Compare commits
884 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| a2938e3d11 | |||
| 2ad967dbe4 | |||
| 7415c090ac | |||
| a1fa995044 | |||
| 3c2ecc6b15 | |||
| aa46055274 | |||
| 2d01f384f1 | |||
| f8d4f980b3 | |||
| 4f5a6c366e | |||
| ecfcf39f30 | |||
| 3975a2676e | |||
| 138ee75a3b | |||
| 0048f228cb | |||
| 2748b920ab | |||
| a92a2312d4 | |||
| 945ce5cdb0 | |||
| ce13900148 | |||
| 4c77ad6ee4 | |||
| 0bc4246425 | |||
| e05607aee1 | |||
| a360ba1734 | |||
| c661b963b9 | |||
| e374dc1696 | |||
| 116e0c7f38 | |||
| 45596d5289 | |||
| 342e7b873d | |||
| 00410c4496 | |||
| 8b9276bbee | |||
| 3238786ea1 | |||
| 07ebbcbcb3 | |||
| ca555abcf9 | |||
| 63893c3fa2 | |||
| f8ae34706e | |||
| f8e89fbe11 | |||
| 30d208010c | |||
| 017c7efb43 | |||
| 0c69fd559a | |||
| c991258b93 | |||
| 9f89692dcd | |||
| c28575a4eb | |||
| c9db9c2317 | |||
| 16a09304b4 | |||
| 58a88d1ac0 | |||
| b740878697 | |||
| 173c81c2d2 | |||
| ee4c77c59f | |||
| 30ec12fdd5 | |||
| 269ec0566f | |||
| a0a95c95d4 | |||
| 1335b7c1da | |||
| 6d14ef8083 | |||
| 26a492acf3 | |||
| f2741e8038 | |||
| 8d1a6975d2 | |||
| c414bf0aaf | |||
| 99f4864674 | |||
| 784cbeff5b | |||
| 9302f860ae | |||
| ac8a5e7f0d | |||
| 798fc16bbf | |||
| 0f65c9267d | |||
| be45231ccb | |||
| 279aea683b | |||
| 8aa8f791fc | |||
| 6464e69e21 | |||
| a93812e4e5 | |||
| 225f942044 | |||
| d951d5b1cd | |||
| 2082ccbf59 | |||
| 473e795277 | |||
| a09f653f52 | |||
| 90fe6dd528 | |||
| 57a2ccf777 | |||
| 205b9bc05f | |||
| 14d5d52789 | |||
| 9c218b419f | |||
| 517fb2f410 | |||
| 35c2821d71 | |||
| e4812b3903 | |||
| 4cc11066b2 | |||
| 85b64d77b7 | |||
| db7948d7d5 | |||
| 3d40c0562d | |||
| 146bcc0e70 | |||
| 8d9f6c2583 | |||
| ac32d8b706 | |||
| 15c1dad340 | |||
| 6d8baf7c30 | |||
| 7ced682ff5 | |||
| 89cab4f5e6 | |||
| a0afb79898 | |||
| d6fa3b3fd5 | |||
| f91bb96071 | |||
| 3b6644d195 | |||
| 652b468ec2 | |||
| af110d37f2 | |||
| 38967568ca | |||
| df79631a72 | |||
| 95f0fa8a92 | |||
| 1c6ff53b60 | |||
| 1dbf44c00d | |||
| 1259a0648b | |||
| b0055f6229 | |||
| 90040afc44 | |||
| 59bc96bdc2 | |||
| 676ffee542 | |||
| 77136e4c13 | |||
| 604e13775f | |||
| 02380a74e3 | |||
| 133c1e927f | |||
| 2290798a83 | |||
| fd600b11a6 | |||
| b5c9f5c4c3 | |||
| b8a5b1ed8e | |||
| ca74bb17b8 | |||
| 69d8331195 | |||
| eab5c1975c | |||
| e67b525388 | |||
| 5171e56b82 | |||
| f467848448 | |||
| 7e4ddcfe8a | |||
| 3152be5fb3 | |||
| b076944dc5 | |||
| 3a07228509 | |||
| 24a2f2e3a0 | |||
| b32dd4a876 | |||
| 4f4bd81228 | |||
| 59b23d79c6 | |||
| 8c14630e35 | |||
| cc32de8ef9 | |||
| 44696c1375 | |||
| 82088a8110 | |||
| d5e45b2278 | |||
| bdfef2975c | |||
| b4bb4b64a1 | |||
| 3e91c5e1ad | |||
| 2b88d85505 | |||
| 50651970b8 | |||
| 4a8906dd8a | |||
| 68e2769a13 | |||
| 17c998e99a | |||
| 35758f51f2 | |||
| e8102b0a9b | |||
| 04f2bc9aa7 | |||
| d070178dd3 | |||
| c9ec7fad52 | |||
| f0a6ca4d53 | |||
| fd92470e23 | |||
| 8369664445 | |||
| 35e1adfe82 | |||
| eb91fc5e5d | |||
| d186fdb34c | |||
| 0f04f71b7e | |||
| 87f1959be7 | |||
| a538055e81 | |||
| 0e345aaf6d | |||
| c976dd339d | |||
| 71cef62436 | |||
| 3a29055044 | |||
| 59d66e6963 | |||
| 46bc43a80f | |||
| 7fa60b2e44 | |||
| c78893f912 | |||
| 0d2a4e1a9e | |||
| 088f14c697 | |||
| 4bf7be7bd5 | |||
| b2ab6891c5 | |||
| 39ab5bcba8 | |||
| 42f131c09f | |||
| 89dca6ffdc | |||
| b7f36f93d5 | |||
| 58320d5082 | |||
| a461804a65 | |||
| 817f6cc59d | |||
| 108936169c | |||
| f60ae085e6 | |||
| 85dda09f95 | |||
| 4f479a98d4 | |||
| 35ba948dde | |||
| 6b4ed52f10 | |||
| dcf5f8671c | |||
| 5340291add | |||
| 1c6fe58574 | |||
| 9f2111af73 | |||
| 2ed6c6d479 | |||
| 01ac2d3791 | |||
| eac687df5a | |||
| 6a2785aef7 | |||
| 849cbf3a47 | |||
| a0c614ece3 | |||
| 1b97f088cb | |||
| 097399cdeb | |||
| 7ee152881e | |||
| 3074f8eb81 | |||
| 748208775f | |||
| 5df17050bf | |||
| 92df0eb2bf | |||
| 995195935b | |||
| be8376eb88 | |||
| b650a45b9c | |||
| 8a20e22239 | |||
| 7c5014d803 | |||
| 62ac1b4bdd | |||
| 0633c08ec9 | |||
| cf87cc9214 | |||
| f908432eb3 | |||
| 1bd291c57c | |||
| b277df6705 | |||
| ec4d597c59 | |||
| d2ef49384e | |||
| b5dc36f278 | |||
| 41976e2b60 | |||
| 3dac1b9936 | |||
| d2bb56647f | |||
| 224422eed6 | |||
| 3c26f7a205 | |||
| 9ac9809f27 | |||
| 7bf6e984ef | |||
| 10f78985e7 | |||
| dc95f66a95 | |||
| d8f4d5f91e | |||
| 47f56f0230 | |||
| b4018c4c30 | |||
| 43fbdd3b45 | |||
| 803d032077 | |||
| 9d2d884313 | |||
| c0600e655a | |||
| 671ed89f2a | |||
| e0372643e1 | |||
| b5cf1d2fc7 | |||
| c1ca9044bd | |||
| 52c2a92013 | |||
| 541ab961d8 | |||
| 849794cd2c | |||
| f47fa2cb04 | |||
| 7a162dd97a | |||
| b123bace1b | |||
| 483490cc25 | |||
| 8d60e39fdc | |||
| e7dff91cf3 | |||
| ab5776449c | |||
| a229582238 | |||
| a0df8fde62 | |||
| e4a3aa9295 | |||
| be98c5d12d | |||
| bc6a71b1f5 | |||
| 26f1e2ca9c | |||
| 75d850cfd2 | |||
| f4870ca5c6 | |||
| 235d5400e1 | |||
| 491d5ba4fd | |||
| d42eadfeb9 | |||
| 9a40821069 | |||
| 2975f539ff | |||
| 64ca584199 | |||
| 5263469e21 | |||
| c367e0b64e | |||
| 183b3aacd2 | |||
| 101950ce92 | |||
| 239ae94389 | |||
| 55e850d825 | |||
| 62af45d99f | |||
| 1ac038ab24 | |||
| 77a925ab66 | |||
| d0d33d3ae7 | |||
| 9b7eceddc8 | |||
| 24af02154c | |||
| 86ec14e594 | |||
| 8a29338837 | |||
| 29918c6ca5 | |||
| 80a44e84dc | |||
| 5497b1babb | |||
| bef70aa377 | |||
| 0d30f77889 | |||
| e27bb3e993 | |||
| 179d5efc81 | |||
| b55e38801d | |||
| e704ec5c6f | |||
| 6cda6bb34c | |||
| 46f0248466 | |||
| 310ec57fd7 | |||
| cd82b2b869 | |||
| 126a1cc398 | |||
| bf650f05b3 | |||
| f2606a7502 | |||
| b07fe52ee0 | |||
| b07358b329 | |||
| 2aea8077f9 | |||
| 41f9c14297 | |||
| 135687f04a | |||
| b140e70b58 | |||
| ec987b57f6 | |||
| 596677232c | |||
| 9d74e139e5 | |||
| d2a93c3102 | |||
| bc475cad67 | |||
| 45d6212fd2 | |||
| f45d75ed22 | |||
| b03407289f | |||
| 55a794e6ec | |||
| 93ed476e7d | |||
| 10faa303bc | |||
| 6fa371cb0d | |||
| 18a2691b4b | |||
| f7bd3f7932 | |||
| f8dee4620a | |||
| 800e24616a | |||
| d63a435787 | |||
| a9c2809ce3 | |||
| fa61159dd0 | |||
| a215e000e9 | |||
| f16a624b35 | |||
| 61c2896cb8 | |||
| 22ebc3f205 | |||
| 8fa9f443ec | |||
| bb72ccf1a5 | |||
| 2e73456f5c | |||
| 3e49a2b4b7 | |||
| 4694e4050b | |||
| 59b9eeff49 | |||
| 1744fad8c2 | |||
| e46d942ca6 | |||
| 93a6136863 | |||
| 230bde94e7 | |||
| 20fffc8bb7 | |||
| 861a3f3a30 | |||
| ee52102943 | |||
| 26516f667e | |||
| 5586f48ad5 | |||
| cc6e3c92d2 | |||
| a2ef5782d0 | |||
| 0c1c0e21b8 | |||
| ffcc38cf05 | |||
| cc24b68584 | |||
| 8a70067b92 | |||
| 33b227c45b | |||
| fb68be952d | |||
| f413ee087d | |||
| 6495f5dd30 | |||
| 8e09f0590b | |||
| 08d346df9c | |||
| 12cf96e358 | |||
| 765a720d1c | |||
| cace62f94c | |||
| 767c96850d | |||
| b73e78edbb | |||
| 7914cc119d | |||
| 2b13eb2a6c | |||
| 8768e64e97 | |||
| 9212b9ca09 | |||
| 0d0f197682 | |||
| 281e34d1b7 | |||
| 287ba38905 | |||
| ed9dbff4e0 | |||
| 6ba4e48521 | |||
| b7269f2295 | |||
| 5ab317d4a6 | |||
| 431bcf7afa | |||
| 41909e8c5b | |||
| 56245426eb | |||
| 3adcb2c157 | |||
| 6d12185cc9 | |||
| 258c9ffb2c | |||
| dede431dd9 | |||
| 6312d29d80 | |||
| ab5f26545b | |||
| 6567c1342d | |||
| 3d6c2e023c | |||
| 89d930335b | |||
| 04393cd47d | |||
| 28f0cf6cee | |||
| 1af9a9637f | |||
| 1031d671fb | |||
| ee91b22317 | |||
| 220183ed78 | |||
| 504d2ca171 | |||
| d535aa94a1 | |||
| 0376a1909b | |||
| f757077780 | |||
| 9f7114a4a1 | |||
| 7d03da0890 | |||
| 4e0cecae7f | |||
| 72dbb76a15 | |||
| cceb926af3 | |||
| 0d7d29fa57 | |||
| be3276fcdd | |||
| 09c94a170c | |||
| f2a18004a7 | |||
| 1a3ff1bd28 | |||
| a5d3c779c7 | |||
| 9d32e60dc2 | |||
| f6913f56ea | |||
| 801fe8408f | |||
| cf4a979836 | |||
| 91f2946310 | |||
| 2bd7a3c31d | |||
| a681f6759b | |||
| cb849524f3 | |||
| 1f5951693a | |||
| 87748ffd4c | |||
| 0580f5a928 | |||
| 88d9fdec2e | |||
| 506a40ce44 | |||
| bf0e185bd6 | |||
| 5b3ccec10d | |||
| eb07581502 | |||
| 934a2b6878 | |||
| bec6ab47b6 | |||
| 49480f1548 | |||
| 18a3c62d9b | |||
| 6322cf3234 | |||
| 4e2b154342 | |||
| bb1019d1ec | |||
| c2d32030a2 | |||
| 162170fd7b | |||
| ea728e7c5e | |||
| aea6ba4bcd | |||
| ab357c14fc | |||
| 606aa43da0 | |||
| 8bfa802665 | |||
| ff5b73c0b3 | |||
| 86c95014a4 | |||
| 288c950c5e | |||
| b27d4de850 | |||
| 61063ebade | |||
| 3e70e26278 | |||
| 66e7e42800 | |||
| 0fecec14b8 | |||
| a7f24ccb76 | |||
| 08a1bc71c0 | |||
| 04e896a4b4 | |||
| 5dcfb80b36 | |||
| 9da60c39ce | |||
| 379860e457 | |||
| bcfa2d6c79 | |||
| 8b492bbc47 | |||
| a49b7b0f58 | |||
| c781ac414a | |||
| 656dca6edb | |||
| 830adfd151 | |||
| 6f7c8e4ef8 | |||
| 2ba6678766 | |||
| 71a47d1bed | |||
| 51bf6321ea | |||
| aa8916e7c6 | |||
| 2e24da2a0b | |||
| c94ccafb61 | |||
| 80a827d3da | |||
| 6909c8da48 | |||
| c07105a796 | |||
| c40c061a9f | |||
| a9bd27ce5c | |||
| 2e36c4ea2d | |||
| 4e45385a8d | |||
| cf5e925c10 | |||
| 709255d995 | |||
| f3cb636294 | |||
| e3f440b1d0 | |||
| f6b94dd830 | |||
| 3911a1d395 | |||
| ebd3648fd6 | |||
| f698f09cb7 | |||
| 86aa5dae05 | |||
| 179c82ffb4 | |||
| 233017f01f | |||
| 597bbfeacd | |||
| 99a169c17e | |||
| 0613ac90cd | |||
| 78871d829a | |||
| d40a7bf9eb | |||
| b27f576f29 | |||
| 073dfd8b88 | |||
| 509dd57c2e | |||
| 7a837b7a14 | |||
| dee864116a | |||
| e51d0bef97 | |||
| 2fd78112ab | |||
| 5c14bd2888 | |||
| 84b4665e02 | |||
| 26d626a47c | |||
| 6ff6299c65 | |||
| 071e68d99d | |||
| 78c1094d93 | |||
| 56fc639c9f | |||
| 51084a9054 | |||
| f8ae5c93e9 | |||
| ad286c0692 | |||
| a483b3903d | |||
| 6564d39777 | |||
| 8f1b7230fe | |||
| c0b7608965 | |||
| 56dd4132c4 | |||
| 91494cb496 | |||
| 9057eade95 | |||
| a28317b263 | |||
| 25c3603266 | |||
| ae6f2dd11c | |||
| 3aaa1771d5 | |||
| 2034396a3c | |||
| 0cad668065 | |||
| f644a11b82 | |||
| d7e3b2ef29 | |||
| fc5ec87478 | |||
| ed4023127b | |||
| 2bd4e5f5f6 | |||
| d2dcbc26f8 | |||
| 2f05eefe9a | |||
| 7d1afa78b9 | |||
| dac9b020e0 | |||
| eb77b79df9 | |||
| 456998f043 | |||
| c09f07edd9 | |||
| 66320c498c | |||
| 8cb8a0a146 | |||
| aeed8a6ea4 | |||
| c82537462b | |||
| a8a02ff560 | |||
| 72a9df19c8 | |||
| 5b9b9634f9 | |||
| c279a91c03 | |||
| ef6a764509 | |||
| 4db5afdf7e | |||
| 7867187451 | |||
| 4f8e6ec42a | |||
| 64c8a13773 | |||
| 395ab4a287 | |||
| 15dc862056 | |||
| f2daa616d1 | |||
| 64a50f5ad3 | |||
| 1d0f86144c | |||
| 89e93bba9d | |||
| 3290d4c7d6 | |||
| ca22befc93 | |||
| b08df5b9c0 | |||
| ebd3c3291c | |||
| 16728d2f26 | |||
| 34dab66f44 | |||
| 3a111c7499 | |||
| 3600c94ec5 | |||
| e2f8b00e00 | |||
| 65ed1eba48 | |||
| 7fff7977fe | |||
| add5922aac | |||
| a94b54a533 | |||
| bea82b9da6 | |||
| 2e7debe282 | |||
| 1cee5a359c | |||
| b08862405e | |||
| d57e1a6756 | |||
| c9172c5bc9 | |||
| 5d5e877a05 | |||
| 1e794c87ae | |||
| d9cb1b545a | |||
| 23f611f14d | |||
| 42b28d0d69 | |||
| d0cf5f7b65 | |||
| 4699c817e8 | |||
| 4f490c16e9 | |||
| bcdab7a632 | |||
| 7f51af7cbc | |||
| b4ae60cac8 | |||
| 4d03d96e8b | |||
| a39ffebc3a | |||
| 4bba6082ed | |||
| b111632965 | |||
| 0a34b34bfe | |||
| 6b821ece22 | |||
| d3b2096bfd | |||
| 9f1b12bf06 | |||
| e64fca4b04 | |||
| b941e73f4f | |||
| c57873d3cb | |||
| f3bc3275ac | |||
| 8df26e6c5c | |||
| 5c8ecb8150 | |||
| 3928f7740a | |||
| 1767f73e6b | |||
| 9e7d5e93ab | |||
| 70c6ee93a2 | |||
| 5cbf8504ef | |||
| 9a393b023d | |||
| 30bf464f73 | |||
| 9fb1f8934b | |||
| f3f02b23a0 | |||
| 7668cdd32c | |||
| f9dafdcf09 | |||
| d284a419c1 | |||
| b45844e3d9 | |||
| 6caa7e0fff | |||
| 1669fffb8d | |||
| 18aa86eebd | |||
| 075e49d3f4 | |||
| a6695b8365 | |||
| 06ee48b391 | |||
| fcaeffbbd4 | |||
| 6146a9a641 | |||
| 83de8e40d5 | |||
| 30590c46a3 | |||
| a3a5e56287 | |||
| 185c96d63a | |||
| be61ad6eb4 | |||
| 222dfd2259 | |||
| b06e1c7e1d | |||
| 6876abba51 | |||
| 0798466a01 | |||
| 2cda782273 | |||
| 7d1c9554b6 | |||
| a29d16f1a8 | |||
| 6d0c1c0f17 | |||
| 5ed4b5c25b | |||
| 6fe89c5e44 | |||
| fda8c37641 | |||
| 6d5a0ff3a1 | |||
| f8718dd355 | |||
| 85af686797 | |||
| 0f6ec3f15f | |||
| 44644c50ee | |||
| 9749f7eacc | |||
| d9a2bdb9df | |||
| 57e678c94b | |||
| 516f127cfd | |||
| e477add103 | |||
| ba3d577875 | |||
| 917e4f47c4 | |||
| 0143dac247 | |||
| d2390f3616 | |||
| 949ea73402 | |||
| d1e2fe0efe | |||
| 584ada12bf | |||
| 3ead72f654 | |||
| 9ce96d3bd3 | |||
| 5549c003d9 | |||
| 46105bf90b | |||
| 73ce3b3702 | |||
| 1c6225dc2f | |||
| 44874542c8 | |||
| 31f2846aff | |||
| bc08011e72 | |||
| 7cccc216d0 | |||
| 09493603f6 | |||
| e799bd0ba9 | |||
| 40247b0382 | |||
| cd2e9c5119 | |||
| 0b6f7b12b1 | |||
| 86e42ba291 | |||
| e0a18cafd3 | |||
| 8c2f77cab6 | |||
| c1bd6ba1e1 | |||
| df59b89fbb | |||
| 8fd9cc160c | |||
| 28e3f07b63 | |||
| 513d902df1 | |||
| fce14a9f51 | |||
| 884107da01 | |||
| caa79a354a | |||
| 5bb873a2fe | |||
| bc0442d7df | |||
| cfcd33552b | |||
| 5f6b9fd5ba | |||
| 469dce4a2d | |||
| 55d32de331 | |||
| 4491d2d3cb | |||
| f9669b9b9a | |||
| 246d5f37c7 | |||
| 293bfb03dd | |||
| 4def4e696b | |||
| b6e58c030a | |||
| bf00308ab2 | |||
| e3e786e35e | |||
| fd67794574 | |||
| 104b502919 | |||
| a18cd3ba92 | |||
| 0676cad200 | |||
| 3b1d217310 | |||
| 93bcb2e7ba | |||
| ebc70f7919 | |||
| e32af0196e | |||
| 3e5c121c56 | |||
| e644f6ed2c | |||
| 551a7c72f3 | |||
| 05b121841e | |||
| c29aea89ee | |||
| 103e70ccc5 | |||
| ec7ecbe2dd | |||
| 7a06dbb87e | |||
| 1234e434fa | |||
| 2d374f982e | |||
| 4e73630a95 | |||
| e867baa5f9 | |||
| 04b750cb52 | |||
| 97c7b12542 | |||
| 0dfec752a3 | |||
| f16f68e103 | |||
| 4b7f8f9b77 | |||
| 9969d50833 | |||
| 7355c63845 | |||
| 16cac6442a | |||
| 5009ae5548 | |||
| 32647e285e | |||
| 6df334ea68 | |||
| f8501042c1 | |||
| be085b8f6c | |||
| ef557761dd | |||
| 15377ac391 | |||
| ad5fdef6ac | |||
| 0cb5943be8 | |||
| fb593d5f28 | |||
| 645c913e4f | |||
| b4f4cca875 | |||
| 6027513574 | |||
| 849188fdab | |||
| a9c14a5306 | |||
| 2da36a14d1 | |||
| 2ee451f5f7 | |||
| f2d7e94948 | |||
| 2031dfc08a | |||
| 34ede14877 | |||
| 2af3098e5a | |||
| 2e44511b13 | |||
| 7bc4aa7e72 | |||
| e2458bce97 | |||
| ae9789fccc | |||
| 45ef25ea27 | |||
| ad2d413c0b | |||
| 30924ff1e0 | |||
| 383c48968f | |||
| bbe8627a3f | |||
| 2bd36604e2 | |||
| 9ed47ef531 | |||
| 139f98a872 | |||
| c825895190 | |||
| 42e835ebb8 | |||
| a7d5fdf54e | |||
| 3b4e41f6ec | |||
| 5505e1de7d | |||
| 6d329e418b | |||
| 3a11afb57f | |||
| df86e02c9e | |||
| deebc1383e | |||
| 19f2f1a9d3 | |||
| 4dc13ecdd8 | |||
| b4b6e356ef | |||
| 9000f40e61 | |||
| f137c0c05a | |||
| b43a02a9aa | |||
| 30be715900 | |||
| 71cf8e14cb | |||
| ffd4863b23 | |||
| 4c17098bb8 | |||
| bcfdd18599 | |||
| 067662d280 | |||
| 93d02e4686 | |||
| 12de115305 | |||
| b5d13296c6 | |||
| 86288265ad | |||
| a559d94a44 | |||
| 1eb6870853 | |||
| f88c3e9c12 | |||
| 942ca477a6 | |||
| b0e33fb473 | |||
| d58b627b98 | |||
| b85fc35f9a | |||
| bcb466fb76 | |||
| 6db721b5dd | |||
| 140c65e52b | |||
| 29e8d77ce0 | |||
| b66a4ea919 | |||
| d3d59e5024 | |||
| 5285da0418 | |||
| a76e69d709 | |||
| 4d0d775d16 | |||
| 98f67e90d5 | |||
| fee67c2e1a | |||
| c295f26a00 | |||
| 8a09c45f28 | |||
| 79ead42ade | |||
| 94e52e1d17 | |||
| 3931beee81 | |||
| d293c17d21 | |||
| 1a3920e5dc | |||
| ffc3eb1a24 | |||
| 2f5d4a7318 | |||
| 70553f4253 | |||
| 8d39fb4094 | |||
| 7d10b2370f | |||
| 31ec7650ac | |||
| c014920dc1 | |||
| 17e3d4e1ee | |||
| b01c785805 | |||
| 0eea71f878 | |||
| ec7a287801 | |||
| 4bc585a2fe | |||
| 429f2d6765 | |||
| a0c7e3cf04 | |||
| 9cd68129da | |||
| aa6f6117b7 | |||
| 6fa9c87aa4 | |||
| ee14cf9438 | |||
| 0391bbb376 | |||
| 28ada0c634 | |||
| 2c233d23ad | |||
| 59c628803a | |||
| 6b830bc77f | |||
| f30081a313 | |||
| c15648c6b5 | |||
| a02917f502 | |||
| 70d8bd04c0 | |||
| ad2cee0cae | |||
| 756a7122ad | |||
| 3d6ebde756 | |||
| daa30aa992 | |||
| 39459eb238 | |||
| 0325e2f646 | |||
| 93b8b5631f | |||
| 60ab1ce0c1 | |||
| 2f186df52d | |||
| 452e07d432 | |||
| 05d1404b9c | |||
| 2acee24332 | |||
| e7639e55f8 | |||
| f978eca477 | |||
| eb3ac2b367 | |||
| 968d386b36 | |||
| 38cb3d0227 | |||
| 6f606dd5f9 | |||
| bab616cf11 | |||
| 966adc6291 | |||
| 518cb6ec7c | |||
| 34bcd4c237 | |||
| a121127082 | |||
| 50326e94b1 | |||
| 160723b5b4 | |||
| 7991125293 | |||
| 96f61bff30 | |||
| a94488f584 | |||
| f2cf673d3a | |||
| c4595a3dd6 | |||
| 5db118e64b | |||
| 1620c56808 | |||
| e88e0026b1 | |||
| ace9b49e28 | |||
| da90751add | |||
| 8cc566f7b5 | |||
| 02ad199905 | |||
| c3e0811d86 | |||
| 499d1c5709 | |||
| cf16ec45e1 | |||
| daa15dcceb | |||
| 32556cbe5e | |||
| 74d9c674f5 | |||
| a4da558fa0 | |||
| dba6d1d57f | |||
| b01c4338c9 | |||
| 811d947da3 | |||
| de7bf7efe6 | |||
| 5537df9927 | |||
| 81fea93741 | |||
| df1065a2d8 | |||
| c2e3bf2145 | |||
| a4d849ef68 | |||
| 957c9f3853 | |||
| 3958b6b0e1 | |||
| 5d70feb573 | |||
| a22af69335 | |||
| 1213149a2f | |||
| 398b6f75cd | |||
| e46e05e7c5 | |||
| 166028836d | |||
| 3cbe66ba8c | |||
| 99de537a2e | |||
| 1d0afdf9f7 | |||
| 4db6667923 | |||
| 80e16e44aa | |||
| 58b134b793 | |||
| 6efefac2df | |||
| 0c9670ddf0 | |||
| 53c65ddc6a | |||
| 33371c5164 | |||
| 64dd1419c5 | |||
| 6e8ed95ada | |||
| 39c9f9e9e8 | |||
| 89666fc4fe | |||
| 0eff3897e3 | |||
| df77a8a81a |
10
.gitignore
vendored
@ -10,10 +10,20 @@ torch/lib/build
|
||||
torch/lib/tmp_install
|
||||
torch/lib/include
|
||||
torch/lib/torch_shm_manager
|
||||
torch/csrc/cudnn/cuDNN.cpp
|
||||
torch/csrc/nn/THNN.cwrap
|
||||
torch/csrc/nn/THNN.cpp
|
||||
torch/csrc/nn/THCUNN.cwrap
|
||||
torch/csrc/nn/THCUNN.cpp
|
||||
docs/src/**/*
|
||||
test/data/legacy_modules.t7
|
||||
test/htmlcov
|
||||
test/.coverage
|
||||
*/*.pyc
|
||||
*/**/*.pyc
|
||||
*/**/**/*.pyc
|
||||
*/**/**/**/*.pyc
|
||||
*/**/**/**/**/*.pyc
|
||||
*/*.so*
|
||||
*/**/*.so*
|
||||
*/**/*.dylib*
|
||||
|
||||
@ -3,8 +3,6 @@ language: python
|
||||
python:
|
||||
- 2.7.8
|
||||
- 2.7
|
||||
- 3.3
|
||||
- 3.4
|
||||
- 3.5
|
||||
- nightly
|
||||
|
||||
@ -32,3 +30,9 @@ sudo: false
|
||||
|
||||
matrix:
|
||||
fast_finish: true
|
||||
include:
|
||||
env: LINT_CHECK
|
||||
python: "2.7"
|
||||
addons: true
|
||||
install: pip install pep8
|
||||
script: pep8 setup.py
|
||||
|
||||
33
Dockerfile
Normal file
@ -0,0 +1,33 @@
|
||||
FROM nvidia/cuda:8.0-cudnn5-devel-ubuntu14.04
|
||||
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
build-essential \
|
||||
cmake \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libjpeg-dev \
|
||||
libpng-dev &&\
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN curl -o ~/miniconda.sh -O https://repo.continuum.io/miniconda/Miniconda3-4.2.12-Linux-x86_64.sh && \
|
||||
chmod +x ~/miniconda.sh && \
|
||||
~/miniconda.sh -b -p /opt/conda && \
|
||||
rm ~/miniconda.sh && \
|
||||
/opt/conda/bin/conda install conda-build && \
|
||||
/opt/conda/bin/conda create -y --name pytorch-py35 python=3.5.2 numpy scipy ipython mkl&& \
|
||||
/opt/conda/bin/conda clean -ya
|
||||
ENV PATH /opt/conda/envs/pytorch-py35/bin:$PATH
|
||||
RUN conda install --name pytorch-py35 -c soumith magma-cuda80
|
||||
# This must be done before pip so that requirements.txt is available
|
||||
WORKDIR /opt/pytorch
|
||||
COPY . .
|
||||
|
||||
RUN cat requirements.txt | xargs -n1 pip install --no-cache-dir && \
|
||||
TORCH_CUDA_ARCH_LIST="3.5 5.2 6.0 6.1+PTX" TORCH_NVCC_FLAGS="-Xfatbin -compress-all" \
|
||||
CMAKE_LIBRARY_PATH=/opt/conda/envs/pytorch-py35/lib \
|
||||
CMAKE_INCLUDE_PATH=/opt/conda/envs/pytorch-py35/include \
|
||||
pip install -v .
|
||||
|
||||
WORKDIR /workspace
|
||||
RUN chmod -R a+w /workspace
|
||||
339
README.md
@ -1,32 +1,34 @@
|
||||
# pytorch [alpha-4]
|
||||
<p align="center"><img width="40%" src="docs/source/_static/img/pytorch-logo-dark.png" /></p>
|
||||
|
||||
- [What is PyTorch?](#what-is-pytorch)
|
||||
- [Reasons to consider PyTorch](#reasons-to-consider-pytorch)
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
PyTorch is a python package that provides two high-level features:
|
||||
- Tensor computation (like numpy) with strong GPU acceleration
|
||||
- Deep Neural Networks built on a tape-based autograd system
|
||||
|
||||
You can reuse your favorite python packages such as numpy, scipy and Cython to extend PyTorch when needed.
|
||||
|
||||
We are in an early-release Beta. Expect some adventures and rough edges.
|
||||
|
||||
- [More About PyTorch](#more-about-pytorch)
|
||||
- [Installation](#installation)
|
||||
- [Binaries](#binaries)
|
||||
- [From source](#from-source)
|
||||
- [Docker image](#docker-image)
|
||||
- [Getting Started](#getting-started)
|
||||
- [Communication](#communication)
|
||||
- [Timeline](#timeline)
|
||||
- [pytorch vs torch: important changes](#pytorch-vs-torch-important-changes)
|
||||
- [Releases and Contributing](#releases-and-contributing)
|
||||
- [The Team](#the-team)
|
||||
|
||||
| Python | **`Linux CPU`** | **`Linux GPU`** |
|
||||
|--------|--------------------|------------------|
|
||||
| 2.7.8 | [](https://travis-ci.com/apaszke/pytorch) | |
|
||||
| 2.7 | [](https://travis-ci.com/apaszke/pytorch) | [](https://build.pytorch.org/job/pytorch-master-py2) |
|
||||
| 3.3 | [](https://travis-ci.com/apaszke/pytorch) | |
|
||||
| 3.4 | [](https://travis-ci.com/apaszke/pytorch) | |
|
||||
| 3.5 | [](https://travis-ci.com/apaszke/pytorch) | [](https://build.pytorch.org/job/pytorch-master-py3) |
|
||||
| Nightly| [](https://travis-ci.com/apaszke/pytorch) | |
|
||||
| System | Python | Status |
|
||||
| --- | --- | --- |
|
||||
| Linux CPU | 2.7.8, 2.7, 3.5, nightly | [](https://travis-ci.org/pytorch/pytorch) |
|
||||
| Linux GPU | 2.7 | [](https://build.pytorch.org/job/pytorch-master-py2) |
|
||||
| Linux GPU | 3.5 | [](https://build.pytorch.org/job/pytorch-master-py3) |
|
||||
|
||||
The project is still under active development and is likely to drastically change in short periods of time.
|
||||
We will be announcing API changes and important developments via a newsletter, github issues and post a link to the issues on slack.
|
||||
Please remember that at this stage, this is an invite-only closed alpha, and please don't distribute code further.
|
||||
This is done so that we can control development tightly and rapidly during the initial phases with feedback from you.
|
||||
## More about PyTorch
|
||||
|
||||
## What is PyTorch?
|
||||
|
||||
PyTorch is a library that consists of the following components:
|
||||
At a granular level, PyTorch is a library that consists of the following components:
|
||||
|
||||
| \_ | \_ |
|
||||
| ------------------------ | --- |
|
||||
@ -43,204 +45,185 @@ Usually one uses PyTorch either as:
|
||||
- A replacement for numpy to use the power of GPUs.
|
||||
- a deep learning research platform that provides maximum flexibility and speed
|
||||
|
||||
## Reasons to consider PyTorch
|
||||
Elaborating further:
|
||||
|
||||
### A GPU-ready Tensor library
|
||||
|
||||
If you use numpy, then you have used Tensors (a.k.a ndarray).
|
||||
|
||||
<p align=center><img width="30%" src="docs/source/_static/img/tensor_illustration.png" /></p>
|
||||
|
||||
PyTorch provides Tensors that can live either on the CPU or the GPU, and accelerate
|
||||
compute by a huge amount.
|
||||
|
||||
We provide a wide variety of tensor routines to accelerate and fit your scientific computation needs
|
||||
such as slicing, indexing, math operations, linear algebra, reductions.
|
||||
And they are fast!
|
||||
|
||||
### Dynamic Neural Networks: Tape based Autograd
|
||||
|
||||
PyTorch has a unique way of building neural networks: using and replaying a tape recorder.
|
||||
|
||||
Most frameworks such as `TensorFlow`, `Theano`, `Caffe` and `CNTK` have a static view of the world.
|
||||
One has to build a neural network, and reuse the same structure again and again.
|
||||
Changing the way the network behaves means that one has to start from scratch.
|
||||
|
||||
With PyTorch, we use a technique called Reverse-mode auto-differentiation, which allows you to
|
||||
change the way your network behaves arbitrarily with zero lag or overhead. Our inspiration comes
|
||||
from several research papers on this topic, as well as current and past work such as
|
||||
[autograd](https://github.com/twitter/torch-autograd),
|
||||
[autograd](https://github.com/HIPS/autograd),
|
||||
[Chainer](http://chainer.org), etc.
|
||||
|
||||
While this technique is not unique to PyTorch, it's one of the fastest implementations of it to date.
|
||||
You get the best of speed and flexibility for your crazy research.
|
||||
|
||||
<p align=center><img width="80%" src="docs/source/_static/img/dynamic_graph.gif" /></p>
|
||||
|
||||
### Python first
|
||||
|
||||
PyTorch is not a Python binding into a monolothic C++ framework.
|
||||
It is built to be deeply integrated into Python.
|
||||
You can use it naturally like you would use numpy / scipy / scikit-learn etc.
|
||||
You can write your new neural network layers in Python itself, using your favorite libraries.
|
||||
PyTorch is not a Python binding into a monolothic C++ framework.
|
||||
It is built to be deeply integrated into Python.
|
||||
You can use it naturally like you would use numpy / scipy / scikit-learn etc.
|
||||
You can write your new neural network layers in Python itself, using your favorite libraries
|
||||
and use packages such as Cython and Numba.
|
||||
Our goal is to not reinvent the wheel where appropriate.
|
||||
|
||||
### Imperativeness first. What you see is what you get!
|
||||
### Imperative experiences
|
||||
|
||||
PyTorch is designed to be intuitive and easy to use.
|
||||
When you are debugging your program, or receive error messages / stack traces, you are always guaranteed to get
|
||||
error messages that are easy to understand and a stack-trace that points to exactly where your code was defined.
|
||||
Never spend hours debugging your code because of bad stack traces or asynchronous and opaque execution engines.
|
||||
PyTorch is designed to be intuitive, linear in thought and easy to use.
|
||||
When you execute a line of code, it gets executed. There isn't an asynchronous view of the world.
|
||||
When you drop into a debugger, or receive error messages and stack traces, understanding them is straight-forward.
|
||||
The stack-trace points to exactly where your code was defined.
|
||||
We hope you never spend hours debugging your code because of bad stack traces or asynchronous and opaque execution engines.
|
||||
|
||||
### Performance and Memory usage
|
||||
### Fast and Lean
|
||||
|
||||
PyTorch is as fast as the fastest deep learning framework out there. We integrate acceleration frameworks such as Intel MKL and NVIDIA CuDNN for maximum speed.
|
||||
PyTorch has minimal framework overhead. We integrate acceleration libraries
|
||||
such as Intel MKL and NVIDIA (CuDNN, NCCL) to maximize speed.
|
||||
At the core, it's CPU and GPU Tensor and Neural Network backends
|
||||
(TH, THC, THNN, THCUNN) are written as independent libraries with a C99 API.
|
||||
They are mature and have been tested for years.
|
||||
|
||||
The memory usage in PyTorch is extremely efficient, and we've written custom memory allocators for the GPU to make sure that your
|
||||
deep learning models are maximally memory efficient. This enables you to train bigger deep learning models than before.
|
||||
Hence, PyTorch is quite fast -- whether you run small or large neural networks.
|
||||
|
||||
### Multi-GPU ready
|
||||
The memory usage in PyTorch is extremely efficient compared to Torch or some of the alternatives.
|
||||
We've written custom memory allocators for the GPU to make sure that
|
||||
your deep learning models are maximally memory efficient.
|
||||
This enables you to train bigger deep learning models than before.
|
||||
|
||||
PyTorch is fully powered to efficiently use Multiple GPUs for accelerated deep learning.
|
||||
We integrate efficient multi-gpu collectives such as NVIDIA NCCL to make sure that you get the maximal Multi-GPU performance.
|
||||
### Extensions without pain
|
||||
|
||||
### Simple Extension API to interface with C
|
||||
Writing new neural network modules, or interfacing with PyTorch's Tensor API was designed to be straight-forward
|
||||
and with minimal abstractions.
|
||||
|
||||
You can write new neural network layers in Python using the torch API
|
||||
[or your favorite numpy based libraries such as SciPy](https://github.com/pytorch/tutorials/blob/master/Creating%20extensions%20using%20numpy%20and%20scipy.ipynb).
|
||||
|
||||
If you want to write your layers in C/C++, we provide an extension API based on
|
||||
[cffi](http://cffi.readthedocs.io/en/latest/) that is efficient and with minimal boilerplate.
|
||||
There is no wrapper code that needs to be written. [You can see an example here](https://github.com/pytorch/extension-ffi).
|
||||
|
||||
Writing new neural network modules, or interfacing with PyTorch's Tensor API is a breeze, thanks to an easy to use
|
||||
extension API that is efficient and easy to use.
|
||||
|
||||
## Installation
|
||||
|
||||
### Binaries
|
||||
- Anaconda
|
||||
```bash
|
||||
conda install pytorch -c https://conda.anaconda.org/t/6N-MsQ4WZ7jo/soumith
|
||||
conda install pytorch torchvision -c soumith
|
||||
```
|
||||
|
||||
### From source
|
||||
|
||||
If you are installing from source, we highly recommend installing an [Anaconda](https://www.continuum.io/downloads) environment.
|
||||
You will get a high-quality BLAS library (MKL) and you get a controlled compiler version regardless of your Linux distro.
|
||||
|
||||
Once you have [anaconda](https://www.continuum.io/downloads) installed, here are the instructions.
|
||||
|
||||
If you want to compile with CUDA support, install
|
||||
- [NVIDIA CUDA](https://developer.nvidia.com/cuda-downloads) 7.5 or above
|
||||
- [NVIDIA CuDNN](https://developer.nvidia.com/cudnn) v5.x
|
||||
|
||||
#### Install optional dependencies
|
||||
|
||||
On Linux
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
pip install .
|
||||
export CMAKE_PREFIX_PATH=[anaconda root directory]
|
||||
|
||||
# Install basic dependencies
|
||||
conda install numpy mkl setuptools cmake gcc cffi
|
||||
|
||||
# Add LAPACK support for the GPU
|
||||
conda install -c soumith magma-cuda75 # or magma-cuda80 if CUDA 8.0
|
||||
```
|
||||
|
||||
On OSX
|
||||
```bash
|
||||
export CMAKE_PREFIX_PATH=[anaconda root directory]
|
||||
conda install numpy setuptools cmake cffi
|
||||
```
|
||||
|
||||
#### Install PyTorch
|
||||
```bash
|
||||
export MACOSX_DEPLOYMENT_TARGET=10.9 # if OSX
|
||||
pip install -r requirements.txt
|
||||
python setup.py install
|
||||
```
|
||||
|
||||
### Docker image
|
||||
|
||||
Dockerfiles are supplied to build images with cuda support and cudnn v5 and cudnn v6 RC. Build them as usual
|
||||
```
|
||||
docker build . -t pytorch-cudnnv5
|
||||
```
|
||||
or
|
||||
```
|
||||
docker build . -t pytorch-cudnnv6 -f tools/docker/Dockerfile-v6
|
||||
```
|
||||
and run them with nvidia-docker:
|
||||
```
|
||||
nvidia-docker run --rm -ti --ipc=host pytorch-cudnnv5
|
||||
```
|
||||
Please note that pytorch uses shared memory to share data between processes, so if torch multiprocessing is used (e.g.
|
||||
for multithreaded data loaders) the default shared memory segment size that container runs with is not enough, and you
|
||||
should increase shared memory size either with --ipc=host or --shm-size command line options to nvidia-docker run.
|
||||
|
||||
|
||||
## Getting Started
|
||||
|
||||
Three pointers to get you started:
|
||||
- [Tutorials: notebooks to get you started with understanding and using PyTorch](https://github.com/pytorch/tutorials)
|
||||
- [Examples: easy to understand pytorch code across all domains](https://github.com/pytorch/examples)
|
||||
- The API Reference: [http://pytorch.org/api/](http://pytorch.org/api/)
|
||||
- The API Reference: [http://pytorch.org/docs/](http://pytorch.org/docs/)
|
||||
|
||||
## Communication
|
||||
* forums: discuss implementations, research, etc. http://discuss.pytorch.org
|
||||
* github issues: bug reports, feature requests, install issues, RFCs, thoughts, etc.
|
||||
* slack: general chat, online discussions, collaboration etc. https://pytorch.slack.com/ . If you need a slack invite, ping me at soumith@pytorch.org
|
||||
* slack: general chat, online discussions, collaboration etc. https://pytorch.slack.com/ . If you need a slack invite, ping us at soumith@pytorch.org
|
||||
* newsletter: no-noise, one-way email newsletter with important announcements about pytorch. You can sign-up here: http://eepurl.com/cbG0rv
|
||||
|
||||
## Timeline
|
||||
## Releases and Contributing
|
||||
|
||||
We will run the alpha releases weekly for 6 weeks.
|
||||
After that, we will reevaluate progress, and if we are ready, we will hit beta-0. If not, we will do another two weeks of alpha.
|
||||
PyTorch has a 90 day release cycle (major releases).
|
||||
It's current state is Beta (v0.1.6), we expect no obvious bugs. Please let us know if you encounter a bug by [filing an issue](https://github.com/pytorch/pytorch/issues).
|
||||
|
||||
* ~~alpha-0: Working versions of torch, cutorch, nn, cunn, optim fully unit tested with seamless numpy conversions~~
|
||||
* ~~alpha-1: Serialization to/from disk with sharing intact. initial release of the new neuralnets package based on a Chainer-like design~~
|
||||
* ~~alpha-2: sharing tensors across processes for hogwild training or data-loading processes. a rewritten optim package for this new nn.~~
|
||||
* ~~alpha-3: binary installs, contbuilds, etc.~~
|
||||
* ~~alpha-4: multi-GPU support, cudnn integration, imagenet / resnet example~~
|
||||
* alpha-5: a ton of examples across vision, nlp, speech, RL -- this phase might make us rethink parts of the APIs, and hence want to do this in alpha than beta
|
||||
* alpha-6: Putting a simple and efficient story around multi-machine training. Probably simplistic like torch-distlearn. Building the website, release scripts, more documentation, etc.
|
||||
* beta-0: First public release
|
||||
We appreciate all contributions. If you are planning to contribute back bug-fixes, please do so without any further discussion.
|
||||
|
||||
The beta phases will be leaning more towards working with all of you, convering your use-cases, active development on non-core aspects.
|
||||
If you plan to contribute new features, utility functions or extensions to the core, please first open an issue and discuss the feature with us.
|
||||
Sending a PR without discussion might end up resulting in a rejected PR, because we might be taking the core in a different direction than you might be aware of.
|
||||
|
||||
## pytorch vs torch: important changes
|
||||
**For the next release cycle, these are the 3 big features we are planning to add:**
|
||||
|
||||
We've decided that it's time to rewrite/update parts of the old torch API, even if it means losing some of backward compatibility.
|
||||
1. [Distributed PyTorch](https://github.com/pytorch/pytorch/issues/241) (a draft implementation is present in this [branch](https://github.com/apaszke/pytorch-dist) )
|
||||
2. Backward of Backward - Backpropagating through the optimization process itself. Some past and recent papers such as
|
||||
[Double Backprop](http://yann.lecun.com/exdb/publis/pdf/drucker-lecun-91.pdf) and [Unrolled GANs](https://arxiv.org/abs/1611.02163) need this.
|
||||
3. Lazy Execution Engine for autograd - This will enable us to optionally introduce caching and JIT compilers to optimize autograd code.
|
||||
|
||||
**[This tutorial](https://github.com/pytorch/tutorials/blob/master/Introduction%20to%20PyTorch%20for%20former%20Torchies.ipynb) takes you through the biggest changes**
|
||||
and walks you through PyTorch
|
||||
|
||||
For brevity,
|
||||
## The Team
|
||||
|
||||
#### Tensors:
|
||||
- clear separation of in-place and out-of-place operations
|
||||
- zero-indexing
|
||||
- no camel casing for Tensor functions
|
||||
- an efficient Numpy bridge (with zero memory copy)
|
||||
- CUDA tensors have clear and intuitive semantics
|
||||
PyTorch is a community driven project with several skillful engineers and researchers contributing to it.
|
||||
|
||||
#### New neural network module (Combines nn, nngraph, autograd):
|
||||
|
||||
1. Design inspired from Chainer
|
||||
2. Modules no longer hold state. State is held in the graph
|
||||
1. Access state via hooks
|
||||
2. Execution engine
|
||||
1. imperative execution engine (default)
|
||||
2. lazy execution engine
|
||||
1. allows graph optimizations and automatic in-place / fusing operations
|
||||
4. Model structure is defined by its code
|
||||
1. You can use loops and arbitrarily complicated conditional statements
|
||||
|
||||
**To reiterate, we recommend that you go through [This tutorial](https://github.com/pytorch/tutorials/blob/master/Introduction%20to%20PyTorch%20for%20former%20Torchies.ipynb)**
|
||||
|
||||
### Serialization
|
||||
|
||||
Pickling tensors is supported, but requires making a temporary copy of all data in memory and breaks sharing.
|
||||
|
||||
For this reason we're providing `torch.load` and `torch.save`, that are free of these problems.
|
||||
|
||||
They have the same interfaces as `pickle.load` (file object) and `pickle.dump` (serialized object, file object) respectively.
|
||||
|
||||
For now the only requirement is that the file should have a `fileno` method, which returns a file descriptor number (this is already implemented by objects returned by `open`).
|
||||
|
||||
Objects are serialized in a tar archive consisting of four files:
|
||||
- `sys_info` - protocol version, byte order, long size, etc.
|
||||
- `pickle` - pickled object
|
||||
- `tensors` - tensor metadata
|
||||
- `storages` - serialized data
|
||||
|
||||
### Multiprocessing with Tensor sharing
|
||||
|
||||
We made PyTorch to seamlessly integrate with python multiprocessing.
|
||||
What we've added specially in torch.multiprocessing is the seamless ability to efficiently share and send
|
||||
tensors over from one process to another. ([technical details of implementation](http://github.com/pytorch/pytorch/wiki/Multiprocessing-Technical-Notes))
|
||||
This is very useful for example in:
|
||||
- Writing parallelized data loaders
|
||||
- Training models "hogwild", where several models are trained in parallel, sharing the same set of parameters.
|
||||
|
||||
Here are a couple of examples for torch.multiprocessing
|
||||
|
||||
```python
|
||||
# loaders.py
|
||||
# Functions from this file run in the workers
|
||||
|
||||
def fill(queue):
|
||||
while True:
|
||||
tensor = queue.get()
|
||||
tensor.fill_(10)
|
||||
queue.put(tensor)
|
||||
|
||||
def fill_pool(tensor):
|
||||
tensor.fill_(10)
|
||||
```
|
||||
|
||||
```python
|
||||
# Example 1: Using multiple persistent processes and a Queue
|
||||
# process.py
|
||||
|
||||
import torch
|
||||
import torch.multiprocessing as multiprocessing
|
||||
from loaders import fill
|
||||
|
||||
# torch.multiprocessing.Queue automatically moves Tensor data to shared memory
|
||||
# So the main process and worker share the data
|
||||
queue = multiprocessing.Queue()
|
||||
buffers = [torch.Tensor(2, 2) for i in range(4)]
|
||||
for b in buffers:
|
||||
queue.put(b)
|
||||
processes = [multiprocessing.Process(target=fill, args=(queue,)).start() for i in range(10)]
|
||||
```
|
||||
|
||||
```python
|
||||
# Example 2: Using a process pool
|
||||
# pool.py
|
||||
|
||||
import torch
|
||||
from torch.multiprocessing import Pool
|
||||
from loaders import fill_pool
|
||||
|
||||
tensors = [torch.Tensor(2, 2) for i in range(100)]
|
||||
pool = Pool(10)
|
||||
pool.map(fill_pool, tensors)
|
||||
```
|
||||
|
||||
#### Some notes on new nn implementation
|
||||
|
||||
As shown above, structure of the networks is fully defined by control-flow embedded in the code. There are no rigid containers known from Lua. You can put an `if` in the middle of your model and freely branch depending on any condition you can come up with. All operations are registered in the computational graph history.
|
||||
|
||||
There are two main objects that make this possible - variables and functions. They will be denoted as squares and circles respectively.
