Summary:
During development it is common practice to put `type: ignore` comments on lines that are correct, but `mypy` doesn't recognize this. This often stems from the fact, that the used `mypy` version wasn't able to handle the used pattern.
With every new release `mypy` gets better at handling complex code. In addition to fix all the previously accepted but now failing patterns, we should also revisit all `type: ignore` comments to see if they are still needed or not. Fortunately, we don't need to do it manually: by adding `warn_unused_ignores = True` to the configuration, `mypy` will error out in case it encounters an `type: ignore` that is no longer needed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60006
Reviewed By: jbschlosser, malfet
Differential Revision: D29133237
Pulled By: albanD
fbshipit-source-id: 41e82edc5cd5affa7ccedad044b59b94dad4425a
Summary:
Do not reorder tests unless they are in IN_CI, this causes local development test ordering indeterministic. most of use branch out from viable strict not head of master.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59565
Reviewed By: ejguan
Differential Revision: D28943906
Pulled By: walterddr
fbshipit-source-id: e742e7ce4b3fc017d7563b01e93c4cd774d0a537
Summary:
The run-specified-test-cases option would allow us to specify a list of test cases to run by having a CSV with minimally two columns: test_filename and test_case_name.
This PR also adds .json to some files we use for better clarity.
Usage:
`python test/run_test.py --run-specified-test-cases <csv_file>` where the csv file can look like:
```
test_filename,test_case_name,test_total_time,windows_only_failure_sha_count,total_sha_count,windows_failure_count,linux_failure_count,windows_total_count,linux_total_count
test_cuda,test_cudnn_multiple_threads_same_device,8068.8409659525,46,3768,53,0,2181,6750
test_utils,test_load_standalone,8308.8062920459,14,4630,65,0,2718,8729
test_ops,test_forward_mode_AD_acosh_cuda_complex128,91.652619369806,11,1971,26,1,1197,3825
test_ops,test_forward_mode_AD_acos_cuda_complex128,91.825633094915,11,1971,26,1,1197,3825
test_profiler,test_source,60.93786725749,9,4656,21,3,2742,8805
test_profiler,test_profiler_tracing,203.09352795241,9,4662,21,3,2737,8807
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59487
Test Plan:
Without specifying the option, everything should be as they were before.
Running `python test/run_test.py --run-specified-test-cases windows_smoke_tests.csv` resulted in this paste P420276949 (you can see internally). A snippet looks like:
```
(pytorch) janeyx@janeyx-mbp pytorch % python test/run_test.py --run-specified-test-cases windows_smoke_tests.csv
Loading specified test cases to run from windows_smoke_tests.csv.
Processed 28 test cases.
Running test_cpp_extensions_jit ... [2021-06-04 17:24:41.213644]
Executing ['/Users/janeyx/miniconda3/envs/pytorch/bin/python', 'test_cpp_extensions_jit.py', '-k', 'test_jit_cuda_archflags'] ... [2021-06-04 17:24:41.213781]
s
----------------------------------------------------------------------
Ran 1 test in 0.000s
OK (skipped=1)
...
```
With pytest, an example executable would be:
`Running test_dataloader ... [2021-06-04 17:37:57.643039]
Executing ['/Users/janeyx/miniconda3/envs/pytorch/bin/python', '-m', 'pytest', 'test_dataloader.py', '-v', '-k', 'test_segfault or test_timeout'] ... [2021-06-04 17:37:57.643327]`
Reviewed By: samestep
Differential Revision: D28913223
Pulled By: janeyx99
fbshipit-source-id: 0d1f9910973426b8756815c697b483160517b127
Summary:
Implements an idea by ngimel to improve the performance of `torch.flip` via a clever hack into TI to bypass the fact that TI is not designed to work with negative indices.
Something that might be added is vectorisation support on CPU, given how simple the implementation is now.
Some low-hanging fruits that I did not implement:
- Write it as a structured kernel
- Migrate the tests to opinfos
- Have a look at `cumsum_backward` and `cumprod_backward`, as I think that they could be implemented faster with `flip`, now that `flip` is fast.
