mirror of
https://github.com/huggingface/peft.git
synced 2025-10-20 23:43:47 +08:00
Compare commits
80 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| a478ab9bce | |||
| eb07373477 | |||
| f1980e9be2 | |||
| 8777b5606d | |||
| 4497d6438c | |||
| 3d898adb26 | |||
| 842b09a280 | |||
| 91c69a80ab | |||
| c1199931de | |||
| 5e788b329d | |||
| 48dc4c624e | |||
| d2b99c0b62 | |||
| 27c2701555 | |||
| a43ef6ec72 | |||
| c81b6680e7 | |||
| 8358b27445 | |||
| b9451ab458 | |||
| ce4e6f3dd9 | |||
| 53eb209387 | |||
| a84414f6de | |||
| 2c532713ad | |||
| 94f00b7d27 | |||
| 7820a539dd | |||
| 47601bab7c | |||
| 99901896cc | |||
| 5c7fe97753 | |||
| aa18556c56 | |||
| e6bf09db80 | |||
| 681ce93cc1 | |||
| 85ad682530 | |||
| e19ee681ac | |||
| 83d6d55d4b | |||
| 7dfb472424 | |||
| a78f8a0495 | |||
| 6175ee2c4c | |||
| a3537160dc | |||
| 75925b1aae | |||
| 1ef0f89a0c | |||
| e6ef85a711 | |||
| 6f2803e8a7 | |||
| 1c9d197693 | |||
| 592b1dd99f | |||
| 3240c0bb36 | |||
| e8fbcfcac3 | |||
| 1a8928c5a4 | |||
| 173dc3dedf | |||
| dbf44fe316 | |||
| 648fcb397c | |||
| 7aadb6d9ec | |||
| 49842e1961 | |||
| 44d0ac3f25 | |||
| 43a9a42991 | |||
| 145b13c238 | |||
| 8ace5532b2 | |||
| c1281b96ff | |||
| ca7b46209a | |||
| 81285f30a5 | |||
| c9b225d257 | |||
| af7414a67d | |||
| 6d6149cf81 | |||
| a31dfa3001 | |||
| afa7739131 | |||
| f1ee1e4c0f | |||
| ed5a7bff6b | |||
| 42a793e2f5 | |||
| eb8362bbe1 | |||
| 5733ea9f64 | |||
| 36c7e3b441 | |||
| 0e80648010 | |||
| be0e79c271 | |||
| 5acd392880 | |||
| 951119fcfa | |||
| 29d608f481 | |||
| 15de814bb4 | |||
| a29a12701e | |||
| 3bd50315a6 | |||
| 45186ee04e | |||
| c8e215b989 | |||
| d1735e098c | |||
| c53ea2c9f4 |
@ -1 +0,0 @@
|
||||
include LICENSE
|
||||
5
Makefile
5
Makefile
@ -7,13 +7,12 @@ check_dirs := src tests examples
|
||||
# this target runs checks on all files
|
||||
quality:
|
||||
black --check $(check_dirs)
|
||||
isort --check-only $(check_dirs)
|
||||
flake8 $(check_dirs)
|
||||
ruff $(check_dirs)
|
||||
doc-builder style src tests --max_len 119 --check_only
|
||||
|
||||
# Format source code automatically and check is there are any problems left that need manual fixing
|
||||
style:
|
||||
black $(check_dirs)
|
||||
isort $(check_dirs)
|
||||
ruff $(check_dirs) --fix
|
||||
doc-builder style src tests --max_len 119
|
||||
|
||||
45
README.md
45
README.md
@ -26,7 +26,7 @@ Seamlessly integrated with 🤗 Accelerate for large scale models leveraging Dee
|
||||
Supported methods:
|
||||
|
||||
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685.pdf)
|
||||
2. Prefix Tuning: [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
|
||||
2. Prefix Tuning: [Prefix-Tuning: Optimizing Continuous Prompts for Generation](https://aclanthology.org/2021.acl-long.353/), [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
|
||||
3. P-Tuning: [GPT Understands, Too](https://arxiv.org/pdf/2103.10385.pdf)
|
||||
4. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/pdf/2104.08691.pdf)
|
||||
|
||||
@ -52,7 +52,7 @@ model.print_trainable_parameters()
|
||||
|
||||
### Get comparable performance to full finetuning by adapting LLMs to downstream tasks using consumer hardware
|
||||
|
||||
GPU memory required for adapting LLMs on the few-shot dataset `ought/raft/twitter_complaints`. Here, settings considered
|
||||
GPU memory required for adapting LLMs on the few-shot dataset [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints). Here, settings considered
|
||||
are full finetuning, PEFT-LoRA using plain PyTorch and PEFT-LoRA using DeepSpeed with CPU Offloading.
|
||||
|
||||
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
|
||||
@ -63,9 +63,9 @@ Hardware: Single A100 80GB GPU with CPU RAM above 64GB
|
||||
| bigscience/mt0-xxl (12B params) | OOM GPU | 56GB GPU / 3GB CPU | 22GB GPU / 52GB CPU |
|
||||
| bigscience/bloomz-7b1 (7B params) | OOM GPU | 32GB GPU / 3.8GB CPU | 18.1GB GPU / 35GB CPU |
|
||||
|
||||
Performance of PEFT-LoRA tuned `bigscience/T0_3B` on `ought/raft/twitter_complaints` leaderboard.
|
||||
A point to note is that we didn't try to sequeeze performance by playing around with input instruction templates, LoRA hyperparams and other training related hyperparams. Also, we didn't use the larger 13B mt0-xxl model.
|
||||
So, we are already seeing comparable performance to SoTA with parameter efficient tuning. Also, the final checkpoint size is just `19MB` in comparison to `11GB` size of the backbone `bigscience/T0_3B` model.
|
||||
Performance of PEFT-LoRA tuned [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) on [`ought/raft/twitter_complaints`](https://huggingface.co/datasets/ought/raft/viewer/twitter_complaints) leaderboard.
|
||||
A point to note is that we didn't try to sequeeze performance by playing around with input instruction templates, LoRA hyperparams and other training related hyperparams. Also, we didn't use the larger 13B [mt0-xxl](https://huggingface.co/bigscience/mt0-xxl) model.
|
||||
So, we are already seeing comparable performance to SoTA with parameter efficient tuning. Also, the final checkpoint size is just `19MB` in comparison to `11GB` size of the backbone [`bigscience/T0_3B`](https://huggingface.co/bigscience/T0_3B) model.
|
||||
|
||||
| Submission Name | Accuracy |
|
||||
| --------- | ---- |
|
||||
@ -77,9 +77,9 @@ So, we are already seeing comparable performance to SoTA with parameter efficien
|
||||
|
||||
### Parameter Efficient Tuning of Diffusion Models
|
||||
|
||||
GPU memory required by different settings during training is given below. The final checkpoint size is `8.8 MB``.
|
||||
GPU memory required by different settings during training is given below. The final checkpoint size is `8.8 MB`.
|
||||
|
||||
Hardware: Single A100 80GB GPU with CPU RAM above 64G
|
||||
Hardware: Single A100 80GB GPU with CPU RAM above 64GB
|
||||
|
||||
| Model | Full Finetuning | PEFT-LoRA | PEFT-LoRA with Gradient Checkpoitning |
|
||||
| --------- | ---- | ---- | ---- |
|
||||
@ -125,13 +125,15 @@ Try out the 🤗 Gradio Space which should run seamlessly on a T4 instance:
|
||||
|
||||
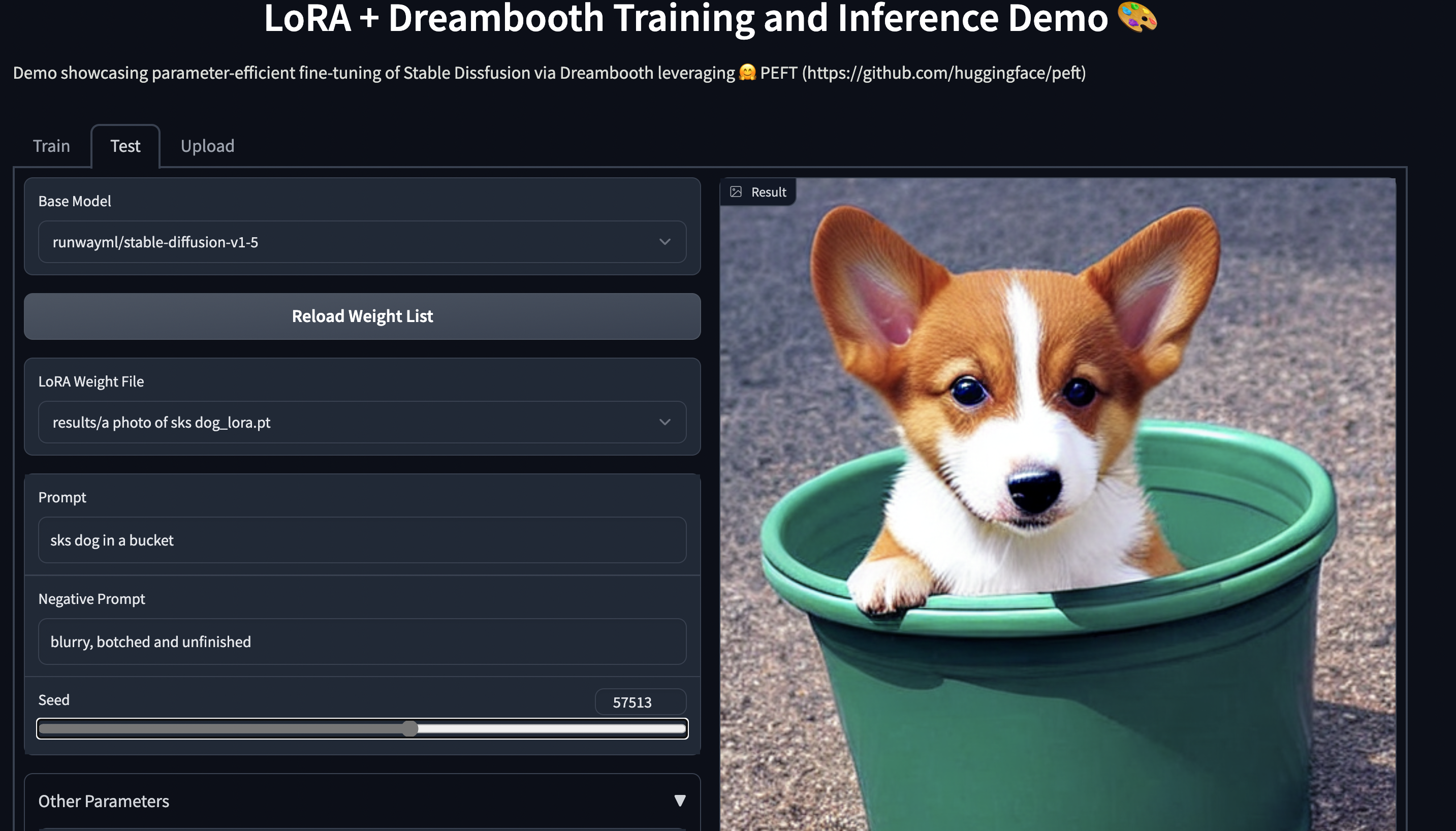
|
||||
|
||||
### Parameter Efficient Tuning of LLMs for RLHF components such as Ranker and Policy [ToDo]
|
||||
### Parameter Efficient Tuning of LLMs for RLHF components such as Ranker and Policy
|
||||
- Here is an exmaple in [trl](https://github.com/lvwerra/trl) library using PEFT+INT8 for tuning policy model: [gpt2-sentiment_peft.py](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt2-sentiment_peft.py)
|
||||
- Example using PEFT for both reward model and policy [ToDo]
|
||||
|
||||
### INT8 training of large models in Colab using PEFT LoRA and bits_and_bytes
|
||||
|
||||
Here is now a demo on how to fine tune OPT-6.7b (14GB in fp16) in a Google colab: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
|
||||
- Here is now a demo on how to fine tune [OPT-6.7b](https://huggingface.co/facebook/opt-6.7b) (14GB in fp16) in a Google colab: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)
|
||||
|
||||
Here is now a demo on how to fine tune wishper-large (1.5B params) (14GB in fp16) in a Google colab: [ToDo]
|
||||
- Here is now a demo on how to fine tune [whishper-large](openai/whisper-large-v2) (1.5B params) (14GB in fp16) in a Google colab: [](https://colab.research.google.com/drive/1DOkD_5OUjFa0r5Ik3SgywJLJtEo2qLxO?usp=sharing) and [](https://colab.research.google.com/drive/1vhF8yueFqha3Y3CpTHN6q9EVcII9EYzs?usp=sharing)
|
||||
|
||||
### Save compute and storage even for medium and small models
|
||||
|
||||
@ -139,9 +141,9 @@ Save storage by avoiding full finetuning of models on each of the downstream tas
|
||||
With PEFT methods, users only need to store tiny checkpoints in the order of `MBs` all the while retaining
|
||||
performance comparable to full finetuning.
|
||||
|
||||
An example of using LoRA for the task of adaping `LayoutLMForTokenClassification` on `FUNSD` dataset is given in `~examples/token_classification/PEFT_LoRA_LayoutLMForTokenClassification_on_FUNSD.py`. We can observe that with only `0.62 %` of parameters being trainable, we achieve performance (F1 0.777) comparable to full finetuning (F1 0.786) (without any hyerparam tuning runs for extracting more performance), and the checkpoint of this is only `2.8MB`. Now, if there are `N` such datasets, just have these PEFT models one for each dataset and save a lot of storage without having to worry about the problem of catastrophic forgetting or overfitting of backbone/base model.
|
||||
An example of using LoRA for the task of adapting `LayoutLMForTokenClassification` on `FUNSD` dataset is given in `~examples/token_classification/PEFT_LoRA_LayoutLMForTokenClassification_on_FUNSD.py`. We can observe that with only `0.62 %` of parameters being trainable, we achieve performance (F1 0.777) comparable to full finetuning (F1 0.786) (without any hyerparam tuning runs for extracting more performance), and the checkpoint of this is only `2.8MB`. Now, if there are `N` such datasets, just have these PEFT models one for each dataset and save a lot of storage without having to worry about the problem of catastrophic forgetting or overfitting of backbone/base model.
|
||||
|
||||
Another example is fine-tuning `roberta-large` on `MRPC` GLUE dataset suing differenct PEFT methods. The notebooks are given in `~examples/sequence_classification`.
|
||||
Another example is fine-tuning [`roberta-large`](https://huggingface.co/roberta-large) on [`MRPC` GLUE](https://huggingface.co/datasets/glue/viewer/mrpc) dataset suing differenct PEFT methods. The notebooks are given in `~examples/sequence_classification`.
|
||||
|
||||
|
||||
## PEFT + 🤗 Accelerate
|
||||
@ -151,10 +153,10 @@ Use 🤗 Accelerate for inferencing on consumer hardware with small resources.
|
||||
|
||||
### Example of PEFT model training using 🤗 Accelerate's DeepSpeed integration
|
||||
|
||||
Currently DeepSpeed requires PR [ZeRO3 handling frozen weights](https://github.com/microsoft/DeepSpeed/pull/2653) to fix [[REQUEST] efficiently deal with frozen weights during training](https://github.com/microsoft/DeepSpeed/issues/2615) issue. An example is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py`.
|
||||
a. First, run `accelerate` config --config_file ds_zero3_cpu.yaml` and answer the questionnaire.
|
||||
DeepSpeed version required `v0.8.0`. An example is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py`.
|
||||
a. First, run `accelerate config --config_file ds_zero3_cpu.yaml` and answer the questionnaire.
|
||||
Below are the contents of the config file.
|
||||
```
|
||||
```yaml
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 1
|
||||
@ -179,7 +181,7 @@ Use 🤗 Accelerate for inferencing on consumer hardware with small resources.
