mirror of
https://github.com/huggingface/peft.git
synced 2025-10-20 23:43:47 +08:00
Compare commits
223 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 0649947396 | |||
| b5acf5d6be | |||
| 748f7968f3 | |||
| 47b3712898 | |||
| 2558dd872d | |||
| 6f41990da4 | |||
| d8fec400c7 | |||
| 32f3878870 | |||
| cb08d095a5 | |||
| 86d086ec37 | |||
| 02ae6bcb37 | |||
| 77b7238b90 | |||
| 3edcebf713 | |||
| e0cb15e2ee | |||
| 3ec55f4ac4 | |||
| 608a90ded9 | |||
| e19f7bf424 | |||
| 250b7eb85f | |||
| f5f7b67d60 | |||
| 7a22b7daf0 | |||
| e7b47ac01d | |||
| 8bc3c0861d | |||
| 383e1fab0e | |||
| d0fa70aeb6 | |||
| b1d6c77108 | |||
| f0d3c6b892 | |||
| 3d9529d190 | |||
| 835181460c | |||
| 3d6520e2eb | |||
| 5a4b9cade6 | |||
| 144b7345c2 | |||
| bdb856786e | |||
| ed865e2812 | |||
| 56773b9a92 | |||
| c8974c5880 | |||
| 7671926243 | |||
| 9f0cfc9919 | |||
| 811169939f | |||
| b0f1bb468c | |||
| 31c884e934 | |||
| 88875f1cf5 | |||
| 0d283ae0e6 | |||
| e07095a654 | |||
| 5b60ec0204 | |||
| dfac641c63 | |||
| 26726bf1dd | |||
| 16ec3f995a | |||
| ca6bbb594f | |||
| 2e821c1dc8 | |||
| 8452d71e14 | |||
| 02b5aeddf9 | |||
| c4c826c0c0 | |||
| d582b68c7f | |||
| 4537317961 | |||
| ffb8512396 | |||
| 78daa4cf76 | |||
| 65b75a6798 | |||
| a62b337940 | |||
| 8221246f2f | |||
| 8e979fc732 | |||
| a86b29a217 | |||
| 8dd45b75d7 | |||
| 91e4b0879d | |||
| a18734d87a | |||
| 6008f272a5 | |||
| a9425d1409 | |||
| 3b63996964 | |||
| 3eb6bbacee | |||
| 5471c9a1be | |||
| d28fffb917 | |||
| 6dca6d2292 | |||
| a1fe368bfc | |||
| 234bbabd9b | |||
| e3840c249e | |||
| 7e84dec20b | |||
| e7e95c004b | |||
| e597388305 | |||
| 7662f342e0 | |||
| b58b13b528 | |||
| 98f4db2c79 | |||
| c43cc5028e | |||
| 84abf5a5ab | |||
| 34f3fba2b3 | |||
| 9119b780eb | |||
| 7e5335d093 | |||
| 096fe53737 | |||
| 90aa2c1e05 | |||
| 01732176e0 | |||
| aa2ca83ca7 | |||
| 1b3b7b5b2a | |||
| bc9426f10b | |||
| 3967fcc8ea | |||
| 23213cad8d | |||
| 2efc36ccdf | |||
| cc27cfd478 | |||
| b74c2f644d | |||
| 470b66c639 | |||
| f81147268e | |||
| 37dd675f91 | |||
| 7b7e4b2194 | |||
| 043d5c0bd6 | |||
| 8a0dce2fb9 | |||
| ede3c7df22 | |||
| cf467d8aa0 | |||
| 47c4d9578c | |||
| 65513e5db4 | |||
| f5a95930c2 | |||
| 963e3128ed | |||
| 8db74d42c4 | |||
| a564779b67 | |||
| cde8f1af2b | |||
| 25dec602f3 | |||
| 83de1af281 | |||
| 5f2084698b | |||
| e95dc1360b | |||
| 234774345b | |||
| 7d0c0a33d3 | |||
| 7716dd86e9 | |||
| 60ec4d8502 | |||
| 6e953810af | |||
| a1c472f08f | |||
| 055e4dbe1e | |||
| c1a83fd692 | |||
| 7da7f85188 | |||
| eba459553c | |||
| 9bb83ed1a5 | |||
| b5492db514 | |||
| ddf90a8b2f | |||
| 97f3ed577e | |||
| 17273aa4bf | |||
| fc78a2491e | |||
| 497bbeafbd | |||
| 21d8d467dc | |||
| e805a3173a | |||
| 9350ab8a9d | |||
| 912ad41e96 | |||
| ce925d844a | |||
| d1be2696fd | |||
| 4da2876a10 | |||
| a30e006bb2 | |||
| fff24008eb | |||
| dffde4537f | |||
| 9d943672c0 | |||
| 1a7f3e3478 | |||
| 68b90a14d7 | |||
| 75e4ef3536 | |||
| 5e4aa7eb92 | |||
| 5eb5b492af | |||
| a2d96d097a | |||
| 30889ef260 | |||
| 67918efb49 | |||
| 189a9a666d | |||
| bfc102c0c0 | |||
| 1c1c7fdaa6 | |||
| 4a15595822 | |||
| bb2471d926 | |||
| 54ca31153d | |||
| ebbff4023a | |||
| 62237dc9b1 | |||
| eaa5eef28e | |||
| bf54136a79 | |||
| a43ec59762 | |||
| 0089ebd272 | |||
| fe01d6de85 | |||
| f9b673ea37 | |||
| dc28a61e82 | |||
| 71585d611f | |||
| c6bcf91ca1 | |||
| 4354a7d496 | |||
| f36f50acb4 | |||
| 777c0b6ad7 | |||
| 6451cbd70c | |||
| 7d28536b18 | |||
| eb2c12d99a | |||
| c6b28a22b8 | |||
| e96eef9ea1 | |||
| 54ee2fb1af | |||
| cbd783b4df | |||
| 26504a0119 | |||
| 4186c9b104 | |||
| 8665e2b571 | |||
| cbf346d962 | |||
| 2a0fb71f4f | |||
| c4cf9e7d3b | |||
| cf04d0353f | |||
| 4023da904f | |||
| 6fe1aac65d | |||
| 799420aef1 | |||
| 993836ff90 | |||
| 1c9679ac71 | |||
| e745ffd7d0 | |||
| 029dcd5a1c | |||
| 482a2a6d9a | |||
| 119de1715c | |||
| a0a46c06db | |||
| 3708793ba9 | |||
| 46a84bd395 | |||
| bd544bb2ce | |||
| 55c37e9c0b | |||
| 997e6ec5ab | |||
| ddb114af0a | |||
| 4b02148af2 | |||
| 0f1e9091cc | |||
| 88e2e75cc3 | |||
| c9df262d69 | |||
| 67a08009ff | |||
| 971dd6e815 | |||
| ee6f6dcee7 | |||
| 21c304f6f6 | |||
| e73967edea | |||
| b08e6faf2b | |||
| 5c13ea3b12 | |||
| 00b820061e | |||
| 504d3c8329 | |||
| fc9f4b3176 | |||
| 895513c465 | |||
| c893394808 | |||
| 86562eec49 | |||
| b467e3de5c | |||
| 2ab005f3ab | |||
| b482391b80 | |||
| d56df7fc64 | |||
| a87ff4c744 |
21
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
21
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@ -15,17 +15,17 @@ body:
|
||||
attributes:
|
||||
label: Who can help?
|
||||
description: |
|
||||
Your issue will be replied to more quickly if you can figure out the right person to tag with @
|
||||
Your issue will be replied to more quickly if you can figure out the right person to tag with @.
|
||||
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
|
||||
|
||||
|
||||
All issues are read by one of the core maintainers, so if you don't know who to tag, just leave this blank and
|
||||
a core maintainer will ping the right person.
|
||||
|
||||
|
||||
Please tag fewer than 3 people.
|
||||
|
||||
Library: @pacman100 @younesbelkada @sayakpaul
|
||||
|
||||
Documentation: @stevhliu and @MKhalusova
|
||||
|
||||
Library: @pacman100 @younesbelkada @benjaminbossan @sayakpaul
|
||||
|
||||
Documentation: @stevhliu
|
||||
|
||||
placeholder: "@Username ..."
|
||||
|
||||
@ -55,12 +55,11 @@ body:
|
||||
label: Reproduction
|
||||
description: |
|
||||
Please provide a code sample that reproduces the problem you ran into. It can be a Colab link or just a code snippet.
|
||||
Please provide the simplest reproducer as possible so that we can quickly fix the issue.
|
||||
Please provide the simplest reproducer as possible so that we can quickly fix the issue. When you paste
|
||||
the error message, please include the full traceback.
|
||||
|
||||
placeholder: |
|
||||
Reproducer:
|
||||
|
||||
|
||||
Reproducer:
|
||||
|
||||
- type: textarea
|
||||
id: expected-behavior
|
||||
|
||||
143
.github/workflows/build_docker_images.yml
vendored
143
.github/workflows/build_docker_images.yml
vendored
@ -10,6 +10,9 @@ concurrency:
|
||||
group: docker-image-builds
|
||||
cancel-in-progress: false
|
||||
|
||||
env:
|
||||
CI_SLACK_CHANNEL: ${{ secrets.CI_DOCKER_CHANNEL }}
|
||||
|
||||
jobs:
|
||||
latest-cpu:
|
||||
name: "Latest Peft CPU [dev]"
|
||||
@ -42,6 +45,15 @@ jobs:
|
||||
push: true
|
||||
tags: huggingface/peft-cpu
|
||||
|
||||
- name: Post to Slack
|
||||
if: always()
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: "C06LKJB31RU"
|
||||
title: 🤗 Results of the PEFT-CPU docker build
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
latest-cuda:
|
||||
name: "Latest Peft GPU [dev]"
|
||||
runs-on: ubuntu-latest
|
||||
@ -72,3 +84,134 @@ jobs:
|
||||
context: ./docker/peft-gpu
|
||||
push: true
|
||||
tags: huggingface/peft-gpu
|
||||
|
||||
- name: Post to Slack
|
||||
if: always()
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: "C06LKJB31RU"
|
||||
title: 🤗 Results of the PEFT-GPU docker build
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
latest-cuda-bnb-source:
|
||||
name: "Latest Peft GPU + bnb source [dev]"
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
sudo ls -l /usr/local/lib/
|
||||
sudo ls -l /usr/share/
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
sudo rm -rf /usr/local/lib/android
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
- name: Login to DockerHub
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
|
||||
- name: Build and Push GPU
|
||||
uses: docker/build-push-action@v4
|
||||
with:
|
||||
context: ./docker/peft-gpu-bnb-source
|
||||
push: true
|
||||
tags: huggingface/peft-gpu-bnb-source
|
||||
|
||||
- name: Post to Slack
|
||||
if: always()
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: "C06LKJB31RU"
|
||||
title: 🤗 Results of the PEFT-GPU (bnb source / HF latest) docker build
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
latest-cuda-bnb-source-latest:
|
||||
name: "Latest Peft GPU + bnb source [accelerate / peft / transformers latest]"
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
sudo ls -l /usr/local/lib/
|
||||
sudo ls -l /usr/share/
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
sudo rm -rf /usr/local/lib/android
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
- name: Login to DockerHub
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
|
||||
- name: Build and Push GPU
|
||||
uses: docker/build-push-action@v4
|
||||
with:
|
||||
context: ./docker/peft-gpu-bnb-latest
|
||||
push: true
|
||||
tags: huggingface/peft-gpu-bnb-latest
|
||||
|
||||
- name: Post to Slack
|
||||
if: always()
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: "C06LKJB31RU"
|
||||
title: 🤗 Results of the PEFT-GPU (bnb source / HF source) docker build
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
latest-cuda-bnb-source-multi:
|
||||
name: "Latest Peft GPU + bnb (multi-backend) source [accelerate / peft / transformers source]"
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
sudo ls -l /usr/local/lib/
|
||||
sudo ls -l /usr/share/
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
sudo rm -rf /usr/local/lib/android
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
- name: Login to DockerHub
|
||||
uses: docker/login-action@v1
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_PASSWORD }}
|
||||
|
||||
- name: Build and Push GPU
|
||||
uses: docker/build-push-action@v4
|
||||
with:
|
||||
context: ./docker/peft-gpu-bnb-multi-source
|
||||
push: true
|
||||
tags: huggingface/peft-gpu-bnb-multi-source
|
||||
|
||||
- name: Post to Slack
|
||||
if: always()
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
slack_channel: "C06LKJB31RU"
|
||||
title: 🤗 Results of the PEFT-GPU (bnb source multi-backend / HF latest) docker build
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
|
||||
|
||||
|
||||
3
.github/workflows/build_documentation.yml
vendored
3
.github/workflows/build_documentation.yml
vendored
@ -14,6 +14,7 @@ jobs:
|
||||
commit_sha: ${{ github.sha }}
|
||||
package: peft
|
||||
notebook_folder: peft_docs
|
||||
custom_container: huggingface/transformers-doc-builder
|
||||
secrets:
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
|
||||
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
|
||||
|
||||
1
.github/workflows/build_pr_documentation.yml
vendored
1
.github/workflows/build_pr_documentation.yml
vendored
@ -14,3 +14,4 @@ jobs:
|
||||
commit_sha: ${{ github.event.pull_request.head.sha }}
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: peft
|
||||
custom_container: huggingface/transformers-doc-builder
|
||||
|
||||
133
.github/workflows/nightly-bnb.yml
vendored
Normal file
133
.github/workflows/nightly-bnb.yml
vendored
Normal file
@ -0,0 +1,133 @@
|
||||
name: BNB from source self-hosted runner with slow tests (scheduled)
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "0 2 * * *"
|
||||
|
||||
env:
|
||||
RUN_SLOW: "yes"
|
||||
IS_GITHUB_CI: "1"
|
||||
# To be able to run tests on CUDA 12.2
|
||||
NVIDIA_DISABLE_REQUIRE: "1"
|
||||
SLACK_API_TOKEN: ${{ secrets.SLACK_API_TOKEN }}
|
||||
|
||||
|
||||
jobs:
|
||||
run_all_tests_single_gpu:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
docker-image-name: ["huggingface/peft-gpu-bnb-source:latest", "huggingface/peft-gpu-bnb-latest:latest", "huggingface/peft-gpu-bnb-multi-source:latest"]
|
||||
runs-on: [self-hosted, single-gpu, nvidia-gpu, t4, ci]
|
||||
env:
|
||||
CUDA_VISIBLE_DEVICES: "0"
|
||||
TEST_TYPE: "single_gpu_${{ matrix.docker-image-name }}"
|
||||
container:
|
||||
image: ${{ matrix.docker-image-name }}
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Pip install
|
||||
run: |
|
||||
source activate peft
|
||||
pip install -e . --no-deps
|
||||
pip install pytest-reportlog pytest-cov parameterized datasets scipy einops
|
||||
pip install "pytest>=7.2.0,<8.0.0" # see: https://github.com/huggingface/transformers/blob/ce4fff0be7f6464d713f7ac3e0bbaafbc6959ae5/setup.py#L148C6-L148C26
|
||||
mkdir transformers-clone && git clone https://github.com/huggingface/transformers.git transformers-clone # rename to transformers clone to avoid modules conflict
|
||||
if [ "${{ matrix.docker-image-name }}" == "huggingface/peft-gpu-bnb-latest:latest" ]; then
|
||||
cd transformers-clone
|
||||
transformers_version=$(pip show transformers | grep '^Version:' | cut -d ' ' -f2 | sed 's/\.dev0//')
|
||||
echo "Checking out tag for Transformers version: v$transformers_version"
|
||||
git fetch --tags
|
||||
git checkout tags/v$transformers_version
|
||||
cd ..
|
||||
fi
|
||||
- name: Run examples on single GPU
|
||||
if: always()
|
||||
run: |
|
||||
source activate peft
|
||||
make tests_examples_single_gpu_bnb
|
||||
|
||||
- name: Run core tests on single GPU
|
||||
if: always()
|
||||
run: |
|
||||
source activate peft
|
||||
make tests_core_single_gpu_bnb
|
||||
|
||||
- name: Run transformers tests on single GPU
|
||||
if: always()
|
||||
run: |
|
||||
source activate peft
|
||||
make transformers_tests
|
||||
|
||||
- name: Generate Report
|
||||
if: always()
|
||||
run: |
|
||||
pip install slack_sdk tabulate
|
||||
python scripts/log_reports.py --slack_channel_name bnb-daily-ci-collab >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
run_all_tests_multi_gpu:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
docker-image-name: ["huggingface/peft-gpu-bnb-source:latest", "huggingface/peft-gpu-bnb-latest:latest", "huggingface/peft-gpu-bnb-multi-source:latest"]
|
||||
runs-on: [self-hosted, multi-gpu, nvidia-gpu, t4, ci]
|
||||
env:
|
||||
CUDA_VISIBLE_DEVICES: "0,1"
|
||||
TEST_TYPE: "multi_gpu_${{ matrix.docker-image-name }}"
|
||||
container:
|
||||
image: ${{ matrix.docker-image-name }}
|
||||
options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Pip install
|
||||
run: |
|
||||
source activate peft
|
||||
pip install -e . --no-deps
|
||||
pip install pytest-reportlog pytest-cov parameterized datasets scipy einops
|
||||
pip install "pytest>=7.2.0,<8.0.0" # see: https://github.com/huggingface/transformers/blob/ce4fff0be7f6464d713f7ac3e0bbaafbc6959ae5/setup.py#L148C6-L148C26
|
||||
mkdir transformers-clone && git clone https://github.com/huggingface/transformers.git transformers-clone
|
||||
if [ "${{ matrix.docker-image-name }}" == "huggingface/peft-gpu-bnb-latest:latest" ]; then
|
||||
cd transformers-clone
|
||||
transformers_version=$(pip show transformers | grep '^Version:' | cut -d ' ' -f2 | sed 's/\.dev0//')
|
||||
echo "Checking out tag for Transformers version: v$transformers_version"
|
||||
git fetch --tags
|
||||
git checkout tags/v$transformers_version
|
||||
cd ..
|
||||
fi
|
||||
|
||||
- name: Run core GPU tests on multi-gpu
|
||||
if: always()
|
||||
run: |
|
||||
source activate peft
|
||||
|
||||
- name: Run examples on multi GPU
|
||||
if: always()
|
||||
run: |
|
||||
source activate peft
|
||||
make tests_examples_multi_gpu_bnb
|
||||
|
||||
- name: Run core tests on multi GPU
|
||||
if: always()
|
||||
run: |
|
||||
source activate peft
|
||||
make tests_core_multi_gpu_bnb
|
||||
|
||||
- name: Run transformers tests on multi GPU
|
||||
if: always()
|
||||
run: |
|
||||
source activate peft
|
||||
make transformers_tests
|
||||
|
||||
- name: Generate Report
|
||||
if: always()
|
||||
run: |
|
||||
pip install slack_sdk tabulate
|
||||
python scripts/log_reports.py --slack_channel_name bnb-daily-ci-collab >> $GITHUB_STEP_SUMMARY
|
||||
5
.github/workflows/nightly.yml
vendored
5
.github/workflows/nightly.yml
vendored
@ -49,6 +49,11 @@ jobs:
|
||||
run: |
|
||||
source activate peft
|
||||
make tests_core_single_gpu
|
||||
|
||||
- name: Run regression tests on single GPU
|
||||
run: |
|
||||
source activate peft
|
||||
make tests_regression
|
||||
|
||||
- name: Generate Report
|
||||
if: always()
|
||||
|
||||
59
.github/workflows/test-docker-build.yml
vendored
Normal file
59
.github/workflows/test-docker-build.yml
vendored
Normal file
@ -0,0 +1,59 @@
|
||||
name: Test Docker images (on PR)
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
paths:
|
||||
# Run only when DockerFile files are modified
|
||||
- "docker/**"
|
||||
jobs:
|
||||
get_changed_files:
|
||||
name: "Build all modified docker images"
|
||||
runs-on: ubuntu-latest
|
||||
outputs:
|
||||
matrix: ${{ steps.set-matrix.outputs.matrix }}
|
||||
steps:
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
- name: Get changed files
|
||||
id: changed-files
|
||||
uses: tj-actions/changed-files@1c8e6069583811afb28f97afeaf8e7da80c6be5c #v42
|
||||
with:
|
||||
files: docker/**
|
||||
json: "true"
|
||||
- name: Run step if only the files listed above change
|
||||
if: steps.changed-files.outputs.any_changed == 'true'
|
||||
id: set-matrix
|
||||
env:
|
||||
ALL_CHANGED_FILES: ${{ steps.changed-files.outputs.all_changed_files }}
|
||||
run: |
|
||||
echo "matrix=${{ steps.changed-files.outputs.all_changed_files}}" >> $GITHUB_OUTPUT
|
||||
build_modified_files:
|
||||
needs: get_changed_files
|
||||
name: Build Docker images on modified files
|
||||
runs-on: ubuntu-latest
|
||||
if: ${{ needs.get_changed_files.outputs.matrix }} != ''
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
docker-file: ${{ fromJson(needs.get_changed_files.outputs.matrix) }}
|
||||
steps:
|
||||
- name: Cleanup disk
|
||||
run: |
|
||||
sudo ls -l /usr/local/lib/
|
||||
sudo ls -l /usr/share/
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
sudo rm -rf /usr/local/lib/android
|
||||
sudo rm -rf /usr/share/dotnet
|
||||
sudo du -sh /usr/local/lib/
|
||||
sudo du -sh /usr/share/
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
- name: Build Docker image
|
||||
uses: docker/build-push-action@v4
|
||||
with:
|
||||
file: ${{ matrix.docker-file }}
|
||||
context: .
|
||||
push: False
|
||||
28
.github/workflows/tests-main.yml
vendored
Normal file
28
.github/workflows/tests-main.yml
vendored
Normal file
@ -0,0 +1,28 @@
|
||||
name: tests on transformers main
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [main]
|
||||
paths-ignore:
|
||||
- 'docs/**'
|
||||
|
||||
jobs:
|
||||
tests:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python 3.11
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: 3.11
|
||||
cache: "pip"
|
||||
cache-dependency-path: "setup.py"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
# cpu version of pytorch
|
||||
pip install -U git+https://github.com/huggingface/transformers.git
|
||||
pip install -e .[test]
|
||||
- name: Test with pytest
|
||||
run: |
|
||||
make test
|
||||
6
.github/workflows/tests.yml
vendored
6
.github/workflows/tests.yml
vendored
@ -3,7 +3,11 @@ name: tests
|
||||
on:
|
||||
push:
|
||||
branches: [main]
|
||||
paths-ignore:
|
||||
- 'docs/**'
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- 'docs/**'
|
||||
|
||||
jobs:
|
||||
check_code_quality:
|
||||
@ -29,7 +33,7 @@ jobs:
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.8", "3.9", "3.10", "3.11"]
|
||||
os: ["ubuntu-latest", "macos-latest", "windows-latest"]
|
||||
os: ["ubuntu-latest", "macos-12", "windows-latest"]
|
||||
runs-on: ${{ matrix.os }}
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@ -138,4 +138,4 @@ dmypy.json
|
||||
.DS_Store
|
||||
|
||||
# More test things
|
||||
wandb
|
||||
wandb
|
||||
|
||||
13
.pre-commit-config.yaml
Normal file
13
.pre-commit-config.yaml
Normal file
@ -0,0 +1,13 @@
|
||||
repos:
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
rev: v0.2.1
|
||||
hooks:
|
||||
- id: ruff
|
||||
args:
|
||||
- --fix
|
||||
- id: ruff-format
|
||||
- repo: https://github.com/pre-commit/pre-commit-hooks
|
||||
rev: v4.5.0
|
||||
hooks:
|
||||
- id: check-merge-conflict
|
||||
- id: check-yaml
|
||||
24
Makefile
24
Makefile
@ -1,19 +1,19 @@
|
||||
.PHONY: quality style test docs
|
||||
|
||||
check_dirs := src tests examples docs
|
||||
check_dirs := src tests examples docs scripts docker
|
||||
|
||||
# Check that source code meets quality standards
|
||||
|
||||
# this target runs checks on all files
|
||||
quality:
|
||||
black --check $(check_dirs)
|
||||
ruff $(check_dirs)
|
||||
ruff format --check $(check_dirs)
|
||||
doc-builder style src/peft tests docs/source --max_len 119 --check_only
|
||||
|
||||
# Format source code automatically and check is there are any problems left that need manual fixing
|
||||
style:
|
||||
black $(check_dirs)
|
||||
ruff $(check_dirs) --fix
|
||||
ruff format $(check_dirs)
|
||||
doc-builder style src/peft tests docs/source --max_len 119
|
||||
|
||||
test:
|
||||
@ -35,5 +35,21 @@ tests_common_gpu:
|
||||
python -m pytest tests/test_decoder_models.py $(if $(IS_GITHUB_CI),--report-log "common_decoder.log",)
|
||||
python -m pytest tests/test_encoder_decoder_models.py $(if $(IS_GITHUB_CI),--report-log "common_encoder_decoder.log",)
|
||||
|
||||
tests_examples_multi_gpu_bnb:
|
||||
python -m pytest -m "multi_gpu_tests and bitsandbytes" tests/test_gpu_examples.py $(if $(IS_GITHUB_CI),--report-log "multi_gpu_examples.log",)
|
||||
|
||||
tests_examples_single_gpu_bnb:
|
||||
python -m pytest -m "single_gpu_tests and bitsandbytes" tests/test_gpu_examples.py $(if $(IS_GITHUB_CI),--report-log "single_gpu_examples.log",)
|
||||
|
||||
tests_core_multi_gpu_bnb:
|
||||
python -m pytest -m "multi_gpu_tests and bitsandbytes" tests/test_common_gpu.py $(if $(IS_GITHUB_CI),--report-log "core_multi_gpu.log",)
|
||||
|
||||
tests_core_single_gpu_bnb:
|
||||
python -m pytest -m "single_gpu_tests and bitsandbytes" tests/test_common_gpu.py $(if $(IS_GITHUB_CI),--report-log "core_single_gpu.log",)
|
||||
|
||||
# For testing transformers tests for bnb runners
|
||||
transformers_tests:
|
||||
RUN_SLOW=1 python -m pytest transformers-clone/tests/quantization/bnb $(if $(IS_GITHUB_CI),--report-log "transformers_tests.log",)
|
||||
|
||||
tests_regression:
|
||||
python -m pytest --regression tests/regression/ $(if $(IS_GITHUB_CI),--report-log "regression_tests.log",)
|
||||
python -m pytest -s --regression tests/regression/ $(if $(IS_GITHUB_CI),--report-log "regression_tests.log",)
|
||||
|
||||
436
README.md
436
README.md
@ -19,25 +19,24 @@ limitations under the License.
|
||||
<p>State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods</p>
|
||||
</h3>
|
||||
|
||||
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model's parameters. Fine-tuning large-scale PLMs is often prohibitively costly. In this regard, PEFT methods only fine-tune a small number of (extra) model parameters, thereby greatly decreasing the computational and storage costs. Recent State-of-the-Art PEFT techniques achieve performance comparable to that of full fine-tuning.
|
||||
Fine-tuning large pretrained models is often prohibitively costly due to their scale. Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of large pretrained models to various downstream applications by only fine-tuning a small number of (extra) model parameters instead of all the model's parameters. This significantly decreases the computational and storage costs. Recent state-of-the-art PEFT techniques achieve performance comparable to fully fine-tuned models.
|
||||
|
||||
Seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
|
||||
PEFT is integrated with Transformers for easy model training and inference, Diffusers for conveniently managing different adapters, and Accelerate for distributed training and inference for really big models.
|
||||
|
||||
Supported methods:
|
||||
> [!TIP]
|
||||
> Visit the [PEFT](https://huggingface.co/PEFT) organization to read about the PEFT methods implemented in the library and to see notebooks demonstrating how to apply these methods to a variety of downstream tasks. Click the "Watch repos" button on the organization page to be notified of newly implemented methods and notebooks!
|
||||
|
||||
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/abs/2106.09685)
|
||||
2. Prefix Tuning: [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://aclanthology.org/2021.acl-long.353/), [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
|
||||
3. P-Tuning: [GPT Understands, Too](https://arxiv.org/abs/2103.10385)
|
||||
4. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/abs/2104.08691)
|
||||
5. AdaLoRA: [Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning](https://arxiv.org/abs/2303.10512)
|
||||
6. $(IA)^3$: [Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning](https://arxiv.org/abs/2205.05638)
|
||||
7. MultiTask Prompt Tuning: [Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning](https://arxiv.org/abs/2303.02861)
|
||||
8. LoHa: [FedPara: Low-Rank Hadamard Product for Communication-Efficient Federated Learning](https://arxiv.org/abs/2108.06098)
|
||||
9. LoKr: [KronA: Parameter Efficient Tuning with Kronecker Adapter](https://arxiv.org/abs/2212.10650) based on [Navigating Text-To-Image Customization:From LyCORIS Fine-Tuning to Model Evaluation](https://arxiv.org/abs/2309.14859) implementation
|
||||
10. LoftQ: [LoftQ: LoRA-Fine-Tuning-aware Quantization for Large Language Models](https://arxiv.org/abs/2310.08659)
|
||||
11. OFT: [Controlling Text-to-Image Diffusion by Orthogonal Finetuning](https://arxiv.org/abs/2306.07280)
|
||||
Check the PEFT Adapters API Reference section for a list of supported PEFT methods, and read the [Adapters](https://huggingface.co/docs/peft/en/conceptual_guides/adapter), [Soft prompts](https://huggingface.co/docs/peft/en/conceptual_guides/prompting), and [IA3](https://huggingface.co/docs/peft/en/conceptual_guides/ia3) conceptual guides to learn more about how these methods work.
|
||||
|
||||
## Getting started
|
||||
## Quickstart
|
||||
|
||||
Install PEFT from pip:
|
||||
|
||||
```bash
|
||||
pip install peft
|
||||
```
|
||||
|
||||
Prepare a model for training with a PEFT method such as LoRA by wrapping the base model and PEFT configuration with `get_peft_model`. For the bigscience/mt0-large model, you're only training 0.19% of the parameters!
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForSeq2SeqLM
|
||||
@ -52,17 +51,35 @@ peft_config = LoraConfig(
|
||||
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
|
||||
"trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
|
||||
```
|
||||
|
||||
## Use Cases
|
||||
To load a PEFT model for inference:
|
||||
|
||||
### Get comparable performance to full finetuning by adapting LLMs to downstream tasks using consumer hardware
|
||||
```py
|
||||
from peft import AutoPeftModelForCausalLM
|
||||
from transformers import AutoTokenizer
|
||||
import torch
|
||||
|
||||
GPU memory required for adapting LLMs on the few-shot dataset [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints). Here, settings considered
|
||||
are full finetuning, PEFT-LoRA using plain PyTorch and PEFT-LoRA using DeepSpeed with CPU Offloading.
|
||||
model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora").to("cuda")
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
|
||||
|
||||
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
|
||||
model.eval()
|
||||
inputs = tokenizer("Preheat the oven to 350 degrees and place the cookie dough", return_tensors="pt")
|
||||
|
||||
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)
|
||||
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
|
||||
|
||||
"Preheat the oven to 350 degrees and place the cookie dough in the center of the oven. In a large bowl, combine the flour, baking powder, baking soda, salt, and cinnamon. In a separate bowl, combine the egg yolks, sugar, and vanilla."
|
||||
```
|
||||
|
||||
## Why you should use PEFT
|
||||
|
||||
There are many benefits of using PEFT but the main one is the huge savings in compute and storage, making PEFT applicable to many different use cases.
|
||||
|
||||
### High performance on consumer hardware
|
||||
|
||||
Consider the memory requirements for training the following models on the [ought/raft/twitter_complaints](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints) dataset with an A100 80GB GPU with more than 64GB of CPU RAM.
|
||||
|
||||
| Model | Full Finetuning | PEFT-LoRA PyTorch | PEFT-LoRA DeepSpeed with CPU Offloading |
|
||||
| --------- | ---- | ---- | ---- |
|
||||
@ -70,9 +87,7 @@ Hardware: Single A100 80GB GPU with CPU RAM above 64GB
|
||||
| bigscience/mt0-xxl (12B params) | OOM GPU | 56GB GPU / 3GB CPU | 22GB GPU / 52GB CPU |
|
||||
| bigscience/bloomz-7b1 (7B params) | OOM GPU | 32GB GPU / 3.8GB CPU | 18.1GB GPU / 35GB CPU |
|
||||
|
||||
Performance of PEFT-LoRA tuned [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) on [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints) leaderboard.
|
||||
A point to note is that we didn't try to squeeze performance by playing around with input instruction templates, LoRA hyperparams and other training related hyperparams. Also, we didn't use the larger 13B [mt0-xxl](https://huggingface.co/bigscience/mt0-xxl) model.
|
||||
So, we are already seeing comparable performance to SoTA with parameter efficient tuning. Also, the final additional checkpoint size is just `19MB` in comparison to `11GB` size of the backbone [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) model, but one still has to load the original full size model.
|
||||
With LoRA you can fully finetune a 12B parameter model that would've otherwise run out of memory on the 80GB GPU, and comfortably fit and train a 3B parameter model. When you look at the 3B parameter model's performance, it is comparable to a fully finetuned model at a fraction of the GPU memory.
|
||||
|
||||
| Submission Name | Accuracy |
|
||||
| --------- | ---- |
|
||||
@ -80,367 +95,58 @@ So, we are already seeing comparable performance to SoTA with parameter efficien
|
||||
| Flan-T5 | 0.892 |
|
||||
| lora-t0-3b | 0.863 |
|
||||
|
||||
**Therefore, we can see that performance comparable to SoTA is achievable by PEFT methods with consumer hardware such as 16GB and 24GB GPUs.**
|
||||
> [!TIP]
|
||||
> The bigscience/T0_3B model performance isn't optimized in the table above. You can squeeze even more performance out of it by playing around with the input instruction templates, LoRA hyperparameters, and other training related hyperparameters. The final checkpoint size of this model is just 19MB compared to 11GB of the full bigscience/T0_3B model. Learn more about the advantages of finetuning with PEFT in this [blog post](https://www.philschmid.de/fine-tune-flan-t5-peft).
|
||||
|
||||
An insightful blogpost explaining the advantages of using PEFT for fine-tuning FlanT5-XXL: [https://www.philschmid.de/fine-tune-flan-t5-peft](https://www.philschmid.de/fine-tune-flan-t5-peft)
|
||||
### Quantization
|
||||
|
||||
### Parameter Efficient Tuning of Diffusion Models
|
||||
Quantization is another method for reducing the memory requirements of a model by representing the data in a lower precision. It can be combined with PEFT methods to make it even easier to train and load LLMs for inference.
|
||||
|
||||
GPU memory required by different settings during training is given below. The final checkpoint size is `8.8 MB`.
|
||||
* Learn how to finetune [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) with QLoRA and the [TRL](https://huggingface.co/docs/trl/index) library on a 16GB GPU in the [Finetune LLMs on your own consumer hardware using tools from PyTorch and Hugging Face ecosystem](https://pytorch.org/blog/finetune-llms/) blog post.
|
||||
* Learn how to finetune a [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) model for multilingual automatic speech recognition with LoRA and 8-bit quantization in this [notebook](https://colab.research.google.com/drive/1DOkD_5OUjFa0r5Ik3SgywJLJtEo2qLxO?usp=sharing) (see this [notebook](https://colab.research.google.com/drive/1vhF8yueFqha3Y3CpTHN6q9EVcII9EYzs?usp=sharing) instead for an example of streaming a dataset).
|
||||
|
||||
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
|
||||
### Save compute and storage
|
||||
|
||||
PEFT can help you save storage by avoiding full finetuning of models on each of downstream task or dataset. In many cases, you're only finetuning a very small fraction of a model's parameters and each checkpoint is only a few MBs in size (instead of GBs). These smaller PEFT adapters demonstrate performance comparable to a fully finetuned model. If you have many datasets, you can save a lot of storage with a PEFT model and not have to worry about catastrophic forgetting or overfitting the backbone or base model.
|
||||
|
||||
## PEFT integrations
|
||||
|
||||
PEFT is widely supported across the Hugging Face ecosystem because of the massive efficiency it brings to training and inference.
|
||||
|
||||
### Diffusers
|
||||
|
||||
The iterative diffusion process consumes a lot of memory which can make it difficult to train. PEFT can help reduce the memory requirements and reduce the storage size of the final model checkpoint. For example, consider the memory required for training a Stable Diffusion model with LoRA on an A100 80GB GPU with more than 64GB of CPU RAM. The final model checkpoint size is only 8.8MB!
|
||||
|
||||
| Model | Full Finetuning | PEFT-LoRA | PEFT-LoRA with Gradient Checkpointing |
|
||||
| --------- | ---- | ---- | ---- |
|
||||
| CompVis/stable-diffusion-v1-4 | 27.5GB GPU / 3.97GB CPU | 15.5GB GPU / 3.84GB CPU | 8.12GB GPU / 3.77GB CPU |
|
||||
|
||||
> [!TIP]
|
||||
> Take a look at the [examples/lora_dreambooth/train_dreambooth.py](examples/lora_dreambooth/train_dreambooth.py) training script to try training your own Stable Diffusion model with LoRA, and play around with the [smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth) Space which is running on a T4 instance. Learn more about the PEFT integration in Diffusers in this [tutorial](https://huggingface.co/docs/peft/main/en/tutorial/peft_integrations#diffusers).
|
||||
|
||||
**Training**
|
||||
An example of using LoRA for parameter efficient dreambooth training is given in [`examples/lora_dreambooth/train_dreambooth.py`](examples/lora_dreambooth/train_dreambooth.py)
|
||||
### Accelerate
|
||||
|
||||
```bash
|
||||
export MODEL_NAME= "CompVis/stable-diffusion-v1-4" #"stabilityai/stable-diffusion-2-1"
|
||||
export INSTANCE_DIR="path-to-instance-images"
|
||||
export CLASS_DIR="path-to-class-images"
|
||||
export OUTPUT_DIR="path-to-save-model"
|
||||
[Accelerate](https://huggingface.co/docs/accelerate/index) is a library for distributed training and inference on various training setups and hardware (GPUs, TPUs, Apple Silicon, etc.). PEFT models work with Accelerate out of the box, making it really convenient to train really large models or use them for inference on consumer hardware with limited resources.
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--class_data_dir=$CLASS_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--train_text_encoder \
|
||||
--with_prior_preservation --prior_loss_weight=1.0 \
|
||||
--instance_prompt="a photo of sks dog" \
|
||||
--class_prompt="a photo of dog" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--num_class_images=200 \
|
||||
--use_lora \
|
||||
--lora_r 16 \
|
||||
--lora_alpha 27 \
|
||||
--lora_text_encoder_r 16 \
|
||||
--lora_text_encoder_alpha 17 \
|
||||
--learning_rate=1e-4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--gradient_checkpointing \
|
||||
--max_train_steps=800
|
||||
```
|
||||
### TRL
|
||||
|
||||
Try out the 🤗 Gradio Space which should run seamlessly on a T4 instance:
|
||||
[smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth).
|
||||
PEFT can also be applied to training LLMs with RLHF components such as the ranker and policy. Get started by reading:
|
||||
|
||||
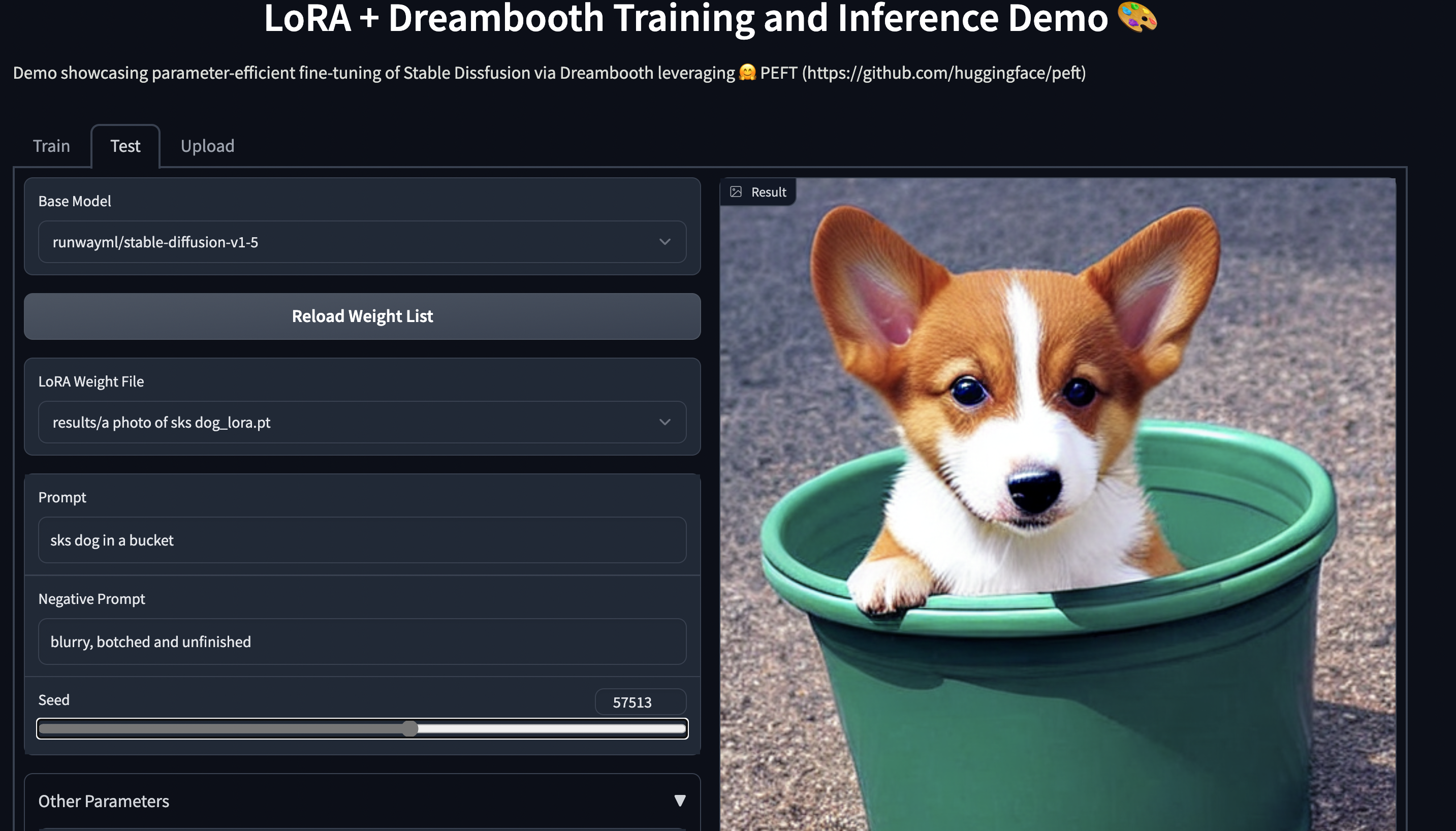
|
||||
* [Fine-tune a Mistral-7b model with Direct Preference Optimization](https://towardsdatascience.com/fine-tune-a-mistral-7b-model-with-direct-preference-optimization-708042745aac) with PEFT and the [TRL](https://huggingface.co/docs/trl/index) library to learn more about the Direct Preference Optimization (DPO) method and how to apply it to a LLM.
|
||||
* [Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU](https://huggingface.co/blog/trl-peft) with PEFT and the [TRL](https://huggingface.co/docs/trl/index) library, and then try out the [gpt2-sentiment_peft.ipynb](https://github.com/huggingface/trl/blob/main/examples/notebooks/gpt2-sentiment.ipynb) notebook to optimize GPT2 to generate positive movie reviews.
|
||||
* [StackLLaMA: A hands-on guide to train LLaMA with RLHF](https://huggingface.co/blog/stackllama) with PEFT, and then try out the [stack_llama/scripts](https://github.com/huggingface/trl/tree/main/examples/research_projects/stack_llama/scripts) for supervised finetuning, reward modeling, and RL finetuning.
|
||||
|
||||
**NEW** ✨ Multi Adapter support and combining multiple LoRA adapters in a weighted combination
|
||||

|
||||
## Model support
|
||||
|
||||
**NEW** ✨ Dreambooth training for Stable Diffusion using LoHa and LoKr adapters [`examples/stable_diffusion/train_dreambooth.py`](examples/stable_diffusion/train_dreambooth.py)
|
||||
Use this [Space](https://stevhliu-peft-methods.hf.space) or check out the [docs](https://huggingface.co/docs/peft/main/en/index) to find which models officially support a PEFT method out of the box. Even if you don't see a model listed below, you can manually configure the model config to enable PEFT for a model. Read the [New transformers architecture](https://huggingface.co/docs/peft/main/en/developer_guides/custom_models#new-transformers-architectures) guide to learn how.
|
||||
|
||||
### Parameter Efficient Tuning of LLMs for RLHF components such as Ranker and Policy
|
||||
- Here is an example in [trl](https://github.com/lvwerra/trl) library using PEFT+INT8 for tuning policy model: [gpt2-sentiment_peft.py](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt2-sentiment_peft.py) and corresponding [Blog](https://huggingface.co/blog/trl-peft)
|
||||
- Example using PEFT for Instruction finetuning, reward model and policy : [stack_llama](https://github.com/lvwerra/trl/tree/main/examples/research_projects/stack_llama/scripts) and corresponding [Blog](https://huggingface.co/blog/stackllama)
|
||||
## Contribute
|
||||
|
||||
### INT8 training of large models in Colab using PEFT LoRA and bitsandbytes
|
||||
|
||||
- Here is now a demo on how to fine tune [OPT-6.7b](https://huggingface.co/facebook/opt-6.7b) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
|
||||
|
||||
- Here is now a demo on how to fine tune [whisper-large](https://huggingface.co/openai/whisper-large-v2) (1.5B params) (14GB in fp16) in a Google Colab: [](https://colab.research.google.com/drive/1DOkD_5OUjFa0r5Ik3SgywJLJtEo2qLxO?usp=sharing) and [](https://colab.research.google.com/drive/1vhF8yueFqha3Y3CpTHN6q9EVcII9EYzs?usp=sharing)
|
||||
|
||||
### Save compute and storage even for medium and small models
|
||||
|
||||
Save storage by avoiding full finetuning of models on each of the downstream tasks/datasets,
|
||||
With PEFT methods, users only need to store tiny checkpoints in the order of `MBs` all the while retaining
|
||||
performance comparable to full finetuning.
|
||||
|
||||
An example of using LoRA for the task of adapting `LayoutLMForTokenClassification` on `FUNSD` dataset is given in `~examples/token_classification/PEFT_LoRA_LayoutLMForTokenClassification_on_FUNSD.py`. We can observe that with only `0.62 %` of parameters being trainable, we achieve performance (F1 0.777) comparable to full finetuning (F1 0.786) (without any hyperparam tuning runs for extracting more performance), and the checkpoint of this is only `2.8MB`. Now, if there are `N` such datasets, just have these PEFT models one for each dataset and save a lot of storage without having to worry about the problem of catastrophic forgetting or overfitting of backbone/base model.
|
||||
|
||||
Another example is fine-tuning [`roberta-large`](https://huggingface.co/roberta-large) on [`MRPC` GLUE](https://huggingface.co/datasets/glue/viewer/mrpc) dataset using different PEFT methods. The notebooks are given in `~examples/sequence_classification`.
|
||||
|
||||
|
||||
## PEFT + 🤗 Accelerate
|
||||
|
||||
PEFT models work with 🤗 Accelerate out of the box. Use 🤗 Accelerate for Distributed training on various hardware such as GPUs, Apple Silicon devices, etc during training.
|
||||
Use 🤗 Accelerate for inferencing on consumer hardware with small resources.
|
||||
|
||||
### Example of PEFT model training using 🤗 Accelerate's DeepSpeed integration
|
||||
|
||||
DeepSpeed version required `v0.8.0`. An example is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py`.
|
||||
a. First, run `accelerate config --config_file ds_zero3_cpu.yaml` and answer the questionnaire.
|
||||
Below are the contents of the config file.
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 1
|
||||
gradient_clipping: 1.0
|
||||
offload_optimizer_device: cpu
|
||||
offload_param_device: cpu
|
||||
zero3_init_flag: true
|
||||
zero3_save_16bit_model: true
|
||||
zero_stage: 3
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
dynamo_backend: 'NO'
|
||||
fsdp_config: {}
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
megatron_lm_config: {}
|
||||
mixed_precision: 'no'
|
||||
num_machines: 1
|
||||
num_processes: 1
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
use_cpu: false
|
||||
```
|
||||
b. run the below command to launch the example script
|
||||
```bash
|
||||
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
|
||||
```
|
||||
|
||||
c. output logs:
|
||||
```bash
|
||||
GPU Memory before entering the train : 1916
|
||||
GPU Memory consumed at the end of the train (end-begin): 66
|
||||
GPU Peak Memory consumed during the train (max-begin): 7488
|
||||
GPU Total Peak Memory consumed during the train (max): 9404
|
||||
CPU Memory before entering the train : 19411
|
||||
CPU Memory consumed at the end of the train (end-begin): 0
|
||||
CPU Peak Memory consumed during the train (max-begin): 0
|
||||
CPU Total Peak Memory consumed during the train (max): 19411
|
||||
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
|
||||
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
|
||||
GPU Memory before entering the eval : 1982
|
||||
GPU Memory consumed at the end of the eval (end-begin): -66
|
||||
GPU Peak Memory consumed during the eval (max-begin): 672
|
||||
GPU Total Peak Memory consumed during the eval (max): 2654
|
||||
CPU Memory before entering the eval : 19411
|
||||
CPU Memory consumed at the end of the eval (end-begin): 0
|
||||
CPU Peak Memory consumed during the eval (max-begin): 0
|
||||
CPU Total Peak Memory consumed during the eval (max): 19411
|
||||
accuracy=100.0
|
||||
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
|
||||
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
|
||||
```
|
||||
|
||||
### Example of PEFT model inference using 🤗 Accelerate's Big Model Inferencing capabilities
|
||||
An example is provided in [this notebook](https://github.com/huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_accelerate_big_model_inference.ipynb).
|
||||
|
||||
|
||||
## Models support matrix
|
||||
|
||||
Find models that are supported out of the box below. Note that PEFT works with almost all models -- if it is not listed, you just need to [do some manual configuration](https://huggingface.co/docs/peft/developer_guides/custom_models).
|
||||
|
||||
### Causal Language Modeling
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|
||||
|--------------| ---- | ---- | ---- | ---- | ---- |
|
||||
| GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| Bloom | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| OPT | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPT-J | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| LLaMA | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| ChatGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| Mistral | ✅ | | | | |
|
||||
|
||||
### Conditional Generation
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|
||||
| --------- | ---- | ---- | ---- | ---- | ---- |
|
||||
| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
### Sequence Classification
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|
||||
| --------- | ---- | ---- | ---- | ---- | ---- |
|
||||
| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPT-2 | ✅ | ✅ | ✅ | ✅ | |
|
||||
| Bloom | ✅ | ✅ | ✅ | ✅ | |
|
||||
| OPT | ✅ | ✅ | ✅ | ✅ | |
|
||||
| GPT-Neo | ✅ | ✅ | ✅ | ✅ | |
|
||||
| GPT-J | ✅ | ✅ | ✅ | ✅ | |
|
||||
| Deberta | ✅ | | ✅ | ✅ | |
|
||||
| Deberta-v2 | ✅ | | ✅ | ✅ | |
|
||||
|
||||
### Token Classification
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|
||||
| --------- | ---- | ---- | ---- | ---- | ---- |
|
||||
| BERT | ✅ | ✅ | | | |
|
||||
| RoBERTa | ✅ | ✅ | | | |
|
||||
| GPT-2 | ✅ | ✅ | | | |
|
||||
| Bloom | ✅ | ✅ | | | |
|
||||
| OPT | ✅ | ✅ | | | |
|
||||
| GPT-Neo | ✅ | ✅ | | | |
|
||||
| GPT-J | ✅ | ✅ | | | |
|
||||
| Deberta | ✅ | | | | |
|
||||
| Deberta-v2 | ✅ | | | | |
|
||||
|
||||
### Text-to-Image Generation
|
||||
|
||||
| Model | LoRA | LoHa | LoKr | OFT | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|
||||
| --------- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
|
||||
| Stable Diffusion | ✅ | ✅ | ✅ | ✅ | | | |
|
||||
|
||||
|
||||
### Image Classification
|
||||
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|
||||
| --------- | ---- | ---- | ---- | ---- | ---- |
|
||||
| ViT | ✅ | | | | |
|
||||
| Swin | ✅ | | | | |
|
||||
|
||||
### Image to text (Multi-modal models)
|
||||
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3
|
||||
| --------- | ---- | ---- | ---- | ---- | ---- |
|
||||
| Blip-2 | ✅ | | | | |
|
||||
|
||||
___Note that we have tested LoRA for [ViT](https://huggingface.co/docs/transformers/model_doc/vit) and [Swin](https://huggingface.co/docs/transformers/model_doc/swin) for fine-tuning on image classification. However, it should be possible to use LoRA for any compatible model [provided](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&search=vit) by 🤗 Transformers. Check out the respective
|
||||
examples to learn more. If you run into problems, please open an issue.___
|
||||
|
||||
The same principle applies to our [segmentation models](https://huggingface.co/models?pipeline_tag=image-segmentation&sort=downloads) as well.
|
||||
|
||||
### Semantic Segmentation
|
||||
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning | IA3 |
|
||||
| --------- | ---- | ---- | ---- | ---- | ---- |
|
||||
| SegFormer | ✅ | | | | |
|
||||
|
||||
|
||||
## Caveats:
|
||||
|
||||
1. Below is an example of using PyTorch FSDP for training. However, it doesn't lead to
|
||||
any GPU memory savings. Please refer issue [[FSDP] FSDP with CPU offload consumes 1.65X more GPU memory when training models with most of the params frozen](https://github.com/pytorch/pytorch/issues/91165).
|
||||
|
||||
```python
|
||||
from peft.utils.other import fsdp_auto_wrap_policy
|
||||
|
||||
...
|
||||
|
||||
if os.environ.get("ACCELERATE_USE_FSDP", None) is not None:
|
||||
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
|
||||
|
||||
model = accelerator.prepare(model)
|
||||
```
|
||||
|
||||
Example of parameter efficient tuning with [`mt0-xxl`](https://huggingface.co/bigscience/mt0-xxl) base model using 🤗 Accelerate is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py`.
|
||||
a. First, run `accelerate config --config_file fsdp_config.yaml` and answer the questionnaire.
|
||||
Below are the contents of the config file.
|
||||
```yaml
|
||||
command_file: null
|
||||
commands: null
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config: {}
|
||||
distributed_type: FSDP
|
||||
downcast_bf16: 'no'
|
||||
dynamo_backend: 'NO'
|
||||
fsdp_config:
|
||||
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
|
||||
fsdp_backward_prefetch_policy: BACKWARD_PRE
|
||||
fsdp_offload_params: true
|
||||
fsdp_sharding_strategy: 1
|
||||
fsdp_state_dict_type: FULL_STATE_DICT
|
||||
fsdp_transformer_layer_cls_to_wrap: T5Block
|
||||
gpu_ids: null
|
||||
machine_rank: 0
|
||||
main_process_ip: null
|
||||
main_process_port: null
|
||||
main_training_function: main
|
||||
megatron_lm_config: {}
|
||||
mixed_precision: 'no'
|
||||
num_machines: 1
|
||||
num_processes: 2
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_name: null
|
||||
tpu_zone: null
|
||||
use_cpu: false
|
||||
```
|
||||
b. run the below command to launch the example script
|
||||
```bash
|
||||
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
|
||||
```
|
||||
|
||||
2. When using ZeRO3 with zero3_init_flag=True, if you find the gpu memory increase with training steps. we might need to update deepspeed after [deepspeed commit 42858a9891422abc](https://github.com/microsoft/DeepSpeed/commit/42858a9891422abcecaa12c1bd432d28d33eb0d4) . The related issue is [[BUG] Peft Training with Zero.Init() and Zero3 will increase GPU memory every forward step ](https://github.com/microsoft/DeepSpeed/issues/3002)
|
||||
|
||||
## 🤗 PEFT as a utility library
|
||||
|
||||
### Injecting adapters directly into the model
|
||||
|
||||
Inject trainable adapters on any `torch` model using `inject_adapter_in_model` method. Note the method will make no further change to the model.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from peft import inject_adapter_in_model, LoraConfig
|
||||
|
||||
class DummyModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.embedding = torch.nn.Embedding(10, 10)
|
||||
self.linear = torch.nn.Linear(10, 10)
|
||||
self.lm_head = torch.nn.Linear(10, 10)
|
||||
|
||||
def forward(self, input_ids):
|
||||
x = self.embedding(input_ids)
|
||||
x = self.linear(x)
|
||||
x = self.lm_head(x)
|
||||
return x
|
||||
|
||||
lora_config = LoraConfig(
|
||||
lora_alpha=16,
|
||||
lora_dropout=0.1,
|
||||
r=64,
|
||||
bias="none",
|
||||
target_modules=["linear"],
|
||||
)
|
||||
|
||||
model = DummyModel()
|
||||
model = inject_adapter_in_model(lora_config, model)
|
||||
|
||||
dummy_inputs = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7]])
|
||||
dummy_outputs = model(dummy_inputs)
|
||||
```
|
||||
|
||||
Learn more about the [low level API in the docs](https://huggingface.co/docs/peft/developer_guides/low_level_api).
|
||||
|
||||
### Mixing different adapter types
|
||||
|
||||
Ususally, it is not possible to combine different adapter types in the same model, e.g. combining LoRA with AdaLoRA, LoHa, or LoKr. Using a mixed model, this can, however, be achieved:
|
||||
|
||||
```python
|
||||
from peft import PeftMixedModel
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM").eval()
|
||||
peft_model = PeftMixedModel.from_pretrained(model, <path-to-adapter-0>, "adapter0")
|
||||
peft_model.load_adapter(<path-to-adapter-1>, "adapter1")
|
||||
peft_model.set_adapter(["adapter0", "adapter1"])
|
||||
result = peft_model(**inputs)
|
||||
```
|
||||
|
||||
The main intent is to load already trained adapters and use this only for inference. However, it is also possible to create a PEFT model for training by passing `mixed=True` to `get_peft_model`:
|
||||
|
||||
```python
|
||||
from peft import get_peft_model, LoraConfig, LoKrConfig
|
||||
|
||||
base_model = ...
|
||||
config0 = LoraConfig(...)
|
||||
config1 = LoKrConfig(...)
|
||||
peft_model = get_peft_model(base_model, config0, "adapter0", mixed=True)
|
||||
peft_model.add_adapter(config1, "adapter1")
|
||||
peft_model.set_adapter(["adapter0", "adapter1"])
|
||||
for batch in dataloader:
|
||||
...
|
||||
```
|
||||
|
||||
## Contributing
|
||||
|
||||
If you would like to contribute to PEFT, please check out our [contributing guide](https://huggingface.co/docs/peft/developer_guides/contributing).
|
||||
If you would like to contribute to PEFT, please check out our [contribution guide](https://huggingface.co/docs/peft/developer_guides/contributing).
|
||||
|
||||
## Citing 🤗 PEFT
|
||||
|
||||
If you use 🤗 PEFT in your publication, please cite it by using the following BibTeX entry.
|
||||
To use 🤗 PEFT in your publication, please cite it by using the following BibTeX entry.
|
||||
|
||||
```bibtex
|
||||
@Misc{peft,
|
||||
@ -449,4 +155,4 @@ If you use 🤗 PEFT in your publication, please cite it by using the following
|
||||
howpublished = {\url{https://github.com/huggingface/peft}},
|
||||
year = {2022}
|
||||
}
|
||||
```
|
||||
```
|
||||
11
docker/README.md
Normal file
11
docker/README.md
Normal file
@ -0,0 +1,11 @@
|
||||
# PEFT Docker images
|
||||
|
||||
Here we store all PEFT Docker images used in our testing infrastructure. We use python 3.8 for now on all our images.
|
||||
|
||||
- `peft-cpu`: PEFT compiled on CPU with all other HF libraries installed on main branch
|
||||
- `peft-gpu`: PEFT complied for NVIDIA GPUs wih all other HF libraries installed on main branch
|
||||
- `peft-gpu-bnb-source`: PEFT complied for NVIDIA GPUs with `bitsandbytes` and all other HF libraries installed from main branch
|
||||
- `peft-gpu-bnb-latest`: PEFT complied for NVIDIA GPUs with `bitsandbytes` complied from main and all other HF libraries installed from latest PyPi
|
||||
- `peft-gpu-bnb-multi-source`: PEFT complied for NVIDIA GPUs with `bitsandbytes` complied from `multi-backend` branch and all other HF libraries installed from main branch
|
||||
|
||||
`peft-gpu-bnb-source` and `peft-gpu-bnb-multi-source` are essentially the same, with the only difference being `bitsandbytes` compiled on another branch. Make sure to propagate the changes you applied on one file to the other!
|
||||
@ -11,6 +11,7 @@ RUN apt-get update && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
|
||||
# Install audio-related libraries
|
||||
RUN apt-get update && \
|
||||
apt install -y ffmpeg
|
||||
@ -48,4 +49,4 @@ RUN apt-get update && \
|
||||
RUN echo "source activate peft" >> ~/.profile
|
||||
|
||||
# Activate the virtualenv
|
||||
CMD ["/bin/bash"]
|
||||
CMD ["/bin/bash"]
|
||||
|
||||
68
docker/peft-gpu-bnb-latest/Dockerfile
Normal file
68
docker/peft-gpu-bnb-latest/Dockerfile
Normal file
@ -0,0 +1,68 @@
|
||||
# Builds GPU docker image of PyTorch
|
||||
# Uses multi-staged approach to reduce size
|
||||
# Stage 1
|
||||
# Use base conda image to reduce time
|
||||
FROM continuumio/miniconda3:latest AS compile-image
|
||||
# Specify py version
|
||||
ENV PYTHON_VERSION=3.8
|
||||
# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl git wget software-properties-common git-lfs && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
# Install audio-related libraries
|
||||
RUN apt-get update && \
|
||||
apt install -y ffmpeg
|
||||
|
||||
RUN apt install -y libsndfile1-dev
|
||||
RUN git lfs install
|
||||
|
||||
# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
RUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip
|
||||
|
||||
# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
# We don't install pytorch here yet since CUDA isn't available
|
||||
# instead we use the direct torch wheel
|
||||
ENV PATH /opt/conda/envs/peft/bin:$PATH
|
||||
# Activate our bash shell
|
||||
RUN chsh -s /bin/bash
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
# Stage 2
|
||||
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04 AS build-image
|
||||
COPY --from=compile-image /opt/conda /opt/conda
|
||||
ENV PATH /opt/conda/bin:$PATH
|
||||
|
||||
RUN chsh -s /bin/bash
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
# Install apt libs
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl git wget cmake && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
# Activate the conda env and install transformers + accelerate from latest pypi
|
||||
# Also clone BNB and build it from source.
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install -U --no-cache-dir \
|
||||
librosa \
|
||||
"soundfile>=0.12.1" \
|
||||
scipy \
|
||||
transformers \
|
||||
accelerate \
|
||||
peft \
|
||||
optimum \
|
||||
auto-gptq && \
|
||||
git clone https://github.com/TimDettmers/bitsandbytes && cd bitsandbytes && \
|
||||
cmake -B . -DCOMPUTE_BACKEND=cuda -S . && \
|
||||
cmake --build . && \
|
||||
pip install -e . && \
|
||||
pip freeze | grep bitsandbytes
|
||||
|
||||
RUN echo "source activate peft" >> ~/.profile
|
||||
|
||||
# Activate the virtualenv
|
||||
CMD ["/bin/bash"]
|
||||
68
docker/peft-gpu-bnb-multi-source/Dockerfile
Normal file
68
docker/peft-gpu-bnb-multi-source/Dockerfile
Normal file
@ -0,0 +1,68 @@
|
||||
# Builds GPU docker image of PyTorch
|
||||
# Uses multi-staged approach to reduce size
|
||||
# Stage 1
|
||||
# Use base conda image to reduce time
|
||||
FROM continuumio/miniconda3:latest AS compile-image
|
||||
# Specify py version
|
||||
ENV PYTHON_VERSION=3.8
|
||||
# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl git wget software-properties-common git-lfs && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
# Install audio-related libraries
|
||||
RUN apt-get update && \
|
||||
apt install -y ffmpeg
|
||||
|
||||
RUN apt install -y libsndfile1-dev
|
||||
RUN git lfs install
|
||||
|
||||
# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
RUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip
|
||||
|
||||
# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
# We don't install pytorch here yet since CUDA isn't available
|
||||
# instead we use the direct torch wheel
|
||||
ENV PATH /opt/conda/envs/peft/bin:$PATH
|
||||
# Activate our bash shell
|
||||
RUN chsh -s /bin/bash
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
# Stage 2
|
||||
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04 AS build-image
|
||||
COPY --from=compile-image /opt/conda /opt/conda
|
||||
ENV PATH /opt/conda/bin:$PATH
|
||||
|
||||
RUN chsh -s /bin/bash
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
# Install apt libs
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl git wget cmake && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
# Activate the conda env and install transformers + accelerate from source
|
||||
# Also clone BNB and build it from source.
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install -U --no-cache-dir \
|
||||
librosa \
|
||||
"soundfile>=0.12.1" \
|
||||
scipy \
|
||||
git+https://github.com/huggingface/transformers \
|
||||
git+https://github.com/huggingface/accelerate \
|
||||
peft[test]@git+https://github.com/huggingface/peft \
|
||||
optimum \
|
||||
auto-gptq && \
|
||||
git clone https://github.com/TimDettmers/bitsandbytes && cd bitsandbytes && git checkout multi-backend-refactor && \
|
||||
cmake -B . -DCOMPUTE_BACKEND=cuda -S . && \
|
||||
cmake --build . && \
|
||||
pip install -e . && \
|
||||
pip freeze | grep bitsandbytes
|
||||
|
||||
RUN echo "source activate peft" >> ~/.profile
|
||||
|
||||
# Activate the virtualenv
|
||||
CMD ["/bin/bash"]
|
||||
68
docker/peft-gpu-bnb-source/Dockerfile
Normal file
68
docker/peft-gpu-bnb-source/Dockerfile
Normal file
@ -0,0 +1,68 @@
|
||||
# Builds GPU docker image of PyTorch
|
||||
# Uses multi-staged approach to reduce size
|
||||
# Stage 1
|
||||
# Use base conda image to reduce time
|
||||
FROM continuumio/miniconda3:latest AS compile-image
|
||||
# Specify py version
|
||||
ENV PYTHON_VERSION=3.8
|
||||
# Install apt libs - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl git wget software-properties-common git-lfs && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
# Install audio-related libraries
|
||||
RUN apt-get update && \
|
||||
apt install -y ffmpeg
|
||||
|
||||
RUN apt install -y libsndfile1-dev
|
||||
RUN git lfs install
|
||||
|
||||
# Create our conda env - copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
RUN conda create --name peft python=${PYTHON_VERSION} ipython jupyter pip
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip
|
||||
|
||||
# Below is copied from https://github.com/huggingface/accelerate/blob/main/docker/accelerate-gpu/Dockerfile
|
||||
# We don't install pytorch here yet since CUDA isn't available
|
||||
# instead we use the direct torch wheel
|
||||
ENV PATH /opt/conda/envs/peft/bin:$PATH
|
||||
# Activate our bash shell
|
||||
RUN chsh -s /bin/bash
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
# Stage 2
|
||||
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04 AS build-image
|
||||
COPY --from=compile-image /opt/conda /opt/conda
|
||||
ENV PATH /opt/conda/bin:$PATH
|
||||
|
||||
RUN chsh -s /bin/bash
|
||||
SHELL ["/bin/bash", "-c"]
|
||||
|
||||
# Install apt libs
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl git wget cmake && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
# Activate the conda env and install transformers + accelerate from source
|
||||
# Also clone BNB and build it from source.
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install -U --no-cache-dir \
|
||||
librosa \
|
||||
"soundfile>=0.12.1" \
|
||||
scipy \
|
||||
git+https://github.com/huggingface/transformers \
|
||||
git+https://github.com/huggingface/accelerate \
|
||||
peft[test]@git+https://github.com/huggingface/peft \
|
||||
optimum \
|
||||
auto-gptq && \
|
||||
git clone https://github.com/TimDettmers/bitsandbytes && cd bitsandbytes && \
|
||||
cmake -B . -DCOMPUTE_BACKEND=cuda -S . && \
|
||||
cmake --build . && \
|
||||
pip install -e . && \
|
||||
pip freeze | grep bitsandbytes
|
||||
|
||||
RUN echo "source activate peft" >> ~/.profile
|
||||
|
||||
# Activate the virtualenv
|
||||
CMD ["/bin/bash"]
|
||||
@ -40,12 +40,22 @@ SHELL ["/bin/bash", "-c"]
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install --no-cache-dir bitsandbytes optimum auto-gptq
|
||||
|
||||
# Add autoawq for quantization testing
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.2.4/autoawq-0.2.4-cp38-cp38-linux_x86_64.whl
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ_kernels/releases/download/v0.0.6/autoawq_kernels-0.0.6-cp38-cp38-linux_x86_64.whl
|
||||
|
||||
# Install apt libs
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl git wget && \
|
||||
apt-get clean && \
|
||||
rm -rf /var/lib/apt/lists*
|
||||
|
||||
# Add eetq for quantization testing
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install git+https://github.com/NetEase-FuXi/EETQ.git
|
||||
|
||||
# Activate the conda env and install transformers + accelerate from source
|
||||
RUN source activate peft && \
|
||||
python3 -m pip install -U --no-cache-dir \
|
||||
@ -56,6 +66,14 @@ RUN source activate peft && \
|
||||
git+https://github.com/huggingface/accelerate \
|
||||
peft[test]@git+https://github.com/huggingface/peft
|
||||
|
||||
# Add aqlm for quantization testing
|
||||
RUN source activate peft && \
|
||||
pip install aqlm[gpu]>=1.0.2
|
||||
|
||||
# Add HQQ for quantization testing
|
||||
RUN source activate peft && \
|
||||
pip install hqq
|
||||
|
||||
RUN source activate peft && \
|
||||
pip freeze | grep transformers
|
||||
|
||||
|
||||
@ -7,57 +7,60 @@
|
||||
- local: install
|
||||
title: Installation
|
||||
|
||||
- title: Task guides
|
||||
- title: Tutorial
|
||||
sections:
|
||||
- local: task_guides/seq2seq-prefix-tuning
|
||||
title: Prefix tuning for conditional generation
|
||||
- local: task_guides/clm-prompt-tuning
|
||||
title: Prompt tuning for causal language modeling
|
||||
- local: task_guides/ptuning-seq-classification
|
||||
title: P-tuning for sequence classification
|
||||
- title: LoRA
|
||||
sections:
|
||||
- local: task_guides/image_classification_lora
|
||||
title: Image classification
|
||||
- local: task_guides/semantic_segmentation_lora
|
||||
title: Semantic segmentation
|
||||
- local: task_guides/token-classification-lora
|
||||
title: Token classification
|
||||
- local: task_guides/semantic-similarity-lora
|
||||
title: Semantic similarity
|
||||
- local: task_guides/int8-asr
|
||||
title: int8 training for automatic speech recognition
|
||||
- local: task_guides/dreambooth_lora
|
||||
title: DreamBooth
|
||||
- local: tutorial/peft_model_config
|
||||
title: Configurations and models
|
||||
- local: tutorial/peft_integrations
|
||||
title: Integrations
|
||||
|
||||
- title: PEFT method guides
|
||||
sections:
|
||||
- local: task_guides/prompt_based_methods
|
||||
title: Prompt-based methods
|
||||
- local: task_guides/lora_based_methods
|
||||
title: LoRA methods
|
||||
- local: task_guides/ia3
|
||||
title: IA3
|
||||
|
||||
- title: Developer guides
|
||||
sections:
|
||||
- local: developer_guides/model_merging
|
||||
title: Model merging
|
||||
- local: developer_guides/quantization
|
||||
title: Quantization
|
||||
- local: developer_guides/lora
|
||||
title: LoRA
|
||||
- local: developer_guides/custom_models
|
||||
title: Working with custom models
|
||||
title: Custom models
|
||||
- local: developer_guides/low_level_api
|
||||
title: PEFT low level API
|
||||
title: Adapter injection
|
||||
- local: developer_guides/mixed_models
|
||||
title: Mixing different adapter types
|
||||
title: Mixed adapter types
|
||||
- local: developer_guides/contributing
|
||||
title: Contributing to PEFT
|
||||
title: Contribute to PEFT
|
||||
- local: developer_guides/troubleshooting
|
||||
title: Troubleshooting
|
||||
- local: developer_guides/checkpoint
|
||||
title: PEFT checkpoint format
|
||||
|
||||
- title: 🤗 Accelerate integrations
|
||||
sections:
|
||||
- local: accelerate/deepspeed-zero3-offload
|
||||
- local: accelerate/deepspeed
|
||||
title: DeepSpeed
|
||||
- local: accelerate/fsdp
|
||||
title: Fully Sharded Data Parallel
|
||||
|
||||
- title: Conceptual guides
|
||||
sections:
|
||||
- local: conceptual_guides/lora
|
||||
title: LoRA
|
||||
- local: conceptual_guides/adapter
|
||||
title: Adapters
|
||||
- local: conceptual_guides/prompting
|
||||
title: Prompting
|
||||
title: Soft prompts
|
||||
- local: conceptual_guides/ia3
|
||||
title: IA3
|
||||
- local: conceptual_guides/oft
|
||||
title: OFT/BOFT
|
||||
|
||||
- sections:
|
||||
- sections:
|
||||
@ -89,12 +92,28 @@
|
||||
title: LyCORIS
|
||||
- local: package_reference/multitask_prompt_tuning
|
||||
title: Multitask Prompt Tuning
|
||||
- local: package_reference/oft
|
||||
title: OFT
|
||||
- local: package_reference/boft
|
||||
title: BOFT
|
||||
- local: package_reference/poly
|
||||
title: Polytropon
|
||||
- local: package_reference/p_tuning
|
||||
title: P-tuning
|
||||
- local: package_reference/prefix_tuning
|
||||
title: Prefix tuning
|
||||
- local: package_reference/prompt_tuning
|
||||
title: Prompt tuning
|
||||
- local: package_reference/layernorm_tuning
|
||||
title: Layernorm tuning
|
||||
- local: package_reference/vera
|
||||
title: VeRA
|
||||
- local: package_reference/helpers
|
||||
title: Helpers
|
||||
title: Adapters
|
||||
- sections:
|
||||
- local: package_reference/merge_utils
|
||||
title: Model merge
|
||||
title: Utilities
|
||||
title: API reference
|
||||
|
||||
|
||||
@ -1,167 +0,0 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# DeepSpeed
|
||||
|
||||
[DeepSpeed](https://www.deepspeed.ai/) is a library designed for speed and scale for distributed training of large models with billions of parameters. At its core is the Zero Redundancy Optimizer (ZeRO) that shards optimizer states (ZeRO-1), gradients (ZeRO-2), and parameters (ZeRO-3) across data parallel processes. This drastically reduces memory usage, allowing you to scale your training to billion parameter models. To unlock even more memory efficiency, ZeRO-Offload reduces GPU compute and memory by leveraging CPU resources during optimization.
|
||||
|
||||
Both of these features are supported in 🤗 Accelerate, and you can use them with 🤗 PEFT. This guide will help you learn how to use our DeepSpeed [training script](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You'll configure the script to train a large model for conditional generation with ZeRO-3 and ZeRO-Offload.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 To help you get started, check out our example training scripts for [causal language modeling](https://github.com/huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_accelerate_ds_zero3_offload.py) and [conditional generation](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You can adapt these scripts for your own applications or even use them out of the box if your task is similar to the one in the scripts.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Configuration
|
||||
|
||||
Start by running the following command to [create a DeepSpeed configuration file](https://huggingface.co/docs/accelerate/quicktour#launching-your-distributed-script) with 🤗 Accelerate. The `--config_file` flag allows you to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
|
||||
|
||||
The configuration file is used to set the default options when you launch the training script.
|
||||
|
||||
```bash
|
||||
accelerate config --config_file ds_zero3_cpu.yaml
|
||||
```
|
||||
|
||||
You'll be asked a few questions about your setup, and configure the following arguments. In this example, you'll use ZeRO-3 and ZeRO-Offload so make sure you pick those options.
|
||||
|
||||
```bash
|
||||
`zero_stage`: [0] Disabled, [1] optimizer state partitioning, [2] optimizer+gradient state partitioning and [3] optimizer+gradient+parameter partitioning
|
||||
`gradient_accumulation_steps`: Number of training steps to accumulate gradients before averaging and applying them.
|
||||
`gradient_clipping`: Enable gradient clipping with value.
|
||||
`offload_optimizer_device`: [none] Disable optimizer offloading, [cpu] offload optimizer to CPU, [nvme] offload optimizer to NVMe SSD. Only applicable with ZeRO >= Stage-2.
|
||||
`offload_param_device`: [none] Disable parameter offloading, [cpu] offload parameters to CPU, [nvme] offload parameters to NVMe SSD. Only applicable with ZeRO Stage-3.
|
||||
`zero3_init_flag`: Decides whether to enable `deepspeed.zero.Init` for constructing massive models. Only applicable with ZeRO Stage-3.
|
||||
`zero3_save_16bit_model`: Decides whether to save 16-bit model weights when using ZeRO Stage-3.
|
||||
`mixed_precision`: `no` for FP32 training, `fp16` for FP16 mixed-precision training and `bf16` for BF16 mixed-precision training.
|
||||
```
|
||||
|
||||
An example [configuration file](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/accelerate_ds_zero3_cpu_offload_config.yaml) might look like the following. The most important thing to notice is that `zero_stage` is set to `3`, and `offload_optimizer_device` and `offload_param_device` are set to the `cpu`.
