c47464ed95
[PyTorch] Further reduce cost of TypeMeta::_typeMetaData (by 10x!) ( #98105 )
...
Currently we should be paying a small cost for the
thread-safe initialization of `index`. Now we should eliminate that
cost. (10x figure in the title comes from internal benchmark that just
calls `TypeMeta::Match<caffe2::Tensor>()` in a loop).
Differential Revision: [D44597852](https://our.internmc.facebook.com/intern/diff/D44597852/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98105
Approved by: https://github.com/ezyang
2023-04-12 17:44:48 +00:00
ee0143bf65
distinguish mutability of TensorImpl::data<T>() ( #98719 )
...
There already is a mutable_data<T>() with different semantics, so we
introduce new names:
TensorImpl::(mutable_)?data_dtype_initialized<T>().
Differential Revision: [D44824778](https://our.internmc.facebook.com/intern/diff/D44824778/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98719
Approved by: https://github.com/ezyang
2023-04-12 07:24:35 +00:00
457afe48fd
[caffe2] Micro-optimizations in BlobGetMutableTensor ( #98103 )
...
Make sure we don't call Tensor::GetDevice() twice. Remove redundant branch for the case when tensor->dtype() == options.dtype(); in this case we end up calling raw_mutable_data(options.dtype()) anyway!
Differential Revision: [D44596695](https://our.internmc.facebook.com/intern/diff/D44596695/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98103
Approved by: https://github.com/jerryzh168
2023-04-10 19:43:02 +00:00
2400cb1d57
distinguish mutability of TensorImpl::data() ( #97776 )
...
See D44409928.
Differential Revision: [D44459999](https://our.internmc.facebook.com/intern/diff/D44459999/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97776
Approved by: https://github.com/ezyang
2023-04-09 20:21:56 +00:00
5f5d675587
remove unused CAFFE2_VERSION macros ( #97337 )
...
remove unused CAFFE2_VERSION macros
Summary:
Nothing reads these and they are completely subsumed by TORCH_VERSION.
Getting rid of these will be helpful for build unification, since they
are also not used internally.
Test Plan: Rely on CI.
Reviewers: sahanp
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/97337
Approved by: https://github.com/malfet
2023-03-24 16:02:35 +00:00
8bce88d9de
[caffe2] dont call cudnnDestroy on thread exit (crashes on windows with cuda 11/12) ( #95382 )
...
Summary:
My team has been hitting a mysterious crash for a few months on a windows binary that uses Caffe2 inside a worker thread.
When this thread gets destroyed, there is an error at this line in context_gpu.h where the state of this operation gives CUDNN_STATUS_INTERNAL_ERROR instead of CUDNN_STATUS_SUCCESS.
When enabling cudnn debug logs (via the env variables nvidia specifies), I can see that the context is destroyed twice, even though this code only destroys it once, so something mysterious is causing a double free.
This seems very very similar to the issue/fix described here for pytorch:
https://github.com/pytorch/pytorch/issues/17658
https://github.com/apache/tvm/pull/8267
And pytorch handles this in the same way, by just not calling cudnnDestroy
This seems to have become an issue with cuda11, but I tested cuda12 as well and found that the issue persists so this needs to be somehow fixed.
Test Plan:
CI
I checked that the specific windows binary I am using is able to create and drestroy caffe2-invoking threads without causing the application to crash.
buck run arvr/mode/win/cuda11/opt //arvr/projects/nimble/prod/tools/MonoHandTrackingVis
Differential Revision: D43538017
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95382
Approved by: https://github.com/malfet
2023-03-10 06:42:51 +00:00
d0e4ca233e
some reference and move fixes ( #95942 )
...
This PR introduces some modifications:
1. We find out some const function parameters that can be passed by reference and add the reference.
2. We find more opportunists of passing by value and change them accordingly.
3. Some use-after-move errors are fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95942
Approved by: https://github.com/Skylion007
2023-03-10 03:44:09 +00:00
fa65ae8f56
cleanup unused include ( #93359 )
...
