Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
Performance benchmarks on 6 popular models from 1-64 GPUs compiled with
torchinductor show performance gains or parity with eager, and showed
regressions without DDPOptimizer. *Note: resnet50 with small batch size shows a regression with optimizer, in part due to failing to compile one subgraph due to input mutation, which will be fixed.
(hf_Bert, hf_T5_large, hf_T5, hf_GPT2_large, timm_vision_transformer, resnet50)
Correctness checks are implemented in CI (test_dynamo_distributed.py),
via single-gpu benchmark scripts iterating over many models
(benchmarks/dynamo/torchbench.py/timm_models.py/huggingface.py),
and via (multi-gpu benchmark scripts in torchbench)[https://github.com/pytorch/benchmark/tree/main/userbenchmark/ddp_experiments].
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88523
Approved by: https://github.com/davidberard98
### Summary
Making dynamo treat the nn.Modules inside FSDP wrappers as 'Unspecialized'
results in dynamo-produced graphs where nn.module parameters are inputs
to the graph rather than attributes of the outer graphmodule.
This helps in FSDP since it forces dynamo to pick the latest copy
of the parameters off the user's nn.Module (which FSDP mutates every pre_forward),
solving the ordering issue in backward.
### Details
Imagine this toy model
```
class MyModule(torch.nn.Module):
def __init__(self, a, b):
super(MyModule, self).__init__()
self.net = nn.Sequential(
nn.Linear(a, b),
nn.ReLU(),
)
def forward(self, x):
return self.net(x)
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net = nn.Sequential(
*[MyModule(10, 10000)]
+ [MyModule(10000, 1000)]
+ [MyModule(1000, 5)]
)
def forward(self, x):
return self.net(x)
```
