# LoRA
LoRA is low-rank decomposition method to reduce the number of trainable parameters which speeds up finetuning large models and uses less memory. In PEFT, using LoRA is as easy as setting up a [`LoraConfig`] and wrapping it with [`get_peft_model`] to create a trainable [`PeftModel`].
This guide explores in more detail other options and features for using LoRA.
## Initialization
The initialization of LoRA weights is controlled by the parameter `init_lora_weights` in [`LoraConfig`]. By default, PEFT initializes LoRA weights with Kaiming-uniform for weight A and zeros for weight B resulting in an identity transform (same as the reference [implementation](https://github.com/microsoft/LoRA)).
It is also possible to pass `init_lora_weights="gaussian"`. As the name suggests, this initializes weight A with a Gaussian distribution and zeros for weight B (this is how [Diffusers](https://huggingface.co/docs/diffusers/index) initializes LoRA weights).
```py
from peft import LoraConfig
config = LoraConfig(init_lora_weights="gaussian", ...)
```
There is also an option to set `init_lora_weights=False` which is useful for debugging and testing. This should be the only time you use this option. When choosing this option, the LoRA weights are initialized such that they do *not* result in an identity transform.
```py
from peft import LoraConfig
config = LoraConfig(init_lora_weights=False, ...)
```
### PiSSA
[PiSSA](https://huggingface.co/papers/2404.02948) initializes the LoRA adapter using the principal singular values and singular vectors. This straightforward modification allows PiSSA to converge more rapidly than LoRA and ultimately attain superior performance. Moreover, PiSSA reduces the quantization error compared to QLoRA, leading to further enhancements.
Configure the initialization method to "pissa", which may take several minutes to execute SVD on the pre-trained model:
```python
from peft import LoraConfig
config = LoraConfig(init_lora_weights="pissa", ...)
```
Alternatively, execute fast SVD, which takes only a few seconds. The number of iterations determines the trade-off between the error and computation time:
```python
lora_config = LoraConfig(init_lora_weights="pissa_niter_[number of iters]", ...)
```
For detailed instruction on using PiSSA, please follow [these instructions](https://github.com/huggingface/peft/tree/main/examples/pissa_finetuning).
### CorDA
[CorDA](https://huggingface.co/papers/2406.05223) builds task-aware LoRA adapters from weight decomposition oriented by the context of downstream task to learn (instruction-previewed mode, IPM) or world knowledge to maintain (knowledge-preserved mode, KPM).
The KPM not only achieves better performance than LoRA on fine-tuning tasks, but also mitigates the catastrophic forgetting of pre-trained world knowledge.
When preserving pre-trained knowledge is not a concern,
the IPM is favored because it can further accelerate convergence and enhance the fine-tuning performance.
You need to configure the initialization method to "corda", and specify the mode of IPM or KPM and the dataset to collect covariance matrices.
```py
@torch.no_grad()
def run_model():
# Assume `model` and `dataset` is in context...
model.eval()
for batch in dataset:
model(**batch)
corda_config = CordaConfig(
corda_method="kpm",
)
lora_config = LoraConfig(
init_lora_weights="corda",
corda_config=corda_config,
)
preprocess_corda(model, lora_config, run_model=run_model)
peft_model = get_peft_model(model, lora_config)
```
For detailed instruction on using CorDA, please follow [these instructions](https://github.com/huggingface/peft/tree/main/examples/corda_finetuning).
### OLoRA
[OLoRA](https://huggingface.co/papers/2406.01775) utilizes QR decomposition to initialize the LoRA adapters. OLoRA translates the base weights of the model by a factor of their QR decompositions, i.e., it mutates the weights before performing any training on them. This approach significantly improves stability, accelerates convergence speed, and ultimately achieves superior performance.
You just need to pass a single additional option to use OLoRA:
```python
from peft import LoraConfig
config = LoraConfig(init_lora_weights="olora", ...)
```
For more advanced usage, please refer to our [documentation](https://github.com/huggingface/peft/tree/main/examples/olora_finetuning).
### EVA
[EVA](https://huggingface.co/papers/2410.07170) performs SVD on the input activations of each layer and uses the right-singular vectors to initialize LoRA weights. It is therefore a data-driven initialization scheme. Furthermore EVA adaptively allocates ranks across layers based on their "explained variance ratio" - a metric derived from the SVD analysis.
You can use EVA by setting `init_lora_weights="eva"` and defining [`EvaConfig`] in [`LoraConfig`]:
```python
from peft import LoraConfig, EvaConfig
peft_config = LoraConfig(
init_lora_weights = "eva",
eva_config = EvaConfig(rho = 2.0),
...
)
```
The parameter `rho` (≥ 1.0) determines how much redistribution is allowed. When `rho=1.0` and `r=16`, LoRA adapters are limited to exactly 16 ranks, preventing any redistribution from occurring. A recommended value for EVA with redistribution is 2.0, meaning the maximum rank allowed for a layer is 2r.
It is recommended to perform EVA initialization on an accelerator(e.g. CUDA GPU, Intel XPU) as it is much faster. To optimize the amount of available memory for EVA, you can use the `low_cpu_mem_usage` flag in [`get_peft_model`]:
```python
peft_model = get_peft_model(model, peft_config, low_cpu_mem_usage=True)
```
Then, call [`initialize_lora_eva_weights`] to initialize the EVA weights (in most cases the dataloader used for eva initialization can be the same as the one used for finetuning):
```python
initialize_lora_eva_weights(peft_model, dataloader)
```
EVA works out of the box with bitsandbytes. Simply initialize the model with `quantization_config` and call [`initialize_lora_eva_weights`] as usual.
