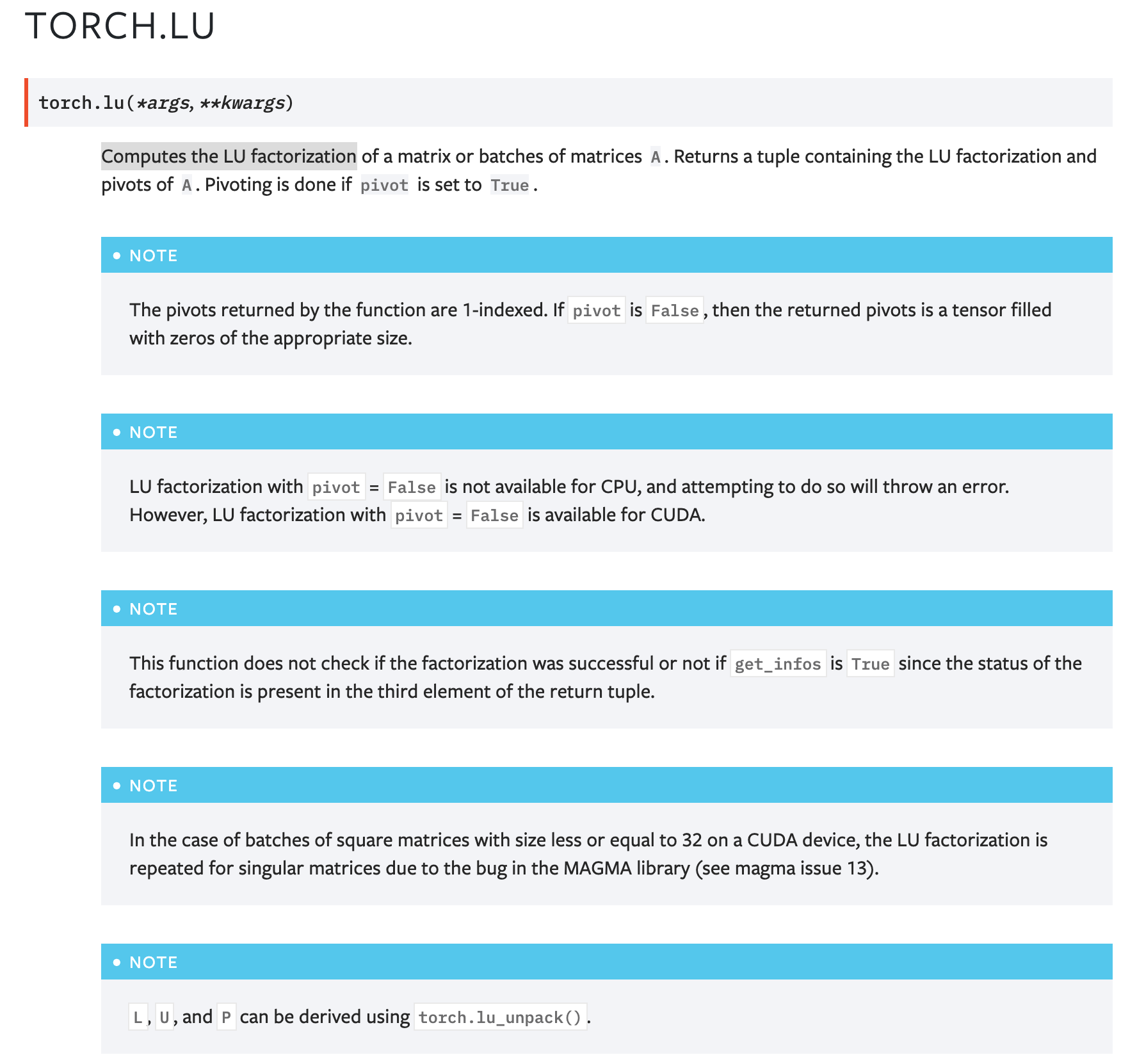
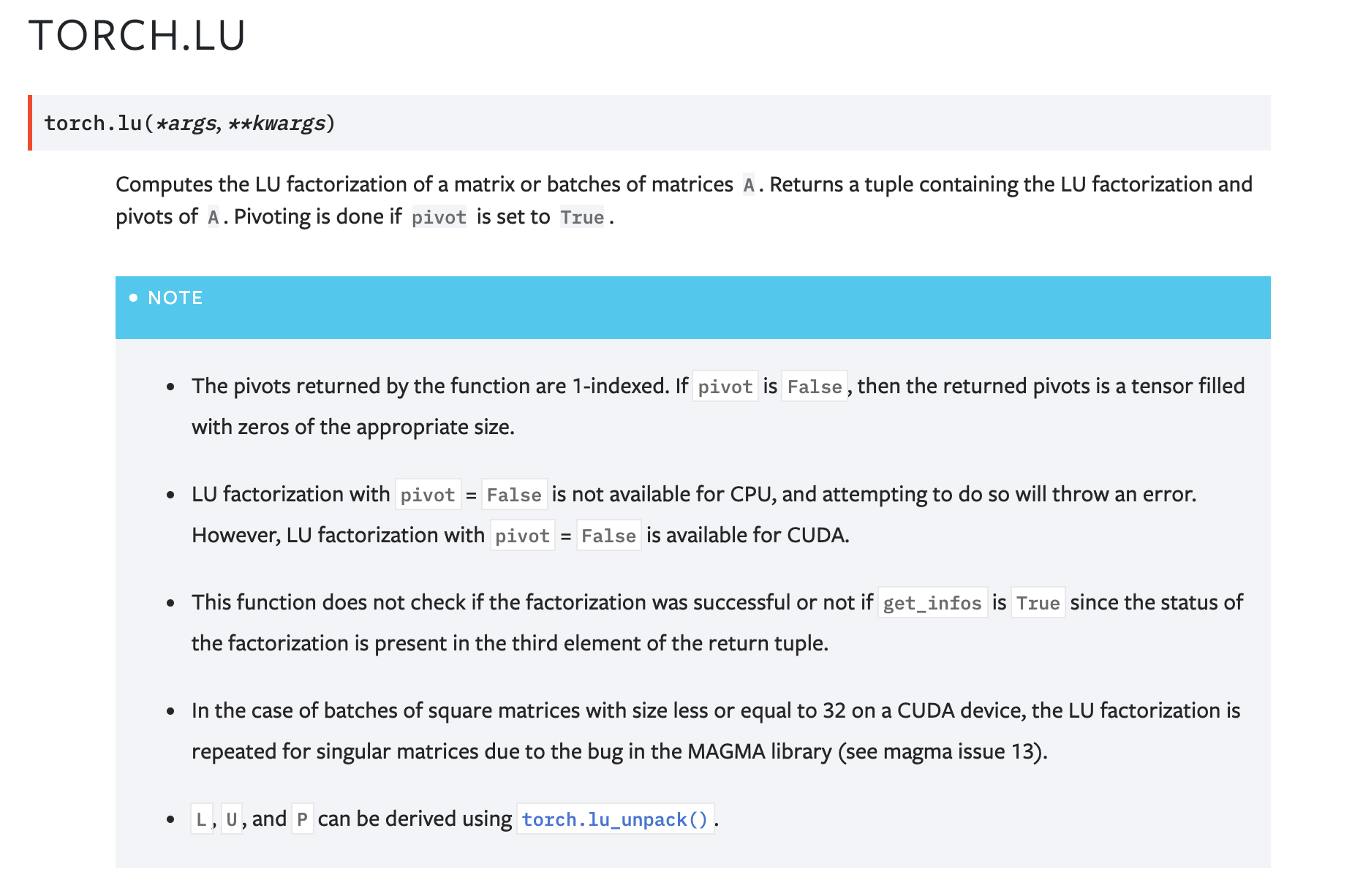
**BC-breaking note**:
This PR deprecates `torch.lu` in favor of `torch.linalg.lu_factor`.
A upgrade guide is added to the documentation for `torch.lu`.
Note this PR DOES NOT remove `torch.lu`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77636
Approved by: https://github.com/malfet
I figured these out by unconditionally turning on a no-op torch function
mode on the test suite and then fixing errors as they showed up. Here's
what I found:
- _parse_to failed internal assert when __torch_function__'ed because it
claims its name is "to" to the argument parser; added a name override
so we know how to find the correct name
- Infix operator magic methods on Tensor did not uniformly handle
__torch_function__ and TypeError to NotImplemented. Now, we always
do the __torch_function__ handling in
_wrap_type_error_to_not_implemented and your implementation of
__torch_function__ gets its TypeErrors converted to NotImplemented
(for better or for worse; see
https://github.com/pytorch/pytorch/issues/75462 )
- A few cases where code was incorrectly testing if a Tensor was
Tensor-like in the wrong way, now use is_tensor_like (in grad
and in distributions). Also update docs for has_torch_function to
push people to use is_tensor_like.
