Summary:
Support adding type annotations for class methods and nn.Module methods which are not invoked under the hood of MonkeyType
** Changes **
* This PR involves a slight change in how the example inputs are passed while scripting `class` and `nn.Module` objects.
* The example inputs passed to `_script_pdt` is of the following format:
- example_inputs= [(obj.method1, (arg_list)), (obj.method2, (arg_list)),]
* For nn.Modules, to infer types for `forward` methods, example_inputs can be passed in two ways:
- example_inputs= [(obj.forward, (arg_list, ))]
- example_inputs = [(obj, (arg_list, ) )]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57202
Reviewed By: desertfire
Differential Revision: D28382827
Pulled By: nikithamalgifb
fbshipit-source-id: 5481467f3e909493bf3f439ee312056943508534
Summary:
Adds support for type inference of nn.Module methods using monkeytype in JIT
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57165
Reviewed By: gmagogsfm
Differential Revision: D28064983
Pulled By: nikithamalgifb
fbshipit-source-id: 303eaf8d7a27e74be09874f70f519b4c1081645b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54915
TorchScript and torch.package have different mangling schemes. To avoid
them interfering with each other, we should undo the torch.package
mangling before processing anything with TorchScript (since TS
independently makes sure that no names collide).
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D27410472
Pulled By: suo
fbshipit-source-id: d1cc013c532d9abb7fb9615122bc465ded4785bb
Summary:
This is to prepare for new language reference spec that needs to describe `torch.jit.Attribute` and `torch.jit.annotate`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54485
Reviewed By: SplitInfinity, nikithamalgifb
Differential Revision: D27406843
Pulled By: gmagogsfm
fbshipit-source-id: 98983b9df0f974ed69965ba4fcc03c1a18d1f9f5
Summary:
This simplifies our handling and allows passing CompilationUnits from Python to C++ defined functions via PyBind easily.
Discussed on Slack with SplitInfinity
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50614
Reviewed By: anjali411
Differential Revision: D25938005
Pulled By: SplitInfinity
fbshipit-source-id: 94aadf0c063ddfef7ca9ea17bfa998d8e7b367ad
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49242
Fixes https://github.com/pytorch/pytorch/issues/45072
As discussed with zdevito gchanan cpuhrsch and suo, this change allows developers to create custom preparations for their modules before scripting. This is done by adding a `__prepare_scriptable__` method to a module which returns the prepared scriptable module out-of-place. It does not expand the API surface for end users.
Prior art by jamesr66a: https://github.com/pytorch/pytorch/pull/42244
Test Plan: Imported from OSS
Reviewed By: dongreenberg
Differential Revision: D25500303
fbshipit-source-id: d3ec9005de27d8882fc29d02f0d08acd2a5c6b2c
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45072
As discussed with zdevito gchanan cpuhrsch and suo, this change allows developers to create custom preparations for their modules before scripting. This is done by adding a `__prepare_scriptable__` method to a module which returns the prepared scriptable module out-of-place. It does not expand the API surface for end users.
Prior art by jamesr66a: https://github.com/pytorch/pytorch/pull/42244
cc: zhangguanheng66
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45645
Reviewed By: dongreenberg, ngimel
Differential Revision: D24039990
Pulled By: zhangguanheng66
fbshipit-source-id: 4ddff2d353124af9c2ef22db037df7e3d26efe65
Summary:
`graph` is automatically cached even when the underlying graph changes -- this PR hardcodes a fix to that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46960
Reviewed By: mrshenli
Differential Revision: D24582185
Pulled By: bwasti
fbshipit-source-id: 16aeeba251830886c92751dd5c9bda8699d62803
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45261
**Summary**
This commit enables `unused` syntax for ignoring
properties. Inoring properties is more intuitive with this feature enabled.
`ignore` is not supported because class type properties cannot be
executed in Python (because they exist only as TorchScript types) like
an `ignored` function and module properties that cannot be scripted
are not added to the `ScriptModule` wrapper so that they
may execute in Python.
**Test Plan**
This commit updates the existing unit tests for class type and module
properties to test properties ignored using `unused`.
Test Plan: Imported from OSS
Reviewed By: navahgar, Krovatkin, mannatsingh
Differential Revision: D23971881
Pulled By: SplitInfinity
fbshipit-source-id: 8d3cc1bbede7753d6b6f416619e4660c56311d33
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43872
This PR allows the recursive scripting to have a separate
submodule_stubs_fn to create its submodule with specific user provided
rules.
