@bypass-github-export-checks
This change ensures that vulkan event start/end times are correctly synced with their parent CPU times.
This sometimes requires increasing CPU event durations (to fully contain their child events) and delaying CPU event start times (to prevent overlaps), so this should not be used unless Vulkan events are being profiled and it is ok to use this modified timestamp/duration information instead of the the original information.
Differential Revision: [D39893109](https://our.internmc.facebook.com/intern/diff/D39893109/)
**NOTE FOR REVIEWERS**: This PR has internal Meta-specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39893109/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90672
Approved by: https://github.com/kimishpatel
Summary:
Originally reverted this diff D37116110 (c9aa74a37f) because
```
> /usr/local/bin/buck build //caffe2/test/cpp/lite_interpreter_runtime/...
BUILD FAILED
The rule //caffe2:backend_interface_libAndroid could not be found.
Please check the spelling and whether it is one of the 1866 targets in /data/users/batanasov/fbsource/fbcode/caffe2/TARGETS. (52107 bytes)
1 similar targets in /data/users/batanasov/fbsource/fbcode/caffe2/TARGETS are:
//caffe2:backend_interface_lib
This error happened while trying to get dependency '//caffe2:backend_interface_libAndroid' of target '//caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profilerAndroid'
At //caffe2:backend_interface_libAndroid (ovr_config//platform/linux:x86_64-fbcode)
At //caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profilerAndroid (ovr_config//platform/linux:x86_64-fbcode)
```
The add test_mobile_profiler was not meant to be built with Android or other mobile platforms, so we are changing the test to a cpp_unittest
Test Plan:
```
buck test //caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler
Parsing buck files: finished in 0.9 sec
Creating action graph: finished in 26.5 sec
Downloaded 2/2 artifacts, 1.30 Mbytes, 0.0% cache miss (for updated rules)
Building: finished in 16.5 sec (100%) 18451/18451 jobs, 3/18451 updated
Total time: 44.0 sec
More details at https://www.internalfb.com/intern/buck/build/8bee82c1-66a9-4fae-805f-e4ef5505d25d
BUILD SUCCEEDED
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 6904f989-5c17-4c5b-9a4f-ffb643dfcc43
Trace available for this run at /tmp/tpx-20220726-114727.001729-6904f989-5c17-4c5b-9a4f-ffb643dfcc43/trace.log
RemoteExecution session id: reSessionID-6904f989-5c17-4c5b-9a4f-ffb643dfcc43-tpx
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/844425183404951
✓ ListingSuccess: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler : 3 tests discovered (17.640)
✓ Pass: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler - MobileProfiler.Backend (0.206)
✓ Pass: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler - MobileProfiler.BackendMemoryEvents (0.271)
✓ Pass: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler - MobileProfiler.ModuleHierarchy (0.268)
Summary
Pass: 3
ListingSuccess: 1
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/844425183404951
```
Differential Revision: D38166171
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82243
Approved by: https://github.com/salilsdesai
Summary:
Testing for successful recording of backend events. Testing checks that the trace file successfully adds the memory recording from the backend at execute. The record in the trace file looks like:
```
{
"ph": "i", "cat": "cpu_instant_event", "s": "t", "name": "[memory]",
"pid": 847267, "tid": 847267,
"ts": 1655333276408215,
"args": {
"Device Type": 0, "Device Id": -1, "Addr": 108370615407104, "Bytes": 16384, "Total Allocated": 16384, "Total Reserved": 49152
}
}
```
Test Plan:
```
buck test //caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler
Parsing buck files: finished in 1.6 sec
Creating action graph: finished in 30.9 sec
Downloaded 0/5 artifacts, 0.00 bytes, 100.0% cache miss (for updated rules)
Building: finished in 37.9 sec (100%) 25314/25314 jobs, 5/25314 updated
Total time: 01:10.5 min
More details at https://www.internalfb.com/intern/buck/build/ef1c4324-13d3-494e-bce7-8004047d5f89
BUILD SUCCEEDED
Tpx test run coordinator for Facebook. See https://fburl.com/tpx for details.