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 1
|
||||
gradient_clipping: 1.0
|
||||
offload_optimizer_device: cpu
|
||||
offload_param_device: cpu
|
||||
zero3_init_flag: true
|
||||
zero3_save_16bit_model: true
|
||||
zero_stage: 3
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
dynamo_backend: 'NO'
|
||||
fsdp_config: {}
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
megatron_lm_config: {}
|
||||
mixed_precision: 'no'
|
||||
num_machines: 1
|
||||
num_processes: 1
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
## The important parts
|
||||
|
||||
Let's dive a little deeper into the script so you can see what's going on, and understand how it works.
|
||||
|
||||
Within the [`main`](https://github.com/huggingface/peft/blob/2822398fbe896f25d4dac5e468624dc5fd65a51b/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py#L103) function, the script creates an [`~accelerate.Accelerator`] class to initialize all the necessary requirements for distributed training.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Feel free to change the model and dataset inside the `main` function. If your dataset format is different from the one in the script, you may also need to write your own preprocessing function.
|
||||
|
||||
</Tip>
|
||||
|
||||
The script also creates a configuration for the 🤗 PEFT method you're using, which in this case, is LoRA. The [`LoraConfig`] specifies the task type and important parameters such as the dimension of the low-rank matrices, the matrices scaling factor, and the dropout probability of the LoRA layers. If you want to use a different 🤗 PEFT method, make sure you replace `LoraConfig` with the appropriate [class](../package_reference/tuners).
|
||||
|
||||
```diff
|
||||
def main():
|
||||
+ accelerator = Accelerator()
|
||||
model_name_or_path = "facebook/bart-large"
|
||||
dataset_name = "twitter_complaints"
|
||||
+ peft_config = LoraConfig(
|
||||
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
|
||||
)
|
||||
```
|
||||
|
||||
Throughout the script, you'll see the [`~accelerate.Accelerator.main_process_first`] and [`~accelerate.Accelerator.wait_for_everyone`] functions which help control and synchronize when processes are executed.
|
||||
|
||||
The [`get_peft_model`] function takes a base model and the [`peft_config`] you prepared earlier to create a [`PeftModel`]:
|
||||
|
||||
```diff
|
||||
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
|
||||
+ model = get_peft_model(model, peft_config)
|
||||
```
|
||||
|
||||
Pass all the relevant training objects to 🤗 Accelerate's [`~accelerate.Accelerator.prepare`] which makes sure everything is ready for training:
|
||||
|
||||
```py
|
||||
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler = accelerator.prepare(
|
||||
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler
|
||||
)
|
||||
```
|
||||
|
||||
The next bit of code checks whether the DeepSpeed plugin is used in the `Accelerator`, and if the plugin exists, then the `Accelerator` uses ZeRO-3 as specified in the configuration file:
|
||||
|
||||
```py
|
||||
is_ds_zero_3 = False
|
||||
if getattr(accelerator.state, "deepspeed_plugin", None):
|
||||
is_ds_zero_3 = accelerator.state.deepspeed_plugin.zero_stage == 3
|
||||
```
|
||||
|
||||
Inside the training loop, the usual `loss.backward()` is replaced by 🤗 Accelerate's [`~accelerate.Accelerator.backward`] which uses the correct `backward()` method based on your configuration:
|
||||
|
||||
```diff
|
||||
for epoch in range(num_epochs):
|
||||
with TorchTracemalloc() as tracemalloc:
|
||||
model.train()
|
||||
total_loss = 0
|
||||
for step, batch in enumerate(tqdm(train_dataloader)):
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
total_loss += loss.detach().float()
|
||||
+ accelerator.backward(loss)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
```
|
||||
|
||||
That is all! The rest of the script handles the training loop, evaluation, and even pushes it to the Hub for you.
|
||||
|
||||
## Train
|
||||
|
||||
Run the following command to launch the training script. Earlier, you saved the configuration file to `ds_zero3_cpu.yaml`, so you'll need to pass the path to the launcher with the `--config_file` argument like this:
|
||||
|
||||
```bash
|
||||
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
|
||||
```
|
||||
|
||||
You'll see some output logs that track memory usage during training, and once it's completed, the script returns the accuracy and compares the predictions to the labels:
|
||||
|
||||
```bash
|
||||
GPU Memory before entering the train : 1916
|
||||
GPU Memory consumed at the end of the train (end-begin): 66
|
||||
GPU Peak Memory consumed during the train (max-begin): 7488
|
||||
GPU Total Peak Memory consumed during the train (max): 9404
|
||||
CPU Memory before entering the train : 19411
|
||||
CPU Memory consumed at the end of the train (end-begin): 0
|
||||
CPU Peak Memory consumed during the train (max-begin): 0
|
||||
CPU Total Peak Memory consumed during the train (max): 19411
|
||||
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
|
||||
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
|
||||
GPU Memory before entering the eval : 1982
|
||||
GPU Memory consumed at the end of the eval (end-begin): -66
|
||||
GPU Peak Memory consumed during the eval (max-begin): 672
|
||||
GPU Total Peak Memory consumed during the eval (max): 2654
|
||||
CPU Memory before entering the eval : 19411
|
||||
CPU Memory consumed at the end of the eval (end-begin): 0
|
||||
CPU Peak Memory consumed during the eval (max-begin): 0
|
||||
CPU Total Peak Memory consumed during the eval (max): 19411
|
||||
accuracy=100.0
|
||||
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
|
||||
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
|
||||
```
|
||||
447
docs/source/accelerate/deepspeed.md
Normal file
447
docs/source/accelerate/deepspeed.md
Normal file
@ -0,0 +1,447 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# DeepSpeed
|
||||
|
||||
[DeepSpeed](https://www.deepspeed.ai/) is a library designed for speed and scale for distributed training of large models with billions of parameters. At its core is the Zero Redundancy Optimizer (ZeRO) that shards optimizer states (ZeRO-1), gradients (ZeRO-2), and parameters (ZeRO-3) across data parallel processes. This drastically reduces memory usage, allowing you to scale your training to billion parameter models. To unlock even more memory efficiency, ZeRO-Offload reduces GPU compute and memory by leveraging CPU resources during optimization.
|
||||
|
||||
Both of these features are supported in 🤗 Accelerate, and you can use them with 🤗 PEFT.
|
||||
|
||||
## Compatibility with `bitsandbytes` quantization + LoRA
|
||||
|
||||
Below is a table that summarizes the compatibility between PEFT's LoRA, [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) library and DeepSpeed Zero stages with respect to fine-tuning. DeepSpeed Zero-1 and 2 will have no effect at inference as stage 1 shards the optimizer states and stage 2 shards the optimizer states and gradients:
|
||||
|
||||
| DeepSpeed stage | Is compatible? |
|
||||
|---|---|
|
||||
| Zero-1 | 🟢 |
|
||||
| Zero-2 | 🟢 |
|
||||
| Zero-3 | 🟢 |
|
||||
|
||||
For DeepSpeed Stage 3 + QLoRA, please refer to the section [Use PEFT QLoRA and DeepSpeed with ZeRO3 for finetuning large models on multiple GPUs](#use-peft-qlora-and-deepspeed-with-zero3-for-finetuning-large-models-on-multiple-gpus) below.
|
||||
|
||||
For confirming these observations, we ran the SFT (Supervised Fine-tuning) [offical example scripts](https://github.com/huggingface/trl/tree/main/examples) of the [Transformers Reinforcement Learning (TRL) library](https://github.com/huggingface/trl) using QLoRA + PEFT and the accelerate configs available [here](https://github.com/huggingface/trl/tree/main/examples/accelerate_configs). We ran these experiments on a 2x NVIDIA T4 GPU.
|
||||
|
||||
# Use PEFT and DeepSpeed with ZeRO3 for finetuning large models on multiple devices and multiple nodes
|
||||
|
||||
This section of guide will help you learn how to use our DeepSpeed [training script](https://github.com/huggingface/peft/blob/main/examples/sft/train.py) for performing SFT. You'll configure the script to do SFT (supervised fine-tuning) of Llama-70B model with LoRA and ZeRO-3 on 8xH100 80GB GPUs on a single machine. You can configure it to scale to multiple machines by changing the accelerate config.
|
||||
|
||||
## Configuration
|
||||
|
||||
Start by running the following command to [create a DeepSpeed configuration file](https://huggingface.co/docs/accelerate/quicktour#launching-your-distributed-script) with 🤗 Accelerate. The `--config_file` flag allows you to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
|
||||
|
||||
The configuration file is used to set the default options when you launch the training script.
|
||||
|
||||
```bash
|
||||
accelerate config --config_file deepspeed_config.yaml
|
||||
```
|
||||
|
||||
You'll be asked a few questions about your setup, and configure the following arguments. In this example, you'll use ZeRO-3 so make sure you pick those options.
|
||||
|
||||
```bash
|
||||
`zero_stage`: [0] Disabled, [1] optimizer state partitioning, [2] optimizer+gradient state partitioning and [3] optimizer+gradient+parameter partitioning
|
||||
`gradient_accumulation_steps`: Number of training steps to accumulate gradients before averaging and applying them. Pass the same value as you would pass via cmd argument else you will encounter mismatch error.
|
||||
`gradient_clipping`: Enable gradient clipping with value. Don't set this as you will be passing it via cmd arguments.
|
||||
`offload_optimizer_device`: [none] Disable optimizer offloading, [cpu] offload optimizer to CPU, [nvme] offload optimizer to NVMe SSD. Only applicable with ZeRO >= Stage-2. Set this as `none` as don't want to enable offloading.
|
||||
`offload_param_device`: [none] Disable parameter offloading, [cpu] offload parameters to CPU, [nvme] offload parameters to NVMe SSD. Only applicable with ZeRO Stage-3. Set this as `none` as don't want to enable offloading.
|
||||
`zero3_init_flag`: Decides whether to enable `deepspeed.zero.Init` for constructing massive models. Only applicable with ZeRO Stage-3. Set this to `True`.
|
||||
`zero3_save_16bit_model`: Decides whether to save 16-bit model weights when using ZeRO Stage-3. Set this to `True`.
|
||||
`mixed_precision`: `no` for FP32 training, `fp16` for FP16 mixed-precision training and `bf16` for BF16 mixed-precision training. Set this to `True`.
|
||||
```
|
||||
|
||||
Once this is done, the corresponding config should look like below and you can find it in config folder at [deepspeed_config.yaml](https://github.com/huggingface/peft/blob/main/examples/sft/configs/deepspeed_config.yaml):
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
debug: false
|
||||
deepspeed_config:
|
||||
deepspeed_multinode_launcher: standard
|
||||
gradient_accumulation_steps: 4
|
||||
offload_optimizer_device: none
|
||||
offload_param_device: none
|
||||
zero3_init_flag: true
|
||||
zero3_save_16bit_model: true
|
||||
zero_stage: 3
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 8
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
## Launch command
|
||||
|
||||
The launch command is available at [run_peft_deepspeed.sh](https://github.com/huggingface/peft/blob/main/examples/sft/run_peft_deepspeed.sh) and it is also shown below:
|
||||
```bash
|
||||
accelerate launch --config_file "configs/deepspeed_config.yaml" train.py \
|
||||
--seed 100 \
|
||||
--model_name_or_path "meta-llama/Llama-2-70b-hf" \
|
||||
--dataset_name "smangrul/ultrachat-10k-chatml" \
|
||||
--chat_template_format "chatml" \
|
||||
--add_special_tokens False \
|
||||
--append_concat_token False \
|
||||
--splits "train,test" \
|
||||
--max_seq_len 2048 \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 5 \
|
||||
--log_level "info" \
|
||||
--logging_strategy "steps" \
|
||||
--evaluation_strategy "epoch" \
|
||||
--save_strategy "epoch" \
|
||||
--push_to_hub \
|
||||
--hub_private_repo True \
|
||||
--hub_strategy "every_save" \
|
||||
--bf16 True \
|
||||
--packing True \
|
||||
--learning_rate 1e-4 \
|
||||
--lr_scheduler_type "cosine" \
|
||||
--weight_decay 1e-4 \
|
||||
--warmup_ratio 0.0 \
|
||||
--max_grad_norm 1.0 \
|
||||
--output_dir "llama-sft-lora-deepspeed" \
|
||||
--per_device_train_batch_size 8 \
|
||||
--per_device_eval_batch_size 8 \
|
||||
--gradient_accumulation_steps 4 \
|
||||
--gradient_checkpointing True \
|
||||
--use_reentrant False \
|
||||
--dataset_text_field "content" \
|
||||
--use_flash_attn True \
|
||||
--use_peft_lora True \
|
||||
--lora_r 8 \
|
||||
--lora_alpha 16 \
|
||||
--lora_dropout 0.1 \
|
||||
--lora_target_modules "all-linear" \
|
||||
--use_4bit_quantization False
|
||||
```
|
||||
|
||||
Notice that we are using LoRA with rank=8, alpha=16 and targeting all linear layers. We are passing the deepspeed config file and finetuning 70B Llama model on a subset of the ultrachat dataset.
|
||||
|
||||
## The important parts
|
||||
|
||||
Let's dive a little deeper into the script so you can see what's going on, and understand how it works.
|
||||
|
||||
The first thing to know is that the script uses DeepSpeed for distributed training as the DeepSpeed config has been passed. The `SFTTrainer` class handles all the heavy lifting of creating the PEFT model using the peft config that is passed. After that, when you call `trainer.train()`, `SFTTrainer` internally uses 🤗 Accelerate to prepare the model, optimizer and trainer using the DeepSpeed config to create DeepSpeed engine which is then trained. The main code snippet is below:
|
||||
|
||||
```python
|
||||
# trainer
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
peft_config=peft_config,
|
||||
packing=data_args.packing,
|
||||
dataset_kwargs={
|
||||
"append_concat_token": data_args.append_concat_token,
|
||||
"add_special_tokens": data_args.add_special_tokens,
|
||||
},
|
||||
dataset_text_field=data_args.dataset_text_field,
|
||||
max_seq_length=data_args.max_seq_length,
|
||||
)
|
||||
trainer.accelerator.print(f"{trainer.model}")
|
||||
|
||||
# train
|
||||
checkpoint = None
|
||||
if training_args.resume_from_checkpoint is not None:
|
||||
checkpoint = training_args.resume_from_checkpoint
|
||||
trainer.train(resume_from_checkpoint=checkpoint)
|
||||
|
||||
# saving final model
|
||||
trainer.save_model()
|
||||
```
|
||||
|
||||
## Memory usage
|
||||
|
||||
In the above example, the memory consumed per GPU is 64 GB (80%) as seen in the screenshot below:
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/peft_deepspeed_mem_usage.png"/>
|
||||
</div>
|
||||
<small>GPU memory usage for the training run</small>
|
||||
|
||||
## More resources
|
||||
You can also refer this blog post [Falcon 180B Finetuning using 🤗 PEFT and DeepSpeed](https://medium.com/@sourabmangrulkar/falcon-180b-finetuning-using-peft-and-deepspeed-b92643091d99) on how to finetune 180B Falcon model on 16 A100 GPUs on 2 machines.
|
||||
|
||||
|
||||
# Use PEFT QLoRA and DeepSpeed with ZeRO3 for finetuning large models on multiple GPUs
|
||||
|
||||
In this section, we will look at how to use QLoRA and DeepSpeed Stage-3 for finetuning 70B llama model on 2X40GB GPUs.
|
||||
For this, we first need `bitsandbytes>=0.43.0`, `accelerate>=0.28.0`, `transformers>4.38.2`, `trl>0.7.11` and `peft>0.9.0`. We need to set `zero3_init_flag` to true when using Accelerate config. Below is the config which can be found at [deepspeed_config_z3_qlora.yaml](https://github.com/huggingface/peft/blob/main/examples/sft/configs/deepspeed_config_z3_qlora.yaml):
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
debug: false
|
||||
deepspeed_config:
|
||||
deepspeed_multinode_launcher: standard
|
||||
offload_optimizer_device: none
|
||||
offload_param_device: none
|
||||
zero3_init_flag: true
|
||||
zero3_save_16bit_model: true
|
||||
zero_stage: 3
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 2
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
Launch command is given below which is available at [run_peft_qlora_deepspeed_stage3.sh](https://github.com/huggingface/peft/blob/main/examples/sft/run_peft_deepspeed.sh):
|
||||
```
|
||||
accelerate launch --config_file "configs/deepspeed_config_z3_qlora.yaml" train.py \
|
||||
--seed 100 \
|
||||
--model_name_or_path "meta-llama/Llama-2-70b-hf" \
|
||||
--dataset_name "smangrul/ultrachat-10k-chatml" \
|
||||
--chat_template_format "chatml" \
|
||||
--add_special_tokens False \
|
||||
--append_concat_token False \
|
||||
--splits "train,test" \
|
||||
--max_seq_len 2048 \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 5 \
|
||||
--log_level "info" \
|
||||
--logging_strategy "steps" \
|
||||
--evaluation_strategy "epoch" \
|
||||
--save_strategy "epoch" \
|
||||
--push_to_hub \
|
||||
--hub_private_repo True \
|
||||
--hub_strategy "every_save" \
|
||||
--bf16 True \
|
||||
--packing True \
|
||||
--learning_rate 1e-4 \
|
||||
--lr_scheduler_type "cosine" \
|
||||
--weight_decay 1e-4 \
|
||||
--warmup_ratio 0.0 \
|
||||
--max_grad_norm 1.0 \
|
||||
--output_dir "llama-sft-qlora-dsz3" \
|
||||
--per_device_train_batch_size 2 \
|
||||
--per_device_eval_batch_size 2 \
|
||||
--gradient_accumulation_steps 2 \
|
||||
--gradient_checkpointing True \
|
||||
--use_reentrant True \
|
||||
--dataset_text_field "content" \
|
||||
--use_flash_attn True \
|
||||
--use_peft_lora True \
|
||||
--lora_r 8 \
|
||||
--lora_alpha 16 \
|
||||
--lora_dropout 0.1 \
|
||||
--lora_target_modules "all-linear" \
|
||||
--use_4bit_quantization True \
|
||||
--use_nested_quant True \
|
||||
--bnb_4bit_compute_dtype "bfloat16" \
|
||||
--bnb_4bit_quant_storage_dtype "bfloat16"
|
||||
```
|
||||
|
||||
Notice the new argument being passed `bnb_4bit_quant_storage_dtype` which denotes the data type for packing the 4-bit parameters. For example, when it is set to `bfloat16`, **32/4 = 8** 4-bit params are packed together post quantization.
|
||||
|
||||
In terms of training code, the important code changes are:
|
||||
|
||||
```diff
|
||||
...
|
||||
|
||||
bnb_config = BitsAndBytesConfig(
|
||||
load_in_4bit=args.use_4bit_quantization,
|
||||
bnb_4bit_quant_type=args.bnb_4bit_quant_type,
|
||||
bnb_4bit_compute_dtype=compute_dtype,
|
||||
bnb_4bit_use_double_quant=args.use_nested_quant,
|
||||
+ bnb_4bit_quant_storage=quant_storage_dtype,
|
||||
)
|
||||
|
||||
...
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.model_name_or_path,
|
||||
quantization_config=bnb_config,
|
||||
trust_remote_code=True,
|
||||
attn_implementation="flash_attention_2" if args.use_flash_attn else "eager",
|
||||
+ torch_dtype=quant_storage_dtype or torch.float32,
|
||||
)
|
||||
```
|
||||
|
||||
Notice that `torch_dtype` for `AutoModelForCausalLM` is same as the `bnb_4bit_quant_storage` data type. That's it. Everything else is handled by Trainer and TRL.
|
||||
|
||||
## Memory usage
|
||||
|
||||
In the above example, the memory consumed per GPU is **36.6 GB**. Therefore, what took 8X80GB GPUs with DeepSpeed Stage 3+LoRA and a couple of 80GB GPUs with DDP+QLoRA now requires 2X40GB GPUs. This makes finetuning of large models more accessible.
|
||||
|
||||
# Use PEFT and DeepSpeed with ZeRO3 and CPU Offloading for finetuning large models on a single GPU
|
||||
This section of guide will help you learn how to use our DeepSpeed [training script](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You'll configure the script to train a large model for conditional generation with ZeRO-3 and CPU Offload.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 To help you get started, check out our example training scripts for [causal language modeling](https://github.com/huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_accelerate_ds_zero3_offload.py) and [conditional generation](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py). You can adapt these scripts for your own applications or even use them out of the box if your task is similar to the one in the scripts.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Configuration
|
||||
|
||||
Start by running the following command to [create a DeepSpeed configuration file](https://huggingface.co/docs/accelerate/quicktour#launching-your-distributed-script) with 🤗 Accelerate. The `--config_file` flag allows you to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
|
||||
|
||||
The configuration file is used to set the default options when you launch the training script.
|
||||
|
||||
```bash
|
||||
accelerate config --config_file ds_zero3_cpu.yaml
|
||||
```
|
||||
|
||||
You'll be asked a few questions about your setup, and configure the following arguments. In this example, you'll use ZeRO-3 along with CPU-Offload so make sure you pick those options.
|
||||
|
||||
```bash
|
||||
`zero_stage`: [0] Disabled, [1] optimizer state partitioning, [2] optimizer+gradient state partitioning and [3] optimizer+gradient+parameter partitioning
|
||||
`gradient_accumulation_steps`: Number of training steps to accumulate gradients before averaging and applying them.
|
||||
`gradient_clipping`: Enable gradient clipping with value.
|
||||
`offload_optimizer_device`: [none] Disable optimizer offloading, [cpu] offload optimizer to CPU, [nvme] offload optimizer to NVMe SSD. Only applicable with ZeRO >= Stage-2.
|
||||
`offload_param_device`: [none] Disable parameter offloading, [cpu] offload parameters to CPU, [nvme] offload parameters to NVMe SSD. Only applicable with ZeRO Stage-3.
|
||||
`zero3_init_flag`: Decides whether to enable `deepspeed.zero.Init` for constructing massive models. Only applicable with ZeRO Stage-3.
|
||||
`zero3_save_16bit_model`: Decides whether to save 16-bit model weights when using ZeRO Stage-3.
|
||||
`mixed_precision`: `no` for FP32 training, `fp16` for FP16 mixed-precision training and `bf16` for BF16 mixed-precision training.
|
||||
```
|
||||
|
||||
An example [configuration file](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/accelerate_ds_zero3_cpu_offload_config.yaml) might look like the following. The most important thing to notice is that `zero_stage` is set to `3`, and `offload_optimizer_device` and `offload_param_device` are set to the `cpu`.
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 1
|
||||
gradient_clipping: 1.0
|
||||
offload_optimizer_device: cpu
|
||||
offload_param_device: cpu
|
||||
zero3_init_flag: true
|
||||
zero3_save_16bit_model: true
|
||||
zero_stage: 3
|
||||
distributed_type: DEEPSPEED
|
||||
downcast_bf16: 'no'
|
||||
dynamo_backend: 'NO'
|
||||
fsdp_config: {}
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
megatron_lm_config: {}
|
||||
mixed_precision: 'no'
|
||||
num_machines: 1
|
||||
num_processes: 1
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
## The important parts
|
||||
|
||||
Let's dive a little deeper into the script so you can see what's going on, and understand how it works.
|
||||
|
||||
Within the [`main`](https://github.com/huggingface/peft/blob/2822398fbe896f25d4dac5e468624dc5fd65a51b/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py#L103) function, the script creates an [`~accelerate.Accelerator`] class to initialize all the necessary requirements for distributed training.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Feel free to change the model and dataset inside the `main` function. If your dataset format is different from the one in the script, you may also need to write your own preprocessing function.
|
||||
|
||||
</Tip>
|
||||
|
||||
The script also creates a configuration for the 🤗 PEFT method you're using, which in this case, is LoRA. The [`LoraConfig`] specifies the task type and important parameters such as the dimension of the low-rank matrices, the matrices scaling factor, and the dropout probability of the LoRA layers. If you want to use a different 🤗 PEFT method, make sure you replace `LoraConfig` with the appropriate [class](../package_reference/tuners).
|
||||
|
||||
```diff
|
||||
def main():
|
||||
+ accelerator = Accelerator()
|
||||
model_name_or_path = "facebook/bart-large"
|
||||
dataset_name = "twitter_complaints"
|
||||
+ peft_config = LoraConfig(
|
||||
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
|
||||
)
|
||||
```
|
||||
|
||||
Throughout the script, you'll see the [`~accelerate.Accelerator.main_process_first`] and [`~accelerate.Accelerator.wait_for_everyone`] functions which help control and synchronize when processes are executed.
|
||||
|
||||
The [`get_peft_model`] function takes a base model and the [`peft_config`] you prepared earlier to create a [`PeftModel`]:
|
||||
|
||||
```diff
|
||||
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
|
||||
+ model = get_peft_model(model, peft_config)
|
||||
```
|
||||
|
||||
Pass all the relevant training objects to 🤗 Accelerate's [`~accelerate.Accelerator.prepare`] which makes sure everything is ready for training:
|
||||
|
||||
```py
|
||||
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler = accelerator.prepare(
|
||||
model, train_dataloader, eval_dataloader, test_dataloader, optimizer, lr_scheduler
|
||||
)
|
||||
```
|
||||
|
||||
The next bit of code checks whether the DeepSpeed plugin is used in the `Accelerator`, and if the plugin exists, then we check if we are using ZeRO-3. This conditional flag is used when calling `generate` function call during inference for syncing GPUs when the model parameters are sharded:
|
||||
|
||||
```py
|
||||
is_ds_zero_3 = False
|
||||
if getattr(accelerator.state, "deepspeed_plugin", None):
|
||||
is_ds_zero_3 = accelerator.state.deepspeed_plugin.zero_stage == 3
|
||||
```
|
||||
|
||||
Inside the training loop, the usual `loss.backward()` is replaced by 🤗 Accelerate's [`~accelerate.Accelerator.backward`] which uses the correct `backward()` method based on your configuration:
|
||||
|
||||
```diff
|
||||
for epoch in range(num_epochs):
|
||||
with TorchTracemalloc() as tracemalloc:
|
||||
model.train()
|
||||
total_loss = 0
|
||||
for step, batch in enumerate(tqdm(train_dataloader)):
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
total_loss += loss.detach().float()
|
||||
+ accelerator.backward(loss)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
```
|
||||
|
||||
That is all! The rest of the script handles the training loop, evaluation, and even pushes it to the Hub for you.
|
||||
|
||||
## Train
|
||||
|
||||
Run the following command to launch the training script. Earlier, you saved the configuration file to `ds_zero3_cpu.yaml`, so you'll need to pass the path to the launcher with the `--config_file` argument like this:
|
||||
|
||||
```bash
|
||||
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
|
||||
```
|
||||
|
||||
You'll see some output logs that track memory usage during training, and once it's completed, the script returns the accuracy and compares the predictions to the labels:
|
||||
|
||||
```bash
|
||||
GPU Memory before entering the train : 1916
|
||||
GPU Memory consumed at the end of the train (end-begin): 66
|
||||
GPU Peak Memory consumed during the train (max-begin): 7488
|
||||
GPU Total Peak Memory consumed during the train (max): 9404
|
||||
CPU Memory before entering the train : 19411
|
||||
CPU Memory consumed at the end of the train (end-begin): 0
|
||||
CPU Peak Memory consumed during the train (max-begin): 0
|
||||
CPU Total Peak Memory consumed during the train (max): 19411
|
||||
epoch=4: train_ppl=tensor(1.0705, device='cuda:0') train_epoch_loss=tensor(0.0681, device='cuda:0')
|
||||
100%|████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:27<00:00, 3.92s/it]
|
||||
GPU Memory before entering the eval : 1982
|
||||
GPU Memory consumed at the end of the eval (end-begin): -66
|
||||
GPU Peak Memory consumed during the eval (max-begin): 672
|
||||
GPU Total Peak Memory consumed during the eval (max): 2654
|
||||
CPU Memory before entering the eval : 19411
|
||||
CPU Memory consumed at the end of the eval (end-begin): 0
|
||||
CPU Peak Memory consumed during the eval (max-begin): 0
|
||||
CPU Total Peak Memory consumed during the eval (max): 19411
|
||||
accuracy=100.0
|
||||
eval_preds[:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
|
||||
dataset['train'][label_column][:10]=['no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint', 'no complaint', 'no complaint', 'complaint', 'complaint', 'no complaint']
|
||||
```
|
||||
|
||||
# Caveats
|
||||
1. Merging when using PEFT and DeepSpeed is currently unsupported and will raise error.
|
||||
2. When using CPU offloading, the major gains from using PEFT to shrink the optimizer states and gradients to that of the adapter weights would be realized on CPU RAM and there won't be savings with respect to GPU memory.
|
||||
3. DeepSpeed Stage 3 and qlora when used with CPU offloading leads to more GPU memory usage when compared to disabling CPU offloading.
|
||||
@ -6,17 +6,14 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
[Fully sharded data parallel](https://pytorch.org/docs/stable/fsdp.html) (FSDP) is developed for distributed training of large pretrained models up to 1T parameters. FSDP achieves this by sharding the model parameters, gradients, and optimizer states across data parallel processes and it can also offload sharded model parameters to a CPU. The memory efficiency afforded by FSDP allows you to scale training to larger batch or model sizes.
|
||||
|
||||
<Tip warning={true}>
|
||||
Both of these features are supported in 🤗 Accelerate, and you can use them with 🤗 PEFT.
|
||||
|
||||
Currently, FSDP does not confer any reduction in GPU memory usage and FSDP with CPU offload actually consumes 1.65x more GPU memory during training. You can track this PyTorch [issue](https://github.com/pytorch/pytorch/issues/91165) for any updates.
|
||||
|
||||
</Tip>
|
||||
|
||||
FSDP is supported in 🤗 Accelerate, and you can use it with 🤗 PEFT. This guide will help you learn how to use our FSDP [training script](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py). You'll configure the script to train a large model for conditional generation.
|
||||
# Use PEFT and FSDP
|
||||
This section of guide will help you learn how to use our DeepSpeed [training script](https://github.com/huggingface/peft/blob/main/examples/sft/train.py) for performing SFT. You'll configure the script to do SFT (supervised fine-tuning) of Llama-70B model with LoRA and FSDP on 8xH100 80GB GPUs on a single machine. You can configure it to scale to multiple machines by changing the accelerate config.
|
||||
|
||||
## Configuration
|
||||
|
||||
Begin by running the following command to [create a FSDP configuration file](https://huggingface.co/docs/accelerate/main/en/usage_guides/fsdp) with 🤗 Accelerate. Use the `--config_file` flag to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
|
||||
Start by running the following command to [create a FSDP configuration file](https://huggingface.co/docs/accelerate/quicktour#launching-your-distributed-script) with 🤗 Accelerate. The `--config_file` flag allows you to save the configuration file to a specific location, otherwise it is saved as a `default_config.yaml` file in the 🤗 Accelerate cache.
|
||||
|
||||
The configuration file is used to set the default options when you launch the training script.
|
||||
|
||||
@ -24,105 +21,271 @@ The configuration file is used to set the default options when you launch the tr
|
||||
accelerate config --config_file fsdp_config.yaml
|
||||
```
|
||||
|
||||
You'll be asked a few questions about your setup, and configure the following arguments. For this example, make sure you fully shard the model parameters, gradients, optimizer states, leverage the CPU for offloading, and wrap model layers based on the Transformer layer class name.
|
||||
You'll be asked a few questions about your setup, and configure the following arguments. In this example, you'll answer the questionnaire as shown in the image below.
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/fsdp-peft-config.png"/>
|
||||
</div>
|
||||
<small>Creating Accelerate's config to use FSDP</small>
|
||||
|
||||
```bash
|
||||
`Sharding Strategy`: [1] FULL_SHARD (shards optimizer states, gradients and parameters), [2] SHARD_GRAD_OP (shards optimizer states and gradients), [3] NO_SHARD
|
||||
`Offload Params`: Decides Whether to offload parameters and gradients to CPU
|
||||
`Auto Wrap Policy`: [1] TRANSFORMER_BASED_WRAP, [2] SIZE_BASED_WRAP, [3] NO_WRAP
|
||||
`Transformer Layer Class to Wrap`: When using `TRANSFORMER_BASED_WRAP`, user specifies comma-separated string of transformer layer class names (case-sensitive) to wrap ,e.g,
|
||||
`BertLayer`, `GPTJBlock`, `T5Block`, `BertLayer,BertEmbeddings,BertSelfOutput`...
|
||||
`Min Num Params`: minimum number of parameters when using `SIZE_BASED_WRAP`
|
||||
`Backward Prefetch`: [1] BACKWARD_PRE, [2] BACKWARD_POST, [3] NO_PREFETCH
|
||||
`State Dict Type`: [1] FULL_STATE_DICT, [2] LOCAL_STATE_DICT, [3] SHARDED_STATE_DICT
|
||||
```
|
||||
Once this is done, the corresponding config should look like below and you can find it in config folder at [fsdp_config.yaml](https://github.com/huggingface/peft/blob/main/examples/sft/configs/fsdp_config.yaml):
|
||||
|
||||
For example, your FSDP configuration file may look like the following:
|
||||
|
||||
```yaml
|
||||
command_file: null
|
||||
commands: null
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config: {}
|
||||
debug: false
|
||||
distributed_type: FSDP
|
||||
downcast_bf16: 'no'
|
||||
dynamo_backend: 'NO'
|
||||
fsdp_config:
|
||||
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
|
||||
fsdp_backward_prefetch_policy: BACKWARD_PRE
|
||||
fsdp_offload_params: true
|
||||
fsdp_sharding_strategy: 1
|
||||
fsdp_state_dict_type: FULL_STATE_DICT
|
||||
fsdp_transformer_layer_cls_to_wrap: T5Block
|
||||
gpu_ids: null
|
||||
fsdp_backward_prefetch: BACKWARD_PRE
|
||||
fsdp_cpu_ram_efficient_loading: true
|
||||
fsdp_forward_prefetch: false
|
||||
fsdp_offload_params: false
|
||||
fsdp_sharding_strategy: FULL_SHARD
|
||||
fsdp_state_dict_type: SHARDED_STATE_DICT
|
||||
fsdp_sync_module_states: true
|
||||
fsdp_use_orig_params: false
|
||||
machine_rank: 0
|
||||
main_training_function: main
|
||||
mixed_precision: bf16
|
||||
num_machines: 1
|
||||
num_processes: 8
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
## Launch command
|
||||
|
||||
The launch command is available at [run_peft_fsdp.sh](https://github.com/huggingface/peft/blob/main/examples/sft/run_peft_fsdp.sh) and it is also shown below:
|
||||
```bash
|
||||
accelerate launch --config_file "configs/fsdp_config.yaml" train.py \
|
||||
--seed 100 \
|
||||
--model_name_or_path "meta-llama/Llama-2-70b-hf" \
|
||||
--dataset_name "smangrul/ultrachat-10k-chatml" \
|
||||
--chat_template_format "chatml" \
|
||||
--add_special_tokens False \
|
||||
--append_concat_token False \
|
||||
--splits "train,test" \
|
||||
--max_seq_len 2048 \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 5 \
|
||||
--log_level "info" \
|
||||
--logging_strategy "steps" \
|
||||
--evaluation_strategy "epoch" \
|
||||
--save_strategy "epoch" \
|
||||
--push_to_hub \
|
||||
--hub_private_repo True \
|
||||
--hub_strategy "every_save" \
|
||||
--bf16 True \
|
||||
--packing True \
|
||||
--learning_rate 1e-4 \
|
||||
--lr_scheduler_type "cosine" \
|
||||
--weight_decay 1e-4 \
|
||||
--warmup_ratio 0.0 \
|
||||
--max_grad_norm 1.0 \
|
||||
--output_dir "llama-sft-lora-fsdp" \
|
||||
--per_device_train_batch_size 8 \
|
||||
--per_device_eval_batch_size 8 \
|
||||
--gradient_accumulation_steps 4 \
|
||||
--gradient_checkpointing True \
|
||||
--use_reentrant False \
|
||||
--dataset_text_field "content" \
|
||||
--use_flash_attn True \
|
||||
--use_peft_lora True \
|
||||
--lora_r 8 \
|
||||
--lora_alpha 16 \
|
||||
--lora_dropout 0.1 \
|
||||
--lora_target_modules "all-linear" \
|
||||
--use_4bit_quantization False
|
||||
```
|
||||
|
||||
Notice that we are using LoRA with rank=8, alpha=16 and targeting all linear layers. We are passing the FSDP config file and finetuning the 70B Llama model on a subset of the [ultrachat dataset](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k).
|
||||
|
||||
## The important parts
|
||||
|
||||
Let's dive a little deeper into the script so you can see what's going on, and understand how it works.
|
||||
|
||||
The first thing to know is that the script uses FSDP for distributed training as the FSDP config has been passed. The `SFTTrainer` class handles all the heavy lifting of creating PEFT model using the peft config that is passed. After that when you call `trainer.train()`, Trainer internally uses 🤗 Accelerate to prepare model, optimizer and trainer using the FSDP config to create FSDP wrapped model which is then trained. The main code snippet is below:
|
||||
|
||||
```python
|
||||
# trainer
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
tokenizer=tokenizer,
|
||||
args=training_args,
|
||||
train_dataset=train_dataset,
|
||||
eval_dataset=eval_dataset,
|
||||
peft_config=peft_config,
|
||||
packing=data_args.packing,
|
||||
dataset_kwargs={
|
||||
"append_concat_token": data_args.append_concat_token,
|
||||
"add_special_tokens": data_args.add_special_tokens,
|
||||
},
|
||||
dataset_text_field=data_args.dataset_text_field,
|
||||
max_seq_length=data_args.max_seq_length,
|
||||
)
|
||||
trainer.accelerator.print(f"{trainer.model}")
|
||||
if model_args.use_peft_lora:
|
||||
# handle PEFT+FSDP case
|
||||
trainer.model.print_trainable_parameters()
|
||||
if getattr(trainer.accelerator.state, "fsdp_plugin", None):
|
||||
from peft.utils.other import fsdp_auto_wrap_policy
|
||||
|
||||
fsdp_plugin = trainer.accelerator.state.fsdp_plugin
|
||||
fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(trainer.model)
|
||||
|
||||
# train
|
||||
checkpoint = None
|
||||
if training_args.resume_from_checkpoint is not None:
|
||||
checkpoint = training_args.resume_from_checkpoint
|
||||
trainer.train(resume_from_checkpoint=checkpoint)
|
||||
|
||||
# saving final model
|
||||
if trainer.is_fsdp_enabled:
|
||||
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
|
||||
trainer.save_model()
|
||||
```
|
||||
|
||||
|
||||
Here, one main thing to note currently when using FSDP with PEFT is that `use_orig_params` needs to be `False` to realize GPU memory savings. Due to `use_orig_params=False`, the auto wrap policy for FSDP needs to change so that trainable and non-trainable parameters are wrapped separately. This is done by the code snippt below which uses the util function `fsdp_auto_wrap_policy` from PEFT:
|
||||
|
||||
```
|
||||
if getattr(trainer.accelerator.state, "fsdp_plugin", None):
|
||||
from peft.utils.other import fsdp_auto_wrap_policy
|
||||
|
||||
fsdp_plugin = trainer.accelerator.state.fsdp_plugin
|
||||
fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(trainer.model)
|
||||
```
|
||||
|
||||
## Memory usage
|
||||
|
||||
In the above example, the memory consumed per GPU is 72-80 GB (90-98%) as seen in the screenshot below. The slight increase in GPU memory at the end is when saving the model using `FULL_STATE_DICT` state dict type instead of the `SHARDED_STATE_DICT` so that the model has adapter weights that can be loaded normally with `from_pretrained` method during inference:
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/peft_fsdp_mem_usage.png"/>
|
||||
</div>
|
||||
<small>GPU memory usage for the training run</small>
|
||||
|
||||
# Use PEFT QLoRA and FSDP for finetuning large models on multiple GPUs
|
||||
|
||||
In this section, we will look at how to use QLoRA and FSDP for finetuning 70B llama model on 2X24GB GPUs. [Answer.AI](https://www.answer.ai/) in collaboration with bitsandbytes and Hugging Face 🤗 open sourced code enabling the usage of FSDP+QLoRA and explained the whole process in their insightful blogpost [You can now train a 70b language model at home](https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html). This is now integrated in Hugging Face ecosystem.
|
||||
|
||||
For this, we first need `bitsandbytes>=0.43.0`, `accelerate>=0.28.0`, `transformers>4.38.2`, `trl>0.7.11` and `peft>0.9.0`. We need to set `fsdp_cpu_ram_efficient_loading=true`, `fsdp_use_orig_params=false` and `fsdp_offload_params=true`(cpu offloading) when using Accelerate config. When not using accelerate launcher, you can alternately set the environment variable `export FSDP_CPU_RAM_EFFICIENT_LOADING=true`. Here, we will be using accelerate config and below is the config which can be found at [fsdp_config_qlora.yaml](https://github.com/huggingface/peft/blob/main/examples/sft/configs/fsdp_config_qlora.yaml):
|
||||
|
||||
```yml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
debug: false
|
||||
distributed_type: FSDP
|
||||
downcast_bf16: 'no'
|
||||
fsdp_config:
|
||||
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
|
||||
fsdp_backward_prefetch: BACKWARD_PRE
|
||||
fsdp_cpu_ram_efficient_loading: true
|
||||
fsdp_forward_prefetch: false
|
||||
fsdp_offload_params: true
|
||||
fsdp_sharding_strategy: FULL_SHARD
|
||||
fsdp_state_dict_type: SHARDED_STATE_DICT
|
||||
fsdp_sync_module_states: true
|
||||
fsdp_use_orig_params: false
|
||||
machine_rank: 0
|
||||
main_process_ip: null
|
||||
main_process_port: null
|
||||
main_training_function: main
|
||||
megatron_lm_config: {}
|
||||
mixed_precision: 'no'
|
||||
num_machines: 1
|
||||
num_processes: 2
|
||||
rdzv_backend: static
|
||||
same_network: true
|
||||
tpu_name: null
|
||||
tpu_zone: null
|
||||
tpu_env: []
|
||||
tpu_use_cluster: false
|
||||
tpu_use_sudo: false
|
||||
use_cpu: false
|
||||
```
|
||||
|
||||
## The important parts
|
||||
Launch command is given below which is available at [run_peft_qlora_fsdp.sh](https://github.com/huggingface/peft/blob/main/examples/sft/run_peft_qlora_fsdp.sh):
|
||||
```
|
||||
accelerate launch --config_file "configs/fsdp_config_qlora.yaml" train.py \
|
||||
--seed 100 \
|
||||
--model_name_or_path "meta-llama/Llama-2-70b-hf" \
|
||||
--dataset_name "smangrul/ultrachat-10k-chatml" \
|
||||
--chat_template_format "chatml" \
|
||||
--add_special_tokens False \
|
||||
--append_concat_token False \
|
||||
--splits "train,test" \
|
||||
--max_seq_len 2048 \
|
||||
--num_train_epochs 1 \
|
||||
--logging_steps 5 \
|
||||
--log_level "info" \
|
||||
--logging_strategy "steps" \
|
||||
--evaluation_strategy "epoch" \
|
||||
--save_strategy "epoch" \
|
||||
--push_to_hub \
|
||||
--hub_private_repo True \
|
||||
--hub_strategy "every_save" \
|
||||
--bf16 True \
|
||||
--packing True \
|
||||
--learning_rate 1e-4 \
|
||||
--lr_scheduler_type "cosine" \
|
||||
--weight_decay 1e-4 \
|
||||
--warmup_ratio 0.0 \
|
||||
--max_grad_norm 1.0 \
|
||||
--output_dir "llama-sft-qlora-fsdp" \
|
||||
--per_device_train_batch_size 2 \
|
||||
--per_device_eval_batch_size 2 \
|
||||
--gradient_accumulation_steps 2 \
|
||||
--gradient_checkpointing True \
|
||||
--use_reentrant True \
|
||||
--dataset_text_field "content" \
|
||||
--use_flash_attn True \
|
||||
--use_peft_lora True \
|
||||
--lora_r 8 \
|
||||
--lora_alpha 16 \
|
||||
--lora_dropout 0.1 \
|
||||
--lora_target_modules "all-linear" \
|
||||
--use_4bit_quantization True \
|
||||
--use_nested_quant True \
|
||||
--bnb_4bit_compute_dtype "bfloat16" \
|
||||
--bnb_4bit_quant_storage_dtype "bfloat16"
|
||||
```
|
||||
|
||||
Let's dig a bit deeper into the training script to understand how it works.
|
||||
Notice the new argument being passed, `bnb_4bit_quant_storage_dtype`, which denotes the data type for packing the 4-bit parameters. For example, when it is set to `bfloat16`, **32/4 = 8** 4-bit params are packed together post quantization. When using mixed precision training with `bfloat16`, `bnb_4bit_quant_storage_dtype` can be either `bfloat16` for pure `bfloat16` finetuning, or `float32` for automatic mixed precision (this consumes more GPU memory). When using mixed precision training with `float16`, `bnb_4bit_quant_storage_dtype` should be set to `float32` for stable automatic mixed precision training.
|
||||
|
||||
The [`main()`](https://github.com/huggingface/peft/blob/2822398fbe896f25d4dac5e468624dc5fd65a51b/examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py#L14) function begins with initializing an [`~accelerate.Accelerator`] class which handles everything for distributed training, such as automatically detecting your training environment.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Feel free to change the model and dataset inside the `main` function. If your dataset format is different from the one in the script, you may also need to write your own preprocessing function.
|
||||
|
||||
</Tip>
|
||||
|
||||
The script also creates a configuration corresponding to the 🤗 PEFT method you're using. For LoRA, you'll use [`LoraConfig`] to specify the task type, and several other important parameters such as the dimension of the low-rank matrices, the matrices scaling factor, and the dropout probability of the LoRA layers. If you want to use a different 🤗 PEFT method, replace `LoraConfig` with the appropriate [class](../package_reference/tuners).
|
||||
|
||||
Next, the script wraps the base model and `peft_config` with the [`get_peft_model`] function to create a [`PeftModel`].
|
||||
In terms of training code, the important code changes are:
|
||||
|
||||
```diff
|
||||
def main():
|
||||
+ accelerator = Accelerator()
|
||||
model_name_or_path = "t5-base"
|
||||
base_path = "temp/data/FinancialPhraseBank-v1.0"
|
||||
+ peft_config = LoraConfig(
|
||||
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
|
||||
)
|
||||
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
|
||||
+ model = get_peft_model(model, peft_config)
|
||||
```
|
||||
...
|
||||
|
||||
Throughout the script, you'll see the [`~accelerate.Accelerator.main_process_first`] and [`~accelerate.Accelerator.wait_for_everyone`] functions which help control and synchronize when processes are executed.
|
||||
bnb_config = BitsAndBytesConfig(
|
||||
load_in_4bit=args.use_4bit_quantization,
|
||||
bnb_4bit_quant_type=args.bnb_4bit_quant_type,
|
||||
bnb_4bit_compute_dtype=compute_dtype,
|
||||
bnb_4bit_use_double_quant=args.use_nested_quant,
|
||||
+ bnb_4bit_quant_storage=quant_storage_dtype,
|
||||
)
|
||||
|
||||
After your dataset is prepared, and all the necessary training components are loaded, the script checks if you're using the `fsdp_plugin`. PyTorch offers two ways for wrapping model layers in FSDP, automatically or manually. The simplest method is to allow FSDP to automatically recursively wrap model layers without changing any other code. You can choose to wrap the model layers based on the layer name or on the size (number of parameters). In the FSDP configuration file, it uses the `TRANSFORMER_BASED_WRAP` option to wrap the [`T5Block`] layer.
|
||||
...
|
||||
|
||||
```py
|
||||
if getattr(accelerator.state, "fsdp_plugin", None) is not None:
|
||||
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
|
||||
```
|
||||
|
||||
Next, use 🤗 Accelerate's [`~accelerate.Accelerator.prepare`] function to prepare the model, datasets, optimizer, and scheduler for training.
|
||||
|
||||
```py
|
||||
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler = accelerator.prepare(
|
||||
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
args.model_name_or_path,
|
||||
quantization_config=bnb_config,
|
||||
trust_remote_code=True,
|
||||
attn_implementation="flash_attention_2" if args.use_flash_attn else "eager",
|
||||
+ torch_dtype=quant_storage_dtype or torch.float32,
|
||||
)
|
||||
```
|
||||
|
||||
From here, the remainder of the script handles the training loop, evaluation, and sharing your model to the Hub.
|
||||
Notice that `torch_dtype` for `AutoModelForCausalLM` is same as the `bnb_4bit_quant_storage` data type. That's it. Everything else is handled by Trainer and TRL.
|
||||
|
||||
## Train
|
||||
## Memory usage
|
||||
|
||||
Run the following command to launch the training script. Earlier, you saved the configuration file to `fsdp_config.yaml`, so you'll need to pass the path to the launcher with the `--config_file` argument like this:
|
||||
In the above example, the memory consumed per GPU is **19.6 GB** while CPU RAM usage is around **107 GB**. When disabling CPU offloading, the GPU memory usage is **35.6 GB/ GPU**. Therefore, what took 16X80GB GPUs for full finetuning, 8X80GB GPUs with FSDP+LoRA, and a couple of 80GB GPUs with DDP+QLoRA, now requires 2X24GB GPUs. This makes finetuning of large models more accessible.
|
||||
|
||||
```bash
|
||||
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
|
||||
```
|
||||
## More resources
|
||||
You can also refer the [llama-recipes](https://github.com/facebookresearch/llama-recipes/?tab=readme-ov-file#fine-tuning) repo and [Getting started with Llama](https://llama.meta.com/get-started/#fine-tuning) guide on how to finetune using FSDP and PEFT.
|
||||
|
||||
Once training is complete, the script returns the accuracy and compares the predictions to the labels.
|
||||
## Caveats
|
||||
1. Merging when using PEFT and FSDP is currently unsupported and will raise error.
|
||||
2. Passing `modules_to_save` config parameter to is untested at present.
|
||||
3. GPU Memory saving when using CPU Offloading is untested at present.
|
||||
4. When using FSDP+QLoRA, `paged_adamw_8bit` currently results in an error when saving a checkpoint.
|
||||
95
docs/source/conceptual_guides/adapter.md
Normal file
95
docs/source/conceptual_guides/adapter.md
Normal file
@ -0,0 +1,95 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Adapters
|
||||
|
||||
Adapter-based methods add extra trainable parameters after the attention and fully-connected layers of a frozen pretrained model to reduce memory-usage and speed up training. The method varies depending on the adapter, it could simply be an extra added layer or it could be expressing the weight updates ∆W as a low-rank decomposition of the weight matrix. Either way, the adapters are typically small but demonstrate comparable performance to a fully finetuned model and enable training larger models with fewer resources.
|
||||
|
||||
This guide will give you a brief overview of the adapter methods supported by PEFT (if you're interested in learning more details about a specific method, take a look at the linked paper).
|
||||
|
||||
## Low-Rank Adaptation (LoRA)
|
||||
|
||||
<Tip>
|
||||
|
||||
LoRA is one of the most popular PEFT methods and a good starting point if you're just getting started with PEFT. It was originally developed for large language models but it is a tremendously popular training method for diffusion models because of its efficiency and effectiveness.
|
||||
|
||||
</Tip>
|
||||
|
||||
As mentioned briefly earlier, [LoRA](https://hf.co/papers/2106.09685) is a technique that accelerates finetuning large models while consuming less memory.
|
||||
|
||||
LoRA represents the weight updates ∆W with two smaller matrices (called *update matrices*) through low-rank decomposition. These new matrices can be trained to adapt to the new data while keeping the overall number of parameters low. The original weight matrix remains frozen and doesn't receive any further updates. To produce the final results, the original and extra adapted weights are combined. You could also merge the adapter weights with the base model to eliminate inference latency.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_animated.gif"/>
|
||||
</div>
|
||||
|
||||
This approach has a number of advantages:
|
||||
|
||||
* LoRA makes finetuning more efficient by drastically reducing the number of trainable parameters.
|
||||
* The original pretrained weights are kept frozen, which means you can have multiple lightweight and portable LoRA models for various downstream tasks built on top of them.
|
||||
* LoRA is orthogonal to other parameter-efficient methods and can be combined with many of them.
|
||||
* Performance of models finetuned using LoRA is comparable to the performance of fully finetuned models.
|
||||
|
||||
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. However, for simplicity and further parameter efficiency, LoRA is typically only applied to the attention blocks in Transformer models. The resulting number of trainable parameters in a LoRA model depends on the size of the update matrices, which is determined mainly by the rank `r` and the shape of the original weight matrix.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora.png"/>
|
||||
</div>
|
||||
<small><a href="https://hf.co/papers/2103.10385">Navigating Text-To-Image Customization: From LyCORIS Fine-Tuning to Model Evaluation</a></small>
|
||||
|
||||
## Low-Rank Hadamard Product (LoHa)
|
||||
|
||||
Low-rank decomposition can impact performance because the weight updates are limited to the low-rank space, which can constrain a model's expressiveness. However, you don't necessarily want to use a larger rank because it increases the number of trainable parameters. To address this, [LoHa](https://huggingface.co/papers/2108.06098) (a method originally developed for computer vision) was applied to diffusion models where the ability to generate diverse images is an important consideration. LoHa should also work with general model types, but the embedding layers aren't currently implemented in PEFT.
|
||||
|
||||
LoHa uses the [Hadamard product](https://en.wikipedia.org/wiki/Hadamard_product_(matrices)) (element-wise product) instead of the matrix product. ∆W is represented by four smaller matrices instead of two - like in LoRA - and each pair of these low-rank matrices are combined with the Hadamard product. As a result, ∆W can have the same number of trainable parameters but a higher rank and expressivity.
|
||||
|
||||
## Low-Rank Kronecker Product (LoKr)
|
||||
|
||||
[LoKr](https://hf.co/papers/2309.14859) is very similar to LoRA and LoHa, and it is also mainly applied to diffusion models, though you could also use it with other model types. LoKr replaces the matrix product with the [Kronecker product](https://en.wikipedia.org/wiki/Kronecker_product) instead. The Kronecker product decomposition creates a block matrix which preserves the rank of the original weight matrix. Another benefit of the Kronecker product is that it can be vectorized by stacking the matrix columns. This can speed up the process because you're avoiding fully reconstructing ∆W.
|
||||
|
||||
## Orthogonal Finetuning (OFT)
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/oft.png"/>
|
||||
</div>
|
||||
<small><a href="https://hf.co/papers/2306.07280">Controlling Text-to-Image Diffusion by Orthogonal Finetuning</a></small>
|
||||
|
||||
[OFT](https://hf.co/papers/2306.07280) is a method that primarily focuses on preserving a pretrained model's generative performance in the finetuned model. It tries to maintain the same cosine similarity (hyperspherical energy) between all pairwise neurons in a layer because this better captures the semantic information among neurons. This means OFT is more capable at preserving the subject and it is better for controllable generation (similar to [ControlNet](https://huggingface.co/docs/diffusers/using-diffusers/controlnet)).
|
||||
|
||||
OFT preserves the hyperspherical energy by learning an orthogonal transformation for neurons to keep the cosine similarity between them unchanged. In practice, this means taking the matrix product of an orthogonal matrix with the pretrained weight matrix. However, to be parameter-efficient, the orthogonal matrix is represented as a block-diagonal matrix with rank `r` blocks. Whereas LoRA reduces the number of trainable parameters with low-rank structures, OFT reduces the number of trainable parameters with a sparse block-diagonal matrix structure.
|
||||
|
||||
## Orthogonal Butterfly (BOFT)
|
||||
|
||||
[BOFT](https://hf.co/papers/2311.06243) is a method that primarily focuses on preserving a pretrained model's generative performance in the finetuned model. It tries to maintain the same cosine similarity (hyperspherical energy) between all pairwise neurons in a layer because this better captures the semantic information among neurons. This means OFT is more capable at preserving the subject and it is better for controllable generation (similar to [ControlNet](https://huggingface.co/docs/diffusers/using-diffusers/controlnet)).
|
||||
|
||||
OFT preserves the hyperspherical energy by learning an orthogonal transformation for neurons to keep the cosine similarity between them unchanged. In practice, this means taking the matrix product of an orthogonal matrix with the pretrained weight matrix. However, to be parameter-efficient, the orthogonal matrix is represented as a block-diagonal matrix with rank `r` blocks. Whereas LoRA reduces the number of trainable parameters with low-rank structures, OFT reduces the number of trainable parameters with a sparse block-diagonal matrix structure.
|
||||
|
||||
## Adaptive Low-Rank Adaptation (AdaLoRA)
|
||||
|
||||
[AdaLoRA](https://hf.co/papers/2303.10512) manages the parameter budget introduced from LoRA by allocating more parameters - in other words, a higher rank `r` - for important weight matrices that are better adapted for a task and pruning less important ones. The rank is controlled by a method similar to singular value decomposition (SVD). The ∆W is parameterized with two orthogonal matrices and a diagonal matrix which contains singular values. This parametrization method avoids iteratively applying SVD which is computationally expensive. Based on this method, the rank of ∆W is adjusted according to an importance score. ∆W is divided into triplets and each triplet is scored according to its contribution to model performance. Triplets with low importance scores are pruned and triplets with high importance scores are kept for finetuning.
|
||||
|
||||
## Llama-Adapter
|
||||
|
||||
[Llama-Adapter](https://hf.co/papers/2303.16199) is a method for adapting Llama into a instruction-following model. To help adapt the model for instruction-following, the adapter is trained with a 52K instruction-output dataset.
|
||||
|
||||
A set of of learnable adaption prompts are prefixed to the input instruction tokens. These are inserted into the upper layers of the model because it is better to learn with the higher-level semantics of the pretrained model. The instruction-output tokens prefixed to the input guide the adaption prompt to generate a contextual response.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/llama-adapter.png"/>
|
||||
</div>
|
||||
<small><a href="https://hf.co/papers/2303.16199">LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention</a></small>
|
||||
|
||||
To avoid adding noise to the tokens, the adapter uses zero-initialized attention. On top of this, the adapter adds a learnable gating factor (initialized with zeros) to progressively add information to the model during training. This prevents overwhelming the model's pretrained knowledge with the newly learned instructions.
|
||||
@ -1,114 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# LoRA
|
||||
|
||||
This conceptual guide gives a brief overview of [LoRA](https://arxiv.org/abs/2106.09685), a technique that accelerates
|
||||
the fine-tuning of large models while consuming less memory.
|
||||
|
||||
To make fine-tuning more efficient, LoRA's approach is to represent the weight updates with two smaller
|
||||
matrices (called **update matrices**) through low-rank decomposition. These new matrices can be trained to adapt to the
|
||||
new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn't receive
|
||||
any further adjustments. To produce the final results, both the original and the adapted weights are combined.
|
||||
|
||||
This approach has a number of advantages:
|
||||
|
||||
* LoRA makes fine-tuning more efficient by drastically reducing the number of trainable parameters.
|
||||
* The original pre-trained weights are kept frozen, which means you can have multiple lightweight and portable LoRA models for various downstream tasks built on top of them.
|
||||
* LoRA is orthogonal to many other parameter-efficient methods and can be combined with many of them.
|
||||
* Performance of models fine-tuned using LoRA is comparable to the performance of fully fine-tuned models.
|
||||
* LoRA does not add any inference latency because adapter weights can be merged with the base model.
|
||||
|
||||
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable
|
||||
parameters. However, for simplicity and further parameter efficiency, in Transformer models LoRA is typically applied to
|
||||
attention blocks only. The resulting number of trainable parameters in a LoRA model depends on the size of the low-rank
|
||||
update matrices, which is determined mainly by the rank `r` and the shape of the original weight matrix.
|
||||
|
||||
## Merge LoRA weights into the base model
|
||||
|
||||
While LoRA is significantly smaller and faster to train, you may encounter latency issues during inference due to separately loading the base model and the LoRA model. To eliminate latency, use the [`~LoraModel.merge_and_unload`] function to merge the adapter weights with the base model which allows you to effectively use the newly merged model as a standalone model.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_diagram.png"/>
|
||||
</div>
|
||||
|
||||
This works because during training, the smaller weight matrices (*A* and *B* in the diagram above) are separate. But once training is complete, the weights can actually be merged into a new weight matrix that is identical.
|
||||
|
||||
## Utils for LoRA
|
||||
|
||||
Use [`~LoraModel.merge_adapter`] to merge the LoRa layers into the base model while retaining the PeftModel.
|
||||
This will help in later unmerging, deleting, loading different adapters and so on.
|
||||
|
||||
Use [`~LoraModel.unmerge_adapter`] to unmerge the LoRa layers from the base model while retaining the PeftModel.
|
||||
This will help in later merging, deleting, loading different adapters and so on.
|
||||
|
||||
Use [`~LoraModel.unload`] to get back the base model without the merging of the active lora modules.
|
||||
This will help when you want to get back the pretrained base model in some applications when you want to reset the model to its original state.
|
||||
For example, in Stable Diffusion WebUi, when the user wants to infer with base model post trying out LoRAs.
|
||||
|
||||
Use [`~LoraModel.delete_adapter`] to delete an existing adapter.
|
||||
|
||||
Use [`~LoraModel.add_weighted_adapter`] to combine multiple LoRAs into a new adapter based on the user provided weighing scheme.
|
||||
|
||||
## Common LoRA parameters in PEFT
|
||||
|
||||
As with other methods supported by PEFT, to fine-tune a model using LoRA, you need to:
|
||||
|
||||
1. Instantiate a base model.
|
||||
2. Create a configuration (`LoraConfig`) where you define LoRA-specific parameters.
|
||||
3. Wrap the base model with `get_peft_model()` to get a trainable `PeftModel`.
|
||||
4. Train the `PeftModel` as you normally would train the base model.
|
||||
|
||||
`LoraConfig` allows you to control how LoRA is applied to the base model through the following parameters:
|
||||
|
||||
- `r`: the rank of the update matrices, expressed in `int`. Lower rank results in smaller update matrices with fewer trainable parameters.
|
||||
- `target_modules`: The modules (for example, attention blocks) to apply the LoRA update matrices.
|
||||
- `alpha`: LoRA scaling factor.
|
||||
- `bias`: Specifies if the `bias` parameters should be trained. Can be `'none'`, `'all'` or `'lora_only'`.
|
||||
- `modules_to_save`: List of modules apart from LoRA layers to be set as trainable and saved in the final checkpoint. These typically include model's custom head that is randomly initialized for the fine-tuning task.
|
||||
- `layers_to_transform`: List of layers to be transformed by LoRA. If not specified, all layers in `target_modules` are transformed.
|
||||
- `layers_pattern`: Pattern to match layer names in `target_modules`, if `layers_to_transform` is specified. By default `PeftModel` will look at common layer pattern (`layers`, `h`, `blocks`, etc.), use it for exotic and custom models.
|
||||
- `rank_pattern`: The mapping from layer names or regexp expression to ranks which are different from the default rank specified by `r`.
|
||||
- `alpha_pattern`: The mapping from layer names or regexp expression to alphas which are different from the default alpha specified by `lora_alpha`.
|
||||
|
||||
## LoRA examples
|
||||
|
||||
For an example of LoRA method application to various downstream tasks, please refer to the following guides:
|
||||
|
||||
* [Image classification using LoRA](../task_guides/image_classification_lora)
|
||||
* [Semantic segmentation](../task_guides/semantic_segmentation_lora)
|
||||
|
||||
While the original paper focuses on language models, the technique can be applied to any dense layers in deep learning
|
||||
models. As such, you can leverage this technique with diffusion models. See [Dreambooth fine-tuning with LoRA](../task_guides/task_guides/dreambooth_lora) task guide for an example.
|
||||
|
||||
## Initialization options
|
||||
|
||||
The initialization of LoRA weights is controlled by the parameter `init_lora_weights` of the `LoraConfig`. By default, PEFT initializes LoRA weights the same way as the [reference implementation](https://github.com/microsoft/LoRA), i.e. using Kaiming-uniform for weight A and initializing weight B as zeros, resulting in an identity transform.
|
||||
|
||||
It is also possible to pass `init_lora_weights="gaussian"`. As the name suggests, this results in initializing weight A with a Gaussian distribution (weight B is still zeros). This corresponds to the way that [diffusers](https://huggingface.co/docs/diffusers/index) initializes LoRA weights.
|
||||
|
||||
When quantizing the base model, e.g. for QLoRA training, consider using the [LoftQ initialization](https://arxiv.org/abs/2310.08659), which has been shown to improve the performance with quantization. The idea is that the LoRA weights are initialized such that the quantization error is minimized. To use this option, *do not* quantize the base model. Instead, proceed as follows:
|
||||
|
||||
```python
|
||||
from peft import LoftQConfig, LoraConfig, get_peft_model
|
||||
|
||||
base_model = AutoModelForCausalLM.from_pretrained(...) # don't quantize here
|
||||
loftq_config = LoftQConfig(loftq_bits=4, ...) # set 4bit quantization
|
||||
lora_config = LoraConfig(..., init_lora_weights="loftq", loftq_config=loftq_config)
|
||||
peft_model = get_peft_model(base_model, lora_config)
|
||||
```
|
||||
|
||||
Finally, there is also an option to set `initialize_lora_weights=False`. When choosing this option, the LoRA weights are initialized such that they do *not* result in an identity transform. This is useful for debugging and testing purposes and should not be used otherwise.
|
||||
107
docs/source/conceptual_guides/oft.md
Normal file
107
docs/source/conceptual_guides/oft.md
Normal file
@ -0,0 +1,107 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Orthogonal Finetuning (OFT and BOFT)
|
||||
|
||||
This conceptual guide gives a brief overview of [OFT](https://arxiv.org/abs/2306.07280) and [BOFT](https://arxiv.org/abs/2311.06243), a parameter-efficient fine-tuning technique that utilizes orthogonal matrix to multiplicatively transform the pretrained weight matrices.
|
||||
|
||||
To achieve efficient fine-tuning, OFT represents the weight updates with an orthogonal transformation. The orthogonal transformation is parameterized by an orthogonal matrix multiplied to the pretrained weight matrix. These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are multiplied togethor.
|
||||
|
||||
Orthogonal Butterfly (BOFT) generalizes OFT with Butterfly factorization and further improves its parameter efficiency and finetuning flexibility. In short, OFT can be viewed as a special case of BOFT. Different from LoRA that uses additive low-rank weight updates, BOFT uses multiplicative orthogonal weight updates. The comparison is shown below.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://raw.githubusercontent.com/wy1iu/butterfly-oft/main/assets/BOFT_comparison.png"/>
|
||||
</div>
|
||||
|
||||
|
||||
BOFT has some advantages compared to LoRA:
|
||||
|
||||
* BOFT proposes a simple yet generic way to finetune pretrained models to downstream tasks, yielding a better preservation of pretraining knowledge and a better parameter efficiency.
|
||||
* Through the orthogonality, BOFT introduces a structural constraint, i.e., keeping the [hyperspherical energy](https://arxiv.org/abs/1805.09298) unchanged during finetuning. This can effectively reduce the forgetting of pretraining knowledge.
|
||||
* BOFT uses the butterfly factorization to efficiently parameterize the orthogonal matrix, which yields a compact yet expressive learning space (i.e., hypothesis class).
|
||||
* The sparse matrix decomposition in BOFT brings in additional inductive biases that are beneficial to generalization.
|
||||
|
||||
In principle, BOFT can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. Given the target layers for injecting BOFT parameters, the number of trainable parameters can be determined based on the size of the weight matrices.
|
||||
|
||||
## Merge OFT/BOFT weights into the base model
|
||||
|
||||
Similar to LoRA, the weights learned by OFT/BOFT can be integrated into the pretrained weight matrices using the merge_and_unload() function. This function merges the adapter weights with the base model which allows you to effectively use the newly merged model as a standalone model.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://raw.githubusercontent.com/wy1iu/butterfly-oft/main/assets/boft_merge.png"/>
|
||||
</div>
|
||||
|
||||
This works because during training, the orthogonal weight matrix (R in the diagram above) and the pretrained weight matrices are separate. But once training is complete, these weights can actually be merged (multiplied) into a new weight matrix that is equivalent.
|
||||
|
||||
## Utils for OFT / BOFT
|
||||
|
||||
### Common OFT / BOFT parameters in PEFT
|
||||
|
||||
As with other methods supported by PEFT, to fine-tune a model using OFT or BOFT, you need to:
|
||||
|
||||
1. Instantiate a base model.
|
||||
2. Create a configuration (`OFTConfig` or `BOFTConfig`) where you define OFT/BOFT-specific parameters.
|
||||
3. Wrap the base model with `get_peft_model()` to get a trainable `PeftModel`.
|
||||
4. Train the `PeftModel` as you normally would train the base model.
|
||||
|
||||
|
||||
### BOFT-specific paramters
|
||||
|
||||
`BOFTConfig` allows you to control how OFT/BOFT is applied to the base model through the following parameters:
|
||||
|
||||
- `boft_block_size`: the BOFT matrix block size across different layers, expressed in `int`. Smaller block size results in sparser update matrices with fewer trainable paramters. **Note**, please choose `boft_block_size` to be divisible by most layer's input dimension (`in_features`), e.g., 4, 8, 16. Also, please only
|
||||
specify either `boft_block_size` or `boft_block_num`, but not both simultaneously or leaving both to 0, because `boft_block_size` x `boft_block_num` must equal the layer's input dimension.
|
||||
- `boft_block_num`: the number of BOFT matrix blocks across different layers, expressed in `int`. Fewer blocks result in sparser update matrices with fewer trainable paramters. **Note**, please choose `boft_block_num` to be divisible by most layer's input dimension (`in_features`), e.g., 4, 8, 16. Also, please only
|
||||
specify either `boft_block_size` or `boft_block_num`, but not both simultaneously or leaving both to 0, because `boft_block_size` x `boft_block_num` must equal the layer's input dimension.
|
||||
- `boft_n_butterfly_factor`: the number of butterfly factors. **Note**, for `boft_n_butterfly_factor=1`, BOFT is the same as vanilla OFT, for `boft_n_butterfly_factor=2`, the effective block size of OFT becomes twice as big and the number of blocks become half.
|
||||
- `bias`: specify if the `bias` parameters should be trained. Can be `"none"`, `"all"` or `"boft_only"`.
|
||||
- `boft_dropout`: specify the probability of multiplicative dropout.
|
||||
- `target_modules`: The modules (for example, attention blocks) to inject the OFT/BOFT matrices.
|
||||
- `modules_to_save`: List of modules apart from OFT/BOFT matrices to be set as trainable and saved in the final checkpoint. These typically include model's custom head that is randomly initialized for the fine-tuning task.
