setup.py clean now won't remove paths matching .gitignore patterns across the entire OS. Instead, now only files from the repository will be removed.
`/build_*` had to be removed from .gitignore because with the wildcard fixed, build_variables.bzl file was deleted on cleanup.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91503
Approved by: https://github.com/soumith
Summary:
This diff is reverting D42257039
D42257039 has been identified to be causing the following test or build failures:
Tests affected:
- [assistant/neural_dm/rl/modules/tests:action_mask_classifier_test - main](https://www.internalfb.com/intern/test/281475048940766/)
Here's the Multisect link:
https://www.internalfb.com/intern/testinfra/multisect/1493969
Here are the tasks that are relevant to this breakage:
T93770103: 1 test started failing for oncall assistant_multimodal in the last 2 weeks
We're generating a revert to back out the changes in this diff, please note the backout may land if someone accepts it.
Test Plan: NA
Reviewed By: weiwangmeta
Differential Revision: D42272391
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91548
Approved by: https://github.com/kit1980
## Job
Test running on most CI jobs.
## Test binary
* `test_main.cpp`: entry for gtest
* `test_operator_registration.cpp`: test cases for gtest
## Helper sources
* `operator_registry.h/cpp`: simple operator registry for testing purpose.
* `Evalue.h`: a boxed data type that wraps ATen types, for testing purpose.
* `selected_operators.yaml`: operators Executorch care about so far, we should cover all of them.
## Templates
* `NativeFunctions.h`: for generating headers for native functions. (not compiled in the test, since we will be using `libtorch`)
* `RegisterCodegenUnboxedKernels.cpp`: for registering boxed operators.
* `Functions.h`: for declaring operator C++ APIs. Generated `Functions.h` merely wraps `ATen/Functions.h`.
## Build files
* `CMakeLists.txt`: generate code to register ops.
* `build.sh`: driver file, to be called by CI job.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89596
Approved by: https://github.com/ezyang
E.g. `test_cpp_extensions_aot_ninja` fails as it includes `vec.h` which requires the vec/vsx/* headers and `sleef.h`. The latter is also required for AVX512 builds on non MSVC compilers.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85547
Approved by: https://github.com/kit1980
In this PR, we replace OMP SIMD with `aten::vec` to optimize TorchInductor vectorization performance. Take `res=torch.exp(torch.add(x, y))` as the example. The generated code is as follows if `config.cpp.simdlen` is 8.
```C++
extern "C" void kernel(const float* __restrict__ in_ptr0,
const float* __restrict__ in_ptr1,
float* __restrict__ out_ptr0,
const long ks0,
const long ks1)
{
#pragma omp parallel num_threads(48)
{
#pragma omp for
for(long i0=0; i0<((ks0*ks1) / 8); ++i0)
{
auto tmp0 = at::vec::Vectorized<float>::loadu(in_ptr0 + 8*i0);
auto tmp1 = at::vec::Vectorized<float>::loadu(in_ptr1 + 8*i0);
auto tmp2 = tmp0 + tmp1;
auto tmp3 = tmp2.exp();
tmp3.store(out_ptr0 + 8*i0);
}
#pragma omp for simd simdlen(4)
for(long i0=8*(((ks0*ks1) / 8)); i0<ks0*ks1; ++i0)
{
auto tmp0 = in_ptr0[i0];
auto tmp1 = in_ptr1[i0];
auto tmp2 = tmp0 + tmp1;
auto tmp3 = std::exp(tmp2);
out_ptr0[i0] = tmp3;
}
}
}
```
The major pipeline is as follows.
- Check whether the loop body could be vectorized by `aten::vec`. The checker consists of two parts. [One ](bf66991fc4/torch/_inductor/codegen/cpp.py (L702))is to check whether all the `ops` have been supported. The [other one](355326faa3/torch/_inductor/codegen/cpp.py (L672)) is to check whether the data access could be vectorized.
- [`CppSimdVecKernelChecker`](355326faa3/torch/_inductor/codegen/cpp.py (L655))
- Create the `aten::vec` kernel and original omp simd kernel. Regarding the original omp simd kernel, it serves for the tail loop when the loop is vectorized.