Running with tpx session id: 17f300d4-9a78-4302-9e9e-d7ab79ba1ff0
Trace available for this run at /tmp/tpx-20220615-165413.567757-17f300d4-9a78-4302-9e9e-d7ab79ba1ff0/trace.log
RemoteExecution session id: reSessionID-17f300d4-9a78-4302-9e9e-d7ab79ba1ff0-tpx
Started reporting to test run: https://www.internalfb.com/intern/testinfra/testrun/7881299443250383
✓ ListingSuccess: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler : 3 tests discovered (37.049)
✓ Pass: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler - MobileProfiler.Backend (0.402)
✓ Pass: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler - MobileProfiler.ModuleHierarchy (0.487)
✓ Pass: caffe2/test/cpp/lite_interpreter_runtime:test_mobile_profiler - MobileProfiler.BackendMemoryEvents (0.280)
Summary
Pass: 3
ListingSuccess: 1
Finished test run: https://www.internalfb.com/intern/testinfra/testrun/7881299443250383
If you need help understanding your runs, please follow the wiki: https://fburl.com/posting_in_tpx_users
```
Differential Revision: D37116110
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80351
Approved by: https://github.com/kimishpatel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78563
The profiler assembles a call hierarchy by replaying recorded events. There is an assert to ensure that the events form a well structured tree; however many of the inputs are from external sources and small differences (e.g. recording time in a lower precision) leads to traces which violate that assumption. For now this is acceptable; the post processing can handle resolving these descrepencies. As a result, I am relaxing the assert to only test event types where we expect the framework to be able to enforce these strong structural requirements.
Differential Revision: [D36787787](https://our.internmc.facebook.com/intern/diff/D36787787/)
Approved by: https://github.com/suo
Summary:
RFC: https://github.com/pytorch/rfcs/pull/40
This PR (re)introduces python codegen for unboxing wrappers. Given an entry of `native_functions.yaml` the codegen should be able to generate the corresponding C++ code to convert ivalues from the stack to their proper types. To trigger the codegen, run
```
tools/jit/gen_unboxing.py -d cg/torch/share/ATen
```
Merged changes on CI test. In https://github.com/pytorch/pytorch/issues/71782 I added an e2e test for static dispatch + codegen unboxing. The test exports a mobile model of mobilenetv2, load and run it on a new binary for lite interpreter: `test/mobile/custom_build/lite_predictor.cpp`.
## Lite predictor build specifics
1. Codegen: `gen.py` generates `RegisterCPU.cpp` and `RegisterSchema.cpp`. Now with this PR, once `static_dispatch` mode is enabled, `gen.py` will not generate `TORCH_LIBRARY` API calls in those cpp files, hence avoids interaction with the dispatcher. Once `USE_LIGHTWEIGHT_DISPATCH` is turned on, `cmake/Codegen.cmake` calls `gen_unboxing.py` which generates `UnboxingFunctions.h`, `UnboxingFunctions_[0-4].cpp` and `RegisterCodegenUnboxedKernels_[0-4].cpp`.
2. Build: `USE_LIGHTWEIGHT_DISPATCH` adds generated sources into `all_cpu_cpp` in `aten/src/ATen/CMakeLists.txt`. All other files remain unchanged. In reality all the `Operators_[0-4].cpp` are not necessary but we can rely on linker to strip them off.
## Current CI job test coverage update
Created a new CI job `linux-xenial-py3-clang5-mobile-lightweight-dispatch-build` that enables the following build options:
* `USE_LIGHTWEIGHT_DISPATCH=1`
* `BUILD_LITE_INTERPRETER=1`
* `STATIC_DISPATCH_BACKEND=CPU`
This job triggers `test/mobile/lightweight_dispatch/build.sh` and builds `libtorch`. Then the script runs C++ tests written in `test_lightweight_dispatch.cpp` and `test_codegen_unboxing.cpp`. Recent commits added tests to cover as many C++ argument type as possible: in `build.sh` we installed PyTorch Python API so that we can export test models in `tests_setup.py`. Then we run C++ test binary to run these models on lightweight dispatch enabled runtime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69881
Reviewed By: iseeyuan
Differential Revision: D33692299
Pulled By: larryliu0820
fbshipit-source-id: 211e59f2364100703359b4a3d2ab48ca5155a023
(cherry picked from commit 58e1c9a25e3d1b5b656282cf3ac2f548d98d530b)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66421
Original commit changeset: ab6bb8fe4e83
Plus this incldes BUILD.bazel changes, the reason for the revert.
Test Plan: See original diff
Reviewed By: gdankel
Differential Revision: D31542513
fbshipit-source-id: ee30aca2d6705638f97e04b77a9ae31fe5cc4ebb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64397
This diff exposes a way to add events to kineto profiler from external
source.
