**Summary**
Update onednn from v2.7.3 to v3.1.1.
It is bc-breaking as some APIs are changed on oneDNN side. Changes include:
- PyTorch code where oneDNN is directly called
- Submodule `third_party/ideep` to adapt to oneDNN's new API.
- CMAKE files to fix build issues.
**Test plan**
Building issues and correctness are covered by CI checks.
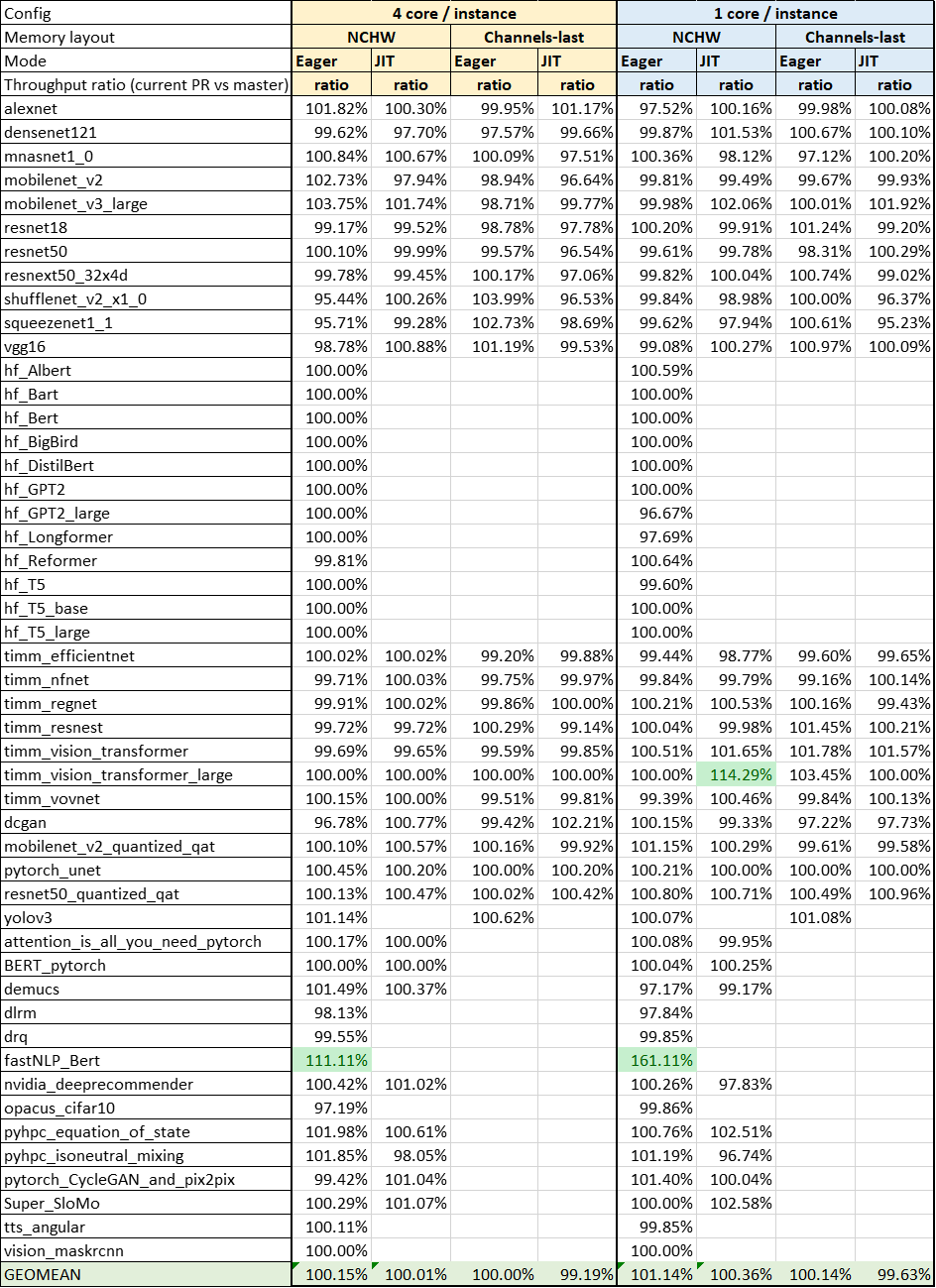
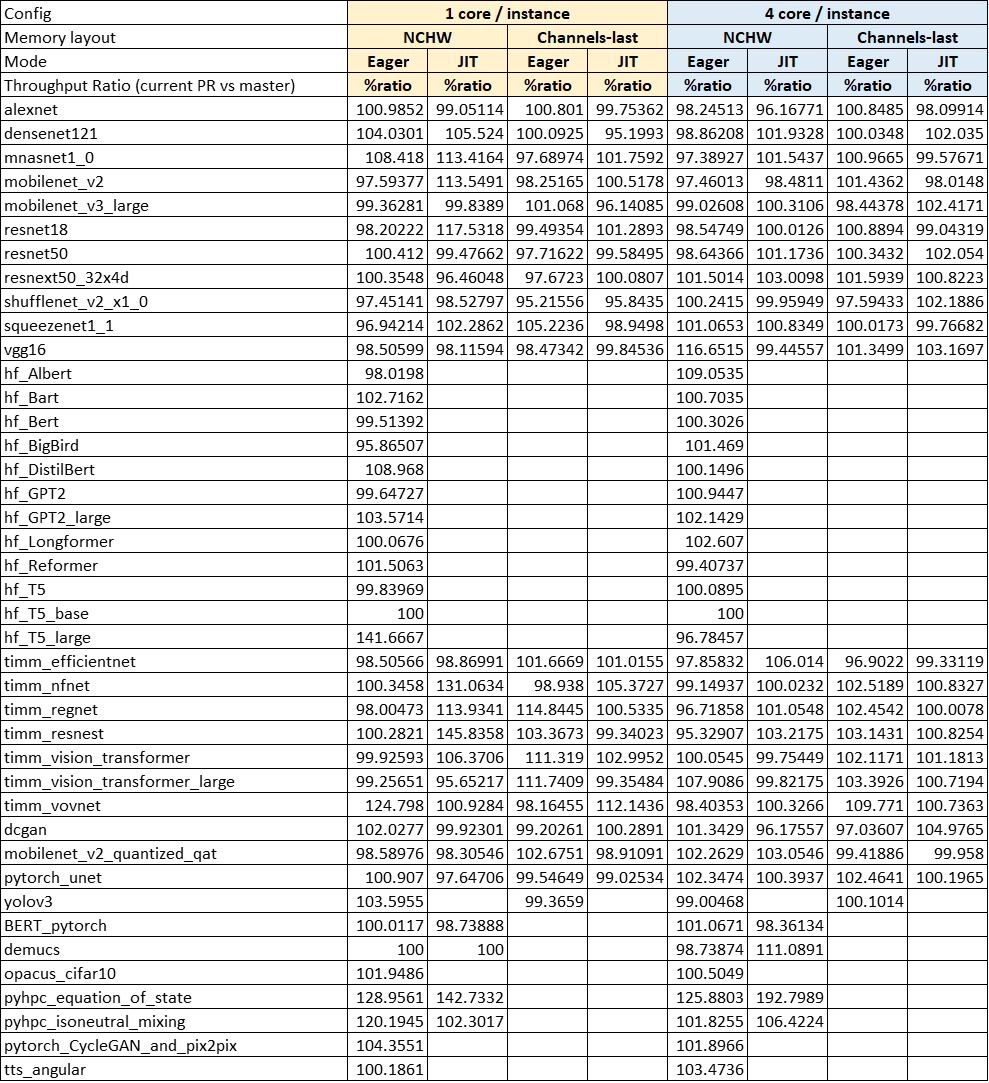
