Summary:
- Add a "BUILD_JNI" option that enables building PyTorch JNI bindings and
fbjni. This is off by default because it adds a dependency on jni.h.
- Update to the latest fbjni so we can inhibit building its tests,
because they depend on gtest.
- Set JAVA_HOME and BUILD_JNI in Linux binary build configurations if we
can find jni.h in Docker.
Test Plan:
- Built on dev server.
- Verified that libpytorch_jni links after libtorch when both are built
in a parallel build.
Differential Revision: D18536828
fbshipit-source-id: 19cb3be8298d3619352d02bb9446ab802c27ec66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29861
Follow https://github.com/pytorch/pytorch/issues/6570 to run ./run_host_tests.sh for Mac Build, we saw error below:
```error: cannot initialize a parameter of type 'const facebook::jni::JPrimitiveArray<_jlongArray *>::T *' (aka 'const long *') with an rvalue of type
'std::__1::vector<long long, std::__1::allocator<long long> >::value_type *' (aka 'long long *')
jTensorShape->setRegion(0, tensorShapeVec.size(), tensorShapeVec.data());```
ghstack-source-id: 93961091
Test Plan: Run ./run_host_tests.sh and verify build succeed.
Reviewed By: dreiss
Differential Revision: D18519087
fbshipit-source-id: 869be12c82e6e0f64c878911dc12459defebf40b
Summary:
The issue with previous build was that after phabricators lint error about double quotes I changed:
`$GRADLE_PATH $GRADLE_PARAMS` -> `"$GRADLE_PATH" "$GRADLE_PARAMS"`
which ended in error:
```
Nov 13 17:16:38 + /opt/gradle/gradle-4.10.3/bin/gradle '-p android assembleRelease --debug --stacktrace --offline'
Nov 13 17:16:40 Starting a Gradle Daemon (subsequent builds will be faster)
Nov 13 17:16:41
Nov 13 17:16:41 FAILURE: Build failed with an exception.
Nov 13 17:16:41
Nov 13 17:16:41 * What went wrong:
Nov 13 17:16:41 The specified project directory '/var/lib/jenkins/workspace/ android assembleRelease --debug --stacktrace --offline' does not exist.
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29738
Differential Revision: D18486605
Pulled By: IvanKobzarev
fbshipit-source-id: 2b06600feb9db35b49e097a6d44422f50e46bb20
Summary:
https://github.com/pytorch/pytorch/issues/29159
Introducing GRADLE_OFFLINE environment variable to use '--offline' gradle argument which will only use local gradle cache without network.
As it is cache and has some expiration logic - before every start of gradle 'touch' files to update last access time.
Deploying new docker images that includes prefetching to gradle cache all android dependencies, commit with update of docker images: df07dd5681
Reenable android gradle jobs on CI (revert of 54e6a7eede)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29262
Differential Revision: D18455666
Pulled By: IvanKobzarev
fbshipit-source-id: 8fb0b54fd94e13b3144af2e345c6b00b258dcc0f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29617
As for internal build, we will use mobile interpreter instead of full jit, so we will need to separate the existing pytorch_jni.cpp into pytorch_jni_jit.cpp and pytorch_jni_common.cpp. pytorch_jni_common.cpp will be used both from pytorch_jni_jit.cpp(open_source) and future pytorch_jni_lite.cpp(internal).
ghstack-source-id: 93691214
Test Plan: buck build xplat/caffe2/android:pytorch
Reviewed By: dreiss
Differential Revision: D18387579
fbshipit-source-id: 26ab845c58a0959bc0fdf1a2b9a99f6ad6f2fc9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29412
Originally, this was going to be Android-only, so the name wasn't too
important. But now that we're planning to distribute it with libtorch,
we should give it a more distinctive name.
Test Plan:
Ran tests according to
https://github.com/pytorch/pytorch/issues/6570#issuecomment-548537834
Reviewed By: IvanKobzarev
Differential Revision: D18405207
fbshipit-source-id: 0e6651cb34fb576438f24b8a9369e10adf9fecf9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29455
- Don't need to load native library.
- Shape is now private.
Test Plan: Ran test.
Reviewed By: IvanKobzarev
Differential Revision: D18405213
fbshipit-source-id: e1d1abcf2122332317693ce391e840904b69e135
Summary:
Reason:
To have one-step build for test android application based on the current code state that is ready for profiling with simpleperf, systrace etc. to profile performance inside the application.