> [!TIP]
> For further instructions on using EVA, please refer to our [documentation](https://github.com/huggingface/peft/tree/main/examples/eva_finetuning).
### LoftQ
#### Standard approach
When quantizing the base model for QLoRA training, consider using the [LoftQ initialization](https://huggingface.co/papers/2310.08659), which has been shown to improve performance when training quantized models. The idea is that the LoRA weights are initialized such that the quantization error is minimized. To use LoftQ, follow [these instructions](https://github.com/huggingface/peft/tree/main/examples/loftq_finetuning).
In general, for LoftQ to work best, it is recommended to target as many layers with LoRA as possible, since those not targeted cannot have LoftQ applied. This means that passing `LoraConfig(..., target_modules="all-linear")` will most likely give the best results. Also, you should use `nf4` as quant type in your quantization config when using 4bit quantization, i.e. `BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4")`.
#### A more convenient way
An easier but more limited way to apply LoftQ initialization is to use the convenience function `replace_lora_weights_loftq`. This takes the quantized PEFT model as input and replaces the LoRA weights in-place with their LoftQ-initialized counterparts.
```python
from peft import replace_lora_weights_loftq
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(load_in_4bit=True, ...)
base_model = AutoModelForCausalLM.from_pretrained(..., quantization_config=bnb_config)
# note: don't pass init_lora_weights="loftq" or loftq_config!
lora_config = LoraConfig(task_type="CAUSAL_LM")
peft_model = get_peft_model(base_model, lora_config)
replace_lora_weights_loftq(peft_model)
```
`replace_lora_weights_loftq` also allows you to pass a `callback` argument to give you more control over which layers should be modified or not, which empirically can improve the results quite a lot. To see a more elaborate example of this, check out [this notebook](https://github.com/huggingface/peft/blob/main/examples/loftq_finetuning/LoftQ_weight_replacement.ipynb).
`replace_lora_weights_loftq` implements only one iteration step of LoftQ. This means that only the LoRA weights are updated, instead of iteratively updating LoRA weights and quantized base model weights. This may lead to lower performance but has the advantage that we can use the original quantized weights derived from the base model, instead of having to keep an extra copy of modified quantized weights. Whether this tradeoff is worthwhile depends on the use case.
At the moment, `replace_lora_weights_loftq` has these additional limitations:
- Model files must be stored as a `safetensors` file.
- Only bitsandbytes 4bit quantization is supported.
> [!TIP]
> Learn more about how PEFT works with quantization in the [Quantization](quantization) guide.
### Rank-stabilized LoRA
Another way to initialize [`LoraConfig`] is with the [rank-stabilized LoRA (rsLoRA)](https://huggingface.co/papers/2312.03732) method. The LoRA architecture scales each adapter during every forward pass by a fixed scalar which is set at initialization and depends on the rank `r`. The scalar is given by `lora_alpha/r` in the original implementation, but rsLoRA uses `lora_alpha/math.sqrt(r)` which stabilizes the adapters and increases the performance potential from using a higher `r`.
```py
from peft import LoraConfig
config = LoraConfig(use_rslora=True, ...)
```
### Activated LoRA (aLoRA)
Activated LoRA (aLoRA) is a low rank adapter architecture for Causal LMs that allows for reusing existing base model KV cache for more efficient inference. This approach is best suited for inference pipelines which rely on the base model for most tasks/generations, but use aLoRA adapter(s) to perform specialized task(s) within the chain. For example, checking or correcting generated outputs of the base model. In these settings, inference times can be sped up by an order of magnitude or more. For more information on aLoRA and many example use cases, see https://huggingface.co/papers/2504.12397.
This technique scans for the last occurence of an invocation sequence (`alora_invocation_tokens`) in each input (this can be as short as 1 token), and activates the adapter weights on tokens starting with the beginning of the invocation sequence (any inputs after the invocation sequence are also adapted, and all generated tokens will use the adapted weights). Weights on prior tokens are left un-adapted -- making the cache for those tokens interchangeable with base model cache due to the causal attention mask in Causal LMs. Usage is very similar to standard LoRA, with the key difference that this invocation sequence must be specified when the adapter is created:
```py
from peft import LoraConfig
config = LoraConfig(alora_invocation_tokens=alora_invocation_tokens, task_type="CAUSAL_LM", ...)
```
where `alora_invocation_tokens` is a list of integer token ids. Given a desired invocation string, this can be obtained as
```
invocation_string = "placeholder"
alora_invocation_tokens = tokenizer.encode(invocation_string, add_special_tokens=False).
```
where the tokenizer is the tokenizer for the base model. Note that we have `add_special_tokens=False` to avoid adding SOS/EOS tokens in our search string (which will most likely cause failure to find).
**Notes**
* aLoRA is only supported for `task_type=CAUSAL_LM` tasks due to its focus on cache reuse.
* Since the weights are adapted on fewer tokens, often (not always) aLoRA requires higher rank (`r`) than LoRA. `r=32` can be a good starting point.
* aLoRA weights cannot be merged into the base model by definition, since the adapter weights are selectively applied to a subset of tokens. Attempts to merge will throw errors.
* Beam search is not yet supported.
* It is generally not recommended to add new tokens to the tokenizer that are not present in the base model, as this can complicate the target use case of both the base model and adapter model operating on overlapping context. That said, there is a possible workaround by first efficiently adding [trainable tokens](https://huggingface.co/docs/peft/en/package_reference/trainable_tokens) to the base model prior to training the adapter.
