All this time, PyTorch and ONNX has different strategy for None in output. And in internal test, we flatten the torch outputs to see if the rest of them matched. However, this doesn't work anymore in scripting after Optional node is introduced, since some of None would be kept.
#83184 forces script module to keep all Nones from Pytorch, but in ONNX, the model only keeps the ones generated with Optional node, and deletes those meaningless None.
This PR uses Optional node to keep those meaningless None in output as well, so when it comes to script module result comparison, Pytorch and ONNX should have the same amount of Nones.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84789
Approved by: https://github.com/BowenBao
Fix#82589
Why:
1. **full_check** works in `onnx::checker::check_model` function as it turns on **strict_mode** in `onnx::shape_inference::InferShapes()` which I think that was the intention of this part of code.
2. **strict_mode** catches failed shape type inference (invalid ONNX model from onnx perspective) and ONNXRUNTIME can't run these invalid models, as ONNXRUNTIME actually rely on ONNX shape type inference to optimize ONNX graph. Why we don't set it True for default? >>> some of existing users use other platform, such as caffe2 to run ONNX model which doesn't need valid ONNX model to run.
3. This PR doesn't change the original behavior of `check_onnx_proto`, but add a warning message for those models which can't pass strict shape type inference, saying the models would fail on onnxruntime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83186
Approved by: https://github.com/justinchuby, https://github.com/thiagocrepaldi, https://github.com/jcwchen, https://github.com/BowenBao
Extend `register_custom_op` to support onnx-script local function. The FunctionProto from onnx-script is represented by custom op and inserted into ModelProto for op execution.
NOTE: I did experiments on >2GB case of a simple model with large initializers:
```python
import torch
class Net(torch.nn.Module):
def __init__(self, B, C):
super().__init__()
self.layer_norm = torch.nn.LayerNorm((B, C), eps=1e-3)
def forward(self, x):
return self.layer_norm(x)
N, B, C = 3, 25000, 25000
model = Net(B, C)
x = torch.randn(N, B, C)
torch.onnx.export(model, x, "large_model.onnx", opset_version=12)
```
And it turns out we won't get model_bytes > 2GB after `_export_onnx` pybind cpp function, as we split initializer in external files in that function, and have serialization before return the model bytes, which protobuf is not allowed to be larger than 2GB at any circumstances.
The test cases can be found in the next PR #86907 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86906
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Follow-up for #87735
Once again, because BUILD_CAFFE2=0 is not tested for ONNX exporter, one scenario slipped through. A use case where the model can be exported without aten fallback when operator_export_type=ONNX_ATEN_FALLBACK and BUILD_CAFFE2=0
A new unit test has been added, but it won't prevent regressions if BUILD_CAFFE2=0 is not executed on CI again
Fixes#87313
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88504
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Update `register_custom_op_symbolic`'s behavior to _only register the symbolic function at a single version_. This is more aligned with the semantics of the API signature.
As a result of this change, opset 7 and opset 8 implementations are now seen as fallback when the opset_version >= 9. Previously any ops internally registered to opset < 9 are not discoverable by an export version target >= 9. Updated the test to reflect this change.
The implication of this change is that users will need to register a symbolic function to the exact version when they want to override an existing symbolic. They are not impacted if (1) an implementation does not existing for the op, or (2) they are already registering to the exact version for export.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85636
Approved by: https://github.com/BowenBao
Update `unconvertible_ops` to create a list of unconvertible ops using the updated registry.
- Use fewer passes in the jit process instead to avoid errors during conversion in the ONNX fallback mode
- Actually check the registry to find implemented ops
- Fix type hints for `_create_jit_graph` and `_jit_pass_onnx_remove_inplace_ops_for_onnx`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85595
Approved by: https://github.com/BowenBao
`_set_opset_version` and `_set_operator_export_type` are previously deprecated. This PR decorates them with the deprecation decorator, so warnings are emitted.