Where FSDP is recursively wrapped around each `MyModule`, then dynamo-compiled, with dynamo already configured to skip/break in FSDP code. You'd expect to get 3 compiled AOT functions, corresponding to the contents of `MyModule`, and then see FSDP's communication ops happen inbetween them (eagerly). This almost happens (everything works out fine in forward), but in backward there is an ordering issue.
FSDP creates a flat buffer for all the parameters that are bucketed together, and then creates views into this buffer to replace the original parameters. On each iteration of forward, it creates a new view after 'filling' the flatbuffer with data from an all-gather operation, to 'unshard' the parameters from remote devices. Dynamo traces the first such view and stores it in a compiled graphmodule.
During tracing, we see (1) view created for first MyModule, (2) compile first MyModule, (3) ... for the rest of layers
Then during runtime, we see (A) view created for first MyModule (and orphaned), (B) execute first compiled MyModule, using old view, ...
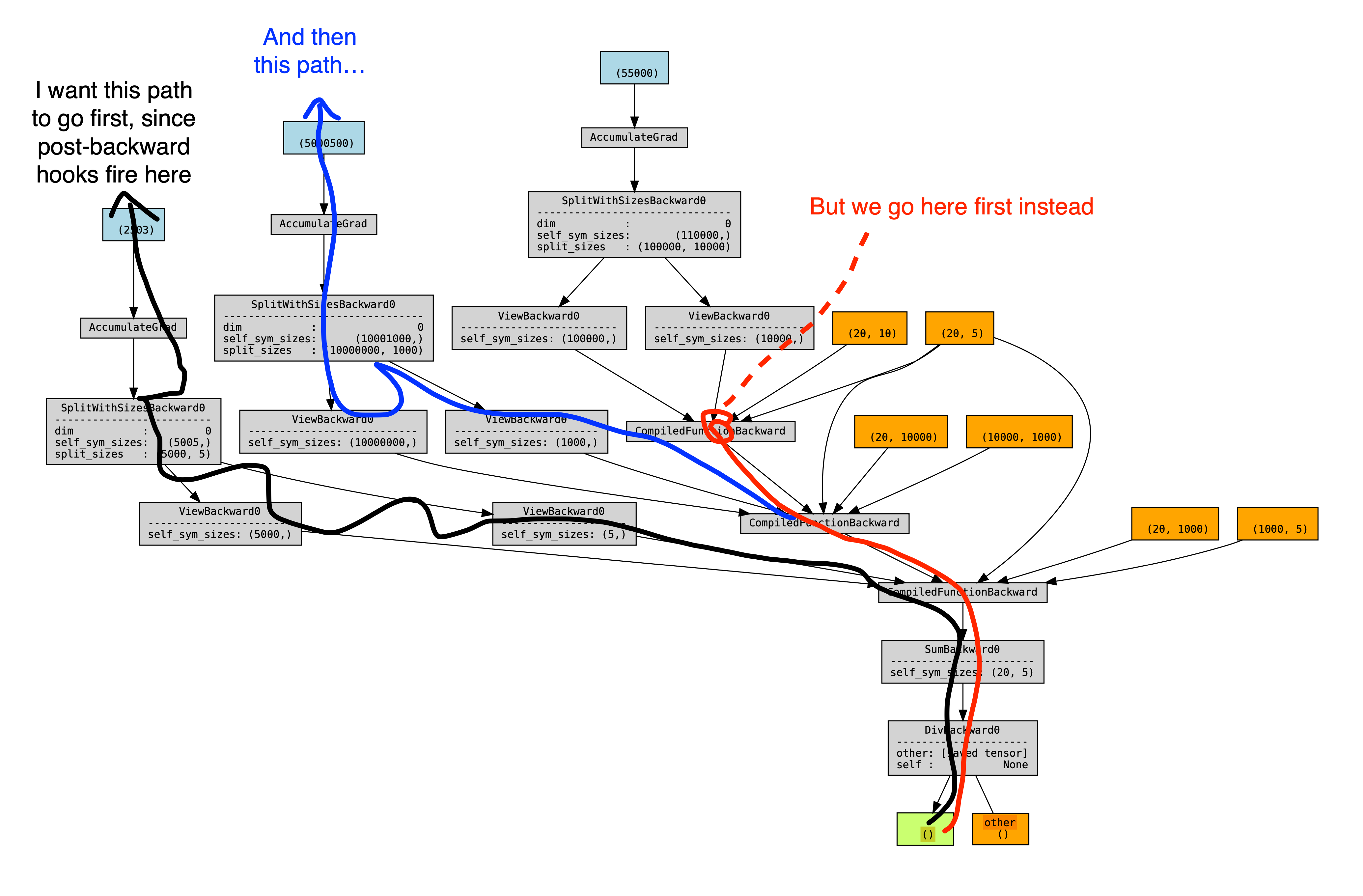
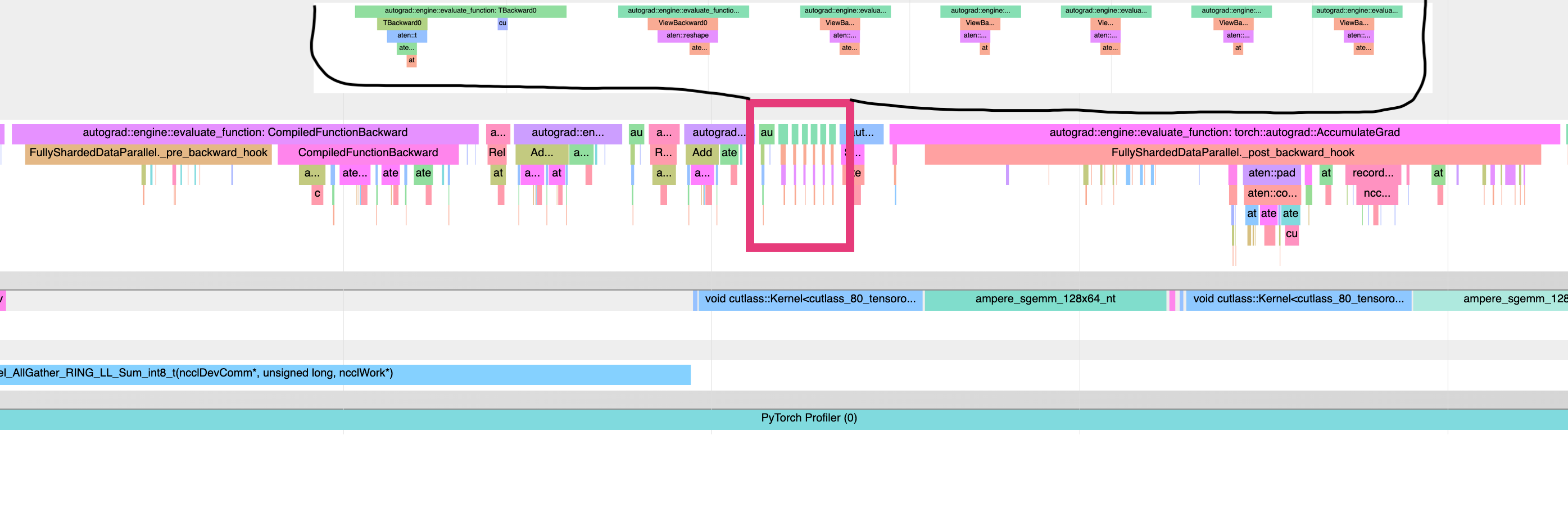
This is a problem, because we want backward hooks to run right after each compiled-backward, but autograd executes those hooks in an order mirroring their execution order during forward. Since we are forever using the views created during steps (1, 3, .. N), which all happen before the steps (A, B, ...), this means that all the hooks will happen after all the compiled backwards. An illustration of the problem - a torchviz graph showing the 2 possible orderings of autograd, and a profile showing the view-backwards ops happening after all the compiled backwards, and before all the backward hooks.