#### Choice of invocation sequence and SFT design
Each input must have the `alora_invocation_tokens` sequence present, it is not added automatically. To maximize model performance without compromising cache reuse, it is recommended to have the adapter weights activated early, i.e. at the start of any adapter-specific prompting, but after any long inputs such as prior generations or documents. As with any model,
formatting should be consistent between train and test.
Consider the following example, where the base model has a chat template,
and the goal is to train the adapter to generate a desired output.
* Option 1: If there is no task-specific prompt, i.e. the input is a chat history with the `assistant` prompt, then the chat template's `assistant` prompt (e.g. `<|start_of_role|>assistant<|end_of_role|>`) is a natural choice for the invocation string. See the model's chat template to find the prompt for the model.
* Option 2: If there is a task-specific prompt for the adapter that describes the task the adapter is learning, and that prompt is put as a `user` turn immediately prior to the generation, then the chat template's `user` prompt (e.g. `<|start_of_role|>user<|end_of_role|>`) is a natural choice for the invocation string.
Once deciding on an invocation string, get the model tokenizer and obtain `alora_invocation_tokens` as
```
alora_invocation_tokens = tokenizer.encode(invocation_string, add_special_tokens=False).
```
An example inference setup is at [alora finetuning](https://github.com/huggingface/peft/blob/main/examples/alora_finetuning/alora_finetuning.py).
**Note** If using custom strings for the invocation string, make sure that the start and end of the string are special tokens to avoid issues with tokenization at the boundaries.
To see why, imagine that 'a', 'b', 'c', and 'ab' are tokens in your tokenizer (numbers 1, 2, 3, 4 respectively). Suppose that your alora_invocation_tokens = [2, 3]. Now imagine your input string is "abc". Because "ab" is a token, this will get tokenized as [4,3]. So the alora_invocation_tokens will fail to be found, despite the string "bc" being in it. If the start and end of the invocation string are special tokens, however, this failure case will never happen since special tokens are never tokenized into the same token with other characters.
#### Using (and reusing) cache for generation
The main purpose of Activated LoRA is to make KV cache interchangeable between the base model and aLoRA adapter models **prior to the invocation sequence** since base and adapted KV values are not compatible. Specifically, keys and values stored during one model generation can be used in subsequent generations to avoid expensive prefill operations for context tokens. When sharing cache between the base model and aLoRA adapters, there are 2 main patterns:
1. The base model has generated something, and an aLoRA adapter is then called to do a followup generation. Example: the base model answers a question, and an aLoRA trained to detect hallucinations checks the base model response.
2. An aLoRA adapter has generated something, and the base model or a different aLoRA adapter is called to do a followup generation where there is partial context overlap with the original aLoRA. Example: The user provides a query, and an aLoRA rewrites the query to be more self-contained and improve retrieval in a RAG system. Then, documents are retrieved and loaded into context, an aLoRA checks if these documents are indeed relevant to the question, and then the base model generates an answer.
To demonstrate the above behaviors when using caching, we're using [DynamicCache](https://huggingface.co/docs/transformers/en/kv_cache) from `transformers`. Care must be taken to ensure that adapted cache values are not mixed with base cache values. In particular, an extra step is required for sharing the cache when there is partial context overlap (pattern 2).
**Pattern 1: Base model followed by aLoRA** Here, the entire input and generation from the base model is input into the aLoRA adapter, along with the invocation sequence:
```
from transformers import DynamicCache
...
cache = DynamicCache()
inputs_base = tokenizer(prompt_base, return_tensors="pt")
# Generate from base model and save cache
with model_alora.disable_adapter():
output = model_alora.generate(inputs_base["input_ids"].to(device),attention_mask=inputs_base["attention_mask"].to(device),past_key_values = cache,return_dict_in_generate=True)
output_text_base = tokenizer.decode(output.sequences[0])
cache = output.past_key_values
# Generate with aLoRA adapter from cache
prompt_alora = output_text + INVOCATION_STRING
inputs_alora = tokenizer(prompt_alora, return_tensors="pt").to(device)
output = model_alora.generate(**inputs_alora, past_key_values=cache)
output_text_alora = tokenizer.decode(output[0])
# Note: cache is now tainted with adapter values and cannot be used in base model from here on!
```
**Pattern 2: aLoRA generation followed by base model (or another aLoRA) with partial context overlap** Here, we prefill the shared context using the base model, and then generate.
```
from transformers import DynamicCache
import copy
...
cache = DynamicCache()
inputs_shared = tokenizer(prompt_shared, return_tensors="pt").to(device)
# Prefill from base model and save cache
with model_alora.disable_adapter():
with torch.no_grad():
model_alora(**inputs_shared, past_key_values=cache)
cache_copy = copy.deepcopy(cache)
# Generate from aLoRA using prefilled cache
prompt_alora = prompt_shared + INVOCATION_STRING
inputs_alora = tokenizer(prompt_alora, return_tensors="pt").to(device)
output = model_alora.generate(**inputs_alora, past_key_values=cache)
output_text_alora = tokenizer.decode(output[0])
# Generate from base model using saved cache not tainted by aLoRA KV values
prompt_base = prompt_shared
inputs_base = tokenizer(prompt_base, return_tensors="pt").to(device)
with model_alora.disable_adapter():
output = model_alora.generate(**inputs_base, past_key_values=cache_copy)
output_text_base = tokenizer.decode(output[0])
```
### Weight-Decomposed Low-Rank Adaptation (DoRA)
This technique decomposes the updates of the weights into two parts, magnitude and direction. Direction is handled by normal LoRA, whereas the magnitude is handled by a separate learnable parameter. This can improve the performance of LoRA, especially at low ranks. For more information on DoRA, see https://huggingface.co/papers/2402.09353.
