Refactor torchscript based exporter logic to move them to a single (private) location for better code management. Original public module and method apis are preserved.
- Updated module paths in `torch/csrc/autograd/python_function.cpp` accordingly
- Removed `check_onnx_broadcast` from `torch/autograd/_functions/utils.py` because it is private&unused
@albanD / @soulitzer could you review changes in `torch/csrc/autograd/python_function.cpp` and
`torch/autograd/_functions/utils.py`? Thanks!
## BC Breaking
- **Deprecated members in `torch.onnx.verification` are removed**
Differential Revision: [D81236421](https://our.internmc.facebook.com/intern/diff/D81236421)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/161323
Approved by: https://github.com/titaiwangms, https://github.com/angelayi
beartype has served us well in identifying type errors and ensuring we call internal functions with the correct arguments (thanks!). However, the value of having beartype is diminished because of the following:
1. When beartype improves support for better Dict[] type checking, it discovered typing mistakes in some functions that were previously uncaught. This caused the exporter to fail with newer versions beartype when it used to succeed. Since we cannot fix PyTorch and release a new version just because of this, it creates confusion for users that have beartype in their environment from using torch.onnx
2. beartype adds an additional call line in the traceback, which makes the already thick dynamo stack even larger, affecting readability when users diagnose errors with the traceback.
3. Since the typing annotations need to be evaluated, we cannot use new syntaxes like `|` because we need to maintain compatibility with Python 3.8. We don't want to wait for PyTorch take py310 as the lowest supported Python before using the new typing syntaxes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/130484
Approved by: https://github.com/titaiwangms
beartype has served us well in identifying type errors and ensuring we call internal functions with the correct arguments (thanks!). However, the value of having beartype is diminished because of the following:
1. When beartype improves support for better Dict[] type checking, it discovered typing mistakes in some functions that were previously uncaught. This caused the exporter to fail with newer versions beartype when it used to succeed. Since we cannot fix PyTorch and release a new version just because of this, it creates confusion for users that have beartype in their environment from using torch.onnx
2. beartype adds an additional call line in the traceback, which makes the already thick dynamo stack even larger, affecting readability when users diagnose errors with the traceback.
3. Since the typing annotations need to be evaluated, we cannot use new syntaxes like `|` because we need to maintain compatibility with Python 3.8. We don't want to wait for PyTorch take py310 as the lowest supported Python before using the new typing syntaxes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/130484
Approved by: https://github.com/titaiwangms
beartype has served us well in identifying type errors and ensuring we call internal functions with the correct arguments (thanks!). However, the value of having beartype is diminished because of the following:
1. When beartype improves support for better Dict[] type checking, it discovered typing mistakes in some functions that were previously uncaught. This caused the exporter to fail with newer versions beartype when it used to succeed. Since we cannot fix PyTorch and release a new version just because of this, it creates confusion for users that have beartype in their environment from using torch.onnx
2. beartype adds an additional call line in the traceback, which makes the already thick dynamo stack even larger, affecting readability when users diagnose errors with the traceback.
3. Since the typing annotations need to be evaluated, we cannot use new syntaxes like `|` because we need to maintain compatibility with Python 3.8. We don't want to wait for PyTorch take py310 as the lowest supported Python before using the new typing syntaxes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/130484
Approved by: https://github.com/titaiwangms
- In #102759, the support for `quantized::conv_transposeNd` was introduced. This incorrectly set `output_padding` to all zeros. Turns out, you can specify output_padding in PyTorch, but this parameter was not being unpacked correctly and thus did not show up in the python torch->onnx code.
- This adds unpacking of output_padding in `unpack_quantized_weights.cpp` when needed. It also adds this as a parameter in the python functions and uses that (and removes the all-zero defaults)
- Another issue with #102759 is that it only added these new ops to opset10 without adding the ability to specify axis in opset13. This PR also fixes this.
Fixes#104206
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104207
Approved by: https://github.com/BowenBao
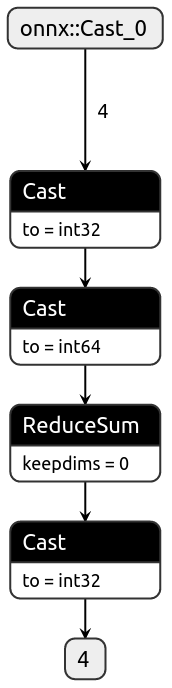
This PR conditionally inserts a cast operator after a reduction operation to match the specified dtype in the exported ONNX model. The code changes affect **opset9**, and **opset13**.
I understand there's an [automatic upcast to int64](c91a41fd68/torch/onnx/symbolic_opset9.py (L783)) before reduction most likely to prevent overflow so I left that alone and only conditionally add casting back to desired dtype.