|
||||
|
||||
|
||||
|
||||
## BOFT Example Usage
|
||||
|
||||
For an example of the BOFT method application to various downstream tasks, please refer to the following guides:
|
||||
|
||||
Take a look at the following step-by-step guides on how to finetune a model with BOFT:
|
||||
- [Dreambooth finetuning with BOFT](../task_guides/boft_dreambooth)
|
||||
- [Controllable generation finetuning with BOFT (ControlNet)](../task_guides/boft_controlnet)
|
||||
|
||||
For the task of image classification, one can initialize the BOFT config for a DinoV2 model as follows:
|
||||
|
||||
```py
|
||||
import transformers
|
||||
from transformers import AutoModelForSeq2SeqLM, BOFTConfig
|
||||
from peft import BOFTConfig, get_peft_model
|
||||
|
||||
config = BOFTConfig(
|
||||
boft_block_size=4,
|
||||
boft_n_butterfly_factor=2,
|
||||
target_modules=["query", "value", "key", "output.dense", "mlp.fc1", "mlp.fc2"],
|
||||
boft_dropout=0.1,
|
||||
bias="boft_only",
|
||||
modules_to_save=["classifier"],
|
||||
)
|
||||
|
||||
model = transformers.Dinov2ForImageClassification.from_pretrained(
|
||||
"facebook/dinov2-large",
|
||||
num_labels=100,
|
||||
)
|
||||
|
||||
boft_model = get_peft_model(model, config)
|
||||
```
|
||||
@ -2,8 +2,7 @@
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
|
||||
# Prompting
|
||||
# Soft prompts
|
||||
|
||||
Training large pretrained language models is very time-consuming and compute-intensive. As they continue to grow in size, there is increasing interest in more efficient training methods such as *prompting*. Prompting primes a frozen pretrained model for a specific downstream task by including a text prompt that describes the task or even demonstrates an example of the task. With prompting, you can avoid fully training a separate model for each downstream task, and use the same frozen pretrained model instead. This is a lot easier because you can use the same model for several different tasks, and it is significantly more efficient to train and store a smaller set of prompt parameters than to train all the model's parameters.
|
||||
|
||||
@ -12,16 +11,16 @@ There are two categories of prompting methods:
|
||||
- hard prompts are manually handcrafted text prompts with discrete input tokens; the downside is that it requires a lot of effort to create a good prompt
|
||||
- soft prompts are learnable tensors concatenated with the input embeddings that can be optimized to a dataset; the downside is that they aren't human readable because you aren't matching these "virtual tokens" to the embeddings of a real word
|
||||
|
||||
This conceptual guide provides a brief overview of the soft prompt methods included in 🤗 PEFT: prompt tuning, prefix tuning, and P-tuning.
|
||||
This conceptual guide provides a brief overview of the soft prompt methods included in 🤗 PEFT: prompt tuning, prefix tuning, P-tuning, and multitask prompt tuning.
|
||||
|
||||
## Prompt tuning
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/prompt-tuning.png"/>
|
||||
</div>
|
||||
<small>Only train and store a significantly smaller set of task-specific prompt parameters <a href="https://arxiv.org/abs/2104.08691">(image source)</a>.</small>
|
||||
<small>Only train and store a significantly smaller set of task-specific prompt parameters <a href="https://hf.co/papers/2104.08691">(image source)</a>.</small>
|
||||
|
||||
Prompt tuning was developed for text classification tasks on T5 models, and all downstream tasks are cast as a text generation task. For example, sequence classification usually assigns a single class label to a sequence of text. By casting it as a text generation task, the tokens that make up the class label are *generated*. Prompts are added to the input as a series of tokens. Typically, the model parameters are fixed which means the prompt tokens are also fixed by the model parameters.
|
||||
[Prompt tuning](https://hf.co/papers/2104.08691) was developed for text classification tasks on T5 models, and all downstream tasks are cast as a text generation task. For example, sequence classification usually assigns a single class label to a sequence of text. By casting it as a text generation task, the tokens that make up the class label are *generated*. Prompts are added to the input as a series of tokens. Typically, the model parameters are fixed which means the prompt tokens are also fixed by the model parameters.
|
||||
|
||||
The key idea behind prompt tuning is that prompt tokens have their own parameters that are updated independently. This means you can keep the pretrained model's parameters frozen, and only update the gradients of the prompt token embeddings. The results are comparable to the traditional method of training the entire model, and prompt tuning performance scales as model size increases.
|
||||
|
||||
@ -32,9 +31,9 @@ Take a look at [Prompt tuning for causal language modeling](../task_guides/clm-p
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/prefix-tuning.png"/>
|
||||
</div>
|
||||
<small>Optimize the prefix parameters for each task <a href="https://arxiv.org/abs/2101.00190">(image source)</a>.</small>
|
||||
<small>Optimize the prefix parameters for each task <a href="https://hf.co/papers/2101.00190">(image source)</a>.</small>
|
||||
|
||||
Prefix tuning was designed for natural language generation (NLG) tasks on GPT models. It is very similar to prompt tuning; prefix tuning also prepends a sequence of task-specific vectors to the input that can be trained and updated while keeping the rest of the pretrained model's parameters frozen.
|
||||
[Prefix tuning](https://hf.co/papers/2101.00190) was designed for natural language generation (NLG) tasks on GPT models. It is very similar to prompt tuning; prefix tuning also prepends a sequence of task-specific vectors to the input that can be trained and updated while keeping the rest of the pretrained model's parameters frozen.
|
||||
|
||||
The main difference is that the prefix parameters are inserted in **all** of the model layers, whereas prompt tuning only adds the prompt parameters to the model input embeddings. The prefix parameters are also optimized by a separate feed-forward network (FFN) instead of training directly on the soft prompts because it causes instability and hurts performance. The FFN is discarded after updating the soft prompts.
|
||||
|
||||
@ -47,9 +46,9 @@ Take a look at [Prefix tuning for conditional generation](../task_guides/seq2seq
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/p-tuning.png"/>
|
||||
</div>
|
||||
<small>Prompt tokens can be inserted anywhere in the input sequence, and they are optimized by a prompt encoder <a href="https://arxiv.org/abs/2103.10385">(image source)</a>.</small>
|
||||
<small>Prompt tokens can be inserted anywhere in the input sequence, and they are optimized by a prompt encoder <a href="https://hf.co/papers/2103.10385">(image source)</a>.</small>
|
||||
|
||||
P-tuning is designed for natural language understanding (NLU) tasks and all language models.
|
||||
[P-tuning](https://hf.co/papers/2103.10385) is designed for natural language understanding (NLU) tasks and all language models.
|
||||
It is another variation of a soft prompt method; P-tuning also adds a trainable embedding tensor that can be optimized to find better prompts, and it uses a prompt encoder (a bidirectional long-short term memory network or LSTM) to optimize the prompt parameters. Unlike prefix tuning though:
|
||||
|
||||
- the prompt tokens can be inserted anywhere in the input sequence, and it isn't restricted to only the beginning
|
||||
@ -58,4 +57,21 @@ It is another variation of a soft prompt method; P-tuning also adds a trainable
|
||||
|
||||
The results suggest that P-tuning is more efficient than manually crafting prompts, and it enables GPT-like models to compete with BERT-like models on NLU tasks.
|
||||
|
||||
Take a look at [P-tuning for sequence classification](../task_guides/ptuning-seq-classification) for a step-by-step guide on how to train a model with P-tuning.
|
||||
Take a look at [P-tuning for sequence classification](../task_guides/ptuning-seq-classification) for a step-by-step guide on how to train a model with P-tuning.
|
||||
|
||||
## Multitask prompt tuning
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/mpt.png"/>
|
||||
</div>
|
||||
<small><a href="https://hf.co/papers/2103.10385">Multitask prompt tuning enables parameter-efficient transfer learning</a>.</small>
|
||||
|
||||
[Multitask prompt tuning (MPT)](https://hf.co/papers/2103.10385) learns a single prompt from data for multiple task types that can be shared for different target tasks. Other existing approaches learn a separate soft prompt for each task that need to be retrieved or aggregated for adaptation to target tasks. MPT consists of two stages:
|
||||
|
||||
1. source training - for each task, its soft prompt is decomposed into task-specific vectors. The task-specific vectors are multiplied together to form another matrix W, and the Hadamard product is used between W and a shared prompt matrix P to generate a task-specific prompt matrix. The task-specific prompts are distilled into a single prompt matrix that is shared across all tasks. This prompt is trained with multitask training.
|
||||
2. target adaptation - to adapt the single prompt for a target task, a target prompt is initialized and expressed as the Hadamard product of the shared prompt matrix and the task-specific low-rank prompt matrix.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/mpt-decomposition.png"/>
|
||||
</div>
|
||||
<small><a href="https://hf.co/papers/2103.10385">Prompt decomposition</a>.</small>
|
||||
|
||||
250
docs/source/developer_guides/checkpoint.md
Normal file
250
docs/source/developer_guides/checkpoint.md
Normal file
@ -0,0 +1,250 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# PEFT checkpoint format
|
||||
|
||||
This document describes how PEFT's checkpoint files are structured and how to convert between the PEFT format and other formats.
|
||||
|
||||
## PEFT files
|
||||
|
||||
PEFT (parameter-efficient fine-tuning) methods only update a small subset of a model's parameters rather than all of them. This is nice because checkpoint files can generally be much smaller than the original model files and are easier to store and share. However, this also means that to load a PEFT model, you need to have the original model available as well.
|
||||
|
||||
When you call [`~PeftModel.save_pretrained`] on a PEFT model, the PEFT model saves three files, described below:
|
||||
|
||||
1. `adapter_model.safetensors` or `adapter_model.bin`
|
||||
|
||||
By default, the model is saved in the `safetensors` format, a secure alternative to the `bin` format, which is known to be susceptible to [security vulnerabilities](https://huggingface.co/docs/hub/security-pickle) because it uses the pickle utility under the hood. Both formats store the same `state_dict` though, and are interchangeable.
|
||||
|
||||
The `state_dict` only contains the parameters of the adapter module, not the base model. To illustrate the difference in size, a normal BERT model requires ~420MB of disk space, whereas an IA³ adapter on top of this BERT model only requires ~260KB.
|
||||
|
||||
2. `adapter_config.json`
|
||||
|
||||
The `adapter_config.json` file contains the configuration of the adapter module, which is necessary to load the model. Below is an example of an `adapter_config.json` for an IA³ adapter with standard settings applied to a BERT model:
|
||||
|
||||
```json
|
||||
{
|
||||
"auto_mapping": {
|
||||
"base_model_class": "BertModel",
|
||||
"parent_library": "transformers.models.bert.modeling_bert"
|
||||
},
|
||||
"base_model_name_or_path": "bert-base-uncased",
|
||||
"fan_in_fan_out": false,
|
||||
"feedforward_modules": [
|
||||
"output.dense"
|
||||
],
|
||||
"inference_mode": true,
|
||||
"init_ia3_weights": true,
|
||||
"modules_to_save": null,
|
||||
"peft_type": "IA3",
|
||||
"revision": null,
|
||||
"target_modules": [
|
||||
"key",
|
||||
"value",
|
||||
"output.dense"
|
||||
],
|
||||
"task_type": null
|
||||
}
|
||||
```
|
||||
|
||||
The configuration file contains:
|
||||
|
||||
- the adapter module type stored, `"peft_type": "IA3"`
|
||||
- information about the base model like `"base_model_name_or_path": "bert-base-uncased"`
|
||||
- the revision of the model (if any), `"revision": null`
|
||||
|
||||
If the base model is not a pretrained Transformers model, the latter two entries will be `null`. Other than that, the settings are all related to the specific IA³ adapter that was used to fine-tune the model.
|
||||
|
||||
3. `README.md`
|
||||
|
||||
The generated `README.md` is the model card of a PEFT model and contains a few pre-filled entries. The intent of this is to make it easier to share the model with others and to provide some basic information about the model. This file is not needed to load the model.
|
||||
|
||||
## Convert to PEFT format
|
||||
|
||||
When converting from another format to the PEFT format, we require both the `adapter_model.safetensors` (or `adapter_model.bin`) file and the `adapter_config.json` file.
|
||||
|
||||
### adapter_model
|
||||
|
||||
For the model weights, it is important to use the correct mapping from parameter name to value for PEFT to load the file. Getting this mapping right is an exercise in checking the implementation details, as there is no generally agreed upon format for PEFT adapters.
|
||||
|
||||
Fortunately, figuring out this mapping is not overly complicated for common base cases. Let's look at a concrete example, the [`LoraLayer`](https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora/layer.py):
|
||||
|
||||
```python
|
||||
# showing only part of the code
|
||||
|
||||
class LoraLayer(BaseTunerLayer):
|
||||
# All names of layers that may contain (trainable) adapter weights
|
||||
adapter_layer_names = ("lora_A", "lora_B", "lora_embedding_A", "lora_embedding_B")
|
||||
# All names of other parameters that may contain adapter-related parameters
|
||||
other_param_names = ("r", "lora_alpha", "scaling", "lora_dropout")
|
||||
|
||||
def __init__(self, base_layer: nn.Module, **kwargs) -> None:
|
||||
self.base_layer = base_layer
|
||||
self.r = {}
|
||||
self.lora_alpha = {}
|
||||
self.scaling = {}
|
||||
self.lora_dropout = nn.ModuleDict({})
|
||||
self.lora_A = nn.ModuleDict({})
|
||||
self.lora_B = nn.ModuleDict({})
|
||||
# For Embedding layer
|
||||
self.lora_embedding_A = nn.ParameterDict({})
|
||||
self.lora_embedding_B = nn.ParameterDict({})
|
||||
# Mark the weight as unmerged
|
||||
self._disable_adapters = False
|
||||
self.merged_adapters = []
|
||||
self.use_dora: dict[str, bool] = {}
|
||||
self.lora_magnitude_vector: Optional[torch.nn.ParameterDict] = None # for DoRA
|
||||
self._caches: dict[str, Any] = {}
|
||||
self.kwargs = kwargs
|
||||
```
|
||||
|
||||
In the `__init__` code used by all `LoraLayer` classes in PEFT, there are a bunch of parameters used to initialize the model, but only a few are relevant for the checkpoint file: `lora_A`, `lora_B`, `lora_embedding_A`, and `lora_embedding_B`. These parameters are listed in the class attribute `adapter_layer_names` and contain the learnable parameters, so they must be included in the checkpoint file. All the other parameters, like the rank `r`, are derived from the `adapter_config.json` and must be included there (unless the default value is used).
|
||||
|
||||
Let's check the `state_dict` of a PEFT LoRA model applied to BERT. When printing the first five keys using the default LoRA settings (the remaining keys are the same, just with different layer numbers), we get:
|
||||
|
||||
- `base_model.model.encoder.layer.0.attention.self.query.lora_A.weight`
|
||||
- `base_model.model.encoder.layer.0.attention.self.query.lora_B.weight`
|
||||
- `base_model.model.encoder.layer.0.attention.self.value.lora_A.weight`
|
||||
- `base_model.model.encoder.layer.0.attention.self.value.lora_B.weight`
|
||||
- `base_model.model.encoder.layer.1.attention.self.query.lora_A.weight`
|
||||
- etc.
|
||||
|
||||
Let's break this down:
|
||||
|
||||
- By default, for BERT models, LoRA is applied to the `query` and `value` layers of the attention module. This is why you see `attention.self.query` and `attention.self.value` in the key names for each layer.
|
||||
- LoRA decomposes the weights into two low-rank matrices, `lora_A` and `lora_B`. This is where `lora_A` and `lora_B` come from in the key names.
|
||||
- These LoRA matrices are implemented as `nn.Linear` layers, so the parameters are stored in the `.weight` attribute (`lora_A.weight`, `lora_B.weight`).
|
||||
- By default, LoRA isn't applied to BERT's embedding layer, so there are _no entries_ for `lora_A_embedding` and `lora_B_embedding`.
|
||||
- The keys of the `state_dict` always start with `"base_model.model."`. The reason is that, in PEFT, we wrap the base model inside a tuner-specific model (`LoraModel` in this case), which itself is wrapped in a general PEFT model (`PeftModel`). For this reason, these two prefixes are added to the keys. When converting to the PEFT format, it is required to add these prefixes.
|
||||
|
||||
<Tip>
|
||||
|
||||
This last point is not true for prefix tuning techniques like prompt tuning. There, the extra embeddings are directly stored in the `state_dict` without any prefixes added to the keys.
|
||||
|
||||
</Tip>
|
||||
|
||||
When inspecting the parameter names in the loaded model, you might be surprised to find that they look a bit different, e.g. `base_model.model.encoder.layer.0.attention.self.query.lora_A.default.weight`. The difference is the *`.default`* part in the second to last segment. This part exists because PEFT generally allows the addition of multiple adapters at once (using an `nn.ModuleDict` or `nn.ParameterDict` to store them). For example, if you add another adapter called "other", the key for that adapter would be `base_model.model.encoder.layer.0.attention.self.query.lora_A.other.weight`.
|
||||
|
||||
When you call [`~PeftModel.save_pretrained`], the adapter name is stripped from the keys. The reason is that the adapter name is not an important part of the model architecture; it is just an arbitrary name. When loading the adapter, you could choose a totally different name, and the model would still work the same way. This is why the adapter name is not stored in the checkpoint file.
|
||||
|
||||
<Tip>
|
||||
|
||||
If you call `save_pretrained("some/path")` and the adapter name is not `"default"`, the adapter is stored in a sub-directory with the same name as the adapter. So if the name is "other", it would be stored inside of `some/path/other`.
|
||||
|
||||
</Tip>
|
||||
|
||||
In some circumstances, deciding which values to add to the checkpoint file can become a bit more complicated. For example, in PEFT, DoRA is implemented as a special case of LoRA. If you want to convert a DoRA model to PEFT, you should create a LoRA checkpoint with extra entries for DoRA. You can see this in the `__init__` of the previous `LoraLayer` code:
|
||||
|
||||
```python
|
||||
self.lora_magnitude_vector: Optional[torch.nn.ParameterDict] = None # for DoRA
|
||||
```
|
||||
|
||||
This indicates that there is an optional extra parameter per layer for DoRA.
|
||||
|
||||
### adapter_config
|
||||
|
||||
All the other information needed to load a PEFT model is contained in the `adapter_config.json` file. Let's check this file for a LoRA model applied to BERT:
|
||||
|
||||
```json
|
||||
{
|
||||
"alpha_pattern": {},
|
||||
"auto_mapping": {
|
||||
"base_model_class": "BertModel",
|
||||
"parent_library": "transformers.models.bert.modeling_bert"
|
||||
},
|
||||
"base_model_name_or_path": "bert-base-uncased",
|
||||
"bias": "none",
|
||||
"fan_in_fan_out": false,
|
||||
"inference_mode": true,
|
||||
"init_lora_weights": true,
|
||||
"layer_replication": null,
|
||||
"layers_pattern": null,
|
||||
"layers_to_transform": null,
|
||||
"loftq_config": {},
|
||||
"lora_alpha": 8,
|
||||
"lora_dropout": 0.0,
|
||||
"megatron_config": null,
|
||||
"megatron_core": "megatron.core",
|
||||
"modules_to_save": null,
|
||||
"peft_type": "LORA",
|
||||
"r": 8,
|
||||
"rank_pattern": {},
|
||||
"revision": null,
|
||||
"target_modules": [
|
||||
"query",
|
||||
"value"
|
||||
],
|
||||
"task_type": null,
|
||||
"use_dora": false,
|
||||
"use_rslora": false
|
||||
}
|
||||
```
|
||||
|
||||
This contains a lot of entries, and at first glance, it could feel overwhelming to figure out all the right values to put in there. However, most of the entries are not necessary to load the model. This is either because they use the default values and don't need to be added or because they only affect the initialization of the LoRA weights, which is irrelevant when it comes to loading the model. If you find that you don't know what a specific parameter does, e.g., `"use_rslora",` don't add it, and you should be fine. Also note that as more options are added, this file will get more entries in the future, but it should be backward compatible.
|
||||
|
||||
At the minimum, you should include the following entries:
|
||||
|
||||
```json
|
||||
{
|
||||
"target_modules": ["query", "value"],
|
||||
"peft_type": "LORA"
|
||||
}
|
||||
```
|
||||
|
||||
However, adding as many entries as possible, like the rank `r` or the `base_model_name_or_path` (if it's a Transformers model) is recommended. This information can help others understand the model better and share it more easily. To check which keys and values are expected, check out the [config.py](https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora/config.py) file (as an example, this is the config file for LoRA) in the PEFT source code.
|
||||
|
||||
## Model storage
|
||||
|
||||
In some circumstances, you might want to store the whole PEFT model, including the base weights. This can be necessary if, for instance, the base model is not available to the users trying to load the PEFT model. You can merge the weights first or convert it into a Transformer model.
|
||||
|
||||
### Merge the weights
|
||||
|
||||
The most straightforward way to store the whole PEFT model is to merge the adapter weights into the base weights:
|
||||
|
||||
```python
|
||||
merged_model = model.merge_and_unload()
|
||||
merged_model.save_pretrained(...)
|
||||
```
|
||||
|
||||
There are some disadvantages to this approach, though:
|
||||
|
||||
- Once [`~LoraModel.merge_and_unload`] is called, you get a basic model without any PEFT-specific functionality. This means you can't use any of the PEFT-specific methods anymore.
|
||||
- You cannot unmerge the weights, load multiple adapters at once, disable the adapter, etc.
|
||||
- Not all PEFT methods support merging weights.
|
||||
- Some PEFT methods may generally allow merging, but not with specific settings (e.g. when using certain quantization techniques).
|
||||
- The whole model will be much larger than the PEFT model, as it will contain all the base weights as well.
|
||||
|
||||
But inference with a merged model should be a bit faster.
|
||||
|
||||
### Convert to a Transformers model
|
||||
|
||||
Another way to save the whole model, assuming the base model is a Transformers model, is to use this hacky approach to directly insert the PEFT weights into the base model and save it, which only works if you "trick" Transformers into believing the PEFT model is not a PEFT model. This only works with LoRA because other adapters are not implemented in Transformers.
|
||||
|
||||
```python
|
||||
model = ... # the PEFT model
|
||||
...
|
||||
# after you finish training the model, save it in a temporary location
|
||||
model.save_pretrained(<temp_location>)
|
||||
# now load this model directly into a transformers model, without the PEFT wrapper
|
||||
# the PEFT weights are directly injected into the base model
|
||||
model_loaded = AutoModel.from_pretrained(<temp_location>)
|
||||
# now make the loaded model believe that it is _not_ a PEFT model
|
||||
model_loaded._hf_peft_config_loaded = False
|
||||
# now when we save it, it will save the whole model
|
||||
model_loaded.save_pretrained(<final_location>)
|
||||
# or upload to Hugging Face Hub
|
||||
model_loaded.push_to_hub(<final_location>)
|
||||
```
|
||||
|
||||
@ -14,79 +14,78 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Contributing to PEFT
|
||||
# Contribute to PEFT
|
||||
|
||||
We are happy to accept contributions to PEFT. If you plan to contribute, please read this document to make the process as smooth as possible.
|
||||
We are happy to accept contributions to PEFT. If you plan to contribute, please read this to make the process as smooth as possible.
|
||||
|
||||
## Installation
|
||||
|
||||
The installation instructions can be found [here](https://huggingface.co/docs/peft/install). If you want to provide code contributions to PEFT, you should choose the "source" installation method.
|
||||
For code contributions to PEFT, you should choose the ["source"](../install#source) installation method.
|
||||
|
||||
If you are new to creating a pull request, follow [these instructions from GitHub](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request).
|
||||
If you are new to creating a pull request, follow the [Creating a pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request) guide by GitHub.
|
||||
|
||||
## Running tests and code quality checks
|
||||
## Tests and code quality checks
|
||||
|
||||
Regardless of the type of contribution (unless it’s only about the docs), you should run tests and code quality checks before creating a PR to ensure that your contribution doesn’t break anything and follows the standards of the project.
|
||||
Regardless of the contribution type (unless it’s only about the docs), you should run tests and code quality checks before creating a PR to ensure your contribution doesn’t break anything and follows the project standards.
|
||||
|
||||
We provide a Makefile to facilitate those steps. Run the code below for the unit test:
|
||||
We provide a Makefile to execute the necessary tests. Run the code below for the unit test:
|
||||
|
||||
```sh
|
||||
make test
|
||||
```
|
||||
|
||||
Run one of the following to either check or check and fix code quality and style:
|
||||
Run one of the following to either only check or check and fix code quality and style:
|
||||
|
||||
```sh
|
||||
make quality # just check
|
||||
make style # check and fix
|
||||
```
|
||||
|
||||
You can also set up [`pre-commit`](https://pre-commit.com/) to run these fixes
|
||||
automatically as Git commit hooks.
|
||||
|
||||
Running all the tests can take a couple of minutes. Therefore, during development, it can be useful to run only those tests specific to your change:
|
||||
```bash
|
||||
$ pip install pre-commit
|
||||
$ pre-commit install
|
||||
```
|
||||
|
||||
Running all the tests can take a couple of minutes, so during development it can be more efficient to only run tests specific to your change:
|
||||
|
||||
```sh
|
||||
pytest tests/ -k <name-of-test>
|
||||
```
|
||||
|
||||
This should finish much quicker and allow faster iteration. Before creating the PR, however, please still run the whole test suite, as some changes can inadvertently break tests that at first glance are unrelated.
|
||||
This should finish much quicker and allow for faster iteration. However, you should still run the whole test suite before creating a PR because your change can inadvertently break tests that at first glance are unrelated.
|
||||
|
||||
If your change is specific to a hardware setting (e.g. it requires CUDA), take a look at `tests/test_gpu_examples.py` and `tests/test_common_gpu.py` – maybe it makes sense to add a test there. If your change could have an effect on saving and loading models, please run the tests with the `--regression` flag to trigger regression tests.
|
||||
If your change is specific to a hardware setting (e.g., it requires CUDA), take a look at [tests/test_gpu_examples.py](https://github.com/huggingface/peft/blob/1c1c7fdaa6e6abaa53939b865dee1eded82ad032/tests/test_gpu_examples.py) and [tests/test_common_gpu.py](https://github.com/huggingface/peft/blob/1c1c7fdaa6e6abaa53939b865dee1eded82ad032/tests/test_common_gpu.py) to see if it makes sense to add tests there. If your change could have an effect on saving and loading models, please run the tests with the `--regression` flag to trigger regression tests.
|
||||
|
||||
It can happen that while you’re working on your PR, the underlying code base changes due to other changes being merged. If that happens – especially when there is a merge conflict – please update your branch to be on the latest changes. This can be a merge or a rebase, whatever you prefer. We will squash and merge the PR once it’s ready.
|
||||
It can happen that while you’re working on your PR, the underlying code base changes due to other changes being merged. If that happens – especially when there is a merge conflict – please update your branch with the latest changes. This can be a merge or a rebase, and we'll squash and merge the PR once it’s ready.
|
||||
|
||||
## PR description
|
||||
|
||||
When opening the PR, please provide a nice description of the change you provide. If it relates to other issues or PRs, please reference them. Providing a good description will not only help the reviewers review your code better and faster, it can also later be used (as a basis) for the commit message, which helps with long term maintenance of the project.
|
||||
When opening a PR, please provide a nice description of the change you're proposing. If it relates to other issues or PRs, please reference them. Providing a good description not only helps the reviewers review your code better and faster, it can also be used later (as a basis) for the commit message which helps with long term maintenance of the project.
|
||||
|
||||
If your code makes some non-trivial changes, it can also be a good idea to add comments to the code to explain those changes. For example, if you had to iterate on your implementation multiple times because the most obvious way didn’t work, it’s a good indication that a code comment is needed.
|
||||
If your code makes some non-trivial changes, it may also be a good idea to add comments to the code to explain those changes. For example, if you had to iterate on your implementation multiple times because the most obvious way didn’t work, it’s a good indication that a code comment is needed.
|
||||
|
||||
## Providing a bugfix
|
||||
## Bugfixes
|
||||
|
||||
Please give a description of the circumstances that lead to the bug. If there is an existing issue, please link to it (e.g. “Resolves #12345”).
|
||||
Please give a description of the circumstances that led to the bug. If there is an existing issue, please link to it (e.g., “Resolves #12345”).
|
||||
|
||||
Ideally, when a bugfix is provided, it should be accompanied by a test for this bug. The test should fail with the current code and pass with the bugfix. Add a comment to the test that references the issue or PR. Without such a test, it is difficult to prevent regressions in the future.
|
||||
Ideally when a bugfix is provided, it should be accompanied by a test for the bug. The test should fail with the current code and pass with the bugfix. Add a comment to the test that references the issue or PR. Without a test, it is more difficult to prevent regressions in the future.
|
||||
|
||||
## Adding a new fine-tuning method
|
||||
## Add a new fine-tuning method
|
||||
|
||||
New parameter-efficient fine-tuning methods are developed all the time. If you would like to add a new, promising method to PEFT, please follow these steps.
|
||||
New parameter-efficient fine-tuning methods are developed all the time. If you would like to add a new and promising method to PEFT, please follow these steps.
|
||||
|
||||
**Requirements**
|
||||
1. Before you start to implement the new method, please open a GitHub issue with your proposal. This way, the maintainers can give you some early feedback.
|
||||
2. Please add a link to the source (usually a paper) of the method. Some evidence should be provided there is general interest in using the method. We will not add new methods that are freshly published, but there is no evidence of demand for it.
|
||||
3. When implementing the method, it makes sense to look for existing implementations that already exist as a guide. Moreover, when you structure your code, please take inspiration from the other PEFT methods. For example, if your method is similar to LoRA, it makes sense to structure your code similarly or even reuse some functions or classes where it makes sense (some code duplication is okay, but don’t overdo it).
|
||||
4. Ideally, in addition to the implementation of the new method, there should also be examples (notebooks, scripts), documentation, and an extensive test suite that proves the method works with a variety of tasks. However, this can be more challenging so it is acceptable to only provide the implementation and at least one working example. Documentation and tests can be added in follow up PRs.
|
||||
5. Once you have something that seems to be working, don’t hesitate to create a draft PR even if it’s not in a mergeable state yet. The maintainers are happy to give you feedback and guidance along the way.
|
||||
|
||||
1. Please add a link to the source (usually a paper) of the method.
|
||||
2. Some evidence should be provided that there is general interest in using the method. We will not add new methods that are freshly published but without evidence that there is demand for it.
|
||||
3. Ideally, we want to not only add the implementation of the new method, but also examples (notebooks, scripts), documentation, and an extensive test suite that proves that the method works with a variety of tasks. However, this can be very daunting. Therefore, it is also acceptable to only provide the implementation and at least one working example. Documentation and tests can be added in follow up PRs.
|
||||
## Add other features
|
||||
|
||||
**Steps**
|
||||
|
||||
Before you start to implement the new method, please open an issue on GitHub with your proposal. That way, the maintainers can give you some early feedback.
|
||||
|
||||
When implementing the method, it makes sense to look for existing implementations that already exist as a guide. Moreover, when you structure your code, please take inspiration from the other PEFT methods. For example, if your method is similar to LoRA, it makes sense to structure your code similarly or even re-use some functions or classes where it makes sense (but don’t overdo it, some code duplication is okay).
|
||||
|
||||
Once you have something that seems to be working, don’t hesitate to create a draft PR, even if it’s not in a mergeable state yet. The maintainers will be happy to give you feedback and guidance along the way.
|
||||
|
||||
## Adding other features
|
||||
|
||||
It is best if you first open an issue on GitHub with a proposal to add the new feature. That way, you can discuss with the maintainers if it makes sense to add the feature before spending too much time on implementing it.
|
||||
It is best if you first open an issue on GitHub with a proposal to add the new feature. This way, you can discuss with the maintainers if it makes sense to add the feature before spending too much time on implementing it.
|
||||
|
||||
New features should generally be accompanied by tests and documentation or examples. Without the latter, users will have a hard time discovering your cool new feature.
|
||||
|
||||
|
||||
@ -14,13 +14,13 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Working with custom models
|
||||
# Custom models
|
||||
|
||||
Some fine-tuning techniques, such as prompt tuning, are specific to language models. That means in 🤗 PEFT, it is
|
||||
assumed a 🤗 Transformers model is being used. However, other fine-tuning techniques - like
|
||||
[LoRA](../conceptual_guides/lora) - are not restricted to specific model types.
|
||||
|
||||
In this guide, we will see how LoRA can be applied to a multilayer perceptron and a computer vision model from the [timm](https://huggingface.co/docs/timm/index) library.
|
||||
In this guide, we will see how LoRA can be applied to a multilayer perceptron, a computer vision model from the [timm](https://huggingface.co/docs/timm/index) library, or a new 🤗 Transformers architecture.
|
||||
|
||||
## Multilayer perceptron
|
||||
|
||||
@ -46,7 +46,7 @@ class MLP(nn.Module):
|
||||
return self.seq(X)
|
||||
```
|
||||
|
||||
This is a straightforward multilayer perceptron with an input layer, a hidden layer, and an output layer.
|
||||
This is a straightforward multilayer perceptron with an input layer, a hidden layer, and an output layer.
|
||||
|
||||
<Tip>
|
||||
|
||||
@ -130,7 +130,7 @@ those are a major building block of this model, we should apply LoRA to the 2D c
|
||||
those layers, let's look at all the layer names:
|
||||
|
||||
```python
|
||||
print([(n, type(m)) for n, m in MLP().named_modules()])
|
||||
print([(n, type(m)) for n, m in model.named_modules()])
|
||||
```
|
||||
|
||||
This will print a very long list, we'll only show the first few:
|
||||
@ -222,3 +222,19 @@ If that doesn't help, check the existing modules in your model architecture with
|
||||
Additionally, linear layers are common targets to be adapted (e.g. in [QLoRA paper](https://arxiv.org/abs/2305.14314), authors suggest to adapt them as well). Their names will often contain the strings `fc` or `dense`.
|
||||
|
||||
If you want to add a new model to PEFT, please create an entry in [constants.py](https://github.com/huggingface/peft/blob/main/src/peft/utils/constants.py) and open a pull request on the [repository](https://github.com/huggingface/peft/pulls). Don't forget to update the [README](https://github.com/huggingface/peft#models-support-matrix) as well.
|
||||
|
||||
## Verify parameters and layers
|
||||
|
||||
You can verify whether you've correctly applied a PEFT method to your model in a few ways.
|
||||
|
||||
* Check the fraction of parameters that are trainable with the [`~PeftModel.print_trainable_parameters`] method. If this number is lower or higher than expected, check the model `repr` by printing the model. This shows the names of all the layer types in the model. Ensure that only the intended target layers are replaced by the adapter layers. For example, if LoRA is applied to `nn.Linear` layers, then you should only see `lora.Linear` layers being used.
|
||||
|
||||
```py
|
||||
peft_model.print_trainable_parameters()
|
||||
```
|
||||
|
||||
* Another way you can view the adapted layers is to use the `targeted_module_names` attribute to list the name of each module that was adapted.
|
||||
|
||||
```python
|
||||
print(peft_model.targeted_module_names)
|
||||
```
|
||||
|
||||
318
docs/source/developer_guides/lora.md
Normal file
318
docs/source/developer_guides/lora.md
Normal file
@ -0,0 +1,318 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# LoRA
|
||||
|
||||
LoRA is low-rank decomposition method to reduce the number of trainable parameters which speeds up finetuning large models and uses less memory. In PEFT, using LoRA is as easy as setting up a [`LoraConfig`] and wrapping it with [`get_peft_model`] to create a trainable [`PeftModel`].
|
||||
|
||||
This guide explores in more detail other options and features for using LoRA.
|
||||
|
||||
## Initialization
|
||||
|
||||
The initialization of LoRA weights is controlled by the parameter `init_lora_weights` in [`LoraConfig`]. By default, PEFT initializes LoRA weights with Kaiming-uniform for weight A and zeros for weight B resulting in an identity transform (same as the reference [implementation](https://github.com/microsoft/LoRA)).
|
||||
|
||||
It is also possible to pass `init_lora_weights="gaussian"`. As the name suggests, this initializes weight A with a Gaussian distribution and zeros for weight B (this is how [Diffusers](https://huggingface.co/docs/diffusers/index) initializes LoRA weights).
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
config = LoraConfig(init_lora_weights="gaussian", ...)
|
||||
```
|
||||
|
||||
There is also an option to set `init_lora_weights=False` which is useful for debugging and testing. This should be the only time you use this option. When choosing this option, the LoRA weights are initialized such that they do *not* result in an identity transform.
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
config = LoraConfig(init_lora_weights=False, ...)
|
||||
```
|
||||
|
||||
### PiSSA
|
||||
[PiSSA](https://arxiv.org/abs/2404.02948) initializes the LoRA adapter using the principal singular values and singular vectors. This straightforward modification allows PiSSA to converge more rapidly than LoRA and ultimately attain superior performance. Moreover, PiSSA reduces the quantization error compared to QLoRA, leading to further enhancements.
|
||||
|
||||
Configure the initialization method to "pissa", which may take several minutes to execute SVD on the pre-trained model:
|
||||
```python
|
||||
from peft import LoraConfig
|
||||
config = LoraConfig(init_lora_weights="pissa", ...)
|
||||
```
|
||||
Alternatively, execute fast SVD, which takes only a few seconds. The number of iterations determines the trade-off between the error and computation time:
|
||||
```python
|
||||
lora_config = LoraConfig(init_lora_weights="pissa_niter_[number of iters]", ...)
|
||||
```
|
||||
For detailed instruction on using PiSSA, please follow [these instructions](https://github.com/fxmeng/peft/tree/main/examples/pissa_finetuning).
|
||||
|
||||
### LoftQ
|
||||
|
||||
#### Standard approach
|
||||
|
||||
When quantizing the base model for QLoRA training, consider using the [LoftQ initialization](https://arxiv.org/abs/2310.08659), which has been shown to improve performance when training quantized models. The idea is that the LoRA weights are initialized such that the quantization error is minimized. To use LoftQ, follow [these instructions](https://github.com/huggingface/peft/tree/main/examples/loftq_finetuning).
|
||||
|
||||
In general, for LoftQ to work best, it is recommended to target as many layers with LoRA as possible, since those not targeted cannot have LoftQ applied. This means that passing `LoraConfig(..., target_modules="all-linear")` will most likely give the best results. Also, you should use `nf4` as quant type in your quantization config when using 4bit quantization, i.e. `BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4")`.
|
||||
|
||||
#### A more convienient way
|
||||
|
||||
An easier but more limited way to apply LoftQ initialization is to use the convenience function `replace_lora_weights_loftq`. This takes the quantized PEFT model as input and replaces the LoRA weights in-place with their LoftQ-initialized counterparts.
|
||||
|
||||
```python
|
||||
from peft import replace_lora_weights_loftq
|
||||
from transformers import BitsAndBytesConfig
|
||||
|
||||
bnb_config = BitsAndBytesConfig(load_in_4bit=True, ...)
|
||||
base_model = AutoModelForCausalLM.from_pretrained(..., quantization_config=bnb_config)
|
||||
# note: don't pass init_lora_weights="loftq" or loftq_config!
|
||||
lora_config = LoraConfig(task_type="CAUSAL_LM")
|
||||
peft_model = get_peft_model(base_model, lora_config)
|
||||
replace_lora_weights_loftq(peft_model)
|
||||
```
|
||||
|
||||
`replace_lora_weights_loftq` also allows you to pass a `callback` argument to give you more control over which layers should be modified or not, which empirically can improve the results quite a lot. To see a more elaborate example of this, check out [this notebook](https://github.com/huggingface/peft/blob/main/examples/loftq_finetuning/LoftQ_weight_replacement.ipynb).
|
||||
|
||||
`replace_lora_weights_loftq` implements only one iteration step of LoftQ. This means that only the LoRA weights are updated, instead of iteratevily updating LoRA weights and quantized base model weights. This may lead to lower performance but has the advantage that we can use the original quantized weights derived from the base model, instead of having to keep an extra copy of modified quantized weights. Whether this tradeoff is worthwhile depends on the use case.
|
||||
|
||||
At the moment, `replace_lora_weights_loftq` has these additional limitations:
|
||||
|
||||
- Model files must be stored as a `safetensors` file.
|
||||
- Only bitsandbytes 4bit quantization is supported.
|
||||
|
||||
<Tip>
|
||||
|
||||
Learn more about how PEFT works with quantization in the [Quantization](quantization) guide.
|
||||
|
||||
</Tip>
|
||||
|
||||
### Rank-stabilized LoRA
|
||||
|
||||
Another way to initialize [`LoraConfig`] is with the [rank-stabilized LoRA (rsLoRA)](https://huggingface.co/papers/2312.03732) method. The LoRA architecture scales each adapter during every forward pass by a fixed scalar which is set at initialization and depends on the rank `r`. The scalar is given by `lora_alpha/r` in the original implementation, but rsLoRA uses `lora_alpha/math.sqrt(r)` which stabilizes the adapters and increases the performance potential from using a higher `r`.
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
config = LoraConfig(use_rslora=True, ...)
|
||||
```
|
||||
|
||||
### Weight-Decomposed Low-Rank Adaptation (DoRA)
|
||||
|
||||
This technique decomposes the updates of the weights into two parts, magnitude and direction. Direction is handled by normal LoRA, whereas the magnitude is handled by a separate learnable parameter. This can improve the performance of LoRA, especially at low ranks. For more information on DoRA, see https://arxiv.org/abs/2402.09353.
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
config = LoraConfig(use_dora=True, ...)
|
||||
```
|
||||
|
||||
#### Caveats
|
||||
|
||||
- DoRA only supports linear and Conv2d layers at the momement.
|
||||
- DoRA introduces a bigger overhead than pure LoRA, so it is recommended to merge weights for inference, see [`LoraModel.merge_and_unload`].
|
||||
- DoRA should work with weights quantized with bitsandbytes ("QDoRA"). However, issues have been reported when using QDoRA with DeepSpeed Zero2.
|
||||
|
||||
### QLoRA-style training
|
||||
|
||||
The default LoRA settings in PEFT add trainable weights to the query and value layers of each attention block. But [QLoRA](https://hf.co/papers/2305.14314), which adds trainable weights to all the linear layers of a transformer model, can provide performance equal to a fully finetuned model. To apply LoRA to all the linear layers, like in QLoRA, set `target_modules="all-linear"` (easier than specifying individual modules by name which can vary depending on the architecture).
|
||||
|
||||
```py
|
||||
config = LoraConfig(target_modules="all-linear", ...)
|
||||
```
|
||||
|
||||
### Memory efficient Layer Replication with LoRA
|
||||
|
||||
An approach used to improve the performance of models is to expand a model by duplicating layers in the model to build a larger model from a pretrained model of a given size. For example increasing a 7B model to a 10B model as described in the [SOLAR](https://arxiv.org/abs/2312.15166) paper. PEFT LoRA supports this kind of expansion in a memory efficient manner that supports further fine-tuning using LoRA adapters attached to the layers post replication of the layers. The replicated layers do not take additional memory as they share the underlying weights so the only additional memory required is the memory for the adapter weights. To use this feature you would create a config with the `layer_replication` argument.
|
||||
|
||||
```py
|
||||
config = LoraConfig(layer_replication=[[0,4], [2,5]], ...)
|
||||
```
|
||||
|
||||
Assuming the original model had 5 layers `[0, 1, 2 ,3, 4]`, this would create a model with 7 layers arranged as `[0, 1, 2, 3, 2, 3, 4]`. This follows the [mergekit](https://github.com/arcee-ai/mergekit) pass through merge convention where sequences of layers specified as start inclusive and end exclusive tuples are stacked to build the final model. Each layer in the final model gets its own distinct set of LoRA adpaters.
|
||||
|
||||
[Fewshot-Metamath-OrcaVicuna-Mistral-10B](https://huggingface.co/abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B) is an example of a model trained using this method on Mistral-7B expanded to 10B. The
|
||||
[adapter_config.json](https://huggingface.co/abacusai/Fewshot-Metamath-OrcaVicuna-Mistral-10B/blob/main/adapter_config.json) shows a sample LoRA adapter config applying this method for fine-tuning.
|
||||
|
||||
## Merge adapters
|
||||
|
||||
While LoRA is significantly smaller and faster to train, you may encounter latency issues during inference due to separately loading the base model and the LoRA adapter. To eliminate latency, use the [`~LoraModel.merge_and_unload`] function to merge the adapter weights with the base model. This allows you to use the newly merged model as a standalone model. The [`~LoraModel.merge_and_unload`] function doesn't keep the adapter weights in memory.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
from peft import PeftModel
|
||||
|
||||
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
|
||||
model = PeftModel.from_pretrained(base_model, peft_model_id)
|
||||
model.merge_and_unload()
|
||||
```
|
||||
|
||||
If you need to keep a copy of the weights so you can unmerge the adapter later or delete and load different ones, you should use the [`~LoraModel.merge_adapter`] function instead. Now you have the option to use [`~LoraModel.unmerge_adapter`] to return the base model.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
from peft import PeftModel
|
||||
|
||||
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
|
||||
model = PeftModel.from_pretrained(base_model, peft_model_id)
|
||||
model.merge_adapter()
|
||||
|
||||
# unmerge the LoRA layers from the base model
|
||||
model.unmerge_adapter()
|
||||
```
|
||||
|
||||
The [`~LoraModel.add_weighted_adapter`] function is useful for merging multiple LoRAs into a new adapter based on a user provided weighting scheme in the `weights` parameter. Below is an end-to-end example.
|
||||
|
||||
First load the base model:
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForCausalLM
|
||||
from peft import PeftModel
|
||||
import torch
|
||||
|
||||
base_model = AutoModelForCausalLM.from_pretrained(
|
||||
"mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, device_map="auto"
|
||||
)
|
||||
```
|
||||
|
||||
Then we load the first adapter:
|
||||
|
||||
```python
|
||||
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
|
||||
model = PeftModel.from_pretrained(base_model, peft_model_id, adapter_name="sft")
|
||||
```
|
||||
|
||||
Then load a different adapter and merge it with the first one:
|
||||
|
||||
```python
|
||||
weighted_adapter_name = "sft-dpo"
|
||||
model.load_adapter("alignment-handbook/zephyr-7b-dpo-lora", adapter_name="dpo")
|
||||
model.add_weighted_adapter(
|
||||
adapters=["sft", "dpo"],
|
||||
weights=[0.7, 0.3],
|
||||
adapter_name=weighted_adapter_name,
|
||||
combination_type="linear"
|
||||
)
|
||||
model.set_adapter(weighted_adapter_name)
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
There are several supported methods for `combination_type`. Refer to the [documentation](../package_reference/lora#peft.LoraModel.add_weighted_adapter) for more details. Note that "svd" as the `combination_type` is not supported when using `torch.float16` or `torch.bfloat16` as the datatype.
|
||||
|
||||
</Tip>
|
||||
|
||||
Now, perform inference:
|
||||
|
||||
```python
|
||||
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
|
||||
prompt = "Hey, are you conscious? Can you talk to me?"
|
||||
inputs = tokenizer(prompt, return_tensors="pt")
|
||||
inputs = {k: v.to("cuda") for k, v in inputs.items()}
|
||||
|
||||
with torch.no_grad():
|
||||
generate_ids = model.generate(**inputs, max_length=30)
|
||||
outputs = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
print(outputs)
|
||||
```
|
||||
|
||||
## Load adapters
|
||||
|
||||
Adapters can be loaded onto a pretrained model with [`~PeftModel.load_adapter`], which is useful for trying out different adapters whose weights aren't merged. Set the active adapter weights with the [`~LoraModel.set_adapter`] function.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
from peft import PeftModel
|
||||
|
||||
base_model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1")
|
||||
peft_model_id = "alignment-handbook/zephyr-7b-sft-lora"
|
||||
model = PeftModel.from_pretrained(base_model, peft_model_id)
|
||||
|
||||
# load different adapter
|
||||
model.load_adapter("alignment-handbook/zephyr-7b-dpo-lora", adapter_name="dpo")
|
||||
|
||||
# set adapter as active
|
||||
model.set_adapter("dpo")
|
||||
```
|
||||
|
||||
To return the base model, you could use [`~LoraModel.unload`] to unload all of the LoRA modules or [`~LoraModel.delete_adapter`] to delete the adapter entirely.
|
||||
|
||||
```py
|
||||
# unload adapter
|
||||
model.unload()
|
||||
|
||||
# delete adapter
|
||||
model.delete_adapter("dpo")
|
||||
```
|
||||
|
||||
## Inference with different LoRA adapters in the same batch
|
||||
|
||||
Normally, each inference batch has to use the same adapter(s) in PEFT. This can sometimes be annoying, because we may have batches that contain samples intended to be used with different LoRA adapters. For example, we could have a base model that works well in English and two more LoRA adapters, one for French and one for German. Usually, we would have to split our batches such that each batch only contains samples of one of the languages, we cannot combine different languages in the same batch.
|
||||
|
||||
Thankfully, it is possible to mix different LoRA adapters in the same batch using the `adapter_name` argument. Below, we show an examle of how this works in practice. First, let's load the base model, English, and the two adapters, French and German, like this:
|
||||
|
||||
```python
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM
|
||||
from peft import PeftModel
|
||||
|
||||
model_id = ...
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_id)
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
# load the LoRA adapter for French
|
||||
peft_model = PeftModel.from_pretrained(model, <path>, adapter_name="adapter_fr")
|
||||
# next, load the LoRA adapter for German
|
||||
peft_model.load_adapter(<path>, adapter_name="adapter_de")
|
||||
```
|
||||
|
||||
Now, we want to generate text on a sample that contains all three languages: The first three samples are in English, the next three are in French, and the last three are in German. We can use the `adapter_names` argument to specify which adapter to use for each sample. Since our base model is used for English, we use the special string `"__base__"` for these samples. For the next three samples, we indicate the adapter name of the French LoRA fine-tune, in this case `"adapter_fr"`. For the last three samples, we indicate the adapter name of the German LoRA fine-tune, in this case `"adapter_de"`. This way, we can use the base model and the two adapters in a single batch.
|
||||
|
||||
```python
|
||||
inputs = tokenizer(
|
||||
[
|
||||
"Hello, my dog is cute",
|
||||
"Hello, my cat is awesome",
|
||||
"Hello, my fish is great",
|
||||
"Salut, mon chien est mignon",
|
||||
"Salut, mon chat est génial",
|
||||
"Salut, mon poisson est super",
|
||||
"Hallo, mein Hund ist süß",
|
||||
"Hallo, meine Katze ist toll",
|
||||
"Hallo, mein Fisch ist großartig",
|
||||
],
|
||||
return_tensors="pt",
|
||||
padding=True,
|
||||
)
|
||||
|
||||
adapter_names = [
|
||||
"__base__", "__base__", "__base__",
|
||||
"adapter_fr", "adapter_fr", "adapter_fr",
|
||||
"adapter_de", "adapter_de", "adapter_de",
|
||||
]
|
||||
output = peft_model.generate(**inputs, adapter_names=adapter_names, max_new_tokens=20)
|
||||
```
|
||||
|
||||
Note that the order does not matter here, i.e. the samples in the batch don't need to be grouped by adapter as in the example above. We just need to ensure that the `adapter_names` argument is aligned correctly with the samples.
|
||||
|
||||
### Caveats
|
||||
|
||||
Using this features has some drawbacks, namely:
|
||||
|
||||
- It only works for inference, not for training.
|
||||
- Disabling adapters using the `with model.disable_adapter()` context takes precedence over `adapter_names`.
|
||||
- You cannot pass `adapter_names` when some adapter weights where merged with base weight using the `merge_adapter` method. Please unmerge all adapters first by calling `model.unmerge_adapter()`.
|
||||
- For obvious reasons, this cannot be used after calling `merge_and_unload()`, since all the LoRA adapters will be merged into the base weights in this case.
|
||||
- This feature does not currently work with DoRA, so set `use_dora=False` in your `LoraConfig` if you want to use it.
|
||||
- There is an expected overhead for inference with `adapter_names`, especially if the amount of different adapters in the batch is high. This is because the batch size is effectively reduced to the number of samples per adapter. If runtime performance is your top priority, try the following:
|
||||
- Increase the batch size.
|
||||
- Try to avoid having a large number of different adapters in the same batch, prefer homogeneous batches. This can be achieved by buffering samples with the same adapter and only perform inference with a small handfull of different adapters.
|
||||
- Take a look at alternative implementations such as [LoRAX](https://github.com/predibase/lorax), [punica](https://github.com/punica-ai/punica), or [S-LoRA](https://github.com/S-LoRA/S-LoRA), which are specialized to work with a large number of different adapters.
|
||||
@ -14,25 +14,25 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# PEFT as a utility library
|
||||
# Adapter injection
|
||||
|
||||
Let's cover in this section how you can leverage PEFT's low level API to inject trainable adapters into any `torch` module.
|
||||
The development of this API has been motivated by the need for super users to not rely on modeling classes that are exposed in PEFT library and still be able to use adapter methods such as LoRA, IA3 and AdaLoRA.
|
||||
With PEFT, you can inject trainable adapters into any `torch` module which allows you to use adapter methods without relying on the modeling classes in PEFT. Currently, PEFT supports injecting [LoRA](../conceptual_guides/adapter#low-rank-adaptation-lora), [AdaLoRA](../conceptual_guides/adapter#adaptive-low-rank-adaptation-adalora), and [IA3](../conceptual_guides/ia3) into models because for these adapters, inplace modification of the model is sufficient for finetuning it.
|
||||
|
||||
## Supported tuner types
|
||||
Check the table below to see when you should inject adapters.
|
||||
|
||||
Currently the supported adapter types are the 'injectable' adapters, meaning adapters where an inplace modification of the model is sufficient to correctly perform the fine tuning. As such, only [LoRA](../conceptual_guides/lora), AdaLoRA and [IA3](../conceptual_guides/ia3) are currently supported in this API.
|
||||
| Pros | Cons |
|
||||
|---|---|
|
||||
| the model is modified inplace, keeping all the original attributes and methods | manually write the `from_pretrained` and `save_pretrained` utility functions from Hugging Face to save and load adapters |
|
||||
| works for any `torch` module and modality | doesn't work with any of the utility methods provided by `PeftModel` such as disabling and merging adapters |
|
||||
|
||||
## `inject_adapter_in_model` method
|
||||
To perform the adapter injection, use the [`inject_adapter_in_model`] method. This method takes 3 arguments, the PEFT config, the model, and an optional adapter name. You can also attach multiple adapters to the model if you call [`inject_adapter_in_model`] multiple times with different adapter names.
|
||||
|
||||
To perform the adapter injection, simply use `inject_adapter_in_model` method that takes 3 arguments, the PEFT config and the model itself and an optional adapter name. You can also attach multiple adapters in the model if you call multiple times `inject_adapter_in_model` with different adapter names.
|
||||
For example, to inject LoRA adapters into the `linear` submodule of the `DummyModel` module:
|
||||
|
||||
Below is a basic example usage of how to inject LoRA adapters into the submodule `linear` of the module `DummyModel`.
|
||||
```python
|
||||
import torch
|
||||
from peft import inject_adapter_in_model, LoraConfig
|
||||
|
||||
|
||||
class DummyModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
@ -62,7 +62,7 @@ dummy_inputs = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7]])
|
||||
dummy_outputs = model(dummy_inputs)
|
||||
```
|
||||
|
||||
If you print the model, you will notice that the adapters have been correctly injected into the model
|
||||
Print the model to see that the adapters have been correctly injected.
|
||||
|
||||
```bash
|
||||
DummyModel(
|
||||
@ -84,8 +84,8 @@ DummyModel(
|
||||
(lm_head): Linear(in_features=10, out_features=10, bias=True)
|
||||
)
|
||||
```
|
||||
Note that it should be up to users to properly take care of saving the adapters (in case they want to save adapters only), as `model.state_dict()` will return the full state dict of the model.
|
||||
In case you want to extract the adapters state dict you can use the `get_peft_model_state_dict` method:
|
||||
|
||||
To only save the adapter, use the [`get_peft_model_state_dict`] function:
|
||||
|
||||
```python
|
||||
from peft import get_peft_model_state_dict
|
||||
@ -94,14 +94,4 @@ peft_state_dict = get_peft_model_state_dict(model)
|
||||
print(peft_state_dict)
|
||||
```
|
||||
|
||||
## Pros and cons
|
||||
|
||||
When to use this API and when to not use it? Let's discuss in this section the pros and cons
|
||||
|
||||
Pros:
|
||||
- The model gets modified in-place, meaning the model will preserve all its original attributes and methods
|
||||
- Works for any torch module, and any modality (vision, text, multi-modal)
|
||||
|
||||
Cons:
|
||||
- You need to manually writing Hugging Face `from_pretrained` and `save_pretrained` utility methods if you want to easily save / load adapters from the Hugging Face Hub.
|
||||
- You cannot use any of the utility method provided by `PeftModel` such as disabling adapters, merging adapters, etc.
|
||||
Otherwise, `model.state_dict()` returns the full state dict of the model.
|
||||
|
||||
@ -10,13 +10,11 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Working with mixed adapter types
|
||||
# Mixed adapter types
|
||||
|
||||
Normally, it is not possible to mix different adapter types in 🤗 PEFT. For example, even though it is possible to create a PEFT model that has two different LoRA adapters (that can have different config options), it is not possible to combine a LoRA adapter with a LoHa adapter. However, by using a mixed model, this works as long as the adapter types are compatible.
|
||||
Normally, it isn't possible to mix different adapter types in 🤗 PEFT. You can create a PEFT model with two different LoRA adapters (which can have different config options), but it is not possible to combine a LoRA and LoHa adapter. With [`PeftMixedModel`] however, this works as long as the adapter types are compatible. The main purpose of allowing mixed adapter types is to combine trained adapters for inference. While it is possible to train a mixed adapter model, this has not been tested and is not recommended.
|
||||
|
||||
## Loading different adapter types into a PEFT model
|
||||
|
||||
To load different adapter types into a PEFT model, proceed the same as if you were loading two adapters of the same type, but use `PeftMixedModel` instead of `PeftModel`:
|
||||
To load different adapter types into a PEFT model, use [`PeftMixedModel`] instead of [`PeftModel`]:
|
||||
|
||||
```py
|
||||
from peft import PeftMixedModel
|
||||
@ -28,12 +26,12 @@ peft_model.load_adapter(<path_to_adapter2>, adapter_name="other")
|
||||
peft_model.set_adapter(["default", "other"])
|
||||
```
|
||||
|
||||
The last line is necessary if you want to activate both adapters, otherwise, only the first adapter would be active. Of course, you can add more different adapters by calling `add_adapter` repeatedly.
|
||||
The [`~PeftMixedModel.set_adapter`] method is necessary to activate both adapters, otherwise only the first adapter would be active. You can keep adding more adapters by calling [`~PeftModel.add_adapter`] repeatedly.
|
||||
|
||||
Currently, the main purpose of mixed adapter types is to combine trained adapters for inference. Although it is technically also possible to train a mixed adapter model, this has not been tested and is not recommended.
|
||||
[`PeftMixedModel`] does not support saving and loading mixed adapters. The adapters should already be trained, and loading the model requires a script to be run each time.
|
||||
|
||||
## Tips
|
||||
|
||||
- Not all adapter types can be combined. See `peft.tuners.mixed.COMPATIBLE_TUNER_TYPES` for a list of compatible types. An error will be raised if you are trying to combine incompatible adapter types.
|
||||
- It is possible to mix multiple adapters of the same type. This can be useful to combine adapters with very different configs.
|
||||
- If you want to combine a lot of different adapters, it is most performant to add the same types of adapters consecutively. E.g., add LoRA1, LoRA2, LoHa1, LoHa2 in this order, instead of LoRA1, LoHa1, LoRA2, LoHa2. The order will make a difference for the outcome in most cases, but since no order is better a priori, it is best to choose the order that is most performant.
|
||||
- Not all adapter types can be combined. See [`peft.tuners.mixed.COMPATIBLE_TUNER_TYPES`](https://github.com/huggingface/peft/blob/1c1c7fdaa6e6abaa53939b865dee1eded82ad032/src/peft/tuners/mixed/model.py#L35) for a list of compatible types. An error will be raised if you try to combine incompatible adapter types.
|
||||
- It is possible to mix multiple adapters of the same type which can be useful for combining adapters with very different configs.
|
||||
- If you want to combine a lot of different adapters, the most performant way to do it is to consecutively add the same adapter types. For example, add LoRA1, LoRA2, LoHa1, LoHa2 in this order, instead of LoRA1, LoHa1, LoRA2, and LoHa2. While the order can affect the output, there is no inherently *best* order, so it is best to choose the fastest one.
|
||||
|
||||
140
docs/source/developer_guides/model_merging.md
Normal file
140
docs/source/developer_guides/model_merging.md
Normal file
@ -0,0 +1,140 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Model merging
|
||||
|
||||
Training a model for each task can be costly, take up storage space, and the models aren't able to learn new information to improve their performance. Multitask learning can overcome some of these limitations by training a model to learn several tasks, but it is expensive to train and designing a dataset for it is challenging. *Model merging* offers a solution to these challenges by combining multiple pretrained models into one model, giving it the combined abilities of each individual model without any additional training.
|
||||
|
||||
PEFT provides several methods for merging models like a linear or SVD combination. This guide focuses on two methods that are more efficient for merging LoRA adapters by eliminating redundant parameters:
|
||||
|
||||
* [TIES](https://hf.co/papers/2306.01708) - TrIm, Elect, and Merge (TIES) is a three-step method for merging models. First, redundant parameters are trimmed, then conflicting signs are resolved into an aggregated vector, and finally the parameters whose signs are the same as the aggregate sign are averaged. This method takes into account that some values (redundant and sign disagreement) can degrade performance in the merged model.
|
||||
* [DARE](https://hf.co/papers/2311.03099) - Drop And REscale is a method that can be used to prepare for other model merging methods like TIES. It works by randomly dropping parameters according to a drop rate and rescaling the remaining parameters. This helps to reduce the number of redundant and potentially interfering parameters among multiple models.
|
||||
|
||||
Models are merged with the [`~LoraModel.add_weighted_adapter`] method, and the specific model merging method is specified in the `combination_type` parameter.
|
||||
|
||||
## Merge method
|
||||
|
||||
With TIES and DARE, merging is enabled by setting `combination_type` and `density` to a value of the weights to keep from the individual models. For example, let's merge three finetuned [TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T) models: [tinyllama_lora_nobots](https://huggingface.co/smangrul/tinyllama_lora_norobots), [tinyllama_lora_sql](https://huggingface.co/smangrul/tinyllama_lora_sql), and [tinyllama_lora_adcopy](https://huggingface.co/smangrul/tinyllama_lora_adcopy).
|
||||
|
||||
<Tip warninig={true}>
|
||||
|
||||
When you're attempting to merge fully trained models with TIES, you should be aware of any special tokens each model may have added to the embedding layer which are not a part of the original checkpoint's vocabulary. This may cause an issue because each model may have added a special token to the same embedding position. If this is the case, you should use the [`~transformers.PreTrainedModel.resize_token_embeddings`] method to avoid merging the special tokens at the same embedding index.
|
||||
|
||||
<br>
|
||||
|
||||
This shouldn't be an issue if you're only merging LoRA adapters trained from the same base model.
|
||||
|
||||
</Tip>
|
||||
|
||||
Load a base model and can use the [`~PeftModel.load_adapter`] method to load and assign each adapter a name:
|
||||
|
||||
```py
|
||||
from peft import PeftConfig, PeftModel
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
import torch
|
||||
|
||||
config = PeftConfig.from_pretrained("smangrul/tinyllama_lora_norobots")
|
||||
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, load_in_4bit=True, device_map="auto").eval()
|
||||
tokenizer = AutoTokenizer.from_pretrained("smangrul/tinyllama_lora_norobots")
|
||||
|
||||
model = PeftModel.from_pretrained(model, "smangrul/tinyllama_lora_norobots", adapter_name="norobots")
|
||||
_ = model.load_adapter("smangrul/tinyllama_lora_sql", adapter_name="sql")
|
||||
_ = model.load_adapter("smangrul/tinyllama_lora_adcopy", adapter_name="adcopy")
|
||||
```
|
||||
|
||||
Set the adapters, weights, `adapter_name`, `combination_type`, and `density` with the [`~LoraModel.add_weighted_adapter`] method.
|
||||
|
||||
<hfoptions id="merge-method">
|
||||
<hfoption id="TIES">
|
||||
|
||||
Weight values greater than `1.0` typically produce better results because they preserve the correct scale. A good default starting value for the weights is to set all values to `1.0`.
|
||||
|
||||
```py
|
||||
adapters = ["norobots", "adcopy", "sql"]
|
||||
weights = [2.0, 1.0, 1.0]
|
||||
adapter_name = "merge"
|
||||
density = 0.2
|
||||
model.add_weighted_adapter(adapters, weights, adapter_name, combination_type="ties", density=density)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="DARE">
|
||||
|
||||
```py
|
||||
adapters = ["norobots", "adcopy", "sql"]
|
||||
weights = [2.0, 0.3, 0.7]
|
||||
adapter_name = "merge"
|
||||
density = 0.2
|
||||
model.add_weighted_adapter(adapters, weights, adapter_name, combination_type="dare_ties", density=density)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
Set the newly merged model as the active model with the [`~LoraModel.set_adapter`] method.
|
||||
|
||||
```py
|
||||
model.set_adapter("merge")
|
||||
```
|
||||
|
||||
Now you can use the merged model as an instruction-tuned model to write ad copy or SQL queries!
|
||||
|
||||
<hfoptions id="ties">
|
||||
<hfoption id="instruct">
|
||||
|
||||
```py
|
||||
messages = [
|
||||
{"role": "user", "content": "Write an essay about Generative AI."},
|
||||
]
|
||||
text = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
|
||||
inputs = tokenizer(text, return_tensors="pt")
|
||||
inputs = {k: v.to("cuda") for k, v in inputs.items()}
|
||||
outputs = model.generate(**inputs, max_new_tokens=256, do_sample=True, top_p=0.95, temperature=0.2, repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
|
||||
print(tokenizer.decode(outputs[0]))
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="ad copy">
|
||||
|
||||
```py
|
||||
messages = [
|
||||
{"role": "system", "content": "Create a text ad given the following product and description."},
|
||||
{"role": "user", "content": "Product: Sony PS5 PlayStation Console\nDescription: The PS5 console unleashes new gaming possibilities that you never anticipated."},
|
||||
]
|
||||
text = tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
|
||||
inputs = tokenizer(text, return_tensors="pt")
|
||||
inputs = {k: v.to("cuda") for k, v in inputs.items()}
|
||||
outputs = model.generate(**inputs, max_new_tokens=128, do_sample=True, top_p=0.95, temperature=0.2, repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
|
||||
print(tokenizer.decode(outputs[0]))
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="SQL">
|
||||
|
||||
```py
|
||||
text = """Table: 2-11365528-2
|
||||
Columns: ['Team', 'Head Coach', 'President', 'Home Ground', 'Location']
|
||||
Natural Query: Who is the Head Coach of the team whose President is Mario Volarevic?
|
||||
SQL Query:"""
|
||||
|
||||
inputs = tokenizer(text, return_tensors="pt")
|
||||
inputs = {k: v.to("cuda") for k, v in inputs.items()}
|
||||
outputs = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1, eos_token_id=tokenizer("</s>").input_ids[-1])
|
||||
print(tokenizer.decode(outputs[0]))
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
200
docs/source/developer_guides/quantization.md
Normal file
200
docs/source/developer_guides/quantization.md
Normal file
@ -0,0 +1,200 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Quantization
|
||||
|
||||
Quantization represents data with fewer bits, making it a useful technique for reducing memory-usage and accelerating inference especially when it comes to large language models (LLMs). There are several ways to quantize a model including:
|
||||
|
||||
* optimizing which model weights are quantized with the [AWQ](https://hf.co/papers/2306.00978) algorithm
|
||||
* independently quantizing each row of a weight matrix with the [GPTQ](https://hf.co/papers/2210.17323) algorithm
|
||||
* quantizing to 8-bit and 4-bit precision with the [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) library
|
||||
* quantizing to as low as 2-bit precision with the [AQLM](https://arxiv.org/abs/2401.06118) algorithm
|
||||
|
||||
However, after a model is quantized it isn't typically further trained for downstream tasks because training can be unstable due to the lower precision of the weights and activations. But since PEFT methods only add *extra* trainable parameters, this allows you to train a quantized model with a PEFT adapter on top! Combining quantization with PEFT can be a good strategy for training even the largest models on a single GPU. For example, [QLoRA](https://hf.co/papers/2305.14314) is a method that quantizes a model to 4-bits and then trains it with LoRA. This method allows you to finetune a 65B parameter model on a single 48GB GPU!
|
||||
|
||||
In this guide, you'll see how to quantize a model to 4-bits and train it with LoRA.
|
||||
|
||||
## Quantize a model
|
||||
|
||||
[bitsandbytes](https://github.com/TimDettmers/bitsandbytes) is a quantization library with a Transformers integration. With this integration, you can quantize a model to 8 or 4-bits and enable many other options by configuring the [`~transformers.BitsAndBytesConfig`] class. For example, you can:
|
||||
|
||||
* set `load_in_4bit=True` to quantize the model to 4-bits when you load it
|
||||
* set `bnb_4bit_quant_type="nf4"` to use a special 4-bit data type for weights initialized from a normal distribution
|
||||
* set `bnb_4bit_use_double_quant=True` to use a nested quantization scheme to quantize the already quantized weights
|
||||
* set `bnb_4bit_compute_dtype=torch.bfloat16` to use bfloat16 for faster computation
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import BitsAndBytesConfig
|
||||
|
||||
config = BitsAndBytesConfig(
|
||||
load_in_4bit=True,
|
||||
bnb_4bit_quant_type="nf4",
|
||||
bnb_4bit_use_double_quant=True,
|
||||
bnb_4bit_compute_dtype=torch.bfloat16,
|
||||
)
|
||||
```
|
||||
|
||||
Pass the `config` to the [`~transformers.AutoModelForCausalLM.from_pretrained`] method.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", quantization_config=config)
|
||||
```
|
||||
|
||||
Next, you should call the [`~peft.utils.prepare_model_for_kbit_training`] function to preprocess the quantized model for training.
|
||||
|
||||
```py
|
||||
from peft import prepare_model_for_kbit_training
|
||||
|
||||
model = prepare_model_for_kbit_training(model)
|
||||
```
|
||||
|
||||
Now that the quantized model is ready, let's set up a configuration.
|
||||
|
||||
## LoraConfig
|
||||
|
||||
Create a [`LoraConfig`] with the following parameters (or choose your own):
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=8,
|
||||
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM"
|
||||
)
|
||||
```
|
||||
|
||||
Then use the [`get_peft_model`] function to create a [`PeftModel`] from the quantized model and configuration.
|
||||
|
||||
```py
|
||||
from peft import get_peft_model
|
||||
|
||||
model = get_peft_model(model, config)
|
||||
```
|
||||
|
||||
You're all set for training with whichever training method you prefer!
|
||||
|
||||
### LoftQ initialization
|
||||
|
||||
[LoftQ](https://hf.co/papers/2310.08659) initializes LoRA weights such that the quantization error is minimized, and it can improve performance when training quantized models. To get started, follow [these instructions](https://github.com/huggingface/peft/tree/main/examples/loftq_finetuning).
|
||||
|
||||
In general, for LoftQ to work best, it is recommended to target as many layers with LoRA as possible, since those not targeted cannot have LoftQ applied. This means that passing `LoraConfig(..., target_modules="all-linear")` will most likely give the best results. Also, you should use `nf4` as quant type in your quantization config when using 4bit quantization, i.e. `BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4")`.
|
||||
|
||||
### QLoRA-style training
|
||||
|
||||
QLoRA adds trainable weights to all the linear layers in the transformer architecture. Since the attribute names for these linear layers can vary across architectures, set `target_modules` to `"all-linear"` to add LoRA to all the linear layers:
|
||||
|
||||
```py
|
||||
config = LoraConfig(target_modules="all-linear", ...)
|
||||
```
|
||||
|
||||
## AQLM quantization
|
||||
|
||||
Additive Quantization of Language Models ([AQLM](https://arxiv.org/abs/2401.06118)) is a Large Language Models compression method. It quantizes multiple weights together and takes advantage of interdependencies between them. AQLM represents groups of 8-16 weights as a sum of multiple vector codes. This allows it to compress models down to as low as 2-bit with considerably low accuracy losses.
|
||||
|
||||
Since the AQLM quantization process is computationally expensive, a use of prequantized models is recommended. A partial list of available models can be found in the official aqlm [repository](https://github.com/Vahe1994/AQLM).
|
||||
|
||||
The models support LoRA adapter tuning. To tune the quantized model you'll need to install the `aqlm` inference library: `pip install aqlm>=1.0.2`. Finetuned LoRA adapters shall be saved separately, as merging them with AQLM quantized weights is not possible.
|
||||
|
||||
```py
|
||||
quantized_model = AutoModelForCausalLM.from_pretrained(
|
||||
"BlackSamorez/Mixtral-8x7b-AQLM-2Bit-1x16-hf-test-dispatch",
|
||||
torch_dtype="auto", device_map="auto", low_cpu_mem_usage=True,
|
||||
)
|
||||
|
||||
peft_config = LoraConfig(...)
|
||||
|
||||
quantized_model = get_peft_model(quantized_model, peft_config)
|
||||
```
|
||||
|
||||
You can refer to the [Google Colab](https://colab.research.google.com/drive/12GTp1FCj5_0SnnNQH18h_2XFh9vS_guX?usp=sharing) example for an overview of AQLM+LoRA finetuning.
|
||||
|
||||
## EETQ quantization
|
||||
|
||||
You can also perform LoRA fine-tuning on EETQ quantized models. [EETQ](https://github.com/NetEase-FuXi/EETQ) package offers simple and efficient way to perform 8-bit quantization, which is claimed to be faster than the `LLM.int8()` algorithm. First, make sure that you have a transformers version that is compatible with EETQ (e.g. by installing it from latest pypi or from source).