Using `include-what-you-use` tool to find out and remove some unused includes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93359
Approved by: https://github.com/malfet
2023-02-04 02:15:50 +00:00
dd25111250
[caffe2] Remove OperatorBase::newstyle_outputs_ ( #67093 )
...
`OperatorBase` maintains `output_tensors_` and `newstyle_outputs_`
which hold the same list of tensors except one is
`vector<caffe2::Tensor>` and the other is `List<at::Tensor>`.
This instead maintains only `output_tensors_` and handles the
conversions inside of export_caffe2_op_to_c10.
Differential Revision: [D32289811](https://our.internmc.facebook.com/intern/diff/D32289811 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67093
Approved by: https://github.com/dagitses , https://github.com/malfet
2023-01-23 22:41:59 +00:00
6f749fd171
Fixes to DSA infra ( #91835 )
...
Differential Revision: D42397325
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91835
Approved by: https://github.com/soumith
2023-01-12 21:54:26 +00:00
bac33ea8b6
[CUDA] Drop CUDA 10 support ( #89582 )
...
CC @ptrblck @ngimel @malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89582
Approved by: https://github.com/malfet , https://github.com/ngimel
2023-01-05 05:11:53 +00:00
50ec416599
Fix C2 Ambiguous namespace ( #89534 )
...
Summary: cuda:: is a ambiguous namespace. Make it explicit c10::cuda
Differential Revision: D41469007
/caffe2/caffe2/core/context_gpu.cu(564): error: "caffe2::cuda" is ambiguous/caffe2/caffe2/core/context_gpu.cu(564): error: expected a ";"/caffe2/caffe2/core/context_gpu.cu(568): warning #12-D: parsing restarts here after previous syntax error
Remark: The warnings can be suppressed with "-diag-suppress <warning-number>"/caffe2/caffe2/core/context_gpu.cu(569): error: "caffe2::cuda" is ambiguous/caffe2/caffe2/core/context_gpu.cu(628): error: "caffe2::cuda" is ambiguous
4 errors detected in the compilation of "/caffe2/caffe2/core/context_gpu.cu".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89534
Approved by: https://github.com/malfet
2022-12-07 23:36:41 +00:00
fbd08fb358
Introduce TORCH_DISABLE_GPU_ASSERTS ( #84190 )
...
- Asserts for CUDA are enabled by default
- Disabled for ROCm by default by setting `TORCH_DISABLE_GPU_ASSERTS` to `ON`
- Can be enabled for ROCm by setting above variable to`OFF` during build or can be forcefully enabled by setting `ROCM_FORCE_ENABLE_GPU_ASSERTS:BOOL=ON`
This is follow up changes as per comment in PR #81790 , comment [link](https://github.com/pytorch/pytorch/pull/81790#issuecomment-1215929021 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84190
Approved by: https://github.com/jeffdaily , https://github.com/malfet
2022-11-04 04:43:05 +00:00
0fa23663cc
Revert "Introduce TORCH_DISABLE_GPU_ASSERTS ( #84190 )"
...
This reverts commit 1e2c4a6e0e60dda763b53f00f25ee5c1f1e5233d.
Reverted https://github.com/pytorch/pytorch/pull/84190 on behalf of https://github.com/malfet due to Needs internal changes, has to be landed via co-dev
2022-11-02 18:13:37 +00:00
1e2c4a6e0e
Introduce TORCH_DISABLE_GPU_ASSERTS ( #84190 )
...
- Asserts for CUDA are enabled by default
- Disabled for ROCm by default by setting `TORCH_DISABLE_GPU_ASSERTS` to `ON`
- Can be enabled for ROCm by setting above variable to`OFF` during build or can be forcefully enabled by setting `ROCM_FORCE_ENABLE_GPU_ASSERTS:BOOL=ON`
This is follow up changes as per comment in PR #81790 , comment [link](https://github.com/pytorch/pytorch/pull/81790#issuecomment-1215929021 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84190
Approved by: https://github.com/jeffdaily , https://github.com/malfet
2022-11-02 17:41:57 +00:00
23b79e6f48
Update CMakeLists.txt ( #87030 )
...
