Since its introduction ~4 years ago, the test `test_sort_large` has always been deselected because it requires 200GB of CUDA memory. Now, as we do have GPUs this big, it gets selected, but fails with `var_mean` not being a member if `torch.Tensor` and `var_mean` accepting only floating point tensors.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/155546
Approved by: https://github.com/eqy
Continuation of https://github.com/pytorch/pytorch/pull/131909. This PR makes numpy tests compatible with numpy>=2.0.0. Specifically it deals with APIs that have been removed from numpy-2.0.
Changes in this PR:
1. Use `numpy.exceptions.ComplexWarning` if `numpy.exceptions` namespace is present. In numpy-2.0 `numpy.ComplexWarning` has been removed in favor of using `numpy.exceptions.ComplexWarning` (see [numpy-2.0 migration guide](https://numpy.org/devdocs/numpy_2_0_migration_guide.html#changes-to-namespaces)). Note that `numpy.exceptions` was introduced in numpy-1.25.0 hence does not exist in numpy<=1.24.x.
2. Do the same for `numpy.exceptions.VisibleDeprecationWarning`
3. Use `np.sort(...,axis=0)` over `np.msort()`(`np.msort()` removed in numpy-2.0)
4. Use `np.pad()` over `np.lib.pad()` (`np.lib` removed in numpy-2.0)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/136152
Approved by: https://github.com/atalman
Fixes some files in #123062
Run lintrunner on files:
test_shape_ops.py
test_show_pickle.py
test_sort_and_select.py
```bash
$ lintrunner --take UFMT --all-files
ok No lint issues.
Successfully applied all patches.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127165
Approved by: https://github.com/ezyang
Fixes some files in #123062
Run lintrunner on files:
test_shape_ops.py
test_show_pickle.py
test_sort_and_select.py
```bash
$ lintrunner --take UFMT --all-files
ok No lint issues.
Successfully applied all patches.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127165
Approved by: https://github.com/ezyang
This patch reuses `radix_sort` from fbgemm and makes `torch.(arg)sort` work in parallel for tensors filled with integers.
In GNN workloads we often use `torch.(arg)sort`, for example, to calculate permutation from CSR to CSC storage format. Till now, sorting one-dimensional data was performed sequentially. Recently, `radix_sort` implementation from FBGEMM was moved to common utilities and was also enhanced, to cover negative numbers ([pytorch/FBGEMM#1672](https://github.com/pytorch/FBGEMM/pull/1672)). This gives us an opportunity to reuse `radix_sort` to accelerate 1D integer sorting in PyTorch.
Benchmark results, measured on a single socket, 56C machine:
Before (int64):
```
size: 64000, average run time (from 100 runs): 6.592ms
size: 128000, average run time (from 100 runs): 9.798ms
size: 256000, average run time (from 100 runs): 19.199ms
size: 512000, average run time (from 100 runs): 36.394ms
size: 1024000, average run time (from 100 runs): 70.371ms
size: 2048000, average run time (from 100 runs): 137.752ms
size: 4096000, average run time (from 100 runs): 287.257ms
```
After(int64):
```
size: 64000, average run time (from 100 runs): 1.553ms
size: 128000, average run time (from 100 runs): 1.853ms
size: 256000, average run time (from 100 runs): 2.873ms
size: 512000, average run time (from 100 runs): 4.323ms
size: 1024000, average run time (from 100 runs): 7.184ms
size: 2048000, average run time (from 100 runs): 14.250ms
size: 4096000, average run time (from 100 runs): 29.374ms
```
Notes:
Average speedup from measured tensor sizes is 7.7x.
For smaller types (e.g. int32/int16), even higher speedup is observed, as fewer passes are required.
Depends on #100236.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100081
Approved by: https://github.com/mingfeima, https://github.com/ngimel
Follow up to gh-77100
Instead of calling `at::arange`, I repurpose the existing kernels to
achieve the same effect. I've also fixed the 2d case bug where
the pointer was advanced by `n` which equals `nsegment * nsort` after
only processing `nsort` elements.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77188
Approved by: https://github.com/ngimel
Fixes#75730
Previously, `torch.unique` returned a tensor of size `[0]` when the dimension supplied to `dim` is zero length. Instead, I've changed `torch.unique` to return a tensor matching the input size.
Changes:
- Modify `torch.unique` to return an an empty tensor of size `sizes` as the values output, when `dim` is zero length in the input tensor.
