Fixes#147208
**Summary**
The `flip` op causes memory corruption for `torch.quint4x2` and `torch.quint2x4` inputs. It is because the TensorIterator-based implementation does not support multiple elements per byte. And `torch.quint4x2` and `torch.quint2x4` are deprecated in PyTorch. So, we add a check here to throw a runtime error if input dtyps is `torch.quint4x2` or `torch.quint2x4`.
**Test plan**
```
pytest -s test/test_shape_ops.py -k test_flip_unsupported_dtype
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/147430
Approved by: https://github.com/mingfeima, https://github.com/ngimel
Fixes some files in #123062
Run lintrunner on files:
test_shape_ops.py
test_show_pickle.py
test_sort_and_select.py
```bash
$ lintrunner --take UFMT --all-files
ok No lint issues.
Successfully applied all patches.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127165
Approved by: https://github.com/ezyang
Fixes some files in #123062
Run lintrunner on files:
test_shape_ops.py
test_show_pickle.py
test_sort_and_select.py
```bash
$ lintrunner --take UFMT --all-files
ok No lint issues.
Successfully applied all patches.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127165
Approved by: https://github.com/ezyang
The reason for enabling sparse/dense_dim() for strided tensors is to have more meaningful error messages:
For instance, compare
```
NotImplementedError: Could not run 'aten::sparse_dim' with arguments from the 'CPU' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::sparse_dim' is only available for these backends: [SparseCPU, SparseCUDA, SparseMeta, SparseCsrCPU, SparseCsrCUDA, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradHIP, AutogradXLA, AutogradMPS, AutogradIPU, AutogradXPU, AutogradHPU, AutogradVE, AutogradLazy, AutogradMeta, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, AutogradNestedTensor, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
```
[master] vs
```
RuntimeError: addmm: matrices expected, got 0D tensor
```
[this PR] where the latter message gives a hint of which function is to blame for dealing with unexpected inputs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86203
Approved by: https://github.com/cpuhrsch
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63554
Following https://github.com/pytorch/pytorch/pull/61840#issuecomment-884087809, this deprecates all the dtype getters publicly exposed in the `torch.testing` namespace. The reason for this twofold:
1. If someone is not familiar with the C++ dispatch macros PyTorch uses, the names are misleading. For example `torch.testing.floating_types()` will only give you `float32` and `float64` skipping `float16` and `bfloat16`.
2. The dtype getters provide very minimal functionality that can be easily emulated by downstream libraries.
We thought about [providing an replacement](https://gist.github.com/pmeier/3dfd2e105842ad0de4505068a1a0270a), but ultimately decided against it. The major problem is BC: by keeping it, either the namespace is getting messy again after a new dtype is added or we need to somehow version the return values of the getters.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D30662206
Pulled By: mruberry
fbshipit-source-id: a2bdb10ab02ae665df1b5b76e8afa9af043bbf56
Summary:
This PR will ideally add `ref` argument to `OpInfo` base class. The idea is to add reference checks for all the ops _eligible_. For more discussion, please check https://github.com/pytorch/pytorch/issues/58294
* [x] Migrate (but not removing yet) and modify helper functions from `UnaryUfuncOpInfo` class to `OpInfo` base class.
* [x] Test the reference checks for multiple ops. (also decide a list of different and eligible ops for this)
* [x] Handle possible edge cases (for example: `uint64` isn't implemented in PyTorch but is there in NumPy, and this needs to be handled -- more on this later) -- _Update_: We decided that these reference tests should only test for values and not types.
* [x] Create a sample PR for a single (of all different categories?) on adding reference functions to the eligible ops. -- _Update_: This is being done in this PR only.
* [x] ~Remove reference tests from `test_unary_ufuncs.py` and test to make sure that nothing breaks.~ (*Update*: We won't be touching Unary Ufunc reference tests in this PR)
* [x] Add comments, remove unnecessary prints/comments (added for debugging).
Note: To keep the PR description short, examples of edge cases encountered have been mentioned in the comments below.
cc: mruberry pmeier kshitij12345
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59369
Reviewed By: ngimel
Differential Revision: D29347252
Pulled By: mruberry
fbshipit-source-id: 69719deddb1d23c53db45287a7e66c1bfe7e65bb
Summary:
Implements an idea by ngimel to improve the performance of `torch.flip` via a clever hack into TI to bypass the fact that TI is not designed to work with negative indices.
Something that might be added is vectorisation support on CPU, given how simple the implementation is now.
Some low-hanging fruits that I did not implement:
- Write it as a structured kernel
- Migrate the tests to opinfos
- Have a look at `cumsum_backward` and `cumprod_backward`, as I think that they could be implemented faster with `flip`, now that `flip` is fast.