Fix Caffe2_CPU_INCLUDE with Caffe2_GPU_INCLUDE. The expanding parent scope should be with the same variable name. The compilation in certain build configurations is corrected with this fix.
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87030
Approved by: https://github.com/kit1980
2022-10-28 04:56:40 +00:00
7a3afe61d2
Check all CUDA API calls for errors in caffe2/ ( #81816 )
...
Test Plan: Sandcastle
Differential Revision: D35194868
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81816
Approved by: https://github.com/ezyang
2022-10-28 00:41:06 +00:00
e0229d6517
Remove caffe2 mobile ( #84338 )
...
We're no longer building Caffe2 mobile as part of our CI, and it adds a lot of clutter to our make files. Any lingering internal dependencies will use the buck build and so wont be effected.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84338
Approved by: https://github.com/dreiss
2022-09-08 01:49:55 +00:00
e23d159bc5
[PyTorch][caffe2] Add CAFFE2_{DECLARE,DEFINE}_KNOWN_TYPE ( #83707 )
...
It looks like we aren't getting inlining for the defined `_typeMetaData` functions from CAFFE_KNOWN_TYPE and there's some cost associated with that. I added new macros that fix this problem; I will migrate to them in a follow-up after I get buy-in from reviewers.
Differential Revision: [D36883685](https://our.internmc.facebook.com/intern/diff/D36883685/ )
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36883685/ )!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83707
Approved by: https://github.com/ezyang
2022-08-30 23:09:49 +00:00
eda217ab67
Reland symint_numel ( #84281 )
...
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84281
Approved by: https://github.com/ezyang
2022-08-30 21:53:34 +00:00
44a975335e
Revert "Re-land sym_numel ( #82374 ) ( #82726 ) ( #82731 ) ( #82855 )" ( #84207 )
...
This reverts commit bfebf254dd92f3ed35154597166e7e71fb04f31b.
Differential Revision: [D39104562](https://our.internmc.facebook.com/intern/diff/D39104562 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84207
Approved by: https://github.com/robieta
2022-08-30 13:22:58 +00:00
1665715cb0
add sym_strides() function, use in fake/proxy tensors ( #81300 )
...
Add `TensorImpl::sym_strides`, bind it to python with `torch.ops.aten.sym_strides`, and use it in `ProxyTensor` and `FakeTensor`.
Before, `ProxyTensor` was generating `ProxySymInt`'s for the sizes, but not for the strides. Internally we still represent strides with a `SymIntArrayRef` though, so I ran into some weird issues where sizes were showing up as `ProxySymInt`, but strides were `PySymInt`'s.
Differential Revision: [D38594558](https://our.internmc.facebook.com/intern/diff/D38594558 )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81300
Approved by: https://github.com/ezyang
2022-08-16 14:31:27 +00:00
bfebf254dd
Re-land sym_numel ( #82374 ) ( #82726 ) ( #82731 ) ( #82855 )
...
### Description
This is a reland of (#82374 ) (#82726 ) (#82731 )
This PR has no extra fixes, it simply updates the **correct** pin to point to the XLA side that has the corresponding changes.
### Issue
<!-- Link to Issue ticket or RFP -->
### Testing
<!-- How did you test your change? -->
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82855
Approved by: https://github.com/ezyang , https://github.com/qihqi
2022-08-05 03:36:09 +00:00
78bd95b13a
Revert "Re-land sym_numel ( #82374 ) ( #82726 ) ( #82731 )"
...
This reverts commit c90e00cf85a4ac11e6fd96963e5e95944aefc5b4.
Reverted https://github.com/pytorch/pytorch/pull/82731 on behalf of https://github.com/zengk95 due to This is breaking XLA tests on trunk. It seems to have passed on PR and was able to checkout that commit c90e00cf85
2022-08-04 22:45:26 +00:00
c90e00cf85
Re-land sym_numel ( #82374 ) ( #82726 ) ( #82731 )
...
