Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71746
This PR contains the following improvements:
- It exposes a new environment variable `TORCH_CPP_LOG_LEVEL` that enables users to set the log level of c10 logging facility (supports both GLOG and c10 loggers). Valid values are `INFO`, `WARNING`, `ERROR`, and `FATAL` or their numerical equivalents `0`, `1`, `2`, and `3`.
- It implements an `initLogging()` function and calls it as part of `torch._C` module import to ensure that the underlying logging facility is correctly initialized in Python.
With these changes a user can dynamically set the log level of c10 as in the following example:
```
$ TORCH_CPP_LOG_LEVEL=INFO python my_torch_script.py
```
ghstack-source-id: 149822703
Test Plan: Run existing tests.
Reviewed By: malfet
Differential Revision: D33756252
fbshipit-source-id: 7fd078c03a598595d992de0b474a23cec91838af
(cherry picked from commit 01d6ec6207faedf259ed1368730e9e197cb3e1c6)
* Prefix c10d log messages with `[c10d]` for easier troubleshooting (#73144)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73144
This PR formats c10d log messages written by the `C10D_INFO/WARN/ERROR` macros by prefixing them with the `[c10d]` tag for easier troubleshooting. See #73121 for a specific customer request.
Note though that this is a temporary fix to unblock our users. Ideally our global logging facility should natively support component-based preambles.
ghstack-source-id: 149748943
Test Plan: N/A
Reviewed By: rohan-varma
Differential Revision: D34363975
fbshipit-source-id: 6b8096ac4b2fa344406c866a2e7665541cb60b34
(cherry picked from commit af14aef18d0239f04730545596a05536e0f9c857)
* Refactor TORCH_DISTRIBUTED_DEBUG implementation (#73166)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73166
This PR refactors, cleans up, and optimizes the implementation of `TORCH_DISTRIBUTED_DEBUG`. It also introduces three new user APIs: `get_debug_level()`, `set_debug_level()`, and `set_debug_level_from_env()` to retrieve and modify the debug level after a process has started.
ghstack-source-id: 149778566
Test Plan: Run the existing unit tests.
Reviewed By: rohan-varma
Differential Revision: D34371226
fbshipit-source-id: e18443b411adcbaf39b2ec999178c198052fcd5b
(cherry picked from commit 26d6bb1584b83a0490d8b766482656a5887fa21d)
* Introduce debug and trace log levels in c10d (#73167)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73167
This PR adds `C10D_DEBUG` and `C10D_TRACE` macros to enable fine grained logging in c10d. It also updates some log statements of `socket` to make its output less noisy.
ghstack-source-id: 149778567
Test Plan: Manual testing with different socket conditions.
Reviewed By: rohan-varma
Differential Revision: D34371426
fbshipit-source-id: a852b05ec353b18b0540ce5f803666c3da21ddd7
(cherry picked from commit 4519b06ac57f177dfc086bc10e8e1a746ba0870d)
* Make "server socket not listening" warning logs less noisy (#73149)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73149
This PR improves the handling of the "server socket not yet listening" warning log in c10d `socket`. Instead of outputting it after every failed attempt (meaning every second), it is now written every 20 seconds. Note though that if the log level is set to `INFO`, we keep writing a detailed message every second as before with additional `errno` information.
With log level set to `WARN` the output looks like:
```
[W socket.cpp:598] [c10d] No socket on (127.0.0.1, 29501) is listening yet, will retry.
[W socket.cpp:598] [c10d] No socket on (127.0.0.1, 29501) is listening yet, will retry.
...
[E socket.cpp:726] [c10d] The client socket has timed out after 300s while trying to connect to (127.0.0.1, 29501).
```
With log level set to `INFO` (a.k.a. verbose or debug level) the output looks like:
```
[I socket.cpp:515] [c10d] The client socket will attempt to connect to an IPv6 address of (127.0.0.1, 29501).
[I socket.cpp:582] [c10d] The client socket is attempting to connect to [localhost]:29501.
[I socket.cpp:643] [c10d] The server socket on [localhost]:29501 is not yet listening (errno: 111 - Connection refused), will retry.
[W socket.cpp:598] [c10d] No socket on (127.0.0.1, 29501) is listening yet, will retry.
[I socket.cpp:582] [c10d] The client socket is attempting to connect to [localhost]:29501.
[I socket.cpp:643] [c10d] The server socket on [localhost]:29501 is not yet listening (errno: 111 - Connection refused), will retry.
[I socket.cpp:582] [c10d] The client socket is attempting to connect to [localhost]:29501.
[I socket.cpp:643] [c10d] The server socket on [localhost]:29501 is not yet listening (errno: 111 - Connection refused), will retry.
[I socket.cpp:582] [c10d] The client socket is attempting to connect to [localhost]:29501.
[I socket.cpp:643] [c10d] The server socket on [localhost]:29501 is not yet listening (errno: 111 - Connection refused), will retry.
...
[W socket.cpp:598] [c10d] No socket on (127.0.0.1, 29501) is listening yet, will retry.
...
[E socket.cpp:726] [c10d] The client socket has timed out after 300s while trying to connect to (127.0.0.1, 29501).
```
ghstack-source-id: 149778565
Test Plan: Run manual tests to verify the correctness of the log message.
Reviewed By: rohan-varma
Differential Revision: D34365217
fbshipit-source-id: 296d01fa8b1ba803432903c10686d8a75145e539
(cherry picked from commit 8ae5aff0c5ffcc3e87d27d2deba6fedf8cef45cd)
* Rename `_get_debug_mode` to `get_debug_level` in distributed.py
Summary:
Adding documentation about compiling extension with CUDA 11.5 and Windows
Example of failure: https://github.com/pytorch/pytorch/runs/4408796098?check_suite_focus=true
Note: Don't use torch/extension.h In CUDA 11.5 under windows in your C++ code:
Use aten instead of torch interface in all cuda 11.5 code under windows. It has been failing with errors, due to a bug in nvcc.
Example use:
>>> #include <ATen/ATen.h>
>>> at::Tensor SigmoidAlphaBlendForwardCuda(....)
Instead of:
>>> #include <torch/extension.h>
>>> torch::Tensor SigmoidAlphaBlendForwardCuda(...)
Currently open issue for nvcc bug: https://github.com/pytorch/pytorch/issues/69460
Complete Workaround code example: cb170ac024
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73013
Reviewed By: malfet, seemethere
Differential Revision: D34306134
Pulled By: atalman
fbshipit-source-id: 3c5b9d7a89c91bd1920dc63dbd356e45dc48a8bd
(cherry picked from commit 87098e7f17fca1b98c90fafe2dde1defb6633f49)
Summary:
This is to avoid the directory , where the sccache is installed, couldn't be deleted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72794
Reviewed By: H-Huang
Differential Revision: D34222877
Pulled By: janeyx99
fbshipit-source-id: 2765d6f49b375d15598586ed83ae4c5e667e7226
(cherry picked from commit 551e21ca582c80d88a466b7bfe4eda9dee0c9a5f)
Co-authored-by: Yi Zhang <zhanyi@microsoft.com>
Adding usage examples for IterDataPipes, with additional improvements for description of `groupby`, `IterDataPipe`, `MapDataPipe`.
Differential Revision: [D34313793](https://our.internmc.facebook.com/intern/diff/D34313793)
A typical use case for `TensorExprKernel` is to create the kernel once and call it multiple times, possibly in parallel. For the parallel calls to work, we need to ensure that the run() method calls do not change any state in `TensorExprKernel`.
Before this change, the `run()` method was modifying the sizes and strides vectors when dynamic shapes were present. This manifested as a data race when running a model with Static Runtime.
ghstack-source-id: 149398820
Differential Revision: [D34287960](https://our.internmc.facebook.com/intern/diff/D34287960/)
Co-authored-by: Raghavan Raman <raghavanr@fb.com>
* [DataPipe] Fixing MapDataPipe docstrings
[ghstack-poisoned]
* [DataPipe] Fixing IterDataPipe docstrings
[ghstack-poisoned]
* [DataPipe] Add docstrings for IterDataPipe and MapDataPipe, along with small doc changes for consistency
[ghstack-poisoned]
Summary:
Fixes https://github.com/pytorch/pytorch/issues/72655
Please note: Readme.md file change will be done after this change is performed and release specific change is done, so that I will reference the commit of the release specific change in the readme as an example
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72719
Reviewed By: seemethere
Differential Revision: D34177045
Pulled By: atalman
fbshipit-source-id: 2abb7af8cf1337704933c19c0d06022034ec77b4
(cherry picked from commit 31ff276d5e2cacc0e0592d624f3d486d5e8cfd1c)
Summary:
Should fix the following [error](https://github.com/pytorch/pytorch/runs/5058514346#step:13:88):
```
+ git --git-dir /pytorch/pytorch/.git describe --tags --match 'v[0-9]*.[0-9]*.[0-9]*' --exact
fatal: not a git repository: '/pytorch/pytorch/.git'
```
By setting `workdir` correctly for GHA linux and Windows builds
Also, abort `tagged_version` if GIT_DIR does not exist (as this script should only be executed in context of git folder.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72628
Reviewed By: atalman
Differential Revision: D34120721
Pulled By: malfet
fbshipit-source-id: 035e93e243e601f9c24659cd247f9c029210fba5
(cherry picked from commit 3a6c97b6ddb185d706494f64423a761fee8fce09)
(cherry picked from commit b6df02bbbb5b786b198938ffb5d90fa5251df3eb)
Summary:
This PR was opened as copy of https://github.com/pytorch/pytorch/pull/68812 by request https://github.com/pytorch/pytorch/pull/68812#issuecomment-1030215862.
-----
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate the wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR also fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72357
Reviewed By: albanD
Differential Revision: D34012245
Pulled By: ngimel
fbshipit-source-id: 2b66c173cc3458d8c766b542d0d569191cdce310
(cherry picked from commit fa29e65611ea5028bf6d2d3c151d79e6c9e4ffef)
Summary:
Let's make the documentation for `torch.sparse.sampled_addmm` searchable in the PyTorch documentation.
This PR shall be cherry-picked for the next 1.11 release.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72312
Reviewed By: davidberard98
Differential Revision: D34045230
Pulled By: cpuhrsch
fbshipit-source-id: c1b1dc907443284857f48c8ce1efab22c6701bbe
(cherry picked from commit 225929ecf20eb369f862b091818f5af16ee78f88)
Summary:
Tests under `test/onnx/test_models_onnxruntime.py` complains `AttributeError: 'TestModels' object has no attribute 'onnx_shape_inference'`.
This failure in CI appears suddenly without any code changes to related files. It is likely due to different test case run order. The test code was badly written such that test class `TestModels_new_jit_API`, if called first, will assign `TestModels.onnx_shape_inference = True`, circumventing this problem. On the other hand, if `TestModels` is called first, `AttributeError` will be raised.
Fixes https://github.com/pytorch/pytorch/issues/72337
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72350
Reviewed By: jbschlosser, seemethere, janeyx99
Differential Revision: D34010794
Pulled By: malfet
fbshipit-source-id: 816f7bee89ea0251bb5df8f482b68f8dc4823997
(cherry picked from commit b39b23bec5dfd3f2fd24a0d781757c20ff94b1db)
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Remove forcing CUDNN_STATIC when CAFFE2_STATIC_LINK_CUDA is set
Since we are transitioning to using dynamic loading for multiple pytorch dependecies and CUDNN is the first step in this transition, hence we want to remove forcing CUDNN to statically load, and instead load it dynamically.
Tested using following workflow:
https://github.com/pytorch/pytorch/actions/runs/1790666862
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72290
Reviewed By: albanD
Differential Revision: D34003793
Pulled By: atalman
fbshipit-source-id: 41bda7ac019a612ee53ceb18d1e372b1bb3cb68e
(cherry picked from commit 4a01940e681f996017d924b08946188ef352ef41)
Co-authored-by: Andrey Talman <atalman@fb.com>
* release 1.11 Install torch from test channel, Pin builder and xla repo (#72217)
* Make svd / svdvals fully functorch compatible (#72181)
Summary:
This should (hopefully) make all the CI from `functorch` go green (including jvp's!) after changing `VARIADIC_BDIMS_BOXED(_svd_helper);` with `VARIADIC_BDIMS_BOXED(_linalg_svd);` and removing all the skip and xfails associated to `linalg.svdvals`.
Locally, there's just one test that started failing because of this, and that is `test_vmapjvpall_norm_nuc_cpu_float32`. I have no idea what's going on here, but it's a jvp product, so not a regression, and it might very well be caused by the jvp of other operation within `norm_nuc` as this is a composite operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72181
Reviewed By: ngimel
Differential Revision: D33952744
Pulled By: zou3519
fbshipit-source-id: 2a2510d97eed4a0bfc25615264ddd36e38856efe
(cherry picked from commit 5805fa107c3a91c58f8ecc9778cfc87aa7f64233)
Co-authored-by: Andrey Talman <atalman@fb.com>
Co-authored-by: lezcano <lezcano-93@hotmail.com>
* release 1.11 Install torch from test channel, Pin builder and xla repo (#72217)
* [1.11] Remove torch.vmap (#65496)
torch.vmap is a prototype feature and should not be in the stable
binary. This PR:
- Removes the torch.vmap API
- Removes the documentation entry for torch.vmap
- Changes the vmap tests to use an internal API instead of torch.vmap.
Test Plan:
- Tested locally (test_torch, test_autograd, test_type_hints, test_vmap),
but also wait for CI.
Co-authored-by: Andrey Talman <atalman@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71957
Update users of flatbuffer serializer/loader to use the version in torch/csrc.
Test Plan:
sandcastle
Ran `buck run :test_models -- -k test_aten_relu` passes
Reviewed By: gmagogsfm
Differential Revision: D33720611
fbshipit-source-id: 6cdf7ab43ffca83327a677853be8f4918c47d53d
(cherry picked from commit 4f59e3547e2cd346a3f2310bc2d1f6a931fb826e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71114
`include-what-you-use` or `iwyu` is a clang-based tool that looks at
the code's AST to figure out which symbols need to be included and
with the help of user-defined mappings it suggests the include
files that are actually needed.
This is very nice for the per-operator headers build because it give
you a list of exactly the `ATen/ops` headers needed by the file. You
still need to manually write the include-guards etc. but at least this
automates the most tedious part.
The header mappings aren't perfect yet so it will still suggest you
include basic c10 components everywhere instead of taking it
transitively from `TensorBase.h`. However, this does provide some
useful mappings and removes bad include paths from the build system
that were causing bad suggestions.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33949901
Pulled By: malfet
fbshipit-source-id: d5b015ef9e168bee4b8717b8e87ccc0608da62a1
(cherry picked from commit ecb2ffb35a5b1509a1275834fbe5c25e60ea1b79)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68462
ATen has a header dependency problem. Whenever an operator is added or modified, it changes `ATen/Functions.h` and `ATen/NativeFunctions.h` which in turn requires essentially every single file to be rebuilt. Per-operator headers allow files to only include the specific operators they use and so minimizes unnecessary rebuilds during incremental builds and improves cache hits in CI builds.
See this note for more details:
3a03af2f50/aten/src/ATen/templates/Functions.h (L20)
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33949899
Pulled By: malfet
fbshipit-source-id: c044c73891eaaa5533dc2fac1b12fcfb1b871312
(cherry picked from commit 3c7f4da61f967b9fc35ecd0dc3e6323a85c300ef)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72164
torch.Tensor ctor creates an empty tensor and this PR makes
ShardedTensor on par with that.
In particular we remove TensorInitParams and instead always a create an empty
tensor and then fill it in for things like ones, zeros, full etc. This is
inline with torch.ones etc. as well since even for those APIs we first create
an empty tensor and then fill it out.
ghstack-source-id: 148318045
Test Plan: waitforbuildbot
Reviewed By: wanchaol
Differential Revision: D33934603
fbshipit-source-id: 5655bbd726f29e74600ebe9f33f9dc5952b528f4
(cherry picked from commit 78b301c78c9d5046e2f0a9818dcbc2cc45e7cdd0)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72266
Within the kernel, we may manipulate `Value *` in `OptimizeCat`, which would invalidate the input `Value *` -> Stride mapping.
Fix for https://github.com/pytorch/pytorch/issues/72173
Test Plan: Imported from OSS
Reviewed By: dagitses, davidberard98
Differential Revision: D33986306
Pulled By: eellison
fbshipit-source-id: dc33cd2b545e49e90d1e46b9fcf1e6dbb4b829db
(cherry picked from commit 5e4555968a0d7b9e42ab6368575137b1c1db814f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70997
This is no longer necessary because the sublibraries that need this
have it specified.
ghstack-source-id: 147786997
Test Plan: Verified manually that this works with Bazel and Buck.
Reviewed By: malfet
Differential Revision: D33477915
fbshipit-source-id: f00f8ac24747711904fe49df4fc9400beec54f3b
(cherry picked from commit 3325437d2b20c398e3edfb389d6d3d3e6ce74d93)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70996
This is no longer necessary and does not exist internally.
ghstack-source-id: 148159361
Test Plan: Relying on CI.
Reviewed By: malfet
Differential Revision: D33477755
fbshipit-source-id: 7d375a0770d5c6277cfdea4bb0e85a9b2b4f40cd
(cherry picked from commit 360f9a548c2e4cde1b97b5902ca62a8e43af4070)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71429
Note that this was untested in OSS Bazel.
ghstack-source-id: 148159363
Test Plan: Tested locally. Rely on CI to validate.
Reviewed By: malfet
Differential Revision: D33638407
fbshipit-source-id: 12ae383ccadc1375b92d9c6a12d43821e48f9dcb
(cherry picked from commit 12be8c195ce11d9697264b1423d1e7ad28a915cb)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70928
ghstack-source-id: 148159366
Test Plan: Ensured that the same number of tests are found and run.
Reviewed By: malfet
Differential Revision: D33455272
fbshipit-source-id: fba1e3409b14794be3e6fe4445c56dd5361cfe9d
(cherry picked from commit b45fce500aa9c3f69915bf0857144ba6d268e649)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72238
Adding missed operator to be emitted either as operator (version 7 and below) and as an instruction (version 8 and above)
ghstack-source-id: 148278722
Test Plan: CI
Reviewed By: JacobSzwejbka
Differential Revision: D33970756
fbshipit-source-id: 876f0ea48dde2ee93fa40d38a264181e2fcf42ce
(cherry picked from commit f2666f99acaf9efa1a066f22319962e841209d54)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70863
ghstack-source-id: 148159368
Test Plan: Ought to be a no-op: rely on CI to validate.
Reviewed By: malfet
Differential Revision: D33367290
fbshipit-source-id: cb550538b9eafaa0117f94077ebd4cb920688881
(cherry picked from commit 077d9578bcbf5e41e806c6acb7a8f7c622f66fe9)
Summary:
Rest of the tests from CUDA testuite is skipped after GPU context corruption is encountered.
For tests decorated with `expectedFailure` creates false impression that entire testsuite is passing.
Remedy it by suppressing the exception and printing the warning about unexpected success if `should_stop_early` is true
Also, prints warning when this happens (to make attribution easier) as well as when this condition is detected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72016
Test Plan:
`python test_ops.py -v -k test_fn_fwgrad_bwgrad_gradient`
Before the change:
```
test_fn_fwgrad_bwgrad_gradient_cpu_complex128 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cpu_float64 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cuda_complex128 (__main__.TestGradientsCUDA) ... expected failure
----------------------------------------------------------------------
Ran 3 tests in 0.585s
OK (expected failures=1)
```
After the change:
```
test_fn_fwgrad_bwgrad_gradient_cpu_complex128 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cpu_float64 (__main__.TestGradientsCPU) ... ok
test_fn_fwgrad_bwgrad_gradient_cuda_complex128 (__main__.TestGradientsCUDA) ... /home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py:1670: UserWarning: TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
warn(f"TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with {rte}")
/home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py:382: UserWarning: Suppressed expected failure that resulted in fatal error
warn("Suppressed expected failure that resulted in fatal error")
unexpected success
----------------------------------------------------------------------
Ran 3 tests in 0.595s
FAILED (unexpected successes=1)
```
And `stderr` from XML file contains requested info:
```
/home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py:1670: UserWarning: TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
warn(f"TEST SUITE EARLY TERMINATION due to torch.cuda.synchronize() failed with {rte}")
/home/conda/miniconda3/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py:382: UserWarning: Suppressed expected failure that resulted in fatal error
warn("Suppressed expected failure that resulted in fatal error")
```
Fixes https://github.com/pytorch/pytorch/issues/71973
Reviewed By: janeyx99, ngimel
Differential Revision: D33854287
Pulled By: malfet
fbshipit-source-id: dd0f5a4d2fcd21ebb7ee50ce4ec4914405a812d0
(cherry picked from commit 0c0baf393158b430e938ff3be3f4b59f85620e35)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71648
This PR is part of a series of PRs addressing https://github.com/pytorch/pytorch/issues/54150,
related to using dispatcher for calls to quantized backends as opposed to if/else conditionals.
This particular PR separates the calls to quantized & non-quantized backends for unsqueeze
using a dispatcher.
Test Plan:
Additional testing was not implemented to test this change because test cases in the existing test suite already make use of the squeeze function for various backends.
Additional testing was not implemented to test this change because test cases in the existing test suite already make use of the squeeze function for various backends.
Differential Revision:
D33809041
D33809041
Reviewed By: albanD, jerryzh168
Pulled By: dzdang
fbshipit-source-id: 304d3311bc88e9bdc0ebc600e4da8e3e661134ad
(cherry picked from commit 978604a03e95f2ec7b542fad60264b61c440e9b9)
Summary:
Since there is no rule in PyTorch (Sparse CSR) for filling zeros, it was decided that only those ops will be supported which do not break 0->0 correspondence. To ensure that this rule is not broken, this PR aims to add a test to ensure this rule is not broken.
`sample_inputs_unary` may or may not generate a zero in the sample input. Hence, this separate test is good for validating the rule, and the support for Sparse CSR.
cc nikitaved pearu cpuhrsch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70302
Reviewed By: albanD
Differential Revision: D33922501
Pulled By: cpuhrsch
fbshipit-source-id: 10f67a220b95a8e75205345a33744ad536fdcf53
(cherry picked from commit ade9bf781852af7be98bd254ec5117ebdd89ec31)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71639
This PR is part of a series of PRs addressing https://github.com/pytorch/pytorch/issues/54150,
related to using dispatcher for calls to quantized backends as opposed to if/else conditionals.
This particular PR separates the calls to quantized & non-quantized backends for squeeze
using a dispatcher.
Test Plan:
Additional testing was not implemented to test this change because test cases in the existing test case already make use of the squeeze function for various backends.
initial
Additional testing was not implemented to test this change because test cases in the existing test case already make use of the squeeze function for various backends.
Differential Revision:
D33798546
D33798546
Reviewed By: jerryzh168
Pulled By: dzdang
fbshipit-source-id: 549cd7b16afb2e93ff453c9b256bab6ce73d57ce
(cherry picked from commit 193591c072e1241445dc1b67bffd925af52e330f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71876
This PR is part of a series of PRs addressing https://github.com/pytorch/pytorch/issues/54150,
related to using dispatcher for calls to quantized backends as opposed to if/else conditionals.
This particular PR doesn't address any dispatcher issues but is the first of 2 stacked PRs that addresses separating
the implementations for quantized & non-quantized squeeze functions.
Differential Revision:
D33798473
D33798473
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Pulled By: dzdang
fbshipit-source-id: d3502eff89c02a110d3d12e6e3d3fab496197842
(cherry picked from commit 2456f7d627d781f9abbe26b22915482682861c7b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71900
This PR is part of a series of PRs addressing https://github.com/pytorch/pytorch/issues/54150,
related to using dispatcher for calls to quantized backends as opposed to if/else conditionals.
This particular PR separates the calls to quantized & non-quantized backends for index_select_cpu_
using a dispatcher.
Differential Revision:
D33809857
D33809857
Test Plan: Imported from OSS
Reviewed By: albanD
Pulled By: dzdang
fbshipit-source-id: 3792a139c3c98e3a22b29304eeef593a091cf928
(cherry picked from commit 88550e01b8ec25a641e8ca751cbef62064d71ac9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71939
This PR is part of a series of PRs addressing https://github.com/pytorch/pytorch/issues/54150,
related to using dispatcher for calls to quantized backends as opposed to if/else conditionals.
This particular PR separates the calls to quantized & non-quantized backends for fill_
using a dispatcher.
Differential Revision:
D33827371
D33827371
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Pulled By: dzdang
fbshipit-source-id: d034f83de844ef777a2d71e5464f582cba634550
(cherry picked from commit 9f38385051e41a32ccc631dc3354caa03188649b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71958
This PR is part of a series of PRs addressing https://github.com/pytorch/pytorch/issues/54150,
related to using dispatcher for calls to quantized backends as opposed to if/else conditionals.
This particular PR isn't dispatcher related but does remove the extraneous torch check for a quant tensor
since the dispatcher already handles a quantized backend for this particular function
Differential Revision:
D33833765
D33833765
Test Plan: Imported from OSS
Reviewed By: ngimel
Pulled By: dzdang
fbshipit-source-id: c3bb531a5c09326bdf724b5185a19ea0a379bba7
(cherry picked from commit f053b8248f895446f6a9d352de4038df6c6d4b2d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71899
This PR is part of a series of PRs addressing https://github.com/pytorch/pytorch/issues/54150,
related to using dispatcher for calls to quantized backends as opposed to if/else conditionals.
This particular PR removes the call to empty_quantized for quantized tensors and substitutes
it for resize_output, which works for quantized tensors, based on current understanding.
Using the dispatcher for this function was determined to be not practical as it would entail
a significant amoutn of duplicate code
Differential Revision:
D33809138
D33809138
Test Plan: Imported from OSS
Reviewed By: jerryzh168
Pulled By: dzdang
fbshipit-source-id: 5bacea37356547ceacea4b3f6b0141ac3a223dcf
(cherry picked from commit 3bb82ff3040c9a7905a3cfe8a57c69cfe0721955)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71854
Support `prim::CreateObject` - this is a native interpreter instruction, so we can't fall back to the JIT for this op.
Test Plan: New unit test exercises creating and modifying custom objects
Reviewed By: d1jang
Differential Revision: D33783759
fbshipit-source-id: 8185ff71b5d441597d712a5d4aab7fc4dddf7034
(cherry picked from commit bd3f52d8e2cd8e20a8d66e2d2b802c1d92088e4e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71807
There's no need to completely disallow `aten::__is__` and `aten::__isnot__`. The only problematic case is when the comparison is between two tensors, e.g. in
```
def forward(x):
y = x.detach()
# Should be false, but we get True
# after our EliminateNoOps pass
return x is y
```
Test Plan: New unit test covers this case
Reviewed By: d1jang
Differential Revision: D33783668
fbshipit-source-id: c9f57fa96937ecce38a21554f12b69c45cc58fe4
(cherry picked from commit 019588f4ca3fcd2b3ae51bccab102f0538745b15)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69735
We want to build a prototype of Megatron-LM so that we can apply PT-D op to models like transformer and other Meta flagship models like
The basic idea of Megatron-LM is as following:
1. Col-wise sharding of linear weight. Perform the linear op for the first layer.
2. Perform a math op (optional), such as ReLU or GeLU. We use GeLU in our example unit test. The input is from step 1.
3. Row-wise sharing of linear weight. Perform the linear op for the second layer. The input is from step 2.
We then save communications to concatenate the col-wise sharding results and spreading the input to different ranks for row-wise sharding.
The change is as following:
1. Return a ShardedTensor for the col-wise sharding in the sharded_linear op.
2. Return a PartialTensors for the row-wise sharding in the sharded_linear op.
3. Leverage APIs already defined for `reshard` to merge/aggregate local results to a fully sync local result if needed.
4. Add helper function to create sharded tensor based on the local result.
5. Add a unit test to test the Megatron-LM idea mentioned above and compare with local ops, including the grad and optimizer so that we can ensure the correctness of the implementation.
6. Refactor the unit test of sharded linear to reflect the changes in the code.
ghstack-source-id: 148273049
Test Plan: Unit test + CI
Reviewed By: pritamdamania87
Differential Revision: D32978221
fbshipit-source-id: 565fc92e7807e19d53b0261f8ace3945bef69e3e
(cherry picked from commit 344abe75202493c8313502e1b22d634568e1b225)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70079
We defined a new concept named `PartialTensor`, which is an abstraction to represent Tensors that need aggregation across multiple devices and multiple processes.
We also defined a API `reshard_output` to reshard a `PartialTensor` to `Tensor` or reshard a `ShardedTensor` to `ShardedTensor/Tensor`. This is done via class `ModuleResharder` which acts like a wrapper of original modules plus the a reshard in the final step.
The `reshard` logic is defined in each class (`ShardedTensor` and `PartialTensor`).
ghstack-source-id: 148273050
Test Plan: Unit test is in the next PR.
Reviewed By: pritamdamania87
Differential Revision: D33121037
fbshipit-source-id: 5f56617ea526b857c5b73df6e069697d428ec359
(cherry picked from commit 58b1457cbcfc9c0bfb3083ef07fbc9e60f0ba51e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72200
This op should still remain private in release 1.11, add underscore before op name to make it happens
Test Plan: buck run mode/opt -c fbcode.enable_gpu_sections=true pytext/fb/tools:benchmark_transformers -- mha --batch-size=10 --max-sequence-length=16
Reviewed By: bdhirsh
Differential Revision: D33952191
fbshipit-source-id: 3f8525ac9c23bb286f51476342113ebc31b8ed59
(cherry picked from commit 6e41bfa4fc242987165fafda1a01735838e3f73d)
Summary:
This should (hopefully) make all the CI from `functorch` go green (including jvp's!) after changing `VARIADIC_BDIMS_BOXED(_svd_helper);` with `VARIADIC_BDIMS_BOXED(_linalg_svd);` and removing all the skip and xfails associated to `linalg.svdvals`.
Locally, there's just one test that started failing because of this, and that is `test_vmapjvpall_norm_nuc_cpu_float32`. I have no idea what's going on here, but it's a jvp product, so not a regression, and it might very well be caused by the jvp of other operation within `norm_nuc` as this is a composite operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72181
Reviewed By: ngimel
Differential Revision: D33952744
Pulled By: zou3519
fbshipit-source-id: 2a2510d97eed4a0bfc25615264ddd36e38856efe
(cherry picked from commit 5805fa107c3a91c58f8ecc9778cfc87aa7f64233)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/71616
This fixes the leaks in my test case. I have not tested it on our big models yet, but will report back if we can.
This potentially impacts allocator performance in that it slightly increases the amount of CPU memory we allocate for data structures, and it means that `process_events` may look at a larger number of events in the case where there are multiple streams with long-running ops on them.
However, I suspect that in general, either:
- An application isn't using very many streams or very many long-running ops, in which case the performance is essentially the same
- Or, they are, which is precisely the case where https://github.com/pytorch/pytorch/issues/71616 bites you, and so freeing memory faster is probably more valuable than the slight CPU overhead here.
I'm not attached to this approach or any of its details, but figured it was worth throwing up for discussion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71745
Reviewed By: soulitzer
Differential Revision: D33948288
Pulled By: ngimel
fbshipit-source-id: 73e95f8a9bbe385a77de483d1c58b857b5d84e81
(cherry picked from commit d233719c072341607e6dab226b5cbfe8d316d91f)
Summary:
When the constant list is empty, previous codegen will generate something like
```
std::vector<c10::IValue>({
}), // constants list,
```
However it will fail quick-check, because it includes trailing spaces. This pr will generate the following instead.
```
std::vector<c10::IValue>(), // constants list,
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72199
ghstack-source-id: 148231023
Test Plan: CI
Reviewed By: tugsbayasgalan
Differential Revision: D33952046
fbshipit-source-id: 359b8a418928c89bbeb446b44774b312c94f03bc
(cherry picked from commit 060490f66724e418a43548c2eaffa3244e780557)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72145
- Added a predicate that allows us not to lower nodes with specific names.
- Added an observer function to help with the debugging
Reviewed By: jasonjk-park, houseroad
Differential Revision: D33785834
fbshipit-source-id: 7bdb7f33851da1118763c85f8e2121d01e4914a2
(cherry picked from commit 4e2268ed45c394822f38ef82334f0c76721556cf)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72176
I went through the manual_cpp_binding operations in
native_functions.yaml looking for important things that people use that
don't go through the dispatcher and came up with this.
There's currently no mechanism for functorch (or Tensor subclasses)
to change the behavior of tensor.requires_grad_() and
tensor.retains_grad() because these don't go through the dispatcher at
all.
This PR adds a hook for functorch to be able to throw an error on these.
In the future they should probably be overridable with torch_dispatch
(or at least configurable!).
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33943151
Pulled By: zou3519
fbshipit-source-id: df7eb0acad1da3adaf8c07e503ccf899e34571a2
(cherry picked from commit bba7207dc77a12ceedfbd16d44e4d287287423bf)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69838
Implement `prim::Loop` with the new `StaticRuntimeBlockRunner` abstraction.
ghstack-source-id: 148186483
Test Plan: New unit tests: `buck test caffe2/benchmark/static_runtime/...`
Reviewed By: d1jang
Differential Revision: D33049595
fbshipit-source-id: 550de5167b46fccd65ff77d092785289b5e5d532
(cherry picked from commit 8baf1753af34f4c166b4680e42589517fd2e508d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69837
Implement `prim::If` with the new `StaticRuntimeBlockRunner` abstraction.
ghstack-source-id: 148186475
Test Plan:
New unit tests: `buck test caffe2/benchmarks/static_runtime/...`
Accuracy test at top of stack
Reviewed By: d1jang
Differential Revision: D33045908
fbshipit-source-id: 281fb4a73528249fa60f65ac26f8ae6737771f55
(cherry picked from commit de3b12dc0871e8ca09891c257e1dfd7cd352aa7c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69836
It is technically possible for the sub-blocks to return zero outputs. This is problematic for `StaticRuntimeBlockRunner`, because it assumes that at least one output is being returned.
Rather than slowing down SR with special logic for this corner case, we can simply force these sub-blocks to return `None`.
ghstack-source-id: 148186453
Test Plan: Sub-blocks with no return values tested at top of stack
Reviewed By: d1jang
Differential Revision: D33050420
fbshipit-source-id: 17d9e19fda6431aa9fd0b155131349bac42bc149
(cherry picked from commit c97fd07bf53e1e253a0e6c733db5ea7c86698fc9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69835
`StaticRuntimeBlockRunner` moves its outputs to the return value at the end of `run_impl`. However, there's a corner case where this can cause problems. If we return a constant, then the only reference in the `constants_` array can be destroyed by this move. We could add special logic to handle this in `run_impl`. But since this is a relatively rare corner case, it's simpler to just add an op that does nothing but create an owned reference to its input. This owned reference can be safely moved out of `StaticRuntimeBlockRunner`.
Note that this also applies to returned values in sub-blocks that are from outer scopes.
ghstack-source-id: 148186452
Test Plan:
`buck test caffe2/benchmarks/static_runtime/...`
Added a new unit test with a graph that simply returns a constant.
Tests with sub-blocks at top of stack.
Reviewed By: d1jang
Differential Revision: D33047519
fbshipit-source-id: 22b6058f0d1da8a6d1d61a6f2866bc518bff482b
(cherry picked from commit a8f89a12ee726aa7d7e546dee25d696eef868ce7)
Summary:
This improves a dry-run of `gen.py` from 0.80s to 0.45s.
`FileManager` in `dry_run` mode doesn't actually need to compute the
environment; it just records the filenames that would have been
written.
cc ezyang bhosmer bdhirsh
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69805
Reviewed By: ngimel
Differential Revision: D33944912
Pulled By: albanD
fbshipit-source-id: 74f22af3f2bd5afdef7105961270198566fa91e5
(cherry picked from commit 6fcdc15954788257b76e14087ba1ebf63fd3ab27)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71539
This is the first of the optimizing changes. One of the issues with kineto sometimes being unavailable is we cannot use it as a storage mechanism. KinetoEvent currently fills this role, however KinetoEvent is VERY expensive. A second issue is that because we currently write to two objects, we hold the state lock for the duration of both event creations which is not ideal.
This applies the following optimizations:
1) Intermediate data is stored in a deque in KinetoThreadLocalState, which saves a data->KinetoObserverContext->KinetoEvent double copy. The new KinetoObserverContext just holds a pointer to the element in the deque.
2) OpEventData is much lighter weight (though still far from ideal)
Test Plan:
Script: P470970719
Result: P470970794
For the base case (no special flags), 40% reduction in the `profiler_kineto` portion of the overhead.
Reviewed By: aaronenyeshi
Differential Revision: D32691800
fbshipit-source-id: 3d90d74000105d0ef1a7cb86d01236610e7e3bbd
(cherry picked from commit fbca1b05bac60ed81d6cd3b2cfdb7ffb94ebeb6a)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70591
This PR makes `torch.asarray` consistent with [the Python Array API](https://data-apis.org/array-api/latest/API_specification/generated/signatures.creation_functions.asarray.html#signatures.creation_functions.asarray) (which also happens to be the same as `torch.as_tensor` behavior). Specifically, it makes `asarray` casting conditional to the presence of the `dtype` argument. This solves the issue when Python scalars (and lists) were passed as input without specifying the `dtype`.
Before:
```python
>>> torch.asarray([True, False])
tensor([1., 0.])