**Edit**
This operation already has OpInfos and it cannot be migrated to a structured kernel because it implements quantisation
Summary of the PR:
- x1.5-3 performance boost on CPU
- x1.5-2 performance boost on CUDA
- Comparable performance across dimensions, regardless of the strides (thanks TI)
- Simpler code
<details>
<summary>
Test Script
</summary>
```python
from itertools import product
import torch
from torch.utils.benchmark import Compare, Timer
def get_timer(size, dims, num_threads, device):
x = torch.rand(*size, device=device)
timer = Timer(
"torch.flip(x, dims=dims)",
globals={"x": x, "dims": dims},
label=f"Flip {device}",
description=f"dims: {dims}",
sub_label=f"size: {size}",
num_threads=num_threads,
)
return timer.blocked_autorange(min_run_time=5)
def get_params():
sizes = ((1000,)*2, (1000,)*3, (10000,)*2)
for size, device in product(sizes, ("cpu", "cuda")):
threads = (1, 2, 4) if device == "cpu" else (1,)
list_dims = [(0,), (1,), (0, 1)]
if len(size) == 3:
list_dims.append((0, 2))
for num_threads, dims in product(threads, list_dims):
yield size, dims, num_threads, device
def compare():
compare = Compare([get_timer(*params) for params in get_params()])
compare.trim_significant_figures()
compare.colorize()
compare.print()
compare()
```
</details>
<details>
<summary>
Benchmark PR
</summary>
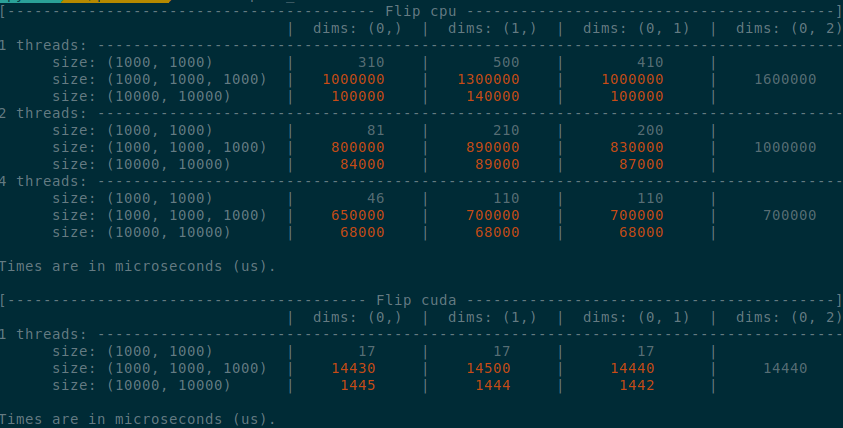
</details>
<details>
<summary>
Benchmark master
</summary>
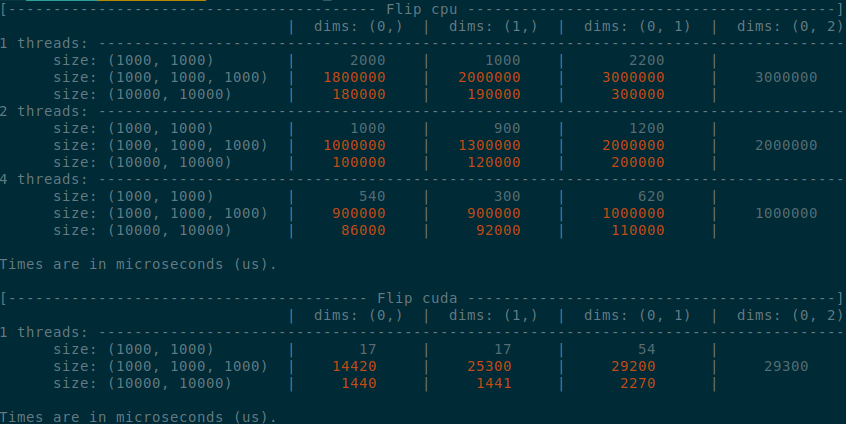
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58747
Reviewed By: agolynski
Differential Revision: D28877076
Pulled By: ngimel
fbshipit-source-id: 4fa6eb519085950176cb3a9161eeb3b6289ec575
Summary:
There are two main changes here:
- THPVariable will actually visit their grad_fn if there are no other reference to the c++ Tensor and no other reference to the grad_fn. The critical observation compared to the existing comment (thanks Ed!) is that if we also check that the c++ Tensor object is not referenced somewhere else, we're sure that no one can change the grad_fn refcount between the traverse and the clear.
- THPVariable don't need a special clear for this new cases as we're the only owner of the c++ Tensor and so the cdata.reset() will necessarily free the Tensor and all its resources.
