@ezyang This is a minor change.
I was using the doctests to check that my install wasn't broken via:
```bash
xdoctest -m torch --style=google --global-exec "from torch import nn\nimport torch.nn.functional as F\nimport torch" --options="+IGNORE_WHITESPACE"
```
And noticed that it stops in the middle to show this matplotlib figure. I added a condition so it only does the pyplot show if a DOCTEST_SHOW environment variable exists. With this fix the above command runs to completion and is an easy way for users to put torch through its paces given just a fresh install.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96522
Approved by: https://github.com/ezyang
Real dtype input to `torch.istft` has been deprecated since PyTorch
1.8, so it is more than passed its due date to be removed.
BC-breaking message:
`torch.istft` no longer supports input in the form of real tensors
with shape `(..., 2)` to mimic complex tensors. Instead, convert
inputs to a complex tensor first before calling `torch.istft`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86628
Approved by: https://github.com/mruberry
This behavior has been deprecated since PyTorch 1.8 but this step of
the deprecation cycle was put on hold in #50102 waiting for JIT
upgraders functionality which doesn't seem to have panned out. I'd say
there has been more than enough of a deprecation period, so we should
just continue.
BC-breaking message:
`torch.stft` takes an optional `return_complex` parameter that
indicates whether the output should be a floating point tensor or a
complex tensor. `return_complex` previously defaulted to `False` for
real input tensors. This PR removes the default and makes
`return_complex` a required argument for real inputs. However, complex
inputs will continue to default to `return_complex=True`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86724
Approved by: https://github.com/mruberry, https://github.com/albanD
This achieves the same things as https://github.com/pytorch/pytorch/pull/85908 but using backends instead of kwargs (which breaks torchscript unfortunately). This also does mean we let go of numpy compatibility BUT the wins here are that users can control what opt einsum they wanna do!
The backend allows for..well you should just read the docs:
```
.. attribute:: torch.backends.opteinsum.enabled
A :class:`bool` that controls whether opt_einsum is enabled (on by default). If so,
torch.einsum will use opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/path_finding.html)
to calculate an optimal path of contraction for faster performance.
.. attribute:: torch.backends.opteinsum.strategy
A :class:`str` that specifies which strategies to try when `torch.backends.opteinsum.enabled` is True.
By default, torch.einsum will try the "auto" strategy, but the "greedy" and "optimal" strategies are
also supported. Note that the "optimal" strategy is factorial on the number of inputs as it tries all
possible paths. See more details in opt_einsum's docs
(https://optimized-einsum.readthedocs.io/en/stable/path_finding.html).
```
In trying (and failing) to land 85908, I discovered that jit script does NOT actually pull from python's version of einsum (because it cannot support variadic args nor kwargs). Thus I learned that jitted einsum does not subscribe to the new opt_einsum path calculation. Overall, this is fine since jit script is getting deprecated, but where is the best place to document this?
## Test plan:
- added tests to CI
- locally tested that trying to set the strategy to something invalid will error properly
- locally tested that tests will pass even if you don't have opt-einsum
- locally tested that setting the strategy when opt-einsum is not there will also error properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86219
Approved by: https://github.com/soulitzer, https://github.com/malfet
Depends on https://github.com/pytorch/pytorch/pull/84890.
This PR adds opt_einsum to CI, enabling path optimization for the multi-input case. It also updates the installation sites to install torch with einsum, but those are mostly to make sure it would work on the user's end (as opt-einsum would have already been installed in the docker or in prior set up steps).
