For free blocks of memory in the allocator, we previously kept a linked list
of the stack frames of previous allocations that lived there. This was only
ever used in one flamegraph visualization and never proved useful at
understanding what was going on. When memory history tracing was added, it
became redundant, since we can see the history of the free space from recording
the previous actions anyway.
This patch removes this functionality and simplifies the snapshot format:
allocated blocks directly have a 'frames' attribute rather than burying stack frames in the history.
Previously the memory history tracked the real size of allocations before rounding.
Since history was added, 'requested_size' has been added directly to the block which records the same information,
so this patch also removes that redundancy.
None of this functionality has been part of a PyTorch release with BC guarentees, so it should be safe to alter
this part of the format.
This patch also updates our visualization tools to work with the simplified format. Visualization tools keep
support for the old format in `_legacy` functions so that during the transition old snapshot files can still be read.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106079
Approved by: https://github.com/eellison
Mostly refactor, that moves all the tests from `test_cuda` that benefit from multiGPU environment into its own file.
- Add `TestCudaMallocAsync` class for Async tests ( to separate them from `TestCudaComm`)
- Move individual tests from `TestCuda` to `TestCudaMultiGPU`
- Move `_create_scaling_models_optimizers` and `_create_scaling_case` to `torch.testing._internal.common_cuda`
- Add newly created `test_cuda_multigpu` to the multigpu periodic test
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at f4d46fa</samp>
This pull request fixes a flaky test and improves the testing of gradient scaling on multiple GPUs. It adds verbose output for two CUDA tests, and refactors some common code into helper functions in `torch/testing/_internal/common_cuda.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104059
Approved by: https://github.com/huydhn
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulation of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Reland to make windows skip the test.
This reverts commit 7b3b6dd4262337c5289d64dd3e824b0614cf68e3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104051
Approved by: https://github.com/aaronenyeshi, https://github.com/malfet
Reference cycles are freed by the cycle collector rather than being cleaned up
when the objects in the cycle first become unreachable. If a cycle points to a tensor,
the CUDA memory for that tensor will not be freed until garbage collection runs.
Accumulatin of CUDA allocations can lead to out of memory errors (OOMs), as well as
non-deterministic allocation behavior which is harder to debug.
This visualizer installs a garbage collection hook to look for cycles containing
CUDA tensors and saves a visualization of the garbage:
```
from torch.cuda._cycleviz import warn_tensor_cycles
warn_tensor_cycles()
# do some work that results in a cycle getting garbage collected
# ...
> WARNING:root:Reference cycle includes a CUDA Tensor see visualization of cycle /tmp/tmpeideu9gl.html
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102656
Approved by: https://github.com/aaronenyeshi
