mirror of
https://github.com/pytorch/pytorch.git
synced 2025-10-20 21:14:14 +08:00
Add fast path of qmean/qstd for quantized CPU (#70172)
Add fast path of qmean and qstd when computation is done in innermost dimensions for quantized CPU. The fast path supports inputs in contiguous memory format. For example: ```python X = torch.randn((2,3,4,5), dtype=torch.float) qX = torch.quantize_per_tensor(X, scale, zero_point, torch_type) # dim can be: -1, (-1, -2), (-1, -2, -3), (-1, -2, -3, -4), 3, (3, 2), (3, 2, 1), (3, 2, 1, 0) or None dim = -1 qY = torch.mean(qX, dim) # qY = torch.std(qX, dim) ``` **Performance test results** Test Env: - Intel® Xeon® CLX-8260 - 1 instance, 4 cores - Using Jemalloc Test method: Create 4d contiguous tensors as inputs, set `dim` to the innermost two dimensions `(-1, -2)`, then do the following tests - Quantize inputs and use the fast path - Quantize inputs and use the reference path - Use fp32 kernel (no quantization) Mean: exec time (us) vs. shape 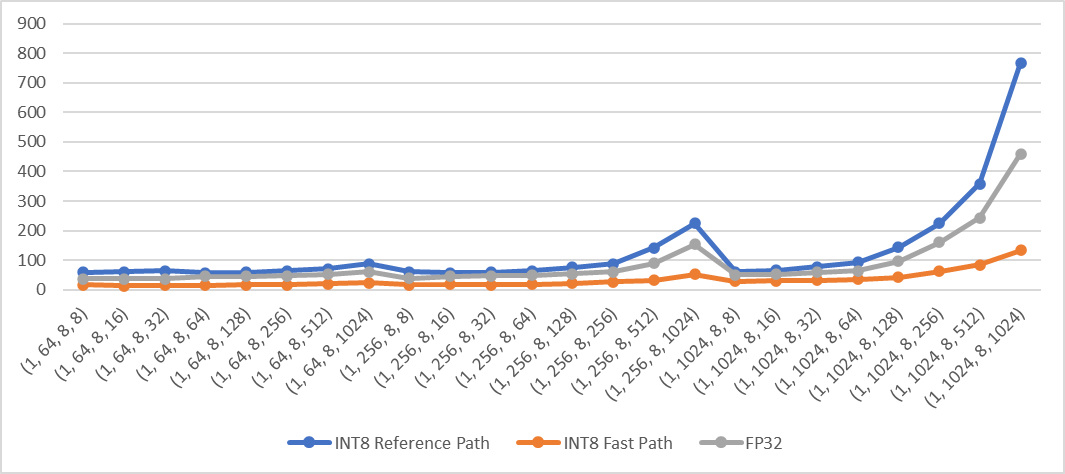 Std: exec time (us) vs. shape 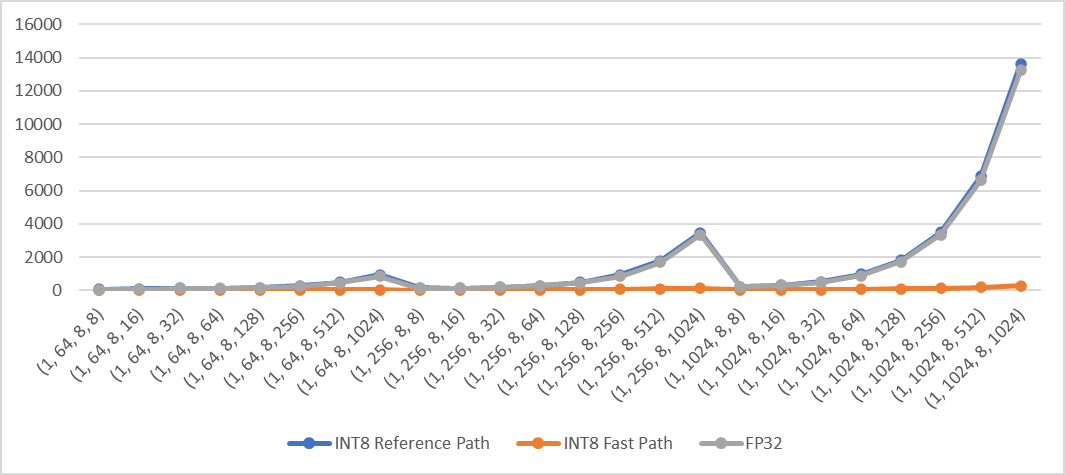 Pull Request resolved: https://github.com/pytorch/pytorch/pull/70172 Approved by: https://github.com/malfet
{kind=link}
{kind=link}
This commit is contained in:
committed by
 PyTorch MergeBot
PyTorch MergeBot
parent
ac5a94789f
commit
c1fa9fdff9
@ -4644,6 +4644,7 @@
|
||||
dispatch:
|
||||
CPU, CUDA: std
|
||||
MPS: std_mps
|
||||
QuantizedCPU: std_quantized_cpu
|
||||
|
||||
- func: std_mean(Tensor self, bool unbiased=True) -> (Tensor, Tensor)
|
||||
device_check: NoCheck # TensorIterator
|
||||
@ -4674,6 +4675,7 @@
|
||||
device_check: NoCheck # TensorIterator
|
||||
dispatch:
|
||||
CPU, CUDA: std_out
|
||||
QuantizedCPU: std_out_quantized_cpu
|
||||
|
||||
- func: std.names_dim(Tensor self, Dimname[1] dim, bool unbiased=True, bool keepdim=False) -> Tensor
|
||||
