Summary:
Ignore mixed upper-case/lower-case style for now
Fix space between function and its arguments violation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35574
Test Plan: CI
Differential Revision: D20712969
Pulled By: malfet
fbshipit-source-id: 0012d430aed916b4518599a0b535e82d15721f78
Summary:
Same to `else`, `endif` and `elseif`.
Also prefer lowercase over uppercase ones
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35343
Test Plan: None at all
Differential Revision: D20638789
Pulled By: malfet
fbshipit-source-id: 8058075693185e66f5dda7b825b725e139d0d000
Summary:
Sometimes it is important to run code with thread sanitizer.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35197
Test Plan: CI
Differential Revision: D20605005
Pulled By: malfet
fbshipit-source-id: bcd1a5191b5f859e12b6df6737c980099b1edc36
Summary:
This makes PyTorch compileable(but not linkable) with `CUDA_SEPARABLE_COMPILATION` option enabled.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34899
Test Plan: CI
Differential Revision: D20501050
Pulled By: malfet
fbshipit-source-id: 02903890a827fcc430a26f397d4d05999cf3a441
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34663
Been bitten by this so many times. Never more.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D20425480
Pulled By: ezyang
fbshipit-source-id: c4489efacc4149c9b57d1b8207cc872970c2501f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34547
This enables threading by passing a threadpool to xnnpack ops.
Test Plan:
python test/test_xnnpack_integration.py
Imported from OSS
Differential Revision: D20370553
fbshipit-source-id: 4db08e73f8c69b9e722b0e11a00621c4e229a31a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34203
Currently cmake and mobile build scripts still build libcaffe2 by
default. To build pytorch mobile users have to set environment variable
BUILD_PYTORCH_MOBILE=1 or set cmake option BUILD_CAFFE2_MOBILE=OFF.
PyTorch mobile has been released for a while. It's about time to change
CMake and build scripts to build libtorch by default.
Changed caffe2 CI job to build libcaffe2 by setting BUILD_CAFFE2_MOBILE=1
environment variable. Only found android CI for libcaffe2 - do we ever
have iOS CI for libcaffe2?
Test Plan: Imported from OSS
Differential Revision: D20267274
Pulled By: ljk53
fbshipit-source-id: 9d997032a599c874d62fbcfc4f5d4fbf8323a12e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34187
Noticed that a recent PR broke Android/iOS CI but didn't break mobile
build with host toolchain. Turns out one mobile related flag was not
set on PYTORCH_BUILD_MOBILE code path:
```
"set(INTERN_DISABLE_MOBILE_INTERP ON)"
```
First, move the INTERN_DISABLE_MOBILE_INTERP macro below, to stay with
other "mobile + pytorch" options - it's not relevant to "mobile + caffe2"
so doesn't need to be set as common "mobile" option;
Second, rename PYTORCH_BUILD_MOBILE env-variable to
BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN - it's a bit verbose but
becomes more clear what it does - there is another env-variable
"BUILD_PYTORCH_MOBILE" used in scripts/build_android.sh, build_ios.sh,
which toggles between "mobile + pytorch" v.s. "mobile + caffe2";
Third, combine BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN with ANDROID/IOS
to avoid missing common mobile options again in future.
Test Plan: Imported from OSS
Differential Revision: D20251864
Pulled By: ljk53
fbshipit-source-id: dc90cc87ffd4d0bf8a78ae960c4ce33a8bb9e912
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34055
Enable custom mobile build with dynamic dispatch for OSS build.
It calls a python util script to calculate transitive dependencies from
the op dependency graph and the list of used root ops, then pass the
result as the op registration whitelist to aten codegen, so that only
these used ops are registered and kept at link time.
For custom build with dynamic dispatch to work correctly, it's critical
to have the accurate list of used ops. Current assumption is that only
those ops referenced by TorchScript model are used. It works well if
client code doesn't call libtorch API (e.g. tensor methods) directly;
otherwise the extra used ops need to be added to the whitelist manually,
as shown by the HACK in prepare_model.py.
