Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32567
As a first change to support proguard.
even if these methods could be not called from java, on jni level we register them and this registration will fail if methods are stripped.
Adding DoNotStrip to all native methods that are registered in OSS.
After integration of consumerProguardFiles in fbjni that prevents stripping by proguard DoNotStrip it will fix errors with proguard on.
Test Plan: Imported from OSS
Differential Revision: D19624684
Pulled By: IvanKobzarev
fbshipit-source-id: cd7d9153e9f8faf31c99583cede4adbf06bab507
Summary:
Without this, dlopen won't look in the proper directory for dependencies
(like libtorch and fbjni).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32247
Test Plan:
Build libpytorch_jni.dylib on Mac, replaced the one from the libtorch
nightly, and was able to run the Java demo.
Differential Revision: D19501498
Pulled By: dreiss
fbshipit-source-id: 13ffdff9622aa610f905d039f951ee9a3fdc6b23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31456
External request https://discuss.pytorch.org/t/jit-android-debugging-the-model/63950
By default torchscript print function goes to stdout. For android it is not seen in logcat by default.
This change propagates it to logcat.
Test Plan: Imported from OSS
Differential Revision: D19171405
Pulled By: IvanKobzarev
fbshipit-source-id: f9c88fa11d90bb386df9ed722ec9345fc6b25a34
Summary: I think this was wrong before?
Test Plan: Not sure.
Reviewed By: IvanKobzarev
Differential Revision: D19221358
fbshipit-source-id: 27e675cac15dde29e026305f4b4e6cc774e15767
Summary:
These were returning incorrect data before. Now we make a contiguous copy
before converting to Java. Exposing raw data to the user might be faster in
some cases, but it's not clear that it's worth the complexity and code size.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221361
fbshipit-source-id: 22ecdad252c8fd968f833a2be5897c5ae483700c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31584
These were returning incorrect data before.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221360
fbshipit-source-id: b3f01de086857027f8e952a1c739f60814a57acd
Summary: These are valid tensors.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221362
fbshipit-source-id: fa9af2fc539eb7381627b3d473241a89859ef2ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30501
**Motivation**:
In current state output of libtorch Module forward,runMethod is mem copied to java ByteBuffer, which is allocated, at least in some versions of android, on java heap. That could lead to intensive garbage collection.
**Change**:
Output java tensor becomes owner of output at::Tensor and holds it (as `pytorch_jni::TensorHybrid::tensor_` field) alive until java part is not destroyed by GC. For that org.pytorch.Tensor becomes 'Hybrid' class in fbjni naming and starts holding member field `HybridData mHybridData;`
If construction of it starts from java side - java constructors of subclasses (we need all the fields initialized, due to this `mHybridData` is not declared final, but works as final) call `this.mHybridData = super.initHybrid();` to initialize cpp part (`at::Tensor tensor_`).
If construction starts from cpp side - cpp side is initialiaed using provided at::Tensor with `makeCxxInstance(std::move(tensor))` and is passed to java method `org.pytorch.Tensor#nativeNewTensor` as parameter `HybridData hybridData`, which holds native pointer to cpp side.
In that case `initHybrid()` method is not called, but parallel set of ctors of subclasses are used, which stores `hybridData` in `mHybridData`.
Renaming:
`JTensor` -> `TensorHybrid`
Removed method:
`JTensor::newAtTensorFromJTensor(JTensor)` becomes trivial `TensorHybrid->cthis()->tensor()`
Test Plan: Imported from OSS
Differential Revision: D18893320
Pulled By: IvanKobzarev
fbshipit-source-id: df94775d2a010a1ad945b339101c89e2b79e0f83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30175
fbjni was opensourced and java part is published as 'com.facebook.fbjni:fbjni-java-only:0.0.3'
switching to it.
We still need submodule fbjni inside the repo (which is already pointing to https://github.com/facebookincubator/fbjni) for so linking.
**Packaging changes**:
before that `libfbjni.so` came from pytorch_android_fbjni dependency, as we also linked fbjni in `pytorch_android/CMakeLists.txt` - it was built in pytorch_android, but excluded for publishing. As we had 2 libfbjni.so there was a hack to exclude it for publishing and resolve duplication locally.
