Pull Request resolved: https://github.com/pytorch/pytorch/pull/77698
This PR adds tree building to the post processing of profiler. The basic algorithm is to sort the events, maintain a stack and a priority queue of event ends, and push/pop accordingly. The logic for merging Python events is still separate in `profiler_kineto.cpp`. That can be removed when Python events have an `EventType`.
Differential Revision: [D36321105](https://our.internmc.facebook.com/intern/diff/D36321105/)
Approved by: https://github.com/aaronenyeshi
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75616
Kineto introduced a new profiler to read performance counters from NVIDIA GPUs (CUPTI Range Profiler API)
Here we are adding support to configure this Kineto range profiler mode
Example
```
with torch.profiler.profile(
activities=[ProfilerActivity.CUDA],
record_shapes=True,
on_trace_ready=trace_handler,
experimental_config=torch.profiler._ExperimentalConfig(
profiler_metrics=[
"kineto__tensor_core_insts",
"dram__bytes_read.sum",
"dram__bytes_write.sum"],
profiler_measure_per_kernel=False),
) as prof:
res = train_batch(modeldef)
prof.step()
```
## Details
* Introduce a new structure `KinetoProfilerConfig` so users can configure Kineto specific options, keeps profiler API consistent.
* Populate configuration options for Kineto.
Test Plan: CI and tested on resnet50
Reviewed By: robieta
Differential Revision: D34489487
fbshipit-source-id: 8ef82d2593f4f4d5824ca634f7d25507bc572caa
(cherry picked from commit 4a2af70629db55a605d4b8d0a54d41df2b247183)
Summary: It's currently possible for C++ callers to check if there is an active profiler. This adds Python API parity. For now we just use `torch._C._autograd` namespace, as this is mostly for first party frameworks like RPC. (We can always move to public API if there is demand.)
Test Plan: Added unit test
Differential Revision: D35602425
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75754
Approved by: https://github.com/rohan-varma
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72292
Integrates the libkineto step() method into pytorch profiler step() invocation.
This enables Kineto to track the iteration count and trigger trace collection on iteration boundaries from outside the process.
Test Plan:
## Test using pytorch profiler step() method
Modified the resnet integration test to use pytorch profiler.
Configure it to capture 3 iterations :
```
ACTIVITIES_COMPRESSION_ALGORITHM=GZIP
ACTIVITIES_MANIFOLD_PATH=gpu_traces/tree/traces/dynocli/0/1643063194/127.0.0.1/
PROFILE_START_ITERATION=200
ACTIVITIES_WARMUP_ITERATIONS=1
ACTIVITIES_ITERATIONS=3
```
Run
dyno gputrace -gpuconf /tmp/kineto_pytorch.conf
The output trace has iterations 202, 203, 204 :) One iteration is skipped due to warmup. (Also its one off due 0 vs 1 indexing)
[Trace link](https://www.internalfb.com/intern/perfdoctor/trace_view?filepath=tree%2Ftraces%2Fdynocli%2F0%2F1643063194%2F127.0.0.1%2Flibkineto_activities_501743.json.gz&bucket=gpu_traces)
{F695716262}
Reviewed By: robieta
Differential Revision: D33825241
fbshipit-source-id: 70983420cf47ebbac7b44bfb6494d314506302c5
(cherry picked from commit 96c06ecc9a80512d85b8941f195360f41d74103f)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72301
First step in resolving #35026.
This adds `PythonRecordFunction` which is a `torch::CustomClassHolder`
for `at::RecordFunction` to keep the ATen code free of torch includes.
And adds new unused internal API functions
`_record_function_enter_new` which return the torchbind object.
Once the FC period is expired, `torch.profiler.record_function` will
be updated to use this new internal API. Then once BC period is
expired, the cpp_custom_type_hack-based API can be removed.
Test Plan: Imported from OSS
Reviewed By: dagitses
Differential Revision: D34586311
Pulled By: robieta
fbshipit-source-id: d3eb9ffad7b348548a2b22c75203a92d1cb5115b
(cherry picked from commit 92d2ca808e5fbd20c9d6645dcabc3f059f9ef2d3)
I was working on an explanation of how to call into the "super"
implementation of some given ATen operation inside of __torch_dispatch__
(https://github.com/albanD/subclass_zoo/blob/main/trivial_tensors.py)
and I kept thinking to myself "Why doesn't just calling super() on
__torch_dispatch__ work"? Well, after this patch, it does! The idea
is if you don't actually unwrap the input tensors, you can call
super().__torch_dispatch__ to get at the original behavior.