Also, if JIT starts calling extra ops independent of specific model,
then the extra ops need to be added to the whitelist as well.
Verified the correctness of the whole process with MobileNetV2:
```
TEST_CUSTOM_BUILD_DYNAMIC=1 test/mobile/custom_build/build.sh
```
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D20193327
Pulled By: ljk53
fbshipit-source-id: 9d369b8864856b098342aea79e0ac8eec04149aa
Summary:
Related issue: https://github.com/pytorch/pytorch/issues/34079
I don't know how much we care about the difference between `-G` and `-lineinfo` in `DEBUG` vs `REL_WITH_DEB_INFO`, but since `-G` never worked, let's just use `-lineinfo` on both `DEBUG` and `REL_WITH_DEB_INFO`. This would resolve the failure in `DEBUG=1` build. Locally tested to work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34153
Reviewed By: ljk53
Differential Revision: D20232049
Pulled By: ngimel
fbshipit-source-id: 4e48ff818850ba911298b0cc159522f33a305aaa
Summary:
Fixes https://github.com/pytorch/pytorch/issues/33899
In the issue, we have
```
TypeError("expected %s (got %s)", dispatch_key, toString(other.key_set()).c_str());
```
which results in `dispatch_key` being interpreted as a c-string by `sprintf`. Adding `__attrbute__((format))` to the `TypeError` constructor allows gcc or clang to detect this at compile time. Then `-Werror=format` makes it a hard error at compile time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34019
Differential Revision: D20194842
Pulled By: ezyang
fbshipit-source-id: fa4448916c309d91e3d949fa65bb3aa7cca5c6a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33722
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding native implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Test Plan:
Build: CI
Functionality: Not exposed
Reviewed By: dreiss
Differential Revision: D20069796
Pulled By: AshkanAliabadi
fbshipit-source-id: d46c1c91d4bea91979ea5bd46971ced5417d309c
Summary:
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding **native** implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Reviewed By: dreiss
Differential Revision: D19521853
Pulled By: AshkanAliabadi
fbshipit-source-id: 99a1fab31d0ece64961df074003bb852c36acaaa
Summary:
The detection of the env variable ONNX_ML has been properly handled in tools/setup_helpers/cmake.py,
line 242.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33424
Differential Revision: D20043991
Pulled By: ezyang
fbshipit-source-id: 91d1d49a5a12f719e67d9507cc203c8a40992f03
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33318
### Summary
Recently, we have a [discussion](https://discuss.pytorch.org/t/libtorch-on-watchos/69073/14) in the forum about watchOS. This PR adds the support for building watchOS libraries.
### Test Plan
- `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=WATCHOS ./scripts/build_ios.sh`
Test Plan: Imported from OSS
Differential Revision: D19896534
Pulled By: xta0
fbshipit-source-id: 7b9286475e895d9fefd998246e7090ac92c4c9b6
Summary:
## Several flags
`/MP[M]`: It is a flag for the compiler `cl`. It leads to object-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
`/maxcpucount:[M]`: It is a flag for the generator `msbuild`. It leads to project-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
`/p:CL_MPCount=[M]`: It is a flag for the generator `msbuild`. It leads the generator to pass `/MP[M]` to the compiler.
`/j[M]`: It is a flag for the generator `ninja`. It leads to object-level multiprocessing. By default, it spawns M processes where M is the number of cores on the PC.
## Reason for the change
1. Object-level multiprocessing is preferred over project-level multiprocessing.
2. ~For ninja, we don't need to set `/MP` otherwise M * M processes will be spawned.~ Actually, it is not correct because in ninja configs, there are only one source file in the command. Therefore, the `/MP` switch should be useless.
3. For msbuild, if it is called through Python configuration scripts, then `/p:CL_MPCount=[M]` will be added, otherwise, we add `/MP` to `CMAKE_CXX_FLAGS`.
