit-source-id: 39e367f42841de6814b1214eb9df7b75f14f747e
Summary:
A future version of cusparse will define "cusparseGetErrorString." This PR simply updates PyTorch's name for this function to "getCusparseErrorString" to avoid the collision.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19591
Differential Revision: D15046871
Pulled By: ezyang
fbshipit-source-id: 821304f75fe84c68a26680a93809a18cfdbd540b
Summary:
Hello everyone :) !!
I've found that lr_scheduler was initialized with last_epoch as -1.
This causes that even after the first step (not the one in init but explicit step of scheduler),
learning rate of scheduler's optimizer remains as the previous.
```python
>>> import torch
>>> cc = torch.nn.Conv2d(10,10,3)
>>> myinitial_lr = 0.1
>>> myoptimizer = torch.optim.Adam(cc.parameters(), lr=myinitial_lr)
>>> mylrdecay = 0.5
>>> myscheduler = torch.optim.lr_scheduler.ExponentialLR(myoptimizer,mylrdecay)
>>> myscheduler.get_lr()
[0.2] # this is because of get_lr calculates lr by 0.1 * 0.5^-1
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.1 # this is not consistent with get_lr value
>>> myscheduler.last_epoch
-1
>>> myscheduler.step()
>>> myscheduler.get_lr()
[0.1] # this should be the value right after the init, not after first step
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.1 # since this is after first step, it should have been decayed as 0.05
>>> myscheduler.last_epoch
0
>>> myscheduler.step()
>>> myscheduler.last_epoch
1
>>> myscheduler.get_lr()
[0.05]
>>> myscheduler.optimizer.param_groups[0]["lr"]
0.05
>>> myscheduler.last_epoch
1
```
First problem is, even after the init of lr_scheduler, you get the inconsistent parameter values.
The second problem is, you are stuck with same learning rate in the first 2 epochs if the step function of lr_scheduler is not called in the beginning of the epoch loop.
Of course, you can avoid this by calling lr_scheduler's step in the beginning,
but I don't think this is proper use since, incase of optimizer, step is called in the end of the iteration loop.
I've simply avoided all above issues by setting last_epoch as 0 after the initialization.
This also makes sense when you init with some value of last_epoch which is not -1.
For example, if you want to init with last epoch 10,
lr should not be set with decayed 1 step further. Which is
last_epoch gets +1 in the previous code.
base_lr * self.gamma ** self.last_epoch
Instead, it should be set with step 10 exact value.
I hope this fix find it's way with all your help :)
I'm really looking forward & excited to become a contributor for pytorch!
Pytorch Rocks!!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/7889
Differential Revision: D15012769
Pulled By: ezyang
fbshipit-source-id: 258fc3009ea7b7390a3cf2e8a3682eafb506b08b
Summary:
n was set as self.in_channels, but not used within the scope of the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19194
Differential Revision: D14937764
Pulled By: ezyang
fbshipit-source-id: 55cb599109309503fee897f77d798fd454fcc02d
Summary:
This is the first part of #18064.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19409
Differential Revision: D15037390
Pulled By: ezyang
fbshipit-source-id: 16a3feed2fd9cc66033696da224a7d5fb7208534
Summary:
Add setting requires_grad = True within torchscript to torch.Tensor
Within constant propagation, we can't insert any constants that require grad.
Also added shape analysis and requires grad analysis to torch.tensor
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19445
Differential Revision: D15039713
Pulled By: eellison
fbshipit-source-id: 47f1931b6fc4a1137c13d80110cc404465bfdf06
Summary:
I believe the existing check in FuseGraph was only `false` if PyTorch was built with NO_CUDA=1. Otherwise, we would create fusion groups even if we're on a CPU-only machine running CPU code. This is confusing. Instead I've made it so that the decision to fuse or not is dependent on if the producer Value is a known CPU tensor. If it is, we skip fusion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19342
Differential Revision: D15038351
Pulled By: jamesr66a
fbshipit-source-id: fce9d83929309a7bf14346833f84b996f3e7f6db
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19516
Explicitly define types that are supported in kernel inputs and outputs.
Also, this allows us to show much nicer error messages if a user writes kernels with wrong argument types.
Reviewed By: ezyang
Differential Revision: D15020306
fbshipit-source-id: 55ebec81e075e874777acd59aa29a5578fc19ef7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19442
For cases like CV, some of ops like transpose and tile will mangle the batch size so that we don't know how to adjust output batch size. In this case, the current solution is just fix the input batch statically and do not adjust output batch size.
Reviewed By: zrphercule
Differential Revision: D15007237
fbshipit-source-id: a21b943a52ee5462d9d7804dfae44360f579f8cf
Summary:
Changelog:
- Rename `potri` to `cholesky_inverse` to remain consistent with names of `cholesky` methods (`cholesky`, `cholesky_solve`)
- Fix all callsites
- Rename all tests
- Create a tentative alias for `cholesky_inverse` under the name `potri` and add a deprecation warning to not promote usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19498
Differential Revision: D15029901
Pulled By: ezyang
fbshipit-source-id: 2074286dc93d8744cdc9a45d54644fe57df3a57a
Summary:
This just plugs into the existing mechanism to do a direct translation to TensorOptions in the backend, so no codegen changes.
After this lands, all native_functions will match the JIT signature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19484
Differential Revision: D15013051
Pulled By: gchanan
fbshipit-source-id: 6818f868d2f765ca3e56e7e6f75fe4f68492466c
Summary:
Remove an useless format checker in mkldnn-bridge to fix the crash issue in DNNLOWP dequantize op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19159
Differential Revision: D15027670
Pulled By: yinghai
fbshipit-source-id: ac97d6ff94de013105108b9596b1bd7621c5aa75
Summary:
In this PR, the fusion alogrithms are improved to support DNNLOWP.
1. Enabled conv fusions for DNNLOWP
2. Fused order switch op into following quantize op
3. Improve conv+sum fusion to parse larger scope/window
4. re-org fusion code to fix random crash issue due to changing graph
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18843
Differential Revision: D15021030
Pulled By: yinghai
fbshipit-source-id: 88d2199d9fc69f392de9bfbe1f291e0ebf78ab08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19418
This change makes Observer class template which always
takes an observer function as argument. Second test-case becomes redundant, hence removing
it.
Reviewed By: jerryzh168
Differential Revision: D15000594
fbshipit-source-id: 9555fe98a5f2054b8fd01e64e9ac2db72c043bfa
Summary:
There are two corrections in this pull request.
The first is specific to gcc-7.4.0.
compiled with -std=c++14 gcc-7.4.0 has __cplusplus = 201402L
This does not meet the check set in Deprecated.h, which asks for >201402L.
The compiler goes down to the __GNUC__ check, which passes and sets C10_DEPRECATED_MESSAGE to a value that c++14 does not appear to support or even recognize, leading to a compile time error.
My recommended solution, which worked for my case, was to change the = into a >=
The second correction comes in response to this error:
caffe2/operators/crash_op.cc: In member function ‘virtual bool caffe2::CrashOp::RunOnDevice()’:
caffe2/operators/crash_op.cc:14:11: error: ‘SIGABRT’ was not declared in this scope
I am merely committing to the repository the solution suggested here (which worked for me)
https://discuss.pytorch.org/t/building-pytorch-from-source-in-conda-fails-in-pytorch-caffe2-operators-crash-op-cc/42859
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19470
Differential Revision: D15019529
Pulled By: ailzhang
fbshipit-source-id: 9ce9d713c860ee5fd4266e5c2a7f336a97d7a90d
Summary:
This was actually getting pretty poor throughput with respect to memory bandwidth. I used this test to measure the memory bandwidth specifically for the AXPY call: https://gist.github.com/jamesr66a/b27ff9ecbe036eed5ec310c0a3cc53c5
And I got ~8 GB/s before this change, but ~14 GB/s after this change.
This seems to speed up the operator overall by around 1.3x (benchmark: https://gist.github.com/jamesr66a/c533817c334d0be432720ef5e54a4166):
== Before ==
time_per_iter 0.0001298875093460083
GB/s 3.082544287868467
== After ==
time_per_iter 0.00010104801654815674
GB/s 3.9623142905451076
The large difference between the local BW increase and the full-op BW increase likely indicates significant time is being spent elsewhere in the op, so I will investigate that.
EDIT: I updated this PR to include a call into caffe2/perfkernels. This is the progression:
before
time_per_iter 8.983819484710693e-05
GB/s 4.456723564864611
After no axpy
time_per_iter 7.19951868057251e-05
GB/s 5.56126065872172
AFter perfkernels
time_per_iter 5.6699180603027346e-05
GB/s 7.061548257694262
After perfkernels no grad
time_per_iter 4.388842582702637e-05
GB/s 9.122769670026413
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19329
Reviewed By: dzhulgakov
Differential Revision: D14969630
Pulled By: jamesr66a
fbshipit-source-id: 42d1015772c87bedd119e33c0aa2c8105160a738
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19515
This is still done by default, but can now be disabled by specifying
`find_unused_parameters=False`. There are use cases where finding
unused parameters results in erroneous behavior, because a subset of
model parameters is used *outside* the `forward` function. One can
argue that doing this is not a good idea, but we should not break
existing use cases without an escape hatch. This configuration
parameter is that escape hatch.
Reviewed By: bddppq
Differential Revision: D15016381
fbshipit-source-id: f2f86b60771b3801ab52776e62b5fd6748ddeed0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19511
In the c10 operator registration API, disallow std::vector arguments and show a nice error message
pointing users towards using ArrayRef instead.
Reviewed By: ezyang
Differential Revision: D15017423
fbshipit-source-id: 157ecc1298bbc598d2e310a16041edf195aaeff5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19503
After reading the arguments from the stack, the c10 kernel wrapper accidentally popped them again, causing a vector to be allocated.
Instead, it should just drop them because they have already been read.
Reviewed By: ezyang
Differential Revision: D15016023
fbshipit-source-id: b694a2929f97fa77cebe247ec2e49820a3c818d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19518
Previous design needs to run the op benchmarks from PyTorch root directory which could lead to `module not found` error in OSS environment. This diff fixes that issue by making the benchmark to be launched in the `benchmarks` folder.
Reviewed By: ilia-cher
Differential Revision: D15020787
fbshipit-source-id: eb09814a33432a66cc857702bc86538cd17bea3b
Summary:
First step at allowing container types within alias analysis.
Since the current implementation hides the concept of Wildcards within alias analysis and does not expose it to memory dag, we cannot represent whether a container type holds a wildcard. As a result, only handle TupleConstruct, where we can directly inspect if any input values are wildcards, and don't handle nested containers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18710
Differential Revision: D15017068
Pulled By: eellison
fbshipit-source-id: 3ee76a5482cef1cc4a10f034593ca21019161c18
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19458
The algorithm in https://fburl.com/ggh9iyvc fails to really ensure topological ordering of nodes. The fix is ugly but effective. I think we need a real topological sort to fix this issue more nicely. Mikhail Zolotukhin, Bram Wasti.
Differential Revision: D15011893
fbshipit-source-id: 130c3aa442f5d578adfb14fbe5f16aa722434942
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19381
Expose QScheme enum in frontend so that people can use it in
quantization configs in modules.
Differential Revision: D14922992
fbshipit-source-id: ab07b8a7ec42c1c1f5fe84a4a0c805adbcad408d
Summary:
Add the defaults field to the copied object.
Prior to this patch, optimizer.__getattr__ has excluded the defaults
attribute of optimizer source object, required by some LR schedulers. (e.g. CyclicLR with momentum)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19308
Differential Revision: D15012801
Pulled By: soumith
fbshipit-source-id: 95801b269f6f9d78d531d4fed95c973b280cc96f
Summary:
This is a simple yet useful addition to the torch.nn modules: an identity module. This is a first draft - please let me know what you think and I will edit my PR.
There is no identity module - nn.Sequential() can be used, however it is argument sensitive so can't be used interchangably with any other module. This adds nn.Identity(...) which can be swapped with any module because it has dummy arguments. It's also more understandable than seeing an empty Sequential inside a model.
See discussion on #9160. The current solution is to use nn.Sequential(). However this won't work as follows:
```python
batch_norm = nn.BatchNorm2d
if dont_use_batch_norm:
batch_norm = Identity
```
Then in your network, you have:
```python
nn.Sequential(
...
batch_norm(N, momentum=0.05),
...
)
```
If you try to simply set `Identity = nn.Sequential`, this will fail since `nn.Sequential` expects modules as arguments. Of course there are many ways to get around this, including:
- Conditionally adding modules to an existing Sequential module
- Not using Sequential but writing the usual `forward` function with an if statement
- ...
**However, I think that an identity module is the most pythonic strategy,** assuming you want to use nn.Sequential.
Using the very simple class (this isn't the same as the one in my commit):
```python
class Identity(nn.Module):
def __init__(self, *args, **kwargs):
super().__init__()
def forward(self, x):
return x
```
we can get around using nn.Sequential, and `batch_norm(N, momentum=0.05)` will work. There are of course other situations this would be useful.
Thank you.
Best,
Miles
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19249
Differential Revision: D15012969
Pulled By: ezyang
fbshipit-source-id: 9f47e252137a1679e306fd4c169dca832eb82c0c
Summary:
This should have been fixed in newest ROCm version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19436
Reviewed By: ezyang
Differential Revision: D15004685
Pulled By: bddppq
fbshipit-source-id: 19fd4cca94c914dc54aabfbb4e62b328aa348a35
Summary:
This is a continuation of efforts into packed accessor awareness.
A very simple example is added, along with the mention that the template can hold more arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19464
Differential Revision: D15012564
Pulled By: soumith
fbshipit-source-id: a19ed536e016fae519b062d847cc58aef01b1b92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18092
Previously, tracing required all inputs to be either tensors,
or tuples of tensor. Now, we allow users to pass dicts as well.
Differential Revision: D14491795
fbshipit-source-id: 7a2df218e5d00f898d01fa5b9669f9d674280be3
Summary:
Strip the doc_string by default from the exported ONNX models (this string has the stack trace and information about the local repos and folders, which can be confidential).
The users can still generate the doc_string by specifying add_doc_string=True in torch.onnx.export().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18882
Differential Revision: D14889684
Pulled By: houseroad
fbshipit-source-id: 26d2c23c8dc3f484544aa854b507ada429adb9b8
Summary:
We are already using custom comparators for sorting (for a good reason), but are still making 2 sorting passes - global sort and stable sorting to bring values into their slices. Using a custom comparator to sort within a slice allows us to avoid second sorting pass and brings up to 50% perf improvement.
t-vi I know you are moving sort to ATen, and changing THC is discouraged, but #18350 seems dormant. I'm fine with #18350 landing first, and then I can put in these changes.
cc umanwizard for review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19379
Differential Revision: D15011019
Pulled By: soumith
fbshipit-source-id: 48e5f5aef51789b166bb72c75b393707a9aed57c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19450
We want to make each operator benchmark as a separate binary. The previous way to run the benchmark is by collecting all operators into a single binary, it is unnecessary when we want to filter a specific operator. This diff aims to resolve that issue.
Reviewed By: ilia-cher
Differential Revision: D14808159
fbshipit-source-id: 43cd25b219c6e358d0cd2a61463b34596bf3bfac
Summary:
Fixes: #19253
Fixing pow(Tensor, float) is straightforward.
The breakage for pow(float, Tensor) is a bit more subtle to trigger, and fixing needs `torch.log` (`math.log` didn't work) from the newly merged #19115 (Thanks ngimel for pointing out this has landed.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19324
Differential Revision: D15003531
Pulled By: ailzhang
fbshipit-source-id: 8b22138fa27a43806b82886fb3a7b557bbb5a865
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19290
Add test cases for the supported argument types
And TODOs for some unsupported ones that we might want to support.
Reviewed By: dzhulgakov
Differential Revision: D14931920
fbshipit-source-id: c47bbb295a54ac9dc62569bf5c273368c834392c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19433
For operator benchmark project, we need to cover a lot of operators, so the interface for adding operators needs to be very clean and simple. This diff is implementing a new interface to add op.
Here is the logic to add new operator to the benchmark:
```
long_config = {}
short_config = {}
map_func
add_test(
[long_config, short_config],
map_func,
[caffe2 op]
[pt op]
)
```
Reviewed By: zheng-xq
Differential Revision: D14791191
fbshipit-source-id: ac6738507cf1b9d6013dc8e546a2022a9b177f05
Summary:
My bad - it might be called in variable and non-variable context. So it's better to just inherit variable-ness from the caller.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19400
Reviewed By: ezyang
Differential Revision: D14994781
Pulled By: dzhulgakov
fbshipit-source-id: cb9d055b44a2e1d7bbf2e937d558e6bc75037f5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19360
We'll return the output object verbatim since it is a freeform object.
We need to find any tensors in this object, though, because we need to
figure out which parameters were used during this forward pass, to
ensure we short circuit reduction for any unused parameters.
Before this commit only lists were handled and the functionality went
untested. This commit adds support for dicts and recursive structures,
and also adds a test case.
Closes#19354.
Reviewed By: mrshenli
Differential Revision: D14978016
fbshipit-source-id: 4bb6999520871fb6a9e4561608afa64d55f4f3a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19388
The old implementation forced a refcount bump when converting at::Tensor to caffe2::Tensor.
Now, it is possible to move it without a refcount bump.
Reviewed By: dzhulgakov
Differential Revision: D14986815
fbshipit-source-id: 92b4b0a6f323ed38376ffad75f960cad250ecd9b
Summary:
Attempt fix for #14057 . This PR fixes the example script in the issue.
The old behavior is a bit confusing here. What happened to pickling is python2 failed to recognize `torch.float32` is in module `torch`, thus it's looking for `torch.float32` in module `__main__`. Python3 is smart enough to handle it.
According to the doc [here](https://docs.python.org/2/library/pickle.html#object.__reduce__), it seems `__reduce__` should return `float32` instead of the old name `torch.float32`. In this way python2 is able to find `float32` in `torch` module.
> If a string is returned, it names a global variable whose contents are pickled as normal. The string returned by __reduce__() should be the object’s local name relative to its module
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18045
Differential Revision: D14990638
Pulled By: ailzhang
fbshipit-source-id: 816b97d63a934a5dda1a910312ad69f120b0b4de
Summary:
Previously to get a list of parameters this code was just putting them in the reverse order in which they were defined, which is not always right. This PR allows parameter lists to define the order themselves. To do this parameter lists need to have a corresponding function that provides the names of the parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18198
Differential Revision: D14966270
Pulled By: driazati
fbshipit-source-id: 59331aa59408660069785906304b2088c19534b2
Summary:
This PR paves the way for support more iterator types in for-in loops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19341
Differential Revision: D14992749
Pulled By: Krovatkin
fbshipit-source-id: e2d4c9465c8ec3fc74fbf23006dcb6783d91795f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19033
torch.distributed.init_process_group() has had many parameters added, but the contract isn't clear. Adding documentation, asserts, and explicit args should make this clearer to callers and more strictly enforced.
Reviewed By: mrshenli
Differential Revision: D14813070
fbshipit-source-id: 80e4e7123087745bed436eb390887db9d1876042
Summary:
Added the ">>>" python interpreter sign(three greater than symbols), so that the edited lines will appear as code, not comments/output, in the documentation. Normally, the interpreter would display "..." when expecting a block, but I'm not sure how this would work on the pytorch docs website. It seems that in other code examples the ">>>" sign is used as well, therefore I used with too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19347
Differential Revision: D14986154
Pulled By: soumith
fbshipit-source-id: 8f4d07d71ff7777b46c459837f350eb0a1f17e84
Summary:
This PR aims to improve Transformer performance on CPU, `bmm()` is one of the major bottlenecks now.
Current logic of `bmm()` on CPU only uses MKL batch gemm when the inputs `A` and `B` are contiguous or transposed. So when `A` or `B` is a slice of a larger tensor, it falls to a slower path.
`A` and `B` are both 3D tensors. MKL is able to handle the batch matrix multiplication on occasion that `A.stride(1) == 1 || A.stride(2) == 1` and `B.stride(1) == || B.stride(2) == 1`.
From [fairseq](https://github.com/pytorch/fairseq) implementation of Transformer, multi-head attention has two places to call bmm(), [here](https://github.com/pytorch/fairseq/blob/master/fairseq/modules/multihead_attention.py#L167) and [here](https://github.com/pytorch/fairseq/blob/master/fairseq/modules/multihead_attention.py#L197), `q`, `k`, `v` are all slices from larger tensor. So the `bmm()` falls to slow path at the moment.
Results on Xeon 6148 (20*2 cores 2.5GHz) indicate this PR improves Transformer training performance by **48%** (seconds per iteration reduced from **5.48** to **3.70**), the inference performance should also be boosted.
Before:
```
| epoch 001: 0%| | 27/25337 [02:27<38:31:26, 5.48s/it, loss=16.871, nll_loss=16.862, ppl=119099.70, wps=865, ups=0, wpb=4715.778, bsz=129.481, num_updates=27, lr=4.05e-06, gnorm=9.133,
```
After:
```
| epoch 001: 0%| | 97/25337 [05:58<25:55:49, 3.70s/it, loss=14.736, nll_loss=14.571, ppl=24339.38, wps=1280, ups=0, wpb=4735.299, bsz=131.134, num_updates=97, lr=1.455e-05, gnorm=3.908,
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19338
Differential Revision: D14986346
Pulled By: soumith
fbshipit-source-id: 827106245af908b8a4fda69ed0288d322b028f08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19287
Since we now have a string-schema-based op registration API, we can also use it when exposing caffe2 operators.
Reviewed By: dzhulgakov
Differential Revision: D14931925
fbshipit-source-id: ec162469d2d94965e8c99d431c801ae7c43849c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19286
The operator registration API now allows registering an operator by only giving the operator name and not the full operator schema,
as long as the operator schema can be inferred from the kernel function.
Reviewed By: dzhulgakov
Differential Revision: D14931921
fbshipit-source-id: 3776ce43d4ce67bb5a3ea3d07c37de96eebe08ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19285
The either type is a tagged union with two members.
This is going to be used in a diff stacked on top to allow a function to return one of two types.
Also, generally, either<Error, Result> is a great pattern for returning value_or_error from a function without using exceptions and we could use this class for that later.
Reviewed By: dzhulgakov
Differential Revision: D14931923
fbshipit-source-id: 7d1dd77b3e5b655f331444394dcdeab24772ab3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19284
Instantiating a dispatch table previously only worked when the op had a tensor argument we could dispatch on.
However, the legacy API for custom operators didn't have dispatch and also worked for operators without tensor arguments, so we need to continue supporting that.
It probably generally makes sense to support this as long as there's only a fallback kernel and no dispatched kernel registered.
This diff adds that functionality.
Reviewed By: dzhulgakov
Differential Revision: D14931926
fbshipit-source-id: 38fadcba07e5577a7329466313c89842d50424f9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19283
Now that the function schema parser is available in ATen/core, we can use it from the operator registration API to register ops based on string schemas.
This does not allow registering operators based on only the name yet - the full schema string needs to be defined.
A diff stacked on top will add name based registration.
Reviewed By: dzhulgakov
Differential Revision: D14931919
fbshipit-source-id: 71e490dc65be67d513adc63170dc3f1ce78396cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19282
This is largely a hack because we need to use the function schema parser from ATen/core
but aren't clear yet on how the final software architecture should look like.
- Add function schema parser files from jit to ATen/core build target.
- Also move ATen/core build target one directory up to allow this.
We only change the build targets and don't move the files yet because this is likely
not the final build set up and we want to avoid repeated interruptions
for other developers. cc zdevito
Reviewed By: dzhulgakov
Differential Revision: D14931922
fbshipit-source-id: 26462e2e7aec9e0964706138edd3d87a83b964e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19281
String<->Number conversions aren't available in the STL used in our Android environment.
This diff adds workarounds for that so that the function schema parser can be compiled for android
Reviewed By: dzhulgakov
Differential Revision: D14931649
fbshipit-source-id: d5d386f2c474d3742ed89e52dff751513142efad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19280
We want to use the function schema parser from ATen/core, but with as little dependencies as possible.
This diff moves the function schema parser into its own file and removes some of its dependencies.
Reviewed By: dzhulgakov
Differential Revision: D14931651
fbshipit-source-id: c2d787202795ff034da8cba255b9f007e69b4aea
Summary:
A few improvements while doing bert model
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19247
Differential Revision: D14989345
Pulled By: ailzhang
fbshipit-source-id: f4846813f62b6d497fbe74e8552c9714bd8dc3c7
Summary:
Op was improperly schematized previously. Evidently checkScript does not test if the outputs are the same type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19370
Differential Revision: D14985159
Pulled By: eellison
fbshipit-source-id: feb60552afa2a6956d71f64801f15e5fe19c3a91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19082
When you have just one line of deletions, just as with additions, there is no count printed.
Without this fix, we ignore all globs with single-line deletions when selecting which lines were changed.
When all the changes in the file were single-line, this meant no line-filtering at all!
Differential Revision: D14860426
fbshipit-source-id: c60e9d84f9520871fc0c08fa8c772c227d06fa27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19362
`float` type is never used in OnnxifiOp....
Reviewed By: bddppq
Differential Revision: D14977970
fbshipit-source-id: 8fee02659dbe408e5a3e0ff95d74c04836c5c281
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18960
empty_affine_quantized creates an empty affine quantized Tensor from scratch.
We might need this when we implement quantized operators.
Differential Revision: D14810261
fbshipit-source-id: f07d8bf89822d02a202ee81c78a17aa4b3e571cc
Summary:
As part of implicitly casting condition statements, we should be casting not expressions as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19361
Differential Revision: D14984275
Pulled By: eellison
fbshipit-source-id: f8dae64f74777154c25f7a6bcdac03cf44cbb60b
Summary:
It turns out that copying bytes is the same no matter what type
they're interpreted as, and memcpy is already vectorized on every
platform of note. Paring this down to the simplest implementation
saves just over 4KB off libtorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19198
Differential Revision: D14922656
Pulled By: resistor
fbshipit-source-id: bb03899dd8f6b857847b822061e7aeb18c19e7b4
Summary:
This adds checks for `mul_`, `add_`, `sub_`, `div_`, the most common
binops. See #17935 for more details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19317
Differential Revision: D14972399
Pulled By: zou3519
fbshipit-source-id: b9de331dbdb2544ee859ded725a5b5659bfd11d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19273
Some of the CIs are failing if the protobuf is not installed. Protobuf is imported as part of the `caffe2.python.core`, and this adds a skip decorator to avoid running tests that depend on `caffe2.python.core`
Reviewed By: jianyuh
Differential Revision: D14936387
fbshipit-source-id: e508a1858727bbd52c951d3018e2328e14f126be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19083
As we have discussed, there are too many of AdjustBatch ops and they incur reallocation overhead and affects the performance. We will eliminate these ops by
- inling the input adjust batch op into Glow
- inling the output adjust batch op into OnnxifiOp and do that only conditionally.
This is the C2 part of the change and requires change from Glow side to work e2e.
Reviewed By: rdzhabarov
Differential Revision: D14860582
fbshipit-source-id: ac2588b894bac25735babb62b1924acc559face6
Summary:
I tried first to convert the `.bat` script to a Bash `.sh` script, but I got this error:
```
[...]/build/win_tmp/ci_scripts/test_python_nn.sh: line 3: fg: no job control
```
Line 3 was where `%TMP_DIR%/ci_scripts/setup_pytorch_env.bat` was invoked.
I found a potential workaround on stack overflow of adding the `monitor` (`-m`) flag to the script, but hat didn't work either:
```
00:58:00 /bin/bash: cannot set terminal process group (3568): Inappropriate ioctl for device
00:58:00 /bin/bash: no job control in this shell
00:58:00 + %TMP_DIR%/ci_scripts/setup_pytorch_env.bat
00:58:00 /c/Jenkins/workspace/pytorch-builds/pytorch-win-ws2016-cuda9-cudnn7-py3-test1/build/win_tmp/ci_scripts/test_python_nn.sh: line 3: fg: no job control
```
So instead I decided to use Python to replace the `.bat` script. I believe this is an improvement in that it's both "table-driven" now and cross-platform.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18756
Differential Revision: D14957570
Pulled By: kostmo
fbshipit-source-id: 87794e64b56ffacbde4fd44938045f9f68f7bc2a
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Now compatible with both torch scripts:
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"), pin_memory=False)`
and
` _1 = torch.zeros([10], dtype=6, layout=0, device=torch.device("cpu"))`
Same checked for all similar functions `rand_like`, `empty_like` and others
It is fixed version of #18455
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18952
Differential Revision: D14801792
Pulled By: VitalyFedyunin
fbshipit-source-id: 8dbc61078ff7a637d0ecdb95d4e98f704d5450ba
Summary:
Unit tests that hang on clock64() calls are now fixed.
test_gamma_gpu_sample is now fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19307
Differential Revision: D14953420
Pulled By: bddppq
fbshipit-source-id: efe807b54e047578415eb1b1e03f8ad44ea27c13
Summary:
I audited the relevant kernel and saw it accumulates a good deal into float
so it should be fine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19293
Differential Revision: D14942274
Pulled By: zou3519
fbshipit-source-id: 36996ba0fbb29fbfb12b27bfe9c0ad1eb012ba3c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19299
I saw larger than 5% performance variation with small operators, this diff aims to reduce the variation by avoiding python overhead. Previously, in the benchmark, we run the main loop for 100 iterations then look at the time. If it's not significant, we will double the number of iterations to rerun and look at the result. We continue this process until it becomes significant. We calculate the time by total_time / number of iterations. The issue is that we are including multiple python trigger overhead.
Now, I change the logic to calculate execution time based on the last run instead of all runs, the equation is time_in_last_run/number of iterations.
Reviewed By: hl475
Differential Revision: D14925287
fbshipit-source-id: cb646298c08a651e27b99a5547350da367ffff47
Summary:
Add input information into generated RecordFunction calls in
VariableType wrappers, JIT operators and a few more locations
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18717
Differential Revision: D14729156
Pulled By: ilia-cher
fbshipit-source-id: 811ac4cbfd85af5c389ef030a7e82ef454afadec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19170
As title
The quantized resnext3d model in production got the following failures without the fix:
```
Caffe2 operator Int8ConvRelu logging error: [enforce fail at conv_pool_op_base.h:463] order == StorageOrder::NCHW. 1 vs 2. Conv3D only supports NCHW on the production quantized model
```
Reviewed By: jspark1105
Differential Revision: D14894276
fbshipit-source-id: ef97772277f322ed45215e382c3b4a3702e47e59
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19118
A bug introduced by D14700576 reported by Yufei (fixed by D14778810 and D14785256) was not detected by our units tests.
This diff improves unit tests to catch such errors (with this diff and without D14778810, we can reproduce the bug Yufei reported).
This improvement also revealed a bug that affects the accuracy when we pre-pack weight and bias together and the pre-packed weight/bias are used by multiple nets. We were modifying the pre-packed bias in-place which was supposed to be constants.
Reviewed By: csummersea
Differential Revision: D14806077
fbshipit-source-id: aa9049c74b6ea98d21fbd097de306447a662a46d
Summary:
closes#18873
Doesn't fail the build on warnings yet.
Also fix most severe shellcheck warnings
Limited to `.jenkins/pytorch/` at this time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18874
Differential Revision: D14936165
Pulled By: kostmo
fbshipit-source-id: 1ee335695e54fe6c387ef0f6606ea7011dad0fd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18953
This removes Python side bucketing code from DistributedDataParallel
and replaces it with calls to the new C++ based bucketing and reducing
code. To confirm this is working well, we ran a test with both the
previous implementation and the new implementation, and confirmed they
are numerically equivalent.
Performance is improved by a couple percent or more, including the
single machine multiple GPU runs.
Closes#13273.
Reviewed By: mrshenli
Differential Revision: D14580911
fbshipit-source-id: 44e76f8b0b7e58dd6c91644e3df4660ca2ee4ae2
Summary:
The derivative of the Cholesky decomposition was previously a triangular matrix.
Changelog:
- Modify the derivative of Cholesky from a triangular matrix to symmetric matrix
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19116
Differential Revision: D14935470
Pulled By: ezyang
fbshipit-source-id: 1c1c76b478c6b99e4e16624682842cb632e8e8b9
Summary:
This PR splits the configuration tree data from the logic used to construct the tree, for both `pytorch` and `caffe2` build configs.
Caffe2 configs are also now illustrated in a diagram.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18517
Differential Revision: D14936170
Pulled By: kostmo
fbshipit-source-id: 7b40a88512627377c5ea0f24765dabfef76ca279
Summary:
The caching allocator tries to free all blocks on an out-of-memory
error. Previously, it did not free blocks that still had outstanding
stream uses. This change synchronizes on the outstanding events and
frees those blocks.
See #19219
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19222
Differential Revision: D14925071
Pulled By: colesbury
fbshipit-source-id: a2e9fe957ec11b00ea8e6c0468436c519667c558
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19218
Sync some contents between fbcode/caffe2 and xplat/caffe2 to move closer towards a world where they are identical.
Reviewed By: dzhulgakov
Differential Revision: D14919916
fbshipit-source-id: 29c6b6d89ac556d58ae3cd02619aca88c79591c1
Summary:
Enable multi-GPU tests that work with ROCm 2.2. Have been run three times on CI to ensure stability.
While there, remove skipIfRocm annotations for tests that depend on MAGMA. They still skip but now for the correct reason (no MAGMA) to improve our diagnostics.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19169
Differential Revision: D14924812
Pulled By: bddppq
fbshipit-source-id: 8b88f58bba58a08ddcd439e899a0abc6198fef64
Summary:
Partially fuse layer_norm by decomposing layer_norm into the batchnorm kernel that computes the stats, and then fusing the affine operations after the reduce operations, this is similar to the batchnorm fusion that apaszke did, it also only works in inference mode now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18266
Differential Revision: D14879877
Pulled By: wanchaol
fbshipit-source-id: 0197d8f2a17ec438d3e53f4c411d759c1ae81efe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18546
We'll expose all combinations of various ways of quantization in the top level dispatch key, that is we have AffineCPUTensor, PerChannelAffineCUDATensor, etc.
QTensor method added:
- is_quantized()
- item()
Differential Revision: D14637671
fbshipit-source-id: 346bc6ef404a570f0efd34e8793056ad3c7855f5
Summary:
If JIT constant propagation doesn't work, we have to handle the ListConstructor in symbolic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19102
Reviewed By: zrphercule
Differential Revision: D14875588
Pulled By: houseroad
fbshipit-source-id: d25c847d224d2d32db50aae1751100080e115022
Summary:
This PR is to fix the CI error:
```
nvidia-docker2 : Depends: nvidia-container-runtime (= 2.0.0+docker18.09.4-1) but 2.0.0+docker18.09.5-1 is to be installed
E: Unable to correct problems, you have held broken packages.
Exited with code 100
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19195
Differential Revision: D14913104
Pulled By: yf225
fbshipit-source-id: d151205f5ffe9cac7320ded3c25baa7e051c3623
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19182
This is a bug discovered by zafartahirov, right now if one of the tensor is QInt
type we'll return undefined, but actually we want to allow ops that accepts
Tensors of the same QInt type to work.
Reviewed By: zafartahirov
Differential Revision: D14909172
fbshipit-source-id: 492fd6403da8c56e180efe9d632a3b7fc879aecf
Summary:
According to https://github.com/pytorch/pytorch/issues/13638#issuecomment-468055428, after the Variable/Tensor merge, we may capture variables without autograd metadata inside an autograd function, and we need a working version counter in these cases. This PR makes it possible by moving `version_counter_` out of autograd metadata and into TensorImpl, so that variables without autograd metadata still have version counters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18223
Differential Revision: D14735123
Pulled By: yf225
fbshipit-source-id: 15f690311393ffd5a53522a226da82f5abb6c65b
Summary:
Currently, a TensorImpl's `is_variable_` is true if and only if the TensorImpl has AutogradMeta. This PR unifies these two concepts by removing `is_variable_` and change `is_variable()` to check existence of AutogradMeta instead.
Removing `is_variable_` is part of the work in Variable/Tensor merge.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19139
Differential Revision: D14893339
Pulled By: yf225
fbshipit-source-id: ceb5e22c3c01f79b5d21d5bdbf4a7d1bc397796a
Summary:
This PR propagates where we use first-class modules objects into the compiler. This creates a transitionary state where:
* compiler.cpp creates Graphs where `self` is a Module class and attributes/parameters/buffers/submodules are looked up with `prim::GetAttr`
* GraphExecutor still runs "lowered graphs" where the self object has been removed by a compiler pass `lower_first_class_method`.
* Tracing still creates "lowered graphs", and a pass "lift_lowered_method" creates a first-class method graph for things.
* This PR separates out Method and Function. A script::Function is a pure Graph with no `self` bound. Similar to Python, a script::Method is just a bound `self` and its underlying `script::Function`.
* This PR also separates CompilationUnit from Module. A CompilationUnit is just a list of named script::Functions. Class's have a CompilationUnit holding the class methods, and Modules also have a CompilationUnit holding their Methods. This avoids the weird circular case Module --has a-> Class -> has a -> Module ...
Details:
* In this transitionary state, we maintain two copies of a Graph, first-class module and lowered. Th first-class one has a self argument that is the module's class type. The lowered one is the lowered graph that uses the initial_ivalues inputs.
* When defining lowered methods using `_defined_lowered` we immediately create the first-class equivalent. The reverse is done lazily, creating lowered_methods on demand from the class.
* The two way conversions will be deleted in a future PR when the executor itself runs first-class objects. However this requires more changes to (1) the traces, (2) the python bindings, and (3) the onnx export pass and would make this PR way to large.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19167
Differential Revision: D14891966
Pulled By: zdevito
fbshipit-source-id: 0b5f03118aa65448a15c7a7818e64089ec93d7ea
Summary:
It's not intended that Storages have 'default' CUDA devices, but this is allowable via the Storage::create_legacy codepath.
This also messages with device_caching, because the initial cache is obtained from the Storage, which may have a 'default' device.
Instead, we materialize a device by allocating 0 bytes via the allocator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18605
Differential Revision: D14680620
Pulled By: gchanan
fbshipit-source-id: 6d43383d836e90beaf12bfe37c3f0506843f5432
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19154
I recently saw some weird workflow error due to empty but set net_type. Maybe we should just fallback to simple net in this case.
Reviewed By: dzhulgakov
Differential Revision: D14890072
fbshipit-source-id: 4e9edf8232298000713bebb0bfdec61e9c5df17d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19147
After #14809 was merged there is no longer a need for getGroupRank.
Every ProcessGroup object has its own rank and size fields which are
accurate for the global group as well as subgroups.
Strictly speaking removing a function in a minor version bump is a big
no-no, but I highly doubt this was ever used outside of
`torch.distributed` itself. This will result in a compile error for
folks who have subclassed the ProcessGroup class though.
If this is a concern we can delay merging until a later point in time,
but eventually this will need to be cleaned up.
Differential Revision: D14889736
fbshipit-source-id: 3846fe118b3265b50a10ab8b1c75425dad06932d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19091
Implements a basic quantized ReLU (uint8). This is a temporary solution before using the `QTensor` type instead of the tuple.
Reviewed By: dzhulgakov
Differential Revision: D14565413
fbshipit-source-id: 7d53cf5628cf9ec135603d6a1fb7c79cd9383019
Summary:
Import MultiheadAttention into the core pytorch framework.
Users now can import MultiheadAttention directly from torch.nn.
See "Attention Is All You Need" for more details related to MultiheadAttention function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18334
Differential Revision: D14577966
Pulled By: zhangguanheng66
fbshipit-source-id: 756c0deff623f3780651d9f9a70ce84516c806d3
Summary:
Remove pointer to nonexistent Note.
It is already removed in "Remove support for CUDNN 6 (#15851)"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19148
Differential Revision: D14891514
Pulled By: soumith
fbshipit-source-id: dd33cfefa3a21e18afae5b3992dea085adaabda8
Summary:
"""
This will verify that the func syntax follows the JIT signature schema. If you are a developer outside the core team, set this to False first to help us track unification. After your tests pass try setting this to True once and leave it set to True if it doesn't trigger any asserts. This means that your signature happens to be compliant. In general, it serves as a means of tracking an ongoing schema unification with the goal of aligning func syntax with other components of PyTorch in order to reduce overall complexity and assert coverage of all functions by each component.
"""
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18956
Differential Revision: D14807952
Pulled By: cpuhrsch
fbshipit-source-id: 42dac49269fb3cd96dc62e0b10820d0c32c7fb0e
Summary:
* `torch.hub.list('pytorch/vision')` - show all available hub models in `pytorch/vision`
* `torch.hub.show('pytorch/vision', 'resnet18')` - show docstring & example for `resnet18` in `pytorch/vision`
* Moved `torch.utils.model_zoo.load_url` to `torch.hub.load_state_dict_from_url` and deprecate `torch.utils.model_zoo`
* We have too many env to control where the cache dir is, it's not very necessary. I actually want to unify `TORCH_HUB_DIR`, `TORCH_HOME` and `TORCH_MODEL_ZOO`, but haven't done it. (more suggestions are welcome!)
* Simplify `pytorch/vision` example in doc, it was used to show how how hub entrypoint can be written so had some confusing unnecessary args.
An example of hub usage is shown below
```
In [1]: import torch
In [2]: torch.hub.list('pytorch/vision', force_reload=True)
Downloading: "https://github.com/pytorch/vision/archive/master.zip" to /private/home/ailzhang/.torch/hub/master.zip
Out[2]: ['resnet18', 'resnet50']
In [3]: torch.hub.show('pytorch/vision', 'resnet18')
Using cache found in /private/home/ailzhang/.torch/hub/vision_master
Resnet18 model
pretrained (bool): a recommended kwargs for all entrypoints
args & kwargs are arguments for the function
In [4]: model = torch.hub.load('pytorch/vision', 'resnet18', pretrained=True)
Using cache found in /private/home/ailzhang/.torch/hub/vision_master
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18758
Differential Revision: D14883651
Pulled By: ailzhang
fbshipit-source-id: 6db6ab708a74121782a9154c44b0e190b23e8309
Summary:
Previously, MPI process groups were created for all processes, even if
they were not part of the created group. Their MPI_Comm member field
would be MPI_COMM_NULL and they would ignore any calls. Their rank and
size were identical to that of the global process group and they had a
special groupRank and groupSize field to capture the _real_ rank.
This also meant assymetry with other process group types, where creating
a new group would either return the process group OR
GroupMember.NON_GROUP_MEMBER. For the MPI process group, it would always
return a process group and an additional check was needed to verify
whether or not a process was indeed part of a process group or not.
This commit changes this such that every MPI process group is a valid
process group, and by extension that we no longer have to special case
MPI to determine whether or not a process is part of a group. Now, if
the value returned by `new_group` is GroupMember.NON_GROUP_MEMBER, the
process is not a member, otherwise it is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14809
Differential Revision: D14887937
Pulled By: pietern
fbshipit-source-id: c5bf86d3b33e524cc5004ee68e30103178fa491d
Summary:
~Sometimes, `init_process_group()`, `store.get()`, and `destory_process_group()` can take more than a few seconds. Hence, removing thread join timeout.~
The error was due to `Address already in use` when starting TPC backend. The solution is to catch the error and report it to the `retry_on_address_already_in_use_error` decorator.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19114
Reviewed By: ezyang
Differential Revision: D14872680
Pulled By: mrshenli
fbshipit-source-id: fc504d02853ca73f76288c0ade564ab20bc01f7e
Summary:
It is done by flattening all tensor lists that are inputs/outputs to the
graph into the inputs/outputs list in the autograd graph.
This is less desirable than simply allowing IValues to exist in the
inputs/outputs of autograd::Function but it is substantially less
intrusive.
CaptureList describes the variables captured for backward in a single class.
UnpackInstructs describes how the flattened inputs to backwards are re-packed into lists.
ailzhang
This PR is also part 2 of covering maskrcnn & bert AD formulas, following #16689.
Ops added in this PR:
```
cat
index
meshgrid
reshape
split
split_with_sizes
stack
unbind
```
I will also add a few perf numbers here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16784
Differential Revision: D14104063
Pulled By: ailzhang
fbshipit-source-id: 5ceadadfd67ccaac60c5fd6740786c5354e252b9
Summary:
Previously the error message would look like:
```
Attempted to set the storage of a tensor on device cuda:0 to a storage on different device cuda. This is no longer allowed; the devices must match.
```
Now it looks like:
```
Attempted to set the storage of a tensor on device "cuda:0" to a storage on different device "cuda". This is no longer allowed; the devices must match.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19068
Reviewed By: dzhulgakov
Differential Revision: D14854257
Pulled By: gchanan
fbshipit-source-id: deb1ef73c2fcbf9338e7d67f2856282db2befac8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19085
This is a bug where input_shapes_ and output_shapes_ will grow indefinitely. Fix it here.
Reviewed By: bertmaher, rdzhabarov
Differential Revision: D14861695
fbshipit-source-id: d59116f27c3b54f5cc5a33533de4b9222dbb7afc
Summary:
Bug fix for https://github.com/pytorch/pytorch/issues/15043, where a large fusion in JIT with a large number of kernel arguments, which exceeds the limit allowed by nvrtc on a cuda device.
The fix is to check the number of arguments before a cuda kernel is generated. If the number exceeds the limit, take the runFallBack() path.
Add a reduced test from the original issue to keep the test time low. The test would fail without this fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18063
Differential Revision: D14691401
Pulled By: soumith
fbshipit-source-id: b98829bc89ed7724e91eda82ae3a5a1151af721a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18902
Fix in D14778810 had an issue that when we fallback to acc32 because the density of outlier is too high W_quantized_ is already modified. In this diff we first just count the number of outliers (without modifying W_quantized_) and only when density is low enough and no need for fallback we modify W_quantized_ and construct an outlier matrix.
Reviewed By: jspark1105
Differential Revision: D14785256
fbshipit-source-id: 03933110a4ca7409686a06b18a9bb921f8657950
Summary:
I've been messing around with vectorizing the fusion compiler in JIT, and noticed that these ops were pathologically slow. I moved them to use TensorIterator + Vec256<> and got some speed wins.
Benchmark script:
```
import torch, time
ops = ['abs', 'neg', 'reciprocal', 'frac']
x = torch.rand(1024, 1024)
NITER = 10000
print('op', 'time per iter (ms)', 'gops/s', 'GB/s', sep='\t')
for op in ops:
s = time.time()
for i in range(NITER):
getattr(x, op)()
elapsed_sec = ((time.time() - s) / NITER)
print(op, elapsed_sec * 1000, (1024*1024/elapsed_sec)/1e9, (1024*1024*4*2) / elapsed_sec / 1e9, sep='\t')
```
Before this change (on my mac with a skylake):
```
op time per iter (ms) gops/s GB/s
abs 0.9730974197387695 1.0775652866097343 8.620522292877874
neg 1.0723679780960083 0.9778136063534356 7.822508850827485
reciprocal 1.2610594034194946 0.8315040490215421 6.6520323921723366
frac 1.1681334018707275 0.8976509004200546 7.181207203360437
```
After this change:
```
op time per iter (ms) gops/s GB/s
abs 0.5031076192855835 2.084198210889721 16.673585687117768
neg 0.4433974027633667 2.3648672578256087 18.91893806260487
reciprocal 0.47145988941192624 2.2241043693195985 17.79283495455679
frac 0.5036592721939087 2.0819154096627024 16.65532327730162
```
So, after this change it looks like we are hitting machine peak for bandwidth and are bandwidth bound.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19041
Differential Revision: D14862037
Pulled By: jamesr66a
fbshipit-source-id: e2032ac0ca962dbf4120bb36812277c260e22912
Summary:
Fixes the problem of #18391
The issue is that when we code gen the ATenOp, we always generated static number of outputs for each operator. E.g. If there's operator from a old model that only requires two outputs, in its createOperator it will only allocate two output blobs, while the newer version of the operator (`unique` in this case) requires more output blob to be allocated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18581
Differential Revision: D14865647
Pulled By: wanchaol
fbshipit-source-id: 85f63fe16d6fe408a09eca84798c7e8cab3070e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19080
OSS: add a tiny unit test utility function to create tensors given shape and data outside of any workspace. I use it in an internal test
Reviewed By: dzhulgakov
Differential Revision: D14814194
fbshipit-source-id: 6d53b235d99a97da812215f5c7f11fecad363c8c
Summary:
Changelog:
- Rename `btrisolve` to `lu_solve` to remain consistent with names of solve methods (`cholesky_solve`, `triangular_solve`, `solve`)
- Fix all callsites
- Rename all tests
- Create a tentative alias for `lu_solve` under the name `btrisolve` and add a deprecation warning to not promote usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18726
Differential Revision: D14726237
Pulled By: zou3519
fbshipit-source-id: bf25f6c79062183a4153015e0ec7ebab2c8b986b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19062
As a temporary demonstration on how to extend this hack further until custom C types are ready.
Reviewed By: ezyang
Differential Revision: D14817809
fbshipit-source-id: 6eaf731e9135313eb858e178abcd9f25380ab8fe
Summary:
closes#16520
Hi pietern, I am not sure if this is the expected way to pass timeout to `Store`, could you please help take a look? Thanks!
Questions:
1. How do I write tests for this? I wanted to do something like `test_barrier_timeout_global`, but it seems I need to set the pg's timeout larger than the `Store`'s default timeout (3 min) to see a difference, which is too long for a unit test. And I do not want to change the `Store`'s default timeout either. Any suggestion?
2. Should I also propagate timeout configuration down to `PrefixStore` in `_new_process_group_helper`?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16571
Differential Revision: D13954527
Pulled By: mrshenli
fbshipit-source-id: 77f2653903f24255207233eb298f7c0321119a87
Summary:
Fixes#18518
I changed the C++ API torch::nn::init::orthogonal_ implementation to match the Python implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18915
Differential Revision: D14851833
Pulled By: ezyang
fbshipit-source-id: 45b5e9741582777c203e9ebed564ab3ac1f94baf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19042
show the model saving step in the log.
Reviewed By: kennyhorror
Differential Revision: D14809385
fbshipit-source-id: c7a1e50ff92bb45b16b1c501d9325b304b07fbd3
Summary:
Partial fix of: https://github.com/pytorch/pytorch/issues/394
- `gels` and `triangular_solve` now returns namedtuple
- refactor test for namedtuple API for better coverage and maintainability
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17195
Differential Revision: D14851875
Pulled By: ezyang
fbshipit-source-id: 9b2cba95564269d2c3a15324ba48751d68ed623c
Summary:
DDP does not support replicating BN layers within a process. Existing BN tests fail if the test environment has more than 8 GPUs. This is fixed by explicitly setting each process to use a single replica.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19049
Differential Revision: D14845286
Pulled By: mrshenli
fbshipit-source-id: 937dda5081d415ece48b21f2781b6b4e008dd42f
Summary:
Define `AT_CPP14_CONSTEXPR` from `constexpr` to empty on Windows with CUDA >= 9.2 as workaround.
Discussed in #18425.
When using CUDA 10.1 on Windows, I faced following errors:
~~~
D:/data/source/pytorch\c10/util/ArrayRef.h(144): error: variable in constexpr function does not have automatic storage duration
detected during instantiation of "const T &c10::ArrayRef<T>::front() const [with T=at::Tensor]"
D:/data/source/pytorch/aten/src\ATen/DeviceGuard.h(30): here
~~~
From documentation of CUDA Toolkit v10.1.105, compiler supports `constexpr` and relaxing requirements (in C++14), but compilation failed.
I suppose this could be compiler bug and require this workaround.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18986
Differential Revision: D14821836
Pulled By: ezyang
fbshipit-source-id: 9800da2fe7291e7c09e8e5e882adebab08d83ae3
Summary:
This is a minimalist PR to add MKL-DNN tensor per discussion from Github issue: https://github.com/pytorch/pytorch/issues/16038
Ops with MKL-DNN tensor will be supported in following-up PRs to speed up imperative path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17748
Reviewed By: dzhulgakov
Differential Revision: D14614640
Pulled By: bddppq
fbshipit-source-id: c58de98e244b0c63ae11e10d752a8e8ed920c533
Summary:
Previously, when a user built PyTorch from source, but set the version string manually to be binary-formatted, it would've simply used CXX11_ABI=0 incorrectly.
We have this information available at runtime with `torch._C._GLIBCXX_USE_CXX11_ABI`, so this PR improves the situation by simply using that information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18994
Differential Revision: D14839393
Pulled By: soumith
fbshipit-source-id: ca92e0810b29ffe688be82326e02a64a5649a3ad
Summary:
This is a fix for issue https://github.com/pytorch/pytorch/issues/18525. The issue is related not only to ONNX export, but can manifest in other scenarios.
An existing test point in test/onnx/test_operators.py has been updated to cover this scenario as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18764
Reviewed By: zrphercule
Differential Revision: D14735166
Pulled By: houseroad
fbshipit-source-id: 5a737c648f64355929ff31eb12bd4869e744768d
Summary:
Almost there, feel free to review.
these c10 operators are exported to _caffe2 domain.
TODO:
- [x] let the onnx checker pass
- [x] test tensor list as argument
- [x] test caffe2 backend and converter
- [x] check the c10 schema can be exported to onnx
- [x] refactor the test case to share some code
- [x] fix the problem in ONNX_ATEN_FALLBACK
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18210
Reviewed By: zrphercule
Differential Revision: D14600916
Pulled By: houseroad
fbshipit-source-id: 2592a75f21098fb6ceb38c5d00ee40e9e01cd144
Summary:
I haven't had a chance to rigorously try these out yet so don't merge yet.
Closes#18725.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18963
Differential Revision: D14832897
Pulled By: ezyang
fbshipit-source-id: 4780e7a34126bc66ddbfd9d808dfc9e0edd77e68
Summary:
the ROCm compiler cannot and will not satisfy them, causing compile time warnings.
Reason being a runtime loop trip count.
Some warnings remain arising from other parts of the ROCm stack - tickets are filed and they will be resolved within these components.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19018
Differential Revision: D14832859
Pulled By: ezyang
fbshipit-source-id: 0d66e4aebe4e56af14dd5e2967d3c374a82be25c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19004
Handling the exception case when the data has min 3.40282e+38 max -3.40282e+38
Reviewed By: jspark1105
Differential Revision: D14822193
fbshipit-source-id: b9771d1584fdf8317f5b8c7f5806be5d27314386
Summary:
1) sparse_dispatches in native_parse was not used anymore, got rid of it.
2) got rid of overloaded sizes_ in SparseTensorImpl, which just uses the base implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18962
Differential Revision: D14811545
Pulled By: gchanan
fbshipit-source-id: 2fa60ef50456b5f605caa63beae1d8d2542fd527
Summary:
* Annotate also two pass reduction with launch bounds
* ifdef some shortcomings of ROCm w.r.t. short-circuit returns - internal tickets filed
* while there, plug memory leak by destroying matrix descriptor after the sparse call (applicable to cuSPARSE)
* while there, fix types for cusparseXcoo2csr as per cuSPARSE documentation
* enable test_dsmm in test_sparse which now passes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18985
Differential Revision: D14822009
Pulled By: bddppq
fbshipit-source-id: 757267a47a63ee56ef396c33059f7eca099f4833
Summary:
Make sure to check if profiler is disabled in push/pop and mark event
functions
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18908
Differential Revision: D14791931
Pulled By: ilia-cher
fbshipit-source-id: e4f5149e69999ee2b9238c21cccad6d27c6a714a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18848
The Observer Module is based on eager mode compute qparam implementation.
Goal is to validate QParam result for EagerMode and Script Mode for simple
model
Observer stats are collected and qparam computed only for activations only at this point
Reviewed By: zafartahirov
Differential Revision: D14720805
fbshipit-source-id: cb2f321b4b9927b37905fdb8eb55c5610d41b351
Summary:
Dear All,
The proposed patch fixes the test code snippets used in cmake infrastructure, and implicit failure to set properly the ```CAFFE2_COMPILER_SUPPORTS_AVX2_EXTENSIONS``` flag. The libcaffe2.so will have some ```UND``` avx2 related references, rendering it unusable.
* Using GCC 9 test code from cmake build infra always fails:
```
$ gcc -O2 -g -pipe -Wall -m64 -mtune=generic -fopenmp -DCXX_HAS_AVX_1 -fPIE -o test.o -c test.c -mavx2
test.c: In function ‘main’:
test.c:11:26: error: incompatible type for argument 1 of ‘_mm256_extract_epi64’
11 | _mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
| ^
| |
| __m256 {aka __vector(8) float}
In file included from /usr/lib/gcc/x86_64-redhat-linux/9/include/immintrin.h:51,
from test.c:4:
/usr/lib/gcc/x86_64-redhat-linux/9/include/avxintrin.h:550:31: note: expected ‘__m256i’ {aka ‘__vector(4) long long int’} but argument is of type ‘__m256’ {aka ‘__vector(8) float’}
550 | _mm256_extract_epi64 (__m256i __X, const int __N)
|
$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/9/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-redhat-linux
Configured with: ../configure --enable-bootstrap --enable-languages=c,c++,fortran,objc,obj-c++,ada,go,d,lto --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-shared --enable-threads=posix --enable-checking=release --enable-multilib --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-gcc-major-version-only --with-linker-hash-style=gnu --enable-plugin --enable-initfini-array --with-isl --enable-offload-targets=nvptx-none --without-cuda-driver --enable-gnu-indirect-function --enable-cet --with-tune=generic --with-arch_32=i686 --build=x86_64-redhat-linux
Thread model: posix
gcc version 9.0.1 20190328 (Red Hat 9.0.1-0.12) (GCC)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18991
Differential Revision: D14821838
Pulled By: ezyang
fbshipit-source-id: 7eb3a854a1a831f6fda8ed7ad089746230b529d7
Summary:
Stacked on https://github.com/pytorch/pytorch/pull/18815 and https://github.com/pytorch/pytorch/pull/18811.
This makes it so that we emit a higher-precision literal for float values in the fusion kernel, as well as assign that to a `double` variable. This prevents us from losing precision for values such as `pi`, but with the previous fixes this will also get downcasted to `float` if downstream operations require it. Therefore, we should not lose performance because of implicit promotions
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18817
Differential Revision: D14820842
Pulled By: jamesr66a
fbshipit-source-id: 519671c6ca5e7adac746a4c4c72760a6d91e332f
Summary:
Closes#18382
Please let me know if any changes are required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18787
Differential Revision: D14821147
Pulled By: soumith
fbshipit-source-id: edd98eab1b3f4151c4ae5148146435ddb2ae678d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18974
When the weight is prepacked and it doesn't contain a prepacked weight for acc32, we shouldn't fallback to acc32.
Reviewed By: bddppq
Differential Revision: D14814067
fbshipit-source-id: aec917322de695e283f0aca1e930c5603d196404
Summary:
Move these 2 ops back to autodiff to unblock xla CI.
I will leave them for my next PR to cleanup symbolic_variable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18969
Differential Revision: D14816811
Pulled By: ailzhang
fbshipit-source-id: dd8a7e133dcad29560d3d1d25691883960117299
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18713
- Quantizer observer node output is hooked up to following node
which mutates the naming for input/output. This is not desired and
required because observer op can be a sync node
- Quantizer is aimed for quantizing tensors so we should insert observer
op for Values that are type tensor
Reviewed By: zafartahirov
Differential Revision: D14715916
fbshipit-source-id: feca04c65a43103b46084d3548998498b19ee599
Summary:
Stacked on https://github.com/pytorch/pytorch/pull/18811
This makes it so that we only emit the *f variants of math functions if the output value's type is FloatTensor, otherwise we call the double variants to prevent loss of precision. This fixes more numerical issues
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18815
Differential Revision: D14816965
Pulled By: jamesr66a
fbshipit-source-id: 464be644168875ede987142281fb2168f4041e81
Summary:
Thanks to dusty-nv , we now have Stable and Weekly wheels provided for the NVIDIA Jetson Platform. They require JetPack 4.2.
He's also maintaining source build instructions.
This PR adds links to the binaries and source build instructions to the README.
The links are dynamic, so when new stable / weekly wheels are available, Dustin will update the same URL to point to the new files
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18990
Differential Revision: D14820158
Pulled By: soumith
fbshipit-source-id: 761a56557decb72ad9c1b9f8a2745667f558eec3
Summary:
- Quantizer pass to mutate IR by inserting quant-dequant nodes
before and after nodes which support quantized ops. This information
will be used by jit compiler to substitute with quantized ops
- This currently covers simple model. It will be expanded later
for subgraph pattern matching to cover more complex patterns
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18446
Differential Revision: D14592265
Pulled By: nishantpdce
fbshipit-source-id: c9ba6c12aa96cb9c117826e386721eec83a55ea6
Summary:
Trainer has been removed long time ago
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18980
Differential Revision: D14819855
Pulled By: ezyang
fbshipit-source-id: f62020e688ebf6663416aec7435bf1f531607941
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18469
ghimport-source-id: 73cb8b58f43f10b1dcfca805fd5b25c4fa977632
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18469 Create Object that represents a Module**
* #18468 slots with explicit value/setValue make more sense in future patches
* #18467 Make Object hold its ClassType
* #18379 Enforce single parent for script submodules
* #18378 Unify namespace of script::Module
* #18314 Add ability to specialize class types to ArgumentSpec
* #18226 Add Slot type to abstract the raw pointers being used for slots.
This changes the underlying storage for script::Module to hold
a ivalue::Object which has slots for all the parameters and attributes.
NamedIValue and Slot are now merged together into one class Slot that stores
the tuple (ivalue::Object, offset) and can be used to read the name, type,
or value of the slot and also to set the value. This cleans up a bunch
of client uses.
This PR does not actually use the module object in any generated code.
A future PR will switch how code is generated to treat modules as
first class.
Differential Revision: D14613508
fbshipit-source-id: d853a7559f58d244de2ef54a781427fcd1060ed0
Summary:
Fixes https://github.com/pytorch/pytorch/issues/10654
The issue is that in tracing `.size` returns an int tensor, and when an int tensor is multiplied by a scalar the int dominates and the scalar gets casted 0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18875
Differential Revision: D14814441
Pulled By: eellison
fbshipit-source-id: a4e96a2698f2fcbf3ec4b2bb4c43a30250f30ad9
Summary:
This adds a C++ function `debugGetFusedKernelCode` as well as a Python binding `_jit_fuser_get_fused_kernel_code` that will, given a FusionGroup graph and a set of specified inputs, return the compiled kernel source code. We can then check the contents of this source code for verification of the fuser codegen backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18884
Differential Revision: D14795508
Pulled By: jamesr66a
fbshipit-source-id: 8f6e9dd13ebbb517737d893b0b5f5e9aa06af124
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18468
ghimport-source-id: d4b41c521f2269a695e03c8e7d05d5542731ee48
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18469 Create Object that represents a Module
* **#18468 slots with explicit value/setValue make more sense in future patches**
* #18467 Make Object hold its ClassType
* #18379 Enforce single parent for script submodules
* #18378 Unify namespace of script::Module
* #18314 Add ability to specialize class types to ArgumentSpec
* #18226 Add Slot type to abstract the raw pointers being used for slots.
Reviewed By: suo
Differential Revision: D14613509
fbshipit-source-id: 9f2208d0efd01465c78cebdc3e8365a9e0adf9ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18467
ghimport-source-id: d51bdd64d2529d08c634c58df1a0870b54ad49fb
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18469 Create Object that represents a Module
* #18468 slots with explicit value/setValue make more sense in future patches
* **#18467 Make Object hold its ClassType**
* #18379 Enforce single parent for script submodules
* #18378 Unify namespace of script::Module
* #18314 Add ability to specialize class types to ArgumentSpec
* #18226 Add Slot type to abstract the raw pointers being used for slots.
Currently it holds a symbol whose unqualified name is the name of the
class. This will get confusing when there are multiple possible registries,
and it makes getting the class type from the object difficult.
The pointer to the class is only 4 more bytes so this patch just puts
it in the object.
Reviewed By: suo
Differential Revision: D14613510
fbshipit-source-id: b35175ba4be83d2522deaa6dad5070d6ec691fed
Summary:
I have experienced that sometimes both were in `__dict__`, but it chose to copy `probs` which loses precision over `logits`. This is especially important when training (bayesian) neural networks or doing other type of optimization, since the loss is heavily affected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18614
Differential Revision: D14793486
Pulled By: ezyang
fbshipit-source-id: d4ff5e34fbb4021ea9de9f58af09a7de00d80a63
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18881
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18878
When the weight is prepacked and it doesn't contain a prepacked weight for acc32, we shouldn't fallback to acc32.
TODO: add unit tests with better coverage
Reviewed By: feiyu1990
Differential Revision: D14778810
fbshipit-source-id: d49a8c4b7c815ab29b77feb53ee730ad63780488
Summary:
The C++ and CUDA implementations of the lerp are not numerically stable. This is discussed on Wikipedia [here](https://en.wikipedia.org/wiki/Linear_interpolation#Programming_language_support). I checked the GPU SASS output and there's no overhead from using the more precise implementation, from Kepler all the way to Turing. I haven't looked at CPU ASM though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18871
Differential Revision: D14793438
Pulled By: ezyang
fbshipit-source-id: 2ddc2e026c5285466cae7d1b4101174253100445
Summary:
As discussed with gchanan we should deduplicate symbolic_variable and symbolic_script to prepare for the future merge with derivatives.yaml.
This PR moves most easy formulas to symbolic_script.
TODO: run benchmarks to make sure no perf regression
cc: apaszke zdevito wanchaol
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17986
Differential Revision: D14766412
Pulled By: ailzhang
fbshipit-source-id: d95a3f876e256c0f505779a71587c985571d3b8f
Summary:
This PR:
* pulls four distinct installation steps out of `build_pytorch.bat` and into their own scripts.
* eliminates the copy step for helper scripts called by `win-build.sh` and `win-test.sh`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18917
Differential Revision: D14807236
Pulled By: kostmo
fbshipit-source-id: 03e91a5834dfd6d68903ad9725eacc099bbf6d53
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18791
As a temporary demonstration on how to extend this hack further until custom C types are ready.
Reviewed By: jamesr66a
Differential Revision: D14742020
fbshipit-source-id: 0f2fd83ae56ab2abe16977a1829ed421e6abe74b
Summary:
Looks like the issue of using `std::` functions is fixed in new rocm version
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18905
Differential Revision: D14792943
Pulled By: bddppq
fbshipit-source-id: af11acbb85872943f23b6e55415db1f0699e7b8f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18711
ghimport-source-id: c9caedc0660b2b7ba3730cd0e1a2e0e9c3cf422b
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18711 [jit] fix side-effects and aliasing for custom ops**
Previously we didn't track aliasing, mutation, or side effects for
custom ops. This PR adds in guards with the most conservative
assumptions possible: the op will
1) have side effects,
2) write to everything
3) produce a wildcard.
In order to tell whether a given operator is a custom op, this PR introduces
the concept of a "reserved" namespace (basically all our builtin namespaces).
Custom ops live in non-reserved namespaces, so a check on the namespace
is sufficient to tell whether a schema/node is "custom" or not.
This is just to get things correct for now. Follow-ups to this:
- Users should be able to specify aliasing/mutability without having to learn
the whole alias annotation schema.
- Relax assumptions a bit. In particular outputs can only alias input tensors,
they don't have to be wildcards.
Fixes#18490
Differential Revision: D14730978
fbshipit-source-id: 540b47a24ccf24145051609bdcc99c97e46e0fe0
Summary:
Expand the list of ops that resize an input in-place to include broadcasting ops and other ops that affect shape. Whoever is reviewing the PR could you please look through pytorch in place ops and see if I missed any.
Expanding the PR from: https://github.com/pytorch/pytorch/pull/17518
This is already being tested in test_resize_input_ops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18812
Differential Revision: D14793410
Pulled By: eellison
fbshipit-source-id: 125f4f5375ac1036fb96fabc9da2aaccc9adc778
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18845
This adds a few CPU only test cases for the reducer class.
Reviewed By: mrshenli
Differential Revision: D14768432
fbshipit-source-id: c008a52206826304e634a95bc14167ed94c97662
Summary:
Fix a few instances of notifying on a CV while holding the lock to release the lock before notifying. This avoids an extra thread suspension when the notified thread tries to grab the lock.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18857
Differential Revision: D14779132
Pulled By: resistor
fbshipit-source-id: b18a05c4c15be1426ebfdffac1c8f002b771cfd7
Summary:
`scripts/build_windows.bat` is the original way to build caffe2 on Windows, but since it is merged into libtorch, the build scripts should be unified because they actually do the same thing except there are some different flags.
The follow-up is to add the tests. Looks like the CI job for caffe2 windows is defined [here](https://github.com/pytorch/ossci-job-dsl/blob/master/src/jobs/caffe2.groovy#L906). Could we make them a separate file, just like what we've done in `.jenkins/pytorch/win-build.sh`? There's a bunch of things we can do there, like using ninja and sccache to accelerate build.
cc orionr yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18683
Differential Revision: D14730188
Pulled By: ezyang
fbshipit-source-id: ea287d7f213d66c49faac307250c31f9abeb0ebe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18833
ghimport-source-id: 6f2be25fcc5e6be3ffe20582e604bd2c1fbab66b
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18833 [STACK] Cache device on TensorImpl; clean up TensorImpl constructors.**
* #18832 [STACK] Disallow changing the device of a tensor via set_.
* #18831 [STACK] Stop swapping in Storages of the wrong device for Tensors.
1) We cache device on TensorImpl. This means we can access the device without a virtual function and allows us to more easily extend TensorImpls (because they don't need to figure out how to store the Device for themselves).
2) Clean up TensorImpl APIs. We had a constructor that took a TensorTypeId and an allocator and would allocate a Storage based on the recognized types of TensorTypeIds. Instead, we just have two different constructors: one for types with a storage, one without.
Reviewed By: dzhulgakov
Differential Revision: D14766230
fbshipit-source-id: 745b8db84dcd6cb58f1a8675ad3ff8d033bc50df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18912
We intentionally test a deprecated API, no need to show the warnings here.
Reviewed By: dzhulgakov
Differential Revision: D14792617
fbshipit-source-id: 9ea2a4106d566064283726eed2c274b98f49a2e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18716
Might be useful as an intermediate stage for some systems that currently use Caffe2 nets as an execution mechanism.
Not sure it's a good idea all together, please comment.
Limitations:
- only Tensor types as inputs/outputs
- the entire module is serialized as a zip archive inside a proto in Caffe2 db, it'd be subject to 4Gb limit and is likely very slow. For small models it'd work though.
- no autograd, though it can be attached in principle
- no way to retrieve parameters inside the script module from C2 runtime perspective (though they potentially can be alias-fetched and stored as individual blobs)
- after deserialization, python wrappers returned don't have correct type (as we don't do module_lookup trick)
Build-wise, I had to add dependency from pybind_state to libtorch.so. I don't think we build Caffe2 python frontend independently anymore, so it should be fine.
Reviewed By: amirshim, houseroad
Differential Revision: D14339599
fbshipit-source-id: 88a37a8abd1f1c4703e5ef937031f222535d4080
Summary:
This refactor lets us track the types of initial values added onto a `Method`. The main motivation for this is the change in `module.cpp`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18252
Differential Revision: D14673459
Pulled By: driazati
fbshipit-source-id: 21200180c47f25bb70898771adfb569856e6c34a
Summary:
Replace link to a file in a private repo with a gist
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18852
Reviewed By: ezyang
Differential Revision: D14778481
Pulled By: izdeby
fbshipit-source-id: 8389aa4bf115ddcfd85079cc2c861404efa678e7
Summary:
return missing_keys and unexpected_keys from load_state_dict so the user can handle them when strict mode is off; also removed an unused variable
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18668
Differential Revision: D14782073
Pulled By: ezyang
fbshipit-source-id: ab3b855eb77bb7422594d971988067e86eef20f2
Summary:
Tested by running the script in #16562 , and there was no error.
Then:
```
>>> print(mat.grad)
tensor([[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.]])
```
which is correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18737
Differential Revision: D14773078
Pulled By: umanwizard
fbshipit-source-id: 8aa36eb6f6aa104263a467d9ac91d61b3bfd05f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18595
There is no need to force the backend to be the same as the global
process group, as long as the backend is "nccl" or "gloo".
Reviewed By: mrshenli
Differential Revision: D14657204
fbshipit-source-id: 868817b9f219e3be8db0761a487f0027ed46663b
Summary:
This was causing some numerical issues in the fuser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18811
Differential Revision: D14767390
Pulled By: jamesr66a
fbshipit-source-id: f1123d1aab5501abad850d2edc996f8aa8dafe04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18832
ghimport-source-id: fde4ad90541ba52dfa02bdd83466f17e6541e535
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18833 [STACK] Cache device on TensorImpl; clean up TensorImpl constructors.
* **#18832 [STACK] Disallow changing the device of a tensor via set_.**
* #18831 [STACK] Stop swapping in Storages of the wrong device for Tensors.
This is necessary to cache the device on a TensorImpl.
Differential Revision: D14766231
fbshipit-source-id: bba61634b2d6252ac0697b96033c9eea680956e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18831
ghimport-source-id: 2741e0d70ebe2c2217572c3af54ddd9d2047e342
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18833 [STACK] Cache device on TensorImpl; clean up TensorImpl constructors.
* #18832 [STACK] Disallow changing the device of a tensor via set_.
* **#18831 [STACK] Stop swapping in Storages of the wrong device for Tensors.**
This is necessary to support device caching, see https://github.com/pytorch/pytorch/pull/18751 and https://github.com/pytorch/pytorch/pull/18578.
In library code, we potentially swap in Storages with the wrong device when device_guard is False. This happens as follows with "view-like" operations.
1) We allocate a tensor on the 'wrong' device (because device_guard is false).
2) We swap out the 'wrong' storage with the 'right' storage using e.g. THCTensor_setStorage.
Instead, we can just construct the Tensor with the correct Storage from the beginning. This is what we do with 'view'.
Note there are two other "view-like" cases where this happens:
1) unfold
2) set_()
Because these aren't performance critical, I just added the device_guard instead of applying the above correction.
For completeness, this also includes a test that all `device_guard: false` functions behave properly under these conditions.
Reviewed By: dzhulgakov
Differential Revision: D14766232
fbshipit-source-id: 0865c3ddae3f415df5da7a9869b1ea9f210e81bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17991
changes:
-Breaks bc: Tensor::type() now returns DeprecatedTypeProperties& rather than Type&.
-Added DeprecatedTypeProperties, it serves as a temporary replacement for Type as the return value of Tensor::type(). This contributes to making Type just for dispatch purposes so that we can make it dtype agnostic.
-Tensor::dispatch_type() now returns Type& like Tensor::type() used to do.
-Changed callsites of Tensor::type() appropriately.
Reviewed By: ezyang
Differential Revision: D14443117
fbshipit-source-id: 239ccb7a09626279a71d1a37f8f82e7f57bf7d9e
Summary:
DLPack can have non-strided tensors, which is represented by a nullptr in the place of dl_tensor.strides.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18510
Differential Revision: D14647328
Pulled By: bwasti
fbshipit-source-id: 5364282810a5772cfc2319fc8133fe86fdd84dd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18838
It turns out that we don't have shape inference function of `Split` op at all. This diff adds that.
Reviewed By: bertmaher
Differential Revision: D14766871
fbshipit-source-id: 535cb4f24bdada603c76579e00e7a39aee93e19f
Summary:
Since parameter.data will create a new torch.Tensor each time, we get duplicate tensors when call _unique_state_dict now. Try to deduplicate it before creating new tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18139
Reviewed By: dzhulgakov
Differential Revision: D14511262
Pulled By: houseroad
fbshipit-source-id: cb69795d0b6509721220650bbb19edeb3459a503
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17026
D14013931 was for FC. This diff is similar optimizations for Conv.
A subtle difference is that in FC, once we fold col_offset into bias during pre-processing step, we can treat everything as if A_zero_offset == 0 (symmetric quantization of A).
In Conv, we can't do this because padding still needs to use the original A_zero_offset.
From requantization point of view, once col_offset folded into bias, we can treat as if we're doing symmetric A quantization.
But, for steps involving padding like im2col, im2col fused with packing, and direct conv for depth-wise/group convolution we still need to pass the original A_zero_offset.
Reviewed By: jianyuh
Differential Revision: D14020276
fbshipit-source-id: c29caefd1127bbc6aff0e9d535939bb0c1ecb66c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18826
ghimport-source-id: 7ffa3bc7ef7402a6d6eb6ba5849e197019d77bf8
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18826 [jit] run cpp tests for non-cuda builds in test_jit.py**
We did all the work of nicely separating our cpp tests that don't require
CUDA, but they aren't run from test_jit.py if CUDA is missing.
Reviewed By: ZolotukhinM
Differential Revision: D14766287
fbshipit-source-id: 9326b3a5c90f6c20fc8cfaf1a1885a363b91f30a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18379
ghimport-source-id: 9895ecc1ff7897e98853dc00675341f36726e7c7
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18379 Enforce single parent for script submodules**
* #18378 Unify namespace of script::Module
* #18314 Add ability to specialize class types to ArgumentSpec
* #18226 Add Slot type to abstract the raw pointers being used for slots.
The assumption that a ScriptModule has a single parent is present in
our serialization format, and likely a few other places. It is not
enforced on creation of script module hierarchies though, meaning that
problems associated with (e.g. replicating a module twice in the output
format) will not be caught until much later in the development cycle.
This patch enforces the property when a submodule is registered.
It also removes NamedModule since it is no longer necessary in this regime.
This will also allow the easy discover of a modules fully-qualified name
without needing to traverse the Module hierarchy.
Differential Revision: D14603722
fbshipit-source-id: 63ab5d0cccf7d66c7833e0adf9023024ca9607cb
Summary:
Per our offline discussion, allow Tensors, ints, and floats to be casted to be bool when used in a conditional
Fix for https://github.com/pytorch/pytorch/issues/18381
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18755
Reviewed By: driazati
Differential Revision: D14752476
Pulled By: eellison
fbshipit-source-id: 149960c92afcf7e4cc4997bccc57f4e911118ff1
Summary:
Fix the layernorm formula when weight and bias passed in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18233
Differential Revision: D14760375
Pulled By: wanchaol
fbshipit-source-id: d6bd3b137bc04c391aa5c24d021d1f811ba2a877
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18378
ghimport-source-id: 55c29bb436a2153d29ff2f4488d99d8863c187b1
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18379 Enforce single parent for script submodules
* **#18378 Unify namespace of script::Module**
* #18314 Add ability to specialize class types to ArgumentSpec
* #18226 Add Slot type to abstract the raw pointers being used for slots.
This removes individual OrderedDicts in favor of a single unified
namespace for all things in a script::Module. This removes a whole
class of bugs where both a method and an parameter could get the
same name, for instance.
Since we no longer have to expose OrderedDict::Item objects, a lot of
downstream code can be simplified.
We no longer now double-store names (both in the key of the dictionary,
and in the object itself).
Differential Revision: D14603723
fbshipit-source-id: b5f7551b3074679623edd6ea70269830353b4d4c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18648
ghimport-source-id: 1cf4a8fe91492621e02217f38cae5d7e0699fb05
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18661 Step 7: remove _unique
* #18655 Step 6: Rename _unique2 to unique and add int? dim
* #18654 Step 5: remove _unque_dim in favor of unique_dim
* #18651 Step 4: add support for unique with dim=None
* #18650 Step 3: Add support for return_counts to torch.unique for dim not None
* #18649 Step 2: Rename _unique_dim2_temporary_will_remove_soon to unique_dim
* **#18648 Step 1: Secretly add return_counts to unique, and refactor unique_dim for performance**
`unique` is fragile, previously I tried to change it in #18391 and #17097, they all pass OSS tests but finally get reverted due to internal failure. My previous work of refactoring unique #18459 is based on #18391, and after #18391 get reverted, I could not work on #18459. To continue working on #18459, #18391, and #17097 without worrying about internal failures, I am suggesting the following steps for the improvements of `unique` and `unique_dim`. soumith Please take this and there is no need to put #18391 back.
The motivation is basically to move forward as much as possible without causing any internal failures. So I will try to divide it into steps and sort from low probability of internal failure to high probability. (I don't know what the internal failure is, so I have to guess). Let's merge these PR stack one by one until we enounter internal failure.
Step 1: Create two new ATen operators, `_unique2_temporary_will_remove_soon` and `_unique_dim2_temporary_will_remove_soon` and keep `_unique` and `_unique_dim` unchanged. The backend of these two functions and `_unique` and `_unique_dim` are all the same, the only difference is the temporary ones support `return_counts` but not the `_unique` and `_unique_dim`. Step one is mostly #18391 + #18459. The cuda8 errors has been fixed. At this point, there is no user visible API change, so no docs are updated. `torch.unique` does not support `return_counts` yet, and `return_counts` is tested through the newly added temporary operators. This step just added two new ATen operators, so there shouldn't be any internal failure.
Step 2: Rename `_unique_dim2_temporary_will_remove_soon` to `unique_dim`. This should cause no internal failure either, because no change to existing operators. The only thing to worry about is to delete `unique_dim` from python side because we don't want users to use it. At this point, C++ users now have `return_counts` support for `unique_dim`.
Step 3: Update the docs of `torch.unique` and use `unique_dim` inside `torch.unique` to support `return_counts` In the docs, we should say `torch.unique` with None dim support does not support `return_counts` yet. This might cause internal failure.
Step 4: Rename `_unique2_temporary_will_remove_soon` to `_unique2` and use `_unique2` inside `torch.unique` to support `return_counts`. Update the docs saying that `torch.unique` with None dim now support `return_counts`. This might cause internal failure.
Step 5: Remove `_unique_dim`. This might cause internal failure.
Step 6: Rename `_unique2` to `unique`, add optional `dim` argument to make it looks like the signature of Python's `torch.unique`. Inside `torch.unique`, use `unique` and get rid of `unique_dim`. Unbind `unique_dim` totally from Python at codegen. This is likely to cause internal fail.
Step 7: Remove `_unique`. This is very likely to cause internal failure.
This PR
======
This PR is for step 1. This create two new ATen operators, `_unique2_temporary_will_remove_soon` and `_unique_dim2_temporary_will_remove_soon` and implement `return_counts` inside them and do refactor for performance improvements.
Please review ngimel VitalyFedyunin. They are mostly copied from #18391 and #18459, so the review should be easy.
Below is a benchmark on a tensor of shape `torch.Size([15320, 2])`:
Before
---------
```python
print(torch.__version__)
%timeit a.unique(dim=0, sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(dim=0, sorted=True, return_inverse=True); torch.cuda.synchronize()
```
```
1.0.1
192 µs ± 1.61 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
548 ms ± 3.39 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
```python
print(torch.__version__)
%timeit a.unique(sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(sorted=True, return_inverse=True); torch.cuda.synchronize()
```
```
1.0.1
226 µs ± 929 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
302 µs ± 7.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
After
-------
```python
print(torch.__version__)
%timeit a.unique(dim=0, sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(dim=0, sorted=True, return_inverse=True); torch.cuda.synchronize()
%timeit torch._unique_dim2_temporary_will_remove_soon(a, dim=0, sorted=True, return_inverse=False, return_counts=True); torch.cuda.synchronize()
%timeit torch._unique_dim2_temporary_will_remove_soon(a, dim=0, sorted=True, return_inverse=True, return_counts=True); torch.cuda.synchronize()
```
```
1.1.0a0+83ab8ac
190 µs ± 2.14 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
237 µs ± 1.23 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
219 µs ± 2.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
263 µs ± 1.15 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
```python
print(torch.__version__)
%timeit a.unique(sorted=True, return_inverse=False); torch.cuda.synchronize()
%timeit a.unique(sorted=True, return_inverse=True); torch.cuda.synchronize()
%timeit torch._unique2_temporary_will_remove_soon(a, sorted=True, return_inverse=False, return_counts=True); torch.cuda.synchronize()
%timeit torch._unique2_temporary_will_remove_soon(a, sorted=True, return_inverse=True, return_counts=True); torch.cuda.synchronize()
```
```
1.1.0a0+83ab8ac
232 µs ± 2.21 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
301 µs ± 1.65 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
264 µs ± 7.67 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
339 µs ± 9.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Differential Revision: D14730905
fbshipit-source-id: 10026b4b98628a8565cc28a13317d29adf1225cc
Summary:
If the input `network` resides on multiple GPUs, `devices` must be a 2D list with `devices[0]` matching `network`'s devices. See #18591
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18687
Differential Revision: D14706162
Pulled By: mrshenli
fbshipit-source-id: dca630d3308f2dbcf8b75629c452d7a64092ba42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18230
Implementing minimum qtensor API to unblock other workstreams in quantization
Changes:
- Added Quantizer which represents different quantization schemes
- Added qint8 as a data type for QTensor
- Added a new ScalarType QInt8
- Added QTensorImpl for QTensor
- Added following user facing APIs
- quantize_linear(scale, zero_point)
- dequantize()
- q_scale()
- q_zero_point()
Reviewed By: dzhulgakov
Differential Revision: D14524641
fbshipit-source-id: c1c0ae0978fb500d47cdb23fb15b747773429e6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18560
We have to import python protobuf here **before** we load cpp extension.
Otherwise it breaks under certain build conditions if cpp implementation of
protobuf is used. Presumably there's some registry in protobuf library and
python side has to initialize the dictionary first, before static
initialization in python extension does so. Otherwise, duplicated protobuf
descriptors will be created and it can lead to obscure errors like
Parameter to MergeFrom() must be instance of same class: expected caffe2.NetDef got caffe2.NetDef.
I think it also fixes https://github.com/facebookarchive/caffe2/issues/1573
Reviewed By: ezyang, iroot900
Differential Revision: D14622054
fbshipit-source-id: 2499eb88ecdee85ff8d845859048f7ae5da2a480
Summary:
to make test_operators.py more stable. in future, we will bump this up manually, and I think it's acceptable, since ir_version should be bumped too often.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18768
Reviewed By: zrphercule
Differential Revision: D14741514
Pulled By: houseroad
fbshipit-source-id: 0369dbc55424e345a113e49fc104a441ea290d58
Summary:
Introduce this check to see whether it will break any existing workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18145
Reviewed By: dzhulgakov
Differential Revision: D14511711
Pulled By: houseroad
fbshipit-source-id: a7bb6ac84c9133fe94d3fe2f1a8566faed14a136
Summary:
The mkldnn-bridge is upgraded in this PR to support DNNLOWP operators.
Meanwhile, APIs have been updated in caffe2 to use latest version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16308
Differential Revision: D14697018
Pulled By: yinghai
fbshipit-source-id: ca952589098accb08295fd5aa92924c61e74d69c
Summary:
Fixes : #6469
1. `ATen/native/native_functions.yml` had [dispatch](03e7953a98/aten/src/ATen/native/native_functions.yaml (L451-L455)) variants for for `embedding_dense_backward` , however `embedding_backward` explicitly made [call](03e7953a98/aten/src/ATen/native/Embedding.cpp (L35-L45)) to it, thus leading to error.
2. In case of CUDA type tensor, the function crashed used to crash on dereferencing of indices's data [pointer](03e7953a98/aten/src/ATen/native/Embedding.cpp (L93)).
Both have been solved and checked against (on CUDA and CPU)
1. As mentioned in the issue
```
import torch
class Test(torch.nn.Module):
def __init__(self):
super(Test,self).__init__()
self.embd = torch.nn.Embedding(1000, 100)
self.dense = torch.nn.Linear(100, 1)
def forward(self, inp):
inp = self.embd(inp)
return self.dense(inp)
test = Test()
inp = torch.tensor([0,1,2,1,1])
out = test(inp)
raw_loss = out.mean(dim=0)
loss_grad = torch.autograd.grad(outputs=raw_loss,
inputs=list(test.parameters()),
retain_graph=True, create_graph=True, only_inputs=True)
norm = sum([param.norm()**2 for param in loss_grad])
loss = raw_loss + norm
loss.backward(retain_graph=True)
print(test.embd.weight.grad)
```
2. Test Script
```
import torch
import time
start = time.time()
l = [1,1]*100
input = torch.tensor([[1,0],[1,0]],device='cpu')
embedding_matrix = torch.tensor([[1.0,3.0],[2.0,4]],requires_grad=True,device='cpu')
sq = embedding_matrix * embedding_matrix
emb = torch.nn.functional.embedding(input, sq,scale_grad_by_freq=False)
print('Embedding Matrix')
print(embedding_matrix)
print('-----------------')
sum_ = emb.sum()#prod.sum()
loss_grad, = torch.autograd.grad(outputs=sum_,inputs=embedding_matrix,create_graph=True)
print('Gradient')
print(loss_grad)
print('-----------------')
sum2_ = sum_ + loss_grad.sum()
print(sum2_)
sum2_.backward()
print(embedding_matrix.grad)
print(time.time() - start)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9078
Reviewed By: ezyang
Differential Revision: D14691901
Pulled By: soumith
fbshipit-source-id: 78e2612ba39080be564c876311671eb5a0119a0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18749
ghimport-source-id: 9026a037f5e11cdb9ccd386f4b6b5768b9c3259b
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18751 Disallow changing the device of a tensor via set_.
* #18750 Use non-legacy constructors for tensor deserialization.
* **#18749 Add device and dtype to storage.**
The goal here is to fix our serialization, which currently depends on the legacy constructors. Having dtype and device on Storage allows us to use the non-legacy constructors.
This fits somewhat along our goal of removing Storage, my having Storage act like a Tensor.
Differential Revision: D14729516
fbshipit-source-id: bf4a3e8669ad4859931f4a3fa56df605cbc08dcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18750
ghimport-source-id: f1475cfb67841c41d9867d4429ba9125d5c7dd07
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18751 Disallow changing the device of a tensor via set_.
* **#18750 Use non-legacy constructors for tensor deserialization.**
* #18749 Add device and dtype to storage.
Deserialization currently uses legacy constructors. This is bad because we need to maintain them, but there is a more immediate problem:
1) We are trying to implement device caching on TensorImpl to get rid of a virtual dispatch
2) This doesn't work if one is able to change the device of a Tensor underlying a Variable.
3) Deserialization does 2)
So the plan is to change deserialization, then enforce that we don't change the device out from underneath a Variable.
Differential Revision: D14729513
fbshipit-source-id: 090d6cdb375b94dc1bf4f554b2df243952b8cdc6
Summary:
It's not used and unfold's use of `device_guard: False` is scary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18773
Differential Revision: D14736526
Pulled By: gchanan
fbshipit-source-id: 6281a284bee45fa5038783e4c1ed4d1ed7ca81ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18531
Currently we use C10_LOG_EVERY_MS to log the data type change, but it pollutes the log of some service,
we would like to change it to C10_LOG_FIRST_N to prevent that.
Reviewed By: dzhulgakov
Differential Revision: D14647704
fbshipit-source-id: b84e4002bd4aa94d616133cd1049c3d4ab05386e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18284
ghimport-source-id: 5a92c03fda19072ffb6afd40e0f56806716c7be6
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18296 [jit] Add namespacing for ScriptClasses
* **#18284 [jit] make test module hook use save/load**
* #18211 [jit] Turn script_type_parser into a class
* #18148 [jit] python interop for script classes
Instead of python-printing and comparing strings (which does not capture
depdency information, etc.), use save/load on in-memory buffers and
compare the main module contents inside the buffer
Reviewed By: ailzhang
Differential Revision: D14581129
fbshipit-source-id: 52264ae9ce076775ab3fd1a0c32c8d6f6677a903
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18314
ghimport-source-id: 8cecb768d476ab19c9460f39c8f94a764e4cb052
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18314 Add ability to specialize class types to ArgumentSpec**
* #18226 Add Slot type to abstract the raw pointers being used for slots.
Differential Revision: D14574395
fbshipit-source-id: cc3af6e56e9ae52990f4a1ad56ecceaa2d493577
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18740
Test utilities for writing Caffe2/PyTorch performance microbenchmarks. Brief description of the file structure
* benchmark_core.py : core utiltiites for running microbenchmark tests
* benchmark_caffe2.py : Caffe2 specific benchmark utilitites
* benchmark_pytorch.py: PyTorch specific benchmark utilities
* benchmark_runner.py : Main function. Currently it can run the microbenchmark tests in a stand-alone mode. The next step is to have this integrate with AI-PEP.
The utilities are located at https://github.com/pytorch/pytorch/tree/master/test to have access to both Caffe2/PyTorch Python's frontend.
Include two operator microbenchmarks; support both Caffe2/PyTorch:
* MatMul
* Add
Reference: PyTorch benchmarks : https://github.com/pytorch/benchmark/tree/master/timing/python. In this work, we start with two example binary operators MatMul and Add, but eventually we should to cover unary operators like in the PyTorch benchmark repo.
Reviewed By: zheng-xq
Differential Revision: D13887111
fbshipit-source-id: b7a56b95448c9ec3e674b0de0ffb96af4439bfce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18166
ghimport-source-id: a8e2ba2d966e49747a55701c4f6863c5e24d6f14
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18166 Bool Tensor for CUDA**
* #18165 Resolved comments from Bool Tensor for CPU PR
------
This PR enables bool tensor creation and some basic operations for the CPU backend. This is a part of Bool Tensor feature implementation work. The whole plan looks like this:
1. Storage Implementation [Done]
2. Tensor Creation.
a) CPU [Done]
b) CUDA [This PR]
3. Tensor Conversions.
4. Tensor Indexing.
5. Tensor Operations.
6. Back compatibility related changes.
Change:
Enable bool tensor in CUDA with the following operations:
torch.zeros
torch.tensor
torch.ones
torch.rand/rand_like/randint/randint_like
torch.full
torch.full_like
torch.empty
torch.empty_like
Tested via unit tests and local scripts.
Differential Revision: D14605104
fbshipit-source-id: b7d7340a7d70edd03a109222d271e68becba762c
Summary:
To debug a `one of the variables needed for gradient computation has been modified by an inplace operation` error, I wanted to know *which* variable has been modified, so I extended the error message with what information is easily available at this point.
Before:
```
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
```
After:
```
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [80, 1]], which is output 0 of UnsqueezeBackward0, is at version 1, not expected version 0. Hint: enable anomaly detection to find the forward pass operation which modified it.
```
The hint to enable anomaly detection is only shown when it is not enabled. It's meant to save people some googling. I'd even go further and reference `torch.autograd.set_detect_anomaly(True)`, but maybe we're not running Python?
Disclaimer: I haven't looked at other parts of the code to check if using `std::stringstream` is acceptable practice, let me know if it isn't. Similarly, I haven't checked about indentation practices.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18523
Differential Revision: D14683249
Pulled By: soumith
fbshipit-source-id: f97a99d4aabea7461df766d66cd72300b48e2350
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18763
Without `link_whole` flag in opt-builds some of the files are not linked into `_C_impl` library, which causes some of static initializers not to run (namely, registering an cutomPythonOperation from python_interpreter.cpp). This diff fixes it.
Differential Revision: D14732471
fbshipit-source-id: 57cff6b4b6d479ad7ab7fd29f677746d91d6ff45
Summary:
Fix the bug introduced by #18681 where an undefined variable was being used to limit max cpu count when building for Windows without Ninja.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18748
Differential Revision: D14733209
Pulled By: soumith
fbshipit-source-id: 52fc0dd4dde99da75a6956b63f02da2e647eed4f
Summary:
Argument dim=-1 doesn't work for torch.cross. The signature of the torch.cross has been changed to c10::optional<int64_t> dim instead of int64_t. So based on document "If dim is not given, it defaults to the first dimension found with the size 3." and if dim is specified (even negative) it will use the correspondent dim.
Fixes#17229
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17582
Differential Revision: D14483063
Pulled By: ifedan
fbshipit-source-id: f9699093ec401cb185fd33ca4563c8a46cdcd746
Summary:
Multiple configurations is the default (eg. Release;Debug) on Windows and this check always broke this configuration as CMAKE_BUILD_TYPE was not set. The workaround was to always set CMAKE_BUILD_TYPE to Debug or Release, which was very unfortunate.
The correct method is to use generator expressions that expand depending on the current CONFIG being processed.
Side note: Anywhere else CMAKE_BUILD_TYPE is checked should probably be fixed too.
Note that the CMakeLists.txt forces it in to Release mode. However, I came across this error when importing the prebuilt Config in to another project, where CMAKE_BUILD_TYPE was not set.
> 3>CMake Error at pre_built/pytorch-1.0.1/share/cmake/Caffe2/public/cuda.cmake:380 (message):
> 3> Unknown cmake build type:
Proper support for configurations would mean we can build debug and release at the same time and as you can see, it is less CMake code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18548
Differential Revision: D14730790
Pulled By: ezyang
fbshipit-source-id: 70ae16832870d742c577c34a50ec7564c3da0afb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18577
This is also part of the legacy API and we need to support it if we want to replace it.
Reviewed By: dzhulgakov
Differential Revision: D14671432
fbshipit-source-id: 007abf4ab816647a509fc08e35d79b6c1aa55b03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18551
This is helpful for defining a set of operators as an interface but not adding concrete kernels just yet.
The registration logic will ensure that any other libraries that add kernels for these schemas exactly match the schema defined here.
Reviewed By: dzhulgakov
Differential Revision: D14660208
fbshipit-source-id: 7adb5a4876cff5a0ad21d92d8c450cb889f00cc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18550
When the operator registration API is used wrongly, in most cases we should now get a nice compiler error
instead of weird template error messages.
This is done by making the enable_if conditions more broad so they also match error cases,
but then having static_asserts against these error cases inside the function.
Before that, since the function didn't match, the error message said something like "no function found to match your call",
now it will show the error message specified in the static_asserts.
Reviewed By: dzhulgakov
Differential Revision: D14659178
fbshipit-source-id: 7ca4fb72d9051eadf0a7e2717b962bf1213a52b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18547
- Argument indices in the error messages are 1-indexed not 0-indexed.
- Add test cases that a mismatching signature actually shows the correct error messages
Reviewed By: dzhulgakov
Differential Revision: D14656695
fbshipit-source-id: 55e45634baa3117e18b8687ea6b2a2f83715bdf6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18703
`zeroPtr` is sometimes a `std::string` tensor, so `memset` to 0 is undefined behavior.
This might be accidentally safe with `std::string` implementation that use SSO (Small String Optimization), but will crash otherwise.
Reviewed By: zheng-xq
Differential Revision: D14714458
fbshipit-source-id: 012a18464e6514d38ff791509b88ddc3fc55b2b1
Summary:
Make it possible to construct a pinned memory tensor without creating a storage first and without calling pin_memory() function. It is also faster, as copy operation is unnecessary.
Supported functions:
```python
torch.rand_like(t, pin_memory=True)
torch.randn_like(t, pin_memory=True)
torch.empty_like(t, pin_memory=True)
torch.full_like(t, 4, pin_memory=True)
torch.zeros_like(t, pin_memory=True)
torch.ones_like(t, pin_memory=True)
torch.tensor([10,11], pin_memory=True)
torch.randn(3, 5, pin_memory=True)
torch.rand(3, pin_memory=True)
torch.zeros(3, pin_memory=True)
torch.randperm(3, pin_memory=True)
torch.empty(6, pin_memory=True)
torch.ones(6, pin_memory=True)
torch.eye(6, pin_memory=True)
torch.arange(3, 5, pin_memory=True)
```
Part of the bigger: `Remove Storage` plan.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18455
Reviewed By: ezyang
Differential Revision: D14672084
Pulled By: VitalyFedyunin
fbshipit-source-id: 9d0997ec00f59500ee018f8b851934d334012124
Summary:
Hi. It seems that when building CPP-extensions with CUDA for Windows, an `extra_cuda_cflags` options are not properly forwarded to `nvcc`.
Use of extra CUDA options is necessary to build, for instance, a InplaceABN (https://github.com/mapillary/inplace_abn), which requires `--expt-extended-lambda` option.
This PR adds one line that correctly appends `extra_cuda_cflags`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18638
Differential Revision: D14704270
Pulled By: ezyang
fbshipit-source-id: e1e330d193d9afd5707a5437a74c0499460d2b90
Summary:
At some point, we needed these functions to deal with autograd dispatching to the sparse of TH version of a backwards. But we rewrote all backwards definitions in terms of native functions, so this is no longer necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18696
Differential Revision: D14710834
Pulled By: gchanan
fbshipit-source-id: b22568c58eefc79d672555bd8832398ccd965cb7
Summary:
Added stubs for:
* The `device` module
* The `cuda` module
* Parts of the `optim` module
* Began adding stubs for the `autograd` module. I'll annotate more later but `no_grad` and friends are probably the most used exports from it so it seemed like a good place to start.
This would close#16996, although comments on that issue reference other missing stubs so maybe it's worth keeping open as an umbrella issue.
The big remaining missing package is `nn`.
Also added a `py.typed` file so mypy will pick up on the type stubs. That closes#17639.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18511
Differential Revision: D14715053
Pulled By: ezyang
fbshipit-source-id: 9e4882ac997063650e6ce47604b3eaf1232c61c9
Summary:
Peephole optimize ops that just require Dimensioned Tensor Type, which is what we specialize graphs on.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18549
Differential Revision: D14690827
Pulled By: eellison
fbshipit-source-id: 9d7439eb584f0a5b877f5aa53cf80150f00e7e5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18542
This adds the deprecated API for defining kernels as lambdas. The new API for defining kernels as lambdas was introduced in D14653005.
Reviewed By: dzhulgakov
Differential Revision: D14653551
fbshipit-source-id: 99900f1436716c69e52c83b68333b642ec2c8558
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18444
This adds the deprecated function based API to c10::RegisterOperators().
This is the API currently exposed under jit::RegisterOperators() and we need to support it for backwards compatibility.
Reviewed By: dzhulgakov
Differential Revision: D14514218
fbshipit-source-id: c77676851cfd431d66f18fd8038cf153a3a7d7cc
Summary:
This commit adds the `c10d::Reducer` class that hooks into autograd
and performs gradient bucketing and reduction. These are the core
parts of `nn.parallel.DistributedDataParallel` that up to now were
only usable for CUDA models.
This should enable the following:
* Distributed data parallelism for models defined using the C++ frontend.
* Allow overlap of gradient computation and reduction for non-CUDA models.
* Enable distributed data parallelism for models with some unused parameters.
This does not include any logic for computing bucket assignment, which
can be done separately; either by observing autograd execution order
(this is what Apex does), or by assigning buckets based on some
maximum byte size, or both.
Also see #17757 and #13273.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18251
Reviewed By: mrshenli
Differential Revision: D14571899
Pulled By: pietern
fbshipit-source-id: 20f95eefd288dfe8cfffe0a28ca22fa7c9c3cd4c
Summary:
If none of the outputs require_grad, we don't actually check gradgrad, instead we will check that their numerical gradients are 0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18190
Differential Revision: D14563388
Pulled By: ifedan
fbshipit-source-id: a4eb94c9eb60f14dbe6986cd8cef1fe78a7bc839
Summary:
The last time I tried to land it there was a merge race with the docs coverage test lol. Re-landing with the fix.
Re-land of https://github.com/pytorch/pytorch/pull/18304
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18570
Reviewed By: driazati
Differential Revision: D14707285
Pulled By: eellison
fbshipit-source-id: 3a0265928aa8cad78961723d8bf0fbf871fdb71d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18672
In Skylake, when n < 128 or k < 128, acc16 is slower.
Reviewed By: jianyuh
Differential Revision: D14700576
fbshipit-source-id: 80ca9f1af4626637eed9c5ca49f95ae744811189
Summary:
Since we are going to add ideep to ATen, and ATen is always compiled, it makes sense to have the registration in ATen rather than C2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18335
Reviewed By: bddppq
Differential Revision: D14578652
Pulled By: gchanan
fbshipit-source-id: 4d77fcfc21a362b21d5291a127498aa722548873
Summary:
`python setup.py develop` fails with following messages.
~~~
...
-- Building with NumPy bindings
-- Not using cuDNN
-- Not using MIOpen
-- Not using CUDA
-- Using MKLDNN
-- Not using NCCL
-- Building without distributed package
Copying extension caffe2.python.caffe2_pybind11_state
Copying caffe2.python.caffe2_pybind11_state from torch\Lib\site-packages\caffe2\python\caffe2_pybind11_state.cp37-win_amd64.pyd to C:\data\source\pytorch\build\lib.win-amd64-3.7\caffe2\python\caffe2_pybind11_state.cp37-win_amd64.pyd
copying torch\Lib\site-packages\caffe2\python\caffe2_pybind11_state.cp37-win_amd64.pyd -> C:\data\source\pytorch\build\lib.win-amd64-3.7\caffe2\python
building 'torch._C' extension
creating build\temp.win-amd64-3.7
creating build\temp.win-amd64-3.7\Release
creating build\temp.win-amd64-3.7\Release\torch
creating build\temp.win-amd64-3.7\Release\torch\csrc
...
creating C:\data\source\pytorch\build\lib.win-amd64-3.7\torch
C:\Program Files (x86)\Microsoft Visual Studio\2017\Professional\VC\Tools\MSVC\14.16.27023\bin\HostX64\x64\link.exe /nologo /INCREMENTAL:NO /LTCG /nodefaultlib:libucrt.lib ucrt.lib /DLL /MANIFEST:EMBED,ID=2 /MANIFESTUAC:NO /LIBPATH:C:\data\source\pytorch\torch\lib /LIBPATH:C:\data\dlenv\libs /LIBPATH:C:\data\dlenv\PCbuild\amd64 "/LIBPATH:C:\Program Files (x86)\Microsoft Visual Studio\2017\Professional\VC\Tools\MSVC\14.16.27023\ATLMFC\lib\x64" "/LIBPATH:C:\Program Files (x86)\Microsoft Visual Studio\2017\Professional\VC\Tools\MSVC\14.16.27023\lib\x64" "/LIBPATH:C:\Program Files (x86)\Windows Kits\NETFXSDK\4.6.1\lib\um\x64" "/LIBPATH:C:\Program Files (x86)\Windows Kits\10\lib\10.0.17763.0\ucrt\x64" "/LIBPATH:C:\Program Files (x86)\Windows Kits\10\lib\10.0.17763.0\um\x64" shm.lib torch_python.lib /EXPORT:PyInit__C build\temp.win-amd64-3.7\Release\torch/csrc/stub.obj /OUT:build\lib.win-amd64-3.7\torch\_C.cp37-win_amd64.pyd /IMPLIB:build\temp.win-amd64-3.7\Release\torch/csrc\_C.cp37-win_amd64.lib /NODEFAULTLIB:LIBCMT.LIB
ライブラリ build\temp.win-amd64-3.7\Release\torch/csrc\_C.cp37-win_amd64.lib とオブジェクト build\temp.win-amd64-3.7\Release\torch/csrc\_C.cp37-win_amd64.exp を作成中
コード生成しています。
コード生成が終了しました。
copying build\lib.win-amd64-3.7\torch\_C.cp37-win_amd64.pyd -> torch
copying build\lib.win-amd64-3.7\caffe2\python\caffe2_pybind11_state.cp37-win_amd64.pyd -> caffe2\python
copying build/temp.win-amd64-3.7/Release/torch/csrc/_C.cp37-win_amd64.lib -> build/lib.win-amd64-3.7/torch/lib/_C.lib
error: could not create 'build/lib.win-amd64-3.7/torch/lib/_C.lib': No such file or directory
~~~
When `python setup.py install` is executed, `torch/lib` has been created by previous process (copying many files) and this copy succeeds. But in develop mode, that process does not executed and this copy fails.
This patch creates `torch/lib` directory if do not exist.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18666
Differential Revision: D14704269
Pulled By: ezyang
fbshipit-source-id: b2d7c698a906b945bf34bb78f17b91b4fdfd3294
Summary:
MSVC errors on these flags as they are not supported
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18686
Differential Revision: D14704254
Pulled By: ezyang
fbshipit-source-id: 936d33ed6b7474d7774a49505cdac50dbe8dd99a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18239
When min is inf or nan, we get UBSAN errors
Reviewed By: csummersea
Differential Revision: D14537668
fbshipit-source-id: e70ffb5ecd2b10793356070c69fdabf8f25b203e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18628
ghimport-source-id: d94b81a6f303883d97beaae25344fd591e13ce52
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18629 Provide flake8 install instructions.
* **#18628 Delete duplicated technical content from contribution_guide.rst**
There's useful guide in contributing_guide.rst, but the
technical bits were straight up copy-pasted from CONTRIBUTING.md,
and I don't think it makes sense to break the CONTRIBUTING.md
link. Instead, I deleted the duplicate bits and added a cross
reference to the rst document.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14701003
fbshipit-source-id: 3bbb102fae225cbda27628a59138bba769bfa288
Summary:
If a test triggers autodiff, it must have a `DifferentiableGraph` in its differentiated forward graph, and this subgraph must have either the original aten node, or the corresponding nodes used in AD formula.
Typically a forward differentiable graph looks like this:
```
graph(%i0 : Float(),
%i1 : Float()):
%3 : Float() = prim::DifferentiableGraph_0(%i0, %i1)
return (%3)
with prim::DifferentiableGraph_0 = graph(%0 : Float(),
%1 : Float()):
%2 : Float() = aten::max(%0, %1)
return (%2)
```
which tells us `aten::max(Tensor self, Tensor other) -> Tensor` is symbolically differentiable.
Update: there're a lot of cases (fusions/ConstantChunk/python implementations) that breaks it so I decided to make the check optionally take node names if different from function name.
~~[OLD]Theoretically I could also check if `aten::max` is in the differentiable block or not to be more precise, but there're also cases like `chunk` where in a differentiable block it's replaced with a prim node (ConstantChunk) and we will have to special case them. Any suggestions here (to be more precise or no) is very welcome!~~
We used to have a list containing nn tests should be run against AD, I moved it to an field when constructing our test(either torch or nn). I think it's cleaner this way, and it matches the fact that for the same op we support one schema of it but not all, in this way we could just turn on the corresponding test which triggers that supported schema.
cc: apaszke zdevito wanchaol ngimel for a review
[Done] :
- Going through a manual second pass of all tests to check if they should enable AD test or not....
- Add a readme about how to add AD for an op and how to add/enable its test in test_jit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18509
Differential Revision: D14696811
Pulled By: ailzhang
fbshipit-source-id: c5e693277baac585cd3aed5ab2c0e7faa5e6f29f
Summary:
Problem:
```cpp
// This function expects a `Variable` as input
inline PyObject* wrap(at::Tensor tensor) {
return THPVariable_Wrap(Variable(std::move(tensor)));
}
inline PyObject* wrap(at::Scalar scalar) {
// This function calls `wrap(at::Tensor tensor)` (the function above), but since
// `scalar_to_tensor(...)` returns a `Tensor` and not a `Variable`, the call to
// `wrap(at::Tensor tensor)` will fail with "Tensor that was converted to Variable
// was not actually a Variable", which is not what we want.
return wrap(scalar_to_tensor(scalar));
}
```
The right fix is to call `make_variable(...)` with the tensor returned from `scalar_to_tensor(scalar)`.
This unblocks https://github.com/pytorch/pytorch/pull/18230 as it is the only patch that hits this code path now. All other native functions that return Scalar (such as `item()` or `_local_scalar_dense()`) either has custom-defined implementation that doesn't go through this path, or is not exposed to Python at all.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18632
Differential Revision: D14689293
Pulled By: yf225
fbshipit-source-id: be7ba5d3de83a69533a2997de97ad92989ff78ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
This is meant to resolve#18249, where I pointed out a few things that could improve the CTCLoss docs.
My main goal was to clarify:
- Target sequences are sequences of class indices, excluding the blank index
- Lengths of `target` and `input` are needed for masking unequal length sequences, and do not necessarily = S, which is the length of the longest sequence in the batch.
I thought about Thomas's suggestion to link the distill.pub article, but I'm not sure about it. I think that should be up to y'all to decide.
I have no experience with .rst, so it might not render as expected :)
t-vi ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18415
Differential Revision: D14691969
Pulled By: soumith
fbshipit-source-id: 381a2d52307174661c58053ae9dfae6e40cbfd46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18443
Allow registering a kernel without a dispatch key. In this case, the kernel becomes a fallback kernel that is called whenever no other kernel matches.
This is also useful for the legacy function based API (since that API doesn't know about dispatch keys) or any other custom ops that don't care about dispatch
and just want one kernel to be called no matter the dispatch key.
Reviewed By: dzhulgakov
Differential Revision: D14603258
fbshipit-source-id: 242dc8871dad2989ca25079854d0cc97429e7199
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18302
These might be use cases we want to support in the future, but they don't work yet.
Let's at least report an error instead of doing segfaults or worse.
Reviewed By: dzhulgakov
Differential Revision: D14572346
fbshipit-source-id: 49262ce131493bc887defe2978d8b22f202cd8cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18301
Move code out of headers and templates into source files and non-templates.
Reviewed By: dzhulgakov
Differential Revision: D14572347
fbshipit-source-id: 9fd5d62d54000a95e93076cd73f591ba2c5c2653
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18256
This diff infers the function schema from the kernel function/functor and checks that it matches the specified function schema.
This diff does not allow (yet) to omit specifying the function schema in the registration API. That will come in a future diff.
Reviewed By: dzhulgakov
Differential Revision: D14552738
fbshipit-source-id: 00202b489ede19f26ae686c97416b38c72c11532
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18162
- Adds the API to register a functor- and function-based kernel.
- Change the experimental c10 ops to use this new API instead of the old one
- Deletes the old APIs in KernelRegistration.h and OpSchemaRegistration.h
Reviewed By: dzhulgakov
Differential Revision: D14514239
fbshipit-source-id: 35b2f6e8f62964e54886450a6a5fac812ed20f26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18161
This introduces version 0 for the new operator registration.
For now, it only works with kernels that are defined as stack-based functions.
This is actually not the intended public API for defining kernels, but it's the basis which is going to be used to define the public APIs (see diffs on top for them),
and it's also the API used for exposing caffe2 operators.
This diff also switches the mechanism for exposing caffe2 operators to the new mechanism.
Reviewed By: dzhulgakov
Differential Revision: D14514231
fbshipit-source-id: 454ab7b5b46a10203aa27b175400d23f818dd1df
Summary:
caffe2_py2_cuda9_0_cudnn7_ubuntu16_04_build is failing
```
...
Mar 29 04:44:46 Need to get 174 MB of archives.
Mar 29 04:44:46 After this operation, 576 MB of additional disk space will be used.
Mar 29 04:44:46 Do you want to continue? [Y/n] Abort.
Exited with code 1
...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18609
Differential Revision: D14694990
Pulled By: bddppq
fbshipit-source-id: 260446a8650f660a2baf123a3f17efdf0a8d6c64
Summary:
* adds attributes to `ScriptModule.__getattr__` so they can be accessed in Python after re-importing
* full support for all the possible values for an `int64_t`
* this necessitated a bunch more `pushWhatever` functions, so re-introduced a templated version to cut down on duplicate code
* tests to validate references / value sharing works
* adds `torch.jit.Unpickler` which people can use to de-serialize the pickle files into Python / have a quick reference on how to do this without PyTorch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18188
Differential Revision: D14527490
Pulled By: driazati
fbshipit-source-id: efd15579cc04aa2e28c4b2c9490d82d849dee559
Summary:
For MKL-DNN,the filter data will be reorderd to primitive format, it takes a lot of time.
So the patch provide a method to convert filter format before training.
And "OptimizeForIdeep" will be changed to "OptimizeForMkldnn" in this patch.
This patch depends on https://github.com/pytorch/pytorch/pull/12866
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15171
Differential Revision: D14590741
Pulled By: yinghai
fbshipit-source-id: 07971c9977edac3c8eec08ca2c39cda639683492
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16373
motivation: https://github.com/pytorch/pytorch/pull/12407
This is a manual diff.
most of the fixes should be:
```
auto* Y = Output(0);
Y->Resize(dims);
Y->raw_mutable_data(dtype);
```
-->
```
auto* Y = Output(0, dims, at::dtype(dtype));
```
But there might be other cases.
Reviewed By: dzhulgakov
Differential Revision: D13725460
fbshipit-source-id: 649a4b0e42f62cda1a60171dd9fa3e440dc9dca1
Summary:
This adds `hash()` which supports `int`, `str`, and `float`. It relies on `std::hash` which is implementation defined, so the result of `hash()` in TorchScript is not the same as in Python, but should satisfy the same properties.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18258
Differential Revision: D14692317
Pulled By: driazati
fbshipit-source-id: 909df5d024bb3feea157d5a203b7de53c72261c9
Summary:
Start of breaking up test_jit.py
New files will have the format test_jit_* so they are easily grepable but remain in the same directory so we don't have to go through multiple sources for imports.
I am adding a test that's expected to fail to be sure it's running.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18590
Reviewed By: wanchaol
Differential Revision: D14677094
Pulled By: eellison
fbshipit-source-id: 9782c6aa9525bb6f332fc75cfff004c83a417522
Summary:
This defines a generic counters API that users can utilize to provide monitoring functionality in e.g. a production service. We expose both counters for runtime internals as well as a TorchScript API to create user-defined counters. Synopsis of the API:
- `torch/csrc/jit/script/logging.h` specifies the externally-facing API in C++
- `torch/jit/_logging.py` specifies the Python API
We use an interface, `LoggerBase`, to define the interactions between users and a logging backend. Implementing a subclass of `LoggerBase` allows the user to handle these events in a custom way, such as logging into a DB or calling into an infra-specific counters API.
From the frontend perspective, we can create log events in two ways:
1. We provide an `add_stat_value(name, val)` function. This calls into the Logger backend with a key/value pair. For example, we might call `add_stat_value('foo', 1)` to bump an event counter.
2. We provide a `time_point()` function to record a timestamp in nanoseconds. This can be used in conjunction with `add_stat_value` to record runtime wall clock durations.
Examples of frontend usage can be found in `test_jit.py TestLogging`.
We provide a trivial `LockingLogger` implementation as an example and for testing purposes. It is likely not ready for production usage. It demonstrates that a backend implementing the API can do things like specify aggregation types and report these aggregate stats via the `get_counters()` API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18235
Differential Revision: D14545060
Pulled By: jamesr66a
fbshipit-source-id: 04099543a1898cfdd411511e46e03d5dce9b4881
Summary:
They are called as (outputs, inputs) and were named (inputs, outputs).
Possible follow up fix is to make the outputs argument an lvalue to allow for calling multiple post hooks without ever copying outputs vector. It looks like the copy is now forced because the hook takes a const reference as input and returns an value. This would change the prototype of the function, so needs further discussion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18140
Differential Revision: D14684498
Pulled By: pietern
fbshipit-source-id: 1bd3ddbdd1ff7fe0a18241de5a9ec745a4e7ef07
Summary:
The last time I tried to land it there was a merge race with the docs coverage test lol. Re-landing with the fix.
Re-land of https://github.com/pytorch/pytorch/pull/18304
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18570
Differential Revision: D14668859
Pulled By: eellison
fbshipit-source-id: 3825a35ddc6179a0d433d70d22b5c1a96c20b21a
Summary:
In blob feeder for ideep device, the wrong device option is given and led to a crash issue.
This patch aims to correct the device option to fix this bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18552
Differential Revision: D14679838
Pulled By: yinghai
fbshipit-source-id: bde11e6a6fe44822166881dcb7c9bd0b34b4ecf3
Summary:
Previously, we were not able to assign names to `nn::Sequential`'s submodules. This PR adds this feature to match the Python API. Example use:
```cpp
Sequential sequential(named_submodule({
{"linear", Linear(10, 3)},
{"conv2d", Conv2d(1, 2, 3)},
{"dropout", Dropout(0.5)},
{"batchnorm", BatchNorm(5)},
{"embedding", Embedding(4, 10)},
{"lstm", LSTM(4, 5)}
}));
```
It also enables loading parameters of Python `nn.Sequential` module with custom submodules names into C++ frontend, unblocking https://github.com/pytorch/vision/pull/728#issuecomment-466661344.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17552
Differential Revision: D14246834
Pulled By: yf225
fbshipit-source-id: 3030b5c5d68f6dd5d3e37ac4b4f98dc6d6d9ba72
Summary:
Changelog:
- Renames `btriunpack` to `lu_unpack` to remain consistent with the `lu` function interface.
- Rename all relevant tests, fix callsites
- Create a tentative alias for `lu_unpack` under the name `btriunpack` and add a deprecation warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18529
Differential Revision: D14683161
Pulled By: soumith
fbshipit-source-id: 994287eaa15c50fd74c2f1c7646edfc61e8099b1
Summary:
Kindly let me know if its okay and if any places i need to make a fix. Closes#18534
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18604
Differential Revision: D14680712
Pulled By: soumith
fbshipit-source-id: 030e4a3d8f7839cbe2b8a3ef386323f0d39eb81a
Summary:
Changelog:
- Renames `btrifact` and `btrifact_with_info` to `lu`to remain consistent with other factorization methods (`qr` and `svd`).
- Now, we will only have one function and methods named `lu`, which performs `lu` decomposition. This function takes a get_infos kwarg, which when set to True includes a infos tensor in the tuple.
- Rename all tests, fix callsites
- Create a tentative alias for `lu` under the name `btrifact` and `btrifact_with_info`, and add a deprecation warning to not promote usage.
- Add the single batch version for `lu` so that users don't have to unsqueeze and squeeze for a single square matrix (see changes in determinant computation in `LinearAlgebra.cpp`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18435
Differential Revision: D14680352
Pulled By: soumith
fbshipit-source-id: af58dfc11fa53d9e8e0318c720beaf5502978cd8
Summary:
Deleting batch tensor since we are no longer maintaining the project and keeping it functional is blocking other improvements.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18575
Differential Revision: D14671126
Pulled By: eellison
fbshipit-source-id: b42d5b699c4d12171ed95e6d3a977532167f0d2c
Summary:
This will allow pathlib.Path object to the torch.load as an input argument.
Fixes#16607
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18562
Differential Revision: D14668255
Pulled By: soumith
fbshipit-source-id: 0ae4f7c210918582912f2d1ef2a98f1ab288c540
Summary:
Addind the same warning message already present in the mse_loss function to the L1 losses when input and target sizes are different.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18565
Differential Revision: D14671415
Pulled By: soumith
fbshipit-source-id: 01f5e1fb1ea119dbb2aecf1d94d0cb462f284982
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18226
ghimport-source-id: b9ec8651212875b30971cc6859d2ddec6559ae3a
If modules become first-class IValues, then the slots will no longer be raw pointers but (IValue, index) pairs. This commit inserts the Slot abstraction so that this change can be made in later patches.
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18226 Add Slot type to abstract the raw pointers being used for slots.**
Differential Revision: D14542022
fbshipit-source-id: b81d7f4334c983d663e7551bda82df43680d7c5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18512
Ceil and Floor have been supported since version 6 of ONNX: export them using the native onnx ops instead of an Aten op.
Similarly, support for the Where op has been added in version 9, so we don't need to wrap these op in an Aten op.
Reviewed By: houseroad
Differential Revision: D14635130
fbshipit-source-id: d54a2b6e295074a6214b5939b21051a6735c9958
Summary:
While benchmarking a kernel with broadcasted inputs, I noticed
that is was much slower than a hand-coded kernel for the smae task.
The kernel in question computed a * b + c for a of shape
32 x 32 x 10240 and b and c of shape 1 x 32 x 1.
This patch accellerates said kernel from 450us to 250us on my GTX1080Ti.
I didn't change half because there doesn't seem to be __ldg for
half.
An alternative could be to sprinkle const and restrict.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18540
Differential Revision: D14657840
Pulled By: soumith
fbshipit-source-id: 408847346ec12d1d1d9b119ac50bbc70f0d9ed33
Summary:
This implements a cyclical learning rate (CLR) schedule with an optional inverse cyclical momentum. More info about CLR: https://github.com/bckenstler/CLR
This is finishing what #2016 started. Resolves#1909.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18001
Differential Revision: D14451845
Pulled By: sampepose
fbshipit-source-id: 8f682e0c3dee3a73bd2b14cc93fcf5f0e836b8c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18538
ghimport-source-id: 665b09f158d1c5dd94686d4212792504b55b7f73
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18538 Completely synchronize behavior of Facebook flake8 and public flake8.**
Previously, developers at Facebook had the very funny experience
wherein /usr/local/bin/flake8 behaved differently than a freshly
installed flake8 from pip. In this commit, I add enough ignores to
.flake8 and install enough plugins to make the Facebook flake8
and public flake8 line up exactly. These means you don't have
to care which flake8 you use; they all will report accurate information
on your Python files.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14652336
fbshipit-source-id: ba7776eaa139cf2e3df2e65349da6fd7c99acca4
Summary:
This allows you to embed checks in IR, making the test more readable.
E.g.
```
graph_str = 'graph(%0 : Double(5, 5)):
# CHECK: aten::relu
%1 : Double(5, 5) = aten::relu(%0)
return (%1)'
FileCheck().run(graph_str, parseIR(graph_str))
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18304
Differential Revision: D14652372
Pulled By: eellison
fbshipit-source-id: 7430b9d1dc2b7584704375aac02d7392ecec76a0
Summary:
Previously we were moving nodes with writers into differentiable subgraphs, without necessarily preserving whether or not they were written to. This can lead to bugs with CSE, which needs that context.
I'm not completely sure if there's anything else we can do to be more aggresive here - inline these nodes and not run CSE and just run constant pooling, or possibly something else, but I think we should land this correctness condition first and then possibly think further.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18491
Differential Revision: D14648562
Pulled By: eellison
fbshipit-source-id: bc1e444774ccdb708e22f0e06a477a221a231f9e
Summary:
Is Tensor has been brought up as misleading a couple times, rename it isCompleteTensor for clarity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18437
Differential Revision: D14605223
Pulled By: eellison
fbshipit-source-id: 189f67f12cbecd76516a04e67d8145c260c79036
Summary:
Enable unit tests working with ROCm 2.3. In particular, these are unit tests where we skipped for double data types previously and some tests for multi-GPU setups.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18537
Differential Revision: D14651822
Pulled By: ezyang
fbshipit-source-id: 7dd575504ebe235a91489866c91000e9754b1235
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18494
Today we have some C2 end2end test run requiring reading model data from external filesystem (for example, Gluster and AWS). This could be a source for flaky test when the external filesystems are not reachable during the tests.
In this diff, we add try/catch logic around where we download models and open model files from external system. In case such attempts fails, we will catch the excption and let the unittest skip the current test instead of failure.
I also refactor the code a little bit by removing some duplicated logic on downloading and build the c2 model data. It has been duplicated in two classes and a few functions...
Reviewed By: yinghai
Differential Revision: D14442241
fbshipit-source-id: da8bf56c8d096efa34ca2070de5cd10a18aad70c
Summary:
We are about to merge onnxifi quantization support soon. Before that, I would like to merge this diff seperately to make sure it doesnt break anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18486
Reviewed By: bddppq, houseroad
Differential Revision: D14626419
Pulled By: yinghai
fbshipit-source-id: 504c1eae60be1e629203267b59defb8b69d82c0a
Summary:
There are a number of pages in the docs that serve insecure content. AFAICT this is the sole source of that.
I wasn't sure if docs get regenerated for old versions as part of the automation, or if those would need to be manually done.
cf. https://github.com/pytorch/pytorch.github.io/pull/177
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18508
Differential Revision: D14645665
Pulled By: zpao
fbshipit-source-id: 003563b06048485d4f539feb1675fc80bab47c1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18507
ghimport-source-id: 1c3642befad2da78a7e5f39d6d58732b85c76267
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18507 Upgrade flake8-bugbear to master, fix the new lints.**
It turns out Facebobok is internally using the unreleased master
flake8-bugbear, so upgrading it grabs a few more lints that Phabricator
was complaining about but we didn't get in open source.
A few of the getattr sites that I fixed look very suspicious (they're
written as if Python were a lazy language), but I didn't look more
closely into the matter.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14633682
fbshipit-source-id: fc3f97c87dca40bbda943a1d1061953490dbacf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18385
By moving the weight offload into the backend initialization function, we can instantiate the backend once by creating the OnnxifiOp once and then clean up the parameter workspace. And we need to keep hold of that instantiated net (OnnxifiOp) without cleaning it. Subsequent ctor of OnnxifiOp of the same model will hit the cached backend and they will not look into weight offloading, which is safe as the weight is already gone.
Reviewed By: ipiszy
Differential Revision: D14590379
fbshipit-source-id: f7f34016e09777ad3df0af487885cd14658e1044
Summary:
Added full instructions for how to use the `ccache` package. Thanks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18495
Differential Revision: D14635351
Pulled By: ezyang
fbshipit-source-id: 158e1052bae580e95f73644252fdbddcc0213128
Summary:
This depend on https://github.com/pytorch/pytorch/pull/16039
This prevent people (reviewer, PR author) from forgetting adding things to `tensors.rst`.
When something new is added to `_tensor_doc.py` or `tensor.py` but intentionally not in `tensors.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16057
Differential Revision: D14619550
Pulled By: ezyang
fbshipit-source-id: e1c6dd6761142e2e48ec499e118df399e3949fcc
Summary:
arguments order is okay to be different
ajyu
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18466
Differential Revision: D14627258
Pulled By: bddppq
fbshipit-source-id: 430e1fb1bea2c5639a547ae7c1652368788c86b9
Summary:
Set value as tensor of 1 element instead of scalar, according to ONNX spec.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18199
Reviewed By: dzhulgakov
Differential Revision: D14542588
Pulled By: houseroad
fbshipit-source-id: 70dc978d870ebe6ef37c519ba4a20061c3f07372
Summary:
More ops for https://github.com/pytorch/pytorch/issues/394. ~~Also need to rebase after landing #16186, because we need to update the whitelist of the new unit test added in #16186.~~
cc: ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17093
Differential Revision: D14620068
Pulled By: ezyang
fbshipit-source-id: deec5ffc9bf7624e0350c85392ee59789bad4237
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18160
When exposing a c10 operator to the caffe2 frontend, don't use the operator schema but use the operator name instead.
This allows us to get rid of the existing mechanism for operator schema registration in a diff stacked on top.
Reviewed By: dzhulgakov
Differential Revision: D14513420
fbshipit-source-id: 6b08a9c6d9497eaf18b62361dd44bc07c7b4b76b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18242
ghimport-source-id: b949d312a48226a34f90304162e910acee7c95cd
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18242 Test running a CUDA build on CPU machine.**
* #18362 Add ability to query if built with CUDA and MKL-DNN.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14584429
fbshipit-source-id: b54de5b33f0c795a7d9605d30576cdf9b74050fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18485
I don't know how (1) we landed the wrong version of the patch and (2) how
this passed the push blocking test
Reviewed By: pjh5
Differential Revision: D14621961
fbshipit-source-id: 0a3953d7adcdc79727a61c2acff65f436dcafe55
Summary:
This PR adds a Global Site Tag to the site.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17690
Differential Revision: D14620816
Pulled By: zou3519
fbshipit-source-id: c02407881ce08340289123f5508f92381744e8e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18165
ghimport-source-id: 55cb3fb63a25c2faab1725b4ec14c688bf45bd38
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18166 Bool Tensor for CUDA
* **#18165 Resolved comments from Bool Tensor for CPU PR**
-------
------------
This is a follow up PR that resolves some additional feedback on one the of previous Bool Tensor PRs.
gchanan, here is a list of almost all the comments from the original PR with respective fixes and replies:
**[utils/python_scalars.h]** why is this converting from uint8_t and not bool? (comment?)
When i was adding this, i was testing by creating a tensor and then calling its .tolist(). it worked for bool and uint8_t equally good so i left uint8_t as thought it makes more sense as we are calling PyBool_FromLong. �Changing it to bool.
**[ATen/Dispatch.h]**better name?.
fixed.
**[test/test_torch.py]** what about other factories, such as full? (and more).
There is a test that goes through the factory methods - test_tensor_factories_empty. i added some bool cases above it and added a comment that once CUDA will be done, i will unite them and it will iterate not just between CUDA and CPU but also all types. ��Adding all bool cases now. Will unite in CUDA PR.
**[generic/THTensorMath.h]** any changes in this file actually needed?
Bad merge. Fixed.
**[TH/THTensor.h]** this generates code for random, clampedRandom, and cappedRandom -- do we have tests for all of these with bool?
Added
**[c10/core/ScalarType.h]** I'm not very confident about the lack of Bool here -- can you look at the call sites and see what makes sense to do here?
Added bool to the macro and created a similar one without for a single case which fails the build with errors:
_./torch/csrc/jit/symbolic_variable.h:79:20: error: ambiguous overload for ‘operator*’ (operand types are ‘const torch::jit::SymbolicVariable’ and ‘torch::jit::Value*’)
return (*this) * insertConstant(rhs);_
Differential Revision: D14605105
fbshipit-source-id: abf82d50e8f8c50b386545ac068268651b28496d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18445
ghimport-source-id: 30d018737bf6989bc68b7e3676f44e0ca6141fde
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18242 Test running a CUDA build on CPU machine.
* **#18445 Unify cudaGetDeviceCount implementations.**
I went about doing this by searching for calls to cudaGetDeviceCount,
and then methodically replacing them with references to c10::cuda::device_count()
or at::cuda::device_count().
There is a point to doing this: the various implementations wildly differed
in their handling of what to do when cudaGetDeviceCount returns an error.
The final standardized behavior is that **all errors are swallowed** and
we return device count of zero. This indirectly fixes running CUDA builds
on CPU, which was broken in #17847.
I added 'noexcept' to the 'deviceCount' virtual method on DeviceGuardImpl.
This is a BC-breaking change for anyone inheriting from DeviceGuardImpl
but all you need to do is put 'noexcept' on your method and it is backwards
compatible with older libtorch.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14612189
fbshipit-source-id: 3c8d186e3dd623c0e27625212c7ce30f75d943cb
Summary:
`SobolEngine` is a quasi-random sampler used to sample points evenly between [0,1]. Here we use direction numbers to generate these samples. The maximum supported dimension for the sampler is 1111.
Documentation has been added, tests have been added based on Balandat 's references. The implementation is an optimized / tensor-ized implementation of Balandat 's implementation in Cython as provided in #9332.
This closes#9332 .
cc: soumith Balandat
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10505
Reviewed By: zou3519
Differential Revision: D9330179
Pulled By: ezyang
fbshipit-source-id: 01d5588e765b33b06febe99348f14d1e7fe8e55d
Summary:
Simplify or eliminate boolean and/or expressions, optimize unwrapping a value that cannot be None, and optimize using `is` with a None and a non-None value
Since peephole optimize is now introducing constants, i added another constant propagation pass after running it.
Previously i had a PR that did this & optimized shape ops - i will add the shape optimizations in a separate PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18259
Differential Revision: D14602749
Pulled By: eellison
fbshipit-source-id: 1c3f5a67067d8dfdf55d7b78dcb616472ea8a267
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/12598
This PR was originally authorized by ptrblck at https://github.com/pytorch/pytorch/pull/15495, but since there was no update for months after the request change, I clone that branch and resolve the code reviews here. Hope everything is good now. Especially, the implementation of count is changed from ptrblck's original algorithm to the one ngimel suggest, i.e. using `unique_by_key` and `adjacent_difference`.
The currently implementation of `_unique_dim` is VERY slow for computing inverse index and counts, see https://github.com/pytorch/pytorch/issues/18405. I will refactor `_unique_dim` in a later PR. For this PR, please allow me to keep the implementation as is.
cc: ptrblck ezyang ngimel colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18391
Reviewed By: soumith
Differential Revision: D14605905
Pulled By: VitalyFedyunin
fbshipit-source-id: 555f5a12a8e28c38b10dfccf1b6bb16c030bfdce
Summary:
Dropout is now eligible for fusion, and generated fused kernels are just as fast as dropout in ATen. Change its lowering in symbolic script so that it can actually be fused. Still special-cased for cuda, because without fusion this lowering is less efficient than current (bernoulli_ * input). Testing is covered by the test case that ailzhang added (test_dropout_cuda).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18375
Differential Revision: D14611938
Pulled By: soumith
fbshipit-source-id: 11b18f4784e6c9265e382a8f8deca7add8df3b37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18155
- Make a python decorator caffe2_flaky for caffe2 operator unit tests.
- The environment variable CAFFE2_RUN_FLAKY_TESTS are now used to mark flaky test mode
During test run,
- If flaky tests mode are on, only flaky tests are run
- If flaky tests mode are off, only non-flaky tests are run
Mark ctc_beam_search_decoder_op_test as flaky
Reviewed By: ezyang, salexspb
Differential Revision: D14468816
fbshipit-source-id: dceb4a48daeb5437ad9cc714bef3343e9761f3a4
Summary:
This PR did two things:
1. Enable scalar->float specialization in symbolic script, so AD formula that contains scalar in the schema, should write `float` instead.
2. add addcmul, lerp to AD and fuser.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18081
Differential Revision: D14490493
Pulled By: wanchaol
fbshipit-source-id: b3b86d960d5f051b30733bc908b19786111cdaa4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18362
ghimport-source-id: 374b7ab97e2d6a894368007133201f510539296f
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18242 Test running a CUDA build on CPU machine.
* **#18362 Add ability to query if built with CUDA and MKL-DNN.**
Fixes#18108.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14584430
fbshipit-source-id: 7605a1ac4e8f2a7c70d52e5a43ad7f03f0457473
Summary:
This is to fix#16141 and similar issues.
The idea is to track a reference to every shared CUDA Storage and deallocate memory only after a consumer process deallocates received Storage.
ezyang Done with cleanup. Same (insignificantly better) performance as in file-per-share solution, but handles millions of shared tensors easily. Note [ ] documentation in progress.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16854
Differential Revision: D13994490
Pulled By: VitalyFedyunin
fbshipit-source-id: 565148ec3ac4fafb32d37fde0486b325bed6fbd1
Summary:
Also asserts in storage_initialized that there is a storage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18347
Differential Revision: D14582028
Pulled By: gchanan
fbshipit-source-id: df3f5d181188f39e361839169fd054539c3b2839
Summary:
There's no reason we can't check this, but I'm punting on implementing it for now. But it currently segfaults, so this is an improvements.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18338
Differential Revision: D14580308
Pulled By: gchanan
fbshipit-source-id: 44d4cafeab12e1beeb3453a2d4068d221c2e9c4f
Summary:
Previously it would look for the Config even if it was not written.
Fixed#18419
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18421
Differential Revision: D14597139
Pulled By: ezyang
fbshipit-source-id: c212cbf5dc91564c12d9d07e507c8285e11c6bdf
Summary:
This reverts commit 7cc7ed1322405ba3c627b9c5661a330f92c4183d.
I think it's better to sort out the issues raised in #18407 firs. I'm sorry for not stopping it earlier.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18411
Differential Revision: D14594937
Pulled By: soumith
fbshipit-source-id: 3c90b7fa7694e2f59e55607acecde4a47af801ea
Summary:
Sorry for not sending these fixes in a single PR. I found this compiler warning when I was working on something else, and I just go to GitHub and modify the file directly for convenience...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18406
Differential Revision: D14594180
Pulled By: soumith
fbshipit-source-id: 92f48513bc62fbe2c67c759d68830a973296e43b
Summary:
To address the issue of broadcasting giving the wrong result in `nn.MSELoss()` as mentioned here https://github.com/pytorch/pytorch/issues/16045 . In particular, the issue often arises when computing the loss between tensors with shapes (n, 1) and (n,)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18349
Differential Revision: D14594176
Pulled By: soumith
fbshipit-source-id: f23ae68a4bf42f3554ad7678a314ba2c7532a6db
Summary:
Previously, we would continue to run requires grad on a loop body when the outputs and inputs disagreed. This adds a check so that we don't continue running if the results haven't changed since the last run.
Fix for https://github.com/pytorch/pytorch/issues/18320
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18361
Differential Revision: D14584332
Pulled By: eellison
fbshipit-source-id: 696b225f80a2036318540946428b525985a9e735
Summary:
This specializes optional tensor inputs to either a DimensionedTensorType or, when None is passed,
UndefinedTensor (aka AutogradZeroTensorType).
This works because we already have different specs and thus separate plans for the two cases.
It enhances the shape analysis - because now unwrapped optional tensors will have DimensionedTensorType with appropriate shape and required grad etc.
Also, when combined with "if-pruning" (which I understand #18259 works towards), we actually get much nicer concrete graphs, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18360
Differential Revision: D14590577
Pulled By: soumith
fbshipit-source-id: cac204a506d1d38b15703cbcc67a6b75fd4979f4
Summary:
Currently, `THPVariable_Wrap(…)` and `THPVariable_NewWithVar(…)` depend on the existence of `pyobj_` in the autograd metadata of a Variable to convert the Variable to a Python tensor. However, after the Variable/Tensor merge, there will be Variables that don't contain autograd metadata, and to allow the conversion from non-autograd-meta Variable to a Python tensor we need to store the `pyobj_` outside of autograd metadata and in a place where it will always be available.
This PR makes it possible by moving `pyobj_` into TensorImpl, so that `THPVariable_Wrap(…)` and `THPVariable_NewWithVar(…)` can always access a Variable's `pyobj_` and convert the Variable to a Python tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18225
Differential Revision: D14562616
Pulled By: yf225
fbshipit-source-id: 18d4aaace70eee6120abaf9276036d1f8f51b18d
Summary:
Adds a suggestion to add to __constants__ when a torch.nn.Module attr is accessed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18164
Differential Revision: D14580060
Pulled By: eellison
fbshipit-source-id: 0c5adc21d7341a5691d4b45930947cb1ba84c8e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18211
ghimport-source-id: 73b81e9ec631937b14db1da10991831788a6894b
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18296 [jit] Add namespacing for ScriptClasses
* #18284 [jit] make test module hook use save/load
* **#18211 [jit] Turn script_type_parser into a class**
* #18148 [jit] python interop for script classes
If we are namespacing classes, the type parser will need to carry around
some state about which namespaces to look in. This PR just wraps it in a
class in preparation.
Also, subscriptToType can no longer be static, since parseTypeFromExpr
may give different results depending on the namespaces available, so
it's been made a regular function instead of a static map lookup.
Reviewed By: eellison
Differential Revision: D14581128
fbshipit-source-id: 711315472ccde1920abf9fdb5a871ac27fb86787
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18148
ghimport-source-id: 40a9d745dc9aeba53d098743323fcbd50ca65137
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18148 py interop**
Support for converting classes between the Python–TorchScript boundary. Like other TorchScript values, ScriptClasses are native Python values when used in Python and IValues when used in TorchScript.
Notably, there is a copy across this boundary, which will be surprising to users who will expect standard Python reference semantics. I have some ideas for fixing that, but it's a more involved process.
Reviewed By: jamesr66a
Differential Revision: D14526259
fbshipit-source-id: 5916e3032488a42dc7da756c1826d7c040a21ebd
Summary:
Fix for https://github.com/pytorch/pytorch/issues/17583
There's an unrelated issue right now causing a segfault when printing tensor so that might have to fixed first for this to land
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18298
Differential Revision: D14584266
Pulled By: eellison
fbshipit-source-id: 4e7850dadc78ef1e98ad40b9d8adc0fef42acf48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18345
ghimport-source-id: 9649d76bb194866859d62e6ba2a3a265c96ebba5
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18345 Make it possible to trigger XLA/slow tests via commit message.**
Four variants are supported: `[xla ci] [ci xla] [xla test] [test xla]`; substitute
xla with slow for slow tests.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14584557
fbshipit-source-id: fcbfdfb28246823135bb3d3910baae073d16e81d
Summary:
so that functions like `def fn(x, p:float)` can be fused. Fixes#9940 and #11186. Fuses only float (not integer) arguments to simplify assembling arguments for fusion launch.
CPU fusion is disabled in CI and this won't be tested, but I tested it locally.
cc t-vi, apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18087
Differential Revision: D14581206
Pulled By: wanchaol
fbshipit-source-id: ccb0cf79b1751706f9b2cdf1715115eae5a39fb6
Summary:
Two functions were not directed ad NVRTC.
It's a bit hard to test this, as the fuser usually produces correct code - unless I try to hack on it. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18327
Differential Revision: D14579285
Pulled By: soumith
fbshipit-source-id: 1be7ba461cc473d514ba619507742a47d4d7c97e
Summary:
this is handy when testing various core dump related
things. If in the future we want to unit test our future gdb debugger
extensions, we can use this op to generate a core dump for us within a
unit test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18207
Differential Revision: D14482186
Pulled By: salexspb
fbshipit-source-id: 39a9fffbdd4bd083597f544d1c783a82cf023a89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18194
Add a util method to cleanup external inputs and outputs from a NetDef
The following conditions will be met after the modification
- No duplicate external inputs
- No duplicate external outputs
- Going through list of ops in order, all op inputs must be outputs
from other ops, or registered as external inputs.
- All external outputs must be outputs of some operators.
Reviewed By: ZolotukhinM
Differential Revision: D14528589
fbshipit-source-id: c8d82fda1946aa3696abcbec869a4a8bb22f09b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18267
Motivation: we don't actually want to use it for real under any circumstances. This is an idea to unblock our internal progress and parallelize workstreams. We can easily define schemas for all ops in question and implement forwarding to C2 ops which is NOT going to be performant. Then several things can be happening in parallel:
* move code of ops outside of C2 ops that depend on protobuf into c10
* development of optimization/fusion passes
* building python-level wrappers with clean API
* improving perf
This demonstrates, Relu, quant, dequant. It seems to cover all use cases necessary (maybe except weights prepacking). Ideally I'd demonstrate Conv, but will get to it later in a separate PR (contributions welcomed)
Reviewed By: ezyang
Differential Revision: D14531232
fbshipit-source-id: 4cd4a71ae0cb373c6c0e81f965c442b82a1b4069
Summary: Removing the maximum number of blocks limit from the operator and making the nesterov parameter templated to remove branching.
Reviewed By: BIT-silence
Differential Revision: D14567003
fbshipit-source-id: 394c2039ee214adc6ccd2e562e4e9563d307131f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18291
ghimport-source-id: d6e95e899bd320407967df41435801e54864ba62
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18292 Add test for #17271 (torch.exp incorrect for 2**31 size tensor)
* **#18291 Correctly call superclass setUp in TestCase subclasses.**
This makes PYTORCH_TEST_SKIP_FAST work correctly for more
tests, reducing the wasted testing effort on our slow_test job.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14567643
fbshipit-source-id: 40cf1d6556e0dd0a0550ff3d9ffed8b6000f8191
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18129
A lot of tensor interference function assume the operator passes the schema.
So call Verity to make sure this is actually the case.
Created diff before to add checking in Concat (https://github.com/pytorch/pytorch/pull/17110), but I encountered lot more places where this is assumed (for example ElementwiseOpShapeInference)
Reviewed By: mdschatz
Differential Revision: D14503933
fbshipit-source-id: cf0097b8c3e4beb1cded6b61e092a6adee4b8fcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18246
Simplifies histogram collection and quantization process.
Histogram collection before this diff was something like this
```
from caffe2.quantization.server import dnnlowp_pybind11
...
dnnlowp_pybind11.ObserveHistogramOfOutput(hist_file)
for ...
workspace.RunNet(predict_net)
dnnlowp_pybind11.ClearNetObservers() # This is to trigger Stop function in the observer to dump out histogram file but this can have unintended consequence of also clearing all the other useful observers we attached
```
After this diff we can
```
workspace.CreateNet(predict_net) # Note we need to create net to have a net to attach observer
histogram_observer = dnnlowp_pybind11.AddHistogramObserver(predic_net, hist_file)
for ...
workspace.RunNet(predict_net)
predict_net.RemoveObserver(histogram_observer)
```
Choosing quantization parameters of weights before this diff was something like this
```
dnnlowp_pybind11.ObserveHistogramOfOutput(weight_hist_file)
workspace.RunNetOnce(init_net)
dnnlowp_pybind11.ClearNetObservers() # Has same issue as the histogram collection example above
dnnlowp_pybind11.RegisterQuantizationParamsWithHistogram(
weight_hist_file, is_weight=True, qparams_output_file_name=qparams_file
)
workspace.CreateNet(init_net, overwrite=True)
dnnlowp_pybind11.ClearNetObservers()
logger.info("Loading quantization params from {}".format(qparams_file))
blobs_to_qparams = {}
with open(qparams_file) as f:
lines = f.readlines()
for line in lines:
op_id, op_type, output_id, tensor_name, mini, maxi, scale, zero_point, precision = (
line.split()
)
op_id = int(op_id)
output_id = int(output_id)
op = net.Proto().op[op_id]
if op_type != op.type or op.output[output_id] != tensor_name:
print(
"Corrupt qparams file {} {} {} {} {}".format(
qparams_file, op_type, op.type, op.output[output_id], tensor_name
)
)
blobs_to_qparams[tensor_name] = QuantizationParam(float(scale), int(zero_point))
```
After this diff this can be simplified to
```
blobs_to_qparams = {}
for op in init_net.Proto().op:
for output in op.output:
scale, zero_point = dnnlowp_pybind11.ChooseQuantizationParams(output)
blobs_to_qparams[output] = QuantizationParam(scale, zero_point)
```
Reviewed By: dskhudia
Differential Revision: D14544694
fbshipit-source-id: 4fd06cd63256201e2e9d15c39f503138d1be53c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18257
support adding op in global_init_net. because pred_init_net is per thread, and just doesn't cut it.
Reviewed By: jspark1105
Differential Revision: D14552695
fbshipit-source-id: 53dd44c84ad019019ab9f35fc04d076b7f941ddc
Summary:
* Adds more headers for easier scanning
* Adds some line breaks so things are displayed correctly
* Minor copy/spelling stuff
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18234
Reviewed By: ezyang
Differential Revision: D14567737
Pulled By: driazati
fbshipit-source-id: 046d991f7aab8e00e9887edb745968cb79a29441
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18290
Some such as `Tile` will mess up our tracking of batch size and for now it makes sense to stop the shape inference on these ops so that we don't lower it and downstream ops without proper batch info.
Reviewed By: zrphercule
Differential Revision: D14463550
fbshipit-source-id: 2792481efa540f2a7dd310e677c213860c3053ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18159
In some instances, the call to forward could clash with std::forward. Fully qualify it to make sure it gets the right one
Reviewed By: ezyang
Differential Revision: D14512189
fbshipit-source-id: 6242607dbe54fcdb93229c1a4aaee8b84a88caa1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18158
They didn't work when called from other namespaces before because they didn't fully specify the c10 namespace.
Reviewed By: ezyang
Differential Revision: D14512187
fbshipit-source-id: a496b89a1bbe2b56137cfae03ab94a60f38d7068
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18090
This schema inference is needed by the c10 operator registration mechanism. Move it to c10.
It is going to be used by diffs stacked on top.
Reviewed By: ezyang
Differential Revision: D14491454
fbshipit-source-id: 0f8ddcdbd91467c8347d315dd443a1ca8b216481
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18038
Now that we have named overloads, we can allow registering the same function schema multiple times and just check it's identical.
This is going to be used in custom op registration since they register the schema every time a kernel is registered.
Reviewed By: dzhulgakov
Differential Revision: D14467494
fbshipit-source-id: 2c26cf72a64b65f120afe05e989302ec42597515
Summary:
Changelog:
- Renames `trtrs` to `triangular_solve` to remain consistent with `cholesky_solve` and `solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `triangular_solve` under the name `trtrs`, and add a deprecation warning to not promote usage.
- Move `isnan` to _torch_docs.py
- Remove unnecessary imports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18213
Differential Revision: D14566902
Pulled By: ezyang
fbshipit-source-id: 544f57c29477df391bacd5de700bed1add456d3f
Summary:
Fixes Typo and a Link in the `docs/source/community/contribution_guide.rst`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18237
Differential Revision: D14566907
Pulled By: ezyang
fbshipit-source-id: 3a75797ab6b27d28dd5566d9b189d80395024eaf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18236
ghimport-source-id: 2bb80d017c2ea833669a2d55b340a922b2d44685
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18236 Enable running of slow tests in CI.**
* #18231 Add a decorator for marking slow tests.
These tests only run on master, as they are slow.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14563115
fbshipit-source-id: f54ddef4abedc7e872e58657fc9ac537952773d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18278
ghimport-source-id: 3c35f6e7229c3c2b3a27d96370d7c05fad58365e
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18278 Shut up compiler about unused this_type.**
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14563050
fbshipit-source-id: 4b516f6c9ef3784d1430f793f304066c351b1a93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18231
ghimport-source-id: 78c230f60c41877fe91b89c8c979b160f36f856b
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18231 Add a decorator for marking slow tests.**
The general strategy:
- It's a normal skip decorator, which triggers a skip if
PYTORCH_TEST_WITH_SLOW is not set.
- It also annotates the method in question that says it's
slow. We use this to implement a catch-all skipper in
setUp that skips all non-slow tests when
PYTORCH_TEST_SKIP_FAST is set.
I added a little smoketest to test_torch and showed that I get:
```
Ran 432 tests in 0.017s
OK (skipped=431)
```
when running with PYTORCH_TEST_WITH_SLOW=1 and PYTORCH_TEST_SKIP_FAST=1
CI integration coming in later patch, as well as nontrivial uses of
this decorator.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14544441
fbshipit-source-id: 54435ce4ec827193e019887178c09ebeae3ae2c9
Summary:
This moves median to ATen.
- median with dimension reduces to kthvalue
- median without dimension (aka medianall) is implemented in parallel to kthvalue because we would not want to reshape (copying for non-contiguous) and then copy again in kthvalue. We can sue the helper functions we moved from kthvalue.
- `median_cuda` was accidentally already put into ATen in #17544.
- The quickselect algorthm without indices for CPU in TH is now obsolete and removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17637
Differential Revision: D14346510
Pulled By: ezyang
fbshipit-source-id: c07ad144efbd6b4194179bb1c02635862521d8cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18181
ghimport-source-id: 9c23551584a1a1b0b7ac246367f3a7ae1c50b315
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18184 Fix B903 lint: save memory for data classes with slots/namedtuple
* **#18181 Fix B902 lint error: invalid first argument.**
* #18178 Fix B006 lint errors: using mutable structure in default argument.
* #18177 Fix lstrip bug revealed by B005 lint
A variety of sins were committed:
- Some code was dead
- Some code was actually a staticmethod
- Some code just named it the wrong way
- Some code was purposely testing the omitted case
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14530876
fbshipit-source-id: 292a371d9a76ddc7bfcfd38b6f0da9165290a58e
Summary:
Two small refinements to the shape analysis:
- `detach` can set requires grad to false for dimensioned tensors (not sure if I would also need to deal with Complete?).
- add `batch_norm_stats`.
I noticed these while looking at what's going on when trying to code batch norm manually. (Hi wanchaol )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18271
Differential Revision: D14561303
Pulled By: ezyang
fbshipit-source-id: 64a6879392e77403c44f2ed82f84b6397754d0ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18177
ghimport-source-id: fbbf915b66762fc88bc5b541464e71ba27500958
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18184 Fix B903 lint: save memory for data classes with slots/namedtuple
* #18181 Fix B902 lint error: invalid first argument.
* #18178 Fix B006 lint errors: using mutable structure in default argument.
* **#18177 Fix lstrip bug revealed by B005 lint**
lstrip() doesn't strip a prefix; it strips all of the characters
in the passed in string. B005 lint revealed this. Replaced with
substring operation.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14530873
fbshipit-source-id: 13b3438fcc3cce13b5110730dc3d0b528a52930f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18240
For rare cases when dst_bin_width == 0 we should just put all numbers to an arbitrary bin.
Reviewed By: csummersea
Differential Revision: D14544685
fbshipit-source-id: 02d04ff8bd1555d6cf7e7eeb1196a4ab3325a9e5
Summary:
Why do we need this workaround? `PythonArgParser` handles these two cases well.
The discussion started at https://github.com/pytorch/pytorch/pull/6201#issuecomment-378724406. The conclusion at that time by goldsborough was:
> Because we wanted to allow `dim=None` in Python and route to a different function. Essentially the problem was wanting to wrap the C++ function in Python. AFAIK there is no way of translating `dim=None` behavior into C++? So Richard and I came up with this strategy
Maybe at that time `PythonArgParser` was not powerful enough to handle the routing of two function with same name but different C++ signature.
Will keep an eye on the CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17103
Differential Revision: D14523503
Pulled By: VitalyFedyunin
fbshipit-source-id: cae3e2678062da2eccd93b51d4050578c7a9ab80
Summary:
Fix#17801 to add an exception regarding `ignore_index` in the documentation for `torch.nn.CrossEntropyLoss` and `torch.nn.NLLLoss`
If any other files/functions are hit, I'd be glad to incorporate the changes there too! 😊
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18117
Differential Revision: D14542079
Pulled By: ezyang
fbshipit-source-id: 7b918ac61f441dde7d3d6782d080c500cf2097f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17943
Together with xw285cornell came up with a solution for static destruction
order fiasco that caused the NCCL context to be destroyed **after**
the CUDA context was already destroyed. In this commit we destroy all
cached NCCL contexts as soon as the last NCCL related Caffe2 operator
instance is destructed, thereby avoiding a dependency on static
variable destruction.
Reviewed By: xw285cornell
Differential Revision: D14429724
fbshipit-source-id: fe5ce4b02b1002af8d9f57f6fa089b7a80e316ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17905
support adding op in global_init_net. because pred_init_net is per thread, and just doesn't cut it.
Reviewed By: jspark1105
Differential Revision: D14114134
fbshipit-source-id: 112bb2ceb9d3d5e663dd430585567f4eaa2db35f
Summary:
So, we will keep the names of ONNX initializers the same as the names in PyTorch state dict.
Later, we will make this as the default behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17551
Reviewed By: dzhulgakov
Differential Revision: D14491920
Pulled By: houseroad
fbshipit-source-id: f355c02e1b90d7ebbebf4be7c0fb6ae208ec795f
Summary:
- Remove single batch TH/THC implementations
- Remove `_batch_trtrs_lower` from `multivariate_normal`
- Add tests for batched behavior
- Modify trtrs_backward to accommodate for batched case
- Modify docs
In a future PR, this will be renamed to `triangular_solve`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18025
Differential Revision: D14523004
Pulled By: ifedan
fbshipit-source-id: 11c6a967d107f969b60e5a5c73ce6bb8099ebbe1
Summary:
I don't know if we actually want to expose this or not, but it's useful for debugging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18197
Reviewed By: ezyang
Differential Revision: D14530712
Pulled By: gchanan
fbshipit-source-id: 98fdba9cf113738f0db3a198c49365de536b9919
Summary:
Loop analysis indicates that there is a runtime trip count and hence
unrolling cannot take place.
This will silence compile-time warnings we have been observing with recent ROCm releases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18204
Differential Revision: D14539875
Pulled By: ezyang
fbshipit-source-id: a7ea7f2a95603754296b76a6b62a154f56f4ad4d
Summary:
Further breakup test_misc.h. The remaining tests don't directly map to a jit file so I left them in test_misc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18191
Differential Revision: D14533442
Pulled By: eellison
fbshipit-source-id: 7f538ce0aea208b6b55a4716dfcf039548305041
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18193
ghimport-source-id: 540859cf0b238a9832f45b3f4c2351e3343fc1a2
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18193 Turn on Travis builds for ghstack PRs.**
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14529945
fbshipit-source-id: 4476e996e311a04f2a997ca9b7c4cf2157dd6286
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18195
ghimport-source-id: 05102cb115c6bd6d141f51905e20155bcd79a908
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18195 [build] do not throw when unicode is seen in pull request info**
Differential Revision: D14529707
fbshipit-source-id: 2f6a31b01b3a9b044fd24be466cc5325b70929ad
Summary:
The type of each `initial_ivalue` is completely known at some point but that information is discarded by the time a call to it is emitted. This PR is kind of a hack, as a better (longer) solution, the method should know about the type of each initial value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18156
Differential Revision: D14525768
Pulled By: driazati
fbshipit-source-id: 52d53e9711a07a4551c988bd95fe997e654aa465
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18138
ghimport-source-id: be62a71ef98714e6f168a00f84120f612363528e
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18138 Enable flake8-bugbear line length checking.**
flake8-bugbear's line length checker (B950) which permits violations
of up to 10% but specifies the "true" limit when you go over.
I had to ignore a bunch of flake8-bugbear's other checks when I
turned this on. They're good checks though (they're turned on
in fbcode) and we should fix them eventually.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Reviewed By: salexspb
Differential Revision: D14508678
fbshipit-source-id: 2610ecc0dd43cc0788d77f4d024ebd85b26b8d41
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18146
ghimport-source-id: 4b061c27c5c44ef0d06066490ed16cab3d0c7a64
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18146 [jit] fix bug in alias analysis**
We handled hasWriters() incorrectly in the case of wildcards. There's
even a comment describing the correct behavior. Sad!
Much thanks to t-vi for tracking this down and suggesting the fix!
Differential Revision: D14524208
fbshipit-source-id: 8010b54257241bd64013a0d0a8b6e7d22d8c70af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18123
the motivation of this fix is to resolve things like:
for(auto i = 0; i < N; i++) where N is bigger than int32
These instances of comparison were found by enabling -Wsign-compare
There are way too many things to fix, so issuing this as a series of fixes
The plan is to fix all these issues and then enable this flag into Caffe2 to catch future instances
Reviewed By: ZolotukhinM
Differential Revision: D14497094
fbshipit-source-id: bca3927a2188bd33a508fa503ba221c220cdaefe
Summary:
The momentum buffer is initialized to the value of
d_p, but the current code takes the long way to do this:
1. Create a buffer of zeros
2. Multiply the buffer by the momentum coefficient
3. Add d_p to the buffer
All of these can be collapsed into a single step:
1. Create a clone of d_p
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18114
Differential Revision: D14509122
Pulled By: ezyang
fbshipit-source-id: 4a79b896201d5ff20770b7ae790c244ba744edb8
Summary:
In aten we have a _fused_dropout implementation for CUDA case. As ngimel suggested if we discard it in JIT AD, it hurts performance.
It doesn't seem ideal to include backend specific implementation in AD, but this is helpful to prevent performance regression atm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17756
Differential Revision: D14368999
Pulled By: ailzhang
fbshipit-source-id: 9a371c5020f630e8f6e496849ec9772b6f196169
Summary:
Addresses #15738, using fritzo's suggestion. This adds a `torch._sample_dirichlet` method in `Distributions.cpp` and `Distributions.cu`.
- For CPU, this leads to no perf hit since all we do is to promote the `alpha` to double when getting the gamma samples (the gamma sampler anyways uses `accscalar_t`(double for CPU)) and cast it back to float32 on return.
- I have added an analogous method for CUDA as well, but the default sampler for CUDA uses scalar_t for efficiency, so I have kept it as that. With this, I do not see the bias towards 1 as reported in #15738 with `float32`, but there is a spurious mode at 0.5, as would be expected. Users would need to explicitly use `float64` for GPU to not see the spurious mode at 0.5. (EDIT: see note below, it appears that the bias issue is still there for certain builds).
Added some tests and checked that there is no perf regression. My experience with C++ is very limited, so apologies in advance if I missed something basic. cc. ailzhang, fritzo, fmassa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17488
Differential Revision: D14410301
Pulled By: ezyang
fbshipit-source-id: 62b2f694b4642685eab06db96d74ce28e05c3992
Summary:
It's wrong and unused. Use one of the many other constructors instead :).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18137
Differential Revision: D14508364
Pulled By: gchanan
fbshipit-source-id: 19c6ff78ad9d9221d0874425edd02b78627c4ca7
Summary:
There are multiple backends for a device type, so we just kill this function.
Also, kill an getNonVariableType instance which was also underspecified.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18135
Differential Revision: D14507474
Pulled By: gchanan
fbshipit-source-id: fc791a76d4b851b23d09a070725f3838621eb13d
Summary:
This gets rid of 'aten_sparse' which was used at one time with legacy THS code, but is now only overloaded in native_parse.py.
The way that 'aten_sparse' worked was wonky -- it extended all backends (default [CPU, CUDA]) to include sparse.
But this is totally unnecessary; we already have the backends we need to generate for from type_method_definition_dispatch.
codegen changes: fc37c8e171/diff.txt
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18144
Reviewed By: ezyang
Differential Revision: D14511324
Pulled By: gchanan
fbshipit-source-id: 8bb4ac4cf0985f8756790779a22bc229e18e8e7f
Summary:
Fix#16428 by correcting type of 'swap' from `float` to `bool`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18115
Differential Revision: D14516615
Pulled By: ezyang
fbshipit-source-id: c61a45d533f3a443edf3c31c1ef3d9742bf46d2b
Summary:
Allows serialization/loading of attributes (`IValue`s of any type).
* metadata (attribute name, type) is stored in the `model.json`
* The binary format is a subset of the `pickle` module that supports the operations necessary for `IValue`s
* Attributes are serialized in the order they are defined on a module to a list in a single `attributes` file, with submodule attributes coming first. This order directly matches the order attributes are listed in `model.json`
* This can be inspected in Python with `pickle.load()` or with `pickletools` (PyTorch need not be installed for this to work)
* A class is used to store a tensor's index into the tensor table of the model, so to unpickle the file you have to use a custom Unpickler:
```python
class TensorID(object):
def __setstate__(self, id):
self.id = id
class JitUnpickler(pickle.Unpickler):
def find_class(self, module, name):
if module == '__main__' and name == 'TensorID':
return TensorID
JitUnpickler(open("my_model/attributes.pkl", "rb")).load()
```
* pickle format: https://svn.python.org/projects/python/trunk/Lib/pickletools.py
* It currently does not support/guarantee that anything saved out with `pickle` (i.e. if you edit `attributes` with `pickle` directly) instead of our tools will be imported correctly
Also will fix#17683 and fix#16367
Followup Work:
* document format / choice of pickle: #17951
* create an example
* list specializations
* int size specializations, large binputs
* do a first pass over attributes to output only necessary `BINPUT` ops
* attribute reassignment (e.g `self.my_attribute = new_value`)
* `tensor.save("some_checkpoint.pkl")` support with tensors embedded in Pickle file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17423
Differential Revision: D14470965
Pulled By: driazati
fbshipit-source-id: 6a21a9939efdbe59b4bc57fd31d6d630bab5297e
Summary:
Changelog:
- Renames `gesv` to `solve` to remain consistent with `cholesky_solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `solve` under the name `gesv`, and add a deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18060
Differential Revision: D14503117
Pulled By: zou3519
fbshipit-source-id: 99c16d94e5970a19d7584b5915f051c030d49ff5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18107
Pull Request resolved: https://github.com/pytorch/translate/pull/396
also:
1. fix issues with OptionalType not having a createWithContainedType (PyTorch diff)
2. Delete tests for ONNX full beam search export (nobody is using it and it just makes things harder. Currently ONNX doesn't support `_unwrap_optional`)
Reviewed By: jmp84
Differential Revision: D14483771
fbshipit-source-id: 0e37ef1cb5a16d03a535eef808b0488b98802128
Summary:
...because gcc will have failures with very strange error messages
if you do.
This affects people with Debian/Ubuntu-provided NVCC, the PR should
not change anything for anyone else.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18127
Differential Revision: D14504386
Pulled By: soumith
fbshipit-source-id: 1aea168723cdc71cdcfffb3193ee116108ae755e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18121
ghimport-source-id: 70c273bfbcb68f7b25cf87f5614c662960864758
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18121 [jit] fix double free in test_jit**
These definitions used to be in anonymous namespace so they weren't exported from the translation unit. #18071 put those in a `test` namespace so I guess they were getting their destructors called twice on exit somehow. Making them static again fixes the problem.
Reviewed By: ezyang
Differential Revision: D14498349
fbshipit-source-id: f969781695dcbebdfcfce667fce5b986222a373e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18059
Replace resize_dim() with set_sizes_and_strides() in `THTensor_(squeeze)` in aten/src/TH/generic/THTensor.cpp and `THCTensor_(squeeze)` in aten/src/THC/generic/THCTensor.cpp
Reviewed By: ezyang
Differential Revision: D14471066
fbshipit-source-id: 1c8c412ff09246c4df6843736e3bf0279bfadea8
Summary:
sphinx doesn't understand hyphen. it does not merge the two halves together in html.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18118
Differential Revision: D14498012
Pulled By: mrshenli
fbshipit-source-id: d6f4cfddc0a8e3a8f91578da43c26ca9c6fff3ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18072
ghimport-source-id: 9653731602c72f299e095dd50e3afe6bcc8b01d6
Stack:
* **#18072 properly device_guard IndexTensor and BoolTensor.**
* #18073 Change one_hot from IndexTensor to Tensor.
Currently IndexTensor and BoolTensors do not have device_guards applied to them.
