This word appears often in class descriptions and is not consistently spelled. Update comments and some function names to use the correct spelling consistently. Facilitates searching the codebase.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/155944
Approved by: https://github.com/Skylion007
Changes:
1. Bump `ruff` from 0.7.4 to 0.8.4
2. Change `%`-formatted strings to f-string
3. Change arguments with the `__`-prefix to positional-only arguments with the `/` separator in function signature.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/143753
Approved by: https://github.com/Skylion007
The `usort` config in `pyproject.toml` has no effect due to a typo. Fixing the typo make `usort` do more and generate the changes in the PR. Except `pyproject.toml`, all changes are generated by `lintrunner -a --take UFMT --all-files`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127126
Approved by: https://github.com/kit1980
The `usort` config in `pyproject.toml` has no effect due to a typo. Fixing the typo make `usort` do more and generate the changes in the PR. Except `pyproject.toml`, all changes are generated by `lintrunner -a --take UFMT --all-files`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/127126
Approved by: https://github.com/kit1980
ghstack dependencies: #127122, #127123, #127124, #127125
Adds a ruff lint rule to ban raising raw exceptions. Most of these should at the very least be runtime exception, value errors, type errors or some other errors. There are hundreds of instance of these bad exception types already in the codebase, so I have noqa'd most of them. Hopefully this error code will get commiters to rethink what exception type they should raise when they submit a PR.
I also encourage people to gradually go and fix all the existing noqas that have been added so they can be removed overtime and our exception typing can be improved.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/124570
Approved by: https://github.com/ezyang
This replaces a bunch of unnecessary lambdas with the operator package. This is semantically equivalent, but the operator package is faster, and arguably more readable. When the FURB rules are taken out of preview, I will enable it as a ruff check.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/116027
Approved by: https://github.com/malfet
Applies PLW0108 which removes useless lambda calls in Python, the rule is in preview so it is not ready to be enabled by default just yet. These are the autofixes from the rule.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/113602
Approved by: https://github.com/albanD
Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73875
Previously we had a few settings:
- getExecutor - which toggled between Profiling Executor and Legacy
- getGraphOptimize - if true, overrides PE/Legacy to run with simple executor (no optimizations)
and then...
- getProfilingMode - which would set PE to 0 specializtions.
The last mode is redundant with getGraphOptimize, we should just remove it and use getGraphOptimize in these cases. It would lead to potentially invalid combinations of logic - what does mean if getProfilingMode is true but getExecutor is set to false ? This would lead to a bug in specialize_autograd_zero in this case, see: https://github.com/pytorch/pytorch/blob/master/torch%2Fcsrc%2Fjit%2Fpasses%2Fspecialize_autogradzero.cpp#L93.
The tests here are failing but get fixed with the PR above it, so i'll squash for landing.
Test Plan: Imported from OSS
Reviewed By: cpuhrsch
Differential Revision: D34938130
Pulled By: eellison
fbshipit-source-id: 1a9c0ae7f6d1cfddc2ed3499a5af611053ae5e1b
(cherry picked from commit cf69ce3d155ba7d334022c42fb2cee54bb088c23)
Summary:
This PR adds an implementation for `aten::cat` in NNC without any conditionals. This version is not enabled by default.
Here is the performance of some micro benchmarks with and without conditionals. There is up to 50% improvement in performance without conditionals for some of the shapes.
aten::cat implementation in NNC **with** conditionals
```
$ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion concat
pt: concat2d2input_fwd_cpu_1_160_1_14_1: 5.44 us, SOL 0.26 GB/s, algorithmic 0.51 GB/s
pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.75 us, SOL 1.05 GB/s, algorithmic 2.10 GB/s
pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.87 us, SOL 4.05 GB/s, algorithmic 8.11 GB/s
pt: concat2d2input_fwd_cpu_20_580_20_174_1: 14.52 us, SOL 8.31 GB/s, algorithmic 16.62 GB/s
pt: concat2d2input_fwd_cpu_8_512_8_512_1: 9.58 us, SOL 6.84 GB/s, algorithmic 13.68 GB/s
```
aten::cat implementation in NNC **without** conditionals
```
$ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion --cat_wo_conditionals concat
pt: concat2d2input_fwd_cpu_1_160_1_14_1: 4.67 us, SOL 0.30 GB/s, algorithmic 0.60 GB/s
pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.65 us, SOL 1.07 GB/s, algorithmic 2.14 GB/s
pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.10 us, SOL 4.56 GB/s, algorithmic 9.12 GB/s
pt: concat2d2input_fwd_cpu_20_580_20_174_1: 7.44 us, SOL 16.22 GB/s, algorithmic 32.44 GB/s
pt: concat2d2input_fwd_cpu_8_512_8_512_1: 6.46 us, SOL 10.14 GB/s, algorithmic 20.29 GB/s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53128
Reviewed By: bertmaher
Differential Revision: D26758613
Pulled By: navahgar
fbshipit-source-id: 00f56b7da630b42bc6e7ddd4444bae0cf3a5780a
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
As discussed with suo , having it in `torch._C.XX` means that it automatically gets added to `torch.XX` which is unfortunate. Making it `torch._C._XX` means that it won't be added to `torch.`.