|
||||
use_cpu: false
|
||||
```
|
||||
b. run the below command to launch the example script
|
||||
```
|
||||
```bash
|
||||
accelerate launch --config_file ds_zero3_cpu.yaml examples/peft_lora_seq2seq_accelerate_ds_zero3_offload.py
|
||||
```
|
||||
|
||||
@ -222,6 +224,7 @@ An example is provided in `~examples/causal_language_modeling/peft_lora_clm_acce
|
||||
| OPT | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPT-Neo | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPT-J | ✅ | ✅ | ✅ | ✅ |
|
||||
| GPT-NeoX-20B | ✅ | ✅ | ✅ | ✅ |
|
||||
|
||||
### Conditional Generation
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
|
||||
@ -269,7 +272,7 @@ An example is provided in `~examples/causal_language_modeling/peft_lora_clm_acce
|
||||
| ViT | ✅ | | | |
|
||||
| Swin | ✅ | | | |
|
||||
|
||||
___Note that we have tested LoRA for https://huggingface.co/docs/transformers/model_doc/vit and [https://huggingface.co/docs/transformers/model_doc/swin] for fine-tuning on image classification. However, it should be possible to use LoRA for any compatible model [provided](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&search=vit) by 🤗 Transformers. Check out the respective
|
||||
___Note that we have tested LoRA for [ViT](https://huggingface.co/docs/transformers/model_doc/vit) and [Swin](https://huggingface.co/docs/transformers/model_doc/swin) for fine-tuning on image classification. However, it should be possible to use LoRA for any compatible model [provided](https://huggingface.co/models?pipeline_tag=image-classification&sort=downloads&search=vit) by 🤗 Transformers. Check out the respective
|
||||
examples to learn more. If you run into problems, please open an issue.___
|
||||
|
||||
The same principle applies to our [segmentation models](https://huggingface.co/models?pipeline_tag=image-segmentation&sort=downloads) as well.
|
||||
@ -279,6 +282,8 @@ The same principle applies to our [segmentation models](https://huggingface.co/m
|
||||
| Model | LoRA | Prefix Tuning | P-Tuning | Prompt Tuning |
|
||||
| --------- | ---- | ---- | ---- | ---- |
|
||||
| SegFormer | ✅ | | | |
|
||||
|
||||
|
||||
## Caveats:
|
||||
|
||||
1. Below is an example of using PyTorch FSDP for training. However, it doesn't lead to
|
||||
@ -295,10 +300,10 @@ any GPU memory savings. Please refer issue [[FSDP] FSDP with CPU offload consume
|
||||
model = accelerator.prepare(model)
|
||||
```
|
||||
|
||||
Example of parameter efficient tuning with `mt0-xxl` base model using 🤗 Accelerate is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py`.
|
||||
Example of parameter efficient tuning with [`mt0-xxl`](https://huggingface.co/bigscience/mt0-xxl) base model using 🤗 Accelerate is provided in `~examples/conditional_generation/peft_lora_seq2seq_accelerate_fsdp.py`.
|
||||
a. First, run `accelerate config --config_file fsdp_config.yaml` and answer the questionnaire.
|
||||
Below are the contents of the config file.
|
||||
```
|
||||
```yaml
|
||||
command_file: null
|
||||
commands: null
|
||||
compute_environment: LOCAL_MACHINE
|
||||
@ -329,7 +334,7 @@ any GPU memory savings. Please refer issue [[FSDP] FSDP with CPU offload consume
|
||||
use_cpu: false
|
||||
```
|
||||
b. run the below command to launch the example script
|
||||
```
|
||||
```bash
|
||||
accelerate launch --config_file fsdp_config.yaml examples/peft_lora_seq2seq_accelerate_fsdp.py
|
||||
```
|
||||
|
||||
|
||||
@ -30,7 +30,7 @@
|
||||
"import os\n",
|
||||
"from transformers import AutoTokenizer\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from transformers import default_data_collator,get_linear_schedule_with_warmup\n",
|
||||
"from transformers import default_data_collator, get_linear_schedule_with_warmup\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"\n",
|
||||
@ -40,10 +40,10 @@
|
||||
"dataset_name = \"twitter_complaints\"\n",
|
||||
"text_column = \"Tweet text\"\n",
|
||||
"label_column = \"text_label\"\n",
|
||||
"max_length=64\n",
|
||||
"max_length = 64\n",
|
||||
"lr = 1e-3\n",
|
||||
"num_epochs = 50\n",
|
||||
"batch_size=8\n"
|
||||
"batch_size = 8"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -63,7 +63,6 @@
|
||||
" lambda x: {\"text_label\": [classes[label] for label in x[\"Label\"]]},\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" \n",
|
||||
")\n",
|
||||
"print(dataset)\n",
|
||||
"dataset[\"train\"][0]"
|
||||
@ -118,6 +117,8 @@
|
||||
" tokenizer.pad_token_id = tokenizer.eos_token_id\n",
|
||||
"target_max_length = max([len(tokenizer(class_label)[\"input_ids\"]) for class_label in classes])\n",
|
||||
"print(target_max_length)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def preprocess_function(examples):\n",
|
||||
" batch_size = len(examples[text_column])\n",
|
||||
" inputs = [f\"{text_column} : {x} Label : \" for x in examples[text_column]]\n",
|
||||
@ -127,44 +128,43 @@
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" label_input_ids = labels[\"input_ids\"][i] + [tokenizer.pad_token_id]\n",
|
||||
" #print(i, sample_input_ids, label_input_ids)\n",
|
||||
" model_inputs[\"input_ids\"][i] = sample_input_ids + label_input_ids \n",
|
||||
" # print(i, sample_input_ids, label_input_ids)\n",
|
||||
" model_inputs[\"input_ids\"][i] = sample_input_ids + label_input_ids\n",
|
||||
" labels[\"input_ids\"][i] = [-100] * len(sample_input_ids) + label_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [1] * len(model_inputs[\"input_ids\"][i])\n",
|
||||
" #print(model_inputs)\n",
|
||||
" # print(model_inputs)\n",
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" label_input_ids = labels[\"input_ids\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id]*(max_length-len(sample_input_ids)) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0]*(max_length-len(sample_input_ids)) + model_inputs[\"attention_mask\"][i]\n",
|
||||
" labels[\"input_ids\"][i] = [-100]*(max_length-len(sample_input_ids)) + label_input_ids \n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id] * (\n",
|
||||
" max_length - len(sample_input_ids)\n",
|
||||
" ) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[\n",
|
||||
" \"attention_mask\"\n",
|
||||
" ][i]\n",
|
||||
" labels[\"input_ids\"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids\n",
|
||||
" model_inputs[\"input_ids\"][i] = torch.tensor(model_inputs[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"attention_mask\"][i] = torch.tensor(model_inputs[\"attention_mask\"][i][:max_length])\n",
|
||||
" labels[\"input_ids\"][i] = torch.tensor(labels[\"input_ids\"][i][:max_length]) \n",
|
||||
" labels[\"input_ids\"][i] = torch.tensor(labels[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"labels\"] = labels[\"input_ids\"]\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"processed_datasets = dataset.map(\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"train_dataset = processed_datasets[\"train\"]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" "
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -178,23 +178,28 @@
|
||||
" batch_size = len(examples[text_column])\n",
|
||||
" inputs = [f\"{text_column} : {x} Label : \" for x in examples[text_column]]\n",
|
||||
" model_inputs = tokenizer(inputs)\n",
|
||||
" #print(model_inputs)\n",
|
||||
" # print(model_inputs)\n",
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id]*(max_length-len(sample_input_ids)) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0]*(max_length-len(sample_input_ids)) + model_inputs[\"attention_mask\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id] * (\n",
|
||||
" max_length - len(sample_input_ids)\n",
|
||||
" ) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[\n",
|
||||
" \"attention_mask\"\n",
|
||||
" ][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = torch.tensor(model_inputs[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"attention_mask\"][i] = torch.tensor(model_inputs[\"attention_mask\"][i][:max_length])\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"processed_datasets = dataset.map(\n",
|
||||
" test_preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" test_preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"eval_dataset = processed_datasets[\"train\"]\n",
|
||||
"test_dataset = processed_datasets[\"test\"]\n",
|
||||
@ -236,7 +241,8 @@
|
||||
],
|
||||
"source": [
|
||||
"from peft import PeftModel, PeftConfig\n",
|
||||
"max_memory={0: \"1GIB\", 1: \"1GIB\", 2: \"2GIB\", 3: \"10GIB\", \"cpu\":\"30GB\"}\n",
|
||||
"\n",
|
||||
"max_memory = {0: \"1GIB\", 1: \"1GIB\", 2: \"2GIB\", 3: \"10GIB\", \"cpu\": \"30GB\"}\n",
|
||||
"peft_model_id = \"smangrul/twitter_complaints_bigscience_bloomz-7b1_LORA_CAUSAL_LM\"\n",
|
||||
"\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n",
|
||||
@ -251,7 +257,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"#model"
|
||||
"# model"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -343,7 +349,7 @@
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"], max_new_tokens=10)\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n"
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -397,7 +403,7 @@
|
||||
"accuracy = correct / total * 100\n",
|
||||
"print(f\"{accuracy=}\")\n",
|
||||
"print(f\"{eval_preds[:10]=}\")\n",
|
||||
"print(f\"{dataset['train'][label_column][:10]=}\")\n"
|
||||
"print(f\"{dataset['train'][label_column][:10]=}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -416,7 +422,7 @@
|
||||
" outputs = model.generate(**batch, max_new_tokens=10)\n",
|
||||
" preds = outputs[:, max_length:].detach().cpu().numpy()\n",
|
||||
" test_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))\n",
|
||||
" if len(test_preds)>100:\n",
|
||||
" if len(test_preds) > 100:\n",
|
||||
" break\n",
|
||||
"test_preds"
|
||||
]
|
||||
|
||||
@ -4,9 +4,12 @@ import sys
|
||||
import threading
|
||||
|
||||
import numpy as np
|
||||
import psutil
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
from transformers import (
|
||||
AutoModelForCausalLM,
|
||||
AutoTokenizer,
|
||||
@ -15,10 +18,7 @@ from transformers import (
|
||||
set_seed,
|
||||
)
|
||||
|
||||
import psutil
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig, TaskType, get_peft_model
|
||||
from tqdm import tqdm
|
||||
|
||||
|
||||
def levenshtein_distance(str1, str2):
|
||||
@ -280,7 +280,9 @@ def main():
|
||||
outputs = accelerator.unwrap_model(model).generate(
|
||||
**batch, synced_gpus=is_ds_zero_3, max_new_tokens=10
|
||||
) # synced_gpus=True for DS-stage 3
|
||||
preds = outputs[:, max_length:].detach().cpu().numpy()
|
||||
outputs = accelerator.pad_across_processes(outputs, dim=1, pad_index=tokenizer.pad_token_id)
|
||||
preds = accelerator.gather(outputs)
|
||||
preds = preds[:, max_length:].detach().cpu().numpy()
|
||||
eval_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
|
||||
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
@ -304,6 +306,9 @@ def main():
|
||||
|
||||
correct = 0
|
||||
total = 0
|
||||
assert len(eval_preds) == len(
|
||||
dataset["train"][label_column]
|
||||
), f"{len(eval_preds)} != {len(dataset['train'][label_column])}"
|
||||
for pred, true in zip(eval_preds, dataset["train"][label_column]):
|
||||
if pred.strip() == true.strip():
|
||||
correct += 1
|
||||
@ -322,15 +327,17 @@ def main():
|
||||
outputs = accelerator.unwrap_model(model).generate(
|
||||
**batch, synced_gpus=is_ds_zero_3, max_new_tokens=10
|
||||
) # synced_gpus=True for DS-stage 3
|
||||
test_preds.extend(
|
||||
tokenizer.batch_decode(outputs[:, max_length:].detach().cpu().numpy(), skip_special_tokens=True)
|
||||
)
|
||||
outputs = accelerator.pad_across_processes(outputs, dim=1, pad_index=tokenizer.pad_token_id)
|
||||
preds = accelerator.gather(outputs)
|
||||
preds = preds[:, max_length:].detach().cpu().numpy()
|
||||
test_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
|
||||
|
||||
test_preds_cleaned = []
|
||||
for _, pred in enumerate(test_preds):
|
||||
test_preds_cleaned.append(get_closest_label(pred, classes))
|
||||
|
||||
test_df = dataset["test"].to_pandas()
|
||||
assert len(test_preds_cleaned) == len(test_df), f"{len(test_preds_cleaned)} != {len(test_df)}"
|
||||
test_df[label_column] = test_preds_cleaned
|
||||
test_df["text_labels_orig"] = test_preds
|
||||
accelerator.print(test_df[[text_column, label_column]].sample(20))
|
||||
|
||||
@ -8,31 +8,31 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from transformers import AutoModelForCausalLM\n",
|
||||
"from peft import get_peft_config,get_peft_model, PrefixTuningConfig, TaskType, PeftType\n",
|
||||
"from peft import get_peft_config, get_peft_model, PrefixTuningConfig, TaskType, PeftType\n",
|
||||
"import torch\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"import os\n",
|
||||
"from transformers import AutoTokenizer\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from transformers import default_data_collator,get_linear_schedule_with_warmup\n",
|
||||
"from transformers import default_data_collator, get_linear_schedule_with_warmup\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"\n",
|
||||
"device = \"cuda\"\n",
|
||||
"model_name_or_path = \"bigscience/bloomz-560m\"\n",
|
||||
"tokenizer_name_or_path = \"bigscience/bloomz-560m\"\n",
|
||||
"peft_config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, \n",
|
||||
" num_virtual_tokens=30)\n",
|
||||
"peft_config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=30)\n",
|
||||
"\n",
|
||||
"dataset_name = \"twitter_complaints\"\n",
|
||||
"checkpoint_name = f\"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt\".replace(\"/\", \"_\")\n",
|
||||
"checkpoint_name = f\"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt\".replace(\n",
|
||||
" \"/\", \"_\"\n",
|
||||
")\n",
|
||||
"text_column = \"Tweet text\"\n",
|
||||
"label_column = \"text_label\"\n",
|
||||
"max_length=64\n",
|
||||
"max_length = 64\n",
|
||||
"lr = 3e-2\n",
|
||||
"num_epochs = 50\n",
|
||||
"batch_size=8\n",
|
||||
"\n"
|
||||
"batch_size = 8"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -112,7 +112,6 @@
|
||||
" lambda x: {\"text_label\": [classes[label] for label in x[\"Label\"]]},\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" \n",
|
||||
")\n",
|
||||
"print(dataset)\n",
|
||||
"dataset[\"train\"][0]"
|
||||
@ -167,6 +166,8 @@
|
||||
" tokenizer.pad_token_id = tokenizer.eos_token_id\n",
|
||||
"target_max_length = max([len(tokenizer(class_label)[\"input_ids\"]) for class_label in classes])\n",
|
||||
"print(target_max_length)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def preprocess_function(examples):\n",
|
||||
" batch_size = len(examples[text_column])\n",
|
||||
" inputs = [f\"{text_column} : {x} Label : \" for x in examples[text_column]]\n",
|
||||
@ -176,47 +177,45 @@
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" label_input_ids = labels[\"input_ids\"][i] + [tokenizer.pad_token_id]\n",
|
||||
" #print(i, sample_input_ids, label_input_ids)\n",
|
||||
" model_inputs[\"input_ids\"][i] = sample_input_ids + label_input_ids \n",
|
||||
" # print(i, sample_input_ids, label_input_ids)\n",
|
||||
" model_inputs[\"input_ids\"][i] = sample_input_ids + label_input_ids\n",
|
||||
" labels[\"input_ids\"][i] = [-100] * len(sample_input_ids) + label_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [1] * len(model_inputs[\"input_ids\"][i])\n",
|
||||
" #print(model_inputs)\n",
|
||||
" # print(model_inputs)\n",
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" label_input_ids = labels[\"input_ids\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id]*(max_length-len(sample_input_ids)) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0]*(max_length-len(sample_input_ids)) + model_inputs[\"attention_mask\"][i]\n",
|
||||