- is_grads_batched was dropped from grad in handle_torch_function, now
fixed
- Report that you have a torch function even if torch function is
disabled if a mode is enabled. This makes it possible for a mode
to return NotImplemented, pass to a subclass which does some
processing and then pass back to the mode even after the subclass
disables __torch_function__ (so the tensors are treated "as if"
they are regular Tensors). This brings the C++ handling behavior
in line with the Python behavior.
- Make the Python implementation of overloaded types computation match
the C++ version: when torch function is disabled, there are no
overloaded types (because they all report they are not overloaded).
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75484
Approved by: https://github.com/zou3519
This creates a `histogramdd` operator with overloads matching the `Union`
behaviour used in the functional variant. Moving into C++ is preferred because
it can handle torch function automatically instead of needing to differentiate
between the overloads manually.
This also adds a new return type: `std::tuple<Tensor, std::vector<Tensor>>`. For
which I've updated `wrap` to be completely generic for tuples and removed the
old manual definitions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74200
Approved by: https://github.com/ezyang
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71993
I've kept the symbol `torch.functional.istft` because it looks like public API,
but it could just as easily be moved to `_torch_docs.py`.
Moving this into its own PR until TorchScript starts recognizing `input`
as a keyword argument.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D34461399
Pulled By: anjali411
fbshipit-source-id: 3275fb74bef2fa0e030e61f7ee188daf8b5b2acf
(cherry picked from commit 5b4b083de894eba9ab16cea53b77746bcfd0fe32)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72833Closes#72550
The latest version of librosa breaks backward compatibility in two
ways:
- Everything except the input tensor is now keyword-only
- `pad_mode` now defaults to `'constant'` for zero-padding
https://librosa.org/doc/latest/generated/librosa.stft.html
This changes the test to match the old behaior even when using the new
library and updates the documentation to explicitly say that
`torch.stft` doesn't exactly follow the librosa API. This was always
true (`torch.stft` it has new arguments, a different default window
and supports complex input), but it can't hurt to be explicit.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D34386897
Pulled By: mruberry
fbshipit-source-id: 6adc23f48fcb368dacf70602e9197726d6b7e0c1
(cherry picked from commit b5c5ed41963022c9f26467279ed098fb905fa00a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68367
- bmm_test.py was using syntax not allowed in 3.6
- Some suppressions were not placed on the correct line.
With this file,
```
lintrunner --paths-cmd='git grep -Il .'
```
passes successfully.
Test Plan: Imported from OSS
Reviewed By: janeyx99, mrshenli
Differential Revision: D32436644
Pulled By: suo
fbshipit-source-id: ae9300c6593d8564fb326822de157d00f4aaa3c2
Summary:
This is step 3/7 of https://github.com/pytorch/pytorch/issues/50276. It only adds support for the argument but doesn't implement new indexing modes yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62722
Test Plan:
Verified this is not FC breaking by adding logging to both meshgrid
overloads and then called meshgrid twice:
`meshgrid(*tensors)`
and
`meshgrid(*tensors, indexing='ij')`
This confirmed that the former signature triggered the original native
function and the latter signature triggered the new native function.
Reviewed By: H-Huang
Differential Revision: D30394313
Pulled By: dagitses
fbshipit-source-id: e265cb114d8caae414ee2305dc463b34fdb57fa6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62793
This is mostly a quick fix. I think the more correct fix could be updating `unique_dim` to `_unique_dim` which could be BC-breaking for C++ users (� maybe). Maybe something else I am missing.
~~Not sure how to add a test for it.~~ Have tested it locally.
We can add a test like following. Tested this locally, it fails currently but passes with the fix.
```python
def test_wildcard_import(self):
exec('from torch import *')
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63080
Reviewed By: gchanan
Differential Revision: D30738711
Pulled By: zou3519
fbshipit-source-id: b86d0190e45ba0b49fd2cffdcfd2e3a75cc2a35e
Summary:
The PR fixes two issues:
- See https://github.com/pytorch/pytorch/issues/62747 and https://github.com/pytorch/audio/issues/1409. The length mismatch when the given ``length`` parameter is longer than expected. Add padding logic in consistent with librosa.
