Summary:
Related issue: https://github.com/pytorch/pytorch/issues/58833
__changes__
- slowpath tests: pass every dtype&device tensors and compare the behavior with regular functions including inplace
- check of #cudaLaunchKernel
- rename `ForeachUnaryFuncInfo` -> `ForeachFuncInfo`: This change is mainly for the future binary/pointwise test refactors
cc: ngimel ptrblck mcarilli
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58960
Reviewed By: ejguan
Differential Revision: D28926135
Pulled By: ngimel
fbshipit-source-id: 4eb21dcebbffffaf79259e31961626e0707fb8d1
Summary:
Echo on https://github.com/pytorch/pytorch/pull/58260#discussion_r637467625
similar to `test_unsupported_dtype` which only check exception raised on the first sample. we should do similar things for unsupported_backward as well. The goal for both test is to remind developer to
1. add a new dtype to the support list if they are fulling runnable without failure (over all samples)
2. replace the skip mechanism which will indefinitely ignore tests without warning
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59455
Test Plan: CI.
Reviewed By: mruberry
Differential Revision: D28927169
Pulled By: walterddr
fbshipit-source-id: 2993649fc17a925fa331e27c8ccdd9b24dd22c20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59553
Added a test for 0x0 sparse coo input for sparse_unary_ufuncs.
This test fails for `conj` on master.
Modified `unsupportedTypes` for test_sparse_consistency, complex dtypes
pass, but float16 doesn't pass for `conj` because `to_dense()` doesn't
work with float16.
Fixes https://github.com/pytorch/pytorch/issues/59549
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D28968215
Pulled By: anjali411
fbshipit-source-id: 44e99f0ce4aa45b760d79995a021e6139f064fea
Summary:
Implements an idea by ngimel to improve the performance of `torch.flip` via a clever hack into TI to bypass the fact that TI is not designed to work with negative indices.
Something that might be added is vectorisation support on CPU, given how simple the implementation is now.
Some low-hanging fruits that I did not implement:
- Write it as a structured kernel
- Migrate the tests to opinfos
- Have a look at `cumsum_backward` and `cumprod_backward`, as I think that they could be implemented faster with `flip`, now that `flip` is fast.
**Edit**
This operation already has OpInfos and it cannot be migrated to a structured kernel because it implements quantisation
Summary of the PR:
- x1.5-3 performance boost on CPU
- x1.5-2 performance boost on CUDA
- Comparable performance across dimensions, regardless of the strides (thanks TI)
- Simpler code
<details>
<summary>
Test Script
</summary>
```python
from itertools import product
import torch
from torch.utils.benchmark import Compare, Timer
def get_timer(size, dims, num_threads, device):
x = torch.rand(*size, device=device)
timer = Timer(
"torch.flip(x, dims=dims)",
globals={"x": x, "dims": dims},
label=f"Flip {device}",
description=f"dims: {dims}",
sub_label=f"size: {size}",
num_threads=num_threads,
)
return timer.blocked_autorange(min_run_time=5)
def get_params():