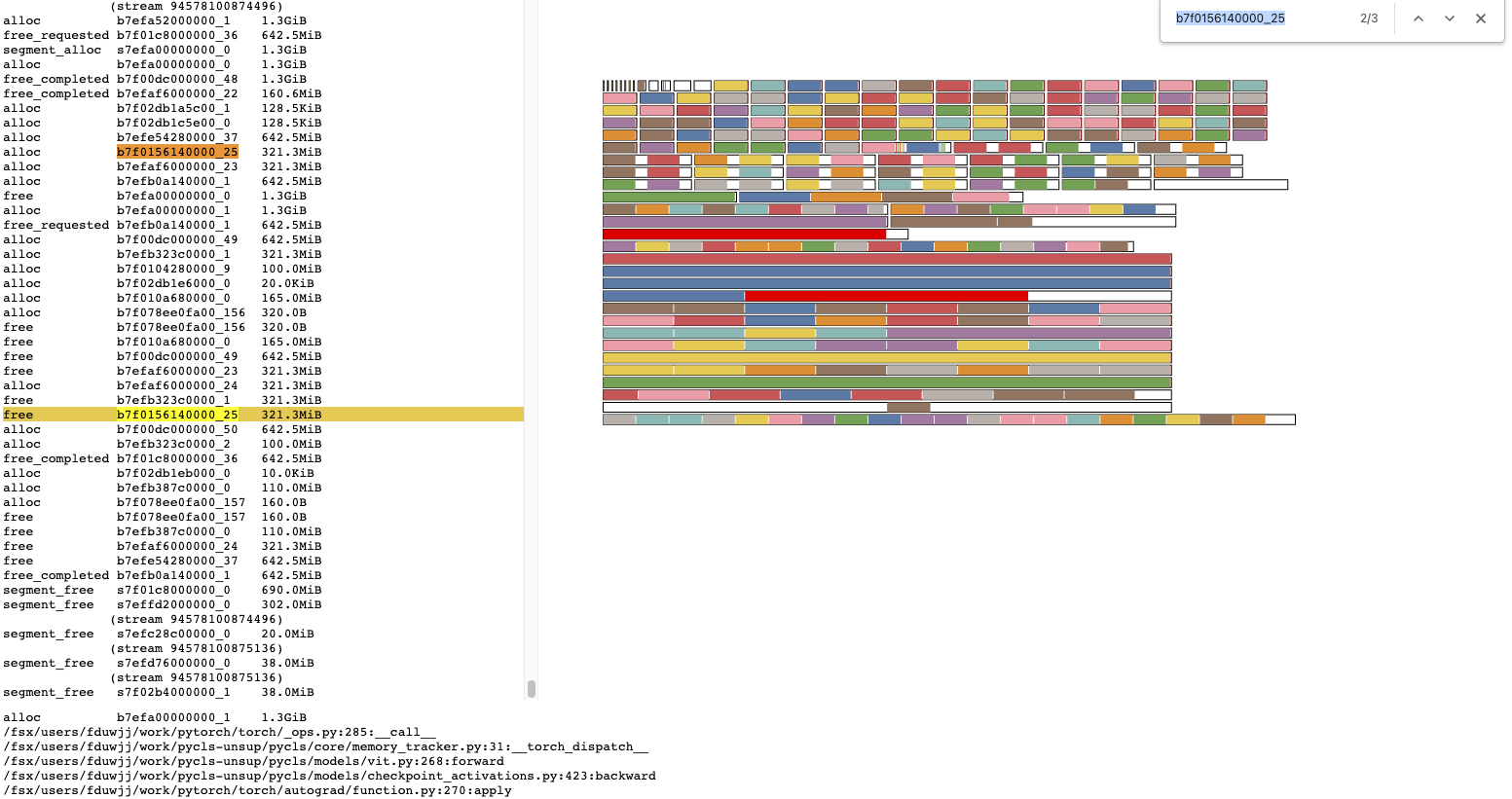
This replaces the invidual visualization routines in _memory_viz.py with
a single javascript application.
The javascript application can load pickled snapshot dumps directly using
drag/drop, requesting them via fetch, or by embedding them in a webpage.
The _memory_viz.py commands use the embedding approach.
We can also host MemoryViz.js on a webpage to use the drag/drop approach, e.g.
https://zdevito.github.io/assets/viz/
(eventually this should be hosted with the pytorch docs).
All views/multiple cuda devices are supported on one page.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103565
Approved by: https://github.com/eellison, https://github.com/albanD
Skip all cuda graph-related unit tests by setting env var `PYTORCH_TEST_SKIP_CUDAGRAPH=1`
This PR refactors the `TEST_CUDA` python variable in test_cuda.py into common_utils.py. This PR also creates a new python variable `TEST_CUDA_GRAPH` in common_utils.py, which has an env var switch to turn off all cuda graph-related tests.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103032
Approved by: https://github.com/malfet
Do not try to parse raised exception for no good reason
Add short description
Reduce script to a single line
<!--
copilot:poem
-->
### <samp>🤖 Generated by Copilot at ea4164e</samp>
> _`test_no_triton_on_import`_
> _Cleans up the code, adds docs_
> _No hidden errors_
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102674
Approved by: https://github.com/cpuhrsch, https://github.com/albanD
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 08f7a6a</samp>
This pull request adds support for triton kernels in `torch` and `torch/cuda`, and refactors and tests the existing triton kernel for BSR matrix multiplication. It also adds a test case to ensure that importing `torch` does not implicitly import `triton`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98403
Approved by: https://github.com/malfet, https://github.com/cpuhrsch
On Arm, I got
```
Traceback (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5260, in test_cpp_memory_snapshot_pickle
mem = run()
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5257, in run
t = the_script_fn()
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 496, in prof_func_call
return prof_callable(func_call, *args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/testing/_internal/common_utils.py", line 493, in prof_callable
return callable(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "/opt/pytorch/pytorch/test/test_cuda.py", line 5254, in the_script_fn
@torch.jit.script
def the_script_fn():
return torch.rand(311, 411, device='cuda')
~~~~~~~~~~ <--- HERE
RuntimeError: record_context_cpp is not support on non-linux non-x86_64 platforms
```
dfe484a3b3/torch/csrc/profiler/unwind/unwind.cpp (L4-L24) seems related
Pull Request resolved: https://github.com/pytorch/pytorch/pull/101366
Approved by: https://github.com/zdevito
When we run cudagraph trees we are not allowed to have permanent workspace allocations like in cublas because we might need to reclaim that memory for a previous cudagraph recording, and it is memory that is not accounted for in output weakrefs so it does not work with checkpointing. Previously, I would check that we didn't have any additional allocations through snapshotting. This was extremely slow so I had to turn it off.