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import EetqConfig
|
||||
|
||||
config = EetqConfig("int8")
|
||||
```
|
||||
|
||||
Pass the `config` to the [`~transformers.AutoModelForCausalLM.from_pretrained`] method.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", quantization_config=config)
|
||||
```
|
||||
|
||||
and create a `LoraConfig` and pass it to `get_peft_model`:
|
||||
|
||||
```py
|
||||
from peft import LoraConfig, get_peft_model
|
||||
|
||||
config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=8,
|
||||
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM"
|
||||
)
|
||||
|
||||
model = get_peft_model(model, config)
|
||||
```
|
||||
|
||||
## HQQ quantization
|
||||
|
||||
The models that is quantized using Half-Quadratic Quantization of Large Machine Learning Models ([HQQ](https://mobiusml.github.io/hqq_blog/)) support LoRA adapter tuning. To tune the quantized model, you'll need to install the `hqq` library with: `pip install hqq`.
|
||||
|
||||
```py
|
||||
from hqq.engine.hf import HQQModelForCausalLM
|
||||
|
||||
quantized_model = HQQModelForCausalLM.from_quantized(save_dir_or_hfhub, device='cuda')
|
||||
|
||||
peft_config = LoraConfig(...)
|
||||
|
||||
quantized_model = get_peft_model(quantized_model, peft_config)
|
||||
```
|
||||
|
||||
Or using transformers version that is compatible with HQQ (e.g. by installing it from latest pypi or from source).
|
||||
|
||||
```python
|
||||
from transformers import HqqConfig, AutoModelForCausalLM
|
||||
|
||||
quant_config = HqqConfig(nbits=4, group_size=64)
|
||||
|
||||
quantized_model = AutoModelForCausalLM.from_pretrained(save_dir_or_hfhub, device='cuda', quantization_config=quant_config)
|
||||
|
||||
peft_config = LoraConfig(...)
|
||||
|
||||
quantized_model = get_peft_model(quantized_model, peft_config)
|
||||
```
|
||||
|
||||
## Next steps
|
||||
|
||||
If you're interested in learning more about quantization, the following may be helpful:
|
||||
|
||||
* Learn more about details about QLoRA and check out some benchmarks on its impact in the [Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA](https://huggingface.co/blog/4bit-transformers-bitsandbytes) blog post.
|
||||
* Read more about different quantization schemes in the Transformers [Quantization](https://hf.co/docs/transformers/main/quantization) guide.
|
||||
@ -20,7 +20,7 @@ If you encounter any issue when using PEFT, please check the following list of c
|
||||
|
||||
## Examples don't work
|
||||
|
||||
Examples often rely on the most recent package versions, so please ensure they're up-to-date. In particular, check the version of the following packages:
|
||||
Examples often rely on the most recent package versions, so please ensure they're up-to-date. In particular, check the following package versions:
|
||||
|
||||
- `peft`
|
||||
- `transformers`
|
||||
@ -39,9 +39,39 @@ Installing PEFT from source is useful for keeping up with the latest development
|
||||
python -m pip install git+https://github.com/huggingface/peft
|
||||
```
|
||||
|
||||
## ValueError: Attempting to unscale FP16 gradients
|
||||
|
||||
This error probably occurred because the model was loaded with `torch_dtype=torch.float16` and then used in an automatic mixed precision (AMP) context, e.g. by setting `fp16=True` in the [`~transformers.Trainer`] class from 🤗 Transformers. The reason is that when using AMP, trainable weights should never use fp16. To make this work without loading the whole model in fp32, add the following to your code:
|
||||
|
||||
```python
|
||||
peft_model = get_peft_model(...)
|
||||
|
||||
# add this:
|
||||
for param in model.parameters():
|
||||
if param.requires_grad:
|
||||
param.data = param.data.float()
|
||||
|
||||
# proceed as usual
|
||||
trainer = Trainer(model=peft_model, fp16=True, ...)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
Alternatively, you can use the [`~utils.cast_mixed_precision_params`] function to correctly cast the weights:
|
||||
|
||||
```python
|
||||
from peft import cast_mixed_precision_params
|
||||
|
||||
peft_model = get_peft_model(...)
|
||||
cast_mixed_precision_params(peft_model, dtype=torch.float16)
|
||||
|
||||
# proceed as usual
|
||||
trainer = Trainer(model=peft_model, fp16=True, ...)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Bad results from a loaded PEFT model
|
||||
|
||||
There can be several reasons for getting a poor result from a loaded PEFT model, which are listed below. If you're still unable to troubleshoot the problem, see if anyone else had a similar [issue](https://github.com/huggingface/peft/issues) on GitHub, and if you can't find any, open a new issue.
|
||||
There can be several reasons for getting a poor result from a loaded PEFT model which are listed below. If you're still unable to troubleshoot the problem, see if anyone else had a similar [issue](https://github.com/huggingface/peft/issues) on GitHub, and if you can't find any, open a new issue.
|
||||
|
||||
When opening an issue, it helps a lot if you provide a minimal code example that reproduces the issue. Also, please report if the loaded model performs at the same level as the model did before fine-tuning, if it performs at a random level, or if it is only slightly worse than expected. This information helps us identify the problem more quickly.
|
||||
|
||||
@ -55,7 +85,7 @@ If your model outputs are not exactly the same as previous runs, there could be
|
||||
|
||||
### Incorrectly loaded model
|
||||
|
||||
Please ensure that you load the model correctly. A common error is trying to load a _trained_ model with `get_peft_model`, which is incorrect. Instead, the loading code should look like this:
|
||||
Please ensure that you load the model correctly. A common error is trying to load a _trained_ model with [`get_peft_model`] which is incorrect. Instead, the loading code should look like this:
|
||||
|
||||
```python
|
||||
from peft import PeftModel, PeftConfig
|
||||
@ -71,7 +101,7 @@ For some tasks, it is important to correctly configure `modules_to_save` in the
|
||||
|
||||
As an example, this is necessary if you use LoRA to fine-tune a language model for sequence classification because 🤗 Transformers adds a randomly initialized classification head on top of the model. If you do not add this layer to `modules_to_save`, the classification head won't be saved. The next time you load the model, you'll get a _different_ randomly initialized classification head, resulting in completely different results.
|
||||
|
||||
In PEFT, we try to correctly guess the `modules_to_save` if you provide the `task_type` argument in the config. This should work for transformers models that follow the standard naming scheme. It is always a good idea to double check though because we can't guarantee all models follow the naming scheme.
|
||||
PEFT tries to correctly guess the `modules_to_save` if you provide the `task_type` argument in the config. This should work for transformers models that follow the standard naming scheme. It is always a good idea to double check though because we can't guarantee all models follow the naming scheme.
|
||||
|
||||
When you load a transformers model that has randomly initialized layers, you should see a warning along the lines of:
|
||||
|
||||
@ -81,3 +111,132 @@ You should probably TRAIN this model on a down-stream task to be able to use it
|
||||
```
|
||||
|
||||
The mentioned layers should be added to `modules_to_save` in the config to avoid the described problem.
|
||||
|
||||
### Extending the vocabulary
|
||||
|
||||
For many language fine-tuning tasks, extending the model's vocabulary is necessary since new tokens are being introduced. This requires extending the embedding layer to account for the new tokens and also storing the embedding layer in addition to the adapter weights when saving the adapter.
|
||||
|
||||
Save the embedding layer by adding it to the `target_modules` of the config. The embedding layer name must follow the standard naming scheme from Transformers. For example, the Mistral config could look like this:
|
||||
|
||||
```python
|
||||
config = LoraConfig(..., target_modules=["embed_tokens", "lm_head", "q_proj", "v_proj"])
|
||||
```
|
||||
|
||||
Once added to `target_modules`, PEFT automatically stores the embedding layer when saving the adapter if the model has the [`~transformers.PreTrainedModel.get_input_embeddings`] and [`~transformers.PreTrainedModel.get_output_embeddings`]. This is generally the case for Transformers models.
|
||||
|
||||
If the model's embedding layer doesn't follow the Transformer's naming scheme, you can still save it by manually passing `save_embedding_layers=True` when saving the adapter:
|
||||
|
||||
```python
|
||||
model = get_peft_model(...)
|
||||
# train the model
|
||||
model.save_pretrained("my_adapter", save_embedding_layers=True)
|
||||
```
|
||||
|
||||
For inference, load the base model first and resize it the same way you did before you trained the model. After you've resized the base model, you can load the PEFT checkpoint.
|
||||
|
||||
For a complete example, please check out [this notebook](https://github.com/huggingface/peft/blob/main/examples/causal_language_modeling/peft_lora_clm_with_additional_tokens.ipynb).
|
||||
|
||||
### Check layer and model status
|
||||
|
||||
Sometimes a PEFT model can end up in a bad state, especially when handling multiple adapters. There can be some confusion around what adapters exist, which one is active, which one is merged, etc. To help investigate this issue, call the [`~peft.PeftModel.get_layer_status`] and the [`~peft.PeftModel.get_model_status`] methods.
|
||||
|
||||
The [`~peft.PeftModel.get_layer_status`] method gives you a detailed overview of each targeted layer's active, merged, and available adapters.
|
||||
|
||||
```python
|
||||
>>> from transformers import AutoModel
|
||||
>>> from peft import get_peft_model, LoraConfig
|
||||
|
||||
>>> model_id = "google/flan-t5-small"
|
||||
>>> model = AutoModel.from_pretrained(model_id)
|
||||
>>> model = get_peft_model(model, LoraConfig())
|
||||
|
||||
>>> model.get_layer_status()
|
||||
[TunerLayerStatus(name='model.encoder.block.0.layer.0.SelfAttention.q',
|
||||
module_type='lora.Linear',
|
||||
enabled=True,
|
||||
active_adapters=['default'],
|
||||
merged_adapters=[],
|
||||
requires_grad={'default': True},
|
||||
available_adapters=['default']),
|
||||
TunerLayerStatus(name='model.encoder.block.0.layer.0.SelfAttention.v',
|
||||
module_type='lora.Linear',
|
||||
enabled=True,
|
||||
active_adapters=['default'],
|
||||
merged_adapters=[],
|
||||
requires_grad={'default': True},
|
||||
available_adapters=['default']),
|
||||
...]
|
||||
|
||||
>>> model.get_model_status()
|
||||
TunerModelStatus(
|
||||
base_model_type='T5Model',
|
||||
adapter_model_type='LoraModel',
|
||||
peft_types={'default': 'LORA'},
|
||||
trainable_params=344064,
|
||||
total_params=60855680,
|
||||
num_adapter_layers=48,
|
||||
enabled=True,
|
||||
active_adapters=['default'],
|
||||
merged_adapters=[],
|
||||
requires_grad={'default': True},
|
||||
available_adapters=['default'],
|
||||
)
|
||||
```
|
||||
|
||||
In the model state output, you should look out for entries that say `"irregular"`. This means PEFT detected an inconsistent state in the model. For instance, if `merged_adapters="irregular"`, it means that for at least one adapter, it was merged on some target modules but not on others. The inference results will most likely be incorrect as a result.
|
||||
|
||||
The best way to resolve this issue is to reload the whole model and adapter checkpoint(s). Ensure that you don't perform any incorrect operations on the model, e.g. manually merging adapters on some modules but not others.
|
||||
|
||||
Convert the layer status into a pandas `DataFrame` for an easier visual inspection.
|
||||
|
||||
```python
|
||||
from dataclasses import asdict
|
||||
import pandas as pd
|
||||
|
||||
df = pd.DataFrame(asdict(layer) for layer in model.get_layer_status())
|
||||
```
|
||||
|
||||
It is possible to get this information for non-PEFT models if they are using PEFT layers under the hood, but some information like the `base_model_type` or the `peft_types` cannot be determined in that case. As an example, you can call this on a [diffusers](https://huggingface.co/docs/diffusers/index) model like so:
|
||||
|
||||
```python
|
||||
>>> import torch
|
||||
>>> from diffusers import StableDiffusionPipeline
|
||||
>>> from peft import get_model_status, get_layer_status
|
||||
|
||||
>>> path = "runwayml/stable-diffusion-v1-5"
|
||||
>>> lora_id = "takuma104/lora-test-text-encoder-lora-target"
|
||||
>>> pipe = StableDiffusionPipeline.from_pretrained(path, torch_dtype=torch.float16)
|
||||
>>> pipe.load_lora_weights(lora_id, adapter_name="adapter-1")
|
||||
>>> pipe.load_lora_weights(lora_id, adapter_name="adapter-2")
|
||||
>>> get_layer_status(pipe.text_encoder)
|
||||
[TunerLayerStatus(name='text_model.encoder.layers.0.self_attn.k_proj',
|
||||
module_type='lora.Linear',
|
||||
enabled=True,
|
||||
active_adapters=['adapter-2'],
|
||||
merged_adapters=[],
|
||||
requires_grad={'adapter-1': False, 'adapter-2': True},
|
||||
available_adapters=['adapter-1', 'adapter-2']),
|
||||
TunerLayerStatus(name='text_model.encoder.layers.0.self_attn.v_proj',
|
||||
module_type='lora.Linear',
|
||||
enabled=True,
|
||||
active_adapters=['adapter-2'],
|
||||
merged_adapters=[],
|
||||
requires_grad={'adapter-1': False, 'adapter-2': True},
|
||||
available_adapters=['adapter-1', 'adapter-2']),
|
||||
...]
|
||||
|
||||
>>> get_model_status(pipe.unet)
|
||||
TunerModelStatus(
|
||||
base_model_type='other',
|
||||
adapter_model_type='None',
|
||||
peft_types={},
|
||||
trainable_params=797184,
|
||||
total_params=861115332,
|
||||
num_adapter_layers=128,
|
||||
enabled=True,
|
||||
active_adapters=['adapter-2'],
|
||||
merged_adapters=[],
|
||||
requires_grad={'adapter-1': False, 'adapter-2': True},
|
||||
available_adapters=['adapter-1', 'adapter-2'],
|
||||
)
|
||||
```
|
||||
|
||||
31
docs/source/package_reference/boft.md
Normal file
31
docs/source/package_reference/boft.md
Normal file
@ -0,0 +1,31 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# BOFT
|
||||
|
||||
[Orthogonal Butterfly (BOFT)](https://hf.co/papers/2311.06243) is a generic method designed for finetuning foundation models. It improves the paramter efficiency of the finetuning paradigm -- Orthogonal Finetuning (OFT), by taking inspiration from Cooley-Tukey fast Fourier transform, showing favorable results across finetuning different foundation models, including large vision transformers, large language models and text-to-image diffusion models.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language*.
|
||||
|
||||
## BOFTConfig
|
||||
|
||||
[[autodoc]] tuners.boft.config.BOFTConfig
|
||||
|
||||
## BOFTModel
|
||||
|
||||
[[autodoc]] tuners.boft.model.BOFTModel
|
||||
12
docs/source/package_reference/helpers.md
Normal file
12
docs/source/package_reference/helpers.md
Normal file
@ -0,0 +1,12 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# Document Title
|
||||
|
||||
A collection of helper functions for PEFT.
|
||||
|
||||
## Checking if a model is a PEFT model
|
||||
|
||||
[[autodoc]] helpers.check_if_peft_model
|
||||
- all
|
||||
34
docs/source/package_reference/layernorm_tuning.md
Normal file
34
docs/source/package_reference/layernorm_tuning.md
Normal file
@ -0,0 +1,34 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# LayerNorm Tuning
|
||||
|
||||
LayerNorm Tuning ([LN Tuning](https://huggingface.co/papers/2312.11420)) is a PEFT method that only fine-tunes the parameters of the LayerNorm layers in a model.
|
||||
The paper has tested the performance of this method on large language models and has shown that it can achieve strong performance with a significant reduction in the number of trainable parameters and GPU memory usage.
|
||||
However, the method is not limited to language models and can be applied to any model that uses LayerNorm layers.
|
||||
In this implementation, the default is that all layernorm layers inside a model is finetuned, but it could be used to target other layer types such as `MLP` or `Attention` layers, this can be done by specifying the `target_modules` in the `LNTuningConfig`.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*This paper introduces an efficient strategy to transform Large Language Models (LLMs) into Multi-Modal Large Language Models (MLLMs). By conceptualizing this transformation as a domain adaptation process, i.e., transitioning from text understanding to embracing multiple modalities, we intriguingly note that, within each attention block, tuning LayerNorm suffices to yield strong performance. Moreover, when benchmarked against other tuning approaches like full parameter finetuning or LoRA, its benefits on efficiency are substantial. For example, when compared to LoRA on a 13B model scale, performance can be enhanced by an average of over 20% across five multi-modal tasks, and meanwhile, results in a significant reduction of trainable parameters by 41.9% and a decrease in GPU memory usage by 17.6%. On top of this LayerNorm strategy, we showcase that selectively tuning only with conversational data can improve efficiency further. Beyond these empirical outcomes, we provide a comprehensive analysis to explore the role of LayerNorm in adapting LLMs to the multi-modal domain and improving the expressive power of the model.*
|
||||
|
||||
## LNTuningConfig
|
||||
|
||||
[[autodoc]] tuners.ln_tuning.config.LNTuningConfig
|
||||
|
||||
## LNTuningModel
|
||||
|
||||
[[autodoc]] tuners.ln_tuning.model.LNTuningModel
|
||||
@ -28,4 +28,8 @@ The abstract from the paper is:
|
||||
|
||||
## LoraModel
|
||||
|
||||
[[autodoc]] tuners.lora.model.LoraModel
|
||||
[[autodoc]] tuners.lora.model.LoraModel
|
||||
|
||||
## Utility
|
||||
|
||||
[[autodoc]] utils.loftq_utils.replace_lora_weights_loftq
|
||||
|
||||
33
docs/source/package_reference/merge_utils.md
Normal file
33
docs/source/package_reference/merge_utils.md
Normal file
@ -0,0 +1,33 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Model merge
|
||||
|
||||
PEFT provides several internal utilities for [merging LoRA adapters](../developer_guides/model_merging) with the TIES and DARE methods.
|
||||
|
||||
[[autodoc]] utils.merge_utils.prune
|
||||
|
||||
[[autodoc]] utils.merge_utils.calculate_majority_sign_mask
|
||||
|
||||
[[autodoc]] utils.merge_utils.disjoint_merge
|
||||
|
||||
[[autodoc]] utils.merge_utils.task_arithmetic
|
||||
|
||||
[[autodoc]] utils.merge_utils.ties
|
||||
|
||||
[[autodoc]] utils.merge_utils.dare_linear
|
||||
|
||||
[[autodoc]] utils.merge_utils.dare_ties
|
||||
@ -14,9 +14,9 @@ rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Multitask Prompt Tuning
|
||||
# Multitask prompt tuning
|
||||
|
||||
[Multitask Prompt Tuning](https://huggingface.co/papers/2303.02861) decomposes the soft prompts of each task into a single learned transferable prompt instead of a separate prompt for each task. The single learned prompt can be adapted for each task by multiplicative low rank updates.
|
||||
[Multitask prompt tuning](https://huggingface.co/papers/2303.02861) decomposes the soft prompts of each task into a single learned transferable prompt instead of a separate prompt for each task. The single learned prompt can be adapted for each task by multiplicative low rank updates.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
|
||||
31
docs/source/package_reference/oft.md
Normal file
31
docs/source/package_reference/oft.md
Normal file
@ -0,0 +1,31 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# OFT
|
||||
|
||||
[Orthogonal Finetuning (OFT)](https://hf.co/papers/2306.07280) is a method developed for adapting text-to-image diffusion models. It works by reparameterizing the pretrained weight matrices with it's orthogonal matrix to preserve information in the pretrained model. To reduce the number of parameters, OFT introduces a block-diagonal structure in the orthogonal matrix.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Large text-to-image diffusion models have impressive capabilities in generating photorealistic images from text prompts. How to effectively guide or control these powerful models to perform different downstream tasks becomes an important open problem. To tackle this challenge, we introduce a principled finetuning method -- Orthogonal Finetuning (OFT), for adapting text-to-image diffusion models to downstream tasks. Unlike existing methods, OFT can provably preserve hyperspherical energy which characterizes the pairwise neuron relationship on the unit hypersphere. We find that this property is crucial for preserving the semantic generation ability of text-to-image diffusion models. To improve finetuning stability, we further propose Constrained Orthogonal Finetuning (COFT) which imposes an additional radius constraint to the hypersphere. Specifically, we consider two important finetuning text-to-image tasks: subject-driven generation where the goal is to generate subject-specific images given a few images of a subject and a text prompt, and controllable generation where the goal is to enable the model to take in additional control signals. We empirically show that our OFT framework outperforms existing methods in generation quality and convergence speed*.
|
||||
|
||||
## OFTConfig
|
||||
|
||||
[[autodoc]] tuners.oft.config.OFTConfig
|
||||
|
||||
## OFTModel
|
||||
|
||||
[[autodoc]] tuners.oft.model.OFTModel
|
||||
@ -52,3 +52,26 @@ A `PeftModel` for getting extracting features/embeddings from transformer models
|
||||
|
||||
[[autodoc]] PeftModelForFeatureExtraction
|
||||
- all
|
||||
|
||||
## PeftMixedModel
|
||||
|
||||
A `PeftModel` for mixing different adapter types (e.g. LoRA and LoHa).
|
||||
|
||||
[[autodoc]] PeftMixedModel
|
||||
- all
|
||||
|
||||
## Utilities
|
||||
|
||||
[[autodoc]] utils.cast_mixed_precision_params
|
||||
|
||||
[[autodoc]] get_peft_model
|
||||
|
||||
[[autodoc]] inject_adapter_in_model
|
||||
|
||||
[[autodoc]] utils.get_peft_model_state_dict
|
||||
|
||||
[[autodoc]] utils.prepare_model_for_kbit_training
|
||||
|
||||
[[autodoc]] get_layer_status
|
||||
|
||||
[[autodoc]] get_model_status
|
||||
|
||||
44
docs/source/package_reference/poly.md
Normal file
44
docs/source/package_reference/poly.md
Normal file
@ -0,0 +1,44 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Polytropon
|
||||
|
||||
[Polytropon](https://hf.co/papers/2202.13914) is a multitask model with a number of different LoRA adapters in it's "inventory". The model learns the correct combination of adapters from the inventory with a routing function to choose the best subset of modules for a specific task. PEFT also supports [Multi-Head Adapter Routing (MHR)](https://hf.co/papers/2211.03831) for Polytropon which builds on and improves the routing function by combining the adapter heads more granularly. The adapter heads are separated into disjoint blocks and a different routing function is learned for each one, allowing for more expressivity.
|
||||
|
||||
<hfoptions id="paper">
|
||||
<hfoption id="Combining Modular Skills in Multitask Learning">
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*A modular design encourages neural models to disentangle and recombine different facets of knowledge to generalise more systematically to new tasks. In this work, we assume that each task is associated with a subset of latent discrete skills from a (potentially small) inventory. In turn, skills correspond to parameter-efficient (sparse / low-rank) model parameterisations. By jointly learning these and a task-skill allocation matrix, the network for each task is instantiated as the average of the parameters of active skills. To favour non-trivial soft partitions of skills across tasks, we experiment with a series of inductive biases, such as an Indian Buffet Process prior and a two-speed learning rate. We evaluate our latent-skill model on two main settings: 1) multitask reinforcement learning for grounded instruction following on 8 levels of the BabyAI platform; and 2) few-shot adaptation of pre-trained text-to-text generative models on CrossFit, a benchmark comprising 160 NLP tasks. We find that the modular design of a network significantly increases sample efficiency in reinforcement learning and few-shot generalisation in supervised learning, compared to baselines with fully shared, task-specific, or conditionally generated parameters where knowledge is entangled across tasks. In addition, we show how discrete skills help interpretability, as they yield an explicit hierarchy of tasks.*
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Multi-Head Adapter Routing for Cross-Task Generalization">
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Parameter-efficient fine-tuning (PEFT) for cross-task generalization consists in pre-training adapters on a multi-task training set before few-shot adaptation to test tasks. Polytropon [Ponti et al., 2023] (Poly) jointly learns an inventory of adapters and a routing function that selects a (variable-size) subset of adapters for each task during both pre-training and few-shot adaptation. In this paper, we investigate the role that adapter routing plays in its success and design new variants based on our findings. First, we build on the intuition that finer-grained routing provides more expressivity. Hence, we propose MHR (Multi-Head Routing), which combines subsets of adapter parameters and outperforms Poly under a comparable parameter budget; by only fine-tuning the routing function and not the adapters (MHR-z), we achieve competitive performance with extreme parameter efficiency. Second, we find that Poly/MHR performance is a result of better multi-task optimization, rather than modular inductive biases that facilitate adapter recombination and local adaptation, as previously hypothesized. In fact, we find that MHR exhibits higher gradient alignment between tasks than any other method. Since this implies that routing is only crucial during multi-task pre-training, we propose MHR-mu, which discards routing and fine-tunes the average of the pre-trained adapters during few-shot adaptation. This establishes MHR-mu as an effective method for single-adapter fine-tuning.*.
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## PolyConfig
|
||||
|
||||
[[autodoc]] tuners.poly.config.PolyConfig
|
||||
|
||||
## PolyModel
|
||||
|
||||
[[autodoc]] tuners.poly.model.PolyModel
|
||||
41
docs/source/package_reference/vera.md
Normal file
41
docs/source/package_reference/vera.md
Normal file
@ -0,0 +1,41 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# VeRA: Vector-based Random Matrix Adaptation
|
||||
|
||||
[VeRA](https://huggingface.co/papers/2310.11454) is a parameter-efficient fine-tuning technique that is similar to LoRA but requires even fewer extra parameters while promising similar or even better performance. As such, it is particularly useful when the parameter budget is very limited, e.g. when scaling to very large models. The reduction of the count of trainable parameters is achieved by sharing the same low-rank matrices across all layers, and only training two additional vectors per layer.
|
||||
|
||||
When saving the adapter parameters, it's possible to eschew storing the low rank matrices by setting `save_projection=False` on the `VeraConfig`. In that case, these matrices will be restored based on the fixed random seed from the `projection_prng_key` argument. This cuts down on the size of the checkpoint, but we cannot guarantee reproducibility on all devices and for all future versions of PyTorch. If you want to ensure reproducibility, set `save_projection=True` (which is the default).
|
||||
|
||||
VeRA currently has the following constraints:
|
||||
|
||||
- All targeted parameters must have the same shape.
|
||||
- Only `nn.Linear` layers are supported.
|
||||
- Quantized layers are not supported.
|
||||
|
||||
If these constraints don't work for your use case, use LoRA instead.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
> Low-rank adapation (LoRA) is a popular method that reduces the number of trainable parameters when finetuning large language models, but still faces acute storage challenges when scaling to even larger models or deploying numerous per-user or per-task adapted models. In this work, we present Vector-based Random Matrix Adaptation (VeRA), which significantly reduces the number of trainable parameters compared to LoRA, yet maintains the same performance. It achieves this by using a single pair of low-rank matrices shared across all layers and learning small scaling vectors instead. We demonstrate its effectiveness on the GLUE and E2E benchmarks, image classification tasks, and show its application in instruction-tuning of 7B and 13B language models.
|
||||
|
||||
## VeRAConfig
|
||||
|
||||
[[autodoc]] tuners.vera.config.VeraConfig
|
||||
|
||||
## VeRAModel
|
||||
|
||||
[[autodoc]] tuners.vera.model.VeraModel
|
||||
@ -1,293 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Prompt tuning for causal language modeling
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Prompting helps guide language model behavior by adding some input text specific to a task. Prompt tuning is an additive method for only training and updating the newly added prompt tokens to a pretrained model. This way, you can use one pretrained model whose weights are frozen, and train and update a smaller set of prompt parameters for each downstream task instead of fully finetuning a separate model. As models grow larger and larger, prompt tuning can be more efficient, and results are even better as model parameters scale.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Read [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/abs/2104.08691) to learn more about prompt tuning.
|
||||
|
||||
</Tip>
|
||||
|
||||
This guide will show you how to apply prompt tuning to train a [`bloomz-560m`](https://huggingface.co/bigscience/bloomz-560m) model on the `twitter_complaints` subset of the [RAFT](https://huggingface.co/datasets/ought/raft) dataset.
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
!pip install -q peft transformers datasets
|
||||
```
|
||||
|
||||
## Setup
|
||||
|
||||
Start by defining the model and tokenizer, the dataset and the dataset columns to train on, some training hyperparameters, and the [`PromptTuningConfig`]. The [`PromptTuningConfig`] contains information about the task type, the text to initialize the prompt embedding, the number of virtual tokens, and the tokenizer to use:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
|
||||
from peft import get_peft_config, get_peft_model, PromptTuningInit, PromptTuningConfig, TaskType, PeftType
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
import os
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
|
||||
device = "cuda"
|
||||
model_name_or_path = "bigscience/bloomz-560m"
|
||||
tokenizer_name_or_path = "bigscience/bloomz-560m"
|
||||
peft_config = PromptTuningConfig(
|
||||
task_type=TaskType.CAUSAL_LM,
|
||||
prompt_tuning_init=PromptTuningInit.TEXT,
|
||||
num_virtual_tokens=8,
|
||||
prompt_tuning_init_text="Classify if the tweet is a complaint or not:",
|
||||
tokenizer_name_or_path=model_name_or_path,
|
||||
)
|
||||
|
||||
dataset_name = "twitter_complaints"
|
||||
checkpoint_name = f"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt".replace(
|
||||
"/", "_"
|
||||
)
|
||||
text_column = "Tweet text"
|
||||
label_column = "text_label"
|
||||
max_length = 64
|
||||
lr = 3e-2
|
||||
num_epochs = 50
|
||||
batch_size = 8
|
||||
```
|
||||
|
||||
## Load dataset
|
||||
|
||||
For this guide, you'll load the `twitter_complaints` subset of the [RAFT](https://huggingface.co/datasets/ought/raft) dataset. This subset contains tweets that are labeled either `complaint` or `no complaint`:
|
||||
|
||||
```py
|
||||
dataset = load_dataset("ought/raft", dataset_name)
|
||||
dataset["train"][0]
|
||||
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2}
|
||||
```
|
||||
|
||||
To make the `Label` column more readable, replace the `Label` value with the corresponding label text and store them in a `text_label` column. You can use the [`~datasets.Dataset.map`] function to apply this change over the entire dataset in one step:
|
||||
|
||||
```py
|
||||
classes = [k.replace("_", " ") for k in dataset["train"].features["Label"].names]
|
||||
dataset = dataset.map(
|
||||
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
)
|
||||
dataset["train"][0]
|
||||
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2, "text_label": "no complaint"}
|
||||
```
|
||||
|
||||
## Preprocess dataset
|
||||
|
||||
Next, you'll setup a tokenizer; configure the appropriate padding token to use for padding sequences, and determine the maximum length of the tokenized labels:
|
||||
|
||||
```py
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
|
||||
if tokenizer.pad_token_id is None:
|
||||
tokenizer.pad_token_id = tokenizer.eos_token_id
|
||||
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
|
||||
print(target_max_length)
|
||||
3
|
||||
```
|
||||
|
||||
Create a `preprocess_function` to:
|
||||
|
||||
1. Tokenize the input text and labels.
|
||||
2. For each example in a batch, pad the labels with the tokenizers `pad_token_id`.
|
||||
3. Concatenate the input text and labels into the `model_inputs`.
|
||||
4. Create a separate attention mask for `labels` and `model_inputs`.
|
||||
5. Loop through each example in the batch again to pad the input ids, labels, and attention mask to the `max_length` and convert them to PyTorch tensors.
|
||||
|
||||
```py
|
||||
def preprocess_function(examples):
|
||||
batch_size = len(examples[text_column])
|
||||
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
|
||||
targets = [str(x) for x in examples[label_column]]
|
||||
model_inputs = tokenizer(inputs)
|
||||
labels = tokenizer(targets)
|
||||
for i in range(batch_size):
|
||||
sample_input_ids = model_inputs["input_ids"][i]
|
||||
label_input_ids = labels["input_ids"][i] + [tokenizer.pad_token_id]
|
||||
# print(i, sample_input_ids, label_input_ids)
|
||||
model_inputs["input_ids"][i] = sample_input_ids + label_input_ids
|
||||
labels["input_ids"][i] = [-100] * len(sample_input_ids) + label_input_ids
|
||||
model_inputs["attention_mask"][i] = [1] * len(model_inputs["input_ids"][i])
|
||||
# print(model_inputs)
|
||||
for i in range(batch_size):
|
||||
sample_input_ids = model_inputs["input_ids"][i]
|
||||
label_input_ids = labels["input_ids"][i]
|
||||
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
|
||||
max_length - len(sample_input_ids)
|
||||
) + sample_input_ids
|
||||
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
|
||||
"attention_mask"
|
||||
][i]
|
||||
labels["input_ids"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids
|
||||
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
|
||||
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
|
||||
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
|
||||
model_inputs["labels"] = labels["input_ids"]
|
||||
return model_inputs
|
||||
```
|
||||
|
||||
Use the [`~datasets.Dataset.map`] function to apply the `preprocess_function` to the entire dataset. You can remove the unprocessed columns since the model won't need them:
|
||||
|
||||
```py
|
||||
processed_datasets = dataset.map(
|
||||
preprocess_function,
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
remove_columns=dataset["train"].column_names,
|
||||
load_from_cache_file=False,
|
||||
desc="Running tokenizer on dataset",
|
||||
)
|
||||
```
|
||||
|
||||
Create a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) from the `train` and `eval` datasets. Set `pin_memory=True` to speed up the data transfer to the GPU during training if the samples in your dataset are on a CPU.
|
||||
|
||||
```py
|
||||
train_dataset = processed_datasets["train"]
|
||||
eval_dataset = processed_datasets["test"]
|
||||
|
||||
|
||||
train_dataloader = DataLoader(
|
||||
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
|
||||
)
|
||||
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
|
||||
```
|
||||
|
||||
## Train
|
||||
|
||||
You're almost ready to setup your model and start training!
|
||||
|
||||
Initialize a base model from [`~transformers.AutoModelForCausalLM`], and pass it and `peft_config` to the [`get_peft_model`] function to create a [`PeftModel`]. You can print the new [`PeftModel`]'s trainable parameters to see how much more efficient it is than training the full parameters of the original model!
|
||||
|
||||
```py
|
||||
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
|
||||
model = get_peft_model(model, peft_config)
|
||||
print(model.print_trainable_parameters())
|
||||
"trainable params: 8192 || all params: 559222784 || trainable%: 0.0014648902430985358"
|
||||
```
|
||||
|
||||
Setup an optimizer and learning rate scheduler:
|
||||
|
||||
```py
|
||||
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
|
||||
lr_scheduler = get_linear_schedule_with_warmup(
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=0,
|
||||
num_training_steps=(len(train_dataloader) * num_epochs),
|
||||
)
|
||||
```
|
||||
|
||||
Move the model to the GPU, then write a training loop to start training!
|
||||
|
||||
```py
|
||||
model = model.to(device)
|
||||
|
||||
for epoch in range(num_epochs):
|
||||
model.train()
|
||||
total_loss = 0
|
||||
for step, batch in enumerate(tqdm(train_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
total_loss += loss.detach().float()
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
model.eval()
|
||||
eval_loss = 0
|
||||
eval_preds = []
|
||||
for step, batch in enumerate(tqdm(eval_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
with torch.no_grad():
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
eval_loss += loss.detach().float()
|
||||
eval_preds.extend(
|
||||
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
|
||||
)
|
||||
|
||||
eval_epoch_loss = eval_loss / len(eval_dataloader)
|
||||
eval_ppl = torch.exp(eval_epoch_loss)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
|
||||
```
|
||||
|
||||
## Share model
|
||||
|
||||
You can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
Use the [`~transformers.PreTrainedModel.push_to_hub`] function to upload your model to a model repository on the Hub:
|
||||
|
||||
```py
|
||||
peft_model_id = "your-name/bloomz-560m_PROMPT_TUNING_CAUSAL_LM"
|
||||
model.push_to_hub("your-name/bloomz-560m_PROMPT_TUNING_CAUSAL_LM", use_auth_token=True)
|
||||
```
|
||||
|
||||
Once the model is uploaded, you'll see the model file size is only 33.5kB! 🤏
|
||||
|
||||
## Inference
|
||||
|
||||
Let's try the model on a sample input for inference. If you look at the repository you uploaded the model to, you'll see a `adapter_config.json` file. Load this file into [`PeftConfig`] to specify the `peft_type` and `task_type`. Then you can load the prompt tuned model weights, and the configuration into [`~PeftModel.from_pretrained`] to create the [`PeftModel`]:
|
||||
|
||||
```py
|
||||
from peft import PeftModel, PeftConfig
|
||||
|
||||
peft_model_id = "stevhliu/bloomz-560m_PROMPT_TUNING_CAUSAL_LM"
|
||||
|
||||
config = PeftConfig.from_pretrained(peft_model_id)
|
||||
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
|
||||
model = PeftModel.from_pretrained(model, peft_model_id)
|
||||
```
|
||||
|
||||
Grab a tweet and tokenize it:
|
||||
|
||||
```py
|
||||
inputs = tokenizer(
|
||||
f'{text_column} : {"@nationalgridus I have no water and the bill is current and paid. Can you do something about this?"} Label : ',
|
||||
return_tensors="pt",
|
||||
)
|
||||
```
|
||||
|
||||
Put the model on a GPU and *generate* the predicted label:
|
||||
|
||||
```py
|
||||
model.to(device)
|
||||
|
||||
with torch.no_grad():
|
||||
inputs = {k: v.to(device) for k, v in inputs.items()}
|
||||
outputs = model.generate(
|
||||
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"], max_new_tokens=10, eos_token_id=3
|
||||
)
|
||||
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
|
||||
[
|
||||
"Tweet text : @nationalgridus I have no water and the bill is current and paid. Can you do something about this? Label : complaint"
|
||||
]
|
||||
```
|
||||
@ -1,277 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# DreamBooth fine-tuning with LoRA
|
||||
|
||||
This guide demonstrates how to use LoRA, a low-rank approximation technique, to fine-tune DreamBooth with the
|
||||
`CompVis/stable-diffusion-v1-4` model.
|
||||
|
||||
Although LoRA was initially designed as a technique for reducing the number of trainable parameters in
|
||||
large-language models, the technique can also be applied to diffusion models. Performing a complete model fine-tuning
|
||||
of diffusion models is a time-consuming task, which is why lightweight techniques like DreamBooth or Textual Inversion
|
||||
gained popularity. With the introduction of LoRA, customizing and fine-tuning a model on a specific dataset has become
|
||||
even faster.
|
||||
|
||||
In this guide we'll be using a DreamBooth fine-tuning script that is available in
|
||||
[PEFT's GitHub repo](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth). Feel free to explore it and
|
||||
learn how things work.
|
||||
|
||||
## Set up your environment
|
||||
|
||||
Start by cloning the PEFT repository:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/peft
|
||||
```
|
||||
|
||||
Navigate to the directory containing the training scripts for fine-tuning Dreambooth with LoRA:
|
||||
|
||||
```bash
|
||||
cd peft/examples/lora_dreambooth
|
||||
```
|
||||
|
||||
Set up your environment: install PEFT, and all the required libraries. At the time of writing this guide we recommend
|
||||
installing PEFT from source.
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
pip install git+https://github.com/huggingface/peft
|
||||
```
|
||||
|
||||
## Fine-tuning DreamBooth
|
||||
|
||||
Prepare the images that you will use for fine-tuning the model. Set up a few environment variables:
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
|
||||
export INSTANCE_DIR="path-to-instance-images"
|
||||
export CLASS_DIR="path-to-class-images"
|
||||
export OUTPUT_DIR="path-to-save-model"
|
||||
```
|
||||
|
||||
Here:
|
||||
- `INSTANCE_DIR`: The directory containing the images that you intend to use for training your model.
|
||||
- `CLASS_DIR`: The directory containing class-specific images. In this example, we use prior preservation to avoid overfitting and language-drift. For prior preservation, you need other images of the same class as part of the training process. However, these images can be generated and the training script will save them to a local path you specify here.
|
||||
- `OUTPUT_DIR`: The destination folder for storing the trained model's weights.
|
||||
|
||||
To learn more about DreamBooth fine-tuning with prior-preserving loss, check out the [Diffusers documentation](https://huggingface.co/docs/diffusers/training/dreambooth#finetuning-with-priorpreserving-loss).
|
||||
|
||||
Launch the training script with `accelerate` and pass hyperparameters, as well as LoRa-specific arguments to it such as:
|
||||
|
||||
- `use_lora`: Enables LoRa in the training script.
|
||||
- `lora_r`: The dimension used by the LoRA update matrices.
|
||||
- `lora_alpha`: Scaling factor.
|
||||
- `lora_text_encoder_r`: LoRA rank for text encoder.
|
||||
- `lora_text_encoder_alpha`: LoRA alpha (scaling factor) for text encoder.
|
||||
|
||||
Here's what the full set of script arguments may look like:
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--class_data_dir=$CLASS_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--train_text_encoder \
|
||||
--with_prior_preservation --prior_loss_weight=1.0 \
|
||||
--num_dataloader_workers=1 \
|
||||
--instance_prompt="a photo of sks dog" \
|
||||
--class_prompt="a photo of dog" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--num_class_images=200 \
|
||||
--use_lora \
|
||||
--lora_r 16 \
|
||||
--lora_alpha 27 \
|
||||
--lora_text_encoder_r 16 \
|
||||
--lora_text_encoder_alpha 17 \
|
||||
--learning_rate=1e-4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--gradient_checkpointing \
|
||||
--max_train_steps=800
|
||||
```
|
||||
|
||||
If you are running this script on Windows, you may need to set the `--num_dataloader_workers` to 0.
|
||||
|
||||
## Inference with a single adapter
|
||||
|
||||
To run inference with the fine-tuned model, first specify the base model with which the fine-tuned LoRA weights will be combined:
|
||||
|
||||
```python
|
||||
import os
|
||||
import torch
|
||||
|
||||
from diffusers import StableDiffusionPipeline
|
||||
from peft import PeftModel, LoraConfig
|
||||
|
||||
MODEL_NAME = "CompVis/stable-diffusion-v1-4"
|
||||
```
|
||||
|
||||
Next, add a function that will create a Stable Diffusion pipeline for image generation. It will combine the weights of
|
||||
the base model with the fine-tuned LoRA weights using `LoraConfig`.
|
||||
|
||||
```python
|
||||
def get_lora_sd_pipeline(
|
||||
ckpt_dir, base_model_name_or_path=None, dtype=torch.float16, device="cuda", adapter_name="default"
|
||||
):
|
||||
unet_sub_dir = os.path.join(ckpt_dir, "unet")
|
||||
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
|
||||
if os.path.exists(text_encoder_sub_dir) and base_model_name_or_path is None:
|
||||
config = LoraConfig.from_pretrained(text_encoder_sub_dir)
|
||||
base_model_name_or_path = config.base_model_name_or_path
|
||||
|
||||
if base_model_name_or_path is None:
|
||||
raise ValueError("Please specify the base model name or path")
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(base_model_name_or_path, torch_dtype=dtype).to(device)
|
||||
pipe.unet = PeftModel.from_pretrained(pipe.unet, unet_sub_dir, adapter_name=adapter_name)
|
||||
|
||||
if os.path.exists(text_encoder_sub_dir):
|
||||
pipe.text_encoder = PeftModel.from_pretrained(
|
||||
pipe.text_encoder, text_encoder_sub_dir, adapter_name=adapter_name
|
||||
)
|
||||
|
||||
if dtype in (torch.float16, torch.bfloat16):
|
||||
pipe.unet.half()
|
||||
pipe.text_encoder.half()
|
||||
|
||||
pipe.to(device)
|
||||
return pipe
|
||||
```
|
||||
|
||||
Now you can use the function above to create a Stable Diffusion pipeline using the LoRA weights that you have created during the fine-tuning step.
|
||||
Note, if you're running inference on the same machine, the path you specify here will be the same as `OUTPUT_DIR`.
|
||||
|
||||
```python
|
||||
pipe = get_lora_sd_pipeline(Path("path-to-saved-model"), adapter_name="dog")
|
||||
```
|
||||
|
||||
Once you have the pipeline with your fine-tuned model, you can use it to generate images:
|
||||
|
||||
```python
|
||||
prompt = "sks dog playing fetch in the park"
|
||||
negative_prompt = "low quality, blurry, unfinished"
|
||||
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
|
||||
image.save("DESTINATION_PATH_FOR_THE_IMAGE")
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_dog_park.png" alt="Generated image of a dog in a park"/>
|
||||
</div>
|
||||
|
||||
|
||||
## Multi-adapter inference
|
||||
|
||||
With PEFT you can combine multiple adapters for inference. In the previous example you have fine-tuned Stable Diffusion on
|
||||
some dog images. The pipeline created based on these weights got a name - `adapter_name="dog"`. Now, suppose you also fine-tuned
|
||||
this base model on images of a crochet toy. Let's see how we can use both adapters.
|
||||
|
||||
First, you'll need to perform all the steps as in the single adapter inference example:
|
||||
|
||||
1. Specify the base model.
|
||||
2. Add a function that creates a Stable Diffusion pipeline for image generation uses LoRA weights.
|
||||
3. Create a `pipe` with `adapter_name="dog"` based on the model fine-tuned on dog images.
|
||||
|
||||
Next, you're going to need a few more helper functions.
|
||||
To load another adapter, create a `load_adapter()` function that leverages `load_adapter()` method of `PeftModel` (e.g. `pipe.unet.load_adapter(peft_model_path, adapter_name)`):
|
||||
|
||||
```python
|
||||
def load_adapter(pipe, ckpt_dir, adapter_name):
|
||||
unet_sub_dir = os.path.join(ckpt_dir, "unet")
|
||||
text_encoder_sub_dir = os.path.join(ckpt_dir, "text_encoder")
|
||||
pipe.unet.load_adapter(unet_sub_dir, adapter_name=adapter_name)
|
||||
if os.path.exists(text_encoder_sub_dir):
|
||||
pipe.text_encoder.load_adapter(text_encoder_sub_dir, adapter_name=adapter_name)
|
||||
```
|
||||
|
||||
To switch between adapters, write a function that uses `set_adapter()` method of `PeftModel` (see `pipe.unet.set_adapter(adapter_name)`)
|
||||
|
||||
```python
|
||||
def set_adapter(pipe, adapter_name):
|
||||
pipe.unet.set_adapter(adapter_name)
|
||||
if isinstance(pipe.text_encoder, PeftModel):
|
||||
pipe.text_encoder.set_adapter(adapter_name)
|
||||
```
|
||||
|
||||
Finally, add a function to create weighted LoRA adapter.
|
||||
|
||||
```python
|
||||
def create_weighted_lora_adapter(pipe, adapters, weights, adapter_name="default"):
|
||||
pipe.unet.add_weighted_adapter(adapters, weights, adapter_name)
|
||||
if isinstance(pipe.text_encoder, PeftModel):
|
||||
pipe.text_encoder.add_weighted_adapter(adapters, weights, adapter_name)
|
||||
|
||||
return pipe
|
||||
```
|
||||
|
||||
Let's load the second adapter from the model fine-tuned on images of a crochet toy, and give it a unique name:
|
||||
|
||||
```python
|
||||
load_adapter(pipe, Path("path-to-the-second-saved-model"), adapter_name="crochet")
|
||||
```
|
||||
|
||||
Create a pipeline using weighted adapters:
|
||||
|
||||
```python
|
||||
pipe = create_weighted_lora_adapter(pipe, ["crochet", "dog"], [1.0, 1.05], adapter_name="crochet_dog")
|
||||
```
|
||||
|
||||
Now you can switch between adapters. If you'd like to generate more dog images, set the adapter to `"dog"`:
|
||||
|
||||
```python
|
||||
set_adapter(pipe, adapter_name="dog")
|
||||
prompt = "sks dog in a supermarket isle"
|
||||
negative_prompt = "low quality, blurry, unfinished"
|
||||
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_dog_supermarket.png" alt="Generated image of a dog in a supermarket"/>
|
||||
</div>
|
||||
|
||||
In the same way, you can switch to the second adapter:
|
||||
|
||||
```python
|
||||
set_adapter(pipe, adapter_name="crochet")
|
||||
prompt = "a fish rendered in the style of <1>"
|
||||
negative_prompt = "low quality, blurry, unfinished"
|
||||
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_fish.png" alt="Generated image of a crochet fish"/>
|
||||
</div>
|
||||
|
||||
Finally, you can use combined weighted adapters:
|
||||
|
||||
```python
|
||||
set_adapter(pipe, adapter_name="crochet_dog")
|
||||
prompt = "sks dog rendered in the style of <1>, close up portrait, 4K HD"
|
||||
negative_prompt = "low quality, blurry, unfinished"
|
||||
image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_dreambooth_crochet_dog.png" alt="Generated image of a crochet dog"/>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
239
docs/source/task_guides/ia3.md
Normal file
239
docs/source/task_guides/ia3.md
Normal file
@ -0,0 +1,239 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# IA3
|
||||
|
||||
[IA3](../conceptual_guides/ia3) multiplies the model's activations (the keys and values in the self-attention and encoder-decoder attention blocks, and the intermediate activation of the position-wise feedforward network) by three learned vectors. This PEFT method introduces an even smaller number of trainable parameters than LoRA which introduces weight matrices instead of vectors. The original model's parameters are kept frozen and only these vectors are updated. As a result, it is faster, cheaper and more efficient to finetune for a new downstream task.
|
||||
|
||||
This guide will show you how to train a sequence-to-sequence model with IA3 to *generate a sentiment* given some financial news.
|
||||
|
||||
<Tip>
|
||||
|
||||
Some familiarity with the general process of training a sequence-to-sequence would be really helpful and allow you to focus on how to apply IA3. If you’re new, we recommend taking a look at the [Translation](https://huggingface.co/docs/transformers/tasks/translation) and [Summarization](https://huggingface.co/docs/transformers/tasks/summarization) guides first from the Transformers documentation. When you’re ready, come back and see how easy it is to drop PEFT in to your training!
|
||||
|
||||
</Tip>
|
||||
|
||||
## Dataset
|
||||
|
||||
You'll use the sentences_allagree subset of the [financial_phrasebank](https://huggingface.co/datasets/financial_phrasebank) dataset. This subset contains financial news with 100% annotator agreement on the sentiment label. Take a look at the [dataset viewer](https://huggingface.co/datasets/financial_phrasebank/viewer/sentences_allagree) for a better idea of the data and sentences you'll be working with.
|
||||
|
||||
Load the dataset with the [`~datasets.load_dataset`] function. This subset of the dataset only contains a train split, so use the [`~datasets.train_test_split`] function to create a train and validation split. Create a new `text_label` column so it is easier to understand what the `label` values `0`, `1`, and `2` mean.
|
||||
|
||||
```py
|
||||
from datasets import load_dataset
|
||||
|
||||
ds = load_dataset("financial_phrasebank", "sentences_allagree")
|
||||
ds = ds["train"].train_test_split(test_size=0.1)
|
||||
ds["validation"] = ds["test"]
|
||||
del ds["test"]
|
||||
|
||||
classes = ds["train"].features["label"].names
|
||||
ds = ds.map(
|
||||
lambda x: {"text_label": [classes[label] for label in x["label"]]},
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
)
|
||||
|
||||
ds["train"][0]
|
||||
{'sentence': 'It will be operated by Nokia , and supported by its Nokia NetAct network and service management system .',
|
||||
'label': 1,
|
||||
'text_label': 'neutral'}
|
||||
```
|
||||
|
||||
Load a tokenizer and create a preprocessing function that:
|
||||
|
||||
1. tokenizes the inputs, pads and truncates the sequence to the `max_length`
|
||||
2. apply the same tokenizer to the labels but with a shorter `max_length` that corresponds to the label
|
||||
3. mask the padding tokens
|
||||
|
||||
```py
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
text_column = "sentence"
|
||||
label_column = "text_label"
|
||||
max_length = 128
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("bigscience/mt0-large")
|
||||
|
||||
def preprocess_function(examples):
|
||||
inputs = examples[text_column]
|
||||
targets = examples[label_column]
|
||||
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
|
||||
labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")
|
||||
labels = labels["input_ids"]
|
||||
labels[labels == tokenizer.pad_token_id] = -100
|
||||
model_inputs["labels"] = labels
|
||||
return model_inputs
|
||||
```
|
||||
|
||||
Use the [`~datasets.Dataset.map`] function to apply the preprocessing function to the entire dataset.
|
||||
|
||||
```py
|
||||
processed_ds = ds.map(
|
||||
preprocess_function,
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
remove_columns=ds["train"].column_names,
|
||||
load_from_cache_file=False,
|
||||
desc="Running tokenizer on dataset",
|
||||
)
|
||||
```
|
||||
|
||||
Create a training and evaluation [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader), and set `pin_memory=True` to speed up data transfer to the GPU during training if your dataset samples are on a CPU.
|
||||
|
||||
```py
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import default_data_collator
|
||||
|
||||
train_ds = processed_ds["train"]
|
||||
eval_ds = processed_ds["validation"]
|
||||
|
||||
batch_size = 8
|
||||
|
||||
train_dataloader = DataLoader(
|
||||
train_ds, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
|
||||
)
|
||||
eval_dataloader = DataLoader(eval_ds, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
|
||||
```
|
||||
|
||||
## Model
|
||||
|
||||
Now you can load a pretrained model to use as the base model for IA3. This guide uses the [bigscience/mt0-large](https://huggingface.co/bigscience/mt0-large) model, but you can use any sequence-to-sequence model you like.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForSeq2SeqLM
|
||||
|
||||
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/mt0-large")
|
||||
```
|
||||
|
||||
### PEFT configuration and model
|
||||
|
||||
All PEFT methods need a configuration that contains and specifies all the parameters for how the PEFT method should be applied. Create an [`IA3Config`] with the task type and set the inference mode to `False`. You can find additional parameters for this configuration in the [API reference](../package_reference/ia3#ia3config).
|
||||
|
||||
<Tip>
|
||||
|
||||
Call the [`~PeftModel.print_trainable_parameters`] method to compare the number of trainable parameters of [`PeftModel`] versus the number of parameters in the base model!
|
||||
|
||||
</Tip>
|
||||
|
||||
Once the configuration is setup, pass it to the [`get_peft_model`] function along with the base model to create a trainable [`PeftModel`].
|
||||
|
||||
```py
|
||||
from peft import IA3Config, get_peft_model
|
||||
|
||||
peft_config = IA3Config(task_type="SEQ_2_SEQ_LM")
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 282,624 || all params: 1,229,863,936 || trainable%: 0.022980103060766553"
|
||||
```
|
||||
|
||||
### Training
|
||||
|
||||
Set up an optimizer and learning rate scheduler.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import get_linear_schedule_with_warmup
|
||||
|
||||
lr = 8e-3
|
||||
num_epochs = 3
|
||||
|
||||
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
|
||||
lr_scheduler = get_linear_schedule_with_warmup(
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=0,
|
||||
num_training_steps=(len(train_dataloader) * num_epochs),
|
||||
)
|
||||
```
|
||||
|
||||
Move the model to the GPU and create a training loop that reports the loss and perplexity for each epoch.
|
||||
|
||||
```py
|
||||
from tqdm import tqdm
|
||||
|
||||
device = "cuda"
|
||||
model = model.to(device)
|
||||
|
||||
for epoch in range(num_epochs):
|
||||
model.train()
|
||||
total_loss = 0
|
||||
for step, batch in enumerate(tqdm(train_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
total_loss += loss.detach().float()
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
model.eval()
|
||||
eval_loss = 0
|
||||
eval_preds = []
|
||||
for step, batch in enumerate(tqdm(eval_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
with torch.no_grad():
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
eval_loss += loss.detach().float()
|
||||
eval_preds.extend(
|
||||
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
|
||||
)
|
||||
|
||||
eval_epoch_loss = eval_loss / len(eval_dataloader)
|
||||
eval_ppl = torch.exp(eval_epoch_loss)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
|
||||
```
|
||||
|
||||
## Share your model
|
||||
|
||||
After training is complete, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method. You'll need to login to your Hugging Face account first and enter your token when prompted.
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
account = <your-hf-account-name>
|
||||
peft_model_id = f"{account}/mt0-large-ia3"
|
||||
model.push_to_hub(peft_model_id)
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
To load the model for inference, use the [`~AutoPeftModelForSeq2SeqLM.from_pretrained`] method. Let's also load a sentence of financial news from the dataset to generate a sentiment for.
|
||||
|
||||
```py
|
||||
from peft import AutoPeftModelForSeq2SeqLM
|
||||
|
||||
model = AutoPeftModelForSeq2SeqLM.from_pretrained("<your-hf-account-name>/mt0-large-ia3").to("cuda")
|
||||
tokenizer = AutoTokenizer.from_pretrained("bigscience/mt0-large")
|
||||
|
||||
i = 15
|
||||
inputs = tokenizer(ds["validation"][text_column][i], return_tensors="pt")
|
||||
print(ds["validation"][text_column][i])
|
||||
"The robust growth was the result of the inclusion of clothing chain Lindex in the Group in December 2007 ."
|
||||
```
|
||||
|
||||
Call the [`~transformers.GenerationMixin.generate`] method to generate the predicted sentiment label.
|
||||
|
||||
```py
|
||||
with torch.no_grad():
|
||||
inputs = {k: v.to(device) for k, v in inputs.items()}
|
||||
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
|
||||
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
|
||||
['positive']
|
||||
```
|
||||
@ -1,433 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Image classification using LoRA
|
||||
|
||||
This guide demonstrates how to use LoRA, a low-rank approximation technique, to fine-tune an image classification model.
|
||||
By using LoRA from 🤗 PEFT, we can reduce the number of trainable parameters in the model to only 0.77% of the original.
|
||||
|
||||
LoRA achieves this reduction by adding low-rank "update matrices" to specific blocks of the model, such as the attention
|
||||
blocks. During fine-tuning, only these matrices are trained, while the original model parameters are left unchanged.
|
||||
At inference time, the update matrices are merged with the original model parameters to produce the final classification result.
|
||||
|
||||
For more information on LoRA, please refer to the [original LoRA paper](https://arxiv.org/abs/2106.09685).
|
||||
|
||||
## Install dependencies
|
||||
|
||||
Install the libraries required for model training:
|
||||
|
||||
```bash
|
||||
!pip install transformers accelerate evaluate datasets peft -q
|
||||
```
|
||||
|
||||
Check the versions of all required libraries to make sure you are up to date:
|
||||
|
||||
```python
|
||||
import transformers
|
||||
import accelerate
|
||||
import peft
|
||||
|
||||
print(f"Transformers version: {transformers.__version__}")
|
||||
print(f"Accelerate version: {accelerate.__version__}")
|
||||
print(f"PEFT version: {peft.__version__}")
|
||||
"Transformers version: 4.27.4"
|
||||
"Accelerate version: 0.18.0"
|
||||
"PEFT version: 0.2.0"
|
||||
```
|
||||
|
||||
## Authenticate to share your model
|
||||
|
||||
To share the fine-tuned model at the end of the training with the community, authenticate using your 🤗 token.
|
||||
You can obtain your token from your [account settings](https://huggingface.co/settings/token).
|
||||
|
||||
```python
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
## Select a model checkpoint to fine-tune
|
||||
|
||||
Choose a model checkpoint from any of the model architectures supported for [image classification](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads). When in doubt, refer to
|
||||
the [image classification task guide](https://huggingface.co/docs/transformers/v4.27.2/en/tasks/image_classification) in
|
||||
🤗 Transformers documentation.
|
||||
|
||||
```python
|
||||
model_checkpoint = "google/vit-base-patch16-224-in21k"
|
||||
```
|
||||
|
||||
## Load a dataset
|
||||
|
||||
To keep this example's runtime short, let's only load the first 5000 instances from the training set of the [Food-101 dataset](https://huggingface.co/datasets/food101):
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
dataset = load_dataset("food101", split="train[:5000]")
|
||||
```
|
||||
|
||||
## Dataset preparation
|
||||
|
||||
To prepare the dataset for training and evaluation, create `label2id` and `id2label` dictionaries. These will come in
|
||||
handy when performing inference and for metadata information:
|
||||
|
||||
```python
|
||||
labels = dataset.features["label"].names
|
||||
label2id, id2label = dict(), dict()
|
||||
for i, label in enumerate(labels):
|
||||
label2id[label] = i
|
||||
id2label[i] = label
|
||||
|
||||
id2label[2]
|
||||
"baklava"
|
||||
```
|
||||
|
||||
Next, load the image processor of the model you're fine-tuning:
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor
|
||||
|
||||
image_processor = AutoImageProcessor.from_pretrained(model_checkpoint)
|
||||
```
|
||||
|
||||
The `image_processor` contains useful information on which size the training and evaluation images should be resized
|
||||
to, as well as values that should be used to normalize the pixel values. Using the `image_processor`, prepare transformation
|
||||
functions for the datasets. These functions will include data augmentation and pixel scaling:
|
||||
|
||||
```python
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
Normalize,
|
||||
RandomHorizontalFlip,
|
||||
RandomResizedCrop,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
|
||||
normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
|
||||
train_transforms = Compose(
|
||||
[
|
||||
RandomResizedCrop(image_processor.size["height"]),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
normalize,
|
||||
]
|
||||
)
|
||||
|
||||
val_transforms = Compose(
|
||||
[
|
||||
Resize(image_processor.size["height"]),
|
||||
CenterCrop(image_processor.size["height"]),
|
||||
ToTensor(),
|
||||
normalize,
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def preprocess_train(example_batch):
|
||||
"""Apply train_transforms across a batch."""
|
||||
example_batch["pixel_values"] = [train_transforms(image.convert("RGB")) for image in example_batch["image"]]
|
||||
return example_batch
|
||||
|
||||
|
||||
def preprocess_val(example_batch):
|
||||
"""Apply val_transforms across a batch."""
|
||||
example_batch["pixel_values"] = [val_transforms(image.convert("RGB")) for image in example_batch["image"]]
|
||||
return example_batch
|
||||
```
|
||||
|
||||
Split the dataset into training and validation sets:
|
||||
|
||||
```python
|
||||
splits = dataset.train_test_split(test_size=0.1)
|
||||
train_ds = splits["train"]
|
||||
val_ds = splits["test"]
|
||||
```
|
||||
|
||||
Finally, set the transformation functions for the datasets accordingly:
|
||||
|
||||
```python
|
||||
train_ds.set_transform(preprocess_train)
|
||||
val_ds.set_transform(preprocess_val)
|
||||
```
|
||||
|
||||
## Load and prepare a model
|
||||
|
||||
Before loading the model, let's define a helper function to check the total number of parameters a model has, as well
|
||||
as how many of them are trainable.
|
||||
|
||||
```python
|
||||
def print_trainable_parameters(model):
|
||||
trainable_params = 0
|
||||
all_param = 0
|
||||
for _, param in model.named_parameters():
|
||||
all_param += param.numel()
|
||||
if param.requires_grad:
|
||||
trainable_params += param.numel()
|
||||
print(
|
||||
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
|
||||
)
|
||||
```
|
||||
|
||||
It's important to initialize the original model correctly as it will be used as a base to create the `PeftModel` you'll
|
||||
actually fine-tune. Specify the `label2id` and `id2label` so that [`~transformers.AutoModelForImageClassification`] can append a classification
|
||||
head to the underlying model, adapted for this dataset. You should see the following output:
|
||||
|
||||
```
|
||||
Some weights of ViTForImageClassification were not initialized from the model checkpoint at google/vit-base-patch16-224-in21k and are newly initialized: ['classifier.weight', 'classifier.bias']
|
||||
```
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
|
||||
|
||||
model = AutoModelForImageClassification.from_pretrained(
|
||||
model_checkpoint,
|
||||
label2id=label2id,
|
||||
id2label=id2label,
|
||||
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
|
||||
)
|
||||
```
|
||||
|
||||
Before creating a `PeftModel`, you can check the number of trainable parameters in the original model:
|
||||
|
||||
```python
|
||||
print_trainable_parameters(model)
|
||||
"trainable params: 85876325 || all params: 85876325 || trainable%: 100.00"
|
||||
```
|
||||
|
||||
Next, use `get_peft_model` to wrap the base model so that "update" matrices are added to the respective places.
|
||||
|
||||
```python
|
||||
from peft import LoraConfig, get_peft_model
|
||||
|
||||
config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=16,
|
||||
target_modules=["query", "value"],
|
||||
lora_dropout=0.1,
|
||||
bias="none",
|
||||
modules_to_save=["classifier"],
|
||||
)
|
||||
lora_model = get_peft_model(model, config)
|
||||
print_trainable_parameters(lora_model)
|
||||
"trainable params: 667493 || all params: 86466149 || trainable%: 0.77"
|
||||
```
|
||||
|
||||
Let's unpack what's going on here.
|
||||
To use LoRA, you need to specify the target modules in `LoraConfig` so that `get_peft_model()` knows which modules
|
||||
inside our model need to be amended with LoRA matrices. In this example, we're only interested in targeting the query and
|
||||
value matrices of the attention blocks of the base model. Since the parameters corresponding to these matrices are "named"
|
||||
"query" and "value" respectively, we specify them accordingly in the `target_modules` argument of `LoraConfig`.
|
||||
|
||||
We also specify `modules_to_save`. After wrapping the base model with `get_peft_model()` along with the `config`, we get
|
||||
a new model where only the LoRA parameters are trainable (so-called "update matrices") while the pre-trained parameters
|
||||
are kept frozen. However, we want the classifier parameters to be trained too when fine-tuning the base model on our
|
||||
custom dataset. To ensure that the classifier parameters are also trained, we specify `modules_to_save`. This also
|
||||
ensures that these modules are serialized alongside the LoRA trainable parameters when using utilities like `save_pretrained()`
|
||||
and `push_to_hub()`.
|
||||
|
||||
Here's what the other parameters mean:
|
||||
|
||||
- `r`: The dimension used by the LoRA update matrices.
|
||||
- `alpha`: Scaling factor.
|
||||
- `bias`: Specifies if the `bias` parameters should be trained. `None` denotes none of the `bias` parameters will be trained.
|
||||
|
||||
`r` and `alpha` together control the total number of final trainable parameters when using LoRA, giving you the flexibility
|
||||
to balance a trade-off between end performance and compute efficiency.
|
||||
|
||||
By looking at the number of trainable parameters, you can see how many parameters we're actually training. Since the goal is
|
||||
to achieve parameter-efficient fine-tuning, you should expect to see fewer trainable parameters in the `lora_model`
|
||||
in comparison to the original model, which is indeed the case here.
|
||||
|
||||
## Define training arguments
|
||||
|
||||
For model fine-tuning, use [`~transformers.Trainer`]. It accepts
|
||||
several arguments which you can wrap using [`~transformers.TrainingArguments`].
|
||||
|
||||
```python
|
||||
from transformers import TrainingArguments, Trainer
|
||||
|
||||
|
||||
model_name = model_checkpoint.split("/")[-1]
|
||||
batch_size = 128
|
||||
|
||||
args = TrainingArguments(
|
||||
f"{model_name}-finetuned-lora-food101",
|
||||
remove_unused_columns=False,
|
||||
evaluation_strategy="epoch",
|
||||
save_strategy="epoch",
|
||||
learning_rate=5e-3,
|
||||
per_device_train_batch_size=batch_size,
|
||||
gradient_accumulation_steps=4,
|
||||
per_device_eval_batch_size=batch_size,
|
||||
fp16=True,
|
||||
num_train_epochs=5,
|
||||
logging_steps=10,
|
||||
load_best_model_at_end=True,
|
||||
metric_for_best_model="accuracy",
|
||||
push_to_hub=True,
|
||||
label_names=["labels"],
|
||||
)
|
||||
```
|
||||
|
||||
Compared to non-PEFT methods, you can use a larger batch size since there are fewer parameters to train.
|
||||
You can also set a larger learning rate than the normal (1e-5 for example).
|
||||
|
||||
This can potentially also reduce the need to conduct expensive hyperparameter tuning experiments.
|
||||
|
||||
## Prepare evaluation metric
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import evaluate
|
||||
|
||||
metric = evaluate.load("accuracy")
|
||||
|
||||
|
||||
def compute_metrics(eval_pred):
|
||||
"""Computes accuracy on a batch of predictions"""
|
||||
predictions = np.argmax(eval_pred.predictions, axis=1)
|
||||
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
|
||||
```
|
||||
|
||||
The `compute_metrics` function takes a named tuple as input: `predictions`, which are the logits of the model as Numpy arrays,
|
||||
and `label_ids`, which are the ground-truth labels as Numpy arrays.
|
||||
|
||||
## Define collation function
|
||||
|
||||
A collation function is used by [`~transformers.Trainer`] to gather a batch of training and evaluation examples and prepare them in a
|
||||
format that is acceptable by the underlying model.
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
|
||||
def collate_fn(examples):
|
||||
pixel_values = torch.stack([example["pixel_values"] for example in examples])
|
||||
labels = torch.tensor([example["label"] for example in examples])
|
||||
return {"pixel_values": pixel_values, "labels": labels}
|
||||
```
|
||||
|
||||
## Train and evaluate
|
||||
|
||||
Bring everything together - model, training arguments, data, collation function, etc. Then, start the training!
|
||||
|
||||
```python
|
||||
trainer = Trainer(
|
||||
lora_model,
|
||||
args,
|
||||
train_dataset=train_ds,
|
||||
eval_dataset=val_ds,
|
||||
tokenizer=image_processor,
|
||||
compute_metrics=compute_metrics,
|
||||
data_collator=collate_fn,
|
||||
)
|
||||
train_results = trainer.train()
|
||||
```
|
||||
|
||||
In just a few minutes, the fine-tuned model shows 96% validation accuracy even on this small
|
||||
subset of the training dataset.
|
||||
|
||||
```python
|
||||
trainer.evaluate(val_ds)
|
||||
{
|
||||
"eval_loss": 0.14475855231285095,
|
||||
"eval_accuracy": 0.96,
|
||||
"eval_runtime": 3.5725,
|
||||
"eval_samples_per_second": 139.958,
|
||||
"eval_steps_per_second": 1.12,
|
||||
"epoch": 5.0,
|
||||
}
|
||||
```
|
||||
|
||||
## Share your model and run inference
|
||||
|
||||
Once the fine-tuning is done, share the LoRA parameters with the community like so:
|
||||
|
||||
```python
|
||||
repo_name = f"sayakpaul/{model_name}-finetuned-lora-food101"
|
||||
lora_model.push_to_hub(repo_name)
|
||||
```
|
||||
|
||||
When calling [`~transformers.PreTrainedModel.push_to_hub`] on the `lora_model`, only the LoRA parameters along with any modules specified in `modules_to_save`
|
||||
are saved. Take a look at the [trained LoRA parameters](https://huggingface.co/sayakpaul/vit-base-patch16-224-in21k-finetuned-lora-food101/blob/main/adapter_model.bin).
|
||||
You'll see that it's only 2.6 MB! This greatly helps with portability, especially when using a very large model to fine-tune (such as [BLOOM](https://huggingface.co/bigscience/bloom)).
|
||||
|
||||
Next, let's see how to load the LoRA updated parameters along with our base model for inference. When you wrap a base model
|
||||
with `PeftModel`, modifications are done *in-place*. To mitigate any concerns that might stem from in-place modifications,
|
||||
initialize the base model just like you did earlier and construct the inference model.
|
||||
|
||||
```python
|
||||
from peft import PeftConfig, PeftModel
|
||||
|
||||
|
||||
config = PeftConfig.from_pretrained(repo_name)
|
||||
model = AutoModelForImageClassification.from_pretrained(
|
||||
config.base_model_name_or_path,
|
||||
label2id=label2id,
|
||||
id2label=id2label,
|
||||
ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
|
||||
)
|
||||
# Load the LoRA model
|
||||
inference_model = PeftModel.from_pretrained(model, repo_name)
|
||||
```
|
||||
|
||||
Let's now fetch an example image for inference.