" labels[\"input_ids\"][i] = [-100]*(max_length-len(sample_input_ids)) + label_input_ids \n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id] * (\n",
|
||||
" max_length - len(sample_input_ids)\n",
|
||||
" ) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[\n",
|
||||
" \"attention_mask\"\n",
|
||||
" ][i]\n",
|
||||
" labels[\"input_ids\"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids\n",
|
||||
" model_inputs[\"input_ids\"][i] = torch.tensor(model_inputs[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"attention_mask\"][i] = torch.tensor(model_inputs[\"attention_mask\"][i][:max_length])\n",
|
||||
" labels[\"input_ids\"][i] = torch.tensor(labels[\"input_ids\"][i][:max_length]) \n",
|
||||
" labels[\"input_ids\"][i] = torch.tensor(labels[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"labels\"] = labels[\"input_ids\"]\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"processed_datasets = dataset.map(\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"train_dataset = processed_datasets[\"train\"]\n",
|
||||
"eval_dataset = processed_datasets[\"train\"]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
" )\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" "
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
")\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -230,23 +229,28 @@
|
||||
" batch_size = len(examples[text_column])\n",
|
||||
" inputs = [f\"{text_column} : {x} Label : \" for x in examples[text_column]]\n",
|
||||
" model_inputs = tokenizer(inputs)\n",
|
||||
" #print(model_inputs)\n",
|
||||
" # print(model_inputs)\n",
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id]*(max_length-len(sample_input_ids)) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0]*(max_length-len(sample_input_ids)) + model_inputs[\"attention_mask\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id] * (\n",
|
||||
" max_length - len(sample_input_ids)\n",
|
||||
" ) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[\n",
|
||||
" \"attention_mask\"\n",
|
||||
" ][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = torch.tensor(model_inputs[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"attention_mask\"][i] = torch.tensor(model_inputs[\"attention_mask\"][i][:max_length])\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"test_dataset = dataset[\"test\"].map(\n",
|
||||
" test_preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" test_preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"test_dataloader = DataLoader(test_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)\n",
|
||||
"next(iter(test_dataloader))"
|
||||
@ -308,12 +312,10 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"\n",
|
||||
"# creating model\n",
|
||||
"model = AutoModelForCausalLM.from_pretrained(model_name_or_path)\n",
|
||||
"model = get_peft_model(model, peft_config)\n",
|
||||
"model.print_trainable_parameters()\n",
|
||||
"\n"
|
||||
"model.print_trainable_parameters()"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1155,8 +1157,8 @@
|
||||
" total_loss = 0\n",
|
||||
" for step, batch in enumerate(tqdm(train_dataloader)):\n",
|
||||
" batch = {k: v.to(device) for k, v in batch.items()}\n",
|
||||
"# print(batch)\n",
|
||||
"# print(batch[\"input_ids\"].shape)\n",
|
||||
" # print(batch)\n",
|
||||
" # print(batch[\"input_ids\"].shape)\n",
|
||||
" outputs = model(**batch)\n",
|
||||
" loss = outputs.loss\n",
|
||||
" total_loss += loss.detach().float()\n",
|
||||
@ -1174,13 +1176,15 @@
|
||||
" outputs = model(**batch)\n",
|
||||
" loss = outputs.loss\n",
|
||||
" eval_loss += loss.detach().float()\n",
|
||||
" eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" eval_preds.extend(\n",
|
||||
" tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" eval_epoch_loss = eval_loss/len(train_dataloader)\n",
|
||||
" eval_epoch_loss = eval_loss / len(eval_dataloader)\n",
|
||||
" eval_ppl = torch.exp(eval_epoch_loss)\n",
|
||||
" train_epoch_loss = total_loss/len(eval_dataloader)\n",
|
||||
" train_epoch_loss = total_loss / len(train_dataloader)\n",
|
||||
" train_ppl = torch.exp(train_epoch_loss)\n",
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")\n"
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1217,10 +1221,11 @@
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" inputs = {k: v.to(device) for k, v in inputs.items()}\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3)\n",
|
||||
" outputs = model.generate(\n",
|
||||
" input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3\n",
|
||||
" )\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" "
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1254,11 +1259,12 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from peft import PeftModel, PeftConfig\n",
|
||||
"\n",
|
||||
"peft_model_id = f\"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}\"\n",
|
||||
"\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n",
|
||||
"model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)\n",
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)\n"
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1291,10 +1297,11 @@
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" inputs = {k: v.to(device) for k, v in inputs.items()}\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3)\n",
|
||||
" outputs = model.generate(\n",
|
||||
" input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3\n",
|
||||
" )\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" "
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1338,7 +1345,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.5 (v3.10.5:f377153967, Jun 6 2022, 12:36:10) [Clang 13.0.0 (clang-1300.0.29.30)]"
|
||||
"version": "3.10.5"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
"import os\n",
|
||||
"from transformers import AutoTokenizer\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from transformers import default_data_collator,get_linear_schedule_with_warmup\n",
|
||||
"from transformers import default_data_collator, get_linear_schedule_with_warmup\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"\n",
|
||||
@ -22,22 +22,23 @@
|
||||
"model_name_or_path = \"bigscience/bloomz-560m\"\n",
|
||||
"tokenizer_name_or_path = \"bigscience/bloomz-560m\"\n",
|
||||
"peft_config = PromptTuningConfig(\n",
|
||||
" task_type=TaskType.CAUSAL_LM,\n",
|
||||
" prompt_tuning_init=PromptTuningInit.TEXT,\n",
|
||||
" num_virtual_tokens=8,\n",
|
||||
" prompt_tuning_init_text=\"Classify if the tweet is a complaint or not:\",\n",
|
||||
" tokenizer_name_or_path=model_name_or_path,\n",
|
||||
" )\n",
|
||||
" task_type=TaskType.CAUSAL_LM,\n",
|
||||
" prompt_tuning_init=PromptTuningInit.TEXT,\n",
|
||||
" num_virtual_tokens=8,\n",
|
||||
" prompt_tuning_init_text=\"Classify if the tweet is a complaint or not:\",\n",
|
||||
" tokenizer_name_or_path=model_name_or_path,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"dataset_name = \"twitter_complaints\"\n",
|
||||
"checkpoint_name = f\"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt\".replace(\"/\", \"_\")\n",
|
||||
"checkpoint_name = f\"{dataset_name}_{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}_v1.pt\".replace(\n",
|
||||
" \"/\", \"_\"\n",
|
||||
")\n",
|
||||
"text_column = \"Tweet text\"\n",
|
||||
"label_column = \"text_label\"\n",
|
||||
"max_length=64\n",
|
||||
"max_length = 64\n",
|
||||
"lr = 3e-2\n",
|
||||
"num_epochs = 50\n",
|
||||
"batch_size=8\n",
|
||||
"\n"
|
||||
"batch_size = 8"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -57,7 +58,6 @@
|
||||
" lambda x: {\"text_label\": [classes[label] for label in x[\"Label\"]]},\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" \n",
|
||||
")\n",
|
||||
"print(dataset)\n",
|
||||
"dataset[\"train\"][0]"
|
||||
@ -76,6 +76,8 @@
|
||||
" tokenizer.pad_token_id = tokenizer.eos_token_id\n",
|
||||
"target_max_length = max([len(tokenizer(class_label)[\"input_ids\"]) for class_label in classes])\n",
|
||||
"print(target_max_length)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def preprocess_function(examples):\n",
|
||||
" batch_size = len(examples[text_column])\n",
|
||||
" inputs = [f\"{text_column} : {x} Label : \" for x in examples[text_column]]\n",
|
||||
@ -85,47 +87,45 @@
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" label_input_ids = labels[\"input_ids\"][i] + [tokenizer.pad_token_id]\n",
|
||||
" #print(i, sample_input_ids, label_input_ids)\n",
|
||||
" model_inputs[\"input_ids\"][i] = sample_input_ids + label_input_ids \n",
|
||||
" # print(i, sample_input_ids, label_input_ids)\n",
|
||||
" model_inputs[\"input_ids\"][i] = sample_input_ids + label_input_ids\n",
|
||||
" labels[\"input_ids\"][i] = [-100] * len(sample_input_ids) + label_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [1] * len(model_inputs[\"input_ids\"][i])\n",
|
||||
" #print(model_inputs)\n",
|
||||
" # print(model_inputs)\n",
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" label_input_ids = labels[\"input_ids\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id]*(max_length-len(sample_input_ids)) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0]*(max_length-len(sample_input_ids)) + model_inputs[\"attention_mask\"][i]\n",
|
||||
" labels[\"input_ids\"][i] = [-100]*(max_length-len(sample_input_ids)) + label_input_ids \n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id] * (\n",
|
||||
" max_length - len(sample_input_ids)\n",
|
||||
" ) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[\n",
|
||||
" \"attention_mask\"\n",
|
||||
" ][i]\n",
|
||||
" labels[\"input_ids\"][i] = [-100] * (max_length - len(sample_input_ids)) + label_input_ids\n",
|
||||
" model_inputs[\"input_ids\"][i] = torch.tensor(model_inputs[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"attention_mask\"][i] = torch.tensor(model_inputs[\"attention_mask\"][i][:max_length])\n",
|
||||
" labels[\"input_ids\"][i] = torch.tensor(labels[\"input_ids\"][i][:max_length]) \n",
|
||||
" labels[\"input_ids\"][i] = torch.tensor(labels[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"labels\"] = labels[\"input_ids\"]\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"processed_datasets = dataset.map(\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"train_dataset = processed_datasets[\"train\"]\n",
|
||||
"eval_dataset = processed_datasets[\"train\"]\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
" )\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" "
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
")\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -139,23 +139,28 @@
|
||||
" batch_size = len(examples[text_column])\n",
|
||||
" inputs = [f\"{text_column} : {x} Label : \" for x in examples[text_column]]\n",
|
||||
" model_inputs = tokenizer(inputs)\n",
|
||||
" #print(model_inputs)\n",
|
||||
" # print(model_inputs)\n",
|
||||
" for i in range(batch_size):\n",
|
||||
" sample_input_ids = model_inputs[\"input_ids\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id]*(max_length-len(sample_input_ids)) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0]*(max_length-len(sample_input_ids)) + model_inputs[\"attention_mask\"][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = [tokenizer.pad_token_id] * (\n",
|
||||
" max_length - len(sample_input_ids)\n",
|
||||
" ) + sample_input_ids\n",
|
||||
" model_inputs[\"attention_mask\"][i] = [0] * (max_length - len(sample_input_ids)) + model_inputs[\n",
|
||||
" \"attention_mask\"\n",
|
||||
" ][i]\n",
|
||||
" model_inputs[\"input_ids\"][i] = torch.tensor(model_inputs[\"input_ids\"][i][:max_length])\n",
|
||||
" model_inputs[\"attention_mask\"][i] = torch.tensor(model_inputs[\"attention_mask\"][i][:max_length])\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"test_dataset = dataset[\"test\"].map(\n",
|
||||
" test_preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" test_preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"test_dataloader = DataLoader(test_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)\n",
|
||||
"next(iter(test_dataloader))"
|
||||
@ -198,12 +203,10 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"\n",
|
||||
"# creating model\n",
|
||||
"model = AutoModelForCausalLM.from_pretrained(model_name_or_path)\n",
|
||||
"model = get_peft_model(model, peft_config)\n",
|
||||
"model.print_trainable_parameters()\n",
|
||||
"\n"
|
||||
"model.print_trainable_parameters()"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -996,8 +999,8 @@
|
||||
" total_loss = 0\n",
|
||||
" for step, batch in enumerate(tqdm(train_dataloader)):\n",
|
||||
" batch = {k: v.to(device) for k, v in batch.items()}\n",
|
||||
"# print(batch)\n",
|
||||
"# print(batch[\"input_ids\"].shape)\n",
|
||||
" # print(batch)\n",
|
||||
" # print(batch[\"input_ids\"].shape)\n",
|
||||
" outputs = model(**batch)\n",
|
||||
" loss = outputs.loss\n",
|
||||
" total_loss += loss.detach().float()\n",
|
||||
@ -1015,13 +1018,15 @@
|
||||
" outputs = model(**batch)\n",
|
||||
" loss = outputs.loss\n",
|
||||
" eval_loss += loss.detach().float()\n",
|
||||
" eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" eval_preds.extend(\n",
|
||||
" tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" eval_epoch_loss = eval_loss/len(train_dataloader)\n",
|
||||
" eval_epoch_loss = eval_loss / len(eval_dataloader)\n",
|
||||
" eval_ppl = torch.exp(eval_epoch_loss)\n",
|
||||
" train_epoch_loss = total_loss/len(eval_dataloader)\n",
|
||||
" train_epoch_loss = total_loss / len(train_dataloader)\n",
|
||||
" train_ppl = torch.exp(train_epoch_loss)\n",
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")\n"
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1060,10 +1065,11 @@
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" inputs = {k: v.to(device) for k, v in inputs.items()}\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3)\n",
|
||||
" outputs = model.generate(\n",
|
||||
" input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3\n",
|
||||
" )\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" "
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1109,11 +1115,12 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from peft import PeftModel, PeftConfig\n",
|
||||
"\n",
|
||||
"peft_model_id = f\"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}\"\n",
|
||||
"\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n",
|
||||
"model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)\n",
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)\n"
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1146,10 +1153,11 @@
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" inputs = {k: v.to(device) for k, v in inputs.items()}\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3)\n",
|
||||
" outputs = model.generate(\n",
|
||||
" input_ids=inputs[\"input_ids\"], attention_mask=inputs[\"attention_mask\"], max_new_tokens=10, eos_token_id=3\n",
|
||||
" )\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" "
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1177,7 +1185,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.5 (v3.10.5:f377153967, Jun 6 2022, 12:36:10) [Clang 13.0.0 (clang-1300.0.29.30)]"
|
||||
"version": "3.10.5"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
|
||||
@ -24,14 +24,15 @@
|
||||
],
|
||||
"source": [
|
||||
"from transformers import AutoModelForSeq2SeqLM\n",
|
||||
"from peft import get_peft_config,get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType\n",
|
||||
"from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType\n",
|
||||
"import torch\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"TOKENIZERS_PARALLELISM\"] = \"false\"\n",
|
||||
"from transformers import AutoTokenizer\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from transformers import default_data_collator,get_linear_schedule_with_warmup\n",