The two tests are to ensure:
- That the cycles are indeed collectible by the gc
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58271
Reviewed By: ngimel
Differential Revision: D28796461
Pulled By: albanD
fbshipit-source-id: 62c05930ddd0c48422c79b03118db41a73c1355d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52659
**Summary**
This commit adds `torch._C.ScriptDict`, a dictionary type that has reference
semantics across the Python/TorchScript boundary. That is, modifications
made to instances of `torch._C.ScriptDict` in TorchScript are visible in
Python even when it is not returned from the function. Instances can be
constructed by passing an instance of a Python dictionary to
`torch.jit.script`. In the case of an empty dictionary, its type is
assumed to be `Dict[str, Tensor]` to be consistent with the handling of
empty dictionaries in TorchScript source code.
`torch._C.ScriptDict` is implemented using a modified version of pybind's `stl_bind.h`-style bindings attached to `ScriptDict`, `ScriptDictIterator` and `ScriptDictKeyIterator`, wrapper classes around `c10::impl::GenericDict` and `c10::impl::GenericDict::iterator`. These bindings allow instances of `torch._C.ScriptDict` to be used as if it were a regular `dict` Python. Reference semantics are achieved by simply retrieving the `IValue` contained in `ScriptDict` in `toIValue` (invoked when converting Python arguments to `IValues` before calling TorchScript code).
**Test Plan**
This commit adds `TestScriptDict` to `test_list_dict.py`, a set of tests
that check that all of the common dictionary operations are supported
and that instances have reference semantics across the
Python/TorchScript boundary.
Differential Revision:
D27211605
D27211605
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Pulled By: SplitInfinity
fbshipit-source-id: 446d4e5328375791aa73eb9e8b04dfe3465af960
Summary:
This PR adds a note to the documentation that torch.svd is deprecated together with an upgrade guide on how to use `torch.linalg.svd` and `torch.linalg.svdvals` (Lezcano's instructions from https://github.com/pytorch/pytorch/issues/57549).
In addition, all usage of the old svd function is replaced with a new one from torch.linalg module, except for the `at::linalg_pinv` function, that fails the XLA CI build (https://github.com/pytorch/xla/issues/2755, see failure in draft PR https://github.com/pytorch/pytorch/pull/57772).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57981
Reviewed By: ngimel
Differential Revision: D28345558
Pulled By: mruberry
fbshipit-source-id: 02dd9ae6efe975026e80ca128e9b91dfc65d7213
Summary:
Downloading slow_test list on SC causes timeout, this is even a bigger issue since `common_utils.py` is reused in many internal projects/modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57953
Test Plan: CI
Reviewed By: janeyx99
Differential Revision: D28325527
fbshipit-source-id: ae47c9e43ad6f416008005bb26ceb2f3d6966f2e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55237
In this PR, we reenable fast-gradcheck and resolve misc issues that arise:
Before landing this PR, land #55182 so that slow tests are still being run periodically.
Bolded indicates the issue is handled in this PR, otherwise it is handled in a previous PR.
**Non-determinism issues**:
- ops that do not have deterministic implementation (as documented https://pytorch.org/docs/stable/generated/torch.use_deterministic_algorithms.html#torch.use_deterministic_algorithms)
- test_pad_cuda (replication_pad2d) (test_nn)
- interpolate (test_nn)
- cummin, cummax (scatter_add_cuda_kernel) (test_ops)
- test_fn_gradgrad_prod_cpu_float64 (test_ops)
Randomness:
- RRelu (new module tests) - we fix by using our own generator as to avoid messing with user RNG state (handled in #54480)
Numerical precision issues:
- jacobian mismatch: test_gelu (test_nn, float32, not able to replicate locally) - we fixed this by disabling for float32 (handled in previous PR)
- cholesky_solve (test_linalg): #56235 handled in previous PR
- **cumprod** (test_ops) - #56275 disabled fast gradcheck
Not yet replicated:
- test_relaxed_one_hot_categorical_2d (test_distributions)
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27920906
fbshipit-source-id: 894dd7bf20b74f1a91a5bc24fe56794b4ee24656
Summary:
Under this setting the job should run 3 times a day.
