The dtype documentation has not been updated in awhile, let's do a revamp.
1. combine the duplicated docs for dtypes from `tensors.rst` and `tensor_attributes.rst` to live in `tensor_attributes.rst`, and link to that page from `tensors.rst`
2. split the dtype table into floating point and integer dtypes
3. add the definition of shell dtype
4. add the float8 and MX dtypes as shell dtypes to the dtype table
5. remove legacy quantized dtypes from the table
6. add the definition of various dtype suffixes ("fn", etc)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/156087
Approved by: https://github.com/albanD
# Motivation
Update the doc, to make `torch.device`'s constructor officially support the following methods:
- A device string, which is a string representation of the device type and optionally the device ordinal.
- A device type and a device ordinal.
- A device ordinal, which is treated as the current accelerator type.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/156686
Approved by: https://github.com/albanD
# Motivation
Before this PR, device construction was `cuda` type when only a device index was given. It also returns the `PrivateUser1` type if a `PrivateUser1` type is registered.
```bash
>>> import torch
>>> device = torch.device(0)
>>> device.type
'cuda'
>>> a = torch.tensor([1, 2])
>>> b = a.to(0)
>>> b
tensor([1, 2], device='cuda:0')
```
It works well on CUDA GPU. But it will raise unexpected information and error running on XPU.
```bash
>>> import torch
>>> device = torch.device(0)
>>> device.type
'cuda'
>>> a = torch.tensor([1, 2])
>>> b = a.to(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/xxx/pytorch/torch/cuda/__init__.py", line 302, in _lazy_init
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
```
With this PR, refine the logic to use the currently available device type instead.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/129119
Approved by: https://github.com/albanD, https://github.com/gujinghui, https://github.com/EikanWang
ghstack dependencies: #129463, #129205, #129363
Summary:
Related to gh-36318
Mention `bfloat16` dtype and `BFloat16Tensor` in documentation. The real fix would be to implement cpu operations on 16-bit float `half`, and I couldn't help but notice that `torch.finfo(torch.bfloat16).xxx` crashes for `xxx in ['max', 'min', 'eps']`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37051
Differential Revision: D21476851
Pulled By: ngimel
fbshipit-source-id: fef601d3116d130d67cd3a5654077f31b699409b
Summary:
xref gh-32838, gh-34032
This is a major refactor of parts of the documentation to split it up using sphinx's `autosummary` feature which will build out `autofuction` and `autoclass` stub files and link to them. The end result is that the top module pages like torch.nn.rst and torch.rst are now more like table-of-contents to the actual single-class or single-function documentations pages.
Along the way, I modified many of the docstrings to eliminate sphinx warnings when building. I think the only thing I changed from a non-documentation perspective is to add names to `__all__` when adding them to `globals()` in `torch.__init__.py`
I do not know the CI system: are the documentation build artifacts available after the build, so reviewers can preview before merging?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37419
Differential Revision: D21337640
Pulled By: ezyang
fbshipit-source-id: d4ad198780c3ae7a96a9f22651e00ff2d31a0c0f
Summary:
Improve handling of mixed-type tensor operations.
This PR affects the arithmetic (add, sub, mul, and div) operators implemented via TensorIterator (so dense but not sparse tensor ops).
For these operators, we will now promote to reasonable types where possible, following the rules defined in https://github.com/pytorch/pytorch/issues/9515, and error in cases where the cast would require floating point -> integral or non-boolean to boolean downcasts.
The details of the promotion rules are described here:
https://github.com/nairbv/pytorch/blob/promote_types_strict/docs/source/tensor_attributes.rst
Some specific backwards incompatible examples:
* now `int_tensor * float` will result in a float tensor, whereas previously the floating point operand was first cast to an int. Previously `torch.tensor(10) * 1.9` => `tensor(10)` because the 1.9 was downcast to `1`. Now the result will be the more intuitive `tensor(19)`
* Now `int_tensor *= float` will error, since the floating point result of this operation can't be cast into the in-place integral type result.
See more examples/detail in the original issue (https://github.com/pytorch/pytorch/issues/9515), in the above linked tensor_attributes.rst doc, or in the test_type_promotion.py tests added in this PR:
https://github.com/nairbv/pytorch/blob/promote_types_strict/test/test_type_promotion.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22273
Reviewed By: gchanan
Differential Revision: D16582230
Pulled By: nairbv
fbshipit-source-id: 4029cca891908cdbf4253e4513c617bba7306cb3
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
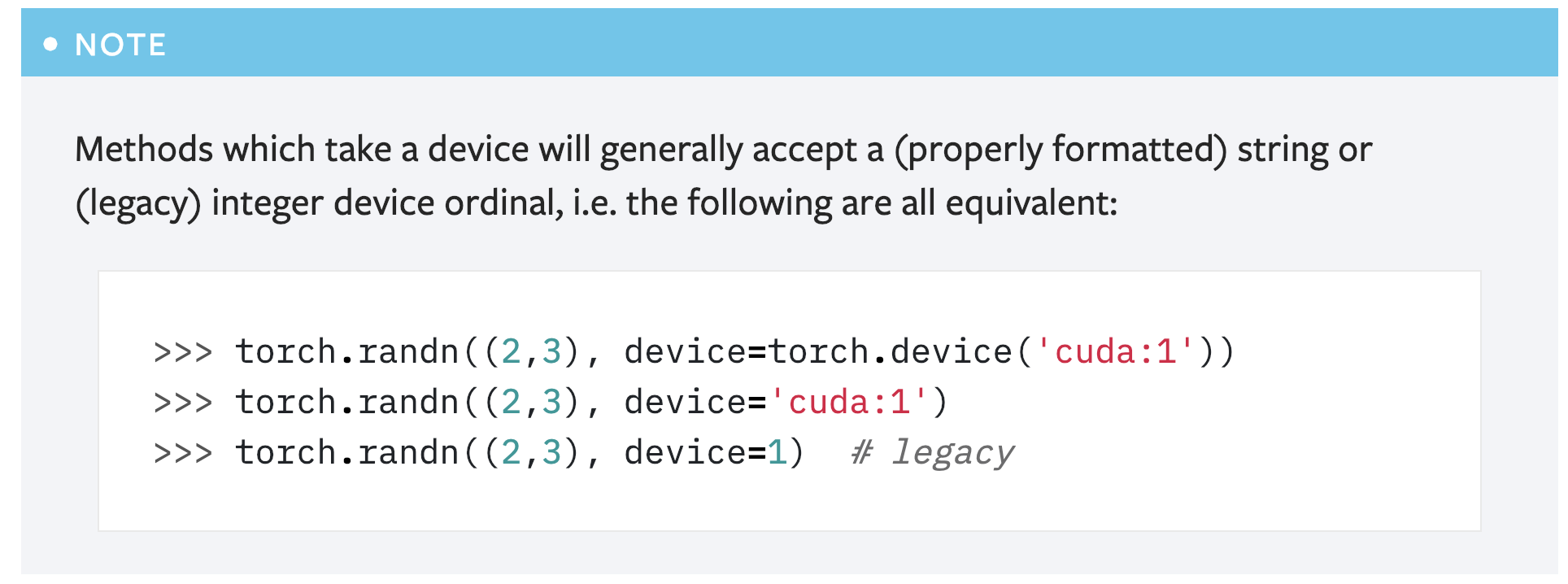
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision: D13989209
Pulled By: gchanan
fbshipit-source-id: ac255d52528da053ebfed18125ee6b857865ccaf
{kind=link}
{kind=link}