|
||||
"from transformers import default_data_collator, get_linear_schedule_with_warmup\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"\n",
|
||||
@ -42,10 +43,10 @@
|
||||
"checkpoint_name = \"financial_sentiment_analysis_lora_v1.pt\"\n",
|
||||
"text_column = \"sentence\"\n",
|
||||
"label_column = \"text_label\"\n",
|
||||
"max_length=128\n",
|
||||
"max_length = 128\n",
|
||||
"lr = 1e-3\n",
|
||||
"num_epochs = 3\n",
|
||||
"batch_size=8\n"
|
||||
"batch_size = 8"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -56,9 +57,7 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# creating model\n",
|
||||
"peft_config = LoraConfig(\n",
|
||||
" task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1\n",
|
||||
")\n",
|
||||
"peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)\n",
|
||||
"\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)\n",
|
||||
"model = get_peft_model(model, peft_config)\n",
|
||||
@ -136,17 +135,16 @@
|
||||
],
|
||||
"source": [
|
||||
"# loading dataset\n",
|
||||
"dataset = load_dataset(\"financial_phrasebank\", 'sentences_allagree')\n",
|
||||
"dataset = load_dataset(\"financial_phrasebank\", \"sentences_allagree\")\n",
|
||||
"dataset = dataset[\"train\"].train_test_split(test_size=0.1)\n",
|
||||
"dataset[\"validation\"] = dataset[\"test\"]\n",
|
||||
"del(dataset[\"test\"])\n",
|
||||
"del dataset[\"test\"]\n",
|
||||
"\n",
|
||||
"classes = dataset[\"train\"].features[\"label\"].names\n",
|
||||
"dataset = dataset.map(\n",
|
||||
" lambda x: {\"text_label\": [classes[label] for label in x[\"label\"]]},\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" \n",
|
||||
")\n",
|
||||
"\n",
|
||||
"dataset[\"train\"][0]"
|
||||
@ -190,36 +188,35 @@
|
||||
"source": [
|
||||
"# data preprocessing\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def preprocess_function(examples):\n",
|
||||
" inputs = examples[text_column]\n",
|
||||
" targets = examples[label_column]\n",
|
||||
" model_inputs = tokenizer(inputs, max_length=max_length, padding=\"max_length\", truncation=True, return_tensors=\"pt\")\n",
|
||||
" labels = tokenizer(targets, max_length=3, padding=\"max_length\", truncation=True, return_tensors=\"pt\")\n",
|
||||
" labels = labels[\"input_ids\"]\n",
|
||||
" labels[labels==tokenizer.pad_token_id] = -100\n",
|
||||
" labels[labels == tokenizer.pad_token_id] = -100\n",
|
||||
" model_inputs[\"labels\"] = labels\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"processed_datasets = dataset.map(\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"train_dataset = processed_datasets[\"train\"]\n",
|
||||
"eval_dataset = processed_datasets[\"validation\"]\n",
|
||||
"\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
" )\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" "
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
")\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -235,7 +232,7 @@
|
||||
" optimizer=optimizer,\n",
|
||||
" num_warmup_steps=0,\n",
|
||||
" num_training_steps=(len(train_dataloader) * num_epochs),\n",
|
||||
")\n"
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -323,13 +320,15 @@
|
||||
" outputs = model(**batch)\n",
|
||||
" loss = outputs.loss\n",
|
||||
" eval_loss += loss.detach().float()\n",
|
||||
" eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" eval_preds.extend(\n",
|
||||
" tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" eval_epoch_loss = eval_loss/len(train_dataloader)\n",
|
||||
" eval_epoch_loss = eval_loss / len(eval_dataloader)\n",
|
||||
" eval_ppl = torch.exp(eval_epoch_loss)\n",
|
||||
" train_epoch_loss = total_loss/len(eval_dataloader)\n",
|
||||
" train_epoch_loss = total_loss / len(train_dataloader)\n",
|
||||
" train_ppl = torch.exp(train_epoch_loss)\n",
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")\n"
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -350,13 +349,13 @@
|
||||
],
|
||||
"source": [
|
||||
"# print accuracy\n",
|
||||
"correct =0\n",
|
||||
"correct = 0\n",
|
||||
"total = 0\n",
|
||||
"for pred,true in zip(eval_preds, dataset[\"validation\"][\"text_label\"]):\n",
|
||||
" if pred.strip()==true.strip():\n",
|
||||
" correct+=1\n",
|
||||
" total+=1 \n",
|
||||
"accuracy = correct/total*100\n",
|
||||
"for pred, true in zip(eval_preds, dataset[\"validation\"][\"text_label\"]):\n",
|
||||
" if pred.strip() == true.strip():\n",
|
||||
" correct += 1\n",
|
||||
" total += 1\n",
|
||||
"accuracy = correct / total * 100\n",
|
||||
"print(f\"{accuracy=} % on the evaluation dataset\")\n",
|
||||
"print(f\"{eval_preds[:10]=}\")\n",
|
||||
"print(f\"{dataset['validation']['text_label'][:10]=}\")"
|
||||
@ -401,11 +400,12 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from peft import PeftModel, PeftConfig\n",
|
||||
"\n",
|
||||
"peft_model_id = f\"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}\"\n",
|
||||
"\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)\n",
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)\n"
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -437,7 +437,7 @@
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"], max_new_tokens=10)\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n"
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -473,7 +473,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.4"
|
||||
"version": "3.10.5"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
|
||||
@ -14,17 +14,17 @@
|
||||
"import os\n",
|
||||
"from transformers import AutoTokenizer\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from transformers import default_data_collator,get_linear_schedule_with_warmup\n",
|
||||
"from transformers import default_data_collator, get_linear_schedule_with_warmup\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"\n",
|
||||
"dataset_name = \"twitter_complaints\"\n",
|
||||
"text_column = \"Tweet text\"\n",
|
||||
"label_column = \"text_label\"\n",
|
||||
"batch_size=8\n",
|
||||
"batch_size = 8\n",
|
||||
"\n",
|
||||
"peft_model_id = \"smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM\"\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n"
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -35,7 +35,7 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"peft_model_id = \"smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM\"\n",
|
||||
"max_memory={0: \"6GIB\", 1: \"0GIB\", 2: \"0GIB\", 3: \"0GIB\", 4: \"0GIB\", \"cpu\":\"30GB\"}\n",
|
||||
"max_memory = {0: \"6GIB\", 1: \"0GIB\", 2: \"0GIB\", 3: \"0GIB\", 4: \"0GIB\", \"cpu\": \"30GB\"}\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path, device_map=\"auto\", max_memory=max_memory)\n",
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id, device_map=\"auto\", max_memory=max_memory)"
|
||||
@ -58,7 +58,6 @@
|
||||
" lambda x: {\"text_label\": [classes[label] for label in x[\"Label\"]]},\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" \n",
|
||||
")\n",
|
||||
"print(dataset)\n",
|
||||
"dataset[\"train\"][0]"
|
||||
@ -73,6 +72,8 @@
|
||||
"source": [
|
||||
"tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)\n",
|
||||
"target_max_length = max([len(tokenizer(class_label)[\"input_ids\"]) for class_label in classes])\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def preprocess_function(examples):\n",
|
||||
" inputs = examples[text_column]\n",
|
||||
" targets = examples[label_column]\n",
|
||||
@ -85,6 +86,7 @@
|
||||
" model_inputs[\"labels\"] = labels\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"processed_datasets = dataset.map(\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
@ -100,18 +102,14 @@
|
||||
"\n",
|
||||
"\n",
|
||||
"def collate_fn(examples):\n",
|
||||
" return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n",
|
||||
" return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True\n",
|
||||
")\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True)\n",
|
||||
"test_dataloader = DataLoader(test_dataset, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" "
|
||||
"test_dataloader = DataLoader(test_dataset, collate_fn=collate_fn, batch_size=batch_size, pin_memory=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -146,7 +144,7 @@
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"].to(\"cuda\"), max_new_tokens=10)\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n"
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -201,7 +199,7 @@
|
||||
"accuracy = correct / total * 100\n",
|
||||
"print(f\"{accuracy=}\")\n",
|
||||
"print(f\"{eval_preds[:10]=}\")\n",
|
||||
"print(f\"{dataset['train'][label_column][:10]=}\")\n"
|
||||
"print(f\"{dataset['train'][label_column][:10]=}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -220,7 +218,7 @@
|
||||
" outputs = model.generate(**batch, max_new_tokens=10)\n",
|
||||
" preds = outputs.detach().cpu().numpy()\n",
|
||||
" test_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))\n",
|
||||
" if len(test_preds)>100:\n",
|
||||
" if len(test_preds) > 100:\n",
|
||||
" break\n",
|
||||
"test_preds"
|
||||
]
|
||||
|
||||
@ -4,15 +4,15 @@ import sys
|
||||
import threading
|
||||
|
||||
import numpy as np
|
||||
import psutil
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
|
||||
|
||||
import psutil
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig, TaskType, get_peft_model
|
||||
from tqdm import tqdm
|
||||
|
||||
|
||||
def levenshtein_distance(str1, str2):
|
||||
@ -217,7 +217,7 @@ def main():
|
||||
tracemalloc.cpu_peaked + b2mb(tracemalloc.cpu_begin)
|
||||
)
|
||||
)
|
||||
train_epoch_loss = total_loss / len(eval_dataloader)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
accelerator.print(f"{epoch=}: {train_ppl=} {train_epoch_loss=}")
|
||||
|
||||
@ -230,7 +230,8 @@ def main():
|
||||
outputs = accelerator.unwrap_model(model).generate(
|
||||
**batch, synced_gpus=is_ds_zero_3
|
||||
) # synced_gpus=True for DS-stage 3
|
||||
preds = outputs.detach().cpu().numpy()
|
||||
outputs = accelerator.pad_across_processes(outputs, dim=1, pad_index=tokenizer.pad_token_id)
|
||||
preds = accelerator.gather(outputs).detach().cpu().numpy()
|
||||
eval_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
|
||||
|
||||
# Printing the GPU memory usage details such as allocated memory, peak memory, and total memory usage
|
||||
@ -254,6 +255,9 @@ def main():
|
||||
|
||||
correct = 0
|
||||
total = 0
|
||||
assert len(eval_preds) == len(
|
||||
dataset["train"][label_column]
|
||||
), f"{len(eval_preds)} != {len(dataset['train'][label_column])}"
|
||||
for pred, true in zip(eval_preds, dataset["train"][label_column]):
|
||||
if pred.strip() == true.strip():
|
||||
correct += 1
|
||||
@ -272,13 +276,16 @@ def main():
|
||||
outputs = accelerator.unwrap_model(model).generate(
|
||||
**batch, synced_gpus=is_ds_zero_3
|
||||
) # synced_gpus=True for DS-stage 3
|
||||
test_preds.extend(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
|
||||
outputs = accelerator.pad_across_processes(outputs, dim=1, pad_index=tokenizer.pad_token_id)
|
||||
preds = accelerator.gather(outputs).detach().cpu().numpy()
|
||||
test_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
|
||||
|
||||
test_preds_cleaned = []
|
||||
for _, pred in enumerate(test_preds):
|
||||
test_preds_cleaned.append(get_closest_label(pred, classes))
|
||||
|
||||
test_df = dataset["test"].to_pandas()
|
||||
assert len(test_preds_cleaned) == len(test_df), f"{len(test_preds_cleaned)} != {len(test_df)}"
|
||||
test_df[label_column] = test_preds_cleaned
|
||||
test_df["text_labels_orig"] = test_preds
|
||||
accelerator.print(test_df[[text_column, label_column]].sample(20))
|
||||
|
||||
@ -2,13 +2,13 @@ import os
|
||||
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup
|
||||
|
||||
from datasets import load_dataset
|
||||
from peft import LoraConfig, TaskType, get_peft_model
|
||||
from peft.utils.other import fsdp_auto_wrap_policy
|
||||
from tqdm import tqdm
|
||||
|
||||
|
||||
def main():
|
||||
@ -108,9 +108,9 @@ def main():
|
||||
eval_loss += loss.detach().float()
|
||||
preds = accelerator.gather_for_metrics(torch.argmax(outputs.logits, -1)).detach().cpu().numpy()
|
||||
eval_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
|
||||
eval_epoch_loss = eval_loss / len(train_dataloader)
|
||||
eval_epoch_loss = eval_loss / len(eval_dataloader)
|
||||
eval_ppl = torch.exp(eval_epoch_loss)
|
||||
train_epoch_loss = total_loss / len(eval_dataloader)
|
||||
train_epoch_loss = total_loss / len(train_dataloader)
|
||||
train_ppl = torch.exp(train_epoch_loss)
|
||||
accelerator.print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
|
||||
|
||||
|
||||
@ -24,15 +24,16 @@
|
||||
],
|
||||
"source": [
|
||||
"from transformers import AutoModelForSeq2SeqLM\n",
|
||||
"from peft import get_peft_config,get_peft_model, get_peft_model_state_dict, PrefixTuningConfig, TaskType\n",
|
||||
"from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, PrefixTuningConfig, TaskType\n",
|
||||
"import torch\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"os.environ[\"TOKENIZERS_PARALLELISM\"] = \"false\"\n",
|
||||
"os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"3\"\n",
|
||||
"from transformers import AutoTokenizer\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from transformers import default_data_collator,get_linear_schedule_with_warmup\n",
|
||||
"from transformers import default_data_collator, get_linear_schedule_with_warmup\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"\n",
|
||||
@ -43,10 +44,10 @@
|
||||
"checkpoint_name = \"financial_sentiment_analysis_prefix_tuning_v1.pt\"\n",
|
||||
"text_column = \"sentence\"\n",
|
||||
"label_column = \"text_label\"\n",
|
||||
"max_length=128\n",
|
||||
"max_length = 128\n",
|
||||
"lr = 1e-2\n",
|
||||
"num_epochs = 5\n",
|
||||
"batch_size=8\n"
|
||||
"batch_size = 8"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -57,9 +58,7 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# creating model\n",
|
||||
"peft_config = PrefixTuningConfig(\n",
|
||||
" task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, num_virtual_tokens=20\n",
|
||||
")\n",
|
||||
"peft_config = PrefixTuningConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, num_virtual_tokens=20)\n",
|
||||
"\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)\n",
|
||||
"model = get_peft_model(model, peft_config)\n",
|
||||
@ -137,17 +136,16 @@
|
||||
],
|
||||
"source": [
|
||||
"# loading dataset\n",
|
||||
"dataset = load_dataset(\"financial_phrasebank\", 'sentences_allagree')\n",
|
||||
"dataset = load_dataset(\"financial_phrasebank\", \"sentences_allagree\")\n",
|
||||
"dataset = dataset[\"train\"].train_test_split(test_size=0.1)\n",
|
||||
"dataset[\"validation\"] = dataset[\"test\"]\n",
|
||||
"del(dataset[\"test\"])\n",
|
||||
"del dataset[\"test\"]\n",
|
||||
"\n",
|
||||
"classes = dataset[\"train\"].features[\"label\"].names\n",
|
||||
"dataset = dataset.map(\n",
|
||||
" lambda x: {\"text_label\": [classes[label] for label in x[\"label\"]]},\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" \n",
|
||||
")\n",
|
||||
"\n",
|
||||
"dataset[\"train\"][0]"
|
||||
@ -203,36 +201,35 @@
|
||||
"source": [
|
||||
"# data preprocessing\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def preprocess_function(examples):\n",
|
||||
" inputs = examples[text_column]\n",
|
||||
" targets = examples[label_column]\n",
|
||||
" model_inputs = tokenizer(inputs, max_length=max_length, padding=\"max_length\", truncation=True, return_tensors=\"pt\")\n",
|
||||
" labels = tokenizer(targets, max_length=2, padding=\"max_length\", truncation=True, return_tensors=\"pt\")\n",
|
||||
" labels = labels[\"input_ids\"]\n",
|
||||
" labels[labels==tokenizer.pad_token_id] = -100\n",
|
||||