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
import requests
|
||||
|
||||
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg" alt="image of beignets"/>
|
||||
</div>
|
||||
|
||||
First, instantiate an `image_processor` from the underlying model repo.
|
||||
|
||||
```python
|
||||
image_processor = AutoImageProcessor.from_pretrained(repo_name)
|
||||
```
|
||||
|
||||
Then, prepare the example for inference.
|
||||
|
||||
```python
|
||||
encoding = image_processor(image.convert("RGB"), return_tensors="pt")
|
||||
```
|
||||
|
||||
Finally, run inference!
|
||||
|
||||
```python
|
||||
with torch.no_grad():
|
||||
outputs = inference_model(**encoding)
|
||||
logits = outputs.logits
|
||||
|
||||
predicted_class_idx = logits.argmax(-1).item()
|
||||
print("Predicted class:", inference_model.config.id2label[predicted_class_idx])
|
||||
"Predicted class: beignets"
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,382 +0,0 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# int8 training for automatic speech recognition
|
||||
|
||||
Quantization reduces the precision of floating point data types, decreasing the memory required to store model weights. However, quantization degrades inference performance because you lose information when you reduce the precision. 8-bit or `int8` quantization uses only a quarter precision, but it does not degrade performance because it doesn't just drop the bits or data. Instead, `int8` quantization *rounds* from one data type to another.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Read the [LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://arxiv.org/abs/2208.07339) paper to learn more, or you can take a look at the corresponding [blog post](https://huggingface.co/blog/hf-bitsandbytes-integration) for a gentler introduction.
|
||||
|
||||
</Tip>
|
||||
|
||||
This guide will show you how to train a [`openai/whisper-large-v2`](https://huggingface.co/openai/whisper-large-v2) model for multilingual automatic speech recognition (ASR) using a combination of `int8` quantization and LoRA. You'll train Whisper for multilingual ASR on Marathi from the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) dataset.
|
||||
|
||||
Before you start, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
!pip install -q peft transformers datasets accelerate evaluate jiwer bitsandbytes
|
||||
```
|
||||
|
||||
## Setup
|
||||
|
||||
Let's take care of some of the setup first so you can start training faster later. Set the `CUDA_VISIBLE_DEVICES` to `0` to use the first GPU on your machine. Then you can specify the model name (either a Hub model repository id or a path to a directory containing the model), language and language abbreviation to train on, the task type, and the dataset name:
|
||||
|
||||
```py
|
||||
import os
|
||||
|
||||
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
|
||||
model_name_or_path = "openai/whisper-large-v2"
|
||||
language = "Marathi"
|
||||
language_abbr = "mr"
|
||||
task = "transcribe"
|
||||
dataset_name = "mozilla-foundation/common_voice_11_0"
|
||||
```
|
||||
|
||||
You can also log in to your Hugging Face account to save and share your trained model on the Hub if you'd like:
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
## Load dataset and metric
|
||||
|
||||
The [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) dataset contains many hours of recorded speech in many different languages. This guide uses the [Marathi](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/mr/train) language as an example, but feel free to use any other language you're interested in.
|
||||
|
||||
Initialize a [`~datasets.DatasetDict`] structure, and load the [`train`] (load both the `train+validation` split into `train`) and [`test`] splits from the dataset into it:
|
||||
|
||||
```py
|
||||
from datasets import load_dataset
|
||||
from datasets import load_dataset, DatasetDict
|
||||
|
||||
common_voice = DatasetDict()
|
||||
|
||||
common_voice["train"] = load_dataset(dataset_name, language_abbr, split="train+validation", use_auth_token=True)
|
||||
common_voice["test"] = load_dataset(dataset_name, language_abbr, split="test", use_auth_token=True)
|
||||
common_voice["train"][0]
|
||||
```
|
||||
|
||||
## Preprocess dataset
|
||||
|
||||
Let's prepare the dataset for training. Load a feature extractor, tokenizer, and processor. You should also pass the language and task to the tokenizer and processor so they know how to process the inputs:
|
||||
|
||||
```py
|
||||
from transformers import AutoFeatureExtractor, AutoTokenizer, AutoProcessor
|
||||
|
||||
feature_extractor = AutoFeatureExtractor.from_pretrained(model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, language=language, task=task)
|
||||
processor = AutoProcessor.from_pretrained(model_name_or_path, language=language, task=task)
|
||||
```
|
||||
|
||||
You'll only be training on the `sentence` and `audio` columns, so you can remove the rest of the metadata with [`~datasets.Dataset.remove_columns`]:
|
||||
|
||||
```py
|
||||
common_voice = common_voice.remove_columns(
|
||||
["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"]
|
||||
)
|
||||
common_voice["train"][0]
|
||||
{
|
||||
"audio": {
|
||||
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f7e1ef6a2d14f20194999aad5040c5d4bb3ead1377de3e1bbc6e9dba34d18a8a/common_voice_mr_30585613.mp3",
|
||||
"array": array(
|
||||
[1.13686838e-13, -1.42108547e-13, -1.98951966e-13, ..., 4.83472422e-06, 3.54798703e-06, 1.63231743e-06]
|
||||
),
|
||||
"sampling_rate": 48000,
|
||||
},
|
||||
"sentence": "आईचे आजारपण वाढत चालले, तसतशी मथीही नीट खातपीतनाशी झाली.",
|
||||
}
|
||||
```
|
||||
|
||||
If you look at the `sampling_rate`, you'll see the audio was sampled at 48kHz. The Whisper model was pretrained on audio inputs at 16kHZ which means you'll need to downsample the audio inputs to match what the model was pretrained on. Downsample the audio by using the [`~datasets.Dataset.cast_column`] method on the `audio` column, and set the `sampling_rate` to 16kHz. The audio input is resampled on the fly the next time you call it:
|
||||
|
||||
```py
|
||||
from datasets import Audio
|
||||
|
||||
common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
|
||||
common_voice["train"][0]
|
||||
{
|
||||
"audio": {
|
||||
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f7e1ef6a2d14f20194999aad5040c5d4bb3ead1377de3e1bbc6e9dba34d18a8a/common_voice_mr_30585613.mp3",
|
||||
"array": array(
|
||||
[-3.06954462e-12, -3.63797881e-12, -4.54747351e-12, ..., -7.74800901e-06, -1.74738125e-06, 4.36312439e-06]
|
||||
),
|
||||
"sampling_rate": 16000,
|
||||
},
|
||||
"sentence": "आईचे आजारपण वाढत चालले, तसतशी मथीही नीट खातपीतनाशी झाली.",
|
||||
}
|
||||
```
|
||||
|
||||
Once you've cleaned up the dataset, you can write a function to generate the correct model inputs. The function should:
|
||||
|
||||
1. Resample the audio inputs to 16kHZ by loading the `audio` column.
|
||||
2. Compute the input features from the audio `array` using the feature extractor.
|
||||
3. Tokenize the `sentence` column to the input labels.
|
||||
|
||||
```py
|
||||
def prepare_dataset(batch):
|
||||
audio = batch["audio"]
|
||||
batch["input_features"] = feature_extractor(audio["array"], sampling_rate=audio["sampling_rate"]).input_features[0]
|
||||
batch["labels"] = tokenizer(batch["sentence"]).input_ids
|
||||
return batch
|
||||
```
|
||||
|
||||
Apply the `prepare_dataset` function to the dataset with the [`~datasets.Dataset.map`] function, and set the `num_proc` argument to `2` to enable multiprocessing (if `map` hangs, then set `num_proc=1`):
|
||||
|
||||
```py
|
||||
common_voice = common_voice.map(prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=2)
|
||||
```
|
||||
|
||||
Finally, create a `DataCollator` class to pad the labels in each batch to the maximum length, and replace padding with `-100` so they're ignored by the loss function. Then initialize an instance of the data collator:
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Dict, List, Union
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataCollatorSpeechSeq2SeqWithPadding:
|
||||
processor: Any
|
||||
|
||||
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
|
||||
input_features = [{"input_features": feature["input_features"]} for feature in features]
|
||||
batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
|
||||
|
||||
label_features = [{"input_ids": feature["labels"]} for feature in features]
|
||||
labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
|
||||
|
||||
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
|
||||
|
||||
if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
|
||||
labels = labels[:, 1:]
|
||||
|
||||
batch["labels"] = labels
|
||||
|
||||
return batch
|
||||
|
||||
|
||||
data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
|
||||
```
|
||||
|
||||
## Train
|
||||
|
||||
Now that the dataset is ready, you can turn your attention to the model. Start by loading the pretrained [`openai/whisper-large-v2`]() model from [`~transformers.AutoModelForSpeechSeq2Seq`], and make sure to set the [`~transformers.BitsAndBytesConfig.load_in_8bit`] argument to `True` to enable `int8` quantization. The `device_map=auto` argument automatically determines how to load and store the model weights:
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForSpeechSeq2Seq
|
||||
|
||||
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_name_or_path, load_in_8bit=True, device_map="auto")
|
||||
```
|
||||
|
||||
You should configure `forced_decoder_ids=None` because no tokens are used before sampling, and you won't need to suppress any tokens during generation either:
|
||||
|
||||
```py
|
||||
model.config.forced_decoder_ids = None
|
||||
model.config.suppress_tokens = []
|
||||
```
|
||||
|
||||
To get the model ready for `int8` quantization, use the utility function [`prepare_model_for_int8_training`](https://github.com/huggingface/peft/blob/34027fe813756897767b9a6f19ae7f1c4c7b418c/src/peft/utils/other.py#L35) to handle the following:
|
||||
|
||||
- casts all the non `int8` modules to full precision (`fp32`) for stability
|
||||
- adds a forward hook to the input embedding layer to calculate the gradients of the input hidden states
|
||||
- enables gradient checkpointing for more memory-efficient training
|
||||
|
||||
```py
|
||||
from peft import prepare_model_for_int8_training
|
||||
|
||||
model = prepare_model_for_int8_training(model)
|
||||
```
|
||||
|
||||
Let's also apply LoRA to the training to make it even more efficient. Load a [`~peft.LoraConfig`] and configure the following parameters:
|
||||
|
||||
- `r`, the dimension of the low-rank matrices
|
||||
- `lora_alpha`, scaling factor for the weight matrices
|
||||
- `target_modules`, the name of the attention matrices to apply LoRA to (`q_proj` and `v_proj`, or query and value in this case)
|
||||
- `lora_dropout`, dropout probability of the LoRA layers
|
||||
- `bias`, set to `none`
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 The weight matrix is scaled by `lora_alpha/r`, and a higher `lora_alpha` value assigns more weight to the LoRA activations. For performance, we recommend setting bias to `None` first, and then `lora_only`, before trying `all`.
|
||||
|
||||
</Tip>
|
||||
|
||||
```py
|
||||
from peft import LoraConfig, PeftModel, LoraModel, LoraConfig, get_peft_model
|
||||
|
||||
config = LoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none")
|
||||
```
|
||||
|
||||
After you set up the [`~peft.LoraConfig`], wrap it and the base model with the [`get_peft_model`] function to create a [`PeftModel`]. Print out the number of trainable parameters to see how much more efficient LoRA is compared to fully training the model!
|
||||
|
||||
```py
|
||||
model = get_peft_model(model, config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 15728640 || all params: 1559033600 || trainable%: 1.0088711365810203"
|
||||
```
|
||||
|
||||
Now you're ready to define some training hyperparameters in the [`~transformers.Seq2SeqTrainingArguments`] class, such as where to save the model to, batch size, learning rate, and number of epochs to train for. The [`PeftModel`] doesn't have the same signature as the base model, so you'll need to explicitly set `remove_unused_columns=False` and `label_names=["labels"]`.
|
||||
|
||||
```py
|
||||
from transformers import Seq2SeqTrainingArguments
|
||||
|
||||
training_args = Seq2SeqTrainingArguments(
|
||||
output_dir="your-name/int8-whisper-large-v2-asr",
|
||||
per_device_train_batch_size=8,
|
||||
gradient_accumulation_steps=1,
|
||||
learning_rate=1e-3,
|
||||
warmup_steps=50,
|
||||
num_train_epochs=3,
|
||||
evaluation_strategy="epoch",
|
||||
fp16=True,
|
||||
per_device_eval_batch_size=8,
|
||||
generation_max_length=128,
|
||||
logging_steps=25,
|
||||
remove_unused_columns=False,
|
||||
label_names=["labels"],
|
||||
)
|
||||
```
|
||||
|
||||
It is also a good idea to write a custom [`~transformers.TrainerCallback`] to save model checkpoints during training:
|
||||
|
||||
```py
|
||||
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
|
||||
|
||||
|
||||
class SavePeftModelCallback(TrainerCallback):
|
||||
def on_save(
|
||||
self,
|
||||
args: TrainingArguments,
|
||||
state: TrainerState,
|
||||
control: TrainerControl,
|
||||
**kwargs,
|
||||
):
|
||||
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
|
||||
|
||||
peft_model_path = os.path.join(checkpoint_folder, "adapter_model")
|
||||
kwargs["model"].save_pretrained(peft_model_path)
|
||||
|
||||
pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
|
||||
if os.path.exists(pytorch_model_path):
|
||||
os.remove(pytorch_model_path)
|
||||
return control
|
||||
```
|
||||
|
||||
Pass the `Seq2SeqTrainingArguments`, model, datasets, data collator, tokenizer, and callback to the [`~transformers.Seq2SeqTrainer`]. You can optionally set `model.config.use_cache = False` to silence any warnings. Once everything is ready, call [`~transformers.Trainer.train`] to start training!
|
||||
|
||||
```py
|
||||
from transformers import Seq2SeqTrainer, TrainerCallback, Seq2SeqTrainingArguments, TrainerState, TrainerControl
|
||||
|
||||
trainer = Seq2SeqTrainer(
|
||||
args=training_args,
|
||||
model=model,
|
||||
train_dataset=common_voice["train"],
|
||||
eval_dataset=common_voice["test"],
|
||||
data_collator=data_collator,
|
||||
tokenizer=processor.feature_extractor,
|
||||
callbacks=[SavePeftModelCallback],
|
||||
)
|
||||
model.config.use_cache = False
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Evaluate
|
||||
|
||||
[Word error rate](https://huggingface.co/spaces/evaluate-metric/wer) (WER) is a common metric for evaluating ASR models. Load the WER metric from 🤗 Evaluate:
|
||||
|
||||
```py
|
||||
import evaluate
|
||||
|
||||
metric = evaluate.load("wer")
|
||||
```
|
||||
|
||||
Write a loop to evaluate the model performance. Set the model to evaluation mode first, and write the loop with [`torch.cuda.amp.autocast()`](https://pytorch.org/docs/stable/amp.html) because `int8` training requires autocasting. Then, pass a batch of examples to the model to evaluate. Get the decoded predictions and labels, and add them as a batch to the WER metric before calling `compute` to get the final WER score:
|
||||
|
||||
```py
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
import gc
|
||||
|
||||
eval_dataloader = DataLoader(common_voice["test"], batch_size=8, collate_fn=data_collator)
|
||||
|
||||
model.eval()
|
||||
for step, batch in enumerate(tqdm(eval_dataloader)):
|
||||
with torch.cuda.amp.autocast():
|
||||
with torch.no_grad():
|
||||
generated_tokens = (
|
||||
model.generate(
|
||||
input_features=batch["input_features"].to("cuda"),
|
||||
decoder_input_ids=batch["labels"][:, :4].to("cuda"),
|
||||
max_new_tokens=255,
|
||||
)
|
||||
.cpu()
|
||||
.numpy()
|
||||
)
|
||||
labels = batch["labels"].cpu().numpy()
|
||||
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
|
||||
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
|
||||
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
|
||||
metric.add_batch(
|
||||
predictions=decoded_preds,
|
||||
references=decoded_labels,
|
||||
)
|
||||
del generated_tokens, labels, batch
|
||||
gc.collect()
|
||||
wer = 100 * metric.compute()
|
||||
print(f"{wer=}")
|
||||
```
|
||||
|
||||
## Share model
|
||||
|
||||
Once you're happy with your results, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method:
|
||||
|
||||
```py
|
||||
model.push_to_hub("your-name/int8-whisper-large-v2-asr")
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
Let's test the model out now!
|
||||
|
||||
Instantiate the model configuration from [`PeftConfig`], and from here, you can use the configuration to load the base and [`PeftModel`], tokenizer, processor, and feature extractor. Remember to define the `language` and `task` in the tokenizer, processor, and `forced_decoder_ids`:
|
||||
|
||||
```py
|
||||
from peft import PeftModel, PeftConfig
|
||||
|
||||
peft_model_id = "smangrul/openai-whisper-large-v2-LORA-colab"
|
||||
language = "Marathi"
|
||||
task = "transcribe"
|
||||
peft_config = PeftConfig.from_pretrained(peft_model_id)
|
||||
model = WhisperForConditionalGeneration.from_pretrained(
|
||||
peft_config.base_model_name_or_path, load_in_8bit=True, device_map="auto"
|
||||
)
|
||||
model = PeftModel.from_pretrained(model, peft_model_id)
|
||||
tokenizer = WhisperTokenizer.from_pretrained(peft_config.base_model_name_or_path, language=language, task=task)
|
||||
processor = WhisperProcessor.from_pretrained(peft_config.base_model_name_or_path, language=language, task=task)
|
||||
feature_extractor = processor.feature_extractor
|
||||
forced_decoder_ids = processor.get_decoder_prompt_ids(language=language, task=task)
|
||||
```
|
||||
|
||||
Load an audio sample (you can listen to it in the [Dataset Preview](https://huggingface.co/datasets/stevhliu/dummy)) to transcribe, and the [`~transformers.AutomaticSpeechRecognitionPipeline`]:
|
||||
|
||||
```py
|
||||
from transformers import AutomaticSpeechRecognitionPipeline
|
||||
|
||||
audio = "https://huggingface.co/datasets/stevhliu/dummy/resolve/main/mrt_01523_00028548203.wav"
|
||||
pipeline = AutomaticSpeechRecognitionPipeline(model=model, tokenizer=tokenizer, feature_extractor=feature_extractor)
|
||||
```
|
||||
|
||||
Then use the pipeline with autocast as a context manager on the audio sample:
|
||||
|
||||
```py
|
||||
with torch.cuda.amp.autocast():
|
||||
text = pipe(audio, generate_kwargs={"forced_decoder_ids": forced_decoder_ids}, max_new_tokens=255)["text"]
|
||||
text
|
||||
"मी तुमच्यासाठी काही करू शकतो का?"
|
||||
```
|
||||
348
docs/source/task_guides/lora_based_methods.md
Normal file
348
docs/source/task_guides/lora_based_methods.md
Normal file
@ -0,0 +1,348 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# LoRA methods
|
||||
|
||||
A popular way to efficiently train large models is to insert (typically in the attention blocks) smaller trainable matrices that are a low-rank decomposition of the delta weight matrix to be learnt during finetuning. The pretrained model's original weight matrix is frozen and only the smaller matrices are updated during training. This reduces the number of trainable parameters, reducing memory usage and training time which can be very expensive for large models.
|
||||
|
||||
There are several different ways to express the weight matrix as a low-rank decomposition, but [Low-Rank Adaptation (LoRA)](../conceptual_guides/adapter#low-rank-adaptation-lora) is the most common method. The PEFT library supports several other LoRA variants, such as [Low-Rank Hadamard Product (LoHa)](../conceptual_guides/adapter#low-rank-hadamard-product-loha), [Low-Rank Kronecker Product (LoKr)](../conceptual_guides/adapter#low-rank-kronecker-product-lokr), and [Adaptive Low-Rank Adaptation (AdaLoRA)](../conceptual_guides/adapter#adaptive-low-rank-adaptation-adalora). You can learn more about how these methods work conceptually in the [Adapters](../conceptual_guides/adapter) guide. If you're interested in applying these methods to other tasks and use cases like semantic segmentation, token classification, take a look at our [notebook collection](https://huggingface.co/collections/PEFT/notebooks-6573b28b33e5a4bf5b157fc1)!
|
||||
|
||||
This guide will show you how to quickly train an image classification model - with a low-rank decomposition method - to identify the class of food shown in an image.
|
||||
|
||||
<Tip>
|
||||
|
||||
Some familiarity with the general process of training an image classification model would be really helpful and allow you to focus on the low-rank decomposition methods. If you're new, we recommend taking a look at the [Image classification](https://huggingface.co/docs/transformers/tasks/image_classification) guide first from the Transformers documentation. When you're ready, come back and see how easy it is to drop PEFT in to your training!
|
||||
|
||||
</Tip>
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed.
|
||||
|
||||
```bash
|
||||
pip install -q peft transformers datasets
|
||||
```
|
||||
|
||||
## Dataset
|
||||
|
||||
In this guide, you'll use the [Food-101](https://huggingface.co/datasets/food101) dataset which contains images of 101 food classes (take a look at the [dataset viewer](https://huggingface.co/datasets/food101/viewer/default/train) to get a better idea of what the dataset looks like).
|
||||
|
||||
Load the dataset with the [`~datasets.load_dataset`] function.
|
||||
|
||||
```py
|
||||
from datasets import load_dataset
|
||||
|
||||
ds = load_dataset("food101")
|
||||
```
|
||||
|
||||
Each food class is labeled with an integer, so to make it easier to understand what these integers represent, you'll create a `label2id` and `id2label` dictionary to map the integer to its class label.
|
||||
|
||||
```py
|
||||
labels = ds["train"].features["label"].names
|
||||
label2id, id2label = dict(), dict()
|
||||
for i, label in enumerate(labels):
|
||||
label2id[label] = i
|
||||
id2label[i] = label
|
||||
|
||||
id2label[2]
|
||||
"baklava"
|
||||
```
|
||||
|
||||
Load an image processor to properly resize and normalize the pixel values of the training and evaluation images.
|
||||
|
||||
```py
|
||||
from transformers import AutoImageProcessor
|
||||
|
||||
image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
|
||||
```
|
||||
|
||||
You can also use the image processor to prepare some transformation functions for data augmentation and pixel scaling.
|
||||
|
||||
```py
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
Normalize,
|
||||
RandomHorizontalFlip,
|
||||
RandomResizedCrop,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
|
||||
normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
|
||||
train_transforms = Compose(
|
||||
[
|
||||
RandomResizedCrop(image_processor.size["height"]),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
normalize,
|
||||
]
|
||||
)
|
||||
|
||||
val_transforms = Compose(
|
||||
[
|
||||
Resize(image_processor.size["height"]),
|
||||
CenterCrop(image_processor.size["height"]),
|
||||
ToTensor(),
|
||||
normalize,
|
||||
]
|
||||
)
|
||||
|
||||
def preprocess_train(example_batch):
|
||||
example_batch["pixel_values"] = [train_transforms(image.convert("RGB")) for image in example_batch["image"]]
|
||||
return example_batch
|
||||
|
||||
def preprocess_val(example_batch):
|
||||
example_batch["pixel_values"] = [val_transforms(image.convert("RGB")) for image in example_batch["image"]]
|
||||
return example_batch
|
||||
```
|
||||
|
||||
Define the training and validation datasets, and use the [`~datasets.Dataset.set_transform`] function to apply the transformations on-the-fly.
|
||||
|
||||
```py
|
||||
train_ds = ds["train"]
|
||||
val_ds = ds["validation"]
|
||||
|
||||
train_ds.set_transform(preprocess_train)
|
||||
val_ds.set_transform(preprocess_val)
|
||||
```
|
||||
|
||||
Finally, you'll need a data collator to create a batch of training and evaluation data and convert the labels to `torch.tensor` objects.
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
def collate_fn(examples):
|
||||
pixel_values = torch.stack([example["pixel_values"] for example in examples])
|
||||
labels = torch.tensor([example["label"] for example in examples])
|
||||
return {"pixel_values": pixel_values, "labels": labels}
|
||||
```
|
||||
|
||||
## Model
|
||||
|
||||
Now let's load a pretrained model to use as the base model. This guide uses the [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) model, but you can use any image classification model you want. Pass the `label2id` and `id2label` dictionaries to the model so it knows how to map the integer labels to their class labels, and you can optionally pass the `ignore_mismatched_sizes=True` parameter if you're finetuning a checkpoint that has already been finetuned.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
|
||||
|
||||
model = AutoModelForImageClassification.from_pretrained(
|
||||
"google/vit-base-patch16-224-in21k",
|
||||
label2id=label2id,
|
||||
id2label=id2label,
|
||||
ignore_mismatched_sizes=True,
|
||||
)
|
||||
```
|
||||
|
||||
### PEFT configuration and model
|
||||
|
||||
Every PEFT method requires a configuration that holds all the parameters specifying how the PEFT method should be applied. Once the configuration is setup, pass it to the [`~peft.get_peft_model`] function along with the base model to create a trainable [`PeftModel`].
|
||||
|
||||
<Tip>
|
||||
|
||||
Call the [`~PeftModel.print_trainable_parameters`] method to compare the number of parameters of [`PeftModel`] versus the number of parameters in the base model!
|
||||
|
||||
</Tip>
|
||||
|
||||
<hfoptions id="loras">
|
||||
<hfoption id="LoRA">
|
||||
|
||||
[LoRA](../conceptual_guides/adapter#low-rank-adaptation-lora) decomposes the weight update matrix into *two* smaller matrices. The size of these low-rank matrices is determined by its *rank* or `r`. A higher rank means the model has more parameters to train, but it also means the model has more learning capacity. You'll also want to specify the `target_modules` which determine where the smaller matrices are inserted. For this guide, you'll target the *query* and *value* matrices of the attention blocks. Other important parameters to set are `lora_alpha` (scaling factor), `bias` (whether `none`, `all` or only the LoRA bias parameters should be trained), and `modules_to_save` (the modules apart from the LoRA layers to be trained and saved). All of these parameters - and more - are found in the [`LoraConfig`].
|
||||
|
||||
```py
|
||||
from peft import LoraConfig, get_peft_model
|
||||
|
||||
config = LoraConfig(
|
||||
r=16,
|
||||
lora_alpha=16,
|
||||
target_modules=["query", "value"],
|
||||
lora_dropout=0.1,
|
||||
bias="none",
|
||||
modules_to_save=["classifier"],
|
||||
)
|
||||
model = get_peft_model(model, config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 667,493 || all params: 86,543,818 || trainable%: 0.7712775047664294"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="LoHa">
|
||||
|
||||
[LoHa](../conceptual_guides/adapter#low-rank-hadamard-product-loha) decomposes the weight update matrix into *four* smaller matrices and each pair of smaller matrices is combined with the Hadamard product. This allows the weight update matrix to keep the same number of trainable parameters when compared to LoRA, but with a higher rank (`r^2` for LoHA when compared to `2*r` for LoRA). The size of the smaller matrices is determined by its *rank* or `r`. You'll also want to specify the `target_modules` which determines where the smaller matrices are inserted. For this guide, you'll target the *query* and *value* matrices of the attention blocks. Other important parameters to set are `alpha` (scaling factor), and `modules_to_save` (the modules apart from the LoHa layers to be trained and saved). All of these parameters - and more - are found in the [`LoHaConfig`].
|
||||
|
||||
```py
|
||||
from peft import LoHaConfig, get_peft_model
|
||||
|
||||
config = LoHaConfig(
|
||||
r=16,
|
||||
alpha=16,
|
||||
target_modules=["query", "value"],
|
||||
module_dropout=0.1,
|
||||
modules_to_save=["classifier"],
|
||||
)
|
||||
model = get_peft_model(model, config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 1,257,317 || all params: 87,133,642 || trainable%: 1.4429753779831676"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="LoKr">
|
||||
|
||||
[LoKr](../conceptual_guides/adapter#low-rank-kronecker-product-lokr) expresses the weight update matrix as a decomposition of a Kronecker product, creating a block matrix that is able to preserve the rank of the original weight matrix. The size of the smaller matrices are determined by its *rank* or `r`. You'll also want to specify the `target_modules` which determines where the smaller matrices are inserted. For this guide, you'll target the *query* and *value* matrices of the attention blocks. Other important parameters to set are `alpha` (scaling factor), and `modules_to_save` (the modules apart from the LoKr layers to be trained and saved). All of these parameters - and more - are found in the [`LoKrConfig`].
|
||||
|
||||
```py
|
||||
from peft import LoKrConfig, get_peft_model
|
||||
|
||||
config = LoKrConfig(
|
||||
r=16,
|
||||
alpha=16,
|
||||
target_modules=["query", "value"],
|
||||
module_dropout=0.1,
|
||||
modules_to_save=["classifier"],
|
||||
)
|
||||
model = get_peft_model(model, config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 116,069 || all params: 87,172,042 || trainable%: 0.13314934162033282"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="AdaLoRA">
|
||||
|
||||
[AdaLoRA](../conceptual_guides/adapter#adaptive-low-rank-adaptation-adalora) efficiently manages the LoRA parameter budget by assigning important weight matrices more parameters and pruning less important ones. In contrast, LoRA evenly distributes parameters across all modules. You can control the average desired *rank* or `r` of the matrices, and which modules to apply AdaLoRA to with `target_modules`. Other important parameters to set are `lora_alpha` (scaling factor), and `modules_to_save` (the modules apart from the AdaLoRA layers to be trained and saved). All of these parameters - and more - are found in the [`AdaLoraConfig`].
|
||||
|
||||
```py
|
||||
from peft import AdaLoraConfig, get_peft_model
|
||||
|
||||
config = AdaLoraConfig(
|
||||
r=8,
|
||||
init_r=12,
|
||||
tinit=200,
|
||||
tfinal=1000,
|
||||
deltaT=10,
|
||||
target_modules=["query", "value"],
|
||||
modules_to_save=["classifier"],
|
||||
)
|
||||
model = get_peft_model(model, config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 520,325 || all params: 87,614,722 || trainable%: 0.5938785036606062"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
### Training
|
||||
|
||||
For training, let's use the [`~transformers.Trainer`] class from Transformers. The [`Trainer`] contains a PyTorch training loop, and when you're ready, call [`~transformers.Trainer.train`] to start training. To customize the training run, configure the training hyperparameters in the [`~transformers.TrainingArguments`] class. With LoRA-like methods, you can afford to use a higher batch size and learning rate.
|
||||
|
||||
> [!WARNING]
|
||||
> AdaLoRA has an [`~AdaLoraModel.update_and_allocate`] method that should be called at each training step to update the parameter budget and mask, otherwise the adaptation step is not performed. This requires writing a custom training loop or subclassing the [`~transformers.Trainer`] to incorporate this method. As an example, take a look at this [custom training loop](https://github.com/huggingface/peft/blob/912ad41e96e03652cabf47522cd876076f7a0c4f/examples/conditional_generation/peft_adalora_seq2seq.py#L120).
|
||||
|
||||
```py
|
||||
from transformers import TrainingArguments, Trainer
|
||||
|
||||
account = "stevhliu"
|
||||
peft_model_id = f"{account}/google/vit-base-patch16-224-in21k-lora"
|
||||
batch_size = 128
|
||||
|
||||
args = TrainingArguments(
|
||||
peft_model_id,
|
||||
remove_unused_columns=False,
|
||||
evaluation_strategy="epoch",
|
||||
save_strategy="epoch",
|
||||
learning_rate=5e-3,
|
||||
per_device_train_batch_size=batch_size,
|
||||
gradient_accumulation_steps=4,
|
||||
per_device_eval_batch_size=batch_size,
|
||||
fp16=True,
|
||||
num_train_epochs=5,
|
||||
logging_steps=10,
|
||||
load_best_model_at_end=True,
|
||||
label_names=["labels"],
|
||||
)
|
||||
```
|
||||
|
||||
Begin training with [`~transformers.Trainer.train`].
|
||||
|
||||
```py
|
||||
trainer = Trainer(
|
||||
model,
|
||||
args,
|
||||
train_dataset=train_ds,
|
||||
eval_dataset=val_ds,
|
||||
tokenizer=image_processor,
|
||||
data_collator=collate_fn,
|
||||
)
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Share your model
|
||||
|
||||
Once training is complete, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method. You’ll need to login to your Hugging Face account first and enter your token when prompted.
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
Call [`~transformers.PreTrainedModel.push_to_hub`] to save your model to your repositoy.
|
||||
|
||||
```py
|
||||
model.push_to_hub(peft_model_id)
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
Let's load the model from the Hub and test it out on a food image.
|
||||
|
||||
```py
|
||||
from peft import PeftConfig, PeftModel
|
||||
from transfomers import AutoImageProcessor
|
||||
from PIL import Image
|
||||
import requests
|
||||
|
||||
config = PeftConfig.from_pretrained("stevhliu/vit-base-patch16-224-in21k-lora")
|
||||
model = AutoModelForImageClassification.from_pretrained(
|
||||
config.base_model_name_or_path,
|
||||
label2id=label2id,
|
||||
id2label=id2label,
|
||||
ignore_mismatched_sizes=True,
|
||||
)
|
||||
model = PeftModel.from_pretrained(model, "stevhliu/vit-base-patch16-224-in21k-lora")
|
||||
|
||||
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/beignets.jpeg">
|
||||
</div>
|
||||
|
||||
Convert the image to RGB and return the underlying PyTorch tensors.
|
||||
|
||||
```py
|
||||
encoding = image_processor(image.convert("RGB"), return_tensors="pt")
|
||||
```
|
||||
|
||||
Now run the model and return the predicted class!
|
||||
|
||||
```py
|
||||
with torch.no_grad():
|
||||
outputs = model(**encoding)
|
||||
logits = outputs.logits
|
||||
|
||||
predicted_class_idx = logits.argmax(-1).item()
|
||||
print("Predicted class:", model.config.id2label[predicted_class_idx])
|
||||
"Predicted class: beignets"
|
||||
```
|
||||
305
docs/source/task_guides/prompt_based_methods.md
Normal file
305
docs/source/task_guides/prompt_based_methods.md
Normal file
@ -0,0 +1,305 @@
|
||||
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Prompt-based methods
|
||||
|
||||
A prompt can describe a task or provide an example of a task you want the model to learn. Instead of manually creating these prompts, soft prompting methods add learnable parameters to the input embeddings that can be optimized for a specific task while keeping the pretrained model's parameters frozen. This makes it both faster and easier to finetune large language models (LLMs) for new downstream tasks.
|
||||
|
||||
The PEFT library supports several types of prompting methods (p-tuning, prefix tuning, prompt tuning) and you can learn more about how these methods work conceptually in the [Soft prompts](../conceptual_guides/prompting) guide. If you're interested in applying these methods to other tasks and use cases, take a look at our [notebook collection](https://huggingface.co/spaces/PEFT/soft-prompting)!
|
||||
|
||||
This guide will show you how to train a causal language model - with a soft prompting method - to *generate a classification* for whether a tweet is a complaint or not.
|
||||
|
||||
<Tip>
|
||||
|
||||
Some familiarity with the general process of training a causal language model would be really helpful and allow you to focus on the soft prompting methods. If you're new, we recommend taking a look at the [Causal language modeling](https://huggingface.co/docs/transformers/tasks/language_modeling) guide first from the Transformers documentation. When you're ready, come back and see how easy it is to drop PEFT in to your training!
|
||||
|
||||
</Tip>
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed.
|
||||
|
||||
```bash
|
||||
pip install -q peft transformers datasets
|
||||
```
|
||||
|
||||
## Dataset
|
||||
|
||||
For this guide, you'll use the `twitter_complaints` subset of the [RAFT](https://huggingface.co/datasets/ought/raft) dataset. The `twitter_complaints` subset contains tweets labeled as `complaint` and `no complaint` and you can check out the [dataset viewer](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints) for a better idea of what the data looks like.
|
||||
|
||||
Use the [`~datasets.load_dataset`] function to load the dataset and create a new `text_label` column so it is easier to understand what the `Label` values, `1` and `2` mean.
|
||||
|
||||
```py
|
||||
from datasets import load_dataset
|
||||
|
||||
ds = load_dataset("ought/raft", "twitter_complaints")
|
||||
|
||||
classes = [k.replace("_", " ") for k in ds["train"].features["Label"].names]
|
||||
ds = ds.map(
|
||||
lambda x: {"text_label": [classes[label] for label in x["Label"]]},
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
)
|
||||
ds["train"][0]
|
||||
{"Tweet text": "@HMRCcustomers No this is my first job", "ID": 0, "Label": 2, "text_label": "no complaint"}
|
||||
```
|
||||
|
||||
Load a tokenizer, define the padding token to use, and determine the maximum length of the tokenized label.
|
||||
|
||||
```py
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloomz-560m")
|
||||
if tokenizer.pad_token_id is None:
|
||||
tokenizer.pad_token_id = tokenizer.eos_token_id
|
||||
target_max_length = max([len(tokenizer(class_label)["input_ids"]) for class_label in classes])
|
||||
print(target_max_length)
|
||||
```
|
||||
|
||||
Create a preprocessing function that tokenizes the tweet text and labels, pad the inputs and labels in each batch, create an attention mask, and truncate sequences to the `max_length`. Then convert the `input_ids`, `attention_mask`, and `labels` to PyTorch tensors.
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
max_length = 64
|
||||
|
||||
def preprocess_function(examples, text_column="Tweet text", label_column="text_label"):
|
||||
batch_size = len(examples[text_column])
|
||||
inputs = [f"{text_column} : {x} Label : " for x in examples[text_column]]
|
||||
targets = [str(x) for x in examples[label_column]]
|
||||
model_inputs = tokenizer(inputs)
|
||||
labels = tokenizer(targets)
|
||||
classes = [k.replace("_", " ") for k in ds["train"].features["Label"].names]
|
||||
for i in range(batch_size):
|
||||
sample_input_ids = model_inputs["input_ids"][i]
|
||||
label_input_ids = labels["input_ids"][i]
|
||||
model_inputs["input_ids"][i] = [tokenizer.pad_token_id] * (
|
||||
max_length - len(sample_input_ids)
|
||||
) + sample_input_ids
|
||||
model_inputs["attention_mask"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[
|
||||
"attention_mask"
|
||||
][i]
|
||||
labels["input_ids"][i] = [-100] * (max_length - len(label_input_ids)) + label_input_ids
|
||||
model_inputs["input_ids"][i] = torch.tensor(model_inputs["input_ids"][i][:max_length])
|
||||
model_inputs["attention_mask"][i] = torch.tensor(model_inputs["attention_mask"][i][:max_length])
|
||||
labels["input_ids"][i] = torch.tensor(labels["input_ids"][i][:max_length])
|
||||
model_inputs["labels"] = labels["input_ids"]
|
||||
return model_inputs
|
||||
```
|
||||
|
||||
Apply the preprocessing function to the entire dataset with the [`~datasets.Dataset.map`] function, and remove the unprocessed columns because the model won't need them.
|
||||
|
||||
```py
|
||||
processed_ds = ds.map(
|
||||
preprocess_function,
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
remove_columns=ds["train"].column_names,
|
||||
load_from_cache_file=False,
|
||||
desc="Running tokenizer on dataset",
|
||||
)
|
||||
```
|
||||
|
||||
Finally, create a training and evaluation [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader). You can set `pin_memory=True` to speed up the data transfer to the GPU during training if the samples in your dataset are on a CPU.
|
||||
|
||||
```py
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import default_data_collator
|
||||
|
||||
train_ds = processed_ds["train"]
|
||||
eval_ds = processed_ds["test"]
|
||||
|
||||
batch_size = 16
|
||||
|
||||
train_dataloader = DataLoader(train_ds, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
|
||||
eval_dataloader = DataLoader(eval_ds, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
|
||||
```
|
||||
|
||||
## Model
|
||||
|
||||
Now let's load a pretrained model to use as the base model for the soft prompt method. This guide uses the [bigscience/bloomz-560m](https://huggingface.co/bigscience/bloomz-560m) model, but you can use any causal language model you want.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("bigscience/bloomz-560m")
|
||||
```
|
||||
|
||||
### PEFT configuration and model
|
||||
|
||||
For any PEFT method, you'll need to create a configuration which contains all the parameters that specify how the PEFT method should be applied. Once the configuration is setup, pass it to the [`~peft.get_peft_model`] function along with the base model to create a trainable [`PeftModel`].
|
||||
|
||||
<Tip>
|
||||
|
||||
Call the [`~PeftModel.print_trainable_parameters`] method to compare the number of trainable parameters of [`PeftModel`] versus the number of parameters in the base model!
|
||||
|
||||
</Tip>
|
||||
|
||||
<hfoptions id="configurations">
|
||||
<hfoption id="p-tuning">
|
||||
|
||||
[P-tuning](../conceptual_guides/prompting#p-tuning) adds a trainable embedding tensor where the prompt tokens can be added anywhere in the input sequence. Create a [`PromptEncoderConfig`] with the task type, the number of virtual tokens to add and learn, and the hidden size of the encoder for learning the prompt parameters.
|
||||
|
||||
```py
|
||||
from peft import PromptEncoderConfig, get_peft_model
|
||||
|
||||
peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 300,288 || all params: 559,514,880 || trainable%: 0.05366935013417338"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="prefix tuning">
|
||||
|
||||
[Prefix tuning](../conceptual_guides/prompting#prefix-tuning) adds task-specific parameters in all of the model layers, which are optimized by a separate feed-forward network. Create a [`PrefixTuningConfig`] with the task type and number of virtual tokens to add and learn.
|
||||
|
||||
```py
|
||||
from peft import PrefixTuningConfig, get_peft_model
|
||||
|
||||
peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 983,040 || all params: 560,197,632 || trainable%: 0.1754809274167014"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="prompt tuning">
|
||||
|
||||
[Prompt tuning](../conceptual_guides/prompting#prompt-tuning) formulates all tasks as a *generation* task and it adds a task-specific prompt to the input which is updated independently. The `prompt_tuning_init_text` parameter specifies how to finetune the model (in this case, it is classifying whether tweets are complaints or not). For the best results, the `prompt_tuning_init_text` should have the same number of tokens that should be predicted. To do this, you can set `num_virtual_tokens` to the number of tokens of the `prompt_tuning_init_text`.
|
||||
|
||||
Create a [`PromptTuningConfig`] with the task type, the initial prompt tuning text to train the model with, the number of virtual tokens to add and learn, and a tokenizer.
|
||||
|
||||
```py
|
||||
from peft import PromptTuningConfig, PromptTuningInit, get_peft_model
|
||||
|
||||
prompt_tuning_init_text = "Classify if the tweet is a complaint or no complaint.\n"
|
||||
peft_config = PromptTuningConfig(
|
||||
task_type="CAUSAL_LM",
|
||||
prompt_tuning_init=PromptTuningInit.TEXT,
|
||||
num_virtual_tokens=len(tokenizer(prompt_tuning_init_text)["input_ids"]),
|
||||
prompt_tuning_init_text=prompt_tuning_init_text,
|
||||
tokenizer_name_or_path="bigscience/bloomz-560m",
|
||||
)
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 8,192 || all params: 559,222,784 || trainable%: 0.0014648902430985358"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
### Training
|
||||
|
||||
Set up an optimizer and learning rate scheduler.
|
||||
|
||||
```py
|
||||
from transformers import get_linear_schedule_with_warmup
|
||||
|
||||
lr = 3e-2
|
||||
num_epochs = 50
|
||||
|
||||
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
|
||||
lr_scheduler = get_linear_schedule_with_warmup(
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=0,
|
||||
num_training_steps=(len(train_dataloader) * num_epochs),
|
||||
)
|
||||
```
|
||||
|
||||
Move the model to the GPU and create a training loop that reports the loss and perplexity for each epoch.
|
||||
|
||||
```py
|
||||
from tqdm import tqdm
|
||||
|
||||
device = "cuda"
|
||||
model = model.to(device)
|
||||
|
||||
for epoch in range(num_epochs):
|
||||
model.train()
|
||||
total_loss = 0
|
||||
for step, batch in enumerate(tqdm(train_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
total_loss += loss.detach().float()
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
model.eval()
|
||||
eval_loss = 0
|
||||
eval_preds = []
|
||||
for step, batch in enumerate(tqdm(eval_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
with torch.no_grad():
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
eval_loss += loss.detach().float()
|
||||
eval_preds.extend(
|
||||
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
|
||||
)
|
||||
|
||||
eval_epoch_loss = eval_loss / len(eval_dataloader)
|
||||
eval_ppl = torch.exp(eval_epoch_loss)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
|
||||
```
|
||||
|
||||
## Share your model
|
||||
|
||||
Once training is complete, you can upload your model to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method. You'll need to login to your Hugging Face account first and enter your token when prompted.
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
account = <your-hf-account-name>
|
||||
peft_model_id = f"{account}/bloomz-560-m-peft-method"
|
||||
model.push_to_hub(peft_model_id)
|
||||
```
|
||||
|
||||
If you check the model file size in the repository, you’ll see that it is a lot smaller than a full sized model!
|
||||
|
||||
<div class="flex flex-col justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
|
||||
<figcaption class="text-center">For example, the adapter weights for a opt-350m model stored on the Hub are only ~6MB compared to the full model size which can be ~700MB.</figcaption>
|
||||
</div>
|
||||
|
||||
## Inference
|
||||
|
||||
Let's load the model for inference and test it out on a tweet!
|
||||
|
||||
```py
|
||||
from peft import AutoPeftModelForCausalLM
|
||||
|
||||
model = AutoPeftModelForCausalLM.from_pretrained("peft_model_id").to("cuda")
|
||||
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloomz-560m")
|
||||
|
||||
i = 15
|
||||
inputs = tokenizer(f'{text_column} : {ds["test"][i]["Tweet text"]} Label : ', return_tensors="pt")
|
||||
print(ds["test"][i]["Tweet text"])
|
||||
"@NYTsupport i have complained a dozen times & yet my papers are still thrown FAR from my door. Why is this so hard to resolve?"
|
||||
```
|
||||
|
||||
Call the [`~transformers.GenerationMixin.generate`] method to generate the predicted classification label.
|
||||
|
||||
```py
|
||||
with torch.no_grad():
|
||||
inputs = {k: v.to(device) for k, v in inputs.items()}
|
||||
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
|
||||
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
|
||||
"['Tweet text : @NYTsupport i have complained a dozen times & yet my papers are still thrown FAR from my door. Why is this so hard to resolve? Label : complaint']"
|
||||
```
|
||||
@ -1,236 +0,0 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# P-tuning for sequence classification
|
||||
|
||||
It is challenging to finetune large language models for downstream tasks because they have so many parameters. To work around this, you can use *prompts* to steer the model toward a particular downstream task without fully finetuning a model. Typically, these prompts are handcrafted, which may be impractical because you need very large validation sets to find the best prompts. *P-tuning* is a method for automatically searching and optimizing for better prompts in a continuous space.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Read [GPT Understands, Too](https://arxiv.org/abs/2103.10385) to learn more about p-tuning.
|
||||
|
||||
</Tip>
|
||||
|
||||
This guide will show you how to train a [`roberta-large`](https://huggingface.co/roberta-large) model (but you can also use any of the GPT, OPT, or BLOOM models) with p-tuning on the `mrpc` configuration of the [GLUE](https://huggingface.co/datasets/glue) benchmark.
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
!pip install -q peft transformers datasets evaluate
|
||||
```
|
||||
|
||||
## Setup
|
||||
|
||||
To get started, import 🤗 Transformers to create the base model, 🤗 Datasets to load a dataset, 🤗 Evaluate to load an evaluation metric, and 🤗 PEFT to create a [`PeftModel`] and setup the configuration for p-tuning.
|
||||
|
||||
Define the model, dataset, and some basic training hyperparameters:
|
||||
|
||||
```py
|
||||
from transformers import (
|
||||
AutoModelForSequenceClassification,
|
||||
AutoTokenizer,
|
||||
DataCollatorWithPadding,
|
||||
TrainingArguments,
|
||||
Trainer,
|
||||
)
|
||||
from peft import (
|
||||
get_peft_config,
|
||||
get_peft_model,
|
||||
get_peft_model_state_dict,
|
||||
set_peft_model_state_dict,
|
||||
PeftType,
|
||||
PromptEncoderConfig,
|
||||
)
|
||||
from datasets import load_dataset
|
||||
import evaluate
|
||||
import torch
|
||||
|
||||
model_name_or_path = "roberta-large"
|
||||
task = "mrpc"
|
||||
num_epochs = 20
|
||||
lr = 1e-3
|
||||
batch_size = 32
|
||||
```
|
||||
|
||||
## Load dataset and metric
|
||||
|
||||
Next, load the `mrpc` configuration - a corpus of sentence pairs labeled according to whether they're semantically equivalent or not - from the [GLUE](https://huggingface.co/datasets/glue) benchmark:
|
||||
|
||||
```py
|
||||
dataset = load_dataset("glue", task)
|
||||
dataset["train"][0]
|
||||
{
|
||||
"sentence1": 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
|
||||
"sentence2": 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
|
||||
"label": 1,
|
||||
"idx": 0,
|
||||
}
|
||||
```
|
||||
|
||||
From 🤗 Evaluate, load a metric for evaluating the model's performance. The evaluation module returns the accuracy and F1 scores associated with this specific task.
|
||||
|
||||
```py
|
||||
metric = evaluate.load("glue", task)
|
||||
```
|
||||
|
||||
Now you can use the `metric` to write a function that computes the accuracy and F1 scores. The `compute_metric` function calculates the scores from the model predictions and labels:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
|
||||
def compute_metrics(eval_pred):
|
||||
predictions, labels = eval_pred
|
||||
predictions = np.argmax(predictions, axis=1)
|
||||
return metric.compute(predictions=predictions, references=labels)
|
||||
```
|
||||
|
||||
## Preprocess dataset
|
||||
|
||||
Initialize the tokenizer and configure the padding token to use. If you're using a GPT, OPT, or BLOOM model, you should set the `padding_side` to the left; otherwise it'll be set to the right. Tokenize the sentence pairs and truncate them to the maximum length.
|
||||
|
||||
```py
|
||||
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
|
||||
padding_side = "left"
|
||||
else:
|
||||
padding_side = "right"
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
|
||||
if getattr(tokenizer, "pad_token_id") is None:
|
||||
tokenizer.pad_token_id = tokenizer.eos_token_id
|
||||
|
||||
|
||||
def tokenize_function(examples):
|
||||
# max_length=None => use the model max length (it's actually the default)
|
||||
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
|
||||
return outputs
|
||||
```
|
||||
|
||||
Use [`~datasets.Dataset.map`] to apply the `tokenize_function` to the dataset, and remove the unprocessed columns because the model won't need those. You should also rename the `label` column to `labels` because that is the expected name for the labels by models in the 🤗 Transformers library.
|
||||
|
||||
```py
|
||||
tokenized_datasets = dataset.map(
|
||||
tokenize_function,
|
||||
batched=True,
|
||||
remove_columns=["idx", "sentence1", "sentence2"],
|
||||
)
|
||||
|
||||
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
|
||||
```
|
||||
|
||||
Create a collator function with [`~transformers.DataCollatorWithPadding`] to pad the examples in the batches to the `longest` sequence in the batch:
|
||||
|
||||
```py
|
||||
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, padding="longest")
|
||||
```
|
||||
|
||||
## Train
|
||||
|
||||
P-tuning uses a prompt encoder to optimize the prompt parameters, so you'll need to initialize the [`PromptEncoderConfig`] with several arguments:
|
||||
|
||||
- `task_type`: the type of task you're training on, in this case it is sequence classification or `SEQ_CLS`
|
||||
- `num_virtual_tokens`: the number of virtual tokens to use, or in other words, the prompt
|
||||
- `encoder_hidden_size`: the hidden size of the encoder used to optimize the prompt parameters
|
||||
|
||||
```py
|
||||
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=20, encoder_hidden_size=128)
|
||||
```
|
||||
|
||||
Create the base `roberta-large` model from [`~transformers.AutoModelForSequenceClassification`], and then wrap the base model and `peft_config` with [`get_peft_model`] to create a [`PeftModel`]. If you're curious to see how many parameters you're actually training compared to training on all the model parameters, you can print it out with [`~peft.PeftModel.print_trainable_parameters`]:
|
||||
|
||||
```py
|
||||
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 1351938 || all params: 355662082 || trainable%: 0.38011867680626127"
|
||||
```
|
||||
|
||||
From the 🤗 Transformers library, set up the [`~transformers.TrainingArguments`] class with where you want to save the model to, the training hyperparameters, how to evaluate the model, and when to save the checkpoints:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
output_dir="your-name/roberta-large-peft-p-tuning",
|
||||
learning_rate=1e-3,
|
||||
per_device_train_batch_size=32,
|
||||
per_device_eval_batch_size=32,
|
||||
num_train_epochs=2,
|
||||
weight_decay=0.01,
|
||||
evaluation_strategy="epoch",
|
||||
save_strategy="epoch",
|
||||
load_best_model_at_end=True,
|
||||
)
|
||||
```
|
||||
|
||||
Then pass the model, `TrainingArguments`, datasets, tokenizer, data collator, and evaluation function to the [`~transformers.Trainer`] class, which'll handle the entire training loop for you. Once you're ready, call [`~transformers.Trainer.train`] to start training!
|
||||
|
||||
```py
|
||||
trainer = Trainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=tokenized_datasets["train"],
|
||||
eval_dataset=tokenized_datasets["test"],
|
||||
tokenizer=tokenizer,
|
||||
data_collator=data_collator,
|
||||
compute_metrics=compute_metrics,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Share model
|
||||
|
||||
You can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
Upload the model to a specifc model repository on the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] function:
|
||||
|
||||
```py
|
||||
model.push_to_hub("your-name/roberta-large-peft-p-tuning", use_auth_token=True)
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
Once the model has been uploaded to the Hub, anyone can easily use it for inference. Load the configuration and model:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from peft import PeftModel, PeftConfig
|
||||
from transformers import AutoModelForSequenceClassification, AutoTokenizer
|
||||
|
||||
peft_model_id = "smangrul/roberta-large-peft-p-tuning"
|
||||
config = PeftConfig.from_pretrained(peft_model_id)
|
||||
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
|
||||
model = PeftModel.from_pretrained(inference_model, peft_model_id)
|
||||
```
|
||||
|
||||
Get some text and tokenize it:
|
||||
|
||||
```py
|
||||
classes = ["not equivalent", "equivalent"]
|
||||
|
||||
sentence1 = "Coast redwood trees are the tallest trees on the planet and can grow over 300 feet tall."
|
||||
sentence2 = "The coast redwood trees, which can attain a height of over 300 feet, are the tallest trees on earth."
|
||||
|
||||
inputs = tokenizer(sentence1, sentence2, truncation=True, padding="longest", return_tensors="pt")
|
||||
```
|
||||
|
||||
Pass the inputs to the model to classify the sentences:
|
||||
|
||||
```py
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs).logits
|
||||
print(outputs)
|
||||
|
||||
paraphrased_text = torch.softmax(outputs, dim=1).tolist()[0]
|
||||
for i in range(len(classes)):
|
||||
print(f"{classes[i]}: {int(round(paraphrased_text[i] * 100))}%")
|
||||
"not equivalent: 4%"
|
||||
"equivalent: 96%"
|
||||
```
|
||||
@ -1,297 +0,0 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# LoRA for semantic similarity tasks
|
||||
|
||||
Low-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the number of trainable parameters with low-rank representations. The weight matrix is broken down into low-rank matrices that are trained and updated. All the pretrained model parameters remain frozen. After training, the low-rank matrices are added back to the original weights. This makes it more efficient to store and train a LoRA model because there are significantly fewer parameters.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Read [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) to learn more about LoRA.
|
||||
|
||||
</Tip>
|
||||
|
||||
In this guide, we'll be using a LoRA [script](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth) to fine-tune a [`intfloat/e5-large-v2`](https://huggingface.co/intfloat/e5-large-v2) model on the [`smangrul/amazon_esci`](https://huggingface.co/datasets/smangrul/amazon_esci) dataset for semantic similarity tasks. Feel free to explore the script to learn how things work in greater detail!
|
||||
|
||||
## Setup
|
||||
|
||||
Start by installing 🤗 PEFT from [source](https://github.com/huggingface/peft), and then navigate to the directory containing the training scripts for fine-tuning DreamBooth with LoRA:
|
||||
|
||||
```bash
|
||||
cd peft/examples/feature_extraction
|
||||
```
|
||||
|
||||
Install all the necessary required libraries with:
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
Next, import all the necessary libraries:
|
||||
|
||||
- 🤗 Transformers for loading the `intfloat/e5-large-v2` model and tokenizer
|
||||
- 🤗 Accelerate for the training loop
|
||||
- 🤗 Datasets for loading and preparing the `smangrul/amazon_esci` dataset for training and inference
|
||||
- 🤗 Evaluate for evaluating the model's performance
|
||||
- 🤗 PEFT for setting up the LoRA configuration and creating the PEFT model
|
||||
- 🤗 huggingface_hub for uploading the trained model to HF hub
|
||||
- hnswlib for creating the search index and doing fast approximate nearest neighbor search
|
||||
|
||||
<Tip>
|
||||
|
||||
It is assumed that PyTorch with CUDA support is already installed.
|
||||
|
||||
</Tip>
|
||||
|
||||
## Train
|
||||
|
||||
Launch the training script with `accelerate launch` and pass your hyperparameters along with the `--use_peft` argument to enable LoRA.
|
||||
|
||||
This guide uses the following [`LoraConfig`]:
|
||||
|
||||
```py
|
||||
peft_config = LoraConfig(
|
||||
r=8,
|
||||
lora_alpha=16,
|
||||
bias="none",
|
||||
task_type=TaskType.FEATURE_EXTRACTION,
|
||||
target_modules=["key", "query", "value"],
|
||||
)
|
||||
```
|
||||
|
||||
Here's what a full set of script arguments may look like when running in Colab on a V100 GPU with standard RAM:
|
||||
|
||||
```bash
|
||||
accelerate launch \
|
||||
--mixed_precision="fp16" \
|
||||
peft_lora_embedding_semantic_search.py \
|
||||
--dataset_name="smangrul/amazon_esci" \
|
||||
--max_length=70 --model_name_or_path="intfloat/e5-large-v2" \
|
||||
--per_device_train_batch_size=64 \
|
||||
--per_device_eval_batch_size=128 \
|
||||
--learning_rate=5e-4 \
|
||||
--weight_decay=0.0 \
|
||||
--num_train_epochs 3 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--output_dir="results/peft_lora_e5_ecommerce_semantic_search_colab" \
|
||||
--seed=42 \
|
||||
--push_to_hub \
|
||||
--hub_model_id="smangrul/peft_lora_e5_ecommerce_semantic_search_colab" \
|
||||
--with_tracking \
|
||||
--report_to="wandb" \
|
||||
--use_peft \
|
||||
--checkpointing_steps "epoch"
|
||||
```
|
||||
|
||||
## Dataset for semantic similarity
|
||||
|
||||
The dataset we'll be using is a small subset of the [esci-data](https://github.com/amazon-science/esci-data.git) dataset (it can be found on Hub at [smangrul/amazon_esci](https://huggingface.co/datasets/smangrul/amazon_esci)).
|
||||
Each sample contains a tuple of `(query, product_title, relevance_label)` where `relevance_label` is `1` if the product matches the intent of the `query`, otherwise it is `0`.
|
||||
|
||||
Our task is to build an embedding model that can retrieve semantically similar products given a product query.
|
||||
This is usually the first stage in building a product search engine to retrieve all the potentially relevant products of a given query.
|
||||
Typically, this involves using Bi-Encoder models to cross-join the query and millions of products which could blow up quickly.
|
||||
Instead, you can use a Transformer model to retrieve the top K nearest similar products for a given query by
|
||||
embedding the query and products in the same latent embedding space.
|
||||
The millions of products are embedded offline to create a search index.
|
||||
At run time, only the query is embedded by the model, and products are retrieved from the search index with a
|
||||
fast approximate nearest neighbor search library such as [FAISS](https://github.com/facebookresearch/faiss) or [HNSWlib](https://github.com/nmslib/hnswlib).
|
||||
|
||||
|
||||
The next stage involves reranking the retrieved list of products to return the most relevant ones;
|
||||
this stage can utilize cross-encoder based models as the cross-join between the query and a limited set of retrieved products.
|
||||
The diagram below from [awesome-semantic-search](https://github.com/rom1504/awesome-semantic-search) outlines a rough semantic search pipeline:
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/semantic_search_pipeline.png"
|
||||
alt="Semantic Search Pipeline"/>
|
||||
</div>
|
||||
|
||||
For this task guide, we will explore the first stage of training an embedding model to predict semantically similar products
|
||||
given a product query.
|
||||
|
||||
## Training script deep dive
|
||||
|
||||
We finetune [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) which tops the [MTEB benchmark](https://huggingface.co/spaces/mteb/leaderboard) using PEFT-LoRA.
|
||||
|
||||
[`AutoModelForSentenceEmbedding`] returns the query and product embeddings, and the `mean_pooling` function pools them across the sequence dimension and normalizes them:
|
||||
|
||||
```py
|
||||
class AutoModelForSentenceEmbedding(nn.Module):
|
||||
def __init__(self, model_name, tokenizer, normalize=True):
|
||||
super(AutoModelForSentenceEmbedding, self).__init__()
|
||||
|
||||
self.model = AutoModel.from_pretrained(model_name)
|
||||
self.normalize = normalize
|
||||
self.tokenizer = tokenizer
|
||||
|
||||
def forward(self, **kwargs):
|
||||
model_output = self.model(**kwargs)
|
||||
embeddings = self.mean_pooling(model_output, kwargs["attention_mask"])
|
||||
if self.normalize:
|
||||
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
|
||||
|
||||
return embeddings
|
||||
|
||||
def mean_pooling(self, model_output, attention_mask):
|
||||
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
|
||||
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
|
||||
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
|
||||
|
||||
def __getattr__(self, name: str):
|
||||
"""Forward missing attributes to the wrapped module."""
|
||||
try:
|
||||
return super().__getattr__(name) # defer to nn.Module's logic
|
||||
except AttributeError:
|
||||
return getattr(self.model, name)
|
||||
|
||||
|
||||
def get_cosine_embeddings(query_embs, product_embs):
|
||||
return torch.sum(query_embs * product_embs, axis=1)
|
||||
|
||||
|
||||
def get_loss(cosine_score, labels):
|
||||
return torch.mean(torch.square(labels * (1 - cosine_score) + torch.clamp((1 - labels) * cosine_score, min=0.0)))
|
||||
```
|
||||
|
||||
The `get_cosine_embeddings` function computes the cosine similarity and the `get_loss` function computes the loss. The loss enables the model to learn that a cosine score of `1` for query and product pairs is relevant, and a cosine score of `0` or below is irrelevant.
|
||||
|
||||
Define the [`PeftConfig`] with your LoRA hyperparameters, and create a [`PeftModel`]. We use 🤗 Accelerate for handling all device management, mixed precision training, gradient accumulation, WandB tracking, and saving/loading utilities.
|
||||
|
||||
## Results
|
||||
|
||||
The table below compares the training time, the batch size that could be fit in Colab, and the best ROC-AUC scores between a PEFT model and a fully fine-tuned model:
|
||||
|
||||
|
||||
| Training Type | Training time per epoch (Hrs) | Batch Size that fits | ROC-AUC score (higher is better) |
|
||||
| ----------------- | ------------- | ---------- | -------- |
|
||||
| Pre-Trained e5-large-v2 | - | - | 0.68 |
|
||||
| PEFT | 1.73 | 64 | 0.787 |
|
||||
| Full Fine-Tuning | 2.33 | 32 | 0.7969 |
|
||||
|
||||
The PEFT-LoRA model trains **1.35X** faster and can fit **2X** batch size compared to the fully fine-tuned model, and the performance of PEFT-LoRA is comparable to the fully fine-tuned model with a relative drop of **-1.24%** in ROC-AUC. This gap can probably be closed with bigger models as mentioned in [The Power of Scale for Parameter-Efficient Prompt Tuning
|
||||
](https://huggingface.co/papers/2104.08691).
|
||||
|
||||
## Inference
|
||||
|
||||
Let's go! Now we have the model, we need to create a search index of all the products in our catalog.
|
||||
Please refer to `peft_lora_embedding_semantic_similarity_inference.ipynb` for the complete inference code.
|
||||
|
||||
1. Get a list of ids to products which we can call `ids_to_products_dict`:
|
||||
|
||||
```bash
|
||||
{0: 'RamPro 10" All Purpose Utility Air Tires/Wheels with a 5/8" Diameter Hole with Double Sealed Bearings (Pack of 2)',
|
||||
1: 'MaxAuto 2-Pack 13x5.00-6 2PLY Turf Mower Tractor Tire with Yellow Rim, (3" Centered Hub, 3/4" Bushings )',
|
||||
2: 'NEIKO 20601A 14.5 inch Steel Tire Spoon Lever Iron Tool Kit | Professional Tire Changing Tool for Motorcycle, Dirt Bike, Lawn Mower | 3 pcs Tire Spoons | 3 Rim Protector | Valve Tool | 6 Valve Cores',
|
||||
3: '2PK 13x5.00-6 13x5.00x6 13x5x6 13x5-6 2PLY Turf Mower Tractor Tire with Gray Rim',
|
||||
4: '(Set of 2) 15x6.00-6 Husqvarna/Poulan Tire Wheel Assy .75" Bearing',
|
||||
5: 'MaxAuto 2 Pcs 16x6.50-8 Lawn Mower Tire for Garden Tractors Ridings, 4PR, Tubeless',
|
||||
6: 'Dr.Roc Tire Spoon Lever Dirt Bike Lawn Mower Motorcycle Tire Changing Tools with Durable Bag 3 Tire Irons 2 Rim Protectors 1 Valve Stems Set TR412 TR413',
|
||||
7: 'MARASTAR 21446-2PK 15x6.00-6" Front Tire Assembly Replacement-Craftsman Mower, Pack of 2',
|
||||
8: '15x6.00-6" Front Tire Assembly Replacement for 100 and 300 Series John Deere Riding Mowers - 2 pack',
|
||||
9: 'Honda HRR Wheel Kit (2 Front 44710-VL0-L02ZB, 2 Back 42710-VE2-M02ZE)',
|
||||
10: 'Honda 42710-VE2-M02ZE (Replaces 42710-VE2-M01ZE) Lawn Mower Rear Wheel Set of 2' ...
|
||||
```
|
||||
|
||||
2. Use the trained [smangrul/peft_lora_e5_ecommerce_semantic_search_colab](https://huggingface.co/smangrul/peft_lora_e5_ecommerce_semantic_search_colab) model to get the product embeddings:
|
||||
|
||||
```py
|
||||
# base model
|
||||
model = AutoModelForSentenceEmbedding(model_name_or_path, tokenizer)
|
||||
|
||||
# peft config and wrapping
|
||||
model = PeftModel.from_pretrained(model, peft_model_id)
|
||||
|
||||
device = "cuda"
|
||||
model.to(device)
|
||||
model.eval()
|
||||
model = model.merge_and_unload()
|
||||
|
||||
import numpy as np
|
||||
num_products= len(dataset)
|
||||
d = 1024
|
||||
|
||||
product_embeddings_array = np.zeros((num_products, d))
|
||||
for step, batch in enumerate(tqdm(dataloader)):
|
||||
with torch.no_grad():
|
||||
with torch.amp.autocast(dtype=torch.bfloat16, device_type="cuda"):
|
||||
product_embs = model(**{k:v.to(device) for k, v in batch.items()}).detach().float().cpu()
|
||||
start_index = step*batch_size
|
||||
end_index = start_index+batch_size if (start_index+batch_size) < num_products else num_products
|
||||
product_embeddings_array[start_index:end_index] = product_embs
|
||||
del product_embs, batch
|
||||
```
|
||||
|
||||
3. Create a search index using HNSWlib:
|
||||
|
||||
```py
|
||||
def construct_search_index(dim, num_elements, data):
|
||||
# Declaring index
|
||||
search_index = hnswlib.Index(space = 'ip', dim = dim) # possible options are l2, cosine or ip
|
||||
|
||||
# Initializing index - the maximum number of elements should be known beforehand
|
||||
search_index.init_index(max_elements = num_elements, ef_construction = 200, M = 100)
|
||||
|
||||
# Element insertion (can be called several times):
|
||||
ids = np.arange(num_elements)
|
||||
search_index.add_items(data, ids)
|
||||
|
||||
return search_index
|
||||
|
||||
product_search_index = construct_search_index(d, num_products, product_embeddings_array)
|
||||
```
|
||||
|
||||
4. Get the query embeddings and nearest neighbors:
|
||||
|
||||
```py
|
||||
def get_query_embeddings(query, model, tokenizer, device):
|
||||
inputs = tokenizer(query, padding="max_length", max_length=70, truncation=True, return_tensors="pt")
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
query_embs = model(**{k:v.to(device) for k, v in inputs.items()}).detach().cpu()
|
||||
return query_embs[0]
|
||||
|
||||
|
||||
def get_nearest_neighbours(k, search_index, query_embeddings, ids_to_products_dict, threshold=0.7):
|
||||
# Controlling the recall by setting ef:
|
||||
search_index.set_ef(100) # ef should always be > k
|
||||
|
||||
# Query dataset, k - number of the closest elements (returns 2 numpy arrays)
|
||||
labels, distances = search_index.knn_query(query_embeddings, k = k)
|
||||
|
||||
return [(ids_to_products_dict[label], (1-distance)) for label, distance in zip(labels[0], distances[0]) if (1-distance)>=threshold]
|
||||
```
|
||||
|
||||
5. Let's test it out with the query `deep learning books`:
|
||||
|
||||
```py
|
||||
query = "deep learning books"
|
||||
k = 10
|
||||
query_embeddings = get_query_embeddings(query, model, tokenizer, device)
|
||||
search_results = get_nearest_neighbours(k, product_search_index, query_embeddings, ids_to_products_dict, threshold=0.7)
|
||||
|
||||
print(f"{query=}")
|
||||
for product, cosine_sim_score in search_results:
|
||||
print(f"cosine_sim_score={round(cosine_sim_score,2)} {product=}")
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```bash
|
||||
query='deep learning books'
|
||||
cosine_sim_score=0.95 product='Deep Learning (The MIT Press Essential Knowledge series)'
|
||||
cosine_sim_score=0.93 product='Practical Deep Learning: A Python-Based Introduction'
|
||||
cosine_sim_score=0.9 product='Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems'
|
||||
cosine_sim_score=0.9 product='Machine Learning: A Hands-On, Project-Based Introduction to Machine Learning for Absolute Beginners: Mastering Engineering ML Systems using Scikit-Learn and TensorFlow'
|
||||
cosine_sim_score=0.9 product='Mastering Machine Learning on AWS: Advanced machine learning in Python using SageMaker, Apache Spark, and TensorFlow'
|
||||
cosine_sim_score=0.9 product='The Hundred-Page Machine Learning Book'
|
||||
cosine_sim_score=0.89 product='Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems'
|
||||
cosine_sim_score=0.89 product='Machine Learning: A Journey from Beginner to Advanced Including Deep Learning, Scikit-learn and Tensorflow'
|
||||
cosine_sim_score=0.88 product='Mastering Machine Learning with scikit-learn'
|
||||
cosine_sim_score=0.88 product='Mastering Machine Learning with scikit-learn - Second Edition: Apply effective learning algorithms to real-world problems using scikit-learn'
|
||||
```
|
||||
|
||||
Books on deep learning and machine learning are retrieved even though `machine learning` wasn't included in the query. This means the model has learned that these books are semantically relevant to the query based on the purchase behavior of customers on Amazon.
|
||||
|
||||
The next steps would ideally involve using ONNX/TensorRT to optimize the model and using a Triton server to host it. Check out 🤗 [Optimum](https://huggingface.co/docs/optimum/index) for related optimizations for efficient serving!
|
||||
@ -1,446 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# Semantic segmentation using LoRA
|
||||
|
||||
This guide demonstrates how to use LoRA, a low-rank approximation technique, to finetune a SegFormer model variant for semantic segmentation.
|
||||
By using LoRA from 🤗 PEFT, we can reduce the number of trainable parameters in the SegFormer model to only 14% of the original trainable parameters.
|
||||
|
||||
LoRA achieves this reduction by adding low-rank "update matrices" to specific blocks of the model, such as the attention
|
||||
blocks. During fine-tuning, only these matrices are trained, while the original model parameters are left unchanged.
|
||||
At inference time, the update matrices are merged with the original model parameters to produce the final classification result.
|
||||
|
||||
For more information on LoRA, please refer to the [original LoRA paper](https://arxiv.org/abs/2106.09685).
|
||||
|
||||
## Install dependencies
|
||||
|
||||
Install the libraries required for model training:
|
||||
|
||||
```bash
|
||||
!pip install transformers accelerate evaluate datasets peft -q
|
||||
```
|
||||
|
||||
## Authenticate to share your model
|
||||
|
||||
To share the finetuned model with the community at the end of the training, authenticate using your 🤗 token.
|
||||
You can obtain your token from your [account settings](https://huggingface.co/settings/token).
|
||||
|
||||
```python
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
## Load a dataset
|
||||
|
||||
To ensure that this example runs within a reasonable time frame, here we are limiting the number of instances from the training
|
||||
set of the [SceneParse150 dataset](https://huggingface.co/datasets/scene_parse_150) to 150.
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
ds = load_dataset("scene_parse_150", split="train[:150]")
|
||||
```
|
||||
|
||||
Next, split the dataset into train and test sets.
|
||||
|
||||
```python
|
||||
ds = ds.train_test_split(test_size=0.1)
|
||||
train_ds = ds["train"]
|
||||
test_ds = ds["test"]
|
||||
```
|
||||
|
||||
## Prepare label maps
|
||||
|
||||
Create a dictionary that maps a label id to a label class, which will be useful when setting up the model later:
|
||||
* `label2id`: maps the semantic classes of the dataset to integer ids.
|
||||
* `id2label`: maps integer ids back to the semantic classes.
|
||||
|
||||
```python
|
||||
import json
|
||||
from huggingface_hub import cached_download, hf_hub_url
|
||||
|
||||
repo_id = "huggingface/label-files"
|
||||
filename = "ade20k-id2label.json"
|
||||
id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename, repo_type="dataset")), "r"))
|
||||
id2label = {int(k): v for k, v in id2label.items()}
|
||||
label2id = {v: k for k, v in id2label.items()}
|
||||
num_labels = len(id2label)
|
||||
```
|
||||
|
||||
## Prepare datasets for training and evaluation
|
||||
|
||||
Next, load the SegFormer image processor to prepare the images and annotations for the model. This dataset uses the
|
||||
zero-index as the background class, so make sure to set `do_reduce_labels=True` to subtract one from all labels since the
|
||||
background class is not among the 150 classes.
|
||||
|
||||
```python
|
||||
from transformers import AutoImageProcessor
|
||||
|
||||
checkpoint = "nvidia/mit-b0"
|
||||
image_processor = AutoImageProcessor.from_pretrained(checkpoint, do_reduce_labels=True)
|
||||
```
|
||||
|
||||
Add a function to apply data augmentation to the images, so that the model is more robust against overfitting. Here we use the
|
||||
[ColorJitter](https://pytorch.org/vision/stable/generated/torchvision.transforms.ColorJitter.html) function from
|
||||
[torchvision](https://pytorch.org/vision/stable/index.html) to randomly change the color properties of an image.
|
||||
|
||||
```python
|
||||
from torchvision.transforms import ColorJitter
|
||||
|
||||
jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
|
||||
```
|
||||
|
||||
Add a function to handle grayscale images and ensure that each input image has three color channels, regardless of
|
||||
whether it was originally grayscale or RGB. The function converts RGB images to array as is, and for grayscale images
|
||||
that have only one color channel, the function replicates the same channel three times using `np.tile()` before converting
|
||||
the image into an array.
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
|
||||
def handle_grayscale_image(image):
|
||||
np_image = np.array(image)
|
||||
if np_image.ndim == 2:
|
||||
tiled_image = np.tile(np.expand_dims(np_image, -1), 3)
|
||||
return Image.fromarray(tiled_image)
|
||||
else:
|
||||
return Image.fromarray(np_image)
|
||||
```
|
||||
|
||||
Finally, combine everything in two functions that you'll use to transform training and validation data. The two functions
|
||||
are similar except data augmentation is applied only to the training data.