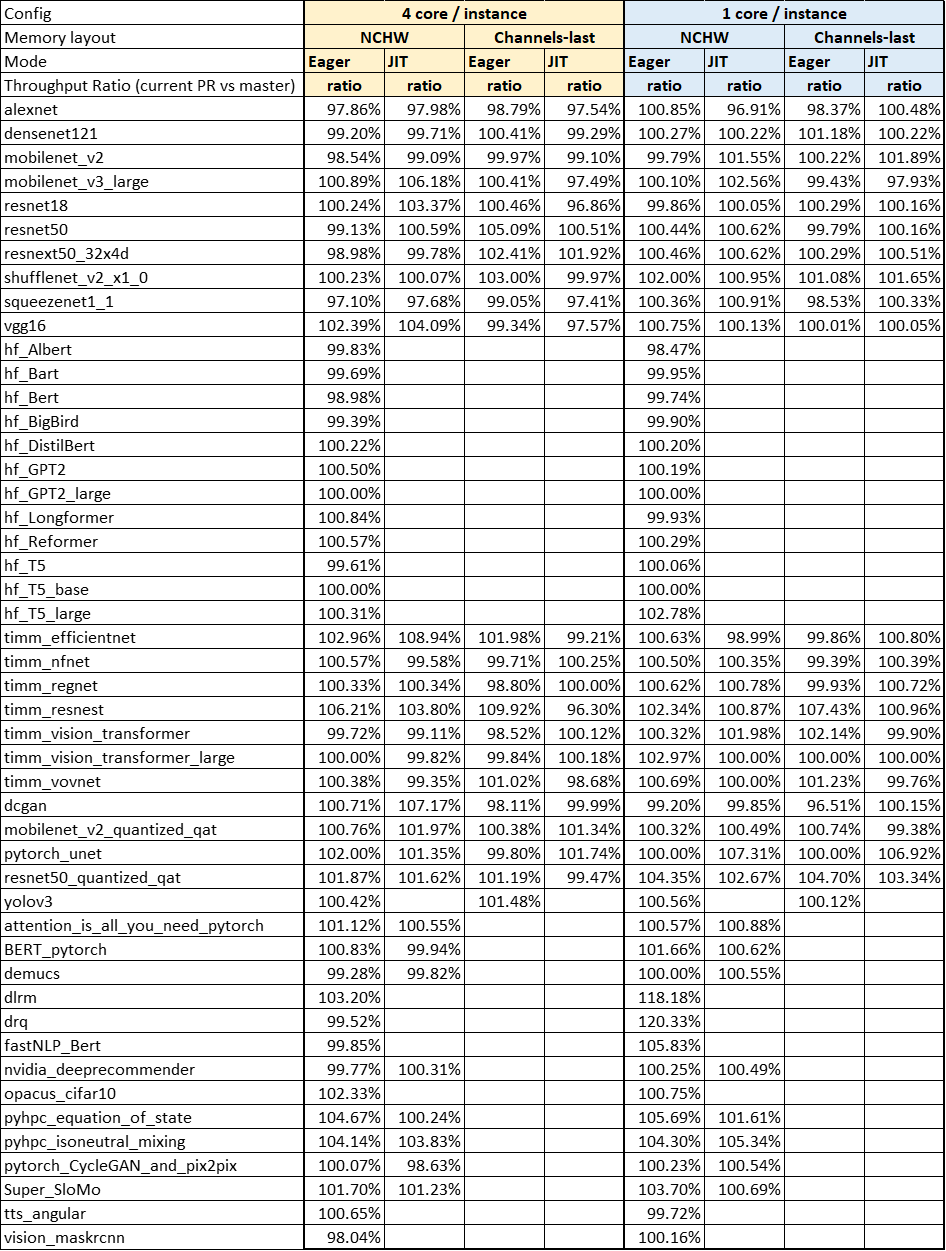
For performance, we have run TorchBench models to ensure there is no regression. Below is the comparison before and after oneDNN update.

Note:
- Base commit of PyTorch: da322ea
- CPU: Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz (Ice Lake)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97957
Approved by: https://github.com/jgong5, https://github.com/jerryzh168
This change aims to make bazel build more embeeding-friendly.
Namely, when PyTorch is included as an external repo in another project, it is usually included like this
```
native.local_repository(
name = "pytorch",
path = ...,
repo_mapping = repo_mapping,
)
```
Or
```
http_archive(
name = "pytorch",
urls = ...
repo_mapping = repo_mapping,
)
```
In this case, references to `@//` would resolve to the top-level WORKSPACE that includes PyTorch.