## Parameters to control debug symbols stripping
Introducing /CMakeLists parameter `ANDROID_DEBUG_SYMBOLS` to be able not to strip symbols for pytorch (not add linker flag `-s`)
which is checked in `scripts/build_android.sh`
On gradle side stripping happens by default, and to prevent it we have to specify
```
android {
packagingOptions {
doNotStrip "**/*.so"
}
}
```
which is now controlled by new gradle property `nativeLibsDoNotStrip `
## Test_App
`android/test_app` - android app with one MainActivity that does inference in cycle
`android/build_test_app.sh` - script to build libtorch with debug symbols for specified android abis and adds `NDK_DEBUG=1` and `-PnativeLibsDoNotStrip=true` to keep all debug symbols for profiling.
Script assembles all debug flavors:
```
└─ $ find . -type f -name *apk
./test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
./test_app/app/build/outputs/apk/resnet/debug/test_app-resnet-debug.apk
```
## Different build configurations
Module for inference can be set in `android/test_app/app/build.gradle` as a BuildConfig parameters:
```
productFlavors {
mobilenetQuant {
dimension "model"
applicationIdSuffix ".mobilenetQuant"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_MOBILENET_QUANT'))
addManifestPlaceholders([APP_NAME: "PyMobileNetQuant"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-mobilenet\"")
}
resnet {
dimension "model"
applicationIdSuffix ".resnet"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_RESNET18'))
addManifestPlaceholders([APP_NAME: "PyResnet"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-resnet\"")
}
```
In that case we can setup several apps on the same device for comparison, to separate packages `applicationIdSuffix`: 'org.pytorch.testapp.mobilenetQuant' and different application names and logcat tags as `manifestPlaceholder` and another BuildConfig parameter:
```
─ $ adb shell pm list packages | grep pytorch
package:org.pytorch.testapp.mobilenetQuant
package:org.pytorch.testapp.resnet
```
In future we can add another BuildConfig params e.g. single/multi threads and other configuration for profiling.
At the moment 2 flavors - for resnet18 and for mobilenetQuantized
which can be installed on connected device:
```
cd android
```
```
gradle test_app:installMobilenetQuantDebug
```
```
gradle test_app:installResnetDebug
```
## Testing:
```
cd android
sh build_test_app.sh
adb install -r test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
```
```
cd $ANDROID_NDK
python simpleperf/run_simpleperf_on_device.py record --app org.pytorch.testapp.mobilenetQuant -g --duration 10 -o /data/local/tmp/perf.data
adb pull /data/local/tmp/perf.data
python simpleperf/report_html.py
```
Simpleperf report has all symbols:
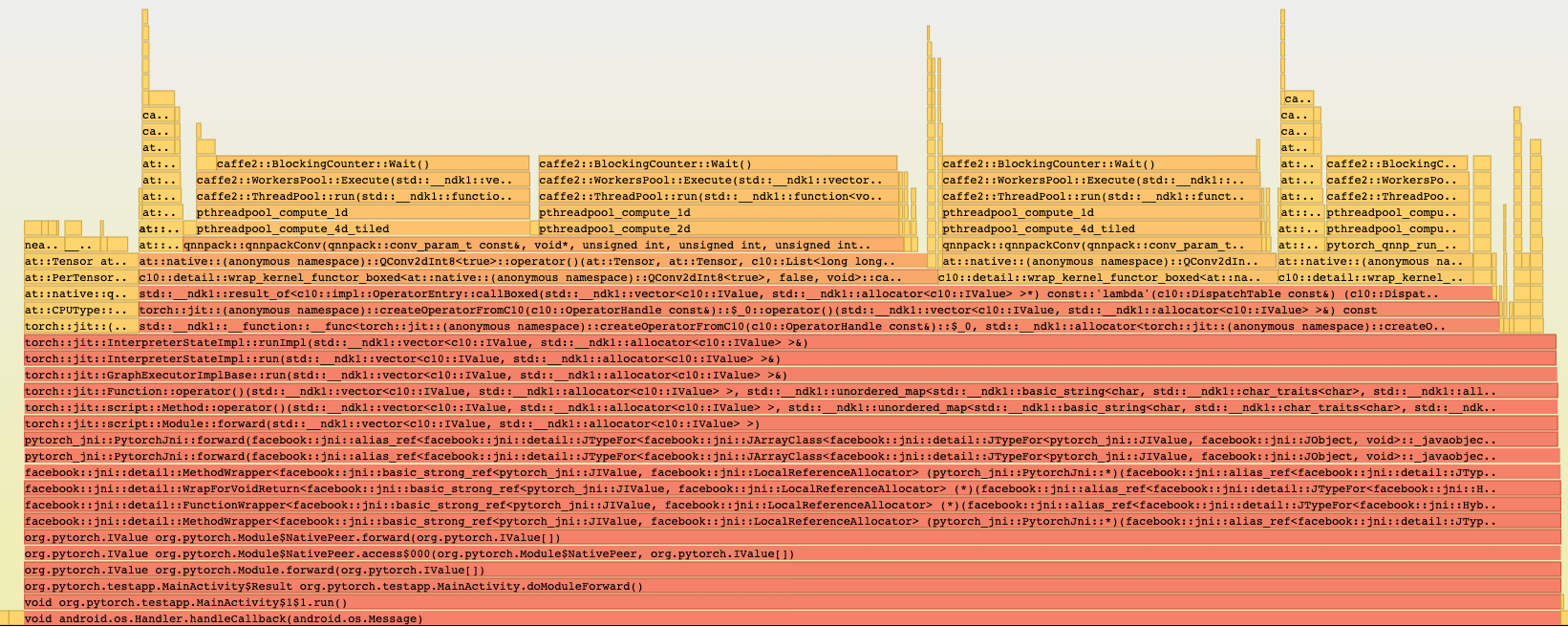