```py
from peft import LoraConfig
config = LoraConfig(use_dora=True, ...)
```
If parts of the model or the DoRA adapter are offloaded to CPU you can get a significant speedup at the cost of some temporary (ephemeral) VRAM overhead by using `ephemeral_gpu_offload=True` in `config.runtime_config`.
```py
from peft import LoraConfig, LoraRuntimeConfig
config = LoraConfig(use_dora=True, runtime_config=LoraRuntimeConfig(ephemeral_gpu_offload=True), ...)
```
A `PeftModel` with a DoRA adapter can also be loaded with `ephemeral_gpu_offload=True` flag using the `from_pretrained` method as well as the `load_adapter` method.
```py
from peft import PeftModel
model = PeftModel.from_pretrained(base_model, peft_model_id, ephemeral_gpu_offload=True)
```
DoRA is optimized (computes faster and takes less memory) for models in the evaluation mode, or when dropout is set to 0. We reuse the
base result at those times to get the speedup.
Running [dora finetuning](https://github.com/huggingface/peft/blob/main/examples/dora_finetuning/dora_finetuning.py)
with `CUDA_VISIBLE_DEVICES=0 ZE_AFFINITY_MASK=0 time python examples/dora_finetuning/dora_finetuning.py --quantize --lora_dropout 0 --batch_size 16 --eval_step 2 --use_dora`
on a 4090 with gradient accumulation set to 2 and max step to 20 resulted with the following observations:
| | Without Optimization | With Optimization |
| :--: | :--: | :--: |
| train_runtime | 359.7298 | **279.2676** |
| train_samples_per_second | 1.779 | **2.292** |
| train_steps_per_second | 0.056 | **0.072** |
#### Caveats
- DoRA only supports embedding, linear, and Conv2d layers at the moment.
- DoRA introduces a bigger overhead than pure LoRA, so it is recommended to merge weights for inference, see [`LoraModel.merge_and_unload`].
- DoRA should work with weights quantized with bitsandbytes ("QDoRA"). However, issues have been reported when using QDoRA with DeepSpeed Zero2.
### QLoRA-style training
The default LoRA settings in PEFT add trainable weights to the query and value layers of each attention block. But [QLoRA](https://hf.co/papers/2305.14314), which adds trainable weights to all the linear layers of a transformer model, can provide performance equal to a fully finetuned model. To apply LoRA to all the linear layers, like in QLoRA, set `target_modules="all-linear"` (easier than specifying individual modules by name which can vary depending on the architecture).
```py
config = LoraConfig(target_modules="all-linear", ...)
```
### Memory efficient Layer Replication with LoRA
An approach used to improve the performance of models is to expand a model by duplicating layers in the model to build a larger model from a pretrained model of a given size. For example increasing a 7B model to a 10B model as described in the [SOLAR](https://huggingface.co/papers/2312.15166) paper. PEFT LoRA supports this kind of expansion in a memory efficient manner that supports further fine-tuning using LoRA adapters attached to the layers post replication of the layers. The replicated layers do not take additional memory as they share the underlying weights so the only additional memory required is the memory for the adapter weights. To use this feature you would create a config with the `layer_replication` argument.
```py
config = LoraConfig(layer_replication=[[0,4], [2,5]], ...)
```
Assuming the original model had 5 layers `[0, 1, 2 ,3, 4]`, this would create a model with 7 layers arranged as `[0, 1, 2, 3, 2, 3, 4]`. This follows the [mergekit](https://github.com/arcee-ai/mergekit) pass through merge convention where sequences of layers specified as start inclusive and end exclusive tuples are stacked to build the final model. Each layer in the final model gets its own distinct set of LoRA adapters.
[Fewshot-Metamath-OrcaVicuna-Mistral-10B](https://huggingface.co/abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B) is an example of a model trained using this method on Mistral-7B expanded to 10B. The
[adapter_config.json](https://huggingface.co/abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B/blob/main/adapter_config.json) shows a sample LoRA adapter config applying this method for fine-tuning.
### Fine grained control over ranks and alpha (scaling)
By default, all layers targeted with LoRA will have the same rank `r` and the same `lora_alpha` (which determines the LoRA scaling), depending on what was specified in the [`LoraConfig`]. In some cases, however, you may want to indicate different values for different layers. This is possible by passing the `rank_pattern` and `alpha_pattern` arguments to [`LoraConfig`]. These arguments should be dictionaries with the key being the layer name and the value being the rank/alpha value. The keys can be [regular expressions](https://docs.python.org/3/library/re.html) (regex). All LoRA layers that are not explicitly mentioned in `rank_pattern` and `alpha_pattern` will take the default `r` and `lora_alpha` values.
To give an example, let's assume that we have a model with the following structure:
```python
>>> print(model)
Outer(
(foo): Linear(...)
(module): Middle(
(foo): Linear(...)
(foobar): Linear(...)
(module): Inner(
(foo): Linear(...)
(barfoo): Linear(...)
)
)
)
```
- `rank_pattern={"foo": 42}` will match all 3 `foo` layers. Neither `foobar` nor `barfoo` are matched.
- `rank_pattern={"^foo": 42}` will only match the `foo` layer of the model, but neither `module.foo` nor `module.module.foo`. This is because the `^` means "start of string" when using regular expressions, and only `foo` starts with `"foo"`, the other layer names have prefixes.