That makes upgrades harder because we need to carry around this patch.
Note that under some edge-case circumstances even `//` resolves to the top-level `WORKSPACE`.
This change makes the embedding of the bazel build easier without compromising anything for the main repo, since the `@pytorch//` still refers to the same thing.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89660
Approved by: https://github.com/kit1980
Summary:
This PR upgrades oneDNN to v2.6.0.
v2.6.0 changes:
- Improved performance for future Intel Xeon® Scalable processors (code name Sapphire Rapids). The functionality requires Linux kernel 5.16 or later.
- Improved performance of matmul primitive for processors with Intel AVX-512 support.
- Introduced bfloat16 destination support for int8 convolution, matmul and inner product primitives for processors with Intel AVX-512 support and or future Intel Xeon® Scalable processors (code name Sapphire Rapids)
- Extended RNN primitive with support for [AUGRU cell](https://oneapi-src.github.io/oneDNN/dev_guide_rnn.html#augru).
- Added support for non-zero negative slope in ReLU post-op for batch normalization primitive.
- Introduced support for mixed source and destination data types in softmax primitive.
- Introduced [persistent cache API](https://oneapi-src.github.io/oneDNN/dev_guide_persistent_cache.html). This functionality allows to serialize and reuse JIT kernels.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75398
Reviewed By: dagitses, bigfootjon
Differential Revision: D35976827
Pulled By: frank-wei
fbshipit-source-id: a77ae15cd77fc7c114ab9722453c28dc64aac679
(cherry picked from commit e376698d3c772aaa2dfbe51a4d1a75c8d17d0eee)
Summary:
This PR upgrades oneDNN to v2.5.2, and includes some building support for oneDNN v2.5.2.
v2.4 changes:
- Improved performance for future Intel Xeon Scalable processor (code name Sapphire Rapids). The functionality is disabled by default and should be enabled via CPU dispatcher control.
- Improved binary primitive performance for cases when one of the tensors is broadcasted.
- Improved performance of reduction primitive, reorder, shuffle primitives.
- Improved performance of depthwise convolution forward propagation for processors with Intel AVX5-12 support
- Improved performance of forward inner product primitive for the shapes with minibatch equal to 1 for processors with Intel AVX-512 support
- Improved performance of int8 matmul and inner product primitives for processors with Intel AVX2 and Intel DL Boost support
v2.5 changes:
- Improved performance for future Intel Xeon Scalable processors (code name Sapphire Rapids). The functionality is now enabled by default and requires Linux kernel 5.16.
- Improved performance of matmul primitive for processors with Intel AVX-512 support.
v2.5.2 changes:
- Fixed performance regression in binary primitive with broadcast
- Fixed segmentation fault in depthwise convolution primitive for shapes with huge spatial size for processors with Intel AVX-512 support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71546
Reviewed By: george-qi
Differential Revision: D33827108
Pulled By: VitalyFedyunin
fbshipit-source-id: 8f5a19b331c82af5b0783f081e061e1034a93952
(cherry picked from commit 9705212fe9b7b0838cc010d040c37d1175be83ce)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69216
This cleans up 4 pre-processor defines not used by any code:
- HAVE_GCC_GET_CPUID
- USE_GCC_GET_CPUID
- USE_AVX
- USE_AVX2
`cpuid` isn't used in PyTorch any more, we only use `cpuinfo`.
`USE_AVX*` is also not used, instead `HAVE_*_CPU_DEFINITIONS` tells
you which `CPU_CAPABILITY` flags are being compiled.
There is also `fbgemm`'s code path adding `third_party` as an include
path, despite `fbgemm` having a dedicated include directory and a
CMake setup that properly includes it.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33794424
Pulled By: malfet
fbshipit-source-id: 99d504af088818d4a26c2f6ce67ec0d59a5eb703
(cherry picked from commit 2e099d41f0e2f7d96c6013ac83223a75f4e4f862)
Summary:
This PR upgrades oneDNN to [v2.3.3](https://github.com/oneapi-src/oneDNN/releases/tag/v2.3.3) and includes [Graph API preview release](https://github.com/oneapi-src/oneDNN/releases/tag/graph-v0.2) in one package.