4. ~It may be a possible fix for https://github.com/pytorch/pytorch/issues/28271, https://github.com/pytorch/pytorch/issues/27463 and https://github.com/pytorch/pytorch/issues/25393. Because `/MP` is also passed to `nvcc`.~ It is probably not true. Because `/MP` should not be effective given there is only one source file per command.
## Reference
1. https://docs.microsoft.com/en-us/cpp/build/reference/mp-build-with-multiple-processes?view=vs-2019
2. https://github.com/Microsoft/checkedc-clang/wiki/Parallel-builds-of-clang-on-Windows
3. https://blog.kitware.com/cmake-building-with-all-your-cores/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33120
Differential Revision: D19817227
Pulled By: ezyang
fbshipit-source-id: f8d01f835016971729c7a8d8a0d1cb8a8c2c6a5f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32276
Include mobile interpreter in mobile code analysis pass, which has some
manually registered ops in temporary namespaces.
The mobile interpreter is still under development and these ops will be
removed in the future. This is a temporary step for internal build
experiment.
Test Plan: Imported from OSS
Differential Revision: D19426818
Pulled By: ljk53
fbshipit-source-id: 507453dc801e5f93208f1baea12400beccda9ca5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31116
Changelist:
- remove BUILD_NAMEDTENSOR macro
- remove torch._C._BUILD_NAMEDTENSOR
- remove all python behavior that relies on torch._C._BUILD_NAMEDTENSOR
Future:
- In the next diff, I will remove all usages of
ATen/core/EnableNamedTensor.h since that header doesn't do anything
anymore
- After that, we'll be done with the BUILD_NAMEDTENSOR removal.
Test Plan: - run CI
Differential Revision: D18934951
Pulled By: zou3519
fbshipit-source-id: 0a0df0f1f0470d0a01c495579333a2835aac9f5d
Summary:
${CMAKE_HOST_SYSTEM_PROCESSOR} get processor name by `uname -p` on linux and `%PROCESSOR_ARCHITECTURE%` on windows
1. %PROCESSOR_ARCHITECTURE% has value in (AMD64|IA64|ARM64) for 64-bit processor, and (x86) for 32-bit processor
2. `uname -p` has value like "(x86_64|i[3-6]+86)"
We cannot tell intel cpu from other cpus by ${CMAKE_HOST_SYSTEM_PROCESSOR}. It is the architecture, not provider.
i. e. Intel CPU i7-9700K CPU on windows get "AMD64"
reference:
[MSDN](https://docs.microsoft.com/zh-cn/windows/win32/winprog64/wow64-implementation-details?redirectedfrom=MSDN)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30564
Differential Revision: D18763031
Pulled By: ezyang
fbshipit-source-id: 11ae20e66b4b89bde1dcf4df6177606a3374c671
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30144
Create script to produce libtorch that only contains ops needed by specific
models. Developers can use this workflow to further optimize mobile build size.
Need keep a dummy stub for unused (stripped) ops because some JIT side
logic requires certain function schemas to be existed in the JIT op
registry.
Test Steps:
1. Build "dump_operator_names" binary and use it to dump root ops needed
by a specific model:
```
build/bin/dump_operator_names --model=mobilenetv2.pk --output=mobilenetv2.yaml
```
2. The MobileNetV2 model should use the following ops:
```
- aten::t
- aten::dropout
- aten::mean.dim
- aten::add.Tensor
- prim::ListConstruct
- aten::addmm
- aten::_convolution
- aten::batch_norm
- aten::hardtanh_
- aten::mm
```
NOTE that for some reason it outputs "aten::addmm" but actually uses "aten::mm".
You need fix it manually for now.