This PR relands sym_numel #82374 and fixes the ios build break in this commit : 8cbd0031c5https://github.com/pytorch/pytorch/pull/82731
Approved by: https://github.com/malfet
2022-08-04 21:05:24 +00:00
d0e6e5a5bb
Revert "sym_numel ( #82374 )" ( #82726 )
...
TSIA
It looks like this PR #82374 is breaking mac builds on trunk but I can't revert it normally since there's a merge conflict in the XLA hash.
<img width="1753" alt="image" src="https://user-images.githubusercontent.com/34172846/182644661-b7fdda4b-e5ce-45c3-96a2-ad6737d169ae.png ">
I reverted it and resolved the conflict using the old XLA hash that this commit was based upon
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82726
Approved by: https://github.com/albanD , https://github.com/janeyx99
2022-08-03 15:23:47 +00:00
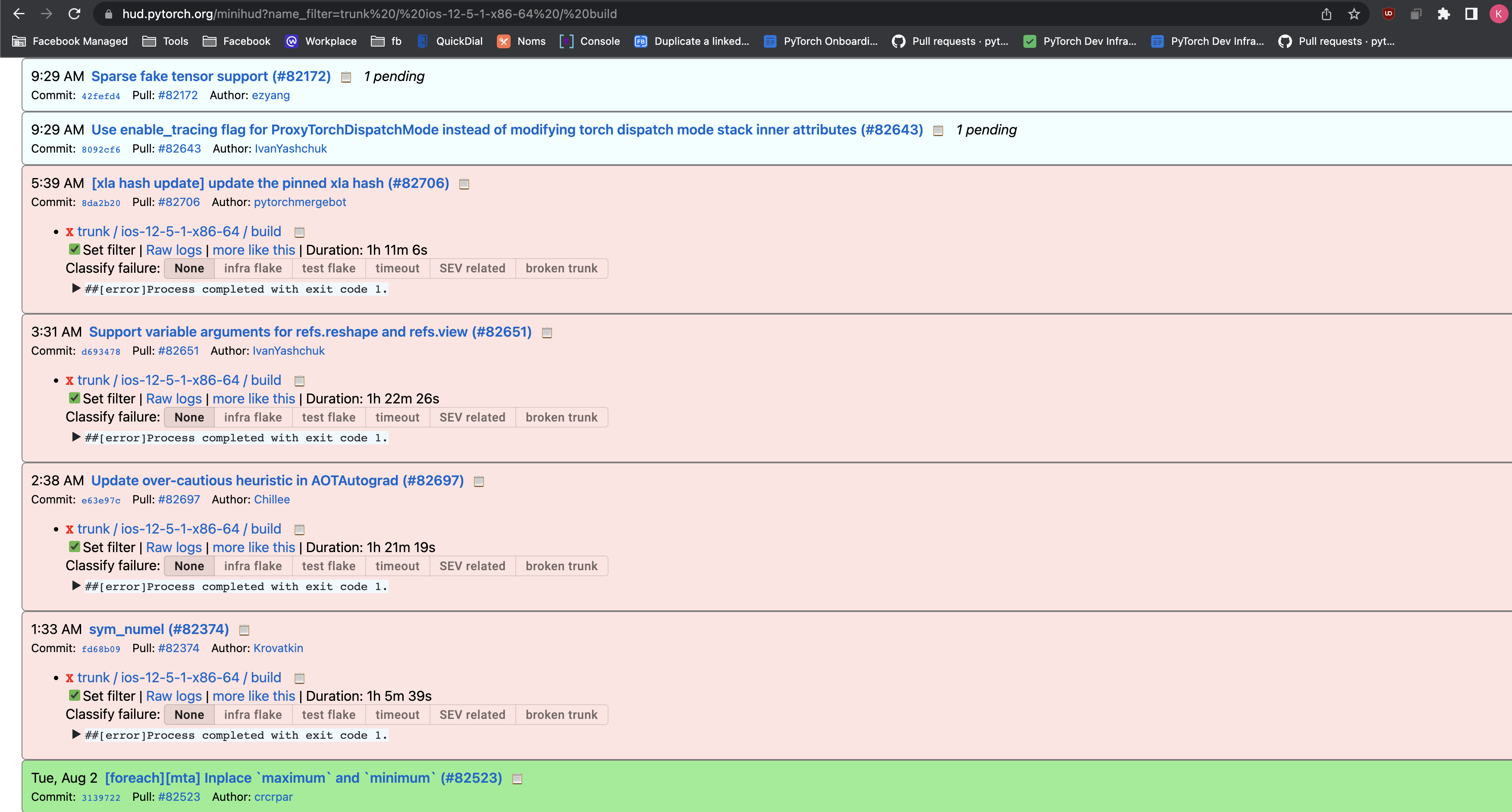
fd68b0931f
sym_numel ( #82374 )
...