- Remove usage of `_set_opset_version` and `_set_operator_export_type` in favor of setting the globals vars directly in torch.onnx internal
- Update `GLOBALS.operator_export_type`'s default to not be None to tighten types
- Remove usage of `_set_onnx_shape_inference`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85165
Approved by: https://github.com/BowenBao, https://github.com/AllenTiTaiWang
This PR create the `GraphContext` class and relays all graph methods to _C.Graph as well as implements the `g.op` method. The GraphContext object is passed into the symbolic functions in place of _C.Graph for compatibility with existing symbolic functions.
This way (1) we can type annotate all `g` args because the method is defined and (2) we can use additional context information in symbolic functions. (3) no more monkey patching on `_C.Graph`
Also
- Fix return type of `_jit_pass_fixup_onnx_controlflow_node`
- Create `torchscript.py` to house torch.Graph related functions
- Change `GraphContext.op` to create nodes in the Block instead of the Graph
- Create `add_op_with_blocks` to handle scenarios where we need to directly manipulate sub-blocks. Update loop and if symbolic functions to use this function.
## Discussion
Should we put all the context inside `SymbolicContext` and make it an attribute in the `GraphContext` class? This way we only define two attributes `GraphContext.graph` and `GraphContext.context`. Currently all context attributes are directly defined in the class.
### Decision
Keep GraphContext flatand note that it will change in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84728
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
## Summary
The change brings the new registry for symbolic functions in ONNX. The `SymbolicRegistry` class in `torch.onnx._internal.registration` replaces the dictionary and various functions defined in `torch.onnx.symbolic_registry`.
The new registry
- Has faster lookup by storing only functions in the opset version they are defined in
- Is easier to manage and interact with due to its class design
- Builds the foundation for the more flexible registration process detailed in #83787
Implementation changes
- **Breaking**: Remove `torch.onnx.symbolic_registry`
- `register_custom_op_symbolic` and `unregister_custom_op_symbolic` in utils maintain their api for compatibility
- Update _onnx_supported_ops.py for doc generation to include quantized ops.
- Update code to register python ops in `torch/csrc/jit/passes/onnx.cpp`
## Profiling results
-0.1 seconds in execution time. -34% time spent in `_run_symbolic_function`. Tested on the alexnet example in public doc.
### After
```
└─ 1.641 export <@beartype(torch.onnx.utils.export) at 0x7f19be17f790>:1
└─ 1.641 export torch/onnx/utils.py:185
└─ 1.640 _export torch/onnx/utils.py:1331
├─ 0.889 _model_to_graph torch/onnx/utils.py:1005
│ ├─ 0.478 _optimize_graph torch/onnx/utils.py:535
│ │ ├─ 0.214 PyCapsule._jit_pass_onnx_graph_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ ├─ 0.190 _run_symbolic_function torch/onnx/utils.py:1670
│ │ │ └─ 0.145 Constant torch/onnx/symbolic_opset9.py:5782
