DoRA: Weight-Decomposed Low-Rank Adaptation
Introduction
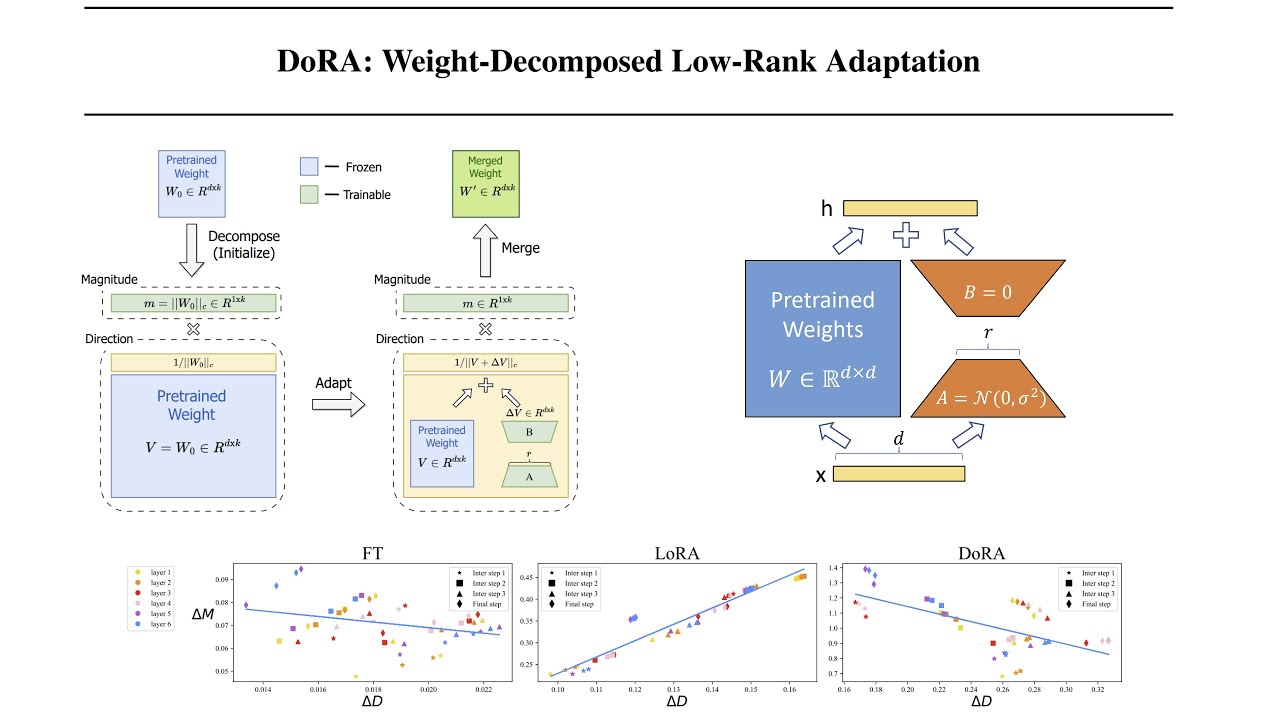
DoRA is a novel approach that leverages low rank adaptation through weight decomposition analysis to investigate the inherent differences between full fine-tuning and LoRA. DoRA initially decomposes the pretrained weight into its magnitude and directional components and finetunes both of them. Because the directional component is large in terms of parameter numbers, we further decompose it with LoRA for efficient finetuning. This results in enhancing both the learning capacity and training stability of LoRA while avoiding any additional inference overhead.
Quick start
import torch
from peft import LoraConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForCausalLM, Trainer
from datasets import load_dataset
model = AutoModelForCausalLM.from_pretrained("huggyllama/llama-7b", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
dataset = load_dataset("timdettmers/openassistant-guanaco", split="train")
lora_config = LoraConfig(
use_dora=True
)
peft_model = get_peft_model(model, lora_config)
trainer = transformers.Trainer(
model=peft_model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=2048,
tokenizer=tokenizer,
)
trainer.train()
peft_model.save_pretrained("dora-llama-3-8b")
There is no additional change needed to your standard LoRA procedure, except for specifying use_dora = True option in your lora configuration.
Run the finetuning script simply by running:
python examples/dora_finetuning/dora_finetuning.py --base_model meta-llama/Meta-Llama-3-8B --data_path timdettmers/openassistant-guanaco
This 👆🏻 by default will load the model in peft set up with LoRA config. Now if you wanna quickly compare it with Dora, all you need to do is to input --use_dora in the command line. So same above example would be 👇🏻;
python examples/dora_finetuning/dora_finetuning.py --base_model meta-llama/Meta-Llama-3-8B --data_path timdettmers/openassistant-guanaco --use_dora
DoRA also supports quantization. To use 4-bit quantization try:
python examples/dora_finetuning/dora_finetuning.py --base_model meta-llama/Meta-Llama-3-8B --quantize
Similarly, by default the LoRA layers are the attention and MLP layers of LLama model, if you get to choose a different set of layers for LoRA to be applied on, you can simply define it using:
python examples/dora_finetuning/dora_finetuning.py --lora_target_modules "q_proj,k_proj,v_proj,o_proj"
Full example of the script
python dora_finetuning.py \
--base_model "PATH_TO_MODEL" \
--data_path "PATH_TO_DATASET" \
--output_dir "PATH_TO_OUTPUT_DIR" \
--batch_size 1 \
--num_epochs 3 \
--learning_rate 3e-4 \
--cutoff_len 512 \
--val_set_size 500 \
--use_dora \
--quantize \
--eval_step 10 \
--save_step 100 \
--lora_r 16 \
--lora_alpha 32 \
--lora_dropout 0.05 \
--lora_target_modules "q_proj,k_proj,v_proj,o_proj" \
--hub_model_id "YOUR_HF_REPO" \
--push_to_hub
Use the model on 🤗
You can load and use the model as any other 🤗 models.
from transformers import AutoModel
model = AutoModel.from_pretrained("ShirinYamani/huggyllama-llama-7b-finetuned")
DoRA vs. LoRA
In general, DoRA finetuning on diffusion models is still experimental and is likely to require different hyperparameter values to perform best compared to LoRA.
Specifically, people have noticed 2 differences to take into account in your training:
-
LoRA seem to converge faster than DoRA (so a set of parameters that may lead to overfitting when training a LoRA may be working well for a DoRA)
-
DoRA quality superior to LoRA especially in lower ranks: The difference in quality of DoRA of rank 8 and LoRA of rank 8 appears to be more significant than when training ranks of 32 or 64 for example.
Citation
@article{liu2024dora,
title={DoRA: Weight-Decomposed Low-Rank Adaptation},
author={Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung},
journal={arXiv preprint arXiv:2402.09353},
year={2024}
}