### Description
This PR makes `numel` symint-aware similar to `sym_sizes()` and `sym_strides()`. Similar to https://github.com/pytorch/pytorch/pull/81300 . This PR is the part of a bigger project to support dynamic_shapes.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82374
Approved by: https://github.com/ezyang
2022-08-03 06:33:45 +00:00
41b54c303d
Revert "Fix crash on unload torch cpu dll ( #67632 )"
...
This reverts commit a54c9a419e1f025546b69b9c393b5f96dc26539f.
Reverted https://github.com/pytorch/pytorch/pull/67632 on behalf of https://github.com/ezyang due to crashing in fbcode
2022-08-02 00:56:18 +00:00
a54c9a419e
Fix crash on unload torch cpu dll ( #67632 )
...
Trying to rebase https://github.com/pytorch/pytorch/pull/61290 into latest pytorch:master
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67632
Approved by: https://github.com/ezyang
2022-07-31 21:37:56 +00:00
82712b7985
[PyTorch] Support ExclusivelyOwned<caffe2::Tensor> ( #81964 )
...
Since `caffe2::Tensor` also shares `TensorImpl`, we can apply `ExclusivelyOwned` to it as needed.
Differential Revision: [D38066340](https://our.internmc.facebook.com/intern/diff/D38066340/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81964
Approved by: https://github.com/ezyang
2022-07-27 22:14:40 +00:00
4f34cd6d1e
Replace all CHECK_ and DCHECK_ with TORCH_* macros ( #82032 )
...
Avoid exposing defines that conflict with google logging, since this blocks external usage of libtorch in certain cases.
All the 'interesting' changes should be in these two files, and the rest should just be mechanical changes via sed.
c10/util/logging_is_not_google_glog.h
c10/util/logging_is_google_glog.h
Fixes https://github.com/pytorch/pytorch/issues/81415
cc @miladm @malfet
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82032
Approved by: https://github.com/soumith , https://github.com/miladm
2022-07-26 01:20:44 +00:00
86b86202b5
fix torch.config can't respect USE_MKLDNN flag issue ( #75001 )
...
Fixes https://github.com/pytorch/pytorch/issues/74949 , which reports that torch.config can't respect USE_MKLDNN flag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75001
Approved by: https://github.com/malfet
2022-07-17 15:00:48 +00:00
3c7044728b
Enable Intel® VTune™ Profiler's Instrumentation and Tracing Technology APIs (ITT) to PyTorch ( #63289 )
...
More detailed description of benefits can be found at #41001 . This is Intel's counterpart of NVidia’s NVTX (https://pytorch.org/docs/stable/autograd.html#torch.autograd.profiler.emit_nvtx ).
ITT is a functionality for labeling trace data during application execution across different Intel tools.
For integrating Intel(R) VTune Profiler into Kineto, ITT needs to be integrated into PyTorch first. It works with both standalone VTune Profiler [(https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler.html ](https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler.html )) and Kineto-integrated VTune functionality in the future.
It works for both Intel CPU and Intel XPU devices.
Pitch
Add VTune Profiler's ITT API function calls to annotate PyTorch ops, as well as developer customized code scopes on CPU, like NVTX for NVidia GPU.
This PR rebases the code changes at https://github.com/pytorch/pytorch/pull/61335 to the latest master branch.