This PR first does the quick checking to see if we are in an error state, then if we are does the slow logic of creating snapshot. Also turns on history recording so we get a stacktrace of where the bad allocation came from.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99985
Approved by: https://github.com/zdevito
Why?
* To reduce the latency of hot path in https://github.com/pytorch/pytorch/pull/97377
Concern - I had to add `set_offset` in all instances of `GeneratorImpl`. I don't know if there is a better way.
~~~~
import torch
torch.cuda.manual_seed(123)
print(torch.cuda.get_rng_state())
torch.cuda.set_rng_state_offset(40)
print(torch.cuda.get_rng_state())
tensor([123, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
tensor([123, 0, 0, 0, 0, 0, 0, 0, 40, 0, 0, 0, 0, 0,
0, 0], dtype=torch.uint8)
~~~~
Reland of https://github.com/pytorch/pytorch/pull/98965
(cherry picked from commit 8214fe07e8a200e0fe9ca4264bb6fca985c4911e)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/99565
Approved by: https://github.com/anijain2305
Common advice we give for handling memory fragmentation issues is to
allocate a big block upfront to reserve memory which will get split up later.
For programs with changing tensor sizes this can be especially helpful to
avoid OOMs that happen the first time we see a new largest input and would
otherwise have to allocate new segments.
However the issue with allocating a block upfront is that is nearly impossible
to correctly estimate the size of that block. If too small, space in the block
will run out and the allocator will allocate separate blocks anyway. Too large,
and other non-PyTorch libraries might stop working because they cannot allocate
any memory.
This patch provides the same benefits as using a pre-allocating block but
without having to choose its size upfront. Using the cuMemMap-style APIs,
it adds the ability to expand the last block in a segment when more memory is
needed.
Compared to universally using cudaMallocAsync to avoid fragmentation,
this patch can fix this common fragmentation issue while preserving most
of the existing allocator behavior. This behavior can be enabled and disabled dynamically.
This should allow users to, for instance, allocate long-lived parameters and state in individual buffers,
and put temporary state into the large expandable blocks, further reducing
fragmentation.
See inline comments for information about the implementation and its limitations.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96995
Approved by: https://github.com/eellison
CUDA Graph Trees
Design doc: https://docs.google.com/document/d/1ZrxLGWz7T45MSX6gPsL6Ln4t0eZCSfWewtJ_qLd_D0E/edit
Not currently implemented :
- Right now, we are using weak tensor refs from outputs to check if a tensor has dies. This doesn't work because a) aliasing, and b) aot_autograd detaches tensors (see note [Detaching saved tensors in AOTAutograd]). Would need either https://github.com/pytorch/pytorch/issues/91395 to land to use storage weak refs or manually add a deleter fn that does what I want. This is doable but theres some interactions with the caching allocator checkpointing so saving for a stacked pr.
- Reclaiming memory from the inputs during model recording. This isn't terribly difficult but deferring to another PR. You would need to write over the input memory during warmup, and therefore copy the inputs to cpu. Saving for a stacked pr.
- Warning on overwriting previous generation outputs. and handling nested torch.compile() calls in generation tracking
Differential Revision: [D43999887](https://our.internmc.facebook.com/intern/diff/D43999887)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89146
Approved by: https://github.com/ezyang
This refactors the stack trace facility specific to memory profiling
in python+cuda to make a generic facility to generate combined stack
traces.
The generic facility (combined_traceback.h) does not require
python to be around to work, but will return python stacks if it is
present.
This facility is then used to add support for stack trace gathering in memory profiling that
happens directly from C++.
It is also used to expose a python API for gathering and symbolizing
combineds stacks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95541
Approved by: https://github.com/ezyang
When we checkpoint the state of the private pool allocator, we will need to make sure that its current live allocated blocks will get properly cleaned up when the tensors they correspond to die. Return DataPtrs for these new allocated blocks that the callee can swap onto live Tensors.
The exact api for setting the checkpoint can be manipulated after this as the cudagraph implementation is built out, but this at least shows its sufficiently general.
This should be the last PR touching cuda caching allocator necessary for new cudagraphs integration.