|
||||
|
||||

|
||||
|
||||
Variables are the objects that hold a reference to a tensor (and optionally to gradient w.r.t. that tensor), and to the function in the computational graph that created it. Variables created explicitly by the user (`Variable(tensor)`) have a Leaf function node associated with them.
|
||||
|
||||
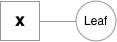
|
||||
|
||||
Functions are simple classes that define a function from a tuple of inputs to a tuple of outputs, and a formula for computing gradient w.r.t. it's inputs. Function objects are instantiated to hold references to other functions, and these references allow to reconstruct the history of a computation. An example graph for a linear layer (`Wx + b`) is shown below.
|
||||
|
||||
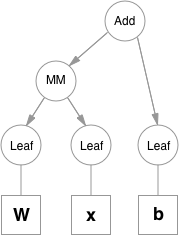
|
||||
|
||||
Please note that function objects never hold references to Variable objects, except for when they're necessary in the backward pass. This allows to free all the unnecessary intermediate values. A good example for this is addition when computing e.g. (`y = Wx + My`):
|
||||
|
||||
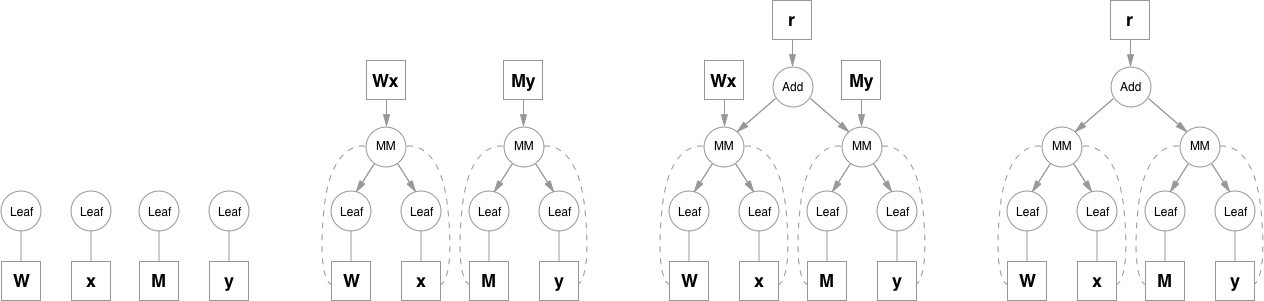
|
||||
|
||||
Matrix multiplication operation keeps references to it's inputs because it will need them, but addition doesn't need `Wx` and `My` after it computes the result, so as soon as they go out of scope they are freed. To access intermediate values in the forward pass you can either copy them when you still have a reference, or you can use a system of hooks that can be attached to any function. Hooks also allow to access and inspect gradients inside the graph.
|
||||
|
||||
Another nice thing about this is that a single layer doesn't hold any state other than it's parameters (all intermediate values are alive as long as the graph references them), so it can be used multiple times before calling backward. This is especially convenient when training RNNs. You can use the same network for all timesteps and the gradients will sum up automatically.
|
||||
|
||||
To compute backward pass you can call `.backward()` on a variable if it's a scalar (a 1-element Variable), or you can provide a gradient tensor of matching shape if it's not. This creates an execution engine object that manages the whole backward pass. It's been introduced, so that the code for analyzing the graph and scheduling node processing order is decoupled from other parts, and can be easily replaced. Right now it's simply processing the nodes in topological order, without any prioritization, but in the future we can implement algorithms and heuristics for scheduling independent nodes on different GPU streams, deciding which branches to compute first, etc.
|
||||
PyTorch is currently maintained by [Adam Paszke](https://apaszke.github.io/), [Sam Gross](https://github.com/colesbury) and [Soumith Chintala](http://soumith.ch) with major contributions coming from 10s of talented individuals in various forms and means. A non-exhaustive but growing list needs to mention: Sergey Zagoruyko, Adam Lerer, Francisco Massa, Andreas Kopf, James Bradbury, Zeming Lin, Yuandong Tian, Guillaume Lample, Marat Dukhan, Natalia Gimelshein.
|
||||
|
||||
Note: this project is unrelated to [hughperkins/pytorch](https://github.com/hughperkins/pytorch) with the same name. Hugh is a valuable contributor in the Torch community and has helped with many things Torch and PyTorch.
|
||||
|
||||
@ -685,17 +685,21 @@ endif()
|
||||
|
||||
|
||||
# CUDA_NVCC_EXECUTABLE
|
||||
cuda_find_host_program(CUDA_NVCC_EXECUTABLE
|
||||
NAMES nvcc
|
||||
PATHS "${CUDA_TOOLKIT_ROOT_DIR}"
|
||||
ENV CUDA_PATH
|
||||
ENV CUDA_BIN_PATH
|
||||
PATH_SUFFIXES bin bin64
|
||||
NO_DEFAULT_PATH
|
||||
)
|
||||
# Search default search paths, after we search our own set of paths.
|
||||
cuda_find_host_program(CUDA_NVCC_EXECUTABLE nvcc)
|
||||
mark_as_advanced(CUDA_NVCC_EXECUTABLE)
|
||||
if(DEFINED ENV{CUDA_NVCC_EXECUTABLE})
|
||||
SET(CUDA_NVCC_EXECUTABLE "$ENV{CUDA_NVCC_EXECUTABLE}")
|
||||
else(DEFINED ENV{CUDA_NVCC_EXECUTABLE})
|
||||
cuda_find_host_program(CUDA_NVCC_EXECUTABLE
|
||||
NAMES nvcc
|
||||
PATHS "${CUDA_TOOLKIT_ROOT_DIR}"
|
||||
ENV CUDA_PATH
|
||||
ENV CUDA_BIN_PATH
|
||||
PATH_SUFFIXES bin bin64
|
||||
NO_DEFAULT_PATH
|
||||
)
|
||||
# Search default search paths, after we search our own set of paths.
|
||||
cuda_find_host_program(CUDA_NVCC_EXECUTABLE nvcc)
|
||||
mark_as_advanced(CUDA_NVCC_EXECUTABLE)
|
||||
endif(DEFINED ENV{CUDA_NVCC_EXECUTABLE})
|
||||
|
||||
if(CUDA_NVCC_EXECUTABLE AND NOT CUDA_VERSION)
|
||||
# Compute the version.
|
||||
|
||||
20
docs/Makefile
Normal file
@ -0,0 +1,20 @@
|
||||
# Minimal makefile for Sphinx documentation
|
||||
#
|
||||
|
||||
# You can set these variables from the command line.
|
||||
SPHINXOPTS =
|
||||
SPHINXBUILD = sphinx-build
|
||||
SPHINXPROJ = PyTorch
|
||||
SOURCEDIR = source
|
||||
BUILDDIR = build
|
||||
|
||||
# Put it first so that "make" without argument is like "make help".
|
||||
help:
|
||||
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
|
||||
.PHONY: help Makefile
|
||||
|
||||
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||
%: Makefile
|
||||
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
@ -1,435 +0,0 @@
|
||||
#! /usr/bin/env python
|
||||
# encoding: utf-8
|
||||
"""
|
||||
Very lightweight docstring to Markdown converter. Modified for use in pytorch
|
||||
|
||||
|
||||
### License
|
||||
|
||||
Copyright © 2013 Thomas Gläßle <t_glaessle@gmx.de>
|
||||
|
||||
This work is free. You can redistribute it and/or modify it under the
|
||||
terms of the Do What The Fuck You Want To Public License, Version 2, as
|
||||
published by Sam Hocevar. See the COPYING file for more details.
|
||||
|
||||
This program is free software. It comes without any warranty, to the
|
||||
extent permitted by applicable law.
|
||||
|
||||
|
||||
### Description
|
||||
|
||||
Little convenience tool to extract docstrings from a module or class and
|
||||
convert them to GitHub Flavoured Markdown:
|
||||
|
||||
https://help.github.com/articles/github-flavored-markdown
|
||||
|
||||
Its purpose is to quickly generate `README.md` files for small projects.
|
||||
|
||||
|
||||
### API
|
||||
|
||||
The interface consists of the following functions:
|
||||
|
||||
- `doctrim(docstring)`
|
||||
- `doc2md(docstring, title)`
|
||||
|
||||
You can run this script from the command line like:
|
||||
|
||||
$ doc2md.py [-a] [--no-toc] [-t title] module-name [class-name] > README.md
|
||||
|
||||
|
||||
### Limitations
|
||||
|
||||
At the moment this is suited only for a very specific use case. It is
|
||||
hardly forseeable, if I will decide to improve on it in the near future.
|
||||
|
||||
"""
|
||||
import re
|
||||
import sys
|
||||
import inspect
|
||||
|
||||
__all__ = ['doctrim', 'doc2md']
|
||||
|
||||
doctrim = inspect.cleandoc
|
||||
|
||||
def unindent(lines):
|
||||
"""
|
||||
Remove common indentation from string.
|
||||
|
||||
Unlike doctrim there is no special treatment of the first line.
|
||||
|
||||
"""
|
||||
try:
|
||||
# Determine minimum indentation:
|
||||
indent = min(len(line) - len(line.lstrip())
|
||||
for line in lines if line)
|
||||
except ValueError:
|
||||
return lines
|
||||
else:
|
||||
return [line[indent:] for line in lines]
|
||||
|
||||
def escape_markdown(line):
|
||||
line = line.replace('[', '\[').replace(']', '\]')
|
||||
line = line.replace('(', '\(').replace(')', '\)')
|
||||
line = line.replace('{', '\{').replace('}', '\}')
|
||||
line = line.replace('\\', '\\\\')
|
||||
line = line.replace('`', '\`')
|
||||
line = line.replace('*', '\*')
|
||||
line = line.replace('_', '\_')
|
||||
line = line.replace('#', '\#')
|
||||
line = line.replace('+', '\+')
|
||||
line = line.replace('-', '\-')
|
||||
line = line.replace('.', '\.')
|
||||
line = line.replace('!', '\!')
|
||||
return line
|
||||
|
||||
def code_block(lines, language=''):
|
||||
"""
|
||||
Mark the code segment for syntax highlighting.
|
||||
"""
|
||||
return ['```' + language] + lines + ['```']
|
||||
|
||||
def doctest2md(lines):
|
||||
"""
|
||||
Convert the given doctest to a syntax highlighted markdown segment.
|
||||
"""
|
||||
is_only_code = True
|
||||
lines = unindent(lines)
|
||||
for line in lines:
|
||||
if not line.startswith('>>> ') and not line.startswith('... ') and line not in ['>>>', '...']:
|
||||
is_only_code = False
|
||||
break
|
||||
if is_only_code:
|
||||
orig = lines
|
||||
lines = []
|
||||
for line in orig:
|
||||
lines.append(line[4:])
|
||||
return lines
|
||||
|
||||
def doc_code_block(lines, language):
|
||||
if language == 'python':
|
||||
lines = doctest2md(lines)
|
||||
return code_block(lines, language)
|
||||
|
||||
_args_section = re.compile('^\s*Args:\s*')
|
||||
def is_args_check(line):
|
||||
return _args_section.match(line)
|
||||
|
||||
def args_block(lines):
|
||||
out = ['']
|
||||
out += ['Parameter | Default | Description']
|
||||
out += ['--------- | ------- | -----------']
|
||||
for line in lines:
|
||||
matches = re.findall(r'\s*([^:]+):\s*(.*?)\s*(Default:\s(.*))?\s*$', line)
|
||||
assert matches != None
|
||||
name = matches[0][0]
|
||||
description = matches[0][1]
|
||||
default = matches[0][3]
|
||||
out += [name + ' | ' + default + ' | ' + description]
|
||||
return out
|
||||
|
||||
_returns_section = re.compile('^\s*Returns:\s*')
|
||||
def is_returns_check(line):
|
||||
return _returns_section.match(line)
|
||||
|
||||
_image_section = re.compile('^\s*Image:\s*')
|
||||
def is_image_check(line):
|
||||
return _image_section.match(line)
|
||||
|
||||
_example_section = re.compile('^\s*Returns:\s*|^\s*Examples:\s*')
|
||||
def is_example_check(line):
|
||||
return _example_section.match(line)
|
||||
|
||||
_inputshape_section = re.compile('^\s*Returns:\s*|^\s*Input Shape:\s*')
|
||||
def is_inputshape_check(line):
|
||||
return _inputshape_section.match(line)
|
||||
|
||||
_outputshape_section = re.compile('^\s*Returns:\s*|^\s*Output Shape:\s*')
|
||||
def is_outputshape_check(line):
|
||||
return _outputshape_section.match(line)
|
||||
|
||||
|
||||
#def get_docargs(line)
|
||||
|
||||
_reg_section = re.compile('^#+ ')
|
||||
def is_heading(line):
|
||||
return _reg_section.match(line)
|
||||
|
||||
def get_heading(line):
|
||||
assert is_heading(line)
|
||||
part = line.partition(' ')
|
||||
return len(part[0]), part[2]
|
||||
|
||||
def make_heading(level, title):
|
||||
return '#'*max(level, 1) + ' ' + title
|
||||
|
||||
def find_sections(lines):
|
||||
"""
|
||||
Find all section names and return a list with their names.
|
||||
"""
|
||||
sections = []
|
||||
for line in lines:
|
||||
if is_heading(line):
|
||||
sections.append(get_heading(line))
|
||||
return sections
|
||||
|
||||
def make_toc(sections):
|
||||
"""
|
||||
Generate table of contents for array of section names.
|
||||
"""
|
||||
if not sections:
|
||||
return []
|
||||
outer = min(n for n,t in sections)
|
||||
refs = []
|
||||
for ind,sec in sections:
|
||||
ref = sec.lower()
|
||||
ref = ref.replace(' ', '-')
|
||||
ref = ref.replace('?', '')
|
||||
refs.append(" "*(ind-outer) + "- [%s](#%s)" % (sec, ref))
|
||||
return refs
|
||||
|
||||
def _doc2md(lines, shiftlevel=0):
|
||||
_doc2md.md = []
|
||||
_doc2md.is_code = False
|
||||
_doc2md.is_code_block = False
|
||||
_doc2md.is_args = False
|
||||
_doc2md.is_returns = False
|
||||
_doc2md.is_inputshape = False
|
||||
_doc2md.is_outputshape = False
|
||||
_doc2md.code = []
|
||||
def reset():
|
||||
if _doc2md.is_code:
|
||||
_doc2md.is_code = False
|
||||
_doc2md.code += doc_code_block(code, 'python')
|
||||
_doc2md.code += ['']
|
||||
if _doc2md.is_code_block:
|
||||
_doc2md.is_code_block = False
|
||||
_doc2md.code += doc_code_block(code_block, 'python')
|
||||
_doc2md.code += ['']
|
||||
|
||||
if _doc2md.is_args:
|
||||
_doc2md.is_args = False
|
||||
_doc2md.md += args_block(args)
|
||||
|
||||
if _doc2md.is_returns:
|
||||
_doc2md.is_returns = False
|
||||
_doc2md.md += returns
|
||||
|
||||
_doc2md.is_inputshape = False
|
||||
_doc2md.is_outputshape = False
|
||||
|
||||
for line in lines:
|
||||
trimmed = line.lstrip()
|
||||
if is_args_check(line):
|
||||
reset()
|
||||
_doc2md.is_args = True
|
||||
_doc2md.md += ['']
|
||||
_doc2md.md += ['#' * (shiftlevel+2) + ' Constructor Arguments']
|
||||
args = []
|
||||
elif is_returns_check(line):
|
||||
reset()
|
||||
_doc2md.is_returns = True
|
||||
_doc2md.md += ['']
|
||||
_doc2md.md += ['#' * (shiftlevel+2) + ' Returns']
|
||||
returns = []
|
||||
elif is_example_check(line):
|
||||
reset()
|
||||
elif is_inputshape_check(line):
|
||||
reset()
|
||||
inputshape = re.findall(r'\s*Input\sShape:\s*(.*)\s*:\s*(.*)\s*$', line)[0]
|
||||
elif is_outputshape_check(line):
|
||||
reset()
|
||||
outputshape = re.findall(r'\s*Output\sShape:\s*(.*)\s*:\s*(.*)\s*$', line)[0]
|
||||
_doc2md.md += ['']
|
||||
_doc2md.md += ['#' * (shiftlevel+2) + ' Expected Shape']
|
||||
_doc2md.md += [' | Shape | Description ']
|
||||
_doc2md.md += ['------ | ----- | ------------']
|
||||
_doc2md.md += [' input | ' + inputshape[0] + ' | ' + inputshape[1]]
|
||||
_doc2md.md += ['output | ' + outputshape[0] + ' | ' + outputshape[1]]
|
||||
elif is_image_check(line):
|
||||
reset()
|
||||
_doc2md.md += ['']
|
||||
filename = re.findall(r'\s*Image:\s*(.*?)\s*$', line)
|
||||
_doc2md.md += ['<img src="image/' + filename[0] + '" >']
|
||||
elif _doc2md.is_code == False and trimmed.startswith('>>> '):
|
||||
reset()
|
||||
_doc2md.is_code = True
|
||||
code = [line]
|
||||
elif _doc2md.is_code_block == False and trimmed.startswith('```'):
|
||||
reset()
|
||||
_doc2md.is_code_block = True
|
||||
code_block = []
|
||||
elif _doc2md.is_code_block == True and trimmed.startswith('```'):
|
||||
# end of code block
|
||||
reset()
|
||||
elif _doc2md.is_code_block:
|
||||
if line:
|
||||
code_block.append(line)
|
||||
else:
|
||||
reset()
|
||||
elif shiftlevel != 0 and is_heading(line):
|
||||
reset()
|
||||
level, title = get_heading(line)
|
||||
_doc2md.md += [make_heading(level + shiftlevel, title)]
|
||||
elif _doc2md.is_args:
|
||||
if line:
|
||||
args.append(line)
|
||||
else:
|
||||
reset()
|
||||
elif _doc2md.is_returns:
|
||||
if line:
|
||||
returns.append(line)
|
||||
else:
|
||||
reset()
|
||||
elif _doc2md.is_code:
|
||||
if line:
|
||||
code.append(line)
|
||||
else:
|
||||
reset()
|
||||
else:
|
||||
reset()
|
||||
_doc2md.md += [line]
|
||||
reset()
|
||||
_doc2md.code += _doc2md.md
|
||||
return _doc2md.code
|
||||
|
||||
def doc2md(docstr, title, min_level=1, more_info=False, toc=True):
|
||||
"""
|
||||
Convert a docstring to a markdown text.
|
||||
"""
|
||||
text = doctrim(docstr)
|
||||
lines = text.split('\n')
|
||||
|
||||
sections = find_sections(lines)
|
||||
if sections:
|
||||
level = min(n for n,t in sections) - 1
|
||||
else:
|
||||
level = 1
|
||||
|
||||
shiftlevel = 0
|
||||
if level < min_level:
|
||||
shiftlevel = min_level - level
|
||||
level = min_level
|
||||
sections = [(lev+shiftlevel, tit) for lev,tit in sections]
|
||||
|
||||
md = [
|
||||
make_heading(level, title),
|
||||
"",
|
||||
lines.pop(0),
|
||||
""
|
||||
]
|
||||
if toc:
|
||||
md += make_toc(sections)
|
||||
md += _doc2md(lines, shiftlevel)
|
||||
if more_info:
|
||||
return (md, sections)
|
||||
else:
|
||||
return "\n".join(md)
|
||||
|
||||
def mod2md(module, title, title_api_section, toc=True):
|
||||
"""
|
||||
Generate markdown document from module, including API section.
|
||||
"""
|
||||
docstr = module.__doc__ or " "
|
||||
|
||||
text = doctrim(docstr)
|
||||
lines = text.split('\n')
|
||||
|
||||
sections = find_sections(lines)
|
||||
if sections:
|
||||
level = min(n for n,t in sections) - 1
|
||||
else:
|
||||
level = 1
|
||||
|
||||
api_md = []
|
||||
api_sec = []
|
||||
if title_api_section :
|
||||
# sections.append((level+1, title_api_section))
|
||||
for name, entry in iter(sorted(module.__dict__.items())):
|
||||
if name[0] != '_' and entry.__doc__:
|
||||
#api_sec.append((level+1, name))
|
||||
#api_md += ['', '']
|
||||
if entry.__doc__:
|
||||
md, sec = doc2md(entry.__doc__, name,
|
||||
min_level=level+1, more_info=True, toc=False)
|
||||
api_sec += sec
|
||||
api_md += md
|
||||
|
||||
sections += api_sec
|
||||
|
||||
# headline
|
||||
md = [
|
||||
make_heading(level, title),
|
||||
"",
|
||||
lines.pop(0),
|
||||
""
|
||||
]
|
||||
|
||||
# main sections
|
||||
if toc:
|
||||
md += make_toc(sections)
|
||||
md += _doc2md(lines)
|
||||
|
||||
if toc:
|
||||
md += ['']
|
||||
md += make_toc(api_sec)
|
||||
md += api_md
|
||||
|
||||
return "\n".join(md)
|
||||
|
||||
def main(args=None):
|
||||
# parse the program arguments
|
||||
import argparse
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Convert docstrings to markdown.')
|
||||
|
||||
parser.add_argument(
|
||||
'module', help='The module containing the docstring.')
|
||||
group = parser.add_mutually_exclusive_group()
|
||||
group.add_argument(
|
||||
'entry', nargs='?',
|
||||
help='Convert only docstring of this entry in module.')
|
||||
group.add_argument(
|
||||
'-a', '--all', dest='all', action='store_true',
|
||||
help='Create an API section with the contents of module.__all__.')
|
||||
parser.add_argument(
|
||||
'-t', '--title', dest='title',
|
||||
help='Document title (default is module name)')
|
||||
parser.add_argument(
|
||||
'--no-toc', dest='toc', action='store_false', default=True,
|
||||
help='Do not automatically generate the TOC')
|
||||
args = parser.parse_args(args)
|
||||
|
||||
import importlib
|
||||
import inspect
|
||||
import os
|
||||
|
||||
def add_path(*pathes):
|
||||
for path in reversed(pathes):
|
||||
if path not in sys.path:
|
||||
sys.path.insert(0, path)
|
||||
|
||||
file = inspect.getfile(inspect.currentframe())
|
||||
add_path(os.path.realpath(os.path.abspath(os.path.dirname(file))))
|
||||
add_path(os.getcwd())
|
||||
|
||||
mod_name = args.module
|
||||
if mod_name.endswith('.py'):
|
||||
mod_name = mod_name.rsplit('.py', 1)[0]
|
||||
title = args.title or mod_name.replace('_', '-')
|
||||
|
||||
module = importlib.import_module(mod_name)
|
||||
|
||||
if args.all:
|
||||
print(mod2md(module, title, 'API', toc=args.toc))
|
||||
|
||||
else:
|
||||
if args.entry:
|
||||
docstr = module.__dict__[args.entry].__doc__ or ''
|
||||
else:
|
||||
docstr = module.__doc__ or ''
|
||||
|
||||
print(doc2md(docstr, title, toc=args.toc))
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
@ -1,6 +0,0 @@
|
||||
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
|
||||
pushd $SCRIPT_DIR
|
||||
|
||||
python doc2md.py torch.nn --no-toc --all >../nn.md
|
||||
|
||||
popd
|
||||
{kind=link}
|
Before Width: | Height: | Size: 5.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.0 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 8.5 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 19 KiB |
{kind=link}
|
Before Width: | Height: | Size: 19 KiB |
{kind=link}
|
Before Width: | Height: | Size: 20 KiB |
{kind=link}
|
Before Width: | Height: | Size: 12 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 19 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.7 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
Before Width: | Height: | Size: 6.8 KiB |
{kind=link}
|
Before Width: | Height: | Size: 5.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 7.2 KiB |
36
docs/make.bat
Normal file
@ -0,0 +1,36 @@
|
||||
@ECHO OFF
|
||||
|
||||
pushd %~dp0
|
||||
|
||||
REM Command file for Sphinx documentation
|
||||
|
||||
if "%SPHINXBUILD%" == "" (
|
||||
set SPHINXBUILD=sphinx-build
|
||||
)
|
||||
set SOURCEDIR=source
|
||||
set BUILDDIR=build
|
||||
set SPHINXPROJ=PyTorch
|
||||
|
||||
if "%1" == "" goto help
|
||||
|
||||
%SPHINXBUILD% >NUL 2>NUL
|
||||
if errorlevel 9009 (
|
||||
echo.
|
||||
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
||||
echo.installed, then set the SPHINXBUILD environment variable to point
|
||||
echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
||||
echo.may add the Sphinx directory to PATH.
|
||||
echo.
|
||||
echo.If you don't have Sphinx installed, grab it from
|
||||
echo.http://sphinx-doc.org/
|
||||
exit /b 1
|
||||
)
|
||||
|
||||
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
|
||||
goto end
|
||||
|
||||
:help
|
||||
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS%
|
||||
|
||||
:end
|
||||
popd
|
||||
1370
docs/nn.md
2
docs/requirements.txt
Normal file
@ -0,0 +1,2 @@
|
||||
sphinx
|
||||
-e git://github.com/snide/sphinx_rtd_theme.git#egg=sphinx_rtd_theme
|
||||
114
docs/source/_static/css/pytorch_theme.css
Normal file
@ -0,0 +1,114 @@
|
||||
body {
|
||||
font-family: "Lato","proxima-nova","Helvetica Neue",Arial,sans-serif;
|
||||
}
|
||||
|
||||
/* Default header fonts are ugly */
|
||||
h1, h2, .rst-content .toctree-wrapper p.caption, h3, h4, h5, h6, legend, p.caption {
|
||||
font-family: "Lato","proxima-nova","Helvetica Neue",Arial,sans-serif;
|
||||
}
|
||||
|
||||
/* Use white for docs background */
|
||||
.wy-side-nav-search {
|
||||
background-color: #fff;
|
||||
}
|
||||
|
||||
.wy-nav-content-wrap, .wy-menu li.current > a {
|
||||
background-color: #fff;
|
||||
}
|
||||
|
||||
@media screen and (min-width: 1400px) {
|
||||
.wy-nav-content-wrap {
|
||||
background-color: rgba(0, 0, 0, 0.0470588);
|
||||
}
|
||||
|
||||
.wy-nav-content {
|
||||
background-color: #fff;
|
||||
}
|
||||
}
|
||||
|
||||
/* Fixes for mobile */
|
||||
.wy-nav-top {
|
||||
background-color: #fff;
|
||||
background-image: url('../img/pytorch-logo-dark.svg');
|
||||
background-repeat: no-repeat;
|
||||
background-position: center;
|
||||
padding: 0;
|
||||
margin: 0.4045em 0.809em;
|
||||
color: #333;
|
||||
}
|
||||
|
||||
.wy-nav-top > a {
|
||||
display: none;
|
||||
}
|
||||
|
||||
@media screen and (max-width: 768px) {
|
||||
.wy-side-nav-search>a img.logo {
|
||||
height: 60px;
|
||||
}
|
||||
}
|
||||
|
||||
/* This is needed to ensure that logo above search scales properly */
|
||||
.wy-side-nav-search a {
|
||||
display: block;
|
||||
}
|
||||
|
||||
/* This ensures that multiple constructors will remain in separate lines. */
|
||||
.rst-content dl:not(.docutils) dt {
|
||||
display: table;
|
||||
}
|
||||
|
||||
/* Use our red for literals (it's very similar to the original color) */
|
||||
.rst-content tt.literal, .rst-content tt.literal, .rst-content code.literal {
|
||||
color: #F05732;
|
||||
}
|
||||
|
||||
.rst-content tt.xref, a .rst-content tt, .rst-content tt.xref,
|
||||
.rst-content code.xref, a .rst-content tt, a .rst-content code {
|
||||
color: #404040;
|
||||
}
|
||||
|
||||
/* Change link colors (except for the menu) */
|
||||
|
||||
a {
|
||||
color: #F05732;
|
||||
}
|
||||
|
||||
a:hover {
|
||||
color: #F05732;
|
||||
}
|
||||
|
||||
|
||||
a:visited {
|
||||
color: #D44D2C;
|
||||
}
|
||||
|
||||
.wy-menu a {
|
||||
color: #b3b3b3;
|
||||
}
|
||||
|
||||
.wy-menu a:hover {
|
||||
color: #b3b3b3;
|
||||
}
|
||||
|
||||
/* Default footer text is quite big */
|
||||
footer {
|
||||
font-size: 80%;
|
||||
}
|
||||
|
||||
footer .rst-footer-buttons {
|
||||
font-size: 125%; /* revert footer settings - 1/80% = 125% */
|
||||
}
|
||||
|
||||
footer p {
|
||||
font-size: 100%;
|
||||
}
|
||||
|
||||
/* For hidden headers that appear in TOC tree */
|
||||
/* see http://stackoverflow.com/a/32363545/3343043 */
|
||||
.rst-content .hidden-section {
|
||||
display: none;
|
||||
}
|
||||
|
||||
nav .hidden-section {
|
||||
display: inherit;
|
||||
}
|
||||
BIN
docs/source/_static/img/dynamic_graph.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 258 KiB |
BIN
docs/source/_static/img/pytorch-logo-dark.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
24
docs/source/_static/img/pytorch-logo-dark.svg
Normal file
{kind=link}
@ -0,0 +1,24 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<!-- Generator: Adobe Illustrator 21.0.0, SVG Export Plug-In . SVG Version: 6.00 Build 0) -->
|
||||
<svg version="1.1" id="Layer_1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" x="0px" y="0px"
|
||||
viewBox="0 0 199.7 40.2" style="enable-background:new 0 0 199.7 40.2;" xml:space="preserve">
|
||||
<style type="text/css">
|
||||
.st0{fill:#F05732;}
|
||||
.st1{fill:#9E529F;}
|
||||
.st2{fill:#333333;}
|
||||
</style>
|
||||
<path class="st0" d="M102.7,12.2c-1.3-1-1.8,3.9-4.4,3.9c-3,0-4-13-6.3-13c-0.7,0-0.8-0.4-7.9,21.3c-2.9,9,4.4,15.8,11.8,15.8
|
||||
c4.6,0,12.3-3,12.3-12.6C108.2,20.5,104.7,13.7,102.7,12.2z M95.8,35.3c-3.7,0-6.7-3.1-6.7-7c0-3.9,3-7,6.7-7s6.7,3.1,6.7,7
|
||||
C102.5,32.1,99.5,35.3,95.8,35.3z"/>
|
||||
<path class="st1" d="M99.8,0c-0.5,0-1.8,2.5-1.8,3.6c0,1.5,1,2,1.8,2c0.8,0,1.8-0.5,1.8-2C101.5,2.5,100.2,0,99.8,0z"/>
|
||||
<path class="st2" d="M0,39.5V14.9h11.5c5.3,0,8.3,3.6,8.3,7.9c0,4.3-3,7.9-8.3,7.9H5.2v8.8H0z M14.4,22.8c0-2.1-1.6-3.3-3.7-3.3H5.2
|
||||
v6.6h5.5C12.8,26.1,14.4,24.8,14.4,22.8z"/>
|
||||
<path class="st2" d="M35.2,39.5V29.4l-9.4-14.5h6l6.1,9.8l6.1-9.8h5.9l-9.4,14.5v10.1H35.2z"/>
|
||||
<path class="st2" d="M63.3,39.5v-20h-7.2v-4.6h19.6v4.6h-7.2v20H63.3z"/>
|
||||
<path class="st2" d="M131.4,39.5l-4.8-8.7h-3.8v8.7h-5.2V14.9H129c5.1,0,8.3,3.4,8.3,7.9c0,4.3-2.8,6.7-5.4,7.3l5.6,9.4H131.4z
|
||||
M131.9,22.8c0-2-1.6-3.3-3.7-3.3h-5.5v6.6h5.5C130.3,26.1,131.9,24.9,131.9,22.8z"/>
|
||||
<path class="st2" d="M145.6,27.2c0-7.6,5.7-12.7,13.1-12.7c5.4,0,8.5,2.9,10.3,6l-4.5,2.2c-1-2-3.2-3.6-5.8-3.6
|
||||
c-4.5,0-7.7,3.4-7.7,8.1c0,4.6,3.2,8.1,7.7,8.1c2.5,0,4.7-1.6,5.8-3.6l4.5,2.2c-1.7,3.1-4.9,6-10.3,6
|
||||
C151.3,39.9,145.6,34.7,145.6,27.2z"/>
|
||||
<path class="st2" d="M194.5,39.5V29.1h-11.6v10.4h-5.2V14.9h5.2v9.7h11.6v-9.7h5.3v24.6H194.5z"/>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 1.7 KiB |
BIN
docs/source/_static/img/tensor_illustration.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
53
docs/source/autograd.rst
Normal file
@ -0,0 +1,53 @@
|
||||
.. role:: hidden
|
||||
:class: hidden-section
|
||||
|
||||
Automatic differentiation package - torch.autograd
|
||||
==================================================
|
||||
|
||||
.. automodule:: torch.autograd
|
||||
.. currentmodule:: torch.autograd
|
||||
|
||||
.. autofunction:: backward
|
||||
|
||||
Variable
|
||||
--------
|
||||
|
||||
API compatibility
|
||||
^^^^^^^^^^^^^^^^^
|
||||
|
||||
Variable API is nearly the same as regular Tensor API (with the exception
|
||||
of a couple in-place methods, that would overwrite inputs required for
|
||||
gradient computation). In most cases Tensors can be safely replaced with
|
||||
Variables and the code will remain to work just fine. Because of this,
|
||||
we're not documenting all the operations on variables, and you should
|
||||
refere to :class:`torch.Tensor` docs for this purpose.
|
||||
|
||||
In-place operations on Variables
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Supporting in-place operations in autograd is a hard matter, and we discourage
|
||||
their use in most cases. Autograd's aggressive buffer freeing and reuse makes
|
||||
it very efficient and there are very few occasions when in-place operations
|
||||
actually lower memory usage by any significant amount. Unless you're operating
|
||||
under heavy memory pressure, you might never need to use them.
|
||||
|
||||
In-place correctness checks
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
All :class:`Variable` s keep track of in-place operations applied to them, and
|
||||
if the implementation detects that a variable was saved for backward in one of
|
||||
the functions, but it was modified in-place afterwards, an error will be raised
|
||||
once backward pass is started. This ensures that if you're using in-place
|
||||
functions and not seing any errors, you can be sure that the computed gradients
|
||||
are correct.
|
||||
|
||||
|
||||
.. autoclass:: Variable
|
||||
:members:
|
||||
|
||||
:hidden:`Function`
|
||||
------------------
|
||||
|
||||
.. autoclass:: Function
|
||||
:members:
|
||||
|
||||
243
docs/source/conf.py
Normal file
@ -0,0 +1,243 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
#
|
||||
# PyTorch documentation build configuration file, created by
|
||||
# sphinx-quickstart on Fri Dec 23 13:31:47 2016.
|
||||
#
|
||||
# This file is execfile()d with the current directory set to its
|
||||
# containing dir.
|
||||
#
|
||||
# Note that not all possible configuration values are present in this
|
||||
# autogenerated file.
|
||||
#
|
||||
# All configuration values have a default; values that are commented out
|
||||
# serve to show the default.
|
||||
|
||||
# If extensions (or modules to document with autodoc) are in another directory,
|
||||
# add these directories to sys.path here. If the directory is relative to the
|
||||
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
||||
#
|
||||
# import os
|
||||
# import sys
|
||||
# sys.path.insert(0, os.path.abspath('.'))
|
||||
import torch
|
||||
try:
|
||||
import torchvision
|
||||
except ImportError:
|
||||
import warnings
|
||||
warnings.warn('unable to load "torchvision" package')
|
||||
import sphinx_rtd_theme
|
||||
|
||||
|
||||
# -- General configuration ------------------------------------------------
|
||||
|
||||
# If your documentation needs a minimal Sphinx version, state it here.
|
||||
#
|
||||
# needs_sphinx = '1.0'
|
||||
|
||||
# Add any Sphinx extension module names here, as strings. They can be
|
||||
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
||||
# ones.
|
||||
extensions = [
|
||||
'sphinx.ext.autodoc',
|
||||
'sphinx.ext.autosummary',
|
||||
'sphinx.ext.doctest',
|
||||
'sphinx.ext.intersphinx',
|
||||
'sphinx.ext.todo',
|
||||
'sphinx.ext.coverage',
|
||||
'sphinx.ext.mathjax',
|
||||
'sphinx.ext.napoleon',
|
||||
'sphinx.ext.viewcode',
|
||||
]
|
||||
|
||||
napoleon_use_ivar = True
|
||||
|
||||
# Add any paths that contain templates here, relative to this directory.
|
||||
templates_path = ['_templates']
|
||||
|
||||
# The suffix(es) of source filenames.
|
||||
# You can specify multiple suffix as a list of string:
|
||||
#
|
||||
# source_suffix = ['.rst', '.md']
|
||||
source_suffix = '.rst'
|
||||
|
||||
# The master toctree document.
|
||||
master_doc = 'index'
|
||||
|
||||
# General information about the project.
|
||||
project = 'PyTorch'
|
||||
copyright = '2017, Torch Contributors'
|
||||
author = 'Torch Contributors'
|
||||
|
||||
# The version info for the project you're documenting, acts as replacement for
|
||||
# |version| and |release|, also used in various other places throughout the
|
||||
# built documents.
|
||||
#
|
||||
# The short X.Y version.
|
||||
version = '0.1.6'
|
||||
# The full version, including alpha/beta/rc tags.
|
||||
release = '0.1.6'
|
||||
|
||||
# The language for content autogenerated by Sphinx. Refer to documentation
|
||||
# for a list of supported languages.
|
||||
#
|
||||
# This is also used if you do content translation via gettext catalogs.
|
||||
# Usually you set "language" from the command line for these cases.
|
||||
language = None
|
||||
|
||||
# List of patterns, relative to source directory, that match files and
|
||||
# directories to ignore when looking for source files.
|
||||
# This patterns also effect to html_static_path and html_extra_path
|
||||
exclude_patterns = []
|
||||
|
||||
# The name of the Pygments (syntax highlighting) style to use.
|
||||
pygments_style = 'sphinx'
|
||||
|
||||
# If true, `todo` and `todoList` produce output, else they produce nothing.
|
||||
todo_include_todos = True
|
||||
|
||||
|
||||
# -- Options for HTML output ----------------------------------------------
|
||||
|
||||
# The theme to use for HTML and HTML Help pages. See the documentation for
|
||||
# a list of builtin themes.
|
||||
#
|
||||
html_theme = 'sphinx_rtd_theme'
|
||||
html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
|
||||
|
||||
# Theme options are theme-specific and customize the look and feel of a theme
|
||||
# further. For a list of options available for each theme, see the
|
||||
# documentation.
|
||||
#
|
||||
html_theme_options = {
|
||||
'collapse_navigation': False,
|
||||
'display_version': False,
|
||||
'logo_only': True,
|
||||
}
|
||||
|
||||
html_logo = '_static/img/pytorch-logo-dark.svg'
|
||||
|
||||
# Add any paths that contain custom static files (such as style sheets) here,
|
||||
# relative to this directory. They are copied after the builtin static files,
|
||||
# so a file named "default.css" will overwrite the builtin "default.css".
|
||||
html_static_path = ['_static']
|
||||
|
||||
# html_style_path = 'css/pytorch_theme.css'
|
||||
html_context = {
|
||||
'css_files': [
|
||||
'https://fonts.googleapis.com/css?family=Lato',
|
||||
'_static/css/pytorch_theme.css'
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
# -- Options for HTMLHelp output ------------------------------------------
|
||||
|
||||
# Output file base name for HTML help builder.
|
||||
htmlhelp_basename = 'PyTorchdoc'
|
||||
|
||||
|
||||
# -- Options for LaTeX output ---------------------------------------------
|
||||
|
||||
latex_elements = {
|
||||
# The paper size ('letterpaper' or 'a4paper').
|
||||
#
|
||||
# 'papersize': 'letterpaper',
|
||||
|
||||
# The font size ('10pt', '11pt' or '12pt').
|
||||
#
|
||||
# 'pointsize': '10pt',
|
||||
|
||||
# Additional stuff for the LaTeX preamble.
|
||||
#
|
||||
# 'preamble': '',
|
||||
|
||||
# Latex figure (float) alignment
|
||||
#
|
||||
# 'figure_align': 'htbp',
|
||||
}
|
||||
|
||||
# Grouping the document tree into LaTeX files. List of tuples
|
||||
# (source start file, target name, title,
|
||||
# author, documentclass [howto, manual, or own class]).
|
||||
latex_documents = [
|
||||
(master_doc, 'pytorch.tex', 'PyTorch Documentation',
|
||||
'Torch Contributors', 'manual'),
|
||||
]
|
||||
|
||||
|
||||
# -- Options for manual page output ---------------------------------------
|
||||
|
||||
# One entry per manual page. List of tuples
|
||||
# (source start file, name, description, authors, manual section).
|
||||
man_pages = [
|
||||
(master_doc, 'PyTorch', 'PyTorch Documentation',
|
||||
[author], 1)
|
||||
]
|
||||
|
||||
|
||||
# -- Options for Texinfo output -------------------------------------------
|
||||
|
||||
# Grouping the document tree into Texinfo files. List of tuples
|
||||
# (source start file, target name, title, author,
|
||||
# dir menu entry, description, category)
|
||||
texinfo_documents = [
|
||||
(master_doc, 'PyTorch', 'PyTorch Documentation',
|
||||
author, 'PyTorch', 'One line description of project.',
|
||||
'Miscellaneous'),
|
||||
]
|
||||
|
||||
|
||||
# Example configuration for intersphinx: refer to the Python standard library.
|
||||
intersphinx_mapping = {
|
||||
'python': ('https://docs.python.org/', None),
|
||||
'numpy': ('http://docs.scipy.org/doc/numpy/', None),
|
||||
}
|
||||
|
||||
# -- A patch that prevents Sphinx from cross-referencing ivar tags -------
|
||||
# See http://stackoverflow.com/a/41184353/3343043
|
||||
|
||||
from docutils import nodes
|
||||
from sphinx.util.docfields import TypedField
|
||||
from sphinx import addnodes
|
||||
|
||||
def patched_make_field(self, types, domain, items):
|
||||
# type: (List, unicode, Tuple) -> nodes.field
|
||||
def handle_item(fieldarg, content):
|
||||
par = nodes.paragraph()
|
||||
par += addnodes.literal_strong('', fieldarg) # Patch: this line added
|
||||
#par.extend(self.make_xrefs(self.rolename, domain, fieldarg,
|
||||
# addnodes.literal_strong))
|
||||
if fieldarg in types:
|
||||
par += nodes.Text(' (')
|
||||
# NOTE: using .pop() here to prevent a single type node to be
|
||||
# inserted twice into the doctree, which leads to
|
||||
# inconsistencies later when references are resolved
|
||||
fieldtype = types.pop(fieldarg)
|
||||
if len(fieldtype) == 1 and isinstance(fieldtype[0], nodes.Text):
|
||||
typename = u''.join(n.astext() for n in fieldtype)
|
||||
typename = typename.replace('int', 'python:int')
|
||||
typename = typename.replace('long', 'python:long')
|
||||
typename = typename.replace('float', 'python:float')
|
||||
typename = typename.replace('type', 'python:type')
|
||||
par.extend(self.make_xrefs(self.typerolename, domain, typename,
|
||||
addnodes.literal_emphasis))
|
||||
else:
|
||||
par += fieldtype
|
||||
par += nodes.Text(')')
|
||||
par += nodes.Text(' -- ')
|
||||
par += content
|
||||
return par
|
||||
|
||||
fieldname = nodes.field_name('', self.label)
|
||||
if len(items) == 1 and self.can_collapse:
|
||||
fieldarg, content = items[0]
|
||||
bodynode = handle_item(fieldarg, content)
|
||||
else:
|
||||
bodynode = self.list_type()
|
||||
for fieldarg, content in items:
|
||||
bodynode += nodes.list_item('', handle_item(fieldarg, content))
|
||||
fieldbody = nodes.field_body('', bodynode)
|
||||
return nodes.field('', fieldname, fieldbody)
|
||||
|
||||
TypedField.make_field = patched_make_field
|
||||
27
docs/source/cuda.rst
Normal file
@ -0,0 +1,27 @@
|
||||
torch.cuda
|
||||
===================================
|
||||
|
||||
.. currentmodule:: torch.cuda
|
||||
|
||||
.. automodule:: torch.cuda
|
||||
:members:
|
||||
|
||||
Communication collectives
|
||||
-------------------------
|
||||
|
||||
.. autofunction:: torch.cuda.comm.broadcast
|
||||
|
||||
.. autofunction:: torch.cuda.comm.reduce_add
|
||||
|
||||
.. autofunction:: torch.cuda.comm.scatter
|
||||
|
||||
.. autofunction:: torch.cuda.comm.gather
|
||||
|
||||
Streams and events
|
||||
------------------
|
||||
|
||||
.. autoclass:: Stream
|
||||
:members:
|
||||
|
||||
.. autoclass:: Event
|
||||
:members:
|
||||
7
docs/source/data.rst
Normal file
@ -0,0 +1,7 @@
|
||||
torch.utils.data
|
||||
===================================
|
||||
|
||||
.. automodule:: torch.utils.data
|
||||
.. autoclass:: Dataset
|
||||
.. autoclass:: TensorDataset
|
||||
.. autoclass:: DataLoader
|
||||
6
docs/source/ffi.rst
Normal file
@ -0,0 +1,6 @@
|
||||
torch.utils.ffi
|
||||
===============
|
||||
|
||||
.. currentmodule:: torch.utils.ffi
|
||||
.. autofunction:: create_extension
|
||||
|
||||
54
docs/source/index.rst
Normal file
@ -0,0 +1,54 @@
|
||||
.. PyTorch documentation master file, created by
|
||||
sphinx-quickstart on Fri Dec 23 13:31:47 2016.
|
||||
You can adapt this file completely to your liking, but it should at least
|
||||
contain the root `toctree` directive.
|
||||
|
||||
:github_url: https://github.com/pytorch/pytorch
|
||||
|
||||
PyTorch documentation
|
||||
===================================
|
||||
|
||||
PyTorch is an optimized tensor library for deep learning using GPUs and CPUs.
|
||||
|
||||
.. toctree::
|
||||
:glob:
|
||||
:maxdepth: 1
|
||||
:caption: Notes
|
||||
|
||||
notes/*
|
||||
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
:caption: Package Reference
|
||||
|
||||
torch
|
||||
tensors
|
||||
storage
|
||||
nn
|
||||
optim
|
||||
torch.autograd <autograd>
|
||||
torch.multiprocessing <multiprocessing>
|
||||
torch.legacy <legacy>
|
||||
cuda
|
||||
ffi
|
||||
data
|
||||
model_zoo
|
||||
|
||||
.. toctree::
|
||||
:glob:
|
||||
:maxdepth: 1
|
||||
:caption: torchvision Reference
|
||||
|
||||
torchvision/torchvision
|
||||
torchvision/datasets
|
||||
torchvision/models
|
||||
torchvision/transforms
|
||||
torchvision/utils
|
||||
|
||||
|
||||
Indices and tables
|
||||
==================
|
||||
|
||||
* :ref:`genindex`
|
||||
* :ref:`modindex`
|
||||
4
docs/source/legacy.rst
Normal file
@ -0,0 +1,4 @@
|
||||
Legacy package - torch.legacy
|
||||
===================================
|
||||
|
||||
.. automodule:: torch.legacy
|
||||
5
docs/source/model_zoo.rst
Normal file
@ -0,0 +1,5 @@
|
||||
torch.utils.model_zoo
|
||||
===================================
|
||||
|
||||
.. automodule:: torch.utils.model_zoo
|
||||
.. autofunction:: load_url
|
||||
88
docs/source/multiprocessing.rst
Normal file
@ -0,0 +1,88 @@
|
||||
Multiprocessing package - torch.multiprocessing
|
||||
===============================================
|
||||
|
||||
.. automodule:: torch.multiprocessing
|
||||
.. currentmodule:: torch.multiprocessing
|
||||
|
||||
.. warning::
|
||||
|
||||
If the main process exits abruptly (e.g. because of an incoming signal),
|
||||
Python's ``multiprocessing`` sometimes fails to clean up its children.
|
||||
It's a known caveat, so if you're seeing any resource leaks after
|
||||
interrupting the interpreter, it probably means that this has just happened
|
||||
to you.
|
||||
|
||||
Strategy management
|
||||
-------------------
|
||||
|
||||
.. autofunction:: get_all_sharing_strategies
|
||||
.. autofunction:: get_sharing_strategy
|
||||
.. autofunction:: set_sharing_strategy
|
||||
|
||||
Sharing CUDA tensors
|
||||
--------------------
|
||||
|
||||
Sharing CUDA tensors between processes is supported only in Python 3, using
|
||||
a ``spawn`` or ``forkserver`` start methods. :mod:`python:multiprocessing` in
|
||||
Python 2 can only create subprocesses using ``fork``, and it's not supported
|
||||
by the CUDA runtime.
|
||||
|
||||
.. warning::
|
||||
|
||||
CUDA API requires that the allocation exported to other processes remains
|
||||
valid as long as it's used by them. You should be careful and ensure that
|
||||
CUDA tensors you shared don't go out of scope as long as it's necessary.
|
||||
This shouldn't be a problem for sharing model parameters, but passing other
|
||||
kinds of data should be done with care. Note that this restriction doesn't
|
||||
apply to shared CPU memory.
|
||||
|
||||
|
||||
Sharing strategies
|
||||
------------------
|
||||
|
||||
This section provides a brief overview into how different sharing strategies
|
||||
work. Note that it applies only to CPU tensor - CUDA tensors will always use
|
||||
the CUDA API, as that's the only way they can be shared.
|
||||
|
||||
File descriptor - ``file_descriptor``
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
|
||||
.. note::
|
||||
|
||||
This is the default strategy (except for macOS and OS X where it's not
|
||||
supported).
|
||||
|
||||
This strategy will use file descriptors as shared memory handles. Whenever a
|
||||
storage is moved to shared memory, a file descriptor obtained from ``shm_open``
|
||||
is cached with the object, and when it's going to be sent to other processes,
|
||||
the file descriptor will be transferred (e.g. via UNIX sockets) to it. The
|
||||
receiver will also cache the file descriptor and ``mmap`` it, to obtain a shared
|
||||
view onto the storage data.
|
||||
|
||||
Note that if there will be a lot of tensors shared, this strategy will keep a
|
||||
large number of file descriptors open most of the time. If your system has low
|
||||
limits for the number of open file descriptors, and you can't rise them, you
|
||||
should use the ``file_system`` strategy.
|
||||
|
||||
File system - ``file_system``
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
This strategy will use file names given to ``shm_open`` to identify the shared
|
||||
memory regions. This has a benefit of not requiring the implementation to cache
|
||||
the file descriptors obtained from it, but at the same time is prone to shared
|
||||
memory leaks. The file can't be deleted right after its creation, because other
|
||||
processes need to access it to open their views. If the processes fatally
|
||||
crash, or are killed, and don't call the storage destructors, the files will
|
||||
remain in the system. This is very serious, because they keep using up the
|
||||
memory until the system is restarted, or they're freed manually.
|
||||
|
||||
To counter the problem of shared memory file leaks, :mod:`torch.multiprocessing`
|
||||
will spawn a daemon named ``torch_shm_manager`` that will isolate itself from
|
||||
the current process group, and will keep track of all shared memory allocations.
|
||||
Once all processes connected to it exit, it will wait a moment to ensure there
|
||||
will be no new connections, and will iterate over all shared memory files
|
||||
allocated by the group. If it finds that any of them still exist, they will be
|
||||
deallocated. We've tested this method and it prooved to be robust to various
|
||||
failures. Still, if your system has high enough limits, and ``file_descriptor``
|
||||
is a supported strategy, we do not recommend switching to this one.
