Add _int_mm primitive that binds cuBLAS int8@int8 -> int32 matmul and that translates to Triton based mm templates under max autotune. This is a very useful first step towards better supporting quantization on the GPU. This is a not a user facing API, but an internal primitive.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94339
Approved by: https://github.com/ngimel, https://github.com/jansel
Currently, if we multiply a transposed batch of matrices with shape
[b, m, n] and a matrix with shape [n, k], when computing the gradient
of the matrix, we instantiate a matrix of shape [b, n, k]. This may be
a very large matrix. Instead, we fold the batch of matrices into a
matrix, which avoids creating any large intermediary tensor.
Note that multiplying a batch of matrices and a matrix naturally occurs
within an attention module, so this case surely happens in the wild.
In particular, this issue was found while investigating the OOMs caused by the
improved folding algorithm in the next PR of this stack. See https://github.com/pytorch/pytorch/pull/76828#issuecomment-1432359980
This PR fixes those OOMs and decreases the memory footprint of the
backward of matmul.
I understand this is a tricky one, so I put it on its own PR to discuss it.
Differential Revision: [D43541495](https://our.internmc.facebook.com/intern/diff/D43541495)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95261
Approved by: https://github.com/ezyang
Follow-up of #89582 to drop flags like `CUDA11OrLater` in tests. Note that in some places it appears that `TEST_WITH_ROCM` is _implicitly_ guarded against via the `CUDA11OrLater` version check, based on my best-guess of how `torch.version.cuda` would behave in ROCM builds, so I've added `not TEST_WITH_ROCM` in cases where ROCM wasn't previously explicitly allowed.
CC @ptrblck @malfet @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92605
Approved by: https://github.com/ngimel
This achieves the same things as https://github.com/pytorch/pytorch/pull/85908 but using backends instead of kwargs (which breaks torchscript unfortunately). This also does mean we let go of numpy compatibility BUT the wins here are that users can control what opt einsum they wanna do!
The backend allows for..well you should just read the docs:
```
.. attribute:: torch.backends.opteinsum.enabled
A :class:`bool` that controls whether opt_einsum is enabled (on by default). If so,
torch.einsum will use opt_einsum (https://optimized-einsum.readthedocs.io/en/stable/path_finding.html)
to calculate an optimal path of contraction for faster performance.
.. attribute:: torch.backends.opteinsum.strategy
A :class:`str` that specifies which strategies to try when `torch.backends.opteinsum.enabled` is True.
By default, torch.einsum will try the "auto" strategy, but the "greedy" and "optimal" strategies are
also supported. Note that the "optimal" strategy is factorial on the number of inputs as it tries all
possible paths. See more details in opt_einsum's docs
(https://optimized-einsum.readthedocs.io/en/stable/path_finding.html).
```
In trying (and failing) to land 85908, I discovered that jit script does NOT actually pull from python's version of einsum (because it cannot support variadic args nor kwargs). Thus I learned that jitted einsum does not subscribe to the new opt_einsum path calculation. Overall, this is fine since jit script is getting deprecated, but where is the best place to document this?
## Test plan:
- added tests to CI