Internally, this is implemented by disabling PythonKey and then
redispatching. This implementation of disabled_torch_dispatch is
not /quite/ right, and some reasons why are commented in the code.
There is then some extra work I have to do to make sure we recognize
disabled_torch_dispatch as the "default" implementation (so we don't
start slapping PythonKey on all tensors, including base Tensors),
which is modeled the same way as how disabled_torch_function is done.
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73684
Approved by: albanD
Summary:
Reland of https://github.com/pytorch/pytorch/pull/72623 that was reverted for the tls cleanup was removed.
From close inspection on the counting of the number of available keys, I think there is one more since the guard is actually one after the last usable key. With this update assert, the last updated key will still be <=63 which will fit just fine.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72832
Reviewed By: H-Huang
Differential Revision: D34228571
Pulled By: albanD
fbshipit-source-id: ce5e10a841ea87386727346cfc8d9327252574c4
(cherry picked from commit 59d3b863534a37ac3463e2814bc9599c322669ee)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69798
One of the major sources of complexity in `profiler_kineto.cpp` is that kineto may or may not be available. The code (including the types) follows two related but often distict codepaths, and large sections may or may not be `#ifdef`'d out.
Optimizing such code which preserving correctness is quite difficult; at one point I realized that I had broken the non-Kineto case, because moving work into the finalize step runs astray of a very large `#ifdef` around the finalize logic.
In order to make optimization more tractable, I gathered all of the calls to Kineto APIs and isolated them in the `kineto_shim.h/.cpp` files: the header allows callers to pretend as though Kineto is always available (mostly), and the cpp file hides most of the horrible `#ifdef`s so they don't pollute the main profiler code.
Test Plan: Unit tests.
Reviewed By: aaronenyeshi
Differential Revision: D32690568
fbshipit-source-id: 9a276654ef0ff9d40817c2f88f95071683f150c5
Summary:
When default hooks are set, they are pushed onto a stack.
When nesting context-manager, only the inner-most hooks will
be applied.
There is special care needed to update the TLS code. See also https://github.com/pytorch/pytorch/issues/70940 (i.e. do we need to be storing the enabled flag as well?)
Fixes https://github.com/pytorch/pytorch/issues/70134
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70932
Reviewed By: mruberry
Differential Revision: D33530370
Pulled By: albanD
fbshipit-source-id: 3197d585d77563f36c175d3949115a0776b309f4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69255
One thing that I've found as I optimize profier is that there's a lot of intermingled code, where the kineto profiler relies on the legacy (autograd) profiler for generic operations. This made optimization hard because I had to manage too many complex dependencies. (Exaserbated by the USE_KINETO #ifdef's sprinkled around.) This PR is the first of several to restructure the profiler(s) so the later optimizations go in easier.
Test Plan: Unit tests
Reviewed By: aaronenyeshi
Differential Revision: D32671972
fbshipit-source-id: efa83b40dde4216f368f2a5fa707360031a85707
Summary:
There were two issues with the original PR:
1) My assumption that bound C functions could be trusted to stay alive was not valid. I'm still not entirely sure what was dying, but I've just added a cache so that the first time I see a function I collect the repr just like I was already doing with Python functions.