device_check: NoCheck # TensorIterator
|
||||
|
||||
@ -163,6 +163,20 @@ using qnormalize_fn = void (*)(
|
||||
double /* eps */,
|
||||
Tensor* /* Y */);
|
||||
|
||||
using qmean_inner_dim_fn = void (*)(
|
||||
const Tensor& /* X */,
|
||||
IntArrayRef /* dim */,
|
||||
bool /* keepdim */,
|
||||
c10::optional<ScalarType> /* opt_dtype */,
|
||||
Tensor& /* Y */);
|
||||
|
||||
using qstd_inner_dim_fn = void (*)(
|
||||
const Tensor& /* X */,
|
||||
OptionalIntArrayRef /* dim */,
|
||||
optional<int64_t> /* unbiased */,
|
||||
bool /* keepdim */,
|
||||
Tensor& /* Y */);
|
||||
|
||||
DECLARE_DISPATCH(qadaptive_avg_pool2d_fn, qadaptive_avg_pool2d_nhwc_stub);
|
||||
DECLARE_DISPATCH(qadaptive_avg_pool3d_fn, qadaptive_avg_pool3d_ndhwc_stub);
|
||||
DECLARE_DISPATCH(qadd_scalar_fn, qadd_scalar_relu_stub);
|
||||
@ -194,6 +208,8 @@ DECLARE_DISPATCH(qtanh_fn, qtanh_stub);
|
||||
DECLARE_DISPATCH(qthreshold_fn, qthreshold_stub);
|
||||
DECLARE_DISPATCH(qtopk_fn, qtopk_stub);
|
||||
DECLARE_DISPATCH(qupsample_bilinear2d_fn, qupsample_bilinear2d_nhwc_stub);
|
||||
DECLARE_DISPATCH(qmean_inner_dim_fn, qmean_inner_dim_stub);
|
||||
DECLARE_DISPATCH(qstd_inner_dim_fn, qstd_inner_dim_stub);
|
||||
|
||||
} // namespace native
|
||||
} // namespace at
|
||||
|
||||
@ -1,12 +1,42 @@
|
||||
#include <ATen/ATen.h>
|
||||
#include <ATen/NamedTensorUtils.h>
|
||||
#include <ATen/NativeFunctions.h>
|
||||
#include <ATen/native/quantized/cpu/QuantizedOps.h>
|
||||
#include <ATen/native/quantized/cpu/init_qnnpack.h>
|
||||
#include <ATen/native/quantized/cpu/QnnpackUtils.h>
|
||||
#include <caffe2/utils/threadpool/pthreadpool-cpp.h>
|
||||
|
||||
namespace at {
|
||||
namespace native {
|
||||
|
||||
DEFINE_DISPATCH(qmean_inner_dim_stub);
|
||||
DEFINE_DISPATCH(qstd_inner_dim_stub);
|
||||
|
||||
// If mean/std is taken in the innermost dims, the fast path can be used.