This PR also updates the windows build_pytorch.bat script to use the same bdist_wheel and install commands as on Linux, replacing the `setup.py install` that'll become deprecated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85574
Approved by: https://github.com/huydhn, https://github.com/soulitzer
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
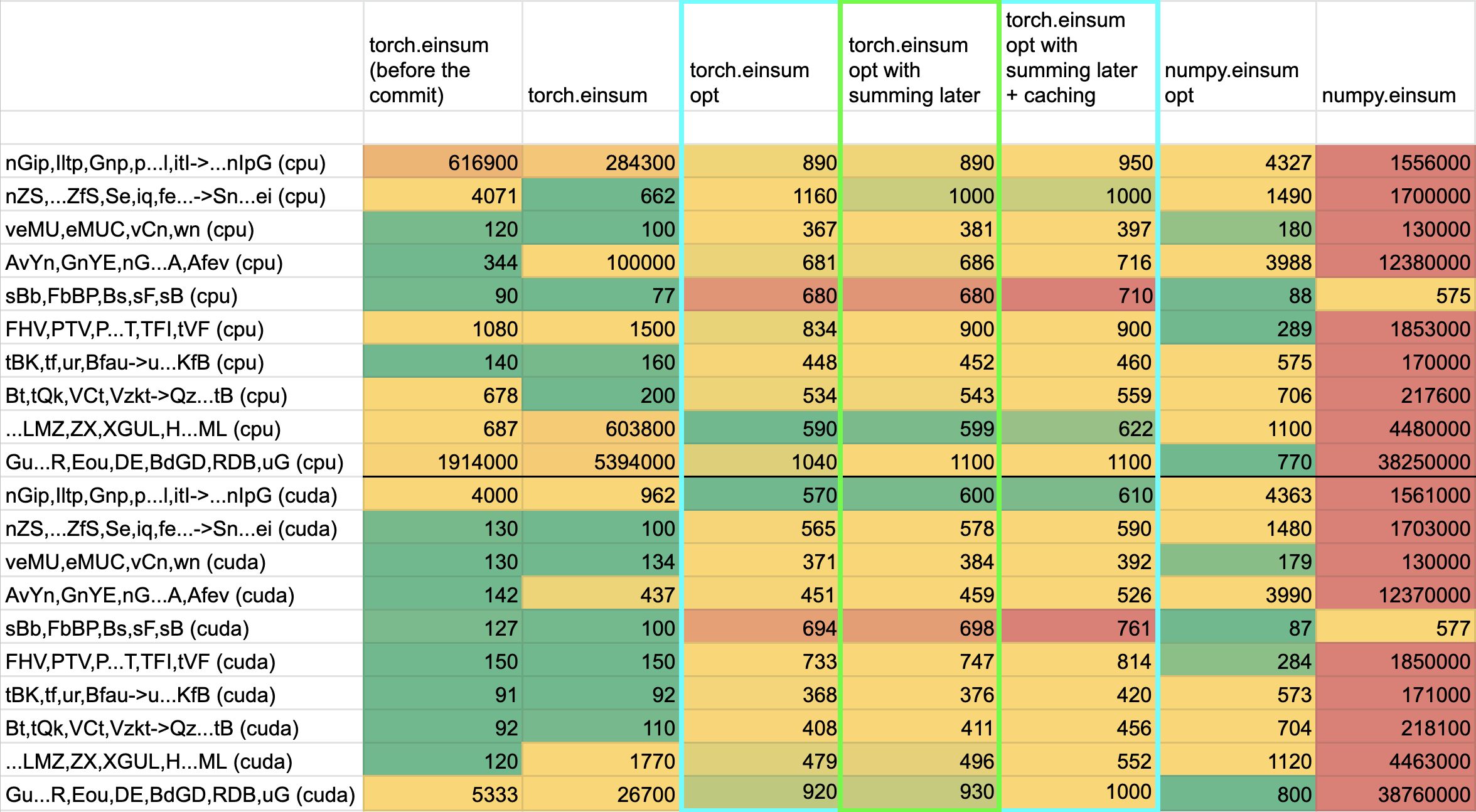
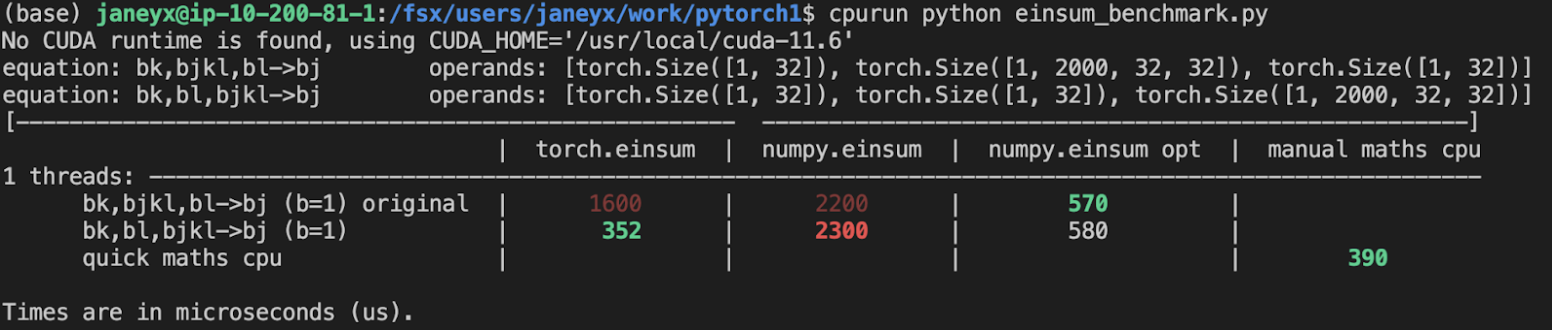
## Benchmarking:
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
`torch.norm` is very odd. Some notable issues are:
- The default value of `"fro"` in `torch.norm` has an odd behaviour when `dim=None`. This is handled in the new dispatch
- The treatment of the `dtype` argument in `torch.norm` was completely wrong. This should fix it
- Some `out=` variants in the previous implementation were also wrong. This should fix those.