This is bad in the case where the only tensor(s) are IndexTensors or BoolTensors, because no device guard is present.
The only case this currently happens is with one_hot which ends up not mattering because of the way the implementation is written. But I wanted to make sure we are covered here.
Reviewed By: ezyang
Differential Revision: D14485249
fbshipit-source-id: e57b28086fa1ad2fdd248bb1220e8a2e42da03e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18093
ghimport-source-id: 021adc52aa7bfe5fff74531c76a8cd28cab30b2a
Stack:
* **#18093 [jit] fix corner case for optional aliasing**
Occasionally the compiler can insert constant Nones to make types line
up. In that case, don't try to make a pointer from the optional type to
None, since we know statically that None won't be mutated or whatever.
Reviewed By: shannonzhu
Differential Revision: D14493004
fbshipit-source-id: 6564065f39d99ee5af664f3a0fe235892973d9be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18040
Add flag to fails if float point exceptions is detected in operator runs
Sample exception
Exception [enforce fail at operator.h:837] !std::fetestexcept(FE_DIVBYZERO). Division by zero floating point exception (FE_DIVBYZERO) reported.
Error from operator:
input: "1" input: "0" output: "out" name: "" type: "Div"
Reviewed By: jspark1105
Differential Revision: D14467731
fbshipit-source-id: fad030b1d619a5a661ff2114edb947e4562cecdd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18084
data_strategy parameter was not used in some of unit tests for optimizers
Reviewed By: hyuen
Differential Revision: D14487830
fbshipit-source-id: d757cd06aa2965f4c0570a4a18ba090b98820ef4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18037
The FunctionSchema can now store an overload name and the parser knows how to parse it. Specify like this:
my_func.overload1(arg1: Tensor) -> Tensor
my_func.overload2(arg1: Tensor, arg2: Tensor) -> Tensor
Reviewed By: zdevito
Differential Revision: D14467497
fbshipit-source-id: 8832b32f07351bb61090357b17b77a6a2fed3650
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18036
- Add macros to export c10 cuda operators to caffe2 frontend
- Instead of having a separate caffe2 registry for the c10 operator wrappers, use the existing caffe2 registries
Reviewed By: ezyang
Differential Revision: D14467495
fbshipit-source-id: 7715ed2e38d2bbe16f1446ae82c17193a3fabcb9
Summary:
Changes:
1) https://github.com/pytorch/pytorch/pull/17527 changed dispatch macros to be ScalarType based instead of at::Type based. This broke cpp extensions that relied on dispatch macros. Since IMO these should be ScalarType based (and some extensions have already updated), we allow either at::Type or at::ScalarType to be passed, but passing at::Type will result in a deprecated warning.
2) Reintroduce macros that were deleted (AT_DISPATCH_ALL_TYPES_AND_HALF, AT_DISPATCH_COMPLEX_TYPES, AT_DISPATCH_ALL_TYPES_AND_HALF_AND_COMPLEX, AT_DISPATCH_ALL_TYPES_AND_COMPLEX); the AND_HALF ones now give a deprecated warning because there are more extensible macros that were introduced in their place.
3) Makes AT_DISPATCH_ALL_TYPES_AND_COMPLEX_AND into a ScalarType based macro (and updates usages). This was the result of a logical merge conflicts.
4) Adds a new macro, C10_DEPRECATED_MESSAGE for passing a deprecated message to the compiler. I didn't spend much time seeing if this can be enabled for versions before C++14.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17996
Reviewed By: ezyang
Differential Revision: D14446203
Pulled By: gchanan
fbshipit-source-id: 1da56e2e9c15aa8f913ebbf6bf1110c5b6dc375e
Summary:
Breakup test_misc so that a test for a file is in test_filename. I think we might want to wait on moving test files into the source directory, since that would involve moving some tests over to the C10 folder, and this goes 99% of the way for test discoverability IMO anyway.
I added a file test_utils for common functions invoked in the tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18071
Differential Revision: D14485787
Pulled By: eellison
fbshipit-source-id: dcb20d1978d490999d435ea20c1d0503413a5c80
Summary:
Stack:
⚫ **#17856 [jit] support serialization of classes** [💛](https://our.intern.facebook.com/intern/diff/D14402599/)
Add support for saving/loading TorchScript modules that depend on user-defned classes.
We track class dependencies the same we track tensor constants, then write them
all out such that we can just compile them in order before compiling the module
hierarchy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17856
Reviewed By: shannonzhu
Differential Revision: D14461599
Pulled By: suo
fbshipit-source-id: 7115f87e069fd00dc8381d7de9997864fef7ea9f
Summary:
The C10 ops are not registered as custom ops in PyTorch. So we have to add the explicit support for it, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17899
Reviewed By: dzhulgakov
Differential Revision: D14436999
Pulled By: houseroad
fbshipit-source-id: a31fdf13a5c84f9b156a7288e0ffa57deb23b83f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17993
ghimport-source-id: 5427773f6306bdeddffd9a3ae032acc3f253f458
Stack:
* #17926 Implement at::has_internal_overlap helper function
* #17927 Error out on in-place (unary) ops on tensors that have internal overlap
* **#17993 [easy] Delete dead code in THTensorMoreMath.cpp**
We seem to have new implementations already for these in ATen.
Reviewed By: ezyang
Differential Revision: D14457838
fbshipit-source-id: 8481aad74b2127bd28c0f3e09740889fc0488a31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17927
ghimport-source-id: 626d321e430b6b5c0ea3aa1eb9df8c1e2d058bf8
Stack:
* #17926 Implement at::has_internal_overlap helper function
* **#17927 Error out on in-place (unary) ops on tensors that have internal overlap**
On the way to #17935.
Works for CPU and CUDA on the following ops:
- abs_, acos_, asin_, atan_, ceil_, cos_, erf_, erfc_, exp_, expm1_
- floor_, log_, log10_, log1p_, log2_, round_, rsqrt_,
- sin_, sqrt_, tan_, tanh_, trunc_
This PR adds a check to see if the out/result tensor has internal
overlap. If it does, then we error out because the result **may** be
incorrect.
This is overly conservative; there are some cases where if the result is
the same as the input, the inplace operation is OK (such as floor_,
round_, and trunc_). However, the current code isn't organized in such a
way that this is easy to check, so enabling those will come in the future.
Reviewed By: ezyang
Differential Revision: D14438871
fbshipit-source-id: 15e12bf1fdb2ab7f74bb806e22bc74840bd6abd1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17926
ghimport-source-id: 9f7572b5d43e474492363fa17dcb86a6c27ca13c
Stack:
* **#17926 Implement at::has_internal_overlap helper function**
* #17927 Error out on in-place (unary) ops on tensors that have internal overlap
On the way to #17935.
Checks if a tensor's sizes/strides indicate that multiple elements share
the same memory location. This problem in general is hard so
at::has_internal_overlap implements two heuristics and avoids solving
the general problem:
if a tensor is contiguous, it cannot have internal overlap
if a tensor has any zero strides, it does have internal overlap
otherwise, return MemOverlap::kTooHard to indicate that there might be
overlap, but we don't know.
Reviewed By: ezyang
Differential Revision: D14438858
fbshipit-source-id: 607ab31771315921ab6165b2a1f072ac3e75925a
Summary:
In python2, float values get truncated. We are storing default float values as floats (not 100% sure why?), which results in the defaults being truncated in the JIT and not matching the (specified) native function signatures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18044
Reviewed By: ezyang
Differential Revision: D14469868
Pulled By: gchanan
fbshipit-source-id: a456de599e8dab106966bcac7a6033f02ce3cdd2
Summary:
Currently, we cannot run a checkpointed function with None argument.
```python
out = torch.utils.checkpoint.checkpoint(run_fn, input_var, None)
```
```
File "/home/tunz/anaconda3/envs/torchdev/lib/python3.7/site-packages/torch/utils/checkpoint.py", line 14, in detach_variable
x = inp.detach()
AttributeError: 'NoneType' object has no attribute 'detach'
```
This PR makes checkpoint function to safely handle None argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17969
Differential Revision: D14475148
Pulled By: ezyang
fbshipit-source-id: 9afe9e9aac511a6df1e1620e9ac341536890d451
Summary:
According to https://docs.python.org/3/tutorial/inputoutput.html, it is good practice to use the "with" keyword when dealing with file objects. If not, you should call f.close() to close the file and immediately free up any system resources used by it. Thus, I adjust the open file function to "with open() as f".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18017
Differential Revision: D14475112
Pulled By: ezyang
fbshipit-source-id: d1c0821e39cb8a09f86d6d08b437b4a99746416c
Summary:
This is now working in rocm 2.2
cc xw285cornell
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18043
Differential Revision: D14477493
Pulled By: bddppq
fbshipit-source-id: 4d2dab1d5dbdbd4d6189162c074b19c4e9882c7d
Summary:
The output format of NonZero in ONNX(numpy https://docs.scipy.org/doc/numpy/reference/generated/numpy.nonzero.html) differs from that in PyTorch:
In ONNX: `[rank_of_input, num_of_nonzeros]`, whereas in PyTorch: `[num_of_nonzeros, rank_of_input]`.
To resolve the difference a Transpose op after the nonzero output is added in the exporter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18047
Differential Revision: D14475081
Pulled By: ezyang
fbshipit-source-id: 7a3e4899f3419766b6145d3e9261e92859e81dc4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17958
In some places, we need 64-bit for corner cases even though it's going to be rare.
In some places, we were using 64-bit unnecessarily.
Reviewed By: hyuen
Differential Revision: D14435523
fbshipit-source-id: e01ab73029ff780133af7ff4bbbe2e17926ed5a2
Summary:
Fix a very common typo in my name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17949
Differential Revision: D14475162
Pulled By: ezyang
fbshipit-source-id: 91c2c364c56ecbbda0bd530e806a821107881480
Summary:
ROCm 2.2 was released today, if we respin the CI docker images with the attached, PyTorch/Caffe2 will support ROCm 2.2
Changes necessary:
* for the Ubuntu target, HIP PR 934 needs to be applied to fix the forceinline definition. ROCm 2.3 will contain this.
* two unit tests proof flaky on different platforms, disable them defensively.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18007
Differential Revision: D14473903
Pulled By: bddppq
fbshipit-source-id: b1939f11d1c765a3bf71bb244b15f6ceb0e816d3
Summary:
Fixes#17558
The flattened tuple `Optional[Tuple[int, int]]` could either result in 1 (`None`) or 2 (`int` and `int`) values, so allow this case in `ArgumentSpec`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17826
Differential Revision: D14415290
Pulled By: driazati
fbshipit-source-id: 971bfa39502cfb8f08a991f16ffed6d138e48dc9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18039
We basically flatten the whole net in order to ease the ONNXIFI transform. An alternative way is to ONNXIFI the internal net of the If op, which can be done by adding interfacing inputs/outputs that the internal then_net or else_net referred to the inputs/outputs of the If op. This will be left as an TODO option.
Reviewed By: zrphercule
Differential Revision: D14452132
fbshipit-source-id: 00ad48d40da6fb8eabf9cca36701bcf61cbe4edc
Summary:
Modified Tensor Iterator gpu reduction kernel.
Creating multiple accumulator during thread reduce, this removes data dependency
between unrolled loops, expose instruction level parallelism that benefits
latency bounded kernels (e.g. welford used by `torch.std`)
This approach increases register usage, such that we need to tune unrolling
factors to prevent register spilling.
Current implementation tune down the unrolling factor to 2 for welford (register
heavy kernel), while keeping it unchanged (4) for the rest of reduction kernels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17667
Differential Revision: D14368325
Pulled By: umanwizard
fbshipit-source-id: 9d64c0dccabdb1b7c3922a6557224af704a1974e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17965
ghimport-source-id: 0d3d6340141d8413ce524a8d8ed0d308854ee7ef
Stack:
* (to be filled)
Also added it to the python bindings. Not for any particular reason,
just because otherwise the function gets elided (even in debug mode!)
and thus can't be called from the debugger
Reviewed By: eellison
Differential Revision: D14442654
fbshipit-source-id: 2868bb32ccb80b04f9483883faa702f63a7948bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17781
The wrapper for calling a c10 operator from caffe2 is now based on a runtime FunctionSchema instead of compile time information. This way, it can be created for any c10 operator schema with just one invocation to a simple macro instead of having to define arguments and more as compile time structures.
Furthermore, previously, the wrapper assumed there's an argument present for preallocated outputs, but that was only true for caffe2 operators exported to c10. So the wrapper only worked correctly for calling caffe2->c10->caffe2. Now with the new implementation, it works for any c10 operator.
Also, binary size for this should be much smaller.
Reviewed By: ezyang
Differential Revision: D14375054
fbshipit-source-id: bac7ab8e63929e6e2a148eacac41ed092009aa86
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17743
- caffe2::Operator::SetOutputTensor() can now be used in operators that are called from c10/PyTorch.
- If the operator uses SetOutputTensor() instead of XOutput(), the wrapper doesn't preallocate an empty tensor for the operator anymore. Only outputs accessed in XOutput() will get an output tensor preallocated.
- Remove the copying of the vector with output tensors into a vector with pointer to output tensors.
- Preallocated outputs are now passed in as one TensorList argument on the stack. This TensorList argument has a well-defined name so other wrappers (i.e. the wrapper calling from c2 into c10) can recognize and use it).
- Macros for exporting caffe2 operators to c10 are simplified. Instead of having `c10_op_handle_for_c2_op`, we now pass in the operator handle as a template argument.
- `SetOutputTensor` and `OutputTensorOrUndefined` now work with operators exported to c10
Reviewed By: ezyang
Differential Revision: D14362434
fbshipit-source-id: 44a5e717204f21ea8e9728437429d9b84906f9f5
Summary:
1. Kernel size is larger than input
2. Expected output size to be less than zero
Test case added:
- invalid_conv1d
- Relevant test cases for conv2d and conv3d exists
Fixes#17247
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17436
Reviewed By: mrshenli
Differential Revision: D14354272
Pulled By: fmassa
fbshipit-source-id: 94b98621aa03b1f60d151ef9399ed3da55d41b42
Summary: https://github.com/pytorch/pytorch/pull/17995 's CI has verified it should fix the CI.
Reviewed By: bddppq
Differential Revision: D14447674
fbshipit-source-id: 50085db9ae7421b5be216ed0a2216234babfdf6c
Summary:
```
In file included from /var/lib/jenkins/workspace/aten/src/ATen/native/hip/BatchLinearAlgebra.hip:3:
In file included from /var/lib/jenkins/workspace/aten/src/ATen/hip/HIPContext.h:5:
/var/lib/jenkins/workspace/aten/src/ATen/hip/impl/HIPStreamMasqueradingAsCUDA.h:107:1: warning: control reaches end of non-void function [-Wreturn-type]
}
^
1 warning generated.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17961
Reviewed By: houseroad
Differential Revision: D14436421
Pulled By: bddppq
fbshipit-source-id: 962665602178699d7c7b55f4ca7ff1eb72ee0349
Summary:
Our AVX2 routines use functions such as _mm256_extract_epi64
that do not exist on 32 bit systems even when they have AVX2.
This disables AVX2 when _mm256_extract_epi64 does not exist.
This fixes the "local" part of #17901 (except disabling FBGEMM),
but there also is sleef to be updated and NNPACK to be fixed,
see the bug report for further discussion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17915
Differential Revision: D14437338
Pulled By: soumith
fbshipit-source-id: d4ef7e0801b5d1222a855a38ec207dd88b4680da
Summary:
FBGEMM doesn't work on x86 32bit and prior to this patch, it will
generate x86_64 objects in a build that is supposed to be x86 32bit.
FBGEMM actually relies on registers not available on x86_32, so
we disable it.
This takes of one element of #17901. There are more dependencies
and a separate PR (#17915) regarding AVX detection for the code in the
main repository.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17922
Differential Revision: D14437340
Pulled By: soumith
fbshipit-source-id: bd9fc98cf607d9b0bc28127fbbc8b04fa10eecbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17925
There's no need for OpKernel to keep the cache creator around if we initialize cache on construction.
This basically means, kernel caches are now constructed when the kernel is looked up from the dispatcher, and not delayed to the first call anymore.
This gives us the benefit of cheaper calling because now kernel calling doesn't have to check if the cache is already initialized.
Also, this improves thread-safety. Now, OpKernel is thread-safe if the kernel is thread-safe.
Reviewed By: ezyang
Differential Revision: D14424907
fbshipit-source-id: a0d09a3a560dfe78aab53d558c9ebb91b57722df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17957
So developer knows what action should be taken when model contains nondeterministic node
Reviewed By: dzhulgakov
Differential Revision: D14435923
fbshipit-source-id: 12d930185852f78c54efc8e90c51aa7c7c7faab5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17947
Instead of having a gtest and a no-gtest file that you have to remember to register tests in, add a single registration point and use some macro magic to make it work for both gtest and non-gtest builds
Reviewed By: eellison
Differential Revision: D14431302
fbshipit-source-id: e1abac135992577a943eaa7abcc81a6ed31fa6e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17917
D14375995 introduced instantiation of the following templates with `bool` type (more specifically `To` is `int64_t`, `From` is `bool`):
```
template <typename To, typename From>
typename std::enable_if<std::is_integral<From>::value, bool>::type overflows(
From f) {
using limit = std::numeric_limits<typename scalar_value_type<To>::type>;
if (!limit::is_signed && std::numeric_limits<From>::is_signed) {
// allow for negative numbers to wrap using two's complement arithmetic.
// For example, with uint8, this allows for `a - b` to be treated as
// `a + 255 * b`.
return f > limit::max() ||
(f < 0 && -static_cast<uint64_t>(f) > limit::max());
} else {
return f < limit::lowest() || f > limit::max();
}
}
template <typename To, typename From>
typename std::enable_if<std::is_floating_point<From>::value, bool>::type
overflows(From f) {
using limit = std::numeric_limits<typename scalar_value_type<To>::type>;
if (limit::has_infinity && std::isinf(static_cast<double>(f))) {
return false;
}
if (!limit::has_quiet_NaN && (f != f)) {
return true;
}
return f < limit::lowest() || f > limit::max();
}
```
MSVC gives C4804 warning and because "treat warnings as errors" is on it fails to build on Windows. Disabling such warning for those 2 templates.
Reviewed By: mingzhe09088
Differential Revision: D14421157
fbshipit-source-id: e72ba34406628c84da48518b32a46f851819bad1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17939
Instead of just asserting min <= 0 and max >= 0 , we adjust histogram to include 0 in the range.
We need to include 0 in the range during norm error minimization to correctly represent our quantization method that includes 0.
Reviewed By: csummersea
Differential Revision: D14428732
fbshipit-source-id: 6669a9d2c7d409ec3b31aee0afe48071986b9b71
Summary:
This improves locality and affinity by keeping work on the same
threads preferentially to starting work on new ones, and reduces
contention on the threadpool lock more generally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17808
Differential Revision: D14391282
Pulled By: resistor
fbshipit-source-id: 3aec81656a50460a725aa4187c61864295d4f46e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17931
When converting from NetDef to IR and back, the prefix string should be removed so the operator types are preserved in caffe2.
Reviewed By: ZolotukhinM
Differential Revision: D14425954
fbshipit-source-id: 2807e7337b0f804f126970768b1250a4a8c5f35c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17618
Base on the code, we only add key to `missing_keys` and `unexpected_keys` if `$strict` is `True`. The documentation is confusing.
This diff also fix one FLAKE8 warning.
Reviewed By: ailzhang
Differential Revision: D14280593
fbshipit-source-id: d368f5596bdf74ff62ee4d28d79120f5af91e0a3
Summary:
This PR removes dead code from THTensorMath.h
I found these unused methods while working on a PR where i plan to move fill and zero methods from TH/THC to Aten.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17873
Differential Revision: D14407013
Pulled By: izdeby
fbshipit-source-id: a3551c5d91e7b380931a8b3bd4b3ae972d16911d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17807
Lint also detected a bug in test_linspace where we weren't
actually testing the CUDA case.
Differential Revision: D14388241
fbshipit-source-id: e219e46400f4952c6b384bca3baa0724ef94acde
Summary:
Stack:
⚫ **#17804 Eliminate the use of Type.** [💛](https://our.intern.facebook.com/intern/diff/D14382165/)
at::CPU produces Type object which is then casted into TensorOptions, instead directly using TensorOptions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17804
Differential Revision: D14407851
Pulled By: ezyang
fbshipit-source-id: 6462d698305b7c24382c1bfd440d3227bd28d9e4
Summary:
IIRC we decided to remove warning in code in #11568. This got reverted accidentally in #14123.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17921
Differential Revision: D14422811
Pulled By: ailzhang
fbshipit-source-id: 7067264bd1d3e3b7861d29e18ade2969ed705ca1
Summary:
This PR allows Scalars to be castable with `int()` and `float()`, allows scalars to match with float arguments, and prints out a better error message if `x.item()` is used as an int.
Scalars are a very uncommon case, and I don't think we want to add the maintenance burden of building out op coverage for it. It's more maintainable to better handle converting it to int/float.
Fix https://github.com/pytorch/pytorch/issues/17652
Also note: https://github.com/pytorch/pytorch/issues/16849
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17875
Differential Revision: D14411138
Pulled By: eellison
fbshipit-source-id: a4e957cefb0ffd10ddb234d92f6d1558cfce8751
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17810
Partially addresses #12728. Also, switch the element_size bindings
to use the new function, rather than the method on Type.
We don't add Python bindings yet, as they need to be special
(they will be properties.)
Differential Revision: D14388790
fbshipit-source-id: 294183d0c8a59b0c13f2bf21d6f1cd557333e83b
Summary:
These changes add the following new Python bindings:
- Values have a 'type' property now that allows getting to the 'type' object
- Blocks have now inputs and outputs as well as returnNode and paramNode properties
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17822
Differential Revision: D14410123
Pulled By: ezyang
fbshipit-source-id: 64ef79f85a7a43b83e4b127b1d39efcaa64b74dc
Summary:
This PR causes kthvalue to be consistent with sort
(i.e. treat NaN as larger than any number), so that
`a.kthvalue(n) == a.sort()[n - 1]`.
One drawback is that median with a NaN argument does not return NaN,
which is a deviation from NumPy.
Thank you, ngimel, for raising this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17824
Differential Revision: D14410092
Pulled By: ezyang
fbshipit-source-id: bdec2d8272dc4c65bcf2f9b8995e237774c44c02
Summary:
Fixes some minor grammatical mistakes in the doc of `loss.py`.
I think in the doc:
> Note that for some losses, there multiple elements per sample.
the "are" is lost between "there" and "multiple".
This mistake takes place in all the descriptions of parameter `size_average` and there are 17 of them.
It's minor but perfects the doc I think. 😁
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17892
Differential Revision: D14418177
Pulled By: ezyang
fbshipit-source-id: 412759f2f9b215819463bf8452ab0e0513218cd6
Summary:
This PR resolves two concurrent issues discovered when running the test in windows. Details about the windows test can be found here: https://github.com/pytorch/pytorch/issues/17609
The change covers two fixes:
1. update running_preloaders_ upfront before creating worker thread to prevent underflow.
2. add a lock when updating stop_ to prevent dead lock in condition variable cv_write_.
The fix has been tested on both Windows and Linux. With --gtest_repeat=1000, the tests runs smoothly without issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17778
Differential Revision: D14404910
Pulled By: soumith
fbshipit-source-id: 2fbb8007e4b0bce4613e9a9fd31b8aace1bbfa8d
Summary:
Motivation:
- Earlier, `torch.btrifact` could not handle tensors with greater than 3 dimensions. This is because of the check:
> AT_CHECK(THTensor_(nDimension)(a) == 3, "expected 3D tensor, got size: ", a->sizes());
What is in this PR?:
- Move `btrifact` to ATen
- Remove relation to TH/THC.
- Handle tensors with more than three dimensions
- Tests
- Docs modifications: added a note about the non-pivoting variant.
[blocked due to old magma-cuda binaries]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14964
Differential Revision: D14405106
Pulled By: soumith
fbshipit-source-id: f051f5d6aaa45f85836a2867176c065733563184
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17628
This is not hooked up anywhere yet, just adding support.
This shares the same restrictions as the python frontend—namely, that the only exprs allowed right now are method defs.
Reviewed By: shannonzhu
Differential Revision: D14291654
fbshipit-source-id: 7798e5ff412a52ef8803c7bae8f439e50968a73a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17624
Just to make sure this path works
Reviewed By: shannonzhu
Differential Revision: D14288056
fbshipit-source-id: b719c0e90252b6821b1f9b22d3d98982985a6cb3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17585
Create a sugared value that represents a class during initialization. This is
so that assignments to attributes correctly define attributes in __init__ but
raise an error elsewhere.
Reviewed By: shannonzhu
Differential Revision: D14263403
fbshipit-source-id: 09b2feeb272302f00a79c2a0302fbdf5483aed6a
Summary:
This is not used anywhere and wasn't cleaned up prior to 1.0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17718
Reviewed By: janewangfb
Differential Revision: D14355154
Pulled By: pietern
fbshipit-source-id: f8ff3c8f50cd6365b369a5c5b85d72d8940df048
Summary:
Last batch of IR expect files removed. Includes some removal of expect files that are no longer used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17886
Differential Revision: D14414435
Pulled By: eellison
fbshipit-source-id: 0bfd7ce66ac2f72a57f15f45ebd60b95e80b6c16
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17859
this has been fixed due to improvements in shape analysis
Reviewed By: driazati
Differential Revision: D14402781
fbshipit-source-id: 4ef2722ffedd9c8ac1eff55c244b421d7d3715ed
Summary:
Currently the following code gives an error on python 2 because `ret` is a structseq which is not a tuple
```python
ret = a.max(dim=0)
ret1 = torch.max(a, dim=0, out=ret)
```
This PR modify tuple check in python arg parser to allow structseq to be input of operators where tuple is expected, which would make the above code work.
Depend on: https://github.com/pytorch/pytorch/pull/17136
Partially fixes: https://github.com/pytorch/pytorch/issues/16813
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17208
Differential Revision: D14280198
Pulled By: VitalyFedyunin
fbshipit-source-id: beffebfd3951c4f5c7c8fe99a5847616a89491f3
Summary: Adding new documents to the PyTorch website to describe how PyTorch is governed, how to contribute to the project, and lists persons of interest.
Reviewed By: orionr
Differential Revision: D14394573
fbshipit-source-id: ad98b807850c51de0b741e3acbbc3c699e97b27f
Summary:
This PR removes dead code from THTensorMath.h
I found these unused methods while working on a PR where i plan to move **fill** and **zero** methods from TH/THC to Aten.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17769
Differential Revision: D14372732
Pulled By: izdeby
fbshipit-source-id: 94fd3b52c691ebc89d2bdc8905452e7498038bf5
Summary:
In the loss doc description, replace the deprecated 'reduct' and 'size_average' parameters with the 'reduction' parameter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17300
Differential Revision: D14195789
Pulled By: soumith
fbshipit-source-id: 625e650ec20f13b2d22153a4a535656cf9c8f0eb
Summary:
Indices in Subset were stored as tensors earlier
passing as list in random_split to ensure integer indexing
fixes: #17466
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17649
Differential Revision: D14400250
Pulled By: soumith
fbshipit-source-id: cd20a959f33773c4babf8e861ea37ec61c2713a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17640
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17311
I've extended our model metadata framework in this diff to support
traced modules as well. Re-used a lot of components from the previous
implementation of ScriptModule metadata.
Tracing is a little different from Scripting since you can't just create a
subclass of TopLevelTraceModule (type returned by torch.jit.trace) and attach
metadata the way we did for ScriptModule. As a result, I've introduced a
separate API torch.fb.jit_trace which returns an instance of
TracedModuleWithMetadata which is a subclass of TopLevelTracedModule. As a
result, we can now attach metadata to this instance.
Reviewed By: dzhulgakov
Differential Revision: D14117966
fbshipit-source-id: 3eee5eef733cb8d6a219c02e2f41d08698eca326
Summary:
1. Move ATen threadpool & open registration mechanism to C10
2. Move the `global_work_queue` to use this open registration mechanism, to allow users to substitute in their own
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17788
Reviewed By: zdevito
Differential Revision: D14379707
Pulled By: jamesr66a
fbshipit-source-id: 949662d0024875abf09907d97db927f160c54d45
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17813
We have a lot of manually written out dict() constructors,
and (1) I don't think use of curly brace syntax is much
of an improvement and (2) it seems like a waste of time to
fix them all.
Reviewed By: eellison
Differential Revision: D14390136
fbshipit-source-id: 6199bef4dea75b6079bcb9d9e8acf20a2e1a86e1
Summary:
CreateDB actually returns nullptr when db type is unknown and throws when the file is missing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17795
Reviewed By: ezyang
Differential Revision: D14383226
Pulled By: dzhulgakov
fbshipit-source-id: 1dcf75a6b4ba8b64a24d4e5daf02db3189d56b7b
Summary:
This causes the tracer to record the select / cast to int operation instead of just an int constant
Fixes#15319 but relies on a fix for #17583 first
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17727
Differential Revision: D14377886
Pulled By: driazati
fbshipit-source-id: 59453def54ba72756303f723993844dbeb5d2f8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17742
This path isn't used anymore, and is incompatible with the changes stacked on top of this diff.
Removing it.
cc bwasti to check and confirm these can really be deleted
Reviewed By: ezyang
Differential Revision: D14362426
fbshipit-source-id: 32cdc19f28c2a981ae1e204901420998367ee588
Summary:
We used to have different ATen Tensor types, but we don't anymore. This was just being maintained by a codegen'ed comment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17782
Reviewed By: ezyang
Differential Revision: D14378004
Pulled By: gchanan
fbshipit-source-id: 1bbf276393a391252d372cc385230c784bd78588
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17764
Original commit changeset: f1923fdca4a1
reverted int8 ops fixes the original runtime regression.
We'll ignore the memory regression since it is flaky, see D14228484
Reviewed By: dzhulgakov
Differential Revision: D13885233
fbshipit-source-id: ccbe4b94acb44b7b4cb3ae4d73e3f6091e1e1195
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17548
expose half float operators to OSS
common/math/Float16.h is the original implementation
this is substituted by caffe2/c10/util/Half.h
from the comments seems like the both implementations don't handle denormals
Reviewed By: jspark1105
Differential Revision: D14244200
fbshipit-source-id: f90ba28c5bf6a2b451b429cc4925b8cc376ac651
Summary:
1) The changes in the new opset won't affect internal pipeline.
2) The CI won't be affected by the ONNX changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17736
Reviewed By: zrphercule
Differential Revision: D14358710
Pulled By: houseroad
fbshipit-source-id: 4ef15d2246b50f6875ee215ce37ecf92d555ca6a
Summary:
Similar to `nn.Parameter`s, this PR lets you store any `IValue` on a module as an attribute on a `ScriptModule` (only from the Python front-end currently). To mark something as an attribute, it should wrapped in `jit.Attribute(value, type)` (ex. `self.table = torch.jit.Attribute(table, Dict[str, torch.Tensor])`)
Followup Work:
* (de)serializing for use in C++
* change `self.training` to be a `bool` attribute instead of a buffer
* mutable attributes
* string frontend support
* documentation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17309
Differential Revision: D14354316
Pulled By: driazati
fbshipit-source-id: 67e08ab5229366b67fbc837e67b58831a4fb3318
Summary:
Currently, serialization of model parameters in ONNX export depends on the order in which they are stored in a container (`list` on Python side and `std::vector` on C++ side). This has worked fine till now, but if we need to do any pass on that graph that mutates the parameter list, then strictly order-based serialization may not work.
This PR is the first in a set to bring in more passes (such as constant folding) related to ONNX export. This PR lays the groundwork by moving the serialization in ONNX export from order-based to name based approach, which is more amenable to some of the passes.
houseroad - As discussed this change uses a map for export, and removes the code from `export.cpp` that relies on the order to compute initializer names.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17420
Differential Revision: D14361993
Pulled By: houseroad
fbshipit-source-id: da93e945d55755c126de06641f35df87d1648cc4
Summary:
Use flake8 installed with mypy checks so that our linter matches fbcode. Mypy type errors also provide valuable signal
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17721
Differential Revision: D14357778
Pulled By: eellison
fbshipit-source-id: d8c9ea3fe3b5f550c3b70fe259e0eabf95e4c92d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17726
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17725
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17461
Implementing a standalone LSTM Operator in Caffe2 adopted from this Aten implementation: diffusion/FBS/browse/master/fbcode/caffe2/aten/src/ATen/native/RNN.cpp. The most tricky thing in this exercise was that caffe2::Tensor has no copy constructor that made it necessary to implement a custom templated copy constructor for the different Tensor containers used in the code. Also there was no way to use off-the-shelf C2 operators in my code easily so I had to copy some code that is doing basic matmul, cat, split, transpose and linear as utility functions.
Two things missing:
- Profiling this implementation against the current ONNXified LSTM op
- Make this operator available to use in PyTorch
Reviewed By: dzhulgakov
Differential Revision: D14351575
fbshipit-source-id: 3b99b53212cf593c7a49e45580b5a07b90809e64
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17729
When doing "import torch" in fbcode, previously the caffe2 cuda kernels weren't loaded because libcaffe2_gpu.so wasn't loaded.
Once you also did "from caffe2.python import workspace", then the cuda kernels were loaded because that triggered a runtime mechanism for loading libcaffe2_gpu.so.
We want the cuda kernels to always be available, so this diff adds a dependency from caffe2:libtorch_cuda to caffe2:caffe2_gpu.
Reviewed By: ezyang
Differential Revision: D14353498
fbshipit-source-id: 76a9fe69f231b308ab40eac393bb216c6fad3658
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17734
If input is not BATCH, we will skip adjust its batch size during onnxifi transformation. So when we take hints, we take it as CONSTANT but later need to change it to BATCH if possible.
Reviewed By: jackm321
Differential Revision: D14355983
fbshipit-source-id: 63eb54a44afb1565c71486fdd73db07ca0ac4fd4
Summary:
xxtemp, colesbury, bhushan23, zou3519, convert gpu round behavior to half-to-even, consistent with torch cpu version and numpy. You feedback are welcomed.
See #16498
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17443
Differential Revision: D14261786
Pulled By: VitalyFedyunin
fbshipit-source-id: 98156436b545d72769831a89e2775d43ad913ebc
Summary:
Eventually we should remove these when we're certain that all our ops
handle memory overlaps correctly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17576
Differential Revision: D14349990
Pulled By: zou3519
fbshipit-source-id: c3a09f6113b9b1bf93e7f13c0b426c45b2cdf21f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17545
This diff avoids renaming boundary inputs of net during onnxifi transform.
It also removes adding mappings for the initializer during onnxifi op creation.
Thus gets read of the mapped ws creation during onnxifi op creation.
Reviewed By: zrphercule
Differential Revision: D14243161
fbshipit-source-id: 6eafa920c45f6a6bfacbbb443e8e84cf9778644c
Summary:
Another batch of removing expect files.
One note - I removed the Batched expect files without adding equivalent tests since they are already being tested in another ways, and we are no longer actively maintaining that project.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17581
Differential Revision: D14343578
Pulled By: eellison
fbshipit-source-id: ce0b1fd2b5b4ec80ad9003bab1b58f41645d3da6
Summary:
- Summary:
Added synchronized batch normalization, allows synchronization of stats across mini-batches between processes within a process group.
Current implementation uses a mixture of extended ATen native functions (cpp cuda extension) + torch.nn.modules (c10d python API)
- User-facing api:
1. torch.nn.utils.convert_sync_batchnorm(modules, process_group=None)
2. torch.nn.SyncBatchNorm(num_features, eps=1e-5, momentum=0.1, affine=True, track_running_stats=True, ***process_group=None***)
- supported use case:
DistributedDataParallel with ***single-gpu multi-process***
a. User creates model containing `torch.nn.SyncBatchNorm` layers through one of the ways listed below:
1. use layers directly:
torch.nn.SyncBatchNorm(...)
similar API as with torch.nn.BatchNormXd(...)
with added argument `process_group` which is used to limit the scope of
synchronization within each process group. Default value is None, which
implies synchronization across all GPUs
2. use torch.nn.utils.convert_sync_batchnorm(modules, process_group)
recursively convert all `torch.nn.BatchNormXd` into `torch.nn.SyncBatchNorm`
preserving values of parameters/buffers.
the utility function also allows user to specify process_group value to all
converted layers.
b. user wraps their model with
`torch.distributed.parallel.DataParallelDistributed`, from this point, user
should follow the general guidelines for DDP use guide
- Error checking
For use cases not supported, we error out:
1. Application launched without ddp:
> import torch
> sbn = torch.nn.SyncBatchNorm(10).cuda()
> inp = torch.randn(5, 10, 3, 3).cuda()
> sbn(inp) --> Error!
> AttributeError: SyncBatchNorm is only supported within torch.nn.parallel.DistributedDataParallel
2. Application launched using DDP with multi-GPU per-process:
> ddp_module = nn.parallel.DistributedDataParallel(module, device_ids=device_ids, output_device=args.local_rank)
> ValueError: SyncBatchNorm is only supported for DDP with single GPU per process
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14267
Differential Revision: D14270035
Pulled By: ezyang
fbshipit-source-id: 4956d8fa565c32e9df5408d53719ff9f945f4d6d
Summary:
teng-li is passing the baton to mrshenli. Thanks for all your work on distributed teng-li!! 🎉
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17720
Differential Revision: D14350120
Pulled By: pietern
fbshipit-source-id: edfe784520c54630203cc8fbb296455d3dbf341b
Summary:
Observed the test `TestGroupConvolution.test_group_convolution` to fail with the following error:
```
Falsifying example: test_group_convolution(self=<caffe2.python.operator_test.group_conv_test.TestGroupConvolution testMethod=test_group_convolution>, stride=3, pad=0, kernel=5, size=8, group=4, input_channels_per_group=7, output_channels_per_group=8, batch_size=2, order='NHWC', engine='', use_bias=False, gc=, dc=[, device_type: 1])
You can reproduce this example by temporarily adding reproduce_failure('3.59.1', b'AAAA') as a decorator on your test case
```
This example generated by hypothesis has `group=2, order='NHWC' and dc=[, device_type: 1])`.
I think this example should be skipped.
I have mimicked the change corresponding to [PR#13554](https://github.com/pytorch/pytorch/pull/13554) to skip this example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17715
Differential Revision: D14346642
Pulled By: ezyang
fbshipit-source-id: b1f1fef09f625fdb43d31c7213854e61a96381ba
Summary:
Check for Tuple Matching in isSubvalueOf, since they may contain container types that need to be recursed within isSubvalueOf
Fix for https://github.com/pytorch/pytorch/issues/17650
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17687
Differential Revision: D14324642
Pulled By: eellison
fbshipit-source-id: 7f1e019875286b2640a3b9c003d1635dda8cf543
Summary:
In discussion with houseroad, because Upsample op is being updated in ONNX https://github.com/onnx/onnx/pull/1773 and these tests are blocking it. These tests will be updated once the ONNX PR goes in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17696
Differential Revision: D14338845
Pulled By: houseroad
fbshipit-source-id: cfaf8cf1ab578ae69dd3bf21b1c0681b572b9b6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17623
Despite it's generic sounding name, caffe2::DeviceGuard actually
only worked on CUDA devices. Rename it to something that more
clearly spells out its applicability.
I'm not sure if it's the right call, but in this patch I added
'using CUDAGuard = c10::cuda::CUDAGuard', as this seems to be more
in-line with how the Caffe2 codebase is currently written. More
idiomatic c10 namespace style would be to say cuda::CUDAGuard.
Willing to change this if people shout.
This is a respin of D13156470 (#14284)
Reviewed By: dzhulgakov
Differential Revision: D14285504
fbshipit-source-id: 93b8ab938b064572b3b010c307e1261fde0fff3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17461
Implementing a standalone LSTM Operator in Caffe2 adopted from this Aten implementation: diffusion/FBS/browse/master/fbcode/caffe2/aten/src/ATen/native/RNN.cpp. The most tricky thing in this exercise was that caffe2::Tensor has no copy constructor that made it necessary to implement a custom templated copy constructor for the different Tensor containers used in the code. Also there was no way to use off-the-shelf C2 operators in my code easily so I had to copy some code that is doing basic matmul, cat, split, transpose and linear as utility functions.
Two things missing:
- Profiling this implementation against the current ONNXified LSTM op
- Make this operator available to use in PyTorch
Reviewed By: dzhulgakov
Differential Revision: D14160172
fbshipit-source-id: c33e3f9e8aeae578b64d97593cb031a251216029
Summary:
hip-clang uses triple chevron kernel dispatch syntax. Add an option to the hipification script to skip translating triple chevron to hipLaunchKernelGGL.
Once we switch to hip-clang, this option will be default and subsequently removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17686
Differential Revision: D14327810
Pulled By: bddppq
fbshipit-source-id: 5e1512325077dd3ebb8fb9b5bf35fd1f8d9a4dc3
Summary:
```
NVIDIA changed the CUDA allocation behavior on Pascal GPUs. The
page size increased from 1MB to 2MB and allocations larger than 1MB
are now always page-aligned. Previously, allocations larger than 1MB
were aligned to 128KB boundaries.
This interacted poorly with the caching allocator. The remaining
memory in a page could only be filled by small cudaMalloc calls, but
the caching allocator never cudaMalloc's a chunk smaller than 1MB.
This behavior could also cause a large discrepancy between the memory
usage reported by nvidia-smi and the memory usage reported by
PyTorch, because nvidia-smi counts a partially used page as "full",
while PyTorch only counts the actual memory requested.
This PR makes a few changes to the caching allocator to better support
Pascal and Volta GPUs:
- All cudaMalloc calls are now multiples of 2MB (the page size)
- Requests between 1-10MB allocate (and split) a 20MB block to
reduce wasted space due to rounding
- Small requests are now packed into 2MB blocks (instead of 1MB)
This improves Mask R-CNN memory usage by 10-20% in internal tests on
Volta GPUs. Maxwell performance seems to be largely unchanged, but
it's possible that some use cases suffer slightly.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17120
Differential Revision: D14301536
Pulled By: colesbury
fbshipit-source-id: a8282315ea8f7b8ca149b5066fdeaecd0d404edf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17579
These methods previously just returned 0 when it was not a legacy operator,
making it impossible to convert some operators.
Reviewed By: dzhulgakov
Differential Revision: D14253094
fbshipit-source-id: 72bfdcf6da291a4ab80d1e0ceb20984b86edc408
Summary:
Fixes#17449
Context: before #17186, we don't fuse `clamp` for the case when `min/max` are missing inputs, because they are `prim::None` node, after #17186, we make None a `prim::Constant` node which enables the fusion for `clamp`. But codegen.cpp does not handle the case when `prim::Constant` is not a Double/Int/Bool, this PR makes it so that missing inputs are handled correctly, it is done in the following way:
1. emit nothing when you see `type? = prim::Constant()`
2. when emitRHS, do special casing for aten::clamp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17533
Differential Revision: D14238450
Pulled By: wanchaol
fbshipit-source-id: 61a272154754b13e89021bb86002927f02cde19c
Summary:
1. Enabling int32 indexing for cases where TI cannot accumulate in output due to
incompatible data types (e.g. Welford).
2. Updating Welford kernel to use int32 instead of int64 indexing on GPU.
This change improves performance for torch.var / torch.std
Implementation:
1. Allocated extra buffer to handle accumulation between sub Tensor Iterators.
2. Removed int64 indexing in gpu_reduce_kernel
3. WelfordOps now supports index type / combination typeas a template parameter.
While GPU uses int32_t and float, CPU implementation uses int64_t and double.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17428
Differential Revision: D14264608
Pulled By: umanwizard
fbshipit-source-id: 3eb54451de925b469dbc1127e5ea7443c4431036
Summary:
TH_Index_Base is hard coded to 0 and can be removed from the code base.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17591
Differential Revision: D14269273
Pulled By: izdeby
fbshipit-source-id: d844e261f4af7297bad8a81e7d6dcf0a391b94e6
Summary:
Because of two separate python extensions with different pybind
instances I have to go through void* conversion. Since it's hidden from
user, it's fine.
New APIs added on C2 side:
- workspace.FetchTorch('blob')
- workspace.Workspace.current.blobs['blob'].to_torch()
- workspace.FeedBlob('blob', pytorch_tensor)
Works on CPU an GPU.
The only glitches are with resizing because of variable/tensor split.
But data sharing works properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17190
Reviewed By: ezyang
Differential Revision: D14163882
Pulled By: dzhulgakov
fbshipit-source-id: d18e5b8fcae026f393c842a1149e972515732de2
Summary:
Hi, there.
There is a typo in aten/src/ATen/native_parse.py, and I fix it.
`std::aray` -> `std::array`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17641
Differential Revision: D14301981
Pulled By: ezyang
fbshipit-source-id: a37859cdedcbf6c29333b954486dfa086d6c2176
Summary:
Create a `make_variable` override that moves out of a tensor instead of going through `shallow_copy_and_detach`. Call this override from factory methods like `empty` that create a brand new tensor, do nothing with it, and then copy it into a variable.
Will update this with actual numbers, but it seems to get rid of around 20-40% of the overhead of calling `torch.empty(0)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17565
Differential Revision: D14266130
Pulled By: umanwizard
fbshipit-source-id: f57d5f2ca3f80ee8ee96d50f905e852fd10db941
Summary:
Currently, the fake tqdm implementation requires an input (whereas real tqdm does not).
This caused a problem in torchvision (https://github.com/pytorch/vision/pull/770), and seems likely to cause minor irritations elsewhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17636
Differential Revision: D14296530
Pulled By: ezyang
fbshipit-source-id: bc077d898773c93dab34c985a7b30525a43e558a
Summary:
Various functions aren't used by the JIT, so they're jit-compliant w.r.t. their schema by default.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17631
Differential Revision: D14295559
Pulled By: cpuhrsch
fbshipit-source-id: a2ecdcb5df47eb67c54ec642d88d42e985515142
Summary:
The CPU version is based on the TH version.
The GPU version is based on #8406 by Pararth Shah (thank you).
CPU quickselect based on that in TH's THTensorMoreMath.cpp, but with C++ (quickselectnoindex will be achieved by a different swap)
CPU kthvalue is based on the THTensor function in the same file.
The dim_apply function is a C++ replacement for TH_TENSOR_DIM_APPLYx macros.
The CUDA kernel uses functions adapted from the THCTensorSortK implementation.
In particular radixSelect is from THCTensorTopK.cuh.
The CUDA launcher code replaces a bunch of macros with C++. It will be re-used in one of the following patches.
Plan for further PRs:
- This
- Sort
- TopK + Mode + Median in any order
- Rip out THC stuff.
There may be utility functions / structs in the SortingCommon.cuh that come into
relevance only with sort.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17544
Differential Revision: D14286934
Pulled By: ezyang
fbshipit-source-id: 35dbea050b097e88777ac5fa5c0f499d5e23c738
Summary:
Fixing MSVC errors
```
D:\pytorch-scripts\caffe2_builders\v141\pytorch\aten\src\THC/THCReduce.cuh(144): error C4002: too many actual paramet
ers for macro 'C10_LAUNCH_BOUNDS_1' [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2\caffe2_gpu.vcxp
roj]
D:\pytorch-scripts\caffe2_builders\v141\pytorch\aten\src\THC/THCReduce.cuh(259): error C4002: too many actual paramet
ers for macro 'C10_LAUNCH_BOUNDS_1' [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2\caffe2_gpu.vcxp
roj]
D:/pytorch-scripts/caffe2_builders/v141/pytorch/aten/src/THCUNN/SpatialDilatedMaxPooling.cu(51): error C4002: too man
y actual parameters for macro 'C10_LAUNCH_BOUNDS_1' [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2
\caffe2_gpu.vcxproj]
```
on variadic C10_LAUNCH_BOUNDS as well as Debug linking issues with at::Half in pool_op_cudnn.cc like this one
```
pool_op_cudnn.obj : error LNK2019: unresolved external symbol "public: bool __cdecl caffe2::MaxPoolFunctor<class caff
e2::CUDAContext>::GlobalPoolingBackward<struct c10::Half,2>(int,int,int,struct c10::Half const *,struct c10::Half const
,struct c10::Half const ,struct c10::Half ,class caffe2::CUDAContext )const " (??$GlobalPoolingBackward@UHalf@c10@
@$01@?$MaxPoolFunctor@VCUDAContext@caffe2@@caffe2@QEBA_NHHHPEBUHalf@c10@00PEAU23@PEAVCUDAContext@1@Z) referenced in
function "public: bool __cdecl caffe2::`anonymous namespace'::CuDNNMaxPoolFunctor::GlobalPoolingBackward<struct c10::H
alf,2>(int,int,int,struct c10::Half const ,struct c10::Half const ,struct c10::Half const ,struct c10::Half ,class
caffe2::CUDAContext *)const " (??$GlobalPoolingBackward@UHalf@c10@@$01@CuDNNMaxPoolFunctor@?A0xb936404a@caffe2@QEBA_NH
HHPEBUHalf@c10@00PEAU34@PEAVCUDAContext@2@Z) [D:\pytorch-scripts\caffe2_builders\v141\pytorch\build\Debug\caffe2\caff
e2_gpu.vcxproj]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17201
Differential Revision: D14165732
Pulled By: ezyang
fbshipit-source-id: 875fd9a5b2db6f83fc483f6d750d2c011260eb8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17619
--filler hive --iter -1 will let debugger exhaust all batches from a hive partition before exiting.
add README that summarizes command line options and usage.
Reviewed By: yinghai
Differential Revision: D14220166
fbshipit-source-id: daa23b7e8a9184481c6d7b67acf1599e5c99d74a
Summary:
Sparse Linear in TH(CU)NN implements sparse linear layers without
using sparse matrices.
It is currently not documented in PyTorch and there is no functional or
module interface. This means it is unused from a PyTorch point of view.
The reason for removing it is twofold:
- The module uses sort, which I would like to move to ATen.
- When we implement a SparseLinear layer, we would want to do it
using sparse tensors, so it's not all that useful, anyway.
I checked this on slack with soumith, I hope the above is an accurate
representation. All bad ideas are my own.
This is part of the ongoing work to move
sort/topk/mode/median/kthvalue to ATen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17610
Differential Revision: D14280663
Pulled By: gchanan
fbshipit-source-id: 289231d2c20626855ce2ceecd4f204b460c32378
Summary:
They are previously merged to resolve#17051. However, since it was resolved by the upstream, and it was causing some issues like https://github.com/abjer/tsds/issues/8, I think it's time to revert these changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17567
Differential Revision: D14265241
Pulled By: kostmo
fbshipit-source-id: 7fa2b7dd4ebc5148681acb439cf82d983898694e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17528
as title. register_prim_ops is messy because someone ruined clang-format, but I figured it's okay to include here since this is such a mechanical change
Reviewed By: driazati
Differential Revision: D14236943
fbshipit-source-id: c2b22845837b7f830015510e48ec2ee5202fa407
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17594
The original version of this broke things because a concurrent change raced with it in CI.
Reviewed By: ezyang
Differential Revision: D14266663
fbshipit-source-id: e8ac5dfcb7349b4f2c425d9f0eabbfc964314063
Summary:
It will be better to split the CPU job on CI. But unluckily, we are out of Windows machines.
cc, davidbrownellWork yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17608
Differential Revision: D14281393
Pulled By: soumith
fbshipit-source-id: ae9a6140b7207ce56cfb2da3d812bc3fe060764a
Summary:
- Test updates
1. test_torch: added 0-d test case and t_() test cases
2. test_jit : updated error message for TestAsync.test_async_script_error
- Updating documentation for torch.t()
Adding information regarding new support of 0-D and 1-D tenso
Fixes#17520
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17535
Differential Revision: D14269984
Pulled By: gchanan
fbshipit-source-id: 38b723f31484be939261c88edb33575d242eca65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17549
Currently Dropout is only enabled in training, we enable the option of having dropout in Eval.
This is to follow [1]. This functionality would be used for uncertainty estimation in exploration project.
[1] Gal, Yarin, and Zoubin Ghahramani. "Dropout as a bayesian approximation: Representing model uncertainty in deep learning." international conference on machine learning. 2016.
Reviewed By: Wakeupbuddy
Differential Revision: D14216216
fbshipit-source-id: 87c8c9cc522a82df467b685805f0775c86923d8b
Summary:
The max pooling backwards kernel is currently annotated with launch bounds (256,8).
Adjust the number of waves to 4 (4 times 64 is 256) for ROCm. This improves training performance for torchvision models by up to 15% (AlexNet) on a gfx906 GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17555
Differential Revision: D14277744
Pulled By: bddppq
fbshipit-source-id: 2a62088f7b8a87d1e350c432bf655288967c7883
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17561
The push at the top of the file was missing a corresponding pop
Reviewed By: ezyang
Differential Revision: D14254500
fbshipit-source-id: ff20359b563d6d6dcc68273dc754ab31aa8fad12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17522
Dispatch is still based on the first tensor arg, but that first "tensor arg" is now allowed to be a tensor list.
That is, the first argument that is either Tensor or TensorList will be the deciding factor for dispatch.
If it is a TensorList, then that TensorList must not be empty or dispatch will fail.
Reviewed By: ezyang
Differential Revision: D14235840
fbshipit-source-id: 266c18912d56ce77aa84306c5605c4191f3d882b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17491
Before, there was no way to expose a caffe2 operator that had a variable number of inputs.
Now, this is allowed by giving the operator one tensor list input.
Note that the tensor list must be the first input, and that any other tensor inputs will be ignored and inaccessible in this case.
Reviewed By: ezyang
Differential Revision: D14220705
fbshipit-source-id: 7f921bfb581caf46b229888c409bbcc40f7dda80
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17088
clangr codemod
also manually moved the constructor of a class from the .cpp file to the .h file.
Reviewed By: ezyang
Differential Revision: D14078531
fbshipit-source-id: 2adb4ac0ce523742da6cce3bc3b6c177b816c299
Summary:
HIPGuard interfaces that interacted with HIPStream were previously
totally busted (because the streams had the wrong device type).
This fixes it, following along the same lines of MasqueardingAsCUDA.
Along the way I beefed up the explanatory comment.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc jithunnair-amd iotamudelta bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17469
Differential Revision: D14243396
Pulled By: ezyang
fbshipit-source-id: 972455753a62f8584ba9ab194f9c785db7bb9bde
Summary:
As discussed here #16952, this PR aims at improving the __repr__ for distribution when the provided parameters are torch.Tensor with only one element.
Currently, __repr__() relies on dim() == 0 leading to the following behaviour :
```
>>> torch.distributions.Normal(torch.tensor([1.0]), torch.tensor([0.1]))
Normal(loc: torch.Size([1]), scale: torch.Size([1]))
```
With this PR, the output looks like the following:
```
>>> torch.distributions.Normal(torch.tensor([1.0]), torch.tensor([0.1]))
Normal(loc: 1.0, scale: 0.10000000149011612)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17503
Differential Revision: D14245439
Pulled By: soumith
fbshipit-source-id: a440998905fd60cf2ac9a94f75706021dd9ce5bf
Summary:
See comment inside of code. This fixes a bug where sometimes we would try to avoid printing long lines but would inadvertently reorder the expressions, which can change the semantics of the program
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17557
Differential Revision: D14250608
Pulled By: zdevito
fbshipit-source-id: d44996af4e90fe9ab9508d13cd04adbfc7bb5d1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17511
AliasTracker was doing bookkeeping for three concepts: the points-to graph,
writes, and wildcards.
This PR makes AliasTracker's job clearer: it keeps track of the points-to
graph. Thus it has been renamed MemoryDAG. Write and wildcard information were
pulled back into AliasDb as part of this—I may decide to pull them into their
own little modules since I don't want the alias analysis stuff to get too
bloated.
This refactor is necessary because we want to start tracking information for
aliasing elements that _aren't_ first-class IR Values (e.g. the "stuff" inside
a list). So MemoryDAG can't know too much about Values
Reviewed By: houseroad
Differential Revision: D14231251
fbshipit-source-id: 6cd98ae6fced8d6c1522c2454da77c3c1b2b0504
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17480
This was always part of our "spec" but not implemented
Reviewed By: houseroad
Differential Revision: D14214301
fbshipit-source-id: 118db320b43ec099dc3e730c67d39487474c23ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17478
Enable onnxifi_ext in glow and build an e2e test in caffe2.
Reviewed By: yinghai
Differential Revision: D14190136
fbshipit-source-id: 26245278b487b551623109b14432f675279b17b5
Summary:
+ All quotes for ENV VARS are erroneous;
+ Toolset hasn't be specified;
+ Provide paths for all 3 Visual Studio 2017 products: Community/Professional/Enterprise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17475
Differential Revision: D14262968
Pulled By: soumith
fbshipit-source-id: c0504e0a6be9c697ead83b06b0c5cf569b5c8625
Summary:
The generated_comments are wrong to below generated files:
```bash
./torch/csrc/autograd/generated/VariableType_0.cpp:3:// generated from tools/autograd/templates/VariableType_0.cpp
./torch/csrc/autograd/generated/VariableType_1.cpp:3:// generated from tools/autograd/templates/VariableType_1.cpp
./torch/csrc/autograd/generated/VariableType_2.cpp:3:// generated from tools/autograd/templates/VariableType_2.cpp
./torch/csrc/autograd/generated/VariableType_3.cpp:3:// generated from tools/autograd/templates/VariableType_3.cpp
./torch/csrc/autograd/generated/VariableType_4.cpp:3:// generated from tools/autograd/templates/VariableType_4.cpp
./torch/csrc/autograd/generated/VariableTypeEverything.cpp:3:// generated from tools/autograd/templates/VariableTypeEverything.cpp
./torch/csrc/jit/generated/register_aten_ops_0.cpp:23:// generated from tools/autograd/templates/register_aten_ops_0.cpp
./torch/csrc/jit/generated/register_aten_ops_1.cpp:23:// generated from tools/autograd/templates/register_aten_ops_1.cpp
./torch/csrc/jit/generated/register_aten_ops_2.cpp:23:// generated from tools/autograd/templates/register_aten_ops_2.cpp
```
These generated files were split to speed the compile, however, the template files are not.
After this fix, the comments will look like below:
```bash
./torch/csrc/autograd/generated/VariableType_0.cpp:3:// generated from tools/autograd/templates/VariableType.cpp
./torch/csrc/autograd/generated/VariableType_1.cpp:3:// generated from tools/autograd/templates/VariableType.cpp
......
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17563
Differential Revision: D14260992
Pulled By: soumith
fbshipit-source-id: 038181367fa43bee87837e4170704ddff7f4d6f2
Summary:
resize_ and resize_as resize the input tensor. because our shape analysis
is flow invariant, we don't do shape analysis on any op that relies on a Tensor that can alias a resized Tensor.
E.g. in the following graph the x += 10 x may have been resized.
```
torch.jit.script
def test(x, y):
for i in range(10):
x += 10
x.resize_as_([1 for i in int(range(torch.rand())))
return x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17518
Differential Revision: D14249835
Pulled By: eellison
fbshipit-source-id: f281b468ccb8c29eeb0f68ca5458cc7246a166d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17481
Usually, feature macros are either defined or undefined and checked accordingly.
C10_MOBILE was a weird special case that was always defined but either defined to 1 or to 0.
This caused a lot of confusion for me when trying to disable something from mobile build and it also disabled it
from the server build (because I was using ifdef). Also, I found a place in the existing code base that made
that wrong assumption and used the macro wrongly, see https://fburl.com/y4icohts
Reviewed By: dzhulgakov
Differential Revision: D14214825
fbshipit-source-id: f3a155b6d43d334e8839e2b2e3c40ed2c773eab6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17078
This prevents caffe2 operators from being expsoed to c10 on mobile,
which in turn causes the whole c10 dispatcher to be stripped away
and saves binary size.
We probably want to re-enable the c10 dispatcher for mobile,
but for now this is ok.
Reviewed By: ezyang
Differential Revision: D14077972
fbshipit-source-id: e4dd3e3b60cdfbde91fe0d24102c1d9708d3e5c4
Summary:
And adding timestamps to linux build jobs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17516
Differential Revision: D14244533
Pulled By: pjh5
fbshipit-source-id: 26c38f59e0284c99f987d69ce6a2c2af9116c3c2
Summary:
This PR allows `gather` to optionally return sparse gradients, as requested in #16329. It also allows to autograd engine to accumulate sparse gradients in place when it is safe to do so.
I've commented out size.size() check in `SparseTensor.cpp` that also caused #17152, it does not seem to me that check serves a useful purpose, but please correct me if I'm wrong and a better fix is required.
Motivating example:
For this commonly used label smoothing loss function
```
def label_smoothing_opt(x, target):
padding_idx = 0
smoothing = 0.1
logprobs = torch.nn.functional.log_softmax(x, dim=-1, dtype=torch.float32)
pad_mask = (target == padding_idx)
ll_loss = logprobs.gather(dim=-1, index=target.unsqueeze(1), sparse = True).squeeze(1)
smooth_loss = logprobs.mean(dim=-1)
loss = (smoothing - 1.0) * ll_loss - smoothing * smooth_loss
loss.masked_fill_(pad_mask, 0)
return loss.sum()
```
backward goes from 12.6 ms with dense gather gradients to 7.3 ms with sparse gradients, for 9K tokens x 30K vocab, which is some single percent end-to-end improvement, and also improvement in peak memory required.
Shout-out to core devs: adding python-exposed functions with keyword arguments through native_functions.yaml is very easy now!
cc gchanan apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17182
Differential Revision: D14158431
Pulled By: gchanan
fbshipit-source-id: c8b654611534198025daaf7a634482b3151fbade
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16746
as titled. We use a special url schem elasticzeus for elastic zeus so that we dont need to change the public interface of init_process_group.
Reviewed By: aazzolini, soumith
Differential Revision: D13948151
fbshipit-source-id: 88939dcfa0ad93467dabedad6905ec32e6ec60e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17456
Using an instruction sequence similar to function in fbgemm/src/QuantUtilAvx2.cc
elementwise_sum_benchmark added
Reviewed By: protonu
Differential Revision: D14205695
fbshipit-source-id: 84939c9d3551f123deec3baf7086c8d31fbc873e
Summary:
For some additional context on this change, please, see this [PR](https://github.com/pytorch/pytorch/pull/17376)
As a part of work on Bool Tensor, we will need to add support for a bool type to _fill() and _zero() methods that are currently located in THTensorMath. As we don't need anything else and those methods are not really math related - we are moving them out into separate THTensorFill for simplicity.
Change:
-moved _fill() and _zero() from THTensorMath.h to THTensorFill
-enabled _fill() and _zero() for HALF type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17536
Differential Revision: D14242130
Pulled By: izdeby
fbshipit-source-id: 1d8bd806f0f5510723b9299d360b70cc4ab96afb
Summary:
Causing a problem with spectral norm, although SN won't use that anymore after #13350 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13352
Differential Revision: D14209562
Pulled By: ezyang
fbshipit-source-id: f5e3183e1e7050ac5a66d203de6f8cf56e775134
Summary:
As of MIOpen 1.7.1 as shipped in ROCm 2.1 this works correctly and we can use MIOpen and do not need to fall back
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17472
Differential Revision: D14210323
Pulled By: ezyang
fbshipit-source-id: 4c08d0d4623e732eda304fe04cb722c835ec70e4
Summary:
This only deals with four functions, but is an important first step towards removing BoolTensor and IndexTensor entirely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17193
Differential Revision: D14157829
Pulled By: cpuhrsch
fbshipit-source-id: a36f16d1d88171036c44cc7de60ac9dfed9d14f2
Summary:
Pytorch's tensor.t() is now equivalent with Numpy's ndarray.T for 1D tensor
i.e. tensor.t() == tensor
Test case added:
- test_t
fixes#9687
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17462
Differential Revision: D14214838
Pulled By: soumith
fbshipit-source-id: c5df1ecc8837be22478e3a82ce4854ccabb35765
Summary:
this code is a bit intricate so i refactor it
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16995
Differential Revision: D14050667
Pulled By: ifedan
fbshipit-source-id: 55452339c6518166f3d4bc9898b1fe2f28601dc4
Summary:
First pass at user defined types. The following is contained in this PR:
- `UserType` type, which contains a reference to a module with all methods for the type, and a separate namespace for data attributes (map of name -> TypePtr).
- `UserTypeRegistry`, similar to the operator registry
- `UserObject` which is the runtime representation of the user type (just a map of names -> IValues)
- `UserTypeValue` SugaredValue, to manage getattr and setattr while generating IR, plus compiler.cpp changes to make that work.
- Frontend changes to get `torch.jit.script` to work as a class decorator
- `ClassDef` node in our AST.
- primitive ops for object creation, setattr, and getattr, plus alias analysis changes to make mutation safe.
Things that definitely need to get done:
- Import/export, python_print support
- String frontend doesn't understand class definitions yet
- Python interop (using a user-defined type outside TorchScript) is completely broken
- Static methods (without `self`) don't work
Things that are nice but not essential:
- Method definition shouldn't matter (right now you can only reference a method that's already been defined)
- Class definitions can only contain defs, no other expressions are supported.
Things I definitely won't do initially:
- Polymorphism/inheritance
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17314
Differential Revision: D14194065
Pulled By: suo
fbshipit-source-id: c5434afdb9b39f84b7c85a9fdc2891f8250b5025
Summary:
Not sure the best way to integrate this…I wrote something that focuses on mutability "vertically" through the stack. Should I split it up and distribute it into the various sections, or keep it all together?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17454
Differential Revision: D14222883
Pulled By: suo
fbshipit-source-id: 3c83f6d53bba9186c32ee443aa9c32901a0951c0
Summary:
as title
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17476
Differential Revision: D14218312
Pulled By: suo
fbshipit-source-id: 64df096a3431a6f25cd2373f0959d415591fed15
Summary:
Temporarily disable them for perf consideration. Will figure out a way to do `torch.zeros(sizes, grad.options())` in torchscript before enabling these.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17470
Differential Revision: D14210313
Pulled By: ailzhang
fbshipit-source-id: efaf44df1192ae42f4fe75998ff0073234bb4204
Summary: Update the docs to include the value parameter that was missing in the `scatter_` function.
Differential Revision: D14209225
Pulled By: soumith
fbshipit-source-id: 5c65e4d8fbd93fcd11a0a47605bce6d57570f248
Summary:
Add check and provide useful warning/error information to user if foxi is not checked out.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17477
Reviewed By: zrphercule
Differential Revision: D14212896
Pulled By: houseroad
fbshipit-source-id: 557247d5d8fdc016b1c24c2a21503e59f874ad09
Summary:
Stack:
⚫ **#17453 [jit] simplify aliasdb interface** [💛](https://our.intern.facebook.com/intern/diff/D14205209/)
The previous "getWrites" API relies on the user to do alias checking, which is confusing and inconsistent with the rest of the interface. So replace it with a higher-level call.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17453
Differential Revision: D14209942
Pulled By: suo
fbshipit-source-id: d4aff2af6062ab8465ee006fc6dc603296bcb7ab
Summary:
Previously we were unifying the types of lists across if block outputs. This now fails with Optional subtyping because two types which can be unified have different runtime representations.
```
torch.jit.script
def list_optional_fails(x):
# type: (bool) -> Optional[int]
if x:
y = [1]
else:
y = [None]
return y[0]
```
the indexing op will expect y to be a generic list, but it will find an intlist.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17424
Differential Revision: D14210903
Pulled By: eellison
fbshipit-source-id: 4b8b26ba2e7e5bebf617e40316475f91e9109cc2
Summary:
When switching back to `d0` from a stream on a different device `d1`, we need to restore the current streams on both `d0` and `d1`. The current implementation only does that for `d0`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17439
Differential Revision: D14208919
Pulled By: mrshenli
fbshipit-source-id: 89f2565b9977206256efbec42adbd789329ccad8
Summary:
I originally set out to fix to_sparse for scalars, which had some overly restrictive checking (sparse_dim > 0, which is impossible for a scalar).
This fix uncovered an issue with nonzero: it didn't properly return a size (z, 0) tensor for an input scalar, where z is the number of nonzero elements (i.e. 0 or 1).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17406
Differential Revision: D14185393
Pulled By: gchanan
fbshipit-source-id: f37a6e1e3773fd9cbf69eeca7fdebb3caa192a19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17308
In some cases there is still no RVO/NRVO and std::move is still needed. Latest
Clang gained -Wreturn-std-move warning to detect cases like this (see
https://reviews.llvm.org/D43322).
Reviewed By: igorsugak
Differential Revision: D14150915
fbshipit-source-id: 0df158f0b2874f1e16f45ba9cf91c56e9cb25066
Summary:
as title. These were already added to the tutorials, but I didn't add them to the cpp docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17452
Differential Revision: D14206501
Pulled By: suo
fbshipit-source-id: 89b5c8aaac22d05381bc4a7ab60d0bb35e43f6f5
Summary:
" ProTip! Great commit summaries contain fewer than 50 characters. Place extra information in the extended description."
lol
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17450
Differential Revision: D14206500
Pulled By: suo
fbshipit-source-id: af7ffe299f8c8f04fa8e720847a1f6d576ebafc1
Summary:
The chunk buffer had a possibility to hang when no data is read and the buffer size is lower than chunk size. We detected this while running with larger dataset and hence the fix. I added a test to mimic the situation and validated that the fix is working. Thank you Xueyun for finding this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17409
Differential Revision: D14198546
Pulled By: soumith
fbshipit-source-id: b8ca43b0400deaae2ebb6601fdc65b47f32b0554
Summary:
The CI is broken now, this diff should fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17430
Differential Revision: D14198045
Pulled By: houseroad
fbshipit-source-id: a1c8cb5ccff66f32488702bf72997f634360eb5b
Summary:
This involves another purely cosmetic (ordering) change to the `config.yml` to facilitate simpler logic.
Other changes:
* add some review feedback as comments
* exit with nonzero status on config.yml mismatch
* produce a diagram for pytorch builds
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17427
Differential Revision: D14197618
Pulled By: kostmo
fbshipit-source-id: 267439d3aa4c0a80801adcde2fa714268865900e
Summary:
Previously we only generate one class for each extension backend. This caused issues with scalarType() calls and mapping from variable Types to non-variable types. With this change we generate one Type for each scalar type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17278
Reviewed By: ezyang
Differential Revision: D14161489
Pulled By: li-roy
fbshipit-source-id: 91e6a8f73d19a45946c43153ea1d7bc9d8fb2409
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17384
Better handling of possible net run errors in prof_dag counters.
Reviewed By: yinghai
Differential Revision: D14177619
fbshipit-source-id: 51bc952c684c53136ce97e22281b1af5706f871e
Summary:
Batch of removing expect files, and some tests that no longer test anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17414
Differential Revision: D14196342
Pulled By: eellison
fbshipit-source-id: 75c45649d1dd1ce39958fb02f5b7a2622c1d1d01
Summary:
This will evolve into complete technical docs for the jit. Posting what I have so far so people can start reading it and offering suggestions. Goto to Files Changed and click 'View File' to see markdown formatted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16887
Differential Revision: D14191219
Pulled By: zdevito
fbshipit-source-id: 071a0e7db05e4f2eb657fbb99bcd903e4f46d84a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17375
Previously we create the onnxGraph first and take it to the onnx manager for registration. It doesn't work well in practice. This diff takes "bring your own constructor" approach to reduce the resource spent doing backend compilation.
Reviewed By: kimishpatel, rdzhabarov
Differential Revision: D14173793
fbshipit-source-id: cbc4fe99fc522f017466b2fce88ffc67ae6757cf
Summary:
The benchmarks are now running on gpu cards with more memory
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17416
Differential Revision: D14190493
Pulled By: bddppq
fbshipit-source-id: 66db1ca1fa693d24c24b9bc0185a6dd8a3337103
Summary:
This PR removes a few size of `self` that passed from forward pass to backward pass when `self` is already required in backward pass. This could be reason that cause the potential slow down in #16689 . I will attach a few perf numbers (still a bit volatile among runs tho) I got in the comment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17187
Differential Revision: D14179512
Pulled By: ailzhang
fbshipit-source-id: 5f3b1f6f26a3fef6dec15623b940380cc13656fa
Summary:
This fell through the cracks from the migration from pytorch/builder to circleci. It's technically still racey, but is much less likely now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17381
Differential Revision: D14190137
Pulled By: pjh5
fbshipit-source-id: 2d4cd04ee874cacce47d1d50b87a054b0503bb82
Summary:
Creates a new shared type parser to be shared between the IR parser and the Schema Parser.
Also adds parsing of CompleteTensorType and DimensionedTensorType, and feature-gates that for the IRParser.
Renames the existing type_parser for python annotations, python_type_parser, and names the new one jit_type_parser.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17383
Differential Revision: D14186438
Pulled By: eellison
fbshipit-source-id: bbd5e337917d8862c7c6fa0a0006efa101c76afe
Summary:
Still wip, need more tests and correct handling for opset 8 in symbolics.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16068
Reviewed By: zrphercule
Differential Revision: D14185855
Pulled By: houseroad
fbshipit-source-id: 55200be810c88317c6e80a46bdbeb22e0b6e5f9e
Summary:
reorder some envars for consistency
add readme and notice at the top of config.yml
generate more yaml from Python
closes#17322
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17323
Differential Revision: D14186734
Pulled By: kostmo
fbshipit-source-id: 23b2b2c1960df6f387f1730c8df1ec24a30433fd
Summary:
fallback operators to CPU for onnx support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15270
Differential Revision: D14099496
Pulled By: yinghai
fbshipit-source-id: 52b744aa5917700a802bdf19f7007cdcaa6e640a
Summary:
As of tight now, the script will produce a new generated file which will be inconsistent with the rest.
Test Result:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17370
Differential Revision: D14184943
Pulled By: izdeby
fbshipit-source-id: 5d3b956867bee661256cb4f38f086f33974a1c8b
Summary:
Currently there is a mismatch in naming between Python BatchNorm `running_var` and C++ BatchNorm `running_variance`, which causes JIT model parameters loading to fail (https://github.com/pytorch/vision/pull/728#issuecomment-466067138):
```
terminate called after throwing an instance of 'c10::Error'
what(): No such serialized tensor 'running_variance' (read at /home/shahriar/Build/pytorch/torch/csrc/api/src/serialize/input-archive.cpp:27)
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 0x85 (0x7f2d92d32f95 in /usr/local/lib/libc10.so)
frame #1: torch::serialize::InputArchive::read(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, at::Tensor&, bool) + 0xdeb (0x7f2d938551ab in /usr/local/lib/libtorch.so.1)
frame #2: torch::nn::Module::load(torch::serialize::InputArchive&) + 0x98 (0x7f2d9381cd08 in /usr/local/lib/libtorch.so.1)
frame #3: torch::nn::Module::load(torch::serialize::InputArchive&) + 0xf9 (0x7f2d9381cd69 in /usr/local/lib/libtorch.so.1)
frame #4: torch::nn::Module::load(torch::serialize::InputArchive&) + 0xf9 (0x7f2d9381cd69 in /usr/local/lib/libtorch.so.1)
frame #5: torch::nn::operator>>(torch::serialize::InputArchive&, std::shared_ptr<torch::nn::Module> const&) + 0x32 (0x7f2d9381c7b2 in /usr/local/lib/libtorch.so.1)
frame #6: <unknown function> + 0x2b16c (0x5645f4d1916c in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #7: <unknown function> + 0x27a3c (0x5645f4d15a3c in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #8: <unknown function> + 0x2165c (0x5645f4d0f65c in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #9: <unknown function> + 0x1540b (0x5645f4d0340b in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
frame #10: __libc_start_main + 0xf3 (0x7f2d051dd223 in /usr/lib/libc.so.6)
frame #11: <unknown function> + 0x1381e (0x5645f4d0181e in /home/shahriar/Projects/CXX/build-TorchVisionTest-Desktop_Qt_5_12_1_GCC_64bit-Debug/TorchVisionTest)
```
Renaming C++ BatchNorm `running_variance` to `running_var` should fix this problem.
This is a BC-breaking change, but it should be easy for end user to rename `running_variance` to `running_var` in their call sites.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17371
Reviewed By: goldsborough
Differential Revision: D14172775
Pulled By: yf225
fbshipit-source-id: b9d3729ec79272a8084269756f28a8f7c4dd16b6
Summary:
**WIP**
Attempt 2 at #14831
This adds `nn.LSTM` to the jit standard library. Necessary changes to the module itself are detailed in comments. The main limitation is the lack of a true `PackedSequence`, instead this PR uses an ordinary `tuple` to stand in for `PackedSequence`.
Most of the new code in `rnn.py` is copied to `nn.LSTM` from `nn.RNNBase` to specialize it for LSTM since `hx` is a `Tuple[Tensor, Tensor]` (rather than just a `Tensor` as in the other RNN modules) for LSTM.
As a hack it adds an internal annotation `@_parameter_list` to mark that a function returns all the parameters of a module. The weights for `RNN` modules are passed to the corresponding op as a `List[Tensor]`. In Python this has to be gathered dynamically since Parameters could be moved from CPU to GPU or be deleted and replaced (i.e. if someone calls `weight_norm` on their module, #15766), but in the JIT parameter lists are immutable, hence a builtin to handle this differently in Python/JIT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15744
Differential Revision: D14173198
Pulled By: driazati
fbshipit-source-id: 4ee8113159b3a8f29a9f56fe661cfbb6b30dffcd
Summary:
The test I added was failing lint because a constant was being created that wasn't being destroyed.
It was being inserted to all_nodes, then failing the check
` AT_ASSERT(std::includes(ALL_OF(sum_set), ALL_OF(all_nodes_set)));`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17316
Differential Revision: D14172548
Pulled By: eellison
fbshipit-source-id: 0922db21b7660e0c568c0811ebf09b22081991a4
Summary:
This provides the minimum necessary to allow derivative formulas for things that have a kwarg only specifier in their schema. Support for non-parser frontend default arguments for kwargs is not completed.
Fixes#16921
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17339
Differential Revision: D14160923
Pulled By: zdevito
fbshipit-source-id: 822e964c5a3fe2806509cf24d9f51c6dc01711c3
Summary:
Fix for #17261, SsnL do you have tests for it in your other PR? If not, I'll add to this. Example from #17261 now does not error out (and same for log_softmax).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17330
Differential Revision: D14171529
Pulled By: soumith
fbshipit-source-id: ee925233feb1b44ef9f1d757db59ca3601aadef2
Summary:
Adds about 30 matches due to new functions / misuse of double.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17340
Differential Revision: D14161109
Pulled By: cpuhrsch
fbshipit-source-id: bb3333446b32551f7469206509b480db290f28ee
Summary:
The method will be used in IRParser and in NetDef converter.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17372
Differential Revision: D14172494
Pulled By: ZolotukhinM
fbshipit-source-id: 96cae8422bc73c3c2eb27524f44ec1ee8cae92f3
Summary:
This PR switches from `OperationCreator` to `Operation` to simplify the logic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17183
Differential Revision: D14169829
Pulled By: Krovatkin
fbshipit-source-id: 27f40a30c92e29651cea23f08b5b1f13d7eced8c
Summary:
Our sparse tests still almost exclusively use legacy constructors. This means you can't, for example, easily test scalars (because the legacy constructors don't allow them), and not surprisingly, many operations are broken with sparse scalars.
Note: this doesn't address the SparseTensor constructor itself, because there is a separate incompatibility there that I will address in a follow-on commit, namely, that torch.sparse.FloatTensor() is supported, but torch.sparse_coo_tensor() is not (because the size is ambiguous).
The follow-on PR will explicitly set the size for sparse tensor constructors and add a test for the legacy behavior, so we don't lose it.
Included in this PR are changes to the constituent sparse tensor pieces (indices, values):
1) IndexTensor becomes index_tensor
2) ValueTensor becomes value_tensor if it is a data-based construction, else value_empty.
3) Small changes around using the legacy tensor type directly, e.g. torch.FloatTensor.dtype exists, but torch.tensor isn't a type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17324
Differential Revision: D14159270
Pulled By: gchanan
fbshipit-source-id: 71ee63e1ea6a4bc98f50be41d138c9c72f5ca651
Summary:
Apparently, before the only way we enforced it was size>=0 in alloc_cpu. So empty((5,-5)) would fail but empty((-5,-5)) would hang :)
Please suggest better place to enforce it if any.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17077
Differential Revision: D14077930
Pulled By: dzhulgakov
fbshipit-source-id: 1120513300fd5448e06fa15c2d72f9b0ee5734e4
Summary:
This PR addresses the slowness of MVN's log_prob as reported in #17206.
t-vi I find it complicated to handle permutation dimensions if we squeeze singleton dimensions of bL, so I leave it as-is and keep the old approach. What do you think?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17294
Differential Revision: D14157292
Pulled By: ezyang
fbshipit-source-id: f32590b89bf18c9c99b39501dbee0eeb61e130d0
Summary:
Fix#16650.
Headers such as `ATen/cpu/vml.h` contain `#include <ATen/cpu/vec256/vec256.h>`
for example, but these vec256 headers aren't included, due to commit e4c0bb1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17220
Differential Revision: D14165695
Pulled By: ezyang
fbshipit-source-id: 27b2aa2a734b3719ca4af0565f79623b64b2620f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17297
When `torch.load` needs to load a tensor, no matter which device it will be end up being loaded on, it first creates a CPU storage for it of the necessary size. This storage is allocated but it's not "set" yet, hence no data is written to it: it exists in the kernel's memory map, but it's not resident and doesn't take up physical pages. Then, this storage is passed to the `map_location` function (if the parameter is a string, a device or a map, PyTorch builds that function automatically). The default map for CUDA consists effectively in `lambda storage, _: storage.cuda()` (I omitted the code needed to pick the correct device). This creates a GPU storage and copies over the data of the CPU storage. *This step is unnecessary as we're copying uninitialized memory*. (Surprisingly enough, though, it appears the kernel is smart enough that reading from the unpaged CPU memory doesn't cause it to become paged.) Once `map_location` returns a storage residing on the correct target device, `torch.load` resumes reading the file and copying the tensor's content over into the storage. This will overwrite the content that had previously been written to it, which confirms that the above copy was pointless.
A way to avoid this useless copy is to just create and return a new empty storage on the target GPU, instead of "transforming" the original one.
This does indeed increase the performance:
```
In [5]: torch.save(torch.rand(100, 100, 100), "/tmp/tensor")
In [6]: %timeit torch.load("/tmp/tensor", map_location="cuda")
1.55 ms ± 111 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [7]: %timeit torch.load("/tmp/tensor", map_location=lambda storage, _: torch.cuda.FloatStorage(storage.size()))
1.03 ms ± 44 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Credit for this diff is shared with adamlerer and fmassa.
Differential Revision: D14147673
fbshipit-source-id: a58d4bc0d894ca03a008499334fc2cdd4cc91e9f
Summary:
If something is a TensorList, it should be a list of `TensorType`, not a list of some specialized type.
Fixes#17140, #15642
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17321
Differential Revision: D14158192
Pulled By: suo
fbshipit-source-id: ba8fe6ae8d618c73b23cd00cbcb3111c390c5514
Summary:
Bunch of random stuff I came across while doing UDT stuff. Putting in a separate PR to avoid noise
- fix up the alias analysis list ops to include fork/wait
- improve dump() for aliasDb to print writes
- Move BuiltinFunction::call() to sugaredvalue with the rest of the methods
- formatting and includes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17288
Differential Revision: D14147105
Pulled By: suo
fbshipit-source-id: 62e2a922a1726b684347365dc42c72188f154e9c
Summary:
MKL-DNN support multi-node mode,but not support multi-devices mode,this commit will support multi-devices for MKL-DNN.This commit depend on https://github.com/pytorch/pytorch/pull/11330
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12856
Differential Revision: D13735075
Pulled By: ezyang
fbshipit-source-id: b63f92b7c792051f5cb22e3dda948013676e109b
Summary:
add missing std introduced by #16689 . Investigating why this wasn't caught in CI (nor my local dev environment).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17263
Reviewed By: ezyang
Differential Revision: D14134556
Pulled By: ailzhang
fbshipit-source-id: 6f0753fa858d3997e654924779646228d6d49838
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15034
Rethrow exception happened during RunAsync, ensure that pending tasks
are not executed after marked as finished
Reviewed By: andrewwdye
Differential Revision: D13409649
fbshipit-source-id: 3fd12b3dcf32af4752f8b6e55eb7a92812a5c057
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17132
schedule() function is not supposed to throw exception and is supposed
to succeed in scheduling the full graph of tasks, potential errors (e.g. errors
from underlying thread pool, out of memory exceptions etc) are considered not
recoverable.
The invariant - the graph of tasks is either not executed or
executed in full before the call to finishRun()
Reviewed By: andrewwdye
Differential Revision: D14092457
fbshipit-source-id: a3e5d65dfee5ff5e5e71ec72bb9e576180019698
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17275
Previous implementation used a memcpy inside the kernel. It is more efficient to reduce the data fetched per thread to a single word from memory. This exposes more concurrency and takes advantage of GPU memory coalescing support.
Reviewed By: takatosp1
Differential Revision: D14120147
fbshipit-source-id: c4734003d4342e55147c5b858f232a006af60b68
Summary:
With this patch you can use USE_DISTRIBUTED=OFF (possibly in combination with USE_NCCL=OFF (?))
The significance is partly because the NCCL doesn't build with CUDA 8.
This is written under the assumption that NCCL is required for distributed if not, the USE_DISTRIBUTED check in nccl.py should be replaced by a check for the USE_NCCL environment variable.
Fixes: #17274
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17295
Differential Revision: D14155080
Pulled By: ezyang
fbshipit-source-id: 0d133f7c5b4d118849f041bd4d4cbbd7ffc3c7b4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16723
Removed obsolete argument correct_transform_coords in bbox_transform op.
* It was only for backward compatibility. We should not have models using it now.
Differential Revision: D13937430
fbshipit-source-id: 504bb066137ce408c12dc9dcc2e0a513bad9b7ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17194
we found that there is a per row absolute error due to int8 quant
and a relative error table-wide in case fp16 is used
Reviewed By: csummersea
Differential Revision: D14113353
fbshipit-source-id: c7065aa9d15c453c2e5609f421ad0155145af889
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17198
We come to the point that we need to apply some rules to bind certain ops together to avoid un-inferrable intermediate shapes. We either lower them together to backend or neither. This diff adds a pass for us to add rules like this. The first one is to bind `Gather` with `SparseLengthsWeighted*`.
Reviewed By: ipiszy
Differential Revision: D14118326
fbshipit-source-id: 14bc62e1feddae02a3dd8eae93b8f553d52ac951
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17272
after windows-specific fixes were applied new file was left out of CMakeLists
Reviewed By: orionr
Differential Revision: D14140419
fbshipit-source-id: 6a6c652048ed196ec20241bc2a1d08cbe2a4e155
Summary:
This commit did below enhancements:
1, add doc for build_android.sh;
2, add install step for build_android.sh, thus the headers and libraries can be collected together for further usage conveniently;
3, change the default INSTALL_PREFIX from $PYTORCH_ROOT/install to $PYTORCH_ROOT/build_android/install to make the project directory clean.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17298
Differential Revision: D14149709
Pulled By: soumith
fbshipit-source-id: a3a38cb41f26377e21aa89e49e57e8f21c9c1a39
Summary:
The particular use case reported is Jetson TX2 and maskrcnn.
Fixes#17144
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17296
Differential Revision: D14147886
Pulled By: soumith
fbshipit-source-id: 44d5a89aaeb4cc07d1b53dd90121013be93c419c
Summary:
`TestNN.test_variable_sequence_cuda` sometimes brakes due to CUDA leak.
The cause appears to be too small tolerance breaking float16 sub-test of the test above.
When it breaks it calls abort disrupting correct tear down of the test
and false alarming about the leak.
~~Also, removed annoying **Upsample** module warning.
IMHO this warning is wrong because the module **Upsample** is not deprecated. Seems like it's been mixed
with `nn.functional.upsample` function which is indeed deprecated in favor of `nn.functional.interpolate`, see `torch/nn/functional.py:2387` for details (this replacement is also performed in `test_nn.py`).~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17242
Differential Revision: D14141686
Pulled By: soumith
fbshipit-source-id: faa8f87440d94bdc6ab0ff00be6dad82353115c4
Summary:
Currently, when the input tensor `self` is not contiguous, `tril_` and `triu_` calls `self = self.contiguous()`, which allocates a new contiguous tensor and assign it to `self`. This effectively changes the input tensor `self`'s pointer and will break downstream code after Variable/Tensor merge.
This PR fixes it so that `tril_` and `triu_` always update the input tensor in-place and preserve the input tensor's TensorImpl.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17031
Differential Revision: D14069592
Pulled By: yf225
fbshipit-source-id: d188218f426446a44ccc1d33fc28ac3f828c6a05
Summary:
Some value are copied when it could've been moved.
Detected by compiler flag -Wreturn-std-move
Reviewed By: igorsugak
Differential Revision: D14134303
fbshipit-source-id: 8fc3bb2017108b3d65097cb8447e33f5b6c743b4
Summary:
light weight implementation of LLVM filecheck utility. Currently only handles string matching - regexes & saving a regex to a variable name can be added as needed.
Current intended usage is through FileCheckBuilder python handle, and is shown in the tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16858
Differential Revision: D14096244
Pulled By: eellison
fbshipit-source-id: c7c8d1457691c105e6ccbb3c1a378d96baac2569
Summary:
Trying to land again, make prim::None into a case of prim::Constant. Reverted the previous landing because it broke an important onnx export test.
https://github.com/pytorch/pytorch/pull/16160
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17186
Differential Revision: D14115304
Pulled By: eellison
fbshipit-source-id: 161435fc30460b4e116cdd62c7b2e5b94581dcb7
Summary: The `tensor` be used as `end` clarified in the docs.
Differential Revision: D14132212
Pulled By: ezyang
fbshipit-source-id: e9bca14d5079e5f7adfc18afcb1eec832ef86e9e
Summary:
Reenables rand_like fusion if no tensor is broadcasted in the fusion group. This is a sufficient but not necessary condition for fused rand_like to produce correct results, and it has an unpleasant side effect of falling back to non-fused path if rand_like was optimistically included in the fusion group, but there is a broadcast in the fusion group not necessarily related to rand_like. E.g. before this PR, if the network had (biasAdd -> relu -> dropout), fuser could fuse biasAdd and relu, now it will try fusing the whole thing (if dropout is expressed via rand_like) and fall back every time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16087
Differential Revision: D13720232
Pulled By: zou3519
fbshipit-source-id: 1e19203bec4a59257bfc7078b054a19f00fab4ad
Summary:
This is the first commit from a series of planned changes in order to add boolean tensors to PyTorch. The whole plan looks like this:
0. Storage Implementation (this change)
1. Tensor Creation.
2. Tensor Conversions.
3. Tensor Indexing.
4. Tensor Operations.
5. Back compatibility related changes.
This feature was requested by the community:
https://github.com/pytorch/pytorch/issues/4764https://github.com/pytorch/pytorch/issues/4219https://github.com/pytorch/pytorch/issues/4288
**Change**:
Added boolean type to the Storage class for CPU and CUDA backends.
**Tested via**:
1. unit tests
2. running this:
-> import torch
-> torch.BoolStorage
<class 'torch.BoolStorage'>
-> torch.cuda.BoolStorage
<class 'torch.cuda.BoolStorage'>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16810
Reviewed By: gchanan
Differential Revision: D14087246
Pulled By: izdeby
fbshipit-source-id: 042642ced1cb0fd1bb6bff05f9ca871a5c54ee5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17188
Using flag "-Wreturn-std-move", compiler can identify the cases where a copy
operation
is performed when a move operation would have been available. Wrapped return
statement with std::move to fix.
For some reason, these files are not automatically modded. With D14115372
we should be able to turn on the compile flag
Reviewed By: soumith
Differential Revision: D14115786
fbshipit-source-id: e763b92eecbe4468027fc141d029618d1e9f280b
Summary:
Adding two distrbuted samplers, Random and Sequential to the mix. Similar to python counterpart, DistributedSampler introduces a new method `set_epoch(size_t epoch)` which can be use to shuffle data determinstically between distributed processes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16910
Differential Revision: D14130980
Pulled By: soumith
fbshipit-source-id: ec08b7130c01e2fc6dc3693f7ac622a0a6d60f10
Summary:
del Tensor.grad set PyObject to nullptr
and Tensor.grad = None set PyObject to Py_None
Handling both the cases now
fixes ##16471
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16525
Differential Revision: D14130800
Pulled By: soumith
fbshipit-source-id: ed85c38305bba94d5047311cb58e4e4cedd09832
Summary:
It might need some cleaning up and might be missing some features, but it should be already working for most cases.
This PR is based on top of PR16986 (so please review only the last commit here).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16987
Differential Revision: D14074577
Pulled By: ZolotukhinM
fbshipit-source-id: 712b598f423265655f574bb9903e2066628eaad3
Summary:
similar to softmax there are issues of getting nan randomly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17170
Differential Revision: D14110515
Pulled By: bddppq
fbshipit-source-id: 5c97661184d45a02122fd69d35a839fdf4520c8c
Summary:
Currently the converters are very straightforward, i.e. there is no code for trying to
preserve semantics, we're purely perform conversion from one format to another.
Two things that we might want to add/change:
1. Add semantic conversion as well (but probably it would be a good idea to keep
it separate as a temporary thing).
2. Make sure we don't mess with value names, as they are crucial for current
uses of NetDefs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17123
Differential Revision: D14090244
Pulled By: ZolotukhinM
fbshipit-source-id: 07175fa9235582e1d1da5f10a42a5c1280b1b394
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17062
from jiyan's training jobs it seems like we found a quantization bug
fp32
fp32->rowwise int8 is fine
fp16 is fine
fp16->rowwise int8 is not fine
we are preconverting everything to fp32 and using the existing code, so there is no need to change the epsilon in the case of fp16 since at the time of converting, everything is a float
Reviewed By: jspark1105
Differential Revision: D14063271
fbshipit-source-id: 747297d64ed8c6fdf4be5bb10ac584e1d21a85e6
Summary:
This change simplifies analysis done on constants since prim::None does not need to be handled separately now. To check if a constant node is None, use node->isNone().
Next step will be to remove prim::Undefined.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16160
Differential Revision: D14109636
Pulled By: eellison
fbshipit-source-id: d26fd383976163a2ddd4c24984bd672a541cc876
Summary:
Based on https://github.com/pytorch/pytorch/pull/12413, with the following additional changes:
- Inside `native_functions.yml` move those outplace operators right next to everyone's corresponding inplace operators for convenience of checking if they match when reviewing
- `matches_jit_signature: True` for them
- Add missing `scatter` with Scalar source
- Add missing `masked_fill` and `index_fill` with Tensor source.
- Add missing test for `scatter` with Scalar source
- Add missing test for `masked_fill` and `index_fill` with Tensor source by checking the gradient w.r.t source
- Add missing docs to `tensor.rst`
Differential Revision: D14069925
Pulled By: ezyang
fbshipit-source-id: bb3f0cb51cf6b756788dc4955667fead6e8796e5
Summary:
The main problem there is with differentiating batch norm statically
is that we make a lot of complex run-time decisions about the backend
we choose. Then, the autograd derivatives are implemented for every
backend separately, which makes sense, because they might be saving
buffers containing different values. To resolve the issue, the forward
op returns an index of the chosen backend, and the backward function
takes it as an argument, such that it knows how to interpret the buffers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15403
Differential Revision: D14098815
Pulled By: ailzhang
fbshipit-source-id: 7fcd3e6e0566433e81fe8286fb441c1ecaf198ad
Summary:
/cc goldsborough
Working on #14582
The corresponding python implementations are at: [pytorch/torch/nn/init.py](6302e4001a/torch/nn/init.py (L261-L327))
Here is my initial implementation of Kaiming Initialization. I have not been able to figure out how to successfully run tests locally so I haven't added any yet.
A couple questions:
- Are the enums defined in the right place? I copied their names from Python, but do you prefer different naming conventions for C++?
- To run tests locally do I use `python setup.py test`? Can I run just a subset of the tests somehow?
- Should I add my tests at [test/cpp/api/misc.cpp](https://github.com/pytorch/pytorch/blob/master/test/cpp/api/misc.cpp#L47-L54)?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14718
Differential Revision: D14049159
Pulled By: goldsborough
fbshipit-source-id: 966ac5126875936e69b185b5041f16476ed4cf70
Summary:
In `torch.distributed.launch.py`, it passes `local_rank` as argument and requires user's program to parse it. However, it would be more flexible for users and consistent with other variables, e.g. `RANK`, `MASTER_PORT`, `WORLD_SIZE`, if passing through environment variables.
265ed8ff45/torch/distributed/launch.py (L200-L212)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16360
Differential Revision: D14070372
Pulled By: ezyang
fbshipit-source-id: c3f6a8e55ab513918cad09d1326eccdedb4d98c9
Summary:
The binary ops that are using TensorIterator do a trick in order to only write the code once for out and non-out variants:
1) Have the non-out variant call the out variant with an undefined tensor.
2) the out variant then reassigns the result tensor to the output of the TensorIterator; this is a no-op in the case where a valid tensor was passed and it correctly propagates the result back to the non-out variant, which is legal because it's just reassigning an undefined tensor.
I believe other solutions to this problem would require an unnecessary reference bump, e.g. defining another out variant that returns a Tensor rather than a reference.
Unfortunately, this doesn't work with const-references, which we want to move our output arguments to be (because const doesn't actually provide const correctness here, and writers mistakenly reassign the parameter in the case it isn't an out variant).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17059
Differential Revision: D14068402
Pulled By: gchanan
fbshipit-source-id: 89fef177a1e174dbe2858e2eae0f6d85460b07d1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17158
Because of Reshape op, batch size can be changed. This diff addresses first order issue raised from multiple batch size system. We need to export different real_batch_size for different max_batch_size input and attach it to the right output.
It also fixes a false exception.
Reviewed By: ipiszy
Differential Revision: D14099541
fbshipit-source-id: 0fa9e86826f417a11d2b5dd2ee60dff64a7ce8c4
Summary:
This initial PR splits the `.circleci/config.yml` file into several smaller files that are stitched verbatim back into the original. A proof of concept of dynamically generating yaml for the job configuration list is also introduced.
Since the `config.yml` file must exist in the repo in its final form, there must exist a manual update and check-in step to regenerate `config.yml` from its constituent parts.
Consistency between the checked-in `config.yml` file and the authoritative source data is enforced at build time through TravisCI.
closes#17038
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17039
Reviewed By: yf225
Differential Revision: D14109059
Pulled By: kostmo
fbshipit-source-id: bc04a73145290358854f5a5e552a45e559118fc3
Summary:
This PR add supports for simpler for-in-list loops such as the example below:
```python
torch.ji.python
def sum_list(a):
# type: (List[int]) -> int
sum = 0
for i in a:
sum += i
return sum
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16726
Differential Revision: D14070007
Pulled By: ezyang
fbshipit-source-id: b4d971ee647729a6caa3099ceac34ec5c4f143de
Summary:
one_hot docs is missing [here](https://pytorch.org/docs/master/nn.html#one-hot).
I dug around and could not find a way to get this working properly.
Differential Revision: D14104414
Pulled By: zou3519
fbshipit-source-id: 3f45c8a0878409d218da167f13b253772f5cc963
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17105
To make FC with rowwise quantization faster, reduce code duplication, and make code consistent with Convolution
Reviewed By: csummersea
Differential Revision: D14080461
fbshipit-source-id: 2b0e67b86e7e3029c90751a8824bf80ae1223680
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17145
Prepacked weight contains both weight and bias, so the bias should be obtained from input index 1, not from 2
Reviewed By: jianyuh
Differential Revision: D14097281
fbshipit-source-id: b8b836b85a7b240e2fd1734377c46d9bf2ce3390
Summary:
In the NUMA case, PinnedCPUAllocator's allocate() would return a
DataPtr constructed by DefaultCPUAllocator, which would reference
the Default... Delete() rather than the Pinned... Delete(). That
meant Pinned... Delete() would never run, so cudaHostUnregister()
would never be called when regions were freed.
See: https://github.com/pytorch/pytorch/issues/16280
This change adds a 'naked_allocate()' method to the Default allocator
that just returns a pointer to the allocated memory rather than
wrapping it in a DataPtr. Pinned allocator uses that then constructs
a DataPtr with reference to its own Delete().
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16340
Reviewed By: dzhulgakov
Differential Revision: D13843206
Pulled By: ezyang
fbshipit-source-id: 9efb572e5a01b49ef2a4aceeccc13cd0b1066528
Summary:
This prevent people (reviewer, PR author) from forgetting adding things to `torch.rst`.
When something new is added to `_torch_doc.py` or `functional.py` but intentionally not in `torch.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16039
Differential Revision: D14070903
Pulled By: ezyang
fbshipit-source-id: 60f2a42eb5efe81be073ed64e54525d143eb643e
Summary:
setting the correct math type for cudnn rnn, which is enforced starting from cudnn 7.5+
1. Updating persistent rnn check with input data type instead of rnn math type;
2. Updating rnn type promotion to set correct math type for accumulation;
3. Replace datatype check for filter descriptor from rnn.datatype to input.datatype;
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16825
Differential Revision: D14071190
Pulled By: ezyang
fbshipit-source-id: 1c9a1531ccf510cb0619e830be444c20c5e72f3f
Summary:
In light of the antistatic feature being a part of the released ROCm 2.1, remove
the feature in pyHIPIFY for extraction of kernel arguments and insertion of
static_casts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17055
Differential Revision: D14068478
Pulled By: bddppq
fbshipit-source-id: 6895f490c78247a129aa18c520ff8d4d1a3d3642
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16722
Updated bbox_transform and nms unit test for caffe2 ops.
Differential Revision: D13937416
fbshipit-source-id: 034743d29671c6e73d323a935e2d734ecc071bff
Summary:
support data parallel for ScriptModule.
see unit tests for testing done for this PR. I also tried traced version of resnet18 from torchvision.
I'm yet to try a complete end-to-end data parallel training. This will be next steps.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16891
Differential Revision: D14002222
Pulled By: gqchen
fbshipit-source-id: fce3598169113215599815c6978e66d3c3a8c282
Summary:
Follow up of #14533, add more test coverage for emitif metaprogramming conditions. Also delete some unwrap optional usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16794
Differential Revision: D14096868
Pulled By: wanchaol
fbshipit-source-id: ee1cec609c58d0dd65211249a90207be06649e71
Summary:
When adaptive pooling has to produce a single pixel feature map, it is faster to do so by calling .mean(). Backward calls a pretty inefficient cuda kernel with atomics, which becomes ridiculously slow for halfs. For half this PR provides approx 30x speed-up for adaptive average pooling, which results in 30% end-to-end speed-up on senet. Improvements are smaller for float, but still significant (approx 5x).
Also this PR unifies handling of 3d (no batch dimension) and 4d tensors, using negative dimension indices.
cc ezyang for review.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17011
Reviewed By: ailzhang
Differential Revision: D14078747
Pulled By: soumith
fbshipit-source-id: 0eb9255da2351190a6bcaf68c30e2ae2402a2dd9
Summary:
This updates the example for `torch.mode` to show a case where there is a mode.
Also add a bit of a description to the explanation as well as being a bit more precise about "a" mode rather than "the" mode.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17069
Differential Revision: D14078722
Pulled By: soumith
fbshipit-source-id: 837a238d53a9b8e868511acbdc258633975bea48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17074
There are some common functionalities in backend lowering. This diff creates a base class which hosts these common stuff.
Reviewed By: ipiszy
Differential Revision: D14073192
fbshipit-source-id: 9617603d0e73db6f7fcc5572756b9dbab506dae5
Summary:
I noticed that we were sinking a lot of time into `cat` operations in machine translation on CPU, and drilled down to us doing the cat element-by-element, even though all the inputs were contiguous. The reason was we were doing the cat along a dimension that was not 0, and that caused us to not use the fast `memcpy` branch. This PR generalizes that branch.
Quick benchmark script:
```
import torch, time
tensors = [torch.rand(6, 2, 1024) for i in range(5)]
NITER = 1000
s = time.time()
for i in range(NITER):
torch.cat(tensors, dim=1)
print('time per iter ', (time.time() - s) / NITER)
```
Before:
```
time per iter 8.089399337768554e-05
```
After:
```
time per iter 2.183413505554199e-05
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17032
Differential Revision: D14090038
Pulled By: jamesr66a
fbshipit-source-id: 2c733a84915896008ac95f2233f44894bd2573de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17080
This changes all operators using this macro to the new format
Reviewed By: dzhulgakov
Differential Revision: D14078628
fbshipit-source-id: 67048e485e326765fd49567cc008633d3d500d5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17076
OSS: slightely change the tools/amd_build/build_amd.py to add the output_directory for internal use. Also modify the renaming convention in hipify script to reflect the updated rules.
Reviewed By: bddppq
Differential Revision: D13767218
fbshipit-source-id: cbcadc51daab42197d545f204840dcc18176bb3d
Summary:
- Moved a few functions from `autograd` namespace to `aten` namespace to be visible from JIT nativeResolver.
- Added a hack to loop up keyword only argument. Will add proper support for kw only later
- Simulate function overload in aten using `_<number>` as function name suffix.
- Even `forward` returns multiple outputs like in `kthvalue`, there's at most one requires grad that we currently support.
- Removed the `TensorList` related ops here since partial `TensorList` support is prone to bugs. Our symbolic diff for `cat` was never tested with autodiff, and it seems broken. Need to find another proper way to support these ops(either by properly supporting `TensorList` or sth like `prim::ConstantChunk` and leave them for next PR.
Ops supported in this PR:
```
erf
expand_as
index
kthvalue
mean
permute
pow
rsub
select
sqrt
squeeze
t
to
topk
transpose
view
var
embedding
logsumexp
// grad is None
_dim_arange
contiguous
nonzero
ones_like
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16689
Differential Revision: D14020806
Pulled By: ailzhang
fbshipit-source-id: a5e2c144a7be5a0d39d7ac5f93cb402ec12503a5
Summary:
update:
1. global_reduce check for should_block_y_reduce first.
This avoids the enabling global_reduce without block_y_reduce. Leading to
accessing shared memory during global reduce without allocation.
2. updating block_y_reduce heuristics. Improves perf on tiny tensors
3. adding test case covering old cases where illegal memory access might occur
TensorIterator cuda launch configs update (#16224)
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements:
1. Precise dynamic shared memory allocation.
2. Using warp shuffle for vertical (block_y) reduction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16224
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17040
Differential Revision: D14078295
Pulled By: umanwizard
fbshipit-source-id: ecc55054a5a4035e731f0196d633412225c3b06c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17046
As we are moving to use bound shape inference, we can remove the awkward fake inference run path and make the code cleaner.
Reviewed By: ipiszy
Differential Revision: D14061501
fbshipit-source-id: b3ace98b3dabef3c3359086a0bb1410518cefa26
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17096
LengthsRangeFill will take a batch size of lengths input and expand it into sequence. Later op should follow this type until it hits another batch type moderating op, e.g. SparseLengthsSum.
Reviewed By: ipiszy
Differential Revision: D14079422
fbshipit-source-id: 1a26925d502c32875ea95c160268bf6a256cc955
Summary:
Currently, when you pass a negative index to a `Dataset` created with `ConcatDataset`, it simply passes that index to the first dataset in the list. So if, for example, we took `concatenated_dataset[-1]`, this will give us the last entry of the *first* dataset, rather than the last entry of the *last* dataset, as we would expect.
This is a simple fix to support the expected behavior for negative indices.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15756
Reviewed By: ezyang
Differential Revision: D14081811
Pulled By: fmassa
fbshipit-source-id: a7783fd3fd9e1a8c00fd076c4978ca39ad5a8a2a
Summary:
Add support of count_include_pad end to end test for AveragePool
We can export AveragePool from PyTorch with count_include_pad attribute. However, we don't directly support it in Caffe2's ONNX backend.
We also want to check whether we can pass the end to end test for average pool operator with count_include_pad attribute (pytorch => onnx => caffe2)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17034
Reviewed By: houseroad
Differential Revision: D14060186
Pulled By: dwarakrajagopal
fbshipit-source-id: 10dae532611c71f8c8cfc3fa701cc7c1c1c02695
Summary:
Since we don't do tmp_install any more it's better to include all necessary headers.
cc kostmo for better suggestions of how to list all headers here
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16890
Differential Revision: D14079848
Pulled By: dzhulgakov
fbshipit-source-id: 4522c80d05e5d91f99f6700cde46cac559330d28
Summary:
Some legacy TH code was relying on alloc to throw when called with negative number!!! E.g. `torch.linspace(0, 1, -1)`. And it breaks ASAN build. I still believe alloc should receive size_t, but I added a safety enforce inside.
It should fix ASAN. I'll follow up with a proper fix for empty_cpu (which is probably the right place to do it) separately
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17071
Differential Revision: D14074157
Pulled By: dzhulgakov
fbshipit-source-id: 3ed3bdb873e446edecb558e1df491310fd7179e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16275
Adding a generic string `metadata` field as part of the model to capture additional metadata with the model.
Reviewed By: dzhulgakov
Differential Revision: D13579029
fbshipit-source-id: 7456ef2edbe73bb70bbb31889cecd94e0db329a2
Summary:
libshm_manager doesn't need to depend on all of libtorch. It only uses tiny tempfile.h which can be moved to c10. I could just duplicate the file too, but it's not worth it as c10 is small enough.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17019
Differential Revision: D14052688
Pulled By: dzhulgakov
fbshipit-source-id: 8797d15f8c7c49c49d40b7ab2f43aa3bf6becb0c
Summary:
Currently the converters are very straightforward, i.e. there is no code for trying to
preserve semantics, we're purely perform conversion from one format to another.
Two things that we might want to add/change:
1. Add semantic conversion as well (but probably it would be a good idea to keep
it separate as a temporary thing).
2. Make sure we don't mess with value names, as they are crucial for current
uses of NetDefs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16967
Differential Revision: D14062537
Pulled By: ZolotukhinM
fbshipit-source-id: 88b184ee7276779e5e9152b149d69857515ad98a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16929
Separate CPU reduce functions from math
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision: D13999469
fbshipit-source-id: bd628b15a6e3c1f04cc62aefffb0110690e1c0d1
Summary:
For >2D input, previously the code uses static shape captured during tracing and reshape before/after `Gemm`.
Now we add `-1` to the first `Reshape`, and uses `Shape(X) => Slice(outer) => Concat(with -1 for inner) => Reshape` for the second.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16184
Differential Revision: D14070754
Pulled By: ezyang
fbshipit-source-id: 86c69e9b254945b3406c07e122e57a00dfeba3df
Summary:
This PR fixes following issue: https://github.com/pytorch/pytorch/issues/16828
It is a combination of two things:
1) MKLDNN streams are not thread-safe but are currently shared between different threads. This change makes them thread_local
2) By default MKLDNN primitives can share global memory and can't be invoked from multiple threads. This PR enables the MKLDNN_ENABLE_CONCURRENT_EXEC cmake configuration option that makes them thread-safe.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17022
Differential Revision: D14069052
Pulled By: ezyang
fbshipit-source-id: f8f7fcb86c40f5d751fb35dfccc2f802b6e137c6
Summary:
This removes curly braces from the outputs (we have indentation to indicate scopes), also adds ':' after graph and blocks declaration and removes ';' from the return line. ".expect" tests are updated to keep up with it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16986
Differential Revision: D14062540
Pulled By: ZolotukhinM
fbshipit-source-id: 7f8e2d11619152a21ef7f1f7f8579c49392c3eca
Summary:
Previously, the ChunkBuffer depends on the remaining chunk count to signal end of dataloading. This does not work with distributed samplers where each sampler only loads a subset of chunks. This refactor remove the dependency on the remaining chunk count at the ChunkBuffer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16868
Differential Revision: D14066517
Pulled By: goldsborough
fbshipit-source-id: 293dfe282ceff326dff0876c2f75c2ee4f4463e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16824
There was a big wooly yak getting the deprecated macros to work.
Gory details are in Deprecated.h
Reviewed By: smessmer
Differential Revision: D13978429
fbshipit-source-id: f148e5935ac36eacc481789d22c7a9443164fe95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17027
Glow doesn't support second output of Reshape right now and it's useless. For correctness, we do make sure that the second output of Reshape is of Constant type during bound shape inference.
Reviewed By: ipiszy
Differential Revision: D14056555
fbshipit-source-id: f39cca7ba941bf5a5cc3adc96e2b1f943cc0be93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16942
We can fold col offsets into bias if zero point of activation is constant.
fbgemm still needs to provide an option to pass col offsets in case zero point of activation keep changes (e.g., dynamic quantization).
A trick to optimize static quantization case is setting A zero point to 0 after folding into bias.
This diff also optimizes when weights use symmetric quantization. When B zero point is 0, we use PackAMatrix instead of PackAWithRowOffset .
TODO:
Ideally, PackAWithRowOffset should perform as fast as PackAMatrix when B_zero_point is 0 to make client code simpler
Same in PackAWithIm2Col and depth-wise convolution (group convolution is already doing this)
Reviewed By: csummersea
Differential Revision: D14013931
fbshipit-source-id: e4d313343e2a16a451eb910beed30e35de02a40c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16691
Previous diffs already introduced a macro that registers caffe2 CPU kernels with c10.
This now also registers the CUDA kernels with it.
Reviewed By: bwasti
Differential Revision: D13901619
fbshipit-source-id: c15e5b7081ff10e5219af460779b88d6e091a6a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17025
Extract ShapeInfo and some util functions into a separate file.
Reviewed By: yinghai
Differential Revision: D14017432
fbshipit-source-id: 201db46bce6d52d9355a1a86925aa6206d0336bf
Summary:
Fix issue #12174 for Mac OSX.
PS: This is a duplicate of PR #16968 that got messed up. Sorry for the confusion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16999
Differential Revision: D14050669
Pulled By: zou3519
fbshipit-source-id: a4594c03ae8e0ca91a4836408b6c588720162c9f
Summary:
This fixes the segfault.
Changelog:
- Modify the function calls in LegacyDefinitions for `geqrf_out` and `ormqr_out`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16964
Differential Revision: D14025985
Pulled By: gchanan
fbshipit-source-id: aa50e2c1694cbf3642273ee14b09ba12625c7d33
Summary:
The second input (`lengths`) is not supported.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16727
Differential Revision: D14054105
Pulled By: houseroad
fbshipit-source-id: 36b8d00460f9623696439e1bd2a6bc60b7bb263c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16985
These statements were causing some redundant allocations + copying, so I cleaned
them up
Reviewed By: zdevito, wanchaol
Differential Revision: D14031067
fbshipit-source-id: f760fb29a2561894d52a2663f557b3e9ab1653de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16997
1. Don't create multiple AdjustBatch ops for the same input name. We create it once and hook input to abc_post_adjust_batch.
2. Dangling tensor. The problem for such an error is still with AttachAdjustBatchOp. Considering such as net
```
op {
type : "Relu"
input: "X"
outpu: "Y"
}
op {
type : "Relu"
input: "Y"
output: "Y2"
}
external_output: "Y"
external_output: "Y2"
```
In this the output of first Relu will be used as an internal node as well as output. We cannot simply rename Y into Y_pre_batch_adjust. Basically, we need another pass in to check all the input of the ops in the net and rename Y into Y_pre_batch_adjust.
Reviewed By: bertmaher
Differential Revision: D14041446
fbshipit-source-id: f6553e287a8dfb14e4044cc20afaf3f290e5151b
Summary:
Closes#16983
Remove backticks that are being interpreted by the shell. Add -e option to bash script to avoid future such failures
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16984
Reviewed By: yf225
Differential Revision: D14039128
Pulled By: kostmo
fbshipit-source-id: c31a1895377ca86c1b59e79351843cc8c4fd7de3
Summary:
The use case for making this PR is the following bug :
(with F = torch.nn.functional)
`F.max_pool2d.__module__` is `torch._jit_internal`
`F.max_pool2d.__name__` is `fn`
With this PR you get:
`F.max_pool2d.__module__` is `torch.nn.functional`
`F.max_pool2d.__name__` is `max_pool2d`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16922
Differential Revision: D14020053
Pulled By: driazati
fbshipit-source-id: c109c1f04640f3b2b69bc4790b16fef7714025dd
Summary:
gchanan pointed out in https://github.com/pytorch/pytorch/pull/16389 that `allow_inf` is treating `-inf` and `inf` as equal. This fixes it.
Also fixing #16448 since it's near and 2.1 has released.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16959
Differential Revision: D14025297
Pulled By: gchanan
fbshipit-source-id: 95348309492e7ab65aa4d7aabb5a1800de66c5d6
Summary:
Previously, we used the templated class directly to provide
implementations. However, there is a subtle difference
between this, and CUDAStreamGuard: CUDAStreamGuard has refined types
for the Streams it returns. This lead to a compilation failure
of HIPified ddp.cpp. This commit lines them up more closely,
at the cost of copy-paste.
A possible alternate strategy would have been to extend the
InlineDeviceGuard templates to optionally accept refinements
for Stream. I leave this for future work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16978
Differential Revision: D14045346
Pulled By: ezyang
fbshipit-source-id: 2b101606e62e4db588027c57902ea739a2119410
Summary:
This is needed to check for wrong arguments or --help options
before `build_deps()` is executed. Otherwise command line arguments
are not parsed and checked until `setup()` is run.
Fixes: #16707
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16914
Differential Revision: D14041236
Pulled By: soumith
fbshipit-source-id: 41f635772ccf47f05114775d5a19ae04c495ab3b
Summary:
Fixes the bug for when tensor is created on Caffe2 side, then passed to PT and resized. Now we just initialize allocator correctly.
Note that the code in raw_mutable_data() is still necessary because of non-resizable tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16857
Reviewed By: houseroad
Differential Revision: D14019469
Pulled By: dzhulgakov
fbshipit-source-id: 14d3a3b946d718bbab747ea376903646b885706a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16932
During onnxifi transformation net ssa is rewritten. At the last step the weight
names are changed back to what they were before. The diff keeps the weight
names unchanged thru the process.
Reviewed By: yinghai
Differential Revision: D13972597
fbshipit-source-id: 7c29857f788a674edf625c073b345f2b44267b33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16965
Instead of having one large templated function to wrap the caffe2 op, minimize the amount of templated code.
Non-templated code can be reused between different operators and decreases binary size.
Reviewed By: orionr
Differential Revision: D14018806
fbshipit-source-id: bedd4152eec21dd8c5778446963826316d210543
Summary:
Fixes#16577.
This greatly improves memory efficiency of certain ops like Dropout2d. Previously, they were implemented as `input * mask` where mask never requires_grad, but we didn't use that knowledge in forward, and (in case of a in-place dropout) kept input.clone() for the backward, when it would simply get ignored.
This patch tries to address this situation by emitting some guards for stores like this, but only if they are as simple, as checking if a single value requires_grad.
Interestingly, the same optimizations apply to methods like bmm, baddmm, etc., but _not to mm nor addmm_, because of how their derivatives are defined. Apparently they unnecessarily use `mat1` to compute the derivative of `mat1` just to improve the error message in case `mat1` was sparse. I'd like to apply this optimization to that case, but I don't want to loose the nicer error message, so if anyone has any ideas for solutions, please let me know...
Full list of operators affected by this patch:
* _nnpack_spatial_convolution
* addbmm
* addcdiv
* addcmul
* addmv
* addr
* baddbmm
* bmm
* cross
* div
* dot
* fmod
* ger
* index_add_
* mul
* mv
* scatter_add_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16583
Differential Revision: D13900881
Pulled By: gchanan
fbshipit-source-id: dd0aeb2ab58c4b6aa95b37b46d3255b3e014291c
Summary:
In VariableType.cpp, when a function modifies its input tensors, it should only change the input tensors' storage data in-place, and should never change the input tensors' storage pointers. This PR adds checks for this, and also fixes functions that fail this test.
This is part of the Variable/Tensor merge work (https://github.com/pytorch/pytorch/issues/13638).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16305
Differential Revision: D13897855
Pulled By: yf225
fbshipit-source-id: 0c4fc7eb530d30db88037b1f0981f6f8454d3b79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16906
In C++11, constexpr implies const, so these methods actually wouldn't be rvalue overloads as intended but const rvalue overloads.
Let's only apply the constexpr flag in C++14 to be safe.
Reviewed By: bddppq
Differential Revision: D13998486
fbshipit-source-id: a04d17ef0cc8f45e3d0a1ca9843d194f4f0f6f7f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16399
Catching cudaError_t return values in a few places, because it's nodiscard in rocm. Unless we add -Wno-unused-result, it'll end up with a compilation error.
Also in c10/cuda/test, check whether a host has GPU or not. We were silently throwing out the error before (so not really testing the cuda api).
Reviewed By: bddppq
Differential Revision: D13828281
fbshipit-source-id: 587d1cc31c20b836ce9594e3c18f067d322b2934
Summary:
Here is a stab at implementing an option to zero out infinite losses (and NaN gradients).
It might be nicer to move the zeroing to the respective kernels.
The default is currently `False` to mimic the old behaviour, but I'd be half inclined to set the default to `True`, because the behaviour wasn't consistent between CuDNN and Native anyways and the NaN gradients aren't terribly useful.
This topic seems to come up regularly, e.g. in #14335
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16199
Differential Revision: D14020462
Pulled By: ezyang
fbshipit-source-id: 5ba8936c66ec6e61530aaf01175dc49f389ae428
Summary:
Merge binaries "convert_image_to_tensor" and "caffe2_benchmark" to remove the overhead of writing to/reading from Tensor file.
*TODO next: TensorProtos is another overhead. No need for de-serialization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16875
Reviewed By: sf-wind
Differential Revision: D13997726
Pulled By: ZhizhenQin
fbshipit-source-id: 4dec17f0ebb59cf1438b9aba5421db2b41c47a9f
Summary:
I'm seeing a bunch of apt gpg key errors on CI with the following message:
```
An error occurred during the signature verification. The repository is not
updated and the previous index files will be used. GPG error:
https://packagecloud.io trusty InRelease: The following signatures couldn't
be verified because the public key is not available:
NO_PUBKEY 4E6910DFCB68C9CD
```
Most of the times apt will reuse the old cached version, but sometimes this results in a build failure: https://circleci.com/gh/pytorch/pytorch/758366?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link.
This should hopefully fix it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16961
Differential Revision: D14028151
Pulled By: ezyang
fbshipit-source-id: 7648a0a58ece38d8d04916937a9fa17f34f8833e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16911
I think the Thrust package has want we want for /opt/rocm/include/thrust. We probably can stop patching it now.
Reviewed By: bddppq
Differential Revision: D14015177
fbshipit-source-id: 8d9128783a790c39083a1b8b4771c2c18bd67d46
Summary:
Hi,
caffe2/operators/quantized/int8_given_tensor_fill_op.cc expects the value array to be named "values" but the operator schema describe "value" (no s). I guess it is a little typo but it made me losing a bit of time before understanding why I had this error by passing "value" instead of "values":
```
[F int8_given_tensor_fill_op.h:95] Check failed: output->t.numel() == values_.numel() output size: 3 given size: 0
Aborted (core dumped)
```
Thanks,
Eyyüb Sari
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16204
Differential Revision: D14020476
Pulled By: ezyang
fbshipit-source-id: a8a46bfc44ec125e7925ce4b7c79fdf99c890a50
Summary:
Instead of converting coo to csr format of the sparse matrix in the original implementation, in my revision I directly use coo format for sparse dense matrix mutliplication.
On my linux machine it is 5 times faster than the original code:
```
(original code)
SIZE: 15000 DENSITY: 0.01 DEVICE: cpu
torch: 0.39403 seconds
np: 0.00496674 seconds
torch/np: 79.3338
----------------------------------------
(my update)
SIZE: 15000 DENSITY: 0.01 DEVICE: cpu
torch: 0.0812583 seconds
np: 0.00501871 seconds
torch/np: 16.1911
```
Further code feedback and running time tests are highly welcomed. I will keep revise my code if needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16905
Differential Revision: D14020095
Pulled By: ezyang
fbshipit-source-id: 4ab94075344a55b375f22421e97a690e682baed5
Summary:
Renewed attempt at https://github.com/pytorch/pytorch/pull/14171
From the original PR:
> Currently, the pin_memory_batch function in the dataloader will return a batch comprised of any unrecognized type without pinning the data, because it doesn't know how.
>
>This behavior was preventing us from overlapping data prefetching in Mask-RCNN, whose custom collate_fn returns a custom batch type.
The old PR allowed the user to implement batch pinning for custom batch and data types by passing a custom pin function to the dataloader. slayton58 suggested a cleaner approach: allow the user to define a `pin_memory` method on their custom types, and have `pin_memory_batch` [check for the presence of that method](https://github.com/pytorch/pytorch/pull/16743/files#diff-9f154cbd884fe654066b1621fad654f3R56) in the incoming batch as a fallback. I've updated the test and docstrings accordingly.
The old PR was merged but then reverted due to weird cuda OOM errors on windows that may or may not have been related. I have no idea why my changes would cause such errors (then or now) but it's something to keep an eye out for.
fmassa and yf225 who were my POCs on the old PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16743
Differential Revision: D13991745
Pulled By: ezyang
fbshipit-source-id: 74e71f62a03be453b4caa9f5524e9bc53467fa17
Summary:
Fixes: https://github.com/pytorch/pytorch/issues/16233
The following changes are made:
- Modify `TupleType` to store optional field names
- Modify schema matching to return fill in those field names when creating `TupleType` as return type.
- Modify codegen of JIT to copy field names to schema string
- Modify `SchemaParser` to set field names of returned schema.
- Modify `SimpleValue::attr` to emit tuple indexing for named tuple.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16253
Reviewed By: ezyang
Differential Revision: D13954298
Pulled By: zdevito
fbshipit-source-id: 247d483d78a0c9c12d1ba36e1f1ec6c3f1a3007b
Summary:
I found a few sentences in DataParallel docstring confusing, so I suggest this enhancement.
- Arbitrary arguments are allowed to be passed .... *INCLUDING* tensors (Not *EXCLUDING*)
- The original author said that "other types" are shallow-copied but I think actually only some builtin types are (effectively) shallow-copied. And "other types" are shared. Here is an example.
```python
import torch
from torch.nn import Module, DataParallel
from collections import deque
class MyModel(Module):
def forward(self, x):
x.append(None)
model = MyModel(); model.cuda()
model = DataParallel(model)
d = deque()
model.forward(d)
print(d)
```
This is a side note.
As far as I know, copying objects is not a specially frequent operation in python unlike some other languages. Notably, no copying is involved in assignment or function parameter passing. They are only name bindings and it is the whole point of "everything is object" python philosophy, I guess. If one keep this in mind, it may help you dealing with things like multithreading.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15993
Differential Revision: D14020404
Pulled By: ezyang
fbshipit-source-id: a38689c94d0b8f77be70447f34962d3a7cd25e2e
Summary:
This PR is a simple fix for the mistake in the "tensor" and "torch.Tensor"doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16842
Differential Revision: D14020300
Pulled By: ezyang
fbshipit-source-id: 3ab04f1223d6e60f8da578d04d759e385d23acbb
Summary:
This changes the libnvToolsExt dependency to go through CMake find_library.
I have a machine where cuda libs, and libnvToolsExt in particular, are in the "usual library locations". It would be neat if we could find libnvToolsExt and use the path currently hardcoded as default.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16714
Differential Revision: D14020315
Pulled By: ezyang
fbshipit-source-id: 00be27be10b1863ca92fd585f273d50bded850f8
Summary:
The documentation for LogSigmoid says:
> Applies the element-wise function:
> \<blank\>
Now the documentation properly displays the math string.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16900
Differential Revision: D14020097
Pulled By: ezyang
fbshipit-source-id: 41e229d0fcc6b9bb53367be548bf85286dc13546
Summary:
When Variable and Tensor are merged, the dynamic type of the tensors passed to certain functions will become variables, and expecting `type()` on those variables to still return non-Variable types will cause type mismatch error.
One way to fix this problem is to use the thread-local guard `at::AutoNonVariableTypeMode` to force `type()` to return non-Variable type, but ideally we want to limit the use of `at::AutoNonVariableTypeMode` to be only in VariableType.cpp. Another way to fix the problem is to use `at::globalContext().getNonVariableType()` instead to get the non-Variable type of the tensor, which is what this PR is trying to achieve.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16325
Differential Revision: D14012022
Pulled By: yf225
fbshipit-source-id: 77ef1d2a02f78bff0063bdd72596e34046f1e00d
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
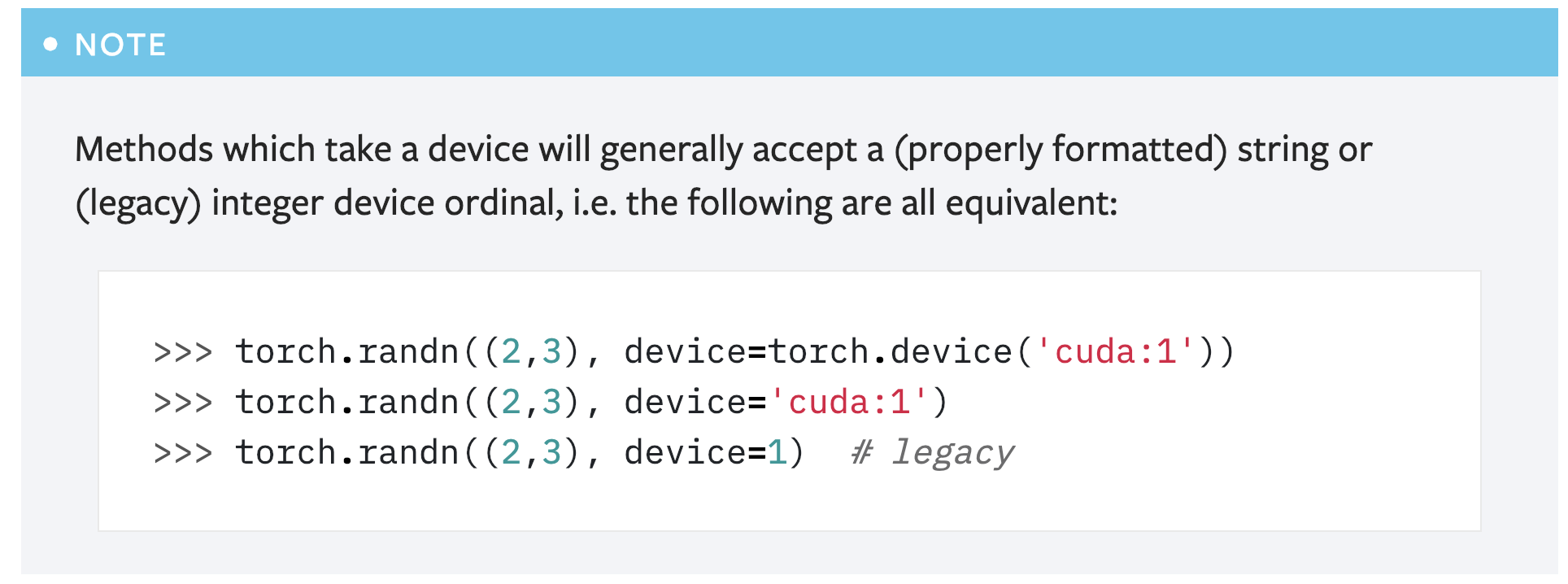
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision: D13989209
Pulled By: gchanan
fbshipit-source-id: ac255d52528da053ebfed18125ee6b857865ccaf
Summary:
Post 2.1 release, packing is fixed and alignas works as expected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16920
Differential Revision: D14018539
Pulled By: bddppq
fbshipit-source-id: 0ed4d9e9f36afb9b970812c3870082fd7f905455
Summary:
It now works post ROCm 2.1 release.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16919
Differential Revision: D14018538
Pulled By: bddppq
fbshipit-source-id: c4e1bafb53204a6d718b2d5054647d5715f23243
Summary:
This is the first round of enabling unit tests that work on ROCm 2.1 in my tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16871
Differential Revision: D13997662
Pulled By: bddppq
fbshipit-source-id: d909a3f7dd5fc8f85f126bf0613751c8e4ef949f
Summary:
This was serializing all calls to `addmm` (and any op that used it, in my case `bmm`) in the entire process, and led to downright atrocious performance in the TorchScript threaded runtime. Removing this gives a 2x throughput boost for high-load machine translation inference.
The original justification for this is dubious: there are other `gemm` callsites in the codebase that are not protected by critical sections. And in caffe2 land we never had any issues with nonreentrant BLAS libraries
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16889
Differential Revision: D14008928
Pulled By: jamesr66a
fbshipit-source-id: 498e2133bd6564dba539a2d9751f4e61afbce608
Summary:
Impl ExpandDims op and fallback to CPU if needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15264
Differential Revision: D13808797
Pulled By: yinghai
fbshipit-source-id: 7795ec303a46e85f84e5490273db0ec76e8b9374
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16721
The very key line is we have to set the stream to the default
stream before calling the allocator. This is very interesting.
It shouldn't be necessary, but seemingly is!
Reviewed By: dzhulgakov
Differential Revision: D13943193
fbshipit-source-id: c21014917d9fe504fab0ad8abbc025787f559287
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16720
I'm taking the deduplication slowly because there is something here
that is causing problems, and I want to figure out what it is.
Reviewed By: dzhulgakov
Differential Revision: D13943194
fbshipit-source-id: cbc08fee5862fdcb393b9dd5b1d2ac7250f77c4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16615
This is another go at landing https://github.com/pytorch/pytorch/pull/16226
Now that the caching allocator is moved to c10_cuda, we can
delete the duplicate copy from Caffe2.
The difference between this and the previous PR is that this
version faithfully maintains the binding code; in particular,
we end up with a SECOND copy of the caching allocator in
this patch. I verified that this code does NOT cause a crash
in the workflow we canaried last time.
In further diffs, I plan to eliminate the second copy, and then
adjust the binding code.
Reviewed By: dzhulgakov
Differential Revision: D13901067
fbshipit-source-id: 66331fd4eadffd0a5defb3cea532d5cd07287872
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16867
Some caffe2 operators (example: BBoxTransform) have not just one template parameter which is the context, but might have multiple template parameters.
Because of this, we can't handle the context parameter inside the macro.
Reviewed By: bwasti
Differential Revision: D13995696
fbshipit-source-id: f55c3be913c8b125445a8d486846fc2fab587a63
Summary:
This PR implements:
1. a fix to issue #12174 - determine the location of cudnn library using `ldconfig`
2. a fix to determine the installed conda packages (in recent versions of conda, the command `conda` is a Bash function that cannot be called within a python script, so using CONDA_EXE environment variable instead)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16859
Differential Revision: D14000399
Pulled By: soumith
fbshipit-source-id: 905658ecacb0ca0587a162fade436de9582d32ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16855
Save the histogram of each net to a separate file
Reviewed By: jspark1105
Differential Revision: D13991610
fbshipit-source-id: a5be4e37a5e63567dcd7fdf99f451ee31bb350a5
Summary:
Some batched updates:
1. bool is a type now
2. Early returns are allowed now
3. The beginning of an FAQ section with some guidance on the best way to do GPU training + CPU inference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16866
Differential Revision: D13996729
Pulled By: suo
fbshipit-source-id: 3b884fd3a4c9632c9697d8f1a5a0e768fc918916
Summary:
During tracing, we record `aten::_convolution` rather than `aten::convolution`. The schema for the former was not present in the shape analysis pass, and resulted in some missing shape information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16837
Differential Revision: D13993831
Pulled By: jamesr66a
fbshipit-source-id: ebb63bf628d81613258caf773a3af5930303ce5a
Summary:
* we do not need EAP packages any longer as the antistatic feature is now in the release
* consistently install the rccl package
* Skip one unit test that has regressed with 2.1
* Follow-up PRs will use 2.1 features once deployed on CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16808
Differential Revision: D13992645
Pulled By: bddppq
fbshipit-source-id: 37ca9a1f104bb140bd2b56d403e32f04c4fbf4f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16834
Inserting AdjustBatch ops will possibly change the names of the input/output, so we need to create a mapping and use the renamed names for external_inputs/outputs and input_shape_info for the onnxifi_net.
Reviewed By: ipiszy
Differential Revision: D13982731
fbshipit-source-id: c18b8a03d01490162929b2ca30c182d166001626
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16643
The test was disabled in D13908117 because it conflicted with another diff that was about to land.
Now fixed the merge conflict and re-landing it.
Reviewed By: ezyang
Differential Revision: D13911775
fbshipit-source-id: b790f1c3a3f207916eea41ac93bc104d011f629b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16548
With this macro, a caffe2 operator can now directly be registered with c10.
No need to write custom wrapper kernels anymore.
Differential Revision: D13877076
fbshipit-source-id: e56846238c5bb4b1989b79855fd44d5ecf089c9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16835
We were using label type `multi_label_dense` to denote both 1) dense representation of integer label 2) embedding label of data type floating number.
This cause some issues as two cases have different assumption, such as for integer label, we will check whether label value is in [0, number_class - 1]. But such check should be skipped for `embedding label`.
Reviewed By: BIT-silence
Differential Revision: D13985048
fbshipit-source-id: 1202cdfeea806eb47647e3f4a1ed9c104f72ad2c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16739
Some code ATen locations seemed to use int, etc. inclorrectly where either
int64_t or size_t was required. Update them to use int64_t for dimension indexing where necessary.
Reviewed By: ezyang
Differential Revision: D13950124
fbshipit-source-id: aaf1cef783bf3c657aa03490f2616c35c816679f
Summary:
Discussed with zdevito and we want to use Variable (with `set_requires_grad(false)`) instead of Tensor in all parts of JIT, to eliminate the distinction and the conceptual overhead when trying to figure out which one to use.
This also helps with the Variable/Tensor merge work tracked at https://github.com/pytorch/pytorch/issues/13638, which will make common functions (such as `numel()` / `sizes()` / `dim()`) on Variable much faster when finished.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16596
Differential Revision: D13979971
Pulled By: yf225
fbshipit-source-id: c69119deec5bce0c22809081115f1012fdbb7d5a
Summary:
List of changes:
- Always push the final state of the doc build docker for debugging purposes.
- Adds code for the stable doc build. This code is never actually run on master, only the v1.0.1 branch. There is a big note for this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16503
Differential Revision: D13972469
Pulled By: zou3519
fbshipit-source-id: 68f459650ef0de200a34edd43fc1372143923972
Summary:
This PR is a follow up of #15460, it did the following things:
* remove the undefined tensor semantic in jit script/tracing mode
* change ATen/JIT schema for at::index and other index related ops with `Tensor?[]` to align with what at::index is really doing and to adopt `optional[tensor]` in JIT
* change python_print to correctly print the exported script
* register both TensorList and ListOfOptionalTensor in JIT ATen ops to support both
* Backward compatibility for `torch.jit.annotate(Tensor, None)`
List of follow ups:
* remove the undefined tensor semantic in jit autograd, autodiff and grad_of
* remove prim::Undefined fully
For easy reviews, please turn on `hide white space changes` in diff settings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16379
Differential Revision: D13855677
Pulled By: wanchaol
fbshipit-source-id: 0e21c14d7de250c62731227c81bfbfb7b7da20ab
Summary:
This adds calls to `super().__init__()` in three classes in torch.distributions.
This is needed when `Distribution` and `Transform` objects are used with multiple inheritance, as e.g. combined with `torch.nn.Module`s. For example
```py
class MyModule(torch.distributions.Transform, torch.nn.Module):
...
```
cc martinjankowiak esling who have wanted to use this pattern, e.g. in #16756
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16772
Differential Revision: D13978633
Pulled By: soumith
fbshipit-source-id: 8bc6cca1747cd74d32135ee2fe588bba2ea796f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16811
As the title. The AdjustBatch ops will be inserted before and after the Onnxifi op to:
1) adjust batch/seq sizes to the ideal batch/seq size before these tensors are processed by the Onnxifi op;
2) adjust batch size to the original batch size for batches generated by the Onnxifi op.
Reviewed By: yinghai
Differential Revision: D13967711
fbshipit-source-id: 471b25ae6a60bf5b7ebee1de6449e0389b6cafff
Summary:
Emphasize on the fact that docker build should be triggered from pytorch repo directory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16812
Differential Revision: D13985531
Pulled By: soumith
fbshipit-source-id: c6511d1e81476eb795b37fb0ad23e8951dbca617
Summary:
Update launch configs for TensorIterator gpu_reduce_kernel. Enable flexible
block dimension to improve efficiency for reduction cases with small fast
dimension.
Previously TensorIterator launches blocks with fixed 32x16 threads.
For cases like:
import torch
torch.randn(2**20, 4, device='cuda').sum(0)
The fixed launch config does handle coalesced memory access efficiently.
Updated launch configure enables flexible block dimension. Combining with
improved reduction scheme (using flexible vertical / horizontal reduction
instead of limited warp / block reduction in the old code), it ensures optimal
memory access pattern even with reduction on dimension with small stride.
Possible future improvements:
1. Precise dynamic shared memory allocation.
2. Using warp shuffle for vertical (block_y) reduction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16224
Differential Revision: D13806753
Pulled By: soumith
fbshipit-source-id: 37e45c7767b5748cf9ecf894fad306e040e2f79f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16535
There is now no need anymore to define the layer norm schema in a central location.
It can just be defined in caffe2 next to the kernel implementation.
Reviewed By: ezyang
Differential Revision: D13869503
fbshipit-source-id: c478153f8fd712ff6d507c794500286eb3583149
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16534
All c10 ops from the c10 dispatcher are now automatically registered with JIT
Reviewed By: dzhulgakov
Differential Revision: D13869275
fbshipit-source-id: 5ab5dec5b983fe661f977f9d29d8036768cdcab6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16676
This op is used for changing batch size (first dimension) of the tensor.
Reviewed By: bertmaher, ipiszy
Differential Revision: D13929200
fbshipit-source-id: 4f2c3faec072d468be8301bf00c80d33adb3b5b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16820
Sometimes parsing histogram was not working correctly due to changes in D13633256
We need to call istringstream clear after str
Reviewed By: csummersea
Differential Revision: D13977509
fbshipit-source-id: ce3e8cb390641d8f0b5c9a7d6d6daadffeddbe11
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16785
There's no EIGEN engine implemented for DeformConv but unit test was checking it.
Reviewed By: BIT-silence
Differential Revision: D13967306
fbshipit-source-id: e29c19f59f5700fc0501c59f45d60443b87ffedc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16597
This diff fixes some bugs in shape inference for `SparseLengthsSumFused8BitRowwise`. And added input shape inference for `Concat` when `add_axis=1`.
Reviewed By: bertmaher
Differential Revision: D13892452
fbshipit-source-id: 6cd95697a6fabe6d78a5ce3cb749a3a1e51c68e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16765
Code changes required to build caffe2 for windows with toolchain used by FB.
Reviewed By: orionr
Differential Revision: D13953258
fbshipit-source-id: 651823ec9d81ac70e32d4cce5bc2472434104733
Summary:
Adding torch/lib64 in .gitignore so that a git status --porcelain
check during CI build and test passes for ppc64le. During build
torch/lib64 is created and contains third-party libraries. This
should be ignored by the porcelain check
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16782
Differential Revision: D13972794
Pulled By: ezyang
fbshipit-source-id: 5459c524eca42d396ac46e756a327980b4b1fa53
Summary:
Since pip 18.0 (2018-07-22), `legacy` is no longer a valid choice for `pip list --format` as can be seen in the [Release Notes](https://pip.pypa.io/en/stable/news/#id62). Therefore, the options now are: `columns`, `freeze` and `json`. With `legacy`, this is how it looked like:
```
[...]
Versions of relevant libraries:
[pip3] numpy (1.16.1)
[pip3] torch (1.0.1)
[pip3] torchvision (0.2.1)
[...]
```
Changing to `freeze`, this is how it looks like:
```
[...]
Versions of relevant libraries:
[pip3] numpy==1.16.1
[pip3] torch==1.0.1
[pip3] torchvision==0.2.1
[...]
```
Currently, this is what happens:
```
[...]
Versions of relevant libraries:
[pip] Could not collect
[...]
```
The `freeze` option is also available in old pip, so this change is backwards compatible. Also, if we would like to keep the old style, which I think it is not necessary, I could easily change that.
---
In case anyone wants to know how `columns` looks like (I prefer `freeze`):
```
[...]
Versions of relevant libraries:
[pip3] numpy 1.16.1
[pip3] torch 1.0.1
[pip3] torchvision 0.2.1
[...]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16798
Differential Revision: D13971793
Pulled By: soumith
fbshipit-source-id: 3721d9079a2afa245e1185f725598901185ea4cd
Summary:
(review top commit only).
As expected, fork/wait introduces some corner cases into the alias analysis. The comments inline should describe the changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16671
Differential Revision: D13963219
Pulled By: suo
fbshipit-source-id: 2bec6fc03a4989cf309fbb9473f3f2ffe2c31431
Summary:
Doubling the sccache timeout from default of 600.
the asan build of #16645 will fail without this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16728
Differential Revision: D13963727
Pulled By: li-roy
fbshipit-source-id: 3614d75c1b46d663fa05b84f99d8a099283a8e64
Summary:
In #16085 , we introduced initial hip-clang bring-up code. Document the use of the __HIP__ macro now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16771
Differential Revision: D13961538
Pulled By: ezyang
fbshipit-source-id: 67f6226abcbe62e2f4efc291c84652199c464ca6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16751
This was made more complicated by the fact that ivalue::IntList
is a thing. So I had to fix all of the sites where we referring
to IValue post facto.
The following codemods were run, in this order:
```
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in IntList IntArrayRef
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in IntArrayRef::create IntList::create
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in ivalue::IntArrayRef ivalue::IntList
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in Tag::IntArrayRef Tag::IntList
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in isIntArrayRef isIntList
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in toIntArrayRef toIntList
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in 'Shared<IntArrayRef>' 'Shared<IntList>'
codemod -m -d . --extensions cc,cpp,cu,cuh,h,hpp,py,cwrap,yaml,in 'intrusive_ptr<IntArrayRef>' 'intrusive_ptr<IntList>'
```
Some manual fixups were done afterwards; they can be reviewed separately
at https://github.com/pytorch/pytorch/pull/16752
Reviewed By: dzhulgakov
Differential Revision: D13954363
fbshipit-source-id: b5c40aacba042402155a2f5a229fa6db7992ac64
Summary:
Adds some operations for dicts to match Python and tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16629
Differential Revision: D13961144
Pulled By: driazati
fbshipit-source-id: b31f27a4320ff62cd118b508fb0a13056535dc7c
Summary:
There is no way to test this until it is merged.
On master jobs that run after a PR is merged, there is no CIRCLE_PR_NUMBER so the binary builds clone pytorch/pytorch/master, which races.
Based off of https://circleci.com/docs/2.0/env-vars/ and the circleci checkout code
```
git config --global url."ssh://git@github.com".insteadOf "https://github.com" || true
git config --global gc.auto 0 || true
if [ -e /home/circleci/project/.git ]
then
cd /home/circleci/project
git remote set-url origin "$CIRCLE_REPOSITORY_URL" || true
else
mkdir -p /home/circleci/project
cd /home/circleci/project
git clone "$CIRCLE_REPOSITORY_URL" .
fi
if [ -n "$CIRCLE_TAG" ]
then
git fetch --force origin "refs/tags/${CIRCLE_TAG}"
else
git fetch --force origin "master:remotes/origin/master"
fi
if [ -n "$CIRCLE_TAG" ]
then
git reset --hard "$CIRCLE_SHA1"
git checkout -q "$CIRCLE_TAG"
elif [ -n "$CIRCLE_BRANCH" ]
then
git reset --hard "$CIRCLE_SHA1"
git checkout -q -B "$CIRCLE_BRANCH"
fi
git reset --hard "$CIRCLE_SHA1"
```
I believe we do no use git tags
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16773
Differential Revision: D13962132
Pulled By: pjh5
fbshipit-source-id: c62d2139f38ff39ecda1509b0bcd8bd102828e40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16478
This diff includes an example registration of a caffe2 op in torch. A previous attempt ran into a static initialization order bug.
Reviewed By: smessmer
Differential Revision: D13854304
fbshipit-source-id: ec463ce2272126d08a5163d1599361ee5b718bbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16730
with Jerry's new updates Tensor must be defined -- as a result I've needed to update the shim for caffe2 ops being used in PyTorch
Reviewed By: smessmer
Differential Revision: D13946950
fbshipit-source-id: 6f77877c61a743f82bdfc2ad04d6ab583000cc18
Summary:
Fixes#16591
This uses uniqueBaseName so that parameters do not end up with suffixes. It changes next_id to be per-base-name rather than global to fix jittering issues when re-importing a re-numbered graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16750
Differential Revision: D13960282
Pulled By: zdevito
fbshipit-source-id: 2156f581d9b95d77bf1f1252074e800b19116555
Summary:
This should enable xla tests thus let master xla tests pass.
As usual, I will add the branch filters back before landing.
Thanks ezyang !
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16761
Differential Revision: D13959746
Pulled By: ailzhang
fbshipit-source-id: 7384da281d093d16edccb4283c74e47ac659eeff
Summary:
I'll test with this really long summary.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce risus sem, mattis vitae commodo vitae, mattis vel ex. Integer nec consectetur ligula, sit amet ultricies risus. Suspendisse potenti. Donec aliquet quam ante. Donec porttitor justo ligula, ut vestibulum erat facilisis a. Nullam eget lobortis nisi. Aenean quis sem id ante eleifend condimentum nec a lacus. Sed sed dolor augue. Proin feugiat, tellus in eleifend cursus, libero nulla lacinia erat, et efficitur dui odio ut ex. In et sem purus. Proin dictum scelerisque magna, nec feugiat dolor lobortis id. Proin ante urna, ultrices in semper et, pulvinar et dui. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae; Mauris ullamcorper neque a pharetra rhoncus.
Aliquam vel semper felis. Integer id massa erat. Morbi leo eros, varius sed viverra eu, dictum nec purus. Fusce vitae mollis sem, non fringilla nulla. Donec tincidunt luctus dolor. Morbi lobortis, magna quis viverra bibendum, lacus tortor pulvinar risus, eu porta tellus nulla vitae dolor. Sed tincidunt, turpis quis facilisis malesuada, nulla eros lobortis lorem, a fermentum mi nisl non quam. Pellentesque vehicula, nisl non eleifend viverra, tellus neque accumsan tellus, id ultricies lacus mi sed sapien. Proin rutrum ultrices quam sit amet euismod. Maecenas vel faucibus libero, nec efficitur mi. Proin felis augue, elementum eget vestibulum non, euismod sed urna. Curabitur purus nisi, interdum nec rutrum id, faucibus nec sapien. Integer consectetur interdum elit, volutpat vulputate velit. Integer et ultricies magna. Fusce blandit lorem urna, quis sodales sapien porttitor in. Nulla nec sodales sem.
Morbi consequat massa sit amet fringilla pretium. Nunc maximus vitae neque auctor pharetra. Morbi gravida feugiat urna, eu sagittis est pulvinar eget. Maecenas ut fermentum ante, eget malesuada neque. In ut maximus magna. Donec nec finibus sapien. Quisque viverra erat lobortis, rhoncus augue sed, hendrerit dui. Donec in feugiat augue, a ultrices justo. Pellentesque rutrum augue sed nulla auctor, a venenatis risus aliquam. Nullam ipsum justo, dictum sit amet elementum eu, eleifend a turpis. Proin ut tellus ut urna volutpat fermentum ac aliquam tellus.
Quisque ultricies est id eros dictum ultrices. Cras eu urna interdum, eleifend felis vitae, vulputate nulla. Cras tincidunt, mi sodales imperdiet tristique, diam odio convallis ligula, ac vulputate enim sapien eu tellus. Phasellus eleifend finibus sapien id ullamcorper. Donec aliquet eleifend consectetur. Proin in nulla venenatis, egestas neque quis, blandit sem. Suspendisse pellentesque arcu vel ligula fermentum maximus. Aliquam non ipsum ut ante pharetra finibus.
Nunc rhoncus purus sit amet risus congue venenatis. Integer id vestibulum neque, et fermentum elit. Nunc sit amet tortor quis mi aliquam vestibulum et in mauris. Pellentesque habitant morbi tristique senectus et netus et malesuada fames ac turpis egestas. Maecenas mollis hendrerit nulla, non tempus neque pharetra ac. Proin commodo bibendum velit, consectetur pretium metus sollicitudin eget. Aliquam malesuada semper tempor. Ut vel vulputate dolor, eu faucibus mauris. Nam commodo quis dolor sit amet eleifend. Phasellus eget massa odio. Donec tempor est at ante finibus lobortis. Suspendisse porttitor imperdiet ultrices. Orci varius natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus.
Nullam id dignissim magna, non suscipit odio. Vestibulum vel maximus erat, suscipit ullamcorper tellus. Fusce egestas augue lorem, in ultricies est vehicula ac. Integer pretium, ex in elementum varius, nisi turpis posuere lectus, nec posuere ligula mi ac ligula. Donec vehicula dolor ut ex elementum, quis scelerisque tellus molestie. Mauris euismod magna ac ornare cursus. Vivamus dapibus quam nec tellus aliquam elementum.
Phasellus ultricies quis augue ut fringilla. Suspendisse eu molestie eros. Suspendisse potenti. Curabitur varius sodales maximus. Etiam nec rutrum est. Sed vulputate suscipit elit, eu condimentum mauris pretium eget. Curabitur convallis commodo dui. Aenean lectus orci, pretium non mi sit amet, commodo imperdiet dui. In hac habitasse platea dictumst. In et ex nisl. Duis justo tortor, finibus at augue vitae, fermentum hendrerit tellus. Donec malesuada justo a molestie posuere. Morbi nisl leo, feugiat ut faucibus ut, mattis id purus.
Vestibulum hendrerit lorem ligula, et ullamcorper nisl lacinia sed. Integer vitae lacinia nunc, sed interdum enim. Aliquam aliquet ipsum vitae eros ornare accumsan. Phasellus venenatis laoreet est, sed feugiat neque lobortis id. Proin pulvinar placerat leo lacinia vehicula. Duis accumsan semper lobortis. Donec elementum nunc non quam aliquam, rutrum fringilla justo interdum. Morbi pulvinar pellentesque massa vitae maximus. Cras condimentum aliquam massa, et pellentesque lorem dictum a. Vivamus at dignissim justo. Donec ligula dui, tempus vestibulum est vel, rutrum blandit arcu. Vivamus iaculis molestie neque in elementum. Sed convallis tempus quam non elementum. Nulla euismod lobortis ligula. Etiam ac mauris eget magna posuere ornare id vitae felis. Nunc efficitur lorem et euismod porttitor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16766
Differential Revision: D13959962
Pulled By: pjh5
fbshipit-source-id: 9b71bdf981d4fda9d8951e2d183db81f349b7f81
Summary:
-In the case where an operator does not support a given data type
an error message is emitted to alert the user, this message is
incorrectly structured. This commit adds to and rearranges the
error message to make it a little clearer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16537
Differential Revision: D13958859
Pulled By: zou3519
fbshipit-source-id: 935fc3adcef2f969042b1db902c9ec004488ea9c
Summary:
As the comment indicates, the issue is only present in some versions of
Python 2, so we should be able to use heavily optimized PyTuple_Check in
most cases, and skip allocation of the strings, and unnecessary lookups
on object's type.
cc ezyang zasdfgbnm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16657
Differential Revision: D13957854
Pulled By: ezyang
fbshipit-source-id: be32eb473ad77a0805e8247d8d583d673d4bdf25
Summary:
This PR updates the logic for using cudnnGet* and cudnnFind*. Current version of cudnn find and get (v7) returns a pair of best algorithm and the convDesc mathType. While we were using the returned algorithm, we didn't update the mathType. As a result, we ended up with a slow choice of algorithm and math type. Without this patch, we are seeing a 10x regression in group convolutions.
Changelist:
- Changed the template arguments to be `perf_t` instead of `algo_t` to unify cudnnFind and cudnnGet. Both cudnnFind and cudnnGet have the same purpose and hence, it made sense to unify them and get rid of `getAlgorithm`.
- Used cudnnGet*_v7 everywhere cudnnGet* was being used.
- Removed all cudnn6 paths (This PR depends on https://github.com/pytorch/pytorch/pull/15851)
Differential Revision: D13957944
Pulled By: ezyang
fbshipit-source-id: a88c39d80ae37f2d686665622302b62b50fab404
Summary:
Move `logsumexp` and `max_values` to `TensorIterator` and use it to make `logsumexp` work for multiple dimensions.
Timings on a tensor of shape `(10,1000000,10)`, for each combination of (cpu, single-threaded cpu, gpu) and dimension:
**before**
208 ms ± 2.72 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
279 ms ± 5.07 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
199 ms ± 2.64 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.11 s ± 33.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.25 s ± 25.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.11 s ± 6.83 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
15.4 ms ± 1.02 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
132 ms ± 30.1 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
39.6 ms ± 19.1 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
**after**
199 ms ± 8.23 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
307 ms ± 8.73 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
207 ms ± 7.62 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
1.16 s ± 8.92 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.26 s ± 47.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
1.13 s ± 13.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
15.4 ms ± 868 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
132 ms ± 27.6 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
39.6 ms ± 21.8 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16475
Differential Revision: D13855746
Pulled By: umanwizard
fbshipit-source-id: aaacc0b967c3f89073487e1952ae6f76b7bd7ad3
Summary:
Pull Request resolved: https://github.com/pytorch/translate/pull/309
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16481
This gives us a boolean flag `quantize` on the `BeamSearch` module that allows us to apply FBGEMM quantization to a pretrained PyTorch model and export this to PyTorch native runtime.
Reviewed By: jmp84
Differential Revision: D13514776
fbshipit-source-id: 3f7cbff0782aae54c9623ad1ea7e66d7f49e2b32
Summary:
Pull Request resolved: https://github.com/pytorch/translate/pull/310
This adds fork/join parallelism to the EncoderEnsemble and DecoderBatchedStepEnsemble models. Note that when run in Python, these calls are no-op, and similarly we remove these calls before exporting to ONNX. But when we run in the PyTorch native runtime, we will now have the opportunity to run these sections in parallel.
Benchmark validation is pending me slogging through FBLearner Flow issues, as usual
Reviewed By: jmp84
Differential Revision: D13827861
fbshipit-source-id: 0cb9df6e10c0ba64a6b81fa374e077bce90f1d5b
Summary:
This PR reworks the mutability API to be simpler (updates passes to use "mayAlias" calls) and improves the caching logic.
The difference is that we now directly express the idea of a "memory location." Leaves in the alias trackers points-to graph are considered unique memory locations, and mayAlias questions can be boiled down whether two values share a leaf.
To speed up queries, some basic path compression has been added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16605
Differential Revision: D13952738
Pulled By: suo
fbshipit-source-id: cfc7fb2b23369f1dc425d1d8ca2c753c193d95dd
Summary:
The idea is to unify the environment variables `JOB_BASE_NAME` and `BUILD_ENVIRONMENT` which controlled the Pytorch and Caffe2 jobs respectively. In this commit, we have converted all the `JOB_BASE_NAME` references in _.jenkins/pytorch/*_ files to `BUILD_ENVIRONMENT`. Then, did the same thing in ._circleci/config.yml_. One thing that we needed to be careful was when both `BUILD_ENVIRONMENT `and `JOB_BASE_NAME` were present under same declaration in _config.yml_ file (e.g., for "caffe2-" stuffs). To ensure that all "==" checks work as expected, we also had to add "*" in some if conditions in _.jenkins/caffe2/build.sh_ file. Finally, removed "-build", "-test", etc. suffixes from `COMPACT_JOB_NAME` variable assignment in the bash script files in _.jenkins/pytorch_ folder, e.g., modify `COMPACT_JOB_NAME="${BUILD_ENVIRONMENT}-build"` to `COMPACT_JOB_NAME="${BUILD_ENVIRONMENT}"`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16649
Differential Revision: D13946392
Pulled By: mmh683
fbshipit-source-id: 790de6abf96de184758e395c9098a50998e05bc5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16673
Replace resize_dim() with set_sizes_and_strides() in THTensor_(unsqueeze1d) in aten/src/TH/generic/THTensor.cpp, as described in T38058642.
Reviewed By: ezyang
Differential Revision: D13928879
fbshipit-source-id: d593cebcc82589cd362ac78884d4e367d0da0ce6
Summary:
Just noticed while building on a machine without cudnn present - it was building but the runtime failed since some methods weren't bound
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16701
Differential Revision: D13937247
Pulled By: dzhulgakov
fbshipit-source-id: c81f05be7a9e64a1a8591036dcf8692c0ed4064e
Summary:
The op was implicitly relying on pos_to_output to be zero-initialized after extending. We're removing this functionality from allocator, thus fixing here. For some reason it wasn't spotted by junk-initialization but was reliably reproducible with standard malloc() if both junk_fill and zero_fill flags are turned off.
cc kittipatv jerryzh168
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16702
Reviewed By: kittipatv
Differential Revision: D13937257
Pulled By: dzhulgakov
fbshipit-source-id: 3ee520b05467108e6c3e64eb3e6c60589bdf3d87
Summary:
This bump includes:
* Memory leak fix where the Gloo transport would hold on to auxiliary
structures for send/recv pairs after they finished.
* Fix write-after-free from Gloo thread during stack unwinding on error.
* Removal of the PATENTS file.
Fixes#16144.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16638
Differential Revision: D13937950
Pulled By: pietern
fbshipit-source-id: 3cfecaf13ee0f214c06681386557a4b1c3e1d6b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16524
- Make it exception safe. When an exception happens during write, the old state is recovered.
- Use RAII instead of try/catch to increment counters in readers. This is more readable, and it also makes it work with reader closures that return void, which previously didn't work because the reader return value was stored on the stack.
- Assert there's no reads or writes happening when it's destructed to avoid destruction race conditions
- Explain the algorithm in detail in comments
- Add test cases
Reviewed By: ezyang
Differential Revision: D13866609
fbshipit-source-id: 01306a282a3f555569caa13d8041486f960d00e2
Summary:
When trying to get a test to pass I was missing an exclamation mark. Instead now I just use a different function in the conditional
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16686
Differential Revision: D13935182
Pulled By: jamesr66a
fbshipit-source-id: 7525a1a829276641dbafe06734f03f6202df6b22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16648
We added onnxGraph sharing keyed on model id and net seq number but we forgot to supply these info to the Onnxifi. Therefore, we will only create ONE onnxGraph whatsoever... This diff adds necessary info to the OnnxifiOp to prevent this from happening.
Reviewed By: bertmaher, rdzhabarov
Differential Revision: D13912356
fbshipit-source-id: fe8982327287a35f32fe3b125d94b617d18c0ab5
Summary:
Adds a decorator `torch.jit.ignore` for Python functions that tells the compiler to skip over these Python values, putting a `prim::Error` in their place which always throws an exception when run.
This lets you have Python-only code in your model in an explicit way, which is useful for debugging, and still be able to save/load the model.
Fixes#15815
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16055
Differential Revision: D13797286
Pulled By: driazati
fbshipit-source-id: 29d36776608ec101649a702952fc6ff3c27655b1
Summary:
Add winograd conv method. Users can select the direct conv or winograd conv in the model file.
We close the origin pr https://github.com/pytorch/pytorch/pull/12154 and create this new one for better rebasing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15196
Differential Revision: D13463721
Pulled By: yinghai
fbshipit-source-id: c5cd5c8aa7622ae7e52aeabd3dbb8ffb99b9b4ee
Summary:
Previously this would fail with the error message:
```
ValueError: Auto nesting doesn't know how to process an input object of type dict. Accepted types: Tensors, or lists/tuples of them
```
Turns out we're not using the line that causes this error (or a side effect of that line), so removing it fixes the issue. Also cleaned up some related dead code (cc apaszke to make sure the code isn't useful in some way)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16616
Differential Revision: D13908352
Pulled By: suo
fbshipit-source-id: 27094f1f4ea0af215b901f7ed3520e94fbc587b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16625
This is a squash of multiple PRs that refactored the old c10 dispatcher into a new one that follows the c10 dispatcher design doc.
It is now unboxed and follows the Stack semantics from JIT. It also uses the runtime JIT schema instead of its own compile time schema definitions.
Reviewed By: ezyang
Differential Revision: D13907069
fbshipit-source-id: edcc4806ccd21474fdfb5a98516219b1956db13d
Summary:
There is a regression in cudnnGet*_v7 that causes slowdown in resnet50 training. I am opening a bug with cuDNN team about this. This reverts commit 38374468832e307ca741901870914857a836dd5d.
ezyang 😿
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16484
Differential Revision: D13924755
Pulled By: soumith
fbshipit-source-id: 8c719345fc443f1289539bfae630eea9224ba4a5
Summary:
Adds better bounds checks for target lengths in CTC loss, checks for integral types for target and prediction lengths, and adds tests for each, according to #15946
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16269
Differential Revision: D13847567
Pulled By: ezyang
fbshipit-source-id: 5d7a975565e02baf78fe388813a1d1ef56dfb212
Summary:
-Skip the test due to flaky behavior on AMD/Rocm
-The fix is expected in Rocm 2.2 ( HSA runtime)
bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16639
Differential Revision: D13915231
Pulled By: bddppq
fbshipit-source-id: 66e1d275836337170b15ceb9d60cfdd3242d4df8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16620
LogfiledbNetLoader loads all external input blobs into a workspace instance, we pack a shared pointer to this loaded workspace into the SingleLoadedNetSupplier.
SingleLoadedNetSupplier will pass this workspace to BlackBoxPredictor to be executed. (D13891759 is a WIP of how it all comes together)
Reviewed By: pjh5
Differential Revision: D13901467
fbshipit-source-id: 20589f898922f5f1aec50be131dad17a8c38e9b2
Summary:
Resolves#15863
Changed the documentation for MultiLabelSoftMarginLoss and MultiLabelMarginLoss to be more explicit about the `target` format.
More than happy to change the messaging based on discussion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16644
Differential Revision: D13912395
Pulled By: soumith
fbshipit-source-id: 24a3c214c5f6f9d043e25b13ac758c1c1211b641
Summary:
We inadvertently switch the OSX build over to ninja on CI. It then fails to respect MAX_JOBS and hits the same scache deadlock bug, this makes the ninja build respect MAX_JOBS.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16641
Differential Revision: D13910751
Pulled By: zdevito
fbshipit-source-id: 61bec500539519b019b74421a13cd87fc1d86090
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16513
compare_exchange_deleter makes it easier to replace a
deleter on a DataPtr with a new one, without requiring
allocating another closure to hold the old deleter.
See comment for details.
This diff was originally landed as part of D13762540
(#16226) but we are reverting that diff D13863610 (#16510)
Reviewed By: smessmer
Differential Revision: D13864245
fbshipit-source-id: 56eda4748238dd3a5130ba6434fda463fe7c690e
Summary:
So that things like below can be JITable, and available in C++ API:
```python
import torch
torch.jit.script
def f(x, y, z):
x.index_add(0, y, z)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12413
Differential Revision: D13899948
Pulled By: suo
fbshipit-source-id: b0006b4bee2d1085c813733e1037e2dcde4ce626
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16630
two PRs landed concurrently - enforcing tensor constraints and refactoring c10. Since it's not a prod code - disable test and I'll let Sebastian to fix it properly.
Reviewed By: ezyang
Differential Revision: D13908117
fbshipit-source-id: 381c5626078b794afa1fc7a95cb1ea529650424c
Summary:
I went through my build log and did what I thought were reasonable fixes to all the C++ compilation warnings that came up
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16411
Differential Revision: D13901006
Pulled By: jamesr66a
fbshipit-source-id: 02df4e3e5a5c8dd9e69ac9f065cd3f2a80645033
Summary:
This PR adds basic support (creation and indexing) for immutable dictionaries in Script. This includes Python/string frontend support and a `IValue::GenericDict` type backed by a `std::unordered_map`. Only `str`, `int`, and `float` are supported as keys, any type can be a value. Structure is pretty similar to list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16208
Differential Revision: D13881686
Pulled By: driazati
fbshipit-source-id: 29ce9835b953c3456f57bcc2bbdf7fe0cbf941c0
Summary:
so that it's included in the hashed key that decides whether to call Find or not. This is required to ensure that Find is run for all devices
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16613
Differential Revision: D13901769
Pulled By: bddppq
fbshipit-source-id: 7d29ea9e40231cd4eef80847afa1307efeb0945c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16514
Original commit changeset: dc371697f14b
Relanding https://github.com/pytorch/pytorch/pull/15860 - the problem was that layer_norm was using at::empty which is not yet on mobile
Reviewed By: ezyang
Differential Revision: D13861480
fbshipit-source-id: e2116da32bc117175c96b9151b1beba9b31eff36
Summary:
This simplifies the process for building on windows, since users no longer have to find and run the vcvarsall.bat file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16540
Differential Revision: D13893596
Pulled By: zdevito
fbshipit-source-id: 79b7ad55c3251b3f573fd8464931138f8a52dd1d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16473
This resolves the issues associated with caffe2 initialization (specifically the REGISTER_FUNCTION_SCHEMA_OPERATOR calls) being run after Torch's static op registration calls.