sizes = ((1000,)*2, (1000,)*3, (10000,)*2)
for size, device in product(sizes, ("cpu", "cuda")):
threads = (1, 2, 4) if device == "cpu" else (1,)
list_dims = [(0,), (1,), (0, 1)]
if len(size) == 3:
list_dims.append((0, 2))
for num_threads, dims in product(threads, list_dims):
yield size, dims, num_threads, device
def compare():
compare = Compare([get_timer(*params) for params in get_params()])
compare.trim_significant_figures()
compare.colorize()
compare.print()
compare()
```
</details>
<details>
<summary>
Benchmark PR
</summary>
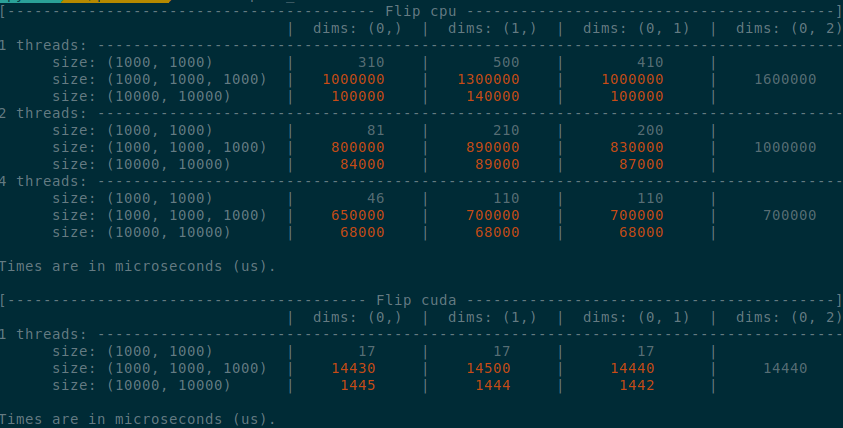
</details>
<details>
<summary>
Benchmark master
</summary>
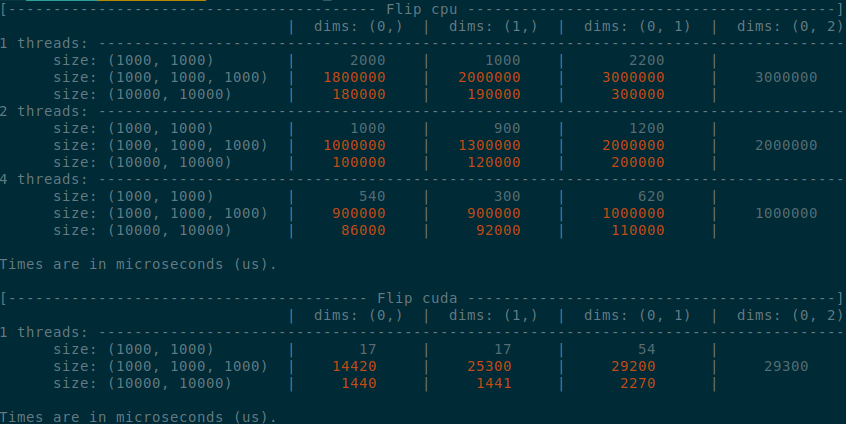
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58747
Reviewed By: agolynski
Differential Revision: D28877076
Pulled By: ngimel
fbshipit-source-id: 4fa6eb519085950176cb3a9161eeb3b6289ec575
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54987
Based off of ezyang (https://github.com/pytorch/pytorch/pull/44799) and bdhirsh (https://github.com/pytorch/pytorch/pull/43702) 's prototype:
Here's a summary of the changes in this PR:
This PR adds a new dispatch key called Conjugate. This enables us to make conjugate operation a view and leverage the specialized library functions that fast path with the hermitian operation (conj + transpose).
1. Conjugate operation will now return a view with conj bit (1) for complex tensors and returns self for non-complex tensors as before. This also means `torch.view_as_real` will no longer be a view on conjugated complex tensors and is hence disabled. To fill the gap, we have added `torch.view_as_real_physical` which would return the real tensor agnostic of the conjugate bit on the input complex tensor. The information about conjugation on the old tensor can be obtained by calling `.is_conj()` on the new tensor.
2. NEW API:
a) `.conj()` -- now returning a view.
b) `.conj_physical()` -- does the physical conjugate operation. If the conj bit for input was set, you'd get `self.clone()`, else you'll get a new tensor with conjugated value in its memory.
c) `.conj_physical_()`, and `out=` variant
d) `.resolve_conj()` -- materializes the conjugation. returns self if the conj bit is unset, else returns a new tensor with conjugated values and conj bit set to 0.
e) `.resolve_conj_()` in-place version of (d)
f) `view_as_real_physical` -- as described in (1), it's functionally same as `view_as_real`, just that it doesn't error out on conjugated tensors.
g) `view_as_real` -- existing function, but now errors out on conjugated tensors.
3. Conjugate Fallback
a) Vast majority of PyTorch functions would currently use this fallback when they are called on a conjugated tensor.
b) This fallback is well equipped to handle the following cases:
- functional operation e.g., `torch.sin(input)`
- Mutable inputs and in-place operations e.g., `tensor.add_(2)`
- out-of-place operation e.g., `torch.sin(input, out=out)`
- Tensorlist input args
- NOTE: Meta tensors don't work with conjugate fallback.
4. Autograd
a) `resolve_conj()` is an identity function w.r.t. autograd
b) Everything else works as expected.