- This new dispatch should make some paths much faster. For example, `torch.norm(x)` where `x` is complex.
I'll try to make the changes in these PRs as incremental as possible as this is a tricky one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81761
Approved by: https://github.com/ngimel
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
This reverts commit a58876ace78df1cfeb136cad592487f34d7e02f1.
Reverted https://github.com/pytorch/pytorch/pull/74727 on behalf of https://github.com/seemethere due to Fails internal use cases, might extend out to external use cases as well. Need to assess overall impact of this change more widely
**BC-breaking note**:
This PR deprecates `torch.lu` in favor of `torch.linalg.lu_factor`.
A upgrade guide is added to the documentation for `torch.lu`.
Note this PR DOES NOT remove `torch.lu`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77636
Approved by: https://github.com/malfet
I figured these out by unconditionally turning on a no-op torch function
mode on the test suite and then fixing errors as they showed up. Here's
what I found:
- _parse_to failed internal assert when __torch_function__'ed because it
claims its name is "to" to the argument parser; added a name override
so we know how to find the correct name
- Infix operator magic methods on Tensor did not uniformly handle
__torch_function__ and TypeError to NotImplemented. Now, we always
do the __torch_function__ handling in
_wrap_type_error_to_not_implemented and your implementation of
__torch_function__ gets its TypeErrors converted to NotImplemented
(for better or for worse; see
https://github.com/pytorch/pytorch/issues/75462 )
- A few cases where code was incorrectly testing if a Tensor was
Tensor-like in the wrong way, now use is_tensor_like (in grad
and in distributions). Also update docs for has_torch_function to
push people to use is_tensor_like.
- is_grads_batched was dropped from grad in handle_torch_function, now
fixed
- Report that you have a torch function even if torch function is
disabled if a mode is enabled. This makes it possible for a mode
to return NotImplemented, pass to a subclass which does some
processing and then pass back to the mode even after the subclass
disables __torch_function__ (so the tensors are treated "as if"
they are regular Tensors). This brings the C++ handling behavior
in line with the Python behavior.
- Make the Python implementation of overloaded types computation match
the C++ version: when torch function is disabled, there are no
overloaded types (because they all report they are not overloaded).
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75484
Approved by: https://github.com/zou3519
This creates a `histogramdd` operator with overloads matching the `Union`
behaviour used in the functional variant. Moving into C++ is preferred because
it can handle torch function automatically instead of needing to differentiate
between the overloads manually.
This also adds a new return type: `std::tuple<Tensor, std::vector<Tensor>>`. For
which I've updated `wrap` to be completely generic for tuples and removed the
old manual definitions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74200
Approved by: https://github.com/ezyang
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71993
I've kept the symbol `torch.functional.istft` because it looks like public API,
but it could just as easily be moved to `_torch_docs.py`.
Moving this into its own PR until TorchScript starts recognizing `input`
as a keyword argument.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D34461399
Pulled By: anjali411
fbshipit-source-id: 3275fb74bef2fa0e030e61f7ee188daf8b5b2acf
(cherry picked from commit 5b4b083de894eba9ab16cea53b77746bcfd0fe32)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72833Closes#72550
The latest version of librosa breaks backward compatibility in two
ways:
- Everything except the input tensor is now keyword-only
- `pad_mode` now defaults to `'constant'` for zero-padding
https://librosa.org/doc/latest/generated/librosa.stft.html
This changes the test to match the old behaior even when using the new
library and updates the documentation to explicitly say that
`torch.stft` doesn't exactly follow the librosa API. This was always
true (`torch.stft` it has new arguments, a different default window
and supports complex input), but it can't hurt to be explicit.
Test Plan: Imported from OSS
Reviewed By: ngimel
Differential Revision: D34386897
Pulled By: mruberry
fbshipit-source-id: 6adc23f48fcb368dacf70602e9197726d6b7e0c1
(cherry picked from commit b5c5ed41963022c9f26467279ed098fb905fa00a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68367
- bmm_test.py was using syntax not allowed in 3.6
- Some suppressions were not placed on the correct line.
With this file,
```
lintrunner --paths-cmd='git grep -Il .'
```
passes successfully.
Test Plan: Imported from OSS
Reviewed By: janeyx99, mrshenli
Differential Revision: D32436644
Pulled By: suo
fbshipit-source-id: ae9300c6593d8564fb326822de157d00f4aaa3c2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}