This can be a backend that executes a subgraph and wants to record this
execution in kineto profiler.
This diff also adds "backend" metadata to identify the backend an event
would have executed on.
Test Plan:
test_lite_interpreter
Imported from OSS
Reviewed By: raziel
Differential Revision: D30710710
fbshipit-source-id: 51399f9b0b647bc2d0076074ad4ea9286d0ef3e2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62419
This diff adds support for cpu only kineto profiler on mobile. Thus
enabling chrome trace generation on mobile. This bring cpp API for
mobile profiling on part with Torchscript.
This is done via:
1. Utilizating debug handle annotations in KinetoEvent.
2. Adding post processing capability, via callbacks, to
KinetoThreadLocalState
3. Creating new RAII stype profiler, KinetoEdgeCPUProfiler, which can be
used in surrounding scope of model execution. This will write chrome
trace to the location specified in profiler constructor.
Test Plan:
MobileProfiler.ModuleHierarchy
Imported from OSS
Reviewed By: raziel
Differential Revision: D29993660
fbshipit-source-id: 0b44f52f9e9c5f5aff81ebbd9273c254c3c03299
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57481
This diff introduces function name to InlinedCallStack.
Since we are using InlinedCallStack for debug information in lite
interpreter as well as delegate backends, where InlinedCallStack cannot
be constructed from model source code, we need to save function name.
In the absence of function name Function* is used to get name of the
function. This is when JIT compiles code at runtime.
When that is not possible, this diff introduces a way to obtain function
name.
Test Plan:
test_backend
test_cs_debug_info_serialization
test_backend
test_cs_debug_info_serialization
Imported from OSS
Differential Revision:
D28159097
D28159097
Reviewed By: raziel, ZolotukhinM
Pulled By: kimishpatel
fbshipit-source-id: deacaea3325e27273f92ae96cf0cd0789bbd6e72
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57441
debug info
Previous diffs did not save operator name in debug info. For delegated
backends that only idenfity op for profiling with debug handle, operator
name should be stores as well.
Furthermore to complete debug informaton also serialize function name.
Test Plan:
Existing lite interpreter and backend tests
Existing lite interpreter and backend tests
Imported from OSS
Differential Revision:
D28144581
D28144581
Reviewed By: raziel
Pulled By: kimishpatel
fbshipit-source-id: 415210f147530a53b444b07f1d6ee699a3570d99
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55462
handles and symbolicate exception callstack thrown from backend.
Objective of this diff is to achieve improve error reporting when
exceptions are raised from lowered backend. We would effectively like to
get the same model level stack trace that you would get without having
lowered some module to backend.
For example:
```
class AA(nn.Module):
def forward(self, x, y):
return x + y
class A(nn.Module):
def __init__(...):
self.AA0 = AA()
def forward(self, x, y):
return self.AA0.forward(x, y) + 3
class B(nn.Module):
def forward(self, x):
return x + 2
class C(nn.Module):
def __init__(...):
self.A0 = A()
self.B0 = B()
def forward(self, x, y):
return self.A0.forward(x, y) + self.B0.forward(x)
```
If the we then do C().forward(torch.rand((2,3)), torch.rand(14,2))) we
will likely see error stack like:
```
C++ exception with description "The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "<string>", line 3, in forward
def forward(self, x, y):
return self.A0.forward(x, y) + self.B0.forward(x)
~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 3, in forward
def forward(self, x, y):
return self.AA0.forward(x, y) + 3
~~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 3, in forward
def forward(self, x, y):
return x + y
~~~~~ <--- HERE
```
We would like to see the same error stack if we lowered C.A0 to some
backend.
With this diff we get something like:
```
Module hierarchy:top(C).A0(backend_with_compiler_demoLoweredModule).AA0(AA)
Traceback of TorchScript (most recent call last):
File "<string>", line 3, in FunctionName_UNKNOWN
def forward(self, x, y):
return self.A0.forward(x, y) + self.B0.forward(x)
~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 5, in FunctionName_UNKNOWN
typed_inputs: List[Any] = [x, y, ]
if self.__backend.is_available() :
_0, = self.__backend.execute(self.__handles["forward"], typed_inputs)
~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
assert isinstance(_0, Tensor)
return _0
File "<string>", line 3, in FunctionName_UNKNOWN
def forward(self, x, y):
return self.AA0.forward(x, y) + 3
~~~~~~~~~~~~~~~~ <--- HERE
File "<string>", line 3, in FunctionName_UNKNOWN
def forward(self, x, y):
return x + y
~~~~~ <--- HERE
```
This is achieved in 3 parts:
Part 1:
A. BackendDebugInfoRecorder:
During backend lowering, in `to_backend`, before calling the preprocess
function corresponding to the backend. This will facilitate recording of
debug info (such as source range + inlined callstack) for the lowered module.