|
||||
705
docs/source/nn.rst
Normal file
@ -0,0 +1,705 @@
|
||||
.. role:: hidden
|
||||
:class: hidden-section
|
||||
|
||||
torch.nn
|
||||
===================================
|
||||
|
||||
.. automodule:: torch.nn
|
||||
.. currentmodule:: torch.nn
|
||||
|
||||
Parameters
|
||||
----------
|
||||
|
||||
.. autoclass:: Parameter
|
||||
:members:
|
||||
|
||||
Containers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`Module`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Module
|
||||
:members:
|
||||
|
||||
Convolution Layers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`Conv1d`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Conv1d
|
||||
:members:
|
||||
|
||||
:hidden:`Conv2d`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Conv2d
|
||||
:members:
|
||||
|
||||
:hidden:`Conv3d`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Conv3d
|
||||
:members:
|
||||
|
||||
:hidden:`ConvTranspose1d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: ConvTranspose1d
|
||||
:members:
|
||||
|
||||
:hidden:`ConvTranspose2d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
|
||||
.. autoclass:: ConvTranspose2d
|
||||
:members:
|
||||
|
||||
:hidden:`ConvTranspose3d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: ConvTranspose3d
|
||||
:members:
|
||||
|
||||
|
||||
Pooling Layers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`MaxPool1d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MaxPool1d
|
||||
:members:
|
||||
|
||||
:hidden:`MaxPool2d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MaxPool2d
|
||||
:members:
|
||||
|
||||
:hidden:`MaxPool3d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MaxPool3d
|
||||
:members:
|
||||
|
||||
:hidden:`MaxUnpool1d`
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MaxUnpool1d
|
||||
:members:
|
||||
|
||||
:hidden:`MaxUnpool2d`
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MaxUnpool2d
|
||||
:members:
|
||||
|
||||
:hidden:`MaxUnpool3d`
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MaxUnpool3d
|
||||
:members:
|
||||
|
||||
:hidden:`AvgPool1d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: AvgPool1d
|
||||
:members:
|
||||
|
||||
:hidden:`AvgPool2d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: AvgPool2d
|
||||
:members:
|
||||
|
||||
:hidden:`AvgPool3d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: AvgPool3d
|
||||
:members:
|
||||
|
||||
:hidden:`FractionalMaxPool2d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: FractionalMaxPool2d
|
||||
:members:
|
||||
|
||||
:hidden:`LPPool2d`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: LPPool2d
|
||||
:members:
|
||||
|
||||
Non-linear Activations
|
||||
----------------------------------
|
||||
|
||||
:hidden:`ReLU`
|
||||
~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: ReLU
|
||||
:members:
|
||||
|
||||
:hidden:`ReLU6`
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: ReLU6
|
||||
:members:
|
||||
|
||||
:hidden:`ELU`
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: ELU
|
||||
:members:
|
||||
|
||||
:hidden:`PReLU`
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: PReLU
|
||||
:members:
|
||||
|
||||
:hidden:`LeakyReLU`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: LeakyReLU
|
||||
:members:
|
||||
|
||||
:hidden:`Threshold`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Threshold
|
||||
:members:
|
||||
|
||||
:hidden:`Hardtanh`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Hardtanh
|
||||
:members:
|
||||
|
||||
:hidden:`Sigmoid`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Sigmoid
|
||||
:members:
|
||||
|
||||
:hidden:`Tanh`
|
||||
~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Tanh
|
||||
:members:
|
||||
|
||||
:hidden:`LogSigmoid`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: LogSigmoid
|
||||
:members:
|
||||
|
||||
:hidden:`Softplus`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Softplus
|
||||
:members:
|
||||
|
||||
:hidden:`Softshrink`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Softshrink
|
||||
:members:
|
||||
|
||||
:hidden:`Softsign`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Softsign
|
||||
:members:
|
||||
|
||||
:hidden:`Tanhshrink`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Tanhshrink
|
||||
:members:
|
||||
|
||||
:hidden:`Softmin`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Softmin
|
||||
:members:
|
||||
|
||||
:hidden:`Softmax`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Softmax
|
||||
:members:
|
||||
|
||||
:hidden:`LogSoftmax`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: LogSoftmax
|
||||
:members:
|
||||
|
||||
|
||||
Normalization layers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`BatchNorm1d`
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: BatchNorm1d
|
||||
:members:
|
||||
|
||||
:hidden:`BatchNorm2d`
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: BatchNorm2d
|
||||
:members:
|
||||
|
||||
:hidden:`BatchNorm3d`
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: BatchNorm3d
|
||||
:members:
|
||||
|
||||
|
||||
Recurrent layers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`RNN`
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: RNN
|
||||
:members:
|
||||
|
||||
:hidden:`LSTM`
|
||||
~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: LSTM
|
||||
:members:
|
||||
|
||||
:hidden:`GRU`
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: GRU
|
||||
:members:
|
||||
|
||||
:hidden:`RNNCell`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: RNNCell
|
||||
:members:
|
||||
|
||||
:hidden:`LSTMCell`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: LSTMCell
|
||||
:members:
|
||||
|
||||
:hidden:`GRUCell`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: GRUCell
|
||||
:members:
|
||||
|
||||
Linear layers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`Linear`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Linear
|
||||
:members:
|
||||
|
||||
|
||||
Dropout layers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`Dropout`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Dropout
|
||||
:members:
|
||||
|
||||
:hidden:`Dropout2d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Dropout2d
|
||||
:members:
|
||||
|
||||
:hidden:`Dropout3d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Dropout3d
|
||||
:members:
|
||||
|
||||
|
||||
Sparse layers
|
||||
----------------------------------
|
||||
|
||||
:hidden:`Embedding`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: Embedding
|
||||
:members:
|
||||
|
||||
|
||||
Loss functions
|
||||
----------------------------------
|
||||
|
||||
:hidden:`L1Loss`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: L1Loss
|
||||
:members:
|
||||
|
||||
:hidden:`MSELoss`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MSELoss
|
||||
:members:
|
||||
|
||||
:hidden:`CrossEntropyLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: CrossEntropyLoss
|
||||
:members:
|
||||
|
||||
:hidden:`NLLLoss`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: NLLLoss
|
||||
:members:
|
||||
|
||||
:hidden:`NLLLoss2d`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: NLLLoss2d
|
||||
:members:
|
||||
|
||||
:hidden:`KLDivLoss`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: KLDivLoss
|
||||
:members:
|
||||
|
||||
:hidden:`BCELoss`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: BCELoss
|
||||
:members:
|
||||
|
||||
:hidden:`MarginRankingLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MarginRankingLoss
|
||||
:members:
|
||||
|
||||
:hidden:`HingeEmbeddingLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: HingeEmbeddingLoss
|
||||
:members:
|
||||
|
||||
:hidden:`MultiLabelMarginLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MultiLabelMarginLoss
|
||||
:members:
|
||||
|
||||
:hidden:`SmoothL1Loss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: SmoothL1Loss
|
||||
:members:
|
||||
|
||||
:hidden:`SoftMarginLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: SoftMarginLoss
|
||||
:members:
|
||||
|
||||
:hidden:`MultiLabelSoftMarginLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MultiLabelSoftMarginLoss
|
||||
:members:
|
||||
|
||||
:hidden:`CosineEmbeddingLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: CosineEmbeddingLoss
|
||||
:members:
|
||||
|
||||
:hidden:`MultiMarginLoss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: MultiMarginLoss
|
||||
:members:
|
||||
|
||||
|
||||
Vision layers
|
||||
----------------
|
||||
|
||||
:hidden:`PixelShuffle`
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: PixelShuffle
|
||||
:members:
|
||||
|
||||
Multi-GPU layers
|
||||
----------------
|
||||
|
||||
:hidden:`DataParallel`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autoclass:: DataParallel
|
||||
:members:
|
||||
|
||||
torch.nn.functional
|
||||
===================
|
||||
|
||||
.. currentmodule:: torch.nn.functional
|
||||
|
||||
Convolution functions
|
||||
----------------------------------
|
||||
|
||||
:hidden:`conv1d`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: conv1d
|
||||
|
||||
:hidden:`conv2d`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: conv2d
|
||||
|
||||
:hidden:`conv3d`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: conv3d
|
||||
|
||||
:hidden:`conv_transpose1d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: conv_transpose1d
|
||||
|
||||
:hidden:`conv_transpose2d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: conv_transpose2d
|
||||
|
||||
:hidden:`conv_transpose3d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: conv_transpose3d
|
||||
|
||||
Pooling functions
|
||||
----------------------------------
|
||||
|
||||
:hidden:`avg_pool1d`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: avg_pool1d
|
||||
|
||||
:hidden:`avg_pool2d`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: avg_pool2d
|
||||
|
||||
:hidden:`avg_pool3d`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: avg_pool3d
|
||||
|
||||
:hidden:`max_pool1d`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: max_pool1d
|
||||
|
||||
:hidden:`max_pool2d`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: max_pool2d
|
||||
|
||||
:hidden:`max_pool3d`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: max_pool3d
|
||||
|
||||
:hidden:`max_unpool1d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: max_unpool1d
|
||||
|
||||
:hidden:`max_unpool2d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: max_unpool2d
|
||||
|
||||
:hidden:`max_unpool3d`
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: max_unpool3d
|
||||
|
||||
:hidden:`lp_pool2d`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: lp_pool2d
|
||||
|
||||
Non-linear activation functions
|
||||
-------------------------------
|
||||
|
||||
:hidden:`threshold`
|
||||
~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: threshold
|
||||
|
||||
|
||||
:hidden:`relu`
|
||||
~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: relu
|
||||
|
||||
:hidden:`hardtanh`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: hardtanh
|
||||
|
||||
:hidden:`relu6`
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: relu6
|
||||
|
||||
:hidden:`elu`
|
||||
~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: elu
|
||||
|
||||
:hidden:`leaky_relu`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: leaky_relu
|
||||
|
||||
:hidden:`prelu`
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: prelu
|
||||
|
||||
:hidden:`rrelu`
|
||||
~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: rrelu
|
||||
|
||||
:hidden:`logsigmoid`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: logsigmoid
|
||||
|
||||
:hidden:`hardshrink`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: hardshrink
|
||||
|
||||
:hidden:`tanhshrink`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: tanhshrink
|
||||
|
||||
:hidden:`softsign`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: softsign
|
||||
|
||||
:hidden:`softplus`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: softplus
|
||||
|
||||
:hidden:`softmin`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: softmin
|
||||
|
||||
:hidden:`softmax`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: softmax
|
||||
|
||||
:hidden:`softshrink`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: softshrink
|
||||
|
||||
:hidden:`log_softmax`
|
||||
~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: log_softmax
|
||||
|
||||
:hidden:`tanh`
|
||||
~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: tanh
|
||||
|
||||
:hidden:`sigmoid`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: sigmoid
|
||||
|
||||
Normalization functions
|
||||
-----------------------
|
||||
|
||||
:hidden:`batch_norm`
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: batch_norm
|
||||
|
||||
Linear functions
|
||||
----------------
|
||||
|
||||
:hidden:`linear`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: linear
|
||||
|
||||
Dropout functions
|
||||
-----------------
|
||||
|
||||
:hidden:`dropout`
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: dropout
|
||||
|
||||
Loss functions
|
||||
--------------
|
||||
|
||||
:hidden:`nll_loss`
|
||||
~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: nll_loss
|
||||
|
||||
|
||||
:hidden:`kl_div`
|
||||
~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: kl_div
|
||||
|
||||
:hidden:`cross_entropy`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: cross_entropy
|
||||
|
||||
:hidden:`binary_cross_entropy`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: binary_cross_entropy
|
||||
|
||||
:hidden:`smooth_l1_loss`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: smooth_l1_loss
|
||||
|
||||
Vision functions
|
||||
----------------
|
||||
|
||||
:hidden:`pixel_shuffle`
|
||||
~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: pixel_shuffle
|
||||
144
docs/source/notes/autograd.rst
Normal file
@ -0,0 +1,144 @@
|
||||
Autograd mechanics
|
||||
==================
|
||||
|
||||
This note will present an overview of how autograd works and records the
|
||||
operations. It's not strictly necessary to understand all this, but we recommend
|
||||
getting familiar with it, as it will help you write more efficient, cleaner
|
||||
programs, and can aid you in debugging.
|
||||
|
||||
.. _excluding-subgraphs:
|
||||
|
||||
Excluding subgraphs from backward
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Every Variable has two flags: :attr:`requires_grad` and :attr:`volatile`.
|
||||
They both allow for fine grained exclusion of subgraphs from gradient
|
||||
computation and can increase efficiency.
|
||||
|
||||
.. _excluding-requires_grad:
|
||||
|
||||
``requires_grad``
|
||||
~~~~~~~~~~~~~~~~~
|
||||
|
||||
If there's a single input to an operation that requires gradient, its output
|
||||
will also require gradient. Conversely, only if all inputs don't require
|
||||
gradient, the output also won't require it. Backward computation is never
|
||||
performed in the subgraphs, where all Variables didn't require gradients.
|
||||
|
||||
.. code::
|
||||
|
||||
>>> x = Variable(torch.randn(5, 5))
|
||||
>>> y = Variable(torch.randn(5, 5))
|
||||
>>> z = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
>>> a = x + y
|
||||
>>> a.requires_grad
|
||||
False
|
||||
>>> b = a + z
|
||||
>>> b.requires_grad
|
||||
True
|
||||
|
||||
This is especially useful when you want to freeze part of your model, or you
|
||||
know in advance that you're not going to use gradients w.r.t. some parameters.
|
||||
For example if you want to finetune a pretrained CNN, it's enough to switch the
|
||||
:attr:`requires_grad` flags in the frozen base, and no intermediate buffers will
|
||||
be saved, until the computation gets to the last layer, where the affine
|
||||
transform will use weights that require gradient, and the output of the network
|
||||
will also require them.
|
||||
|
||||
.. code::
|
||||
|
||||
model = torchvision.models.resnet18(pretrained=True)
|
||||
for param in model.parameters():
|
||||
param.requires_grad = False
|
||||
# Replace the last fully-connected layer
|
||||
# Parameters of newly constructed modules have requires_grad=True by default
|
||||
model.fc = nn.Linear(512, 100)
|
||||
|
||||
# Optimize only the classifier
|
||||
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
|
||||
|
||||
``volatile``
|
||||
~~~~~~~~~~~~
|
||||
|
||||
Volatile is recommended for purely inference mode, when you're sure you won't
|
||||
be even calling `.backward()`. It's more efficient than any other autograd
|
||||
setting - it will use the absolute minimal amount of memory to evaluate the
|
||||
model. ``volatile`` also determines that ``requires_grad is False``.
|
||||
|
||||
Volatile differs from :ref:`excluding-requires_grad` in how the flag propagates.
|
||||
If there's even a single volatile input to an operation, its output is also
|
||||
going to be volatile. Volatility spreads accross the graph much easier than
|
||||
non-requiring gradient - you only need a **single** volatile leaf to have a
|
||||
volatile output, while you need **all** leaves to not require gradient to
|
||||
have an output the doesn't require gradient. Using volatile flag you don't
|
||||
need to change any settings of your model parameters to use it for
|
||||
inference. It's enough to create a volatile input, and this will ensure that
|
||||
no intermediate states are saved.
|
||||
|
||||
.. code::
|
||||
|
||||
>>> regular_input = Variable(torch.randn(5, 5))
|
||||
>>> volatile_input = Variable(torch.randn(5, 5), volatile=True)
|
||||
>>> model = torchvision.models.resnet18(pretrained=True)
|
||||
>>> model(regular_input).requires_grad
|
||||
True
|
||||
>>> model(volatile_input).requires_grad
|
||||
False
|
||||
>>> model(volatile_input).volatile
|
||||
True
|
||||
>>> model(volatile_input).creator is None
|
||||
True
|
||||
|
||||
How autograd encodes the history
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Each Variable has a ``.creator`` attribute, that points to the function, of
|
||||
which it is an output. This is an entry point to a directed acyclic graph (DAG)
|
||||
consisting of :class:`Function` objects as nodes, and references between them
|
||||
being the edges. Every time an operation is performed, a new :class:`Function`
|
||||
representing it is instantiated, its :meth:`~torch.autograd.Function.forward`
|
||||
method is called, and its output :class:`Variable` s creators are set to it.
|
||||
Then, by following the path from any :class:`Variable` to the leaves, it is
|
||||
possible to reconstruct the sequence of operations that has created the data,
|
||||
and automatically compute the gradients.
|
||||
|
||||
An important thing to note is that the graph is recreated from scratch at every
|
||||
iteration, and this is exactly what allows for using arbitrary Python control
|
||||
flow statements, that can change the overall shape and size of the graph at
|
||||
every iteration. You don't have to encode all possible paths before you
|
||||
launch the training - what you run is what you differentiate.
|
||||
|
||||
In-place operations on Variables
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Supporting in-place operations in autograd is a hard matter, and we discourage
|
||||
their use in most cases. Autograd's aggressive buffer freeing and reuse makes
|
||||
it very efficient and there are very few occasions when in-place operations
|
||||
actually lower memory usage by any significant amount. Unless you're operating
|
||||
under heavy memory pressure, you might never need to use them.
|
||||
|
||||
There are two main reasons that limit the applicability of in-place operations:
|
||||
|
||||
1. Overwriting values required to compute gradients. This is why variables don't
|
||||
support ``log_``. Its gradient formula requires the original input, and while
|
||||
it is possible to recreate it by computing the inverse operation, it is
|
||||
numerically unstable, and requires additional work that often defeats the
|
||||
purpose of using these functions.
|
||||
|
||||
2. Every in-place operation actually requires the implementation to rewrite the
|
||||
computational graph. Out-of-place versions simply allocate new objects and
|
||||
keep references to the old graph, while in-place operations, require
|
||||
changing the creator of all inputs to the :class:`Function` representing
|
||||
this operation. This can be tricky, especially if there are many Variables
|
||||
that reference the same storage (e.g. created by indexing or transposing),
|
||||
and in-place functions will actually raise an error if the storage of
|
||||
modified inputs is referenced by any other :class:`Variable`.
|
||||
|
||||
In-place correctness checks
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Every variable keeps a version counter, that is incremented every time it's
|
||||
marked dirty in any operation. When a Function saves any tensors for backward,
|
||||
a version counter of their containing Variable is saved as well. Once you access
|
||||
``self.saved_tensors`` it is checked, and if it's greater than the saved value
|
||||
an error is raised.
|
||||
60
docs/source/notes/cuda.rst
Normal file
@ -0,0 +1,60 @@
|
||||
CUDA semantics
|
||||
==============
|
||||
|
||||
:mod:`torch.cuda` keeps track of currently selected GPU, and all CUDA tensors
|
||||
you allocate will be created on it. The selected device can be changed with a
|
||||
:any:`torch.cuda.device` context manager.
|
||||
|
||||
However, once a tensor is allocated, you can do operations on it irrespectively
|
||||
of your selected device, and the results will be always placed in on the same
|
||||
device as the tensor.
|
||||
|
||||
Cross-GPU operations are not allowed by default, with the only exception of
|
||||
:meth:`~torch.Tensor.copy_`. Unless you enable peer-to-peer memory accesses
|
||||
any attempts to launch ops on tensors spread across different devices will
|
||||
raise an error.
|
||||
|
||||
Below you can find a small example showcasing this::
|
||||
|
||||
x = torch.cuda.FloatTensor(1)
|
||||
# x.get_device() == 0
|
||||
y = torch.FloatTensor(1).cuda()
|
||||
# y.get_device() == 0
|
||||
|
||||
with torch.cuda.device(1):
|
||||
# allocates a tensor on GPU 1
|
||||
a = torch.cuda.FloatTensor(1)
|
||||
|
||||
# transfers a tensor from CPU to GPU 1
|
||||
b = torch.FloatTensor(1).cuda()
|
||||
# a.get_device() == b.get_device() == 1
|
||||
|
||||
z = x + y
|
||||
# z.get_device() == 1
|
||||
|
||||
# even within a context, you can give a GPU id to the .cuda call
|
||||
c = torch.randn(2).cuda(2)
|
||||
# c.get_device() == 2
|
||||
|
||||
Best practices
|
||||
--------------
|
||||
|
||||
Use pinned memory buffers
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
.. warning:
|
||||
|
||||
This is an advanced tip. You overuse of pinned memory can cause serious
|
||||
problems if you'll be running low on RAM, and you should be aware that
|
||||
pinning is often an expensive operation.
|
||||
|
||||
Host to GPU copies are much faster when they originate from pinned (page-locked)
|
||||
memory. CPU tensors and storages expose a :meth:`~torch.Tensor.pin_memory`
|
||||
method, that returns a copy of the object, with data put in a pinned region.
|
||||
|
||||
Also, once you pin a tensor or storage, you can use asynchronous GPU copies.
|
||||
Just pass an additional ``async=True`` argument to a :meth:`~torch.Tensor.cuda`
|
||||
call. This can be used to overlap data transfers with computation.
|
||||
|
||||
You can make the :class:`~torch.utils.data.DataLoader` return batches placed in
|
||||
pinned memory by passing ``pinned=True`` to its constructor.
|
||||
156
docs/source/notes/extending.rst
Normal file
@ -0,0 +1,156 @@
|
||||
Extending PyTorch
|
||||
=================
|
||||
|
||||
In this note we'll cover ways of extending :mod:`torch.nn`,
|
||||
:mod:`torch.autograd`, and writing custom C extensions utilizing our C
|
||||
libraries.
|
||||
|
||||
Extending :mod:`torch.autograd`
|
||||
-------------------------------
|
||||
|
||||
.. currentmodule:: torch.autograd
|
||||
|
||||
Adding operations to :mod:`~torch.autograd` requires implementing a new
|
||||
:class:`Function` subclass for each operation. Recall that :class:`Function` s
|
||||
are what :mod:`~torch.autograd` uses to compute the results and gradients, and
|
||||
encode the operation history. Every new function requires you to implement 3
|
||||
methods:
|
||||
|
||||
- ``__init__`` (*optional*) - if your operation is parametrized by/uses
|
||||
objects different than :class:`Variable` s, you should pass them as arguments
|
||||
to ``__init__``. For example, ``AddConstant`` function takes a scalar to add,
|
||||
while ``Transpose`` requires specifying which two dimensions to swap. If your
|
||||
function doesn't require any additional parameters, you can skip it.
|
||||
- :meth:`~Function.forward` - the code that performs the operation. It can take
|
||||
as many arguments as you want, with some of them being
|
||||
optional, if you specify the default values. Keep in mind that only
|
||||
:class:`Variable` s will be passed in here. You can return either a single
|
||||
:class:`Variable` output, or a :class:`tuple` of :class:`Variable` s if there
|
||||
are multiple. Also, please refer to the docs of :class:`Function` to find
|
||||
descriptions of useful methods that can be called only from
|
||||
:meth:`~Function.forward`.
|
||||
- :meth:`~Function.backward` - gradient formula. It will be given
|
||||
as many arguments as there were outputs, with each of them representing
|
||||
gradient w.r.t. that output. It should return as many :class:`Tensor` s as
|
||||
there were inputs, with each of them containing the gradient w.r.t.
|
||||
corresponding input. If you inputs didn't require gradient (see
|
||||
:attr:`~Variable.needs_input_grad`), or it was non-differentiable, you
|
||||
can return :class:`None`. Also, if you have optional arguments to
|
||||
:meth:`~Variable.forward` you can return more gradients than there were
|
||||
inputs, as long as they're all :any:`python:None`.
|
||||
|
||||
Below you can find code for a ``Linear`` function from :mod:`torch.nn`, with
|
||||
additional comments::
|
||||
|
||||
# Inherit from Function
|
||||
class Linear(Function):
|
||||
|
||||
# bias is an optional argument
|
||||
def forward(self, input, weight, bias=None):
|
||||
self.save_for_backward(input, weight, bias)
|
||||
output = input.mm(weight.t())
|
||||
if bias is not None:
|
||||
output += bias.unsqueeze(0).expand_as(output)
|
||||
return output
|
||||
|
||||
# This function has only a single output, so it gets only one gradient
|
||||
def backward(self, grad_output):
|
||||
# This is a pattern that is very convenient - at the top of backward
|
||||
# unpack saved_tensors and initialize all gradients w.r.t. inputs to
|
||||
# None. Thanks to the fact that additional trailing Nones are
|
||||
# ignored, the return statement is simple even when the function has
|
||||
# optional inputs.
|
||||
input, weight, bias = self.saved_tensors
|
||||
grad_input = grad_weight = grad_bias = None
|
||||
|
||||
# These needs_input_grad checks are optional and there only to
|
||||
# improve efficiency. If you want to make your code simpler, you can
|
||||
# skip them. Returning gradients for inputs that don't require it is
|
||||
# not an error.
|
||||
if self.needs_input_grad[0]:
|
||||
grad_input = grad_output.mm(weight)
|
||||
if self.needs_input_grad[1]:
|
||||
grad_weight = grad_output.t().mm(input)
|
||||
if bias is not None and self.needs_input_grad[2]:
|
||||
grad_bias = grad_output.sum(0).squeeze(0)
|
||||
|
||||
return grad_input, grad_weight, grad_bias
|
||||
|
||||
Now, to make it easier to use these custom ops, we recommend wrapping them in
|
||||
small helper functions::
|
||||
|
||||
def linear(input, weight, bias=None):
|
||||
# First braces create a Function object. Any arguments given here
|
||||
# will be passed to __init__. Second braces will invoke the __call__
|
||||
# operator, that will then use forward() to compute the result and
|
||||
# return it.
|
||||
return Linear()(input, weight, bias)
|
||||
|
||||
Extending :mod:`torch.nn`
|
||||
-------------------------
|
||||
|
||||
.. currentmodule:: torch.nn
|
||||
|
||||
:mod:`~torch.nn` exports two kinds of interfaces - modules and their functional
|
||||
versions. You can extend it in both ways, but we recommend using modules for
|
||||
all kinds of layers, that hold any parameters or buffers, and recommend using
|
||||
a functional form parameter-less operations like activation functions, pooling,
|
||||
etc.
|
||||
|
||||
Adding a functional version of an operation is already fully covered in the
|
||||
section above.
|
||||
|
||||
Adding a :class:`Module`
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Since :mod:`~torch.nn` heavily utilizes :mod:`~torch.autograd`, adding a new
|
||||
:class:`Module` requires implementing a :class:`~torch.autograd.Function`
|
||||
that performs the operation and can compute the gradient. From now on let's
|
||||
assume that we want to implement a ``Linear`` module and we have the function
|
||||
implementated as in the listing above. There's very little code required to
|
||||
add this. Now, there are two functions that need to be implemented:
|
||||
|
||||
- ``__init__`` (*optional*) - takes in arguments such as kernel sizes, numbers
|
||||
of features, etc. and initializes parameters and buffers.
|
||||
- :meth:`~Module.forward` - instantiates a :class:`~torch.autograd.Function` and
|
||||
uses it to perform the operation. It's very similar to a functional wrapper
|
||||
shown above.
|
||||
|
||||
This is how a ``Linear`` module can be implemented::
|
||||
|
||||
class Linear(nn.Module):
|
||||
def __init__(self, input_features, output_features, bias=True):
|
||||
self.input_features = input_features
|
||||
self.output_features = output_features
|
||||
|
||||
# nn.Parameter is a special kind of Variable, that will get
|
||||
# automatically registered as Module's parameter once it's assigned
|
||||
# as an attribute. Parameters and buffers need to be registered, or
|
||||
# they won't appear in .parameters() (doesn't apply to buffers), and
|
||||
# won't be converted when e.g. .cuda() is called. You can use
|
||||
# .register_buffer() to register buffers.
|
||||
# nn.Parameters can never be volatile and, different than Variables,
|
||||
# they require gradients by default.
|
||||
self.weight = nn.Parameter(torch.Tensor(input_features, output_features))
|
||||
if bias is not None:
|
||||
self.bias = nn.Parameter(torch.Tensor(output_features))
|
||||
else:
|
||||
# You should always register all possible parameters, but the
|
||||
# optional ones can be None if you want.
|
||||
self.register_parameter('bias', None)
|
||||
|
||||
# Not a very smart way to initialize weights
|
||||
self.weight.data.uniform_(-0.1, 0.1)
|
||||
if bias is not None:
|
||||
self.bias.data.uniform_(-0.1, 0.1)
|
||||
|
||||
def forward(self, input):
|
||||
# See the autograd section for explanation of what happens here.
|
||||
return Linear()(input, self.weight, self.bias)
|
||||
|
||||
|
||||
Writing custom C extensions
|
||||
---------------------------
|
||||
|
||||
Coming soon. For now you can find an example at
|
||||
`GitHub <https://github.com/pytorch/extension-ffi>`_.
|
||||
127
docs/source/notes/multiprocessing.rst
Normal file
@ -0,0 +1,127 @@
|
||||
Multiprocessing best practices
|
||||
==============================
|
||||
|
||||
:mod:`torch.multiprocessing` is a drop in replacement for Python's
|
||||
:mod:`python:multiprocessing` module. It supports the exact same operations,
|
||||
but extends it, so that all tensors sent through a
|
||||
:class:`python:multiprocessing.Queue`, will have their data moved into shared
|
||||
memory and will only send a handle to another process.
|
||||
|
||||
.. note::
|
||||
|
||||
When a :class:`~torch.autograd.Variable` is sent to another process, both
|
||||
the :attr:`Variable.data` and :attr:`Variable.grad.data` are going to be
|
||||
shared.
|
||||
|
||||
This allows to implement various training methods, like Hogwild, A3C, or any
|
||||
others that require asynchronous operation.
|
||||
|
||||
Sharing CUDA tensors
|
||||
--------------------
|
||||
|
||||
Sharing CUDA tensors between processes is supported only in Python 3, using
|
||||
a ``spawn`` or ``forkserver`` start methods. :mod:`python:multiprocessing` in
|
||||
Python 2 can only create subprocesses using ``fork``, and it's not supported
|
||||
by the CUDA runtime.
|
||||
|
||||
.. warning::
|
||||
|
||||
CUDA API requires that the allocation exported to other processes remains
|
||||
valid as long as it's used by them. You should be careful and ensure that
|
||||
CUDA tensors you shared don't go out of scope as long as it's necessary.
|
||||
This shouldn't be a problem for sharing model parameters, but passing other
|
||||
kinds of data should be done with care. Note that this restriction doesn't
|
||||
apply to shared CPU memory.
|
||||
|
||||
|
||||
Best practices and tips
|
||||
-----------------------
|
||||
|
||||
Avoiding and fighting deadlocks
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
There are a lot of things that can go wrong when a new process is spawned, with
|
||||
the most common cause of deadlocks being background threads. If there's any
|
||||
thread that holds a lock or imports a module, and ``fork`` is called, it's very
|
||||
likely that the subprocess will be in a corrupted state and will deadlock or
|
||||
fail in a different way. Note that even if you don't, Python built in
|
||||
libraries do - no need to look further than :mod:`python:multiprocessing`.
|
||||
:class:`python:multiprocessing.Queue` is actually a very complex class, that
|
||||
spawns multiple threads used to serialize, send and receive objects, and they
|
||||
can cause aforementioned problems too. If you find yourself in such situation
|
||||
try using a :class:`~python:multiprocessing.queues.SimpleQueue`, that doesn't
|
||||
use any additional threads.
|
||||
|
||||
We're trying our best to make it easy for you and ensure these deadlocks don't
|
||||
happen but some things are out of our control. If you have any issues you can't
|
||||
cope with for a while, try reaching out on forums, and we'll see if it's an
|
||||
issue we can fix.
|
||||
|
||||
Reuse buffers passed through a Queue
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Remember that each time you put a :class:`~torch.Tensor` into a
|
||||
:class:`python:multiprocessing.Queue`, it has to be moved into shared memory.
|
||||
If it's already shared, it is a no-op, otherwise it will incur an additional
|
||||
memory copy that can slow down the whole process. Even if you have a pool of
|
||||
processes sending data to a single one, make it send the buffers back - this
|
||||
is nearly free and will let you avoid a copy when sending next batch.
|
||||
|
||||
Asynchronous multiprocess training (e.g. Hogwild)
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
Using :mod:`torch.multiprocessing`, it is possible to train a model
|
||||
asynchronously, with parameters either shared all the time, or being
|
||||
periodically synchronized. In the first case, we recommend sending over the whole
|
||||
model object, while in the latter, we advise to only send the
|
||||
:meth:`~torch.nn.Module.state_dict`.
|
||||
|
||||
We recommend using :class:`python:multiprocessing.Queue` for passing all kinds
|
||||
of PyTorch objects between processes. It is possible to e.g. inherit the tensors
|
||||
and storages already in shared memory, when using the ``fork`` start method,
|
||||
however it is very bug prone and should be used with care, and only by advanced
|
||||
users. Queues, even though they're sometimes a less elegant solution, will work
|
||||
properly in all cases.
|
||||
|
||||
.. warning::
|
||||
|
||||
You should be careful about having global statements, that are not guarded
|
||||
with an ``if __name__ == '__main__'``. If a different start method than
|
||||
``fork`` is used, they will be executed in all subprocesses.
|
||||
|
||||
Hogwild
|
||||
~~~~~~~
|
||||
|
||||
A concrete Hogwild implementation can be found in the `examples repository`__,
|
||||
but to showcase the overall structure of the code, there's also a minimal
|
||||
example below as well::
|
||||
|
||||
import torch.multiprocessing as mp
|
||||
from model import MyModel
|
||||
|
||||
def train(model):
|
||||
# This for loop will break sharing of gradient buffers. It's not
|
||||
# necessary but it reduces the contention, and has a small memory cost
|
||||
# (equal to the total size of parameters).
|
||||
for param in model.parameters():
|
||||
param.grad.data = param.grad.data.clone()
|
||||
# Construct data_loader, optimizer, etc.
|
||||
for data, labels in data_loader:
|
||||
optimizer.zero_grad()
|
||||
loss_fn(model(data), labels).backward()
|
||||
optimizer.step() # This will update the shared parameters
|
||||
|
||||
if __name__ == '__main__':
|
||||
num_processes = 4
|
||||
model = MyModel()
|
||||
# NOTE: this is required for the ``fork`` method to work
|
||||
model.share_memory()
|
||||
processes = []
|
||||
for rank in range(num_processes):
|
||||
p = mp.Process(target=train, args=(model,))
|
||||
p.start()
|
||||
processes.append(p)
|
||||
for p in processes:
|
||||
p.join()
|
||||
|
||||
.. __: https://github.com/pytorch/examples/tree/master/mnist_hogwild
|
||||
116
docs/source/optim.rst
Normal file
@ -0,0 +1,116 @@
|
||||
torch.optim
|
||||
===================================
|
||||
|
||||
.. automodule:: torch.optim
|
||||
|
||||
How to use an optimizer
|
||||
-----------------------
|
||||
|
||||
To use :mod:`torch.optim` you have to construct an optimizer object, that will hold
|
||||
the current state and will update the parameters based on the computed gradients.
|
||||
|
||||
Constructing it
|
||||
^^^^^^^^^^^^^^^
|
||||
|
||||
To construct an :class:`Optimizer` you have to give it an iterable containing the
|
||||
parameters (all should be :class:`~torch.autograd.Variable` s) to optimize. Then,
|
||||
you can specify optimizer-specific options such as the learning rate, weight decay, etc.
|
||||
|
||||
Example::
|
||||
|
||||
optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum=0.9)
|
||||
optimizer = optim.Adam([var1, var2], lr = 0.0001)
|
||||
|
||||
Per-parameter options
|
||||
^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
:class:`Optimizer` s also support specifying per-parameter options. To do this, instead
|
||||
of passing an iterable of :class:`~torch.autograd.Variable` s, pass in an iterable of
|
||||
:class:`dict` s. Each of them will define a separate parameter group, and should contain
|
||||
a ``params`` key, containing a list of parameters belonging to it. Other keys
|
||||
should match the keyword arguments accepted by the optimizers, and will be used
|
||||
as optimization options for this group.
|
||||
|
||||
.. note::
|
||||
|
||||
You can still pass options as keyword arguments. They will be used as
|
||||
defaults, in the groups that didn't override them. This is useful when you
|
||||
only want to vary a single option, while keeping all others consistent
|
||||
between parameter groups.
|
||||
|
||||
|
||||
For example, this is very useful when one wants to specify per-layer learning rates::
|
||||
|
||||
optim.SGD([
|
||||
{'params': model.base.parameters()},
|
||||
{'params': model.classifier.parameters(), 'lr': 1e-3}
|
||||
], lr=1e-2, momentum=0.9)
|
||||
|
||||
This means that ``model.base``'s parameters will use the default learning rate of ``1e-2``,
|
||||
``model.classifier``'s parameters will use a learning rate of ``1e-3``, and a momentum of
|
||||
``0.9`` will be used for all parameters
|
||||
|
||||
Taking an optimization step
|
||||
^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
||||
|
||||
All optimizers implement a :func:`~Optimizer.step` method, that updates the
|
||||
parameters. It can be used in two ways:
|
||||
|
||||
``optimizer.step()``
|
||||
~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
This is a simplified version supported by most optimizers. The function can be
|
||||
called once the gradients are computed using e.g.
|
||||
:func:`~torch.autograd.Variable.backward`.
|
||||
|
||||
Example::
|
||||
|
||||
for input, target in dataset:
|
||||
optimizer.zero_grad()
|
||||
output = model(input)
|
||||
loss = loss_fn(output, target)
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
|
||||
``optimizer.step(closure)``
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
Some optimization algorithms such as Conjugate Gradient and LBFGS need to
|
||||
reevaluate the function multiple times, so you have to pass in a closure that
|
||||
allows them to recompute your model. The closure should clear the gradients,
|
||||
compute the loss, and return it.
|
||||
|
||||
Example::
|
||||
|
||||
for input, target in dataset:
|
||||
def closure():
|
||||
optimizer.zero_grad()
|
||||
output = model(input)
|
||||
loss = loss_fn(output, target)
|
||||
loss.backward()
|
||||
return loss
|
||||
optimizer.step(closure)
|
||||
|
||||
Algorithms
|
||||
----------
|
||||
|
||||
.. autoclass:: Optimizer
|
||||
:members:
|
||||
.. autoclass:: Adadelta
|
||||
:members:
|
||||
.. autoclass:: Adagrad
|
||||
:members:
|
||||
.. autoclass:: Adam
|
||||
:members:
|
||||
.. autoclass:: Adamax
|
||||
:members:
|
||||
.. autoclass:: ASGD
|
||||
:members:
|
||||
.. autoclass:: LBFGS
|
||||
:members:
|
||||
.. autoclass:: RMSprop
|
||||
:members:
|
||||
.. autoclass:: Rprop
|
||||
:members:
|
||||
.. autoclass:: SGD
|
||||
:members:
|
||||
12
docs/source/storage.rst
Normal file
@ -0,0 +1,12 @@
|
||||
torch.Storage
|
||||
===================================
|
||||
|
||||
A :class:`torch.Storage` is a contiguous, one-dimensional array of a single
|
||||
data type.
|
||||
|
||||
Every :class:`torch.Tensor` has a corresponding storage of the same data type.
|
||||
|
||||
.. autoclass:: torch.FloatStorage
|
||||
:members:
|
||||
:undoc-members:
|
||||
:inherited-members:
|
||||
309
docs/source/tensors.rst
Normal file
@ -0,0 +1,309 @@
|
||||
.. currentmodule:: torch
|
||||
|
||||
torch.Tensor
|
||||
===================================
|
||||
|
||||
A :class:`torch.Tensor` is a multi-dimensional matrix containing elements of
|
||||
a single data type.
|
||||
|
||||
Torch defines seven CPU tensor types and eight GPU tensor types:
|
||||
|
||||
======================== =========================== ================================
|
||||
Data type CPU tensor GPU tensor
|
||||
======================== =========================== ================================
|
||||
32-bit floating point :class:`torch.FloatTensor` :class:`torch.cuda.FloatTensor`
|
||||
64-bit floating point :class:`torch.DoubleTensor` :class:`torch.cuda.DoubleTensor`
|
||||
16-bit floating point N/A :class:`torch.cuda.HalfTensor`
|
||||
8-bit integer (signed) :class:`torch.ByteTensor` :class:`torch.cuda.ByteTensor`
|
||||
8-bit integer (unsigned) :class:`torch.CharTensor` :class:`torch.cuda.CharTensor`
|
||||
16-bit integer (signed) :class:`torch.ShortTensor` :class:`torch.cuda.ShortTensor`
|
||||
32-bit integer (signed) :class:`torch.IntTensor` :class:`torch.cuda.IntTensor`
|
||||
64-bit integer (signed) :class:`torch.LongTensor` :class:`torch.cuda.LongTensor`
|
||||
======================== =========================== ================================
|
||||
|
||||
The :class:`torch.Tensor` constructor is an alias for the default tensor type
|
||||
(:class:`torch.FloatTensor`).
|
||||
|
||||
A tensor can be constructed from a Python :class:`list` or sequence:
|
||||
|
||||
::
|
||||
|
||||
>>> torch.FloatTensor([[1, 2, 3], [4, 5, 6]])
|
||||
1 2 3
|
||||
4 5 6
|
||||
[torch.FloatTensor of size 2x3]
|
||||
|
||||
An empty tensor can be constructed by specifying its size:
|
||||
|
||||
::
|
||||
|
||||
>>> torch.IntTensor(2, 4).zero_()
|
||||
0 0 0 0
|
||||
0 0 0 0
|
||||
[torch.IntTensor of size 2x4]
|
||||
|
||||
The contents of a tensor can be accessed and modified using Python's indexing
|
||||
and slicing notation:
|
||||
|
||||
::
|
||||
|
||||
>>> x = torch.FloatTensor([[1, 2, 3], [4, 5, 6]])
|
||||
>>> print(x[1][2])
|
||||
6.0
|
||||
>>> x[0][1] = 8
|
||||
>>> print(x)
|
||||
1 8 3
|
||||
4 5 6
|
||||
[torch.FloatTensor of size 2x3]
|
||||
|
||||
Each tensor has an associated :class:`torch.Storage`, which holds its data.
|
||||
The tensor class provides multi-dimensional, `strided <https://en.wikipedia.org/wiki/Stride_of_an_array>`_
|
||||
view of a storage and defines numeric operations on it.
|
||||
|
||||
.. note::
|
||||
Methods which mutate a tensor are marked with an underscore suffix.
|
||||
For example, :func:`torch.FloatTensor.abs_` computes the absolute value
|
||||
in-place and returns the modified tensor, while :func:`torch.FloatTensor.abs`
|
||||
computes the result in a new tensor.
|
||||
|
||||
.. class:: Tensor()
|
||||
Tensor(*sizes)
|
||||
Tensor(size)
|
||||
Tensor(sequence)
|
||||
Tensor(ndarray)
|
||||
Tensor(tensor)
|
||||
Tensor(storage)
|
||||
|
||||
Creates a new tensor from an optional size or data.
|
||||
|
||||
If no arguments are given, an empty zero-dimensional tensor is returned.
|
||||
If a :class:`numpy.ndarray`, :class:`torch.Tensor`, or :class:`torch.Storage`
|
||||
is given, a new tensor that shares the same data is returned. If a Python
|
||||
sequence is given, a new tensor is created from a copy of the sequence.
|
||||
|
||||
.. automethod:: abs
|
||||
.. automethod:: abs_
|
||||
.. automethod:: acos
|
||||
.. automethod:: acos_
|
||||
.. automethod:: add
|
||||
.. automethod:: add_
|
||||
.. automethod:: addbmm
|
||||
.. automethod:: addbmm_
|
||||
.. automethod:: addcdiv
|
||||
.. automethod:: addcdiv_
|
||||
.. automethod:: addcmul
|
||||
.. automethod:: addcmul_
|
||||
.. automethod:: addmm
|
||||
.. automethod:: addmm_
|
||||
.. automethod:: addmv
|
||||
.. automethod:: addmv_
|
||||
.. automethod:: addr
|
||||
.. automethod:: addr_
|
||||
.. automethod:: apply_
|
||||
.. automethod:: asin
|
||||
.. automethod:: asin_
|
||||
.. automethod:: atan
|
||||
.. automethod:: atan2
|
||||
.. automethod:: atan2_
|
||||
.. automethod:: atan_
|
||||
.. automethod:: baddbmm
|
||||
.. automethod:: baddbmm_
|
||||
.. automethod:: bernoulli
|
||||
.. automethod:: bernoulli_
|
||||
.. automethod:: bmm
|
||||
.. automethod:: byte
|
||||
.. automethod:: cauchy_
|
||||
.. automethod:: ceil
|
||||
.. automethod:: ceil_
|
||||
.. automethod:: char
|
||||
.. automethod:: chunk
|
||||
.. automethod:: clamp
|
||||
.. automethod:: clamp_
|
||||
.. automethod:: clone
|
||||
.. automethod:: contiguous
|
||||
.. automethod:: copy_
|
||||
.. automethod:: cos
|
||||
.. automethod:: cos_
|
||||
.. automethod:: cosh
|
||||
.. automethod:: cosh_
|
||||
.. automethod:: cpu
|
||||
.. automethod:: cross
|
||||
.. automethod:: cuda
|
||||
.. automethod:: cumprod
|
||||
.. automethod:: cumsum
|
||||
.. automethod:: data_ptr
|
||||
.. automethod:: diag
|
||||
.. automethod:: dim
|
||||
.. automethod:: dist
|
||||
.. automethod:: div
|
||||
.. automethod:: div_
|
||||
.. automethod:: dot
|
||||
.. automethod:: double
|
||||
.. automethod:: eig
|
||||
.. automethod:: element_size
|
||||
.. automethod:: eq
|
||||
.. automethod:: eq_
|
||||
.. automethod:: equal
|
||||
.. automethod:: exp
|
||||
.. automethod:: exp_
|
||||
.. automethod:: expand
|
||||
.. automethod:: expand_as
|
||||
.. automethod:: exponential_
|
||||
.. automethod:: fill_
|
||||
.. automethod:: float
|
||||
.. automethod:: floor
|
||||
.. automethod:: floor_
|
||||
.. automethod:: fmod
|
||||
.. automethod:: fmod_
|
||||
.. automethod:: frac
|
||||
.. automethod:: frac_
|
||||
.. automethod:: gather
|
||||
.. automethod:: ge
|
||||
.. automethod:: ge_
|
||||
.. automethod:: gels
|
||||
.. automethod:: geometric_
|
||||
.. automethod:: geqrf
|
||||
.. automethod:: ger
|
||||
.. automethod:: gesv
|
||||
.. automethod:: gt
|
||||
.. automethod:: gt_
|
||||
.. automethod:: half
|
||||
.. automethod:: histc
|
||||
.. automethod:: index
|
||||
.. automethod:: index_add_
|
||||
.. automethod:: index_copy_
|
||||
.. automethod:: index_fill_
|
||||
.. automethod:: index_select
|
||||
.. automethod:: int
|
||||
.. automethod:: inverse
|
||||
.. automethod:: is_contiguous
|
||||
.. autoattribute:: is_cuda
|
||||
:annotation:
|
||||
.. automethod:: is_pinned
|
||||
.. automethod:: is_set_to
|
||||
.. automethod:: is_signed
|
||||
.. automethod:: kthvalue
|
||||
.. automethod:: le
|
||||
.. automethod:: le_
|
||||
.. automethod:: lerp
|
||||
.. automethod:: lerp_
|
||||
.. automethod:: log
|
||||
.. automethod:: log1p
|
||||
.. automethod:: log1p_
|
||||
.. automethod:: log_
|
||||
.. automethod:: log_normal_
|
||||
.. automethod:: long
|
||||
.. automethod:: lt
|
||||
.. automethod:: lt_
|
||||
.. automethod:: map_
|
||||
.. automethod:: masked_copy_
|
||||
.. automethod:: masked_fill_
|
||||
.. automethod:: masked_select
|
||||
.. automethod:: max
|
||||
.. automethod:: mean
|
||||
.. automethod:: median
|
||||
.. automethod:: min
|
||||
.. automethod:: mm
|
||||
.. automethod:: mode
|
||||
.. automethod:: mul
|
||||
.. automethod:: mul_
|
||||
.. automethod:: multinomial
|
||||
.. automethod:: mv
|
||||
.. automethod:: narrow
|
||||
.. automethod:: ndimension
|
||||
.. automethod:: ne
|
||||
.. automethod:: ne_
|
||||
.. automethod:: neg
|
||||
.. automethod:: neg_
|
||||
.. automethod:: nelement
|
||||
.. automethod:: new
|
||||
.. automethod:: nonzero
|
||||
.. automethod:: norm
|
||||
.. automethod:: normal_
|
||||
.. automethod:: numel
|
||||
.. automethod:: numpy
|
||||
.. automethod:: orgqr
|
||||
.. automethod:: ormqr
|
||||
.. automethod:: permute
|
||||
.. automethod:: pin_memory
|
||||
.. automethod:: potrf
|
||||
.. automethod:: potri
|
||||
.. automethod:: potrs
|
||||
.. automethod:: pow
|
||||
.. automethod:: pow_
|
||||
.. automethod:: prod
|
||||
.. automethod:: pstrf
|
||||
.. automethod:: qr
|
||||
.. automethod:: random_
|
||||
.. automethod:: reciprocal
|
||||
.. automethod:: reciprocal_
|
||||
.. automethod:: remainder
|
||||
.. automethod:: remainder_
|
||||
.. automethod:: renorm
|
||||
.. automethod:: renorm_
|
||||
.. automethod:: repeat
|
||||
.. automethod:: resize_
|
||||
.. automethod:: resize_as_
|
||||
.. automethod:: round
|
||||
.. automethod:: round_
|
||||
.. automethod:: rsqrt
|
||||
.. automethod:: rsqrt_
|
||||
.. automethod:: scatter_
|
||||
.. automethod:: select
|
||||
.. automethod:: set_
|
||||
.. automethod:: set_index
|
||||
.. automethod:: share_memory_
|
||||
.. automethod:: short
|
||||
.. automethod:: sigmoid
|
||||
.. automethod:: sigmoid_
|
||||
.. automethod:: sign
|
||||
.. automethod:: sign_
|
||||
.. automethod:: sin
|
||||
.. automethod:: sin_
|
||||
.. automethod:: sinh
|
||||
.. automethod:: sinh_
|
||||
.. automethod:: size
|
||||
.. automethod:: sort
|
||||
.. automethod:: split
|
||||
.. automethod:: sqrt
|
||||
.. automethod:: sqrt_
|
||||
.. automethod:: squeeze
|
||||
.. automethod:: squeeze_
|
||||
.. automethod:: std
|
||||
.. automethod:: storage
|
||||
.. automethod:: storage_offset
|
||||
.. automethod:: storage_type
|
||||
.. automethod:: stride
|
||||
.. automethod:: sub
|
||||
.. automethod:: sub_
|
||||
.. automethod:: sum
|
||||
.. automethod:: svd
|
||||
.. automethod:: symeig
|
||||
.. automethod:: t
|
||||
.. automethod:: t_
|
||||
.. automethod:: tan
|
||||
.. automethod:: tan_
|
||||
.. automethod:: tanh
|
||||
.. automethod:: tanh_
|
||||
.. automethod:: tolist
|
||||
.. automethod:: topk
|
||||
.. automethod:: trace
|
||||
.. automethod:: transpose
|
||||
.. automethod:: transpose_
|
||||
.. automethod:: tril
|
||||
.. automethod:: tril_
|
||||
.. automethod:: triu
|
||||
.. automethod:: triu_
|
||||
.. automethod:: trtrs
|
||||
.. automethod:: trunc
|
||||
.. automethod:: trunc_
|
||||
.. automethod:: type
|
||||
.. automethod:: type_as
|
||||
.. automethod:: unfold
|
||||
.. automethod:: uniform_
|
||||
.. automethod:: unsqueeze
|
||||
.. automethod:: unsqueeze_
|
||||
.. automethod:: var
|
||||
.. automethod:: view
|
||||
.. automethod:: view_as
|
||||
.. automethod:: zero_
|
||||
179
docs/source/torch.rst
Normal file
@ -0,0 +1,179 @@
|
||||
torch
|
||||
===================================
|
||||
.. automodule:: torch
|
||||
|
||||
Tensors
|
||||
----------------------------------
|
||||
.. autofunction:: is_tensor
|
||||
.. autofunction:: is_storage
|
||||
.. autofunction:: set_default_tensor_type
|
||||
.. autofunction:: numel
|
||||
|
||||
|
||||
Creation Ops
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
.. autofunction:: eye
|
||||
.. autofunction:: from_numpy
|
||||
.. autofunction:: linspace
|
||||
.. autofunction:: logspace
|
||||
.. autofunction:: ones
|
||||
.. autofunction:: rand
|
||||
.. autofunction:: randn
|
||||
.. autofunction:: randperm
|
||||
.. autofunction:: range
|
||||
.. autofunction:: zeros
|
||||
|
||||
|
||||
Indexing, Slicing, Joining, Mutating Ops
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
.. autofunction:: cat
|
||||
.. autofunction:: chunk
|
||||
.. autofunction:: gather
|
||||
.. autofunction:: index_select
|
||||
.. autofunction:: masked_select
|
||||
.. autofunction:: nonzero
|
||||
.. autofunction:: split
|
||||
.. autofunction:: squeeze
|
||||
.. autofunction:: stack
|
||||
.. autofunction:: t
|
||||
.. autofunction:: transpose
|
||||
|
||||
|
||||
Random sampling
|
||||
----------------------------------
|
||||
.. autofunction:: manual_seed
|
||||
.. autofunction:: initial_seed
|
||||
.. autofunction:: get_rng_state
|
||||
.. autofunction:: set_rng_state
|
||||
.. autodata:: default_generator
|
||||
.. autofunction:: bernoulli
|
||||
.. autofunction:: multinomial
|
||||
.. autofunction:: normal
|
||||
|
||||
|
||||
Serialization
|
||||
----------------------------------
|
||||
.. autofunction:: save
|
||||
.. autofunction:: load
|
||||
|
||||
|
||||
Parallelism
|
||||
----------------------------------
|
||||
.. autofunction:: get_num_threads
|
||||
.. autofunction:: set_num_threads
|
||||
|
||||
|
||||
Math operations
|
||||
----------------------------------
|
||||
|
||||
Pointwise Ops
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: abs
|
||||
.. autofunction:: acos
|
||||
.. autofunction:: add
|
||||
.. autofunction:: addcdiv
|
||||
.. autofunction:: addcmul
|
||||
.. autofunction:: asin
|
||||
.. autofunction:: atan
|
||||
.. autofunction:: atan2
|
||||
.. autofunction:: ceil
|
||||
.. autofunction:: clamp
|
||||
.. autofunction:: cos
|
||||
.. autofunction:: cosh
|
||||
.. autofunction:: div
|
||||
.. autofunction:: exp
|
||||
.. autofunction:: floor
|
||||
.. autofunction:: fmod
|
||||
.. autofunction:: frac
|
||||
.. autofunction:: lerp
|
||||
.. autofunction:: log
|
||||
.. autofunction:: log1p
|
||||
.. autofunction:: mul
|
||||
.. autofunction:: neg
|
||||
.. autofunction:: pow
|
||||
.. autofunction:: reciprocal
|
||||
.. autofunction:: remainder
|
||||
.. autofunction:: round
|
||||
.. autofunction:: rsqrt
|
||||
.. autofunction:: sigmoid
|
||||
.. autofunction:: sign
|
||||
.. autofunction:: sin
|
||||
.. autofunction:: sinh
|
||||
.. autofunction:: sqrt
|
||||
.. autofunction:: tan
|
||||
.. autofunction:: tanh
|
||||
.. autofunction:: trunc
|
||||
|
||||
|
||||
Reduction Ops
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
.. autofunction:: cumprod
|
||||
.. autofunction:: cumsum
|
||||
.. autofunction:: dist
|
||||
.. autofunction:: mean
|
||||
.. autofunction:: median
|
||||
.. autofunction:: mode
|
||||
.. autofunction:: norm
|
||||
.. autofunction:: prod
|
||||
.. autofunction:: std
|
||||
.. autofunction:: sum
|
||||
.. autofunction:: var
|
||||
|
||||
|
||||
Comparison Ops
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
.. autofunction:: eq
|
||||
.. autofunction:: equal
|
||||
.. autofunction:: ge
|
||||
.. autofunction:: gt
|
||||
.. autofunction:: kthvalue
|
||||
.. autofunction:: le
|
||||
.. autofunction:: lt
|
||||
.. autofunction:: max
|
||||
.. autofunction:: min
|
||||
.. autofunction:: ne
|
||||
.. autofunction:: sort
|
||||
.. autofunction:: topk
|
||||
|
||||
|
||||
Other Operations
|
||||
~~~~~~~~~~~~~~~~~~~~~~
|
||||
.. autofunction:: cross
|
||||
.. autofunction:: diag
|
||||
.. autofunction:: histc
|
||||
.. autofunction:: renorm
|
||||
.. autofunction:: trace
|
||||
.. autofunction:: tril
|
||||
.. autofunction:: triu
|
||||
|
||||
|
||||
BLAS and LAPACK Operations
|
||||
~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
||||
|
||||
.. autofunction:: addbmm
|
||||
.. autofunction:: addmm
|
||||
.. autofunction:: addmv
|
||||
.. autofunction:: addr
|
||||
.. autofunction:: baddbmm
|
||||
.. autofunction:: bmm
|
||||
.. autofunction:: dot
|
||||
.. autofunction:: eig
|
||||
.. autofunction:: gels
|
||||
.. autofunction:: geqrf
|
||||
.. autofunction:: ger
|
||||
.. autofunction:: gesv
|
||||
.. autofunction:: inverse
|
||||
.. autofunction:: mm
|
||||
.. autofunction:: mv
|
||||
.. autofunction:: orgqr
|
||||
.. autofunction:: ormqr
|
||||
.. autofunction:: potrf
|
||||
.. autofunction:: potri
|
||||
.. autofunction:: potrs
|
||||
.. autofunction:: pstrf
|
||||
.. autofunction:: qr
|
||||
.. autofunction:: svd
|
||||
.. autofunction:: symeig
|
||||
.. autofunction:: trtrs
|
||||
|
||||
109
docs/source/torchvision/datasets.rst
Normal file
@ -0,0 +1,109 @@
|
||||
torchvision.datasets
|
||||
====================
|
||||
|
||||
The following dataset loaders are available:
|
||||
|
||||
- `COCO (Captioning and Detection)`_
|
||||
- `LSUN Classification`_
|
||||
- `ImageFolder`_
|
||||
- `Imagenet-12`_
|
||||
- `CIFAR10 and CIFAR100`_
|
||||
|
||||
Datasets have the API:
|
||||
|
||||
- ``__getitem__``
|
||||
- ``__len__``
|
||||
They all subclass from ``torch.utils.data.Dataset``
|
||||
Hence, they can all be multi-threaded (python multiprocessing) using
|
||||
standard torch.utils.data.DataLoader.