## Test int32
```
import torch
import onnx
a = torch.tensor([10, 20, 30, 80], dtype=torch.int32)
def test():
class SumInt32(torch.nn.Module):
def forward(self, a):
return torch.sum(a, dtype=torch.int32)
sumi = SumInt32().eval()
assert sumi(a).dtype == torch.int32
print("Torch model output type matches input type")
torch.onnx.export(sumi, (a), "/tmp/sumi_int32.onnx", opset_version=12)
model = onnx.load("/tmp/sumi_int32.onnx")
assert model.graph.output[0].type.tensor_type.elem_type == onnx.TensorProto.INT32
print("ONNX model output type matches input type")
test()
```
## Test int64
```
import onnx
import torch
a = torch.tensor([10, 20, 30, 80], dtype=torch.int64)
def test():
class SumInt64(torch.nn.Module):
def forward(self, a):
return torch.sum(a, dtype=torch.int64)
sumi = SumInt64().eval()
assert sumi(a).dtype == torch.int64
print("Torch model output type matches input type")
torch.onnx.export(sumi, (a), "/tmp/sumi_int64.onnx", opset_version=12)
model = onnx.load("/tmp/sumi_int64.onnx")
assert model.graph.output[0].type.tensor_type.elem_type == onnx.TensorProto.INT64
print("ONNX model output type matches input type")
test()
```
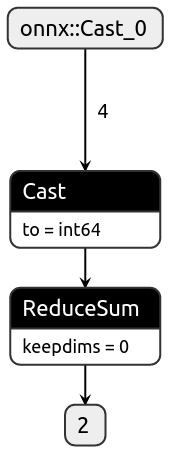
Fixes https://github.com/pytorch/pytorch/issues/100097
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100700
Approved by: https://github.com/thiagocrepaldi
Fixes https://github.com/pytorch/pytorch/issues/84365 and more
This PR addresses not only the issue above, but the entire family of issues related to `torch._C.Value.type()` parsing when `scalarType()` or `dtype()` is not available.
This issue exists before `JitScalarType` was introduced, but the new implementation refactored the bug in because the new api `from_name` and `from_dtype` requires parsing `torch._C.Value.type()` to get proper inputs, which is exactly the root cause for this family of bugs.
Therefore `from_name` and `from_dtype` must be called when the implementor knows the `name` and `dtype` without parsing a `torch._C.Value`. To handle the corner cases hidden within `torch._C.Value`, a new `from_value` API was introduced and it should be used in favor of the former ones for most cases. The new API is safer and doesn't require type parsing from user, triggering JIT asserts in the core of pytorch.
Although CI is passing for all tests, please review carefully all symbolics/helpers refactoring to make sure the meaning/intetion of the old call are not changed in the new call
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87245
Approved by: https://github.com/justinchuby, https://github.com/BowenBao
This PR create the `GraphContext` class and relays all graph methods to _C.Graph as well as implements the `g.op` method. The GraphContext object is passed into the symbolic functions in place of _C.Graph for compatibility with existing symbolic functions.
This way (1) we can type annotate all `g` args because the method is defined and (2) we can use additional context information in symbolic functions. (3) no more monkey patching on `_C.Graph`
Also
- Fix return type of `_jit_pass_fixup_onnx_controlflow_node`
- Create `torchscript.py` to house torch.Graph related functions
- Change `GraphContext.op` to create nodes in the Block instead of the Graph
- Create `add_op_with_blocks` to handle scenarios where we need to directly manipulate sub-blocks. Update loop and if symbolic functions to use this function.
## Discussion
Should we put all the context inside `SymbolicContext` and make it an attribute in the `GraphContext` class? This way we only define two attributes `GraphContext.graph` and `GraphContext.context`. Currently all context attributes are directly defined in the class.
### Decision
Keep GraphContext flatand note that it will change in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84728
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
This is the 4th PR in the series of #83787. It enables the use of `@onnx_symbolic` across `torch.onnx`.
- **Backward breaking**: Removed some symbolic functions from `__all__` because of the use of `@onnx_symbolic` for registering the same function on multiple aten names.
- Decorate all symbolic functions with `@onnx_symbolic`
- Move Quantized and Prim ops out from classes to functions defined in the modules. Eliminate the need for `isfunction` checking, speeding up the registration process by 60%.
- Remove the outdated unit test `test_symbolic_opset9.py`
- Symbolic function registration moved from the first call to `_run_symbolic_function` to init time.