```
if (rootProject.isPublishing()) {
exclude '**/libfbjni.so'
} else {
pickFirst '**/libfbjni.so'
}
```
After this change fbjni.so will be packaged inside pytorch_android.aar artefact and we do not need this gradle logic.
I will update README in separate PR after landing previous PR to readme(https://github.com/pytorch/pytorch/pull/30128) to avoid conflicts
Test Plan: Imported from OSS
Differential Revision: D18982235
Pulled By: IvanKobzarev
fbshipit-source-id: 5097df2557858e623fa480625819a24a7e8ad840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30315
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
This is a reland of https://github.com/pytorch/pytorch/pull/29731 but
I've extracted all of the prep work into separate PRs which can be
landed before this one.
Some things of note:
* torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
* The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/libprotobuf.a(arena.cc.o) is referenced by DSO"
* A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly
* I had to torch_cpu/torch_cuda caffe2_interface_library so that they get whole-archived linked into torch when you statically link. And I had to do this in an *exported* fashion because torch needs to depend on torch_cpu_library. In the end I exported everything and removed the redefinition in the Caffe2Config.cmake. However, I am not too sure why the old code did it in this way in the first place; however, it doesn't seem to have broken anything to switch it this way.
* There's some uses of `__HIP_PLATFORM_HCC__` still in `torch_cpu` code, so I had to apply it to that library too (UGH). This manifests as a failer when trying to run the CUDA fuser. This doesn't really matter substantively right now because we still in-place HIPify, but it would be good to fix eventually. This was a bit difficult to debug because of an unrelated HIP bug, see https://github.com/ROCm-Developer-Tools/HIP/issues/1706Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18790941
Pulled By: ezyang
fbshipit-source-id: 01296f6089d3de5e8365251b490c51e694f2d6c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30428
Reported issue https://discuss.pytorch.org/t/incomprehensible-behaviour/61710
Steps to reproduce:
```
class WrapRPN(nn.Module):
def __init__(self):
super().__init__()
def forward(self, features):
# type: (Dict[str, Tensor]) -> int
return 0
```
```
#include <torch/script.h>
int main() {
torch::jit::script::Module module = torch::jit::load("dict_str_tensor.pt");
torch::Tensor tensor = torch::rand({2, 3});
at::IValue ivalue{tensor};
c10::impl::GenericDict dict{c10::StringType::get(),ivalue.type()};
dict.insert("key", ivalue);
module.forward({dict});
}
```
ValueType of `c10::impl::GenericDict` is from the first specified element as `ivalue.type()`
It fails on type check in` function_schema_inl.h` !value.type()->isSubtypeOf(argument.type())
as `DictType::isSubtypeOf` requires equal KeyType and ValueType, while `TensorType`s are different.
Fix:
Use c10::unshapedType for creating Generic List/Dict
Test Plan: Imported from OSS
Differential Revision: D18717189
Pulled By: IvanKobzarev
fbshipit-source-id: 1e352a9c776a7f7e69fd5b9ece558f1d1849ea57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30472
Add DoNotStrip to nativeNewTensor method.
ghstack-source-id: 94596624
Test Plan:
Triggered build on diff for automation_fbandroid_fallback_release.
buck install -r fb4a
Tested BI cloaking using pytext lite interpreter.
Obverse that logs are sent to scuba table:
{F223408345}
Reviewed By: linbinyu
Differential Revision: D18709087
fbshipit-source-id: 74fa7a0665640c294811a50913a60ef8d6b9b672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30390
Fix the crashes for c++ not able to find java class through Jni
ghstack-source-id: 94499644
Test Plan: buck install -r fb4a
Reviewed By: ljk53
Differential Revision: D18667992
fbshipit-source-id: aa1b19c6dae39d46440f4a3e691054f7f8b1d42e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30285
PR #30144 introduced custom build script to tailor build to specific
models. It requires a list of all potentially used ops at build time.
Some JIT optimization passes can transform the IR by replacing
operators, e.g. decompose pass can replace aten::addmm with aten::mm if
coefficients are 1s.