" labels[labels == tokenizer.pad_token_id] = -100\n",
|
||||
" model_inputs[\"labels\"] = labels\n",
|
||||
" return model_inputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"processed_datasets = dataset.map(\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
" )\n",
|
||||
" preprocess_function,\n",
|
||||
" batched=True,\n",
|
||||
" num_proc=1,\n",
|
||||
" remove_columns=dataset[\"train\"].column_names,\n",
|
||||
" load_from_cache_file=False,\n",
|
||||
" desc=\"Running tokenizer on dataset\",\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"train_dataset = processed_datasets[\"train\"]\n",
|
||||
"eval_dataset = processed_datasets[\"validation\"]\n",
|
||||
"\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
" )\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
" "
|
||||
" train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True\n",
|
||||
")\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -248,7 +245,7 @@
|
||||
" optimizer=optimizer,\n",
|
||||
" num_warmup_steps=0,\n",
|
||||
" num_training_steps=(len(train_dataloader) * num_epochs),\n",
|
||||
")\n"
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -359,13 +356,15 @@
|
||||
" outputs = model(**batch)\n",
|
||||
" loss = outputs.loss\n",
|
||||
" eval_loss += loss.detach().float()\n",
|
||||
" eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True))\n",
|
||||
" eval_preds.extend(\n",
|
||||
" tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True)\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" eval_epoch_loss = eval_loss/len(train_dataloader)\n",
|
||||
" eval_epoch_loss = eval_loss / len(eval_dataloader)\n",
|
||||
" eval_ppl = torch.exp(eval_epoch_loss)\n",
|
||||
" train_epoch_loss = total_loss/len(eval_dataloader)\n",
|
||||
" train_epoch_loss = total_loss / len(train_dataloader)\n",
|
||||
" train_ppl = torch.exp(train_epoch_loss)\n",
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")\n"
|
||||
" print(f\"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -386,13 +385,13 @@
|
||||
],
|
||||
"source": [
|
||||
"# print accuracy\n",
|
||||
"correct =0\n",
|
||||
"correct = 0\n",
|
||||
"total = 0\n",
|
||||
"for pred,true in zip(eval_preds, dataset[\"validation\"][\"text_label\"]):\n",
|
||||
" if pred.strip()==true.strip():\n",
|
||||
" correct+=1\n",
|
||||
" total+=1 \n",
|
||||
"accuracy = correct/total*100\n",
|
||||
"for pred, true in zip(eval_preds, dataset[\"validation\"][\"text_label\"]):\n",
|
||||
" if pred.strip() == true.strip():\n",
|
||||
" correct += 1\n",
|
||||
" total += 1\n",
|
||||
"accuracy = correct / total * 100\n",
|
||||
"print(f\"{accuracy=} % on the evaluation dataset\")\n",
|
||||
"print(f\"{eval_preds[:10]=}\")\n",
|
||||
"print(f\"{dataset['validation']['text_label'][:10]=}\")"
|
||||
@ -437,11 +436,12 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from peft import PeftModel, PeftConfig\n",
|
||||
"\n",
|
||||
"peft_model_id = f\"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}\"\n",
|
||||
"\n",
|
||||
"config = PeftConfig.from_pretrained(peft_model_id)\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)\n",
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)\n"
|
||||
"model = PeftModel.from_pretrained(model, peft_model_id)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -475,7 +475,7 @@
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model.generate(input_ids=inputs[\"input_ids\"], max_new_tokens=10)\n",
|
||||
" print(outputs)\n",
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))\n"
|
||||
" print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -503,7 +503,7 @@
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.10.5 (v3.10.5:f377153967, Jun 6 2022, 12:36:10) [Clang 13.0.0 (clang-1300.0.29.30)]"
|
||||
"version": "3.10.5"
|
||||
},
|
||||
"vscode": {
|
||||
"interpreter": {
|
||||
|
||||
@ -155,7 +155,7 @@
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import transformers \n",
|
||||
"import transformers\n",
|
||||
"import accelerate\n",
|
||||
"import peft"
|
||||
]
|
||||
@ -204,9 +204,7 @@
|
||||
},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model_checkpoint = (\n",
|
||||
" \"google/vit-base-patch16-224-in21k\" # pre-trained model from which to fine-tune\n",
|
||||
")"
|
||||
"model_checkpoint = \"google/vit-base-patch16-224-in21k\" # pre-trained model from which to fine-tune"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -736,17 +734,13 @@
|
||||
"\n",
|
||||
"def preprocess_train(example_batch):\n",
|
||||
" \"\"\"Apply train_transforms across a batch.\"\"\"\n",
|
||||
" example_batch[\"pixel_values\"] = [\n",
|
||||
" train_transforms(image.convert(\"RGB\")) for image in example_batch[\"image\"]\n",
|
||||
" ]\n",
|
||||
" example_batch[\"pixel_values\"] = [train_transforms(image.convert(\"RGB\")) for image in example_batch[\"image\"]]\n",
|
||||
" return example_batch\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def preprocess_val(example_batch):\n",
|
||||
" \"\"\"Apply val_transforms across a batch.\"\"\"\n",
|
||||
" example_batch[\"pixel_values\"] = [\n",
|
||||
" val_transforms(image.convert(\"RGB\")) for image in example_batch[\"image\"]\n",
|
||||
" ]\n",
|
||||
" example_batch[\"pixel_values\"] = [val_transforms(image.convert(\"RGB\")) for image in example_batch[\"image\"]]\n",
|
||||
" return example_batch"
|
||||
]
|
||||
},
|
||||
@ -1099,6 +1093,7 @@
|
||||
"\n",
|
||||
"metric = evaluate.load(\"accuracy\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# the compute_metrics function takes a Named Tuple as input:\n",
|
||||
"# predictions, which are the logits of the model as Numpy arrays,\n",
|
||||
"# and label_ids, which are the ground-truth labels as Numpy arrays.\n",
|
||||
@ -1129,6 +1124,7 @@
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def collate_fn(examples):\n",
|
||||
" pixel_values = torch.stack([example[\"pixel_values\"] for example in examples])\n",
|
||||
" labels = torch.tensor([example[\"label\"] for example in examples])\n",
|
||||
@ -2230,10 +2226,10 @@
|
||||
"\n",
|
||||
"config = PeftConfig.from_pretrained(repo_name)\n",
|
||||
"model = model = AutoModelForImageClassification.from_pretrained(\n",
|
||||
" config.base_model_name_or_path, \n",
|
||||
" config.base_model_name_or_path,\n",
|
||||
" label2id=label2id,\n",
|
||||
" id2label=id2label,\n",
|
||||
" ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint\n",
|
||||
" ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint\n",
|
||||
")\n",
|
||||
"# Load the Lora model\n",
|
||||
"inference_model = PeftModel.from_pretrained(model, repo_name)"
|
||||
|
||||
8315
examples/int8_training/Finetune_flan_t5_large_bnb_peft.ipynb
Normal file
8315
examples/int8_training/Finetune_flan_t5_large_bnb_peft.ipynb
Normal file
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
20602
examples/int8_training/peft_bnb_whisper_large_v2_training.ipynb
Normal file
20602
examples/int8_training/peft_bnb_whisper_large_v2_training.ipynb
Normal file
File diff suppressed because it is too large
Load Diff
@ -51,7 +51,7 @@
|
||||
"logger = get_logger(__name__)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"MODEL_NAME=\"CompVis/stable-diffusion-v1-4\"#\"stabilityai/stable-diffusion-2-1-base\"\n",
|
||||
"MODEL_NAME = \"CompVis/stable-diffusion-v1-4\" # \"stabilityai/stable-diffusion-2-1-base\"\n",
|
||||
"INSTANCE_PROMPT = \"a photo of sks dog\"\n",
|
||||
"ckpt_dir = \"/home/sourab/temp/sd_dog_dreambooth/\""
|
||||
]
|
||||
@ -89,31 +89,32 @@
|
||||
" with open(f\"{ckpt_dir}{instance_prompt}_lora_config.json\", \"r\") as f:\n",
|
||||
" lora_config = json.load(f)\n",
|
||||
" print(lora_config)\n",
|
||||
" \n",
|
||||
"\n",
|
||||
" checkpoint = f\"{ckpt_dir}{instance_prompt}_lora.pt\"\n",
|
||||
" lora_checkpoint_sd = torch.load(checkpoint)\n",
|
||||
" unet_lora_ds = {k:v for k,v in lora_checkpoint_sd.items() if \"text_encoder_\" not in k}\n",
|
||||
" text_encoder_lora_ds = {k.replace(\"text_encoder_\", \"\"):v for k,v in lora_checkpoint_sd.items() if \"text_encoder_\" in k}\n",
|
||||
" \n",
|
||||
" unet_lora_ds = {k: v for k, v in lora_checkpoint_sd.items() if \"text_encoder_\" not in k}\n",
|
||||
" text_encoder_lora_ds = {\n",
|
||||
" k.replace(\"text_encoder_\", \"\"): v for k, v in lora_checkpoint_sd.items() if \"text_encoder_\" in k\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" unet_config = LoraConfig(**lora_config[\"peft_config\"])\n",
|
||||
" pipe.unet = LoraModel(unet_config, pipe.unet)\n",
|
||||
" set_peft_model_state_dict(pipe.unet, unet_lora_ds) \n",
|
||||
" \n",
|
||||
" set_peft_model_state_dict(pipe.unet, unet_lora_ds)\n",
|
||||
"\n",
|
||||
" if \"text_encoder_peft_config\" in lora_config:\n",
|
||||
" text_encoder_config = LoraConfig(**lora_config[\"text_encoder_peft_config\"])\n",
|
||||
" pipe.text_encoder = LoraModel(text_encoder_config, pipe.text_encoder)\n",
|
||||
" set_peft_model_state_dict(pipe.text_encoder, text_encoder_lora_ds)\n",
|
||||
" \n",
|
||||
"\n",
|
||||
" if dtype in (torch.float16, torch.bfloat16):\n",
|
||||
" pipe.unet.half()\n",
|
||||
" pipe.text_encoder.half()\n",
|
||||
" \n",
|
||||
" pipe.to(device) \n",
|
||||
" return pipe\n",
|
||||
" \n",
|
||||
"pipe = load_and_set_lora_ckpt(pipe, ckpt_dir, INSTANCE_PROMPT, \"cuda\", torch.float16)\n",
|
||||
"\n",
|
||||
" "
|
||||
" pipe.to(device)\n",
|
||||
" return pipe\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"pipe = load_and_set_lora_ckpt(pipe, ckpt_dir, INSTANCE_PROMPT, \"cuda\", torch.float16)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -175,9 +176,7 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"prompt = \"sks dog with Eiffel Tower in the background\"\n",
|
||||
"image = pipe(prompt, num_inference_steps=50, \n",
|
||||
" guidance_scale=7.5, \n",
|
||||
" negative_prompt=negative_prompt).images[0]\n",
|
||||
"image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5, negative_prompt=negative_prompt).images[0]\n",
|
||||
"image"
|
||||
]
|
||||
},
|
||||
|
||||
@ -11,7 +11,10 @@ import warnings
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
import datasets
|
||||
import diffusers
|
||||
import numpy as np
|
||||
import psutil
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
@ -19,12 +22,6 @@ import transformers
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.utils import set_seed
|
||||
from torch.utils.data import Dataset
|
||||
from transformers import AutoTokenizer, PretrainedConfig
|
||||
|
||||
import datasets
|
||||
import diffusers
|
||||
import psutil
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDPMScheduler,
|
||||
@ -36,10 +33,13 @@ from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import check_min_version
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
from huggingface_hub import HfFolder, Repository, whoami
|
||||
from peft import LoraConfig, LoraModel, get_peft_model_state_dict
|
||||
from PIL import Image
|
||||
from torch.utils.data import Dataset
|
||||
from torchvision import transforms
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import AutoTokenizer, PretrainedConfig
|
||||
|
||||
from peft import LoraConfig, LoraModel, get_peft_model_state_dict
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
|
||||
@ -170,9 +170,7 @@
|
||||
"\n",
|
||||
"repo_id = \"huggingface/label-files\"\n",
|
||||
"filename = \"ade20k-id2label.json\"\n",
|
||||
"id2label = json.load(\n",
|
||||
" open(cached_download(hf_hub_url(repo_id, filename, repo_type=\"dataset\")), \"r\")\n",
|
||||
")\n",
|
||||
"id2label = json.load(open(cached_download(hf_hub_url(repo_id, filename, repo_type=\"dataset\")), \"r\"))\n",
|
||||
"id2label = {int(k): v for k, v in id2label.items()}\n",
|
||||
"label2id = {v: k for k, v in id2label.items()}\n",
|
||||
"num_labels = len(id2label)"
|
||||
@ -318,12 +316,8 @@
|
||||
" per_category_accuracy = metrics.pop(\"per_category_accuracy\").tolist()\n",
|
||||
" per_category_iou = metrics.pop(\"per_category_iou\").tolist()\n",
|
||||
"\n",
|
||||
" metrics.update(\n",
|
||||
" {f\"accuracy_{id2label[i]}\": v for i, v in enumerate(per_category_accuracy)}\n",
|
||||
" )\n",
|
||||
" metrics.update(\n",
|
||||
" {f\"iou_{id2label[i]}\": v for i, v in enumerate(per_category_iou)}\n",
|
||||
" )\n",
|
||||
" metrics.update({f\"accuracy_{id2label[i]}\": v for i, v in enumerate(per_category_accuracy)})\n",
|
||||
" metrics.update({f\"iou_{id2label[i]}\": v for i, v in enumerate(per_category_iou)})\n",
|
||||
"\n",
|
||||
" return metrics"
|
||||
]
|
||||
@ -1022,9 +1016,7 @@
|
||||
" color_seg[pred_seg == label, :] = color\n",
|
||||
"color_seg = color_seg[..., ::-1] # convert to BGR\n",
|
||||
"\n",
|
||||
"img = (\n",
|
||||
" np.array(image) * 0.5 + color_seg * 0.5\n",
|
||||
") # plot the image with the segmentation map\n",
|
||||
"img = np.array(image) * 0.5 + color_seg * 0.5 # plot the image with the segmentation map\n",
|
||||
"img = img.astype(np.uint8)\n",
|
||||
"\n",
|
||||
"plt.figure(figsize=(15, 10))\n",
|
||||
|
||||
@ -29,13 +29,21 @@
|
||||
"import torch\n",
|
||||
"from torch.optim import AdamW\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from peft import get_peft_config,get_peft_model, get_peft_model_state_dict, set_peft_model_state_dict, LoraConfig, PeftType, \\\n",
|
||||
"PrefixTuningConfig, PromptEncoderConfig\n",
|
||||
"from peft import (\n",
|
||||
" get_peft_config,\n",
|
||||
" get_peft_model,\n",
|
||||
" get_peft_model_state_dict,\n",
|
||||
" set_peft_model_state_dict,\n",
|
||||
" LoraConfig,\n",
|
||||
" PeftType,\n",
|
||||
" PrefixTuningConfig,\n",
|
||||
" PromptEncoderConfig,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"import evaluate\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed\n",
|
||||
"from tqdm import tqdm\n"
|
||||
"from tqdm import tqdm"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -60,13 +68,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"peft_config = LoraConfig(\n",
|
||||
" task_type=\"SEQ_CLS\",\n",
|
||||
" inference_mode=False,\n",
|
||||
" r=8,\n",
|
||||
" lora_alpha=16,\n",
|
||||
" lora_dropout=0.1\n",
|
||||
")\n",
|
||||
"peft_config = LoraConfig(task_type=\"SEQ_CLS\", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)\n",
|
||||
"lr = 3e-4"
|
||||
]
|
||||
},
|
||||
@ -159,19 +161,21 @@
|
||||
" padding_side = \"left\"\n",
|
||||
"else:\n",
|
||||
" padding_side = \"right\"\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)\n",
|
||||
"if getattr(tokenizer, \"pad_token_id\") is None:\n",
|
||||
" tokenizer.pad_token_id = tokenizer.eos_token_id\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"datasets = load_dataset(\"glue\", task)\n",
|
||||
"metric = evaluate.load(\"glue\", task)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def tokenize_function(examples):\n",
|
||||
" # max_length=None => use the model max length (it's actually the default)\n",
|
||||
" outputs = tokenizer(examples[\"sentence1\"], examples[\"sentence2\"], truncation=True, max_length=None)\n",
|
||||
" return outputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"tokenized_datasets = datasets.map(\n",
|
||||
" tokenize_function,\n",
|
||||
" batched=True,\n",
|
||||
@ -182,16 +186,16 @@
|
||||
"# transformers library\n",
|
||||
"tokenized_datasets = tokenized_datasets.rename_column(\"label\", \"labels\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def collate_fn(examples):\n",
|
||||
" return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Instantiate dataloaders.\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n",
|
||||
"train_dataloader = DataLoader(tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)\n",
|
||||
"eval_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"validation\"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n"
