Changes by apply order:
1. Replace all `".."` and `os.pardir` usage with `os.path.dirname(...)`.
2. Replace nested `os.path.dirname(os.path.dirname(...))` call with `str(Path(...).parent.parent)`.
3. Reorder `.absolute()` ~/ `.resolve()`~ and `.parent`: always resolve the path first.
`.parent{...}.absolute()` -> `.absolute().parent{...}`
4. Replace chained `.parent x N` with `.parents[${N - 1}]`: the code is easier to read (see 5.)
`.parent.parent.parent.parent` -> `.parents[3]`
5. ~Replace `.parents[${N - 1}]` with `.parents[${N} - 1]`: the code is easier to read and does not introduce any runtime overhead.~
~`.parents[3]` -> `.parents[4 - 1]`~
6. ~Replace `.parents[2 - 1]` with `.parent.parent`: because the code is shorter and easier to read.~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129374
Approved by: https://github.com/justinchuby, https://github.com/malfet
Changes by apply order:
1. Replace all `".."` and `os.pardir` usage with `os.path.dirname(...)`.
2. Replace nested `os.path.dirname(os.path.dirname(...))` call with `str(Path(...).parent.parent)`.
3. Reorder `.absolute()` ~/ `.resolve()`~ and `.parent`: always resolve the path first.
`.parent{...}.absolute()` -> `.absolute().parent{...}`
4. Replace chained `.parent x N` with `.parents[${N - 1}]`: the code is easier to read (see 5.)
`.parent.parent.parent.parent` -> `.parents[3]`
5. ~Replace `.parents[${N - 1}]` with `.parents[${N} - 1]`: the code is easier to read and does not introduce any runtime overhead.~
~`.parents[3]` -> `.parents[4 - 1]`~
6. ~Replace `.parents[2 - 1]` with `.parent.parent`: because the code is shorter and easier to read.~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129374
Approved by: https://github.com/justinchuby, https://github.com/malfet
Changes by apply order:
1. Replace all `".."` and `os.pardir` usage with `os.path.dirname(...)`.
2. Replace nested `os.path.dirname(os.path.dirname(...))` call with `str(Path(...).parent.parent)`.
3. Reorder `.absolute()` ~/ `.resolve()`~ and `.parent`: always resolve the path first.
`.parent{...}.absolute()` -> `.absolute().parent{...}`
4. Replace chained `.parent x N` with `.parents[${N - 1}]`: the code is easier to read (see 5.)
`.parent.parent.parent.parent` -> `.parents[3]`
5. ~Replace `.parents[${N - 1}]` with `.parents[${N} - 1]`: the code is easier to read and does not introduce any runtime overhead.~
~`.parents[3]` -> `.parents[4 - 1]`~
6. ~Replace `.parents[2 - 1]` with `.parent.parent`: because the code is shorter and easier to read.~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129374
Approved by: https://github.com/justinchuby, https://github.com/malfet
Changes by apply order:
1. Replace all `".."` and `os.pardir` usage with `os.path.dirname(...)`.
2. Replace nested `os.path.dirname(os.path.dirname(...))` call with `str(Path(...).parent.parent)`.
3. Reorder `.absolute()` ~/ `.resolve()`~ and `.parent`: always resolve the path first.
`.parent{...}.absolute()` -> `.absolute().parent{...}`
4. Replace chained `.parent x N` with `.parents[${N - 1}]`: the code is easier to read (see 5.)
`.parent.parent.parent.parent` -> `.parents[3]`
5. ~Replace `.parents[${N - 1}]` with `.parents[${N} - 1]`: the code is easier to read and does not introduce any runtime overhead.~
~`.parents[3]` -> `.parents[4 - 1]`~
6. ~Replace `.parents[2 - 1]` with `.parent.parent`: because the code is shorter and easier to read.~
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129374
Approved by: https://github.com/justinchuby, https://github.com/malfet
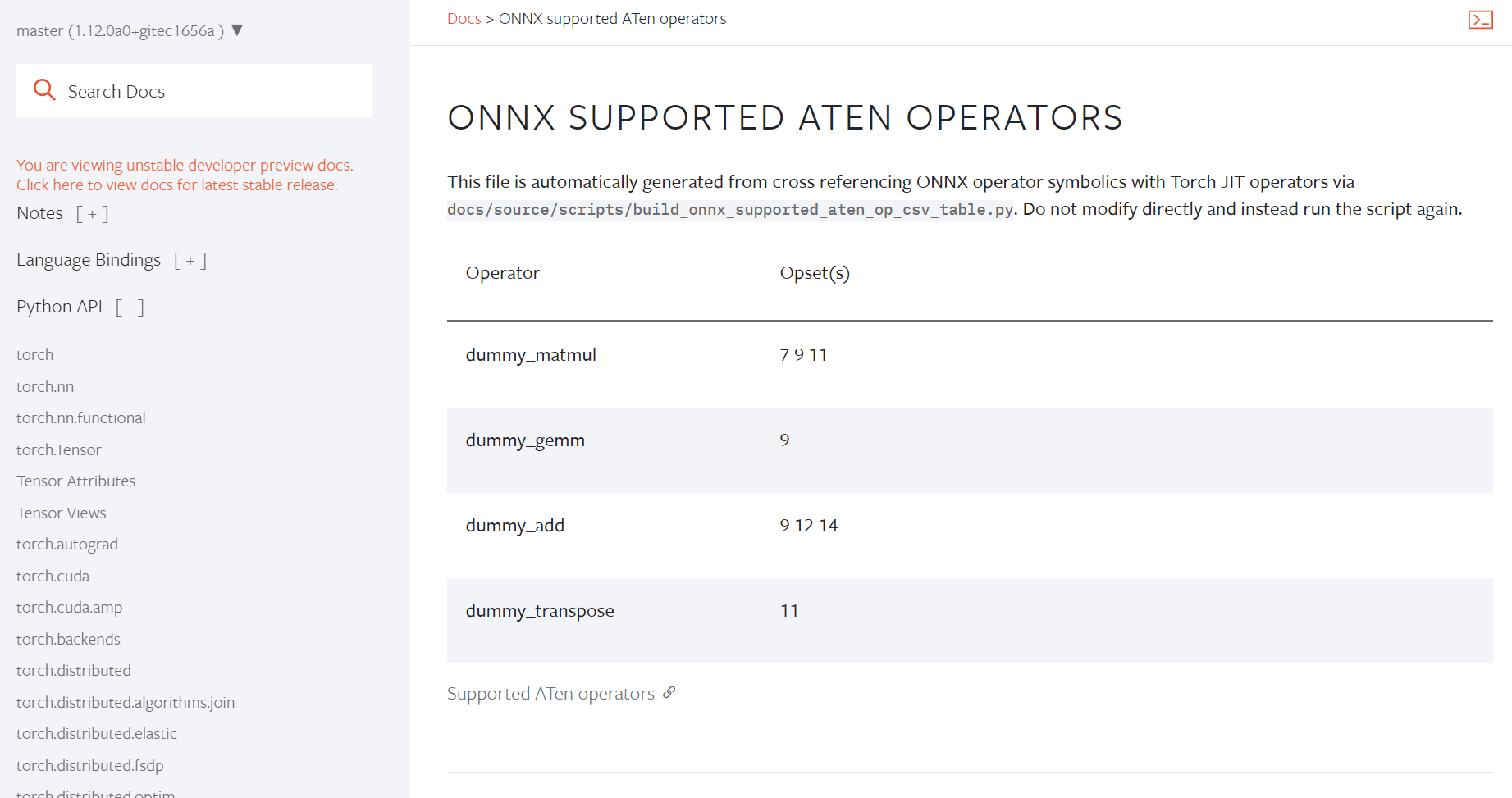
The `usort` config in `pyproject.toml` has no effect due to a typo. Fixing the typo make `usort` do more and generate the changes in the PR. Except `pyproject.toml`, all changes are generated by `lintrunner -a --take UFMT --all-files`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127126
Approved by: https://github.com/kit1980
The `usort` config in `pyproject.toml` has no effect due to a typo. Fixing the typo make `usort` do more and generate the changes in the PR. Except `pyproject.toml`, all changes are generated by `lintrunner -a --take UFMT --all-files`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127126
Approved by: https://github.com/kit1980
ghstack dependencies: #127122, #127123, #127124, #127125
The `usort` config in `pyproject.toml` has no effect due to a typo. Fixing the typo make `usort` do more and generate the changes in the PR. Except `pyproject.toml`, all changes are generated by `lintrunner -a --take UFMT --all-files`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127124
Approved by: https://github.com/Skylion007
ghstack dependencies: #127122, #127123
Recently we updated the `export` API to take an experimental `dynamic_shapes` argument that was meant to subsume the existing `constraints` argument.