5. Testing:
a) All method_tests run with conjugate view tensors.
b) OpInfo tests that run with conjugate views
- test_variant_consistency_eager/jit
- gradcheck, gradgradcheck
- test_conj_views (that only run for `torch.cfloat` dtype)
NOTE: functions like `empty_like`, `zero_like`, `randn_like`, `clone` don't propagate the conjugate bit.
Follow up work:
1. conjugate view RFC
2. Add neg bit to re-enable view operation on conjugated tensors
3. Update linalg functions to call into specialized functions that fast path with the hermitian operation.
Test Plan: Imported from OSS
Reviewed By: VitalyFedyunin
Differential Revision: D28227315
Pulled By: anjali411
fbshipit-source-id: acab9402b9d6a970c6d512809b627a290c8def5f
Summary:
sample_inputs_diff constructs all five positional arguments for [diff ](https://pytorch.org/docs/stable/generated/torch.diff.html) but uses only the first three. This doesn't seem to be intentional.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59181
Test Plan: This change expands coverage of diff's OpInfo sample inputs. Related tests still pass.
Reviewed By: mruberry
Differential Revision: D28878359
Pulled By: saketh-are
fbshipit-source-id: 1466f6c6c341490885c85bc6271ad8b3bcdf3a3e
Summary:
Resubmit of https://github.com/pytorch/pytorch/issues/59108, closes https://github.com/pytorch/pytorch/issues/24754, closes https://github.com/pytorch/pytorch/issues/24616
This reuses `linalg_vector_norm` to calculate the norms. I just add a new kernel that turns the norm into a normalization factor, then multiply the original tensor using a normal broadcasted `mul` operator. The result is less code, and better performance to boot.
#### Benchmarks (CPU):
| Shape | Dim | Before | After (1 thread) | After (8 threads) |
|:------------:|:---:|--------:|-----------------:|------------------:|
| (10, 10, 10) | 0 | 11.6 us | 4.2 us | 4.2 us |
| | 1 | 14.3 us | 5.2 us | 5.2 us |
| | 2 | 12.7 us | 4.6 us | 4.6 us |
| (50, 50, 50) | 0 | 330 us | 120 us | 24.4 us |
| | 1 | 350 us | 135 us | 28.2 us |
| | 2 | 417 us | 130 us | 24.4 us |
#### Benchmarks (CUDA)
| Shape | Dim | Before | After |
|:------------:|:---:|--------:|--------:|
| (10, 10, 10) | 0 | 12.5 us | 12.1 us |
| | 1 | 13.1 us | 12.2 us |
| | 2 | 13.1 us | 11.8 us |
| (50, 50, 50) | 0 | 33.7 us | 11.6 us |
| | 1 | 36.5 us | 15.8 us |
| | 2 | 41.1 us | 15 us |
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59250
Reviewed By: mruberry
Differential Revision: D28820359
Pulled By: ngimel
fbshipit-source-id: 572486adabac8135d52a9b8700f9d145c2a4ed45
Summary:
Fixes https://github.com/pytorch/pytorch/issues/57508
Earlier, a few CUDA `gradgrad` checks (see the list of ops below) were disabled because of them being too slow. There have been improvements (see https://github.com/pytorch/pytorch/issues/57508 for reference) and this PR aimed on:
1. Time taken by `gradgrad` checks on CUDA for the ops listed below.
2. Enabling the tests again if the times sound reasonable
Ops considered: `addbmm, baddbmm, bmm, cholesky, symeig, inverse, linalg.cholesky, linalg.cholesky_ex, linalg.eigh, linalg.qr, lu, qr, solve, triangular_solve, linalg.pinv, svd, linalg.svd, pinverse, linalg.householder_product, linalg.solve`.
For numbers (on time taken) on a separate CI run: https://github.com/pytorch/pytorch/pull/57802#issuecomment-836169691.