3. Run custom build script locally (use Android as an example):
```
SELECTED_OP_LIST=mobilenetv2.yaml scripts/build_pytorch_android.sh armeabi-v7a
```
4. Checkout demo app that uses locally built library instead of
downloading from jcenter repo:
```
git clone --single-branch --branch custom_build git@github.com:ljk53/android-demo-app.git
```
5. Copy locally built libraries to demo app folder:
```
find ${HOME}/src/pytorch/android -name '*.aar' -exec cp {} ${HOME}/src/android-demo-app/HelloWorldApp/app/libs/ \;
```
6. Build demo app with locally built libtorch:
```
cd ${HOME}/src/android-demo-app/HelloWorldApp
./gradlew clean && ./gradlew assembleDebug
```
7. Install and run the demo app.
In-APK arm-v7 libpytorch_jni.so build size reduced from 5.5M to 2.9M.
Test Plan: Imported from OSS
Differential Revision: D18612127
Pulled By: ljk53
fbshipit-source-id: fa8d5e1d3259143c7346abd1c862773be8c7e29a
Summary:
- Add a "BUILD_JNI" option that enables building PyTorch JNI bindings and
fbjni. This is off by default because it adds a dependency on jni.h.
- Update to the latest fbjni so we can inhibit building its tests,
because they depend on gtest.
- Set JAVA_HOME and BUILD_JNI in Linux binary build configurations if we
can find jni.h in Docker.
Test Plan:
- Built on dev server.
- Verified that libpytorch_jni links after libtorch when both are built
in a parallel build.
Differential Revision: D18536828
fbshipit-source-id: 19cb3be8298d3619352d02bb9446ab802c27ec66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29715
Previous we hard code it to enable static dispatch when building mobile
library. Since we are exploring approaches to deprecate static dispatch
we should make it optional. This PR moved the setting from cmake to bash
build scripts which can be overridden.
Test Plan: - verified it's still using static dispatch when building with these scripts.
Differential Revision: D18474640
Pulled By: ljk53
fbshipit-source-id: 7591acc22009bfba36302e3b2a330b1428d8e3f1
Summary:
Reason:
To have one-step build for test android application based on the current code state that is ready for profiling with simpleperf, systrace etc. to profile performance inside the application.
## Parameters to control debug symbols stripping
Introducing /CMakeLists parameter `ANDROID_DEBUG_SYMBOLS` to be able not to strip symbols for pytorch (not add linker flag `-s`)
which is checked in `scripts/build_android.sh`
On gradle side stripping happens by default, and to prevent it we have to specify
```
android {
packagingOptions {
doNotStrip "**/*.so"
}
}
```
which is now controlled by new gradle property `nativeLibsDoNotStrip `
## Test_App
`android/test_app` - android app with one MainActivity that does inference in cycle
`android/build_test_app.sh` - script to build libtorch with debug symbols for specified android abis and adds `NDK_DEBUG=1` and `-PnativeLibsDoNotStrip=true` to keep all debug symbols for profiling.
Script assembles all debug flavors:
```
└─ $ find . -type f -name *apk
./test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
./test_app/app/build/outputs/apk/resnet/debug/test_app-resnet-debug.apk
```
## Different build configurations
Module for inference can be set in `android/test_app/app/build.gradle` as a BuildConfig parameters:
```
productFlavors {
mobilenetQuant {
dimension "model"
applicationIdSuffix ".mobilenetQuant"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_MOBILENET_QUANT'))
addManifestPlaceholders([APP_NAME: "PyMobileNetQuant"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-mobilenet\"")
}
resnet {
dimension "model"
applicationIdSuffix ".resnet"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_RESNET18'))
addManifestPlaceholders([APP_NAME: "PyResnet"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-resnet\"")
}
```
In that case we can setup several apps on the same device for comparison, to separate packages `applicationIdSuffix`: 'org.pytorch.testapp.mobilenetQuant' and different application names and logcat tags as `manifestPlaceholder` and another BuildConfig parameter:
```
─ $ adb shell pm list packages | grep pytorch
package:org.pytorch.testapp.mobilenetQuant
package:org.pytorch.testapp.resnet
```
In future we can add another BuildConfig params e.g. single/multi threads and other configuration for profiling.