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28406
Differential Revision: D18386622
Pulled By: IvanKobzarev
fbshipit-source-id: 3a751192bbc4bc3c6d7f126b0b55086b4d586e7a
Summary:
Copy of android.md from the site + information about Nightly builds
It's a bit of duplication with separate repo pytorch.github.io , but I think more people will find it and we can faster iterate on it and keep in sync with the code.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28533
Reviewed By: dreiss
Differential Revision: D18153638
Pulled By: IvanKobzarev
fbshipit-source-id: 288ef3f153d8e239795a85e3b8992e99f072f3b7
Summary:
The central fbjni repository is now public, so point to it and
take the latest version, which includes support for host builds
and some condensed syntax.
Test Plan: CI
Differential Revision: D18217840
fbshipit-source-id: 454e3e081f7e3155704fed692506251c4018b2a1
Summary:
The Java and Python code were updated, but the test currently fails
because the model was not regenerated.
Test Plan: Ran test.
Reviewed By: xcheng16
Differential Revision: D18217841
fbshipit-source-id: 002eb2d3ed0eaa14b3d7b087b621a6970acf1378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27664
When ANDROID_ABI is not set, find libtorch headers and libraries from
the LIBTORCH_HOME build variable (which must be set by hand), place
output under a "host" directory, and use dynamic linking instead of
static.
This doesn't actually work without some local changes to fbjni, but I
want to get the changes landed to avoid unnecessary merge conflicts.
Test Plan: Imported from OSS
Differential Revision: D18210315
Pulled By: dreiss
fbshipit-source-id: 685a62de3c2a0a52bec7fd6fb95113058456bac8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27663
CMake sets CMAKE_BINARY_DIR and creates it automatically. Using this
allows us to use the -B command-line flag to CMake to specify an
alternate output directory.
Test Plan: Imported from OSS
Differential Revision: D18210316
Pulled By: dreiss
fbshipit-source-id: ba2f6bd4b881ddd00de73fe9c33d82645ad5495d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27662
This adds a new gradle subproject at pytorch_android/host and tweaks
the top-level build.gradle to only run some Android bits on the other
projects.
Referencing Java sources from inside the host directory feels a bit
hacky, but getting host and Android Gradle builds to coexist in the same
directory hit several roadblocks. We can try a bigger refactor to
separate the Android-specific and non-Android-specific parts of the
code, but that seems overkill at this point for 4 Java files.
This doesn't actually run without some local changes to fbjni, but I
want to get the files landed to avoid unnecessary merge conflicts.