Usage example:
```
with torch.autograd.profiler.emit_itt():
for i in range(10):
torch.itt.range_push('step_{}'.format(i))
model(input)
torch.itt.range_pop()
```
cc @ilia-cher @robieta @chaekit @gdankel @bitfort @ngimel @orionr @nbcsm @guotuofeng @guyang3532 @gaoteng-git
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63289
Approved by: https://github.com/malfet
2022-07-13 13:50:15 +00:00
80a700bd1b
[caffe2] Don't copy Tensor dims during deserialization ( #79471 )
...
We can just make an IntArrayRef.
Differential Revision: [D37124427](https://our.internmc.facebook.com/intern/diff/D37124427/ )
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D37124427/ )!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79471
Approved by: https://github.com/ezyang
2022-07-12 21:36:26 +00:00
1454515253
Revert "Enable Intel® VTune™ Profiler's Instrumentation and Tracing Technology APIs (ITT) to PyTorch ( #63289 )"
...
This reverts commit f988aa2b3ff77d5aa010bdaae4e52c6ee345c04d.
Reverted https://github.com/pytorch/pytorch/pull/63289 on behalf of https://github.com/malfet due to broke trunk, see f988aa2b3f
2022-06-30 12:49:41 +00:00
f988aa2b3f
Enable Intel® VTune™ Profiler's Instrumentation and Tracing Technology APIs (ITT) to PyTorch ( #63289 )
...
More detailed description of benefits can be found at #41001 . This is Intel's counterpart of NVidia’s NVTX (https://pytorch.org/docs/stable/autograd.html#torch.autograd.profiler.emit_nvtx ).
ITT is a functionality for labeling trace data during application execution across different Intel tools.
For integrating Intel(R) VTune Profiler into Kineto, ITT needs to be integrated into PyTorch first. It works with both standalone VTune Profiler [(https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler.html ](https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler.html )) and Kineto-integrated VTune functionality in the future.
It works for both Intel CPU and Intel XPU devices.
Pitch
Add VTune Profiler's ITT API function calls to annotate PyTorch ops, as well as developer customized code scopes on CPU, like NVTX for NVidia GPU.
This PR rebases the code changes at https://github.com/pytorch/pytorch/pull/61335 to the latest master branch.
Usage example:
```
with torch.autograd.profiler.emit_itt():
for i in range(10):
torch.itt.range_push('step_{}'.format(i))
model(input)
torch.itt.range_pop()
```
cc @ilia-cher @robieta @chaekit @gdankel @bitfort @ngimel @orionr @nbcsm @guotuofeng @guyang3532 @gaoteng-git
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63289
Approved by: https://github.com/malfet
2022-06-30 05:14:03 +00:00
f96d96a7fc
turn on -Werror=type-limits in our Bazel CPU build
...
Summary:
We also fix any existing issues.
Test Plan: Built locally, rely on CI to confirm.
Reviewers: malfet
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/79139
Approved by: https://github.com/seemethere , https://github.com/osalpekar , https://github.com/albanD
2022-06-10 10:04:08 +00:00
df1f9b9840
Implement sym_sizes to create proper IR for sym ints representing tensor sizes ( #77756 )
...
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77756
Approved by: https://github.com/desertfire
2022-05-20 05:39:03 +00:00
e9d660c331
Revert "Revert "Revert "Implement sym_sizes to create proper IR for sym ints representing tensor sizes ( #76836 )"""
...
This reverts commit acf7136a525422459d97d5f993e30afdff18b1b9.
Reverted https://github.com/pytorch/pytorch/pull/77719 on behalf of https://github.com/suo
2022-05-18 05:06:50 +00:00
acf7136a52
Revert "Revert "Implement sym_sizes to create proper IR for sym ints representing tensor sizes ( #76836 )""
...
This reverts commit c35bd8d423ca53408c3aa39c2280167f3a22cea0.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77719
Approved by: https://github.com/Chillee , https://github.com/malfet
2022-05-18 03:25:43 +00:00
c35bd8d423
Revert "Implement sym_sizes to create proper IR for sym ints representing tensor sizes ( #76836 )"
...