At the moment 2 flavors - for resnet18 and for mobilenetQuantized
which can be installed on connected device:
```
cd android
```
```
gradle test_app:installMobilenetQuantDebug
```
```
gradle test_app:installResnetDebug
```
## Testing:
```
cd android
sh build_test_app.sh
adb install -r test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
```
```
cd $ANDROID_NDK
python simpleperf/run_simpleperf_on_device.py record --app org.pytorch.testapp.mobilenetQuant -g --duration 10 -o /data/local/tmp/perf.data
adb pull /data/local/tmp/perf.data
python simpleperf/report_html.py
```
Simpleperf report has all symbols:
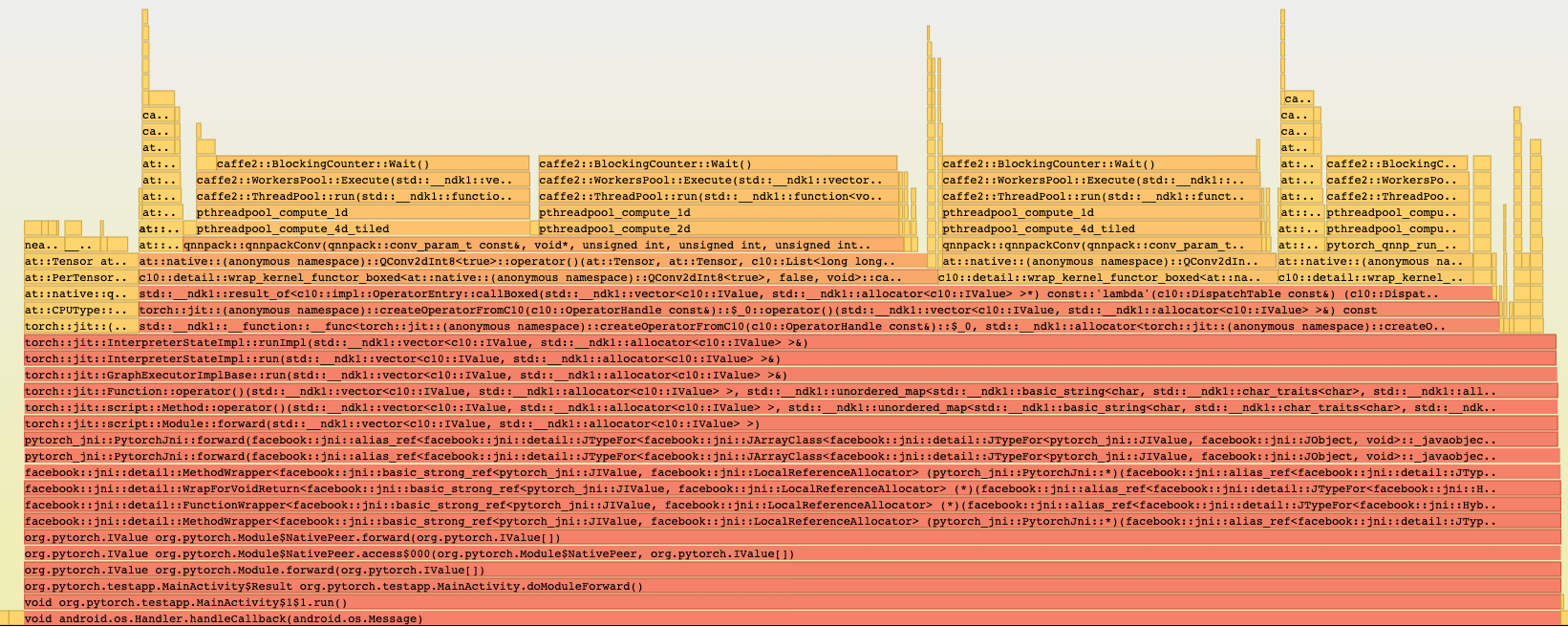
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28406
Differential Revision: D18386622
Pulled By: IvanKobzarev
fbshipit-source-id: 3a751192bbc4bc3c6d7f126b0b55086b4d586e7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29061
It looks like we are too close to the maximum library size on
Windows. Kill Caffe2 operators to get us lower again.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: smessmer
Differential Revision: D18281083
Pulled By: ezyang
fbshipit-source-id: 8a11f9059dbf330f659bd96cc0cc2abc947723a8
Summary:
This PR makes Caffe2 compatible with TensorRT 6. To make sure it works well, new unit test is added. This test checks PyTorch->ONNX->TRT6 inference flow for all classification models from TorhchVision Zoo.