2) `std::regex` is known to be badly broken and prone to segfaults. Because I'm just doing a very simple prefix prune it's fine to do it manually; see `trimPrefix`. Long term we should move all of PyTorch to `re2` as the internal lint suggests, but CMake is hard and I couldn't get it to work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68325
Reviewed By: chaekit
Differential Revision: D32432596
Pulled By: robieta
fbshipit-source-id: 06fb4bcdc6933a3e76f6021ca69dc77a467e4b2e
Summary:
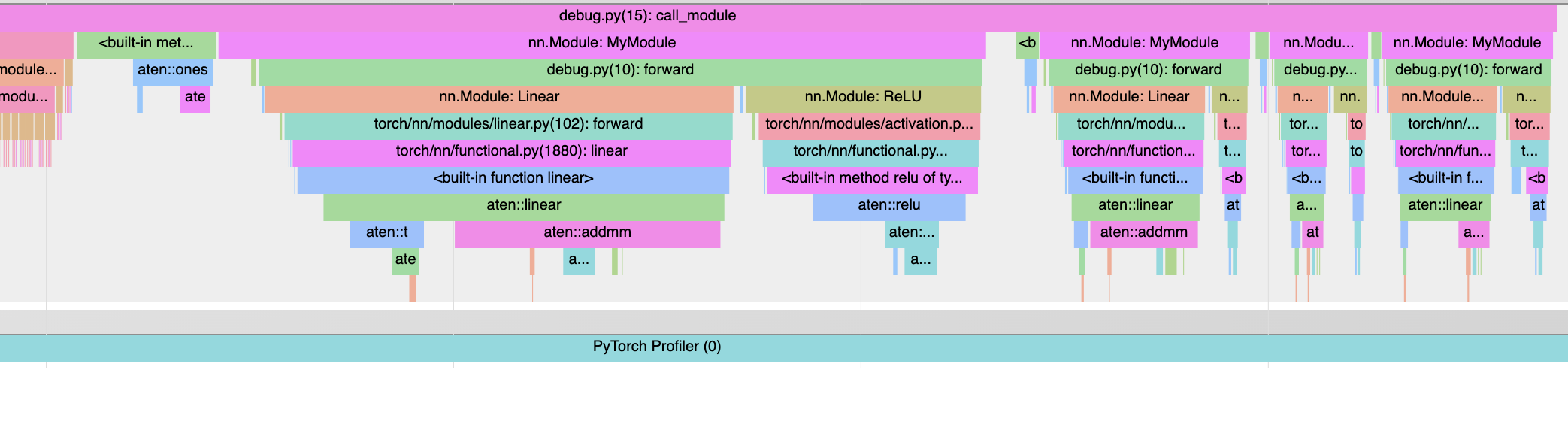
This PR instruments the CPython interpreter and integrates the resulting trace into the PyTorch profiler.
The python tracing logic works by enabling `PyEval_SetProfile`, and then logging the minimal information to track every time python calls or returns from a function. A great deal of care has gone into keeping this process very lightweight; the `RawEvent` struct is only two words and doesn't do anything fancy. When a python function is called, we have to do extra work. If the call is to `nn.Module.__call__`, we simply incref to extend the life of the module. Otherwise we check if we have seen the function before, and if not go through the (somewhat expensive) task of saving the strings which we then cache.
To actually get a useful timeline, we have to replay the events to determine the state of the python stack at any given point. A second round of stack replay is needed to figure out what the last python function was for each torch op so we can reconstruct the correct python stack. All of this is done during post processing, so while we want to be reasonably performant it is no longer imperative to shave every last bit.
I still need to do a bit of refinement (particularly where the tracer interfaces with the profiler), but this should give a good sense of the general structure.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67407
Test Plan:
```
import torch
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(2, 2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.linear(x)
return self.relu(x)
def call_module():
m = MyModule()
for _ in range(4):
m(torch.ones((2, 2)))
def top_level_fn():
with torch.profiler.profile(with_stack=True) as p:
call_module()
p.export_chrome_trace("test_trace.json")
top_level_fn()
```
<img width="1043" alt="Screen Shot 2021-10-27 at 6 43 18 PM" src="https://user-images.githubusercontent.com/13089297/139171803-f95e70f3-24aa-45e6-9d4b-6d437a3f108d.png">
PS: I've tried to comment liberally, particularly around some of the more magical parts. However I do plan on doing another linting and commenting pass. Hopefully it's not too bad right now.
Reviewed By: gdankel, chaekit
Differential Revision: D32178667
Pulled By: robieta
fbshipit-source-id: 118547104a7d887e830f17b94d3a29ee4f8c482f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65736
We ran into some limitations to extract PyTorch operator parameters through hooks or the execution graph. Some of these limitations are not due to the operator not exposing them, rather the inputs for these operators are already fused/processed in some cases (like embedding table). We want to be able to attach some metadata to the user scope record functions allowing the profilers to later extract these information.
The record function C++ API already supports taking inputs and outputs information. The corresponding Python interface does not support them and only allows a string name as record function parameter.
This diff adds support for user to optionally to add additional arguments to the record function in two ways.