Fixes https://github.com/pytorch/pytorch/issues/43729
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D23430176
Pulled By: wanchaol
fbshipit-source-id: 20530d7891ac3345b36f1ed813dc9c650b28d27a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45098
**Summary**
This commit adds support for default arguments in methods of class
types. Similar to how default arguments are supported for regular
script functions and methods on scripted modules, default values are
retrieved from the definition of a TorchScript class in Python as Python
objects, converted to IValues, and then attached to the schemas of
already compiled class methods.
**Test Plan**
This commit adds a set of new tests to TestClassType to test default
arguments.
**Fixes**
This commit fixes#42562.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D23844769
Pulled By: SplitInfinity
fbshipit-source-id: ceedff7703bf9ede8bd07b3abcb44a0f654936bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42390
**Summary**
This commit extends support for properties to include
ScriptModules.
**Test Plan**
This commit adds a unit test that has a ScriptModule with
a user-defined property.
`python test/test_jit_py3.py TestScriptPy3.test_module_properties`
Test Plan: Imported from OSS
Reviewed By: eellison, mannatsingh
Differential Revision: D22880298
Pulled By: SplitInfinity
fbshipit-source-id: 74f6cb80f716084339e2151ca25092b6341a1560
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44233
**Summary**
By default, scripting tries to share concrete and JIT types across
compilations. However, this can lead to incorrect results if a module
extends `torch.jit.ScriptModule`, and injects instance variables into
methods defined using `define`.
This commit detects when this has happened and disables type sharing
for the compilation of the module that uses `define` in `__init__`.
**Test Plan**
This commit adds a test to TestTypeSharing that tests this scenario.
**Fixes**
This commit fixes#43580.
Test Plan: Imported from OSS
Reviewed By: bertmaher
Differential Revision: D23553870
Pulled By: SplitInfinity
fbshipit-source-id: d756e87fcf239befa0012998ce29eeb25728d3e1
Summary:
In case we want to store binary files using `ScriptModule.save(..., _extra_files=...)` functionality. With python3 we can just use bytes only and not bother about it.
I had to do a copy-pasta from pybind sources, maybe we should upstream it, but it'd mean adding a bunch of template arguments to `bind_map` which is a bind untidy.
Let me know if there's a better place to park this function (it seems to be the only invocation of `bind_map` so I put it in the same file)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43241
Reviewed By: zdevito
Differential Revision: D23205244
Pulled By: dzhulgakov
fbshipit-source-id: 8f291eb4294945fe1c581c620d48ba2e81b3dd9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41371
**Summary**
This commit enables the use of `torch.no_grad()` in a with item of a
with statement within JIT. Note that the use of this context manager as
a decorator is not supported.
**Test Plan**
This commit adds a test case to the existing with statements tests for
`torch.no_grad()`.
**Fixes**
This commit fixes#40259.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D22649519
Pulled By: SplitInfinity
fbshipit-source-id: 7fa675d04835377666dfd0ca4e6bc393dc541ab9
Summary:
xref gh-38010 and gh-38011.
After this PR, there should be only two warnings:
```
pytorch/docs/source/index.rst:65: WARNING: toctree contains reference to nonexisting \
document 'torchvision/index'
WARNING: autodoc: failed to import class 'tensorboard.writer.SummaryWriter' from module \
'torch.utils'; the following exception was raised:
No module named 'tensorboard'
```
If tensorboard and torchvision are prerequisites to building docs, they should be added to the `requirements.txt`.
As for breaking up quantization into smaller pieces: I split out the list of supported operations and the list of modules to separate documents. I think this makes the page flow better, makes it much "lighter" in terms of page cost, and also removes some warnings since the same class names appear in multiple sub-modules.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41321
Reviewed By: ngimel
Differential Revision: D22753099
Pulled By: mruberry
fbshipit-source-id: d504787fcf1104a0b6e3d1c12747ec53450841da
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40902
See the bottom of this stack for context.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22360210
Pulled By: suo
fbshipit-source-id: 4275127173a36982ce9ad357aa344435b98e1faf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40807
We pack a lot of logic into `jit/__init__.py`, making it unclear to
developers and users which parts of our API are public vs. internal. This
is one in a series of PRs intended to pull implementation out into
separate files, and leave `__init__.py` as a place to register the
public API.
This PR moves all the tracing-related stuff out, and fixes other spots up
as necessary. Followups will move other core APIs out.
The desired end-state is that we conform to the relevant rules in [PEP 8](https://www.python.org/dev/peps/pep-0008/#public-and-internal-interfaces). In particular:
- Internal implementation goes in modules prefixed by `_`.
- `__init__.py` exposes a public API from these private modules, and nothing more.
- We set `__all__` appropriately to declare our public API.