Note on CMake changes: it has to be done in order to import onnx-tensorrt project. See https://github.com/pytorch/pytorch/issues/18524 for details.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26426
Reviewed By: hl475
Differential Revision: D17495965
Pulled By: houseroad
fbshipit-source-id: 3e8dbe8943f5a28a51368fd5686c8d6e86e7f693
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26565
For OSS mobile build we should keep QNNPACK off and PYTORCH_QNNPACK on
as we don't include caffe2 ops that use third_party/QNNPACK.
Update android/iOS build script to include new libraries accordingly.
Test Plan: - CI build
Differential Revision: D17508918
Pulled By: ljk53
fbshipit-source-id: 0483d45646d4d503b4e5c1d483e4df72cffc6c68
Summary:
USE_STATIC_DISPATCH needs to be exposed as we don't hide header files
containing it for iOS (yet). Otherwise it's error-prone to request all
external projects to set the macro correctly on their own.
Also remove redundant USE_STATIC_DISPATCH definition from other places.
Test Plan:
- build android gradle to confirm linker can still strip out dead code;
- integrate with demo app to confirm inference can run without problem;
Differential Revision: D17484260
Pulled By: ljk53
fbshipit-source-id: 653f597acb2583761b723eff8026d77518007533
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26440
As we are optimizing build size for Android/iOS, it starts diverging
from default build on several build options, e.g.:
- USE_STATIC_DISPATCH=ON;
- disable autograd;
- disable protobuf;
- no caffe2 ops;
- no torch/csrc/api;
...
Create this build_mobile.sh script to 'simulate' mobile build mode
with host toolchain so that people who don't work on mobile regularly
can debug Android/iOS CI error more easily. It might also be used to
build libtorch on devices like raspberry pi natively.
Test Plan:
- run scripts/build_mobile.sh -DBUILD_BINARY=ON
- run build_mobile/bin/speed_benchmark_torch on host machine
Differential Revision: D17466580
Pulled By: ljk53
fbshipit-source-id: 7abb6b50335af5b71e58fb6d6f9c38eb74bd5781
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25816
On Android we will release a small set of native APIs designed for mobile use
cases. All of needed libtorch c++ APIs are called from inside this JNI bridge:
android/pytorch_android/src/main/cpp/pytorch_jni.cpp
With NO_EXPORT set for android static library build, it will hide all
original TORCH, CAFFE2, TH/ATen APIs, which will allow linker to strip
out unused ones from mobile library when producing DSO.
If people choose to directly build libtorch DSO then it will still keep
all c++ APIs as the mobile API layer is not part of libtorch build (yet).
Test Plan:
- build libtorch statically and link into demo app;
- confirm that linker can strip out unused APIs;
Differential Revision: D17247237
Pulled By: ljk53
fbshipit-source-id: de668216b5f2130da0d6988937f98770de571c7a
Summary:
This is the first of a series of changes to reduce build size by cutting
autograd functions from mobile build.
When INTERN_DISABLE_AUTOGRAD is set:
* On CMake side we exclude Functions.h/cpp, VariableType*.h/cpp,
VariableTypeManual.cpp from the build process. Still keep variable_factories.h
as we rely on it to create variables instead of tensors.