This reverts commit fc4c3c9bc758aad4e4be17b432b871c4e75e88c8.
Reverted https://github.com/pytorch/pytorch/pull/76836 on behalf of https://github.com/suo
2022-05-18 02:45:25 +00:00
fc4c3c9bc7
Implement sym_sizes to create proper IR for sym ints representing tensor sizes ( #76836 )
...
LTC Tensors now create real IR (SizeNode) for sym_sizes() in LTCTensorImpl.cpp.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76836
Approved by: https://github.com/ezyang
2022-05-18 00:40:42 +00:00
99339fddd9
move SymInt and SymIntArrayRef to c10/core ( #77009 )
...
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77009
Approved by: https://github.com/ezyang , https://github.com/malfet
2022-05-11 16:21:31 +00:00
f6c275f55d
Remove -Wno-unused-variable from utils.cmake (take 2) ( #75538 )
...
Summary:
[Comment](https://github.com/pytorch/pytorch/pull/62445/files#r680132022 ) claims, it got added for consistency with top level CMakeLists.txt, but `-Wno-unused-variable` is not mentioned there.
Modify violations in 50+ files that were added in the interim by either removing unused variables, or decorating the code with `C10_UNUSED` if local variable is likely used to extend object lifetime until the end of the block.
Caused preventable revert in https://github.com/pytorch/pytorch/pull/72633#issuecomment-1092300787
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75538
Reviewed By: anjali411
Differential Revision: D35747333
Pulled By: malfet
fbshipit-source-id: 3fc5828e44a4c05ba0e89e92613e6ebbdb260626
(cherry picked from commit c179fba21cfa2a0093fad50ccad5a22dd7cff52c)
2022-04-20 17:41:59 +00:00
69e048b090
List of SymInt rebase on master
...
Fixes #ISSUE_NUMBER
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75115
Approved by: https://github.com/ezyang
2022-04-20 02:09:55 +00:00
5c56b2286b
Revert "Remove -Wno-unused-variable from utils.cmake"
...
This reverts commit 018cbe1f5ccccb9194394d6e737310f837f8ad7a.
Reverted https://github.com/pytorch/pytorch/pull/75538 on behalf of https://github.com/seemethere
2022-04-19 17:19:09 +00:00
018cbe1f5c
Remove -Wno-unused-variable from utils.cmake
...
[Comment](https://github.com/pytorch/pytorch/pull/62445/files#r680132022 ) claims, it got added for consistency with top level CMakeLists.txt, but `-Wno-unused-variable` is not mentioned there.
Modify violations in 50+ files that were added in the interim by either removing unused variables, or decorating the code with `C10_UNUSED` if local variable is likely used to extend object lifetime until the end of the block.
Caused preventable revert in https://github.com/pytorch/pytorch/pull/72633#issuecomment-1092300787
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75538
Approved by: https://github.com/cpuhrsch
2022-04-19 15:26:55 +00:00
bdf5a87714
Extend sign-compare warnings to gcc (take 2)
...
Remove `-Wno-sign-compare` option for GCC
Suppress erroneous sign-compare warning in `c10::greater_than_max`(see https://godbolt.org/z/Tr3Msnz99 )
Fix sign-compare in torch/deploy, `caffe2::QTensor::dim32()` and `generate_proposals_op_test.cc`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75544
Approved by: https://github.com/osalpekar
2022-04-13 00:06:52 +00:00
f6e7a2ab64
Fix sign-compare in caffe2 cpp tests
...
Prerequisite change for enabling `-Werror=sign-compare` across PyTorch repo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75084
Approved by: https://github.com/ngimel
2022-04-05 00:08:05 +00:00
6d85e7dafa
Fix sign-compare in caffe2
...
Prerequisite change for enabling `-Werror=sign-compare` across PyTorch repo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75082
Approved by: https://github.com/ngimel
2022-04-05 00:08:05 +00:00
{kind=link}