The fix employs a meyer's singleton wrapped by the constructor of a type. Everything is placed inside a macro to make it easier for users to use.
Reviewed By: smessmer
Differential Revision: D13854306
fbshipit-source-id: ecf60861f229532826fae254974e9af4389055df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16576
allows instantiation of operator with arguments passed by move rather than explicit copies
per Sebastian's suggestion
Reviewed By: smessmer
Differential Revision: D13882416
fbshipit-source-id: bc8d50e73f5a1ae87155b0cf96799b8573a7a8fa
Summary:
Here is a fresh attempt at getting some fusion back in autodiff-generated graphs in the presence of SumToSize.
- The sum to size operator is now `aten::_grad_sum_to_size` to allow symbolic script differentiation (and that in turn would need to use this in place of sum_to_size to signal that it strictly operates on gradients). This is also used in the autodiff code, replacing `prim::SumToSize`.
- `_grad_sum_to_size` is now fusable, `cat`s - which are fused afterwards thanks to Adam's simplification of the code - are only fused if there is no `_grad_sum_to_size` in the fusion group.
- I push the `_grad_sum_to_size` out of the the fusion group when compiling and record the desired summations in the KernelSpec. The reasoning is the following:
- As the autodiff is a repeated applicaiton of the chain rule, we always have the pattern `grad_in = mm(A, grad_out)`, with A often diagonal for cases interesting to the fuser, whence it is `grad_in = a * grad_out` (a pointwise multiplication). We know that only `grad_out` may have AutodiffGradSumToSize applied, so we can commute AutodiffGradSumToSize with the `mul` (and `div` and `neg` are of similar origin).
- For `type_as` the gradient might be giving the type, so just skip SumToSize,
- `add` (which was inserted as `prim::AutogradAdd`) adding gradients when the forward used the same value in several places. This is non-broadcasting, so we know that the two arguments would have the same sizes as inputs - which is good so we don't have to do bookkeeping of the two parts.
Details:
- During fusion, the Tensor arguments are always kept as the first parameters of the fusion group to accomodate indexing assumptions in the fuser.
- The rewriting of the fusion group to record the necessary output transformation and eliminate `_grad_sum_to_size` from the fusion group is now in the fuser compile step.
- In the execution step, the arguments are split into Tensor / Non-Tensor and the non-tensor args are mostly forgotten about except for doing `sum_to_size` at the end. This would want to be improved if/when we fuse nonconstant scalar arguments.
- In a number of places in the fuser, the non-Tensor arguments to the fusion group needed to be ignored.
Thank you, apaszke for the insightful discussion. All bad ideas and errors are my own.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14957
Differential Revision: D13888173
Pulled By: zou3519
fbshipit-source-id: 071992c876e8b845f2b3e6329ae03a835d39a0ea
Summary:
In the warning box on https://pytorch.org/docs/stable/tensors.html#torch.Tensor.new_tensor it says:
> new_tensor() always copies data. [...] If you have a numpy array and want to avoid a copy, use **torch.from_numpy()**.
But then further up the page we have another warning box with the message:
> torch.tensor() always copies data. [...] If you have a numpy array and want to avoid a copy, use **torch.as_tensor()**.
Now I believe this is just a small oversight, since from_numpy is to be deprecated in favour of as_tensor. See for example https://github.com/pytorch/pytorch/issues/6885 and https://github.com/pytorch/pytorch/issues/8611. I suggest to just use **torch.as_tensor()** in both of the warning boxes.
cc gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16587
Differential Revision: D13897038
Pulled By: gchanan
fbshipit-source-id: 2eb3cd47d2c0b5bf4350f980de3be9fe59b4a846
Summary:
applySelect does modify the tensor and removes the top most dimension which makes it complicated to track just using dim and need to use another parameter as real_dim to signify original dimension
fixes#16192
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16495
Differential Revision: D13897182
Pulled By: gchanan
fbshipit-source-id: 105581dbbff6b431cc8e2539a07e0058161e53a1
Summary:
We don't use this in the lambda body anymore. Remove it to fix a warning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16526
Differential Revision: D13867043
Pulled By: umanwizard
fbshipit-source-id: 4c9a9d194fdfcb63fde16823517d2c6c8e2ae93d
Summary:
This just moves thing around to make AliasTracker independently testable and keep things a little more separate. Follow-on PRs will change the interfaces of AliasDb and AliasTracker to be more clearly distinct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16588
Differential Revision: D13891894
Pulled By: suo
fbshipit-source-id: c5b590b5fdd462afefe743e499034068bf35784a
Summary:
Doc doesn't need to be changed. Also clarifies two inaccurate comments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16384
Differential Revision: D13886637
Pulled By: soumith
fbshipit-source-id: 227385008211a6f3ad9135c54fd2d3754cc9daaf
Summary:
- Add libtorch upload jobs
- Unify checkout and env code for binary jobs (san binary test jobs)
- Compress variables passed into binary jobs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16511
Differential Revision: D13893714
Pulled By: pjh5
fbshipit-source-id: b8bd72e1397dec569a8ec3e859e319178c7c6f8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15388
This is another pass to make perfkernels code safer from illegal instruction error.
Removed dependency to c10/util/Logging.h
We're err on the safer side at the expense of some verbosity.
Reviewed By: dskhudia
Differential Revision: D13502902
fbshipit-source-id: 4f833115df885c5b4f8c1ca83b9badea1553f944
Summary:
The current implementation of the `torch.utils.model_zoo.load_url`
function is prone to a race condition when creating the directory in
which it saves the loaded models, since it checks whether the
directory exists and then creates it in two separate steps. The
directory can be created after the check was made but before we
attempt to create the directory, resulting in an unhandled exception.
Instead, try to create the directory directly, and do nothing if it
already exists.
Note: for Python versions ≥ 3.2, we could simply use the
`exist_ok=True` flag on `os.makedirs`, but this is unavailable in
Python 2.7.
Signed-off-by: Antoine Busque <antoine.busque@elementai.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16578
Differential Revision: D13886470
Pulled By: soumith
fbshipit-source-id: 88815c8a65eec96caea32d6e9a7f83802502fdb9
Summary:
As there are no checks that all the functions are actually being used, we can end up with stale entries. This diff removes unused entries from Declarations.cwrap
Testing:
Successful build via "python setup.py develop"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16463
Differential Revision: D13885815
Pulled By: izdeby
fbshipit-source-id: 4e35c2ac9196167af74dff3d4f971210721285f8
Summary:
Start splitting up these tests so we don't have a massive test file. Doesn't change how you run them, since `gtest.cpp` and `no-gtest.cpp` will still collect everything.
Renamed `tests.h` to `test_misc.h` to vaguely discourage people from adding yet more stuff to it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16536
Reviewed By: zdevito, eellison
Differential Revision: D13882215
Pulled By: suo
fbshipit-source-id: 61cf97f3c2c50703dcf6a3a34da01415ecb7e7d6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/16326
Previously we didn't handle module inputs which included Generic Lists. When checking whether a generic list if a subvalue of the input arg type, I currently recurse on every element of the list. This shouldn't be too slow since the innermost list will be specialized and we won't have to check it's elements.
E.g. Tensor[][] -> GenericList [TensorList ].
The error message could be improved, but extracting the complete type of nested lists would have to deal with unifying types across lists / empty lists & typevars so I'm going to save that for a follow up PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16482
Differential Revision: D13882582
Pulled By: eellison
fbshipit-source-id: 3609bc572f0ee9ebf20a77ea5ebc8fa3b165e24b
Summary:
Absolutely no idea why this is needed. This should be a valid argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16575
Differential Revision: D13884796
Pulled By: pjh5
fbshipit-source-id: 6011e721e2870499f6b5e627d5ad00ece08b530b
Summary:
This PR changes the way we store aliasing information from a "set" approach to a "points-to" analysis. Set-based approaches lose information in ways that make it difficult to do "live" updates to the alias DB as one as mutating the graph.
The tradeoff is that simple queries get more expensive, since they require traversing the points-to graph to answer most questions. In practice, this is unlikely to be that costly since we don't have massive aliasing chains, but we could create an approximation/caching layer if this becomes a problem.
My rough plan is:
1. This PR, switching to a points-to graph
2. Make it "live": analyzing a node should record all the edges the node added, so that we can rollback when the node is destroyed.
3. Reduce wildcard scope: we can make the wildcard a special vertex that points to anything that we're not "sure" about; namely, things that have been put inside lists, or graph inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16386
Differential Revision: D13855117
Pulled By: suo
fbshipit-source-id: f009f58143173c275501624eb105d07ab60fe5e1
Summary:
Changelog:
- Modify concantenation of [1] to a tuple by using cases for list and non-list types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16489
Differential Revision: D13875838
Pulled By: soumith
fbshipit-source-id: fade65cc47385986b773b9bde9b4601ab93fe1cf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16462
This file was moved, now we change the includes to the new location and remove the proxy header.
Reviewed By: ezyang
Differential Revision: D13847279
fbshipit-source-id: 4617d52fdcfe785cb7b2154460a6686c437abd8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16282
This changes the core kernel abstraction to be a function taking a stack, popping its arguments from the stack and pushing results to the stack,
instead of getting arguments as ArrayRef<IValue> and returning an output IValue.
Caffe2 operators need to have a way to pass in preallocated output tensors.
The convention for them is to get all inputs *and* outputs on the stack and also return all of them, i.e. a caffe2 op will always have inputs == outputs.
This will probably change in later diffs towards making the outputs in-arguments optional in the JIT schema.
Reviewed By: ezyang
Differential Revision: D13792335
fbshipit-source-id: e9cc2b5e438cc4653e1f701633a154b92b604932
Summary:
This PR contains the implementation of chunk dataset, with the API proposed in PR https://github.com/pytorch/pytorch/pull/15562
A chunk dataset is derived from StatefulDataset. It utilizes worker threads to prefetches chunk data, splits it into batches and caches them into a queue. When get_batch is called from dataloader, batch data is retrieved from the queue, and data in new chunks will be pushed for later following batches.
Chunk dataset uses two samplers (chunk_sampler and example_sampler) to perform sampling. The chunk_sampler decides which chunk to load, and example_sampler shuffles the examples inside a specific chunk. More detail of this sampling approach can be found here: http://martin.zinkevich.org/publications/nips2010.pdf
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15932
Differential Revision: D13868688
Pulled By: soumith
fbshipit-source-id: a43000c478ca2a3c64cc84b3626d6b8b1ad9a07e
Summary:
Rehash of previous attempts. This tries a different approach where we accept the install as specified in cmake (leaving bin/ include/ and lib/ alone), and then try to adjust the rest of the files to this more standard layout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16414
Differential Revision: D13863635
Pulled By: zdevito
fbshipit-source-id: 23725f5c64d7509bf3ca8f472dcdcad074de9828
Summary:
This is particularly useful when using a c10d::Store from tests.
cc jgehring
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16278
Reviewed By: janewangfb
Differential Revision: D13866271
Pulled By: pietern
fbshipit-source-id: c8670b5f4ebd5cd009f2cabbe46cc17a9237d775
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16510
This diff was supposed to be memory usage neutral, but based on
some internal flows involving cuDNN, it was not. Reverting pending
further investigation.
Original commit changeset: 03f1ebf7f11c
Reviewed By: xw285cornell
Differential Revision: D13863610
fbshipit-source-id: 15517e255fd6b0c064b65fb99f0ef19742236cfd
Summary:
In the case of spurious failure, refcount is not incremented -- which leads to underflow once all references are released.
This was discovered when exercising multiprocessing on ppc64le.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16302
Differential Revision: D13845435
Pulled By: ezyang
fbshipit-source-id: 8e264fff9dca8152cb12617e3216d5e48acd9557
Summary:
We have:
- This is an initial stab at creating a type stub `torch/__init__.pyi` .
- This is only tested on Python 3, since that's the only Python version mypy
works on.
- So far, we only aim at doing this for torch functions and torch.Tensor.
- Quite a few methods and functions have to be typed manually. These are
done in `torch/__init__.pyi.in`
For me, PyCharm (the non-paid one) didn't seem to indicate errors in the .pyi when opening and seemed to be able to get the type hint for the few functions I tried, but I don't use PyCharm for my usual PyTorch activities, so I didn't extensively try this out.
An example of a generated PYI is at [this gist](https://gist.github.com/ezyang/bf9b6a5fa8827c52152858169bcb61b1).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12500
Differential Revision: D13695553
Pulled By: ezyang
fbshipit-source-id: 4566c71913ede4e4c23ebc4a72c17151f94e8e21
Summary:
Some HTTP servers dont return Content-Length, account for that
Fixes: https://github.com/pytorch/pytorch/issues/16152
Differential Revision: D13858882
Pulled By: soumith
fbshipit-source-id: e4293e9368ed4c87548d22adec1ce0c25ea4bd8f
Summary:
It looks like `WithInsertionPoint` and `WithCurrentScope` can be easily implemented without
`ResourceGuard` - that helps readability and removes one more dependency. Is there anything I'm missing?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16351
Differential Revision: D13821826
Pulled By: ZolotukhinM
fbshipit-source-id: b203200b345fb5508a97dc8656e6f51cde4cc21f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15860
Few changes (which are harder to split in separate diffs, so together):
- make conversion explicit (as they can throw to avoid surprises)
- fix tensor legacy dispatch not initialized when tensor is created on C2 side
- add a bunch of invariants to enforce
Reviewed By: ezyang
Differential Revision: D13596031
fbshipit-source-id: d20b601e06ba47aeff2f6e8e15769840e2d46108
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16247
Stack is going to be used by the c10 dispatcher.
This just moves the file, also changing the namespace turned out to be more complicated than I thought, I'll leave the namespace for now.
Reviewed By: ezyang
Differential Revision: D13774189
fbshipit-source-id: 66aeee36425e0ea2b3a4f8159604f38572306d57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16180
Only the kernel knows about its state, the caller doesn't see it anymore.
Reviewed By: ezyang
Differential Revision: D13744071
fbshipit-source-id: cb00ff1a881508c1b36ac4123bee1f68ca02ca9c
Summary:
The current uses of `IR_IF` are mostly trivial, so there is not much value in having special macros for it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16354
Differential Revision: D13821823
Pulled By: ZolotukhinM
fbshipit-source-id: 1ca73111f5b4868fa38a1f29c9230540773e5de6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16273
Previously we have SetOutputSize which accept a partially initialized Output Tensor and set it to the correct size,
the diff change this to GetOutputSize that returns the correct size instead.
e.g.
```
auto* Y = Output(0);
ConvPoolOp<Context>::SetOutputSize(X, Y, channels);
...
Y->mutable_data<T>...
```
-->
```
auto sizes = ConvPoolOp<Context>::GetOutputSize(X, channels);
auto* Y = Output(0, sizes, at::dtype<T>());
```
Reviewed By: dzhulgakov
Differential Revision: D13736281
fbshipit-source-id: 64abce3dbaed0b375098463333dfd0ea5a3b1945
Summary:
Working on the tracer was really annoying because a lot of the implementations were in `tracer.h` and editing that file caused us to rebuild almost the whole world. So this moves all the implementations into tracer.cpp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16410
Differential Revision: D13847776
Pulled By: jamesr66a
fbshipit-source-id: ec8500da32b2d4cd990f293a0a96101d3e82f158
Summary:
Fix alias annotations for ops that may return a fresh tensor. The previous version was overly conservative.
Currently there is no actual behavior change in the alias analysis, but we may use the information in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16460
Differential Revision: D13849086
Pulled By: suo
fbshipit-source-id: cd23b314a800e5e077d866e74456d37a321439d5
Summary:
Adds Tensor alias annotations.
This isn't a full implementation of alias annotations, but that isn't required to increase compliance with the JIT signature schema. There are some sanity checks within native_parse.py for their usage, which can also help overall correctness. Otherwise, this exists solely for further alignment between the JIT signature schema and the native_functions.yaml func schema.
This gets us to ~85% matches.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16239
Differential Revision: D13804133
Pulled By: cpuhrsch
fbshipit-source-id: aa5750f2c7e0f08b8c35d6d8f38cb148e9629855
Summary:
Also, because sometimes we have `CMakeCache.txt` but cmake errored out so I'm adding the existence of `'build.ninja'` as another criterion of rerunning cmake.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16426
Differential Revision: D13843801
Pulled By: ezyang
fbshipit-source-id: ea1efb201062f23b7608f8d061997d8a8e293445
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16177
Change the API for calling operators so that it can store state in an OpKernel object.
This diff doesn't store the state there yet, that comes in a follow up diff.
Reviewed By: ezyang
Differential Revision: D13742889
fbshipit-source-id: 20511a9a1b9f850074e50634d4b4acf87f8c6ecd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16246
The op schema says it returns multiple values, so let's actually return multiple values instead of one tuple.
For some reason, this did work when called from python (probably some auto-unpacking),
but once called from JIT, it segfaulted. This diff fixes that.
Reviewed By: dzhulgakov
Differential Revision: D13780147
fbshipit-source-id: fe94f82f4c53b7454f77c4484fca4ac9dc444475
Summary:
swapBytes64 used to use SwapByteOrder_32 and value, both of which dont exist. This commit rewrites that part from scratch.
This happened on Debugbuild on Microsoft compiler. For that case " && !defined(_DEBUG)" is also removed, because _byteswap_uint64 works fine in debug mode (if it is necessary it should me commented why).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16418
Differential Revision: D13843306
Pulled By: ezyang
fbshipit-source-id: dde1c7baeccec3aaa750d4b7200b3f4ccb4a00cb
Summary:
This flag is useful in identifying if a test is taking way too long like the ones in the following snippet when running the test suite with pytest. 9757ad35b0/test/common_utils.py (L814-L835)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16423
Differential Revision: D13843507
Pulled By: ezyang
fbshipit-source-id: 643e1766a85905b3b112ea5ca562135a17896a72
Summary:
cdist is used for calculating distances between collections of observations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16168
Differential Revision: D13739147
Pulled By: ifedan
fbshipit-source-id: 9419c2c166891ac7db40672c72f17848f0b446f9
Summary:
Before this diff, we execute `std::vector<optional<acc_t>> buffer((unsigned)max_threads, optional<acc_t> {});` in every iteration of `foreach_reduced_elt`. Change the code to only execute that line if we need it; i.e., we are actually about to parallelize.
This overhead is quite significant when we are doing a lot of small reductions in single-threaded code.
```
x=torch.randn((1024,10,1024),dtype=torch.float64)
torch.set_num_threads(1)
%timeit x.std(1)
```
Before (with #15845 applied): 708.25 ms
After: 508 ms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15850
Differential Revision: D13612960
Pulled By: umanwizard
fbshipit-source-id: f5e61abfe0027775c97ed81ac09c997fbee741df
Summary:
Made the change requested in #15555
PR was failing build due to a time out error while getting packages using pip.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16416
Differential Revision: D13833873
Pulled By: soumith
fbshipit-source-id: e2200e9e8015558fcd359dfa3d025b25802d62b5
Summary:
This one needs to be merged ASAP because the CUDA build for Windows is skipped at this time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16412
Differential Revision: D13833889
Pulled By: soumith
fbshipit-source-id: 95a401a01fb0f9c1045df0bfd72d8206b8a6f3fd
Summary:
The real fix for https://github.com/pytorch/pytorch/issues/15605.
This is sort of BC breaking because now
```py
In [1]: import torch
In [2]: a = torch.randn(3, 3, requires_grad=True)
In [3]: a.slogdet()
Out[3]: (tensor(1.), tensor(0.1356, grad_fn=<SlogdetBackward>))
In [4]: a.slogdet()[0].requires_grad
Out[4]: False
```
while before this patch ` a.slogdet()[0]` requires grad with `grad_fn=<SlogdetBackward>`. But any use of backproping through this value will meet the error in #15605 so I don't think this is a problem.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16337
Differential Revision: D13832644
Pulled By: soumith
fbshipit-source-id: f96c477e99edcbdbd966888e5c5ea7fd058429a8
Summary:
The documentation stated that operands to einsum should be a list of Tensors, not individual arguments. The function, however, now accepts individual arguments for each Tensor operand *and* a single argument consisting of a list of Tensors. The documentation was updated to reflect this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16323
Differential Revision: D13832647
Pulled By: soumith
fbshipit-source-id: c01c2b350f47674d3170337f493b0ee2ea381b3f
Summary:
These were really annoying to see in the phabricator UI when trying to land PRs that touched test_jit.py, so this fixes them.
One remaining item is the T484 error. Locally, flake8 still chokes on that line even though I put the noqa comment there (and tried varying whitespaces around it etc). Not sure why it still persists...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16409
Differential Revision: D13832658
Pulled By: jamesr66a
fbshipit-source-id: 46356ba6444ae5ee1a141c28489bdcc7c99e39c0
Summary:
Changelog:
- Append a condition that switches to the native CUDA implementation for affine_grid
Fixes#16365
Differential Revision: D13832192
Pulled By: soumith
fbshipit-source-id: 3f484e6673d71e3ba7627b170cb8f1611e12b9b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16374
this fixes the original attempt in OSS (adds to CMake and python build files)
Reviewed By: smessmer
Differential Revision: D13821061
fbshipit-source-id: 82f0dade0145fd04bdf8e3cb3954b5790e918162
Summary:
This commit removes the dependency on `build_pytorch_libs.sh` by moving the remaining functionality that is not expressible in cmake into python. Removing the indirection through bash also removes over 300 lines of environment munging code that is incredibly hard to understand because it passes a lot of secret parameters through `os.env`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16289
Reviewed By: ezyang
Differential Revision: D13821662
Pulled By: zdevito
fbshipit-source-id: d658d26925e3b1169ac1e3d44a159cf8a1f0d9b1
Summary:
1. Improve error message for better debugging info
2. Increase timeout
3. Also apply the windows worker failure detection mechanism on non-Windows platforms, for better robustness
Attempt to fix#14501
cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16249
Differential Revision: D13784702
Pulled By: ezyang
fbshipit-source-id: 09a7cff83ab9edce561ed69f9fb555ab35d1275f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16191
logdevice related modifications for generic feature type
we directly convert the generic feature structures to json strings, which corresponds to the column input in offline and dper
Reviewed By: itomatik
Differential Revision: D13551909
fbshipit-source-id: 807830c50bee569de202530bc3700374757793a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16350
Example usage of the new caffe2 integration
Reviewed By: smessmer
Differential Revision: D13408546
fbshipit-source-id: 87240ca7f48d653a70241d243aa0eb25efa67611
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16173
Helper to make it easy to run ops in caffe2
Reviewed By: smessmer
Differential Revision: D13468240
fbshipit-source-id: 2276c7870af6dcdf829957f005fd16ac1ef319b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16048
This enables full shimming of the operator (previously it was only
Output() shimmed).
Reviewed By: smessmer
Differential Revision: D13468241
fbshipit-source-id: c853b775ab5cdcd968f4a6cc4766e91c3c6b1c45
Summary:
Some cleanups in ir.{h,cpp}. I plan to continue cleaning it up, so this is a first step.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16342
Differential Revision: D13808897
Pulled By: ZolotukhinM
fbshipit-source-id: 2dedb414576c3efbf8e36434145d7f14a66b1ee7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16335
group conv is not implemented with EIGEN engine so this diff disables related tests
Reviewed By: jamesr66a
Differential Revision: D13807204
fbshipit-source-id: 41f6de43da40882f57e64474520e185733caefb7
Summary:
Remove calls to torch.jit._unwrap_optional that are no longer needed.
The remaining instances would require control flow logic for exceptions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16245
Differential Revision: D13804292
Pulled By: eellison
fbshipit-source-id: 08c5cbe4b956519be2333de5cf4e202488aff626
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16341
as in the title
Reviewed By: intermilan
Differential Revision: D13808679
fbshipit-source-id: 0d12d3253f380bec66bc9be899be565861b8163a
Summary:
This PR adds thread-local guard (`at::AutoNonVariableTypeMode`) to make sure that in VariableType.cpp the operations on baseType still dispatch to non-Variable type, even if the parameters will become Variables after the Tensor/Variable merge. We achieve this by making `legacyTensorType()` and `getType()` check the `at::AutoNonVariableTypeMode` guard to decide whether to return non-Variable type for a variable.
This is part of the VariableImpl/TensorImpl merge work: https://github.com/pytorch/pytorch/issues/13638.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15939
Reviewed By: ezyang
Differential Revision: D13640980
Pulled By: yf225
fbshipit-source-id: d12c2543822958558d7d70d36c50999a5eb8783f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16226
Now that the caching allocator is moved to c10_cuda, we can
delete the duplicate copy from Caffe2.
Reviewed By: dzhulgakov, smessmer
Differential Revision: D13762540
fbshipit-source-id: 03f1ebf7f11c68c19aa0d66110156fe228da6138
Summary:
Some renaming and renamespacing also took place. I was originally planning not to do anything, but it turns out that it was easier to make HIPify work by using a namespace CUDACachingAllocator:: rather than THCCachingAllocator_, since :: is a word boundary but _ is not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16119
Reviewed By: smessmer
Differential Revision: D13718768
fbshipit-source-id: 884a481d99027fd3e34471c020f826aa12225656
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16117
This means I can move it to c10_cuda with minimal fuss.
Reviewed By: smessmer
Differential Revision: D13717836
fbshipit-source-id: a94c7dc649af64542480fc1c226b289588886c00
Summary:
In preparation for setting up a doc build job for stable docs, I wanted
to refactor the workflow so that future changes will be easier.
This PR the following changes:
- Refactor the doc push script into a reusable command
- Add command line options for the doc push script.
These don't matter too much for now but will be useful
for setting up future jobs for building different versions of the
docs.
- Instead of checking out pytorch/pytorch:master, we re-use the pytorch
installation inside the docker image.
- Change the sed in the script to a perl command. sed is annoyingly
different across platforms; the perl command is more stable
- Run the script in dry run mode (without pushing the doc build)
whenever a PR is opened. This lets us test changes to the doc build workflow.
Test Plan
- I tested the doc build script locally with my own credentials and it
worked fine.
- Wait for the pytorch_doc_push CI.
- After merging this PR, keep an eye on the pytorch_doc_push CI status.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16265
Differential Revision: D13803511
Pulled By: zou3519
fbshipit-source-id: 4564bca3e74d490f89a1d1da9fb8b98eb44bdbb1
Summary:
pdist was recently patched to remove buggy batch support and fix issues
with large tensors. This fixed missed a few spots, and didn't handle a
few recommendations that this commit addresses.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16210
Differential Revision: D13791914
Pulled By: gchanan
fbshipit-source-id: 0595841be1b298f7268fd4c02a6628acfec918f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16294
In `ReinitializeTensor`, we compare `tensor->GetDevice()` and `options.device()`, but in the callsite, we actually just provide an option with `device_type`, which means the `device_id` will always be default(-1) for `options`, but for tensor, although it is passed a `device` with default `device_id`, when we allocate the data, the `device` of the `tensor` is the `device` of `Storage`, which is the `device` of underlying `DataPtr`, which is the same as the `device` of the `Context` of the operator, which has a non-default `device_id`.
Therefore everytime we do `ReinitializeTensor`, we'll find the `device` does not match, and after the `ReinitializeTensor` call, the `device` still does not match. That's why everytime we'll allocate a new Tensor and cause perf regressions for ops that uses `ReinitializeTensor` on multiple GPUs.
Reviewed By: BIT-silence
Differential Revision: D13795635
fbshipit-source-id: 24d6afa1a0196a32eb0134ee08b4280244cdb0c3
Summary: Some automation to fix uninitialized members for caffe2 code. Ran canary to make sure I don't have any regression in prod, but not sure how to test comprehensively for caffe2
Reviewed By: ezyang
Differential Revision: D13776185
fbshipit-source-id: fb2a479971cc0276d8784be1c44f01252410bd24
Summary:
This PR adds support for overloaded functions as a step toward adding rnn modules to the JIT standard library.
Possible overloads must be manually specified, and when resolving the overload it chooses by the first one that passes the schema matching logic. The structure is very similar to boolean dispatch in #14425. The overload will only work on weak modules.
In order to avoid supporting overloaded methods in Python to match the JIT execution, the current setup offloads that work to the user. In the test added in `test_jit.py`, two methods are used to overload the `forward` method. In order to call `forward` outside the JIT, a Python-only `forward` that does the right argument type switching must also be provided.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15556
Differential Revision: D13576348
Pulled By: driazati
fbshipit-source-id: 7d3bdd4ee5a6088cc20c92f26a696d1ee5b9204b
Summary:
- remove loop node that is guaranteed not to execute
- remove extra loop outputs that are no longer needed
- if we are inlining an if node, only run constant propagation on the block that will execute
- remove the recurse argument since we only expose the Graph Constant Propagation and it's not used
This also includes a few extra hooks to python_ir that I think make it a little be easier to test graph conditions from python.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16244
Differential Revision: D13791635
Pulled By: eellison
fbshipit-source-id: d16351fffcfc8013b02015db200f8fde002e0577
Summary:
- Fix environment variable used to guard binary uploads
- Move common MacOS brew setup-code into a common function to decrease code duplication and also to move that noisy console output into its own CircleCI step
- Split Mac builds into separate build-test and upload jobs. Add one of these jobs to PR runs; add upload jobs to nightly binarybuilds workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16016
Differential Revision: D13791084
Pulled By: pjh5
fbshipit-source-id: 8eeb8e1963d46eab84f0f6dad9f0265163d5bf73
Summary:
Otherwise, it won't work if we sync on this event.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8219
Reviewed By: pietern
Differential Revision: D13788657
Pulled By: teng-li
fbshipit-source-id: 8c96e9691ed2441d7a685fb7ae8fece906f58daf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16176
This makes PyTorch and Caffe2's data() method line up.
Historically, PyTorch made no distinction between tensors
with const or non-const data, and thus provided a
non-const pointer with data() member. Changing the API to
return a const-pointer would break all mutable code, whereas
changing the Caffe2 API to change a pointer doesn't break
any code, *except* for code which required an exact match
on const-ness (e.g., in template arguments). Since the latter
is less disruptive, we've opted for it here.
The few places downstream that broke due to this are fixed
in this patch.
Reviewed By: smessmer
Differential Revision: D13742916
fbshipit-source-id: baa4b4544cfdf7c1f369f4d69a1e0d5953c1bd99
Summary:
This PR applies a few minor modifications leading to 100s of additional matches
Modifications to native_functions.yaml
1) double to float
2) int64_t to int
3) IntList[\d*] to int[\d*]
4) {} to []
5) Tensor? x=[] to Tensor? x=None
6) TensorList to Tensor[]
7) 1e-x to 1e-0x
8) Generator* x = nullptr to Generator? x = None
9) `{.*}` to `[.*]`
Overall this adds about 300 new matches and brings us to about 1/2 compliance of native_functions func with their JIT signature equivalent
While this is still a draft "tools/jit/gen_jit_dispatch.py" contains code to aid in finding close signatures
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16111
Reviewed By: ezyang
Differential Revision: D13738123
Pulled By: cpuhrsch
fbshipit-source-id: d1ec1e089bdb26ec155f6f31ccf768270acb76c7
Summary:
This PR updates the logic for using cudnnGet* and cudnnFind*. Current version of cudnn find and get (v7) returns a pair of best algorithm and the convDesc mathType. While we were using the returned algorithm, we didn't update the mathType. As a result, we ended up with a slow choice of algorithm and math type. Without this patch, we are seeing a 10x regression in group convolutions.
Changelist:
- Changed the template arguments to be `perf_t` instead of `algo_t` to unify cudnnFind and cudnnGet. Both cudnnFind and cudnnGet have the same purpose and hence, it made sense to unify them and get rid of `getAlgorithm`.
- Used cudnnGet*_v7 everywhere cudnnGet* was being used.
- Removed all cudnn6 paths (This PR depends on https://github.com/pytorch/pytorch/pull/15851)
Differential Revision: D13787601
Pulled By: ezyang
fbshipit-source-id: 81fe86727673d021306fe1c99c3e528b7c9ad17f
Summary:
Tune elementwise kernel for AMD architectures by increasing the work group sizes and launch bounds. This change improves training throughput for torchvision models by up to 11% in our tests while exhibiting no significant performance regression.
No functional/performance change for CUDA - just shifting numbers into constrexpr.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16217
Differential Revision: D13776684
Pulled By: bddppq
fbshipit-source-id: edbaebe904598b2de66a9e9a68a1aa219ebc01e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16166
Since we now don't use std::function anymore, we can make kernel registration constexpr again.
Reviewed By: ezyang
Differential Revision: D13738630
fbshipit-source-id: 918fa3a3c8c6f0ddbd0f08b3b143cdf066265387
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16165
Store kernels as direct function pointers instead of std::function.
Using direct function pointers avoids a performance risk std::function would introduce.
Reviewed By: ezyang
Differential Revision: D13738627
fbshipit-source-id: a348906c8a201436699681980a82ca95065a06a0
Summary:
Partially fixes: https://github.com/pytorch/pytorch/issues/394
Implementation detail:
Codegen is modified to generate codes that looks like below:
```C++
static PyObject * THPVariable_svd(PyObject* self_, PyObject* args, PyObject* kwargs)
{
HANDLE_TH_ERRORS
static PythonArgParser parser({
"svd(Tensor input, bool some=True, bool compute_uv=True, *, TensorList[3] out=None)",
}, /*traceable=*/true);
ParsedArgs<6> parsed_args;
auto r = parser.parse(args, kwargs, parsed_args);
static PyStructSequence_Field fields0[] = {
{"U", ""}, {"S", ""}, {"V", ""}, {nullptr}
};
static PyStructSequence_Desc desc0 = {
"torch.return_types.svd_out", nullptr,
fields0, 3
};
static PyTypeObject type0;
static bool namedtuple_type_initialized0 = false;
if (!namedtuple_type_initialized0) {
PyStructSequence_InitType(&type0, &desc0);
namedtuple_type_initialized0 = true;
}
static PyStructSequence_Field fields1[] = {
{"U", ""}, {"S", ""}, {"V", ""}, {nullptr}
};
static PyStructSequence_Desc desc1 = {
"torch.return_types.svd", nullptr,
fields1, 3
};
static PyTypeObject type1;
static bool namedtuple_type_initialized1 = false;
if (!namedtuple_type_initialized1) {
PyStructSequence_InitType(&type1, &desc1);
namedtuple_type_initialized1 = true;
}
if (r.idx == 0) {
if (r.isNone(3)) {
return wrap(&type1, dispatch_svd(r.tensor(0), r.toBool(1), r.toBool(2)));
} else {
auto results = r.tensorlist_n<3>(3);
return wrap(&type0, dispatch_svd(r.tensor(0), r.toBool(1), r.toBool(2), results[0], results[1], results[2]));
}
}
Py_RETURN_NONE;
END_HANDLE_TH_ERRORS
}
```
Types are defined as static member of `THPVariable_${op_name}` functions, and initialized at the first time the function is called.
When parsing function prototypes in `native_functions.yaml`, the parser will set the specified name as `field_name` when see things like `-> (Tensor t1, ...)`. These field names will be the field names of namedtuple. The class of namedtuples will be named `torch.return_types.${op_name}`.
In some python 2, `PyStructSequence` is not a subtype of tuple, so we have to create some functions to check if an object is a tuple or namedtuple for compatibility issue.
Operators in `native_functions.yaml` are changed such that only `max` and `svd` are generated as namedtuple. Tests are added for these two operators to see if the return value works as expected. Docs for these two ops are also updated to explicitly mention the return value is a namedtuple. More ops will be added in later PRs.
There is some issue with Windows build of linker unable to resolve `PyStructSequence_UnnamedField`, and some workaround is added to deal with this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15429
Differential Revision: D13709678
Pulled By: ezyang
fbshipit-source-id: 23a511c9436977098afc49374e9a748b6e30bccf
Summary:
Initial enabling of the upcoming hip-clang compiler for the PyTorch source base.
Changes:
* update the Eigen submodule to a version including our upstreamed hip-clang enabling there
* modify a few ifdef guards with the `__HIP__` macro used by hip-clang
* use `__lane_id` instead of `hc::__lane_id`
* add Debug flags for ROCm to the cmake infrastructure
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16085
Differential Revision: D13709459
Pulled By: ezyang
fbshipit-source-id: 1b7b33fe810a0434766180580d4443ea177eb7c7
Summary:
`torch.distributed.launch.py` will not raise error when `subprocess.Popen` is not return 0.
For better debugging it should always raise an error if processes launched have unusual behavior
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16069
Differential Revision: D13709467
Pulled By: ezyang
fbshipit-source-id: 31d32a5ec8fed7bccd62d845bfba0e670ed3fe20
Summary:
Save reallocation costs, by reserving vectors according to how many elements we expect to put in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16201
Differential Revision: D13762594
Pulled By: ezyang
fbshipit-source-id: 7e3bfe421489dde48a2ddb0920dd155f69baecc0
Summary:
Fixed a few C++ API callsites to work with v1.0.1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16221
Differential Revision: D13759207
Pulled By: yf225
fbshipit-source-id: bd92c2b95a0c6ff3ba5d73cb249d0bc88cfdc340
Summary:
Now it is only necessary to use 'develop' or 'install' to build. Incremental cmake is on by default. `develop --cmake` forces it to rerun.
The NinjaBuilder stuff is dead. It was used to make building _C.so
faster but now _C.so is just an empty stub file.
Removed a bunch of custom build commands from setup.py that are
no longer meaningful now that cmake handles most of the build.
Removed unused targets in build_pytorch_lib.sh/bat
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16162
Differential Revision: D13744155
Pulled By: zdevito
fbshipit-source-id: d836484782c65b7f8e8c7a82620886f7a7777892
Summary:
This PR does three things:
~~Allow `int64_t?` in function schema, which provide an elegant way of implementing null-able int arguments, as discussed in https://github.com/pytorch/pytorch/pull/15208#pullrequestreview-185230081~~
~~Originally implemented in https://github.com/pytorch/pytorch/pull/15235~~
~~Example:~~
```yaml
- func: myop(Tensor self, int64_t? dim=None) -> Tensor
variants: function
```
~~cc: zou3519~~
Edit: implemented in https://github.com/pytorch/pytorch/pull/15234
Previously tried in https://github.com/pytorch/pytorch/pull/12064. There was a problem that C++ does not have kwarg support, which makes it confusing to know whether `unique(t, 1)` actually means `unique(t, dim=1)` or `unique(t, sorted=1)`.
Now I think I have a better idea on how to implement this: there are two ATen operators: `unique` and `unique_dim`. `unique` has the same signature as in python, and exported to both python and C++. `unique_dim` has signature `unique_dim(tensor, dim, sorted=False, return_inverse=False)`, and only exported to C++, which could be used more naturally for a C++ user.
Differential Revision: D13540278
Pulled By: wanchaol
fbshipit-source-id: 3768c76a90b0881f565a1f890459ebccbdfe6ecd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16175
Separate Moments from math and optimize it
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision: D13742472
fbshipit-source-id: 90757d908d38c98ca69818855aaf68315e525992
Summary:
Submitting this PR as an update to existing PR (https://github.com/pytorch/pytorch/pull/15938) on houseroad 's request.
This PR replaces the use of ONNX op `ConstantLike` with `ConstantOfShape` in the ONNX exporter. In addition to removing the call sites in `symbolic.py`, it also replace the call site in `peephole.cpp`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16095
Differential Revision: D13745723
Pulled By: houseroad
fbshipit-source-id: e2a5f534f01adf199df9e27544f7afcfa540e1f0
Summary:
Resolves#15923 where LBFGS threw "Error: a leaf Variable that requires grad has been used in an in-place operation."
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16167
Differential Revision: D13745822
Pulled By: soumith
fbshipit-source-id: 7d1d0511d06838c0c6f4c8a6b53cf15193283059
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16174
Our service creates a new caffe2 workspace for the same underlying network on multiple threads concurrently at service startup time (later these workspaces are being reused for sequential requests), resulting in concurrent quantization via FullyConnectedDNNLowPOp calling GetOrCreateFbgemmPackBMatrix(). The lazily performed quantizations during the first inference in each workspace are all funnelled through GetOrCreateFbgemmPackBMatrix()'s cache_mutex, which means quantization is serialized, so at service startup time only a single CPU core is being used for around a minute until the serial quantization is done.
An better solution would be to avoid the quantization of the same weight matrix of the operator copies in different net copies to begin with, but this here is the simpler solution for our current problem.
Reviewed By: jspark1105
Differential Revision: D13708785
fbshipit-source-id: 537519896b3b939c552d67f400bafc8a69ce11eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16135
Separate affine_channel from math and optimize it
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision: D13727606
fbshipit-source-id: 8980af4afadaf964a18a9da581106fe30896a7e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16065
Before, we registered the caffe2 kernel with the c10 dispatcher using plain C types.
Now, we pass in IValues, which avoids the unwrapping inbetween.
Reviewed By: ezyang
Differential Revision: D13689036
fbshipit-source-id: b976a2c46a5a541f6a926b3df255e8a535e32420
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16051
This changes the kernels stored in the c10 dispatcher from plain C function pointers to IValue-based KernelFunction*.
Note that KernelFunction is currently taking an `ArrayRef<IValue>` as arguments. A later diff will change that to it taking a `Stack*`.
Reviewed By: ezyang
Differential Revision: D13684518
fbshipit-source-id: 1fa54f60cec2e967b92a4a043d6e3ac1627ed991
Summary:
This tests the water for adding back NNPACK in PyTorch, it's a lot better than the fallback THNN versions.
In #6151, we (ezyang and soumith) removed NNPACK support from PyTorch. Of course Maratyszcza might have advice, too. (Or an opinion on the CMake changes.)
The only functional changes are to use NNPack more aggressively on mobile and a .contiguous() to match NNPack's assumption (I stumbled over that while using NNPack for style transfer.)
The CMake changes try to use the NNPack we already have in git.
In terms of lines of code this is a large part of the diff of https://lernapparat.de/pytorch-jit-android/ . As far as I can tell, we don't have MKLDNN on mobile and the native THNN implementation are prohibitively expensive in terms of both CPU and memory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15924
Differential Revision: D13709576
Pulled By: ezyang
fbshipit-source-id: f2e287739909451c173abf046588209a7450ca2c
Summary:
Partial fix for #15804, only w/o dim.
For jcjohnson benchmarking script I'm getting the following results on V100:
Before:
```
unning with N = 10000, M = 10000
cuda (no inverse): 0.98 ms
cpu (no inverse): 0.96 ms
cuda (with inverse): 1.07 ms
cpu (with inverse): 1.76 ms
Running with N = 10000, M = 100000
cuda (no inverse): 0.76 ms
cpu (no inverse): 1.53 ms
cuda (with inverse): 1.23 ms
cpu (with inverse): 3.02 ms
Running with N = 100000, M = 100000
cuda (no inverse): 1.28 ms
cpu (no inverse): 11.22 ms
cuda (with inverse): 69.76 ms
cpu (with inverse): 20.28 ms
Running with N = 100000, M = 1000000
cuda (no inverse): 0.78 ms
cpu (no inverse): 18.78 ms
cuda (with inverse): 133.45 ms
cpu (with inverse): 34.09 ms
Running with N = 500000, M = 500000
cuda (no inverse): 1.43 ms
cpu (no inverse): 61.13 ms
cuda (with inverse): 3315.18 ms
cpu (with inverse): 104.57 ms
Running with N = 500000, M = 5000000
cuda (no inverse): 0.86 ms
cpu (no inverse): 96.44 ms
cuda (with inverse): 5209.93 ms
cpu (with inverse): 176.10 ms
```
After
```
Running with N = 10000, M = 10000
cuda (no inverse): 1.04 ms
cpu (no inverse): 0.94 ms
cuda (with inverse): 0.64 ms
cpu (with inverse): 1.76 ms
Running with N = 10000, M = 100000
cuda (no inverse): 0.77 ms
cpu (no inverse): 1.55 ms
cuda (with inverse): 0.58 ms
cpu (with inverse): 2.79 ms
Running with N = 100000, M = 100000
cuda (no inverse): 1.30 ms
cpu (no inverse): 14.15 ms
cuda (with inverse): 1.63 ms
cpu (with inverse): 20.90 ms
Running with N = 100000, M = 1000000
cuda (no inverse): 0.82 ms
cpu (no inverse): 18.63 ms
cuda (with inverse): 0.61 ms
cpu (with inverse): 33.52 ms
Running with N = 500000, M = 500000
cuda (no inverse): 1.51 ms
cpu (no inverse): 59.81 ms
cuda (with inverse): 1.23 ms
cpu (with inverse): 110.69 ms
Running with N = 500000, M = 5000000
cuda (no inverse): 0.92 ms
cpu (no inverse): 104.26 ms
cuda (with inverse): 0.84 ms
cpu (with inverse): 187.12 ms
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16145
Differential Revision: D13738821
Pulled By: soumith
fbshipit-source-id: 0811fb4ade47e3b466cebbc124e3f3333a986749
Summary:
It turns out that clang-tidy is bundled with travis's standard trusty distribution, so no need to install it manually.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16164
Differential Revision: D13738986
Pulled By: suo
fbshipit-source-id: d0cd76c615625b2ed7f18951289412989f15849d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16049
We might see the pattern
```
if (scale_.numel() != N) {
scale_->Resize(N);
// set initial value for scale_
}
// In class:
Tensor scale_{CPU};
```
before in the code, where `scale_` is a member variable of Type `caffe2::Tensor`
This pattern actually serves two purposes, if `scale_` is partially initialized with device type but not size, this call will
initialize Tensor with the correct size, or if `scale_` is already initialized with size, it will check whether the size
matches a runtime value `N` and if not it will Resize. To rewrite this we'll do the following:
```
if (!scale_.defined() || scale_.numel() != N) {
ReinitializeTensor(&scale_, {N}, at::dtype<float>().device(CPU));
// set initial value for scale_
}
```
There are some variants, if `scale_` is resized to a constant size, we can call `ReinitializeTensor` instead
```
if (scale_.numel() != 1) {
scale_->Resize(1);
}
```
-->
```
ReinitializeTensor(&scale_, {1}, at::dtype<float>().device(CPU));
```
Normal Resize will be refactored directly into ReinitializeTensor:
```
scale_->Resize(N);
```
-->
```
ReinitializeTensor(&scale_, {N}, at::dtype<float>().device(CPU));
```
Reviewed By: dzhulgakov
Differential Revision: D13667883
fbshipit-source-id: 2c7cb61544b72765b594011b99150eb5a1b50836
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16086
[caffe2] RNN operators should inherit step_net device_options
According to NetDef documentaiton, if network has a specific device option it applies to all network operators that do not explicitly specifiy it.
But this does not seem to be the case for RecurrentNetwork operators
Reviewed By: orionr
Differential Revision: D13699552
fbshipit-source-id: 14529bc9504e3b02f763e3c2429be21e46f82b68
Summary:
Add support for type inference for optional type refinement.
If a conditional is of the form "x is None" or "x is not None", or is a boolean expression containing multiple none checks, the proper type refinements are inserted in each branch.
For example:
if optional_tensor is not None and len(optional_tensor) < 2:
# optional_tensor is a Tensor
if optional_tensor1 is not None and optional_tensor2 is not None:
# both optional_tensor1 and optional_tensor2 are Tensors
TODO:
- not run an op for unchecked unwrap optional in the interpreter
- potentially refine types to prim::None (omitted for now to simply things & because it's not an actual use cause).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15587
Differential Revision: D13733810
Pulled By: eellison
fbshipit-source-id: 57c32be9f5a09ab5542ba0144a6059b96de23d7a
Summary:
Mention that if enforce_sorted=True, the user can set
enforce_sorted=False. This is a new flag that is probably hard to
discover unless one throughly reads the docs.
Fixes#15567
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16084
Differential Revision: D13701118
Pulled By: zou3519
fbshipit-source-id: c9aeb47ae9769d28b0051bcedb8f2f51a5a5c260
Summary:
This PR fixes a race condition for TCP init method, when master rank can exit earlier than slave ranks and thus the TCP daemon thread gets shutdown before other slaves are able to access it.
This will let every rank (process) write a special key to the store to mark that they are completed (and thus about to exit). The master rank (who is the server) will always wait until all the ranks to complete before complete itself.
This should fix: https://github.com/pytorch/pytorch/issues/15638
Tested using the repro of https://github.com/pytorch/pytorch/issues/15638 and works fine. Also test_distributed and test_c10d should have already had this coverage.
I had to make rendezvous test in c10d the world size of 1, since it is a single process code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15684
Differential Revision: D13570904
Pulled By: teng-li
fbshipit-source-id: 34f3bc471204bbd29320df359347ad5561c6b589
Summary:
Based on offline discussion it should be less surprising to the users of existing code. Thus caffe2::Tensor is now a move-only class (as it used to be), explicit calls to UnsafeSharedInstance() are necessary to get shared_ptr behavior.
This change also identified a few places that misused the copy constructor - those are fixed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15416
Reviewed By: Yangqing
Differential Revision: D13524598
fbshipit-source-id: aea12d6dff77342606fa88ce4ddddbff266245a7
Summary:
This PR inlines `Attributes` into `Node`. It helps to cleanup the code a little as everything is one place (some of the cleanups are included in the PR).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16098
Differential Revision: D13717637
Pulled By: ZolotukhinM
fbshipit-source-id: c54ae65178a95a01354688921a9ccb1ca699f8eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15856
They seem to be wrong.
cc zdevito to take a look but I think this is now more correct.
It's weird this didn't cause linker errors. Probably, this functionality isn't used across library boundaries yet.
Reviewed By: dzhulgakov
Differential Revision: D13605257
fbshipit-source-id: 7077ca9027c3ac79a4847ec15ead7ddb28696445
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15855
This is preparation work for moving IValue to c10.
Reviewed By: ezyang
Differential Revision: D13605259
fbshipit-source-id: cc545f582ab8607bb02aaf71273cb2710200b295
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16052
We need IValue to take/return Blob as an intrusive_ptr because we want to pass it around and Blob has disabled copying.
This is needed in a diff on top.
Reviewed By: ezyang
Differential Revision: D13684761
fbshipit-source-id: 7cb3d7e9fec39a2bc9f063d4d30404e6d7016eb2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16050
The c10 dispatcher will (soon) depend on IValue and IValue can't be moved to c10 yet because it depends on at::Tensor, which depends on legacy Type dispatch and we don't want the legacy dispatch in c10.
So instead, we move the c10 dispatcher back to ATen/core until we can actually move at::Tensor to c10.
Reviewed By: ezyang
Differential Revision: D13684517
fbshipit-source-id: 1125f4254223907c52f96ff73034f6d4ae9fd0a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16104
PyTorch PR 15784 removed cuda-convnet from the contrib directory. This broke
some internal-only fb dependencies. Moving this to the internal area.
Reviewed By: ezyang
Differential Revision: D13709112
fbshipit-source-id: 2d7811545da67489869b59c350a29817eff693cf
Summary:
Some cleanup to wildcard handling, including one bugfix: previously, we were not considering writes to the wildcard set as part of the potential write set for nodes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16041
Differential Revision: D13705738
Pulled By: suo
fbshipit-source-id: acb8ccbaa70fe47445577ddf24a69f84630de411
Summary:
Confirmed on a local run that all the additional headers are present. This shouldn't be caught in any existing tests though.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16124
Differential Revision: D13720773
Pulled By: pjh5
fbshipit-source-id: 22a42639f5649cac555ecc5a8b6760a8cbfcf01f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15843
RNN/LSTMs only need one bias vector, but our implementation uses two to be compatible with CuDNN. This diff adds a comment to explain this.
Reviewed By: ezyang
Differential Revision: D13602365
fbshipit-source-id: eef5bd9383d9f241dc0ef0472f753b4a44cc19b5
Summary:
Fixes#12643, amends to #3341.
- Allow multidimensional input ~~(but apply softmax over `dim=-1`)~~ with `dim` argument
- Cleaner: Less lines of code
- Faster (1.32x speedup vs original, 2x speedup vs using `torch.Distributions`)
- Small fixes in docstring
- Remove some references in docstring. Was the linked (excellent) ipynb the first to do the straight-through trick? Instead, I propose changing to reference to the two papers most known for it.
- Add deprecationwarning for `eps`. It's not needed anymore.
- Initial commit keeps some code alternatives commented to exploit CI
- As of discussion when `gumbel_softmax` was added (#3341), this was merged into `torch.nn.functional` before all the work with `Distributions` and `Pyro`, and there will probably be multiple other best practices for this in the future.
I've tested building using the `Distributions`-api, but it was too slow, see below.
I therefore propose not using `Distributions` to keep it fast and simple, but adding a comment in docstring that `gumbel_softmax` may be deprecated in the future.
```
dist = torch.distributions.RelaxedOneHotCategorical(temperature=tau, logits=logits, validate_args=False)
y_soft = dist.rsample()
```
Pros:
* Built using tricks like `logsumexp` etc
* Explicitly uses `torch.distributions.utils._finfo` to avoid overflow (old implementation had an `eps` flag)
* Maintained for this exact purpose.
Cons:
* Very slow. Construction of distribution adds overhead see timings below. May be solved in future with speedups of `TransformedDistribution` and `Distribution`.
* Assumes which `dim` to apply softmax over.
```
y_soft = logits.new(logits.shape)
y_soft = (logits - y_soft.exponential_().log()) / tau # Gumbel noise
y_soft = y_soft.softmax(dim) # Gumbel softmax noise
```
Pros:
* Faster
```
import time
start = time.time()
num_draws = 1000000
logits = torch.randn(1,3)
for draw in range(num_draws):
y_draw = gumbel_softmax(logits, hard=True)
counts = counts + y_draw
print(end - start)
>> 12.995795965194702
>> 7.658372640609741
>> 20.3382670879364
````
Decide on which path to chose. I'll commit in changes to the unit tests in a while to show that it passes both old tests and new tests. I'll also remove the commented code about `RelaxedOneHotCategorical`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13339
Differential Revision: D13092434
Pulled By: ezyang
fbshipit-source-id: 4c21788df336f4e9c2ac289022e395b261227b4b
Summary:
If "matches_jit_signature" is set to True for a particular function, we will assume that the func syntax follows the JIT signature syntax. This is a temporary attribute and doesn't need to be set by developers outside the core team. It serves as a means of tracking an ongoing schema unification with the goal of aligning func syntax with other components of PyTorch in order to reduce overall complexity and match coverage of different function descriptions.
Followup PRs might be about removing _out from native_functions.yaml and using Tensor annotations instead, etc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16040
Reviewed By: ezyang
Differential Revision: D13703176
Pulled By: cpuhrsch
fbshipit-source-id: ce248e1823a6f18efa95502f9f3eebf023b4a46c
Summary:
without this "if", code below will throw error " Linear' object has no attribute '_buffers' "
And with this if, error would be "cannot assign buffer before Module.\_\_init\_\_() call", which I think it's more accurate, just like register_parameter.
```
import math
import torch
from torch.nn.parameter import Parameter
from torch.nn import functional as F
from torch.nn import Module
class Linear(Module):
def __init__(self, in_features, out_features, bias=True):
self.in_features = in_features
self.out_features = out_features
self.register_buffer('test', torch.Tensor(out_features, in_features))
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
super(Linear, self).__init__()
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def forward(self, input):
return F.linear(input, self.weight, self.bias)
def extra_repr(self):
return 'in_features={}, out_features={}, bias={}'.format(
self.in_features, self.out_features, self.bias is not None
)
linear = Linear(3,4)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16110
Differential Revision: D13715839
Pulled By: soumith
fbshipit-source-id: c300eff0a8655aade448354cf489a592f7db722a
Summary:
respect grad guard for torch.jit._fork and torch.jit._wait.
Verified that the test failed without the fix, and pass with the fix.
Ideally I would like to enable and disable grad inside the forked function.
It doesn't seems like it's supported at this moment. This code handles that
as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16101
Differential Revision: D13708374
Pulled By: gqchen
fbshipit-source-id: 0533f080c4d0253fb4c61d2a0d3cc22de5721a09
Summary:
1) Reverts https://github.com/pytorch/pytorch/pull/12302 which added support for batched pdist. Except I kept the (non-batched) test improvements that came with that PR, because they are nice to have. Motivation: https://github.com/pytorch/pytorch/issues/15511
2) For the non-batched pdist, improved the existing kernel by forcing fp64 math and properly checking cuda launch errors
3) Added a 'large tensor' test that at least on my machine, fails on the batch pdist implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15901
Reviewed By: ezyang
Differential Revision: D13616730
Pulled By: gchanan
fbshipit-source-id: 620d3f9b9acd492dc131bad9d2ff618d69fc2954
Summary:
PR to update the shape notation for all of the torch.nn modules to take a unified form. The goal is to make these definitions machine-readable and those checkable by unifying the style across all of the different modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15741
Differential Revision: D13709601
Pulled By: ezyang
fbshipit-source-id: fb89a03903fdf0cd0dcf76f3e469b8582b2f3634
Summary:
This issue was discovered by fehiepsi in https://github.com/uber/pyro/issues/1706 with the `log_prob` computation for Binomial, ~and can be seen with `torch.float32` when we have a combination of low probability value and high `total_count` - a test is added to capture this (since scipy only uses float64, the comparison is done using relative tolerance).~
The problem is in the code that tries to pull out the minimum values amongst the logits (written by me earlier, presumably to avoid numerical instability issues), but it is not needed.
EDIT: After a few attempts, I have been unable to reliably show that the change is more numerically stable, and have removed my previous test which fails on linux. The reason is that the issue manifests itself when `total_count` is high and `probs` is very low. However, the precision of `lgamma` when `total_count` is high is bad enough to wash away any benefits. The justification for this still stands though - (a) simplifies code (removes the unnecessary bit), (b) is no worse than the previous implementation, (c) has better continuity behavior as observed by fehiepsi in the issue above.
cc. fehiepsi, alicanb, fritzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15962
Differential Revision: D13709541
Pulled By: ezyang
fbshipit-source-id: 596c6853b6e4d5fba42336afa168a665ab6fbde2
Summary: This PR aims to remove support for cuDNN 6.
Differential Revision: D13709595
Pulled By: ezyang
fbshipit-source-id: 853624db1cf66b0534d7028654c38c2806fb4107
Summary:
Idiomatic pyi files will fail with Python 2 flake8 even
though they would work with mypy. This is because pyi
files generally use Python 3 only syntax. No point
in linting them.
There are currently no pyi files checked in, this is purely
a prophylactic measure.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16105
Reviewed By: zou3519
Differential Revision: D13709409
Pulled By: ezyang
fbshipit-source-id: ec4a959e146f81ccb9533b04348be8dd78808421
Summary:
On some cloud-based x86 systems /sys/ is not mounted.
cpuinfo has a work-around for these systems, but it reports an error if sysfs files fail to read, and this error was confusing to some users (e.g. pytorch/cpuinfo#20). This update downgrades the error to a warning, so it is not reported with default configuration options.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16107
Differential Revision: D13715243
Pulled By: soumith
fbshipit-source-id: f5c4c86422343ca449487f0185f3a8865ccf3b9d
Summary:
1. Added `torch/csrc/cuda/Event.h` and `torch/csrc/cuda/Event.cpp` to bind Python Event class to C++ implementation.
2. Move all CUDA runtime invocations from `torch/cuda/streams.py` to C++
3. Added tests to cover Stream and Event APIs. ~(event IPC handle tests is introduced in #15974)~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15937
Differential Revision: D13649001
Pulled By: mrshenli
fbshipit-source-id: 84ca58f35f6ba679a4ba33150ceba678d760d240
Summary:
- a typo fixed
- made the docs consistent with #5108
And maybe one more change is needed. According to the current docs
> The batch size should be larger than the number of GPUs used **locally**.
But shouldn't the batch size be larger than the number of GPUs used **either locally or remotely**? Sadly, I couldn't experiment this with my single GPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16010
Differential Revision: D13709516
Pulled By: ezyang
fbshipit-source-id: e44459a602a8a834fd365fe46e4063e9e045d5ce
Summary:
There is a little error in the comment, "A->B", so the Task B must start after task A finishes, not "B".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15922
Differential Revision: D13709579
Pulled By: ezyang
fbshipit-source-id: 735afe83f4532b7c7456da3e96209b3e07071f37
Summary:
TensorProto.DataType in caffe2/proto/caffe2.proto has BYTE = 3 defined, while there is no corresponding TypeMeta defined in caffe2/core/types.cc: DataTypeToTypeMeta. This issue failed the C++ tutorial of MNIST + LMDB.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15627
Differential Revision: D13709602
Pulled By: ezyang
fbshipit-source-id: d4826d0f9b3975e6a8478d4bad1abbbedcaea197
Summary:
1. I fixed the importing process, which had some problems
- **I think `setup_helpers` should not be imported as the top level module. It can lead to many future errors. For example, what if `setup_helpers` imports another module from the upper level?** So we need to change it.
- The code is not consistent with other modules in `tools` package. For example, other
modules in the package imports `from tools.setuptools...` not `from setuptools...`.
- **It should be able to run with `python -m tools.build_libtorch` command** because this module is a part of the tools package. Currently, you cannot do that and I think it's simply wrong.
~~2. I Added platform specific warning messages.
- I constantly forgot that I needed to define some environment variables in advance specific to my platform to build libtorch, especially when I'm working at a non pytorch root directory. So I thought adding warnings for common options would be helpful .~~
~~3. Made the build output path configurable. And a few other changes.~~
orionr ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15471
Differential Revision: D13709607
Pulled By: ezyang
fbshipit-source-id: 950d5727aa09f857d973538c50b1ab169d88da38
Summary:
If we use clang with sse4 support, we will have the function redefinition
error between [1] and [2]. This patch try to add some checkings to fix this
problem.
I just turn on USE_NATIVE_ARCH with clang, then I hit the redefinition error.
[1]
caffe2/operators/quantized/int8_simd.h
[2]
third_party/gemmlowp/gemmlowp/fixedpoint/fixedpoint_sse.h
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13859
Differential Revision: D13095694
Pulled By: ezyang
fbshipit-source-id: c65166e4d5a04bb54e2b82c52740af00116ccb0d
Summary:
Use case:
Some data loader tests rely on `psutil` (a third party lib). So they are guarded by `skipIf`. But we want to always test them on CI envs. With `IS_PYTORCH_CI`, we can raise if `psutil` is not found.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16006
Reviewed By: ezyang
Differential Revision: D13673957
Pulled By: yf225
fbshipit-source-id: c63a7138093f45333c0b371fed0bcc88b67f2a22
Summary:
Adding supports for torch.nomr:
i. multi dimensions for dim
ii. dtype that specifies math/output tensor type
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15414
Differential Revision: D13702022
Pulled By: ezyang
fbshipit-source-id: da2676f2b6aff988889b1539d0de8ecd4946823a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15912
Codemod generated with clangr shard mode, 25 files per diff,
To eliminiate partially initialized Tensor, we split the initialization of local Tensor variables into two steps, first declare un uninitialized Tensor, and
call `ReinitializeTensor` to initialize it.
motivation: https://github.com/pytorch/pytorch/pull/12407
Reviewed By: dzhulgakov
Differential Revision: D13586734
fbshipit-source-id: 8485d2c51225343961351c7a2e8f95055534f9a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16081
A simple version of bound shape inference, conditioned on batch size. In addition to doing normal shape inference, it will change the batch size (1st dim of the shape) of the inputs as well as batch size modulating ops such as `SparseLengthsSum`. Probably support to more ops is needed, such as `SparseToDense`. We can build on this.
Reviewed By: jackm321, rdzhabarov
Differential Revision: D13661968
fbshipit-source-id: 6a724a647e109757c26e3e26e15a49725ecc75cc
Summary:
1. Port the FractionalMaxPool3d implementation from THNN/THCUNN to ATen.
2. Expose this function to Python module nn.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15575
Differential Revision: D13612848
Pulled By: chandlerzuo
fbshipit-source-id: 5f474b39005efa7788e984e8a805456dcdc43f6c
Summary:
The cumsum over the probabilities can be not monotonically
non-decreasing. Thus it is hard to detect zero probability
classes using just the cumsum.
This changes the binary search postprocessing to use the
(non-cumulated) distribution instead.
Thank you, jcjohnson, for the bug report with
reproducing case.
Fixes: #13867
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16075
Differential Revision: D13695565
Pulled By: soumith
fbshipit-source-id: 02c4d6f868f0050c1ae7d333f4317c5610e49cd9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16047
Implements single thead safe map enabling sharing of generated graph between
different ops.
Added model_id to every onnxified op to help create a unique id in the map.
Some formatting fix.
Reviewed By: yinghai
Differential Revision: D13663927
fbshipit-source-id: 27417e8fe752fdd48abb6a87966cd76d592e1206
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16061
I discovered I needed to delete these names in preparation of moving
THCCachingAllocator to c10_cuda; might as well also fix all the other
sites too.
Reviewed By: dzhulgakov
Differential Revision: D13686869
fbshipit-source-id: e8cc55d39ac4bfd3e3a22c761f89a7a111ce5f5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16059
Just deleted all __cplusplus ifdef guards; we only ever use
these headers in C++ contexts.
Reviewed By: dzhulgakov
Differential Revision: D13686580
fbshipit-source-id: ce28c4a32f3596bfb17aeeb34904a02899991453
Summary:
The correct logic is as follows:
* If there is an earlier split, we need to combine with its result
* If there is *not* a later split, we need to project before saving into the output.
This should partially f i x #15837 . For example:
```
In [7]: a=torch.ones([1838860800], dtype=torch.float, device="cuda:1")
In [8]: a.mean()
Out[8]: tensor(1., device='cuda:1')
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16023
Differential Revision: D13678449
Pulled By: umanwizard
fbshipit-source-id: ab5078484c88e96bb30121b5cf24a0e8b0a8c2f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15814
Plan is to remove the APIs we want to deprecate one by one and make sure it still builds in sandcastle and ossci
Reviewed By: ezyang
Differential Revision: D12812029
fbshipit-source-id: ea0c3dd882bec95fcd4507160ebc61f598b6d040
Summary:
Treat GenericList similarly to tuples and TensorList: recursively unpack them and assignValueTrace accordingly. Also add interpreter support for ListUnpack on GenericList
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15969
Differential Revision: D13665139
Pulled By: jamesr66a
fbshipit-source-id: cd8cb3dd7475f424e48a69d217f2eac529df9f6a
Summary:
This puts stubs in the autograd profiler for the use of cuda APIs allowing the cuda parts of libtorch to be linked separately from the CPU parts.
This also edits the buck build.
Previous:
For GPU builds:
_C -> csrc -> caffe2
For CPU builds:
_C -> csrc-cpu -> caffe2
Now:
GPU:
_C -> libtorch_cuda -> (libtorch -> caffe2, for CPU)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15898
Reviewed By: ailzhang
Differential Revision: D13617991
Pulled By: zdevito
fbshipit-source-id: 6d84a50bb356a54b4217f93219902755601b00e1
Summary:
1. Add some gloo communication operators into related fallback list;
2. Work around to avoid compiling errors while using fallback operator whose CPU operator inherits from 'OperatorBase' directly like PrefetchOperator;
3. Add new cpu context support for some python module files and resnet50 training example file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11330
Reviewed By: yinghai
Differential Revision: D13624519
Pulled By: wesolwsk
fbshipit-source-id: ce39d57ddb8cd7786db2e873bfe954069d972f4f
Summary:
Previously we were only constant propping prim::Constants, but we should be constant propping prim::None as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15979
Differential Revision: D13664692
Pulled By: eellison
fbshipit-source-id: 01839403576c21fc030c427e49275b8e1210fa8f
Summary:
Similarly to https://github.com/pytorch/pytorch/pull/13777, we apply post-processing quantization to RNN cell modules (`RNNCell`, `LSTMCell`, and `GRUCell`).
A further follow-up PR will involve quantizing the full `RNN`, `GRU`, and `LSTM` modules. This depends on those modules being scriptable as part of the standard library scripting effort, though. Note that infrastructure in this pr such as `gather_quantized_params` is currently unused but should be used in the future when we can port over the full RNN modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15469
Differential Revision: D13545802
Pulled By: jamesr66a
fbshipit-source-id: ad3b694517842893ea619438e9f5e88fd7b96510
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16020
Needs to go over more iterations. For conv, I think we need a high level interface that abstracts out low-level details of which code path will be taken (acc16, outlier-aware, depth-wise, group conv, ...) otherwise the client code will be complex as can be seen from DNNLOWP Conv ops. This will also help us to make interface more stable.
Reviewed By: dskhudia, jianyuh
Differential Revision: D13588996
fbshipit-source-id: 9afce9e441bcaf20437fcc2874fb9d4165a46bcb
Summary:
Timings are the same as for `std` .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15892
Differential Revision: D13651173
Pulled By: umanwizard
fbshipit-source-id: a26bf1021dd972aa9e3e60fb901cd4983bfa190f
Summary:
Use new test utils in converter_nomnigraph_test , and add utils to set device option name, external inputs, outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15751
Differential Revision: D13586228
Pulled By: duc0
fbshipit-source-id: ff809dd7bf9f30641ce2a6fef7e2810f005521c2
Summary:
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc meganset
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15694
Differential Revision: D13573064
Pulled By: zou3519
fbshipit-source-id: 1d0b693d7c26db91826b81e6c98b45a69b5e9bc4
Summary:
In #15964, I learned that `errno` is only meaningful if the function call fails. E.g., on some macos, a successful `fork()` sets `errno` to `EINVAL` in child process. This commit changes the `SYSCALL` macro so error checking is only done when an error happens. This means checking whether `rv == -1` for most calls, but is checking `rv == nullptr` for `inet_ntop`.
Now `SYSCALL` accepts a second argument `success_cond`, which should be an expression returning whether the call succeeded. `SYSCHECK_ERR_RETURN_NEG1` is the shorthand for checking if rv is `-1`.
Any suggestion on better macro names is welcomed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15986
Reviewed By: janewangfb
Differential Revision: D13661790
Pulled By: pietern
fbshipit-source-id: 9551b14b9f88805454a7bfb8e4d39e0f3aed8131
Summary:
bypass-lint
- Change all Caffe2 builds to use setup.py instead of cmake
- Add a -cmake- Caffe2 build configuration that uses cmake and only builds cpp
- Move skipIfCI logic from onnx test scripts to the rest of CI logic
- Removal of old PYTHONPATH/LD_LIBRARY_PATH/etc. env management
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15917
Reviewed By: orionr
Differential Revision: D13637583
Pulled By: pjh5
fbshipit-source-id: c5c5639db0251ba12b6e4b51b2ac3b26a8953153
Summary:
In Python, you can use the call operator to invoke the `forward()` method of a module. In C++ this was currently not possible, because I couldn't figure out how to deduce the return type of a module's `forward()` method under the constraint that `forward()` may not exist at all (since the base module class in C++ does not mandate a `forward()` method). I now figured it out, so the call operator can be used.
ezyang ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15831
Differential Revision: D13652676
Pulled By: goldsborough
fbshipit-source-id: ccab45a15215dda56460e560f0038781b539135f
Summary:
- Fixed a few typos and grammar errors.
- Changed the sentences a bit.
- Changed the format of the tuples to be consistent with padding notations in the other places. For example, `ReflectionPad2d`'s dostring contains :math:`H_{out} = H_{in} + \text{padding\_top} + \text{padding\_bottom}`.
I also made sure that the generated html doesn't break.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15984
Differential Revision: D13649939
Pulled By: soumith
fbshipit-source-id: 0abfa22a7bf1cbc6546ac4859652ce8741d41232
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15996
As reported in issue #15911, gcc 4.9 was getting internal compiler error due to a complex use of lambda function in conv_dnnlowp_op.cc and conv_acc16_op.cc . This diff simplifies them.
Reviewed By: viswanathgs
Differential Revision: D13648264
fbshipit-source-id: 1551ae8a0a7653749185dca51ccceb2471b96b82
Summary:
Tested locally. It could be now be started by running `set EXTRA_CAFFE2_CMAKE_FLAGS= -DTORCH_STATIC=1` before build. If we want to make sure it works, then maybe we should add it into CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15989
Differential Revision: D13649935
Pulled By: soumith
fbshipit-source-id: 956945ed572819d8cf0bc9bd48df3ea9bc6f4a8a
Summary:
This is follow up on #13945 where we had to turn off some TRT tests because some ops were not ready to accept ONNX opset 9+ models. This PR fixes Reshape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15380
Differential Revision: D13649825
Pulled By: houseroad
fbshipit-source-id: b72e62803de5b63cc001c3fe4b3bf64dfa996e94
Summary:
For Inference, if the StopGradient op is inpalce, we just remove it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12152
Differential Revision: D13633946
Pulled By: yinghai
fbshipit-source-id: 57762bcc37b38a1d39cb4af316ca50bfe961b105
Summary:
This is the first of several PRs to simplify AliasDb usage.
- Hide the concept wildcards from users. They are too hard to think about and too easy to forget about.
- Start moving "mutability-safe" graph mutation methods into AliasDb (right now, the various methods that deal with topological move).
Eventually I want to create a "mutability-aware" handle to the graph. If you only use that handle to transform the graph, you can be sure that all transformations are safe with respect to mutability.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15656
Differential Revision: D13615492
Pulled By: suo
fbshipit-source-id: 5c39a157b4ea76f1f976315d06a314a89cc4f22f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15908
"OperatorBase::" is changed to "this->template ".
For example,
# This no longer works
OperatorBase::GetSingleArgument<>()
# Should change to:
this->template GetSingleArgument<>()
https://fb.workplace.com/groups/101100140348621/permalink/576804082778222/
Follow up of D13574832.
Sample Diff:
D9319742, D10045844.
Reviewed By: jspark1105
Differential Revision: D13613574
fbshipit-source-id: 2cb4094557b4af78d41e289816cad3e1194fb82c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15967
Codemod generated with clangr shard mode, 25 files per diff,
To eliminiate partially initialized Tensor, we split the initialization of local Tensor variables into two steps, first declare un uninitialized Tensor, and
call `ReinitializeTensor` to initialize it.
motivation: https://github.com/pytorch/pytorch/pull/12407
Reviewed By: smessmer
Differential Revision: D13586735
fbshipit-source-id: eae2d79e1107a2e813ce3809e690af4706aaa9ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15947
Codemod generated with clangr shard mode, 25 files per diff,
To eliminiate partially initialized Tensor, we split the initialization of local Tensor variables into two steps, first declare un uninitialized Tensor, and
call `ReinitializeTensor` to initialize it.
motivation: https://github.com/pytorch/pytorch/pull/12407
Reviewed By: smessmer
Differential Revision: D13586732
fbshipit-source-id: 5295ab27ca0155f96a4fccf9c0ba8a609101ba24
Summary:
While integrating fork/join into production translation, we found that trying to export `transpose()` where the input is of `TensorType` (rather than `CompleteTensorType`) failed. This is not ideal, since `TensorType` still contains the number of dimensions of the tensor, and that's all the `transpose` symbolic needs.
This PR introduces a pybind binding for `dim()` on `TensorType` (and `CompleteTensorType` by inheritance). We now use this in places where it logically makes sense in the symbolics: those symbolics which only require knowledge of the number of dimensions rather than concrete sizes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15933
Differential Revision: D13639657
Pulled By: jamesr66a
fbshipit-source-id: 6e50e407e93060085fd00a686a928764d0ec888d
Summary:
Implementation LeakyRelu operator for mkl-dnn,the speed-up of a single operation is up to 10X on BDW.
Implementation rashape operator for mkl-dnn,it will resolve occasionally crash issue which use fallback reshape operator.
Implementation CreateBlobQueue and SafeEnqueueBlobs operators,it will resolve crash issue which use fallback operators.
Fallback CreateBlobsQueueDBOp,TensorProtosDBInput,CloseBlobsQueue operators.
Implement adam operator for mkl-dnn,the speed-up of a single operator is up to 6X on BDW.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11696
Reviewed By: yinghai
Differential Revision: D10100438
Pulled By: wesolwsk
fbshipit-source-id: 0b6e06897cc11e0a8e349d80a870b1e72e47f10d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15692
It was leading to ocassional crashes with dynamically linked CUDA because runtime was already destroyed.
Also, unique_ptr<T[]> is more suitable than deque<T> for the purpose.
Reviewed By: Yangqing
Differential Revision: D13571988
fbshipit-source-id: 37eb26dfbe361c49160367b53f87bd037c6c0e46
Summary:
That makes that definition of a "fusable node" much simpler,
as we don't need to keep considering whether something has to be an
"exit node" at every step. The fuser now tries to maximize the
pointwise fusions first, and proceeds to prepending chunks and appending
concats only once a fix point is reached.
This patch not only makes the fuser much simpler to reason about,
making it siginifcantly easier to implement features like SumToSize
fusion, to improve performance of derivative graphs.
cc zou3519 mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15633
Differential Revision: D13575306
Pulled By: zou3519
fbshipit-source-id: 0c55ea61d65d1f1ed3d75a8e1e83bc85a83f3aff
Summary:
Adding bindings for .cpu() and .cuda() to script.
It's worth noting that if the device remains unchanged, than the returned tensor aliases the input, but if it does change than they do not alias each other.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15904
Differential Revision: D13632879
Pulled By: eellison
fbshipit-source-id: 024a04f267909674aa1e510562efd9cb081f407c
Summary:
4GB is still too large and leads to CUDA OOM failures.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15959
Differential Revision: D13635146
Pulled By: mrshenli
fbshipit-source-id: 3dc34a03d6ed65c458839d8fa37cd05bf3bc8106
Summary:
Turns out this has basically been implemented already in Resize.h / Resize.cuh.
Also added some testing, basically just to check that empty_strided behaves equivalently to as_strided.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15948
Differential Revision: D13631098
Pulled By: gchanan
fbshipit-source-id: eb0e04eead45e4cff393ebde340f9d265779e185
Summary:
This PR moves `deviceProperties` from `THCState` struct to `CUDAContext` in ATen and hence, takes one more step towards removing `THCState`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14834
Differential Revision: D13633956
Pulled By: soumith
fbshipit-source-id: 51820ac224fc566f17aa92570fd378cff4248596
Summary:
When compiling for `TORCH_CUDA_ARCH_LIST=7.5` we were getting ptxas warnings (https://github.com/pytorch/pytorch/issues/14310). This was because we had some hardcoded values when using launch_bounds in kernels. The maximum number of threads per multiprocessor is 1024 for Turing architecture (7.5) but 2048 for previous architectures. The hardcoded launch_bounds in the kernel were requesting for 2048 threads when compiling for Turing and hence were generating the warning.
This PR adds a macro that checks for the bounds on the launch bounds value supplied. The max number of threads per block across all architectures is 1024. If a user supplies more than 1024, I just clamp it down to 512. Depending on this value, I set the minimum number of blocks per sm. This PR should resolve https://github.com/pytorch/pytorch/issues/14310. The gradient computation being wrong reported in that PR is probably due to the faulty card.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15461
Differential Revision: D13633952
Pulled By: soumith
fbshipit-source-id: 795aa151109f343ab5433bf3cb070cb6ec896fff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15884
Codemod generated with clangr shard mode, 25 files per diff,
To eliminiate partially initialized Tensor, we split the initialization of local Tensor variables into two steps, first declare un uninitialized Tensor, and
call `ReinitializeTensor` to initialize it.
motivation: https://github.com/pytorch/pytorch/pull/12407
Reviewed By: hyuen
Differential Revision: D13586737
fbshipit-source-id: dc8e49e9f29505b8898bb19f84c1a983f2d811ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15407
Don't ask the tensor for its intrusive pointer if we just want to check if two tensors are the same.
This mirrors ATen APIs.
Reviewed By: dzhulgakov
Differential Revision: D13520389
fbshipit-source-id: 681317f36f480ab60e532bb08a073f98f39770fd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15316
This starts cleaning up the files in c10 according to the module structure we decided on.
Move to c10/util:
- Half.h, Half-inl.h, Half.cpp, bitcasts.h
Move to c10/core:
- Device.h, Device.cpp
- DeviceType.h, DeviceType.cpp
i-am-not-moving-c2-to-c10
Reviewed By: dzhulgakov
Differential Revision: D13498493
fbshipit-source-id: dfcf1c490474a12ab950c72ca686b8ad86428f63
Summary:
Unfortunately I do not know how to test this without merging it first
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15934
Reviewed By: orionr
Differential Revision: D13627472
Pulled By: pjh5
fbshipit-source-id: 35eced1483bbf3c0c3f6f62fb7bbbf2f200e50e6
Summary:
Wasn't clearing optimizer buffers before adding new entries to it during deserialization. Successive calls to `torch::load` with the same optimizer would just append to the buffer container. Also moved `serialize()` function from `torch::optim::detail` into `torch::optim` so users can use it for custom optimizers.
Fixes#15792
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15926
Differential Revision: D13623615
Pulled By: goldsborough
fbshipit-source-id: e193091f25f56a95f2a9648af312cb7caa45f300
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15876
Build changes made it so some .so libraries are now registered after GlobalInit is called. Although this shouldn't be common, it also shouldn't be explicitly excluded. These changes allow for late Caffe2 registration, but also warn in that case.
Reviewed By: kuttas
Differential Revision: D13608186
fbshipit-source-id: 0ca7bcd32516d374077db0c2548cf8c28ccdd5f6
Summary:
Currently these tests are taking most of the time in test_jit.py run, with the
proposed changes the testing time is reduced by ~75%:
```
TestEndToEndHybridFrontendModels.test_neural_style: 203.360s -> 10.650s
TestEndToEndHybridFrontendModels.test_snli: 422.315s -> 9.152s
TestEndToEndHybridFrontendModels.test_super_resolution: 73.362s -> 19.185s
time python test/test_jit.py (real): 13m50.828s -> 3m11.768s
time python test/test_jit.py (user): 85m59.745s -> 13m18.135s
time python test/test_jit.py (sys): 144m9.028s -> 25m58.019s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15906
Differential Revision: D13619659
Pulled By: ZolotukhinM
fbshipit-source-id: 6c22d8740f8ddb865c3a0667af32653723383816
Summary:
Other changes:
1. Avoided using `THCDeviceTensor` by re-calculating the mapping from cuda (blockIdx, threadIdx) to input/output tensor index.
2. Changed Camelcase naming to underscore naming.
Differential Revision: D13546803
fbshipit-source-id: 1df54f13e64934da3d803d9b6586bd5208d42d6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15841
Fix the bugs in dnnlowp to support int8/int16 quantization for sparsenn.
Reviewed By: jspark1105
Differential Revision: D13600878
fbshipit-source-id: 27f06d7c54a663208320c8f211714220a9b49540
Summary:
Python2 doesn't allow to invoke `exec` from a nested function:
File "test/test_jit.py", line 4653
exec(code, globals(), scope)
SyntaxError: unqualified exec is not allowed in function 'test' it is a nested function
This patch wraps exec with a separate function, making it work for both python2
and python3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15882
Differential Revision: D13614235
Pulled By: ZolotukhinM
fbshipit-source-id: 9a074308c2379f089402e0bf5a996cc649d6dbca
Summary:
Optimized CPU version of the nonzero. Now 2x faster (in avg.) than numpy.
Can be further optimized for 1D tensors and boolean tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15190
Differential Revision: D13468570
Pulled By: VitalyFedyunin
fbshipit-source-id: e55ce54d60626a42d9a10a02e407856458b8055e
Summary:
macos builds are broken now with the following error:
```
/usr/local/Homebrew/Library/Homebrew/config.rb:39:in `initialize': no implicit conversion of nil into String (TypeError)
from /usr/local/Homebrew/Library/Homebrew/config.rb:39:in `new'
from /usr/local/Homebrew/Library/Homebrew/config.rb:39:in `<top (required)>'
from /usr/local/Homebrew/Library/Homebrew/vendor/portable-ruby/2.3.7/lib/ruby/2.3.0/rubygems/core_ext/kernel_require.rb:55:in `require'
from /usr/local/Homebrew/Library/Homebrew/vendor/portable-ruby/2.3.7/lib/ruby/2.3.0/rubygems/core_ext/kernel_require.rb:55:in `require'
from /usr/local/Homebrew/Library/Homebrew/global.rb:25:in `<top (required)>'
from /usr/local/Homebrew/Library/Homebrew/brew.rb:13:in `require_relative'
from /usr/local/Homebrew/Library/Homebrew/brew.rb:13:in `<main>'
Exited with code 1
```
No recent commits look suspicious, and I can even reproduce locally on my macbook, so it might be related to some new `brew` updates. Empirically, calling `brew update` first seems to fix this.
Example error build: https://circleci.com/gh/pytorch/pytorch/534392?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15873
Differential Revision: D13608019
Pulled By: soumith
fbshipit-source-id: 1499cb5246929e275a11ca6fccef6ef32918e45e
Summary:
This was causing a problem in #15735 but appears to have been fixed.
Adding this test to prevent regressions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15835
Differential Revision: D13600282
Pulled By: zou3519
fbshipit-source-id: d9939e74d372be71c50122a5f6a615fbd7fa4df6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15865
factored out code used in tests for operators Add, Mul and Sub
into two new methods: a first one to generate the test vectors, a second
one to run the actual tests given a caffe2 and python operator.
Reviewed By: houseroad
Differential Revision: D13526955
fbshipit-source-id: 8970ba5a1305ca19a54a14b51816d4a19f19d678
Summary:
I fixed a very small extra parenthesis in a doctest.
I'm also going to use this issue as a place to propose the eventual inclusion of xdoctest (a pip installable library I wrote) in pytorch's test suite. I think there are a lot of problems with Python's built in doctest module, and I've built xdoctest to fix them. I would love for my project to get some exposure and its addition to PyTorch may benefit both projects. Please see the readme for more details on what xdoctest brings to the table over the builtin doctest module: https://github.com/Erotemic/xdoctest
I came across this small syntax error when working on ensuring xdoctest was compatible with pytorch. It isn't 100% there yet, but I'm working on it. My goal is to ensure that xdoctest is 100% compatible with all of torch's doctest out-of-the-box before writing up the PR. I'm also airing the idea out-loud before I commit too much time into this (or get my hopes up), so I'm attaching this little blurb to a no-brainer-merge PR to (1) demonstrate a little bit of value (because xdoctest flagged this syntax error) and (2) see how its received.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15646
Differential Revision: D13606111
Pulled By: soumith
fbshipit-source-id: d4492801a38ee0ae64ea0326a83239cee4d811a4
Summary:
Thank you, freesouls, for the reproducing example!
This is strictly fixing the bug in gradients for varying length inputs discussed in the middle-to-bottom of the bug report. I'll have a feature patch regarding inf losses -> NaN grads separately.
Fixes: #14401
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15798
Differential Revision: D13605739
Pulled By: soumith
fbshipit-source-id: 167ff42399c7e4cdfbd88d59bac5d25b57c0363f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15199
In order to call it from PyTorch, this op schema can't live in caffe2 but must be included from PyTorch.
Moving it to c10. This is not where it should be in the end (that's why there is a large TODO here),
but an intermediate hack to enable this use case and proof-of-concept.
Reviewed By: ezyang
Differential Revision: D13462124
fbshipit-source-id: 1e187b9def8ef049c91e6de947ea4a85758d711b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15367
This updates flat_hash_map and fixes an issue with singletons across library boundaries
(see the PRs linked at the top of the file)
Reviewed By: ezyang
Differential Revision: D13510912
fbshipit-source-id: e90a297a7a2d69ae3fe48e4fcd8a44ad4b81292a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15324
This was missing but needs to be here, otherwise we can't register schemas without linker errors.
Reviewed By: ezyang
Differential Revision: D13500679
fbshipit-source-id: ba06351cb8ae09ec456cb93e527d388ace578fbb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15195
This removes the use of caffe2::Tensor or at::Tensor in the c10 dispatcher and only uses C10::Tensor.
It also changes output tensors to be passed as `const Tensor&` instead of `Tensor*` because we otherwise can't forward them in operator_c10wrapper.h.
Reviewed By: ezyang
Differential Revision: D13461640
fbshipit-source-id: 7f79925a7d60f01660a24bbfda47391af0c70ed3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14819
This is a minimal wrapper for a c10::TensorImpl,
maybe destined for greatness later when we move caffe2::Tensor or at::Tensor into c10.
Reviewed By: dzhulgakov
Differential Revision: D13348039
fbshipit-source-id: 874f515358e94f35dc7a4c3e55b35fde59c51ff1
Summary:
Allow the comparison function used in ReadyQueue to handle the empty FunctionTasks created by the reentrant autograd.
Fix#11732
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15791
Differential Revision: D13598006
Pulled By: soumith
fbshipit-source-id: 0bfdf28a735fbfe44f0fdbaf8b74a6198e6a1984
Summary:
The overhead of the copy actually makes an appreciable difference when doing a lot of small reductions (i.e., when the reduced dimension is significantly smaller than the non-reduced dimensions.
```
x=torch.randn((1024,10,1024),dtype=torch.float64)
torch.set_num_threads(1)
%timeit x.std(1)
```
Before: 813.0 ms
After: 708.25 ms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15845
Differential Revision: D13603246
Pulled By: umanwizard
fbshipit-source-id: 020d224d76fcb8a0b55b75b0f2937e9508891beb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15553
Add unit test and implementation of NHWC layout for Resize operator.
Also, add pragma parallel loop to old NCHWC layout.
Reviewed By: jspark1105
Differential Revision: D13540762
fbshipit-source-id: eebf252bf0d1efdff180a171d804181045f100a5
Summary:
I fixed an grammatical error on this function previously, but I also realized that its content was also wrong. A weight tensors of a convolutional layer should be at least 3 dimensional, not 2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15830
Differential Revision: D13597968
Pulled By: soumith
fbshipit-source-id: 72a75106e88945c68d6462828b149441cfb5acde
Summary:
Fixes#15223.
This fixes an autograd bug where backprop either fails or produces
gradients of incorrect sizes when tensors with zero-sized dimensions are
involved.
Previously, we were reducing along dimensions that had size greater than 1
when summing to a size in autograd. This is incorrect because we should also reduce
along dimensions with size 0 to produce a tensor of size 1 in that
dimension that then gets viewed to the correct shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15796
Differential Revision: D13593199
Pulled By: zou3519
fbshipit-source-id: 2e2acac34943a9b7fabadc10c9efd4f66db298fd
Summary:
Cache the workspace size information for MIOpen for a given configuration as opposed to inquiring it every time. This reduces overhead significantly as inquiring the workspace size forces a full read of the performance database in MIOpen and this database has grown significantly in recent releases. This caching gets us back to ideal performance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15742
Differential Revision: D13598932
Pulled By: bddppq
fbshipit-source-id: 4e65d247b71dec828293cf0562aac3fbd4fad83a
Summary:
This PR:
- Removes shape logic from the code generator, which was previously relied on to return chunk and concat information
- Copies the logic to detect if a kernel has a rand_like node to the executor, making its pass independent of the code generator
- Fixes a possible segfault where references to a vector still being modified were relied upon
The actual shape logic is unchanged.
The possible segfault is in the handling of the former "flat_inputs" in codegen.cpp. This vector holds pairs, and the second element of these pairs is a reference. In some cases these would be references to items in the vector chunk_desc, which could be added to later, possibly invalidating any references to items in it. I hit a similar segfault in testing when naively making parallel code for "flat_outputs."
I'm submitting this small PR because it's separable, self-contained, has a fix, and I am trying to actively get away from large PRs to encourage more stability and incremental change in the fuser.
ngimel zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15750
Differential Revision: D13597451
Pulled By: zou3519
fbshipit-source-id: 0d48b365779b42849b044ba0286258aacc7b0332
Summary:
The Thrust shipped with ROCm is recent enough to support this API. Minimize divergence between CUDA/ROCm by changing idef guards.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15481
Differential Revision: D13598739
Pulled By: bddppq
fbshipit-source-id: 20d0a7e3887a4050eea65033161561af47411de1
Summary:
This PR contains changes for:
1. Using memory alloc from HIPContext while allocating workspace for MIOpen conv and transpose_conv operators rather than direct HIP mem alloc
2. Minor cleanup and removing an unnecessary sync call from MIOpen conv op
Differential Revision: D13598894
Pulled By: bddppq
fbshipit-source-id: 44886161abdf91cd29c7c93b3e23620e1b09c7c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15418
Previously we are using Resize + ShareData.
Instead, we'll create a function on Tensor that clones itself with same storage.
Suppose we want `t` to `ShareData` with `t0`, Previous:
```
Tensor t(dims, CPU);
t.Resize(t0.sizes());
t.ShareData(t0);
```
Now:
```
Tensor t = t0.Alias();
```
Reviewed By: dzhulgakov
Differential Revision: D13507609
fbshipit-source-id: 6e4275d02f4c3356cbce91127f1b01111dc86b9f
Summary:
Wanted to use `Tensor.isnan` in C++, figured it'd be nice to have, so I made it into a tiny native function.
gchanan ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15722
Differential Revision: D13591315
Pulled By: goldsborough
fbshipit-source-id: a78bd22101fde87a0257f759b9bfcf3b4208f5fa
Summary:
Fixes#15308. Before this change, `torch.save` and `torch.load` would
initialize the CUDA context on GPU 0 if it hadn't been initialized
already, even if the serialized tensors are only on GPU 1.
This PR fixes that bug by using CUDAGuard in the storage serialization
path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15807
Differential Revision: D13593201
Pulled By: zou3519
fbshipit-source-id: 4addc91ea5a5278d56a03f3d422577ee39e99897
Summary:
We don't support reductions yet, but simply decomposing batch_norm
into a kernel that computes the stats, and the fusing everything else
with ReLU and following pointwise ops provides nice speedups.
Note that this is only limited to inference mode for now, because we
don't support convolutions and batch norm in AD, so the fuser isn't
applied to those parts.
This commit gives us a 7% end-to-end speedup for ResNet50 with batch size 32. Note that this only applies to inference mode at the moment due to lack of AD support for CNN operations (I'll be adding that soon), and not to the standard `torchvision` models, because they use in-place ops which aren't supported by the fuser (we need a way of proving that de-inplacing them is safe).
cc zou3519 zdevito mruberry ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15146
Differential Revision: D13548303
Pulled By: zou3519
fbshipit-source-id: a2e2e5abc383f637fae19bd1b423f20c2cbc056a
Summary:
See #15682
Pushing up this small PR to check if I am doing the right thing. If correct, more will follow for other Stream APIs. Questions will be added inline.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15737
Differential Revision: D13581400
Pulled By: mrshenli
fbshipit-source-id: 24afed7847b89b62f0692c79a101ec7ff9d9ee4d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15759
Some flags have too long names. And some other few minor clean ups.
Reviewed By: jianyuh
Differential Revision: D13587353
fbshipit-source-id: f8aee7f167505644f5d8f80fe2eed70201ef1e54
Summary:
* With the update of split output to dynamic list it breaks the export to onnx.
Now split ir becomes two ops: 1. Dynamic[] <= Split(), and 2. out1, out2, out3
<= Prim::ListUnpack. In this fix these two consecutive ops get fused when being
exported to onnx.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15092
Reviewed By: dzhulgakov
Differential Revision: D13583832
Pulled By: houseroad
fbshipit-source-id: 3eb18c871e750921ad6d5cc179254bee9bcf4c99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15758
DNNLOWP Conv operators became very complex due to many options. This diff simplifies them by not allowing fp32 in/out. This is OK for Conv operators because Conv operators are usually used in deep networks where quantizing and dequantizing using separate operators is not much overhead.
Reviewed By: csummersea
Differential Revision: D13587341
fbshipit-source-id: e88c919dae79d1c5b7d787ea539edf5bcb064afc
Summary:
Enable conv+add fusion, same as conv+sum
Caution: only element-wise add is supported on IDEEP without scalar
broadcast. Otherwise, the fusion is illegal.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15268
Differential Revision: D13577375
Pulled By: yinghai
fbshipit-source-id: 92c9c4b667c5ca5f7a262a5bffaa8aa68eeff3bd
Summary:
Adds `List` to eval environment for type lines and allows `List` to be used on PythonOps (follows the same style as the `Tuple` code), fixes#15661
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15721
Differential Revision: D13578540
Pulled By: driazati
fbshipit-source-id: fce54dc3c0931d8b017b2e3483f0ac53826dda94
Summary:
Just changing the version number doesn't seem to work. I needed to also fix macos brew parallel conflict
should this merge together with https://github.com/pytorch/ossci-job-dsl/pull/36 ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15795
Differential Revision: D13591839
Pulled By: yf225
fbshipit-source-id: 6b2a90943e63c8dcc4b6d9159eb54f1b5974c9ac
Summary:
Fix submitted by huntzhan in https://github.com/pytorch/cppdocs/pull/4. The source is in this repo so the patch has to be applied here.
soumith ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15701
Differential Revision: D13591302
Pulled By: goldsborough
fbshipit-source-id: 796957696fd560a9c5fb42265d7b2d018abaebe3
Summary:
Hello,
This is a little patch to fix `DeprecationWarning: invalid escape sequence`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15733
Differential Revision: D13587291
Pulled By: soumith
fbshipit-source-id: ce68db2de92ca7eaa42f78ca5ae6fbc1d4d90e05
Summary:
Fixing error in caffe2_benchmark binary
```
2018-12-29T14:09:59.7867995Z d:\a\1\s\caffe2_builders\v141\pytorch\binaries\benchmark_helper.h(90): error C2678: binary '|=': no operator found which takes a left-hand operand of type 'std::_Iosb<int>::_Openmode' (or there is no acceptable conversion) (compiling source file D:\a\1\s\caffe2_builders\v141\pytorch\binaries\benchmark_helper.cc) [D:\a\1\s\caffe2_builders\v141\pytorch\build\Release\binaries\caffe2_benchmark.vcxproj]
2018-12-29T14:09:59.7868252Z d:\a\1\s\caffe2_builders\v141\pytorch\binaries\benchmark_helper.h(92): error C2678: binary '|=': no operator found which takes a left-hand operand of type 'std::_Iosb<int>::_Openmode' (or there is no acceptable conversion) (compiling source file D:\a\1\s\caffe2_builders\v141\pytorch\binaries\benchmark_helper.cc) [D:\a\1\s\caffe2_builders\v141\pytorch\build\Release\binaries\caffe2_benchmark.vcxproj]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15619
Differential Revision: D13580195
Pulled By: soumith
fbshipit-source-id: b0a4479cd5f7555801b1977aeee96b6433293da7
Summary:
To implement a stream is very annoying, since it is closely defined with the underlying storage streambuffer.
So in this PR, we add ReadAdapterInterface and PyTorchStreamReader will use it. We implement IStreamAdapter as a wrapper of std::istream. And keep the user interface unchanged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15551
Reviewed By: zrphercule
Differential Revision: D13568907
Pulled By: houseroad
fbshipit-source-id: 93708cb801248a6c101f35cb14d1631029365c3c
Summary:
support 0 size in any of the tensor dimensions in mkldnn
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15295
Differential Revision: D13573747
Pulled By: yinghai
fbshipit-source-id: 5bf7a0b9e2567e80f44981a7823be5407fc94e53
Summary:
port replication padding 2D and 3D from legacy TH API implementation
to ATen implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15538
Differential Revision: D13547567
Pulled By: lhuang04
fbshipit-source-id: decfe100d9edfdcfb62f39ee23f37b6cae0d461f
Summary:
Before this pr, rsub did not convert two elements into the same dtype, therefore "1 - x" may export to an onnx model that two elements of rsub having different dtype.
By adding this symbolic patch this bug should be fixed.
Related test cases also created.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15707
Differential Revision: D13583042
Pulled By: zrphercule
fbshipit-source-id: 3a2de47a1a8d1ded1a0adfb911adbe6ac729cdef
Summary:
We are going to have some breaking changes in ConstantLike and related operators in onnx, therefore it is better to disable all related tests for these operators for now.
These operators are not currently supported by caffe2, and are not included in our most recently released onnx, therefore we do not need to worry about internal/external production breaking.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15740
Differential Revision: D13582528
Pulled By: zrphercule
fbshipit-source-id: 92a890c1dc2a833969af69edfea85331bb4d562f
Summary:
This improves the error message for "unknown builtin op" to suggest similarly named ops.
Currently it prints out all operators with a name within two edits.
Related issue: https://github.com/pytorch/pytorch/issues/13409
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15183
Differential Revision: D13578509
Pulled By: eellison
fbshipit-source-id: 5c73408eda1f7aa456f5bd28790c34df0c76aeca
Summary:
see issue #15636
Please note - I build the documents but the HTML is not updated with the edited content.
I did not also build the fork.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15664
Differential Revision: D13571310
Pulled By: soumith
fbshipit-source-id: d43be0f61705693d778cc12c13e86d6b06130ac7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15708
nbits_in_non_outlier == 0 doesn't make sense because it means everything is outlier and we can just use 32-bit accumulation.
Depending on architecture, break-even point between acc16 and acc32 can be different. Adding thresholds for falling back to acc32.
Reviewed By: jianyuh
Differential Revision: D13574832
fbshipit-source-id: b7a37aacbfdc7867e31838dafcdd5f7c2ac282af
Summary:
see #15682
This is a quick fix by implementing the simpler solution as suggested by colesbury. As benchmark result shows, it slows down `Stream.query()` by ~20%, I would be happy to further pursue a more complex solution by implementing this in C++/ATen. But I would still vote for merge this quick fix first just to get rid of the bug sooner.
~Test TBA~ Added
FYI jeffreyksmithjr
now
```python
In [1]: def f():
...: d0 = torch.device('cuda:0')
...: d1 = torch.device('cuda:1')
...: with torch.cuda.device(d0):
...: s0 = torch.cuda.current_stream()
...: with torch.cuda.device(d1):
...: s1 = torch.cuda.current_stream()
...: s0.query()
...: s1.query()
In [4]: %timeit f()
38.1 µs ± 4.2 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [5]: %timeit f()
37.6 µs ± 2.7 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
before
```python
In [4]: %timeit f()
28.5 µs ± 1.74 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [5]: %timeit f()
35.3 µs ± 2.91 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15689
Differential Revision: D13571697
Pulled By: mrshenli
fbshipit-source-id: 4fe697f91248c6419136d37bb5b7147e612e2f4c
Summary:
This PR breaks up `TestJitGenerated` into 3 classes. This makes for
easier testing of specific groups (e.g. run all generated functional
tests without having to wait for the autograd tests)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13992
Differential Revision: D13076371
Pulled By: driazati
fbshipit-source-id: 1267af59be7d69feb690f5805fcd43fea58a7159
Summary:
This PR bypasses checking the user's configuration entirely and always use strict, since the CI considers it a hard failure if you can't pass flake8.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15693
Differential Revision: D13574889
Pulled By: suo
fbshipit-source-id: f5e1c5731cc49b6223b415317033c275bc7d4fec
Summary:
These `std::forward` calls cause VS2017 to emit:
error C2872: 'std': ambiguous symbol
This fix prevents the ambiguity by specifying that `::std` is intended.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15697
Differential Revision: D13573483
Pulled By: goldsborough
fbshipit-source-id: 0439de3523a37a18df7af0cff4a1284a53833ddd
Summary:
s_copy_ was previously special-cased for out of place tracing.
This adds support for inplace tracing, which fixes tracing of
inception_v3
Fixes#15216
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15690
Differential Revision: D13572011
Pulled By: zdevito
fbshipit-source-id: 1d565dec039a4b8c59179254285e61d2517ef9a9
Summary:
Fixes#15353 .
Like cudnn conv implementation, mkldnn also falls back to the default `_convolution_double_backward` as double backward.
This bug wasn't caught by CI before because mkldnn is only used when input scalar type is float, but our tests are all using double as default.
Adding test for float inputs, but mkldnn seems to have imprecision issues similar to cudnn implementation, so here I only check if double backward exists instead of calling `gradgradcheck`. Please correct me if the precision should actually be checked.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15686
Differential Revision: D13571682
Pulled By: ailzhang
fbshipit-source-id: f1762439762370f276cfd59e8b8b8a4dee960a4b
Summary:
This is the an updated version of the earlier PR https://github.com/pytorch/pytorch/pull/15185, since that one was closed.
Currently PyTorch ONNX exporter exports the logical ops (lt, gt, le, ge, eq, ne) with output type in corresponding ONNX ops as type tensor(uint8). But ONNX spec allows for only tensor(bool), which is why models that have these ops fail to load properly.
This issue is captured in #11339. Part of this issue, relating to the allowed input types, has been fixed in ONNX spec by houseroad. This PR fixes the other part pertaining to output type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15677
Reviewed By: dzhulgakov
Differential Revision: D13568450
Pulled By: houseroad
fbshipit-source-id: a6afbea1afdb4edad8f8b1bc492f50b14e5f2fce
Summary:
1. Avoided using `THCDeviceTensor` by re-calculating the mapping from cuda (blockIdx, threadIdx) to input/output tensor index.
2. Changed Camelcase naming to underscore naming.
Profiling:
Legacy:
```bash
$py.test test/test_nn.py -k ReflectionPad1d -v -s
....
=========== 2 passed, 1258 deselected, 800 warnings in 4.35 seconds ============
```
Now:
```bash
$py.test test/test_nn.py -k ReflectionPad1d -v -s
...
=========== 2 passed, 1258 deselected, 800 warnings in 4.03 seconds ============
```
I have two questions about the code. Any insights are appreciated. gchanan zou3519
1. I can verify that [this magic](https://github.com/pytorch/pytorch/blob/master/aten/src/THCUNN/TemporalReflectionPadding.cu#L32-L36) correctly maps output index to input index in different cases. But, I have no idea about how did you come up with this algorithm that merges three categories (in left padding, in original input, in right padding) into a single statement?
2. Why do we need [get contiguous](https://github.com/pytorch/pytorch/blob/master/aten/src/THNN/generic/TemporalReflectionPadding.c#L80) tensors when calculating forward and backward propagation?
Reflection_pad2d porting will come in the next PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15480
Differential Revision: D13544924
Pulled By: mrshenli
fbshipit-source-id: 182045434f210032a82cab721a190da0cd781fbf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15625
3D group conv (both NCHW and NHWC layout) was not correct.
Added group=2 in test_1d_convolution and test_3d_convolution in conv_test
Reviewed By: protonu
Differential Revision: D13562099
fbshipit-source-id: 586e8a7574a2764f2a3b559db6c2415b3ab90453
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15651
Add count_include_pad arg for PoolOpGradient on CPU and fix ARM performance issue.
Reviewed By: houseroad
Differential Revision: D13564257
fbshipit-source-id: 3a143f1122bc507ccb7827e9b46908d5c7203735
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15685
The declaration of "Dequantize" is in "fbsource/fbcode/deeplearning/fbgemm2/QuantUtils.h", so it requires the "namespace fbgemm".
<T> is actually optional, since the type can de deduced from the first argument.
In some places we have "Dequantize<T>(...)", while in other places we have "Dequantize(...)". We'd better unify them. As a reference, all occurrences of "Quantize" are using "fbgemm::Quantize<T>(...)".
Reviewed By: jspark1105
Differential Revision: D13570847
fbshipit-source-id: 7fca9f7f9e4e0d9e5eb27ac44b8707adc3c80717
Summary:
soumith zou3519
I was browsing the code, and think `vec256_int.h` might need a minor revision, but not 100% sure.
1. It currently invert the result by `XOR` with 0. Should it `XOR` with 1 instead?
~2. AVX2 logical operations would set all bits in a byte/word/... to `1` if the condition holds. So functions, such as `_mm256_cmpeq_epi64 ` would return `0/-1` instead of `0/1`. Should it be masked with `1` to make sure it returns 0/1?~
~Would I be correct if I assume that the code revised below is not yet activated, but will be after we port legacy code to ATen?~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15659
Differential Revision: D13565929
Pulled By: mrshenli
fbshipit-source-id: 8ae3daf256c3d915dd855a2215c95275e899ea8c
Summary:
The request changes are to support building Pytorch 1.0 on the Jetson Xavier with Openblas. Jetson Xavier with Jetpack 3.3 has generic lapack installed. To pick up the CUDA accelerated BLAS/Lapack, I had to build Openblas and build/link pytorch from source. Otherwise, I got a runtime error indicating lapack routines were not cuda enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15660
Differential Revision: D13571324
Pulled By: soumith
fbshipit-source-id: 9b148d081d6e7fa7e1824dfdd93283c67f69e683
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15417
Right now the way we test whether Blob contains a CPU tensor is broken in ```PythonOpBase``` is broken, which means non-CPU path might never be taken.
Searching through the codebase, non-gpu path is used in PythonDLPack, and it is used in PytorchOp which is unused. So we'll remove non-gpu path in this diff.
Reviewed By: dzhulgakov
Differential Revision: D13495011
fbshipit-source-id: 9fe9537f05026d2a2cf7051efa81d184de722710
Summary:
Right now it just prints whatever flake8 errors and moves forward with the commit. This is too easy to miss.
It should block the commit so that the user can fix the issue
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15675
Differential Revision: D13567821
Pulled By: suo
fbshipit-source-id: 5f0de40ddd771bad8d6848417408cffbceb03183
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15632
Just formatting and a few lints.
Reviewed By: yinghai
Differential Revision: D13562403
fbshipit-source-id: c56f8ee61f68cdaccc0828a764ff729454f68259
Summary:
Changelog:
- Optimize btriunpack by using `torch.where` instead of indexing, inplace operations instead of out place operations and avoiding costly permutations by computing the final permutation over a list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15286
Differential Revision: D13562038
Pulled By: soumith
fbshipit-source-id: e2c94cfab5322bf1d24bf56d7b056619f553acc6
Summary:
Since #1323 tensors are shared with shared memory, but this feature is not active for numpy.
This PR fix this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14534
Differential Revision: D13561649
Pulled By: soumith
fbshipit-source-id: b6bc9e99fb91e8b675c2ef131fba9fa11c1647c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15588
Use NHWC2NCHW or NCHW2NHWC functions which is easier to understand compared to code using transpose and generalizable to non-2D convolutions.
Reviewed By: csummersea
Differential Revision: D13557674
fbshipit-source-id: c4fdb8850503ea58f6b17b188513ae2b29691ec0
Summary:
This PR removes the TH/THC binding for gesv.
Changelog:
- Remove TH/THC binding
- Port single matrix case to ATen
- Enable test_gesv for CUDA as well
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15510
Differential Revision: D13559990
Pulled By: soumith
fbshipit-source-id: 9da2825e94d3103627e719709e6b1f8b521a07fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15244
This DIFF keeps track of the extra_info information attached to each operator. When getPerOpStas() is called, it attaches the extra_info to the result ProfDagStats protobuf.
Facebook
Net transform attaches a global_op_id which is defined as a tuple of (orig_net_name, original_op_index) to each operator,
The global_op_id is encoded as extra_info in each operator.
Reviewed By: aazzolini
Differential Revision: D13016289
fbshipit-source-id: 3e2719ec7ed0ebe47740b77581c565ff7e79b102
Summary:
Throw a warning when calling `torch.load` on a zip file
Fixes#15570
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15578
Differential Revision: D13555954
Pulled By: driazati
fbshipit-source-id: a37ecdb3dd0c23eff809f86e2f8b74cd48ff7277
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15582
Following convention of having caffe2_ prefix in command line options
Reviewed By: viswanathgs
Differential Revision: D13252055
fbshipit-source-id: 142a6395b832f211f34d0a87ec2d62c1e5fcdc69
Summary:
In this PR, we are moving all functions away from `Variable::Impl`, in order to get rid of `Variable::Impl` (and the `data_` Tensor in it) in the next PR. Some of the functions (such as `set_requires_grad` / `requires_grad` / `grad`) will be living in `AutogradMeta` class, while others (such as `backward()` / `rebase_history()` / `grad_accumulator()` / `grad_fn()`) will be living in `Variable` class.
This is the 2nd PR mentioned in https://github.com/pytorch/pytorch/issues/13638.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15487
Differential Revision: D13553173
Pulled By: yf225
fbshipit-source-id: 691f9432d0cd0640af380c757f3e3a2f64f8851c
Summary:
Short term solution, export group norm as an ATen op to unblock users.
Long term will add GroupNorm to onnx.
Add an end to end test for this one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15569
Differential Revision: D13554293
Pulled By: houseroad
fbshipit-source-id: b4974c9ea2a1b81338ca1e5c6747efe2715d7932
Summary:
Now that `cuda.get/set_rng_state` accept `device` objects, the default value should be an device object, and doc should mention so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14324
Reviewed By: ezyang
Differential Revision: D13528707
Pulled By: soumith
fbshipit-source-id: 32fdac467dfea6d5b96b7e2a42dc8cfd42ba11ee
Summary:
It should be ScriptModule rather than TracedModule :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15559
Differential Revision: D13552058
Pulled By: soumith
fbshipit-source-id: 0aa17639c225818b00d59daec4bc2336f039f658
Summary:
Simple check that runs against your PR's changes and complains if running clang-format would have created a change. Does nothing when run against master, so it's "safe" to accept changes that fail this check and it won't break the build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15543
Reviewed By: soumith
Differential Revision: D13552080
Pulled By: suo
fbshipit-source-id: 462a73894c16e7108806af7fa88440c377d4d0d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15365
On top of D13017791, adding rotated NMS support with the same kernel building
blocks. Results in 218x speedup on avg.
Reviewed By: SuperIRabbit
Differential Revision: D13509114
fbshipit-source-id: c1d33c8dc4bc50b5906b4f01bb0caf1115e2a357
Summary:
Changes originally in this PR:
1. Move Variable::Impl data members into TensorImpl as `AutogradMeta` struct
2. Change Variable::Impl functions to use data members in `AutogradMeta` struct
3. Add `shallow_copy_and_detach()` function to each subclass of TensorImpl
4. Do shallow copy when the user calls `make_variable(tensor)` / `make_variable_view(tensor)` / `variable.set_data(tensor)` / `variable.detach()`
Changes moved from https://github.com/pytorch/pytorch/pull/13645:
1. Add a flag to Variable to disallow size/stride/storage_ptr changes from in-place operations such as `resize_` / `resize_as_` / `set_` / `transpose_`, and set this flag to true when people call `tensor.data` in Python.
2. Write text in the docs to actively discourage changing the shape or storage of `tensor_detached` and expecting `tensor` to also be updated.
This is the 1st+2nd PR mentioned in https://github.com/pytorch/pytorch/issues/13638.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13827
Differential Revision: D13507173
Pulled By: yf225
fbshipit-source-id: b177b08438d534a8197e34e1ad4a837e2db0ed6a
Summary:
In current README.md, `CMAKE_PREFIX_PATH` is set to conda root even when you have activated an virtual environment. When an conda virtualenv is activated, packages are installed in `CONDA_PREFIX`, not conda root. I think `CMAKE_PREFIX_PATH` should also be set to `CONDA_PREFIX` in this case. I think some build issues can be solved with the new instruction. Maybe something like #14954.
soumith,
When I made PR #15335 I was confused and made a wrong point. I think this PR could be the real solution.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15548
Differential Revision: D13549681
Pulled By: soumith
fbshipit-source-id: 42d855b6e49ee58d735d2f4715d3e5752a748693
Summary:
The `EmbeddingBag` module does not include a `from_pretrained` method like the `Embedding` module. I added it for consistency between the two modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15273
Differential Revision: D13547842
Pulled By: soumith
fbshipit-source-id: 8ffde51ff0c1e8fc8310263b6f375da88089ff7d
Summary:
There is an inconsistency in the size of arguments for gesv, which is fixed in this PR.
Changelog:
- Replicate check in CPU as done for CUDA
- Fix argument ordering (minor) in CUDA checking
Fixes#15328
Differential Revision: D13531167
Pulled By: soumith
fbshipit-source-id: c4b4e4fc12880208d08e88d1e47e730ac98c2ad3
Summary:
The PR clang-formats everything in `torch/csrc/jit/` and adds it to the pre-commit hook.
Here is a list of non-mechanical changes:
- I went over each file and fixed up whenever I could tell that clang-format was clobbering comment formatting.
- Made the macros in register_prim_ops a little more clang-format friendly by omitting trailing commas
- Refactored autodiff.cpp to use a helper class with explicit state rather than a bunch of capturing lambdas
- Small improvements to the precommit hook clang-format
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15524
Differential Revision: D13547989
Pulled By: suo
fbshipit-source-id: 3ff1541bb06433ccfe6de6e33f29227a2b5bb493
Summary:
Currently torch.isinf on integral tensor will raise RuntimeError: value cannot be converted to type int16_t without overflow: inf.
This pr will suppress the error and return false(0) for all integral tensors. The behavior will also be consistent with np.isinf
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15489
Reviewed By: zou3519
Differential Revision: D13540786
Pulled By: flashhack
fbshipit-source-id: e730dea849da6a59f3752d347bcfbadfd12c6483
Summary:
I removed the explanation on `num_inputs` parameter. This parameter was removed in #8168
colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15529
Differential Revision: D13547854
Pulled By: soumith
fbshipit-source-id: 8a9ac58f2c93a2533b82ec63089477166ed0bcb9
Summary:
Upgrade MKl-DNN to 0.17 and static build MKL-DNN to fix the potentail build error due to old mkldnn version in host system.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15504
Differential Revision: D13547885
Pulled By: soumith
fbshipit-source-id: 46f790a3d9289c1e153e51c62be17c5206ea8f9a
Summary:
There was a typo in C++ docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15527
Differential Revision: D13547858
Pulled By: soumith
fbshipit-source-id: 1f5250206ca6e13b1b1443869b1e1c837a756cb5
Summary:
Currently re-implements the dataloader for stateful datasets. Outstanding work:
- Refactor DataLoader and DataLoader2 to have common base classes and only differ in specifi pieces of logic,
- Figure out how to not duplicate the `MapDataset` logic for stateful vs. non-stateful
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15096
Differential Revision: D13522043
Pulled By: goldsborough
fbshipit-source-id: 08e461ca51783047f11facc4d27dfa2e4f1e4c2a
Summary:
This makes compatibility with different versions of python a little bit simpler, and fixes a problem where stdin wasn't being read from the terminal properly in the prompt.
zdevito This should fix your EOF exception.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15521
Differential Revision: D13546358
Pulled By: suo
fbshipit-source-id: fb7551a86c888196831c046d9d9848e7ff05b925
Summary:
The precommit hook shouldn't hard fail if there's no `clang-tidy`, just warn and omit the check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15514
Differential Revision: D13545776
Pulled By: suo
fbshipit-source-id: 9bf3f8ee18703c6d1a39eb7776092fb5e120d2a1
Summary:
This does two things:
(1): revert #15114 , which is incorrect and actually just completely disables parallelization in this function (because `at::get_num_threads` returns `-1` unless it has been set explicitly)
(2): Fix our (FB-internal) failing tests that #15114 was intended to fix, by still working correctly in a setup where `#ifdef _OPENMP` is set and `omp_get_max_threads() > 1` , but `#pragma omp parallel` only launches one thread. I believe such an unusual situation only exists in certain unit tests within FB infra but we still need it to work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15483
Differential Revision: D13538940
Pulled By: umanwizard
fbshipit-source-id: a3362c7ac7327ced350d127bb426f82c59e42732
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15082
We didn't have unit test for low-precision rowwise adagrad
Reviewed By: chocjy
Differential Revision: D13300732
fbshipit-source-id: 46e7bdfc82c5a6855eeb6f653c0a96b0b3a20546
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15389
SparseLengthsMean was generating uninitialized data for empty inputs (lengths == 0). We should return zeros.
The unit tests were also not covering this special case which is fixed by this diff.
Reviewed By: salexspb
Differential Revision: D13515970
fbshipit-source-id: 3c35265638f64f13f0262cee930c94f8628005da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15492
Add pthreadpool_create and pthreadpool_destroy, which are used by NNPACK tests.
Reviewed By: Maratyszcza
Differential Revision: D13540997
fbshipit-source-id: 628c599df87b552ca1a3703854ec170243f04d2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15252
We would like to extend the model file format to include strongly type, semantic information
about the model inputs and outputs.
The goal is for a user to be able to consider a model file like a function with
a well defined API describing what the inputs and outputs would be.
Reviewed By: dzhulgakov
Differential Revision: D13009915
fbshipit-source-id: 5df124a876ad03c05fbdaacae0eab659637734c1
Summary:
(otherwise len is not resolvable using torch::jit::compile)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15488
Differential Revision: D13539991
Pulled By: zdevito
fbshipit-source-id: 3ba85fa7b1adb163f9229c568f7997d22321903d
Summary:
This adds `self` to the list of reserved words and also sorts the lines and prevents the tracer from naming values 'self' (which happens in torch/tensor.py)
Fixes#15240
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15318
Differential Revision: D13540192
Pulled By: driazati
fbshipit-source-id: 46ae02e51b1b31d5c62110fa83ba258ea6bada27
Summary:
This adds AD support for adaptive_avg_pool2d, which is necessary for resnet50 in pytorch/vision:master. cc: soumith asuhan dlibenzi
apaszke I saw that autodiff bug you fixed in #15403 , as it doesn't prevent this PR from passing, so I'll leave it for your PR to fix it. :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15459
Differential Revision: D13534732
Pulled By: ailzhang
fbshipit-source-id: 4e48b93e35d5ecfe7bd64b6a132a55b07843f206
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15458
many nets in the wild seem to have outputs that are never produced by the net.
Reviewed By: ZolotukhinM
Differential Revision: D13534185
fbshipit-source-id: 2b23b39c28404c53f68868f3bf6df53c5fea9eab
Summary:
This PR allows a subclass of programs that have return statements that are not final in the graph.
`final_returns.h` contains the a comment describing how this is accomplished.
To minimize complexity in `compiler.cpp`, this pass is done as an AST-to-AST rewrite before the compiler runs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15463
Differential Revision: D13538962
Pulled By: zdevito
fbshipit-source-id: 67105ca873351825b4a364092ab1873779f3e462
Summary:
This PR implements infrastructure for post-processing a model to apply int8 quantization to its `nn.Linear` modules. Highlights of the implementation:
1) Inputs and outputs are `float` (quantized and packed internally), but the weight is quantized and packed ahead of time for efficiency. This implementation performs well in small-batch size GEMM calls. It should not be considered a general-purpose quantized GEMM kernel.
2) Weight packing is dependent on machine architecture (e.g. vector register width), so it is done just-in-time. Concretely, it is done on model load for the weights and it is done during operator execution for the input value.
3) Biases are unquantized
4) We fail loudly if we are attempting to run this on a machine that does not support FBGEMM. This is because we do not want a model's numerics to differ based on which machine it is run on. A model containing these FBGEMM ops *must* be run with FBGEMM
The API can be seen in the added test case. Highlights are:
1) `torch.jit.quantized.quantize_linear_modules` walks the module hierarchy of the passed-in Module and replaces all `nn.Linear` modules with a new `QuantizedLinear` module, which encapsulates the behavior described above.
2) `_pack()` and `_unpack()` script methods are present on `QuantizedLinear` modules. These methods should be called before serialization and after deserialization, respectively. This ensures that the weight matrix is properly packed for the running machine's architecture. Note that in the long term, we would like to move toward a more Pickle-style serialization technique, rather than having these explicit methods that mutate member values. This is blocked on being able to assign attributes in a ScriptMethod, among other things.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13777
Differential Revision: D13383276
Pulled By: jamesr66a
fbshipit-source-id: 00f29c9f34544add2b90107e3cf55a287802c344
Summary:
It is sometimes beneficial to run multiple batches in one benchmark and check the aggregated results.
This PR enables this functionality.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15443
Reviewed By: llyfacebook
Differential Revision: D13531129
Pulled By: sf-wind
fbshipit-source-id: 553a762a5cbadf5a3d9fd6af767ae34899bc1aa2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15473
Revert accidental changes introduced in D13335176
IntList is a range and copying it just copies pointers. Thus pointers would point either on deallocated memory or on the same memory causing equality always pass.
Reviewed By: ezyang
Differential Revision: D13537131
fbshipit-source-id: c97b3533be689bb4cdadd9e612f1284ac50e4bda
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15453
Just move things around to facilitate further development. No logic change.
Reviewed By: rdzhabarov
Differential Revision: D13533959
fbshipit-source-id: eebab1306939e802aacffb24a711d372fd67916c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15174
Previously, Caffe2 maintained a separate per-thread per-device
current logical CUDA stream ID. In this PR, we switch Caffe2 over
to using c10::Stream to manage the current stream, and also
manage the allocation of cudaStream_t objects.
This results in a slight behavior change: previously, Caffe2
would have been willing to allocate an arbitrary number of
CUDA streams, depending on how high the logical stream IDs
went. The c10::Stream pool has a fixed number of streams, once
you exceed it, it wraps around.
Reviewed By: dzhulgakov
Differential Revision: D13451550
fbshipit-source-id: da6cf33ee026932a2d873835f6e090f7b8a7d8dc
Summary:
Fixes#3584.
Motivation: manually sorting sequences, packing them, and then unsorting them
is something a lot of users have complained about doing, especially when we can
offer library support for them.
Overview: we internally sort sequences before packing them and store a list of
`unsorted_indices` that represent how to unsort the sequences inside
PackedSequence. The packing helper functions return PackedSequence with the
`permutation` field and the unpacking helper functions use it to unsort.
To implement this, the following changes were made:
- PackedSequence now keeps `sorted_indices` and `unsorted_indices`.
These two can be thought of as permutations and are inverses of each other.
`sorted_indices` is how the sequences were sorted; `unsorted_indices` is how
to unsort the sequences.
- Added an `enforce_sorted` argument to pack_sequence and pack_padded_sequence
that maintains the legacy behavior of error-ing out on unsorted-sequences.
When `enforce_sorted=True`, these functions maintain their ONNX exportability.
- pack_sequence(sequences, enforce_sorted) takes in unsorted sequences.
- pack_padded_sequence can take in a padded tensor that represents padded,
unsorted sequences.
- pad_packed_sequence unsorts the PackedSequence such that it is still the
inverse operation of packed_padded_sequence.
- RNNs apply `sort_indices` to their input hidden state and apply
`unsort_indices` to their output hidden state. This is to ensure that the
hidden state batches correspond to the user's ordering of input sequences.
NOT BC-Breaking
- The default for pack_sequence and pack_padded_sequence is
`enforce_sorted=True` to avoid breaking ONNX export. To use the new
functionality, pass in `enforce_sorted=False`
Testing Plan
- Modified TestNN.test_pack_sequence, TestNN.test_packed_padded_sequence,
and TestNN.test_variable_sequence (RNN test) to check the behavior
of unsorted sequences, sorted sequences, and sorted sequences with
enforce_sorted=True
- test/test_jit.py has a test to see if RNNs are exportable with
enforce_sorted=True
cc colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15225
Reviewed By: soumith
Differential Revision: D13507138
Pulled By: zou3519
fbshipit-source-id: b871dccd6abefffca81bc4e3efef1873faa242ef
Summary:
I noticed that some users don't even know we have this support. Adding into the doc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15440
Differential Revision: D13531045
Pulled By: teng-li
fbshipit-source-id: 9757c400c0010608758c754df04e603b36035a10
Summary:
According to mypy, the trailing -> None is mandatory.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15448
Differential Revision: D13532179
Pulled By: ezyang
fbshipit-source-id: e8972f8c9ada4657c518cd7bcd46e489ab8ddf5f
Summary:
ROCm 2.0's compiler requires launch_bounds annotations if flat work group sizes are larger than the default of 256.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15400
Differential Revision: D13531239
Pulled By: ezyang
fbshipit-source-id: c0b40600a8c332823da6c7113c644d8dba424a9c
Summary:
This PR adds enough of the infra for supporting closures (inner script functions) in order to allow us to expression symbolic gradients using them. We do not actually ever run graphs that contain these closures. The symbolic_script infrastructure just extracts them out of the original forward graph and turns them into discrete forward/backward pairs. This cuts down on the type annotations necessary to write forward/backward pairs and aligns closely with the "differentiator" function approach to expression reverse-mode AD.
Example:
This code:
```
import torch
r = torch.jit.CompilationUnit(
'''
def mul_forward(self, other):
def backward(grad_output):
grad_self = (grad_output * other).sum_to_size(self.size())
grad_other = (grad_output * self).sum_to_size(other.size())
return grad_self, grad_other
return self * other, backward
''')
print(r.module.code)
```
Will produce this graph (pretty printed for clarity):
```
def mul_forward(self,
self: Tensor,
other: Tensor) -> Tuple[Tensor, Tuple[None, Tuple[Tensor, Tensor]]]:
backward = (self.__lambda, (other, self))
return (torch.mul(self, other), backward)
def __lambda(self,
context: Tuple[Tensor, Tensor],
grad_output: Tensor) -> Tuple[Tensor, Tensor]:
other, self, = context
grad_self = torch.sum_to_size(torch.mul(grad_output, other), torch.size(self))
grad_other = torch.sum_to_size(torch.mul(grad_output, self), torch.size(other))
return (grad_self, grad_other)
```
symbolic_script will then do some modifications to remove the unsuppored prim::Function node, yielding:
```
def mul_forward(self,
self: Tensor,
other: Tensor) -> Tuple[Tensor, Tuple[None, Tuple[Tensor, Tensor]]]:
return (torch.mul(self, other), (other, self))
def backward(self,
context: Tuple[Tensor, Tensor],
grad_output: Tensor) -> Tuple[Tensor, Tensor]:
other, self, = context
grad_self = torch.sum_to_size(torch.mul(grad_output, other), torch.size(self))
grad_other = torch.sum_to_size(torch.mul(grad_output, self), torch.size(other))
return (grad_self, grad_other)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15411
Differential Revision: D13523340
Pulled By: zdevito
fbshipit-source-id: 4d4a269460e595b16802c00ec55ae00e3e682d49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15413
In order to pass arguments to the ios app, need to extarct the arguments
to its own file. Also, in the ios app, do not use the benchmark.json, which
parses the arguments.
This is an incompatible change, needs to add hot fix to the tests.
Reviewed By: llyfacebook
Differential Revision: D13523240
fbshipit-source-id: b559cc7f52d8f50ee206a7ff8d7b59292d855197
Summary:
Currently PyTorch ONNX exporter exports the logical ops (`lt`, `gt`, `le`, `ge`, `eq`) with output type in corresponding ONNX ops as type `tensor(uint8)`. But ONNX spec allows for only `tensor(bool)`, which is why models that have these ops fail to load properly.
This issue is captured in https://github.com/pytorch/pytorch/issues/11339. Part of this issue, relating to the allowed input types, has been fixed in ONNX spec by houseroad. This PR fixes the other part pertaining to output type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15185
Differential Revision: D13494873
Pulled By: houseroad
fbshipit-source-id: 069d2f956a5ae9bf0ac2540a32594a31b01adef8
Summary:
This PR makes some small changes for better consistency in our README and
CONTRIBUTING docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15373
Differential Revision: D13512753
Pulled By: driazati
fbshipit-source-id: 44398ad1894eef521d5f5acb1d06acaad67728cf
Summary:
Followup PR of #14904, and the stretch goal of #12653.
Directly calculate coordinates in the original tensor using column index in the result tensor. Every GPU thread takes care of a column (two numbers) in the output tensor.
The implementation detects and handles precision loss during calculating the square root of a `int64_t` variable, and supports tensors with up to `row * column = 2 ^ 59` numbers.
Algorithm details are describe in [comments of TensorFactories.cu](23ddb6f58a/aten/src/ATen/native/cuda/TensorFactories.cu (L109-L255)).
zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15203
Reviewed By: zou3519
Differential Revision: D13517695
Pulled By: mrshenli
fbshipit-source-id: 86b305d22cac08c8962a3b0cf8e9e620b7ec33ea
Summary:
This updates pdist to work for batched inputs, and updates the
documentation to reflect issues raised.
closes#9406
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12302
Reviewed By: ezyang
Differential Revision: D13528485
Pulled By: erikbrinkman
fbshipit-source-id: 63d93a6e1cc95b483fb58e9ff021758b341cd4de
Summary:
This is the CUDA version of #14535 .
It refactors Reduce.cuh to allow more general classes of reductions to be performed -- we no longer assume that the temporary data returned during reduction is just one scalar, and instead allow an arbitrary accumulate type.
We also allow 64-bit indexing when necessary, since in general we will no longer be able to accumulate directly in the output. (In the cases when we can, we continue to split the tensors until they can be addressed with 32-bits, as before).
As an initial use-case, we implement `std` in multiple dimensions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14990
Differential Revision: D13405097
Pulled By: umanwizard
fbshipit-source-id: a56c24dc2fd5326d417632089bd3f5c4f9f0d2cb
Summary:
This adds `self` to the list of reserved words and also sorts the lines and prevents the tracer from naming values 'self' (which happens in torch/tensor.py)
Fixes#15240
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15318
Differential Revision: D13498974
Pulled By: driazati
fbshipit-source-id: 488efb661476cdcdb8ecb9cb48942f02e3c1e611
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13321
This diff simply refactors the `ProfDAGCounters` into two:
* `ProfDAGCounters` that gathers stats at runtime.
* `ProfDAGReport` which holds the report from the gathered stats once stats collection is done.
This refactoring allow us to implement `+=` for `ProfDAGReport`, which can be used for aggregating same-net reports on each host.
Reviewed By: donglimm
Differential Revision: D12837988
fbshipit-source-id: 0470c5fd6437f12711cab25a15a12965d79b2a91
Summary:
Optional clean up. This PR remove python_default_init from the yaml files, and the code-gen, and utilize optional type to do the work.
This also fix the bug in the #13149 to correctly adopt as_strided backward.
Fixes#9941
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15234
Differential Revision: D13502044
Pulled By: wanchaol
fbshipit-source-id: 774b61fc4414482cf11d56e22bd0275aefb352a4
Summary:
Save error info in the future for parent thread to pick up. Throw the error
when the thread is the root thread.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14523
Differential Revision: D13251756
Pulled By: highker
fbshipit-source-id: b40f9a45665e1a934743f131ec5e8bad5622ce67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15248
OutputTensorCopyFrom takes four arguments: index, a source Tensor, TensorOptions and whether we want to perform an async call.
We want to provide some default option for TensorOptions, (1). default device to context_.device() (2). default dtype to input.dtype(). User can also explicitly provide these options to override default values.
next diff will change the order of TensorOptions parameter so that user don't need to write down tensor options unless they want to override.
Reviewed By: dzhulgakov
Differential Revision: D13453824
fbshipit-source-id: 87401f81c7c3f9fd3d8936c710e6c2e04a59b689
Summary:
Current documentation example doesn't compile. This fixes the doc so the example works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15372
Differential Revision: D13522167
Pulled By: goldsborough
fbshipit-source-id: 5171a5f8e165eafabd9d1a28d23020bf2655f38b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15366
swap the old implementation with a slightly easier one to understand
I ran the tests and compared the number of chains compared to the old algorithm. This one outperforms on every test, but we have yet to see if that impacts performance at all.
old chain 34 nomnigraph chain 25
old chain 46 nomnigraph chain 34
old chain 228 nomnigraph chain 188
old chain 397 nomnigraph chain 338
Reviewed By: ilia-cher
Differential Revision: D13057451
fbshipit-source-id: ccd050bfead6eb94ab9c7b0a70b09a22c2b9e499
Summary:
Same as #14668, and was approved there.
ailzhang , please apply this patch to Horizon's `data_streamer.py`: https://gist.github.com/SsnL/020fdb3d6b7016d81b6ba1d04cc41459 Thank you!
Below is the original description at #14668:
As I am working on tasks in https://github.com/pytorch/pytorch/issues/13023, I realized how unreadable the code is because all functions to be run in multiprocessing must be at top global level. Adding more functionalities to `dataloader.py` will only make things worse.
So in this PR, I refactor `dataloader.py` and move much of it into `data._utils`. E.g., the `_worker_loop` and related methods are now in `data._utils.worker`, signal handling code in `data._utils.signal_handling`, collating code in `data._utils.collate`, etc. This split, IMHO, makes code much clearer. I will base my future changes to DataLoader on top of this.
No functionality is changed, except that I added `torch._six.queue`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15331
Reviewed By: yf225
Differential Revision: D13503120
Pulled By: ailzhang
fbshipit-source-id: 94df16b4d80ad1102c437cde0d5a2e62cffe1f8e
Summary:
Changelog:
- Renames `potrs` to `cholesky_solve` to remain consistent with Tensorflow and Scipy (not really, they call their function chol_solve)
- Default argument for upper in cholesky_solve is False. This will allow a seamless interface between `cholesky` and `cholesky_solve`, since the `upper` argument in both function are the same.
- Rename all tests
- Create a tentative alias for `cholesky_solve` under the name `potrs`, and add deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15334
Differential Revision: D13507724
Pulled By: soumith
fbshipit-source-id: b826996541e49d2e2bcd061b72a38c39450c76d0
Summary:
A number of different passes rely on whether a node has side effects. This centralizes the list of side effectful ops in one place.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15188
Differential Revision: D13508438
Pulled By: eellison
fbshipit-source-id: 2143e782b787731ce007b6dcd50cbde30e1b8dd0
Summary:
For #6593 and #9515
This completes the support for optional<ScalarType> in native, JIT and autograd.
Note: Mostly following the existing implementation for optional<Scalar> that was added in https://github.com/pytorch/pytorch/pull/12582.
This PR introduces a way to make functions accept an optional dtype and it will unblock #9515 by allowing the `dtype` param for type promotion interface:
```
func: name(inputs, *, ScalarType? dtype=None, Casting casting=same_kind)
```
An alternative approach could have been using `ScalarType::Undefined` for the same purpose but without optional, though it would have been a bit hacky.
```
func: name(inputs, *, ScalarType dtype=Undefined, Casting casting=same_kind)
```
Here's an example use of this in action: 971f69eac6
There are already a bunch of native functions that were getting optional `dtype` through function overloading. https://github.com/pytorch/pytorch/pull/15133 is the attempt to migrate all of those. I will send those changes separately after this since some functions (e.g. sum) need quite a bit of change in the codebase. See the commits over there.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15154
Differential Revision: D13457760
Pulled By: tugrulates
fbshipit-source-id: 706134f0bd578683edd416b96329b49a1ba8ab48
Summary:
Pull cpuinfo changes that should make it work on AWS Lambda servers (which don't have `/sys/devices/system/cpu/{possible,present}` files, and probably don't mount sysfs at all).
I'm not 100% sure it will fix the issue, but getting this update in would make it easier for users to test using a nightly build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15385
Reviewed By: soumith
Differential Revision: D13517467
Pulled By: Maratyszcza
fbshipit-source-id: e8e544cd1f9dad304172ebb7b6ba7a8ad7d34e66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15371
Similar to D13387692:
Never call mutable_data from an OpenMP region!!!
Reviewed By: jspark1105
Differential Revision: D13511259
fbshipit-source-id: 100812d2a547c0a1d5018749d5fdc88162375673
Summary:
This PR adds clang-format automation:
- It only checks on whitelisted files, so we can enable incrementally without noise
- There is a pre-commit hook provided that will do the same check, plus prompt users to apply the clang-format changes (no change is made without the user agreeing).
My plan is to migrate over whole files at a time, clang-formatting them and then adding them to the whitelist. Doing it this way should avoid too many merge pains (the most you'll have to is run clang-format on the affected file before rebasing).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15254
Differential Revision: D13515888
Pulled By: suo
fbshipit-source-id: d098eabcc97aa228c4dfce8fc096c3b5a45b591f
Summary:
This separates the different parts of compiler.cpp to make their relationship more clear. In particular it adds:
* sugared_value.{h,cpp} - all the public SugaredValues that the compiler defines and a few that were inside compiler.cpp
* type_parser.{h, cpp} - Turns TreeRef's defining types into TypePtr
* schema_matching.{h, cpp} - infrastructure for matching arguments against overloaded schema and emitting builtin operators with a particular schema.
Retains:
* compiler.{h, cpp} - now responsible simply for the `defineMethodsInModule` infra structure.
Some utility functions like inlineCallTo have moved to ir.h.
Only thing that is not a move is some changes in module.h/cpp that remove multiple returns from `Method::emit_call_to`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15355
Reviewed By: suo, wanchaol
Differential Revision: D13507524
Pulled By: zdevito
fbshipit-source-id: 69ec936a9ff1a383c12a883616346b219c72e393
Summary:
This PR enables autodiff to use the forward/backward graph compiled from python code, instead of using symbolic gradients(modifying the original graph directly).
We put the map in a separate .h file for now to wait for the native_functions.yaml and derivatives.yaml merge. This should ideally go into native_functions.yaml eventually.
This PR should be enough to unblock us for now, we can start writing gradients for aten functions in python.
Differential Revision: D13494635
Pulled By: ailzhang
fbshipit-source-id: f8d51a15243ac46afd09d930c573ccdfcd9fdaaf
Summary:
Modified step_lr for StepLR, MultiStepLR, ExponentialLR and CosineAnnealingLR. In this way, multiple schedulers can be used simultaneously to modify the learning rates.
Related issue: https://github.com/pytorch/pytorch/issues/13022
Added unit tests combining multiple schedulers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14010
Reviewed By: ezyang
Differential Revision: D13494941
Pulled By: chandlerzuo
fbshipit-source-id: 7561270245639ba1f2c00748f8e4a5f7dec7160c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15348
We have a function resize_dim() on TensorImpl in c10/core/TensorImpl.h which lets you change the dimensionality of a tensor, resizing both sizes and strides. Unfortunately, this API is fairly easy to misuse, because it fills in the new entries with garbage when you size it larger. We want to refactor the call sites to use set_sizes_and_strides() instead, so that there is never an intermediate tensor state where the sizes/strides don't make sense. In this diff, resize_dim() is
replaced with set_sizes_and_strides() in aten/src/TH/THTensor.hpp.
Reviewed By: ezyang
Differential Revision: D13505512
fbshipit-source-id: 193bab89f0018c13ca07488be336d8e967746b76
Summary:
Changelog:
- change some expect tests that didn't have to be expect tests,
instead use self.assertAllFused
- Some of the fuser tests weren't using self.assertAllFused.
- Minor test renames
cc apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15134
Differential Revision: D13507481
Pulled By: zou3519
fbshipit-source-id: dd0788530a60bb5ed2f42b961fae3db2b4404b64
Summary:
max and reducemax are smashed together, we need to support one input case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15241
Reviewed By: yinghai
Differential Revision: D13473312
Pulled By: houseroad
fbshipit-source-id: 9b8c847286a2631b006ca900271bc0d26574101a
Summary:
This PR changes Method (just Method not all graphs) to always have a single
return argument.
This is part 1 in a set of changes that will enable us to have better handling if early return statements.
The simplification that this change provides greatly reduces the work for the next step.
This change makes it so that Method and Python handle multiple returns in the same way:
* 0 - None
* 1 - <single value>
* many - Tuple[...]
The result is that a lot of special-case handling in compiler.cpp and its
bindings can be removed. It also fixes several bugs in return handling,
including one where return values were not always checked against their
attributed values.
Notes:
* inferTypeFrom is renamed to be more accurate and discourage use.
* This has uncovered some bugs in other components, which are noted in
the diff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15289
Differential Revision: D13481649
Pulled By: zdevito
fbshipit-source-id: 0e2242a40bb28cca2d0e8be48bede96195e4858c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15322
caffe2 mobile opengl code is not used, deleting it to reduce complications when we perform other changes
Reviewed By: Maratyszcza
Differential Revision: D13499943
fbshipit-source-id: 6479f6b9f50f08b5ae28f8f0bc4a1c4fc3f3c3c2
Summary:
There is still limitation on this: if a script module is somewhere
in the trace, the inputs/outputs can only be tensors or tuples of
tensors.
resolves#15052
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15184
Differential Revision: D13457691
Pulled By: highker
fbshipit-source-id: 8fe46afc41357a0eb8eadd83f687b31d074deb0e
Summary:
…on](#12115)
mean is calculated in two step sum()/numel(). For half precision, data gets
casted back to half after sum().
We fused the division into the reduction kernel by adding pre_op/post_op.
This allows us to do torch.ones(65536).cuda().half().mean() to return correct
result.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14878
Differential Revision: D13491159
Pulled By: soumith
fbshipit-source-id: e83802e1628b6d2615c45e18d7acf991d143a09e
Summary:
Fixes an issue that arose from https://github.com/pytorch/pytorch/pull/13481 where `.shared_memory()` couldn't be called. Effectively undoes all changes to `nn.Module` from that PR and solve the relevant problem in a different way (the goal was to be able to call `._apply()` on the Python wrapper for a C++ module).
soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15305
Differential Revision: D13493937
Pulled By: goldsborough
fbshipit-source-id: 4cb8687f90fc8709a536c5e7eacd0dc8edf6f750
Summary:
The JIT uses `int64_t` for its integer type and `double` for its floating point type, but users quite often want to write `int` or `float` and that currently fails in not-so-nice ways for custom ops. This PR adds a simple `static_assert` to catch these common failure cases.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15247
Differential Revision: D13493941
Pulled By: goldsborough
fbshipit-source-id: c1cd0d10ab5838c75f167c0bdb57e45a0bc1344e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15250
This adds `__repr__` methods to all of the classes under task.py. This makes the objects much easier to interact with when using them in an interactive manner, such as in a Jupyter notebook.
The default `__repr__` method just returns the object ID which is very unhelpful.
Reviewed By: hanli0612
Differential Revision: D13475758
fbshipit-source-id: 6e1b166ec35163b9776c797b6a2e0d002560cd29
Summary:
Addresses #918, interpolation results should be similar to tf
* Adds bicubic interpolation operator to `nn.functional.interpolate`
* Corresponding test in `test_nn.py`
The operator is added in legacy `TH` to be aligned with the other upsampling operators; they can be refactored/moved to ATen all at once when #10482 is resolved
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9849
Differential Revision: D9007525
Pulled By: driazati
fbshipit-source-id: 93ef49a34ce4e5ffd4bda94cd9a6ddc939f0a4cc
Summary:
This PR add isinstance to do static type checking in JIT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15076
Differential Revision: D13471067
Pulled By: wanchaol
fbshipit-source-id: d39b7ed5db9fcca4b503659d02cf7795950ea8ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15126
I want to make people stop manufacturing StreamId from thin air,
and a first step is to make people use the default stream.
Reviewed By: dzhulgakov
Differential Revision: D13432922
fbshipit-source-id: 9f0d8d70646c50d979bde5ba3c3addeebac48a3d
Summary:
Allows 2 functions that are boolean dispatched to have no docstrings (the only case that will fail now is if both functions have docstrings)
Fixes#15281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15306
Differential Revision: D13494884
Pulled By: driazati
fbshipit-source-id: 65fec39ae03a7d6a68ad617c9b270faeb1617930
Summary:
`torch.expand` and `torch.ne` are used often in models and this PR adds ONNX export support for them. ArmenAg has created issue https://github.com/pytorch/pytorch/issues/10882 for this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15050
Differential Revision: D13453036
Pulled By: houseroad
fbshipit-source-id: 4724b4ffcebda6cd6b2acac51d6733cb27318daf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15125
I realized that it is really bad juju if you fake a StreamId
out of thin air, because in general this isn't going to work.
So, make the constructor a lot scarier.
Most "faking StreamId out of thin air" happens because someone
just wants to put something on the default stream.
Reviewed By: dzhulgakov
Differential Revision: D13432800
fbshipit-source-id: a86991d6fc1d8aa4e54e8175e5f06f90856238e6
Summary:
`rsplit` doesn't have kwargs in Python 2 so this line raises an error
Fixes#15135
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12732
Differential Revision: D10458630
Pulled By: driazati
fbshipit-source-id: a63e42fbc0e39e4291480775b516c98122ec05a1
Summary:
Cholesky by default returns the lower triangular matrix, see [docs](https://pytorch.org/docs/stable/torch.html#torch.cholesky).
However `torch.potrs` by default requires the upper triangular matrix. The naming of the variable `u` suggests that the example expects the upper to be returned, so I've added the flag to make that happen in the example.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15215
Differential Revision: D13476468
Pulled By: soumith
fbshipit-source-id: 7b68035f435a2b1be4d363b3f63e407394af949d
Summary:
This makes DCE more granular by tracking live values/aliases through the graph (rather than just nodes). So we can be more aggressive in DCE around control flow blocks. For example, in:
```
%a0 = aten::foo()
%b = aten::foo()
%a2, %b2 = prim::If(%cond) {
block0() {
%a1 = aten::foo(%.0)
%b1 = aten::foo(%b)
} -> (%a1, %b1)
}
return (%a2)
```
we will now dce all the `%b` stuff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14910
Differential Revision: D13476445
Pulled By: suo
fbshipit-source-id: 2bf5db19711c07dde946697a4f4b270bd8baf791
Summary:
A friend of me is learning deep learning and pytorch, and he is confused by the following piece of code from the tutorial https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#gradients :
```python
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
gradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(gradients)
print(x.grad)
```
He don't know where the following line comes from:
```python
gradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
```
What are we computing? Why don't we compute "the gradient of `y` w.r.t `x`"?
In the tutorial, it only says
> You can do many crazy things with autograd!
Which does not explain anything. It seems to be hard for some beginners of deep learning to understand why do we ever do backwards with external gradient fed in and what is the meaning of doing so. So I modified the tutorial in https://github.com/pytorch/tutorials/pull/385
and the docstring correspondingly in this PR, explaining the Jacobian vector product. Please review this PR and https://github.com/pytorch/tutorials/pull/385 together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15197
Differential Revision: D13476513
Pulled By: soumith
fbshipit-source-id: bee62282e9ab72403247384e4063bcdf59d40c3c
Summary:
Several enhancements are implemented:
* Resize the images to be within a boundary between min-size and max-size (can be height and weight). It tries to resize the minimum size to match the min-size and keep the aspect ratio. However, if in that case the maximum size is more than the max-size, then resize the maximum size to be equal to the max-size (and the minimum size is less than min-size). The min/max sizes are specified in argument scale, in a comma separated form. If one of the size is -1, then that size is not a restriction.
* Change the OpenCV resize function arguments from using cv::Size() to the x, y scale. Theoretically they should be the same. But in reality, the two ways of specifying them may result to different resized outputs.
* Once the image is read in, change the data to floats. That means, after resize and other preprocessing steps, the float values are preserved (not truncated to int).
* It is possible to convert data in text format to the blob format.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15204
Reviewed By: llyfacebook
Differential Revision: D13467225
Pulled By: sf-wind
fbshipit-source-id: 7da34a72d43a9603cd7ab953f5821c1222d0178f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15242
Newer version ONNX Reshape gets shape info from a tensor. Hence for static backend, we need to provide this info to it when doing `onnxGetCompatibility` too.
Reviewed By: jackm321
Differential Revision: D13471959
fbshipit-source-id: 8a58e28edd900b6ad54a1dbd63ff2579fbe0e820
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15191
OSS:
just splitting out basic flags from a unit test. So I can extend them in another test where I need to add additional flags.
Reviewed By: yinghai
Differential Revision: D13159184
fbshipit-source-id: 9823e792cf0ed8d0379235c44564862b7d784845
Summary: Record unit of time for torch.cuda.Event's elapsed_time
Differential Revision: D13467646
Pulled By: zou3519
fbshipit-source-id: 4f1f4ef5fa4bc5a1b4775dfcec6ab155e5bf8d6e
Summary:
We need this, for example, to properly call `_unpack` when we have a traced module in the hierarchy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15101
Differential Revision: D13468467
Pulled By: jamesr66a
fbshipit-source-id: c2b6740b12cde6e23395d12e42d4fc2c4c7ca3f2
Summary:
The compiler understands it and profits from knowing it by not using too
many VGPRs as it defaults to 256 default workgroup size.
Fixes a problem in bringup of ROCm 2.0 on gfx906.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15228
Differential Revision: D13470950
Pulled By: bddppq
fbshipit-source-id: f9aa44c7c95299a099c0ea9317b9044cc056acc5
Summary:
tests work on ROCm 1.9.2 as present on CI (fp16 bringup, hipMemset and sparse improvements)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15232
Differential Revision: D13470991
Pulled By: bddppq
fbshipit-source-id: 45acc4f9ea5baaaf7672b86eb022948055779925
Summary:
Some of the codeblocks were showing up as normal text and the "unsupported modules" table was formatted incorrectly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15227
Differential Revision: D13468847
Pulled By: driazati
fbshipit-source-id: eb7375710d4f6eca1d0f44dfc43c7c506300cb1e
Summary:
This PR adds the final set of clang-tidy checks we should add for our codebase: a last set of performance-related checks. Most fixes here are around changing `auto` to `const auto&` in a few places where unnecessary copies were made, and adding `reserve()` calls before loops doing repeated `push_back()`. Also a few cases of calling `std::string::find` with a single-character string literal instead of a single char, which uses a less efficient string search algorithm meant for searching larger substrings.

ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15198
Differential Revision: D13468797
Pulled By: goldsborough
fbshipit-source-id: 2bed1ea1c7c162b7f3e0e1026f17125e88c4d5b2
Summary:
Methods like `module.named_modules()` returns a container of `shared_ptr<nn::Module>`. Currently the `nn::Module` base class does not have Python bindings. This PR fixes this, and adds more unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15193
Differential Revision: D13458713
Pulled By: goldsborough
fbshipit-source-id: 4091fe1b96a1be8db14c6a4307fbacc2b41ff6fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15027
- Make DataRandomFiller able to accept input_dims and input_types for only non intermediate inputs. Add a helper to fill input directly to a workspace
Reviewed By: highker
Differential Revision: D13408345
fbshipit-source-id: 5fc54d33da12e3f0a200e79380d4c695b0339b17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15022
Add setArgument testing utils to make it easy to set argument for an operator
Reviewed By: yinghai
Differential Revision: D13405225
fbshipit-source-id: b5c1859c6819d53c1a44718e2868e3137067df36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15020
Add test utils for assertion of a tensor (sizes and values)
Reviewed By: salexspb
Differential Revision: D13401146
fbshipit-source-id: bc385df074043e03ea884940b5631b96de4a607e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15019
Put some utils to fill tensors to test_utils
Reviewed By: salexspb
Differential Revision: D13386691
fbshipit-source-id: 51d891aad1ca12dc5133c0352df65b8db4f96edb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15180
Test utils to create an operator
On top of D13370461
Reviewed By: ZolotukhinM
Differential Revision: D13382773
fbshipit-source-id: a88040ed5a60f31d3e73f1f958219cd7338dc52e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15014
Currently it looks like many of the simple operations such as comparing tensors, creating tensors, fetching tensors... are too verbose and took effort to write correctly in unit tests.
Easy to use utilities are often more important to increase productivity writing unit tests. While caffe2 python unit tests are relatively easier to write at the moment, the C++ side seems lacking.
In this change I create a test_util, started with assertsTensorEquals, getTensor, createTensor, and we can start putting more easy to use utilities there.
Reviewed By: salexspb
Differential Revision: D13370461
fbshipit-source-id: bee467a127e1d032ef19482f98aa5c776cf508c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14858
This diff doesn't change logic but just takes the existing code and moves it to caffe2::Tensor
Reviewed By: ezyang
Differential Revision: D13365817
fbshipit-source-id: bc73b27a793602cb14200dcdf357aa63233da43c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14656
This diff doesn't move it yet, but prepares it to be moved, i.e. removes all access to class internals.
dzhulgakov: Please comment on if you think it still makes sense to land this even though it's not blocking anymore since we're going to move at::CopyBytes anyhow.
ezyang: There's some changes in the implementation, especially handling undefined dest tensors. Please review carefully.
Reviewed By: ezyang
Differential Revision: D13287688
fbshipit-source-id: 17800ca8a79ab1633f23be58d96f99a160d8ed24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15113
cv::rotatedRectangleIntersection has a known float underflow bug that would cause failure in ```CV_Assert(intersection.size() <= 8)```
For rotated proposals, replace cv::rotatedRectangleIntersection with a correct version that doesn't have underflow problem.
Otherwise, when ```USE_CPP_GENERATE_PROPOSALS = true```, the training would fail.
Reviewed By: viswanathgs
Differential Revision: D13429770
fbshipit-source-id: 5e95d059f3c668f14059a0a83e8e53d8554cdb99
Summary:
Adding support for torch.tensor in script.
The input list is typed as t[], because it can be arbitrarily nested. I added a check a compile time check that the inner type of the list is a bool, float, or int.
Also adds specialization for Boolean Lists, which already existed at the ivalue level but had not been added to the compiler yet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14913
Differential Revision: D13407930
Pulled By: eellison
fbshipit-source-id: d17f1195a22149d5b0d08d76c89a7fab8444f7c5
Summary:
This PR fixes around 250 places in the codebase where we were making unnecessary copies of objects (some large, some small).
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15026
Differential Revision: D13458784
Pulled By: goldsborough
fbshipit-source-id: be5148b2ce09493588d70952e6f6d6ff5ec5199b
Summary:
This PR removes the usage of _finfo defined in torch.distributions.utils and changes the call sites
to use torch.finfo instead
Differential Revision: D13451936
Pulled By: soumith
fbshipit-source-id: 6dbda3a6179d9407bc3396bf1a2baf3e85bc4cf2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14918
When ProtoBuf-Lite is in use, ProtoDebugString just calls SerializeAsString.
This produces binary output, which is not a very suitable "debug" string.
Specifically, we've observed it causing problems when calling code tries to
add the debug string to a Java exception message (which requires valid UTF-8).
Now, we replace all non-ASCII bytes with "?".
This is not a very fast implementation, but generating debug strings shouldn't
be a performance-sensitive operation in any application.
Reviewed By: dzhulgakov
Differential Revision: D13385540
fbshipit-source-id: 8868172baf20efaf53fecf7d666a6980f59b64f5
Summary:
This PR enables C++ frontend modules to be bound into Python and added as submodules of Python modules. For this, I added lots of pybind11 bindings for the `torch::nn::Module` class, and modified the `torch.nn.Module` class in Python to have a new Metaclass that makes `isinstance(m, torch.nn.Module)` return true when `m` is a C++ frontend module. The methods and fields of C++ modules are bound in such a way that they work seamlessly as submodules of Python modules for most operations (one exception I know of: calling `.to()` ends up calling `.apply()` on each submodule with a Python lambda, which cannot be used in C++ -- this may require small changes on Python side).
I've added quite a bunch of tests to verify the bindings and equality with Python. I think I should also try out adding a C++ module as part of some large PyTorch module, like a WLM or something, and see if everything works smoothly.
The next step for inter-op across our system is ScriptModule <-> C++ Frontend Module inter-op. I think this will then also allow using C++ frontend modules from TorchScript.
apaszke zdevito
CC dzhulgakov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13481
Differential Revision: D12981996
Pulled By: goldsborough
fbshipit-source-id: 147370d3596ebb0e94c82cec92993a148fee50a7
Summary:
Before this PR, loop unrolling + the graph fuser was creating multiple
FusionGroups with the same bodies (with different variable names) for
JIT LSTMs. Each FusionGroup got registered to a separate fusion key;
each key resulted in a different compilation for the same
specializations.
This PR makes it so that when registering FusionGroups with the fusion
compiler, the compiler first checks the KernelSpec cache to see if the
FusionGroup's graph exists already. If it does, then return the
corresponding KernelSpec's key to share compiled kernels.
In addition, graphs in the KernelSpec cache are canonicalized before
being cached. I added a flag to the canonicalize pass to remove unique
names of values.
This shortens the compile time for a JIT LSTM (seq_len of 100, loop
unroll factor of 8) from 5.3s to 2.3s. Most of this compile time is
running the graph fuser and/or fusion compiler; while this PR
makes it so that there is only one unique kernel in the forward pass,
there are a lot of different kernels (6) in the backward pass
(after loop unrolling) that should be investigated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14541
Differential Revision: D13324487
Pulled By: zou3519
fbshipit-source-id: b841d82ed35a959b5cfc72db033bf5a7b42cc4fb
Summary:
We don't need THCNumerics here since at::Half can be implicitly converted to float and the cuda math dispatches are handled by `/usr/local/cuda/include/crt/math_functions.hpp` and `cmath`. ATen should be free of THCNumerics after this and when porting kernels from THC, one should not use THCNumerics.
Should close: https://github.com/pytorch/pytorch/issues/11878
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15085
Differential Revision: D13447558
Pulled By: soumith
fbshipit-source-id: 4ff5cbf838edcd01e2d1397e4d7f4f920e9e9fc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14950
Minimize the number of headers included from _avx2.cc files to avoid accidental compilation of functions defined the header files reused by other translation units that can lead to illegal instruction errors.
Reviewed By: dskhudia
Differential Revision: D13394483
fbshipit-source-id: 67149a6fb51f7f047e745bfe395cb6dd4ae7c1ae
Summary:
Now that PyTorch 1.0 is out, this should be updated :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15136
Differential Revision: D13447377
Pulled By: soumith
fbshipit-source-id: bd4e662c53d0699f25d4d90c1b4c1e182b4427c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15110
support casting to string on CPU
Reviewed By: intermilan
Differential Revision: D13429381
fbshipit-source-id: b737a1ba1237b10f692d5c42b42a544b94ba9fd1
Summary:
the speed-up of a single operation is up to 3X .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15106
Differential Revision: D13429596
Pulled By: bddppq
fbshipit-source-id: f8d987cafeac9bef9c3daf7e43ede8c6a4ee2ce5
Summary:
Certain tensor shapes failed when being resized. This pull request addresses the bug found in #13404.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14874
Differential Revision: D13429788
Pulled By: soumith
fbshipit-source-id: 8aa6451dbadce46d6d1c47a01cb26e6559bcfc8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15147
Forgot to take out dnnlowp.cc from avx2 list in a previous diff.
Reviewed By: dskhudia
Differential Revision: D13440686
fbshipit-source-id: 9ada98b6e885c7d5f22c91a735ff60304480b4cb
Summary:
* relax MIOpen if statement to allow fp16/fp32 mixed precision training now supported by ROCm 1.9.2
* use gemm_ex API of rocBLAS in ROCm 1.9.2 instead of the previous hgemm API
* with this: enable all but one half test in test_nn
While there, fix also:
* a group convolution issue w/ MIOpen pertaining to initializing MIOpen on multi-GPU systems properly we detected while working on this
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14994
Differential Revision: D13439869
Pulled By: bddppq
fbshipit-source-id: 75e4eb51a59488882e64b5eabdc30555b25be25e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15103
There are two main optimizations in this diff:
1. We generate all anchors for every single spatial grid first, and then apply
NMS to pick 2000 anchors according to RPN_PRE_NMS_TOP_N. By first sorting the
score and picking the 2000 top ones and then lazily generating only the
corresponding anchors is much faster.
2. Transposing bbox_deltas from (num_anchors * 4, H, W) to
(H, W, num_anchors * 4) was also quite slow - taking about 20ms in the RRPN
case when there are lots of anchors which it's negligible for RPN case (like
0.1 ms). Instead of transponsing, performing all operations in the
(num_anchors, H, W) format speeds things up.
For regular RPN scenario, this gives 5x speedup from 5.84ms to 1.18ms a case
with 35 anchors over a 600x600 image.
For rotated boxes with 245 anchors, the runtime down from 80ms to 27ms per
iter.
Reviewed By: newstzpz
Differential Revision: D13428688
fbshipit-source-id: 6006b332925e01a7c9433ded2ff5dc9e6d96f7d3
Summary:
This is an optimized implementation that does the following:
1. created an empty Tensor of correct size.
2. fill the Tensor with correct values.
The following three designs to fill in the Tensor result in roughly the same performance. Hence, the 2nd option is taken for simpler code, and to return contiguous tensors.
1. Sequential: fill row coordinates first, then columns. This results in two for-loop and more arithmetic operations.
2. Interleaved: fill in index coordinates one by one, which jumps between the two output Tensor rows in every iteration.
3. Transpose: create a n X 2 Tensor, fill the Tensor sequentially, and then transpose it.
<img width="352" alt="screen shot 2018-12-10 at 3 54 39 pm" src="https://user-images.githubusercontent.com/16999635/49769172-07bd3580-fc94-11e8-8164-41839185e9f9.png">
NOTE:
This implementation returns a 2D tensor, instead of a tuple of two tensors. It means that users will not be able to do the following:
```python
x = torch.ones(3, 3)
i = torch.tril_indices(3, 3)
x[i] # need to first convert the 2D tensor into a tuple of two 1D tensors.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14904
Reviewed By: zou3519
Differential Revision: D13433027
Pulled By: mrshenli
fbshipit-source-id: 41c876aafcf584832d7069f7c5929ffb59e0ae6a
Summary:
Documents what is supported in the script standard library.
* Adds `my_script_module._get_method('forward').schema()` method to get function schema from a `ScriptModule`
* Removes `torch.nn.functional` from the list of builtins. The only functions not supported are `nn.functional.fold` and `nn.functional.unfold`, but those currently just dispatch to their corresponding aten ops, so from a user's perspective it looks like they work.
* Allow printing of `IValue::Device` by getting its string representation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14912
Differential Revision: D13385928
Pulled By: driazati
fbshipit-source-id: e391691b2f87dba6e13be05d4aa3ed2f004e31da
Summary:
Fixes#15119. Before this PR, we were propagating constants through
aten::warn AND running it as a part of shape analysis.
This caused aten::warn to be run regardless of if it is
supposed to be run dynamically. This PR adds an exclusion for aten::warn
in constant propagation and shape analysis, similar to that of prim::RaiseException.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15124
Differential Revision: D13432815
Pulled By: zou3519
fbshipit-source-id: 15ab533ce2accb2da3fd4e569070c7979ce61708
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14248
This diff also introduces a horrifying hack to override CUDA's DeviceGuardImpl
with a HIPGuardImplMasqueradingAsCUDA, to accommodate PyTorch's current
behavior of pretending CUDA is HIP when you build with ROCm enabled.
Reviewed By: bddppq
Differential Revision: D13145293
fbshipit-source-id: ee0e207b6fd132f0d435512957424a002d588f02
Summary:
…r_list_unwrap.
These functions use unsafeGetTensorImpl(), which doesn't work with Variables (in a silent way that may blow up later).
So let's do early checking.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15105
Reviewed By: ezyang
Differential Revision: D13429149
Pulled By: gchanan
fbshipit-source-id: b85f6f5b7cdb9a6dd0c40205b924c840a3920ba0
Summary:
Fixes#15038.
aten::_cast_Float(tensor, non_blocking) support was added in #14336.
Its second argument is a bool, but because we don't support generating values
of type bool in the fuser codegen, the codegen errored out.
aten::_cast_Float in the fuser never actually uses its non_blocking
argument, so another way to fix this would be to have a special op for a
fused cast but I thought that we might have fusible ops that do take
bool arguments in the future so this would be good to have.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15057
Differential Revision: D13432091
Pulled By: zou3519
fbshipit-source-id: 455fe574f5f080aca9a112e346b841a2534a8dc3
Summary:
While moving these scenarios into `_test_dim_ops` I accidentally left an empty loop in the actual tests, causing them to do nothing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15077
Differential Revision: D13428759
Pulled By: umanwizard
fbshipit-source-id: 08f53068981d9192c1408878b168e9053f4dc92e
Summary:
When I do this setup in a local Docker development environment,
I get the following error:
x86_64-linux-gnu-gcc: error trying to exec 'cc1plus': execvp: No such file or directory
Somehow, gcc seems to get confused when it gets run from the wrong
directory. Best not to do it.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15078
Differential Revision: D13432143
Pulled By: ezyang
fbshipit-source-id: b18e15f493503a4c8205c85f92a214e49762a7bc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14631
adding a empty name scope to allow people jump out from current namescope.
This could be useful when you want to access blob from parent or sibling scope.
Facebook:
e.g: we encoutered a potential usecase in D13124249 (it's a large diff, please search by EmptyNameScope in that diff), we need to access to a blob declared in root namescope from a device namescope (device namescope has been used by parallel_GPU API). `EmptyNameScope` can help us do that with ease.
I referenced to `EmptyDeviceScope` D6103412 while implementing this one.