B. Instantiate WithBackendDebugInfoRecorder with BackendDebugInfoRecorder.
This initializes thread local pointer to BackendDebugInfoRecorder.
C. generate_debug_handles:
In preprocess function, the backend will call generate_debug_handles
for each method being lowered separately. generate_debug_handles
takes `Graph` of the method being lowered and returns a map
of Node*-to-debug_handles. Backend is responsible for storing debug
handles appropriately so as to raise exception (and later profiling)
using debug handles when the exception being raised corresponds to
particular Node that was lowered.
Inside generate_debug_handles, we will query the current
BackendDebugHandleInfoRecorder, that is issuing debug handles. This debug
handle manager will issue debug handles as well as record
debug_handles-to-<source range, inlined callstack> map.
D. Back in `to_backend`, once the preprocess function is has finished
lowering the module, we will call `stopRecord` on
BackendDebugInfoRecorder. This will return the debug info map. This
debug info is then stored inside the lowered module.
Part 2:
Serialization:
During serialization for bytecode (lite interpreter), we will do two
things:
1. Extract all the source ranges that are contained inside
debug_handles-to-<source range, inlined callstack> map for lowered
module. This will be source range corresponding to debug handles,
including what is there is inlined callstack. Since we replaced original
module with lowered module, we wont be serializing code for the original
module and thus no source range. That is why the source range will have
to be stored separately. We will lump all the source ranges for all the
lowered modules in one single debug_pkl file.
2. Then we will serialize debug_handles-to-<source range, inlined
callstack> map.
Now during deserialization we will be able to reconstruct
debug_handles-to-<source range, inlined callstack> map. Given all
debug_handles are unique we would not need any module information.
Test Plan:
Tests are added in test_backend.cpp
Tests are added in test_backend.cpp
Imported from OSS
Differential Revision:
D27621330
D27621330
Reviewed By: raziel
Pulled By: kimishpatel
fbshipit-source-id: 0650ec68cda0df0a945864658cab226a97ba1890