- Make the same change in the CUDA implementation of `torch.unique`.
- Update `test_unique_dim` to expect an empty tensor with size matching the input tensor.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75764
Approved by: https://github.com/mruberry
Summary:
# Overview
Currently the cuda topk implementation uses only 1 block per slice, which limits the performance for big slices. This PR addresses this issue.
There are 2 parts in the topk calculation, find the kth value (`radixFindKthValues`) in each slice, then gather topk values (`gatherTopK`) based on the kth value. `radixFindKthValues` kernel now supports multiple blocks. `gatherTopK` may also need a multiple block version (separate PR?).
kthvalue, quantile, median could also use the same code (separate PR).
# Benchmark
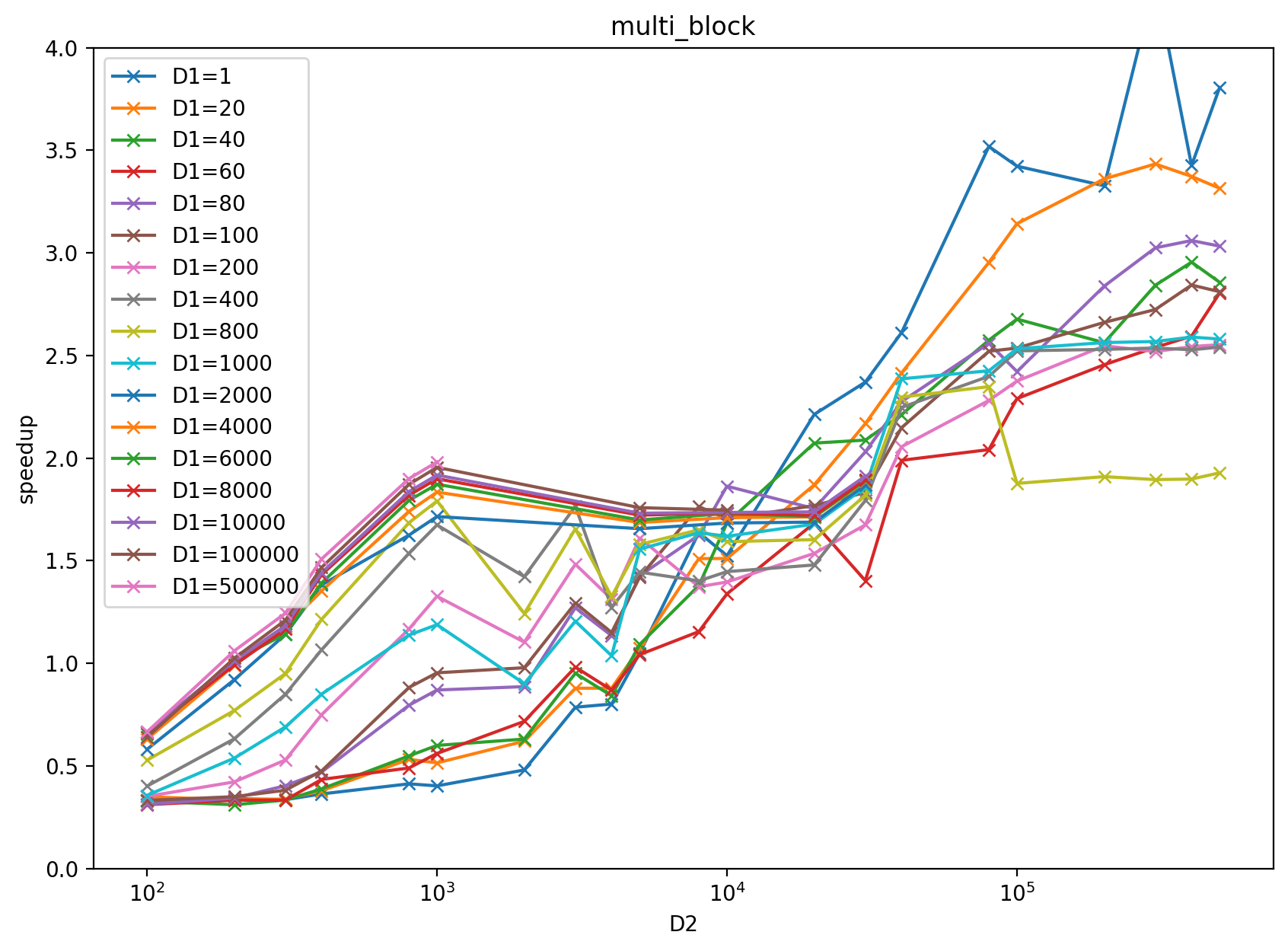
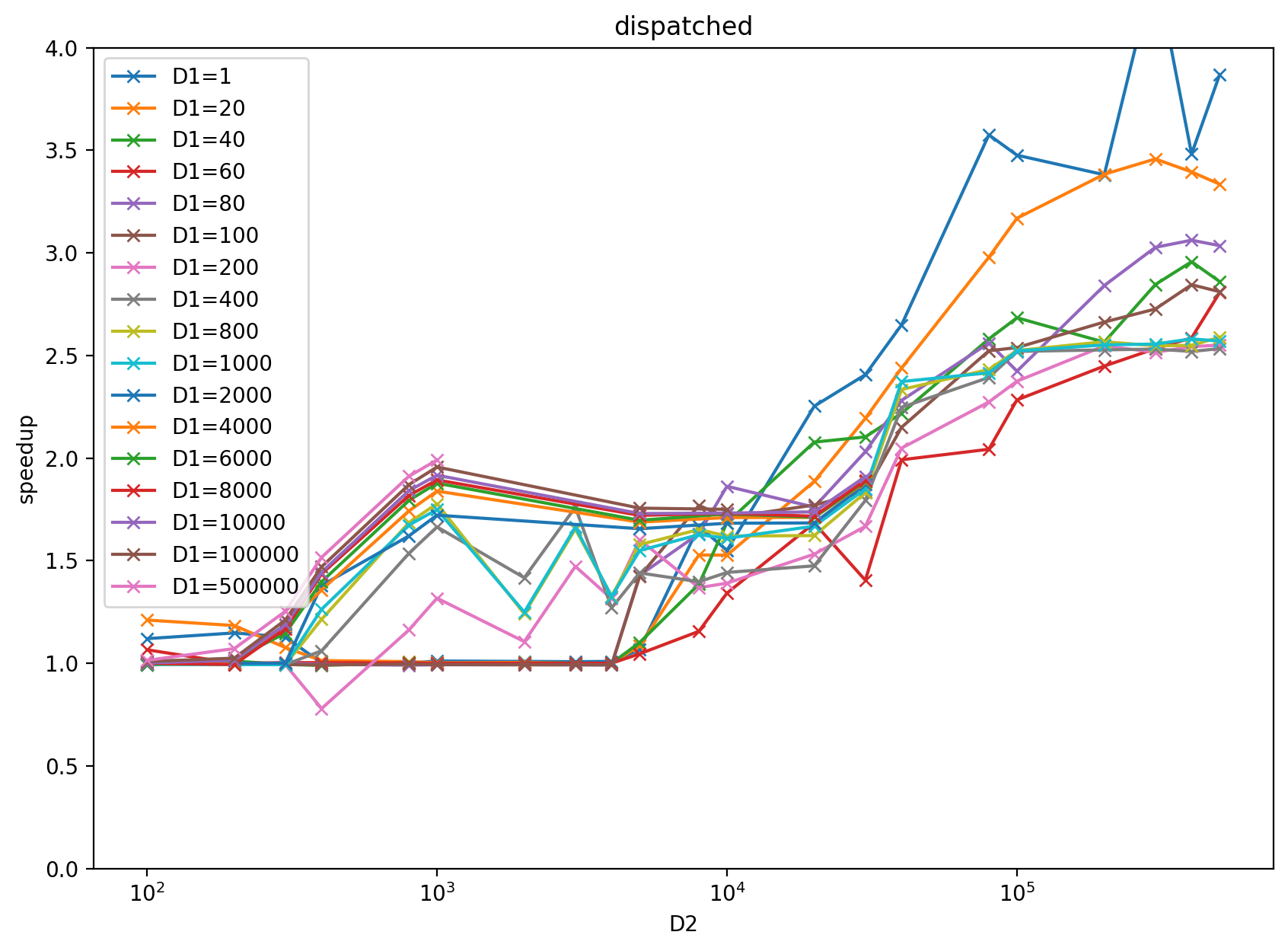
Benchmark result with input `x = torch.randn((D1 (2d884f2263), D2 (9b53d3194c)), dtype=torch.float32)` and `k = 2000` on RTX 3080: https://docs.google.com/spreadsheets/d/1BAGDkTCHK1lROtjYSjuu_nLuFkwfs77VpsVPymyO8Gk/edit?usp=sharing
benchmark plot: left is multiblock, right is dispatched based on heuristics result from the above google sheet.