Reviewed By: yinghai
Differential Revision: D13272240
fbshipit-source-id: d4cde5abcc2336e456b6c6ef086266ef94d86da8
Summary:
Fixes a bug where (de-)/serializing a hierarchy of submodules where one submodule doesn't have any parameters, but its submodules do, doesn't get properly loaded. This had to do with the fact that the old protobuf format couldn't store empty parameters.
Fixes https://github.com/pytorch/pytorch/issues/14891
soumith ezyang ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15033
Differential Revision: D13411322
Pulled By: goldsborough
fbshipit-source-id: 2ef73b2aa93fa9e46b1cbe1fd47d9f134d6016d5
Summary:
…on first and all the values in the next line. This way, it can output arbitrary blob
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15108
Reviewed By: llyfacebook
Differential Revision: D13429346
Pulled By: sf-wind
fbshipit-source-id: 5e0bba2a46fbe8d997dfc3d55a698484552e3af8
Summary:
Provide a pre-commit hook that does flake8 and clang tidy checks. Enables the clang-tidy script to run in parallel to make it fast enough to be used in a pre-commit hook.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15102
Reviewed By: soumith
Differential Revision: D13429629
Pulled By: zdevito
fbshipit-source-id: bd52fe5652f29b033de8d9926d78350b2da4c2fc
Summary:
…_tensor.
This is part of a long series of paring down the Type interface.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15074
Differential Revision: D13421482
Pulled By: gchanan
fbshipit-source-id: 84010ee71fef2cb74d32d5de7858d8ed9f36b885
Summary:
```
This diff changes the HIPification of ATen to be out-of-place.
We now have the following mappings:
- ATen/cuda => ATen/hip
- ATen/native/cuda => ATen/native/hip
- ATen/native/sparse/cuda => ATen/native/sparse/hip
- THC => THH
- THCUNN => THHUNN
The build system is adjusted to know about these new build paths,
and HIPify is taught how to adjust include paths and
THC_GENERIC_FILE appropriately. ATen_hip is now built as
the ATen_hip library, rather than reusing ATen_cuda.
However, despite these new filepaths, none of the identifiers in ATen
have actually changed. So, e.g., THHGeneral.h still defines functions
named THC_blahblah, and HIP still shows up as CUDA in PyTorch itself.
We'll tackle this in a subsequent PR; this diff is just to get the files
out-of-place.
Minor extra improvements:
- Don't edit tmp_install when hipifying
- HIP no longer builds native_cudnn_cpp; it was unnecessary
- Caffe2_HIP_INCLUDES is now Caffe2_HIP_INCLUDE, for consistency
with all the other variables.
- HIP build now properly respects ATEN_CUDA_FILES_GEN_LIB (it
did not previously.)
- You can now override file extension matching in pyHIPIFY
by explicitly specifying its full name in the matching list.
This is used so we can HIPify CMakeLists.txt in some situations.
A little bit of string and ceiling wax:
- gen.py grows a --rocm flag so that it knows to generate CUDA
files which actually refer to the HIP headers (e.g., THH.h)
We'll get rid of this eventually and generate real HIP files,
but not for this PR.
- Management of HIP dependencies is now completely deleted
from the ATen CMakeLists.txt. The old code was dead (because
it was shoveled in ATen_CUDA_DEPENDENCY_LIBS and promptly
ignored by the Caffe2 build system) and didn't actually work.
```
Stacked on https://github.com/pytorch/pytorch/pull/14849 review last commit only
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14866
Differential Revision: D13419475
Pulled By: ezyang
fbshipit-source-id: cb4c843df69a1d8369314c9fab1b7719520fa3db
Summary:
Removing the deprecated functions in `torch/csrc/variable_tensor_functions.h` (like `torch::CPU`) and corresponding implementations from `torch/csrc/torch.cpp` from master after the release.
ezyang gchanan soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15003
Differential Revision: D13418086
Pulled By: goldsborough
fbshipit-source-id: a0accdf6f7b0efa1ec07ac7b74b86ff2da37543f
Summary:
…done once
This allow no-op build to work correctly even when BUILD_CAFFE2_OPS is on.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14982
Differential Revision: D13413960
Pulled By: zdevito
fbshipit-source-id: 6e5412a8c375af8a47c76f548cdd31cff15f3853
Summary:
This PR creates TestFuser inside test_jit.py to be a home for graph fuser
specific tests.
This was a useful exercise because now that all the fuser tests are in
one place, I can spot redundant and bitrotting tests for cleanup in a
future PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15072
Differential Revision: D13421458
Pulled By: zou3519
fbshipit-source-id: 80b1a7712feff75a0c186d1664601c4edbbca694
Summary: Removes all warnings spew for the TestJitGenerated tests
Differential Revision: D13420919
fbshipit-source-id: f251c12f923088ccc5daa2984c15003a67cbd1c1
Summary:
The coverage of scalar-input test cases were not accurate. This patch fixed that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15029
Differential Revision: D13419764
Pulled By: zrphercule
fbshipit-source-id: a14a5cbef432bea8c9126156f5deb1125e1aeb47
Summary:
We were only using this file to configure flake8, and fbcode linters do not recognize tox.ini which causes spurious linter warnings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15065
Differential Revision: D13420774
Pulled By: suo
fbshipit-source-id: e43a46befa36862c8b3c0a90074aec6a66531492
Summary:
Previously we were returning true if either IValue wasn't a tensor, which…is bad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15031
Differential Revision: D13409759
Pulled By: suo
fbshipit-source-id: f8bdcd05d334c1276ce46f55812065d358c1ff5d
Summary:
Currently in caffe2, one cannot properly fetch the content of Int8 blobs.
Upon digging the source code, it turns out that the relevant source code is not being compiled. Adding the source to CMakeLists.txt fixes this issue.
First time ever doing a pull request. Please let me know if there's any rule I should follow. Thanks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15047
Differential Revision: D13417583
Pulled By: bddppq
fbshipit-source-id: dd39575971a3012635edbf97a045d80e4b62a8eb
Summary:
This is broken out of https://github.com/pytorch/pytorch/pull/13733/
We want to install cpp tests so they can ultimately be runnable from that location for Caffe2 tests run from PyTorch builds.
cc pjh5 yf225 anderspapitto
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15000
Reviewed By: pjh5
Differential Revision: D13416253
Pulled By: orionr
fbshipit-source-id: 51280be0a22557a742f90c9f303c58c35cbd4a38
Summary:
This removes FloatToInt style names replacing it with just the destination
name (e.g. FloatToInt -> Float). This makes it more consistent with the
syntax and makes it easier to add type conversions (just add a new
prim::Int op, for instance).
None of these ops get serialized so this should not effect loading of
old models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14947
Differential Revision: D13408409
Pulled By: zdevito
fbshipit-source-id: d773fe863f14d9de893f686832769f8cc8903a8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/15041
Adding an alternative implementation of a task graph based on TBB
Reviewed By: dmudiger
Differential Revision: D13412517
fbshipit-source-id: f5efedd680bbe0072bf38d504e5682ab51dd630f
Summary:
1) at::functions are now also exposed in the at::legacy::th namespace and we move relevant calls over to use them (to avoid merge conflicts)
2) LegacyTHDispatch now handles device-type initialization
3) We generate derived LegacyTHDispatchers, e.g. THLegacyCPULongDispatcher, although they are currently empty.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14852
Reviewed By: ezyang
Differential Revision: D13360852
Pulled By: gchanan
fbshipit-source-id: af6705aeba3593ea5dba9bfc62890e5257bc81f8
Summary:
This PR aligns the Array struct such that cuda vector performance improvements can be utilized.
I tested this by using it on our Philox header. Note how the vector store instruction gets used for cuda vector types and when using alignas on Array, vs when not using alignas on Array.
With cuda vector type (uint4, uint2, float4): https://godbolt.org/z/UaWOmR
With alignas: https://godbolt.org/z/Eeh0t5
Without alignas: https://godbolt.org/z/QT63gq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14920
Differential Revision: D13406751
Pulled By: soumith
fbshipit-source-id: 685b1010ef1f576dde30c278b1e9b642f87c843d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14197
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13642
Previously we pass in a patially initialized Tensor to Deserialize and it will fill
it with the result of deserialization of a tensor proto. Now we want it to return
a Tensor directly since it's just a shared pointer to TensorImpl.
Reviewed By: dzhulgakov
Differential Revision: D12874357
fbshipit-source-id: 12b80a763375da23cfa64a74d6bc186d8d03b94f
Summary:
This can be use to initialize state that is not necessarily eligible for serialization/is implementation-specific. Concretely, I'm going to use this to pack the weight matrices for quantized Linear modules according to the FBGEMM APIs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14655
Differential Revision: D13404438
Pulled By: jamesr66a
fbshipit-source-id: 2d327cef5520fdd716b5b1b29effd60a049e8a4a
Summary:
We've virtualized the destructor for storage, so we
no longer have to forward to a particular backend.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14897
Differential Revision: D13399216
Pulled By: ezyang
fbshipit-source-id: 531d29c3f278477cfa8759f30ab4f304d695b659
Summary:
cc iotamudelta
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14993
Differential Revision: D13405804
Pulled By: ezyang
fbshipit-source-id: c4aa9ed29ee2a4f3abf76c1e0fa8babfd738db35
Summary:
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
cc iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14999
Differential Revision: D13405754
Pulled By: ezyang
fbshipit-source-id: 98459496494390ad1115b4f1f6738d53c14f0745
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14911
In optimized modes the compiler tries to inline all the
`unordered_map::operator[]` calls, creating a massive amount of code
which takes several minutes to optimize. Instead, create a table of
PODs and populate the maps using a simple loop.
Reviewed By: soumith, luciang
Differential Revision: D13382948
fbshipit-source-id: b6752921e0f7213595d26b39e4397f6a3897960b
Summary:
When rewriting `default_collate`, I noticed that `from_numpy` and `as_tensor` and `tensor` all do not work on `np.int8` arrays.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14700
Reviewed By: weiyangfb
Differential Revision: D13305297
Pulled By: soumith
fbshipit-source-id: 2937110f65ed714ee830d50098db292238e9b2a9
Summary:
The other direction of #14700
cc soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14710
Reviewed By: weiyangfb
Differential Revision: D13306052
Pulled By: soumith
fbshipit-source-id: 202d038f139cf05e01069ff8d05268c66354c983
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14881
This diff allows us to pre-quantize and pre-pack weight matrix used in DNNLOWP_ACC16 .
The intended use pattern is run Int8ConvPackWeight in init_net that generates a packed weight and Int8Conv with DNNLOWP_ACC16 engine uses the the packed weight.
Reviewed By: csummersea
Differential Revision: D13374662
fbshipit-source-id: dd02b9a4eb7af1fe208aa857fcd0b445e6e395af
Summary:
1. Changes the prints along the 'rebuild' pathway to respect the '-q' flag of setup.py
A clean rebuild now only prints:
[zdevito@devgpu172.prn2 /data/users/zdevito/pytorch] python setup.py -q rebuild develop
[0/1] Install the project...
-- Install configuration: "RelWithDebInfo"
ninja: no work to do.
ninja: no work to do.
ninja: no work to do.
ninja: no work to do.
ninja: no work to do.
ninja: no work to do.
2. Deletes apparently dead calls to `generate_code`. Now that CMake builds these files,
it appears that it is getting called twice and the second version is never used.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14972
Reviewed By: soumith
Differential Revision: D13396330
Pulled By: zdevito
fbshipit-source-id: 83c45143bbc6a6d2c1cfee929291ec059f2b5dc3
Summary: we now get mkldnn automatically from third_party/ideep
Differential Revision: D13396480
Pulled By: soumith
fbshipit-source-id: 20f819ba4b78cbe9c7d0baeab1c575669cbf6c20
Summary:
This fixes rebuild issues with the ninja part of the build. With this patch all ninja files will now report `nothing to do` if nothing has changed assuming `BUILD_CAFFE2_OPS=0`.
1. This only does the python file processing for caffe2 when BUILD_CAFFE2_OPS=1, this part of the build file is written in such a way that it is always required to rerun and can take substantial time to move files around in the no-op build. In the future this part should be rewritten to use a faster method of copying the files or should treat copying the files as part of the build rules and only run when the files are out of date.
2. This points `sleef` to a patched version that fixes a dead build output that is causing everything to relink all the time. See https://github.com/shibatch/sleef/pull/231#partial-pull-merging for the upstream change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14969
Reviewed By: soumith
Differential Revision: D13395998
Pulled By: zdevito
fbshipit-source-id: ca85b7be9e99c5c578103c144ef0f2c3b927e724
Summary:
fix auto grad summing for IfOp where intermediate output needs renaming.
Bug before this diff:
- we only renames the output of IfOp without changing the subnet ops output
- this results in blob not found error
the unittest provides an example
this diff fix that for IfOp
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14772
Differential Revision: D13327090
Pulled By: harouwu
fbshipit-source-id: ec40ee88526ace3619c54551e223dd71158a02f8
Summary:
This PR does the following:
1) Updates the ONNX export for `torch.zeros_like` and `torch.full_like` ops to use ONNX op `ConstantLike`. This reduces the export of experimental op `ConstantFill`, which may possibly be removed in future, see https://github.com/onnx/onnx/pull/1434).
2) It also adds export support for `torch.ones_like`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14903
Differential Revision: D13383700
Pulled By: houseroad
fbshipit-source-id: 566d00a943e9497172fcd5a034b638a650ab13a2
Summary:
Anywhere we used #include "foo.h", we now say #include <foo.h>
Paths are adjusted to be rooted out of aten/src, torch/lib, or
the root level directory.
I modified CMakeLists.txt by hand to remove TH and THC from
the include paths.
I used the following script to do the canonicalization:
```
import subprocess
import re
import os.path
files = subprocess.check_output(['git', 'ls-files']).decode('utf-8').rstrip().split('\n')
for fn in files:
if not any(fn.endswith(suff) for suff in ['.cu', '.cpp', '.in', '.h', '.hpp', '.cu', '.cuh', '.cc']):
continue
if not any(fn.startswith(pref) for pref in ["aten/", "torch/"]):
continue
with open(fn, 'r') as f:
c = f.read()
def fmt(p):
return "#include <{}>".format(p)
def repl(m):
p = m.group(1)
if p in ["dlfcn.h", "unistd.h", "nvrtc.h", "cuda.h", "cuda_runtime.h", "cstdint", "cudnn.h", "Python.h", "cusparse.h", "cuda_runtime_api.h", "cuda_fp16.h", "cublas_v2.h", "stdint.h", "curand_kernel.h"]:
return fmt(p)
if any(p.startswith(pref) for pref in ["torch/csrc", "c10/", "ATen/", "caffe2/", "TH/", "THC/", "Eigen/", "gtest/", "zdl/", "gloo/", "onnx/", "miopen/"]):
return fmt(p)
for root in ["aten/src", "torch/lib", ""]:
for bad_root in [os.path.dirname(fn), "aten/src/TH", "aten/src/THC", "torch/csrc"]:
new_p = os.path.relpath(os.path.join(bad_root, p), root)
if not new_p.startswith("../") and (os.path.exists(os.path.join(root, new_p)) or os.path.exists(os.path.join(root, new_p + ".in"))):
return fmt(new_p)
print("ERROR: ", fn, p)
return m.group(0)
new_c = re.sub(r'#include "([^"]+)"', repl, c)
if new_c != c:
print(fn)
with open(fn, 'w') as f:
f.write(new_c)
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14849
Reviewed By: dzhulgakov
Differential Revision: D13363445
Pulled By: ezyang
fbshipit-source-id: 52361f878a672785f9306c9e9ab2513128092b68
Summary:
50x-100x speedup compared to current version.
Also, fixes a bug in the current version when batch size exceeds 1 (current version processes only the first image in this case).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14883
Differential Revision: D13390655
Pulled By: Maratyszcza
fbshipit-source-id: 1b33a97bf2d0866d38faa2b42e64fd2859017898
Summary:
Tested on a tensor with 1 billion elements and 3 dimensions on a powerful, highly
multi-core Linux machine.
parallelized: All operations (e.g., `t.std(1)`) that could be done in the old code are now several times faster. All
new operations (e.g., `t.std((0,2))` are significantly faster than the NumPy equivalents.
`t.std((0, 1, 2))`, a new operation, is logically equivalent to the
old `t.std()`, but faster.
serial: The above comment about old operationos now being faster still
holds, but `t.std((t1, ..., tn))` is now a few
times slower than `t.std()`. If this turns out to be important, we can
special-case that to use the old algorithm.
The approach is to create a new method, `TensorIterator::foreach_reduced_elt`,
valid for `TensorIterator`s that represent a dimension reduction. This
method calls a supplied function for each element in the output,
supplying it with the input elements that correspond to that output.
Given that primitive, we can implement reductions like the following pseudocode:
If there is more than one output element:
```
PARALLEL FOR EACH element IN output:
accumulator = identity
SERIAL FOR EACH data_point IN element.corresponding_input:
accumulator.update(data_point)
element = accumulator.to_output()
```
If there is only one output element, we still want to parallelize, so we
do so along the *input* instead:
```
accumulators[n_threads]
PARALLEL FOR EACH input_chunk IN input.chunks():
accumulators[thread_num()] = identity
SERIAL FOR EACH data_point IN input_chunk:
accumulators[thread_num()].update_with_data(data_point)
accumulator = identity
SERIAL FOR EACH acc in accumulators:
accumulator.update_with_other_accumulator(acc)
output_element = accumulator.to_output()
```
Note that accumulators and data points do not have to be the same type
in general, since it might be necessary to track arbitrary amounts of
data at intermediate stages.
For example, for `std`, we use a parallel version of Welford's
algorithm, which requies us to track the mean, second moment, and number
of elements, so the accumulator type for `std` contains three pieces of
data.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14535
Differential Revision: D13283887
Pulled By: umanwizard
fbshipit-source-id: 8586b7bf00bf9f663c55d6f8323301e257f5ec3f
Summary:
* Enable unit tests known to work on ROCm.
* Disable a few that are known to be flaky for the time being.
* Use std::abs for Half
* No more special casing for ROCm in TensorMathReduce
* Document an important detail for a hardcoded block size w.r.t. ROCm in TensorMathReduce
ezyang bddppq for awareness
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14011
Differential Revision: D13387679
Pulled By: bddppq
fbshipit-source-id: 4177f2a57b09d866ccbb82a24318f273e3292f71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14658
Remove this dependency by moving at::CopyBytes to c10.
The implementations for at::CopyBytes will have to live in aten/caffe2 for now because they're not unified for CUDA yet.
They'll be moved into c10/backend/xxx later.
Reviewed By: dzhulgakov
Differential Revision: D13288655
fbshipit-source-id: 1c92379345308b3cd39a402779d7b7999613fc0d
Summary:
Tracing records variable names and we have new types and stuff in the IR, so this updates the graph printouts in the docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14914
Differential Revision: D13385101
Pulled By: jamesr66a
fbshipit-source-id: 6477e4861f1ac916329853763c83ea157be77f23
Summary:
Added a few examples and explains to how publish/load models.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14862
Differential Revision: D13384790
Pulled By: ailzhang
fbshipit-source-id: 008166e84e59dcb62c0be38a87982579524fb20e
Summary:
This will let us install tests and other Caffe2 python code as a part of running Caffe2 tests in PyTorch.
Broken out of https://github.com/pytorch/pytorch/pull/13733/
cc pjh5 yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14898
Reviewed By: pjh5
Differential Revision: D13381123
Pulled By: orionr
fbshipit-source-id: 0ec96629b0570f6cc2abb1d1d6fce084e7464dbe
Summary:
_th_tensor is moving off Type, so these calls need to be replaced.
Unfortunately, replacing these with a full-fledged solution [e.g. from_storage(..., TensorOptions)] is a bit complicated because the storage itself fully defines the Type (modulo variable). It's simpler to just wait for the Variable/Tensor merge rather than to solve this now, so instead I changed the call sites to: at::empty({0}, type.options()).set_(storage...).
This isn't great because we are also trying to get rid of Type::options, but this seems to be the lesser-of-two-evils.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14877
Differential Revision: D13374310
Pulled By: gchanan
fbshipit-source-id: eb953ed041507e6190d6f32e383912e5a08311cd
Summary:
Fixes#14099
I attempted to be as consistent as possible with the formatting, hence why my equation reads d*(k - 1) instead of (k - 1)*d.
Also there is an unused variable on line 46: `n = self.in_channels`. I could fix that here too if that's not too out of scope.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14876
Differential Revision: D13374317
Pulled By: soumith
fbshipit-source-id: a9f110acafa58cdb4206956dbe3ab4738d48292d
Summary:
- allow gradcheck to take sparse tensor as input
- sparse output is not allowed yet at gradcheck
- add backward for `to_dense()` to get around sparse output
- calling gradcheck at test_sparse, so that we can use `_gen_sparse()` and also easily cover coalesced / uncoalesced test cases
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14596
Differential Revision: D13271904
Pulled By: weiyangfb
fbshipit-source-id: 5317484104404fd38058884c86e987546011dd86
Summary:
Otherwise, these tests will fail, even though there are never meant to run on single GPU machines.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14860
Differential Revision: D13369060
Pulled By: teng-li
fbshipit-source-id: 8a637a6d57335491ba8602cd09927700b2bbf8a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14838
The GPU memory tracking logs are incredibly annoying and merely serve
to pollute output. I `VLOG(1)`ed them. Hopefully, this is non-controversial.
Reviewed By: kuttas
Differential Revision: D13343290
fbshipit-source-id: b3cae99346c97b66e97ea660061e15dc5c99b9fc
Summary:
Latest hcc can now properly cast to correct type internally, so there is no need to insert static_cast in hipify scripts anymore.
However the hcc included in the latest ROCm release (1.9.2) doesn't have this fix, so leaving a flag to continue doing static_cast for those using the official ROCm releases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14853
Differential Revision: D13363171
Pulled By: bddppq
fbshipit-source-id: a36476a8511222ff3c933d31788e8a0ffb04f5ca
Summary:
Drop custom hcc/hip as the 1.9.2 release should contain the relevant patches therein.
Most notable feature in 1.9.2 is mixed precision support in rocBLAS and MIOpen. These features will be enabled by subsequent PRs.
bddppq ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14216
Differential Revision: D13354294
Pulled By: bddppq
fbshipit-source-id: 2541d4a196af21c9432c1aff7f6e65b572628028
Summary:
`torch.linspace(0, 1, 1)` fails with `RuntimeError: invalid argument 3: invalid number of points at ../aten/src/TH/generic/THTensorMoreMath.cpp:2119`, while `np.linspace(0, 1, 1)` works fine.
Looking at the code, there is even a comment by gchanan asking: "NumPy allows you to pass different points even if n <= 1 -- should we?"
I would say "yes". Currently, I would need to handle the case of `steps == 1` or `steps == 0` separately, making sure to change the `end` when calling `torch.linspace`. This is impractical. If we support `start != end`, there are two possibilities for the result: Either we ensure the first value in the resulting sequence always equals `start`, or we ensure the last value in the resulting sequence always equals `end`. Numpy chose the former, which also allows it to support a boolean `endpoint` flag. I'd say we should follow numpy.
This PR adapts `linspace` and `logspace` to mimic the behavior of numpy, adapts the tests accordingly, and extends the docstrings to make clear what happens when passing `steps=1`.
If you decide against this PR, the error message should become explicit about what I did wrong, and the documentation should be extended to mention this restriction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14748
Differential Revision: D13356136
Pulled By: ezyang
fbshipit-source-id: db85b8f0a98a5e24b3acd766132ab71c91794a82
Summary:
Removes cast of half to float in torch.sum, with float16 input tensor and
float32 output tensor, instead we cast data when loading input in kernel.
This supposingly would save a kernel launch as well as a full global memory load
on promoted data type (float).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14580
Differential Revision: D13356203
Pulled By: ezyang
fbshipit-source-id: 85e91225b880a65fe3ceb493371b9b36407fdf48
Summary:
Not ready yet, need some comments / help with this. It's good enough for https://github.com/pytorch/xla immediate goals (forward + backward trace fusion), but there are at least two issues with it:
1. If we don't allow it, `test/test_jit.py` fails to cover the change.
2. If we allow the weight to be set, running `test/test_jit.py TestJitGenerated.test_nn_nll_loss` fails with:
```
======================================================================
ERROR: test_nn_nll_loss (__main__.TestJitGenerated)
----------------------------------------------------------------------
Traceback (most recent call last):
File "test/test_jit.py", line 10001, in do_test
fn, f_args_variable, kwargs_variable, no_grad=no_grad)
File "test/test_jit.py", line 9360, in check_against_reference
outputs_test = self.runAndSaveRNG(func, recording_inputs, kwargs)
File "test/test_jit.py", line 425, in runAndSaveRNG
results = func(*inputs, **kwargs)
File "test/test_jit.py", line 9298, in script_fn
self.assertExportImport(CU.the_method.graph, tensors)
File "test/test_jit.py", line 415, in assertExportImport
self.assertExportImportModule(m, inputs)
File "test/test_jit.py", line 419, in assertExportImportModule
self.assertEqual(self.runAndSaveRNG(m.forward, inputs),
File "test/test_jit.py", line 425, in runAndSaveRNG
results = func(*inputs, **kwargs)
RuntimeError:
arguments for call are not valid:
for operator aten::nll_loss_backward(Tensor grad_output, Tensor self, Tensor target, Tensor? weight, int reduction, int ignore_index, Tensor total_weight, *, Tensor out) -> Tensor:
expected a value of type Tensor for argument 'total_weight' but found bool
<internally-created-node>
~ <--- HERE
for operator aten::nll_loss_backward(Tensor grad_output, Tensor self, Tensor target, Tensor? weight, int reduction, int ignore_index, Tensor total_weight) -> Tensor:
expected a value of type Tensor for argument 'total_weight' but found bool
<internally-created-node>
~ <--- HERE
for call at:
<internally-created-node>
~ <--- HERE
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14305
Differential Revision: D13356265
Pulled By: ezyang
fbshipit-source-id: 504d783b2d87f923e698a6a4efc0fd9935a94a41
Summary:
This pull request contains changes for:
1. Added MIOpen RNN API miopenGetRNNLayerBiasSize and miopenGetRNNLayerParamSize.
2. Fixed usage of API miopenGetRNNLayerParam.
3. Modifying the RNN test to run using MIOpen engine.
Differential Revision: D13355699
Pulled By: bddppq
fbshipit-source-id: 6f750657f8049c5446eca893880b397804120b69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14827
We need to send complete IO info when doing `onnxGetBackendCompatibility` to backend like Glow. Previously we are missing some info because sometimes we generate more than one nodes from one C2 op. This fixes the issue.
Reviewed By: jackm321
Differential Revision: D13352049
fbshipit-source-id: 8d8ac70656a0ac42f3a0ccecad61456a4f3b2435
Summary:
Currently, pytorch doesn't dependent on protobuf. So, we don't need to include the protobuf dir in pytorch cmake file.
And if we build caffe2 without custom-protobuf[1], we will have the protobuf mismatched problem.
[1]
92dbd0219f/CMakeLists.txt (L65)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14182
Differential Revision: D13356273
Pulled By: ezyang
fbshipit-source-id: 8120c3452d158dc51d70156433d7b9076c6aed47
Summary:
Fix CMakeLists.txt, so the test for CPU won't run profile_observer_test.cc, as currently it only supports GPU
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14168
Differential Revision: D13356274
Pulled By: ezyang
fbshipit-source-id: 7d105f2e18675e5fab129864958148b0f18d582c
Summary:
I know that including CAFFE2_INCLUDE_DIRS in include headers are not necessary for newer cmakes. But I had this in one of my old projects and **cmake gave me error that "/usr/lib/include" is invalid path**.
It seems like "${_INSTALL_PREFIX}/lib/include" should be changed to "${_INSTALL_PREFIX}/include" as all caffe2 headers are in /include rather than /lib/include/
Please correct me if I am wrong?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14306
Differential Revision: D13356246
Pulled By: ezyang
fbshipit-source-id: e2d5d3c42352e59b245714ad90fd7a9ef48170d7
Summary:
on Windows environment, some ATen core files (Type.h, Tensor.h, TensorMethods.h) are created and it's new line code is CRLF. (maybe enviconment dependant)
therefore, comparing files is failed in generate_outputs()agener917.py and compilation stopped.
this patch generates these files with LF forcibly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14667
Differential Revision: D13356170
Pulled By: ezyang
fbshipit-source-id: ef8cc3a6cc8bf3c45b78e9eb3df98cf47c0d33bb
Summary:
pytorch_theme.css is no longer necessary for the cpp or html docs site build. The new theme styles are located at https://github.com/pytorch/pytorch_sphinx_theme. The Lato font is also no longer used in the new theme.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14779
Differential Revision: D13356125
Pulled By: ezyang
fbshipit-source-id: c7635eb7512c7dcaddb9cad596ab3dbc96480144
Summary:
Implement some simple fixes to clean up windows build by fixing compiler warnings. Three main types of warnings were fixes:
1. GCC specific pragmas were changed to not be used on windows.
2. cmake flags that don't exist on windows were removed from windows build
3. Fix a macro that was defined multiple times on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14490
Differential Revision: D13241988
Pulled By: ezyang
fbshipit-source-id: 38da8354f0e3a3b9c97e33309cdda9fd23c08247
Summary:
See #14554.
I can't figure out how the reported issue can happen. The best next
thing is have more information when this happens again.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14813
Differential Revision: D13351908
Pulled By: pietern
fbshipit-source-id: 61b30fcae2e34da54329d0893ca4921b6ad60f0d
Summary:
It is possible that some sort of contention causes process scheduling
delays which in turn cause the timeout to *not* be hit.
Increased sleep here will decrease the probability of this happening.
Fixes#14555.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14814
Differential Revision: D13351924
Pulled By: pietern
fbshipit-source-id: 1222cf0855408dfcb79f30f94694c790ee998cf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14802
The definetion of THPStorage does not depend on any Real, its macro
defintion is unnecessary, refactor the code so that THPStorage is not macro
defined.
Reviewed By: ezyang
Differential Revision: D13340445
fbshipit-source-id: 343393d0a36c868b9a06eea2ad9b80f5e395e947
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14725
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/33
Renaming FbgemmI8Depthwise.h to FbgemmI8DepthwiseAvx2.h and FbgemmI8Depthwise.cc to FbgemmI8DepthwiseAvx2.cc since FbgemmI8DepthwiseAvx2.cc will be compiled with avx2 flags
Reviewed By: jianyuh
Differential Revision: D13313898
fbshipit-source-id: a8111eacf3d79a466ce0565bfe5f2f0b200a5c33
Summary:
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/28
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14516
This is the first diff in a series of diffs that will separate out avx2 specific code in separate files. The goal is to compile as little as possible code with avx2 and avx512 compiler flags.
Reviewed By: jianyuh
Differential Revision: D13248376
fbshipit-source-id: 401c2e9d3cd96c420fd08c3efa011febce96ffbb
Summary:
```
Improve performance of pyHIPIFY
Changes:
- Pre-compile regexes, don't use regexes when it's not necessary
(this saves us ~15%)
- Compile all substitutions for mappings into a single, non-backtracking
regex using a Trie. This gives big savings.
Before, running pyHIPIFY on all files took 15.8s. Now it takes 3.9s.
```
Stacked on #14769
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14803
Differential Revision: D13342620
Pulled By: ezyang
fbshipit-source-id: 1cfa36b3236bbe24d07080a31cc788a52d740f40
Summary:
This PR fixes#11422
In the old world of CUDA IPC, when we want to share a tensor T from A to B, we have to share the whole CUDA mem allocation where T's storage sit in. And we casted it to the same type of storage of T's.
This causes problem when two different types of storage got allocated to the same CUDA mem block. When we try to reconstruct the second tensor, it will complain about wrong storage type.
In this PR we reconstruct the storage only (not the entire mem block). However, CUDA only allows one open memHandle once per process, we have to save the device pointer in a global cache so that we can reconstruct tensors as they come.
Thanks a ton to ezyang who helped design the solution and debugged the issue!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14736
Differential Revision: D13335899
Pulled By: ailzhang
fbshipit-source-id: cad69db392ed6f8fdc2b93a9dc2899f6d378c371
Summary:
Replaces the `DefaultTensorOptions` with just a global default dtype that you can set and get like in Python.
Also, calls `set_default_dtype` in the implementation of `torch.set_default_dtype`. Right now these two default values are separate but will always be the same. Should we just bind `set_default_dtype` into Python? I think that might be good to do in a separate PR though.
ezyang gchanan
Also CC colesbury who wanted to do this for ATen for a while? What do you think about it?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13748
Differential Revision: D13340207
Pulled By: goldsborough
fbshipit-source-id: 2689b09eb137fabb3a92d1ad1635782bee9398e8
Summary:
2.2-2.9X better performance on ARM when compiled with gcc (same bad perf when compiled with Clang)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14783
Differential Revision: D13332680
Pulled By: Maratyszcza
fbshipit-source-id: 4c1138500c6b3026335e9bfe5f6be43b1ae2cefb
Summary:
I need to preserve ability to HIPify out-of-place files
only, so build_amd.py grows a --out-of-place-only flag.
Stacked on #14757
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14769
Differential Revision: D13340154
Pulled By: ezyang
fbshipit-source-id: 1b855bc79e824ea94517a893236fd2c8ba4cb79d
Summary:
Fixes https://github.com/pytorch/pytorch/issues/14673
As pointed out by vishwakftw , the root case of the `deepcopy` issue was that `storage.clone()` would create a new storage in the default device.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14751
Reviewed By: soumith
Differential Revision: D13323061
Pulled By: fmassa
fbshipit-source-id: bfe46ebd78f0b6cd9518c11d09de7849282ed2a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14733
We often also want to use AVX512VL instruction sets.
We already included AVX512F, AVX512DQ.
Skylake also has AVX512BW, AVX512CD we may want to later.
Reviewed By: duc0
Differential Revision: D13317282
fbshipit-source-id: 82c8e401d82d5c3a5452fb4ccb6e5cb88d242bda
Summary:
Previously their implementation dispatched to prim::Print, which kept
printing the warnings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14770
Differential Revision: D13327629
Pulled By: suo
fbshipit-source-id: b9913f533d4530eb7c29146c39981ba7f72b6b68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14784
TSIA. To give more complete info to `onnxGetBackendCompatibility`.
Reviewed By: bertmaher, rdzhabarov
Differential Revision: D13331989
fbshipit-source-id: 1064b93f7f474788f736e6f0c893dae915c6fb99
Summary:
**Review only the last commit.**
This commit adds a few optimizations to AD, that let us dramatically
reduce the number of sizes we capture from forward.
We now:
- collapse chains of SumToSize
- avoid capturing sizes of tensors that are captured anyway
- more aggressively DCE the reverse code
- run CSE on the primal code to deduplicate `aten::size` calls
cc zou3519 zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14758
Differential Revision: D13324440
Pulled By: zou3519
fbshipit-source-id: 45ccbc13605adcef2b461840c6089d3200000c72
Summary:
When I wrote the frontend API, it is designed on not letting users use the default_group directly on any functions. It should really be private.
All collectives are supposed to either use group.WORLD, or anything that comes out of new_group. That was the initial design.
We need to make a TODO on removing group.WORLD one day. It exists for backward compatibility reasons and adds lots of complexity.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14767
Reviewed By: pietern
Differential Revision: D13330655
Pulled By: teng-li
fbshipit-source-id: ace107e1c3a9b3910a300b22815a9e8096fafb1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14278
In this commit, we make checkpoint_sequential work for models with multiple tensor inputs. Previously, it only processed the first tensor and ignored the rest.
We introduce a new test in test/test_utils.py that replicates the issue referenced in this [GitHub issue](https://github.com/pytorch/pytorch/issues/11093), and we make sure that the test passes by changing the behavior of checkpoint_sequential to process all input tensors.
Reviewed By: ezyang
Differential Revision: D13144672
fbshipit-source-id: 24f58233a65a0f5b80b89c8d8cbced6f814004f7
Summary:
This PR adds `None` buffers as parameters (similarly to #14715). It also cleans up a bunch of the `test_jit.py` tests that should be covered by `common_nn.py` and brings in `criterion_tests` to test loss functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14778
Differential Revision: D13330849
Pulled By: driazati
fbshipit-source-id: 924cc4cf94e0dcd11e811a55222fd2ebc42a9e76
Summary:
This PR:
1. add tests for batchnorm/dropout for train/eval parameter mutatino
2. remove training constants from all our standard library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14780
Differential Revision: D13331578
Pulled By: wanchaol
fbshipit-source-id: d92ca3ce38cc2888688d50fe015e3e22539a20a5
Summary:
The goal here is to have LegacyTHDispatch call into this as well, so LegacyTypeDispatch and LegacyTHDispatch don't have cross dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14723
Reviewed By: ezyang
Differential Revision: D13314017
Pulled By: gchanan
fbshipit-source-id: 8761cb4af2b2269d2e755203e073bfdba535b8c0
Summary:
Dealing with so many `aten::size` calls (in particular calls on elements computed inside fusion groups) requires us to do some extra graph processing in the fuser (to compute the sizes by explicit broadcasts, instead of writing the intermediate tensors only to check their size). This restores the forward expects of LSTM and MiLSTM to a single big kernel. Unfortunately the backward is much harder, because as long as we can't prove that the reductions are unnecessary (or if we can't distribute them over the op), we will not be able to fuse them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14558
Differential Revision: D13321748
Pulled By: zou3519
fbshipit-source-id: c04fc2f70d106d2bfb56206b5aec517a93b79d1f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14754
This isn't hooked up to anything yet, this is just putting the skeleton in place.
The idea here is that the functions generated via Declarations.cwrap and nn.yaml are not actually operators, they are implementation details of operators, and thus don't need to participate in VariableType, JIT dispatch generation.
So, we will split these functions out from the usual Type/operator hierarchy; for now the dispatch will be done by a Type-like class called LegacyTHDispatcher. Once this is done this probably means we can collapse Type to be backend-specific, not Type/ScalarType specific, because all the ScalarType specific code will live in the LegacyTHDispatcher.
Reviewed By: ezyang
Differential Revision: D13321605
fbshipit-source-id: 25d1bbc9827a42d6ab5d69aabbad3eac72bf364c
Summary:
Just to be safe, disable batch mm for mutable ops. We don't lose much for doing this, and we can go back at a calmer time to re-enable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14771
Reviewed By: eellison
Differential Revision: D13327641
Pulled By: suo
fbshipit-source-id: 96611e21ed3cb8492a2cd040f7d33fb58c52bd5e
Summary:
This would solve the tracing problems of #13969.
Fixes: #14732
I would appreciate if this got good scrutiny before applied.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14097
Differential Revision: D13323181
Pulled By: ezyang
fbshipit-source-id: dcd104b497c0bfddb751923c6166a3824b7a3702
Summary:
If both `Utils.hpp` and the `torch` namespace is included in the same file, the compiler won't know which fmap to use. I believe this is because of ADL. This change fixes that issue for me.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14042
Reviewed By: ezyang
Differential Revision: D13283810
Pulled By: ebetica
fbshipit-source-id: b68233336518230ba730e83ddac1226a66896533
Summary:
This PR add resnet to test_jit and convert more nn modules, stacked on #14533 and #14715
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14437
Differential Revision: D13325871
Pulled By: wanchaol
fbshipit-source-id: 6c94a988b36794a373af6541c0c262a07291f7b1
Summary:
Make `at::_local_scalar` more "official" by renaming it to `item()`.
gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13676
Differential Revision: D13003020
Pulled By: goldsborough
fbshipit-source-id: 0ac25f5237fb81a1576304a0a02f840ff44168a4
Summary:
This is towards unifying build_pytorch_amd.py and build_caffe2_amd.py
scripts. There is only one use of hipify_caffe2 left, which is just
to control which files actually get HIPified.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14757
Differential Revision: D13323486
Pulled By: ezyang
fbshipit-source-id: 958cd91be32dfc3c0a9ba9eda507adb5937aebcd
Summary:
Adding Loss modules to script. Some of the modules have an optional tensor parameter. I will wait until wanchao's diff to support optional tensors is landed before landing this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14720
Differential Revision: D13317990
Pulled By: eellison
fbshipit-source-id: 535925bdf126d28d9e7d64077b83ebd836a5beba
Summary:
Fixes#6622 .
We used to average over all elements for kl divergence, which is not aligned with its math definition.
This PR corrects the default reduction behavior of KL divergence that it now naverages over batch dimension.
- In KL, default behavior `reduction=mean` averages over batch dimension. While for most other loss functions, `reduction=mean` averages over all elements.
- We used to support scalar tensor as well. For BC purpose, we still support it, no reduction is performed on scalar tensor.
- Added a new reduction mode called `batchmean` which has the correct behavior for KL. Add a warning to make `batchmean` as default for KL instead of `mean` in next major release.
- [deprecated]I chose to not add a new reduction option, since "mean over batch dimension" is kinda special, and it only makes sense in few cases like KL. We don't want to explain why there's a option "batchmean" but it's not applicable for all other functions. I'm open to discussion on this one, as I cannot think of a perfect solution for this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14457
Differential Revision: D13236016
Pulled By: ailzhang
fbshipit-source-id: 905cc7b3bfc35a11d7cf098b1ebc382170a087a7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13756
This implements general Gather operator for arbitrary axis, sharing the code with BatchGather.
- CPU gather & batch gather logic is now shared through caffe2::gather_helper, for any axis.
- Shared CUDA kernel moved to gather_op.cuh, for any axis.
- Gradients of axis > 0 delegate to BatchGatherGradientOp which now has axis argument.
- BatchGatherOp doc strings updated to have correct rank (q + (r -1)) and output.
- Added tests for axis == 2.
GatherOp supports index wrapping for axis == 0 by default, which was earlier for ONNX.
This diff also extends it to work in Cuda kernel. Added "wrap_indices" argument which specifies
wheather this wrapping should be done; set it to true if you'd like wrapping for any axis.
TBD: Update gradients to support negative indices (separate diff).
TBD: Once we have operator versioning, we'd like to update GatherOp to NOT support axis 0 wrapping
by default, but rather do it only if wrap_indices is set.
Reviewed By: dzhulgakov
Differential Revision: D12983815
fbshipit-source-id: 8add9d67b47fe8c5ba7a335f581ca0530b205cd7
Summary:
As I am working on tasks in https://github.com/pytorch/pytorch/issues/13023, I realized how unreadable the code is because all functions to be run in multiprocessing must be at top global level. Adding more functionalities to `dataloader.py` will only make things worse.
So in this PR, I refactor `dataloader.py` and move much of it into `data._utils`. E.g., the `_worker_loop` and related methods are now in `data._utils.worker`, signal handling code in `data._utils.signal_handling`, collating code in `data._utils.collate`, etc. This split, IMHO, makes code much clearer. I will base my future changes to DataLoader on top of this.
No functionality is changed, except that I added `torch._six.queue`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14668
Reviewed By: soumith
Differential Revision: D13289919
Pulled By: ailzhang
fbshipit-source-id: d701bc7bb48f5dd7b163b5be941a9d27eb277a4c
Summary:
Fixes#14674. We won't have time for a proper fix before the release, so at least disable fusion of nodes that trigger incorrect behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14752
Differential Revision: D13320407
Pulled By: zou3519
fbshipit-source-id: 2400f7c2cd332b957c248e755fdb0dadee68da5d
Summary:
Fix#14610
I can repro the test failure following the steps provided, and this fixes the issue for me. Seems the timing of inserting has to happen after the downloading.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14742
Differential Revision: D13318533
Pulled By: ailzhang
fbshipit-source-id: b9207b4572d5a9443e516d9a84632e3d7b68e477
Summary:
This isn't hooked up to anything yet, this is just putting the skeleton in place.
The idea here is that the functions generated via Declarations.cwrap and nn.yaml are not actually operators, they are implementation details of operators, and thus don't need to participate in VariableType, JIT dispatch generation.
So, we will split these functions out from the usual Type/operator hierarchy; for now the dispatch will be done by a Type-like class called LegacyTHDispatcher. Once this is done this probably means we can collapse Type to be backend-specific, not Type/ScalarType specific, because all the ScalarType specific code will live in the LegacyTHDispatcher.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14708
Reviewed By: ezyang
Differential Revision: D13304654
Pulled By: gchanan
fbshipit-source-id: cfe3e1a28adcc355f67fe143495ee7e5c5118606
Summary:
simple change to allow `print(foo.code)` to give a pretty-printed description of all the methods on a module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14735
Differential Revision: D13317619
Pulled By: zdevito
fbshipit-source-id: dc7f7ba12ba070f2dfccf362995c2a9e0e573cb7
Summary:
Before this PR, tensor.clamp() would return an empty tensor if min and
max were not specified. This is a regression from 0.4.1, which would
throw an error. This PR restores that error message.
Fixes#14470
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14716
Differential Revision: D13311031
Pulled By: zou3519
fbshipit-source-id: 87894db582d5749eaccfc22ba06aac4e10983880
Summary:
This is a stack PR based on https://github.com/pytorch/pytorch/pull/14454.
It enables the restoring the storage to appropriate device.
~~[TODO]: add/modify appropriate tests~~ Done
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14711
Reviewed By: dzhulgakov
Differential Revision: D13315746
Pulled By: houseroad
fbshipit-source-id: fe6f24a45c35e88fd1a2eebc09950d4430fac185
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14728
Move IndexBlob,Index to header file so it can reused.
Differential Revision: D13315898
fbshipit-source-id: 34432c9b8fa08af3d3387f32a940d35b02a59760
Summary:
Only compare the device index if device has it.
Test the tensor restore with some computation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14734
Reviewed By: dzhulgakov
Differential Revision: D13317949
Pulled By: houseroad
fbshipit-source-id: 26b2f2912a9bbc3b660a62283fb403ddab437e49
Summary:
Previously symbolic AD formulas assumed that no broadcasting happened,
and would return gradients of incorrect shapes (possibly leading to
silent errors later).
Fixes a few bugs (known and unknown):
- #11736
- ArgumentSpec didn't compute the input types correctly [(it didn't advance the offset for non-tensor args)](https://github.com/pytorch/pytorch/pull/14485/files#diff-4fd3157a056596aefb8cdf41022a208bR153)
- Symbolic AD could suffer from use after free (dangling pointers in grad map), because [`EliminateDeadCode` could have removed nodes](https://github.com/pytorch/pytorch/pull/14485/files#diff-25d33ad1ed6855684dec79d927ca6142L781) that referenced gradients of certain values.
- Undefined behavior in `aten::size`
During my tests I've also found a few new problems, and I have opened issues for them:
- FusionGroup seems to think that cat nodes broadcast their inputs (#14483)
- `prim::ConstantChunk` derivative formula doesn't handle undefined inputs (#14484)
This patch unfortunately deoptimizes some of our code (Fusion doesn't happen past chunk nodes, and outputs more tensors only because we have to get their size). I know how to fix those issues, but wanted to fix this terrible bug quickly.
cc zou3519 zdevito ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14485
Reviewed By: eellison
Differential Revision: D13312888
Pulled By: suo
fbshipit-source-id: ad46bfb4d0a306ad9451002f8270f7a790f72d58
Summary:
Add support for interpolate and upsampling in weak_script mode.
Because the function parameters are overloaded, i had to add it as a builtin op. For interpolate:
size can be ?int | int[]?, and scale_factor can be ?float | float[]?. Every combination of the two parameters needs to be supported.
The same logic applies for upsample_nearest, upsample_bilinear, and upsample.
There are a few fixes that I came to along the way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14123
Differential Revision: D13278923
Pulled By: eellison
fbshipit-source-id: e59729034369be4ce4b747291a3d1c74e135b869
Summary:
Check whether the codegen'd alias annotations actually track alias creation and writes correctly. This could be made more exhaustive, but it's good enough for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14588
Differential Revision: D13312653
Pulled By: suo
fbshipit-source-id: 98de1610ea86deada71957c75c222fff331a0888
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14642
Unfortunately, TensorOptions depends on this, so we need it in c10.
Reviewed By: ezyang
Differential Revision: D13283495
fbshipit-source-id: 433cd47eb18aac1131be9c5cd650efc583870a20
Summary:
This PR:
1. Handle None value attr in the WeakScriptModuleProxy
2. add back module tests that now passing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14715
Differential Revision: D13313573
Pulled By: wanchaol
fbshipit-source-id: a6b7892707350290a6d69b6f6270ad089bfc954b
Summary:
To enable self.training in script modules, this PR automatically adds a buffer called 'training' if a script method requests self.training. Assignment to self.training is overloaded to assign both to the boolean property and the tensor value.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14719
Differential Revision: D13310569
Pulled By: zdevito
fbshipit-source-id: 406387bb602f8ce5794eeff37642863c75928be5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14625
I want to reorg the test files, but I am too lazy to make the include
paths for test_seed.h work out. So just delete it.
Reviewed By: gchanan
Differential Revision: D13277567
fbshipit-source-id: a3e8e46e4816b6fc0fe926b20779839f9e0a1a06
Summary:
[ note: stacked on expect files changes, will unstack once they land ]
This adds DeviceObjType (cannot use DeviceType it is already an enum)
to the type hierarchy and an isDevice/toDevice pair to IValue.
Previous hacks which used an int[] to represent Device are removed
and at::Device is used instead.
Note: the behavior or .to is only a subset of python, we need to
fix the aten op so that it accepts Option[Device] and Optional[ScalarType].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14666
Reviewed By: suo
Differential Revision: D13290405
Pulled By: zdevito
fbshipit-source-id: 68b4381b292f5418a6a46aaa077f1c902750b134
Summary:
This PR is a part of task to unblock standard library export. Basically we want enable the ability to meta program IF stmt to dynamically emit different branches base on `cond`. This is primarily used to disable certain branch compilation on If, like the below
```python
import torch
class Test(torch.jit.ScriptModule):
def __init__(self, b = None):
self.b = b
def forward(self, input):
x = input
if self.b is not None:
x = self.b(input)
return x
Test()(torch.randn(2, 3))
```
This is also the first step for us to bridge the gap between none simple value and any sugared value in JIT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14533
Differential Revision: D13310526
Pulled By: wanchaol
fbshipit-source-id: 78d1a8127acda5e44d2a8a88f7627c43d29ff244
Summary:
It was previously used to sure that ATen/core was working;
but now we have plenty of headers and C++ files in ATen/core
so this is no longer necessary.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14622
Differential Revision: D13276899
Pulled By: ezyang
fbshipit-source-id: 9bef7eb1882ccdfa3ee7681a3d5b048ea94b59d3
Summary:
We align the restore logic to `torch.load`, we try to restore to the right device, and if the device is not available, an exception is raised. We allow user to remap the device through a parameter `map_location`, it can be 1) a string like 'cuda:0`, `cpu`, 2) a device, torch.device('cpu'), 3) a dict, {'cuda:1', 'cuda:0'}, and a function, and its signature looks like string map_location(tensor, saved_device_string).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14454
Reviewed By: zrphercule
Differential Revision: D13271956
Pulled By: houseroad
fbshipit-source-id: dfd6b6049b0dc07549ddeddf2dea03ac53ba6d49
Summary:
Previously symbolic AD formulas assumed that no broadcasting happened,
and would return gradients of incorrect shapes (possibly leading to
silent errors later).
Fixes a few bugs (known and unknown):
- #11736
- ArgumentSpec didn't compute the input types correctly [(it didn't advance the offset for non-tensor args)](https://github.com/pytorch/pytorch/pull/14485/files#diff-4fd3157a056596aefb8cdf41022a208bR153)
- Symbolic AD could suffer from use after free (dangling pointers in grad map), because [`EliminateDeadCode` could have removed nodes](https://github.com/pytorch/pytorch/pull/14485/files#diff-25d33ad1ed6855684dec79d927ca6142L781) that referenced gradients of certain values.
- Undefined behavior in `aten::size`
During my tests I've also found a few new problems, and I have opened issues for them:
- FusionGroup seems to think that cat nodes broadcast their inputs (#14483)
- `prim::ConstantChunk` derivative formula doesn't handle undefined inputs (#14484)
This patch unfortunately deoptimizes some of our code (Fusion doesn't happen past chunk nodes, and outputs more tensors only because we have to get their size). I know how to fix those issues, but wanted to fix this terrible bug quickly.
cc zou3519 zdevito ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14485
Differential Revision: D13280899
Pulled By: soumith
fbshipit-source-id: 80cc5ec9331be80e1bb9ddfe85b81c2b997e0b0c
Summary:
This PR makes DCE a little smarter in the presence of mutable ops. Previously mutable ops could never be cleaned up, now they can be cleaned up if we can prove there are no live uses of any alias sets that the op writes to.
This behavior is optional; if you pass DCE a block instead of a graph, it will do the same thing as before. Also changed `InlineAutographSubgraph` to use the common subgraph utils.
Tested on traced ResNet, and it gets rid of the dead code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14601
Differential Revision: D13309118
Pulled By: suo
fbshipit-source-id: dac2791e7d2ecf219ae717a2759b83c1e927f254
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14650
this fixes the build for mobile
Reviewed By: dzhulgakov
Differential Revision: D13267458
fbshipit-source-id: 83e7e76e3c875134395b6c43ea791c5b56871642
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14664
This diff just adds a framework to add avx512 kernels.
Please be really really careful about using avx512 kernels unless you're convinced using avx512 will bring good enough *overall* speedups because it can backfire because of cpu frequency going down.
Reviewed By: duc0
Differential Revision: D13281944
fbshipit-source-id: 04fce8619c63f814944b727a99fbd7d35538eac6
Summary:
This PR is a part of task to unblock standard library export. Basically we want enable the ability to meta program IF stmt to dynamically emit different branches base on `cond`. This is primarily used to disable certain branch compilation on If, like the below
```python
import torch
class Test(torch.jit.ScriptModule):
def __init__(self, b = None):
self.b = b
def forward(self, input):
x = input
if self.b is not None:
x = self.b(input)
return x
Test()(torch.randn(2, 3))
```
This is also the first step for us to bridge the gap between none simple value and any sugared value in JIT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14533
Differential Revision: D13272203
Pulled By: wanchaol
fbshipit-source-id: 44a545abb766bbd39b762a6e19f9ebaa295e324b
Summary:
Fixed: https://github.com/pytorch/pytorch/issues/14678
This PR fixed DDP doesn't work after save() and load() for multiple GPUs, because, it needs all these replicating logics and bucketing in the constructor.
So I refactored some of the logics in the constructor to a helper function. And this will be used for load().
Added test too. Tested on 8 GPU machines.
```
tengli@learnfair062:~/pytorch/test$ python run_test.py -i distributed --verbose
Test executor: ['/private/home/tengli/miniconda3/bin/python']
Selected tests: distributed
Running test_distributed ... [2018-12-02 18:33:55.833580]
/public/apps/openmpi/2.1.1/gcc.5.4.0/bin/mpiexec
Running distributed tests for the mpi backend
test_Backend_enum_class (__main__.TestMPI) ... test_Backend_enum_class (__main__.TestMPI) ... test_Backend_enum_class (__main__.TestMPI) ... ok
test_DistributedDataParallel (__main__.TestMPI) ... skipped 'Only Nccl & Gloo backend support DistributedDataParallel'
test_DistributedDataParallelCPU (__main__.TestMPI) ... ok
test_DistributedDataParallel (__main__.TestMPI) ... skipped 'Only Nccl & Gloo backend support DistributedDataParallel'
test_DistributedDataParallelCPU (__main__.TestMPI) ... ok
test_DistributedDataParallel (__main__.TestMPI) ... skipped 'Only Nccl & Gloo backend support DistributedDataParallel'
test_DistributedDataParallelCPU (__main__.TestMPI) ... ok
test_all_gather (__main__.TestMPI) ... ok
test_all_gather (__main__.TestMPI) ... ok
test_all_gather (__main__.TestMPI) ... ok
test_all_gather_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA all gather'
test_all_gather_full_group (__main__.TestMPI) ... ok
test_all_gather_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA all gather'
test_all_gather_full_group (__main__.TestMPI) ... ok
test_all_gather_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA all gather'
test_all_gather_full_group (__main__.TestMPI) ... ok
test_all_gather_group (__main__.TestMPI) ... ok
test_all_gather_group (__main__.TestMPI) ... ok
test_all_gather_group (__main__.TestMPI) ... ok
test_all_gather_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports allgather multigpu'
test_all_reduce_full_group_max (__main__.TestMPI) ... ok
test_all_gather_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports allgather multigpu'
test_all_reduce_full_group_max (__main__.TestMPI) ... ok
test_all_gather_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports allgather multigpu'
test_all_reduce_full_group_max (__main__.TestMPI) ... ok
test_all_reduce_full_group_min (__main__.TestMPI) ... ok
test_all_reduce_full_group_min (__main__.TestMPI) ... ok
test_all_reduce_full_group_min (__main__.TestMPI) ... ok
test_all_reduce_full_group_product (__main__.TestMPI) ... ok
test_all_reduce_full_group_product (__main__.TestMPI) ... ok
test_all_reduce_full_group_product (__main__.TestMPI) ... ok
test_all_reduce_full_group_sum (__main__.TestMPI) ... ok
test_all_reduce_full_group_sum (__main__.TestMPI) ... ok
test_all_reduce_full_group_sum (__main__.TestMPI) ... ok
test_all_reduce_group_max (__main__.TestMPI) ... ok
test_all_reduce_group_max (__main__.TestMPI) ... ok
test_all_reduce_group_max (__main__.TestMPI) ... ok
test_all_reduce_group_min (__main__.TestMPI) ... ok
test_all_reduce_group_min (__main__.TestMPI) ... ok
test_all_reduce_group_min (__main__.TestMPI) ... ok
test_all_reduce_group_product (__main__.TestMPI) ... ok
test_all_reduce_group_product (__main__.TestMPI) ... ok
test_all_reduce_group_product (__main__.TestMPI) ... ok
test_all_reduce_group_sum (__main__.TestMPI) ... ok
test_all_reduce_group_sum (__main__.TestMPI) ... ok
test_all_reduce_group_sum (__main__.TestMPI) ... ok
test_all_reduce_max (__main__.TestMPI) ... ok
test_all_reduce_max (__main__.TestMPI) ... ok
test_all_reduce_max (__main__.TestMPI) ... ok
test_all_reduce_min (__main__.TestMPI) ... ok
test_all_reduce_min (__main__.TestMPI) ... ok
test_all_reduce_min (__main__.TestMPI) ... ok
test_all_reduce_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_all_reduce_product (__main__.TestMPI) ... ok
test_all_reduce_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_all_reduce_product (__main__.TestMPI) ... ok
test_all_reduce_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_all_reduce_product (__main__.TestMPI) ... ok
test_all_reduce_sum (__main__.TestMPI) ... ok
test_all_reduce_sum (__main__.TestMPI) ... ok
test_all_reduce_sum (__main__.TestMPI) ... ok
test_all_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestMPI) ... ok
test_all_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestMPI) ... ok
test_all_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestMPI) ... ok
test_barrier_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_full_group (__main__.TestMPI) ... ok
test_barrier_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_full_group (__main__.TestMPI) ... ok
test_barrier_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_full_group (__main__.TestMPI) ... ok
test_barrier_full_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_group (__main__.TestMPI) ... ok
test_barrier_full_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_group (__main__.TestMPI) ... ok
test_barrier_full_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_group (__main__.TestMPI) ... ok
test_barrier_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_timeout_full_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestMPI) ... ok
test_barrier_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_timeout_full_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestMPI) ... ok
test_barrier_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_timeout_full_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestMPI) ... ok
test_broadcast_cuda (__main__.TestMPI) ... skipped 'Only Gloo and Nccl backend supports CUDA allReduce'
test_broadcast_full_group (__main__.TestMPI) ... ok
test_broadcast_cuda (__main__.TestMPI) ... skipped 'Only Gloo and Nccl backend supports CUDA allReduce'
test_broadcast_full_group (__main__.TestMPI) ... ok
test_broadcast_cuda (__main__.TestMPI) ... skipped 'Only Gloo and Nccl backend supports CUDA allReduce'
test_broadcast_full_group (__main__.TestMPI) ... ok
test_broadcast_group (__main__.TestMPI) ... ok
test_broadcast_group (__main__.TestMPI) ... ok
test_broadcast_group (__main__.TestMPI) ... ok
test_broadcast_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_destroy_full_group (__main__.TestMPI) ... ok
test_broadcast_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_destroy_full_group (__main__.TestMPI) ... ok
test_broadcast_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_destroy_full_group (__main__.TestMPI) ... ok
test_destroy_group (__main__.TestMPI) ... ok
test_destroy_group (__main__.TestMPI) ... ok
test_destroy_group (__main__.TestMPI) ... ok
test_gather (__main__.TestMPI) ... ok
test_gather (__main__.TestMPI) ... ok
test_gather (__main__.TestMPI) ... ok
test_gather_full_group (__main__.TestMPI) ... ok
test_gather_full_group (__main__.TestMPI) ... ok
test_gather_full_group (__main__.TestMPI) ... ok
test_gather_group (__main__.TestMPI) ... ok
test_gather_group (__main__.TestMPI) ... ok
test_gather_group (__main__.TestMPI) ... ok
test_get_backend (__main__.TestMPI) ... ok
test_get_backend (__main__.TestMPI) ... ok
test_get_backend (__main__.TestMPI) ... ok
test_get_default_group (__main__.TestMPI) ... ok
test_get_default_group (__main__.TestMPI) ... ok
test_get_default_group (__main__.TestMPI) ... ok
test_get_rank (__main__.TestMPI) ... ok
test_get_rank (__main__.TestMPI) ... ok
test_get_rank (__main__.TestMPI) ... ok
test_get_rank_size_full_group (__main__.TestMPI) ... ok
test_get_rank_size_full_group (__main__.TestMPI) ... ok
test_get_rank_size_full_group (__main__.TestMPI) ... ok
test_get_rank_size_group (__main__.TestMPI) ... ok
test_get_rank_size_group (__main__.TestMPI) ... ok
test_get_rank_size_group (__main__.TestMPI) ... ok
test_irecv (__main__.TestMPI) ... ok
test_irecv (__main__.TestMPI) ... ok
test_irecv (__main__.TestMPI) ... ok
test_isend (__main__.TestMPI) ... ok
test_isend (__main__.TestMPI) ... ok
test_isend (__main__.TestMPI) ... ok
test_reduce_full_group_max (__main__.TestMPI) ... ok
test_reduce_full_group_max (__main__.TestMPI) ... ok
test_reduce_full_group_max (__main__.TestMPI) ... ok
test_reduce_full_group_min (__main__.TestMPI) ... ok
test_reduce_full_group_min (__main__.TestMPI) ... ok
test_reduce_full_group_min (__main__.TestMPI) ... ok
test_reduce_full_group_product (__main__.TestMPI) ... ok
test_reduce_full_group_product (__main__.TestMPI) ... ok
test_reduce_full_group_product (__main__.TestMPI) ... ok
test_reduce_full_group_sum (__main__.TestMPI) ... ok
test_reduce_full_group_sum (__main__.TestMPI) ... ok
test_reduce_full_group_sum (__main__.TestMPI) ... ok
test_reduce_group_max (__main__.TestMPI) ... ok
test_reduce_group_max (__main__.TestMPI) ... ok
test_reduce_group_max (__main__.TestMPI) ... ok
test_reduce_group_min (__main__.TestMPI) ... ok
test_reduce_group_min (__main__.TestMPI) ... ok
test_reduce_group_min (__main__.TestMPI) ... ok
test_reduce_group_product (__main__.TestMPI) ... ok
test_reduce_group_product (__main__.TestMPI) ... ok
test_reduce_group_product (__main__.TestMPI) ... ok
test_reduce_group_sum (__main__.TestMPI) ... ok
test_reduce_group_sum (__main__.TestMPI) ... ok
test_reduce_group_sum (__main__.TestMPI) ... ok
test_reduce_max (__main__.TestMPI) ... ok
test_reduce_max (__main__.TestMPI) ... ok
test_reduce_max (__main__.TestMPI) ... ok
test_reduce_min (__main__.TestMPI) ... ok
test_reduce_min (__main__.TestMPI) ... ok
test_reduce_min (__main__.TestMPI) ... ok
test_reduce_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports reduce multigpu'
test_reduce_product (__main__.TestMPI) ... ok
test_reduce_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports reduce multigpu'
test_reduce_product (__main__.TestMPI) ... ok
test_reduce_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports reduce multigpu'
test_reduce_product (__main__.TestMPI) ... ok
test_reduce_sum (__main__.TestMPI) ... ok
test_reduce_sum (__main__.TestMPI) ... ok
test_reduce_sum (__main__.TestMPI) ... ok
test_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA reduce'
test_scatter (__main__.TestMPI) ... ok
test_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA reduce'
test_scatter (__main__.TestMPI) ... ok
test_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA reduce'
test_scatter (__main__.TestMPI) ... ok
test_scatter_full_group (__main__.TestMPI) ... ok
test_scatter_full_group (__main__.TestMPI) ... ok
test_scatter_full_group (__main__.TestMPI) ... ok
test_scatter_group (__main__.TestMPI) ... ok
test_scatter_group (__main__.TestMPI) ... ok
test_scatter_group (__main__.TestMPI) ... ok
test_send_recv (__main__.TestMPI) ... ok
test_send_recv (__main__.TestMPI) ... ok
test_send_recv (__main__.TestMPI) ... ok
test_send_recv_any_source (__main__.TestMPI) ... ok
test_send_recv_any_source (__main__.TestMPI) ... ok
test_send_recv_any_source (__main__.TestMPI) ... ok
test_send_recv_with_tag (__main__.TestMPI) ... ok
test_send_recv_with_tag (__main__.TestMPI) ... ok
test_send_recv_with_tag (__main__.TestMPI) ... ok
----------------------------------------------------------------------
Ran 68 tests in 6.315s
OK (skipped=15)
ok
----------------------------------------------------------------------
Ran 68 tests in 6.315s
OK (skipped=15)
ok
----------------------------------------------------------------------
Ran 68 tests in 6.315s
OK (skipped=15)
Running distributed tests for the mpi backend with file init_method
test_Backend_enum_class (__main__.TestMPI) ... test_Backend_enum_class (__main__.TestMPI) ... test_Backend_enum_class (__main__.TestMPI) ... ok
test_DistributedDataParallel (__main__.TestMPI) ... skipped 'Only Nccl & Gloo backend support DistributedDataParallel'
test_DistributedDataParallelCPU (__main__.TestMPI) ... ok
test_DistributedDataParallel (__main__.TestMPI) ... skipped 'Only Nccl & Gloo backend support DistributedDataParallel'
test_DistributedDataParallelCPU (__main__.TestMPI) ... ok
test_DistributedDataParallel (__main__.TestMPI) ... skipped 'Only Nccl & Gloo backend support DistributedDataParallel'
test_DistributedDataParallelCPU (__main__.TestMPI) ... ok
test_all_gather (__main__.TestMPI) ... ok
test_all_gather (__main__.TestMPI) ... ok
test_all_gather (__main__.TestMPI) ... ok
test_all_gather_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA all gather'
test_all_gather_full_group (__main__.TestMPI) ... ok
test_all_gather_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA all gather'
test_all_gather_full_group (__main__.TestMPI) ... ok
test_all_gather_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA all gather'
test_all_gather_full_group (__main__.TestMPI) ... ok
test_all_gather_group (__main__.TestMPI) ... ok
test_all_gather_group (__main__.TestMPI) ... ok
test_all_gather_group (__main__.TestMPI) ... ok
test_all_gather_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports allgather multigpu'
test_all_reduce_full_group_max (__main__.TestMPI) ... ok
test_all_gather_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports allgather multigpu'
test_all_reduce_full_group_max (__main__.TestMPI) ... ok
test_all_gather_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports allgather multigpu'
test_all_reduce_full_group_max (__main__.TestMPI) ... ok
test_all_reduce_full_group_min (__main__.TestMPI) ... ok
test_all_reduce_full_group_min (__main__.TestMPI) ... ok
test_all_reduce_full_group_min (__main__.TestMPI) ... ok
test_all_reduce_full_group_product (__main__.TestMPI) ... ok
test_all_reduce_full_group_product (__main__.TestMPI) ... ok
test_all_reduce_full_group_product (__main__.TestMPI) ... ok
test_all_reduce_full_group_sum (__main__.TestMPI) ... ok
test_all_reduce_full_group_sum (__main__.TestMPI) ... ok
test_all_reduce_full_group_sum (__main__.TestMPI) ... ok
test_all_reduce_group_max (__main__.TestMPI) ... ok
test_all_reduce_group_max (__main__.TestMPI) ... ok
test_all_reduce_group_max (__main__.TestMPI) ... ok
test_all_reduce_group_min (__main__.TestMPI) ... ok
test_all_reduce_group_min (__main__.TestMPI) ... ok
test_all_reduce_group_min (__main__.TestMPI) ... ok
test_all_reduce_group_product (__main__.TestMPI) ... ok
test_all_reduce_group_product (__main__.TestMPI) ... ok
test_all_reduce_group_product (__main__.TestMPI) ... ok
test_all_reduce_group_sum (__main__.TestMPI) ... ok
test_all_reduce_group_sum (__main__.TestMPI) ... ok
test_all_reduce_group_sum (__main__.TestMPI) ... ok
test_all_reduce_max (__main__.TestMPI) ... ok
test_all_reduce_max (__main__.TestMPI) ... ok
test_all_reduce_max (__main__.TestMPI) ... ok
test_all_reduce_min (__main__.TestMPI) ... ok
test_all_reduce_min (__main__.TestMPI) ... ok
test_all_reduce_min (__main__.TestMPI) ... ok
test_all_reduce_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_all_reduce_product (__main__.TestMPI) ... ok
test_all_reduce_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_all_reduce_product (__main__.TestMPI) ... ok
test_all_reduce_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_all_reduce_product (__main__.TestMPI) ... ok
test_all_reduce_sum (__main__.TestMPI) ... ok
test_all_reduce_sum (__main__.TestMPI) ... ok
test_all_reduce_sum (__main__.TestMPI) ... ok
test_all_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestMPI) ... ok
test_all_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestMPI) ... ok
test_all_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestMPI) ... ok
test_barrier_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_full_group (__main__.TestMPI) ... ok
test_barrier_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_full_group (__main__.TestMPI) ... ok
test_barrier_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_full_group (__main__.TestMPI) ... ok
test_barrier_full_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_group (__main__.TestMPI) ... ok
test_barrier_full_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_group (__main__.TestMPI) ... ok
test_barrier_full_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_group (__main__.TestMPI) ... ok
test_barrier_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_timeout_full_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestMPI) ... ok
test_barrier_group_cuda (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_timeout_full_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestMPI) ... ok
test_barrier_group_cuda (__main__.TestMPI) ... skipped "MPI doesn't supports GPU barrier"
test_barrier_timeout_full_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestMPI) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestMPI) ... ok
test_broadcast_cuda (__main__.TestMPI) ... skipped 'Only Gloo and Nccl backend supports CUDA allReduce'
test_broadcast_full_group (__main__.TestMPI) ... ok
test_broadcast_cuda (__main__.TestMPI) ... skipped 'Only Gloo and Nccl backend supports CUDA allReduce'
test_broadcast_full_group (__main__.TestMPI) ... ok
test_broadcast_cuda (__main__.TestMPI) ... skipped 'Only Gloo and Nccl backend supports CUDA allReduce'
test_broadcast_full_group (__main__.TestMPI) ... ok
test_broadcast_group (__main__.TestMPI) ... ok
test_broadcast_group (__main__.TestMPI) ... ok
test_broadcast_group (__main__.TestMPI) ... ok
test_broadcast_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_destroy_full_group (__main__.TestMPI) ... ok
test_broadcast_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_destroy_full_group (__main__.TestMPI) ... ok
test_broadcast_multigpu (__main__.TestMPI) ... skipped "MPI doesn't support broadcast multigpu"
test_destroy_full_group (__main__.TestMPI) ... ok
test_destroy_group (__main__.TestMPI) ... ok
test_destroy_group (__main__.TestMPI) ... ok
test_destroy_group (__main__.TestMPI) ... ok
test_gather (__main__.TestMPI) ... ok
test_gather (__main__.TestMPI) ... ok
test_gather (__main__.TestMPI) ... ok
test_gather_full_group (__main__.TestMPI) ... ok
test_gather_full_group (__main__.TestMPI) ... ok
test_gather_full_group (__main__.TestMPI) ... ok
test_gather_group (__main__.TestMPI) ... ok
test_gather_group (__main__.TestMPI) ... ok
test_gather_group (__main__.TestMPI) ... ok
test_get_backend (__main__.TestMPI) ... ok
test_get_backend (__main__.TestMPI) ... ok
test_get_backend (__main__.TestMPI) ... ok
test_get_default_group (__main__.TestMPI) ... ok
test_get_default_group (__main__.TestMPI) ... ok
test_get_default_group (__main__.TestMPI) ... ok
test_get_rank (__main__.TestMPI) ... ok
test_get_rank (__main__.TestMPI) ... ok
test_get_rank (__main__.TestMPI) ... ok
test_get_rank_size_full_group (__main__.TestMPI) ... ok
test_get_rank_size_full_group (__main__.TestMPI) ... ok
test_get_rank_size_full_group (__main__.TestMPI) ... ok
test_get_rank_size_group (__main__.TestMPI) ... ok
test_get_rank_size_group (__main__.TestMPI) ... ok
test_get_rank_size_group (__main__.TestMPI) ... ok
test_irecv (__main__.TestMPI) ... ok
test_irecv (__main__.TestMPI) ... ok
test_irecv (__main__.TestMPI) ... ok
test_isend (__main__.TestMPI) ... ok
test_isend (__main__.TestMPI) ... ok
test_isend (__main__.TestMPI) ... ok
test_reduce_full_group_max (__main__.TestMPI) ... ok
test_reduce_full_group_max (__main__.TestMPI) ... ok
test_reduce_full_group_max (__main__.TestMPI) ... ok
test_reduce_full_group_min (__main__.TestMPI) ... ok
test_reduce_full_group_min (__main__.TestMPI) ... ok
test_reduce_full_group_min (__main__.TestMPI) ... ok
test_reduce_full_group_product (__main__.TestMPI) ... ok
test_reduce_full_group_product (__main__.TestMPI) ... ok
test_reduce_full_group_product (__main__.TestMPI) ... ok
test_reduce_full_group_sum (__main__.TestMPI) ... ok
test_reduce_full_group_sum (__main__.TestMPI) ... ok
test_reduce_full_group_sum (__main__.TestMPI) ... ok
test_reduce_group_max (__main__.TestMPI) ... ok
test_reduce_group_max (__main__.TestMPI) ... ok
test_reduce_group_max (__main__.TestMPI) ... ok
test_reduce_group_min (__main__.TestMPI) ... ok
test_reduce_group_min (__main__.TestMPI) ... ok
test_reduce_group_min (__main__.TestMPI) ... ok
test_reduce_group_product (__main__.TestMPI) ... ok
test_reduce_group_product (__main__.TestMPI) ... ok
test_reduce_group_product (__main__.TestMPI) ... ok
test_reduce_group_sum (__main__.TestMPI) ... ok
test_reduce_group_sum (__main__.TestMPI) ... ok
test_reduce_group_sum (__main__.TestMPI) ... ok
test_reduce_max (__main__.TestMPI) ... ok
test_reduce_max (__main__.TestMPI) ... ok
test_reduce_max (__main__.TestMPI) ... ok
test_reduce_min (__main__.TestMPI) ... ok
test_reduce_min (__main__.TestMPI) ... ok
test_reduce_min (__main__.TestMPI) ... ok
test_reduce_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports reduce multigpu'
test_reduce_product (__main__.TestMPI) ... ok
test_reduce_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports reduce multigpu'
test_reduce_product (__main__.TestMPI) ... ok
test_reduce_multigpu (__main__.TestMPI) ... skipped 'Only Nccl backend supports reduce multigpu'
test_reduce_product (__main__.TestMPI) ... ok
test_reduce_sum (__main__.TestMPI) ... ok
test_reduce_sum (__main__.TestMPI) ... ok
test_reduce_sum (__main__.TestMPI) ... ok
test_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA reduce'
test_scatter (__main__.TestMPI) ... ok
test_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA reduce'
test_scatter (__main__.TestMPI) ... ok
test_reduce_sum_cuda (__main__.TestMPI) ... skipped 'Only Nccl supports CUDA reduce'
test_scatter (__main__.TestMPI) ... ok
test_scatter_full_group (__main__.TestMPI) ... ok
test_scatter_full_group (__main__.TestMPI) ... ok
test_scatter_full_group (__main__.TestMPI) ... ok
test_scatter_group (__main__.TestMPI) ... ok
test_scatter_group (__main__.TestMPI) ... ok
test_scatter_group (__main__.TestMPI) ... ok
test_send_recv (__main__.TestMPI) ... ok
test_send_recv (__main__.TestMPI) ... ok
test_send_recv (__main__.TestMPI) ... ok
test_send_recv_any_source (__main__.TestMPI) ... ok
test_send_recv_any_source (__main__.TestMPI) ... ok
test_send_recv_any_source (__main__.TestMPI) ... ok
test_send_recv_with_tag (__main__.TestMPI) ... ok
test_send_recv_with_tag (__main__.TestMPI) ... ok
test_send_recv_with_tag (__main__.TestMPI) ... ok
----------------------------------------------------------------------
Ran 68 tests in 6.415s
OK (skipped=15)
ok
----------------------------------------------------------------------
Ran 68 tests in 6.415s
OK (skipped=15)
ok
----------------------------------------------------------------------
Ran 68 tests in 6.415s
OK (skipped=15)
Running distributed tests for the nccl backend
test_Backend_enum_class (__main__.TestDistBackend) ... ok
test_DistributedDataParallel (__main__.TestDistBackend) ... ok
test_DistributedDataParallelCPU (__main__.TestDistBackend) ... skipped 'nccl does not support DistributedDataParallelCPU'
test_all_gather (__main__.TestDistBackend) ... skipped 'Only MPI supports CPU all gather'
test_all_gather_cuda (__main__.TestDistBackend) ... skipped 'CUDA all gather skipped for NCCL'
test_all_gather_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_gather_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_gather_multigpu (__main__.TestDistBackend) ... ok
test_all_reduce_full_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_full_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_full_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_full_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_multigpu (__main__.TestDistBackend) ... skipped 'CUDA all_reduce multigpu skipped for NCCL'
test_all_reduce_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_sum_cuda (__main__.TestDistBackend) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestDistBackend) ... skipped 'NCCL does not support CPU barrier'
test_barrier_cuda (__main__.TestDistBackend) ... ok
test_barrier_full_group (__main__.TestDistBackend) ... skipped 'NCCL does not support CPU barrier'
test_barrier_full_group_cuda (__main__.TestDistBackend) ... ok
test_barrier_group (__main__.TestDistBackend) ... skipped 'NCCL does not support CPU barrier'
test_barrier_group_cuda (__main__.TestDistBackend) ... ok
test_barrier_timeout_full_group (__main__.TestDistBackend) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestDistBackend) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestDistBackend) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_broadcast_cuda (__main__.TestDistBackend) ... ok
test_broadcast_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_broadcast_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_broadcast_multigpu (__main__.TestDistBackend) ... skipped 'NCCL broadcast multigpu skipped'
test_destroy_full_group (__main__.TestDistBackend) ... ok
test_destroy_group (__main__.TestDistBackend) ... ok
test_gather (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_gather_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_gather_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_get_backend (__main__.TestDistBackend) ... ok
test_get_default_group (__main__.TestDistBackend) ... ok
test_get_rank (__main__.TestDistBackend) ... ok
test_get_rank_size_full_group (__main__.TestDistBackend) ... ok
test_get_rank_size_group (__main__.TestDistBackend) ... ok
test_irecv (__main__.TestDistBackend) ... skipped 'Nccl does not support irecv'
test_isend (__main__.TestDistBackend) ... skipped 'Nccl does not support isend'
test_reduce_full_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_full_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_full_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_full_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_multigpu (__main__.TestDistBackend) ... ok
test_reduce_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_sum_cuda (__main__.TestDistBackend) ... ok
test_scatter (__main__.TestDistBackend) ... skipped 'Nccl does not support scatter'
test_scatter_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support scatter'
test_scatter_group (__main__.TestDistBackend) ... skipped 'Nccl does not support scatter'
test_send_recv (__main__.TestDistBackend) ... skipped 'Nccl does not support send/recv'
test_send_recv_any_source (__main__.TestDistBackend) ... skipped 'Nccl does not support send/recv from any source'
test_send_recv_with_tag (__main__.TestDistBackend) ... skipped 'Nccl does not support send/recv'
----------------------------------------------------------------------
Ran 68 tests in 69.549s
OK (skipped=52)
Running distributed tests for the nccl backend with file init_method
test_Backend_enum_class (__main__.TestDistBackend) ... ok
test_DistributedDataParallel (__main__.TestDistBackend) ... ok
test_DistributedDataParallelCPU (__main__.TestDistBackend) ... skipped 'nccl does not support DistributedDataParallelCPU'
test_all_gather (__main__.TestDistBackend) ... skipped 'Only MPI supports CPU all gather'
test_all_gather_cuda (__main__.TestDistBackend) ... skipped 'CUDA all gather skipped for NCCL'
test_all_gather_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_gather_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_gather_multigpu (__main__.TestDistBackend) ... ok
test_all_reduce_full_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_full_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_full_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_full_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_multigpu (__main__.TestDistBackend) ... skipped 'CUDA all_reduce multigpu skipped for NCCL'
test_all_reduce_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_all_reduce_sum_cuda (__main__.TestDistBackend) ... skipped 'Only Gloo backend will have CUDA allReduce tested'
test_barrier (__main__.TestDistBackend) ... skipped 'NCCL does not support CPU barrier'
test_barrier_cuda (__main__.TestDistBackend) ... ok
test_barrier_full_group (__main__.TestDistBackend) ... skipped 'NCCL does not support CPU barrier'
test_barrier_full_group_cuda (__main__.TestDistBackend) ... ok
test_barrier_group (__main__.TestDistBackend) ... skipped 'NCCL does not support CPU barrier'
test_barrier_group_cuda (__main__.TestDistBackend) ... ok
test_barrier_timeout_full_group (__main__.TestDistBackend) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_global (__main__.TestDistBackend) ... skipped 'Only gloo backend supports timeouts'
test_barrier_timeout_group (__main__.TestDistBackend) ... skipped 'Only gloo backend supports timeouts'
test_broadcast (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_broadcast_cuda (__main__.TestDistBackend) ... ok
test_broadcast_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_broadcast_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_broadcast_multigpu (__main__.TestDistBackend) ... skipped 'NCCL broadcast multigpu skipped'
test_destroy_full_group (__main__.TestDistBackend) ... ok
test_destroy_group (__main__.TestDistBackend) ... ok
test_gather (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_gather_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_gather_group (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_get_backend (__main__.TestDistBackend) ... ok
test_get_default_group (__main__.TestDistBackend) ... ok
test_get_rank (__main__.TestDistBackend) ... ok
test_get_rank_size_full_group (__main__.TestDistBackend) ... ok
test_get_rank_size_group (__main__.TestDistBackend) ... ok
test_irecv (__main__.TestDistBackend) ... skipped 'Nccl does not support irecv'
test_isend (__main__.TestDistBackend) ... skipped 'Nccl does not support isend'
test_reduce_full_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_full_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_full_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_full_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_group_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_max (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_min (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_multigpu (__main__.TestDistBackend) ... ok
test_reduce_product (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_sum (__main__.TestDistBackend) ... skipped 'Nccl does not support CPU tensors'
test_reduce_sum_cuda (__main__.TestDistBackend) ... ok
test_scatter (__main__.TestDistBackend) ... skipped 'Nccl does not support scatter'
test_scatter_full_group (__main__.TestDistBackend) ... skipped 'Nccl does not support scatter'
test_scatter_group (__main__.TestDistBackend) ... skipped 'Nccl does not support scatter'
test_send_recv (__main__.TestDistBackend) ... skipped 'Nccl does not support send/recv'
test_send_recv_any_source (__main__.TestDistBackend) ... skipped 'Nccl does not support send/recv from any source'
test_send_recv_with_tag (__main__.TestDistBackend) ... skipped 'Nccl does not support send/recv'
----------------------------------------------------------------------
Ran 68 tests in 70.381s
OK (skipped=52)
``
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14690
Differential Revision: D13294169
Pulled By: teng-li
fbshipit-source-id: 69ccac34c6c016899bfe8fbc50b48d4bfd1d3876
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14623
This is the last piece we need before we can start doing out-of-place
HIPify on ATen. These APIs are not actually used at the moment;
as we still do in-place HIPify which uses CUDA.
Reviewed By: gchanan
Differential Revision: D13277246
fbshipit-source-id: 771efa81c2d2022e29350f25a5b4bb8f49ac6df0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14499
It still needs to stay in hooks, since it's part of the public
C++ API, but I want library code to try to arrange for CuDNN checks
to occur inside CUDA code, where we it's statically obvious if
CuDNN is available (and you don't need to dynamic dispatch.
Reviewed By: gchanan
Differential Revision: D13241355
fbshipit-source-id: 4e668a5914ab890463a12d9e528ba4ecbb7dd7c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14414
The previous functions were CUDA-centric, and lead to lots of places
where we improperly assumed that CUDA is the only game in town (it's not).
Best to delete them.
What are your alternatives? This diff fix some use sites which may give
you some ideas. In particular, the "given a device type, give me the
current device for that device type" might be a good function to enshrine
for real.
Reviewed By: gchanan
Differential Revision: D13218540
fbshipit-source-id: 2f42cd6b9bdab4930d25166b8041c9466a1c6e0a
Summary:
If multiple arguments are specified to c10d allreduce, they are
interpreted as if they are expanding the ranks in the process group.
Therefore, not only is every argument to allreduce an input that must
be considered, it is also an output. The problem that this commit
fixes is that they were not correctly considered as outputs.
The upstream problem is tracked in facebookincubator/gloo#152. Once
this is fixed there we can remove the copies that this commit adds.
This fixes#14676.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14688
Differential Revision: D13294405
Pulled By: pietern
fbshipit-source-id: 078a2a0a0ff12d051392461438f1496201ec3cb9
Summary:
The CUDA initialization for the participating processes can
take long enough for the barrier timeout to trigger on the
process that doesn't participate in the group.
See #14676.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14689
Reviewed By: teng-li
Differential Revision: D13293695
Pulled By: pietern
fbshipit-source-id: 6268dc9acfdb22f70c027e5e4be082f7127c0db4
Summary:
Ok, this corner happens for translation guys, and it only happens in the following corner case:
(1) when the module is registered a parameter that does not requires grad
and
(2) this registered parameter has a unique type (say, double, or half) and it's the only unique type such that itself alone will be put into a separate bucket.
and
(3) it is the last parameter that got registered in the module, such that its bucket reduction is the first to be kicked off.
Once this corner case happens, since it does not require grad, the backward hook won't be kicked off. Now that all other buckets are waiting for its bucket to be kicked off, in this case, no bucket will be kicked off since it's blocked by the first bucket (the unique type parameter).
This PR fixes two things:
(1) Make sure that we will only bucket parameters that requires_grad
(2) Make all-reduction checks in the next iteration. As long as we detect the previous iteration's all-reduction has not been fully kicked off, we will issue an error in the next iteration.
(3) Also removed some unused variables
With this bug fixed, the only case when this error can happen is when the user changed parameters later after wrapping up the module with DDP, like the case in:
https://github.com/pytorch/pytorch/issues/12603
Test covered as well
Without the first fix, I varied that the repro in fbcode hit this error message:
```
result = self.forward(*input, **kwargs)
File "/data/users/tengli/fbsource/fbcode/buck-out/dev/gen/language_technology/neural_mt/os/pytorch_translate/train#link-tree/torch/nn/parallel/distributed.py", line 312, in forward
raise RuntimeError("Not all gradients are all-reduced from "
RuntimeError: Not all gradients are all-reduced from the backward of the previous iteration. This is unexpected and fatal error. Please check and ensure that the model's parameters are not changed after you wrap up the model with DistributedDataParallel.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14675
Differential Revision: D13291083
Pulled By: teng-li
fbshipit-source-id: 2539b699fae843f104b4b8d22721ae82502ba684
Summary:
Stacked on zip commit because it also changes expect files, read only the last commit.
This reduces the number of ways we can print a Type from 3 (python_str, str, operator<<) to 2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14657
Differential Revision: D13288912
Pulled By: zdevito
fbshipit-source-id: f8dd610cea798c511c1d4327395bba54b1aa1697
Summary:
After consulting with Owen, who pointed out the existence of the miniz library, I decided to take one last shot at using zip as our container format.
miniz makes this surprisingly feasible and I think the benefits of using zip are large enough that we should do it.
This replaces our custom container format with a zip archive, preserving all of the
desirable features of our custom format, such as append-oriented writing, and
mmap'able tensor data while adding a bunch of debugging advantages:
1. You can unzip and explore the container to debug what is going on with a model.
2. You can edit the model using a text editor (e.g. change the definition of a method,
or editing the json-serialized meta-data), re-zip the file use OSX's native 'Compress'
option, and re-load the result into pytorch. Note: this enables you to, e.g., print-debug
serialized models.
3. We can easily enable features like compression in the future.
4. Stock python , without pytorch installed, and other programming languages
can reasonably consume this format,using json and zipfile packages, which enables
people to build tools like visualizers without those visualizers depending on pytorch.
This will be especially useful if you want to, for instance, write a visualizer in javascript.
Notes:
* This add miniz (https://github.com/richgel999/miniz) as a dependency. miniz is a self-contained
library for reading/writing zipfiles that unlike other zip libraries also includes libz
compatible compress/decompress support. It is a single header and a single C file without
any other dependencies. Note that the instructions for miniz explicitly state:
> Please use the files from the releases page in your projects. Do not use the git checkout directly!
So we have checked in the 'release' source. Miniz supports zip64, and its API is amenable
to doing zip-align style things to align data.
* Removes 'size' from RecordRef. This allows you to edit files in the zip archive without
editing the meta-data file. Very important if you want to print-debug serialized models.
* PyTorchStreamReader/PyTorchStreamWriter keep mostly the same API (though keys become strings)
However, their implementation is completely swapped out to use miniz.
* Code exists to check for the old magic number to give a decent warning to our preview users
after we change the format.
* Container version information is now put in a stand-alone 'version' file in the archive
and serves a similar purpose to the other container version info.
* All files in the zip archive start at 64-byte boundaries, using an approach similar to
zip-align. Tests check that this property remains true. While the writer does this,
the reader doesn't depend on it, allowing user-created archives that can use compression,
and do not have to align data.
* Added test to check for > 4GB files and archives. Disabled by default because it takes
almost 2 minutes to run.
* torchscript files are now optional: if a submodule does not have methods, it will
not be written.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14521
Reviewed By: jamesr66a
Differential Revision: D13252945
Pulled By: zdevito
fbshipit-source-id: 01209294c0f6543d0fd716f85a38532249c52f8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14383
D11669870 seems to have missed a spot that wasn't triggered before the stacked code above
Reviewed By: smessmer
Differential Revision: D13198269
fbshipit-source-id: 74592bedae0721acee744e31ca95253ea6efdedb
Summary:
JIT world only have double, not float, so when insertConstant, we need to cast the python `float_` to double instead of float. This will fix the incorrect `math.pi` and other high precision constants value
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14417
Differential Revision: D13282975
Pulled By: wanchaol
fbshipit-source-id: 26a4c89ffc044d28598af673aebfec95153a869e
Summary:
Remove no_grad_embedding_renorm_ from aten. Setting the derivatives of the inputs to false has different semantics from calling with no_grad(), because it will not error if an input is modified and then has it's grad accessed.
Instead, make a custom op, and use NoGradGuard.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14639
Differential Revision: D13285604
Pulled By: eellison
fbshipit-source-id: c7d343fe8f22e369669e92799f167674f124ffe7
Summary:
This patch detects and builds c10d and gloo for the C++ API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14037
Reviewed By: ezyang
Differential Revision: D13283801
Pulled By: ebetica
fbshipit-source-id: 006dbb691344819833da6b4b844c1f0572942135
Summary:
These somehow slipped through when we moved all of Declarations.cwrap to functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14624
Reviewed By: ezyang
Differential Revision: D13277434
Pulled By: gchanan
fbshipit-source-id: e83451e2d0fdafb55635d4b757688a501454bf8c
Summary:
This moves `new_module_tests` from `test_nn.py` to `common_nn.py` so
that they can be used in `test_jit.py` without running any of
`test_nn.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14578
Differential Revision: D13268286
Pulled By: driazati
fbshipit-source-id: 6e8654a4c29ab754d656ac83820c14d1c1843e03
Summary:
The lines removed in this diff were no-op, but confusing: the default constructors in `store_handler.h` are implicitly deleted, since `std::runtime_error` has no default constructor.
Clang added a warning for this behavior [in September 2018](https://reviews.llvm.org/rL343285) (note that the warning is not just for cxx2a, despite the slightly confusing commit message), so building pytorch with a recent build of clang trunk causes spew of this warning, which is fixed by the present PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14300
Differential Revision: D13260039
Pulled By: umanwizard
fbshipit-source-id: 92788dbd6794253e788ef26bde250a66d8fb917e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13937
We can now replace s_copy_ with our new _copy_ function. Experimented with moving s_copy_ out of VariableManualType.cpp, but seemed like there was enough special casing to warrant it staying.
Reviewed By: ezyang
Differential Revision: D13053648
fbshipit-source-id: e9e04d460baf4ee49b500212cf91b95221acd769
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13348
Move cross device, cpu to device, device to cpu copies to aten. Most of it is a direct port, main difference is that we dispatch from a single _copy_ function for copies.
Reviewed By: ezyang
Differential Revision: D12850690
fbshipit-source-id: c2e3f336796b4ae38be6027d2ec131a274a6aa8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13603
P
Moved vectorized CPU copy to aten. Notable changes mainly in _copy_same_type_.
Reviewed By: ezyang
Differential Revision: D12936031
fbshipit-source-id: 00d28813e3160595e73d104f76685e13154971c1
Summary:
```
The most significant change is that this fixes the error message when
indexing an empty tensor with an out-of-bounds index. For example:
x = torch.ones(10, 0)
x[:, [3, 4]]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14441
Differential Revision: D13226737
Pulled By: colesbury
fbshipit-source-id: d1c4a35a30e3217e3d1727d13f6b354a4a3b2a24
Summary:
Rebased version of https://github.com/pytorch/pytorch/pull/13337.
I don't think the lint errors in the original PR had to do with files I touched, so hopefully the rebase fixes them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14587
Differential Revision: D13277428
Pulled By: soumith
fbshipit-source-id: f04c186b1dd4889b4250597eef87f9e9bf7b2426
Summary:
This PR fixes an issue of the slowness expanded MVN.
A notebook to show the problem is [here](https://gist.github.com/fehiepsi/b15ac2978f1045d6d96b1d35b640d742). Basically, mvn's sample and log_prob have expensive computations based on `cholesky` and `trtrs`. We can save a lot of computation based on caching the unbroadcasted version of `scale_tril` (or `cov_diag`, `cov_factor` in lowrank mvn).
When expanding, this cached tensor should not be expanded together with other arguments.
Ref: https://github.com/uber/pyro/issues/1586
cc neerajprad fritzo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14557
Differential Revision: D13277408
Pulled By: soumith
fbshipit-source-id: a6b16f999b008d5da148ccf519b7f32d9c6a5351
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14547
Unit tests used in dnnlowp need a better compilation flow as some of them need avx. Disabling for now so that pytorch builds with fbgemm.
Reviewed By: jianyuh
Differential Revision: D13240933
fbshipit-source-id: e2e187b758c5d89e524470cd261ce35493f427a2
Summary:
In CanonalizeOp, addmm is separated into mm and add. But output dimension and type are not preserved for the aten::mm node. Fixing this so that the dumped graph after this pass contains accurate information.
sample output:
before:
%6 : Dynamic = aten::mm(%input.2, %5), scope: LinearModel/Sequential[model]/Linear[full0]
after:
%6 : Float(32, 200) = aten::mm(%input.2, %5), scope: LinearModel/Sequential[model]/Linear[full0]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14602
Differential Revision: D13273754
Pulled By: soumith
fbshipit-source-id: 82e22b5f30e9eb6ba9249c5a2216955421f39cc7
Summary:
* s/environmental/environment/g
* Casing (CUDA, InfiniBand, Ethernet)
* Don't embed torch.multiprocessing.spawn but link to it (not part of the package)
* spawn _function_ instead of _utility_ (it's mentioned after the launch utility which is a proper utility)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14605
Differential Revision: D13273480
Pulled By: pietern
fbshipit-source-id: da6b4b788134645f2dcfdd666d1bbfc9aabd97b1
Summary:
These were not enabled after adding support in the Gloo backend. The
argument checks in ProcessGroupGloo raised an error in two cases:
* If the input tensor list to scatter was ``[None]`` on processes other
than the source process.
* If the output tensor list to gather was ``[None]`` on processes other
than the destination process.
This commit prepares these arguments explicitly instead of boxing them
at the process group call site.
This fixes#14536.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14572
Differential Revision: D13272812
Pulled By: pietern
fbshipit-source-id: 12cb0d85ec92f175365cbada585260f89330aad8
Summary:
If torch.multiprocessing.spawn is used to launch non-daemonic
processes (the default since #14391), the spawned children won't be
automatically terminated when the parent terminates.
On Linux, we can address this by setting PR_SET_PDEATHSIG, which
delivers a configurable signal to child processes when their parent
terminates.
Fixes#14394.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14491
Differential Revision: D13270374
Pulled By: pietern
fbshipit-source-id: 092c9d3c3cea2622c3766b467957bc27a1bd500c
Summary:
This fixed two things:
(1) NCCL group doesn't support 2 or more groups, this is because, we need a group name in ProcessGroupNCCL class to keep track of the ProcessGroup ID within that group name, and also the NCCL unique ID within that group name and process group ID. Otherwise, different processes will create different NCCL PG in different orders and can clash on these names. This will fix the NCCL problem.
(2) When using new_group, each rank should enter this function and update its global group name counter to ensure that every rank always operates on the same group name.
With both fixes: repro code in: https://github.com/pytorch/pytorch/issues/14528 should work with both NCCL and Gloo backends.
```
tengli@learnfair096:~$ python -m torch.distributed.launch --nproc_per_node=8 --nnodes=1 --node_rank=0 --master_addr=127.0.0.1 --master_port=30000 ~/github_issues/nccl_group.py
rank: 0 - val: 6.0
rank: 2 - val: 6.0
rank: 3 - val: 6.0
rank: 1 - val: 6.0
rank: 4 - val: 22.0
rank: 6 - val: 22.0
rank: 5 - val: 22.0
rank: 7 - val: 22.0
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14529
Differential Revision: D13253434
Pulled By: teng-li
fbshipit-source-id: 8eb45882b996b06d951fc9a306d5de86a42e8b84
Summary:
Fixing: https://github.com/pytorch/pytorch/issues/14446
This was a supported behavior in old torch.distributed. We want to support it in the new release.
Test should cover all combination of scenario when we have either env or arg set up for rank or size or both
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14494
Differential Revision: D13253433
Pulled By: teng-li
fbshipit-source-id: c05974d84f1bdf969f74ec45763e11a841fe4848
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14283
According to Yangqing, this code was only used by us to do some end-to-end
performance experiments on the impact of cudaSetDevice and cudaGetDevice. Now
that the frameworks are merged, there are a lot of bare calls to those functions
which are not covered by this flag. It doesn't seem like a priority to restore
this functionality, so I am going to delete it for now. If you want to bring
it back, you'll have to make all get/set calls go through this particular
interfaces.
Reviewed By: dzhulgakov
Differential Revision: D13156472
fbshipit-source-id: 4c6d2cc89ab5ae13f7c816f43729b577e1bd985c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14282
This also is a substantive change, as 'DeviceIndex' and 'StreamId' are
narrower types than 'int'.
Reviewed By: Yangqing, smessmer
Differential Revision: D13156471
fbshipit-source-id: 08aa0f70c4142415b6bd4d17c57da0641c1d0e9a
Summary:
Stacked on https://github.com/pytorch/pytorch/pull/14378, only look at the last commit.
This changes the way methods are defined in TorchScript archives to use
PythonPrint rather than ONNX protobufs.
It also updates torch.proto to directly document the tensor data
structure actually being serialized.
Notes:
* because PythonPrint prints all the methods at once per module, this
removes MethodDef in favor of a single torchscript_area and a separate
caffe2_graphs entry. Note that NetDef's already have method names,
so there is no need or a separate method name entry.
* This switches cpp/pickle area to RecordRef (references to a file in
the container format) since it is possible the data in these arenas
may be large and not suited to json ouput.
* Removes 'annotations' -- annotations should be re-added on the first
commit that actually has a practical use for them. In the current state
it is unlikely they are representing the right information.
* Some expect files have changed because PythonPrint is preserving more
debug name information for parameter names.
* MethodEncoder (the ONNX output format) has been deleted. There is still
some cleanup possible combining EncoderBase and GraphEncode now that there
is only a single pathway using EncoderBase.
* This incorporates the changes from #14397
to define TensorDef
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14400
Reviewed By: suo
Differential Revision: D13231800
Pulled By: zdevito
fbshipit-source-id: af5c1152d0bd6bca8b06c4703f59b161bb19f571
Summary:
Removed an incorrect section. We don't support this. I wrote this from my memory :(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14530
Differential Revision: D13253471
Pulled By: teng-li
fbshipit-source-id: c3f1ffc6c98ef8789157e885776e0b775ec47b15
Summary:
This PR adds a polyfill for `typing.List` for Python versions that don't
support `typing` as a builtin. It also moves the type defintions from
`annotations.py` so that they can be used in `torch.nn`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14482
Differential Revision: D13237570
Pulled By: driazati
fbshipit-source-id: 6575b7025c2d98198aee3b170f9c4323ad5314bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14544
Modern usage is options(). This doesn't have a functional
difference, because all call sites were CPU only (where
getting the device index right doesn't matter.)
Reviewed By: gchanan
Differential Revision: D13258252
fbshipit-source-id: c70f8d618ee9caf37ff2469cceaa439348b6114c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14543
The modern way to do this is to use options(). It doesn't
make a functional difference here because everything is CPU
(so loss of device information is not a big deal), but
it's definitely safer this way.
Reviewed By: gchanan
Differential Revision: D13257847
fbshipit-source-id: afbc9f7f8d4ca5a8b1cf198997c307e27a2c3333
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14421
Last time I looked this, I bailed because it seemed like there were
a lot of sites to fix. Well, I need this to work properly for out-of-place
HIPify, so I took another whack at it. Changes should be pretty self-explanatory.
Reviewed By: gchanan
Differential Revision: D13221302
fbshipit-source-id: ed21e2668a1a629898a47358baf368fe680263a0
Summary:
To convert `max_unpool` functions to weak script, this PR adds support
for `T` as default arguments for `BroadcastingListN[T]`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14361
Differential Revision: D13192231
Pulled By: driazati
fbshipit-source-id: a25b75a0e88ba3dfa22d6a83775e9778d735e249
Summary:
A few months ago we were seeing test failures on certain architectures due to invalid launch configurations of the kernels in aten/src/THCUNN/VolumetricConvolution.cu.
This PR ensures that those kernels are always compiled such that at least one block can be resident on an SM, and such errors will not be encountered at runtime on any architecture after compiling for that architecture.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14564
Differential Revision: D13266136
Pulled By: soumith
fbshipit-source-id: 35464b20848bb0a1168e8f3b233172331c50b35b
Summary:
Goal of this PR is to unify cuda and hip device types in caffe2 python front end.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14221
Differential Revision: D13148564
Pulled By: bddppq
fbshipit-source-id: ef9bd2c7d238200165f217097ac5727e686d887b
Summary:
As a workaround before hcc has fixed high memory usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14566
Differential Revision: D13263555
Pulled By: bddppq
fbshipit-source-id: 479c7a76aff3919f028e03ef345795537480f0fa
Summary:
Previously if it unconditionally tries to load rocm cmake files, so there was no way to disable rocm build. After this change, USE_ROCM=0 will disable rocm build.
Should fix#14025
soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14261
Differential Revision: D13242090
Pulled By: bddppq
fbshipit-source-id: 652ec7d49dce9b357778bfa53a8e04b7079787ab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14434
The referenced classes live now in c10, so we don't need to specify their namespace.
Reviewed By: ezyang
Differential Revision: D13224015
fbshipit-source-id: 6d154b8e3f9a1e38ff0407dbb1151f5c1d5df260
Summary:
This function is only implemented for the subclasses where it makes
sense. If it's not overridden it will throw an error. Having this
function removes the need for a pointer passing hack to pass the
source rank of a recv operation back to the caller. Instead, the
caller can now call `source_rank` on the work object and achieve
the same result.
Closes#11804.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14453
Differential Revision: D13230898
Pulled By: pietern
fbshipit-source-id: ef38f48bfaca8ef9a364e5be122951bafc9f8e49
Summary:
The math symbol was missing a prefix `:`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14532
Differential Revision: D13256077
Pulled By: soumith
fbshipit-source-id: 2359819d8aa664f915be1c436cbb0c0756504028
Summary:
Make Samplers optionally accept new size in their reset() method. This helps dataloader or dataset to reset the sampler for an epoch or a chunk of data with different sizes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13870
Differential Revision: D13240120
Pulled By: soumith
fbshipit-source-id: 19c53f8be13c0fdcf504f0637b0d3e6009a8e599
Summary:
This PR adds weak modules for all activation modules and uses `test_nn` module tests to test weak modules that have been annotated with `weak_module` and therefore are in `torch._jit_internal._weak_types`
Also depends on #14379
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14238
Differential Revision: D13252887
Pulled By: driazati
fbshipit-source-id: e9638cf74089884a32b8f0f38396cf432c02c988
Summary:
Resubmitting PR #14415
The tests added for Embedding + EmbeddingBag had random numbers as input, which affected the random number generator & caused the flakey test to break.
Everything but the last two commits have already been accepted
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14509
Differential Revision: D13247917
Pulled By: eellison
fbshipit-source-id: ea6963c47f666c07687787e2fa82020cddc6aa15
Summary:
(1) Move Caffe2 thread pool to aten
(2) Use the same thread pool definition for PyTorch interpreter
(3) Make ivalue::Future thread-safe
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14114
Reviewed By: ilia-cher
Differential Revision: D13110451
Pulled By: highker
fbshipit-source-id: a83acb6a4bafb7f674e3fe3d58f7a74c68064fac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14269
Removes reference to Context proper and instead adds a bool argument for async copy (the same as `copy_`)
For CopyFrom - I haven't tweaked all callsites yet. Instead I rely on a terrible hack that pointer to context is implicitly converted to bool when passed, haha :) It's not a good code and I propose to fix it in a follow up diff (maybe using clangr tooling).
Reviewed By: ezyang
Differential Revision: D13117981
fbshipit-source-id: 7cb1dc2ba6a4c50ac26614f45ab8318ea96e3138
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14268
Removes the need for Context in Tensor by doing simple dispatch for CopyBytes. It'd eventually be subsumed by Roy Li's changes of proper copy_ op, but before that is done, let's get a clear logic of how copies are implemented and clean up some craft in CopyFrom implementation.
Note, that with these changes, one can probably can get rid of Context::CopyFromCPU/CopyToCPU, but it's a matter for follow up diffs.
This diff doesn't change the API of Tensor yet, but relies on the fact that passing `Context` to CopyFrom makes copy async if the device is CUDA and doesn't have any effect otherwise (that's how Context methods are implemented).
This doesn't change semantics of copy async implementation - as before it blindly calls cudaMemcpyAsync which probably means that it can be misused if invoked separately outside of operator body. I'll leave it for the follow up copy_ unification.
For Extend() we always do async copy - it makes sense as it's an in-place device-device operation and only any further op would be observable.
Note: there are now three ways of invoking copy in C2 code - templated CopyBytes, virtual CopyFromCPU/etc, and double-dispatch free method here. Hopefully we can get rid of the second one.
Also, please advise whether it's c10-worthy :)
Reviewed By: ezyang
Differential Revision: D13117987
fbshipit-source-id: a6772d6dcf3effaf06717da3a656fc9873b310b5
Summary:
Add to the Tensor doc info about `.device`, `.is_cuda`, `.requires_grad`, `.is_leaf` and `.grad`.
Update the `register_backward_hook` doc with a warning stating that it does not work in all cases.
Add support in the `_add_docstr` function to add docstring to attributes.
There is an explicit cast here but I am not sure how to handle it properly. The thing is that the doc field for getsetdescr is written as being a const char * (as all other doc fields in descriptors objects) in cpython online documentation. But in the code, it is the only one that is not const.
I assumed here that it is a bug in the code because it does not follow the doc and the convention of the others descriptors and so I cast out the const.
EDIT: the online doc I was looking at is for 3.7 and in that version both the code and the doc are const. For older versions, both are non const.
Please let me know if this should not be done. And if it should be done if there is a cleaner way to do it !
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14339
Differential Revision: D13243266
Pulled By: ezyang
fbshipit-source-id: 75b7838f7cd6c8dc72b0c61950e7a971baefaeeb
Summary:
This has 4 changes
1) propagate USE_SYSTEM_NCCL. Previously it was ignored and cmake always did a FindPackage
2) respect SCCACHE_DISABLE in our caffe2 sccache wrapper for circleci
3) use SCCACHE_DISABLE when building nccl, because it triggers the same bug as when using CCACHE (already tracked in https://github.com/pytorch/pytorch/issues/13362). This was hidden because we weren't respecting USE_SYSTEM_NCCL, and were never building nccl ourselves in CI
4) In one particular CI configuration (caffe2, cuda 8, cudnn 7), force USE_SYSTEM_NCCL=1. Building the bundled nccl triggers a bug in nvlink. I've done some investigation, but this looks like a tricky, preexisting bug, so rather than hold up this diff I'm tracking it separately in https://github.com/pytorch/pytorch/issues/14486
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14195
Differential Revision: D13237502
Pulled By: anderspapitto
fbshipit-source-id: 1100ac1269c7cd39e2e0b3ba12a56a3ce8977c55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14247
Just a bunch of clean up to get the code in a good state before we
enshrine it in c10.
Billing of changes:
- Inline all "pointer" API functions into their real implementations,
so we don't have a bunch of dead pointer functions hanging around.
- Replace all occurrences of int64_t with DeviceIndex, as appropriate
- Rename device field to device_index
- Add documentation for everything in CUDAStream.h
- Bring CUDAStream to API parity with Stream (e.g., support equality)
- Delete uncheckedSetCurrentCUDAStream, it didn't work anyway because
StreamId to internal pointer conversion has a bunch of ways it can
fail. Just hope for the best!
Reviewed By: dzhulgakov
Differential Revision: D13141949
fbshipit-source-id: a02f34921e3d8294bd77c262bd05da07d1740a71
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14429
- forbid copying
- make final what ought to be
Reviewed By: dzhulgakov
Differential Revision: D13223125
fbshipit-source-id: e6176cc916d4cd8370c835f243ca90d5c3124c4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14139
This seems neither be used nor implemented. Also, it is a c10->aten dependency which we don't want.
Reviewed By: ezyang
Differential Revision: D13112298
fbshipit-source-id: 0407c4c3ac9b02bbd6fca478336cb6a6ae334930
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14424
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14136
Since now Tensor is a shared_ptr, it doesn't make sense to have Tensor* around anymore,
so we want to change Tensor* to Tensor in the interface.
We added functions that work with `Tensor` instead of `Tensor*` in this diff.
To remove Tensor*, we'll do following
```
auto* Y = Ouptut(0);
Y->mutable_data...
```
-->
```
auto Y = Output(0);
Y.mutable_data...
```
But to run clangr codemod, we'll keep both APIs in different names, e.g. `Output` and `XOutput`, and do the refactor and then delete the old method and rename the new method into the old one.
For example for `Output`, we'll first codemod the callsites from `Output` to `XOutput`, then delete the old `Output` and rename `XOutput` to `Output` in the end.
Reviewed By: smessmer
Differential Revision: D12934074
fbshipit-source-id: d0e85f6ef8d13ed4e7a7505faa5db292a507d54c
Summary:
This applies to the gloo backend only. Timeout support for the NCCL and
MPI backends is tracked in issues #14371 and #14372 respectively.
When creating a new process group (either the global one or any subgroup
created through `new_group`) you can specify a timeout keyword
argument (of type datetime.timedelta). This timeout applies to all
collective operations executed against that process group, such that any
operation taking longer than the timeout will throw a runtime error.
Using a different, better catchable error type is tracked in #14433.
This fixes#14376.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14435
Differential Revision: D13234317
Pulled By: pietern
fbshipit-source-id: 973993b67994dc64861c0977cbb6f051ec9d87f6
Summary:
I feel a bit bad writing this patch, because there isn't really
any reason not to use the normal dispatch mechanism for CUDA
and HIP here (so we have *yet another dispatcher*), but I don't
really want to sign up to rewrite DispatchStub to deduplicate the
dispatcher right now.
Need to natively add support for HIP here, as I don't want to
have to HIPify files which are not in a CUDA directory.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14413
Differential Revision: D13220358
Pulled By: ezyang
fbshipit-source-id: cc61218322589a1dc2ab8eb9d5ddd3c616f6b712
Summary:
Add support for Embedding and EmbeddingBag in script. Both functions require with torch.no_grad(), which we don't have any plans to support in the near future. To work around this, I added a embedding_renorm function without derivatives.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14415
Reviewed By: wanchaol
Differential Revision: D13219647
Pulled By: eellison
fbshipit-source-id: c90706aa6fbd48686eb10f3efdb65844be7b8717
Summary:
Multi-dimensional `sum` is already implemented, and it's trivial to implement `mean` in terms of `sum`, so just do it.
Bonus: Fix incomplete language in the `torch.sum` documentation which doesn't take into account multiple dimensions when describing `unsqueeze` (at the same time as introducing similar language in `torch.mean`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14252
Differential Revision: D13161157
Pulled By: umanwizard
fbshipit-source-id: c45da692ba83c0ec80815200c5543302128da75c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/14344 and https://github.com/pytorch/pytorch/issues/6863
The slowdown was due to the fact that we were only summarizing the tensor (for computing the number of digits to print) if its first dimension was larger than the threshold. It now goes over all the dimensions.
Some quick runtime analysis:
Before this PR:
```python
In [1]: import torch; a = torch.rand(1, 1700, 34, 50)
In [2]: %timeit str(a)
13.6 s ± 84.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
```
After this PR
```python
In [1]: import torch; a = torch.rand(1, 1700, 34, 50)
In [2]: %timeit str(a)
2.08 ms ± 395 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [3]: b = a.cuda()
In [4]: %timeit str(b)
8.39 ms ± 45.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14418
Reviewed By: weiyangfb
Differential Revision: D13226950
Pulled By: soumith
fbshipit-source-id: 19eb4b855db4c8f891d0925a9c56ae8a2824bb23
Summary:
- to fix#12241
- add `_sparse_sum()` to ATen, and expose as `torch.sparse.sum()`, not support `SparseTensor.sum()` currently
- this PR depends on #11253, and will need to be updated upon it lands
- [x] implement forward
- [x] implement backward
- performance [benchmark script](https://gist.github.com/weiyangfb/f4c55c88b6092ef8f7e348f6b9ad8946#file-sparse_sum_benchmark-py):
- sum all dims is fastest for sparse tensor
- when input is sparse enough nnz = 0.1%, sum of sparse tensor is faster than dense in CPU, but not necessary in CUDA
- CUDA backward is comparable (<2x) between `sum several dims` vs `sum all dims` in sparse
- CPU backward uses binary search is still slow in sparse, takes `5x` time in `sum [0, 2, 3] dims` vs `sum all dims`
- optimize CUDA backward for now
- using thrust for sort and binary search, but runtime not improved
- both of CPU and CUDA forward are slow in sparse (`sum several dims` vs `sum all dims`), at most `20x` slower in CPU, and `10x` in CUDA
- improve CPU and CUDA forward kernels
(nnz, sizes, sum_dims, keepdim, sum all or dims, bk=backward) | CPU (sparse vs dense) | CUDA(sparse vs dense)
-- | -- | --
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 8.77 µs vs 72.9 µs | 42.5 µs vs 108 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 112 µs vs 4.47 ms | 484 µs vs 407 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 141 µs vs 148 µs | 647 µs vs 231 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 235 µs vs 1.23 ms | 781 µs vs 213 µs
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 48.5 µs vs 360 µs | 160 µs vs 2.03 ms
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 258 µs vs 1.22 ms | 798 µs vs 224 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 204 µs vs 882 µs | 443 µs vs 133 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 709 µs vs 1.15 ms | 893 µs vs 202 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 39.8 µs vs 81 µs | 42.4 µs vs 113 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 747 µs vs 4.7 ms | 2.4 ms vs 414 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 1.04 ms vs 126 µs | 5.03 ms vs 231 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 1.12 ms vs 1.24 ms | 5.99 ms vs 213 µs
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 133 µs vs 366 µs | 463 µs vs 2.03 ms
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 1.56 ms vs 1.22 ms | 6.11 ms vs 229 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 1.53 ms vs 799 µs | 824 µs vs 134 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 5.15 ms vs 1.09 ms | 7.02 ms vs 205 µs
- after improving CPU and CUDA forward kernels
- in `(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD)` forward, CPU takes ~~`171 µs`~~, in which `130 µs` is spent on `coalesce()`, for CUDA, total time is ~~`331 µs`~~, in which `141 µs` is spent on `coalesce()`, we need to reduce time at other places outside `coalesce()`.
- after a few simple tweaks, now in the forward, it is at most `10x` slower in CPU, and `7x` in CUDA. And time takes in `sum dense dims only [2, 3]` is `~2x` of `sum all dims`. Speed of `sum all sparse dims [0, 1]` is on bar with `sum all dims`
(nnz, sizes, sum_dims, keepdim, sum all or dims, bk=backward) | CPU (sparse vs dense) | CUDA(sparse vs dense)
-- | -- | --
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 7 µs vs 69.5 µs | 31.5 µs vs 61.6 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 11.3 µs vs 4.72 ms | 35.2 µs vs 285 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 197 µs vs 124 µs | 857 µs vs 134 µs
(1000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 124 µs vs 833 µs | 796 µs vs 106 µs
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 20.5 µs vs 213 µs | 39.4 µs vs 1.24 ms
(1000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 131 µs vs 830 µs | 881 µs vs 132 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 95.8 µs vs 409 µs | 246 µs vs 87.2 µs
(1000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 624 µs vs 820 µs | 953 µs vs 124 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll) | 45.3 µs vs 72.9 µs | 33.9 µs vs 57.2 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD) | 81.4 µs vs 4.49 ms | 39.7 µs vs 280 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumAll, bk) | 984 µs vs 111 µs | 6.41 ms vs 121 µs
(10000, [1000, 1000, 2, 2], [0, 1], False, sumD, bk) | 1.45 ms vs 828 µs | 6.77 ms vs 113 µs
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD) | 74.9 µs vs 209 µs | 37.7 µs vs 1.23 ms
(10000, [1000, 1000, 2, 2], [2, 3], False, sumD, bk) | 1.48 ms vs 845 µs | 6.96 ms vs 132 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD) | 1.14 ms vs 411 µs | 252 µs vs 87.8 µs
(10000, [1000, 1000, 2, 2], [0, 2, 3], False, sumD, bk) | 4.53 ms vs 851 µs | 7.12 ms vs 128 µs
- time takes in CUDA backward of sparse is super long with large variance (in case of nnz=10000, it normally takes 6-7ms). To improve backward of sparse ops, we will need to debug at places other than CUDA kernels. here is a benchmark of `torch.copy_()`:
```
>>> d = [1000, 1000, 2, 2]
>>> nnz = 10000
>>> I = torch.cat([torch.randint(0, d[0], size=(nnz,)),
torch.randint(0, d[1], size=(nnz,))], 0).reshape(2, nnz)
>>> V = torch.randn(nnz, d[2], d[3])
>>> size = torch.Size(d)
>>> S = torch.sparse_coo_tensor(I, V, size).coalesce().cuda()
>>> S2 = torch.sparse_coo_tensor(I, V, size).coalesce().cuda().requires_grad_()
>>> data = S2.clone()
>>> S.copy_(S2)
>>> y = S * 2
>>> torch.cuda.synchronize()
>>> %timeit y.backward(data, retain_graph=True); torch.cuda.synchronize()
7.07 ms ± 3.06 ms per loop (mean ± std. dev. of 7 runs, 1000 loops each)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12430
Differential Revision: D12878313
Pulled By: weiyangfb
fbshipit-source-id: e16dc7681ba41fdabf4838cf05e491ca9108c6fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14350
acc32 for now. Will have a separate diff for acc16 but that will need another out processing that does sparse convolution without im2col.
Reviewed By: dskhudia
Differential Revision: D13188595
fbshipit-source-id: e8faee46c7ea43e4a600aecb8b8e93e6c860a8c8
Summary:
The doc covers pretty much all we have had on distributed for PT1 stable release, tracked in https://github.com/pytorch/pytorch/issues/14080
Tested by previewing the sphinx generated webpages. All look good.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14444
Differential Revision: D13227675
Pulled By: teng-li
fbshipit-source-id: 752f00df096af38dd36e4a337ea2120ffea79f86
Summary:
Fixed: https://github.com/pytorch/pytorch/issues/14445
Also bumped up timeout to 30 seconds, since on 8-GPU machines, DDP test will take more than 15 seconds sometimes.
Tested on 8 GPU machines:
```
tengli@learnfair062:~/pytorch/test$ python test_c10d.py --verbose
test_dist_broadcast_coalesced_gloo (__main__.DistributedDataParallelTest) ... ok
test_dist_broadcast_coalesced_nccl (__main__.DistributedDataParallelTest) ... skipped 'Test skipped due to known issues'
test_fp16 (__main__.DistributedDataParallelTest) ... ok
test_gloo_backend (__main__.DistributedDataParallelTest) ... ok
test_nccl_backend (__main__.DistributedDataParallelTest) ... ok
test_queue_reduction (__main__.DistributedDataParallelTest) ... ok
test_sync_params_no_buffers (__main__.DistributedDataParallelTest) ... ok
test_sync_params_with_buffers (__main__.DistributedDataParallelTest) ... ok
test_sync_reduction (__main__.DistributedDataParallelTest) ... ok
test_set_get (__main__.FileStoreTest) ... ok
test_set_get (__main__.PrefixFileStoreTest) ... ok
test_set_get (__main__.PrefixTCPStoreTest) ... ok
test_allgather_basics (__main__.ProcessGroupGlooTest) ... ok
test_allgather_checks (__main__.ProcessGroupGlooTest) ... ok
test_allreduce_basics (__main__.ProcessGroupGlooTest) ... ok
test_allreduce_basics_cuda (__main__.ProcessGroupGlooTest) ... ok
test_allreduce_checks (__main__.ProcessGroupGlooTest) ... ok
test_allreduce_stress (__main__.ProcessGroupGlooTest) ... ok
test_allreduce_stress_cuda (__main__.ProcessGroupGlooTest) ... ok
test_broadcast_basics (__main__.ProcessGroupGlooTest) ... ok
test_broadcast_basics_cuda (__main__.ProcessGroupGlooTest) ... ok
test_broadcast_checks (__main__.ProcessGroupGlooTest) ... ok
test_broadcast_stress (__main__.ProcessGroupGlooTest) ... ok
test_broadcast_stress_cuda (__main__.ProcessGroupGlooTest) ... ok
test_gather_basics (__main__.ProcessGroupGlooTest) ... ok
test_gather_checks (__main__.ProcessGroupGlooTest) ... ok
test_reduce_basics (__main__.ProcessGroupGlooTest) ... ok
test_reduce_checks (__main__.ProcessGroupGlooTest) ... ok
test_scatter_basics (__main__.ProcessGroupGlooTest) ... ok
test_scatter_checks (__main__.ProcessGroupGlooTest) ... ok
test_send_recv_all_to_all (__main__.ProcessGroupGlooTest) ... ok
test_timeout_kwarg (__main__.ProcessGroupGlooTest) ... ok
test_allgather_ops (__main__.ProcessGroupNCCLTest) ... ok
test_allreduce_ops (__main__.ProcessGroupNCCLTest) ... ok
test_barrier (__main__.ProcessGroupNCCLTest) ... ok
test_broadcast_ops (__main__.ProcessGroupNCCLTest) ... ok
test_reduce_ops (__main__.ProcessGroupNCCLTest) ... ok
test_common_errors (__main__.RendezvousEnvTest) ... ok
test_nominal (__main__.RendezvousEnvTest) ... ok
test_common_errors (__main__.RendezvousFileTest) ... ok
test_nominal (__main__.RendezvousFileTest) ... ok
test_common_errors (__main__.RendezvousTCPTest) ... ok
test_nominal (__main__.RendezvousTCPTest) ... ok
test_unknown_handler (__main__.RendezvousTest) ... ok
test_address_already_in_use (__main__.TCPStoreTest) ... ok
test_set_get (__main__.TCPStoreTest) ... ok
----------------------------------------------------------------------
Ran 46 tests in 162.980s
OK (skipped=1)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14452
Differential Revision: D13230652
Pulled By: teng-li
fbshipit-source-id: 88580fe55b3a4fbc7a499ca3b591958f11623bf8
Summary:
This PR adds weak modules for all activation modules and uses `test_nn` module tests to test weak modules that have been annotated with `weak_module` and therefore are in `torch._jit_internal._weak_types`
Also depends on #14379
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14238
Differential Revision: D13192230
Pulled By: driazati
fbshipit-source-id: 36488960b6c91448b38c0fa65422539a93af8c5e
Summary:
This PR allows to overload functions based on the value of a parameter (so long as it is a constant). See max_pool1d for an example usage.
This is the first step in enabling the use of max_pool functions for the standard library that can return `Tensor` or `Tuple[Tensor, Tensor]` based on the `return_indices` flag. This will give the JIT identical results to the Python versions of the functions.
Fixes#14081
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14425
Differential Revision: D13222104
Pulled By: driazati
fbshipit-source-id: 8cb676b8b13ebcec3262234698edf4a7d7dcbbe1
Summary:
Port AffineGrid to C++, because script does not support compiling Function classes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14392
Differential Revision: D13219698
Pulled By: eellison
fbshipit-source-id: 3ddad8a84c72010b5a6c6f7f9712be614202faa6
Summary:
When using `setuptools` to build a Python extension, setuptools will automatically add an ABI suffix like `cpython-37m-x86_64-linux-gnu` to the shared library name when using Python 3. This is required for extensions meant to be imported as Python modules. When we use setuptools to build shared libraries not meant as Python modules, for example libraries that define and register TorchScript custom ops, having your library called `my_ops.cpython-37m-x86_64-linux-gnu.so` is a bit annoying compared to just `my_ops.so`, especially since you have to reference the library name when loading it with `torch.ops.load_library` in Python.
This PR fixes this by adding a `with_options` class method to the `torch.utils.cpp_extension.BuildExtension` which allows configuring the `BuildExtension`. In this case, the first option we add is `no_python_abi_suffix`, which we then use in `get_ext_filename` (override from `setuptools.build_ext`) to throw away the ABI suffix.
I've added a test `setup.py` in a `no_python_abi_suffix_test` folder.
Fixes https://github.com/pytorch/pytorch/issues/14188
t-vi fmassa soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14130
Differential Revision: D13216575
Pulled By: goldsborough
fbshipit-source-id: 67dc345c1278a1a4ee4ca907d848bc1fb4956cfa
Summary:
Stacked on #14176, review only the last commit.
* Print parameters to methods as self.weight rather than as extra inputs.
* Print entire set of methods out as a single string
* Update test code to test the module-at-a-time export/import
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14378
Differential Revision: D13198463
Pulled By: zdevito
fbshipit-source-id: 3fab02e8239cfd6f40d6ab6399047bd02cf0a8c8
Summary:
I'd like to NOT HIPify files that are not in a cuda/
directory, so hand-HIPify AccumulateType.h
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14412
Differential Revision: D13221801
Pulled By: ezyang
fbshipit-source-id: d1927cfc956e50a6a5e67168ac0e1ce56ecd1e0b
Summary:
This speeds-up "advanced" indexing (indexing a tensor by a tensor)
on CPU and GPU. There's still a bunch of work to do, including
speeding up indexing by a byte (boolean) mask and speeding up the derivative
calculation for advanced indexing.
Here's some speed comparisons to indexing on master using a little [benchmark script](https://gist.github.com/colesbury/c369db72aad594e5e032c8fda557d909) with 16 OpenMP threads and on a P100. The test cases are listed as (input shape -> output shape).
| Test case | CPU (old vs. new) | CUDA (old vs. new) |
|-----------------------|---------------------|------------------------|
| 1024x1024 -> 512x1024 | 225 us vs. **57 us** | 297 us vs. **47 us** |
| 1024x1024 -> 1024x512 | 208 us vs. **153 us** | 335 us vs. **54 us** |
| 50x50 -> 20000x50 | 617 us vs. **77 us** | 239 us vs. **54 us** |
| 50x50 -> 50x20000 | 575 us vs. **236 us** | 262 us vs. **58 us** |
| 2x5x10 -> 10 | 65 us vs. **18 us** | 612 us vs. **93 us** |
See #11647
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13420
Reviewed By: soumith
Differential Revision: D13088936
Pulled By: colesbury
fbshipit-source-id: 0a5c2ee9aa54e15f96d06692d1694c3b24b924e2
Summary:
`call "C:\\Program Files (x86)\\Microsoft Visual Studio\\2017\\Community\\VC\\Auxiliary\\Build\\vcvarsall.bat" x64` seems to change the working dir to `C:\Users\Administrator\source`, and we need to cd back to the PyTorch directory before running `git submodule update --init --recursive`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14416
Differential Revision: D13222269
Pulled By: yf225
fbshipit-source-id: a0eb3311fb11713b1bb8f52cd13e2c21d5ca9c7b
Summary:
In #14239 we fixed ONNX_ATEN.
In order to make sure its correctness in the future, we should add related test case.
We use torch.fmod() to test ONNX_ATEN.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14259
Differential Revision: D13204610
Pulled By: zrphercule
fbshipit-source-id: e4660c346e5edd201f1458b7d74d7dfac49b94c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14342
Sometimes, when we are creating a TaskGroup, we are in fact creating a TaskGroup for a distributed job. In some cases, we may want to register a few nets as "remote" to a TaskGroup. The remote net should have sufficient attributes on where they should be executed later on.
This diff adds the remote net attribute to the TaskGroup class. It exposes two minimal functionalities: adding a remote net, and getting all remote nets added to a TaskGroup.
Reviewed By: d4l3k
Differential Revision: D13188320
fbshipit-source-id: efe947aec30817e9512a5e18be985713b9356bdc
Summary:
This code doesn't actually do anything, but it will be the
groundwork necessary to change PyTorch's HIPIFY pass from reusing
CUDA identifiers directly, to actually switching to using HIP
identifiers (moving us closer to a world where we can compile
both HIP and CUDA PyTorch side-by-side.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14285
Differential Revision: D13158851
Pulled By: ezyang
fbshipit-source-id: df2462daa5d0d4112455b67bd3067d60ba55cda5
Summary:
This PR adds a `try_outplace` option to the tracer. When `try_outplace` is true, the tracer will attempt to out-of-place ops (similar to how things are done today). When it's false, the correct in-place op is emitted.
I made `try_outplace` false by default, but flipped it to true for ONNX export utils. zdevito jamesr66a, anywhere else I should preserve the existing behavior?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14254
Reviewed By: eellison
Differential Revision: D13166691
Pulled By: suo
fbshipit-source-id: ce39fdf73ac39811c55100e567466d53108e856b
Summary:
[Stacked commit, only review the last commit]
This PR adds support for printing default values in python printing as well as the logic
for parsing default values back in using the parser. For simplicity, this PR simply
creates a subgraph of the constant expressions and then runs that graph to generate the defaults.
A more lightweight approach should be possible later, but would require more machinery.
To make reading code in the printer easier, this also add ir_views.h.
Similar to tree_views.h these classes can provide views of some commonly used IR nodes
that have complicated structure and common operations on that structure.
Currently it has only read-only views for prim::If and prim::Loop,
but we should eventually add helpers to manipulate If/Loop nodes as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14176
Differential Revision: D13198455
Pulled By: zdevito
fbshipit-source-id: dc99ab9692804ccaedb60a55040c0b89ac7a6a6d
Summary:
This adds scalar type support to the fuser, both internally (instead of auto / assuming float) and for the inputs/outputs.
We can now fuse things with input / output of arbitrary scalar type, in particular comparisons and where work well. So it fixes#13384 by returning the right type tensor (and adds a test where byte and double tensors are returned).
The type inference is done by re-calling PropagateTensorShapeOnNode in the compilation, I would venture that it isn't prohibitively expensive compared to the actual compilation. (Propagation was fixed for where to return the second argument's type and amended to handle FusedConcat.)
I'm not sure how to add a check for the code generated by the fuser, but I am not sure we absolutely need to (we'd see if it is invalid / produces wrong results).
Thanks in particular to apaszke, fmassa, mruberry for advice and encouragement! All the errors are my own.
I have discussed order of PRs briefly with mruberry, if this goes in before he submits the PR, he graciously agreed to rebasing his, but I'd happily rebase, too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14336
Differential Revision: D13202620
Pulled By: soumith
fbshipit-source-id: 855159e261fa15f21aca3053bfc05fb3f720a8ef
Summary:
This PR allows to overload functions based on the value of a parameter (so long as it is a constant). See `max_pool1d` for an example usage.
This is the first step in enabling the use of `max_pool` functions for the standard library that can return `Tensor` or `Tuple[Tensor, Tensor]` based on the `return_indices` flag. This will give the JIT identical results to the Python versions of the functions.
Depends on #14232 for `Optional[BroadcastingList[T]]`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14081
Differential Revision: D13192228
Pulled By: driazati
fbshipit-source-id: fce33c400c1fd06e59747d98507c5fdcd8d4c113
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14386
See #13573, #14142, and #14271 for discussion.
This change updates ProcessGroupGloo to ensure that all prior
operations have completed before executing the barrier.
Reviewed By: manojkris
Differential Revision: D13205022
fbshipit-source-id: 673e7e6ca357dc843874d6dd8da590832e1de7fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14298
This is a breaking API change for users of the C++ c10d API. The work
object defined wait() to return a boolean. If the work completed
successfully it would return true, if it didn't it would return false.
It was then up to the user to call the exception() function to figure
out what went wrong. This has proven suboptimal as it allows users to
forget about failure handling and errors may be ignored.
The work class is semantically very similar to std::future, where a
call to get() may throw if the underlying std::promise has set an
exception. This commit changes the semantic of the work class to be
similar to this and turns wait() into a void function that throws if
the work completes with an exception.
The exception() function can still be used to retrieve the exception
if isSuccess() returns false, but now returns an std::exception_ptr
instead of a reference to a std::exception.
Reviewed By: manojkris
Differential Revision: D13158475
fbshipit-source-id: 9cd8569b9e7cbddc867a5f34c6fd0b7be85581b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14297
Adds option structs for allgather and barrier such that we have one
for every collective. Add timeout member field to every one of these
such that we can support per operation timeouts.
Use default constructed options struct for every collective process
group function exposed to Python.
Reviewed By: manojkris
Differential Revision: D13158474
fbshipit-source-id: 3d28977de2f2bd6fc2f42ba3108b63a429338906
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14296
There was mixed usage of "ProcessGroup::Work" and just "Work".
Adding prefix for readability/consistency.
Reviewed By: manojkris
Differential Revision: D13128977
fbshipit-source-id: a54a8784fa91cd6023c723cb83e9f626fb896a30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14295
This is no longer used after moving to Gloo new style algorithms.
Closes#11912.
Reviewed By: manojkris
Differential Revision: D13111781
fbshipit-source-id: 53e347080e29d847cd9da36f2d93af047930690c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14294
This is the final collective to be ported to the new style where there
is no longer a need to keep a cached algorithm instance around. There
is a follow up change incoming to remove the algorithm caching
functionality in ProcessGroupGloo.
Reviewed By: manojkris
Differential Revision: D13111509
fbshipit-source-id: f3ea0d955a62029fc4e7cfc09055e4957e0943ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14340
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/25
Per-group and per-channel quantization in fbgemm
This diff also cleans up explicit template instantiation using macro expansion
This diff also changes randFill interface which was easy to make mistakes of generating integer random numbers for floating point vectors.
Using this in DNNLOWP operators will be done in a separate diff.
Reviewed By: dskhudia
Differential Revision: D13176386
fbshipit-source-id: e46c53e31e21520bded71b8ed86e8b19e010e2dd
Summary:
As reported in #13386, the pooling operations can return wrong results for large inputs. The root of the problem is that while the output shape is initially being computed with integer operations, it is converted to float32 for division by the stride and applying either a `ceil` or a `floor` depending on the `ceil_mode`. Since even moderately large integers (the smallest being 16,777,217) cannot be expressed exactly in float32, this leads to wrong result shapes.
This PR relies purely on integer operations to perform the shape computation, including the ceil/floor distinction. Since I could not stand all that duplicated code, I pulled it out into a `pooling_shape.h` header, similar to the existing `linear_upsampling.h` header. I hope this is acceptable, let me know if you'd like to see it solved differently. I've also added tests to `test_nn.py` that fail without my changes and pass with my changes. They cover `{max,avg}_pool{1,2,3}d()` for CPU and GPU.
Fixes#13386.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14405
Differential Revision: D13215260
Pulled By: soumith
fbshipit-source-id: 802588ce6cba8db6c346448c3b3c0dac14d12b2d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14246
This commit systematically eliminates THCStream entirely from THC, replacing it
with at::cuda::CUDAStream. In places where the previous pointer type showed up
in a public API signature, those functions are now only available to C++
clients. (It would not be too difficult to make a C-compatible version of
CUDAStream, as it's really just a simple struct, but we leave this for
future work.)
All functions in THC that referred to THCStream were expunged in favor of their
modern counterparts.
One annoyance was that I didn't feel like redoing how the torch.cuda.Stream
binding code worked, but I really wanted to get rid of the stored THCStream*
pointer. So I repurposed the bit-packing code I implemented for Stream hashing,
and used that to (reversibly) store streams in a uint64_t cdata field. A perhaps
more future proof solution would be to get rid of cdata entirely, and store the
device and stream ID directly.
Billing of changes:
- All CUDAStream_ pointer API functions are now hidden and anonymously
namespaced (instead of being in the impl namespace). All use sites
rewritten to use the modern C++ API. Since CUDAStreamInternals is no
longer part of the public API, the CUDAStreamInternals constructor and
internals() method have been removed, and replaced with anonymous
functions in the C++ file.
- device_index() returns DeviceIndex rather than int64_t now
- Stream and CUDAStream now have pack/unpack methods. (CUDAStream checks
that the unpacked bit-pattern is for a CUDA device.)
- THCStream.h header is removed entirely
- Most THCStream handling functions in THC API are removed
Reviewed By: gchanan
Differential Revision: D13121531
fbshipit-source-id: 48873262cc0a37c3eec75a7ba1c93c800da40222
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14191
Previously, Device's hash function only worked for CPU and CUDA. Now
it works for everything.
Implementing the bit concatenation was a bit tricky, and I got it wrong the
first time. See Note [Hazard when concatenating signed integers]
Reviewed By: smessmer
Differential Revision: D13119624
fbshipit-source-id: 36bfa139cfc739bb0624f52aaf466438c2428207
Summary:
This should fix the race among multiple processes: https://github.com/pytorch/pytorch/issues/13750
Essentially, the reader is trying to open the file, and will error out if it doesn't exist, we here factor in the timeout option of FileStore to apply a timeout for creating a file (should always be created anyway unless something is wrong), and more importantly, waiting for the file to be created.
Tested on both NFS and local drive, the race disappears when 8 concurrent processes do distributed training.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14388
Differential Revision: D13207178
Pulled By: teng-li
fbshipit-source-id: d3d5d62c4c8f01c0522bf1653c8986155c54ff80
Summary:
I noticed the test `DataLoaderTest.CanDereferenceIteratorMultipleTimes` doesn't test proper progression of the iterator. I also added a test for using `std::copy`.
Fixes https://github.com/pytorch/pytorch/issues/14276
ebetica ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14045
Differential Revision: D13092187
Pulled By: goldsborough
fbshipit-source-id: 57698ec00fa7b914b159677a4ab38b6b25c2860b
Summary:
Most likely a typo.
Tested on 8-GPU machine
```
tengli@learnfair062:~/pytorch/test$ python test_c10d.py ProcessGroupNCCLTest.test_barrier
.
----------------------------------------------------------------------
Ran 1 test in 29.341s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14389
Differential Revision: D13207207
Pulled By: teng-li
fbshipit-source-id: aaffe14237076fe19d94e2fa4d9c093397f07bb9
Summary:
JIT type system hierarchy refinement and refactors:
1. Make NumberType be the base type of IntType FloatType
2. Make single type container like OptionalType and FutureType share SingleElementType base type
3. Some refactors to make it more robust, e.g. adding python_str() for some types so that we have proper python_print serialization format
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14127
Differential Revision: D13112657
Pulled By: wanchaol
fbshipit-source-id: 335c5b25977be2e0a462c7e4a6649c1b653ccb4f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14143
ConvTranspose has a per-operator attribute rename, which meant that the
global attribute rename for kernels => kernel_shape was not applied.
Changing the behavior so that the global renames always apply, but per-op
renames can override those for specific attributes.
Note: The python frontend path isn't actually used for ConvTranspose, but I
thought it would be good to make it consistent.
Reviewed By: yinghai
Differential Revision: D13113395
fbshipit-source-id: cd3f124b4b5c753a506d297138b7d002b51bfb38
Summary:
it doesn't really make sense on a template class. Also it breaks if
you try to build in debug on Windows, so this will save someone some
frustration in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14044
Differential Revision: D13202960
Pulled By: anderspapitto
fbshipit-source-id: 617d78366993d5ecc2ba1f23bb90010f10df41f3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14196
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13641
FeedTensor function used to take a pointer to Tensor and feed the content using Resize
and mutable_data, but since Tensor is a pointer now, we can just return a Tensor instead.
Reviewed By: dzhulgakov
Differential Revision: D13091163
fbshipit-source-id: 9abf2fd320baca76e050530c500dd29f8e2d0211
Summary:
Fixes#12290. Also speeds up JIT LSTM forward pass from 8.8ms to 7.8ms; previously, each JIT lstm cell used 2 fused kernels. Now, it only uses one fused kernel (which is how many kernels cudnn uses).
Explanation:
Let f, g, h be fusible ops.
```
x = f(v, w)
z = g(x, y)
a, b = chunk(z)
c = h(a, b)
```
becomes (before this PR):
```
x = f(v, w)
x', y' = broadcast_tensors([x, y])
ax, bx = chunk(x')
ay, by = chunk(y')
a = g(ax, ay)
b = g(bx, by)
c = h(a, b)
```
The graph fuser then puts g, g, and h into one FusionGroup and is unable
to move `x = f(v, w)` into the FusionGroup.
This PR lets the graph fuser move `x = f(v, w)` into the FusionGroup.
It does this by abstracting the broadcast_tensors + multiple chunk nodes
into one intermediate `prim::BroadcastingChunk[chunks, dim]` node.
A `BroadcastingChunk[chunks, dim](*inputs)` node is equivalent to:
- broadcasting all of *inputs
- chunk-ing each broadcasted input into `chunks` chunks along dim `dim`.
Abstracting the broadcasting chunk behavior away, it is now a lot easier
for the graph fuser to move (broadcast + chunk) past an operation. After
this PR, the above graph becomes:
```
x = f(v, w)
ax, bx, ay, by = BroadcastingChunk(x, y)
a = g(ax, ay)
b = g(bx, by)
c = h(a, b)
```
Now, to move `x = f(v, w)` after the BroadcastingChunk, one just needs
to add f's operands to the BroadcastingChunk:
```
ay, by, av, bv, aw, bw = BroadcastingChunk(y, v, w)
ax = f(av, aw)
by = f(bv, bw)
a = g(ax, ay)
b = g(bx, by)
c = h(a, b)
```
cc apaszke mruberry zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14055
Differential Revision: D13159259
Pulled By: zou3519
fbshipit-source-id: 134e9e645c950384d9be6a06a883a10e17a73d7d
Summary:
Fix a mishandling of `foo[a] = b` when `a` was a tensor. We were assigning to a copy of `foo`, not a view of it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14311
Differential Revision: D13196109
Pulled By: suo
fbshipit-source-id: c929401fda7c4a27622d3fe2b11278b08a7f17f1
Summary:
On clang-7 (internal) a warning, `-Wreturn-std-move`, is being emitted and raised to an error via `-Werror` for the code this PR fixes. The reason is that `autograd::make_variable` returns an `autograd::Variable`, so returning it from a function that returns `at::Tensor` disallows the compiler from eliding the return value (RVO). So let's explicitly convert the `autograd::Variable` to an `at::Tensor` before returning it.
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14113
Differential Revision: D13105638
Pulled By: goldsborough
fbshipit-source-id: 6e1dc31c6512e105ab2a389d18807422ee29283c
Summary:
Follow-up to #13577
The idea is to take each values tensor, concatenate it with zeros before and after itself (along the dimension corresponding to the one we're catting the tensors along), to get a tensor corresponding to the values for that tensor in the result. Then we concatenate all of those together to get the final values tensor. (Hopefully, this will be more clear from the example in the comments).
The indices are more straightforward: since we aren't concatenating along a sparse dimension, they don't change at all, so all we need to do are concatenate the indices from the different tensors together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13761
Differential Revision: D13160343
Pulled By: umanwizard
fbshipit-source-id: 13d7adecd369e0eebdf5bce3d90a51029b66bd1d
Summary:
For custom TorchScript operators, `torch.ops.load_library` must be used and passed the path to the shared library containing the custom ops. Our C++ extensions stuff generally is meant to build a Python module and import it. This PR changes `torch.utils.cpp_extension.load` to have an option to just return the shared library path instead of importing it as a Python module, so you can then pass it to `torch.ops.load_library`. This means folks can re-use `torch.utils.cpp_extension.load` and `torch.utils.cpp_extension.load_inline` to even write their custom ops inline. I think t-vi and fmassa will appreciate this.
soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13941
Differential Revision: D13110592
Pulled By: goldsborough
fbshipit-source-id: 37756307dbf80a81d2ed550e67c8743dca01dc20
Summary:
This handles the input pre-multiplication in RNNs, yielding pretty significant speedups in backward times. This pass depends on loop unrolling, so we'll batch only as many elements as the unrolling factor allows.
cc mruberry ngimel zou3519 zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13456
Differential Revision: D12920339
Pulled By: zou3519
fbshipit-source-id: 5bcd6d259c054a6dea02ae09a9fdf9f030856443
Summary:
This PR is deceptively large because of an indenting change. The actual change is small; I will highlight it inline
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14325
Differential Revision: D13183296
Pulled By: suo
fbshipit-source-id: fcbf6d5317954694ec83e6b8cc1c989f2d8ac298
Summary:
1. Fix execution failure when some of the paths are not defined
2. Users can now optionally override install dir by setting `CMAKE_INSTALL_PREFIX`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14218
Differential Revision: D13180350
Pulled By: soumith
fbshipit-source-id: 8c9680d1285dbf08b49380af1ebfa43ede99babc
Summary:
Currently, the `pin_memory_batch` function in the dataloader will return a batch comprised of any unrecognized type without pinning the data, because it doesn't know how.
This behavior was preventing us from overlapping data prefetching in Mask-RCNN, whose custom `collate_fn` returns a custom batch type.
The present PR adds the ability for the user to pass a `pin_fn` alongside any custom `collate_fn` to handle such custom types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14171
Differential Revision: D13166669
Pulled By: soumith
fbshipit-source-id: ca965f9841d4a259b3ca4413c8bd0d8743d433ab
Summary:
This issue was noticed, and fix proposed, by raulpuric.
Checkpointing is implemented by rerunning a forward-pass segment for each checkpointed segment during backward. This can result in the RNG state advancing more than it would without checkpointing, which can cause checkpoints that include dropout invocations to lose end-to-end bitwise accuracy as compared to non-checkpointed passes.
The present PR contains optional logic to juggle the RNG states such that checkpointed passes containing dropout achieve bitwise accuracy with non-checkpointed equivalents.** The user requests this behavior by supplying `preserve_rng_state=True` to `torch.utils.checkpoint` or `torch.utils.checkpoint_sequential`.
Currently, `preserve_rng_state=True` may incur a moderate performance hit because restoring MTGP states can be expensive. However, restoring Philox states is dirt cheap, so syed-ahmed's [RNG refactor](https://github.com/pytorch/pytorch/pull/13070#discussion_r235179882), once merged, will make this option more or less free.
I'm a little wary of the [def checkpoint(function, *args, preserve_rng_state=False):](https://github.com/pytorch/pytorch/pull/14253/files#diff-58da227fc9b1d56752b7dfad90428fe0R75) argument-passing method (specifically, putting a kwarg after a variable argument list). Python 3 seems happy with it.
Edit: It appears Python 2.7 is NOT happy with a [kwarg after *args](https://travis-ci.org/pytorch/pytorch/builds/457706518?utm_source=github_status&utm_medium=notification). `preserve_rng_state` also needs to be communicated in a way that doesn't break any existing usage. I'm open to suggestions (a global flag perhaps)?
**Batchnorm may still be an issue, but that's a battle for another day.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14253
Differential Revision: D13166665
Pulled By: soumith
fbshipit-source-id: 240cddab57ceaccba038b0276151342344eeecd7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13168
We now have a "using namespace c10" in the at and caffe2 namespaces, we don't need the individual ones anymore
Reviewed By: ezyang
Differential Revision: D11669870
fbshipit-source-id: fc2bb1008e533906914188da4b6eb30e7db6acc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14214
This is to pick up the residual task of T36325466 to make sure that input/output binding of c2 Onnxifi op is positional.
Reviewed By: dzhulgakov
Differential Revision: D13134470
fbshipit-source-id: d1b916dade65c79133b86507cd54ea5166fa6810
Summary:
1. Support `Optional[BroadcastingList1[int]]` like type annotation to accept a int or a list[int]
2. Convert gumbel_softmax, lp pooling weak functions and modules
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14232
Differential Revision: D13164506
Pulled By: wanchaol
fbshipit-source-id: 6c2a2b9a0613bfe907dbb5934122656ce2b05700
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14021
I'm planning to move at::Scalar to c10, and there's a at::toString(Scalar) defined.
Unfortunately, we call it by specifying at::toString() instead of relying on ADL.
This diff changes that to prepare the actual move.
Reviewed By: ezyang
Differential Revision: D13015239
fbshipit-source-id: f2a09f43a96bc5ef20ec2c4c88f7790fd5a04870
Summary:
Cuda headers include cuda version in form of major.minor. But when we do find_package(cuda). CUDA_VERSION variable includes patch number as well which fails following condition.
`
if(NOT ${cuda_version_from_header} STREQUAL ${CUDA_VERSION})
`
**For example:**
I have cuda 10.0 installed. My nvcc output looks like this
`Cuda compilation tools, release 10.0, **V10.0.130**
`
If I compile my application with caffe2. It gives me following error:
```
CMake Error at /usr/share/cmake/Caffe2/public/cuda.cmake:59 (message):
FindCUDA says CUDA version is (usually determined by nvcc), but the CUDA
headers say the version is 10.0. This often occurs when you set both
CUDA_HOME and CUDA_NVCC_EXECUTABLE to non-standard locations, without also
setting PATH to point to the correct nvcc. Perhaps, try re-running this
command again with PATH=/usr/local/cuda/bin:$PATH. See above log messages
for more diagnostics, and see
https://github.com/pytorch/pytorch/issues/8092 for more details.
```
**In this case, it got failed because**
cuda_version_from_header = 10.0
CUDA_VERSION = 10.0.130 (Came from NVCC)
`if(NOT ${cuda_version_from_header} STREQUAL ${CUDA_VERSION})
`
**Fix:**
We should compare header version with **major.minor format** which is given by CUDA_VERSION_STRING
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14302
Differential Revision: D13166485
Pulled By: soumith
fbshipit-source-id: 1b74e756a76c4cc5aa09978f5850f763ed5469b6
Summary:
This covers the very edgy case when we run the same NCCL process group with multiple GPU combinations instead of the last GPU combination. We always keep track of what GPUs have been used previously in the NCCL process group and barrier() itself will synchronize on each GPU's NCCL stream.
Test covered as well. Tested on 8-GPU machine
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14271
Differential Revision: D13164993
Pulled By: teng-li
fbshipit-source-id: 81e04352740ea50b5e943369e74cfcba40bb61c1
Summary:
First draft of an alias analysis pass. It's a big PR unfortunately; a rough table of contents/suggested order of review:
1. `AliasAnalysis` pass, which traverses the graph and builds an `AliasDb`. The basic strategy is to assign alias information to every value of mutable type (list/tuple/tensor), and use the alias annotations of each node's schema to assign alias info to the outputs based on the alias info the inputs. Nodes that aren't explicitly schematized have hand-written analysis rules.
2. Integration of aliasing information into `moveBefore/AfterTopologicallyValid()`. Basically, we pass in an alias DB when we ask for moveBefore/After. Similar to how we can boil down dependency analysis to "what nodes use this node", we can boil down mutability analysis to "what nodes write to an alias set input/output'd by this node".
3. Integration of alias analysis to optimization passes that need it. Right now, it is `GraphFuser`, `CreateAutodiffSubgraphs`, constant prop, and CSE. Not sure if any others need it.
- Testing; still figuring out the best way to do this.
- Eventually we want to integrate the alias db into the graph, but we shouldn't do that until we can guarantee that the information can stay up to date with mutations.
- Do the same thing `python_printer` did for operators and force people to register alias analyzers if they can't schematize their op.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14018
Differential Revision: D13144906
Pulled By: suo
fbshipit-source-id: 1bc964f9121a504c237cef6dfeea6b233694de6a
Summary:
This somehow is not cleaned up after the C++ migration. Unused and can be removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14208
Differential Revision: D13132492
Pulled By: teng-li
fbshipit-source-id: 0f05b6368174664ebb2560c037347c8eb45f7c38
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14210
We left `SparseLengthsWeightedSum` as benchmark is not testing it due to fp16 filler issue. It was flushed out by unit tests. Hence we add the support here.
Reviewed By: bddppq
Differential Revision: D13132320
fbshipit-source-id: b21c30c185c9e1fbf3980641bc3cdc39e85af2e1
Summary:
Add "axis" and "axis_w" arguments in FC to support customized axix to reduce dim.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12971
Reviewed By: bddppq
Differential Revision: D12850675
Pulled By: yinghai
fbshipit-source-id: f1cde163201bd7add53b8475329db1f038a73019
Summary:
Fix ONNX_ATEN mode by adding it to the validateBlock method.
Before this pr, validateBlock will throw an exception when using this mode.
I will add related test cases for ONNX_ATEN mode in a different pr once this is merged, since we dont have any currently.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14239
Differential Revision: D13145443
Pulled By: zrphercule
fbshipit-source-id: 60e7942aa126acfe67bdb428ef231ac3066234b1
Summary:
The build was picking up the empty stub header instead of the generated
one. Because of the large number of include paths we end up passing to
the compiler it is brittle to have both an empty stub file and a
generated file and expect the compiler to pick up the right one.
With the recent change to compile everything from a single CMake run we
can now use native CMake facilities to propagate macros that indicate
backend support. The stanzas target_compile_definitions with the
INTERFACE flag ensure that these macros are set only for downstream
consumers of the c10d target.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14244
Reviewed By: teng-li
Differential Revision: D13144293
Pulled By: pietern
fbshipit-source-id: f49324220db689c68c126b159f4f00a8b9bc1252
Summary:
export - print a method with python_print
import - import a method with import_method
We want to ensure:
export(g) == export(import(export(g)))
That is after after exporting/importing once, the graph will stay exactly
the same. This is less strict that g == import(export(g)) which would
require us to maintain a lot more information about the structure of the
IR and about the names of debug symbols.
This PR addresses this with the following fixes:
* print out double-precision numbers with high enough precision such
that they always parse in the same way
* when creating loop-carried dependencies, sort them
by variable name, ensuring a consistent order
* parse nan correctly
* DCE: remove unused outputs of if statements, and loop-carried dependencies
in loops that are dead both after the loop and inside the body of the
loop.
* Do not set uniqueName for variables whose names are _[0-9]+, these
are probably rare in user code, and we need a way to communicate
that we do not care about a variable name when re-parsing the graph.
Otherwise temporary variable names will jitter around.
* Expand the definition of a constant in printing code to None,
and family.
* Allow re-treeing to work as long as the only thing in its way is a
constant node. These do not have side effects but are sometimes
inserted in a different order when tracing compared to how we print them.
* Print all constant nodes out first in the order in which they are used_val
(or, if they are inlined, ensure they get assigned CONSTANT.cX number
in a consistent order). Cleanup tuples (this is done in the compiler,
but not in the tracer, leading to some tuple indexing jitter if not
done).
* use strtod_l, not std::stod which can throw exceptions
Other:
* Add REL_WITH_DEB_INFO to setup.py. It already existed for the
cmake files. Threading it into setup.py allows us to turn on
debug symbols with optimization everywhere.
* enable round trip testing for all generated graphs. This only adds
~6 seconds to total build time but tests printing for every graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14064
Differential Revision: D13094637
Pulled By: zdevito
fbshipit-source-id: 0a1c6912194d965f15d6b0c6cf838ccc551f161d
Summary:
As we discussed, the tensors in the torch script will be associated with the tensor data in the serialized file. So let's add a table of tensor (actually it's a repeated TensorProto filed) in the ModelDef. TensorProto.name will be the id.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13861
Reviewed By: dzhulgakov
Differential Revision: D13036940
Pulled By: zrphercule
fbshipit-source-id: ecb91b062ac4bc26af2a8d6d12c91d5614efd559
Summary:
This is a feature request from: https://github.com/pytorch/pytorch/issues/13573
As the title says, this PR makes NCCL backend support barrier op.
There are a couple scenarios that need to be addressed:
(1) When there is already a NCCL op happened, we need to record what GPU device(s) the previous op happened and queue the allreduce barrier op on the same GPU device
(2) When there is no NCCL op yet, we will try to use a single GPU and separate each process from a single GPU as the best effort.
As for the async work, during wait, we would like not just wait on the NCCL kernel to be completed, but also block the thread until the current stream and nccl stream return.
`test_distributed` should cover the test. I also manually tested both scenarios.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14142
Differential Revision: D13113391
Pulled By: teng-li
fbshipit-source-id: 96c33d4d129e2977e6892d85d0fc449424c35499
Summary:
This PR inserts `prim::None` constants for undefined tensors. This comes in the standard library if an `Optional[Tensor]` is statically determined to be `None`:
```python
torch.jit.script
def fn(x=None):
# type: (Optional[Tensor]) -> Tensor
return torch.jit._unwrap_optional(x)
torch.jit.script
def fn2():
# type: () -> Tensor
return fn()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14120
Differential Revision: D13124625
Pulled By: driazati
fbshipit-source-id: 9eaa82e478c49c503f68ed89d8c770e8273ea569
Summary:
This PR did three things:
1. It export the BatchNorm functional and module, and rewrite some of the components to stay align with the current supported JIT features
2. In the process of export, add necessary compiler support for in_place op aug assign
4. change the test_jit behavior in add_module_test to utilize a single rng state during module initialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14016
Differential Revision: D13112064
Pulled By: wanchaol
fbshipit-source-id: 31e3aee5fbb509673c781e7dbb6d8884cfa55d91
Summary:
- Move up handling the environment variable from CPU only to all
- Introduce two levels to be enabled with PYTORCH_FUSION_DEBUG=n:
1: print C source
2: print CPU assembly, too (previous effect of PYTORCH_FUSION_DEBUG)
apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14213
Differential Revision: D13135393
Pulled By: soumith
fbshipit-source-id: befa4ebea3b3c97e471393a9f6402b93a6b24031
Summary:
Since they directly include the real ones in core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14230
Differential Revision: D13140323
Pulled By: tugrulates
fbshipit-source-id: d7e3b94e891b2d7fa273d01c0b7edfebdbd7e368
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14163
Some of the names we were using to guard the header file was too short (e.g. DYNAMIC_HISTOGRAM_H).
Reviewed By: csummersea
Differential Revision: D13115451
fbshipit-source-id: cef8c84c62922616ceea17effff7bdf8d67302a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14192
We can only use C10_* in OSS. The build is only broken if built with USE_FBGEMM=ON
Reviewed By: jianyuh
Differential Revision: D13121781
fbshipit-source-id: f0ee9a75997766e63e1da8a53de7ddb98296a171
Summary:
This will address https://github.com/pytorch/pytorch/issues/13574
This error message should be more informative to the user for all the non-multiGPU ops, since we python binding to multi-gpu ops always.
test_distributed should cover all. Also tested both RunTime errors.
```
>>> a = torch.ByteTensor([])
>>> b = [a, a]
>>> dist.all_reduce(b)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/private/home/tengli/pytorch/torch/distributed/distributed_c10d.py", line 809, in all_reduce
_check_single_tensor(tensor, "tensor")
File "/private/home/tengli/pytorch/torch/distributed/distributed_c10d.py", line 207, in _check_single_tensor
"to be a torch.Tensor type".format(param_name))
RuntimeError: Invalid function argument. Expecting parameter: tensor to be a torch.Tensor type
>>> b = ["b"]
>>> dist.all_gather(b, a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/private/home/tengli/pytorch/torch/distributed/distributed_c10d.py", line 1006, in all_gather
_check_tensor_list(tensor_list, "tensor_list")
File "/private/home/tengli/pytorch/torch/distributed/distributed_c10d.py", line 225, in _check_tensor_list
"to be a List[torch.Tensor] type".format(param_name))
RuntimeError: Invalid function argument. Expecting parameter: tensor_list to be a List[torch.Tensor] type
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14204
Differential Revision: D13131526
Pulled By: teng-li
fbshipit-source-id: bca3d881e41044a013a6b90fa187e722b9dd45f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14110
I'm planning to move CUDAStream to c10/cuda, without also moving
CUDAContext, and so it's most convenient if these definitions
are in the actual header file in question.
Reviewed By: smessmer
Differential Revision: D13104693
fbshipit-source-id: 23ce492003091adadaa5ca6a17124213005046c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14109
Previously it was at the top level, because the author was under
the impression that you could only refer to top-level C++ names
from C, but this is not true; you just need to make a stub struct
conditioned on __cplusplus.
Reviewed By: smessmer
Differential Revision: D13104694
fbshipit-source-id: ecb7ae6dcfa4ab4e062aad7a886937dca15fd1b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13920
I want to move CUDAStream and CUDAGuard to c10_cuda without also
bringing along CUDAContext or CUDAEvent for the ride (at least for
now). To do this, I need to eliminate those dependencies.
There's a few functions in CUDAContext.h which don't really need
THCState, so they're separated out and put in general
purpose c10/cuda/CUDAFunctions.h
Reviewed By: smessmer
Differential Revision: D13047468
fbshipit-source-id: 7ed9d5e660f95805ab39d7af25892327edae050e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13479
Increases the lock scope to above Output() calls.
These calls potentially allocate the underlying blob/tensor
objects and multiple invocations race each other over the
same output blobs/tensors.
Reviewed By: bwasti
Differential Revision: D12891629
fbshipit-source-id: a6015cfdb08e352521a1f062eb9d94a971cfbdb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14137
This is a templated header-only class and shouldn't need export/import macros.
Reviewed By: ezyang
Differential Revision: D13111712
fbshipit-source-id: c8c958e75b090d011d25156af22f37f9ca605196
Summary:
When the save/load of script module, we store optimize flag in module instead of encoding it in method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14166
Reviewed By: ezyang
Differential Revision: D13117577
Pulled By: dzhulgakov
fbshipit-source-id: dc322948bda0ac5809d8ef9a345497ebb8f33a61
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14105
Pull Request resolved: https://github.com/facebook/fbshipit/pull/62
Use fbgemm revision file created by ShipIt for updating fbgemm revision for pytorch. We don't have to manually update submodule now.
Reviewed By: yns88
Differential Revision: D13072074
fbshipit-source-id: bef9eabad50f7140179c370a60bd9ca73067b9b5
Summary:
Discovered huge build time difference between caffe2 rocm build and pytorch rocm build (6min vs. 30min), turns out it's because the sccache setup needed in caffe2 docker images are not n pytorch build script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14153
Differential Revision: D13115097
Pulled By: bddppq
fbshipit-source-id: 88414f164b980f0e667c8e138479b4a75ab7692e
Summary:
zdevito soumith
Sorry about the previous PR, had some git issues. This is the same exact code as the previous PR but updated w.r.t pytorch/master.
fixes#13254
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14181
Differential Revision: D13117688
Pulled By: soumith
fbshipit-source-id: 044840b2c7a0101ef43dd16655fd9a0f9981f53f
Summary:
Note there was a hacky way of doing this before by specifying "return:" lists manually; this makes the
return names part of the function declaration itself.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14100
Differential Revision: D13101810
Pulled By: gchanan
fbshipit-source-id: 1c80574cd4e8263764fc65126427b122fe36df35
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13912
The implementation and API of CUDAMultiStreamGuard is less mature,
and it cannot be implemented generically (yet) in c10_cuda. This
might be a reasonable thing to do eventually, but not for now.
Reviewed By: smessmer
Differential Revision: D13046500
fbshipit-source-id: 4ea39ca1344f1ad5ae7c82c98617aa348c327848
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13900
Add c10 cuda library.
Right now, this is not used by anything, and only tests if the CUDA
headers are available (and not, e.g., that linking works.)
Extra changes:
- cmake/public/cuda.cmake now is correctly include guarded, so you
can include it multiple times without trouble.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Reviewed By: smessmer
Differential Revision: D13025313
fbshipit-source-id: fda85b4c35783ffb48ddd6bbb98dbd9154119d86
Summary:
- Improved single-threaded performance due to optimized low-level micro-kernels
- Improved parallelization (previously was parallelized across images in a batch and pixels only, now within channels as well)
- Slightly different result due to different implementation of fixed-point arithmetics (no accuracy loss expected)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14089
Differential Revision: D13110135
Pulled By: Maratyszcza
fbshipit-source-id: 1f149394af5c16940f79a3fd36e183bba1be2497
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14133
Experiment with ultra low precisions on the Resnext-101 URU trunk model
Reviewed By: jspark1105
Differential Revision: D10108518
fbshipit-source-id: f04d74fbe1c9e75efafcd9845719bdb2efbbfe9c
Summary:
They didn't turn up in my tests because I use pytest which doesn't
print debug statements if the tests pass
Differential Revision: D13115227
Pulled By: soumith
fbshipit-source-id: 46a7d47da7412d6b071158a23ab21e7fb0c6e11b
Summary:
Implements batching for the Cholesky decomposition.
Performance could be improved with a dedicated batched `tril` and `triu` op, which is also impeding autograd operations.
Changes made:
- batching code
- tests in `test_torch.py`, `test_cuda.py` and `test_autograd.py`.
- doc string modification
- autograd modification
- removal of `_batch_potrf` in `MultivariateNormal`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14017
Differential Revision: D13087945
Pulled By: ezyang
fbshipit-source-id: 2386db887140295475ffc247742d5e9562a42f6e
Summary:
This reverts commit a1fa9d8cf9b2b0e7373ec420c2487d4dfd0e587c.
[pytorch_linux_trusty_py2_7_9_build](https://circleci.com/gh/pytorch/pytorch/270206?utm_campaign=vcs-integration-link&utm_medium=referral&utm_source=github-build-link/console):
```
Nov 17 07:37:27 + sudo apt-get -qq update
Nov 17 07:37:30 W: Ignoring Provides line with DepCompareOp for package gdb-minimal
Nov 17 07:37:30 W: You may want to run apt-get update to correct these problems
Nov 17 07:37:30 + sudo apt-get -qq install --allow-downgrades --allow-change-held-packages openmpi-bin libopenmpi-dev
Nov 17 07:37:30 E: Command line option --allow-downgrades is not understood
Nov 17 07:37:30 + cleanup
Nov 17 07:37:30 + retcode=100
Nov 17 07:37:30 + set +x
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14146
Differential Revision: D13113912
Pulled By: bddppq
fbshipit-source-id: cd9d371cf72159f03d12a8b56ed5bd2060ebbe59
Summary:
Use the most recent version that disables inline assembly.