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def train_transforms(example_batch):
|
||||
images = [jitter(handle_grayscale_image(x)) for x in example_batch["image"]]
|
||||
labels = [x for x in example_batch["annotation"]]
|
||||
inputs = image_processor(images, labels)
|
||||
return inputs
|
||||
|
||||
|
||||
def val_transforms(example_batch):
|
||||
images = [handle_grayscale_image(x) for x in example_batch["image"]]
|
||||
labels = [x for x in example_batch["annotation"]]
|
||||
inputs = image_processor(images, labels)
|
||||
return inputs
|
||||
```
|
||||
|
||||
To apply the preprocessing functions over the entire dataset, use the 🤗 Datasets `set_transform` function:
|
||||
|
||||
```python
|
||||
train_ds.set_transform(train_transforms)
|
||||
test_ds.set_transform(val_transforms)
|
||||
```
|
||||
|
||||
## Create evaluation function
|
||||
|
||||
Including a metric during training is helpful for evaluating your model's performance. You can load an evaluation
|
||||
method with the [🤗 Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, use
|
||||
the [mean Intersection over Union (IoU)](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate
|
||||
[quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
|
||||
|
||||
```python
|
||||
import torch
|
||||
from torch import nn
|
||||
import evaluate
|
||||
|
||||
metric = evaluate.load("mean_iou")
|
||||
|
||||
|
||||
def compute_metrics(eval_pred):
|
||||
with torch.no_grad():
|
||||
logits, labels = eval_pred
|
||||
logits_tensor = torch.from_numpy(logits)
|
||||
logits_tensor = nn.functional.interpolate(
|
||||
logits_tensor,
|
||||
size=labels.shape[-2:],
|
||||
mode="bilinear",
|
||||
align_corners=False,
|
||||
).argmax(dim=1)
|
||||
|
||||
pred_labels = logits_tensor.detach().cpu().numpy()
|
||||
# currently using _compute instead of compute
|
||||
# see this issue for more info: https://github.com/huggingface/evaluate/pull/328#issuecomment-1286866576
|
||||
metrics = metric._compute(
|
||||
predictions=pred_labels,
|
||||
references=labels,
|
||||
num_labels=len(id2label),
|
||||
ignore_index=0,
|
||||
reduce_labels=image_processor.do_reduce_labels,
|
||||
)
|
||||
|
||||
per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
|
||||
per_category_iou = metrics.pop("per_category_iou").tolist()
|
||||
|
||||
metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
|
||||
metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
|
||||
|
||||
return metrics
|
||||
```
|
||||
|
||||
## Load a base model
|
||||
|
||||
Before loading a base model, let's define a helper function to check the total number of parameters a model has, as well
|
||||
as how many of them are trainable.
|
||||
|
||||
```python
|
||||
def print_trainable_parameters(model):
|
||||
"""
|
||||
Prints the number of trainable parameters in the model.
|
||||
"""
|
||||
trainable_params = 0
|
||||
all_param = 0
|
||||
for _, param in model.named_parameters():
|
||||
all_param += param.numel()
|
||||
if param.requires_grad:
|
||||
trainable_params += param.numel()
|
||||
print(
|
||||
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param:.2f}"
|
||||
)
|
||||
```
|
||||
|
||||
Choose a base model checkpoint. For this example, we use the [SegFormer B0 variant](https://huggingface.co/nvidia/mit-b0).
|
||||
In addition to the checkpoint, pass the `label2id` and `id2label` dictionaries to let the `AutoModelForSemanticSegmentation` class know that we're
|
||||
interested in a custom base model where the decoder head should be randomly initialized using the classes from the custom dataset.
|
||||
|
||||
```python
|
||||
from transformers import AutoModelForSemanticSegmentation, TrainingArguments, Trainer
|
||||
|
||||
model = AutoModelForSemanticSegmentation.from_pretrained(
|
||||
checkpoint, id2label=id2label, label2id=label2id, ignore_mismatched_sizes=True
|
||||
)
|
||||
print_trainable_parameters(model)
|
||||
```
|
||||
|
||||
At this point you can check with the `print_trainable_parameters` helper function that all 100% parameters in the base
|
||||
model (aka `model`) are trainable.
|
||||
|
||||
## Wrap the base model as a PeftModel for LoRA training
|
||||
|
||||
To leverage the LoRa method, you need to wrap the base model as a `PeftModel`. This involves two steps:
|
||||
|
||||
1. Defining LoRa configuration with `LoraConfig`
|
||||
2. Wrapping the original `model` with `get_peft_model()` using the config defined in the step above.
|
||||
|
||||
```python
|
||||
from peft import LoraConfig, get_peft_model
|
||||
|
||||
config = LoraConfig(
|
||||
r=32,
|
||||
lora_alpha=32,
|
||||
target_modules=["query", "value"],
|
||||
lora_dropout=0.1,
|
||||
bias="lora_only",
|
||||
modules_to_save=["decode_head"],
|
||||
)
|
||||
lora_model = get_peft_model(model, config)
|
||||
print_trainable_parameters(lora_model)
|
||||
```
|
||||
|
||||
Let's review the `LoraConfig`. To enable LoRA technique, we must define the target modules within `LoraConfig` so that
|
||||
`PeftModel` can update the necessary matrices. Specifically, we want to target the `query` and `value` matrices in the
|
||||
attention blocks of the base model. These matrices are identified by their respective names, "query" and "value".
|
||||
Therefore, we should specify these names in the `target_modules` argument of `LoraConfig`.
|
||||
|
||||
After we wrap our base model `model` with `PeftModel` along with the config, we get
|
||||
a new model where only the LoRA parameters are trainable (so-called "update matrices") while the pre-trained parameters
|
||||
are kept frozen. These include the parameters of the randomly initialized classifier parameters too. This is NOT we want
|
||||
when fine-tuning the base model on our custom dataset. To ensure that the classifier parameters are also trained, we
|
||||
specify `modules_to_save`. This also ensures that these modules are serialized alongside the LoRA trainable parameters
|
||||
when using utilities like `save_pretrained()` and `push_to_hub()`.
|
||||
|
||||
In addition to specifying the `target_modules` within `LoraConfig`, we also need to specify the `modules_to_save`. When
|
||||
we wrap our base model with `PeftModel` and pass the configuration, we obtain a new model in which only the LoRA parameters
|
||||
are trainable, while the pre-trained parameters and the randomly initialized classifier parameters are kept frozen.
|
||||
However, we do want to train the classifier parameters. By specifying the `modules_to_save` argument, we ensure that the
|
||||
classifier parameters are also trainable, and they will be serialized alongside the LoRA trainable parameters when we
|
||||
use utility functions like `save_pretrained()` and `push_to_hub()`.
|
||||
|
||||
Let's review the rest of the parameters:
|
||||
|
||||
- `r`: The dimension used by the LoRA update matrices.
|
||||
- `alpha`: Scaling factor.
|
||||
- `bias`: Specifies if the `bias` parameters should be trained. `None` denotes none of the `bias` parameters will be trained.
|
||||
|
||||
When all is configured, and the base model is wrapped, the `print_trainable_parameters` helper function lets us explore
|
||||
the number of trainable parameters. Since we're interested in performing **parameter-efficient fine-tuning**,
|
||||
we should expect to see a lower number of trainable parameters from the `lora_model` in comparison to the original `model`
|
||||
which is indeed the case here.
|
||||
|
||||
You can also manually verify what modules are trainable in the `lora_model`.
|
||||
|
||||
```python
|
||||
for name, param in lora_model.named_parameters():
|
||||
if param.requires_grad:
|
||||
print(name, param.shape)
|
||||
```
|
||||
|
||||
This confirms that only the LoRA parameters appended to the attention blocks and the `decode_head` parameters are trainable.
|
||||
|
||||
## Train the model
|
||||
|
||||
Start by defining your training hyperparameters in `TrainingArguments`. You can change the values of most parameters however
|
||||
you prefer. Make sure to set `remove_unused_columns=False`, otherwise the image column will be dropped, and it's required here.
|
||||
The only other required parameter is `output_dir` which specifies where to save your model.
|
||||
At the end of each epoch, the `Trainer` will evaluate the IoU metric and save the training checkpoint.
|
||||
|
||||
Note that this example is meant to walk you through the workflow when using PEFT for semantic segmentation. We didn't
|
||||
perform extensive hyperparameter tuning to achieve optimal results.
|
||||
|
||||
```python
|
||||
model_name = checkpoint.split("/")[-1]
|
||||
|
||||
training_args = TrainingArguments(
|
||||
output_dir=f"{model_name}-scene-parse-150-lora",
|
||||
learning_rate=5e-4,
|
||||
num_train_epochs=50,
|
||||
per_device_train_batch_size=4,
|
||||
per_device_eval_batch_size=2,
|
||||
save_total_limit=3,
|
||||
evaluation_strategy="epoch",
|
||||
save_strategy="epoch",
|
||||
logging_steps=5,
|
||||
remove_unused_columns=False,
|
||||
push_to_hub=True,
|
||||
label_names=["labels"],
|
||||
)
|
||||
```
|
||||
|
||||
Pass the training arguments to `Trainer` along with the model, dataset, and `compute_metrics` function.
|
||||
Call `train()` to finetune your model.
|
||||
|
||||
```python
|
||||
trainer = Trainer(
|
||||
model=lora_model,
|
||||
args=training_args,
|
||||
train_dataset=train_ds,
|
||||
eval_dataset=test_ds,
|
||||
compute_metrics=compute_metrics,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Save the model and run inference
|
||||
|
||||
Use the `save_pretrained()` method of the `lora_model` to save the *LoRA-only parameters* locally.
|
||||
Alternatively, use the `push_to_hub()` method to upload these parameters directly to the Hugging Face Hub
|
||||
(as shown in the [Image classification using LoRA](image_classification_lora) task guide).
|
||||
|
||||
```python
|
||||
model_id = "segformer-scene-parse-150-lora"
|
||||
lora_model.save_pretrained(model_id)
|
||||
```
|
||||
|
||||
We can see that the LoRA-only parameters are just **2.2 MB in size**! This greatly improves the portability when using very large models.
|
||||
|
||||
```bash
|
||||
!ls -lh {model_id}
|
||||
total 2.2M
|
||||
-rw-r--r-- 1 root root 369 Feb 8 03:09 adapter_config.json
|
||||
-rw-r--r-- 1 root root 2.2M Feb 8 03:09 adapter_model.bin
|
||||
```
|
||||
|
||||
Let's now prepare an `inference_model` and run inference.
|
||||
|
||||
```python
|
||||
from peft import PeftConfig
|
||||
|
||||
config = PeftConfig.from_pretrained(model_id)
|
||||
model = AutoModelForSemanticSegmentation.from_pretrained(
|
||||
checkpoint, id2label=id2label, label2id=label2id, ignore_mismatched_sizes=True
|
||||
)
|
||||
|
||||
inference_model = PeftModel.from_pretrained(model, model_id)
|
||||
```
|
||||
|
||||
Get an image:
|
||||
|
||||
```python
|
||||
import requests
|
||||
|
||||
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/semantic-seg-image.png"
|
||||
image = Image.open(requests.get(url, stream=True).raw)
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/semantic-seg-image.png" alt="photo of a room"/>
|
||||
</div>
|
||||
|
||||
Preprocess the image to prepare for inference.
|
||||
|
||||
```python
|
||||
encoding = image_processor(image.convert("RGB"), return_tensors="pt")
|
||||
```
|
||||
|
||||
Run inference with the encoded image.
|
||||
|
||||
```python
|
||||
with torch.no_grad():
|
||||
outputs = inference_model(pixel_values=encoding.pixel_values)
|
||||
logits = outputs.logits
|
||||
|
||||
upsampled_logits = nn.functional.interpolate(
|
||||
logits,
|
||||
size=image.size[::-1],
|
||||
mode="bilinear",
|
||||
align_corners=False,
|
||||
)
|
||||
|
||||
pred_seg = upsampled_logits.argmax(dim=1)[0]
|
||||
```
|
||||
|
||||
Next, visualize the results. We need a color palette for this. Here, we use ade_palette(). As it is a long array, so
|
||||
we don't include it in this guide, please copy it from [the TensorFlow Model Garden repository](https://github.com/tensorflow/models/blob/3f1ca33afe3c1631b733ea7e40c294273b9e406d/research/deeplab/utils/get_dataset_colormap.py#L51).
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
color_seg = np.zeros((pred_seg.shape[0], pred_seg.shape[1], 3), dtype=np.uint8)
|
||||
palette = np.array(ade_palette())
|
||||
|
||||
for label, color in enumerate(palette):
|
||||
color_seg[pred_seg == label, :] = color
|
||||
color_seg = color_seg[..., ::-1] # convert to BGR
|
||||
|
||||
img = np.array(image) * 0.5 + color_seg * 0.5 # plot the image with the segmentation map
|
||||
img = img.astype(np.uint8)
|
||||
|
||||
plt.figure(figsize=(15, 10))
|
||||
plt.imshow(img)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
As you can see, the results are far from perfect, however, this example is designed to illustrate the end-to-end workflow of
|
||||
fine-tuning a semantic segmentation model with LoRa technique, and is not aiming to achieve state-of-the-art
|
||||
results. The results you see here are the same as you would get if you performed full fine-tuning on the same setup (same
|
||||
model variant, same dataset, same training schedule, etc.), except LoRA allows to achieve them with a fraction of total
|
||||
trainable parameters and in less time.
|
||||
|
||||
If you wish to use this example and improve the results, here are some things that you can try:
|
||||
|
||||
* Increase the number of training samples.
|
||||
* Try a larger SegFormer model variant (explore available model variants on the [Hugging Face Hub](https://huggingface.co/models?search=segformer)).
|
||||
* Try different values for the arguments available in `LoraConfig`.
|
||||
* Tune the learning rate and batch size.
|
||||
|
||||
|
||||
@ -1,256 +0,0 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# Prefix tuning for conditional generation
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Prefix tuning is an additive method where only a sequence of continuous task-specific vectors is attached to the beginning of the input, or *prefix*. Only the prefix parameters are optimized and added to the hidden states in every layer of the model. The tokens of the input sequence can still attend to the prefix as *virtual tokens*. As a result, prefix tuning stores 1000x fewer parameters than a fully finetuned model, which means you can use one large language model for many tasks.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Read [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://arxiv.org/abs/2101.00190) to learn more about prefix tuning.
|
||||
|
||||
</Tip>
|
||||
|
||||
This guide will show you how to apply prefix tuning to train a [`t5-large`](https://huggingface.co/t5-large) model on the `sentences_allagree` subset of the [financial_phrasebank](https://huggingface.co/datasets/financial_phrasebank) dataset.
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
!pip install -q peft transformers datasets
|
||||
```
|
||||
|
||||
## Setup
|
||||
|
||||
Start by defining the model and tokenizer, text and label columns, and some hyperparameters so it'll be easier to start training faster later. Set the environment variable `TOKENIZERS_PARALLELSIM` to `false` to disable the fast Rust-based tokenizer which processes data in parallel by default so you can use multiprocessing in Python.
|
||||
|
||||
```py
|
||||
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, default_data_collator, get_linear_schedule_with_warmup
|
||||
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, PrefixTuningConfig, TaskType
|
||||
from datasets import load_dataset
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
import torch
|
||||
import os
|
||||
|
||||
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
||||
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
|
||||
|
||||
device = "cuda"
|
||||
model_name_or_path = "t5-large"
|
||||
tokenizer_name_or_path = "t5-large"
|
||||
|
||||
text_column = "sentence"
|
||||
label_column = "text_label"
|
||||
max_length = 128
|
||||
lr = 1e-2
|
||||
num_epochs = 5
|
||||
batch_size = 8
|
||||
```
|
||||
|
||||
## Load dataset
|
||||
|
||||
For this guide, you'll train on the `sentences_allagree` subset of the [`financial_phrasebank`](https://huggingface.co/datasets/financial_phrasebank) dataset. This dataset contains financial news categorized by sentiment.
|
||||
|
||||
Use 🤗 [Datasets](https://huggingface.co/docs/datasets/index) [`~datasets.Dataset.train_test_split`] function to create a training and validation split and convert the `label` value to the more readable `text_label`. All of the changes can be applied with the [`~datasets.Dataset.map`] function:
|
||||
|
||||
```py
|
||||
from datasets import load_dataset
|
||||
|
||||
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
|
||||
dataset = dataset["train"].train_test_split(test_size=0.1)
|
||||
dataset["validation"] = dataset["test"]
|
||||
del dataset["test"]
|
||||
|
||||
classes = dataset["train"].features["label"].names
|
||||
dataset = dataset.map(
|
||||
lambda x: {"text_label": [classes[label] for label in x["label"]]},
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
)
|
||||
|
||||
dataset["train"][0]
|
||||
{"sentence": "Profit before taxes was EUR 4.0 mn , down from EUR 4.9 mn .", "label": 0, "text_label": "negative"}
|
||||
```
|
||||
|
||||
## Preprocess dataset
|
||||
|
||||
Initialize a tokenizer, and create a function to pad and truncate the `model_inputs` and `labels`:
|
||||
|
||||
```py
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
|
||||
|
||||
|
||||
def preprocess_function(examples):
|
||||
inputs = examples[text_column]
|
||||
targets = examples[label_column]
|
||||
model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")
|
||||
labels = tokenizer(targets, max_length=2, padding="max_length", truncation=True, return_tensors="pt")
|
||||
labels = labels["input_ids"]
|
||||
labels[labels == tokenizer.pad_token_id] = -100
|
||||
model_inputs["labels"] = labels
|
||||
return model_inputs
|
||||
```
|
||||
|
||||
Use the [`~datasets.Dataset.map`] function to apply the `preprocess_function` to the dataset. You can remove the unprocessed columns since the model doesn't need them anymore:
|
||||
|
||||
```py
|
||||
processed_datasets = dataset.map(
|
||||
preprocess_function,
|
||||
batched=True,
|
||||
num_proc=1,
|
||||
remove_columns=dataset["train"].column_names,
|
||||
load_from_cache_file=False,
|
||||
desc="Running tokenizer on dataset",
|
||||
)
|
||||
```
|
||||
|
||||
Create a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader) from the `train` and `eval` datasets. Set `pin_memory=True` to speed up the data transfer to the GPU during training if the samples in your dataset are on a CPU.
|
||||
|
||||
```py
|
||||
train_dataset = processed_datasets["train"]
|
||||
eval_dataset = processed_datasets["validation"]
|
||||
|
||||
train_dataloader = DataLoader(
|
||||
train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
|
||||
)
|
||||
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
|
||||
```
|
||||
|
||||
## Train model
|
||||
|
||||
Now you can setup your model and make sure it is ready for training. Specify the task in [`PrefixTuningConfig`], create the base `t5-large` model from [`~transformers.AutoModelForSeq2SeqLM`], and then wrap the model and configuration in a [`PeftModel`]. Feel free to print the [`PeftModel`]'s parameters and compare it to fully training all the model parameters to see how much more efficient it is!
|
||||
|
||||
```py
|
||||
peft_config = PrefixTuningConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, num_virtual_tokens=20)
|
||||
|
||||
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 983040 || all params: 738651136 || trainable%: 0.13308583065659835"
|
||||
```
|
||||
|
||||
Setup the optimizer and learning rate scheduler:
|
||||
|
||||
```py
|
||||
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
|
||||
lr_scheduler = get_linear_schedule_with_warmup(
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=0,
|
||||
num_training_steps=(len(train_dataloader) * num_epochs),
|
||||
)
|
||||
```
|
||||
|
||||
Move the model to the GPU, and then write a training loop to begin!
|
||||
|
||||
```py
|
||||
model = model.to(device)
|
||||
|
||||
for epoch in range(num_epochs):
|
||||
model.train()
|
||||
total_loss = 0
|
||||
for step, batch in enumerate(tqdm(train_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
total_loss += loss.detach().float()
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
model.eval()
|
||||
eval_loss = 0
|
||||
eval_preds = []
|
||||
for step, batch in enumerate(tqdm(eval_dataloader)):
|
||||
batch = {k: v.to(device) for k, v in batch.items()}
|
||||
with torch.no_grad():
|
||||
outputs = model(**batch)
|
||||
loss = outputs.loss
|
||||
eval_loss += loss.detach().float()
|
||||
eval_preds.extend(
|
||||
tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)
|
||||
)
|
||||
|
||||
eval_epoch_loss = eval_loss / len(eval_dataloader)
|
||||
eval_ppl = torch.exp(eval_epoch_loss)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
|
||||
```
|
||||
|
||||
Let's see how well the model performs on the validation set:
|
||||
|
||||
```py
|
||||
correct = 0
|
||||
total = 0
|
||||
for pred, true in zip(eval_preds, dataset["validation"]["text_label"]):
|
||||
if pred.strip() == true.strip():
|
||||
correct += 1
|
||||
total += 1
|
||||
accuracy = correct / total * 100
|
||||
print(f"{accuracy=} % on the evaluation dataset")
|
||||
print(f"{eval_preds[:10]=}")
|
||||
print(f"{dataset['validation']['text_label'][:10]=}")
|
||||
"accuracy=97.3568281938326 % on the evaluation dataset"
|
||||
"eval_preds[:10]=['neutral', 'positive', 'neutral', 'positive', 'neutral', 'negative', 'negative', 'neutral', 'neutral', 'neutral']"
|
||||
"dataset['validation']['text_label'][:10]=['neutral', 'positive', 'neutral', 'positive', 'neutral', 'negative', 'negative', 'neutral', 'neutral', 'neutral']"
|
||||
```
|
||||
|
||||
97% accuracy in just a few minutes; pretty good!
|
||||
|
||||
## Share model
|
||||
|
||||
You can store and share your model on the Hub if you'd like. Login to your Hugging Face account and enter your token when prompted:
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
Upload the model to a specifc model repository on the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] function:
|
||||
|
||||
```py
|
||||
peft_model_id = "your-name/t5-large_PREFIX_TUNING_SEQ2SEQ"
|
||||
model.push_to_hub("your-name/t5-large_PREFIX_TUNING_SEQ2SEQ", use_auth_token=True)
|
||||
```
|
||||
|
||||
If you check the model file size in the repository, you'll see that it is only 3.93MB! 🤏
|
||||
|
||||
## Inference
|
||||
|
||||
Once the model has been uploaded to the Hub, anyone can easily use it for inference. Load the configuration and model:
|
||||
|
||||
```py
|
||||
from peft import PeftModel, PeftConfig
|
||||
|
||||
peft_model_id = "stevhliu/t5-large_PREFIX_TUNING_SEQ2SEQ"
|
||||
|
||||
config = PeftConfig.from_pretrained(peft_model_id)
|
||||
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
|
||||
model = PeftModel.from_pretrained(model, peft_model_id)
|
||||
```
|
||||
|
||||
Get and tokenize some text about financial news:
|
||||
|
||||
```py
|
||||
inputs = tokenizer(
|
||||
"The Lithuanian beer market made up 14.41 million liters in January , a rise of 0.8 percent from the year-earlier figure , the Lithuanian Brewers ' Association reporting citing the results from its members .",
|
||||
return_tensors="pt",
|
||||
)
|
||||
```
|
||||
|
||||
Put the model on a GPU and *generate* the predicted text sentiment:
|
||||
|
||||
```py
|
||||
model.to(device)
|
||||
|
||||
with torch.no_grad():
|
||||
inputs = {k: v.to(device) for k, v in inputs.items()}
|
||||
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)
|
||||
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
|
||||
["positive"]
|
||||
```
|
||||
@ -1,378 +0,0 @@
|
||||
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
-->
|
||||
|
||||
# LoRA for token classification
|
||||
|
||||
Low-Rank Adaptation (LoRA) is a reparametrization method that aims to reduce the number of trainable parameters with low-rank representations. The weight matrix is broken down into low-rank matrices that are trained and updated. All the pretrained model parameters remain frozen. After training, the low-rank matrices are added back to the original weights. This makes it more efficient to store and train a LoRA model because there are significantly fewer parameters.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Read [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) to learn more about LoRA.
|
||||
|
||||
</Tip>
|
||||
|
||||
This guide will show you how to train a [`roberta-large`](https://huggingface.co/roberta-large) model with LoRA on the [BioNLP2004](https://huggingface.co/datasets/tner/bionlp2004) dataset for token classification.
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```bash
|
||||
!pip install -q peft transformers datasets evaluate seqeval
|
||||
```
|
||||
|
||||
## Setup
|
||||
|
||||
Let's start by importing all the necessary libraries you'll need:
|
||||
|
||||
- 🤗 Transformers for loading the base `roberta-large` model and tokenizer, and handling the training loop
|
||||
- 🤗 Datasets for loading and preparing the `bionlp2004` dataset for training
|
||||
- 🤗 Evaluate for evaluating the model's performance
|
||||
- 🤗 PEFT for setting up the LoRA configuration and creating the PEFT model
|
||||
|
||||
```py
|
||||
from datasets import load_dataset
|
||||
from transformers import (
|
||||
AutoModelForTokenClassification,
|
||||
AutoTokenizer,
|
||||
DataCollatorForTokenClassification,
|
||||
TrainingArguments,
|
||||
Trainer,
|
||||
)
|
||||
from peft import get_peft_config, PeftModel, PeftConfig, get_peft_model, LoraConfig, TaskType
|
||||
import evaluate
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
model_checkpoint = "roberta-large"
|
||||
lr = 1e-3
|
||||
batch_size = 16
|
||||
num_epochs = 10
|
||||
```
|
||||
|
||||
## Load dataset and metric
|
||||
|
||||
The [BioNLP2004](https://huggingface.co/datasets/tner/bionlp2004) dataset includes tokens and tags for biological structures like DNA, RNA and proteins. Load the dataset:
|
||||
|
||||
```py
|
||||
bionlp = load_dataset("tner/bionlp2004")
|
||||
bionlp["train"][0]
|
||||
{
|
||||
"tokens": [
|
||||
"Since",
|
||||
"HUVECs",
|
||||
"released",
|
||||
"superoxide",
|
||||
"anions",
|
||||
"in",
|
||||
"response",
|
||||
"to",
|
||||
"TNF",
|
||||
",",
|
||||
"and",
|
||||
"H2O2",
|
||||
"induces",
|
||||
"VCAM-1",
|
||||
",",
|
||||
"PDTC",
|
||||
"may",
|
||||
"act",
|
||||
"as",
|
||||
"a",
|
||||
"radical",
|
||||
"scavenger",
|
||||
".",
|
||||
],
|
||||
"tags": [0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
}
|
||||
```
|
||||
|
||||
The `tags` values are defined in the label ids [dictionary](https://huggingface.co/datasets/tner/bionlp2004#label-id). The letter that prefixes each label indicates the token position: `B` is for the first token of an entity, `I` is for a token inside the entity, and `0` is for a token that is not part of an entity.
|
||||
|
||||
```py
|
||||
{
|
||||
"O": 0,
|
||||
"B-DNA": 1,
|
||||
"I-DNA": 2,
|
||||
"B-protein": 3,
|
||||
"I-protein": 4,
|
||||
"B-cell_type": 5,
|
||||
"I-cell_type": 6,
|
||||
"B-cell_line": 7,
|
||||
"I-cell_line": 8,
|
||||
"B-RNA": 9,
|
||||
"I-RNA": 10,
|
||||
}
|
||||
```
|
||||
|
||||
Then load the [`seqeval`](https://huggingface.co/spaces/evaluate-metric/seqeval) framework which includes several metrics - precision, accuracy, F1, and recall - for evaluating sequence labeling tasks.
|
||||
|
||||
```py
|
||||
seqeval = evaluate.load("seqeval")
|
||||
```
|
||||
|
||||
Now you can write an evaluation function to compute the metrics from the model predictions and labels, and return the precision, recall, F1, and accuracy scores:
|
||||
|
||||
```py
|
||||
label_list = [
|
||||
"O",
|
||||
"B-DNA",
|
||||
"I-DNA",
|
||||
"B-protein",
|
||||
"I-protein",
|
||||
"B-cell_type",
|
||||
"I-cell_type",
|
||||
"B-cell_line",
|
||||
"I-cell_line",
|
||||
"B-RNA",
|
||||
"I-RNA",
|
||||
]
|
||||
|
||||
|
||||
def compute_metrics(p):
|
||||
predictions, labels = p
|
||||
predictions = np.argmax(predictions, axis=2)
|
||||
|
||||
true_predictions = [
|
||||
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
|
||||
for prediction, label in zip(predictions, labels)
|
||||
]
|
||||
true_labels = [
|
||||
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
|
||||
for prediction, label in zip(predictions, labels)
|
||||
]
|
||||
|
||||
results = seqeval.compute(predictions=true_predictions, references=true_labels)
|
||||
return {
|
||||
"precision": results["overall_precision"],
|
||||
"recall": results["overall_recall"],
|
||||
"f1": results["overall_f1"],
|
||||
"accuracy": results["overall_accuracy"],
|
||||
}
|
||||
```
|
||||
|
||||
## Preprocess dataset
|
||||
|
||||
Initialize a tokenizer and make sure you set `is_split_into_words=True` because the text sequence has already been split into words. However, this doesn't mean it is tokenized yet (even though it may look like it!), and you'll need to further tokenize the words into subwords.
|
||||
|
||||
```py
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, add_prefix_space=True)
|
||||
```
|
||||
|
||||
You'll also need to write a function to:
|
||||
|
||||
1. Map each token to their respective word with the [`~transformers.BatchEncoding.word_ids`] method.
|
||||
2. Ignore the special tokens by setting them to `-100`.
|
||||
3. Label the first token of a given entity.
|
||||
|
||||
```py
|
||||
def tokenize_and_align_labels(examples):
|
||||
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
|
||||
|
||||
labels = []
|
||||
for i, label in enumerate(examples[f"tags"]):
|
||||
word_ids = tokenized_inputs.word_ids(batch_index=i)
|
||||
previous_word_idx = None
|
||||
label_ids = []
|
||||
for word_idx in word_ids:
|
||||
if word_idx is None:
|
||||
label_ids.append(-100)
|
||||
elif word_idx != previous_word_idx:
|
||||
label_ids.append(label[word_idx])
|
||||
else:
|
||||
label_ids.append(-100)
|
||||
previous_word_idx = word_idx
|
||||
labels.append(label_ids)
|
||||
|
||||
tokenized_inputs["labels"] = labels
|
||||
return tokenized_inputs
|
||||
```
|
||||
|
||||
Use [`~datasets.Dataset.map`] to apply the `tokenize_and_align_labels` function to the dataset:
|
||||
|
||||
```py
|
||||
tokenized_bionlp = bionlp.map(tokenize_and_align_labels, batched=True)
|
||||
```
|
||||
|
||||
Finally, create a data collator to pad the examples to the longest length in a batch:
|
||||
|
||||
```py
|
||||
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
|
||||
```
|
||||
|
||||
## Train
|
||||
|
||||
Now you're ready to create a [`PeftModel`]. Start by loading the base `roberta-large` model, the number of expected labels, and the `id2label` and `label2id` dictionaries:
|
||||
|
||||
```py
|
||||
id2label = {
|
||||
0: "O",
|
||||
1: "B-DNA",
|
||||
2: "I-DNA",
|
||||
3: "B-protein",
|
||||
4: "I-protein",
|
||||
5: "B-cell_type",
|
||||
6: "I-cell_type",
|
||||
7: "B-cell_line",
|
||||
8: "I-cell_line",
|
||||
9: "B-RNA",
|
||||
10: "I-RNA",
|
||||
}
|
||||
label2id = {
|
||||
"O": 0,
|
||||
"B-DNA": 1,
|
||||
"I-DNA": 2,
|
||||
"B-protein": 3,
|
||||
"I-protein": 4,
|
||||
"B-cell_type": 5,
|
||||
"I-cell_type": 6,
|
||||
"B-cell_line": 7,
|
||||
"I-cell_line": 8,
|
||||
"B-RNA": 9,
|
||||
"I-RNA": 10,
|
||||
}
|
||||
|
||||
model = AutoModelForTokenClassification.from_pretrained(
|
||||
model_checkpoint, num_labels=11, id2label=id2label, label2id=label2id
|
||||
)
|
||||
```
|
||||
|
||||
Define the [`LoraConfig`] with:
|
||||
|
||||
- `task_type`, token classification (`TaskType.TOKEN_CLS`)
|
||||
- `r`, the dimension of the low-rank matrices
|
||||
- `lora_alpha`, scaling factor for the weight matrices
|
||||
- `lora_dropout`, dropout probability of the LoRA layers
|
||||
- `bias`, set to `all` to train all bias parameters
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 The weight matrix is scaled by `lora_alpha/r`, and a higher `lora_alpha` value assigns more weight to the LoRA activations. For performance, we recommend setting `bias` to `None` first, and then `lora_only`, before trying `all`.
|
||||
|
||||
</Tip>
|
||||
|
||||
```py
|
||||
peft_config = LoraConfig(
|
||||
task_type=TaskType.TOKEN_CLS, inference_mode=False, r=16, lora_alpha=16, lora_dropout=0.1, bias="all"
|
||||
)
|
||||
```
|
||||
|
||||
Pass the base model and `peft_config` to the [`get_peft_model`] function to create a [`PeftModel`]. You can check out how much more efficient training the [`PeftModel`] is compared to fully training the base model by printing out the trainable parameters:
|
||||
|
||||
```py
|
||||
model = get_peft_model(model, peft_config)
|
||||
model.print_trainable_parameters()
|
||||
"trainable params: 1855499 || all params: 355894283 || trainable%: 0.5213624069370061"
|
||||
```
|
||||
|
||||
From the 🤗 Transformers library, create a [`~transformers.TrainingArguments`] class and specify where you want to save the model to, the training hyperparameters, how to evaluate the model, and when to save the checkpoints:
|
||||
|
||||
```py
|
||||
training_args = TrainingArguments(
|
||||
output_dir="roberta-large-lora-token-classification",
|
||||
learning_rate=lr,
|
||||
per_device_train_batch_size=batch_size,
|
||||
per_device_eval_batch_size=batch_size,
|
||||
num_train_epochs=num_epochs,
|
||||
weight_decay=0.01,
|
||||
evaluation_strategy="epoch",
|
||||
save_strategy="epoch",
|
||||
load_best_model_at_end=True,
|
||||
)
|
||||
```
|
||||
|
||||
Pass the model, `TrainingArguments`, datasets, tokenizer, data collator and evaluation function to the [`~transformers.Trainer`] class. The `Trainer` handles the training loop for you, and when you're ready, call [`~transformers.Trainer.train`] to begin!
|
||||
|
||||
```py
|
||||
trainer = Trainer(
|
||||
model=model,
|
||||
args=training_args,
|
||||
train_dataset=tokenized_bionlp["train"],
|
||||
eval_dataset=tokenized_bionlp["validation"],
|
||||
tokenizer=tokenizer,
|
||||
data_collator=data_collator,
|
||||
compute_metrics=compute_metrics,
|
||||
)
|
||||
|
||||
trainer.train()
|
||||
```
|
||||
|
||||
## Share model
|
||||
|
||||
Once training is complete, you can store and share your model on the Hub if you'd like. Log in to your Hugging Face account and enter your token when prompted:
|
||||
|
||||
```py
|
||||
from huggingface_hub import notebook_login
|
||||
|
||||
notebook_login()
|
||||
```
|
||||
|
||||
Upload the model to a specific model repository on the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method:
|
||||
|
||||
```py
|
||||
model.push_to_hub("your-name/roberta-large-lora-token-classification")
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
To use your model for inference, load the configuration and model:
|
||||
|
||||
```py
|
||||
peft_model_id = "stevhliu/roberta-large-lora-token-classification"
|
||||
config = PeftConfig.from_pretrained(peft_model_id)
|
||||
inference_model = AutoModelForTokenClassification.from_pretrained(
|
||||
config.base_model_name_or_path, num_labels=11, id2label=id2label, label2id=label2id
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
|
||||
model = PeftModel.from_pretrained(inference_model, peft_model_id)
|
||||
```
|
||||
|
||||
Get some text to tokenize:
|
||||
|
||||
```py
|
||||
text = "The activation of IL-2 gene expression and NF-kappa B through CD28 requires reactive oxygen production by 5-lipoxygenase."
|
||||
inputs = tokenizer(text, return_tensors="pt")
|
||||
```
|
||||
|
||||
Pass the inputs to the model, and print out the model prediction for each token:
|
||||
|
||||
```py
|
||||
with torch.no_grad():
|
||||
logits = model(**inputs).logits
|
||||
|
||||
tokens = inputs.tokens()
|
||||
predictions = torch.argmax(logits, dim=2)
|
||||
|
||||
for token, prediction in zip(tokens, predictions[0].numpy()):
|
||||
print((token, model.config.id2label[prediction]))
|
||||
("<s>", "O")
|
||||
("The", "O")
|
||||
("Ġactivation", "O")
|
||||
("Ġof", "O")
|
||||
("ĠIL", "B-DNA")
|
||||
("-", "O")
|
||||
("2", "I-DNA")
|
||||
("Ġgene", "O")
|
||||
("Ġexpression", "O")
|
||||
("Ġand", "O")
|
||||
("ĠNF", "B-protein")
|
||||
("-", "O")
|
||||
("k", "I-protein")
|
||||
("appa", "I-protein")
|
||||
("ĠB", "I-protein")
|
||||
("Ġthrough", "O")
|
||||
("ĠCD", "B-protein")
|
||||
("28", "I-protein")
|
||||
("Ġrequires", "O")
|
||||
("Ġreactive", "O")
|
||||
("Ġoxygen", "O")
|
||||
("Ġproduction", "O")
|
||||
("Ġby", "O")
|
||||
("Ġ5", "B-protein")
|
||||
("-", "O")
|
||||
("lip", "I-protein")
|
||||
("oxy", "I-protein")
|
||||
("gen", "I-protein")
|
||||
("ase", "I-protein")
|
||||
(".", "O")
|
||||
("</s>", "O")
|
||||
```
|
||||
152
docs/source/tutorial/peft_integrations.md
Normal file
152
docs/source/tutorial/peft_integrations.md
Normal file
@ -0,0 +1,152 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# PEFT integrations
|
||||
|
||||
PEFT's practical benefits extends to other Hugging Face libraries like [Diffusers](https://hf.co/docs/diffusers) and [Transformers](https://hf.co/docs/transformers). One of the main benefits of PEFT is that an adapter file generated by a PEFT method is a lot smaller than the original model, which makes it super easy to manage and use multiple adapters. You can use one pretrained base model for multiple tasks by simply loading a new adapter finetuned for the task you're solving. Or you can combine multiple adapters with a text-to-image diffusion model to create new effects.
|
||||
|
||||
This tutorial will show you how PEFT can help you manage adapters in Diffusers and Transformers.
|
||||
|
||||
## Diffusers
|
||||
|
||||
Diffusers is a generative AI library for creating images and videos from text or images with diffusion models. LoRA is an especially popular training method for diffusion models because you can very quickly train and share diffusion models to generate images in new styles. To make it easier to use and try multiple LoRA models, Diffusers uses the PEFT library to help manage different adapters for inference.
|
||||
|
||||
For example, load a base model and then load the [artificialguybr/3DRedmond-V1](https://huggingface.co/artificialguybr/3DRedmond-V1) adapter for inference with the [`load_lora_weights`](https://huggingface.co/docs/diffusers/v0.24.0/en/api/loaders/lora#diffusers.loaders.LoraLoaderMixin.load_lora_weights) method. The `adapter_name` argument in the loading method is enabled by PEFT and allows you to set a name for the adapter so it is easier to reference.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
pipeline.load_lora_weights(
|
||||
"peft-internal-testing/artificialguybr__3DRedmond-V1",
|
||||
weight_name="3DRedmond-3DRenderStyle-3DRenderAF.safetensors",
|
||||
adapter_name="3d"
|
||||
)
|
||||
image = pipeline("sushi rolls shaped like kawaii cat faces").images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/test-lora-diffusers.png"/>
|
||||
</div>
|
||||
|
||||
Now let's try another cool LoRA model, [ostris/super-cereal-sdxl-lora](https://huggingface.co/ostris/super-cereal-sdxl-lora). All you need to do is load and name this new adapter with `adapter_name`, and use the [`set_adapters`](https://huggingface.co/docs/diffusers/api/loaders/unet#diffusers.loaders.UNet2DConditionLoadersMixin.set_adapters) method to set it as the currently active adapter.
|
||||
|
||||
```py
|
||||
pipeline.load_lora_weights(
|
||||
"ostris/super-cereal-sdxl-lora",
|
||||
weight_name="cereal_box_sdxl_v1.safetensors",
|
||||
adapter_name="cereal"
|
||||
)
|
||||
pipeline.set_adapters("cereal")
|
||||
image = pipeline("sushi rolls shaped like kawaii cat faces").images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/test-lora-diffusers-2.png"/>
|
||||
</div>
|
||||
|
||||
Finally, you can call the [`disable_lora`](https://huggingface.co/docs/diffusers/api/loaders/unet#diffusers.loaders.UNet2DConditionLoadersMixin.disable_lora) method to restore the base model.
|
||||
|
||||
```py
|
||||
pipeline.disable_lora()
|
||||
```
|
||||
|
||||
Learn more about how PEFT supports Diffusers in the [Inference with PEFT](https://huggingface.co/docs/diffusers/tutorials/using_peft_for_inference) tutorial.
|
||||
|
||||
## Transformers
|
||||
|
||||
🤗 [Transformers](https://hf.co/docs/transformers) is a collection of pretrained models for all types of tasks in all modalities. You can load these models for training or inference. Many of the models are large language models (LLMs), so it makes sense to integrate PEFT with Transformers to manage and train adapters.
|
||||
|
||||
Load a base pretrained model to train.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
|
||||
```
|
||||
|
||||
Next, add an adapter configuration to specify how to adapt the model parameters. Call the [`~PeftModel.add_adapter`] method to add the configuration to the base model.
|
||||
|
||||
```py
|
||||
from peft import LoraConfig
|
||||
|
||||
peft_config = LoraConfig(
|
||||
lora_alpha=16,
|
||||
lora_dropout=0.1,
|
||||
r=64,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM"
|
||||
)
|
||||
model.add_adapter(peft_config)
|
||||
```
|
||||
|
||||
Now you can train the model with Transformer's [`~transformers.Trainer`] class or whichever training framework you prefer.
|
||||
|
||||
To use the newly trained model for inference, the [`~transformers.AutoModel`] class uses PEFT on the backend to load the adapter weights and configuration file into a base pretrained model.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("peft-internal-testing/opt-350m-lora")
|
||||
```
|
||||
|
||||
Alternatively, you can use transformers [Pipelines](https://huggingface.co/docs/transformers/en/main_classes/pipelines) to load the model for conveniently running inference:
|
||||
|
||||
```py
|
||||
from transformers import pipeline
|
||||
|
||||
model = pipeline("text-generation", "peft-internal-testing/opt-350m-lora")
|
||||
print(model("Hello World"))
|
||||
```
|
||||
|
||||
If you're interested in comparing or using more than one adapter, you can call the [`~PeftModel.add_adapter`] method to add the adapter configuration to the base model. The only requirement is the adapter type must be the same (you can't mix a LoRA and LoHa adapter).
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
from peft import LoraConfig
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
|
||||
model.add_adapter(lora_config_1, adapter_name="adapter_1")
|
||||
```
|
||||
|
||||
Call [`~PeftModel.add_adapter`] again to attach a new adapter to the base model.
|
||||
|
||||
```py
|
||||
model.add_adapter(lora_config_2, adapter_name="adapter_2")
|
||||
```
|
||||
|
||||
Then you can use [`~PeftModel.set_adapter`] to set the currently active adapter.
|
||||
|
||||
```py
|
||||
model.set_adapter("adapter_1")
|
||||
output = model.generate(**inputs)
|
||||
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
|
||||
```
|
||||
|
||||
To disable the adapter, call the [disable_adapters](https://github.com/huggingface/transformers/blob/4e3490f79b40248c53ee54365a9662611e880892/src/transformers/integrations/peft.py#L313) method.
|
||||
|
||||
```py
|
||||
model.disable_adapters()
|
||||
```
|
||||
|
||||
The [enable_adapters](https://github.com/huggingface/transformers/blob/4e3490f79b40248c53ee54365a9662611e880892/src/transformers/integrations/peft.py#L336) can be used to enable the adapters again.
|
||||
|
||||
If you're curious, check out the [Load and train adapters with PEFT](https://huggingface.co/docs/transformers/main/peft) tutorial to learn more.
|
||||
182
docs/source/tutorial/peft_model_config.md
Normal file
182
docs/source/tutorial/peft_model_config.md
Normal file
@ -0,0 +1,182 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# PEFT configurations and models
|
||||
|
||||
The sheer size of today's large pretrained models - which commonly have billions of parameters - present a significant training challenge because they require more storage space and more computational power to crunch all those calculations. You'll need access to powerful GPUs or TPUs to train these large pretrained models which is expensive, not widely accessible to everyone, not environmentally friendly, and not very practical. PEFT methods address many of these challenges. There are several types of PEFT methods (soft prompting, matrix decomposition, adapters), but they all focus on the same thing, reduce the number of trainable parameters. This makes it more accessible to train and store large models on consumer hardware.
|
||||
|
||||
The PEFT library is designed to help you quickly train large models on free or low-cost GPUs, and in this tutorial, you'll learn how to setup a configuration to apply a PEFT method to a pretrained base model for training. Once the PEFT configuration is setup, you can use any training framework you like (Transformer's [`~transformers.Trainer`] class, [Accelerate](https://hf.co/docs/accelerate), a custom PyTorch training loop).
|
||||
|
||||
## PEFT configurations
|
||||
|
||||
<Tip>
|
||||
|
||||
Learn more about the parameters you can configure for each PEFT method in their respective API reference page.
|
||||
|
||||
</Tip>
|
||||
|
||||
A configuration stores important parameters that specify how a particular PEFT method should be applied.
|
||||
|
||||
For example, take a look at the following [`LoraConfig`](https://huggingface.co/ybelkada/opt-350m-lora/blob/main/adapter_config.json) for applying LoRA and [`PromptEncoderConfig`](https://huggingface.co/smangrul/roberta-large-peft-p-tuning/blob/main/adapter_config.json) for applying p-tuning (these configuration files are already JSON-serialized). Whenever you load a PEFT adapter, it is a good idea to check whether it has an associated adapter_config.json file which is required.
|
||||
|
||||
<hfoptions id="config">
|
||||
<hfoption id="LoraConfig">
|
||||
|
||||
```json
|
||||
{
|
||||
"base_model_name_or_path": "facebook/opt-350m", #base model to apply LoRA to
|
||||
"bias": "none",
|
||||
"fan_in_fan_out": false,
|
||||
"inference_mode": true,
|
||||
"init_lora_weights": true,
|
||||
"layers_pattern": null,
|
||||
"layers_to_transform": null,
|
||||
"lora_alpha": 32,
|
||||
"lora_dropout": 0.05,
|
||||
"modules_to_save": null,
|
||||
"peft_type": "LORA", #PEFT method type
|
||||
"r": 16,
|
||||
"revision": null,
|
||||
"target_modules": [
|
||||
"q_proj", #model modules to apply LoRA to (query and value projection layers)
|
||||
"v_proj"
|
||||
],
|
||||
"task_type": "CAUSAL_LM" #type of task to train model on
|
||||
}
|
||||
```
|
||||
|
||||
You can create your own configuration for training by initializing a [`LoraConfig`].
|
||||
|
||||
```py
|
||||
from peft import LoraConfig, TaskType
|
||||
|
||||
lora_config = LoraConfig(
|
||||
r=16,
|
||||
target_modules=["q_proj", "v_proj"],
|
||||
task_type=TaskType.CAUSAL_LM,
|
||||
lora_alpha=32,
|
||||
lora_dropout=0.05
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="PromptEncoderConfig">
|
||||
|
||||
```json
|
||||
{
|
||||
"base_model_name_or_path": "roberta-large", #base model to apply p-tuning to
|
||||
"encoder_dropout": 0.0,
|
||||
"encoder_hidden_size": 128,
|
||||
"encoder_num_layers": 2,
|
||||
"encoder_reparameterization_type": "MLP",
|
||||
"inference_mode": true,
|
||||
"num_attention_heads": 16,
|
||||
"num_layers": 24,
|
||||
"num_transformer_submodules": 1,
|
||||
"num_virtual_tokens": 20,
|
||||
"peft_type": "P_TUNING", #PEFT method type
|
||||
"task_type": "SEQ_CLS", #type of task to train model on
|
||||
"token_dim": 1024
|
||||
}
|
||||
```
|
||||
|
||||
You can create your own configuration for training by initializing a [`PromptEncoderConfig`].
|
||||
|
||||
```py
|
||||
from peft import PromptEncoderConfig, TaskType
|
||||
|
||||
p_tuning_config = PromptEncoderConfig(
|
||||
encoder_reprameterization_type="MLP",
|
||||
encoder_hidden_size=128,
|
||||
num_attention_heads=16,
|
||||
num_layers=24,
|
||||
num_transformer_submodules=1,
|
||||
num_virtual_tokens=20,
|
||||
token_dim=1024,
|
||||
task_type=TaskType.SEQ_CLS
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## PEFT models
|
||||
|
||||
With a PEFT configuration in hand, you can now apply it to any pretrained model to create a [`PeftModel`]. Choose from any of the state-of-the-art models from the [Transformers](https://hf.co/docs/transformers) library, a custom model, and even new and unsupported transformer architectures.
|
||||
|
||||
For this tutorial, load a base [facebook/opt-350m](https://huggingface.co/facebook/opt-350m) model to finetune.
|
||||
|
||||
```py
|
||||
from transformers import AutoModelForCausalLM
|
||||
|
||||
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
|
||||
```
|
||||
|
||||
Use the [`get_peft_model`] function to create a [`PeftModel`] from the base facebook/opt-350m model and the `lora_config` you created earlier.
|
||||
|
||||
```py
|
||||
from peft import get_peft_model
|
||||
|
||||
lora_model = get_peft_model(model, lora_config)
|
||||
lora_model.print_trainable_parameters()
|
||||
"trainable params: 1,572,864 || all params: 332,769,280 || trainable%: 0.472659014678278"
|
||||
```
|
||||
|
||||
Now you can train the [`PeftModel`] with your preferred training framework! After training, you can save your model locally with [`~PeftModel.save_pretrained`] or upload it to the Hub with the [`~transformers.PreTrainedModel.push_to_hub`] method.
|
||||
|
||||
```py
|
||||
# save locally
|
||||
lora_model.save_pretrained("your-name/opt-350m-lora")
|
||||
|
||||
# push to Hub
|
||||
lora_model.push_to_hub("your-name/opt-350m-lora")
|
||||
```
|
||||
|
||||
To load a [`PeftModel`] for inference, you'll need to provide the [`PeftConfig`] used to create it and the base model it was trained from.
|
||||
|
||||
```py
|
||||
from peft import PeftModel, PeftConfig
|
||||
|
||||
config = PeftConfig.from_pretrained("ybelkada/opt-350m-lora")
|
||||
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
|
||||
lora_model = PeftModel.from_pretrained(model, "ybelkada/opt-350m-lora")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
By default, the [`PeftModel`] is set for inference, but if you'd like to train the adapter some more you can set `is_trainable=True`.
|
||||
|
||||
```py
|
||||
lora_model = PeftModel.from_pretrained(model, "ybelkada/opt-350m-lora", is_trainable=True)
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
The [`PeftModel.from_pretrained`] method is the most flexible way to load a [`PeftModel`] because it doesn't matter what model framework was used (Transformers, timm, a generic PyTorch model). Other classes, like [`AutoPeftModel`], are just a convenient wrapper around the base [`PeftModel`], and makes it easier to load PEFT models directly from the Hub or locally where the PEFT weights are stored.
|
||||
|
||||
```py
|
||||
from peft import AutoPeftModelForCausalLM
|
||||
|
||||
lora_model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora")
|
||||
```
|
||||
|
||||
Take a look at the [AutoPeftModel](package_reference/auto_class) API reference to learn more about the [`AutoPeftModel`] classes.
|
||||
|
||||
## Next steps
|
||||
|
||||
With the appropriate [`PeftConfig`], you can apply it to any pretrained model to create a [`PeftModel`] and train large powerful models faster on freely available GPUs! To learn more about PEFT configurations and models, the following guide may be helpful:
|
||||
|
||||
* Learn how to configure a PEFT method for models that aren't from Transformers in the [Working with custom models](../developer_guides/custom_models) guide.
|
||||
0
examples/boft_controlnet/__init__.py
Normal file
0
examples/boft_controlnet/__init__.py
Normal file
177
examples/boft_controlnet/boft_controlnet.md
Normal file
177
examples/boft_controlnet/boft_controlnet.md
Normal file
@ -0,0 +1,177 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
|
||||
# Fine-tuning for controllable generation with BOFT (ControlNet)
|
||||
|
||||
This guide demonstrates how to use BOFT, an orthogonal fine-tuning method, to fine-tune Stable Diffusion with either `stabilityai/stable-diffusion-2-1` or `runwayml/stable-diffusion-v1-5` model for controllable generation.
|
||||
|
||||
By using BOFT from 🤗 PEFT, we can significantly reduce the number of trainable parameters while still achieving impressive results in various fine-tuning tasks across different foundation models. BOFT enhances model efficiency by integrating full-rank orthogonal matrices with a butterfly structure into specific model blocks, such as attention blocks, mirroring the approach used in LoRA. During fine-tuning, only these inserted matrices are trained, leaving the original model parameters untouched. During inference, the trainable BOFT paramteres can be merged into the original model, eliminating any additional computational costs.
|
||||
|
||||
As a member of the **orthogonal finetuning** class, BOFT presents a systematic and principled method for fine-tuning. It possesses several unique properties and has demonstrated superior performance compared to LoRA in a variety of scenarios. For further details on BOFT, please consult the [PEFT's GitHub repo's concept guide OFT](https://https://huggingface.co/docs/peft/index), the [original BOFT paper](https://arxiv.org/abs/2311.06243) and the [original OFT paper](https://arxiv.org/abs/2306.07280).
|
||||
|
||||
In this guide we provide a controllable generation (ControlNet) fine-tuning script that is available in [PEFT's GitHub repo examples](https://github.com/huggingface/peft/tree/main/examples/boft_controlnet). This implementation is adapted from [diffusers's ControlNet](https://github.com/huggingface/diffusers/tree/main/examples/controlnet) and [Hecong Wu's ControlLoRA](https://github.com/HighCWu/ControlLoRA). You can try it out and finetune on your custom images.
|
||||
|
||||
## Set up your environment
|
||||
Start by cloning the PEFT repository:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/peft
|
||||
```
|
||||
|
||||
Navigate to the directory containing the training scripts for fine-tuning Dreambooth with BOFT:
|
||||
```bash
|
||||
cd peft/examples/boft_controlnet
|
||||
```
|
||||
|
||||
Set up your environment: install PEFT, and all the required libraries. At the time of writing this guide we recommend installing PEFT from source.
|
||||
|
||||
```bash
|
||||
conda create --name peft python=3.10
|
||||
conda activate peft
|
||||
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia
|
||||
conda install xformers -c xformers
|
||||
pip install -r requirements.txt
|
||||
pip install git+https://github.com/huggingface/peft
|
||||
```
|
||||
|
||||
## Data
|
||||
|
||||
We use the [control-celeba-hq](https://huggingface.co/datasets/oftverse/control-celeba-hq) dataset for landmark-to-face controllable generation. We also provide evaluation scripts to evaluate the controllable generation performance. This task can be used to quantitatively compare different fine-tuning techniques.
|
||||
|
||||
```bash
|
||||
export DATASET_NAME="oftverse/control-celeba-hq"
|
||||
```
|
||||
|
||||
## Train controllable generation (ControlNet) with BOFT
|
||||
|
||||
Start with setting some hyperparamters for BOFT:
|
||||
```bash
|
||||
PEFT_TYPE="boft"
|
||||
BLOCK_NUM=8
|
||||
BLOCK_SIZE=0
|
||||
N_BUTTERFLY_FACTOR=0
|
||||
```
|
||||
|
||||
Here:
|
||||
|
||||
|
||||
Navigate to the directory containing the training scripts for fine-tuning Stable Diffusion with BOFT for controllable generation:
|
||||
|
||||
```bash
|
||||
./train_controlnet.sh
|
||||
```
|
||||
or
|
||||
```bash
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
|
||||
export DATASET_NAME="oftverse/control-celeba-hq"
|
||||
export PROJECT_NAME="controlnet_${PEFT_TYPE}"
|
||||
export RUN_NAME="${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
export CONTROLNET_PATH=""
|
||||
export OUTPUT_DIR="./output/${DATASET_NAME}/${RUN_NAME}"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--resume_from_checkpoint=$RESUME_PATH \
|
||||
--controlnet_model_name_or_path=$CONTROLNET_PATH \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--report_to="wandb" \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--checkpointing_steps=5000 \
|
||||
--max_train_steps=50000 \
|
||||
--validation_steps=2000 \
|
||||
--num_validation_images=12 \
|
||||
--train_batch_size=4 \
|
||||
--dataloader_num_workers=2 \
|
||||
--seed="0" \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--wandb_project_name=$PROJECT_NAME \
|
||||
--wandb_run_name=$RUN_NAME \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--use_boft \
|
||||
--boft_block_num=$BLOCK_NUM \
|
||||
--boft_block_size=$BLOCK_SIZE \
|
||||
--boft_n_butterfly_factor=$N_BUTTERFLY_FACTOR \
|
||||
--boft_dropout=0.1 \
|
||||
--boft_bias="boft_only" \
|
||||
--report_to="wandb" \
|
||||
```
|
||||
|
||||
Run inference on the saved model to sample new images from the validation set:
|
||||
|
||||
```bash
|
||||
./test_controlnet.sh
|
||||
```
|
||||
or
|
||||
```bash
|
||||
ITER_NUM=50000
|
||||
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
|
||||
export RUN_NAME="${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
export DATASET_NAME="oftverse/control-celeba-hq"
|
||||
export CKPT_NAME="checkpoint-${ITER_NUM}"
|
||||
export OUTPUT_DIR="./output/${DATASET_NAME}/${RUN_NAME}/${CKPT_NAME}"
|
||||
export CONTROLNET_PATH="${OUTPUT_DIR}/controlnet/model.safetensors"
|
||||
export UNET_PATH="${OUTPUT_DIR}/unet/${RUN_NAME}"
|
||||
export RESULTS_PATH="${OUTPUT_DIR}/results"
|
||||
|
||||
accelerate launch test_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--controlnet_path=$CONTROLNET_PATH \
|
||||
--unet_path=$UNET_PATH \
|
||||
--adapter_name=$RUN_NAME \
|
||||
--output_dir=$RESULTS_PATH \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
|
||||
```
|
||||
|
||||
Run evaluation on the sampled images to evaluate the landmark reprojection error:
|
||||
|
||||
```bash
|
||||
./eval.sh
|
||||
```
|
||||
or
|
||||
```bash
|
||||
ITER_NUM=50000
|
||||
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
|
||||
export RUN_NAME="${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
export DATASET_NAME="oftverse/control-celeba-hq"
|
||||
export CKPT_NAME="checkpoint-${ITER_NUM}"
|
||||
export OUTPUT_DIR="./output/${DATASET_NAME}/${RUN_NAME}/${CKPT_NAME}"
|
||||
export CONTROLNET_PATH="${OUTPUT_DIR}/controlnet/model.safetensors"
|
||||
export UNET_PATH="${OUTPUT_DIR}/unet/${RUN_NAME}"
|
||||
|
||||
accelerate launch eval.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--controlnet_path=$CONTROLNET_PATH \
|
||||
--unet_path=$UNET_PATH \
|
||||
--adapter_name=$RUN_NAME \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--vis_overlays \
|
||||
```
|
||||
200
examples/boft_controlnet/eval.py
Normal file
200
examples/boft_controlnet/eval.py
Normal file
@ -0,0 +1,200 @@
|
||||
# Copyright 2023-present the HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# The implementation is based on "Parameter-Efficient Orthogonal Finetuning
|
||||
# via Butterfly Factorization" (https://arxiv.org/abs/2311.06243) in ICLR 2024.
|
||||
|
||||
import glob
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import cv2
|
||||
import face_alignment
|
||||
import numpy as np
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from skimage.io import imread
|
||||
from torchvision.utils import save_image
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoTokenizer
|
||||
from utils.args_loader import parse_args
|
||||
from utils.dataset import make_dataset
|
||||
|
||||
|
||||
detect_model = face_alignment.FaceAlignment(face_alignment.LandmarksType.TWO_D, device="cuda:0", flip_input=False)
|
||||
|
||||
# with open('./data/celebhq-text/prompt_val_blip_full.json', 'rt') as f: # fill50k, COCO
|
||||
# for line in f:
|
||||
# val_data = json.loads(line)
|
||||
|
||||
end_list = np.array([17, 22, 27, 42, 48, 31, 36, 68], dtype=np.int32) - 1
|
||||
|
||||
|
||||
def count_txt_files(directory):
|
||||
pattern = os.path.join(directory, "*.txt")
|
||||
txt_files = glob.glob(pattern)
|
||||
return len(txt_files)
|
||||
|
||||
|
||||
def plot_kpts(image, kpts, color="g"):
|
||||
"""Draw 68 key points
|
||||
Args:
|
||||
image: the input image
|
||||
kpt: (68, 3).
|
||||
"""
|
||||
if color == "r":
|
||||
c = (255, 0, 0)
|
||||
elif color == "g":
|
||||
c = (0, 255, 0)
|
||||
elif color == "b":
|
||||
c = (255, 0, 0)
|
||||
image = image.copy()
|
||||
kpts = kpts.copy()
|
||||
radius = max(int(min(image.shape[0], image.shape[1]) / 200), 1)
|
||||
for i in range(kpts.shape[0]):
|
||||
st = kpts[i, :2]
|
||||
if kpts.shape[1] == 4:
|
||||
if kpts[i, 3] > 0.5:
|
||||
c = (0, 255, 0)
|
||||
else:
|
||||
c = (0, 0, 255)
|
||||
image = cv2.circle(image, (int(st[0]), int(st[1])), radius, c, radius * 2)
|
||||
if i in end_list:
|
||||
continue
|
||||
ed = kpts[i + 1, :2]
|
||||
image = cv2.line(image, (int(st[0]), int(st[1])), (int(ed[0]), int(ed[1])), (255, 255, 255), radius)
|
||||
return image
|
||||
|
||||
|
||||
def generate_landmark2d(dataset, input_dir, pred_lmk_dir, gt_lmk_dir, vis=False):
|
||||
print("Generate 2d landmarks ...")
|
||||
os.makedirs(pred_lmk_dir, exist_ok=True)
|
||||
|
||||
imagepath_list = sorted(glob.glob(f"{input_dir}/pred*.png"))
|
||||
|
||||
for imagepath in tqdm(imagepath_list):
|
||||
name = Path(imagepath).stem
|
||||
idx = int(name.split("_")[-1])
|
||||
pred_txt_path = os.path.join(pred_lmk_dir, f"{idx}.txt")
|
||||
gt_lmk_path = os.path.join(gt_lmk_dir, f"{idx}_gt_lmk.jpg")
|
||||
gt_txt_path = os.path.join(gt_lmk_dir, f"{idx}.txt")
|
||||
gt_img_path = os.path.join(gt_lmk_dir, f"{idx}_gt_img.jpg")
|
||||
|
||||
if (not os.path.exists(pred_txt_path)) or (not os.path.exists(gt_txt_path)):
|
||||
image = imread(imagepath) # [:, :, :3]
|
||||
out = detect_model.get_landmarks(image)
|
||||
if out is None:
|
||||
continue
|
||||
|
||||
pred_kpt = out[0].squeeze()
|
||||
np.savetxt(pred_txt_path, pred_kpt)
|
||||
|
||||
# Your existing code for obtaining the image tensor
|
||||
gt_lmk_img = dataset[idx]["conditioning_pixel_values"]
|
||||
save_image(gt_lmk_img, gt_lmk_path)
|
||||
|
||||
gt_img = (dataset[idx]["pixel_values"]) * 0.5 + 0.5
|
||||
save_image(gt_img, gt_img_path)
|
||||
|
||||
gt_img = (gt_img.permute(1, 2, 0) * 255).type(torch.uint8).cpu().numpy()
|
||||
out = detect_model.get_landmarks(gt_img)
|
||||
if out is None:
|
||||
continue
|
||||
|
||||
gt_kpt = out[0].squeeze()
|
||||
np.savetxt(gt_txt_path, gt_kpt)
|
||||
# gt_image = cv2.resize(cv2.imread(gt_lmk_path), (512, 512))
|
||||
|
||||
if vis:
|
||||
gt_lmk_image = cv2.imread(gt_lmk_path)
|
||||
|
||||
# visualize predicted landmarks
|
||||
vis_path = os.path.join(pred_lmk_dir, f"{idx}_overlay.jpg")
|
||||
image = cv2.imread(imagepath)
|
||||
image_point = plot_kpts(image, pred_kpt)
|
||||
cv2.imwrite(vis_path, np.concatenate([image_point, gt_lmk_image], axis=1))
|
||||
|
||||
# visualize gt landmarks
|
||||
vis_path = os.path.join(gt_lmk_dir, f"{idx}_overlay.jpg")
|
||||
image = cv2.imread(gt_img_path)
|
||||
image_point = plot_kpts(image, gt_kpt)
|
||||
cv2.imwrite(vis_path, np.concatenate([image_point, gt_lmk_image], axis=1))
|
||||
|
||||
|
||||
def landmark_comparison(val_dataset, lmk_dir, gt_lmk_dir):
|
||||
print("Calculating reprojection error")
|
||||
lmk_err = []
|
||||
|
||||
pbar = tqdm(range(len(val_dataset)))
|
||||
for i in pbar:
|
||||
# line = val_dataset[i]
|
||||
# img_name = line["image"].split(".")[0]
|
||||
lmk1_path = os.path.join(gt_lmk_dir, f"{i}.txt")
|
||||
lmk1 = np.loadtxt(lmk1_path)
|
||||
lmk2_path = os.path.join(lmk_dir, f"{i}.txt")
|
||||
|
||||
if not os.path.exists(lmk2_path):
|
||||
print(f"{lmk2_path} not exist")
|
||||
continue
|
||||
|
||||
lmk2 = np.loadtxt(lmk2_path)
|
||||
lmk_err.append(np.mean(np.linalg.norm(lmk1 - lmk2, axis=1)))
|
||||
pbar.set_description(f"lmk_err: {np.mean(lmk_err):.5f}")
|
||||
|
||||
print("Reprojection error:", np.mean(lmk_err))
|
||||
np.save(os.path.join(lmk_dir, "lmk_err.npy"), lmk_err)
|
||||
|
||||
|
||||
def main(args):
|
||||
logging_dir = Path(args.output_dir, args.logging_dir)
|
||||
|
||||
accelerator = Accelerator(
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
mixed_precision=args.mixed_precision,
|
||||
log_with=args.report_to,
|
||||
project_dir=logging_dir,
|
||||
)
|
||||
|
||||
# Load the tokenizer
|
||||
if args.tokenizer_name:
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
|
||||
elif args.pretrained_model_name_or_path:
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
subfolder="tokenizer",
|
||||
revision=args.revision,
|
||||
use_fast=False,
|
||||
)
|
||||
|
||||
val_dataset = make_dataset(args, tokenizer, accelerator, "test")
|
||||
|
||||
gt_lmk_dir = os.path.join(args.output_dir, "gt_lmk")
|
||||
if not os.path.exists(gt_lmk_dir):
|
||||
os.makedirs(gt_lmk_dir, exist_ok=True)
|
||||
|
||||
pred_lmk_dir = os.path.join(args.output_dir, "pred_lmk")
|
||||
if not os.path.exists(pred_lmk_dir):
|
||||
os.makedirs(pred_lmk_dir, exist_ok=True)
|
||||
|
||||
input_dir = os.path.join(args.output_dir, "results")
|
||||
|
||||
generate_landmark2d(val_dataset, input_dir, pred_lmk_dir, gt_lmk_dir, args.vis_overlays)
|
||||
|
||||
if count_txt_files(pred_lmk_dir) == len(val_dataset) and count_txt_files(gt_lmk_dir) == len(val_dataset):
|
||||
landmark_comparison(val_dataset, pred_lmk_dir, gt_lmk_dir)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_args()
|
||||
main(args)
|
||||
29
examples/boft_controlnet/eval.sh
Executable file
29
examples/boft_controlnet/eval.sh
Executable file
@ -0,0 +1,29 @@
|
||||
PEFT_TYPE="boft"
|
||||
BLOCK_NUM=8
|
||||
BLOCK_SIZE=0
|
||||
N_BUTTERFLY_FACTOR=1
|
||||
ITER_NUM=50000
|
||||
|
||||
export RUN_NAME="${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
|
||||
export DATASET_NAME="oftverse/control-celeba-hq"
|
||||
export CKPT_NAME="checkpoint-${ITER_NUM}"
|
||||
export OUTPUT_DIR="./output/${DATASET_NAME}/${RUN_NAME}/${CKPT_NAME}"
|
||||
export CONTROLNET_PATH="${OUTPUT_DIR}/controlnet/model.safetensors"
|
||||
export UNET_PATH="${OUTPUT_DIR}/unet/${RUN_NAME}"
|
||||
|
||||
|
||||
accelerate launch eval.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--controlnet_path=$CONTROLNET_PATH \
|
||||
--unet_path=$UNET_PATH \
|
||||
--adapter_name=$RUN_NAME \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--vis_overlays \
|
||||
|
||||
|
||||
8
examples/boft_controlnet/requirements.txt
Normal file
8
examples/boft_controlnet/requirements.txt
Normal file
@ -0,0 +1,8 @@
|
||||
datasets==2.16.1
|
||||
diffusers==0.17.1
|
||||
transformers==4.36.2
|
||||
accelerate==0.25.0
|
||||
wandb==0.16.1
|
||||
scikit-image==0.22.0
|
||||
opencv-python==4.9.0.80
|
||||
face-alignment==1.4.1
|
||||
129
examples/boft_controlnet/test_controlnet.py
Normal file
129
examples/boft_controlnet/test_controlnet.py
Normal file
@ -0,0 +1,129 @@
|
||||
# Copyright 2023-present the HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# The implementation is based on "Parameter-Efficient Orthogonal Finetuning
|
||||
# via Butterfly Factorization" (https://arxiv.org/abs/2311.06243) in ICLR 2024.
|
||||
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
from pathlib import Path
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.utils.checkpoint
|
||||
from accelerate import Accelerator
|
||||
from diffusers import DDIMScheduler
|
||||
from diffusers.utils import check_min_version
|
||||
from safetensors.torch import load_file
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoTokenizer
|
||||
from utils.args_loader import parse_args
|
||||
from utils.dataset import make_dataset
|
||||
from utils.light_controlnet import ControlNetModel
|
||||
from utils.pipeline_controlnet import LightControlNetPipeline
|
||||
from utils.unet_2d_condition import UNet2DConditionNewModel
|
||||
|
||||
|
||||
sys.path.append("../../src")
|
||||
from peft import PeftModel
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.10.0.dev0")
|
||||
device = torch.device("cuda:0")
|
||||
|
||||
|
||||
def main(args):
|
||||
logging_dir = Path(args.output_dir, args.logging_dir)
|
||||
|
||||
accelerator = Accelerator(
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
mixed_precision=args.mixed_precision,
|
||||
log_with=args.report_to,
|
||||
project_dir=logging_dir,
|
||||
)
|
||||
|
||||
# Load the tokenizer
|
||||
if args.tokenizer_name:
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
|
||||
elif args.pretrained_model_name_or_path:
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
subfolder="tokenizer",
|
||||
revision=args.revision,
|
||||
use_fast=False,
|
||||
)
|
||||
|
||||
val_dataset = make_dataset(args, tokenizer, accelerator, "test")
|
||||
|
||||
controlnet_path = args.controlnet_path
|
||||
unet_path = args.unet_path
|
||||
|
||||
controlnet = ControlNetModel()
|
||||
controlnet.load_state_dict(load_file(controlnet_path))
|
||||
unet = UNet2DConditionNewModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
|
||||
unet = PeftModel.from_pretrained(unet, unet_path, adapter_name=args.adapter_name)
|
||||
|
||||
pipe = LightControlNetPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
controlnet=controlnet,
|
||||
unet=unet.model,
|
||||
torch_dtype=torch.float32,
|
||||
requires_safety_checker=False,
|
||||
).to(device)
|
||||
|
||||
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
if not os.path.exists(args.output_dir):
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
exist_lst = [int(img.split("_")[-1][:-4]) for img in os.listdir(args.output_dir)]
|
||||
all_lst = np.arange(len(val_dataset))
|
||||
idx_lst = [item for item in all_lst if item not in exist_lst]
|
||||
|
||||
print("Number of images to be processed: ", len(idx_lst))
|
||||
|
||||
np.random.seed(seed=int(time.time()))
|
||||
np.random.shuffle(idx_lst)
|
||||
|
||||
for idx in tqdm(idx_lst):
|
||||
output_path = os.path.join(args.output_dir, f"pred_img_{idx:04d}.png")
|
||||
|
||||
if not os.path.exists(output_path):
|
||||
data = val_dataset[idx.item()]
|
||||
negative_prompt = "low quality, blurry, unfinished"
|
||||
|
||||
with torch.no_grad():
|
||||
pred_img = pipe(
|
||||
data["text"],
|
||||
[data["conditioning_pixel_values"]],
|
||||
num_inference_steps=50,
|
||||
guidance_scale=7,
|
||||
negative_prompt=negative_prompt,
|
||||
).images[0]
|
||||
|
||||
pred_img.save(output_path)
|
||||
|
||||
# control_img = Image.fromarray(
|
||||
# (data["conditioning_pixel_value"] * 255).numpy().transpose(1, 2, 0).astype(np.uint8)
|
||||
# )
|
||||
# gt_img = Image.fromarray(
|
||||
# ((data["pixel_value"] + 1.0) * 0.5 * 255).numpy().transpose(1, 2, 0).astype(np.uint8)
|
||||
# )
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_args()
|
||||
main(args)
|
||||
29
examples/boft_controlnet/test_controlnet.sh
Executable file
29
examples/boft_controlnet/test_controlnet.sh
Executable file
@ -0,0 +1,29 @@
|
||||
PEFT_TYPE="boft"
|
||||
BLOCK_NUM=8
|
||||
BLOCK_SIZE=0
|
||||
N_BUTTERFLY_FACTOR=1
|
||||
ITER_NUM=50000
|
||||
|
||||
export RUN_NAME="${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
|
||||
export DATASET_NAME="oftverse/control-celeba-hq"
|
||||
export CKPT_NAME="checkpoint-${ITER_NUM}"
|
||||
export OUTPUT_DIR="./output/${DATASET_NAME}/${RUN_NAME}/${CKPT_NAME}"
|
||||
export CONTROLNET_PATH="${OUTPUT_DIR}/controlnet/model.safetensors"
|
||||
export UNET_PATH="${OUTPUT_DIR}/unet/${RUN_NAME}"
|
||||
export RESULTS_PATH="${OUTPUT_DIR}/results"
|
||||
|
||||
|
||||
accelerate launch test_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--controlnet_path=$CONTROLNET_PATH \
|
||||
--unet_path=$UNET_PATH \
|
||||
--adapter_name=$RUN_NAME \
|
||||
--output_dir=$RESULTS_PATH \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
|
||||
|
||||
537
examples/boft_controlnet/train_controlnet.py
Normal file
537
examples/boft_controlnet/train_controlnet.py
Normal file
@ -0,0 +1,537 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright 2023-present the HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# The implementation is based on "Parameter-Efficient Orthogonal Finetuning
|
||||
# via Butterfly Factorization" (https://arxiv.org/abs/2311.06243) in ICLR 2024.
|
||||
|
||||
import itertools
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import datasets
|
||||
import diffusers
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
import transformers
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.utils import set_seed
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDIMScheduler,
|
||||
)
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import check_min_version
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
from packaging import version
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import AutoTokenizer
|
||||
from utils.args_loader import (
|
||||
import_model_class_from_model_name_or_path,
|
||||
parse_args,
|
||||
)
|
||||
from utils.dataset import collate_fn, log_validation, make_dataset
|
||||
from utils.light_controlnet import ControlNetModel
|
||||
from utils.tracemalloc import TorchTracemalloc, b2mb
|
||||
from utils.unet_2d_condition import UNet2DConditionNewModel
|
||||
|
||||
from peft import BOFTConfig, get_peft_model
|
||||
from peft.peft_model import PeftModel
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.16.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
UNET_TARGET_MODULES = ["to_q", "to_v", "to_k", "query", "value", "key"]
|
||||
|
||||
TEXT_ENCODER_TARGET_MODULES = ["q_proj", "v_proj"]
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def save_adaptor(accelerator, output_dir, nets_dict):
|
||||
for net_key in nets_dict.keys():
|
||||
net_model = nets_dict[net_key]
|
||||
unwarpped_net = accelerator.unwrap_model(net_model)
|
||||
|
||||
if isinstance(unwarpped_net, PeftModel):
|
||||
unwarpped_net.save_pretrained(
|
||||
os.path.join(output_dir, net_key),
|
||||
state_dict=accelerator.get_state_dict(net_model),
|
||||
safe_serialization=True,
|
||||
)
|
||||
else:
|
||||
accelerator.save_model(
|
||||
unwarpped_net,
|
||||
os.path.join(output_dir, net_key),
|
||||
safe_serialization=True,
|
||||
)
|
||||
|
||||
|
||||
def main(args):
|
||||
logging_dir = Path(args.output_dir, args.logging_dir)
|
||||
|
||||
accelerator = Accelerator(
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
mixed_precision=args.mixed_precision,
|
||||
log_with=args.report_to,
|
||||
project_dir=logging_dir,
|
||||
)
|
||||
|
||||
if args.report_to == "wandb":
|
||||
wandb_init = {
|
||||
"wandb": {
|
||||
"name": args.wandb_run_name,
|
||||
"mode": "online",
|
||||
}
|
||||
}
|
||||
|
||||
# Make one log on every process with the configuration for debugging.
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
||||
datefmt="%m/%d/%Y %H:%M:%S",
|
||||
level=logging.INFO,
|
||||
)
|
||||
|
||||
logger.info(accelerator.state, main_process_only=False)
|
||||
|
||||
if accelerator.is_local_main_process:
|
||||
datasets.utils.logging.set_verbosity_warning()
|
||||
transformers.utils.logging.set_verbosity_warning()
|
||||
diffusers.utils.logging.set_verbosity_info()
|
||||
else:
|
||||
datasets.utils.logging.set_verbosity_error()
|
||||
transformers.utils.logging.set_verbosity_error()
|
||||
diffusers.utils.logging.set_verbosity_error()
|
||||
|
||||
# If passed along, set the training seed now.
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed)
|
||||
|
||||
# Handle the repository creation
|
||||
if accelerator.is_main_process:
|
||||
if args.output_dir is not None:
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
# Load the tokenizer
|
||||
if args.tokenizer_name:
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
|
||||
elif args.pretrained_model_name_or_path:
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
subfolder="tokenizer",
|
||||
revision=args.revision,
|
||||
use_fast=False,
|
||||
)
|
||||
|
||||
# import correct text encoder class
|
||||
text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
|
||||
|
||||
# Load scheduler and models
|
||||
noise_scheduler = DDIMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
|
||||
text_encoder = text_encoder_cls.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
|
||||
unet = UNet2DConditionNewModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
subfolder="unet",
|
||||
revision=args.revision,
|
||||
)
|
||||
|
||||
controlnet = ControlNetModel()
|
||||
|
||||
if args.controlnet_model_name_or_path != "":
|
||||
logger.info(f"Loading existing controlnet weights from {args.controlnet_model_name_or_path}")
|
||||
controlnet.load_state_dict(torch.load(args.controlnet_model_name_or_path))
|
||||
|
||||
if args.use_boft:
|
||||
config = BOFTConfig(
|
||||
boft_block_size=args.boft_block_size,
|
||||
boft_block_num=args.boft_block_num,
|
||||
boft_n_butterfly_factor=args.boft_n_butterfly_factor,
|
||||
target_modules=UNET_TARGET_MODULES,
|
||||
boft_dropout=args.boft_dropout,
|
||||
bias=args.boft_bias,
|
||||
)
|
||||
unet = get_peft_model(unet, config)
|
||||
unet.print_trainable_parameters()
|
||||
|
||||
vae.requires_grad_(False)
|
||||
controlnet.requires_grad_(True)
|
||||
|
||||
if not args.train_text_encoder:
|
||||
text_encoder.requires_grad_(False)
|
||||
|
||||
unet.train()
|
||||
controlnet.train()
|
||||
|
||||
if args.train_text_encoder and args.use_boft:
|
||||
config = BOFTConfig(
|
||||
boft_block_size=args.boft_block_size,
|
||||
boft_block_num=args.boft_block_num,
|
||||
boft_n_butterfly_factor=args.boft_n_butterfly_factor,
|
||||
target_modules=TEXT_ENCODER_TARGET_MODULES,
|
||||
boft_dropout=args.boft_dropout,
|
||||
bias=args.boft_bias,
|
||||
)
|
||||
text_encoder = get_peft_model(text_encoder, config, adapter_name=args.wandb_run_name)
|
||||
text_encoder.print_trainable_parameters()
|
||||
|
||||
if args.train_text_encoder:
|
||||
text_encoder.train()
|
||||
|
||||
# For mixed precision training we cast the text_encoder and vae weights to half-precision
|
||||
# as these models are only used for inference, keeping weights in full precision is not required.
|
||||
weight_dtype = torch.float32
|
||||
if accelerator.mixed_precision == "fp16":
|
||||
weight_dtype = torch.float16
|
||||
elif accelerator.mixed_precision == "bf16":
|
||||
weight_dtype = torch.bfloat16
|
||||
|
||||
# Move unet, vae and text_encoder to device and cast to weight_dtype
|
||||
unet.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
controlnet.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
if not args.train_text_encoder:
|
||||
text_encoder.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
if is_xformers_available():
|
||||
import xformers
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warning(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
controlnet.enable_xformers_memory_efficient_attention()
|
||||
if args.train_text_encoder and not (args.use_lora or args.use_boft or args.use_oft):
|
||||
text_encoder.enable_xformers_memory_efficient_attention()
|
||||
else:
|
||||
raise ValueError("xformers is not available. Make sure it is installed correctly")
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
controlnet.enable_gradient_checkpointing()
|
||||
unet.enable_gradient_checkpointing()
|
||||
if args.train_text_encoder and not (args.use_lora or args.use_boft or args.use_oft):
|
||||
text_encoder.gradient_checkpointing_enable()
|
||||
|
||||
# Check that all trainable models are in full precision
|
||||
low_precision_error_string = (
|
||||
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
|
||||
" doing mixed precision training, copy of the weights should still be float32."