- [`CppSimdVecKernel`](355326faa3/torch/_inductor/codegen/cpp.py (L601))
- [`CppSimdVecOverrides`](355326faa3/torch/_inductor/codegen/cpp.py (L159)): The ops that we have supported on the top of `aten::vec`
- Create kernel
- [`aten::vec` kernel](355326faa3/torch/_inductor/codegen/cpp.py (L924))
- [`Original CPP kernel - OMP SIMD`](355326faa3/torch/_inductor/codegen/cpp.py (L929))
- Generate code
- [`CppKernelProxy`](355326faa3/torch/_inductor/codegen/cpp.py (L753)) is used to combine the `aten::vec` kernel and original cpp kernel
- [Vectorize the most inner loop](355326faa3/torch/_inductor/codegen/cpp.py (L753))
- [Generate code](355326faa3/torch/_inductor/codegen/cpp.py (L821))
Next steps:
- [x] Support reduction
- [x] Vectorize the tail loop with `aten::vec`
- [ ] Support BF16
- [ ] Optimize the loop condition and loop index calculation by replacing `div` with `add`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87068
Approved by: https://github.com/jgong5, https://github.com/jansel
Adds `/FS` option to `CMAKE_CXX_FLAGS` and `CMAKE_CUDA_FLAGS`.
So far I've encountered this kind of errors:
```
C:\Users\MyUser\AppData\Local\Temp\tmpxft_00004728_00000000-7_cuda.cudafe1.cpp: fatal error C1041: cannot open program database 'C:\Projects\pytorch\build\third_party\gloo\gloo\CMakeFiles\gloo_cuda.dir\vc140.pdb'; if multiple CL.EXE write to the same .PDB file, please use /FS
```
when building with VS 2022.
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
Related issues:
- https://github.com/pytorch/pytorch/issues/87691
- https://github.com/pytorch/pytorch/issues/39989
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88084
Approved by: https://github.com/ezyang
Also, add `torchtriton` and `jinja2` as extra `dynamo` dependency to PyTorch wheels,
Version packages as first 10 characters of pinned repo hash and make `torch[dynamo]` wheel depend on the exact version it was build against.
TODO: Automate uploading to nightly wheels storage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87234
Approved by: https://github.com/msaroufim
The legacy profiler is an eyesore in the autograd folder. At this point the implementation is almost completely decoupled from the rest of profiler, and it is in maintaince mode pending deprecation.
As a result, I'm moving it to `torch/csrc/profiler/standalone`. Unfortuantely BC requires that the symbols remain in `torch::autograd::profiler`, so I've put some basic forwarding logic in `torch/csrc/autograd/profiler.h`.
One strange bit is that `profiler_legacy.h` forward declares `torch::autograd::Node`, but doesn't seem to do anything with it. I think we can delete it, but I want to test to make sure.
(Note: this should not land until https://github.com/pytorch/torchrec/pull/595 is landed.)
Differential Revision: [D39108648](https://our.internmc.facebook.com/intern/diff/D39108648/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85512
Approved by: https://github.com/aaronenyeshi
There is a concept in profiler of a stub that wraps a profiling API. It was introduced for CUDA profiling before Kineto, and ITT has adopted it to call into VTune APIs. However for the most part we don't really interact with them when developing the PyTorch profiler.
Thus it makes sense to unify the fallback registration mechanism and create a subfolder to free up real estate in the top level `torch/csrc/profiler` directory.
Differential Revision: [D39108647](https://our.internmc.facebook.com/intern/diff/D39108647/)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85510
Approved by: https://github.com/aaronenyeshi
https://github.com/pytorch/pytorch/pull/85780 updated all c10d headers in pytorch to use absolute path following the other distributed components. However, the headers were still copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch`, thus external extentions still have to reference the c10d headers as `<c10d/*.h>`, making the usage inconsistent (the only exception was c10d/exception.h, which was copied to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`).
This patch fixes the installation step to copy all c10d headers to `${TORCH_INSTALL_INCLUDE_DIR}/torch/csrc/distributed/c10d`, thus external extensions can consistently reference c10d headers with the absolute path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/86257
Approved by: https://github.com/kumpera
Depends on https://github.com/pytorch/pytorch/pull/84890.
This PR adds opt_einsum to CI, enabling path optimization for the multi-input case. It also updates the installation sites to install torch with einsum, but those are mostly to make sure it would work on the user's end (as opt-einsum would have already been installed in the docker or in prior set up steps).