- Registration is fast:

Pull Request resolved: https://github.com/pytorch/pytorch/pull/84448
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao, https://github.com/thiagocrepaldi
Enable runtime type checking for all torch.onnx public apis, symbolic functions and most helpers (minus two that does not have a checkable type: `_.JitType` does not exist) by adding the beartype decorator. Fix type annotations to makes unit tests green.
Profile:
export `torchvision.models.alexnet(pretrained=True)`
```
with runtime type checking: 21.314 / 10 passes
without runtime type checking: 20.797 / 10 passes
+ 2.48%
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84091
Approved by: https://github.com/BowenBao
Replace runtime errors in torch.onnx with `errors.SymbolicValueError` for more context around jit values.
- Extend `_unimplemented`, `_onnx_unsupported`, `_onnx_opset_unsupported`, `_onnx_opset_unsupported_detailed` errors to include JIT value information
- Replace plain RuntimeError with `errors.SymbolicValueError`
- Clean up: Use `_is_bool` to replace string comparison on jit types
- Clean up: Remove the todo `Remove type ignore after #81112`
#77316
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83332
Approved by: https://github.com/AllenTiTaiWang, https://github.com/thiagocrepaldi, https://github.com/BowenBao
### Description
<!-- What did you change and why was it needed? -->
Remove unused patching methods:
- `torch._C.Graph.constant`
- unpatch `torch._C.Node.__getitem__` and move the helper function to `symbolic_helper`
Add typing annotations
### Issue
<!-- Link to Issue ticket or RFP -->
#76254
### Testing
<!-- How did you test your change? -->
Unit tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83006
Approved by: https://github.com/BowenBao
Re-land #81953
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Deprecated: "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type" in `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82995
Approved by: https://github.com/kit1980
Add `_type_utils` for handling data type conversion among JIT, torch and ONNX.
- Replace dictionary / list indexing with methods in ScalarType
- Breaking: **Remove ScalarType from `symbolic_helper`** and move it to `_type_utils`
- Breaking: **Remove "cast_pytorch_to_onnx", "pytorch_name_to_type", "scalar_name_to_pytorch", "scalar_type_to_onnx", "scalar_type_to_pytorch_type"** from `symbolic_helper`
- Deprecate the type mappings and lists. Remove all internal references
- Move _cast_func_template to opset 9 and remove its reference elsewhere (clean up). Added documentation for easy discovery
Why: List / dictionary indexing and lookup are error-prone and convoluted.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81953
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
Cleaning up onnx module imports to prepare for updating `__init__`.
- Simplify importing the `_C` and `_C._onnx` name spaces
- Remove alias of the symbolic_helper module in imports
- Remove any module level function imports. Import modules instead
- Alias `symbilic_opsetx` as `opsetx`
- Fix some docstrings
Requires:
- https://github.com/pytorch/pytorch/pull/77448
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77423
Approved by: https://github.com/BowenBao
Reduce circular dependencies
- Lift constants and flags from `symbolic_helper` to `_constants` and `_globals`
- Standardized constant naming to make it consistant
- Make `utils` strictly dependent on `symbolic_helper`, removing inline imports from symbolic_helper
- Move side effects from `utils` to `_patch_torch`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77142
Approved by: https://github.com/garymm, https://github.com/BowenBao
PyTorch restricts activations to be in the range (0, 127).
In ONNX, the supported ranges are (0, 255) and (-128, 127),
respectfully, uint8 and int8. This PR extends support for range
(0, 127), by adding additional clipping when detected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76055
Approved by: https://github.com/garymm
Extending the support for quantization with per channel quantization.
An extra attribute `axis` can be found for per channel quantized tensors,
most commonly in quantized weight of Convolution or Linear module.
The PR adds support to correctly parse the `axis` attribute, and map to
ONNX representation in `QuantizeLinear` and `DequantizeLinear`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76002
Approved by: https://github.com/garymm
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62764Fixes#58733
- Support dynamic interleave for cases with dynamic repeat values
- Moved repeat_interleave symbolic from opset 11 to opset 13, as sequence as output types for loop outputs is needed for this change
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D30375179
Pulled By: msaroufim
fbshipit-source-id: 787f96bf91d124fd0483761088c5f4ae930d96a9
Co-authored-by: Shubham Bhokare <shubhambhokare@gmail.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59537
PyTorch sum over empty tensor gives 0, while ONNX produces an error.
torch.sum will be translated into onnx::ReduceSum op. Per the definition of ReduceSum, update the keepdims attribute for this scenario.
Test Plan: Imported from OSS
Reviewed By: nikithamalgifb, ansley
Differential Revision: D29046604
Pulled By: SplitInfinity
fbshipit-source-id: 6f5f3a66cb8eda8b5114b8474dda6fcdbae73469
Co-authored-by: fatcat-z <jiz@microsoft.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}