Test Plan: Imported from OSS
Differential Revision: D18210317
Pulled By: dreiss
fbshipit-source-id: dafb54dde06a5a9a48fc7b7065d9359c5c480795
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28399
This is also to address issue #26764
Turns out it's incorrect to wrap the entire forward() call with
NonVariableTypeMode guard as some JIT passes has is_variable() check and
can be triggered within forward() call, e.g.:
jit/passes/constant_propagation.cpp
Since now we are toggling NonVariableTypeMode per method/op call, we can
remove the guard around forward() now.
Test Plan: - With stacked PRs, verified it can load and run previously failed models.
Differential Revision: D18055850
Pulled By: ljk53
fbshipit-source-id: 3074d0ed3c6e05dbfceef6959874e5916aea316c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26767
Now that we have tagged ivalues, we can accurately recover the type with
`ivalue.type()`. This reomoves the other half-implemented pathways that
were created because we didn't have tags.
Test Plan: Imported from OSS
Differential Revision: D17561191
Pulled By: zdevito
fbshipit-source-id: 26aaa134099e75659a230d8a5a34a86dc39a3c5c
Summary:
All of the test cases move into a base class that is extended by the
intrumentation test and a new "HostTests" class that can be run in
normal Java. (Some changes to the build script and dependencies are
required before the host test can actually run.)
ghstack-source-id: fe1165b513241b92c5f4a81447f5e184b3bfc75e
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27453
Test Plan: Imported from OSS
Reviewed By: IvanKobzarev
Differential Revision: D17800410
fbshipit-source-id: 1184f0caebdfa219f4ccd1464c67826ac0220181
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27359
Adding methods to TensorImageUtils:
```
bitmapToFloatBuffer(..., FloatBuffer outBuffer, int outBufferOffset)
imageYUV420CenterCropToFloat32Tensor(..., FloatBuffer outBuffer, int outBufferOffset)
```
To be able to
- reuse FloatBuffer for inference
- to create batch-Tensor (contains several images/bitmaps)
As we reuse FloatBuffer for example demo app - image classification,
profiler shows less memory allocations (before that for every run we created new input tensor with newly allocated FloatBuffer) and ~-20ms on my PixelXL
Known open question:
At the moment every tensor element is written separatly calling `outBuffer.put()`, which is native call crossing lang boundaries
As an alternative - to allocation `float[]` on java side and fill it and put it in `outBuffer` with one call, reducing native calls, but increasing memory allocation on java side.
Tested locally just eyeballing durations - have not noticed big difference - decided to go with less memory allocations.
Will be good to merge into 1.3.0, but if not - demo app can use snapshot dependencies with this change.
PR with integration to demo app:
https://github.com/pytorch/android-demo-app/pull/6
Test Plan: Imported from OSS
Differential Revision: D17758621
Pulled By: IvanKobzarev
fbshipit-source-id: b4f1a068789279002d7ecc0bc680111f781bf980
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27381
Changing android nightly builds from master to version 1.4.0-SNAPSHOT, as we also have 1.3.0-SNAPSHOT from the branch v1.3.0
Test Plan: Imported from OSS
Differential Revision: D17773620
Pulled By: IvanKobzarev
fbshipit-source-id: c39a1dbf5e06f79c25367c3bc602cc8ce42cd939
Summary:
1. scripts/build_android_libtorch_and_pytorch_android.sh
- Builds libtorch for android_abis (by default for all 4: x86, x86_64, armeabi-v7a, arm-v8a) but cab be specified only custom list as a first parameter e.g. "x86"
- Creates symbolic links inside android/pytorch_android to results of the previous builds:
`pytorch_android/src/main/jniLibs/${abi}` -> `build_android/install/lib`
`pytorch_android/src/main/cpp/libtorch_include/${abi}` -> `build_android/install/include`
- Runs gradle assembleRelease to build aar files
proxy can be specified inside (for devservers)
2. android/run_tests.sh
Running pytorch_android tests, contains instruction how to setup and run android emulator in headless and noaudio mode to run it on devserver