- `rank_pattern={"^module.foo": 42}` matches only `module.foo`, but not `module.module.foo`, for the same reason.
- `rank_pattern={"module.foo": 42}` matches both `module.foo` and `module.module.foo`, but not `foo`.
- `rank_pattern={"^foo": 42, "^module.module.foo": 55}` matches `foo` and `module.module.foo`, respectively, but not `module.foo`.
- There is no need to indicate `$` to mark the end of the match, as this is added automatically by PEFT.
The same logic applies to `alpha_pattern`. If you're in doubt, don't try to get fancy with regular expressions -- just pass the full name for each module with a different rank/alpha, preceded by the `^` prefix, and you should be good.
### Targeting `nn.Parameter` directly
> [!WARNING]
> This feature is experimental and subject to change.
Generally, you should use `target_modules` to target the module (e.g. `nn.Linear`). However, in some circumstances, this is not possible. E.g., in many mixture of expert (MoE) layers in HF Transformers, instead of using `nn.Linear`, an `nn.Parameter` is used. PEFT normally overwrites the `forward` method for LoRA, but for `nn.Parameter`, there is none. Therefore, to apply LoRA to that parameter, it needs to be targeted with `target_parameters`. As an example, for [Llama4](https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164), you can pass: `target_parameters=['feed_forward.experts.gate_up_proj', 'feed_forward.experts.down_proj]`.
#### Caveats
- At the moment, this argument allows to target 2-dim or 3-dim `nn.Parameter`s. It is assumed that in the case of a 3-dim parameter, the 0th dimension is the expert dimension.
- It is currently not possible to add multiple LoRA adapters (via `model.add_adapter` or `model.load_adapter`) that use `target_parameters` at the same time.
## Optimizers
LoRA training can optionally include special purpose optimizers. Currently PEFT supports LoRA-FA and LoRA+.
### LoRA-FA Optimizer
LoRA training can be more effective and efficient using LoRA-FA, as described in [LoRA-FA](https://huggingface.co/papers/2308.03303). LoRA-FA reduces activation memory consumption by fixing the matrix A and only tuning the matrix B. During training, the gradient of B is optimized to approximate the full parameter fine-tuning gradient. Moreover, the memory consumption of LoRA-FA is not sensitive to the rank (since it erases the activation of $A$), therefore it can improve performance by enlarging lora rank without increasing memory consumption.
```py
from peft import LoraConfig, get_peft_model
from peft.optimizers import create_lorafa_optimizer
from transformers import Trainer, get_cosine_schedule_with_warmup
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
config = LoraConfig(...)
model = get_peft_model(base_model, config)
optimizer = create_lorafa_optimizer(
model=model,
r=128,
lora_alpha=32,
lr=7e-5,
)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=100,
num_training_steps=1000,
)
trainer = Trainer(
...,
optimizers=(optimizer, scheduler),
)
```
### LoRA+ optimized LoRA
LoRA training can be optimized using [LoRA+](https://huggingface.co/papers/2402.12354), which uses different learning rates for the adapter matrices A and B, shown to increase finetuning speed by up to 2x and performance by 1-2%.
```py
from peft import LoraConfig, get_peft_model
from peft.optimizers import create_loraplus_optimizer
from transformers import Trainer
import bitsandbytes as bnb
base_model = ...
config = LoraConfig(...)
model = get_peft_model(base_model, config)
optimizer = create_loraplus_optimizer(
model=model,
optimizer_cls=bnb.optim.Adam8bit,
lr=5e-5,
loraplus_lr_ratio=16,
)
scheduler = None
...
trainer = Trainer(
...,
optimizers=(optimizer, scheduler),
)
```
## Efficiently train tokens alongside LoRA
Sometimes it is necessary to not only change some layer's weights but to add new tokens as well. With larger models this can be a memory-costly endeavour. PEFT LoRA adapters support the `trainable_token_indices` parameter which allows tuning of other tokens alongside fine-tuning of specific layers with LoRA. This method only trains the tokens you specify and leaves all other tokens untouched. This saves memory and doesn't throw away learned context of existing token embeddings in contrast to when training the whole embedding matrix. Under the hood this method uses the layer of [`TrainableTokensModel`].
```py
# for layer 'embed_tokens'
config = LoraConfig(trainable_token_indices=[idx_1, idx_2, ...], ...)
# specific embedding layer
config = LoraConfig(trainable_token_indices={'emb_tokens': [idx_1, idx_2, ...]}, ...)
```
In the snippet below we show how to add new tokens to the model and how to train it alongside the other layers in the model.
```py
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import get_peft_model, LoraConfig
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
# we define our new tokens and add them to the tokenizer as special tokens
special_tokens = ['<|start_think|>', '<|stop_think|>']
tokenizer.add_special_tokens({'additional_special_tokens': special_tokens})
# make room for new tokens in the embedding matrix if it isn't big enough already
base_model.resize_token_embeddings(max(len(tokenizer), base_model.model.embed_tokens.num_embeddings))
# typical LoRA config with `trainable_token_indices` targeting embedding layer `embed_tokens`
# and specifically our new tokens we just added
lora_config = LoraConfig(
target_modules='all-linear',
trainable_token_indices={'embed_tokens': tokenizer.convert_tokens_to_ids(special_tokens)},
)
peft_model = get_peft_model(base_model, lora_config)
# proceed to train the model like normal
[...]
```
The token weights are part of your adapter state dict and saved alongside the LoRA weights.
If we would have used full fine-tuning with `modules_to_save=['embed_tokens']` we would have stored the full embedding matrix in the checkpoint, leading to a much bigger file.