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/54579
## Summary
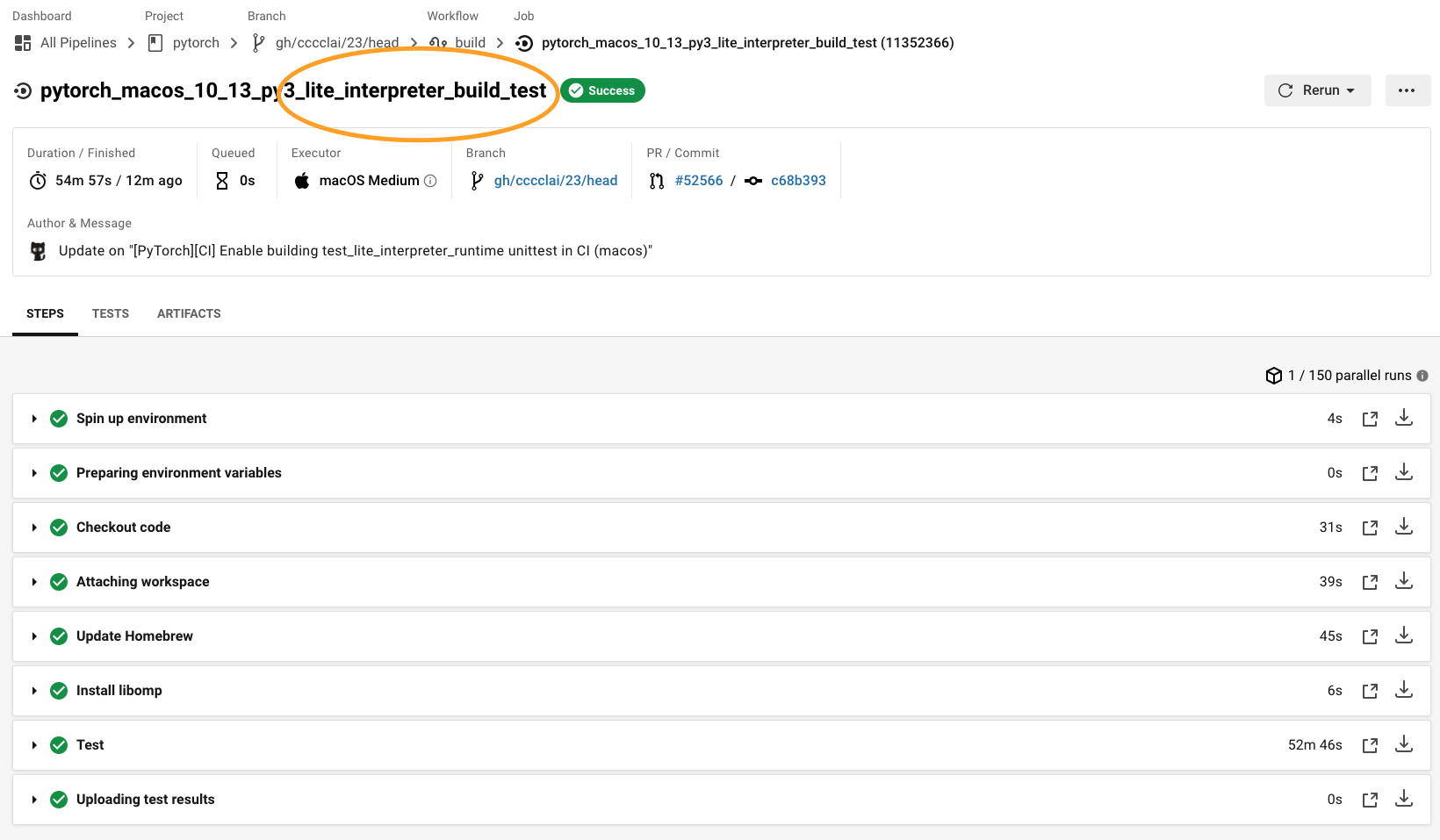
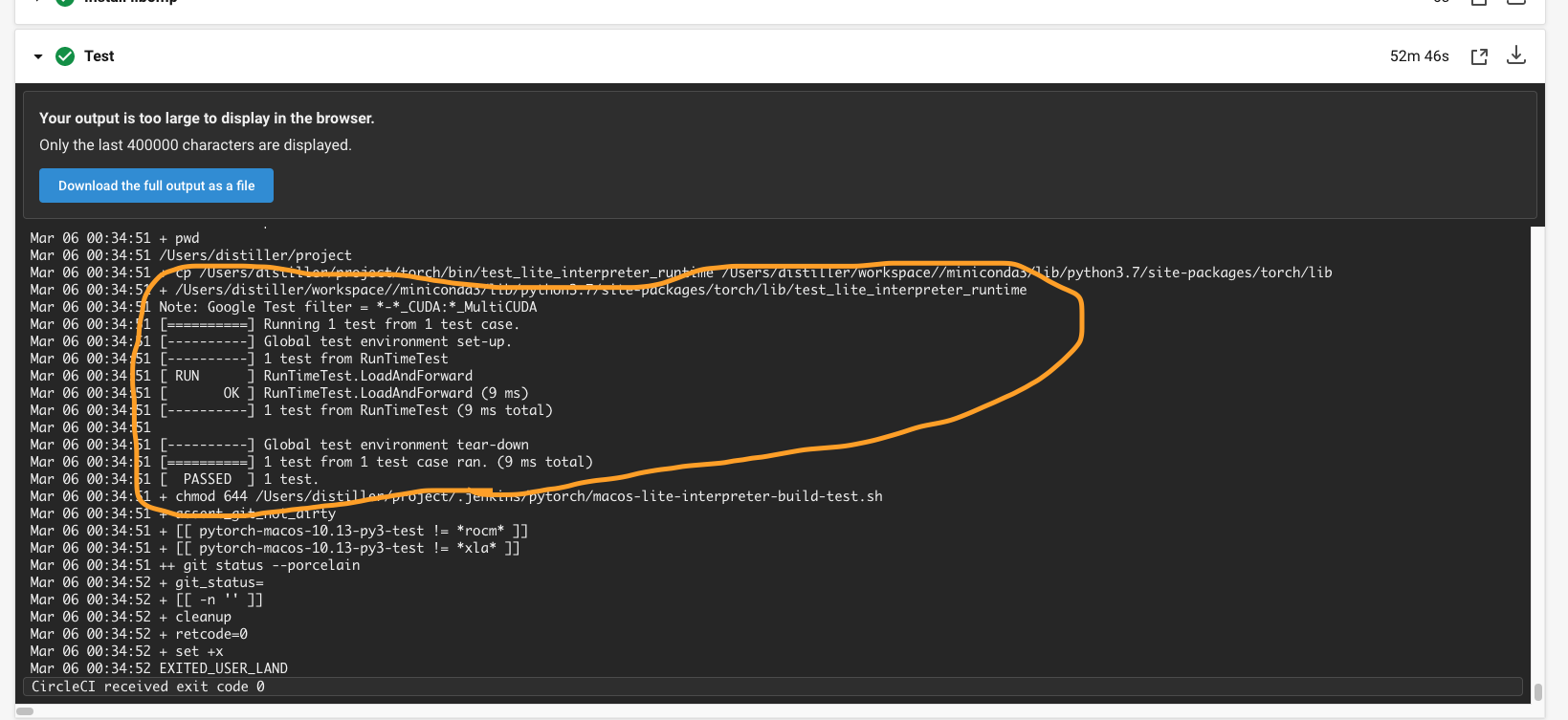
1. Eliminate a few more tests when BUILD_LITE_INTERPRETER is on, such that test_lite_interpreter_runtime can build and run on device.
2. Remove `#include <torch/torch.h>`, because it's not needed.
## Test plan
Set the BUILD_TEST=ON `in build_android.sh`, then run
` BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86`
push binary to android device:
```
adb push ./build_android_x86/bin/test_lite_interpreter_runtime /data/local/tmp
```
Reorganize the folder in `/data/local/tmp` so the test binary and model file is like following:
```
/data/local/tmp/test_bin/test_lite_interpreter_runtime
/data/local/tmp/test/cpp/lite_interpreter_runtime/sequence.ptl
```
such that the model file is in the correct path and can be found by the test_lite_interpreter_runtime.
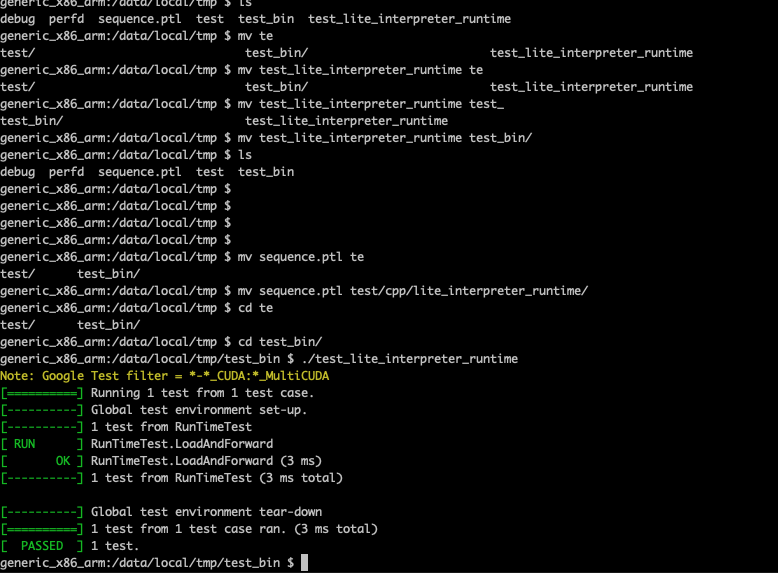
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D27300720
Pulled By: cccclai
fbshipit-source-id: d9526c7d3db8c0d3e76c5a4d604c6877c78afdf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51419