proxy can be specified inside (for devservers)
#Test plan
Scenario to build x86 libtorch and android aars with it and run tests:
```
cd pytorch
sh scripts/build_android_libtorch_and_pytorch_android.sh x86
sh android/run_tests.sh
```
Tested on my devserver - build works, tests passed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26833
Differential Revision: D17673972
Pulled By: IvanKobzarev
fbshipit-source-id: 8cb7c3d131781854589de6428a7557c1ba7471e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26995
Fix current setup, exclude fbjni - we can not use independently pytorch_android:package, for example for testing `gradle pytorch_android:cAT`
But for publishing it works as pytorch_android has dep on fbjni that will be also published
For other cases - we have 2 fbjni.so - one from native build (CMakeLists.txt does add_subdirectory(fbjni_dir)), and from dependency ':fbjni'
We need both of them as ':fbjni' also contains java classes
As a fix: keep excluding for publishing tasks (bintrayUpload, uploadArchives), but else - pickFirst (as we have 2 sources of fbjni.so)
# Testing
gradle cAT works, fbjni.so included
gradle bintrayUpload (dryRun==true) - no fbjni.so
Test Plan: Imported from OSS
Differential Revision: D17637775
Pulled By: IvanKobzarev
fbshipit-source-id: edda56ba555678272249fe7018c1f3a8e179947c
Summary:
- Normalization mean and std specified as parameters instead of hardcode
- imageYUV420CenterCropToFloat32Tensor before this change worked only with square tensors (width==height) - added generalization to support width != height with all rotations and scalings
- javadocs
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26690
Differential Revision: D17556006
Pulled By: IvanKobzarev
fbshipit-source-id: 63f3321ea2e6b46ba5c34f9e92c48d116f7dc5ce
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26565
For OSS mobile build we should keep QNNPACK off and PYTORCH_QNNPACK on
as we don't include caffe2 ops that use third_party/QNNPACK.
Update android/iOS build script to include new libraries accordingly.
Test Plan: - CI build
Differential Revision: D17508918
Pulled By: ljk53
fbshipit-source-id: 0483d45646d4d503b4e5c1d483e4df72cffc6c68
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26525
Create a util function to avoid boilerplate code as we are adding more
libraries.
Test Plan: - build CI;
Differential Revision: D17495394
Pulled By: ljk53
fbshipit-source-id: 9e19f96ede4867bdff5157424fa68b71e6cff8bf
Summary:
USE_STATIC_DISPATCH needs to be exposed as we don't hide header files
containing it for iOS (yet). Otherwise it's error-prone to request all
external projects to set the macro correctly on their own.
Also remove redundant USE_STATIC_DISPATCH definition from other places.
Test Plan:
- build android gradle to confirm linker can still strip out dead code;
- integrate with demo app to confirm inference can run without problem;
Differential Revision: D17484260
Pulled By: ljk53
fbshipit-source-id: 653f597acb2583761b723eff8026d77518007533
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26477
- At inference time we need turn off autograd mode and turn on no-variable
mode since we strip out these modules for inference-only mobile build.
- Both flags are stored in thread-local variables so we cannot simply
set them to false glboally.
- Add "autograd/grad_mode.h" header to all-in-one header 'torch/script.h'
to reduce friction for iOS engs who might need do this manually in their
project.
P.S. I tried to hide AutoNonVariableTypeMode in codegen but figured it's not
very trivial (e.g. there are manually written part not covered by codegen).
Might try it again later.
Test Plan: - Integrate with Android demo app to confirm inference runs correctly.
Differential Revision: D17484259
Pulled By: ljk53
fbshipit-source-id: 06887c8b527124aa0cc1530e8e14bb2361acef31
Summary:
At the moment it includes https://github.com/pytorch/pytorch/pull/26219 changes. That PR is landing at the moment, afterwards this PR will contain only javadocs.