|
||||
|
||||
For example:
|
||||
|
||||
``torch.utils.data.DataLoader(coco_cap, batch_size=args.batchSize, shuffle=True, num_workers=args.nThreads)``
|
||||
|
||||
In the constructor, each dataset has a slightly different API as needed,
|
||||
but they all take the keyword args:
|
||||
|
||||
- ``transform`` - a function that takes in an image and returns a
|
||||
transformed version
|
||||
- common stuff like ``ToTensor``, ``RandomCrop``, etc. These can be
|
||||
composed together with ``transforms.Compose`` (see transforms section
|
||||
below)
|
||||
- ``target_transform`` - a function that takes in the target and
|
||||
transforms it. For example, take in the caption string and return a
|
||||
tensor of word indices.
|
||||
|
||||
COCO
|
||||
~~~~
|
||||
|
||||
This requires the `COCO API to be installed`_
|
||||
|
||||
Captions:
|
||||
^^^^^^^^^
|
||||
|
||||
``dset.CocoCaptions(root="dir where images are", annFile="json annotation file", [transform, target_transform])``
|
||||
|
||||
Example:
|
||||
|
||||
.. code:: python
|
||||
|
||||
import torchvision.datasets as dset
|
||||
import torchvision.transforms as transforms
|
||||
cap = dset.CocoCaptions(root = 'dir where images are',
|
||||
annFile = 'json annotation file',
|
||||
transform=transforms.ToTensor())
|
||||
|
||||
print('Number of samples: ', len(cap))
|
||||
img, target = cap[3] # load 4th sample
|
||||
|
||||
print("Image Size: ", img.size())
|
||||
print(target)
|
||||
|
||||
Output:
|
||||
|
||||
::
|
||||
|
||||
Number of samples: 82783
|
||||
Image Size: (3L, 427L, 640L)
|
||||
[u'A plane emitting smoke stream flying over a mountain.',
|
||||
u'A plane darts across a bright blue sky behind a mountain covered in snow',
|
||||
u'A plane leaves a contrail above the snowy mountain top.',
|
||||
u'A mountain that has a plane flying overheard in the distance.',
|
||||
u'A mountain view with a plume of smoke in the background']
|
||||
|
||||
Detection:
|
||||
^^^^^^^^^^
|
||||
|
||||
``dset.CocoDetection(root="dir where images are", annFile="json annotation file", [transform, target_transform])``
|
||||
|
||||
LSUN
|
||||
~~~~
|
||||
|
||||
``dset.LSUN(db_path, classes='train', [transform, target_transform])``
|
||||
|
||||
- db\_path = root directory for the database files
|
||||
- classes =
|
||||
- ‘train’ - all categories, training set
|
||||
- ‘val’ - all categories, validation set
|
||||
- ‘test’ - all categories, test set
|
||||
- [‘bedroom\_train’, ‘church\_train’, …] : a list of categories to load
|
||||
|
||||
CIFAR
|
||||
~~~~~
|
||||
|
||||
``dset.CIFAR10(root, train=True, transform=None, target_transform=None, download=False)``
|
||||
|
||||
``dset.CIFAR100(root, train=True, transform=None, target_transform=None, download=False)``
|
||||
|
||||
- ``root`` : root directory of dataset where there is folder
|
||||
``cifar-10-batches-py``
|
||||
- ``train`` : ``True`` = Training set, ``False`` = Test set
|
||||
- ``download`` : ``True`` = downloads the dataset from the internet and
|
||||
puts it in root directory. If dataset already downloaded, do
|
||||
|
||||
.. _COCO (Captioning and Detection): #coco
|
||||
.. _LSUN Classification: #lsun
|
||||
.. _ImageFolder: #imagefolder
|
||||
.. _Imagenet-12: #imagenet-12
|
||||
.. _CIFAR10 and CIFAR100: #cifar
|
||||
.. _COCO API to be installed: https://github.com/pdollar/coco/tree/master/PythonAPI
|
||||
11
docs/source/torchvision/models.rst
Normal file
@ -0,0 +1,11 @@
|
||||
torchvision.models
|
||||
===================
|
||||
|
||||
.. currentmodule:: torchvision.models
|
||||
|
||||
|
||||
.. automodule:: torchvision.models
|
||||
:members: alexnet, resnet18, resnet34, resnet50, resnet101, resnet152,
|
||||
vgg11, vgg11_bn, vgg13, vgg13_bn, vgg16, vgg16_bn, vgg19,
|
||||
vgg19_bn
|
||||
:undoc-members:
|
||||
5
docs/source/torchvision/torchvision.rst
Normal file
@ -0,0 +1,5 @@
|
||||
torchvision
|
||||
===================
|
||||
|
||||
The :mod:`torchvision` package consists of popular datasets, model
|
||||
architectures, and common image transformations for computer vision.
|
||||
40
docs/source/torchvision/transforms.rst
Normal file
@ -0,0 +1,40 @@
|
||||
torchvision.transforms
|
||||
======================
|
||||
|
||||
.. currentmodule:: torchvision.transforms
|
||||
|
||||
.. autoclass:: Compose
|
||||
|
||||
Transforms on PIL.Image
|
||||
-----------------------
|
||||
|
||||
.. autoclass:: Scale
|
||||
|
||||
.. autoclass:: CenterCrop
|
||||
|
||||
.. autoclass:: RandomCrop
|
||||
|
||||
.. autoclass:: RandomHorizontalFlip
|
||||
|
||||
.. autoclass:: RandomSizedCrop
|
||||
|
||||
.. autoclass:: Pad
|
||||
|
||||
Transforms on torch.\*Tensor
|
||||
----------------------------
|
||||
|
||||
.. autoclass:: Normalize
|
||||
|
||||
|
||||
Conversion Transforms
|
||||
---------------------
|
||||
|
||||
.. autoclass:: ToTensor
|
||||
|
||||
.. autoclass:: ToPILImage
|
||||
|
||||
Generic Transofrms
|
||||
------------------
|
||||
|
||||
.. autoclass:: Lambda
|
||||
|
||||
9
docs/source/torchvision/utils.rst
Normal file
@ -0,0 +1,9 @@
|
||||
torchvision.utils
|
||||
===================
|
||||
|
||||
.. currentmodule:: torchvision.utils
|
||||
|
||||
.. autofunction:: make_grid
|
||||
|
||||
.. autofunction:: save_image
|
||||
|
||||
219
setup.py
@ -9,21 +9,27 @@ import shutil
|
||||
import sys
|
||||
import os
|
||||
|
||||
# TODO: make this more robust
|
||||
WITH_CUDA = os.path.exists('/Developer/NVIDIA/CUDA-7.5/include') or os.path.exists('/usr/local/cuda/include')
|
||||
DEBUG = False
|
||||
from tools.setup_helpers.env import check_env_flag
|
||||
from tools.setup_helpers.cuda import WITH_CUDA, CUDA_HOME
|
||||
from tools.setup_helpers.cudnn import WITH_CUDNN, CUDNN_LIB_DIR, CUDNN_INCLUDE_DIR
|
||||
DEBUG = check_env_flag('DEBUG')
|
||||
|
||||
################################################################################
|
||||
# Monkey-patch setuptools to compile in parallel
|
||||
################################################################################
|
||||
|
||||
def parallelCCompile(self, sources, output_dir=None, macros=None, include_dirs=None, debug=0, extra_preargs=None, extra_postargs=None, depends=None):
|
||||
|
||||
def parallelCCompile(self, sources, output_dir=None, macros=None,
|
||||
include_dirs=None, debug=0, extra_preargs=None,
|
||||
extra_postargs=None, depends=None):
|
||||
# those lines are copied from distutils.ccompiler.CCompiler directly
|
||||
macros, objects, extra_postargs, pp_opts, build = self._setup_compile(output_dir, macros, include_dirs, sources, depends, extra_postargs)
|
||||
macros, objects, extra_postargs, pp_opts, build = self._setup_compile(
|
||||
output_dir, macros, include_dirs, sources, depends, extra_postargs)
|
||||
cc_args = self._get_cc_args(pp_opts, debug, extra_preargs)
|
||||
|
||||
# compile using a thread pool
|
||||
import multiprocessing.pool
|
||||
|
||||
def _single_compile(obj):
|
||||
src, ext = build[obj]
|
||||
self._compile(obj, src, ext, cc_args, extra_postargs, pp_opts)
|
||||
@ -38,6 +44,7 @@ distutils.ccompiler.CCompiler.compile = parallelCCompile
|
||||
# Custom build commands
|
||||
################################################################################
|
||||
|
||||
|
||||
class build_deps(Command):
|
||||
user_options = []
|
||||
|
||||
@ -72,16 +79,38 @@ class build_module(Command):
|
||||
|
||||
|
||||
class build_ext(setuptools.command.build_ext.build_ext):
|
||||
|
||||
def run(self):
|
||||
# Print build options
|
||||
if WITH_NUMPY:
|
||||
print('-- Building with NumPy bindings')
|
||||
else:
|
||||
print('-- NumPy not found')
|
||||
if WITH_CUDNN:
|
||||
print('-- Detected cuDNN at ' + CUDNN_LIB_DIR + ', ' + CUDNN_INCLUDE_DIR)
|
||||
else:
|
||||
print('-- Not using cuDNN')
|
||||
if WITH_CUDA:
|
||||
print('-- Detected CUDA at ' + CUDA_HOME)
|
||||
else:
|
||||
print('-- Not using CUDA')
|
||||
|
||||
# cwrap depends on pyyaml, so we can't import it earlier
|
||||
from tools.cwrap import cwrap
|
||||
from tools.cwrap.plugins.THPPlugin import THPPlugin
|
||||
from tools.cwrap.plugins.THPLongArgsPlugin import THPLongArgsPlugin
|
||||
from tools.cwrap.plugins.ArgcountSortPlugin import ArgcountSortPlugin
|
||||
from tools.cwrap.plugins.AutoGPU import AutoGPU
|
||||
from tools.cwrap.plugins.BoolOption import BoolOption
|
||||
from tools.cwrap.plugins.KwargsPlugin import KwargsPlugin
|
||||
from tools.cwrap.plugins.NullableArguments import NullableArguments
|
||||
from tools.cwrap.plugins.CuDNNPlugin import CuDNNPlugin
|
||||
thp_plugin = THPPlugin()
|
||||
cwrap('torch/csrc/generic/TensorMethods.cwrap', plugins=[
|
||||
AutoGPU(condition='IS_CUDA'), THPLongArgsPlugin(), THPPlugin(),
|
||||
ArgcountSortPlugin(),
|
||||
BoolOption(), thp_plugin, AutoGPU(condition='IS_CUDA'),
|
||||
ArgcountSortPlugin(), KwargsPlugin()
|
||||
])
|
||||
cwrap('torch/csrc/cudnn/cuDNN.cwrap', plugins=[
|
||||
CuDNNPlugin(), NullableArguments()
|
||||
])
|
||||
# It's an old-style class in Python 2.7...
|
||||
setuptools.command.build_ext.build_ext.run(self)
|
||||
@ -94,6 +123,7 @@ class build(distutils.command.build.build):
|
||||
|
||||
|
||||
class install(setuptools.command.install.install):
|
||||
|
||||
def run(self):
|
||||
if not self.skip_build:
|
||||
self.run_command('build_deps')
|
||||
@ -101,16 +131,22 @@ class install(setuptools.command.install.install):
|
||||
|
||||
|
||||
class clean(distutils.command.clean.clean):
|
||||
|
||||
def run(self):
|
||||
import glob
|
||||
with open('.gitignore', 'r') as f:
|
||||
ignores = f.read()
|
||||
for glob in filter(bool, ignores.split('\n')):
|
||||
shutil.rmtree(glob, ignore_errors=True)
|
||||
for wildcard in filter(bool, ignores.split('\n')):
|
||||
for filename in glob.glob(wildcard):
|
||||
try:
|
||||
os.remove(filename)
|
||||
except OSError:
|
||||
shutil.rmtree(filename, ignore_errors=True)
|
||||
|
||||
# It's an old-style class in Python 2.7...
|
||||
distutils.command.clean.clean.run(self)
|
||||
|
||||
|
||||
|
||||
################################################################################
|
||||
# Configure compile flags
|
||||
################################################################################
|
||||
@ -132,15 +168,35 @@ include_dirs += [
|
||||
os.path.join(cwd, "torch", "csrc"),
|
||||
tmp_install_path + "/include",
|
||||
tmp_install_path + "/include/TH",
|
||||
tmp_install_path + "/include/THPP",
|
||||
]
|
||||
|
||||
extra_link_args.append('-L' + lib_path)
|
||||
|
||||
# we specify exact lib names to avoid conflict with lua-torch installs
|
||||
TH_LIB = os.path.join(lib_path, 'libTH.so.1')
|
||||
THS_LIB = os.path.join(lib_path, 'libTHS.so.1')
|
||||
THC_LIB = os.path.join(lib_path, 'libTHC.so.1')
|
||||
THCS_LIB = os.path.join(lib_path, 'libTHCS.so.1')
|
||||
THNN_LIB = os.path.join(lib_path, 'libTHNN.so.1')
|
||||
THCUNN_LIB = os.path.join(lib_path, 'libTHCUNN.so.1')
|
||||
THPP_LIB = os.path.join(lib_path, 'libTHPP.so.1')
|
||||
if platform.system() == 'Darwin':
|
||||
TH_LIB = os.path.join(lib_path, 'libTH.1.dylib')
|
||||
THS_LIB = os.path.join(lib_path, 'libTHS.1.dylib')
|
||||
THC_LIB = os.path.join(lib_path, 'libTHC.1.dylib')
|
||||
THCS_LIB = os.path.join(lib_path, 'libTHCS.1.dylib')
|
||||
THNN_LIB = os.path.join(lib_path, 'libTHNN.1.dylib')
|
||||
THCUNN_LIB = os.path.join(lib_path, 'libTHCUNN.1.dylib')
|
||||
THPP_LIB = os.path.join(lib_path, 'libTHPP.1.dylib')
|
||||
|
||||
main_compile_args = ['-D_THP_CORE']
|
||||
main_libraries = ['TH', 'shm']
|
||||
main_libraries = ['shm']
|
||||
main_link_args = [TH_LIB, THS_LIB, THPP_LIB]
|
||||
main_sources = [
|
||||
"torch/csrc/Module.cpp",
|
||||
"torch/csrc/Generator.cpp",
|
||||
"torch/csrc/Size.cpp",
|
||||
"torch/csrc/Exceptions.cpp",
|
||||
"torch/csrc/Tensor.cpp",
|
||||
"torch/csrc/Storage.cpp",
|
||||
@ -148,37 +204,58 @@ main_sources = [
|
||||
"torch/csrc/utils.cpp",
|
||||
"torch/csrc/allocators.cpp",
|
||||
"torch/csrc/serialization.cpp",
|
||||
"torch/csrc/autograd/init.cpp",
|
||||
"torch/csrc/autograd/variable.cpp",
|
||||
"torch/csrc/autograd/function.cpp",
|
||||
"torch/csrc/autograd/engine.cpp",
|
||||
]
|
||||
|
||||
try:
|
||||
import numpy as np
|
||||
include_dirs += [np.get_include()]
|
||||
extra_compile_args += ['-DWITH_NUMPY']
|
||||
WITH_NUMPY = True
|
||||
except ImportError:
|
||||
pass
|
||||
WITH_NUMPY = False
|
||||
|
||||
if WITH_CUDA:
|
||||
if platform.system() == 'Darwin':
|
||||
cuda_path = '/Developer/NVIDIA/CUDA-7.5'
|
||||
cuda_include_path = cuda_path + '/include'
|
||||
cuda_lib_path = cuda_path + '/lib'
|
||||
else:
|
||||
cuda_path = '/usr/local/cuda'
|
||||
cuda_include_path = cuda_path + '/include'
|
||||
cuda_lib_path = cuda_path + '/lib64'
|
||||
cuda_lib_dirs = ['lib64', 'lib']
|
||||
cuda_include_path = os.path.join(CUDA_HOME, 'include')
|
||||
for lib_dir in cuda_lib_dirs:
|
||||
cuda_lib_path = os.path.join(CUDA_HOME, lib_dir)
|
||||
if os.path.exists(cuda_lib_path):
|
||||
break
|
||||
include_dirs.append(cuda_include_path)
|
||||
extra_link_args.append('-L' + cuda_lib_path)
|
||||
extra_link_args.append('-Wl,-rpath,' + cuda_lib_path)
|
||||
extra_compile_args += ['-DWITH_CUDA']
|
||||
main_libraries += ['THC']
|
||||
extra_compile_args += ['-DCUDA_LIB_PATH=' + cuda_lib_path]
|
||||
main_link_args += [THC_LIB, THCS_LIB]
|
||||
main_sources += [
|
||||
"torch/csrc/cuda/Module.cpp",
|
||||
"torch/csrc/cuda/Storage.cpp",
|
||||
"torch/csrc/cuda/Stream.cpp",
|
||||
"torch/csrc/cuda/Tensor.cpp",
|
||||
"torch/csrc/cuda/AutoGPU.cpp",
|
||||
"torch/csrc/cuda/utils.cpp",
|
||||
"torch/csrc/cuda/serialization.cpp",
|
||||
]
|
||||
|
||||
if WITH_CUDNN:
|
||||
main_libraries += ['cudnn']
|
||||
include_dirs.append(CUDNN_INCLUDE_DIR)
|
||||
extra_link_args.append('-L' + CUDNN_LIB_DIR)
|
||||
main_sources += [
|
||||
"torch/csrc/cudnn/Module.cpp",
|
||||
"torch/csrc/cudnn/BatchNorm.cpp",
|
||||
"torch/csrc/cudnn/Conv.cpp",
|
||||
"torch/csrc/cudnn/cuDNN.cpp",
|
||||
"torch/csrc/cudnn/Types.cpp",
|
||||
"torch/csrc/cudnn/Handles.cpp",
|
||||
"torch/csrc/cudnn/CppWrapper.cpp",
|
||||
]
|
||||
extra_compile_args += ['-DWITH_CUDNN']
|
||||
|
||||
if DEBUG:
|
||||
extra_compile_args += ['-O0', '-g']
|
||||
extra_link_args += ['-O0', '-g']
|
||||
@ -198,58 +275,70 @@ extensions = []
|
||||
packages = find_packages(exclude=('tools.*',))
|
||||
|
||||
C = Extension("torch._C",
|
||||
libraries=main_libraries,
|
||||
sources=main_sources,
|
||||
language='c++',
|
||||
extra_compile_args=main_compile_args + extra_compile_args,
|
||||
include_dirs=include_dirs,
|
||||
extra_link_args=extra_link_args + [make_relative_rpath('lib')]
|
||||
)
|
||||
libraries=main_libraries,
|
||||
sources=main_sources,
|
||||
language='c++',
|
||||
extra_compile_args=main_compile_args + extra_compile_args,
|
||||
include_dirs=include_dirs,
|
||||
extra_link_args=extra_link_args + main_link_args + [make_relative_rpath('lib')],
|
||||
)
|
||||
extensions.append(C)
|
||||
|
||||
DL = Extension("torch._dl",
|
||||
sources=["torch/csrc/dl.c"],
|
||||
language='c',
|
||||
)
|
||||
sources=["torch/csrc/dl.c"],
|
||||
language='c',
|
||||
)
|
||||
extensions.append(DL)
|
||||
|
||||
THNN = Extension("torch._thnn._THNN",
|
||||
libraries=['TH', 'THNN'],
|
||||
sources=['torch/csrc/nn/THNN.cpp'],
|
||||
language='c++',
|
||||
extra_compile_args=extra_compile_args,
|
||||
include_dirs=include_dirs,
|
||||
extra_link_args=extra_link_args + [make_relative_rpath('../lib')]
|
||||
)
|
||||
sources=['torch/csrc/nn/THNN.cpp'],
|
||||
language='c++',
|
||||
extra_compile_args=extra_compile_args,
|
||||
include_dirs=include_dirs,
|
||||
extra_link_args=extra_link_args + [
|
||||
TH_LIB,
|
||||
THNN_LIB,
|
||||
make_relative_rpath('../lib'),
|
||||
]
|
||||
)
|
||||
extensions.append(THNN)
|
||||
|
||||
if WITH_CUDA:
|
||||
THCUNN = Extension("torch._thnn._THCUNN",
|
||||
libraries=['TH', 'THC', 'THCUNN'],
|
||||
sources=['torch/csrc/nn/THCUNN.cpp'],
|
||||
language='c++',
|
||||
extra_compile_args=extra_compile_args,
|
||||
include_dirs=include_dirs,
|
||||
extra_link_args=extra_link_args + [make_relative_rpath('../lib')]
|
||||
)
|
||||
sources=['torch/csrc/nn/THCUNN.cpp'],
|
||||
language='c++',
|
||||
extra_compile_args=extra_compile_args,
|
||||
include_dirs=include_dirs,
|
||||
extra_link_args=extra_link_args + [
|
||||
TH_LIB,
|
||||
THC_LIB,
|
||||
THCUNN_LIB,
|
||||
make_relative_rpath('../lib'),
|
||||
]
|
||||
)
|
||||
extensions.append(THCUNN)
|
||||
|
||||
setup(name="torch", version="0.1",
|
||||
ext_modules=extensions,
|
||||
cmdclass = {
|
||||
'build': build,
|
||||
'build_ext': build_ext,
|
||||
'build_deps': build_deps,
|
||||
'build_module': build_module,
|
||||
'install': install,
|
||||
'clean': clean,
|
||||
},
|
||||
packages=packages,
|
||||
package_data={'torch': [
|
||||
'lib/*.so*', 'lib/*.dylib*',
|
||||
'lib/torch_shm_manager',
|
||||
'lib/*.h',
|
||||
'lib/include/TH/*.h', 'lib/include/TH/generic/*.h',
|
||||
'lib/include/THC/*.h', 'lib/include/THC/generic/*.h']},
|
||||
install_requires=['pyyaml'],
|
||||
)
|
||||
version = "0.1"
|
||||
if os.getenv('PYTORCH_BUILD_VERSION'):
|
||||
version = os.getenv('PYTORCH_BUILD_VERSION') \
|
||||
+ '_' + os.getenv('PYTORCH_BUILD_NUMBER')
|
||||
|
||||
setup(name="torch", version=version,
|
||||
ext_modules=extensions,
|
||||
cmdclass={
|
||||
'build': build,
|
||||
'build_ext': build_ext,
|
||||
'build_deps': build_deps,
|
||||
'build_module': build_module,
|
||||
'install': install,
|
||||
'clean': clean,
|
||||
},
|
||||
packages=packages,
|
||||
package_data={'torch': [
|
||||
'lib/*.so*', 'lib/*.dylib*',
|
||||
'lib/torch_shm_manager',
|
||||
'lib/*.h',
|
||||
'lib/include/TH/*.h', 'lib/include/TH/generic/*.h',
|
||||
'lib/include/THC/*.h', 'lib/include/THC/generic/*.h']},
|
||||
install_requires=['pyyaml'],
|
||||
)
|
||||
|
||||
@ -1,14 +1,33 @@
|
||||
import sys
|
||||
import argparse
|
||||
import unittest
|
||||
import contextlib
|
||||
from itertools import product
|
||||
from copy import deepcopy
|
||||
|
||||
import torch
|
||||
import torch.cuda
|
||||
from torch.autograd import Variable, Function
|
||||
|
||||
|
||||
torch.set_default_tensor_type('torch.DoubleTensor')
|
||||
|
||||
def run_tests():
|
||||
parser = argparse.ArgumentParser(add_help=False)
|
||||
parser.add_argument('--seed', type=int, default=123)
|
||||
args, remaining = parser.parse_known_args()
|
||||
torch.manual_seed(args.seed)
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.manual_seed_all(args.seed)
|
||||
remaining = [sys.argv[0]] + remaining
|
||||
unittest.main(argv=remaining)
|
||||
|
||||
|
||||
TEST_NUMPY = True
|
||||
try:
|
||||
import numpy
|
||||
except ImportError:
|
||||
TEST_NUMPY = False
|
||||
|
||||
def get_cpu_type(t):
|
||||
assert t.__module__ == 'torch.cuda'
|
||||
@ -78,7 +97,7 @@ class TestCase(unittest.TestCase):
|
||||
|
||||
if torch.is_tensor(x) and torch.is_tensor(y):
|
||||
max_err = 0
|
||||
super(TestCase, self).assertEqual(x.size().tolist(), y.size().tolist())
|
||||
super(TestCase, self).assertEqual(x.size(), y.size())
|
||||
for index in iter_indices(x):
|
||||
max_err = max(max_err, abs(x[index] - y[index]))
|
||||
self.assertLessEqual(max_err, prec, message)
|
||||
@ -95,6 +114,39 @@ class TestCase(unittest.TestCase):
|
||||
pass
|
||||
super(TestCase, self).assertEqual(x, y, message)
|
||||
|
||||
def assertNotEqual(self, x, y, prec=None, message=''):
|
||||
if prec is None:
|
||||
prec = self.precision
|
||||
|
||||
if isinstance(x, Variable) and isinstance(y, Variable):
|
||||
x = x.data
|
||||
y = y.data
|
||||
|
||||
if torch.is_tensor(x) and torch.is_tensor(y):
|
||||
max_err = 0
|
||||
if x.size() != y.size():
|
||||
super(TestCase, self).assertNotEqual(x.size(), y.size())
|
||||
for index in iter_indices(x):
|
||||
max_err = max(max_err, abs(x[index] - y[index]))
|
||||
self.assertGreaterEqual(max_err, prec, message)
|
||||
elif type(x) == str and type(y) == str:
|
||||
super(TestCase, self).assertNotEqual(x, y)
|
||||
elif is_iterable(x) and is_iterable(y):
|
||||
super(TestCase, self).assertNotEqual(x, y)
|
||||
else:
|
||||
try:
|
||||
self.assertGreaterEqual(abs(x - y), prec, message)
|
||||
return
|
||||
except:
|
||||
pass
|
||||
super(TestCase, self).assertNotEqual(x, y, message)
|
||||
|
||||
def assertObjectIn(self, obj, iterable):
|
||||
for elem in iterable:
|
||||
if id(obj) == id(elem):
|
||||
return
|
||||
raise AssertionError("object not found in iterable")
|
||||
|
||||
|
||||
def make_jacobian(input, num_out):
|
||||
if isinstance(input, Variable) and not input.requires_grad:
|
||||
|
||||
@ -7,6 +7,7 @@ import torch
|
||||
import torch.cuda
|
||||
from torch.autograd import Variable
|
||||
from common import TestCase, to_gpu, get_numerical_jacobian, iter_tensors, contiguous
|
||||
import torch.backends.cudnn
|
||||
|
||||
# tarfile module tries to obtain a file object name in python 3.3
|
||||
if sys.version_info[:2] == (3, 3):
|
||||
@ -15,6 +16,8 @@ else:
|
||||
TemporaryFile = tempfile.TemporaryFile
|
||||
|
||||
TEST_CUDA = torch.cuda.is_available()
|
||||
TEST_MULTIGPU = TEST_CUDA and torch.cuda.device_count() >= 2
|
||||
TEST_CUDNN = TEST_CUDA and torch.backends.cudnn.is_acceptable(torch.cuda.FloatTensor(1))
|
||||
PRECISION = 1e-5
|
||||
|
||||
module_tests = [
|
||||
@ -24,6 +27,13 @@ module_tests = [
|
||||
input_size=(4, 10),
|
||||
reference_fn=lambda i,p: torch.mm(i, p[0].t()) + p[1].view(1, -1).expand(4, 8)
|
||||
),
|
||||
dict(
|
||||
module_name='Linear',
|
||||
constructor_args=(10, 8, False),
|
||||
input_size=(4, 10),
|
||||
desc='no_bias',
|
||||
reference_fn=lambda i,p: torch.mm(i, p[0].t())
|
||||
),
|
||||
dict(
|
||||
module_name='Threshold',
|
||||
constructor_args=(2, 1),
|
||||
@ -82,57 +92,17 @@ module_tests = [
|
||||
input_size=(1, 3, 10, 20),
|
||||
reference_fn=lambda i,_: torch.exp(i).div(torch.exp(i).sum(1).expand_as(i))
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm1d',
|
||||
constructor_args=(10,),
|
||||
input_size=(4, 10),
|
||||
desc='affine'
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm1d',
|
||||
constructor_args=(10, 1e-3, 0.3, False),
|
||||
input_size=(4, 10),
|
||||
desc='not_affine'
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm2d',
|
||||
constructor_args=(3,),
|
||||
input_size=(2, 3, 6, 6),
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm2d',
|
||||
constructor_args=(3, 1e-3, 0.8),
|
||||
input_size=(2, 3, 6, 6),
|
||||
desc='momentum',
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm2d',
|
||||
constructor_args=(3, 1e-3, 0.8, False),
|
||||
input_size=(2, 3, 6, 6),
|
||||
desc='no_affine',
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm3d',
|
||||
constructor_args=(3,),
|
||||
input_size=(2, 3, 4, 4, 4)
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm3d',
|
||||
constructor_args=(3, 1e-3, 0.7),
|
||||
input_size=(2, 3, 4, 4, 4),
|
||||
desc='momentum'
|
||||
),
|
||||
dict(
|
||||
module_name='BatchNorm3d',
|
||||
constructor_args=(3, 1e-3, 0.7, False),
|
||||
input_size=(2, 3, 4, 4, 4),
|
||||
desc='no_affine'
|
||||
),
|
||||
dict(
|
||||
module_name='LogSoftmax',
|
||||
input_size=(10, 20),
|
||||
reference_fn=lambda i,_: torch.exp(i).div_(torch.exp(i).sum(1).expand(10, 20)).log_()
|
||||
),
|
||||
dict(
|
||||
module_name='LogSoftmax',
|
||||
input_size=(1, 3, 10, 20),
|
||||
reference_fn=lambda i,_: torch.exp(i).div_(torch.exp(i).sum(1).expand_as(i)).log_(),
|
||||
desc='multiparam'
|
||||
),
|
||||
dict(
|
||||
module_name='ELU',
|
||||
constructor_args=(2.,),
|
||||
@ -289,7 +259,7 @@ criterion_tests = [
|
||||
dict(
|
||||
module_name='MultiLabelMarginLoss',
|
||||
input_size=(5, 10),
|
||||
target=torch.rand(5, 10).mul(10).floor()
|
||||
target=torch.rand(5, 10).mul(10).floor().long()
|
||||
),
|
||||
dict(
|
||||
module_name='MultiLabelSoftMarginLoss',
|
||||
@ -306,7 +276,7 @@ criterion_tests = [
|
||||
dict(
|
||||
module_name='MultiMarginLoss',
|
||||
input_size=(5, 10),
|
||||
target=torch.rand(5).mul(8).floor()
|
||||
target=torch.rand(5).mul(8).floor().long()
|
||||
),
|
||||
dict(
|
||||
module_name='SmoothL1Loss',
|
||||
@ -365,7 +335,7 @@ class NNTestCase(TestCase):
|
||||
|
||||
def _zero_grad_input(self, input):
|
||||
if isinstance(input, Variable):
|
||||
input.grad.zero_()
|
||||
input.grad.data.zero_()
|
||||
elif torch.is_tensor(input):
|
||||
return
|
||||
else:
|
||||
@ -379,8 +349,8 @@ class NNTestCase(TestCase):
|
||||
flat_d_out = d_out.view(-1)
|
||||
|
||||
if jacobian_input:
|
||||
jacobian_input = self._jacobian(input, d_out.nelement())
|
||||
flat_jacobian_input = list(iter_tensors(jacobian_input))
|
||||
jacobian_inp = self._jacobian(input, d_out.nelement())
|
||||
flat_jacobian_input = list(iter_tensors(jacobian_inp))
|
||||
|
||||
if jacobian_parameters:
|
||||
param, d_param = self._get_parameters(module)
|
||||
@ -406,7 +376,7 @@ class NNTestCase(TestCase):
|
||||
|
||||
res = tuple()
|
||||
if jacobian_input:
|
||||
res += jacobian_input,
|
||||
res += jacobian_inp,
|
||||
if jacobian_parameters:
|
||||
res += jacobian_param,
|
||||
|
||||
@ -643,10 +613,10 @@ class CriterionTest(TestBase):
|
||||
|
||||
cpu_output = test_case._forward_criterion(cpu_module, cpu_input, cpu_target)
|
||||
gpu_output = test_case._forward_criterion(gpu_module, gpu_input, gpu_target)
|
||||
test_case.assertEqual(cpu_output, gpu_output, 2e-4)
|
||||
test_case.assertEqual(cpu_output, gpu_output, 4e-4)
|
||||
|
||||
cpu_gradInput = test_case._backward_criterion(cpu_module, cpu_input, cpu_target)
|
||||
gpu_gradInput = test_case._backward_criterion(gpu_module, gpu_input, gpu_target)
|
||||
test_case.assertEqual(cpu_gradInput, gpu_gradInput, 2e-4)
|
||||
test_case.assertEqual(cpu_gradInput, gpu_gradInput, 4e-4)
|
||||
except NotImplementedError:
|
||||
pass
|
||||
|
||||
7
test/data/network1.py
Normal file
@ -0,0 +1,7 @@
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
class Net(nn.Module):
|
||||
def __init__(self):
|
||||
super(Net, self).__init__()
|
||||
self.linear = nn.Linear(10, 20)
|
||||
8
test/data/network2.py
Normal file
@ -0,0 +1,8 @@
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
class Net(nn.Module):
|
||||
def __init__(self):
|
||||
super(Net, self).__init__()
|
||||
self.linear = nn.Linear(10, 20)
|
||||
self.relu = nn.ReLU()
|
||||
@ -1,5 +1,5 @@
|
||||
|
||||
# th test.lua > lua.out
|
||||
th test.lua > lua.out
|
||||
python3 test.py > python.out
|
||||
|
||||
diff lua.out python.out >/dev/null 2>&1
|
||||
|
||||
5060
test/optim/lua.out
@ -1,39 +0,0 @@
|
||||
assert(arg[1])
|
||||
funcs = {
|
||||
'resizeAs', 'add', 'zero', 'mul', 'div', 'abs',
|
||||
'addcmul', 'addcdiv', 'copy', 'sqrt', 'fill',
|
||||
{'cmul', 'mul'},
|
||||
{'cdiv', 'div'},
|
||||
}
|
||||
for _, val in pairs(funcs) do
|
||||
local name, newname
|
||||
if type(val) == 'table' then
|
||||
name = val[1]
|
||||
newname = val[2]
|
||||
else
|
||||
name = val
|
||||
newname = val .. '_'
|
||||
end
|
||||
|
||||
command = "sed -i -r "
|
||||
.. "'/torch\\." .. name .. "\\(/b; " -- short-circuits
|
||||
.. "s/([a-zA-Z]*)\\." .. name .. "\\(" -- substitution
|
||||
.. "/"
|
||||
.. "\\1\\." .. newname .. "\\(/g' " .. arg[1]
|
||||
print(command)
|
||||
os.execute(command)
|
||||
command = "sed -i 's/math\\." .. newname
|
||||
.. "/math\\." .. name .. "/' " .. arg[1]
|
||||
print(command)
|
||||
os.execute(command)
|
||||
end
|
||||
|
||||
funcs = {
|
||||
{'torch\.cmul', 'torch\.mul'},
|
||||
{'torch\.cdiv', 'torch\.div'},
|
||||
}
|
||||
for _, val in pairs(funcs) do
|
||||
command = "sed -i 's/" .. val[1] .. "/" .. val[2] .. "/' " .. arg[1]
|
||||
print(command)
|
||||
os.execute(command)
|
||||
end
|
||||
33
test/optim/test.lua
Normal file
@ -0,0 +1,33 @@
|
||||
local cjson = require 'cjson'
|
||||
require 'optim'
|
||||
|
||||
function rosenbrock(t)
|
||||
x, y = t[1], t[2]
|
||||
return (1 - x) ^ 2 + 100 * (y - x^2)^2
|
||||
end
|
||||
|
||||
function drosenbrock(t)
|
||||
x, y = t[1], t[2]
|
||||
return torch.DoubleTensor({-400 * x * (y - x^2) - 2 * (1 - x), 200 * x * (y - x^2)})
|
||||
end
|
||||
|
||||
local fd = io.open('tests.json', 'r')
|
||||
local tests = cjson.decode(fd:read('*a'))
|
||||
fd:close()
|
||||
|
||||
for i, test in ipairs(tests) do
|
||||
print(test.algorithm)
|
||||
algorithm = optim[test.algorithm]
|
||||
for i, config in ipairs(test.config) do
|
||||
print('================================================================================')
|
||||
params = torch.DoubleTensor({1.5, 1.5})
|
||||
for i = 1, 100 do
|
||||
function closure(x)
|
||||
return rosenbrock(x), drosenbrock(x)
|
||||
end
|
||||
algorithm(closure, params, config)
|
||||
print(string.format('%.8f\t%.8f', params[1], params[2]))
|
||||
end
|
||||
end
|
||||
end
|
||||
|
||||
@ -22,6 +22,7 @@ algorithms = {
|
||||
'rmsprop': optim.rmsprop,
|
||||
'rprop': optim.rprop,
|
||||
'sgd': optim.sgd,
|
||||
'lbfgs': optim.lbfgs,
|
||||
}
|
||||
|
||||
with open('tests.json', 'r') as f:
|
||||
@ -35,4 +36,4 @@ for test in tests:
|
||||
params = torch.DoubleTensor((1.5, 1.5))
|
||||
for i in range(100):
|
||||
algorithm(lambda x: (rosenbrock(x), drosenbrock(x)), params, config)
|
||||
print('{:.12f}\t{:.12f}\t'.format(params[0], params[1]))
|
||||
print('{:.8f}\t{:.8f}\t'.format(params[0], params[1]))
|
||||
|
||||
@ -98,5 +98,12 @@
|
||||
{"learningRate": 1e-4, "nesterov": true, "momentum": 0.95, "dampening": 0},
|
||||
{"weightDecay": 0.2}
|
||||
]
|
||||
},
|
||||
{
|
||||
"algorithm": "lbfgs",
|
||||
"config": [
|
||||
{},
|
||||
{"learningRate": 1e-1}
|
||||
]
|
||||
}
|
||||
]
|
||||
|
||||
@ -1,31 +1,63 @@
|
||||
#!/usr/bin/env bash
|
||||
set -e
|
||||
|
||||
PYCMD=${PYCMD:="python"}
|
||||
COVERAGE=0
|
||||
while [[ "$#" -gt 0 ]]; do
|
||||
case "$1" in
|
||||
-p|--python) PYCMD=$2; shift 2 ;;
|
||||
-c|--coverage) COVERAGE=1; shift 2 ;;
|
||||
--) shift; break ;;
|
||||
*) echo "Invalid argument: $1!" ; exit 1 ;;
|
||||
esac
|
||||
done
|
||||
|
||||
if [[ $COVERAGE -eq 1 ]]; then
|
||||
coverage erase
|
||||
PYCMD="coverage run --parallel-mode --source torch "
|
||||
echo "coverage flag found. Setting python command to: \"$PYCMD\""
|
||||
fi
|
||||
|
||||
pushd "$(dirname "$0")"
|
||||
|
||||
echo "Running torch tests"
|
||||
python test_torch.py
|
||||
$PYCMD test_torch.py $@
|
||||
|
||||
echo "Running autograd tests"
|
||||
python test_autograd.py
|
||||
$PYCMD test_autograd.py $@
|
||||
|
||||
echo "Running sparse tests"
|
||||
$PYCMD test_sparse.py $@
|
||||
|
||||
echo "Running nn tests"
|
||||
python test_nn.py
|
||||
$PYCMD test_nn.py $@
|
||||
|
||||
echo "Running legacy nn tests"
|
||||
python test_legacy_nn.py
|
||||
$PYCMD test_legacy_nn.py $@
|
||||
|
||||
echo "Running optim tests"
|
||||
$PYCMD test_optim.py $@
|
||||
|
||||
echo "Running multiprocessing tests"
|
||||
python test_multiprocessing.py
|
||||
$PYCMD test_multiprocessing.py $@
|
||||
MULTIPROCESSING_METHOD=spawn $PYCMD test_multiprocessing.py $@
|
||||
MULTIPROCESSING_METHOD=forkserver $PYCMD test_multiprocessing.py $@
|
||||
|
||||
echo "Running util tests"
|
||||
python test_utils.py
|
||||
if which nvcc >/dev/null 2>&1
|
||||
then
|
||||
echo "Running cuda tests"
|
||||
python test_cuda.py
|
||||
else
|
||||
echo "nvcc not found in PATH, skipping CUDA tests"
|
||||
$PYCMD test_utils.py $@
|
||||
|
||||
echo "Running dataloader tests"
|
||||
$PYCMD test_dataloader.py $@
|
||||
|
||||
echo "Running cuda tests"
|
||||
$PYCMD test_cuda.py $@
|
||||
|
||||
echo "Running NCCL tests"
|
||||
$PYCMD test_nccl.py $@
|
||||
|
||||
if [[ $COVERAGE -eq 1 ]]; then
|
||||
coverage combine
|
||||
coverage html
|
||||
fi
|
||||
|
||||
popd
|
||||
|
||||
@ -1,25 +1,40 @@
|
||||
import contextlib
|
||||
import gc
|
||||
import sys
|
||||
import math
|
||||
import torch
|
||||
import unittest
|
||||
from copy import deepcopy
|
||||
from collections import OrderedDict
|
||||
|
||||
from common import make_jacobian, TestCase, iter_tensors, get_numerical_jacobian
|
||||
from torch.autograd.functions import *
|
||||
from common import make_jacobian, TestCase, iter_tensors, \
|
||||
get_numerical_jacobian, run_tests
|
||||
from torch.autograd._functions import *
|
||||
from torch.autograd import Variable, Function
|
||||
|
||||
if sys.version_info[0] == 2:
|
||||
import cPickle as pickle
|
||||
else:
|
||||
import pickle
|
||||
|
||||
PRECISION = 1e-4
|
||||
|
||||
|
||||
def iter_gradients(x):
|
||||
if isinstance(x, Variable):
|
||||
if x.requires_grad:
|
||||
yield x.grad
|
||||
yield x.grad.data
|
||||
else:
|
||||
for elem in x:
|
||||
for result in iter_gradients(elem):
|
||||
yield result
|
||||
|
||||
|
||||
def zero_gradients(i):
|
||||
for t in iter_gradients(i):
|
||||
t.zero_()
|
||||
|
||||
|
||||
def get_analytical_jacobian(input, output):
|
||||
jacobian = make_jacobian(input, output.numel())
|
||||
grad_output = output.data.clone().zero_()
|
||||
@ -35,55 +50,160 @@ def get_analytical_jacobian(input, output):
|
||||
|
||||
return jacobian
|
||||
|
||||
|
||||
@contextlib.contextmanager
|
||||
def backward_engine(engine):
|
||||
_prev_engine = Variable._execution_engine
|
||||
Variable._execution_engine = engine()
|
||||
try:
|
||||
yield
|
||||
finally:
|
||||
Variable._execution_engine = _prev_engine
|
||||
|
||||
|
||||
class TestAutograd(TestCase):
|
||||
|
||||
def test_hooks(self):
|
||||
x = Variable(torch.ones(5, 5))
|
||||
y = Variable(torch.ones(5, 5) * 4)
|
||||
x = Variable(torch.ones(5, 5), requires_grad=True)
|
||||
y = Variable(torch.ones(5, 5) * 4, requires_grad=True)
|
||||
|
||||
counter = [0]
|
||||
def bw_hook(inc, grad):
|
||||
self.assertTrue(torch.is_tensor(grad))
|
||||
self.assertIsInstance(grad, Variable)
|
||||
counter[0] += inc
|
||||
|
||||
z = x ** 2 + x * 2 + x * y + y
|
||||
z.register_hook('test', lambda *args: bw_hook(1, *args))
|
||||
test = z.register_hook(lambda *args: bw_hook(1, *args))
|
||||
z.backward(torch.ones(5, 5), retain_variables=True)
|
||||
self.assertEqual(counter[0], 1)
|
||||
|
||||
z.register_hook('test2', lambda *args: bw_hook(2, *args))
|
||||
test2 = z.register_hook(lambda *args: bw_hook(2, *args))
|
||||
z.backward(torch.ones(5, 5), retain_variables=True)
|
||||
self.assertEqual(counter[0], 4)
|
||||
|
||||
z.remove_hook('test2')
|
||||
test2.remove()
|
||||
z.backward(torch.ones(5, 5), retain_variables=True)
|
||||
self.assertEqual(counter[0], 5)
|
||||
|
||||
def test_backward(self):
|
||||
def bw_hook_modify(grad):
|
||||
return grad.mul(2)
|
||||
|
||||
test.remove()
|
||||
z.register_hook(bw_hook_modify)
|
||||
y.grad.data.zero_()
|
||||
z.backward(torch.ones(5, 5), retain_variables=True)
|
||||
self.assertEqual(y.grad.data, (x.data + 1) * 2)
|
||||
|
||||
y.register_hook(bw_hook_modify)
|
||||
y.grad.data.zero_()
|
||||
z.backward(torch.ones(5, 5))
|
||||
self.assertEqual(y.grad.data, (x.data + 1) * 4)
|
||||
|
||||
def test_hook_none(self):