This PR also updates the windows build_pytorch.bat script to use the same bdist_wheel and install commands as on Linux, replacing the `setup.py install` that'll become deprecated.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/85574
Approved by: https://github.com/huydhn, https://github.com/soulitzer
## This PR seeks to:
- [x] add c++ support for an optimize path
- [x] add python opt_einsum path passthrough
- [x] add opt_einsum to OSS requirements, but a soft one
- [x] show benchmark results here
Additional things I've explored + their conclusions:
- **Delaying the summing over dimensions** => added!
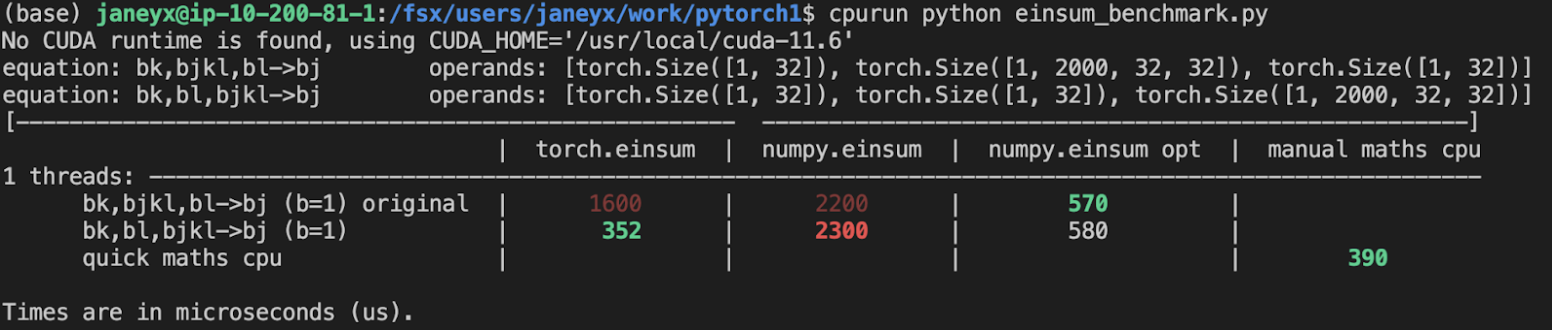
- The idea here is to not incur kernel calls to `sum` as we try to early sum out in einsum. Thus, we collect all the dimensions that need to be summed together in one contraction + sum at the end instead of summing as we go. While this optimization didn't feel like it made things faster for the random cases we've selected (they all summed 1 dim per contraction), it is a good principle and would help more common use cases that would reduce multiple dimensions at a time (like `bxy,xyi,xyj->bij`).
- **Caching contract_path based on equation and tensor sizes** => dropped :(
- The benchmarks were strictly worse for all the cases, and, from scanning the use cases, I observed people do not often call einsum on the same equation/tensor order enough for caching to be justified. I do think caching can be effective in the future, but it would require further investigation.
## Not a part of this PR (but are next steps):
- adding opt_einsum package to OSS CI
- adding it to internal CI
- potentially adding a kwarg path argument to the python API -- if the path is given, we wouldn't have to spend time calculating it, but there would be some time lost validating user input.