|
||||
inline bool is_innnermost_dim(
|
||||
const Tensor& self,
|
||||
IntArrayRef dim) {
|
||||
auto dims = dim.vec();
|
||||
auto ndim = self.dim();
|
||||
maybe_wrap_dims(dims, ndim);
|
||||
std::sort(dims.begin(), dims.end(), std::greater<int64_t>());
|
||||
bool is_innermost = dims.empty() || dims[0] == ndim - 1;
|
||||
for (size_t i = 1; i < dims.size(); ++i) {
|
||||
is_innermost = is_innermost && (dims[i] == dims[i-1] - 1);
|
||||
}
|
||||
return is_innermost;
|
||||
}
|
||||
|
||||
inline bool is_mean_inner_dim_fast_path(
|
||||
const Tensor& self,
|
||||
IntArrayRef dim,
|
||||
c10::optional<ScalarType> opt_dtype) {
|
||||
bool is_fast_path =
|
||||
is_innnermost_dim(self, dim) &&
|
||||
(!opt_dtype.has_value() || opt_dtype.value() == self.scalar_type());
|
||||
return is_fast_path;
|
||||
}
|
||||
|
||||
#ifdef USE_PYTORCH_QNNPACK
|
||||
Tensor qnnpack_mean(const Tensor& input, IntArrayRef dim, bool keepdim) {
|
||||
Tensor output;
|
||||
@ -96,6 +126,13 @@ Tensor& mean_out_quantized_cpu(
|
||||
return result;
|
||||
}
|
||||
#endif
|
||||
|
||||
// Take average in the innermost dimensions
|
||||
if (self.is_contiguous(c10::MemoryFormat::Contiguous) &&
|
||||
is_mean_inner_dim_fast_path(self, dim, opt_dtype)) {
|
||||
qmean_inner_dim_stub(self.device().type(), self, dim, keepdim, opt_dtype, result);
|
||||
return result;
|
||||
}
|
||||
auto self_dequantized = self.dequantize();
|
||||
auto result_dequantized = at::mean(self_dequantized, dim, keepdim, opt_dtype);
|
||||
result = at::quantize_per_tensor(
|
||||
@ -135,5 +172,79 @@ Tensor& mean_out_quantized_cpu(
|
||||
self, dimnames_to_positions(self, dim), keepdim, opt_dtype, result);
|
||||
}
|
||||
|
||||
// qstd
|
||||
inline bool is_std_inner_dim_fast_path(
|
||||
const Tensor& self,
|
||||
OptionalIntArrayRef dim,
|
||||
optional<int64_t> unbiased) {
|
||||
// Do not enter fast path if there are too few elements
|
||||
IntArrayRef dims = dim.has_value() ? dim.value() : IntArrayRef();
|
||||
auto all_dims = std::vector<int64_t>(self.dim());
|
||||
std::iota(all_dims.begin(), all_dims.end(), 0);
|
||||
dims = dims.empty() ? all_dims : dims;
|
||||
bool is_unbiased = unbiased.has_value() ? unbiased.value() : 0;
|
||||
int64_t num_ele = 1;
|
||||
for (auto d : dims) {
|
||||
num_ele *= self.size(d);
|
||||
}
|
||||
if (num_ele == 1 && is_unbiased) {
|
||||
return false;
|
||||
}
|
||||
return is_innnermost_dim(self, dims);
|
||||
}
|
||||
|
||||
Tensor& std_out_quantized_cpu(
|
||||
const Tensor& self,
|
||||
OptionalIntArrayRef dim,
|
||||
optional<int64_t> unbiased,
|
||||
bool keepdim,
|
||||
Tensor& result) {
|
||||
// Fast path
|
||||
if (self.is_contiguous(c10::MemoryFormat::Contiguous) &&
|
||||
is_std_inner_dim_fast_path(self, dim, unbiased)) {
|
||||
qstd_inner_dim_stub(self.device().type(), self, dim, unbiased, keepdim, result);
|
||||
return result;
|
||||
}
|
||||
|
||||
// Reference path
|
||||
auto self_dequantized = self.dequantize();
|
||||
auto result_dequantized = at::std(self_dequantized, dim, unbiased, keepdim);
|
||||
result = at::quantize_per_tensor(
|
||||
result_dequantized,
|
||||
self.q_scale(),
|
||||
self.q_zero_point(),
|
||||
self.scalar_type());
|
||||
return result;
|
||||
}
|
||||
|
||||
Tensor std_quantized_cpu(
|