1. to remain backward compatible with `record_function_op`, we have added an optional string arg to the interface: `with record_function(name, arg_str)`.
2. to support data dependency graph, we also have the new `torch.autograd._record_function_with_args_enter` and `torch.autograd._record_function_with_args_exit` functions to provide an interface where we can give additional tensor arguments. For now we imagine this can be used for debugging or analysis purpose. In this form, we currently support some basic data types as inputs: scalars, string, list, and tensor.
Example usage:
```
# record_function operator with a name and optionally, a string for arguments.
with record_function("## TEST 1 ##", "[1, 2, 3]"):
<actual module or operator>
# more general form of record_function
a = _record_function_with_args_enter("## TEST 2 ##", 1, False, 2.5, [u, u], "hello", u)
<actual module or operator>
_record_function_with_args_exit(a)
```
Corresponding outputs in execution graph:
```
{
"name": "## TEST 2 ##", "id": 7, "parent": 3, "fw_parent": 0, "scope": 5, "tid": 1, "fw_tid": 0,
"inputs": [1,false,2.5,[6,6],"hello",6], "input_shapes": [[],[],[],[[3,4,5],[3,4,5]],[],[3,4,5]], "input_types": ["Int","Bool","Double","GenericList[Tensor(float),Tensor(float)]","String","Tensor(float)"],
"outputs": [], "output_shapes": [], "output_types": []
},
{
"name": "## TEST 1 ##", "id": 3, "parent": 2, "fw_parent": 0, "scope": 5, "tid": 1, "fw_tid": 0,
"inputs": ["1, 2, 3"], "input_shapes": [[]], "input_types": ["String"],
"outputs": [], "output_shapes": [], "output_types": []
},
```
Test Plan:
```
=> buck build caffe2/test:profiler --show-output
=> buck-out/gen/caffe2/test/profiler#binary.par test_profiler.TestRecordFunction
test_record_function (test_profiler.TestRecordFunction) ... Log file: /tmp/libkineto_activities_1651304.json
Net filter:
Target net for iteration count:
Net Iterations: 3
INFO:2021-09-27 01:10:15 1651304:1651304 Config.cpp:424] Trace start time: 2021-09-27 01:10:30
Trace duration: 500ms
Warmup duration: 5s
Net size threshold: 0
GPU op count threshold: 0
Max GPU buffer size: 128MB
Enabled activities: cpu_op,user_annotation,external_correlation,cuda_runtime,cpu_instant_event
Manifold bucket: gpu_traces
Manifold object: tree/traces/clientAPI/0/1632730215/devvm2060.ftw0/libkineto_activities_1651304.json
Trace compression enabled: 1
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:536] Tracing starting in 14s
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:48] Target net for iterations not specified - picking first encountered that passes net filter
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:57] Tracking net PyTorch Profiler for 3 iterations
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:126] Processing 1 CPU buffers
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:686] Recorded nets:
INFO:2021-09-27 01:10:15 1651304:1651304 ActivityProfiler.cpp:689] PyTorch Profiler: 1 iterations
ok
----------------------------------------------------------------------
Ran 1 test in 0.021s
OK
```
Reviewed By: gdankel
Differential Revision: D31165259
fbshipit-source-id: 15920aaef7138c666e5eca2a71c3bf33073eadc4
Summary:
There has an issue when calling **torch.get_autocast_cpu_dtype** and **torch.get_autocast_gpu_dtype**:
```
>>> torch.get_autocast_gpu_dtype()==torch.half
False
>>> torch.get_autocast_cpu_dtype()==torch.bfloat16
False
```
but the expected results should be :
```
>>> torch.get_autocast_gpu_dtype()==torch.half
True
>>> torch.get_autocast_cpu_dtype()==torch.bfloat16
True
```
This PR is about fixing this issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66396
Reviewed By: ejguan
Differential Revision: D31541727
Pulled By: albanD
fbshipit-source-id: 1a0fe070a82590ef2926a517bf48046c2633d168
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64360
This PR adds a (private) enable_python_mode context manager.
(see torch/utils/_python_dispatch.py).
enable_python_mode accepts the type of a __torch_dispatch__ object
as its argument. Whenever an operator gets called inside of the
context manager, it dispatches to the __torch_dispatch__ of
the passed-in type.