To give a bit of an indication how much VRAM can be saved, a rudimentary comparison of the above example was made between training the embedding matrix fully (`modules_to_save=["embed_tokens"]`), using a LoRA for the embedding matrix (`target_modules=[..., "embed_tokens"]`, rank 32) and trainable tokens (`trainable_token_indices=[...]`, 6 tokens). Trainable tokens used about as much VRAM (15,562MB vs. 15,581MB) as LoRA while being specific to the tokens and saved ~1GB of VRAM over fully training the embedding matrix.
## Merge LoRA weights into the base model
While LoRA is significantly smaller and faster to train, you may encounter latency issues during inference due to separately loading the base model and the LoRA adapter. To eliminate latency, use the [`~LoraModel.merge_and_unload`] function to merge the adapter weights with the base model. This allows you to use the newly merged model as a standalone model. The [`~LoraModel.merge_and_unload`] function doesn't keep the adapter weights in memory.
Below is a diagram that explains the intuition of LoRA adapter merging:
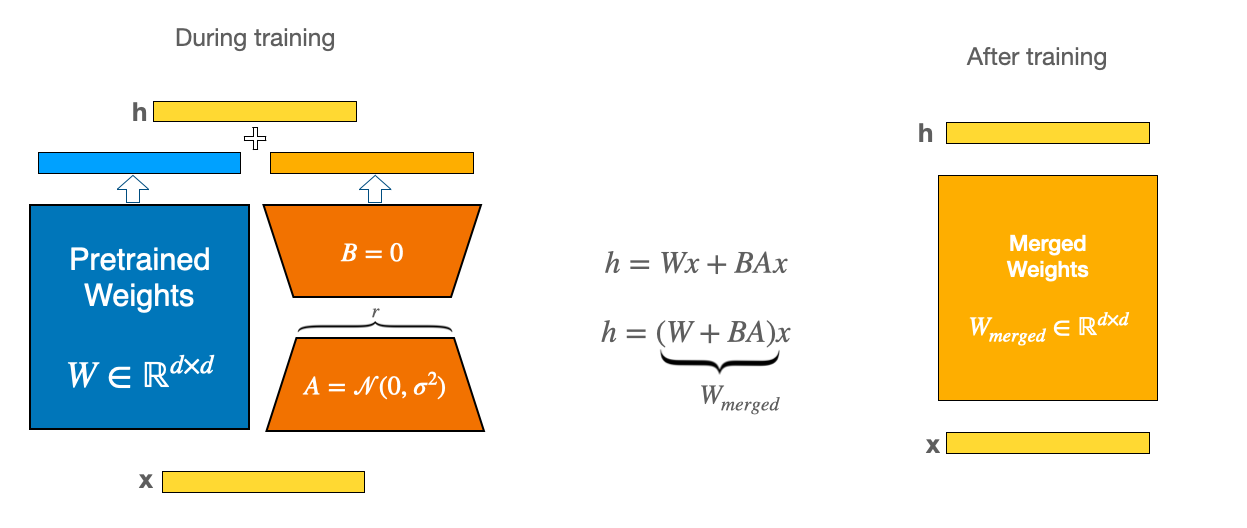
We show in the snippets below how to run that using PEFT.
```py
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.merge_and_unload()
```
If you need to keep a copy of the weights so you can unmerge the adapter later or delete and load different ones, you should use the [`~LoraModel.merge_adapter`] function instead. Now you have the option to use [`~LoraModel.unmerge_adapter`] to return the base model.
```py
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model.merge_adapter()
# unmerge the LoRA layers from the base model
model.unmerge_adapter()
```
The [`~LoraModel.add_weighted_adapter`] function is useful for merging multiple LoRAs into a new adapter based on a user provided weighting scheme in the `weights` parameter. Below is an end-to-end example.
First load the base model:
```python
from transformers import AutoModelForCausalLM
from peft import PeftModel
import torch
base_model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1", dtype=torch.float16, device_map="auto"
)
```
Then we load the first adapter:
```python
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id, adapter_name="sft")
```
Then load a different adapter and merge it with the first one:
```python
weighted_adapter_name = "sft-dpo"
model.load_adapter("alignment-handbook/zephyr-7b-dpo-lora", adapter_name="dpo")
model.add_weighted_adapter(
adapters=["sft", "dpo"],
weights=[0.7, 0.3],
adapter_name=weighted_adapter_name,
combination_type="linear"
)
model.set_adapter(weighted_adapter_name)
```
> [!TIP]
> There are several supported methods for `combination_type`. Refer to the [documentation](../package_reference/lora#peft.LoraModel.add_weighted_adapter) for more details. Note that "svd" as the `combination_type` is not supported when using `torch.float16` or `torch.bfloat16` as the datatype.
Now, perform inference:
```python
device = torch.accelerator.current_accelerator().type if hasattr(torch, "accelerator") else "cuda"
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
prompt = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer(prompt, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
generate_ids = model.generate(**inputs, max_length=30)
outputs = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print(outputs)
```
## Load adapters
Adapters can be loaded onto a pretrained model with [`~PeftModel.load_adapter`], which is useful for trying out different adapters whose weights aren't merged. Set the active adapter weights with the [`~LoraModel.set_adapter`] function.
```py
from transformers import AutoModelForCausalLM
from peft import PeftModel
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
model = PeftModel.from_pretrained(base_model, peft_model_id)
# load different adapter
model.load_adapter("alignment-handbook/zephyr-7b-dpo-lora", adapter_name="dpo")
# set adapter as active
model.set_adapter("dpo")
```
To return the base model, you could use [`~LoraModel.unload`] to unload all of the LoRA modules or [`~LoraModel.delete_adapter`] to delete the adapter entirely.