```
After:
```python
>>> torch.asarray([True, False])
tensor([True, False])
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71757
Reviewed By: mrshenli
Differential Revision: D33774995
Pulled By: anjali411
fbshipit-source-id: 9f293401f993dca4046ceb61f714773ed4cf7c46
(cherry picked from commit 0c6f98ebe7c843a68f624d2d9c3cae39f018bb66)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72084
make fsdp folder to be public
ghstack-source-id: 148173447
Test Plan: unit tests
Reviewed By: mrshenli
Differential Revision: D33903417
fbshipit-source-id: 7852a2adc4af09af48a5ffa52ebf210489f834d5
(cherry picked from commit bd06513cfe2f391941bb0afa611dd39994585513)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72141
We have many sharding components currently:
torch.distributed._sharded_tensor, torch.distributed._sharding_spec,
torch.distributed._sharded_optimizer and more coming.
As a result, organizing all of this under the `torch.distributed._shard`
package. For BC reasons, I'm still keeping the old packages and have them just
reference the new package.
ghstack-source-id: 148150861
ghstack-source-id: 148150861
Test Plan: waitforbuildbot
Reviewed By: fduwjj
Differential Revision: D33904585
fbshipit-source-id: 057e847eb7521b536a3ee4e0f94871aacc752062
(cherry picked from commit 29a70dd7afde6083bab942081020a13278f38e52)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72123
There is a bug to fix the typing system in DataPipe, which would take more than 1 week to fix. I will follow up on it later this month. As branch cut is today, add this PR to disable typing to make sure release works.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D33920610
Pulled By: ejguan
fbshipit-source-id: febff849ab2272fd3b1c5127a20f27eb82992d9c
(cherry picked from commit ee103e62e70b69236294f8228ac8061fd95cd4fd)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72111
For vectorize flag:
- Advertises the use of functorch
For autograd.functional.jvp:
- Advertises the use of functorch and the low-level jvp API, both of
which will be more performant than the double backprop trick.
Test Plan: - view docs
Reviewed By: albanD
Differential Revision: D33918065
Pulled By: zou3519
fbshipit-source-id: 6e19699aa94f0e023ccda0dc40551ad6d932b7c7
(cherry picked from commit b4662ceb99bf79d56727d9f1343669e584af50bd)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72153
Forgot that schemas can have types like foo.bar[]
Test Plan: ci and the extra files regenerated in this diff
Reviewed By: tugsbayasgalan
Differential Revision: D33928283
fbshipit-source-id: 810d25f8f7c1dd7c75e149739fc9f59c6eafe3b9
(cherry picked from commit 6fe5e8c437d1eddb600448ecf323262fc1a4c60b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71579Fixes#1551
As the comment in the code, register a function to terminate persistent workers.
By adding a reference of these workers in `atexit`, it would prevent Python interpreter kills these persistent worker processes before `pin_memorh_thread` exits.
And, if users explicitly kills DataLoader iterator, such function in `atexit` would be a no-op.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D33896537
Pulled By: ejguan
fbshipit-source-id: 36b57eac7523d8aa180180c2b61fc693ea4638ae
(cherry picked from commit 05add2ae0fcd08b6ecb5dc46cfbf4c126c6427ed)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72067
The majority of scripts used to generate the changes are from Richard Barnes (D28874212).
Use irange in PyTorch, which adds some benefits
- const safety
- might help the compiler to generate more efficient binary
- more concise
Originally, I was planning to change everything include the head files. But it caused too many errors in other places, therefore I changed the script to only change the cpp and cc files.
```
#filetypes = ('.cpp', '.cc', '.h', '.hpp')
filetypes = ('.cpp', '.cc')
```
Even only changing the cpp(cc) files, there are still some unknown issues, therefore I limited to **aten** folder to begin with.
```
#target_path = '..'
target_path = '../aten'
```
**Later on, we could run the script for each folder one by one.**
The following files are known to cause issues (such as name space conflicts (already in c10 namespace), loop variable should not be constant etc). We will need to deal with them one by one.
```
excluded_files = ['../c10/util/ConstexprCrc.h',
'../aten/src/ATen/core/jit_type.h',
'../aten/src/ATen/native/Math.h',
'../c10/util/variant.h',
'../c10/util/flags_use_no_gflags.cpp',
'../caffe2/operators/cc_bmm_bg_op.h',
'../aten/src/ATen/core/tensor_type.cpp',
'../aten/src/ATen/native/Linear.cpp',
'../aten/src/ATen/native/ConvolutionTBC.cpp',
'../caffe2/share/fb/mask_rcnn/bbox_concat_batch_splits_op.h',
'../aten/src/ATen/native/BatchLinearAlgebra.cpp',
'../aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp',
'../aten/src/ATen/native/cuda/DistributionTemplates.h',
'../c10/util/sparse_bitset.h',
'../torch/csrc/distributed/c10d/TCPStore.cpp',
'../caffe2/fb/operators/calibration_op.h',
'../torch/csrc/jit/testing/file_check.cpp',
'../torch/csrc/jit/passes/concat_opt.cpp',
'../torch/csrc/jit/tensorexpr/operators/reduction.cpp',
'../torch/fb/operators/select_keys.cpp',
'../torch/fb/operators/calibration/bucketize_calibration.cpp',
'../fb/custom_ops/maskrcnn/int8/int8_aabb_roi_align.cpp',
'../fb/custom_ops/maskrcnn/aabb/aabb_roi_align.cpp',
'../caffe2/fb/tests/RecordIOHelper.cpp',
'../test/cpp/api/rnn.cpp',
'../torch/fb/training_toolkit/common/tdigest/tests/TestBufferedTDigest.cpp'
]
```
I placed **use_irange.py** at cafee2/script and run the script from there.
```
[charleszhang@devvm7388]~/fbsource/fbcode/caffe2/scripts% pwd
/home/charleszhang/fbsource/fbcode/caffe2/scripts
[charleszhang@devvm7388]~/fbsource/fbcode/caffe2/scripts% ls -l use*
-rwxr-xr-x 1 charleszhang users 5174 Jan 27 10:18 use_irange.py
```
The following is **use_irange.py** I used to generate the changes.
```
#!/usr/bin/env python3
# (c) Facebook, Inc. and its affiliates. Confidential and proprietary.
import re
import os
irange_header = "#include <c10/util/irange.h>"
# I recommend using https://regex101.com/ to understand this.
for_loop_regex = re.compile(
r"for\s*\((?:int32_t|int64_t|uint32_t|int64_t|size_t|int|unsigned|auto|std::size_t|short|uint16_t|uint8_t) ([A-Za-z0-9_]+)\s*=\s*([^\s]+)\s*;\s*\1\s*<\s*([^\s]+)\s*;\s*(?:\+\+\1|\1\+\+)\s*\)\s*({?)")
header_regex = re.compile(r'#include ["<][^>"]+(?:[">])')
new_loop_zero = "for (const auto {loop_var} : c10::irange({upper_bound})){bracket}"
new_loop_range = (
"for (const auto {loop_var} : c10::irange({lower_bound}, {upper_bound})){bracket}"
)
#header_insertion_points = (("c10", "alpha"), ("ATen/", "after"), ("torch/", "before"))
def find_c10(data : str) -> int:
insert_at = -1
for m in header_regex.finditer(data):
if "c10/" in m.group(0):
if insert_at is None:
insert_at = m.span()[0]
if irange_header > m.group(0):
insert_at = m.span()[1]
return insert_at
def find_ATen(data : str) -> int:
insert_at = -1
for m in header_regex.finditer(data):
if "ATen/" in m.group(0):
insert_at = m.span()[1]
return insert_at
def find_torch(data : str) -> int:
for m in header_regex.finditer(data):
if "torch/" in m.group(0):
return m.span()[0]
return -1
def find_header_insertion_point(data: str) -> (int, str):
"""Look through headers to find an insertion point."""
m = find_c10(data)
if m != -1:
return m, "after"
else:
m = find_ATen(data)
if m != -1:
return m, "after"
else:
m = find_torch(data)
return m, "before"
def process_one_file(a_file : str):
data = ''
with open(a_file) as f:
data = f.read()
has_for_loop = for_loop_regex.findall(data)
if not has_for_loop:
return
needs_header = has_for_loop and irange_header not in data
if needs_header:
pos, stype = find_header_insertion_point(data)
# we do no change the file if do not know where to insert the head file
# for now, since there are too many of them
if pos == -1:
return
if stype == "after":
data = data[0:pos] + "\n" + irange_header + data[pos:]
else:
data = data[0:pos] + irange_header + "\n" + data[pos:]
start = 0
new_data = ""
for match in for_loop_regex.finditer(data):
loop_text_begin, loop_text_end = match.span()
loop_var = match.group(1)
lower_bound = match.group(2)
upper_bound = match.group(3)
bracket = " {" if match.group(4) == "{" else ""
if lower_bound == "0":
replacement_loop = new_loop_zero.format(
loop_var=loop_var, upper_bound=upper_bound, bracket=bracket
)
else:
replacement_loop = new_loop_range.format(
loop_var=loop_var,
lower_bound=lower_bound,
upper_bound=upper_bound,
bracket=bracket,
)
old_loop = data[loop_text_begin : loop_text_end]
new_data += data[start : loop_text_begin] + replacement_loop
start = loop_text_end
new_data += data[start:]
with open(a_file, "w") as fout:
fout.write(new_data)
#filetypes = ('.cpp', '.cc', '.h', '.hpp')
filetypes = ('.cpp', '.cc')
#target_path = '..'
target_path = '../aten'
excluded_files = ['../c10/util/ConstexprCrc.h',
'../aten/src/ATen/core/jit_type.h',
'../aten/src/ATen/native/Math.h',
'../c10/util/variant.h',
'../c10/util/flags_use_no_gflags.cpp',
'../caffe2/operators/cc_bmm_bg_op.h',
'../aten/src/ATen/core/tensor_type.cpp',
'../aten/src/ATen/native/Linear.cpp',
'../aten/src/ATen/native/ConvolutionTBC.cpp',
'../caffe2/share/fb/mask_rcnn/bbox_concat_batch_splits_op.h',
'../aten/src/ATen/native/BatchLinearAlgebra.cpp',
'../aten/src/ATen/native/quantized/cpu/kernels/QuantizedOpKernels.cpp',
'../aten/src/ATen/native/cuda/DistributionTemplates.h',
'../c10/util/sparse_bitset.h',
'../torch/csrc/distributed/c10d/TCPStore.cpp',
'../caffe2/fb/operators/calibration_op.h',
'../torch/csrc/jit/testing/file_check.cpp',
'../torch/csrc/jit/passes/concat_opt.cpp',
'../torch/csrc/jit/tensorexpr/operators/reduction.cpp',
'../torch/fb/operators/select_keys.cpp',
'../torch/fb/operators/calibration/bucketize_calibration.cpp',
'../fb/custom_ops/maskrcnn/int8/int8_aabb_roi_align.cpp',
'../fb/custom_ops/maskrcnn/aabb/aabb_roi_align.cpp',
'../caffe2/fb/tests/RecordIOHelper.cpp',
'../test/cpp/api/rnn.cpp',
'../torch/fb/training_toolkit/common/tdigest/tests/TestBufferedTDigest.cpp'
]
for current_folder, subfolders, files in os.walk(target_path):
for a_file in files:
if a_file.endswith(filetypes) and current_folder != '../caffe2/torch/jit':
full_path = os.path.join(current_folder, a_file)
if full_path not in excluded_files:
process_one_file(full_path)
```
Test Plan: Sandcastle
Reviewed By: r-barnes
Differential Revision: D33892443
fbshipit-source-id: eb76a3b39e6bebb867ede85f74af9791ee8be566
(cherry picked from commit 28f8a2a6cca5b9a4e4ce4166bdc50135caf1b311)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72008
Fixes #71119
Technically BC-breaking because when an input does not require grad, previously it was returned as-is instead of a view because it didn't need to. Now we will also return a view in that case (whether or not forward AD runs).
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33859553
Pulled By: soulitzer
fbshipit-source-id: 81b3fa371f4c0904630878500aa190492c562367
(cherry picked from commit ee74bc82342e2a42577101cb1aef43330a028a89)
Summary:
This updates flatbuffer submodule from v1.12.1 to v2.0.5, but according to relnotes on [v2.0.0](https://github.com/google/flatbuffers/releases/tag/v2.0.0):
> Note, "2.0" doesn't signify any kind of major overhaul of FlatBuffers, it is merely trying to be more semver compatible, and this release does have breaking changes for some languages much like all releases before it.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72132
Reviewed By: seemethere
Differential Revision: D33923945
Pulled By: malfet
fbshipit-source-id: 9398d35f6bbc4ec05562a25f6ee444b66df94086
(cherry picked from commit 2335d5f69b0b0ee36ead7f5d66cfc47a1954f834)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71986
To address concerns over space increase from control flow.
`op_name_` was only stored as a minor optimization to avoid name lookup during logging, we can safely get rid of it. Thanks to the sampling mechanism, `get_op_name()` is called very infrequently, so this shouldn't cause too much of a regression
ghstack-source-id: 148086244
Test Plan: CI
Reviewed By: d1jang
Differential Revision: D33821005
fbshipit-source-id: 6f74eb30a54a046ca90768aebbcde22e8c435f35
(cherry picked from commit 361ba32e97dbd130938bae10b5159730822c518c)
Summary:
The default initialization of stride order were not correct. This ended up with an expanded tensor showing wrong stride, since stride 0 is ignored by TensorIterator stride computation logic [Computing output strides].
Quick fix with cpp tests as well.
Note that things still look strange when we expand from a rank 1 size 1 tensor, as that gives us inconsistent strides.
```
In [7]: x = torch.rand([1])
In [8]: x.expand(1, 1, 4, 4).stride()
Out[8]: (0, 0, 0, 0)
In [9]: x.expand(4, 4, 1, 1).stride()
Out[9]: (0, 0, 1, 1)
In [10]: x.expand(4, 1, 4, 1).stride()
Out[10]: (0, 0, 0, 1)
```
Meanwhile, scalar tensor seems to work fine.
```
In [2]: x = torch.tensor(1.0)
In [3]: x.expand(4, 1, 1, 4).stride()
Out[3]: (0, 0, 0, 0)
In [4]: x.expand(4, 1, 4, 1).stride()
Out[4]: (0, 0, 0, 0)
In [5]: x.expand(4, 4, 1, 1).stride()
Out[5]: (0, 0, 0, 0)
In [6]: x.expand(1, 1, 4, 4).stride()
Out[6]: (0, 0, 0, 0)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71665
Reviewed By: mrshenli
Differential Revision: D33849958
Pulled By: davidberard98
fbshipit-source-id: 982cd7fa352747d1e094a022475d6d1381ba75e5
(cherry picked from commit 0e0b587fe18ed47f4e801bb55a10641b9decd6e4)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/71720
This PR removes the old warnings for `recompute_scale_factor` and `align_corners`.
Looking at this, I realize that the tests I modified don't really catch whether or not a warning is created for `recompute_scale_factor`. If desired, I can add a couple lines into the tests there to pass a floating point in the `scale_factors` kwarg, along with `recompute_scale_factor=None`.
Let me know how this looks, thanks so much!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72093
Reviewed By: mruberry
Differential Revision: D33917615
Pulled By: albanD
fbshipit-source-id: e822f0a15b813ecf312cdc6ed0b693e7f1d1ca89
(cherry picked from commit c14852b85c79d11adb1307a35cbf82e60ae21d50)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71427
This commit adds a lowering path for the LinearReLU modules
in static quantization mode. This includes torch.nn.qat.Linear,
torch.nn.intrinsic.LinearReLU, and torch.nn.intrinsic.qat.LinearReLU.
Future commits will add support for dynamic quantization and functional
LinearReLU.
Test Plan:
python test/test_quantization.py TestQuantizeFxOps.test_linear_module
Imported from OSS
Reviewed By: george-qi
Differential Revision: D33694742
fbshipit-source-id: 19af11f82b1ad8ade0c307498971c29a3f776036
(cherry picked from commit b3f607de439f2ba7c0a03ad1ac494127685cbf4e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72032
This contains a few channels last changes from benchmarking:
- dont permute back to channels last on dynamic, cpu, perf is not good, and use cases for it are exotic atm
- remove the conditional one handling in permutting channels last symbolic tensor on cuda, it's not needed in the permutation case as tests show
- removing logic in torch/csrc/jit/tensorexpr/loopnest.cpp preventing inlining. the condition in checks is always valid given valid construction of ir
I can split up as needed.
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D33864652
Pulled By: eellison
fbshipit-source-id: f16674fb02dfff22670d8a2f856c5a317fd15717
(cherry picked from commit a9a069783956802e9e2f30c7a06e8e2ca8d210a1)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71651
The only tests that regress are because chunk NYI, the other tests that I touched were passing just because the `assertAllFused` wasn't working correctly. That, and we're no longer compiling conv/matmul w dynamic shapes
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D33801500
Pulled By: eellison
fbshipit-source-id: 074118ab4a975b7db876a4fcdfb9483afb879e79
(cherry picked from commit abaa7948c18bf2dc885efd9323a92449d321afbc)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71650
*
Refactors PE so there is a current fusion strategy set, which will take in a vector of e.g. [(STATIC, 2), (DYNAMIC, 10)] which means fuse two static invocations then fuse 10 dynamic ones, then stop specializing.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33801501
Pulled By: eellison
fbshipit-source-id: ebc7ac3c57e35a3b9bb15ab751f0aa1d25cc9bd5
(cherry picked from commit 8dd89088d3ceae800ea110d0b6949b759d4fe582)
Summary:
Pull Request resolved: https://github.com/pytorch/torchrec/pull/39
Pull Request resolved: https://github.com/facebookresearch/torchrec/pull/6
This makes it so that shared parameters get their own entry in `named_parameters`.
More broadly, this makes it so that
```
params_and_buffers = {**mod.named_named_parameters(remove_duplicate=False), **mod.named_buffers(remove_duplicate=False)}
_stateless.functional_call(mod, params_and_buffers, args, kwargs)
```
is identical to calling the original module's forwards pass.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71542
Reviewed By: jbschlosser, albanD
Differential Revision: D33716716
Pulled By: Chillee
fbshipit-source-id: ff1ed9980bd1a3f7ebaf695ee5e401202b543213
(cherry picked from commit d6e3ad3cd0c694886d4d15a38876835e01f68134)
Summary:
This PR upgrades oneDNN to v2.5.2, and includes some building support for oneDNN v2.5.2.
v2.4 changes:
- Improved performance for future Intel Xeon Scalable processor (code name Sapphire Rapids). The functionality is disabled by default and should be enabled via CPU dispatcher control.
- Improved binary primitive performance for cases when one of the tensors is broadcasted.
- Improved performance of reduction primitive, reorder, shuffle primitives.
- Improved performance of depthwise convolution forward propagation for processors with Intel AVX5-12 support
- Improved performance of forward inner product primitive for the shapes with minibatch equal to 1 for processors with Intel AVX-512 support
- Improved performance of int8 matmul and inner product primitives for processors with Intel AVX2 and Intel DL Boost support
v2.5 changes:
- Improved performance for future Intel Xeon Scalable processors (code name Sapphire Rapids). The functionality is now enabled by default and requires Linux kernel 5.16.
- Improved performance of matmul primitive for processors with Intel AVX-512 support.
v2.5.2 changes:
- Fixed performance regression in binary primitive with broadcast
- Fixed segmentation fault in depthwise convolution primitive for shapes with huge spatial size for processors with Intel AVX-512 support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71546
Reviewed By: george-qi
Differential Revision: D33827108
Pulled By: VitalyFedyunin
fbshipit-source-id: 8f5a19b331c82af5b0783f081e061e1034a93952
(cherry picked from commit 9705212fe9b7b0838cc010d040c37d1175be83ce)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71486
This PR adds upgraders for linspace and linspace.out as the optional step size will be deprecated soon. Old models will be using steps size of 100 when nothing is provided.
Test Plan: buck-out/gen/caffe2/test/jit#binary.par -r TestUpgraders.test_aten_linspace
Reviewed By: cccclai, mruberry
Differential Revision: D33654308
fbshipit-source-id: 0e0138091da0b11d4f49156eeb6bcd7e46102a5b
(cherry picked from commit 931ae4af3200b37d1cebcb7f30e8ba880c1305ec)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70103
I used an argument so it can be disabled. I called it `deterministic_order` because `sort` can be confusing, as it's actually sorted but by dir levels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70435
Reviewed By: albanD
Differential Revision: D33899755
Pulled By: ejguan
fbshipit-source-id: e8a08f03a49120333b2d27f332cd21a3240a02a9
(cherry picked from commit 4616e43ec30ba425585c041f8895196909f94d1b)
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 1280f817bf
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72116
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jasonjk-park
Differential Revision: D33919076
fbshipit-source-id: 8d27fd898af101494e4b54f9abfd27e6169cfd4d
(cherry picked from commit 1731bbd676f8bc739cdb5d9b50cb151816318484)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71200
To quantify how much cublas lt interface can help param bench (https://github.com/facebookresearch/param/) linear perf
On V100 GPU
for b in 512 1024; do for i in {1..5}; param_bench/train/compute/pt/pytorch_linear.py --device gpu --dtype=float16 --hidden-size 1024 --batch-size ${b}; done; done
Before this commit
batch size 512: median 21.4 TF/s (20.7, 20.6, 21.8, 21.6, 21.4)
batch size 1024: median 40.1 TF/s (39.4, 39.3, 40.2, 40.4, 40.1)
After this commit
batch size 512: median 23.5 TF/s (23.2, 23.5, 23.8, 23.9, 23.6 ) 9.8% speedup
batch size 1024: median 41.6 TF/s (42.7, 41.6, 40.4, 41.3, 41.9 ) 3.7% speedup
Reviewed By: jasonjk-park, ngimel
Differential Revision: D32053748
fbshipit-source-id: accf787c8727a2f8fb16fae92de461367ac10442
(cherry picked from commit 254532ac451859982da07648431ccbea12e21397)
Summary:
# Overview
Currently the cuda topk implementation uses only 1 block per slice, which limits the performance for big slices. This PR addresses this issue.
There are 2 parts in the topk calculation, find the kth value (`radixFindKthValues`) in each slice, then gather topk values (`gatherTopK`) based on the kth value. `radixFindKthValues` kernel now supports multiple blocks. `gatherTopK` may also need a multiple block version (separate PR?).
kthvalue, quantile, median could also use the same code (separate PR).
# Benchmark
Benchmark result with input `x = torch.randn((D1 (2d884f2263), D2 (9b53d3194c)), dtype=torch.float32)` and `k = 2000` on RTX 3080: https://docs.google.com/spreadsheets/d/1BAGDkTCHK1lROtjYSjuu_nLuFkwfs77VpsVPymyO8Gk/edit?usp=sharing
benchmark plot: left is multiblock, right is dispatched based on heuristics result from the above google sheet.
<p class="img">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860547-7e450ed2-df09-4292-a02a-cb0e1040eebe.png">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860579-672b88ca-e500-4846-825c-65d31d126df4.png">
</p>
The performance of divide-and-conquer implementation at https://github.com/pytorch/pytorch/pull/39850 is not stable in terms of the D1 (2d884f2263), D2 (9b53d3194c) size increasing, for more detail please check the above google sheet.
<p>
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860563-21d5a5a3-9d6a-4cef-9031-cac4d2d8edee.png">
</p>
# cubin binary size
The cubin binary size for TensorTopK.cubin (topk) and Sorting.cubin (kthvalue, quantile and etc) has been reduced by removing `#pragma unroll` at [SortingRadixSelect.cuh](https://github.com/pytorch/pytorch/pull/71081/files#diff-df06046dc4a2620f47160e1b16b8566def855c0f120a732e0d26bc1e1327bb90L321) and `largest` template argument without much performance regression.
The final binary size before and after the PR is
```
# master
-rw-rw-r-- 1 richard richard 18M Jan 24 20:07 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 16M Jan 24 20:07 Sorting.cu.1.sm_86.cubin
# this PR
-rw-rw-r-- 1 richard richard 5.0M Jan 24 20:11 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 2.5M Jan 24 20:11 Sorting.cu.1.sm_86.cubin
```
script to extract cubin
```
# build with REL_WITH_DEB_INFO=0
# at pytorch directory
cubin_path=build/caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/cubin; mkdir -p $cubin_path; cd $cubin_path; find ../ -type f -name '*cu.o' -exec cuobjdump {} -xelf all \; ; ls -lh *.cubin -S | head -70
```
# benchmark script
```py
import torch
import time
import torch
import pandas as pd
import numpy as np
import torch.utils.benchmark as benchmark
torch.manual_seed(1)
dtype = torch.float
data = []
for d1 in [1, 20, 40, 60, 80, 100, 200, 400, 800, 1000, 2000, 4000, 6000, 8000, 10000, 100000, 500000]:
if d1 <= 1000:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 2000, 3000, 4000, 5000, 8000, 10000, 20000, 30000, 40000, 80000, 100000, 200000, 300000, 400000, 500000]
else:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 5000, 10000, 20000, 30000]
for d2 in D2 (9b53d3194c):
k = 2000 if d2 >= 2000 else d2 // 2
print(f"----------------- D1 (2d884f2263) = {d1}, D2 (9b53d3194c) = {d2} -----------------")
try:
x = torch.randn((d1, d2), dtype=dtype, device="cuda")
m = benchmark.Timer(
stmt='x.topk(k=k, dim=1, sorted=False, largest=True)',
globals={'x': x, 'k': k},
num_threads=1,
).blocked_autorange(min_run_time=1)
print(m)
time_ms = m.median * 1000
except RuntimeError: # OOM
time_ms = -1
data.append([d1, d2, k, time_ms])
df = pd.DataFrame(data=data, columns=['D1 (2d884f2263)', 'D2 (9b53d3194c)', 'k', 'time(ms)'])
print(df)
df.to_csv('benchmark.csv')
```
plot script could be found at: https://github.com/yueyericardo/misc/tree/master/share/topk-script
cc zasdfgbnm ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71081
Reviewed By: albanD
Differential Revision: D33823002
Pulled By: ngimel
fbshipit-source-id: c0482664e9d74f7cafc559a07c6f0b564c9e3ed0
(cherry picked from commit be367b8d076aebf53ab7511f6a8a86834c76c95b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71669
This was relatively inefficient. Rather than looping for each type of stat we want to update, we now do one loop covering all the stats.
ghstack-source-id: 148013645
Reviewed By: ngimel
Differential Revision: D33725458
fbshipit-source-id: 39ef5d65a73d4ef67f259de8c02c7df29487d990
(cherry picked from commit 7ca46689b72ba7611517447a292445571bd02dd7)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71667
We have flat_hash_set because it performs better than std::unordered_set.
ghstack-source-id: 148013648
Reviewed By: ngimel
Differential Revision: D33720595
fbshipit-source-id: aa6077c474dd6fc61ce17e24ebde4056c8bae361
(cherry picked from commit 386082eaf1d4669c7967ba9cdf765d9d677f5cd9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69834
* Modify the `StaticModule` constructor to handle index initialization for sub-blocks.
* Add a new class `StaticRuntimeBlockRunner`. This class is almost exactly like what we've been calling `StaticRuntime` up to this point, except that it does not own a `values_` array. All `StaticRuntimeBlockRunners` hold an unowned reference to a `values_` array owned by `StaticRuntime`. This is a useful abstraction for implementing control flow - it gives us a way for sub-blocks to look up values from surrounding scopes!
ghstack-source-id: 148086245
Test Plan: `buck test caffe2/benchmarks/static_runtime/...`
Reviewed By: d1jang
Differential Revision: D33028039
fbshipit-source-id: 4f01417bad51a0cf09b1680a518308da647be1f6
(cherry picked from commit 3a9feffd929869120c717d35aa55aad8a382783d)
Summary:
Today, the enum is ignored and the generic assert within the equal function is used leading to no information in the error message when this fails.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72070
Reviewed By: bdhirsh
Differential Revision: D33893602
Pulled By: albanD
fbshipit-source-id: 4bc644e9232cbf0bafef22d713948915eb6964ff
(cherry picked from commit bdcc5f5f476f3b9ccd2068f365a734b7df756f02)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61646
There are several passes which are written to handle both
`CallFunction("linear", ...)` and `aten::linear(...)` despite the two being
functionally identical.
This changes `FuseLinear` to alse normalize the `CallFunction` variant to
`aten::linear`. That way each subsequent transformation only has to handle one
form instead of both.
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33754261
Pulled By: albanD
fbshipit-source-id: 42465cea790538481efc881a249dafdda4bba5d4
(cherry picked from commit ebeca9434caf74c5e75f61b98db443779fe5c6a9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61608
See #61544 for an example of issues created by functional wrappers. In this
case, these are directly wrapping the native function with no added
functionality. One exception was `bilinear` which was just missing the default
argument in C++, but was otherwise the same.
I've kept the symbol `torch.functional.istft` because it looks like public API,
but it could just as easily be moved to `_torch_docs.py`.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D31401361
Pulled By: albanD
fbshipit-source-id: 162b74d0b2d4f2e5c4834687a94541960cefdd52
(cherry picked from commit 700cd73ca121d903f04f539af171d3f768565921)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71426
dbr quantization makes faulty assumptions about which arguments are
passed as keyword arguments and which are passed as positional
arguments. This happens to work currently due to a quirk of how
`__torch_function__` is implemented in python functions, but will
break when the operators are moved to C++.
Test Plan: Imported from OSS
Reviewed By: george-qi
Differential Revision: D33754262
Pulled By: albanD
fbshipit-source-id: 63515d7a166449726e1beaba6659443b6261742d
(cherry picked from commit f7b18848455cd95872b2b658111206b71ce4b3f7)
Summary:
This will be needed by functorch to have the expected behavior of randomness:
Dropout generates a tensor of the right size and then calls `bernoulli_` on that. In order to get the expected behavior from ensembled creation, we'll need to make sure that the generated tensor is a batched tensor.This works mostly because most tensors are created as `empty_like` but this one just creates `empty` because it needs a new shape, only for feature dropout. There is also no analogous version in CUDA because this directly calls`_dropout_impl` here (not in native_functions.yaml)
This shouldn't change the behavior outside of functorch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72078
Reviewed By: zou3519
Differential Revision: D33898338
Pulled By: samdow
fbshipit-source-id: 9d9ed59d138d732d9647b2771ccf2ea97cffae1c
(cherry picked from commit e51cf3ebf2c80a65296c7513576042dd58e0de28)
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 35d4dd4eb3
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72068
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: malfet
Differential Revision: D33892960
fbshipit-source-id: 462b24ab3a81862bbfdc8e80fe07ea262e11829f
(cherry picked from commit c5d2b40fa61e185fab1237c07a0ddc875bcb9203)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71992
This reverts commit b7222e15b6a457099b74420e29b3a39a3e8b5f1a.
We are conservatively reverting this because it broke a test in functorch.
The original PR added a `_max_pool1d_cpu` operator. I'm not sure if it
is actually safe to revert this due to the addition of the new operator
(someone may have serialized it between now and then) but because it has
only been two weeks this should be fine.
Test Plan: - wait for tests
Reviewed By: jbschlosser, VitalyFedyunin
Differential Revision: D33882918
Pulled By: zou3519
fbshipit-source-id: f146e82e6b46690376b3d8825dc7f7da62e2c7de
(cherry picked from commit 1606333e6ce23d618863a9b0e504352bd55569bc)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72081
This PR fixes the libstdc++ ABI check in CMake package configuration file (i.e. `TorchConfig.cmake`) The `_GLIBCXX_USE_CXX11_ABI` flag is a property of `libstdc++`, not GNU compiler collection. In its current form C++ libraries built with Clang on Linux fail since the `torch` CMake target propagates `_GLIBCXX_USE_CXX11_ABI` only when used with gcc.
ghstack-source-id: 148056323
Test Plan: Built a dummy C++ library that depends on libtorch with both gcc and clang on Linux
Reviewed By: malfet
Differential Revision: D33899849
fbshipit-source-id: 3e933b2c7a17d1fba086caa8aaec831223760882
(cherry picked from commit 41d18c64c4e88db615ecf6f3ef973bd8f985377a)
Summary:
Revert "[cuDNN] Add a new optimized cuDNN RNN algorithm for small RNN hidden_size (https://github.com/pytorch/pytorch/issues/62143)"
This reverts commit 965b9f483ef99f98af8a5be0e751d41e5ef0efdc.
This new cudnn RNN algorithm is causing some failures in our internal testings.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72089
Reviewed By: mruberry
Differential Revision: D33905226
Pulled By: ngimel
fbshipit-source-id: 5563a2c275e697477cf79bada3b81a33f1bf2aaa
(cherry picked from commit 35c240a8dc4ac65add84e30da1dde33402333892)
Summary:
brianjo, malfet
The documentation team would prefer the [documentation versions] to only have a major.minor version, not major.minor.patch. See also pytorch/pytorch.github.io#921
The regex can be tested by this bash 1-liner (where $tag is something like `v10.1225.0rc1`)
```
echo $tag | sed -e 's/v*\([0-9]*\.[0-9]*\).*/\1/'
```
I have lost track a bit, is the CI run for a tag actually building and pushing documentation?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71985
Reviewed By: mrshenli
Differential Revision: D33845882
Pulled By: malfet
fbshipit-source-id: 3cb644d8b01f5ddf87c0ac7c43e23e9fd292d660
(cherry picked from commit f884bd86740547e3164adde7bdc6318b944f9bdb)
Summary:
Make sure we set GITHUB token in the header for pr-label GHA
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72085
Reviewed By: seemethere
Differential Revision: D33904391
Pulled By: atalman
fbshipit-source-id: 039130a4f94070d78186b018696f53fad6142a8a
(cherry picked from commit f42c74b03c4d37f980d831b4365c6dc0e3fd1613)
Cover more cases of scope inferencing where consecutive nodes don't have valid scope information. Usually these nodes are created in some pass where authors forgot to assign meaningful scope to them.
* One rule of `InferScope` is to check if the current node's outputs' users share the same scope. Recursively run `InferScope` on the user nodes if they are missing scope as well. Since the graph is SSA, the depth is finite.
* Fix one pass that missed scope information for a new node.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71897
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71766
No need for a tensorSubclassLike check here (for functorch at least),
changing the zeros to new_zeros is sufficient.
Test Plan: - tested with functorch
Reviewed By: anjali411
Differential Revision: D33772752
Pulled By: zou3519
fbshipit-source-id: 5779a1c20b032d00a549c58ff905cf768f10467f
(cherry picked from commit a927c664d601d0b1cbbd3cda7dc297364c1d9e94)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71751
Before this PR, each of the above operations were composite and had
in-place variants that were primitive w.r.t. autograd.
The backward passes are not composite compliant due to the op (e.g.
index_copy) decomposing into index_copy_ and index_copy_'s backward
formula having in-place operations in it. To fix this, for each of the
ops mentioned in the title:
- I deleted the autograd formula for the in-place variant and replaced
it with the out-of-place variant
- This makes the forward-ad formula slightly slower because the codegen
generates a temporary but offline discussion suggests it's not worth
maintaining two sets of formulas for this and we can make the autograd
codegen smarter in the future.
- I then replaced instances of grad.clone().inplace_variant_(...) with
grad.outplace_variant(...)
Test Plan:
- run existing tests to check correctness
- run functorch tests
Reviewed By: anjali411
Differential Revision: D33772756
Pulled By: zou3519
fbshipit-source-id: fd22fe1d542e6e2a16af0865c2ddce0e65c04d70
(cherry picked from commit d025ba03270d53e19b2e68e8dd7ae49f2bb84532)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71750
functorch has problems vmap-ing over diag_embed due to the in-place copy_.
This PR adds a backward formula for it so that it becomes a primitive
w.r.t. autograd.
Test Plan: - tested with functorch
Reviewed By: anjali411
Differential Revision: D33772753
Pulled By: zou3519
fbshipit-source-id: da8ff3a10a1de1d60e6de6292003079d4b5ba861
(cherry picked from commit afe9059bfb1f2856e463e6ae988ec0ae86fdd470)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69216
This cleans up 4 pre-processor defines not used by any code:
- HAVE_GCC_GET_CPUID
- USE_GCC_GET_CPUID
- USE_AVX
- USE_AVX2
`cpuid` isn't used in PyTorch any more, we only use `cpuinfo`.
`USE_AVX*` is also not used, instead `HAVE_*_CPU_DEFINITIONS` tells
you which `CPU_CAPABILITY` flags are being compiled.
There is also `fbgemm`'s code path adding `third_party` as an include
path, despite `fbgemm` having a dedicated include directory and a
CMake setup that properly includes it.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33794424
Pulled By: malfet
fbshipit-source-id: 99d504af088818d4a26c2f6ce67ec0d59a5eb703
(cherry picked from commit 2e099d41f0e2f7d96c6013ac83223a75f4e4f862)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69216
Currently `torch_cpu` has command line arguments relating to cuda
libraries e.g. `-DMAGMA_V2`. This happens because
`include_directories` and `add_definitions` indescriminately change
the compile commands of all targets.
Instead creating a proper magma target allows limiting the flags to
just `torch_cuda`.