Differential Revision: [D43999888](https://our.internmc.facebook.com/intern/diff/D43999888)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95020
Approved by: https://github.com/zdevito
Copying note from cuda caching allocator:
```
* Note [Checkpointing PrivatePoolState]
*
* Refer above to Note [Interaction with CUDA graph capture]. Allocations made
* during graph capture are made from a separate private pool. During graph
* capture allocations behave as usual. During graph replay the allocator
* state does not change even as new tensors are created. The private pool
* will not free its blocks to the main caching allocator until cuda graph use
* is finished to prevent an allocation from eager clobbering the memory from
* a live but unaccounted for tensor that was created during replay.
*
* `make_graphed_callables`, a series of separate callables chained in
* successive cuda graphs, can share a memory pool because after a cuda graph
* recording the allocations in the shared private pool exactly reflect the
* tensors that are allocated.
*
* We would like to extend callable chaining to support a graphed callable
* tree. In this scenario, we have a tree of callable chains which will be
* captured with cuda graphs. In the diagram below, we have a tree with four
* callables, A, B, C, and D. Suppose we have captured, and subsequently
* replayed, A, B, and C. Then on a new invocation, we replay A and B, but
* would now like to record D. At this point the private pool will not reflect
* any of the live tensors created during graph replay. Allocations made
* during a new recording with the pool could overwrite those live tensors.
*
* In order to record a new graph capture after replaying prior callables in
* the tree, we need the allocator to reflect the state of the live tensors.
* We checkpoint the state of the private after each recording, and then
* reapply it when we are starting a new recording chain. Additionally, we
* must free the allocations for any tensors that died between the end of our
* previous graph replaying and our new recording (TODO). All of the allocated
* segments that existed in the checkpointed state must still exist in the
* pool. There may also exist new segments, which we will free (TODO : link
* note [live tensors between iterations] when it exists).
*
*
* ---------------> A ---------------> B ---------------> C
* |
* |
* |
* |
* ---------------> D
```
A few TODOs:
- need to add logic for freeing tensors that have died between a last replay and current new recording
- Add logic for free that might be called on a pointer multiple times (because we are manually freeing live tensors)
The two scenarios above have not been exercised in the tests yet.
Differential Revision: [D43999889](https://our.internmc.facebook.com/intern/diff/D43999889)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94653
Approved by: https://github.com/zdevito
Adds the ability to quickly generate stack traces for C++,
and combine Python, TorchScript, and C++ frames into a single trace.
This makes it possible for the memory tracer to record allocations inside
C++ code (e.g. convolution temporaries, backward operators).
The unwinder code is ~10x faster than execinfo.h's backward because it
cache fast unwinder routines for instruction pointers that have already been seen.
It is also only 1.2--2x slower than copying the entire stack (the approach perf takes),
while using 2 orders of magnitude less space per stack.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95357
Approved by: https://github.com/bertmaher
Fixes https://github.com/pytorch/serve/issues/1937
A fairly common query I see folks running while using pytorch is
`nvidia-smi --format=csv,noheader,nounits --query-gpu=utilization.gpu,utilization.memory,memory.total,memory.used,temperature.gpu,power.draw,clocks.current.sm,clocks.current.memory -l 10`
Existing metrics we have
* For kernel utilization`torch.cuda.utilization()`
* For memory utilization we have them under `torch.cuda.memory` the memory allocated with `torch.cuda.memory.memory_allocated()`
* For total available memory we have `torch.cuda.get_device_properties(0).total_memory`
Which means the only metrics we're missing are
* Temperature: now in `torch.cuda.temperature()`
* Power draw: now in `torch.cuda.power()`
* Clock speed: now in `torch.cuda.clock_speed()`
With some important details on each
* Clock speed settings: I picked the SM clock domain which is documented here https://docs.nvidia.com/deploy/nvml-api/group__nvmlDeviceEnumvs.html#group__nvmlDeviceEnumvs_1g805c0647be9996589fc5e3f6ff680c64
* Temperature: I use `pynvml.nvmlDeviceGetTemperature(handle, 0)` where 0 refers to the GPU die temperature
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91717
Approved by: https://github.com/ngimel
With the release of ROCm 5.3 hip now supports a hipGraph implementation.
All necessary backend work and hipification is done to support the same functionality as cudaGraph.
Unit tests are modified to support a new TEST_GRAPH feature which allows us to create a single check for graph support instead of attempted to gather the CUDA level in annotations for every graph test
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88202
Approved by: https://github.com/jithunnair-amd, https://github.com/pruthvistony, https://github.com/malfet
{kind=link}