||||
const Tensor& self,
|
||||
OptionalIntArrayRef dim,
|
||||
optional<int64_t> unbiased,
|
||||
bool keepdim) {
|
||||
Tensor result;
|
||||
std_out_quantized_cpu(self, dim, unbiased, keepdim, result);
|
||||
return result;
|
||||
}
|
||||
|
||||
Tensor std_quantized_cpu(
|
||||
const Tensor& self,
|
||||
DimnameList dim,
|
||||
optional<int64_t> unbiased,
|
||||
bool keepdim) {
|
||||
return std_quantized_cpu(
|
||||
self, dimnames_to_positions(self, dim), unbiased, keepdim);
|
||||
}
|
||||
|
||||
Tensor& std_out_quantized_cpu(
|
||||
Tensor& result,
|
||||
const Tensor& self,
|
||||
DimnameList dim,
|
||||
optional<int64_t> unbiased,
|
||||
bool keepdim) {
|
||||
return std_out_quantized_cpu(
|
||||
self, dimnames_to_positions(self, dim), unbiased, keepdim, result);
|
||||
}
|
||||
|
||||
} // namespace native
|
||||
} // namespace at
|
||||
|
||||
@ -2727,6 +2727,123 @@ void quantized_normalize_kernel(
|
||||
});
|
||||
}
|
||||
|
||||
void qmean_inner_dim_kernel(
|
||||
const Tensor& self,
|
||||
IntArrayRef dim,
|
||||
bool keepdim,
|
||||
c10::optional<ScalarType> opt_dtype,
|
||||
Tensor& result) {
|
||||
// 'opt_dtype' should be none or equal to that of input
|
||||
ScalarType dtype = self.scalar_type();
|
||||
auto in_dims = self.sizes().vec();
|
||||
auto out_dims = in_dims;
|
||||
size_t num_dims_to_squeeze = dim.empty() ? self.dim() : dim.size();
|
||||
int64_t M = 1; // Num of groups
|
||||
int64_t N = 1; // Num of elements to take average of in each group
|
||||
for (size_t i = 0; i < in_dims.size() - num_dims_to_squeeze; ++i) {
|
||||
M *= in_dims[i];
|
||||
}
|
||||
for (size_t i = 0; i < num_dims_to_squeeze; ++i) {
|
||||
auto idx = out_dims.size() - 1 - i;
|
||||
N *= out_dims[idx];
|
||||
out_dims[idx] = 1;
|
||||
}
|
||||
if (!keepdim) {
|
||||
out_dims.erase(out_dims.end() - num_dims_to_squeeze, out_dims.end());
|
||||
}
|
||||
result = at::_empty_affine_quantized(
|
||||
out_dims,
|
||||
at::device(kCPU).dtype(dtype).memory_format(self.suggest_memory_format()),
|
||||
self.q_scale(),
|
||||
self.q_zero_point(),
|
||||
c10::nullopt);
|
||||
|
||||
AT_DISPATCH_QINT_TYPES(self.scalar_type(), "quantized_mean_kernel_impl_cpu", [&]() {
|
||||
scalar_t* X_data = self.data_ptr<scalar_t>();
|
||||
scalar_t* Y_data = result.data_ptr<scalar_t>();
|
||||
|
||||
at::parallel_for(0, M, 1, [&](int64_t start, int64_t end) {
|
||||
for (const auto i : c10::irange(start, end)) {
|
||||
scalar_t* X_ptr = X_data + i * N;
|
||||
scalar_t* Y_ptr = Y_data + i;
|
||||
scalar_t::underlying* X_ptr_underlying = reinterpret_cast<scalar_t::underlying*>(X_ptr);
|
||||
scalar_t::underlying* Y_ptr_underlying = reinterpret_cast<scalar_t::underlying*>(Y_ptr);
|
||||
auto x_sum = hsum(X_ptr_underlying, N);
|
||||
float y_float = static_cast<float>(x_sum) / N;
|
||||
*Y_ptr_underlying = std::nearbyint(y_float);
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
void qstd_inner_dim_kernel(
|
||||
const Tensor& self,
|
||||
OptionalIntArrayRef dim,
|
||||
optional<int64_t> unbiased,
|
||||
bool keepdim,
|
||||
Tensor& result) {
|
||||
ScalarType dtype = self.scalar_type();
|
||||
auto in_dims = self.sizes().vec();
|
||||
auto out_dims = in_dims;
|
||||
size_t num_dims_to_squeeze = dim.has_value() && !dim.value().empty() ?