Test Plan: Imported from OSS
Reviewed By: dagitses
Differential Revision: D33794174
Pulled By: malfet
fbshipit-source-id: 762eabf3b9576bef94e8caa3ed4764c0e2c72b08
(cherry picked from commit f7d127b654330e3b37a134200571122aab08079b)
Summary:
Small clean-up, realized this file isn't necessary after migrating to GHA, so removing this file
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71943
Test Plan: running .circleci/regenerate.sh yields no config changes
Reviewed By: malfet
Differential Revision: D33901182
Pulled By: janeyx99
fbshipit-source-id: e8ff16395c81be25dae5b84619c6b4bfe749ada2
(cherry picked from commit e564c1ed5e2b23db537c25f9312647f13a10ab15)
Summary:
Followup from meeting today where it is not clear who owned these processes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72080
Reviewed By: malfet
Differential Revision: D33898729
Pulled By: janeyx99
fbshipit-source-id: 79d0e8210b8a6b9876eb50af448e6967a88d38bf
(cherry picked from commit 57cd82ef02c8192154d644af317a51d5f6d2f9e8)
Summary:
Description:
- Improved error message for CUDA interpolation with antialiasing
jbschlosser could you please check this PR and the wording if the error message is more clear now ? Thank.
I'm skipping all the tests now and once we are agreed on the wording if any updates are required, I update and restart the tests to ensure nothing is broken.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72066
Reviewed By: VitalyFedyunin
Differential Revision: D33892729
Pulled By: jbschlosser
fbshipit-source-id: 6249c7a1c51aa2e242f4bb8bfbe3f2abab17a8e8
(cherry picked from commit 44eb5391cf4fed54b379e96dfa9f23ef6ab1ecfa)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71979
as titled
add local trt test for easy verification
Test Plan:
buck run mode/opt -c=python.package_style=inplace scripts/wwei6:trt_local_test
buck test mode/dev-nosan caffe2/test/fx2trt/converters:test_hardtanh
Reviewed By: 842974287
Differential Revision: D33824456
fbshipit-source-id: d824b7da09929de66190fd8a077d4e73b68b9909
(cherry picked from commit 19abcadecc6ff8b58991552a874230a068294e0d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72039
As it turned out calling the function `vformat` was a bad idea because it caused a subtle compilation error due to a conflict with `fmt::vformat` and as a result wrong function overload being found during lookup.
(Note: this ignores all push blocking failures!)
Test Plan:
```
buck build //caffe2:libtorch
```
Reviewed By: cbalioglu
Differential Revision: D33864790
fbshipit-source-id: 08f8a1cdb5dfe72707a00a4ab7a859ea0d33b847
(cherry picked from commit 6fbca57d5e76dea88e1fe60431c5a42ab3ff738b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71890
Makes it so that ciflow is the way to trigger binary builds instead of
doing both pushes and ciflow
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D33851317
Pulled By: seemethere
fbshipit-source-id: 5e357bddfe004b996e2e1a9336dbbd622321a83d
(cherry picked from commit 11e061d89c5c9ee2a9fc168b367373f68c1946ec)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68459
This PR implements reminder to assign the release notes and topic labels to each PR when merged. Here is an example of the message that set on the issue related to PR:
> Hey atalman. You merged this PR, but no release notes category and topic labels were added. >
> The list of valid release and topic labels is available https://github.com/pytorch/pytorch/labels?q=release+notes+or+topic
Tested by manually running process_commit.py script in standalone mode passing following commit_hash = "e020414cb25cd763103f77a10c6225ce27cbbb6e" which should resolve to this PR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71917
Reviewed By: malfet
Differential Revision: D33847058
Pulled By: atalman
fbshipit-source-id: 370e0928b792df721b216a8e08b22253f03abda3
(cherry picked from commit dfa86f440f155a3328ad4149a92ea48fcd72f158)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72009
This simplifies the Stats interface by merging IntervalStat and FixedCountStat into a single Stat w/ a specific window size duration and an optional max samples per window. This allows for the original intention of having comparably sized windows (for statistical purposes) while also having a consistent output bandwidth.
Test Plan:
```
buck test //caffe2/test:monitor //caffe2/test/cpp/monitor:monitor
```
Reviewed By: kiukchung
Differential Revision: D33822956
fbshipit-source-id: a74782492421be613a1a8b14341b6fb2e8eeb8b4
(cherry picked from commit 293b94e0b4646521ffe047e5222c4bba7e688464)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71930
Previously `fbcode/caffe2/test/mobile/test_upgrader_bytecode_table_example.cpp` was checked in as intermediate step to make sure upgrader codegen works properly, before upgrader codegen is actually being used.
this change use `buck run mode/opt //caffe2/torch/fb/mobile/upgrader_codegen:upgrader_codegen` to codegen `upgrader_mobile.cpp` and we no longer need to use the checkin file `test_upgrader_bytecode_table_example.cpp` for the codegen unit test.
ghstack-source-id: 147957826
Test Plan:
```
buck test mode/opt //caffe2/test:upgrader_codegen
```
Reviewed By: tugsbayasgalan
Differential Revision: D33746264
fbshipit-source-id: 18de3cae53aed966e67f8dc42976a2d10d3788b3
(cherry picked from commit 661ffa786063d3e47cd7bcbe16b3baf2fff74808)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71938
`generated` will trigger the generated changes and hide the file changes. It's also misleading, because `gen_mobile_upgraders.py` itself is not autogen. Separate the keyword out from `gen_mobile_upgraders.py` so it's easier to see the changes from `gen_mobile_upgraders.py`.
ghstack-source-id: 147957825
Test Plan:
```
buck run mode/opt //caffe2/torch/fb/mobile/upgrader_codegen:upgrader_codegen
```
Reviewed By: tugsbayasgalan
Differential Revision: D33826982
fbshipit-source-id: 593c19f8ef4c9da776b11650863dc43c0b171cd5
(cherry picked from commit 43038d5bc7a41312a005d62f432c5ca19ed79f21)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71742
We have many sharding components currently:
torch.distributed._sharded_tensor, torch.distributed._sharding_spec,
torch.distributed._sharded_optimizer and more coming.
As a result, organizing all of this under the `torch.distributed.shard`
package. For BC reasons, I'm still keeping the old packages and have them just
reference the new package.
ghstack-source-id: 147899768
Test Plan: waitforbuildbot
Reviewed By: fduwjj, wanchaol
Differential Revision: D33755913
fbshipit-source-id: dc692b31e2607063d55dfcb3db33ec53961d5a5b
(cherry picked from commit 5b6885f3587786217f8ce143f2329ceec618404e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72014
`assert("string")` evaluates as `assert(true)` and thus never fires (oops!)
`assert(false && "string")` is the prescribed and supported way clang supports asserting "never" so that a string can be captured
Test Plan: ci pass
Differential Revision: D33824206
fbshipit-source-id: 223443f7ebecd78e1732c13ebb4ae416c0a0b11a
(cherry picked from commit 8e3721d0dc6adb92a9baed96552959f71e27cca4)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72013
Find and replace `assert(!"` with `assert(false && "`
Excludes headers and paths that contain "third-party" or "external"
Clang raises a `-Wstring-conversion` warning when treating a string as a boolean. This is not uncommon for asserts though (e.g. `assert(!"should never happen")`). Clang does permit `expr && "string"` though in order to support these assertion use cases.
Test Plan: ci pass
Differential Revision: D33823092
fbshipit-source-id: 9a1af012215bdc91f8b4162ddb2df28d51539773
(cherry picked from commit 0286910350492eea61050bd9c7d21727b607858c)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
**UPDATE:**
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68812
Reviewed By: mrshenli
Differential Revision: D33844257
Pulled By: ngimel
fbshipit-source-id: fd1c86e37e405b330633d039f49dce466391b66e
(cherry picked from commit c00a9bdeb0dc8d49317b93d19b7b938a4cfb7a38)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71970
- Provide default arg for power SGD convenience wrapper that matches the main API default
Test Plan: CI
Reviewed By: H-Huang
Differential Revision: D33837457
fbshipit-source-id: 8f4efab4992b3fff09456a18db2c83e087c25bdf
(cherry picked from commit 83f52fb3c7c82d4f3cb07a9469cfac6ac5a49658)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71966
Fix a few issues that block migration to fmt 8.x:
1. Format strings must be known at compile time by default
2. `formatter` specialization must be visible when formatting an object
Test Plan: sandcastleit
Reviewed By: cbalioglu
Differential Revision: D33835157
fbshipit-source-id: 642d36ae7cd4a3894aff1a6ecc096f72348df864
(cherry picked from commit 970ad5bc010e48d8c3e8f5818e9ab05a3785968e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71437
The two versions of freeze_module can be easily mixed up. This is to make the distinction more clear.
Test Plan: Imported from OSS
Reviewed By: george-qi
Differential Revision: D33824856
Pulled By: Gamrix
fbshipit-source-id: 206bda52f1346f7d2096f55c4660bca5f0011bdf
(cherry picked from commit d7bc6d372f1eeca63588bb235ac124170916892d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71856
Fix this warning that flags on the MSVC build:
```
caffe2\torch\csrc\jit\frontend\tree_views.h(919): warning C4101: 'e': unreferenced local variable
```
Test Plan: CI
Reviewed By: jamesr66a
Differential Revision: D33784473
fbshipit-source-id: 83e84f419157da6a563f223e9488f8bef4046efb
(cherry picked from commit 5451aaa23ece11ca2b4e592b291f8754fe97a2d0)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71950
This updates the .pyi definitions to match the pybind interfaces.
Test Plan:
```
pyre
```
CI
Reviewed By: kiukchung, edward-io
Differential Revision: D33830311
fbshipit-source-id: 147b1fbfd242dd9cec1cff05768f7a96d9599af4
(cherry picked from commit 347a5ebcc34c4583f80ccaa65b194e6f51714475)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71968
Right now when we output type to python files under `code/`, we directly write the dynamic type representation `Dynamic<>`, which causes server side to load an unsupported type. Instead we should do the fallback in export_module.cpp.
ghstack-source-id: 147856473
Test Plan:
CI
buck test //xplat/pytorch/mobile/test:test_read_all_mobile_model_configs
```
...
[ OK ] GeneralAndSpecial/BackPortTest.BackPortForChunkIdx/37 (39142 ms)
[ RUN ] GeneralAndSpecial/BackPortTest.BackPortForChunkIdx/38
total: 6 success: 6 failure: 0
[ OK ] GeneralAndSpecial/BackPortTest.BackPortForChunkIdx/38 (9651 ms)
[ RUN ] GeneralAndSpecial/BackPortTest.BackPortForChunkIdx/39
total: 4 success: 4 failure: 0
[ OK ] GeneralAndSpecial/BackPortTest.BackPortForChunkIdx/39 (5509 ms)
[----------] 40 tests from GeneralAndSpecial/BackPortTest (806244 ms total)
[----------] Global test environment tear-down
[==========] 41 tests from 2 test cases ran. (810453 ms total)
[ PASSED ] 41 tests.
```
Reviewed By: pavithranrao
Differential Revision: D33830355
fbshipit-source-id: 0be608fadf14daa2b703f31118ab648cb7b75f9b
(cherry picked from commit 6d65049ae5ac1ef6a11d19de48dd4d926b793b34)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72010
We were adding additional CUDA arches to our libtorch builds when we
shouldn't have been
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: atalman
Differential Revision: D33851196
Pulled By: seemethere
fbshipit-source-id: 52055d0cf5b528f45ef0aa33da297cd4175e8dcf
(cherry picked from commit f33b27ecab856a69c52625abf292f51dd2602229)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71666
When JIT autodiff is constructing a gradient computation graph, it will only add gradients for tensors that require_grad. Previously, require_grad information was **not** propagated to the subgraph that autodiff used; as a result, autodiff would calculate *all* gradients, even if requires_grad had never been set during profiling runs. In certain cases, this can lead to performance issues. For example, during training, the gradient of the input data is not needed, but is still computed.
This propagates requires_grad to the subgraph passed into autodiff, so that autodiff will not compute unnecessary gradients.
Test: `./bin/test_jit --gtest_filter="AutodiffRemoveUnusedGradientsTest.Linear"`
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D33725304
Pulled By: davidberard98
fbshipit-source-id: ca7ab4c9a6a26f94f93aff2d5a4135e125323ba1
(cherry picked from commit a97fe0556da1d74d04250c7cbcd1b8e9d8b41ebe)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71578
Use more robust way of extracting upgrader min and max versions
Test Plan: omgitsgreen
Reviewed By: cccclai
Differential Revision: D33690113
fbshipit-source-id: 79a964acb26d7ca1354e104710a285b8da3f46d1
(cherry picked from commit 9e316ee5c12e7bce9b17edebec2eeb38ecabd336)
Summary:
Reference: https://github.com/pytorch/functorch/issues/393
Context :
The derivative of `__getitem__`/`index` is
f5a71ec2d6/tools/autograd/derivatives.yaml (L733-L734)
where `index_backward` is defined as
f5a71ec2d6/torch/csrc/autograd/FunctionsManual.cpp (L3892-L3894)
Problem arises when `grad` is not BatchedTensor but one of the other input is. In that case, `grad.new_zeros` returns an unbatched tensor and call to the inplace `_index_put_impl_` errors as it expects `zeros_like_self` to be Batched.
To avoid this, we dispatch to out-of-place `index_put` if any of the input tensor is subclassed otherwise we dispatch to the inplace `_index_put_impl_`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71779
Reviewed By: albanD
Differential Revision: D33790596
Pulled By: zou3519
fbshipit-source-id: 9d6d81b758740cab7b3db9b905f1e8053f82b835
(cherry picked from commit ba0407a86ef3cabf885cd127649fa6dcd7f75117)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71707
Why?
- detach should behave like jax.stop_gradient in functorch. Because it
does not detach all the way through, functorch (as well as a Tensor
Subclass wrapping a Tensor subclass) won't see it after the first
layer/subclass handles it.
How?
- This PR changes detach to dispatch all the way through to the backend.
- This PR also modifies native::detach to call shallow_copy_and_detach
instead of native::alias. This is because today, the semantics of detach
and alias are differently -- they differ only by
allow_tensor_metadata_change. In the future, we may choose to deprecate
this flag.
- NB: Before and after this PR, detach() shows up twice in
torch_dispatch: https://github.com/pytorch/pytorch/issues/71725. This is
not a regression so I didn't want to fix it in this PR because it is
weird to fix.
Test Plan: - added new tests; run existing tests
Reviewed By: albanD
Differential Revision: D33752860
Pulled By: zou3519
fbshipit-source-id: 40cc2dc8232e75a02586a4ba5b0ef5f16cb76617
(cherry picked from commit f88aae426ec00bba907e9ad5d1cd6ed2c40bf14a)
Summary:
https://github.com/pytorch/pytorch/issues/61447 introduced a mechanism for performing functional calls in a model using the reparametrization API. However, the overhead introduced in a single call was too large.
I tried to address this by modifying the reparametrization code to support spare tensors, but the changes needed were too large due to type checking and several parts of the code expecting actual `nn.Module` objects so this option was not feasible.
resnet50 and call functional with a parameters dict covering the 0, 25, 50, and 100% of the model total parameters.
Used script:
https://gist.github.com/emcastillo/f344a58638bd71d130c71c45f86f0c3a
| % of parameters passed | CPU Time (us) | GPU Time (us) |
|------------------------|---------------|---------------|
| regular call | 5539 | 184909 |
| 0 | 5561 | 184843 |
| 25 | 11363 | 189236 |
| 50 | 18716 | 195378 |
| 75 | 22851 | 198641 |
| 100 | 27441 | 202281 |
This PR just swaps the `__getattr__` of the submodules to look into a dict holding only the parameters when called, greatly reducing the burden of having to instantiate custom modules and calling forward to just retrieve a tensor.
The execution times now are as follows:
| % of parameters passed | CPU Time (us) | GPU Time (us) |
|------------------------|---------------|---------------|
| regular call | 5939 | 187533 |
| 0 | 5899 | 187570 |
| 25 | 8541 | 188953 |
| 50 | 10045 | 189826 |
| 75 | 11049 | 190344 |
| 100 | 11911 | 190800 |
| functorch with 100% params | 14014 | 191727
Now we see that the CPU time overhead is greatly reduced and the GPU time barely increases due to the effective overlap.
cc albanD zou3519
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68969
Reviewed By: george-qi
Differential Revision: D33836360
Pulled By: albanD
fbshipit-source-id: 532561f64b18ca14c6ae2d77dcacb339397a589d
(cherry picked from commit fd4b6bdfbff4cb3d1da47b7fd73f1edfe43ba65c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68711
This PR adds possibility to multiply a single CSR matrix by a batch of dense matrices.
cc nikitaved pearu cpuhrsch IvanYashchuk ngimel
Test Plan: Imported from OSS
Reviewed By: davidberard98
Differential Revision: D33773319
Pulled By: cpuhrsch
fbshipit-source-id: 1623ce9affbc4fdc6d6130a95c5a42022858b62b
(cherry picked from commit 628c8e366d6325fed631edfbe9a35d130c529344)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67693.
Reference LAPACK (used in OpenBLAS) changed info error code for svd when inputs contain non-finite numbers. In PyTorch, we raise an internal assert error for negative `info` error codes because usually, it would indicate wrong implementation. However, this is not the case with SVD now in newer versions of LAPACK. MKL (tried 2021.4.0) still gives a positive error code for this kind of input. This change aligns with the OpenBLAS and MKL behavior in our code.
**UPDATE:**
MKL 2022 has uses the latest reference LAPACK behavior and returns the same `info` as OpenBLAS 0.3.15+
This PR fixes https://github.com/pytorch/pytorch/issues/71645 that is due to the updated MKL version in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68812
Reviewed By: osalpekar
Differential Revision: D32626563
Pulled By: ngimel
fbshipit-source-id: 09042f07cdc9c24ce1fa5cd6f4483340c7b5b06c
(cherry picked from commit aadf50731945ac626936956e229cf2056a291741)
Summary:
The warning in DDP can cause log spamming. Suggest printing this warning every N times instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71755
Reviewed By: albanD
Differential Revision: D33763034
Pulled By: rohan-varma
fbshipit-source-id: 2d2fe691979b0c7f96a40ca6f9cd29a80b4395dd
(cherry picked from commit 7d879b98e24b978cba5d94a753ddfc781a240933)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71866
See title. There is a minimal perf regression for the non-functorch case
(a TLS access and a null check).
Test Plan: Imported from OSS
Reviewed By: soulitzer
Differential Revision: D33825279
Pulled By: zou3519
fbshipit-source-id: afa2ad5a672cc9225d2bb6b46ee7f3f1513c1e02
(cherry picked from commit 17ae1d3e9dcf57193a2d90f755e18994671c9f13)
Summary:
Follow up: we would need to update the links to the tutorial later
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71643
Reviewed By: albanD
Differential Revision: D33713982
Pulled By: soulitzer
fbshipit-source-id: a314ffa4e7d5c5ebdef9c50033f338b06578d71c
(cherry picked from commit ba30daaaa5bb79619332f59e6826f19623bc1697)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70960
This patch uses some bytecode introspection logic to see if a boolean is being used as an assert condition and if so, it records the assert in the fx graph and allows the trace to continue.
Test Plan: Imported from OSS
Reviewed By: jamesr66a
Differential Revision: D33570397
Pulled By: zdevito
fbshipit-source-id: 99d26cede8fe42c96d4032d9353c1ede7eb3d969
(cherry picked from commit 30d002da25b8eca134d44d43596ce78c4ef8c221)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71922
Use proper name in the error message and remove "torchbind", since it's not official in documentation.
Test Plan: Imported from OSS
Reviewed By: cccclai
Differential Revision: D33824899
Pulled By: iseeyuan
fbshipit-source-id: 41968494c04fab39292d9cc4dc6e15cca99cbff4
(cherry picked from commit 9732a52ed264f013e9ba3844f86be11d31444954)
Summary:
These tests were not actually running as they were defined in the local scope of another test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71885
Reviewed By: scottxu0730
Differential Revision: D33806251
Pulled By: jansel
fbshipit-source-id: 48a2d7b472f160759ef55e6fff1f8890511e3345
(cherry picked from commit 9ae14efb25dd034fed60ae99465cd3673c24eed2)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71803
1. Extra check for wrapping with override args,
2. Enhance UT to make sure
`wrap` doesn't wrap outside of ctx.
ghstack-source-id: 147753225
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D33774512
fbshipit-source-id: 1f8d60bdf9b3ba257fee465064a0e25235b3622b
(cherry picked from commit 9ab775b29eddcd193c11398184bee8beffed0327)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71802
Per title
ghstack-source-id: 147753213
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D33774513
fbshipit-source-id: f798ea9f63aa1ae573c6b012cc6e749d126dedea
(cherry picked from commit 631157b3ea834c499cea740df6877644b8e27a10)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71901
We didn't catch this initially because CuDNN is not being tested on CI.
The following tests fail on master (if we build with CuDNN), but pass with this PR:
- `test_forward_mode_AD_nn_functional_batch_norm_cuda_float64`
- `test_forward_mode_AD_nn_functional_instance_norm_cuda_float64`
I don't think it is documented anywhere, but from the tests passing now I'm going to guess `result1` and `result2` return `mean` and `invstd` respectively. Previously, I thought mean and variance were returned because the variables were named `saved_mean` and `saved_var`.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33818652
Pulled By: soulitzer
fbshipit-source-id: ecee760f5aec620dc70f57de4fb3573c8f2f5f31
(cherry picked from commit 73fd3e021c3478fedc7a7ca258269c029b7790a6)
Summary:
Modify _check_output to capture `CalledProcessError` and add
stdout/stderr to the failure message
Also record github actions run id in the failure message (calculated based on `${{ github.run_id}}`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71941
Reviewed By: seemethere
Differential Revision: D33829633
Pulled By: malfet
fbshipit-source-id: 060b2856ca6c71574075effa72b982f9e1d64e6e
(cherry picked from commit a9ad7df9b540f9ab14524a644cab5e06225debe4)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67996
This is necessary for most matrix decompositions in `linalg`.
cc mruberry
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33774418
Pulled By: mruberry
fbshipit-source-id: 576f2dda9d484808b4acf0621514c0ffe26834e6
(cherry picked from commit fb07c50aa9c143aa9dafab57936a8a8a7d3b4ec4)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68522
Some OpInfos were inadvertibly generating samples with `grad_fn`. For
example, when using functions like `transpose()` or `conj()` on the
inputs to generate transposed or conjugated inputs. This PR corrects
this and deactivates the tracking of gradients in all the sampling
functions.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33774420
Pulled By: mruberry
fbshipit-source-id: da0e6189a2d67a2cb0fd458054558d36dbad9b61
(cherry picked from commit 42b0870774ff4a07fbba1d991f3ea0a4dbae735a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69909
This test detected a number of sampling methods that were not generating
the samples as expected, e.g. `index_put`, `cosine_embedding`, `stft`, but
perhaps most notably the generator for `BinOps`.
It also detected that `reminder` and `fmod` did not have implemented the
backward formula for the second input. I added this in the previous PR.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33774422
Pulled By: mruberry
fbshipit-source-id: 76cfc75b1fdfd72ee64aa524665f83a75fe52509
(cherry picked from commit 13ea7b436bc6301be4cf7bb7d559177d895502b3)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69908
I also took this chance to clarify a bit the documentation of these
functions.
cc brianjo mruberry
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33774417
Pulled By: mruberry
fbshipit-source-id: ab4a9014006783d1f87d432ecb959c854374c2d4
(cherry picked from commit f319a75d781bbe12a48ef1ffd21d3874dfee3bfa)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71947
This is a recent regression that blocks our migration to turning `-Wstring-conversion` into an error.
Comment it out until albanD can resolve in the future.
Test Plan: compiles locally
Reviewed By: stephinphection
Differential Revision: D33829899
fbshipit-source-id: 47833d0d8dada087d748ee7e500179ff16f2a138
(cherry picked from commit e3c77ff4458aed174e08a5ec233c606509fb5bc6)
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: 2728266e4c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65595
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: malfet
Differential Revision: D33805315
fbshipit-source-id: 6c341cdff97b9f7c23a1cd69f65e0936da502f29
(cherry picked from commit a2b62c1fa18d93d20fd4d0c56ac60f8aeb1a75d0)
Summary:
I copy-pasted part of std c++ from LLVM, make it a string, and modify it to use it to implement complex support for Jiterator
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71577
Reviewed By: george-qi
Differential Revision: D33820258
Pulled By: ngimel
fbshipit-source-id: 3d4ea834803b99904a79e430f749407635a3cf6d
(cherry picked from commit f2c3b2a9a5d89099c3752605b7c4394f2d61a00d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71623
Enable gather_object on the nccl backend, since we already support `dist.gather` on nccl. This requires user to set the current device properly.
ghstack-source-id: 147754836
Test Plan: distributed_nccl_spawn -r test_gather_object
Reviewed By: zou3519
Differential Revision: D33701042
fbshipit-source-id: 39cff22947a7cac69d0c923b956dc10f25353a6f
(cherry picked from commit 6e6eff497ff9ac4888ba1876740ac80ea1eb2201)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71734
There are two commits that we test sometimes in CI:
1. The merge commit (a test merge between the PR head ref and the latest base ref)
2. The head ref (the exact commit that was at the head of the user's branch when they pushed).
This distinction is fairly subtle; in the case of 1, you are effectively running against a "rebased" version of your PR's branch. The problem is that we use *both* of these commits today, with confusing results—depending on how you put up your PR and what workflows are running, we might be testing two different commits!
We should probably consolidate on one. This would eliminate a subtle but complex part of our CI (I am mildly horrified by the complexity of [this explanation](https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#which-commit-is-used-in-ci), although it's heroic that someone went and documented it lol). This PR consolidates on using the head ref (option 2).
- This is the behavior of phabricator/fbcode, which many PT devs will be more familiar with.
- This is the behavior of ghstack
- Our master branch moves quite quickly, so the chance that there is a substantial divergence between your local test runs and CI is high, with confusing results that are nondeterministic based on when you put up the PR.
- We use a linear history/squash-rebase-merge workflow, which is better modeled by option 2. Option 1 effectively emulates a merge-commit-style workflow.
The primary disadvantage is that now when re-running workflows, you will not be re-running against a "rebased" version of the PR, but the exact head ref that was pushed. Tbh I find it quite unintuitive that what you're testing changes depending on when you press the re-run button, but I know at least malfet does this so it's worth mentioning.
Test Plan: Imported from OSS
Reviewed By: janeyx99, cpuhrsch
Differential Revision: D33827835
Pulled By: suo
fbshipit-source-id: 45c7829f2ed8e097562d0bf16db5fc6a238a86dc
(cherry picked from commit e53fab96905cfab9c3f2e98de51e09006c17842d)
Summary:
The model generation script will check the model version, to ensure the developer run the script before they change operator
Previously, the version use the old model version. However, it's hard for developer to know the old version number. In this change, it use the current max operator version to check. It's less strict, but more developer friendly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71894
ghstack-source-id: 147769215
Test Plan:
first time run:
```
chenlai@devvm5615:~/fbsource/fbcode(b82243650)$ buck run mode/opt //caffe2/torch/fb/mobile/upgrader_codegen:upgrader_test_models_gen
Parsing buck files: finished in 0.7 sec
Downloaded 0/2 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 21.6 sec (100%) 11547/11547 jobs, 2/11547 updated
Total time: 22.4 sec
BUILD SUCCEEDED
TestVersionedDivTensorExampleV7() aten::div.Tensor
INFO:test.jit.fixtures_srcs.generate_models:Processing TestVersionedDivTensorExampleV7
INFO:test.jit.fixtures_srcs.generate_models:Generating model test_versioned_div_tensor_example_v7 and it's save to /data/users/chenlai/fbsource/fbcode/caffe2/test/jit/fixtures/test_versioned_div_tensor_example_v7.ptl
chenlai@devvm5615:~/fbsource/fbcode(b82243650)$
```
second time run:
```
chenlai@devvm5615:~/fbsource/fbcode(b82243650)$ rm caffe2/test/jit/fixtures/test_versioned_div_tensor_example_v4.ptl
chenlai@devvm5615:~/fbsource/fbcode(b82243650)$ buck run mode/opt //caffe2/torch/fb/mobile/upgrader_codegen:upgrader_test_models_gen
Action graph will be rebuilt because files have been added or removed.
Parsing buck files: finished in 2.0 sec
Building... 17.4 sec (99%) 9289/9290 jobs, 0/9290 updated
TestVersionedDivTensorExampleV7() aten::div.Tensor
INFO:test.jit.fixtures_srcs.generate_models:Processing TestVersionedDivTensorExampleV7
INFO:test.jit.fixtures_srcs.generate_models:Model test_versioned_div_tensor_example_v7 already exists, skipping
chenlai@devvm5615:~/fbsource/fbcode(b82243650)$ jf s
```
Reviewed By: tugsbayasgalan
Differential Revision: D33804737
fbshipit-source-id: 7424b81a700703bdf896ec606c2dac8df6dbf8a6
(cherry picked from commit 44b4e37d30077a3160b8a92209af339a6f2fc885)
Summary:
~As per the title, this PR adds OpInfos for `max_unpoolNd` operators. There are a few TODOs:~
* [x] Improve error messages for the rest of the functions in the CUDA file for the un-pooling operators.
~* [x] Raise issues for the failures, and provide descriptions.~
~Note to the reviewers: I'll add descriptions and reasons for the skips, I'm not totally sure about them, hence the skips for now.~
cc: mruberry saketh-are
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67328
Reviewed By: george-qi
Differential Revision: D33818126
Pulled By: albanD
fbshipit-source-id: 8ddc8510be7f4ea19eca3ae7f052aeca590d8d48
(cherry picked from commit bd9903d16ceed7e1a5e0d1ead747df085434a53d)
Summary:
Pretty print inplace operators (`a+=b`, etc) in generated FX code. This is useful because it allows `torch.jit.script()` to parse these operators without error.
I don't believe FX tracing supports inplace ops yet, though I am generating them in torchdynamo and want to be able to lower them with torchscript.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71887
Reviewed By: jamesr66a
Differential Revision: D33806248
Pulled By: jansel
fbshipit-source-id: 5eb9f744caab2f745cefc83ea658e12e9e7a817d
(cherry picked from commit eacbd6bb83571f9e58d84243aeed277e7a4f1fe5)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70029
This PR implements NCCL scatter and add scatter to ProcessGroupNCCL.
NCCL doesn’t directly provide primitives for scatter, so we need to be implemented on top of NCCL’s send/recv API.
1. In ProcessGroupNCCL.cpp, the inputTensors are first flattened, then outputTensors and inputFlattened are passed by the collective class to scatter() function in nccl.cpp.
2. In nccl.cpp, scatter is implemented using ncclSend/ncclRecv: the root rank uses a for loop to send(distribute) the inputTensors to each rank, then all the ranks receive the inputTensor from the root rank.
ghstack-source-id: 147754837
Test Plan:
test_scatter_ops
test_scatter_stress
test_scatter_checks
Reviewed By: pritamdamania87
Differential Revision: D33154823
fbshipit-source-id: 4513e7eaf7d47a60eb67da99dc6c2e9a2882f3fd
(cherry picked from commit 93201f9d4a87c556110e60ceb93826abd71cf518)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66745
This PR implement NCCL gather and add gather to ProcessGroupNCCL using nccl send/recv api.
NCCL doesn’t directly provide primitives for gather, so we need to be implemented on top of NCCL’s send/recv API.
1. In ProcessGroupNCCL.cpp, the outputTensors are first flattened, then inputTensors and outputFlattened are passed by the collective class to gather() function in nccl.cpp.
1. In nccl.cpp, gather is implemented using ncclSend/ncclRecv: all the ranks send inputTensor to the root rank, and the root rank uses a for loop to receive these inputTensors.
ghstack-source-id: 147754838
Test Plan:
test_gather_ops
test_gather_checks
test_gather_stress
Reviewed By: pritamdamania87
Differential Revision: D29616361
fbshipit-source-id: b500d9b8e67113194c5cc6575fb0e5d806dc7782
(cherry picked from commit d560ee732eb559782a2d1d88b3cf118dcfc404bc)
These were left out of the intial migration for some reason so this just
transfers over those tests
Signed-off-by: Eli Uriegas <eliuriegasfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71644
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70253
I included a derivation of the formula in the complex case, as it is
particularly tricky. As far as I know, this is the first time this formula
is derived in the literature.
I also implemented a more efficient and more accurate version of svd_backward.
More importantly, I also added a lax check in the complex case making sure the loss
function just depends on the subspaces spanned by the pairs of singular
vectors, and not their joint phase.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33751982
Pulled By: mruberry
fbshipit-source-id: c2a4a92a921a732357e99c01ccb563813b1af512
(cherry picked from commit 391319ed8f2e0ecc1e034d8eaecfb38f5ea4615f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69827
In general, the current pattern allows for implementing optimisations
for all the backends in a common place (see for example the optimisation
for empty matrices).
After this PR, `torch.svd` is implemented in terms of `linalg.svd` and
`linalg.svdvals`, as expected. This makes it differentiable in the case
when `compute_uv=False`, although this is not particularly important, as
`torch.svd` will eventually be deprecated.
This PR also instantiates smaller `U` / `V` when calling cusolver_gesvdj
in the cases when `full_matrices=False` or `compute_uv=False`.
The memory for auxiliary `U` and `V` in the cases above, needed for some
cuSOLVER routines is allocated raw allocators rather than through fully
fledged tensors, as it's just a blob of memory the algorithm requests.
As the code is better structured now, it was easier to see that `U` and
`Vh` needn't be allocated when calling `svd_cusolver_gesvd`.
Now `linalg.svdvals` work as expected wrt the `out=` parameter.
Note that in the test `test_svd_memory_allocation` we were
passing a tensor of the wrong size and dtype and the test seemed to
pass...
This PR also changes the backward formula to avoid saving the input
matrix, as it's not necessary. In a follow up PR, I will clean the
backward formula and make it more numerically stable and efficient.
This PR also does a number of memory optimisations here and there, and fixes
the call to cusolver_gesvd, which were incorrect for m <= n. To test
this path, I compiled the code with a flag to unconditionally execute
the `if (!gesvdj_convergence_check.empty())` branch, and all the tests
passed.
I also took this chance to simplify the tests for these functions in
`test_linalg.py`, as we had lots of tests that were testing some
functionality that is already currently tested in the corresponding
OpInfos. I used xwang233's feature to test both MAGMA and CUDA
backends. This is particularly good for SVD, as cuSOLVER is always
chosen over MAGMA when available, so testing MAGMA otherwise would be
tricky.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki
Differential Revision: D33751983
Pulled By: mruberry
fbshipit-source-id: 11d48d977946345583d33d14fb11a170a7d14fd2
(cherry picked from commit a1860bd567f2d136e74695275214bc0eaf542028)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70944
Added special net-level/op-level scopes for static runtime. We can use these to add special behavior in record functions when they are invoked from a static runtime context.
Reviewed By: navahgar
Differential Revision: D33458211
fbshipit-source-id: 0b7022100e9f5ac872f4cb5bfba14e92af2c71b0
(cherry picked from commit b486548544c5e822803071756c85e675e37d2dad)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71858
Makes the forked subgraph rewriter code path preserve stack traces.
The strategy is pretty simple for now:
1. find any specified stack trace in pattern graph
2. if found, copy this stack trace to every node in replacement graph
If more complicated logic is needed in the future, we can address it
at a later time.
Test Plan:
```
python test/test_quantization.py TestQuantizeFx.test_stack_trace_preserved_subgraph_rewriter
```
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D33791740
fbshipit-source-id: 38bb4885549a9f954278c6c14fa41f58f1d5f7b7
(cherry picked from commit 5cc32a87ce62ad9a1c8d2240cfe630cbf1cc838d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71865
This PR changes the term "generic error" to "errno" in c10d log outputs and error messages to make the root cause more clear.
```
[W socket.cpp:634] The server socket on [localhost]:29501 is not yet listening (generic error: 111 - Connection refused), will retry.
```
becomes
```
[W socket.cpp:634] The server socket on [localhost]:29501 is not yet listening (errno: 111 - Connection refused), will retry.
```
ghstack-source-id: 147716733
Test Plan: No behavioral change, run existing unit and integration tests.
Reviewed By: H-Huang
Differential Revision: D33792822
fbshipit-source-id: f57b0ec0fc4135e83c46fdc93911edbce9d26ec1
(cherry picked from commit f61dd92a43b8e253b770c3db7da0a1fba9b81cab)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71658
This adds the beginnings of a TensorboardEventHandler which will log stats to Tensorboard.
Test Plan: buck test //caffe2/test:monitor
Reviewed By: edward-io
Differential Revision: D33719954
fbshipit-source-id: e9847c1319255ce0d9cf2d85d8b54b7a3c681bd2
(cherry picked from commit 5c8520a6baea51db02e4e29d0210b3ced60fa18d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70862
ghstack-source-id: 147642558
Test Plan: Should be a no-op, rely on CI to validate.
Reviewed By: malfet
Differential Revision: D33330151
fbshipit-source-id: f566993f47cffa0df85105f3787bb5c6385cf5d6
(cherry picked from commit a17c3865efb6f1fa7e14adb20e5d5ed441543885)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70861
ghstack-source-id: 147642549
Test Plan: Should be a no-op. Rely on CI to validate.
Reviewed By: malfet
Differential Revision: D33329870
fbshipit-source-id: 7dbccaa994737c5fe7195d02dffd61eeceb19ceb
(cherry picked from commit 2b5264ebc49e4a5445c066e07f15bad041f42ac8)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70859
ghstack-source-id: 147642534
Test Plan: Extracting code unmodified to a new library: relying on CI to validate.