## Summary
1. Add an option `BUILD_LITE_INTERPRETER` in `caffe2/CMakeLists.txt` and set `OFF` as default.
2. Update 'build_android.sh' with an argument to swtich `BUILD_LITE_INTERPRETER`, 'OFF' as default.
3. Add a mini demo app `lite_interpreter_demo` linked with `libtorch` library, which can be used for quick test.
## Test Plan
Built lite interpreter version of libtorch and test with Image Segmentation demo app ([android version](https://github.com/pytorch/android-demo-app/tree/master/ImageSegmentation)/[ios version](https://github.com/pytorch/ios-demo-app/tree/master/ImageSegmentation))
### Android
1. **Prepare model**: Prepare the lite interpreter version of model by run the script below to generate the scripted model `deeplabv3_scripted.pt` and `deeplabv3_scripted.ptl`
```
import torch
model = torch.hub.load('pytorch/vision:v0.7.0', 'deeplabv3_resnet50', pretrained=True)
model.eval()
scripted_module = torch.jit.script(model)
# Export full jit version model (not compatible lite interpreter), leave it here for comparison
scripted_module.save("deeplabv3_scripted.pt")
# Export lite interpreter version model (compatible with lite interpreter)
scripted_module._save_for_lite_interpreter("deeplabv3_scripted.ptl")
```
2. **Build libtorch lite for android**: Build libtorch for android for all 4 android abis (armeabi-v7a, arm64-v8a, x86, x86_64) `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh`. This pr is tested on Pixel 4 emulator with x86, so use cmd `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86` to specify abi to save built time. After the build finish, it will show the library path:
```
...
BUILD SUCCESSFUL in 55s
134 actionable tasks: 22 executed, 112 up-to-date
+ find /Users/chenlai/pytorch/android -type f -name '*aar'
+ xargs ls -lah
-rw-r--r-- 1 chenlai staff 13M Feb 11 11:48 /Users/chenlai/pytorch/android/pytorch_android/build/outputs/aar/pytorch_android-release.aar
-rw-r--r-- 1 chenlai staff 36K Feb 9 16:45 /Users/chenlai/pytorch/android/pytorch_android_torchvision/build/outputs/aar/pytorch_android_torchvision-release.aar
```
3. **Use the PyTorch Android libraries built from source in the ImageSegmentation app**: Create a folder 'libs' in the path, the path from repository root will be `ImageSegmentation/app/libs`. Copy `pytorch_android-release` to the path `ImageSegmentation/app/libs/pytorch_android-release.aar`. Copy 'pytorch_android_torchvision` (downloaded from [here](https://oss.sonatype.org/#nexus-search;quick~torchvision_android)) to the path `ImageSegmentation/app/libs/pytorch_android_torchvision.aar` Update the `dependencies` part of `ImageSegmentation/app/build.gradle` to
```
dependencies {
implementation 'androidx.appcompat:appcompat:1.2.0'
implementation 'androidx.constraintlayout:constraintlayout:2.0.2'
testImplementation 'junit:junit:4.12'
androidTestImplementation 'androidx.test.ext:junit:1.1.2'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.3.0'
implementation(name:'pytorch_android-release', ext:'aar')
implementation(name:'pytorch_android_torchvision', ext:'aar')
implementation 'com.android.support:appcompat-v7:28.0.0'
implementation 'com.facebook.fbjni:fbjni-java-only:0.0.3'
}
```
Update `allprojects` part in `ImageSegmentation/build.gradle` to
```
allprojects {
repositories {
google()
jcenter()
flatDir {
dirs 'libs'
}
}
}
```
4. **Update model loader api**: Update `ImageSegmentation/app/src/main/java/org/pytorch/imagesegmentation/MainActivity.java` by
4.1 Add new import: `import org.pytorch.LiteModuleLoader;`
4.2 Replace the way to load pytorch lite model
```
// mModule = Module.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.pt"));
mModule = LiteModuleLoader.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.ptl"));
```
5. **Test app**: Build and run the ImageSegmentation app in Android Studio,

### iOS
1. **Prepare model**: Same as Android.
2. **Build libtorch lite for ios** `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=SIMULATOR BUILD_LITE_INTERPRETER=1 ./scripts/build_ios.sh`
3. **Remove Cocoapods from the project**: run `pod deintegrate`
4. **Link ImageSegmentation demo app with the custom built library**:
Open your project in XCode, go to your project Target’s **Build Phases - Link Binaries With Libraries**, click the **+** sign and add all the library files located in `build_ios/install/lib`. Navigate to the project **Build Settings**, set the value **Header Search Paths** to `build_ios/install/include` and **Library Search Paths** to `build_ios/install/lib`.
In the build settings, search for **other linker flags**. Add a custom linker flag below
```
-all_load
```
Finally, disable bitcode for your target by selecting the Build Settings, searching for Enable Bitcode, and set the value to No.