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -219,7 +223,7 @@
|
||||
"# Instantiate scheduler\n",
|
||||
"lr_scheduler = get_linear_schedule_with_warmup(\n",
|
||||
" optimizer=optimizer,\n",
|
||||
" num_warmup_steps=0.06*(len(train_dataloader) * num_epochs),\n",
|
||||
" num_warmup_steps=0.06 * (len(train_dataloader) * num_epochs),\n",
|
||||
" num_training_steps=(len(train_dataloader) * num_epochs),\n",
|
||||
")"
|
||||
]
|
||||
@ -668,7 +672,7 @@
|
||||
" )\n",
|
||||
"\n",
|
||||
"eval_metric = metric.compute()\n",
|
||||
"print(eval_metric)\n"
|
||||
"print(eval_metric)"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@ -29,13 +29,20 @@
|
||||
"import torch\n",
|
||||
"from torch.optim import AdamW\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from peft import get_peft_config,get_peft_model, get_peft_model_state_dict, set_peft_model_state_dict, PeftType, \\\n",
|
||||
"PrefixTuningConfig, PromptEncoderConfig\n",
|
||||
"from peft import (\n",
|
||||
" get_peft_config,\n",
|
||||
" get_peft_model,\n",
|
||||
" get_peft_model_state_dict,\n",
|
||||
" set_peft_model_state_dict,\n",
|
||||
" PeftType,\n",
|
||||
" PrefixTuningConfig,\n",
|
||||
" PromptEncoderConfig,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"import evaluate\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed\n",
|
||||
"from tqdm import tqdm\n"
|
||||
"from tqdm import tqdm"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -60,12 +67,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"\n",
|
||||
"peft_config = PromptEncoderConfig(\n",
|
||||
" task_type=\"SEQ_CLS\",\n",
|
||||
" num_virtual_tokens=20,\n",
|
||||
" encoder_hidden_size=128\n",
|
||||
")\n",
|
||||
"peft_config = PromptEncoderConfig(task_type=\"SEQ_CLS\", num_virtual_tokens=20, encoder_hidden_size=128)\n",
|
||||
"lr = 1e-3"
|
||||
]
|
||||
},
|
||||
@ -111,19 +113,21 @@
|
||||
" padding_side = \"left\"\n",
|
||||
"else:\n",
|
||||
" padding_side = \"right\"\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)\n",
|
||||
"if getattr(tokenizer, \"pad_token_id\") is None:\n",
|
||||
" tokenizer.pad_token_id = tokenizer.eos_token_id\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"datasets = load_dataset(\"glue\", task)\n",
|
||||
"metric = evaluate.load(\"glue\", task)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def tokenize_function(examples):\n",
|
||||
" # max_length=None => use the model max length (it's actually the default)\n",
|
||||
" outputs = tokenizer(examples[\"sentence1\"], examples[\"sentence2\"], truncation=True, max_length=None)\n",
|
||||
" return outputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"tokenized_datasets = datasets.map(\n",
|
||||
" tokenize_function,\n",
|
||||
" batched=True,\n",
|
||||
@ -134,16 +138,16 @@
|
||||
"# transformers library\n",
|
||||
"tokenized_datasets = tokenized_datasets.rename_column(\"label\", \"labels\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def collate_fn(examples):\n",
|
||||
" return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Instantiate dataloaders.\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n",
|
||||
"train_dataloader = DataLoader(tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)\n",
|
||||
"eval_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"validation\"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n"
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -171,7 +175,7 @@
|
||||
"# Instantiate scheduler\n",
|
||||
"lr_scheduler = get_linear_schedule_with_warmup(\n",
|
||||
" optimizer=optimizer,\n",
|
||||
" num_warmup_steps=0,#0.06*(len(train_dataloader) * num_epochs),\n",
|
||||
" num_warmup_steps=0, # 0.06*(len(train_dataloader) * num_epochs),\n",
|
||||
" num_training_steps=(len(train_dataloader) * num_epochs),\n",
|
||||
")"
|
||||
]
|
||||
@ -640,7 +644,7 @@
|
||||
" )\n",
|
||||
"\n",
|
||||
"eval_metric = metric.compute()\n",
|
||||
"print(eval_metric)\n"
|
||||
"print(eval_metric)"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@ -29,13 +29,21 @@
|
||||
"import torch\n",
|
||||
"from torch.optim import AdamW\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from peft import get_peft_config,get_peft_model, get_peft_model_state_dict, set_peft_model_state_dict, PeftType, \\\n",
|
||||
"PrefixTuningConfig, PromptEncoderConfig, PromptTuningConfig\n",
|
||||
"from peft import (\n",
|
||||
" get_peft_config,\n",
|
||||
" get_peft_model,\n",
|
||||
" get_peft_model_state_dict,\n",
|
||||
" set_peft_model_state_dict,\n",
|
||||
" PeftType,\n",
|
||||
" PrefixTuningConfig,\n",
|
||||
" PromptEncoderConfig,\n",
|
||||
" PromptTuningConfig,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"import evaluate\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed\n",
|
||||
"from tqdm import tqdm\n"
|
||||
"from tqdm import tqdm"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -60,11 +68,8 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"peft_config = PromptTuningConfig(\n",
|
||||
" task_type=\"SEQ_CLS\",\n",
|
||||
" num_virtual_tokens=10\n",
|
||||
")\n",
|
||||
"lr = 1e-3\n"
|
||||
"peft_config = PromptTuningConfig(task_type=\"SEQ_CLS\", num_virtual_tokens=10)\n",
|
||||
"lr = 1e-3"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -109,19 +114,21 @@
|
||||
" padding_side = \"left\"\n",
|
||||
"else:\n",
|
||||
" padding_side = \"right\"\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)\n",
|
||||
"if getattr(tokenizer, \"pad_token_id\") is None:\n",
|
||||
" tokenizer.pad_token_id = tokenizer.eos_token_id\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"datasets = load_dataset(\"glue\", task)\n",
|
||||
"metric = evaluate.load(\"glue\", task)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def tokenize_function(examples):\n",
|
||||
" # max_length=None => use the model max length (it's actually the default)\n",
|
||||
" outputs = tokenizer(examples[\"sentence1\"], examples[\"sentence2\"], truncation=True, max_length=None)\n",
|
||||
" return outputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"tokenized_datasets = datasets.map(\n",
|
||||
" tokenize_function,\n",
|
||||
" batched=True,\n",
|
||||
@ -132,16 +139,16 @@
|
||||
"# transformers library\n",
|
||||
"tokenized_datasets = tokenized_datasets.rename_column(\"label\", \"labels\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def collate_fn(examples):\n",
|
||||
" return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Instantiate dataloaders.\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n",
|
||||
"train_dataloader = DataLoader(tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)\n",
|
||||
"eval_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"validation\"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n"
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -169,7 +176,7 @@
|
||||
"# Instantiate scheduler\n",
|
||||
"lr_scheduler = get_linear_schedule_with_warmup(\n",
|
||||
" optimizer=optimizer,\n",
|
||||
" num_warmup_steps=0.06*(len(train_dataloader) * num_epochs),\n",
|
||||
" num_warmup_steps=0.06 * (len(train_dataloader) * num_epochs),\n",
|
||||
" num_training_steps=(len(train_dataloader) * num_epochs),\n",
|
||||
")"
|
||||
]
|
||||
@ -652,7 +659,7 @@
|
||||
" )\n",
|
||||
"\n",
|
||||
"eval_metric = metric.compute()\n",
|
||||
"print(eval_metric)\n"
|
||||
"print(eval_metric)"
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
@ -29,13 +29,20 @@
|
||||
"import torch\n",
|
||||
"from torch.optim import AdamW\n",
|
||||
"from torch.utils.data import DataLoader\n",
|
||||
"from peft import get_peft_config,get_peft_model, get_peft_model_state_dict, set_peft_model_state_dict, PeftType, \\\n",
|
||||
"PrefixTuningConfig, PromptEncoderConfig\n",
|
||||
"from peft import (\n",
|
||||
" get_peft_config,\n",
|
||||
" get_peft_model,\n",
|
||||
" get_peft_model_state_dict,\n",
|
||||
" set_peft_model_state_dict,\n",
|
||||
" PeftType,\n",
|
||||
" PrefixTuningConfig,\n",
|
||||
" PromptEncoderConfig,\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"import evaluate\n",
|
||||
"from datasets import load_dataset\n",
|
||||
"from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed\n",
|
||||
"from tqdm import tqdm\n"
|
||||
"from tqdm import tqdm"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -60,10 +67,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"peft_config = PrefixTuningConfig(\n",
|
||||
" task_type=\"SEQ_CLS\",\n",
|
||||
" num_virtual_tokens=20\n",
|
||||
")\n",
|
||||
"peft_config = PrefixTuningConfig(task_type=\"SEQ_CLS\", num_virtual_tokens=20)\n",
|
||||
"lr = 1e-2"
|
||||
]
|
||||
},
|
||||
@ -128,19 +132,21 @@
|
||||
" padding_side = \"left\"\n",
|
||||
"else:\n",
|
||||
" padding_side = \"right\"\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)\n",
|
||||
"if getattr(tokenizer, \"pad_token_id\") is None:\n",
|
||||
" tokenizer.pad_token_id = tokenizer.eos_token_id\n",
|
||||
" \n",
|
||||
"\n",
|
||||
"datasets = load_dataset(\"glue\", task)\n",
|
||||
"metric = evaluate.load(\"glue\", task)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def tokenize_function(examples):\n",
|
||||
" # max_length=None => use the model max length (it's actually the default)\n",
|
||||
" outputs = tokenizer(examples[\"sentence1\"], examples[\"sentence2\"], truncation=True, max_length=None)\n",
|
||||
" return outputs\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"tokenized_datasets = datasets.map(\n",
|
||||
" tokenize_function,\n",
|
||||
" batched=True,\n",
|
||||
@ -151,16 +157,16 @@
|
||||
"# transformers library\n",
|
||||
"tokenized_datasets = tokenized_datasets.rename_column(\"label\", \"labels\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def collate_fn(examples):\n",
|
||||
" return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Instantiate dataloaders.\n",
|
||||
"train_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n",
|
||||
"train_dataloader = DataLoader(tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)\n",
|
||||
"eval_dataloader = DataLoader(\n",
|
||||
" tokenized_datasets[\"validation\"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size\n",
|
||||
")\n"
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -188,7 +194,7 @@
|
||||
"# Instantiate scheduler\n",
|
||||
"lr_scheduler = get_linear_schedule_with_warmup(\n",
|
||||
" optimizer=optimizer,\n",
|
||||
" num_warmup_steps=0.06*(len(train_dataloader) * num_epochs),\n",
|
||||
" num_warmup_steps=0.06 * (len(train_dataloader) * num_epochs),\n",
|
||||
" num_training_steps=(len(train_dataloader) * num_epochs),\n",
|
||||
")"
|
||||
]
|
||||
@ -671,7 +677,7 @@
|
||||
" )\n",
|
||||
"\n",
|
||||
"eval_metric = metric.compute()\n",
|
||||
"print(eval_metric)\n"
|
||||
"print(eval_metric)"
|
||||
]
|
||||
}
|
||||
],
|
||||
|
||||
@ -104,6 +104,7 @@
|
||||
"source": [
|
||||
"from PIL import Image, ImageDraw, ImageFont\n",
|
||||
"import os\n",
|
||||
"\n",
|
||||
"base_path = \"/home/sourab/temp/data/dataset\"\n",
|
||||
"\n",
|
||||
"image = Image.open(os.path.join(base_path, \"training_data/images/0000971160.png\"))\n",
|
||||
@ -135,11 +136,11 @@
|
||||
"source": [
|
||||
"import json\n",
|
||||
"\n",
|
||||
"with open(os.path.join(base_path, 'training_data/annotations/0000971160.json')) as f:\n",
|
||||
" data = json.load(f)\n",
|
||||
"with open(os.path.join(base_path, \"training_data/annotations/0000971160.json\")) as f:\n",
|
||||
" data = json.load(f)\n",
|
||||
"\n",
|
||||
"for annotation in data['form']:\n",
|
||||
" print(annotation)"
|
||||
"for annotation in data[\"form\"]:\n",
|
||||
" print(annotation)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -168,17 +169,17 @@
|
||||
"\n",
|
||||
"font = ImageFont.load_default()\n",
|
||||
"\n",
|
||||
"label2color = {'question':'blue', 'answer':'green', 'header':'orange', 'other':'violet'}\n",
|
||||
"label2color = {\"question\": \"blue\", \"answer\": \"green\", \"header\": \"orange\", \"other\": \"violet\"}\n",
|
||||
"\n",
|
||||
"for annotation in data['form']:\n",
|
||||
" label = annotation['label']\n",
|
||||
" general_box = annotation['box']\n",
|
||||
" draw.rectangle(general_box, outline=label2color[label], width=2)\n",
|
||||
" draw.text((general_box[0] + 10, general_box[1] - 10), label, fill=label2color[label], font=font)\n",
|
||||
" words = annotation['words']\n",
|
||||
" for word in words:\n",
|
||||
" box = word['box']\n",
|
||||
" draw.rectangle(box, outline=label2color[label], width=1)\n",
|
||||
"for annotation in data[\"form\"]:\n",
|
||||
" label = annotation[\"label\"]\n",
|
||||
" general_box = annotation[\"box\"]\n",
|
||||
" draw.rectangle(general_box, outline=label2color[label], width=2)\n",
|
||||
" draw.text((general_box[0] + 10, general_box[1] - 10), label, fill=label2color[label], font=font)\n",
|
||||
" words = annotation[\"words\"]\n",
|
||||
" for word in words:\n",
|
||||
" box = word[\"box\"]\n",
|
||||
" draw.rectangle(box, outline=label2color[label], width=1)\n",
|
||||
"\n",
|
||||
"image"
|
||||
]
|
||||
@ -260,6 +261,7 @@
|
||||
"source": [
|
||||
"from torch.nn import CrossEntropyLoss\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"def get_labels(path):\n",
|
||||
" with open(path, \"r\") as f:\n",
|
||||
" labels = f.read().splitlines()\n",
|
||||
@ -267,6 +269,7 @@
|
||||
" labels = [\"O\"] + labels\n",
|
||||
" return labels\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"labels = get_labels(\"data/labels.txt\")\n",
|
||||
"num_labels = len(labels)\n",
|
||||
"label_map = {i: label for i, label in enumerate(labels)}\n",
|
||||
@ -368,27 +371,19 @@
|
||||
" pad_token_segment_id=4 if args.model_type in [\"xlnet\"] else 0,\n",
|
||||
" pad_token_label_id=pad_token_label_id,\n",
|
||||
" )\n",
|
||||
" #if args.local_rank in [-1, 0]:\n",
|
||||
" #logger.info(\"Saving features into cached file %s\", cached_features_file)\n",
|
||||
" #torch.save(features, cached_features_file)\n",
|
||||
" # if args.local_rank in [-1, 0]:\n",
|
||||
" # logger.info(\"Saving features into cached file %s\", cached_features_file)\n",
|
||||
" # torch.save(features, cached_features_file)\n",
|
||||
"\n",
|
||||
" if args.local_rank == 0 and mode == \"train\":\n",
|
||||
" torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache\n",
|
||||
"\n",
|
||||
" self.features = features\n",
|
||||
" # Convert to Tensors and build dataset\n",
|
||||
" self.all_input_ids = torch.tensor(\n",
|
||||
" [f.input_ids for f in features], dtype=torch.long\n",
|
||||
" )\n",
|
||||
" self.all_input_mask = torch.tensor(\n",
|
||||
" [f.input_mask for f in features], dtype=torch.long\n",
|
||||
" )\n",
|
||||
" self.all_segment_ids = torch.tensor(\n",
|
||||
" [f.segment_ids for f in features], dtype=torch.long\n",
|
||||
" )\n",
|
||||
" self.all_label_ids = torch.tensor(\n",
|
||||
" [f.label_ids for f in features], dtype=torch.long\n",
|
||||
" )\n",
|
||||
" self.all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)\n",
|
||||
" self.all_input_mask = torch.tensor([f.input_mask for f in features], dtype=torch.long)\n",
|
||||
" self.all_segment_ids = torch.tensor([f.segment_ids for f in features], dtype=torch.long)\n",
|
||||
" self.all_label_ids = torch.tensor([f.label_ids for f in features], dtype=torch.long)\n",
|
||||
" self.all_bboxes = torch.tensor([f.boxes for f in features], dtype=torch.long)\n",
|
||||
"\n",
|
||||
" def __len__(self):\n",
|
||||
@ -441,9 +436,7 @@
|
||||
" ):\n",
|
||||
" assert (\n",
|
||||
" 0 <= all(boxes) <= 1000\n",
|
||||
" ), \"Error with input bbox ({}): the coordinate value is not between 0 and 1000\".format(\n",
|
||||
" boxes\n",
|
||||
" )\n",
|
||||
" ), \"Error with input bbox ({}): the coordinate value is not between 0 and 1000\".format(boxes)\n",
|
||||
" self.input_ids = input_ids\n",
|
||||
" self.input_mask = input_mask\n",
|
||||