Reviewed By: malfet
Differential Revision: D33329688
fbshipit-source-id: f60327467d197ec1862fb3554f8b83e6c84cab5c
(cherry picked from commit f82e7c0e9beba1113defe6d55cf8a232551e913b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70858
ghstack-source-id: 147642533
Test Plan: Extracted a constant to a new header, trusting CI build to validate.
Reviewed By: malfet
Differential Revision: D33329689
fbshipit-source-id: 8697bb81a5cc3366462ebdf1f214b62d478fa77c
(cherry picked from commit 16663847e179ea1c2a16f2bb538cfe3aca032593)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71879
Two locations of improper macro usage were reported (https://github.com/pytorch/pytorch/issues/71848), and this diff fixes them. In both cases this is behavior-changing, since the incorrect usages would have passed assertion due interpreting the error string as the condition, and both cases should have been 'assert false'.
Test Plan: Run CI
Reviewed By: alanwaketan
Differential Revision: D33800406
fbshipit-source-id: dfe3d9a6455e6eb96cb639022f8813a8bd6520c3
(cherry picked from commit ee551e5a16828f273d7694820fa9d9fa1fa52129)
Summary: Reland for D33282878 (911d527b87) . Land backend change first to maintain FC. Will wait for 2 weeks after this diff is in. And than land the front-end change in next diff.
Test Plan:
test in next diff
time buck test mode/dev-nosan fblearner/flow/projects/langtech/translation:tests -- test_e2e_base_training
Reviewed By: gmagogsfm
Differential Revision: D33342547
fbshipit-source-id: b3dee9a4bdfd78103848c12629e5fccafdd621e3
(cherry picked from commit ae1935f1af755180e5607e870ff365dc17061e4a)
Summary:
Fixes multiple compilation on xla tensor print. Please check the conversation here: https://github.com/pytorch/xla/pull/3253
This is done to avoid compilations during tensor printing. Torch performs some tensor operations like slicing to make the tensor readable. These operations result in compilations. Hence to avoid the compilations, copying the tensor to cpu before printing.
example:
```
dev = xm.xla_device()
def test_linear(input_shape=(8, 1024)):
import pdb
pdb.set_trace()
linear = torch.nn.Linear(in_features=1024, out_features=4096, bias=True).to(dev)
inp = torch.randn(*input_shape).to(dev)
output = linear(inp)
xm.mark_step()
return output
```
Returning from this function would have resulted in 63 compiles, since PDB prints the value of the return output. In this case it is a xla tensor.
Now with the current change, there is no compilation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71147
Reviewed By: shunting314
Differential Revision: D33795177
Pulled By: wconstab
fbshipit-source-id: 74b53d9a1cb7ef67f9d8b0a32064f3896be449b5
(cherry picked from commit a9e0687fc5c9981fb55ea4dc406c283c80fa20c9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71864
A very minor change in one of the warning messages of `socket` to make it clear that it is a transient issue and not an error.
```
[W socket.cpp:634] The server socket on [localhost]:29501 is not yet listening (errno: 111 - Connection refused).
```
becomes
```
[W socket.cpp:634] The server socket on [localhost]:29501 is not yet listening (errno: 111 - Connection refused), will retry.
```
ghstack-source-id: 147716736
Test Plan: No behavioral change. Run the existing unit and integration tests.
Reviewed By: H-Huang
Differential Revision: D33792888
fbshipit-source-id: 79b287325945d0353c4568d84d1b52c820783cfc
(cherry picked from commit 9e5b627551fdf3bd6d06eb669883f9423d0999f1)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69299https://github.com/pytorch/pytorch/pull/68906 + https://github.com/pytorch/pytorch/pull/68749 plugged one correctness hole (non-blocking copies of offset pinned memory tensors) while introducing another (non-blocking copies of pinned memory tensors with a non-standard DataPtr context).
In this revision, we use both the tensor data pointer and context to attempt to identify the originating block in the pinned memory allocator.
Test Plan: New unit tests added to cover the missing case previously.
Reviewed By: yinghai
Differential Revision: D32787087
fbshipit-source-id: 0cb0d29d7c39a13f433eb1cd423dc0d2a303c955
(cherry picked from commit 297157b1a13b5c75d860cac9eba4fe7fe1ad5e6f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71874
Treating a string as a boolean is a clang warning (`-Wstring-conversion`). Clang, however, makes an exception for cases where you `&&` the string, specifically for assertion use cases.
e.g.
```
assert(false && "should never happen!");
```
There a number of checks/asserts that never actually trigger because they were checking against a string, which is always non-zero (and evaluates to true). This will fix all those impotent asserts/checks.
Test Plan: CI Pass
Differential Revision: D33796853
fbshipit-source-id: a895e047173bbea243fba76705e5b1aa5c5db064
(cherry picked from commit 0decb563d10e312f7f6730f740da006ed04fad37)
Export should fail if export_modules_as_functions is set and opset_version<15.
This is because opeset_version < 15 implies IR version < 8, which means no local function support.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71619
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70009
Currently we rely on module.training to decide whether we'll do a qat fusion or ptq fusion, this is
not ideal since training flag has nothing to do with quantization, this PR introduces an extra flag `is_qat`
to control this
Note: currently we still has the constraint that when `is_qat` is True, the modules must be in training mode, we
can relax this constraint later
Test Plan:
```
python test/test_quantization.py TestFuseFx
python test/test_quantization.py TestFusion
```
Imported from OSS
**Static Docs Preview: classyvision**
|[Full Site](https://our.intern.facebook.com/intern/staticdocs/eph/D33178977/V36/classyvision/)|
|**Modified Pages**|
Reviewed By: mruberry
Differential Revision: D33178977
fbshipit-source-id: 0c1499c45526971140d9ad58e2994d1edf5ad770
(cherry picked from commit 2d51f9fb28967f1c5aab260d84b8d32d838f4f26)
This adds `try_revert` repository dispatch that will revert commit
that were previously landed by merge workflow if requested by org member
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71868
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71863
Port number is int in python, but needs to be uint16_t when called for TCPStore constructor.
Related to #67172
Test Plan: Imported from OSS
Reviewed By: cbalioglu
Differential Revision: D33793270
Pulled By: H-Huang
fbshipit-source-id: 89ab47ec8bd7518f9ecbf7d01871fe059b0e77b1
(cherry picked from commit 84bff1f5bb11029ff3fcf7a04faa3b9c7b25286a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71620
Remove from_functional_optim and make it the default constructor since
that is the only way _OptimizerHookState is now being built. Also, no longer
need to expose create_functional_optim helper function
ghstack-source-id: 147577174
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33700593
fbshipit-source-id: ba089ce3bf66ccf8f71cffdd0f4d4bddc03e8b14
(cherry picked from commit a50b2caf0e19f9793fbf18b371d30e3dd8c5c0cf)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71608
Per title
ghstack-source-id: 147577178
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33696382
fbshipit-source-id: 5b638d3edf5f03ba476356d61e96ca604de18c8f
(cherry picked from commit 436b547fb0080c81e656fa4753b5d7275e3a3283)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71135
The NVTX profiler is quite different from the other Kineto cases, so it's worth it to peel it off early so that later logic can assume either KINETO or KINETO_GPU_FALLBACK. This is more important since we're going to change the Kineto internals. (You can see the python tracer was unnecessarily coupled to NVTX just because the control logic was intermingled.)
There's also no reason to put the legacy observer state in the header rather than the cpp file now that the kineto profiler doesn't need it, so we should shield it from prying eyes.
The recent headaches with TLS downcasting and RPC integration (D32678163 (7ea86dfdb1), D33283314 (681e78bace), D33437773 (7d6535cab3)) have made crystal clear that we need a lot more safety in the profiler, particularly as we shift things around.
Test Plan: Unit tests. This is no longer a performance PR.
Reviewed By: aaronenyeshi
Differential Revision: D32710829
fbshipit-source-id: f9138598b3cfeba71872905a7afab3c03c0d56e7
(cherry picked from commit 059a39d8e3b184337ddd401cfd242c47b8ad0538)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/65908
Added a new overload instead of updating the current signature. (Had issues with JIT and **maybe** it would have been FC breaking)
TODO:
* [x] Don't compute `std::pow(10, decimals)` for each element.
* [x] Update docs (https://docs-preview.pytorch.org/66195/generated/torch.round.html?highlight=round#torch.round)
* [x] Add tests
* ~~Should we try to make it composite?~~
* ~~Should we add specialized test with more values of `decimals` outside of OpInfo with larger range of values in input tensor?~~
cc mruberry rgommers
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66195
Reviewed By: anjali411
Differential Revision: D31821385
Pulled By: mruberry
fbshipit-source-id: 9a03fcb809440f0c83530108284e69c345e1850f
(cherry picked from commit 50b67c696880b8dcfc42796956b4780b83bf7a7e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71705
This fixes a crash `resetMemory` caused by trying to access a `TensorImpl` via a borrowed `IValue` after it had already been destroyed. We need to clean up all borrows *before* we destroy the owning `IValue`, not after.
ghstack-source-id: 147688982
Test Plan:
New unit test covers this case
ICE w/ inline_cvr v0 [finishes successfully](https://www.internalfb.com/intern/unidash/dashboard/ads_infra_cost_estimation/a_metrics/?e[select_ESTIMATION_RUN_ID]=ICE_mikeiovine_16431103211c65), didn't see any nnpi errors
Reviewed By: ajyu
Differential Revision: D33725435
fbshipit-source-id: f8dd109382b5cf54df6f194f8dcb5c0812b174bb
(cherry picked from commit 31339d9d38e63248d2ac3646be71008ed731f16c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71775
Mobile is running into segfaults at the `compiledWithCuDNN()` call as described in T110194934. This fix works around this with an #ifdef following the approach done [here](d32b7d9585/aten/src/ATen/native/Convolution.cpp (L1076-L1088)). TBD how to fix the underlying cause.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33778888
Pulled By: jbschlosser
fbshipit-source-id: 2a22b2eaa858ee6adf5b3c25a1c470c6aebc3f87
(cherry picked from commit e90a6bb402f45f45b7219f453ca38ee85603f3eb)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70855
This library is depended on by parts of util so it has to go next.
ghstack-source-id: 147170897
Test Plan: Rely on CI.
Reviewed By: malfet
Differential Revision: D33329527
fbshipit-source-id: 28a111f602ee085c1d9b0acec29790488f8c8f0b
(cherry picked from commit e3601b94ff4a89caeb0c012a0d946613934646b9)
Summary:
Implements allreduce_coalesced for ProcessGroupNCCL as an NCCL group of allreduces on separate tensors, as proposed in https://github.com/pytorch/pytorch/issues/38995#issuecomment-882804595. In recent versions of NCCL, performance of grouped comms has improved significantly. A group can execute with just one kernel, so a grouped comm on a set of unflattened tensors can be more performant than flattening+a single flat nccl call.
The same approach can easily extend to broadcast_coalesced and reduce_coalesced.
I'm still not sure how (hypothetical) all_gather_coalesced and reduce_scatter_coalesced ops should be exposed or implemented, because we need to consider "_base" variants where the output or input tensor is pre-flattened. For example, https://github.com/pytorch/pytorch/issues/61781 effectively wants "allgather_base_coalesced".
I'm also not sure how the _multigpu variants should enter the picture. With the approach I've written here, ProcessGroupNCCL::allreduce accepts a vector of tensors that are either all on the same device (in which case it'll do an allreduce_coalesced) or all on different devices (in which case it'll do an allreduce_multigpu). In other words it can do _coalesced or _multigpu but not both at once.
for some reason github wont let me add agolynski to the reviewers
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62140
Reviewed By: fduwjj
Differential Revision: D33781010
Pulled By: cbalioglu
fbshipit-source-id: f0c233da9ebae57d7ccecf6d8dc432d936d4d3ce
(cherry picked from commit e43cb81d300bd9e9926f6e01ae77f4accb12c258)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70854
We can't do the entire package since parts of it depend on //c10/core.
ghstack-source-id: 147170901
Test Plan: Rely on CI.
Reviewed By: malfet
Differential Revision: D33321821
fbshipit-source-id: 6d634da872a382a60548e2eea37a0f9f93c6f080
(cherry picked from commit 0afa808367ff92b6011b61dcbb398a2a32e5e90d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71790
If a leaf module is specified, it means we should treat it as a blackbox and we should just avoid rewriting it too.
Test Plan:
```
buck test caffe2/test:test_fx_acc_tracer
```
with a new unit test.
Reviewed By: jfix71, houseroad, wushirong
Differential Revision: D33731903
fbshipit-source-id: 0560d9e8435b40f30d9b99dc3b2f47d1a04eb38b
(cherry picked from commit 747e9e44ee1792bd6ac5089ced4ffe5f43b09316)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71606
Per title
ghstack-source-id: 147577172
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33694037
fbshipit-source-id: a148d5ce6031f0cc20f33785cfe2c27d1fc2d682
(cherry picked from commit ace3261e0cd6898e3203cf30e78e17e80e5fc42f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71186
So far we've only supported scalar inputs, but couldn't handle scalar outputs
or intermediates. This PR adds it.
Scalar outputs are returned as 0-dim tensors. If the kernel is invoked on a
stack of IValues, we correctly convert the results to scalar IValues when
needed. If the kernel is invoked with a vector of void* pointers, everything
works out of the box without any conversions.
Lowerings for scalar operators are a bit tricky. Usual lowerings return a pair
<Buf, Stmt> (aka Tensor), but for scalar operators we also want to have the
corresponding Var that the lowering function supposedly creates (in theory we
could just use Loads and Stores, but I'm worried it can affect performance as
there is no guarantee this will be optimized by LLVM). So, what we do here to
work around this is we return a fake buf + stmt that sets the corresponding
var. Then outside of the lowering we create a real buffer and generate a Store
to it with the value from the variable we passed as the base handle of the fake
buf. This real buffer is then treated as usual by the rest of the system and we
can use it if we need to return this scalar value as a kernel output. If we do
not need to return it, then the Store will be deleted by the DCE pass.
Differential Revision:
D33539324
D33539324
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: ab4524b9820ce204f106effcf6232ed33d4ee223
(cherry picked from commit 7faa0939f08e7235c2a7faa49da5eb84372165e7)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71640
Moving this function into the cpp file caused a small regression in
empty_cpu's callgrind instruction count, so moving it back.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33712880
Pulled By: ngimel
fbshipit-source-id: 64b3cb76308da38a3f0384de69500bea6ce6a30b
(cherry picked from commit d3791bc986d12a2e995bfb65fed5c35ddf7a9ae6)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71752
Added coverage for reshape specifically which required a fix. The problem for `acc_ops.reshape` as best as I understand:
- `torch.reshape` requires the `shape` arg to be a `tuple` of `ints`
- If `torch.reshape` is passed a `tuple` where the first element is not an `int`, it throws a TypeError e.g. `TypeError: reshape(): argument 'shape' (position 2) must be tuple of ints, not tuple`
- If the `shape` we're reshaping to is an FX Proxy then this type error will be thrown. This happens when the first element of the `shape` tuple is a Proxy because it's input-dependent.
- As a workaround we use `tensor.reshape` instead of `torch.reshape`, which doesn't do equivalent type checking for a `tuple` of `ints`.
Also remove unnecessary `acc_utils.get_field_from_acc_out_ty()` with cast to `TensorMetadata`.
Test Plan: Added test coverage
Reviewed By: yinghai
Differential Revision: D33760455
fbshipit-source-id: bff5563bf9e3d9e9318901b56211151d2c0e4eb2
(cherry picked from commit d5c1b9732a208dd305a3215920f1ea23e2f327f7)
Summary:
Hi,
The PR fixes https://github.com/pytorch/pytorch/issues/71096. It aims to scan all the test files and replace ` ALL_TENSORTYPES` and `ALL_TENSORTYPES2` with `get_all_fp_dtypes`.
I'm looking forward to your viewpoints!
Thanks!
cc: janeyx99 kshitij12345
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71153
Reviewed By: jbschlosser, mruberry
Differential Revision: D33533346
Pulled By: anjali411
fbshipit-source-id: 75e79ca2756c1ddaf0e7e0289257fca183a570b3
(cherry picked from commit da54b54dc5f1c7d9db92dab98c2db177d944cc7e)
Summary:
This PR twiddles the parameters of the conv layer in `test_conv_large` to better avoid NaN values. Previously, this test would cause a NaN to be computed for `scale` (propagated from `.mean()` on the `.grad` tensor). This NaN would then be propagated to the scaled gradients via division, resulting in a bogus `assertEqual` check as `NaN == NaN` is by default true. (This behavior was observed on V100 and A100).
To improve visibility of failures in the event of NaNs in `grad1`, scale is now computed from `grad2`.
Interestingly enough, we discovered this issue when trying out some less common setups that broke this test; it turns out those breakages were cases where there were no NaN values (leading to an actual `assertEqual` check that would fail for `float16`).
CC ptrblck ngimel puririshi98
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71521
Reviewed By: anjali411
Differential Revision: D33776705
Pulled By: ngimel
fbshipit-source-id: a1ec4792cba04c6322b22ef5b80ce08579ea4cf6
(cherry picked from commit d207bd9b87f8e8c2cb13182b7295c17e19dc3dba)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71294
This message will be visible to both internal and OSS users.
Test Plan: sandcastle
Reviewed By: dhruvbird, cccclai
Differential Revision: D33575804
fbshipit-source-id: a672e065f80aa20abd344951f0aaa07104defaf7
(cherry picked from commit 53703bed101c2a3f04bf85191681a95a137d1146)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71168
In this PR we want to enable the reference path by default for CopyNodeQuantizeHandler
Test Plan:
python test/test_quantization.py TestQuantizeFx
python test/test_quantization.py TestQuantizeFxOps
Imported from OSS
Reviewed By: andrewor14
Differential Revision: D33715995
fbshipit-source-id: eda44892fcea3a1cba54ac75bc020f73e1becc8c
(cherry picked from commit a2cf63f68d36a3847dd3d2fae7614469ffaab51b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71747
The getter is trivial as it's just creating a view tensor, but the
setter is actually copying data so does call into kernel code.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33770046
Pulled By: albanD
fbshipit-source-id: f0a70acaef790ae1e5b2f68ac4ce046e850c9624
(cherry picked from commit 36a0109400b256b32a185fcd05f21f302197c081)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71728
Fixes gh-68739
For simple indexing this adds a `gil_scoped_release` before calling
`set_item`. For tuple indexing, the slicing operation is done with the
GIL because otherwise it would have to re-aquire the GIL for each
element in the tuple. However, the GIL is released for the final
`copy_to` operation which is where the actual kernels are called.
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33770047
Pulled By: albanD
fbshipit-source-id: 67304a65e2cbf3b3ba9843687d9c63926d29298f
(cherry picked from commit d0a85046b7a497df8f377ff43f1667982ede7f2a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69826
This simplifies the logic needed to handle the defaultBackend flag in linalg functions.
cc ngimel jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mikaylagawarecki, ngimel
Differential Revision: D33751984
Pulled By: mruberry
fbshipit-source-id: 6963820be38d4f2d82ebb5196dfcccf034ad6784
(cherry picked from commit 49c81220160062a05bc10a25d487a1f14a2959cd)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67919
The compatibility check on `edge_order` in `pre_check_gradient` now looks only at dim argument if it is present, otherwise it checks all dimensions.
Previously, it would check all dimensions regardless of the dim argument and throw unnecessary errors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67926
Reviewed By: albanD
Differential Revision: D33760621
Pulled By: mruberry
fbshipit-source-id: d490cd8610c68ff3787e670fc947de3cbf2db062
(cherry picked from commit 45bc56de9e287f715186378682e22bc6ac7a6ccc)
Summary:
As issue https://github.com/pytorch/pytorch/issues/59750 is fixed, this PR is to remove the workaround implemented for it on ROCm.
Enabled hasPrimaryContext() related PyTorch unit tests on ROCm.
cc: amathews-amd, jithunnair-amd
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71146
Reviewed By: anjali411
Differential Revision: D33754615
Pulled By: albanD
fbshipit-source-id: b3a5c65a20c6d52d5f2ffc9e6f9628c819329b5d
(cherry picked from commit cfdd12166cfd1365de0ebe5a75ce40ac7fde15cc)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71778
This assert was broken (never triggers). Fixing the assert leads to test failures. We need to fix those test failures, so a FIXME has been filed. The urgency is avoiding the compile time failure that will come with enabling `-Wstring-conversion` as an error.
Test Plan: CI Pass
Reviewed By: r-barnes
Differential Revision: D33754171
fbshipit-source-id: 834b070b94007af583d0fc6c022f23b6703f3fbc
(cherry picked from commit ac8f905fb11c75b470b964f5ff5157e79d4c4b60)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71767
This will fix a ton of broken asserts that should always fire but never actually fire.
All would have been caught with `-Wstring-conversion` warnings enabled.
Test Plan: CI Pass
Differential Revision: D33754170
fbshipit-source-id: fa47dbf3b3e6cc27a2dfbdce7ac0416c47122ad7
(cherry picked from commit 23802fe3b5e14bbee6affc1393f3966603f5a983)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71717
Add a setting class for trt splitter which has a specific setting `use_implicit_batch_dim`. Further diffs will try to merge `fx2trt/split.py` and trt splitter.
Test Plan: CI
Reviewed By: wushirong
Differential Revision: D33745251
fbshipit-source-id: 5192da9c9b69d86839a8f26636852d405a40cfe7
(cherry picked from commit e2b0ccb1fab82eb54145404f7fce82294693f9a4)
Summary:
This moves the warning to the legacy function where it belongs, improves the phrasing, and adds examples.
There may be more to do to make `from_dlpack` more discoverable as a follow-up, because in multiple issues/PR we discovered people wanted new things (e.g., a memoryview-like object, or `__array_interface__` support) that `from_dlpack` already provides.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70437
Reviewed By: albanD
Differential Revision: D33760552
Pulled By: mruberry
fbshipit-source-id: e8a61fa99d42331cc4bf3adfe494cab13ca6d499
(cherry picked from commit 880ad9665956078958af93132a4c6ae820bbaac9)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71604
Implement 2 helper functions:
- as_functional_optim which takes in a torch.optim class type and arguments and
creates the corresponding functional optimizer.
- create_functional_optim which takes in the functional optimizer class type
and constructs it. Note that as_functional_optim calls into
create_functional_optim.
The first will be used in future PRs as described in
https://github.com/pytorch/pytorch/issues/67570 to create a functional
optimizer from a traditional optimizer. The latter is used in
_OptimizerHookState to create a functional optimizer.
Both new helper functions are covered by unittests.
ghstack-source-id: 147577170
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33688995
fbshipit-source-id: 8b2daafd1b914efa90877cc4313aa9a428546fc1
(cherry picked from commit 42fdae2991b93754501852802c292556c9addc6c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71602
The design in https://github.com/pytorch/pytorch/issues/67570 requires
`_OptimizerHookState` to be created directly from a functional optimizer. Add
support and tests for this. Also refactor a few tests.
ghstack-source-id: 147577175
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33687477
fbshipit-source-id: f3c789aa77773f918e01a8d0cf08739b2edf07b3
(cherry picked from commit 4851e1c6d4a200d6efcc8354c98936ab4044f761)
Summary:
We found a discrepancy between cpu & CUDA when using RNN modules where input shapes containing 0s would cause an invalid configuration argument error in CUDA (kernel grid size is 0), while returning a valid tensor in CPU cases.
A reproducer:
```
import torch
x = torch.zeros((5, 0, 3)).cuda()
gru = torch.nn.GRU(input_size=3, hidden_size=4).to("cuda")
gru(x)
```
Run with `CUDA_LAUNCH_BLOCKING=1` set.
cc ngimel albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71696
Reviewed By: mikaylagawarecki
Differential Revision: D33743674
Pulled By: ngimel
fbshipit-source-id: e9334175d10969fdf1f9c63985910d944bbd26e7
(cherry picked from commit 70838ba69bbfd1b39f6c208f9dbefaad3f11d47e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64929
Auto categorized 63% of the commits for PyTorch 1.10 release (2.2k out of 3.4k commits)
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D33768760
Pulled By: anjali411
fbshipit-source-id: 0655090af83e923f8c26fa1ce9f190edc542b97e
(cherry picked from commit 2fe30f77b83cbcfcb8fc09f728c8853600e8f303)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71711
This will fix a ton of broken asserts that should always fire but never actually fire.
All would have been caught with `-Wstring-conversion` warnings enabled.
Test Plan: CI Pass
Differential Revision: D33743605
fbshipit-source-id: 062641f9d5d02c6e317c5a286fd01017cf77237f
(cherry picked from commit 639b42e04b78c35389a1e3a12ae46901d7808e53)
Summary:
This change is to automate the process to generate the old models for testing upgraders. Developer will
1. Add a module in `caffe2/test/jit/fixtures_srcs/fixtures_src.py`
2. Register the module in `caffe2/test/jit/fixtures_srcs/generate_models.py`
3. Run `python test/jit/fixtures_src/generate_models.py`
The model will be dumped to `test/jit/fixtures`.
This script also ensure:
1. The output model operator version is as expected
2. The output model will include the changed operator
Example log:
```
(base) chenlai@chenlai-mp pytorch % python3 /Users/chenlai/pytorch/test/jit/fixtures_src/generate_models.py
TestVersionedDivTensorExampleV4() aten::div.Tensor
INFO:__main__:Processing TestVersionedDivTensorExampleV4
INFO:__main__:Generating model test_versioned_div_tensor_example_v4 and it's save to /Users/chenlai/pytorch/test/jit/fixtures/test_versioned_div_tensor_example_v4.ptl
```
The second time to run
```
(base) chenlai@chenlai-mp pytorch % python3 /Users/chenlai/pytorch/test/jit/fixtures_src/generate_models.py
TestVersionedDivTensorExampleV4() aten::div.Tensor
INFO:__main__:Processing TestVersionedDivTensorExampleV4
INFO:__main__:Model test_versioned_div_tensor_example_v4 already exists, skipping
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70629
ghstack-source-id: 147585826
Test Plan:
OSS
```
python3 /Users/chenlai/pytorch/test/jit/fixtures_src/generate_models.py
```
Internal:
```
buck run mode/opt //caffe2/torch/fb/mobile/upgrader_codegen:upgrader_test_models_gen
```
Reviewed By: iseeyuan, tugsbayasgalan
Differential Revision: D33410841
fbshipit-source-id: 28e2b851a30f12a74e4ac8a539d76e83bbc4fb3a
(cherry picked from commit 6614f1bdf360b69bcf9eb4bca30707e5bd0e8a2b)
Summary:
This fixes a number of unused variable warnings that appear when compiling with LLVM-12 on platform010. Fixes are made by removing the variable when possible or by using `/* */` comments to unname the variable when a shared interface is used or eliminating the variable entirely would require extensive changes or risk modifying a public API.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71685
Test Plan: Sandcastle
Reviewed By: luciang, meyering
Differential Revision: D33728264
fbshipit-source-id: 49286ad7f5271ca1cb48dc70039097305285c948
(cherry picked from commit a2306cddd67b5f2d83d7c2829aea7cb3d1ce767e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71569
Not sure if this is the right API
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33695395
Pulled By: soulitzer
fbshipit-source-id: 652b5758f15d901f98ff0da94e977030c7f3415b
(cherry picked from commit 9421a6846ad35cebbb84bd052769527505092a0c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71531
Based on the comment above the original internal assert, this is the desired check.
1. Don't error, and automatically make jvp return a view for that tensor output (this is easier than I originally thought: https://github.com/pytorch/pytorch/pull/71531#discussion_r789211877)
2. Error (currently doing)
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33695399
Pulled By: soulitzer
fbshipit-source-id: dba49890a55ad1dd59ed5c41faa96bf7cfc9e562
(cherry picked from commit fdb0f266f51e939e122676ab378f4cacba4295aa)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71597
Problem: _jit_to_backend overrides get/set state. This means any attributes added to the module after lowering will not be preserved after serialization. For edge workflows the biggest problem here is it breaks bundled_inputs.
Solution?:
Real quick and easy way to handle issues with to_backend overriding get/set state. Wraps the lowered module in another module and has forwarding functions for the api specified in 'method_compile_spec'.
The tradeoff with this approach is now the actual workhorse of the module is 1 layer deep which might make debugging slightly grosser/more difficult/confusing. The other approach Martin David and I talked about would be to only lower the portions that require custom get/set state logic. This leaves the top level the same, and only specific backened internals are changed. Personally I'm not sure how much that really addresses the debugging concern all that well. It seems like if you cracked the model open you'd still run into similar amounts of confusion with a lot of the variables and logic referenced coming from another module.
The other concern with this approach is whether or not 'compile_spec' specifies the public api of the module (since thats our source of truth for this wrapper). While it may not be enforced, it certainly seems to be true by convention and the to_backend api already uses it as a source of truth for all functions that get generated in the resulting module. I say we just formally commit to this (compile spec keys being functions) being the contract of the api instead of just assuming it to be the case and then having weird behavior if its not.
Test Plan:
New Unit Test
CI to check for existing behavior and contracts.
manually tested in a notebook with bundled inputs.
{P475790313}
Reviewed By: raziel
Differential Revision: D33694257
fbshipit-source-id: 9ff27db421eba41bac083dff11a22e9e40a36970
(cherry picked from commit 91ef49977ef0bf18242df381a3ee805c24d6f68d)
Summary:
Fixes typo's in `aten/src/ATen/native/README.md`. The following were the fixes:
- Update string type to `c10::string_view` instead of `std::string`.
- Update the link `torch/_python_dispatcher.py`, which was broken.
**Link to docs:** https://github.com/pytorch/pytorch/tree/master/aten/src/ATen/native/README.md
Thanks!
cc: mruberry kshitij12345
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71395
Reviewed By: mikaylagawarecki
Differential Revision: D33743229
Pulled By: mruberry
fbshipit-source-id: 9deebffede20bf68dfc8e45088c8ab2dffb7564c
(cherry picked from commit 8bedb2cb60aa62b189f6341cf2d92fe46e9f3f7a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71706
This fixes a bug in singleCheckErrors introduced by #69437 (thanks
Lezcano for the catch). Checking existence of a substring in a larger
string is done with (name.find(text) != name.npos) but we omitted the
second half of the check.
Test Plan: - Code reading; I guess there are no tests for this in CI
Reviewed By: mikaylagawarecki
Differential Revision: D33742822
Pulled By: zou3519
fbshipit-source-id: a12017bb12b941282704bd2110e8632f02c24b04
(cherry picked from commit afb5a04a44232671961d554139e5e19ee711fcab)
Summary:
Allows disabling issues to disable all parametrized tests with dtypes.
Tested locally with:
1. .pytorch-disabled-tests.json as
```
{"test_bitwise_ops (__main__.TestBinaryUfuncs)": ["https://github.com/pytorch/pytorch/issues/99999", ["mac"]]}
```
and running `python test_binary_ufuncs.py --import-disabled-tests -k test_bitwise_ops` yields all tests skipped.
2. .pytorch-disabled-tests.json as
```
{"test_bitwise_ops_cpu_int16 (__main__.TestBinaryUfuncsCPU)": ["https://github.com/pytorch/pytorch/issues/99999", ["mac"]]}
```
and running `python test_binary_ufuncs.py --import-disabled-tests -k test_bitwise_ops` yields only `test_bitwise_ops_cpu_int16` skipped.
NOTE: this only works with dtype parametrization, not all prefixes, e.g., disabling `test_async_script` would NOT disable `test_async_script_capture`. This is the most intuitive behavior, I believe, but I can be convinced otherwise.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71499
Reviewed By: mruberry
Differential Revision: D33742723
Pulled By: janeyx99
fbshipit-source-id: 98a84f9e80402978fa8d22e0f018e6c6c4339a72
(cherry picked from commit 3f778919caebd3f5cae13963b4824088543e2311)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71642
Missing comma was causing string concatenation in a list of strings
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D33713185
Pulled By: davidberard98
fbshipit-source-id: a2458629d78202713a5bb2f8c720ff9b81939c31
(cherry picked from commit b077598f1d41948ebe05e2d644ba2dd37446b900)
Summary:
Narrow the scope of https://github.com/pytorch/pytorch/issues/69730.
Once there's an error, stop the script.
Since it's a random error, it most likely has something with the environment.
Let's see the stat.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71693
Reviewed By: seemethere, mikaylagawarecki
Differential Revision: D33742733
Pulled By: janeyx99
fbshipit-source-id: b453957c2cb450eb79b89614db426b50eef1d14f
(cherry picked from commit cd32fa53d994c4c4590cd7f4962671330eda28c1)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71267
Refactors `SeenOpInfo` to be a dataclass, to be consistent with
`QTensorInfo`, so we can get real typing. Fixes the type errors. No logic change.
Test Plan:
```
python test/test_quantization.py -k DBR
```
Reviewed By: HDCharles
Differential Revision: D33567129
Pulled By: vkuzo
fbshipit-source-id: 55f89d7a497b6db1fd9956255d964663032a0401
(cherry picked from commit 7fdec92b9cc9ecbc8ca7224cfec5668543cd8cfc)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71253
Before this PR, observers were inserted at the same time as
we recorded ops seen while tracing with example input. This is not
ideal because for function fusion (not yet implemented),
we need to be able to look ahead from the current op to properly
insert observers.
This PR refactors observer insertion in DBR quantization to happen
in a separate pass after the ops are recorded. There is no functionality
change in this diff, but this PR will make it easier to implement
function fusion in a future PR.
Note: the qconfig is still used during tracing to assign each
op an inference dtype. This is not ideal, in the future we may move this
step to happen as a separate pass as well. The reason we keep it as is
in this PR because some more refactoring would be needed to allow
this to both happen in a separate pass as well as survive module
boundaries.
Test Plan:
```
python test/test_quantization.py -k DBR
```
Reviewed By: wenleix
Differential Revision: D33558280
Pulled By: vkuzo
fbshipit-source-id: 54e9cea6ad05317a8c7c92be005d33653617bed6
(cherry picked from commit 2985849916dbd194b6bf44cc3c360e9450da6828)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71245
This is a refactor to make a future PR of making observer
insertion be a separate pass easier.
1. adds orig_dtype, so we always record what was seen while tracing
2. switches from namedtuple to dataclass, so we can have more explicit types
Test Plan: CI and mypy
Reviewed By: HDCharles
Differential Revision: D33558281
Pulled By: vkuzo
fbshipit-source-id: b9f87e25a3538fee145f020916a31699046a9c11
(cherry picked from commit 3c8db243605220e990e3c7280ed475d6e90c32fb)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71233
Some keys in qconfig_dict are not implemented yet for DBR quant.
However, FX graph mode quantization modifies qconfig_dict inplace,
so if users use the same dict for DBR and FX they may hit errors.
This PR reduces the chance of these errors by only throwing an
exception in DBR quant if the unsupported keys have nonempty values.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_qconfig_dict_unsupported_only_crashes_when_nonempty
```
Reviewed By: samdow
Differential Revision: D33552398
Pulled By: vkuzo
fbshipit-source-id: 4191ad7ae23929455fef6acaf2c045c65db0b0bd
(cherry picked from commit 8b1911f33e1298225055aff375c0479760767468)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70757
This is an initial PR on a way to preserve stack traces throughout FX
graph mode quantization. It preserves the stack traces for ops
for all of the quantize handlers. A future PR will add stack traces
for dtype transitions.
Test Plan:
```
python test/test_quantization.py
TestQuantizeFx.test_stack_trace_preserved
```
Note: the above only tests a single case. In a future PR, once we
expand coverage, we can expand the utility functions to check for stack
traces on all tests.