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828002-32dbbd15-8fc3-4281-93e9-227ab5e32683.png">
<img width="2069" alt="image" src="https://user-images.githubusercontent.com/4984825/202828632-33e40729-9a7f-4e68-9ce1-571e3a8dd2dd.png">
A solution is to make dynamo not specialize on these nn modules. It is worth pointing out that this nn.module specialization is de-facto failing, as we are modifying .parameters and this bypasses dynamo's __setattr__ monkeypatch, which should have automatically kicked us out to Unspecialized and forced a recompile.
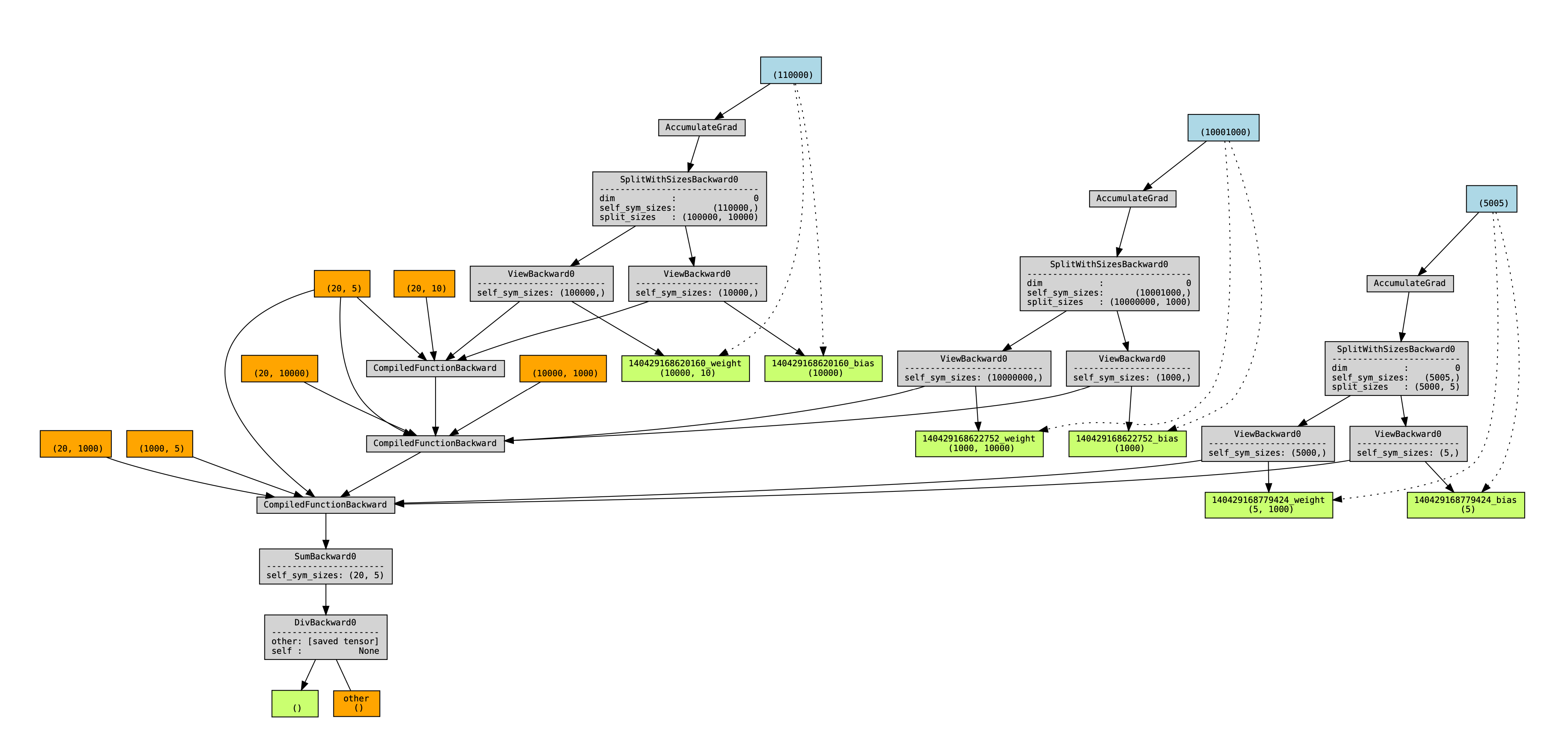
After unspecializing, the new views (created during steps A, C, ...) are actually _used_ at runtime by the module, making their creation order interleaved, making autograd execute their backwards interleaved.