Example usage:
```
with enable_python_mode(LoggingTensor):
z = torch.empty([])
assert isinstance(z, LoggingTensor)
```
There are quite a few changes that were made to support this.
First, we added TorchDispatchTypeObject, a C++ struct that represents the
type of a `__torch_dispatch__` object (e.g. LoggingTensor).
It holds both the PyObject* representing the class and a PyInterpreter*
so we know which Python interpreter it came from.
Next, we updated the concrete_dispatch_fn in python_variable.cpp to accept
a `const std::shared_ptr<TorchDispatchTypeObject>&` argument. When this
is null, dispatching happens as usual. When it is non-null, we prepend
the TorchDispatchTypeObject's PyObject* to the overloaded args list so that
it is considered first for dispatch.
To get that to work, we changed how `handle_torch_dispatch_no_python_arg_parser`
works. The "overloaded args list" previously only consisted of Tensor PyObjects,
but now it can have types in addition to Tensors!
- We renamed `append_overloaded_arg` to `append_overloaded_arg`
- We added a new `append_overloaded_type` that appends a type to
overloaded_args
- We added special handling in `handle_torch_dispatch_no_python_arg_parser`
and `append_overloaded_arg` to handle types in addition to Tensors.
Then, there is PythonMode and PythonModeTLS.
- We reuse the DispatchKey::Python dispatch key as a mode key
- We use PythonMode::enter and PythonMode::exit to enable/disable
DispatchKey::Python and set the PythonModeTLS.
- PythonModeTLS stores a TorchDispatchTypeObject as metadata.
- PythonMode is in libtorch_python, and PythonModeTLS is in ATen.
This split is due to the libtorch_python library boundary (because we need
to save TLS in ATen/ThreadLocalState)
- We modify the PythonFallbackKernel to look up
the relevant TorchDispatchTypeObject (if Python Mode is active) and
dispatch using it.
There are two more miscellaneous changes:
- internal_new_from_data (torch/csrc/utils/tensor_new.cpp) gets an
exclude guard. enable_python_mode currently does not handle
torch.tensor and the exclude guard is to prevent a bug.
Future:
- This PR does not allow for the nesting of Python modes. In the future we
should be able to enable this with a more sane no_dispatch API and by changing
the TLS to a stack. For now I did not need this for CompositeImplicitAutograd testing.
Test Plan: - new tests
Reviewed By: ezyang
Differential Revision: D30698082
Pulled By: zou3519
fbshipit-source-id: 7094a90eee6aa51f8b71bc4d91cfb6f49e9691f8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63552
In this PR, we want to exclude these 2 cases in the `Autocast` weight cache usages:
- Using `torch.jit.trace` under the `Autocast`
As report in https://github.com/pytorch/pytorch/issues/50231 and several other discussions, using `torch.jit.trace` under the `Autocast`, the trace process would hit Autocast's weight cache and fails. So we should disable weight cache under the trace process.
- Using `Autocast` with `Grad mode`
- Usually we are using `Grad mode` for training. Since in the training phase, the weight will change in every step. So we doesn't need to cache the weight.
- For the recommended `Autocast` training case in the [doc](https://pytorch.org/docs/stable/amp.html), `Autocast` will clear the cache every step leaving the context. We should disable it to save the clear operations.
```
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
for input, target in data:
optimizer.zero_grad()
with autocast():
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
```
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D30644913
Pulled By: ezyang
fbshipit-source-id: ad7bc87372e554e7aa1aa0795e9676871b3974e7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63496
This PR adds a (private) enable_python_mode context manager.
(see torch/utils/_python_dispatch.py).
enable_python_mode accepts the type of a __torch_dispatch__ object
as its argument. Whenever an operator gets called inside of the
context manager, it dispatches to the __torch_dispatch__ of
the passed-in type.
Example usage:
```
with enable_python_mode(LoggingTensor):
z = torch.empty([])
assert isinstance(z, LoggingTensor)
```
There are quite a few changes that were made to support this.
First, we added TorchDispatchTypeObject, a C++ struct that represents the
type of a `__torch_dispatch__` object (e.g. LoggingTensor).
It holds both the PyObject* representing the class and a PyInterpreter*
so we know which Python interpreter it came from.