This PR deprecates `constraints` (with a warning on its use, but without actually removing it). Simultaneously it replaces all uses of `constraints` in docs, examples, and tests with corresponding uses of `dynamic_shapes` (preserving behavior). This exercise fortunately revealed some minor bugs in the implementation which have also been fixed in this PR.
Some uses of `constraints` still remain, e.g., when `torch._dynamo.export` is called directly. (Meta-internal uses will be updated in a separate diff.)
Differential Revision: D49676049
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110143
Approved by: https://github.com/tugsbayasgalan
Solving #105242.
During export, the exported function's signature changes multiple times. Suppose we'd like to export f as shown in following example:
```python
def f(arg1, arg2, kw1, kw2):
pass
args = (arg1, arg2)
kwargs = {"kw2":arg3, "kw1":arg4}
torch.export(f, args, kwargs)
```
The signature changes mutiple times during export process in the following order:
1. **gm_torch_level = dynamo.export(f, *args, \*\*kwargs)**. In this step, we turn all kinds of parameters such as **postional_only**, **var_positioinal**, **kw_only**, and **var_kwargs** into **positional_or_kw**.It also preserves the positional and kword argument names in original function (i.e. f in this example) [here](https://github.com/pytorch/pytorch/blob/main/torch/_dynamo/export.py#L546C13-L546C27). The order of kwargs will be the **key order** of kwargs (after python 3.6, the order is the insertion of order of keys) instead of the original function signature and the order is baked into a _orig_args varaible of gm_torch_level's pytree info. So we'll have:
```python
def gm_torch_level(arg1, arg2, kw2, kw1)
```
Such difference is acceptable as it's transparent to users of export.
2. **gm_aot_export = aot_export_module(gm_torch_level, pos_or_kw_args)**. In this step, we need to turn kwargs into positional args in the order of how gm_torch_level expected, which is stored in _orig_args. The returned gm_aot_export has the graph signature of flat_args, in_spec = pytree.tree_flatten(pos_or_kw_args):
``` python
flat_args, _ = pytree.tree_flatten(pos_or_kw_args)
def gm_aot_export(*flat_args)
```
3. **exported_program(*args, \*\*kwargs)**. The epxorted artifact is exported_program, which is a wrapper over gm_aot_export and has the same calling convention as the original function "f". To do this, we need to 1. specialize the order of kwargs into pos_or_kw_args and 2. flatten the pos_or_kw_args into what gm_aot_export expected. We can combine the two steps into one with :
```python
_, in_spec = pytree.tree_flatten((args, kwargs))
# Then during exported_program.__call__(*args, **kwargs)
flat_args = fx_pytree.tree_flatten_spec((args, kwargs), in_spec)
```
, where kwargs is treated as a normal pytree whose keyorder is preserved in in_spec.
Implementation-wise, we treat _orig_args in dynamo exported graph module as single source of truth and kwags are ordered following it.
Test plan:
See added tests in test_export.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/105337
Approved by: https://github.com/angelayi, https://github.com/tugsbayasgalan
Summary:
This improves the documentation page for backend_config_dict to render
the configurations in a human readable format, such as
```
{
'pattern': torch.nn.modules.pooling.AdaptiveAvgPool1d,
'dtype_configs': [
{
'input_dtype': torch.quint8,
'output_dtype': torch.quint8,
},
{
'input_dtype': torch.float16,
'weight_dtype': torch.float16,
'bias_dtype': torch.float16,
'output_dtype': torch.float16,
},
],
'observation_type': ObservationType.OUTPUT_SHARE_OBSERVER_WITH_INPUT,
},
```
The results are also now sorted alphabetically by the normalized name of
the root op in the pattern.
A couple of utility functions are created to help with this. If in the future
we convert backend_config_dict to use typed objects, we can move this logic
to the objects at that time.