The new torchviz graph (this time with names added for the view tensors):
<img width="2043" alt="image" src="https://user-images.githubusercontent.com/4984825/202828480-d30005ba-0d20-45d8-b647-30b7ff5e91d3.png">
And a new profile showing the interleaving of compiled backwards and hooks, allowing overlapping of reduce-scatter.
<img width="2293" alt="image" src="https://user-images.githubusercontent.com/4984825/202828533-bb20a041-19b8-499c-b3cf-02808933df47.png">
@jansel @davidberard98 @aazzolini @mrshenli @awgu @ezyang @soumith @voznesenskym @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89330
Approved by: https://github.com/davidberard98
Mainly wanted to confirm torchrun works fine with dynamo/ddp,
but it is also a better system than manually launching processes.
Partially addresses issue #1779
New run commands
------------
single process:
python benchmarks/dynamo/distributed.py [args]
multi-gpu (e.g. 2 gpu on one host):
torchrun --nproc_per_node 2 benchmarks/dynamo/distributed.py [args]
Pull Request resolved: https://github.com/pytorch/pytorch/pull/89149
Approved by: https://github.com/aazzolini
Dynamo+AotAutograd needs a way to wrap all tensors (whether
inputs or params/buffers) in FakeTensor wrappers, and
FSDP's mangling of parameters hides them from this wrapping.
This PR unblocks running hf_bert and hf_T5 with FSDP under dynamo, whether using recursive wrapping around transformer layers or only applying FSDP around the whole model. Perf/memory validation and possibly optimization is the next step.
`python benchmarks/dynamo/distributed.py --torchbench_model hf_Bert --fsdp --dynamo aot_eager`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_Bert --fsdp --dynamo aot_eager --fsdp_wrap`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_T5 --fsdp --dynamo aot_eager`
`python benchmarks/dynamo/distributed.py --torchbench_model hf_T5 --fsdp --dynamo aot_eager --fsdp_wrap`
The problem:
Dynamo (Actually aot_autograd) trips up with FSDP becuase it must
wrap all input tensors in FakeTensor wrappers, and it only knows
to wrap graph inputs or named_(parameters, buffers). FSDP's
pre_forward hook sets views (which are not nn.param) into the flatparam
as attrs on the module with the same name as the original param, but
they will not show up in named_parameters.
- in use_orig_params mode, FSDP still de-registers
params during pre-forward hook, then re-registers them
post-forward
- during forward (between the hooks), the params are setattr'd
on the module as regular view tensors, not nn.Parameters
- note: use_orig_params is the recommended way to use FSDP,
and use_orig_params=False is being deprecated. So i only consider
use_orig_params=True for this enablement
The solution:
- adding them to named_buffers is not possible because it interferes
with how FSDP's `_apply` works
- since they are not actual nn.parameters, register_parameter will
complain about registering them
- simply seting `module._parameters[name] = view` seems to be a viable
workaround, despite being hacky, and FSDP code does modify _parameters
directly already.
Note: Manual checkpointing still isn't working with FSDP+dynamo,
so that will have to be addressed in a follow up.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88781
Approved by: https://github.com/ezyang, https://github.com/awgu
Util for convenient local benchmarking/debugging of distributed models. Not to be confused with the 'real' distributed benchmark script we use for torchbench experiments on slurm. Tries to be simple/hackable and let you use different combinations of DDP/FSDP with models and dynamo backends.
Example usage
`python benchmarks/dynamo/distributed.py --toy_model --dynamo inductor --ddp`
`--dynamo` flag accepts normal dynamo backends (plus 'print' which literally prints graphs to screen)
`--torchbench_model <model_name>` works in place of `--toy_model`
`--fsdp` is WIP
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87419
Approved by: https://github.com/jansel
{kind=link}
{kind=link}
{kind=link}
{kind=link}