- locally tested that trying to set the strategy to something invalid will error properly
- locally tested that tests will pass even if you don't have opt-einsum
- locally tested that setting the strategy when opt-einsum is not there will also error properly
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86219
Approved by: https://github.com/soulitzer, https://github.com/malfet
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
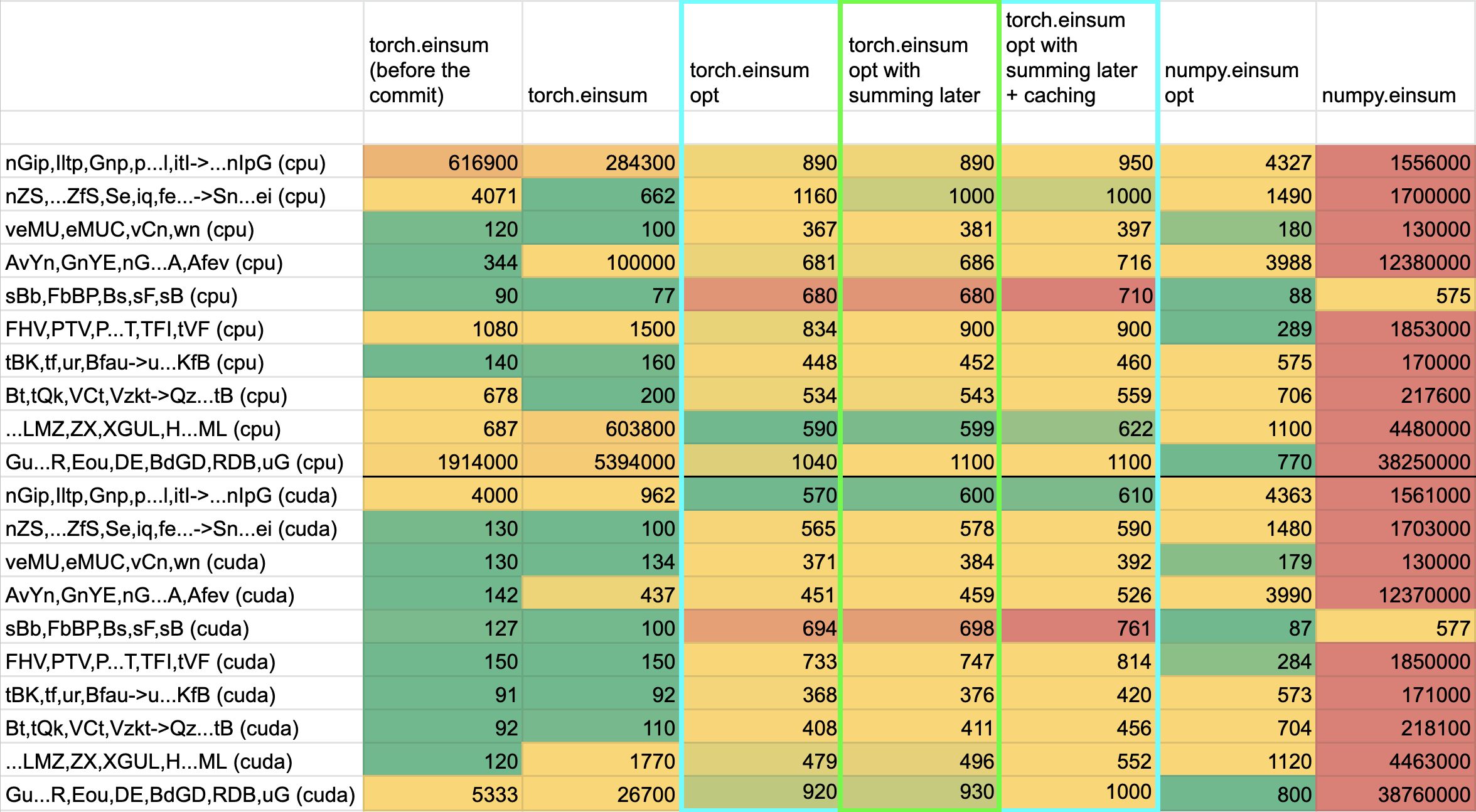
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
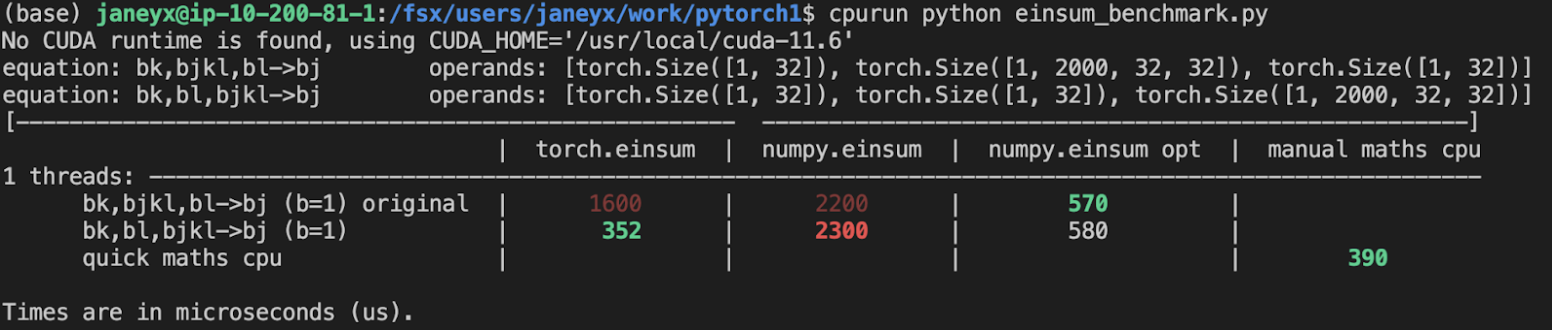
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
Summary: test_inverse_errors_large and test_linalg_solve_triangular fail for dtype=float64 when invoked on GPUs on Meta internal testing infra. Skip in Meta internal testing.
Test Plan: (observe tests skipped on Meta internal infra)
Reviewed By: mikekgfb
Differential Revision: D39785331
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85577
Approved by: https://github.com/malfet
Summary:
Re-submit for approved PR that was then reverted: https://github.com/pytorch/pytorch/pull/85084
Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85432
Approved by: https://github.com/zrphercule
Summary: Create unit test to detect cuBLAS breakage via large differences between CPU and GPU addmm invocations
Test Plan:
Sample unit test output --
[...]
test_cublas_addmm_size_10000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_10000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_1000_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_bfloat16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float16 (test_linalg.TestLinalgCPU) ... ok
test_cublas_addmm_size_100_cpu_float32 (test_linalg.TestLinalgCPU) ... ok
[...]
Reviewed By: mikekgfb
Differential Revision: D39433029
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85084
Approved by: https://github.com/zrphercule
`torch.norm` is very odd. Some notable issues are:
- The default value of `"fro"` in `torch.norm` has an odd behaviour when `dim=None`. This is handled in the new dispatch
- The treatment of the `dtype` argument in `torch.norm` was completely wrong. This should fix it
- Some `out=` variants in the previous implementation were also wrong. This should fix those.
- This new dispatch should make some paths much faster. For example, `torch.norm(x)` where `x` is complex.
I'll try to make the changes in these PRs as incremental as possible as this is a tricky one.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81761
Approved by: https://github.com/ngimel
As per title. I corrected a thing or two from my previous implementation
to make for better errors in some weird edge-cases and have a more clear
understanding of when does this function support low_precision types and
when it doesn't.
We also use the optimisation for bfloat16 within `vector_norm` within
this function.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81113
Approved by: https://github.com/ngimel
This PR also adds complex support for logdet, and makes all these
functions support out= and be composite depending on one function. We
also extend the support of `logdet` to complex numbers and improve the
docs of all these functions.
We also use `linalg_lu_factor_ex` in these functions, so we remove the
synchronisation present before.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79742
Approved by: https://github.com/IvanYashchuk, https://github.com/albanD
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}