- See https://github.com/pytorch/pytorch/issues/62323. The current implementations checks if the min value of window_envelop.abs() is greater than zero. In librosa they normalize the signal on non-zero values by indexing. Like
```
approx_nonzero_indices = ifft_window_sum > util.tiny(ifft_window_sum)
y[approx_nonzero_indices] /= ifft_window_sum[approx_nonzero_indices]
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63469
Reviewed By: fmassa
Differential Revision: D30695827
Pulled By: nateanl
fbshipit-source-id: d034e53f0d65b3fd1dbd150c9c5acf3faf25a164
Summary:
torch.norm has a couple documentation issues, like https://github.com/pytorch/pytorch/issues/44552 and https://github.com/pytorch/pytorch/issues/38595, but since it's deprecated this PR simply clarifies that the documentation (and implementation) of torch.norm maybe be incorrect. This should be additional encouragement for users to migrate to torch.linalg.vector_norm and torch.linalg.matrix_norm.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63310
Reviewed By: ngimel
Differential Revision: D30337997
Pulled By: mruberry
fbshipit-source-id: 0fdcc438f36e4ab29e21e0a64709e4f35a2467ba
Summary:
In one of my previous PRs that rewrite `tensordot` implementation, I mistakenly take empty value of `dims_a` and `dims_b` as illegal values. This turns out to be not true. Empty `dims_a` and `dims_b` are supported, in fact common when `dims` is passed as an integer. This PR removes the unnecessary check.
Fixes https://github.com/pytorch/pytorch/issues/61096
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61331
Reviewed By: eellison
Differential Revision: D29578910
Pulled By: gmagogsfm
fbshipit-source-id: 96e58164491a077ddc7a1d6aa6ccef8c0c9efda2
Summary:
There is a very common error when writing docs: One forgets to write a matching `` ` ``, and something like ``:attr:`x`` is rendered in the docs. This PR fixes most (all?) of these errors (and a few others).
I found these running ``grep -r ">[^#<][^<]*\`"`` on the `docs/build/html/generated` folder. The regex finds an HTML tag that does not start with `#` (as python comments in example code may contain backticks) and that contains a backtick in the rendered HTML.
This regex has not given any false positive in the current codebase, so I am inclined to suggest that we should add this check to the CI. Would this be possible / reasonable / easy to do malfet ?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60474
Reviewed By: mrshenli
Differential Revision: D29309633
Pulled By: albanD
fbshipit-source-id: 9621e0e9f87590cea060dd084fa367442b6bd046
Summary:
Improved torch.einsum testing and fixed a bug where lower case letters appeared before upper case letters in the sorted order which is inconsistent with NumPy.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59731
Reviewed By: SplitInfinity, ansley
Differential Revision: D29183078
Pulled By: heitorschueroff
fbshipit-source-id: a33980d273707da2d60a387a2af2fa41527ddb68
Summary:
This PR adds an alternative way of calling `torch.einsum`. Instead of specifying the subscripts as letters in the `equation` parameter, one can now specify the subscripts as a list of integers as in `torch.einsum(operand1, subscripts1, operand2, subscripts2, ..., [subscripts_out])`. This would be equivalent to `torch.einsum('<subscripts1>,<subscripts2>,...,->[<subscript_out>]', operand1, operand2, ...)`
TODO
- [x] Update documentation
- [x] Add more error checking
- [x] Update tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56625
Reviewed By: zou3519
Differential Revision: D28062616
Pulled By: heitorschueroff
fbshipit-source-id: ec50ad34f127210696e7c545e4c0675166f127dc
Summary:
Backward methods for `torch.lu` and `torch.lu_solve` require the `torch.lu_unpack` method.
However, while `torch.lu` is a Python wrapper over a native function, so its gradient is implemented via `autograd.Function`,
`torch.lu_solve` is a native function, so it cannot access `torch.lu_unpack` as it is implemented in Python.
Hence this PR presents a native (ATen) `lu_unpack` version. It is also possible to update the gradients for `torch.lu` so that backward+JIT is supported (no JIT for `autograd.Function`) with this function.
~~The interface for this method is different from the original `torch.lu_unpack`, so it is decided to keep it hidden.~~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46913
Reviewed By: albanD
Differential Revision: D28355725
Pulled By: mruberry
fbshipit-source-id: 281260f3b6e93c15b08b2ba66d5a221314b00e78
Summary:
**BC-breaking note**
This PR updates the deprecation notice for torch.norm to point users to the new torch.linalg.vector_norm and torch.linalg.matrix_norm functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57986
Reviewed By: nikithamalgifb
Differential Revision: D28353625
Pulled By: heitorschueroff
fbshipit-source-id: 5de77d89f0e84945baa5fea91f73918dc7eeafd4
Summary:
This one's easy. I also included a bugfix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57735
Reviewed By: bdhirsh
Differential Revision: D28318277
Pulled By: mruberry
fbshipit-source-id: c3c4546a11ba5b555b99ee79b1ce6c0649fa7323
{kind=link}
{kind=link}
{kind=link}