|
||||
# WARNING: this is a test for autograd internals.
|
||||
# You should never have to use such things in your code.
|
||||
class NoneGradientFunction(Function):
|
||||
def forward(self, x, y):
|
||||
assert self.needs_input_grad[0]
|
||||
assert not self.needs_input_grad[1]
|
||||
return x, y
|
||||
|
||||
def backward(self, grad_x, grad_y):
|
||||
return grad_x, None
|
||||
|
||||
fn = NoneGradientFunction()
|
||||
fn._backward_hooks = OrderedDict()
|
||||
was_called = [False]
|
||||
def hook(grad_input, grad_output):
|
||||
self.assertIsInstance(grad_input, tuple)
|
||||
self.assertIsInstance(grad_output, tuple)
|
||||
self.assertIsNotNone(grad_input[0])
|
||||
self.assertIsNone(grad_input[1])
|
||||
self.assertIsNotNone(grad_output[0])
|
||||
self.assertIsNotNone(grad_output[1])
|
||||
was_called[0] = True
|
||||
fn._backward_hooks[id(hook)] = hook
|
||||
|
||||
x = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
y = Variable(torch.randn(5, 5))
|
||||
sum(fn(x, y)).sum().backward()
|
||||
self.assertTrue(was_called[0])
|
||||
|
||||
def _test_backward(self):
|
||||
v_t = torch.randn(5, 5)
|
||||
x_t = torch.randn(5, 5)
|
||||
y_t = torch.rand(5, 5) + 0.1
|
||||
z_t = torch.randn(5, 5)
|
||||
grad_output = torch.randn(5, 5)
|
||||
v = Variable(v_t)
|
||||
x = Variable(x_t)
|
||||
y = Variable(y_t)
|
||||
z = Variable(z_t)
|
||||
v = Variable(v_t, requires_grad=True)
|
||||
x = Variable(x_t, requires_grad=True)
|
||||
y = Variable(y_t, requires_grad=True)
|
||||
z = Variable(z_t, requires_grad=True)
|
||||
|
||||
v.backward(grad_output)
|
||||
self.assertEqual(v.grad, grad_output)
|
||||
self.assertEqual(v.grad.data, grad_output)
|
||||
|
||||
a = x + (y * z) + 4 * z**2 * x / y
|
||||
a.backward(grad_output)
|
||||
x_grad = 4 * z_t.pow(2) / y_t + 1
|
||||
y_grad = z_t - 4 * x_t * z_t.pow(2) / y_t.pow(2)
|
||||
z_grad = 8 * x_t * z_t / y_t + y_t
|
||||
self.assertEqual(x.grad, x_grad * grad_output)
|
||||
self.assertEqual(y.grad, y_grad * grad_output)
|
||||
self.assertEqual(z.grad, z_grad * grad_output)
|
||||
self.assertEqual(x.grad.data, x_grad * grad_output)
|
||||
self.assertEqual(y.grad.data, y_grad * grad_output)
|
||||
self.assertEqual(z.grad.data, z_grad * grad_output)
|
||||
|
||||
def test_backward(self):
|
||||
self._test_backward()
|
||||
|
||||
@unittest.skip("BasicEngine is out of date")
|
||||
def test_backward_basic_engine(self):
|
||||
with backward_engine(torch.autograd.engine.BasicEngine):
|
||||
self._test_backward()
|
||||
|
||||
def test_multi_backward(self):
|
||||
x = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
y = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
|
||||
q = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
|
||||
a = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
b = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
|
||||
q2 = q * 2
|
||||
z = x + y + q2
|
||||
c = a * b + q2
|
||||
grad_z = torch.randn(5, 5)
|
||||
grad_c = torch.randn(5, 5)
|
||||
torch.autograd.backward([z, c], [grad_z, grad_c])
|
||||
|
||||
self.assertEqual(x.grad.data, grad_z)
|
||||
self.assertEqual(y.grad.data, grad_z)
|
||||
self.assertEqual(a.grad.data, grad_c * b.data)
|
||||
self.assertEqual(b.grad.data, grad_c * a.data)
|
||||
self.assertEqual(q.grad.data, (grad_c + grad_z) * 2)
|
||||
|
||||
def test_multi_backward_stochastic(self):
|
||||
x = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
y = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
|
||||
z = x + y
|
||||
q = torch.normal(x)
|
||||
q.reinforce(torch.randn(5, 5))
|
||||
|
||||
torch.autograd.backward([z, q], [torch.ones(5, 5), None])
|
||||
|
||||
def test_multi_backward_no_grad(self):
|
||||
x = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
y = Variable(torch.randn(5, 5), requires_grad=False)
|
||||
|
||||
z = x + y
|
||||
q = y * 2
|
||||
|
||||
torch.autograd.backward([z, q], [torch.ones(5, 5), torch.ones(5, 5)])
|
||||
self.assertEqual(x.grad.data, torch.ones(5, 5))
|
||||
|
||||
def test_volatile(self):
|
||||
x = Variable(torch.ones(5, 5))
|
||||
x = Variable(torch.ones(5, 5), requires_grad=True)
|
||||
y = Variable(torch.ones(5, 5) * 4, volatile=True)
|
||||
|
||||
z = x ** 2
|
||||
@ -91,7 +211,7 @@ class TestAutograd(TestCase):
|
||||
self.assertTrue(z.requires_grad)
|
||||
self.assertIsNotNone(z.creator)
|
||||
z.backward(torch.ones(5, 5))
|
||||
self.assertEqual(x.grad, torch.ones(5, 5) * 2)
|
||||
self.assertEqual(x.grad.data, torch.ones(5, 5) * 2)
|
||||
|
||||
w = z + y
|
||||
self.assertTrue(w.volatile)
|
||||
@ -99,16 +219,50 @@ class TestAutograd(TestCase):
|
||||
self.assertRaises(RuntimeError, lambda: w.backward(torch.ones(5, 5)))
|
||||
self.assertIsNone(w.creator)
|
||||
|
||||
def test_indexing(self):
|
||||
x = torch.range(1, 16).resize_(4, 4)
|
||||
y = Variable(x)
|
||||
self.assertEqual(x[1], y[1].data)
|
||||
self.assertEqual(x[1, 1], y[1, 1].data[0])
|
||||
self.assertEqual(x[1:], y[1:].data)
|
||||
self.assertEqual(x[:2], y[:2].data)
|
||||
self.assertEqual(x[:2, 2], y[:2, 2].data)
|
||||
self.assertEqual(x[1:2, 2], y[1:2, 2].data)
|
||||
self.assertEqual(x[1, 2:], y[1, 2:].data)
|
||||
|
||||
def test_compare(self):
|
||||
x = Variable(torch.randn(5, 5))
|
||||
self.assertRaises(TypeError, lambda: x > 4)
|
||||
|
||||
def test_requires_grad(self):
|
||||
x = Variable(torch.randn(5, 5))
|
||||
y = Variable(torch.randn(5, 5))
|
||||
z = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
a = x + y
|
||||
self.assertFalse(a.requires_grad)
|
||||
b = a + z
|
||||
self.assertTrue(b.requires_grad)
|
||||
def error():
|
||||
raise RuntimeError
|
||||
# Make sure backward isn't called on these
|
||||
a._backward_hooks = OrderedDict()
|
||||
x._backward_hooks = OrderedDict()
|
||||
y._backward_hooks = OrderedDict()
|
||||
a._backward_hooks['test'] = error
|
||||
x._backward_hooks['test'] = error
|
||||
y._backward_hooks['test'] = error
|
||||
b.backward(torch.ones(5, 5))
|
||||
|
||||
def test_inplace(self):
|
||||
x = Variable(torch.ones(5, 5))
|
||||
y = Variable(torch.ones(5, 5) * 4)
|
||||
x = Variable(torch.ones(5, 5), requires_grad=True)
|
||||
y = Variable(torch.ones(5, 5) * 4, requires_grad=True)
|
||||
|
||||
z = x * y
|
||||
q = z + y
|
||||
w = z * y
|
||||
z.dirty = True
|
||||
z.add_(2)
|
||||
# Add doesn't need it's inputs to do backward, so it shouldn't raise
|
||||
q.backward(torch.ones(5, 5))
|
||||
q.backward(torch.ones(5, 5), retain_variables=True)
|
||||
# Mul saves both inputs in forward, so it should raise
|
||||
self.assertRaises(RuntimeError, lambda: w.backward(torch.ones(5, 5)))
|
||||
|
||||
@ -123,19 +277,143 @@ class TestAutograd(TestCase):
|
||||
# q uses dirty z, so it should raise
|
||||
self.assertRaises(RuntimeError, lambda: q.backward(torch.ones(5, 5)))
|
||||
|
||||
x.grad.zero_()
|
||||
x.grad.data.zero_()
|
||||
m = x / 2
|
||||
z = m + y / 8
|
||||
q = z * y
|
||||
r = z + y
|
||||
prev_version = z._version
|
||||
w = z.exp_()
|
||||
self.assertTrue(z.dirty)
|
||||
self.assertNotEqual(z._version, prev_version)
|
||||
r.backward(torch.ones(5, 5), retain_variables=True)
|
||||
self.assertEqual(x.grad, torch.ones(5, 5) / 2)
|
||||
self.assertEqual(x.grad.data, torch.ones(5, 5) / 2)
|
||||
w.backward(torch.ones(5, 5), retain_variables=True)
|
||||
self.assertEqual(x.grad, torch.Tensor(5, 5).fill_((1 + math.e) / 2))
|
||||
self.assertEqual(x.grad.data, torch.Tensor(5, 5).fill_((1 + math.e) / 2))
|
||||
self.assertRaises(RuntimeError, lambda: q.backward(torch.ones(5, 5)))
|
||||
|
||||
leaf = Variable(torch.ones(5, 5), requires_grad=True)
|
||||
x = leaf.clone()
|
||||
x.add_(10)
|
||||
self.assertEqual(x.data, torch.ones(5, 5) * 11)
|
||||
# x should be still usable
|
||||
y = x + 2
|
||||
y.backward(torch.ones(5, 5))
|
||||
self.assertEqual(leaf.grad.data, torch.ones(5, 5))
|
||||
z = x * y
|
||||
x.add_(2)
|
||||
self.assertRaises(RuntimeError, lambda: z.backward(torch.ones(5, 5)))
|
||||
|
||||
def test_shared_storage(self):
|
||||
x = Variable(torch.ones(5, 5))
|
||||
y = x.t()
|
||||
z = x[1]
|
||||
self.assertRaises(RuntimeError, lambda: x.add_(2))
|
||||
self.assertRaises(RuntimeError, lambda: y.add_(2))
|
||||
self.assertRaises(RuntimeError, lambda: z.add_(2))
|
||||
|
||||
def _test_setitem(self, size, index):
|
||||
x = Variable(torch.ones(*size), requires_grad=True)
|
||||
y = x + 2
|
||||
y_version = y._version
|
||||
y[index] = 2
|
||||
self.assertNotEqual(y._version, y_version)
|
||||
y.backward(torch.ones(*size))
|
||||
expected_grad = torch.ones(*size)
|
||||
if isinstance(index, Variable):
|
||||
index = index.data
|
||||
expected_grad[index] = 0
|
||||
self.assertEqual(x.grad.data, expected_grad)
|
||||
|
||||
def _test_setitem_tensor(self, size, index):
|
||||
x = Variable(torch.ones(*size), requires_grad=True)
|
||||
y = x + 2
|
||||
y_version = y._version
|
||||
value = Variable(torch.Tensor(x[index].size()).fill_(7), requires_grad=True)
|
||||
y[index] = value
|
||||
self.assertNotEqual(y._version, y_version)
|
||||
y.backward(torch.ones(*size))
|
||||
expected_grad_input = torch.ones(*size)
|
||||
if isinstance(index, Variable):
|
||||
index = index.data
|
||||
expected_grad_input[index] = 0
|
||||
self.assertEqual(x.grad.data, expected_grad_input)
|
||||
self.assertEqual(value.grad.data, torch.ones(value.size()))
|
||||
|
||||
def test_setitem(self):
|
||||
self._test_setitem((5, 5), 1)
|
||||
self._test_setitem((5,), 1)
|
||||
self._test_setitem((1,), 0)
|
||||
self._test_setitem_tensor((5, 5), 3)
|
||||
self._test_setitem_tensor((5,), 3)
|
||||
|
||||
def test_setitem_mask(self):
|
||||
mask = torch.ByteTensor(5, 5).bernoulli_()
|
||||
self._test_setitem((5, 5), Variable(mask))
|
||||
self._test_setitem((5,), Variable(mask[0]))
|
||||
self._test_setitem((1,), Variable(mask[0, 0:1]))
|
||||
self._test_setitem_tensor((5, 5), Variable(mask))
|
||||
self._test_setitem_tensor((5,), Variable(mask[0]))
|
||||
|
||||
def test_unused_output(self):
|
||||
x = Variable(torch.randn(10, 10), requires_grad=True)
|
||||
outputs = x.chunk(5)
|
||||
o = outputs[2]
|
||||
o = o * 4 + 2
|
||||
o.sum().backward()
|
||||
expected_grad = torch.zeros(10, 10)
|
||||
expected_grad[4:6] = 4
|
||||
self.assertEqual(x.grad.data, expected_grad)
|
||||
|
||||
x.grad.data.zero_()
|
||||
grad_output = torch.randn(2, 10)
|
||||
outputs = x.chunk(5)
|
||||
outputs[0].backward(grad_output)
|
||||
expected_grad = torch.zeros(10, 10)
|
||||
expected_grad[:2] = grad_output
|
||||
self.assertEqual(x.grad.data, expected_grad)
|
||||
|
||||
def test_gc_in_destructor(self):
|
||||
"""
|
||||
Previously, if a Function destructor triggered a garbage collection,
|
||||
the Variable's tp_dealloc handler would get called twice leading to a
|
||||
segfault.
|
||||
"""
|
||||
class CollectOnDelete(Function):
|
||||
def __del__(self):
|
||||
gc.collect()
|
||||
|
||||
for i in range(10):
|
||||
Variable(torch.randn(10, 10), creator=CollectOnDelete())
|
||||
|
||||
@unittest.skipIf(not torch.cuda.is_available() or torch.cuda.device_count() < 2,
|
||||
"CUDA not available or <2 GPUs detected")
|
||||
def test_unused_output_gpu(self):
|
||||
from torch.nn.parallel._functions import Broadcast
|
||||
x = Variable(torch.randn(5, 5).float().cuda(), requires_grad=True)
|
||||
outputs = Broadcast(list(range(torch.cuda.device_count())))(x)
|
||||
y = outputs[-1] * 2
|
||||
y.sum().backward()
|
||||
self.assertEqual(x.grad.data, torch.ones(5, 5) * 2)
|
||||
|
||||
def test_detach(self):
|
||||
x = Variable(torch.randn(10, 10), requires_grad=True)
|
||||
y = x + 2
|
||||
y = y.detach()
|
||||
z = y * 4 + 2
|
||||
self.assertFalse(y.requires_grad)
|
||||
self.assertFalse(z.requires_grad)
|
||||
|
||||
x = Variable(torch.randn(10, 10), requires_grad=True)
|
||||
y = x * 2
|
||||
y = y.detach()
|
||||
self.assertFalse(y.requires_grad)
|
||||
self.assertFalse(y.creator.requires_grad)
|
||||
z = x + y
|
||||
z.sum().backward()
|
||||
# This is an incorrect gradient, but we assume that's what the user
|
||||
# wanted. detach() is an advanced option.
|
||||
self.assertEqual(x.grad.data, torch.ones(10, 10))
|
||||
|
||||
def test_type_conversions(self):
|
||||
import torch.cuda
|
||||
x = Variable(torch.randn(5, 5))
|
||||
@ -156,9 +434,290 @@ class TestAutograd(TestCase):
|
||||
self.assertIs(type(x2.data), torch.cuda.FloatTensor)
|
||||
self.assertIs(x2.get_device(), 1)
|
||||
|
||||
def test_return_leaf(self):
|
||||
class Identity(Function):
|
||||
def forward(self, a, b):
|
||||
return a, a + b
|
||||
|
||||
def index_variable(num_indices, max_indices):
|
||||
index = torch.randperm(max_indices)[:num_indices].long()
|
||||
def backward(self, grad_a, grad_b):
|
||||
return grad_a + grad_b, grad_b
|
||||
|
||||
class Inplace(InplaceFunction):
|
||||
def forward(self, a, b):
|
||||
self.mark_dirty(a)
|
||||
return a.add_(b), b + 2
|
||||
|
||||
def backward(self, grad_a, grad_b):
|
||||
return grad_a, grad_a + grad_b
|
||||
|
||||
x = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
y = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
|
||||
q, p = Identity()(x, y)
|
||||
# Make sure hooks only receive grad from usage of q, not x.
|
||||
q.register_hook(
|
||||
lambda grad: self.assertEqual(grad.data, torch.ones(5, 5)))
|
||||
(q + p + x).sum().backward()
|
||||
self.assertEqual(x.grad.data, torch.ones(5, 5) * 3)
|
||||
self.assertEqual(y.grad.data, torch.ones(5, 5))
|
||||
del q, p # these need to be freed, or next part will raise an error
|
||||
|
||||
def test_return_leaf_inplace(self):
|
||||
class Inplace(InplaceFunction):
|
||||
def forward(self, a, b):
|
||||
self.mark_dirty(a)
|
||||
return a.add_(b), b + 2
|
||||
|
||||
def backward(self, grad_a, grad_b):
|
||||
return grad_a, grad_a + grad_b
|
||||
|
||||
x = Variable(torch.randn(5, 5))
|
||||
y = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
|
||||
fn = Inplace(True)
|
||||
q, p = fn(x, y)
|
||||
self.assertIs(q, x)
|
||||
self.assertIs(q.creator, fn)
|
||||
self.assertTrue(q.requires_grad)
|
||||
q.sum().backward()
|
||||
self.assertEqual(y.grad.data, torch.ones(5, 5))
|
||||
|
||||
def test_leaf_assignment(self):
|
||||
x = Variable(torch.randn(5, 5))
|
||||
y = Variable(torch.randn(5), requires_grad=True)
|
||||
z = Variable(torch.randn(5), requires_grad=True)
|
||||
|
||||
x[0] = y
|
||||
x[1] = 2 * z
|
||||
self.assertTrue(x.requires_grad)
|
||||
self.assertIsNot(x.creator, None)
|
||||
x.sum().backward()
|
||||
self.assertEqual(y.grad.data, torch.ones(5))
|
||||
self.assertEqual(z.grad.data, torch.ones(5) * 2)
|
||||
|
||||
def test_backward_copy(self):
|
||||
# This tests checks backward engine for a very subtle bug that appreared
|
||||
# in one of the initial versions of autograd. Gradients tensors were
|
||||
# simply stored in lists while the function waited for all its gradients
|
||||
# to be computed. However, sometimes an output was used multiple times,
|
||||
# so the gradients needed to be summed. Engine used to keep a need_copy
|
||||
# set of tensors that will need a clone upon next addition and removed
|
||||
# them from the set as soon as the clone was performed. However, this
|
||||
# could lead to incorrect results if the same gradient tensor was
|
||||
# buffered in three places in the graph:
|
||||
# 1. When accumulating gradients in one of these places it was cloned
|
||||
# and removed from need_copy set.
|
||||
# 2. When accumulating in second place, it wasn't in the need_copy set,
|
||||
# so the gradients were simply accumulated in-place (which already
|
||||
# modified the grad in 3rd place)
|
||||
# 3. When accumulating in the third place, it wasn't in the need_copy set
|
||||
# as well, so the incoming gradient was summed in-place, yielding
|
||||
# incorrect results in all functions, except the first one.
|
||||
x = Variable(torch.ones(5, 5), requires_grad=True)
|
||||
y = Variable(torch.ones(5, 5), requires_grad=True)
|
||||
# Simulate that we're in the middle of the graph
|
||||
a = x + 2
|
||||
b = y + 2
|
||||
c = x + 2
|
||||
# This op will just return grad_output two times in backward
|
||||
add1 = a + b
|
||||
add2 = add1 + c
|
||||
# Simulate a long branch, so grad_output will get buffered.
|
||||
for i in range(4):
|
||||
a = a * 2
|
||||
b = b * 2
|
||||
c = c * 2
|
||||
branch = a + b + c
|
||||
out = add2 + branch
|
||||
# expected gradients are:
|
||||
# for x: 34 (16 from final a, 16 from final c, 2 from add2)
|
||||
# for y: 17 (16 from final b, 1 from add2)
|
||||
grad_output = torch.ones(5, 5)
|
||||
out.backward(grad_output)
|
||||
self.assertEqual(x.grad.data, torch.ones(5, 5) * 34)
|
||||
self.assertEqual(y.grad.data, torch.ones(5, 5) * 17)
|
||||
|
||||
def test_functional_blas(self):
|
||||
def compare(fn, *args):
|
||||
unpacked_args = tuple(arg.data if isinstance(arg, Variable) else arg
|
||||
for arg in args)
|
||||
self.assertEqual(fn(*args).data, fn(*unpacked_args))
|
||||
|
||||
def test_blas_add(fn, x, y, z):
|
||||
# Checks all signatures
|
||||
compare(fn, x, y, z)
|
||||
compare(fn, 0.5, x, y, z)
|
||||
compare(fn, 0.5, x, 0.25, y, z)
|
||||
|
||||
def test_blas(fn, x, y):
|
||||
compare(fn, x, y)
|
||||
|
||||
test_blas(torch.mm, Variable(torch.randn(2, 10)),
|
||||
Variable(torch.randn(10, 4)))
|
||||
test_blas_add(torch.addmm, Variable(torch.randn(2, 4)),
|
||||
Variable(torch.randn(2, 10)), Variable(torch.randn(10, 4)))
|
||||
test_blas(torch.bmm, Variable(torch.randn(4, 2, 10)),
|
||||
Variable(torch.randn(4, 10, 4)))
|
||||
test_blas_add(torch.addbmm, Variable(torch.randn(2, 4)),
|
||||
Variable(torch.randn(4, 2, 10)), Variable(torch.randn(4, 10, 4)))
|
||||
test_blas_add(torch.baddbmm, Variable(torch.randn(4, 2, 4)),
|
||||
Variable(torch.randn(4, 2, 10)), Variable(torch.randn(4, 10, 4)))
|
||||
test_blas(torch.mv, Variable(torch.randn(2, 10)),
|
||||
Variable(torch.randn(10)))
|
||||
test_blas_add(torch.addmv, Variable(torch.randn(2)),
|
||||
Variable(torch.randn(2, 10)), Variable(torch.randn(10)))
|
||||
test_blas(torch.ger, Variable(torch.randn(5)),
|
||||
Variable(torch.randn(6)))
|
||||
test_blas_add(torch.addr, Variable(torch.randn(5, 6)),
|
||||
Variable(torch.randn(5)), Variable(torch.randn(6)))
|
||||
|
||||
def test_save_none_for_backward(self):
|
||||
test_case = self
|
||||
class MyFn(Function):
|
||||
def forward(self, input):
|
||||
self.save_for_backward(None, input, None)
|
||||
return input * input
|
||||
|
||||
def backward(self, grad_output):
|
||||
n1, input, n2 = self.saved_tensors
|
||||
test_case.assertIsNone(n1)
|
||||
test_case.assertIsNone(n2)
|
||||
return 2 * input * grad_output
|
||||
|
||||
x = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
y = MyFn()(x)
|
||||
y.sum().backward()
|
||||
self.assertEqual(x.grad.data, 2 * x.data)
|
||||
|
||||
def test_too_many_grads(self):
|
||||
class MyFn(Function):
|
||||
def forward(self, input):
|
||||
return input
|
||||
|
||||
def backward(self, grad_output):
|
||||
return grad_output, None, None
|
||||
|
||||
x = Variable(torch.randn(5, 5), requires_grad=True)
|
||||
y = MyFn()(x)
|
||||
y.sum().backward()
|
||||
self.assertEqual(x.grad.data, x.data.clone().fill_(1))
|
||||
|
||||
def test_stochastic(self):
|
||||
x = Variable(torch.rand(2, 10), requires_grad=True)
|
||||
stddevs = Variable(torch.rand(2, 10) * 5, requires_grad=True)
|
||||
y = (x * 2).clamp(0, 1)
|
||||
y = y / y.sum(1).expand_as(y)
|
||||
samples_multi = y.multinomial(5)
|
||||
samples_multi_flat = y[0].multinomial(5)
|
||||
samples_bernoulli = y.bernoulli()
|
||||
samples_norm = torch.normal(y)
|
||||
samples_norm_std = torch.normal(y, stddevs)
|
||||
z = samples_multi * 2 + 4
|
||||
z = z + samples_multi_flat.unsqueeze(0).expand_as(samples_multi)
|
||||
z = torch.cat([z, z], 1)
|
||||
z = z.double()
|
||||
z = z + samples_bernoulli + samples_norm + samples_norm_std
|
||||
last_sample = torch.normal(z, 4)
|
||||
z = last_sample + 2
|
||||
self.assertFalse(z.requires_grad)
|
||||
|
||||
self.assertRaises(RuntimeError, lambda: z.backward(retain_variables=True))
|
||||
samples_multi.reinforce(torch.randn(2, 5))
|
||||
self.assertRaises(RuntimeError, lambda: z.backward(retain_variables=True))
|
||||
samples_multi_flat.reinforce(torch.randn(5))
|
||||
self.assertRaises(RuntimeError, lambda: z.backward(retain_variables=True))
|
||||
samples_bernoulli.reinforce(torch.randn(2, 10))
|
||||
self.assertRaises(RuntimeError, lambda: z.backward(retain_variables=True))
|
||||
samples_norm.reinforce(torch.randn(2, 10))
|
||||
self.assertRaises(RuntimeError, lambda: z.backward(retain_variables=True))
|
||||
samples_norm_std.reinforce(torch.randn(2, 10))
|
||||
# We don't have to specify rewards w.r.t. last_sample - it doesn't
|
||||
# require gradient
|
||||
|
||||
last_sample.backward(retain_variables=True)
|
||||
z.backward()
|
||||
|
||||
self.assertGreater(x.grad.data.abs().sum(), 0)
|
||||
|
||||
def test_stochastic_sequence(self):
|
||||
x = Variable(torch.rand(10).clamp_(0, 1), requires_grad=True)
|
||||
b = x.bernoulli()
|
||||
n1 = torch.normal(b, x)
|
||||
n2 = torch.normal(n1, 2)
|
||||
|
||||
b.reinforce(torch.randn(10))
|
||||
n1.reinforce(torch.randn(10))
|
||||
n2.reinforce(torch.randn(10))
|
||||
|
||||
n2.backward()
|
||||
|
||||
self.assertGreater(x.grad.data.abs().sum(), 0)
|
||||
|
||||
def test_stochastic_output(self):
|
||||
x = Variable(torch.rand(10), requires_grad=True)
|
||||
b = x.clone().clamp(0, 1).bernoulli()
|
||||
b.reinforce(torch.randn(10))
|
||||
b.backward()
|
||||
self.assertGreater(x.grad.data.abs().sum(), 0)
|
||||
|
||||
def test_pickle(self):
|
||||
x = Variable(torch.randn(10, 10), requires_grad=True)
|
||||
y = Variable(torch.randn(10, 10), volatile=True)
|
||||
z = Variable(torch.randn(10, 10), requires_grad=False)
|
||||
|
||||
def assert_strict_equal(var1, var2):
|
||||
self.assertEqual(var1.data, var2.data)
|
||||
self.assertEqual(var1.requires_grad, var2.requires_grad)
|
||||
self.assertEqual(var1.volatile, var2.volatile)
|
||||
|
||||
serialized = [pickle.dumps([x, y, z], protocol=p) for p in range(3)]
|
||||
for dump in serialized:
|
||||
xc, yc, zc = pickle.loads(dump)
|
||||
assert_strict_equal(xc, x)
|
||||
assert_strict_equal(yc, y)
|
||||
assert_strict_equal(zc, z)
|
||||
|
||||
def test_dep_nograd(self):
|
||||
class F1(Function):
|
||||
def forward(self, input):
|
||||
out = torch.randn(input.size())
|
||||
self.mark_non_differentiable(out)
|
||||
return input, out
|
||||
|
||||
def backward(self, grad_output, ignored):
|
||||
return grad_output
|
||||
|
||||
class F2(Function):
|
||||
def forward(self, input, ignored):
|
||||
return input
|
||||
|
||||
def backward(self, grad_output):
|
||||
return grad_output, None
|
||||
|
||||
x = Variable(torch.randn(5), requires_grad=True)
|
||||
a, b = F1()(x)
|
||||
b = b + 1 # separate F1 from F2 by another op
|
||||
self.assertTrue(a.requires_grad)
|
||||
self.assertFalse(b.requires_grad)
|
||||
c = F2()(a, b)
|
||||
c.backward(torch.ones(c.size()))
|
||||
self.assertEqual(x.grad.data, torch.ones(x.size()))
|
||||
|
||||
|
||||
def index_variable(shape, max_indices):
|
||||
if not isinstance(shape, tuple):
|
||||
shape = (shape,)
|
||||
index = torch.rand(*shape).mul_(max_indices).floor_().long()
|
||||
return Variable(index, requires_grad=False)
|
||||
|
||||
def gather_variable(shape, index_dim, max_indices):
|
||||
assert len(shape) == 2
|
||||
assert index_dim < 2
|
||||
batch_dim = 1 - index_dim
|
||||
index = torch.LongTensor(*shape)
|
||||
for i in range(shape[index_dim]):
|
||||
index.select(index_dim, i).copy_(
|
||||
torch.randperm(max_indices)[:shape[batch_dim]])
|
||||
return Variable(index, requires_grad=False)
|
||||
|
||||
|
||||
@ -177,13 +736,15 @@ function_tests = [
|
||||
(MulConstant, (3.14,), ((L, L),) ),
|
||||
(DivConstant, (3.14, True), (torch.rand(L, L) + 1e-1,), 'by_tensor' ),
|
||||
(PowConstant, (3.14,), (torch.rand(L, L),) ),
|
||||
(PowConstant, (3.14, True), (torch.rand(L, L),), 'tensor_power' ),
|
||||
(Transpose, (0, 1), (torch.rand(L, L),) ),
|
||||
(Transpose, (2, 0), (torch.rand(S, S, S),), '3d' ),
|
||||
(Permute, (0, 4, 3, 5, 1, 2), ((1, 2, 3, 4, 5, 6),), ),
|
||||
(Index, (1, 2), (torch.rand(S, S, S),) ),
|
||||
(Permute, ((0, 4, 3, 5, 1, 2),), ((1, 2, 3, 4, 5, 6),) ),
|
||||
(Index, ((1, 2),), (torch.rand(S, S, S),) ),
|
||||
(Index, (slice(0, 3),), (torch.rand(S, S, S),), 'slice' ),
|
||||
(Index, ((slice(0, 3), 1),),(torch.rand(S, S, S),), 'slice_index' ),
|
||||
(View, (S*S, S), (torch.rand(S, S, S),) ),
|
||||
(Expand, (S, 5, S, 5), ((S, 1, S, 1),) ),
|
||||
(Expand, ((S, 5, S, 5),), ((S, 1, S, 1),) ),
|
||||
(Exp, (), (torch.rand(S, S, S),) ),
|
||||
(Log, (), (torch.rand(S, S, S) + 1e-2,) ),
|
||||
(Log1p, (), (torch.rand(S, S, S),) ),
|
||||
@ -200,7 +761,7 @@ function_tests = [
|
||||
(Asin, (), (torch.randn(S, S, S).clamp(-0.9, 0.9),) ),
|
||||
(Acos, (), (torch.randn(S, S, S).clamp(-0.9, 0.9),) ),
|
||||
(Atan, (), ((S, S, S),) ),
|
||||
(Cinv, (), (torch.rand(S, S, S) + 0.1,) ),
|
||||
(Reciprocal, (), (torch.rand(S, S, S) + 0.1,) ),
|
||||
(Cmax, (), ((S, S, S), (S, S, S)) ),
|
||||
(Cmin, (), ((S, S, S), (S, S, S)) ),
|
||||
(Round, (), ((S, S, S),) ),
|
||||
@ -239,10 +800,10 @@ function_tests = [
|
||||
(Mode, (0,), ((S, S, S),), ),
|
||||
(Kthvalue, (2, 0), ((S, S, S),), ),
|
||||
(Median, (0,), ((S, S, S),), ),
|
||||
(Norm, (1.5,), (torch.rand(S, S, S),), '1.5' ),
|
||||
(Norm, (1.5,), (torch.rand(S, S, S),), '1_5' ),
|
||||
(Norm, (), ((S, S, S),), '2' ),
|
||||
(Norm, (3,), ((S, S, S),), '3' ),
|
||||
(Norm, (1.5, 0), (torch.rand(S, S, S),), '1.5_dim' ),
|
||||
(Norm, (1.5, 0), (torch.rand(S, S, S),), '1_5_dim' ),
|
||||
(Norm, (2, 0), ((S, S, S),), '2_dim' ),
|
||||
(Norm, (3, 0), ((S, S, S),), '3_dim' ),
|
||||
(Addcmul, (), ((S, S), (S, S), (S, S)) ),
|
||||
@ -250,9 +811,13 @@ function_tests = [
|
||||
(Addcdiv, (), ((S, S), (S, S), torch.rand(S, S) + 1e-2) ),
|
||||
(Addcdiv, (0.6,), ((S, S), (S, S), torch.rand(S, S) + 1e-2), 'scale'),
|
||||
(IndexAdd, (0,), ((S, S), index_variable(2, S), (2, S)) ),
|
||||
(IndexCopy, (0,), ((S, S), index_variable(2, S), (2, S)) ),
|
||||
# (IndexCopy, (0,), ((S, S), index_variable(2, S), (2, S)) ),
|
||||
(IndexFill, (0, 2), ((S, S), index_variable(2, S)) ),
|
||||
(IndexSelect, (0,), ((S, S), index_variable(2, S)) ),
|
||||
(Gather, (0,), ((M, S), gather_variable((S, S), 1, M)) ),
|
||||
(Gather, (1,), ((M, S), gather_variable((M, S//2), 0, S)), 'dim1'),
|
||||
(Scatter, (0,), ((M, S), gather_variable((S, S), 1, M), (S, S))),
|
||||
(Scatter, (1,), ((M, S), gather_variable((M, S//2), 0, S), (M, S//2)), 'dim1'),
|
||||
(Concat, (0,), ((1, S, S), (2, S, S), (3, S, S)) ),
|
||||
(Resize, (S*S, S), ((S, S, S),) ),
|
||||
(Diag, (), ((S, S),), '2d' ),
|
||||
@ -293,8 +858,9 @@ method_tests = [
|
||||
('transpose', (1, 2, 3), (1, 2) ),
|
||||
('t', (1, 2), () ),
|
||||
('view', (S, S, S), (S*S, S), ),
|
||||
('view_as', (S, S, S), ((S*S, S),) ),
|
||||
('view_as', (S, S, S), ((S*S, S),) ),
|
||||
('expand', (S, 1, S), (S, S, S) ),
|
||||
('expand', (torch.Size([S, 1, S]),), (S, S, S), 'size' ),
|
||||
('exp', (S, S, S), () ),
|
||||
('log', (S, S, S), () ),
|
||||
('log1p', (S, S, S), () ),
|
||||
@ -311,7 +877,7 @@ method_tests = [
|
||||
('asin', (S, S, S), () ),
|
||||
('acos', (S, S, S), () ),
|
||||
('atan', (S, S, S), () ),
|
||||
('cinv', (S, S, S), () ),
|
||||
('reciprocal', (S, S, S), () ),
|
||||
('round', (S, S, S), () ),
|
||||
('sign', (S, S, S), () ),
|
||||
('trunc', (S, S, S), () ),
|
||||
@ -321,10 +887,10 @@ method_tests = [
|
||||
('fmod', (S, S, S), (1.5,) ),
|
||||
('remainder', (S, S, S), (1.5,) ),
|
||||
('lerp', (S, S, S), ((S, S, S), 0.4) ),
|
||||
('cmax', (S, S, S), ((S, S, S),) ),
|
||||
('cmax', (S, S, S), (0.5,), 'constant' ),
|
||||
('cmin', (S, S, S), ((S, S, S),) ),
|
||||
('cmin', (S, S, S), (0.5,), 'constant' ),
|
||||
('max', (S, S, S), () ),
|
||||
('max', (S, S, S), ((S, S, S),), 'elementwise' ),
|
||||
('min', (S, S, S), () ),
|
||||
('min', (S, S, S), ((S, S, S),), 'elementwise' ),
|
||||
('mean', (S, S, S), () ),
|
||||
('mean', (S, S, S), (1,), 'dim' ),
|
||||
('sum', (S, S, S), () ),
|
||||
@ -342,8 +908,6 @@ method_tests = [
|
||||
('addr', (S, M), ((S,), (M,)), ),
|
||||
('addr', (S, M), (0.2, 0.6, (S,), (M,)), 'coef' ),
|
||||
('dot', (L,), ((L,),), ),
|
||||
('max', (S, S, S), () ),
|
||||
('min', (S, S, S), () ),
|
||||
('addcmul', (S, S), ((S, S), (S, S)) ),
|
||||
('addcmul', (S, S), (0.5, (S, S), (S, S)), 'scale' ),
|
||||
('addcdiv', (S, S), ((S, S), (S, S)) ),
|
||||
@ -353,7 +917,6 @@ method_tests = [
|
||||
('dist', (S, S, S), ((S, S, S),) ),
|
||||
('dist', (S, S, S), ((S, S, S), 4), '4' ),
|
||||
('index_select', (S, S, S), (0, index_variable(2, S)) ),
|
||||
('cat', (1, S, S), ((Variable(torch.randn(2, S, S)), Variable(torch.randn(3, S, S))), 0)),
|
||||
('diag', (M, M), (), '2d' ),
|
||||
('diag', (M,), (), '1d' ),
|
||||
('tril', (M, M), () ),
|
||||
@ -377,6 +940,7 @@ method_tests = [
|
||||
# TODO: mode, median, sort, kthvalue, topk (problem with indices)
|
||||
# TODO: indexAdd, indexCopy, indexFill
|
||||
# TODO: resize, resize_as (tensors only have resize_ and resize_as_)
|
||||
# TODO: clamp with min/max
|
||||
|
||||
|
||||
def create_input(call_args):
|
||||
@ -384,12 +948,12 @@ def create_input(call_args):
|
||||
call_args = (call_args,)
|
||||
def map_arg(arg):
|
||||
if isinstance(arg, tuple) and not isinstance(arg[0], Variable):
|
||||
return Variable(torch.randn(*arg).double())
|
||||
return Variable(torch.randn(*arg).double(), requires_grad=True)
|
||||
elif torch.is_tensor(arg):
|
||||
if isinstance(arg, torch.FloatTensor):
|
||||
return Variable(arg.double())
|
||||
return Variable(arg.double(), requires_grad=True)
|
||||
else:
|
||||
return Variable(arg)
|
||||
return Variable(arg, requires_grad=True)
|
||||
else:
|
||||
return arg
|
||||
return tuple(map_arg(arg) for arg in call_args)
|
||||
@ -419,6 +983,8 @@ for test in function_tests:
|
||||
if not isinstance(output, tuple):
|
||||
output = (output,)
|
||||
for i, o in enumerate(output):
|
||||
if not o.requires_grad:
|
||||
continue
|
||||
analytical = get_analytical_jacobian(input, o)
|
||||
def fn(input):
|
||||
tmp = cls(*constructor_args)(*input)
|
||||
@ -442,9 +1008,9 @@ for test in function_tests:
|
||||
# Check that gradient is the same
|
||||
for inp_i, i in zip(inplace_input, input):
|
||||
if inp_i.grad is not None:
|
||||
inp_i.grad.zero_()
|
||||
inp_i.grad.data.zero_()
|
||||
if i.grad is not None:
|
||||
i.grad.zero_()
|
||||
i.grad.data.zero_()
|
||||
for io, o in zip(inplace_output, output):
|
||||
grad = torch.randn(*io.size()).double()
|
||||
io.backward(grad)
|
||||
@ -456,6 +1022,13 @@ for test in function_tests:
|
||||
setattr(TestAutograd, test_name, do_test)
|
||||
|
||||
|
||||
EXCLUDE_FUNCTIONAL = {
|
||||
'addmm',
|
||||
'addbmm',
|
||||
'baddbmm',
|
||||
'addmv',
|
||||
'addr',
|
||||
}
|
||||
for test in method_tests:
|
||||
name, self_size, args = test[:3]
|
||||
test_name = 'test_' + name + ('_' + test[3] if len(test) == 4 else '')
|
||||
@ -472,6 +1045,16 @@ for test in method_tests:
|
||||
self.assertEqual(unpack_variables(output_variable), output_tensor)
|
||||
# TODO: check that both have changed after adding all inplace ops
|
||||
|
||||
# functional interface tests
|
||||
if hasattr(torch, name) and name not in EXCLUDE_FUNCTIONAL:
|
||||
f_args_variable = (self_variable,) + args_variable
|
||||
f_args_tensor = (self_tensor,) + args_tensor
|
||||
output_variable = getattr(torch, name)(*f_args_variable)
|
||||
output_tensor = getattr(torch, name)(*f_args_tensor)
|
||||
if not torch.is_tensor(output_tensor) and not isinstance(output_tensor, tuple):
|
||||
output_tensor = torch.DoubleTensor((output_tensor,))
|
||||
self.assertEqual(unpack_variables(output_variable), output_tensor)
|
||||
|
||||
check(name)
|
||||
inplace_name = name + '_'
|
||||
if hasattr(Variable(torch.ones(1)), inplace_name):
|
||||
@ -487,4 +1070,4 @@ for test in method_tests:
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
unittest.main()
|
||||
run_tests()
|
||||
|
||||
@ -7,7 +7,12 @@ import torch
|
||||
import torch.cuda
|
||||
import torch.cuda.comm as comm
|
||||
|
||||
from common import TestCase, get_gpu_type, to_gpu, freeze_rng_state
|
||||
from common import TestCase, get_gpu_type, to_gpu, freeze_rng_state, run_tests
|
||||
|
||||
if not torch.cuda.is_available():
|
||||
print('CUDA not available, skipping tests')
|
||||
import sys
|
||||
sys.exit()
|
||||
|
||||
def is_floating(t):
|
||||
return type(t) in [torch.FloatTensor, torch.DoubleTensor,
|
||||
@ -23,6 +28,11 @@ types = [
|
||||
torch.ByteTensor,
|
||||
]
|
||||
|
||||
float_types = [
|
||||
torch.FloatTensor,
|
||||
torch.DoubleTensor
|
||||
] # TODO: add half...