<p class="img">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860547-7e450ed2-df09-4292-a02a-cb0e1040eebe.png">
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860579-672b88ca-e500-4846-825c-65d31d126df4.png">
</p>
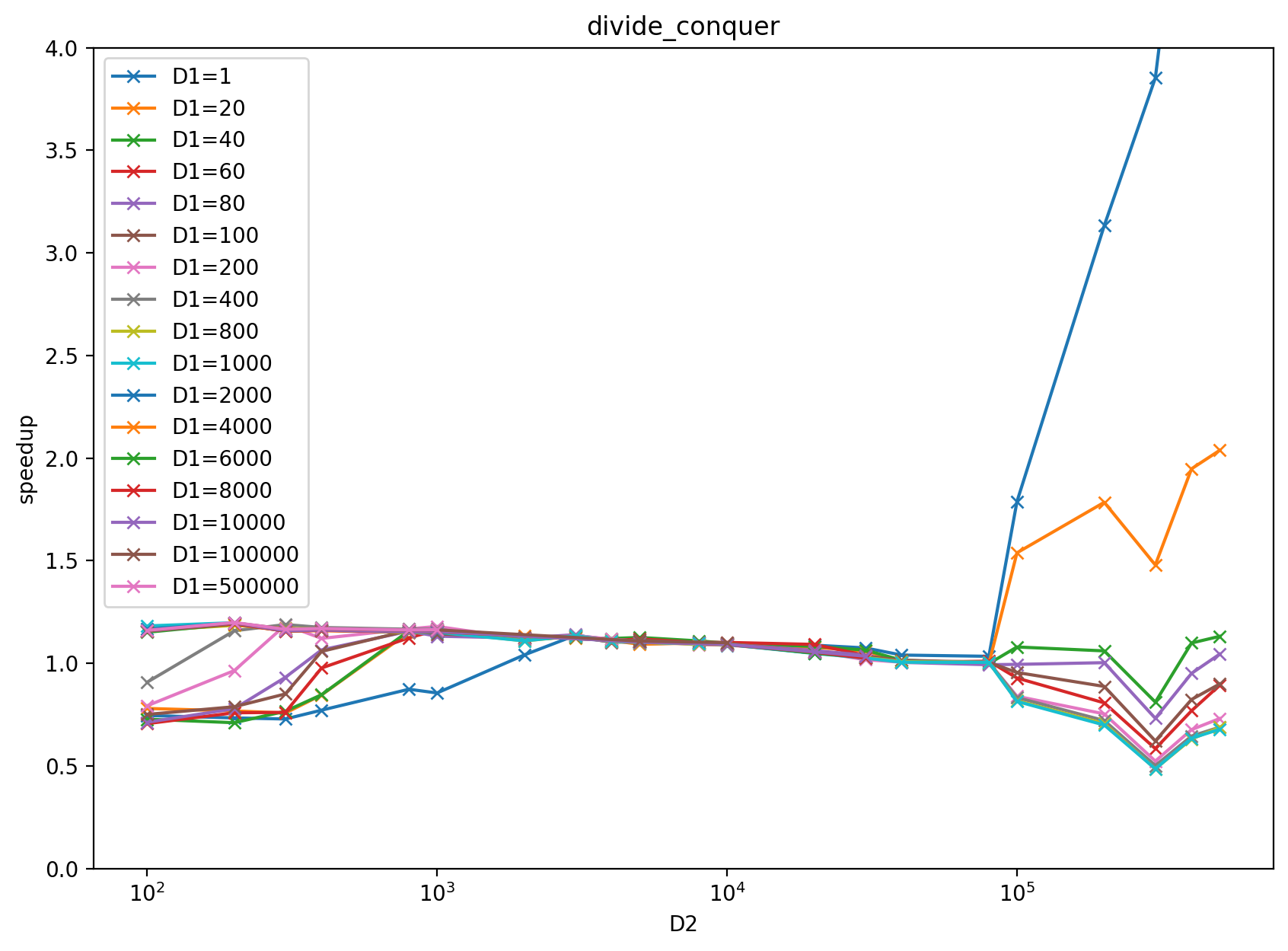
The performance of divide-and-conquer implementation at https://github.com/pytorch/pytorch/pull/39850 is not stable in terms of the D1 (2d884f2263), D2 (9b53d3194c) size increasing, for more detail please check the above google sheet.