│ │ │ └─ 0.139 _graph_op torch/onnx/_patch_torch.py:18
│ │ │ └─ 0.134 PyCapsule._jit_pass_onnx_node_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ └─ 0.033 [self]
```
### Before
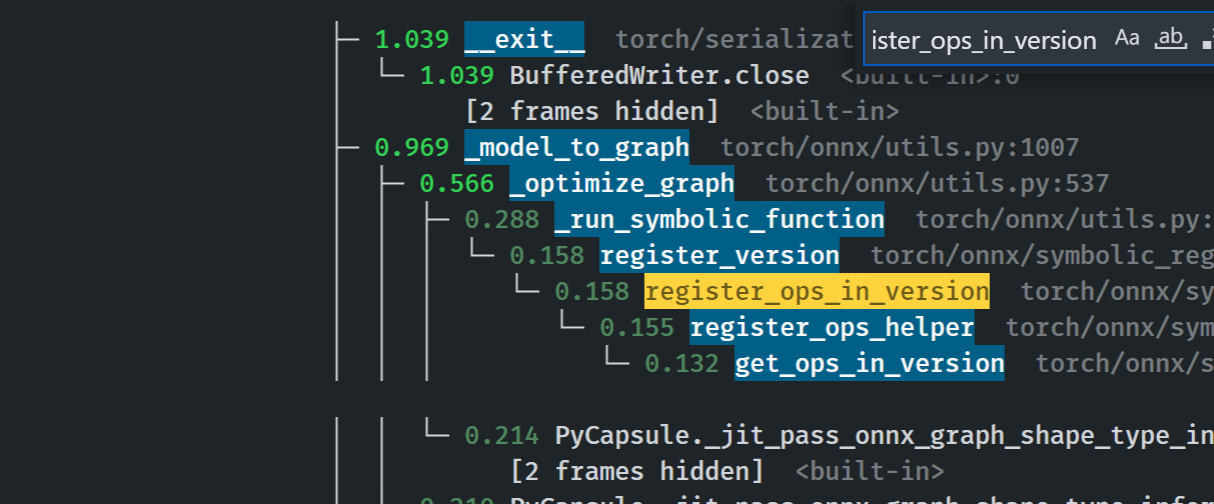
### Start up time
The startup process takes 0.03 seconds. Calls to `inspect` will be eliminated when we switch to using decorators for registration in #84448

Pull Request resolved: https://github.com/pytorch/pytorch/pull/84382
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
The default value for params_dict in _optimize_graph, which is None, throw the following error:
> _C._jit_pass_onnx_unpack_quantized_weights(
> TypeError: _jit_pass_onnx_unpack_quantized_weights(): incompatible function arguments. The following argument types are supported:
> 1. (arg0: torch::jit::Graph, arg1: Dict[str, IValue], arg2: bool) -> Dict[str, IValue]
Replacing it by an empty dict fixes the issue (and makes more sense).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83996
Approved by: https://github.com/BowenBao
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi
This PR provides a temporary fix on #84092 in exporter to avoid more cases falling into this bug.
A long-term fix will be provided later.
A simple repro with torch.onnx.export is still under investigation, as torch.jit.trace() is not the API we call inside torch.onnx.export, and it may introduce the difference. Therefore, a test case is provided here only.
A specific test one can use,
```python
import torch
import onnxruntime
from onnxruntime.training.ortmodule import DebugOptions, LogLevel
from onnxruntime.training.ortmodule import ORTModule
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.cv1 = torch.nn.Conv2d(3, 3, 5, 2, 1)
def forward(self, x):
x = self.cv1(x)
return x
x = torch.randn(10, 3, 20, 20) * 2
m = MyModule().eval()
x = x.cuda()
m = m.cuda()
debug_options = DebugOptions(log_level=LogLevel.VERBOSE, save_onnx=True, onnx_prefix="ViT-B")
m = ORTModule(m, debug_options=debug_options)
with torch.cuda.amp.autocast(dtype=torch.float16, cache_enabled=True):
loss = m(x)
```
AND make assertion fail in ORTModule
17ccd6fa02/orttraining/orttraining/python/training/ortmodule/_io.py (L578-L581)
Without the fix, the user will see the weight/bias of Conv node becomes constant.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84219
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi
Introduce `_jit_pass_onnx_assign_node_and_value_names` to parse and assign
scoped name for nodes and values in exported onnx graph.
Module layer information is obtained from `ONNXScopeName` captured in `scope`
attribute in nodes. For nodes, the processed onnx node name are stored in
attribute `onnx_name`. For values, the processed onnx output name are stored
as `debugName`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82040
Approved by: https://github.com/AllenTiTaiWang, https://github.com/justinchuby, https://github.com/abock
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao
Introduce `_jit_pass_onnx_assign_node_and_value_names` to parse and assign
scoped name for nodes and values in exported onnx graph.