- oneDNN will be located at `pytorch/third_party/ideep/mkl-dnn/third_party/oneDNN`
- The version of oneDNN will be [v2.3.3](https://github.com/oneapi-src/oneDNN/releases/tag/v2.3.3)
The main changes on CPU:
- v2.3
- Extended primitive cache to improve primitive descriptor creation performance.
- Improved primitive cache performance in multithreaded configurations.
- Introduced initial optimizations for bfloat16 compute functionality for future Intel Xeon Scalable processor (code name Sapphire Rapids).
- Improved performance of binary primitive and binary post-op for cases with broadcast and mixed source and destination formats.
- Improved performance of reduction primitive
- Improved performance of depthwise convolution primitive with NHWC activations for training cases
- v2.3.1
- Improved int8 GEMM performance for processors with Intel AVX2 and Intel DL Boost support
- Fixed integer overflow for inner product implementation on CPUs
- Fixed out of bounds access in GEMM implementation for Intel SSE 4.1
- v2.3.2
- Fixed performance regression in fp32 inner product primitive for processors with Intel AVX512 support
- v2.3.3
- Reverted check for memory descriptor stride validity for unit dimensions
- Fixed memory leak in CPU GEMM implementation
More changes can be found in https://github.com/oneapi-src/oneDNN/releases.
- The Graph API provides flexible API for aggressive fusion, and the preview2 supports fusion for FP32 inference. See the [Graph API release branch](https://github.com/oneapi-src/oneDNN/tree/dev-graph-preview2) and [spec](https://spec.oneapi.io/onednn-graph/latest/introduction.html) for more details. A separate PR will be submitted to integrate the oneDNN Graph API to Torchscript graph.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63748
Reviewed By: albanD
Differential Revision: D32153889
Pulled By: malfet
fbshipit-source-id: 536071168ffe312d452f75d54f34c336ca3778c1
Summary:
This PR is to upgrade onednn to v2.2.3 (including v2.2 and v2.2.3 changes) which has the following main changes about CPU:
v2.2 changes:
Improved performance of compute functionality for future Intel Core processor with Intel AVX2 and Intel DL Boost instructions support (code name Alder Lake).
Improved fp32 inner product forward propagation performance for processors with Intel AVX-512 support.
Improved dnnl_gemm performance for cases with n=1 on all supported processors.
v2.2.3 changes:
Fixed a bug in int8 depthwise convolution ptimitive with groups and 1d spatial size for processors with Intel AVX-512 and Intel AVX2 support
Fixed correctness issue for PReLU primitive on Intel Processor Graphics
Fixed corretness issue in reorder for blocked layouts with zero padding
Improved performance of weights reorders used by BRGEMM-based convolution primitive for processors with Intel AVX-512 support
More changes can be found in https://github.com/oneapi-src/oneDNN/releases.
Ideep used version is pytorch-rls-v2.2.3.
OneDNN used version is v2.2.3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57928
Reviewed By: bdhirsh
Differential Revision: D29037857
Pulled By: VitalyFedyunin
fbshipit-source-id: db74534858bdcf5d6c7dcf58e224fc756188bc31
Summary:
Bump oneDNN (mkl-dnn) to 1.7 for bug fixes and performance optimizations
- Fixes https://github.com/pytorch/pytorch/issues/42115. Fixed build issue on Windows for the case when oneDNN is built as submodule
- Fixes https://github.com/pytorch/pytorch/issues/45746. Fixed segmentation fault for convolution weight gradient on systems with Intel AVX512 support
This PR also contains a few changes in ideep for follow-up update (not enabled in current PR yet):
- Performance improvements for the CPU path of Convolution
- Channel-last support
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47853
Reviewed By: bdhirsh
Differential Revision: D25275268
Pulled By: VitalyFedyunin
fbshipit-source-id: 75a589d57e3d19a7f23272a67045ad7494f1bdbe
{kind=link}
{kind=link}
{kind=link}