* In source code we gate a couple autograd references (in autograd/variable.cpp)
with C10_MOBILE (technically we should use a dedicated c macro but its
maintenance cost is higher than cmake macro as we have several build systems
to change).
* Pass --disable-autograd flag to codegen script, which will stop generating
Functions/VariableType code. And for variable_factories.h it will stop
generating tracing code.
Edit: in this diff we will keep Functions.h/cpp to avoid changing source code.
Why we need this change if it's already not calling VariableType and autograd
stuff with USE_STATIC_DISPATCH=ON for mobile?
It's trying to reduce static library size for iOS build, for which it's
relatively harder to strip size with linker approach.
Why we need make involved change into codegen script?
There isn't a global config system in codegen - autograd/env.py provides similar
functionality but it says not adding anything there.
Test Plan:
- will check CI;
- test mobile build in sample app;
Differential Revision: D17202733
Pulled By: ljk53
fbshipit-source-id: 5701c6639b39ce58aba9bf5489a08d30d1dcd299
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25650
This PR removes protobuf dependencies from mobile build altogether:
- caffe2/proto: protobuf files, including caffe2.proto and torch.proto;
- caffe2 components that depend on caffe2.proto, including most part of
caffe2/core, caffe2/utils;
- libprotobuf / libprotobuf-lite dependencies;
- protobuf compiler;
- some utils class, e.g.: netdef_converter.cpp;
- introduce a macro to disable third_party/onnx which depends on protobuf;
Test Plan:
- builds;
- link with demo app to make sure it can load and run a model in pickle format;
Differential Revision: D17183548
Pulled By: ljk53
fbshipit-source-id: fe60b48674f29c4a9b58fd1cf8ece44191491531
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25759
In #25260, USE_DISTRIBUTED was defaulted to OFF for Windows and macOS
only. The Android builds didn't run for the PR and started to fail
when it was merged to master. It turns out the mobile builds
explicitly disable USE_DISTRIBUTED but only after the USE_DISTRIBUTED
option, and derivative dependent options were defined. The result
being that USE_GLOO was enabled while USE_DISTRIBUTED was disabled.
This commit ensures that USE_DISTRIBUTED defaults to OFF unless the
build is for a supported platform.
ghstack-source-id: 89613698
Test Plan: N/A
Differential Revision: D17224842
fbshipit-source-id: 459039b79ad5240e81dfa3caf486858d6e77ba4b
Summary:
It doesn't seem to be used anywhere once down to CMake in this repo or any submodules
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25720
Differential Revision: D17225088
Pulled By: pietern
fbshipit-source-id: a24b080e6346a203b345e2b834fe095e3b9aece0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25696
Move the flag from CI to CMake so it's less magic and can be reused by
iOS build as well.
Test Plan: - will check CI
Differential Revision: D17202734
Pulled By: ljk53
fbshipit-source-id: da4f150cbcf2bb5624def386ce3699eff2a7446f
Summary:
In facebookincubator/gloo#212, a libuv based Gloo transport was introduced,
which allows us to use Gloo on macOS (and later perhaps also Windows). This
commit updates CMake code to enable building with USE_DISTRIBUTED=1 on macOS.
A few notes:
* The Caffe2 ops are not compiled, for they depend on `gloo::transport::tcp`.
* The process group implementation uses `gloo::transport::tcp` on Linux (because of `epoll(2)` on Linux and `gloo::transport::uv` on macOS).
* The TCP store works but sometimes crashes on process termination.
* The distributed tests are not yet run.
* The nightly builds don't use `USE_DISTRIBUTED=1`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25260
Reviewed By: mrshenli
Differential Revision: D17202381
Pulled By: pietern
fbshipit-source-id: ca80a82e78a05b4154271d2fb0ed31c8d9f26a7c
{kind=link}