Fixes https://github.com/pytorch/pytorch/issues/117361
The implementation here slightly diverges from what was proposed in the issue, so I will recap what this PR is doing here. Today, when doing computations involving size-like unbacked SymInts, we assume for all operations that the compile time range of the integer is `[2, inf]`, even though at runtime we also accept zero and one.
This PR removes the carte blanche assumption, and instead does the analysis in a much more limited and controlled fashion: only for guards which we have designated as "size oblivious" are we willing to do the analysis under the assumption that the range of all size-like unbacked SymInts is `[2, inf]`; otherwise, we will faithfully only do analysis with `[0, inf]` (or whatever the user provided) bounds.
The infra pieces of this PR are:
* Remove runtime_var_to_range from torch/fx/experimental/symbolic_shapes.py; modify `_constrain_range_for_size` to refine the range without clamping min to 2, and instead add the symbol to a `size_like` set in the ShapeEnv
* When evaluating an expression, if the expression is requested to be evaluated in a `size_oblivious` way, we attempt to statically compute the value of the expression with the assumption that all symbols in `size_like` are updated to assume that they are `>= 2`.
* Add Python and C++ APIs for guarding on a SymBool in a size-oblivious way. In C++, I also need to add some helpers for performing symbolic comparisons, since the stock comparisons immediately specialize in the "normal" way.
The rest of the changes of the PR are marking various spots in PyTorch framework code as size oblivious, based on what our current test suite exercises.
As you review the places where we have marked things as size oblivious, it may become clear why I ended up not opting for the "designate a branch as the default branch when it's not statically obvious which way to go": for some of the conditions, this answer is rather non-obvious. I think potentially there is another refinement on top of this PR, which is something like "I don't care if you can't figure it out with ValueRange analysis, go down this path anyway if there are unbacked sizes involved." But even if we add this API, I think we are obligated to attempt the ValueRange analysis first, since it can lead to better outcomes sometimes (e.g., we are able to figure out that something is contiguous no matter what the unbacked size is.)
When is it permissible to mark something as size oblivious? Heuristically, it is OK anywhere in framework code if it gets you past a guard on unbacked SymInt problem. It is somewhat difficult to provide a true semantic answer, however. In particular, these annotations don't have any observational equivalence guarantee; for example, if I have `torch.empty(u0, 1).squeeze()`, we will always produce a `[u0]` size tensor, even though if `u0 == 1` PyTorch will actually produce a `[]` size tensor. The argument that I gave to Lezcano is that we are in fact defining an alternate semantics for a "special" size = 0, 1, for which we have these alternate eager mode semantics. In particular, suppose that we have a constant `special1` which semantically denotes 1, but triggers alternate handling rules. We would define `torch.empty(special1, 1).squeeze()` to always produce a `[special1]` size tensor, making its semantics coincide with unbacked SymInt semantics. In this model, the decision to designate guards as size oblivious is simply a user API question: you put them where ever you need some handling for special1! As we conservatively error out whenever it is not obvious what `special1` semantics should be, it is always valid to expand these semantics to cover more cases (although you can always choose the wrong semantics!)
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118579
Approved by: https://github.com/eellison, https://github.com/lezcano
All single element list types are `Tensor[]` so they will always be Tuple.
I don't know of any way to easily access the pyi type and compare that to a real run so no testing here :(
Pull Request resolved: https://github.com/pytorch/pytorch/pull/118238
Approved by: https://github.com/ezyang
This PR also contains a basket of fixes that were turned up by now testing more arguments with SymInt. I fixed as many of the easy ones as I could easily get earlier in this stack and a bunch here, but there are some more annoying ones I xfailed.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/113452
Approved by: https://github.com/Chillee
ghstack dependencies: #113877, #113911
Fixes#88919
@mruberry @peterbell10
This PR adds a warning to the .cpp STFT and ISTFT functions if a window is not provided.
It also describes the warning in the documentation on `functional.py`.
Finally, it adds unit tests to check if the warning is being produced.
I have audited for internal calls of `stft` and `istft` on Pytorch and haven't found any.
Thank you for the opportunity to contribute!
Eric
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110695
Approved by: https://github.com/ezyang
It's not mentioned in `__all__`, so moving `import torch.backends.opt_einsum
as opt_einsum` into `einsum` function to delay `torch.backends` import and hide it completely from the module scope.
level module.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102004
Approved by: https://github.com/janeyx99
@ezyang This is a minor change.
I was using the doctests to check that my install wasn't broken via:
```bash
xdoctest -m torch --style=google --global-exec "from torch import nn\nimport torch.nn.functional as F\nimport torch" --options="+IGNORE_WHITESPACE"
```
And noticed that it stops in the middle to show this matplotlib figure. I added a condition so it only does the pyplot show if a DOCTEST_SHOW environment variable exists. With this fix the above command runs to completion and is an easy way for users to put torch through its paces given just a fresh install.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96522
Approved by: https://github.com/ezyang
Real dtype input to `torch.istft` has been deprecated since PyTorch
1.8, so it is more than passed its due date to be removed.