```py
# unload adapter
model.unload()
# delete adapter
model.delete_adapter("dpo")
```
## Inference with different LoRA adapters in the same batch
Normally, each inference batch has to use the same adapter(s) in PEFT. This can sometimes be annoying, because we may have batches that contain samples intended to be used with different LoRA adapters. For example, we could have a base model that works well in English and two more LoRA adapters, one for French and one for German. Usually, we would have to split our batches such that each batch only contains samples of one of the languages, we cannot combine different languages in the same batch.
Thankfully, it is possible to mix different LoRA adapters in the same batch using the `adapter_name` argument. Below, we show an example of how this works in practice. First, let's load the base model, English, and the two adapters, French and German, like this:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
model_id = ...
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# load the LoRA adapter for French
peft_model = PeftModel.from_pretrained(model, , adapter_name="adapter_fr")
# next, load the LoRA adapter for German
peft_model.load_adapter(, adapter_name="adapter_de")
```
Now, we want to generate text on a sample that contains all three languages: The first three samples are in English, the next three are in French, and the last three are in German. We can use the `adapter_names` argument to specify which adapter to use for each sample. Since our base model is used for English, we use the special string `"__base__"` for these samples. For the next three samples, we indicate the adapter name of the French LoRA fine-tune, in this case `"adapter_fr"`. For the last three samples, we indicate the adapter name of the German LoRA fine-tune, in this case `"adapter_de"`. This way, we can use the base model and the two adapters in a single batch.
```python
inputs = tokenizer(
[
"Hello, my dog is cute",
"Hello, my cat is awesome",
"Hello, my fish is great",
"Salut, mon chien est mignon",
"Salut, mon chat est génial",
"Salut, mon poisson est super",
"Hallo, mein Hund ist süß",
"Hallo, meine Katze ist toll",
"Hallo, mein Fisch ist großartig",
],
return_tensors="pt",
padding=True,
)
adapter_names = [
"__base__", "__base__", "__base__",
"adapter_fr", "adapter_fr", "adapter_fr",
"adapter_de", "adapter_de", "adapter_de",
]
output = peft_model.generate(**inputs, adapter_names=adapter_names, max_new_tokens=20)
```
Note that the order does not matter here, i.e. the samples in the batch don't need to be grouped by adapter as in the example above. We just need to ensure that the `adapter_names` argument is aligned correctly with the samples.
Additionally, the same approach also works with the `modules_to_save` feature, which allows for saving and reusing specific neural network layers, such as custom heads for classification tasks, across different LoRA adapters.
### Caveats
Using this feature has some drawbacks, namely:
- It only works for inference, not for training.
- Disabling adapters using the `with model.disable_adapter()` context takes precedence over `adapter_names`.
- You cannot pass `adapter_names` when some adapter weights were merged with base weight using the `merge_adapter` method. Please unmerge all adapters first by calling `model.unmerge_adapter()`.
- For obvious reasons, this cannot be used after calling `merge_and_unload()`, since all the LoRA adapters will be merged into the base weights in this case.
- This feature does not currently work with DoRA, so set `use_dora=False` in your `LoraConfig` if you want to use it.
- The `modules_to_save` feature is currently only supported for the layers of types `Linear`, `Embedding`, `Conv2d` and `Conv1d`.
- There is an expected overhead for inference with `adapter_names`, especially if the amount of different adapters in the batch is high. This is because the batch size is effectively reduced to the number of samples per adapter. If runtime performance is your top priority, try the following:
- Increase the batch size.
- Try to avoid having a large number of different adapters in the same batch, prefer homogeneous batches. This can be achieved by buffering samples with the same adapter and only perform inference with a small handful of different adapters.
- Take a look at alternative implementations such as [LoRAX](https://github.com/predibase/lorax), [punica](https://github.com/punica-ai/punica), or [S-LoRA](https://github.com/S-LoRA/S-LoRA), which are specialized to work with a large number of different adapters.
## Composing and Reusing LoRA Adapters
### Arrow
[Arrow](https://huggingface.co/papers/2405.11157) is a modular routing algorithm designed to combine multiple pre-trained task-specific LoRA adapters to solve a given task. Rather than merging all adapters naively, Arrow introduces a **gradient-free, token-wise mixture-of-experts (MoE) routing mechanism**. At inference time, it first computes a _prototype_ for each LoRA by extracting the top right singular vector from its SVD decomposition. Each token representation is then compared to these prototypes via cosine similarity to obtain routing coefficients. Tokens are assigned to the top-k most relevant LoRA adapters, with the coefficients normalized through softmax, and their outputs linearly combined. This allows effective reuse of existing LoRA modules for new tasks and leads to stronger zero-shot generalization.
In PEFT, Arrow is enabled through ```ArrowConfig``` and ```create_arrow_model```. You can also configure parameters such as ```top_k``` (the number of LoRA adapters combined per token), ```router_temperature``` (the softmax temperature applied to the routing coefficients), and ```rng_seed``` (for reproducibility).