**Edit**
This operation already has OpInfos and it cannot be migrated to a structured kernel because it implements quantisation
Summary of the PR:
- x1.5-3 performance boost on CPU
- x1.5-2 performance boost on CUDA
- Comparable performance across dimensions, regardless of the strides (thanks TI)
- Simpler code
<details>
<summary>
Test Script
</summary>
```python
from itertools import product
import torch
from torch.utils.benchmark import Compare, Timer
def get_timer(size, dims, num_threads, device):
x = torch.rand(*size, device=device)
timer = Timer(
"torch.flip(x, dims=dims)",
globals={"x": x, "dims": dims},
label=f"Flip {device}",
description=f"dims: {dims}",
sub_label=f"size: {size}",
num_threads=num_threads,
)
return timer.blocked_autorange(min_run_time=5)
def get_params():
sizes = ((1000,)*2, (1000,)*3, (10000,)*2)
for size, device in product(sizes, ("cpu", "cuda")):
threads = (1, 2, 4) if device == "cpu" else (1,)
list_dims = [(0,), (1,), (0, 1)]
if len(size) == 3:
list_dims.append((0, 2))
for num_threads, dims in product(threads, list_dims):
yield size, dims, num_threads, device
def compare():
compare = Compare([get_timer(*params) for params in get_params()])
compare.trim_significant_figures()
compare.colorize()
compare.print()
compare()
```
</details>
<details>
<summary>
Benchmark PR
</summary>
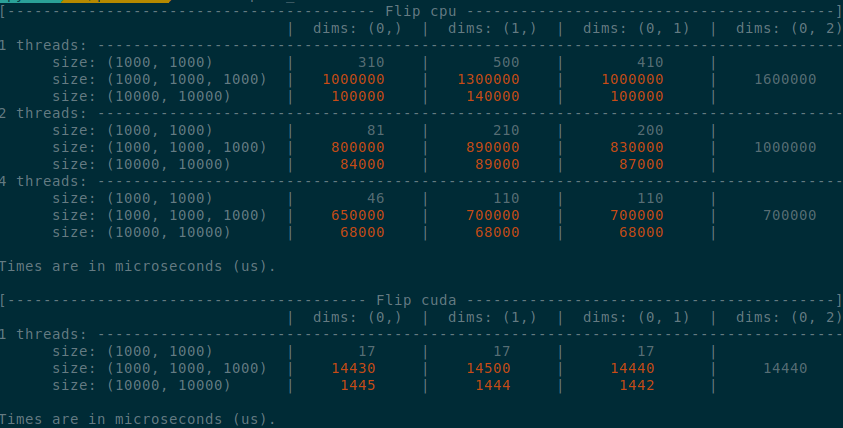
</details>
<details>
<summary>
Benchmark master
</summary>
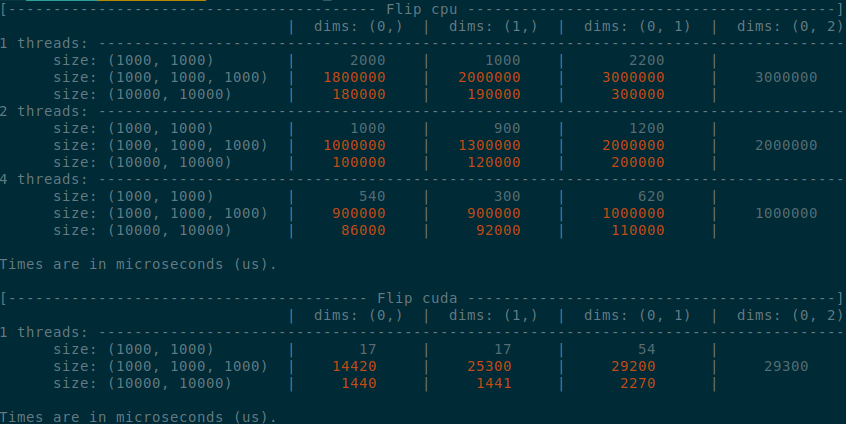
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58747
Reviewed By: agolynski
Differential Revision: D28877076
Pulled By: ngimel
fbshipit-source-id: 4fa6eb519085950176cb3a9161eeb3b6289ec575
Summary:
Stack:
* https://github.com/pytorch/pytorch/issues/54954 Fixed OpInfo jit tests failing for TensorList inputs
* __#54922 Added support for TensorList inputs in OpInfo__
Updated OpInfo to accept either a `Tensor` or `TensorList` as `sample.input` and added workarounds to make this work with gradcheck.
Note: JIT testing support for TensorList inputs will be added in a follow up PR.
Fixes https://github.com/pytorch/pytorch/issues/51996
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54922
Reviewed By: H-Huang
Differential Revision: D27448952
Pulled By: heitorschueroff
fbshipit-source-id: 3f24a56f6180eb2d044dcfc89ba59fce8acfe278
Summary:
This PR:
- Updates the structure of the SampleInput class to require the "input" attribute be a tensor
- Limits unary ufuncs to test only the uint8, long, float16, bfloat16, float and cfloat dtypes by default
- Limits variant testing to the float dtype
- Removes test_variant_consistency from test_unary_ufuncs.py since it's now redundant with variant testing in test_ops.py
- Adds backwards supported testing to clarify failures that were coming from variant testing
This should decrease test e2e time.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53255
Reviewed By: ngimel
Differential Revision: D27043643
Pulled By: mruberry
fbshipit-source-id: 91d6b483ad6e2cd1b9ade939d42082980ae14217
Summary:
Fixes https://github.com/pytorch/pytorch/issues/49982
The method flip_check_errors was being called in cuda file which had a condition to throw an exception for when dims size is <=0 changed that to <0 and added seperate condition for when equal to zero to return from the method... the return was needed because after this point the method was performing check expecting a non-zero size dims ...
Also removed the comment/condition written to point to the issue
mruberry kshitij12345 please review this once
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50325
Reviewed By: zhangguanheng66
Differential Revision: D25869559
Pulled By: mruberry
fbshipit-source-id: a831df9f602c60cadcf9f886ae001ad08b137481
Summary:
Creates multiple new test suites to have fewer tests in test_torch.py, consistent with previous test suite creation like test_unary_ufuncs.py and test_linalg.py.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47356
Reviewed By: ngimel
Differential Revision: D25202268
Pulled By: mruberry
fbshipit-source-id: 75fde3ca76545d1b32b86d432a5cb7a5ba8f5bb6
{kind=link}
{kind=link}