I suspect inline assembly causes miscompilation on some versions of gcc7.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14128
Reviewed By: bddppq
Differential Revision: D13112370
Pulled By: Maratyszcza
fbshipit-source-id: 36cc95dc51390a293b72c18ae982c3a515a11981
Summary:
- NEON2SSE is a header that implements NEON intrinsics on top fo SSE intrinsics
- Upstream repo provides NEON_2_SSE.h header, but internally it was imported as neon2sse.h
- This patch fix incompatibilities between internal and upstream versions
Reviewed By: hlu1
Differential Revision: D13096755
fbshipit-source-id: 65e1df9a2a5e74bd52c9aee9be27469ba938cd8c
Summary:
QNNPACK contains assembly files, and CMake tries to build them for wrong architectures in multi-arch builds. This patch has two effects:
- Disables QNNPACK in multi-arch iOS builds
- Specifies a single `IOS_ARCH=arm64` by default (covers most iPhones/iPads on the market)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14125
Differential Revision: D13112366
Pulled By: Maratyszcza
fbshipit-source-id: b369083045b440e41d506667a92e41139c11a971
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13693
We can't directly call the caffe2::Operator class from c10 yet because that class isn't deprotobuffed yet.
Instead, we factor out the kernel into a reusable static method and call it from the caffe2::Operator and
also register it with c10.
Reviewed By: ezyang
Differential Revision: D12912242
fbshipit-source-id: c57502f14cea7a8be281f9787b175bb6e402d00c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14111
It was already in TARGETs, but we forgot it in cmake.
Reviewed By: ezyang
Differential Revision: D13105166
fbshipit-source-id: f09549e98ebca751339b5ada1150e00cc4cd9540
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14135
Update atol scale of dnnlowp test. Can't reproduce the flaky test error in the task locally even after setting the same seed value, but found according to comments in check_quantized_results_close(), atol_scale should be 1/1.9=0.526315789473684, which is larger than current value 0.51. So increase the atol_scale to 0.53.
Reviewed By: jspark1105
Differential Revision: D13108415
fbshipit-source-id: 1e8840659fdf0092f51b439cf499858795f9706a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13327
Add cost inference function to non-linear ops. Since the actual flops of the non-linear operator depends on the implementation, we use the number of non-linear operations as the proxy for the analytical flops for non-linear operators.
Reviewed By: jspark1105
Differential Revision: D10439558
fbshipit-source-id: 9aeb05bac8b5c7ae5d351ebf365e0a81cf4fc227
Summary:
The `$BUILD_ENVIRONMENT` checks work in `test.sh` but not `build.sh`, this PR is trying to figure out why.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14124
Reviewed By: teng-li
Differential Revision: D13112483
Pulled By: yf225
fbshipit-source-id: 5f65997586648805cf52217a261389625b5535e1
Summary:
This will be super helpful to the user
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14039
Differential Revision: D13089200
Pulled By: teng-li
fbshipit-source-id: 29e7507bd8fe5a0c58a85c52f976bfca282b4c1b
Summary:
This is needed for moving nn functions to native functions, but since some functions are already named
this way, I'm going to stop binding pre-emptively so we can check if there are any current dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14101
Differential Revision: D13102219
Pulled By: gchanan
fbshipit-source-id: 6bbcca33a03ab1bf648f1b73cadfe84339fa3050
Summary:
Before this patch, the JIT does not allow Module's forward to take
structured objects.
This patch allows cooperative objects to do so.
Cooperative means:
- It has a method self._jit_unwrap() that returns (a list/tuple of)
tensors. These are then used in _iter_tensors.
- It has a method self._jit_wrap(flattened_input) that takes
(a list/tuple?) the flattened_unput (potentially more than it needs)
and returns itself (updated) and the unconsumed flattened_inputs.
This is then used in the _unflatten mechanism.
This is all it takes to permit maskrcnn-benchmark to use
its structured BoxList/ImageList types and trace it without calling
the .forward directly.
I'll push a model working with this patch in
https://github.com/facebookresearch/maskrcnn-benchmark/pull/138
I must admit I haven't fully checked whether there are ONNX changes needed before it, too, can profit, but I would be hopeful that anything currently usable remains so.
fmassa zdevito
So the main downside that I'm aware of is that people will later want to use more elaborate mechanisms, but I think this could be done by just amending what wrap/unwrap are returning / consuming.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13961
Differential Revision: D13103927
Pulled By: soumith
fbshipit-source-id: 2cbc724cc4b53197388b662f75d9e601a495c087
Summary:
This PR adds a `SharedDataset` to the C++ frontend data API, which allows wrapping a shared_ptr to a dataset into a class that conforms to the `Dataset` interface (with `get_batch`). This enables use cases where a custom dataset is (1) thread-safe and (2) expensive to copy. All workers will reference a single instance of this dataset. No additional copies are incurred.
jaliyae apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13800
Differential Revision: D13075610
Pulled By: goldsborough
fbshipit-source-id: 4ffdfd7959d49b042c0e254110085f62a0bfeb6c
Summary:
Hi guys,
I'd like to build Caffe2 with more supported options in Windows with Microsoft Visual Studios.
This is the first pull request.
Running scripts/build_windows_shared.bat is able to build Caffe2 with both CMAKE_BUILD_TYPE=Debug and CMAKE_BUILD_TYPE=Release with Visual Studio 14 2015.
CUDA is 9.0, cudnn is 7.0.5, glog, gflags and lmdb are supported on my system.
Python is 3.5, Detectron works from python interface as well.
It was even possible to debug detectron code and step into caffe2_gpu.dll with pdbs built.
What is disappointing, that c10/experimental ops don't build with this Visual Studio generator, I added special option INCLUDE_EXPERIMENTAL_C10_OPS (default ON) to deal with it in build_windows_shared.bat.
After this pull request the next step is to add Visual Studio 2017 support in the script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13550
Reviewed By: ezyang
Differential Revision: D13042597
Pulled By: orionr
fbshipit-source-id: f313f909f599cd582a1d000eff766eef3a9fc4fc
Summary:
This should resolve the issue on ppc64le getting FAIL: test_proper_exit (__main__.TestDataLoader). This only happens when the CI build machine is very busy and fails with a timeout.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14107
Differential Revision: D13103859
Pulled By: soumith
fbshipit-source-id: 268be80b59840853c5025f3211af272f68608fe5
Summary:
xw285cornell
- To make hip files to have unique filename extension we change hip files from _hip.cc to .hip (it's the only blessing option other than .cu in hipcc 3d51a1fb01/bin/hipcc (L552)).
- Change to use host compiler to compile .cc|.cpp files. Previously we use hcc to compile them which is unnecessary
- Change the hipify script to not replace "gpu" with "hip" in the filename of the generated hipified files. Previously we do this because hcc has a bug when linking files that have same filename. We have now changed to use host linker to do linking so this is unnecessary anymore.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14036
Reviewed By: xw285cornell
Differential Revision: D13091813
Pulled By: bddppq
fbshipit-source-id: ea3d887751d8abb39d75f5d5104aa66ce66b9ee0
Summary:
Turns out we don't have any centos test CI job
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14091
Differential Revision: D13104722
Pulled By: bddppq
fbshipit-source-id: 22fe92ad4b7f2c391eea16b8b95658fa1ee605e2
Summary:
- This should help TestJit.test_lstm_fusion_concat_cuda
to be less flaky. (Checked on manual_seed 0..99)
Fixes: #14026
- Revert the renaming of test_fused_abs that was introduced
to game the order of tests to avoid the flakiness above.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14094
Differential Revision: D13100174
Pulled By: soumith
fbshipit-source-id: 91bb63b07a960a81dddfc0bf25c67696c0f6c46d
Summary:
This is the next minimal step towards moving _C into cmake. For now,
leave _C in setup.py, but reduce it to an empty stub file. All of its
sources are now part of the new torch-python cmake target.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12742
Reviewed By: soumith
Differential Revision: D13089691
Pulled By: anderspapitto
fbshipit-source-id: 1c746fda33cfebb26e02a7f0781fefa8b0d86385
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14103
Addressing T34828781, we change THPDtype_New so that it throws a RuntimeError if the length of name is greater than buffer size (DTYPE_NAME_LEN) - instead of truncating the string to fit the buffer.
Reviewed By: ezyang
Differential Revision: D13094600
fbshipit-source-id: d0dbf8fdfa342630c31f4d8ca7230d5f24a1254a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13949
This diff adds support to fillers for `SparseLengthsWeight*` ops. It does 3 things:
1. Add the fillers for `SparseLengthsWeight*` ops
2. Add filling heuristics to consider the path of `LengthsRangeFill` -> `Gather` -> `SparseLengthsWeightedSum`, where the length input is shared by `LengthsRangeFill` and `SparseLengthsWeightedSum`. Therefore, we need to carefully bound the value of that length input so that at `Gather`, it does not index out-of-bound for the weight input of `Gather`.
3. Fix and simplify the logic of `math::RandFixedSum`, where we just keep rejecting the generated value if it violates the invariants.
Reviewed By: highker
Differential Revision: D13048216
fbshipit-source-id: bfe402e07e6421b28548047d18b298c148e0ec87
Summary:
torch.nn.utils.rnn.pack_padded_sequence segment fault if not in
decreasing order #13324
We were seeing this segfault on throw, pre-emptively checking avoids
this:
*** Error in `/home/bvaughan/anaconda3/bin/python': double free or corruption (!prev): 0x00005555566e7510 ***
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13933
Differential Revision: D13090389
Pulled By: nairbv
fbshipit-source-id: 6f6b319e74cb55830be799e9c46bc33aa59256d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13795
Add ability for dot string generation for a single subgraph and python bindings (which is pretty useful for model exploration in Python)
Restructure DotGenerator class a bit to make it easy to implement this feature
Reviewed By: bwasti
Differential Revision: D13010512
fbshipit-source-id: 825665438394b7e6968ab6da167b477af82a7b62
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14074
expose inducesEdges and addNode to python's NNSubgraph. This make it easy to manually construct a NNSubgraph in python
Reviewed By: bwasti
Differential Revision: D13092885
fbshipit-source-id: a94ed0b318162e27e3a4b5a4954eb6d169da7405
Summary:
- Fix the test for TORCH_INSTALL_PREFIX in the environment.
The previous version didn't actually work.
- Add a guess path to find_package for Caffe2. I'd suspect that
it's close to the Torch one.
I noticed these while compiling PyTorch custom ops, in particular for the C++ side when you don't want to go through Python.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13849
Differential Revision: D13090186
Pulled By: ezyang
fbshipit-source-id: cfe98900ab8695f008506a8d0b072cfd9c673f8f
Summary:
This reverts commit 37cb357d8da3427900b8f72f6de7e77b77dcdbae.
Try to see if it unbreaks master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14082
Differential Revision: D13095888
Pulled By: bddppq
fbshipit-source-id: c728f80f233b4d9daaf65f43202d8104651029a9
Summary:
Address https://github.com/pytorch/pytorch/issues/14063
This is a lot easier to use, follow the NCCL convention since they provide the similar NCCL_SOCKET_IFNAME.
We can later document this better.
Tested on my two hosts, and work out of the box
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14065
Differential Revision: D13095522
Pulled By: teng-li
fbshipit-source-id: 131dff212626f1aab7e752427f1b684845b909dc
Summary:
Currently after performing export it gives two entries of externel_input
of input data in predict_net proto because it extends the externel_input
twice once seperately using input blob and one it is extendind all the entries
of external_input from proto in which input blob is already included
Signed-off-by: Parth Raichura <parth.raichura@softnautics.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12979
Differential Revision: D12916349
Pulled By: soumith
fbshipit-source-id: 4d4a1c68c0936f8de3f4e380aea1393fe193cd2d
Summary:
I got some build errors when modifying the `bernoulli_tensor_cuda_kernel` in my Generator refactor https://github.com/pytorch/pytorch/pull/13070. Turns out the functions signature for `CUDA_tensor_apply1` was a little wrong. This PR fixes it. Following is the code and error I was getting before this patch:
Code:
```
template<typename scalar_t, typename prob_t>
void bernoulli_tensor_cuda_kernel(
at::Tensor& ret, const at::Tensor& p,
std::pair<uint64_t, uint64_t> seeds) {
// The template argument `4` below indicates that we want to operate on four
// element at each time. See NOTE [ CUDA_tensor_applyN helpers ] for details.
at::cuda::CUDA_tensor_apply2<scalar_t, prob_t, 4>(
ret, p,
[seeds] __device__(scalar_t& v1, const prob_t& p1) {
at::cuda::Philox4_32_10 engine(
seeds.first,
blockIdx.x * blockDim.x + threadIdx.x,
seeds.second);
auto x = at::cuda::standard_uniform_distribution(engine);
assert(0 <= p1 && p1 <= 1);
v1 = static_cast<scalar_t>(x <= p1);
}
);
}
```
Error:
```
ov 15 23:43:03 /var/lib/jenkins/workspace/aten/src/ATen/cuda/CUDAApplyUtils.cuh(236): error: no suitable conversion function from "const lambda [](uint8_t &)->void" to "int" exists
Nov 15 23:43:03 detected during:
Nov 15 23:43:03 instantiation of "void at::cuda::<unnamed>::ApplyOp1<Op, scalar, IndexType, ADims, remaining_steps, Offsets...>::apply(at::cuda::detail::TensorInfo<scalar, IndexType> &, const Op &, int, IndexType, Offsets...) [with Op=lambda [](uint8_t &)->void, scalar=uint8_t, IndexType=unsigned int, ADims=1, remaining_steps=1, Offsets=<>]"
Nov 15 23:43:03 (282): here
Nov 15 23:43:03 instantiation of "void at::cuda::<unnamed>::kernelPointwiseApply1<Op,scalar,IndexType,ADims,step>(at::cuda::detail::TensorInfo<scalar, IndexType>, IndexType, Op) [with Op=lambda [](uint8_t &)->void, scalar=uint8_t, IndexType=unsigned int, ADims=1, step=1]"
Nov 15 23:43:03 (735): here
Nov 15 23:43:03 instantiation of "__nv_bool at::cuda::CUDA_tensor_apply1<scalar,step,Op>(at::Tensor, Op, at::cuda::TensorArgType) [with scalar=uint8_t, step=1, Op=lambda [](uint8_t &)->void]"
Nov 15 23:43:03 (774): here
Nov 15 23:43:03 instantiation of "__nv_bool at::cuda::CUDA_tensor_apply1<scalar,Op>(at::Tensor, Op, at::cuda::TensorArgType) [with scalar=uint8_t, Op=lambda [](uint8_t &)->void]"
Nov 15 23:43:03 /var/lib/jenkins/workspace/aten/src/ATen/native/cuda/Distributions.cu(118): here
Nov 15 23:43:03 instantiation of "void <unnamed>::bernoulli_scalar_cuda_kernel<scalar_t>(at::Tensor &, double, std::pair<uint64_t, uint64_t>) [with scalar_t=uint8_t]"
Nov 15 23:43:03 /var/lib/jenkins/workspace/aten/src/ATen/native/cuda/Distributions.cu(227): here
Nov 15 23:43:03
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14056
Differential Revision: D13095362
Pulled By: soumith
fbshipit-source-id: 6416bc91616ec76036479062a66517557a14d1b9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14048
Setting USE_FBGEMM to OFF by default until we figure out properly separating avx2 code. See [this issue](https://github.com/pytorch/pytorch/issues/13993). Pytorch can still be compiled with fbgemm by using USE_FBGEMM=ON.
Reviewed By: jspark1105
Differential Revision: D13090454
fbshipit-source-id: 6e0e92612e4362a306e376df3dc33e8edeb066e9
Summary:
Deletes the `OptionsGuard` from ATen. This works towards the goal of reworking `DefaultTensorOptions`. `OptionsGuard` is troublesome because it relies on mutating thread local state. This PR fixes those code locations and then deletes the `OptionsGuard`.
ezyang gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13738
Differential Revision: D13000962
Pulled By: goldsborough
fbshipit-source-id: c8143ee75070c2280f5fd1d9af86f8ce14279b72
Summary:
I think this will be it. So for one, the previous test was bullshit because it was returning the thread id instead of the sample index (which is the thing whose ordering is enforced). Just turning up the number of threads to 10 from 4 made this very obvious. I also think there is a race condition, which may or may not have surfaced, in that there was nothing stopping one worker to get multiple batches, which would screw with the whole ordering logic. I've added a barrier struct such that workers wait for all workers to be in the `get_batch` function before actually doing something.
Fixes https://github.com/pytorch/pytorch/issues/14002
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14038
Differential Revision: D13088132
Pulled By: goldsborough
fbshipit-source-id: 4bded63756c6a49502ee07ef8709a03073e7e05f
Summary:
xw285cornell
Unfortunately it's not easy to add -Werror=reorder flag since there are out of order initializations in thrust headers as well, and the rocm cmake macro hip_include_directories doesn't offer a way to include headers as external headers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14015
Reviewed By: soumith
Differential Revision: D13081104
Pulled By: bddppq
fbshipit-source-id: 2540421cb29cf556c79f2d86c460bde6ea5a182e
Summary:
Avoid false failure by checking for the presence of the test data in setup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13627
Differential Revision: D13090324
Pulled By: ezyang
fbshipit-source-id: e85571943d168c0007212d7b1a5b99ffa0c39235
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13825
async_polling was an intermediate step towards async_scheduling and is not used
Reviewed By: yinghai
Differential Revision: D13019059
fbshipit-source-id: eee6ba53e7f476ddb481afba3bf1768303864d32
Summary:
* Add hooks to get a callback whenever a valid graph is produced in the compiler or through tracing. These hooks can be used to pretty_print and then reparse every graph our tests produce to check that the serialization function works correctly. Currently this is guarded by an environment variable since there are a few remaining failures.
* Fix printing bugs: True and False rather than 1 and 0, print 0. for floating point zero
* Change behavior of NoneType. It is now no longer a subtype of Optional but instead implicitly converts to it, returning a prim::Node with an Option[T] type for some specific T. This allows functions like `_unwrap_optional` to correctly match against a None while still deriving the right type.
* Fix a bug where empty blocks did not correctly emit "pass" in printer.
* Fix a bug where prim::Undefine sometimes cannot be printed as None because it is being used in a schema-less op. This should be fixable once Optional[T] always uses the same None object.
* Other minor printing bugs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13959
Reviewed By: jamesr66a
Differential Revision: D13073519
Pulled By: zdevito
fbshipit-source-id: 4167a6b614f2e87b4d21823275a26be5ba4fc3dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13875
This replaces a using declaration with an explicit constructor
Reviewed By: mnovakovic
Differential Revision: D13033260
fbshipit-source-id: ce4cc5667ee66abdeebd1e49466c3cf3a65ffb96
Summary:
Grab bag of additions to alias annotations that were useful when writing the alias analysis pass. Not very organized since these were mostly split off from that PR.
- Switch alias sets to actual sets, since we will want to union them.
- Correctly parse alias set unions `a|b`, and correctly parse wildcards
- Move writes into `AliasInfo`, which cleans up some code that was passing a `writes` vector everywhere and simplifies tracking aliased writes during analysis.
- Change Tensor list extraction ops to return wildcard tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13632
Differential Revision: D13088038
Pulled By: suo
fbshipit-source-id: 49dc5d0e9cd4895427fea3a87b0ec325bd5fe437
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/14005
the partial initialization of tensor is no longer supported, we need to fix multiple places
Reviewed By: hl475
Differential Revision: D13078206
fbshipit-source-id: a1be2bd2a9f573db54e1366a0d7a17cc2e0db0c9
Summary:
This PR did two thing:
1. it fix the optional import/export to include any type including tensor types (previously we only support base types), this is essential to unblock optional tensor type annotation in our test logic
2. it tries to export mult_margin_loss functional to serve as a example of optional undefined tensor use case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13877
Differential Revision: D13076090
Pulled By: wanchaol
fbshipit-source-id: c9597295efc8cf4b6462f99a93709aae8dcc0df8
Summary:
Also fixed a warning
As a thought while trying to solve #12854
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13998
Reviewed By: pietern
Differential Revision: D13078615
Pulled By: teng-li
fbshipit-source-id: eb25c429d7dd28b42e4e95740a690d5794a0c716
Summary:
Avoid throwing on match errors. In general, it's not good to throw when failure is expected.
But the real reason I'm doing this is it makes it annoying to set a breakpoint on exceptions in my debugger 😛
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13989
Differential Revision: D13069980
Pulled By: suo
fbshipit-source-id: 636d4371f8a5be45c935198b73cdea06275b1e9e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13689
Now that typeid.h lives in c10/util, the include paths should reflect that.
Reviewed By: ezyang
Differential Revision: D12912237
fbshipit-source-id: e54225f049f690de77cb6d5f417994b211a6e1fb
Summary:
Migrate the `CreateAutodiffSubgraphs` pass to use topologically-safe moves instead of DynamicDAG. This is to unify the interface that we use for determining safe node moves to prepare for mutability.
The pass looks a lot like GraphFuser now, and there's a lot of code duplication. I plan to pull common stuff out into a "subgraph manipulation utils" thing, but didn't want to clutter this PR.
Future steps:
- Get rid of code duplication (see above)
- Use DynamicDAG to back the `moveBefore/After` calls.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13862
Differential Revision: D13072871
Pulled By: suo
fbshipit-source-id: 92e7880ef444e0aefd51df60964bba7feaf42ae0
Summary:
- Speed up hipify_python.py by blacklisting useless (and quite large)
directory trees that it would otherwise recurse into
- Pass around relative paths instead of absolute paths. This makes it
easier to do filename matches based on the root of the tree.
- Redo the streaming output to contain more useful information
- Make it handle c10/cuda correctly, rewrite c10::cuda to
c10::hip, and the header name from CUDAMathCompat.h to
CUDAHIPCompat.h
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13973
Differential Revision: D13062374
Pulled By: ezyang
fbshipit-source-id: f0858dd18c94d449ff5dbadc22534c695dc0f8fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13987
Gather and BatchGather are also used in sparse network.
Reviewed By: bddppq, houseroad
Differential Revision: D13067290
fbshipit-source-id: e09572a5c4544768f9e1af48166f7c8d78127e63
Summary:
Libtorch is missing some symbols when generated on windows, causing linker errors when using it.
It seems like there were some issues in the past with enabling CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS to export all symbols during the build.
(See the link below :
- Enabling CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS : https://github.com/pytorch/pytorch/pull/3617?fbclid=IwAR084kOPgLUvYjpJMvGG_Q22IPcvmzlywamytdhxd5U3hELkESO6yM8BGfo
- Disabling CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS : https://github.com/pytorch/pytorch/issues/9092?fbclid=IwAR0QSeEcXNh8A1zrgCQvsEq-0S0GJvHBywhZ6kDvoHe6TeRUsTNRzzgXea0 and https://github.com/pytorch/pytorch/pull/9693?fbclid=IwAR2cSya4fbeHvF-BYkXk2NesXjQ3ZWg9vHJ3ivrT9GDJYqHSpg518KAMzW8 )
So enabling CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS is not an option. But some symbols are still missing for Libtorch to be working.
We added some functions to TORCH_API in this PR, but we might be missing some.
(We also tried adding the whole structure Method (struct TORCH_API Method { ... }) instead of adding the functions separately, but the build fails with a "one or more multiply defined symbols found" error)
Do you have any recommendations on how to detect functions that should/shouldn't be in TORCH_API, so the build is successful and the generated Libtorch has all the required exported symbols?
I also attached toch_exports_missing.txt, which contains the symbols that are exported with the CMAKE_WINDOWS_EXPORT_ALL_SYMBOLS flag enabled but not in the current Libtorch version.
( by generating the output for both torch.dll libraries with "dumpbin /EXPORTS torch.dll" and comparing both outputs and generating the difference)
So any symbol that could be missing from Libtorch should be in this list, but the list has more than 8000 symbols, and I am not sure which ones require to be exported and added to TORCH_API.
This PR currently exports the missing symbols for torch::jit::script::Method that appears in the attached list (in the exception of defaultSchemaFor, and emit_call_to that cause a "multiply defined symbols" error).
[torch_exports_missing.txt](https://github.com/pytorch/pytorch/files/2558466/torch_exports_missing.txt)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13672
Differential Revision: D12959348
Pulled By: soumith
fbshipit-source-id: ef7e85b047b3937dc6aa01ba67e4e01f8eae4eca
Summary:
I'm now traveling and don't have access to a good computer to compile test by myself. Will see the outcome of CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12199
Differential Revision: D13062326
Pulled By: nairbv
fbshipit-source-id: 85873525caa94906ccaf2c739eb4cd55a72a4ffd
Summary:
Pull Request resolved: https://github.com/pytorch/FBGEMM/pull/9
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13960
The vectorized code was rounding to even in halfway cases with _mm256_round_ps + (_MM_FROUND_TO_NEAREST_INT |_MM_FROUND_NO_EXC) (see more details in https://software.intel.com/en-us/node/523819), but we were still using std::round in a couple of places which does rounding away from zero in halfway cases.
With this diff, we use std::nearbyint in all scalar code (except a few cases where we don't care exact rounding mode and uses rint which is the fastest in general) to be more consistent. nearbyint is the same as what the vectorized code does only when the current rounding mode is FE_TONEAREST but in practice this is OK because we almost always use the default rounding mode FE_TONEAREST.
This is inspired by Marat's diff for mobile quantization.
Reviewed By: dskhudia
Differential Revision: D13017719
fbshipit-source-id: 6b8f99db7ea2e233aa2e3bd2adf622e03ed6258e
Summary:
The behavior of the edge case 0 is not self-evident for the `torch.sign` function ( I personally expected a result of 1):
```python
>>> a = torch.tensor([0.7, -1.2, 0., 2.3])
>>> a
tensor([ 0.7000, -1.2000, 0.0000, 2.3000])
>>> torch.sign(a)
tensor([ 1., -1., 0., 1.])
```
This is not currently documented, I think it is worth it to give a simple example showing this behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13771
Differential Revision: D13044520
Pulled By: ailzhang
fbshipit-source-id: c3011ccbdf1c13348f6c7242b06a9aa52ebc9204
Summary:
This includes everything in nn.yaml except for convolutions, multi_margin_loss, multi_label_margin_loss, nll_loss, and nll_loss2d.
Note that scalar_check False just means we don't do any extra scalar checks (we could elide this from the generated code, which I may do in a later commit).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13906
Reviewed By: ezyang
Differential Revision: D13044507
Pulled By: gchanan
fbshipit-source-id: ebd3bdca2bcf512ca44de1ce3be81946f6c0828e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13954
- Remove extra include directories from BASIC_C_FLAGS. We suspect that
in some rare cases on Windows, this can cause us to get confused about
which header to include. Make this agree with build_pytorch_libs.sh
Ditto with BASIC_CUDA_FLAGS
- Delete CWRAP_FILES from both places; it's unused in sh, and it's
dead in CMAKE
- Delete NO_NNPACK in Windows, replace with USE_NNPACK (I'm not sure
if this actually does anything on Windows lol)
- Delete a bunch of defunct cmake arguments from the build (NOT
build_caffe2) target.
Reviewed By: soumith
Differential Revision: D13056152
fbshipit-source-id: efcc06c65a9f3606666196f3fe5db268844d44d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13838
According to Sebastian, the detail convention is specifically for header-private
functionality. That's not what c10/detail is; it's general, library private headers
which may be used in multiple places within PyTorch. Rename it to impl to avoid
the confusion in nomenclature.
Reviewed By: smessmer
Differential Revision: D13024368
fbshipit-source-id: 050f2632d83a69e3ae53ded88e8f938c5d61f0ef
Summary:
Changed at::empty to allocate the correct amount of memory instead of
"allocate 0 memory and then resize it to the necessary size".
This leads to a 300 ns speedup for at::empty for a cuda tensor of size (64, 2048).
(1790ns -> 1460ns for at::empty).
Also does the following:
Removes DeviceGuards for:
- empty_* functions that end up calling functions that already have a
DeviceGuard
- t(), which gets called a lot in LSTMs,
- Remove one of the two DeviceGuard that at::empty(...) uses. It only
needs one for correctness, the other comes from the resize_
implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13785
Reviewed By: ezyang
Differential Revision: D13004938
Pulled By: zou3519
fbshipit-source-id: f45b7e6abe06c05d1f81cc53e190c7bab6d1c116
Summary:
Previously the fusion compiler would allocate an empty tensor and then
resize it to the correct size. This PR changes the fusion compiler to
allocate a tensor of the correct size the first time around. The
difference between these approaches for a single tensor is around 400ns;
for something like LSTMCell's FusionGroup that emits 8 outputs this is
theoretically a 3us win.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13914
Differential Revision: D13046728
Pulled By: zou3519
fbshipit-source-id: e2f28c0dc2ee5bcfee0efe10610039694691415c
Summary:
This addressed: https://github.com/pytorch/pytorch/issues/11874
and we will have the identical file init_method behavior as the previous THD file init.
Also the FileStore::add bug is pretty annoying.
Two bugs:
(1) Add doesn't append to the end of the file.
(2) Cache doesn't get updated.
Both are fixed and tests are covered.
I examined the /tmp to ensure that all temp files are auto deleted after test_c10d.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13708
Reviewed By: pietern
Differential Revision: D12972810
Pulled By: teng-li
fbshipit-source-id: 917255390aa52845f6b0ad0f283875a7a704da48
Summary:
Allow schema matching against string literals to work even with
white space and other minor differences.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13952
Differential Revision: D13056043
Pulled By: zdevito
fbshipit-source-id: 0b502ce8311587308370285f7062914fce34faf0
Summary:
Attempts to unflake the dataloader ordering enforcement test. I think the issue was that the `thread_counter` variable was not atomic. I've made it atomic, and also global just to make it a bit clearer.
Fixes https://github.com/pytorch/pytorch/issues/13634
colesbury SsnL ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13919
Differential Revision: D13051718
Pulled By: goldsborough
fbshipit-source-id: b9f7f6317701a8b861a1d5c6a9b2b17b44782561
Summary:
This pull request contains changes for:
1. Removing ConvTranspose related changes from caffe2/operators/hip/conv_op_miopen.cc
2. Adding the file caffe2/operators/hip/conv_transpose_op_miopen.cc
3. Modifying the tests to run convTranspose op using MIOpen engine
Differential Revision: D13055099
Pulled By: bddppq
fbshipit-source-id: ca284f8f9a073005b22013c375cc958257815865
Summary:
The size of the shared and global memory buffers were incorrect for float16.
They were sized based on float16 elements, but the buffers store intermediate
float32 values.
Fixes#13909
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13926
Differential Revision: D13048334
Pulled By: colesbury
fbshipit-source-id: 5a07df53f1152d5920258e91ed3f1e1de89b29e1
Summary:
* Correctly adds annotate when needed for lists
* Parser/Emitter handles octal escapes so we do not fail for some strings.
* more complete keyword list in pretty printer
* floating point numbers are always printed with a decimal to ensure
we never mistake them in parsing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13879
Differential Revision: D13037860
Pulled By: zdevito
fbshipit-source-id: f09ab174fc33402a429b21a5bfaf72e15c802cad
Summary:
This PR adds Windows support for the C++ frontend. A lot of declarations were missing `TORCH_API` macros, and lots of code just did not compile on MSVC.
ebetica ezyang orionr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11716
Reviewed By: orionr
Differential Revision: D13038253
Pulled By: goldsborough
fbshipit-source-id: c8e5a45efd26117aeb99e768b56fcd5a89fcb9f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13917
There is a bug in UnpackSegments cuda op when setting "max_length".
"buck test mode/opt //caffe2/caffe2/python/operator_test:pack_ops_test -- test_pack_with_max_length_ops"
fails on trunk.
This diff fixed this bug.
Reviewed By: xianjiec
Differential Revision: D13045106
fbshipit-source-id: 4d640d61405bb86326dc33c81145824060cf987e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13820
We would like to provide an option to show additional info of the net to be benchmarked.
Reviewed By: highker, rdzhabarov
Differential Revision: D13018219
fbshipit-source-id: d3ec69901bdae58117a482ddd2c327b0f8cf7cb6
Summary: Currently Lambdarank applies exponential emphasis on relevance, i.e., g=2^rel when calculating dcg, this diff adds options that supports g=rel in the loss function.
Reviewed By: itomatik
Differential Revision: D9891514
fbshipit-source-id: 64730d467a665670edd37e6dc1c077987991d1a8
Summary:
Convert some more functions to match up with features added. Some
conversions were unsuccessful but the type line was left in for later.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13707
Differential Revision: D13030210
Pulled By: driazati
fbshipit-source-id: 02d5712779b83b7f18d0d55539e336321335e0cc
Summary:
This PR makes weak modules in `nn.Sequential` get properly compiled
when used
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13889
Differential Revision: D13039559
Pulled By: driazati
fbshipit-source-id: d3266305f0e206b2a19b63230ac2ab8f02faa603
Summary:
When loading a non-existant / non-openeable file, the current error message is
```
Expected to read 8 bytes but got %llu bytes0
```
This
- fixes two ASSERTM formatting calls (including the above),
- throws a more specific error message if the ifstream constructor sets `.fail`.
Here is someone apparently confused by the current message: https://github.com/facebookresearch/maskrcnn-benchmark/pull/138#issuecomment-437848307
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13894
Differential Revision: D13043228
Pulled By: soumith
fbshipit-source-id: b348b482c66d5e420874ae6e101b834106b89e82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13878
This removes a dependency to another header to simplify moving this header to c10.
Also fix some include paths to prepare that move
Reviewed By: ezyang
Differential Revision: D13036478
fbshipit-source-id: cbddb5281498256fddcbebce61aa606c51b7b8d7
Summary:
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
CC sinkingsugar
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13829
Differential Revision: D13019452
Pulled By: ezyang
fbshipit-source-id: cf8b58b25a484720d9a612df6dd591c91af6f45a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13844
In S163230, we've found CuDNN 7 upgrade causes accuracy drop in training convolution network such as ResNeXt-101 (~0% accuracy), and video R(2+1)D (65 --> 63%).
We've fixed this in Caffe2 D9601217, and we should do the same to ATen as well.
Reviewed By: ezyang
Differential Revision: D13025486
fbshipit-source-id: 04f4f0d9af6287b0400ca1842fb2cdac1f8cdb70
Summary:
Some of our arch people (mkolod, Aditya Agrawal, kevinstephano) notified me that the sequence number annotations weren't showing up for forward methods of custom autograd functions, which was breaking their nvprof dump parsing. Two one-line fixes in the appropriate code paths.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13876
Differential Revision: D13042381
Pulled By: ezyang
fbshipit-source-id: a114118f5c07ad4ba482e7a4892d08805b23c65b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13641
FeedTensor function used to take a pointer to Tensor and feed the content using Resize
and mutable_data, but since Tensor is a pointer now, we can just return a Tensor instead.
Reviewed By: ezyang
Differential Revision: D12873145
fbshipit-source-id: 653735c20d611ff6ac9e380d8b3c721cb396a28f
Summary:
fix cuda native batch norm for small feature planes.
1. fixed warp reduction divergent call of WARP_SHFL_XOR, causes hang with CUDA_ARCH > 7.0
2. split Normalization.cu into two files for code reuse, preparation for sync BN
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13765
Differential Revision: D13043331
Pulled By: soumith
fbshipit-source-id: bf8565bff6ba782475ad0e4be37ea53c8052eadf
Summary:
Using `"-Xcompiler -fPIC"` causes nvcc to emit the following:
nvcc fatal : Unknown option 'Xcompiler -fPIC'
As per fixes lower down in the file (see also issue #7126 on GitHub),
the fix is to replace it with `"-Xcompiler" "-fPIC"`. This one was
apparently missed when the original fix was applied.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13904
Differential Revision: D13043189
Pulled By: soumith
fbshipit-source-id: 6dc6d325671e4d08cd8e6242ffc93b3bd1f65351
Summary:
This is what we would want to check in anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13842
Differential Revision: D13025463
Pulled By: gchanan
fbshipit-source-id: d1ff9b10f4adc811bbd3db15b440ed00c16c82d1
Summary:
torch.randn(big_number_here, dtype=torch.int8) is wrong because randn
isn't implemented for torch.int8. I've changed it to use torch.empty
instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13864
Differential Revision: D13032130
Pulled By: zou3519
fbshipit-source-id: d157b651b47b8bd736f3895cc242f07de4c1ea12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13814
D10333829 implemented 3D conv in NHWC in fp32 ops so int8 ops don't need special handling anymore.
Reviewed By: hx89
Differential Revision: D13017666
fbshipit-source-id: 41df449f5e21c4c7134cc5c480e559f8c247069b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13798
The semantics of C2 and ONNX Concat is a bit different. C2 concat accepts "add_axis" arg and will raise the dim if so. It's equivalent of attaching a Reshape after plain concat in ONNX.
Reviewed By: rdzhabarov
Differential Revision: D13012867
fbshipit-source-id: da23e555bae709fd2a373b04dcb9db4e984ae315
Summary:
This enables the distributions and utils test sets for ROCm.
Individual tests are enabled that now pass due to fixes in HIP/HCC/libraries versions in white rabbit.
For attention: bddppq ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13166
Differential Revision: D12814759
Pulled By: bddppq
fbshipit-source-id: ea70e775c707d7a8d2776fede6154a755adef43e
Summary:
There was a bug in the uniqueness check that only made the first run
unique
Reviewed By: duc0
Differential Revision: D13013504
fbshipit-source-id: ecf7526d0fafd7968f1301734123f93968efef46
Summary:
Moving CUDA 10 build to CircleCI so that we have one less job running on Jenkins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13858
Differential Revision: D13031916
Pulled By: yf225
fbshipit-source-id: 57aa54941d7f529e7094c8d037b836ec2fb6191c
Summary:
The python lib path on Windows was set to an incorrect path. This fixes it to be consistent with Linux.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13848
Differential Revision: D13030945
Pulled By: soumith
fbshipit-source-id: 7fb9013ffe66cff98018aea25fdb5cda03cbceb1
Summary:
1) Use the hip-thrust version of Thrust as opposed to the GH master. (ROCm 267)
2) CentOS 7.5 docker (ROCm 279)
* Always install the libraries at docker creation for ubuntu.
* Add Dockerfile for CentOS ROCm
* Enable the centos build
* Source devtoolset in bashrc
* Set locales correctly depending on whether we are on Ubuntu or CentOS
* Install a newer cmake for CentOS
* Checkout thrust as there is no package for CentOS yet.
PyTorch/Caffe2 on ROCm passed tests: https://github.com/ROCmSoftwarePlatform/pytorch/pull/280
For attention: bddppq ezyang
Docker rebuild for Ubuntu not urgent (getting rid of Thrust checkout and package install is mainly cosmetic). If docker for CentOS 7.5 is wanted, build is necessary. Build of PyTorch tested by me in CentOS docker. PyTorch unit tests work mostly, however, a test in test_jit causes a python recursion error that seems to be due to the python2 on CentOS as we haven't ever seen this on Ubuntu - hence please do not enable unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12899
Differential Revision: D13029424
Pulled By: bddppq
fbshipit-source-id: 1ca8f4337ec6a603f2742fc81046d5b8f8717c76
Summary:
Extend `isAfter` to work for nodes in different blocks. This is useful if we want to ask a question like "are any of the uses of value `v` after this node", since uses may be inside inner blocks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13855
Differential Revision: D13030528
Pulled By: suo
fbshipit-source-id: f681405396f3ec68eec1a2cb92e40873921a4b78
Summary:
Used in docs/source/scripts/build_activation_images.py.
Don't know if we need a specific version. I installed the latest version (3.0.2) and that works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13828
Differential Revision: D13030294
Pulled By: pietern
fbshipit-source-id: b4e7b381182036645924453a1e2abb719090bbc4
Summary:
Right now we dont have coverage info of how many pytorch operators can be exported to onnx. This pr will add torch.nn operators to it, while later functional modules will be added as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13788
Differential Revision: D13010448
Pulled By: zrphercule
fbshipit-source-id: 19349cabaeff42fda3620bb494f7ec4360d96b76
Summary:
* Adds `OptionalType` support for import/export
* Optionals get exported along with their contained type, i.e. 'Optional[int]'
* Allows concrete types and `None` to be passed to an op that takes an optional
* Converts `softmax`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13647
Differential Revision: D12954672
Pulled By: driazati
fbshipit-source-id: 159e9bfb7f3e398bec3912d414c393098cc7455a
Summary:
This removes dynamic allocations for sizes/strides for tensors with <= 5
dims. This should cover the most common tensor use cases; we use a lot
of 4D tensors in images (N, C, H, W) and LSTMs use tensors with 3 or fewer dims.
Benchmarking results can be found here:
https://gist.github.com/zou3519/ce4182722ae7e2a228bc8b57ae60b0e9
The quick summary is that this PR:
- makes aten LSTM's forward pass ~1ms faster and improves JIT lstm perf
as well
- Tensor as_strided is now 200ns faster for dimensions <= 5
- at::empty performance is 200ns slower for dimensions > 5. For dims <= 5,
there is no noticeable perf change.
- Variable ops are 200-500ns faster because Variables never used their
sizes/strides fields in the first place.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13649
Differential Revision: D12950409
Pulled By: zou3519
fbshipit-source-id: 0bd87ec9f712ddc0d533a347d781e3a91a954b90
Summary:
Get pretty printer ready for use as a serialization format
This PR adds a bunch of functionality to the pretty printer (now called python_printer to reflect
the fact that it will be used to output valid python source). The idea is to get the printer
ready for use as serialization format. This PR does not have tests beyond what the pretty
printer already had. PRs stacked on this one will do round-trip export/import to test this functionality more robustly.
Notes:
* PythonPrinter is an evolution of the original pretty printer. However, much of it has changed so it is best just to
read it as a new implementation. Trying to correlate it to the original implementation is probably not much help.
* The printer tries to get reasonably close to how the original function was likely written, such as
writing expressions rather than making intermediates when possible. We may decide to turn this off
for the actual serialization, but it is useful for pretty printing.
* tensor field access was changed so that prim::device and family have schema
* fixed a bug in the compiler where setUniqueName gets called even when a value already has one.
this sometimes assigned really poor names to graph inputs
* Graph::insert gains an optional range argument to make range-preserving inserts easier.
* prim:: ops that can have schema now have schema. This is because when we parse them back in,
we will need the schema to correctly set their output types.
* there is code in the python printer to complain if you try to add a prim op and do not update the printer.
* BuiltinModule is generalized to take an operator namespace and a version number for work in future commits.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13616
Reviewed By: goldsborough
Differential Revision: D13008252
Pulled By: zdevito
fbshipit-source-id: 32b33bc6410d6ca1c6f02bd6e050f8d5eea32083
Summary:
and write derivatives in terms of native functions.
This is the same as https://github.com/pytorch/pytorch/pull/13648 but has a fix for the canonicalize op jit pass to propagate shape information.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13796
Reviewed By: ezyang
Differential Revision: D13012281
Pulled By: gchanan
fbshipit-source-id: 88d0d91e72b5967c51ff865350fcbdd7ffed92ef
Summary:
While trying to understand why two implementations of the same model, one in Python, one using the C++ api (via some [ocaml wrappers](https://github.com/LaurentMazare/ocaml-torch)) did not perform equally well, I noticed that the Python and C++ implementation of SGD slightly differ on weight decay.
- In the [Python version](https://github.com/pytorch/pytorch/blob/master/torch/optim/sgd.py#L91-L93) weight decay is applied *before* momentum (and so momentum applies to the weight decay).
- In the C++ implementation the weight decay is applied *after* momentum.
In the couple computer-vision models I have looked at the Python version performs a little better so this PR tweaks the C++ implementation to perform weight-decay *before* momentum. This is possibly caused by having more regularization - maybe increasing the weight decay while keeping the current code would hold the same improvements however a nice advantage of this change is to put the C++ and Python version in line. After this change my Python and C++/ocaml models performed similarly when using the same weight-decay parameter.
Maybe there was some real reason to have weight decay after momentum in the C++ version but I haven't found any.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13801
Differential Revision: D13020709
Pulled By: soumith
fbshipit-source-id: 7c2ac245577dd04bc3728aec4af0477120a60f13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13342
This PR introduces a few new concepts:
- DeviceGuardImplInterface, and implementations for CPU and CUDA, which
provide a generic interface for interfacing with device and stream state,
without requiring a direct dependency on the code in question.
- InlineDeviceGuard, a general template for generating both specialized
and dynamically dispatched device guard implementations. Dynamic
dispatch is done by specializing it on a VirtualGuardImpl.
- Provide a device-independent DeviceGuard class, which can be used even
from CPU code. It uses the aforementioned dynamic dispatch.
- CUDA-specialized CUDAGuard class, which doesn't have a dynamic dispatch
but can only be used from CUDA.
- StreamGuard, which is the same as above, but for streams rather than
devices.
- Optional variants of all the aforementioned guards, which are a no-op if
no device/stream is specified
- CUDAMultiStreamGuard, specifically for the case when we want to set
a device on every guard.
There are some subtle semantic changes, which have been thoroughly documented
in the class definition.
BC-breaking changes:
- Move constructor/assignment have been removed from all device guard
implementations.
- In some cases where you previously wrote 'set_device' (or 'set_stream'), you now must write
'reset_device', because if you switch devices/device types, the stream/device on the
previous device is unset. This is different from previous behavior.
- CUDAGuard no longer handles streams, or multiple streams. Use CUDAStreamGuard
or CUDAMultiStreamGuard as appropriate for your use case.
Reviewed By: dzhulgakov
Differential Revision: D12849620
fbshipit-source-id: f61956256f0b12be754b3234fcc73c2abc1be04e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13549
caffe2/perfkernels has a nice framework to switch btw implementations optimized for different instructions at runtime.
This can be a good preparation to implement avx512 adagrad kernels.
Reviewed By: hyuen
Differential Revision: D12882872
fbshipit-source-id: a8f0419f6a9fd4e9b864c454dad0a80db267190c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13812
Original commit changeset: 2cf95bdc5ed8
Looks like in iOS, `uint64_t` is not the same as `size_t`. :( Fixed it here.
Reviewed By: houseroad
Differential Revision: D13017390
fbshipit-source-id: d33854ce341225aba372fb945c3704edc14f9411
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13816
If common.find_free_port() returns the same port over and over again,
and the TCPStore fails to bind to it over and over again, this
function has the potential to loop forever. If we can't find a free
port after 10 tries, we are safe to assume something is wrong...
Differential Revision: D13017700
fbshipit-source-id: 2139a0ea0f30ce08b5571f80ae0551f1fa7ba4a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13815
If the TCPStoreDaemon was constructed and destructed shortly after, it
was possible for the controlPipeFd_ to get initialized by the
background thread after the stop() function was already called. Then,
the destructor hangs on waiting for the thread to terminate, when the
termination signal (closing the write side of the control pipe) will
never happen.
Differential Revision: D13017697
fbshipit-source-id: 9528286fbfc773237990f1a666605d27bac2c0e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13745
We need to support types beside `int64` and `float`.
Reviewed By: bddppq, rdzhabarov
Differential Revision: D12967258
fbshipit-source-id: 688076e6f504b2bf24bba89714df87a678c5638a
Summary:
* Switch to __ffsll in Embedding which is the correct intrinsic here.
* Fix WARP_BALLOT and ffsll in LookupTable as well.
Fix comes from iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13804
Differential Revision: D13016184
Pulled By: bddppq
fbshipit-source-id: 2287a78ee9e592630336a073ad1e55a90e1f946d
Summary:
InterpresterStateImpl con continue its lifecycle by increment the ref
count itself. This patch also removes InterpresterState::clone()
interface that conflicts with intrusive_ptr_target that disallows copy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13784
Differential Revision: D13015451
Pulled By: highker
fbshipit-source-id: a05f1ea6549d52ec693ccffefaa4d520b2474b8c
Summary:
We're relying on the default function schema (which contains no argument information) in places where we don't need to. This is bad because alias analysis will be very conservative when it doesn't have schema information present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13790
Differential Revision: D13009185
Pulled By: suo
fbshipit-source-id: 023516937bd3dcae8a969185a89c55f38d691ba5
Summary:
- This is a straightforward PR, building up on the batch inverse PR, except for one change:
- The GENERATE_LINALG_HELPER_n_ARGS macro has been removed, since it is not very general and the resulting code is actually not very copy-pasty.
Billing of changes:
- Add batching for `potrs`
- Add relevant tests
- Modify doc string
Minor changes:
- Remove `_gesv_single`, `_getri_single` from `aten_interned_strings.h`.
- Add test for CUDA `potrs` (2D Tensor op)
- Move the batched shape checking to `LinearAlgebraUtils.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13453
Reviewed By: soumith
Differential Revision: D12942039
Pulled By: zou3519
fbshipit-source-id: 1b8007f00218e61593fc415865b51c1dac0b6a35
Summary:
Add a markdown document summarizing the coverage of serialized operator tests. This currently only takes into account what has been covered by the tests with respect to the entire registry of c2 operators.
Next, we will break down the coverage by which operators have unit tests associated with them, which have hypothesis tests, and which have tests more specifically calling assertReferenceChecks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13703
Reviewed By: dzhulgakov
Differential Revision: D12970810
Pulled By: ajyu
fbshipit-source-id: 4f0cd057b1cf734371333e24d26cbab630a170e1
Summary:
```
The new error message now looks like (from Python):
RuntimeError: CUDA out of memory. Tried to allocate 16.00 GiB (GPU 0; 11.93 GiB total capacity; 4.00 GiB already allocated; 7.33 GiB free; 179.00 KiB cached)
Summary of terms:
"total capacity": total global memory on GPU
"already allocated": memory allocated by the program using the
caching allocator
"free": free memory as reported by the CUDA API
"cached": memory held by the allocator but not used by the program
The "allocated" amount does not include memory allocated outside
of the caching allocator, such as memory allocated by other programs
or memory held by the driver.
The sum of "allocated" + "free" + "cached" may be less than the
total capacity due to memory held by the driver and usage by other
programs.
Note that at this point cuda_malloc_retry has already returned all
possible "cached" memory to the driver. The only remaining "cached"
memory is split from a larger block that is partially in-use.
```
This also fixes an issue where on out-of-memory could cause an unrelated subsequent CUDA kernel launch to fail because `cudaGetLastError()` was not cleared.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13751
Differential Revision: D13007177
Pulled By: colesbury
fbshipit-source-id: ea7121461b3f2a34646102959b45bde19f2fabab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13742
Along the way, I switch us to globbing directories by hand,
so we don't actually pick up generated cpp files in c10/build
(if you're doing the normal idiom for a cmake build.)
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Reviewed By: dzhulgakov
Differential Revision: D12988039
fbshipit-source-id: 08b7ec50cfef82b767b4ca9972e5ba65bc45bcbb
Summary:
This PR is a part of task to unblock standard library export.
* we treat None differently from Tensor and other types, when passing None as Tensor, it's an undefined tensor rather than the None IValue.
* Refine the type system so that we have correct tensor types hierarchy (Dynamic/Tensor/CompleteTensor), Dynamic should be at the top of the inheritance hierarchy.
* It also tries to export bilinear as an example of undefined tensor(None) input.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13650
Differential Revision: D12967026
Pulled By: wanchaol
fbshipit-source-id: 6aedccc7ce2a12fadd13d9e620c03e1260103a5a
Summary:
UndefinedBehaviorSanitizer: null-pointer-use ../fbcode/third-party-buck/gcc-5-glibc-2.23/build/libgcc/include/c++/5.5.0/bits/stl_vector.h:794:16
```
Here we take the address of the first element in the empty vector. Fix the error by guarding against empty source.
Reviewed By: pixelb
Differential Revision: D12989957
fbshipit-source-id: ac5ec366385df835b546bd1756e30cd762f13a7a
Summary:
We have an MNIST reader in the C++ data API, so we can get rid of the custom one currently implemented in the integration tests.
ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13737
Differential Revision: D12990936
Pulled By: goldsborough
fbshipit-source-id: 125a1910ec91d53dbf121570fc9eec6ccfba0477
Summary:
We now have submodules that have submodules
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13769
Reviewed By: soumith
Differential Revision: D13000203
Pulled By: SsnL
fbshipit-source-id: 63c0c19c6c9d25ae3bf255a2421a82ca68278866
Summary:
There's no reason we need these as the native function wrapper calls into the function anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13721
Differential Revision: D12977449
Pulled By: gchanan
fbshipit-source-id: 54701ebe2f0bb2b55484cb437501c626e6471347
Summary:
When tracing scripted functions, we used to only allow Tensor arguments.
This enables tracing script modules with List[Tensor] or Tuple[Tensor, Tensor] arguments (passing
tuples).
Fixes: #13566
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13597
Differential Revision: D12990464
Pulled By: soumith
fbshipit-source-id: fdce3afcb1e09f3c26d6ce834c01bf18d261f47c
Summary:
Upon calling wait(), save the forked thread and the current thread to a
task queue. A idling thread (which currently is single threaded) should
pick a ready task and run till there is nothing in the task queue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13212
Differential Revision: D12884522
Pulled By: highker
fbshipit-source-id: b3942a0ee63c148e05f5f41bdc73007fa3c3368e
Summary:
This adds torch.jit.annotate for annotating the type of an intermediate.
This is Py2/3 compatible, e.g.:
```
from torch.jit import annotate
from typing import List
torch.jit.script
def foo():
a = annotate(List[int], [])
```
This is needed to output valid python programs from our IR. It removes
the need for the empty list constructors.
A future patch can add support to the C++ parser and Python 3,
via desugaring:
```
a : int = b
a = anntoate(int, b)
```
But this functionality is not required for serialization so is not added in this patch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13752
Differential Revision: D12989885
Pulled By: zdevito
fbshipit-source-id: 161573a7352094543dc0d33a892f2a3b9103d847
Summary:
This PR contains changes for:
1. Adding HIP top_k operator in Caffe2
2. Added HIP equivalent definitions of GPUDefs and GPUScanUtils
3. Removing the top_k operator test from ROCm test ignore list
4. Bug fixes in related code in THC/THCAsmUtils.cuh
Differential Revision: D12986451
Pulled By: bddppq
fbshipit-source-id: 6d5241fb674eaeb7cde42166426ac88043b83504
Summary:
CircleCI now offers 60x OSX concurrency, which is 2x of what we currently have in Jenkins. This should help alleviate the OSX CI wait time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13731
Differential Revision: D12993737
Pulled By: yf225
fbshipit-source-id: f475ad9a1d031eda95b7cacdaf52f31fbb2f4f93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13740
We would like to rename the old fbgemm to “fbgemm0”, and the new fbgemm2 to “fbgemm”:
This DIFF changes all namespace fbgemm2 to namespace fbgemm.
The purpose is to avoid the confusion of "fbgemm2" when we release our FBGEMM open source.
Reviewed By: jspark1105
Differential Revision: D12850449
fbshipit-source-id: 08cc47864b157e36fbceddb7a10bf26218c67bd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13701
We would like to rename the old fbgemm to “fbgemm0”, and the new fbgemm2 to “fbgemm”:
This DIFF changes all namespace fbgemm to namespace fbgemm0.
Reviewed By: jspark1105
Differential Revision: D12848727
fbshipit-source-id: 47935e9e2c4714a7ce1bfc3f7e4d6a334130132e
Summary:
MKLDNN is not supported on ppc64le change USE_MKLDNN to OFF for ppc64le
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13759
Differential Revision: D12993121
Pulled By: soumith
fbshipit-source-id: 539d5cfcff2c03b59fa71e10b52fac333a64c381
Summary:
`clang_tidy.py` doesn't run with Python2 right now. Needs a minor fix
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13735
Differential Revision: D12990613
Pulled By: goldsborough
fbshipit-source-id: ad19b229a14188fd048dde198a7f4c3483aeff95
Summary:
With this change applied, `torch.cat` works for sparse tensors.
The algorithm is just to concatenate the values, and give the new values the proper indices (which will be the same as their old indices in every dimension except the catted dimension, and their old indices plus the sum of the size of every previous tensor in the catted dimension).
This is my first time contributing to PyTorch so please feel free to tell me if this approach seems totally wrong.
Coming next: `torch.stack` for sparse tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13577
Differential Revision: D12980948
Pulled By: umanwizard
fbshipit-source-id: 51ebdafee7fcd56d9762dcae9ebe5b4ab8e1dd6b
Summary:
This is probably slow but it should make the traces more understandable and make debugging easier. Any suggestions for how to make it faster (i.e. make it so we don't have to traverse all of locals() and globals()) would be appreciated
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13441
Differential Revision: D12879763
Pulled By: jamesr66a
fbshipit-source-id: b84133dc2ef9ca6cfbfaf2e3f9106784cc42951e
Summary:
H/t kalisp for pointing it out
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13706
Differential Revision: D12983983
Pulled By: ezyang
fbshipit-source-id: 6a43cdde142fe64550121b16716f206e7c4d68d6
Summary:
update roll to behave as in numpy.roll when dimension to roll not specified.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13588
Differential Revision: D12964295
Pulled By: nairbv
fbshipit-source-id: de9cdea1a937773033f081f8c1505a40e4e08bc1
Summary:
Update range documentation to show that we don't support start or increment parameters
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13730
Differential Revision: D12982016
Pulled By: eellison
fbshipit-source-id: cc1462fc1af547ae80c6d3b87999b7528bade8af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13440
Time based tracing is easier to look at when multiple nets are running asynchronously.
This diff also adds an option to change the path to dump trace files.
Reviewed By: aazzolini, ilia-cher
Differential Revision: D12479259
fbshipit-source-id: 94d379634ba7b90c111c92b1136ffa4226b8bb8c
Summary:
1. Removes the flag "/FORCE:UNRESOLVED" that shouldn't be used.
2. Fix the code logic for ONNX_BUILD_MAIN_LIBS on Windows
3. Add a patch for protobuf using CMake
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13100
Differential Revision: D12978950
Pulled By: orionr
fbshipit-source-id: db9eb8136acf5712cfb5a24ed228b7934d873331
Summary:
To support `_Reduction` in the jit this PR moves it out to a new file so that it goes through the paths for python modules in the script compiler and converts `F.ctc_loss` to weak script
Depends on #13484 for saving rng state
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13401
Differential Revision: D12868501
Pulled By: driazati
fbshipit-source-id: 23cec0fb135744578c73e31ac825e238db495d27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13377
* Enable junk fill for the default CPU allocator. The first diff only enables this for the tests. A second diff will change the default of zero-fill to false.
* Fix tests to use 64-bit counters that IterOp and LearningRateOp demands.
* Fix kernels that uses uninitialized memory.
Reviewed By: salexspb
Differential Revision: D10866512
fbshipit-source-id: 17860e77e63a203edf46d0da0335608f77884821
Summary:
Support things like `foo[0] = bar` in script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13486
Differential Revision: D12964550
Pulled By: suo
fbshipit-source-id: 3dda8ffd683d1b045787c65bfa0c7d43b0455658
Summary:
When we added to in #13146, we did not emit the cast correctly in one of the dispatch overloads, then when we call .cpu(), the dtype will always be the default float type, which is wrong.
CC jamesr66a eellison
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13700
Differential Revision: D12968699
Pulled By: wanchaol
fbshipit-source-id: c1aaf2bf6a163643ce5360797da61c68271d8bf8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13660
Any change in server side quantized operator was triggering ios-sanity-check with more than 5 hours testing time. I suspect this was because the operator code was synced with xplat directory. This diff moves server side quantized operators to caffe2/caffe2/quantization/server to avoid this issue.
Reviewed By: hx89
Differential Revision: D12955420
fbshipit-source-id: b6c824b9de5e2a696f8c748e1b2c77d81d46746b
Summary:
In `broadcast_coalesced`, since multiple variables can be "views" of a big flattened tensor, they can share the same version counter. However, this base flat tensor is not exposed and they don't share any memory locations, so this is not necessary. Furthermore, it can cause problems, e.g., when two buffers are broadcast together in `DataParallel` and one of them is modified in-place during `forward` but the other is needed in backward, autograd engine will complain.
Fixing the bug discovered at https://github.com/pytorch/pytorch/pull/13350#issuecomment-436011370
edit: This is a very real problem. E.g., consider using Spectral Norm + Batch Norm together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13594
Differential Revision: D12967311
Pulled By: SsnL
fbshipit-source-id: 52998dbabe149f575cf0fb79e7016f0b95e4b9e5
Summary:
- a walk around for #13292, a complete fix requires investigation on the root cause when using advanced indexing
- this PR brings in `filp()` CUDA implementation for CPU kernel
- with this change:
```
>>> t = torch.randn(1, 3, 4, 5)
>> t.flip(1, 3).shape
torch.Size([1, 3, 4, 5])
```
- performance:
```
====== with this PR ======
>>> a = torch.randn(1000, 1000)
>>> %timeit -r 100 a.flip(0, 1)
1.98 ms ± 579 µs per loop (mean ± std. dev. of 100 runs, 1000 loops each)
====== Perf at previous PR #7873 ======
100 loops, best of 3: 11 ms per loop
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13344
Differential Revision: D12968003
Pulled By: weiyangfb
fbshipit-source-id: 66f434049d143a0575a35b5c983b3e0577a1a28d
Summary:
This is a redo of the previous move which broke OS X and Windows tests -- RTTI seemed to be broken
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13455
Differential Revision: D12883775
Pulled By: bwasti
fbshipit-source-id: 2b6c65e8150e6f89624c6ee99c389335c6fb4bb8
Summary:
Removes the last uses of `.data()` in implementation code of the C++ frontend.
CC yf225
ezyang ebetica apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13675
Differential Revision: D12966061
Pulled By: goldsborough
fbshipit-source-id: fbc0c83c3ba56598ff853bc7b1ddf9005fdd9c41
Summary:
Previously, we did not distinguish between `a = b` (simple assignment),
and `a, = b` (tuple destructuring of a singleton tuple).
The second case would fail in the string frontend, and would not unpack
in the python frontend. This patch fixes both issues and also cleans up
the error reporting for unexpected expressions on the LHS.
Will likely conflict with #13486
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13656
Differential Revision: D12964566
Pulled By: zdevito
fbshipit-source-id: 992b19e5068aef59a78cd23cb0e59a9eeb7755d1
Summary:
The stylesheet at docs/source/_static/css/pytorch_theme.css is no longer necessary for the html docs build. The new html docs theme styles are located at https://github.com/pytorch/pytorch_sphinx_theme.
The Lato font is also no longer used in the new theme.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13699
Differential Revision: D12967448
Pulled By: soumith
fbshipit-source-id: 7de205162a61e3acacfd8b499660d328ff3812ec
Summary:
We weren't running C++ extensions tests in CI.
Also, let's error hard when `ninja` is not available instead of skipping C++ extensions tests.
Fixes https://github.com/pytorch/pytorch/issues/13622
ezyang soumith yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13646
Differential Revision: D12961468
Pulled By: goldsborough
fbshipit-source-id: 917c8a14063dc40e6ab79a0f7d345ae2d3566ba4
Summary:
We only need this for backward, for FWD cast, the non-fine-grained bucketing should be better since it's sequential anyway.
Test should be covered all by c10d test, reduced bucket size to make bucketing happen in c10d test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13607
Differential Revision: D12944515
Pulled By: teng-li
fbshipit-source-id: d982e8dca2874c91d39b30b73a85bfbeb768c508
Summary:
Also add docs for get_backend, Backend, and reduce_op
fixes#11803
cc The controller you requested could not be found. pietern apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11830
Differential Revision: D9927991
Pulled By: SsnL
fbshipit-source-id: a2ffb70826241ba84264f36f2cb173e00b19af48
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13629
Previously we have a Tensor which has a initialized storage(therefore a known device_type) and
then we'll call CopyFrom on it to initialize the sizes and data.
We want to eliminate partially initialized Tensor by replacing the pattern of calling CopyFrom with a partially initialized Tensor with either splitting that to undefined Tensor + initialization API(1)(3) or combine all the initialization in the same step(2).
1. member variable initialization + CopyFrom
Previously we have a tensor that is initialized with device_type, and then use CopyFrom to populate the content, now we remove the partial initialization by make the original member variable an undefined Tensor and use ReinitializeFrom to copy from another Tensor.
2. Output + CopyFrom
Previously, we first get a tensor with device_type, and then CopyFrom another Tensor,
We changed it two combining these two operations into OperatorBase::OutputTensor.
3. Output + custom functions
Example can be found in TransformGPU function.
In this case we move the part that initializes the tensor outside of the function, and do that explicitly outside so that we could reuse the Output functions to make a fully initialized Tensor.
Note that to keep the original semantics, both of the APIs has a caching effect based on device_type, which means we only create a Tensor object when device_type does not match or the Tensor is undefined, otherwise, we will reuse the original Tensor object.
Reviewed By: dzhulgakov
Differential Revision: D12848855
fbshipit-source-id: 37bb4ddc1698ebea533b73006eeb1218faa8ddf8
Summary:
In particular, this was breaking the logic for cudnn algorithm to fall back to a less memory hungry algorithm if the selected one OOM when creating the workspace.
c10::Error are subclass of `std::exception` and not `std::runtime_error`.
I removed `runtime_error` in all places in our code and replaced them with `const exception`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13665
Differential Revision: D12958396
Pulled By: soumith
fbshipit-source-id: af557efd9887b013140113d3067de157ffcf8465
Summary:
In the example for ConvTranspose3d, the docstring had "Conv3d" instead of "ConvTranspose3d" in one instance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13668
Differential Revision: D12958372
Pulled By: soumith
fbshipit-source-id: 5ec901e20b90f4eed2bf04c5b417183ec2096447
Summary:
This is a pre-cursor diff to Python <-> C++ frontend integration -- I have a follow-up PR coming for that. This PR changes the C++ frontend module interface to replace the custom "cursor"s I introduced some time ago with `OrderedDict`. I introduced cursors at the time as a convenient way of applying functions and query operations on a modules' parameters, buffers and modules, allowing things like `module.parameters().map(my_func)`. However, I noticed that (1) this functionality is easily implement-able on top of a regular data structure and (2) more importantly, using OrderedDicts is much, much easier for Python integration. This is especially true given that ScriptModule today also uses OrderedDict. Since C++ frontend modules and ScriptModules will soon too share as many implementation details as possible, it is overall the best move to ditch the custom cursor datastructure and pervasively use OrderedDict everywhere.
For this I did:
1. Changed the C++ frontend module interface to more closely match the Python one by providing `parameters()`, `named_parameters()` and other methods Python provides. This is very important for the following diff which binds these into Python for inter-op with Python modules.
2. In lieu of the `Cursor::apply()` method I added `nn::Module::apply`. This again is one more unifying step between Python and C++, since Python modules have an apply function too.
3. Deleted all uses of Cursor.
4. Tidied and beefed up the `OrderedDict` class. In particular, I made `OrderedDict::Item` store an `std::pair` under the hood, because that is trivial to bind into Python and saved me a lot of headaches. `key` and `value` become methods instead of fields, which they should have been from the very start anyway because it allows exactly these kinds of changes, as per usual good software engineering principle of encapsulation.
5. Added many tests for the OrderedDict use in `nn::Module`.
ebetica ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13427
Differential Revision: D12894092
Pulled By: goldsborough
fbshipit-source-id: 715770c95a9643753a1db26d7f9da9a78619a15d
Summary:
Due to a logic bug, tracing is broken for custom ops. Unfortunately, there also weren't any tests for tracing custom ops.
The fix is a single line change of moving `pop(stack, std::get<Is>(arguments)...);` before `node = getTracedNode<Is...>(schema, arguments);`. Other changes are added tests and improved commenting/formatting.
Fixes https://github.com/pytorch/pytorch/issues/13564
CC The controller you requested could not be found. fmassa
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13654
Differential Revision: D12952887
Pulled By: goldsborough
fbshipit-source-id: 87d256576f787c58e8d8f5c13a0fecd0ec62a602
Summary:
Followup to #12841
Changed these to not require type dispatch:
tensor.type().is_cuda() -> tensor.is_cuda()
tensor.type().is_sparse() -> tensor.is_sparse()
isVariable(tensor.type()) -> tensor.is_variable()
This probably does not affect performance
very much in most cases but it is nice to have.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13590
Reviewed By: ezyang
Differential Revision: D12929301
Pulled By: zou3519
fbshipit-source-id: 8ac5c6200c579dd7a44fb4ee58fc9bb170feb1d7
Summary:
This should improve the performance of wrapping a tensor in a Variable
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13630
Reviewed By: ezyang
Differential Revision: D12944960
Pulled By: zou3519
fbshipit-source-id: 89fa78a563e46a747d851a90ffd1b5cf3cd2d0d7
Summary:
Since json is a builtin module in Python (>= 2.6), this makes pyhipify
can be invoked without installing any extra dependencies.
petrex iotamudelta
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13595
Differential Revision: D12931045
Pulled By: bddppq
fbshipit-source-id: 31d68fb6e730fd9d11593550ca531423cb0596e9
Summary:
C2GEMMContext is a remnant of old times when Int8 ops used gemmlowp.
It is no longer needed: formerly gemmlowp-based ops use QNNPACK with pthreadpool interface, and other ops (Int8Add, Int8ChannelShuffle) use Caffe2 thread pool interface directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13443
Differential Revision: D12887773
Pulled By: Maratyszcza
fbshipit-source-id: bd2732e2c187b399c8a82efebdd244457720256b
Summary:
- Move batch norm from TH(CU)NN to native
- Speedups in many cases (e.g. #12006) for CUDA due to new block/grid layout and Welford-type mean/variance calculations (the latter for training mode)
- It splits the forward kernel in two pieces and reuses the evaluation kernel for the transformation.
- We change the meaning of save_mean and save_invstd (aka save_var) to accscalar to maintain reasonable precision.
Compared to the ill-fated #12368
- I changed the CPU kernel to not call `.sum()` from within parallel for. This seemed to have caused the breakage (NaN-results) in TestModels.test_dcgan_netG (thank you houseroad for the repro, errors in assessment of the fix are my own)
- I updated the Half->Float upcasting in tensors to go through `t.type().scalarType()` instead of `t.dtype()`.
- I have merged master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13263
Differential Revision: D12946254
Pulled By: SsnL
fbshipit-source-id: 3bb717ee250fbccaf10afe73722996aa4713d10d
Summary:
This finishes a TODO to get torch.jit.script to go through the same
pathway as methods, removing the need for forward_schema and
for compileFunction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13640
Differential Revision: D12949713
Pulled By: zdevito
fbshipit-source-id: 3d1a5f14910d97a68670a3fd416bdbfe457f621d
Summary:
Problems with SN and DP after #12671 :
1. in eval mode, `weight_orig` is not getting correct gradient #12737 .
Fix: keep `v` vector around as a buffer and always calculate `W = W_orig / (u @ W_orig @ v)` even in eval.
2. in training mode, the `weight` buffer of the parallelized module is never updated, if someone touches `weight_orig` and/or `weight` and makes them not sharing storage. So in `eval` the weight used is wrong.
Fix: Make `weight` not a buffer anymore and always calculate it as above.
3. #12671 changed SN to update `u` in-place to make DP work correctly, but then it breaks backward through two forwards (e.g., the common GAN loss `D(real) - D(fake)`) because the vectors needed to backprop the 1st forward is changed in the 2nd forward.
Fix: This PR clones `u` and `v` before using them.
To maintain BC, I added a hook interface for producing and loading state_dict. This is ugly and we should really have better interface for spectral_norm. But for the purpose to fix this issue, I make this patch. Even if we have a better interface, BC mechanism for legacy loading legacy state_dict still needs to be done.
cc The controller you requested could not be found. crcrpar
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13350
Differential Revision: D12931044
Pulled By: SsnL
fbshipit-source-id: 8be6f934eaa62414d76d2c644dedd7e1b7eb31ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13582
Worker nodes sometimes witness timeout failures when getting session_id blob from Zeus, which due to delays in master node setting the blob.
This diff will add flexibility to specify longer timeout for getting blobs from Zeus.
Reviewed By: pietern
Differential Revision: D12926156
fbshipit-source-id: b1a4d1d9cf7de084785bfa4a8a0cd3cfd095ba5c
Summary:
Correctly propagate the error msg from a python op to the JIT interpreter. In the interpreter we wrap the exception and re-throw it as a Runtime Exception. Potentially in a future diff we can throw the same type of python exception as was originally thrown.
Fix for https://github.com/pytorch/pytorch/issues/13560
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13624
Differential Revision: D12948756
Pulled By: eellison
fbshipit-source-id: 94cdf4c376143c5e40dcb9716aefb3c1e2d957db
Summary:
RTTI can't be used on android so this is needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13591
Differential Revision: D12914402
Pulled By: bwasti
fbshipit-source-id: be8c8c679bb20c7faaa7e62cd92854cedc19cb3a
Summary:
I was hitting this error:
caffe2/caffe2/operators/stats_put_ops.h:66:25: runtime error: 9.22337e+18 is outside the range of representable values of type 'long'
So, the assignment from int64_t to float loses some precision and because of that we overflow.
Reproduced this issue with this diff D12945013
Reviewed By: mlappelbaum, jdshi-fb
Differential Revision: D12927086
fbshipit-source-id: 7eae7fe25ab49d5ac15279335bd5b1fa89d6e683
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13522
Currently Tensor is a shared pointer to the underlying implementation, rather than a value, copying
the pointer will share the underlying TensorImpl, ShareData probably don't make sense anymore.
Reviewed By: dzhulgakov
Differential Revision: D12871708
fbshipit-source-id: d3773c66b7ed0bf1c37e886f69f59aec158b216b
Summary:
In TorchScript and C++ extensions we currently advocate a mix of `torch::` and `at::` namespace usage. In the C++ frontend I had instead exported all symbols from `at::` and some from `c10::` into the `torch::` namespace. This is far, far easier for users to understand, and also avoid bugs around creating tensors vs. variables. The same should from now on be true for the TorchScript C++ API (for running and loading models) and all C++ extensions.
Note that since we're just talking about typedefs, this change does not break any existing code.
Once this lands I will update stuff in `pytorch/tutorials` too.
zdevito ezyang gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13523
Differential Revision: D12942787
Pulled By: goldsborough
fbshipit-source-id: 76058936bd8707b33d9e5bbc2d0705fc3d820763
Summary:
This helper addresses a common pattern where one spawns N processes to
work on some common task (e.g. parallel preprocessing or multiple
training loops).
A straightforward approach is to use the multiprocessing API directly
and then consecutively call join on the resulting processes.
This pattern breaks down in the face of errors. If one of the
processes terminates with an exception or via some signal, and it is
not the first process that was launched, the join call on the first
process won't be affected. This helper seeks to solve this by waiting
on termination from any of the spawned processes. When any process
terminates with a non-zero exit status, it terminates the remaining
processes, and raises an exception in the parent process. If the
process terminated with an exception, it is propagated to the parent.
If the process terminated via a signal (e.g. SIGINT, SIGSEGV), this is
mentioned in the exception as well.
Requires Python >= 3.4.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13518
Reviewed By: orionr
Differential Revision: D12929045
Pulled By: pietern
fbshipit-source-id: 00df19fa16a568d1e22f37a2ba65677ab0cce3fd
Summary:
In #11846 , we immigranted all catch tests in Aten/test/ to use gtest except of basic.cpp for a GPU bug (valgrind related).
In this PR, we will find out what the bug is, and immigrant last piece of aten catch to use gtest.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12142
Differential Revision: D12946980
Pulled By: zrphercule
fbshipit-source-id: cf3b21f23ddec3e363ac8ec4bdeb4bc4fe35f83b
Summary:
Add a builtin to refine the type of Optional[T] -> T. This is a short-term solution to unblock porting of the the standard library.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13599
Reviewed By: driazati, wanchaol
Differential Revision: D12943193
Pulled By: eellison
fbshipit-source-id: 31c893a78d813313bbbc1d8212b5c04e403cfb4d
Summary:
Also speeds up tensor.is_variable(), tensor.layout(), and
tensor.device(). This PR speeds up tensor.options() from 54ns to 17ns,
resulting in a comparable speedup in torch.as_strided performance:
https://gist.github.com/zou3519/7645262a4f89e237405857925bb872c3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13330
Differential Revision: D12847695
Pulled By: zou3519
fbshipit-source-id: 60b303671b0cce7b6140068c7f90c31d512643be
Summary:
Some extra documentation for other bits too.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13621
Differential Revision: D12943416
Pulled By: ezyang
fbshipit-source-id: c922995e420d38c2698ce59c5bf4ffa9eb68da83
Summary:
The motivational of this PR is to enforce mkldnn to use the same omp version of caffe2 framework.
Meanwhile, do not change other assumptions within mkldnn.
Previously, the MKL_cmake_included is set in caffe2 in order to disable omp seeking in mkldnn.
But, with such change, mkldnn has no chance to adapt for mkl found by caffe2.
Then, some building flags of mkl will be not set in mkldnn.
For example, USE_MKL, USE_CBLAS, etc.
In this PR, we enforce set the MKLIOMP5LIB for mkldnn according to caffe2, and tell the mkl root path in MKLROOT for mkldnn. Then, mkldnn is built as expected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13449
Differential Revision: D12899504
Pulled By: yinghai
fbshipit-source-id: 22a196bd00b4ef0a11d350a32c049304613edf52
Summary:
- fixes weights-contiguous requirement for THCUNN Convolutions
- Add tests that conv backward pass works for non-contiguous weights
- fix RNN tests / error messages to be consistent and pass
- relax weight grad precision for fp16 for a particular test
- fix regression of CMAKE_PREFIX_PATH not passing through
- add missing skipIfNoLapack annotations where needed
Differential Revision: D12918456
Pulled By: soumith
fbshipit-source-id: 8642d36bffcc6f2957800d6afa1e10bef2a91d05
Summary: Adding Fetching Real number representation for int8 tensor in workpace.py
Reviewed By: harouwu
Differential Revision: D12936556
fbshipit-source-id: f8756a37bce21c93d44d52faf5da9c9bd6473f4a
Summary:
This PR adds functions defined in `torch._C._nn` as builtin functions (including inplace variants). This allows for the conversion of more functions to weak script
NB: many `torch.nn.functional` functions will have to be slightly rewritten to avoid early returns (as with `threshold` in this PR)
Converts these functions to weak script:
* `threshold`
* `relu`
* `hardtanh`
* `relu6`
* `elu`
* `selu`
* `celu`
* `leaky_relu`
* `rrelu`
* `tanh`
* `sigmoid`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13322
Differential Revision: D12852203
Pulled By: driazati
fbshipit-source-id: 220670df32cb1ff39d120bdc04aa1bd41209c809
Summary:
Functionality test shouldn't be affected since we have both backends testing for the same thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13606
Differential Revision: D12937185
Pulled By: teng-li
fbshipit-source-id: 03d897b6690f7932654fdb7d11a07016dfffa751
Summary:
Variable owns a Tensor which already has a Storage/StorageImpl
if necessary. The Variable ctor was unnecessarily allocating *another*
Storage/StorageImpl, which costs around 200ns.
This PR gets rid of that behavior and cuts the `as_variable` time from
670ns to 475ns, reducing Variable overhead
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13580
Differential Revision: D12925495
Pulled By: zou3519
fbshipit-source-id: 4f5ec33776baa848d1c318abcf40b57125b3bed7
Summary:
We updated the description of upsample_op in onnx: https://github.com/onnx/onnx/pull/1467
Therefore, we need to support the new upsample_op in caffe2-onnx backend as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13272
Reviewed By: houseroad
Differential Revision: D12833656
Pulled By: zrphercule
fbshipit-source-id: 21af5282abaae12d2d044e4018a2b152aff79917
Summary:
This PR:
- Replaces c10d's CUDAEvent with ATen's, removing the two associated c10d files
- Updates c10d's usage of CUDAEvent to reflect the ATen API
- Updates c10d's usage of streams to reflect the ATen API
- Removes use of historic THCState in the touched c10d files
- (EDIT) Fixes a bug in CUDAEvent.h where events could be recorded on the wrong device. Now adds a device guard for this case.
The controller you requested could not be found. pietern
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13464
Reviewed By: teng-li
Differential Revision: D12924291
Pulled By: pietern
fbshipit-source-id: b8ebe3e01e53d74e527ad199cca3aa11915c1fc0
Summary:
Removes aten/README.md (and some other files dating from when aten was its own repo), and moves the not outdated documentation into a note called "Tensor Basics". I updated the text lightly but did not overhaul the content.
CC zdevito
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13601
Differential Revision: D12934480
Pulled By: goldsborough
fbshipit-source-id: 012a4267b4d6f27e4d5d55d6fc66363ddca10b41
Summary:
The PR did two things:
1. fix the bug in erase_number_type on node inputs
2. handle negative indices for dim-reduce in caffe2
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12888
Reviewed By: houseroad
Differential Revision: D12833486
Pulled By: wanchaol
fbshipit-source-id: c3ceb400d91f0173b73ad95e392b010c3c14db7d
Summary:
This PR brings to changes to the recently landed C++ Frontend dataloader:
1. Removes the `size()` method from `BatchDataset`. This makes it cleaner to implement unsized ("infinite stream") datasets. The method was not used much beyond initial configuration.
2. Makes the index type of a dataset a template parameter of `BatchDataset` and `Sampler`. This essentially allows custom index types instead of only `vector<size_t>`. This greatly improves flexibility.
See the `InfiniteStreamDataset` and `TestIndex` datasets in the tests for what this enables.
Some additional minor updates and code movements too.
apaszke SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12960
Differential Revision: D12893342
Pulled By: goldsborough
fbshipit-source-id: ef03ea0f11a93319e81fba7d52a0ef1a125d3108
Summary:
To convert `nn.functional.dropout`
* `_VF` had to be exposed as a Python module so this PR adds a module class to forward to `torch._C._VariableFunctions`
* rng state between calls in the tests needed to be made consistent
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13484
Differential Revision: D12929622
Pulled By: driazati
fbshipit-source-id: 78b455db9c8856b94d2dda573fb7dc74d5784f56
Summary:
If there is no return type then the returns of the schema are not
checked against the returns in the graph, so this PR adds an error if
that case is detected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13525
Differential Revision: D12929524
Pulled By: driazati
fbshipit-source-id: da562e979482393098830bbded26729a2499152a
Summary:
This PR restructures the public-facing C++ headers in a backwards compatible way. The problem right now is that the C++ extension header `torch/extension.h` does not include the C++ frontend headers from `torch/torch.h`. However, those C++ frontend headers can be convenient. Further, including the C++ frontend main header `torch/torch.h` in a C++ extension currently raises a warning because we want to move people away from exclusively including `torch/torch.h` in extensions (which was the correct thing 6 months ago), since that *used* to be the main C++ extension header but is now the main C++ frontend header. In short: it should be possible to include the C++ frontend functionality from `torch/torch.h`, but without including that header directly because it's deprecated for extensions.
For clarification: why is `torch/torch.h` deprecated for extensions? Because for extensions we need to include Python stuff, but for the C++ frontend we don't want this Python stuff. For now the python stuff is included in `torch/torch.h` whenever the header is used from a C++ extension (enabled by a macro passed by `cpp_extensions.py`) to not break existing users, but this should change in the future.
The overall fix is simple:
1. C++ frontend sub-headers move from `torch/torch.h` into `torch/all.h`.
2. `torch/all.h` is included in:
1. `torch/torch.h`, as is.
2. `torch/extensions.h`, to now also give C++ extension users this functionality.
With the next release we can then:
1. Remove the Python includes from `torch/torch.h`
2. Move C++-only sub-headers from `all.h` back into `torch.h`
3. Make `extension.h` include `torch.h` and `Python.h`
This will then break old C++ extensions that include `torch/torch.h`, since the correct header for C++ extensions is `torch/extension.h`.
I've also gone ahead and deprecated `torch::CPU` et al. since those are long due to die.
ezyang soumith apaszke fmassa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13482
Differential Revision: D12924999
Pulled By: goldsborough
fbshipit-source-id: 5bb7bdc005fcb7b525195b769065176514efad8a
Summary:
Clean it up from my queue:
https://github.com/pytorch/pytorch/issues/12721
```
>>> torch.distributed.init_process_group(backend="tcp")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/private/home/tengli/pytorch/torch/distributed/distributed_c10d.py", line 275, in init_process_group
backend = DistBackend(backend)
File "/private/home/tengli/pytorch/torch/distributed/distributed_c10d.py", line 55, in __new__
raise ValueError("TCP backend has been deprecated. Please use "
ValueError: TCP backend has been deprecated. Please use Gloo or MPI backends for collective operations on CPU tensors.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13596
Differential Revision: D12931196
Pulled By: teng-li
fbshipit-source-id: bb739b107ad7454e2e0a17430087161fedd4c392
Summary:
When go to mixed precision fp16 training, DDP randomly hangs. Initially, I thought this smells like a similar NCCL bug I filed a while ago. It turns out it's not. Again, I am seeing different rank process has different size. How could this even happen?
It turns out that take_tensors will generate a list of bucketed tensors in an un deterministic order, because, the key to the map is a pointer. An interesting bug digging and fix.
Now fp16 DDP training should be fully working now.
Also, added another take_tensor fine grained helper that aims to improve the performance of DDP, making it a TODO to replace the DDP take_tensors with that.
Fixed: https://github.com/pytorch/pytorch/issues/12150
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13496
Differential Revision: D12920985
Pulled By: teng-li
fbshipit-source-id: 26f3edae7be45a80fa7b2410a2e5a1baab212d9c
Summary:
Also, add an assertion in the GraphExecutor to make sure we don't
access memory out of bounds.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13553
Differential Revision: D12924796
Pulled By: soumith
fbshipit-source-id: ea2a134084538484178b8ebad33d6716a8e1d633
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13497
This replaces the existing broadcast implementation with the new style collective call in the gloo backend. The CUDA path copies CUDA tensors to CPU tensors and then runs the CPU broadcast implementation.
Reviewed By: teng-li
Differential Revision: D12890013
fbshipit-source-id: 43f346fb2814f421bedc7babf89169703a46bb9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13426
This replaces the existing allreduce implementation with the new style collective call in the gloo backend. This is the first one to include both a CPU and a CUDA path. The CUDA path copies CUDA tensors to CPU tensors and then runs the CPU allreduce implementation. This is not much different from the current situation in the case where there is a single input tensor per call (which is the case when called from DistributedDataParallel).
Reviewed By: teng-li
Differential Revision: D12855689
fbshipit-source-id: 574281d762dd29149fa7f634fb71f8f6a9787598
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13425
This adds support for the new style reduce collective call in the gloo backend.
Reviewed By: teng-li
Differential Revision: D12869404
fbshipit-source-id: 93c641e6aba3b03c796bda80737547c565cfa571
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13424
This adds support for the allgather collective call in the gloo backend. The gloo implementation does not support multiple inputs per rank (nor one or more outputs per rank), so we use a temporary flattened buffer and unflatten once the collective finishes.
Reviewed By: teng-li
Differential Revision: D12832009
fbshipit-source-id: 2f5c1934a338589cef1d3192bd92ada135fecd7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13423
This adds support for the gather collective call in the gloo backend. The gloo implementation does not yet support the mode where the root has multiple output tensors (one per rank), so we use a temporary flattened buffer and unflatten on the root once the collective finishes.
Reviewed By: teng-li
Differential Revision: D12811647
fbshipit-source-id: 90fe8af8c390090b7d4ef43aa74f4e3e67ab9d0b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13422
This adds support for the scatter collective call in the gloo backend. This is the first of the new style collectives that do not expect to be created once and used many times. This commit contains some shortcuts to make this new style work side by side with the existing implementations (such as the std::tuple with nullptr's). These shortcuts are temporary until we have moved over all collectives to this new style.
Reviewed By: teng-li
Differential Revision: D12310219
fbshipit-source-id: 32e68717f819d5980f0e469d297204948351cefc
Summary:
```
The previous threshold implementation was not vectorized or parallelized.
This speeds up ResNet-50 CPU inference [1] from ~88 ms to ~67 ms
CPU timings:
https://gist.github.com/colesbury/d0d1be6974841d62696dbde329a8fde8
1 thread (before vs. after)
10240: 17.4 us vs. 6.9 µs per loop
102400: 141 us vs. 39.8 µs per loop
16 threads (before vs. after)
10240: 17.4 us vs. 6.7 µs per loop
102400: 141 us vs. 14.3 µs per loop
CUDA timings are not measurably different.
[1]: compiled with MKL-DNN, 8 threads, batch norm merged into convolutions
https://gist.github.com/colesbury/8a64897dae97558b3b82da665048c782
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13182
Reviewed By: soumith
Differential Revision: D12825105
Pulled By: colesbury
fbshipit-source-id: 557da608ebb87db8a04adbb0d2882af4f2eb3c15
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13562
submodule update for fbgemm. This version of fbgemm has cmake minimum required same as pytorch. Without this, OSS build fails.
Reviewed By: jianyuh
Differential Revision: D12920951
fbshipit-source-id: 9ef532e715e3f7612fecc8430736633cf6b17f34
Summary:
Built on top of #13108, so please review only the last commit.
This makes the graph fuser ignore input types (device/scalar type) when considering graphs for fusion, making it much more robust to shape-prop failures. Those properties are now checked at run time, as part of the kernel validation. This should enable graph fusions in `jit_premul` and `jit_multilayer` timelines in our benchmarks.
One regression is that I've disabled fusions of comparison ops (and `type_as`). That's because there's really no good way to ensure that those are really valid, and are a source of bugs (I filed #13384).
cc ngimel mruberry zdevito zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13387
Differential Revision: D12888104
Pulled By: zou3519
fbshipit-source-id: c233ea599679c34ac70fb4d8b8497c60aad9e480
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13539
This is used by OCR's FPN model to detect small/dense text. Just a simple
permutations along the batch dim based on the input indices, and we can avoid
the unnecessary quantize/dequantize ops.
Reviewed By: csummersea
Differential Revision: D12894055
fbshipit-source-id: d25639a5ffc2c490a0ee7ef307302eb2953c307e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12733
Conv in NHWC layout only works for 2D images. This has been a pain point when implementing quantized 3D convolution because we need NHWC layout for best performance (note that NHWC layout in general gives better performance in CPU not just for quantized operators). For example, our quantized ops have a functionality to measure quantized error operator by operator but this needs running a shadow fp32 operator, but this is not easy when there's no 3D conv in NHWC layout is available (currently we're doing layout conversion on the fly for the shadow fp32 operator which is error prone). Some of Caffe2 frameworks like brew generates error when we try to create a 3D conv op in NHWC layout. This was also a blocker for using aibench because aibench is using brew.
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision: D10333829
fbshipit-source-id: 2d203ee1db833cd3f9d39353219e3894b46c4389
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13318
add a context to describe fpga
this will remove the need of having opencl with fpga engine
the next step is to change the opencl implementation to explicitly use the fpga context
Reviewed By: soumith
Differential Revision: D12828795
fbshipit-source-id: 0700a83672d117d7aa3d941cd39c2ae627cb6e5f
Summary:
Now gradcheck properly accept a single Tensor as input. It was almost supported already but not completely.
Should fix the confusion from #13540
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13543
Differential Revision: D12918526
Pulled By: soumith
fbshipit-source-id: a5bad69af0aea48c146f58df2482cabf91e24a01
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13538
In architectures such as FPN (https://arxiv.org/abs/1612.03144), few Conv
ops share the same weight and bias and are run at different scales of
the input. Since 'bias_scale = input_scale * weight_scale', sharing
the same bias blob among multiple Conv ops means that we need
different bias scale for each of the ops. To achieve this, we just
duplicate those bias blobs that are used by multiple Conv ops before performing
int8 rewrite.
Reviewed By: csummersea
Differential Revision: D12854062
fbshipit-source-id: 42a2951877819339b117f13f01816291a4fa6596
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13537
plot_hist.py and dnnlowp_fc_perf_comparison.py were not supposed to be in operators/quantized/server
Reviewed By: hx89
Differential Revision: D12916259
fbshipit-source-id: f5bc0c01a4924cad6f82eff624ba5f79becbea33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13554
D10233252 broke ROCM test.
We don't have group conv in NHWC for hip yet and this diff omits related tests.
Reviewed By: hyuen
Differential Revision: D12917880
fbshipit-source-id: 9baf36a8cb061ee8cf393b2c438a2d1460ce5cd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13217
Caffe2 proto headers are not included in pytorch package data (https://github.com/pytorch/pytorch/blob/master/setup.py#L1180). However, they are required for building custom Caffe2 ops living outside PyTorch/Caffe2 repo (e.g. custom Detectron ops).
Reviewed By: pjh5
Differential Revision: D12815881
fbshipit-source-id: 4d1aaa6a69a2193247586e85e4244fbbdb3e8192
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13216
Caffe2 headers are placed under `lib/include` in pytorch package data (https://github.com/pytorch/pytorch/blob/master/setup.py#L1201). However, `CAFFE2_INCLUDE_DIRS` path is set to `"${_INSTALL_PREFIX}/include"` which does not exist in package data. This results in issues when trying to build custom Caffe2 ops living outside Caffe2/PyTorch repo (e.g. custom Detectron ops).
Reviewed By: pjh5
Differential Revision: D12815878
fbshipit-source-id: 7cb1b4a729f8242b7437e3f30dace3b9cf044144
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11745
use_scratch was introduced in D5834868 but D8944686 refactored GemmStridedBatched and use_scratch is not used anywhere and not documented as far as I can tell.
Reviewed By: BIT-silence
Differential Revision: D9846488
fbshipit-source-id: 915d92aa57bc211888dfb09ad657f7c2b4f4b71c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12428
Group conv in NHWC layout was enabled in CPU after D7547497.
In D7547497, unit test of group conv in NHWC layout in CPU was enabled in group_conv_test.py but not in conv_test.py . This diff also enables it in conv_test.py .
Reviewed By: BIT-silence
Differential Revision: D10233252
fbshipit-source-id: aeeaf3eedc60e1cf6321b5a1dbe6a561e3aacbde
Summary:
Workaround a cmake-ninja bug, which doesn't track the dependency between xxx-generated-xxx.cu and updating the timestamp of build.ninja, (the consequence being cmake is rerun on a next rebuild).
This was surfaced after analyzing the outputs of `ninja -d explain install`
Now, compared to https://github.com/pytorch/pytorch/pull/11487#issue-214450604 we're seeing:
```
python setup.py rebuild develop # first time - ~1m 42s
python setup.py rebuild develop # second time - ~12 s
```
This gets even faster if we replace the default linker with multithreaded linkers like `lld` or `gold`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13293
Differential Revision: D12916346
Pulled By: soumith
fbshipit-source-id: 3817c09a9a687fa2273f90444e5071ce1bb47260
Summary:
Enables almost all `modernize-*` checks in clang-tidy. This warns against things such as:
- Use of `const std::string&` instead of new-style `std::string` + move,
- Using old-style loops instead of range-for loops,
- Use of raw `new`
- Use of `push_back` instead of `emplace_back`
- Use of `virtual` together with `override` (`override` is sufficient)
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13196
Differential Revision: D12891837
Pulled By: goldsborough
fbshipit-source-id: 4d0f782a09eb391ee718d3d66f74c095ee121c09
Summary:
This PR is unifying BLAS check between Caffe2 and ATen. It skips redundant BLAS check for ATen in certain conditions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13514
Reviewed By: orionr
Differential Revision: D12905272
Pulled By: mingzhe09088
fbshipit-source-id: 05163704f363c97a762ff034f88a67bd32ac01d0
Summary:
There should really be a single place to erase or do special treatment to the prim::ListConstruct during ONNX export, this will make it consistent across different calls. e.g it will give a correct output graph in the following case:
```python
class Test(torch.nn.Module):
def forward(self, input):
return torch.cat([input, torch.zeros(input.size(0), 1).type_as(input)], dim=1)
```
Before this PR, we have the onnx graph as:
```
graph(%0 : Byte(2, 3)) {
%1 : Long() = onnx::Constant[value={0}](), scope: Test
%2 : Dynamic = onnx::Shape(%0), scope: Test
%3 : Long() = onnx::Gather[axis=0](%2, %1), scope: Test
%4 : Long() = onnx::Constant[value={1}](), scope: Test
%5 : Dynamic = onnx::Unsqueeze[axes=[0]](%3)
%6 : Dynamic = onnx::Unsqueeze[axes=[0]](%4)
%7 : int[] = onnx::Concat[axis=0](%5, %6)
%8 : Float(2, 1) = onnx::ConstantFill[dtype=1, input_as_shape=1, value=0](%7), scope: Test
%9 : Byte(2, 1) = onnx::Cast[to=2](%8), scope: Test
%10 : Byte(2, 4) = onnx::Concat[axis=1](%0, %9), scope: Test
return (%10);
}
```
Which is wrong since onnx does not have a concept of `int[]`, here is the onnx graph after this PR:
```
graph(%0 : Byte(2, 3)) {
%1 : Long() = onnx::Constant[value={0}](), scope: Test
%2 : Dynamic = onnx::Shape(%0), scope: Test
%3 : Long() = onnx::Gather[axis=0](%2, %1), scope: Test
%4 : Long() = onnx::Constant[value={1}](), scope: Test
%5 : Dynamic = onnx::Unsqueeze[axes=[0]](%3)
%6 : Dynamic = onnx::Unsqueeze[axes=[0]](%4)
%7 : Dynamic = onnx::Concat[axis=0](%5, %6)
%8 : Float(2, 1) = onnx::ConstantFill[dtype=1, input_as_shape=1, value=0](%7), scope: Test
%9 : Byte(2, 1) = onnx::Cast[to=2](%8), scope: Test
%10 : Byte(2, 4) = onnx::Concat[axis=1](%0, %9), scope: Test
return (%10);
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13195
Differential Revision: D12812541
Pulled By: wanchaol
fbshipit-source-id: db6be8bf0cdc85c426d5cbe09a28c5e5d860eb3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13480
Revert D12845220 since the MKL functions are using multi-thread while the single-thread run is slower than eigen version.
i-am-not-moving-c2-to-c10
Reviewed By: houseroad
Differential Revision: D12891751
fbshipit-source-id: 2a61727b269a304daeee2af6ff7fee7820cb5344
Summary:
I found a bug about compiling the cuda file when I install maskrcnn-benchmark lib.
`python setup.py build develop` will throw the error:
```
File "/usr/local/lib/python2.7/dist-packages/torch/utils/cpp_extension.py", line 214, in unix_wrap_compile
original_compile(obj, src, ext, cc_args, cflags, pp_opts)
File "/usr/lib/python2.7/distutils/unixccompiler.py", line 125, in _compile
self.spawn(compiler_so + cc_args + [src, '-o', obj] +
TypeError: coercing to Unicode: need string or buffer, list found
```
For more information, please see [issue](https://github.com/facebookresearch/maskrcnn-benchmark/issues/99).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13509
Differential Revision: D12902675
Pulled By: soumith
fbshipit-source-id: b9149f5de21ae29f94670cb2bbc93fa368f4e0f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13500
This diff migrate dnnlowp related files and operators from deeplearning/quantization/caffe2 and deeplearning/quantization/dnnlowp to the open source directory.
Reviewed By: jspark1105
Differential Revision: D10842192
fbshipit-source-id: 53d0666d0ae47a01db9c48114345d746b0a4f11f
Summary:
Essentially makes cuDNN to think of those kernels like of Nx1 ones.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12902
Reviewed By: BIT-silence
Differential Revision: D10852862
Pulled By: soumith
fbshipit-source-id: 7416cf6d131177340d21cbf1d42c1daa6c7cad8c
Summary:
There are a couple subtle bugs in the way varargs is implemented:
1. it fails if you pass 0 arguments, because it doesn't handle the case when there are 0 varargs, and because Operator::matches was not updated.
2. it breaks all the named-based lookups on nodes. For instance node->get<int>(attr::value)
will return a single entry of the varargs if you look it up by name.
Furthermore it complicates some assumptions about the positional arguments (e.g. they use to be
1-to-1 with node inputs but with varargs they are not).
Because varargs are only being used for format, this diff instead
just allows format to take any value as input, regardless of type. It just provides a way to set is_vararg
from the schema but does not restrict the type of the varargs things. This is inline with
the pre-existing behavior for is_vararg so it doesn't require Operator::matches changes.
This also keeps format inline with how print works, and is closer to the python implementation of format. Note that the implementation
of format already worked with arbitrary IValues so restricting to strings was just making it more conservative than needed.
This also fixes the implementation of format to work when there are 0 arguments or text before and after a format string, where it would not print things.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13492
Differential Revision: D12896989
Pulled By: zdevito
fbshipit-source-id: 21425bac8edc81709030a7408180494edea0a54b
Summary:
This PR changes the compiler to correctly emit in-place operators for augmented assignments (`+=` and friends).
- To better match the Python AST structure, add an `AugAssign` tree view and make `Assign` apply only to `=` assignments.
- Emit those `AugAssign` exprs in the compiler, dispatching to in-place aten ops for tensors and lowering to simple assignments for scalar types.
- In order to preserve (suspect) ONNX export semantics, add a pass to lower the in-place operators to out-of-place operators.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13364
Differential Revision: D12899734
Pulled By: suo
fbshipit-source-id: bec83be0062cb0235eb129aed78d6110a9e2c146
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13495
If the user has one data file to put in, the data is filled up in every iteration,
which actually flushes the caches. The retrieved latency is larger than the latency
when the caches are warm. Instead of doing that, we should only rely on wipe_cache
variable to wipe the caches.
The change is to skip filling the data if the input only has one size and it is
not the first iteration
Reviewed By: hl475
Differential Revision: D12897946
fbshipit-source-id: ee54ed09b8ec85fcefe930858420b90d494ad972
Summary:
Goodbye, World! This PR removes the world tokens and associated pass and switches lists over to the new mutability/aliasing annotations.
Should resolve#12780 since we are disabling optimization pending alias analysis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13406
Differential Revision: D12886463
Pulled By: suo
fbshipit-source-id: e64e55905aebdcad273b39862df3209f823f5408
Summary:
Fixes#13326
Also now you can use `run_test.py` with `pytest`. E.g.,
```
python run_test.py -vci distributed -pt
```
Yes it works with `distributed` and `cpp_extension`.
cc zou3519 vishwakftw
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13416
Differential Revision: D12895622
Pulled By: SsnL
fbshipit-source-id: 2d18106f3a118d642a666bfb1318f41c859c3df7
Summary:
As titled, this PR is a part of tasks to unblock exporting the standard library.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13336
Differential Revision: D12888912
Pulled By: wanchaol
fbshipit-source-id: 6213a17a75a593ae45999994fd9562f29b7d42df
Summary:
libcaffe2.so depends on libgloo.a for the ops in caffe2/contrib/gloo.
Symbols in libgloo.a that are not used are ignored and don't end up in
libcaffe2.so. libc10d.a depends on the caffe2 target, which in turn
depends on the gloo target, and it expects all libgloo.a symbols to be
part of libcaffe2.so. Symbols from libgloo.a that are not used in
libcaffe2.so remain undefined in libc10d.a.
To fix this, we link to libgloo.a when linking _C.so, such that any
gloo symbols in libc10d.a are resolved when linking _C.so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13462
Differential Revision: D12892830
Pulled By: pietern
fbshipit-source-id: 7560b3899b62f76081b394498480e513a84cefab
Summary:
Small edits to caffe2/core hipify to make it compile in fbcode.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13457
Reviewed By: bddppq
Differential Revision: D12883472
Pulled By: xw285cornell
fbshipit-source-id: 1da231d721311d105892db13ed726240398ba49e
Summary:
Add npair builtins to unblock standard library. As with broadcasting list, the only occurrences are with int/floats.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13473
Differential Revision: D12890844
Pulled By: eellison
fbshipit-source-id: c360bb581d0f967cb51b858b6f964c300992d62a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11884
In cpu mode, current convNd uses Im2ColNdNCHWImpl, which is generic implementation to handle convolutional layer for arbitrary number of dimensions. In video modeling, we use convNd for filter dimension=3.
The problem of current convNd is that Im2ColNdNCHWImpl is much slower than Im2Col used by conv2d for the filters with same Flops. For example, a (1, 7, 7) 3d filter takes 5 times longer than a (7, 7) 2d filter at inference time.
This diff extends Im2Col to 3d case (Im2Col3dNCHWImpl), and this optimization for 3d convolution gives 4~5 times faster inference time on cpu for various video models:
{F128300920}
i-am-not-moving-c2-to-c10
Reviewed By: BIT-silence
Differential Revision: D8245940
fbshipit-source-id: 75231d65c9dd56059dfe31701e26021fd1ff2a85
Summary:
This PR performs a renaming of the function `potrf` responsible for the Cholesky
decomposition on positive definite matrices to `cholesky` as NumPy and TF do.
Billing of changes
- make potrf cname for cholesky in Declarations.cwrap
- modify the function names in ATen/core
- modify the function names in Python frontend
- issue warnings when potrf is called to notify users of the change
Reviewed By: soumith
Differential Revision: D10528361
Pulled By: zou3519
fbshipit-source-id: 19d9bcf8ffb38def698ae5acf30743884dda0d88
Summary:
I've had to generously increase the range of the CreateADSubgraphs pass, because even though it collapses the RNN loop to a single differentiable subgraphs and a few other nodes, the range uses the distances in the original graph...
cc zdevito zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13228
Differential Revision: D12871316
Pulled By: zou3519
fbshipit-source-id: 32da6f30f7821e4339034f1a4dec41ed0849abfb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13437
revert
transform the NCHW Convolution operators to NHWC and the tensors around these operators
Reviewed By: bwasti
Differential Revision: D12871789
fbshipit-source-id: 6509a29fa1654424d22904df0d3e60f8cd9c0ec7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13436
revert
Add a utility function to convert a list of caffe2_pb2.Argument to a dictionary.
Reviewed By: bwasti
Differential Revision: D12871811
fbshipit-source-id: 486ad09f3f37723c92a946c486ce3e24a649b4e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13429
Made the SSA transformation idempotent. This ensures that if a caffe2 graph is already in SSA form, the name of the ONNX models inputs/outputs match these of the caffe2 graph.
Avoid evaluating the model by running it if the shapes of all the blobs are present in the value_info map. This speeds up the conversion and decrease its memory usage in the case of medium to large nets.
Reviewed By: abadams
Differential Revision: D12873354
fbshipit-source-id: d695b28e610562afa9a41c2d4da05be212ccb488
Summary:
```
Both allocate "pinned" memory on the host (CPU). The allocator returned
by at::cuda::getPinnedMemoryAllocator caches allocations, while
getTHCudaHostAllocator would synchronize on frees.
```
This is super minor, but I want to avoid people grabbing getTHCudaHostAllocator by accident. (It's not currently used anywhere).
We still need a better API for allocating pinned memory from both C++ and Python. (See https://github.com/pytorch/pytorch/issues/2206)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13451
Differential Revision: D12883037
Pulled By: colesbury
fbshipit-source-id: 5d327e715acc1ded9b19660f84ecd23c8334d1c1
Summary:
Arguments have an optional fixed length list field which allows either a list or a single element that will be broadcast to a fixed length.
This PR exposes that as a denotable argument, mostly to cover the many instances in which this used in the standard library. It appears in the standard library with ints & floats. Since this is not really a pattern we want to promote moving forward, I did not expose this for booleans or tensors.
We could consider making the optional static length part of the list type, instead of the argument, which would make some of this code much nicer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13142
Differential Revision: D12876047
Pulled By: eellison
fbshipit-source-id: e7359d2a878b4627fc2b9ebc090f9849ee524693
Summary:
Adding assert statements to unblock standard library.
The same limitations that apply to the existing implementation of Exceptions apply to this as well
(No control-flow logic, & we ignore the specific Exception thrown).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13408
Reviewed By: driazati
Differential Revision: D12876451
Pulled By: eellison
fbshipit-source-id: 767ba5a50ba7c5dd6a857ed4845ac076a81cf305
Summary:
As per ezyang's suggestion
Previously, tensor.as_strided would:
- allocate a tensor `result` and a storage
- throw away that storage in favor of the input tensor's storage.
This PR makes tensor.as_strided not allocate a storage just to throw it
away. This speeds up as_strided from 770ns to 344ns.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13411
Reviewed By: ezyang
Differential Revision: D12870309
Pulled By: zou3519
fbshipit-source-id: 1415e656f4d1931585c9a6006dcd4670123352d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12347
add sleep time between net and operator runs, and between each iteration.
Reviewed By: sf-wind
Differential Revision: D10209308
fbshipit-source-id: 9a42b47e1fdc14b42dba6bb3ff048fe8e2934615
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12862
This is a redo of the previous move in a way that doesn't migrate the namespace -- also will check for the windows cudnn build failure
Reviewed By: Yangqing
Differential Revision: D10459665
fbshipit-source-id: 563dec9987aa979702e6d71072ee2f4b2d969d69
Summary:
It is a operator to copy blob from ideep device to ideep device.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12820
Reviewed By: ezyang
Differential Revision: D10850956
Pulled By: yinghai
fbshipit-source-id: f25bff6238cefe847eb98277979fa59139bff843
Summary:
This PR principally redesigns the fuser's logical flow to be hierarchical, with device-independent logic directing (relatively little) device-specific logic. This design is based on reviews of XLA, TVM, internal design review at NVIDIA and discussions with fuser owners at Facebook. To further vet the design I have begun developing the next significant PR (extended fusion logic) on top of this architecture and it has made the work significantly easier. This PR also improves fuser modularity, which should make it easier for others to contribute to. Unfortunately, this PR is large and its nature has made breaking it into smaller pieces challenging. Future PRs should be smaller.
The fusion flow is now:
- Fusions are "registered" and "upfront compilation" occurs. The fusion specifications, which includes the graph, go into a thread-safe device-independent cache. Upfront compilation generates some information used later during shape inference.
- Fusions are run, which passes them to an executor that performs shape inference, requests an instantiated fusion from the specification's thread-safe store, and launches them. Launch logic eventually defers to device-specific logic.
- Fusions not previously instantiated are compiled. Compilation is device-specific and arg-specific. Compilation logic eventually defers to device-specific logic.
- If the fusion could not be run because fusion on the requested device is disabled or shape inference fails a fallback is invoked.
This flow can be thought of as PyTorch IR -> Device-Independent Fusion Logic -> Device-Specific Fusion Logic. The current upstream logic is, by contrast, PyTorch IR -> Device-Specific Logic -> Device-Independent Logic, which results in needless code duplication and lack of conceptual clarity. That was my mistake when splitting the fuser off from the rest of the jit and our reviews since then have been incredibly helpful in understanding why the approach in this PR is better.
This PR does not only move code around. It also fixes few couple bugs and makes some logical/code changes.
Bug fixes:
- thread-safety is improved with caches preventing concurrent access
- the nvrtc version is now reviewed to determine the appropriate compute architecture to compile for, fixing a bug that would cause runtime errors if a user's nvrtc didn't support the compute architecture their gpu reported
- an issue with DeviceGuard not setting the device properly and failing silently is worked-around (ezyang mentioned he was reviewing the dynamic registration DeviceGuard uses, which may resolve the issue)
Code/Logical changes:
- "const" now appears many more places (note: I cast const away in operator.h because of some obscure build issues -- I think we should be able to fix this and will take a look while this goes through testing)
- The new flow allowed some redundant code to be removed (AnnotatedGraph is gone, for example, and the more straightforward flow eliminated duplication of effort elsewhere)
- Fallback logic is now also invoked if a fusion is requested on a device that cannot handle fusions
- Use of macros to determine which files are compiled is reduced (though they may come back if the Windows build is unhappy)
- There is no more "common" code or folder, the device-independent logic being at the forefront of the fuser replaces and improves upon the goal of sharing code
apaszke who I promised naming rights to
zdevito who correctly pointed out that the device-independent logic should be the bulk of what the fuser is doing
ngimel who contributed to the design of this architecture
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13108
Reviewed By: gchanan, fmassa
Differential Revision: D12850608
Pulled By: soumith
fbshipit-source-id: 24e2df6dfa97591ee36aeca8944519678c301fa3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13349
When we get a Tensor that was created in ATen, it will have an allocator set.
Such tensors, before, crashed when you called raw_mutable_data on them.
This diff fixes that.
Reviewed By: ezyang, teng-li
Differential Revision: D12850833
fbshipit-source-id: 51a5f7030afc4854b439cb3698d0ccd8dd101e2c
Summary:
We lost HIP support in last refactoring 620ece2668
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13400
Differential Revision: D12868211
Pulled By: bddppq
fbshipit-source-id: 72dbfda105b826bee28ddf480e88fca7d63f93d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13370
This diff adds a new net type (simple_refcount) that does one thing: for all
intermediate results produced by a net, it will keep refcount about internal
usage, and when it finishes its consumption, the net will delete the blob
content to mimic the case of dynamic allocation. In fact, this would also be
the behavior when we go functional: anything that is not explicitly marked as
input or output will be up to the executor for lifetime management.
See the comments in net_simple_refcount.cc for details.
Reviewed By: dzhulgakov
Differential Revision: D12855489
fbshipit-source-id: 594a47a786305d595fd505b6700864dd1d9c72aa
Summary:
This reverts commit b1fe541de35381e3a31a9e71db2be4b3af59dbcc.
some CI confusion made it look like this diff needed to be reverted; however the actual issue was elsewhere
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13407
Differential Revision: D12869650
Pulled By: anderspapitto
fbshipit-source-id: 3a436d41fc8434f9aa79b145f20904c99093eef4
Summary:
Fixes#13376, `len(tensor)` was converting tensor to a 1 element list and returning 1 every time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13398
Differential Revision: D12867630
Pulled By: driazati
fbshipit-source-id: 28f3580a072d763df0980b3149c49d1894842ec9
Summary:
Recent PR #13366 added --user to pip install breaks ppc64le testing when using test.sh. This fix makes it not be used for ppc64le builds/test as both ninja and hypothesis are already in ppc64le docker images.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13388
Differential Revision: D12870164
Pulled By: soumith
fbshipit-source-id: b66bafc06ad2c5116bb5ef5e4681cf9c776084aa
Summary:
The newest version of `mkl` in conda only supports Python 3.6.7, and installing it as dependency will automatically downgrade Python from 3.7 to 3.6.7, which creates environment divergence between Windows CI build and test jobs. This PR pins Python version to 3.6.7, so that Windows CI build and test jobs have the same conda environment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13410
Differential Revision: D12870201
Pulled By: yf225
fbshipit-source-id: 2c5a41ad4bcc72e02d12ea6529550d5e1cdd45ef
Summary:
This PR adds `aten::format` as a builtin op for strings with the basic formatting semantics of Python.
It also adds varargs to the schema parser (with the limitation that the varargs item is the last argument, i.e. `(*args, **kwargs)` is not supported) and to the compiler
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13157
Differential Revision: D12832537
Pulled By: driazati
fbshipit-source-id: 17c1a5615bb286c648fc9e38f2ebe501b064c732
Summary:
In these cases, the native function doesn't do anything different besides checking so there is no semantic change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13394
Differential Revision: D12861272
Pulled By: gchanan
fbshipit-source-id: ef7403ef3ce0326ccb12178434ce0cf14b28426e
Summary:
There is no property name "INTERFACE_INCLUDE_DIRECTORIES" for pybind11::pybind11. This will cause cmake error if there exists a system installation of pybind11. In addition, pybind11_INCLUDE_DIRS is already set once "find_package(pybind11 CONFIG)" finds pybind11.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12188
Differential Revision: D10362655
Pulled By: soumith
fbshipit-source-id: 9c5d13295c4a2cf9aacd03e195994287d06ed15c
Summary:
Currently, exceptions thrown in at::parallel_for() will cause a hard crash
if the code is executed by a background thread. This catches the exception
and re-throws it in the main thread.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13393
Differential Revision: D12861142
Pulled By: colesbury
fbshipit-source-id: d53f5ff830ef8c11f90477eb63e5016f7ef1a698
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13332
Add a utility function to convert a list of caffe2_pb2.Argument to a dictionary.
Reviewed By: bwasti
Differential Revision: D10861211
fbshipit-source-id: da2fcc3e3b4dbf8decbe14a8e2d5621b3fcc377f
Summary:
This is used commonly in `nn` functions. This PR adds it as a weak
module (and also alters the conversion of weak modules to strong modules
to accept ordinary `object`s)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13057
Differential Revision: D10846618
Pulled By: driazati
fbshipit-source-id: 028b9f852d40e2e53ee85b93282c98cef8cd336b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13275
This resulted in a bunch of knock-on changes, which I will now
describe:
- s/original_index/original_device/
- s/last_index/last_device/
- A bunch of places that used set_index, now use CUDAGuard (which does have
set_index) because they were CUDA-specific code.
Major caveat: DeviceGuard doesn't *actually* work non-CUDA/CPU devices, To make
that happen, I plan on totally replacing the implementation of DeviceGuard; what
I mostly care about here is wrangling the API into an acceptable state.
Reviewed By: gchanan
Differential Revision: D12832080
fbshipit-source-id: 7de068c7cec35663dc8a533026a626331336e61d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13232
DeviceGuard should be device agnostic, which means that it shouldn't
assume that int64_t means select the CUDA device.
Reviewed By: gchanan
Differential Revision: D10858024
fbshipit-source-id: b40e8337e4046906fd8f83a95e6206367fb29dbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13133
c10::Stream is a device agnostic object which represents a stream
on some device (defined as c10::Device). The primary benefit of
introducing this object is that we can easily refer to it from code
in the non-CUDA library (since it doesn't actually refer to any
CUDA specific bits.)
Streams are identified by an ID into an appropriate pool. There's
some work to translate to and from pointers to the pool; see inline
comments.
Reviewed By: gchanan
Differential Revision: D10855883
fbshipit-source-id: cc447f11a528432e41c2edc789f40e7a6f17bdd3
Summary:
Fix https://github.com/pytorch/pytorch/issues/13200
Tested on 8 GPU machines since CI doesn't have this many GPUs, so multi-GPU test won't be triggered
```
tengli@learnfair096:~/pytorch/test$ python run_test.py -i distributed --verbose
Selected tests: distributed
Running test_distributed ... [2018-10-29 20:32:46.355858]
/public/apps/openmpi/2.1.1/gcc.5.4.0/bin/mpiexec
Running distributed tests for the gloo backend
test_DistBackend (__main__.TestDistBackend) ... ok
test_DistributedDataParallel (__main__.TestDistBackend) ... ok
test_DistributedDataParallelCPU (__main__.TestDistBackend) ... ok
```
Also I would like to bump up the bucket size of broadcast to higher for performance reasons
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13291
Differential Revision: D12842840
Pulled By: teng-li
fbshipit-source-id: e8c50f15ebf2ab3e2cd1b51d365e41a6106b98fe
Summary:
caffe2 docker images uses native system python, which requires sudo to do pip install.
In pytorch rocm Ci we use caffe2 docker image
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13366
Differential Revision: D12855748
Pulled By: bddppq
fbshipit-source-id: 3e53fa203fa6bb3c43d4065c38c2b61e47f45f1e
Summary:
I don't have a full analysis, but ccache appears to often fail while
nccl. To work around this, run the NCCL build with CCACHE_DISABLE.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13340
Differential Revision: D12855467
Pulled By: anderspapitto
fbshipit-source-id: 63eb12183ab9d03dd22090f084688ae6390fe8bd
Summary:
Including some hang fixes. Tested locally and distributed works fine
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13353
Differential Revision: D12853714
Pulled By: teng-li
fbshipit-source-id: be72b9ffb48cffdb590e5452b0a4ec597f052685
Summary:
This is a first step towards adding exceptions. We need minimal support in order to begin converting the torch library to weak script mode (which is the main goal here).
Some limitations (that are documented in the tests & compiler):
1. Cannot assign exceptions to variables
2. Any name after raise is being treated as a valid Exception
3. No control flow analysis yet. Below a will be undefined:
if True:
a = 1
else:
raise Exception("Hi")
return a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12789
Differential Revision: D12848936
Pulled By: eellison
fbshipit-source-id: 1f60ceef2381040486123ec797e97d65b074862d
Summary:
Since it fails due to insufficient precision for DoubleTensor .sum() on ROCm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13341
Differential Revision: D12851335
Pulled By: bddppq
fbshipit-source-id: e211c3868b685aa705160ce98a2a18a915ad493f
Summary:
Currently, `a = 1 - torch.tensor([1]).to('cuda:1')` puts `a` in `cuda:1` but reports `a.device` as `cuda:0` which is incorrect, and it causes illegal memory access error when trying to access `a`'s memory (e.g. when printing). This PR fixes the error.
Fixes https://github.com/pytorch/pytorch/issues/10850.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12956
Differential Revision: D12835992
Pulled By: yf225
fbshipit-source-id: 5737703d2012b14fd00a71dafeedebd8230a0b04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13265
Make changes to make hipify_python script to work with fbcode.
1. Add TARGETS file
2. Make hipify_python a module as well as a standalone script.
Reviewed By: bddppq
Differential Revision: D10851216
fbshipit-source-id: cacd04df6fe2084832256d1916d62dccea86baa9
Summary: Made the clangr rule more robust and it discovered more callsites.
Reviewed By: smessmer
Differential Revision: D12825017
fbshipit-source-id: 3be1eeb7ea697b36ef89e78ba64c0ee1259439c4
Summary:
```
… parallel region.
The two_pass_reduction code allocates a buffer of size at::max_threads().
When called within a parallel region, at::parallel_for only uses 1 thread
so some of this buffer is not written.
This makes two changes:
1) two_pass_reduction is not called when already in a parallel region
2) two_pass_reduction fills unwritten buffer elements with the identity
(the value in dst)
```
cc The controller you requested could not be found. SsnL: I think this should fix the NaNs in BatchNorm when calling sum() within a parallel region.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13274
Differential Revision: D12840034
Pulled By: colesbury
fbshipit-source-id: d32e80909a98a0f1bb1c80689fe5089b7019ef59
Summary:
These assertions aren't necessary because these conditions are checked inside the ATen ops, and right now they're not very user-friendly because they don't have an error message or reference the dimension of the tensor being checked. Let's just remove them (the error then comes from ATen with a friendlier message).
ezyang ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13283
Differential Revision: D12840730
Pulled By: goldsborough
fbshipit-source-id: 1902056c7d673f819c85f9164558e8d01507401c
Summary:
Better to keep it in the main repo, so we will have the correct dependencies.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13287
Reviewed By: zrphercule
Differential Revision: D12834665
Pulled By: houseroad
fbshipit-source-id: 3a0afaa705a9b8f4168fcd482123bcabcf083579
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13320
simple_async has been deprecated via the network override rule for a while,
and we should be able to safely remove it.
This also clears up 2 tech debts:
(1) in rnn executor, rely on the executor override to get the right net.
(2) clearly mark checkExecutorOverride as a potential change to net_type by making it c++ style guide compliant.
Reviewed By: dzhulgakov
Differential Revision: D12840709
fbshipit-source-id: 667702045fa024f5bdc87a9c28ea1786c78432b3
Summary:
Made the previous description for max_norm more precise, avoiding 'this' and describing what actually happens in the code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13310
Differential Revision: D12840813
Pulled By: SsnL
fbshipit-source-id: 98090c884267a62ce93cd85da84252d46926dfa5
Summary:
Turns out that getting rid of the multiple passes in fusion is a little more involved, so leaving it off for another day.
Expect test changes are just things moving around with new orders, but I would appreciate if someone glanced at them for something crazy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13271
Differential Revision: D12832752
Pulled By: michaelsuo
fbshipit-source-id: 55f16c80a97601744a06df2ead45cef7b3a19c08
Summary:
1. Refactor DDPG predictor. Merge the critic predictor with ParametricDQNPredictor since they are the same
2. Fix bug where loss was multiplied by the batch size
3. Create DDPGFeedPredictor which uses the feed predictor output format
4. Add support for gridworld simulation memoization to DDPG. Also memoize normalization tables.
Reviewed By: kittipatv
Differential Revision: D10161240
fbshipit-source-id: 2813890043de1241c1fb9b9c2b6a897403f9fc12
Summary:
It seems that we can fix the test timeout issue by running CPU build and test on different machines (I manually ran this patch through the CI 50 times to confirm this). The actual reason of timeout is still unknown, but I suspect it has to do with memory / disk space.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13284
Differential Revision: D12840371
Pulled By: yf225
fbshipit-source-id: af326f0358355602ee458696c3ffb325922e5289
Summary:
Depends on #13072
Adds support for tuples as variables instead of just as literals. Before, tuples would give the error `python value of type 'tuple' cannot be used as a value`. This PR adds a flag on `SugaredValue` to determine in a value is a tuple or not.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13086
Differential Revision: D10846632
Pulled By: driazati
fbshipit-source-id: 7b5d6ae9426ca3dd476fee3f929357d7b180faa7
Summary:
This moves away from using tensor.set_(...) for as_strided, which went
through TH and was weirdly slow/complicated. The new as_strided has a
new invariant that it will never resize the storage to a larger size
(the previous as_strided allowed that behavior but it seemed weird and
none of our code relied on it.)
This offers a small speedup on as_strided: it went from 1300ns to
1100ns although the benchmarks get a little noisy here.
Also on the changelog is a quick fix to resize_ code to avoid unsigned
underflow. I'll rewrite the resize_ zero dim logic in a future diff, it
doesn't make sense the way it is written right now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13185
Reviewed By: ezyang
Differential Revision: D12809160
Pulled By: zou3519
fbshipit-source-id: 3885df9d863baab2b2f8d8e2f8e2bfe660a49d85
Summary:
This PR special cases tensor.storage_offset to avoid dispatches in the
common case. tensor.storage_offset is important for torch.as_strided
performance, because as_strided(sizes, strides) shares an implementation
with as_strided(sizes, strides, storage_offset) and it might not be the
best if there were two separate implementations (including backward
implementations).
This PR reduces times on a tensor.storage_offset
microbenchmark from 22ns to 2ns (these numbers are pretty stable). For
a torch.as_strided benchmark, this PR reduces numbers from 1042 to
928ns, a 100ns improvement, but this number is noisy and goes up and
down.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13267
Reviewed By: ezyang
Differential Revision: D12829828
Pulled By: zou3519
fbshipit-source-id: df907731e2398ce2baf1c8b1860a561ccc456f78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13239
Previous diff missed the if (dtype_initialized) check, duh.
Also, for safety of spamming - using LOG_EVERY_MS if it's available
Reviewed By: kennyhorror
Differential Revision: D12818938
fbshipit-source-id: 76590bd1b28010fb13f5d33423c8eac1395e9f76
Summary:
[Edit: after applied colesbury 's suggestions]
* Hub module enable users to share code + pretrained weights through github repos.
Example usage:
```
hub_model = hub.load(
'ailzhang/vision:hub', # repo_owner/repo_name:branch
'wrapper1', # entrypoint
1234, # args for callable [not applicable to resnet18]
pretrained=True) # kwargs for callable
```
* Protocol on repo owner side: example https://github.com/ailzhang/vision/tree/hub
* The "published" models should be at least in a branch/tag. It can't be a random commit.
* Repo owner should have the following field defined in `hubconf.py`
* function/entrypoint with function signature `def wrapper1(pretrained=False, *args, **kwargs):`
* `pretrained` allows users to load pretrained weights from repo owner.
* `args` and `kwargs` are passed to the callable `resnet18`, repo owner should clearly specify their help message in the docstring
```
def wrapper1(pretrained=False, *args, **kwargs):
"""
pretrained (bool): a recommended kwargs for all entrypoints
args & kwargs are arguments for the function
"""
from torchvision.models.resnet import resnet18
model = resnet18(*args, **kwargs)
checkpoint = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
if pretrained:
model.load_state_dict(model_zoo.load_url(checkpoint, progress=False))
return model
```
* Hub_dir
* `hub_dir` specifies where the intermediate files/folders will be saved. By default this is `~/.torch/hub`.
* Users can change it by either setting the environment variable `TORCH_HUB_DIR` or calling `hub.set_dir(PATH_TO_HUB_DIR)`.
* By default, we don't cleanup files after loading so that users can use cache next time.
* Cache logic :
* We used the cache by default if it exists in `hub_dir`.
* Users can force a fresh reload by calling `hub.load(..., force_reload=True)`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12228
Differential Revision: D10511470
Pulled By: ailzhang
fbshipit-source-id: 12ac27f01d33653f06b2483655546492f82cce38
Summary:
Looks like a print() snuck in by accident with a recent PR and it's printing a lot of spew when the tests are run.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13280
Differential Revision: D12833449
Pulled By: michaelsuo
fbshipit-source-id: 5b50fd4b03bb73e5ca44cabdc99609c10017ff55
Summary:
Enables most of `cppcoreguidelines-*` checks for clang-tidy. Major fixes included:
- Uninitialized members,
- Use of `const_cast`,
- Use of raw `new`
ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12959
Differential Revision: D11349285
Pulled By: goldsborough
fbshipit-source-id: 9e24d643787dfe7ede69f96223c8c0179bd1b2d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13264
Simply change the initialization order to make hcc happy. Otherwise will have to add -Wno-error=reorder.
Reviewed By: bddppq
Differential Revision: D12827635
fbshipit-source-id: 6f4cd67209f2aa8ae85cfbdc53df0efb3b3cc473
Summary:
ezyang on the template hack
smessmer on SFINAE of the `TensorOptions(Device)`
goldsborough on the C++ API test changes
zdevito on the `jit` codegen changes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13146
Reviewed By: ezyang
Differential Revision: D12823809
Pulled By: SsnL
fbshipit-source-id: 98d65c401c98fda1c6fa358e4538f86c6495abdc
Summary:
Small change -- the benefit is that the docs will show
``<required parameter>`` instead of ``<object object>``
for these required parameters.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13202
Reviewed By: SsnL
Differential Revision: D12826252
Pulled By: jma127
fbshipit-source-id: 5f2c8495e5c56920377e4e012b8711e8f2a6e30e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13206
Add has device option for checking if a node has a device option set
Reviewed By: bwasti
Differential Revision: D12815365
fbshipit-source-id: 58477df93777f470cfb30cd75f02a659a7017b7c
Summary:
They appear to timeout 30% of the time when run on CircleCI.
Long term plan is to switch to using some binaries which
are not provided by Travis.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13252
Differential Revision: D12828812
Pulled By: ezyang
fbshipit-source-id: 7189e2a3200ae08c4ece16a27357ff0fd06f3adb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13205
CopyFrom without context argument does the sync copy on the current gpu - exactly what most of the places need.
This diff kills about 60% of CopyFrom usages. Most common pattern is gpu->cpu copy with further FinishDeviceComputation - the latter can be just killed.
Reviewed By: Yangqing
Differential Revision: D11236076
fbshipit-source-id: eb790ca494dfc5d5e3a7d850b45d6f73221bb204
Summary:
1. Refactors `TestTorch` into `TestTorchMixin` (subclass of `object`) and `TestTorch` (subclass of `TestCase`, MRO `(TestCase, TestTorchMixin)`, only defined if `__name__ == '__main__'`). So other scripts won't accidentally run it.
2. Adds an assertion in `load_tests` that each script only runs cases defined in itself.
cc yf225 ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13250
Differential Revision: D12823734
Pulled By: SsnL
fbshipit-source-id: 7a169f35fe0794ce76e310d8a137d9a3265c012b
Summary:
onnx always has a million branches so this is noisy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13260
Differential Revision: D12827640
Pulled By: anderspapitto
fbshipit-source-id: 55eced08970cc0a888bd8f7bc8670eea48deb288
Summary:
always build nccl from within the main cmake build, rather than via a separate invocation in build_pytorch_libs.sh. Use the existing caffe2 codepaths
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13150
Differential Revision: D12815674
Pulled By: anderspapitto
fbshipit-source-id: a710b6f242d159b9816911a25ee2c4b8c3f855aa
Summary:
This PR makes the ABI compatibility check for C++ extensions more robust by resolving the real path of the compiler binary, such that e.g. `"c++"` is resolved to the path of g++. This more robust than assuming that `c++ --version` will contain the word "gcc".
CC jcjohnson
Closes#10114
soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13092
Differential Revision: D12810448
Pulled By: goldsborough
fbshipit-source-id: 6ac460e24496c0d8933b410401702363870b7568
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13132
Expose more of the C++ API to python
Reviewed By: duc0
Differential Revision: D10855086
fbshipit-source-id: 98cc89bc72ef91ed1c59c1a19688e047765cf90b
Summary:
The experimental ops for the c10 dispatcher have accidentally been disabled in the oss build when the directory changed from `c10` to `experimental/c10`. This PR re-enables them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12821
Differential Revision: D10446779
Pulled By: smessmer
fbshipit-source-id: ac58cd1ba1281370e62169ec26052d0962225375
Summary:
This will enable the updated attribute and input format of operator upsample.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13152
Reviewed By: houseroad
Differential Revision: D12812491
Pulled By: zrphercule
fbshipit-source-id: d5db200365f1ab2bd1f052667795841d7ee6beb3
Summary:
Reductions that used global memory, but didn't reduce
across threads in a warp did not have enough global memory
allocated for their intermediate results. These reductions
that were non-contiguous in their reduced dimension and
large enough to benefit from reducing across blocks in a
grid.
Fixes#13209
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13211
Differential Revision: D12815772
Pulled By: colesbury
fbshipit-source-id: f78be2cb302e7567a76097ca3ba1e7b801c0cdad
Summary:
Adding string equality comparison, and concat. Both are used in the standard library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12992
Differential Revision: D10513681
Pulled By: eellison
fbshipit-source-id: 1f845ef50be7850fdd3366951b20dc2a805c21fd
Summary:
AsyncDBConnMarkedDownDBException As we discussed, this changes the backward pass profiler annotations such that 1. they're demangled and 2. if they came from a custom Python-side autograd function, they show a unique name based on the name of that Python-side function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13154
Differential Revision: D12808952
Pulled By: colesbury
fbshipit-source-id: 4119dbaed7714b87c440a81d3a1835c5b24c7e68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13125
Previously, it returned a vector of THCStream*, which we eventually turned
into CUDAStream. No need to spatter the conversion code everywhere: just
do it correctly to begin with. An important side effect of doing it this
way is that we no longer pass nullptr to CUDAStream; instead, we create
the default stream. I will rely on this in a later patch.
Reviewed By: gchanan
Differential Revision: D10853224
fbshipit-source-id: f6bd6594eba4626eb41a4a5e67fc64c9bbb46a1a
Summary:
The old test took 2min to run.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
See #13233
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13236
Differential Revision: D12823474
Pulled By: ezyang
fbshipit-source-id: c800492a96e41a4cd18d41901f411d9d4e978613
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12904
Enabling support for saving exceptions in async parts of CPU ops via
event().SaveException(). The error contract for CPU ops becomes:
- return false in sync part -> net->Run() returns false
- throw in sync part -> net->Run() rethrows the same exception
- SetFinished("error msg") in async part -> net->Run() returns false
- event().SetFinishedWithException() in async part -> net->Run() rethrows the same
exception
Reviewed By: andrewwdye
Differential Revision: D10479130
fbshipit-source-id: 850ee9cbf83b04dd24b25eba359439b0cf7853c0
Summary:
Previously, the move constructor performed a swap
between the item being moved in, and the uninitialized
garbage from the object itself.
I didn't bother adding a test because I shortly intend
to kill this class entirely. But the fix is so easy that
I wanted to put it in in case I don't get around to doing
this.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13183
Reviewed By: pietern
Differential Revision: D12809062
Pulled By: ezyang
fbshipit-source-id: 0d94bb9796fb7d30621256bfb401a4f89ba8ddc8
Summary:
Future now is an IValue. prim::Wait now is replaced by aten::wait
This PR is built on top of #12925
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12976
Differential Revision: D10861483
Pulled By: highker
fbshipit-source-id: 9e17926a625bc502fb12335ef9ce819f25776be7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13199
D10524381 removed inclusion of int8_simd.h in Caffe2 Int8 operators, and although the resuling code still compiles and works, it is up to 50% end-to-end slower (no SIMD!) on some models
Reviewed By: bertmaher
Differential Revision: D12813095
fbshipit-source-id: 03a713a4c070c0ad1e79e71e91d09eaddc0751eb
Summary:
This pull request contains changes for:
1. Adding a generalized MIOpen activation class to be used by activation operators
2. Refactoring MIOpen ReLU op to use the new class
3. Adding ELU, Tanh and Sigmoid MIOpen ops
Differential Revision: D12810112
Pulled By: bddppq
fbshipit-source-id: 9519b3a0cd733b906bcba5d8948be089029c43ac
Summary:
Here is my stab at ```dense.to_sparse```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12171
Differential Revision: D10859078
Pulled By: weiyangfb
fbshipit-source-id: 5df72f72ba4f8f10e283402ff7731fd535682664
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13203
Minor changes in the test workflow to run the model on CPUs
Reviewed By: stephenyan1231
Differential Revision: D9925797
fbshipit-source-id: b7b1fb2658ab68b1ffc2b1f7b314958ea4732b32
Summary:
Add new methods to move a node before/after another node while preserving data data dependencies.
Any suggestions for a pithier name for the methods would be appreciated 😃
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13026
Differential Revision: D10854574
Pulled By: QueryConnectionException
fbshipit-source-id: b42751cac18d1e23940e35903c8e6a54a395292e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13114
Using one thread pool creator for all device types
Reviewed By: manojkris, wesolwsk
Differential Revision: D10851533
fbshipit-source-id: 32ca51d7932ba7faa8137df26315f52ecb4c6157
Summary:
Addresses #9499. Completed work on the forward function, tests should be passing for that. Working on backward function now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10885
Differential Revision: D9643786
Pulled By: SsnL
fbshipit-source-id: 2930d6f3d2975c45b2ba7042c55773cbdc8fa3ac
Summary:
Implements serialization and deserialization for samplers in the C++ frontend dataloader.
apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12999
Differential Revision: D10859676
Pulled By: goldsborough
fbshipit-source-id: cd132100fd35323e5a3df33e314511750806f48d
Summary:
Added getNextRecord/hasNextRecord methods. Even the model data is stored at the end, we can still read the file from the beginning.
Added gtest to cover reader and writer's code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12993
Reviewed By: yinghai
Differential Revision: D10860086
Pulled By: houseroad
fbshipit-source-id: 01b1380f8f50f5e853fe48a8136e3176eb3b0c29
Summary:
As titled, this PR is a part of tasks to unblock exporting the standard library
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13161
Differential Revision: D10866927
Pulled By: wanchaol
fbshipit-source-id: 50038dbe6840b097b98cbed9d46a189a64e82302
Summary:
This commit is a minimial initial pass at adding inplace and _out variants to the JIT.
It changes gen_jit_dispatch.py to add bindings for these operators, and it also
supplements the FunctionSchema with alias information for these operators and for
viewing operators.
Tests are very minimal and will need to be improved in future commits.
Notes:
* Custom operator tests needed to be changed since _out variants add overloads, which
the custom operator pipeline does not handle when called from python. This commit
registers special test ops in the _test namespace for this purpose.
* Extends the schema parser to parse alias annotations more robustly.
* Extends FunctionSchema with `writes()` a set of alias set names that the op will write to,
and `annotatedType()` which will return AnnotatedType objects which contain the alias_set
information that was parsed from the schema.
* Disables all optimizations in graph executor when a mutable operator is found. This
is something that will be improved in the future but is necessary for correctness now.
* Adds annotate_ops to gen_jit_dispatch which adds aliasing information to all of the
aten ops.
* Adds AnnotatedType to the type hierarchy which is used to mark List and Tensor types
with their alias_set. These types only appear in schema when you call annotatedType
and are erased from types in normal use.
* Extends jit::Type with .containedTypes() and .withContained(new_types). The first returns all types contained
within the type (e.g. T for T[], or {T,L} for a tuple (T, L)). The second constructs a new
version of the same type, replacing the contained types with new_types. This simplifies
a lot of logic for recursively cleaning up types.
* Refactor List[T] into a common part that is shared with Annotated[T] and can be shared
with Optional[T] and Future[T] when they are merged.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13093
Differential Revision: D10848176
Pulled By: zdevito
fbshipit-source-id: d057f23eeb99cde8881129b42d3f151ed5e7655d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12768
Note: DefaultTensorOptions no longer fits in 64-bits.
I kept functions that take ScalarType as input to minimize changes for now.
Reviewed By: ezyang
Differential Revision: D10419671
fbshipit-source-id: 9cc8c5982fde9ff243e03d55c0c52c2aa2c7efd8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12767
In preparation of using TypeMeta in TensorOptions. We need TensorOptions to fit in 128-bits, this isn't possible if both TypeMeta and Device are 64-bit.
Reviewed By: ezyang
Differential Revision: D10416051
fbshipit-source-id: 23c75db14650f7f3045b1298977f61a0690a8534
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12766
In preparation of using TypeMeta in TensorOptions.
Reviewed By: ezyang
Differential Revision: D10232118
fbshipit-source-id: 5c69a524fa38e50aa555fb9feb87540bc3575a63
Summary:
This is the same as https://github.com/pytorch/pytorch/pull/12889 with the addmm changes stripped out, since that appears to cause onnx broadcasting issues I don't understand.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13128
Reviewed By: ezyang
Differential Revision: D10853911
Pulled By: gchanan
fbshipit-source-id: 08ec8629331972f0c332ccd036980fd9c87562b0
Summary:
See D10380678 for the discussion.
Caffe2 serialization code was able to handle dtype uninitalized tensor as long as their numel was 0 O_O.
For safety to unblock the push I'm preserving this behavior with critical. As we fix all occurrences of old API, we can delete this test.
Reviewed By: kennyhorror
Differential Revision: D10866562
fbshipit-source-id: e172bd045fdfca660ff05b426e001f5f2f03f408
Summary:
Does
```cpp
namespace torch {
using c10::optional;
using c10::nullopt;
}
```
So that users can be oblivious of our changes with ATen/c10 happening in the background, and also don't have to deal with multiple namespaces (which is very confusing).
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12927
Differential Revision: D10510630
Pulled By: goldsborough
fbshipit-source-id: e456264f2fbca3eda277712de11cdd8acc77fbd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13080
This is the first step to untangle this logic:
- moves stream id to thread local mechanically
- relies on the fact that the value of thread local is valid in conjunction with CUDAContext only until the next SwitchToDevice is called - we should move to proper RAII in the following diffs
Follow up diffs are going to move more stuff outside of CUDAContext (by making gpu_id thread local too) and simplify the CopyFrom.
The only expected change in behavior is that before CopyFrom would do copy on stream logical id 0 if the context was created on the fly and now it'd do so on the current stream. Since it'd block explicitly, I don't think it matters much.
Also, observers were semi-broken by waiting on the potentially wrong stream. It can be fixed later - I renamed the method to avoid abuse.
Reviewed By: ezyang
Differential Revision: D10525134
fbshipit-source-id: 5d495a21490bebe060a76389f1b47bdf12cbc59e
Summary:
- Speed up the case of #12006 in the forward
- The backward still isn't as fast as one might hope (factor 2-3 in the #12006 case).
- More extensive benchmarking shows not so great performance compared
to CuDNN for cases with many channels, e.g. bs=8-128 / c=1024 / f=1024.
- We change the meaning of save_mean and save_invstd (aka save_var) to accscalar to
maintain reasonable precision.
Needless to say that I would happily separate the TensorAccessor fixes in a separate PR, as they're fixes and unrelated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12368
Differential Revision: D10559696
Pulled By: SsnL
fbshipit-source-id: f0d0d1e0912e17b15b8fb7a2c03d0fe757598419
Summary:
While using gbenchmark, I found `tensor.resize_({0})` would take 300ns
if tensor already has the correct size. This is important for
`at::empty({0})` perf because `at::empty` always calls `resize_`, which
in turn is a important for JIT perf: the fusion compiler creates empty
tensors and then `resize_`s them to computed sizes. Most of the 300ns is
due to DeviceGuard (200ns)
Summary of findings:
- `at::empty({0}, cuda)`: 851ns
- `empty_tensor.resize({0})`: 308ns
- `DeviceGuard(tensor)`: ctor + dtor: 200ns (Going to look into this
next because it impacts `resize_` perf).
- vdispatch overhead (`tensor.resize_()` vs
`at::native::resize__cuda(tensor)`): ~10ns
This PR rips out the TH `resize_` implementation and adds it to ATen
with the following modifications:
- DeviceGuard used only after the same-size check.
- Same-size check rewritten for simplicity. The new check doesn't
affect perf.
- empty_cpu / empty_cuda avoid the dispatch overhead to
tensor.resize_.
Timing with this PR:
- `at::empty({0}, cuda)`: 363ns
- `empty_tensor.resize_({0})`: 17ns
Future:
- Investigate `resize_(sizes)` slowness when `tensor.sizes() != sizes`
- Should tell resize_as_ to use the new resize_ implementation...
(because resize_as_ is in TH, it is calling the old TH resize_)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12824
Differential Revision: D10449209
Pulled By: zou3519
fbshipit-source-id: cecae5e6caf390017c07cd44a8eaf2fa6e3fdeb6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13144
The intention of this diff is to prevent prevent predictor service from crashing by the "Check failed: timestep >= 0 && timestep < _T" error, as a bandage, before D10848803 can be landed (assuming D10848803 replaces the CHECKs into CAFFE_ENFORCEs, too).
Reviewed By: ilia-cher
Differential Revision: D10857963
fbshipit-source-id: bb56ad83aa867a2d25953aa7ffd84b078f8bf84a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13004
Implement BucketWeighted model layer, which learns a weight for each possible score in an IdScoreList. Here, we assume that the scores in the IdScoreList have already been converted into the appropriate 'buckets'. If this is not done, then essentially each score represents its own bucket.
We assume that the scores/buckets are integers, and if max_score is not set, we assume that the maximum cardinality of the score is less than or equal to the cardinality of the ids.
Reviewed By: chonglinsun
Differential Revision: D10413186
fbshipit-source-id: 743e643a1b36adf124502a8b6b29976158cdb130
Summary:
Now we have everything from c10::optional, we can delete this and keep a single version in c10.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12965
Differential Revision: D10504042
Pulled By: wanchaol
fbshipit-source-id: c0ec3892e92968cca264ae8924c19111674631ba
Summary:
just a sanity check to make sure everything is in order
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13037
Differential Revision: D10854563
Pulled By: michaelsuo
fbshipit-source-id: 409303c4cbf058b75e24bf2213b49e9d79cb862e
Summary:
The existing default timeout was set at 10 seconds, which is too low
for asynchronous tasks that depend on a barrier to resynchronize.
Having a single timeout for all operations is not ideal and this will
be addressed in future commits.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13056
Reviewed By: teng-li
Differential Revision: D10558746
Pulled By: pietern
fbshipit-source-id: d857ea55b1776fc7d0baf2efd77951b5d98beabb
Summary:
This PR adds optional type to ATen native, autograd, JIT schema and Python Arg parser, closes#9513. It allows us to use optional default values (including None) for function signature and implementations like clamp, etc., and also let us remove the python_default_init hack.
Follow up:
remove python_default_init completely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12582
Differential Revision: D10417423
Pulled By: wanchaol
fbshipit-source-id: 1c80f0727bb528188b47c595629e2996be269b89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12949
Currently the default chunk size in save operation is 1MB and I don't find a way to configure it at runtime. Add a parameter to configure chunk size in SaveOp.
Reviewed By: mraway, xsh6528
Differential Revision: D10454037
fbshipit-source-id: a5cd8f9846aea4b1e3612a3fcfa431b68bda8104
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13134
For tensor, we plan to do the following renaming:
```
* t.ndim() → t.dim()
* t.size() → t.numel()
* dims() → t.sizes()
* t.meta() → t.dtype()
* t.dim(d) → t.size(d)
```
This diff adds new APIs in caffe2::Tensor so we can start codemod,
we'll remove old API after the codemod
Reviewed By: ezyang
Differential Revision: D10856028
fbshipit-source-id: 1638997e234d7b3113ef8be65a16246f902273c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13082
Follow up of D10511254. For these cases we can move to preferred `optional` without namespace right away.
Reviewed By: ezyang, Yangqing
Differential Revision: D10844117
fbshipit-source-id: 99a59e692fb4b236b299579f937f1536d443d899
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12991
Remove the file proxying. Before we can do land `using namespace c10` everywhere, we just keep the one off namespace proxy. The follow up diff is going to replace explicit at::optional but keep just `optional` usage
Reviewed By: ezyang, Yangqing
Differential Revision: D10511254
fbshipit-source-id: 8297c61d7e9810ae215a18869a6ec9b63f55d202
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13141
This is an example diff to show what lint rules are being applied.
Reviewed By: mingzhe09088
Differential Revision: D10858478
fbshipit-source-id: cbeb013f10f755b0095478adf79366e7cf7836ff
Summary:
clang-format-6 run on all cpp,cc,c,cu,cxx,hpp,hxx,h files under /c10d and /thd
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13138
Differential Revision: D10857742
Pulled By: teng-li
fbshipit-source-id: f99bc62f56019c05acdfa8e8c4f0db34d23b4c52
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12950
For backwards compatibility, we want the c10 symbols to be reachable from caffe2 and aten.
When we move classes from at/caffe2 to c10, this
1. allow keeping backwards compatibility with third paty code we can't control
2. allows splitting diffs that move such classes into two diffs, where one only fixes the includes and the second one fixes the namespaces.
Reviewed By: ezyang
Differential Revision: D10496244
fbshipit-source-id: 914818688fad8c079889dfdc6242bc228b539f0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13024
There's a TensorList type in ivalue.h and one in ScalarType.h, and they are different.
This diff moves IValue types into an ivalue namespace so we can merge the namespaces without conflicts.
Reviewed By: ezyang
Differential Revision: D10518929
fbshipit-source-id: cb760b6804a399880d2bff3acf9a3422d99fc0b8
Summary:
Removes test_jit.cpp, which was supposed to have been deleted in https://github.com/pytorch/pytorch/pull/12030
I had to move zou3519's dynamic DAG tests into `test/cpp/jit/tests.h` too. No other changes to `test_jit.cpp` seem to have happened in the meantime.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12988
Differential Revision: D10854320
Pulled By: goldsborough
fbshipit-source-id: 7ab533e6e494e34a16ce39bbe62b1150e48fcb58
Summary:
* Disable MIOpen convolution on double tensors
* MIOpen: set group count in convolution descriptor
* MIOpen: Honor Max Dim (ROCm 222)
* MIOpen: Batchnorm - Allow half/half and half/float, disallow double
* Limit MIOpen batchnorm to same-precision
* Fix maxdim check. (ROCm 246)
* Fix reversed logic in DISABLE_MIOPEN (ROCm 253)
* Export LANG/LC_ALL also for the test step.
* Make tensors contiguous before calling MIOpen batch norm
* Actually pass dilation to MIOpen.
* Do not use MIOpen if there is dilation and the group size is > 1. - This is officially not supported currently.
* Fixes for miopenforward bias call
* Modified init conv descriptor param values and used same value for dilation
* MIOpen: disable transposed convolutions
For attention: bddppq ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13048
Differential Revision: D10785250
Pulled By: bddppq
fbshipit-source-id: f9d9797de644652280d59308e5ea5cc07d177fd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12843
This adds a cuda implementation for the UpsampleBilinearOp and UpsampleBilinearGradientOp.
The CUDA code is based off of the corresponding ResizeNearest operators but with bilinear interpolation logic taken from the CPU implementation.
Reviewed By: houseroad
Differential Revision: D10453776
fbshipit-source-id: b29ac330b72465974ddb27c0587bca590773fdec
Summary:
std::memcpy has UB when either of src or dest are NULL, even if length
is 0. This can and does happen when the input tensors are scalar tensors.
This triggered UBSAN on #12824 but it is strange that it has not
been triggered before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13121
Differential Revision: D10853113
Pulled By: zou3519
fbshipit-source-id: c4b4ad5e41de6f73dc755e0c25bc9947576a742d
Summary:
Adds the attribute name to the error message and fixes the corresponding
test to actually run
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13072
Differential Revision: D10846622
Pulled By: driazati
fbshipit-source-id: a7eee6320c28140c4937ede3d4e4685cfce08d84
Summary:
This adds support for reductions like sum() and mul() to TensorIterator.
Performance is similar to existing optimized code for CPU, and generally
better than existing code for CUDA kernels.
The templatized CUDA kernel requires fewer instantiations than the
existing THCReduce/THCReduceAll code. For example, sum() previously
generated 43 CUDA kernels, while it now requires only one (larger)
CUDA kernel. I suspect this should reduce code-size and
compilation time, but I haven't measured it.
Below are timings for sum() on [CPU](https://ark.intel.com/products/81908/Intel-Xeon-Processor-E5-2680-v3-30M-Cache-2_50-GHz) (12 threads and 1 thread) and CUDA with various tensor sizes.
CPU
| Reduction (dim) | Master | PR | Master (1 thread) | PR (1 thread) |
|----------------------|---------|---------|-------------------|---------------|
| 1024x1024 (all) | 22 us | 34 us | 136 us | 147 us |
| 1024x1024 (0) | 30 us | 28 us | 160 us | 160 us |
| 1024x1024 (1) | 25 us | 25 us | 171 us | 146 us |
| 1024x10x1024 (all) | 542 us | 550 us | 4.14 ms | 3.11 ms |
| 1024x10x1024 (0) | 658 us | 690 us | 6.80 ms | 5.93 ms |
| 1024x10x1024 (1) | 761 us | 757 us | 3.34 ms | 3.52 ms |
| 1024x10x1024 (2) | 538 us | 545 us | 3.73 ms | 3.04 ms |
| 1024x1024x1024 (all) | 72 ms | 71 ms | 364 ms | 357 ms |
| 1024x1024x1024 (0) | 94 ms | 90 ms | 935 ms | 927 ms |
| 1024x1024x1024 (1) | 80 ms | 86 ms | 881 ms | 688 ms |
| 1024x1024x1024 (2) | 71 ms | 71 ms | 456 ms | 354 ms |
CUDA
| Reduction (dim) | M40 base | M40 PR | P100 base | P100 PR |
|----------------------|----------|---------|-----------|-----------|
| 1024x10x1024 (all) | 238 us | 182 us | 136 us | 97 us |
| 1024x10x1024 (0) | 166 us | 179 us | 105 us | 84 us |
| 1024x10x1024 (1) | 181 us | 182 us | 89 us | 91 us |
| 1024x10x1024 (2) | 180 us | 168 us | 88 us | 79 us |
| 1024x1024x1024 (all) | 17.5 ms | 16.4 ms | 8.23 ms | 7.48 ms |
| 1024x1024x1024 (0) | 27.2 ms | 28.6 ms | 7.63 ms | 7.38 ms |
| 1024x1024x1024 (1) | 16.5 ms | 16.3 ms | 7.66 ms | 7.40 ms |
| 1024x1024x1024 (2) | 17.8 ms | 16.4 ms | 8.37 ms | 7.31 ms |
Timings were generated with this script:
https://gist.github.com/colesbury/d3238b266d8a9872fe6f68f77619b379
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11908
Differential Revision: D10071760
Pulled By: colesbury
fbshipit-source-id: 40e37a0e6803f1628b94cc5a52a10dfbb601f3d6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13109
The "right" strategy of creating a socket, binding to an undefined port, closing the socket, and reusing the port it was bound to, was subject to a race condition. Another process could bind to that same port sooner than the tests would, causing an "Address already in use" failure when rank 0 would try and bind to that same port. The THD tests have been using a fixed port since forever. Time will tell if this fixes#12876.
Differential Revision: D10850614
fbshipit-source-id: c19f12bb4916141187ee8ddb52880f5f418310dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12656
I originally wanted to do this in two steps, but deleting the Storage-only
constructor also changes the default numel state (which breaks tests),
so easiest to do it all in one go.)
- I still need a way to compute the correct TensorTypeId for all of the
Caffe2 constructors; rather than hard-code it, I wrote a function
in at::detail::computeTensorTypeId() to do this calculation. Maybe
this function could be used more widely, but for now, it's used
by Caffe2 only.
- Added a pile more TensorTypeId for all of Caffe2's supported DeviceTypes
- Because I still can't put arbitrary TypeMeta in TensorOptions, the
TensorTypeId() calculation doesn't respect dtype. For now, this is
not a problem, but this might block work to split non-POD dtypes
into their own TensorTypeId.
Reviewed By: li-roy
Differential Revision: D10380678
fbshipit-source-id: 10c5d12020596fc9f27d5579adffad00513af363
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13043
memset on nullptr is undefined-behavior and as a result filament_test is failing in dev build. This diff is making operator to handle empty output properly, so we can return that test back.
I'm not sure either this is even valid to call this op with input that would require empty memset (empty batch?). Will leave this to ninghz and sunnieshang to decide.
Reviewed By: xianjiec
Differential Revision: D10525605
fbshipit-source-id: a911cdbd62fc3d948328981fd01cd205ec2ad99f
Summary:
- Moved sync_reduction to C++
- Use a dedicated CUDA stream for memcpy
- Also use a dedicated CUDA stream for memcpy in queue_reduction
Added test as well.
CI should cover both DDP and unittest
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12954
Differential Revision: D10520069
Pulled By: teng-li
fbshipit-source-id: 64348e4e43c15f9695a4c28b036c232587ecfb65
Summary:
We want to move _C into the same cmake invocation that builds
libcaffe2 and libtorch. However, _C depends on THD and c10d, which in
turn depend on libcaffe2. That means that we can't move _C into that
cmake file unless we do these two first. This change does so.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12775
Differential Revision: D10457374
Pulled By: anderspapitto
fbshipit-source-id: 2c1aa3b8a418a73d2112e93c7da53a2e70cf7bba
Summary:
Fixed issue:
https://github.com/pytorch/pytorch/issues/12921
Build and works with mpich, all test passed.
We should add MPICH to CI at one point of time alter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13083
Reviewed By: soumith
Differential Revision: D10844833
Pulled By: teng-li
fbshipit-source-id: e8cdc866ee1ee7a33e469017ea562a08da119d53
Summary:
As the title says, we should always use the current stream on device in NCCL.
This can unblock ezyang on his further work
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13089
Reviewed By: ezyang
Differential Revision: D10847172
Pulled By: teng-li
fbshipit-source-id: 7fc7c4248b5efa1971d2af4d43f62d3379debfe4
Summary:
Fixes#12578#9395.
* Fix and simplify print logic
* Follow numpy print rule eb2bd11870/numpy/core/arrayprint.py (L859)
> scientific notation is used when absolute value of the smallest number is < 1e-4 or maximum > 1e8 or the ratio of the maximum absolute value to the minimum is > 1e3
I hope I didn't break anything since there seems to be a lot of edge cases here... Here are some easy sanity checks.
```
In [5]: torch.tensor(1)
Out[5]: tensor(1)
Out[2]: array(1) # numpy
In [6]: torch.tensor(10)
Out[6]: tensor(10)
Out[3]: array(10) # numpy
In [8]: torch.tensor(99000000)
Out[8]: tensor(99000000)
Out[5]: array(99000000) # numpy
In [9]: torch.tensor(100000000)
Out[9]: tensor(100000000)
Out[6]: array(100000000) # numpy
In [10]: torch.tensor(100000001)
Out[10]: tensor(100000001)
Out[7]: array(100000001) # numpy
In [11]: torch.tensor(1000000000)
Out[11]: tensor(1000000000)
Out[8]: array(1000000000) # numpy
In [12]: torch.tensor([1, 1000])
Out[12]: tensor([ 1, 1000])
Out[9]: array([ 1, 1000]) # numpy
In [13]: torch.tensor([1, 1010])
Out[13]: tensor([ 1, 1010])
Out[10]: array([ 1, 1010]) # numpy
```
For floating points, we use scientific when `max/min > 1000 || max > 1e8 || min < 1e-4`
Lines with "old" are old behaviors that either has precision issue, or not aligned with numpy
```
In [14]: torch.tensor(0.01)
Out[14]: tensor(0.0100)
Out[11]: array(0.01) # numpy
In [15]: torch.tensor(0.1)
Out[15]: tensor(0.1000)
Out[12]: array(0.1) # numpy
In [16]: torch.tensor(0.0001)
Out[16]: tensor(0.0001)
Out[14]: array(0.0001) # numpy
In [17]: torch.tensor(0.00002)
Out[17]: tensor(2.0000e-05)
Out[15]: array(2e-05) # numpy
Out[5]: tensor(0.0000) # old
In [18]: torch.tensor(1e8)
Out[18]: tensor(100000000.)
Out[16]: array(100000000.0) # numpy
In [19]: torch.tensor(1.1e8)
Out[19]: tensor(1.1000e+08)
Out[17]: array(1.1e8) # numpy 1.14.5, In <= 1.13 this was not using scientific print
Out[10]: tensor(110000000.) # old
In [20]: torch.tensor([0.01, 10.])
Out[20]: tensor([ 0.0100, 10.0000])
Out[18]: array([ 0.01, 10. ]) # numpy
In [21]: torch.tensor([0.01, 11.])
Out[21]: tensor([1.0000e-02, 1.1000e+01])
Out[19]: array([ 1.00000000e-02, 1.10000000e+01]) # numpy
Out[7]: tensor([ 0.0100, 11.0000]) # old
```
When print floating number in int mode, we still need to respect rules to use scientific mode first
```
In [22]: torch.tensor([1., 1000.])
Out[22]: tensor([ 1., 1000.])
Out[20]: array([ 1., 1000.]) # numpy
In [23]: torch.tensor([1., 1010.])
Out[23]: tensor([1.0000e+00, 1.0100e+03])
Out[21]: array([ 1.00000000e+00, 1.01000000e+03]) # numpy
Out[9]: tensor([ 1., 1010.]) # old
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12746
Differential Revision: D10443800
Pulled By: ailzhang
fbshipit-source-id: f5e4e3fe9bf0b44af2c64c93a9ed42b73fa613f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13068
Basic ops.def update and converter.cc updates
This is the standard way to ingest networks into nomnigraph
redo of D10412639
Reviewed By: ZolotukhinM
Differential Revision: D10560324
fbshipit-source-id: c8ccb0aabde6ee8f823657ee5cd3ed9ed6c45549
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13067
Cleaning up the interface for nomnigraph in C++ world
redo of D10438090
Reviewed By: ZolotukhinM
Differential Revision: D10560323
fbshipit-source-id: e4e084284615e813836a7d031b5a71e8d80b0e62
Summary:
This is mostly for reusing all the cudnn test cases in our python operator_tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12278
Differential Revision: D10842592
Pulled By: bddppq
fbshipit-source-id: 4b3ed91fca64ff02060837b3270393bc2f9a9898
Summary:
Our convolution ops and such expect three dimensional images, but the images in the MNIST dataset of the C++ frontend currently only have two.
apaszke ebetica soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13060
Differential Revision: D10560754
Pulled By: goldsborough
fbshipit-source-id: a2cc877b4f43434482bec902c941fafb7a157d5d
Summary:
`warnings.warn` is used commonly thoughout `nn.functional`, so this adds
support for it by forwarding its arguments to `print`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12964
Differential Revision: D10559427
Pulled By: driazati
fbshipit-source-id: 5b591f6f446c906418f9fc7730c17e301f263d9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13007
No reason to use the hook if it's set, this helps fbcode traces.
This slightly pessimizes the stack trace for ATen functions,
because we are no longer skipping all of the frames we should.
This is probably OK.
Reviewed By: Yangqing
Differential Revision: D10518499
fbshipit-source-id: be54e490df3c3fde7ff894b5b1473442ffc7ded3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13071
In the case where a process got stuck and timed out on joining, we would see a None != 1 assertion error in the code path where the exit statuses are compared. This implies that the first process exited with exit code 1 and another one didn't exit at all. With this commit the error message is more descriptive.
Differential Revision: D10785266
fbshipit-source-id: c8cc02d07ea4fdc6f5374afd9a0aac72218fe61d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13062
Gold (the linker) isn't able to gc unreferenced string constants, but
converting these to arrays puts them in their own data sections and reduces
(Android) binary size as a result.
I'm told even in server builds, this reduces binary size by a few dozen bytes
and speeds up startup by a few hundred ns. :-P
Reviewed By: Yangqing
Differential Revision: D10510808
fbshipit-source-id: 247ba9574e7a9b6a8204d33052994b08c401c197
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12616
Focusing on operators in common use on mobile.
Also use GRADIENT_OPERATOR_SCHEMA.
Reviewed By: Yangqing
Differential Revision: D10245216
fbshipit-source-id: 5cc023da170149b637fe3c729d3756af948aa265
Summary:
rather than pass a list through a text file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12951
Differential Revision: D10528309
Pulled By: anderspapitto
fbshipit-source-id: d94befcd61b6304815859694b623046f256462df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13002
Batch dim wasn't handled in the CPU impl (will fail for inputs with N > 1).
Fixing that here.
Differential Revision: D10515159
fbshipit-source-id: ee7e4f489d2d4de793f550b31db7c0e2ba3651e8
Summary:
We are beginning to use this class in a wider reaching set of use-cases. This PR refactors it so that we always access schema properties through methods. This will make adding extra information like alias information easier (i.e. we can a version of `type()` that returns the type with alias information and another version that returns a type without that information).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12967
Differential Revision: D10502674
Pulled By: zdevito
fbshipit-source-id: a88783ed8f20ab3be6460c12da95f9f940891c44
Summary:
This is used to patch our cmake cuda scripts - should be in the installation script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13013
Reviewed By: ir413
Differential Revision: D10519104
Pulled By: Yangqing
fbshipit-source-id: 542049224ea41068f32d4c0f6399c7e8b684f764
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12883
Attempting to do this again. last try broke oss ci: D10421896
Reallocation of strides_ if there's no change in dim seems to cause the error that broke internal flow last time. This fixes that. Found a potential race condition in caffe2 counter ops that might be the cause, we will investigate that.
Reviewed By: ezyang
Differential Revision: D10469960
fbshipit-source-id: 478186ff0d2f3dba1fbff6231db715322418d79c
Summary:
these are pretty spammy - unless we have a reason to keep them, let's not
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13017
Differential Revision: D10528295
Pulled By: anderspapitto
fbshipit-source-id: 5514371a6e61e13ec070cc5517488523d42f2935
Summary:
Closes#2119.
There was a small bug where the output_size got sliced with `[-2:]`
where we really meant to slice it as `[2:]` (to remove the batch and
channel dimensions).
Added a new test for this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12952
Differential Revision: D10510678
Pulled By: zou3519
fbshipit-source-id: 4c04a5007fc6d002e1806d6fe981b43d33d6a4f2
Summary:
In order to support tensorboardX and other visualization tools, we need to make sure a non-empty scope is set on all nodes added by the JIT. This attempts to do this, but is still a WIP.
This is a new version of https://github.com/pytorch/pytorch/pull/10749
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12400
Reviewed By: ezyang
Differential Revision: D10224380
Pulled By: orionr
fbshipit-source-id: d1bccd0eee9ef7c4354112c6a39a5987bfac2994
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13019
It just makes the semantic meaning of the int32_t a little
bit clearer.
Reviewed By: zou3519
Differential Revision: D10520295
fbshipit-source-id: 45b0bd1b6afddee17072b628d8e9b87d7c86e501
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12940
Dmytro was reading this code and requested that we rename the interface
to something that made it more obvious that pooling was going on.
Seems reasonable to me! Final name is a suggestion from Pieter.
Reviewed By: dzhulgakov
Differential Revision: D10492071
fbshipit-source-id: b1c2cac760f666968d58166be649dabfe1127c5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13006
In Caffe2, Concat can have 2 outputs. The second being the output shape of the 1st output. In ONNX, Concat only has 1 output. So when we do the exporting, we need to add a `Shape` to the first output and generate the second output from it.
Differential Revision: D10517698
fbshipit-source-id: 38e974423e2506b16d37b49d51c27ad87b73e63a
Summary:
`inspect.stack()` calls are slow since they access a bunch of extra info about the frame. This PR instead uses `inspect.currentframe()` and goes up the stack until it reaches the correct frame. [Context](stackoverflow.com/questions/17407119/python-inspect-stack-is-slow)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12859
Differential Revision: D10509912
Pulled By: driazati
fbshipit-source-id: b85325adf1b3c85a1a3a82e96e567b8be498531b
Summary:
Basic ops.def update and converter.cc updates
This is the standard way to ingest networks into nomnigraph
Reviewed By: duc0
Differential Revision: D10412639
fbshipit-source-id: a4c523fda96bbe0e31de0d9fcf795ae9c7377c90
Summary: Cleaning up the interface for nomnigraph in C++ world
Reviewed By: duc0
Differential Revision: D10438090
fbshipit-source-id: 6b4309b8a4b3730f3309edf0047d4006a001895b
Summary:
TSIA - we want to deprecate numba in fbcode when moving to new compiler tiers.