|
||||
)
|
||||
|
||||
if accelerator.unwrap_model(controlnet).dtype != torch.float32:
|
||||
raise ValueError(
|
||||
f"Controlnet loaded as datatype {accelerator.unwrap_model(controlnet).dtype}. {low_precision_error_string}"
|
||||
)
|
||||
|
||||
if accelerator.unwrap_model(unet).dtype != torch.float32:
|
||||
raise ValueError(
|
||||
f"UNet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
|
||||
)
|
||||
|
||||
# Enable TF32 for faster training on Ampere GPUs,
|
||||
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
|
||||
if args.allow_tf32:
|
||||
torch.backends.cuda.matmul.allow_tf32 = True
|
||||
|
||||
if args.scale_lr:
|
||||
args.learning_rate = (
|
||||
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
|
||||
)
|
||||
|
||||
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
|
||||
if args.use_8bit_adam:
|
||||
try:
|
||||
import bitsandbytes as bnb
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
|
||||
)
|
||||
|
||||
optimizer_class = bnb.optim.AdamW8bit
|
||||
else:
|
||||
optimizer_class = torch.optim.AdamW
|
||||
|
||||
params_to_optimize = [param for param in controlnet.parameters() if param.requires_grad]
|
||||
params_to_optimize += [param for param in unet.parameters() if param.requires_grad]
|
||||
|
||||
if args.train_text_encoder:
|
||||
params_to_optimize += [param for param in text_encoder.parameters() if param.requires_grad]
|
||||
|
||||
# Optimizer creation
|
||||
optimizer = optimizer_class(
|
||||
params_to_optimize,
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
# Load the dataset
|
||||
train_dataset = make_dataset(args, tokenizer, accelerator, "train")
|
||||
val_dataset = make_dataset(args, tokenizer, accelerator, "test")
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset,
|
||||
shuffle=True,
|
||||
collate_fn=collate_fn,
|
||||
batch_size=args.train_batch_size,
|
||||
num_workers=args.dataloader_num_workers,
|
||||
)
|
||||
|
||||
# Scheduler and math around the number of training steps.
|
||||
overrode_max_train_steps = False
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
if args.max_train_steps is None:
|
||||
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
|
||||
overrode_max_train_steps = True
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
args.lr_scheduler,
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
|
||||
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
|
||||
num_cycles=args.lr_num_cycles,
|
||||
power=args.lr_power,
|
||||
)
|
||||
|
||||
# Prepare everything with our `accelerator`.
|
||||
controlnet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
controlnet, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
if args.train_text_encoder:
|
||||
text_encoder = accelerator.prepare(text_encoder)
|
||||
|
||||
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
if overrode_max_train_steps:
|
||||
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
|
||||
# Afterwards we recalculate our number of training epochs
|
||||
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
# The trackers initializes automatically on the main process.
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers(args.wandb_project_name, config=vars(args), init_kwargs=wandb_init)
|
||||
|
||||
# Train!
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataset)}")
|
||||
logger.info(f" Num batches each epoch = {len(train_dataloader)}")
|
||||
logger.info(f" Num Epochs = {args.num_train_epochs}")
|
||||
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
|
||||
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
|
||||
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
|
||||
logger.info(f" Total optimization steps = {args.max_train_steps}")
|
||||
|
||||
global_step = 0
|
||||
first_epoch = 0
|
||||
|
||||
# Potentially load in the weights and states from a previous save
|
||||
|
||||
if args.resume_from_checkpoint:
|
||||
if args.resume_from_checkpoint != "latest":
|
||||
path = os.path.basename(args.resume_from_checkpoint)
|
||||
else:
|
||||
# Get the most recent checkpoint
|
||||
dirs = os.listdir(args.output_dir)
|
||||
if "checkpoint-current" in dirs:
|
||||
path = "checkpoint-current"
|
||||
dirs = [d for d in dirs if d.startswith("checkpoint") and d.endswith("0")]
|
||||
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
|
||||
|
||||
else:
|
||||
dirs = [d for d in dirs if d.startswith("checkpoint")]
|
||||
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
|
||||
path = dirs[-1] if len(dirs) > 0 else None
|
||||
|
||||
if path is None:
|
||||
accelerator.print(
|
||||
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
|
||||
)
|
||||
args.resume_from_checkpoint = None
|
||||
initial_global_step = 0
|
||||
else:
|
||||
accelerator.print(f"Resuming from checkpoint {path}")
|
||||
accelerator.load_state(os.path.join(args.output_dir, path))
|
||||
if path.split("-")[1] == "current":
|
||||
global_step = int(dirs[-1].split("-")[1])
|
||||
else:
|
||||
global_step = int(path.split("-")[1])
|
||||
|
||||
initial_global_step = global_step
|
||||
resume_global_step = global_step * args.gradient_accumulation_steps
|
||||
first_epoch = global_step // num_update_steps_per_epoch
|
||||
resume_step = resume_global_step % (num_update_steps_per_epoch * args.gradient_accumulation_steps)
|
||||
else:
|
||||
initial_global_step = 0
|
||||
|
||||
progress_bar = tqdm(
|
||||
range(0, args.max_train_steps),
|
||||
initial=initial_global_step,
|
||||
desc="Steps",
|
||||
disable=not accelerator.is_local_main_process,
|
||||
)
|
||||
|
||||
progress_bar.set_description("Steps")
|
||||
|
||||
for epoch in range(first_epoch, args.num_train_epochs):
|
||||
with TorchTracemalloc() as tracemalloc:
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
# Skip steps until we reach the resumed step
|
||||
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
|
||||
if step % args.gradient_accumulation_steps == 0:
|
||||
progress_bar.update(1)
|
||||
if args.report_to == "wandb":
|
||||
accelerator.print(progress_bar)
|
||||
continue
|
||||
|
||||
with accelerator.accumulate(controlnet), accelerator.accumulate(unet):
|
||||
# Convert images to latent space
|
||||
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
latents = latents * vae.config.scaling_factor
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device
|
||||
)
|
||||
timesteps = timesteps.long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
|
||||
|
||||
controlnet_image = batch["conditioning_pixel_values"].to(dtype=weight_dtype)
|
||||
|
||||
# Get the guided hint for the UNet (320 dim)
|
||||
guided_hint = controlnet(
|
||||
controlnet_cond=controlnet_image,
|
||||
)
|
||||
|
||||
# Predict the noise residual
|
||||
model_pred = unet(
|
||||
noisy_latents,
|
||||
timesteps,
|
||||
guided_hint=guided_hint,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
).sample
|
||||
|
||||
# Get the target for loss depending on the prediction type
|
||||
if noise_scheduler.config.prediction_type == "epsilon":
|
||||
target = noise
|
||||
elif noise_scheduler.config.prediction_type == "v_prediction":
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
|
||||
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
|
||||
accelerator.backward(loss)
|
||||
|
||||
if accelerator.sync_gradients:
|
||||
params_to_clip = (
|
||||
itertools.chain(controlnet.parameters(), text_encoder.parameters())
|
||||
if args.train_text_encoder
|
||||
else itertools.chain(
|
||||
controlnet.parameters(),
|
||||
)
|
||||
)
|
||||
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=args.set_grads_to_none)
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
if args.report_to == "wandb":
|
||||
accelerator.print(progress_bar)
|
||||
global_step += 1
|
||||
|
||||
step_save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
|
||||
|
||||
if accelerator.is_main_process:
|
||||
if global_step % args.validation_steps == 0 or global_step == 1:
|
||||
logger.info(f"Running validation... \n Generating {args.num_validation_images} images.")
|
||||
logger.info("Running validation... ")
|
||||
|
||||
with torch.no_grad():
|
||||
log_validation(val_dataset, text_encoder, unet, controlnet, args, accelerator)
|
||||
|
||||
if global_step % args.checkpointing_steps == 0:
|
||||
save_adaptor(accelerator, step_save_path, {"controlnet": controlnet, "unet": unet})
|
||||
|
||||
# save text_encoder if any
|
||||
if args.train_text_encoder:
|
||||
save_adaptor(accelerator, step_save_path, {"text_encoder": text_encoder})
|
||||
|
||||
accelerator.save_state(step_save_path)
|
||||
|
||||
logger.info(f"Saved {global_step} state to {step_save_path}")
|
||||
logger.info(f"Saved current state to {step_save_path}")
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
accelerator.print(f"GPU Memory before entering the train : {b2mb(tracemalloc.begin)}")
|
||||
accelerator.print(f"GPU Memory consumed at the end of the train (end-begin): {tracemalloc.used}")
|
||||
accelerator.print(f"GPU Peak Memory consumed during the train (max-begin): {tracemalloc.peaked}")
|
||||
accelerator.print(
|
||||
f"GPU Total Peak Memory consumed during the train (max): {tracemalloc.peaked + b2mb(tracemalloc.begin)}"
|
||||
)
|
||||
|
||||
accelerator.print(f"CPU Memory before entering the train : {b2mb(tracemalloc.cpu_begin)}")
|
||||
accelerator.print(f"CPU Memory consumed at the end of the train (end-begin): {tracemalloc.cpu_used}")
|
||||
accelerator.print(f"CPU Peak Memory consumed during the train (max-begin): {tracemalloc.cpu_peaked}")
|
||||
accelerator.print(
|
||||
f"CPU Total Peak Memory consumed during the train (max): {tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)}"
|
||||
)
|
||||
|
||||
# Create the pipeline using using the trained modules and save it.
|
||||
accelerator.wait_for_everyone()
|
||||
accelerator.end_training()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_args()
|
||||
main(args)
|
||||
42
examples/boft_controlnet/train_controlnet.sh
Executable file
42
examples/boft_controlnet/train_controlnet.sh
Executable file
@ -0,0 +1,42 @@
|
||||
PEFT_TYPE="boft"
|
||||
BLOCK_NUM=8
|
||||
BLOCK_SIZE=0
|
||||
N_BUTTERFLY_FACTOR=1
|
||||
|
||||
export DATASET_NAME="oftverse/control-celeba-hq"
|
||||
export PROJECT_NAME="controlnet_${PEFT_TYPE}"
|
||||
export RUN_NAME="${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
export CONTROLNET_PATH=""
|
||||
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
|
||||
export OUTPUT_DIR="./output/${DATASET_NAME}/${RUN_NAME}"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--resume_from_checkpoint=$RESUME_PATH \
|
||||
--controlnet_model_name_or_path=$CONTROLNET_PATH \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--report_to="wandb" \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--checkpointing_steps=500 \
|
||||
--max_train_steps=50000 \
|
||||
--validation_steps=5000 \
|
||||
--num_validation_images=12 \
|
||||
--train_batch_size=4 \
|
||||
--dataloader_num_workers=2 \
|
||||
--seed="0" \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--wandb_project_name=$PROJECT_NAME \
|
||||
--wandb_run_name=$RUN_NAME \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--use_boft \
|
||||
--boft_block_num=$BLOCK_NUM \
|
||||
--boft_block_size=$BLOCK_SIZE \
|
||||
--boft_n_butterfly_factor=$N_BUTTERFLY_FACTOR \
|
||||
--boft_dropout=0.1 \
|
||||
--boft_bias="boft_only" \
|
||||
1
examples/boft_controlnet/utils/__init__.py
Normal file
1
examples/boft_controlnet/utils/__init__.py
Normal file
@ -0,0 +1 @@
|
||||
|
||||
447
examples/boft_controlnet/utils/args_loader.py
Normal file
447
examples/boft_controlnet/utils/args_loader.py
Normal file
@ -0,0 +1,447 @@
|
||||
import argparse
|
||||
import os
|
||||
from typing import Optional
|
||||
|
||||
from huggingface_hub import HfFolder, whoami
|
||||
from transformers import PretrainedConfig
|
||||
|
||||
|
||||
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
|
||||
if token is None:
|
||||
token = HfFolder.get_token()
|
||||
if organization is None:
|
||||
username = whoami(token)["name"]
|
||||
return f"{username}/{model_id}"
|
||||
else:
|
||||
return f"{organization}/{model_id}"
|
||||
|
||||
|
||||
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
|
||||
text_encoder_config = PretrainedConfig.from_pretrained(
|
||||
pretrained_model_name_or_path,
|
||||
subfolder="text_encoder",
|
||||
revision=revision,
|
||||
)
|
||||
model_class = text_encoder_config.architectures[0]
|
||||
|
||||
if model_class == "CLIPTextModel":
|
||||
from transformers import CLIPTextModel
|
||||
|
||||
return CLIPTextModel
|
||||
elif model_class == "RobertaSeriesModelWithTransformation":
|
||||
from diffusers.pipelines.alt_diffusion.modeling_roberta_series import (
|
||||
RobertaSeriesModelWithTransformation,
|
||||
)
|
||||
|
||||
return RobertaSeriesModelWithTransformation
|
||||
else:
|
||||
raise ValueError(f"{model_class} is not supported.")
|
||||
|
||||
|
||||
def parse_args(input_args=None):
|
||||
parser = argparse.ArgumentParser(description="Simple example of a ControlNet training script.")
|
||||
parser.add_argument(
|
||||
"--pretrained_model_name_or_path",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="Path to pretrained model or model identifier from huggingface.co/models.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--controlnet_model_name_or_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Path to pretrained controlnet model or model identifier from huggingface.co/models."
|
||||
" If not specified controlnet weights are initialized from unet.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--revision",
|
||||
type=str,
|
||||
default=None,
|
||||
required=False,
|
||||
help=(
|
||||
"Revision of pretrained model identifier from huggingface.co/models. Trainable model components should be"
|
||||
" float32 precision."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tokenizer_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Pretrained tokenizer name or path if not the same as model_name",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--output_dir",
|
||||
type=str,
|
||||
default="controlnet-model",
|
||||
help="The output directory where the model predictions and checkpoints will be written.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cache_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help="The directory where the downloaded models and datasets will be stored.",
|
||||
)
|
||||
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
|
||||
parser.add_argument(
|
||||
"--resolution",
|
||||
type=int,
|
||||
default=512,
|
||||
help=(
|
||||
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
|
||||
" resolution"
|
||||
),
|
||||
)
|
||||
parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
|
||||
|
||||
parser.add_argument(
|
||||
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
|
||||
)
|
||||
|
||||
parser.add_argument("--num_train_epochs", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--max_train_steps",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--checkpointing_steps",
|
||||
type=int,
|
||||
default=500,
|
||||
help=(
|
||||
"Save a checkpoint of the training state every X updates. Checkpoints can be used for resuming training via `--resume_from_checkpoint`. "
|
||||
"In the case that the checkpoint is better than the final trained model, the checkpoint can also be used for inference."
|
||||
"Using a checkpoint for inference requires separate loading of the original pipeline and the individual checkpointed model components."
|
||||
"See https://huggingface.co/docs/diffusers/main/en/training/dreambooth#performing-inference-using-a-saved-checkpoint for step by step"
|
||||
"instructions."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--checkpoints_total_limit",
|
||||
type=int,
|
||||
default=None,
|
||||
help=("Max number of checkpoints to store."),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--resume_from_checkpoint",
|
||||
type=str,
|
||||
default=None,
|
||||
help=(
|
||||
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
|
||||
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--gradient_accumulation_steps",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--gradient_checkpointing",
|
||||
action="store_true",
|
||||
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--learning_rate",
|
||||
type=float,
|
||||
default=5e-6,
|
||||
help="Initial learning rate (after the potential warmup period) to use.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--scale_lr",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_scheduler",
|
||||
type=str,
|
||||
default="constant",
|
||||
help=(
|
||||
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
|
||||
' "constant", "constant_with_warmup"]'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_num_cycles",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
|
||||
)
|
||||
parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
|
||||
parser.add_argument(
|
||||
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dataloader_num_workers",
|
||||
type=int,
|
||||
default=0,
|
||||
help=(
|
||||
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
|
||||
),
|
||||
)
|
||||
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
|
||||
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
|
||||
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
|
||||
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
|
||||
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
|
||||
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
|
||||
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
|
||||
parser.add_argument(
|
||||
"--hub_model_id",
|
||||
type=str,
|
||||
default=None,
|
||||
help="The name of the repository to keep in sync with the local `output_dir`.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--logging_dir",
|
||||
type=str,
|
||||
default="logs",
|
||||
help=(
|
||||
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
|
||||
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--allow_tf32",
|
||||
action="store_true",
|
||||
help=(
|
||||
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
|
||||
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--report_to",
|
||||
type=str,
|
||||
default="wandb",
|
||||
help=(
|
||||
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
|
||||
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--wandb_key",
|
||||
type=str,
|
||||
default=None,
|
||||
help=("If report to option is set to wandb, api-key for wandb used for login to wandb "),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--wandb_project_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help=("If report to option is set to wandb, project name in wandb for log tracking "),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--wandb_run_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help=("If report to option is set to wandb, project name in wandb for log tracking "),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
|
||||
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
|
||||
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--set_grads_to_none",
|
||||
action="store_true",
|
||||
help=(
|
||||
"Save more memory by using setting grads to None instead of zero. Be aware, that this changes certain"
|
||||
" behaviors, so disable this argument if it causes any problems. More info:"
|
||||
" https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html"
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dataset_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help=(
|
||||
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
|
||||
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
|
||||
" or to a folder containing files that 🤗 Datasets can understand."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dataset_config_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help="The config of the Dataset, leave as None if there's only one config.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--train_data_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help=(
|
||||
"A folder containing the training data. Folder contents must follow the structure described in"
|
||||
" https://huggingface.co/docs/datasets/image_dataset#imagefolder. In particular, a `metadata.jsonl` file"
|
||||
" must exist to provide the captions for the images. Ignored if `dataset_name` is specified."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--image_column", type=str, default="image", help="The column of the dataset containing the target image."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--conditioning_image_column",
|
||||
type=str,
|
||||
default="conditioning_image",
|
||||
help="The column of the dataset containing the controlnet conditioning image.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_column",
|
||||
type=str,
|
||||
default="text",
|
||||
help="The column of the dataset containing a caption or a list of captions.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--max_train_samples",
|
||||
type=int,
|
||||
default=None,
|
||||
help=(
|
||||
"For debugging purposes or quicker training, truncate the number of training examples to this "
|
||||
"value if set."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--proportion_empty_prompts",
|
||||
type=float,
|
||||
default=0,
|
||||
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_prompt",
|
||||
type=str,
|
||||
default=None,
|
||||
nargs="+",
|
||||
help=(
|
||||
"A set of prompts evaluated every `--validation_steps` and logged to `--report_to`."
|
||||
" Provide either a matching number of `--validation_image`s, a single `--validation_image`"
|
||||
" to be used with all prompts, or a single prompt that will be used with all `--validation_image`s."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_image",
|
||||
type=str,
|
||||
default=None,
|
||||
nargs="+",
|
||||
help=(
|
||||
"A set of paths to the controlnet conditioning image be evaluated every `--validation_steps`"
|
||||
" and logged to `--report_to`. Provide either a matching number of `--validation_prompt`s, a"
|
||||
" a single `--validation_prompt` to be used with all `--validation_image`s, or a single"
|
||||
" `--validation_image` that will be used with all `--validation_prompt`s."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num_validation_images",
|
||||
type=int,
|
||||
default=4,
|
||||
help="Number of images to be generated for each `--validation_image`, `--validation_prompt` pair",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_steps",
|
||||
type=int,
|
||||
default=100,
|
||||
help=(
|
||||
"Run validation every X steps. Validation consists of running the prompt"
|
||||
" `args.validation_prompt` multiple times: `args.num_validation_images`"
|
||||
" and logging the images."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tracker_project_name",
|
||||
type=str,
|
||||
default="train_controlnet",
|
||||
help=(
|
||||
"The `project_name` argument passed to Accelerator.init_trackers for"
|
||||
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
|
||||
),
|
||||
)
|
||||
|
||||
# evaluation arguments
|
||||
parser.add_argument("--controlnet_path", type=str, default=None, help="Path to pretrained controlnet.")
|
||||
parser.add_argument("--unet_path", type=str, default=None, help="Path to pretrained unet.")
|
||||
parser.add_argument("--adapter_name", type=str, default=None, help="Name of the adapter to use.")
|
||||
parser.add_argument("--vis_overlays", action="store_true", help="Whether to visualize the landmarks.")
|
||||
|
||||
# self-invented arguments
|
||||
|
||||
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
|
||||
|
||||
parser.add_argument(
|
||||
"--name",
|
||||
type=str,
|
||||
help=("The name of the current experiment run, consists of [data]-[prompt]"),
|
||||
)
|
||||
|
||||
# BOFT args
|
||||
parser.add_argument("--use_boft", action="store_true", help="Whether to use BOFT for parameter efficient tuning")
|
||||
parser.add_argument("--boft_block_num", type=int, default=8, help="The number of BOFT blocks")
|
||||
parser.add_argument("--boft_block_size", type=int, default=0, help="The size of BOFT blocks")
|
||||
parser.add_argument("--boft_n_butterfly_factor", type=int, default=0, help="The number of butterfly factors")
|
||||
parser.add_argument("--boft_dropout", type=float, default=0.1, help="BOFT dropout, only used if use_boft is True")
|
||||
parser.add_argument(
|
||||
"--boft_bias",
|
||||
type=str,
|
||||
default="none",
|
||||
help="Bias type for BOFT. Can be 'none', 'all' or 'boft_only', only used if use_boft is True",
|
||||
)
|
||||
|
||||
if input_args is not None:
|
||||
args = parser.parse_args(input_args)
|
||||
else:
|
||||
args = parser.parse_args()
|
||||
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
if args.dataset_name is None and args.train_data_dir is None:
|
||||
raise ValueError("Specify either `--dataset_name` or `--train_data_dir`")
|
||||
|
||||
if args.dataset_name is not None and args.train_data_dir is not None:
|
||||
raise ValueError("Specify only one of `--dataset_name` or `--train_data_dir`")
|
||||
|
||||
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
|
||||
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
|
||||
|
||||
if args.validation_prompt is not None and args.validation_image is None:
|
||||
raise ValueError("`--validation_image` must be set if `--validation_prompt` is set")
|
||||
|
||||
if args.validation_prompt is None and args.validation_image is not None:
|
||||
raise ValueError("`--validation_prompt` must be set if `--validation_image` is set")
|
||||
|
||||
if (
|
||||
args.validation_image is not None
|
||||
and args.validation_prompt is not None
|
||||
and len(args.validation_image) != 1
|
||||
and len(args.validation_prompt) != 1
|
||||
and len(args.validation_image) != len(args.validation_prompt)
|
||||
):
|
||||
raise ValueError(
|
||||
"Must provide either 1 `--validation_image`, 1 `--validation_prompt`,"
|
||||
" or the same number of `--validation_prompt`s and `--validation_image`s"
|
||||
)
|
||||
|
||||
if args.resolution % 8 != 0:
|
||||
raise ValueError(
|
||||
"`--resolution` must be divisible by 8 for consistently sized encoded images between the VAE and the controlnet encoder."
|
||||
)
|
||||
|
||||
return args
|
||||
207
examples/boft_controlnet/utils/dataset.py
Normal file
207
examples/boft_controlnet/utils/dataset.py
Normal file
@ -0,0 +1,207 @@
|
||||
import random
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import wandb
|
||||
from datasets import load_dataset
|
||||
from diffusers import DDIMScheduler
|
||||
from PIL import Image
|
||||
from torchvision import transforms
|
||||
from utils.pipeline_controlnet import LightControlNetPipeline
|
||||
|
||||
|
||||
def image_grid(imgs, rows, cols):
|
||||
assert len(imgs) == rows * cols
|
||||
|
||||
w, h = imgs[0].size
|
||||
grid = Image.new("RGB", size=(cols * w, rows * h))
|
||||
|
||||
for i, img in enumerate(imgs):
|
||||
grid.paste(img, box=(i % cols * w, i // cols * h))
|
||||
return grid
|
||||
|
||||
|
||||
def log_validation(val_dataset, text_encoder, unet, controlnet, args, accelerator):
|
||||
pipeline = LightControlNetPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
controlnet=accelerator.unwrap_model(controlnet, keep_fp32_wrapper=True),
|
||||
unet=accelerator.unwrap_model(unet, keep_fp32_wrapper=True).model,
|
||||
text_encoder=accelerator.unwrap_model(text_encoder, keep_fp32_wrapper=True),
|
||||
safety_checker=None,
|
||||
revision=args.revision,
|
||||
)
|
||||
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
|
||||
pipeline.set_progress_bar_config(disable=True)
|
||||
|
||||
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
|
||||
|
||||
image_logs = []
|
||||
|
||||
for idx in range(args.num_validation_images):
|
||||
data = val_dataset[idx]
|
||||
validation_prompt = data["text"]
|
||||
validation_image = data["conditioning_pixel_values"]
|
||||
|
||||
image = pipeline(
|
||||
validation_prompt,
|
||||
[validation_image],
|
||||
num_inference_steps=50,
|
||||
generator=generator,
|
||||
)[0][0]
|
||||
|
||||
image_logs.append(
|
||||
{
|
||||
"validation_image": validation_image,
|
||||
"image": image,
|
||||
"validation_prompt": validation_prompt,
|
||||
}
|
||||
)
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
formatted_images = []
|
||||
|
||||
for log in image_logs:
|
||||
image = log["image"]
|
||||
validation_prompt = log["validation_prompt"]
|
||||
validation_image = log["validation_image"]
|
||||
|
||||
formatted_images.append(wandb.Image(validation_image, caption="Controlnet conditioning"))
|
||||
|
||||
image = wandb.Image(image, caption=validation_prompt)
|
||||
formatted_images.append(image)
|
||||
|
||||
tracker.log({"validation": formatted_images})
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
def make_dataset(args, tokenizer, accelerator, split="train"):
|
||||
# Get the datasets: you can either provide your own training and evaluation files (see below)
|
||||
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
|
||||
|
||||
# In distributed training, the load_dataset function guarantees that only one local process can concurrently
|
||||
# download the dataset.
|
||||
if args.dataset_name is not None:
|
||||
# Downloading and loading a dataset from the hub.
|
||||
dataset = load_dataset(
|
||||
args.dataset_name,
|
||||
args.dataset_config_name,
|
||||
cache_dir=args.cache_dir,
|
||||
)
|
||||
else:
|
||||
if args.train_data_dir is not None:
|
||||
dataset = load_dataset(
|
||||
args.train_data_dir,
|
||||
cache_dir=args.cache_dir,
|
||||
)
|
||||
# See more about loading custom images at
|
||||
# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
|
||||
|
||||
# Preprocessing the datasets.
|
||||
# We need to tokenize inputs and targets.
|
||||
column_names = dataset[split].column_names
|
||||
|
||||
# Get the column names for input/target.
|
||||
if args.image_column is None:
|
||||
image_column = column_names[0]
|
||||
else:
|
||||
image_column = args.image_column
|
||||
if image_column not in column_names:
|
||||
raise ValueError(
|
||||
f"`--image_column` value '{args.image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
|
||||
)
|
||||
|
||||
if args.caption_column is None:
|
||||
caption_column = column_names[1]
|
||||
else:
|
||||
caption_column = args.caption_column
|
||||
if caption_column not in column_names:
|
||||
raise ValueError(
|
||||
f"`--caption_column` value '{args.caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
|
||||
)
|
||||
|
||||
if args.conditioning_image_column is None:
|
||||
conditioning_image_column = column_names[2]
|
||||
else:
|
||||
conditioning_image_column = args.conditioning_image_column
|
||||
if conditioning_image_column not in column_names:
|
||||
raise ValueError(
|
||||
f"`--conditioning_image_column` value '{args.conditioning_image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
|
||||
)
|
||||
|
||||
def tokenize_captions(examples, is_train=True):
|
||||
captions = []
|
||||
for caption in examples[caption_column]:
|
||||
if random.random() < args.proportion_empty_prompts:
|
||||
captions.append("")
|
||||
elif isinstance(caption, str):
|
||||
captions.append(caption)
|
||||
elif isinstance(caption, (list, np.ndarray)):
|
||||
# take a random caption if there are multiple
|
||||
captions.append(random.choice(caption) if is_train else caption[0])
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Caption column `{caption_column}` should contain either strings or lists of strings."
|
||||
)
|
||||
inputs = tokenizer(
|
||||
captions, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt"
|
||||
)
|
||||
return inputs.input_ids
|
||||
|
||||
image_transforms = transforms.Compose(
|
||||
[
|
||||
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
|
||||
transforms.CenterCrop(args.resolution),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize([0.5], [0.5]),
|
||||
]
|
||||
)
|
||||
|
||||
conditioning_image_transforms = transforms.Compose(
|
||||
[
|
||||
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
|
||||
transforms.CenterCrop(args.resolution),
|
||||
transforms.ToTensor(),
|
||||
]
|
||||
)
|
||||
|
||||
def preprocess_train(examples):
|
||||
images = [image.convert("RGB") for image in examples[image_column]]
|
||||
images = [image_transforms(image) for image in images]
|
||||
|
||||
conditioning_images = [image.convert("RGB") for image in examples[conditioning_image_column]]
|
||||
conditioning_images = [conditioning_image_transforms(image) for image in conditioning_images]
|
||||
|
||||
examples["pixel_values"] = images
|
||||
examples["conditioning_pixel_values"] = conditioning_images
|
||||
examples["input_ids"] = tokenize_captions(examples)
|
||||
|
||||
return examples
|
||||
|
||||
with accelerator.main_process_first():
|
||||
if args.max_train_samples is not None:
|
||||
dataset[split] = dataset[split].shuffle(seed=args.seed).select(range(args.max_train_samples))
|
||||
# Set the training transforms
|
||||
split_dataset = dataset[split].with_transform(preprocess_train)
|
||||
|
||||
return split_dataset
|
||||
|
||||
|
||||
def collate_fn(examples):
|
||||
pixel_values = torch.stack([example["pixel_values"] for example in examples])
|
||||
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
|
||||
|
||||
conditioning_pixel_values = torch.stack([example["conditioning_pixel_values"] for example in examples])
|
||||
conditioning_pixel_values = conditioning_pixel_values.to(memory_format=torch.contiguous_format).float()
|
||||
|
||||
input_ids = torch.stack([example["input_ids"] for example in examples])
|
||||
|
||||
return {
|
||||
"pixel_values": pixel_values,
|
||||
"conditioning_pixel_values": conditioning_pixel_values,
|
||||
"input_ids": input_ids,
|
||||
}
|
||||
263
examples/boft_controlnet/utils/light_controlnet.py
Normal file
263
examples/boft_controlnet/utils/light_controlnet.py
Normal file
@ -0,0 +1,263 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
||||
from diffusers.models.attention_processor import AttentionProcessor, AttnProcessor
|
||||
from diffusers.models.modeling_utils import ModelMixin
|
||||
from diffusers.models.unet_2d_blocks import (
|
||||
CrossAttnDownBlock2D,
|
||||
DownBlock2D,
|
||||
)
|
||||
from diffusers.utils import BaseOutput, logging
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
@dataclass
|
||||
class ControlNetOutput(BaseOutput):
|
||||
down_block_res_samples: Tuple[torch.Tensor]
|
||||
mid_block_res_sample: torch.Tensor
|
||||
|
||||
|
||||
class ControlNetConditioningEmbedding(nn.Module):
|
||||
"""
|
||||
Quoting from https://arxiv.org/abs/2302.05543: "Stable Diffusion uses a pre-processing method similar to VQ-GAN
|
||||
[11] to convert the entire dataset of 512 × 512 images into smaller 64 × 64 “latent images” for stabilized
|
||||
training. This requires ControlNets to convert image-based conditions to 64 × 64 feature space to match the
|
||||
convolution size. We use a tiny network E(·) of four convolution layers with 4 × 4 kernels and 2 × 2 strides
|
||||
(activated by ReLU, channels are 16, 32, 64, 128, initialized with Gaussian weights, trained jointly with the full
|
||||
model) to encode image-space conditions ... into feature maps ..."
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
conditioning_embedding_channels: int,
|
||||
conditioning_channels: int = 3,
|
||||
block_out_channels: Tuple[int] = (16, 32, 96, 256),
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.conv_in = nn.Conv2d(conditioning_channels, block_out_channels[0], kernel_size=3, padding=1)
|
||||
|
||||
self.blocks = nn.ModuleList([])
|
||||
|
||||
for i in range(len(block_out_channels) - 1):
|
||||
channel_in = block_out_channels[i]
|
||||
channel_out = block_out_channels[i + 1]
|
||||
self.blocks.append(nn.Conv2d(channel_in, channel_in, kernel_size=3, padding=1))
|
||||
self.blocks.append(nn.Conv2d(channel_in, channel_out, kernel_size=3, padding=1, stride=2))
|
||||
|
||||
self.conv_out = zero_module(
|
||||
nn.Conv2d(block_out_channels[-1], conditioning_embedding_channels, kernel_size=3, padding=1)
|
||||
)
|
||||
|
||||
def forward(self, conditioning):
|
||||
embedding = self.conv_in(conditioning)
|
||||
embedding = F.silu(embedding)
|
||||
|
||||
for block in self.blocks:
|
||||
embedding = block(embedding)
|
||||
embedding = F.silu(embedding)
|
||||
|
||||
embedding = self.conv_out(embedding)
|
||||
|
||||
return embedding
|
||||
|
||||
|
||||
class ControlNetModel(ModelMixin, ConfigMixin):
|
||||
_supports_gradient_checkpointing = True
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
in_channels: int = 4,
|
||||
out_channels: int = 320,
|
||||
controlnet_conditioning_channel_order: str = "rgb",
|
||||
conditioning_embedding_out_channels: Optional[Tuple[int]] = (16, 32, 96, 256),
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# for control image
|
||||
self.controlnet_cond_embedding = ControlNetConditioningEmbedding(
|
||||
conditioning_embedding_channels=out_channels,
|
||||
block_out_channels=conditioning_embedding_out_channels,
|
||||
)
|
||||
|
||||
@property
|
||||
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.attn_processors
|
||||
def attn_processors(self) -> Dict[str, AttentionProcessor]:
|
||||
r"""
|
||||
Returns:
|
||||
`dict` of attention processors: A dictionary containing all attention processors used in the model with
|
||||
indexed by its weight name.
|
||||
"""
|
||||
# set recursively
|
||||
processors = {}
|
||||
|
||||
def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
|
||||
if hasattr(module, "set_processor"):
|
||||
processors[f"{name}.processor"] = module.processor
|
||||
|
||||
for sub_name, child in module.named_children():
|
||||
fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
|
||||
|
||||
return processors
|
||||
|
||||
for name, module in self.named_children():
|
||||
fn_recursive_add_processors(name, module, processors)
|
||||
|
||||
return processors
|
||||
|
||||
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attn_processor
|
||||
def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
|
||||
r"""
|
||||
Parameters:
|
||||
`processor (`dict` of `AttentionProcessor` or `AttentionProcessor`):
|
||||
The instantiated processor class or a dictionary of processor classes that will be set as the processor
|
||||
of **all** `Attention` layers.
|
||||
In case `processor` is a dict, the key needs to define the path to the corresponding cross attention processor. This is strongly recommended when setting trainable attention processors.:
|
||||
|
||||
"""
|
||||
count = len(self.attn_processors.keys())
|
||||
|
||||
if isinstance(processor, dict) and len(processor) != count:
|
||||
raise ValueError(
|
||||
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
||||
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
||||
)
|
||||
|
||||
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
||||
if hasattr(module, "set_processor"):
|
||||
if not isinstance(processor, dict):
|
||||
module.set_processor(processor)
|
||||
else:
|
||||
module.set_processor(processor.pop(f"{name}.processor"))
|
||||
|
||||
for sub_name, child in module.named_children():
|
||||
fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
|
||||
|
||||
for name, module in self.named_children():
|
||||
fn_recursive_attn_processor(name, module, processor)
|
||||
|
||||
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_default_attn_processor
|
||||
def set_default_attn_processor(self):
|
||||
"""
|
||||
Disables custom attention processors and sets the default attention implementation.
|
||||
"""
|
||||
self.set_attn_processor(AttnProcessor())
|
||||
|
||||
# Copied from diffusers.models.unet_2d_condition.UNet2DConditionModel.set_attention_slice
|
||||
def set_attention_slice(self, slice_size):
|
||||
r"""
|
||||
Enable sliced attention computation.
|
||||
|
||||
When this option is enabled, the attention module will split the input tensor in slices, to compute attention
|
||||
in several steps. This is useful to save some memory in exchange for a small speed decrease.
|
||||
|
||||
Args:
|
||||
slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
|
||||
When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
|
||||
`"max"`, maximum amount of memory will be saved by running only one slice at a time. If a number is
|
||||
provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
|
||||
must be a multiple of `slice_size`.
|
||||
"""
|
||||
sliceable_head_dims = []
|
||||
|
||||
def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
|
||||
if hasattr(module, "set_attention_slice"):
|
||||
sliceable_head_dims.append(module.sliceable_head_dim)
|
||||
|
||||
for child in module.children():
|
||||
fn_recursive_retrieve_sliceable_dims(child)
|
||||
|
||||
# retrieve number of attention layers
|
||||
for module in self.children():
|
||||
fn_recursive_retrieve_sliceable_dims(module)
|
||||
|
||||
num_sliceable_layers = len(sliceable_head_dims)
|
||||
|
||||
if slice_size == "auto":
|
||||
# half the attention head size is usually a good trade-off between
|
||||
# speed and memory
|
||||
slice_size = [dim // 2 for dim in sliceable_head_dims]
|
||||
elif slice_size == "max":
|
||||
# make smallest slice possible
|
||||
slice_size = num_sliceable_layers * [1]
|
||||
|
||||
slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
|
||||
|
||||
if len(slice_size) != len(sliceable_head_dims):
|
||||
raise ValueError(
|
||||
f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
|
||||
f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
|
||||
)
|
||||
|
||||
for i in range(len(slice_size)):
|
||||
size = slice_size[i]
|
||||
dim = sliceable_head_dims[i]
|
||||
if size is not None and size > dim:
|
||||
raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
|
||||
|
||||
# Recursively walk through all the children.
|
||||
# Any children which exposes the set_attention_slice method
|
||||
# gets the message
|
||||
def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
|
||||
if hasattr(module, "set_attention_slice"):
|
||||
module.set_attention_slice(slice_size.pop())
|
||||
|
||||
for child in module.children():
|
||||
fn_recursive_set_attention_slice(child, slice_size)
|
||||
|
||||
reversed_slice_size = list(reversed(slice_size))
|
||||
for module in self.children():
|
||||
fn_recursive_set_attention_slice(module, reversed_slice_size)
|
||||
|
||||
def _set_gradient_checkpointing(self, module, value=False):
|
||||
if isinstance(module, (CrossAttnDownBlock2D, DownBlock2D)):
|
||||
module.gradient_checkpointing = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
controlnet_cond: torch.FloatTensor,
|
||||
) -> Union[ControlNetOutput, Tuple]:
|
||||
# check channel order
|
||||
channel_order = self.config.controlnet_conditioning_channel_order
|
||||
|
||||
if channel_order == "rgb":
|
||||
# in rgb order by default
|
||||
...
|
||||
elif channel_order == "bgr":
|
||||
controlnet_cond = torch.flip(controlnet_cond, dims=[1])
|
||||
else:
|
||||
raise ValueError(f"unknown `controlnet_conditioning_channel_order`: {channel_order}")
|
||||
|
||||
# 2. pre-process
|
||||
|
||||
controlnet_cond = self.controlnet_cond_embedding(controlnet_cond)
|
||||
|
||||
return controlnet_cond
|
||||
|
||||
|
||||
def zero_module(module):
|
||||
for p in module.parameters():
|
||||
nn.init.zeros_(p)
|
||||
return module
|
||||
452
examples/boft_controlnet/utils/pipeline_controlnet.py
Normal file
452
examples/boft_controlnet/utils/pipeline_controlnet.py
Normal file
@ -0,0 +1,452 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, Dict, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL.Image
|
||||
import torch
|
||||
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
|
||||
from diffusers.pipelines.controlnet.pipeline_controlnet import StableDiffusionControlNetPipeline
|
||||
from diffusers.utils import BaseOutput, is_compiled_module, logging
|
||||
from torch.nn import functional as F
|
||||
from utils.light_controlnet import ControlNetModel
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
@dataclass
|
||||
class LightControlNetPipelineOutput(BaseOutput):
|
||||
"""
|
||||
Output class for Stable Diffusion pipelines.
|
||||
|
||||
Args:
|
||||
images (`List[PIL.Image.Image]` or `np.ndarray`)
|
||||
List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
|
||||
num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
|
||||
nsfw_content_detected (`List[bool]`)
|
||||
List of flags denoting whether the corresponding generated image likely represents "not-safe-for-work"
|
||||
(nsfw) content, or `None` if safety checking could not be performed.
|
||||
"""
|
||||
|
||||
images: Union[List[PIL.Image.Image], np.ndarray]
|
||||
nsfw_content_detected: Optional[List[bool]]
|
||||
|
||||
|
||||
class LightControlNetPipeline(StableDiffusionControlNetPipeline):
|
||||
_optional_components = ["safety_checker", "feature_extractor"]
|
||||
|
||||
def check_inputs(
|
||||
self,
|
||||
prompt,
|
||||
image,
|
||||
callback_steps,
|
||||
negative_prompt=None,
|
||||
prompt_embeds=None,
|
||||
negative_prompt_embeds=None,
|
||||
controlnet_conditioning_scale=1.0,
|
||||
):
|
||||
if (callback_steps is None) or (
|
||||
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
|
||||
):
|
||||
raise ValueError(
|
||||
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
|
||||
f" {type(callback_steps)}."
|
||||
)
|
||||
|
||||
if prompt is not None and prompt_embeds is not None:
|
||||
raise ValueError(
|
||||
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
|
||||
" only forward one of the two."
|
||||
)
|
||||
elif prompt is None and prompt_embeds is None:
|
||||
raise ValueError(
|
||||
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
|
||||
)
|
||||
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
if negative_prompt is not None and negative_prompt_embeds is not None:
|
||||
raise ValueError(
|
||||
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
|
||||
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
|
||||
)
|
||||
|
||||
if prompt_embeds is not None and negative_prompt_embeds is not None:
|
||||
if prompt_embeds.shape != negative_prompt_embeds.shape:
|
||||
raise ValueError(
|
||||
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
|
||||
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
|
||||
f" {negative_prompt_embeds.shape}."
|
||||
)
|
||||
|
||||
# `prompt` needs more sophisticated handling when there are multiple
|
||||
# conditionings.
|
||||
if isinstance(self.controlnet, MultiControlNetModel):
|
||||
if isinstance(prompt, list):
|
||||
logger.warning(
|
||||
f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
|
||||
" prompts. The conditionings will be fixed across the prompts."
|
||||
)
|
||||
|
||||
# Check `image`
|
||||
is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
|
||||
self.controlnet, torch._dynamo.eval_frame.OptimizedModule
|
||||
)
|
||||
|
||||
if (
|
||||
isinstance(self.controlnet, ControlNetModel)
|
||||
or is_compiled
|
||||
and isinstance(self.controlnet._orig_mod, ControlNetModel)
|
||||
):
|
||||
self.check_image(image, prompt, prompt_embeds)
|
||||
elif (
|
||||
isinstance(self.controlnet, MultiControlNetModel)
|
||||
or is_compiled
|
||||
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
|
||||
):
|
||||
if not isinstance(image, list):
|
||||
raise TypeError("For multiple controlnets: `image` must be type `list`")
|
||||
|
||||
# When `image` is a nested list:
|
||||
# (e.g. [[canny_image_1, pose_image_1], [canny_image_2, pose_image_2]])
|
||||
elif any(isinstance(i, list) for i in image):
|
||||
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
|
||||
elif len(image) != len(self.controlnet.nets):
|
||||
raise ValueError(
|
||||
"For multiple controlnets: `image` must have the same length as the number of controlnets."
|
||||
)
|
||||
|
||||
for image_ in image:
|
||||
self.check_image(image_, prompt, prompt_embeds)
|
||||
else:
|
||||
assert False
|
||||
|
||||
# Check `controlnet_conditioning_scale`
|
||||
if (
|
||||
isinstance(self.controlnet, ControlNetModel)
|
||||
or is_compiled
|
||||
and isinstance(self.controlnet._orig_mod, ControlNetModel)
|
||||
):
|
||||
if not isinstance(controlnet_conditioning_scale, float):
|
||||
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
|
||||
elif (
|
||||
isinstance(self.controlnet, MultiControlNetModel)
|
||||
or is_compiled
|
||||
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
|
||||
):
|
||||
if isinstance(controlnet_conditioning_scale, list):
|
||||
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
|
||||
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
|
||||
elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
|
||||
self.controlnet.nets
|
||||
):
|
||||
raise ValueError(
|
||||
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
|
||||
" the same length as the number of controlnets"
|
||||
)
|
||||
else:
|
||||
assert False
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]] = None,
|
||||
image: Union[
|
||||
torch.FloatTensor,
|
||||
PIL.Image.Image,
|
||||
np.ndarray,
|
||||
List[torch.FloatTensor],
|
||||
List[PIL.Image.Image],
|
||||
List[np.ndarray],
|
||||
] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
num_inference_steps: int = 50,
|
||||
guidance_scale: float = 7.5,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
num_images_per_prompt: Optional[int] = 1,
|
||||
eta: float = 0.0,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
callback_steps: int = 1,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
controlnet_conditioning_scale: Union[float, List[float]] = 1.0,
|
||||
guess_mode: bool = False,
|
||||
):
|
||||
r"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
||||
instead.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
|
||||
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
|
||||
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
|
||||
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
|
||||
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
|
||||
height and/or width are passed, `image` is resized according to them. If multiple ControlNets are
|
||||
specified in init, images must be passed as a list such that each element of the list can be correctly
|
||||
batched for input to a single controlnet.
|
||||
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
||||
The width in pixels of the generated image.
|
||||
num_inference_steps (`int`, *optional*, defaults to 50):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
guidance_scale (`float`, *optional*, defaults to 7.5):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. If not defined, one has to pass
|
||||
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
|
||||
less than `1`).
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
eta (`float`, *optional*, defaults to 0.0):
|
||||
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
|
||||
[`schedulers.DDIMScheduler`], will be ignored for others.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
prompt_embeds (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
|
||||
provided, text embeddings will be generated from `prompt` input argument.
|
||||
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
||||
argument.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between
|
||||
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
||||
plain tuple.
|
||||
callback (`Callable`, *optional*):
|
||||
A function that will be called every `callback_steps` steps during inference. The function will be
|
||||
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
|
||||
callback_steps (`int`, *optional*, defaults to 1):
|
||||
The frequency at which the `callback` function will be called. If not specified, the callback will be
|
||||
called at every step.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
|
||||
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
|
||||
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
|
||||
corresponding scale as a list.
|
||||
guess_mode (`bool`, *optional*, defaults to `False`):
|
||||
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
|
||||
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
|
||||
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
|
||||
When returning a tuple, the first element is a list with the generated images, and the second element is a
|
||||
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
|
||||
(nsfw) content, according to the `safety_checker`.
|
||||
"""
|
||||
|
||||
# 1. Check inputs. Raise error if not correct
|
||||
self.check_inputs(
|
||||
prompt,
|
||||
image,
|
||||
callback_steps,
|
||||
negative_prompt,
|
||||
prompt_embeds,
|
||||
negative_prompt_embeds,
|
||||
controlnet_conditioning_scale,
|
||||
)
|
||||
|
||||
# 2. Define call parameters
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif prompt is not None and isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
batch_size = prompt_embeds.shape[0]
|
||||
|
||||
device = self._execution_device
|
||||
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
|
||||
|
||||
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
|
||||
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
|
||||
|
||||
# 3. Encode input prompt
|
||||
text_encoder_lora_scale = (
|
||||
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
||||
)
|
||||
prompt_embeds = self._encode_prompt(
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
lora_scale=text_encoder_lora_scale,
|
||||
)
|
||||
|
||||
# 4. Prepare image
|
||||
if isinstance(controlnet, ControlNetModel):
|
||||
image = self.prepare_image(
|
||||
image=image,
|
||||
width=width,
|
||||
height=height,
|
||||
batch_size=batch_size * num_images_per_prompt,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
device=device,
|
||||
dtype=controlnet.dtype,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
guess_mode=guess_mode,
|
||||
)
|
||||
height, width = image.shape[-2:]
|
||||
elif isinstance(controlnet, MultiControlNetModel):
|
||||
images = []
|
||||
|
||||
for image_ in image:
|
||||
image_ = self.prepare_image(
|
||||
image=image_,
|
||||
width=width,
|
||||
height=height,
|
||||
batch_size=batch_size * num_images_per_prompt,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
device=device,
|
||||
dtype=controlnet.dtype,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
guess_mode=guess_mode,
|
||||
)
|
||||
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
height, width = image[0].shape[-2:]
|
||||
else:
|
||||
assert False
|
||||
|
||||
# 5. Prepare timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps = self.scheduler.timesteps
|
||||
|
||||
# 6. Prepare latent variables
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
latents = self.prepare_latents(
|
||||
batch_size * num_images_per_prompt,
|
||||
num_channels_latents,
|
||||
height,
|
||||
width,
|
||||
prompt_embeds.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
)
|
||||
|
||||
# 7. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
||||
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
||||
|
||||
# 8. Denoising loop
|
||||
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
|
||||
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(timesteps):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
# controlnet(s) inference
|
||||
if guess_mode and do_classifier_free_guidance:
|
||||
# Infer ControlNet only for the conditional batch.
|
||||
control_model_input = latents
|
||||
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
|
||||
else:
|
||||
control_model_input = latent_model_input
|
||||
|
||||
# Get the guided hint for the UNet (320 dim)
|
||||
guided_hint = self.controlnet(
|
||||
controlnet_cond=image,
|
||||
)
|
||||
|
||||
# Predict the noise residual
|
||||
noise_pred = self.unet(
|
||||
latent_model_input,
|
||||
t,
|
||||
guided_hint=guided_hint,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
)[0]
|
||||
|
||||
# perform guidance
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
||||
# call the callback, if provided
|
||||
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
||||
progress_bar.update()
|
||||
if callback is not None and i % callback_steps == 0:
|
||||
callback(i, t, latents)
|
||||
|
||||
# If we do sequential model offloading, let's offload unet and controlnet
|
||||
# manually for max memory savings
|
||||
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
||||
self.unet.to("cpu")
|
||||
self.controlnet.to("cpu")
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
if not output_type == "latent":
|
||||
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
|
||||
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
|
||||
else:
|
||||
image = latents
|
||||
has_nsfw_concept = None
|
||||
|
||||
if has_nsfw_concept is None:
|
||||
do_denormalize = [True] * image.shape[0]
|
||||
else:
|
||||
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
|
||||
|
||||
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
|
||||
|
||||
# Offload last model to CPU
|
||||
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
||||
self.final_offload_hook.offload()
|
||||
|
||||
if not return_dict:
|
||||
return (image, has_nsfw_concept)
|
||||
|
||||
return LightControlNetPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
||||
58
examples/boft_controlnet/utils/tracemalloc.py
Normal file
58
examples/boft_controlnet/utils/tracemalloc.py
Normal file
@ -0,0 +1,58 @@
|
||||
import gc
|
||||
import threading
|
||||
|
||||
import psutil
|
||||
import torch
|
||||
|
||||
|
||||
# Converting Bytes to Megabytes
|
||||
def b2mb(x):
|
||||
return int(x / 2**20)
|
||||
|
||||
|
||||
# This context manager is used to track the peak memory usage of the process
|
||||
class TorchTracemalloc:
|
||||
def __enter__(self):
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.reset_max_memory_allocated() # reset the peak gauge to zero
|
||||
self.begin = torch.cuda.memory_allocated()
|
||||
self.process = psutil.Process()
|
||||
|
||||
self.cpu_begin = self.cpu_mem_used()
|
||||
self.peak_monitoring = True
|
||||
peak_monitor_thread = threading.Thread(target=self.peak_monitor_func)
|
||||
peak_monitor_thread.daemon = True
|
||||
peak_monitor_thread.start()
|
||||
return self
|
||||
|
||||
def cpu_mem_used(self):
|
||||
"""get resident set size memory for the current process"""
|
||||
return self.process.memory_info().rss
|
||||
|
||||
def peak_monitor_func(self):
|
||||
self.cpu_peak = -1
|
||||
|
||||
while True:
|
||||
self.cpu_peak = max(self.cpu_mem_used(), self.cpu_peak)
|
||||
|
||||
# can't sleep or will not catch the peak right (this comment is here on purpose)
|
||||
# time.sleep(0.001) # 1msec
|
||||
|
||||
if not self.peak_monitoring:
|
||||
break
|
||||
|
||||
def __exit__(self, *exc):
|
||||
self.peak_monitoring = False
|
||||
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
self.end = torch.cuda.memory_allocated()
|
||||
self.peak = torch.cuda.max_memory_allocated()
|
||||
self.used = b2mb(self.end - self.begin)
|
||||
self.peaked = b2mb(self.peak - self.begin)
|
||||
|
||||
self.cpu_end = self.cpu_mem_used()
|
||||
self.cpu_used = b2mb(self.cpu_end - self.cpu_begin)
|
||||
self.cpu_peaked = b2mb(self.cpu_peak - self.cpu_begin)
|
||||
# print(f"delta used/peak {self.used:4d}/{self.peaked:4d}")
|
||||
277
examples/boft_controlnet/utils/unet_2d_condition.py
Normal file
277
examples/boft_controlnet/utils/unet_2d_condition.py
Normal file
@ -0,0 +1,277 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Dict, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from diffusers.utils import BaseOutput, logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
@dataclass
|
||||
class UNet2DConditionOutput(BaseOutput):
|
||||
"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Hidden states conditioned on `encoder_hidden_states` input. Output of last layer of model.
|
||||
"""
|
||||
|
||||
sample: torch.FloatTensor
|
||||
|
||||
|
||||
class UNet2DConditionNewModel(UNet2DConditionModel):
|
||||
def forward(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
guided_hint: Optional[torch.Tensor] = None,
|
||||
class_labels: Optional[torch.Tensor] = None,
|
||||
timestep_cond: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
||||
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
||||
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
||||
encoder_attention_mask: Optional[torch.Tensor] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[UNet2DConditionOutput, Tuple]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
||||
timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
|
||||
encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
|
||||
encoder_attention_mask (`torch.Tensor`):
|
||||
(batch, sequence_length) cross-attention mask, applied to encoder_hidden_states. True = keep, False =
|
||||
discard. Mask will be converted into a bias, which adds large negative values to attention scores
|
||||
corresponding to "discard" tokens.
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
||||
cross_attention_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
added_cond_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified includes additonal conditions that can be used for additonal time
|
||||
embeddings or encoder hidden states projections. See the configurations `encoder_hid_dim_type` and
|
||||
`addition_embed_type` for more information.
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
|
||||
returning a tuple, the first element is the sample tensor.
|
||||
"""
|
||||
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
||||
# The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
|
||||
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
||||
# on the fly if necessary.
|
||||
default_overall_up_factor = 2**self.num_upsamplers
|
||||
|
||||
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
logger.info("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
|
||||
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension
|
||||
# expects mask of shape:
|
||||
# [batch, key_tokens]
|
||||
# adds singleton query_tokens dimension:
|
||||
# [batch, 1, key_tokens]
|
||||
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
||||
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
||||
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
||||
if attention_mask is not None:
|
||||
# assume that mask is expressed as:
|
||||
# (1 = keep, 0 = discard)
|
||||
# convert mask into a bias that can be added to attention scores:
|
||||
# (keep = +0, discard = -10000.0)
|
||||
attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
|
||||
attention_mask = attention_mask.unsqueeze(1)
|
||||
|
||||
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
||||
if encoder_attention_mask is not None:
|
||||
encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
|
||||
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
||||
|
||||
# 0. center input if necessary
|
||||
if self.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
||||
# This would be a good case for the `match` statement (Python 3.10+)
|
||||
is_mps = sample.device.type == "mps"
|
||||
if isinstance(timestep, float):
|
||||
dtype = torch.float32 if is_mps else torch.float64
|
||||
else:
|
||||
dtype = torch.int32 if is_mps else torch.int64
|
||||
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
||||
elif len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps.expand(sample.shape[0])
|
||||
|
||||
t_emb = self.time_proj(timesteps)
|
||||
|
||||
# `Timesteps` does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
t_emb = t_emb.to(dtype=sample.dtype)
|
||||
|
||||
emb = self.time_embedding(t_emb, timestep_cond)
|
||||
|
||||
if self.class_embedding is not None:
|
||||
if class_labels is None:
|
||||
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
||||
|
||||
if self.config.class_embed_type == "timestep":
|
||||
class_labels = self.time_proj(class_labels)
|
||||
|
||||
# `Timesteps` does not contain any weights and will always return f32 tensors
|
||||
# there might be better ways to encapsulate this.
|
||||
class_labels = class_labels.to(dtype=sample.dtype)
|
||||
|
||||
class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
|
||||
|
||||
if self.config.class_embeddings_concat:
|
||||
emb = torch.cat([emb, class_emb], dim=-1)
|
||||
else:
|
||||
emb = emb + class_emb
|
||||
|
||||
if self.config.addition_embed_type == "text":
|
||||
aug_emb = self.add_embedding(encoder_hidden_states)
|
||||
emb = emb + aug_emb
|
||||
elif self.config.addition_embed_type == "text_image":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
||||
)
|
||||
|
||||
image_embs = added_cond_kwargs.get("image_embeds")
|
||||
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
||||
|
||||
aug_emb = self.add_embedding(text_embs, image_embs)
|
||||
emb = emb + aug_emb
|
||||
|
||||
if self.time_embed_act is not None:
|
||||
emb = self.time_embed_act(emb)
|
||||
|
||||
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
||||
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
||||
)
|
||||
|
||||
image_embeds = added_cond_kwargs.get("image_embeds")
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
||||
|
||||
# 2. pre-process and insert conditioning (ControlNet)
|
||||
# Note: the added "guided_hint" is the only difference between this implementation and the original UNet2DConditionModel
|
||||
sample = self.conv_in(sample)
|
||||
sample = guided_hint + sample if guided_hint is not None else sample
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in self.down_blocks:
|
||||
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
encoder_attention_mask=encoder_attention_mask,
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
if down_block_additional_residuals is not None:
|
||||
new_down_block_res_samples = ()
|
||||
|
||||
for down_block_res_sample, down_block_additional_residual in zip(
|
||||
down_block_res_samples, down_block_additional_residuals
|
||||
):
|
||||
down_block_res_sample = down_block_res_sample + down_block_additional_residual
|
||||
new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
|
||||
|
||||
down_block_res_samples = new_down_block_res_samples
|
||||
|
||||
# 4. mid
|
||||
if self.mid_block is not None:
|
||||
sample = self.mid_block(
|
||||
sample,
|
||||
emb,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
encoder_attention_mask=encoder_attention_mask,
|
||||
)
|
||||
|
||||
if mid_block_additional_residual is not None:
|
||||
sample = sample + mid_block_additional_residual
|
||||
|
||||
# 5. up
|
||||
for i, upsample_block in enumerate(self.up_blocks):
|
||||
is_final_block = i == len(self.up_blocks) - 1
|
||||
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
|
||||
# if we have not reached the final block and need to forward the
|
||||
# upsample size, we do it here
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
|
||||
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
upsample_size=upsample_size,
|
||||
attention_mask=attention_mask,
|
||||
encoder_attention_mask=encoder_attention_mask,
|
||||
)
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
|
||||
# 6. post-process
|
||||
if self.conv_norm_out:
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
if not return_dict:
|
||||
return (sample,)
|
||||
|
||||
return UNet2DConditionOutput(sample=sample)
|
||||
1
examples/boft_dreambooth/.gitignore
vendored
Normal file
1
examples/boft_dreambooth/.gitignore
vendored
Normal file
@ -0,0 +1 @@
|
||||
data/
|
||||
0
examples/boft_dreambooth/__init__.py
Normal file
0
examples/boft_dreambooth/__init__.py
Normal file
165
examples/boft_dreambooth/boft_dreambooth.md
Normal file
165
examples/boft_dreambooth/boft_dreambooth.md
Normal file
@ -0,0 +1,165 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
|
||||
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
|
||||
rendered properly in your Markdown viewer.
|
||||
|
||||
-->
|
||||
|
||||
# DreamBooth fine-tuning with BOFT
|
||||
|
||||
This guide demonstrates how to use BOFT, an orthogonal fine-tuning method, to fine-tune Dreambooth with either `stabilityai/stable-diffusion-2-1` or `runwayml/stable-diffusion-v1-5` model.
|
||||
|
||||
By using BOFT from 🤗 PEFT, we can significantly reduce the number of trainable parameters while still achieving impressive results in various fine-tuning tasks across different foundation models. BOFT enhances model efficiency by integrating full-rank orthogonal matrices with a butterfly structure into specific model blocks, such as attention blocks, mirroring the approach used in LoRA. During fine-tuning, only these inserted matrices are trained, leaving the original model parameters untouched. During inference, the trainable BOFT paramteres can be merged into the original model, eliminating any additional computational costs.
|
||||
|
||||
As a member of the **orthogonal finetuning** class, BOFT presents a systematic and principled method for fine-tuning. It possesses several unique properties and has demonstrated superior performance compared to LoRA in a variety of scenarios. For further details on BOFT, please consult the [PEFT's GitHub repo's concept guide OFT](https://https://huggingface.co/docs/peft/index), the [original BOFT paper](https://arxiv.org/abs/2311.06243) and the [original OFT paper](https://arxiv.org/abs/2306.07280).
|
||||
|
||||
In this guide we provide a Dreambooth fine-tuning script that is available in [PEFT's GitHub repo examples](https://github.com/huggingface/peft/tree/main/examples/boft_dreambooth). This implementation is adapted from [peft's lora_dreambooth](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth). You can try it out and finetune on your custom images.
|
||||
|
||||
## Set up your environment
|
||||
|
||||
Start by cloning the PEFT repository:
|
||||
|
||||
```bash
|
||||
git clone --recursive https://github.com/huggingface/peft
|
||||
```
|
||||
|
||||
Navigate to the directory containing the training scripts for fine-tuning Dreambooth with BOFT:
|
||||
|
||||
```bash
|
||||
cd peft/examples/boft_dreambooth
|
||||
```
|
||||
|
||||
Set up your environment: install PEFT, and all the required libraries. At the time of writing this guide we recommend installing PEFT from source. The following environment setup should work on A100 and H100:
|
||||
|
||||
```bash
|
||||
conda create --name peft python=3.10
|
||||
conda activate peft
|
||||
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=11.8 -c pytorch -c nvidia
|
||||
conda install xformers -c xformers
|
||||
pip install -r requirements.txt
|
||||
pip install git+https://github.com/huggingface/peft
|
||||
```
|
||||
|
||||
## Download the data
|
||||
|
||||
[dreambooth](https://github.com/google/dreambooth) dataset should have been automatically cloned in the following structure when running the training script.
|
||||
|
||||
```
|
||||
boft_dreambooth
|
||||
├── data
|
||||
│ ├── data_dir
|
||||
│ └── dreambooth
|
||||
│ └── data
|
||||
│ ├── backpack
|
||||
│ └── backpack_dog
|
||||
│ ...
|
||||
```
|
||||
|
||||
You can also put your custom images into `boft_dreambooth/data/dreambooth`.
|
||||
|
||||
## Finetune Dreambooth with BOFT
|
||||
|
||||
```bash
|
||||
./train_dreambooth.sh
|
||||
```
|
||||
|
||||
or using the following script arguments:
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
export INSTANCE_DIR="path-to-instance-images"
|
||||
export CLASS_DIR="path-to-class-images"
|
||||
export OUTPUT_DIR="path-to-save-model"
|
||||
```
|
||||
|
||||
Here:
|
||||
|
||||
- `INSTANCE_DIR`: The directory containing the images that you intend to use for training your model.
|
||||
- `CLASS_DIR`: The directory containing class-specific images. In this example, we use prior preservation to avoid overfitting and language-drift. For prior preservation, you need other images of the same class as part of the training process. However, these images can be generated and the training script will save them to a local path you specify here.
|
||||
- `OUTPUT_DIR`: The destination folder for storing the trained model's weights.
|
||||
|
||||
To learn more about DreamBooth fine-tuning with prior-preserving loss, check out the [Diffusers documentation](https://huggingface.co/docs/diffusers/training/dreambooth#finetuning-with-priorpreserving-loss).
|
||||
|
||||
Launch the training script with `accelerate` and pass hyperparameters, as well as LoRa-specific arguments to it such as:
|
||||
|
||||
- `use_boft`: Enables BOFT in the training script.
|
||||
- `boft_block_size`: the BOFT matrix block size across different layers, expressed in `int`. Smaller block size results in sparser update matrices with fewer trainable paramters. **Note**, please choose it to be dividable to most layer `in_features` dimension, e.g., 4, 8, 16. Also, you can only specify either `boft_block_size` or `boft_block_num`, but not both simultaneously, because `boft_block_size` x `boft_block_num` = layer dimension.
|
||||
- `boft_block_num`: the number of BOFT matrix blocks across different layers, expressed in `int`. Fewer blocks result in sparser update matrices with fewer trainable paramters. **Note**, please choose it to be dividable to most layer `in_features` dimension, e.g., 4, 8, 16. Also, you can only specify either `boft_block_size` or `boft_block_num`, but not both simultaneously, because `boft_block_size` x `boft_block_num` = layer dimension.
|
||||
- `boft_n_butterfly_factor`: the number of butterfly factors. **Note**, for `boft_n_butterfly_factor=1`, BOFT is the same as vanilla OFT, for `boft_n_butterfly_factor=2`, the effective block size of OFT becomes twice as big and the number of blocks become half.
|
||||
- `bias`: specify if the `bias` paramteres should be traind. Can be `none`, `all` or `boft_only`.
|
||||
- `boft_dropout`: specify the probability of multiplicative dropout.
|
||||
|
||||
Here's what the full set of script arguments may look like:
|
||||
|
||||
```bash
|
||||
PEFT_TYPE="boft"
|
||||
BLOCK_NUM=8
|
||||
BLOCK_SIZE=0
|
||||
N_BUTTERFLY_FACTOR=1
|
||||
|
||||
VALIDATION_PROMPT=${PROMPT_LIST[@]}
|
||||
INSTANCE_PROMPT="a photo of ${UNIQUE_TOKEN} ${CLASS_TOKEN}"
|
||||
CLASS_PROMPT="a photo of ${CLASS_TOKEN}"
|
||||
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
export PROJECT_NAME="dreambooth_${PEFT_TYPE}"
|
||||
export RUN_NAME="${SELECTED_SUBJECT}_${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
export INSTANCE_DIR="./data/dreambooth/dataset/${SELECTED_SUBJECT}"
|
||||
export CLASS_DIR="./data/class_data/${CLASS_TOKEN}"
|
||||
export OUTPUT_DIR="./data/output/${PEFT_TYPE}"
|
||||
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--class_data_dir="$CLASS_DIR" \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--wandb_project_name=$PROJECT_NAME \
|
||||
--wandb_run_name=$RUN_NAME \
|
||||
--with_prior_preservation --prior_loss_weight=1.0 \
|
||||
--instance_prompt="$INSTANCE_PROMPT" \
|
||||
--validation_prompt="$VALIDATION_PROMPT" \
|
||||
--class_prompt="$CLASS_PROMPT" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--num_dataloader_workers=2 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--num_class_images=200 \
|
||||
--use_boft \
|
||||
--boft_block_num=$BLOCK_NUM \
|
||||
--boft_block_size=$BLOCK_SIZE \
|
||||
--boft_n_butterfly_factor=$N_BUTTERFLY_FACTOR \
|
||||
--boft_dropout=0.1 \
|
||||
--boft_bias="boft_only" \
|
||||
--learning_rate=3e-5 \
|
||||
--max_train_steps=1010 \
|
||||
--checkpointing_steps=200 \
|
||||
--validation_steps=200 \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--report_to="wandb" \
|
||||
```
|
||||
|
||||
or use this training script:
|
||||
|
||||
```bash
|
||||
./train_dreambooth.sh $idx
|
||||
```
|
||||
|
||||
with the `$idx` corresponds to different subjects.
|
||||
|
||||
If you are running this script on Windows, you may need to set the `--num_dataloader_workers` to 0.
|
||||
|
||||
## Inference with a single adapter
|
||||
|
||||
To run inference with the fine-tuned model, simply run the jupyter notebook `dreambooth_inference.ipynb` for visualization with `jupyter notebook` under `./examples/boft_dreambooth`.