```
python test/test_quantization.py
TestQuantizeFx.test_stack_trace_preserved
```
Imported from OSS
Differential Revision:
D33432485
D33432485
Reviewed By: jerryzh168
Pulled By: vkuzo
fbshipit-source-id: 56c56850393132487430a850fa1def826a9c39c0
(cherry picked from commit c11155b31eb9d228380501860f522a8c89eb2040)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71601
Moves current prototype optimizer overlap to its own file for a better
namespace. No code changes besides a few comment fixes. Note that this code is
still prototype and not expected to be used by an end user.
ghstack-source-id: 147458826
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33662678
fbshipit-source-id: 3cc931323230a4b66c02b9e6f744aaf5c48d4d34
(cherry picked from commit 5070595c7f6de85f75249eb22cbd561f9450fcc2)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71600
These tests in test_c10d_nccl test a subset of functionality that's
already covered by distributed_test.py, no need for these additional tests.
ghstack-source-id: 147458823
Test Plan: CI
Reviewed By: cbalioglu
Differential Revision: D33662679
fbshipit-source-id: 2d1c1223fdd72a851c537b4793a71d65190d2553
(cherry picked from commit 14565ac5a6e059ec06af8583fcefa80626c95990)
Rename `checkout_pytorch` to `checkout` and assign `submodules` argument
a default values, which allow one to replace 10+
`common.checkout_pytorch("recursive")` with `common.checkout()`
And also use the same macro to checkout builder in binary builds
workflow
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71664
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70618
`at::native::empty_cuda` is called directly in some places to avoid
the extra dispatch, however it's features like device guards and a
`TensorOptions` overload.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33623676
Pulled By: ngimel
fbshipit-source-id: 3ac56c4f8acc90281323195a34fc0a1ef8148fbe
(cherry picked from commit 4aaf8b29d0de927ec9ced9f8749a96b2be9c4a89)
Summary:
Should alleviate instances of "blah not a repository" that happen due to non-ephemeral runners not cleaning up properly.
https://github.com/pytorch/pytorch/runs/4902228068?check_suite_focus=true
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71655
Reviewed By: malfet
Differential Revision: D33719058
Pulled By: janeyx99
fbshipit-source-id: 4ff35893d00c99026154d71e4d1ae7a54ac5c42a
(cherry picked from commit 13ca9d1f91b9101a6350d3caf45fbc158e7ae47a)
Summary: Add session based margin loss into caffe2 operator. This is the first diff make these 2 loss available to dper3
Test Plan:
unit test succeeds with gradient check for both new loss function
buck test //caffe2/caffe2/python/operator_test:softmax_l2r_operator_test
buck test //caffe2/caffe2/python/operator_test:margin_loss_l2r_operator_test
E2E test in bento notebook with model training in N1488923
margin loss model: f318207967 f318207399
Notice that the E2E test is run with dper change in D33532976 to change a full model
Reviewed By: devashisht
Differential Revision: D32902460
fbshipit-source-id: 8f21b9109f500583431156908b632e503ed90dbd
(cherry picked from commit 1592111aa4ed6cfdd7ca5f54de70396e9610757c)
Summary:
This adds argument names and docstrings so the docs are a lot more understandable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71481
Test Plan:
docs/tests CI should suffice
Reviewed By: edward-io
Differential Revision: D33661255
Pulled By: d4l3k
fbshipit-source-id: 686835dfe331b92a51f4409ec37f8ee6211e49d3
(cherry picked from commit 0a6accda1bec839bbc9387d80caa51194e81d828)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70617
This reduces the divergence between the code generated for
`create_out` different devices, and means the `TensorOptions` don't
need to be unpacked.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33623680
Pulled By: ngimel
fbshipit-source-id: 54f36774a8530be99c26a54270d4d95f3e38d684
(cherry picked from commit b22ba92e27e638f96a290835b71ad162411fa535)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70021
`RegisterSchema.cpp` only uses strings to register operator schemas,
so doesn't need to include any operator headers at all (except
indirectly through `torch/library.h`).
`RegisterBackendSelect.cpp` only needs the dispatcher API.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33160028
Pulled By: albanD
fbshipit-source-id: 68fb5cb8775077b6f174428a1fcced2a7836b714
(cherry picked from commit 35774ad7ac6ebbb6d17552ca9eb76fd3c06dcf43)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71621
Moves this feature to beta as discussed, and cleans up some docs.
Synced offline with wayi1 who mentioned that the current names are preferred
as he works to prototype hierarchical allreduce as discussed in this RFC: https://github.com/pytorch/pytorch/issues/71325.
ghstack-source-id: 147382940
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D33700444
fbshipit-source-id: 8eb543f5b02a119d0790a5c0919e6def6383a067
(cherry picked from commit 656e9809b2429d1924e008164a1f4ca770700a9a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71525
Closes https://github.com/pytorch/pytorch/issues/71496. Use file init
for test as opposed to TCP init which runs into some port racing conditions as
seen in the failures for that issue.
ghstack-source-id: 147300691
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D33676165
fbshipit-source-id: fcf83f7c7541d3521d3e38481195b0c7cb081691
(cherry picked from commit ea091c4af7d864e4d2ebcda6f72d04e17ae7bd82)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71579Fixes#1551
As the comment in the code, register a function to terminate persistent workers. Using `atexit` to make sure termination of persistent workers always happens at the end (after pin_memory_thread exits).
We need such mechanism because Python interpreter would clean up worker process before DataLoader iterator in some rare cases.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D33694867
Pulled By: ejguan
fbshipit-source-id: 0847f4d424a0cd6b3c0be8235d505415970254e8
(cherry picked from commit 18ad4621af5b5ff3c66b56051a00f6bfd3bf7a51)
Summary:
I noticed after creating https://github.com/pytorch/pytorch/issues/71553 that the test ownership lint was not working properly.
This fixes my egregious mistake and fixes the broken lints.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71554
Reviewed By: malfet
Differential Revision: D33690732
Pulled By: janeyx99
fbshipit-source-id: ba4dfbcd98038e4afd63e326832ae40935d2501e
(cherry picked from commit 1bbc3d343ac143f10b3d4052496812fccfd9e853)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71501
This option disabled the memory planner. Supporting it would require us to add multiple versions of ops that borrow their inputs (because they rely on the memory planner to support that), and I'm not aware of a particular need to continue supporting it.
ghstack-source-id: 147385569
Test Plan: CI, rerun broken test from task
Reviewed By: mikeiovine
Differential Revision: D33669290
fbshipit-source-id: ecb01995891aecb5f4d0da2d9c51eed1f8fe489a
(cherry picked from commit 5e4fefb109b6c92d59fc7e24d69f1b6b2780c776)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68693
Generation of python bindings for native functions is split over 8
different files. One for each namespace, with the torch namespace
split into 3 shards, and methods in their own file as well. This
change ensures that editing any single (non-method) operator only
causes one of these files to be rebuilt.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596270
Pulled By: albanD
fbshipit-source-id: 0570ec69e7476b8f1bc21138ba18fe8f95ebbe3f
(cherry picked from commit ba0fc71a3a6835e49b332a8be52bf798fa2726b3)
In CI PRs are being tagged like `ciflow/cpu/$PR_NUMBER` which is
causing version strings to be set as non-numbers. This breaks the
caffe2 build because it uses CAFFE2_VERSION_MAJOR etc. as numbers.
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71562
Previously we have some unsupported ops and the perf improvement is not promising (10% on batch size 32)
```
Unsupported node types in the model:
acc_ops.reshape: ((), {'input': torch.float16})
mean: ((torch.float16,), {})
```
After the diff stack, we don't have any unsupported nodes.
Also moved `lower_to_trt` to lower.py.
Test Plan: buck run mode/dev-nosan -c python.package_style=inplace scripts/dsy842974287/cu_model:vision
Reviewed By: wushirong
Differential Revision: D33483843
fbshipit-source-id: 4a54e25af3e5a6e4a299737994b60b999f529aa6
(cherry picked from commit add0077c27e7155fff7aaab96c506a872a00b83c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70616
This adds `at::detail::empty_cuda` and
`at::detail::empty_strided_cuda` to complement the cpu and meta APIs.
These functions also include the `lazyInitCUDA` and `DeviceGuard` that
are missing from the `at::native::empty_cuda` interface and so is
safer to use.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33623677
Pulled By: ngimel
fbshipit-source-id: 1c38e84881083df8e025250388f0c8f392974b92
(cherry picked from commit 4bc48c7008acf2394db7d02dee69dd7a8cfb87b8)
Summary:
This PR ensures that the input iterator is always in front of the output
iterator. Thus, we won't have a out of bound issue since the input
iterator will meet the end before output iterator meets.
Fixes https://github.com/pytorch/pytorch/issues/71089
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71540
Reviewed By: mruberry
Differential Revision: D33688123
Pulled By: ngimel
fbshipit-source-id: f57718931d09a0fbea76ac1bd6cc8c7150af0978
(cherry picked from commit dc6e0e219a9e9b9ccea9ff5406458b56f556b2e4)
Summary:
if python3 is the one running the tests but there exists a "python" installed as python2.7 the test will fail with a syntax issue
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71021
Reviewed By: zou3519
Differential Revision: D33667073
Pulled By: albanD
fbshipit-source-id: 8e489b491439be1740fc32ca5c7cdceb2145771e
(cherry picked from commit 5adfece429fcfe6ace778dd67f060d04a3d54699)
Summary:
For some ONNX exported models, the inputs/outputs names have sometimes a numeric value and this makes pretty hard to inspect the generated graphs in the case of large models.
The solution in this PR was initially submitted to our internal utilities library by take-cheeze https://github.com/pfnet/pytorch-pfn-extras/pull/102
Now we would like to upstream this change by adding an extra kwarg when exporting the model to allow replacing these numeric names with actual debuggable ones.
As an example, the following code shows that the module output is `3`
```python
g, p, o = _model_to_graph(module, torch.ones(1, 10))
for n in g.nodes():
for v in n.outputs():
print(v.debugName())
```
output
```
3
```
With this PR
```
v3_Gemm
```
This allows identifying this out as a value from the associated Gemm layer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68976
Reviewed By: jansel
Differential Revision: D33662246
Pulled By: msaroufim
fbshipit-source-id: 45f56eef2a84d9a318db20c6a6de6c2743b9cd99
(cherry picked from commit 513c1d28f1708ccf8224caa92165de702cf43fc3)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71519
Remove inplace hardtanh in fx quantized op test case
Test Plan:
python3 test/test_quantization.py TestQuantizeFxOps.test_clamp
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D33675227
fbshipit-source-id: a496150ca4b485f953f68e24ddf9beb8ed1d94c0
(cherry picked from commit f65a888900aeef812bb3e6d8a231395c95914db9)
Fix the wiki URL.
Also minor reorganization in onnx.rst.
[ONNX] restore documentation of public functions (#69623)
The build-docs check requires all public functions to be documented.
These should really not be public, but we'll fix that later.'
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71609
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71596
Adds a dry_run to test out push as well as adding in a debug flag to
allow you to see what git commands are running
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet, bigfootjon
Differential Revision: D33695224
Pulled By: seemethere
fbshipit-source-id: 03bf6a3f2d9594089e134d95c3d35a6779ba7a26
(cherry picked from commit a75a402f9d02d5e4c709e25ca385264f854945d1)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71508
"==" is the more universal way to test type equalities, and also ::get() doesn't incur any refcount overhead now, so we can swtich to == instead of relying on type kinds.
ghstack-source-id: 147353057
Test Plan:
CI
buck test xplat/caffe2/android:pytorch_jni_common_test
Differential Revision: D33672433
fbshipit-source-id: 5973fd40de48b8017b5c3ebaa55bcf5b4b391aa3
(cherry picked from commit db84a4b566d1f2f17cda8785e11bc11739e6f50c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70380
A small change in `Tensor`'s `enforce_invariants` that addresses tensor types that don't use the regular storage mechanism.
ghstack-source-id: 147328303
Test Plan: Existing unit tests.
Reviewed By: zou3519
Differential Revision: D33304602
fbshipit-source-id: c8cc41ed38a3eec147f40fe1029fd059748c87b5
(cherry picked from commit da4e87f20b0ec8bb1003e519ed39ba32de62a89d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71581
Fixes https://github.com/pytorch/pytorch/issues/71553
Test Plan:
add ciflow/windows to CI
buck test //caffe2/test:monitor -- --stress-runs 100 test_interval_sec
I don't have a windows machine so need to rely on CI to test
Reviewed By: edward-io
Differential Revision: D33691540
fbshipit-source-id: 69f28f1dfa7243e4eeda642f9bef6d5d168381d2
(cherry picked from commit 5d24dc7c2f5e8e0f48fdd602b1eaa3a8e6929715)
Summary:
Test PeekableIterator behavior
Add `.github/scripts/test_*.py` to list of tests run by test_tools
workflow and pin Python version to 3.7 in test_tools workflow
Change PeekableIterator inheritance from collections.abc.Iterator, to
typing.Iterator, which is a correct alias starting from Python-3.7
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71580
Reviewed By: bigfootjon
Differential Revision: D33690659
Pulled By: malfet
fbshipit-source-id: 71f270b15138230772e2eed0da66cdfcb34825cc
(cherry picked from commit 42abb07396fa90272afb0b56508bd3a1f5c4ccbe)
Summary:
This PR implements the workflow changes described in https://fb.quip.com/oi8wAvajpR4g. Combined with the bot logic in d928549336 (can be moved to probot but is easier to test there), it fully implements the proposal.
The CIFlow comment is slightly outdated now but is still technically correct (all the commands will continue to work as before, just through a different mechanism).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70321
Reviewed By: atalman, janeyx99
Differential Revision: D33690370
Pulled By: suo
fbshipit-source-id: 8d81ffeb249cdae53c5526798a4a504560d0204f
(cherry picked from commit 5ed8d0dfae6dcf8bacaf6e4229e7b40b5c2b2446)
Summary:
A header is used only in the .cc file and it is included by the public header. This causes errors when I try to include the public header.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71307
Reviewed By: zou3519
Differential Revision: D33650700
Pulled By: ngimel
fbshipit-source-id: d08dd335208da3aaafe333522d9525976c513151
(cherry picked from commit 94805495a0d30c54f22b0609db177d7ac3e26093)
Summary:
Also adds a mechanism for all workflows to do this
Signed-off-by: Eli Uriegas <eliuriegasfb.com>
cc jeffdaily sunway513 jithunnair-amd ROCmSupport KyleCZH
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71567
Reviewed By: malfet
Differential Revision: D33687713
Pulled By: seemethere
fbshipit-source-id: a3c7ef41ed04f9caa82c180961d2f4b7c24582dd
(cherry picked from commit eef2eafffd4c6311eff73d86fffaa42460cd2603)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71445
A reference to the ShardedTensor was always added to the global map
`_sharded_tensor_map`, that never got cleaned up since the map always held a
reference to the ShardedTensor.
A couple of fixes for this:
1) Add to the global map only for `init_rrefs=True` since only this codepath
requires this.
2) Add a `weakref` to the global map to avoid having a reference to the
ShardedTensor forever that never gets cleaned up.
ghstack-source-id: 147299580
Test Plan: waitforbuildbot
Reviewed By: fduwjj
Differential Revision: D33641013
fbshipit-source-id: c552fa3359186514445fd5715bec93f67dc2262d
(cherry picked from commit d25f1a645313dcbf8c37158d80c42c983262cec2)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71483
claify that peak memory saving should be checked after first iteration when using gradient_as_bucket_view
ghstack-source-id: 147271113
Test Plan: unit test
Reviewed By: rohan-varma
Differential Revision: D33662424
fbshipit-source-id: f760da38e166ae85234e526ddf1526269ea25d42
(cherry picked from commit a40dda20daa2fe051fcaa8fee5f3641aeea1da1c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71459
1. add static_graph feature to DDP constructor;
2. still keep _set_static_graph() API, so that existing use cases are not affected, also it can be called internally by DDP constructor
3. four cases are covered:
static_graph = False, _set_static_graph() is called;
static_graph = False, _set_static_graph() is not called;
static_graph = True, _set_static_graph() is not called;
static_graph = True, _set_static_graph() is called;
ghstack-source-id: 147263797
Test Plan: unit tests
Reviewed By: rohan-varma
Differential Revision: D33646738
fbshipit-source-id: 8c1730591152aab91afce7133d2adf1efd723855
(cherry picked from commit dc246a1129a8ce5f70e551d7d8e00e0dab8ec6af)
Summary:
While implementing https://github.com/pytorch/pytorch/issues/70275, I thought that it will be useful if there is a `torch.distributions.constraints` to check the positive-semidefiniteness of matrix random variables.
This PR implements it with `torch.linalg.eigvalsh`, different from `torch.distributions.constraints.positive_definite` implemented with `torch.linalg.cholesky_ex`.
Currently, `torch.linalg.cholesky_ex` returns only the order of the leading minor that is not positive-definite in symmetric matrices and we can't check positive semi-definiteness by the mechanism.
cc neerajprad
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71375
Reviewed By: H-Huang
Differential Revision: D33663990
Pulled By: neerajprad
fbshipit-source-id: 02cefbb595a1da5e54a239d4f17b33c619416518
(cherry picked from commit 43eaea5bd861714f234e9efc1a7fb571631298f4)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71491
Changed the Cudnn and CudnnTranspose cases to only make the input
contiguous when it is needed for the grad_weight computation.
Reading the implementation of cudnn_convolution_transpose_backward and
cudnn_convolution_backward give me confidence that `input` isn't used
for the grad_weight computation. However, the memory format logic is so
convoluted that I'm 100$ sure this correct. All the tests though
and on request I can directly pass `backend_memory_format` to
{cudnn_convolution_backward, cudnn_convolution_transpose_backward}.
Test Plan: - pytest test/test_nn.py -v -k "conv"
Reviewed By: jbschlosser
Differential Revision: D33664694
Pulled By: zou3519
fbshipit-source-id: 9f4929686fe34f7aaf5331bfa49e98022b9d6c08
(cherry picked from commit 9e2ba0daca88139f7941bcb56bbc23825585d7a2)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71490
Deleted unnecessary .contiguous() calls in convolution_backward. The
CudaDepthwise3d case always hits _depthwise_3d_backward_cuda_out,
which will make arguments contiguous as necessary.
Changed _depthwise_3d_backward_cuda_out
- to make the input contiguous only when we're computing grad_weight
- to make the weight contiguous only when we're computing grad_input
Test Plan: - pytest test/test_nn.py -v -k "conv"
Reviewed By: jbschlosser
Differential Revision: D33664696
Pulled By: zou3519
fbshipit-source-id: d01d4f213e21ef4778de089a158933737b191cdf
(cherry picked from commit c6eb977c94a07f9812567a43b125b453eb5c5051)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71489
Deleted unnecessary .contiguous() calls in convolution_backward. The
CudaDepthwise2d case always hits conv_depthwise2d_backward_cuda_out,
which makes the grad_output / self contiguous.
Changed conv_depthwise2d_backward_cuda_out to change `self_` (aka the
image input to convolution) to be contiguous only when we're computing
the grad_weight. This is because when we are computing the grad_input,
we only need the values from the grad_output and the weight.
Test Plan: - pytest test/test_nn.py -v -k "conv"
Reviewed By: jbschlosser
Differential Revision: D33664697
Pulled By: zou3519
fbshipit-source-id: 7a755fa8a076809c5490422d69fdf7ed80c8e29a
(cherry picked from commit 862ae63bab74113b3607b1bbc0a82f27992550fe)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69437
linalg.{inv, cholesky} are problematic because they call .data_ptr().
This makes them not composite compliant (e.g. meta tensors will not run
on them correctly). This PR makes them composite compliant by adding a
new native_functions operator that does error checking,
`_linalg_check_errors(Tensor info, str api_name, bool is_matrix`
that is a primitive with respect to autograd.
This PR modifies linalg.inv and linalg.cholesky to call the new error
check function. I also needed to refactor singleCheckErrors and
batchCheckErrors to accept a c10::string_view instead of a
`const char*`; you can convert `const char*` to c10::string_view but not
the other way around because `string_view` does not require null
terminated buffers.
Finally, there is a bugfix in `__torch_dispatch__` for this PR for
the composite compliant testing mechanism. Previously,
`__torch_dispatch__` could not handle operators with no returns; this PR
fixes that. No returns in C++ is equivalent to a single None return in
Python.
Test Plan: - composite compliant tests
Reviewed By: albanD
Differential Revision: D32883666
Pulled By: zou3519
fbshipit-source-id: d5a3f52ebab116c93e1a54a203eacc8f787de7e2
(cherry picked from commit 9e24c9599a043877ab4f289469be55550c996a79)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70215
A few renaming, formatting, and additional tests to make the unit tests better.
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33344610
Pulled By: NivekT
fbshipit-source-id: bb36f7452bdc44964c9ce0650c7ae308ba2c5aa5
(cherry picked from commit 0aae20cb27038b7b3598520db4304a604f1e6799)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71453
As title
Test Plan: unit test
Reviewed By: frank-wei
Differential Revision: D33646384
fbshipit-source-id: d86326c93e4d6bd59c9152592721f0e6ecf7f6fb
(cherry picked from commit d886380edef3388d60d529100332f9d9564f0913)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68945
This PR enables the Python conversion functions for `Storage` (specifically `UntypedStorage`) and also cleans up some remnants of the deprecated typed storages from `DynamicTypes.cpp`.
ghstack-source-id: 147245110
Test Plan: Run the existing unit and integration tests.
Reviewed By: albanD
Differential Revision: D32676505
fbshipit-source-id: 3a3f6db4fb0da5c78dd406c96ab70bdc37015521
(cherry picked from commit d6427b94cf88b078bd228d43cd2afbabf0773b39)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70476
1) Support a single dimension for inputs
2) Test several error cases
Partially addresses https://github.com/pytorch/pytorch/issues/65638
ghstack-source-id: 146307607
Test Plan: waitforbuildbot
Reviewed By: fduwjj
Differential Revision: D33344357
fbshipit-source-id: 4de7a7177452951dbcce76f27441703447609e6f
(cherry picked from commit 96dfded5697e451b54f113f99b6d0da6f6af500d)
Summary:
Following subfolders of the project were identified as one that can be
merged on github first and then asynchronously merged into Meta
codebase:
## ONNX exporter
PRs that include only files under `torch/onnx`, `torch/csrc/jit/passes/onnx` and `test/onnx` and are reviewed by garymm
## CUDA fusers
PRs that include only files under `torch/csrc/jit/codegen/fuser/cuda`, `torch/csrc/jit/codegen/cuda` or `benchmarks/cpp/nvfuser` and reviewed by csarofeen or ngimel
## OSS CI
PR that include only files under `.circleci`, `.github` and `.jenkins` and reviewed either by seemethere or myself
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71514
Reviewed By: bigfootjon
Differential Revision: D33673050
Pulled By: malfet
fbshipit-source-id: 21b909d49cb73ff79879b3ea0568e53ef65aa08c
(cherry picked from commit 520226c1bf341fe6a9e1cd42f18da73c43386062)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71140
Structured kernels need to use the borrowing variants of the build APIs to TensorIterator. (I am working on a debug check for this, but it is currently too strict, and relaxing it does not catch these bugs.)
ghstack-source-id: 147191022
Test Plan: CI
Reviewed By: bdhirsh
Differential Revision: D33520003
fbshipit-source-id: 3b0ff9036acdb78ae6fc7489ed0ed487d5ff080f
(cherry picked from commit 80ef4e14e33718a9ad5aaefc218bb773e3b15a5c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71423
Replacing this math with a load seems to improve perf.
ghstack-source-id: 147171800
Test Plan: ptvsc2_predictor_bench runs on model from mikeiovine courtesy of mikeiovine
Reviewed By: mikeiovine, xiaomengy
Differential Revision: D33552176
fbshipit-source-id: f21a4cd66c13b9fcb7bcf48f356bdc85e94c4216
(cherry picked from commit 0354fcb9889e7345321fe4dc9e30495a67709a4d)
Summary:
From https://github.com/pytorch/pytorch/issues/67626: RRefProxy (rref.rpc_async, rref.rpc_sync, rref.remote) currently uses a blocking RPC call to the owner
This is done by chaining async calls. In the sync case we wait on the
resulting Future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70206
Test Plan:
I ran rpc_tests using tensorpipe_rpc_agent_test_fixture.py and had to
adjust test_rref_proxy_timeout to the new behavior.
I ran into test_tensorpipe_set_default_timeout failing due to the
timeout being too small. Doesn't look related to this change.
mrshenli
Fixes https://github.com/pytorch/pytorch/issues/67626
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Reviewed By: pritamdamania87
Differential Revision: D33243348
Pulled By: kumpera
fbshipit-source-id: e1e8c34bb3d170407c0a793e2e585357f905d3c6
(cherry picked from commit 1ad5a7ceea17d00872e593650ef50d85bb232cda)
Summary:
The block and thread extent calculations in `cuda_codegen` should be using `int64_t` instead of `int`. The updated test, `test_dynamic_shapes`, fails without this change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71428
Reviewed By: samdow
Differential Revision: D33640374
Pulled By: navahgar
fbshipit-source-id: 64c340ad2a9a1fa1fe066cf1c5dfc3b546b7be6d
(cherry picked from commit 6ea546ce116fc05d9d7e225bc29f7fe86be439de)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71031
During the conversion stage, we might create some constants when size op is called and size is static. Raising error here causes problem for this case. Generally speaking it doesn't hurt to allow not const folding.
Test Plan:
Test with D33483843 on shufflenet.
Added unit tests.
Reviewed By: wushirong
Differential Revision: D33484183
fbshipit-source-id: 5b32c06297e56965befd7e83fe8ca273e3665cee
(cherry picked from commit e6b79bd3dd626f4b0035b9792a246fc09098d5ef)
Summary:
This one, will react to `repo_dispatch` event sent by PyTorch Probot
when `pytorchbot merge this` command is issued
At the moment, workflow will only attempt to merge PRs which has not
been created from forked repo and that match rules defined in
`.github/merge_rules.json`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71488
Reviewed By: bigfootjon
Differential Revision: D33665142
Pulled By: malfet
fbshipit-source-id: e22daa1892523e62d7b7a941960636a6514cb7d7
(cherry picked from commit 92059bab073e2cd6ca6e9f946ffc2f956e22895c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68953
This PR consolidates the almost identical lvalue and rvalue implementations of shallow_copy_and_detach into a single templated function.
ghstack-source-id: 147238376
Test Plan: Run existing unit tests.
Reviewed By: fduwjj
Differential Revision: D32679741
fbshipit-source-id: 89a870335d2e09ffd005c943733a787d20d352f9
(cherry picked from commit 750344c8600e05d4ab593956257c8191919eeef8)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70853
We support both configurations, so we should ensure they both work.
ghstack-source-id: 147170900
Test Plan: This is adding a test to CI.
Reviewed By: malfet
Differential Revision: D33304505
fbshipit-source-id: 7074b6b98d05f60801bb1d74bc9ac1458c768d28
(cherry picked from commit 8e4134b77789a157be5ba3df1d07f9bb308ca3b6)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70852
This is the first change that uses a common build file, build.bzl, to
hold most of the build logic.
ghstack-source-id: 147170895
Test Plan: Relying on internal and external CI.
Reviewed By: malfet
Differential Revision: D33299331
fbshipit-source-id: a66afffba6deec76b758dfb39bdf61d747b5bd99
(cherry picked from commit d9163c56f55cfc97c20f5a6d505474d5b8839201)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70851
This is a step towards OSS/fbcode convergence since OSS uses this file
in both CMake and Bazel.
ghstack-source-id: 147170896
Test Plan: Relying on the extensive CI internal tests for this.
Reviewed By: malfet
Differential Revision: D33299102
fbshipit-source-id: c650dd4755f8d696d5fce81c583d5c73782e3990
(cherry picked from commit 741ca140c82f728e3b349d703a7de239e5bbf13c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71450
att
Test Plan: no test
Reviewed By: jfix71
Differential Revision: D33515471
fbshipit-source-id: ded40ca117f63c971d6c5ed4556932cc71c009ca
(cherry picked from commit a9f66d5921241645191c1df3292dc6e784860165)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71457
Today DynamicType is hard to be created because we have separare APIs for different types. In this diff we introduce an easier API to create types like the following:
```
#include <ATen/core/type_factory.h>
auto type = dynT<ListType>(dynT<TensorType>()); // etc...
```
ghstack-source-id: 147211236
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D33647746
fbshipit-source-id: c850cf31ae781244eac805906a2fc110ef065a70
(cherry picked from commit 8cfd51d75f010ca6f7f98b7e8ef807ead4d5f8f3)
Summary:
On a CPU-only build of pytorch `torch._C._jit_set_nvfuser_enabled(False)` would throw an error (even though it is a no-op operation), with this fix:
```
>>> torch._C._jit_set_nvfuser_enabled(False)
False
>>> torch._C._jit_set_nvfuser_enabled(True)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Running CUDA fuser is only supported on CUDA builds.
>>>
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71358
Reviewed By: eellison
Differential Revision: D33601135
Pulled By: jansel
fbshipit-source-id: c764df2fa197ce7b4f71e5df0a91cd988766e99c
(cherry picked from commit a801df93210302e918eca7134d3c0a19ac5bae5d)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71091
Fixes https://github.com/pytorch/pytorch/issues/65394
The masked sum on a full input tensor (of any layout) with an all-true mask is the same as the sum on the strided input tensor (after applying `to_dense` to sparse inputs).
Since masked sum uses `torch.sparse.sum` then, for the simplicity of masked reductions implementations, its reduction behavior ought to be defined by the behavior of the `torch.sum`. This PR implements the behavioral connection with respect to the directional summation of empty sparse tensors that correspond to all-zero strided tensors.
cc nikitaved pearu cpuhrsch
Test Plan: Imported from OSS
Reviewed By: davidberard98
Differential Revision: D33651750
Pulled By: cpuhrsch
fbshipit-source-id: 703891bff88c8da6270b4272f5d2da81688db67d
(cherry picked from commit 53f97e80f7520594e9977ad61a1a727dadade645)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69060
Saved variable hooks checkpointing was added in https://github.com/pytorch/pytorch/pull/69508, this PR adds some tests for DDP.
Specifically, we can support almost all DDP use cases with this new API, such as dynamic module with find_unused_parameters=True. One case remains to be supported, which is static_graph + non-reentrant based checkpointing. The underlying reason this does not work is https://github.com/pytorch/pytorch/issues/58111.
ghstack-source-id: 147219887
Test Plan: CI
Reviewed By: zhaojuanmao
Differential Revision: D32712126
fbshipit-source-id: ba5ae9ca77fd8929ee020c7dc97838bae9a1931b
(cherry picked from commit 9c7f93e21728d1627d85c351a21e7c8da832bff7)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71462
Fixes
```
6 aienv/aienv_ig_reels_base:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
6 deep_entity_classification/si_dec_gnn:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
6 feed_recommendation_infra/multifeed_execution_graph_service_nosan:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
12 mobile_cv/mobile-vision_experimental:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
30 mobile_cv/mobile-vision_xraymobilev2_detection_caffe2:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
42 aienv/aienv:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
128 feed_recommendation_infra/multifeed_recagg_dev:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
136 fluent2/fblearner_flow_projects_fluent2_nosan:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
1338 f6/f6_nosan:caffe2/modules/detectron/upsample_nearest_op.h:65:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
```
Test Plan: Sandcastle
Reviewed By: luciang
Differential Revision: D33641869
fbshipit-source-id: 8424849cfac5cb0109272dec2086863067bbde66
(cherry picked from commit d18429905c7661486ed8ec0cdcdd7d94b9c62762)
Summary:
Reference https://github.com/pytorch/pytorch/issues/69991
Refactored such that only `out` variant copies the result into `out` otherwise we just return the result of the composite functions as is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70894
Reviewed By: samdow
Differential Revision: D33641742
Pulled By: zou3519
fbshipit-source-id: 671be13b31a7fff3afc0b7976706a5ecfc51ccac
(cherry picked from commit e7d5ac9af319be327adc16d2d7048139a4b2ddd3)
Summary:
The sccache compilation log is often misleading.
We can move it to its own group so people don't see it right away
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71444
Reviewed By: atalman
Differential Revision: D33659650
Pulled By: janeyx99
fbshipit-source-id: f22fd21640a8747beeacce8857bbb8281efd76f4
(cherry picked from commit e25970abf99801fc04d4ae15f8f5ffe63dd1dc41)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70266
Addresses some of the issues mentioned in
https://github.com/pytorch/pytorch/issues/65638. ShardedLinear implementation
only support 2D inputs.
On the other hand `nn.Linear` supports arbitrary dimensions for inputs and
outputs. As a result, in this PR I've added support to ensure that
ShardedLinear supports arbitrary input dims as well.
ghstack-source-id: 147206607
Test Plan: waitforbuildbot
Reviewed By: wanchaol
Differential Revision: D33267630
fbshipit-source-id: 0460994c3aa33348b80547d9274206ef90cb29b6
(cherry picked from commit 7c289e1dbf491008e091ed0a49f98f2ebcfb4175)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71461
After operator versioning work, the version in model file is used for operator versioning, while bytecode_version is used for bytecode versioning (for bytecode schema). They are two seperate things now and this comparison is not needed.
ghstack-source-id: 147209286
Test Plan: CI
Reviewed By: iseeyuan, tugsbayasgalan
Differential Revision: D33648592
fbshipit-source-id: beaa136a728f88435176a00c07b2d521210f107f
(cherry picked from commit e90e650e1a5134473117eda802d679171e035082)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70615
This adds `at::detail::empty_meta` and
`at::detail::empty_strided_meta` to complement the cpu API.
Test Plan: Imported from OSS
Reviewed By: samdow
Differential Revision: D33623678
Pulled By: ngimel
fbshipit-source-id: 59e003116361fb547ec2c633bbc15a7973e21d0e
(cherry picked from commit b4f5836fa106418755381abedf327125bde744ef)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70614
This creates an `empty_strided_generic` function which, similar to
`empty_generic`, is a device-independent tensor constructor. This also
adds `at::detail::empty_strided_cpu` to complement
`at::detail::empty_cpu`.
Test Plan: Imported from OSS
Reviewed By: samdow
Differential Revision: D33623679
Pulled By: ngimel
fbshipit-source-id: 85994e88d664870bf425f398dfcdfc467885c694
(cherry picked from commit 2ff2a89df5752cfad667463aa3c3bffe8479ec9a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71447
Changes the nightly build trigger to be based on pushes to the `nightly`
branch instead of being based on the tagged push. This aligns it with
our current CircleCI trigger and should make it so that it's easily
viewable using tools like https://hud.pytorch.org/ci/pytorch/pytorch/nightly
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D33647102
Pulled By: seemethere
fbshipit-source-id: c6757da35b7ec2d68bf36160dd7f3cb9ed040899
(cherry picked from commit 99b7b22650440e82fe5b150af3db53cf8c9deabd)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70613
This refactors `at::detail::empty_cpu` to use only `TensorBase` so you
can construct tensors without including `Tensor.h`. It also adds a
`TensorOptions` version to reduce friction in operators moving from
the `at::empty` API.
Test Plan: Imported from OSS
Reviewed By: samdow
Differential Revision: D33623682
Pulled By: ngimel
fbshipit-source-id: 7a7b08bc2ed06830a3d698197a0c8389a096dc1d
(cherry picked from commit 2e17ad0bbd6dea2ea99c264fe3ea66414c991c8e)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71443
cogwheel test inline_cvr_infer_canary_pyper_model_publish is timing out.
The convert_fx call takes > 20 mins for local and local_ro sub modules, which used to take ~ 2 mins.
Test Plan:
Fblearn flow run
* the following cmd took 1113 seconds before the diff and 5002 seconds after.
flow-cli clone-locally 320014219 --run-as-secure-group pytorch_at_scale --operators pyper_model_publish_workflow.pyper_model_publish_workflow.process_torch_package_model_files.process_non_sparse_parameters[0]
Cogwheel test
* Cogwheel test with packages in B3588 (the last good run) took 4694.48s
* Cogwheel test with packages in B3590 (the first timeout) took 13975.83s
* Cogwheel test with the following packages took 4535.04s
* all packages in B3588 except the model publish
* the model publish built with D33469839 (043e84b3d2) reversed (created D33633570)
Reviewed By: albanD, jerryzh168
Differential Revision: D33633570
fbshipit-source-id: dc5e777c48a90c551641a3f79126461f6a60449e
(cherry picked from commit 03ab65023a9f4175584ddac1cca7eab51397c84a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71363
Looks like DDP example is currently broken as per
https://discuss.pytorch.org/t/official-ddp-example-is-broken/141493. Fix the
issue by setting the correct env variable.
ghstack-source-id: 147080377
Test Plan: CI
Reviewed By: mrshenli
Differential Revision: D33607250
fbshipit-source-id: e0e7d03cc365c186253b959c4c5405a5e3609218
(cherry picked from commit 32472884ec04d0e9b348b07d645dd1027389f8e8)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71417
I accidentally changed CPU_INSTANT_EVENT to CPU_OP, which broke TensorBoard.
Test Plan: Make memory profiling unit test check this case.
Reviewed By: aaronenyeshi
Differential Revision: D33637286
fbshipit-source-id: c95945f6b85cd4168820bd4d2a9203274a0a5bd6
(cherry picked from commit b1e258672af4b83d824b8c8eb565af0ffdfa895b)
Summary:
As it is a pretty big package and to be used during normal
course of PyTorch initialization
Fixes https://github.com/pytorch/pytorch/issues/71280
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71345
Reviewed By: seemethere
Differential Revision: D33594547
Pulled By: malfet
fbshipit-source-id: e0abea82dbdc29914512b610692701140d3e68a2
(cherry picked from commit 1ff7f65cc1ad499a71457368894ca14bed069749)
Summary:
In file graph_executor.cpp, line 963, a '\n' is missing in GRAPH_DEBUG, which all other GRAPH_DEBUG places here holds.
The output in GRAPH_DEBUG seems weird.
[DEBUG graph_executor.cpp:963] After CheckInplace (end of runOptimization)graph(%0 : Float(*, *, *, *, requires_grad=0, device=cpu),
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70421
Reviewed By: Gamrix
Differential Revision: D33596430
Pulled By: davidberard98
fbshipit-source-id: 0e7c3c02ce44bf925f0c45e96a382104059fe397
(cherry picked from commit 55899528a266363d27e0cf5e82b1b94524509756)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71431
Adds a PR trigger based on paths to the binary build workflows to make
it easier to test / verify changes to the binary build workflows without
adding a bunch of skipped checks to the majority of our workflows
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: atalman
Differential Revision: D33641276
Pulled By: seemethere
fbshipit-source-id: 0ed65cbcebf06dfe998f81d67df817250dd1a716
(cherry picked from commit 598b55fd1894b7edb21f208b1c86fd6a377ebc69)
Summary:
Use `pytorchmergebot` credentials to do the merge
Infer sync branch name from the workflow rather than hardcode it
Move common functions from `syncbranches.py` to `gitutils.py`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71420
Reviewed By: bigfootjon
Differential Revision: D33638846
Pulled By: malfet
fbshipit-source-id: a568fd9ca04f4f142a7f5f64363e9516f5f4ef1c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69407
This generates aten_interned_strings.h from `native_functions.yaml`
which is more like how it was originally done. The items deleted from
`interned_strings.h` are duplicates that need to be removed in order
for the code to compile, some of the remaining items may still be out
of date but it is fairly benign even if that's the case.