Converted the old test to a non-numba regular python op test.
Reviewed By: xw285cornell
Differential Revision: D10519910
fbshipit-source-id: 0e9188a6d0fc159100f0db704b106fbfde3c5833
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12848
Updated all non-test uses of protobuf::MessageLite::SerializeAsString to call
SerializeAsString_EnforceCheck so that the return value is checked and can
throw an exception if failing.
Most of the affected code was called from classes derived from BlobSerializeBase.
Didn't touch most tests and ENFORCE calls because they usually do checks
anyway.
Original commit changeset: c0760e73ecc7
Reviewed By: dzhulgakov
Differential Revision: D10453456
fbshipit-source-id: d2f2b7b4578e721924354149f08f627c7e3bf070
Summary:
We cannot use copying as it loses recorded callbacks and thus after copying
tracked values are no longer tracked.
Reviewed By: bwasti, duc0
Differential Revision: D10510057
fbshipit-source-id: b64fdef3fb28fc26fe55eba41f4b5007ba6894de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12878
Python 3.6 headers define their own ssize_t, which clashes with our definition.
Luckily, they also define a `HAVE_SSIZE_T` macro we can use to check for this case.
Reviewed By: ezyang
Differential Revision: D10467239
fbshipit-source-id: 661675ad1e30a6ca26d6790eaa75657ef6bf37c2
Summary:
* Enable disabled functions for ROCm (ROCm 252)
* fixes for topk fp16 (ROCm 270)
* HIP needs kernel invocation to be explicitly templated to be able to take non-const arg as const kernel arg (ROCm 281)
For attention: bddppq ezyang
Full set of PyTorch/Caffe2 tests on ROCm here: https://github.com/ROCmSoftwarePlatform/pytorch/pull/283
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12973
Differential Revision: D10516072
Pulled By: bddppq
fbshipit-source-id: 833b3de1544dfa4886a34e2b5ea53d77b6f0ba9e
Summary:
The legal function cublasHandle_t cublas_handle() was hipified to the
clearly illegal rocblas_handle rocblas_handle(). It should not work and
correctly fails with gcc as the host compiler as it induces an
ambiguity.
Function now hipifies to rocblas_handle rocblashandle()
Fixes long standing issue we've observed in PyTorch when base compiler is gcc.
For attention: bddppq ezyang
Tests on ROCm PyTorch/Caffe2: https://github.com/ROCmSoftwarePlatform/pytorch/pull/284
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12957
Differential Revision: D10501227
Pulled By: bddppq
fbshipit-source-id: 568cb80801c0d14c9b1b61e3a7db387a5c21acf4
Summary:
Adds support for weak script modules created that get compiled to `ScriptModule`s once added as a submodule of a `ScriptModule`:
```python
weak_module
class Test(torch.nn.Module):
...
weak_script_method
def forward(self, x):
...
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12682
Differential Revision: D10458626
Pulled By: driazati
fbshipit-source-id: 10ae23cb83cdafc4646cee58f399e14b2e60acd4
Summary:
- exhaustive_search attribute will be blacklisted so it
will be discarded from the coverted onnx model. At present
it throws error while verifying the onnx model
Signed-off-by: Parth Raichura <parth.raichura@softnautics.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12805
Differential Revision: D10502374
Pulled By: ezyang
fbshipit-source-id: 0926dfa3237a8a431184e7f7250146e5b0cbfb85
Summary:
expecttest and test_expecttest are the implementation and tests
for this functionality. I wired it up to the --accept flag,
but there's also a new environment variable EXPECTTEST_ACCEPT
which may be more convenient to trigger. Haven't tested if this
works in fbcode.
There may be a few expect tests which will benefit from inline
treatment, but I just did one to show it works.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12825
Reviewed By: teng-li
Differential Revision: D10448630
Pulled By: ezyang
fbshipit-source-id: 3d339f82e2d00891309620a60e13039fa1ed8b46
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12961
According to zdevito - this is not used at all, so we are removing it for safety.
It is also possible that this native_parser.py will completely go away in the
near future.
Reviewed By: zdevito
Differential Revision: D10501616
fbshipit-source-id: 3218708e6150d3c94d730fbd25ae1f7abb5718b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12806
Make sure to update success_ status at the end of the run when going through
task statuses
Reviewed By: aazzolini
Differential Revision: D10443704
fbshipit-source-id: 79f8f7fe1eccb78f6e2859f3b1e66dc44347bcc8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12932
I was looking at some assembly for some code I was working on,
and felt a desire to have likely()/unlikely() macros. I checked
if we already had them, and we didn't. This commit adds them,
and fixes up all known use sites to make use of it.
Reviewed By: Maratyszcza
Differential Revision: D10488399
fbshipit-source-id: 7476da208907480d49f02b37c7345c17d85c3db7
Summary:
fully working version by using continuing on goldsborough 's initial version.
waiting on the stream guard to be merged before adding more stream perf logics into the c++ version
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12852
Differential Revision: D10468696
Pulled By: teng-li
fbshipit-source-id: 8e46d408796973817abfd9dbd6566e0ca5b7a13f
Summary:
**ZeroDivisionError** occurs when `cuda_prof_exec_time` is small enough.
This situation is normal for a project that has little CUDA work.
Or someone does not make his work transferred to CUDA successfully. In this time he profiles the code, this error occurs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11987
Differential Revision: D10488568
Pulled By: soumith
fbshipit-source-id: db8c1e9e88a00943c100958ebef41a1cb56e7e65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12938
We will be using C10_USE_MINIMAL_GLOG. Also, this will be in exported flags,
so dependent libraries won't need to define it.
Reviewed By: smessmer, BIT-silence
Differential Revision: D10468993
fbshipit-source-id: 04ae3ae17122d46b1b512d4202ab014365b87f4a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12900
Workspace sometimes will be populated with input tensors for shape inference but net.external_input() is not a reliable way to tell weights from input in the workspace. We say in some usecases where net.external_input() is empty. In this case, we need to give user an option to provide input hint.
Reviewed By: bddppq
Differential Revision: D10476822
fbshipit-source-id: 1a3fa2df69b959d5b952a7824eba9e6c713f4f07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12905
This diff does some clean up of the multithread benchmark code:
1. Split implementation to `.cc` file to separate implementation and improve build
2. Make `MutatingNetSupplier` more generic by providing the mutating function as an argument instead of virtual method.
3. Fix AI benchmark by sticking to the original option names
Reviewed By: highker
Differential Revision: D10479238
fbshipit-source-id: afa201fc287e3fdbb232db24513ecf8024501f66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12706
If both branches are valid C++ code independent from the type passed in, then we can just use if/else inside of a constexpr function
to decide between the cases. Only if one branch would be invalid code (say because type T doesn't have a default constructor), we'd
need "constexpr if" or SFINAE.
Reviewed By: ezyang
Differential Revision: D10400927
fbshipit-source-id: 16d9855913af960b68ee406388d6b9021bfeb34a
Summary:
On my devgpu, `cmake` is newer than `cmake3`. Using `cmake3` causes compilation to fail. Instead of blindly using `cmake3`, we pick the newer of the two.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12916
Differential Revision: D10481922
Pulled By: SsnL
fbshipit-source-id: 8340136c459e25da9f5fc4f420c7e67cadc28aff
Summary:
This PR implements a DataLoader API for the C++ frontend.
The components present in this API largely match the Python API. It consists of:
- `Dataset`s: Conceptually a function from a set of indices to a batch of examples;
- `Transform`s: A functional transformation of a dataset. A `Map<D, T>` for Dataset `D` and transform `T` is itself a dataset;
- `Sampler`s: Specify a strategy for generating indices for a new batch;
- A `DataLoader`, with the ability to automatically parallelize fetching of samples across multiple worker threads;
Note that collation functions fall naturally out of the `Map<Dataset, Transform>` abstraction.
Things that are missing right now that maybe should be added:
- Memory pinning for CUDA tensors
The API was designed to be generalizable to almost any kind of dataset, transform or sampling strategy, while providing a convenient API out of the box. To achieve this, it is quite heavily templatized on various possible input types.
There are many parts to this PR! Right now, I would like feedback on:
- Your impression of the general usability of the API;
- Your impression of which parts seem too complex or overthought;
- The implementation of the parallelization aspects of the DataLoader. I've followed the Python implementation in some matters, but also differ in others. I think my implementation is a little cleaner and decouples components slightly better than the Python dataloader.
I haven't added too many comments yet, as this is fresh out of the oven. Let me know if anything is unclear from the code itself.
There also aren't any tests yet. I will write a comprehensive test suite once we agree on the API and implementation.
apaszke ezyang The controller you requested could not be found. pietern
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11918
Reviewed By: ezyang
Differential Revision: D9998881
Pulled By: goldsborough
fbshipit-source-id: 22cf357b63692bea42ddb1cc2abc71dae5030aea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12588
By default, this is an alias for REGISTER_CPU_OPERATOR. If gradients are not
required (e.g., on mobile) it can be converted to a no-op by defining
CAFFE2_NO_GRADIENT_OPS, resulting in a smaller build.
GRADIENT_OPERATOR_SCHEMA works similarly.
CAFFE2_NO_GRADIENT_OPS also converts REGISTER_GRADIENT to a no-op.
Use these macros in fully_connected_op.cc as an example.
Follow-up diffs will convert more operators.
I had to introduce MACRO_EXPAND to handle the way Visual Studio expands
VA_ARGS.
Reviewed By: Yangqing
Differential Revision: D10209468
fbshipit-source-id: 4116d9098b97646bb30a00f2a7d46aa5d7ebcae0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12897
UnsafeCoalesce Op is used during memonger days when we try to coalesce operators
for better efficienct computation kernels. It creates a little bit of an unsafe
underlying memory storage pattern.
With the new tensor unification I am not sure if it is still safe for us to do
so, so I propose we delete it for the sake of safety.
Reviewed By: bddppq, ilia-cher
Differential Revision: D10475980
fbshipit-source-id: b1a838c9f47d681c309ee8e2f961b432236e157e
Summary:
I spent a couple of minutes trying to understand which shape corresponds to checkpoint and which one to the model
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12870
Differential Revision: D10466600
Pulled By: SsnL
fbshipit-source-id: 3b68530b1b756462a2acd59e3a033ff633567a6b
Summary:
This is designed to make it easier to see how your codegen changes affected actual generated code.
Limitations:
A) This is NOT robust; if new directories are added that include generated files, they need to be added to tools/generated_dirs.txt. Note that subdirectories of the list are not included.
B) This is particular to my workflow which I don't claim is generally applicable. Ideally we would have a script that pumped out a diff that could be attached to PRs.
C) Only works on OSS and definitely won't work on windows.
How to use:
1) python setup.py ...
2) tools/git_add_generated_dirs
3) Edit codegen
4) python setup.py ...
4) git diff to see changes
5) If satisfied: tools/git_reset_generated_dirs, commit, etc.
If not satisfied: Go to 3)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12835
Reviewed By: ezyang
Differential Revision: D10452255
Pulled By: gchanan
fbshipit-source-id: 294fc74d41d1b840c7a26d20e05efd0aff154635
Summary:
* Moves `weak_script` annotation to `torch/_jit_internal.py` folder to resolve dependency issue between `torch.jit` and `torch.nn`
* Add `torch._jit.weak_script` to `tanhshrink` and `softsign`, their tests now pass instead of giving an `unknown builtin op` error
* Blacklist converted `torch.nn.functional` functions from appearing in the builtin op list if they don't actually have corresponding `aten` ops
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12723
Differential Revision: D10452986
Pulled By: driazati
fbshipit-source-id: c7842bc2d3ba0aaf7ca6e1e228523dbed3d63c36
Summary:
This test flushes out the issue that IDEEP cannot handle tensor with dims like (0, 2), which is a valid tensor shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8459
Differential Revision: D10419328
Pulled By: yinghai
fbshipit-source-id: c5efcd152364a544180a8305c47a2a2d126ab070
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12881
TSIA. This should not change any functionality.
Remaining work:
- change the build script to deprecate use of CAFFE2_USE_MINIMAL_GOOGLE_GLOG and use a C10 macro instead.
- Unify the exception name (EnforceNotMet -> Error)
- Unify the logging and warning APIs (like AT_WARNING)
Reviewed By: dzhulgakov
Differential Revision: D10441597
fbshipit-source-id: 4784dc0cd5af83dacb10c4952a2d1d7236b3f14d
Summary:
`OMP_NUM_THREADS` and `MKL_NUM_THREADS` are set to 4 by default in the docker images, which causes `nproc` to only show 4 cores in the docker containers by default, and building PyTorch is slow in this default case. We likely don't need these two flags to be set, and this PR tests that hypothesis.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12836
Differential Revision: D10468218
Pulled By: yf225
fbshipit-source-id: 7a57962c962e162a8d97f730626825aa1e371c7f
Summary:
Add strings to our set of built-in types for annotations. This is used in the the functional library.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12731
Differential Revision: D10453153
Pulled By: eellison
fbshipit-source-id: f54177c0c529f2e09f7ff380ddb476c3545ba5b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12845
Attempting to do this again.
Reallocation of strides_ if there's no change in dim seems to cause the error that broke internal flow last time. This fixes that. Found a potential race condition in caffe2 counter ops that might be the cause, we will investigate that.
Reviewed By: ezyang
Differential Revision: D10421896
fbshipit-source-id: b961ea0bca79757991013a2d60cfe51565689ee9
Summary:
I got annoyed at waiting for OSS to tell me my c10d builds were busted, so
I also added support for building the test scripts in fbcode and fixed the
warnings this uncovered.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12849
Reviewed By: pietern
Differential Revision: D10457671
fbshipit-source-id: 5b0e36c606e397323f313f09dfce64d2df88faed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12736
This updates UpsampleBilinearOp and UpsampleBilinearGradientOp to support scales to bring it inline with ResizeNearestOp https://github.com/pytorch/pytorch/pull/12720.
Reviewed By: houseroad
Differential Revision: D10416228
fbshipit-source-id: f339b7e06979c9c566afb4cee64a2d939b352957
Summary:
I'm trying to do some transformations on Declarations.cwrap and this makes things overly difficult and doesn't do anything useful.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12832
Reviewed By: ezyang
Differential Revision: D10450771
Pulled By: gchanan
fbshipit-source-id: 1abb1bce27b323dd3e93b52240e7627cd8e56566
Summary:
Currently while converting from caffe2 to onnx it doesn't
blacklist the exhaustive_search attribute in support_onnx_export.
So conversion fails when onnx model is verified using C.check_model.
Signed-off-by: Parth Raichura <parth.raichura@softnautics.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12815
Differential Revision: D10457777
Pulled By: ezyang
fbshipit-source-id: dc2183d8abef8cd753b348f2eaa62c952a058920
Summary:
There will be a link error when the caffe2 doesn't use its protobuf under third_party. The pytorch will always link that protobuf. The pytorch doesn't use the protobuf directly. We could remove it from
the list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12451
Differential Revision: D10262676
Pulled By: ezyang
fbshipit-source-id: c2ff3fdf757fc21ed689e7f663c082064b1a0bca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12777
Enables JIT tests in FBCode. Changes pybind11 code to avoid mixing py::args with positinally matched arguments because old versions of PyBind11 leak memory in this case.
Reviewed By: jamesr66a
Differential Revision: D10419708
fbshipit-source-id: 74bc466001b5d363132d1af32e96841b38601827
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12729
This may have a dependency on D10380678 if size_from_dim(0)
was required because numel() used to return -1 in some cases.
This is no longer true.
Reviewed By: li-roy, dzhulgakov
Differential Revision: D10415069
fbshipit-source-id: 39f46f56249ecaf3533f62a0205b3a45d519d789
Summary:
It's the best coding practice to always include dynamically declared module level methods in the "__all__" field. Otherwise, IDEs (such as PyCharm) with referenced module inspectors will complain "Cannot find reference ..." .
This PR adds 'rand' and 'randn' in __init.py__' .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12762
Differential Revision: D10427541
Pulled By: ezyang
fbshipit-source-id: ec0704dfd91e78d7ad098b42cfd4bd1ad0e119df
Summary:
I think the original author wrote 2.0f in attempt to double in size, but this argument takes a percentage increase, not a factor increase.
Created from Diffusion's 'Open in Editor' feature.
Reviewed By: jamesr66a
Differential Revision: D10412946
fbshipit-source-id: 95eb3d284255f232b7782bb1d2c9c2ef8aa6f8a7
Summary:
These were indiscriminately dumping `onnx::` instructions into traces, and making it so you couldn't run the traces in the JIT interpreter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12803
Differential Revision: D10443526
Pulled By: jamesr66a
fbshipit-source-id: 07172004bf31be9f61e498b5772759fe9262e9b3
Summary: Added 2 years ago in D3665603, never used, kill it.
Reviewed By: ezyang
Differential Revision: D10421336
fbshipit-source-id: 1b027a9ef2b71d0dd2c572cd4338bc8e046320d8
Summary:
1. Change scope ownership model so they can be shared across Graphs.
Now scopes own their parent and are intrusive pointers. Graphs
no longer require a scope_root and cloning a node automatically
clones its scope. This causes some changes in expect files for
trace+script things. As far as I can tell these are not bugs but
a different way of interpreting how scopes should propagate.
Big traces like that of alexnet keep their scopes unchanged.
2. Remove VariableType.cpp dependency on a symbol being in the pre-
declared symbol list.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12804
Differential Revision: D10447922
Pulled By: zdevito
fbshipit-source-id: dcfcaf514bbe5687047df0f79c2be536ea539281
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12811
L1 version of this operator was super slow and timing out one of our
unit-tests. This diff is addressing TODO and making it fast.
Reviewed By: chocjy
Differential Revision: D10444267
fbshipit-source-id: 550b701b6a5cb3f2540997fd7d8b920400b983a6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11135
This diff does not have any logic change; it simply move files/functions/classes around.
Open source (almost all) necessary dependency for multithreaded predictor bench.
The benchmark itself can be open sourced once the predictor is open sourced.
Reviewed By: salexspb
Differential Revision: D9602006
fbshipit-source-id: 386c9483e2c64c8b7d36e4600189c4e0b7e159ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12799
Updated all non-test uses of protobuf::MessageLite::SerializeAsString to call
SerializeAsString_EnforceCheck so that the return value is checked and can
throw an exception if failing.
Most of the affected code was called from classes derived from BlobSerializeBase.
Didn't touch most tests and ENFORCE calls because they usually do checks
anyway.
Reviewed By: ezyang
Differential Revision: D10416438
fbshipit-source-id: cb842e3e26b0918829d71267a375d4dd40600d58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12681
- Get rid of NodeMatchCriteria as a template parameter, which was too generic. So MatchNode<NodeMatchCriteria> becomes MatchNode<GraphType>, and MatchStore stores the predicate on GraphType::NodeRef.
- Similarly, get rid of NNNodeMatchCriteria
Now one can just pass in a function pointer NodeRef -> bool to NNMatchNode constructor directly like this
mg.createNode(is<Relu>)
- Merge static utilities in SubgraphMatcher class into MatchGraph class
- Rename MatchNode to MatchPredicate
Change use cases and tests to make it work
Reviewed By: ZolotukhinM
Differential Revision: D10386907
fbshipit-source-id: 43874bd154e3d7c29ce07b4b74eca8a7a9f3078a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12782
We have seen the "Address already in use" error popup a few times when instantiating the TCPStore. The port that it uses is dynamically generated through common.find_free_port(), which binds a new socket to a random port, closes the socket, and returns the port that the OS had assigned. If some other process grabs that port in the time between closing the socket and the TCPStore binding to it, the bind error shows up. This commit changes most tests to use the FileStore instead and includes a retry when testing the TCPStore.
Differential Revision: D10433401
fbshipit-source-id: 8dd575ac91a3cddd1cc41ddb0ff4311ddc58c813
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11711
Added GPU support for spatial batch normalization. This functions by reducing values from GPUs onto a CPU and broadcasting those results back to each GPU. We have run several experiments, and found these results to be better than those without spatial bn: https://fb.quip.com/fr7HAeDliPB8
Reviewed By: enosair
Differential Revision: D9547420
fbshipit-source-id: ccbd2937efd6cfd61182fff2f098fb7c5ae8aeb1
Summary:
This is likely currently broken due to symbol visibility issues, but we will investigate it using this PR.
CC orionr yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11527
Differential Revision: D10444104
Pulled By: goldsborough
fbshipit-source-id: 4c447beeb9671598ecfc846cb5c507ef143459fe
Summary:
There is currently no obvious way for users to move their `script::Module` to GPU memory. This PR implements the `to()` functions that C++ frontend modules have.
zdevito apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12710
Differential Revision: D10444103
Pulled By: goldsborough
fbshipit-source-id: daa0ec7e7416c683397ee392c6e78b48273f72c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12794
common.py is used in base_module for almost all tests in test/. The
name of this file is so common that can easily conflict with other dependencies
if they happen to have another common.py in the base module. Rename the file to
avoid conflict.
Reviewed By: orionr
Differential Revision: D10438204
fbshipit-source-id: 6a996c14980722330be0a9fd3a54c20af4b3d380
Summary:
I found a bug in norm() and fixed it (and added tests to make sure it's fixed)
here is how to reproduce it:
```python
import torch
x = torch.FloatTensor([[10, 12, 13], [4, 0, 12]])
print(torch.norm(x, -40, dim=0, keepdim=True)) #output is tensor([[ 4.0000, 0.0000, 11.9853]])
print(torch.norm(x, float('-inf'), dim=0, keepdim=True)) #output is tensor([[1., 1., 1.]]) which is wrong!
from numpy.linalg import norm as np_norm
x = x.numpy()
print(np_norm(x, ord=-40, axis=0)) #output is array([[4., 0., 11.985261]])
print(np_norm(x, ord=float('-inf'), axis=0)) #output is array([[4., 0., 12.0]])
```
it's related to [#6817](https://github.com/pytorch/pytorch/issues/6817) and [#6969](https://github.com/pytorch/pytorch/pull/6969)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12722
Differential Revision: D10427687
Pulled By: soumith
fbshipit-source-id: 936a7491d1e2625410513ee9c39f8c910e8e6803
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12792
This is a follow up diff after D10238910.
Only non-codemod change is the removal of ATen/Error.h and ATen/core/Error.h. Other files are basically changing the inclusion path + clang format for inclusion order.
Reviewed By: bddppq
Differential Revision: D10437824
fbshipit-source-id: 7f885f80ab5827468d1351cfb2765d0e3f555a69
Summary:
THPSize_pynew is called from the Python C API and may throw exceptions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12770
Differential Revision: D10431180
Pulled By: colesbury
fbshipit-source-id: 93dd1b604ac6bc05d4eb02b97e3f79a73aec73c5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12407
We want to use tensor factory to refactor the caffe2's old way of initialize Tensor by Resize and mutable_data
in order to eliminate uninitialized Tensor.
Previously when we want to create a Tensor in caffe2, we'll do the following
```
Tensor x(CPU); // device type provided
x.Resize({1, 2, 3}); // size provided
x.mutable_data<float>(); // data type provided and memory allocated
```
This leaves Tensor in not fully initialized state during the process, to eliminate this, we
want to provide all the needed information in the begining. ATen already has its TensorFactories: https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/TensorFactories.cpp, and there is a TensorOption, we want to adopt the same interface to ease future refactoring.
In the callsite, we used to have `Output(i)` that returns a `Blob` that contains an uninitialized `Tensor` and we'll call Resize and mutable_data afterwards to provide dimension and data type,
```
// uninitialized tensor
auto* Y = Output(0);
// set dimensions
Y->Resize({1, 2, 3});
// actually allocate the data
auto* data = Y->mutable_data<float>();
// After this step, Tensor is fully initialized.
```
We want to change it to the following:
```
// provide dimensions and TensorOptions which include device type and data type.
// This will set all the information of Tensor properly and also allocate memory.
auto* Y = Output(0, {1, 2, 3}, at::device({context_.device_type()}).template dtype<T>());
// Tensor is fully initialized after this step
// following `mutable_data` call won't allocate memory.
auto* data = Y->mutable_data<float>();
```
microbenchmarks
```
============================================================================
caffe2/caffe2/fb/benchmarks/core_overhead_benchmark.ccrelative time/iter iters/s
============================================================================
OperatorNewOutputTensorAPI 3.27us 306.05K
OperatorOldOutputTensorAPI 3.55us 281.54K
============================================================================
```
Reviewed By: ezyang
Differential Revision: D10207890
fbshipit-source-id: f54ddacaa057b7c6bc7d5a8290171f35e9e40e29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12714
This is a short change to enable c10 namespace in caffe2. We did not enable
it before due to gflags global variable confusion, but it should have been
mostly cleaned now. Right now, the plan on record is that namespace caffe2 and
namespace aten will fully be supersets of namespace c10.
Most of the diff is codemod, and only two places of non-codemod is in caffe2/core/common.h, where
```
using namespace c10;
```
is added, and in Flags.h, where instead of creating aliasing variables in c10 namespace, we directly put it in the global namespace to match gflags (and same behavior if gflags is not being built with).
Reviewed By: dzhulgakov
Differential Revision: D10390486
fbshipit-source-id: 5e2df730e28e29a052f513bddc558d9f78a23b9b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11926
With the preparation work of diffs stacked below, we're now able to remove this call to Blob::ShareExternal(),
preparing for removing that function from Blob,
Reviewed By: dzhulgakov
Differential Revision: D9884563
fbshipit-source-id: 7dd5c5fe02be0df7a44be45587c1dd7c474126ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11925
This is step 1 in the refactoring to remove Blob::ShareExternal(), i.e. Blob would then always own its contents.
ShareExternal() is for example used to pass non-owning blobs to serialization. This diff prepares removing that.
Reviewed By: ezyang
Differential Revision: D9884177
fbshipit-source-id: d01df9a613a4fc62e5679fe45bfc47e2c899b818
Summary:
`torch.isfinite()` used to crash on int inputs.
```
>>> import torch
>>> a = torch.tensor([1, 2])
>>> torch.isfinite(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/scratch/pytorch/torch/functional.py", line 262, in isfinite
return (tensor == tensor) & (tensor.abs() != inf)
RuntimeError: value cannot be converted to type int64_t without overflow: inf
```
But this is a easy special case and numpy also supports it.
```
>>> import numpy as np
>>> a = np.array([1, 2])
>>> a.dtype
dtype('int64')
>>> np.isfinite(a)
array([ True, True], dtype=bool)
```
So added a hacky line to handle non-floating-point input. Since pytorch raises exception when overflow, we can safely assume all valid int tensors are infinite numbers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12750
Differential Revision: D10428204
Pulled By: ailzhang
fbshipit-source-id: f39b2d0975762c91cdea23c766ff1e21d85d57a5
Summary:
Possible fix for #11326. Testing in CI for windows code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12739
Differential Revision: D10417038
Pulled By: zdevito
fbshipit-source-id: 1d5f2f9a24eceef7047dc218669faca8a187c65c
Summary:
- fix math formula
- test plan: build html and view on a browser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12740
Differential Revision: D10419430
Pulled By: weiyangfb
fbshipit-source-id: b8eee9e75c3ce6e37535e3de597431ef5030e9ac
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12761
, is not really , and thus it can fail some of the Python 2 import.
Reviewed By: weiyangfb
Differential Revision: D10423231
fbshipit-source-id: 3738c0b9d2f52aa47eef06250f84c5933a38783f
Summary:
Fixes#12251
In the docs the actual key word argument was supposed to be `tensors` but instead it is given as `seq` for doing `torch.cat` operation.
zou3519 can you review this code? I don't have access to request for code reviews.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12741
Differential Revision: D10419682
Pulled By: ezyang
fbshipit-source-id: a0ec9c3f4aeba23ac3a99e2ae89bd07d2b9ddb58
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11500
Since TypeMeta already stores a destructor, and we removed the ability from Blob to store a custom destructor in a diff stacked below this, there is now no reason for Blob to store it again.
Reviewed By: ezyang
Differential Revision: D9763423
fbshipit-source-id: d37a792ffd6928ed1906f5ba88bd4f1d1e2b3781
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12307
This adds non-placement variants of New/Delete to TypeMeta.
In a future diff, this is going to be used from Blob to destruct its contents.
Reviewed By: dzhulgakov
Differential Revision: D10184116
fbshipit-source-id: 7dc5592dbb9d7c4857c0ec7b8570329b33ce5017
Summary:
Fixed the second example in NLLLoss.
The LogSoftmax activation was missing after the convolution layer. Without this activation, the second example loss was sometimes negative.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12703
Differential Revision: D10419694
Pulled By: ezyang
fbshipit-source-id: 98bfefd1050290dd5b29d3ce18fe075103db4674
Summary:
include atomicAdd commentary as this is less well known
There is some discussion in #12207
Unfortunately, I cannot seem to get the ..include working in `_tensor_docs.py` and `_torch_docs.py`. I could use a hint for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12217
Differential Revision: D10419739
Pulled By: SsnL
fbshipit-source-id: eecd04fb7486bd9c6ee64cd34859d61a0a97ec4e
Summary:
I struggled with yet another DataLoader hang for the entire evening. After numerous experiments, I realized that it is unsafe to do anything when Python is shutting down. We also unfortunately implement our DataLaoder cleaning-up logic in `__del__`, a function that may or may not be called during shutdown, and if called, may or may not be called before core library resources are freed.
Fortunately, we are already setting all our workers and pin_memory_thread as daemonic. So in case of Python shutting down, we can just do a no-op in `__del__` and rely on the automatic termination of daemonic children.
An `atexit` hook is used to detect Python exit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12700
Differential Revision: D10419027
Pulled By: SsnL
fbshipit-source-id: 5753e70d03e69eb1c9ec4ae2154252d51e2f79b0
Summary:
- Fix broken sparse_coo_examples, update output
- Tensor(...) to tensor(...)
- Fix arguments to math.log to be floats
While the last might be debateable, mypy currently complains when passing an int to math.log. As it is not essential for our examples, let's be clean w.r.t. other people's expectations.
These popped up while checking examples in the context of #12500 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12707
Differential Revision: D10415256
Pulled By: SsnL
fbshipit-source-id: c907b576b02cb0f89d8f261173dbf4b3175b4b8d
Summary:
Where is declared as:
```
where(Tensor condition, Tensor self, Tensor other)
```
Previously the compiler assumed that self must be the first argument.
But this is not true in practice for `where` and for a few other exceptions.
This changes the compiler to take an explicit self argument which gets matched
to the `self` that appears in the schema.
Note that this requires renaming a variant of pow, which referred to
an exponent Tensor as `self` because otherwise that would cause `t^3`
to match against `t` being the exponent.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12385
Differential Revision: D10364658
Pulled By: zdevito
fbshipit-source-id: 39e030c6912dd19b4b0b9e35fcbabc167b4cc255
Summary: Add a mapping for conversion -- this will help with debugging as well but is directly used by the TUI stacked on top of this
Reviewed By: duc0
Differential Revision: D10396130
fbshipit-source-id: cdd39278f0ed563bb828b1aebbbd228f486d89c8
Summary:
This PR removes some duplication in `recurrent_op_cudnn.cc`. Instead of 4 of the same exact descriptor, should work fine with just 1. I don't see any other code that relies on those being 4 separate locations, but if that is what you need you can always allocate additional descriptors as necessary.
Have not fully tested this thing out, just something I noticed when I was reading through the descriptor code.
Cheers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8321
Differential Revision: D10363744
Pulled By: ezyang
fbshipit-source-id: 733c8242fb86866f1d64cfd79c54ee7bedb03b84
Summary:
Module.to uses the Tensor.to parsing facility.
It should not, however, accept "copy" as a keyword/fourth positional
argument.
See #12571 for discussion.
Thank you SsnL for noticing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12617
Differential Revision: D10392053
Pulled By: ezyang
fbshipit-source-id: b67a5def7993189b4b47193abc7b741b7d07512c
Summary:
This is for Caffe2 optimization.
WIth this optimization, the following two ops can boost a lot. (Test with MaskRCNN, on SKX8180 one socket)
BatchPermutation op: reduced from 8.296387 ms to 1.4501984 ms.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12153
Differential Revision: D10362823
Pulled By: ezyang
fbshipit-source-id: 04d1486f6c7db49270992cd8cde41092154e62ee
Summary:
Before and after coming after I run the tests on CI
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12610
Differential Revision: D10419483
Pulled By: ezyang
fbshipit-source-id: 5543e971f8362e4cea64f332ba44a26c2145caea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12696
In majority of the case, we use `InheritOnnxSchema(type_)`. This diff makes declaration of such case easier.
Reviewed By: bddppq
Differential Revision: D10395109
fbshipit-source-id: 914c1041387d5be386048d923eb832244fc506c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12691
We check input(0) but not input(1) in BatchMatMul. This may result in a protobuf exception which won't be caught by upstream and causing termination of the program. Check that with `CAFFE_ENFORCE` will be caught by upstream inference function. Plus, it will print out clean stack tracing showing where went wrong.
Reviewed By: bddppq, houseroad, BIT-silence
Differential Revision: D10391130
fbshipit-source-id: daf8dcd8fcf9629a0626edad660dff54dd9aeae3
Summary:
The mapping protocol stipulates that when `__delitem__` is called, this is passed to `__setitem__` [(well, the same function in the C extension interface)](https://docs.python.org/3/c-api/typeobj.html#c.PyMappingMethods.mp_ass_subscript) with NULL data.
PyTorch master crashes in this situation, with this patch, it does not anymore.
Test code (careful, sefaults your interpreter):
```python
import torch
a = torch.randn(5)
del a[2]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12726
Differential Revision: D10414244
Pulled By: colesbury
fbshipit-source-id: c49716e1a0a3d9a117ce88fc394858f1df36ed79
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12306
In a future diff, I'm going to introduce non-placement constructor and destructor to TypeMeta.
To make it less ambigous, this diff is first renaming the existing ones to PlacementXXX.
Reviewed By: dzhulgakov
Differential Revision: D10184117
fbshipit-source-id: 119120ebc718048bdc1d66e0cc4d6a7840e666a4
Summary:
This PR contains changes for:
1. Removing MIOpen softmax operator. Will be added later with the required functionality
2. Enabling softmax_ops_test on ROCm target
Differential Revision: D10416079
Pulled By: bddppq
fbshipit-source-id: 288099903aa9e0c3378e068fffe6e7d6a9a84841
Summary:
There were two problems with SN + DP:
1. In SN, the updated _u vector is saved back to module via a `setattr`. However, in DP, everything is run on a replica, so those updates are lost.
2. In DP, the buffers are broadcast via a `broadcast_coalesced`, so on replicas they are all views. Therefore, the `detach_` call won't work.
Fixes are:
1. Update _u vector in-place so, by the shared storage between 1st replica and the parallelized module, the update is retained
2. Do not call `detach_`.
3. Added comments in SN about the subtlety.
4. Added a note to the DP doc on this particular behavior of DP.
cc crcrpar taesung89 The controller you requested could not be found. yaoshengfu
Fixes https://github.com/pytorch/pytorch/issues/11476
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12671
Differential Revision: D10410232
Pulled By: SsnL
fbshipit-source-id: c447951844a30366d8c196bf9436340e88f3b6d9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12593
size() returns numel_, but what we really want is nbytes(), which is the capacity.
Reviewed By: salexspb
Differential Revision: D10354488
fbshipit-source-id: f7b37ad79ae78290ce96f37c65caa37d91686f95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12685
In this diff, we push the fake run of the net into the ONNXIFI transformer, because
1. We cannot do shape inference for every op
2. Since the net has been SSA rewritten, we cannot use shape info from outer workspace directly.
In addition, this diff adds input shape info when querying the `onnxBackendCompatibility` function.
Reviewed By: bddppq
Differential Revision: D10390164
fbshipit-source-id: 80475444da2170c814678ed0ed3298e28a1fba92
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12381
The workflow passes after D10150834, so we can restore strides.
Reviewed By: ezyang
Differential Revision: D10220313
fbshipit-source-id: aaf9edebf4ff739cbe45b2d32e77918fce47ba34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12697
Latest LLVM started reporting double free related to this code. The stack trace: P60181558
Fix it by using the leaky Meyers' singleton
Reviewed By: meyering
Differential Revision: D10352976
fbshipit-source-id: 11afc2999235831da10c73609d1153d04742ba18
Summary:
They aren't needed anymore now that at::empty can handle all backends.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12687
Differential Revision: D10390740
Pulled By: gchanan
fbshipit-source-id: 521d6f92448798aa368186685662451e191c0b05
Summary:
All factory functions are now implemeneted in terms of TensorOptions, which is passed through Type, if necessary.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12684
Differential Revision: D10390224
Pulled By: gchanan
fbshipit-source-id: fb536271735e6e0e542f021e407529998b0482eb
Summary:
This PR makes the clang-tidy CI get its diff by comparing the current commit against the base branch that the PR is targeting.
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12674
Differential Revision: D10397692
Pulled By: goldsborough
fbshipit-source-id: 7fd9e22c92dd885112cd5c003c732d1c12667157
Summary:
Simple additions that make it vastly easier to use nomnigraph in
python
Reviewed By: duc0
Differential Revision: D10383027
fbshipit-source-id: 441a883b84d4c53cca4f9c6fcc70e58692b8f782
Summary:
Move a lot of methods that don't have an obvious reason for being inline out-of-line. This cleans up the header and should help reduce the problem of touching IR.h and having to rebuild the world.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12551
Differential Revision: D10384808
Pulled By: resistor
fbshipit-source-id: 314af89e3282f35fdc94fa3fd3000e3040c8cb6b
Summary:
Using Transpose + Reshape, not using DepthToSpace, since they are not available in C2 yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12192
Reviewed By: BIT-silence
Differential Revision: D10129913
Pulled By: houseroad
fbshipit-source-id: b60ee6d53b8ee95fd22f12e628709b951a83fab6
Summary:
Fixes: #12669
Thank you Changmao Cheng for reporting this on the forum with a small example!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12677
Differential Revision: D10391989
Pulled By: ezyang
fbshipit-source-id: 5aa7a705bdb8ce6511a8eb1b3a207f22741046bf
Summary:
This seems to be a typo that never got caught - no actual functionality changes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12688
Differential Revision: D10391704
Pulled By: Yangqing
fbshipit-source-id: ce633776957628c4881956c5423bfab78294d512
Summary:
Add AdaptiveAvgPool2d and AdaptiveMaxPool2d to ONNX.symbolic
Due to limitations in ONNX only output_size=1 is supported.
AdaptiveAvgPool2d -> GlobalAveragePool
AdaptiveMaxPool2d -> GlobalMaxPool
Fixes#5310
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9711
Differential Revision: D10363462
Pulled By: ezyang
fbshipit-source-id: ccc9f8ef036e1e54579753e50813b09a6f1890da
Summary:
Discussed in #11379, #12545. Eigen submodule needs to be updated to f59336cee3 to support building with CUDA arch >= 5.3.
It seems there was a similar fix checked in from #6746, but later the Eigen submodule is switched to the current mirror #7793 at a point the fix was not included.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12191
Differential Revision: D10362557
Pulled By: ezyang
fbshipit-source-id: 548541e2c93f412bf6680ee80b8da572846f80d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12575
Just my guess as to why those tests are failing. Waiting on sandcastle to see if the tests resolve themselves.
Reviewed By: mlappelbaum, wesolwsk
Differential Revision: D10305051
fbshipit-source-id: 455597b12bbe27dd6c16f7d0274f2c939949d878
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12661
Was disabled since workspace.has_mkldnn is now set to false
Reviewed By: yinghai
Differential Revision: D10383913
fbshipit-source-id: ad6dc705f0606b3711e8b450dc384ad3ebb87686
Summary:
This PR does three things:
1. Add support for serializing to `ostream` and deserializing from `istream`s in addition to files. This is after https://github.com/pytorch/pytorch/pull/11932 added support for streams in `torch::jit::ExportModule` and `torch::jit::load`.
2. Update the internal interface for how things get serialized into archives (e.g. use the more idiomatic `operator<<` instead of a `save` method). *The external interface does not change*.
3. Add documentation.
ezyang ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12421
Reviewed By: ezyang
Differential Revision: D10248529
Pulled By: goldsborough
fbshipit-source-id: 6cde6abd0174e3fbf3579c05376a32db0b53755f
Summary:
Gloo was updated with `type` usage for cudaPointerAttributes which resolves the `__CUDA_DEPRECATED` warnings in our CUDA 10 CI. This PR brings in that change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12574
Differential Revision: D10342450
Pulled By: ezyang
fbshipit-source-id: d50564bfcd8623a20b82b0052fba441c8358c17b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12654
The previous diff managed to get the macros working, but they've been quite unmaintainable.
This diff improves the situation a bit.
- Before, there were three global variables for each registered type: type id, type name and a global type meta instance. Now, it's only type id and type meta, type name is gone. I also wanted to get rid of type id, but that doesn't work due to issues with static initialization ordering (type ids for types are requested during static initialization time, meh)
- Instead of repeating the whole CAFFE_KNOWN_TYPE macro for GCC and non-GCC because they need different export flags, define it only once and use a EXPORT_IF_NOT_GCC macro.
- The CAFFE_KNOWN_TYPE macro has to delegate to a _CAFFE_KNOWN_TYPE_DEFINE_TYPEMETADATA_INSTANCE macro, because of the counter. The pattern was copied for the macros for preallocated types. However, there we don't use a counter but use the preallocated id, so there's no need to delegate to a separate macro.
Reviewed By: ezyang
Differential Revision: D10379903
fbshipit-source-id: 50a32a5cb55ab85db49618a5f1ee4e8b06e0dfb2
Summary:
… Type.
This allows one to write a cpu/cuda split 'factory' function that uses TensorOptions.
Also move all remaining native_functions with either function or method variants that use Type to use TensorOptions.
Thus, there are no more Types in the public function / method API.
I believe there is a _lot_ of opportunity for cleanup here, as the old tensor, th_tensor, native_tensor and sparse variants can probably be removed, but let's do that in a follow-on patch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12071
Reviewed By: ezyang
Differential Revision: D10041600
Pulled By: gchanan
fbshipit-source-id: 30ebc17146d344bc3e32ccec7b98b391aac5470b
Summary:
... they are basically the same class and I didn't see it in the initial PR. I also got resolvers back onto std::functions by keeping the function_table logic local to defineMethodInModules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12589
Differential Revision: D10383103
Pulled By: zdevito
fbshipit-source-id: 1b0a85eb4f112bc28256cac44446d671d803d3a2
Summary:
This commit adds the hooks in schema parser for futures, options,
mutable alias sets, marking writes, and named output arguments that
need to exist for other upcoming work.
This also fixes that problem where you could not declare Lists of Lists.
Implementation of most of these features is left NYI. This commit should
avoid merge conflicts for these individual features on the schema parser.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12585
Differential Revision: D10382229
Pulled By: zdevito
fbshipit-source-id: 41d794e58ca462cf3a389861c533c68944dc560b
Summary:
after an analogous breakup of VariableType.cpp, the generated
register_aten_ops.cpp is now the slowest-to-compile file in a typical
incremental rebuild by a wide margin. Therefore, give it the same
treatment - the generated code is split across several files to allow
parallel compilation.
Note that the existing code takes some care to arrange that overloads
of the same op name are given in a particular order. This diff
preserves that behavior, by treating all overloads of the same name as
a single indivisible unit, and sharding based on these groups rather
than on individual constructors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12615
Reviewed By: ezyang
Differential Revision: D10367363
Pulled By: anderspapitto
fbshipit-source-id: 07db5f9cb79748040909716349626412a13bc86e
Summary:
Currently when developing on the shared Windows debug machine, it's very easy to accidentally wipe out someone else's working binary because the conda environment is shared. This PR fixes that by always installing conda in the user's directory instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12663
Differential Revision: D10386130
Pulled By: yf225
fbshipit-source-id: 1242ef8b2b4239c4a96459a59eb0255b44ed9628
Summary:
There are still a few work to be done:
- Move logging and unify AT_WARN with LOG(ERROR).
- A few header files are still being plumbed through, need cleaning.
- caffe2::EnforceNotMet aliasing is not done yet.
- need to unify the macros. See c10/util/Exception.h
This is mainly a codemod and not causing functional changes. If you find your job failing and trace back to this diff, usually it can be fixed by the following approaches:
(1) add //caffe2/c10:c10 to your dependency (or transitive dependency).
(2) change objects such as at::Error, at::Optional to the c10 namespace.
(3) change functions to the c10 namespace. Especially, caffe2::MakeString is not overridden by the unified c10::str function. Nothing else changes.
Please kindly consider not reverting this diff - it involves multiple rounds of rebasing and the fix is usually simple. Contact jiayq@ or AI Platform Dev for details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12354
Reviewed By: orionr
Differential Revision: D10238910
Pulled By: Yangqing
fbshipit-source-id: 7794d5bf2797ab0ca6ebaccaa2f7ebbd50ff8f32
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12623
Mark Storage functions as const so that they they can be exposed outside of TensorImpl when calling storage()
Based on this discussion https://github.com/zdevito/ATen/issues/27#issuecomment-330717839
Also potentially useful in the effort to remove ShareExternalPointer
Reviewed By: ezyang
Differential Revision: D10370201
fbshipit-source-id: 43cf3803a4aa7b94fdf0c3a604d7db769ca0bdd5
Summary:
The pytorch.org site redirects all of the http:// requests to the https:// site anyway, so the comments and error messages might as well refer directly to the https:// site. The GitHub project description should also be updated to point to https://pytorch.org
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12636
Differential Revision: D10377099
Pulled By: soumith
fbshipit-source-id: f47eaba1dd3eecc5dbe62afaf7022573dc3fd039
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12289
When we have a all sync net, the chaining algorithm will generate one single group. And we want to just run that in the serving thread instead of scheduling it onto the worker queue. This will closely mimic the behavior of simple net and gives us the expected performance.
Reviewed By: ilia-cher
Differential Revision: D10174323
fbshipit-source-id: 1dae11a478936634f8ef1e4aa43d7884d6362e52
Summary:
We should not clean up Miniconda environment when the user is running `win-test.sh` locally.
This would help reproduce #11527 locally.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12073
Differential Revision: D10053497
Pulled By: yf225
fbshipit-source-id: 11027500e7917a7cb79270c811379e11dbbb6476
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12630
Instead of providing mutable accessors, our "mutators" now
return new copies of TensorOptions. Since TensorOptions is
simply two 64-bit integers, this is not a big efficiency
problem.
There may be some sites that assumed that TensorOptions was
mutable. They need to be fixed.
Reviewed By: SsnL
Differential Revision: D10249293
fbshipit-source-id: b3d17acc37e78c0b90ea2c29515de5dd01209bd3
Summary:
Add dtype argument to softmax/log_softmax functions.
Computing softmax in fp32 precision is necessary for mixed precision training, and converting output of the previous layer into fp32 and then reading it as fp32 in softmax is expensive, memory and perf-wise, this PR allows one to avoid it.
For most input data/dtype combinations, input data is converted to dtype and then softmax is computed. If input data is half type and dtype is fp32, kernels with the corresponding template arguments are called.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11719
Reviewed By: ezyang
Differential Revision: D10175514
Pulled By: zou3519
fbshipit-source-id: 06d285af91a0b659932236d41ad63b787eeed243
Summary:
test_proper_exit in the dataloader test bucket includes
(as its docstring) a reassuring message about complaints that
may appear during the test. The message is displayed
when the tests are run in verbose mode.
But the docstring includes a line break, and the unittest
framework only prints the first line of the docstring (see
shortDesription()). As a result, the 2nd (more reassuring)
half of the message is not displayed.
Catenate the docstring onto a single line so all is visible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12612
Differential Revision: D10368786
Pulled By: ezyang
fbshipit-source-id: 14b259a6d6a3491d4290148eae56e6ab06f2a9b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12382
implement fp16-> (uint8 + scale and bias in fp32)
this is similar to fp32 rowwise quantization
we could have done scale and bias in fp16 but not too motivated since we are not saving much and those datatypes have to be converted to fp32 to process since x86 doesn't support half float operations anyways
Reviewed By: csummersea
Differential Revision: D10220463
fbshipit-source-id: 6c382026de881f03798c2e5fc43abfc80f84ea1f
Summary:
_Implements pytorch/pytorch#11914, cc: ezyang_
Implements `__cuda_array_interface__` for non-sparse cuda tensors,
providing compatibility with numba (and other cuda projects...).
Adds `numba` installation to the `xenial-cuda9` jenkins test environments via direct installation in `.jenkins/pytorch/test.sh` and numba-oriented test suite in `test/test_numba_integration.py`.
See interface reference at:
https://numba.pydata.org/numba-doc/latest/cuda/cuda_array_interface.html
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11984
Differential Revision: D10361430
Pulled By: ezyang
fbshipit-source-id: 6e7742a7ae4e8d5f534afd794ab6f54f67808b63
Summary:
This PR gets rid of unnecessary copy of weight gradients in cudnn rnn. Also removes unnecessary check for input size when deciding whether to use persistent rnn, and adds doc string explaining when persistent rnn can be used. cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12600
Differential Revision: D10359981
Pulled By: soumith
fbshipit-source-id: 0fce11b527d543fabf21e6e9213fb2879853d7fb
Summary:
On my devgpu, this brings the time taken for `touch torch/csrc/jit/type.h && time python setup.py rebuild develop` (debug mode, multicore build) down from 75 seconds to 62 seconds. For the `ninja install` of libtorch portion, which this affects, the reduction is from 52 seconds to 35.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12493
Reviewed By: zdevito
Differential Revision: D10315988
Pulled By: anderspapitto
fbshipit-source-id: 316dc4ab81134aaa17a568cfc07408b7ced08c2e
Summary:
there is already a BUILD_TEST flag in the root-level cmake file. Removing this makes sure it doesn't interfere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12583
Differential Revision: D10348620
Pulled By: anderspapitto
fbshipit-source-id: 3957783b947183e76a4479a740508c0dc1c56930
Summary:
This resolves an issue where the `model.Copy` operation would
copy to the wrong GPU, such that the below `net.Sum` operation
would use an input argument for which p2p access was not enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12342
Differential Revision: D10343181
Pulled By: ezyang
fbshipit-source-id: fd2d6d0ec6c09cda2db0a9a4f8086b3560e5a3ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12605
Some compilers define 'long' as a separate type from 'int32_t' or 'int64_t', some don't.
Before, we had a cmake check setting a macro and depending on the macro, we either defined a separate type id for long or didn't.
Then, we removed the cmake check and used compiler detection macros directly. This is, however, error prone.
This new approach uses SFINAE to register a type id for 'long' only if it's a separate type.
Reviewed By: Prowindy
Differential Revision: D10359443
fbshipit-source-id: aa371cbb43658c8cd3664ba3d9b0dedbaa225c1d
Summary:
Properly set cmake python_library and include_dirs hints, so that systems with multiple version of python can still find the correct libraries and header files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12569
Differential Revision: D10359910
Pulled By: soumith
fbshipit-source-id: 2238dcbed7aac8a818c9435e6bba46cda5f81cad
Summary:
- This was one of the few functions left out from the list of functions in
NumPy's `linalg` module
- `multi_mm` is particularly useful for DL research, for quick analysis of
deep linear networks
- Added tests and doc string
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12380
Differential Revision: D10357136
Pulled By: SsnL
fbshipit-source-id: 52b44fa18d6409bdeb76cbbb164fe4e88224458e
Summary:
Implement contiguous as `aten::contiguous` so it can be recorded during tracing. This was causing issues with both the trace checker as well as when a `contiguous()`-ed tensor was used downstream in a view that expected certain strides
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12541
Differential Revision: D10304028
Pulled By: jamesr66a
fbshipit-source-id: dc4c878771d052f5a0e9674f610fdec3c6782c41
Summary:
We will still have an informal notion of codeowner, but it
is not necessary to get a review from these people in particular
for these directories.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12584
Differential Revision: D10348999
Pulled By: ezyang
fbshipit-source-id: 97331ec4bab9f1aa02af82b71ad525a44ad1e7fe
Summary:
SsnL As per your review in https://github.com/pytorch/pytorch/pull/12017/, I added a max plan number for CUDA 10 path. Our internal cuFFT team couldn't suggest a number since the limit depends on host/device memory. That is, a plan allocates some buffers on the device and also creates objects for the plans on the host side. I raised this number to 4x arbitrarily per you suggestion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12553
Differential Revision: D10320832
Pulled By: SsnL
fbshipit-source-id: 3148d45cd280dffb2039756e2f6a74fbc7aa086d
Summary:
* switches docker files over to white rabbit release - removed custom package installs
* skips five tests that regressed in that release
* fixes some case-sensitivity issues in ROCm supplied cmake files by sed'ing them in the docker
* includes first changes to the infrastructure to support upcoming hip-clang compiler
* prints ROCm library versions as part of the build (as discussed w/ ezyang )
* explicitly searches for miopengemm
* installs the new hip-thrust package to be able to remove the explicit Thrust checkout in a future revision
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12577
Differential Revision: D10350165
Pulled By: bddppq
fbshipit-source-id: 60f9c9caf04a48cfa90f4c37e242d944a175ab31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12178
Fisher GAN calls processor_util.add_mlp, which inject the layer norm through the
normalizer. We allow to use alternative impl for LayerNorn in the normalizer.
Reviewed By: Wakeupbuddy
Differential Revision: D9235528
fbshipit-source-id: 88c126c658102926613242ef84a481f6de1676ed
Summary:
If any inputs require_grad then the graph executor does differential subgraph slicing. The existing algorithm combines adjacent differentiable Node*.
There are two major motivations. The first is improving fusion opportunities: the graph fusion pass runs after differential subgraph slicing. This means that only nodes that are a part of the same differential subgraph may be considered for fusion. If something like the following happens,
```
y = f(x)
k = not_differentiable_op(m)
z = g(y)
```
and f and g are both fusible and differentiable operations, then they will be inserted into different differential subgraphs and not fused together.
The second is to enable JIT optimizations on backward passes for things like an (automatically) unrolled LSTM. Right now, in an unrolled LSTM, we see something like the following:
```
lstm_cell()
non_differentiable_list_op()
lstm_cell()
non_differentiable_list_op()
lstm_cell()
non_differentiable_list_op()
```
Each lstm_cell itself is differentiable and gets put into a separate differential subgraph. During the backwards pass, each prim::DifferentiableSubgraph has its own graph executor: these graph executors cannot talk to each other. It is better if we combined all of the lstm_cells (where applicable) into one differential subgraph so their backward passes are combined into one graph executor that can perform better optimizations than several separate graph executors.
Think about the computation graph as a DAG where edges are data dependencies and vertices are operations (the nodes). Each vertex is either black or red; a vertex is colored black if it is differentiable and red otherwise. The goal is to contract edges (merge nodes) to have the fewest black vertices remaining such that the graph is still a DAG.
The algorithm is the following:
- Take the Graph& and create a shadow "DynamicDAG" object to wrap Node* and edges. Each Vertex holds multiple Node* (but starts out holding one Node*) and each edge is a data dependency.
- Greedily contract vertices in the DynamicDAG if they are "differentiable". This operation is unrelated to the Graph&.
- A Vertex is "differentiable" if all the nodes it holds is differentiable.
- When contracting vertices, combine their Node* contents.
- The DynamicDAG keeps its vertices in topological order and complains if the contraction is invalid so everything is good.
- Take the DynamicDAG: reorder the nodes in the Graph& to match the topological order in the DynamicDAG.
- Finally, go through each Vertex in the DynamicDAG: if it contains multiple Node* then merge all of them into a prim::DifferentiableGraph.
The DynamicDAG is based off of the dynamic top sort algorithm in [this paper](https://www.doc.ic.ac.uk/~phjk/Publications/DynamicTopoSortAlg-JEA-07.pdf) by Pearce and Kelly.
Each contractEdge(producer, consumer) call is `O(|AR| log |AR| * min(|out_edges(producer)|, |in_edges(consumer)|)` where `AR` is the "affected region" (defined as the set of nodes that, in topological order, are between producer and consumer). By only considering contractions such that `|ord(producer) - ord(consumer)| < threshold1` and `|out_edges(producer)| < threshold2` we can make each contractEdge(producer, consumer) call take constant time. The resulting algorithm is linear in the number of nodes.
Added a lot of small test cases.
Looking for suggestions on the following:
- what big computation graphs should I run this on to test how fast or slow it is?
- what things other than correctness should I be thinking about when I test this?
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12175
Differential Revision: D10302564
Pulled By: zou3519
fbshipit-source-id: 8a94d130d82f8a1713cc28483afef9a72d83d61a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12544
`running_mutex_` inside async_scheduling net is used to guard access to the `running_` variable. So we don't need to acquire that lock when we are actually running the net. This will help us prevent potential double locking situation when we decide to run the root nodes inline.
Reviewed By: ilia-cher
Differential Revision: D10304745
fbshipit-source-id: 5f701b2c22b06ff5bee7f2c37ac634326748f579
Summary:
There's some action at a distance issues and not having this is disabling quantization in C2 for prod use cases
ref T34831022
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12538
Differential Revision: D10302931
Pulled By: jamesr66a
fbshipit-source-id: 700dc8c5c4297e942171992266ffb67b815be754
Summary:
1. Fix BN translator
IntelCaffe and NVCaffe fuse BN+Scale, and the "BatchNorm" op contains 5 params including (scale and bias)
2. Fix Scale translator
the translated outputs of scale have the same names with those of Conv.
All their names are output + '_w' and output + '_b'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10056
Differential Revision: D10099205
Pulled By: yinghai
fbshipit-source-id: 73a73868e3e16c495e8b233fdb1d373d556a9537
Summary:
Fixed printing issue for TensorTypeID. It used to print a hex of the ID, e.g.
/x1
Now it prints the ID as a string, e.g.
1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12402
Reviewed By: ezyang
Differential Revision: D10224026
Pulled By: lauragustafson
fbshipit-source-id: a9ca841d08c546fccbb948a17f06a29fea66f3fb
Summary:
Hi, I found that there was two statement of `col2im` in `im2col.h` and think the former one
may be redundant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12514
Differential Revision: D10328721
Pulled By: ezyang
fbshipit-source-id: d225547848803511c7cc58bd9df1cc6832a537fb
Summary:
Fixes#12260#2896
```
torch.multinomial(torch.FloatTensor([0, 1, 0, 0]), 3, replacement=False)
```
The old behavior is that we return `0` after we run out of postive categories. Now we raise an error based on discussion in the issue thread.
- Add testcase for cpu & cuda case, in cuda case `n_samples=1` is a simple special case, so we test against `n_sample=2` instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12490
Differential Revision: D10278794
Pulled By: ailzhang
fbshipit-source-id: d04de7a60f60d0c0d648b975db3f3961fcf42db1
Summary:
We will rotate the credentials if the new setting works.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12552
Differential Revision: D10322121
Pulled By: yf225
fbshipit-source-id: 158f2f89b83a751566a912869a4400d5be6e5765
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12390
Introduce a no op optimizer for when we don't want updates to happen, but don't want to affect downstream processes.
Reviewed By: mlappelbaum
Differential Revision: D10209812
fbshipit-source-id: 2af4ebc0fb42e78ea851c3a9f4860f3d224037b6
Summary:
Pull a patch that fixes remaining incompatibility with Microsoft compiler on Windows
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12554
Differential Revision: D10319736
Pulled By: Maratyszcza
fbshipit-source-id: bcd88581df48f2678ef81e095f947391104f24d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12304
- make ExtractDeviceOption to be a free function.
- Add a Strorage(at::Device) constructor in order to preserve the device_id.
Reviewed By: dzhulgakov
Differential Revision: D10069839
fbshipit-source-id: a5f3994a39bdf1b7503b39bb42c228e438b52bfa
Summary:
Following up #11488 conversation with orionr
And our brief conversation at PTDC about ATen with soumith and apaszke
This PR enables a very slim build focused on ATen particularly without caffe2 and protobuf among other dependencies.
WIth this PR NimTorch tests pass fully, including AD, convolutions, wasm, etc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12443
Reviewed By: mingzhe09088
Differential Revision: D10249313
Pulled By: orionr
fbshipit-source-id: 4f50503f08b79f59e7717fca2b4a1f420d908707
Summary:
Try to fix the "submodule not found" infra error: https://circleci.com/gh/pytorch/pytorch/48431 by switching to use the official git client (instead of CircleCI's default git client).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12542
Differential Revision: D10305027
Pulled By: yf225
fbshipit-source-id: 42db0694efb468d9460ef51d7b4b2bd90d78ff24
Summary:
Pull a patch that makes FP16 compatible with Microsoft compiler on Windows
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12539
Reviewed By: hyuen
Differential Revision: D10303487
Pulled By: Maratyszcza
fbshipit-source-id: 4e20ece6338e4d0663cd3591914ce333f0972693
Summary:
This PR:
1. Makes clang-tidy diff against `master` instead of `HEAD~1` in CI, which makes much more sense
2. Enables all checks in the `bugprone-*` category (see https://clang.llvm.org/extra/clang-tidy/checks/list.html) except one about parantheses in macros, because it doesn't always apply too well for us.
Fixed some nice code smells.
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12378
Differential Revision: D10247972
Pulled By: goldsborough
fbshipit-source-id: 97dc9e262effa6874d2854584bf41a86684eb8bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12424
Some compilers define 'long' as a separate type from 'int32_t' or 'int64_t', some don't.
Before, we had a cmake check setting a macro and depending on the macro, we either defined a separate type id for long or didn't.
Then, we removed the cmake check and used compiler detection macros directly. This is, however, error prone.
This new approach uses SFINAE to register a type id for 'long' only if it's a separate type.
Reviewed By: Yangqing, dzhulgakov
Differential Revision: D10209620
fbshipit-source-id: 68f09339e279a9a56b95caeef582c557371b518d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10970
Fixing a possible case when next iteration of a net may be started prematurely.
We have to ensure that resetting running_ flag is done *after* finalizeEvents
(e.g. waiting for the rest of net's event to be finished).
Reviewed By: heslami
Differential Revision: D9545442
fbshipit-source-id: bc324a180b1e93054b051981817be7985f52b4cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12466
Moves type.{h,cpp} and functional.h to ATen/core
move is necessary for IR merging -- slimmed down from this diff: D9819906
Reviewed By: ezyang
Differential Revision: D10242680
fbshipit-source-id: b71eeec98dfe9496e751a91838d538970ff05b25
Summary:
* Enable more tests that relied on CPU LAPACK at compile time.
* enabled min/max tests in test_cuda (ROCm 236)
bddppq ezyang
Tests ran as part of the ROCm CI here: https://github.com/ROCmSoftwarePlatform/pytorch/pull/255
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12486
Differential Revision: D10262534
Pulled By: ezyang
fbshipit-source-id: 167a06fc8232af006f4b33dcc625815fd4b06d6b
Summary:
The C++ docs for `at::Tensor` are currently broken because we moved the place `Tensor.h` gets generated to without updating our docs. I use `GEN_TO_SOURCE=1` when generating ATen files, so the `Tensor.h` file should end up in `aten/src/ATen/core/Tensor.h` if i understand correctly.
dzhulgakov ezyang gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12469
Differential Revision: D10248521
Pulled By: goldsborough
fbshipit-source-id: 8d8a11f0f6e2703b8d767dbc523fc34a4374f345
Summary:
`COMMIT_SOURCE` is missing in the current CircleCI config, which is used in perf tests to decide whether to store the new numbers as baseline.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12491
Differential Revision: D10274426
Pulled By: yf225
fbshipit-source-id: 047ef6cc61a12738062f9940d1bfd4c3bf152909
Summary:
* Topk part 1: fix intrinsincs for 64 wave front (#224)
64 in a wave front - intrinsics change.
* Disable in-place sorting on ROCm. (#237)
It is known to hang - use the Thrust fallback
Skip one test - fails with the fallback.
* Topk fixes (#239)
* Spec (https://docs.nvidia.com/cuda/pdf/ptx_isa_6.3.pdf) Sec 9.7.1.19 (bfe) and 9.7.1.20 (bfi) requires pos and len to be limited to 0...255
* Spec (https://docs.nvidia.com/cuda/pdf/ptx_isa_6.3.pdf) Sec 9.7.1.19 requires extracted bits to be in LSBs
* Correct logic for getLaneMaskLe. Previous logic would return 0x0 instead of 0xffffffffffffffff for lane 63
* Round up blockDim.x to prevent negative index for smem
bddppq ezyang
Note the one additional skipped test resulting from using the thrust sort fallback for all sizes. We are working on getting bitonic to work properly (and always). Until then, this needs to be skipped on ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12337
Differential Revision: D10259481
Pulled By: ezyang
fbshipit-source-id: 5c8dc6596d7a3103ba7b4b550cba895f38c8148e
Summary:
Modifies the DistributedSampler logic. Now each process samples elements with
a given interval, instead of a consecutive section.
This eliminates the possibility where the DataLoader uses padded data while
dropping the real data. It happens when:
1. DistributedSampler padded data; and
2. DataLoader drops_last is effectively true, and drops less then the number
of padded data.
from the example down, we see that data (10, 11, 12) are padded through
duplicating data sample (1, 2, 3)
The old sampler drops legit original data (3, 6, 9) and introduces duplication
(10, 11) into the training set; while the new sampler logic samples correct data
points from the data set.
This example has been added to dataloader unit test
example:
```
data after shuffle: 1, 2, 3, 4, 5, 6, 7, 8, 9
padded data : 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12
old sampler: -> DataLoader with (batch_size=2 and drop_last=True)
p 1: 1, 2, 3 1, 2
p 2: 4, 5, 6 4, 5
p 3: 7, 8, 9 7, 8
p 4:10,11,12 10,11
new sampler: ->
p 1: 1, 5, 9 1, 5
p 2: 2, 6,10 2, 6
p 3: 3, 7,11 3, 7
p 4: 4, 8,12 4, 8
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12474
Differential Revision: D10260410
Pulled By: SsnL
fbshipit-source-id: 710856571260f42ce25955b81a5b8008e04938cf
Summary:
Performance oriented code will use AVX/AVX2, so we don't need SSE specific code anymore. This will also reduce the probability of running into an error on legacy CPUs.
On top of this convolve is covered by modern libraries such as MKLDNN, which are much more performant and which we now build against by default (even for builds from source).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12109
Differential Revision: D10055134
Pulled By: colesbury
fbshipit-source-id: 789b8a34d5936d9c144bcde410c30f7eb1c776fa
Summary:
The value_info proto field was being processed in BuildGraph, but control flow blocks used buildBlocks instead. This PR moves moves that step to BuildBlock.
I removed DecoderBase because it was making the code confusing and we never needed it in the first place.
closes#12319
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12351
Differential Revision: D10212411
Pulled By: li-roy
fbshipit-source-id: 47f289a462a1ab7391ff57368185401673980233
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12237
This diff creates named functions and cleans up a lot of the basic block usage throughout the code
Reviewed By: duc0
Differential Revision: D10134363
fbshipit-source-id: d0c4ae0bbb726236a15251dbfd529d4fddcd9e9f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12235
SSA is actually implicitly maintained so not only was this function not implemented, it never should be implemented.
Reviewed By: duc0
Differential Revision: D10133928
fbshipit-source-id: e8e5e2386f8b57812b0be2c380af85ed07cd3152
Summary:
Changes in this PR:
1. Intermediate Docker image is shared from build stage to test stage through ECR, in order to fix the Caffe2 flaky CUDA tests.
2. There are ~7 Caffe2 operator tests that are only flaky in `caffe2_py2_gcc4_8_ubuntu14_04_test` on CPU. Disabling those tests on that config only, which is okay to do because we are still running those tests in other test jobs.
After this PR is merged, CircleCI will be running on master automatically, and will be running on PRs if the author rebased their PR onto the newest master (which we will ask all the authors to do when we switch off Jenkins for Linux).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12389
Differential Revision: D10224267
Pulled By: yf225
fbshipit-source-id: dd1a90a425c3d13b870d3d328cb301eee2e6e2cd
Summary:
Previously we tested if default-construction was noexcept, which
doesn't really mean that the move constructor is noexcept too.
Shuts up clang-tidy.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
CC goldsborough
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12369
Differential Revision: D10217348
Pulled By: ezyang
fbshipit-source-id: b46437d8ac7a8d756cf03ed0c6bf4400db7ecde7
Summary:
- Removed the old nccl file
- Make open-source NCCL a submodule
- CMake to make NCCL itself
NCCL2 now is in the default build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12359
Reviewed By: orionr, yns88
Differential Revision: D10219665
Pulled By: teng-li
fbshipit-source-id: 134ff47057512ba617b48bf390c1c816fff3f881
Summary:
ATenOp was handling `torch.where` incorrectly. Whereas the `torch.where` overload (and `aten::` function) had arguments in the order `Tensor condition, Tensor self, Tensor other`, ATenOp was emitting code that assumed that `self` was the 0th argument, and thus was trying to interpret the wrong value as the condition.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12353
Differential Revision: D10218435
Pulled By: jamesr66a
fbshipit-source-id: afe31c5d4f941e5fa500e6b0ef941346659c8d95
Summary:
This test only runs when you have torchvision installed, which is not the case on CI builds. When I run test_jit on my local machine, this fails, so fixing up the expect file here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12458
Differential Revision: D10244344
Pulled By: jamesr66a
fbshipit-source-id: 728c5d9e6c37f807a0780066f20f6c31de84d544
Summary:
Adding back import{Node,Edge} as move{Node,Edge} and adding a new
function moveSubgraph. Previous diff broke OSS
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12303
Differential Revision: D10182522
Pulled By: bwasti
fbshipit-source-id: 9619431d6d1a44f128613a4f6d8b7f31232ccf28
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11957
For distributed inference, we want to use async_scheduling net to run the net as we need its async part. However, according to the profiling, async_net has big overhead of dispatching tasks onto worker threads. This diff improves the issue by generating a smaller number of chains/tasks by grouping the sync ops that can be run in one shot. Note that it also schedule individual async ops as a single chain because unlike gpu ops, rpc ops are not guaranteed to be linearized at the remote site. For example, if you have two rps ops `op1->op2`, op2 won't implicitly block until op1 finishes. Therefore we need to put each of the async op as one chain as async_scheduling net will only sync the tail of the chain.
For the all sync op nets, this change give us `1.5X` slower than simple_net, while without the change, it is `7X` slower.
Next step is to work on the executor to make the task scheduling faster. And add a fallback path to be able to run ops inline if it's a all-sync net.
Reviewed By: ilia-cher
Differential Revision: D9874140
fbshipit-source-id: fcd45328698c29211f2c06ee3287194acda12227
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12433
To test 3d conv, we need to pass lists in spec argument. We also don't want to set use_cudnn=True which is the default in brew.
Reviewed By: llyfacebook, csummersea
Differential Revision: D10234315
fbshipit-source-id: 96a39992a97e020d6e9dac103e6d64df0cc1020b
Summary:
Add a pass to move all constants to the beginning of the graph, and deduplicate.
This extends https://github.com/pytorch/pytorch/pull/10231 to also handle constants introduced in inlining, constant propagation, etc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12222
Reviewed By: driazati
Differential Revision: D10201616
Pulled By: eellison
fbshipit-source-id: bc9c5be26868c8b5414257a0d4462de025aeb9bd
Summary:
A possible fix for the problem stated in #12410.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12446
Differential Revision: D10238572
Pulled By: soumith
fbshipit-source-id: 17ade148c4036d2481b878e5cd7d9d67c1e3626e
Summary: When testing D10220313, I ran into this bug.
Reviewed By: aazzolini
Differential Revision: D10224295
fbshipit-source-id: f46d7333612bce437c1ae6c0b0b579fc2a639665
Summary:
In our #better-engineering quest of removing all uses of catch in favor of gtest, this PR ports JIT tests to gtest. After #11846 lands, we will be able to delete catch.
I don't claim to use/write these tests much (though I wrote the custom operator tests) so please do scrutinize whether you will want to write tests in the way I propose. Basically:
1. One function declaration per "test case" in test/cpp/jit/test.h
2. One definition in test/cpp/jit/test.cpp
3. If you want to be able to run it in Python, add it to `runJitTests()` which is called from Python tests
4. If you want to be able to run it in C++, add a `JIT_TEST` line in test/cpp/jit/gtest.cpp
Notice also I was able to share support code between C++ frontend and JIT tests, which is healthy.
ezyang apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12030
Differential Revision: D10207745
Pulled By: goldsborough
fbshipit-source-id: d4bae087e4d03818b72b8853cd5802d79a4cf32e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12408
Using static_cast is better than reinterpret_cast because it will cause a compile time error in the following cases, while reinterpret_cast would run into undefined behavior and likely segfault:
- Src and Dst are not related through inheritance (say converting int* to double*)
- Src and Dst are related through virtual inheritance
This `dynamic_cast_if_rtti` is still unsafe because `dynamic_cast` and `static_cast` behave differently if the runtime type is not what you expected (i.e. dynamic_cast returns nullptr or throws whereas static_cast has undefined behavior), but it's much safer than doing reinterpret_cast.
Reviewed By: Yangqing
Differential Revision: D10227820
fbshipit-source-id: 530bebe9fe1ff88646f435096d7314b65622f31a
Summary:
Same as before, but with "initialTensorOptions()" instead of "TensorOptions(false)".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12403
Differential Revision: D10225427
Pulled By: gchanan
fbshipit-source-id: 60bd025a5cc15bdbbab6eafc91ea55f5f2c3117e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12295
Add ability to use custom implementations of thread pool instead of TaskThreadPool
Reviewed By: yinghai
Differential Revision: D10046685
fbshipit-source-id: 95da8c938b8e60b728484c520319b09b0c87ff11
Summary:
This PR is the start of weak script mode for functions
Weak scripts allow you to compile a graph from Python code at runtime by annotating with `torch.jit.weak_script` for use in the JIT without affecting eager execution. Scripts are compiled lazily on the first call in a graph to avoid long Python startup times.
apaszke zdevito ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11963
Differential Revision: D10183451
Pulled By: driazati
fbshipit-source-id: 128750994d5eb148a984f8aba4113525c3e248c8
Summary:
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
CC deepakn94
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12370
Differential Revision: D10220135
Pulled By: ezyang
fbshipit-source-id: 6d1a8a383951ae52753e4f75a14b8080bf02b815
Summary:
* Remove duplicate math transpilation function
* Modify regex to expand matches to more __device__ functions
* Try a different tack. Apply math transpilations only to .cu and .cuh files
* Undo change that's not required anymore since we're not using regex to detect device functions
This should address "overtranspilation" as observed in another PR.
bddppq ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12387
Differential Revision: D10226798
Pulled By: bddppq
fbshipit-source-id: fa4aac8cd38d8f7ef641fad5129ed4714c0fada5
Summary:
this removes a bunch of spam output from the build. This is
(1) cleaner
(2) a couple seconds faster in some cases, e.g. my slow-rendering emacs-based shell
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12392
Differential Revision: D10225340
Pulled By: anderspapitto
fbshipit-source-id: 477ee76d24f8db50084b1e261db8c22733de923b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12180
I had to fix a lot of call sites, because a lot of places assume that
you can actually get a const vector&, and if the internal representation
of sizes in a tensor is NOT a vector, it's not possible to fulfill
this API contract.
Framework changes:
- I deleted TensorImpl::dims(); caffe2::Tensor::dims() just forwards to
sizes() now.
- De-templatized SetDims; now it is an explicit list of ArrayRef and
variadic overloads. This makes implicit conversions work again,
so I don't need to explicitly list the std::vector cases too.
- As a knock-on effect, this causes Reset() to accept at::IntList as well as
const std::vector<int64_t>&
- Edited variadic overloads of SetDims to all forward to the underlying
arbitrary-dim implementation, reducing code duplication. (It's probably
marginally less efficient in the new world.)
- Replace Tensor constructor accepting const std::vector<int64_t>& with at::IntList
- Make MKLTensor accept ArrayRef along with vector in constructor and
Reset (unfortunately, no implicit conversions here, since it's templated on
index type.)
- There are a few other places, like cudnn, where I changed functions
that previously took const std::vector<int64_t>& to take at::IntList
instead.
Classification of call site changes:
- 'const std::vector<int64_t>& x_dims = x.dims()' ==>
'at::IntList x_dims = x.dims()'
- 'std::vector<int64_t> x_dims = x.dims()' ==>
'std::vector<int64_t> x_dims = x.dims().vec()' (we need a copy!)
Usually this is because we're about to mutably modify the vector
to compute some new dimension. However, it also very commonly occurs in the
form: 'x_dims_ = x.dims()' because we frequently cache sizes in operators.
- Instead of constructing std::vector<int64_t>{blah, blah}, construct an
at::IntList directly
ArrayRef changes:
- cbegin()/cend() iterators, they operate the same aas begin()/end() because
everything on ArrayRef is const.
- Moved operator<< into ArrayRef.h, so that it's always available when
working with ArrayRef. I also templated it, so it now works on an
ArrayRef of any type.
- Add operator== overload for ArrayRef, and also add variants to permit
comparison of ArrayRef with std::vector, a very common operation.
(The non-templated version of operator== can get these automatically
via implicit conversion, but with templates C++ refuses to do
any explicit conversions.)
I'm planning to audit all dims() call sites to make sure they don't
expect 'auto x = t.dims()' to give you an x whose lifetime can validly
outlive the tensor.
I opted not to do a dims() to sizes() rename, because dims() also matches
the protobufs accessor. Bad news!
Reviewed By: jerryzh168
Differential Revision: D10111759
fbshipit-source-id: a2a81dc4b92c22ad4b3b8ef4077a7e97b6479452
Summary:
Previously, we were only enabling Flush-To-Zero (FTZ) and
Denormals-Are-Zero (DAZ) when compiling with SSE3 enabled. After,
Christian's patch (https://github.com/pytorch/pytorch/pull/12109) we
won't be compiling core files with SSE3 or SSE4 enabled, to better
support older AMD processors.
This moves the FTZ and DAZ code behind a runtime CPU check in
preparation for that change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12386
Differential Revision: D10222237
Pulled By: colesbury
fbshipit-source-id: 7ffe32561ab965e1e5f9eb6e679602bbf4775538
Summary:
Obviously, the grads of conv weight and conv input are not relevant to the bias, but the original `convXd_input` and `convXd_weight` methods receive a `bias` parameter. What's more, while the doc says `bias` should have the shape `(out_channels,)`, one will get a `RuntimeError` if the bias != None and in_channels != out_channels, for the weight of transposed conv has the shape `(in_channels, out_channels, kH, kW)` while the weight of vanilla conv has the shape `(out_channels, in_channels, kH, kW)`
```
RuntimeError: Given transposed=1, weight of size [channel1, channel2, kH, kW], expected bias to be 1-dimensional with channel2 elements, but got bias of size [channel1] instead
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12281
Differential Revision: D10217370
Pulled By: ezyang
fbshipit-source-id: bc00b439e5ae539276a5e678bdb92af700197bb2
Summary:
This is to move us along the path to removing Type from the public API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12355
Reviewed By: ezyang
Differential Revision: D10212616
Pulled By: gchanan
fbshipit-source-id: c9cd128d1111ab219cb0b2f3bf5b632502ab97c0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12288
Current implementation of Tensor takes an intrusive_ptr as an argument for storing data. But instead of requiring users to explicitly pass an intrusive_ptr we want them to pass args for intrusive ptr directly which are forwarded internally through new helper function called make_tensor
Reviewed By: ezyang
Differential Revision: D10152661
fbshipit-source-id: bfa72de161ace3fd1c4573427abcd1bfbd12e29e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12328
- Delete reset() from Storage, as it makes it easy to accidentally
create a null storage.
- Immediately reject a storage if it is null when passed in
Reviewed By: dzhulgakov
Differential Revision: D10200448
fbshipit-source-id: 14bfa45f8f59859cc350bd9e20e3ef8692e3991d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12103
This defers lookup of defaults to the site where we read
out of TensorOptions. THIS IS A BC-BREAKING BEHAVIOR CHANGE,
but we expect the bulk of uses of OptionsGuard don't allocate TensorOptions
inside the OptionsGuard region, and then use it outside of the region
(the situation where behavior could change.)
I also optimize the size of TensorOptions by rearranging fields, so that we
always fit in two 64-bit words.
Reviewed By: goldsborough
Differential Revision: D10052523
fbshipit-source-id: f454a15b4dbf8cd17bc902ab7d2016f2f689ed13
Summary:
The changes are made to clarify how the parsing between the yaml files and header files of THNN and THCUNN works. As issue #12320 shows it is not that easy to understand the existing code without a hint to the important files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12367
Differential Revision: D10217459
Pulled By: ezyang
fbshipit-source-id: 9b3e64dea4f156843814840e736dc3230332060c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12340
`long` and `int64_t` are the same type on 64-bit Android.
Reviewed By: Yangqing
Differential Revision: D10204892
fbshipit-source-id: 2d5bf707bf87b99fc597c9292b59f032e9004620
Summary:
* Replaces `prim::PythonOp` with the name of the function being called
* Delays printing values used in `prim::Return` nodes until the return
node itself if that is the only place the value is used to remove some
useless assigns
zdevito apaszke ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12179
Differential Revision: D10132661
Pulled By: driazati
fbshipit-source-id: cbc4ac34137ed5872049082e25d19eb1ebc71208
Summary:
All usages of the `ndarray` construct have now been guarded with `USE_NUMPY`. This eliminates the requirement of NumPy while building PyTorch from source.
Fixes#11757
Reviewed By: Yangqing
Differential Revision: D10031862
Pulled By: SsnL
fbshipit-source-id: 32d84fd770a7714d544e2ca1895a3d7c75b3d712
Summary:
This is to fix cmake-time compilation error.
When we change script to build Caffe2 with mkldnn, we run into some cmake-time compilation support check (like in libsleef) failed due to incorrect setting of CMAKE_REQUIRED_LIBRARIES. It is a global setting which can interfere camke compilation if it is not clean up properly. FindBLAS.cmake and FindLAPACK.cmake didn't clean this flag, and causes incorrect building of libsleef.so.
yinghai gujinghui
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12195
Differential Revision: D10159314
Pulled By: yinghai
fbshipit-source-id: 04908738f7d005579605b9c2a58d54f035d3baf4
Summary:
- Removed the old nccl file
- Make open-source NCCL a submodule
- CMake to make NCCL itself
NCCL2 now is in the default build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12312
Differential Revision: D10190845
Pulled By: teng-li
fbshipit-source-id: 08d42253b774149a66919d194f88b34628c39bae
Summary:
Tensors cannot be created globally because of static initialization order issues. So tensors for the optim_baseline test must be created lazily instead. This is fine because these functions will only be called once (in the respective test).
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12301
Differential Revision: D10201008
Pulled By: goldsborough
fbshipit-source-id: 59a041f437354e7c6600e5655b3e2d0647dbde9e
Summary:
CAFFE2_UNIQUE_LONG_TYPEMETA has been a tricky variable defined only from cmake - this is an experiment to remove it and see what exact compilers need that one set.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12311
Reviewed By: dzhulgakov
Differential Revision: D10187777
Pulled By: Yangqing
fbshipit-source-id: 03e4ede4eafc291e947e0449382bc557cb624b34
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11465
It happened in one of my testing workflow run that deserialization of dataset_cursor failed. The reason it fails is due to the offset vector is serialized only when it's non-empty, but deserialization always process offset_blob whenever it is called. Though I'm still checking the reason why the offset of dataset_cursor is empty, I think it's good to remove this discrepancy.
Reviewed By: aazzolini, Tianshu-Bao
Differential Revision: D9737636
fbshipit-source-id: bb111933f534b092f29469680ff29e59617655f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12274
We use caffe2::int8::Int8TensorCPU for quantized tensor with uint8_t element type.
Reviewed By: llyfacebook
Differential Revision: D10156452
fbshipit-source-id: 52cf2bedc9dbb433cd5d03f0b76723f7df6a7361
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12029
In order to remove New() function in StaticContext(to remove StaticContext) and converge to the Allocator design, we'll first change the return type of New to at::DataPtr.
Reviewed By: ezyang
Differential Revision: D9889990
fbshipit-source-id: 3257c763530b987025f428741bdd2e089d11bad4
Summary:
At long last, we will have clang-tidy enabled in CI. For a while I thought I could clean up the project enough to enable clang-tidy with all checks enabled, but I figure it's smarter to set up the minimal checks and at least have those in CI. We can fix more going forward.
ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12213
Differential Revision: D10183069
Pulled By: goldsborough
fbshipit-source-id: 7ecd2d368258f46efe23a2449c0a206d10f3a769
Summary:
If a PythonOp throws an error it raises an exception to the interpreter and also releases the GIL which causes [pybind to segfault](https://github.com/potassco/clingo/issues/42)
This fix catches pybind errors while the GIL is still held and throws a `python_error` to re-capture the GIL
Fixes#12118
apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12243
Differential Revision: D10182787
Pulled By: driazati
fbshipit-source-id: 719d4a7c3294af201e061cf7141bec3ca0fb1f04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12279
By some reason if we don't write to the wipe buffer, it doesn't really wipe out everything from caches in x86.
We also need to wipe out cache after initializing input blobs.
Reviewed By: Maratyszcza
Differential Revision: D10161211
fbshipit-source-id: c34414dd8b83947805010d7d57e4134d56de1430
Summary:
Fix things in onnxwhile op to support nested loops, correctly track loop carried deps. Nested loops should be fully supported together with https://github.com/onnx/onnx/pull/1453
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12124
Differential Revision: D10108817
Pulled By: wanchaol
fbshipit-source-id: 51b948024da857c9962833213ee792f47f054e48
Summary:
If block is missing control inputs when do caffe2 net execution, this PR add them back and remove the un-SSA semantics
jamesr66a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12224
Differential Revision: D10135408
Pulled By: wanchaol
fbshipit-source-id: 746c870bde54ed4ca627167361db1b3f36cd235c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12266
- Put all byte-size fields together (booleans and TensorTypeId),
so they can be coalesced into a single word.
- Replace std::vector<int64_t> strides with
std::unique_ptr<int64_t[]>, saving two words.
Reviewed By: dzhulgakov
Differential Revision: D10150834
fbshipit-source-id: f54f38eec34732f3ff7e52e00b1371d7b5b210eb
Summary:
This PR adds a bool type to `IValue` and puts it into place.
* changes conds for `prim::If` and `prim::Loop` to use `bool` type
* changes operators that take `bool`s to match their native ops
* fixes ambiguous `aten` ops `aten::std` and `aten::var`
* fixes tests in `test_jit.py TestJitGenerated`
```
'test_std_dim',
'test_std_dim_1d',
'test_std_dim_1d_neg0',
'test_std_dim_neg0',
'test_var_dim',
'test_var_dim_1d',
'test_var_dim_1d_neg0',
'test_var_dim_neg0'
```
* adds `prim::BoolToTensor` and `prim::TensorToBool`
apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11834
Differential Revision: D9928570
Pulled By: driazati
fbshipit-source-id: 373c53df2f1a8ffa9e33d9a517002fbeef25f3eb
Summary: Adding back import{Node,Edge} as move{Node,Edge} and adding a new function moveSubgraph
Reviewed By: duc0, yyetim
Differential Revision: D10128131
fbshipit-source-id: b0e17ec2802cb211b6455578fdb17dab2a7a425b
Summary:
Hi, I think it might be better to use https instead of http in the README.md.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12258
Differential Revision: D10162279
Pulled By: soumith
fbshipit-source-id: 4658aa75175909b4fea6972b437765d8b49c749f
Summary:
This variable is already being used so this just serves to document that. I think it's an important variable, too, so it should definitely be documented there somewhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12265
Differential Revision: D10162261
Pulled By: soumith
fbshipit-source-id: e0d01e012c2fedea63372de9967a8eaa3745fe94
Summary:
The code that reads a blob from input files are broken. Fixing them. Also, add a binary that converts input files to blobs that can be used by Caffe2 directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12211
Reviewed By: llyfacebook
Differential Revision: D10121845
Pulled By: sf-wind
fbshipit-source-id: 6e48bb594680bcb3186d8d43276b602041c30d3e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12250
We use caffe2::int8::Int8TensorCPU for quantized tensor with uint8_t element type.
Reviewed By: llyfacebook
Differential Revision: D10121216
fbshipit-source-id: b63cd3a75f87e043cc3c83de4f3520b6ffbf1d07
Summary:
We now have a proper download link for libtorch.
ezyang soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12263
Differential Revision: D10149216
Pulled By: goldsborough
fbshipit-source-id: e9caefed1c7f8e25d7623d72c8548bfdb6114329
Summary:
Strides appear to cause a huge memory regression in some of our internal
training workflows. This diff stems the bleeding, while we figure out exactly
what happened.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12236
Reviewed By: dzhulgakov
Differential Revision: D10134319
fbshipit-source-id: 1547c89a65c05473c409c0977c19c99dcaefb89c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12122
We are deprecating support for c extensions. Please use cpp extension in the future.
Reviewed By: Yangqing
Differential Revision: D10060541
fbshipit-source-id: 4f7149e06a254bd7af463fd7aa9740f65369963a
Summary:
Original commit changeset: f5614a5d2607
D9986213 is causing Multifeed Aggregator a [huge performance different](https://our.intern.facebook.com/intern/ads/analyze_canary/412951953278781781/) and is blocking aggregator push since last Friday night: https://fburl.com/feedtools/b6izvwjz
We need to land this revert ASAP to unblock aggregator push.
Reviewed By: orionr
Differential Revision: D10123245
fbshipit-source-id: d83da8e00a1250f5d09811a0a587c127e377aab2
Summary:
Allow trailing commas in assign statements or tuples, which also allows single element tuples.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11723
Differential Revision: D10052162
Pulled By: eellison
fbshipit-source-id: 344d908a3ad942a23ebd9f341794bc9734226aa8
Summary:
We're waiting for the libtorch links to show up on the website. I had a fake link in the docs so far which is misleading. This PR changes it to a temporary markdown file until the web people fix the site tomorrow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12212
Differential Revision: D10121872
Pulled By: goldsborough
fbshipit-source-id: f1bd1315f7333b9168e99983f3f6b679c9b0c52a
Summary:
- fix https://github.com/pytorch/pytorch/issues/12120
- add `torch.argsort`, `torch.pdist`, `broadcast_tensors` to *.rst files
- add parameter dim to `torch.unique` doc
- fix table and args for `torch.norm`
- test plan: make html and check docs in browser
gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12126
Differential Revision: D10087006
Pulled By: weiyangfb
fbshipit-source-id: 25f65c43d14e02140d0da988d8742c7ade3d8cc9
Summary:
Currently when tracing optimizations are performed twice. This means that optimizing passes, like the fusion pass, are also called twice. This is unnecessary and this PR turns off optimizations when checking the trace (since the trace is independent of optimizations). This should improve performance and debugging.
apaszke who proposed this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12172
Reviewed By: ezyang
Differential Revision: D10109250
Pulled By: apaszke
fbshipit-source-id: 8b3385eae143446820f1b61ca7576d7c07f9b248
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11955
Adding a `filter<T>(NNModule)` function to easily get inputs/outputs of a DAI-style NNModule.
Reviewed By: duc0
Differential Revision: D9997696
fbshipit-source-id: 818c4f2e3093e0d02b35e6632b426e8d3189c21e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11954
Adding an alternative to external_input and external_output for use in some distributed settings
Reviewed By: aazzolini
Differential Revision: D9997121
fbshipit-source-id: 1b5cc03fd3051368a3edc69e7bc472386f5746b5
Summary:
In current upstream float scalars are always written into kernels with:
`out << std::scientific << v << "f";`
When the floats are special values like NaN, +inf, or -inf this produces nonsense that causes compilation to fail. This fix updates the conversion of float scalars to device-specific special values. The appropriate macros are added to the CPU and CUDA resource strings. Note that a NAN macro was not necessary on the CPU since math.h defines NAN.
To verify this fix I updated the test_clamp_fusion test in test_jit.py. I wanted to test -inf, too, but -inf is not currently accepted by the interpreter.
Edit:
Forgot to mention, this partially addresses issue #12067.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12070
Reviewed By: ezyang
Differential Revision: D10044704
Pulled By: soumith
fbshipit-source-id: 8f4a930862d66a7d37d985e3f6a6fb724579e74c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11891
maybe_wrap_dim is a slightly more general function, which is able
to, under some circumstances, treat 0 as a "valid" dimension even
with a tensor is scalar. canonical_axis_index_ never accepts
this behavior, so it always passes false.
Reviewed By: jerryzh168
Differential Revision: D9968320
fbshipit-source-id: 13c98fff0880d7bfcd00911a76c8aa10d37bd183
Summary:
This allows us to call the type argument with name other than `self_ty`. ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11903
Differential Revision: D10105029
Pulled By: SsnL
fbshipit-source-id: 0fbdc728123ebc1154d080628cb41a085ba3e6d7
Summary:
This functionality replaces the Scalar-Tensor builtin operators,
with builtin functions.
Builtin functions are used in place of operators where one operator
can be defined using a composition of another. This simplifies later
optimization passes by allowing us to have fewer operator.
In the future, builtin functions can be used for other purposes.
For example, we can define derivative functions as code rather than
building graphs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12141
Reviewed By: ezyang
Differential Revision: D10088065
Pulled By: zdevito
fbshipit-source-id: a2acb06346e649c4c8a2fe423b420871161c21cf
Summary:
This fixes a broadcasting error with the `StudentT` distribution
- [x] added a regression test
- [x] strengthened parameter broadcasting tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12148
Differential Revision: D10099226
Pulled By: soumith
fbshipit-source-id: 0c5eb14180d158f8fff28ceb9e7cd3471c2bb803
Summary:
goldsborough Modify the docs to match the changes made in #4999
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12158
Differential Revision: D10103964
Pulled By: SsnL
fbshipit-source-id: 1b8692da86aca1a52e8d2e6cea76a5ad1f71e058
Summary:
This PR replaces the use of `std::FILE` with `istream`/`ostream` for JIT serialization.
It uses this mechanism to add the possibility to serialize to/from binary buffers, in addition to files, both in `libtorch` and from Python.
`getExportImportCopy` in `test_jit.py` has been updated so that both file and buffer codepaths are exercised during tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11932
Differential Revision: D10084303
Pulled By: apaszke
fbshipit-source-id: b850801b3932922fa1dbac6fdaed5063d58bc20d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11349
Special case BatchGather and BatchGatherGradient for block_size=1. This makes BatchGather 3-4X faster and BatchGatherGradient 10X for this case.
Reviewed By: jspark1105, ilia-cher
Differential Revision: D7218043
fbshipit-source-id: ea12042239a8adc92b9efcbd0b66e354fb43f4c7
Summary:
This PR implements the design that we discussed. Changes:
- Added a World token IValue and type. The IValue is basically a dummy struct for now, in the future we may extend it (say, add thread-local state).
- Effectful ops explicitly declare they are mutable by having World tokens as inputs and outputs in their schema.
- Purely functional ops that use mutable values will get "fenced" and the world token will be threaded through the fences
- AnnotateEffects pass which wires up all the world tokens together.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10700
Reviewed By: eellison
Differential Revision: D9547881
Pulled By: michaelsuo
fbshipit-source-id: ebbd786c31f15bf45e2ddb0c188438ff2f5f3c88
Summary:
Previously, doRead/doWrite were functions that could return partial reads/writes,
and we checked for this case inconsistently in the call sites of serialization.cpp.
Now, these functions do NOT return the amount of bytes read/written, and instead
handle the necessary checking loop themselves.
Fixes#12042. Maybe.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12143
Differential Revision: D10097027
Pulled By: ezyang
fbshipit-source-id: fd222ab8a825bed352153648ad396acfe124a3e1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12090
This is a slight pessimization because we need to do a
full recompute of is_contiguous(), even though a modification
of dim-0 is guaranteed to preserve contiguity.
Reviewed By: jerryzh168
Differential Revision: D10050905
fbshipit-source-id: b99233e21c9f4275b0db6e76740462e5430ce152
Summary:
reduce sum negative indices turn to positive as caffe2 not supporting it. GE/LE symbolic operand order is wrong..
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12123
Reviewed By: houseroad
Differential Revision: D10095467
Pulled By: wanchaol
fbshipit-source-id: eb20248de5531c25040ee68b89bd18743498138d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11971
- Switched TensorImpl::data<T>() to use Storage::unsafe_data<T>() to work
around an outstanding bug in the Storage::data<T>() implementation
where it only works on Ts which are valid ScalarType
- Qualify a bunch of identifiers which still live in caffe2:: namespace
- strides returns an IntList now
- s/update_strides/update_to_contiguous_strides/
- Correctly compute type_id_ for the Storage only constructor from Caffe2.
This is special cased to only work for CPU and CUDA dense tensors.
- Fix some signed-unsigned comparisons in Caffe2 code (OSS build for
ATen/core has more restrictive warning tests.)
Reviewed By: jerryzh168
Differential Revision: D9995559
fbshipit-source-id: 9c74032e011189e1c7e9a98d20f2bd1e25ad2e5c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11970
Adds an ATen-core-headers target, which caffe2_cpu_internal depends
on, and makes ATen-core depend on caffe2_headers. If you link against
ATen-core, you must ALSO link against caffe2_cpu_internal; if you
link against caffe2_cpu_internal, you must ALSO link against ATen-core,
otherwise you'll have undefined symbols.
Then, we merge template data<T>() method with Caffe2 implementation,
demonstrating that includes to Caffe2 (core) from ATen/core are working
Reviewed By: jerryzh168
Differential Revision: D9967509
fbshipit-source-id: 3d220c38b2c3c646f8ff2884fdcc889fa9276c7a
Summary:
Export symbols for pybind and other libs after caffe2 rebase
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11975
Differential Revision: D10042615
Pulled By: yinghai
fbshipit-source-id: 6de562d99403099113093716834abc51bf726e94
Summary:
the speed-up of a single operation is up to 6X on BDW.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11686
Reviewed By: yinghai
Differential Revision: D9828129
Pulled By: wesolwsk
fbshipit-source-id: 7dbacea90609e18438f6fe1229c641937d0696c8
Summary:
As reported in Issue #10726, the jit compiler, when running on ppc64le, may produce an isomorphic output but fail a diff test against the expected output file. The expected output file is created from a test that was ran on x86_64. This ensures that if ppc64le test output is different, the output is instead compared to an expected output file created when the test is run on a ppc64le system.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11579
Differential Revision: D10080890
Pulled By: soumith
fbshipit-source-id: 7249bf6b5dfa7c853368a3688a982bc9ed642bc9
Summary:
This does 6 things:
- add c10/util/Registry.h as the unified registry util
- cleaned up some APIs such as export condition
- fully remove aten/core/registry.h
- fully remove caffe2/core/registry.h
- remove a bogus aten/registry.h
- unifying all macros
- set up registry testing in c10
Also, an important note that we used to mark the templated Registry class as EXPORT - this should not happen, because one should almost never export a template class. This PR fixes that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12077
Reviewed By: ezyang
Differential Revision: D10050771
Pulled By: Yangqing
fbshipit-source-id: 417b249b49fed6a67956e7c6b6d22374bcee24cf
Summary:
Apply weight decay for Adam in-place instead of via copy.
Synced offline with soumith , who mentioned that it should be OK. This is also consistent with other optimizers, e.g. eee01731a5/torch/optim/sgd.py (L93)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12107
Reviewed By: soumith
Differential Revision: D10071787
Pulled By: jma127
fbshipit-source-id: 5fd7939c79039693b225c44c4c80450923b8d673
Summary:
You can't GetDeviceType an undefined tensor, so test for this case
first. This allows you to safely move tensors out of blobs.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12125
Reviewed By: smessmer
Differential Revision: D10080075
Pulled By: ezyang
fbshipit-source-id: bb99b089b6daa9d4db99015208f939d7ce4d4a79
Summary:
migrant all tests in aten to use gtest except of basic.cpp
Sinc features of gtest are different from catch test, some of the tests has been re-writted with similar meaning.
Basic test has some version conflict with valgrind according to CI, therefore this testcase is still implementing catch.
It will be resolved by a different pr.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11846
Differential Revision: D10080860
Pulled By: zrphercule
fbshipit-source-id: 439d4cf33fb6ccbe79b797860342853c63e59081
Summary:
I wrote some high level docs for the larger PyTorch C++ universe and the C++ frontend specifically. Happy for reviews, but let's please also land this ASAP so I can point users at something that looks more ready baked than the C++ docs landing page (https://pytorch.org/cppdocs) does right now.
ezyang soumith
CC ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12079
Differential Revision: D10080785
Pulled By: goldsborough
fbshipit-source-id: 3028de41373f307468eb1e3802aa27871c93b2e3
Summary:
We generate specialized list operations for int, float, and Tensor lists so that small lists of integers like the arguments to conv do not involve tons of boxing code.
This PR adds a fallback GenericList for List types that contain any other type. It does so by adding type variables to `jit::Type`, and machinery for matching/replacing the type variables during `tryMatchSchema` and operator lookup.
It also modifies the builtin list ops to include a fallback that works on a GenericList object that simply holds IValues. This is distinguished from IValue's tuple type so that conversion to/from Python still happens losslessly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12040
Differential Revision: D10037098
Pulled By: zdevito
fbshipit-source-id: 0c5f2864d12e7d33554bf34cc29e5fb700dde150
Summary:
An efficient atomicAdd for halfs has been added in `cuda_fp16.h` in CUDA 10:
```__CUDA_FP16_DECL__ __half atomicAdd(__half *address, __half val);```
Through this change, PyTorch will be able to utilize efficient atomicAdd when building with CUDA 10.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12108
Differential Revision: D10053385
Pulled By: soumith
fbshipit-source-id: 946c90691a8f6bdcf6d6e367a507ac3c9970b750
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12065
Had compilation issues using CAFFE_DURATION in some contexts, specifically due to namespace resolution. Since this is a macro, it should fully qualify.
Reviewed By: heslami
Differential Revision: D10036132
fbshipit-source-id: b8d55dfe5e991ca702ce5b7483f0ffc699882c85
Summary:
Couple questions:
1) I used the log1p implementation in #8969 as a guide especially for testing. I'm not sure what the ```skipIfROCM``` annotation is for, so unsure if i need it for my test.
2) I implemented the branching logic in the narrow function itself; is this the right place to do so? I noticed that there a number of places where sparse-specific logic is handled with just an if statement in this file. Or should I implement a separate dispatch in native_functions.yml as in the log1p?
And of course, happy to make any any other updates/changes that I may have missed as well. This is my first PR to the project.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11342
Differential Revision: D9978430
Pulled By: weiyangfb
fbshipit-source-id: e73dc20302ab58925afb19e609e31f4a38c634ad
Summary:
The earlier tests had around 80 warnings, and now there are 6 warnings: these are due to JIT
The changes remove the wrapping of a Tensor by a Tensor constructor, which emits warnings due to the changes in https://github.com/pytorch/pytorch/pull/11061 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12038
Differential Revision: D10033392
Pulled By: apaszke
fbshipit-source-id: b1faf368e650d062d7983f9932511bee4702a893
Summary:
This unifies our versions across setup.py, libtorch, and libcaffe2. CMake has a default version (bumped to 1.0.0) that can be overridden by setup.py. The versions are also printed as a part of cmake/Summary.cmake to make sure they are correct.
cc Yangqing ezyang soumith goldsborough pjh5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12053
Differential Revision: D10041878
Pulled By: orionr
fbshipit-source-id: a98a01771f6c008d1016ab63ab785c3a88c3ddb0
Summary:
This PR does a few things:
Previously test_jit.py only tested autograd on backward graphs.
This is because we borrow from test_autograd and construct graphs with a small
number of nodes. Because the number of nodes is small (typically 1-2), those graph
do not end up containing autodiff subgraphs, so autodiff never gets tested.
This PR enables autodiff testing by doing the following:
- added disableDebugAutodiffSubgraphInlining fn to graph_executor to disable
autodiff subgraph inlining.
- (implementation) added autodiffSubgraphNodeThreshold and autodiffSubgraphInlineThreshold.
These are set to their default values (2, 5) but disableDebugAutodiffSubgraphInlining()
sets both to 1, disabling subgraph inlining and allowing 1-node autodiff subgraphs.
- The relevant backward jit tests disable autodiff subgraph inlining so they
will test the autodiff versions of the operators instead of autograd whenever
an autodiff variant exists.
- We don't run the tests that do inline autodiff subgraphs anymore.
This has no impact on testing correctness because the assumption is
that autograd functions are correct and are tested in test_autograd.py
This allows the graph fuser to work better because a lot of these ops were previously not autodiff-compatible but fusible. On a more concrete example, lstm backward contains a lot of tensor-scalar operations; these autodiff formulas help its double backward pass.
Included:
- arithmetic overloads
- abs, acos, asin, atan, ceil, cos, cosh, exp, expm1, floor, fmod, frac, log, log10, log1p, log2 reciprocal, remainder, round, sin, sinh, tan, trunc, rsqrt
TestJitGenerated tests autodiff for all of the added operations.
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11832
Differential Revision: D10031256
Pulled By: zou3519
fbshipit-source-id: 9daf9900a5ad187743609cd0fbbd10b15411ad93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11548
This removes getting/setting the DestroyCall of a Blob,
paving the way to removing DestroyCall from Blob entirely and using the destructor stored in TypeMeta instead.
Use sites have been fixed in diffs stacked below this.
Reviewed By: dzhulgakov
Differential Revision: D9775191
fbshipit-source-id: 97d72d0c62843849057f295c27f391e63c99c521
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11414
caffe2::Blob can be stored in an IValue. This is a precondition for caffe2 to switch from Blob to IValue.
Reviewed By: ezyang
Differential Revision: D9731326
fbshipit-source-id: 462a39d2d9ab6f85b99b1670848c6976a3de417c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11924
Previous diffs removed Blob -> caffe2 dependencies, now we can move it to ATen/core.
This is pre-work for allowing storing Blob in IValue.
Reviewed By: ezyang
Differential Revision: D9980641
fbshipit-source-id: 32082a673ec94c42c20b2298adced8bb7ca94d07
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12021
TestPilot runs stress tests in parallel. These fail for serialized tests because extracting (and subsequent deletion) of binary data during the process isn't threadsafe. Extract zips into tempfile to avoid this problem.
Also remove some accidentally checked in zips of a test that we didn't end up including for now.
Reviewed By: houseroad
Differential Revision: D10013682
fbshipit-source-id: 6e13b850b38dee4106d3c10a9372747d17b67c5a
Summary:
TSIA. Right now we should basically use C10_EXPORT and C10_IMPORT for explicitly marking dllexport and dllimport, as a continued effort of the C10 unification.
This is a codemod by mechanically doing the following change:
CAFFE2_{EXPORT,IMPORT} -> C10_{EXPORT,IMPORT}
AT_CORE_{EXPORT,IMPORT} -> C10_{EXPORT,IMPORT}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12019
Reviewed By: ezyang, teng-li
Differential Revision: D10016276
Pulled By: Yangqing
fbshipit-source-id: a420d62c43d1110105fc88f9e9076e28a3203164
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12058
Methods on TensorImpl have to be written very carefully, because
when you have a VariableImpl subclass of TensorImpl, usually the
local fields on the TensorImpl are not valid; instead, you have to
forward to the "wrapped" tensor. Functions which are virtualized
are probably handled correctly by Variable, but functions which
are NOT cannot be handled correctly and shouldn't be called if you
have a Variable. This diff add checks to determine if this is
the case or not.
Reviewed By: jerryzh168
Differential Revision: D10034589
fbshipit-source-id: 650b2036ca9a044c0ab4abdf6f825521a64e1fc2
Summary:
This PR establish a baseline so that we can build IDEEP ops in the new work flow. From this baseline, we need to
- Merge the CMakefile of MKLDNN from caffe2 and Pytorch
- Get rid of `USE_MKL=ON`.
Build command from now on:
```
EXTRA_CAFFE2_CMAKE_FLAGS="-DUSE_MKL=ON -DINTEL_COMPILER_DIR=/opt/IntelComposerXE/2017.0.098" python setup.py build_deps
```
gujinghui
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12026
Differential Revision: D10041199
Pulled By: yinghai
fbshipit-source-id: b7310bd84a494ac899d8e25da368b63feed4eeaf
Summary:
LLVM trunk emits an error diagnostic when attempting to compile caffe2. The
identifiers following the `template` keywords are not templates, so the use of
the keyword does not make sense in this context.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12037
Reviewed By: ezyang
Differential Revision: D10024531
Pulled By: modocache
fbshipit-source-id: da4b9ba405d9f7fd633ab8c1a61c77da9c1a1f89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12036
Sometimes you have a TypeIdentifier, and no way to get to
the TypeMeta. Still nice to be able to read out the name.
This should be obsoleted by smessmer's patches.
Reviewed By: gchanan, mingzhe09088
Differential Revision: D10024554
fbshipit-source-id: 42cdceefd5c59be0441254665f66f5edc829f422
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11902
Previously, they were going through THTensor_getStoragePtr which
incurred a null pointer check on storage. Now they use unsafe_data
method which doesn't do this check.
I don't know if this actually make things go faster, but I get
an added bonus of reducing code duplication, so we should take
this change anyway :)
Reviewed By: SsnL
Differential Revision: D9977654
fbshipit-source-id: f45c74828213a0439480755ad0b2d7f8858cb327
Summary:
Users generally expect ./configure to find libraries
installed in /usr/local and /usr, so search for nccl
there too.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12063
Differential Revision: D10036248
Pulled By: ezyang
fbshipit-source-id: d331ddd2ccc8ac9846fb54222db284b1ec371659
Summary:
The gpu_unary_kernel function was not handling arrays that
cannot use 32-bit indexing. This functions was only called directly
by CUDA division by a scalar. Other arithmetic operations go through
gpu_binary_kernel, which already properly handled large arrays.
This bug sometimes manifested as a crash and sometimes as an incorrect
answer.
Fixes#11788
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12023
Differential Revision: D10034017
Pulled By: colesbury
fbshipit-source-id: b17300f327de54035746bf02f576766007c9b144
Summary:
This PR is a minor change, just adds a simple `magma_queue_destroy` function to the implementation of `Gesv`.
Also, I have replaced calls for obtaining handles with those already written in ATen.
```
THCState_getCurrentSparseHandle(at::globalContext().getTHCState()) --> getCurrentCUDASparseHandle()
THCState_getCurrentBlasHandle(at::globalContext().getTHCState()) --> getCurrentCUDABlasHandle()
```
Differential Revision: D10032204
Pulled By: soumith
fbshipit-source-id: ccd11989ecdc357313f0b661a2468f75d3aecb0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12043
Re-trying D9979976, this time with all call sites fixed.
D9979976 got reverted because there was a call site that wasn't covered by sandcastle it seems.
I fixed it and used 'grep' to ensure there aren't any more call sites in fbsource.
Reviewed By: ezyang
Differential Revision: D10026392
fbshipit-source-id: cd341514a8e53a40147ea0ee3e52f63bb6444157
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12020
- make it less verbose to create random blobs in python unit test by adding some test helper methods
- move str_compare test helper method to test_util.py
Reviewed By: ZolotukhinM
Differential Revision: D10003637
fbshipit-source-id: cb79d2ad508341f750a1bb8f564e87d055c65652
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12034
We need ATen and Caffe2 to line up, and the rule is
that if you have any private/protected members, you
should declare it as a class. Class we go.
(There are some other obvious candidates for this treatment,
but I've kept this patch just to Tensor)
Reviewed By: gchanan, mingzhe09088
Differential Revision: D10024467
fbshipit-source-id: 17cfe2741ba9c3f56cb87d6f5d1afd3c61a8e4fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12046
This /sounds/ like a good idea in theory, but a feature
like this must be implemented very carefully, because if
you just plop the Git version in a header (that is included
by every file in your project, as macros.h is), then every
time you do a 'git pull', you will do a FULL rebuild, because
macros.h is going to regenerate to a new version and of course
you have to rebuild a source file if a header file changes.
I don't have time to implement it correctly, so I'm axing
the feature instead. If you want git versions in, e.g.,
nightly builds, please explicitly specify that when you feed
in the version.
Reviewed By: pjh5
Differential Revision: D10030556
fbshipit-source-id: 499d001c7b8ccd4ef15ce10dd6591c300c7df27d
Summary:
This makes a few changes wrt Type, with the ultimate goal of removing Type from the public Methods/Functions. In particular:
1) Removes factory functions from Type, into TypeExtendedInterface.
2) sparse_coo_tensor is now a first class at:: namespace function, with TensorOptions overloads.
3) We move from Type-based sparse_coo_tensor dispatch to function-based.
Note we still require a number of changes to get rid of tType in the public interface, in particular TensorOptions needs to support CUDA vs non-CUDA dispatch. That is coming in a future patch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12025
Reviewed By: ezyang
Differential Revision: D10017205
Pulled By: gchanan
fbshipit-source-id: 00807a37b09ed33f0656aaa165bb925abb026320
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12035
This brings it in line with Caffe2's naming
Reviewed By: mingzhe09088
Differential Revision: D10024485
fbshipit-source-id: a6feef82a56b5eb3043b0821ea802ba746e542a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12033
These are reasonable sensible default values. One key
pick is -1 for numel: this is because in Caffe2, a tensor
may be in "un-allocated" with no storage state; this is
historically represented in Caffe2 with numel_ == -1
Reviewed By: mingzhe09088
Differential Revision: D10024439
fbshipit-source-id: a167d727a7665daac7e7a1e98c0c89d8f1da6fa6
Summary: The controller you requested could not be found. Original commit changeset: 2ea17724e223
Differential Revision:
D10026321
Ninja: stable broken
fbshipit-source-id: faf87cb7cc0f78c2c10d4aa6fceea279cd27acd6
Summary:
As pytuple should be a constant type (since obj is constant), potential errors would occur without
this const decorator, e.g., when compiling against PyPy. Although PyPy is not supported yet, it
would still be useful if we remove this compilation issue (out of very few numbers of compilation
issues) to allow hackers playing with them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11857
Differential Revision: D10024149
Pulled By: soumith
fbshipit-source-id: aa7e08e58f6369233a11477113351dccd3854ba8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11923
This is pre-work to allow moving Blob to ATen/core, which cannot depend on caffe2 anymore.
(1) Removing the Blob -> Tensor dependency allows us to move Blob to ATen/core and use it inside IValue without having to wait for the Tensor merge to be complete.
(2) In the final Blob design, we want it to be a very small class that doesn't have any special treatment for Tensor (or to be more correct, doesn't allow storing Tensor anymore), so this is anyhow the direction we want to go.
This changes call sites that will have to be moved to IValue later, but they cannot be moved to IValue directly, because for that, IValue first needs to be able to store Blob, which in turn first needs this diff and some other changes coming up in future diffs.
Codemods:
$ codemod --extensions h,hpp,c,cpp,cc "([a-zA-Z0-9_]+)\\.IsTensorType\\(" "BlobIsTensorType(\\1, "
$ codemod --extensions h,hpp,c,cpp,cc "([a-zA-Z0-9_]+)->IsTensorType\\(" "BlobIsTensorType(*\\1, "
$ codemod --extensions h,hpp,c,cpp,cc "([a-zA-Z0-9_]+)\\.GetMutableTensor\\(" "BlobGetMutableTensor(\\1, "
$ codemod --extensions h,hpp,c,cpp,cc "([a-zA-Z0-9_]+)->GetMutableTensor\\(" "BlobGetMutableTensor(*\\1, "
It is, however, not only these codemods because regex based refactoring was only able to match a small amount of the call sites. To catch more, I wouldn've needed a AST aware tool like clangr, which I didn't figure out how to use.
Reviewed By: ezyang
Differential Revision: D9979976
fbshipit-source-id: 2ea17724e223b5b73b44f99362727759ca689e61
Summary:
Source build doc section **LAPACK GPU** only lists magma-cuda80
The magma-cuda version should reflect the installed version of cuda.
- Verified on ubuntu with magma-cuda92 with build and test
- Verified 91 is available
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12000
Differential Revision: D10024158
Pulled By: soumith
fbshipit-source-id: a34c85a5e87b52657f1e6f7b21d235306ab7b2aa
Summary:
The MPI async work class returned a temporary as reference, which is
invalid (hat tip to colesbury for noticing it). This change fixes that and
uses a std::exception_ptr to hold on to the exception if applicable, and
then returns the reference by throwing it and returning it, like the
existing code path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11947
Differential Revision: D10019928
Pulled By: pietern
fbshipit-source-id: 5a8ed0e894615a09224ca5e48c8b3104275a3019
Summary:
When running /test/onnx/test_models.py, we see deprecation warnings in the test points for `super_resolution` and `squeezenet` models. This change updates those models to use the recommended methods, instead of the deprecated ones.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11827
Reviewed By: houseroad
Differential Revision: D10023998
Pulled By: ezyang
fbshipit-source-id: ee4e14304678c532ebd574e7bd143e3b311995ab
Summary:
Because we emit a lot of them in our symbolic AD. This brings down the backward time of an LSTM I'm testing from 14.2ms to 12.5ms (a 15% improvement).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11801
Differential Revision: D9916815
Pulled By: apaszke
fbshipit-source-id: 2d9cb886c424ccd43b9f996aad89950d3bddf494
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11688
As a first step to remove static context(merge with allocator), we'll create a
global registries for context constructors, and remove CreateContext function from tensor.
Reviewed By: ezyang, dzhulgakov
Differential Revision: D9779821
fbshipit-source-id: 8b239ea50af7a0556fde2382f58f79194f0e3dc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12018
Tried to use the file and ran into a small bug, this fixes it
Differential Revision: D10013231
fbshipit-source-id: 4cf8c29cf9e2cedd7a28fa0cc0196e5144a54bf2
Summary:
Currently the C++ API and C++ extensions are effectively two different, entirely orthogonal code paths. This PR unifies the C++ API with the C++ extension API by adding an element of Python binding support to the C++ API. This means the `torch/torch.h` included by C++ extensions, which currently routes to `torch/csrc/torch.h`, can now be rerouted to `torch/csrc/api/include/torch/torch.h` -- i.e. the main C++ API header. This header then includes Python binding support conditioned on a define (`TORCH_WITH_PYTHON_BINDINGS`), *which is only passed when building a C++ extension*.
Currently stacked on top of https://github.com/pytorch/pytorch/pull/11498
Why is this useful?
1. One less codepath. In particular, there has been trouble again and again due to the two `torch/torch.h` header files and ambiguity when both ended up in the include path. This is now fixed.
2. I have found that it is quite common to want to bind a C++ API module back into Python. This could be for simple experimentation, or to have your training loop in Python but your models in C++. This PR makes this easier by adding pybind11 support to the C++ API.
3. The C++ extension API simply becomes richer by gaining access to the C++ API headers.
soumith ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11510
Reviewed By: ezyang
Differential Revision: D9998835
Pulled By: goldsborough
fbshipit-source-id: 7a94b44a9d7e0377b7f1cfc99ba2060874d51535
Summary:
Changes the result type of half type and any integer type to return half
type (instead of float or double).
This is based on top of #11808. The first new commit is "Make promoteType(half, integer) -> half". I'll rebase on top of master once that PR lands.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11941
Differential Revision: D10014122
Pulled By: colesbury
fbshipit-source-id: 16a5eb3406a5712069201d872d8736d0599e9411
Summary:
Or even taking them as inputs. This prevents optimizations to happen
either inside the differentiable subgraphs, or in the surrounding graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11809
Differential Revision: D10009680
Pulled By: apaszke
fbshipit-source-id: face638566228e470a6deec48dc2aa3a1cce26d4
Summary:
Old per-API+arch headers reside in
/opt/android_ndk/r*/platforms/android-*/arch-*/usr/include/
New Unified headers reside in
/opt/android_ndk/r*/sysroot/usr/include/
Unified headers are not exactly drop-in replacements for the old ones. Old headers had some nested includes that are absent in the unified versions, so we need to explicitly include them.
Reviewed By: mzlee
Differential Revision: D9952200
fbshipit-source-id: 6515e1d1ab576069db499c3fb23a69d507279c8c
Summary:
Some of these symbols are used by device_test.cc .
d0db23e95a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11965
Reviewed By: bwasti
Differential Revision: D10002439
Pulled By: bddppq
fbshipit-source-id: 4ae95b9c888b3c7685d0ffdbcbfa3441bcf90091
Summary:
This PR is a large codemod to rewrite all C++ API tests with GoogleTest (gtest) instead of Catch.
You can largely trust me to have correctly code-modded the tests, so it's not required to review every of the 2000+ changed lines. However, additional things I changed were:
1. Moved the cmake parts for these tests into their own `CMakeLists.txt` under `test/cpp/api` and calling `add_subdirectory` from `torch/CMakeLists.txt`
2. Fixing DataParallel tests which weren't being compiled because `USE_CUDA` wasn't correctly being set at all.
3. Updated README
ezyang ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11953
Differential Revision: D9998883
Pulled By: goldsborough
fbshipit-source-id: affe3f320b0ca63e7e0019926a59076bb943db80
Summary:
- fixes https://github.com/pytorch/pytorch/issues/10723
- migrate PReLU to ATen and deprecate legacy PReLU
- performance:
CPU with weight.numel() = 1
```
>>> m = nn.PReLU()
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
100 loops, best of 100: 9.43 ms per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
10 loops, best of 100: 24.4 ms per loop
>>> m = nn.PReLU()
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 695 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 2.47 ms per loop
```
CPU with weight.numel() = channels
```
>>> m = nn.PReLU(100)
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 603 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 13.3 ms per loop
>>> m = nn.PReLU(100)
>>> x = torch.randn(100, 100, 100, requires_grad=True)
>>> %timeit -r 100 y = m(x)
1000 loops, best of 100: 655 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 y.backward(retain_graph=True)
100 loops, best of 100: 2.45 ms per loop
```
CUDA with weight.numel() = 1
```
>>> m = nn.PReLU().cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
10000 loops, best of 100: 187 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.01 ms per loop
>>> m = nn.PReLU().cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
1000 loops, best of 100: 195 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.28 ms per loop
```
CUDA with weight.numel() = channel
```
>>> m = nn.PReLU(100).cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
1000 loops, best of 100: 174 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.27 ms per loop
>>> m = nn.PReLU(100).cuda()
>>> x = torch.randn(100, 100, 100, requires_grad=True).cuda()
>>> %timeit -r 100 torch.cuda.synchronize(); y = m(x); torch.cuda.synchronize();
10000 loops, best of 100: 181 µs per loop
>>> y = m(x).sum()
>>> %timeit -r 100 torch.cuda.synchronize(); y.backward(retain_graph=True); torch.cuda.synchronize();
100 loops, best of 100: 2.26 ms per loop
```
The huge performance regression in CPU when weight.numel() = 1 is addressed by replacing at::CPU_tensor_apply* with parallelized kernels.
ezyang SsnL zou3519 soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11758
Differential Revision: D9995799
Pulled By: weiyangfb
fbshipit-source-id: d289937c78075f46a54dafbde92fab0cc4b5b86e
Summary:
This eliminates the need for any heuristics regarding stack size limits.
This is a re-do #11534 with a fix to properly handle cases where
multiple edges exist between a pair of functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11611
Differential Revision: D9991198
Pulled By: resistor
fbshipit-source-id: fecd2c5cac7e78f82a0f20cf33268bb1617bb4a0
Summary:
Previously, aten::view returned a Dynamic type when attr::size is a prim::ListConstruct.
See [this for a repro](https://gist.github.com/zou3519/cbd610472ba3369f556fa612a7d93b28).
This prevented a pre-multipled lstm input graph from being fusible (aten::view is necessary
to do premultiplication).
If aten::view is passed an output of a prim::ListConstruct node, then shape prop should
be able to figure out its TensorType because we statically know the number of inputs to
prim::ListConstruct. This PR implements that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11877
Differential Revision: D9972356
Pulled By: zou3519
fbshipit-source-id: cb87786f6e7f222d4b8f07d8f2a9de34859cb6a5
Summary:
This is pretty important because a common situation of passing LSTM hidden states as a tuple completely trashes performance of a network.
Cleans up all our propagation/undef specialization passes, at a cost of increased complexity of `ArgumentSpec` and `GraphExecutor`. An alternative would be to simply flatten all tuple inputs to a graph ahead of time, but that might just end up being confusing in the future (you never know if you're working with a graph that can have tuple or not).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11863
Differential Revision: D9992814
Pulled By: apaszke
fbshipit-source-id: 0a565a3b23e32f8fa72c0534e07c1ce6187739fc
Summary:
Previously, we didn't cast any 0-dim tensors used in CUDA operations. We
can only avoid the casts for 0-dim CPU tensors used in CUDA operations.
Fixes#11795
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11808
Differential Revision: D9922406
Pulled By: colesbury
fbshipit-source-id: 940b8a8534770aa5cd70d5d09b96be0f0f8146ff
Summary:
- Disable addmm fusion. The reason for this is explained in the comment.
- Tiny change in `stack.h` that lets us avoid constructing an unnecessary temporary `IValue` on the (C++) stack (it will only get created on the interpreter stack directly).
- Fixed a correctness issue in requires grad propagation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11654
Reviewed By: colesbury
Differential Revision: D9813739
Pulled By: apaszke
fbshipit-source-id: 23e83bc8605802f39bfecf447efad9239b9421c3
Summary:
Spruriously added in #11261
I had a PR to catch these automatically (#11279), but it had some issues
passing on some CI environments but not others (e.g. for
`test_nn_group_norm`), any ideas?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11916
Differential Revision: D9992065
Pulled By: driazati
fbshipit-source-id: 05cfa8ed9af939e8ffd5827847ee7bfe0be799b2
Summary:
`-O0` is problematic for compiling sleef kernels since they consist of a bunch of vector intrinsics. In `-O0`, the compiler spills *every* intermediate value to the stack. In one example (TestEndToEndHybridFrontendModels.test_snli in test_jit.py) the function `Sleef_tanhf8_u10avx2` would spill 30kB of AVX registers onto the stack and run two orders of magnitude slower than in opt mode, causing the test to take minutes rather than seconds. I've verified that this behavior is not present with `-O1`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11942
Differential Revision: D9994658
Pulled By: jamesr66a
fbshipit-source-id: cdd9474c6ae3aa9898d5715ac19a900f5f90468a
Summary:
Deleted this section by mistake in last PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11938
Reviewed By: SsnL
Differential Revision: D9993258
Pulled By: brianjo
fbshipit-source-id: 2552178cebd005a1105a22930c4d128c67247378
Summary:
- fix PR https://github.com/pytorch/pytorch/pull/11061 by moving `detach_()` and `set_requires_grad()` to `torch.tensor_ctor()` and `tensor.new_tensor`, and also removed warnings and `args_requires_grad` from `internal_new_from_data `
- with this patch, the returned tensor from `tensor_ctor()` and `new_tensor` will be detached from source tensor, and set requires_grad based on the input args
- `torch.as_tensor` retains its behavior as documented
gchanan apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11815
Differential Revision: D9932713
Pulled By: weiyangfb
fbshipit-source-id: 4290cbc57bd449954faadc597c24169a7b2d8259
Summary:
We do this by being more NaN tolerant.
Fixes: #9062
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11933
Differential Revision: D9991129
Pulled By: soumith
fbshipit-source-id: c99b04462c1bee90d00eeabb0c111de12f855f4d
Summary:
The sample code in the docstring of `torch.jit.createResolutionCallback` is not working:
`createResolutionCallback()` gets the frame of `bar`. In order to get the frame of `baz`, one need to use `createResolutionCallback(1)`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11921
Differential Revision: D9989123
Pulled By: soumith
fbshipit-source-id: a7166defdccbbf6979f7df4c871298e6b9a2b415
Summary:
There are two parts:
- Optional tensors cannot be dispatch tensors because dispatch
tensors cannot be optional.
- While the kernel dealt with undefined grad_outs, the logistics
around it did not fully accomodate grad_hy being undefined.
Fixes: #11800
Thank you, mttk for the reproduction!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11872
Differential Revision: D9978527
Pulled By: apaszke
fbshipit-source-id: e622c288d2eac93bd8388e141fb773f2588e2b8f
Summary:
I also fix a bug that crept in while we had incorrect semantics where UndefinedTensorImpl was a CPU tensor, and thus some moves which shouldn't have been legal didn't crash. Moving out the Tensor* also moved out the Tensor* in the blob, and it's not supported to store an undefined tensor in a blob.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11738
Reviewed By: gchanan
Differential Revision: D9847859
fbshipit-source-id: db6be0f76a8e6526a89fd0e87b6a23b9cc820c8d
Summary:
This PR fixes#11913.
In order to test for this, the model is serialized twice in `getExportImportCopy`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11915
Differential Revision: D9984697
Pulled By: soumith
fbshipit-source-id: ae0250c179000c03db1522b99410f6ecb9681297
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11817
Blob::Serialize() and Blob::Deserialize() are now free functions SerializeBlob(), DeserializeBlob() instead.
This takes away access to Blob internals from them and makes future refactorings easier.
Reviewed By: ezyang
Differential Revision: D9882726
fbshipit-source-id: 3251ebd4b53fc12f5e6924a6e4a8db3846ab3729
Summary:
This PR serves two purposes:
1. Design an abstraction over a serialization scheme for C++ modules, optimizers and tensors in general,
2. Add serialization to the ONNX/PyTorch proto format.
This is currently a rough prototype I coded up today, to get quick feedback.
For this I propose the following serialization interface within the C++ API:
```cpp
namespace torch { namespace serialize {
class Reader {
public:
virtual ~Reader() = default;
virtual void read(const std::string& key, Tensor& tensor, bool is_buffer = false) = 0;
virtual void finish() { }
};
class Writer {
public:
virtual ~Reader() = default;
virtual void writer(const std::string& key, const Tensor& tensor, bool is_buffer = false) = 0;
virtual void finish() { }
};
}} // namespace torch::serialize
```
There are then subclasses of these two for (1) Cereal and (2) Protobuf (called the "DefaultWriter" and "DefaultReader" to hide the implementation details). See `torch/serialize/cereal.h` and `torch/serialize/default.h`. This abstraction and subclassing for these two allows us to:
1. Provide a cereal-less serialization forward that we can ship and iterate on going forward,
2. Provide no-friction backwards compatibility with existing C++ API uses, mainly StarCraft.
The user-facing API is (conceptually):
```cpp
void torch::save(const Module& module, Writer& writer);
void torch::save(const Optimizer& optimizer, Writer& writer);
void torch::read(Module& module, Reader& reader);
void torch::read(Optimizer& optimizer, Reader& reader);
```
with implementations for both optimizers and modules that write into the `Writer` and read from the `Reader`
ebetica ezyang zdevito dzhulgakov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11619
Differential Revision: D9984664
Pulled By: goldsborough
fbshipit-source-id: e03afaa646221546e7f93bb8dfe3558e384a5847
Summary:
- Finishes unifying Half type in pytorch and caffe2
- As a side effect, aten_op works for fp16 now
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11676
Reviewed By: weiyangfb
Differential Revision: D9829019
Pulled By: li-roy
fbshipit-source-id: b8c9663873c10fe64c90ef180dc81af2e866674e
Summary:
This PR contains changes for:
1. Performance enhancements for group conv using MIOpen
2. Performance enhancements by removing unnecessary computations while running pooling through MIOpen
3. Added check for bwdData comptutation while running MIOpen convGradient operator
4. Fix in MIOpen poolingGradient operator to compute window size for global pooling case
5. Minor code cleanup in MIOpen spatial batch norm operator
Differential Revision: D9979050
Pulled By: bddppq
fbshipit-source-id: fabc7a44a2f9ca0307d99564d1ce8fe1de9a6fbb
Summary:
Python never closes shared library it `dlopen`s. This means that calling `load` or `load_inline` (i.e. building a JIT C++ extension) with the same C++ extension name twice in the same Python process will never re-load the library, even if the compiled source code and the underlying shared library have changed. The only way to circumvent this is to create a new library and load it under a new module name.
I fix this, of course, by introducing a layer of indirection. Loading a JIT C++ extension now goes through an `ExtensionVersioner`, which hashes the contents of the source files as well as build flags, and if this hash changed, bumps an internal version stored for each module name. A bump in the version will result in the ninja file being edited and a new shared library and effectively a new C++ extension to be compiled. For this the version name is appended as `_v<version>` to the extension name for all versions greater zero.
One caveat is that if you were to update your code many times and always re-load it in the same process, you may end up with quite a lot of shared library objects in your extension's folder under `/tmp`. I imagine this isn't too bad, since extensions are typically small and there isn't really a good way for us to garbage collect old libraries, since we don't know what still has handles to them.
Fixes https://github.com/pytorch/pytorch/issues/11398 CC The controller you requested could not be found.
ezyang gchanan soumith fmassa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11725
Differential Revision: D9948244
Pulled By: goldsborough
fbshipit-source-id: 695bbdc1f1597c5e4306a45cd8ba46f15c941383
Summary:
This patch adds fused forward and backward for clamp to the jit.
This is one item of #11118 . If it's OK, I'd be happy to also add some more of #11118 .
The patch depends on #11150 , which I merged into master as a base. I'll rebase it when that or #10981 is merged.
This is first serious jit patch, thank you, ngimel and the others for their guidance. All errors are my own.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11574
Differential Revision: D9943090
Pulled By: apaszke
fbshipit-source-id: c40954b8c28c374baab8d3bd89acc9250580dc67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11893
This is needed to run binaries compiled with CUDA support on on CPU-only machines.
Reviewed By: teng-li
Differential Revision: D9972872
fbshipit-source-id: 7e4107925b3cd4d2fcf84ae532e800ab65f4b563
Summary:
Fixes#11518
Upstream PR submitted at https://gitlab.kitware.com/cmake/cmake/merge_requests/2400
On some embedded platforms, the NVIDIA driver is verbose logging unexpected output to stdout.
One example is Drive PX2, where we see something like this whenever a CUDA program is run:
```
nvrm_gpu: Bug 200215060 workaround enabled.
```
This patch does a regex on the output of the architecture detection program to only capture architecture patterns.
It's more robust than before, but not fool-proof.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11851
Differential Revision: D9968362
Pulled By: soumith
fbshipit-source-id: b7952a87132ab05c724b287b76de263f1f671a0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11710
Added a test to check that output and gradient values are correctly
calculated wehn combine_spatial_bn is true on data parallel model
Reviewed By: enosair
Differential Revision: D9833660
fbshipit-source-id: 14d29fbebefa9dc303ffae06f9899ea4bde23025
Summary:
Two improvements to C++ extensions:
1. In verbose mode, show the ninja build output (the exact compile commands, very useful)
2. When raising an error, don't show the `CalledProcessError` that shows ninja failing, only show the `RuntimeError` with the captured stdout
soumith fmassa ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11724
Differential Revision: D9922459
Pulled By: goldsborough
fbshipit-source-id: 5b319bf24348eabfe5f4c55d6d8e799b9abe523a
Summary:
Following through on warning that indexing 0-dim tensor would be an
error in PyTorch 0.5 and to use `item()` instead
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11679
Reviewed By: soumith
Differential Revision: D9833570
Pulled By: driazati
fbshipit-source-id: ac19f811fa7320d30b7f60cf66b596d6de684d86
Summary:
This fixes the numerical problem in log_softmax cpu code when inputs are big but their differences are small.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11866
Differential Revision: D9946799
Pulled By: soumith
fbshipit-source-id: 11fe8d92b91ef6b7a66f33fbce37ec2f0f0929be
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11816
The file isn't in the std:: namespace, so is_same
must be qualified.
Reviewed By: smessmer
Differential Revision: D9923774
fbshipit-source-id: 126532e27f08b5616ca46be1293d5d837920f588
Summary:
+ https://github.com/pytorch/pytorch/issues/10236 : torch.bernoulli's out kwarg is broken
fixed in moving `bernoulli_out` to ATen
+ https://github.com/pytorch/pytorch/issues/9917 : BUG torch.bernoulli(p.expand(shape)) is broken
fixed in moving all `bernoulli` ops in ATen to use the modern apply utils methods
+ https://github.com/pytorch/pytorch/issues/10357 : torch.bernoulli inconsistent gpu/cpu results
fixed by adding CUDA asserts
In order to use `curand_uniform4`, I made some changes to `CUDAApplyUtils.cuh`. Specifically, I introduced an optional template parameter `int step` to the `CUDA_tensor_applyN` methods, representing that we want to process `step` values at each time for each of the `N` tensors.
The calling convention for `step = 1` (default) isn't changed. But if `step > 1`, the given lambda `op` must take in `int n` as its first argument, representing the number of valid values, because there may not be full `step` values at the boundary. E.g., here is what the `bernoulli(self, p_tensor)` call look like:
```cpp
// The template argument `4` below indicates that we want to operate on four
// element at each time. See NOTE [ CUDA_tensor_applyN helpers ] for details.
at::cuda::CUDA_tensor_apply2<scalar_t, prob_t, 4>(
ret, p,
[seeds] __device__(
int n, scalar_t& v1, scalar_t& v2, scalar_t& v3, scalar_t& v4,
const prob_t& p1, const prob_t& p2, const prob_t& p3, const prob_t& p4) {
curandStatePhilox4_32_10_t state;
curand_init(
seeds.first,
blockIdx.x * blockDim.x + threadIdx.x,
seeds.second,
&state);
float4 rand = curand_uniform4(&state);
switch (n) {
case 4: {
assert(0 <= p4 && p4 <= 1);
v4 = static_cast<scalar_t>(rand.w <= p4);
}
case 3: {
assert(0 <= p3 && p3 <= 1);
v3 = static_cast<scalar_t>(rand.z <= p3);
}
case 2: {
assert(0 <= p2 && p2 <= 1);
v2 = static_cast<scalar_t>(rand.y <= p2);
}
case 1: {
assert(0 <= p1 && p1 <= 1);
v1 = static_cast<scalar_t>(rand.x <= p1);
}
}
}
);
```
Benchmarking on `torch.rand(200, 300, 400)` 20 times, each time with 20 loops:
post patch
```
➜ ~ numactl --cpunodebind 1 --membind 1 -- taskset -c 12,13,14,15,16,17,18,19,20,21,22,23 env CUDA_LAUNCH_BLOCKING=1 python bern.py
torch.bernoulli(x)
6.841588497161865 +- 0.05413117632269859
torch.bernoulli(xc)
0.05963418632745743 +- 0.0008014909108169377
x.bernoulli_()
0.4024486541748047 +- 0.0021550932433456182
xc.bernoulli_()
0.02167394384741783 +- 2.3818030967959203e-05
```
pre-patch
```
➜ ~ numactl --cpunodebind 1 --membind 1 -- taskset -c 12,13,14,15,16,17,18,19,20,21,22,23 env CUDA_LAUNCH_BLOCKING=1 python bern.py
torch.bernoulli(x)
12.394511222839355 +- 0.0966421514749527
torch.bernoulli(xc)
0.08970972150564194 +- 0.0038722590543329716
x.bernoulli_()
1.654480218887329 +- 0.02364428900182247
xc.bernoulli_()
0.058352887630462646 +- 0.003094920190051198
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10273
Differential Revision: D9831294
Pulled By: SsnL
fbshipit-source-id: 65e0655a36b90d5278b675d35cb5327751604088
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11875
Seems like the refactor to predictor_config dropped some functionality that is now blocking other teams
rFBS2b30208263c14ce7039f27c618a3b232bf11ee33 is the change that was missed
hoping to land this quickly :)
Reviewed By: jonmorton
Differential Revision: D9948324
fbshipit-source-id: 1628f7c51c06319fa7ca5dc9d59799135bb82c5f
Summary:
A missing environment variable raised a missing key error. Now it
raises a more descriptive error of the actual problem, for example:
ValueError: Error initializing torch.distributed using env:// rendezvous: environment variable WORLD_SIZE expected, but not set
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11782
Differential Revision: D9888962
Pulled By: pietern
fbshipit-source-id: 5947e7a7bf7aa45f13bbd7b5e997529f26cc92d6
Summary:
This PR adds empty sparse tensor tests to `test_sparse.py`, and also fix various places in internal code to make the tests pass.
**[NOTE] API CHANGE:**
- `coalesce` on sparse tensor will always be performed out-of-place now (meaning the original tensor will never be affected)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11228
Differential Revision: D9930449
Pulled By: yf225
fbshipit-source-id: 7c62439b216a6badf7938a10741c358ff18a556d
Summary:
To illustrate the benefits of this commit, I'll use the time/iter I got from one of the JIT benchmarks on my machine.
| Run | Time |
|----------------------------------------------|-------------------------|
| No profiler | 45ms |
| With profiler | 56ms |
| Use `clock_gettime` instead of `std::chrono` | 48ms |
| Touch all pages on block allocation | 48ms (less jitter) |
| Use `const char*` instead of `std::string` | 47ms (even less jitter) |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11773
Differential Revision: D9886858
Pulled By: apaszke
fbshipit-source-id: 58f926f09e95df0b11ec687763a72b06b66991d0
Summary:
I noticed I was including `torch/nn/pimpl.h` in the optimizer library just to access `TORCH_ARG`, even though that file includes a lot of irrelevant code. Let's save some re-compilation time by refactoring this macro into a separate logical file. #small-wins
ebetica ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11787
Differential Revision: D9924447
Pulled By: goldsborough
fbshipit-source-id: 5acd4ba559ffb2a3e97277e74bb731d7b1074dcf
Summary:
currently grad assignment for half type fails with a misleading RuntimeError
```
RuntimeError: torch.cuda.sparse.HalfTensor is not enabled.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11781
Differential Revision: D9931884
Pulled By: soumith
fbshipit-source-id: 03e946c3833d1339a99585c9aa2dbb670f8bf459
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11779
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11731
This Predictor provides threadsafe interface and also
cleans-up activations after each run. So in multi-model setup
activation space doesn't explode
Reviewed By: highker
Differential Revision: D9842374
fbshipit-source-id: bfe253ae5fc813e73a347c5147ff6b58d50781ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11704
Add plan name to the logging in RunPlan
Reviewed By: Tianshu-Bao
Differential Revision: D9802416
fbshipit-source-id: 45c359dba0a5d992e303b3cdcf34624881a631d8
Summary:
Currently one of our GPU perf tests `test_gpu_speed_mnist` reports NaN after this commit (https://github.com/pytorch/pytorch/pull/8018), and we didn't have the logic in place to raise error when this happens. This PR fixes the problem and will also update the baseline properly even if its previous value is NaN.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11588
Differential Revision: D9831798
Pulled By: yf225
fbshipit-source-id: b95eee38d69b3b8273f48b8ac7b7e0e79cf756ed
Summary:
Adds some pretty-printing capability to the IR graph to make debugging easier/more human readable, see `torch/csrc/jit/test_jit.cpp:925` and onwards for example outputs. Results aren't perfect yet but it's a start.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10319
Reviewed By: zdevito
Differential Revision: D9558402
Pulled By: driazati
fbshipit-source-id: 1d61c02818daa4c9bdca36d1477d1734cfc7d043
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11818
To do this, I have to move the static context registry into ATen/core.
I take the opportunity to convert it into an unordered_map.
Reviewed By: Yangqing
Differential Revision: D9924348
fbshipit-source-id: 8d92b9e8b4246ce608eba24ecef7ad5f8b9b6582
Summary:
This should not be there since logging does not depend on protobuf.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11814
Reviewed By: ezyang
Differential Revision: D9923819
Pulled By: Yangqing
fbshipit-source-id: 4d4edaea1a2e317f5db6e92c35d58c85dd35c5fb
Summary:
The PR fixes#10873
The context is aten::add and aten::sub ST overloads don't have alpha, so onnx symbolic does not match.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10972
Reviewed By: jamesr66a
Differential Revision: D9724224
Pulled By: wanchaol
fbshipit-source-id: eb5d1b09fa8f1604b288f4a62b8d1f0bc66611af
Summary:
For example, outputs of control blocks often have Dynamic type, and when we try to export them to ONNX we get an invalid proto, since `elem_type` is not populated on the TypeInfoProto. This makes it so at least we can get past the checker, since having a dynamic typed output from a control block should still be semantically valid
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11810
Differential Revision: D9922754
Pulled By: jamesr66a
fbshipit-source-id: 5c66113cc302a9d9b8b9f5a8605473d3c6ad5af1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11805
Some of our headers in Caffe2 pollute the macro namespace with things like MAX,
MIN, CHECK, so I renamed these in places where this is a problem.
This patch courtesy of gchanan, extracted out of #11721
Reviewed By: Yangqing
Differential Revision: D9917757
fbshipit-source-id: 17fc692ca04b208dcb8ae00731ed60e393284f7c
Summary:
I have no idea how to run distributed tests locally so I'll let CI do this. Hopefully everything still works with `IntEnum`.
cc mcarilli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11715
Reviewed By: pietern
Differential Revision: D9889646
Pulled By: SsnL
fbshipit-source-id: 1e2a487cb6fe0bd4cc67501c9d72a295c35693e2
Summary:
Followup to [the serialized test framework](https://github.com/pytorch/pytorch/pull/10594)
Round 1 for refactoring tests, starting alphabetically. I added some functionality, so I wanted to send out some of these initial changes sooner.
I'm skipping all tests that don't explicitly call assertReferenceChecks. Some tests directly call np.allclose, and others are simply TestCase (rather than HypothesisTestCase).
1. Start alphabetically producing serialized outputs for test functions, annotating those we want to include with `serialized_test_util.given`. So far I've only added one test per operator, but this already does seem to add quite a few tests.
2. Add functionality to allow us to generate outputs using pytest by adding pytest argument options. This allows us to skip adding a `__main__` function to quite a few tests.
3. Catch any exceptions generating the gradient operator and skip serializing/reading it, since certain operators don't have gradients.
4. Add functionality to better handle jagged array inputs, which numpy doesn't handle very well. We simply explicitly do the conversion to dtype=object.
5. Make only one file per test function, rather than 4, to reduce the number of files in the github repo.
I also noticed that there is some hypothesis handling that makes `serialized_test_util.given` not compatible with adding more hypothesis decorators on top. For example, there are tests that do
```
settings(...)
given(...)
def test_my_stuff(...)
```
But there is a hypothesis handler that explicitly checks that `given` is called below `settings`, so we cannot refactor this to `serialized_test_util.given`. I've just avoided decorating these kinds of tests for now, I hope that's alright.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11350
Reviewed By: houseroad
Differential Revision: D9693857
Pulled By: ajyu
fbshipit-source-id: a9b4279afbe51c90cf2025c5ac6b2db2111f4af7
Summary:
This PR adds empty sparse tensor tests to `test_sparse.py`, and also fix various places in internal code to make the tests pass.
**[NOTE] API CHANGE:**
- `coalesce` on sparse tensor will always be performed out-of-place now (meaning the original tensor will never be affected)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11228
Differential Revision: D9755189
Pulled By: yf225
fbshipit-source-id: e9d36f437db1a132c423d3a282ff405a084ae7cc
Summary:
Adds vararg support for meshgrid and adds checks for all the tensor arguments to have the same dtype and device.
Fixes: [#10823](https://github.com/pytorch/pytorch/issues/10823), #11446
The earlier pull request closed without any changes because I had some rebasing issues, so I made another pull request to close out #10823. Sorry for the inconvenience.
Differential Revision: D9892876
Pulled By: ezyang
fbshipit-source-id: 93d96cafc876102ccbad3ca2cc3d81cb4c9bf556
Summary:
Simple change to allow ModuleList subclasses's `__getitem__(slice)` to return class of subclass rather than ModuleList
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11694
Differential Revision: D9892824
Pulled By: ezyang
fbshipit-source-id: b75e9c196487f55cb93f0dab6c20d850e8e759ff
Summary:
Related to #11624 adding maxes to the function def of embedding_bag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11784
Differential Revision: D9892598
Pulled By: ezyang
fbshipit-source-id: e6372ccf631826ddf1e1885b2f8f75f354a36c0b
Summary:
Since we're making parts of the JIT public as part of loading script modules, they should be on the cppdocs website.
Orthogonal: We decided not to export things like `IValue` into the `torch` namespace, so `RegisterOperators` shouldn't be there either.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11712
Differential Revision: D9837578
Pulled By: goldsborough
fbshipit-source-id: 4c06d2fa9dd4b4216951f27424c2ce795febab9c
Summary:
tset_potri -> test_potri, even though it has been like this for a long time
More a curiosity than grave functionality...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11770
Reviewed By: ezyang
Differential Revision: D9884767
Pulled By: soumith
fbshipit-source-id: 9bedde2e94ade281ab1ecc2293ca3cb1a0107387
Summary:
I was reading this a couple times before figuring out it's also the entry point for the MPI_COMM_WORLD.
Reordered statements and added comment to clarify.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11764
Differential Revision: D9882834
Pulled By: pietern
fbshipit-source-id: a9282d55368815925fd695a2541354e5aec599da
Summary:
The PR aims to resolve issues related to BUILD_PYTHON and BUILD_TEST after FULL_CAFFE2 is removed on Windows.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11385
Reviewed By: orionr
Differential Revision: D9884906
Pulled By: mingzhe09088
fbshipit-source-id: fc114c0cbff6223f1ec261161e4caecc1fef5dd6
Summary:
```
I'm using AT_HOST_DEVICE outside of Half.h in an upcoming PR. Since this
changes code without making any semantic changes, I wanted to make this
change in a separate PR.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10945
Differential Revision: D9539821
Pulled By: colesbury
fbshipit-source-id: 0daae40ea78b077a543f7bfeec06b225634540de
Summary:
We now have CI machines with different number of amd gpus.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11771
Differential Revision: D9889837
Pulled By: bddppq
fbshipit-source-id: dacf728a282f209e3f2419da186e59528a08ca6a
Summary:
The second part of T32009899
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11556
Differential Revision: D9888224
Pulled By: zrphercule
fbshipit-source-id: cb0d0ba5d9c7ad601ee3bce0d932ce9cbbc40908
Summary: Cleaning up converter.cc and allowing networks that have "pass through" inputs (that are also outputs but aren't actually consumed by the network)
Reviewed By: duc0
Differential Revision: D9759435
fbshipit-source-id: 1ddfcc60a1b865a06682e4022230dfecc4b89ec3
Summary:
It is currently tedious to change code generation because it takes two steps: change the code gen, then gen.py fails because of file mismatch. Just add an environment option of generating directly to source.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11759
Differential Revision: D9867259
Pulled By: gchanan
fbshipit-source-id: 3cf8024d9e302f382cf8b8a44cb843fb086f8597
Summary:
This fixes#8515 which was mostly issues in the test themselves. As long
as `math` is imported in the scope in which the script runs it resolves
to a `prim::Constant` with value `inf` correctly. This PR adds this to
the `test_jit.py` tests involving `inf` and adds a test to demonstrate
`inf` in a non-generated test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11302
Differential Revision: D9684336
Pulled By: driazati
fbshipit-source-id: 73df2848dfdb45ab50690a7c88df8fda269a64eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11748
For avx512, we need to align at a multiple of 64B not 32B
Regardless of avx512, it's in general a good idea to be cache line aligned.
Reviewed By: ilia-cher
Differential Revision: D9845056
fbshipit-source-id: b1d3ed67749c0c1a64acd5cc230a1279e8023512
Summary:
I'm just doing the honors and bumping the version to 1.0.0.
1.0 preview and RC releases will have the 1.0.0.dev{date} tag
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11717
Reviewed By: SsnL
Differential Revision: D9840857
Pulled By: soumith
fbshipit-source-id: 4c9c2e01dccb3c521dab26c49e1569d970a87ace
Summary:
Previously, it was a necessity to include TensorMethods.h after Tensor.h in order to get the tensor method definitions.
We abstracted this away from users by making sure ATen.h did this correctly; but we don't have any equivalent for ATen/core.
In order to solve this dependency issue, we now forward declare Tensor in the Type declaration, which breaks the dependency cycle.
Type.h now includes Tensor.h (for backwards compatibility) and Tensor.h now includes TensorMethods.h, so there is no longer include dependency restrictions.
We could get rid of TensorMethods.h completely now, but that would involve coordinating a code generation change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11720
Reviewed By: ezyang
Differential Revision: D9841488
Pulled By: gchanan
fbshipit-source-id: 1668199095e096c1790e646b5dc9f61ec1b33c0a
Summary:
A couple fixes I deem necessary to the TorchScript C++ API after writing the tutorial:
1. When I was creating the custom op API, I created `torch/op.h` as the one-stop header for creating custom ops. I now notice that there is no good header for the TorchScript C++ story altogether, i.e. when you just want to load a script module in C++ without any custom ops necessarily. The `torch/op.h` header suits that purpose just as well of course, but I think we should rename it to `torch/script.h`, which seems like a great name for this feature.
2. The current API for the CMake we provided was that we defined a bunch of variables like `TORCH_LIBRARY_DIRS` and `TORCH_INCLUDES` and then expected users to add those variables to their targets. We also had a CMake function that did that for you automatically. I now realized a much smarter way of doing this is to create an `IMPORTED` target for the libtorch library in CMake, and then add all this stuff to the link interface of that target. Then all downstream users have to do is `target_link_libraries(my_target torch)` and they get all the proper includes, libraries and compiler flags added to their target. This means we can get rid of the CMake function and all that stuff. orionr AFAIK this is a much, much better way of doing all of this, no?
3. Since we distribute libtorch with `D_GLIBCXX_USE_CXX11_ABI=0`, dependent libraries must set this flag too. I now add this to the interface compile options of this imported target.
4. Fixes to JIT docs.
These could likely be 4 different PRs but given the release I wouldn't mind landing them all asap.
zdevito dzhulgakov soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11682
Differential Revision: D9839431
Pulled By: goldsborough
fbshipit-source-id: fdc47b95f83f22d53e1995aa683e09613b4bfe65
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11706
This is necessary to handle use-cases when Storage is not set (because the
tensor in question doesn't have a notion of storage.)
Reviewed By: orionr
Differential Revision: D9833361
fbshipit-source-id: e90a384019f44f57682b687d129b54e85b6fabb9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11701
There's one extra multiply from TypeMeta::itemsize() which needs
to be characterized. For all existing Caffe2 uses, storage_offset
is zero.
Reviewed By: li-roy
Differential Revision: D9831230
fbshipit-source-id: 353678edf76d2ccc297a73475a34f6ab2a20d1e1
Summary:
This will allow us to break the dependency cycle between Tensor and Type, because currently Type has defaulted Tensor (reference) arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11675
Reviewed By: ezyang
Differential Revision: D9819720
Pulled By: gchanan
fbshipit-source-id: a9577ac34a358120075129ab0654e7862d1dace6
Summary:
This way it shows up in all current and future setup.py commands, as otherwise we'd have to override every once to have them all call copy_protos. This is needed because the nightly packages still do not include caffe2_pb2, because setup.py bdist does not go through setup.py install or setup.py develop
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11726
Reviewed By: orionr
Differential Revision: D9844075
Pulled By: pjh5
fbshipit-source-id: 57b469e48010aacd0c08c214ba8a7e5d757feefa
Summary:
We use these annotations during function declarations, not definitions. See the description of compiler error [C2491](https://msdn.microsoft.com/en-us/library/62688esh.aspx) for more details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11367
Reviewed By: ezyang
Differential Revision: D9697923
Pulled By: orionr
fbshipit-source-id: 1e539c02957851386f887e6d0510ce83117a1695
Summary:
This PR vectorizes the CPU grid sample 2d forward and backward kernels. Specifically,
1. add `.data()` in `TensorAccessor`
2. support non-void return value for declaring CPU kernel stub
2. add `bool at:: geometry_is_contiguous(IntList sizes, IntList strides)`
1. The following vectorized CPU primitives are added:
+ `gather<scale>(baseaddr, vindex)`: `result[i] = baseaddr[vindex[i] * scale]`
+ `mask_gather<scale>(src, baseaddr, vindex, mask)`: `result[i] = mask[i] ? baseaddr[vindex[i] * scale] : src[i]`.
+ comparison ops
+ binary logical ops
+ `min(a, b)`
+ `cast<dst_t, src_t>(src_vec)`: changing dtype but keeping the bit representation
+ `blendv(a, b, mask)`: `result[i] = mask[i] ? b[i] : a[i]`.
+ ctor with multiple values (i.e., `setr`)
+ `arange(start = 0, step = 1)`: constructs a vector with values specified by the arange parameters
+ `convert_to_int_of_same_size(vec)`: convert floating point vector to corresponding integral type of same size
+ `interleave2(a, b)` & `deinterleave2(x, y)`: interleave or deinterleaves two vectors. E.g., for `interleave`:
```
inputs:
{a0, a1, a2, a3, a4, a5, a6, a7}
{b0, b1, b2, b3, b4, b5, b6, b7}
outputs:
{a0, b0, a1, b1, a2, b2, a3, b3}
{a4, b4, a5, b5, a6, b6, a7, b7}
```
2. Grid sample CPU kernel implementations are described in the following note (also in `GridSampleKernel.cpp`:
```
NOTE [ Grid Sample CPU Kernels ]
Implementation of vectorized grid sample CPU kernels is divided into three
parts:
1. `ComputeLocation` struct
Transforms grid values into interpolation locations of the input tensor
for a particular spatial dimension, basing on the size of that dimension
in input tensor, and the padding mode.
```
```cpp
template<typename scalar_t, GridSamplerPadding padding>
struct ComputeLocation {
using Vec = Vec256<scalar_t>;
// ctor
ComputeLocation(int64_t size);
// Given grid values `in`, return the interpolation locations after
// un-normalization and padding mechanism (elementwise).
Vec apply(const Vec &in) const;
// Similar to `apply`, but also returns `d apply(in) / d in`
// (elementwise).
// this is often used in gradient computation.
std::pair<Vec, Vec> apply_get_grad(const Vec &in) const;
};
```
```
2. `ApplyGridSample` struct
Owns N `ComputeLocation` structs, where N is the number of spatial
dimensions. Given N input grid vectors (one for each spatial dimension)
and spatial offset, it gets the interpolation locations from
`ComputeLocation`s, applies interpolation procedure, and then writes to
the output (or grad_input & grad_grid in backward).
```
```cpp
template<typename scalar_t, int spatial_dim,
GridSamplerInterpolation interp,
GridSamplerPadding padding>
struct ApplyGridSample {
// ctor
ApplyGridSample(const TensorAccessor<scalar_t, 4>& input);
// Applies grid sampling (forward) procedure:
// 1. computes interpolation locations from grid values `grid_x` and
// `grid_y`,
// 2. interpolates output values using the locations and input data
// in `inp_slice`, and
// 3. writes the first `len` values in the interpolated vector to
// `out_slice` with spatial offset being `offset`.
//
// This assimes that `grid_x` and `grid_y` all contain valid grid
// values \in [-1, 1], even at indices greater than `len`.
//
// The `*_slice` argument namess mean samples within a batch (i.e.,
// with the batch dimension sliced out).
void forward(TensorAccessor<scalar_t, 3>& out_slice,
const TensorAccessor<scalar_t, 3>& inp_slice,
int64_t offset, const Vec& grid_x, const Vec& grid_y,
int64_t len) const;
// Applies grid sampling (backward) procedure. Arguments semantics
// and strategy are similar to those of `forward`.
void backward(TensorAccessor<scalar_t, 3>& gInp_slice,
TensorAccessor<scalar_t, 3>& gGrid_slice,
const TensorAccessor<scalar_t, 3>& gOut_slice,
const TensorAccessor<scalar_t, 3>& inp_slice,
int64_t offset, const Vec& grid_x, const Vec& grid_y,
int64_t len) const;
}
```
```
3. `grid_sample_2d_grid_slice_iterator` function
Among the tensors we work with, we know that the output tensors are
contiguous (i.e., `output` in forward, and `grad_input` & `grad_grid` in
backward), we need to randomly read `input` anyways, and `grad_output`
usually comes from autograd and is often contiguous. So we base our
iterating strategy on the geometry of grid.
`grid_sample_2d_grid_slice_iterator` function provides an abstract to
efficiently iterates through a `grid` slice (without batch dimension).
See comments of that function on the specific cases and strategies used.
```
```cpp
template<typename scalar_t, typename ApplyFn>
void grid_sample_2d_grid_slice_iterator(
const TensorAccessor<scalar_t, 3>& grid_slice,
const ApplyFn &apply_fn);
// `apply_fn` is a function/lambda that can be called as if it has
// declaration:
// void apply_fn(const Vec256<scalar_t>& grid_x,
// const Vec256<scalar_t>& grid_y,
// int64_t spatial_offset, int64_t len);
```
```
`apply_fn` will be called multiple times, and together cover the entire
output spatial space. Therefore, e.g., to implement forward 2d grid
sample, we can do
```
```cpp
ApplyGridSample<scalar_t, 2, interp, padding> grid_sample(input_accessor);
for (int n = 0; n < input_accessor.size(0); n++) {
grid_sample_2d_grid_slice_iterator(
grid_accessor[n],
[&](const Vec256<scalar_t>& grid_x, const Vec256<scalar_t>& grid_y,
int64_t spatial_offset, int64_t len) {
grid_sample.forward(out_accessor[n], input_accessor[n],
spatial_offset, grid_x, grid_y, len);
});
}
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10980
Differential Revision: D9564867
Pulled By: SsnL
fbshipit-source-id: 5b7c3c7ea63af00eec230ae9ee1c3e6c6c9679b4
Summary:
Changing `max` to `fmaxf` in `LabelCrossEntropy` kernel for hip to work correctly.
bddppq petrex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11733
Differential Revision: D9846783
Pulled By: bddppq
fbshipit-source-id: c1b394d2ba7ee0e819f7bf3b36b53d1962de5522
Summary:
Fixes#11452 .
Based on the discussion with SsnL and soumith , we want to bring back Upsample as a module instead of introducing a new nn.interpolate module for now. If anyone want to do downsample, they should use `nn.functional.interpolate ` instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11568
Differential Revision: D9804359
Pulled By: ailzhang
fbshipit-source-id: 2b232d55fc83c2b581bf336f1ee8d1cf1c1159ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11355
There is no reason to implement refcounting manually in this case.
Given the correct NullType, toIntrusivePtr() and moveToIntrusivePtr() will do the right thing.
Reviewed By: ezyang
Differential Revision: D9694918
fbshipit-source-id: 8aae4d66aec32ca5f85c438d66339bd80b72b656
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11353
Before, there was one extra member in the union that had to be at least as large as the largest other member, because it was used for copying.
Now, this isn't needed anymore and we copy the union directly.
Reviewed By: ezyang
Differential Revision: D9694326
fbshipit-source-id: 42b2f7d51ac5d4ea5ebafea3a598b018e10fed68
Summary:
Current behavior is that each process (main and workers) will print trace from `KeyboardInterrupt`. And the main process will also print
```
RuntimeError: DataLoader worker (pid 46045) exited unexpectedly with exit code 1. Details are lost due to multiprocessing. Rerunning with nm_workers=0 may give better error trace.
```
due to our SIGCLD handler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11718
Differential Revision: D9840844
Pulled By: SsnL
fbshipit-source-id: 1a05060bb02907fef5aac3f274d2c84f9f42d187
Summary:
Otherwise each build produces 65MB of warnings log, which makes the CI hard to debug.
iotamudelta Jorghi12
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11698
Differential Revision: D9840356
Pulled By: bddppq
fbshipit-source-id: b69bf6a5c38a97b188221f9c084c608ffc9b37c8
Summary:
1. Document the Sequential module in the C++ API at a high, why-does-this-exist, and low, how-to-use, level
2. Change the Sequential tests to be in a style that makes them easier to convert to gtest. No code changes.
ebetica ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11648
Differential Revision: D9834526
Pulled By: goldsborough
fbshipit-source-id: 39f2f5c6cbbf8ed5a1b69986978c8ef127036de1
Summary:
This PR splits the CPU and CUDA fusion compilers, putting them into a new jit/fusers/ directory with jit/fusers/common for common components. In particular:
- A fusion interface is created that allows "fusion handles" to be requested
- The CPU and CUDA fusers implement this interface, with dispatch determined by device
- The fusion compilers, fusion function specializations and resource strings are split
- CPU-specific classes like TempFile and DynamicLibrary are in the CPU fuser
- Common classes likes TensorDesc and the base fusion function class are in jit/fusers/common
- There is still some specialization in jit/fusers/common, but these specializations are small(-ish)
- Updates the build system to remove the dummy interface on Windows and minimize the use of macros
This structure should allow in-flight PRs to easily rebase while providing a clear interface to the fusers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10981
Reviewed By: soumith
Differential Revision: D9701999
Pulled By: apaszke
fbshipit-source-id: 3b6bec7b97e0444b2a93caa38d9b897f2e68c1b3
Summary:
Fixes#11663
`TensorIterator` was replacing the op tensors with type casted tensors
which ended up producing side effects in binary ops like `a.float() * b`
where `a` and `b` are `LongTensor`s.
colesbury ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11708
Differential Revision: D9834016
Pulled By: driazati
fbshipit-source-id: 4082eb9710b31dfc741161a0fbdb9a8eba8fe39d
Summary:
Often, we find ourselves looking at some long-running kernel or emit_nvtx range on an nvvp profile and trying to connect it to the offending line in a training script. If the op is in the forward pass that's easy: ops are enqueued explicitly from the Python side, so tracking it down with manual nvtx ranges supplemented by the built-in emit_nvtx ranges is straightforward. If the op is in the backward pass, it's much more difficult. From the Python side, all you can do is wrap loss.backward() in an nvtx range, and if you also use emit_nvtx, the automatic ranges provide only local information. Right now, the only consistent way to connect backward-pass kernels to their associated forward-pass lines of Python is to understand your script line by line, and know exactly where in the backward pass you are.
This PR augments the existing nvtx machinery to bridge the gap between forward and backward, allowing connection of backward-pass Function apply calls to the forward-pass operations that required/created those Functions.
The method is simple and surgical. During the forward pass, when running with emit_nvtx, the nvtx range for each function in VariableType is tagged with the current sequence number. During the backward pass, the nvtx range associated with each Function's operator() is tagged with that Function's stashed sequence number, which can be compared to "current sequence numbers" from the forward pass to locate the associated op.
Double-backward is not a problem. If a backward pass with create_graph = True is underway, the relationship between backward and double-backward is conceptually the same as the relationship between forward and backward: The functions in VariableType still spit out current-sequence-number-tagged ranges, the Function objects they create still stash those sequence numbers, and in the eventual double-backward execution, their operator() ranges are still tagged with the stashed numbers, which can be compared to "current sequence numbers" from the backward pass.
Minor caveats:
- The sequence number is thread-local, and many VariableType functions (specifically, those without a derivative explicitly defined in derivatives.yaml) don't create an associated function object (instead delegating that to sub-functions further down the call chain, perhaps called from within at::native functions that route back through VariableType by calling at::function_name). So the correspondence of stashed sequence numbers in Function operator() ranges with numbers in forward-pass ranges is not guaranteed to be 1 to 1. However, it's still a vast improvement over the current situation, and I don't think this issue should be a blocker.
- Feel free to litigate my use of stringstream in profiler.cpp. I did it because it was easy and clean. If that's too big a hammer, let's figure out something more lightweight.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10881
Differential Revision: D9833371
Pulled By: apaszke
fbshipit-source-id: 1844f2e697117880ef5e31394e36e801d1de6088
Summary:
This is causing codegen problems in caffe2, when we try to remove the circular Tensor/Type declarations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11673
Differential Revision: D9819341
Pulled By: gchanan
fbshipit-source-id: f2c2cd96e8a16f6de6aa4889e71b8a78e12e9256
Summary:
We'll have separate docs for the C++ frontend, right now this file is just misleading
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11703
Differential Revision: D9832847
Pulled By: goldsborough
fbshipit-source-id: 2e8b30ccf6b5cba9d0526e6261160f7c6211a35c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11597
We should always CHECK pointers which we plan to dereference
if they are inputs to the function. Nobody knows how the function will
be called in the future.
Reviewed By: yinghai
Differential Revision: D9800002
fbshipit-source-id: 7fd05f4717f2256d1b09a9e75475b12de6685b03
Summary:
…cuda())
While I was at it, I audited all other ways I know how we might get a CUDA
type from PyTorch and fixed more constructors which don't work.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11533
Differential Revision: D9775786
Pulled By: ezyang
fbshipit-source-id: cd07cdd375fdf74945539ec475a48bf08cbc0c17
Summary:
There's no reason they need to be in Type.h and this moves us along the path of not having circular dependencies (so we can get rid of TensorMethods.h).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11650
Reviewed By: ezyang
Differential Revision: D9812271
Pulled By: gchanan
fbshipit-source-id: 8b70db9a5eb0a332398ab2e8998eeaf7d2eea6d7
Summary:
This adds a small check in `Dirichlet` and `Categorical` `__init__` methods to ensure that scalar parameters are not admissible.