|
||||
186
examples/boft_dreambooth/dreambooth_inference.ipynb
Normal file
186
examples/boft_dreambooth/dreambooth_inference.ipynb
Normal file
@ -0,0 +1,186 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "acab479f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import os\n",
|
||||
"\n",
|
||||
"import torch\n",
|
||||
"from accelerate.logging import get_logger\n",
|
||||
"from diffusers import StableDiffusionPipeline\n",
|
||||
"from diffusers.utils import check_min_version\n",
|
||||
"\n",
|
||||
"from peft import PeftModel\n",
|
||||
"\n",
|
||||
"# Will error if the minimal version of diffusers is not installed. Remove at your own risks.\n",
|
||||
"check_min_version(\"0.10.0.dev0\")\n",
|
||||
"\n",
|
||||
"logger = get_logger(__name__)\n",
|
||||
"\n",
|
||||
"MODEL_NAME = \"stabilityai/stable-diffusion-2-1\"\n",
|
||||
"# MODEL_NAME=\"runwayml/stable-diffusion-v1-5\"\n",
|
||||
"\n",
|
||||
"PEFT_TYPE=\"boft\"\n",
|
||||
"BLOCK_NUM=8\n",
|
||||
"BLOCK_SIZE=0\n",
|
||||
"N_BUTTERFLY_FACTOR=1\n",
|
||||
"SELECTED_SUBJECT=\"backpack\"\n",
|
||||
"EPOCH_IDX = 200\n",
|
||||
"\n",
|
||||
"PROJECT_NAME=f\"dreambooth_{PEFT_TYPE}\"\n",
|
||||
"RUN_NAME=f\"{SELECTED_SUBJECT}_{PEFT_TYPE}_{BLOCK_NUM}{BLOCK_SIZE}{N_BUTTERFLY_FACTOR}\"\n",
|
||||
"OUTPUT_DIR=f\"./data/output/{PEFT_TYPE}\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "06cfd506",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def get_boft_sd_pipeline(\n",
|
||||
" ckpt_dir, base_model_name_or_path=None, epoch=int, dtype=torch.float32, device=\"cuda\", adapter_name=\"default\"\n",
|
||||
"):\n",
|
||||
"\n",
|
||||
" if base_model_name_or_path is None:\n",
|
||||
" raise ValueError(\"Please specify the base model name or path\")\n",
|
||||
"\n",
|
||||
" pipe = StableDiffusionPipeline.from_pretrained(\n",
|
||||
" base_model_name_or_path, torch_dtype=dtype, requires_safety_checker=False\n",
|
||||
" ).to(device)\n",
|
||||
" \n",
|
||||
" load_adapter(pipe, ckpt_dir, epoch, adapter_name)\n",
|
||||
"\n",
|
||||
" if dtype in (torch.float16, torch.bfloat16):\n",
|
||||
" pipe.unet.half()\n",
|
||||
" pipe.text_encoder.half()\n",
|
||||
"\n",
|
||||
" pipe.to(device)\n",
|
||||
" return pipe\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def load_adapter(pipe, ckpt_dir, epoch, adapter_name=\"default\"):\n",
|
||||
" \n",
|
||||
" unet_sub_dir = os.path.join(ckpt_dir, f\"unet/{epoch}\", adapter_name)\n",
|
||||
" text_encoder_sub_dir = os.path.join(ckpt_dir, f\"text_encoder/{epoch}\", adapter_name)\n",
|
||||
" \n",
|
||||
" if isinstance(pipe.unet, PeftModel):\n",
|
||||
" pipe.unet.load_adapter(unet_sub_dir, adapter_name=adapter_name)\n",
|
||||
" else:\n",
|
||||
" pipe.unet = PeftModel.from_pretrained(pipe.unet, unet_sub_dir, adapter_name=adapter_name)\n",
|
||||
" \n",
|
||||
" if os.path.exists(text_encoder_sub_dir):\n",
|
||||
" if isinstance(pipe.text_encoder, PeftModel):\n",
|
||||
" pipe.text_encoder.load_adapter(text_encoder_sub_dir, adapter_name=adapter_name)\n",
|
||||
" else:\n",
|
||||
" pipe.text_encoder = PeftModel.from_pretrained(pipe.text_encoder, text_encoder_sub_dir, adapter_name=adapter_name)\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"def set_adapter(pipe, adapter_name):\n",
|
||||
" pipe.unet.set_adapter(adapter_name)\n",
|
||||
" if isinstance(pipe.text_encoder, PeftModel):\n",
|
||||
" pipe.text_encoder.set_adapter(adapter_name)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "98a0d8ac",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"prompt = \"a photo of sks backpack on a wooden floor\"\n",
|
||||
"negative_prompt = \"low quality, blurry, unfinished\""
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "d4e888d2",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"pipe = get_boft_sd_pipeline(OUTPUT_DIR, MODEL_NAME, EPOCH_IDX, adapter_name=RUN_NAME)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f1c1a1c0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]\n",
|
||||
"image"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3a1aafdf-8cf7-4e47-9471-26478034245e",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# load and reset another adapter\n",
|
||||
"# WARNING: requires training DreamBooth with `boft_bias=None`\n",
|
||||
"\n",
|
||||
"SELECTED_SUBJECT=\"dog\"\n",
|
||||
"EPOCH_IDX = 200\n",
|
||||
"RUN_NAME=f\"{SELECTED_SUBJECT}_{PEFT_TYPE}_{BLOCK_NUM}{BLOCK_SIZE}{N_BUTTERFLY_FACTOR}\"\n",
|
||||
"\n",
|
||||
"load_adapter(pipe, OUTPUT_DIR, epoch=EPOCH_IDX, adapter_name=RUN_NAME)\n",
|
||||
"set_adapter(pipe, adapter_name=RUN_NAME)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "c7091ad0-2005-4528-afc1-4f9d70a9a535",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"%%time\n",
|
||||
"prompt = \"a photo of sks dog running on the beach\"\n",
|
||||
"negative_prompt = \"low quality, blurry, unfinished\"\n",
|
||||
"image = pipe(prompt, num_inference_steps=50, guidance_scale=7, negative_prompt=negative_prompt).images[0]\n",
|
||||
"image"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "f534eca2-94a4-432b-b092-7149ac44b12f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python [conda env:peft] *",
|
||||
"language": "python",
|
||||
"name": "conda-env-peft-py"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.13"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
13
examples/boft_dreambooth/requirements.txt
Normal file
13
examples/boft_dreambooth/requirements.txt
Normal file
@ -0,0 +1,13 @@
|
||||
transformers==4.36.2
|
||||
accelerate==0.25.0
|
||||
evaluate
|
||||
tqdm
|
||||
datasets==2.16.1
|
||||
diffusers==0.17.1
|
||||
Pillow
|
||||
huggingface_hub
|
||||
safetensors
|
||||
nb_conda_kernels
|
||||
ipykernel
|
||||
ipywidgets
|
||||
wandb==0.16.1
|
||||
612
examples/boft_dreambooth/train_dreambooth.py
Normal file
612
examples/boft_dreambooth/train_dreambooth.py
Normal file
@ -0,0 +1,612 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright 2023-present the HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# The implementation is based on "Parameter-Efficient Orthogonal Finetuning
|
||||
# via Butterfly Factorization" (https://arxiv.org/abs/2311.06243) in ICLR 2024.
|
||||
|
||||
import hashlib
|
||||
import itertools
|
||||
import logging
|
||||
import math
|
||||
import os
|
||||
from contextlib import nullcontext
|
||||
from pathlib import Path
|
||||
|
||||
import datasets
|
||||
import diffusers
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
import transformers
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.utils import ProjectConfiguration, set_seed
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDIMScheduler,
|
||||
DiffusionPipeline,
|
||||
DPMSolverMultistepScheduler,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import check_min_version
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
from huggingface_hub import Repository
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import AutoTokenizer
|
||||
from utils.args_loader import (
|
||||
get_full_repo_name,
|
||||
import_model_class_from_model_name_or_path,
|
||||
parse_args,
|
||||
)
|
||||
from utils.dataset import DreamBoothDataset, PromptDataset, collate_fn
|
||||
from utils.tracemalloc import TorchTracemalloc, b2mb
|
||||
|
||||
from peft import BOFTConfig, get_peft_model
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.16.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
UNET_TARGET_MODULES = ["to_q", "to_v", "to_k", "query", "value", "key", "to_out.0", "add_k_proj", "add_v_proj"]
|
||||
TEXT_ENCODER_TARGET_MODULES = ["q_proj", "v_proj"]
|
||||
|
||||
|
||||
def save_adaptor(accelerator, step, unet, text_encoder, args):
|
||||
unwarpped_unet = accelerator.unwrap_model(unet)
|
||||
unwarpped_unet.save_pretrained(
|
||||
os.path.join(args.output_dir, f"unet/{step}"), state_dict=accelerator.get_state_dict(unet)
|
||||
)
|
||||
if args.train_text_encoder:
|
||||
unwarpped_text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
unwarpped_text_encoder.save_pretrained(
|
||||
os.path.join(args.output_dir, f"text_encoder/{step}"),
|
||||
state_dict=accelerator.get_state_dict(text_encoder),
|
||||
)
|
||||
|
||||
|
||||
def main(args):
|
||||
validation_prompts = list(filter(None, args.validation_prompt[0].split(".")))
|
||||
|
||||
logging_dir = Path(args.output_dir, args.logging_dir)
|
||||
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
|
||||
|
||||
accelerator = Accelerator(
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
mixed_precision=args.mixed_precision,
|
||||
log_with=args.report_to,
|
||||
project_dir=accelerator_project_config,
|
||||
)
|
||||
if args.report_to == "wandb":
|
||||
import wandb
|
||||
|
||||
wandb_init = {
|
||||
"wandb": {
|
||||
"name": args.wandb_run_name,
|
||||
"mode": "online",
|
||||
}
|
||||
}
|
||||
|
||||
# Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
|
||||
# This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
|
||||
# TODO (patil-suraj): Remove this check when gradient accumulation with two models is enabled in accelerate.
|
||||
if args.train_text_encoder and args.gradient_accumulation_steps > 1 and accelerator.num_processes > 1:
|
||||
raise ValueError(
|
||||
"Gradient accumulation is not supported when training the text encoder in distributed training. "
|
||||
"Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
|
||||
)
|
||||
|
||||
# Make one log on every process with the configuration for debugging.
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
||||
datefmt="%m/%d/%Y %H:%M:%S",
|
||||
level=logging.INFO,
|
||||
)
|
||||
logger.info(accelerator.state, main_process_only=False)
|
||||
if accelerator.is_local_main_process:
|
||||
datasets.utils.logging.set_verbosity_warning()
|
||||
transformers.utils.logging.set_verbosity_warning()
|
||||
diffusers.utils.logging.set_verbosity_info()
|
||||
else:
|
||||
datasets.utils.logging.set_verbosity_error()
|
||||
transformers.utils.logging.set_verbosity_error()
|
||||
diffusers.utils.logging.set_verbosity_error()
|
||||
|
||||
# If passed along, set the training seed now.
|
||||
global_seed = hash(args.wandb_run_name) % (2**32)
|
||||
set_seed(global_seed)
|
||||
|
||||
# Generate class images if prior preservation is enabled.
|
||||
if args.with_prior_preservation:
|
||||
class_images_dir = Path(args.class_data_dir)
|
||||
if not class_images_dir.exists():
|
||||
class_images_dir.mkdir(parents=True)
|
||||
cur_class_images = len(list(class_images_dir.iterdir()))
|
||||
|
||||
if cur_class_images < args.num_class_images:
|
||||
torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
|
||||
if args.prior_generation_precision == "fp32":
|
||||
torch_dtype = torch.float32
|
||||
elif args.prior_generation_precision == "fp16":
|
||||
torch_dtype = torch.float16
|
||||
elif args.prior_generation_precision == "bf16":
|
||||
torch_dtype = torch.bfloat16
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
torch_dtype=torch_dtype,
|
||||
safety_checker=None,
|
||||
revision=args.revision,
|
||||
)
|
||||
pipeline.set_progress_bar_config(disable=True)
|
||||
|
||||
num_new_images = args.num_class_images - cur_class_images
|
||||
logger.info(f"Number of class images to sample: {num_new_images}.")
|
||||
|
||||
sample_dataset = PromptDataset(args.class_prompt, num_new_images)
|
||||
sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
|
||||
|
||||
sample_dataloader = accelerator.prepare(sample_dataloader)
|
||||
pipeline.to(accelerator.device)
|
||||
|
||||
for example in tqdm(
|
||||
sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
|
||||
):
|
||||
images = pipeline(example["prompt"]).images
|
||||
|
||||
for i, image in enumerate(images):
|
||||
hash_image = hashlib.sha1(image.tobytes()).hexdigest()
|
||||
image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
|
||||
image.save(image_filename)
|
||||
|
||||
del pipeline
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
# Handle the repository creation
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub:
|
||||
if args.hub_model_id is None:
|
||||
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
|
||||
else:
|
||||
repo_name = args.hub_model_id
|
||||
repo = Repository(args.output_dir, clone_from=repo_name) # noqa: F841
|
||||
|
||||
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
|
||||
if "step_*" not in gitignore:
|
||||
gitignore.write("step_*\n")
|
||||
if "epoch_*" not in gitignore:
|
||||
gitignore.write("epoch_*\n")
|
||||
elif args.output_dir is not None:
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
# Load the tokenizer
|
||||
if args.tokenizer_name:
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
|
||||
elif args.pretrained_model_name_or_path:
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
subfolder="tokenizer",
|
||||
revision=args.revision,
|
||||
use_fast=False,
|
||||
)
|
||||
|
||||
# import correct text encoder class
|
||||
text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
|
||||
|
||||
# Load scheduler and models
|
||||
noise_scheduler = DDIMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
|
||||
text_encoder = text_encoder_cls.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
|
||||
)
|
||||
|
||||
if args.use_boft:
|
||||
config = BOFTConfig(
|
||||
boft_block_size=args.boft_block_size,
|
||||
boft_block_num=args.boft_block_num,
|
||||
boft_n_butterfly_factor=args.boft_n_butterfly_factor,
|
||||
target_modules=UNET_TARGET_MODULES,
|
||||
boft_dropout=args.boft_dropout,
|
||||
bias=args.boft_bias,
|
||||
)
|
||||
unet = get_peft_model(unet, config, adapter_name=args.wandb_run_name)
|
||||
unet.print_trainable_parameters()
|
||||
|
||||
vae.requires_grad_(False)
|
||||
unet.train()
|
||||
|
||||
if args.train_text_encoder and args.use_boft:
|
||||
config = BOFTConfig(
|
||||
boft_block_size=args.boft_block_size,
|
||||
boft_block_num=args.boft_block_num,
|
||||
boft_n_butterfly_factor=args.boft_n_butterfly_factor,
|
||||
target_modules=TEXT_ENCODER_TARGET_MODULES,
|
||||
boft_dropout=args.boft_dropout,
|
||||
bias=args.boft_bias,
|
||||
)
|
||||
text_encoder = get_peft_model(text_encoder, config, adapter_name=args.wandb_run_name)
|
||||
text_encoder.print_trainable_parameters()
|
||||
text_encoder.train()
|
||||
else:
|
||||
text_encoder.requires_grad_(False)
|
||||
|
||||
# For mixed precision training we cast the text_encoder and vae weights to half-precision
|
||||
# as these models are only used for inference, keeping weights in full precision is not required.
|
||||
weight_dtype = torch.float32
|
||||
if accelerator.mixed_precision == "fp16":
|
||||
weight_dtype = torch.float16
|
||||
elif accelerator.mixed_precision == "bf16":
|
||||
weight_dtype = torch.bfloat16
|
||||
|
||||
# Move unet, vae and text_encoder to device and cast to weight_dtype
|
||||
unet.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
text_encoder.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
if is_xformers_available():
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
else:
|
||||
raise ValueError("xformers is not available. Make sure it is installed correctly")
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing()
|
||||
# below fails when using boft so commenting it out
|
||||
if args.train_text_encoder and not args.use_boft:
|
||||
text_encoder.gradient_checkpointing_enable()
|
||||
|
||||
# Enable TF32 for faster training on Ampere GPUs,
|
||||
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
|
||||
if args.allow_tf32:
|
||||
torch.backends.cuda.matmul.allow_tf32 = True
|
||||
|
||||
if args.scale_lr:
|
||||
args.learning_rate = (
|
||||
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
|
||||
)
|
||||
|
||||
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
|
||||
if args.use_8bit_adam:
|
||||
try:
|
||||
import bitsandbytes as bnb
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
|
||||
)
|
||||
|
||||
optimizer_class = bnb.optim.AdamW8bit
|
||||
else:
|
||||
optimizer_class = torch.optim.AdamW
|
||||
|
||||
# Optimizer creation
|
||||
params_to_optimize = [param for param in unet.parameters() if param.requires_grad]
|
||||
|
||||
if args.train_text_encoder:
|
||||
params_to_optimize += [param for param in text_encoder.parameters() if param.requires_grad]
|
||||
|
||||
optimizer = optimizer_class(
|
||||
params_to_optimize,
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
# Download the official dreambooth dataset from the official repository: https://github.com/google/dreambooth.git
|
||||
data_path = os.path.join(os.getcwd(), "data", "dreambooth")
|
||||
if not os.path.exists(data_path):
|
||||
os.makedirs(os.path.join(os.getcwd(), "data"), exist_ok=True)
|
||||
os.system(f"git clone https://github.com/google/dreambooth.git '{data_path}'")
|
||||
|
||||
# Dataset and DataLoaders creation:
|
||||
train_dataset = DreamBoothDataset(
|
||||
instance_data_root=args.instance_data_dir,
|
||||
instance_prompt=args.instance_prompt,
|
||||
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
|
||||
class_prompt=args.class_prompt,
|
||||
tokenizer=tokenizer,
|
||||
size=args.resolution,
|
||||
center_crop=args.center_crop,
|
||||
)
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset,
|
||||
batch_size=args.train_batch_size,
|
||||
shuffle=True,
|
||||
collate_fn=lambda examples: collate_fn(examples, args.with_prior_preservation),
|
||||
num_workers=args.num_dataloader_workers,
|
||||
)
|
||||
|
||||
# Scheduler and math around the number of training steps.
|
||||
overrode_max_train_steps = False
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
if args.max_train_steps is None:
|
||||
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
|
||||
overrode_max_train_steps = True
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
args.lr_scheduler,
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
|
||||
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
|
||||
num_cycles=args.lr_num_cycles,
|
||||
power=args.lr_power,
|
||||
)
|
||||
|
||||
# Prepare everything with our `accelerator`.
|
||||
if args.train_text_encoder:
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
else:
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
# For mixed precision training we cast the text_encoder and vae weights to half-precision
|
||||
# as these models are only used for inference, keeping weights in full precision is not required.
|
||||
weight_dtype = torch.float32
|
||||
if accelerator.mixed_precision == "fp16":
|
||||
weight_dtype = torch.float16
|
||||
elif accelerator.mixed_precision == "bf16":
|
||||
weight_dtype = torch.bfloat16
|
||||
|
||||
# Move vae and text_encoder to device and cast to weight_dtype
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
if not args.train_text_encoder:
|
||||
text_encoder.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
if overrode_max_train_steps:
|
||||
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
|
||||
# Afterwards we recalculate our number of training epochs
|
||||
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
# The trackers initializes automatically on the main process.
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers(args.wandb_project_name, config=vars(args), init_kwargs=wandb_init)
|
||||
|
||||
# Train!
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataset)}")
|
||||
logger.info(f" Num batches each epoch = {len(train_dataloader)}")
|
||||
logger.info(f" Num Epochs = {args.num_train_epochs}")
|
||||
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
|
||||
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
|
||||
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
|
||||
logger.info(f" Total optimization steps = {args.max_train_steps}")
|
||||
global_step = 0
|
||||
first_epoch = 0
|
||||
|
||||
# Potentially load in the weights and states from a previous save
|
||||
if args.resume_from_checkpoint:
|
||||
if args.resume_from_checkpoint != "latest":
|
||||
path = os.path.basename(args.resume_from_checkpoint)
|
||||
else:
|
||||
# Get the most recent checkpoint
|
||||
dirs = os.listdir(args.output_dir)
|
||||
dirs = [d for d in dirs if d.startswith("checkpoint")]
|
||||
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
|
||||
path = dirs[-1] if len(dirs) > 0 else None
|
||||
accelerator.print(f"Resuming from checkpoint {path}")
|
||||
accelerator.load_state(os.path.join(args.output_dir, path))
|
||||
global_step = int(path.split("-")[1])
|
||||
|
||||
resume_global_step = global_step * args.gradient_accumulation_steps
|
||||
first_epoch = resume_global_step // num_update_steps_per_epoch
|
||||
resume_step = resume_global_step % num_update_steps_per_epoch
|
||||
|
||||
# Only show the progress bar once on each machine.
|
||||
progress_bar = tqdm(range(global_step, args.max_train_steps), disable=not accelerator.is_local_main_process)
|
||||
progress_bar.set_description("Steps")
|
||||
|
||||
if args.train_text_encoder:
|
||||
text_encoder.train()
|
||||
|
||||
for epoch in range(first_epoch, args.num_train_epochs):
|
||||
unet.train()
|
||||
|
||||
with TorchTracemalloc() if not args.no_tracemalloc else nullcontext() as tracemalloc:
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
# Skip steps until we reach the resumed step
|
||||
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:
|
||||
if step % args.gradient_accumulation_steps == 0:
|
||||
progress_bar.update(1)
|
||||
if args.report_to == "wandb":
|
||||
accelerator.print(progress_bar)
|
||||
continue
|
||||
|
||||
with accelerator.accumulate(unet):
|
||||
# Convert images to latent space
|
||||
latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
latents = latents * vae.config.scaling_factor
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device
|
||||
)
|
||||
timesteps = timesteps.long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
|
||||
|
||||
# Predict the noise residual
|
||||
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
|
||||
|
||||
# Get the target for loss depending on the prediction type
|
||||
if noise_scheduler.config.prediction_type == "epsilon":
|
||||
target = noise
|
||||
elif noise_scheduler.config.prediction_type == "v_prediction":
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
|
||||
|
||||
if args.with_prior_preservation:
|
||||
# Chunk the noise and model_pred into two parts and compute the loss on each part separately.
|
||||
model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
|
||||
target, target_prior = torch.chunk(target, 2, dim=0)
|
||||
|
||||
# Compute instance loss
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
|
||||
# Compute prior loss
|
||||
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
|
||||
|
||||
# Add the prior loss to the instance loss.
|
||||
loss = loss + args.prior_loss_weight * prior_loss
|
||||
else:
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
|
||||
accelerator.backward(loss)
|
||||
|
||||
if accelerator.sync_gradients:
|
||||
params_to_clip = (
|
||||
itertools.chain(unet.parameters(), text_encoder.parameters())
|
||||
if args.train_text_encoder
|
||||
else unet.parameters()
|
||||
)
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
if args.report_to == "wandb":
|
||||
accelerator.print(progress_bar)
|
||||
global_step += 1
|
||||
|
||||
if global_step % args.checkpointing_steps == 0 and global_step != 0:
|
||||
if accelerator.is_main_process:
|
||||
save_adaptor(accelerator, global_step, unet, text_encoder, args)
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if (
|
||||
args.validation_prompt is not None
|
||||
and (step + num_update_steps_per_epoch * epoch) % args.validation_steps == 0
|
||||
and global_step > 10
|
||||
):
|
||||
unet.eval()
|
||||
|
||||
logger.info(
|
||||
f"Running validation... \n Generating {len(validation_prompts)} images with prompt:"
|
||||
f" {validation_prompts[0]}, ......"
|
||||
)
|
||||
# create pipeline
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
safety_checker=None,
|
||||
revision=args.revision,
|
||||
)
|
||||
# set `keep_fp32_wrapper` to True because we do not want to remove
|
||||
# mixed precision hooks while we are still training
|
||||
pipeline.unet = accelerator.unwrap_model(unet, keep_fp32_wrapper=True)
|
||||
pipeline.text_encoder = accelerator.unwrap_model(text_encoder, keep_fp32_wrapper=True)
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
pipeline.set_progress_bar_config(disable=True)
|
||||
|
||||
# run inference
|
||||
if args.seed is not None:
|
||||
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
|
||||
else:
|
||||
generator = None
|
||||
# images = []
|
||||
# for _ in range(args.num_validation_images):
|
||||
# image = pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
|
||||
# images.append(image)
|
||||
|
||||
images = []
|
||||
val_img_dir = os.path.join(
|
||||
args.output_dir,
|
||||
f"validation/{global_step}",
|
||||
args.wandb_run_name,
|
||||
)
|
||||
os.makedirs(val_img_dir, exist_ok=True)
|
||||
|
||||
for val_promot in validation_prompts:
|
||||
image = pipeline(val_promot, num_inference_steps=50, generator=generator).images[0]
|
||||
image.save(os.path.join(val_img_dir, f"{'_'.join(val_promot.split(' '))}.png"[1:]))
|
||||
images.append(image)
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
|
||||
if tracker.name == "wandb":
|
||||
import wandb
|
||||
|
||||
tracker.log(
|
||||
{
|
||||
"validation": [
|
||||
wandb.Image(image, caption=f"{i}: {validation_prompts[i]}")
|
||||
for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
if not args.no_tracemalloc:
|
||||
accelerator.print(f"GPU Memory before entering the train : {b2mb(tracemalloc.begin)}")
|
||||
accelerator.print(f"GPU Memory consumed at the end of the train (end-begin): {tracemalloc.used}")
|
||||
accelerator.print(f"GPU Peak Memory consumed during the train (max-begin): {tracemalloc.peaked}")
|
||||
accelerator.print(
|
||||
f"GPU Total Peak Memory consumed during the train (max): {tracemalloc.peaked + b2mb(tracemalloc.begin)}"
|
||||
)
|
||||
|
||||
accelerator.print(f"CPU Memory before entering the train : {b2mb(tracemalloc.cpu_begin)}")
|
||||
accelerator.print(f"CPU Memory consumed at the end of the train (end-begin): {tracemalloc.cpu_used}")
|
||||
accelerator.print(f"CPU Peak Memory consumed during the train (max-begin): {tracemalloc.cpu_peaked}")
|
||||
accelerator.print(
|
||||
f"CPU Total Peak Memory consumed during the train (max): {tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)}"
|
||||
)
|
||||
|
||||
if args.push_to_hub:
|
||||
repo.push_to_hub(commit_message="End of training", blocking=False, auto_lfs_prune=True)
|
||||
accelerator.end_training()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_args()
|
||||
main(args)
|
||||
191
examples/boft_dreambooth/train_dreambooth.sh
Executable file
191
examples/boft_dreambooth/train_dreambooth.sh
Executable file
@ -0,0 +1,191 @@
|
||||
IDX=$1
|
||||
PROMPT_IDX=$((IDX % 25))
|
||||
CLASS_IDX=$((IDX % 30))
|
||||
|
||||
# Define the UNIQUE_TOKEN, CLASS_TOKENs, and SUBJECT_NAMES
|
||||
UNIQUE_TOKEN="qwe"
|
||||
|
||||
SUBJECT_NAMES=(
|
||||
"backpack" "backpack_dog" "bear_plushie" "berry_bowl" "can"
|
||||
"candle" "cat" "cat2" "clock" "colorful_sneaker"
|
||||
"dog" "dog2" "dog3" "dog5" "dog6"
|
||||
"dog7" "dog8" "duck_toy" "fancy_boot" "grey_sloth_plushie"
|
||||
"monster_toy" "pink_sunglasses" "poop_emoji" "rc_car" "red_cartoon"
|
||||
"robot_toy" "shiny_sneaker" "teapot" "vase" "wolf_plushie"
|
||||
)
|
||||
|
||||
CLASS_TOKENs=(
|
||||
"backpack" "backpack" "stuffed animal" "bowl" "can"
|
||||
"candle" "cat" "cat" "clock" "sneaker"
|
||||
"dog" "dog" "dog" "dog" "dog"
|
||||
"dog" "dog" "toy" "boot" "stuffed animal"
|
||||
"toy" "glasses" "toy" "toy" "cartoon"
|
||||
"toy" "sneaker" "teapot" "vase" "stuffed animal"
|
||||
)
|
||||
|
||||
CLASS_TOKEN=${CLASS_TOKENs[$CLASS_IDX]}
|
||||
SELECTED_SUBJECT=${SUBJECT_NAMES[$CLASS_IDX]}
|
||||
|
||||
if [[ $CLASS_IDX =~ ^(0|1|2|3|4|5|8|9|17|18|19|20|21|22|23|24|25|26|27|28|29)$ ]]; then
|
||||
PROMPT_LIST=(
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in the jungle."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in the snow."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on the beach."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on a cobblestone street."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of pink fabric."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of a wooden floor."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a city in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a mountain in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a blue house in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of a purple rug in a forest."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a wheat field in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a tree and autumn leaves in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with the Eiffel Tower in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} floating on top of water."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} floating in an ocean of milk."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of green grass with sunflowers around it."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of a mirror."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of the sidewalk in a crowded street."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of a dirt road."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of a white rug."
|
||||
"a red ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a purple ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a shiny ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a wet ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a cube shaped ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
)
|
||||
|
||||
prompt_test_list=(
|
||||
"a ${CLASS_TOKEN} in the jungle"
|
||||
"a ${CLASS_TOKEN} in the snow"
|
||||
"a ${CLASS_TOKEN} on the beach"
|
||||
"a ${CLASS_TOKEN} on a cobblestone street"
|
||||
"a ${CLASS_TOKEN} on top of pink fabric"
|
||||
"a ${CLASS_TOKEN} on top of a wooden floor"
|
||||
"a ${CLASS_TOKEN} with a city in the background"
|
||||
"a ${CLASS_TOKEN} with a mountain in the background"
|
||||
"a ${CLASS_TOKEN} with a blue house in the background"
|
||||
"a ${CLASS_TOKEN} on top of a purple rug in a forest"
|
||||
"a ${CLASS_TOKEN} with a wheat field in the background"
|
||||
"a ${CLASS_TOKEN} with a tree and autumn leaves in the background"
|
||||
"a ${CLASS_TOKEN} with the Eiffel Tower in the background"
|
||||
"a ${CLASS_TOKEN} floating on top of water"
|
||||
"a ${CLASS_TOKEN} floating in an ocean of milk"
|
||||
"a ${CLASS_TOKEN} on top of green grass with sunflowers around it"
|
||||
"a ${CLASS_TOKEN} on top of a mirror"
|
||||
"a ${CLASS_TOKEN} on top of the sidewalk in a crowded street"
|
||||
"a ${CLASS_TOKEN} on top of a dirt road"
|
||||
"a ${CLASS_TOKEN} on top of a white rug"
|
||||
"a red ${CLASS_TOKEN}"
|
||||
"a purple ${CLASS_TOKEN}"
|
||||
"a shiny ${CLASS_TOKEN}"
|
||||
"a wet ${CLASS_TOKEN}"
|
||||
"a cube shaped ${CLASS_TOKEN}"
|
||||
)
|
||||
|
||||
else
|
||||
PROMPT_LIST=(
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in the jungle."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in the snow."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on the beach."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on a cobblestone street."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of pink fabric."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of a wooden floor."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a city in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a mountain in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} with a blue house in the background."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} on top of a purple rug in a forest."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} wearing a red hat."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} wearing a santa hat."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} wearing a rainbow scarf."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} wearing a black top hat and a monocle."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in a chef outfit."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in a firefighter outfit."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in a police outfit."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} wearing pink glasses."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} wearing a yellow shirt."
|
||||
"a ${UNIQUE_TOKEN} ${CLASS_TOKEN} in a purple wizard outfit."
|
||||
"a red ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a purple ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a shiny ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a wet ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
"a cube shaped ${UNIQUE_TOKEN} ${CLASS_TOKEN}."
|
||||
)
|
||||
|
||||
prompt_test_list=(
|
||||
"a ${CLASS_TOKEN} in the jungle"
|
||||
"a ${CLASS_TOKEN} in the snow"
|
||||
"a ${CLASS_TOKEN} on the beach"
|
||||
"a ${CLASS_TOKEN} on a cobblestone street"
|
||||
"a ${CLASS_TOKEN} on top of pink fabric"
|
||||
"a ${CLASS_TOKEN} on top of a wooden floor"
|
||||
"a ${CLASS_TOKEN} with a city in the background"
|
||||
"a ${CLASS_TOKEN} with a mountain in the background"
|
||||
"a ${CLASS_TOKEN} with a blue house in the background"
|
||||
"a ${CLASS_TOKEN} on top of a purple rug in a forest"
|
||||
"a ${CLASS_TOKEN} wearing a red hat"
|
||||
"a ${CLASS_TOKEN} wearing a santa hat"
|
||||
"a ${CLASS_TOKEN} wearing a rainbow scarf"
|
||||
"a ${CLASS_TOKEN} wearing a black top hat and a monocle"
|
||||
"a ${CLASS_TOKEN} in a chef outfit"
|
||||
"a ${CLASS_TOKEN} in a firefighter outfit"
|
||||
"a ${CLASS_TOKEN} in a police outfit"
|
||||
"a ${CLASS_TOKEN} wearing pink glasses"
|
||||
"a ${CLASS_TOKEN} wearing a yellow shirt"
|
||||
"a ${CLASS_TOKEN} in a purple wizard outfit"
|
||||
"a red ${CLASS_TOKEN}"
|
||||
"a purple ${CLASS_TOKEN}"
|
||||
"a shiny ${CLASS_TOKEN}"
|
||||
"a wet ${CLASS_TOKEN}"
|
||||
"a cube shaped ${CLASS_TOKEN}"
|
||||
)
|
||||
fi
|
||||
|
||||
VALIDATION_PROMPT=${PROMPT_LIST[@]}
|
||||
INSTANCE_PROMPT="a photo of ${UNIQUE_TOKEN} ${CLASS_TOKEN}"
|
||||
CLASS_PROMPT="a photo of ${CLASS_TOKEN}"
|
||||
|
||||
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
|
||||
# export MODEL_NAME="runwayml/stable-diffusion-v1-5"
|
||||
|
||||
PEFT_TYPE="boft"
|
||||
BLOCK_NUM=8
|
||||
BLOCK_SIZE=0
|
||||
N_BUTTERFLY_FACTOR=1
|
||||
|
||||
export PROJECT_NAME="dreambooth_${PEFT_TYPE}"
|
||||
export RUN_NAME="${SELECTED_SUBJECT}_${PEFT_TYPE}_${BLOCK_NUM}${BLOCK_SIZE}${N_BUTTERFLY_FACTOR}"
|
||||
export INSTANCE_DIR="./data/dreambooth/dataset/${SELECTED_SUBJECT}"
|
||||
export CLASS_DIR="./data/class_data/${CLASS_TOKEN}"
|
||||
export OUTPUT_DIR="./data/output/${PEFT_TYPE}"
|
||||
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--class_data_dir="$CLASS_DIR" \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--wandb_project_name=$PROJECT_NAME \
|
||||
--wandb_run_name=$RUN_NAME \
|
||||
--with_prior_preservation --prior_loss_weight=1.0 \
|
||||
--instance_prompt="$INSTANCE_PROMPT" \
|
||||
--validation_prompt="$VALIDATION_PROMPT" \
|
||||
--class_prompt="$CLASS_PROMPT" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--num_dataloader_workers=2 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--num_class_images=200 \
|
||||
--use_boft \
|
||||
--boft_block_num=$BLOCK_NUM \
|
||||
--boft_block_size=$BLOCK_SIZE \
|
||||
--boft_n_butterfly_factor=$N_BUTTERFLY_FACTOR \
|
||||
--boft_dropout=0.1 \
|
||||
--boft_bias="boft_only" \
|
||||
--learning_rate=3e-5 \
|
||||
--max_train_steps=1010 \
|
||||
--checkpointing_steps=200 \
|
||||
--validation_steps=200 \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--report_to="wandb" \
|
||||
0
examples/boft_dreambooth/utils/__init__.py
Normal file
0
examples/boft_dreambooth/utils/__init__.py
Normal file
363
examples/boft_dreambooth/utils/args_loader.py
Normal file
363
examples/boft_dreambooth/utils/args_loader.py
Normal file
@ -0,0 +1,363 @@
|
||||
import argparse
|
||||
import os
|
||||
import warnings
|
||||
from typing import Optional
|
||||
|
||||
from huggingface_hub import HfFolder, whoami
|
||||
from transformers import PretrainedConfig
|
||||
|
||||
|
||||
def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
|
||||
text_encoder_config = PretrainedConfig.from_pretrained(
|
||||
pretrained_model_name_or_path,
|
||||
subfolder="text_encoder",
|
||||
revision=revision,
|
||||
)
|
||||
model_class = text_encoder_config.architectures[0]
|
||||
|
||||
if model_class == "CLIPTextModel":
|
||||
from transformers import CLIPTextModel
|
||||
|
||||
return CLIPTextModel
|
||||
elif model_class == "RobertaSeriesModelWithTransformation":
|
||||
from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
|
||||
|
||||
return RobertaSeriesModelWithTransformation
|
||||
else:
|
||||
raise ValueError(f"{model_class} is not supported.")
|
||||
|
||||
|
||||
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
|
||||
if token is None:
|
||||
token = HfFolder.get_token()
|
||||
if organization is None:
|
||||
username = whoami(token)["name"]
|
||||
return f"{username}/{model_id}"
|
||||
else:
|
||||
return f"{organization}/{model_id}"
|
||||
|
||||
|
||||
def parse_args(input_args=None):
|
||||
parser = argparse.ArgumentParser(description="Simple example of a Dreambooth training script.")
|
||||
parser.add_argument(
|
||||
"--pretrained_model_name_or_path",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="Path to pretrained model or model identifier from huggingface.co/models.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--revision",
|
||||
type=str,
|
||||
default=None,
|
||||
required=False,
|
||||
help="Revision of pretrained model identifier from huggingface.co/models.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tokenizer_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Pretrained tokenizer name or path if not the same as model_name",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--instance_data_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="A folder containing the training data of instance images.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--class_data_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
required=False,
|
||||
help="A folder containing the training data of class images.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--instance_prompt",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="The prompt with identifier specifying the instance",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--class_prompt",
|
||||
type=str,
|
||||
default=None,
|
||||
help="The prompt to specify images in the same class as provided instance images.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--with_prior_preservation",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="Flag to add prior preservation loss.",
|
||||
)
|
||||
parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
|
||||
parser.add_argument(
|
||||
"--num_class_images",
|
||||
type=int,
|
||||
default=100,
|
||||
help=(
|
||||
"Minimal class images for prior preservation loss. If there are not enough images already present in"
|
||||
" class_data_dir, additional images will be sampled with class_prompt."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_prompt",
|
||||
nargs="+",
|
||||
help="A prompt that is used during validation to verify that the model is learning.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num_validation_images",
|
||||
type=int,
|
||||
default=4,
|
||||
help="Number of images that should be generated during validation with `validation_prompt`.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_steps",
|
||||
type=int,
|
||||
default=500,
|
||||
help=(
|
||||
"Run dreambooth validation every X steps. Dreambooth validation consists of running the prompt"
|
||||
" `args.validation_prompt` multiple times: `args.num_validation_images`."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--output_dir",
|
||||
type=str,
|
||||
default="text-inversion-model",
|
||||
help="The output directory where the model predictions and checkpoints will be written.",
|
||||
)
|
||||
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
|
||||
parser.add_argument(
|
||||
"--resolution",
|
||||
type=int,
|
||||
default=512,
|
||||
help=(
|
||||
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
|
||||
" resolution"
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution"
|
||||
)
|
||||
parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
|
||||
|
||||
parser.add_argument(
|
||||
"--set_grads_to_none",
|
||||
action="store_true",
|
||||
help=(
|
||||
"Save more memory by using setting grads to None instead of zero. Be aware, that this changes certain"
|
||||
" behaviors, so disable this argument if it causes any problems. More info:"
|
||||
" https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html"
|
||||
),
|
||||
)
|
||||
|
||||
# boft args
|
||||
parser.add_argument("--use_boft", action="store_true", help="Whether to use BOFT for parameter efficient tuning")
|
||||
parser.add_argument("--boft_block_num", type=int, default=4, help="The number of BOFT blocks")
|
||||
parser.add_argument("--boft_block_size", type=int, default=0, help="The size of BOFT blocks")
|
||||
parser.add_argument("--boft_n_butterfly_factor", type=int, default=2, help="The number of butterfly factors")
|
||||
parser.add_argument("--boft_dropout", type=float, default=0.1, help="BOFT dropout, only used if use_boft is True")
|
||||
parser.add_argument(
|
||||
"--boft_bias",
|
||||
type=str,
|
||||
default="none",
|
||||
help="Bias type for BOFT. Can be 'none', 'all' or 'boft_only', only used if use_boft is True",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num_dataloader_workers", type=int, default=1, help="Num of workers for the training dataloader."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_tracemalloc",
|
||||
default=False,
|
||||
action="store_true",
|
||||
help="Flag to stop memory allocation tracing during training. This could speed up training on Windows.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
|
||||
)
|
||||
parser.add_argument("--num_train_epochs", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--max_train_steps",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--checkpointing_steps",
|
||||
type=int,
|
||||
default=500,
|
||||
help=(
|
||||
"Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
|
||||
" checkpoints in case they are better than the last checkpoint, and are also suitable for resuming"
|
||||
" training using `--resume_from_checkpoint`."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--resume_from_checkpoint",
|
||||
type=str,
|
||||
default=None,
|
||||
help=(
|
||||
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
|
||||
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--gradient_accumulation_steps",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of updates steps to accumulate before performing a backward/update pass.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--gradient_checkpointing",
|
||||
action="store_true",
|
||||
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--learning_rate",
|
||||
type=float,
|
||||
default=5e-6,
|
||||
help="Initial learning rate (after the potential warmup period) to use.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--scale_lr",
|
||||
action="store_true",
|
||||
default=False,
|
||||
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_scheduler",
|
||||
type=str,
|
||||
default="constant",
|
||||
help=(
|
||||
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
|
||||
' "constant", "constant_with_warmup"]'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_num_cycles",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
|
||||
)
|
||||
parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
|
||||
parser.add_argument(
|
||||
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
|
||||
)
|
||||
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
|
||||
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
|
||||
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
|
||||
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
|
||||
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
|
||||
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
|
||||
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
|
||||
parser.add_argument(
|
||||
"--hub_model_id",
|
||||
type=str,
|
||||
default=None,
|
||||
help="The name of the repository to keep in sync with the local `output_dir`.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--logging_dir",
|
||||
type=str,
|
||||
default="logs",
|
||||
help=(
|
||||
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
|
||||
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--allow_tf32",
|
||||
action="store_true",
|
||||
help=(
|
||||
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
|
||||
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--report_to",
|
||||
type=str,
|
||||
default="wandb",
|
||||
help=(
|
||||
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
|
||||
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--wandb_key",
|
||||
type=str,
|
||||
default=None,
|
||||
help=("If report to option is set to wandb, api-key for wandb used for login to wandb "),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--wandb_project_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help=("If report to option is set to wandb, project name in wandb for log tracking "),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--wandb_run_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help=("If report to option is set to wandb, project name in wandb for log tracking "),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
|
||||
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
|
||||
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--prior_generation_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=["no", "fp32", "fp16", "bf16"],
|
||||
help=(
|
||||
"Choose prior generation precision between fp32, fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
|
||||
" 1.10.and an Nvidia Ampere GPU. Default to fp16 if a GPU is available else fp32."
|
||||
),
|
||||
)
|
||||
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
|
||||
parser.add_argument(
|
||||
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
|
||||
)
|
||||
|
||||
if input_args is not None:
|
||||
args = parser.parse_args(input_args)
|
||||
else:
|
||||
args = parser.parse_args()
|
||||
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
# Sanity checks
|
||||
# if args.dataset_name is None and args.train_data_dir is None:
|
||||
# raise ValueError("Need either a dataset name or a training folder.")
|
||||
|
||||
if args.with_prior_preservation:
|
||||
if args.class_data_dir is None:
|
||||
raise ValueError("You must specify a data directory for class images.")
|
||||
if args.class_prompt is None:
|
||||
raise ValueError("You must specify prompt for class images.")
|
||||
else:
|
||||
# logger is not available yet
|
||||
if args.class_data_dir is not None:
|
||||
warnings.warn("You need not use --class_data_dir without --with_prior_preservation.")
|
||||
if args.class_prompt is not None:
|
||||
warnings.warn("You need not use --class_prompt without --with_prior_preservation.")
|
||||
|
||||
return args
|
||||
126
examples/boft_dreambooth/utils/dataset.py
Normal file
126
examples/boft_dreambooth/utils/dataset.py
Normal file
@ -0,0 +1,126 @@
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from PIL import Image
|
||||
from torch.utils.data import Dataset
|
||||
from torchvision import transforms
|
||||
|
||||
|
||||
class DreamBoothDataset(Dataset):
|
||||
"""
|
||||
A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
|
||||
It pre-processes the images and the tokenizes prompts.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
instance_data_root,
|
||||
instance_prompt,
|
||||
tokenizer,
|
||||
class_data_root=None,
|
||||
class_prompt=None,
|
||||
size=512,
|
||||
center_crop=False,
|
||||
):
|
||||
self.size = size
|
||||
self.center_crop = center_crop
|
||||
self.tokenizer = tokenizer
|
||||
|
||||
self.instance_data_root = Path(instance_data_root)
|
||||
if not self.instance_data_root.exists():
|
||||
raise ValueError("Instance images root doesn't exists.")
|
||||
|
||||
self.instance_images_path = list(Path(instance_data_root).iterdir())
|
||||
self.num_instance_images = len(self.instance_images_path)
|
||||
self.instance_prompt = instance_prompt
|
||||
self._length = self.num_instance_images
|
||||
|
||||
if class_data_root is not None:
|
||||
self.class_data_root = Path(class_data_root)
|
||||
self.class_data_root.mkdir(parents=True, exist_ok=True)
|
||||
self.class_images_path = list(self.class_data_root.iterdir())
|
||||
self.num_class_images = len(self.class_images_path)
|
||||
self._length = max(self.num_class_images, self.num_instance_images)
|
||||
self.class_prompt = class_prompt
|
||||
else:
|
||||
self.class_data_root = None
|
||||
|
||||
self.image_transforms = transforms.Compose(
|
||||
[
|
||||
transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
|
||||
transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize([0.5], [0.5]),
|
||||
]
|
||||
)
|
||||
|
||||
def __len__(self):
|
||||
return self._length
|
||||
|
||||
def __getitem__(self, index):
|
||||
example = {}
|
||||
instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
|
||||
if not instance_image.mode == "RGB":
|
||||
instance_image = instance_image.convert("RGB")
|
||||
example["instance_images"] = self.image_transforms(instance_image)
|
||||
example["instance_prompt_ids"] = self.tokenizer(
|
||||
self.instance_prompt,
|
||||
truncation=True,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
return_tensors="pt",
|
||||
).input_ids
|
||||
|
||||
if self.class_data_root:
|
||||
class_image = Image.open(self.class_images_path[index % self.num_class_images])
|
||||
if not class_image.mode == "RGB":
|
||||
class_image = class_image.convert("RGB")
|
||||
example["class_images"] = self.image_transforms(class_image)
|
||||
example["class_prompt_ids"] = self.tokenizer(
|
||||
self.class_prompt,
|
||||
truncation=True,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
return_tensors="pt",
|
||||
).input_ids
|
||||
|
||||
return example
|
||||
|
||||
|
||||
def collate_fn(examples, with_prior_preservation=False):
|
||||
input_ids = [example["instance_prompt_ids"] for example in examples]
|
||||
pixel_values = [example["instance_images"] for example in examples]
|
||||
|
||||
# Concat class and instance examples for prior preservation.
|
||||
# We do this to avoid doing two forward passes.
|
||||
if with_prior_preservation:
|
||||
input_ids += [example["class_prompt_ids"] for example in examples]
|
||||
pixel_values += [example["class_images"] for example in examples]
|
||||
|
||||
pixel_values = torch.stack(pixel_values)
|
||||
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
|
||||
|
||||
input_ids = torch.cat(input_ids, dim=0)
|
||||
|
||||
batch = {
|
||||
"input_ids": input_ids,
|
||||
"pixel_values": pixel_values,
|
||||
}
|
||||
return batch
|
||||
|
||||
|
||||
class PromptDataset(Dataset):
|
||||
"A simple dataset to prepare the prompts to generate class images on multiple GPUs."
|
||||
|
||||
def __init__(self, prompt, num_samples):
|
||||
self.prompt = prompt
|
||||
self.num_samples = num_samples
|
||||
|
||||
def __len__(self):
|
||||
return self.num_samples
|
||||
|
||||
def __getitem__(self, index):
|
||||
example = {}
|
||||
example["prompt"] = self.prompt
|
||||
example["index"] = index
|
||||
return example
|
||||
58
examples/boft_dreambooth/utils/tracemalloc.py
Normal file
58
examples/boft_dreambooth/utils/tracemalloc.py
Normal file
@ -0,0 +1,58 @@
|
||||
import gc
|
||||
import threading
|
||||
|
||||
import psutil
|
||||
import torch
|
||||
|
||||
|
||||
# Converting Bytes to Megabytes
|
||||
def b2mb(x):
|
||||
return int(x / 2**20)
|
||||
|
||||
|
||||
# This context manager is used to track the peak memory usage of the process
|
||||
class TorchTracemalloc:
|
||||
def __enter__(self):
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.reset_max_memory_allocated() # reset the peak gauge to zero
|
||||
self.begin = torch.cuda.memory_allocated()
|
||||
self.process = psutil.Process()
|
||||
|
||||
self.cpu_begin = self.cpu_mem_used()
|
||||
self.peak_monitoring = True
|
||||
peak_monitor_thread = threading.Thread(target=self.peak_monitor_func)
|
||||
peak_monitor_thread.daemon = True
|
||||
peak_monitor_thread.start()
|
||||
return self
|
||||
|
||||
def cpu_mem_used(self):
|
||||
"""get resident set size memory for the current process"""
|
||||
return self.process.memory_info().rss
|
||||
|
||||
def peak_monitor_func(self):
|
||||
self.cpu_peak = -1
|
||||
|
||||
while True:
|
||||
self.cpu_peak = max(self.cpu_mem_used(), self.cpu_peak)
|
||||
|
||||
# can't sleep or will not catch the peak right (this comment is here on purpose)
|
||||
# time.sleep(0.001) # 1msec
|
||||
|
||||
if not self.peak_monitoring:
|
||||
break
|
||||
|
||||
def __exit__(self, *exc):
|
||||
self.peak_monitoring = False
|
||||
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
self.end = torch.cuda.memory_allocated()
|
||||
self.peak = torch.cuda.max_memory_allocated()
|
||||
self.used = b2mb(self.end - self.begin)
|
||||
self.peaked = b2mb(self.peak - self.begin)
|
||||
|
||||
self.cpu_end = self.cpu_mem_used()
|
||||
self.cpu_used = b2mb(self.cpu_end - self.cpu_begin)
|
||||
self.cpu_peaked = b2mb(self.cpu_peak - self.cpu_begin)
|
||||
# print(f"delta used/peak {self.used:4d}/{self.peaked:4d}")
|
||||
1388
examples/causal_language_modeling/peft_ln_tuning_clm.ipynb
Normal file
1388
examples/causal_language_modeling/peft_ln_tuning_clm.ipynb
Normal file
File diff suppressed because it is too large
Load Diff
@ -3,7 +3,6 @@ import os
|
||||
import sys
|
||||
import threading
|
||||
|
||||
import numpy as np
|
||||
import psutil
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
@ -23,23 +22,23 @@ from peft import LoraConfig, TaskType, get_peft_model
|
||||
|
||||
def levenshtein_distance(str1, str2):
|
||||
# TC: O(N^2)
|
||||
# SC: O(N^2)
|
||||
# SC: O(N)
|
||||
if str1 == str2:
|
||||
return 0
|
||||
num_rows = len(str1) + 1
|
||||
num_cols = len(str2) + 1
|
||||
dp_matrix = np.empty((num_rows, num_cols))
|
||||
dp_matrix[0, :] = range(num_cols)
|
||||
dp_matrix[:, 0] = range(num_rows)
|
||||
|
||||
dp_matrix = list(range(num_cols))
|
||||
for i in range(1, num_rows):
|
||||
prev = dp_matrix[0]
|
||||
dp_matrix[0] = i
|
||||
for j in range(1, num_cols):
|
||||
temp = dp_matrix[j]
|
||||
if str1[i - 1] == str2[j - 1]:
|
||||
dp_matrix[i, j] = dp_matrix[i - 1, j - 1]
|
||||
dp_matrix[j] = prev
|
||||
else:
|
||||
dp_matrix[i, j] = min(dp_matrix[i - 1, j - 1], dp_matrix[i - 1, j], dp_matrix[i, j - 1]) + 1
|
||||
|
||||
return dp_matrix[num_rows - 1, num_cols - 1]
|
||||
dp_matrix[j] = min(prev, dp_matrix[j], dp_matrix[j - 1]) + 1
|
||||
prev = temp
|
||||
return dp_matrix[num_cols - 1]
|
||||
|
||||
|
||||
def get_closest_label(eval_pred, classes):
|
||||
@ -250,22 +249,18 @@ def main():
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
accelerator.print("GPU Memory before entering the train : {}".format(b2mb(tracemalloc.begin)))
|
||||
accelerator.print("GPU Memory consumed at the end of the train (end-begin): {}".format(tracemalloc.used))
|
||||
accelerator.print("GPU Peak Memory consumed during the train (max-begin): {}".format(tracemalloc.peaked))
|
||||
accelerator.print(f"GPU Memory before entering the train : {b2mb(tracemalloc.begin)}")
|
||||
accelerator.print(f"GPU Memory consumed at the end of the train (end-begin): {tracemalloc.used}")
|
||||
accelerator.print(f"GPU Peak Memory consumed during the train (max-begin): {tracemalloc.peaked}")
|
||||
accelerator.print(
|
||||
"GPU Total Peak Memory consumed during the train (max): {}".format(
|
||||
tracemalloc.peaked + b2mb(tracemalloc.begin)
|
||||
)
|
||||
f"GPU Total Peak Memory consumed during the train (max): {tracemalloc.peaked + b2mb(tracemalloc.begin)}"
|
||||
)
|
||||
|
||||
accelerator.print("CPU Memory before entering the train : {}".format(b2mb(tracemalloc.cpu_begin)))
|
||||
accelerator.print("CPU Memory consumed at the end of the train (end-begin): {}".format(tracemalloc.cpu_used))
|
||||
accelerator.print("CPU Peak Memory consumed during the train (max-begin): {}".format(tracemalloc.cpu_peaked))
|
||||
accelerator.print(f"CPU Memory before entering the train : {b2mb(tracemalloc.cpu_begin)}")
|
||||
accelerator.print(f"CPU Memory consumed at the end of the train (end-begin): {tracemalloc.cpu_used}")
|
||||
accelerator.print(f"CPU Peak Memory consumed during the train (max-begin): {tracemalloc.cpu_peaked}")
|
||||
accelerator.print(
|
||||
"CPU Total Peak Memory consumed during the train (max): {}".format(
|
||||
tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)
|
||||
)
|
||||
f"CPU Total Peak Memory consumed during the train (max): {tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)}"
|
||||
)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
@ -286,22 +281,18 @@ def main():
|
||||
eval_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
|
||||
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
accelerator.print("GPU Memory before entering the eval : {}".format(b2mb(tracemalloc.begin)))
|
||||
accelerator.print("GPU Memory consumed at the end of the eval (end-begin): {}".format(tracemalloc.used))
|
||||
accelerator.print("GPU Peak Memory consumed during the eval (max-begin): {}".format(tracemalloc.peaked))
|
||||
accelerator.print(f"GPU Memory before entering the eval : {b2mb(tracemalloc.begin)}")
|
||||
accelerator.print(f"GPU Memory consumed at the end of the eval (end-begin): {tracemalloc.used}")
|
||||
accelerator.print(f"GPU Peak Memory consumed during the eval (max-begin): {tracemalloc.peaked}")
|
||||
accelerator.print(
|
||||
"GPU Total Peak Memory consumed during the eval (max): {}".format(
|
||||
tracemalloc.peaked + b2mb(tracemalloc.begin)
|
||||
)
|
||||
f"GPU Total Peak Memory consumed during the eval (max): {tracemalloc.peaked + b2mb(tracemalloc.begin)}"
|
||||
)
|
||||
|
||||
accelerator.print("CPU Memory before entering the eval : {}".format(b2mb(tracemalloc.cpu_begin)))
|
||||
accelerator.print("CPU Memory consumed at the end of the eval (end-begin): {}".format(tracemalloc.cpu_used))
|
||||
accelerator.print("CPU Peak Memory consumed during the eval (max-begin): {}".format(tracemalloc.cpu_peaked))
|
||||
accelerator.print(f"CPU Memory before entering the eval : {b2mb(tracemalloc.cpu_begin)}")
|
||||
accelerator.print(f"CPU Memory consumed at the end of the eval (end-begin): {tracemalloc.cpu_used}")
|
||||
accelerator.print(f"CPU Peak Memory consumed during the eval (max-begin): {tracemalloc.cpu_peaked}")
|
||||
accelerator.print(
|
||||
"CPU Total Peak Memory consumed during the eval (max): {}".format(
|
||||
tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)
|
||||
)
|
||||
f"CPU Total Peak Memory consumed during the eval (max): {tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)}"
|
||||
)
|
||||
|
||||
correct = 0
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
" PeftConfig,\n",
|
||||
" PeftModel,\n",
|
||||
" get_peft_model,\n",
|
||||
" prepare_model_for_int8_training,\n",
|
||||
" prepare_model_for_kbit_training,\n",
|
||||
")\n",
|
||||
"from transformers import (\n",
|
||||
" AutoModelForCausalLM,\n",
|
||||
|
||||
@ -98,7 +98,7 @@ lr_scheduler = get_linear_schedule_with_warmup(
|
||||
num_warmup_steps=0,
|
||||
num_training_steps=(len(train_dataloader) * num_epochs),
|
||||
)
|
||||
model.base_model.peft_config.total_step = len(train_dataloader) * num_epochs
|
||||
model.base_model.peft_config["default"].total_step = len(train_dataloader) * num_epochs
|
||||
|
||||
|
||||
# training and evaluation
|
||||
|
||||
@ -3,7 +3,6 @@ import os
|
||||
import sys
|
||||
import threading
|
||||
|
||||
import numpy as np
|
||||
import psutil
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
@ -17,23 +16,23 @@ from peft import LoraConfig, TaskType, get_peft_model
|
||||
|
||||
def levenshtein_distance(str1, str2):
|
||||
# TC: O(N^2)
|
||||
# SC: O(N^2)
|
||||
# SC: O(N)
|
||||
if str1 == str2:
|
||||
return 0
|
||||
num_rows = len(str1) + 1
|
||||
num_cols = len(str2) + 1
|
||||
dp_matrix = np.empty((num_rows, num_cols))
|
||||
dp_matrix[0, :] = range(num_cols)
|
||||
dp_matrix[:, 0] = range(num_rows)
|
||||
|
||||
dp_matrix = list(range(num_cols))
|
||||
for i in range(1, num_rows):
|
||||
prev = dp_matrix[0]
|
||||
dp_matrix[0] = i
|
||||
for j in range(1, num_cols):
|
||||
temp = dp_matrix[j]
|
||||
if str1[i - 1] == str2[j - 1]:
|
||||
dp_matrix[i, j] = dp_matrix[i - 1, j - 1]
|
||||
dp_matrix[j] = prev
|
||||
else:
|
||||
dp_matrix[i, j] = min(dp_matrix[i - 1, j - 1], dp_matrix[i - 1, j], dp_matrix[i, j - 1]) + 1
|
||||
|
||||
return dp_matrix[num_rows - 1, num_cols - 1]
|
||||
dp_matrix[j] = min(prev, dp_matrix[j], dp_matrix[j - 1]) + 1
|
||||
prev = temp
|
||||
return dp_matrix[num_cols - 1]
|
||||
|
||||
|
||||
def get_closest_label(eval_pred, classes):
|
||||
@ -201,22 +200,18 @@ def main():
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
accelerator.print("GPU Memory before entering the train : {}".format(b2mb(tracemalloc.begin)))
|
||||
accelerator.print("GPU Memory consumed at the end of the train (end-begin): {}".format(tracemalloc.used))
|
||||
accelerator.print("GPU Peak Memory consumed during the train (max-begin): {}".format(tracemalloc.peaked))
|
||||
accelerator.print(f"GPU Memory before entering the train : {b2mb(tracemalloc.begin)}")
|
||||
accelerator.print(f"GPU Memory consumed at the end of the train (end-begin): {tracemalloc.used}")
|
||||
accelerator.print(f"GPU Peak Memory consumed during the train (max-begin): {tracemalloc.peaked}")
|
||||
accelerator.print(
|
||||
"GPU Total Peak Memory consumed during the train (max): {}".format(
|
||||
tracemalloc.peaked + b2mb(tracemalloc.begin)
|
||||
)
|
||||
f"GPU Total Peak Memory consumed during the train (max): {tracemalloc.peaked + b2mb(tracemalloc.begin)}"
|
||||
)
|
||||
|
||||
accelerator.print("CPU Memory before entering the train : {}".format(b2mb(tracemalloc.cpu_begin)))
|
||||
accelerator.print("CPU Memory consumed at the end of the train (end-begin): {}".format(tracemalloc.cpu_used))
|
||||
accelerator.print("CPU Peak Memory consumed during the train (max-begin): {}".format(tracemalloc.cpu_peaked))
|
||||
accelerator.print(f"CPU Memory before entering the train : {b2mb(tracemalloc.cpu_begin)}")
|
||||
accelerator.print(f"CPU Memory consumed at the end of the train (end-begin): {tracemalloc.cpu_used}")
|
||||
accelerator.print(f"CPU Peak Memory consumed during the train (max-begin): {tracemalloc.cpu_peaked}")
|
||||
accelerator.print(
|
||||
"CPU Total Peak Memory consumed during the train (max): {}".format(
|
||||
tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)
|
||||
)
|
||||
f"CPU Total Peak Memory consumed during the train (max): {tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)}"
|
||||
)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
@ -236,22 +231,18 @@ def main():
|
||||
eval_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
|
||||
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
accelerator.print("GPU Memory before entering the eval : {}".format(b2mb(tracemalloc.begin)))
|
||||
accelerator.print("GPU Memory consumed at the end of the eval (end-begin): {}".format(tracemalloc.used))
|
||||
accelerator.print("GPU Peak Memory consumed during the eval (max-begin): {}".format(tracemalloc.peaked))
|
||||
accelerator.print(f"GPU Memory before entering the eval : {b2mb(tracemalloc.begin)}")
|
||||
accelerator.print(f"GPU Memory consumed at the end of the eval (end-begin): {tracemalloc.used}")
|
||||
accelerator.print(f"GPU Peak Memory consumed during the eval (max-begin): {tracemalloc.peaked}")
|
||||
accelerator.print(
|
||||
"GPU Total Peak Memory consumed during the eval (max): {}".format(
|
||||
tracemalloc.peaked + b2mb(tracemalloc.begin)
|
||||
)
|
||||
f"GPU Total Peak Memory consumed during the eval (max): {tracemalloc.peaked + b2mb(tracemalloc.begin)}"
|
||||
)
|
||||
|
||||
accelerator.print("CPU Memory before entering the eval : {}".format(b2mb(tracemalloc.cpu_begin)))
|
||||
accelerator.print("CPU Memory consumed at the end of the eval (end-begin): {}".format(tracemalloc.cpu_used))
|
||||
accelerator.print("CPU Peak Memory consumed during the eval (max-begin): {}".format(tracemalloc.cpu_peaked))
|
||||
accelerator.print(f"CPU Memory before entering the eval : {b2mb(tracemalloc.cpu_begin)}")
|
||||
accelerator.print(f"CPU Memory consumed at the end of the eval (end-begin): {tracemalloc.cpu_used}")
|
||||
accelerator.print(f"CPU Peak Memory consumed during the eval (max-begin): {tracemalloc.cpu_peaked}")
|
||||
accelerator.print(
|
||||
"CPU Total Peak Memory consumed during the eval (max): {}".format(
|
||||
tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)
|
||||
)
|
||||
f"CPU Total Peak Memory consumed during the eval (max): {tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)}"
|
||||
)
|
||||
|
||||
correct = 0
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023-present the HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@ -28,12 +27,11 @@ from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.utils import set_seed
|
||||
from datasets import DatasetDict, load_dataset
|
||||
from huggingface_hub import Repository, create_repo
|
||||
from huggingface_hub import HfApi
|
||||
from torch import nn
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModel, AutoTokenizer, SchedulerType, default_data_collator, get_scheduler
|
||||
from transformers.utils import get_full_repo_name
|
||||
|
||||
from peft import LoraConfig, TaskType, get_peft_model
|
||||
|
||||
@ -42,7 +40,7 @@ logger = get_logger(__name__)
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description="Training a PEFT model for Sematic Search task")
|
||||
parser = argparse.ArgumentParser(description="Training a PEFT model for Semantic Search task")
|
||||
parser.add_argument("--dataset_name", type=str, default=None, help="dataset name on HF hub")
|
||||
parser.add_argument(
|
||||
"--max_length",
|
||||
@ -138,12 +136,12 @@ def parse_args():
|
||||
parser.add_argument(
|
||||
"--sanity_test",
|
||||
action="store_true",
|
||||
help="Whether to enable experiment trackers for logging.",
|
||||
help="Whether to enable sanity test.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_peft",
|
||||
action="store_true",
|
||||
help="Whether to enable experiment trackers for logging.",
|
||||
help="Whether to use PEFT.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
@ -170,9 +168,11 @@ def load_model_hook(models, input_dir):
|
||||
|
||||
class AutoModelForSentenceEmbedding(nn.Module):
|
||||
def __init__(self, model_name, tokenizer, normalize=True):
|
||||
super(AutoModelForSentenceEmbedding, self).__init__()
|
||||
super().__init__()
|
||||
|
||||
self.model = AutoModel.from_pretrained(model_name) # , load_in_8bit=True, device_map={"":0})
|
||||
self.model = AutoModel.from_pretrained(
|
||||
model_name
|
||||
) # , quantizaton_config=BitsAndBytesConfig(load_in_8bit=True), device_map={"":0})
|
||||
self.normalize = normalize
|
||||
self.tokenizer = tokenizer
|
||||
|
||||
@ -235,12 +235,13 @@ def main():
|
||||
# Handle the repository creation
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub:
|
||||
if args.hub_model_id is None:
|
||||
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
|
||||
else:
|
||||
repo_name = args.hub_model_id
|
||||
create_repo(repo_name, exist_ok=True, token=args.hub_token)
|
||||
repo = Repository(args.output_dir, clone_from=repo_name, token=args.hub_token)
|
||||
api = HfApi(token=args.hub_token)
|
||||
|
||||
# Create repo (repo_name from args or inferred)
|
||||
repo_name = args.hub_model_id
|
||||
if repo_name is None:
|
||||
repo_name = Path(args.output_dir).absolute().name
|
||||
repo_id = api.create_repo(repo_name, exist_ok=True).repo_id
|
||||
|
||||
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
|
||||
if "step_*" not in gitignore:
|
||||
@ -486,7 +487,12 @@ def main():
|
||||
if epoch < args.num_train_epochs - 1
|
||||
else "End of training"
|
||||
)
|
||||
repo.push_to_hub(commit_message=commit_message, blocking=False, auto_lfs_prune=True)
|
||||
api.upload_folder(
|
||||
repo_id=repo_id,
|
||||
folder_path=args.output_dir,
|
||||
commit_message=commit_message,
|
||||
run_as_future=True,
|
||||
)
|
||||
accelerator.wait_for_everyone()
|
||||
accelerator.end_training()
|
||||
|
||||
|
||||
@ -82,7 +82,7 @@
|
||||
" def __init__(self, model_name, tokenizer, normalize=True):\n",
|
||||
" super(AutoModelForSentenceEmbedding, self).__init__()\n",
|
||||
"\n",
|
||||
" self.model = AutoModel.from_pretrained(model_name) # , load_in_8bit=True, device_map={\"\":0})\n",
|
||||
" self.model = AutoModel.from_pretrained(model_name) # , quantizaton_config=BitsAndBytesConfig(load_in_8bit=True), device_map={\"\":0})\n",
|
||||
" self.normalize = normalize\n",
|
||||
" self.tokenizer = tokenizer\n",
|
||||
"\n",
|
||||
|
||||
@ -165,11 +165,11 @@ You can also directly load adapters from the Hub using the commands below:
|
||||
|
||||
# import torch
|
||||
# from peft import PeftModel, PeftConfig
|
||||
# from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
# from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
|
||||
#
|
||||
# peft_model_id = "ybelkada/opt-6.7b-lora"
|
||||
# config = PeftConfig.from_pretrained(peft_model_id)
|
||||
# model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, return_dict=True, load_in_8bit=True, device_map='auto')
|
||||
# model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path, return_dict=True, quantization_config=BitsAndBytesConfig(load_in_8bit=True), device_map='auto')
|
||||
# tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
|
||||
#
|
||||
## Load the Lora model
|
||||
|
||||
@ -1743,7 +1743,7 @@
|
||||
],
|
||||
"source": [
|
||||
"trainer = Trainer(\n",
|
||||
" model,\n",
|
||||
" lora_model,\n",
|
||||
" args,\n",
|
||||
" train_dataset=train_ds,\n",
|
||||
" eval_dataset=val_ds,\n",
|
||||
|
||||
@ -195,7 +195,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"ds = load_dataset('beans')"
|
||||
"ds = load_dataset(\"beans\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -228,7 +228,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"ds_train[0]['image']"
|
||||
"ds_train[0][\"image\"]"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -247,8 +247,8 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"def process(batch):\n",
|
||||
" x = torch.cat([transform(img).unsqueeze(0) for img in batch['image']])\n",
|
||||
" y = torch.tensor(batch['labels'])\n",
|
||||
" x = torch.cat([transform(img).unsqueeze(0) for img in batch[\"image\"]])\n",
|
||||
" y = torch.tensor(batch[\"labels\"])\n",
|
||||
" return {\"x\": x, \"y\": y}"
|
||||
]
|
||||
},
|
||||
@ -464,11 +464,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"config = peft.LoraConfig(\n",
|
||||
" r=8,\n",
|
||||
" target_modules=r\".*\\.mlp\\.fc\\d\",\n",
|
||||
" modules_to_save=[\"head.fc\"]\n",
|
||||
")"
|
||||
"config = peft.LoraConfig(r=8, target_modules=r\".*\\.mlp\\.fc\\d\", modules_to_save=[\"head.fc\"])"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -494,7 +490,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"device = 'cuda' if torch.cuda.is_available() else 'cpu'\n",
|
||||
"device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
|
||||
"peft_model = peft.get_peft_model(model, config).to(device)\n",
|
||||
"optimizer = torch.optim.Adam(peft_model.parameters(), lr=2e-4)\n",
|
||||
"criterion = torch.nn.CrossEntropyLoss()\n",
|
||||
@ -681,7 +677,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"x = ds_train[:1]['x']\n",
|
||||
"x = ds_train[:1][\"x\"]\n",
|
||||
"y_peft = peft_model(x.to(device))\n",
|
||||
"y_loaded = loaded(x)\n",
|
||||
"torch.allclose(y_peft.cpu(), y_loaded)"
|
||||
|
||||
@ -301,11 +301,11 @@
|
||||
"os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\n",
|
||||
"\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"from transformers import AutoModelForSeq2SeqLM, AutoTokenizer\n",
|
||||
"from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, BitsAndBytesConfig\n",
|
||||
"\n",
|
||||
"model_name = \"google/flan-t5-large\"\n",
|
||||
"\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(model_name, load_in_8bit=True)\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name)"
|
||||
]
|
||||
},
|
||||
@ -327,7 +327,7 @@
|
||||
"id": "4o3ePxrjEDzv"
|
||||
},
|
||||
"source": [
|
||||
"Some pre-processing needs to be done before training such an int8 model using `peft`, therefore let's import an utiliy function `prepare_model_for_int8_training` that will: \n",
|
||||
"Some pre-processing needs to be done before training such an int8 model using `peft`, therefore let's import an utiliy function `prepare_model_for_kbit_training` that will: \n",
|
||||
"- Casts all the non `int8` modules to full precision (`fp32`) for stability\n",
|
||||
"- Add a `forward_hook` to the input embedding layer to enable gradient computation of the input hidden states\n",
|
||||
"- Enable gradient checkpointing for more memory-efficient training"
|
||||
@ -342,9 +342,9 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from peft import prepare_model_for_int8_training\n",
|
||||
"from peft import prepare_model_for_kbit_training\n",
|
||||
"\n",
|
||||
"model = prepare_model_for_int8_training(model)"
|
||||
"model = prepare_model_for_kbit_training(model)"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@ -219,9 +219,9 @@
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import bitsandbytes as bnb\n",
|
||||
"from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM\n",
|
||||
"from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM, BitsAndBytesConfig\n",
|
||||
"\n",
|
||||
"model = AutoModelForCausalLM.from_pretrained(\"facebook/opt-6.7b\", load_in_8bit=True)\n",
|
||||
"model = AutoModelForCausalLM.from_pretrained(\"facebook/opt-6.7b\", quantization_config=BitsAndBytesConfig(load_in_8bit=True))\n",
|
||||
"\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(\"facebook/opt-6.7b\")"
|
||||
]
|
||||
@ -235,7 +235,7 @@
|
||||
"source": [
|
||||
"### Prepare model for training\n",
|
||||
"\n",
|
||||
"Some pre-processing needs to be done before training such an int8 model using `peft`, therefore let's import an utiliy function `prepare_model_for_int8_training` that will: \n",
|
||||
"Some pre-processing needs to be done before training such an int8 model using `peft`, therefore let's import an utiliy function `prepare_model_for_kbit_training` that will: \n",
|
||||
"- Casts all the non `int8` modules to full precision (`fp32`) for stability\n",
|
||||
"- Add a `forward_hook` to the input embedding layer to enable gradient computation of the input hidden states\n",
|
||||
"- Enable gradient checkpointing for more memory-efficient training"
|
||||
@ -249,9 +249,9 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from peft import prepare_model_for_int8_training\n",
|
||||
"from peft import prepare_model_for_kbit_training\n",
|
||||
"\n",
|
||||
"model = prepare_model_for_int8_training(model)"
|
||||
"model = prepare_model_for_kbit_training(model)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1459,12 +1459,12 @@
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"from peft import PeftModel, PeftConfig\n",
|
||||
"from transformers import AutoModelForCausalLM, AutoTokenizer\n",
|
||||
"from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig\n",
|
||||
"\n",
|
||||
"peft_model_id = \"ybelkada/opt-6.7b-lora\"\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n",
|
||||
"model = AutoModelForCausalLM.from_pretrained(\n",
|
||||
" config.base_model_name_or_path, return_dict=True, load_in_8bit=True, device_map=\"auto\"\n",
|
||||
" config.base_model_name_or_path, return_dict=True, quantization_config=BitsAndBytesConfig(load_in_8bit=True), device_map=\"auto\"\n",
|
||||
")\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)\n",
|
||||
"\n",
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2023-present the HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@ -15,7 +14,7 @@
|
||||
import torch
|
||||
from datasets import load_dataset
|
||||
from torch.utils.data import DataLoader, Dataset
|
||||
from transformers import AutoModelForVision2Seq, AutoProcessor
|
||||
from transformers import AutoModelForVision2Seq, AutoProcessor, BitsAndBytesConfig
|
||||
|
||||
from peft import LoraConfig, get_peft_model
|
||||
|
||||
@ -29,7 +28,9 @@ config = LoraConfig(
|
||||
)
|
||||
|
||||
# We load our model and processor using `transformers`
|
||||
model = AutoModelForVision2Seq.from_pretrained("Salesforce/blip2-opt-2.7b", load_in_8bit=True)
|
||||
model = AutoModelForVision2Seq.from_pretrained(
|
||||
"Salesforce/blip2-opt-2.7b", quantization_config=BitsAndBytesConfig(load_in_8bit=True)
|
||||
)
|
||||
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
|
||||
|
||||
# Get our peft model and print the number of trainable parameters
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user