BC-breaking message:
`torch.istft` no longer supports input in the form of real tensors
with shape `(..., 2)` to mimic complex tensors. Instead, convert
inputs to a complex tensor first before calling `torch.istft`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86628
Approved by: https://github.com/mruberry
This behavior has been deprecated since PyTorch 1.8 but this step of
the deprecation cycle was put on hold in #50102 waiting for JIT
upgraders functionality which doesn't seem to have panned out. I'd say
there has been more than enough of a deprecation period, so we should
just continue.
BC-breaking message:
`torch.stft` takes an optional `return_complex` parameter that
indicates whether the output should be a floating point tensor or a
complex tensor. `return_complex` previously defaulted to `False` for
real input tensors. This PR removes the default and makes
`return_complex` a required argument for real inputs. However, complex
inputs will continue to default to `return_complex=True`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86724
Approved by: https://github.com/mruberry, https://github.com/albanD
This achieves the same things as https://github.com/pytorch/pytorch/pull/85908 but using backends instead of kwargs (which breaks torchscript unfortunately). This also does mean we let go of numpy compatibility BUT the wins here are that users can control what opt einsum they wanna do!
The backend allows for..well you should just read the docs:
```
.. attribute:: torch.backends.opteinsum.enabled
A :class:`bool` that controls whether opt_einsum is enabled (on by default). If so,
torch.einsum will use opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/path_finding.html)
to calculate an optimal path of contraction for faster performance.
.. attribute:: torch.backends.opteinsum.strategy
A :class:`str` that specifies which strategies to try when `torch.backends.opteinsum.enabled` is True.
By default, torch.einsum will try the "auto" strategy, but the "greedy" and "optimal" strategies are
also supported. Note that the "optimal" strategy is factorial on the number of inputs as it tries all
possible paths. See more details in opt_einsum's docs
(https://optimized-einsum.readthedocs.io/en/stable/path_finding.html).
```
In trying (and failing) to land 85908, I discovered that jit script does NOT actually pull from python's version of einsum (because it cannot support variadic args nor kwargs). Thus I learned that jitted einsum does not subscribe to the new opt_einsum path calculation. Overall, this is fine since jit script is getting deprecated, but where is the best place to document this?