" self.segment_ids = segment_ids\n",
|
||||
@ -460,9 +453,9 @@
|
||||
" image_file_path = os.path.join(data_dir, \"{}_image.txt\".format(mode))\n",
|
||||
" guid_index = 1\n",
|
||||
" examples = []\n",
|
||||
" with open(file_path, encoding=\"utf-8\") as f, open(\n",
|
||||
" box_file_path, encoding=\"utf-8\"\n",
|
||||
" ) as fb, open(image_file_path, encoding=\"utf-8\") as fi:\n",
|
||||
" with open(file_path, encoding=\"utf-8\") as f, open(box_file_path, encoding=\"utf-8\") as fb, open(\n",
|
||||
" image_file_path, encoding=\"utf-8\"\n",
|
||||
" ) as fi:\n",
|
||||
" words = []\n",
|
||||
" boxes = []\n",
|
||||
" actual_bboxes = []\n",
|
||||
@ -546,17 +539,17 @@
|
||||
" sequence_a_segment_id=0,\n",
|
||||
" mask_padding_with_zero=True,\n",
|
||||
"):\n",
|
||||
" \"\"\" Loads a data file into a list of `InputBatch`s\n",
|
||||
" `cls_token_at_end` define the location of the CLS token:\n",
|
||||
" - False (Default, BERT/XLM pattern): [CLS] + A + [SEP] + B + [SEP]\n",
|
||||
" - True (XLNet/GPT pattern): A + [SEP] + B + [SEP] + [CLS]\n",
|
||||
" `cls_token_segment_id` define the segment id associated to the CLS token (0 for BERT, 2 for XLNet)\n",
|
||||
" \"\"\"Loads a data file into a list of `InputBatch`s\n",
|
||||
" `cls_token_at_end` define the location of the CLS token:\n",
|
||||
" - False (Default, BERT/XLM pattern): [CLS] + A + [SEP] + B + [SEP]\n",
|
||||
" - True (XLNet/GPT pattern): A + [SEP] + B + [SEP] + [CLS]\n",
|
||||
" `cls_token_segment_id` define the segment id associated to the CLS token (0 for BERT, 2 for XLNet)\n",
|
||||
" \"\"\"\n",
|
||||
"\n",
|
||||
" label_map = {label: i for i, label in enumerate(label_list)}\n",
|
||||
"\n",
|
||||
" features = []\n",
|
||||
" for (ex_index, example) in enumerate(examples):\n",
|
||||
" for ex_index, example in enumerate(examples):\n",
|
||||
" file_name = example.file_name\n",
|
||||
" page_size = example.page_size\n",
|
||||
" width, height = page_size\n",
|
||||
@ -567,17 +560,13 @@
|
||||
" token_boxes = []\n",
|
||||
" actual_bboxes = []\n",
|
||||
" label_ids = []\n",
|
||||
" for word, label, box, actual_bbox in zip(\n",
|
||||
" example.words, example.labels, example.boxes, example.actual_bboxes\n",
|
||||
" ):\n",
|
||||
" for word, label, box, actual_bbox in zip(example.words, example.labels, example.boxes, example.actual_bboxes):\n",
|
||||
" word_tokens = tokenizer.tokenize(word)\n",
|
||||
" tokens.extend(word_tokens)\n",
|
||||
" token_boxes.extend([box] * len(word_tokens))\n",
|
||||
" actual_bboxes.extend([actual_bbox] * len(word_tokens))\n",
|
||||
" # Use the real label id for the first token of the word, and padding ids for the remaining tokens\n",
|
||||
" label_ids.extend(\n",
|
||||
" [label_map[label]] + [pad_token_label_id] * (len(word_tokens) - 1)\n",
|
||||
" )\n",
|
||||
" label_ids.extend([label_map[label]] + [pad_token_label_id] * (len(word_tokens) - 1))\n",
|
||||
"\n",
|
||||
" # Account for [CLS] and [SEP] with \"- 2\" and with \"- 3\" for RoBERTa.\n",
|
||||
" special_tokens_count = 3 if sep_token_extra else 2\n",
|
||||
@ -640,9 +629,7 @@
|
||||
" padding_length = max_seq_length - len(input_ids)\n",
|
||||
" if pad_on_left:\n",
|
||||
" input_ids = ([pad_token] * padding_length) + input_ids\n",
|
||||
" input_mask = (\n",
|
||||
" [0 if mask_padding_with_zero else 1] * padding_length\n",
|
||||
" ) + input_mask\n",
|
||||
" input_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + input_mask\n",
|
||||
" segment_ids = ([pad_token_segment_id] * padding_length) + segment_ids\n",
|
||||
" label_ids = ([pad_token_label_id] * padding_length) + label_ids\n",
|
||||
" token_boxes = ([pad_token_box] * padding_length) + token_boxes\n",
|
||||
@ -682,7 +669,7 @@
|
||||
" page_size=page_size,\n",
|
||||
" )\n",
|
||||
" )\n",
|
||||
" return features\n"
|
||||
" return features"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -694,16 +681,20 @@
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"from transformers import LayoutLMTokenizer\n",
|
||||
"#from .unilm.layoutlm.data.funsd import FunsdDataset, InputFeatures\n",
|
||||
"\n",
|
||||
"# from .unilm.layoutlm.data.funsd import FunsdDataset, InputFeatures\n",
|
||||
"from torch.utils.data import DataLoader, RandomSampler, SequentialSampler\n",
|
||||
"\n",
|
||||
"batch_size = 16\n",
|
||||
"args = {'local_rank': -1,\n",
|
||||
" 'overwrite_cache': True,\n",
|
||||
" 'data_dir': '/home/sourab/temp/data/',\n",
|
||||
" 'model_name_or_path':'microsoft/layoutlm-base-uncased',\n",
|
||||
" 'max_seq_length': 512,\n",
|
||||
" 'model_type': 'layoutlm',\n",
|
||||
" }\n",
|
||||
"args = {\n",
|
||||
" \"local_rank\": -1,\n",
|
||||
" \"overwrite_cache\": True,\n",
|
||||
" \"data_dir\": \"/home/sourab/temp/data/\",\n",
|
||||
" \"model_name_or_path\": \"microsoft/layoutlm-base-uncased\",\n",
|
||||
" \"max_seq_length\": 512,\n",
|
||||
" \"model_type\": \"layoutlm\",\n",
|
||||
"}\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# class to turn the keys of a dict into attributes (thanks Stackoverflow)\n",
|
||||
"class AttrDict(dict):\n",
|
||||
@ -711,6 +702,7 @@
|
||||
" super(AttrDict, self).__init__(*args, **kwargs)\n",
|
||||
" self.__dict__ = self\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"args = AttrDict(args)\n",
|
||||
"\n",
|
||||
"tokenizer = LayoutLMTokenizer.from_pretrained(\"microsoft/layoutlm-base-uncased\")\n",
|
||||
@ -718,15 +710,11 @@
|
||||
"# the LayoutLM authors already defined a specific FunsdDataset, so we are going to use this here\n",
|
||||
"train_dataset = FunsdDataset(args, tokenizer, labels, pad_token_label_id, mode=\"train\")\n",
|
||||
"train_sampler = RandomSampler(train_dataset)\n",
|
||||
"train_dataloader = DataLoader(train_dataset,\n",
|
||||
" sampler=train_sampler,\n",
|
||||
" batch_size=batch_size)\n",
|
||||
"train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=batch_size)\n",
|
||||
"\n",
|
||||
"eval_dataset = FunsdDataset(args, tokenizer, labels, pad_token_label_id, mode=\"test\")\n",
|
||||
"eval_sampler = SequentialSampler(eval_dataset)\n",
|
||||
"eval_dataloader = DataLoader(eval_dataset,\n",
|
||||
" sampler=eval_sampler,\n",
|
||||
" batch_size=batch_size)"
|
||||
"eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=batch_size)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -828,14 +816,10 @@
|
||||
],
|
||||
"source": [
|
||||
"from peft import get_peft_config, PeftModel, get_peft_model, LoraConfig, TaskType\n",
|
||||
"\n",
|
||||
"peft_config = LoraConfig(\n",
|
||||
" task_type=TaskType.TOKEN_CLS,\n",
|
||||
" inference_mode=False,\n",
|
||||
" r=16,\n",
|
||||
" lora_alpha=16,\n",
|
||||
" lora_dropout=0.1,\n",
|
||||
" bias=\"all\"\n",
|
||||
" )\n",
|
||||
" task_type=TaskType.TOKEN_CLS, inference_mode=False, r=16, lora_alpha=16, lora_dropout=0.1, bias=\"all\"\n",
|
||||
")\n",
|
||||
"peft_config"
|
||||
]
|
||||
},
|
||||
@ -883,7 +867,7 @@
|
||||
"source": [
|
||||
"print(model.model.layoutlm.encoder.layer[0].attention.self.query.weight)\n",
|
||||
"print(model.model.layoutlm.encoder.layer[0].attention.self.query.lora_A.weight)\n",
|
||||
"print(model.model.classifier.weight)\n"
|
||||
"print(model.model.classifier.weight)"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -909,50 +893,52 @@
|
||||
"source": [
|
||||
"from transformers import AdamW, get_linear_schedule_with_warmup\n",
|
||||
"from tqdm import tqdm\n",
|
||||
"\n",
|
||||
"num_train_epochs = 100\n",
|
||||
"\n",
|
||||
"optimizer = torch.optim.AdamW(model.parameters(), lr=3e-3)\n",
|
||||
"lr_scheduler = get_linear_schedule_with_warmup(\n",
|
||||
" optimizer=optimizer,\n",
|
||||
" num_warmup_steps=0.06*(len(train_dataloader) * num_train_epochs),\n",
|
||||
" num_warmup_steps=0.06 * (len(train_dataloader) * num_train_epochs),\n",
|
||||
" num_training_steps=(len(train_dataloader) * num_train_epochs),\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"global_step = 0\n",
|
||||
"\n",
|
||||
"t_total = len(train_dataloader) * num_train_epochs # total number of training steps \n",
|
||||
"t_total = len(train_dataloader) * num_train_epochs # total number of training steps\n",
|
||||
"\n",
|
||||
"#put the model in training mode\n",
|
||||
"# put the model in training mode\n",
|
||||
"model.train()\n",
|
||||
"for epoch in range(num_train_epochs):\n",
|
||||
" for batch in tqdm(train_dataloader, desc=\"Training\"):\n",
|
||||
" input_ids = batch[0].to(device)\n",
|
||||
" bbox = batch[4].to(device)\n",
|
||||
" attention_mask = batch[1].to(device)\n",
|
||||
" token_type_ids = batch[2].to(device)\n",
|
||||
" labels = batch[3].to(device)\n",
|
||||
" for batch in tqdm(train_dataloader, desc=\"Training\"):\n",
|
||||
" input_ids = batch[0].to(device)\n",
|
||||
" bbox = batch[4].to(device)\n",
|
||||
" attention_mask = batch[1].to(device)\n",
|
||||
" token_type_ids = batch[2].to(device)\n",
|
||||
" labels = batch[3].to(device)\n",
|
||||
"\n",
|
||||
" # forward pass\n",
|
||||
" outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids,\n",
|
||||
" labels=labels)\n",
|
||||
" loss = outputs.loss\n",
|
||||
" # forward pass\n",
|
||||
" outputs = model(\n",
|
||||
" input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids, labels=labels\n",
|
||||
" )\n",
|
||||
" loss = outputs.loss\n",
|
||||
"\n",
|
||||
" # print loss every 100 steps\n",
|
||||
" if global_step % 10 == 0:\n",
|
||||
" print(f\"Loss after {global_step} steps: {loss.item()}\")\n",
|
||||
" # print loss every 100 steps\n",
|
||||
" if global_step % 10 == 0:\n",
|
||||
" print(f\"Loss after {global_step} steps: {loss.item()}\")\n",
|
||||
"\n",
|
||||
" # backward pass to get the gradients \n",
|
||||
" loss.backward()\n",
|
||||
" # backward pass to get the gradients\n",
|
||||
" loss.backward()\n",
|
||||
"\n",
|
||||
" #print(\"Gradients on classification head:\")\n",
|
||||
" #print(model.classifier.weight.grad[6,:].sum())\n",
|
||||
" # print(\"Gradients on classification head:\")\n",
|
||||
" # print(model.classifier.weight.grad[6,:].sum())\n",
|
||||
"\n",
|
||||
" # update\n",
|
||||
" optimizer.step()\n",
|
||||
" lr_scheduler.step()\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" global_step += 1"
|
||||
" # update\n",
|
||||
" optimizer.step()\n",
|
||||
" lr_scheduler.step()\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" global_step += 1"
|
||||
]
|
||||
},
|
||||
{
|
||||
@ -1006,8 +992,9 @@
|
||||
" labels = batch[3].to(device)\n",
|
||||
"\n",
|
||||
" # forward pass\n",
|
||||
" outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids,\n",
|
||||
" labels=labels)\n",
|
||||
" outputs = model(\n",
|
||||
" input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids, labels=labels\n",
|
||||
" )\n",
|
||||
" # get the loss and logits\n",
|
||||
" tmp_eval_loss = outputs.loss\n",
|
||||
" logits = outputs.logits\n",
|
||||
@ -1021,9 +1008,7 @@
|
||||
" out_label_ids = labels.detach().cpu().numpy()\n",
|
||||
" else:\n",
|
||||
" preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)\n",
|
||||
" out_label_ids = np.append(\n",
|
||||
" out_label_ids, labels.detach().cpu().numpy(), axis=0\n",
|
||||
" )\n",
|
||||
" out_label_ids = np.append(out_label_ids, labels.detach().cpu().numpy(), axis=0)\n",
|
||||
"\n",
|
||||
"# compute average evaluation loss\n",
|
||||
"eval_loss = eval_loss / nb_eval_steps\n",
|
||||
@ -1070,7 +1055,7 @@
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"model.save_pretrained(\"peft_layoutlm\")\n"
|
||||
"model.save_pretrained(\"peft_layoutlm\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
|
||||
@ -1,3 +1,36 @@
|
||||
[tool.black]
|
||||
line-length = 119
|
||||
target-version = ['py36']
|
||||
|
||||
[tool.ruff]
|
||||
ignore = ["C901", "E501", "E741", "W605"]
|
||||
select = ["C", "E", "F", "I", "W"]
|
||||
line-length = 119
|
||||
|
||||
[tool.ruff.isort]
|
||||
lines-after-imports = 2
|
||||
known-first-party = ["peft"]
|
||||
|
||||
[isort]
|
||||
default_section = "FIRSTPARTY"
|
||||
known_first_party = "peft"
|
||||
known_third_party = [
|
||||
"numpy",
|
||||
"torch",
|
||||
"accelerate",
|
||||
"transformers",
|
||||
]
|
||||
line_length = 119
|
||||
lines_after_imports = 2
|
||||
multi_line_output = 3
|
||||
include_trailing_comma = true
|
||||
force_grid_wrap = 0
|
||||
use_parentheses = true
|
||||
ensure_newline_before_comments = true
|
||||
|
||||
[tool.pytest]
|
||||
doctest_optionflags = [
|
||||
"NORMALIZE_WHITESPACE",
|
||||
"ELLIPSIS",
|
||||
"NUMBER",
|
||||
]
|
||||
23
setup.cfg
23
setup.cfg
@ -1,23 +0,0 @@
|
||||
[isort]
|
||||
default_section = FIRSTPARTY
|
||||
ensure_newline_before_comments = True
|
||||
force_grid_wrap = 0
|
||||
include_trailing_comma = True
|
||||
known_first_party = pet
|
||||
known_third_party =
|
||||
numpy
|
||||
torch
|
||||
accelerate
|
||||
transformers
|
||||
|
||||
line_length = 119
|
||||
lines_after_imports = 2
|
||||
multi_line_output = 3
|
||||
use_parentheses = True
|
||||
|
||||
[flake8]
|
||||
ignore = E203, E722, E501, E741, W503, W605
|
||||
max-line-length = 119
|
||||
|
||||
[tool:pytest]
|
||||
doctest_optionflags=NUMBER NORMALIZE_WHITESPACE ELLIPSIS
|
||||
9
setup.py
9
setup.py
@ -12,18 +12,18 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from setuptools import setup
|
||||
from setuptools import find_packages
|
||||
from setuptools import find_packages, setup
|
||||
|
||||
extras = {}
|
||||
extras["quality"] = ["black ~= 22.0", "isort >= 5.5.4", "flake8 >= 3.8.3"]
|
||||
extras["quality"] = ["black ~= 22.0", "ruff>=0.0.241"]
|
||||
extras["docs_specific"] = ["hf-doc-builder"]
|
||||
extras["dev"] = extras["quality"] + extras["docs_specific"]
|
||||
|
||||
setup(
|
||||
name="peft",
|
||||
version="0.1.0.dev0",
|
||||
version="0.2.0",
|
||||
description="Parameter-Efficient Fine-Tuning (PEFT)",
|
||||
license_files=["LICENSE"],
|
||||
long_description=open("README.md", "r", encoding="utf-8").read(),
|
||||
long_description_content_type="text/markdown",
|
||||
keywords="deep learning",
|
||||
@ -43,7 +43,6 @@ setup(
|
||||
"torch>=1.13.0",
|
||||
"transformers",
|
||||
"accelerate",
|
||||
"bitsandbytes",
|
||||
],
|
||||
extras_require=extras,
|
||||
classifiers=[
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
__version__ = "0.1.0.dev0"
|
||||
__version__ = "0.2.0"
|
||||
|
||||
from .mapping import MODEL_TYPE_TO_PEFT_MODEL_MAPPING, PEFT_TYPE_TO_CONFIG_MAPPING, get_peft_config, get_peft_model
|
||||
from .peft_model import (
|
||||
@ -47,6 +47,7 @@ from .utils import (
|
||||
TaskType,
|
||||
bloom_model_postprocess_past_key_value,
|
||||
get_peft_model_state_dict,
|
||||
prepare_model_for_int8_training,
|
||||
set_peft_model_state_dict,
|
||||
shift_tokens_right,
|
||||
)
|
||||
|
||||
@ -16,18 +16,18 @@
|
||||
import inspect
|
||||
import os
|
||||
import warnings
|
||||
from contextlib import contextmanager
|
||||
|
||||
import torch
|
||||
from accelerate import dispatch_model, infer_auto_device_map
|
||||
from accelerate.hooks import AlignDevicesHook, add_hook_to_module, remove_hook_from_submodules
|
||||
from accelerate.utils import get_balanced_memory
|
||||
from huggingface_hub import hf_hub_download
|
||||
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
||||
from transformers import PreTrainedModel
|
||||
from transformers.modeling_outputs import SequenceClassifierOutput, TokenClassifierOutput
|
||||
from transformers.utils import PushToHubMixin
|
||||
|
||||
from huggingface_hub import hf_hub_download
|
||||
|
||||
from .tuners import LoraModel, PrefixEncoder, PromptEmbedding, PromptEncoder
|
||||
from .utils import (
|
||||
TRANSFORMERS_MODELS_TO_PREFIX_TUNING_POSTPROCESS_MAPPING,
|
||||
@ -154,7 +154,9 @@ class PeftModel(PushToHubMixin, torch.nn.Module):
|
||||
f"Please check that the file {WEIGHTS_NAME} is present at {model_id}."