When the environment variable, `PYTORCH_TEST_WITH_SLOW_GRADCHECK` is set to `ON`, set the default value for `fast_mode` in gradchack wrapper as False. This would be overriden by whatever value the user explicitly passes in.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55182
Reviewed By: albanD
Differential Revision: D27919236
Pulled By: soulitzer
fbshipit-source-id: 3a55ec6edcfc6e65fbc3a8a09c63aaea1bd1c5bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56434
If we hit multiple TORCH_WARN from different sources when running the
statement, it makes more sense to me that we want to check the regex is
met in any one of the warning messages instead of all messages.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D27871946
Pulled By: ailzhang
fbshipit-source-id: 5940a8e43e4cc91aef213ef01e48d506fd9a1132
Summary:
As this diff shows, currently there are a couple hundred instances of raw `noqa` in the codebase, which just ignore all errors on a given line. That isn't great, so this PR changes all existing instances of that antipattern to qualify the `noqa` with respect to a specific error code, and adds a lint to prevent more of this from happening in the future.
Interestingly, some of the examples the `noqa` lint catches are genuine attempts to qualify the `noqa` with a specific error code, such as these two:
```
test/jit/test_misc.py:27: print(f"{hello + ' ' + test}, I'm a {test}") # noqa E999
test/jit/test_misc.py:28: print(f"format blank") # noqa F541
```
However, those are still wrong because they are [missing a colon](https://flake8.pycqa.org/en/3.9.1/user/violations.html#in-line-ignoring-errors), which actually causes the error code to be completely ignored:
- If you change them to anything else, the warnings will still be suppressed.
- If you add the necessary colons then it is revealed that `E261` was also being suppressed, unintentionally:
```
test/jit/test_misc.py:27:57: E261 at least two spaces before inline comment
test/jit/test_misc.py:28:35: E261 at least two spaces before inline comment
```
I did try using [flake8-noqa](https://pypi.org/project/flake8-noqa/) instead of a custom `git grep` lint, but it didn't seem to work. This PR is definitely missing some of the functionality that flake8-noqa is supposed to provide, though, so if someone can figure out how to use it, we should do that instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56272
Test Plan:
CI should pass on the tip of this PR, and we know that the lint works because the following CI run (before this PR was finished) failed:
- https://github.com/pytorch/pytorch/runs/2365189927
Reviewed By: janeyx99
Differential Revision: D27830127
Pulled By: samestep
fbshipit-source-id: d6dcf4f945ebd18cd76c46a07f3b408296864fcb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/50699.
The root cause was that some floating-point assertions had a "greater than or **equal to**" condition. The "equal to" part was causing flakiness due to strict equality check (`==`) in `TestCase.assertGreaterEqual()`. This PR introduces a new assertion method called `assertGreaterAlmostEqual()` in `common_utils.py` that mitigates the problem by behaving similar to `TestCase.assertAlmostEqual()`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56192
Reviewed By: zhaojuanmao
Differential Revision: D27804724
Pulled By: cbalioglu
fbshipit-source-id: bc44a41ca4ce45dfee62fb3769fb47bfd9028831
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55682Fixes#55648
For now it downloads and writes the relevant files to the system's temp dir and marks it as valid for 3 hours.
Test Plan: Imported from OSS
Reviewed By: malfet, nikithamalgifb
Differential Revision: D27685616
Pulled By: driazati
fbshipit-source-id: 27469b85fe4b6b4addde6b22bf795bca3d4990ef
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54769
Follow-up to #53820. This
- makes the `asserts.py` module private as per suggestion from rgommers in https://github.com/pytorch/pytorch/pull/53820#issuecomment-802661387. With this the functions should only be accessible through `torch.testing`, giving us the option the change the underlying structure later.
- moves the code from `torch/testing/__init__.py` to `torch/testing/_core.py` (happy to accept other name suggestions). Otherwise we can't import the new `_asserts.py` in `torch/testing/__init__.py` due to circular imports.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D27438451
Pulled By: mruberry
fbshipit-source-id: c7292b4d5709185b42b4aac8016648562688040e
Summary:
Stack:
* https://github.com/pytorch/pytorch/issues/54954 Fixed OpInfo jit tests failing for TensorList inputs
* __#54922 Added support for TensorList inputs in OpInfo__
Updated OpInfo to accept either a `Tensor` or `TensorList` as `sample.input` and added workarounds to make this work with gradcheck.
Note: JIT testing support for TensorList inputs will be added in a follow up PR.