Next, we updated the concrete_dispatch_fn in python_variable.cpp to accept
a `const std::shared_ptr<TorchDispatchTypeObject>&` argument. When this
is null, dispatching happens as usual. When it is non-null, we prepend
the TorchDispatchTypeObject's PyObject* to the overloaded args list so that
it is considered first for dispatch.
To get that to work, we changed how `handle_torch_dispatch_no_python_arg_parser`
works. The "overloaded args list" previously only consisted of Tensor PyObjects,
but now it can have types in addition to Tensors!
- We renamed `append_overloaded_arg` to `append_overloaded_arg`
- We added a new `append_overloaded_type` that appends a type to
overloaded_args
- We added special handling in `handle_torch_dispatch_no_python_arg_parser`
and `append_overloaded_arg` to handle types in addition to Tensors.
Then, there is PythonMode and PythonModeTLS.
- We reuse the DispatchKey::Python dispatch key as a mode key
- We use PythonMode::enter and PythonMode::exit to enable/disable
DispatchKey::Python and set the PythonModeTLS.
- PythonModeTLS stores a TorchDispatchTypeObject as metadata.
- PythonMode is in libtorch_python, and PythonModeTLS is in ATen.
This split is due to the libtorch_python library boundary (because we need
to save TLS in ATen/ThreadLocalState)
- We modify the PythonFallbackKernel to look up
the relevant TorchDispatchTypeObject (if Python Mode is active) and
dispatch using it.
There are two more miscellaneous changes:
- internal_new_from_data (torch/csrc/utils/tensor_new.cpp) gets an
exclude guard. enable_python_mode currently does not handle
torch.tensor and the exclude guard is to prevent a bug.
Future:
- This PR does not allow for the nesting of Python modes. In the future we
should be able to enable this with a more sane no_dispatch API and by changing
the TLS to a stack. For now I did not need this for CompositeImplicitAutograd testing.
Test Plan: - new tests
Reviewed By: malfet, albanD
Differential Revision: D30543236
Pulled By: zou3519
fbshipit-source-id: ef5444d96a5a957d1657b7e37dce80f9a497d452
Summary:
This PR implements the necessary hooks/stubs/enums/etc for complete ONNX Runtime (ORT) Eager Mode integration. The actual extension will live out of tree at https://github.com/pytorch/ort.
We have been [working on this at Microsoft](https://github.com/microsoft/onnxruntime-pytorch/tree/eager-ort/torch_onnxruntime) for the last few months, and are finally ready to contribute the PyTorch core changes upstream (nothing major or exciting, just the usual boilerplate for adding new backends).
The ORT backend will allow us to ferry [almost] all torch ops into granular ONNX kernels that ORT will eagerly execute against any devices it supports (therefore, we only need a single ORT backend from a PyTorch perspective).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58248
Reviewed By: astaff
Differential Revision: D30344992
Pulled By: albanD
fbshipit-source-id: 69082b32121246340d686e16653626114b7714b2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62417
This diff adds an option to make enableProfiler enable callbacks only
for certain RecordScopes.
Why?
Profiling has some overhead when we repeatedly execute callbacks for
alls copes. On mobile side when we often have small quantized models
this overhead can be large. We observed that by only profiling top level
op and skipping profiling of other atend ops called within we can limit
this overhead. For example, instead of profling at::conv2d -> at::convolution ->
at::convolution_ and further more if ops like transpose etc. are called,
skipping profiling of those. Of course this limits the visibility, but
at the least this way we get a choice.
Test Plan: Imported from OSS
Reviewed By: ilia-cher
Differential Revision: D29993659
fbshipit-source-id: 852d3ae7822f0d94dc6e507bd4019b60d488ef69
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61792
KinetoEvent
This PR adds module hierarchy information to events.
What is module hierarchy information attached to events?
During profiling a TorchScript module, when events are added, we ask JIT
what is the module hierarchy associated with the node being
executed. At the time of execution of that node, there might be multiple
frames in the stack of interpreter. For each frame, we find
corresponding node and the corresponding module hierarchy is queried.
Module hierarchy corresponding to the node is associated with node's
InlinedCallStack. InlinedCallStack of node tracks the path via which the
node is inlined. Thus during the inlining process we annotate
module information corresponding to the CallMethod nodes being inlined.