## Testing:
- Added more tests to CI
## Benchmarking:
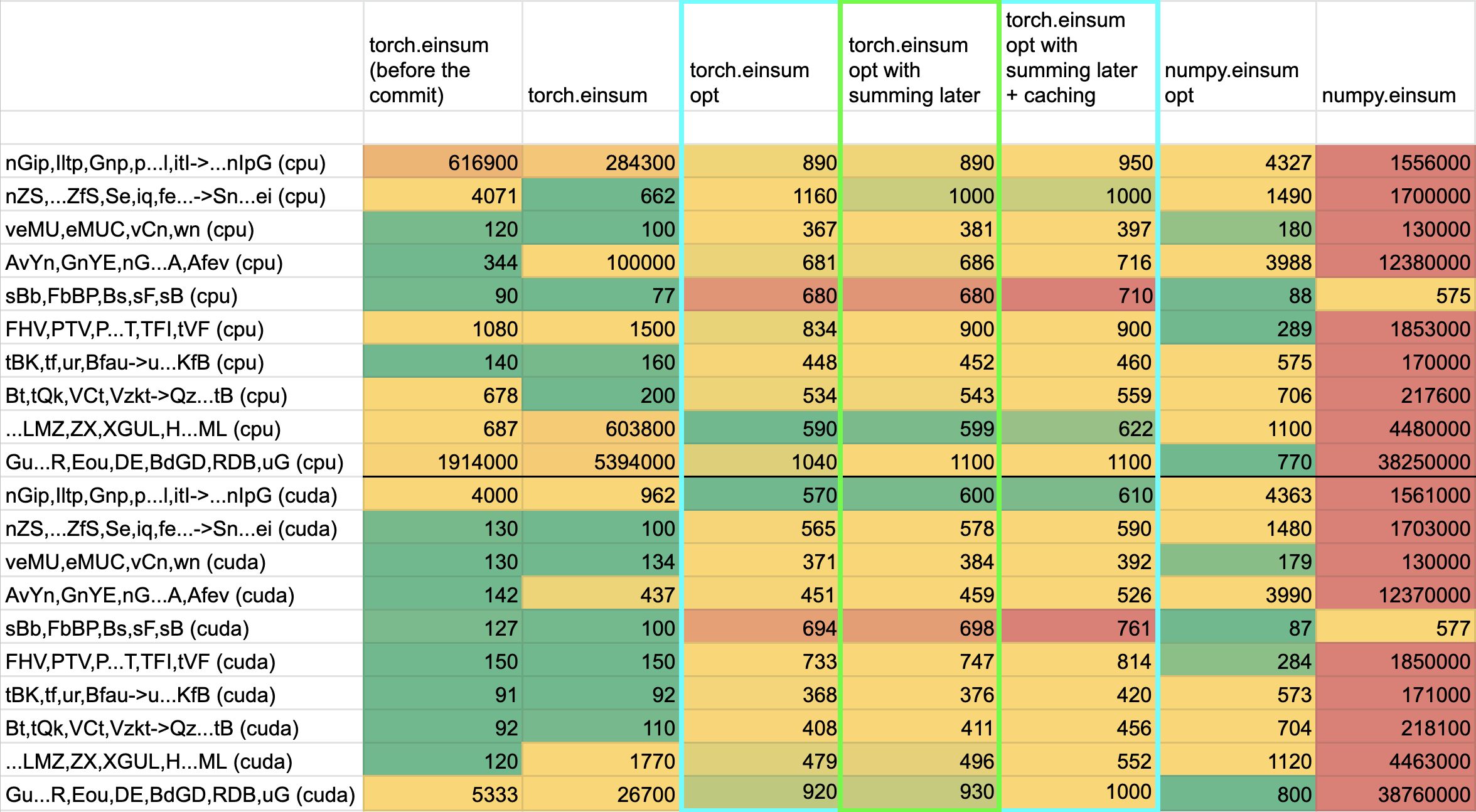
**TL;DRs**
- **torch.einsum with opt_einsum is a definite win for the production case**.
- **torch.einsum with opt_einsum installed is consistently fast, but has an overhead** of needing to find the path. If the path is already found/optimal, it will be slightly slower.
- The einsum overhead decreases for bigger dimensions.
- **torch.einsum without opt_einsum installed is comparable to before this commit**, with occasional slowness potentially due to not reshaping/squeezing as we contract until the end.
- For many of the random generated cases, the dimensions were too similar and small where an optimal order wasn't that much more optimal than just going left to right. However, in production, dimensions are commonly quite distinct (batch size will be small, but the data will be huge).
- **torch.einsum opt is comparable (slightly faster overall) compared to numpy.einsum opt for the cpu case**. This is interesting given that torch.einsum currently spends time computing the path, but numpy.einsum takes it as input.
- **torch.einsum opt is significantly faster than numpy.einsum opt for the gpu case**. This is because numpy doesn't take advantage of GPUs.
The following benchmarks were done on an A100 GPU and Linux CPUs. The line in the first chart separates GPU (on top) from CPU, and the line in the second graph separates CPU (on top) and then GPU. Sorry it's flipped 😛 .