**Motivation**
Currently, `Dirichlet` throws no error when provided with a scalar parameter, but if we `expand` a scalar instance, it inherits the empty event shape from the original instance and gives unexpected results.
The alternative to this check is to promote `event_shape` to be `torch.Size((1,))` if the original instance was a scalar, but that seems to add a bit more complexity (and changes the behavior of `expand` in that it would affect the `event_shape` as well as the `batch_shape` now). Does this seem reasonable? cc. alicanb, fritzo.
```python
In [4]: d = dist.Dirichlet(torch.tensor(1.))
In [5]: d.sample()
Out[5]: tensor(1.0000)
In [6]: d.log_prob(d.sample())
Out[6]: tensor(0.)
In [7]: e = d.expand([3])
In [8]: e.sample()
Out[8]: tensor([0.3953, 0.1797, 0.4250]) # interpreted as events
In [9]: e.log_prob(e.sample())
Out[9]: tensor(0.6931) # wrongly summed out
In [10]: e.batch_shape
Out[10]: torch.Size([3])
In [11]: e.event_shape
Out[11]: torch.Size([]) # cannot be empty
```
Additionally, based on review comments, this removes `real_vector` constraint. This was only being used in `MultivariateNormal`, but I am happy to revert this if we want to keep it around for backwards compatibility.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11589
Differential Revision: D9818271
Pulled By: soumith
fbshipit-source-id: f9bbba90ed6f04e0b5bdfa169e70ca20b280fc74
Summary:
This PR:
- adds a `.expand` method for `TransformedDistribution` along the lines of #11341.
- uses this method to simplify `.expand` in distribution classes that subclass off of `TransformedDistribution`.
- restores testing of `TransformedDistribution` fixtures.
- fixes some bugs wherein we were not setting certain attributes in the expanded instances, and adds tests for `.mean` and `.variance` which use these attributes.
There are many cases where users directly use `TransformedDistribution` rather than subclassing off it. In such cases, it seems rather inconvenient to have to write a separate class just to define a `.expand` method. The default implementation should suffice in these cases.
cc. fritzo, vishwakftw, alicanb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11607
Differential Revision: D9818225
Pulled By: soumith
fbshipit-source-id: 2c4b3812b9a03e6985278cfce0f9a127ce536f23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11576
Previously, they were spattered throughout the codebase.
We now follow this convention:
- LegacyTypeDispatch gives you Type
- Context gives you TypeExtendedInterface
- Tensor::type() gives you Type
- at::getType() gives you TypeExtendedInterface
I change some sites to use getType() over type().
Reviewed By: SsnL
Differential Revision: D9790187
fbshipit-source-id: 5e2577cb590a5bbf5df530f3763d3b3c0b4625ca
Summary:
This adds tests in tests/test_distributions.py to ensure that all methods of `Distribution` objects are jittable.
I've replaced a few samplers with jittable versions:
- `.uniform_()` -> `torch.rand()`
- `.exponential_()` -> `-(-torch.rand()).log1p()`
- `.normal_()` -> `torch.normal(torch.zeros(...), torch.ones(...), ...)`
Some jit failures remain, and are marked in test_distributions.py
- `Cauchy` and `HalfCauchy` do not support sampling due to missing `.cauchy_()`
- `Binomial` does not support `.enumerate_support()` due to `arange` ignoring its first arg.
- `MultivariateNormal`, `LowRankMultivariateNormal` do not support `.mean`, `.entropy`
- [x] Currently some tests fail (I've skipped those) due to unavailability of `aten::uniform` and `aten::cauchy` in the jit. Can someone suggest how to add these? I tried to add declarations to `torch/csrc/ir.cpp` and `torch/csrc/passes/shape_analysis.cpp`, but that resulted in "Couldn't find operator" errors.
- [x] There are still lots of `TracerWarning`s that something doesn't match something. I'm not sure whether these are real.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11560
Differential Revision: D9816327
Pulled By: apaszke
fbshipit-source-id: 72ec998ea13fc4c76d1ed003d9502e0fbaf728b8
Summary:
current torch.norm() runs sequentially on CPU. This PR did parallelization and vectorization of torch.norm() on ATen CPU path, roughly provide 2 order of magnitude performance boost.
Performance is benchmarks on Xeon skylake 8180, 2*28 cores 2.5GHz, using the following script:
```python
import torch
from time import time
count = 1000
size = 1000*1000
def test_norm(p=2):
a = torch.randn(size)
tstart = time()
for i in range(count):
torch.norm(a, p)
tend = time()
print("norm on size %d tensor p = %d: %f s" % (size, p, (tend-tstart)))
for p in range(4):
test_norm(p)
```
without this optimization,
```
(intel-pytorch) [mingfeim@mlt-skx065 unit_tests]$ python test_norm.py
norm on size 1000000 tensor p = 0: 1.071235 s
norm on size 1000000 tensor p = 1: 1.069149 s
norm on size 1000000 tensor p = 2: 1.068212 s
norm on size 1000000 tensor p = 3: 69.735312 s
```
and with this optimization,
```
(pytorch-tf) [mingfeim@mlt-skx053 unit_tests]$ python test_norm.py
norm on size 1000000 tensor p = 0: 0.127507 s
norm on size 1000000 tensor p = 1: 0.011867 s
norm on size 1000000 tensor p = 2: 0.011907 s
norm on size 1000000 tensor p = 3: 0.014470 s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11565
Differential Revision: D9804484
Pulled By: ezyang
fbshipit-source-id: 52899f30ac26139d00684d07edfb47cb9b25d871
Summary:
Previously, we would pretty much assume that all floating point tensors do require grad, which might result in some unnecessary compute.
I don't really like the fact that `TensorType` uses `tensor.is_variable() && tensor.requires_grad()` to infer the value of `requires_grad`, but changing constants to keep variables turns out to be pretty hard. I got halfway there, but it would still need some more work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11586
Reviewed By: ezyang
Differential Revision: D9813648
Pulled By: apaszke
fbshipit-source-id: 77f77756d18ff7632fca3aa68ce855e1d7f3bdb8
Summary:
I'm reading the doc of `torch.nn.functional.pad` and it looks a bit confusing to me. Hopefully this PR makes it clearer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11623
Differential Revision: D9818255
Pulled By: soumith
fbshipit-source-id: 4f6b17b0211c6927007f44bfdf42df5f84d47536
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11659
This is less error-prone and less code.
Reviewed By: smessmer
Differential Revision: D9814536
fbshipit-source-id: 028510e31e2fa7a9fa11c1398b0743c5cd085dd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11657
Previously, we had a constructor in TensorImpl for every constructor in Tensor.
This was unnecessary and wordy: Tensor is the user-visible class, so it deserves
the constructors, but TensorImpl is internal and doesn't need it. So
I replaced TensorImpl with a single, Storage accepting constructor, and then
rewrote Tensor to use that constructor.
Reviewed By: jerryzh168
Differential Revision: D9813742
fbshipit-source-id: 7501b54fe5f39180f1bc07573fd7c1640b0f4e89
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11656
The mis-capitalization really sticks up my craw. I know why (we
already have a static function named GetDeviceType), but let's
name it differently.
```
codemod -d . --extensions cc,cpp,cu,cuh,h,py,hpp,TARGETS GetDevicetype device_type
```
Reviewed By: jerryzh168
Differential Revision: D9813544
fbshipit-source-id: fe462f4bc40b03e74921f8cf5ebd9cfc52e7e636
Summary:
The isCompleted function is changed to being non-const to accomodate
setting some internal status on the work object in the case of
completion. Previously, it was only checking a member field, but for the
MPI backend it calls MPI_Test to poll for completion of an asynchronous
request.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11630
Reviewed By: SsnL
Differential Revision: D9808008
Pulled By: pietern
fbshipit-source-id: 18b70825b1fb4d561a552fa75e9475a522852cd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11396
std::move and std::forward in C++11 aren't constexpr (they are in C++14).
This caused a build issue orionr was working on.
It should be fixed by this diff
Reviewed By: orionr
Differential Revision: D9724805
fbshipit-source-id: 0d9047dce611385d659cc71a6c04cc7a6a40a5ae
Summary:
Requires https://github.com/onnx/onnx/pull/1377
This PR makes it so that slices with dynamic boundary values can be exported from pytorch and run in caffe2 via ONNX.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11255
Differential Revision: D9790216
Pulled By: jamesr66a
fbshipit-source-id: 6adfcddc5788df4d34d7ca98341077140402a3e2
Summary:
Currently, because of some setup.py logic, `ninja` caching of the `generate_code.py` build step was broken. This resulted in `generate_code.py` running every single time builds were happening, regardless of whether inputs changed.
This updated logic fixes the input caching
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11644
Reviewed By: orionr
Differential Revision: D9814348
Pulled By: soumith
fbshipit-source-id: 2012960908d0f600488d410094095cfd72adc34f
Summary:
This also removes the usage of torch.onnx.symbolic_override in instance_norm. Fixes#8439.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10792
Differential Revision: D9800643
Pulled By: li-roy
fbshipit-source-id: fa13a57de5a31fbfa2d4d02639d214c867b9e1f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11642
This is just a preparatory change to help with future
refactoring:
- I want to reduce the number of includes that tensor_impl.h
depends on, but
- I need to keep tensor.h providing all Caffe2 headers, because
users may be relying on tensor.h transitively providing those
headers.
Introducing a level of indirection lets me do both at the same time.
Reviewed By: jerryzh168
Differential Revision: D9810823
fbshipit-source-id: 8dfaac4b8768051a22898be8fcaf787ecc57eb13
Summary:
Before this PR it would warn that "dropout is non deterministic and can
cause problems when checking trace", so I disabled the trace checking.
cc zdevito apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11639
Differential Revision: D9812493
Pulled By: zou3519
fbshipit-source-id: fab86928a5fba8b218b47543533aaf7c82a10b4a
Summary:
Arg parser allowed additional positional args to be parsed into keyword-only params.
Fixes a couple cases:
- The positional argument happens to be of the right type, and it just works silently. Now, we fail as expected.
- The positional argument fails later down the line. Now, we fail at the appropriate time and get a better error message.
Pre-fix:
```
>>> torch.cuda.LongTensor((6, 0), 1, 1, 0)
tensor([6, 0], device='cuda:1')
```
Post-fix:
```
>>> torch.cuda.LongTensor((6, 0), 1, 1, 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: new() received an invalid combination of arguments - got (tuple, int, int, int), but expected one of:
* (torch.device device)
* (torch.Storage storage)
* (Tensor other)
* (tuple of ints size, torch.device device)
* (object data, torch.device device)
```
Pre-fix:
```
>>> a = torch.tensor(5)
>>> a.new_zeros((5,5), 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: new_zeros(): argument 'dtype' (position 2) must be torch.dtype, not int
```
Post-fix:
```
>>> a = torch.tensor(5)
>>> a.new_zeros((5,5), 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: new_zeros() takes 1 positional argument but 2 were given
```
fixes#8351
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10499
Differential Revision: D9811093
Pulled By: li-roy
fbshipit-source-id: ce946270fd11b264ff1b09765db3300879491f76
Summary:
In order to comply with Python's rules on implicit casting of
non-booleans to booleans, this PR removes implicit casting in favor of
explicit casts via `bool()`
cc zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11503
Differential Revision: D9780869
Pulled By: driazati
fbshipit-source-id: c753acaca27f4e79dddf424c6b04674f44a6aad9
Summary:
- Just a simple fix to support `fill_`
- And a fix for indexing in `pytorch-complex`
Differential Revision: D9804061
Pulled By: ezyang
fbshipit-source-id: 631129b3fa220a9670770b3766f14a8e03633bdf
Summary:
Add guards against using sparse tensor by checking the conversion from IValue -> PyObject & PyObject -> IValue.
This diff also changes the behavior in constant propagation to not run python ops even if all ops are constant because of possible mutation to global state. This came up in trying to run get_sparse(), and I'm including it here to make it easier to land.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11550
Differential Revision: D9804712
Pulled By: eellison
fbshipit-source-id: 9fe7daf721c6d6e48df4925c0f9c775873bcdc77
Summary:
Clean up some generated tests after we have newly nice features like var args.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11403
Differential Revision: D9800545
Pulled By: wanchaol
fbshipit-source-id: e9973b113f78dc38cf99a81b6ede3fa3485f1cfa
Summary:
* Many op in lstm part of the model don't have implementation in ideep/mkl, and it doesn't make sense to copy back and forth for the few available ops because majority of RNN will be on CPU
* Thus the strategy is to enable mkl only for the resnet18 part of the model, then switch to default cpu engine for the lstm part
* The net may contain some external_inputs falsely added during ONNX->Caffe2. Canary in service shows their existence could leads to service crash (presumably due to these blob somehow get shared between threads). They're now manually removed which seem to be enough to avoid the crash.
Reviewed By: viswanathgs
Differential Revision: D8888763
fbshipit-source-id: da7761bcb7d876ff7bbb6640ae4b24712c0b1de6
Summary:
After discussions in #11584 , new PR for just the test skip and hgemm integration.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11593
Differential Revision: D9798527
Pulled By: ezyang
fbshipit-source-id: e2ef5609676571caef2f8e6844909fe3a11d8b3e
Summary:
I am working on unifying the C++ extensions and C++ API, and one constraint for this is that we will want to be able to build the C++ API without cereal, since we won't want to ship it with the Python `torch` package.
For this I introduce a `TORCH_WITH_CEREAL` option to CMake. If on, the C++ API will be built with cereal and thus serialization support. If off, serialization functions will throw exceptions, but the library will otherwise still compile the same. __This option is on by default, so for regular C++ API users nothing will change__. However, from C++ extensions, we'll be able to turn it off. This effectively means we won't be searching for any cereal headers from C++ API headers, which wouldn't be installed in the Python package.
ebetica ezyang soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11498
Differential Revision: D9784803
Pulled By: goldsborough
fbshipit-source-id: 5d0a1f2501993012d28cf3d730f45932b483abc4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11470
In order to reduce build sizes, we are identifying files that can be split up into smaller units, allowing us to only include the ops we need.
Reviewed By: orionr, ajtulloch
Differential Revision: D9725819
fbshipit-source-id: def1074a33dffe99bd6a7e6e48aa9e5be3d04a6a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11587
To help debug the issue in T33295362, we add some checks in the function.
Possible crashing site in `GetTensorInfo`
1. tc is nullptr, which is checked.
2. tc->capacity_nbytes() hits nullptr, this is unlikely because storage is not a pointer and compute of capacity_nbytes doesn't involve pointers. It's numel * itermsize().
3. tc->ExtractDeviceOption hits nullpt. One possibility raw_data() is nullptr because tc->ExtractDeviceOption will use that. This is checked.
4. Tensor itself which is not a reference. This is also checked.
Reviewed By: salexspb
Differential Revision: D9793484
fbshipit-source-id: 3fc72746fc310a23ae45553bbe0d269a4b9edb72
Summary:
Documents the `AnyModule` class in the C++ API.
Also changed the API to be friendlier by default. Calling `AnyModule::forward` used to return an `AnyModule::Value` which you had to call `.get<T>()` on to cast to a concrete type. I changed the name of that `forward` method to `any_forward` and instead made `forward` templated on a `ReturnType` template parameter which you can supply to do the `.get<T>` cast for you automatically. I default this parameter to `torch::Tensor` so that it can often be omitted. So where you used to have to write
```cpp
any_module.forward(...).get<int>();
any_module.forward(...).get<torch::Tensor>();
```
you now write
```cpp
any_module.forward<int>(...);
any_module.forward(...);
```
ebetica ezyang soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11580
Differential Revision: D9798626
Pulled By: goldsborough
fbshipit-source-id: 060b4ea28facaffc417f53b80b846a9dff9acb73
Summary:
This eliminates the need for any heuristics regarding stack size limits.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11534
Differential Revision: D9779866
Pulled By: resistor
fbshipit-source-id: 96753eead7904bbdc2869fb01f7bd42141032347
Summary:
This PR contains a C++ implementation of weight norm. The user-side exposure of weight norm through torch.nn.utils.weight_norm is unchanged.
If running on the GPU, and the norm is requested over the first or last dimension of the weight tensor, the forward pass is carried out using the fused kernels I wrote for our Fairseq GTC hero run, which offer superior performance to primitive ops and superior numerical stability when running in FP16. In the common case that the backward pass is not itself constructing a graph (ie not attempting to set up double backward) the backward pass will be carried out using another fused kernel. If the backward pass is constructing a graph, an alternate code path is taken, which does the math using differentiable primitive ops. In this way, the implementation allows double backward, even if the fused kernel was used in forward (although in this case, you don't benefit from the performance and stability of the fused backward kernel).
If running on the CPU, or if norming over an interior dim, the forward pass is carried out using double-differentiable primitive ops.
Figuring out how to generate all the right plumbing for this was tricky, but it was a fun experience learning how the autogenerator works and how the graph is constructed. Thanks to colesbury for useful guidance on this front.
I do have a few lingering questions:
- Should I unify my return statements (ie by default-constructing Tensors outside if blocks and using operator= within)?
- What is the significance of `non_blocking` when calling e.g. `auto norms = saved_norms.to(saved_g.type().scalarType(), non_blocking=True/False);`? I am currently omitting `non_blocking`, so it defaults to False, but I didn't see any associated synchronizes on the timeline, so I'm wondering what it means.
- Is there an "official" mapping from at::ScalarTypes to corresponding accumulate types, as there are for the PODs + Half in [AccumulateType.h](https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/AccumulateType.h)? I looked for an equivalent mapping for ScalarTypes, didn't find one, and ended up rigging it myself (` at::ScalarType AccType = g.type().scalarType() == at::ScalarType::Half ? at::ScalarType::Float : g.type().scalarType();`).
- Are sparse tensors a concern? Should I include another check for sparse tensors in the `_weight_norm` entry point, and send those along the fallback CPU path as well?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10842
Differential Revision: D9735531
Pulled By: ezyang
fbshipit-source-id: 24431d46532cf5503876b3bd450d5ca775b3eaee
Summary:
This changes the way module import works so that when a module
is reloaded in python it becomes a ScriptModule and not a _C.ScriptModule
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11552
Differential Revision: D9782751
Pulled By: zdevito
fbshipit-source-id: 9576850b75494b228ce3def94c0d371a4a44b11d
Summary:
Also adds two additional tests that check for memory leaks while the relevant graph executors are alive:
- (minimal test): Create a ScriptModule, keep it alive, and test that it does not leak memory while it is alive
- (large test) Do MNIST training with a traced MNIST module and test that no memory is leaked while the traced module (with graph executor) is alive
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11544
Reviewed By: apaszke
Differential Revision: D9778479
Pulled By: zou3519
fbshipit-source-id: 2d6cdea81dd1264f2c0396b662f70fdafecb3647
Summary:
Fixes:
```
/bin/ld: warning: libnccl.so.1, needed by /data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so, not found (try using -rp
ath or -rpath-link)
/data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so: undefined reference to `ncclAllReduce'
/data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so: undefined reference to `ncclBcast'
/data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so: undefined reference to `ncclCommInitAll'
/data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so: undefined reference to `ncclGetErrorString'
/data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so: undefined reference to `ncclReduceScatter'
/data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so: undefined reference to `ncclAllGather'
/data/users/ezyang/pytorch-tmp/build/lib/libcaffe2_gpu.so: undefined reference to `ncclReduce'
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11575
Differential Revision: D9789956
Pulled By: ezyang
fbshipit-source-id: 63e48763cc233be9d137cec721b239159b511a24
Summary:
This PR:
1. Documents `BatchNorm`,
2. Makes a number of API changes after reconsidering some quirks:
1. The default value for the `stateful` parameter used to be `false`, but the most common usage of `BatchNorm` out of the wild is certainly stateful, and the default in Python is also statefulness. So we change the default to stateful.
2. The `pure_forward` function used to use the internal running mean and variance variables instead of the ones supplied to that function call when `stateful` was true, which certainly seems odd. When you call `pure_forward` you would certainly expect the values you pass explicitly to be used. This is now fixed.
3. Adds tests for `BatchNorm`, finally.
ebetica apaszke ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11484
Reviewed By: pjh5
Differential Revision: D9779618
Pulled By: goldsborough
fbshipit-source-id: 59ba760e085c01454b75644b24b22317b688e459
Summary:
- Incorporates MKL addition by mingfeima Thank you! (but all errors are my own)
- Native CPU implementation: defer to matrix multiplication for
small batches and parallelize over batch dimension for large
batches.
- Add bmm test for CUDA just to be sure.
This is a partial fix for #10661, getting down to a factor ~5.
Considerable overhead is incurred for the setup in einsum. It might
be more efficient to eventually define an optimized contraction
functions for arbitrary and several dimensions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11292
Differential Revision: D9784941
Pulled By: ezyang
fbshipit-source-id: f6dded2c6f5e8f0461fb38f31f9a824992a58358
Summary:
Make test work with CPU only build, also fixed the test failures for a long time
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11567
Differential Revision: D9785740
Pulled By: teng-li
fbshipit-source-id: 61c43b758c1ee53117e30de8074583e6faea863a
Summary:
This makes torch.distributed works for CPU only build.
Also added one more CI test case to cover MPI CPU build.
All CI tests should cover this change
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11513
Differential Revision: D9784546
Pulled By: teng-li
fbshipit-source-id: 0976a6b0fd199670926f0273e17ad7d2805e42e7
Summary:
Also, fix a performance bug in `ensureUnique`. Previously it formatted the warning string even though we weren't tracing, so all that work would *always* happen in the hot path and be for nothing.
A sample of how the new warnings look like:
```
tmp.py:4: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can't record the data flow of Pytho
n values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
int(x)
tmp.py:5: TracerWarning: torch.tensor results are registered as constants in the trace. You can safely ignore this warning if you use this fun
ction to create tensors out of constant variables that would be the same every time you call this function. In any other case, this might caus
e the trace to be incorrect.
torch.tensor([1.])
tmp.py:6: TracerWarning: There are 2 live references to the data region being modified when tracing in-place operator add_. This might cause t
he trace to be incorrect, because all other views that also reference this data will not not reflect this change in the trace! On the other ha
nd, if all other views use the same memory, but are disjoint (e.g. are outputs of torch.split), this might still be safe.
torch.split(y, 2, dim=1)[0].add_(2)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11545
Differential Revision: D9782975
Pulled By: apaszke
fbshipit-source-id: 5b3abd31366e59c69e0b7ff278042b5563deb5a9
Summary:
This fixes the build when CuDNN was not found on the system.
From the `git blame`, it looks like the bug has been around for 2 years :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11562
Differential Revision: D9784589
Pulled By: soumith
fbshipit-source-id: b33153436dced0a503c9833cdf52f7093f3394b4
Summary:
This adds a Note on making experiments reproducible.
It also adds Instructions for building the Documentation to `README.md`. Please ping if I missed any requirements.
I'm not sure what to do about the submodule changes. Please advise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11329
Differential Revision: D9784939
Pulled By: ezyang
fbshipit-source-id: 5c5acbe343d1fffb15bdcb84c6d8d925c2ffcc5e
Summary:
Ping ezyang
This addresses your comment in #114. Strangely, when running the doc build (`make html`) none of my changes are actually showing, could you point out what I'm doing wrong?
Once #11329 is merged it might make sense to link to the reproducibility note everywhere.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11434
Differential Revision: D9751208
Pulled By: ezyang
fbshipit-source-id: cc672472449564ff099323c39603e8ff2b2d35c9
Summary: The PyTorch C++ API has `torch.nn.init` equivalents that the RNNG can use to initialize the state of its StackRNNs. This gets rid of the `fanInOut_` methods on `Parser` and tidies up `xavierInitialState` a little.
Reviewed By: wowitsmrinal
Differential Revision: D9472595
fbshipit-source-id: c202116f32383d3b4bba064c2c0d2656311e1170
Summary:
This PR does two things:
1. Replaces the implementation of the `Dropout` module with a call to the ATen function,
2. Replaces `Dropout2d` with a new `FeatureDropout` module that shall take the place of `Dropout2d` and `Dropout3d`. I contemplated calling it `Dropout2d` and making `Dropout3d` an alias for it, but similar to our decision for `BatchNorm{1,2,3}d` (c.f. https://github.com/pytorch/pytorch/pull/9188), we can deviate from Python PyTorch in favor of the ideal-world solution, which is to have a single module, since both actually just call `feature_dropout`.
I also replaced the implementation of `dropout3d` with a call to `dropout2d` in Python. The code is the same and it's easier for developers to parse than having to manually match the tokens to make sure it's really 100% the same code (which it is, if I matched the tokens correctly).
ebetica ezyang SsnL
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11458
Differential Revision: D9756603
Pulled By: goldsborough
fbshipit-source-id: fe847cd2cda2b6da8b06779255d76e32a974807c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11520
Previously, we had Type which was a catch all interface for all
functions and methods we could possibly want to do dynamic dispatch
on. However, we want to check in a non-autogenerated Tensor class
to ATen/core, and to do this, we must also check in a non-autogenerated
Type class which we can do dispatch on. In principle, we could
put the full Type interface in ATen/core, but this would be
a bad developer experience, since any time you add a new free
function, you'd have to regenerate the checked in Type header.
For a better dev experience, we split Type into a two parts,
Type, which will be checked in (though not in this diff), and
TypeExtendedInterface, which will NOT be checked in. Type contains
just enough methods to let Tensor be defined, and leaves the
rest to TypeExtendedInterface.
Some complications:
- We (very unfortunately) have overloaded virtual methods. Because
of C++'s rules, we cannot move one overload without doing some
extra work to make sure that overload in a superclass and an
overload in a subclass resolve together. I've chosen to resolve
this problem simply by moving ALL overloads of a method which
occurs in Tensor to Type.
- There are some places where we take a type() object and call
a method on it, which is not a Tensor base method. I've eliminated
some where possible, but in other cases calling the method on type
is the ONLY way to invoke it; in that case, I've just inserted
a cast. Further refactoring is necessary.
Reviewed By: gchanan
Differential Revision: D9771708
fbshipit-source-id: c59d39fe919cd6f42be6dca699d474346ea3c614
Summary:
The previous error was caused by mpi_test not depending on MPI_CXX_LIBRARIES. This might solve the problem.
Not tested locally - waiting for CI test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11416
Reviewed By: mingzhe09088
Differential Revision: D9771694
Pulled By: Yangqing
fbshipit-source-id: 53e7b4f64eadc88313bc4dd9b8e3f7931cda6e91
Summary:
This works around #11535 by avoiding `arange(n, out=x)` and `eye(n, out=x)` in `torch.distributions`. I've confirmed that the `.enumerate_support()` methods are now jittable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11542
Differential Revision: D9777805
Pulled By: apaszke
fbshipit-source-id: fa38f2f1acfc0a289f725fd8c92478573cfdbefb
Summary: Printing for complex numbers requires loading and storing between `Py_complex` and `std::complex`. This patch aims to support this for the plugin.
Differential Revision: D9771808
Pulled By: ezyang
fbshipit-source-id: 024865f1945d63ddb5efc775a35438c8ea06408e
Summary:
This whitelists train/eval functions in script modules, and tests that nested nn.Modules still work.
This also changes the code for calling python functions from script to allow non-tensor inputs/outputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11505
Differential Revision: D9765466
Pulled By: zdevito
fbshipit-source-id: 1177bff931324422b69e18fa0bbaa82e3c98ec69
Summary:
ezyang delivering my promise to you :)
Basically, now aten tests can use gtest as part of our test harness unification effort. I also converted one test (atest.cpp) to show how one can do this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11429
Reviewed By: ezyang
Differential Revision: D9762934
Pulled By: Yangqing
fbshipit-source-id: 68ec3a748403c6bd88399b1e756200985a4e07e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11413
LengthsTileOp was implemented using a sequence of device memcopies initiated on the CPU. This was very slow. I changed it to use a kernel. TUM benchmark QPS improved from 13k QPS to 20k QPS as a result.
Reviewed By: manojkris, xianjiec
Differential Revision: D9724988
fbshipit-source-id: 2f98c697730982734d7c6a26d0b6967310d49900
Summary:
Provide a TensorAccessor-Like interface for CUDA as discussed in #8366.
Compared to TensorAccessor
- the CUDATensorAccessor copies the sizes and strides while on the host (I didn't implement a host indexing function, though) to enable transfer to the device, on the device, `[]` works like for TensorAccessors,
- instantiation is from TensorAccessors in order to allow using `.accessor<..>`. The drawback is that it you cannot use `auto` for the variable declaration, but the alternative would be a cuda-specific `.accessor`-like function,
- there is a PtrTraits argument to enable `__restrict__`,
Example for the intended use:
```
...
template <typename scalar_t>
__global__ void
apply_homography_2d_kernel(cuda::CUDATensorAccessor<scalar_t, 4> dest_a,
cuda::CUDATensorAccessor<scalar_t, 4> src_a,
cuda::CUDATensorAccessor<float, 2> transform) {
...
}
template <typename scalar_t>
Tensor apply_homography_2d_template(Tensor& res, const Tensor& image, const Tensor& transform) {
...
cuda::CUDATensorAccessor<scalar_t, 4> image_a(image.accessor<scalar_t, 4>());
cuda::CUDATensorAccessor<scalar_t, 4> res_a(res.accessor<scalar_t, 4>());
cuda::CUDATensorAccessor<float, 2> transform_a(transform.accessor<float, 2>());
auto stream = at::cuda::getCurrentCUDAStream();
apply_homography_2d_kernel<scalar_t>
<<<grid, block, 0, stream>>>(res_a, image_a, transform_a);
return res;
}
...
```
I could use a hint where to put a test for this (e.g. doing a plain vanilla matrix multiplication with a custom kernel) and comparing with the aten mm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11373
Differential Revision: D9735573
Pulled By: ezyang
fbshipit-source-id: 482b218a0d514e19a8b692bbc77c0e37082cfded
Summary: Considering these increase the size of the message stack, I didn't touch the code outside `ATen/native`
Differential Revision: D9754283
Pulled By: soumith
fbshipit-source-id: 04198ec4fd0c4abae09eeba92c493a783408537a
Summary:
This PR adds the "merge to master" step before the build step in CircleCI, so that all PR commits are built against master instead of against the PR's branch. Note that all PRs still need to rebase to master to pick up this new config, so it won't apply to old PR branches retroactively.
To check in CI: make sure it's performing the git merge to master appropriately in "Merge Onto Master" step.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11443
Differential Revision: D9775628
Pulled By: yf225
fbshipit-source-id: 8083db6b098d234a44ae4481f40a486e9906f6f8
Summary:
Disable all CircleCI jobs until we are ready to move forward with them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11523
Differential Revision: D9774462
Pulled By: yf225
fbshipit-source-id: c5724e71eb68bac4df958b4f7bcc380050668b3c
Summary:
Need to link CUDA statically for benchmarking purpose.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10596
Reviewed By: llyfacebook
Differential Revision: D9370738
Pulled By: sf-wind
fbshipit-source-id: 4464d62473e95fe8db65b0bd3b301f262bf269bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11486
I discovered these by narrowing the interface on Type, and then
fixing call sites outside of core plumbing code which depended
on these methods being provided.
Reviewed By: cpuhrsch
Differential Revision: D9757935
fbshipit-source-id: 3abda0c98919a448a326a757671d438964f6909f
Summary:
I noticed warnings from within pybind11 being shown when building C++ extensions. This can be avoided by including non-user-supplied headers with `-isystem` instead of `-I`
I hope this works on Windows.
soumith ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11459
Differential Revision: D9764444
Pulled By: goldsborough
fbshipit-source-id: b288572106078f347f0342f158f9e2b63a58c235
Summary:
This speeds up incremental builds by doing the following changes:
- Uses `rsync` instead of `cp` (when `rsync` is found) which is a bit smarter in doing "maybe copy"
- Introduces a `rebuild` mode which does not rerun `cmake` in `build_pytorch_libs.sh`.
*Note: `rebuild` should only be used if you dont add / remove files to the build, as `cmake` is not rerun*
Current no-op rebuild speedup:
- 1m 15s -> 20s
There are some lingering bugs. No-op rebuilds rerun `cmake` for two rebuilds (likely that cmake logic is dependent on the install folder, hence kicking off rebuild).
So what you see
```
python setup.py rebuild develop # first time - ~5 mins
python setup.py rebuild develop # second time - ~3 mins
python setup.py rebuild develop # third time - ~2 mins
python setup.py rebuild develop # fourth time - ~20 seconds
python setup.py rebuild develop # fifth time - ~20 seconds
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11487
Differential Revision: D9769087
Pulled By: soumith
fbshipit-source-id: 20fbecde33af6426149c13767e8734fb3be783c5
Summary:
ATen has had a separate build target in the past, but with our move to a root-level CMakeLists.txt file this makes less sense and is harder to maintain. Also, as we blend code between Caffe2 and ATen this will become even less maintainable.
Talked to ezyang about this, but also cc zdevito, Yangqing, and soumith. If this is too difficult, I will revert, but want to see if we can simplify for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11488
Differential Revision: D9770266
Pulled By: orionr
fbshipit-source-id: c7ba52a1676d84e2d052dad4c042b666f49451cd
Summary:
This adds a `.expand` method for distributions that is akin to the `torch.Tensor.expand` method for tensors. It returns a new distribution instance with batch dimensions expanded to the desired `batch_shape`. Since this calls `torch.Tensor.expand` on the distribution's parameters, it does not allocate new memory for the expanded distribution instance's parameters.
e.g.
```python
>>> d = dist.Normal(torch.zeros(100, 1), torch.ones(100, 1))
>>> d.sample().shape
torch.Size([100, 1])
>>> d.expand([100, 10]).sample().shape
torch.Size([100, 10])
```
We have already been using the `.expand` method in Pyro in our [patch](https://github.com/uber/pyro/blob/dev/pyro/distributions/torch.py#L10) of `torch.distributions`. We use this in our models to enable dynamic broadcasting. This has also been requested by a few users on the distributions slack, and we believe will be useful to the larger community.
Note that currently, there is no convenient and efficient way to expand distribution instances:
- Many distributions use `TransformedDistribution` (or wrap over another distribution instance. e.g. `OneHotCategorical` uses a `Categorical` instance) under the hood, or have lazy parameters. This makes it difficult to collect all the relevant parameters, broadcast them and construct new instances.
- In the few cases where this is even possible, the resulting implementation would be inefficient since we will go through a lot of broadcasting and args validation logic in `__init__.py` that can be avoided.
The `.expand` method allows for a safe and efficient way to expand distribution instances. Additionally, this bypasses `__init__.py` (using `__new__` and populating relevant attributes) since we do not need to do any broadcasting or args validation (which was already done when the instance was first created). This can result in significant savings as compared to constructing new instances via `__init__` (that said, the `sample` and `log_prob` methods will probably be the rate determining steps in many applications).
e.g.
```python
>>> a = dist.Bernoulli(torch.ones([10000, 1]), validate_args=True)
>>> %timeit a.expand([10000, 100])
15.2 µs ± 224 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
>>> %timeit dist.Bernoulli(torch.ones([10000, 100]), validate_args=True)
11.8 ms ± 153 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
```
cc. fritzo, apaszke, vishwakftw, alicanb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11341
Differential Revision: D9728485
Pulled By: soumith
fbshipit-source-id: 3b94c23bc6a43ee704389e6287aa83d1e278d52f
Summary:
This enabled `torch.einsum` both in tracing and in script mode. It's used all over Pyro at the moment, and is needed for any use of the JIT in there.
Fixes#11157.
zdevito fritzo neerajprad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11506
Differential Revision: D9764787
Pulled By: apaszke
fbshipit-source-id: 9b5251b9e7c5897034602bd07ff67b425d33326c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11418
Several improvements that aim to make the APIs more straightforward to use
- Get rid of helper methods subgraph and nonTerminal . Users now should create a NNMatchGraph directly via graph's createNode and createEdge API
- Get rid of operatorSubgraph helper method
- invertGraphTraversal flag applies to both the match graph and the scanned graph. This allows user to create match graph in the same direction as the scanned graph, thus reduce confusion.
- additional parameters of matchNode (count, includeInSubgraph, nonTerminal) are removed from the constructors and moved into setter methods. (We no longer enforce that MatchNode is immutable but this helps improve code clarity).
- Tests are updated to reflect the changes
Follow up changes:
- Possibly clean up the tests further. This change aims to minimally modify the unit tests.
- Help a validity check that enforce the current limitation of the match graph (single source node), and throws if the match graph does not satisfy the criteria.
- Have the single source node be detected automatically and callers just need to pass in the matchGraph instead of the source node reference.
Differential Revision: D9732565
fbshipit-source-id: ae8320e2bc89b867f6bb4b1c1aad635f4b219fa1
Summary:
The old `torch.distributed` will go to `torch.distributed.deprecated`
The old DDP will go to `torch.nn.parallel.deprecated`
Now `torch.nn.parallel.DDP` will use c10d DDP
Now `torch.distributed` will use C10d frontend API
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11405
Reviewed By: pietern
Differential Revision: D9733733
Pulled By: teng-li
fbshipit-source-id: d6a3f3e73f8d3a7fcb1f4baef53c78063b8cbb08
Summary:
Add flags for LMDB and LevelDB, default `OFF`. These can be enabled with
```
USE_LMDB=1 USE_LEVELDB=1 python setup.py build_deps
```
Also add a flag to build Caffe2 ops, which is default `ON`. Disable with
```
NO_CAFFE2_OPS=1 python setup.py build_deps
```
cc Yangqing soumith pjh5 mingzhe09088
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11462
Reviewed By: soumith
Differential Revision: D9758156
Pulled By: orionr
fbshipit-source-id: 95fd206d72fdf44df54fc5d0aeab598bff900c63
Summary:
Skip torch tests as well when NO_TEST=1 environment variable is set. Also remove the separate ATen code path for not being built with Caffe2, since it will always be built with Caffe2.
cc The controller you requested could not be found.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11415
Reviewed By: soumith
Differential Revision: D9758179
Pulled By: orionr
fbshipit-source-id: e3e3327364fccdc57a703aeaad8c4f30452973fb
Summary:
There's a bunch of legacy code where people are explicitly instantiating Variable, and these call-sites have thus far been untraceable (appearing as prim::Constant nodes with the tensor value at the time of tracing). This makes it so that the new variable inherits the traced Value* from the tensor it's being constructed from
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11463
Differential Revision: D9756529
Pulled By: jamesr66a
fbshipit-source-id: da99c6a7621957a305f2699ec9cb9def69b1b2d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10974
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10291
This new operator will do the following:
Given a LENGTHS vector and n_splits, output a "split" LENGTHS vector where:
1. Each length in input vector is split into n_splits values (thus output vector should have LENGTHS.size(0) * n_splits elements)
2. The new lengths in output should be evenly split, and if the length is not divisible by n_splits, then order new values in descending order. (e.g. n_splits = 3, length = 5 -> 2 2 1)
3. If n_splits > some element in the array, its split elements will contain 0s. (e.g. n_splits = 3, length = 2 - > 1 1 0)
Reviewed By: bddppq, chocjy
Differential Revision: D9013119
fbshipit-source-id: 82bf3371ec08c41fc3379177f0007afc142e0d84
Summary:
This PR is stacked on https://github.com/pytorch/pytorch/pull/10610, and only adds changes in one file `.jenkins/pytorch/test.sh`, where we now build the custom op tests and run them.
I'd also like to take this PR to discuss whether the [`TorchConfig.cmake`](https://github.com/pytorch/pytorch/blob/master/cmake/TorchConfig.cmake.in) I made is robust enough (we will also see in the CI) orionr Yangqing dzhulgakov what do you think?
Also ezyang for CI changes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10611
Differential Revision: D9597627
Pulled By: goldsborough
fbshipit-source-id: f5af8164c076894f448cef7e5b356a6b3159f8b3
Summary:
Many constructors like `torch.zeros` or `torch.randn` didn't support
size tracing correctly which is fixed by this pass. Same issue has been
fixed in legacy tensor constructors.
Additionally, new tensor constructors, which do not participate in
tracing (most notably `torch.tensor`, `torch.as_tensor` and
`torch.from_numpy`) raise a warning when they are used.
Finally, entering a traceable operation disables the tracing in its body.
This is needed because
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11288
Reviewed By: ezyang
Differential Revision: D9751183
Pulled By: apaszke
fbshipit-source-id: 51444a39d76a3e164adc396c432fd5ee3c8d5f7f
Summary:
NCCL1 uses `int` as its numerical type for fields like `count`, which makes broadcasting tensors larger than `2 << 31 - 1` impossible, and raises opaque error `invalid arguments`. NCCL2 greatly increase the limit on many platforms by using `size_t`. This patch statically detects this type, and raises properly if the broadcast tensor exceeds the limit.
No test because I don't think our test suite should broadcast big tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11466
Differential Revision: D9754753
Pulled By: SsnL
fbshipit-source-id: 73506450cae047e06b5b225b39efdb42d5d26685
Summary:
Normalizing by the world size before the reduction is less likely to cause overflow in FP16 training.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11109
Differential Revision: D9594708
Pulled By: myleott
fbshipit-source-id: 93ab53cb782ee1cbe1264e529b333490a0940338
Summary:
I'm 80% sure that this fixes the math bug. But I can't repro locally so I don't know.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11472
Differential Revision: D9755328
Pulled By: SsnL
fbshipit-source-id: 130be664d3c6ceee3c0c166c1a86fc9ec3b79d74
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11294
The Tensor(ptr, retain) constructor is error prone and circumvents the intrusive_ptr safety.
This diff removes that and pushes the responsibility to callers.
Step by step, manual refcounting can be pushed back and possibly eliminated in the end.
Reviewed By: ezyang
Differential Revision: D9663476
fbshipit-source-id: 7f010e5e47b137a9575960201c5bf5d552c5c2f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11260
This is needed to make something like this work:
intrusive_ptr<TensorImpl, UndefinedTensorImpl> a = make_intrusive<SparseTensorImpl>(...);
Reviewed By: ezyang
Differential Revision: D9652089
fbshipit-source-id: 19c65e98460ccb27bc69e36d7e558cb9d6e67615
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11258
The two intrusive_ptr constructors in Tensor can be combined into one implementation that does both, moving and copying.
Reviewed By: ezyang
Differential Revision: D9652088
fbshipit-source-id: 5efca02654ba305c99c20bbeb83551469d17a51d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11238
- when moving an IValue, free the old value instead of keeping it allocated
- making classes final
- moving std::string
- making ConstantList const
Reviewed By: ezyang
Differential Revision: D9644700
fbshipit-source-id: ab7228368e4f00f664ba54e1242b0307d91c5e7e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11167
Narrow the Blob API as preparation for merging Blob/IValue
- get rid of templated IsType and Operator::InputIsType / OutputIsType
- Use 'using' instead of 'typedef' for DestroyCall (just for readability)
Reviewed By: ezyang
Differential Revision: D9623916
fbshipit-source-id: 952f0b0cf5a525094b02e8d2798dd57a56a9e1d8
Summary:
Checking assertExportImport for all of the generated test jit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10982
Differential Revision: D9636935
Pulled By: eellison
fbshipit-source-id: f3f1ce77d454848098f2ac7e0fa18bf8564890be
Summary:
`Process.start()` actually take some time as it needs to start a
process and pass the arguments over via a pipe. Therefore, we
only add a worker to self.workers list after it started, so
that we do not call `.join()` if program dies before it starts,
and `__del__` tries to join it but will get:
AssertionError: can only join a started process.
Example trace when such error happens:
```py
[unrelated]
File "/private/home/ssnl/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 500, in __iter__
return _DataLoaderIter(self)
File "/private/home/ssnl/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 292, in __init__
w.start()
File "/private/home/ssnl/miniconda3/lib/python3.7/multiprocessing/process.py", line 112, in start
self._popen = self._Popen(self)
File "/private/home/ssnl/miniconda3/lib/python3.7/multiprocessing/context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/private/home/ssnl/miniconda3/lib/python3.7/multiprocessing/context.py", line 277, in _Popen
return Popen(process_obj)
File "/private/home/ssnl/miniconda3/lib/python3.7/multiprocessing/popen_fork.py", line 20, in __init__
self._launch(process_obj)
File "/private/home/ssnl/miniconda3/lib/python3.7/multiprocessing/popen_fork.py", line 70, in _launch
self.pid = os.fork()
KeyboardInterrupt
Exception ignored in: <function _DataLoaderIter.__del__ at 0x7fa704d5aa60>
Traceback (most recent call last):
File "/private/home/ssnl/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 398, in __del__
self._shutdown_workers()
File "/private/home/ssnl/miniconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 392, in _shutdown_workers
w.join()
File "/private/home/ssnl/miniconda3/lib/python3.7/multiprocessing/process.py", line 139, in join
assert self._popen is not None, 'can only join a started process'
AssertionError: can only join a started process
```
No test because hard to reliably trigger.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11432
Reviewed By: ezyang
Differential Revision: D9735430
Pulled By: SsnL
fbshipit-source-id: a8912d9bb4063f210d6236267b178173810e2351
Summary:
as discussed with ezyang and slayton58 , this might be a nice convenience to be able to use code in extensions just as in ATen.
also split off `tracing_state.h` from `torch/jit/tracer.h` fix#11204 to bee able to use the utility functions
pytorchbot it's not a jit patch per se.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11425
Differential Revision: D9735556
Pulled By: ezyang
fbshipit-source-id: 466c92bbdb1d7d7a970eba1c26b7583fe9756139
Summary:
A recent build regression is that we need a system GoogleTest for builds to pass.
This was because, when building with Gloo, gloo is trying to build it's own tests, which look for system gtest [here](https://github.com/facebookincubator/gloo/blob/master/cmake/Dependencies.cmake#L72-L80) (because we're not using full cmake build and making it aware of third_party/GoogleTest, but instead, we are building it isolated using tools/build_pytorch_libs.sh
Traditionally, we didn't ask Gloo to build it's tests, but because we added `-DBUILD_TEST=1` by default to all builds (in refactoring variable names), we accidentally started asking Gloo to build it's tests.
This PR overrides the Gloo flags and asks it to not build tests (like it used to)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11431
Differential Revision: D9736387
Pulled By: soumith
fbshipit-source-id: 59e84edae780123b793bdaea5fd9ac46156cd0af
Summary:
This PR parallels `masked_fill` on CPU, currently it runs in sequential on CPU.
the following script is used to benchmark and verify this PR. On Xeon skylake 8180 (2 sockets * 28 cores),
it runs `4.20` sec without the PR and `0.11` sec with the PR.
```python
import torch
import random
from time import time
size = 10 * 1000 * 1000
count = 100
def test_masked_fill():
dst = torch.randn(size)
dst_ = dst.clone()
mask = torch.rand(size).mul(2).floor().byte()
val = random.random()
tstart = time()
for i in range(count):
dst.masked_fill_(mask, val)
tend = time()
print("masked_fill_: %f" % (tend-tstart))
for i in range(size):
if mask[i]:
if dst[i] != val:
print("fail")
else:
if dst[i] != dst_[i]:
print("fail1")
print("test_masked_fill: PASS")
test_masked_fill()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11359
Differential Revision: D9735578
Pulled By: ezyang
fbshipit-source-id: d437ad7c6dace1910d0c18d6d9ede80efb44fae4
Summary:
Added AVX optimizations for pdist using Vec256. This brings single threaded performance up to speed with scipy, but the current implementation greatly hurts performance without AVX enabled. Is there a way to special case out AVX on dispatch and call the non Vec256 code? Or is the way I used Vec256 completely wrong?
Single threaded comparison to scipy
============================
This is the time to compute the pdist of a 2048 x 2048 float matrix with only one thread for various values of p between torch and scipy. p = 3 is the code path for arbitrary p, and so is much slower than the other values.
p | torch | scipy
-----|-----------|------
0 | 6.27 s ± 393 ms | 7.23 s ± 498 ms
1 | 5.49 s ± 201 ms | 43.4 s ± 1.09 s
2 | 5.74 s ± 474 ms | 53.8 s ± 3.52 s
∞ | 5.59 s ± 292 ms | 47.4 s ± 2.03 s
3 | really slow | gave up
Result by AVX support
================
This is the time to compute the distance and gradient of a 2048 x 2048 float matrix with all threads by AVX support. `before` is the old code, `default` is no AVX support, etc. Interestingly the AVX optimizations provided a great benefit over the old unoptimized code, but drastically hurt performance when compiled without AVX optimizations. p = 3 is the code path for arbitrary p, and so is much slower than the other values.
Results for p = 0
----------------
avx | dist | grad
----|------|-----
before | 514 ms ± 87.5 ms | 191 µs ± 35 µs
default | 3.47 s ± 183 ms | 201 µs ± 24.6 µs
avx | 123 ms ± 18.2 ms | 281 µs ± 130 µs
avx2 | 103 ms ± 11.4 ms | 216 µs ± 74.4 µs
Results for p = 1
----------------
avx | dist | grad
----|------|-----
before | 426 ms ± 35 ms | 6.21 s ± 187 ms
default | 2.6 s ± 123 ms | 5.62 s ± 273 ms
avx | 104 ms ± 6.37 ms | 833 ms ± 44.3 ms
avx2 | 106 ms ± 3.59 ms | 924 ms ± 86.2 ms
Results for p = 2
-----------------
avx | dist | grad
----|------|-----
before | 425 ms ± 45.4 ms | 6.31 s ± 125 ms
default | 3.04 s ± 187 ms | 3.55 s ± 242 ms
avx | 110 ms ± 3.66 ms | 896 ms ± 21.8 ms
avx2 | 113 ms ± 4.68 ms | 934 ms ± 25.2 ms
Results for p = ∞
------------------
avx | dist | grad
----|------|-----
before | 501 ms ± 39.5 ms | 6.64 s ± 321 ms
default | 2.15 s ± 92.9 ms | 8.43 s ± 355 ms
avx | 104 ms ± 5.52 ms | 835 ms ± 36.7 ms
avx2 | 100 ms ± 3.41 ms | 864 ms ± 67 ms
Results for p = 3
-----------------
avx | dist | grad
----|------|-----
before | 22.6 s ± 413 ms | 11.1 s ± 242 ms
default | 24.9 s ± 1 s | 11.2 s ± 293 ms
avx | 2.69 s ± 148 ms | 5.63 s ± 88.4 ms
avx2 | 2.48 s ± 31.8 ms | 5.61 s ± 114 ms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11230
Differential Revision: D9735503
Pulled By: erikbrinkman
fbshipit-source-id: a9da619249e4ca2625b39ca1ca7f5543c3086bfb
Summary:
If pybind is build with cmake and installed, we should use config file instead of the Findpybind11 shipped with caffe2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11423
Differential Revision: D9735557
Pulled By: ezyang
fbshipit-source-id: 28a39e579fa045060aa1a716e5fd7dbcf7b89569
Summary:
Fixes the issue discussed in #10838. `hidden_size` should be the last dimension regardless if we're in ONNX or PyTorch.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11368
Differential Revision: D9734814
Pulled By: soumith
fbshipit-source-id: 7f69947a029964e092c7b88d1d79b188a417bf5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11420
Surprisingly tricky! Here are the major pieces:
- We grow a even yet more ludicrous macro
AT_FORALL_SCALAR_TYPES_WITH_COMPLEX_EXCEPT_COMPLEX_HALF
which does what it says on the tin. This is because I was
too lazy to figure out how to define the necessary conversions
in and out of ComplexHalf without triggering ambiguity problems.
It doesn't seem to be as simple as just Half. Leave it for
when someone actually wants this.
- Scalar now can hold std::complex<double>. Internally, it is
stored as double[2] because nvcc chokes on a non-POD type
inside a union.
- overflow() checking is generalized to work with complex.
When converting *to* std::complex<T>, all we need to do is check
for overflow against T. When converting *from* complex, we
must check (1) if To is not complex, that imag() == 0
and (2) for overflow componentwise.
- convert() is generalized to work with complex<->real conversions.
Complex to real drops the imaginary component; we rely on
overflow checking to tell if this actually loses fidelity. To get
the specializations and overloads to work out, we introduce
a new Converter class that actually is specializable.
- Complex scalars convert into Python complex numbers
- This probably fixes complex tensor printing, but there is no way
to test this right now.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Reviewed By: cpuhrsch
Differential Revision: D9697878
Pulled By: ezyang
fbshipit-source-id: 181519e56bbab67ed1e5b49c691b873e124d7946
Summary:
vishwakftw Your patch needed some updates because the default native function dispatches changed from `[function, method]` to `[function]`. The CI was run before that change happened so it still shows green, but the internal test caught it.
I did some changes when rebasing and updating so I didn't just force push to your branch. Let's see if this passes CI and internal test. If it does, let me know if you want me to force push to your branch or use this PR instead.
Note to reviewers: patch was already approved at #10068 .
cc yf225
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11421
Differential Revision: D9733407
Pulled By: SsnL
fbshipit-source-id: cf2ed293bb9942dcc5158934ff4def2f63252599
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11331
In the previous commit, we added a bare-bones LegacyTypeDispatch in ATen/core.
This is not sufficient for the use cases we need: we not only need to be able to
get a Type, but we also need to be able to *initialize* the Types if its the first time
we have retrieved a CPU/CUDA/Complex type. I hemmed and hawed about how
to do this; the strategy this PR takes is to introduce a new "hooks" interface
specifically for initializing CPU/CUDA/Complex (which still lives in Context). We then
move all "user-friendly" functions to LegacyTypeDispatch.
Here were some other options which I considered, but don't work:
- Assume that Type is already initialized, because we only intend to call Type
from Tensor methods, where we already have a Tensor. This does not work
because Caffe2 created tensors will not have gone through the standard
Type codepath, and will have skipped initialization.
- Move CUDAHooks and ComplexHooks to ATen/core. Besides being sucky,
this isn't even a complete fix, because I still need to initialize CPU hooks
(so you *still* need another hooks interface).
Reviewed By: cpuhrsch
Differential Revision: D9666612
fbshipit-source-id: ac7004b230044b67d13caa81fdfaf3c6ab915e3f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11274
We don't want to put all of Context into ATen/core, but one
particular part cannot be avoided: the type registry, because
implementations of TensorMethods will need to get a Type,
and then do a virtual call on it.
I needed to do a little bit of (temporary) footwork to get this
in without also moving Type, because unique_ptr<Type> expects
to be able to see the destructor of Type (but it's forward declared
right now). So instead I put the destructor as an explicit functor. We
can get rid of this once Type actually moves in ATen/core
Reviewed By: cpuhrsch
Differential Revision: D9657449
fbshipit-source-id: 940931493bf4f1f6a8dad03f34633cacdd63dd0b
Summary:
to 300 seconds to be safe. It used to be no timeout in THD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11409
Differential Revision: D9731709
Pulled By: teng-li
fbshipit-source-id: 0ce011dcca507cbf063176ad4995405c77dd0cdd
Summary:
Currently gradient is copied into .grad if it is None. This PR aim to remove the copy when it is not absolutely needed.
It is generally an improvement of speed and memory usage. And here is a case it may help a lot:
Normally, people do optimizer.zero_grad() every minibatch before backward. It will translate into a memset, and later a point-wise add.
When there is some large weight in the network, one optimization people can always do is set parameter.grad to None instead of zero_grad. This will remove memset and change point-wise add to a memcpy.
Here is result running following script on V100 GPU. It is 100 iterations of forward/backward/zero_grad on single 1-billion word benchmark size embedding.
`Zero grad: 2.123847723007202`
`None grad: 1.3342866897583008`
With the backend change of this PR, the unnecessary memcpy is removed, thus further speed up is achieved.
`Zero grad: 2.124978542327881`
`None grad: 0.4396955966949463`
[benchmark.txt](https://github.com/pytorch/pytorch/files/2341800/benchmark.txt)
Some details on the code change:
.detach() is used because we need to get rid of new_grad being a view without copy data. This should be safe in first-order only mode.
data need to be contiguous, otherwise `grad_variable.data() += new_grad.data();` below will fail.
Only the last variable that has reference to the temp gradient will grab its buffer.
ngimel, mcarilli and mruberry helped on finalizing this PR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11165
Differential Revision: D9728874
Pulled By: soumith
fbshipit-source-id: b8fb822a2dff6e812bbddd215d8e384534b2fd78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11247
Previously, the default for a declaration in native_functions.yaml
was ['function', 'method'], i.e., generate both a method and
function for every binding. We now believe this is inappropriate:
the majority of new kernels added to PyTorch should live as
free functions, NOT methods. Thus, we change the default accordingly.
I also took the opportunity to de-method some "internal" functions
that had a leading underscore. While, strictly speaking, this is a
BC breaking change, I believe it is highly unlikely anyone was using
these directly.
Reviewed By: yf225
Differential Revision: D9648570
fbshipit-source-id: 8b94647b824e0899d6d18aa5585aaedc9d9957d2
Summary:
This is mainly to pick up the change 20074be19a to avoid polluting the CMAKE_DEBUG_POSTFIX variable. cc orionr .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11388
Reviewed By: orionr
Differential Revision: D9720931
Pulled By: Yangqing
fbshipit-source-id: 18a60d0409e74316f74d364f4fe16bf0d0198413
Summary:
Moves the code for the complex registration code into an out-of-line C++ extension to de-noise the test_cpp_extensions.py file. Let's keep it nice and tidy so we can point our users at it for usage examples.
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11397
Differential Revision: D9725335
Pulled By: goldsborough
fbshipit-source-id: 290618f2ee711b1895cdb8f05276034dfe315c6d
Summary:
~~This PR fixes#8525 by renaming `split_with_sizes` to `split` so that 2 `aten::split` ops are
generated (previously `aten::split(self, int, int)` and `aten::split_with_sizes(self, int[], int)` were generated)~~
~~`split_with_sizes` was made in PR #5443, but I don't see a reason for it to have
a different name than `split` rather than just overload `split`.~~
This PR fixes#8525 by adding `register_special_ops.cpp` to mirror Python dispatching from `split` to `split` and `split_with_sizes` in [tensor.py](https://github.com/pytorch/pytorch/blob/master/torch/tensor.py#L279).
It also fixes#8520 by adding an `int[]` wherever it sees `torch.Size`
In a follow up PR this could also be used to fix some of the other `unknown builtin op` test errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11051
Differential Revision: D9582443
Pulled By: driazati
fbshipit-source-id: d27201f85937d72e45e851eaa1460dd3dd1b61a9
Summary:
This seems to be causing different versions of OpenMPI being picked up
by different parts of the build. Not a good practice to include absolute
paths anyway, so let's try removing it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11386
Reviewed By: teng-li
Differential Revision: D9724349
Pulled By: pietern
fbshipit-source-id: 3dfef91c81f2e97e5125284aff9e7e98f8761917
Summary:
Continuing pjh5's work to remove FULL_CAFFE2 flag completely.
With these changes you'll be able to also do something like
```
NO_TEST=1 python setup.py build_deps
```
and this will skip building tests in caffe2, aten, and c10d. By default the tests are built.
cc mingzhe09088 Yangqing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11321
Reviewed By: mingzhe09088
Differential Revision: D9694950
Pulled By: orionr
fbshipit-source-id: ff5c4937a23d1a263378a196a5eda0cba98af0a8
Summary:
In addition to documentation, this cleans up a few error message formats.
It also adds infra to find which operators are supported by the JIT automatically, which is then used in the generation of the docs.
The wording and formatting of the docs is not yet polished, but having this will allow our document writers to make faster progress.
Followup PRs will polish the docs and fix formatting issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11357
Differential Revision: D9721277
Pulled By: zdevito
fbshipit-source-id: 153a0d5be1efb314511bcfc0cec48643d78ea48b
Summary:
Add a barrier() to wait for all PG created before destroy
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11391
Differential Revision: D9727383
Pulled By: teng-li
fbshipit-source-id: 689d62c978e642b68f4949dcf29982e34869ada4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11382
We found this cudnn bug in S163230 that causes accuracy loss. We fix this in D9601217, but due to the reimplementation of spatialBN it's overwritten. Let's land this fix again.
Reviewed By: kuttas
Differential Revision: D9702347
fbshipit-source-id: 11547e9edaf7b2ba7f4aa7263ffb4f0281bbf078
Summary:
The next function I'm moving to C++ is `sync_params`. It is stacked on top of https://github.com/pytorch/pytorch/pull/9729, so some changes will go away when it lands and I rebase.
I also split code into a `.h` and `.cpp` file for better code organization.
The controller you requested could not be found. pietern apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9805
Differential Revision: D9688604
Pulled By: goldsborough
fbshipit-source-id: 4467104d3f9e2354425503b9e4edbd59603e20a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11336
Move `context_base.h` header to `ATen/core` and the implementations are in `caffe2/core/context_base.cc`
Reviewed By: ezyang
Differential Revision: D9670493
fbshipit-source-id: ce5bf2b3b4c80e9b62819f4332ce68af82720055
Summary:
This PR cleans up the `at::Tensor` class by removing all methods that start with an underscore in favor of functions in the `at::` namespace. This greatly cleans up the `Tensor` class and makes it clearer what is the public and non-public API.
For this I changed `native_functions.yaml` and `Declarations.cwrap` to make all underscore methods `variant: function` (or add such a statement to begin with), and then fixed all code locations using the underscore methods.
ezyang colesbury gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11152
Differential Revision: D9683607
Pulled By: goldsborough
fbshipit-source-id: 97f869f788fa56639c05a439e2a33be49f10f543
Summary:
Add the gpu kernel version.
The parallelism I went with performs poorly when there are a large number of vectors, but they're all short, as I don't allocate the thread pool to wrap in that case.
Test Plan
---------
```
python -m unittest test_torch.TestTorch.test_pdist_{empty,scipy} test_nn.TestNN.test_pdist{,_zeros,_empty_row,_empty_col,_cpu_gradgrad_unimplemented,_cuda_gradgrad_unimplemented} test_jit.TestJitGenerated.test_nn_pdist
```
Current performance specs are a little underwhelming, I'm in the process of debugging.
size | torch | torch cuda | scipy
-----|-------|------------|------
16 x 16 | 9.13 µs ± 3.55 µs | 9.86 µs ± 81.5 ns | 15.8 µs ± 1.2 µs
16 x 1024 | 15 µs ± 224 ns | 9.48 µs ± 88.7 ns | 88.7 µs ± 8.83 µs
1024 x 16 | 852 µs ± 6.03 µs | 7.84 ms ± 6.22 µs | 4.7 ms ± 166 µs
1024 x 1024 | 34.1 ms ± 803 µs | 11.5 ms ± 6.24 µs | 273 ms ± 6.7 ms
2048 x 2048 | 261 ms ± 3.5 ms | 77.5 ms ± 41.5 µs | 2.5 s ± 97.6 ms
4096 x 4096 | 2.37 s ± 154 ms | 636 ms ± 2.97 µs | 25.9 s ± 394 ms
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11102
Differential Revision: D9697305
Pulled By: erikbrinkman
fbshipit-source-id: 2b4f4b816c02b3715a85d8db3f4e77479d19bb99
Summary:
This is so that TensorImpl does not have to depend on Tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11337
Differential Revision: D9684421
Pulled By: gchanan
fbshipit-source-id: d2af93420ca6d493429c251cfe5a34e9289c4484
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11273
This one might strike you as a bit surprising, but it's necessary
to expose this interface in ATen/core, because we need to be
able to get a true Variable type from Variable tensors, and
to do that we need to go through the hooks interface.
Reviewed By: gchanan
Differential Revision: D9656548
fbshipit-source-id: 28bb5aee6ac304e8cd5fa1e4c65452c336647161
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11270
Still need to deduplicate this with caffe2/core/registry.h,
but this will be a bit tricky because the current formulation
of the macro is namespace sensitive (i.e., the macro for classes
defined in at:: namespace won't work if you call from caffe2::
namespace).
Reviewed By: gchanan
Differential Revision: D9654871
fbshipit-source-id: 2207d1f2cc6d50bd41bf64ce0eb0b8523b05d9d9
Summary:
After submitting PR #9726, PR #10581 created a different CUDAEvent class. The CUDAEvent proposed in #9726 was similar to the c10d::CUDAEvent class with additional testing and functionality. In particular, it was movable but not copyable. The CUDAEvent created by #10581 is refcounted and copyable. This PR retains the refcounting of the latter PR while fixing several bugs, adding tests, and extending the functionality to support testing and usage like in PR #8354. In particular, this PR:
- Adds set_device() to CUDAContext
- Adds three CUDAEvent tests to stream_test.cpp
- Fixes three bugs:
- Refcounting was broken. Destroying an of the RAIIs holding a particular CUDAEvent would destroy the event UNLESS it was the last RAII (the check was backwards).
- Moving an event would cause a segfault.
- Events were not destroyed on the device they were created on. See PR #9415 (pietern)
- Adds the happened() and recordOnce() functions
- Changes the record() functions to not be const
- Adds additional assertions to verify correctness
This PR does not:
- Make c10d use the ATen CUDAEvent (this is appropriate for a separate PR)
Whether events should be refcounted is an interesting question. It adds some atomic operations and makes event creation eager. Making events movable but not copyable (like the c10d events) avoids these costs and allows events to be lazily constructed. Lazy construction is preferable when working with containers (like std::array or std::vector) and because the event's device can be set automatically to the first stream it's recorded on. With eager construction the user is required to understand that events have a device and acquire the device of the stream the event will be recorded on upfront. This can be seen here:
542aadd9a7/aten/src/ATen/native/cudnn/RNN.cpp (L1130-L1132)
and that file is the only one which currently uses the ATen CUDAEvent.
Refcounting does allow single writer multi-reader scenarios, although these scenarios can be also be supported by providing indirect access to the underlying CUDAEvent. I believe all current and planned usage scenarios do not require refcounting, and if desired I can update this PR to remove refcounting and make the ATen event movable but not copyable like the c10d event. I think not refcounting is preferable because it can improve performance, ease usability, and simplify the code (as seen with two of the above bugs).
I have decided to separate this from PR #8354 since while it's required for PR #8354 the changes are, clearly, of independent interest. PR #8354 has a new dependency on this one, however. I am closing PR #9726 in favor of this PR.
apaszke ezyang pietern
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11293
Differential Revision: D9665836
Pulled By: soumith
fbshipit-source-id: a1513fa4f9761e2f304d126e402f6b6950e1c1d2
Summary:
This adds an optional `expand=True` kwarg to the `distribution.expand_support()` method, to get a distribution's support without expanding the values over the distribution's `batch_shape`.
- The default `expand=True` preserves the current behavior, whereas `expand=False` collapses the batch dimensions.
e.g.
```python
In [47]: d = dist.OneHotCategorical(torch.ones(3, 5) * 0.5)
In [48]: d.batch_shape
Out[48]: torch.Size([3])
In [49]: d.enumerate_support()
Out[49]:
tensor([[[1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0.]],
[[0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0.]],
[[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.]],
[[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 1., 0.]],
[[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1.]]])
In [50]: d.enumerate_support().shape
Out[50]: torch.Size([5, 3, 5])
In [51]: d.enumerate_support(expand=False)
Out[51]:
tensor([[[1., 0., 0., 0., 0.]],
[[0., 1., 0., 0., 0.]],
[[0., 0., 1., 0., 0.]],
[[0., 0., 0., 1., 0.]],
[[0., 0., 0., 0., 1.]]])
In [52]: d.enumerate_support(expand=False).shape
Out[52]: torch.Size([5, 1, 5])
```
**Motivation:**
- Currently `enumerate_support` builds up tensors of size `support + batch_shape + event_shape`, but the values are *repeated* over the `batch_shape` (adding little in the way of information). This can lead to expensive matrix operations over large tensors when `batch_shape` is large (see, example above), often leading to OOM issues. We use `expand=False` in Pyro for message passing inference. e.g. when enumerating over the state space in a Hidden Markov Model. This creates sparse tensors that capture the markov dependence, and allows for the possibility of using optimized matrix operations over these sparse tensors. `expand=True`, on the other hand, will create tensors that scale exponentially in size with the length of the Markov chain.
- We have been using this in our [patch](https://github.com/uber/pyro/blob/dev/pyro/distributions/torch.py) of `torch.distributions` in Pyro. The interface has been stable, and it is already being used in a few Pyro algorithms. We think that this is more broadly applicable and will be of interest to the larger distributions community.
cc. apaszke, fritzo, alicanb
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11231
Differential Revision: D9696290
Pulled By: soumith
fbshipit-source-id: c556f8ff374092e8366897ebe3f3b349538d9318
Summary:
This actually ended up being a lot more involved than I thought. The basic
problem is that in some of our build environments, thread local state is not
supported. The correct way to test if this is the case is using the
(undocumented) CAFFE2_FB_LIMITED_MOBILE_CAPABILITY macro.
On mobile, OptionGuard is not available, and you have to do everything
by hand. There's a static_assert to check if you accidentally use
OptionGuard in this case and give you a better error message in this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11244
Reviewed By: gchanan
Differential Revision: D9646190
fbshipit-source-id: cf4016f79b47705a96ee9b6142eb34c95abb2bd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11323
If you do pass it this, you'll get a pointer to
UndefinedTensor; probably not what you want!
Reviewed By: Yangqing
Differential Revision: D9676205
fbshipit-source-id: 0bd3c22c2c40ac2958f95fc7a73b908af291cf22
Summary:
We need to remove nomnigraph from the list of public libraries in order to support libtorch extensions. Easiest way to do this is to include it into the Caffe2 source like all other caffe2/core/ code.
However, because the headers are in a different place, we need to include them for linked libraries (pybind, tests, etc).
On an upside, this means that nomnigraph is now default hidden visibility too.
FYI peterjc123 xkszltl goldsborough bwasti Yangqing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11303
Reviewed By: pjh5
Differential Revision: D9694932
Pulled By: orionr
fbshipit-source-id: 5db3eb20bc5ddc873ce9151236b74663fbb33ed8
Summary:
* purge hcSPARSE now that rocSPARSE is available
* integrate a custom hcc and HIP
* hcc brings two important compiler fixes (fixes hundreds of unit tests)
* HIP brings a smart dispatcher that allows us to avoid a lot of static_casts (we haven't yet removed the automatic static_casts but this catches some occurrences the script did not catch)
* mark 5 unit tests skipping that have regressed w/ the new hcc (we don't know yet what is at fault)
* optimize bitonic sort - the comparator is always an empty struct - therefore passing it by value saves at least 3 bytes. It also removes an ambiguity around passing references to `__global__` functions
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11198
Differential Revision: D9652340
Pulled By: ezyang
fbshipit-source-id: f5af1d891189da820e3d13b7bed91a7a43154690
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10888
Add cuda version of SpatialBNOp also optimize SpatialBN on CPU
Reviewed By: houseroad
Differential Revision: D9512435
fbshipit-source-id: 6f828c88d56d30dc9a2f98a297a161c35cc511b1
Summary:
Fixed a few bugs that were not tested in the c10d frontend APIs, including
get_rank, get_world_size, and destroy_process_group of a given group.
These APIs are added to the CI tests.
Also added all the group related tests, including full-group, and partial groups (existing ones), since both will hit different code paths.
Also removed experimental APIs for c10d initially used in DDP, now we don't use it anyway.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11318
Reviewed By: pietern
Differential Revision: D9675896
Pulled By: teng-li
fbshipit-source-id: a2eac2c57933effa2d139855f786e64919a95bfc
Summary:
On the way to #10774
This PR adds advanced indexing with tensors.
The approach is to desugar advanced indexing into an at::index op.
This is exactly how normal pytorch does it.
[(I used this code as reference)](https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/python_variable_indexing.cpp)
Supporting sequences is a little tricky because JIT script doesn't have
an easy way to turn arbitrary n-dimensional python lists into a tensor
(it would be easy if we supported `torch.tensor`), so that'll come
in a future PR.
cc jamesr66a zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10862
Differential Revision: D9659449
Pulled By: zou3519
fbshipit-source-id: 56d293720d44c0fd27909e18327ab3985ddfced6
Summary:
In #9466 I got rid of storage views and eliminated all places where
they were used... OR SO I THOUGHT. In actuality, under certain
conditions (specifically, if you trained a CUDA multiprocessing model
shared over CUDA IPC and then serialized your parameters), you could
also serialize storage slices to the saved model format. In #9466,
I "fixed" the case when you loaded the legacy model format (really,
just unshared the storages--not strictly kosher but if you aren't
updating the parameters, shouldn't matter), but NOT the modern model format, so
such models would fail.
So, I could have applied the legacy model format fix too, but
hyperfraise remarked that he had applied a fix that was effectively
the same as unsharing the storages, but it had caused his model to
behave differently. So I looked into it again, and realized that
using a custom deleter, I could simulate the same behavior as old
storage slices. So back they come.
In principle, I could also reimplement storage views entirely using
our allocators, but I'm not going to do that unless someone really
really wants it.
Fixes#10120.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11314
Reviewed By: ailzhang
Differential Revision: D9671966
Pulled By: ezyang
fbshipit-source-id: fd863783d03b6a6421d6b9ae21ce2f0e44a0dcce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11190
As discussed with Alexander Sidorov, params_bytes refer to the number of bytes we're reading for parameters, not the size of parameters. They only differ in sparse operators.
Reviewed By: mdschatz
Differential Revision: D9628635
fbshipit-source-id: 9e2aed0cf59388928dc69b8534cf254f0347c9c8
Summary:
This is an experimental build on top of what orionr and mingzhe09088 built.
Essentially, the idea is that we will need separate *_API versions for different shared libraries. If this theory is right, I'll try to clean up the design a bit and document it properly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11266
Reviewed By: orionr
Differential Revision: D9682942
Pulled By: Yangqing
fbshipit-source-id: c79653199e67a1500c9174f39f8b0357324763f3
Summary:
We shouldn't use system Eigen in any cases when building with setup.py. If people want to use system Eigen (not from third_party) they can build with CMake for now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11334
Reviewed By: pjh5
Differential Revision: D9689450
Pulled By: orionr
fbshipit-source-id: baf616b9f195692942151ad201611dcfe7d927ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11098
Added a test for testing CPU version across multiple devices.
Reviewed By: enosair, BIT-silence
Differential Revision: D9584520
fbshipit-source-id: 0d8c85e6d402bc7b34d5f8f16ef655ff9b61b49e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11338
The `min_` and `max_` value of the filler is in `double` format but when we are filling a specific type of tensor, their value can exceed the type limits, resulting in crash. This diff checks the type limits first and if `min_`/`max_` is out of the limits, it will clip it.
Reviewed By: highker
Differential Revision: D9684455
fbshipit-source-id: 6da98a03c57f3296abaddc7c5cfc1c836c611eb0
Summary:
This will allow users to set customized timeout option for the store.
Tested by my own debug print to make sure that C++ actually used the timeout
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11265
Differential Revision: D9666164
Pulled By: teng-li
fbshipit-source-id: 4eb6441783da106a3fd59b95457e503e83e4640f
Summary:
This lets you compile builtin functions from C++ without having a dependence on Python
```cpp
auto module = torch::jit::compile(JIT"(
def my_script_method(x, y):
return torch.relu(x) + y
)");
IValue result = module->run_method("my_script_method", 1, 2);
```
goldsborough zdevito apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10847
Differential Revision: D9543461
Pulled By: driazati
fbshipit-source-id: 6160dae094030ca144a0df93cb9f26aa78c8cf27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11315
Rename unit tests file to make it consistent with fb cpp style guideline "The unittest for MyFoo.cpp should be named MyFooTest.cpp."
Reviewed By: yinghai
Differential Revision: D9671519
fbshipit-source-id: 44ed6794f6e479d190916db8064eee692e3ad876
Summary:
1. Add documentation to Linear and improve documentation for RNNs
2. Fix preprocessing in C++ docs by adding correct include path
3. Make myself and ebetica codeowner of docs/cpp to improve development speed
ebetica ezyang soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11313
Differential Revision: D9683615
Pulled By: goldsborough
fbshipit-source-id: 84ea32f9ea6b4060744aabbf5db368776a30f0b5
Summary:
Turns out that '' net.type is not acceptable to CreateNet.
But empty net.type is acceptable.
Fix that in this diff. Also this is related to T33613083
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11286
Reviewed By: Maratyszcza, wat3rBro
Differential Revision: D9659920
Pulled By: harouwu
fbshipit-source-id: d68f24b754e18e1121f029656d885c48ab101946
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11291
In S163230, we've found CuDNN 7 upgrade causes accuracy drop in training convolution network such as ResNeXt-101 (~0% accuracy), and video R(2+1)D (65 --> 63%).
Our current theory for this accuracy loss is because of the new "CUDNN_BATCHNORM_SPATIAL_PERSISTENT" in spatialBN operator. In Caffe 2, we've made this mode as default. According to CuDNN manual (https://fburl.com/z996mr13), this mode may introduce some limitation in the input data range and cause overflow (which outputs NaN). NaN is probably not the case, because we're seeing a few percent of accuracy drop but not gradient explosion or failure. However, this "performance-optimized" code path may introduce accuracy loss (which is not caught by our unit test case because the input data range is [-0.5-0.5].
Reviewed By: kuttas, stephenyan1231
Differential Revision: D9601217
fbshipit-source-id: 73c2690c19cb1f02ea4e5e2200f50128df4f377b
Summary:
this is a fix that's needed for building extensions with a
pre-packaged pytorch. Consider the scenario where
(1) pytorch is compiled and packaged on machine A
(2) the package is downloaded and installed on machine B
(3) an extension is compiled on machine B, using the downloaded package
Before this patch, stage (1) would embed absolute paths to the system
installation of mkl into the generated Caffe2Config.cmake, leading to
failures in stage (3) if mkl was not at the same location on B as on
A. After this patch, only a reference to the wrapper library is
embedded, which is re-resolved on machine B.
We are already using a similar approach for cuda.
Testing: built a package on jenkins, downloaded locally and compiled an extension. Works with this patch, fails without.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11298
Differential Revision: D9683150
Pulled By: anderspapitto
fbshipit-source-id: 06a80c3cd2966860ce04f76143b358de15f94aa4
Summary:
Now that we're building everything together, making all distributed flags conditional of USE_DISTRIBUTED being set.
cc pietern The controller you requested could not be found. cpuhrsch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11221
Reviewed By: Yangqing
Differential Revision: D9664267
Pulled By: orionr
fbshipit-source-id: a296cda5746ad150028c97160f8beacba955ff73
Summary:
Fixes#8560.
Unblocks #10715.
The assert (nDim <= uncompressedDims) was being triggered for a scalar
tensor because we compute nDim to be 1 for a scalar tensor but
uncompressedDim = 0.
This PR changes it so that we compute nDim to be 0 for a scalar tensor. This
works because indexing in a kernel depends on nDim. If nDim = 0, then
offset is always 0, which is what we want.
Some other (small) changes were necessary to make this work:
- One cannot define a 0-length array `IndexType arr[0]` so the code
guards against that
- Needed to change some of the maxTensorInfoSize logic to handle the
case when uncompressedDim == 0.
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10952
Differential Revision: D9544607
Pulled By: zou3519
fbshipit-source-id: 2b873f47e2377125e1f94eb1b310a95cda51476c
Summary:
Distributed Data Parallel CPU module for c10d. This is basically the same code as Distributed Data Parallel CPU module for THD, since c10d now has the exact same front-end interface as torch.distributed.
We will keep both in the first release and remove the THD one once c10d is stable enough.
Test fully covered just as THD too.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11168
Differential Revision: D9674963
Pulled By: teng-li
fbshipit-source-id: ecf52a7189374ca7930c2be305218167fdd822a7
Summary:
Linting `torch/csrc/` (non-recursive) and `torch/csrc/autograd` (non-recursive).
Fixed things like:
- `typedef` vs `using`
- Use `.empty()` instead of comparing with empty string/using `.size() == 0`
- Use range for loops instead of old style loops (`modernize-`)
- Remove some `virtual` + `override`
- Replace `stdint.h` with `cstdint`
- Replace `return Type(x, y)` with `return {x, y}`
- Use boolean values (`true`/`false`) instead of numbers (1/0)
- More ...
ezyang apaszke cpuhrsch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11050
Differential Revision: D9597505
Pulled By: goldsborough
fbshipit-source-id: cb0fb4793ade885a8dbf4b10484487b84c64c7f2
Summary: Closing the gap a bit on API, allowing users to go NetDef -> nomnigraph -> NetDef in python now
Reviewed By: duc0
Differential Revision: D9670495
fbshipit-source-id: 6497518ffc05a186deb0d657e06317980d39ddd5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11256
- in deleteNode method, remove optional deleteEdge flag as it's not used
- in deleteEdge method, remove optional removeRef flag as it's not used
- in replaceNode method, remove optional newHead_ parameter as it's not used - also simplifying the implementation by just calling replaceInEdges and replaceOutEdges
- remove importNode & importEdge as they're not in used
- add getEdgeIfExists that is like getEdge() but returns nullptr instead of throwing when the edge does not exist
- reduce verbosity in the basic graph unit test and add more test cases for ReplaceEdges
Differential Revision: D9650913
fbshipit-source-id: 6c18b37bef0d2abe1b57fb4fc47bfdbcee387694
Summary:
I'm setting up an automatic sync job for cppdocs and need two fixes to the cpp docs config:
1. Right now the cppdocs use the `torch` package to figure out the version. For C++ docs all I really need from the built package are the generated Tensor.h and Functions.h files. I can actually generate those directly via `aten/src/ATen/gen.py`, so I can skip building PyTorch altogether and save 10 minutes in the sync job! For this I need to avoid using the torch package in the docs.
2. Internal proxy issues prevent using the git link for sphinx_rtd_theme. We can just use the pip package for the cppdocs (not for the normal PyTorch docs)
soumith ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11300
Differential Revision: D9667193
Pulled By: goldsborough
fbshipit-source-id: 5567e0b3d3bdce03f5856babdb4ff76bcee91846
Summary:
This PR adds all PyTorch and Caffe2 job configs to CircleCI.
Steps for the CircleCI mini-trial:
- [ ] Make sure this PR passes Jenkins CI and fbcode internal tests
- [x] Approve this PR
- [ ] Ask CircleCI to turn up the number of build machines
- [ ] Land this PR so that the new `.circleci/config.yml` will take effect
Several Caffe2 tests are flaky on CircleCI machines and hence skipped when running on CircleCI. A proper fix for them will be worked on after a successful mini-trial.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11264
Differential Revision: D9656793
Pulled By: yf225
fbshipit-source-id: 7832e90018f3dff7651489c04a179d6742168fe1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11254
Previously we use DeviceType in caffe2.proto directly, but it's an `enum` and have implicit conversion to int, which does not have type safety, e.g. we have to explicitly check for a device type is valid in event.h:
```
template <int d>
struct EventCreateFunctionRegisterer {
explicit EventCreateFunctionRegisterer(EventCreateFunction f) {
static_assert(d < MaxDeviceTypes, "");
Event::event_creator_[d] = f;
}
};
```
at::DeviceType is an `enum class`, and it does not have implicit conversion to int, and provides better type safety guarantees. In this diff we have done the following refactor(taking CPU as an example):
1. caffe2::DeviceType → caffe2::DeviceTypeProto
2. caffe2::CPU → caffe2::PROTO_CPU
3. caffe2::DeviceType = at::DeviceType
4. caffe2::CPU = at::DeviceType::CPU
codemod -d caffe2/caffe2 --extensions h,cc,cpp 'device_type\(\), ' 'device_type(), PROTO_'
+ some manual changes
In short, after this diff, in c++, caffe2::CPU refers to the at::DeviceType::CPU and the old proto caffe2::CPU will be caffe2::PROTO_CPU.
In python side, we have a temporary workaround that alias `caffe2_pb2.CPU = caffe2_pb2.PROOT_CPU` to make the change easier to review and this will be removed later.
Reviewed By: ezyang
Differential Revision: D9545704
fbshipit-source-id: 461a28a4ca74e616d3ee183a607078a717fd38a7
Summary:
Persistent rnns provide much better performance on V100 with half input data for a variety of cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11248
Differential Revision: D9665687
Pulled By: ezyang
fbshipit-source-id: 2bd09a7eb1f5190aadb580977b0ba956e21a7dd5
Summary:
- In Python 2, use of `/` (regardless of int/float/Tensor) causes a compiler error if
`from __future__ import division` is not imported in the file.
- The / operator is universally set to do "true" division for integers
- Added a `prim::FloorDiv` operator because it is used in loop unrolling.
The error if users use '/' in python 2 without importing from __future__
occurs when building the JIT AST.
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11016
Differential Revision: D9613527
Pulled By: zou3519
fbshipit-source-id: 0cebf44d5b8c92e203167733692ad33c4ec9dac6
Summary:
The existing tests had every rank run send to every other rank and only
then switch to recv mode. This only works if the send operations are
non-blocking and the passed tensors are immediately copied to some kind
of send buffer. Instead, every send must be matched with a recv on the
other side, because from the API perspective they may block.
E.g. imagine a 1GB tensor being sent to every other rank. It can only go
through if there is a recv on the other side, or it will deadlock.
This change reflects this in the send/recv unit tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11275
Differential Revision: D9658197
Pulled By: pietern
fbshipit-source-id: fb6a3fc03b42343a9dfeed0def30d94914e76974
Summary:
Found these when compiling the new master with gcc 7.3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11257
Differential Revision: D9656612
Pulled By: SsnL
fbshipit-source-id: 7acb19e13204c010238dab7bc6973cc97b96f9a4
Summary:
This PR adds a .travis.yml check for our C++ documentation. The goal is to avoid any documentation/comments in our C++ code that would break the doxygen output and possibly ruin the C++ documentation site (currently https://pytorch.org/cppdocs).
For this, we:
1. Run doxygen and record any warnings,
2. Filter out some known bogus warnings,
3. Count the remaining warnings,
4. Fail the check if (3) is non-zero.
soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11124
Differential Revision: D9651011
Pulled By: goldsborough
fbshipit-source-id: 30f776d23bb6d6c482c54db32828b4b99547e87b
Summary:
Allows mulitplication of e.g. numpy.float32 with tensors.
This came up with #9468
If you want this and after the other patch is done, I'll add tests (but that would be conflicting, so I prefer to wait).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9659
Differential Revision: D8948078
Pulled By: weiyangfb
fbshipit-source-id: c7dcc57b63e2f100df837f70e1299395692f1a1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10874
Fixes the log message "WARNING:data_workers:Warning, data loading lagging behind: name=0" where instead of source name the size of a queue is reported
Reviewed By: panshen1, Novitial
Differential Revision: D9506606
fbshipit-source-id: 03717cfa9b991afb335ef877378afa3b52fd8f22
Summary:
`__repr__` currently fails for distributions with lazy attributes in PyTorch master, throwing a `KeyError`. This fixes the issue.
**Additionally:**
- Added `logits` to `arg_constraints` for distributions that accept either `probs` or `logits`. This is both to have `__repr__` display the `logits` param when available, and to be able to do validation checks (e.g. NaN checks) when the logit parametrization is used. fritzo, alicanb - I think there were reasons why we had not done so in the first place, but I am unable to recall now. It passes all the tests, but let me know if there is something that I am missing at the moment.
- There are certain distributions, e.g. `OneHotCategorical` which won't show any parameters because it uses a `categorical` instance under the hood and neither `logits` / `probs` in `arg_constraints` are present in the instance's `__dict__`. This isn't addressed in this PR.
cc. vishwakftw, fritzo, nadavbh12, apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11263
Differential Revision: D9654959
Pulled By: apaszke
fbshipit-source-id: 16f5b20243fe8e2c13e9c528050d4df0b8ea6e45
Summary:
This PR adds a hooks interface for registering types for complex
scalar types, and a sample implementation of the hook in
test_cpp_extensions.
The hook registration is patterned off of the existing CUDA hooks.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
CC The controller you requested could not be found.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11216
Differential Revision: D9654840
Pulled By: ezyang
fbshipit-source-id: 7b97646280d584f8ed6e14ee10a4abcd04cf2987
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11127
it's invalid to capture `predicate` by reference as it's a local variable. capture it by value instead.
Differential Revision: D9600115
fbshipit-source-id: 92e0130d0a74908380b75ade5c3492df49e25941
Summary:
Also, make `torch.isclose` work with integral tensors and refactor `_check_trace` a bit.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11246
Differential Revision: D9652701
Pulled By: apaszke
fbshipit-source-id: fb0bdbfd1952e45e153541e4d471b423a5659f25
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11123
this adds an operator that fills a tensor with a uniform(min, max)
the implementation is to use the fp32 generator and convert to fp16
if performance becomes an issue we could resort to intrinsics
Reviewed By: jspark1105, chocjy
Differential Revision: D9598142
fbshipit-source-id: 5aeab99acf7c3596fa6c33611d9d2c484f7c1145
Summary:
keep net type info when generating model complete net. This will keep the performance optimization option
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11032
Reviewed By: wat3rBro
Differential Revision: D9564125
Pulled By: harouwu
fbshipit-source-id: c6546af9b1d4ff5eddf6124e24a5da1b8baf47df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11215
I found these by deleting the implicit conversion of Type to
TensorOptions and then fixing sites. This isn't a complete
refactor, because I ran out of steam after fixing this many
and decided to keep the implicit conversion. Still, why
waste a perfectly good refactor?
Reviewed By: gchanan, cpuhrsch
Differential Revision: D9634750
fbshipit-source-id: 4d8fb778e13e6e24b888b1314a02709b2cb00b62
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11205
Our short term plan for supporting out of tree complex development requires an
external library to add a custom subclass of Type without access to the
code generation facilities in ATen. This commit reorganizes Type so
as to minimize the amount of boilerplate you have to write when making
a subclass of Type.
In particular, it:
- Creates a new CPUTypeDefault/CUDATypeDefault class, which you are
intended to inherit from, which provides default implementations
of CPU/CUDA that is layout/dtype agnostic.
- Adds new getCPUAllocator() and getCUDAAllocator() functions, as
a more public API to get your hands on Allocator
- Adds allocator() and getDeviceFromPtr(), abstracting the device
specific parts of storage() methods; these methods are now
implemented in base TypeDefault.
- Delete the static typeString() method, which is now dead.
- Move is_cuda/is_sparse/is_distributed to TypeDefault.
Reviewed By: SsnL
Differential Revision: D9631619
fbshipit-source-id: 40b600d99691230e36e03eb56434c351cbc2aa3a
Summary:
Just pulling this out of https://github.com/pytorch/pytorch/pull/10611
Make sure we can support environments where we don't have libprotobuf installed when we link-local protobuf.
cc goldsborough Yangqing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11161
Differential Revision: D9650282
Pulled By: orionr
fbshipit-source-id: 447b5e54cd2639973b4b10f58590d1c693a988d4
Summary:
Will use USE_DISTRIBUTED for both c10d and THD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11237
Differential Revision: D9647825
Pulled By: teng-li
fbshipit-source-id: 06e0ec9b5e2f8f38780fc88718f8499463e9e969
Summary:
This was lingering after #10731.
cc orionr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11240
Differential Revision: D9645437
Pulled By: pietern
fbshipit-source-id: d02c33354b094be3bb0872cf54a45721e20c4e7d
Summary:
This PR resolved the following compilation errors on devgpu:
/home/mingzhe0908/pytorch/build/lib/libcaffe2_gpud.so: undefined reference to `caffe2::CAFFE2_PLEASE_ADD_OPERATOR_SCHEMA_FOR_Tan()'
/home/mingzhe0908/pytorch/build/lib/libcaffe2_gpud.so: undefined reference to `caffe2::CAFFE2_PLEASE_ADD_OPERATOR_SCHEMA_FOR_MaxPool3D()'
....
The same error has been happening with caffe2 build with debug mode before build_caffe2 was removed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11233
Reviewed By: orionr
Differential Revision: D9645527
Pulled By: mingzhe09088
fbshipit-source-id: 68a45aa7fd815cac41b7fd64cfd9838b3226345a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11060
Adding synthetic data generation to the filler.h file (the exact distribution to be replaced later on).
Reviewed By: highker
Differential Revision: D9417594
fbshipit-source-id: 5d66dfbcb254a5961c36b7d3a081332c7372dac7
Summary:
there are multiple views of the tensor live.
Also adds recording for copy_ because this is the critical in place
op where these views will cause LHS indexing to fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11129
Differential Revision: D9600195
Pulled By: zdevito
fbshipit-source-id: bfd8f5befa47377e36d704dbdb11023c608fe9a3
Summary:
TSIA. apaszke pointed out that it might be better to use third party folder in default, since system Eigen may often be out of date and does not have the version we need to compile successfully.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11020
Differential Revision: D9562548
Pulled By: Yangqing
fbshipit-source-id: d8ab8a6ebe1f3d9eec638ef726cf5dc4dcf777b5
Summary:
Adding short circuit evaluation to AND or OR. The second expression of and AND or OR gets lifted into an if branch, which is conditionally evaluated.
BatchOps was using the expression `dims = dims1 or dims2`, where dims is often an empty tensor. This nows throws an error, because dims1 gets cast to a boolean, and you can't convert an empty tensor to a scalar. It now matches the behavior of pytorch in python.
One thing that came up is if the second expression in an and/or in python gets returned, it does not get coerced to a boolean.
`tensor == (False or tensor)`
`tensor == (True and tensor)`
We do not currently support this.
edit: wording
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11116
Differential Revision: D9618168
Pulled By: eellison
fbshipit-source-id: 93b202be2f222d41f85d38d9c95f04d1749e8343
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11189
Replaces it with an operator TensorOptions() method on
Type, reestablishing the implicit conversion. I originally
wanted to get rid of the implicit conversion entirely, but
there were a *lot* of use-sites, so I added it back to avoid
a huge codemod. In this patch, I only had to fix sites that
used the optional device_index API.
Reviewed By: cpuhrsch
Differential Revision: D9628281
fbshipit-source-id: 5fe2a68eefb77a3c9bb446f03a94ad723ef90210
Summary:
Example:
```sh
python run_test.py -i sparse -- TestSparse.test_factory_size_check -f
```
With this, the `--verbose` option is redundant (one can call `python run_test.py -- -v` instead of `python run_test.py -v`. But since this is (probably) a frequently used flag, I didn't remove the existing easier-to-use option.
cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11209
Differential Revision: D9632215
Pulled By: SsnL
fbshipit-source-id: ff522802da11ef0a0714578be46e4a44f6343d44
Summary:
We don't generate a corresponding Type implementations for them,
so this doesn't do anything at the moment.
We don't plan on supporting complex32 in the near future, but
it is added to reserve the name and number in case we do at
some point in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11173
Reviewed By: SsnL
Differential Revision: D9627477
Pulled By: ezyang
fbshipit-source-id: f49a44ab1c92d8a33130c249ac7b234f210a65e6
Summary:
In the state dict loading code, it would print the error message referring to the shape of the loaded parameters and the parameters in the initialised model with the formatting in the wrong order. Swapped them round to fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11200
Differential Revision: D9631160
Pulled By: SsnL
fbshipit-source-id: 03d9446303bd417fef67027b10d7a27de06486be
Summary:
Disables two of the unit tests in test_cuda that got introduced after test_cuda was enabled that fail on ROCm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11191
Differential Revision: D9628702
Pulled By: ezyang
fbshipit-source-id: 4c298c728f42bb43d39b57967aa3e44385980265
Summary:
This is necessary to allow us to use the complex header
which defines real (and is very sad if real is macro'ed).
We should also fix accreal, ureal, Real and REAL, but
only 'real' is the real blocker.
```
codemod -d aten/src/TH --extensions c,cc,cpp,cu,cuh,h,TARGETS,py,hpp '\breal\b' scalar_t
codemod -d aten/src/THC --extensions c,cc,cpp,cu,cuh,h,TARGETS,py,hpp '\breal\b' scalar_t
codemod -d aten/src/THNN --extensions c,cc,cpp,cu,cuh,h,TARGETS,py,hpp '\breal\b' scalar_t
codemod -d aten/src/THCUNN --extensions c,cc,cpp,cu,cuh,h,TARGETS,py,hpp '\breal\b' scalar_t
```
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11163
Reviewed By: SsnL
Differential Revision: D9619906
Pulled By: ezyang
fbshipit-source-id: 922cb3a763c0bffecbd81200c1cefc6b8ea70942
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11013
Previously, the parent class Type also contained a large number
of implementations, for things like broadcasting and native
functions that didn't need dispatch. We'd like to be able
to reference this interface from Tensor even when we don't
have any of these implementations are available.
To do this, we convert Type into a truly pure virtual interface,
and move all of the implementations to TypeDefault.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11181
Differential Revision: D9561478
Pulled By: ezyang
fbshipit-source-id: 13c49d80bc547551adf524b1cf1d691bfe311133
Summary:
* improve docker packages (install OpenBLAS to have at-compile-time LAPACK functionality w/ optimizations for both Intel and AMD CPUs)
* integrate rocFFT (i.e., enable Fourier functionality)
* fix bugs in ROCm caused by wrong warp size
* enable more test sets, skip the tests that don't work on ROCm yet
* don't disable asserts any longer in hipification
* small improvements
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10893
Differential Revision: D9615053
Pulled By: ezyang
fbshipit-source-id: 864b4d27bf089421f7dfd8065e5017f9ea2f7b3b
Summary:
This places all constants in the entry block of the graph, and de-duplicates them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10231
Differential Revision: D9601501
Pulled By: resistor
fbshipit-source-id: daa10ed8c99e9894830d6f3e5d65c8d3ab5ea899
Summary:
Previously when we had a slicing expression like `x[0:5, 0]`, where the sliced tensor was of size `5` in dimension 0, we would skip dispatching the actual slice call as an optimization.
This caused incorrect behavior under tracing, as we would not record the slice op and thus if we encountered an input with a different shape while running the trace, we would get incorrect results.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11156
Differential Revision: D9622252
Pulled By: jamesr66a
fbshipit-source-id: 822f2e8f01504e131f53bd9ef51c171c7913a7cc
Summary:
This makes it so `detach` and `detach_` are traceable and also adds a pass to erase them before ONNX export
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11038
Differential Revision: D9588038
Pulled By: jamesr66a
fbshipit-source-id: 263dd3147e24fcb0c716743f37fdb9f84c0015e7
Summary:
Will need to be accessible by caffe2
This also removes a bunch of unnecessary includes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11154
Reviewed By: ezyang
Differential Revision: D9618681
Pulled By: cpuhrsch
fbshipit-source-id: 838a87b75d9c3959e145fd5fca13b63bc5de7bd3
Summary:
```
In file included from third-party-buck/gcc-5-glibc-2.23/build/pybind11/889256a/include/pybind11/cast.h:13:0,
from third-party-buck/gcc-5-glibc-2.23/build/pybind11/889256a/include/pybind11/attr.h:13,
from third-party-buck/gcc-5-glibc-2.23/build/pybind11/889256a/include/pybind11/pybind11.h:43,
from caffe2/torch/csrc/utils/pybind.h:6,
from caffe2/torch/csrc/jit/pybind.h:5,
from caffe2/torch/csrc/jit/script/init.h:3,
from caffe2/torch/csrc/jit/script/init.cpp:1:
third-party-buck/gcc-5-glibc-2.23/build/pybind11/889256a/include/pybind11/pytypes.h:118:19: note: declared here
In file included from caffe2/torch/csrc/jit/pybind.h:12:0,
from caffe2/torch/csrc/jit/python_ir.cpp:4:
caffe2/torch/csrc/jit/pybind_utils.h: In function 'torch::jit::IValue torch::jit::argumentToIValue(const torch::jit::FunctionSchema&, size_t, pybind11::handle)':
caffe2/torch/csrc/jit/pybind_utils.h:138:226: warning: 'pybind11::str pybind11::detail::object_api<Derived>::str() const [with Derived = pybind11::detail::accessor<pybind11::detail::accessor_policies::str_attr>]' is deprecated: Use py::str(obj) instead [-Wdeprecated-declarations]
```
apaszke zdevito ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11107
Differential Revision: D9598040
Pulled By: goldsborough
fbshipit-source-id: 4a055353ac08d54a2bbca49573ff099310de3666
Summary:
ATen's doc/ folder is manually maintained and can thus cause confusion with the generated file. We now have proper online documentation for ATen, which is superior to ATen doc/. Let's delete ATen/doc.
ezyang apaszke soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11158
Differential Revision: D9618782
Pulled By: goldsborough
fbshipit-source-id: 0ef14f84947601a0589aa4a41e5c8619783426fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11035
Instead, inline its definition into Tensor. We need
to do this so we can avoid needing to getType() from
TensorImpl.
Reviewed By: cpuhrsch
Differential Revision: D9564516
fbshipit-source-id: 19fdaa2b93419e21572b9916714aee4165cb3390
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11031
The eventual plan is to get rid of TensorImpl::type()
entirely; but first we need a function to call.
Reviewed By: cpuhrsch
Differential Revision: D9564206
fbshipit-source-id: b59a9ccfaed44199f185eff392835cec89ccda8e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11023
I'd like TensorOptions to not know anything about Context, so I can
move it to ATen/core without pulling in Context. To do this, the
type() method has to go, since it consults the context to get a Type.
Reviewed By: cpuhrsch
Differential Revision: D9562467
fbshipit-source-id: 61a18a76eb042a5e70b64b963501e9d68c25d4f0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11144
We can move them now that TensorMethods no longer references Tensor.
Reviewed By: cpuhrsch
Differential Revision: D9613800
fbshipit-source-id: 99ad1dd7d77eb319000769230b7016294cf1980f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11027
Using swap() as a primitive, copy and move assignment become much easier.
Reviewed By: ezyang
Differential Revision: D9563753
fbshipit-source-id: e74faf39b596f097de758bfe038639565807040a
Summary:
This completely removes BUILD_CAFFE2 from CMake. There is still a little bit of "full build" stuff in setup.py that enables USE_CUDNN and BUILD_PYTHON, but otherwise everything should be enabled for PyTorch as well as Caffe2. This gets us a lot closer to full unification.
cc mingzhe09088, pjh5, ezyang, smessmer, Yangqing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8338
Reviewed By: mingzhe09088
Differential Revision: D9600513
Pulled By: orionr
fbshipit-source-id: 9f6ca49df35b920d3439dcec56e7b26ad4768b7d
Summary:
Added MPI group support.
And this will make all previous group test cases of MPI passed.
Also, release the MPI thread level support by serializing different PG's MPI ops. This is required.
The build is fixed too
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11128
Differential Revision: D9602188
Pulled By: teng-li
fbshipit-source-id: 1d618925ae5fb7b47259b23051cc181535aa7497
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11101
I'd like to invert the dependency between Tensor and TensorOptions
(such that Tensor includes TensorOptions); to do this, I'd prefer
there to not be a Tensor constructor. Eventually, all references
of Tensor will disappear from TensorOptions.h
Reviewed By: cpuhrsch
Differential Revision: D9585627
fbshipit-source-id: dd4a28b2c06b1e55f629762915f03c2b6c34d840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11122
these changes add fixes to device.cc that are appropriate to create the intra-device-copies for opencl
Reviewed By: bwasti
Differential Revision: D9553292
fbshipit-source-id: e59f17916b5df30a504adee0718f9cecfe28f35a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11021
We can now store a boolean saying if we want a Variable or not,
and context can use VariableHooks to get a VariableType if we
request one.
Reviewed By: cpuhrsch
Differential Revision: D9562312
fbshipit-source-id: 84653cd789622764132252406a5ea1a83eee3360
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11096
To discourage willy-nilly use, and make it clearer that it
is not a Variable
Reviewed By: cpuhrsch
Differential Revision: D9583699
fbshipit-source-id: 4fbde0c01ae3deb2c7ef8c125a9028f089b203ae
Summary:
Generate serialized test inputs/outputs/backward graphs of tests inside `caffe2/python/operator_test` that call assertSerializedOperatorCheck(). Tests should be decorated with serialized_test.collect_tests.given_and_seeded to run hypothesis tests that are actually random and a single fixed seeded hypothesis tests.
To use:
1. Refactor your test to be a SerializedTestCase
1a. Decorate it with given_and_seeded
1b. Call testWithArgs in main
2. Run your test with -g to generate the output. Check it in.
3. Subsequent runs of the test without generating the output will check against the checked in test case.
Details:
Run your test with `python caffe2/python/operator_test/[your_test].py -g`
Outputs are in `caffe2/python/serialized_test/data`. The operator tests outputs are in a further subdirectory `operator_test`, to allow for other tests in the future (model zoo tests?)
Currently, we've only refactored weighted_sum_test to use this, but in the next diff, we'll refactor as many as possible. The directory structure may also change as usually there are multiple tests in a single file, so we may create more structure to account for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10594
Reviewed By: ezyang
Differential Revision: D9370359
Pulled By: ajyu
fbshipit-source-id: 2ce77389cd8bcc0255d3bccd61569833e545ede8
Summary:
**Review last commit only.** Stacked on top of #10949.
This commit fixes a number of issues connected to caching
differentiability status of graphs inside graph executors,
and changes the rules for optimization of differentiable subgraphs.
Previously every one of those was instantiated as a separate graph
executor, but now they are simply heavier-optimized graph regions,
and graph executors are only instantiated for their backward.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10977
Differential Revision: D9600626
Pulled By: apaszke
fbshipit-source-id: dad09a0f586e396afbd5406319c1cd54fbb8a3d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11095
We used getType to mean a lot of things.
- getVariableTypeFromBaseType: given a base Type (non-Variable type)
compute the Variable Type which corresponds to it.
- getVariableType: like at::getType, but return the Variable type
rather than the plain type.
This rename makes it clearer at the use-site what things are what,
and will make a subsequent rename of at::getType easier.
Reviewed By: gchanan, cpuhrsch
Differential Revision: D9583630
fbshipit-source-id: 2667ec98e7607bc466920c7415a8c651fd56dfca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11080
- Add a new TensorOptions(Device, ScalarType) constructor,
which serves roughly the same role as getType used to.
We shouldn't get too wild with these constructors, but
since this particular one was widely used by getType,
it seems worth adding.
- Change DLPack DeviceType conversion to at::DeviceType,
rather than at::Backend. While I'm at, add a few more
conversions that at::DeviceType understands.
- Add a new overload of from_blob which understands strides.
Reviewed By: gchanan, cpuhrsch
Differential Revision: D9578734
fbshipit-source-id: 28288ec053aae8765e23925ab91023398d632d6b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11077
getType now supports retrieving variable types, so make it clearer
when a getType function does NOT give you a variable type.
```
codemod -d . --extensions cc,cpp,cu,cuh,h getTypeOpt getNonVariableTypeOpt
```
Reviewed By: gchanan
Differential Revision: D9578398
fbshipit-source-id: 3ee502ac5c714849917f11ddc71de8eacfdaa9d3
Summary:
Operators like aten::chunk used to return a number of tensors, but
now return a list. To make it easier to do shape prop through
aten::chunk and fuse it, I've also introduced prim::ConstantChunk,
which behaves like the previous implementation (has a variable length
output list).
The downside of this PR is that the introduction of more lists to the IR causes the LSTM and MiLSTM graphs to be considered as non-differentiable by the graph executor. I verified that they are still optimize correctly, and my next patch (that changes how the specializations/differentiation works) will restore those.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10949
Reviewed By: zdevito
Differential Revision: D9556823
Pulled By: apaszke
fbshipit-source-id: 33e63b17fc7247cac6cfc05eb7eb9bf069b499ee
Summary:
update to the latest observer usage syntax
add an example of HistogramObservers
Reviewed By: jspark1105
Differential Revision: D6878439
fbshipit-source-id: c9521f2daecfc7f0c17de6a944dce58e568e3dbe
Summary:
How did we get so many uses of `NULL` again?
ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11047
Differential Revision: D9566799
Pulled By: goldsborough
fbshipit-source-id: 83469f352ac69aa65bdaf1a1a21f922d892e0db3
Summary:
I've been seeing a lot of warnings about multiple declarations of this. Hopefully this fixes it.
cc Yangqing mingzhe09088 ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11045
Reviewed By: mingzhe09088
Differential Revision: D9582756
Pulled By: orionr
fbshipit-source-id: 6171485609a2f2f357d6e1c44e26b4ecfcdb4ce6
Summary:
This is needed because the JIT declares some custom autograd functions.
colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11082
Differential Revision: D9580456
Pulled By: apaszke
fbshipit-source-id: 6bf00c1188a20b2ee6ecf60e5a0099f8263ad55a
Summary:
This was done because it surprising for a decorator to run a function
rather than wrap it, and not simplify the syntax for tracing modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11069
Reviewed By: jamesr66a
Differential Revision: D9583192
Pulled By: zdevito
fbshipit-source-id: b914b7ab4c73c255086465a6576eef3a22de1e13
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11026
ezyang fixed a bug with moving or copying an intrusive_ptr into itself.
This diff adds test cases for it.
Reviewed By: ezyang
Differential Revision: D9563464
fbshipit-source-id: 3a3b3f681124730d2500b276c0135c3bba7875ae
Summary:
This PR creates a stream pool per issue #9646. When a new stream is requested, that device it's requested on lazily creates two pools, one low priority and one high priority, of 32 streams each. Streams are returned from these pools round-robin. That is, stream 0 is returned, then stream 1... then stream 31, then stream 0... This PR also takes the opportunity to clean up the stream API, reducing its complexity and verbosity.
Change notes:
- There are now 3 sets of streams per device, the default stream, the low priority streams, and the high priority streams. These streams live in lazily initialized pools and are destroyed on shutdown.
- All stream refcounting has been removed (the pools pattern replaces it).
- Setting a stream now sets it on its device. Streams are associated with a device and the previous
requirement to specify that device was unnecessary.
- There is no exposure for setting the flags on a stream. This may also seem like a regression but the flag was always set to cudaStreamNonBlocking.
- Streams are now low or high priority whereas previously the priority could be set with an integer. In practice, however, the range for priorities is -1 to 0 on the latest hardware. -1 is high priority, 0 is low priority (aka default priority). Low vs. high actually clarifies this behavior if people were trying finer separations. (E.g., if someone tried streams with priorities 0, 1, and 2, they would actually all have priority 0, historically, and the intended behavior would not be respected.)
- Unused THCStream and THCState stream-related functions were removed.
- A new test of pooling behavior was added in stream_test.
fyi: colesbury, apaszke, goldsborough
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9938
Reviewed By: SsnL
Differential Revision: D9569036
Pulled By: ezyang
fbshipit-source-id: 12ed673fe373170d0cf4d65cb570de016c53ee7d
Summary:
The warnings are erroneous as far as i can see,
so tweak things to avoid. The (unsigned int) cast is
to avoid passing -1 to a size_t time. This was triggered
in gcc8's lto build only, giving:
caffe2/aten/src/TH/generic/THTensor.cpp: In function ‘THFloatTensor_squeeze1d’:
lto1: error: ‘__builtin_memset’ specified size 18446744073709551608
exceeds maximum object size 9223372036854775807 [-Werror=stringop-overflow=]
In function ‘newImpl’,
inlined from ‘operator new’ at common/memory/OperatorOverride.cpp:86:23,
inlined from ‘allocate’ at third-party-buck/platform007/build/libgcc/include/c++/7.3.0/ext/new_allocator.h:111:0,
inlined from ‘allocate’ at third-party-buck/platform007/build/libgcc/include/c++/7.3.0/bits/alloc_traits.h:436:0,
inlined from ‘_M_allocate’ at third-party-buck/platform007/build/libgcc/include/c++/7.3.0/bits/stl_vector.h:172:0,
inlined from ‘_M_default_append’ at third-party-buck/platform007/build/libgcc/include/c++/7.3.0/bits/vector.tcc:571:0,
inlined from ‘resize’ at third-party-buck/platform007/build/libgcc/include/c++/7.3.0/bits/stl_vector.h:671:0,
inlined from ‘THTensor_resizeDim’ at caffe2/aten/src/TH/THTensor.hpp:123:0,
inlined from ‘THFloatTensor_squeeze1d.part.198’ at caffe2/aten/src/TH/generic/THTensor.cpp:429:0,
inlined from ‘THFloatTensor_squeeze1d’:
common/memory/OperatorOverride.cpp:86:23: error:
argument 1 value ‘18446744073709551608’ exceeds maximum object size 9223372036854775807 [-Werror=alloc-size-larger-than=]
void* ptr = malloc(size);
Reviewed By: soumith
Differential Revision: D9568621
fbshipit-source-id: 4569a4be897d669caa3f283f4b84ec829e8d77ad
Summary:
Also add single grad whitelist to the jit test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10782
Reviewed By: ezyang
Differential Revision: D9583378
Pulled By: erikbrinkman
fbshipit-source-id: 069e5ae68ea7f3524dec39cf1d5fe9cd53941944
Summary:
I've had `torch/lib/python3.6` show up as part of the build for some time now. It's not ignored which means I need to be extra careful about checking in files, or I end up with a thousand of them in my index.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11083
Differential Revision: D9580453
Pulled By: apaszke
fbshipit-source-id: 369e4fe87962696532d111b24f2a4a99b9572bf2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10826
Add strides, and make sure the strides are consistent with sizes, and is_contiguous, for all the Caffe2 functions.
is_contiguous means strides_[dim-1] = 1 and strides_[i] = strides_[i+1] * max(size_[i+1], 1);
Reviewed By: ezyang
Differential Revision: D9354480
fbshipit-source-id: 3643871b70f1111b7ffdd9fdd9fe9bec82635963
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10976
The app can run in XCode with the benchmark metrics collected.
It can also run when building with buck
Reviewed By: llyfacebook
Differential Revision: D9546755
fbshipit-source-id: 60ad0112946f8cf57138417f6838a58ed6d2c90f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11046
As suggested by jerryzh168, temporary fix for a new constraint that was added D9350686 is to remove this assert. Long term jerryzh168 is going to work out a better way of handling this.
Reviewed By: jerryzh168
Differential Revision: D9566323
fbshipit-source-id: e4630c7cbe0cc68a084974ea7048654811fae01f
Summary:
Currently our `skipIfLapack` has uses a try-catch block and regex match the error message. It is highly unreliable. This PR adds `hasLAPACK` and `hasMAGMA` on ATen context, and expose the flags to python.
Also fixes refcounting bug with `PyModule_AddObject`. The method steals reference, but we didn't `Py_INCREF` in some places before calling it with `Py_True` or `Py_False`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11024
Differential Revision: D9564898
Pulled By: SsnL
fbshipit-source-id: f46862ec3558d7e0058ef48991cd9c720cb317e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11048
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10739
I wanted to assert that the blobs in the workspace of the new session after loading checkpoint are exactly the same as the blobs in the workspace of the old session before saving to a checkpoint.
But I found that when calling `task.get_step()`, a dummy task output blob, `task:output/ConstIntFill:0`, is added. Also a dummy net `task:output` was also added along with it. See https://fburl.com/937lf2yk
This makes it hard to assert "Equal", forcing me to assert "LessThan" or "GreaterThan".
This adding a dummy TaskOutput when user specifies no TaskOutput is a hack.
The reason for this is that ZMQ socket can't send empty blob list.
As a result, if the Task on the Worker had no output,
The master would never stop waiting and hang forever. See https://fburl.com/rd7fhy6p and imagine `socket.recv(net, 0)`.
TaskOuput is at user layer. The hack shouldn't be exposed to user layer, polluting user workspaces.
Instead, we should move the creating of the dummy blob to some deeper layer,
and remove the dummy blob in the workspace afterwards to avoid polluting user workspaces.
After this change, the workaround becomes totally transparent and no side-effect to users.
Reviewed By: mraway
Differential Revision: D9566744
fbshipit-source-id: 18292dd64a6d48192c34034200a7c9811d2172af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11052
Delete the test case for Predictor with constructing by MetaNetDef since the constructor
actually has been deprecated. The broken PR is for construcing predictor from DB instance.
Reviewed By: highker
Differential Revision: D9566935
fbshipit-source-id: 5511883953a2d3f6eb0a4f1c5518a1bc4b3ffbdc
Summary:
Not subclassed except by Tensor. Also requried to align further with
caffe2.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11036
Reviewed By: ezyang
Differential Revision: D9565640
Pulled By: cpuhrsch
fbshipit-source-id: ff7203a2c95d3f3956282b4f2d8dda6c2b93f4a6
Summary:
Things like torch.zeros now appear in traces rather than constants.
To continue to support our current level of ONNX export, we run
constant prop to turn these back into constants where possible before
export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10935
Differential Revision: D9527427
Pulled By: zdevito
fbshipit-source-id: 552a8bcc01b911251dab7d7026faafdd7a3c758a
Summary:
Initial version of `unique` supporting a `dim` argument.
As discussed in [this issue](https://github.com/pytorch/pytorch/issues/9997) I added the `dim` argument to `torch.unique` with the same behavior like [numpy](https://docs.scipy.org/doc/numpy-1.14.0/reference/generated/numpy.unique.html).
Since the implementation is based on `std/thrust::unique`, the `tensor` always needs to be sorted. The `sorted` argument in `torch.unique` does not have any function, as in the CUDA version of the plain `torch.unique`.
To check the performance and equal behavior between `torch.unique` and `np.unique`, I've used [this gist](https://gist.github.com/ptrblck/ac0dc862f4e1766f0e1036c252cdb105).
Currently we achieve the following timings for an input of `x = torch.randint(2, (1000, 1000))`:
(The values are calculated by taking the average of the times for both dimension)
| Device | PyTorch (return_inverse=False) | Numpy (return_inverse=False) | PyTorch (return_inverse=True) | Numpy (return_inverse=True) |
| --- | --- | --- | --- | --- |
| CPU | ~0.007331s | ~0.022452s | ~0.011139s | ~0.044800s |
| GPU | ~0.006154s | - | ~0.105373s | - |
Many thanks to colesbury for the awesome mentoring and the valuable advices on the general implementation and performance issues!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10423
Differential Revision: D9517289
Pulled By: soumith
fbshipit-source-id: a4754f805223589c2847c98b8e4e39d8c3ddb7b5
Summary: When conversion fails, dump more information to help fix up the netdef
Reviewed By: hyuen, yinghai
Differential Revision: D9558667
fbshipit-source-id: 8917cc61c9be6285697e4f8395a9dbc7135f618e
Summary:
1. Support ops needed for inference of Faster-RCNN/Mask-RCNN needed in Detectron, mostly direct fallbacks.
2. Use CPU device to hold 0-dim tensors and integer tensors in both fallback op and blob feeder, needed by Detectron models.
3. Ignore 0-dim tensor in MKL-DNN concat operator.
4. Generate dynamic library of Detectron module for CPU device.
This PR obsoletes #9164.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10157
Differential Revision: D9276837
Pulled By: yinghai
fbshipit-source-id: dc364932ae4a2e7fcefdee70b5fce3c0cee91b6f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10955
Add GPU version of HardSigmoid Op to Caffe2. Updated test file to
include GPU tests.
Reviewed By: enosair
Differential Revision: D9499353
fbshipit-source-id: fcb51902063d0c3e4b10354533a8a42cf827c545
Summary:
This probably fixes the logging test error that orionr is encountering - haven't tested locally but wanted to send out a PR to kick off CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10983
Reviewed By: ezyang
Differential Revision: D9552607
Pulled By: Yangqing
fbshipit-source-id: 9ac019031ffd9c03972144df04a836e5dcdafe02
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10920
Update the black box predictor and the related code to use the
constructor with PredictorConfig.
Reviewed By: highker
Differential Revision: D9516972
fbshipit-source-id: fbd7ece934d527e17dc6bcc740b4e67e778afa1d
Summary:
The PR includes:
(1) torch.distributed.c10d, which now includes the complete backward compatible frontend API for `torch.distributed`
(2) `env://` init method functionality
(3) Minor change to `test_distributed.py`, which is now a test for `torch.distributed.c10d`.
(4) The old `test_distributed.py' is now moved to `test_distributed_thd`
(5) Miscellaneous bug fixes.
(6) DDP CPU test is removed since c10d doesn't have this support yet, but this is a very easy test after moving DDP CPU's dependency to torch.distributed.c10d.
(7) CI config to test MPI, NCCL, and Gloo backend of c10d
**Now all the distributed test including c10d DDP can pass with the c10d frontend API**
TODO: (in a separate PR)
MPI subgroup support, once this is added, CI group test will be enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10871
Differential Revision: D9554514
Pulled By: teng-li
fbshipit-source-id: fb686ad42258526c8b4372148e82969fac4f42dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10987
some code style update to make it consistent with fb cpp style
Reviewed By: yinghai
Differential Revision: D9550130
fbshipit-source-id: 6aef9878676c08e7d384383c95e7ba8c5c9a1bce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/11003
Need a interface to re-write the graph after the net is built and after adding gradient ops.
Reviewed By: aazzolini, harouwu
Differential Revision: D9557827
fbshipit-source-id: 2e082f0321c0776e488a29e18047d950948e7c37
Summary:
The goal here is to separate out the base Type into core; as it was done previously we need all derived Types to be defined when we compile the base Type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10947
Reviewed By: gchanan
Differential Revision: D9540025
Pulled By: ezyang
fbshipit-source-id: 49f0b5acb3c378348ef3a55780abb73e4ae27edd
Summary:
Fixes#10851
Speeds up profiling results dramatically.
For the following script:
```
import torch
import time
ITER = 2000
x = torch.randn(1, 1, requires_grad=True)
with torch.autograd.profiler.profile() as prof:
y = x
for i in range(ITER):
y = 3 * y - 2 * y
y.backward()
start = time.time()
print("Done running. Preparing prof")
x = str(prof)
print("Done preparing prof results")
end = time.time()
print("Elapsed: {}".format(end - start))
```
I get 7s before / 0.13s after these changes.
cc apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10969
Differential Revision: D9556129
Pulled By: zou3519
fbshipit-source-id: 26b421686f8a42cdaace6382567d403e6385dc12
Summary:
Breaking this out of https://github.com/pytorch/pytorch/pull/8338
mingzhe09088's fix of the docstrings for Windows builds. Unfortunately some versions of Windows seem to try and parse the `#` inside the string as a pre-processor declaration. We might need to change this to something else later, but want to get this landed first.
cc mingzhe09088 Yangqing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10998
Reviewed By: mingzhe09088
Differential Revision: D9557480
Pulled By: orionr
fbshipit-source-id: c6a6237c27b7cf35c81133fd9faefead675a9f59
Summary:
Breaking out of https://github.com/pytorch/pytorch/pull/8338
This test fails once we start building with `-DUSE_GLOG=OFF` since the non-glog logging case doesn't support flushing or streaming to the right location. For now, we just disable this test in that case.
cc Yangqing mingzhe09088
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10999
Reviewed By: mingzhe09088
Differential Revision: D9557488
Pulled By: orionr
fbshipit-source-id: 8b306f210411dfc8ccc404bdccf77ddcd36a4830
Summary:
PyTorch exporting test and end to end cases.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10924
Reviewed By: Ac2zoom
Differential Revision: D9548210
Pulled By: houseroad
fbshipit-source-id: 2381d1ad92a4e07f97060eb65c9fd09f60ad3de6
Summary:
This is part of splitting Context from what needs to go in ATen/core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10951
Differential Revision: D9540369
Pulled By: gchanan
fbshipit-source-id: 73b0e8c4493785fbab368a989f46137c51f6ea0b
Summary:
Fix#10345, which only happens in CUDA case.
* Instead of returning some random buffer, we fill it with zeros.
* update torch.symeig doc.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10645
Reviewed By: soumith
Differential Revision: D9395762
Pulled By: ailzhang
fbshipit-source-id: 0f3ed9bb6a919a9c1a4b8eb45188f65a68bfa9ba
Summary:
This fixes multiple bugs in the handling of negative indices in both slicing and gather operations. These were uncovered by @[1466077526:Elias Ellison]'s diff D9493614, which made it so that we actually emit negative indices when we see them in PyTorch code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10973
Reviewed By: jhcross
Differential Revision: D9546183
Pulled By: jamesr66a
fbshipit-source-id: 6cb0e84e8ad399e47e24a96c44025f644c17b375
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10739
I wanted to assert that the blobs in the workspace of the new session after loading checkpoint are exactly the same as the blobs in the workspace of the old session before saving to a checkpoint.
But I found that when calling `task.get_step()`, a dummy task output blob, `task:output/ConstIntFill:0`, is added. Also a dummy net `task:output` was also added along with it. See https://fburl.com/937lf2yk
This makes it hard to assert "Equal", forcing me to assert "LessThan" or "GreaterThan".
This adding a dummy TaskOutput when user specifies no TaskOutput is a hack.
The reason for this is that ZMQ socket can't send empty blob list.
As a result, if the Task on the Worker had no output,
The master would never stop waiting and hang forever. See https://fburl.com/rd7fhy6p and imagine `socket.recv(net, 0)`.
TaskOuput is at user layer. The hack shouldn't be exposed to user layer, polluting user workspaces.
Instead, we should move the creating of the dummy blob to some deeper layer,
and remove the dummy blob in the workspace afterwards to avoid polluting user workspaces.
After this change, the workaround becomes totally transparent and no side-effect to users.
Reviewed By: mraway
Differential Revision: D9413150
fbshipit-source-id: 51aaf3201e26570b4fcf5738e9b9aa17c58777ac
Summary:
TODO: integrate into torch.onnx.export -- separate PR
*Problem:* We have a facility to trace PyTorch operations on Python code, but there are several failure modes where the trace is not representative of the actual underlying computation:
* The tracer encountered dynamic control flow
* Some computation escaped the tracer, and appeared as a Constant tensor node in the graph
* Some stateful function was traced, e.g. someone did an optimization in Python by memoizing function outputs
*Objective*: In an ideal world, this whole process would be automated and the user can trust that the system will magically capture the intended semantics from the program. Realistically speaking, we will likely have to settle with a human-in-the-loop error reporting system, allowing for the user to identify problems and modify the source code to allow for tracing.
*Stage 1* (this PR): Output-level checking & graph diff. torch.jit.trace gains a kwarg 'check_inputs', which is a list of tuples of input arguments. We will iterate through the list and trace the function again for each set of check inputs. We'll also interpret the original trace with these inputs and compare output values and graphs, printing a diff of the graph if there is a difference.
Examples:
```
torch.jit.trace(torch.rand(3, 4), check_inputs=[(torch.rand(4, 5),)])
def foo(x):
y = torch.arange(0, x.shape[0]).float()
return x + y.unsqueeze(1)
```
```
torch.jit.TracingCheckError: Tracing failed sanity checks!
ERROR: Graphs differed across invocations!
Graph diff:
graph(%0 : Dynamic) {
- %1 : Dynamic = prim::Constant[value= 0 1 2 [ CPULongType{3} ]]()
? ^
+ %1 : Dynamic = prim::Constant[value= 0 1 2 3 [ CPULongType{4} ]]()
? +++ ^
%2 : int = prim::Constant[value=0]()
%3 : Dynamic = aten::_cast_Float(%1, %2)
%4 : int = prim::Constant[value=1]()
%5 : Dynamic = aten::unsqueeze(%3, %4)
%6 : int = prim::Constant[value=1]()
%7 : Dynamic = aten::add(%0, %5, %6)
return (%7);
}
Node diff:
- %1 : Dynamic = prim::Constant[value= 0 1 2 [ CPULongType{3} ]]()
? ^
+ %1 : Dynamic = prim::Constant[value= 0 1 2 3 [ CPULongType{4} ]]()
? +++ ^
Trace source location:
dank.py(5): foo
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(402): wrapper
dank.py(3): <module>
Check source location:
dank.py(5): foo
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(281): check_trace
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(408): wrapper
dank.py(3): <module>
ERROR: Tensor-valued Constant nodes differed in value across invocations. This often indicates that the tracer has encountered untraceable code.
Node:
%1 : Dynamic = prim::Constant[value= 0 1 2 [ CPULongType{3} ]]()
Source Location:
dank.py(5): foo
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(402): wrapper
dank.py(3): <module>
Comparison exception:
Not equal to tolerance rtol=1e-07, atol=0
(shapes (3,), (4,) mismatch)
x: array([0, 1, 2])
y: array([0, 1, 2, 3])
```
==
```
torch.jit.trace(torch.rand(3, 4), check_inputs=[(torch.rand(3, 4),)])
def foo(x):
y = x.data
return x + y
```
```
torch.jit.TracingCheckError: Tracing failed sanity checks!
ERROR: Traced function outputs do not match the Python function outputs.
ERROR: Tensor-valued Constant nodes differed in value across invocations. This often indicates that the tracer has encountered untraceable code.
Node:
%1 : Dynamic = prim::Constant[value=<Tensor>]()
Source Location:
dank.py(6): foo
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(402): wrapper
dank.py(3): <module>
Comparison exception:
Not equal to tolerance rtol=1e-07, atol=0
(mismatch 100.0%)
x: array([0.397137, 0.956105, 0.169478, 0.560292, 0.392568, 0.108441,
0.97645 , 0.34412 , 0.951246, 0.793061, 0.557595, 0.770245],
dtype=float32)
y: array([0.243178, 0.315964, 0.972041, 0.0215 , 0.927751, 0.457512,
0.951092, 0.97883 , 0.048688, 0.118066, 0.779345, 0.271272],
dtype=float32)
```
==
```
import torch
torch.jit.trace(torch.rand(3, 4), check_inputs=[(torch.rand(4, 4),)])
def foo(x):
for _ in range(x.size(0)):
x = torch.neg(x)
return x
```
```
torch.jit.TracingCheckError: Tracing failed sanity checks!
ERROR: Traced function outputs do not match the Python function outputs.
ERROR: Graphs differed across invocations!
Graph diff:
graph(%0 : Dynamic) {
%1 : Dynamic = aten::neg(%0)
%2 : Dynamic = aten::neg(%1)
%3 : Dynamic = aten::neg(%2)
+ %4 : Dynamic = aten::neg(%3)
- return (%3);
? ^
+ return (%4);
? ^
}
```
==
```
import torch
def foo(x):
if not hasattr(foo, 'cache'):
foo.cache = torch.neg(x)
return x + foo.cache
traced = torch.jit.trace(torch.rand(3, 4), check_inputs=[(torch.rand(3, 4),)])(foo)
```
```
torch.jit.TracingCheckError: Tracing failed sanity checks!
ERROR: Traced function outputs do not match the Python function outputs.
ERROR: Graphs differed across invocations!
Graph diff:
graph(%0 : Dynamic) {
- %1 : Dynamic = aten::neg(%0)
+ %1 : Dynamic = prim::Constant[value=<Tensor>]()
%2 : int = prim::Constant[value=1]()
%3 : Dynamic = aten::add(%0, %1, %2)
return (%3);
}
Node diff:
- %1 : Dynamic = aten::neg(%0)
+ %1 : Dynamic = prim::Constant[value=<Tensor>]()
Trace source location:
test.py(5): foo
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(402): wrapper
test.py(8): <module>
Check source location:
test.py(6): foo
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(281): check_trace
/Users/jamesreed/onnx-fairseq/pytorch/torch/jit/__init__.py(408): wrapper
test.py(8): <module>
```
The following two examples show instances where program semantics are lost in the Python -> trace transformation, and repeated invocation does not give us useful debug information. Further design in underway for catching these scenarios.
```
import torch
torch.jit.trace(torch.rand(3, 4), check_inputs=[(torch.rand(3, 4),)])
def foo(x):
for i in range(3):
x[i, :] = torch.zeros(4)
return x
```
```
torch.jit.TracingCheckError: Tracing failed sanity checks!
ERROR: Traced function outputs do not match the Python function outputs.
Exception:
Not equal to tolerance rtol=1e-07, atol=0
(mismatch 100.0%)
x: array([0.830221, 0.915481, 0.940281, 0.555241], dtype=float32)
y: array([0., 0., 0., 0.], dtype=float32)
```
==
```
import torch
torch.jit.trace(torch.rand(3, 4), check_inputs=[(torch.rand(5, 6),)])
def foo(x):
x.view(-1).add_(-x.view(-1))
return x
```
```
torch.jit.TracingCheckError: Tracing failed sanity checks!
ERROR: Traced function outputs do not match the Python function outputs.
Exception:
Not equal to tolerance rtol=1e-07, atol=0
(mismatch 100.0%)
x: array([0.734441, 0.445327, 0.640592, 0.30076 , 0.891674, 0.124771],
dtype=float32)
y: array([0., 0., 0., 0., 0., 0.], dtype=float32)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10841
Differential Revision: D9499945
Pulled By: jamesr66a
fbshipit-source-id: 1f842a32d0b0645259cc43b29700b86d99c59a45
Summary:
This PR adds argument checking for script method invocation from C++. For this I had to:
1. The schema of a method is currently not serialized in script modules, so we now store the function schema in the `doc_string` field of the ONNX proto. Upon loading of a serialized script module, we parse the schema into the structured C++ form and assign it to the loaded method,
2. Inside `Method::operator()`, we now verify the number and types of arguments.
CC The controller you requested could not be found.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10872
Differential Revision: D9521219
Pulled By: goldsborough
fbshipit-source-id: 5cb3d710af6f500e7579dad176652c9b11a0487d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10929
Workspace classes methods were missing on the Python side.
Being able to write the New Checkpoint Framework with more control of the workspace and cleaner implementation.
Added
- ws.feed_blob(name, arr)
- ws.remove_blob(name)
Reviewed By: mraway
Differential Revision: D9486867
fbshipit-source-id: ea02d2e3a39d716a5a3da0482f57d4ac4c893763
Summary: Adds basic nomnigraph python bindings for quickly playing with the graphs.
Reviewed By: duc0
Differential Revision: D9441936
fbshipit-source-id: fd70f8ea279b28c766e40f124008800acd94bddd
Summary:
The previous NCCL all gather doesn't work as expected. This is a fully working async version. Tested on both C++ and Python Frontend.
Multi-node:
```
tengli@learnfair042:~/new_pytorch/pytorch/torch/lib/build/c10d/test$ TMPFILE="/private/home/tengli/temp/tengli-test" RANK=0 WORLD_SIZE=2 ./ProcessGroupNCCLTest
Multi-node world size: 2 rank: 0
Allreduce test successful
Broadcast test successful
Reduce test successful
Allgather test successful
tengli@learnfair117:~/new_pytorch/pytorch/torch/lib/build/c10d/test$ TMPFILE="/private/home/tengli/temp/tengli-test" RANK=1 WORLD_SIZE=2 ./ProcessGroupNCCLTest
Multi-node world size: 2 rank: 1
Allreduce test successful
Broadcast test successful
Reduce test successful
Allgather test successful
```
CI test:
```
test_set_get (__main__.FileStoreTest) ... ok
test_set_get (__main__.PrefixFileStoreTest) ... ok
test_set_get (__main__.PrefixTCPStoreTest) ... ok
test_allreduce_ops (__main__.ProcessGroupGlooTest) ... ok
test_broadcast_ops (__main__.ProcessGroupGlooTest) ... ok
test_allgather_ops (__main__.ProcessGroupNCCLTest) ... ok
test_allreduce_ops (__main__.ProcessGroupNCCLTest) ... ok
test_broadcast_ops (__main__.ProcessGroupNCCLTest) ... ok
test_reduce_ops (__main__.ProcessGroupNCCLTest) ... ok
test_common_errors (__main__.RendezvousFileTest) ... ok
test_nominal (__main__.RendezvousFileTest) ... ok
test_common_errors (__main__.RendezvousTCPTest) ... ok
test_nominal (__main__.RendezvousTCPTest) ... ok
test_unknown_handler (__main__.RendezvousTest) ... ok
test_set_get (__main__.TCPStoreTest) ... ok
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10932
Differential Revision: D9542067
Pulled By: teng-li
fbshipit-source-id: 25513eddcc3119fd736875d69dfb631b10f4ac86
Summary:
Running `--accept` on a test doesn't tell you explicitly which sub-test is being updated, this PR fixes that
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10559
Differential Revision: D9353977
Pulled By: driazati
fbshipit-source-id: a9d4014386ff0fe388a092f3dcf50f157e460f04
Summary:
Changes the approach for resolving builtin ops so that the following works
```
add = torch.add
script
def foo(x):
return add(x, x)
```
This handles cases when people alias torch and torch.nn.functional to
shorter names.
This works by building a table of id -> builtin name for the know builtin
ops in torch, torch.nn.functional, and for any user-defined
op created by accessing in torch.ops.foo.bar
This allows us to clean up many SugaredValue types in the compiler.
Notes:
* we now consider any attributes on python modules to be constants
(e.g. math.pi, and torch.double).
* fixes a bug where we incorrectly allowed attribute lookup on arbitrary
pyton objects. It is now restricted to modules only.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10927
Differential Revision: D9527522
Pulled By: zdevito
fbshipit-source-id: 0280422af08b4b0f48f302766d5a9c0deee47660
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10804
Make ShareData and ShareExternalPointer to create new storage when the old one is used by multiple tensors.
When we need to modify the field of storage, we'll create a new storage instead.
Reviewed By: ezyang
Differential Revision: D9350686
fbshipit-source-id: 68d2b6b886b0367b0fc4fabfd55b9a480e7388ca
Summary:
Currently we assume to find cudnn includes and libraries in the `CUDA_HOME` root. But this is not always true. So we now support a `CUDNN_HOME`/`CUDNN_PATH` environment variable that can have its own `/include` and `/lib64` folder.
This means cudnn extensions now also get support on the FAIR cluster.
soumith fmassa
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10922
Differential Revision: D9526856
Pulled By: goldsborough
fbshipit-source-id: 5c64a5ff7cd428eb736381c24736006b21f8b6db
Summary:
Since we don't need `torch.autograd.Variable` anymore, I removed `torch.autograd.Variable` from `onnx.rst`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10810
Differential Revision: D9500960
Pulled By: zou3519
fbshipit-source-id: 1bc820734c96a8c7cb5d804e6d51a95018db8e7f
Summary:
More support for tuples has uncovered a bug in constant prop where
it assumed it can create constant nodes of tuples, even though we
cannot easily create a single prim::Constant to represent a tuples.
This fix checks when we cannot represent an IValue as a prim::Constant
and then stops propagating the node.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10923
Reviewed By: orionr
Differential Revision: D9523417
Pulled By: zdevito
fbshipit-source-id: 745058c4388d9a5e0fc1553eaa2731e31bc03205
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10824
API additions:
- Tensor(c10::intrusive_ptr<TensorImpl,UndefinedTensor>&&)
- Tensor(const c10::intrusive_ptr<TensorImpl,UndefinedTensor>&)
- Tensor::operator=(Tensor&&) && (for completeness sake)
- TensorBase::unsafeGetTensorImpl()
- TensorBase::unsafeReleaseTensorImpl()
- TensorBase::getIntrusivePtr()
- TensorImpl::type_id()
- Tensor::set_data()
- Tensor::is_same(Tensor)
- Tensor::use_count()
- Tensor::type_id()
- Tensor::scalar_type()
- WeakTensor::is_same(WeakTensor)
- intrusive_ptr::weak_use_count()
- weak_intrusive_ptr::weak_use_count()
- c10::raw::intrusive_ptr::{incref,decref,make_weak}
- c10::raw::weak_intrusive_ptr::{incref,decref,lock}
API changes:
- Tensor::pImpl is no longer public (and now named tensor_impl_)
- Most methods accessed this way are now accessible on Tensor
maybe_zero_dim() and set_wrapped_number() being prominent exceptions
(they are now accessed through unsafeGetTensorImpl())
- Type is no longer friend of Tensor
- TensorBase::reset(TensorImpl*) is deleted
- TensorBase::reset(TensorImpl*, bool should_retain) is deleted
- TensorBase::swap(TensorBaseImpl&) is deleted; use std::swap instead
- TensorBase::get() is deleted; use unsafeGetTensorImpl() instead
- TensorBase::detach() is deleted; use unsafeReleaseTensorImpl() instead
- TensorBase::retain() is deleted; use _raw_incref() instead
- TensorBase::release() is deleted; use _raw_decref() instead
- WeakTensor lost most of its methods (it no longer inherits from
TensorBase)
- TensorImpl::storage() is now a const method
- Tensor(TensorBase) constructor removed, instead
we go through getIntrusivePtr(). I'm not sure about
this change; I happened to have accidentally removed the
TensorBase constructor and decided to fix call sites,
but I could go the other way.
- detail::set_data() is deleted; use Tensor::set_data() instead
- c10::raw_intrusive_ptr_target removed; use the functions in c10::raw instead.
(The reason for this change, is that it is invalid to cast an intrusive_ptr_target*
to a raw_intrusive_ptr_target* to take advantage of the methods. But there is
no reason the incref/decref methods shouldn't also work on intrusive_ptr_target;
it is primarily an API consideration. We can be more standards compliant by
keeping them as functions, which are universally applicable.)
- intrusive_ptr::reclaim() and weak_intrusive_ptr::reclaim() now work on
pointers of the NullType. (This counts as a bug fix, because the documentation
specified that pointers produced by release() are valid to reclaim(), and
a release() on a null intrusive_ptr produces the NullType::singleton())
Bug fixes:
- Dispatch code for mutable references incorrectly returned
a reference to a value argument (which would immediately
go out of scope). They now correctly return a tensor by
value.
- intrusive_ptr copy/move assignment did not work correctly when
an object was assigned to itself. We now check for this case and
no-op if so. (This bug manifested itself as a Tensor mysteriously
becoming an UndefinedTensor after lines of code like
'x = x.mul_(y)')
Other changes:
- The checked cast functions in Utils.h have now been
renamed and detemplatized into checked unwrap functions.
- Added type_id() and scalar_type() methods to Tensor
- pImpl is no longer public
- Documented what the && overloads are doing
- All occurrences of 'new TensorImpl' (and similar spellings, like 'new THTensor')
have been expunged. This is NO LONGER a valid way to create a new
tensor, and if you do this, upon your first incref, you will catch an ASSERT
failure saying that only tensors created by intrusive_ptr::release() are valid
to reclaim(). Use c10::make_intrusive instead in this situation.
- IValue is adjusted to use intrusive_ptr instead of Retainable, and all
other sub-classes of Retainable were modified to use intrusive_ptr.
When doing this, I had to make the constructors of sub-classes like
ConstantList public, so that c10::make_intrusive could invoke them. Fortunately,
if you incorrectly stack allocate a ConstantList, and then try to get an
intrusive_ptr to it, it will fail, as stack allocated ConstantLists have refcount 0.
- IValue very narrowly sidesteps the problem of handling NullType, as it
considers intrusive_ptr<TensorImpl> identical to intrusive_ptr<TensorImpl, UndefinedTensor>
which is not always true. This was always the case, but there's now a comment
explaining what's going on.
Some MSVC bugs were uncovered during the preparation of this patch.
They are documented as comments in the code.
Reviewed By: gchanan
Differential Revision: D9481140
fbshipit-source-id: 14a8ea0c231ed88b5715fb86d92730926f9f92fc
Summary:
The goal of this PR is to enable miopen engine(for hip devices) for recurrent operator and also enable corresponding unit test.
bddppq petrex
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10840
Differential Revision: D9518980
Pulled By: bddppq
fbshipit-source-id: 214661e79a47c5dc6b712ef0fba986bd99db051f
Summary:
Previously when tracing slicing & select negative indices would get normalized, fixing the index to the size of the traced tensor. This makes the behavior the same as script so aten::select with negative indices is emitted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10560
Differential Revision: D9493614
Pulled By: eellison
fbshipit-source-id: ce7a8bae59863723247208d86b9f2948051ccc6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10877
change default value of DeviceOption.numa_node_id to 0 and use has_numa_node_id() to check existence
Reviewed By: ilia-cher
Differential Revision: D9473891
fbshipit-source-id: 91ac6a152f445644691023110c93d20a3ce80d43
Summary:
* Fix the necessary pathways so that tuples and lists can be inputs to the script.
* prevent linear algebra functions from being run in shape prop because
they frequently will error out for nonsense data.
* favor schema-driven python input conversion where possible.
remaining cases where we directly create Stacks without schema are
only for debugging
* Make the error messages when calling script/trace functions more pythonic
* Simplify FlattenTuples -- now that tuples are supported we can choose to only flatten tuples when needed. This may have to be revisited pending onnx test results, but is necessary for making tuple io work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10812
Differential Revision: D9477982
Pulled By: zdevito
fbshipit-source-id: ed06fc426e6ef6deb404602a26c435a7fc40ea0c
Summary:
The scalar situation has gotten a lot better and now we can
remove all instances of FIXME_zerol().
cc zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10900
Differential Revision: D9514206
Pulled By: zou3519
fbshipit-source-id: e4e522f324126c5454cd6de14b832d2d1f6cb0ce
Summary:
PackedSequence is never supposed to be created by user, but unfortunately some community repo is already doing this (e.g., [here](7c191048ce/torchmoji/model_def.py (L218-L229))). Some change we made break the calling pattern `PackedSequence(data=x, batch_sizes=y)`. This patch adds back support for that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9864
Differential Revision: D9011739
Pulled By: SsnL
fbshipit-source-id: 0e2012655d7f4863ec54803550df30874ec35d75
Summary:
Please review the expects carefully to make sure there are no regressions. I tried to go over them one by one when they changed, but it's sometimes easy to miss finer details.
Summary of changes:
- Renamed `TensorType` to `CompleteTensorType`. Added a new `TensorType` which records only the scalar type, number of dimensions, and device of a value. The argument behind the rename is to encourage people to use `CompleteTensorType` less, as most passes will only have limited information available. To make transition easier `complete_type->cast<TensorType>()` works, and makes our passes work with both kinds of specialization if they don't need extra the extra detail.
- Renamed `ArgumentSpec` to `CompleteArgumentSpec`. Added a new `ArgumentSpec`, which matches argument only at the level of the new `TensorType`.
- Shape analysis can process graphs with both `CompleteTensorType` and `TensorType`.
- Fuser was a part that heavily relied on full shape information being available. Now, we simply try to fuse the largest possible graphs, and have to do run-time checks to make sure they match the code we generate. If they don't, we fall back to regular interpretation. The shape checks are implementing using an optimized method exploiting algebraic properties of shapes with broadcasting, and the relations of broadcasting with pointwise ops. A full written proof of correctness of the shape checking algorithm is included in a comment in `graph_fuser.cpp`.
zdevito ezyang mruberry ngimel csarofeen
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10844
Differential Revision: D9498705
Pulled By: apaszke
fbshipit-source-id: 0c53c2fcebd871cc2a29c260f8d012276479cc61
Summary: Update all the caller for the new interface
Reviewed By: highker
Differential Revision: D9323167
fbshipit-source-id: a39335ceb402db0719f5f2314085ba9a81380308
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10239
Make Conv + BN fusion also work for 3D convolutions
Reviewed By: duc0
Differential Revision: D9176314
fbshipit-source-id: 6604aa569c5c3afdb4480a5810890bc617e449c4
Summary:
This disables the symbolic override hacks and makes tracing emit the recently added ATen ops for RNNs (`aten::lstm`, `aten::gru`, ...). I managed to reuse pretty much all of the translation code for their symbolics.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10638
Differential Revision: D9385830
Pulled By: apaszke
fbshipit-source-id: ff06ef7b1ae7c3b7774825e0991bc3887e1ff59b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10759
Adding a basic registry pattern to pybindstate so that we can have separate 'cc' files register module updates. This is substantially cleaner than using multiple pybind modules (which have been known to cause bugs)
Reviewed By: bddppq
Differential Revision: D9441878
fbshipit-source-id: af9e9e98385e92b58ca50e935678328c62684d8e
Summary:
**Summary**: This PR is a followup of mruberry's https://github.com/pytorch/pytorch/pull/9318/. It tries to achieve the following:
- Specializing std common math functions for `at::Half` type.
- Create `CUDANumerics.cuh` to contain necessary parts from `THCNumerics.cuh`.
- Update `THCNumerics.cuh` with new usage and comments to demonstrate the best practice for developers and hence, making way for its deprecation.
- Remove legacy/redundant code path.
- Remove unused CUDA HALF macros (see separate PR https://github.com/pytorch/pytorch/pull/10147)
**Comments**: `CUDANumerics.cuh` contains mathematical functions that are either not in the std namespace or are specialized for compilation with CUDA NVCC or CUDA NVRTC. This header is derived from the legacy `THCNumerics.cuh`. Following are some rationale behind why some functions were kept while others were removed:
- All arithmetic can now be done in ATen using binary cuda kernel or CUDA tensor pointwise apply (check https://github.com/pytorch/pytorch/pull/8919 and `CUDAApplyUtils`). `at::Half` comparisons rely on implicit conversion to float.
- Functions that are c/c++ standard compliant, have been specialized for user defined types, for instance, the std namespace has been opened up for `at::Half`, that defines math function definitions for `at::Half`. Check `Half-inl.h`
- Some standard compliant functions are specialized here for performance reasons. For instance, `powi` is used for `pow` calculation on integral types. Moreover, `abs`, `isinf`, `isnan` are specialized to save one API call vs when used with std. Although this is subject to change, depending on if we really care about saving one API call.
- Numeric limits such as `max/min` is removed since they call standard defines. Moreover, numeric limits for
`at::Half` is present in `Half-inl.h`. I understood that HIP has some issue with `std::numeric_limits` and this the related github issue I found: https://github.com/ROCm-Developer-Tools/HIP/issues/374. AlexVlx mentions that the issue can be avoided by launching `std::numeric_limits` in `__device__`. Since, we are launching lambdas with device contexts, I don't see an issue why `std::numeric_limits` won't compile on HIP if launched with device context within a kernel, unless I am not aware of the real reason why max/min was there in THCNumerics in the first place. (Haven't ever tried a build with HIP).
Here are some reference PRs that was handy in refactoring TH into ATen:
- https://github.com/pytorch/pytorch/pull/6786
- https://github.com/pytorch/pytorch/pull/5475
- https://github.com/pytorch/pytorch/pull/9401
- https://github.com/pytorch/pytorch/pull/8689
- https://github.com/pytorch/pytorch/pull/8919
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10301
Differential Revision: D9204758
Pulled By: soumith
fbshipit-source-id: 09f489c1656458c02367b6cd31c3eeeca5acdc8a
Summary:
This is along the way of removing Tensor as a member of the tagged union in Scalar. This simplifies ordering dependencies, because currently Scalar and Tensor both depend on each other (so we introduce a TensorBase). Also, this API isn't particularly useful publicly: we can't autograd through Scalars, so you still need a Tensor overload basically everywhere anyway.
I'm undecided what the final API should be here. We could keep a Tensor constructor on Scalar, but have it generate a local scalar; this is convenient but given this API used to be non-synchronizing, it may not be the best.
For now, I'm just using _local_scalar, which is clear, although we should get rid of the prefix _ if that's the API we intend to promote.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10852
Reviewed By: ezyang
Differential Revision: D9496766
Pulled By: gchanan
fbshipit-source-id: 16f39b57536b9707132a5a4d915650c381bb57db
Summary:
The schema_ field is a private and internal cache for nodes, and no
methods meant to manipulate it should be publicly visible. This call
wasn't even necessary at its call site, since removeInput will reset the
schema by itself.
zdevito jamesr66a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10822
Reviewed By: zdevito
Differential Revision: D9498683
Pulled By: apaszke
fbshipit-source-id: 42e1743e3737cb7d81f88e556204487d328c0e47
Summary:
When matching schema, first try to match without adding TensorToNum conversions. Then make another pass where TensorToNum conversions are allowed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10180
Differential Revision: D9438153
Pulled By: eellison
fbshipit-source-id: 80541b5abd06e9d4187e89dda751f44dab6f58c5
Summary:
Since ONNX opset version >5, Reshape changed semantics to take a shape tensor as input instead of relying on `shape` attribute to decide what shape to reshape to. ONNXIFI op has been postponing this change as some of the backends such as TensorRT were not ready. Now that the backends have adopted this semantics, we can remove the legacy mode and output opset version 7 ONNX models.
This change also flushes out some of the bugs and new requirement.
- Converting shape info into int64 tensor
- Fix a bug when we output the shape tensor in the mapped workspace instead of the original workspace
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10848
Reviewed By: houseroad
Differential Revision: D9495121
Pulled By: yinghai
fbshipit-source-id: a6f44a89274c35b33fae9a429813ebf21d9a3d1a
Summary:
Currently on PyTorch AMD, memory accesses on the TensorInfo struct contained in the Operators passed into the kernelPointwiseApply kernel leads to hangs on the HCC runtime. Permuting the argument order such that the operator is first alleviates this issue and the kernel hangs disappear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10829
Reviewed By: ezyang
Differential Revision: D9492561
Pulled By: Jorghi12
fbshipit-source-id: d0f0e2ab7180e55846db909f2744b8c8b110205e
Summary:
We no longer use nanopb in PyTorch (or Caffe2) so removing. All protobuf manipulation should go through standard protobuf, which is statically linked inside libcaffe2.so by default.
cc zdevito pjh5 ezyang Yangqing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10772
Reviewed By: pjh5
Differential Revision: D9465894
Pulled By: orionr
fbshipit-source-id: 8cdf9f1d3953b7a48478d381814d7107df447201
Summary:
In prep for making FULL_CAFFE2 default, users shouldn't be required to have protobuf installed.
cc pjh5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10771
Reviewed By: pjh5
Differential Revision: D9474458
Pulled By: orionr
fbshipit-source-id: 3e28f5ce64d125a0a0418ce083f9ec73aec62492
Summary:
This is a small part of the effort to remove Tensor as a tagged member in Scalar because it is inconsistent with how we normally do overloads.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10828
Differential Revision: D9485049
Pulled By: gchanan
fbshipit-source-id: 103f5cc03bb7775cd2d3a0a5c0c5924838055f03
Summary:
Part of #10774.
This PR does the following:
- Support ast.ExtSlice in the frontend. This is done by returning a
list of ast.Index and ast.Slice.
- Support multidimensional indexing with ints and slices
The general approach is to desugar multidimensional indexing into
at::slice, at::select operations. This is exactly how normal pytorch
does indexing (by desugaring it into at::slice, at::select, and other ops).
I used [this code](https://github.com/pytorch/pytorch/blob/master/torch/csrc/autograd/python_variable_indexing.cpp) as reference.
We should be able to copy the rest of this to implement the missing
indexing features in script (indexing with ellipses, tensors, sequences, etc).
After I'm done implementing the missing indexing features in future prs, I can try to
templatize python_variable_indexing.cpp so that it can work with both JIT
script and normal pytorch indexing, but right now I'm not sure if that's
a good idea or not.
cc zdevito jamesr66a apaszke wanchaol
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10787
Differential Revision: D9481402
Pulled By: zou3519
fbshipit-source-id: 78c9fa42771a037d157879e23e20b87401cf1837
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10797
A few operators enforces in-place output (e.g., running mean/var for SpatialBN). Functional right now doesn't follow the inplace_enforced_ rules in OpSchema and therefore, the RunNetOnce() will fail on OpSchema->Verify(). Edit the output_names in Functional following the rules to pass check.
Reviewed By: jerryzh168
Differential Revision: D9470582
fbshipit-source-id: 168efeccecc32184bd1d02f3fefe8e61faa4e0f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10835
The last diff of constructor cause performance regression in cold run.
This one tried to fix this.
Reviewed By: highker
Differential Revision: D9489617
fbshipit-source-id: a77c2e2c903a73e2ad9806b4f9c209cdb751442f
Summary:
Added Prefix Store support.
This will make group be backward compatible.
Test is covered too.
```
tengli@devfair033:~/new_pytorch/pytorch/torch/lib/build/c10d/test$ ./FileStoreTest
Using temporary file: /tmp/testoglRl4
Using temporary file: /tmp/testepZIpB
Test succeeded
tengli@devfair033:~/new_pytorch/pytorch/torch/lib/build/c10d/test$ ./TCPStoreTest
Test succeeded
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10762
Differential Revision: D9484032
Pulled By: teng-li
fbshipit-source-id: 85754af91fe3f5605087c4a2f79ae930a9fd1387
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10605
Make isSubgraphMatch returns a subgraph and map from MatchNodes to graph nodes in the result, which makes it easier to write graph fusion logic. Also include some more helper methods for NN subgraph matcher.
Reviewed By: bwasti
Differential Revision: D9374931
fbshipit-source-id: 3a273295eec81a43027ec3a9e835d27f00853df9
Summary:
apaszke recently ported RNNs from Python into ATen, which means we can replace our implementation in the C++ API (written by ebetica) with the ATen implementation, which cleans up a lot of code (+99, -323). Thanks apaszke!
I also added the `bidirectional` and `batch_first` options to the C++ API RNN options, just because why not.
apaszke ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10761
Differential Revision: D9443885
Pulled By: goldsborough
fbshipit-source-id: b6ef7566b9ced2b2f0b2e1f46c295b6f250c65a8
Summary:
* first integration of MIOpen for batch norm and conv on ROCm
* workaround a ROCm compiler bug exposed by elementwise_kernel through explicit capture of variables in the densest packing
* workaround a ROCm compiler bug exposed by having `extern "C" __host__` as a definition and just `__host__` in the implementation through the hipify script
* use fabs() in accordance with C++11 for double absolute, not ::abs() which is integer-only on ROCm
* enable test_sparse set on CI, skip tests that don't work currently on ROCm
* enable more tests in test_optim after the elementwise_bug got fixed
* enable more tests in test_dataloader
* improvements to hipification and ROCm build
With this, resnet18 on CIFAR data trains without hang or crash in our tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10612
Reviewed By: bddppq
Differential Revision: D9423872
Pulled By: ezyang
fbshipit-source-id: 22c0c985217d65c593f35762b3eb16969ad96bdd
Summary:
Things like `zeros(1,2,3, dtype=torch.int)` are now supported in the script by altering tryMatchSchema to auto-construct the list `[1,2,3]` when it sees inlined members of the list as the last positional arguments.
I suggest reading the commits individually, since the first two incrementally change how we do tryMatchSchema to get it ready for adding vararg list conversion, while the third actually does the modification.
closes#10632closes#8516
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10250
Differential Revision: D9478235
Pulled By: zdevito
fbshipit-source-id: 0c48caf7a6184e463d9293d97015e9884758ef9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10779
The idea is to let classes opt-in to providing these methods
by default.
Reviewed By: jerryzh168
Differential Revision: D9466076
fbshipit-source-id: b6beee084cc71d53ce446cdc171d798eeb48dc12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10766
Added a `Workspace::ForEach(...)` API for accessing the global set of
existing Workspace instances. This is used in the signal handler to print blob
info on the thread receiving a fatal signal.
Reviewed By: mraway
Differential Revision: D9147768
fbshipit-source-id: a94d0b5e6c88390a969ef259ecb8790173af01a4
Summary:
This seems to save a few percent in binary size in libcaffe2_gpu.so, but
the effect may not be real. In fact, deleting some functions can cause
the binary size to increase (perhaps due to alignment issues).
cc orionr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10707
Differential Revision: D9409009
Pulled By: colesbury
fbshipit-source-id: 282931e562e84e316a33ac6da4788c04c2984f08
Summary:
To prepare THCState for refactoring into ATen, this PR removes unused THCState code paths. In particular, it:
- Removes the UVA Allocator
- Removes the THDefaultDeviceAllocator
- Respects the 1 BLAS and 1 sparse handle per device reality
- Removes kernel p2p access
- Removes setting p2p access
- Removes the GCHandler code path
- Removes many unused THCState_... functions
- Removes THCThreadLocal.h/.cpp
It does not change the preexisting external behavior of any remaining function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9735
Differential Revision: D9438558
Pulled By: SsnL
fbshipit-source-id: dde9acbec237a18bb6b75683e0526f7ff1c9a6ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10509
This diff enables CUDA implementation of LARS operator in caffe2.
Reviewed By: enosair
Differential Revision: D9318356
fbshipit-source-id: 365b9f01e3afd4d9d3ba49155e72e728119f40c5
Summary:
When 0-sized dimension support is added, we expect an empty sparse tensor to be a 1-dimensional tensor of size `[0]`, with `sparseDims == 1` and `denseDims == 0`. Also, we expect the following invariants to be preserved at all times:
```
_sparseDims + _denseDims = len(shape)
_indices.shape: dimensionality: 2, shape: (_sparseDims, nnz)
_values.shape: dimensionality: 1 + _denseDims. shape: (nnz, shape[_sparseDims:])
```
This PR fixes various places where the invariants are not strictly enforced when 0-sized dimension support is enabled.
Tested and `test_sparse.py` passes locally on both CPU and CUDA with the `USE_TH_SIZE_ZERO_DIM` flag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9279
Differential Revision: D8936683
Pulled By: yf225
fbshipit-source-id: 12f5cd7f52233d3b26af6edc20b4cdee045bcb5e
Summary:
This uses zou3519's new `torch.broadcast_tensors()` #10075 to make `Categorical.log_prob()` and the `*Normal.__init__()` methods jittable. Previously `.log_prob()` was failing due to calls to `torch._C.infer_size()` with errors like
```
def log_prob(self, value):
if self._validate_args:
self._validate_sample(value)
> value_shape = torch._C._infer_size(value.size(), self.batch_shape) if self.batch_shape else value.size()
E RuntimeError: expected int at position 0, but got: Tensor
```
After this change I'm able to jit many more of Pyro's tests.
Reviewed By: ezyang
Differential Revision: D9477487
Pulled By: apaszke
fbshipit-source-id: 5f39b29c6b8fa606ad30b02fefe2dfb618e883d6
Summary:
When emitting if Branches, check that the types on each value returned are equivalent. As with reassignment of values, tensors are not forced to be the same shape or subtype.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10281
Differential Revision: D9466566
Pulled By: eellison
fbshipit-source-id: 746abdeb34a0f68806b8e73726ad5003b536911c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9483
The interface is updated to accept the config to construct the predictor.
Reviewed By: highker
Differential Revision: D8872999
fbshipit-source-id: 3ca54d644970823fc33c0ade9a005e12f52e2b24
Summary:
This will make pybind version of MPI PG work. The issue is the scope of the tensor list won't be available for the MPI worker thread. So we pass the vector by value instead.
Also added recv_anysource pybind to make it work. The front-end API will wrap one level up with an int for this function. So taking a tensor should be the easiest way for now.
Also added abort pybind and fixed the flaky test.
```
tengli@devfair033:~/new_pytorch/pytorch/torch/lib/build/c10d/test$ mpirun -np 8 ProcessGroupMPITest
Test successful
Test successful
Test successful
Test successful
Test successful
Test successful
Test successful
Test successful
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10606
Differential Revision: D9474393
Pulled By: teng-li
fbshipit-source-id: cca236c333656431e87d0d3573eeae9232c598b0
Summary:
Augassign (i.e., `x += 1`) gets desugared to an assignment of a binop (`x = x + 1`).
Right now we assert that the RHS of the binop is a tensor,
but it really doesn't have to be because we support scalar/scalar ops and also
list-list ops (i.e., `[1, 2] + [2, 3]`).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10730
Differential Revision: D9465110
Pulled By: zou3519
fbshipit-source-id: 7b118622701f09ce356aca81b8db743d9611097b
Summary:
Multiple failing external and internal CI signals were ignored when this commit
was landed. goldsborough please fix the text failures and resubmit this change as a
new PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10785
Reviewed By: ezyang
Differential Revision: D9466791
Pulled By: jamesr66a
fbshipit-source-id: b260e93bac95d05fd627c64e620b6aefb5045949
Summary:
ONNX doesn't support this. Instead flatten the inputs to the ListConstruct op and inline it into the subsequent usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10713
Differential Revision: D9458508
Pulled By: jamesr66a
fbshipit-source-id: 0b41e69320e694bb2f304c6221864a39121e4694
Summary:
I included "legacy" includes in the old spots for Backend, Generator, Layout; it seemed unlikely that the other ones had direct user includes.
This is another step on the path to move Type/Tensor to ATen/core.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10740
Reviewed By: ezyang
Differential Revision: D9435888
Pulled By: gchanan
fbshipit-source-id: 89f4f0f445d4498a059d3a79069ba641b22bbcac
Summary:
Don't regex against strings that may have come from the backtrace.
Better to just not regex at all.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10702
Reviewed By: ezyang
Differential Revision: D9406154
Pulled By: jsrmath
fbshipit-source-id: 9b17abee2a6e737a32c05f1e3963aef4b6638a47
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10053
Tensor in Pytorch 1.0 will have
Tensor -> TensorImpl -> Storage -> StorageImpl
In this diff we split Storage from Tensor in order to align with this design.
We'll have Tensor -> Storage -> StorageImpl after this diff
Reviewed By: ezyang
Differential Revision: D9384781
fbshipit-source-id: 40ded2437715a3a2cc888ef28cbca9a25b1d5350
Summary:
I've tested locally that this works to build static and non-static binaries with and without CUDA.
In terms of ongoing testing, I am working on incorporating this into the release package generation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10754
Differential Revision: D9457423
Pulled By: anderspapitto
fbshipit-source-id: aa1dcb17c67c0f0c493a9cf93aca4a6e06b21666
Summary: The code in Operator::SyncDevice had some duplicate logic and using FinishDeviceComputation sufficed in this case.
Reviewed By: yinghai
Differential Revision: D9348288
fbshipit-source-id: d8d874bab491e6d448fcd5fa561a8b99d502753b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10362
This diff implements a manual export from PyText's CRF module to the caffe2 CRF layer.
Note that most of the changes in caffe2/python/crf.py are just formatting changes, the only relevant change is the new class CRFUtils.
Reviewed By: hikushalhere
Differential Revision: D9234126
fbshipit-source-id: 1a67d709034660e8b3d5ac840560b56de63e3f69
Summary:
```
Use intrusive_ptr in Storage; replace unique_ptr<Storage> with Storage
This patch does two major changes:
- It replaces the use of Retainable in Storage with a new implementation
based on intrusive_ptr. This will be necessary because Caffe2 will
be using this class to implement intrusive_ptrs, and we need to
line these up for the merge. One good thing about the new implementation is
that the default copy/move constructors/assignment operators and destructor
work automatically, instead of needing to be hardcoded into Storage/Tensor.
- It replaces all places where we returned std::unique_ptr<Storage> with
Storage, collapsing an unnecessary double indirection that is no longer
necessary now that we have correctly working copy/move constructors.
I didn't initially want to do step (2), but it was very important to
eliminate all bare uses of new Storage and new StorageImpl, and this making
the API change was the most straightforward way to do this.
HOW TO FIX YOUR CODE IN THE NEW API
- You no longer need to dereference the result of tensor.storage() to pass
it to set. So, instead of:
x.set_(*y.storage());
just write:
x.set_(y.storage());
- If you were accessing methods on StorageImpl via the pImpl() method, you
must use the dot operator to run pImpl(). Even better; just drop pImpl,
we now have method forwarding. So, instead of:
storage->pImpl()->data();
just do:
storage->data();
// storage.pImpl()->data() works too but is not as recommended
- storage->getDevice() is no more; instead use storage->device().index()
MISC CODE UPDATES
- retain, release, weak_retain, weak_release and weak_lock are now
reimplemented using the "blessed API", and renamed to make it
clearer that their use is discouraged.
- nvcc OS X and general OS X portability improvements to intrusive_ptr
- A new comment in intrusive_ptr describing how stack allocated
intrusive_ptr_targets work differently than heap allocated ones
from c10::make_intrusive
CAVEAT EMPTOR
- THStorage_weakRetain used to work on strong pointers, but it NO LONGER
works with intrusive_ptr. You must reclaim the strong pointer into a
real strong pointer, construct a weak pointer from it, and then release
the strong and weak pointers. See StorageSharing.cpp for an example.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10488
Reviewed By: gchanan
Differential Revision: D9306134
Pulled By: ezyang
fbshipit-source-id: 02d58ef62dab8e4da6131e1a24834a65c21048e2
Summary:
The optimized code for `linear()` which uses `addmm` when a bias is given was duplicated three times in the ATen and the C++ API. Let's just have `at::linear` and use that everywhere.
apaszke ezyang (who mentioned this in #10481)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10755
Differential Revision: D9443881
Pulled By: goldsborough
fbshipit-source-id: a64862d1649b5961043d58401625ec267d97d9f3
Summary:
zdevito et al came to the conclusion that the ONNX spec does not mandate the widening conversion of integral types when serializing tensor data into raw_data, as opposed to serializing the data into int32_data. PyTorch recently made this change in the export code, which caused import in caffe2 to break because it did not match semantics. This fixes that
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10718
Differential Revision: D9423712
Pulled By: jamesr66a
fbshipit-source-id: 479fbae67b028bf4f9c1ca1812c2c7b0c6cccd12
Summary:
Fixes `__getattr__` to adhere to its Python API contract, and wraps `range()` call in a list since it does not return one anymore in Python 3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10525
Reviewed By: ezyang
Differential Revision: D9441360
Pulled By: tomdz
fbshipit-source-id: d489c0e7cefecc4699ca866fd55ddbfa629688d4
Summary:
This PR adds support for using custom ops in ScriptModules, the last step for our custom op strategy. You can now write
```
import torch
torch.ops.load_library('libcustom_ops.so')
class Model(torch.jit.ScriptModule):
def __init__(self):
super(Model, self).__init__()
torch.jit.script_method
def forward(self, input):
return torch.ops.custom.op(input) + 1
model = Model()
model.forward(torch.ones(5)) # Works
model.save("model.pt") # Works
model = torch.jit.load("model.pt") # Works
```
You can then load the `model.pt` in C++ and execute its `forward` method!