## Test plan:
- added tests to CI
- locally tested that trying to set the strategy to something invalid will error properly
- locally tested that tests will pass even if you don't have opt-einsum
- locally tested that setting the strategy when opt-einsum is not there will also error properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86219
Approved by: https://github.com/soulitzer, https://github.com/malfet
Depends on https://github.com/pytorch/pytorch/pull/84890.
This PR adds opt_einsum to CI, enabling path optimization for the multi-input case. It also updates the installation sites to install torch with einsum, but those are mostly to make sure it would work on the user's end (as opt-einsum would have already been installed in the docker or in prior set up steps).
This PR also updates the windows build_pytorch.bat script to use the same bdist_wheel and install commands as on Linux, replacing the `setup.py install` that'll become deprecated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85574
Approved by: https://github.com/huydhn, https://github.com/soulitzer
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
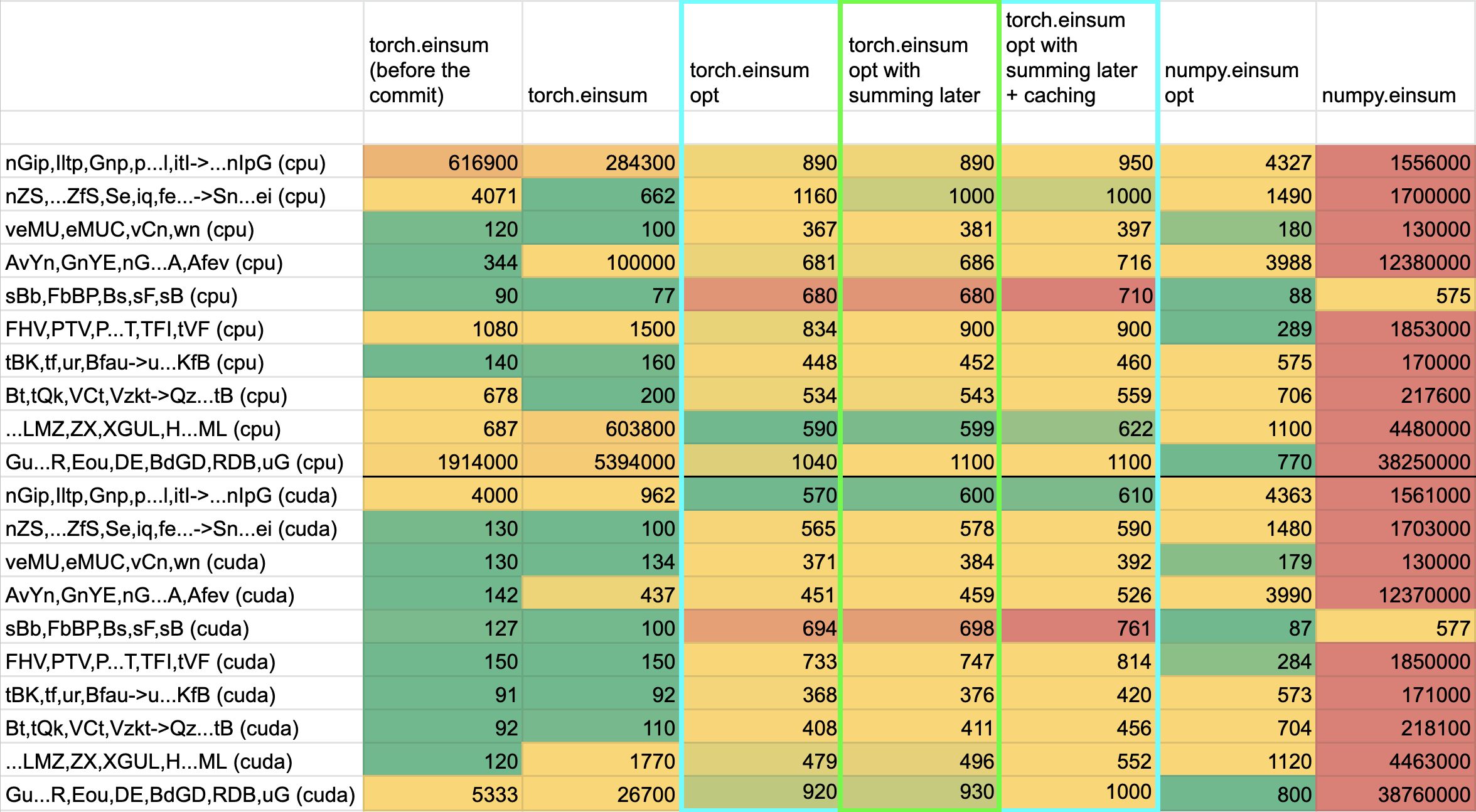
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
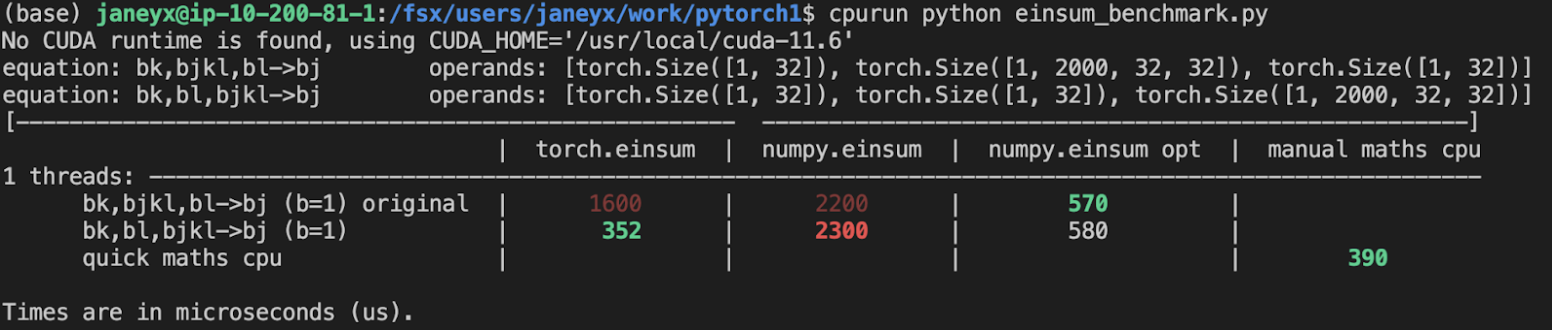
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
`torch.norm` is very odd. Some notable issues are:
- The default value of `"fro"` in `torch.norm` has an odd behaviour when `dim=None`. This is handled in the new dispatch
- The treatment of the `dtype` argument in `torch.norm` was completely wrong. This should fix it
- Some `out=` variants in the previous implementation were also wrong. This should fix those.
- This new dispatch should make some paths much faster. For example, `torch.norm(x)` where `x` is complex.
I'll try to make the changes in these PRs as incremental as possible as this is a tricky one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81761
Approved by: https://github.com/ngimel
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
This reverts commit a58876ace78df1cfeb136cad592487f34d7e02f1.
Reverted https://github.com/pytorch/pytorch/pull/74727 on behalf of https://github.com/seemethere due to Fails internal use cases, might extend out to external use cases as well. Need to assess overall impact of this change more widely
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}