Let me know if that approach to hide it is not good and we can update that.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51690
Reviewed By: gchanan
Differential Revision: D26243207
Pulled By: albanD
fbshipit-source-id: 3eb91a96635e90a6b98df799e3a732833dd280d5
Summary:
This is a tiny PR for two minor fixes:
1. Added `torch._C._jit_set_texpr_fuser_enabled(False)` to enable shape inference on nv fuser runs.
2. Renamed dynamic benchmark module names to avoid multiple matching. i.e. `simple_element` with `dynamic_simple_element`. I guess it'd be much easier if the pattern matching was based on `startswith`. Would be happy to update that if agreed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46778
Reviewed By: zhangguanheng66
Differential Revision: D24516911
Pulled By: bertmaher
fbshipit-source-id: 839f9a3e058f9d7aca17b2e6eb8b558e0e48e8f4
Summary:
This PR modifies `benchmarks/tensorexpr`. It follows up[ https://github.com/pytorch/pytorch/issues/44101](https://github.com/pytorch/pytorch/pull/44101) and further supports characterizing fusers with dynamic shape benchmarks. Dynamic shape condition models the use case when the input tensor shape changes in each call to the graph.
Changes include:
Added an auxiliary class `DynamicShape `that provides a simple API for enabling dynamic shapes in existing test cases, example can be found with `DynamicSimpleElementBench`
Created new bench_cls: `DynamicSimpleElementBench`, `DynamicReduce2DInnerBench`, `DynamicReduce2DOuterBench`, and `DynamicLSTM`. They are all dynamic shaped versions of existing benchmarks and examples of enabling dynamic shape with `DynamicShape`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46107
Reviewed By: glaringlee
Differential Revision: D24229400
Pulled By: bertmaher
fbshipit-source-id: 889fece5ea87d0f6f6374d31dbe11b1cd1380683
Summary:
Modified files in `benchmarks/tensorexpr` to add support for NVIDIA's Fuser for the jit compiler.
This support has some modifications besides adding an option to support the NVIDIA fuser:
* Adds FP16 Datatype support
* Fixes SOL/Algo calculations to generally use the data type instead of being fixed to 4 bytes
* Adds IR printing and kernel printing knobs
* Adds a knob `input_iter` to create ranges of inputs currently only for reductions
* Adds further reduction support for Inner and Outer dimension reductions that are compatible with the `input_iter` knob.
* Added `simple_element`, `reduce2d_inner`, and `reduce2d_outer` to isolate performance on elementwise and reduction operations in the most minimal fashion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44101
Reviewed By: ngimel
Differential Revision: D23713658
Pulled By: bertmaher
fbshipit-source-id: d6b83cfab559aefe107c23b3c0f2df9923b3adc1
Summary:
This commit allows one to use an environment variable to enable the fuser in torch/csrc/jit/tensorexpr/
```
PYTORCH_TENSOREXPR=1 python benchmark.py
```
This commit also changes the registration to happen by default, removing the requirement for the python exposed "_jit_register_tensorexpr_fuser"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35341
Reviewed By: ZolotukhinM
Differential Revision: D20676348
Pulled By: bwasti
fbshipit-source-id: 4c997cdc310e7567c03905ebff72b3e8a4c2f464
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34230
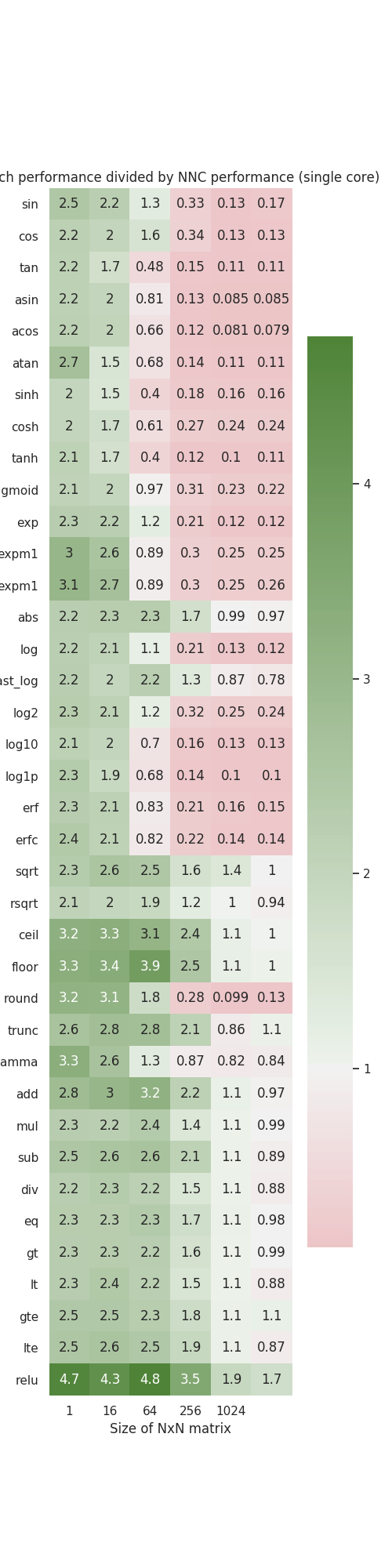
This PR adds some benchmarks that we used to assess tensor expressions performance.
Differential Revision: D20251830
Test Plan: Imported from OSS
Pulled By: ZolotukhinM
fbshipit-source-id: bafd66ce32f63077e3733112d854f5c750d5b1af
{kind=link}