Production example (see [colab benchmark](https://colab.research.google.com/drive/1V2s4v1dOOKwRvp5T_DC-PNUosOV9FFJx?authuser=1#scrollTo=WZoQkC8Mdt6I) for more context):
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012636-9a68bfa7-2601-43b1-afeb-b4e0877db6a4.png">
Randomly generated examples (the same ones as in https://github.com/pytorch/pytorch/pull/60191)
<img width="1176" alt="image" src="https://user-images.githubusercontent.com/31798555/192012804-1c639595-b3e6-48c9-a385-ad851c13e1c2.png">
Open below to see old + not super relevant benchmarking results:
<details>
Benchmark results BEFORE this PR (on Linux -- I will update devices so they are consistent later):
<img width="776" alt="image" src="https://user-images.githubusercontent.com/31798555/190807274-18f71fce-556e-47f4-b18c-e0f7d0c0d5aa.png">
Benchmark results with the code on this PR (on my x86 mac):
For the CPU internal use case --

For the general use case --
It looks like numpy opt still does better in several of these random cases, but torch einsum opt is consistently faster than torch.einsum.

<details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84890
Approved by: https://github.com/albanD, https://github.com/soulitzer
Move functorch/functorch into `functorch` folder
- Add functorch/CMakeLists.txt that adds `functorch` native python exension
- Modify `setup.py` to package pytorch and functorch together into a single wheel
- Modify `functorch.__version__` is not equal to that of `torch.__version__`
- Add dummy `functorch/setup.py` file for the projects that still want to build it
Differential Revision: [D39058811](https://our.internmc.facebook.com/intern/diff/D39058811)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83464
Approved by: https://github.com/zou3519
# Summary:
- I added a new submodule Cutlass pointing to 2.10 release. The inclusion of flash_attention code should be gated by the flag: USE_FLASH_ATTENTION. This is defaulted to off resulting in flash to not be build anywhere. This is done on purpose since we don't have A100 machines to compile and test on.
- Only looked at CMake did not attempt bazel or buck yet.
- I included the mha_fwd from flash_attention that has ben refactored to use cutlass 2.10. There is currently no backwards kernel on this branch. That would be a good follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81434
Approved by: https://github.com/cpuhrsch
Fixes#81181 by creating a temporary LICENCE file that has all the third-party licenses concatenated together when creating a wheel. Also update the `third_party/LICENSES_BUNDLED.txt` file.
The `third_party/LICENSES_BUNDLED.txt` file is supposed to be tested via `tests/test_license.py`, but the test is not running?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81500
Approved by: https://github.com/rgommers, https://github.com/seemethere
Description:
While using Pytorch header
"torch/csrc/jit/serialization/export.h" got compilation error.
File export_bytecode.h accesses
"#include <torch/csrc/jit/mobile/function.h>"
This mobile folder isn't present in torch installation dir.
This PR adds mobile folder to torch installation setup.
Fixes#79190
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79864
Approved by: https://github.com/ngimel
Syncing nvfuser devel branch to upstream master. https://github.com/csarofeen/pytorch/
Bug fixes and minor refactor
Squashed commits to WAR github API
Commits that's actually in this PR from the devel branch:
```
4c60e7dff22a494632370e5df55c011007340d06 Add examples infrastructure for using nvFuser in a standalone program (#1725)
02a05d98334ffa580d73ccb28fdb8c577ad296fe Fix issue #1751 (#1753)
8a69aa320bd7629e1709fe5ceb7104d2c88ec84c Refactor NvFuser transpose API to match eager mode behavior (#1746)
ffdf6b7709048170d768217fcd7083fc8387f932 Remove BroadcastWithoutStride. (#1738)
02bab16035e70734450c02124f5cdaa95cf5749d Fix flipping of a boolean flag (#1745)
465d66890c8242e811224359cbdb1c2915490741 cleanup (#1744)
26d354e68720bc7dd2d3b1338ac01b707a230b6a fixing noncontig broadcast (#1742)
856b6b2f9073662dd98ca22ba6c3540e20eb1cdd Add IterDomainBuilder (#1736)
1fd974f912cd4c1e21cbd16e2abb23598d66a02f fixing warning for gcc7 (#1732)
de2740a43a869f8272c2648e091d7b8235097db9 disabling complex in python tests for #1730 (#1733)
fbbbe0a2e7c7a63e0e2719b8bfccb759b714221a fixing MSVC build (#1728)
b5feee5e2b28be688dbddc766f3c0220389c8175 Fix the fused reduction runtime kernel (#1729)
5247682dff5980bb66edf8d3aac25dea2ef2ced5 Re-entrant GroupedGridReduction (#1727)
```
RUN_TORCHBENCH: nvfuser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79147
Approved by: https://github.com/davidberard98
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}