|
||||
dim.value().size() :
|
||||
self.dim();
|
||||
int64_t M = 1; // Num of groups
|
||||
int64_t N = 1; // Num of elements to take std of in each group
|
||||
for (size_t i = 0; i < in_dims.size() - num_dims_to_squeeze; ++i) {
|
||||
M *= in_dims[i];
|
||||
}
|
||||
for (size_t i = 0; i < num_dims_to_squeeze; ++i) {
|
||||
auto idx = out_dims.size() - 1 - i;
|
||||
N *= out_dims[idx];
|
||||
out_dims[idx] = 1;
|
||||
}
|
||||
if (!keepdim) {
|
||||
out_dims.erase(out_dims.end() - num_dims_to_squeeze, out_dims.end());
|
||||
}
|
||||
int64_t den = N; // Denominator when computing mean and deviation
|
||||
if (unbiased.has_value() && unbiased.value() == 1) {
|
||||
den -= 1;
|
||||
}
|
||||
auto x_scale = self.q_scale();
|
||||
auto x_zp = self.q_zero_point();
|
||||
result = at::_empty_affine_quantized(
|
||||
out_dims,
|
||||
at::device(kCPU).dtype(dtype).memory_format(self.suggest_memory_format()),
|
||||
x_scale,
|
||||
x_zp,
|
||||
c10::nullopt);
|
||||
|
||||
AT_DISPATCH_QINT_TYPES(self.scalar_type(), "quantized_std_kernel_impl_cpu", [&]() {
|
||||
scalar_t* X_data = self.data_ptr<scalar_t>();
|
||||
scalar_t* Y_data = result.data_ptr<scalar_t>();
|
||||
|
||||
at::parallel_for(0, M, 1, [&](int64_t start, int64_t end) {
|
||||
for (const auto i : c10::irange(start, end)) {
|
||||
scalar_t* X_ptr = X_data + i * N;
|
||||
scalar_t* Y_ptr = Y_data + i;
|
||||
scalar_t::underlying* X_ptr_underlying = reinterpret_cast<scalar_t::underlying*>(X_ptr);
|
||||
scalar_t::underlying* Y_ptr_underlying = reinterpret_cast<scalar_t::underlying*>(Y_ptr);
|
||||
auto x_sum_shifted = hsum(X_ptr_underlying, N);
|
||||
auto x_sum_sq_shifted = hsum_sq(X_ptr_underlying, N);
|
||||
// Use double for intermediate variables to avoid accuracy issue
|
||||
// Mean with zero point
|
||||
double x_mean_shifted_div_scale_x = static_cast<double>(x_sum_shifted) / N;
|
||||
double x_mean_unbiased_shifted_div_scale_x = static_cast<double>(x_sum_shifted) / den;
|
||||
// variance / x_scale^2
|
||||
double x_var_div_scale_x_sq =
|
||||
std::max(static_cast<double>(x_sum_sq_shifted) / den -
|
||||
2 * x_mean_shifted_div_scale_x * x_mean_unbiased_shifted_div_scale_x +
|
||||
x_mean_shifted_div_scale_x * x_mean_shifted_div_scale_x * N / den, (double)0.0);
|
||||
double y_float = std::sqrt(x_var_div_scale_x_sq) * x_scale;
|
||||
*Y_ptr_underlying = at::native::quantize_val<scalar_t>(
|
||||
x_scale, x_zp, y_float)
|
||||
.val_;
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
#ifdef USE_FBGEMM
|
||||
void quantize_tensor_per_tensor_affine_cpu(
|
||||
const Tensor& rtensor,
|
||||
@ -3709,6 +3826,8 @@ REGISTER_NO_AVX512_DISPATCH(quantize_tensor_per_tensor_affine_sub_byte_stub);
|
||||
REGISTER_NO_AVX512_DISPATCH(dequantize_tensor_per_tensor_affine_sub_byte_stub);
|
||||
REGISTER_NO_AVX512_DISPATCH(masked_fill_kernel_quantized_stub);
|
||||
REGISTER_NO_AVX512_DISPATCH(index_put_kernel_quantized_stub);
|
||||
REGISTER_NO_AVX512_DISPATCH(qmean_inner_dim_stub);
|
||||
REGISTER_NO_AVX512_DISPATCH(qstd_inner_dim_stub);
|
||||
#else
|
||||
REGISTER_DISPATCH(dequantize_tensor_per_channel_affine_stub,
|
||||
&dequantize_tensor_per_channel_affine_cpu);
|
||||
@ -3779,6 +3898,8 @@ REGISTER_DISPATCH(
|
||||
REGISTER_DISPATCH(
|
||||
index_put_kernel_quantized_stub,
|