|
||||
|
||||
def number(floating, integer, t):
|
||||
name = type(t).__name__
|
||||
if 'Double' in name or 'Float' in name or 'Half' in name:
|
||||
@ -40,6 +50,9 @@ def make_tensor(t, *sizes):
|
||||
def small_2d(t):
|
||||
return make_tensor(t, S, S)
|
||||
|
||||
def small_2d_scaled(t, scale=10):
|
||||
return make_tensor(t, S, S).mul(scale)
|
||||
|
||||
def small_3d(t):
|
||||
return make_tensor(t, S, S, S)
|
||||
|
||||
@ -49,6 +62,9 @@ def medium_1d(t):
|
||||
def medium_2d(t):
|
||||
return make_tensor(t, M, M)
|
||||
|
||||
def medium_2d_scaled(t, scale=10):
|
||||
return make_tensor(t, M, M).mul(scale)
|
||||
|
||||
def small_3d_ones(t):
|
||||
return t(S, S, S).copy_(torch.ones(S, S, S))
|
||||
|
||||
@ -59,6 +75,18 @@ def small_3d_positive(t):
|
||||
def small_3d_unique(t):
|
||||
return t(S, S, S).copy_(torch.range(1, S*S*S))
|
||||
|
||||
def small_1d_lapack(t):
|
||||
return t(1, 3).copy_(torch.range(1, 3).view(3))
|
||||
|
||||
def small_2d_lapack(t):
|
||||
return t(3, 3).copy_(torch.range(1, 9).view(3, 3))
|
||||
|
||||
def small_2d_lapack_skinny(t):
|
||||
return t(3, 4).copy_(torch.range(1, 12).view(3, 4))
|
||||
|
||||
def small_2d_lapack_fat(t):
|
||||
return t(4, 3).copy_(torch.range(1, 12).view(4, 3))
|
||||
|
||||
def new_t(*sizes):
|
||||
def tmp(t):
|
||||
return t(*sizes).copy_(torch.randn(*sizes))
|
||||
@ -74,16 +102,16 @@ tests = [
|
||||
('mul', small_3d, lambda t: [small_3d_positive(t)], 'tensor' ),
|
||||
('div', small_3d, lambda t: [number(3.14, 3, t)], ),
|
||||
('div', small_3d, lambda t: [small_3d_positive(t)], 'tensor' ),
|
||||
('pow', small_3d, lambda t: [number(3.14, 3, t)], ),
|
||||
('pow', small_3d, lambda t: [small_3d(t).abs_()], 'tensor' ),
|
||||
('addbmm', small_2d, lambda t: [small_3d(t), small_3d(t)], ),
|
||||
('pow', small_3d, lambda t: [number(3.14, 3, t)], None, float_types),
|
||||
('pow', small_3d, lambda t: [small_3d(t).abs_()], 'tensor', float_types),
|
||||
('addbmm', small_2d, lambda t: [small_3d(t), small_3d(t)], None, float_types),
|
||||
('addbmm', small_2d, lambda t: [number(0.4, 2, t), small_3d(t), small_3d(t)], 'scalar' ),
|
||||
('addbmm', small_2d, lambda t: [number(0.5, 3, t), number(0.4, 2, t), small_3d(t), small_3d(t)], 'two_scalars' ),
|
||||
('baddbmm', small_3d, lambda t: [small_3d(t), small_3d(t)], ),
|
||||
('baddbmm', small_3d, lambda t: [number(0.4, 2, t), small_3d(t), small_3d(t)], 'scalar' ),
|
||||
('baddbmm', small_3d, lambda t: [number(0.5, 3, t), number(0.4, 2, t), small_3d(t), small_3d(t)], 'two_scalars' ),
|
||||
('addcdiv', small_3d, lambda t: [small_3d(t), small_3d(t)], ),
|
||||
('addcdiv', small_3d, lambda t: [number(0.4, 2, t), small_3d(t), small_3d(t)], 'scalar' ),
|
||||
('addcdiv', small_2d_lapack, lambda t: [small_2d_lapack(t).mul(2), small_2d_lapack(t)], ),
|
||||
('addcdiv', small_2d_lapack, lambda t: [number(2.8, 1, t), small_2d_lapack(t).mul(2), small_2d_lapack(t)], 'scalar' ),
|
||||
('addcmul', small_3d, lambda t: [small_3d(t), small_3d(t)], ),
|
||||
('addcmul', small_3d, lambda t: [number(0.4, 2, t), small_3d(t), small_3d(t)], 'scalar' ),
|
||||
('addmm', medium_2d, lambda t: [medium_2d(t), medium_2d(t)], ),
|
||||
@ -92,20 +120,16 @@ tests = [
|
||||
('addmv', medium_1d, lambda t: [medium_2d(t), medium_1d(t)], ),
|
||||
('addmv', medium_1d, lambda t: [number(0.4, 2, t), medium_2d(t), medium_1d(t)], 'scalar' ),
|
||||
('addmv', medium_1d, lambda t: [number(0.5, 3, t), number(0.4, 2, t), medium_2d(t), medium_1d(t)], 'two_scalars' ),
|
||||
('addmv', medium_1d, lambda t: [medium_2d(t), medium_1d(t)], ),
|
||||
('addmv', medium_1d, lambda t: [number(0.4, 2, t), medium_2d(t), medium_1d(t)], 'scalar' ),
|
||||
('addmv', medium_1d, lambda t: [number(0.5, 3, t), number(0.4, 2, t), medium_2d(t), medium_1d(t)], 'two_scalars' ),
|
||||
('addr', medium_2d, lambda t: [medium_1d(t), medium_1d(t)], ),
|
||||
('addr', medium_2d, lambda t: [number(0.4, 2, t), medium_1d(t), medium_1d(t)], 'scalar' ),
|
||||
('addr', medium_2d, lambda t: [number(0.5, 3, t), number(0.4, 2, t), medium_1d(t), medium_1d(t)], 'two_scalars' ),
|
||||
('addr', medium_2d, lambda t: [number(0.5, 3, t), number(0.4, 2, t), medium_1d(t), medium_1d(t)], 'two_scalars' ),
|
||||
('atan2', medium_2d, lambda t: [medium_2d(t)], ),
|
||||
('atan2', medium_2d, lambda t: [medium_2d(t)], None, float_types),
|
||||
('fmod', small_3d, lambda t: [3], 'value' ),
|
||||
('fmod', small_3d, lambda t: [small_3d_positive(t)], 'tensor' ),
|
||||
('chunk', medium_2d, lambda t: [4], ),
|
||||
('chunk', medium_2d, lambda t: [4, 1], 'dim' ),
|
||||
('clamp', medium_2d, lambda t: [-0.1, 0.5], ),
|
||||
('clamp', medium_2d_scaled, lambda t: [-1, 5], ),
|
||||
('clone', medium_2d, lambda t: [], ),
|
||||
('cmax', medium_2d, lambda t: [medium_2d(t)], ),
|
||||
('cmin', medium_2d, lambda t: [medium_2d(t)], ),
|
||||
('contiguous', medium_2d, lambda t: [], ),
|
||||
('cross', new_t(M, 3, M), lambda t: [new_t(M, 3, M)(t)], ),
|
||||
('cumprod', small_3d, lambda t: [1], ),
|
||||
@ -113,14 +137,14 @@ tests = [
|
||||
('dim', small_3d, lambda t: [], ),
|
||||
('dist', small_2d, lambda t: [small_2d(t)], ),
|
||||
('dist', small_2d, lambda t: [small_2d(t), 3], '3_norm' ),
|
||||
('dist', small_2d, lambda t: [small_2d(t), 2.5], '2.5_norm' ),
|
||||
('dist', small_2d, lambda t: [small_2d(t), 2.5], '2_5_norm' ),
|
||||
('dot', medium_1d, lambda t: [medium_1d(t)], ),
|
||||
('element_size', medium_1d, lambda t: [], ),
|
||||
('eq', small_3d_ones, lambda t: [small_3d(t)], ),
|
||||
('eq', small_3d_ones, lambda t: [small_3d_ones(t)], 'equal' ),
|
||||
('ne', small_3d_ones, lambda t: [small_3d(t)], ),
|
||||
('ne', small_3d_ones, lambda t: [small_3d_ones(t)], 'equal' ),
|
||||
('equal', small_3d_ones, lambda t: [small_3d_ones(t)], ),
|
||||
('equal', small_3d_ones, lambda t: [small_3d_ones(t)], 'equal' ),
|
||||
('equal', small_3d_ones, lambda t: [small_3d(t)], ),
|
||||
('expand', new_t(M, 1, M), lambda t: [M, 4, M], ),
|
||||
('expand_as', new_t(M, 1, M), lambda t: [new_t(M, 4, M)(t)], ),
|
||||
@ -135,18 +159,21 @@ tests = [
|
||||
('is_same_size', medium_2d, lambda t: [medium_2d(t)], 'positive' ),
|
||||
('is_set_to', medium_2d, lambda t: [medium_2d(t)], ),
|
||||
# TODO: positive case
|
||||
('is_size', medium_2d, lambda t: [torch.LongStorage((M, M))], ),
|
||||
('kthvalue', small_3d_unique, lambda t: [3], ),
|
||||
('kthvalue', small_3d_unique, lambda t: [3, 1], 'dim' ),
|
||||
('lerp', small_3d, lambda t: [small_3d(t), 0.3], ),
|
||||
('max', small_3d_unique, lambda t: [], ),
|
||||
('max', small_3d_unique, lambda t: [1], 'dim' ),
|
||||
('max', medium_2d, lambda t: [medium_2d(t)], 'elementwise' ),
|
||||
('min', small_3d_unique, lambda t: [], ),
|
||||
('min', small_3d_unique, lambda t: [1], 'dim' ),
|
||||
('min', medium_2d, lambda t: [medium_2d(t)], 'elementwise' ),
|
||||
('mean', small_3d, lambda t: [], ),
|
||||
('mean', small_3d, lambda t: [1], 'dim' ),
|
||||
('mode', small_3d, lambda t: [], ),
|
||||
('mode', small_3d, lambda t: [1], 'dim' ),
|
||||
('remainder', small_3d, lambda t: [3], 'value' ),
|
||||
('remainder', small_3d, lambda t: [small_3d_positive(t)], 'tensor' ),
|
||||
('std', small_3d, lambda t: [], ),
|
||||
('std', small_3d, lambda t: [1], 'dim' ),
|
||||
('var', small_3d, lambda t: [], ),
|
||||
@ -166,7 +193,7 @@ tests = [
|
||||
('sum', small_2d, lambda t: [], ),
|
||||
('sum', small_3d, lambda t: [1], 'dim' ),
|
||||
('renorm', small_3d, lambda t: [2, 1, 1], '2_norm' ),
|
||||
('renorm', small_3d, lambda t: [1.5, 1, 1], '1.5_norm' ),
|
||||
('renorm', small_3d, lambda t: [1.5, 1, 1], '1_5_norm' ),
|
||||
('repeat', small_2d, lambda t: [2, 2, 2], ),
|
||||
('size', new_t(1, 2, 3, 4), lambda t: [], ),
|
||||
('sort', small_3d_unique, lambda t: [], ),
|
||||
@ -192,12 +219,18 @@ tests = [
|
||||
('view_as', small_3d, lambda t: [t(100, 10)], ),
|
||||
('zero', small_3d, lambda t: [], ),
|
||||
('zeros', small_3d, lambda t: [1, 2, 3, 4], ),
|
||||
('rsqrt', lambda t: small_3d(t) + 1, lambda t: [], ),
|
||||
('sinh', lambda t: small_3d(t).clamp(-1, 1), lambda t: [], ),
|
||||
('tan', lambda t: small_3d(t).clamp(-1, 1), lambda t: [], ),
|
||||
('rsqrt', lambda t: small_3d(t) + 1, lambda t: [], None, float_types),
|
||||
('sinh', lambda t: small_3d(t).clamp(-1, 1), lambda t: [], None, float_types),
|
||||
('tan', lambda t: small_3d(t).clamp(-1, 1), lambda t: [], None, float_types),
|
||||
# lapack tests
|
||||
('qr', small_2d_lapack, lambda t: [], 'square', float_types),
|
||||
('qr', small_2d_lapack_skinny, lambda t: [], 'skinny', float_types),
|
||||
('qr', small_2d_lapack_fat, lambda t: [], 'fat', float_types),
|
||||
|
||||
]
|
||||
|
||||
# TODO: random functions, cat, gather, scatter, index*, masked*, resize, resizeAs, storage_offset, storage, stride, unfold
|
||||
# TODO: random functions, cat, gather, scatter, index*, masked*,
|
||||
# resize, resizeAs, storage_offset, storage, stride, unfold
|
||||
|
||||
custom_precision = {
|
||||
'addbmm': 1e-4,
|
||||
@ -211,32 +244,50 @@ custom_precision = {
|
||||
|
||||
simple_pointwise = [
|
||||
'abs',
|
||||
'acos',
|
||||
'asin',
|
||||
'atan',
|
||||
'ceil',
|
||||
'cinv',
|
||||
'cos',
|
||||
'cosh',
|
||||
'exp',
|
||||
'floor',
|
||||
'fmod',
|
||||
'frac',
|
||||
'log',
|
||||
'log1p',
|
||||
'neg',
|
||||
'remainder',
|
||||
'round',
|
||||
'sigmoid',
|
||||
'sign',
|
||||
'sin',
|
||||
'sqrt',
|
||||
'tanh',
|
||||
'trunc',
|
||||
]
|
||||
for fn in simple_pointwise:
|
||||
tests.append((fn, small_3d, lambda t: []))
|
||||
|
||||
simple_pointwise_float = [
|
||||
'log',
|
||||
'log1p',
|
||||
'sigmoid',
|
||||
'sin',
|
||||
'sqrt',
|
||||
'tanh',
|
||||
'acos',
|
||||
'asin',
|
||||
'atan',
|
||||
'cos',
|
||||
'cosh',
|
||||
'exp',
|
||||
'reciprocal',
|
||||
'floor',
|
||||
'frac',
|
||||
'neg',
|
||||
'round',
|
||||
'trunc',
|
||||
'ceil',
|
||||
]
|
||||
|
||||
for fn in simple_pointwise_float:
|
||||
tests.append((fn, small_3d, lambda t: [], None, float_types))
|
||||
|
||||
_cycles_per_ms = None
|
||||
def get_cycles_per_ms():
|
||||
"""Approximate number of cycles per millisecond for torch.cuda._sleep"""
|
||||
global _cycles_per_ms
|
||||
if _cycles_per_ms is None:
|
||||
start = torch.cuda.Event(enable_timing=True)
|
||||
end = torch.cuda.Event(enable_timing=True)
|
||||
start.record()
|
||||
torch.cuda._sleep(1000000)
|
||||
end.record()
|
||||
end.synchronize()
|
||||
_cycles_per_ms = 1000000 / start.elapsed_time(end)
|
||||
return _cycles_per_ms
|
||||
|
||||
def compare_cpu_gpu(tensor_constructor, arg_constructor, fn, t, precision=1e-5):
|
||||
def tmp(self):
|
||||
cpu_tensor = tensor_constructor(t)
|
||||
@ -251,6 +302,11 @@ def compare_cpu_gpu(tensor_constructor, arg_constructor, fn, t, precision=1e-5):
|
||||
if 'unimplemented data type' in reason:
|
||||
raise unittest.SkipTest('unimplemented data type')
|
||||
raise
|
||||
except AttributeError as e:
|
||||
reason = e.args[0]
|
||||
if 'object has no attribute' in reason:
|
||||
raise unittest.SkipTest('unimplemented data type')
|
||||
raise
|
||||
# If one changes, another should change as well
|
||||
self.assertEqual(cpu_tensor, gpu_tensor, precision)
|
||||
self.assertEqual(cpu_args, gpu_args, precision)
|
||||
@ -276,6 +332,26 @@ class TestCuda(TestCase):
|
||||
z = z.cuda()
|
||||
self.assertEqual(z.get_device(), 0)
|
||||
|
||||
@unittest.skipIf(torch.cuda.device_count() < 2, "only one GPU detected")
|
||||
def test_copy_device(self):
|
||||
x = torch.randn(5, 5).cuda()
|
||||
with torch.cuda.device(1):
|
||||
y = x.cuda()
|
||||
self.assertEqual(y.get_device(), 1)
|
||||
self.assertIs(y.cuda(), y)
|
||||
z = y.cuda(0)
|
||||
self.assertEqual(z.get_device(), 0)
|
||||
self.assertIs(z.cuda(0), z)
|
||||
|
||||
x = torch.randn(5, 5)
|
||||
with torch.cuda.device(1):
|
||||
y = x.cuda()
|
||||
self.assertEqual(y.get_device(), 1)
|
||||
self.assertIs(y.cuda(), y)
|
||||
z = y.cuda(0)
|
||||
self.assertEqual(z.get_device(), 0)
|
||||
self.assertIs(z.cuda(0), z)
|
||||
|
||||
def test_serialization(self):
|
||||
x = torch.randn(5, 5).cuda()
|
||||
y = torch.IntTensor(2, 5).fill_(0).cuda()
|
||||
@ -378,10 +454,11 @@ class TestCuda(TestCase):
|
||||
y = torch.randn(2, 5).cuda(1)
|
||||
result = comm.gather((x, y), dim)
|
||||
|
||||
expected_size = x.size()
|
||||
expected_size = list(x.size())
|
||||
expected_size[dim] += y.size(dim)
|
||||
expected_size = torch.Size(expected_size)
|
||||
self.assertEqual(result.get_device(), 0)
|
||||
self.assertTrue(result.is_size(expected_size))
|
||||
self.assertEqual(result.size(), expected_size)
|
||||
|
||||
index = [slice(None, None), slice(None, None)]
|
||||
index[dim] = slice(0, x.size(dim))
|
||||
@ -395,6 +472,13 @@ class TestCuda(TestCase):
|
||||
def test_gather_dim(self):
|
||||
self._test_gather(1)
|
||||
|
||||
def test_from_sequence(self):
|
||||
seq = [list(range(i*4,i*4+4)) for i in range(5)]
|
||||
reference = torch.range(0, 19).resize_(5, 4)
|
||||
for t in types:
|
||||
cuda_type = get_gpu_type(t)
|
||||
self.assertEqual(cuda_type(seq), reference)
|
||||
|
||||
def test_manual_seed(self):
|
||||
with freeze_rng_state():
|
||||
x = torch.zeros(4, 4).float().cuda()
|
||||
@ -406,6 +490,158 @@ class TestCuda(TestCase):
|
||||
self.assertEqual(x, y)
|
||||
self.assertEqual(torch.cuda.initial_seed(), 2)
|
||||
|
||||
def test_serialization(self):
|
||||
x = torch.randn(4, 4).cuda()
|
||||
with tempfile.NamedTemporaryFile() as f:
|
||||
torch.save(x, f)
|
||||
f.seek(0)
|
||||
x_copy = torch.load(f)
|
||||
self.assertEqual(x_copy, x)
|
||||
self.assertIs(type(x_copy), type(x))
|
||||
self.assertEqual(x_copy.get_device(), x.get_device())
|
||||
|
||||
def test_serialization_empty(self):
|
||||
x = [torch.randn(4, 4).cuda(), torch.cuda.FloatTensor()]
|
||||
with tempfile.NamedTemporaryFile() as f:
|
||||
torch.save(x, f)
|
||||
f.seek(0)
|
||||
x_copy = torch.load(f)
|
||||
for original, copy in zip(x, x_copy):
|
||||
self.assertEqual(copy, original)
|
||||
self.assertIs(type(copy), type(original))
|
||||
self.assertEqual(copy.get_device(), original.get_device())
|
||||
|
||||
@unittest.skipIf(torch.cuda.device_count() < 2, "detected only one GPU")
|
||||
def test_multigpu_serialization(self):
|
||||
x = [torch.randn(4, 4).cuda(0), torch.randn(4, 4).cuda(1)]
|
||||
with tempfile.NamedTemporaryFile() as f:
|
||||
torch.save(x, f)
|
||||
f.seek(0)
|
||||
x_copy = torch.load(f)
|
||||
for original, copy in zip(x, x_copy):
|
||||
self.assertEqual(copy, original)
|
||||
self.assertIs(type(copy), type(original))
|
||||
self.assertEqual(copy.get_device(), original.get_device())
|
||||
|
||||
@unittest.skipIf(torch.cuda.device_count() < 2, "detected only one GPU")
|
||||
def test_multigpu_serialization_remap(self):
|
||||
x = [torch.randn(4, 4).cuda(0), torch.randn(4, 4).cuda(1)]
|
||||
def gpu_remap(storage, location):
|
||||
if location == 'cuda:1':
|
||||
return storage.cuda(0)
|
||||
|
||||
with tempfile.NamedTemporaryFile() as f:
|
||||
torch.save(x, f)
|
||||
f.seek(0)
|
||||
x_copy = torch.load(f, map_location=gpu_remap)
|
||||
|
||||
for original, copy in zip(x, x_copy):
|
||||
self.assertEqual(copy, original)
|
||||
self.assertIs(type(copy), type(original))
|
||||
self.assertEqual(copy.get_device(), 0)
|
||||
|
||||
@unittest.skipIf(torch.cuda.device_count() < 2, "detected only one GPU")
|
||||
def test_multigpu_serialization_remap_dict(self):
|
||||
x = [torch.randn(4, 4).cuda(0), torch.randn(4, 4).cuda(1)]
|
||||
with tempfile.NamedTemporaryFile() as f:
|
||||
torch.save(x, f)
|
||||
f.seek(0)
|
||||
x_copy = torch.load(f, map_location={'cuda:1': 'cuda:0'})
|
||||
for original, copy in zip(x, x_copy):
|
||||
self.assertEqual(copy, original)
|
||||
self.assertIs(type(copy), type(original))
|
||||
self.assertEqual(copy.get_device(), 0)
|
||||
|
||||
@unittest.skipIf(torch.cuda.device_count() < 2, "detected only one GPU")
|
||||
def test_cuda_set_device(self):
|
||||
x = torch.randn(5, 5)
|
||||
with torch.cuda.device(1):
|
||||
self.assertEqual(x.cuda().get_device(), 1)
|
||||
torch.cuda.set_device(0)
|
||||
self.assertEqual(x.cuda().get_device(), 0)
|
||||
with torch.cuda.device(1):
|
||||
self.assertEqual(x.cuda().get_device(), 1)
|
||||
self.assertEqual(x.cuda().get_device(), 0)
|
||||
torch.cuda.set_device(1)
|
||||
self.assertEqual(x.cuda().get_device(), 0)
|
||||
|
||||
def test_is_tensor(self):
|
||||
for t in types:
|
||||
tensor = get_gpu_type(t)()
|
||||
self.assertTrue(torch.is_tensor(tensor))
|
||||
self.assertTrue(torch.is_tensor(torch.cuda.HalfTensor()))
|
||||
|
||||
def test_cuda_synchronize(self):
|
||||
torch.cuda.synchronize()
|
||||
|
||||
def test_streams(self):
|
||||
default_stream = torch.cuda.current_stream()
|
||||
user_stream = torch.cuda.Stream()
|
||||
self.assertEqual(torch.cuda.current_stream(), default_stream)
|
||||
self.assertNotEqual(default_stream, user_stream)
|
||||
self.assertEqual(default_stream.cuda_stream, 0)
|
||||
self.assertNotEqual(user_stream.cuda_stream, 0)
|
||||
with torch.cuda.stream(user_stream):
|
||||
self.assertEqual(torch.cuda.current_stream(), user_stream)
|
||||
self.assertTrue(user_stream.query())
|
||||
# copy 10 MB tensor from CPU-GPU which should take some time
|
||||
tensor1 = torch.ByteTensor(10000000).pin_memory()
|
||||
tensor2 = tensor1.cuda(async=True)
|
||||
self.assertFalse(default_stream.query())
|
||||
default_stream.synchronize()
|
||||
self.assertTrue(default_stream.query())
|
||||
|
||||
@unittest.skipIf(torch.cuda.device_count() < 2, "detected only one GPU")
|
||||
def test_streams_multi_gpu(self):
|
||||
default_stream = torch.cuda.current_stream()
|
||||
self.assertEqual(default_stream.device, 0)
|
||||
stream = torch.cuda.Stream(device=1)
|
||||
self.assertEqual(stream.device, 1)
|
||||
with torch.cuda.device(1):
|
||||
self.assertEqual(torch.cuda.current_stream().device, 1)
|
||||
self.assertNotEqual(torch.cuda.current_stream(), default_stream)
|
||||
|
||||
@unittest.skipIf(torch.cuda.device_count() < 2, "multi-GPU not supported")
|
||||
def test_tensor_device(self):
|
||||
self.assertEqual(torch.cuda.FloatTensor(1).get_device(), 0)
|
||||
self.assertEqual(torch.cuda.FloatTensor(1, device=1).get_device(), 1)
|
||||
with torch.cuda.device(1):
|
||||
self.assertEqual(torch.cuda.FloatTensor(1).get_device(), 1)
|
||||
self.assertEqual(torch.cuda.FloatTensor(1, device=0).get_device(), 0)
|
||||
self.assertEqual(torch.cuda.FloatTensor(1, device=None).get_device(), 1)
|
||||
|
||||
def test_events(self):
|
||||
stream = torch.cuda.current_stream()
|
||||
event = torch.cuda.Event(enable_timing=True)
|
||||
self.assertTrue(event.query())
|
||||
start_event = torch.cuda.Event(enable_timing=True)
|
||||
stream.record_event(start_event)
|
||||
torch.cuda._sleep(int(50 * get_cycles_per_ms()))
|
||||
stream.record_event(event)
|
||||
self.assertFalse(event.query())
|
||||
event.synchronize()
|
||||
self.assertTrue(event.query())
|
||||
self.assertGreater(start_event.elapsed_time(event), 0)
|
||||
|
||||
def test_caching_pinned_memory(self):
|
||||
cycles_per_ms = get_cycles_per_ms()
|
||||
|
||||
# check that allocations are re-used after deletion
|
||||
t = torch.FloatTensor([1]).pin_memory()
|
||||
ptr = t.data_ptr()
|
||||
del t
|
||||
t = torch.FloatTensor([1]).pin_memory()
|
||||
self.assertEqual(t.data_ptr(), ptr, 'allocation not reused')
|
||||
|
||||
# check that the allocation is not re-used if it's in-use by a copy
|
||||
gpu_tensor = torch.cuda.FloatTensor([0])
|
||||
torch.cuda._sleep(int(50 * cycles_per_ms)) # delay the copy
|
||||
gpu_tensor.copy_(t, async=True)
|
||||
del t
|
||||
t = torch.FloatTensor([1]).pin_memory()
|
||||
self.assertNotEqual(t.data_ptr(), ptr, 'allocation re-used too soon')
|
||||
self.assertEqual(list(gpu_tensor), [1])
|
||||
|
||||
|
||||
for decl in tests:
|
||||
for t in types:
|
||||
@ -416,23 +652,29 @@ for decl in tests:
|
||||
desc = ''
|
||||
elif len(decl) == 4:
|
||||
name, constr, arg_constr, desc = decl
|
||||
elif len(decl) == 5:
|
||||
name, constr, arg_constr, desc, type_subset = decl
|
||||
if t not in type_subset:
|
||||
continue
|
||||
|
||||
precision = custom_precision.get(name, TestCuda.precision)
|
||||
for inplace in (True, False):
|
||||
if inplace:
|
||||
name = name + '_'
|
||||
if not hasattr(tensor, name):
|
||||
name_inner = name + '_'
|
||||
else:
|
||||
name_inner = name
|
||||
if not hasattr(tensor, name_inner):
|
||||
continue
|
||||
if not hasattr(gpu_tensor, name):
|
||||
print("Ignoring {}, because it's not implemented by torch.cuda.{}".format(name, gpu_tensor.__class__.__name__))
|
||||
if not hasattr(gpu_tensor, name_inner):
|
||||
print("Ignoring {}, because it's not implemented by torch.cuda.{}".format(name_inner, gpu_tensor.__class__.__name__))
|
||||
continue
|
||||
|
||||
test_name = 'test_' + t.__name__ + '_' + name
|
||||
test_name = 'test_' + t.__name__ + '_' + name_inner
|
||||
if desc:
|
||||
test_name += '_' + desc
|
||||
|
||||
assert not hasattr(TestCase, test_name)
|
||||
setattr(TestCuda, test_name, compare_cpu_gpu(constr, arg_constr, name, t, precision))
|
||||
assert not hasattr(TestCuda, test_name), "Duplicated test name: " + test_name
|
||||
setattr(TestCuda, test_name, compare_cpu_gpu(constr, arg_constr, name_inner, t, precision))
|
||||
|
||||
if __name__ == '__main__':
|
||||
unittest.main()
|
||||
run_tests()
|
||||
|
||||
162
test/test_dataloader.py
Normal file
@ -0,0 +1,162 @@
|
||||
import math
|
||||
import sys
|
||||
import torch
|
||||
import traceback
|
||||
import unittest
|
||||
from torch.utils.data import Dataset, TensorDataset, DataLoader
|
||||
from common import TestCase, run_tests
|
||||
from common_nn import TEST_CUDA
|
||||
|
||||
|
||||
class TestTensorDataset(TestCase):
|
||||
|
||||
def test_len(self):
|
||||
source = TensorDataset(torch.randn(15, 10, 2, 3, 4, 5), torch.randperm(15))
|
||||
self.assertEqual(len(source), 15)
|
||||
|
||||
def test_getitem(self):
|
||||
t = torch.randn(15, 10, 2, 3, 4, 5)
|
||||
l = torch.randn(15, 10)
|
||||
source = TensorDataset(t, l)
|
||||
for i in range(15):
|
||||
self.assertEqual(t[i], source[i][0])
|
||||
self.assertEqual(l[i], source[i][1])
|
||||
|
||||
def test_getitem_1d(self):
|
||||
t = torch.randn(15)
|
||||
l = torch.randn(15)
|
||||
source = TensorDataset(t, l)
|
||||
for i in range(15):
|
||||
self.assertEqual(t[i:i+1], source[i][0])
|
||||
self.assertEqual(l[i:i+1], source[i][1])
|
||||
|
||||
|
||||
class ErrorDataset(Dataset):
|
||||
def __init__(self, size):
|
||||
self.size = size
|
||||
|
||||
def __len__(self):
|
||||
return self.size
|
||||
|
||||
|
||||
class TestDataLoader(TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.data = torch.randn(100, 2, 3, 5)
|
||||
self.labels = torch.randperm(50).repeat(2)
|
||||
self.dataset = TensorDataset(self.data, self.labels)
|
||||
|
||||
def _test_sequential(self, loader):
|
||||
batch_size = loader.batch_size
|
||||
for i, (sample, target) in enumerate(loader):
|
||||
idx = i * batch_size
|
||||
self.assertEqual(sample, self.data[idx:idx+batch_size])
|
||||
self.assertEqual(target, self.labels[idx:idx+batch_size].view(-1, 1))
|
||||
self.assertEqual(i, math.floor((len(self.dataset)-1) / batch_size))
|
||||
|
||||
def _test_shuffle(self, loader):
|
||||
found_data = {i: 0 for i in range(self.data.size(0))}
|
||||
found_labels = {i: 0 for i in range(self.labels.size(0))}
|
||||
batch_size = loader.batch_size
|
||||
for i, (batch_samples, batch_targets) in enumerate(loader):
|
||||
for sample, target in zip(batch_samples, batch_targets):
|
||||
for data_point_idx, data_point in enumerate(self.data):
|
||||
if data_point.eq(sample).all():
|
||||
self.assertFalse(found_data[data_point_idx])
|
||||
found_data[data_point_idx] += 1
|
||||
break
|
||||
self.assertEqual(target, self.labels.narrow(0, data_point_idx, 1))
|
||||
found_labels[data_point_idx] += 1
|
||||
self.assertEqual(sum(found_data.values()), (i+1) * batch_size)
|
||||
self.assertEqual(sum(found_labels.values()), (i+1) * batch_size)
|
||||
self.assertEqual(i, math.floor((len(self.dataset)-1) / batch_size))
|
||||
|
||||
def _test_error(self, loader):
|
||||
it = iter(loader)
|
||||
errors = 0
|
||||
while True:
|
||||
try:
|
||||
it.next()
|
||||
except NotImplementedError:
|
||||
errors += 1
|
||||
except StopIteration:
|
||||
self.assertEqual(errors,
|
||||
math.ceil(float(len(loader.dataset))/loader.batch_size))
|
||||
return
|
||||
|
||||
|
||||
def test_sequential(self):
|
||||
self._test_sequential(DataLoader(self.dataset))
|
||||
|
||||
def test_sequential_batch(self):
|
||||
self._test_sequential(DataLoader(self.dataset, batch_size=2))
|
||||
|
||||
@unittest.skipIf(not TEST_CUDA, "CUDA unavailable")
|
||||
def test_sequential_pin_memory(self):
|
||||
loader = DataLoader(self.dataset, batch_size=2, pin_memory=True)
|
||||
for input, target in loader:
|
||||
self.assertTrue(input.is_pinned())
|
||||
self.assertTrue(target.is_pinned())
|
||||
|
||||
def test_shuffle(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, shuffle=True))
|
||||
|
||||
def test_shuffle_batch(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, batch_size=2, shuffle=True))
|
||||
|
||||
def test_sequential_workers(self):
|
||||
self._test_sequential(DataLoader(self.dataset, num_workers=4))
|
||||
|
||||
def test_seqential_batch_workers(self):
|
||||
self._test_sequential(DataLoader(self.dataset, batch_size=2, num_workers=4))
|
||||
|
||||
def test_shuffle_workers(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, shuffle=True, num_workers=4))
|
||||
|
||||
def test_shuffle_batch_workers(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, batch_size=2, shuffle=True, num_workers=4))
|
||||
|
||||
@unittest.skipIf(not TEST_CUDA, "CUDA unavailable")
|
||||
def test_shuffle_pin_memory(self):
|
||||
loader = DataLoader(self.dataset, batch_size=2, shuffle=True, num_workers=4, pin_memory=True)
|
||||
for input, target in loader:
|
||||
self.assertTrue(input.is_pinned())
|
||||
self.assertTrue(target.is_pinned())
|
||||
|
||||
def test_error(self):
|
||||
self._test_error(DataLoader(ErrorDataset(100), batch_size=2, shuffle=True))
|
||||
|
||||
def test_error_workers(self):
|
||||
self._test_error(DataLoader(ErrorDataset(41), batch_size=2, shuffle=True, num_workers=4))
|
||||
|
||||
@unittest.skipIf(not TEST_CUDA, "CUDA unavailable")
|
||||
def test_partial_workers(self):
|
||||
"check that workers exit even if the iterator is not exhausted"
|
||||
loader = iter(DataLoader(self.dataset, batch_size=2, num_workers=4, pin_memory=True))
|
||||
workers = loader.workers
|
||||
pin_thread = loader.pin_thread
|
||||
for i, sample in enumerate(loader):
|
||||
if i == 3:
|
||||
break
|
||||
del loader
|
||||
for w in workers:
|
||||
w.join(1.0) # timeout of one second
|
||||
self.assertFalse(w.is_alive(), 'subprocess not terminated')
|
||||
self.assertEqual(w.exitcode, 0)
|
||||
pin_thread.join(1.0)
|
||||
self.assertFalse(pin_thread.is_alive())
|
||||
|
||||
def test_len(self):
|
||||
def check_len(dl, expected):
|
||||
self.assertEqual(len(dl), expected)
|
||||
n = 0
|
||||
for sample in dl:
|
||||
n += 1
|
||||
self.assertEqual(n, expected)
|
||||
check_len(self.dataset, 100)
|
||||
check_len(DataLoader(self.dataset, batch_size=2), 50)
|
||||
check_len(DataLoader(self.dataset, batch_size=3), 34)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run_tests()
|
||||
@ -7,7 +7,7 @@ import torch
|
||||
import torch.legacy.nn as nn
|
||||
from common_nn import NNTestCase, ModuleTest, CriterionTest, iter_tensors, \
|
||||
module_tests, criterion_tests, TEST_CUDA, PRECISION
|
||||
from common import to_gpu, freeze_rng_state
|
||||
from common import to_gpu, freeze_rng_state, run_tests
|
||||
|
||||
class OldModuleTest(ModuleTest):
|
||||
def __init__(self, *args, **kwargs):
|
||||
@ -28,6 +28,9 @@ class OldModuleTest(ModuleTest):
|
||||
# Test .clearState()
|
||||
module.clearState()
|
||||
|
||||
# test if module can be printed
|
||||
module.__repr__()
|
||||
|
||||
if self.check_inplace:
|
||||
input2 = deepcopy(input)
|
||||
module_ip = self.constructor(*self.constructor_args, inplace=True)
|
||||
@ -42,7 +45,7 @@ class OldModuleTest(ModuleTest):
|
||||
# TODO: hessian tests
|
||||
tests = [
|
||||
OldModuleTest(nn.Add,
|
||||
(torch.LongStorage([5, 4]),),
|
||||
(torch.Size([5, 4]),),
|
||||
input_size=(3, 5, 4),
|
||||
desc='3D'),
|
||||
OldModuleTest(nn.Add,
|
||||
@ -54,6 +57,36 @@ tests = [
|
||||
input_size=(3, 5, 4),
|
||||
reference_fn=lambda i,_: i + 3.5,
|
||||
check_inplace=True),
|
||||
OldModuleTest(nn.BatchNormalization,
|
||||
(10,),
|
||||
input_size=(4, 10),
|
||||
desc='affine'),
|
||||
OldModuleTest(nn.BatchNormalization,
|
||||
(10, 1e-3, 0.3, False),
|
||||
input_size=(4, 10),
|
||||
desc='not_affine'),
|
||||
OldModuleTest(nn.SpatialBatchNormalization,
|
||||
(3,),
|
||||
input_size=(2, 3, 6, 6)),
|
||||
OldModuleTest(nn.SpatialBatchNormalization,
|
||||
(3, 1e-3, 0.8),
|
||||
input_size=(2, 3, 6, 6),
|
||||
desc='momentum'),
|
||||
OldModuleTest(nn.SpatialBatchNormalization,
|
||||
(3, 1e-3, 0.8, False),
|
||||
input_size=(2, 3, 6, 6),
|
||||
desc='no_affine'),
|
||||
OldModuleTest(nn.VolumetricBatchNormalization,
|
||||
(3,),
|
||||
input_size=(2, 3, 4, 4, 4)),
|
||||
OldModuleTest(nn.VolumetricBatchNormalization,
|
||||
(3, 1e-3, 0.7),
|
||||
input_size=(2, 3, 4, 4, 4),
|
||||
desc='momentum'),
|
||||
OldModuleTest(nn.VolumetricBatchNormalization,
|
||||
(3, 1e-3, 0.7, False),
|
||||
input_size=(2, 3, 4, 4, 4),
|
||||
desc='no_affine'),
|
||||
OldModuleTest(nn.CMul,
|
||||
(5, 6),
|
||||
input_size=(10, 5, 6),
|
||||
@ -149,16 +182,16 @@ tests = [
|
||||
OldModuleTest(nn.Sum,
|
||||
(1,),
|
||||
input_size=(2, 4, 5),
|
||||
reference_fn=lambda i,_: i.sum(1)),
|
||||
reference_fn=lambda i,_: i.sum(1).squeeze(1)),
|
||||
OldModuleTest(nn.Sum,
|
||||
(1, True),
|
||||
input_size=(2, 4, 5),
|
||||
reference_fn=lambda i,_: i.sum(1).div(i.size(1)),
|
||||
reference_fn=lambda i,_: i.sum(1).div(i.size(1)).squeeze(1),
|
||||
desc='sizeAverage'),
|
||||
OldModuleTest(nn.Mean,
|
||||
(1,),
|
||||
input_size=(2, 4, 5),
|
||||
reference_fn=lambda i,_: torch.mean(i, 1)),
|
||||
reference_fn=lambda i,_: torch.mean(i, 1).squeeze(1)),
|
||||
OldModuleTest(lambda: nn.Sequential().add(nn.GradientReversal()).add(nn.GradientReversal()),
|
||||
input_size=(4, 3, 2, 2),
|
||||
fullname='GradientReversal'),
|
||||
@ -911,7 +944,7 @@ class TestNN(NNTestCase):
|
||||
assert not noncontig.is_contiguous()
|
||||
output = module.forward(noncontig)
|
||||
self.assertEqual(output, noncontig)
|
||||
self.assertTrue(output.contiguous())
|
||||
self.assertTrue(output.is_contiguous())
|
||||
|
||||
# Check that these don't raise errors
|
||||
module.__repr__()
|
||||
@ -1109,7 +1142,91 @@ class TestNN(NNTestCase):
|
||||
module.__repr__()
|
||||
str(module)
|
||||
|
||||
def _build_net(self):
|
||||
return (nn.Sequential()
|
||||
.add(nn.Concat(0)
|
||||
.add(nn.Linear(2, 5))
|
||||
.add(nn.Linear(2, 5)))
|
||||
.add(nn.ReLU())
|
||||
.add(nn.Linear(10, 20)))
|
||||
|
||||
def test_parameters(self):
|
||||
net = self._build_net()
|
||||
concat = net.modules[0]
|
||||
param, grad = net.parameters()
|
||||
|
||||
self.assertEqual(len(param), 6)
|
||||
self.assertEqual(len(grad), 6)
|
||||
|
||||
self.assertObjectIn(concat.modules[0].weight, param)
|
||||
self.assertObjectIn(concat.modules[0].bias, param)
|
||||
self.assertObjectIn(concat.modules[1].weight, param)
|
||||
self.assertObjectIn(concat.modules[1].bias, param)
|
||||
self.assertObjectIn(net.modules[2].weight, param)
|
||||
self.assertObjectIn(net.modules[2].bias, param)
|
||||
|
||||
self.assertObjectIn(concat.modules[0].gradWeight, grad)
|
||||
self.assertObjectIn(concat.modules[0].gradBias, grad)
|
||||
self.assertObjectIn(concat.modules[1].gradWeight, grad)
|
||||
self.assertObjectIn(concat.modules[1].gradBias, grad)
|
||||
self.assertObjectIn(net.modules[2].gradWeight, grad)
|
||||
self.assertObjectIn(net.modules[2].gradBias, grad)
|
||||
|
||||
def test_flattenParameters(self):
|
||||
net = self._build_net()
|
||||
param, grad_param = net.flattenParameters()
|
||||
self.assertEqual(param.dim(), 1)
|
||||
self.assertEqual(param.size(0), 250)
|
||||
self.assertEqual(grad_param.dim(), 1)
|
||||
self.assertEqual(grad_param.size(0), 250)
|
||||
|
||||
def test_findModules(self):
|
||||
net = self._build_net()
|
||||
modules, containers = net.findModules(nn.Linear)
|
||||
self.assertEqual(len(modules), 3)
|
||||
self.assertEqual(len(modules), len(containers))
|
||||
self.assertObjectIn(net.modules[0].modules[0], modules)
|
||||
self.assertObjectIn(net.modules[0].modules[1], modules)
|
||||
self.assertObjectIn(net.modules[2], modules)
|
||||
self.assertObjectIn(net.modules[0], containers)
|
||||
self.assertEqual(containers.count(net.modules[0]), 2)
|
||||
self.assertObjectIn(net, containers)
|
||||
for m, c in zip(modules, containers):
|
||||
self.assertObjectIn(m, c.modules)
|
||||
|
||||
def test_apply(self):
|
||||
net = self._build_net()
|
||||
seen_modules = set()
|
||||
def callback(module):
|
||||
self.assertNotIn(module, seen_modules)
|
||||
seen_modules.add(module)
|
||||
net.apply(callback)
|
||||
self.assertEqual(len(seen_modules), 6)
|
||||
|
||||
def test_listModules(self):
|
||||
net = self._build_net()
|
||||
module_list = list()
|
||||
def callback(module):
|
||||
module_list.append(module)
|
||||
net.apply(callback)
|
||||
self.assertEqual(module_list, net.listModules())
|
||||
|
||||
def test_replace(self):
|
||||
ref_net = self._build_net()
|
||||
net = self._build_net()
|
||||
def callback(module):
|
||||
if isinstance(module, nn.ReLU):
|
||||
return nn.Tanh()
|
||||
return module
|
||||
net.replace(callback)
|
||||
|
||||
for module, reference in zip(net.listModules(), ref_net.listModules()):
|
||||
if isinstance(reference, nn.ReLU):
|
||||
self.assertIsInstance(module, nn.Tanh)
|
||||
else:
|
||||
self.assertIsInstance(module, type(reference))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
prepare_tests()
|
||||
unittest.main()
|
||||
run_tests()
|
||||
|
||||
@ -1,16 +1,23 @@
|
||||
import os
|
||||
import contextlib
|
||||
import gc
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
import unittest
|
||||
import contextlib
|
||||
from sys import platform
|
||||
|
||||
import torch
|
||||
import torch.cuda
|
||||
import torch.multiprocessing as mp
|
||||
from common import TestCase
|
||||
from torch.autograd import Variable
|
||||
from torch.nn import Parameter
|
||||
from common import TestCase, run_tests
|
||||
|
||||
|
||||
HAS_SHM_FILES = os.path.isdir('/dev/shm')
|
||||
TEST_CUDA_IPC = torch.cuda.is_available() and \
|
||||
sys.version_info[0] == 3 and \
|
||||
sys.platform != 'darwin'
|
||||
|
||||
|
||||
def simple_fill(queue, event):
|
||||
@ -24,6 +31,60 @@ def simple_pool_fill(tensor):
|
||||
return tensor.add(1)
|
||||
|
||||
|
||||
def send_tensor(queue, event, tp):
|
||||
t = torch.ones(5, 5).type(tp)
|
||||
queue.put(t)
|
||||
queue.put(t)
|
||||
event.wait()
|
||||
|
||||
|
||||
def sum_tensors(inq, outq):
|
||||
with torch.cuda.device(1):
|
||||
tensors = inq.get()
|
||||
for tensor in tensors:
|
||||
outq.put((tensor.sum(), tensor.get_device(),
|
||||
tensor.numel(), tensor.storage().size()))
|
||||
|
||||
|
||||
def queue_get_exception(inqueue, outqueue):
|
||||
os.close(2) # hide expected error message
|
||||
try:
|
||||
torch.zeros(5, 5).cuda()
|
||||
except Exception as e:
|
||||
outqueue.put(e)
|
||||
else:
|
||||
outqueue.put('no exception')
|
||||
|
||||
|
||||
# Multiply by two in a separate stream
|
||||
def cuda_multiply_two(queue, ready, done):
|
||||
ready.set()
|
||||
with torch.cuda.stream(torch.cuda.Stream()):
|
||||
cuda_event, tensor = queue.get()
|
||||
cuda_event.wait()
|
||||
tensor.mul_(2)
|
||||
cuda_event.record()
|
||||
done.set()
|
||||
del cuda_event
|
||||
|
||||
|
||||
def autograd_sharing(queue, ready, master_modified):
|
||||
var = queue.get()
|
||||
ready.set()
|
||||
master_modified.wait()
|
||||
|
||||
expected_var = torch.range(1, 25).view(5, 5)
|
||||
expected_var[0,0] = 1000
|
||||
is_ok = var.data.equal(expected_var)
|
||||
var.data[:] = torch.ones(5, 5)
|
||||
|
||||
if var.grad is not None:
|
||||
is_ok &= var.grad.data.equal(torch.ones(5, 5) * 4)
|
||||
var.grad.data[:] = torch.ones(5, 5)
|
||||
|
||||
queue.put(is_ok)
|
||||
|
||||
|
||||
@contextlib.contextmanager
|
||||
def fs_sharing():
|
||||
prev_strategy = mp.get_sharing_strategy()
|
||||
@ -41,24 +102,30 @@ class leak_checker(object):
|
||||
self.test_case = test_case
|
||||
|
||||
def __enter__(self):
|
||||
self.next_fd = self._get_next_fd()
|
||||
self.next_fds = self._get_next_fds(10)
|
||||
return self
|
||||
|
||||
def __exit__(self, *args):
|
||||
if args[0] is None:
|
||||
gc.collect()
|
||||
self.test_case.assertEqual(self.next_fd, self._get_next_fd())
|
||||
# Check that the 10th available file-descriptor at the end of the
|
||||
# test is no more than 4 higher than the 10th available at the
|
||||
# start. This attempts to catch file descriptor leaks, but allows
|
||||
# one-off initialization that may use up a file descriptor
|
||||
available_fds = self._get_next_fds(10)
|
||||
self.test_case.assertLessEqual(
|
||||
available_fds[-1] - self.next_fds[-1], 4)
|
||||
self.test_case.assertFalse(self.has_shm_files())
|
||||
return False
|
||||
|
||||
def check_pid(self, pid):
|
||||
self.checked_pids.append(pid)
|
||||
|
||||
def _get_next_fd(self):
|
||||
def _get_next_fds(self, n=1):
|
||||
# dup uses the lowest-numbered unused descriptor for the new descriptor
|
||||
fd = os.dup(0)
|
||||
os.close(fd)
|
||||
return fd
|
||||
fds = [os.dup(0) for i in range(n)]
|
||||
for fd in fds:
|
||||
os.close(fd)
|
||||
return fds
|
||||
|
||||
def has_shm_files(self, wait=True):
|
||||
if not HAS_SHM_FILES:
|
||||
@ -84,14 +151,14 @@ class TestMultiprocessing(TestCase):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super(TestMultiprocessing, self).__init__(*args, **kwargs)
|
||||
|
||||
def _test_sharing(self):
|
||||
def do_test():
|
||||
x = torch.zeros(5, 5)
|
||||
q = mp.Queue()
|
||||
e = mp.Event()
|
||||
def _test_sharing(self, ctx=mp, type=torch.FloatTensor, repeat=1):
|
||||
def test_fill():
|
||||
x = torch.zeros(5, 5).type(type)
|
||||
q = ctx.Queue()
|
||||
e = ctx.Event()
|
||||
data = [x, x[:, 1]]
|
||||
q.put(data)
|
||||
p = mp.Process(target=simple_fill, args=(q, e))
|
||||
p = ctx.Process(target=simple_fill, args=(q, e))
|
||||
lc.check_pid(p.pid)
|
||||
p.start()
|
||||
e.wait()
|
||||
@ -100,14 +167,30 @@ class TestMultiprocessing(TestCase):
|
||||
p.join(1)
|
||||
self.assertFalse(p.is_alive())
|
||||
|
||||
with leak_checker(self) as lc:
|
||||
do_test()
|
||||
def test_receive():
|
||||
q = ctx.Queue()
|
||||
e = ctx.Event()
|
||||
p = ctx.Process(target=send_tensor, args=(q, e, type))
|
||||
lc.check_pid(p.pid)
|
||||
p.start()
|
||||
t1 = q.get()
|
||||
t2 = q.get()
|
||||
self.assertTrue(t1.eq(1).all())
|
||||
self.assertTrue(id(t1.storage()) == id(t2.storage()))
|
||||
e.set()
|
||||
p.join(1)
|
||||
self.assertFalse(p.is_alive())
|
||||
|
||||
def _test_preserve_sharing(self):
|
||||
with leak_checker(self) as lc:
|
||||
for i in range(repeat):
|
||||
test_fill()
|
||||
test_receive()
|
||||
|
||||
def _test_preserve_sharing(self, ctx=mp, repeat=1):
|
||||
def do_test():
|
||||
x = torch.randn(5, 5)
|
||||
data = [x.storage(), x.storage()[1:4], x, x[2], x[:,1]]
|
||||
q = mp.Queue()
|
||||
q = ctx.Queue()
|
||||
q.put(data)
|
||||
new_data = q.get()
|
||||
self.assertEqual(new_data, data, 0)
|
||||
@ -120,63 +203,210 @@ class TestMultiprocessing(TestCase):
|
||||
# self.assertEqual(new_data[1], new_data[0][1:4], 0)
|
||||
|
||||
with leak_checker(self):
|
||||
do_test()
|
||||
for i in range(repeat):
|
||||
do_test()
|
||||
|
||||
def _test_pool(self):
|
||||
def _test_pool(self, ctx=mp, repeat=1):
|
||||
def do_test():
|
||||
p = mp.Pool(2)
|
||||
p = ctx.Pool(2)
|
||||
for proc in p._pool:
|
||||
lc.check_pid(proc.pid)
|
||||
|
||||
buffers = (torch.zeros(2, 2) for i in range(4))
|
||||
buffers = [torch.zeros(2, 2) for i in range(4)]
|
||||
results = p.map(simple_pool_fill, buffers, 1)
|
||||
self.assertEqual(len(results), len(buffers))
|
||||
for r in results:
|
||||
self.assertEqual(r, torch.ones(2, 2) * 5, 0)
|
||||
self.assertEqual(len(results), 4)
|
||||
for b in buffers:
|
||||
self.assertEqual(b, torch.ones(2, 2) * 4, 0)
|
||||
|
||||
p.close()
|
||||
p.join()
|
||||
|
||||
with leak_checker(self) as lc:
|
||||
do_test()
|
||||
for i in range(repeat):
|
||||
do_test()
|
||||
|
||||
@unittest.skipIf(platform == 'darwin', "file descriptor strategy is not supported on OS X")
|
||||
def test_fd_sharing(self):
|
||||
self._test_sharing()
|
||||
self._test_sharing(repeat=20)
|
||||
|
||||
@unittest.skipIf(platform == 'darwin', "file descriptor strategy is not supported on OS X")
|
||||
def test_fd_preserve_sharing(self):
|
||||
self._test_preserve_sharing()
|
||||
self._test_preserve_sharing(repeat=20)
|
||||
|
||||
@unittest.skipIf(platform == 'darwin', "file descriptor strategy is not supported on OS X")
|
||||
def test_fd_pool(self):
|
||||
self._test_pool()
|
||||
self._test_pool(repeat=20)
|
||||
|
||||
def test_fs_sharing(self):
|
||||
with fs_sharing():
|
||||
self._test_sharing()
|
||||
self._test_sharing(repeat=20)
|
||||
|
||||
def test_fs_preserve_sharing(self):
|
||||
with fs_sharing():
|
||||
self._test_preserve_sharing()
|
||||
self._test_preserve_sharing(repeat=20)
|
||||
|
||||
def test_fs_pool(self):
|
||||
with fs_sharing():
|
||||
self._test_pool()
|
||||
self._test_pool(repeat=20)
|
||||
|
||||
@unittest.skipIf(not HAS_SHM_FILES, "don't not how to check if shm files exist")
|
||||
def test_fs(self):
|
||||
with fs_sharing(), leak_checker(self) as lc:
|
||||
def queue_put():
|
||||
x = torch.DoubleStorage(4)
|
||||
q = mp.Queue()
|
||||
self.assertFalse(lc.has_shm_files())
|
||||
q.put(x)
|
||||
time.sleep(0.05) # queue serializes asynchronously
|
||||
self.assertTrue(lc.has_shm_files(wait=False))
|
||||
q.get()
|
||||
del x
|
||||
del q # We have to clean up fds for leak_checker
|
||||
|
||||
with fs_sharing(), leak_checker(self) as lc:
|
||||
for i in range(20):
|
||||
queue_put()
|
||||
|
||||
def test_inherit_tensor(self):
|
||||
class SubProcess(mp.Process):
|
||||
def __init__(self, tensor):
|
||||
super(SubProcess, self).__init__()
|
||||
self.tensor = tensor
|
||||
|
||||
def run(self):
|
||||
self.tensor.add_(3)
|
||||
|
||||
t = torch.zeros(5, 5)
|
||||
p = SubProcess(t.share_memory_())
|
||||
p.start()
|
||||
p.join()
|
||||
self.assertEqual(t, torch.ones(5, 5) * 3, 0)
|
||||
|
||||
@unittest.skipIf(not TEST_CUDA_IPC, 'CUDA IPC not available')
|
||||
def test_cuda(self):
|
||||
torch.cuda.FloatTensor([1]) # initialize CUDA outside of leak checker
|
||||
self._test_sharing(mp.get_context('spawn'), torch.cuda.FloatTensor)
|
||||
|
||||
|
||||
@unittest.skipIf(not TEST_CUDA_IPC, 'CUDA IPC not available')
|
||||
def test_cuda_small_tensors(self):
|
||||
# Check multiple small tensors which will likely use the same
|
||||
# underlying cached allocation
|
||||
ctx = mp.get_context('spawn')
|
||||
tensors = []
|
||||
for i in range(5):
|
||||
tensors += [torch.range(i * 5, (i * 5) + 4).cuda()]
|
||||
|
||||
inq = ctx.Queue()
|
||||
outq = ctx.Queue()
|
||||
inq.put(tensors)
|
||||
p = ctx.Process(target=sum_tensors, args=(inq, outq))
|
||||
p.start()
|
||||
|
||||
results = []
|
||||
for i in range(5):
|
||||
results.append(outq.get())
|
||||
p.join()
|
||||
|
||||
for i, tensor in enumerate(tensors):
|
||||
v, device, tensor_size, storage_size = results[i]
|
||||
self.assertEqual(v, torch.range(i * 5, (i * 5) + 4).sum())
|
||||
self.assertEqual(device, 0)
|
||||
self.assertEqual(tensor_size, 5)
|
||||
self.assertEqual(storage_size, 5)
|
||||
|
||||
@unittest.skipIf(not torch.cuda.is_available(), 'CUDA not available')
|
||||
def test_cuda_bad_call(self):
|
||||
# Initialize CUDA
|
||||
t = torch.zeros(5, 5).cuda().cpu()
|
||||
inq = mp.Queue()
|
||||
outq = mp.Queue()
|
||||
p = mp.Process(target=queue_get_exception, args=(inq, outq))
|
||||
p.start()
|
||||
inq.put(t)
|
||||
p.join()
|
||||
self.assertIsInstance(outq.get(), RuntimeError)
|
||||
|
||||
@unittest.skipIf(not TEST_CUDA_IPC, 'CUDA IPC not available')
|
||||
def test_event(self):
|
||||
ctx = mp.get_context('spawn')
|
||||
queue = ctx.Queue()
|
||||
ready = ctx.Event()
|
||||
done = ctx.Event()
|
||||
p = ctx.Process(target=cuda_multiply_two, args=(queue, ready, done))
|
||||
p.start()
|
||||
|
||||
ready.wait()
|
||||
with torch.cuda.stream(torch.cuda.Stream()):
|
||||
tensor = torch.cuda.FloatTensor([1, 1, 1, 1])