Missing for this was the fact that the script compiler didn't know to convert `ops.custom.op` into a `BuiltinFunction` which then emits a function call. For this I came up with the following strategy inside `torch/csrc/jit/scrip/init.cpp`:
1. When we access `torch.ops`, we return a `CustomOpValue` (subclass of `PythonValue`), whose purpose is only to return a `CustomOpNamespaceValue` (subclass of `PythonValue`) whenever something under it is accessed.
2. `CustomOpNamespaceValue` will then for each field accessed on it return a `BuiltinFunction`.
This doesn't reduce performance for any calls that are not to `torch.ops` (as opposed to inspecting every function call's name the call site, for example).
I also had to fix `BuiltinFunction` to not assume the namespace is always `aten::`.
A lot of other changes are just tidying up the Python and C++ test harness before I integrate it in CI.
zdevito dzhulgakov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10610
Differential Revision: D9387832
Pulled By: goldsborough
fbshipit-source-id: c00f431db56c7502a66fe1f813fe78067f428ecb
Summary:
This should resolves "error C2280: 'std::unique_ptr<caffe2::ObserverBase<caffe2::OperatorBase>,std::default_delete<_Ty>> &std::unique_ptr<_Ty,std::default_delete<_Ty>>::operator =(const std::unique_ptr<_Ty,std::default_delete<_Ty>> &)': attempting to reference a deleted function" from Visual Studio.
It should also make error message more human-readable in case if something really messed up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10593
Reviewed By: orionr
Differential Revision: D9436397
Pulled By: mingzhe09088
fbshipit-source-id: 31711667297b4160196134a34365da734db1c61d
Summary:
Let's run CI tests to see what fails given the changes that just landed in https://github.com/pytorch/pytorch/pull/10624
cc mingzhe09088 ezyang Yangqing
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10692
Reviewed By: mingzhe09088
Differential Revision: D9423617
Pulled By: orionr
fbshipit-source-id: 3bda1f118d13f8dd8e823727c93167cae747d8cf
Summary:
Set the build environment before installing sccache in order to make sure the docker images have the links set up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10640
Reviewed By: yf225
Differential Revision: D9399593
Pulled By: Jorghi12
fbshipit-source-id: a062fed8b7e83460fe9d50a7a27c0f20bcd766c4
Summary:
This is part of moving the (base) Type to ATen/core; Some Type methods have default argument of type THNN Reduction.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10703
Differential Revision: D9406060
Pulled By: gchanan
fbshipit-source-id: 789bb3387c58bd083cd526a602649105274e1ef6
Summary:
This will make the common case more natural (no need to do `_construct_empty_tensor_list()`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10705
Differential Revision: D9411622
Pulled By: michaelsuo
fbshipit-source-id: 2d91fbc5787426748d6e1c8e7bbeee737544dc96
Summary:
The broadcast is used by default when the opset version is greater then 6.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10108
Reviewed By: bddppq
Differential Revision: D9176934
Pulled By: houseroad
fbshipit-source-id: b737bd87b0ddc241c657d35856d1273c9950eeba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10651
EnsureCPUOutputOp will copy the input from another Context to CPU, but currently there is no guarantee that the Copy will be executed.
Differential Revision: D9390046
fbshipit-source-id: af3ff19cf46560264cb77d2ab8821f0cc5be74f6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10551
Renaming from "subtree" -> "subgraph" to improve clarity of subgraph matcher APIs since it now supports DAG
This is pure renaming, no functionalities change.
Reviewed By: bwasti
Differential Revision: D9348311
fbshipit-source-id: 4b9267845950f3029dfe385ce3257d3abb8bdad4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10549
Support dag matching in nomnigraph. This is done by maintaining a map from node in the MatchGraph to node in the input graph, and additionally enforce that same nodes in the MatchGraph must match to same nodes in the input graph (with the exception of multiplicity i.e. when count != 1 on the MatchGraph node).
In a follow up diff, I'll rename the API that refers to subtree as subgraph to improve clarity.
Reviewed By: bwasti
Differential Revision: D9347322
fbshipit-source-id: 171491b98c76852240a253279c2654e96dd12632
Summary:
Some more `ATEN_API` additions for hidden visibility.
Running CI tests to see what fails to link.
cc Yangqing mingzhe09088 ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10624
Reviewed By: mingzhe09088
Differential Revision: D9392728
Pulled By: orionr
fbshipit-source-id: e0f0861496b12c9a4e40c10b6e0c9e0df18e8726
Summary:
Minor fix for the cuDNN cache. Previously we would skip the event reinitialization when an RNN function would be called on GPU 0, and then on GPU 1, but it would be in eval mode on GPU1. That would cause us to skip event re-initialization, and cause an incorrect resource handle error when trying to record the event.
soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10662
Reviewed By: soumith
Differential Revision: D9393629
Pulled By: apaszke
fbshipit-source-id: e64c1c1d2860e80f5a7ba727d0b01aeb5f762d90
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9888
Limiter cannot be shared or copied; just pass it to the first reader.
Reviewed By: xianjiec
Differential Revision: D9008871
fbshipit-source-id: e20cd785b26b1844e156efc3833ca77cfc3ffe82
Summary:
Trigonometry functions are newly added to ONNX in a recent PR https://github.com/onnx/onnx/pull/869
This PR makes pytorch support exporting graphs with trigonometry functions.
This PR might need to wait until it is ready to change
```python
_onnx_opset_version = 6
```
to
```python
_onnx_opset_version = 7
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/7540
Differential Revision: D9395041
Pulled By: bddppq
fbshipit-source-id: bdf3e9d212b911c8c4eacf5a0753bb092e4748d2
Summary:
There is no reason that user should do an extra import to use DistributedSampler.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10671
Differential Revision: D9395189
Pulled By: SsnL
fbshipit-source-id: 8f41d93813c8fb52fe012f76980c6a261a8db9b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10478
- Removed Backend constructor from Device, and fixed all
use-sites to use DeviceType::CPU instead of kCPU, or
use a new function backendToDeviceType to perform
the conversion.
- New method device_type() on Type; it gives you the
underlying device type, e.g., CPU for SparseCPU.
- We add backward compatibility for kCPU/kCUDA uses,
by introducing a new special type which is implicitly
convertible to both DeviceType and Backend. As long as
you don't define a function that's overloaded on both
DeviceType and Backend (but not on BackendOrDeviceType),
the implicit conversions will ensure that uses
of at::Device(at::kCPU) keep working. We fixed use-sites in
the library, but did NOT fix sites in the test code, so that
we can exercise this BC code.
Reviewed By: Yangqing
Differential Revision: D9301861
fbshipit-source-id: 9a9d88620500715c7b37e655b4fd761f6dd72716
Summary:
... to avoid slow at::chunk (it is slow due to tensor initialization). Picking up from #10026
This is done through the following:
1) Absorb starting chunks into FusionGroup as a part of the graph fuser
pass.
2) When compiling a kernel, emit a `std::vector<ConcatDesc>` that describes if an input (of the original graph) will be chunked.
3) When launching a kernel, `use std::vector<ConcatDesc>` to chunk an
input tensor on the CPU. This chunk directly takes in an at::Tensor and creates
four TensorInfo structs in-place in the argument list, bypassing the creation of intermediate Tensors.
- Expect test and correctness test to see if a single chunk is fused
by the graph fuser
- Correctness test for a variety of chunks (dimension = beginning,
middle, end) and tensors (contiguous, non-contiguous, edge case
(splitSize = 1) for both CPU/CUDA
- Expect test for multiple chunks fused into the same kernel and
correctness test.
cc zdevito apaszke
LSTM forward pass, 1 layer, 512 hidden size and input size, 100 seq length, requires_grad=False on all inputs and weights.
After changes:
```
thnn cudnn jit
8.8468 6.5797 9.3470
```
Before changes:
```
thnn cudnn jit
9.9221 6.6539 11.2550
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10178
Differential Revision: D9382661
Pulled By: zou3519
fbshipit-source-id: 1f8a749208fbdd45559775ce98cf4eb9558448f8
Summary:
Take 2 of #10543
The problem was that between commit and merge there was added one more run point `tools/build_libtorch.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10659
Differential Revision: D9393540
Pulled By: soumith
fbshipit-source-id: 8ebfed600fc735fd1cb0489b161ec80e3db062e0
Summary:
Fixes#10096
If the only thing preventing a simple mappable operator from being fused
into a fusion group is that its Tensor inputs are not of the same shape as the
output, then the graph fuser inserts explicit expand nodes for those
inputs.
This helps the graph fuser not miss out on any fusion opportunities
involving simple mappable operations that have Tensor inputs. This PR
doesn't do anything for the scalar case; that can be addressed later.
Test Plan
- Simple expect test case
- Added expect tests for a raw LSTMCell. The expands help speed up the
forwards pass by allowing more operations to be fused into the LSTMCell's single
FusionGroup.
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10325
Differential Revision: D9379308
Pulled By: zou3519
fbshipit-source-id: 86d2202eb97e9bb16e511667b7fe177aeaf88245
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10630
`onnxTensorDescriptorV1.name` points to the string buffer. We use a vector of strings to serve as the storage. This means we cannot reallocate the vector because that may invalidate the `onnxTensorDescriptorV1.name` pointers. Solution is to reserve a large enough vector so that it won't reallocate.
Reviewed By: bddppq, houseroad
Differential Revision: D9381838
fbshipit-source-id: f49c5719aafcc0829c79f95a2a39a175bcad7bfe
Summary:
This is on the way to resolving #9940.
Fixes#10501
This PR modifies graph fuser to fuse operations that have constant
scalar arguments. These constant scalar arguments are directly inlined
into the kernel body.
The context for this is that LSTM backward (in particular, sigmoid
backward) has many add(x, 1.) operations. This PR should be sufficient for
LSTM backward to get fused by the graph fuser.
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10511
Differential Revision: D9378896
Pulled By: zou3519
fbshipit-source-id: 6a7a2987f5b6e8edaaf4b599cd200df33361650f
Summary:
This is still not the final PR, but it removes all blockers for actually using the RNN functions directly in the JIT. Next patch should be final, and will actually remove the symbolic_override code, and change it to proper symbolics for those ATen functions. Turns out the symbolic code can be also cleaned up a bit, and I'll do that too.
zdevito ezyang
colesbury (for minor DispatchStub.h) changes
There was no way to handle those in the JIT for now, and they turned
out to be completely unnecessary. It should make the Python and C++
module code much simpler too, since all the logic is now centralized
in the native functions.
The downside is that RNN modules no longer own their dropout buffers,
which are shared per-device instead (with appropriate locking and
synchronization). This might appear as a perf regression at first, but
in reality it's highly unlikely that anyone will want to run cuDNN RNNs
on the same GPU in parallel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10581
Reviewed By: colesbury
Differential Revision: D9365541
Pulled By: apaszke
fbshipit-source-id: 3ef8677ee5481bae60c74a9117a2508665b476b5
Summary:
The PR is the first step to integrate torch.nn library with JIT. It adds the tests for nn functional interfaces in trace/script mode, and tries to find out the different between torch.nn.functional ops and the ATen ops, to see the work need to be done in order to support a full set of nn functional in script mode.
Some statistics in summary:
- Totally 84 useful functions in torch.nn.functional (the number does not include helper funcs and deprecated funcs in torch.nn.functional).
- 7 functions/ops does not support higher gradient, so just excluded from the whole test.
- 36 functions is different with the Aten op for different reasons. Among those 36 functions, bunch of them (roughly around 10-15) are just naming difference and simple transformation using other ops inside the function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10409
Differential Revision: D9350694
Pulled By: wanchaol
fbshipit-source-id: 8fce6f30d8d25ace5a544a57b219fe61f5a092f8
Summary:
Inlining if branches which have constant inputs. If an if node gets inlined, the set of mutated variables returned by its ancestors may have changed. In the following example the block should
return a mutated set of (a) and not (a, b).
```
if cond:
if True:
a = a - 1
else:
b = b - 1
```
To calculate this we recursively update mutate variables in if branches from the leaf nodes up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10084
Reviewed By: michaelsuo
Differential Revision: D9340429
Pulled By: eellison
fbshipit-source-id: b0dd638a5cace9fdec3130460428fca655ce4b98
Summary:
https://github.com/pytorch/pytorch/pull/10100 recently take external input/output in nomnigraph. This PR makes adjust to
0. Relax some of the conditions on external input
1. Update NNModule inputs/outputs when pruning the input/output.
2. Avoiding copying external input/output as nomnigraph already takes care of it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10598
Reviewed By: bwasti
Differential Revision: D9371730
Pulled By: yinghai
fbshipit-source-id: 9273be5041dc4cc8585587f47cb6721e518a06a8
Summary:
Custom python installation, which have no aliases to `python` or `python3` can't be found by cmake `findPythonInterp` without extra cmake argument.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10543
Differential Revision: D9378844
Pulled By: ezyang
fbshipit-source-id: 022e20aab7e27a5a56b8eb91b6026151116193c7
Summary:
Fix "error LNK2019: unresolved external symbol" from "CAFFE_KNOWN_TYPE" in tests where we should use dllexport instead of AT_CORE_API(=dllimport).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10602
Differential Revision: D9377394
Pulled By: Yangqing
fbshipit-source-id: 993062a461ffce393f2321c5391db5afb9b4e7ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10282
This diff removes the unused/deprecated features from the code base.
Reviewed By: manojkris
Differential Revision: D9169859
fbshipit-source-id: d6447b7916a7c687b44b20da868112e6720ba245
Summary:
This is the last step in the custom operator implementation: providing a way to build from C++ and Python. For this I:
1. Created a `FindTorch.cmake` taken largely from ebetica with a CMake function to easily create simple custom op libraries
2. Created a ` torch/op.h` header for easy inclusion of necessary headers,
3. Created a test directory `pytorch/test/custom_operator` which includes the basic setup for a custom op.
1. It defines an op in `op.{h,cpp}`
2. Registers it with the JIT using `RegisterOperators`
3. Builds it into a shared library via a `CMakeLists.txt`
4. Binds it into Python using a `setup.py`. This step makes use of our C++ extension setup that we already have. No work, yey!
The pure C++ and the Python builds are separate and not coupled in any way.
zdevito soumith dzhulgakov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10226
Differential Revision: D9296839
Pulled By: goldsborough
fbshipit-source-id: 32f74cafb6e3d86cada8dfca8136d0dfb1f197a0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10599
Not spawning threads with spin-lock synchronization is bad because they will switch to `condvar` wait, which increases wake-up latency next time they are needed.
Reviewed By: ajtulloch
Differential Revision: D9366664
fbshipit-source-id: 3b9e4a502aeefaf0ddc4795303a855d98980b02e
Summary:
This commit adds the ``buffers()`` and ``named_buffers()`` methods as
analogues of ``parameters()`` and ``named_parameters()``.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10554
Reviewed By: SsnL
Differential Revision: D9367762
Pulled By: jma127
fbshipit-source-id: f2042e46a7e833dce40cb41681dbd80d7885c74e
Summary:
A continuation of https://github.com/pytorch/pytorch/pull/10504 for GPU, torch, etc. builds.
I was testing with
```
FULL_CAFFE2=1 python setup.py build_deps | tee ~/log.txt
cat ~/log.txt | egrep 'undefined refer' | sort | less
```
I'll rebase on master when Yangqing's changes in 10504 land, but putting up for some testing.
cc mingzhe09088 anderspapitto ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10507
Reviewed By: Yangqing
Differential Revision: D9359606
Pulled By: orionr
fbshipit-source-id: c2a3683b3ea5839689f5d2661da0bc9055a54cd2
Summary:
Resubmit #10416 with fixed tests . This is to remove implicit conversion from gpu to cpu in when calling numpy to keep behavior match others.
It requires users to move the tensor back to cpu() before call numpy functions on it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10553
Differential Revision: D9350212
Pulled By: ailzhang
fbshipit-source-id: 9317d8fea925d4b20ae3150e2c1b39ba5c9c9d0a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10494
Adding the AllredubeBcube routines as they are now available in gloo.
Reviewed By: wesolwsk
Differential Revision: D8269473
fbshipit-source-id: 6a3a32291bbf1fbb328b3ced0f2a753dc5caf4e5
Summary:
The ONNXIFI backend will absorb the constant weight in Conv, so we should not add it as an input. This is just a test artifacts. Note that Onnxifi transformer will do the right thing when cutting the graph to absorb the weights.
rdzhabarov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10575
Reviewed By: houseroad
Differential Revision: D9357339
Pulled By: yinghai
fbshipit-source-id: a613fa3acafa687295312f5211f8e9d7f77b39cd
Summary:
delete build_caffe2.sh, replace with build_libtorch.py as suggested by peter (and copy-pasted from his draft PR). This ensures that all consumers of the torch CMake file go through as unified a path as possible.
In order to change the surrounding infrastructure as little as possible, I made some tweaks to enable build_pytorch_libs.sh to generate the test binaries relative to the current directory, rather than hardcoding to pytorch/build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10508
Differential Revision: D9354398
Pulled By: anderspapitto
fbshipit-source-id: 05b03df087935f88fca7ccefc676af477ad2d1e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10546
Have you ever written an operator<< overload in the caffe2 namespace
in a core Caffe2 header, and then been stunned when some completely
unrelated code started breaking? This diff fixes this problem!
The problem looks like this:
1. You're building against a really old version of glog (think 0.3.2,
or something like that)
2. This version of glog defines operator<< overloads for std containers
in the global namespace
3. You add a new overload in your current namespace (e.g., caffe2).
Congratulations: this overload is *preferentially* chosen over
the global namespace one for all calls to << in that namespace.
And since it doesn't actually have std::vector overloads, unrelated
Caffe2 code breaks.
Newer versions of glog have a fix for this: they have the line:
namespace std { using ::operator<<; }
in their header. So let's help old versions of glog out and do this ourselves.
In our new world order, operator<< overloads defined in the global namespace
won't work (unless they're for std containers, which work because of ADL).
So this diff also moves all those overloads to the correct namespace.
Reviewed By: dzhulgakov
Differential Revision: D9344540
fbshipit-source-id: 6246ed50b86312668ebbd7b039fcd1233a3609cf
Summary:
This PR removes the `using Tensor = autograd::Variable;` alias from `torch/tensor.h`, which means `torch::Tensor` is now `at::Tensor`. This PR fixes up some last uses of `.data()` and tidies up the resulting code. For example, I was able to remove `TensorListView` such that code like
```
auto loss = torch::stack(torch::TensorListView(policy_loss)).sum() +
torch::stack(torch::TensorListView(value_loss)).sum();
```
is now
```
auto loss = torch::stack(policy_loss).sum() + torch::stack(value_loss).sum();
```
CC jgehring
ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10516
Differential Revision: D9324691
Pulled By: goldsborough
fbshipit-source-id: a7c1cb779c9c829f89cea55f07ac539b00c78449
Summary:
fixed NCCL test, which is not run in CI. We should enable it soon.
```
~/new_pytorch/pytorch/test$ python test_c10d.py
...............
----------------------------------------------------------------------
Ran 15 tests in 13.099s
OK
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10557
Reviewed By: ailzhang
Differential Revision: D9353286
Pulled By: teng-li
fbshipit-source-id: 5a722975beaa601203f51c723522cc881f2d2090
Summary:
Properly annotated all apis for cpu front. Checked with cmake using
cmake -DUSE_ATEN=ON -DUSE_CUDA=OFF -DBUILD_ATEN=ON
and resulting libcaffe2.so has about 11k symbols.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10504
Reviewed By: ezyang
Differential Revision: D9316491
Pulled By: Yangqing
fbshipit-source-id: 215659abf350af7032e9a4b0f28a856babab2454
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10439
Update Im2Col related to make preparation for group conv in NHWC order.
Reviewed By: houseroad
Differential Revision: D9285344
fbshipit-source-id: 1377b0243acb880d2ad9cf73084529a787dcb97d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10528
adding 2 features to core and model_helper
- reroute_tensor which supports op insertion on net level
- model_helper complete net and cut net used for full graph analysis
Differential Revision: D9330345
fbshipit-source-id: 56341d3f500e72069ee306e20266c8590ae7985a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10053
Tensor in Pytorch 1.0 will have
Tensor -> TensorImpl -> Storage -> StorageImpl
In this diff we split Storage from Tensor in order to align with this design.
We'll have Tensor -> Storage -> StorageImpl after this diff
Reviewed By: dzhulgakov
Differential Revision: D9076734
fbshipit-source-id: ea9e1094ecf8c6eaeaa642413c56c6a95fb3d14e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10526
Resubmitting these changes. Previously they caused issues with multifeed, which I fixed with D9280622
Reviewed By: yinghai
Differential Revision: D9327323
fbshipit-source-id: ec69428039b45c6221a5403b8fe9a83637857f04
Summary:
Implemented via a wrapper, thank you Richard for the suggestion!
Fixes: #9929
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10067
Differential Revision: D9083388
Pulled By: soumith
fbshipit-source-id: 9ab21cd35278b01962e11d3e70781829bf4a36da
Summary:
This should make ASAN tests run faster.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9902
Differential Revision: D9032986
Pulled By: yf225
fbshipit-source-id: 3d2edec2d7ce78bc995d25865aa82ba6d3f971d0
Summary:
Pull a fix in FP16 for compilation bug when using Intel Compiler
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10548
Differential Revision: D9349469
Pulled By: Maratyszcza
fbshipit-source-id: 43e6dc5c3c18319d31eca23426770c73795feec5
Summary:
In my environment, it looks like setup.py hangs when running
```
FULL_CAFFE2=1 python setup.py build_deps
```
Removing this fixes things, but we might also want to look at `tests_require`, which came over from `setup_caffe2.py`.
cc pjh5
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10530
Differential Revision: D9349597
Pulled By: orionr
fbshipit-source-id: 589145eca507dfaf16386884ee2fbe60299660b4
Summary:
This PR removes couple of macros throughout TH* as part of the re-factoring effort for ATen. Removing these macros should avoid confusion among developers who are trying to move things from TH* to ATen. This PR is part of the THCNumerics deprecation that I have been working on following up on mruberry's https://github.com/pytorch/pytorch/pull/9318. I am separating these two commits to see if removal of these macros doesn't upset the pytorch public CI, as well as internal builds.
- Commit 1248de7baf removes the code paths guarded by `CUDA_HALF_INSTRUCTIONS` macro. Since the macro was removed in commit 2f186df52d, `ifdef CUDA_HALF_INSTRUCTIONS` would return false and hence the code path that is kept after this change is for the false case of `ifdef CUDA_HALF_INSTRUCTIONS`
- Commit 520c99b057 removes the code paths guarded by `CUDA_HALF_TENSOR` macro. Since Pytorch now provides support for only CUDA 8.0 and above, `CUDA_HALF_TENSOR` is always true since CUDA 8.0 satisfies `CUDA_HAS_FP16` and hence, the code path that is kept after this change is for the true case of `ifdef CUDA_HALF_TENSOR`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10147
Differential Revision: D9345940
Pulled By: soumith
fbshipit-source-id: c9392261dd432d304f1cdaf961760cbd164a59d0
Summary:
This is the first of two changes that are supposed to improve how we handle RNNs in the JIT. They still get traced as `PythonOp`s, but now it will be much easier to actually expose them to the JIT as e.g. `aten::lstm`, and ignore the Python interpreter entirely. This needs some symbolic adjustments that will be part of a second PR.
Even when we fix symbolics, there will still be a bit of a problem with statefulness of the cuDNN API (we need a mutable cache for the dropout state, but our IR has no way of representing that).
zdevito ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10481
Reviewed By: ezyang
Differential Revision: D9341113
Pulled By: apaszke
fbshipit-source-id: 0ae30ead72a1b12044b7c12369d11e5ca8ec30b5
Summary:
In the shortcut for n_sample=1, when category 0 has 0 weight,
we should not map the (uniform) sample 0 to category 0.
The conversion uniform->multinomial was apparently written to work on
a (0,1] range (like curand uses), but PyTorch uses a [0,1) range.
Fixes: #4858. Thank you, Roy Fejgin for reporting.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9960
Reviewed By: soumith
Differential Revision: D9341793
Pulled By: ailzhang
fbshipit-source-id: 6b1a96419a7bc58cc594f761f34c6408ff6354cf
Summary:
Since we can't specify version number to `choco install curl`, we should not assume that `7.57.0` is the curl version that's in the Windows AMI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10476
Differential Revision: D9303129
Pulled By: yf225
fbshipit-source-id: 198544be68330860fbcf93c99bc995f4e280bda7
Summary:
Support broadcasting in _kl_categorical_categorical
this makes it possible to do:
```
import torch.distributions as dist
import torch
p_dist = dist.Categorical(torch.ones(1,10))
q_dist = dist.Categorical(torch.ones(100,10))
dist.kl_divergence(p_dist, q_dist)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10533
Differential Revision: D9341252
Pulled By: soumith
fbshipit-source-id: 34575b30160b43b6c9e4c3070dd7ef07c00ff5d7
Summary:
Two tests in the 'nn' test bucket may fail when the torch.half
(float16) data type is used. The assertions used in the tests
intend to allow slight floating point imprecision in the results,
but the tolerances used for the comparisons are too strict for
the half type.
Relax the tolerances so that slight float16 imprecision won't
cause test failures.
The affected tests are:
- test_variable_sequence_cuda
- test_Conv2d_groups_nobias
For more information, see issue:
https://github.com/pytorch/pytorch/issues/7420
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10519
Differential Revision: D9343751
Pulled By: soumith
fbshipit-source-id: 90aedf48f6e22dd4fed9c7bde7cd7c7b6885845a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10512
SubtreeMatchCriteria now becomes a graph of MatchNode
MatchNode consists of NodeMatchCriteria, nonTerminal and count. This is a cleaner internal representation of the data structure and will bring us much closer to DAG matching.
Note that I still keep the debugString method because convertToDotGraph doesn't currently work with Subgraph.
Reviewed By: bwasti
Differential Revision: D9321695
fbshipit-source-id: 58a76f007a9a95d18cf807d419c2b595e9bc847f
Summary:
optimize max and min reduction for ATen CPU path, current code path from TH module runs in sequential on CPU.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10343
Differential Revision: D9330799
Pulled By: ezyang
fbshipit-source-id: 5b8271e0ca3e3e73f88a9075aa541c8756001b7c
Summary:
I've implemented affine grid generation for volumetric (5d) inputs. The implementation is based off of the spatial implementation, extended by one dimension. I have a few questions about my implementation vs. the existing one that I will add inline.
I have some extensive test cases for the forward pass here: https://gist.github.com/elistevens/6e3bfb20d8d0652b83bd16b3e911285b However, they use `pytest.fixture` extensively, so I'm not sure the best way to incorporate them into the pytorch test suite. Suggestions? I have not tested backwards at all.
Diff probably best viewed with whitespace changes ignored.
Thanks for considering!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8322
Differential Revision: D9332335
Pulled By: SsnL
fbshipit-source-id: 1b3a91d078ef41a6d0a800514e49298fd817e4df
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10395
Order switch ops (NCHW2NHWC and NHWC2NCHW) were only supporting 2D images.
This diff generalizes them to 1D and 3D, and also add a unit test we didn't have.
Reviewed By: protonu
Differential Revision: D9261177
fbshipit-source-id: 56e7ec54c9a8fb71781ac1336f3f28cf024b4bda
Summary:
We can't rely on the ATen fallback pathway here because we need to parse out the constant attributes explicitly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10513
Reviewed By: dzhulgakov
Differential Revision: D9322133
Pulled By: jamesr66a
fbshipit-source-id: 52af947e6c44532ef220cb4b94838ca838b5df06
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10390
Fixed a bug in box_with_nms_limit where it may produce more bounding boxes than specified.
* The original code first finds the threshold for the boxes at the 'detectons_per_im' position, and filters out boxes lower than the threshold.
* In some cases that there are multiple boxes have the same threshold, the op will return more boxes than 'detectons_per_im'.
Reviewed By: wat3rBro
Differential Revision: D9252726
fbshipit-source-id: 63f40829bcd275cb181692bc7547c384cee01499
Summary:
Background: we run pytorch in embedded C++ pipelines, running in C++ GUIs in https://github.com/Kitware/VIAME and without this addition, the call was failing with the below error, but only on certain windows platforms/configurations:
OSError: [WinError6] The handle is invalid
At:
C:\Program Files\VIAME\Python36\site-packages\torch\cuda_init_.py(162):_lazy_init
C:\Program Files\VIAME\Python36\site-packages\torch\nn\modules\module.py(249): <lambda>
C:\Program Files\VIAME\Python36\site-packages\torch\nn\modules\module.py(182): _apply
C:\Program Files\VIAME\Python36\site-packages\torch\nn\modules\module.py(176): _apply
C:\Program Files\VIAME\Python36\site-packages\torch\nn\modules\module.py(249): cuda
C:\Program Files\VIAME\lib\python3.6None\site-packages\kwiver\arrows\pytorch\pytorch_resnet_f_extractor.py(74):_init_
C:\Program Files\VIAME\lib\python3.6None\site-packages\kwiver\processes\resnet_descriptors.py(132): _configure
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10379
Differential Revision: D9330772
Pulled By: ezyang
fbshipit-source-id: 657ae7590879004558158d3c4abef2ec11d9ed57
Summary:
Breaking out of #8338
This PR is a workaround for a bug with CUDA9.2 + GCC7.
Here is the error this PR fixed:
.../pytorch/caffe2/operators/elementwise_ops.h: In constructor ‘caffe2::BinaryElementwiseWithArgsOp<InputTypes, Context, Functor, OutputTypeMap>::BinaryElementwiseWithArgsOp(const caffe2::OperatorDef&, caffe2::Workspace*)’:
.../pytorch/caffe2/operators/elementwise_ops.h:106:189: error: ‘GetSingleArgument<bool>’ is not a member of ‘caffe2::BinaryElementwiseWithArgsOp<InputTypes, Context, Functor, OutputTypeMap>’
BinaryElementwiseWithArgsOp(const OperatorDef& operator_def, Workspace* ws)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10510
Reviewed By: orionr
Differential Revision: D9319742
Pulled By: mingzhe09088
fbshipit-source-id: ce59e3db14539f071f3c20301e77ca36a6fc3f81
Summary:
Previously, it's easy to do `x[0].accessor<float, 2>()`. However, x[0] is a temporary, so the accessor will point to invalid strides/sizes and probably segfault. With this change, such unsafe code is a compile error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10518
Reviewed By: goldsborough
Differential Revision: D9329288
Pulled By: ebetica
fbshipit-source-id: d08763bee9a19a898b9d1ea5ba648f27baa1992f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10514
fix the bug which break the windows build in fused_rowwise_random_quantization_ops.h
Reviewed By: ezyang, jspark1105
Differential Revision: D9322291
fbshipit-source-id: a6a27e87423b6caa973414ffd7ccb12076f2e1e4
Summary:
setup.py is the official install script, setup_caffe2.py is not used any more
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10520
Reviewed By: yinghai
Differential Revision: D9325548
Pulled By: bddppq
fbshipit-source-id: 3dda87f3dff061b574fd1d5c91859044f065ee33
Summary:
After this, all combinations of {String frontend, Python AST Frontend}{Python 3-style type annotations, MyPy-style type comments}{Script method, Script function} should properly accept type annotations.
Possible TODOs:
- Clean up the functions marked HACK
- Clean up the Subscript tree-view to better match the Python AST versions
- Can we use this for Python functions? That's the only place annotations.get_signature() is still needed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10279
Differential Revision: D9319726
Pulled By: jamesr66a
fbshipit-source-id: b13f7d4f066b0283d4fc1421a1abb9305c3b28fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10267
isSubtreeMatch now returns a SubtreeMatchResult which contains a match flag and a debugMessage string that contains the reason why a subtree is not matched (if requested).
Reviewed By: bwasti
Differential Revision: D9182429
fbshipit-source-id: 530591fad592d02fb4c31fc398960a14ec90c86a
Summary:
Provided python binding for these four ops. Also provided nccl binding test.
Based on https://github.com/pytorch/pytorch/pull/10058
Please only review init.cpp, and test file.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10159
Reviewed By: yf225
Differential Revision: D9323192
Pulled By: teng-li
fbshipit-source-id: b03822009d3a785ec36fecce2fc3071d23f9994e
Summary:
Added
- Reduce (both NCCL and MPI)
- AllGather (both NCCL and MPI)
- Gather (MPI)
- Scatter (MPI)
for c10d process groups. This basically finalizes all supported ops for C10d to match THD.
All ops are tested as well.
```
mpirun -np 8 ./ProcessGroupMPITest
Test successful
Test successful
Test successful
Test successful
Test successful
Test successful
Test successful
Test successful
```
```
./ProcessGroupNCCLTest
Allreduce test successful
Broadcast test successful
Reduce test successful
Allgather test successful
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10058
Reviewed By: yf225
Differential Revision: D9316312
Pulled By: teng-li
fbshipit-source-id: 6a6253268d34332327406b1f87335d1402f7133f
Summary:
After talking to users of the C++ API we found that having the tensor type be `autograd::Variable` causes more complications than having it be `at::Tensor`. It used to be a problem because `at::Tensor` didn't have the "autograd API" of variable (e.g. `detach()` or `grad()` methods), but those methods are now on `at::Tensor`. As such, we want to make a last big breaking change to have the tensor type be `at::Tensor`, while factory methods like `torch::ones` will return `Variable`s disguised as `at::Tensor`. This will make many things easier, like calling functions in ATen that take vectors of tensors.
This PR makes a small step in this direction by updating the optimizer classes to not use `.data()` on `Variable` to access the underlying `at::Tensor`. Using `.data()` is effectively a hack to work around our modification rules for tensors that require grad. The proper way of doing things is to use `with torch.no_grad` or equivalently `NoGradGuard` in C++ to guard in-place operations.
The next step can then simply redefine `torch::Tensor` to be `at::Tensor`. This transition should be smooth, since all methods available on `Variable` are at this point available on `at::Tensor`.
For this PR I:
1. Modified the implementations of optimizers to not use `.data()`. This means the implementations are now different from PyTorch, which still uses the legacy method of using `.data`.
2. To properly verify (1), I added more fine-grained test cases to our optimizer tests, e.g. `SGD` with and without `weight_decay`, then with `nesterov` etc. Generally more tests = more happy!
3. Minor cleanup of the optimizer codebase
ebetica apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10490
Differential Revision: D9318229
Pulled By: goldsborough
fbshipit-source-id: fb386700f37840542bc5d323f308ea88fe5ea5c5
Summary:
Now, run `python test/onnx/test_operators.py --no-onnx`, we won't introduce any onnx python dependence. (No onnx/protobuf python packages needs to be installed)
The major changes:
- output pbtxt from C++ exporter directly, so the floating format may be slightly different. (This should be fine, since it's just to guard ONNX exporting.)
- ONNX python packages are only imported if we run the ONNX related checks. Those checks are disabled when using `--no-onnx` flag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10151
Reviewed By: jamesr66a
Differential Revision: D9130706
Pulled By: houseroad
fbshipit-source-id: ea28cf5db8399929179698ee535137f209e9ce6f
Summary:
There are three classes `RNNCell`, `LSTMCell`, `GRUCell` inherited from `RNNCellBase`, all defining the identical initialization function `reset_parameters`. Lets move it to the common base.
Another option is to have different initialization for RNN, LSTM and GRU. Maybe those weights whose output is processed with sigmoid (i.e. gain=1) should be initialized differently from those going to tanh (gain=5/3)?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10399
Differential Revision: D9316978
Pulled By: SsnL
fbshipit-source-id: a2d9408f0b5c971a3e6c3d42e4673725cf03ecc1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10244
Use CAFFE_ENFORCE_EQ(x, y) instead of CAFFE_ENFORCE(x == y) in conv_op_impl.h for error messages with more information.
Reviewed By: viswanathgs
Differential Revision: D9177091
fbshipit-source-id: cf8d10afec1ce6793d3ae0b62f05648722a4130b
Summary:
It just calls into `ninja install`. For iterative work on
libtorch.so/_C.so,
`python setup.py rebuild_libtorch develop` should provide quick iteration
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10036
Differential Revision: D9317869
Pulled By: anderspapitto
fbshipit-source-id: 45ea45a1b445821add2fb9d823a724fc319ebdd2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10389
Added some unit test for box_with_nms_limit_op.
Reviewed By: wat3rBro
Differential Revision: D9237860
fbshipit-source-id: 2d65744bd387314071b68d2a0c934289fc64a731
Summary:
Test only for existence for now. I had to skip a lot of them so there a FIXME in the test.
Also I'm not testing torch.* because of namespace issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10311
Differential Revision: D9196341
Pulled By: SsnL
fbshipit-source-id: 9c2ca1ffe660bc1cc664474993f8a21198525ccc
Summary:
- Exposed get_debug_graph for ScriptModule (gets the debug graph for its
forward Method)
- Added forward/backward expect tests for lstm and milstm cells. These
are intended to prevent regressions
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10506
Differential Revision: D9316590
Pulled By: zou3519
fbshipit-source-id: 3c2510d8363e9733ccbc5c7cc015cd1d028efecf
Summary:
This commit adds the ability to insert a node with inputs, using the schema to check the inputs are valid types, fill in any default values, and perform standard implicit conversions. Since it is schema based, it will discover and use the right overload.
Constructors to `NamedValue` enable it to be constructed using `IValue` constants so it is possible to use constant values in the input list as well:
```
g.insert(aten::add, {v, 3});
```
Keyword arguments are also supported:
```
g.insert(aten::add, {v}, {{"other", t}, {"scalar", 1}});
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10198
Differential Revision: D9307252
Pulled By: zdevito
fbshipit-source-id: 644620aa85047d1eae1288383a619d50fec44d9b
Summary:
AffineChannel is being used by public Detectron models, e.g. Mask-RCNN and Faster-RCNN. This PR folds this op into convolution the same way as BN to speed up inference.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10293
Differential Revision: D9276789
Pulled By: yinghai
fbshipit-source-id: fbf6dd2c1be05f5713f760752e7245b1320a122b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10100
nomnigraph has until this point tried to ignore external input and output, as they aren't very well defined (does order matter?). but for DCE and some of Keren's work they are becoming necessary. I went ahead and added this to the core nomnigraph converter
Reviewed By: yinghai
Differential Revision: D9105487
fbshipit-source-id: a2e10e3cc84515611d6ab7d4bc54cf99b77729c0
Summary:
Fixes#10456
The graph fuser was fusing together groups with prim::FusedConcat (the producer) with other ops (the consumer) if the consumer is fusable. For example,
```
import torch
torch.jit.script
def fn(x, y, z):
x1 = x + y
y1 = x - y
w = torch.cat([x1, y1])
return w + z
x = torch.randn(2, 2, dtype=torch.float, device='cpu')
y = torch.randn(2, 2, dtype=torch.float, device='cpu')
z = torch.randn(4, 2, dtype=torch.float, device='cpu')
fn(x, y, z)
fn.graph_for(x, y, z)
```
produced the following graph:
```
graph(%x : Float(2, 2)
%y : Float(2, 2)
%z : Float(4, 2)) {
%3 : int = prim::Constant[value=1]()
%y1 : Float(2, 2) = aten::sub(%x, %y, %3)
%8 : int = prim::Constant[value=0]()
%14 : Float(4, 2) = prim::FusionGroup_0[device=-1](%z, %y1, %x, %y)
return (%14);
}
with prim::FusionGroup_0 = graph(%1 : Float(4, 2)
%5 : Float(2, 2)
%7 : Float(2, 2)
%8 : Float(2, 2)) {
%11 : int = prim::Constant[value=1]()
%9 : int = prim::Constant[value=1]()
%x1 : Float(2, 2) = aten::add(%7, %8, %9)
%w : Float(4, 2) = prim::FusedConcat[dim=0](%x1, %5)
%2 : int = prim::Constant[value=1]()
%3 : Float(4, 2) = aten::add(%w, %1, %2)
return (%3);
}
```
this is a problem because it violates two invariants:
1) all inputs to the FusionGroup must have the same size
2) prim::FusedConcat's output must not be used inside the FusionGroup
This PR fixes this problem by checking if the output to a FusionGroup came from a prim::FusedConcat node when deciding whether to fuse the consumer and producer.
If the producer is a value that came from a prim::FusedConcat node in a FusionGroup, then consumer & producer do not get fused.
cc apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10466
Differential Revision: D9296686
Pulled By: zou3519
fbshipit-source-id: ed826fa9c436b42c04ca7d4d790cece804c162bd
Summary:
A bootcamper was confused by the word "locally" and thought it meant on his macbook as opposed to his FB dev machine. Besides the confusion for the FB context, the word "locally" isn't really necessary at all
soumith ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10495
Reviewed By: soumith
Differential Revision: D9311480
Pulled By: goldsborough
fbshipit-source-id: 2779c7c60f903a1822a50d140ed32a346feec39e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10426
We were seeing linker errors for TanhGradientOperator in multifeed. Since we only use the float specialization, we might as well define it that way.
Reviewed By: yinghai
Differential Revision: D9280622
fbshipit-source-id: d2ffb698c73a84bb062de5e1f3bda741330e4228
Summary:
This operator implements b (1/2/4/8) bit stochastic quantization of a floating
matrix in a row-wise fashion. 8/b floating values are concatenated to a byte
and returned in uint8 tensor. PR: https://github.com/pytorch/pytorch/pull/8629
Reviewed By: harouwu
Differential Revision: D8493264
fbshipit-source-id: 01f64066568a1e5a2b87c6d2134bd31cdf119c02
Summary:
* some small leftovers from the last PR review
* enable more unit test sets for CI
* replace use of hcRNG w/ rocRAND (docker image was already updated w/ newer rocRAND)
* use rocBLAS instead of hipBLAS to allow convergence w/ Caffe2
* use strided_batched gemm interface also from the batched internal interface
* re-enable Dropout.cu as we now have philox w/ rocRAND
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10406
Reviewed By: Jorghi12
Differential Revision: D9277093
Pulled By: ezyang
fbshipit-source-id: 7ef2f6fe4ead77e501ed7aea5c3743afe2466ca2
Summary:
```
This removes PyObjectFinalizer. We were seeing SIGSEGV at exit in some
programs that use multiprocessing. The backtrace pointed to
StorageRef.__del__ being called from subtype_dealloc. My guess is that
the Python interpreter was shutdown before all C++ Storage objects were
deallocated. Deallocating the C++ Storage called the finalizer which
called back into Python after it was no longer safe to do so.
This avoids a callback from C++ into Python during Storage finalization.
Instead, dead Storage objects (expired weak references) are collected
periodically when shared_cache exceeds a limit. The limit is scaled with
2x the number of live references, which places an upper bound on the
amount of extra memory held by dead Storage objects. In practice, this
should be very small.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10407
Differential Revision: D9272400
Pulled By: colesbury
fbshipit-source-id: ecb14d9c6d54ffc91e134c34a4e770a4d09048a2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10278
Translation to Backend happens immediately before we go into the
Type universe; otherwise we use TensorTypeId.
I allocated TensorTypeId corresponding exactly to existing ATen
Backend. Only CPUTensorId and CUDATensorId are relevant in the
Caffe2 universe.
Reviewed By: gchanan
Differential Revision: D9184060
fbshipit-source-id: 9d3989c26f70b90f1bbf98b2a96c57e2b0a46597
Summary:
This PR provides 4 fixes / features:
1. torch::nn::Cloneable inherits virtually from torch::nn::Module. We want to pass around a module with new functions, and the best way to do this is to do a diamond inheritance pattern, i.e.
```c++
struct MySuperModuleImpl : virtual public torch::nn::Module {
virtual void myFunction() = 0;
}
struct MySuperModule : public torch::nn::Cloneable<MySuperModule>, MySuperModuleImple {};
struct MyModule : public MySuperModule<MyModule> {
void myFunction() override;
};
```
This way, we can simply pass around MySuperModuleImpl around instead of torch::nn::Module.
2. Optimizer options are public now, since there's no way to decay the LR or modify it during training otherwise
3. Serialization functions creates autograd history and calls copy_! Bad!
4. Optimizers did not create buffers after add_parameters was called.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9837
Reviewed By: goldsborough
Differential Revision: D9199746
Pulled By: ebetica
fbshipit-source-id: 76d6b22e589a42637b7cc0b5bcd3c6b6662fb299
Summary:
Explanation copied from code:
// Motivation about the gflags wrapper:
// (1) We would need to make sure that the gflags version and the non-gflags
// version of Caffe2 are going to expose the same flags abstraction. One should
// explicitly use caffe2::FLAGS_flag_name to access the flags.
// (2) For flag names, it is recommended to start with caffe2_ to distinguish it
// from regular gflags flags. For example, do
// CAFFE2_DEFINE_BOOL(caffe2_my_flag, true, "An example");
// to allow one to use caffe2::FLAGS_caffe2_my_flag.
// (3) Gflags has a design issue that does not properly expose the global flags,
// if one builds the library with -fvisibility=hidden. The current gflags (as of
// Aug 2018) only deals with the Windows case using dllexport, and not the Linux
// counterparts. As a result, we will explciitly use CAFFE2_EXPORT to export the
// flags defined in Caffe2. This is done via a global reference, so the flag
// itself is not duplicated - under the hood it is the same global gflags flag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10444
Differential Revision: D9296726
Pulled By: Yangqing
fbshipit-source-id: a867d67260255cc46bf0a928122ff71a575d3966
Summary:
On Windows, the FindRocksDB script doesn't detect rocksdb installation built by cmake.
And it doesn't include/link the RocksDB dependencies either, like:
* `Snappy`
* `Shlwapi.lib`
* `Rpcrt4.lib`
This PR try to detect in config mode first before using private find module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/7315
Differential Revision: D9287587
Pulled By: Yangqing
fbshipit-source-id: 314a36a14bfe04aa45013349c5537163fb4c5c00
Summary:
There's no need to hack.
Using `CUDA_LINK_LIBRARIES_KEYWORD` is the normal way.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10437
Differential Revision: D9287579
Pulled By: Yangqing
fbshipit-source-id: d3d575ea8c3235576ba971e4b7493ddb435f92f3
Summary:
Building caffe2 and pytorch separately will end up duplicated symbols as they now share some basic libs. And it's especially bad for registry. This PR fixes our CI and build them in one shot with shared symbols.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10427
Reviewed By: bddppq
Differential Revision: D9282372
Pulled By: yinghai
fbshipit-source-id: 0514931ea88277029a68fa5368ff4336472f132e
Summary:
Optimize the max_pooling operation for inference path by setting the "inference" flag to the underlying MKL-DNN, saving the computation and store of max indices which is only needed for training. To make the API compatible, training mode is still the default and inference mode is set in the optimizeForIdeep path.
Test shows the speed-up of a single max_pooling operation is up to 7X on BDW.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10156
Differential Revision: D9276755
Pulled By: yinghai
fbshipit-source-id: ad533d53aabb8ccb3b592da984d6269d9b794a8a
Summary:
This should just work now that sizes/strides are unified between TH and ATen.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10414
Differential Revision: D9274681
Pulled By: gchanan
fbshipit-source-id: 69eb766f4e3a5b6c57b15837cffdef513b6d7817
Summary:
```
Correctly share CUDA Parameters, requires_grad and hooks.
Previously, the following was true:
- If you put a Parameter for a CUDA tensor
in multiprocessing queue (or otherwise tried to transfer it),
this failed, saying that we cannot pickle CUDA storage.
This is issue #9996.
- If you put a leaf Tensor that requires_grad=True through the
multiprocessing queue, it would come out the other end as
requires_grad=False (It should have come out the other end
as requires_grad=True). Similarly, backwards hooks were
lost.
- If you put a non-leaf Tensor that requires_grad=True through
the multiprocessing queue, it would come out the other end
as requires_grad=False.
The root cause for the first issue was that implementation of
reductions for Parameter used the superclass implementation
(tensor) in __reduce_ex__, but this always picks up the
non-ForkingPickler reduction, which doesn't work with CUDA tensors.
So, we registered a new ForkingPickler specifically for Parameter,
and adjusted the code to correctly rewrap a Tensor in a Parameter
if it was originally a parameter.
While working on this, we realized that requires_grad and backwards
hooks would not be preserved in the ForkingPickler reduction
implementation. We fixed the reducer to save these parameters.
However, Adam Paszke pointed out that we shouldn't allow sending
requires_grad=True, non-leaf Tensors over a multiprocessing
queue, since we don't actually support autograd over process
boundar. We now throw an error in this case; this may cause
previously working code to fail, but this is easy enough to fix;
just detach() the tensor before sending it. The error message says
so.
Fixes#9996.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10220
Differential Revision: D9160746
Pulled By: ezyang
fbshipit-source-id: a39c0dbc012ba5afc7a9e646da5c7f325b3cf05c
Summary:
closes#9702 .
cc jph00
Commit structure:
1. Change the index calculation logic. I will explain using 1-D for simplicity.
Previously we have (in pseudo code):
```
// 1. get the float locations from grid
scalar_t x = from_grid()
// 2. find the integral surrounding indices
int x_left = floor(x)
int x_right = x_left + 1
// 3. calculate the linear interpolate weights
scalar_t w_left = x_right - x
scalar_t w_right = x - x_left
// 4. manipulate the integral surrounding indices if needed
// (e.g., clip for border padding_mode)
x_left = manipulate(x_left, padding_mode)
x_right = manipulate(x_right, padding_mode)
// 5. interpolate
output_val = interpolate(w_left, w_right, x_left, x_right)
```
This is actually incorrect (and also unintuitive) because it calculates the
weights before manipulate out-of-boundary indices. Fortunately, this
isn't manifested in both of the current supported modes, `'zeros'` and
`'border'` padding:
+ `'zeros'`: doesn't clip
+ `'border'`: clips, but for out-of-bound `x` both `x_left` and `x_right` are
clipped to the same value, so weights don't matter
But this is a problem with reflection padding, since after each time we reflect,
the values of `w_left` and `w_right` should be swapped.
So in this commit I change the algorithm to (numbers corresponding to the
ordering in the above pseudo-code)
```
1. get float location
4. clip the float location
2. find the integral surrounding indices
3. calculate the linear interpolate weights
```
In the backward, because of this change, I need to add new variables to track
`d manipulate_output / d manipulate_input`, which is basically a multiplier
on the gradient calculated for `grid`. From benchmarking this addition doesn't
cause obvious slow downs.
2. Implement reflection padding. The indices will keep being reflected until
they become within boundary.
Added variant of `clip_coordinates` and `reflect_coordinates` to be used in
backward. E.g.,
```cpp
// clip_coordinates_set_grad works similarly to clip_coordinates except that
// it also returns the `d output / d input` via pointer argument `grad_in`.
// This is useful in the backward pass of grid_sampler.
scalar_t clip_coordinates_set_grad(scalar_t in, int64_t clip_limit, scalar_t *grad_in)
```
For example, if `in` is clipped in `'border'` mode, `grad_in` is set to `0`.
If `in` is reflected **odd** times in `'reflection'` mode, `grad_in`
is set to `-1`.
3. Implement nearest interpolation.
4. Add test cases
5. Add better input checking
Discussed with goldsborough for moving `operator<<` of `at::Device`,
`at::DeviceType` and `at::Layout` into `at` namespace. (Otherwise
`AT_CHECK` can't find them.)
6. Support empty tensors. cc gchanan
+ Make empty tensors not acceptable by cudnn.
+ Add `AT_ASSERT(kernel block size > 0)` if using `GET_BLOCKS`
+ Cache `numel` in `TensorGeometry`
I was going to use `numel` to test if cudnn descriptor should accept a
tensor, but it isn't used eventually. I can revert this if needed.
7. Add more test cases, including on input checking and empty tensors
8. Remove an obsolete comment
9. Update docs. Manually tested by generating docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10051
Differential Revision: D9123950
Pulled By: SsnL
fbshipit-source-id: ac3b4a0a36b39b5d02e83666cc6730111ce216f6
Summary:
I am using this to test a CI job to upload pip packages, and so am using the Caffe2 namespace to avoid affecting the existing pytorch packages.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9544
Reviewed By: orionr
Differential Revision: D9267111
Pulled By: pjh5
fbshipit-source-id: a68162ed29d2eb9ce353d8435ccb5f16c3b0b894
Summary:
This was used as a convenient way for us to convert c1 models. Now that conversion is more or less done, we should probably require any users who need to convert c1 models to explicitly install c1. This PR removes the explicit c1 proto (which was copied from c1) in favor of explicit installation.
Note that caffe_translator would still work properly, only difference is that now users need to install c1 separately.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10380
Differential Revision: D9267981
Pulled By: Yangqing
fbshipit-source-id: a6ce5d9463e6567976da83f2d08b2c3d94d14390
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10360
It seems `lengths_host_.CopyFrom(lengthsInput, &context_);` is asynchronous w.r.t. the host while `lengths_host_.CopyFrom(lengthsInput);` is synchronous.
However, according to jerryzh168, `lengths_host_.CopyFrom(lengths, &context_); context_.FinishDeviceComputation();` is the safest way to guarantee synchronization.
Reviewed By: jerryzh168
Differential Revision: D9197923
fbshipit-source-id: 827eb63d9d15c1274851e8301a793aed39d4fa6b
Summary:
As in the title. I also did a small refactor that let us loose almost 400 loc. This is a first step in moving the RNN code to C++.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10305
Reviewed By: ezyang
Differential Revision: D9196227
Pulled By: apaszke
fbshipit-source-id: 54da905519aade29baa63ab1774a3ee1db5663ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10163
- Remove dependency on caffe2/core/common.h for ATen/core/typeid.h
Unfortunately, Windows seems to rely on typeid.h including this
header, so it is still included from the forwarding header
caffe2/core/typeid.h
- Deduplicate Demangle/DemangleType with their ATen equivalents
Reviewed By: smessmer
Differential Revision: D9132432
fbshipit-source-id: 21f2c89e58ca1e795f1b2caa316361b729a5231b
Summary:
Copy of #10191 because these changes didn't land with the diff.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10394
Differential Revision: D9260816
Pulled By: li-roy
fbshipit-source-id: 7dc16919cfab6221fda1d44e98c5b900cfb40558
Summary:
Before we had 0-dim tensors in TH, we were flexible in what we accepted wrt to the difference between size [] and size [1] tensors in backwards functions because they were identical in TH. So, we had backwards definitions that were technically incorrect, but happened to work. This often masks shape issues, adds greatly to code complexity and thus IMO isn't worth keeping.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10382
Differential Revision: D9244618
Pulled By: gchanan
fbshipit-source-id: 2c29c53a8ffe8710843451202cad6b4323af10e8
Summary:
This makes clamp and relu faster (fixes#10276).
The extra copying was introduced when clamp moved to ATen and
the _th_clamp_ wrapper was used to forward to TH/THC,
we remove that and add _th_clamp(_out) instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10352
Reviewed By: ezyang
Differential Revision: D9233590
Pulled By: SsnL
fbshipit-source-id: 4f86a045498e5e577fb22656c71f171add7ed0ac
Summary:
If an `at::test` function is added, gcc can't figure out the `std::thread(test, -1)` resolution.
It is not a problem for current code. I bumped into this when playing with native functions. But I think it is a good to just prevent it from happening in future by removing `using namespace at;`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10381
Differential Revision: D9241614
Pulled By: SsnL
fbshipit-source-id: 972ac3cecff3a50602b3fba463ae1ebd3f53d036
Summary:
When only part of the outputs of unbind are used in a backward,
the gradients for the others are undefined. This sets those
to zero in to_tensor_list.
Fixes: #9977
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9995
Differential Revision: D9239610
Pulled By: soumith
fbshipit-source-id: eb8d1b3f2b4e615449f9d856e10b946910df9147
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10334
Keep kEps in one place to make sure they are consistent
Reviewed By: xianjiec
Differential Revision: D9202280
fbshipit-source-id: 35d173ce1d1a361b5b8cdbf1eac423e906e7c801
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10218
SubtreeMatchCriteria now supports:
- nonTerminal flag : if this is set, it means we only match the root of the subtree and do not care about the children. Example use case: to match an "input" node but does not care how the input is produced.
Additional tests for these new logic are added to subgraph_matcher_test.cc.
Subgraph matching APIs for NNGraph is also added.
(Further enhancement to make the SubgraphMatching API constructs a Subgraph object/more diagnostic information will go later).
Reviewed By: bwasti
Differential Revision: D9156092
fbshipit-source-id: 3f28ac15d9edd474b3e0cd51fd7e6f973299d061
Summary:
Current Dockerfile builds pytorch using default python within miniconda, which happens to be Python 3.6
This patch allows users to specify which python should be installed in the default miniconda environment used by the pytorch dockerfile. I have tested the build for python 2.7, 3.5, 3.6 and 3.7. Python 2.7 required typing and cython
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10317
Differential Revision: D9204401
Pulled By: ezyang
fbshipit-source-id: 11355cab3bf448bbe8369a2ed1de0d409c9a2d6e
Summary:
This PR adds tracing infrastructure for custom operators. It also simplifies the tracer overall, and changes the codegen to do more metaprogramming there instead of via C++ (which was necessary for the custom op tracing).
To give an example of the tracer/metaprogramming change, what used to look like this in `VariableType.cpp`:
```
jit::tracer::PreTraceInfo trace_info;
if (jit::tracer::isTracing()) {
trace_info = jit::tracer::preRecordTrace(jit::aten::index_select, "self", self, "dim", dim, "index", index);
}
```
is now simply the inlined version of `preRecordTrace`, minus C++ metaprogramming:
```
torch::jit::Node* node = nullptr;
if (jit::tracer::isTracing()) {
auto& graph = jit::tracer::getTracingState()->graph;
node = graph->create(jit::aten::index_select_out, /*outputs=*/0);
jit::tracer::recordSourceLocation(node);
jit::tracer::addInputs(node, "result", result);
jit::tracer::addInputs(node, "self", self);
jit::tracer::addInputs(node, "dim", dim);
jit::tracer::addInputs(node, "index", index);
graph->appendNode(node);
}
```
zdevito apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10212
Differential Revision: D9199615
Pulled By: goldsborough
fbshipit-source-id: cd4b603c1dc01340ead407228e109c99bdba2cfc
Summary:
While waiting for dropout to be fully ported to ATen, here's performance fix for the most common dropout case. Dropout is still in python function, I just added efficient path to it. I could not make inplace work, because generator always generates `return self` for inplace function, and I need to return both original tensor and mask, so inplace goes on the existing pass. Even with non-inplace version, since mask is now a ByteTensor, memory used is just a little larger than for inplace dropout, due to savings on mask.
Once dropout is moved to aten, these kernels still can be used for efficient implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9666
Reviewed By: SsnL
Differential Revision: D8948077
Pulled By: ezyang
fbshipit-source-id: 52990ef769471d957e464af635e5f9b4e519567a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10228
Sometimes, for all items in the minibatch in test mode, input length will be
equal to max time steps. This avoids having to pass in an external tensor.
Differential Revision: D9174378
fbshipit-source-id: 22f7d5c311c855d9c3ac59f2a5e773279bd69974
Summary:
This PR extends the existing type and shape metadata tracing and verification done in autograd with device information. This expansion of tracing is required for #8354, is likely useful in other scenarios, and is a healthy sanity check, just like type and shape tracing.
The precise changes are:
- TypeAndShape -> InputMetadata, now includes device()
- Creating InputMetadata is simplified to just require a tensor, and callers were updated to use this simpler invocation wherever possible
- The gradient accumulator of a variable is now reset when set_data() is called if either the type or device changes, and this reset now locks to avoid contention with acquiring the gradient accumulator
- Mismatched devices during backward() will throw a runtime error, just like mismatched type and shape
- (Bonus!) Two uninitialized pointers in THCReduce are now initialized (to nullptr) to prevent build warnings
fyi colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9796
Reviewed By: goldsborough
Differential Revision: D9119325
Pulled By: ezyang
fbshipit-source-id: 76d1861b8d4f74db0575ff1f3bd965e18f9463de
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10274
Good C++ libraries don't take up un-namespaced identifiers
like DISABLE_COPY_AND_ASSIGN. Re-prefix this.
Follow up fix: codemod Caffe2 to use the new macro, delete
the forwarding definition
Reviewed By: mingzhe09088
Differential Revision: D9181939
fbshipit-source-id: 857d099de1c2c0c4d0c1768c1ab772d59e28977c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10268
Running torch.distributed.init_process_group fails with more than ~64 processes, with various errors like connection refused or connection reset by peer. After some digging, it looks like the root cause is that all workers have to connect to master via TCP (both in Zeus init and in DataChannelTCP - look for `connect()`), and the listening socket only has a backlog of 64.
I increased the backlog to 1024, that seems like enough for reasonable purposes (the hard limit is 65535 in /proc/sys/net/core/somaxconn). There's probably a more correct way to do this that involves retries when connection is refused.
Reviewed By: soumith
Differential Revision: D9182216
fbshipit-source-id: 2f71c4995841db26c670cec344f1e3c7a80a7936
Summary:
Previously, `tensor[i:]` was transformed to `tensor[i:-1]`. This incorrectly leaves off the last element. Noticed this when implementing slicing for list types.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10286
Differential Revision: D9193292
Pulled By: michaelsuo
fbshipit-source-id: df372b815f9a3b8029830dd9e8769f9985a890e7
Summary:
I changed the name of this builtin to match Python's native style, but forgot to change the compiler error to match.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10265
Differential Revision: D9192963
Pulled By: michaelsuo
fbshipit-source-id: 225ca4cd50fbbe3b31c369deeb3123a84342aab1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10264
Since we now have DISABLE_COPY_AND_ASSIGN macro in the file,
CoreAPI is no longer an accurate name.
Reviewed By: dzhulgakov
Differential Revision: D9181687
fbshipit-source-id: a9cc5556be9c43e6aaa22671f755010707caef67
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10263
Auxiliary changes that were needed:
- Add DISABLE_COPY_AND_ASSIGN to CoreAPI.h (maybe we should rename this file
now)
Reviewed By: dzhulgakov
Differential Revision: D9181321
fbshipit-source-id: 975687068285b5a94a57934817c960aeea2bbafa
Summary:
When we directly use -std=c++11, it propagates to the downstream applications.
Problems:
1. Gcc flags propagating to nvcc.
2. nvcc flags propagating to nvcc. (Which throws an error like redeclaration of std flag)
This PR will fix these propagation issues!
Similar problem:
https://github.com/FloopCZ/tensorflow_cc/pull/92https://github.com/CGAL/cgal/issues/2775
Requires: Cmake 3.12
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10098
Differential Revision: D9187110
Pulled By: ezyang
fbshipit-source-id: 0e00e6aa3119c77a5b3ea56992ef3bbfecd71d80
Summary:
This PR for the ROCm target does the following:
* enable some unit tests on ROCm
* fix a missing static_cast that breaks BatchNorm call on ROCm
* fix BatchNorm to work on ROCm w/ ROCm warp sizes etc
* improve the pyhipify script by introducing kernel scope to some transpilations and other improvements
* fix a linking issue on ROCm
* for more unit test sets: mark currently broken tests broken (to be fixed)
* enable THINLTO (phase one) to parallelize linking
* address the first failing of the elementwise kernel by removing non-working ROCm specialization
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10266
Differential Revision: D9184178
Pulled By: ezyang
fbshipit-source-id: 03bcd1fe4ca4dd3241f09634dbd42b6a4c350297
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10261
1. Reserve
Currently, Reserve will allocate new memory and old data in the tensor is also preserved,
and Resize is relying on this behavior in some call-site, e.g. https://github.com/pytorch/pytorch/blob/master/caffe2/operators/reservoir_sampling.cc#L103, where we should be using Extend.
We want to bring semantics of Reserve to be more aligned with std::vector, i.e. we want it to be
an optimization about memory allocation and remove the semantics about preserving the data. We'll remove the guarantee that data will be preserved after Reserve, and Extend will be the only API that preserves old data when we do in-place extension of memory. This also helps with the later refactoring on split Storage from Tensor.
Also, we'll only pass in the outer dimension to Reserve which means the later dimensions should be set before we call Reserve.
2. Extend/Shrink
Previously, Extend actually means ExtendBy and Shrink means ShrinkTo, I would like to add a ExtendTo for convenience, and change Shrink to ShrinkTo.
Old functions calling Extend is still there, although it actually means Extend by, but I think it still makes sense to have it.
3. Usage Patterns
The expected usage patterns right now is:
```
t->Resize({0, 32, 32, 32});
t->template mutable_data<T>(); // set meta_
t->Reserve(100);
auto* t_data = t->template mutable_data<T>();
// feed data to tensor using t_data
for (int i = 0; i < 100; ++i) {
t->Extend(1, 50, &context_);
// you can continue to use t_data if you have reserved enough space
// otherwise, you should call t->template mutable_data<T> again to
// get the new data pointer since Extend will allocate new memory even
// though the original data is preserved.
}
```
Reviewed By: ezyang
Differential Revision: D9128147
fbshipit-source-id: e765f6566d73deafe2abeef0b2cc0ebcbfebd096
Summary:
the new entrypoint is `./tools/build_pytorch_libs.sh caffe2`
this will also speed up CI builds a bit, since we will no longer be compiling all of libtorch twice
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9836
Differential Revision: D9182634
Pulled By: anderspapitto
fbshipit-source-id: 0b9a20ab04f5df2d5c4e7777e4dc468ab25b9ce2
Summary:
Turns out some people are using this via the C-API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10259
Differential Revision: D9180135
Pulled By: gchanan
fbshipit-source-id: 68f59beabf7f8093e67581d7e7ebfe8dff9e6b69
Summary:
Using Visual Studio Code and Visual Studio, these IDEs store configurations to `FOLDER/.vscode` and `FOLDER/.vs`.
But "setup.py clean" deletes these folders because those are described in `.gitignore` file.
To prevent this, add "BEGIN NOT-CLEAN-FILES" marker to `.gitignore` file and "setup.py clean" ignores lines after this marker.
Discussed in #10206
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10233
Differential Revision: D9175515
Pulled By: ezyang
fbshipit-source-id: 24074a7e6e505a3d51382dc5ade5c65c97deda37
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10197
Support generic feature in DPER2
For now since we only have one generic type 1, we are directly adding the parsed feature record to embedding feature.
For new feature types with specific structure, there should also be corresponding coding changes expected.
Reviewed By: itomatik
Differential Revision: D8788177
fbshipit-source-id: 9aaa6f35ece382acb4072ec5e57061bb0727f184
Summary:
Fixes#10032
When capturing an output, GraphExecutorAutogradFunction creates
SavedVariable with is_output=False and owns it:
https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/graph_executor.cpp#L87
Constructing SavedVariable with is_output=False makes it own a copy of
the shared_ptr<GraphExecutorAutogradFunction>, which causes a reference
cycle:
6456b944fd/torch/csrc/autograd/saved_variable.cpp (L27)
The solution in this PR is to construct the SavedVariable with
is_output=True if the captured value is an output.
Test Plan
Turn on cuda memory checking for JitTestCase. If the test's name
includes "cuda" or "gpu" in it, the cuda memory checking test happens.
cc zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10222
Reviewed By: ezyang
Differential Revision: D9162995
Pulled By: zou3519
fbshipit-source-id: aeace85a09160c7a7e79cf35f6ac61eac87cbf66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10175
Previously, we had at::Device::Type and caffe2::DeviceType (from protobuf),
intended to help us distinguish between CPU, CUDA, etc. devices.
This replaces at::Device::Type entirely with at::DeviceType, which in turn
is a direct, 'enum class' version of the protobuf generated caffe2::DeviceType
'enum'. We can't eliminate the 'enum' because this would a pretty drastic
API change (enum is interconvertible with integers, enum class is not) but
we can make the two line up exactly and share code for, e.g., printing.
Reviewed By: Yangqing
Differential Revision: D9137156
fbshipit-source-id: 566385cd6efb1ed722b25e6f7849a910b50342ab
Summary:
- New concept of a message stack; you can add messages
using AppendMessage
- New concept of a caller; it's just a way to pass along
some arbitrary extra information in the exception
Coming soon is changing Caffe2 to use at::Error instead of
EnforceNotMet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10183
Differential Revision: D9139996
Pulled By: ezyang
fbshipit-source-id: 6979c289ec59bc3566a23d6619bafba2c1920de9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10224
It doesn't work with Caffe2; use AT_CORE_API from ATen/core/CoreAPI.h
instead.
Reviewed By: smessmer
Differential Revision: D9162467
fbshipit-source-id: 3c7d83c1ccb722ebac469296bdd7c3982ff461e5
Summary:
The basic game plan is to stop accessing the type_ field directly,
and instead using the stored backend_, scalar_type_ and
is_variable_ to look up the appropriate Type from Context.
Storage of backend_ and scalar_type_ are new.
At some future point in time, I'd like to look at this code
carefully to see if I can get everything in this codepath inlining.
I didn't do it in this patch because there are circular include
problems making things difficult.
Some other details:
- Added Device::backend() which does what it says on the tin
- SparseTensorImpl is temporarily hard-coded to root in at::Context
for the appropriate context. If/when we put this in shared code,
we'll have to break this dep too, but for now it should be OK.
- There's a stupid problem with globalContext() deadlocking if
you didn't actually initialize it before loading libtorch.so
(which is bringing along the variable hooks). I fixed this by
reordering the static initializers. Fixes#9784
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10210
Differential Revision: D9150697
Pulled By: ezyang
fbshipit-source-id: 89e2006c88688bcfab0dcee82dc369127c198c35
Summary:
- fixes#9141, #9301
- use logsigmoid at multilabel_soft_margin_loss to make it more stable (NOT fixing legacy MultiLabelSoftMarginCriterion)
- return (N) instead of (N, C) to match the same behavior as MultiMarginLoss
- Note that with this PR, the following behavior is expected:
```
loss = F.multilabel_soft_margin_loss(outputs, labels, reduction='none')
loss_mean = F.multilabel_soft_margin_loss(outputs, labels, reduction='elementwise_mean')
loss_sum = F.multilabel_soft_margin_loss(outputs, labels, reduction='sum')
loss.sum() == loss_sum # True
loss.mean() == loss_mean # True
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9965
Differential Revision: D9038402
Pulled By: weiyangfb
fbshipit-source-id: 0fa94c7b3cd370ea62bd6333f1a0e9bd0b8ccbb9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10217
It's only used in debug printing and is not that reliable anyway. If we want to implement it later - we should do it proper accounting for shared storages.
Reviewed By: jerryzh168
Differential Revision: D9155685
fbshipit-source-id: 48320d41a0c4155645f3ba622ef88730a4567895
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9360
This implements a first set of c10 operators, namely the ones needed for the multithread predictor benchmark.
All implementations are CPU-only and experimental. They're not meant to be used in production.
They can be used, however, to test calling simple c10 MLPs from Caffe2 or PyTorch when working on these integration paths.
Reviewed By: dzhulgakov
Differential Revision: D8811698
fbshipit-source-id: 826789c38b2bfdb125a5c0d03c5aebf627785482
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9369
This adds the capability for caffe2 to call c10 operators and adds a dummy c10 sigmoid op as a proof of concept.
I used this test script to make sure it works:
from caffe2.python import workspace, model_helper
import numpy as np
data1 = np.random.rand(16, 100).astype(np.float32)
workspace.FeedBlob("data1", data1)
m = model_helper.ModelHelper(name="my net")
sigmoid1 = m.net.C10Sigmoid_DontUseThisOpYet("data1", "sigmoid1")
sigmoid2 = m.net.Sigmoid("data1", "sigmoid2")
workspace.RunNetOnce(m.param_init_net)
workspace.CreateNet(m.net)
data1 = np.random.rand(16, 100).astype(np.float32)
workspace.FeedBlob("data1", data1)
workspace.RunNet(m.name, 1)
print(workspace.FetchBlob("data1"))
print(workspace.FetchBlob("sigmoid1"))
print(workspace.FetchBlob("sigmoid2"))
(and check that both sigmoid outputs are the same)
Reviewed By: ezyang
Differential Revision: D8814669
fbshipit-source-id: eeb0e7a854727f1617a3c592a662a7e5ae226f40
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10214
Seems we're passing weak pointers over C API boundaries. Need this API there too.
Reviewed By: ezyang
Differential Revision: D9154505
fbshipit-source-id: c9889689b87dad5d918f93ba231e01704b8d2479
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10130
Update some include paths to make them internally consistent
Reviewed By: ezyang
Differential Revision: D9119906
fbshipit-source-id: b44e5cab8e8e795ee18afe9ffc6caf1f2b413467
Summary:
This PR adds a way to infer the JIT/script schema of a function from its signature, and then create an operator from the schema and implementation. The implementation function is wrapped into another function, which pops values from the stack into an argument tuple, then invokes the function and pushes the return value back onto the stack, sometimes unpacking the return value if it is a tuple.
Currently the method is called `createOperator`. We may want to think of a nicer way of registering ops in tandem with `RegisterOperators`. It might be very cumbersome to add a template constructor to `Operator`, so maybe we can come up with a chaining method on `RegisterOperators` like `RegisterOperators(schema, func).op(schema.func).op(schema, func)` -- it has to work at startup time (for a static variable) though. We can solve this in another PR.
zdevito apaszke smessmer dzhulgakov
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10048
Differential Revision: D9125975
Pulled By: goldsborough
fbshipit-source-id: de9e59888757573284a43787ae5d94384bfe8f9a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10192
- release_resources() method must be non-const because it modifies the object
- for intrusive_ptr<const MyClass>, this needs to be const_cast :(
Reviewed By: ezyang
Differential Revision: D9143808
fbshipit-source-id: 9203ff7a7ff3bec165931279371c6e75d4f0ca8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10133
This is useful for C APIs where we want to give owning pointers to/from other languages.
Reviewed By: ezyang
Differential Revision: D9121493
fbshipit-source-id: f903f5830f587b2ba69c0636ddcf1a066bbac2e0
Summary:
The PR allows int→float and float→int casts. Current we only allow `tensor→int` and `tensor→float` casts.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10168
Differential Revision: D9141163
Pulled By: wanchaol
fbshipit-source-id: 5e5591a98b4985a675641dfc9a385b2a0bf8e208
Summary:
Previously, `foo = [bar, baz]` would construct a TupleType of fixed arity. This would cause code like:
```
foo = [2]
if True:
foo = [2, 2]
```
to fail to compile, since `(int)` is not the same as `(int, int)`.
This PR changes things so that list literals construct ListTypes, which can be resized.
Potentially breaking changes introduced:
- Empty list literals are now disallowed, `_constructEmptyFooList()` builtins are required to replace them.
- Iterable variable unpacking where the rhs is a list is now disallowed. (Tuples still work)
- Lists must have a single type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10193
Differential Revision: D9147166
Pulled By: michaelsuo
fbshipit-source-id: bbd1b97b0b6b7cb0e6f9d6aefa1ee9c731e63039
Summary:
* Changes `insertConstant(g, val)` to `g.insertConstant(val)`.
* Moves SourceRange to its own file to enable it.
* Cleans up dead attribute code in schema matching and graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10177
Differential Revision: D9137789
Pulled By: zdevito
fbshipit-source-id: 8a73cfb01a576f02e7e4dce019be9c0a0002989d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9897
Add an IntrusivePtr class to do intrusive refcounting with a shared_ptr-like interface.
Reviewed By: ezyang
Differential Revision: D9018619
fbshipit-source-id: 5de8706aab8eea2e30bead0f59bd6a7ca4d20011
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10173
With D9024330, `Extend` fundtion is no more a template, which makes
the `template` keyword here invalid. For some reason current version of LLVM
doesn't catch this, but the latest one does.
Reviewed By: jerryzh168
Differential Revision: D9133462
fbshipit-source-id: 54ac9aad01f81b9b4e7b6e2864b8961478d2d860
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9905
This diff improves lars operator in Caffe2 by applying clipping to the computed learning rate
Reviewed By: pjh5
Differential Revision: D9020606
fbshipit-source-id: b579f1d628113c09366feac9406002f1ef4bd54f
Summary:
This PR adds strings to the ast and implements them for print statements. Strings are lifted as attributes to the print node. They must be arguments to print itself, not as an argument for an object that is passed to print. If they are encountered elsewhere a NYI exception will be thrown.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9324
Reviewed By: jramseyer
Differential Revision: D8807128
Pulled By: eellison
fbshipit-source-id: 984401ff458ed18d473c6d1bd86750e56c77d078
Summary:
This is part of the process of removing THLongStorage to represent sizes/strides.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10146
Differential Revision: D9126611
Pulled By: gchanan
fbshipit-source-id: b0d995a4c51dfd54bf76dcfee9a69f37f9d01652
Summary:
In this changeset:
* improvements to `hipify-python.py`
* marking unit tests broken for ROCm
* reducing the number of jobs for the built to avoid out of memory issues
* switch to Thrust/cub-hip master for the CI
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9653
Differential Revision: D9117791
Pulled By: ezyang
fbshipit-source-id: a6c3c7b81f2bda9825974bf9bf89a97767244352
Summary:
Enabled support for generating random numbers in fusion compiler. Currently a philox RNG implemented by Tensorflow is used, as the NVRTC couldn't resolve the curand.h header correctly. The two implementation should have exact same behavior according to our tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9795
Differential Revision: D8999029
Pulled By: SsnL
fbshipit-source-id: f0d2616a699a942e2f370bdb02ac77b9c463d7b8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10081
Add new utility that make it easier to write graph transformation. Callers now only need to take care of the actual transformation logic. The subgraph matching is simplified because callers only need to specify a simple construct for subtree matching criteria.
The utlity is SubgraphMatcher::replaceSubtree
Some notes:
- replaceSubtree takes a subtree matching criteria, and a lambda that takes a subtree root. It does't not handle any transformations itself. Callers should be responsible for the transformation part, including deleting all nodes in the matched subtree(s). We could enhance this to also handle the deletion part if it turns out to be useful.
- Only sub tree matching is supported for now but we can add general DAG sub-graph support later if needed.
Reviewed By: bwasti
Differential Revision: D9073297
fbshipit-source-id: 465a0ad11caafde01196fbb2eda2d4d8e550c3b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9860
For 3D group convolution, in the case of CUDNN 7 and NCHWD order, filter dim is (M, C/group_, k_h, h_w, k_d).
According to CUDA doc (https://docs.nvidia.com/deeplearning/sdk/cudnn-developer-guide/index.html#grouped-convolutions), the existing implementation is incorrect, and will crash the 3d video model training with group convolution.
In the implementation, `filter.dims(1)` is already `C/group_`. So don't need to divide it by `group_` again.
Reviewed By: BIT-silence
Differential Revision: D9008807
fbshipit-source-id: 2f0d6eb47f4e16d7417a7e3baeba709e3254154f
Summary:
Implement IR transformation for control flow
- `prim::Constant`: clone to new graph directly
- `prim::NumToTensor`: create a `BatchTensor` from output tensor with `batch_size = 1`
- `prim::TensorToNum`: clone to new graph
- `prim::ListConstruct`: clone to new graph
- `prim::If`: execute both `if_block` and `else_block` and combine results from them using `cond`
- `prim::Loop`:
- for loop
- while loop: change while `cond` to `cond_any`, use `cond` to update outputs
test case: hand-written LSTM, greedy search, beam search
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9392
Differential Revision: D8822369
Pulled By: ChunliF
fbshipit-source-id: 8f03c95757d32e8c4580eeab3974fd1bc429a1e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10152
- Moved from namespace c10::guts to at
- I fixed the use sites, since there were only three of them
- Macro renamed from C10_ to AT_
Reviewed By: smessmer
Differential Revision: D9123652
fbshipit-source-id: bef3c0ace046ebadb82ad00ab73371f026749085
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10139
We want CaffeTypeId to be interconvertible with at::ScalarType, and
this means we should have the numbers line up exactly. Fortunately
this is not too hard to do.
Reviewed By: smessmer
Differential Revision: D9123058
fbshipit-source-id: 7e9bd59ca25a552afe9d2d0a16cedc4f6311f911
Summary:
This exposes expand_outplace to python. Fixes#8076. Fixes#10041.
I didn't name it torch.broadcast because numpy.broadcast does something
slightly different (it returns an object with the correct shape
information).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10075
Differential Revision: D9125816
Pulled By: zou3519
fbshipit-source-id: ebe17c8bb54a73ec84b8f76ce14aff3e9c56f4d1
Summary:
Previously, the parser was emitting list literals for tuples, but the IR was representing list literals internally with TupleTypes.
For implementing most list operations, I think it will be helpful distinguish between lists (dynamic size, homogeneous types) and tuples (fixed arity, heterogeneous types)
This diff modifies the parser logic to emit tuple literals. This frees us to represent lists as ListType in the IR, while still properly mapping tuple literals to TupleTypes.
A following diff will actually switch over list literals to emit ListTypes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10128
Differential Revision: D9121305
Pulled By: michaelsuo
fbshipit-source-id: e0cad07ae8bac680f7f8113d10e5129d5a1a511d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10138
Note that `TensorCPU` and `TensorGPU` are all refined to be `Tensor` now. Basically they are the same thing. So check like `blob.IsType<TensorCPU>()` is no longer safe as `TensorGPU` can pass the check too.
We need to systematically weed out the such usage in our codebase... @[100008320710723:jerryzh]
Reviewed By: houseroad
Differential Revision: D9115273
fbshipit-source-id: 13b293c73691002eac34e095cdcd96c27183e875
Summary:
This rewrites checked_convert to use stringstreams, eliminating the use of to_string which is not available on Android stdc++.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10137
Reviewed By: smessmer
Differential Revision: D9122340
fbshipit-source-id: b7c1bff70e36217305f2b3333c51543ef8ff3d9c
Summary:
This will be needed soon because I want to move Half.h into
ATen/core, and then I cannot have a TH dependency.
I also took the liberty of making the code more strict-aliasing
safe (this is not actually useful, since we will never built Torch
with strict aliasing) by replacing pointer casts between
float and unsigned with a memcpy instead.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10134
Differential Revision: D9121920
Pulled By: ezyang
fbshipit-source-id: 3b1f86a7c5880e8ac1a589a51f0635bb72e1fd40
Summary:
…e_/is_variable_
The basic game plan is to stop accessing the type_ field directly,
and instead using the stored backend_, scalar_type_ and
is_variable_ to look up the appropriate Type from Context.
Storage of backend_ and scalar_type_ are new.
At some future point in time, I'd like to look at this code
carefully to see if I can get everything in this codepath inlining.
I didn't do it in this patch because there are circular include
problems making things difficult.
Some other details:
- Added Device::backend() which does what it says on the tin
- SparseTensorImpl is temporarily hard-coded to root in at::Context
for the appropriate context. If/when we put this in shared code,
we'll have to break this dep too, but for now it should be OK.
- There's a stupid problem with globalContext() deadlocking if
you didn't actually initialize it before loading libtorch.so
(which is bringing along the variable hooks). I didn't fix
it in this PR; it's tracked in #9784
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9787
Reviewed By: cpuhrsch
Differential Revision: D8980971
Pulled By: ezyang
fbshipit-source-id: 2b4d867abfdc3999a836a220c638c109053145a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9740
- Remove implicit ArrayRef -> vector conversion
- Fix 4 call sites that accidentally did an implicit expensive vector conversion but wouldn't have needed to
- Remove explicit vector conversion from 4 call sites that also didn't need to do that
Reviewed By: ezyang
Differential Revision: D8961693
fbshipit-source-id: 980da9f988083c0072497f9dbcbbf6f516fa311c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9610
Mostly making some stuff in ArrayRef constexpr to give it better perf.
Reviewed By: ezyang
Differential Revision: D8926785
fbshipit-source-id: af6d4b05fbc69d20855a80f3edc2b501577a742b
Summary:
in particular, make not building tests actually work
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10091
Differential Revision: D9121366
Pulled By: anderspapitto
fbshipit-source-id: d7d38cf759aa46bff90d3b4f695c20f29039ae75
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10107
This header is needed for ATen/core stuff
This diff also fixes an issue in C++17.h when run in C++17 enabled compilers.
Reviewed By: ezyang
Differential Revision: D9095209
fbshipit-source-id: d45947956019a7095875f48746b88c414e8865bc
Summary:
zdevito explained that the attributed versions of `Operator`s are no longer necessary. This PR does two things:
1. Removes all code associated with attributed operators,
2. Adds a second kind of state to `Operator` where it is constructed with an `Operation` directly instead of an `OperationCreator`. This will be useful to test custom operators which don't require a node (you can just retrieve it directly).
Now rebased on top of https://github.com/pytorch/pytorch/pull/9801
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10080
Differential Revision: D9113668
Pulled By: goldsborough
fbshipit-source-id: 1276a191c7cf89da1c38488769f2105ce2664750
Summary:
Extracted from https://github.com/pytorch/pytorch/pull/8338
Updating Eigen submodule to fix an issue we saw with BUILD_ATEN and BUILD_CAFFE2 removal.
cc mingzhe09088 ezyang smessmer
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10095
Reviewed By: mingzhe09088
Differential Revision: D9109877
Pulled By: orionr
fbshipit-source-id: 90e36c298d8a22398558d70dc5f68a95a7687d6b
Summary:
It's not a particularly pretty process right now, but it may as well
be documented. I'm not aware of an ideal location for this, so I'm
just dropping it in the docs/ folder for now as recommended by
soumith
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10087
Differential Revision: D9119681
Pulled By: anderspapitto
fbshipit-source-id: cd4afb642f3778c888d66a501bc697d0b0c88388
Summary:
This also makes Backtrace more portable, by disabling its functionality for
mobile builds as well.
It also handles Caffe2 static Windows builds by introducing a new variable,
AT_CORE_STATIC_WINDOWS, which must be set if you're building
ATen on Windows as part of a static library.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10092
Reviewed By: gchanan, smessmer
Differential Revision: D9094393
Pulled By: ezyang
fbshipit-source-id: 93281f9302bd378605a26589ae308faf1dac7df4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10035
This is an initial diff which refactors some of the components in the Seq2SeqModelCaffe2EnsembleDecoder class.
Reviewed By: jmp84
Differential Revision: D9026372
fbshipit-source-id: 449635208f24494209ae2fb78a19fca872970ea8
Summary:
This PR depends on the tests added in #9670. It moves the first, tiny function from the c10d DDP to C++: `dist_broadcast_coalesced`. Let me know if ` torch/csrc/distributed/c10d/ddp.h` will be a good place to put these rewritten functions.
pietern The controller you requested could not be found. apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9729
Differential Revision: D8985308
Pulled By: goldsborough
fbshipit-source-id: dc459fe9040273714044152063585e746974752f
Summary:
I opened an issue explaining some of my frustrations with the current state of schedulers.
While most points that I raised in [that issue](https://github.com/pytorch/pytorch/issues/8741#issuecomment-404449697) need to be discussed more thoroughly before being implemented, there are some that are not so difficult to fix.
This PR changes the way the LambdaLR scheduler gets serialized:
> The lr_lambda functions are only saved if the are callable objects (which can be stateful).
> There is no point in saving functions/lambdas as you need their definition before unpickling and they are stateless.
This has the big advantage that the scheduler is serializable, even if you use lambda functions or locally defined functions (aka a function in a function).
Does this functionality need any unit tests?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9927
Differential Revision: D9055505
Pulled By: soumith
fbshipit-source-id: 6c1cec588beedd098ec7d2bce6a9add27f29e48f
Summary:
There is a regression in softmin in 0.4.1 that was not present in 0.4.0. The behavior of softmin(x) should match softmax(-x) however instead it is implemented (in v0.4.1) as -softmax(x). These are not the same. The fix is trivial because the bug is due to operator precedence.
This is a major regression that broke my training. I'm not sure how a unit test did not catch this.
```
x = torch.tensor([1, 2, 3.5, 4])
print(F.softmin(x, dim=0)) # this has the wrong output in 0.4.1 but correct in 0.4.0
print(F.softmax(-x, dim=0)) # this is what softmax should be
print(F.softmax(x, dim=0))
print(-F.softmax(x, dim=0)) # this is how softmax is implemented incorrectly
```
In 0.4.1 this produces
tensor([-0.0278, -0.0755, -0.3385, -0.5581])
tensor([0.6668, 0.2453, 0.0547, 0.0332])
tensor([0.0278, 0.0755, 0.3385, 0.5581])
tensor([-0.0278, -0.0755, -0.3385, -0.5581])
In 0.4.0 this produces the correct values
tensor([ 0.6668, 0.2453, 0.0547, 0.0332])
tensor([ 0.6668, 0.2453, 0.0547, 0.0332])
tensor([ 0.0278, 0.0755, 0.3385, 0.5581])
tensor([-0.0278, -0.0755, -0.3385, -0.5581])
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10066
Differential Revision: D9106995
Pulled By: soumith
fbshipit-source-id: 7332503c6077e8461ad6cd72422c749cf6ca595b
Summary:
This is a cleanup and refactoring.
In its original form (changeset 6fdf915c057a) this diff caused a 5% regression
on ads CPU. The root cause was an omission of link_whole = True, causing
symbols to be stripped in mode/opt and forcing the converter to fallback
causing patterns to be unmatched in the graph transform logic. This version of
the diff tests for link_whole by including a C++ test of the transform
Reviewed By: yinghai
Differential Revision: D9040511
fbshipit-source-id: 3e19b89989aa68b021762d12af2d0b4111280b22
Summary:
`.bat` file's EOL is LF, so a build is failed on some Windows machines.
To fix this, add `.gitattributes` and set batch file's EOL to CRLF.
Discussion is in #9677.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9813
Differential Revision: D9026486
Pulled By: soumith
fbshipit-source-id: 341eaa677c35f8476a7eda1bac9827385072eb29
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10044
The test was subtly broken! This transform wasn't writing to the correct blob and the test did not catch that because it was looking at the old version.
thanks @[100022211048576:kerenzhou] for catching this
Reviewed By: Jokeren
Differential Revision: D9075520
fbshipit-source-id: c31ff0afcd78dd2dc7ffc240e2e89eeda87f1fb4
Summary:
This should prevent slow startup times, and will not report as many
errors during static initialization time which are hard to debug
ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9801
Reviewed By: goldsborough
Differential Revision: D8986603
Pulled By: zdevito
fbshipit-source-id: 440d43ab5e8cffe0b15118cb5fda36391ed06dbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10059
Without virtual dtor, it could induce incorrect sized deallocation, messing up the memory. And unfortunately, sized deallocation cannot be detected by ASAN, yet.
Reviewed By: jerryzh168
Differential Revision: D9080526
fbshipit-source-id: c136cf653134e75b074326be2bc03627da42446f
Summary:
The affected files are all files that are planned to be moved
to ATen/core; the includes are for headers which are NOT slated
for movement.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10085
Differential Revision: D9093746
Pulled By: ezyang
fbshipit-source-id: 2beeffdae26d03d631d2d51b40bf6303759a2f50
Summary:
This lays out initial support for taking and returning a richer set
of types than only tensors. Floats and ints are already valid, lists are
straightforward to add, tuples need some discussion.
Based on top of #9948. Review only the last commit.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9969
Reviewed By: zdevito
Differential Revision: D9076973
Pulled By: apaszke
fbshipit-source-id: 5a1fe912ea6b79ab2bfd0dcce265eb05855b5ff0
Summary:
_pointwise loss has some python special casing, we converted reduction to aten enums too early.
fixes#10009
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10018
Differential Revision: D9075489
Pulled By: li-roy
fbshipit-source-id: 4bf2f5e2911e757602c699ee1ec58223c61d0162
Summary:
This PR fixes#9418 .
Openmpi 1.10 segfaults in MPI_Bcast with CUDA buffer. And it's a retired openmpi version.
I've tested on 2.1.1 and 3.0.0 and they work well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10015
Reviewed By: soumith
Differential Revision: D9088103
Pulled By: ailzhang
fbshipit-source-id: fc0a45e5cd016093ef0dbb9f371cbf67170d7045
Summary:
The CPU and CUDA variants are a direct transposition of Graves et al.'s description of the algorithm with the
modification that is is in log space.
The there also is a binding for the (much faster) CuDNN implementation.
This could eventually fix#3420
I still need to add tests (TestNN seems much more elaborate than the other testing) and fix the bugs than invariably turn up during the testing. Also, I want to add some more code comments.
I could use feedback on all sorts of things, including:
- Type handling (cuda vs. cpu for the int tensors, dtype for the int tensors)
- Input convention. I use log probs because that is what the gradients are for.
- Launch parameters for the kernels
- Errors and obmissions and anything else I'm not even aware of.
Thank you for looking!
In terms of performance it looks like it is superficially comparable to WarpCTC (and thus, but I have not systematically investigated this).
I have read CuDNN is much faster than implementations because it does *not* use log-space, but also the gathering step is much much faster (but I avoided trying tricky things, it seems to contribute to warpctc's fragility). I might think some more which existing torch function (scatter or index..) I could learn from for that step.
Average timings for the kernels from nvprof for some size:
```
CuDNN:
60.464us compute_alphas_and_betas
16.755us compute_grads_deterministic
Cuda:
121.06us ctc_loss_backward_collect_gpu_kernel (= grads)
109.88us ctc_loss_gpu_kernel (= alphas)
98.517us ctc_loss_backward_betas_gpu_kernel (= betas)
WarpCTC:
299.74us compute_betas_and_grad_kernel
66.977us compute_alpha_kernel
```
Of course, I still have the (silly) outer blocks loop rather than computing consecutive `s` in each thread which I might change, and there are a few other things where one could look for better implementations.
Finally, it might not be unreasonable to start with these implementations, as the performance of the loss has to be seen in the context of the entire training computation, so this would likely dilute the relative speedup considerably.
My performance measuring testing script:
```
import timeit
import sys
import torch
num_labels = 10
target_length = 30
input_length = 50
eps = 1e-5
BLANK = 0#num_labels
batch_size = 16
torch.manual_seed(5)
activations = torch.randn(input_length, batch_size, num_labels + 1)
log_probs = torch.log_softmax(activations, 2)
probs = torch.exp(log_probs)
targets = torch.randint(1, num_labels+1, (batch_size * target_length,), dtype=torch.long)
targets_2d = targets.view(batch_size, target_length)
target_lengths = torch.tensor(batch_size*[target_length])
input_lengths = torch.tensor(batch_size*[input_length])
activations = log_probs.detach()
def time_cuda_ctc_loss(grout, *args):
torch.cuda.synchronize()
culo, culog_alpha = torch._ctc_loss(*args)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
def time_cudnn_ctc_loss(groupt, *args):
torch.cuda.synchronize()
culo, cugra= torch._cudnn_ctc_loss(*args)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
def time_warp_ctc_loss(grout, *args):
torch.cuda.synchronize()
culo = warpctc.ctc_loss(*args, blank_label=BLANK, size_average=False, length_average=False, reduce=False)
g, = torch.autograd.grad(culo, args[0], grout)
torch.cuda.synchronize()
if sys.argv[1] == 'cuda':
lpcu = log_probs.float().cuda().detach().requires_grad_()
args = [lpcu, targets_2d.cuda(), input_lengths.cuda(), target_lengths.cuda(), BLANK]
grout = lpcu.new_ones((batch_size,))
torch.cuda.synchronize()
print(timeit.repeat("time_cuda_ctc_loss(grout, *args)", number=1000, globals=globals()))
elif sys.argv[1] == 'cudnn':
lpcu = log_probs.float().cuda().detach().requires_grad_()
args = [lpcu, targets.int(), input_lengths.int(), target_lengths.int(), BLANK, True]
grout = lpcu.new_ones((batch_size,))
torch.cuda.synchronize()
print(timeit.repeat("time_cudnn_ctc_loss(grout, *args)", number=1000, globals=globals()))
elif sys.argv[1] == 'warpctc':
import warpctc
activations = activations.cuda().detach().requires_grad_()
args = [activations, input_lengths.int(), targets.int(), target_lengths.int()]
grout = activations.new_ones((batch_size,), device='cpu')
torch.cuda.synchronize()
print(timeit.repeat("time_warp_ctc_loss(grout, *args)", number=1000, globals=globals()))
```
I'll also link to a notebook that I used for writing up the algorithm in simple form and then test the against implementations against it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9628
Differential Revision: D8952453
Pulled By: ezyang
fbshipit-source-id: 18e073f40c2d01a7c96c1cdd41f6c70a06e35860
Summary:
I previous did some transformations, e.g. _nDimension,_dim -> nDimensionLegacyAll, nDimension -> nDimensionLegacyNoScalars.
But this didn't touch dim(), which needs to be updated to support scalars. Instead of doing an (ugly) move, I audited the call sites and updated the cases that could be size 1.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10023
Differential Revision: D9068996
Pulled By: gchanan
fbshipit-source-id: c63820767dd1496e908a5a96c34968482193f2c5
Summary:
We missed the upsample symbolic when bumping up the opset to 7.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10001
Reviewed By: bddppq
Differential Revision: D9067212
Pulled By: houseroad
fbshipit-source-id: 3e285d2800a32cb04fa82f8e7f261bdd010a8883
Summary:
ATenCore.h is a dummy header to just test that this is working at all.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10019
Reviewed By: smessmer
Differential Revision: D9067262
Pulled By: ezyang
fbshipit-source-id: 58bab9c0aa83b56335e36b719b9b6505400d8dee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9890
Minor cleanups for Graph.h to make it more consistent with our style guide
Also fix opt/device.cc and binary_match_test.cc to not access subgraph.nodes_ which is now private
Reviewed By: bwasti
Differential Revision: D9017108
fbshipit-source-id: 9f5cba4a2cd2a452a955005f4704f6c120bbc1d5
Summary:
Adding a constant propagation pass to the JIT. I have added examples to the expect files.
There are a couple of special cases which have not been implemented here. IF nodes with constant conditions can be inlined with the correct block. WHILE nodes can be removed if the condition is false. I have added a test for each case in test_jit.py file as expected failures.
To be consistent with DCE, python ops & CPP ops are treated as not having side-effects.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8808
Reviewed By: wanchaol
Differential Revision: D8906770
Pulled By: eellison
fbshipit-source-id: 10ad796d89f80b843566c9ddad6a0abd1f3dc74c
Summary:
This causes numpy to yield to the torch functions,
e.g. instead of numpy array/scalar __mul__ converting the tensor to
an array, it will now arrange for the Tensor __rmul__ to be called.
Fixes case 2 of #9468
I also makes case 3 and 4 equivalent but does not fix them.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9651
Differential Revision: D8948079
Pulled By: ezyang
fbshipit-source-id: bd42c04e96783da0bd340f37f4ac3559e9bbf8db
Summary:
More clang tidy cleanups in `torch/csrc`. This time:
1. `hicpp-use-equals-default` recommends `= default` instead of `{}` for constructors/destructors. This is better practice because it expresses the intent better (https://stackoverflow.com/questions/6502828/what-does-default-mean-after-a-class-function-declaration)
2. `readability-inconsistent-declaration-parameter-name` enforces that parameter names in the declaration match parameter names in the definition. This is just generally useful and can prevent confusion and bugs.
Also updated my script a little bit.
apaszke ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9737
Differential Revision: D9069069
Pulled By: goldsborough
fbshipit-source-id: f7b3f3a4eb4c9fadc30425a153566d3b613a41ae
Summary:
These could use some autograd tests, which are coming in a later PR, but using them in autograd is probably pretty rare.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9947
Reviewed By: ezyang
Differential Revision: D9032778
Pulled By: gchanan
fbshipit-source-id: fa5a6509d3bac31ea4fae25143e82de62daabfbd
Summary:
Not sure if anybody is interested but I managed to infer a `GRU` fine in `wasm` using ATen's compiled with emscripten. It was quite trivial to fix the configuration.
It also passes most of the tests, specially all scalar tensor tests.
The command line to configure was, but could be simplified:
```
emconfigure cmake -DAT_LINK_STYLE=STATIC -DCAFFE2_CMAKE_BUILDING_WITH_MAIN_REPO=OFF -DCMAKE_C_FLAGS="-Wno-implicit-function-declaration -DEMSCRIPTEN -s DISABLE_EXCEPTION_CATCHING=0" -DCMAKE_CXX_FLAGS="-Wno-implicit-function-declaration -DEMSCRIPTEN -s DISABLE_EXCEPTION_CATCHING=0" -DCMAKE_INSTALL_PREFIX=/home/sugar/aten-wasm ../
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9803
Differential Revision: D9004610
Pulled By: ezyang
fbshipit-source-id: db26c59f27162ed80f6aee2973c4cb9252d3d1e4
Summary:
Fixes#9818.
It seems original Python doesn't add `[PYTHONPATH]\Library\bin` into `PATH`. We try to add it before dll loading process.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9920
Differential Revision: D9040825
Pulled By: soumith
fbshipit-source-id: c07fff71b2aea254a396042ab677696f6829aac7
Summary:
Minor addition to the docstring of `torch.nn.optim.Adam`, adding the default argument description for the `amsgrad` argument to the docstring for concistency.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9971
Differential Revision: D9040820
Pulled By: soumith
fbshipit-source-id: 168744a6bb0d1422331beffd7e694b9d6f61900c
Summary:
This was introduced in #9826 following the corresponding cuda file context_gpu.cu file, tests have passed in the PR, at that point master was 94439d7df. However during the long landing process, a new master commit aebf3b4 has come in that removed the `CAFFE_KNOWN_TYPE(Tensor<HIPContext>)` in context_hip.cc file, which then has broken the HIP BlobStatGetter, and we did NOT run tests again during merge and so when #9826 later landed to master the rocm tests start breaking.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9973
Differential Revision: D9040671
Pulled By: bddppq
fbshipit-source-id: f3b16cabaf681fc0535ca733db0b48430868f922
Summary:
Supersedes #8925
This PR fixes#8502, it fixes the gradients problem for clamp when passing None to the function, and add support for the NoneLiteral and NoneType in script to enable clamp tests. Now we could have corner cases like:
```python
torch.jit.script
def func():
x = torch.randn(3, 3, requires_grad=True)
y = torch.clamp(x, None, 0) # max = 0
y = torch.clamp(x, min=None, max=0)
```
In both JIT and Aten, we use Scalar(NAN) as a sentinel value when passing None type to function clamp, this is the current way we used to support None type in JIT and to solve the gradient problem when user explicitly passing None into clamp.
In JIT side, we create a tensor(NAN) and undefinedTensor if we encounter None when matching the function schema, and later in the interpreter, it will translate to Scalar(NAN) if needed.
Ideally we don't need clamp_min and clamp_max in ATenNative/Autograd and could only support clamp after this change, but since bunch of other operators (e.g. Activation.cpp, Loss.cpp) is using clamp_min in several places, we will still have the functions available, but all python invocations will only call clamp instead of clamp_min/max (with calling underlying th_max/th_min in clamp).
zdevito jamesr66a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9596
Reviewed By: zdevito
Differential Revision: D8940839
Pulled By: wanchaol
fbshipit-source-id: c543a867b82e0ab8c99384773b173fdde2605d28
Summary:
This is a follow-up to https://github.com/pytorch/pytorch/pull/9794 that contains only the serialization library and exposes a cleaner API. This should later be incorporated into the module export code
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9900
Reviewed By: zdevito
Differential Revision: D9021057
Pulled By: jamesr66a
fbshipit-source-id: 01af74a7fdd1b90b2f5484644c3121d8ba9eb3b3
Summary:
If we have this "spatial" attribute and its value equals to 1, we could just remove this attribute and convert this op to caffe2 SpatialBN.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9492
Differential Revision: D8988165
Pulled By: houseroad
fbshipit-source-id: a9218dc9cd5fab43deb371f290f81285f5283231
Summary:
We only support special case. The original dim is not supported by ONNX.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9660
Reviewed By: bddppq
Differential Revision: D8965507
Pulled By: houseroad
fbshipit-source-id: 021dffdf0489c2d3a50bfd1e0c4cfd00d4a3d776
Summary:
The goal of this PR is to update the hip files to reflect relevant changes in cuda source files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9826
Differential Revision: D9032840
Pulled By: bddppq
fbshipit-source-id: 504e55c46308eebfee3c9a7beea1f294fe03470f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9747
Currently the ctc_greedy_decoder op initializes the `merge_repeated` argument only if it has been provided by the user. Change to initialize in all cases.
Reviewed By: houseroad
Differential Revision: D8963635
fbshipit-source-id: 18955c7c26a77d9d7f5137e4dec085252ffabfeb
Summary:
```
This adds TensorIterator, a helper class for computing element-wise
operations that's intended to replace the CPU and CUDA apply utils
functions.
CPU kernels are implemented as functions that operate on strided 1-d
tensors compared to CPUApplyUtils which operated individual elements. This
allows the kernels to handle vectorization, while TensorIterator handles
parallelization and non-coalesced dimensions.
GPU kernels continue to operate on elements, but the number of
specializations is reduced. The contiguous case remains the same. The
non-contiguous case uses a single (reduced) shape for all operands and
the fast integer division from THCIntegerDivider. To avoid extra
specializations for indexing with 64-bits, large operations are split
into smaller operations that can be indexed with 32-bits.
Major semantic changes:
- No more s_add, s_mul, s_div, or s_sub. Broadcasting is handled by
TensorIterator. The autograd engine performs the reduction assuming
standard broadcasting if the gradient shape does not match the
expected shape. Functions that do not use standard broadcasting rules
should either continue to trace the expand calls or handle the
reduction in their derivative formula.
- Use ONNX v7, which supports broadcasting ops.
Performance impact:
- Small increased fixed overhead (~0.5 us)
- Larger overhead for wrapped numbers (~2.5 us)
- No significant change for ops on contiguous tensors
- Much faster worst-case performance for non-contiguous GPU tensors
- Faster CPU bias addition (~2x)
- Faster GPU bias addition (~30% faster)
Future work:
- Decrease overhead, especially for wrapping numbers in Tensors
- Handle general inter-type operations
- Extend to unary ops and reductions
- Use buffering for compute-bound operations on non-contiguous tensors
(pull in from CPUApplyUtils)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8919
Differential Revision: D8677600
Pulled By: colesbury
fbshipit-source-id: 61bc9cc2a36931dfd00eb7153501003fe0584afd
Summary: Minor fix for a bug introduced by D9004285
Reviewed By: anderspapitto
Differential Revision: D9028762
fbshipit-source-id: 9b9c5eef30e61d7ae19784e0418fa29bad2b5564
Summary:
I hope this helps me for the windows build failure in #9628 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9904
Differential Revision: D9026715
Pulled By: soumith
fbshipit-source-id: bb97d41d060823f5a37bfc9a1659815b8b9f4eab
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9939
Pull Request resolved: https://github.com/facebookresearch/weakly-supervised-action-detection/pull/13
Pull Request resolved: https://github.com/pytorch/translate/pull/166
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9125
Closes https://github.com/pytorch/pytorch/pull/9125
Use inheritance for polymorphism, and remove template parameter
This is to change the templating in call sites, the core implementations will change later
Before Caffe2 Tensor class was compile-time fixed to bind to a particular device/context. With this change, we're making it a runtime property (stored inside the tensor), but preserve the same semantics. For example, one has to specify device type in order to create a Tensor - there are no uninitialized tensors. More specifically the changes are:
1. We added an extra argument *DeviceType* to most of the constructors of the tensor, e.g. (Tensor(DeviceType type)),
2. Semantics of constructor Tensor(const Tensor<SrcContext>& src, ContextForCopy* context); is changed, in this constructor, the second context is passed in to enable us to call the templated Copy function, it could be in a different context as source and target previously, now we'll enforce that the context should have same device type as src, if it is provided.
3. To preserve 'get-or-construct' semantics of Blob, we added specialized getter Blob::GetMutableTensor that verifies both that Blob contains a Tensor and that it's of a correct type
4. Specifically, Tensor type is not default-constructible any more (as we don't have unknown device tensors) and thus some of the code handling STL containers needs to change
Note: Some changes are postponed just to keep this diff a bit smaller. Please see `TODO`s.
Reviewed By: ezyang, houseroad
Differential Revision: D9024330
fbshipit-source-id: e0b8295d2dc6ebe2963383ded5af799ad17164ba
Summary:
This was showing up in the n-dimensional empty tests as flaky because it's reading uninitialized cuda memory.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9907
Differential Revision: D9021413
Pulled By: gchanan
fbshipit-source-id: 31542b7597919df9afd6e528bb108a4a3e8eaf60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9895
The primary goal here was to remove THTensor::_dim, which isn't part of the API moving forward.
Instead, we provide 3 options for getting the dimensionality (this is temporary although non-trivial to remove!):
```
nDimension corresponds to the "true" ATen dimension. TODO: implement.
nDimensionLegacyNoScalars correpsonds to the ATen dimension, except scalars are viewed as 1-dimensional tensors.
nDimensionLegacyAll corresponds to the ATen dimension, except scalars are viewed as 1-dimensional tensors
and tensors with a dimension of size zero are collapsed to 0-dimensional tensors.
```
So in this patch, nDimension -> nDimensionLegacyNoScalars and _dim/_nDimension goes to nDimensionLegacyAll.
These are just codemods.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9835
Reviewed By: ezyang
Differential Revision: D8999338
Pulled By: gchanan
fbshipit-source-id: a4d676ac728f6f36ca09604a41e888d545ae9311
Summary:
Hello! I just find a small spell mistake while reading this source code. Just PR it, Thx!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9868
Reviewed By: gchanan, ezyang
Differential Revision: D9016030
Pulled By: soumith
fbshipit-source-id: fc3877177be080adbdbda99a169e401691292ebb
Summary:
Based on top of #9763 (first 3 commits belong to that PR). The first commits from this PR are "Stop using attributes ..."
I tried to separate the changes into fairly meaningful commits. I can't split them up into smaller PRs, because everything starts working and all tests pass only after the whole sequence, but hopefully this will make reviewing somewhat easier.
Known issues/regressions/future tasks:
- `aten::lerp` and `aten::clamp` are no longer fusable
- `CreateAutodiffSubgraphs` needs a rewrite
- It is much more strict now, and will miss a lot of opportunities, especially when viewing ops are involved. Our previous approach was "ignore the assumption on shape availability in gradient formulas to determine differentiability, and hope that shape prop will be robust enough to actually deliver them before we differentiate", which obviously doesn't scale well to more complex cases. We should either work on reducing the size dependency of grad formulas (feasible e.g. for `view`/`reshape`, unfeasible for `squeeze`/`unsqueeze`), or make `CreateAutodiffSubgraphs` integrate some kind of "I could integrate this node into an AD subgraph, but will I be able to infer the shape of its input" reasoning (kind of like a limited shape prop, that doesn't infer anything, and only tells if it *could* infer something).
- It sometimes creates constant-only (or constants + one node) graphs, which is useless
- Broken `aten::add` in auto-batching, because it gained a non-tensor input. I changed the test for pointwise operations to use `aten::mul` instead, but I needed to disable the LSTM cell test. I'm not sure how scalar constants should be implemented in this case, because I don't fully understand our format. cc: ChunliF
- Graph import does some hacks to recover type of constants. This code should be removed once we'll gain the ability to export the IR along with value types.
- There's still a fair amount of dead code that can be removed. I didn't want to make this diff any bigger, and removing it is an easy task.
- Graph fuser could be improved to use signature matching (possibly using `OperatorSet`) instead of basing on node kinds.
- Manual constant propagation for the `ListConstruct` node in `torch/onnx/utils.py` should be replaced with a proper constant propagation pass (or we should ensure that the one we have handles at least this case before we remove this code).
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9807
Reviewed By: ezyang
Differential Revision: D9004285
Pulled By: apaszke
fbshipit-source-id: fe88026a765f6b687354add034c86402362508b7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9901
Added support for UINT8 datatype for additional data (prefetching and
output) by ImageInputOp
Reviewed By: ashwinb
Differential Revision: D9018964
fbshipit-source-id: f938a8a072c15c0ee521b2f16788c024b08cd37f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9855
Support production models with predictor benchmark
Two new flags are added:
`--update_prod`: pull production data (netdef, input types, input dims) from Hive and store locally
`--use_prod`: run benchmark with local production data with the same workload as in production.
By default, 300 models will be loaded.
production vs benchmark
avg net run time:
(collected by prod: https://fburl.com/scuba/6lb91zfx and bench: https://fburl.com/ngjj1dc8)
**prod: `408us` vs bench: `543us`**
(With prod data distribution, this should be even closer)
framework overhead (as of 2018-07-22):
prod:
```
9.111% BlackBoxPredictor::Run
4.602% SimpleNet::Run
2.377% Operator::Run
1.786% BlackBoxPredictor::AllocateMemory
1.372% Observable::StartAllObservers
1.358% Observable::StartObserver
1.206% Blob::GetMutable
```
bench:
```
8.577% BlackBoxPredictor::operator()
3.276% SimpleNet::Run
1.954% Operator::Run
1.697% BlackBoxPredictor::AllocateMemory
1.477% Tensor::ShareData
1.230% Blob::GetMutable
1.034% Observable::StartObserver
```
Reviewed By: yinghai
Differential Revision: D8942996
fbshipit-source-id: 27355d7bb5a9fd8d0a40195261d13a97fa24ce17
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9581
Mostly to simplify code. Should also improve performance but order switch ops
don't take much time anyway.
Reviewed By: viswanathgs
Differential Revision: D8909766
fbshipit-source-id: 17a302d5bf4aba2755d88223fc01a41fd72c5919
Summary:
Follow up task of #9584.
Commit 1:
- change expect/cast to return shared pointers instead of raw pointer
- isSubtypeOf accept TypePtr instead. Use `x->isSubtypeOf(NumberType::get())` rather than `x->isSubtypeOf(*NumberType::get())`
Commit 2:
- to address enable_shared_from_this pitfalls, we make the constructor private and expose the factory method to make sure user can only create it using our factory method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9786
Reviewed By: zdevito
Differential Revision: D8980441
Pulled By: wanchaol
fbshipit-source-id: e5c923fc57a701014310e77cf29985b43bb25364
Summary:
This PR fixes#9743 .
Adding backward support when loading a checkpoint from 0.3.* with 1dim tensor, they are now 0 dim tensor in 0.4+.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9781
Differential Revision: D8988196
Pulled By: ailzhang
fbshipit-source-id: a7a1bc771d597394208430575d5a4d23b9653fef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9891
Add an argument to benchmark binary to specify the seconds to sleep before the run and after the warmup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9880
Reviewed By: llyfacebook
Differential Revision: D9014254
Pulled By: sf-wind
fbshipit-source-id: d5566186c8ed768f1e170e9266c5f2d6077391e0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9847
CTCBeamSearchDecoder and CTCGreedyDecoder do not currently support IDEEP
execution. Add fallback operators to allow IDEEP execution of models that use
these operators.
Reviewed By: yinghai
Differential Revision: D9006234
fbshipit-source-id: fc539ba67b07d1f960d28564d8adde0be8690649
Summary:
And let Gemm conversion to inspect the input `C` to try converting to FC.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9870
Reviewed By: houseroad
Differential Revision: D9013198
Pulled By: bddppq
fbshipit-source-id: b4c509cfccca238262e1c406b004e66cef256321
Summary:
This is blocking the IR operator unification, because I need to be able to pass scalars to backward functions.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9763
Reviewed By: zou3519
Differential Revision: D8978457
Pulled By: apaszke
fbshipit-source-id: 570b4c3409322459cb0f2592069730a7d586ab20
Summary:
I don't think this file is used anywhere, I guess we'll find out!
(Weirdly this failed lint on one of my PRs even though it shouldn't).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9843
Differential Revision: D9003949
Pulled By: gchanan
fbshipit-source-id: 26d580d1e7cdd30e82e5f4176244e51fd7cd616d
Summary:
Pull Request resolved: https://github.com/facebookresearch/weakly-supervised-action-detection/pull/13
Pull Request resolved: https://github.com/pytorch/translate/pull/166
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9125
Closes https://github.com/pytorch/pytorch/pull/9125
Use inheritance for polymorphism, and remove template parameter
This is to change the templating in call sites, the core implementations will change later
Before Caffe2 Tensor class was compile-time fixed to bind to a particular device/context. With this change, we're making it a runtime property (stored inside the tensor), but preserve the same semantics. For example, one has to specify device type in order to create a Tensor - there are no uninitialized tensors. More specifically the changes are:
1. We added an extra argument *DeviceType* to most of the constructors of the tensor, e.g. (Tensor(DeviceType type)),
2. Semantics of constructor Tensor(const Tensor<SrcContext>& src, ContextForCopy* context); is changed, in this constructor, the second context is passed in to enable us to call the templated Copy function, it could be in a different context as source and target previously, now we'll enforce that the context should have same device type as src, if it is provided.
3. To preserve 'get-or-construct' semantics of Blob, we added specialized getter Blob::GetMutableTensor that verifies both that Blob contains a Tensor and that it's of a correct type
4. Specifically, Tensor type is not default-constructible any more (as we don't have unknown device tensors) and thus some of the code handling STL containers needs to change
Note: Some changes are postponed just to keep this diff a bit smaller. Please see `TODO`s.
Reviewed By: xw285cornell
Differential Revision: D8121878
fbshipit-source-id: 4a5e9a677ba4ac82095df959851a054c81eccf81
Summary:
The PR contains:
Fixes for running MIOpen conv operator in a multi worker scenario, along with a performance fix
Fixing a typo in MIOpen pool op and adding some extra checks for MIOpen spatial BN op
bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9842
Differential Revision: D9012512
Pulled By: bddppq
fbshipit-source-id: 270e1323c20fbfbc4b725f9a4ff34cd073ddaaa8
Summary:
I split it into two parts, _local_scalar and _local_scalar_dense (unchecked)
so I could reuse the sparse logic in both paths.
_local_scalar became a method on Tensor to work around a circular
include problem.
This is resurrected copy of #9652
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9762
Differential Revision: D8972348
Pulled By: ezyang
fbshipit-source-id: 2232dbfc8e1286b8a4a1c67d285c13a7771aad4c
Summary:
We think this will band-aid some of the new Caffe2 test failures.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9830
Differential Revision: D9008052
Pulled By: ezyang
fbshipit-source-id: 84f1c0faea429d758d760965d6cbfe9e4c72eb19
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9831
Follow up to D8980903 - replace dataIterator with nodeIterator where the data isn't used.
Reviewed By: pjh5
Differential Revision: D8998351
fbshipit-source-id: c333847ecd8b6d8075352322845839b94a63aecc
Summary:
https://github.com/pytorch/pytorch/pull/9755 broke this, but it was only tested if size zero dims were turned on (it can still happen even if that isn't turned on, because we support size [0] tensors).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9825
Differential Revision: D8997303
Pulled By: gchanan
fbshipit-source-id: 911dce112f73fad0f3980a7f4f9423df0f2d923d
Summary:
This was used to build Caffe2 Docker version 170.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9828
Differential Revision: D8997808
Pulled By: ezyang
fbshipit-source-id: f48938b2b71bc86578c9d9b46c281ed05478724e
Summary:
…o dim.
Manifest:
1) The scalar boolean is now in THTensor, although it isn't hooked up at the TH level yet.
2) setScalar is gone, everything now goes through the maybeScalar equivalent (which is renamed)
3) all "scalars" in this context now refer to "zero_dim" in order to differentiate this concept from the "Scalar" class.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9783
Differential Revision: D8978911
Pulled By: gchanan
fbshipit-source-id: f09254be4bebad0e4c510fefe4158b4f7e92efe1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9790
- Add way to check if a NodeRef is in a graph
- Make a nodeIterator (similar to dataIterator) but only iterate through nodes.
Reviewed By: bwasti
Differential Revision: D8980903
fbshipit-source-id: b20504a46715858752e25242303125a15a709b88
Summary:
Temporarily need this to prevent sccache from breaking when I move sccache install to the DockerFile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9810
Differential Revision: D8991684
Pulled By: Jorghi12
fbshipit-source-id: 14cd0278f53a72372f9bbe27b228980f8d3c1d4a
Summary:
The tutorials url with http is not valid, replacing it with https.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9812
Differential Revision: D8991344
Pulled By: ezyang
fbshipit-source-id: c12faa57905b50eadc320f9938c39c4139bd093b
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/6890. (backward pass for non-symmetric eigen-decomposition is not implemented in other packages, e.g. autograd, mxnet, tensorflow, presumably because the eigenvalues can be imaginary for the general case, and AFAIK we cannot support complex numbers).
This patch adds a backward function for the symmetric eigen-decomposition function `torch.symeig`. The formula used is taken from [here](http://eprints.maths.ox.ac.uk/1079/1/NA-08-01.pdf). Unit tests are added to verify correctness.
There is still one outstanding issue, which is how to handle the case where the `symeig` is called with `eigenvectors=False`. In this case, the eigenvectors are returned as a zero tensor, but the backward computation for the eigenvalues depends on the eigenvectors. There was a previous attempt to implement this in https://github.com/pytorch/pytorch/pull/2026, where apaszke mentioned that the `eigenvectors` argument should be overridden so that they are saved for the backwards pass. The forward code is autogenerated, though, and it isn't clear to me how that would be done. I'd appreciate any guidance. For now, there is a unit test that will fail until that issue is resolved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8586
Reviewed By: ezyang
Differential Revision: D8872760
Pulled By: SsnL
fbshipit-source-id: 76614495d0f9c118fec163a428f32e5480b4d115
Summary:
The primary use-site of typeString was checked_cast_tensor.
I did a little more than I needed in this patch, to set
the stage for actually deleting the tensor type.
Specifically, I modified checked_cast_tensor to explicitly
take Backend and ScalarType, the idea being that once we
remove the tensor subclasses, we will delete the T template
parameter.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9764
Differential Revision: D8969196
Pulled By: ezyang
fbshipit-source-id: 9de92b974b2c28f12ddad13429917515810f24c6
Summary:
This implements the two-parameter Weibull distribution, with scale $\lambda$ and shape $k$ parameters as described on [Wikipedia](https://en.wikipedia.org/wiki/Weibull_distribution).
**Details**
- We implement as a transformed exponential distribution, as described [here](https://en.wikipedia.org/wiki/Weibull_distribution#Related_distributions).
- The `weibull_min` variance function in scipy does not yet support a vector of distributions, so our unit test uses a scalar distribution instead of a vector.
Example of the bug:
```
>>> sp.stats.expon(np.array([0.5, 1, 2])).var() # fine
array([1., 1., 1.])
>>> sp.stats.weibull_min(c=np.array([0.5, 1, 2])).var() # buggy
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.7/site-packages/scipy/stats/_distn_infrastructure.py", line 490, in var
return self.dist.var(*self.args, **self.kwds)
File "/usr/local/lib/python3.7/site-packages/scipy/stats/_distn_infrastructure.py", line 1242, in var
res = self.stats(*args, **kwds)
File "/usr/local/lib/python3.7/site-packages/scipy/stats/_distn_infrastructure.py", line 1038, in stats
if np.isinf(mu):
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9454
Differential Revision: D8863574
Pulled By: SsnL
fbshipit-source-id: 1ad3e175b469eee2b6af98e7b379ea170d3d9787
Summary:
I got some tensor->variable conversion exceptions from `torch/csrc/autograd/variable.h`, which used the `TORCH_ASSERTM` macros instead of `AT_CHECK`, so they didn't have backtraces. This was such a substantial loss for debugability that I decided to update the whole codebase to use the backtrace-enabled ATen macros instead of `TORCH_ASSERT` and `JIT_ASSERT`, the latter having been an alias of the former.
ezyang apaszke zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9575
Differential Revision: D8924566
Pulled By: goldsborough
fbshipit-source-id: 7a4013b13eec9dbf024cef94cf49fca72f61d441
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9770
Add zero ops to operators that do not have a valid schema
Reviewed By: hlu1
Differential Revision: D8957472
fbshipit-source-id: d8d0a351183e88ace2e050a87c1e1c363af67e33
Summary:
Before I can rewrite portions of the c10d DDP in C++ I need proper tests in place to make sure I am not breaking anything as I port code. There were no tests for the c10d DDP in place so I wrote some.
I refactored the c10d tests to derive some tests cases from a general `MultiGPUTestCase` and followed lots of patterns from `test_distributed.py` w.r.t. how tests are skipped (such that the main process doesn't initialize CUDA, which I found is a super important detail!!!).
I am largely unfamiliar with this code so feel free to scrutinize. The DDP test code itself is also largely taken from `test_distributed.py` but more inlined which I find easier to read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9670
Differential Revision: D8977724
Pulled By: goldsborough
fbshipit-source-id: 186eab38a72384d7992a2ec5c89f304ad42d5944
Summary:
Fixes: #9754
Maybe this could also make its way into 0.4.1, it is a severe debugging headache if you hit this...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9755
Reviewed By: ezyang
Differential Revision: D8967178
Pulled By: zou3519
fbshipit-source-id: 151ed24e3a15a0c67014e411ac808fb893929a42
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9643
Current map interface assumes float data type, which is not always correct.
Reviewed By: kennyhorror
Differential Revision: D8455784
fbshipit-source-id: b94a31267760f7f97c15aa4b03008affc347fd10
Summary:
When building iOS apps with a caffe2 dependency, we were seeing the `caffe2/caffe2/mobile/contrib/ios/mpscnn/mpscnn.mm:33:17: error: method 'copyWithZone:' in protocol 'NSCopying' not implemented [-Werror,-Wprotocol]`. This fixes it by implementing a shallow copy with that method.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9748
Reviewed By: jerryzh168
Differential Revision: D8954332
Pulled By: williamtwilson
fbshipit-source-id: 0cd44408257c0bd3f4ffb80312ea9d13d13e5ff3
Summary:
This can hardly be called an improvement (we now print
CPUFloatType instead of CPUFloatTensor) but it was the
simplest way I could think of devirtualizing this function in
the short term. Probably need some sort of native function
that gives string information about a tensor.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Approved in #9710
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9758
Differential Revision: D8966935
Pulled By: ezyang
fbshipit-source-id: a4641affe0a6153f90cdd9f4f2a1100e46d1a2db
Summary:
Not in the same format. Skip at the moment.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9751
Reviewed By: yinghai
Differential Revision: D8965636
Pulled By: houseroad
fbshipit-source-id: 81d39c2f5625c14c0e1ee11408b5f7267b53798f
Summary:
ebetica made me aware that `nn::Module::clone()` always clones to the current device (usually CPU) instead of preserving the device of each parameter. This PR changes the signature of `clone` from
`shared_ptr<Module> clone()`
to
`shared_ptr<Module> clone(optional<Device> device = nullopt)`
with semantics of:
1. If a `device` is given, all parameters/buffers are moved to that device,
2. If no `device` is supplied (default), parameters/buffers retain their device.
ezyang apaszke ebetica
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9609
Differential Revision: D8957367
Pulled By: goldsborough
fbshipit-source-id: 0d409ae645ed2b8d97d6fc060240de2f3d4bc6c8
Summary:
I renamed the variable in the `Embedding` module from `weight` to `table` a few months ago, because it seemed like a more meaningful name. Turns out it's not such a good idea because it deviates from PyTorch, which unnecessarily breaks C++->Python translated code.
ebetica ezyang apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9720
Differential Revision: D8955647
Pulled By: goldsborough
fbshipit-source-id: 77228b07d2b733866e8cdecaa6d0686eef4cc3ea
Summary:
The underlying reason why this is even an issue is that the conversion
into and out of the 'fictional' onnx operators is done in an unhygenic
order. This doesn't address that, but it does fix the one observable
case where this produces an incorrect result, and unblocks some other
work being done.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9657
Differential Revision: D8940824
Pulled By: anderspapitto
fbshipit-source-id: ea827a24c85447fe4ae470336a746329598eee84
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9718
This patch switches the interpreter to use IValue's primitive numbers rather than tensors for computing on integers and floats. In addition to preparing the interpreter for first-class support of other types, this cleans up the handling of primitive numbers, making it possible to just use the normal operator overloading dispatch to find the right implementation for numbers. As a result of this change, a lot of other functionality needed to be updated since it was the first time we use non-tensors in a lot of places in the code base.
Notes:
* Fixes code_template.py so that multi-line strings are indented correctly when used on a standalone line
* Cast operators (`int(x)`) now are functional. Some tests have addition conversions to integers because
we no longer allow implicit tensor -> integer conversions following the same convention as in python
* prim::ListConstruct/createList has been added to the interpreter for creating lists and this has
replaced aten::stack for integers lists
* gen_jit_dispatch.py has been refactored so that non-tensor types use operators on IValues to extract
the primitives
* IValue gains a .to<T> method that is the equivalent of tensor_as but for IValue instead of at::Tensor
* `constant_as<T>` is switched over to using IValues's `.to<T>` method, to make conversion from constant->IValue->C++ type
more consistent. This functionality combined with `toIValue(Value*)` replaces the `tensor_as` and `as_tensor` family of functions.
* conditional expressions (if, loop) and operators related to them are now computed on integers rather than tensors
* IValue gains constructors for constructing from at::Scalar and converting to it. However, IValue itself will always store
the scalars as a double or int64.
* To align with python 3 syntax, TK_INT, TK_FLOAT, and TK_BOOL have been removed from the parser, and int/float/bool are just treated as special identifiers in the compiler,
along with print. These are represented as special sugared values with a `call` method implemented. For int/float/bool this implements casting behavior.
* Dropped shared_from_this from Type/Module. They were not needed and they making debugging harder because they internally throw/catch exceptions.
* Shape propagation has been updated to support running nodes that include floating point primitive types, this required some refactoring of internal functions.
* TensorToNum and NumToTensor have actual implementations as operators now
* regster_prim_ops now contains implementations of math operators for float/int primitive types, and for mixed (prim <+> tensor) versions. This removes the need for special handling in compiler.cpp
* Primitive math is now entirely handled by letting the compiler choose the right overloads. This removes tons of special casing in the compiler.
* incorporates eellison's change to allow casting from return values. Due to the addition of primitive support, the code need slight modifications, so I just pre-merged it here.
* stack.h gains generic vararg versions of push/pop that know how to convert to/from C++ types:
```
at::Tensor a;
at::Scalar b;
pop(stack, a, b);
at::Tensor c = a + b;
push(stack, c);
```
apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9584
Reviewed By: apaszke
Differential Revision: D8910546
Pulled By: zdevito
fbshipit-source-id: 0f3e60d4d22217f196a8f606549430e43b7e7e30
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9667
MKL-DNN doesn't support 64-bit integger (cfee61bf81/include/mkldnn_types.h (L62-L75)). So force converting from `TensorCPU<long>` to `s32` Ideep tensor will cause memory issue. This diff gives an alternative solution, where we just fall through to TensorCPU. The reasoning is that since MKL-DNN doesn't support 64 bit integer tensor, downstream ops have to be in CPUConext. So there is no reason force converting to ideep tensor and back.
Reviewed By: pjh5
Differential Revision: D8943544
fbshipit-source-id: f514903cda27e34b8887271c9df56c8220895116
Summary:
This is a modification of the strategy from https://github.com/pytorch/pytorch/pull/8919 and https://github.com/pytorch/pytorch/pull/9579.
```
Previously, the CPU architecture-specific kernels self-registered with
the DispatchStub. When linking as part of a static library, this requires
the flag --whole-archive to be passed to the linker to ensure that the
object files for the kernels are included. Caffe2 and TensorFlow use that
strategy.
We ran into some issues with --whole-archive blowing up the binary size
of some downstream projects in Facebook. This PR avoids --whole-archive
for CPU kernels. The downside is that the generic code needs to be aware
of whether kernels are compiled with AVX and with AVX2 (via
HAVE_AVX_CPU_DEFINITION and HAVE_AVX2_CPU_DEFINITION).
The CUDA kernels still self-register with DispatchStub because the CPU
library is not aware of whether the CUDA library will be available at
runtime.
There are a few major changes to DispatchStub
- The environment variable ATEN_CPU_CAPABILITY overrides the CPU
capability detection code (Previous ATEN_DISABLE_AVX/AVX2)
- DispatchStub is defined in the generic native code instead of the
CPU_CAPABILITY_DEFAULT kernel.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9664
Differential Revision: D8943350
Pulled By: colesbury
fbshipit-source-id: 329229b0ee9ff94fc001b960287814bd734096ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9717
D8722560 was landed with some build errors, unfortunately the c10 code isn't part of contbuild yet.
Fixing them.
Differential Revision: D8954141
fbshipit-source-id: 2a082fb8041626e45ccd609f37a8ef807f6dad8a
Summary:
This is to simplify the data format during benchmarking. After this change, we can use the same benchmarking harness data conversion method to parse data from multiple binaries.
This change should be coordinated with the PR: https://github.com/facebook/FAI-PEP/pull/63
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9555
Reviewed By: pjh5
Differential Revision: D8903024
Pulled By: sf-wind
fbshipit-source-id: 61cabcff99f0873729142ec6cb6dc230c685d13a
Summary:
This pull request implements low rank multivariate normal distribution where the covariance matrix has the from `W @ W.T + D`. Here D is a diagonal matrix, W has shape n x m where m << n. It used "matrix determinant lemma" and "Woodbury matrix identity" to save computational cost.
During the way, I also revise MultivariateNormal distribution a bit. Here are other changes:
+ `torch.trtrs` works with cuda tensor. So I tried to use it instead of `torch.inverse`.
+ Use `torch.matmul` instead of `torch.bmm` in `_batch_mv`. The former is faster and simpler.
+ Use `torch.diagonal` for `_batch_diag`
+ Reimplement `_batch_mahalanobis` based on `_batch_trtrs_lower`.
+ Use trtrs to compute term2 of KL.
+ `variance` relies on `scale_tril` instead of `covariance_matrix`
TODO:
- [x] Resolve the fail at `_gradcheck_log_prob`
- [x] Add test for KL
cc fritzo stepelu apaszke
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8635
Differential Revision: D8951893
Pulled By: ezyang
fbshipit-source-id: 488ee3db6071150c33a1fb6624f3cfd9b52760c3
Summary:
…unctions.
This also unifies the error checkign between scatter/scatterAdd on CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9658
Differential Revision: D8941527
Pulled By: gchanan
fbshipit-source-id: 750bbac568f607985088211887c4167b67be11ea
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9683
This pops off `refcount_`, `storage_`, `storage_offset_`; there are now no more direct accesses to these fields and we can make them private (with appropriate friending).
Stacked on #9561
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9591
Reviewed By: SsnL
Differential Revision: D8922246
Pulled By: ezyang
fbshipit-source-id: dfae023d790e29ce652e2eab9a1628bbe97b318d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9665
In data_parallel_model, we isolate synchronizing barrier init net into its own from the param_init_net, so that we could have finer granularity of control over the barrier net.
Reviewed By: andrewwdye
Differential Revision: D8375389
fbshipit-source-id: ce0c8c1c8e4bd82b7078a1b07abaced3f149d578
Summary:
**REVIEW LAST COMMIT ONLY**
As discussed in our yesterday's meeting. Nodes can be now matched to particular overloads using the `matches(...)` function:
```cpp
n->matches("aten::type_as(Tensor self, Tensor other) -> Tensor")
```
This also changes the shape prop and peephole passes to use those functions for matching. This fixes a few bugs, makes them much more robust, and prepares us for removal of attributes.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9567
Reviewed By: zdevito
Differential Revision: D8938482
Pulled By: apaszke
fbshipit-source-id: eb2382eeeae99692aada2d78d5d0c87c8ef1545e
Summary:
This PR contains the change for explicit conversion between ushort and __half required for ROCm 1.8.2 support
bddppq
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9663
Differential Revision: D8943937
Pulled By: bddppq
fbshipit-source-id: 16102f9dbc68ed4ece2e8fc244825c3992c24901
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9637
Adding a method to run plan in background. The intended use is to run BlueWhale's data reading & preprocessing net in background while the GPU is training.
Reviewed By: MisterTea
Differential Revision: D8906439
fbshipit-source-id: b1c73ca7327e2d87a8f873924e05ab3d161a3f1e
Summary:
ezyang noticed that the CUDAStream files lived under ATen/ despite being CUDA-specific, and suggested porting them to ATen/cuda and exposing them with a new CUDAContext. This PR does that. It also:
- Moves ATen's CUDA-specific exceptions for ATen/cudnn to ATen/cuda for consistency
- Moves getDeviceProperties() and getCurrentCUDASparseHandle() to CUDAContext from CUDAHooks
The separation between CUDAContext and CUDAHooks is straightforward. Files that are in CUDA-only builds should rely on CUDAContext, while CUDAHooks is for runtime dispatch in files that can be included in CPU-only builds. A comment in CUDAContext.h explains this pattern. Acquiring device properties and CUDA-specific handles is something only done in builds with CUDA, for example, so I moved them from CUDAHooks to CUDAContext.
This PR will conflict with #9277 and I will merge with master after #9277 goes in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9435
Reviewed By: soumith
Differential Revision: D8917236
Pulled By: ezyang
fbshipit-source-id: 219718864234fdd21a2baff1dd3932ff289b5751
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9636
Make sure that the blobs are registered to the net
Reviewed By: pjh5
Differential Revision: D8924883
fbshipit-source-id: f09422a2d4d5ba8bf6cfbfd00172097b5ab1fcd6
Summary:
In the repr funciton of LPPoolNd(..) class, there was a missing '='. (`kernel_size{kernel_size}`)
Link to line in the code: https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/pooling.py#L694
Original:
return 'norm_type={norm_type}, kernel_size{kernel_size}, stride={stride}, ' \
'ceil_mode={ceil_mode}'.format(**self.__dict__)
Fixed:
return 'norm_type={norm_type}, kernel_size={kernel_size}, stride={stride}, ' \
'ceil_mode={ceil_mode}'.format(**self.__dict__)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9629
Differential Revision: D8932913
Pulled By: soumith
fbshipit-source-id: 9030dff6b14659b5c7b6992d87ef53ec8891f674
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9598
The "max_length" should be passed to UnPackSegmentsOp if "max_length" is given when calling PackSegmentsOp.
Reviewed By: jerryzh168
Differential Revision: D8919799
fbshipit-source-id: 8c97aa717b69177b8a5d5d56892817d488853840
Summary:
This PR adds machinery to cache the schema in an IR node, and allows lookups of (possibly) constant inputs by their names (instead of position). The new methods are:
- `at::optional<T> get<T>(Symbol name)` - if the argument called name is a constant, then casts it to type `T` and returns it. If it's not constant returns `nullopt`. Raises an error if there's no argument with that name.
- `at::optional<IValue> get<T>(Symbol name)` - like above, but packs the result in an IValue
- `Value* getValue(Symbol name)` - retrieves a `Value*` for an argument (no need to know its position).
All above functions currently inspect the attributes as well, but that's only so that I could start using them in other places in the JIT without disrupting our current functionality. I wanted this diff to be a preparation that doesn't change the semantics too much, and so both the tracer and script create nodes with attributes. The next PR will put that to a stop, and hopefully the changes we need to make to other components will be simpler thanks to what I did here.
One more thing I'd like to do before actually stopping creating the non-attributed nodes is to have a convenient way of creating a schema programmatically, matching nodes against it, and creating them without having to pack inputs into flat argument lists (which is quite error prone).
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9505
Reviewed By: ezyang
Differential Revision: D8915496
Pulled By: apaszke
fbshipit-source-id: 39d14fc9a9d73d8494f128367bf70357dbba83f5
Summary:
This fix will prevent errors like (found in `bincount`)
```
RuntimeError: %s not implemented for '%s'bincounttorch.FloatTensor
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9625
Differential Revision: D8932945
Pulled By: soumith
fbshipit-source-id: 794e3b58d662779402ab318e274661826a5db8b2
Summary:
fixes#4176 cc vishwakftw
I didn't do `:math:` and `\neg` because I am using double ticks so they render more similarly with `:attr:`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9630
Differential Revision: D8933022
Pulled By: SsnL
fbshipit-source-id: 31d8551f415b624c2ff66b25d886f20789846508
Summary:
As in the title. Lets us simplify a lot of code.
Depends on #9363, so please review only the last commit.
zdevito
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9414
Reviewed By: zdevito
Differential Revision: D8836496
Pulled By: apaszke
fbshipit-source-id: 9b3c3d1f001a9dc522f8478abc005b6b86cfa3e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9501
Added a new stat value to log static states like CPU and memory usage.
Reviewed By: pjh5
Differential Revision: D8872254
fbshipit-source-id: 469e94cab99029a3da55f8986dddeadac076e2a8
Summary:
This PR adds the functional version of `DataParallel` (i.e. `data_parallel`) to the C++ frontend.
For this, I had to:
1. Add "differentiable" versions of scatter and gather, which perform their inverse operation in the backward pass, to C++. I've added them under `torch/csrc/autograd/functions/comm.{h,cpp}`. I had to move some utilities from `VariableType.cpp` into `torch/csrc/autograd/functions/utils.h`, and changed them a bit to fix the `const_cast`s for which there were `TODO`s,
2. Implement the `replicate`, `parallel_apply` and the combining `data_parallel` functions in C++.
`replicate` is implemented based on our existing `clone()` interface, along with the ability to set the current device via `at::OptionsGuard` (so nice).
`parallel_apply` is implemented using `at::parallel_for` (CC cpuhrsch) and [follows the code from PyTorch](https://github.com/pytorch/pytorch/blob/master/torch/nn/parallel/parallel_apply.py).
Added lots of tests for these things.
apaszke ezyang ebetica colesbury
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9234
Differential Revision: D8865182
Pulled By: goldsborough
fbshipit-source-id: 4f1fecf2b3f3bc1540c071dfb2d23dd45de433e4
Summary:
In our pimpl system, default constructing a module holder default constructs the contained module. This means `Linear linear;` is ill-formed, since `Linear` doesn't have a default constructor. Instead we require `Linear linear = nullptr;` to get the empty state of the `Linear`. This PR makes the error message for the ill-formed case nicer.
I had to change the forwarding constructors of most of our modules for this, but that's a minor adjustment.
E.g.
```
Linear linear;
In file included from /home/psag/pytorch/pytorch/torch/csrc/api/include/torch/nn/module.h:5:0,
from /home/psag/pytorch/pytorch/test/cpp/api/module.cpp:3:
/home/psag/pytorch/pytorch/torch/csrc/api/include/torch/nn/pimpl.h: In instantiation of ‘torch::nn::ModuleHolder<Contained>::ModuleHolder() [with Contained = torch::nn::LinearImpl]’:
/home/psag/pytorch/pytorch/torch/csrc/api/include/torch/nn/modules/dropout.h:45:1: required from here
/home/psag/pytorch/pytorch/torch/csrc/api/include/torch/nn/pimpl.h:46:5: error: static assertion failed: You are trying to default construct a module which has no default constructor. Use = nullptr to give it the empty state (like an empt
y std::shared_ptr).
static_assert(
```
ebetica ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9565
Differential Revision: D8903666
Pulled By: goldsborough
fbshipit-source-id: 5e6b788921a27a44359db89afdc2b057facc5cec
Summary:
This is a few files taken from https://github.com/pytorch/pytorch/pull/8919. They're unchanged from the latest versions of that PR.
```
This is part of https://github.com/pytorch/pytorch/pull/8919. It's
separated to make it easier to merge the PR in pieces.
There are a few major changes to DispatchStub
- The environment variable ATEN_CPU_CAPABILITY overrides the CPU
capability detection code (Previous ATEN_DISABLE_AVX/AVX2)
- DispatchStub is defined in the generic native code instead of the
CPU_CAPABILITY_DEFAULT kernel.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9579
Differential Revision: D8909000
Pulled By: colesbury
fbshipit-source-id: fdeb606270b06acdab3c01dba97ec9d81584ecc0
Summary:
* THTensor now stores `sizes_` and `strides_` which is a `std::vector<int64_t>`
* Anywhere a "public" API function made use of a int64_t* of sizes, I opted to just finagle it out of the tensor using THTensor_getSizePtr rather than try to rewrite all of these sites to use ArrayRef. They should use ArrayRef eventually, but not yet.
* There are new utility functions for resizing sizes/strides in one go (THTensor_resizeDim), or replacing sizes and strides with completely new values (THTensor_setSizesAndStrides)
* Anywhere you said `t->size[n] = 0`, we now say `THTensor_setSizeAt(t, n, 0)`, ditto for strides
* Anywhere you said `t->size[n]`, we now say `t->size(n)` (coming soon: ditto for strides)
Previous review of just the `std::vector` change in #9518, but I'm planning to merge this all in one go.
Note for gchanan: review from commit "ci" and after
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9561
Reviewed By: cpuhrsch
Differential Revision: D8901926
Pulled By: ezyang
fbshipit-source-id: 483cf275060ab0a13845cba1ece39dd127142510
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9594
When the input vector is a zero vector, the previous GPU code will give Nan in backward. We fix this.
Reviewed By: pjh5
Differential Revision: D8849732
fbshipit-source-id: 87b1fb1ee05dfdb0d43bcbe67e36f15896fe1706
Summary:
The underlying reason why this is even an issue is that the conversion
into and out of the 'fictional' onnx operators is done in an unhygenic
order. This doesn't address that, but it does fix the one observable
case where this produces an incorrect result, and unblocks some other
work being done.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9593
Differential Revision: D8919125
Pulled By: anderspapitto
fbshipit-source-id: a88ca979c3b9d439863e223717d3697180c26121
Summary:
This is mainly straightforward, with two exceptions:
1) cublasSgemv, cublasDgemv appear to have a bug where (x,0).mv(0) does not handle beta, whereas cublasSgemm, cublasDgemm do for case where (x,0).mm(0,y). This is handled by manually calling zero / mul.
2) I fixed a bug in btrifact that was broken even when dealing with non-empty tensors. Basically, if out.stride(0) was 1, because the underlying BLAS call expects column-major matrices, to get a column-major tensor, out.transpose_(0, 1) would be called. But this is just wrong, as if the batch dimension (0) doesn't match the size of the columns (1), you don't even have a tensor of the correct shape.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9573
Reviewed By: ezyang
Differential Revision: D8906144
Pulled By: gchanan
fbshipit-source-id: de44d239a58afdd74d874db02f2022850dea9a56
Summary:
0. Fixes#9479
1. rewrites `as_strided` as a native function. This is fine because `set_` does the scalar check.
2. allow using `self` in `python_default_init`. Previously `python_variable_methods.cpp` has `self` as an input `PyObject *`, and use `self_` as the unpacked tensor. But `python_torch_functions.cpp` just use `self` as the unpacked tensor, making it impossible to use `self` in `python_default_init`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9538
Differential Revision: D8894556
Pulled By: SsnL
fbshipit-source-id: ca7877b488e12557b7fb94e781346dcb55d3b299
Summary:
The goal of this PR is to add an infrastructure; to convert(hipify) CUDA ops into [HIP](https://github.com/ROCm-Developer-Tools/HIP) ops , at **compile** time.
Note that HIP ops, which are portable c++ code, can run on AMD and NVIDIA platform.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9322
Differential Revision: D8884707
Pulled By: bddppq
fbshipit-source-id: dabc6319546002c308c10528238e6684f7aef0f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9509
generate_proposals_op_util_nms.h conditionally requires OpenCV in some cases,
and earlier this was checking just CV_MAJOR_VERSION macro, but that is
undefined unless opencv.hpp is included. Adding `-DCAFFE2_USE_OPENCV` to
TARGETS when opencv is included in external_deps to check for this correctly.
Thanks jinghuang for flagging this issue!
Differential Revision: D8880401
fbshipit-source-id: 65abbcf4ffe3feffc0ee2560882cb8eb0b7476f9
Summary:
This is the first step of refactoring the Predictor. In this diff the config struct
is introduced and the internal data structure of Predictor has been updated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9434
Differential Revision: D8843262
Pulled By: fishbone
fbshipit-source-id: 23f5e4751614e3fedc9a04060d69331bfdecf864
Summary:
Prior to this diff, there have been two ways of compiling the bulk of the torch codebase. There was no interaction between them - you had to pick one or the other.
1) with setup.py. This method
- used the setuptools C extension functionality
- worked on all platforms
- did not build test_jit/test_api binaries
- did not include the C++ api
- always included python functionality
- produced _C.so
2) with cpp_build. This method
- used CMake
- did not support Windows or ROCM
- was capable of building the test binaries
- included the C++ api
- did not build the python functionality
- produced libtorch.so
This diff combines the two.
1) cpp_build/CMakeLists.txt has become torch/CMakeLists.txt. This build
- is CMake-based
- works on all platforms
- builds the test binaries
- includes the C++ api
- does not include the python functionality
- produces libtorch.so
2) the setup.py build
- compiles the python functionality
- calls into the CMake build to build libtorch.so
- produces _C.so, which has a dependency on libtorch.so
In terms of code changes, this mostly means extending the cmake build to support the full variety of environments and platforms. There are also a small number of changes related to the fact that there are now two shared objects - in particular, windows requires annotating some symbols with dllimport/dllexport, and doesn't allow exposing thread_local globals directly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/8792
Reviewed By: ezyang
Differential Revision: D8764181
Pulled By: anderspapitto
fbshipit-source-id: abec43834f739049da25f4583a0794b38eb0a94f
Summary:
THCStream was recently moved to ATen by mruberry: https://github.com/pytorch/pytorch/pull/8997. This PR now introduces a guard class that replaces `AutoStream` from `torch/csrc/` and also uses this new stream interface.
I had to extend the `CUDAStream` interface with unchecked calls, so that we can reset the stream without throwing an exception in the guard's destructor.
colesbury apaszke ezyang
Fixes https://github.com/pytorch/pytorch/issues/7800
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9277
Differential Revision: D8865183
Pulled By: goldsborough
fbshipit-source-id: 67c9bc09629d92fa5660286b5eec08fde9108cd7
Summary:
….txt setting
In the ROCm branches we will experiment with turning this on.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9543
Differential Revision: D8897990
Pulled By: ezyang
fbshipit-source-id: ae9d25d1b79ee421d49436593edf8c7e49b3a4e5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9438
Current implementation of create_from_proto doesn't work as expected: it
duplicates networks and execution steps by copying original PlanDef first and
adding each step one-by-one later.
Reviewed By: pjh5
Differential Revision: D8850316
fbshipit-source-id: 9b02836d6e6ee1c91cfdd3b4c4804f14137dc22b
One may no longer make changes to the `.circleci/config.yml` file directly.
Instead, one must edit these Python scripts or files in the `verbatim-sources/` directory.
Usage
----------
1. Make changes to these scripts.
2. Run the `regenerate.sh` script in this directory and commit the script changes and the resulting change to `config.yml`.
You'll see a build failure on TravisCI if the scripts don't agree with the checked-in version.
Motivation
----------
These scripts establish a single, authoritative source of documentation for the CircleCI configuration matrix.
The documentation, in the form of diagrams, is automatically generated and cannot drift out of sync with the YAML content.
Furthermore, consistency is enforced within the YAML config itself, by using a single source of data to generate
multiple parts of the file.
* Facilitates one-off culling/enabling of CI configs for testing PRs on special targets
Also see https://github.com/pytorch/pytorch/issues/17038
Future direction
----------------
### Declaring sparse config subsets
See comment [here](https://github.com/pytorch/pytorch/pull/17323#pullrequestreview-206945747):
In contrast with a full recursive tree traversal of configuration dimensions,
> in the future future I think we actually want to decrease our matrix somewhat and have only a few mostly-orthogonal builds that taste as many different features as possible on PRs, plus a more complete suite on every PR and maybe an almost full suite nightly/weekly (we don't have this yet). Specifying PR jobs in the future might be easier to read with an explicit list when we come to this.
about: Report an issue related to https://pytorch.org/docs
---
## 📚 Documentation
<!-- A clear and concise description of what content in https://pytorch.org/docs is an issue. If this has to do with the general https://pytorch.org website, please file an issue at https://github.com/pytorch/pytorch.github.io/issues/new/choose instead. If this has to do with https://pytorch.org/tutorials, please file an issue at https://github.com/pytorch/tutorials/issues/new -->
about: Submit a proposal/request for a new PyTorch feature
---
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
## Pitch
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
# Let the test pass if baseline number is NaN (which happened in
# the past when we didn't have logic for catching NaN numbers)
ifmath.isnan(mean)ormath.isnan(sigma):
mean=sys.maxsize
sigma=0.001
sample_stats_data=json.loads(args.sample_stats)
sample_mean=sample_stats_data['mean']
sample_sigma=sample_stats_data['sigma']
sample_mean=float(sample_stats_data['mean'])
sample_sigma=float(sample_stats_data['sigma'])
print("sample mean: ",sample_mean)
print("sample sigma: ",sample_sigma)
ifmath.isnan(sample_mean):
raiseException('''Error: sample mean is NaN''')
elifmath.isnan(sample_sigma):
raiseException('''Error: sample sigma is NaN''')
z_value=(sample_mean-mean)/sigma
print("z-value: ",z_value)
@ -50,8 +61,10 @@ print("z-value: ", z_value)
ifz_value>=3:
raiseException('''\n
z-value >= 3, there is high chance of perf regression.\n
To reproduce this regression, run `cd .jenkins/pytorch/perf_test/ && bash '''+test_name+'''.sh` on your local machine and compare the runtime before/after your code change.
''')
To reproduce this regression, run
`cd .jenkins/pytorch/perf_test/ && bash {}.sh` on your local machine
and compare the runtime before/after your code change.
'''.format(test_name))
else:
print("z-value < 3, no perf regression detected.")
if ! python perf-tests/modules/test_cpu_torch.py ${ARGS};then
echo"To reproduce this regression, run \`cd .jenkins/pytorch/perf_test/ && bash "${FUNCNAME[0]}".sh\` on your local machine and compare the runtime before/after your code change."
echo"To reproduce this regression, run \`cd .jenkins/pytorch/perf_test/ && bash ${FUNCNAME[0]}.sh\` on your local machine and compare the runtime before/after your code change."
if ! python perf-tests/modules/test_cpu_torch_tensor.py ${ARGS};then
echo"To reproduce this regression, run \`cd .jenkins/pytorch/perf_test/ && bash "${FUNCNAME[0]}".sh\` on your local machine and compare the runtime before/after your code change."
echo"To reproduce this regression, run \`cd .jenkins/pytorch/perf_test/ && bash ${FUNCNAME[0]}.sh\` on your local machine and compare the runtime before/after your code change."
echo "NOTE: To run \`import torch\`, please make sure to activate the conda environment by running \`call C:\\Jenkins\\Miniconda3\\Scripts\\activate.bat C:\\Jenkins\\Miniconda3\` in Command Prompt before running Git Bash."
) else (
7z a %IMAGE_COMMIT_TAG%.7z C:\\Jenkins\\Miniconda3\\Lib\\site-packages\\torch && python ci_scripts\\upload_image.py %IMAGE_COMMIT_TAG%.7z
echo NOTE: To run `import torch`, please make sure to activate the conda environment by running `call %CONDA_PARENT_DIR%\Miniconda3\Scripts\activate.bat %CONDA_PARENT_DIR%\Miniconda3` in Command Prompt before running Git Bash.
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
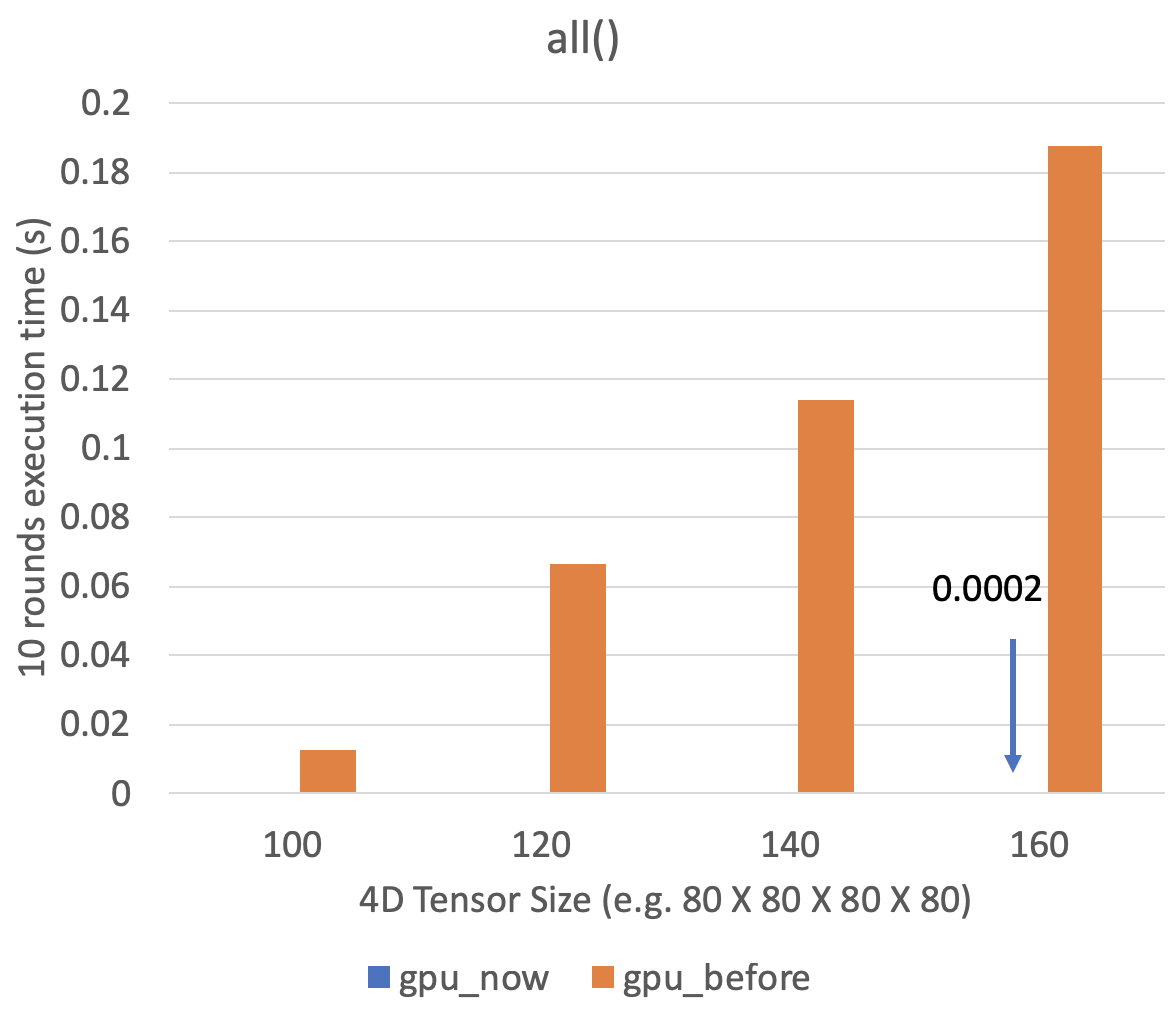{kind=link}
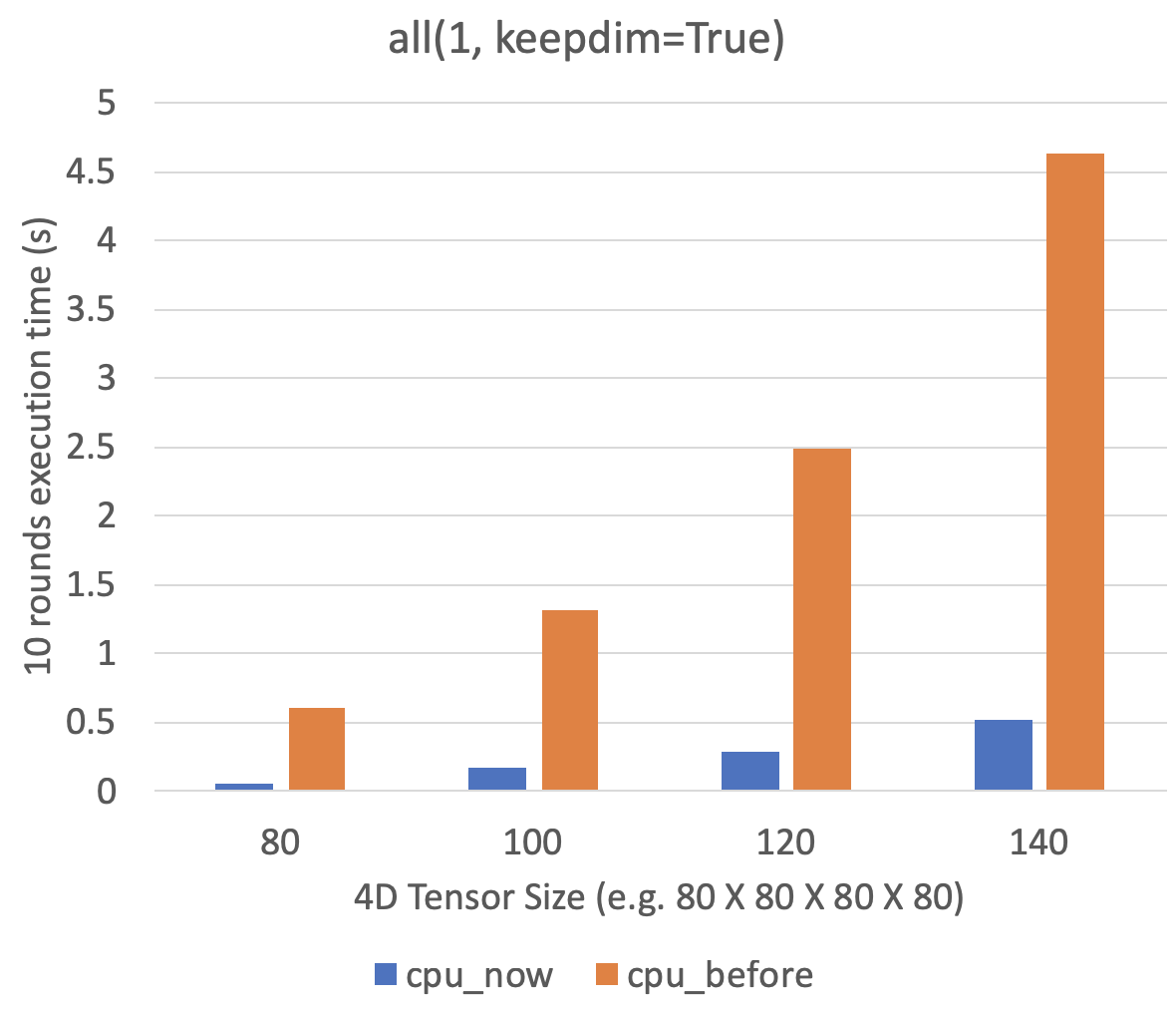{kind=link}
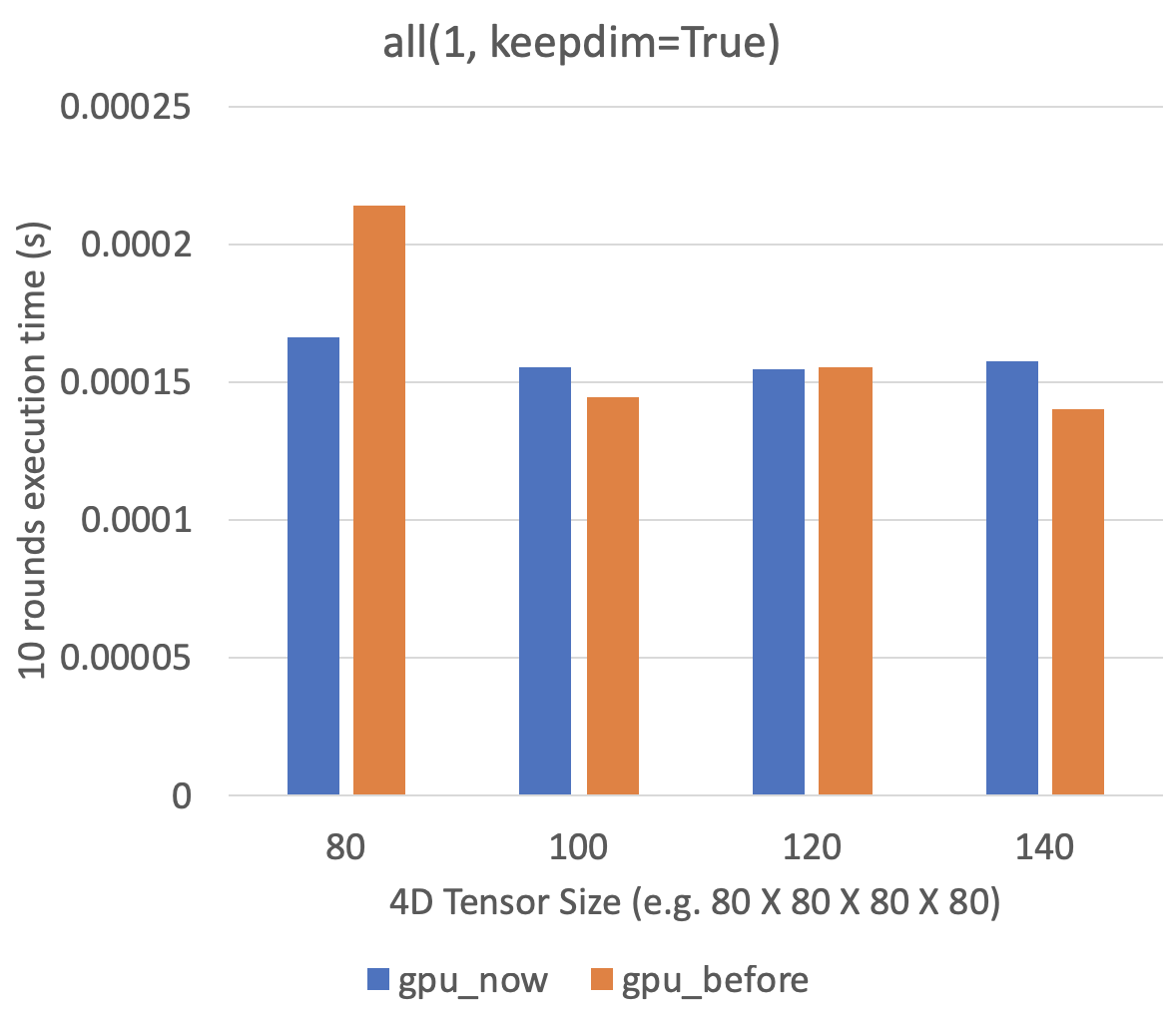{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
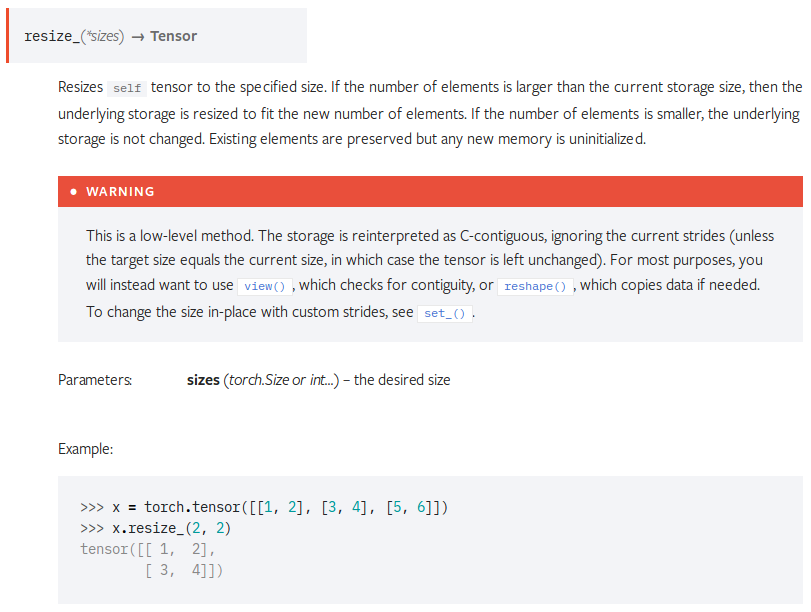{kind=link}
{kind=link}
{kind=link}
{kind=link}