With this PR, chrome trace will contain additional metadata:
"Module Hierarchy". This can look like this:
TOP(ResNet)::forward.SELF(ResNet)::_forward_impl.layer1(Sequential)::forward.0(BasicBlock)::forward.conv1(Conv2d)::forward.SELF(Conv2d)::_conv_forward
It contains module instance, type name and the method name in the
callstack.
Test Plan:
test_profiler
Imported from OSS
Reviewed By: raziel, ilia-cher
Differential Revision: D29745442
fbshipit-source-id: dc8dfaf7c5b8ab256ff0b2ef1e5ec265ca366528
Summary:
When using saved tensors hooks (especially default hooks),
if the user defines a `pack_hook` that modifies its input,
it can cause some surprising behavior.
The goal of this PR is to prevent future user headache by catching
inplace modifications of the input of `pack_hook` and raising an error if
applicable.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62717
Reviewed By: albanD
Differential Revision: D30255243
Pulled By: Varal7
fbshipit-source-id: 8d73f1e1b50b697a59a2849b5e21cf0aa7493b76
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61931
This PR consolidates the profiling code around a new C++ implementation
(profiler_kineto.h/cpp) and uses it unconditionally from
torch.autograd.profiler/torch.profiler:
1. Always use profiler_kineto.h/cpp as the C++ implementation
2. Simplify profiler.py to remove unneeded parts depending on legacy
impl
3. Move some of the legacy logic into profiler_legacy.py (to be fully
deleted later)
Test Plan:
USE_KINETO=1 USE_CUDA=1 USE_MKLDNN=1 BLAS=MKL BUILD_BINARY=1 python setup.py develop install --cmake
python test/test_profiler.py -v
USE_KINETO=0 USE_CUDA=1 USE_MKLDNN=1 BLAS=MKL BUILD_BINARY=1 python setup.py develop install --cmake
python test/test_profiler.py -v
Imported from OSS
Reviewed By: gdankel
Differential Revision: D29801599
fbshipit-source-id: 9794d29f2af38dddbcd90dbce4481fc8575fa29e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62563
Expose a pair of functions to Python users: torch.autograd.graph.set_saved_tensors_default_hooks(pack, unpack) and torch.autograd.graph.reset_saved_tensors_default_hooks().
These functions control the hooks applied to saved tensors: all tensors saved in that context will be packed using the pack function, then unpacked accordingly when needed.
Currently, this works by simply calling register_hooks (cf #60975) directly at the end of the constructor of a SavedVariable. This could be optimized further by not performing the copy before registering default hooks, but this would require a small refactor. Edit: the refactor is done in #61927.
A current limitation is that if users create tensors in this context, they will not be able to register additional hooks on the saved tensor.
For instance, to perform something like #28997, one could define a pack function that saves to disk whenever the tensor size is too big and returns a filename, then unpack simply reads the content of the file and outputs a tensor, e.g.:
```
def pack(x):
name = os.path.join(tmp_dir, str(uuid.uuid4()))
torch.save(x, name)
return name
def unpack(name):
return torch.load(name)
```
Relanding previous PR: https://github.com/pytorch/pytorch/pull/61834
Original PR led to timeout error in: https://www.internalfb.com/mast/job/yuguo-release_canary_offline_training-inlinecvrp_a-canary_offline_train_28a7ecfc
Now passing: https://www.internalfb.com/mast/job/quach-release_canary_offline_training-inlinecvrp_a-canary_offline_train_9bb57e98
The difference with the new version is we don't need to acquire the GIL when calling `PyDefaultSavedVariableHooks::get_hooks`.
Test Plan: Imported from OSS
Reviewed By: iramazanli
Differential Revision: D30045405
Pulled By: Varal7
fbshipit-source-id: 7f6c07af3a56fe8835d5edcc815c15ea4fb4e332
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61834
Expose a pair of functions to Python users: torch.autograd.graph.set_saved_tensors_default_hooks(pack, unpack) and torch.autograd.graph.reset_saved_tensors_default_hooks().
These functions control the hooks applied to saved tensors: all tensors saved in that context will be packed using the pack function, then unpacked accordingly when needed.
Currently, this works by simply calling register_hooks (cf #60975) directly at the end of the constructor of a SavedVariable. This could be optimized further by not performing the copy before registering default hooks, but this would require a small refactor. Edit: the refactor is done in #61927.