Module layer information is obtained from `ONNXScopeName` captured in `scope`
attribute in nodes. For nodes, the processed onnx node name are stored in
attribute `onnx_name`. For values, the processed onnx output name are stored
as `debugName`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82040
Approved by: https://github.com/AllenTiTaiWang, https://github.com/justinchuby, https://github.com/abock
This PR adds an internal wrapper on the [beartype](https://github.com/beartype/beartype) library to perform runtime type checking in `torch.onnx`. It uses beartype when it is found in the environment and is reduced to a no-op when beartype is not found.
Setting the env var `TORCH_ONNX_EXPERIMENTAL_RUNTIME_TYPE_CHECK=ERRORS` will turn on the feature. setting `TORCH_ONNX_EXPERIMENTAL_RUNTIME_TYPE_CHECK=DISABLED` will disable all checks. When not set and `beartype` is installed, a warning message is emitted.
Now when users call an api with invalid arguments e.g.
```python
torch.onnx.export(conv, y, path, export_params=True, training=False)
# traning should take TrainingModel, not bool
```
they get
```
Traceback (most recent call last):
File "bisect_m1_error.py", line 63, in <module>
main()
File "bisect_m1_error.py", line 59, in main
reveal_error()
File "bisect_m1_error.py", line 32, in reveal_error
torch.onnx.export(conv, y, cpu_model_path, export_params=True, training=False)
File "<@beartype(torch.onnx.utils.export) at 0x1281f5a60>", line 136, in export
File "pytorch/venv/lib/python3.9/site-packages/beartype/_decor/_error/errormain.py", line 301, in raise_pep_call_exception
raise exception_cls( # type: ignore[misc]
beartype.roar.BeartypeCallHintParamViolation: @beartyped export() parameter training=False violates type hint <class 'torch._C._onnx.TrainingMode'>, as False not instance of <protocol "torch._C._onnx.TrainingMode">.
```
when `TORCH_ONNX_EXPERIMENTAL_RUNTIME_TYPE_CHECK` is not set and `beartype` is installed, a warning message is emitted.
```
>>> torch.onnx.export("foo", "bar", "f")
<stdin>:1: CallHintViolationWarning: Traceback (most recent call last):
File "/home/justinchu/dev/pytorch/torch/onnx/_internal/_beartype.py", line 54, in _coerce_beartype_exceptions_to_warnings
return beartyped(*args, **kwargs)
File "<@beartype(torch.onnx.utils.export) at 0x7f1d4ab35280>", line 39, in export
File "/home/justinchu/anaconda3/envs/pytorch/lib/python3.9/site-packages/beartype/_decor/_error/errormain.py", line 301, in raise_pep_call_exception
raise exception_cls( # type: ignore[misc]
beartype.roar.BeartypeCallHintParamViolation: @beartyped export() parameter model='foo' violates type hint typing.Union[torch.nn.modules.module.Module, torch.jit._script.ScriptModule, torch.jit.ScriptFunction], as 'foo' not <protocol "torch.jit.ScriptFunction">, <protocol "torch.nn.modules.module.Module">, or <protocol "torch.jit._script.ScriptModule">.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/justinchu/dev/pytorch/torch/onnx/_internal/_beartype.py", line 63, in _coerce_beartype_exceptions_to_warnings
return func(*args, **kwargs)
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 482, in export
_export(
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 1422, in _export
with exporter_context(model, training, verbose):
File "/home/justinchu/anaconda3/envs/pytorch/lib/python3.9/contextlib.py", line 119, in __enter__
return next(self.gen)
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 177, in exporter_context
with select_model_mode_for_export(
File "/home/justinchu/anaconda3/envs/pytorch/lib/python3.9/contextlib.py", line 119, in __enter__
return next(self.gen)
File "/home/justinchu/dev/pytorch/torch/onnx/utils.py", line 95, in select_model_mode_for_export
originally_training = model.training
AttributeError: 'str' object has no attribute 'training'
```
We see the error is caught right when the type mismatch happens, improving from what otherwise would become `AttributeError: 'str' object has no attribute 'training'`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83673
Approved by: https://github.com/BowenBao
Legacy code has onnx_shape_inference=False by default, which is misleading
as every other export api sets it to True unless otherwise overriden by caller.