Test plan:
```
cd docs
make html
cd build
python -m server.http
// renders correctly, example: https://gist.github.com/vkuzo/76adfc7c89e119c59813a733fa2cd56f
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77535
Approved by: https://github.com/andrewor14
Summary:
Following https://github.com/pytorch/rfcs/blob/master/RFC-0019-Extending-PyTorch-Quantization-to-Custom-Backends.md we implemented
the backend configuration for fbgemm/qnnpack backend, currently it was under fx folder, but we'd like to use this for all different
workflows, including eager, fx graph and define by run quantization, this PR moves it to torch.ao.quantization namespace so that
it can be shared by different workflows
Also moves some utility functions specific to fx to fx/backend_config_utils.py and some files are kept in fx folder (quantize_handler.py and fuse_handler.py)
Test Plan:
python test/teset_quantization.py TestQuantizeFx
python test/teset_quantization.py TestQuantizeFxOps
python test/teset_quantization.py TestQuantizeFxModels
python test/test_quantization.py TestAOMigrationQuantization
python test/test_quantization.py TestAOMigrationQuantizationFx
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75823
Approved by: https://github.com/vkuzo
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75126
Quantization has a high volume of configurations of how to quantize an
op for a reference model representation which is useful for a lowering
step for a backend. An example of this is
```
{'dtype_configs': [{'input_dtype': torch.quint8,
'output_dtype': torch.quint8}],
'observation_type': <ObservationType.OUTPUT_USE_DIFFERENT_OBSERVER_AS_INPUT: 0>,
'pattern': <class 'torch.nn.modules.conv.ConvTranspose1d'>},
```
These configs are checked into master, and they are created with Python functions.
Therefore, there is no easy way for the user to see what the configs actually
are without running some Python code.
This PR is one approach to document these configs. Here is what this is doing:
1. during documentation build, write a text file of the configs
2. render that text file on a quantization page, with some additional context
In the future, this could be extended to autogenerate better looking tables
such as: op support per backend and dtype, op support per valid quantization settings per backend,
etc.
Test Plan:
```
cd docs
make html
cd html
python -m http.server 8000
// render http://[::]:8000/quantization-backend-configuration.html
// it renders correctly
```
Reviewed By: ejguan
Differential Revision: D35365461
Pulled By: vkuzo
fbshipit-source-id: d60f776ccb57da9db3d09550e4b27bd5e725635a
(cherry picked from commit 14865c0e23bc080120342c8f9278f0fae8eb8fbd)
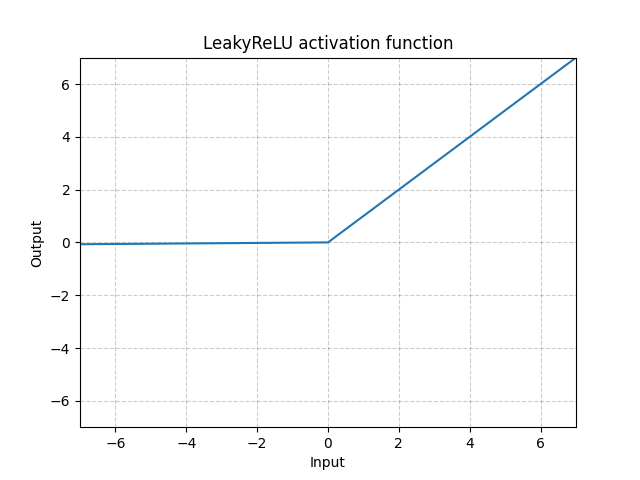
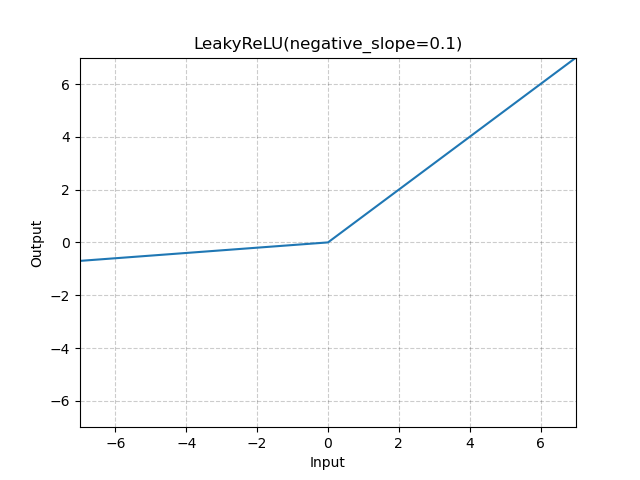
Summary:
Related to https://github.com/pytorch/pytorch/issues/30987. Fix the following task:
- [ ] Remove the use of `.data` in all our internal code:
- [ ] ...
- [x] `docs/source/scripts/build_activation_images.py` and `docs/source/notes/extending.rst`
In `docs/source/scripts/build_activation_images.py`, I used `nn.init` because the snippet already assumes `nn` is available (the class inherits from `nn.Module`).
cc albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65358
Reviewed By: malfet
Differential Revision: D31061790
Pulled By: albanD
fbshipit-source-id: be936c2035f0bdd49986351026fe3e932a5b4032
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}