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D32923636
Pulled By: albanD
fbshipit-source-id: a0fd6b3714e70454c5f4ea9b19da5e047d2a4687
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70850
We support both, so we want to ensure both continue to work.
ghstack-source-id: 146960552
Test Plan: Tested manually. A subsequent diff adds this test configuration to CI.
Reviewed By: malfet
Differential Revision: D33297464
fbshipit-source-id: 70e1431d0907d480c576239af93ef57036d5e4d7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70848
This is the C10 library, it that's the main lib we are building
here. While here, use `local_defines` instead of `copts` for this
definition. Both `copts` and `local_defines` only apply to the
compilation units in the library, and not transitively.
ghstack-source-id: 146998039
Test Plan: We are relying on CI to verify this doesn't cause any problems.
Reviewed By: malfet
Differential Revision: D33429420
fbshipit-source-id: b3fc84c0588bd43346e3f9f77e851d293bde9428
Summary:
This PR adds a persistent filesystem cache for jitted kernels. The cache is disabled on Windows because it relies on POSIX headers.
The cache writes, by default, to `~/.cache/torch/kernels`, but the location can be controlled by setting the `PYTORCH_KERNEL_CACHE_PATH`. A separate environment variable, `USE_PYTORCH_KERNEL_CACHE`, will disable all caching logic when set to zero.
The use of a persistent fileystem cache dramatically lowers the "first call time" for an operator AFTER its has been compiled, because it skips (most of) the jit compilation process. On systems where we're compiling only to ptx that ptx still has to be just-in-time compiled by the driver API, so an additional latency of around 10 milliseconds is expected at first call time. On systems which compile to SASS the additional first call time latency is about one millisecond. This compares with times of 150 milliseconds+ for just-in-time kernel compilation.
Files in the cache use a mostly human readable string that includes an SHA1 hash of the CUDA C string used to generate them. Note that this is not an SHA1 hash of the file's contents, because the contents are the compiled ptx or SASS. No verification is done when the file is loaded to ensure the kernel is what's expected, but it's far more likely you'll be struck by a meteor than observe two file names conflict. Using SHA1 hashes to generate unique ids this way is a common practice (GitHub does it, too).
This cache design could be reused by other fusion systems and should allow us to jiterate more operations without fear of regressing the "incremental development" scenario where users are tweaking or extending programs slightly, rerunning then, and then repeating that process again and again. Without a cache each run of the program would have to recompile every jitted kernel, but with this cache we expect a negligible impact to the user experience.
cc kshitij12345, xwang233
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71350
Reviewed By: ngimel
Differential Revision: D33626671
Pulled By: mruberry
fbshipit-source-id: d55df53416fbe46348623846f699f9b998e6c318
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70612
The device information is embedded in the `DataPtr` returned from the
allocator, so this argument is completely ignored.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33623681
Pulled By: ngimel
fbshipit-source-id: bea64707bb17d46debb0ed7c1175493df56fee77
Summary:
This PR enables `test_block_triangular` tests on the CPU.
These tests revealed that there was a problem with how the nnz==0 case is handled. Now we return a tensor filled with NaNs both on CUDA and CPU.
cc nikitaved pearu cpuhrsch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71304
Reviewed By: davidberard98
Differential Revision: D33600482
Pulled By: cpuhrsch
fbshipit-source-id: d09cb619f8b6e54b9f07eb16765ad1c183c42487
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71369
Suppress `-Wimplicit-int-float-conversion` in `TypeSafeSignMath.h` when building with clang
Test Plan: CI check
Reviewed By: r-barnes
Differential Revision: D33612983
fbshipit-source-id: cff1239bc252d4a2f54a50a2bbcd48aeb8bf31ca
Summary:
This PR removes the PyTorch nightly dependencies of TorchBench CI. Instead, it relies on the bisection script to install TorchBench dependencies (https://github.com/pytorch/benchmark/pull/694).
This will unblock TorchBench CI users when the nightly build fails (e.g., https://github.com/pytorch/pytorch/issues/71260)
RUN_TORCHBENCH: resnet18
TORCHBENCH_BRANCH: xz9/optimize-bisection
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71323
Reviewed By: wconstab
Differential Revision: D33591713
Pulled By: xuzhao9
fbshipit-source-id: f1308ea33ece1f18196c993b40978351160ccc0c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71356
Suppress remaining header based warnings in `caffe2/c10` when building with `clang`
Test Plan: CI pass
Reviewed By: r-barnes
Differential Revision: D33600097
fbshipit-source-id: e1c0d84a0bad768eb03e047d62b5379cf28b48e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71072
This PR replaces the old logic of loading frozen torch through cpython by directly loading zipped torch modules directly onto deploy interpreter. We use elf file to load the zip file as its' section and load it back in the interpreter executable. Then, we directly insert the zip file into sys.path of the each initialized interpreter. Python has implicit ZipImporter module that can load modules from zip file as long as they are inside sys.path.
Test Plan: buck test //caffe2/torch/csrc/deploy:test_deploy
Reviewed By: shunting314
Differential Revision: D32442552
fbshipit-source-id: 627f0e91e40e72217f3ceac79002e1d8308735d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71254
when we configure linear and relu with the same qconfig, we currently have utility functions to also
generate a qconfig for the fused linear relu module, but this code is not called in correct order before
which resulted in unexpected behaviors. This PR fixes the issue. Please see test case for more details.
(Test case is from Supriya)
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_fused_module_qat_swap
Imported from OSS
Reviewed By: supriyar
Differential Revision: D33558321
fbshipit-source-id: d95114dc4b77264e603c262c2da02a3de4acba69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71290
The existing code called an out-of-line hash function on a constant. This is just going to get the same random-looking 64-bit integer every time, so I just changed the constant to an integer I generated with `hex(random.randint(0x1000000000000000, 0xFFFFFFFFFFFFFFFF))` to get the same effect but without the runtime hashing.
ghstack-source-id: 146991945
Test Plan: CI
Reviewed By: wconstab
Differential Revision: D33574676
fbshipit-source-id: d6ce1e1cc0db67dfede148b7e3173508ec311ea8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71341
Old models containing UnionType need to be loaded even if they don't actually use Unions.
This is not the best solution, we need to catch this error on the compiler side instead, but before doing that we can land this first to at least mitigate model loading crash issues.
ghstack-source-id: 147056684
Test Plan:
CI
Verified with jaebong on his device locally.
Differential Revision: D33593276
fbshipit-source-id: fac4bc85c652974c7c10186a29f36e3e411865ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71252
Same old problem, same old solution.
Interestingly, I tried using c10::irange instead, but that caused really bad assembly to be generated -- we lost inlining for lots of the loop body!
ghstack-source-id: 146939573
Test Plan:
CI
Spot-checked assembly before/after and confirmed that loop termination value was recomputed before and not after
Reviewed By: mikeiovine
Differential Revision: D33558118
fbshipit-source-id: 9fda2f1f89bacba2e8b5e61ba432871e973201fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71247
Most uses of toIntVector() were for a Tensor shape. We have DimVector to avoid heap allocations in those cases, so let's use it.
ghstack-source-id: 146933314
Test Plan: CI -- if we think DimVector is good in general then I think we have to think this change is good?
Reviewed By: mikeiovine
Differential Revision: D33556198
fbshipit-source-id: cf2ad92c2d0b99ab1df4da0f6843e6ccb9a6320b
Summary:
Not sure what is going on, but numba=0.55.0 currently installed in for example 308535385114.dkr.ecr.us-east-1.amazonaws.com/pytorch/pytorch-linux-bionic-py3.7-clang9:0d18ad2827487386d2a7864b11fec5bc83de6545 is build against newer version of numpy, which was apparently silently fixed on the pypi side (as latest numba download is numba-0.55.0-1-cp37-cp37m-manylinux2014_x86_64.manylinux_2_17_x86_64.whl )
Fixes https://github.com/pytorch/pytorch/issues/71320
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71327
Reviewed By: suo, seemethere, atalman, janeyx99
Differential Revision: D33589002
Pulled By: malfet
fbshipit-source-id: d362a2b2fd045bc1720cd7fdc4c7b18b7d607fc4
Summary:
Distributed sampler sets different indices for different processes. By doing this, it assumes that the data is the same across the board and in the same order. This may seem trivial, however, there are times that users don't guarantee the order items are gonna have, because they rely on something such as the order the filesystem lists a directory (which is not guaranteed and may vary on different computers), or the order a `set` is iterated.
I think it's better to make it clearer.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70104
Reviewed By: bdhirsh
Differential Revision: D33569539
Pulled By: rohan-varma
fbshipit-source-id: 68ff028cb360cadaee8c441256c1b027a57c7089
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70971
"root_module" and "reference_quantized_module_for_root" are only used in convert, removed
them for fused module and qat module swapping configurations
We may be able to remove some other fields as well.
Test Plan:
python test/fx2trt/test_quant_trt.py TestQuantizeFxTRTOps
Imported from OSS
Reviewed By: andrewor14
Differential Revision: D33470739
fbshipit-source-id: 67e6d58d7a3ec9fbd8c13527e701c06119aeb219
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71291
This commit removes torch::lazy::convertShapes since it's no longer used.
In addition, it replaces a numel logic within LTCTensorImpl.
Test Plan:
./build/bin/test_lazy
CI in lazy_tensor_staging branch
Reviewed By: wconstab
Differential Revision: D33575084
Pulled By: alanwaketan
fbshipit-source-id: b104ef39fd552822e1f4069eab2cb942d48423a6
Summary:
In `TestLRScheduler._test()`, an unused variable `optimizers` is created. This PR is a minor refactoring that removes the variable and the loop block that populates the set.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70668
Reviewed By: wenleix
Differential Revision: D33586236
Pulled By: albanD
fbshipit-source-id: cabf870a8221f144df9d3e2f2b564cdc5c255f5a
Summary:
The leak was causing long running inference loops to exhaust system memory. I tracked down the issue and noted that ModRound can be copied by value without worrying about a performance hit.
I originally branched from release/1.10 and made these changes. This commit includes the same changes but from master as requested in the original PR https://github.com/pytorch/pytorch/pull/71077
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71285
Reviewed By: wenleix
Differential Revision: D33575821
Pulled By: ZolotukhinM
fbshipit-source-id: 64333f6cbb2c222f05481499c9cae4c7e0116af6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/67512.
The accuracy requirement for non-contiguous inputs when using complex64 was too high so I reduced it to upto 1e-3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70034
Reviewed By: anjali411
Differential Revision: D33530382
Pulled By: mruberry
fbshipit-source-id: 057daf75dc5feca5bb2f4428922eb7489435da60
Summary:
Use `Py_ssize_t` when calling Python API
Use `c10::irange` to automatically infer loop type
Use `size_t` or `unsigned` for unsigned type
Partially addresses https://github.com/pytorch/pytorch/issues/69948
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71250
Reviewed By: atalman
Differential Revision: D33569724
Pulled By: malfet
fbshipit-source-id: c9eb75be9859d586c00db2f824c68840488a2822
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71275
Currently it's taking more than 10 minutes to run the conformance test. Instead we should use parametrized test to shard into test segments so that they can run in parallel.
ghstack-source-id: 146990608
Test Plan:
```
[zhxchen17@devbig560.ftw3 /data/users/zhxchen17/fbsource/fbcode] buck test mode/dev-tsan //caffe2/test/cpp/jit:jit -- -r 'LiteInterpreterDynamicTypeTestFixture'
Building... 34.9 sec (99%) 12110/12111 jobs, 0/12111 updated
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: ebea52b3-7c7f-46be-9f69-18e2e7b040cc
Trace available for this run at /tmp/tpx-20220113-113635.717778/trace.log
RemoteExecution session id: reSessionID-ebea52b3-7c7f-46be-9f69-18e2e7b040cc-tpx
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/4222124735827748
✓ ListingSuccess: caffe2/test/cpp/jit:jit : 431 tests discovered (11.173)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/0 (51.331)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/1 (65.614)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/3 (76.875)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/5 (77.271)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/4 (78.871)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/6 (78.984)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/7 (84.068)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/2 (85.198)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/8 (88.815)
✓ Pass: caffe2/test/cpp/jit:jit - Conformance/LiteInterpreterDynamicTypeTestFixture.Conformance/9 (90.332)
Summary
Pass: 10
ListingSuccess: 1
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/4222124735827748
```
Reviewed By: qihqi
Differential Revision: D33570442
fbshipit-source-id: 5c49e03b0f88068d444c84b4adeaaf45433ce1fa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69549
[ONNX] minor clarifications of docstrings
1. Make description of ONNX_ATEN_FALLBACK more accurate (after #67460).
2. Specify minimum and maximum values for opset_version. This is pretty
important information and we should make users dig through source
code to find it.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32994267
Pulled By: msaroufim
fbshipit-source-id: ba641404107baa23506d337eca742fc1fe9f0772
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71104
This shouldn't change any functionality given that those
variables were not used. It should be noted that a similar variable is
used in add_observer which is why it wasn't removed from there.
ghstack-source-id: 146940043
Test Plan:
python test/test_quantization.py
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D33510352
fbshipit-source-id: c66ed72c2b71a6e1822f9311467adaa1f4b730d0
Summary:
`diff_type` kind of naturally should be `ptrdiff_t`, as `ssize_t` is actually defined [here](https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/sys_types.h.html) as :
> The type ssize_t shall be capable of storing values at least in the range [-1, {SSIZE_MAX}].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71271
Reviewed By: atalman
Differential Revision: D33569304
Pulled By: malfet
fbshipit-source-id: 57dafed5fc42a1f91cdbed257e76cec4fdfbbebe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71110
as mentioned in https://github.com/pytorch/pytorch/issues/70480 the dynamic conv ops are currently missing a key feature to bring their performance in line with other dynamic ops, this diff disables conv/convT from being automatically quantized with convert dynamic
Test Plan: buck test //caffe2/test:quantization --test-selectors test_quantized_module#TestDynamicQuantizedModule
Reviewed By: vkuzo
Differential Revision: D33511152
fbshipit-source-id: 50618fbe734c898664c390f896e70c68f1df3208
Summary:
This reverts commit 14922a136f940e2f9bc9d04d7963b8141138efa0.
Re-enable xla test config since PTXLA head is back to green -- https://app.circleci.com/pipelines/github/pytorch/xla.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71202
Reviewed By: wenleix
Differential Revision: D33569109
Pulled By: seemethere
fbshipit-source-id: ee0985768d1dfaa6c28865ae5b3dbce2a4a340f7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71220
This is to allow using this function for uint8 as well as int8
Test Plan:
buck test caffe2/test:quantization
This primarily tests T=uint8
Reviewed By: kimishpatel
Differential Revision: D33520713
fbshipit-source-id: 9640cf0a446e4c4e76887d643d72b767945bae76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71219
qnnpack kernel does not support broadcasting
Test Plan: buck test caffe2/test:quantization
Reviewed By: kimishpatel
Differential Revision: D33520613
fbshipit-source-id: 93c5226d53cb7b90ed495ff7b14158f7171d25bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71218
This asserts quint8 support, and fails with a helpful error message when attempted to use with a different qdtype
Test Plan: buck test caffe2/test:quantization
Reviewed By: kimishpatel
Differential Revision: D33455785
fbshipit-source-id: 6ec728f59bb707c2d941b50e6375a698c66284c0
Summary:
The many times a day was probably not intentional
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71255
Reviewed By: suo, atalman
Differential Revision: D33559155
Pulled By: janeyx99
fbshipit-source-id: c8703cea6f3188c9bcb0867b895261808d3164ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71161
Users should import these DataPipes from [TorchData](https://github.com/pytorch/data) if they would like to use them. We will be checking for any downstream library usage before landing this PR.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33532272
Pulled By: NivekT
fbshipit-source-id: 9dbfb21baf2d1183e0aa379049ad8304753e08a1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69546
The arg is not used and was previously deprecated.
Also remove torch.onnx._export_to_pretty_string. It's redundant with the
public version.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D32994270
Pulled By: msaroufim
fbshipit-source-id: f8f3933b371a0d868d9247510bcd73c31a9d6fcc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71113
This diff adds a variety of missing ~~out variants~~/native ops. Most of these are trivial, so I included them all in one diff.
Native ops
* `aten::mul` (list variant)
* `aten::sub` (int variant)
* `aten::add` (list variant)
* `aten::Int`
Out variants
* ~~`aten::gt`~~ (codegen will handle)
* ~~`aten::eq`~~ (codegen will handle)
ghstack-source-id: 146927552
Test Plan: `buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest`
Reviewed By: hlu1
Differential Revision: D33510756
fbshipit-source-id: df385958b9561955b2e866dab2e4c050abd26766
Summary:
T109800703
In runtime fallback to server JIT type if a DynamicType is parsed.
Test Plan: local headset
Reviewed By: scramsby
Differential Revision: D33557763
fbshipit-source-id: f5fe7dabf668de2f55cc26f9ebe8bcbccd570ce3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69853
We can implement this overload more efficiently.
ghstack-source-id: 146924693
Test Plan:
patched alias_analysis tests
Time reported to initialize a predictor by static runtime when given ctr_mobile_feed local_ro net is 9.5s instead of 10.5s.
Reviewed By: mikeiovine
Differential Revision: D33039731
fbshipit-source-id: 52559d678e9eb00e335b9e0db304e7a5840ea397
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70201
Included functions:
save_mobile_module -> saves a mobile::Module to flatbuffer
load_mobile_module_from_file -> loads a flatbuffer into mobile::Module
parse_mobile_module -> parses from bytes or deserialized flatbuffer module object
Compared to previous attempts, this diff only adds flatbuffer to cmake target and leaves fbcode/xplat ones unchanged.
Test Plan: unittest
Reviewed By: malfet, gmagogsfm
Differential Revision: D33239362
fbshipit-source-id: b9ca36b83d6af2d78cc50b9eb9e2a6fa7fce0763
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67781
Update `LLVMCodeGen` in NNC to use the given kernel function name while emitting code.
This was earlier committed as D31445799 (c30dc52739) and got reverted as part of a stack of diffs that included a cache for `PyTorchLLVMJIT`, which was the likely culprit.
Test Plan:
```
buck test mode/opt //caffe2/test/cpp/tensorexpr:tensorexpr -- --exact 'caffe2/test/cpp/tensorexpr:tensorexpr - LLVM.CodeGenKernelFuncName'
```
Reviewed By: ZolotukhinM, bdhirsh
Differential Revision: D32145958
fbshipit-source-id: 5f4e0400c4fa7cabce5b91e6de2a294fa0cad88e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68692
ADInplaceOrViewType is a sharded file, so by only including specific
operator headers, we ensure that changing one (non-method) operator
only needs one shard to be re-compiled.
This also ports the generated code over to the `at::_ops` interface,
and the code generator itself to using `write_sharded` instead of
re-implementing its own version of sharding.
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D33217916
Pulled By: albanD
fbshipit-source-id: 90f1868f72644f1b5aa023cefd6a102bbbec95af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71166
Remove the use of deprecated old interface
Test Plan: CI
Reviewed By: jiyuanzFB
Differential Revision: D33533494
fbshipit-source-id: 930eb93cd67c7a9bb77708cc48914aa0c9f1c841
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71181
This diff introduces the patterns module that defines a pattern-replacement pair for the experimental multi subgraph rewriter.
Test Plan: Tested locally. Unit test suite forthcoming.
Reviewed By: ajauhri
Differential Revision: D32374542
fbshipit-source-id: 4ae8da575976e96b02c5c33c6ae2a0943fc7f126
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70957
Adds nightly trigger for github actions using a workflow that will pull
down viable/strict and tag it as `nightly` and then re-push it up to the
repository.
Also removes CircleCI linux binary builds since they will now be
outmoded in favor of our new GHA workflow
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D33535609
Pulled By: seemethere
fbshipit-source-id: ca6402df37db46e1872ff25befe96afa12e7b1af
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70973
clang12 builds fail like this:
caffe2/c10/core/TensorImpl.h:2615:1: error: static_assert failed due to requirement 'sizeof(void *) != sizeof(long) || sizeof(c10::TensorImpl) == sizeof(long) * 24' "You changed the size of TensorImpl on 64-bit arch.See Note [TensorImpl size constraints] on how to proceed."
Yet eliciting the size of that struct with this one-line addition:
char (*__show_sizeof)[sizeof( TensorImpl )] = 1;
reports that its size is indeed 192 (aka 8 * 24):
caffe2/c10/core/TensorImpl.h:2615:8: error: cannot initialize a variable of type 'char (*)[192]' with an rvalue of type 'int'
On closer inspection we determined that failures were occurring because TensorImpl was sometimes of size 208 and other times of size 192. The 192 size was expected and TensorImpl was hard-coded to raise an error for any other case on a 64-bit system, including the one we found where the size was 208.
Additional investigation revealed that systems using GCC 11 and CUDA 11040 with either C++ 201402 and 201703 would sometimes yield TensorImpl sizes of 208 whereas systems newer systems without CUDA would always yield sizes of 192.
The difference turned out to be that `std::unique_ptr` on NVCC systems is sometimes of size 16 and other times of size 8, accounting fully for the observed difference in TensorImpl sizes. We have not yet been able to find a set of preprocessor macros that predict when each size will occur.
To handle the situation, we've added extensive debugging information to the TensorImpl size-checking logic. A number of preprocessing definitions capture compiler versions and other information to help understand what changes might have affected the size of TensorImpl. The size of each member of TensorImpl is now individually checked, along with the total size. Template-based comparison functions are used to provide compile-time outputs about the system state as well as the observed and expected sizes of each item considered.
The template-based comparison functions cause the code to break if it's run on a 32-bit system because the templates and their associated static_asserts are compiled whether or not they'll ultimately be used. In C++17 we could prevent this using `if constexpr`; however, PyTorch is pinned to C++14, so we cannot. Instead, we check pointer size (`#if UINTPTR_MAX == 0xFFFFFFFF`) to determine which system we're on and provide separate checks for 32 vs 64-bit systems.
A final wrinkle is that 32-bit systems have some variations in data size as well. We handle these by checking that the relevant items are `<=` the expected values.
In summary...
Improvements over the previous situation:
* Added checks for 32-bit systems
* The sizes of individual fields are now checked
* Compile-time size results (expected versus observed) are provided
* Compile-time compiler and system info is provided
* Landing this diff will actually enable checks of TensorImpl size; they are currently disabled to expedite LLVM-12 + newer CUDA upgrade efforts.
Some work that could still be done:
* Figure out what preprocessor flags (if any) predict the size of `std::unique_ptr` for 64-bit systems and of various elements of 32-bit systems.
Test Plan: Building no longer triggers that static_assert failure.
Reviewed By: luciang
Differential Revision: D32749655
fbshipit-source-id: 481f84da6ff61b876a5aaba89b8589ec54d59fbe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71016
I found out that `split_module` doesn't preserve default values for arguments. In trying to fix that, I noticed that `Graph.placeholder` doesn't make it easy to add a default argument when making a placeholder. This PR addresses both of those issues
Test Plan: Imported from OSS
Reviewed By: ansley
Differential Revision: D33482218
Pulled By: jamesr66a
fbshipit-source-id: 57ebcdab25d267333fb1034994e08fc1bdb128ee
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71244
Binary builds adds a lot of skipped jobs to the default ciflow workflow
so we're commenting out the pull_request trigger for now until the new
ciflow mechanism becomes available
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D33555049
Pulled By: seemethere
fbshipit-source-id: 2d0d4704e7297d5931b2c9705ee4dfb26760736e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69567
This exposes torch.monitor events and stats via pybind11 to the underlying C++ implementation.
* The registration interface is a tad different since it takes a lambda function in Python where as in C++ it's a full class.
* This has a small amount of changes to the counter interfaces since there's no way to create an initializer list at runtime so they now also take a vector.
* Only double based stats are provided in Python since it's intended more for high level stats where float imprecision shouldn't be an issue. This can be changed down the line if need arises.
```
events = []
def handler(event):
events.append(event)
handle = register_event_handler(handler)
log_event(Event(type="torch.monitor.TestEvent", timestamp=datetime.now(), metadata={"foo": 1.0}))
```
D32969391 is now included in this diff.
This cleans up the naming for events. type is now name, message is gone, and metadata is renamed data.
Test Plan: buck test //caffe2/test:monitor //caffe2/test/cpp/monitor:monitor
Reviewed By: kiukchung
Differential Revision: D32924141
fbshipit-source-id: 563304c2e3261a4754e40cca39fc64c5a04b43e8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70647
It wasn't checking for the null state and it wasn't used.
ghstack-source-id: 146819525
Test Plan: CI
Reviewed By: hlu1
Differential Revision: D33414728
fbshipit-source-id: 7fcd648577cbfc35320c5c3ca9a19a14bd4d6858
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70638
We are seeing these assertions fire infrequently. Add more information to aid in debugging when they fire.
ghstack-source-id: 146819527
Test Plan: CI
Reviewed By: bdhirsh
Differential Revision: D33412651
fbshipit-source-id: 7e35faf9f4eeaa5f2455a4392e00f62fe692811c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71197
Adds back legacy support for emmbedded interpreter to use .data section in internal use cases. Specifically this allows for dynamic loading of python extension files.
Test Plan: buck test mode/opt //caffe2/torch/csrc/deploy:test_deploy_gpu_legacy
Reviewed By: shunting314
Differential Revision: D33542636
fbshipit-source-id: b49f94163c91619934bc35595304b9e84d0098fc
Summary:
Our docker builds have not been running with our previous cron, changes this so it should work hopefully.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71232
Reviewed By: ejguan
Differential Revision: D33552231
Pulled By: janeyx99
fbshipit-source-id: 1a3e1607b03d37614eedf04093d73f1b96698840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71196
`caffe2` headers contain code that can elicit warnings when built with strict compiler flags. Rather than force downstream/consuming code to weaken their compiler flags, suppress those warnings in the header using `#pragma clang diagnostic` suppressions.
Test Plan: CI Pass
Reviewed By: malfet
Differential Revision: D33536233
fbshipit-source-id: 74404e7a5edaf244f79f7a0addd991a84442a31f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71172
Break down div to smaller ops to make those div ops look like all other elementwise ops.
Use operator div ops instead of torch div if possible to avoid converting literal numbers to torch tensor (like in the following).
```
a = 1
b = 2
// `c` would be 0.5
c = a / b
// `c` would be torch.tensor([0.5])
c = torch.div(a, b)
```
The problem we saw on shufflenet is that there's size op followed by a div op which results in int64 tensors in acc traced graph (acc tracer turns operator.div to acc_ops.div which uses torch.div). And trt splitter splits out the reshape op that consumes the div op because we have a rule to split out ops that takes in int64 tensors as inputs.
Test Plan: Unit tests.
Reviewed By: wushirong
Differential Revision: D33482231
fbshipit-source-id: 508a171520c4e5b4188cfc5c30c1370ba9db1c55
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71171
Editing two warnings to more accurately portray the deprecation plan for the DataPipes
cc VitalyFedyunin ejguan NivekT
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33535785
Pulled By: NivekT
fbshipit-source-id: b902aaa3637ade0886c86a57b58544ff7993fd91
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70464
Add handling of strided input tensors to dynamic fusion. This is done with the same set of input striding specializations as https://github.com/pytorch/pytorch/pull/60684/:
```
S_ONE, // STRIDE_ONE: packed
S_CONT, // STRIDE_CONTIGUOUS: stride[i + 1] * sizes[i + 1]
S_TRAN_CONT, // STRIDE_TRANSPOSED_CONTIGUOUS: stride[i-1] * sizes[i-1]
S_AS_ARG, // STRIDE_AS_ARG: stride passed in as runtime value
```
and then two additional specializations for a) contiguous tensor and b) channels-last tensor. channels-last is a common case and we should optimize for it. additionally, tensors natively store whether they are contiguous/channels-last contiguous, which makes it faster to check if tensors follow this pattern.
Output striding will be done in a follow up.
The striding is stored on both the TensorGroup node and on the guard node. The striding descriptors are stored as a vector of strings on the node for debugability and to make use of storing ivalues as attributes on nodes.
As an example:
```
%8 : Double(10, 11, 12, 13, strides=[1716, 1, 143, 11], requires_grad=0, device=cpu) = prim::TensorExprGroup_0[symbolic_shape_inputs=[-37, -36, -35, -34], striding_inputs_desc=[["TENSOR_CONT_CHANNELS_LAST"]](%x, %24, %23, %22, %21)```
```
Test Plan: Imported from OSS
Reviewed By: navahgar
Differential Revision: D33458649
Pulled By: eellison
fbshipit-source-id: c42616d3c683d70f6258180d23d3841a31a6030d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71144
This wasn't being used anywhere. It was originally intended for the SR flow but we're doing something else now.
Test Plan: Imported from OSS
Reviewed By: navahgar, ZolotukhinM
Differential Revision: D33521061
Pulled By: eellison
fbshipit-source-id: 0574698a2b7409df6feb703f81e806d886225307
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70528
This PR adds checks for the backward of `linalg.eigh`, similar to those
deduced in https://github.com/pytorch/pytorch/pull/70253
It also makes its the implementation parallel that of the (fwd/bwd) derivative of
`torch.linalg.eig` and it makes most OpInfo tests pass.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33530149
Pulled By: albanD
fbshipit-source-id: 1f368b8d450d4e9e8ae74d3881c78513c27eb956
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70527
This PR adds checks for the backward of `linalg.eig`, similar to those
deduced in https://github.com/pytorch/pytorch/pull/70253
It also modifies the function so that it does not save the input matrix,
as it's not necessary.
It also corrects the forward AD formula for it to be correct. Now all
the tests pass for `linalg.eig` and `linalg.eigvals`.
It also updates the docs to reflect better what's going on here.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D33530148
Pulled By: albanD
fbshipit-source-id: 984521a04f81ecb28ac1c4402b0243c63dd6959d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70304
Without this patch `TensorLikePair` will try to instantiate everything although it should only do so for tensor-likes. This is problematic if it is used before a different pair that would be able to handle the inputs but never gets to do so, because `TensorLikePair` bails out before.
```python
from torch.testing._comparison import assert_equal, TensorLikePair, ObjectPair
assert_equal("a", "a", pair_types=(TensorLikePair, ObjectPair))
```
```
ValueError: Constructing a tensor from <class 'str'> failed with
new(): invalid data type 'str'.
```
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33542995
Pulled By: mruberry
fbshipit-source-id: 77a5cc0abad44356c3ec64c7ec46e84d166ab2dd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68728
This removes the ability for `assert_close` to `.coalesce()` the tensors internally. Additionally, we now also check `.sparse_dim()`. Sparse team: please make sure that is the behavior you want for all sparse COO comparisons in the future. #67796 will temporarily keep BC by always coalescing, but in the future `TestCase.assertEqual` will no longer do that.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33542996
Pulled By: mruberry
fbshipit-source-id: a8d2322c6ee1ca424e3efb14ab21787328cf28fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68802
Without this patch, the error message of comparing meta tensors looks like this after #68722 was merged:
```python
>>> t = torch.empty((), device="meta")
>>> assert_close(t, t)
NotImplementedError: Could not run 'aten::abs.out' with arguments from the 'Meta' backend. [...]
[...]
The above exception was the direct cause of the following exception:
[...]
RuntimeError: Comparing
TensorLikePair(
id=(),
actual=tensor(..., device='meta', size=()),
expected=tensor(..., device='meta', size=()),
rtol=1.3e-06,
atol=1e-05,
equal_nan=False,
check_device=True,
check_dtype=True,
check_layout=True,
check_stride=False,
check_is_coalesced=True,
)
resulted in the unexpected exception above. If you are a user and see this message during normal operation please file an issue at https://github.com/pytorch/pytorch/issues. If you are a developer and working on the comparison functions, please except the previous error and raise an expressive `ErrorMeta` instead.
```
Thus, we follow our own advice and turn it into an expected exception until #68592 is resolved:
```python
>>> t = torch.empty((), device="meta")
>>> assert_close(t, t)
ValueError: Comparing meta tensors is currently not supported
```
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33542999
Pulled By: mruberry
fbshipit-source-id: 0fe1ddee15b5decdbd4c5dd84f03804ca7eac95b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68977
Follow-up to #68722 to address the review comments that were left open before merge.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33542998
Pulled By: mruberry
fbshipit-source-id: 23c567cd328f83ae4df561ac8ee6c40c259408c9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71170
As with an output in a tuple return, an output in a list return will not have any further uses that would make adding it directly to the list's contained elements give incorrect behavior. This unblocks a use case in op authoring.
cc Chillee
Test Plan: Imported from OSS
Reviewed By: d1jang
Differential Revision: D33535608
Pulled By: eellison
fbshipit-source-id: 2066d28e98c2f5d1b3d7e0206c7e39a27b3884b1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69776
If we have an node output which is an optional type, but both if blocks produce a non-optional value, we can try to refine the if output type, which can open up further optimization opportunities.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33515235
Pulled By: eellison
fbshipit-source-id: 34f6ab94ac4238498f9db36a1b673c5d165e832e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69645
As noted in code comment:
existing device operator is registered with input name `a`, which prevents torch.device(type="cuda") from working. add shim-layer here
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33515231
Pulled By: eellison
fbshipit-source-id: c04af8158a9568a20cd5fbbbd573f6efab98fd60
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70509
TypeFactory will construct DynamicType when building on Edge platforms. We use this facility to make FunctionSchema return DynamicType all the time for OptionalType. We don't explicitly use DynamicTypeFactory everywhere because that requires too many changes and will split the entire aten codebase.
ghstack-source-id: 146818621
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D33306737
fbshipit-source-id: d7ce00b438f7c03b43945d578280cfd254b1f634
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68083
This PR adds support for `torch.randn_like(sparse_csr_tensor)`.
It creates a new sparse csr tensor with same indices but different values that are normally distributed.
In addition `.normal_()` and `torch.empty_like` were implemented because `randn_like` is a composite of these two functions.
cc nikitaved pearu cpuhrsch IvanYashchuk
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33511280
Pulled By: cpuhrsch
fbshipit-source-id: 6129083e8bc6cc5af2e0191294bd5e4e864f6c0e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71175
D33330022 was landed with a Meta test failure (ghstack clobbered the fix),
resubmitting the Meta-only part to fix CI.
Test Plan:
```
buck test mode/opt //caffe2/test:test_fx_acc_tracer -- --exact 'caffe2/test:test_fx_acc_tracer - test_quantized_batch_norm2d (fx_acc.test_acc_tracer.AccTracerTest)' --run-disabled
```
Reviewed By: HDCharles
Differential Revision: D33531994
fbshipit-source-id: 39dc945c54fb9a7205c9d4114ede6b5ab99c5012
Summary:
Previously for single input matrix A and batched matrix B, matrix A was expanded and cloned before computing the LU decomposition and solving the linear system.
With this PR the LU decomposition is computed once for a single matrix and then expanded&cloned if required by a backend library call for the linear system solving.
Here's a basic comparison:
```python
# BEFORE THE PR
In [1]: import torch
In [2]: a = torch.randn(256, 256)
In [3]: b = torch.randn(1024, 256, 2)
In [4]: %%timeit
...: torch.linalg.solve(a, b)
...:
...:
329 ms ± 17.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# WITH THIS PR
In [1]: import torch
In [2]: a = torch.randn(256, 256)
In [3]: b = torch.randn(1024, 256, 2)
In [4]: %%timeit
...: torch.linalg.solve(a, b)
...:
...:
21.4 ms ± 23 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
```
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69752
Reviewed By: albanD
Differential Revision: D33028236
Pulled By: mruberry
fbshipit-source-id: 7a0dd443cd0ece81777c68b29438750f6524ac24
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69798
One of the major sources of complexity in `profiler_kineto.cpp` is that kineto may or may not be available. The code (including the types) follows two related but often distict codepaths, and large sections may or may not be `#ifdef`'d out.
Optimizing such code which preserving correctness is quite difficult; at one point I realized that I had broken the non-Kineto case, because moving work into the finalize step runs astray of a very large `#ifdef` around the finalize logic.
In order to make optimization more tractable, I gathered all of the calls to Kineto APIs and isolated them in the `kineto_shim.h/.cpp` files: the header allows callers to pretend as though Kineto is always available (mostly), and the cpp file hides most of the horrible `#ifdef`s so they don't pollute the main profiler code.
Test Plan: Unit tests.
Reviewed By: aaronenyeshi
Differential Revision: D32690568
fbshipit-source-id: 9a276654ef0ff9d40817c2f88f95071683f150c5
Summary:
When default hooks are set, they are pushed onto a stack.
When nesting context-manager, only the inner-most hooks will
be applied.
There is special care needed to update the TLS code. See also https://github.com/pytorch/pytorch/issues/70940 (i.e. do we need to be storing the enabled flag as well?)
Fixes https://github.com/pytorch/pytorch/issues/70134
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70932
Reviewed By: mruberry
Differential Revision: D33530370
Pulled By: albanD
fbshipit-source-id: 3197d585d77563f36c175d3949115a0776b309f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71178
This should no longer be needed as we now set a lifecycle policy on ECR
and we also don't generate lots of temporary containers anymore.
Test Plan: Imported from OSS
Reviewed By: seemethere
Differential Revision: D33537851
Pulled By: suo
fbshipit-source-id: b97b7525be6f62ec8771dfb6a7ee13b22b78ac5a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70233
Make type parser to produce DynamicType for all base types which don't have type arguments, and return DynamicType pointer for IValue::type().
ghstack-source-id: 146818622
Test Plan: no behavior change.