A current limitation is that if users create tensors in this context, they will not be able to register additional hooks on the saved tensor.
For instance, to perform something like #28997, one could define a pack function that saves to disk whenever the tensor size is too big and returns a filename, then unpack simply reads the content of the file and outputs a tensor, e.g.:
```
def pack(x):
name = os.path.join(tmp_dir, str(uuid.uuid4()))
torch.save(x, name)
return name
def unpack(name):
return torch.load(name)
```
Test Plan: Imported from OSS
Reviewed By: zou3519
Differential Revision: D29792193
Pulled By: Varal7
fbshipit-source-id: 33e931230ef59faa3ec8b5d11ef7c05539bce77c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59760
See https://github.com/pytorch/pytorch/issues/59049
There are some moving parts to this PR, I'll structure this explanation so the straightforward parts go first, and then the less straightforward parts.
**The actual dispatch to Python.** The core logic of dispatch to Python lives in `concrete_dispatch_fn` in `torch/csrc/autograd/python_variable.cpp`. It takes the input IValue stack, scans all the arguments for Tensor arguments, and defers most of the heavy lifting to `handle_torch_function_no_python_arg_parser` which actually does all of the logic for calling out to torch dispatch (in particular, this function handles multiple dispatch situations for you). Because we have a different function name than regular `__torch_function__` handling, `handle_torch_function_no_python_arg_parser` is generalized to accept a magic method name to look for when testing if Tensors have custom handling or not. Unlike `__torch_function__`, by default there is no `__torch_dispatch__` on Tensor classes.
**Maintaining the Python dispatch key.** In order to get to the dispatch to Python logic, we must tag Tensors with the `__torch_dispatch__` magic method with the newly added Python dispatch key (separated from PythonFuncTorch to allow for a transitional period while they migrate to this mechanism). We expose a new private property `_is_python_dispatch` that assists in debugging if a Tensor is participating in Python dispatch or not. We apply the Python dispatch key the first time a PyObject for a Tensor is constructed (THPVariable_NewWithVar), testing if `__torch_dispatch__` exists with then newly added `check_has_torch_dispatch`.
**Shallow copy and detach.** For the simple examples tested in this PR, most creations of Tensor route through the dispatcher. The exception to this is `shallow_copy_and_detach`, which bypasses the dispatcher and is used when saving tensors for backwards. When a Tensor is Python dispatch, we override the behavior of `shallow_copy_and_detach` to instead directly call into `__torch_dispatch__` to perform a `detach` operation (in the same way it would be invoked if you called `detach` directly). Because this Python call is triggered directly from c10::TensorImpl, it must be indirected through `PyInterpreter::detach`, which is the general mechanism for dynamic dispatching to the Python interpreter associated with a TensorImpl.
**torchdeploy compatibility.** The dispatch to Python logic cannot be directly registered to the dispatcher as it is compiled in the Python library, which will get loaded multiple times per torchdeploy interpreter. Thus, we must employ a two phase process. First, we register a fallback inside a non-Python library (aten/src/ATen/core/PythonFallbackKernel.cpp). Its job is to determine the appropriate PyInterpreter to handle the Python dispatch by going through all of the arguments and finding the first argument that has a PyObject/PyInterpreter. With this PyInterpreter, it makes another dynamic dispatch via "dispatch" which will go to the correct torchdeploy interpreter to handle dispatching to actual Python.
**Testing.** We provide a simple example of a LoggingTensor for testing, which can be used to generate TorchScript-like traces to observe what operations are being called when a Tensor is invoked. Although a LoggingTensor would be better implemented via an is-a relationship rather than a has-a relationship (as is done in the test), we've done it this way to show that arbitrarily complex compositions of tensors inside a tensor work properly.
**Known limitations.**
* We haven't adjusted any operator code, so some patterns may not work (as they lose the Python subclass in an unrecoverable way)
* `__torch_function__` must be explicitly disabled with `_disabled_torch_function_impl` otherwise things don't work quite correctly (in particular, what is being disabled is default subclass preservation behavior.)
* We don't ever populate kwargs, even when an argument is kwarg-only
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision:
D29017912
D29017912
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Pulled By: ezyang
fbshipit-source-id: a67714d9e541d09203a8cfc85345b8967db86238
{kind=link}