cc: mruberry albanD pmeier
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57802
Reviewed By: ngimel
Differential Revision: D28784106
Pulled By: mruberry
fbshipit-source-id: 9b15238319f143c59f83d500e831d66d98542ff8
Summary:
Context:
The Error message when `broadcasts_input` is marked incorrectly is uninformative [See Error Currently]
https://github.com/pytorch/pytorch/pull/57941#discussion_r631749435
Error Currently
```
Traceback (most recent call last):
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 326, in test_variant_consistency_eager
_test_consistency_helper(samples, variants)
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 310, in _test_consistency_helper
variant_forward = variant(cloned,
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 227, in __exit__
self._raiseFailure("{} not raised".format(exc_name))
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 164, in _raiseFailure
raise self.test_case.failureException(msg)
AssertionError: RuntimeError not raised
```
Error After PR
```
Traceback (most recent call last):
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 329, in test_variant_consistency_eager
_test_consistency_helper(samples, variants)
File "/home/kshiteej/Pytorch/pytorch_i0_promotion/test/test_ops.py", line 313, in _test_consistency_helper
variant_forward = variant(cloned,
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 227, in __exit__
self._raiseFailure("{} not raised".format(exc_name))
File "/home/kshiteej/.conda/envs/pytorch-cuda-dev/lib/python3.8/unittest/case.py", line 164, in _raiseFailure
raise self.test_case.failureException(msg)
AssertionError: RuntimeError not raised : inplace variant either allowed resizing or you have marked the sample SampleInput(input=Tensor, args=(tensor([[[ 2.1750, -8.5027, -3.1403, -6.9942, 3.2609],
[-2.5057, -5.9123, -5.4633, 6.1203, -8.2124],
[-3.5802, -8.4869, -6.0700, 2.3431, -8.1955],
[-7.3316, 1.3248, -6.8661, 7.1483, -8.0719],
[ 4.5977, -4.0448, -6.2044, -2.1314, -8.4956]],
[[ 3.2769, -8.4360, 1.2826, 7.1749, 4.7653],
[-0.2816, -2.5997, -4.7659, -3.7814, 3.9704],
[-2.1778, -3.8117, -6.0276, -0.8423, -5.9646],
[ 8.6544, -3.0922, 0.2558, -4.9318, -4.7596],
[ 4.5583, 4.3830, 5.8793, 0.9713, -2.1481]],
[[-1.0447, 0.9334, 7.6405, -4.8933, -7.4010],
[ 7.7168, -8.4266, -5.5980, -6.9368, 7.1309],
[-8.7720, -5.0890, -0.4975, 1.9518, 1.7074],
[-8.5783, 8.5510, -8.5459, -3.5451, 8.4319],
[ 8.5052, -8.9149, -6.6298, -1.2750, -5.7367]],
[[-6.5625, 8.2795, -4.9311, 1.9501, -7.1777],
[-8.4035, 1.1136, -7.6418, -7.0726, -2.8281],
[ 4.2668, -0.2883, -6.2246, 2.3396, 1.2911],
[ 4.6550, -1.9525, 4.4873, -3.8061, -0.8653],
[-3.4256, 4.4423, 8.2937, -5.3456, -4.2624]],
[[ 7.6128, -6.3932, 4.7131, -5.4938, 6.4792],
[-6.5385, 2.4385, 4.5570, 3.7803, -8.3281],
[-2.9785, -4.4745, -1.1778, -8.9324, 1.3663],
[ 3.7437, 3.5171, -6.3135, -8.4519, -2.7033],
[-5.0568, -8.4630, -4.2870, -3.7284, -1.5238]]], device='cuda:0',
dtype=torch.float32, requires_grad=True),), broadcasts_input=True) incorrectly with `broadcasts_self=True
```
**NOTE**:
Printing the sample looks very verbose and it may be hard to figure out which sample is incorrectly configured if there are multiple samples with similar input shapes.
Two Options to make this error less verbose
* Don't print the sample and just print `inplace variant either allowed resizing or you have marked one of the sample incorrectly with broadcasts_self=True`
* Have some mechanism to name samples which will be printed in the `repr` (which will need extra machinery)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58295
Reviewed By: ngimel
Differential Revision: D28627308
Pulled By: mruberry
fbshipit-source-id: b3bdeacac3cf9c0d984f0b85410ecce474291d20
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57768
Note that this PR implements formulas only for ops that are supported by OpInfo.
Test Plan: Imported from OSS
Reviewed By: zou3519, malfet
Differential Revision: D28387766
Pulled By: albanD
fbshipit-source-id: b4ba1cf1ac1dfd46cdd889385c9c2d5df3cf7a71
Summary:
This warning makes downstream users of OpInfo error when they use this opinfo, unless they actually run the operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58682
Reviewed By: mruberry
Differential Revision: D28577334
Pulled By: Chillee
fbshipit-source-id: f10e64f8ad3fb50907531d8cb89ce5b0d06ac076
{kind=link}
{kind=link}
{kind=link}