Disabling optimization pass can ensure that the list of ops we dump from
the model is the list of ops that are needed.
Test Plan: - rerun the test on PR #30144 to verify the raw list without aten::mm works.
Differential Revision: D18652777
Pulled By: ljk53
fbshipit-source-id: 084751cb9a9ee16d8df7e743e9e5782ffd8bc4e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30206
- --whole-archive isn't needed because we link libtorch as a dynamic
dependency, rather than static.
- --gc-sections isn't necessary because most (all?) of the code in our
JNI library is used (and we're not staticly linking libtorch).
Removing this one is useful because it's not supported by lld.
Test Plan:
Built on Linux. Library size was unchanged.
Upcoming diff enables Mac JNI build.
Differential Revision: D18653500
Pulled By: dreiss
fbshipit-source-id: 49ce46fb86a775186f803ada50445b4b2acb54a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29731
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
Some subtleties about the patch:
- There were a few functions that crossed CPU-CUDA boundary without API macros. I just added them, easy enough. An inverse situation was aten/src/THC/THCTensorRandom.cu where we weren't supposed to put API macros directly in a cpp file.
- DispatchStub wasn't getting all of its symbols related to static members on DispatchStub exported properly. I tried a few fixes but in the end I just moved everyone off using DispatchStub to dispatch CUDA/HIP (so they just use normal dispatch for those cases.) Additionally, there were some mistakes where people incorrectly were failing to actually import the declaration of the dispatch stub, so added includes for those cases.
- torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
- The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
- In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/l
ibprotobuf.a(arena.cc.o) is referenced by DSO"
- A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly. This situation also happens with custom C++ extensions.
- There's a ROCm compiler bug where extern "C" on functions is not respected. There's a little workaround to handle this.
- Because I was too lazy to check if HIPify was converting TORCH_CUDA_API into TORCH_HIP_API, I just made it so HIP build also triggers the TORCH_CUDA_API macro. Eventually, we should translate and keep the nature of TORCH_CUDA_API constant in all cases.
Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18632773
Pulled By: ezyang
fbshipit-source-id: ea717c81e0d7554ede1dc404108603455a81da82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30180
Just applying `clang-format -i` to not mix it with other changes
Test Plan: Imported from OSS
Differential Revision: D18627473
Pulled By: IvanKobzarev
fbshipit-source-id: ed341e356fea31b8515de29d5ea2ede07e8b66a2
Summary:
- Add a "BUILD_JNI" option that enables building PyTorch JNI bindings and
fbjni. This is off by default because it adds a dependency on jni.h.
- Update to the latest fbjni so we can inhibit building its tests,
because they depend on gtest.
- Set JAVA_HOME and BUILD_JNI in Linux binary build configurations if we
can find jni.h in Docker.
Test Plan:
- Built on dev server.
- Verified that libpytorch_jni links after libtorch when both are built
in a parallel build.
Differential Revision: D18536828
fbshipit-source-id: 19cb3be8298d3619352d02bb9446ab802c27ec66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29861
Follow https://github.com/pytorch/pytorch/issues/6570 to run ./run_host_tests.sh for Mac Build, we saw error below:
```error: cannot initialize a parameter of type 'const facebook::jni::JPrimitiveArray<_jlongArray *>::T *' (aka 'const long *') with an rvalue of type
'std::__1::vector<long long, std::__1::allocator<long long> >::value_type *' (aka 'long long *')
jTensorShape->setRegion(0, tensorShapeVec.size(), tensorShapeVec.data());```
ghstack-source-id: 93961091
Test Plan: Run ./run_host_tests.sh and verify build succeed.
Reviewed By: dreiss
Differential Revision: D18519087
fbshipit-source-id: 869be12c82e6e0f64c878911dc12459defebf40b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29617
As for internal build, we will use mobile interpreter instead of full jit, so we will need to separate the existing pytorch_jni.cpp into pytorch_jni_jit.cpp and pytorch_jni_common.cpp. pytorch_jni_common.cpp will be used both from pytorch_jni_jit.cpp(open_source) and future pytorch_jni_lite.cpp(internal).
ghstack-source-id: 93691214
Test Plan: buck build xplat/caffe2/android:pytorch
Reviewed By: dreiss
Differential Revision: D18387579
fbshipit-source-id: 26ab845c58a0959bc0fdf1a2b9a99f6ad6f2fc9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29412
Originally, this was going to be Android-only, so the name wasn't too
important. But now that we're planning to distribute it with libtorch,
we should give it a more distinctive name.