|
||||
# Use a sleep kernel to test events. Without the event, the
|
||||
# multiply happens before the add.
|
||||
event = torch.cuda.Event(interprocess=True)
|
||||
torch.cuda._sleep(20000000) # about 30 ms
|
||||
tensor.add_(1)
|
||||
event.record()
|
||||
queue.put((event, tensor))
|
||||
done.wait() # must wait until subprocess records event
|
||||
event.synchronize()
|
||||
self.assertEqual(list(tensor), [4, 4, 4, 4])
|
||||
p.join()
|
||||
|
||||
def _test_autograd_sharing(self, var):
|
||||
ready = mp.Event()
|
||||
master_modified = mp.Event()
|
||||
queue = mp.Queue()
|
||||
p = mp.Process(target=autograd_sharing, args=(queue, ready, master_modified))
|
||||
p.start()
|
||||
queue.put(var)
|
||||
|
||||
ready.wait()
|
||||
var.data[0,0] = 1000
|
||||
if var.grad is not None:
|
||||
var.grad.data[:] = torch.ones(5, 5) * 4
|
||||
master_modified.set()
|
||||
|
||||
worker_ok = queue.get()
|
||||
self.assertTrue(worker_ok)
|
||||
|
||||
self.assertEqual(var.data, torch.ones(5, 5))
|
||||
if var.grad is not None:
|
||||
self.assertEqual(var.grad.data, torch.ones(5, 5))
|
||||
p.join()
|
||||
|
||||
def test_variable_sharing(self):
|
||||
configs = [
|
||||
(True, False),
|
||||
(False, False),
|
||||
(False, True),
|
||||
]
|
||||
for requires_grad, volatile in configs:
|
||||
var = Variable(torch.range(1, 25).view(5, 5),
|
||||
requires_grad=requires_grad,
|
||||
volatile=volatile)
|
||||
self._test_autograd_sharing(var)
|
||||
|
||||
def test_parameter_sharing(self):
|
||||
param = Parameter(torch.range(1, 25).view(5, 5))
|
||||
self._test_autograd_sharing(param)
|
||||
|
||||
def _test_is_shared(self):
|
||||
t = torch.randn(5, 5)
|
||||
self.assertFalse(t.is_shared())
|
||||
t.share_memory_()
|
||||
self.assertTrue(t.is_shared())
|
||||
|
||||
@unittest.skipIf(platform == 'darwin', "file descriptor strategy is not supported on OS X")
|
||||
def test_is_shared(self):
|
||||
self._test_is_shared()
|
||||
|
||||
def test_fs_is_shared(self):
|
||||
with fs_sharing():
|
||||
self._test_is_shared()
|
||||
|
||||
@unittest.skipIf(not torch.cuda.is_available(), 'CUDA not available')
|
||||
def test_is_shared_cuda(self):
|
||||
t = torch.randn(5, 5).cuda()
|
||||
self.assertTrue(t.is_shared())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
unittest.main()
|
||||
|
||||
run_tests()
|
||||
|
||||
90
test/test_nccl.py
Normal file
@ -0,0 +1,90 @@
|
||||
import unittest
|
||||
|
||||
import torch
|
||||
import torch.cuda.nccl as nccl
|
||||
import torch.cuda
|
||||
|
||||
from common import TestCase, run_tests
|
||||
|
||||
if not torch.cuda.is_available():
|
||||
print('CUDA not available, skipping tests')
|
||||
import sys
|
||||
sys.exit()
|
||||
|
||||
nGPUs = torch.cuda.device_count()
|
||||
|
||||
|
||||
class TestNCCL(TestCase):
|
||||
|
||||
@unittest.skipIf(nGPUs < 2, "only one GPU detected")
|
||||
def test_broadcast(self):
|
||||
expected = torch.FloatTensor(128).uniform_()
|
||||
tensors = [expected.cuda()]
|
||||
for device in range(1, torch.cuda.device_count()):
|
||||
with torch.cuda.device(device):
|
||||
tensors.append(torch.cuda.FloatTensor(128))
|
||||
|
||||
nccl.broadcast(tensors)
|
||||
for i in range(torch.cuda.device_count()):
|
||||
self.assertEqual(tensors[i], expected)
|
||||
|
||||
@unittest.skipIf(nGPUs < 2, "only one GPU detected")
|
||||
def test_reduce(self):
|
||||
tensors = [torch.FloatTensor(128).uniform_() for i in range(nGPUs)]
|
||||
expected = torch.FloatTensor(128).zero_()
|
||||
for t in tensors:
|
||||
expected.add_(t)
|
||||
|
||||
tensors = [tensors[i].cuda(i) for i in range(nGPUs)]
|
||||
nccl.reduce(tensors)
|
||||
|
||||
self.assertEqual(tensors[0], expected)
|
||||
|
||||
@unittest.skipIf(nGPUs < 2, "only one GPU detected")
|
||||
def test_all_reduce(self):
|
||||
tensors = [torch.FloatTensor(128).uniform_() for i in range(nGPUs)]
|
||||
expected = torch.FloatTensor(128).zero_()
|
||||
for t in tensors:
|
||||
expected.add_(t)
|
||||
|
||||
tensors = [tensors[i].cuda(i) for i in range(nGPUs)]
|
||||
nccl.all_reduce(tensors)
|
||||
|
||||
for tensor in tensors:
|
||||
self.assertEqual(tensor, expected)
|
||||
|
||||
@unittest.skipIf(nGPUs < 2, "only one GPU detected")
|
||||
def test_all_gather(self):
|
||||
inputs = [torch.FloatTensor(128).uniform_() for i in range(nGPUs)]
|
||||
expected = torch.cat(inputs, 0)
|
||||
|
||||
inputs = [inputs[i].cuda(i) for i in range(nGPUs)]
|
||||
outputs = [torch.cuda.FloatTensor(128 * nGPUs, device=i)
|
||||
for i in range(nGPUs)]
|
||||
nccl.all_gather(inputs, outputs)
|
||||
|
||||
for tensor in outputs:
|
||||
self.assertEqual(tensor, expected)
|
||||
|
||||
@unittest.skipIf(nGPUs < 2, "only one GPU detected")
|
||||
def test_reduce_scatter(self):
|
||||
in_size = 32 * nGPUs
|
||||
out_size = 32
|
||||
|
||||
inputs = [torch.FloatTensor(in_size).uniform_() for i in range(nGPUs)]
|
||||
expected = torch.FloatTensor(in_size).zero_()
|
||||
for t in inputs:
|
||||
expected.add_(t)
|
||||
expected = expected.view(nGPUs, 32)
|
||||
|
||||
inputs = [inputs[i].cuda(i) for i in range(nGPUs)]
|
||||
outputs = [torch.cuda.FloatTensor(out_size, device=i)
|
||||
for i in range(nGPUs)]
|
||||
nccl.reduce_scatter(inputs, outputs)
|
||||
|
||||
for i in range(nGPUs):
|
||||
self.assertEqual(outputs[i], expected[i])
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run_tests()
|
||||
1119
test/test_nn.py
347
test/test_optim.py
Normal file
@ -0,0 +1,347 @@
|
||||
import unittest
|
||||
import functools
|
||||
from copy import deepcopy
|
||||
import torch
|
||||
import torch.optim as optim
|
||||
import torch.legacy.optim as old_optim
|
||||
from torch.autograd import Variable
|
||||
|
||||
from common import TestCase, run_tests
|
||||
|
||||
|
||||
def rosenbrock(tensor):
|
||||
x, y = tensor
|
||||
return (1 - x) ** 2 + 100 * (y - x ** 2) ** 2
|
||||
|
||||
|
||||
def drosenbrock(tensor):
|
||||
x, y = tensor
|
||||
return torch.DoubleTensor((-400 * x * (y - x**2) - 2 * (1 - x), 200 * (y - x**2)))
|
||||
|
||||
|
||||
def wrap_old_fn(old_fn, **config):
|
||||
def wrapper(closure, params, state):
|
||||
return old_fn(closure, params, config, state)
|
||||
return wrapper
|
||||
|
||||
|
||||
class TestOptim(TestCase):
|
||||
|
||||
def _test_rosenbrock(self, constructor, old_fn):
|
||||
params_t = torch.Tensor([1.5, 1.5])
|
||||
state = {}
|
||||
|
||||
params = Variable(torch.Tensor([1.5, 1.5]), requires_grad=True)
|
||||
optimizer = constructor([params])
|
||||
|
||||
solution = torch.Tensor([1, 1])
|
||||
initial_dist = params.data.dist(solution)
|
||||
|
||||
def eval():
|
||||
optimizer.zero_grad()
|
||||
loss = rosenbrock(params)
|
||||
loss.backward()
|
||||
# loss.backward() will give **slightly** different
|
||||
# gradients, than drosenbtock, because of a different ordering
|
||||
# of floating point operations. In most cases it doesn't matter,
|
||||
# but some optimizers are so sensitive that they can temporarily
|
||||
# diverge up to 1e-4, just to converge again. This makes the
|
||||
# comparison more stable.
|
||||
params.grad.data.copy_(drosenbrock(params.data))
|
||||
return loss
|
||||
|
||||
for i in range(2000):
|
||||
optimizer.step(eval)
|
||||
old_fn(lambda _: (rosenbrock(params_t), drosenbrock(params_t)),
|
||||
params_t, state)
|
||||
self.assertEqual(params.data, params_t)
|
||||
|
||||
self.assertLessEqual(params.data.dist(solution), initial_dist)
|
||||
|
||||
def _test_basic_cases_template(self, weight, bias, input, constructor):
|
||||
weight = Variable(weight, requires_grad=True)
|
||||
bias = Variable(bias, requires_grad=True)
|
||||
input = Variable(input)
|
||||
optimizer = constructor(weight, bias)
|
||||
|
||||
def fn():
|
||||
optimizer.zero_grad()
|
||||
y = weight.mv(input)
|
||||
if y.is_cuda and bias.is_cuda and y.get_device() != bias.get_device():
|
||||
y = y.cuda(bias.get_device())
|
||||
loss = (y + bias).pow(2).sum()
|
||||
loss.backward()
|
||||
return loss
|
||||
|
||||
initial_value = fn().data[0]
|
||||
for i in range(200):
|
||||
optimizer.step(fn)
|
||||
self.assertLess(fn().data[0], initial_value)
|
||||
|
||||
def _test_state_dict(self, weight, bias, input, constructor):
|
||||
weight = Variable(weight, requires_grad=True)
|
||||
bias = Variable(bias, requires_grad=True)
|
||||
input = Variable(input)
|
||||
|
||||
def fn_base(optimizer, weight, bias):
|
||||
optimizer.zero_grad()
|
||||
loss = (weight.mv(input) + bias).pow(2).sum()
|
||||
loss.backward()
|
||||
return loss
|
||||
|
||||
optimizer = constructor(weight, bias)
|
||||
fn = functools.partial(fn_base, optimizer, weight, bias)
|
||||
|
||||
# Prime the optimizer
|
||||
for i in range(20):
|
||||
optimizer.step(fn)
|
||||
# Clone the weights and construct new optimizer for them
|
||||
weight_c = Variable(weight.data.clone(), requires_grad=True)
|
||||
bias_c = Variable(bias.data.clone(), requires_grad=True)
|
||||
optimizer_c = constructor(weight_c, bias_c)
|
||||
fn_c = functools.partial(fn_base, optimizer_c, weight_c, bias_c)
|
||||
# Load state dict
|
||||
state_dict = deepcopy(optimizer.state_dict())
|
||||
state_dict_c = deepcopy(optimizer.state_dict())
|
||||
optimizer_c.load_state_dict(state_dict_c)
|
||||
# Run both optimizations in parallel
|
||||
for i in range(20):
|
||||
optimizer.step(fn)
|
||||
optimizer_c.step(fn_c)
|
||||
self.assertEqual(weight, weight_c)
|
||||
self.assertEqual(bias, bias_c)
|
||||
# Make sure state dict wasn't modified
|
||||
self.assertEqual(state_dict, state_dict_c)
|
||||
|
||||
def _test_basic_cases(self, constructor, ignore_multidevice=False):
|
||||
self._test_state_dict(
|
||||
torch.randn(10, 5),
|
||||
torch.randn(10),
|
||||
torch.randn(5),
|
||||
constructor
|
||||
)
|
||||
self._test_basic_cases_template(
|
||||
torch.randn(10, 5),
|
||||
torch.randn(10),
|
||||
torch.randn(5),
|
||||
constructor
|
||||
)
|
||||
# non-contiguous parameters
|
||||
self._test_basic_cases_template(
|
||||
torch.randn(10, 5, 2)[...,0],
|
||||
torch.randn(10, 2)[...,0],
|
||||
torch.randn(5),
|
||||
constructor
|
||||
)
|
||||
# CUDA
|
||||
if not torch.cuda.is_available():
|
||||
return
|
||||
self._test_basic_cases_template(
|
||||
torch.randn(10, 5).cuda(),
|
||||
torch.randn(10).cuda(),
|
||||
torch.randn(5).cuda(),
|
||||
constructor
|
||||
)
|
||||
# Multi-GPU
|
||||
if not torch.cuda.device_count() > 1 or ignore_multidevice:
|
||||
return
|
||||
self._test_basic_cases_template(
|
||||
torch.randn(10, 5).cuda(0),
|
||||
torch.randn(10).cuda(1),
|
||||
torch.randn(5).cuda(0),
|
||||
constructor
|
||||
)
|
||||
|
||||
def _build_params_dict(self, weight, bias, **kwargs):
|
||||
return [dict(params=[weight]), dict(params=[bias], **kwargs)]
|
||||
|
||||
def test_sgd(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.SGD(params, lr=1e-3),
|
||||
wrap_old_fn(old_optim.sgd, learningRate=1e-3)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.SGD(params, lr=1e-3, momentum=0.9,
|
||||
dampening=0, weight_decay=1e-4),
|
||||
wrap_old_fn(old_optim.sgd, learningRate=1e-3, momentum=0.9,
|
||||
dampening=0, weightDecay=1e-4)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.SGD([weight, bias], lr=1e-3)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.SGD(
|
||||
self._build_params_dict(weight, bias, lr=1e-2),
|
||||
lr=1e-3)
|
||||
)
|
||||
|
||||
def test_adam(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adam(params, lr=1e-2),
|
||||
wrap_old_fn(old_optim.adam, learningRate=1e-2)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adam(params, lr=1e-2, weight_decay=1e-2),
|
||||
wrap_old_fn(old_optim.adam, learningRate=1e-2, weightDecay=1e-2)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adam([weight, bias], lr=1e-3)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adam(
|
||||
self._build_params_dict(weight, bias, lr=1e-2),
|
||||
lr=1e-3)
|
||||
)
|
||||
|
||||
def test_adadelta(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adadelta(params),
|
||||
wrap_old_fn(old_optim.adadelta)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adadelta(params, rho=0.95),
|
||||
wrap_old_fn(old_optim.adadelta, rho=0.95)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adadelta(params, weight_decay=1e-2),
|
||||
wrap_old_fn(old_optim.adadelta, weightDecay=1e-2)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adadelta([weight, bias])
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adadelta(
|
||||
self._build_params_dict(weight, bias, rho=0.95))
|
||||
)
|
||||
|
||||
def test_adagrad(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adagrad(params, lr=1e-1),
|
||||
wrap_old_fn(old_optim.adagrad, learningRate=1e-1)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adagrad(params, lr=1e-1, lr_decay=1e-3),
|
||||
wrap_old_fn(old_optim.adagrad, learningRate=1e-1, learningRateDecay=1e-3)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adagrad(params, lr=1e-1, weight_decay=1e-2),
|
||||
wrap_old_fn(old_optim.adagrad, learningRate=1e-1, weightDecay=1e-2)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adagrad([weight, bias], lr=1e-1)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adagrad(
|
||||
self._build_params_dict(weight, bias, lr=1e-2),
|
||||
lr=1e-1)
|
||||
)
|
||||
|
||||
def test_adamax(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adamax(params, lr=1e-1),
|
||||
wrap_old_fn(old_optim.adamax, learningRate=1e-1)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adamax(params, lr=1e-1, weight_decay=1e-2),
|
||||
wrap_old_fn(old_optim.adamax, learningRate=1e-1, weightDecay=1e-2)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Adamax(params, lr=1e-1, betas=(0.95, 0.998)),
|
||||
wrap_old_fn(old_optim.adamax, learningRate=1e-1, beta1=0.95, beta2=0.998)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adagrad([weight, bias], lr=1e-1)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adagrad(
|
||||
self._build_params_dict(weight, bias, lr=1e-2),
|
||||
lr=1e-1)
|
||||
)
|
||||
|
||||
def test_rmsprop(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.RMSprop(params, lr=1e-2),
|
||||
wrap_old_fn(old_optim.rmsprop, learningRate=1e-2)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.RMSprop(params, lr=1e-2, weight_decay=1e-2),
|
||||
wrap_old_fn(old_optim.rmsprop, learningRate=1e-2, weightDecay=1e-2)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.RMSprop(params, lr=1e-2, alpha=0.95),
|
||||
wrap_old_fn(old_optim.rmsprop, learningRate=1e-2, alpha=0.95)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adagrad([weight, bias], lr=1e-2)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Adagrad(
|
||||
self._build_params_dict(weight, bias, lr=1e-3),
|
||||
lr=1e-2)
|
||||
)
|
||||
|
||||
def test_asgd(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.ASGD(params, lr=1e-3),
|
||||
wrap_old_fn(old_optim.asgd, eta0=1e-3)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.ASGD(params, lr=1e-3, alpha=0.8),
|
||||
wrap_old_fn(old_optim.asgd, eta0=1e-3, alpha=0.8)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.ASGD(params, lr=1e-3, t0=1e3),
|
||||
wrap_old_fn(old_optim.asgd, eta0=1e-3, t0=1e3)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.ASGD([weight, bias], lr=1e-3, t0=100)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.ASGD(
|
||||
self._build_params_dict(weight, bias, lr=1e-2),
|
||||
lr=1e-3, t0=100)
|
||||
)
|
||||
|
||||
def test_rprop(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Rprop(params, lr=1e-3),
|
||||
wrap_old_fn(old_optim.rprop, stepsize=1e-3)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Rprop(params, lr=1e-3, etas=(0.6, 1.1)),
|
||||
wrap_old_fn(old_optim.rprop, stepsize=1e-3, etaminus=0.6, etaplus=1.1)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.Rprop(params, lr=1e-3, step_sizes=(1e-4, 3)),
|
||||
wrap_old_fn(old_optim.rprop, stepsize=1e-3, stepsizemin=1e-4, stepsizemax=3)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Rprop([weight, bias], lr=1e-3)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.Rprop(
|
||||
self._build_params_dict(weight, bias, lr=1e-2),
|
||||
lr=1e-3)
|
||||
)
|
||||
|
||||
def test_lbfgs(self):
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.LBFGS(params),
|
||||
wrap_old_fn(old_optim.lbfgs)
|
||||
)
|
||||
self._test_rosenbrock(
|
||||
lambda params: optim.LBFGS(params, lr=5e-2, max_iter=5),
|
||||
wrap_old_fn(old_optim.lbfgs, learningRate=5e-2, maxIter=5)
|
||||
)
|
||||
self._test_basic_cases(
|
||||
lambda weight, bias: optim.LBFGS([weight, bias]),
|
||||
ignore_multidevice=True
|
||||
)
|
||||
|
||||
def test_invalid_param_type(self):
|
||||
with self.assertRaises(TypeError):
|
||||
optim.SGD(Variable(torch.randn(5, 5)), lr=3)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run_tests()
|
||||
219
test/test_sparse.py
Normal file
@ -0,0 +1,219 @@
|
||||
import torch
|
||||
from torch import sparse
|
||||
|
||||
import itertools
|
||||
import random
|
||||
import unittest
|
||||
from common import TestCase, run_tests
|
||||
from numbers import Number
|
||||
|
||||
SparseTensor = sparse.DoubleTensor
|
||||
|
||||
|
||||
class TestSparse(TestCase):
|
||||
@staticmethod
|
||||
def _gen_sparse(d, nnz, with_size):
|
||||
v = torch.randn(nnz)
|
||||
if isinstance(with_size, Number):
|
||||
i = (torch.rand(d, nnz) * with_size).type(torch.LongTensor)
|
||||
x = SparseTensor(i, v)
|
||||
else:
|
||||
i = torch.rand(d, nnz) * \
|
||||
torch.Tensor(with_size).repeat(nnz, 1).transpose(0, 1)
|
||||
i = i.type(torch.LongTensor)
|
||||
x = SparseTensor(i, v, torch.Size(with_size))
|
||||
|
||||
return x, i, v
|
||||
|
||||
def test_basic(self):
|
||||
x, i, v = self._gen_sparse(3, 10, 100)
|
||||
|
||||
self.assertEqual(i, x.indices())
|
||||
self.assertEqual(v, x.values())
|
||||
|
||||
x, i, v = self._gen_sparse(3, 10, [100, 100, 100])
|
||||
self.assertEqual(i, x.indices())
|
||||
self.assertEqual(v, x.values())
|
||||
self.assertEqual(x.ndimension(), 3)
|
||||
self.assertEqual(x.nnz(), 10)
|
||||
for i in range(3):
|
||||
self.assertEqual(x.size(i), 100)
|
||||
|
||||
# Make sure we can access empty indices / values
|
||||
x = SparseTensor()
|
||||
self.assertEqual(x.indices().numel(), 0)
|
||||
self.assertEqual(x.values().numel(), 0)
|
||||
|
||||
def test_to_dense(self):
|
||||
i = torch.LongTensor([
|
||||
[0, 1, 2, 2],
|
||||
[0, 0, 0, 3],
|
||||
[0, 0, 1, 4],
|
||||
])
|
||||
v = torch.Tensor([2, 1, 3, 4])
|
||||
x = SparseTensor(i, v, torch.Size([3, 4, 5]))
|
||||
res = torch.Tensor([
|
||||
[[2, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0]],
|
||||
[[1, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0]],
|
||||
[[0, 3, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 4]],
|
||||
])
|
||||
|
||||
x.to_dense() # Tests double to_dense for memory corruption
|
||||
x.to_dense()
|
||||
x.to_dense()
|
||||
self.assertEqual(res, x.to_dense())
|
||||
|
||||
def test_contig(self):
|
||||
i = torch.LongTensor([
|
||||
[1, 0, 35, 14, 39, 6, 71, 66, 40, 27],
|
||||
[92, 31, 62, 50, 22, 65, 89, 74, 56, 34],
|
||||
])
|
||||
v = torch.Tensor([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
|
||||
x = SparseTensor(i, v, torch.Size([100, 100]))
|
||||
exp_i = torch.LongTensor([
|
||||
[0, 1, 6, 14, 27, 35, 39, 40, 66, 71],
|
||||
[31, 92, 65, 50, 34, 62, 22, 56, 74, 89],
|
||||
])
|
||||
exp_v = torch.Tensor([2, 1, 6, 4, 10, 3, 5, 9, 8, 7])
|
||||
x.contiguous()
|
||||
self.assertEqual(exp_i, x.indices())
|
||||
self.assertEqual(exp_v, x.values())
|
||||
|
||||
i = torch.LongTensor([
|
||||
[2, 0, 2, 1],
|
||||
[0, 0, 3, 0],
|
||||
[1, 0, 4, 0],
|
||||
])
|
||||
v = torch.Tensor([3, 2, 4, 1])
|
||||
x = SparseTensor(i, v, torch.Size([3, 4, 5]))
|
||||
exp_i = torch.LongTensor([
|
||||
[0, 1, 2, 2],
|
||||
[0, 0, 0, 3],
|
||||
[0, 0, 1, 4],
|
||||
])
|
||||
exp_v = torch.Tensor([2, 1, 3, 4])
|
||||
|
||||
x.contiguous()
|
||||
self.assertEqual(exp_i, x.indices())
|
||||
self.assertEqual(exp_v, x.values())
|
||||
|
||||
# Duplicate indices
|
||||
i = torch.LongTensor([
|
||||
[0, 0, 2, 0],
|
||||
[0, 0, 3, 0],
|
||||
[0, 0, 4, 0],
|
||||
])
|
||||
v = torch.Tensor([3, 2, 4, 1])
|
||||
x = SparseTensor(i, v, torch.Size([3, 4, 5]))
|
||||
exp_i = torch.LongTensor([
|
||||
[0, 2],
|
||||
[0, 3],
|
||||
[0, 4],
|
||||
])
|
||||
exp_v = torch.Tensor([6, 4])
|
||||
|
||||
x.contiguous()
|
||||
self.assertEqual(exp_i, x.indices())
|
||||
self.assertEqual(exp_v, x.values())
|
||||
|
||||
def test_transpose(self):
|
||||
x = self._gen_sparse(4, 20, 5)[0]
|
||||
y = x.to_dense()
|
||||
|
||||
for i, j in itertools.combinations(range(4), 2):
|
||||
x = x.transpose_(i, j)
|
||||
y = y.transpose(i, j)
|
||||
self.assertEqual(x.to_dense(), y)
|
||||
|
||||
x = x.transpose(i, j)
|
||||
y = y.transpose(i, j)
|
||||
self.assertEqual(x.to_dense(), y)
|
||||
|
||||
def test_mm(self):
|
||||
def test_shape(di, dj, dk):
|
||||
x, _, _ = self._gen_sparse(2, 20, [di, dj])
|
||||
t = torch.randn(di, dk)
|
||||
y = torch.randn(dj, dk)
|
||||
alpha = random.random()
|
||||
beta = random.random()
|
||||
|
||||
expected = torch.addmm(alpha, t, beta, x.to_dense(), y)
|
||||
res = torch.addmm(alpha, t, beta, x, y)
|
||||
self.assertEqual(res, expected)
|
||||
|
||||
expected = torch.addmm(t, x.to_dense(), y)
|
||||
res = torch.addmm(t, x, y)
|
||||
self.assertEqual(res, expected)
|
||||
|
||||
expected = torch.mm(x.to_dense(), y)
|
||||
res = torch.mm(x, y)
|
||||
self.assertEqual(res, expected)
|
||||
|
||||
test_shape(10, 100, 100)
|
||||
test_shape(100, 1000, 200)
|
||||
test_shape(64, 10000, 300)
|
||||
|
||||
def test_saddmm(self):
|
||||
def test_shape(di, dj, dk):
|
||||
x = self._gen_sparse(2, 20, [di, dj])[0]
|
||||
t = self._gen_sparse(2, 20, [di, dk])[0]
|
||||
y = torch.randn(dj, dk)
|
||||
alpha = random.random()
|
||||
beta = random.random()
|
||||
|
||||
expected = torch.addmm(alpha, t.to_dense(), beta, x.to_dense(), y)
|
||||
res = torch.saddmm(alpha, t, beta, x, y)
|
||||
self.assertEqual(res.to_dense(), expected)
|
||||
|
||||
expected = torch.addmm(t.to_dense(), x.to_dense(), y)
|
||||
res = torch.saddmm(t, x, y)
|
||||
self.assertEqual(res.to_dense(), expected)
|
||||
|
||||
expected = torch.mm(x.to_dense(), y)
|
||||
res = torch.smm(x, y)
|
||||
self.assertEqual(res.to_dense(), expected)
|
||||
|
||||
test_shape(7, 5, 3)
|
||||
test_shape(1000, 100, 100)
|
||||
test_shape(3000, 64, 300)
|
||||
|
||||
def test_spadd(self):
|
||||
def test_shape(*shape):
|
||||
x, _, _ = self._gen_sparse(len(shape), 10, shape)
|
||||
y = torch.randn(*shape)
|
||||
r = random.random()
|
||||
|
||||
expected = y + r * x.to_dense()
|
||||
res = torch.add(y, r, x)
|
||||
|
||||
self.assertEqual(res, expected)
|
||||
|
||||
# Non contiguous dense tensor
|
||||
s = list(shape)
|
||||
s[0] = shape[-1]
|
||||
s[-1] = shape[0]
|
||||
y = torch.randn(*s).transpose_(0, len(s) - 1)
|
||||
r = random.random()
|
||||
|
||||
expected = y + r * x.to_dense()
|
||||
res = torch.add(y, r, x)
|
||||
|
||||
self.assertEqual(res, expected)
|
||||
|
||||
test_shape(5, 6)
|
||||
test_shape(10, 10, 10)
|
||||
test_shape(50, 30, 20)
|
||||
test_shape(5, 5, 5, 5, 5, 5)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
run_tests()
|
||||
1016
test/test_torch.py
@ -1,3 +1,4 @@
|
||||
from __future__ import print_function
|
||||
import sys
|
||||
import os
|
||||
import math
|
||||
@ -5,17 +6,20 @@ import shutil
|
||||
import random
|
||||
import tempfile
|
||||
import unittest
|
||||
import torch
|
||||
import torch.cuda
|
||||
import sys
|
||||
import traceback
|
||||
import torch
|
||||
import torch.cuda
|
||||
import warnings
|
||||
from torch.autograd import Variable
|
||||
from torch.utils.trainer import Trainer
|
||||
from torch.utils.trainer.plugins import *
|
||||
from torch.utils.trainer.plugins.plugin import Plugin
|
||||
from torch.utils.data import *
|
||||
from torch.utils.serialization import load_lua
|
||||
|
||||
from common import TestCase
|
||||
HAS_CUDA = torch.cuda.is_available()
|
||||
|
||||
from common import TestCase, run_tests
|
||||
|
||||
try:
|
||||
import cffi
|
||||
@ -56,7 +60,7 @@ class SimplePlugin(Plugin):
|
||||
class ModelMock(object):
|
||||
def __init__(self):
|
||||
self.num_calls = 0
|
||||
self.output = Variable(torch.ones(1, 1))
|
||||
self.output = Variable(torch.ones(1, 1), requires_grad=True)
|
||||
|
||||
def __call__(self, i):
|
||||
self.num_calls += 1
|
||||
@ -81,12 +85,14 @@ class OptimizerMock(object):
|
||||
self.num_evals = 0
|
||||
|
||||
def step(self, closure):
|
||||
for i in range(random.randint(1, self.max_evals)):
|
||||
for i in range(random.randint(self.min_evals, self.max_evals)):
|
||||
loss = closure()
|
||||
self.num_evals += 1
|
||||
loss.backward()
|
||||
self.num_steps += 1
|
||||
|
||||
def zero_grad(self):
|
||||
pass
|
||||
|
||||
|
||||
class DatasetMock(object):
|
||||
def __iter__(self):
|
||||
@ -114,8 +120,9 @@ class TestTrainer(TestCase):
|
||||
]
|
||||
|
||||
def setUp(self):
|
||||
self.trainer = Trainer(ModelMock(), CriterionMock(), OptimizerMock(),
|
||||
DatasetMock())
|
||||
self.optimizer = OptimizerMock()
|
||||
self.trainer = Trainer(ModelMock(), CriterionMock(),
|
||||
self.optimizer, DatasetMock())
|
||||
self.num_epochs = 3
|
||||
self.dataset_size = len(self.trainer.dataset)
|
||||
self.num_iters = self.num_epochs * self.dataset_size
|
||||
@ -170,120 +177,8 @@ class TestTrainer(TestCase):
|
||||
def test_model_gradient(self):
|
||||
self.trainer.run(epochs=self.num_epochs)
|
||||
output_var = self.trainer.model.output
|
||||
expected_grad = torch.ones(1, 1) * 2 * self.num_iters
|
||||
self.assertEqual(output_var.grad, expected_grad)
|
||||
|
||||
|
||||
class TestTensorDataset(TestCase):
|
||||
|
||||
def test_len(self):
|
||||
source = TensorDataset(torch.randn(15, 10, 2, 3, 4, 5), torch.randperm(15))
|
||||
self.assertEqual(len(source), 15)
|
||||
|
||||
def test_getitem(self):
|
||||
t = torch.randn(15, 10, 2, 3, 4, 5)
|
||||
l = torch.randn(15, 10)
|
||||
source = TensorDataset(t, l)
|
||||
for i in range(15):
|
||||
self.assertEqual(t[i], source[i][0])
|
||||
self.assertEqual(l[i], source[i][1])
|
||||
|
||||
def test_getitem_1d(self):
|
||||
t = torch.randn(15)
|
||||
l = torch.randn(15)
|
||||
source = TensorDataset(t, l)
|
||||
for i in range(15):
|
||||
self.assertEqual(t[i:i+1], source[i][0])
|
||||
self.assertEqual(l[i:i+1], source[i][1])
|
||||
|
||||
|
||||
class ErrorDataset(Dataset):
|
||||
def __init__(self, size):
|
||||
self.size = size
|
||||
|
||||
def __len__(self):
|
||||
return self.size
|
||||
|
||||
class TestDataLoader(TestCase):
|
||||
|
||||
def setUp(self):
|
||||
self.data = torch.randn(100, 2, 3, 5)
|
||||
self.labels = torch.randperm(50).repeat(2)
|
||||
self.dataset = TensorDataset(self.data, self.labels)
|
||||
|
||||
def _test_sequential(self, loader):
|
||||
batch_size = loader.batch_size
|
||||
for i, (sample, target) in enumerate(loader):
|
||||
idx = i * batch_size
|
||||
self.assertEqual(sample, self.data[idx:idx+batch_size])
|
||||
self.assertEqual(target, self.labels[idx:idx+batch_size].view(-1, 1))
|
||||
self.assertEqual(i, math.floor((len(self.dataset)-1) / batch_size))
|
||||
|
||||
def _test_shuffle(self, loader):
|
||||
found_data = {i: 0 for i in range(self.data.size(0))}
|
||||
found_labels = {i: 0 for i in range(self.labels.size(0))}
|
||||
batch_size = loader.batch_size
|
||||
for i, (batch_samples, batch_targets) in enumerate(loader):
|
||||
for sample, target in zip(batch_samples, batch_targets):
|
||||
for data_point_idx, data_point in enumerate(self.data):
|
||||
if data_point.eq(sample).all():
|
||||
self.assertFalse(found_data[data_point_idx])
|
||||
found_data[data_point_idx] += 1
|
||||
break
|
||||
self.assertEqual(target, self.labels.narrow(0, data_point_idx, 1))
|
||||
found_labels[data_point_idx] += 1
|
||||
self.assertEqual(sum(found_data.values()), (i+1) * batch_size)
|
||||
self.assertEqual(sum(found_labels.values()), (i+1) * batch_size)
|
||||
self.assertEqual(i, math.floor((len(self.dataset)-1) / batch_size))
|
||||
|
||||
def _test_error(self, loader):
|
||||
it = iter(loader)
|
||||
errors = 0
|
||||
while True:
|
||||
try:
|
||||
it.next()
|
||||
except NotImplementedError:
|
||||
msg = "".join(traceback.format_exception(*sys.exc_info()))
|
||||
self.assertTrue("_processBatch" in msg)
|
||||
errors += 1
|
||||
except StopIteration:
|
||||
self.assertEqual(errors,
|
||||
math.ceil(float(len(loader.dataset))/loader.batch_size))
|
||||
return
|
||||
|
||||
|
||||
def test_sequential(self):
|
||||
self._test_sequential(DataLoader(self.dataset))
|
||||
|
||||
def test_sequential_batch(self):
|
||||
self._test_sequential(DataLoader(self.dataset, batch_size=2))
|
||||
|
||||
def test_shuffle(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, shuffle=True))
|
||||
|
||||
def test_shuffle_batch(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, batch_size=2, shuffle=True))
|
||||
|
||||
|
||||
def test_sequential_workers(self):
|
||||
# still use test shuffle here because the workers may shuffle the order
|
||||
self._test_shuffle(DataLoader(self.dataset, num_workers=4))
|
||||
|
||||
def test_seqential_batch_workers(self):
|
||||
# still use test shuffle here because the workers may shuffle the order
|
||||
self._test_shuffle(DataLoader(self.dataset, batch_size=2, num_workers=4))
|
||||
|
||||
def test_shuffle_workers(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, shuffle=True, num_workers=4))
|
||||
|
||||
def test_shuffle_batch_workers(self):
|
||||
self._test_shuffle(DataLoader(self.dataset, batch_size=2, shuffle=True, num_workers=4))
|
||||
|
||||
def test_error(self):
|
||||
self._test_error(DataLoader(ErrorDataset(100), batch_size=2, shuffle=True))
|
||||
|
||||
def test_error_workers(self):
|
||||
self._test_error(DataLoader(ErrorDataset(41), batch_size=2, shuffle=True, num_workers=4))
|
||||
expected_grad = torch.ones(1, 1) * 2 * self.optimizer.num_evals
|
||||
self.assertEqual(output_var.grad.data, expected_grad)
|
||||
|
||||
|
||||
test_dir = os.path.abspath(os.path.dirname(str(__file__)))
|
||||
@ -326,7 +221,7 @@ class TestFFI(TestCase):
|
||||
self.assertRaises(torch.FatalError,
|
||||
lambda: cpulib.bad_func(tensor, 2, 1.5))
|
||||
|
||||
@unittest.skipIf(not HAS_CFFI, "ffi tests require cffi package")
|
||||
@unittest.skipIf(not HAS_CFFI or not HAS_CUDA, "ffi tests require cffi package")
|
||||
def test_gpu(self):
|
||||
compile_extension(
|
||||
name='gpulib',
|
||||
@ -353,6 +248,120 @@ class TestFFI(TestCase):
|
||||
lambda: gpulib.cuda_func(ctensor.storage(), 2, 1.5))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
unittest.main()
|
||||
class TestLuaReader(TestCase):
|
||||
|
||||
@staticmethod
|
||||
def _module_test(name, test):
|
||||
def do_test(self):
|
||||
module = test['module']
|
||||
input = test['input']
|
||||
grad_output = test['grad_output']
|
||||
if hasattr(self, '_transform_' + name):
|
||||
input = getattr(self, '_transform_' + name)(input)
|
||||
output = module.forward(input)
|
||||
module.zeroGradParameters()
|
||||
grad_input = module.backward(input, grad_output)
|
||||
self.assertEqual(output, test['output'])
|
||||
self.assertEqual(grad_input, test['grad_input'])
|
||||
if module.parameters() is not None:
|
||||
params, d_params = module.parameters()
|
||||
self.assertEqual(params, test['params'])
|
||||
self.assertEqual(d_params, test['d_params'])
|
||||
else:
|
||||
self.assertFalse('params' in test and test['params'])
|
||||
self.assertFalse('params' in test and test['d_params'])
|
||||
return do_test
|
||||
|
||||
@staticmethod
|
||||
def _criterion_test(name, test):
|
||||
def do_test(self):
|
||||
module = test['module']
|
||||
input = test['input']
|
||||
if name == 'L1Cost':
|
||||
target = None
|
||||
else:
|
||||
target = test['target']
|
||||
if hasattr(self, '_transform_' + name):
|
||||
input, target = getattr(self, '_transform_' + name)(input, target)
|
||||
|
||||
output = module.forward(input, target)
|
||||
grad_input = module.backward(input, target)
|
||||
self.assertEqual(output, test['loss'])
|
||||
self.assertEqual(grad_input, test['grad_input'])
|
||||
return do_test
|
||||
|
||||
@classmethod
|
||||
def _download_data(cls, test_file_path):
|
||||
if os.path.exists(test_file_path):
|
||||
return
|
||||
print('Downloading test file for TestLuaReader.')
|
||||
DATA_URL = 'https://s3.amazonaws.com/pytorch/legacy_modules.t7'
|
||||
urllib = cls._get_urllib('request')
|
||||
data = urllib.urlopen(DATA_URL, timeout=15).read()
|
||||
with open(test_file_path, 'wb') as f:
|
||||
f.write(data)
|
||||
|
||||
@staticmethod
|
||||
def _get_urllib(submodule):
|
||||
if sys.version_info < (3,):
|
||||
import urllib2
|
||||
return urllib2
|
||||
else:
|
||||
import urllib.error
|
||||
import urllib.request
|
||||
return getattr(urllib, submodule)
|
||||
|
||||
@classmethod
|
||||
def init(cls):
|
||||
data_dir = os.path.join(os.path.dirname(__file__), 'data')
|
||||
test_file_path = os.path.join(data_dir, 'legacy_modules.t7')
|
||||
urllib = cls._get_urllib('error')
|
||||
try:
|
||||
cls._download_data(test_file_path)
|
||||
except urllib.URLError as e:
|
||||
warnings.warn(("Couldn't download the test file for TestLuaReader! "
|
||||
"Tests will be incomplete!"), RuntimeWarning)
|
||||
return
|
||||
|
||||
tests = load_lua(test_file_path)
|
||||
for name, test in tests['modules'].items():
|
||||
test_name = 'test_' + name.replace('nn.', '')
|
||||
setattr(cls, test_name, cls._module_test(name, test))
|
||||
for name, test in tests['criterions'].items():
|
||||
test_name = 'test_' + name.replace('nn.', '')
|
||||
setattr(cls, test_name, cls._criterion_test(name, test))
|
||||
|
||||
def _transform_Index(self, input):
|
||||
return [input[0], input[1].sub(1)]
|
||||
|
||||
def _transform_LookupTable(self, input):
|
||||
return input.sub(1)
|
||||
|
||||
def _transform_MultiLabelMarginCriterion(self, input, target):
|
||||
return input, target.sub(1)
|
||||
|
||||
def _transform_ClassNLLCriterion(self, input, target):
|
||||
return input, target.sub(1)
|
||||
|
||||
def _transform_SpatialClassNLLCriterion(self, input, target):
|
||||
return input, target.sub(1)
|
||||
|
||||
def _transform_ClassSimplexCriterion(self, input, target):
|
||||
return input, target.sub(1)
|
||||
|
||||
def _transform_CrossEntropyCriterion(self, input, target):
|
||||
return input, target.sub(1)
|
||||
|
||||
def _transform_ParallelCriterion(self, input, target):
|
||||
return input, [target[0].sub(1), target[1]]
|
||||
|
||||
def _transform_MultiCriterion(self, input, target):
|
||||
return input, target.sub(1)
|
||||
|
||||
def _transform_MultiMarginCriterion(self, input, target):
|
||||
return input, target.sub(1)
|
||||
|
||||
|
||||
TestLuaReader.init()
|
||||
if __name__ == '__main__':
|
||||
run_tests()
|
||||
|
||||
@ -3,7 +3,7 @@ import yaml
|
||||
from string import Template
|
||||
from copy import deepcopy
|
||||
from .plugins import ArgcountChecker, OptionalArguments, ArgumentReferences, \
|
||||
BeforeCall, ConstantArguments, ReturnArguments, GILRelease
|
||||
BeforeAfterCall, ConstantArguments, ReturnArguments, GILRelease
|
||||
|
||||
|
||||
class cwrap(object):
|
||||
@ -26,7 +26,7 @@ class cwrap(object):
|
||||
|
||||
FUNCTION_CALL_TEMPLATE = Template("$capture_result$cname($arg_unpack);")
|
||||
|
||||
DEFAULT_PLUGIN_CLASSES = [ArgcountChecker, ConstantArguments, OptionalArguments, ArgumentReferences, BeforeCall, ReturnArguments, GILRelease]
|
||||
DEFAULT_PLUGIN_CLASSES = [ArgcountChecker, ConstantArguments, OptionalArguments, ArgumentReferences, BeforeAfterCall, ReturnArguments, GILRelease]
|
||||
|
||||
def __init__(self, source, destination=None, plugins=[], default_plugins=True):
|
||||
if destination is None:
|
||||
@ -40,6 +40,7 @@ class cwrap(object):
|
||||
for plugin in self.plugins:
|
||||
plugin.initialize(self)
|
||||
|
||||
self.base_path = os.path.dirname(os.path.abspath(source))
|
||||
with open(source, 'r') as f:
|
||||
declarations = f.read()
|
||||
|
||||
@ -55,8 +56,10 @@ class cwrap(object):
|
||||
declaration_lines = []
|
||||
output = []
|
||||
in_declaration = False
|
||||
i = 0
|
||||
|
||||
for line in lines:
|
||||
while i < len(lines):
|
||||
line = lines[i]
|
||||
if line == '[[':
|
||||
declaration_lines = []
|
||||
in_declaration = True
|
||||
@ -79,8 +82,15 @@ class cwrap(object):
|
||||
output.append(wrapper)
|
||||
elif in_declaration:
|
||||
declaration_lines.append(line)
|
||||
elif '!!inc ' == line[:6]:
|
||||
fname = os.path.join(self.base_path, line[6:].strip())
|
||||
with open(fname, 'r') as f:
|
||||
included = f.read().split('\n')
|
||||
# insert it into lines at position i+1
|
||||
lines[i+1:i+1] = included
|
||||
else:
|
||||
output.append(line)
|
||||
i += 1
|
||||
|
||||
return '\n'.join(output)
|
||||
|
||||
@ -138,7 +148,13 @@ class cwrap(object):
|
||||
return self.search_plugins('get_wrapper_template', (declaration,), lambda _: None)
|
||||
|
||||
def get_arg_accessor(self, arg, option):
|
||||
return self.search_plugins('get_arg_accessor', (arg, option), lambda arg,_: 'PyTuple_GET_ITEM(args, {})'.format(arg['idx']))
|
||||
def wrap_accessor(arg, _):
|
||||
if arg.get('idx') is None:
|
||||
raise RuntimeError("Missing accessor for '{} {}'".format(
|
||||
arg['type'], arg['name']))
|
||||
return 'PyTuple_GET_ITEM(args, {})'.format(arg['idx'])
|
||||
|
||||
return self.search_plugins('get_arg_accessor', (arg, option), wrap_accessor)
|
||||
|
||||
def generate_wrapper(self, declaration):
|
||||
wrapper = ''
|
||||
@ -153,7 +169,12 @@ class cwrap(object):
|
||||
result = []
|
||||
for arg in arguments:
|
||||
accessor = self.get_arg_accessor(arg, option)
|
||||
res = getattr(self, base_fn_name)(arg, option).substitute(arg=accessor)
|
||||
tmpl = getattr(self, base_fn_name)(arg, option)
|
||||
if tmpl is None:
|
||||
fn = 'check' if base_fn_name == 'get_type_check' else 'unpack'
|
||||
raise RuntimeError("Missing type {} for '{} {}'".format(
|
||||
fn, arg['type'], arg['name']))
|
||||
res = tmpl.substitute(arg=accessor, idx=arg.get('idx'))
|
||||
for plugin in self.plugins:
|
||||
res = getattr(plugin, plugin_fn_name)(res, arg, accessor)
|
||||
result.append(res)
|
||||
@ -164,7 +185,10 @@ class cwrap(object):
|
||||
lambda arg: not 'ignore_check' in arg or not arg['ignore_check'],
|
||||
option['arguments']))
|
||||
option['num_checked_args'] = len(checked_args)
|
||||
for i, arg in enumerate(checked_args):
|
||||
idx_args = list(filter(
|
||||
lambda arg: not arg.get('ignore_check') and not arg.get('no_idx'),
|
||||
option['arguments']))
|
||||
for i, arg in enumerate(idx_args):
|
||||
arg['idx'] = i
|
||||
|
||||
# Generate checks
|
||||
|
||||
@ -7,6 +7,6 @@ class ArgcountChecker(CWrapPlugin):
|
||||
checks = '__argcount == 0'
|
||||
else:
|
||||
indent = '\n '
|
||||
checks = '__argcount == {} &&'.format(option['num_checked_args']) + \
|
||||
indent + checks
|
||||
argcount = option['num_checked_args'] + option.get('argcount_offset', 0)
|
||||
checks = '__argcount == {} &&'.format(str(argcount)) + indent + checks
|
||||
return checks
|
||||
|
||||
27
tools/cwrap/plugins/BeforeAfterCall.py
Normal file
@ -0,0 +1,27 @@
|
||||
from . import CWrapPlugin
|
||||
from string import Template
|
||||
|
||||
class BeforeAfterCall(CWrapPlugin):
|
||||
|
||||
def initialize(self, cwrap):
|
||||
self.cwrap = cwrap
|
||||
|
||||
def insert_snippet(self, template, option, offset, name):
|
||||
prepend_str = option.get(name)
|
||||
if prepend_str is None:
|
||||
return
|
||||
if '$' in prepend_str:
|
||||
before_call_template = Template(option[name])
|
||||
args = {'arg' + str(i): self.cwrap.get_arg_accessor(arg, option) for i, arg
|
||||
in enumerate(option['arguments'])}
|
||||
prepend_str = before_call_template.substitute(args)
|
||||
template.insert(offset, prepend_str)
|
||||
|
||||
def process_option_code_template(self, template, option):
|
||||
if option.get('before_call') or option.get('after_call'):
|
||||
call_idx = template.index('$call')
|
||||
self.insert_snippet(template, option, call_idx, 'before_call')
|
||||
# call position might have changed
|
||||
call_idx = template.index('$call')
|
||||
self.insert_snippet(template, option, call_idx+1, 'after_call')
|
||||
return template
|
||||
@ -1,19 +0,0 @@
|
||||
from . import CWrapPlugin
|
||||
from string import Template
|
||||
|
||||
class BeforeCall(CWrapPlugin):
|
||||
|
||||
def initialize(self, cwrap):
|
||||
self.cwrap = cwrap
|
||||
|
||||
def process_option_code_template(self, template, option):
|
||||
if option.get('before_call', False):
|
||||
call_idx = template.index('$call')
|
||||
prepend_str = option['before_call']
|
||||
if '$' in prepend_str:
|
||||
before_call_template = Template(option['before_call'])
|
||||
args = {'arg' + str(i): self.cwrap.get_arg_accessor(arg, option) for i, arg
|
||||
in enumerate(option['arguments'])}
|
||||
prepend_str = before_call_template.substitute(args)
|
||||
template.insert(call_idx, prepend_str)
|
||||
return template
|
||||
19
tools/cwrap/plugins/BoolOption.py
Normal file
@ -0,0 +1,19 @@
|
||||
from . import CWrapPlugin
|
||||
from string import Template
|
||||
|
||||
class BoolOption(CWrapPlugin):
|
||||
|
||||
UNPACK_TEMPLATE = Template('$arg == Py_True ? $if_true : $if_false')
|
||||
|
||||
def is_bool_option(self, arg):
|
||||
return arg['type'] == 'bool' and 'if_true' in arg and 'if_false' in arg
|
||||
|
||||
def get_type_check(self, arg, option):
|
||||
if self.is_bool_option(arg):
|
||||
return Template('PyBool_Check($arg)')
|
||||
|
||||
def get_type_unpack(self, arg, option):
|
||||
if self.is_bool_option(arg):
|
||||
return Template(self.UNPACK_TEMPLATE.safe_substitute(
|
||||
if_true=arg['if_true'], if_false=arg['if_false']))
|
||||
|
||||
162
tools/cwrap/plugins/CuDNNPlugin.py
Normal file
@ -0,0 +1,162 @@
|
||||
from string import Template
|
||||
from copy import deepcopy
|
||||
from . import CWrapPlugin
|
||||
from itertools import product
|
||||
|
||||
class CuDNNPlugin(CWrapPlugin):
|
||||
|
||||
TYPE_UNPACK = {
|
||||
'THTensor*': Template('((THPVoidTensor*)$arg)->cdata'),
|
||||
'int': Template('THPUtils_unpackLong($arg)'),
|
||||
'std::vector<int>': Template('THPUtils_unpackIntTuple($arg)'),
|
||||
'cudnnDataType_t': Template('$arg'),
|
||||
'cudnnHandle_t': Template('$arg'),
|
||||
'Convolution*': Template('(Convolution*)THPWrapper_get($arg)'),
|
||||
'bool': Template('$arg == Py_True'),
|
||||
'double': Template('THPDoubleUtils_unpackReal($arg)'),
|
||||
}
|
||||
|
||||
TYPE_CHECK = {
|
||||
'Convolution*': Template('THPWrapper_check($arg)'),
|
||||
'THTensor*': Template('(PyObject*)Py_TYPE($arg) == tensorClass'),
|
||||
'int': Template('THPUtils_checkLong($arg)'),
|
||||
'std::vector<int>': Template('THPUtils_checkIntTuple($arg)'),
|
||||
'bool': Template('PyBool_Check($arg)'),
|
||||
'double': Template('THPDoubleUtils_checkReal($arg)'),
|
||||
}
|
||||
|
||||
RETURN_WRAPPER = {
|
||||
'Convolution*': Template('return THPWrapper_New($result, [](void* arg) { delete (Convolution*)arg; });'),
|
||||
}
|
||||
|
||||
METHODS_DECLARATION = Template("""
|
||||
static PyMethodDef _THCUDNN_methods[] = {
|
||||
$methods
|
||||
{NULL}
|
||||
};
|
||||
|
||||
PyMethodDef* THCUDNN_methods()
|
||||
{
|
||||
return _THCUDNN_methods;
|
||||
}
|
||||
""")
|
||||
|
||||
WRAPPER_TEMPLATE = Template("""\
|
||||
static PyObject * $name(PyObject *self, PyObject *args, PyObject *kwargs)
|
||||
{
|
||||
HANDLE_TH_ERRORS
|
||||
int __tuplecount = args ? PyTuple_Size(args) : 0;
|
||||
int __dictcount = kwargs ? PyDict_Size(kwargs) : 0;
|
||||
int __argcount = __tuplecount + __dictcount;
|
||||
PyObject* tensorClass = getTensorClass(args);
|
||||
THCPAutoGPU __autogpu_guard = THCPAutoGPU(args);
|
||||
|
||||
$options
|
||||
}
|
||||
|
||||
THPUtils_invalidArguments(args, kwargs, "$readable_name", $num_options, $expected_args);
|
||||
return NULL;
|
||||
END_HANDLE_TH_ERRORS
|
||||
}
|
||||
""")
|
||||
|
||||
RELEASE_ARG = Template("_${name}_guard.release();")
|
||||
|
||||
TYPE_NAMES = {
|
||||
'THTensor*': '" THPTensorStr "',
|
||||
'long': 'int',
|
||||
'bool': 'bool',
|
||||
'int': 'int',
|
||||
}
|
||||
|
||||
def __init__(self):
|
||||
self.declarations = []
|
||||
|
||||
def get_type_unpack(self, arg, option):
|
||||
return self.TYPE_UNPACK.get(arg['type'], None)
|
||||
|
||||
def get_type_check(self, arg, option):
|
||||
return self.TYPE_CHECK.get(arg['type'], None)
|
||||
|
||||
def get_wrapper_template(self, declaration):
|
||||
arg_desc = []
|
||||
for option in declaration['options']:
|
||||
option_desc = [self.TYPE_NAMES.get(arg['type'], arg['type']) + ' ' + arg['name']
|
||||
for arg in option['arguments']
|
||||
if not arg.get('ignore_check', False)]
|
||||
# TODO: this should probably go to THPLongArgsPlugin
|
||||
if option_desc:
|
||||
arg_desc.append('({})'.format(', '.join(option_desc)))
|
||||
else:
|
||||
arg_desc.append('no arguments')
|
||||
arg_desc.sort(key=len)
|
||||
arg_desc = ['"' + desc + '"' for desc in arg_desc]
|
||||
arg_str = ', '.join(arg_desc)
|
||||
readable_name = declaration['python_name']
|
||||
return Template(self.WRAPPER_TEMPLATE.safe_substitute(
|
||||
readable_name=readable_name, num_options=len(arg_desc),
|
||||
expected_args=arg_str))
|
||||
|
||||
def get_return_wrapper(self, option):
|
||||
return self.RETURN_WRAPPER.get(option['return'], None)
|
||||
|
||||
def get_arg_accessor(self, arg, option):
|
||||
name = arg['name']
|
||||
if name == 'self':
|
||||
return 'self'
|
||||
elif name == 'dataType':
|
||||
return 'getCudnnDataType(tensorClass)'
|
||||
elif name == 'handle':
|
||||
return 'getCudnnHandle()'
|
||||
|
||||
def process_declarations(self, declarations):
|
||||
for declaration in declarations:
|
||||
declaration.setdefault('python_name', '_{}'.format(declaration['name']))
|
||||
declaration['name'] = 'THCUDNN_{}'.format(declaration['name'])
|
||||
self.declarations.append(declaration)
|
||||
for option in declaration['options']:
|
||||
for arg in option['arguments']:
|
||||
if arg['name'] in ['self', 'state', 'dataType', 'handle']:
|
||||
arg['ignore_check'] = True
|
||||
declaration['options'] = self.filter_unique_options(declaration['options'])
|
||||
return declarations
|
||||
|
||||
def filter_unique_options(self, options):
|
||||
def signature(option):
|
||||
return '#'.join(arg['type'] for arg in option['arguments'] if not 'ignore_check' in arg or not arg['ignore_check'])
|
||||
seen_signatures = set()
|
||||
unique = []
|
||||
for option in options:
|
||||
sig = signature(option)
|
||||
if sig not in seen_signatures:
|
||||
unique.append(option)
|
||||
seen_signatures.add(sig)
|
||||
return unique
|
||||
|
||||
def preprocessor_guard(self, code, condition):
|
||||
return '#if ' + condition + '\n' + code + '#endif\n'
|
||||
|
||||
def process_wrapper(self, code, declaration):
|
||||
if 'defined_if' in declaration:
|
||||
return self.preprocessor_guard(code, declaration['defined_if'])
|
||||
return code
|
||||
|
||||
def process_all_unpacks(self, code, option):
|
||||
return 'state, ' + code
|
||||
|
||||
def declare_methods(self):
|
||||
methods = ''
|
||||
for declaration in self.declarations:
|
||||
extra_flags = ' | ' + declaration.get('method_flags') if 'method_flags' in declaration else ''
|
||||
if not declaration.get('only_register'):
|
||||
extra_flags += ' | METH_KEYWORDS'
|
||||
entry = Template(' {"$python_name", (PyCFunction)$name, METH_VARARGS$extra_flags, NULL},\n').substitute(
|
||||
python_name=declaration['python_name'], name=declaration['name'], extra_flags=extra_flags
|
||||
)
|
||||
if 'defined_if' in declaration:
|
||||
entry = self.preprocessor_guard(entry, declaration['defined_if'])
|
||||
methods += entry
|
||||
return self.METHODS_DECLARATION.substitute(methods=methods)
|
||||
|
||||
def process_full_file(self, code):
|
||||
return code + self.declare_methods()
|
||||
59
tools/cwrap/plugins/KwargsPlugin.py
Normal file
@ -0,0 +1,59 @@
|
||||
from . import CWrapPlugin
|
||||
from string import Template
|
||||
|
||||
class KwargsPlugin(CWrapPlugin):
|
||||
|
||||
ACCESSOR_TEMPLATE = Template('(__tuplecount > $idx ? PyTuple_GET_ITEM(args, $idx) : __kw_$name)')
|
||||
KWARG_ONLY_ACCESSOR_TEMPLATE = Template('__kw_$name')
|
||||
CHECK_TEMPLATE = Template('(__tuplecount > $idx || __kw_$name) && $code')
|
||||
KWARG_ONLY_CHECK_TEMPLATE = Template('__kw_$name && $code')
|
||||
WRAPPER_TEMPLATE = Template("""
|
||||
$declarations
|
||||
if (kwargs) {
|
||||
$lookups
|
||||
}
|
||||
""")
|
||||
|
||||
def process_declarations(self, declarations):