Fixes https://github.com/pytorch/pytorch/issues/51996
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54922
Reviewed By: H-Huang
Differential Revision: D27448952
Pulled By: heitorschueroff
fbshipit-source-id: 3f24a56f6180eb2d044dcfc89ba59fce8acfe278
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53511
torch.det does depend on torch.prod, which in turn depends on several other functions, and they also depend on torch.prod, so there is a circular relationship, hence this PR will enable complex backward support for several functions at once.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48125
Reviewed By: pbelevich
Differential Revision: D27188589
Pulled By: anjali411
fbshipit-source-id: bbb80f8ecb83a0c3bea2b917627d3cd3b84eb09a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53682
With this, under the meta device, 101 tests passed and 16953 skipped.
It ain't much, but it's a start.
Some various bits and bobs:
- NotImplementedError suppression at test level is implemented
in the same way as CUDA memory leak check, i.e., by wrapping
test methods and monkeypatching them back in.
- I had to reimplement assertRaises/assertRaisesRegex from scratch to
ignore NotImplementedError when _ignore_not_implemented_error is True.
The implementation relies on a small amount of private API that hasn't
changed since 2010
- expectedAlertNondeterministic doesn't really work so I skipped them
all; there's probably a way to do it better
I tested this using `pytest --disable-warnings --tb=native -k meta --sw
test/*.py` and a pile of extra patches to make collection actually work
(lol).
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D26955539
Pulled By: ezyang
fbshipit-source-id: ac21c8734562497fdcca3b614a28010bc4c03d74
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44378 by providing a wider range of drivers similar to what SciPy is doing.
The supported CPU drivers are `gels, gelsy, gelsd, gelss`.
The CUDA interface has only `gels` implemented but only for overdetermined systems.
The current state of this PR:
- [x] CPU interface
- [x] CUDA interface
- [x] CPU tests
- [x] CUDA tests
- [x] Memory-efficient batch-wise iteration with broadcasting which fixes https://github.com/pytorch/pytorch/issues/49252
- [x] docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49093
Reviewed By: albanD
Differential Revision: D26991788
Pulled By: mruberry
fbshipit-source-id: 8af9ada979240b255402f55210c0af1cba6a0a3c
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
Fixes https://github.com/pytorch/pytorch/issues/44378 by providing a wider range of drivers similar to what SciPy is doing.
The supported CPU drivers are `gels, gelsy, gelsd, gelss`.
The CUDA interface has only `gels` implemented but only for overdetermined systems.
The current state of this PR:
- [x] CPU interface
- [x] CUDA interface
- [x] CPU tests
- [x] CUDA tests
- [x] Memory-efficient batch-wise iteration with broadcasting which fixes https://github.com/pytorch/pytorch/issues/49252
- [x] docs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49093
Reviewed By: H-Huang
Differential Revision: D26723384
Pulled By: mruberry
fbshipit-source-id: c9866a95f14091955cf42de22f4ac9e2da009713
Summary:
This way, we can have a mapping from the test files we directly execute (the tests [here](https://github.com/pytorch/pytorch/blob/master/test/run_test.py#L20)) to the test suites that we store data for in XML reports.
This will come in use later for categorizing the tests we run in CI.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52791
Reviewed By: samestep
Differential Revision: D26655086
Pulled By: janeyx99
fbshipit-source-id: 94be32f80d7bc0ea1a7a11d4c4b1d3d8e774c5ea
Summary:
Take 2 of https://github.com/pytorch/pytorch/issues/50914
This change moves the early termination logic into common_utils.TestCase class.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52126
Test Plan: CI with ci-all tag
Reviewed By: malfet
Differential Revision: D26391762
Pulled By: walterddr
fbshipit-source-id: a149ecc47ccda7f2795e107fb95915506ae060b4
Summary:
This is a follow up on https://github.com/pytorch/pytorch/issues/49869.
Previously CUDA early termination only happens for generic test classes that extends from `DeviceTypeTestBase`. However, JIT test cases which extends from common_utils.TestCase cannot benefit from the early termination.
This change moves the early termination logic into common_utils.TestCase class.
- all tests extended from common_utils.TestCase now should early terminate if CUDA assert occurs.
- For TestCases that extends from common_device_type.DeviceTypeTestBase, still only do torch.cuda.synchronize() when RTE is thrown.
- For TestCases extends common_utils.TestCase, regardless of whether a test case uses GPU or not, it will always synchronize CUDA as long as `torch.cuda.is_initialize()` returns true.
- Disabling this on common_distributed.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50914
Reviewed By: malfet
Differential Revision: D26019289
Pulled By: walterddr
fbshipit-source-id: ddc7c1c0d00db4d073a6c8bc5b7733637a7e77d1
{kind=link}
{kind=link}