Reviewed By: iseeyuan
Differential Revision: D33137219
fbshipit-source-id: 1612c924f5619261ebb21359936309b41b2754f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71120
D33283314 (681e78bace) is causing jobs to fail when profiled, which is not ideal.
Test Plan:
pyper-online-cli launch 306587531 AI_INFRA ads_global_pyper_sla oncall_model_store --training_package_version training_platform:9344fe410969bdf614bc89cff0280281 --training_stage ONLINE --training_environment DEV --timeout 1728000
(Courtesy of yanjzhou)
Reviewed By: xw285cornell
Differential Revision: D33437773
fbshipit-source-id: 5c492f83146ff82557cfc1142aade3432cf73ca5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71103
Previously the implementation of empty_like for sparse COO was a
conditional path in generic implementation.
This PR makes use of the Dispatcher and moves the implementation into a
separate function.
cc nikitaved pearu cpuhrsch
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D33511240
Pulled By: cpuhrsch
fbshipit-source-id: 9a84f82a27e3cf0ac819d867b86df6d10ddf7fa7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70212
Use DynamicType instead of ListType all over the place in Lite Interpreter. Namely we need to modify the following places:
1. Type parser which produces the Type constants.
2. IValue::type() which returns reflected Type from IValues.
3. Helper functions to construct the container value.
4. Typechecks which test whether a type instance is a particular container type.
ghstack-source-id: 146818619
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D33176931
fbshipit-source-id: 9144787f5fc4778538e5c665946974eb6171a2e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71139
These variables were being interpreted as being quoted in the GITHUB_ENV
file meaning they didn't register correctly when attempting to do the
actual binary_upload.sh leading to binaries not actually getting
uploaded.
This remedies that
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: malfet, b0noI
Differential Revision: D33519952
Pulled By: seemethere
fbshipit-source-id: 727f6d4e5dbdfd0a3e2c76058bee9430b2c717a9
Summary:
Hi, PyTorch Team!
I am very much interested in starting up my contribution to PyTorch. I made several contributions in NumPy and CuPy, but this is my first PR towards PyTorch. I aim to contribute more in the upcoming future.
The PR fixes https://github.com/pytorch/pytorch/issues/70972https://github.com/pytorch/pytorch/issues/70975.
#### Aim of PR
The functions like `Tensor.ravel`, `Tensor.tril`, `Tensor.tril_`, `Tensor.triu`, and `Tensor.triu_` had a couple of typos in docs. The PR aims to resolve that.
I'm looking forward to your viewpoints. Thanks!
cc: kshitij12345 vadimkantorov Lezcano TestSomething22
cc brianjo mruberry
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71057
Reviewed By: preeti1205
Differential Revision: D33502911
Pulled By: mruberry
fbshipit-source-id: 8ce0b68a29658a5a0be79bc807dfa7d71653532d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70990
Releasing `decode` API for domains to let them implement custom `decode` DataPipe for now.
Test Plan: Imported from OSS
Reviewed By: NivekT
Differential Revision: D33477620
Pulled By: ejguan
fbshipit-source-id: d3c30ba55c327f4849d56f42d328a932a31777ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70205
Use DynamicType instead of TupleType all over the place in Lite Interpreter. Namely we need to modify the following places:
1. Type parser which produces the Type constants.
2. IValue::type() which returns reflected Type from IValues.
3. Helper functions to construct the container value.
4. Typechecks which test whether a type instance is a particular container type.
ghstack-source-id: 146818620
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D33176925
fbshipit-source-id: 00f7a5db37ba772c912643c733db6c52dfdc695d
Summary:
This patch moves a CUDA-specific file, `CUDAGeneratorImpl.h` to `ATen/cuda` as the following TODO comment in `CUDAGeneratorImpl.h` suggests:
```
// TODO: this file should be in ATen/cuda, not top level
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70650
Reviewed By: jianyuh, xw285cornell
Differential Revision: D33414890
Pulled By: shintaro-iwasaki
fbshipit-source-id: 4ff839205f4e4ea4c8767f164d583eb7072f1b8b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71027
Fix issue #61054. remove warning
reduce_range=True which caused the error message "UserWarning: Please use quant_min and quant_max to specify the range for observers".
Test Plan:
python test/test_quantization.py TestFakeQuantizeOps
Imported from OSS
Reviewed By: jerryzh168
Differential Revision: D33484341
fbshipit-source-id: 97c3d4658926183f88a0c4665451dd7f913d30e6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70078
This commit adds a serialization test for DBR.
Test Plan:
python test/test_quantization.py TestQuantizeDBR.test_serialization
Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D33405192
fbshipit-source-id: 39c4cca49aff8b960f4dec6c272fbd0da267fa95
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67254
Fixes https://github.com/pytorch/pytorch/issues/65997
BC breaking:
`output = torch.ops._test.leaky_relu(self=torch.tensor(-1.0))` now fails with the error `TypeError: __call__() got multiple values for argument 'self'` since we call into `OpOverloadBundle`'s `__call__` method that has `self` bound to it as its first argument.
Follow up work:
1. disallow `default` as an overload name for aten operators.
2. Add a method to obtain a list of all overloads (exclude the ones registered by JIT)
3. Add methods/properties to `OpOverload` to access more schema information (types of input and output args etc)
cc ezyang gchanan
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D33469839
Pulled By: anjali411
fbshipit-source-id: c3fc43460f1c7c9651c64b4d46337be21c400621
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70202
Use DynamicType instead of DictType all over the place in Lite Interpreter. Namely we need to modify the following places:
1. Type parser which produces the Type constants.
2. IValue::type() which returns reflected Type from IValues.
3. Helper functions to construct the container value.
4. Typechecks which test whether a type instance is a particular container type.
ghstack-source-id: 146735648
Test Plan: no behavior change.
Reviewed By: iseeyuan
Differential Revision: D33137257
fbshipit-source-id: 971bf431658c422ea9353cc32cdab66e98876e9d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65645
This is a retry of PR: https://github.com/pytorch/pytorch/pull/59492
Latest Changes: Added more tests, added the getOrCreateDB pattern, updated logic to remove unnecessary checks
addressed all comments.
Adding code to find common expressions from the two subblocks of an if
operation and hoist them before the if block.
This also allows Dead Code Elimination to
then eliminate some if blocks.
Test Plan: python test_jit.py TestIfHoisting
Reviewed By: eellison
Differential Revision: D33302065
Pulled By: Gamrix
fbshipit-source-id: a5a184a480cf07354359aaca344c6e27b687a3c2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71116
As title, add more inline documentation for code.
Test Plan:
no
pingpoke
Reviewed By: 842974287
Differential Revision: D33465611
fbshipit-source-id: 6b5529893098e5591470c2f41a0d8989e3cfccb9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70871
We had previously handled reusing memory in the optimized kernel execution path, but not yet handled it if we hit the unoptimized fallback.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33458652
Pulled By: eellison
fbshipit-source-id: 4eb62181ed02c95813a99638f5e2d0f9347b5c08
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70508
We can create the code object at compile time instead or runtime to speed it up. This also makes unnecessary the compilation cache. TODO: figure out if theres a way to cache InterpreterState object
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33458648
Pulled By: eellison
fbshipit-source-id: 710389741e7c6210528f2f96ab496fcd533d942a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70463
Fix for https://github.com/pytorch/pytorch/issues/52940
When we call inlining on a fallback function, insert the runtime optimized version of its graph.
Test Plan: Imported from OSS
Reviewed By: jbschlosser, davidberard98
Differential Revision: D33458651
Pulled By: eellison
fbshipit-source-id: fd7e5e2b5273a1677014ba1a766538c3ee9cad76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68388
Updates the gpu architectures as well as adding a trigger for
on_pull_request for the binary build workflows so that we can iterate on
this later
TODO:
* Create follow up PR to enable nightly linux GHA builds / disable CircleCI nighlty linux builds
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D33462294
Pulled By: seemethere
fbshipit-source-id: 5fa30517550d36f504b491cf6c1e5c9da56d8191
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70641
Raises a not implemented error if we attempt to pickle an object which uses a mocked module. Now we no longer have to load the object to get this check, and instead happens right on the saving path.
Review History is on https://github.com/pytorch/pytorch/pull/69793 PR was moved to a different branch due to original branch getting corrupted.
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D33414365
Pulled By: PaliC
fbshipit-source-id: 6d72ddb05c47a3d060e9622ec0b6e5cd6c6c71c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71025
TL;DR In come cases:
1) user imports `dill`, which mutates `_Pickler.dispatch`,
2) user imports lib that imports `torch.package`
3) `PackagePickler.dispatch = _Pickler.dispatch.copy()` makes a copy of the mutated table
4) user calls `dill.extend(use_dill=False)` to reset `_Pickler.dispatch`, expecting everything to be okay
5) `PackagePickler` is used to pickle something like `ModuleDict`. `PackagePickler.dispatch` has stale entries to dill pickle functions like `save_module_dict`, which sometimes hard-code calls to `StockPickler.save_global`, which is unaware of torch.package module prefixes.
6) Exception is raised, e.g. `Got unhandled exception Can't pickle <class '<torch_package_2>.caffe2.mylib'>: it's not found as <class '<torch_package_2>.caffe2.mylib'>`
Differential Revision: D33483672
fbshipit-source-id: d7cd2a925bedf27c02524a6a4c3132a262f5c984
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70628
event_listener thread is used to log process tracebacks when a timed
out process sends it a request to get its traceback. Although, this thread is
created in `_run` function which is overridden by some classes such as
`TestDistBackend` so those tests did not have this feature. Move the
event_listener setup logic to `run_test` which is called by all distributed
test classes, which enables it for all distributed tests. Also modify logger
setup to ensure that logging.info calls are printed in the subprocess.
ghstack-source-id: 146714642
Test Plan: CI
Reviewed By: jaceyca, fduwjj
Differential Revision: D33410613
fbshipit-source-id: aa616d69d251bc9d04e45781c501d2244f011843
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70649
As described in https://fb.quip.com/oxpiA1uDBjgP
This implements the first parts of the RFC, and is a rough draft showing the approach. The idea is that for the first cut we can maintain very close (identical I believe in this diff) numerical equivalence to the existing nn.MHA implementation, which is what this diff attempts to do. In subsequent implementations, once we have a working and adopted native self-attention implementation, we could then explore alternative implementations, etc.
The current implementation is similar to existing dedicated implementations such as LightSeq/FasterTransformer/DeepSpeed, and for MHA on both CPUs and GPUs is between 1.2x and 2x faster depending on the setting. It makes some approximations/restrictions (doesn't handle masking in masked softmax, etc), but these shouldn't materially impact performance.
This does the first few items:
* add native_multi_head_attention(...) , native_multi_head_attention_backward(..) to native_functions.yaml
* Implement native_multi_head_attention(..) on GPU, extracting bits and pieces out of LS/DS/FT as appropriate
* Implement native_multi_head_attention(..) on CPU
The backward implementation is still WIP, but the idea would be to:
* Hook these up in derivatives.yaml
Implement native_multi_head_attention_backward(..) on GPU, extracting out bits and pieces out of LS/DS (not FT since it’s inference only)
* Implement native_multi_head_attention_backward(..) on CPU
* In torch.nn.functional.multi_head_attention_forward 23321ba7a3/torch/nn/functional.py (L4953), add some conditionals to check if we are being called in a BERT/ViT-style encoder fashion, and invoke the native function directly.
Test Plan: TODO
Reviewed By: mikekgfb
Differential Revision: D31829981
fbshipit-source-id: c430344d91ba7a5fbee3138e50b3e62efbb33d96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71007
A string copy at Line 417 is currently consuming 125,749,287,000 cycles/day. I suspect the issue is with a copy-on-return, but we can experiment with introducing a reference in the middle to see if that produces a good savings without changing the interface.
Reference
```
["Inline caffe2::ArgumentHelper::GetSingleArgument @ caffe2/caffe2/utils/proto_utils.cc:417"]
```
Test Plan: Sandcastle
Reviewed By: xw285cornell
Differential Revision: D33478883
fbshipit-source-id: e863e359c0c718fcd0d52fd4b3c7858067de0670
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70338
Today Unpickler is used by both server and mobile for deserializing model, and it always fallback to mobile parser when there's no type resolver provided by user. However this is not intended as server and mobile type parser supports different things. In this diff we provide a default fallback using script parser and opt it out for all mobile cases.
ghstack-source-id: 146727330
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D33284352
fbshipit-source-id: 997c4f110b36eee6596e8f23f6a87bf91a4197ed
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70121
Code move all TensorType dependencies into a separate `tensor_type.cpp`, so that we don't link with it in the min runtime accidentally.
ghstack-source-id: 146727331
(Note: this ignores all push blocking failures!)
Test Plan: no behavior change.
Reviewed By: gmagogsfm
Differential Revision: D33102286
fbshipit-source-id: e9fe176201bd2696cb8c65c670fcf225e81e8908
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70120
Before the change:
```
c10::Type t = ivalue.type();
```
After the change:
```
c10::Type t = ivalue.type();
c10::DynamicType d = ivalue.type<c10::DynamicType>(); // new path
```
The new path will be adopted in PyTorch Lite Interpreter to support lightweight type reflection. Note that type getters are selected at compile time so no performance overhead. The benefits of having a DynamicType will be elaborated in a separate document, but in short, DynamicType provides an isolated type system for controlling binary size bloat, and shrink down ~20 supported Type symbols into one so that the size taken by specializations and function name symbols are greatly reduced.
Lite Interpreter should only use the `<DynamicType>` variant of the interfaces from aten, to reduce binary size.
ghstack-source-id: 146727334
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: gmagogsfm
Differential Revision: D33102276
fbshipit-source-id: c5354e7d88f9de260c9b02636214b40fe15f8a10
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70119
JIT type and IValue have a mutual dependency because of various reasons today. It makes things worse when we have `jit_type.h` and `ivalue.h` mutually include each other, causing non deterministic name resolutions at different translation units, preventing us safely use symbols from `jit_type.h` in `ivalue.h` . This diff doesn't address the mutual dependency between JIT type and IValue at linking level, but at header level.
We choose to remove include of `ivalue.h` from `jit_type.h` because it's way harder to make a type-free header for IValue. The way we achieve this is by removing EnumType (which is the only type depending on IValue in JIT types) from `jit_type.h`, and let downstream users to specifiy an explicit `enum_type.h` as needed. We also move some IValue inline member function definitions back to `ivalue_inl.h` so that `jit_type.h` doesn't need IValue definition to be present.
We also remove a seemingly accidental include of `jit_type.h` from `ATen/core/List_inl.h` so that `ivalue.h` can include `jit_type.h` directly, otherwise due to another mutual inclusion between `ivalue.h` and `List_inl.h` we can still get nondeterministic behavior.
ghstack-source-id: 146727333
(Note: this ignores all push blocking failures!)
Test Plan: no behavior change.
Reviewed By: gmagogsfm
Differential Revision: D33155792
fbshipit-source-id: d39d24688004c2ec16c50dbfdeedb7b55f71cd36
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70964
Accidently deleted before, adding this back. We'll make this more complete after
the structure is finalized
Test Plan:
no test needed
Imported from OSS
Reviewed By: dagitses
Differential Revision: D33470738
fbshipit-source-id: 00459a4b00514d3d0346de68788fab4cad8a5d12
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70927
Earlier, when replacing deq-ref-quant modules, we get non-duplicate
named modules only. When model contains dupicate names, the lowering fails the
second time.
This PR allows duplicates when getting the named modules.
Test Plan: buck test //caffe2/torch/fb/model_transform/quantization/tests:fx_quant_api_test
Reviewed By: jerryzh168
Differential Revision: D33440028
fbshipit-source-id: f2fabd49a293beb90d7b4bf471610cde6279fd66
Summary:
Main logic of the workflow is implemented in `syncbranches.py` script,
which computes patch-id's of divergent history (as determined by `git
merge-base`) and treats all patches present in sync branch with
non-matching patch-ids as ones missing in target branch
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71013
Reviewed By: bigfootjon
Differential Revision: D33480885
Pulled By: malfet
fbshipit-source-id: bd72c061720d0cba49c6754ec4e94437d8a5c262
Summary:
Here 20 is a bad example, since the warmup step is set as 100. 200 iterations will make much more sense.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70974
Reviewed By: dagitses
Differential Revision: D33474576
Pulled By: rohan-varma
fbshipit-source-id: 4c7043108897848bde9503d77999971ad5567aa6
Summary:
The workspace should be totally empty before checking out PyTorch; this
is especially important with non-ephemeral runners.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71018
Reviewed By: robieta
Differential Revision: D33482985
Pulled By: suo
fbshipit-source-id: cafa123d2b893bfbdad62295586b5b79f1542b3a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69483
To avoid accidental linking to Union type and Optional type in Edge runtimes, we can separate these types into different files, so that we don't accidentally link with them in type.cpp.
ghstack-source-id: 146670525
Test Plan: just code move.
Reviewed By: ejguan
Differential Revision: D32264607
fbshipit-source-id: c60b6246f21f3eb0a67f827a9782f70ce5200da7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68137
A small step to replace existing OptionalType usage to DynamicType in Edge runtime.
ghstack-source-id: 146670520
Test Plan: CI
Reviewed By: iseeyuan
Differential Revision: D32264617
fbshipit-source-id: 62d3ffad40901842deac19ca2098ea5ca132e718
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69482
Add a test to enumerate a number of JIT type combinations and see if their subtyping behavior is preserved in the new DynamicType system.
ghstack-source-id: 146670526
Test Plan: buck test mode/opt //caffe2/test/cpp/jit:jit -- --exact 'caffe2/test/cpp/jit:jit - LiteInterpreterTest.DynamicType'
Reviewed By: gmagogsfm
Differential Revision: D32891263
fbshipit-source-id: 728211b39778e93db011b69b0a4047df78a8fc5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68136
DynamicType is an extension to existing server JIT types. Today using normal server types on Edge is a bit problematic because in embedded environments we don't need the full spectrum of types but we still build with these unneeded dependencies.
Is it possible to just get rid of unneeded JIT types from Edge builds? It's not easy to do so at this moment. For example, on Edge we don't support Union type, but we have to pull in the dependency of Union type because Optional type is being supported which inherits from Union type, so Union type has to be included in the build. Although we could split Union type and Optional type, it could be argued that the root cause is every time we use anything inheriting from `c10::Type`, we don't have the direct evidence of how much dependency we pull in, because we do virtual calls and we don't know what exactly we're calling with server JIT types. If we don't know, it's highly possible that the linker doesn't know either so it cannot effectively strip unused methods.
To address this problem, one option is to implement a separate `DynamicType` which has simpler behavior and doesn't store different types as different symbols in binary but rather raw data (or "tag"). This could increase the binary size by several KBs, so I included several binary size reductions in the same stack, hoping at least we don't regress the binary size.
Currently `DynamicType` inherits from `c10::Type` because I want to reduce the migration cost of `DynamicType` by making it interfacing with existing server JIT types. In the future `DynamicType` should be implemented as a separate class without relying on `c10::Type` to make things both simpler and leaner.
ghstack-source-id: 146670522
Test Plan: in the next diff.
Reviewed By: VitalyFedyunin
Differential Revision: D32264615
fbshipit-source-id: 180eb0998a14eacc1d8b28db39870d84fcc17d5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68038
Replace const std::function& to c10::function_ref because the former uses type erasure and adds 5-10 KB size overhead and adds another level of indirection to call the underlying functions. In contrast a non-owning c10::function_ref will just compile down to a raw function pointer which should be much smaller.
ghstack-source-id: 146670523
Test Plan: eyes
Reviewed By: iseeyuan, mrshenli
Differential Revision: D32264619
fbshipit-source-id: 558538fd882b8e1f4e72c4fd5e9d36d05f301e1e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63688
CppFunction is used for function registration, so it's not performance-sensitive. Outlining the destructor should reduce code size.
ghstack-source-id: 146648927
Test Plan: Mobile buildsizebot
Reviewed By: dhruvbird
Differential Revision: D30462640
fbshipit-source-id: de410f933bf936c16769a10a52092469007c8487
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69922
D32596934 (65f54bc000) made the serial stack implementation a bit brittle. It introduced a new container type: `VarStackNodeWrapper`. This type was used as a template parameter in the serial stack implementation.
The other type used in the serial stack implementation is `at::ArrayRef<at::Tensor>`. Ideally, the interface of `VarStackNodeWrapper` should be as close as possible to this other type. However, because the new container type did not have an iterator, expressions like this would fail to compile:
```
for (const auto& tensor : tensors) {
// do something
}
```
Introducing this iterator will make the code easier to maintain going forward.
Test Plan:
`buck test caffe2/benchmarks/static_runtime:static_runtime_cpptest -- Stack`
I consider this a `VarStack` implementation detail, so I'd prefer not to test it directly. We can test it implicitly by adding some code to the serial stack implementation that uses the iterator.
Reviewed By: swolchok
Differential Revision: D33101489
fbshipit-source-id: 7cf44c072d230c41bd9113cf2393bc6a6645a5b5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70810
Adapt to LLVM top-of-tree APIs.
For context: LLVM is moving towards opaque pointers for IR values: https://llvm.org/docs/OpaquePointers.html
I also changed some `value->getScalarType()->getPointerElementType()` expressions to directly reference relevant types. This is simpler and more in line with the intentions of the opaque IR pointers. (In fact I would expect those expressions to break in the future). I did not fix places where the relevant type wasn't obvious to me though.
Test Plan:
-
```
$ cd fbsource/fbcode
$ tp2_update_fbcode llvm-fb --branch=staging
# symlinks point to d9c037cf2b4f0268cb1897b99c8c87c5d0232616 TP2 revision
$ buck build mode/opt-clang-thinlto unicorn:index_server -c unicorn.hfsort="1" -c cxx.profile="fbcode//fdo/autofdo/unicorn/index_server:autofdo" -c cxx.modules=False -c cxx.extra_cxxflags="-Wforce-no-error"
```
- Check sandcastle jobs
Reviewed By: modiking
Differential Revision: D33431503
fbshipit-source-id: 33f39d0a0c0f4b805ab877a811ea0a670f834abf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70867
This commit syncs LazyGraphExecutor and LazyTensor with the staging branch's
latest changes.
Test Plan: CI in the lazy_tensor_staging branch.
Reviewed By: wconstab, desertfire
Differential Revision: D33440005
Pulled By: alanwaketan
fbshipit-source-id: 0dd72643dbf81a87fc4b05019b6564fcb28f1979
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66847
Trimming means that we try to remove a small portion of the graph while
keeping it valid, and we try performing this step that N times. This is
useful for debugging when we try to find a minimal example reproducing
the issue at hand.
Differential Revision:
D31751397
D31751397
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: 07d8ba1435af8fd2d7b8cf00db6685543fe97a85
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70535
This also fixes handling of inputs that happen to be outputs (they
require copy).
Test Plan: Imported from OSS
Reviewed By: pbelevich
Differential Revision: D33399116
Pulled By: ZolotukhinM
fbshipit-source-id: 9845838eb653b82ae47b527631b51893990d5319
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66515
These passes should not be used generally as they change API of the
model's forward method, but they help experimenting with the model and
ironing out all the kinks before it can be compiled properly. In the
long run ideally we should provide a better way to enable such
experiments.
Differential Revision:
D31590862
D31590862
Test Plan: Imported from OSS
Reviewed By: navahgar
Pulled By: ZolotukhinM
fbshipit-source-id: 74ded34c6c871d4cafa29f43dc27c7e71daff8fc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66514
These passes will
1) help us analyze the graph before trying to compile it
and report errors upfront if it's not possible,
2) fill in missing strides/dtype/device info in JIT IR. Ideally, this
should be done by a dedicated JIT pass, but until it's available, we'll
be using a hack-around defined here.
Differential Revision:
D31590860
D31590860
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Pulled By: ZolotukhinM
fbshipit-source-id: fe8fdefbeacae8079958dd0b4b27809cc0acb34b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70248
Modified loops in files under fbsource/fbcode/caffe2/ from the format
```
for(TYPE var=x0;var<x_max;x++)
```
to the format
```
for(const auto var: irange(xmax))
```
This was achieved by running r-barnes's loop upgrader script (D28874212) with some modification to exclude all files under /torch/jit and a number of reversions or unused variable suppression warnings added by hand.
Test Plan: Sandcastle
Reviewed By: malfet
Differential Revision: D32813863
fbshipit-source-id: 527244b4a2b220fdfe7f17dee3599603f492a2ca
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70501
This PR migrates prim string ops to be registered into JIT op registry instead of dispatcher. Since the implementation of these ops are backend agnostic, there's no need to go through dispatcher. Relying on `test_jit_string.py` to verify the correctness of these ops. I'm also adding tests to make sure all the operators are covered.
Test Plan: Rely on `test_jit_string.py`.
Reviewed By: iseeyuan
Differential Revision: D33351638
fbshipit-source-id: ecc8359da935a32d3a31add2c395a149a0d8892f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69579
This should help us avoid reference counting overhead on singleton Type subclasses without a major rewrite of the Type subsystem.
ghstack-source-id: 146643993
Test Plan:
Ran //caffe2/caffe2/fb/high_perf_models/pytorch/benchmark_framework_overheads:cpp_benchmark with arguments `--op empty -niter 40 --stressTestRecordFunction --captureRecordFunctionInputs` on devbig with turbo off.
Before:
```
I1206 13:47:15.037441 1201670 bench.cpp:144] Mean 0.737675
I1206 13:47:15.037463 1201670 bench.cpp:145] Median 0.736725
I1206 13:47:15.037468 1201670 bench.cpp:146] Min 0.722897
I1206 13:47:15.037473 1201670 bench.cpp:147] stddev 0.00508187
I1206 13:47:15.037482 1201670 bench.cpp:148] stddev / mean 0.00688903
```
After:
```
I1206 13:48:16.830123 1205612 bench.cpp:144] Mean 0.66988
I1206 13:48:16.830150 1205612 bench.cpp:145] Median 0.663956
I1206 13:48:16.830157 1205612 bench.cpp:146] Min 0.65986
I1206 13:48:16.830164 1205612 bench.cpp:147] stddev 0.0335928
I1206 13:48:16.830171 1205612 bench.cpp:148] stddev / mean 0.0501475
```
Static runtime startup is also improved; for CMF local_ro, time to initialize a predictor went from 10.01s to 9.59s.
(Note: I wish I had a production workload to demonstrate the advantage of this on. I tried ctr_mobile_feed local_ro net but it was neutral. Anything that manipulates types or List/Dict a lot might be promising.)
Reviewed By: suo
Differential Revision: D32923880
fbshipit-source-id: c82ed6689b3598e61047fbcb2149982173127ff0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70410
Trying again after #70174 was reverted. Earlier the env
variable was read into a static var in C++ causing state to be retained
and causing test failures. Static type is removed in this PR.
Test Plan: Imported from OSS
Reviewed By: ZolotukhinM
Differential Revision: D33321435
fbshipit-source-id: 6d108eb00cac9150a142ccc3c9a65a1867dd7de4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70619
This Diff improves `hipify_python`, which is needed for AMD GPUs.
Change 1:
```
if (c == "," or ind == len(kernel_string) - 1) and closure == 0:
```
This is needed to deal with the following case (ex: https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/test/cuda_vectorized_test.cu#L111)
```
kernel<<<val, func()>>>(...)
// In this case, kernel_string is "val, func()"
// so closure gets 0 when ind == len(kernel_string) - 1.
```
Change 2:
```
mask_comments()
```
This is needed to deal with a case where "<<<" is included in a comment or a string literal (ex: https://github.com/pytorch/pytorch/blob/master/torch/csrc/deploy/interpreter/builtin_registry.cpp#L71)
```
abc = "<<<XYZ>>>"
// Though this <<<XYZ>>> is irrelevant to CUDA kernels,
// the current script attempts to hipify this and fails.
```
Test Plan:
This patch fixes errors I encountered by running
```
python3 tools/amd_build/build_amd.py
```
I confirmed, with Linux `diff`, that this patch does not change HIP code that was generated successfully with the original script.
Reviewed By: hyuen
Differential Revision: D33407743
fbshipit-source-id: bec822e040a154be4cda1c294536792ca8d596ae
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70372
Enables basic support for `torch.nn.ModuleList` in DBR quant
by stopping it from being a leaf. For now, we
require the user to check for `AutoQuantizationState` if they are
looping over the contents without any bounds checking.
In future PRs, we can explore how to solve this without requiring
user code changes.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_module_list
```
Reviewed By: VitalyFedyunin
Differential Revision: D33302329
Pulled By: vkuzo
fbshipit-source-id: 1604748d4b6c2b9d14b50df46268246da807d539
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70349
Makes sure that child modules of non traceable leaf modules
do not participate in quantization swaps. This should feature complete
the `non_traceable_module_class` feature.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_prepare_custom_config_dict_non_traceable_module_class
```
Reviewed By: VitalyFedyunin
Differential Revision: D33296246
Pulled By: vkuzo
fbshipit-source-id: 08287429c89ee6aa42d13ca3060a74679a478181
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70335
Adds test case that functions are not quantized inside custom leaf modules.
No logic change needed as it already works correctly.
Note: FX scripting rewriter does not go into modules without auto-quant,
which is why we are using torch.jit.trace to look at the graph.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_prepare_custom_config_dict_non_traceable_module_class
```
Reviewed By: jerryzh168
Differential Revision: D33286370
Pulled By: vkuzo
fbshipit-source-id: 26c81c9e1ce7c4d38ddc1e318730cf1eaa25ff69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70330
Starts adding support for custom leaf modules, part 1/x.
In this PR, we ensure that leaf modules and all of their children
do not get `AutoQuantizationState` objects attached to them.
The API is matching prepare_fx, using the `prepare_custom_config_dict`
argument and the `non_traceable_module_class` key within that dict.
The next couple of PRs will ensure that modules and functions in
leaves do not get quantized, keeping it separate to make PRs smaller.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_prepare_custom_config_dict_non_traceable_module_class
```
Reviewed By: jerryzh168
Differential Revision: D33285310
Pulled By: vkuzo
fbshipit-source-id: 532025fda5532b420fad0a4a0847074d1ac4ad93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70329
Fixes a crash in DBR when a child module does not return any tensors.
This happens sometimes in user models.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_child_module_does_not_return_tensor
```
Reviewed By: VitalyFedyunin
Differential Revision: D33285309
Pulled By: vkuzo
fbshipit-source-id: 42b8cffb5ee02ce171a3e6c64d140bb5f217225a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70328
Currently linear with bias crashes DBR convert step, this PR fixes it.
This unbreaks testing DBR on some customer models.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBRIndividualOps.test_linear_functional_nobias
```
Reviewed By: jerryzh168
Differential Revision: D33285311
Pulled By: vkuzo
fbshipit-source-id: 757c7270be9e3ff9cdf2609b1e426e9fd34e50ff
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70257
Makes dynamic quantization for linear module work in DBR quant.
Coverage for more ops and functionals will be in future PRs.
Test Plan:
```
python test/test_quantization.py -k DBR
```
Reviewed By: jerryzh168
Differential Revision: D33262300
Pulled By: vkuzo
fbshipit-source-id: c1cb0f9dd3f42216ad6ba19f4222b171ff170174
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70256
Somewhere in previous PRs we started attaching AutoQuantState
to observers. This PR removes this, as that has not purpose
and makes model debugging more complicated.
Test Plan:
```
python test/test_quantization.py -k DBR
```
Reviewed By: jerryzh168
Differential Revision: D33262299
Pulled By: vkuzo
fbshipit-source-id: a3543b44c517325d57f5ed03b961a8955049e682
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70385
This commit sync gen_lazy_tensor.py from the lazy_tensor_staging branch
to the master.
Test Plan: CI in the lazy_tensor_staging branch.
Reviewed By: wconstab
Differential Revision: D33306232
Pulled By: alanwaketan
fbshipit-source-id: a15c72b22418637f851a6cd4901a9f5c4be75449
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70799
Add op support in fx2trt for leaky_relu
1. add support in acc_ops and corresponding unit test
2. add support in acc_ops_converters and corresponding unit test
Reviewed By: 842974287
Differential Revision: D33399095
fbshipit-source-id: 978340e64b35ffefabdc48273ddfa86b5ee1816e
Summary:
Removes unused pytorch-job-specs.yml
It looks like the recent android GHA jobs use upload_binary_size_to_scuba.py, but a portion of the script was still using CIRCLE only variables
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70643
Reviewed By: ngimel
Differential Revision: D33455659
Pulled By: janeyx99
fbshipit-source-id: cfe79a674641ed3327c7650d2107ace2a5050983
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70601
`&` has lower precedence than `==`, so `==` will be evaluated first. This behavior should not be intended. This patch fixes it.
Test Plan: 🧐 Carefully check the change.
Reviewed By: hyuen
Differential Revision: D33397964
fbshipit-source-id: e3ac5b04e4688dfbf9d8ac3e5c4aa72282bf6ee9
Summary:
Helps fix a part of https://github.com/pytorch/pytorch/issues/69865
The first commit just migrates everything as is.
The second commit uses the "device" variable instead of passing "cuda" everywhere
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70872
Reviewed By: jbschlosser
Differential Revision: D33455941
Pulled By: janeyx99
fbshipit-source-id: 9d9ec8c95f1714c40d55800e652ccd69b0c314dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70432
Scale and zero_point need to be buffers for serialization to work
on them properly. This PR moves them to buffers. This is BC breaking,
but the "before" state was completely broken (scale + zp were not
serialized at all) so there is no value in trying to handle it.
Test Plan:
```
python test/test_quantization.py TestStaticQuantizedModule.test_batch_norm2d_serialization
python test/test_quantization.py TestStaticQuantizedModule.test_batch_norm3d_serialization
```
```
python test/test_quantization.py TestStaticQuantizedModule.test_batch_norm2d_serialization
```
Imported from OSS
Differential Revision:
D33330022
D33330022
Reviewed By: jerryzh168
Pulled By: vkuzo
fbshipit-source-id: 673c61f1a9f8f949fd9e6d09a4dbd9e5c9d5fd04
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70326
See D24145988 for context: it allows loops such as for(int i=0;i<10;i++) to be expressed as for(const auto i : c10::irange(10)). This is nice because it auto-types the loops and adds const-safety to the iteration variable.
Test Plan: buck run //caffe2/torch/fb/sparsenn:test
Reviewed By: r-barnes
Differential Revision: D33243400
fbshipit-source-id: b1f1b4163f4bf662031baea9e5268459b40c69a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70869
Makes linux runners non-ephemeral to reduce the amount of
CreateInstance calls that we have going towards AWS as well as to reduce
the amount of github API calls we make in order to create new instances.
Should help alleviate some of the queuing issues we may observe due to
AWS / Github rate limits
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D33436874
Pulled By: seemethere
fbshipit-source-id: b2736fb4c9d175b1b0e2efb5017dcb4a8d4c05f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68185
As per title
We also fix the first input to `handle_r_to_c` fo `rsub`as it was
flipped for the two inputs.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684855
Pulled By: mruberry
fbshipit-source-id: ffeab8d561e657105b314a883260f00d0ae59bbf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68184
This was in the TODO list as the three operations are very similar.
Did this as one of them was failing in the noncontig tests and I wanted
to make sure that all of them were tested properly, as they all appear
in the derivative formulas of each other.
After this PR, these operations do pass the noncontiguous tests.
cc mruberry
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684854
Pulled By: mruberry
fbshipit-source-id: 5db58be8d1e1fce434eab9cdf410cbf1024bbdf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68183
We do so in favour of
`make_fullrank_matrices_with_distinct_singular_values` as this latter
one not only has an even longer name, but also generates inputs
correctly for them to work with the PR that tests noncontig inputs
latter in this stack.
We also heavily simplified the generation of samples for the SVD, as it was
fairly convoluted and it was not generating the inputs correclty for
the noncontiguous test.
To do the transition, we also needed to fix the following issue, as it was popping
up in the tests:
Fixes https://github.com/pytorch/pytorch/issues/66856
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684853
Pulled By: mruberry
fbshipit-source-id: e88189c8b67dbf592eccdabaf2aa6d2e2f7b95a4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67014
LAPACK functions return negative infos when there was an unexpected
input. This happens (for example) when the user does not specify
matrices of the correct size. We already check all this things on the
PyTorch end, so this check that induces a synchronisation is
unnecessary.
I also took this chance to avoid some code repetition in the computation
of the determinant of `P`. I also changed the use of `ExclusivelyOwned<Tensor>`
by regular `Tensors` + moving into the tuple, which should be as efficient or more.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684851
Pulled By: mruberry
fbshipit-source-id: dc046d1cce4c07071d16c4e2eda36412bd734e0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67789
`at::defaultStride` was added in https://github.com/pytorch/pytorch/pull/18779.
As it was noted in that PR, it differs from the actual computation of
the default strides when one or more of the dimensions of the tensor are
zero. See https://github.com/pytorch/pytorch/pull/18779#discussion_r272296140
We add two functions, `contiguous_strides` and `contiguous_strides_vec`
which correct this issue and we replace the previous (wrong) uses of
`defaultStride`.
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D32684852
Pulled By: mruberry
fbshipit-source-id: 62997a5a97a4241a12e73e2be2e192b80b491cb1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
In the [docstring](https://github.com/pytorch/pytorch/blob/master/torch/fx/passes/graph_drawer.py#L54-L60) we mention `get_dot_graph but it is not defined, so I defined it here.