- All use of JIT-internal functionality outside the JIT are removed (in particular, ONNX is relying on a number internal APIs). Since they will need to be imported explicitly, it will be easier to catch new uses of internal APIs in review.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D22320645
Pulled By: suo
fbshipit-source-id: 0720ea9976240e09837d76695207e89afcc58270
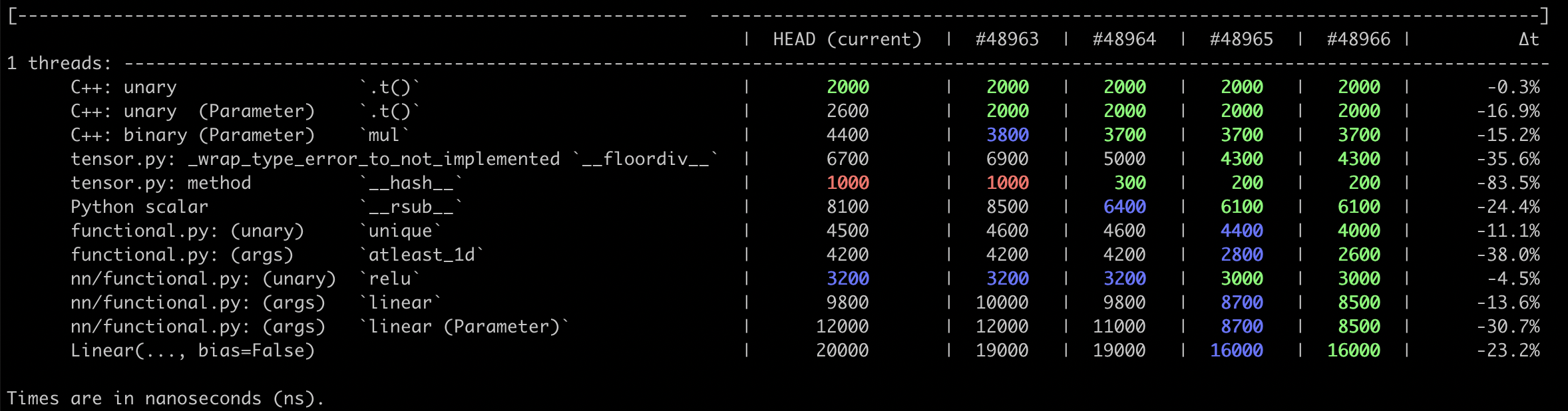{kind=link}
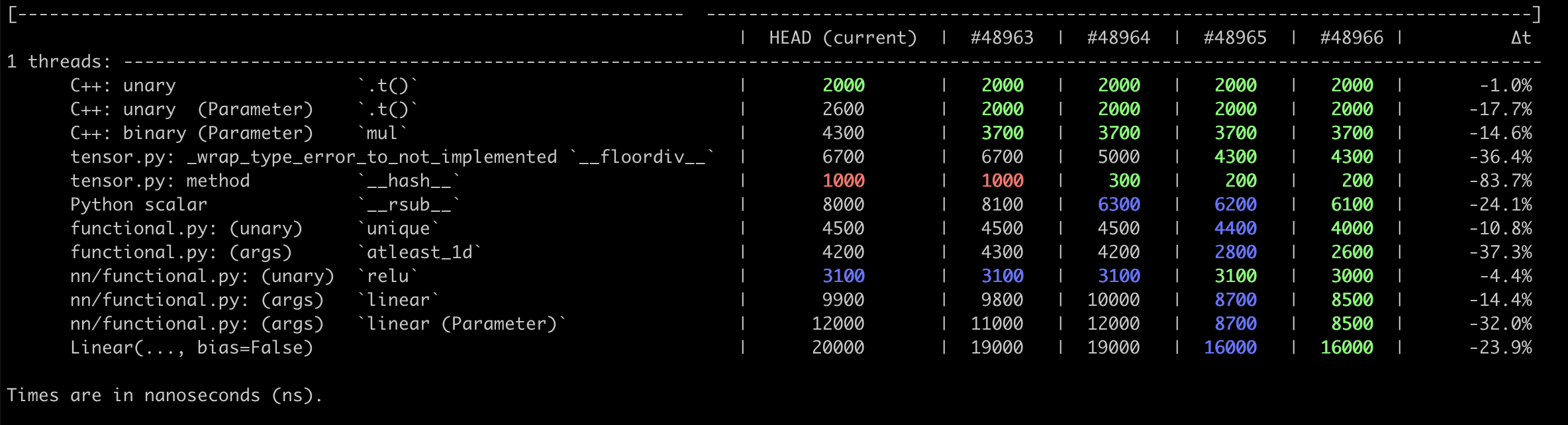{kind=link}
{kind=link}