There is only two tests that need updating according to this change.
* test_utility_funs.py::test_constant_fold_shape. The resulting number of nodes
in graph is increased by 1, due to that previously the extra constant node was
added as initializer.
* test_utility_funs.py::test_onnx_function_substitution_pass. Enabling onnx
shape inference discovered discrepancy in test input shape and supplied dynamic
axes arguments.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82767
Approved by: https://github.com/justinchuby, https://github.com/abock
### Description
<!-- What did you change and why was it needed? -->
Remove unused patching methods:
- `torch._C.Graph.constant`
- unpatch `torch._C.Node.__getitem__` and move the helper function to `symbolic_helper`
Add typing annotations
### Issue
<!-- Link to Issue ticket or RFP -->
#76254
### Testing
<!-- How did you test your change? -->
Unit tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83006
Approved by: https://github.com/BowenBao
Part of #79263
Previously, all quantized PyTorch tensors are all casted to the dtypes which comply with ONNX's definition, i.e. `scale` is casted to `double`, and `zero_point` is casted to `int64`. These casts lead to inconsistent dtypes when comparing PyTorch's outputs and ONNX runtime's outputs.
Now, `cast_onnx_accepted` argument is added to `unpack_quantized_tensor` function. When making example inputs for ONNX, we cast them to the ONNX compliant dtypes; otherwise, they are casted to PyTorch default types for quantization.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79690
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
Add flag (inline_autograd) to enable inline export of model consisting of autograd functions. Currently, this flag should only be used in TrainingMode.EVAL and not for training.
An example:
If a model containing ``autograd.Function`` is as follows
```
class AutogradFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i.exp()
result = result.log()
ctx.save_for_backward(result)
return result
```
Then the model is exported as
```
graph(%0 : Float):
%1 : Float = ^AutogradFunc(%0)
return (%1)
```
If inline_autograd is set to True, this will be exported as
```
graph(%0 : Float):
%1 : Float = onnx::Exp(%0)
%2 : Float = onnx::Log(%1)
return (%2)
```
If one of the ops within the autograd module is not supported, that particular node is exported as is mirroring ONNX_FALLTHROUGH mode
Fixes: #61813
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74765
Approved by: https://github.com/BowenBao, https://github.com/malfet
- Remove wrappers in `__init__` around utils and instead expose those functions directly. Move the docstrings from `__init__` to corresponding functions in utils
- Annotate `torch.onnx.export` types
- Improve docstrings
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78231
Approved by: https://github.com/BowenBao
When `TrainingMode.PRESERVE` is set for export, the exporter used to change the model's training mode based on some logic. Now we respect the option and not touch the model's training state.
- Previously `_set_training_mode`'s behavior doesn't match what the global variable expects. This PR removes the deprecated `_set_training_mode` and makes the type correct.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78583
Approved by: https://github.com/BowenBao
A graph is exported for each set of inputs. The exported graphs are then compared
to each other, and discrepancies are reported. This function first checks the jit
graph, and then the onnx graph.
Unless otherwise specified, the jit/ONNX graph is expected to be the same, regardless
of the inputs it used for exporting. A discrepancy would imply the graph exported is
not accurate when running with other set of inputs, which will typically results in
runtime error or output mismatches.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78323
Approved by: https://github.com/justinchuby, https://github.com/garymm
Use pyupgrade(https://github.com/asottile/pyupgrade) and flynt to modernize python syntax
```sh
pyupgrade --py36-plus --keep-runtime-typing torch/onnx/**/*.py
pyupgrade --py36-plus --keep-runtime-typing test/onnx/**/*.py
flynt torch/onnx/ --line-length 120
```
- Use f-strings for string formatting
- Use the new `super()` syntax for class initialization
- Use dictionary / set comprehension
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77935
Approved by: https://github.com/BowenBao
{kind=link}
{kind=link}
{kind=link}