|
||||
# We don't have access to declaration or options in get_arg_accessor
|
||||
# and process_single_check, so we have to push the flag down to
|
||||
# the args.
|
||||
for declaration in declarations:
|
||||
if declaration.get('no_kwargs'):
|
||||
for option in declaration['options']:
|
||||
for arg in option['arguments']:
|
||||
arg['no_kwargs'] = True
|
||||
return declarations
|
||||
|
||||
def get_arg_accessor(self, arg, option):
|
||||
if arg.get('no_kwargs'):
|
||||
return
|
||||
if arg.get('kwarg_only'):
|
||||
return self.KWARG_ONLY_ACCESSOR_TEMPLATE.substitute(name=arg['name'])
|
||||
return self.ACCESSOR_TEMPLATE.substitute(idx=arg['idx'], name=arg['name'])
|
||||
|
||||
def process_single_check(self, code, arg, arg_accessor):
|
||||
if arg.get('no_kwargs'):
|
||||
return code
|
||||
if arg.get('kwarg_only'):
|
||||
return self.KWARG_ONLY_CHECK_TEMPLATE.substitute(name=arg['name'], code=code)
|
||||
return self.CHECK_TEMPLATE.substitute(idx=arg['idx'], name=arg['name'], code=code)
|
||||
|
||||
def process_wrapper(self, code, declaration):
|
||||
if declaration.get('no_kwargs'):
|
||||
return code
|
||||
seen_args = set()
|
||||
args = []
|
||||
for option in declaration['options']:
|
||||
for arg in option['arguments']:
|
||||
name = arg['name']
|
||||
if (not arg.get('ignore_check') and
|
||||
not arg.get('no_kwargs') and
|
||||
name not in seen_args):
|
||||
seen_args.add(name)
|
||||
args.append(name)
|
||||
declarations = '\n '.join(['PyObject *__kw_{} = NULL;'.format(name) for name in args])
|
||||
lookups = '\n '.join(['__kw_{name} = PyDict_GetItemString(kwargs, "{name}");'.format(name=name) for name in args])
|
||||
start_idx = code.find('{') + 1
|
||||
new_code = self.WRAPPER_TEMPLATE.substitute(declarations=declarations, lookups=lookups)
|
||||
return code[:start_idx] + new_code + code[start_idx:]
|
||||
@ -22,18 +22,37 @@ class OptionalArguments(CWrapPlugin):
|
||||
# PyYAML interprets NULL as None...
|
||||
arg['name'] = 'NULL' if arg['default'] is None else arg['default']
|
||||
new_options.append(option_copy)
|
||||
declaration['options'] = self.filter_unique_options(declaration['options'] + new_options)
|
||||
declaration['options'] = self.filter_unique_options(new_options)
|
||||
return declarations
|
||||
|
||||
def filter_unique_options(self, options):
|
||||
def signature(option):
|
||||
return '#'.join(arg['type'] for arg in option['arguments'] if not 'ignore_check' in arg or not arg['ignore_check'])
|
||||
def signature(option, kwarg_only_count):
|
||||
if kwarg_only_count == 0:
|
||||
kwarg_only_count = None
|
||||
else:
|
||||
kwarg_only_count = -kwarg_only_count
|
||||
arg_signature = '#'.join(
|
||||
arg['type']
|
||||
for arg in option['arguments'][:kwarg_only_count]
|
||||
if not arg.get('ignore_check'))
|
||||
if kwarg_only_count is None:
|
||||
return arg_signature
|
||||
kwarg_only_signature = '#'.join(
|
||||
arg['name'] + '#' + arg['type']
|
||||
for arg in option['arguments'][kwarg_only_count:]
|
||||
if not arg.get('ignore_check'))
|
||||
return arg_signature + "#-#" + kwarg_only_signature
|
||||
seen_signatures = set()
|
||||
unique = []
|
||||
for option in options:
|
||||
sig = signature(option)
|
||||
if sig not in seen_signatures:
|
||||
unique.append(option)
|
||||
seen_signatures.add(sig)
|
||||
for num_kwarg_only in range(0, len(option['arguments'])+1):
|
||||
sig = signature(option, num_kwarg_only)
|
||||
if sig not in seen_signatures:
|
||||
if num_kwarg_only > 0:
|
||||
for arg in option['arguments'][-num_kwarg_only:]:
|
||||
arg['kwarg_only'] = True
|
||||
unique.append(option)
|
||||
seen_signatures.add(sig)
|
||||
break
|
||||
return unique
|
||||
|
||||
|
||||
@ -30,11 +30,14 @@ class StandaloneExtension(CWrapPlugin):
|
||||
'THDoubleTensor*': Template('THPDoubleTensor_CData((THPDoubleTensor*)$arg)'),
|
||||
'THLongTensor*': Template('THPLongTensor_CData((THPLongTensor*)$arg)'),
|
||||
'THIntTensor*': Template('THPIntTensor_CData((THPIntTensor*)$arg)'),
|
||||
'THCudaHalfTensor*': Template('THCPHalfTensor_CData((THCPHalfTensor*)$arg)'),
|
||||
'THCudaTensor*': Template('THCPFloatTensor_CData((THCPFloatTensor*)$arg)'),
|
||||
'THCudaDoubleTensor*': Template('THCPDoubleTensor_CData((THCPDoubleTensor*)$arg)'),
|
||||
'THCudaLongTensor*': Template('THCPLongTensor_CData((THCPLongTensor*)$arg)'),
|
||||
'half': Template('THPHalfUtils_unpackReal($arg)'),
|
||||
'float': Template('THPFloatUtils_unpackReal($arg)'),
|
||||
'double': Template('THPDoubleUtils_unpackReal($arg)'),
|
||||
'bool': Template('THPUtils_unpackLong($arg)'),
|
||||
'bool': Template('($arg == Py_True ? true : false)'),
|
||||
'int': Template('THPUtils_unpackLong($arg)'),
|
||||
'long': Template('THPUtils_unpackLong($arg)'),
|
||||
'void*': Template('(void*)THPUtils_unpackLong($arg)'),
|
||||
@ -46,11 +49,14 @@ class StandaloneExtension(CWrapPlugin):
|
||||
'THFloatTensor*': Template('(PyObject*)Py_TYPE($arg) == THPFloatTensorClass'),
|
||||
'THLongTensor*': Template('(PyObject*)Py_TYPE($arg) == THPLongTensorClass'),
|
||||
'THIntTensor*': Template('(PyObject*)Py_TYPE($arg) == THPIntTensorClass'),
|
||||
'THCudaHalfTensor*': Template('THCPHalfTensor_Check($arg)'),
|
||||
'THCudaTensor*': Template('(PyObject*)Py_TYPE($arg) == THCPFloatTensorClass'),
|
||||
'THCudaDoubleTensor*': Template('THCPDoubleTensor_Check($arg)'),
|
||||
'THCudaLongTensor*': Template('(PyObject*)Py_TYPE($arg) == THCPLongTensorClass'),
|
||||
'float': Template('THPDoubleUtils_checkReal($arg)'),
|
||||
'half': Template('THPHalfUtils_checkReal($arg)'),
|
||||
'float': Template('THPFloatUtils_checkReal($arg)'),
|
||||
'double': Template('THPDoubleUtils_checkReal($arg)'),
|
||||
'bool': Template('THPUtils_checkLong($arg)'),
|
||||
'bool': Template('PyBool_Check($arg)'),
|
||||
'int': Template('THPUtils_checkLong($arg)'),
|
||||
'long': Template('THPUtils_checkLong($arg)'),
|
||||
'void*': Template('THPUtils_checkLong($arg)'),
|
||||
@ -64,7 +70,7 @@ PyObject * $name(PyObject *_unused, PyObject *args)
|
||||
int __argcount = args ? PyTuple_Size(args) : 0;
|
||||
$options
|
||||
} else {
|
||||
THPUtils_invalidArguments(args, "$name", 1, $expected_args);
|
||||
THPUtils_invalidArguments(args, NULL, "$name", 1, $expected_args);
|
||||
return NULL;
|
||||
}
|
||||
END_HANDLE_TH_ERRORS
|
||||
@ -73,7 +79,9 @@ PyObject * $name(PyObject *_unused, PyObject *args)
|
||||
|
||||
TYPE_NAMES = {
|
||||
'THGenerator*': 'Generator',
|
||||
'THCudaHalfTensor*': 'torch.cuda.HalfTensor',
|
||||
'THCudaTensor*': 'torch.cuda.FloatTensor',
|
||||
'THCudaDoubleTensor*': 'torch.cuda.DoubleTensor',
|
||||
'THCudaLongTensor*': 'torch.cuda.LongTensor',
|
||||
'THDoubleTensor*': 'torch.DoubleTensor',
|
||||
'THFloatTensor*': 'torch.FloatTensor',
|
||||
@ -85,6 +93,7 @@ PyObject * $name(PyObject *_unused, PyObject *args)
|
||||
'long': 'int',
|
||||
'int': 'int',
|
||||
'real': 'float',
|
||||
'half': 'float',
|
||||
'double': 'float',
|
||||
'float': 'float',
|
||||
'accreal': 'float',
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
from string import Template
|
||||
from . import CWrapPlugin
|
||||
|
||||
class THPLongArgsPlugin(CWrapPlugin):
|
||||
PARSE_LONG_ARGS = Template("""\
|
||||
THLongStoragePtr __long_args_guard;
|
||||
try {
|
||||
__long_args_guard = THPUtils_getLongStorage(args, $num_checked);
|
||||
} catch (std::exception &e) {
|
||||
goto invalid_arguments;
|
||||
}
|
||||
THLongStorage* __long_args = __long_args_guard.get();
|
||||
""")
|
||||
|
||||
def get_arg_accessor(self, arg, option):
|
||||
if 'long_args' in option and option['long_args'] and arg['name'] == 'long_args':
|
||||
return '__long_args'
|
||||
|
||||
def get_type_unpack(self, arg, option):
|
||||
if option.get('long_args', False) and arg['name'] == 'long_args':
|
||||
return Template('$arg')
|
||||
|
||||
def process_declarations(self, declarations):
|
||||
for declaration in declarations:
|
||||
for option in declaration['options']:
|
||||
if not 'long_args' in option or not option['long_args']:
|
||||
continue
|
||||
for arg in option['arguments']:
|
||||
if arg['name'] == 'long_args':
|
||||
arg['ignore_check'] = True
|
||||
return declarations
|
||||
|
||||
def process_all_checks(self, code, option):
|
||||
if 'long_args' in option and option['long_args']:
|
||||
code = code.replace('__argcount ==', '__argcount >')
|
||||
return code
|
||||
|
||||
def process_wrapper(self, code, declaration):
|
||||
if any(map(lambda opt: opt.get('long_args'), declaration['options'])):
|
||||
invalid_arguments_idx = code.find('THPUtils_invalidArguments')
|
||||
newline_idx = code.rfind('\n', 0, invalid_arguments_idx)
|
||||
code = code[:newline_idx] + '\ninvalid_arguments:' + code[newline_idx:]
|
||||
return code
|
||||
|
||||
def process_option_code(self, code, option):
|
||||
if 'long_args' in option and option['long_args']:
|
||||
lines = code.split('\n')
|
||||
end_checks = 0
|
||||
for i, line in enumerate(lines):
|
||||
if ') {' in line:
|
||||
end_checks = i
|
||||
break
|
||||
lines = lines[:end_checks+1] + [self.PARSE_LONG_ARGS.substitute(num_checked=option['num_checked_args'])] + lines[end_checks+1:]
|
||||
code = '\n'.join(lines)
|
||||
return code
|
||||
|
||||
@ -1,7 +1,8 @@
|
||||
from string import Template
|
||||
from copy import deepcopy
|
||||
from . import CWrapPlugin
|
||||
from itertools import product
|
||||
from itertools import product, chain
|
||||
from collections import OrderedDict
|
||||
|
||||
class THPPlugin(CWrapPlugin):
|
||||
|
||||
@ -13,13 +14,24 @@ class THPPlugin(CWrapPlugin):
|
||||
'THTensor*': Template('((THPTensor*)$arg)->cdata'),
|
||||
'THBoolTensor*': Template('((THPBoolTensor*)$arg)->cdata'),
|
||||
'THIndexTensor*': Template('((THPIndexTensor*)$arg)->cdata'),
|
||||
|
||||
'THSFloatTensor*': Template('((THSPFloatTensor*)$arg)->cdata'),
|
||||
'THSDoubleTensor*': Template('((THSPDoubleTensor*)$arg)->cdata'),
|
||||
'THSLongTensor*': Template('((THSPLongTensor*)$arg)->cdata'),
|
||||
'THSIntTensor*': Template('((THSPIntTensor*)$arg)->cdata'),
|
||||
'THSTensor*': Template('((THSPTensor*)$arg)->cdata'),
|
||||
'THSBoolTensor*': Template('((THSPBoolTensor*)$arg)->cdata'),
|
||||
'THSIndexTensor*': Template('((THSPIndexTensor*)$arg)->cdata'),
|
||||
|
||||
'THLongStorage*': Template('((THPLongStorage*)$arg)->cdata'),
|
||||
'THStorage*': Template('((THPStorage*)$arg)->cdata'),
|
||||
'THGenerator*': Template('((THPGenerator*)$arg)->cdata'),
|
||||
'THSize*': Template('__size.get()'),
|
||||
'THStride*': Template('__stride.get()'),
|
||||
'void*': Template('THPUtils_unpackLong($arg)'),
|
||||
'long': Template('THPUtils_unpackLong($arg)'),
|
||||
'int': Template('THPUtils_unpackLong($arg)'),
|
||||
'bool': Template('THPUtils_unpackLong($arg)'),
|
||||
'bool': Template('($arg == Py_True ? true : false)'),
|
||||
'float': Template('THPFloatUtils_unpackReal($arg)'),
|
||||
'double': Template('THPDoubleUtils_unpackReal($arg)'),
|
||||
'real': Template('THPUtils_(unpackReal)($arg)'),
|
||||
@ -35,111 +47,120 @@ class THPPlugin(CWrapPlugin):
|
||||
'THTensor*': Template('(PyObject*)Py_TYPE($arg) == THPTensorClass'),
|
||||
'THBoolTensor*': Template('(PyObject*)Py_TYPE($arg) == THPBoolTensorClass'),
|
||||
'THIndexTensor*': Template('(PyObject*)Py_TYPE($arg) == THPIndexTensorClass'),
|
||||
|
||||
'THSDoubleTensor*': Template('(PyObject*)Py_TYPE($arg) == THSPDoubleTensorClass'),
|
||||
'THSFloatTensor*': Template('(PyObject*)Py_TYPE($arg) == THSPFloatTensorClass'),
|
||||
'THSLongTensor*': Template('(PyObject*)Py_TYPE($arg) == THSPLongTensorClass'),
|
||||
'THSIntTensor*': Template('(PyObject*)Py_TYPE($arg) == THSPIntTensorClass'),
|
||||
'THSTensor*': Template('(PyObject*)Py_TYPE($arg) == THSPTensorClass'),
|
||||
'THSBoolTensor*': Template('(PyObject*)Py_TYPE($arg) == THSPBoolTensorClass'),
|
||||
'THSIndexTensor*': Template('(PyObject*)Py_TYPE($arg) == THSPIndexTensorClass'),
|
||||
|
||||
'THLongStorage*': Template('(PyObject*)Py_TYPE($arg) == THPLongStorageClass'),
|
||||
'THStorage*': Template('(PyObject*)Py_TYPE($arg) == THPStorageClass'),
|
||||
'THGenerator*': Template('(PyObject*)Py_TYPE($arg) == THPGeneratorClass'),
|
||||
'THSize*': Template('THPUtils_tryUnpackLongs($arg, __size)'),
|
||||
'THStride*': Template('THPUtils_tryUnpackLongs($arg, __stride)'),
|
||||
'void*': Template('THPUtils_checkLong($arg)'),
|
||||
'long': Template('THPUtils_checkLong($arg)'),
|
||||
'int': Template('THPUtils_checkLong($arg)'),
|
||||
'bool': Template('THPUtils_checkLong($arg)'),
|
||||
'bool': Template('PyBool_Check($arg)'),
|
||||
'float': Template('THPFloatUtils_checkReal($arg)'),
|
||||
'double': Template('THPDoubleUtils_checkReal($arg)'),
|
||||
'real': Template('THPUtils_(checkReal)($arg)'),
|
||||
# TODO
|
||||
'accreal': Template('THPUtils_(checkReal)($arg)'),
|
||||
'accreal': Template('THPUtils_(checkAccreal)($arg)'),
|
||||
}
|
||||
|
||||
SIZE_VARARG_CHECK = Template('THPUtils_tryUnpackLongVarArgs(args, $idx, __size)')
|
||||
|
||||
RETURN_WRAPPER = {
|
||||
'THTensor*': Template('return THPTensor_(New)($result);'),
|
||||
'THSTensor*': Template('return THSPTensor_(New)($result);'),
|
||||
'THLongTensor*': Template('return THPLongTensor_New($result);'),
|
||||
'THLongStorage*': Template('return THPLongStorage_New($result);'),
|
||||
# TODO: make it smarter - it should return python long if result doesn't fit into an int
|
||||
'long': Template('return PyInt_FromLong($result);'),
|
||||
# TODO
|
||||
'accreal': Template('return PyFloat_FromDouble($result);'),
|
||||
'accreal': Template('return THPUtils_(newAccreal)($result);'),
|
||||
'self': Template('Py_INCREF(self);\nreturn (PyObject*)self;'),
|
||||
'real': Template('return THPUtils_(newReal)($result);'),
|
||||
}
|
||||
|
||||
TENSOR_METHODS_DECLARATION = Template("""
|
||||
static PyMethodDef THPTensor_$stateless(methods)[] = {
|
||||
$methods
|
||||
{NULL}
|
||||
static PyMethodDef TH${sparse}PTensor_$stateless(methods)[] = {
|
||||
$methods
|
||||
{NULL}
|
||||
};
|
||||
""")
|
||||
|
||||
WRAPPER_TEMPLATE = Template("""\
|
||||
PyObject * $name(PyObject *self, PyObject *args)
|
||||
PyObject * $name(PyObject *self, PyObject *args, PyObject *kwargs)
|
||||
{
|
||||
HANDLE_TH_ERRORS
|
||||
int __argcount = args ? PyTuple_Size(args) : 0;
|
||||
int __tuplecount = args ? PyTuple_Size(args) : 0;
|
||||
int __dictcount = kwargs ? PyDict_Size(kwargs) : 0;
|
||||
int __argcount = __tuplecount + __dictcount;
|
||||
$variables
|
||||
$init
|
||||
|
||||
$options
|
||||
}
|
||||
|
||||
THPUtils_invalidArguments(args, "$readable_name", $num_options, $expected_args);
|
||||
THPUtils_invalidArguments(args, kwargs, "$readable_name", $num_options, $expected_args);
|
||||
return NULL;
|
||||
END_HANDLE_TH_ERRORS
|
||||
}
|
||||
""")
|
||||
|
||||
ALLOCATE_TMPL = Template("""\
|
||||
THP${type}TensorPtr _${name}_guard = (THP${type}Tensor*) THP${type}Tensor_NewEmpty();
|
||||
if (!_${name}_guard.get()) return NULL;
|
||||
THP${type}Tensor* $name = _${name}_guard.get();
|
||||
""")
|
||||
|
||||
ALLOCATE_TYPE = {
|
||||
'THTensor*': Template("""\
|
||||
THTensorPtr _th_$name = THTensor_(new)(LIBRARY_STATE_NOARGS);
|
||||
THPTensorPtr _${name}_guard = (THPTensor*)THPTensor_(New)(_th_$name.get());
|
||||
THPTensor* $name = _${name}_guard.get();
|
||||
if (!$name)
|
||||
return NULL;
|
||||
_th_$name.release();
|
||||
"""),
|
||||
'THLongTensor*': Template("""\
|
||||
THLongTensorPtr _th_$name = THLongTensor_new(LIBRARY_STATE_NOARGS);
|
||||
THPLongTensorPtr _${name}_guard = (THPLongTensor*)THPLongTensor_New(_th_$name.get());
|
||||
THPLongTensor* $name = _${name}_guard.get();
|
||||
if (!$name)
|
||||
return NULL;
|
||||
_th_$name.release();
|
||||
"""),
|
||||
'THBoolTensor*': Template("""
|
||||
ALLOCATE_CUDA = Template("""\
|
||||
#if IS_CUDA
|
||||
THCByteTensorPtr _t_$name = THCudaByteTensor_new(LIBRARY_STATE_NOARGS);
|
||||
THCPByteTensorPtr _${name}_guard = (THCPByteTensor*)THCPByteTensor_New(_t_$name);
|
||||
THCPByteTensor *$name = _${name}_guard.get();
|
||||
${cuda}
|
||||
#else
|
||||
THByteTensorPtr _t_$name = THByteTensor_new();
|
||||
THPByteTensorPtr _${name}_guard = (THPByteTensor*)THPByteTensor_New(_t_$name);
|
||||
THPByteTensor *$name = _${name}_guard.get();
|
||||
${cpu}
|
||||
#endif
|
||||
if (!$name)
|
||||
return NULL;
|
||||
_t_$name.release();
|
||||
"""),
|
||||
'THIndexTensor*': Template("""
|
||||
#if IS_CUDA
|
||||
THCLongTensorPtr _t_$name = THCudaLongTensor_new(LIBRARY_STATE_NOARGS);
|
||||
THCPLongTensorPtr _${name}_guard = (THCPLongTensor*)THCPLongTensor_New(_t_$name);
|
||||
THCPLongTensor *$name = _${name}_guard.get();
|
||||
#else
|
||||
THLongTensorPtr _t_$name = THLongTensor_new();
|
||||
THPLongTensorPtr _${name}_guard = (THPLongTensor*)THPLongTensor_New(_t_$name);
|
||||
THPLongTensor *$name = _${name}_guard.get();
|
||||
#endif
|
||||
if (!$name)
|
||||
return NULL;
|
||||
_t_$name.release();
|
||||
"""),
|
||||
}
|
||||
""")
|
||||
|
||||
RELEASE_ARG = Template("_${name}_guard.release();")
|
||||
def _allocate(typename, tmpl, cuda_tmpl=None, sparse=False):
|
||||
code = tmpl.safe_substitute(type=typename)
|
||||
if typename == '':
|
||||
code = code.replace('NewEmpty', '(NewEmpty)')
|
||||
if cuda_tmpl:
|
||||
cuda_code = code.replace('THP', 'THCP')
|
||||
code = cuda_tmpl.substitute(cuda=cuda_code, cpu=code)
|
||||
if sparse:
|
||||
code = code.replace('THP', 'THSP')
|
||||
code = code.replace('THCP', 'THCSP')
|
||||
return Template(code)
|
||||
|
||||
ALLOCATE_TYPE = {
|
||||
'THTensor*': _allocate('', ALLOCATE_TMPL),
|
||||
'THLongTensor*': _allocate('Long', ALLOCATE_TMPL),
|
||||
'THIntTensor*': _allocate('Int', ALLOCATE_TMPL),
|
||||
'THBoolTensor*': _allocate('Byte', ALLOCATE_TMPL, ALLOCATE_CUDA),
|
||||
'THIndexTensor*': _allocate('Long', ALLOCATE_TMPL, ALLOCATE_CUDA),
|
||||
|
||||
'THSTensor*': _allocate('', ALLOCATE_TMPL, sparse=True),
|
||||
}
|
||||
|
||||
TYPE_NAMES = {
|
||||
'THTensor*': '" THPTensorStr "',
|
||||
'THSTensor*': '" THSPTensorStr "',
|
||||
'THStorage*': '" THPStorageStr "',
|
||||
'THGenerator*': 'Generator',
|
||||
'THLongStorage*': 'LongStorage',
|
||||
'THLongTensor*': 'LongTensor',
|
||||
'THBoolTensor*': 'ByteTensor',
|
||||
'THIndexTensor*': 'LongTensor',
|
||||
'THFloatTensor*': 'FloatTensor',
|
||||
'THDoubleTensor*': 'DoubleTensor',
|
||||
'THGenerator*': 'torch.Generator',
|
||||
'THLongStorage*': '" THPModuleStr "LongStorage',
|
||||
'THLongTensor*': '" THPModuleStr "LongTensor',
|
||||
'THIntTensor*': '" THPModuleStr "IntTensor',
|
||||
'THBoolTensor*': '" THPModuleStr "ByteTensor',
|
||||
'THIndexTensor*': '" THPModuleStr "LongTensor',
|
||||
'THFloatTensor*': '" THPModuleStr "FloatTensor',
|
||||
'THDoubleTensor*': '" THPModuleStr "DoubleTensor',
|
||||
'THSize*': 'torch.Size',
|
||||
'THStride*': 'tuple',
|
||||
'long': 'int',
|
||||
'real': '" RealStr "',
|
||||
'double': 'float',
|
||||
@ -147,40 +168,71 @@ PyObject * $name(PyObject *self, PyObject *args)
|
||||
'bool': 'bool',
|
||||
}
|
||||
|
||||
OUT_INIT = """
|
||||
__out = kwargs ? PyDict_GetItemString(kwargs, "out") : NULL;
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.declarations = []
|
||||
self.stateless_declarations = []
|
||||
self.docstrings = []
|
||||
|
||||
def get_type_unpack(self, arg, option):
|
||||
return self.TYPE_UNPACK.get(arg['type'], None)
|
||||
|
||||
def get_type_check(self, arg, option):
|
||||
if arg['type'] == 'THSize*' and arg.get('long_args', False):
|
||||
return self.SIZE_VARARG_CHECK
|
||||
return self.TYPE_CHECK.get(arg['type'], None)
|
||||
|
||||
# TODO: argument descriptions shouldn't be part of THP, but rather a general cwrap thing
|
||||
def get_wrapper_template(self, declaration):
|
||||
arg_desc = []
|
||||
for option in declaration['options']:
|
||||
option_desc = [self.TYPE_NAMES[arg['type']] + ' ' + arg['name']
|
||||
for arg in option['arguments']
|
||||
if not arg.get('ignore_check', False)]
|
||||
# TODO: this should probably go to THPLongArgsPlugin
|
||||
if option.get('long_args'):
|
||||
option_desc.append('int ...')
|
||||
if option_desc:
|
||||
arg_desc.append('({})'.format(', '.join(option_desc)))
|
||||
arg_desc = OrderedDict()
|
||||
|
||||
def format_arg(arg, var_args=False):
|
||||
if var_args and arg.get('long_args', False):
|
||||
return 'int ... ' + arg['name']
|
||||
else:
|
||||
arg_desc.append('no arguments')
|
||||
arg_desc.sort(key=len)
|
||||
return self.TYPE_NAMES[arg['type']] + ' ' + arg['name']
|
||||
|
||||
def format_args(args, var_args=False):
|
||||
option_desc = [format_arg(arg, var_args)
|
||||
for arg in args
|
||||
if not arg.get('ignore_check', False)
|
||||
and not arg.get('output')]
|
||||
output_args = list(filter(lambda a: a.get('output'), args))
|
||||
if output_args:
|
||||
if len(output_args) > 1:
|
||||
out_type = 'tuple['
|
||||
out_type += ', '.join(
|
||||
self.TYPE_NAMES[arg['type']] for arg in output_args)
|
||||
out_type += ']'
|
||||
option_desc += ['#' + out_type + ' out']
|
||||
else:
|
||||
arg = output_args[0]
|
||||
option_desc += ['#' + self.TYPE_NAMES[arg['type']] + ' out']
|
||||
|
||||
if option_desc:
|
||||
return '({})'.format(', '.join(option_desc))
|
||||
else:
|
||||
return 'no arguments'
|
||||
|
||||
for option in declaration['options']:
|
||||
arg_desc[format_args(option['arguments'], False)] = True
|
||||
arg_desc[format_args(option['arguments'], True)] = True
|
||||
|
||||
arg_desc = sorted(list(arg_desc.keys()), key=len)
|
||||
arg_desc = ['"' + desc + '"' for desc in arg_desc]
|
||||
arg_str = ', '.join(arg_desc)
|
||||
variables_str = '\n'.join(declaration.get('variables', []))
|
||||
init_str = '\n'.join(declaration.get('init', []))
|
||||
if 'stateless' in declaration['name']:
|
||||
readable_name = 'torch.' + declaration['python_name']
|
||||
else:
|
||||
readable_name = declaration['python_name']
|
||||
return Template(self.WRAPPER_TEMPLATE.safe_substitute(
|
||||
readable_name=readable_name, num_options=len(arg_desc),
|
||||
expected_args=arg_str))
|
||||
expected_args=arg_str, variables=variables_str, init=init_str))
|
||||
|
||||
def get_return_wrapper(self, option):
|
||||
return self.RETURN_WRAPPER.get(option['return'], None)
|
||||
@ -188,93 +240,165 @@ PyObject * $name(PyObject *self, PyObject *args)
|
||||
def get_arg_accessor(self, arg, option):
|
||||
if arg['name'] == 'self':
|
||||
return 'self'
|
||||
if 'allocate' in arg and arg['allocate']:
|
||||
return arg['name']
|
||||
if arg.get('output'):
|
||||
if not option['output_provided']:
|
||||
return arg['name']
|
||||
if option['output_count'] == 1:
|
||||
return '__out'
|
||||
else:
|
||||
return 'PyTuple_GET_ITEM(__out, {})'.format(arg['output_idx'])
|
||||
|
||||
def process_docstrings(self):
|
||||
for declaration in self.declarations:
|
||||
docstr = declaration.get('docstring_method')
|
||||
if docstr is None:
|
||||
continue
|
||||
declaration['docstring_content'] = docstr.replace('\n', '\\n')
|
||||
declaration['docstring_var'] = 'docstr_' + declaration['python_name']
|
||||
for declaration in self.stateless_declarations:
|
||||
docstr = declaration.get('docstring_stateless')
|
||||
if docstr is None:
|
||||
continue
|
||||
declaration['docstring_content'] = docstr.replace('\n', '\\n')
|
||||
declaration['docstring_var'] = 'stateless_docstr_' + declaration['python_name']
|
||||
|
||||
def generate_out_options(self, declaration):
|
||||
new_options = []
|
||||
declaration.setdefault('init', [])
|
||||
declaration['init'] += [self.OUT_INIT]
|
||||
for option in declaration['options']:
|
||||
out_idx = []
|
||||
for i, arg in enumerate(option['arguments']):
|
||||
if arg.get('output'):
|
||||
out_idx.append(i)
|
||||
if not out_idx:
|
||||
option['has_output'] = True
|
||||
option['output_provided'] = False
|
||||
new_options.append(option)
|
||||
continue
|
||||
for output_provided in (True, False):
|
||||
option_copy = deepcopy(option)
|
||||
option_copy['has_output'] = True
|
||||
option_copy['output_provided'] = output_provided
|
||||
option_copy['output_count'] = len(out_idx)
|
||||
for i, idx in enumerate(out_idx):
|
||||
arg = option_copy['arguments'][idx]
|
||||
arg['output_idx'] = i
|
||||
if not output_provided:
|
||||
arg['ignore_check'] = True
|
||||
else:
|
||||
option_copy['argcount_offset'] = -len(out_idx) + 1
|
||||
arg['no_kwargs'] = True
|
||||
arg['no_idx'] = True
|
||||
new_options.append(option_copy)
|
||||
declaration['options'] = new_options
|
||||
|
||||
def process_declarations(self, declarations):
|
||||
new_declarations = []
|
||||
register_only = [d for d in declarations if d.get('only_register', False)]
|
||||
declarations = [d for d in declarations if not d.get('only_register', False)]
|
||||
|
||||
def has_arg_type(declaration, type_name):
|
||||
return any(arg['type'] == type_name
|
||||
for option in declaration['options']
|
||||
for arg in option['arguments'])
|
||||
|
||||
def has_long_args(declaration):
|
||||
return any(arg.get('long_args', False)
|
||||
for option in declaration['options']
|
||||
for arg in option['arguments'])
|
||||
|
||||
def has_output_args(declaration):
|
||||
return any(arg.get('output')
|
||||
for option in declaration['options']
|
||||
for arg in option['arguments'])
|
||||
|
||||
for declaration in declarations:
|
||||
if declaration.get('only_register', False):
|
||||
continue
|
||||
declaration.setdefault('python_name', declaration['name'])
|
||||
declaration.setdefault('variables', [])
|
||||
if has_arg_type(declaration, 'THSize*'):
|
||||
declaration['variables'] += ['THLongStoragePtr __size;']
|
||||
if has_arg_type(declaration, 'THStride*'):
|
||||
declaration['variables'] += ['THLongStoragePtr __stride;']
|
||||
if has_output_args(declaration):
|
||||
declaration['variables'] += ['PyObject *__out;']
|
||||
self.generate_out_options(declaration)
|
||||
if has_long_args(declaration):
|
||||
declaration['no_kwargs'] = True
|
||||
for option in declaration['options']:
|
||||
option['cname'] = 'TH{}Tensor_({})'.format(
|
||||
'S' if option.get('sparse', False) else '', option['cname'])
|
||||
if declaration.get('with_stateless', False) or declaration.get('only_stateless', False):
|
||||
stateless_declaration = self.make_stateless(deepcopy(declaration))
|
||||
stateless_declaration = self.make_stateless(declaration)
|
||||
new_declarations.append(stateless_declaration)
|
||||
self.stateless_declarations.append(stateless_declaration)
|
||||
if declaration.get('only_stateless', False):
|
||||
continue
|
||||
|
||||
self.declarations.append(declaration)
|
||||
declaration['name'] = 'THPTensor_({})'.format(declaration['name'])
|
||||
declaration['name'] = 'TH{}PTensor_({})'.format(
|
||||
'S' if declaration.get('sparse', False) else '', declaration['name'])
|
||||
for option in declaration['options']:
|
||||
option['cname'] = 'THTensor_({})'.format(option['cname'])
|
||||
for arg in option['arguments']:
|
||||
if arg['name'] == 'self':
|
||||
arg['ignore_check'] = True
|
||||
if 'allocate' in arg and arg['allocate']:
|
||||
arg['ignore_check'] = True
|
||||
# TODO: we can probably allow duplicate signatures once we implement
|
||||
# keyword arguments
|
||||
declaration['options'] = self.filter_unique_options(declaration['options'])
|
||||
|
||||
|
||||
declarations = [d for d in declarations if not d.get('only_stateless', False)]
|
||||
self.declarations.extend(filter(lambda x: not x.get('only_stateless', False), register_only))
|
||||
self.stateless_declarations.extend(filter(lambda x: x.get('only_stateless', False), register_only))
|
||||
return declarations + new_declarations
|
||||
|
||||
self.process_docstrings()
|
||||
|
||||
all_declarations = declarations + new_declarations
|
||||
return all_declarations
|
||||
|
||||
def make_stateless(self, declaration):
|
||||
declaration['name'] = 'THPTensor_stateless_({})'.format(declaration['name'])
|
||||
new_options = []
|
||||
declaration = deepcopy(declaration)
|
||||
declaration['name'] = 'TH{}PTensor_stateless_({})'.format(
|
||||
'S' if declaration.get('sparse', False) else '', declaration['name'])
|
||||
for option in declaration['options']:
|
||||
option['cname'] = 'THTensor_({})'.format(option['cname'])
|
||||
allocated = []
|
||||
for i, arg in enumerate(option['arguments']):
|
||||
if 'allocate' in arg and arg['allocate']:
|
||||
arg['ignore_check'] = True
|
||||
allocated.append(i)
|
||||
for arg in option['arguments']:
|
||||
if arg['name'] == 'self':
|
||||
arg['name'] = 'source'
|
||||
for permutation in product((True, False), repeat=len(allocated)):
|
||||
option_copy = deepcopy(option)
|
||||
for i, bit in zip(allocated, permutation):
|
||||
arg = option_copy['arguments'][i]
|
||||
# By default everything is allocated, so we don't have to do anything
|
||||
if not bit:
|
||||
del arg['allocate']
|
||||
del arg['ignore_check']
|
||||
new_options.append(option_copy)
|
||||
declaration['options'] = self.filter_unique_options(declaration['options'] + new_options)
|
||||
return declaration
|
||||
|
||||
def filter_unique_options(self, options):
|
||||
def signature(option):
|
||||
return '#'.join(arg['type'] for arg in option['arguments'] if not 'ignore_check' in arg or not arg['ignore_check'])
|
||||
seen_signatures = set()
|
||||
unique = []
|
||||
for option in options:
|
||||
sig = signature(option)
|
||||
if sig not in seen_signatures:
|
||||
unique.append(option)
|
||||
seen_signatures.add(sig)
|
||||
return unique
|
||||
|
||||
def declare_methods(self, stateless):
|
||||
def declare_methods(self, stateless, sparse):
|
||||
tensor_methods = ''
|
||||
for declaration in (self.declarations if not stateless else self.stateless_declarations):
|
||||
extra_flags = ' | ' + declaration.get('method_flags') if 'method_flags' in declaration else ''
|
||||
entry = Template(' {"$python_name", (PyCFunction)$name, METH_VARARGS$extra_flags, NULL},\n').substitute(
|
||||
python_name=declaration['python_name'], name=declaration['name'], extra_flags=extra_flags
|
||||
if declaration.get('sparse', False) != sparse:
|
||||
continue
|
||||
flags = 'METH_VARARGS'
|
||||
flags += ' | ' + declaration.get('method_flags') if 'method_flags' in declaration else ''
|
||||
if not declaration.get('only_register'):
|
||||
flags += ' | METH_KEYWORDS'
|
||||
if declaration.get('override_method_flags'):
|
||||
flags = declaration['override_method_flags']
|
||||
entry = Template(' {"$python_name", (PyCFunction)$name, $flags, $docstring},\n').substitute(
|
||||
python_name=declaration['python_name'], name=declaration['name'], flags=flags,
|
||||
docstring=declaration.get('docstring_var', 'NULL')
|
||||
)
|
||||
if 'defined_if' in declaration:
|
||||
entry = self.preprocessor_guard(entry, declaration['defined_if'])
|
||||
tensor_methods += entry
|
||||
return self.TENSOR_METHODS_DECLARATION.substitute(methods=tensor_methods, stateless=('' if not stateless else 'stateless_'))
|
||||
return self.TENSOR_METHODS_DECLARATION.substitute(
|
||||
methods=tensor_methods,
|
||||
stateless=('' if not stateless else 'stateless_'),
|
||||
sparse=('' if not sparse else 'S'),
|
||||
)
|
||||
|
||||
def process_full_file(self, code):
|
||||
# We have to find a place before all undefs
|
||||
idx = code.find('// PUT DEFINITIONS IN HERE PLEASE')
|
||||
return code[:idx] + self.declare_methods(False) + self.declare_methods(True) + code[idx:]
|
||||
return (code[:idx]
|
||||
+ self.declare_methods(False, False)
|
||||
+ self.declare_methods(True, False)
|
||||
+ self.declare_methods(False, True)
|
||||
+ self.declare_methods(True, True)
|
||||
+ code[idx:]
|
||||
)
|
||||
|
||||
def preprocessor_guard(self, code, condition):
|
||||
return '#if ' + condition + '\n' + code + '#endif\n'
|
||||
@ -287,10 +411,45 @@ PyObject * $name(PyObject *self, PyObject *args)
|
||||
def process_all_unpacks(self, code, option):
|
||||
return 'LIBRARY_STATE ' + code
|
||||
|
||||
def process_all_checks(self, code, option):
|
||||
if option.get('has_output'):
|
||||
indent = " " * 10
|
||||
if option['output_provided']:
|
||||
checks = "__out != NULL &&\n" + indent
|
||||
if option['output_count'] > 1:
|
||||
checks += "PyTuple_Check(__out) &&\n" + indent
|
||||
length_check = "PyTuple_GET_SIZE(__out) == {} &&\n".format(
|
||||
option['output_count'])
|
||||
checks += length_check + indent
|
||||
code = checks + code
|
||||
else:
|
||||
code = "__out == NULL &&\n" + indent + code
|
||||
|
||||
if any(arg.get('long_args', False) for arg in option['arguments']):
|
||||
code = code.replace('__argcount ==', '__argcount >=')
|
||||
expected = str(int(option.get('output_provided', False)))
|
||||
code = '__dictcount == ' + expected + ' &&\n ' + code
|
||||
|
||||
return code
|
||||
|
||||
def process_option_code_template(self, template, option):
|
||||
new_args = []
|
||||
for arg in option['arguments']:
|
||||
if 'allocate' in arg and arg['allocate']:
|
||||
if not option.get('output_provided', True) and arg.get('output'):
|
||||
new_args.append(self.ALLOCATE_TYPE[arg['type']].substitute(name=arg['name']))
|
||||
template = new_args + template
|
||||
return template
|
||||
|
||||
def generate_docstrings_cpp(self):
|
||||
template = Template('char* $name = "$content";')
|
||||
return '\n\n'.join(
|
||||
template.substitute(name=decl['docstring_var'], content=decl['docstring_content'])
|
||||
for decl in chain(self.declarations, self.stateless_declarations)
|
||||
if 'docstring_var' in decl)
|
||||
|
||||
def generate_docstrings_h(self):
|
||||
template = Template('extern char* $name;')
|
||||
return '\n\n'.join(
|
||||
template.substitute(name=decl['docstring_var'])
|
||||
for decl in chain(self.declarations, self.stateless_declarations)
|
||||
if 'docstring_var' in decl)
|
||||
|
||||
@ -52,8 +52,9 @@ from .NullableArguments import NullableArguments
|
||||
from .OptionalArguments import OptionalArguments
|
||||
from .ArgcountChecker import ArgcountChecker
|
||||
from .ArgumentReferences import ArgumentReferences
|
||||
from .BeforeCall import BeforeCall
|
||||
from .BeforeAfterCall import BeforeAfterCall
|
||||
from .ConstantArguments import ConstantArguments
|
||||
from .ReturnArguments import ReturnArguments
|
||||
from .GILRelease import GILRelease
|
||||
from .AutoGPU import AutoGPU
|
||||
from .CuDNNPlugin import CuDNNPlugin
|
||||
|
||||
40
tools/docker/Dockerfile-v6
Normal file
@ -0,0 +1,40 @@
|
||||
FROM nvidia/cuda:8.0-devel-ubuntu14.04
|
||||
|
||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
||||
build-essential \
|
||||
cmake \
|
||||
git \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libjpeg-dev \
|
||||
libpng-dev &&\
|
||||
rm -rf /var/lib/apt/lists/*
|
||||
|
||||
|
||||
RUN curl -fsSL http://developer.download.nvidia.com/compute/redist/cudnn/v6.0/cudnn-8.0-linux-x64-v6.0-rc.tgz -O && \
|
||||
tar -xzf cudnn-8.0-linux-x64-v6.0-rc.tgz -C /usr/local && \
|
||||
rm cudnn-8.0-linux-x64-v6.0-rc.tgz && \
|
||||
ldconfig
|
||||
RUN ln -s /usr/local/cuda/lib64/libcudnn.so.6.0.5 /usr/lib/x86_64-linux-gnu/libcudnn.so.6.0.5
|
||||
|
||||
RUN curl -o ~/miniconda.sh -O https://repo.continuum.io/miniconda/Miniconda3-4.2.12-Linux-x86_64.sh && \
|
||||
chmod +x ~/miniconda.sh && \
|
||||
~/miniconda.sh -b -p /opt/conda && \
|
||||
rm ~/miniconda.sh && \
|
||||
/opt/conda/bin/conda install conda-build && \
|
||||
/opt/conda/bin/conda create -y --name pytorch-py35 python=3.5.2 numpy scipy ipython mkl&& \
|
||||
/opt/conda/bin/conda clean -ya
|
||||
ENV PATH /opt/conda/envs/pytorch-py35/bin:$PATH
|
||||
RUN conda install --name pytorch-py35 -c soumith magma-cuda80
|
||||
# This must be done before pip so that requirements.txt is available
|
||||
WORKDIR /opt/pytorch
|
||||
COPY . .
|
||||
|
||||
RUN cat requirements.txt | xargs -n1 pip install --no-cache-dir && \
|
||||
TORCH_CUDA_ARCH_LIST="3.5 5.2 6.0 6.1+PTX" TORCH_NVCC_FLAGS="-Xfatbin -compress-all" \
|
||||
CMAKE_LIBRARY_PATH=/opt/conda/envs/pytorch-py35/lib \
|
||||
CMAKE_INCLUDE_PATH=/opt/conda/envs/pytorch-py35/include \
|
||||
pip install -v .
|
||||
|
||||
WORKDIR /workspace
|
||||
RUN chmod -R a+w /workspace
|
||||
@ -1 +1 @@
|
||||
from .generate_wrappers import generate_wrappers
|
||||
from .generate_wrappers import generate_wrappers, wrap_function, import_module
|
||||
|
||||
@ -34,6 +34,7 @@ FUNCTION_TEMPLATE = Template("""\
|
||||
|
||||
COMMON_TRANSFORMS = {
|
||||
'THIndex_t': 'long',
|
||||
'THCIndex_t': 'long',
|
||||
'THInteger_t': 'int',
|
||||
}
|
||||
COMMON_CPU_TRANSFORMS = {
|
||||
@ -41,6 +42,10 @@ COMMON_CPU_TRANSFORMS = {
|
||||
'THIndexTensor*': 'THLongTensor*',
|
||||
'THIntegerTensor*': 'THIntTensor*',
|
||||
}
|
||||
COMMON_GPU_TRANSFORMS = {
|
||||
'THCState*': 'void*',
|
||||
'THCIndexTensor*': 'THCudaLongTensor*',
|
||||
}
|
||||
|
||||
TYPE_TRANSFORMS = {
|
||||
'Float': {
|
||||
@ -51,15 +56,26 @@ TYPE_TRANSFORMS = {
|
||||
'THTensor*': 'THDoubleTensor*',
|
||||
'real': 'double',
|
||||
},
|
||||
'CudaHalf': {
|
||||
'THCTensor*': 'THCudaHalfTensor*',
|
||||
'real': 'half',
|
||||
},
|
||||
'Cuda': {
|
||||
'THCState*': 'void*',
|
||||
'THIndexTensor*': 'THCudaLongTensor*',
|
||||
}
|
||||
'THCTensor*': 'THCudaTensor*',
|
||||
'real': 'float',
|
||||
},
|
||||
'CudaDouble': {
|
||||
'THCTensor*': 'THCudaDoubleTensor*',
|
||||
'real': 'double',
|
||||
},
|
||||
}
|
||||
for t, transforms in TYPE_TRANSFORMS.items():
|
||||
transforms.update(COMMON_TRANSFORMS)
|
||||
TYPE_TRANSFORMS['Float'].update(COMMON_CPU_TRANSFORMS)
|
||||
TYPE_TRANSFORMS['Double'].update(COMMON_CPU_TRANSFORMS)
|
||||
|
||||
for t in ['Float', 'Double']:
|
||||
TYPE_TRANSFORMS[t].update(COMMON_CPU_TRANSFORMS)
|
||||
for t in ['CudaHalf', 'Cuda', 'CudaDouble']:
|
||||
TYPE_TRANSFORMS[t].update(COMMON_GPU_TRANSFORMS)
|
||||
|
||||
|
||||
def wrap_function(name, type, arguments):
|
||||
@ -102,11 +118,9 @@ def wrap_cunn():
|
||||
wrapper = '#include <TH/TH.h>\n'
|
||||
wrapper += '#include <THC/THC.h>\n\n\n'
|
||||
cunn_functions = thnn_utils.parse_header(thnn_utils.THCUNN_H_PATH)
|
||||
# Get rid of Cuda prefix
|
||||
for function in cunn_functions:
|
||||
function.name = function.name[4:]
|
||||
for fn in cunn_functions:
|
||||
wrapper += wrap_function(fn.name, 'Cuda', fn.arguments)
|
||||
for t in ['CudaHalf', 'Cuda', 'CudaDouble']:
|
||||
wrapper += wrap_function(fn.name, t, fn.arguments)
|
||||
with open('torch/csrc/nn/THCUNN.cwrap', 'w') as f:
|
||||
f.write(wrapper)
|
||||
cwrap('torch/csrc/nn/THCUNN.cwrap', plugins=[
|
||||
|
||||