Test Plan:
Ran tests according to
https://github.com/pytorch/pytorch/issues/6570#issuecomment-548537834
Reviewed By: IvanKobzarev
Differential Revision: D18405207
fbshipit-source-id: 0e6651cb34fb576438f24b8a9369e10adf9fecf9
Summary:
Reason:
To have one-step build for test android application based on the current code state that is ready for profiling with simpleperf, systrace etc. to profile performance inside the application.
## Parameters to control debug symbols stripping
Introducing /CMakeLists parameter `ANDROID_DEBUG_SYMBOLS` to be able not to strip symbols for pytorch (not add linker flag `-s`)
which is checked in `scripts/build_android.sh`
On gradle side stripping happens by default, and to prevent it we have to specify
```
android {
packagingOptions {
doNotStrip "**/*.so"
}
}
```
which is now controlled by new gradle property `nativeLibsDoNotStrip `
## Test_App
`android/test_app` - android app with one MainActivity that does inference in cycle
`android/build_test_app.sh` - script to build libtorch with debug symbols for specified android abis and adds `NDK_DEBUG=1` and `-PnativeLibsDoNotStrip=true` to keep all debug symbols for profiling.
Script assembles all debug flavors:
```
└─ $ find . -type f -name *apk
./test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
./test_app/app/build/outputs/apk/resnet/debug/test_app-resnet-debug.apk
```
## Different build configurations
Module for inference can be set in `android/test_app/app/build.gradle` as a BuildConfig parameters:
```
productFlavors {
mobilenetQuant {
dimension "model"
applicationIdSuffix ".mobilenetQuant"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_MOBILENET_QUANT'))
addManifestPlaceholders([APP_NAME: "PyMobileNetQuant"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-mobilenet\"")
}
resnet {
dimension "model"
applicationIdSuffix ".resnet"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_RESNET18'))
addManifestPlaceholders([APP_NAME: "PyResnet"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-resnet\"")
}
```
In that case we can setup several apps on the same device for comparison, to separate packages `applicationIdSuffix`: 'org.pytorch.testapp.mobilenetQuant' and different application names and logcat tags as `manifestPlaceholder` and another BuildConfig parameter:
```
─ $ adb shell pm list packages | grep pytorch
package:org.pytorch.testapp.mobilenetQuant
package:org.pytorch.testapp.resnet