Applied all dreiss comments from previous version.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26149
Differential Revision: D17490720
Pulled By: IvanKobzarev
fbshipit-source-id: f340dee660d5ffe40c96b43af9312c09f85a000b
Summary:
fbjni is used during linking `libpytorch.so` and is specified in `pytorch_android/CMakeLists.txt` and as a result its included as separate `libfbjni.so` and is included to `pytorch_android.aar`
We also have java part of fbjni and its connected to pytorch_android as gradle dependency which contains `libfbjni.so`
As a result when we specify gradle dep `'org.pytorch:pytorch_android'` (it has libjni.so) and it has transitive dep `'org.pytorch:pytorch_android_fbjni'` that has `libfbjni.so` and we will have gradle ambiguity error about this
Fix - excluding libfbjni.so from pytorch_android.aar packaging, using `libfbjni.so` from gradle dep `'org.pytorch:pytorch_android_fbjni'`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26382
Differential Revision: D17468723
Pulled By: IvanKobzarev
fbshipit-source-id: fcad648cce283b0ee7e8b2bab0041a2e079002c6
Summary:
After offline discussion with dzhulgakov :
- In future we will introduce creation of byte signed and byte unsigned dtype tensors, but java has only signed byte - we will have to add some separation for it in method names ( java types and tensor types can not be clearly mapped) => Returning type in method names
- fixes in error messages
- non-static method Tensor.numel()
- Change Tensor toString() to be more consistent with python
Update on Sep 16:
Type renaming on java side to uint8, int8, int32, float32, int64, float64
```
public abstract class Tensor {
public static final int DTYPE_UINT8 = 1;
public static final int DTYPE_INT8 = 2;
public static final int DTYPE_INT32 = 3;
public static final int DTYPE_FLOAT32 = 4;
public static final int DTYPE_INT64 = 5;
public static final int DTYPE_FLOAT64 = 6;
```
```
public static Tensor newUInt8Tensor(long[] shape, byte[] data)
public static Tensor newInt8Tensor(long[] shape, byte[] data)
public static Tensor newInt32Tensor(long[] shape, int[] data)
public static Tensor newFloat32Tensor(long[] shape, float[] data)
public static Tensor newInt64Tensor(long[] shape, long[] data)
public static Tensor newFloat64Tensor(long[] shape, double[] data)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26219
Differential Revision: D17406467
Pulled By: IvanKobzarev
fbshipit-source-id: a0d7d44dc8ce8a562da1a18bd873db762975b184
Summary:
Applying dzhulgakov review comments
org.pytorch.Tensor:
- dims renamed to shape
- typeCode to dtype
- numElements to numel
newFloatTensor, newIntTensor... to newTensor(...)
Add support of dtype=long, double
Resorted in code byte,int,float,long,double
For if conditions order float,int,byte,long,double as I expect that float and int branches will be used more often
Tensor.toString() does not have data, only numel (data buffer capacity)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26183
Differential Revision: D17374332
Pulled By: IvanKobzarev
fbshipit-source-id: ee93977d9c43c400b6c054b6286080321ccb81bc
Summary:
The main part is to switch at::Tensor creation from usage of `torch::empty(torch::IntArrayRef(...))->ShareExternalPointer(...) to torch::from_blob(...)`
Removed explicit set of `device CPU` as `at::TensorOptions` by default `device CPU`
And renaming of local variables removing `input` prefix to make them shorter
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25973
Differential Revision: D17356837
Pulled By: IvanKobzarev
fbshipit-source-id: 679e099b8aebd787dbf8ed422dae07a81243e18f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25984
Link static libtorch libraries into pytorch.so (API library for android)
with "-Wl,--gc-sections" flag to remove unused symbols in libtorch.
Test Plan:
- full gradle CI with stacked PR;
- will check final artifacts.tgz size change;
Differential Revision: D17312859
Pulled By: ljk53
fbshipit-source-id: 99584d15922867a7b3c3d661ba238a6f99f43db5
Summary:
Gradle tasks for publishing to bintray and jcenter, mavencentral; snapshot buidls go to oss.sonatype.org
Those gradle changes adds tasks:
bintrayUpload - publishing on bintray, in 'facebook' org
uploadArchives - uploading to maven repos
Gradle tasks are copied from facebook open sourced libraries like https://github.com/facebook/litho, https://github.com/facebookincubator/spectrum
To do the publishing we need to provide somehow (e.g. in ~/.gradle/gradle.properties)
```
signing.keyId=
signing.password=
signing.secretKeyRingFile=
bintrayUsername=
bintrayApiKey=
bintrayGpgPassword=
SONATYPE_NEXUS_USERNAME=
SONATYPE_NEXUS_PASSWORD=
```
android/libs/fbjni is submodule, to be able to add publishing tasks to it (it needs to be published as separate maven dependency) - I created `android/libs/fbjni_local` that has only `build.gradle` with release tasks.