**
5. Update library and api**
5.1 Update `TorchModule.mm``
To use the custom built libraries the project, replace `#import <LibTorch/LibTorch.h>` (in `TorchModule.mm`) which is needed when using LibTorch via Cocoapods with the code below:
```
//#import <LibTorch/LibTorch.h>
#include "ATen/ATen.h"
#include "caffe2/core/timer.h"
#include "caffe2/utils/string_utils.h"
#include "torch/csrc/autograd/grad_mode.h"
#include "torch/script.h"
#include <torch/csrc/jit/mobile/function.h>
#include <torch/csrc/jit/mobile/import.h>
#include <torch/csrc/jit/mobile/interpreter.h>
#include <torch/csrc/jit/mobile/module.h>
#include <torch/csrc/jit/mobile/observer.h>
```
5.2 Update `ViewController.swift`
```
// if let filePath = Bundle.main.path(forResource:
// "deeplabv3_scripted", ofType: "pt"),
// let module = TorchModule(fileAtPath: filePath) {
// return module
// } else {
// fatalError("Can't find the model file!")
// }
if let filePath = Bundle.main.path(forResource:
"deeplabv3_scripted", ofType: "ptl"),
let module = TorchModule(fileAtPath: filePath) {
return module
} else {
fatalError("Can't find the model file!")
}
```
### Unit test
Add `test/cpp/lite_interpreter`, with one unit test `test_cores.cpp` and a light model `sequence.ptl` to test `_load_for_mobile()`, `bc.find_method()` and `bc.forward()` functions.
### Size:
**With the change:**
Android:
x86: `pytorch_android-release.aar` (**13.8 MB**)
IOS:
`pytorch/build_ios/install/lib` (lib: **66 MB**):
```
(base) chenlai@chenlai-mp lib % ls -lh
total 135016
-rw-r--r-- 1 chenlai staff 3.3M Feb 15 20:45 libXNNPACK.a
-rw-r--r-- 1 chenlai staff 965K Feb 15 20:45 libc10.a
-rw-r--r-- 1 chenlai staff 4.6K Feb 15 20:45 libclog.a
-rw-r--r-- 1 chenlai staff 42K Feb 15 20:45 libcpuinfo.a
-rw-r--r-- 1 chenlai staff 39K Feb 15 20:45 libcpuinfo_internals.a
-rw-r--r-- 1 chenlai staff 1.5M Feb 15 20:45 libeigen_blas.a
-rw-r--r-- 1 chenlai staff 148K Feb 15 20:45 libfmt.a
-rw-r--r-- 1 chenlai staff 44K Feb 15 20:45 libpthreadpool.a
-rw-r--r-- 1 chenlai staff 166K Feb 15 20:45 libpytorch_qnnpack.a
-rw-r--r-- 1 chenlai staff 384B Feb 15 21:19 libtorch.a
-rw-r--r-- 1 chenlai staff **60M** Feb 15 20:47 libtorch_cpu.a
```
`pytorch/build_ios/install`:
```
(base) chenlai@chenlai-mp install % du -sh *
14M include
66M lib
2.8M share
```
**Master (baseline):**
Android:
x86: `pytorch_android-release.aar` (**16.2 MB**)
IOS:
`pytorch/build_ios/install/lib` (lib: **84 MB**):
```
(base) chenlai@chenlai-mp lib % ls -lh
total 172032
-rw-r--r-- 1 chenlai staff 3.3M Feb 17 22:18 libXNNPACK.a
-rw-r--r-- 1 chenlai staff 969K Feb 17 22:18 libc10.a
-rw-r--r-- 1 chenlai staff 4.6K Feb 17 22:18 libclog.a
-rw-r--r-- 1 chenlai staff 42K Feb 17 22:18 libcpuinfo.a
-rw-r--r-- 1 chenlai staff 1.5M Feb 17 22:18 libeigen_blas.a
-rw-r--r-- 1 chenlai staff 44K Feb 17 22:18 libpthreadpool.a
-rw-r--r-- 1 chenlai staff 166K Feb 17 22:18 libpytorch_qnnpack.a
-rw-r--r-- 1 chenlai staff 384B Feb 17 22:19 libtorch.a
-rw-r--r-- 1 chenlai staff 78M Feb 17 22:19 libtorch_cpu.a
```
`pytorch/build_ios/install`:
```
(base) chenlai@chenlai-mp install % du -sh *
14M include
84M lib
2.8M share
```
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D26518778
Pulled By: cccclai
fbshipit-source-id: 4503ffa1f150ecc309ed39fb0549e8bd046a3f9c
{kind=link}
{kind=link}
{kind=link}
{kind=link}