<p>
<img width=49% src="https://user-images.githubusercontent.com/9999318/150860563-21d5a5a3-9d6a-4cef-9031-cac4d2d8edee.png">
</p>
# cubin binary size
The cubin binary size for TensorTopK.cubin (topk) and Sorting.cubin (kthvalue, quantile and etc) has been reduced by removing `#pragma unroll` at [SortingRadixSelect.cuh](https://github.com/pytorch/pytorch/pull/71081/files#diff-df06046dc4a2620f47160e1b16b8566def855c0f120a732e0d26bc1e1327bb90L321) and `largest` template argument without much performance regression.
The final binary size before and after the PR is
```
# master
-rw-rw-r-- 1 richard richard 18M Jan 24 20:07 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 16M Jan 24 20:07 Sorting.cu.1.sm_86.cubin
# this PR
-rw-rw-r-- 1 richard richard 5.0M Jan 24 20:11 TensorTopK.cu.1.sm_86.cubin
-rw-rw-r-- 1 richard richard 2.5M Jan 24 20:11 Sorting.cu.1.sm_86.cubin
```
script to extract cubin
```
# build with REL_WITH_DEB_INFO=0
# at pytorch directory
cubin_path=build/caffe2/CMakeFiles/torch_cuda.dir/__/aten/src/ATen/native/cuda/cubin; mkdir -p $cubin_path; cd $cubin_path; find ../ -type f -name '*cu.o' -exec cuobjdump {} -xelf all \; ; ls -lh *.cubin -S | head -70
```
# benchmark script
```py
import torch
import time
import torch
import pandas as pd
import numpy as np
import torch.utils.benchmark as benchmark
torch.manual_seed(1)
dtype = torch.float
data = []
for d1 in [1, 20, 40, 60, 80, 100, 200, 400, 800, 1000, 2000, 4000, 6000, 8000, 10000, 100000, 500000]:
if d1 <= 1000:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 2000, 3000, 4000, 5000, 8000, 10000, 20000, 30000, 40000, 80000, 100000, 200000, 300000, 400000, 500000]
else:
D2 (9b53d3194c) = [100, 200, 300, 400, 800, 1000, 5000, 10000, 20000, 30000]
for d2 in D2 (9b53d3194c):
k = 2000 if d2 >= 2000 else d2 // 2
print(f"----------------- D1 (2d884f2263) = {d1}, D2 (9b53d3194c) = {d2} -----------------")
try:
x = torch.randn((d1, d2), dtype=dtype, device="cuda")
m = benchmark.Timer(
stmt='x.topk(k=k, dim=1, sorted=False, largest=True)',
globals={'x': x, 'k': k},
num_threads=1,
).blocked_autorange(min_run_time=1)
print(m)
time_ms = m.median * 1000
except RuntimeError: # OOM
time_ms = -1
data.append([d1, d2, k, time_ms])
df = pd.DataFrame(data=data, columns=['D1 (2d884f2263)', 'D2 (9b53d3194c)', 'k', 'time(ms)'])
print(df)
df.to_csv('benchmark.csv')
```
plot script could be found at: https://github.com/yueyericardo/misc/tree/master/share/topk-script
cc zasdfgbnm ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71081
Reviewed By: albanD
Differential Revision: D33823002
Pulled By: ngimel
fbshipit-source-id: c0482664e9d74f7cafc559a07c6f0b564c9e3ed0
(cherry picked from commit be367b8d076aebf53ab7511f6a8a86834c76c95b)
Summary:
This PR ensures that the input iterator is always in front of the output
iterator. Thus, we won't have a out of bound issue since the input
iterator will meet the end before output iterator meets.
Fixes https://github.com/pytorch/pytorch/issues/71089
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71540
Reviewed By: mruberry
Differential Revision: D33688123
Pulled By: ngimel
fbshipit-source-id: f57718931d09a0fbea76ac1bd6cc8c7150af0978
(cherry picked from commit dc6e0e219a9e9b9ccea9ff5406458b56f556b2e4)
{kind=link}
{kind=link}
{kind=link}