pytorch_android dependency for ':fbjni' changed from implementation -> api as implementation treated as 'private' dependency which is translated to scope=runtime in maven pom file, api works as 'compile'
Testing:
it's already published on bintray with version 0.0.4 and can be used in gradle files as
```
repositories {
maven {
url "https://dl.bintray.com/facebook/maven"
}
}
dependencies {
implementation 'com.facebook:pytorch_android:0.0.4'
implementation 'com.facebook:pytorch_android_torchvision:0.0.4'
}
```
It was published in com.facebook group
I requested sync to jcenter from bintray, that usually takes 2-3 days
Versioning added version suffixes to aar output files and circleCI jobs for android start failing as they expected just pytorch_android.aar pytorch_android_torchvision.aar, without any version
To avoid it - I changed circleCI android jobs to zip *.aar files and publish as single artifact with name artifacts.zip, I will add kostmo to check this part, if circleCI jobs finish ok - everything works :)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25351
Reviewed By: kostmo
Differential Revision: D17135886
Pulled By: IvanKobzarev
fbshipit-source-id: 64eebac670bbccaaafa1b04eeab15760dd5ecdf9
Summary:
Introducing circleCI jobs for pytorch_android gradle builds, the ultimate goal of it at the moment - to run:
```
gradle assembleRelease -p ~/workspace/android/pytorch_android assembleRelease
```
To assemble android gradle build (aar) we need to have results of libtorch-android shared library with headers for 4 android abis, so pytorch_android_gradle_build requires 4 jobs
```
- pytorch_android_gradle_build:
requires:
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_x86_32_build
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_x86_64_build
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_arm_v7a_build
- pytorch_linux_xenial_py3_clang5_android_ndk_r19c_arm_v8a_build
```
All jobs use the same base docker_image, differentiate them by committing docker images with different android_abi -suffixes (like it is now for xla and namedtensor): (it's in `&pytorch_linux_build_defaults`)
```
if [[ ${BUILD_ENVIRONMENT} == *"namedtensor"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-namedtensor
elif [[ ${BUILD_ENVIRONMENT} == *"xla"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-xla
elif [[ ${BUILD_ENVIRONMENT} == *"-x86"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-x86
elif [[ ${BUILD_ENVIRONMENT} == *"-arm-v7a"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-arm-v7a
elif [[ ${BUILD_ENVIRONMENT} == *"-arm-v8a"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-arm-v8a
elif [[ ${BUILD_ENVIRONMENT} == *"-x86_64"* ]]; then
export COMMIT_DOCKER_IMAGE=$output_image-android-x86_64
else
export COMMIT_DOCKER_IMAGE=$output_image
fi
```
pytorch_android_gradle_build job copies headers and libtorch.so, libc10.so results from libtorch android docker images, to workspace first and to android_abi=x86 docker image afterwards, to run there final gradle build calling `.circleci/scripts/build_android_gradle.sh`
For PR jobs we have only `pytorch_linux_xenial_py3_clang5_android_ndk_r19c_x86_32_build` libtorch android build => it will have separate gradle build `pytorch_android_gradle_build-x86_32` that does not do docker copying,
it calls the same `.circleci/scripts/build_android_gradle.sh` which has only-x86_32 logic by condition on BUILD_ENVIRONMENT:
`[[ "${BUILD_ENVIRONMENT}" == *-gradle-build-only-x86_32* ]]`
And has filtering to un only for PR as for other runs we will have the full build. Filtering checks `-z "${CIRCLE_PULL_REQUEST:-}"`
```
- run:
name: filter_run_only_on_pr
no_output_timeout: "5m"
command: |
echo "CIRCLE_PULL_REQUEST: ${CIRCLE_PULL_REQUEST:-}"
if [ -z "${CIRCLE_PULL_REQUEST:-}" ]; then
circleci step halt
fi
```
Updating docker images to the version with gradle, android_sdk, openjdk - jenkins job with them https://ci.pytorch.org/jenkins/job/pytorch-docker-master/339/
pytorch_android_gradle_build successful run: https://circleci.com/gh/pytorch/pytorch/2604797#artifacts/containers/0
pytorch_android_gradle_build-x86_32 successful run: https://circleci.com/gh/pytorch/pytorch/2608945#artifacts/containers/0
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25286
Reviewed By: kostmo
Differential Revision: D17115861
Pulled By: IvanKobzarev
fbshipit-source-id: bc88fd38b38ed0d0170d719fffa375772bdea142
{kind=link}
{kind=link}
{kind=link}