Not sure if this is preferred, or should we update the docstring to use `get_main_dot_graph`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70541
Test Plan:
```
g = FxGraphDrawer(symbolic_traced, "resnet18")
with open("a.svg", "w") as f:
f.write(g.get_dot_graph().create_svg())
```
Reviewed By: khabinov
Differential Revision: D33378080
Pulled By: mostafaelhoushi
fbshipit-source-id: 7feea2425a12d5628ddca15beff0fe5110f4a111
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69936
Currently, the optimizers in `torch/optim/_multi_tensor/` all override the base Optimizer class' implementation of `zero_grad` with the same foreach zero_grad implementation (e.g. [here](https://github.com/pytorch/pytorch/blob/master/torch/optim/_multi_tensor/adadelta.py#L93-L114)). There is a TODO that indicates that this should be refactored to the base class once the foreach ops are in good shape. This PR is intended to address that TODO.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D33346748
Pulled By: mikaylagawarecki
fbshipit-source-id: 6573f4776aeac757b6a778894681868191a1b4c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67254
Fixes https://github.com/pytorch/pytorch/issues/65997
TODO: disallow `default` as an overload name for aten operators.
BC breaking:
`output = torch.ops._test.leaky_relu(self=torch.tensor(-1.0))` now fails with the error `TypeError: __call__() got multiple values for argument 'self'` since we call into `OpOverloadBundle`'s `__call__` method that has `self` bound to it as its first argument.
cc ezyang gchanan
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33262228
Pulled By: anjali411
fbshipit-source-id: 600dbf511514ea9b41aea3e6b1bc1102dab08909
Summary:
Those scripts are run on 8 vCPU instances, so passing at least `-j6` makes sense
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70866
Reviewed By: atalman
Differential Revision: D33435083
Pulled By: malfet
fbshipit-source-id: c879ed928da0b77346a92976d2fe9ad92ba01b5e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65432
There is no reason to do an extra write to the input DataPtr (via `std::swap`) before returning a new DataPtr.
ghstack-source-id: 146471376
Test Plan:
Inspected assembly for this function to verify that we are
really getting fewer instructions generated. I don't have a specific
application for this at the moment, but it's clearly better IMO.
Reviewed By: mikeiovine
Differential Revision: D31097807
fbshipit-source-id: 06ff6f5fc675df0f38b0315b4147ed959243b6d0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70623
Strides on lazy tensor should only be read after calling setup_size_properties. This fixes a failure in hf_Longformer.
Test Plan: CI on the lazy_tensor_staging branch
Reviewed By: wconstab, alanwaketan
Differential Revision: D33410142
Pulled By: desertfire
fbshipit-source-id: ccb2ba8d258bdb88f6b51be6196563f9c4c06cbf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70658
Config '--exclude-distributed-test' was intended to disabled fx2trt test on normal docker test suite, but test is auto disabled now. Remove config.
Test Plan:
CI
https://github.com/pytorch/pytorch/actions/runs/1656375648
Reviewed By: houseroad
Differential Revision: D33417803
fbshipit-source-id: 9dfb4cbd6fa9ad18a4be989ee86d1f8a298347f9
Summary:
The CMake build defaults to `USE_PER_OPERATOR_HEADERS = 1` which
generates extra headers in the `ATen/ops` folder that don't exist
otherwise. In particular, fb-internal builds using buck don't support
these headers and so all includes must be guarded with
`#ifdef AT_PER_OPERATOR_HEADERS`.
This adds a CI run which builds with `USE_PER_OPERATOR_HEADERS = 0` so
open source contributions don't have to wait for their PR to be
imported to find out it doesn't work in fb-internal. This flag
shouldn't effect runtime behavior though, so I don't run any tests.
cc seemethere malfet pytorch/pytorch-dev-infra
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69907
Reviewed By: malfet, atalman
Differential Revision: D33411864
Pulled By: seemethere
fbshipit-source-id: 18b34d7a83dc81cf8a6c396ba8369e1789f936e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70605
broadcast_object_list casted the sum of all object lengths to int from long causing overflows.
Test Plan:
Add a Tensor with >2GB storage requirement (in distributed_test.py) to object broadcast.
This Tensor is only added if test are running at Meta as github tests will oom.
Without fix the length will overflow and the program will request a negative sized Tensor:
```
RuntimeError: Trying to create tensor with negative dimension -2147482417: [-2147482417]
```
With fix it will pass the test.
Test used on server with GPUs:
buck test mode/dev-nosan //caffe2/test/distributed:distributed_nccl_spawn --local -- broadcast_object
buck test mode/dev-nosan //caffe2/test/distributed:distributed_gloo_spawn --local -- broadcast_object
Reviewed By: r-barnes
Differential Revision: D33405741
fbshipit-source-id: 972165f8297b3f5d475636e6127ed4a49adacab1
Summary:
Due to a merge conflict, the new bazel cuda build does something
rather obnoxious. It runs ATen codegen with `--per-operator-headers`
enabled and extracts a subset of the generated files; then calls it
again without the flag to extract the CUDA files.
This PR instead calls the codegen once but keeps track of what is
CPU and what is CUDA in separate lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70147
Reviewed By: VitalyFedyunin
Differential Revision: D33413020
Pulled By: malfet
fbshipit-source-id: 4b502c38a209d1aa63d715e2336df6fc5aac2212
Summary:
Fixes https://github.com/pytorch/pytorch/issues/70185
The extraheader block in docs/source/_templates/layout.html overrides the one from the pytorch theme. The theme block adds Google Analytics, so they were missing from the `master` documentation. This came up in PR pytorch/pytorch.github.io#899.
brianjo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70187
Reviewed By: bdhirsh
Differential Revision: D33248466
Pulled By: malfet
fbshipit-source-id: b314916a3f0789b6617cf9ba6bd938bf5ca27242
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70247
Stops calling the eager mode quantization `convert` function
from DBR quant convert, and instead implements the module swaps
manually. This will make it easier to support quantization types
other than static int8 in future PRs.
Test Plan:
```
python test/test_quantization.py -k DBR
```
Reviewed By: jerryzh168
Differential Revision: D33255924
Pulled By: vkuzo
fbshipit-source-id: afdfd61d71833d987bb38aa4d8c3d214f900c03e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70246
Breaks up the large `TestQuantizeDBR` test case into
1. `TestQuantizeDBRIndividualOps` for testing functionality of ops
2. `TestQuantizeDBRMultipleOps` for testing non-fusion interactions between ops
3. `TestQuantizeDBR` for everything else
We may need to refactor this more in the future, but this should
unblock things for the near future.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
python test/test_quantization.py TestQuantizeDBRIndividualOps
python test/test_quantization.py TestQuantizeDBRMultipleOps
```
Reviewed By: jerryzh168
Differential Revision: D33255925
Pulled By: vkuzo
fbshipit-source-id: 82db1a644867e9303453cfedffed2d81d083c9cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70200
Adds the logic to record not just the subgraphs which are quantizeable,
but also the set of ops (not subgraph) which are quantizeable. This changes
the information recorded during tracing as follows (an example):
```
// before
1. subgraph of conv1 -> conv2
2. no other information about other ops
// after
1. subgraph of conv1 -> conv2
2. set of types of ops which were not quantizeable but were encountered during tracing
```
This has two uses:
1. easier development of DBR quant to cover more ops, as now the ops which are not being quantized are easier to inspect
2. easier understanding for the user of what DBR quant is doing or not doing for a model
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR.test_unsupported_ops_recorded
```
Reviewed By: VitalyFedyunin
Differential Revision: D33240997
Pulled By: vkuzo
fbshipit-source-id: 3168eae286387e6cb01df3ae60dc13620fb784d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70196
Deletes the custom DBR static quant module mapping, and reuses
the global ones.
Test coverage for all the ops will be in future PRs.
Test Plan:
```
python test/test_quantization.py TestQuantizeDBR
```
Reviewed By: jerryzh168
Differential Revision: D33240998
Pulled By: vkuzo
fbshipit-source-id: da248b28d7b681794fa0494ff31fd065680f6fef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69696
Using `find` is not portable as it won't be there on Windows for example. We can use `glob` with the recursive option added in Python 3.5 instead.
Test Plan: CircleCI
Reviewed By: xta0
Differential Revision: D32994229
fbshipit-source-id: 4a755c4313300142c051f533d0b3876dc9035da0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70561
When building with strict(er) compiler warnings on Windows, clang complains that `__FUNCSIC__` is a proprietary language extension. When using clang, it seems we can use `__PRETTY_FUNCTION__` instead, like we do on other platforms. This is also in line with the logic on L100:127.
Test Plan: CI
Reviewed By: kalman5
Differential Revision: D33386400
fbshipit-source-id: d45afa92448042ddcd1f68adc7a9ef4643276b31
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70133
we were creating `sstream` + string concats via `getNvtxStr` even when there were no inputs and wasting precious time. this diff avoids `stringstream` when there is no input to squeeze performance. 60% reduction in overhead
Test Plan:
Before
```
I1214 22:48:07.964118 2971180 bench.cpp:154] Mean 0.970494
I1214 22:48:07.964139 2971180 bench.cpp:155] Median 0.969054
I1214 22:48:07.964144 2971180 bench.cpp:156] Min 0.962247
I1214 22:48:07.964148 2971180 bench.cpp:157] stddev 0.00774841
I1214 22:48:07.964154 2971180 bench.cpp:158] stddev / mean 0.00798398
```
After
```
I1214 22:59:00.039872 3437853 bench.cpp:154] Mean 0.384333
I1214 22:59:00.039896 3437853 bench.cpp:155] Median 0.384886
I1214 22:59:00.039899 3437853 bench.cpp:156] Min 0.370235
I1214 22:59:00.039902 3437853 bench.cpp:157] stddev 0.00435907
I1214 22:59:00.039907 3437853 bench.cpp:158] stddev / mean 0.0113419
```
Reviewed By: aaronenyeshi, robieta
Differential Revision: D33137501
fbshipit-source-id: ce0e8cf9aef7ea22fd8aed927e76be4ca375efc3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70621
Pytorch doesn't have support for qint16 yet. Add an option to handle qint16 via int16 & qint32 data types.
* For qint16 tensors in NNAPI, the user sends a qint32 tensor. We convert the qint32 to int16 for the converter and set the zero point and scale for nnapi
* inputs to the model have to have fixed scale and zero point and are only supported for testing
* Added a flag use_int16_for_qint16 which will be used maintain backwards compatibility in the converter when true qint16 is supported in PyTorch
ghstack-source-id: 146507483
Test Plan: pytest test/test_nnapi.py
Reviewed By: dreiss
Differential Revision: D33285124
fbshipit-source-id: b6376fa1bb18a0b9f6a18c545f600222b650cb66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68122
See code comments for details; in brief, we repurpose support
for borrowing `Tensor`s in `MaybeOwned` to make the `select_tensor`
output a borrowed IValue that we have to clean up manually.
If we have any other ops that always create a new reference to an
existing Tensor, we can easily apply this same optimization.
ghstack-source-id: 146482212
Test Plan:
See perf measurements on ctr_mobile_feed local_ro net for this stack: P467203421
(local is neutral: P467267554)
--do_profile output for local_ro (updated Dec 10):
```
swolchok@devbig032 /d/u/s/f/fbcode> tail Stable.profile.txt
First iter time: 0.989023 ms
Number of operators: 2037
Total number of managed tensors: 1597
Total number of managed output tensors: 0
Total number of unmanaged values: 2568
Number of unmanaged values requiring cleanup: 2568
Number of unmanaged values not requiring cleanup: 0
Total memory managed: 50368 bytes
Total number of reused tensors: 1010
Total number of 'out' variant nodes/total number of nodes: 2001/2037 (98.2327%)
swolchok@devbig032 /d/u/s/f/fbcode> ttail TMCC^C
swolchok@devbig032 /d/u/s/f/fbcode> tail TMCOFastAliasing.profile.txt
First iter time: 0.994703 ms
Number of operators: 2551
Total number of managed tensors: 1146
Total number of managed output tensors: 0
Total number of unmanaged values: 4047
Number of unmanaged values requiring cleanup: 3533
Number of unmanaged values not requiring cleanup: 514
Total memory managed: 50048 bytes
Total number of reused tensors: 559
Total number of 'out' variant nodes/total number of nodes: 2001/2551 (78.4398%)
```
for local: (also Dec 10):
```
==> Stable.local.profile.txt <==
First iter time: 9.0909 ms
Number of operators: 1766
Total number of managed tensors: 1894
Total number of managed output tensors: 0
Total number of unmanaged values: 2014
Number of unmanaged values requiring cleanup: 2014
Number of unmanaged values not requiring cleanup: 0
Total memory managed: 4541440 bytes
Total number of reused tensors: 847
Total number of 'out' variant nodes/total number of nodes: 1744/1766 (98.7542%)
==> TMCOFastAliasing.local.profile.txt <==
First iter time: 7.5512 ms
Number of operators: 2378
Total number of managed tensors: 1629
Total number of managed output tensors: 0
Total number of unmanaged values: 3503
Number of unmanaged values requiring cleanup: 2891
Number of unmanaged values not requiring cleanup: 612
Total memory managed: 3949312 bytes
Total number of reused tensors: 586
Total number of 'out' variant nodes/total number of nodes: 1744/2378 (73.3389%)
```
Reviewed By: hlu1
Differential Revision: D32318674
fbshipit-source-id: a2d781105936fda2a3436d32ea22a196f82dc783
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67223
ghstack-source-id: 146482215
Test Plan:
See perf measurements on ctr_mobile_feed local_ro net for this stack: P467203421
(local is neutral: P467267554)
Reviewed By: hlu1
Differential Revision: D31776259
fbshipit-source-id: f84fcaa05029577213f3bf2ae9d4b987b68480b3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67221
Update memory leak checks to not require that output tensors are cleaned up.
ghstack-source-id: 146464297
Test Plan: Tests should still pass; reviewers to confirm that this is OK in principle
Reviewed By: d1jang
Differential Revision: D31847567
fbshipit-source-id: bb7ff2f2ed701e2d7de07d8032a1281fccabd6a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67394
ghstack-source-id: 146464294
Test Plan:
Added new test, which failed but now passes.
Checked perf on ctr_mobile_feed local net (still not on recordio inputs yet), looks neutral
```
Stable, local
========================================
I1027 13:40:23.411118 2156917 PyTorchPredictorBenchLib.cpp:131] PyTorch predictor: number of prediction threads 1
I1027 13:40:48.708222 2156917 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.16975. Iters per second: 162.081
I1027 13:41:13.915948 2156917 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.1487. Iters per second: 162.636
I1027 13:41:38.984462 2156917 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.11408. Iters per second: 163.557
I1027 13:42:04.138948 2156917 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.13566. Iters per second: 162.982
I1027 13:42:29.342630 2156917 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.14269. Iters per second: 162.795
I1027 13:42:29.342669 2156917 PyTorchPredictorBenchLib.cpp:264] Mean milliseconds per iter: 6.14218, standard deviation: 0.0202164
0
FixToDtypeChanges, local
========================================
I1027 13:44:59.632668 2176333 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.11023. Iters per second: 163.66
I1027 13:45:24.894635 2176333 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.16308. Iters per second: 162.257
I1027 13:45:50.275280 2176333 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.17868. Iters per second: 161.847
I1027 13:46:15.637431 2176333 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.18688. Iters per second: 161.632
I1027 13:46:40.670816 2176333 PyTorchPredictorBenchLib.cpp:249] PyTorch run finished. Milliseconds per iter: 6.10549. Iters per second: 163.787
I1027 13:46:40.670863 2176333 PyTorchPredictorBenchLib.cpp:264] Mean milliseconds per iter: 6.14887, standard deviation: 0.03843706
```
Reviewed By: hlu1
Differential Revision: D31972722
fbshipit-source-id: 7a445b325a29020b31dd2bd61e4171ecc2793b15
Summary:
This PR was not my worst debugging annoyance, nor my smallest in lines changed, but it has the highest `debugging annoyance/lines changed` ratio.
The current pattern
```
self.num_batches_tracked = self.num_batches_tracked + 1
```
, if captured, deletes an eagerly-allocated tensor and overwrites it with a captured tensor. Replays read from the (deallocated) original tensor's address.
This can cause
1. an IMA on graph replay
2. failure to actually increment `num_batches_tracked` during graph replay, because every replay reads from the old location without adding to it
3. numerical corruption if the allocator reassigns the original tensor's memory to some unrelated tensor
4. combinations of 1, 2, and 3, depending on global allocation patterns and if/when the BN module is called eagerly sometimes between replays
(ask me how I know).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70444
Reviewed By: albanD
Differential Revision: D33342203
Pulled By: ngimel
fbshipit-source-id: 5f201cc25030517e75af010bbaa88c452155df21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68949
This reuses the existing `neg_kernel` and `conj_kernel`
implementations for copy, saving some binary size and compile time.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D33064390
Pulled By: anjali411
fbshipit-source-id: eb0ee94ed3db44ae828ea078ba616365f97a7ff5
Summary:
According to dispatch table computation logic, if no kernel
register to a certain dispatch key, will use CompositeExplicitAutograd
backend kernel, so we need add sparseXPU key to the alias key pool.
Signed-off-by: Ma, Jing1 <jing1.ma@intel.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70443
Reviewed By: jbschlosser
Differential Revision: D33406004
Pulled By: bdhirsh
fbshipit-source-id: 009037739c818676901b10465632d3fef5ba14f2
Summary:
https://www.torch-ci.com/minihud shows 2 recent failures due to timing out. Increasing to 30m to see if it could be alleviated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70644
Reviewed By: suo, malfet, seemethere, atalman
Differential Revision: D33413604
Pulled By: janeyx99
fbshipit-source-id: 756a7ad94c589e39b8567acbfc3e769dc0b9113f
Summary:
I did not realize the WORKFLOW_ID variable in our GHA scripts concatenated RUN_ID and RUN_NUMBER.
For flaky tests collection, we should be only using RUN_ID, which makes it easier for us to write queries on the data
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70604
Reviewed By: suo
Differential Revision: D33409503
Pulled By: janeyx99
fbshipit-source-id: 932405989dc1a406dfe9da9a7f513ca127c8d436
Summary:
Currently when you register a kernel implementation to a dispatch stub,
it takes the function signature from the function pointer you pass in.
That means if you get the signature wrong, it fails at runtime with a
link error instead of failing during the compilation. This also means
that when registering nullptr you need to manually specify the type.
Instead, taking the type from `DispatchStub::FnPtr` means quicker time
to signal on failure and better error messages. The only downside is
you need to actually include the DispatchStub declaration which for
some CPU kernels was missing, so I've had to add them here.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67880
Reviewed By: mrshenli
Differential Revision: D33400922
Pulled By: ngimel
fbshipit-source-id: 2da22f053ef82da5db512986e5b968d97a681617
Summary:
https://github.com/pytorch/pytorch/issues/66406
implemented z arch 14/15 vector SIMD additions.
so far besides bfloat all other types have their SIMD implementation.
it has 99% coverage and currently passing the local test.
it is concise and the main SIMD file is only one header file
it's using template metaprogramming, mostly. but still, there are a few macrosses left with the intention not to modify PyTorch much
Sleef supports z15
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66407
Reviewed By: mrshenli
Differential Revision: D33370163
Pulled By: malfet
fbshipit-source-id: 0e5a57f31b22a718cd2a9ac59753fb468cdda140
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70367
This PR renames the `FileLoaderIterDataPipe` to `FileOpenerIterDataPipe`. For the sake of not breaking many CI tests immediately, it still preserves `FileLoader` as an alias. This will allow downstream libraries/users to migrate their use cases before we fully remove all references to `FileLoader` from PyTorch.
Fixes https://github.com/pytorch/data/issues/103. More detailed discussion about this decision is also in the linked issue.
cc VitalyFedyunin ejguan NivekT pmeier Nayef211
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D33301648
Pulled By: NivekT
fbshipit-source-id: 59278dcd44e372df0ba2001a4eecbf9792580d0b
Summary:
The windows 1st shard was silently failing to run (more details here https://github.com/pytorch/pytorch/issues/70010) because the code to run them was never reached. It was silently failing because our CI still returned green for those workflow jobs, because the exit code from the batch script DID NOT PROPAGATE to the calling bash script.
The key here is that even though we have
```
if ERRORLEVEL 1 exit \b 1
```
The exit code 1 was NOT propagating back to the bash script, as the `exit \b 1` was within an `if` statement and the batch script was actually run in a cmd shell, so the bash script win-test.sh continued without erroring. Moving the `exit \b 1` to be standalone fixes it.
More details for this can be found in this stack overflow https://stackoverflow.com/a/55290133
Evidence that now a failure in the .bat would fail the whole job:
https://github.com/pytorch/pytorch/runs/4621483334?check_suite_focus=true
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70011
Reviewed By: seemethere, samdow
Differential Revision: D33303020
Pulled By: janeyx99
fbshipit-source-id: 8920a43fc6c4b67fecf90f3fca3908c314522cd6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70579
Fixes
```
36 stderr: caffe2/caffe2/operators/batch_permutation_op.cc:25:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
3 caffe2/caffe2/operators/batch_permutation_op.cc:25:1: error: loop not vectorized: the optimizer was unable to perform the requested transformation; the transformation might be disabled or specified as part of an unsupported transformation ordering [-Werror,-Wpass-failed=transform-warning]
```
Test Plan: Sandcastle
Reviewed By: meyering
Differential Revision: D33378925
fbshipit-source-id: 5ae3bfb8fadfa91a13ff0dcf5fae2ce7864ea90e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68691
TraceType is a sharded file, so by only including specific operator
headers, we ensure that changing one (non-method) operator only needs
one shard to be re-compiled.
This also changes all the included autograd and jit headers from
including `ATen/ATen.h` to just including `ATen/core/Tensor.h`.
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D33336948
Pulled By: albanD
fbshipit-source-id: 4e40371592b9a5a7e7fcd1d8cecae11ffb873113
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70152
This is to demonstrate our backend_config_dict works for one of
our internal use cases
Test Plan:
python test/fx2trt/test_quant_trt.py
Imported from OSS
Reviewed By: vkuzo, raghuramank100
Differential Revision: D33205161
fbshipit-source-id: dca8570816baaf85a79f2be75378d46c3af0e454
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70287
This PR adds the support to configuring qat modules for fused/non-fused modules
TODO: there are some redundant configs, especially for fused op patterns, we can clean them up later
Test Plan:
python test/fx2trt/test_quant_trt.py TestQuantizeFxTRTOps
Imported from OSS
Reviewed By: vkuzo
Differential Revision: D33274057
fbshipit-source-id: b2e6a078211320d97c41ffadd3ecedfab57e3b77
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70151
this supports converting an observed standalone module to quantized standalone module
in the new convert flow (convert observers to quant-dequant operators)
Test Plan:
```
python test/test_quant_trt.py TestConvertFxDoNotUse
```
Imported from OSS
Reviewed By: supriyar
Differential Revision: D33205163
fbshipit-source-id: 01ea44fb2a8ffe30bec1dd5678e7a72797bafafc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69312
Enable packing weights to be compatible with depthwise specific conv3d kernels
ghstack-source-id: 146346778
Test Plan:
- Existing 2d weight packing uses do not break (phabricator tests)
- Test 3d weight packing when used in depthwise conv3d later in this diff stack (D31966574)
Reviewed By: kimishpatel
Differential Revision: D32045036
fbshipit-source-id: a2323f74f7d30d92d4ed91315f59539ecad729ec
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69311
Enable setting up indirection buffer to be compatible with depthwise specific conv3d kernels
ghstack-source-id: 146346788
Test Plan:
- Existing 2d indirection buffer uses do not break (phabricator tests)
- Test 3d indirection buffer when used in depthwise conv3d later in this diff stack (D31966574)
Reviewed By: kimishpatel
Differential Revision: D31999533
fbshipit-source-id: a403d8dcad6e50641b9235e0b574129b2dfb5412
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69310
Extract computing step height and step width into helper function and store them in operator struct since the same calculation is used in many places before this diff.
ghstack-source-id: 146346783
Test Plan: Phabricator tests
Reviewed By: kimishpatel
Differential Revision: D32553327
fbshipit-source-id: e5bf07416f4c1ccde9975f835767392ad7a851c1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69309
Test correctness of QNNPack Conv3d
- Add Depth dimension to ConvolutionOperatorTester
- Add tests which use it
Includes John's changes in D32388572
ghstack-source-id: 146346786
Test Plan:
Build the Test
- ```cd caffe2/aten/src/ATen/native/quantized/cpu/qnnpack```
- ```./scripts/build-android-arm64.sh```
- Test binary is outputted to ```build/android/arm64-v8a```
Run the Test
- ```test_name=convolution-test```
- ```chmod +x build/android/arm64-v8a/$test_name```
- Send the binary to android device and execute it, ex. connect to one world and ```adb push build/android/arm64-v8a/$test_name /data/local/tmp/$test_name``` then ```adb shell /data/local/tmp/$test_name```
Reviewed By: kimishpatel
Differential Revision: D32217846
fbshipit-source-id: eba200c136894461bf76b2a5416540fe8781d588
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70263
Leverage the hypothesis library as it's more systematic way for testing. To write a test, it needs two parts:
1. A function that looks like a normal test in your test framework of choice but with some additional arguments
2. A given decorator that specifies how to provide those arguments.
ghstack-source-id: 146344955
Test Plan:
```
buck test mode/opt //caffe2/test:jit
python test/test_jit.py TestSaveLoadForOpVersion
```
Reviewed By: iseeyuan
Differential Revision: D33244389
fbshipit-source-id: c93d23f3d9575ebcb4e927a8caee42f4c3a6939d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69959
GraphModule is an implementation detail, We don't want to expose it in quantization apis
Test Plan:
python test/test_quantization.py TestQuantizeFx.test_quantized_model_type
Imported from OSS
Reviewed By: supriyar
Differential Revision: D33119103
fbshipit-source-id: d8736ff08b42ee009d6cfd74dcb3f6150f71f3d2
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
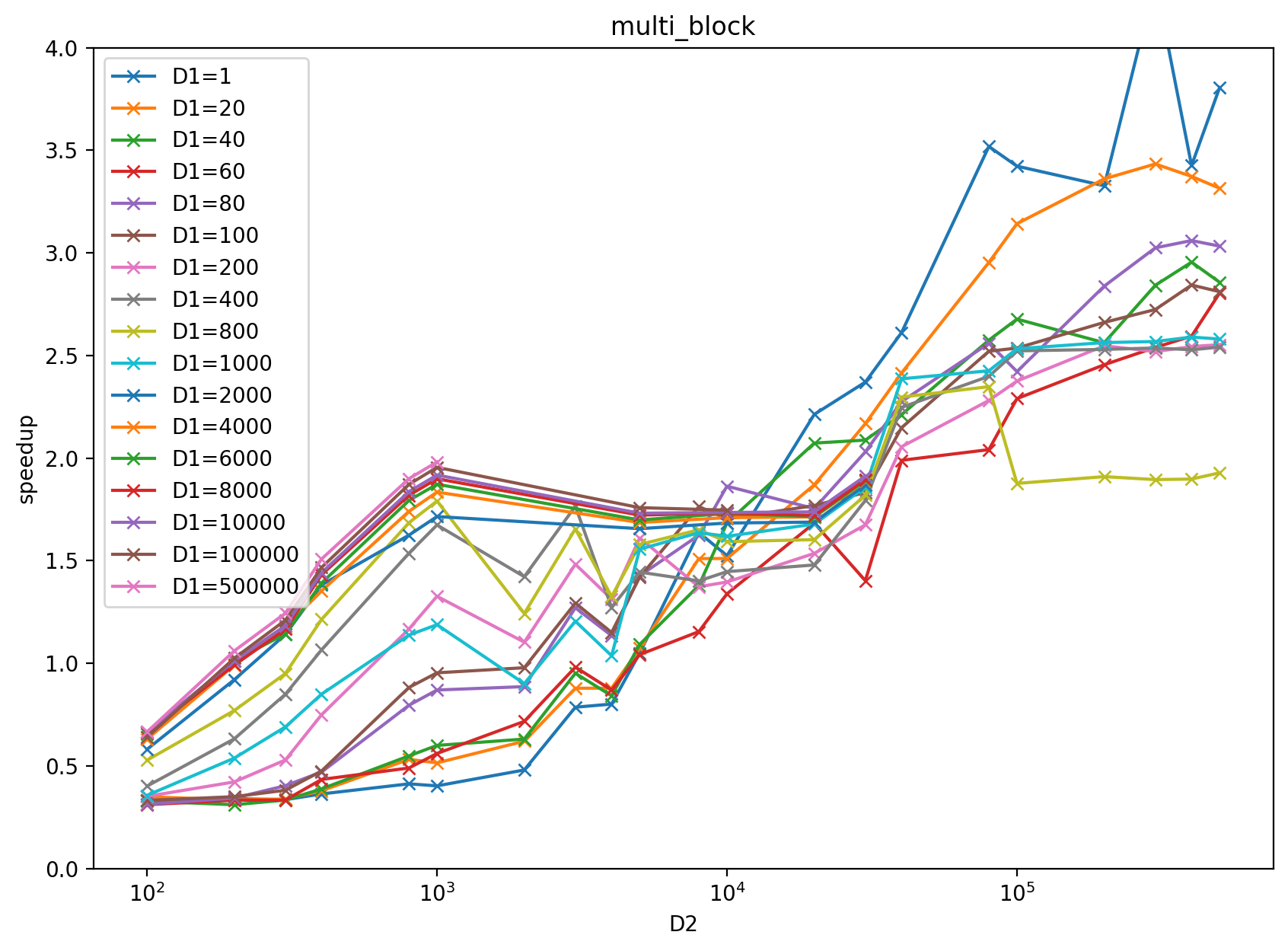{kind=link}
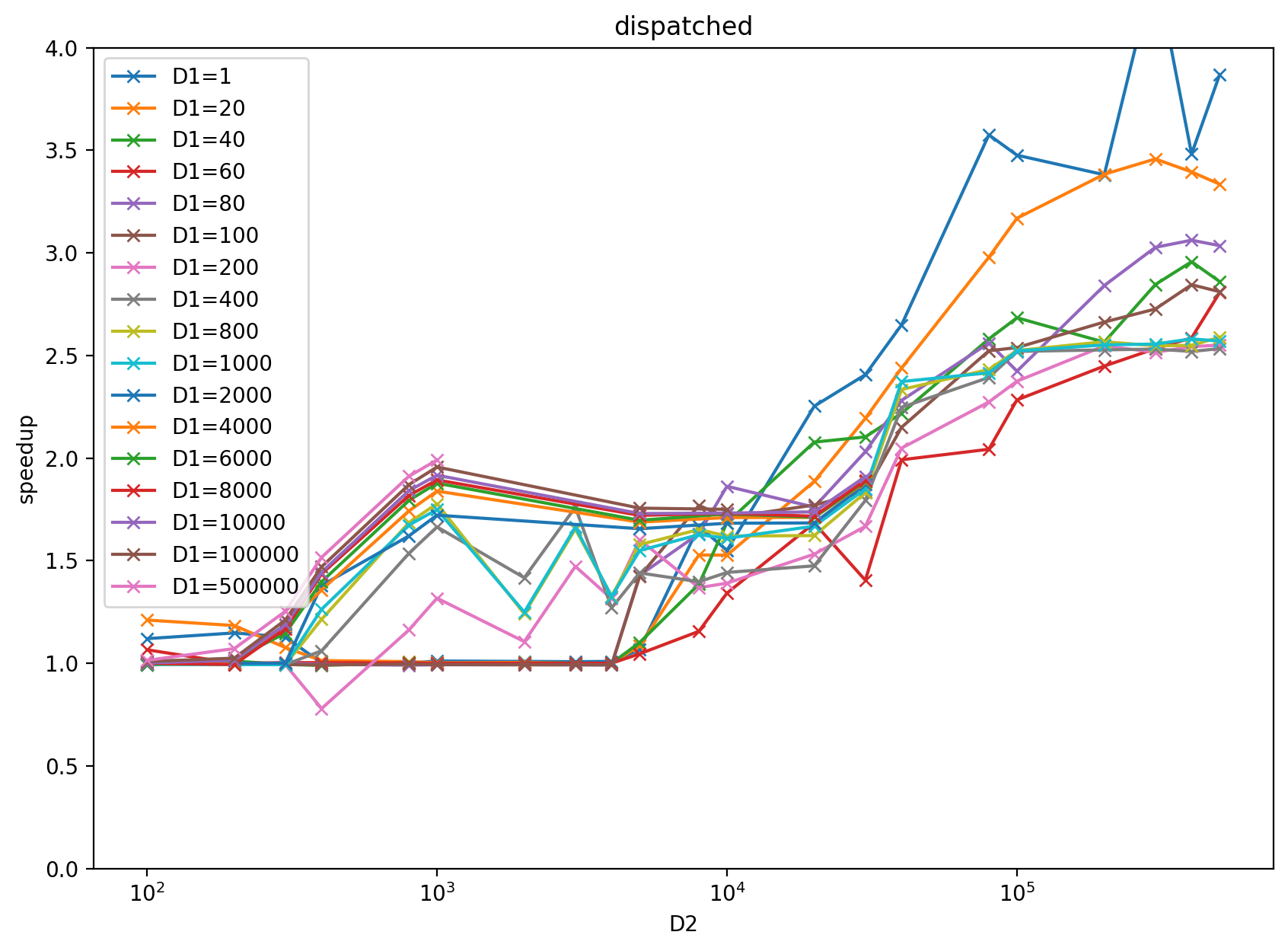{kind=link}
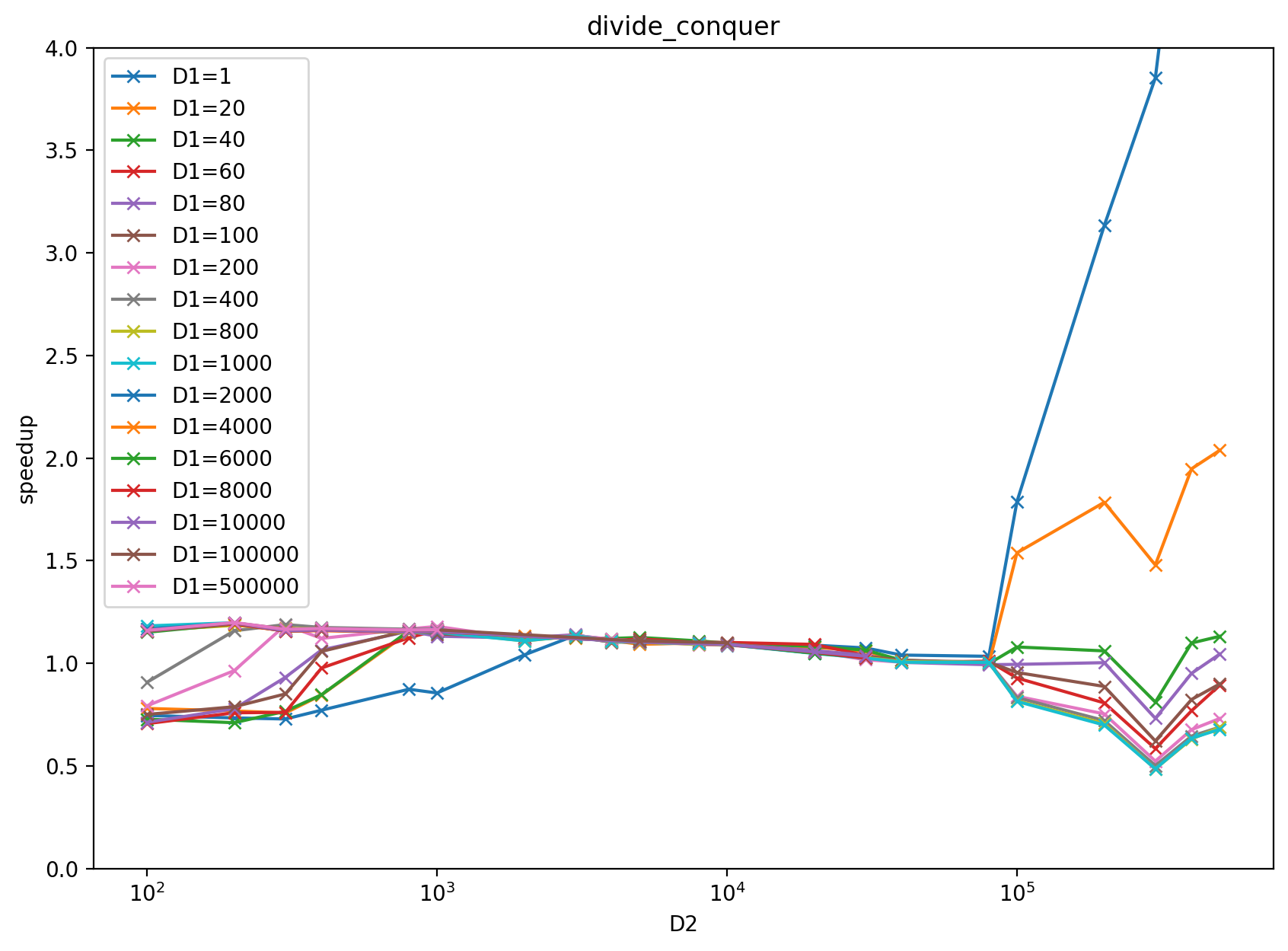{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}