||||
&index_put_kernel_quantized_cpu);
|
||||
REGISTER_DISPATCH(qmean_inner_dim_stub, &qmean_inner_dim_kernel);
|
||||
REGISTER_DISPATCH(qstd_inner_dim_stub, &qstd_inner_dim_kernel);
|
||||
#endif // CPU_CAPABILITY_AVX512 && _WIN32
|
||||
|
||||
} // namespace native
|
||||
|
||||
@ -2144,21 +2144,24 @@ class TestQuantizedOps(TestCase):
|
||||
torch.testing.assert_close(out.dequantize(), ref.dequantize())
|
||||
self.assertNotEqual(out.stride(), sorted(out.stride()))
|
||||
|
||||
@given(X=hu.tensor(shapes=hu.array_shapes(min_dims=1, max_dims=5,
|
||||
min_side=1, max_side=4),
|
||||
qparams=hu.qparams()),
|
||||
dim=st.integers(-1, 5))
|
||||
@override_qengines
|
||||
def test_mean(self, X, dim):
|
||||
X, (scale, zero_point, torch_type) = X
|
||||
assume(dim < X.ndim)
|
||||
qX = torch.quantize_per_tensor(torch.tensor(X).float(), scale, zero_point, torch_type)
|
||||
|
||||
Y = torch.mean(qX.dequantize(), dim)
|
||||
Y = torch.quantize_per_tensor(Y, scale, zero_point, torch_type).dequantize()
|
||||
qY = torch.mean(qX, dim)
|
||||
|
||||
self.assertEqual(Y, qY.dequantize())
|
||||
def test_mean(self):
|
||||
scale_list = (1, 0.25)
|
||||
zero_point_list = (0, 2)
|
||||
shapes = ((4,), (4, 4), (4, 4, 4), (4, 4, 4, 4), (4, 4, 4, 4, 4))
|
||||
dtypes = (torch.quint8, torch.qint8)
|
||||
dims = ((), (-1,), (0,), (1,), (2,), (3,), (0, 1), (1, 2), (3, 4))
|
||||
test_cases = itertools.product(scale_list, zero_point_list, shapes, dtypes, dims)
|
||||
op = torch.mean
|
||||
for scale, zp, shape, dtype, dim in test_cases:
|
||||
if not all([d < len(shape) for d in dim]):
|
||||
continue
|
||||
X = torch.randn(*shape) * 10
|
||||
qX = torch.quantize_per_tensor(X, scale, zp, dtype)
|
||||
Y = op(qX.dequantize(), dim)
|
||||
Y = torch.quantize_per_tensor(Y, scale, zp, dtype).dequantize()
|
||||
qY = op(qX, dim)
|
||||
self.assertEqual(Y, qY.dequantize())
|
||||
|
||||
@skipIfNoQNNPACK
|
||||
@given(keep=st.booleans())
|
||||
@ -2177,6 +2180,28 @@ class TestQuantizedOps(TestCase):
|
||||
MQ = XQ.mean((2, 3), keepdim=keep)
|
||||
self.assertTrue(torch.equal(MQ, YQ))
|
||||
|
||||
@override_qengines
|
||||
def test_std(self):
|
||||
scale_list = (1, 0.25)
|
||||
zero_point_list = (0, 2)
|
||||
shapes = ((4,), (4, 4), (4, 4, 4), (4, 4, 4, 4), (4, 4, 4, 4, 4))
|
||||
dtypes = (torch.quint8, torch.qint8)
|
||||
dims = ((), (-1,), (0,), (1,), (2,), (3,), (0, 1), (1, 2), (3, 4))
|
||||
unbiased_list = (True, False)
|
||||
keep_dim_list = (True, False)
|
||||
test_cases = itertools.product(scale_list, zero_point_list, shapes,
|
||||
dtypes, dims, unbiased_list, keep_dim_list)
|
||||
op = torch.std
|
||||
for scale, zp, shape, dtype, dim, unbiased, keep_dim in test_cases:
|
||||
if not all([d < len(shape) for d in dim]):
|
||||
continue
|
||||
X = torch.randn(*shape) * 10
|
||||
qX = torch.quantize_per_tensor(X, scale, zp, dtype)
|
||||
Y = op(qX.dequantize(), dim, unbiased, keep_dim)
|
||||
Y = torch.quantize_per_tensor(Y, scale, zp, dtype).dequantize()
|
||||
qY = op(qX, dim, unbiased, keep_dim)
|
||||
self.assertEqual(Y, qY.dequantize())
|
||||
|
||||
"""Tests the correctness of the quantized equal op."""
|
||||
@given(X=hu.tensor(shapes=hu.array_shapes(1, 5, 1, 5),
|
||||
qparams=hu.qparams()),
|
||||
|
||||
Reference in New Issue
Block a user