```
In future we can add another BuildConfig params e.g. single/multi threads and other configuration for profiling.
At the moment 2 flavors - for resnet18 and for mobilenetQuantized
which can be installed on connected device:
```
cd android
```
```
gradle test_app:installMobilenetQuantDebug
```
```
gradle test_app:installResnetDebug
```
## Testing:
```
cd android
sh build_test_app.sh
adb install -r test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
```
```
cd $ANDROID_NDK
python simpleperf/run_simpleperf_on_device.py record --app org.pytorch.testapp.mobilenetQuant -g --duration 10 -o /data/local/tmp/perf.data
adb pull /data/local/tmp/perf.data
python simpleperf/report_html.py
```
Simpleperf report has all symbols:
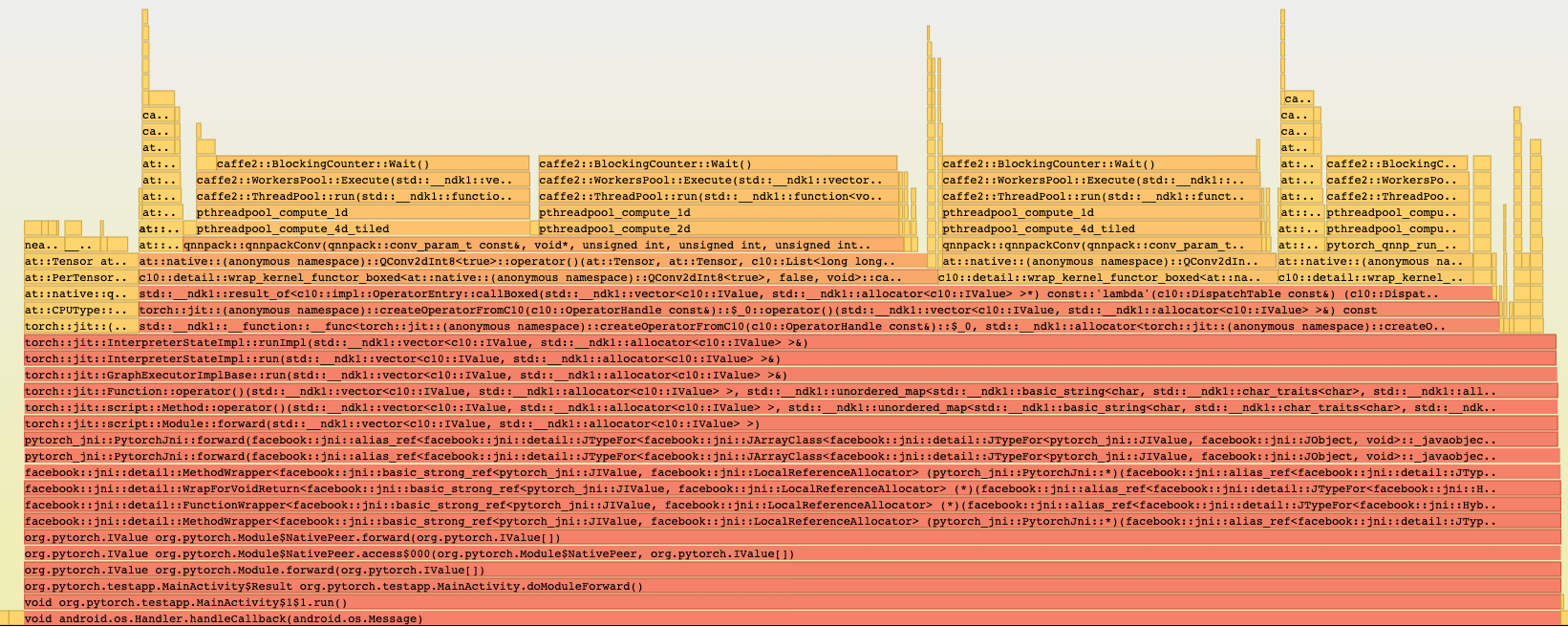
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28406
Differential Revision: D18386622
Pulled By: IvanKobzarev
fbshipit-source-id: 3a751192bbc4bc3c6d7f126b0b55086b4d586e7a
Summary:
The central fbjni repository is now public, so point to it and
take the latest version, which includes support for host builds
and some condensed syntax.
Test Plan: CI
Differential Revision: D18217840
fbshipit-source-id: 454e3e081f7e3155704fed692506251c4018b2a1
Summary:
The Java and Python code were updated, but the test currently fails
because the model was not regenerated.
Test Plan: Ran test.
Reviewed By: xcheng16
Differential Revision: D18217841
fbshipit-source-id: 002eb2d3ed0eaa14b3d7b087b621a6970acf1378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27664
When ANDROID_ABI is not set, find libtorch headers and libraries from
the LIBTORCH_HOME build variable (which must be set by hand), place
output under a "host" directory, and use dynamic linking instead of
static.
This doesn't actually work without some local changes to fbjni, but I
want to get the changes landed to avoid unnecessary merge conflicts.
Test Plan: Imported from OSS
Differential Revision: D18210315
Pulled By: dreiss
fbshipit-source-id: 685a62de3c2a0a52bec7fd6fb95113058456bac8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27663
CMake sets CMAKE_BINARY_DIR and creates it automatically. Using this
allows us to use the -B command-line flag to CMake to specify an
alternate output directory.
Test Plan: Imported from OSS
Differential Revision: D18210316
Pulled By: dreiss
fbshipit-source-id: ba2f6bd4b881ddd00de73fe9c33d82645ad5495d
{kind=link}
{kind=link}