```py
from peft import create_arrow_model, ArrowConfig
from transformers import AutoModelForCausalLM
# Loading the model
base_model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
# Creating the Arrow config
arrow_config = ArrowConfig(
top_k=3,
router_temperature=1.0,
rng_seed=42,
)
# The LoRA adapters below were trained on a clustered FLAN dataset.
# Task clustering was performed using the Model-Based Clustering (MBC) method,
# as described in the Arrow paper.
# While one could train a separate LoRA for each task and let Arrow route tokens among them,
# training LoRAs on clusters of tasks instead provides an indirect optimization for
# transfer across the multi-task dataset.
task_specific_adapter_paths = [
f"TahaBa/phi3-mini-clustered-flan/ts_expert_{i}" for i in range(10)
]
# Creating the Arrow model
model = create_arrow_model(
base_model=base_model,
task_specific_adapter_paths=task_specific_adapter_paths,
arrow_config=arrow_config,
)
# Now the forward path could be called on this model, like a normal PeftModel.
```
Furthermore, you can add or remove adapters after calling ```create_arrow_model```—for example, to fine-tune a new adapter or discard an unnecessary one. Once the adapters are in place, you can activate the ```"arrow_router"``` for inference to use Arrow. Note that if you add a new LoRA adapter after ```create_arrow_model``` and want to fine-tune it, you must explicitly set the new adapter as active, since ```"arrow_router"``` is activated by default in ```create_arrow_model```.
```py
from trl import SFTTrainer, SFTConfig
# Adding a new adapter and activating it
model.add_adapter(adapter_name='new_adapter')
model.set_adapter('new_adapter')
# Now the model could be trained along the `new_adapter`.
trainer = SFTTrainer(
model=model,
args=SFTConfig(...),
...
)
# Once the training is done, you can activate `arrow_router` and use it in inference
model.set_adapter('arrow_router') # Model is ready to be used at inference time now
```
### GenKnowSub
[GenKnowSub](https://aclanthology.org/2025.acl-short.54/) augments Arrow by purifying task-specific LoRA adapters before routing. The key idea is to subtract general knowledge encoded in LoRA space—based on the [forgetting-via-negation principle](https://huggingface.co/papers/2212.04089)—so that task adapters become more isolated and focused on task-relevant signals. Concretely, GenKnowSub estimates a low-dimensional “general” subspace from a set of general (non task-specific) LoRA adapters and removes this component from each task adapter’s LoRA update prior to Arrow’s token-wise routing. This typically improves compositionality and reduces interference when combining many task adapters.
In PEFT, enable GenKnowSub by setting ```use_gks=True``` in ArrowConfig, and providing ```general_adapter_paths``` in ```create_arrow_model```:
```py
from peft import create_arrow_model, ArrowConfig
from transformers import AutoModelForCausalLM
# Loading the model
base_model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
# Creating the Arrow config
arrow_config = ArrowConfig(
top_k=3,
router_temperature=1.0,
use_gks=True,
rng_seed=42,
)
# Path to task-specific, trained on flan clustered dataset (as we explained before.)
task_specific_adapter_paths = [
f"TahaBa/phi3-mini-clustered-flan/ts_expert_{i}" for i in range(10)
]
# These general adapters are trained on English, German, and French Wikipedia dataset,
# with causal language modelling objective, each pair like: (507 token tsentence, 5 token completion), and the loss computed on the completion
general_adapter_paths = [
"TahaBa/phi3-mini-general-adapters/cluster0_batch16_prop1.0_langen/checkpoint-17",
"TahaBa/phi3-mini-general-adapters/cluster0_batch16_prop1.0_langfr/checkpoint-35",
"TahaBa/phi3-mini-general-adapters/cluster0_batch16_prop1.0_langger/checkpoint-17"
]
# Creating the Arrow model
model = create_arrow_model(
base_model=base_model,
task_specific_adapter_paths=task_specific_adapter_paths,
general_adapter_paths=general_adapter_paths,
arrow_config=arrow_config,
)
# Now the forward path could be called on this model, like a normal PeftModel.
```
To encode general knowledge, GenKnowSub subtracts the average of the provided general adapters from each task-specific adapter once, before routing begins. Furthermore, the ability to add or remove adapters after calling ```create_arrow_model``` (as described in the Arrow section) is still supported in this case.
> [!TIP]
> **Things to keep in mind when using Arrow + GenKnowSub:**
>
> - All LoRA adapters (task-specific and general) must share the same ```rank``` and ```target_modules```.
>
> - Any inconsistency in these settings will raise an error in ```create_arrow_model```.
>
> - Having different scaling factors (```lora_alpha```) across task adapters is supported — Arrow handles them automatically.
>
> - Merging the ```"arrow_router"``` is not supported, due to its dynamic routing behavior.
>
> - In create_arrow_model, task adapters are loaded as ```task_i``` and general adapters as ```gks_j``` (where ```i``` and ```j``` are indices). The function ensures consistency of ```target_modules```, ```rank```, and whether adapters are applied to ```Linear``` or ```Linear4bit``` layers. It then adds the ```"arrow_router"``` module and activates it. Any customization of this process requires overriding ```create_arrow_model```.
>
> - This implementation is compatible with 4-bit quantization (via bitsandbytes):
>
> ```py
> from transformers import AutoModelForCausalLM, BitsAndBytesConfig
> import torch
>
> # Quantisation config
> bnb_config = BitsAndBytesConfig(
> load_in_4bit=True,
> bnb_4bit_quant_type="nf4",
> bnb_4bit_compute_dtype=torch.bfloat16,
> bnb_4bit_use_double_quant=False,
> )
>
> # Loading the model
> base_model = AutoModelForCausalLM.from_pretrained(
> "microsoft/Phi-3-mini-4k-instruct",
> dtype=torch.bfloat16,
> device_map="auto",
> quantization_config=bnb_config,
> )
>
> # Now call create_arrow_model() as we explained before.
> ```