|
||||
)
|
||||
|
||||
adapters_weights = torch.load(filename)
|
||||
adapters_weights = torch.load(
|
||||
filename, map_location=torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
)
|
||||
# load the weights into the model
|
||||
model = set_peft_model_state_dict(model, adapters_weights)
|
||||
if getattr(model, "hf_device_map", None) is not None:
|
||||
@ -182,7 +184,6 @@ class PeftModel(PushToHubMixin, torch.nn.Module):
|
||||
return model
|
||||
|
||||
def _setup_prompt_encoder(self):
|
||||
num_transformer_submodules = 0
|
||||
transformer_backbone = None
|
||||
for name, module in self.base_model.named_children():
|
||||
for param in module.parameters():
|
||||
@ -192,8 +193,11 @@ class PeftModel(PushToHubMixin, torch.nn.Module):
|
||||
if transformer_backbone is None:
|
||||
transformer_backbone = module
|
||||
self.transformer_backbone_name = name
|
||||
num_transformer_submodules += 1
|
||||
self.peft_config.num_transformer_submodules = 2 if self.peft_config.task_type == TaskType.SEQ_2_SEQ_LM else 1
|
||||
|
||||
if self.peft_config.num_transformer_submodules is None:
|
||||
self.peft_config.num_transformer_submodules = (
|
||||
2 if self.peft_config.task_type == TaskType.SEQ_2_SEQ_LM else 1
|
||||
)
|
||||
|
||||
for named_param, value in list(transformer_backbone.named_parameters()):
|
||||
if value.shape[0] == self.base_model.config.vocab_size:
|
||||
@ -265,9 +269,14 @@ class PeftModel(PushToHubMixin, torch.nn.Module):
|
||||
trainable_params = 0
|
||||
all_param = 0
|
||||
for _, param in self.named_parameters():
|
||||
all_param += param.numel()
|
||||
num_params = param.numel()
|
||||
# if using DS Zero 3 and the weights are initialized empty
|
||||
if num_params == 0 and hasattr(param, "ds_numel"):
|
||||
num_params = param.ds_numel
|
||||
|
||||
all_param += num_params
|
||||
if param.requires_grad:
|
||||
trainable_params += param.numel()
|
||||
trainable_params += num_params
|
||||
print(
|
||||
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
|
||||
)
|
||||
@ -283,10 +292,29 @@ class PeftModel(PushToHubMixin, torch.nn.Module):
|
||||
"""
|
||||
Forward pass of the model.
|
||||
"""
|
||||
return self.get_base_model()(*args, **kwargs)
|
||||
|
||||
@contextmanager
|
||||
def disable_adapter(self):
|
||||
"""
|
||||
Disables the adapter module.
|
||||
"""
|
||||
if isinstance(self.peft_config, PromptLearningConfig):
|
||||
return self.base_model(*args, **kwargs)
|
||||
old_forward = self.forward
|
||||
self.forward = self.base_model.forward
|
||||
else:
|
||||
return self.base_model.model(*args, **kwargs)
|
||||
self.base_model.disable_adapter_layers()
|
||||
yield
|
||||
if isinstance(self.peft_config, PromptLearningConfig):
|
||||
self.forward = old_forward
|
||||
else:
|
||||
self.base_model.enable_adapter_layers()
|
||||
|
||||
def get_base_model(self):
|
||||
"""
|
||||
Returns the base model.
|
||||
"""
|
||||
return self.base_model if isinstance(self.peft_config, PromptLearningConfig) else self.base_model.model
|
||||
|
||||
|
||||
class PeftModelForSequenceClassification(PeftModel):
|
||||
@ -384,6 +412,7 @@ class PeftModelForSequenceClassification(PeftModel):
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.word_embeddings(input_ids)
|
||||
prompts = self.get_prompt(batch_size=batch_size)
|
||||
prompts = prompts.to(inputs_embeds.dtype)
|
||||
inputs_embeds = torch.cat((prompts, inputs_embeds), dim=1)
|
||||
return self.base_model(inputs_embeds=inputs_embeds, **kwargs)
|
||||
|
||||
@ -542,6 +571,7 @@ class PeftModelForCausalLM(PeftModel):
|
||||
prefix_labels = torch.full((batch_size, self.peft_config.num_virtual_tokens), -100).to(self.device)
|
||||
kwargs["labels"] = torch.cat((prefix_labels, labels), dim=1)
|
||||
prompts = self.get_prompt(batch_size=batch_size)
|
||||
prompts = prompts.to(inputs_embeds.dtype)
|
||||
inputs_embeds = torch.cat((prompts, inputs_embeds), dim=1)
|
||||
return self.base_model(inputs_embeds=inputs_embeds, **kwargs)
|
||||
|
||||
@ -577,10 +607,10 @@ class PeftModelForCausalLM(PeftModel):
|
||||
model_kwargs["past_key_values"] = past_key_values
|
||||
else:
|
||||
if model_kwargs["past_key_values"] is None:
|
||||
inputs_embeds = self.word_embeddings(model_kwargs["input_ids"])
|
||||
prompts = self.get_prompt(batch_size=model_kwargs["input_ids"].shape[0])
|
||||
model_kwargs["inputs_embeds"] = torch.cat(
|
||||
(prompts, self.word_embeddings(model_kwargs["input_ids"])), dim=1
|
||||
)
|
||||
prompts = prompts.to(inputs_embeds.dtype)
|
||||
model_kwargs["inputs_embeds"] = torch.cat((prompts, inputs_embeds), dim=1)
|
||||
model_kwargs["input_ids"] = None
|
||||
|
||||
return model_kwargs
|
||||
@ -691,14 +721,23 @@ class PeftModelForSeq2SeqLM(PeftModel):
|
||||
kwargs["attention_mask"] = torch.cat((prefix_attention_mask, attention_mask), dim=1)
|
||||
# concat prompt labels
|
||||
if labels is not None:
|
||||
prefix_labels = torch.full((batch_size, self.peft_config.num_virtual_tokens), -100).to(self.device)
|
||||
kwargs["labels"] = torch.cat((prefix_labels, labels), dim=1)
|
||||
if self.peft_config.num_transformer_submodules == 1:
|
||||
kwargs["labels"] = labels
|
||||
elif self.peft_config.num_transformer_submodules == 2:
|
||||
prefix_labels = torch.full((batch_size, self.peft_config.num_virtual_tokens), -100).to(self.device)
|
||||
kwargs["labels"] = torch.cat((prefix_labels, labels), dim=1)
|
||||
prompts = self.get_prompt(batch_size=batch_size)
|
||||
prompts = prompts.to(inputs_embeds.dtype)
|
||||
inputs_embeds = torch.cat((prompts[:, : self.peft_config.num_virtual_tokens], inputs_embeds), dim=1)
|
||||
decoder_inputs_embeds = torch.cat(
|
||||
(prompts[:, self.peft_config.num_virtual_tokens :], decoder_inputs_embeds), dim=1
|
||||
)
|
||||
return self.base_model(inputs_embeds=inputs_embeds, decoder_inputs_embeds=decoder_inputs_embeds, **kwargs)
|
||||
if self.peft_config.num_transformer_submodules == 1:
|
||||
return self.base_model(inputs_embeds=inputs_embeds, **kwargs)
|
||||
elif self.peft_config.num_transformer_submodules == 2:
|
||||
decoder_inputs_embeds = torch.cat(
|
||||
(prompts[:, self.peft_config.num_virtual_tokens :], decoder_inputs_embeds), dim=1
|
||||
)
|
||||
return self.base_model(
|
||||
inputs_embeds=inputs_embeds, decoder_inputs_embeds=decoder_inputs_embeds, **kwargs
|
||||
)
|
||||
|
||||
def generate(self, **kwargs):
|
||||
if not isinstance(self.peft_config, PromptLearningConfig):
|
||||
@ -824,6 +863,7 @@ class PeftModelForTokenClassification(PeftModel):
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.word_embeddings(input_ids)
|
||||
prompts = self.get_prompt(batch_size=batch_size)
|
||||
prompts = prompts.to(inputs_embeds.dtype)
|
||||
inputs_embeds = torch.cat((prompts, inputs_embeds), dim=1)
|
||||
return self.base_model(inputs_embeds=inputs_embeds, **kwargs)
|
||||
|
||||
|
||||
@ -12,22 +12,30 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import importlib
|
||||
import math
|
||||
import re
|
||||
import warnings
|
||||
from dataclasses import asdict, dataclass, field
|
||||
from enum import Enum
|
||||
from typing import List, Optional
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from transformers.pytorch_utils import Conv1D
|
||||
|
||||
import bitsandbytes as bnb
|
||||
|
||||
from ..utils import PeftConfig, PeftType, transpose
|
||||
|
||||
|
||||
def is_bnb_available():
|
||||
return importlib.util.find_spec("bitsandbytes") is not None
|
||||
|
||||
|
||||
if is_bnb_available():
|
||||
import bitsandbytes as bnb
|
||||
|
||||
|
||||
@dataclass
|
||||
class LoraConfig(PeftConfig):
|
||||
"""
|
||||
@ -35,7 +43,7 @@ class LoraConfig(PeftConfig):
|
||||
|
||||
Args:
|
||||
r (`int`): Lora attention dimension
|
||||
target_modules (`List[str]`): The names of the modules to apply Lora to.
|
||||
target_modules (`Union[List[str],str]`): The names of the modules to apply Lora to.
|
||||
lora_alpha (`float`): The alpha parameter for Lora scaling.
|
||||
lora_dropout (`float`): The dropout probability for Lora layers.
|
||||
merge_weights (`bool`):
|
||||
@ -48,7 +56,13 @@ class LoraConfig(PeftConfig):
|
||||
"""
|
||||
|
||||
r: int = field(default=8, metadata={"help": "Lora attention dimension"})
|
||||
target_modules: Optional[list] = field(default=None, metadata={"help": "List of modules to replace with Lora"})
|
||||
target_modules: Optional[Union[List[str], str]] = field(
|
||||
default=None,
|
||||
metadata={
|
||||
"help": "List of module names or regex expression of the module names to replace with Lora."
|
||||
"For example, ['q', 'v'] or '.*decoder.*(SelfAttention|EncDecAttention).*(q|v)$' "
|
||||
},
|
||||
)
|
||||
lora_alpha: int = field(default=None, metadata={"help": "Lora alpha"})
|
||||
lora_dropout: float = field(default=None, metadata={"help": "Lora dropout"})
|
||||
merge_weights: bool = field(
|
||||
@ -106,22 +120,32 @@ class LoraModel(torch.nn.Module):
|
||||
self.forward = self.model.forward
|
||||
|
||||
def _find_and_replace(self):
|
||||
loaded_in_8bit = getattr(self.model, "is_loaded_in_8bit", False)
|
||||
if loaded_in_8bit and not is_bnb_available():
|
||||
raise ImportError(
|
||||
"To use Lora with 8-bit quantization, please install the `bitsandbytes` package. "
|
||||
"You can install it with `pip install bitsandbytes`."
|
||||
)
|
||||
is_target_modules_in_base_model = False
|
||||
kwargs = {
|
||||
"r": self.peft_config.r,
|
||||
"lora_alpha": self.peft_config.lora_alpha,
|
||||
"lora_dropout": self.peft_config.lora_dropout,
|
||||
"fan_in_fan_out": self.peft_config.fan_in_fan_out,
|
||||
"merge_weights": self.peft_config.merge_weights,
|
||||
"merge_weights": self.peft_config.merge_weights or self.peft_config.inference_mode,
|
||||
}
|
||||
key_list = [key for key, _ in self.model.named_modules()]
|
||||
for key in key_list:
|
||||
if any(key.endswith(target_key) for target_key in self.peft_config.target_modules):
|
||||
if isinstance(self.peft_config.target_modules, str):
|
||||
target_module_found = re.fullmatch(self.peft_config.target_modules, key)
|
||||
else:
|
||||
target_module_found = any(key.endswith(target_key) for target_key in self.peft_config.target_modules)
|
||||
if target_module_found:
|
||||
if not is_target_modules_in_base_model:
|
||||
is_target_modules_in_base_model = True
|
||||
parent, target, target_name = self._get_submodules(key)
|
||||
bias = target.bias is not None
|
||||
if isinstance(target, bnb.nn.Linear8bitLt) and self.peft_config.enable_lora is None:
|
||||
if loaded_in_8bit and isinstance(target, bnb.nn.Linear8bitLt):
|
||||
kwargs.update(
|
||||
{
|
||||
"has_fp16_weights": target.state.has_fp16_weights,
|
||||
@ -130,13 +154,19 @@ class LoraModel(torch.nn.Module):
|
||||
"index": target.index,
|
||||
}
|
||||
)
|
||||
new_module = Linear8bitLt(target.in_features, target.out_features, bias=bias, **kwargs)
|
||||
if self.peft_config.enable_lora is None:
|
||||
new_module = Linear8bitLt(target.in_features, target.out_features, bias=bias, **kwargs)
|
||||
else:
|
||||
kwargs.update({"enable_lora": self.peft_config.enable_lora})
|
||||
new_module = MergedLinear8bitLt(target.in_features, target.out_features, bias=bias, **kwargs)
|
||||
elif isinstance(target, torch.nn.Linear) and self.peft_config.enable_lora is None:
|
||||
new_module = Linear(target.in_features, target.out_features, bias=bias, **kwargs)
|
||||
elif self.peft_config.enable_lora is not None:
|
||||
kwargs.update({"enable_lora": self.peft_config.enable_lora})
|
||||
if isinstance(target, Conv1D):
|
||||
in_features, out_features = target.weight.shape
|
||||
in_features, out_features = (
|
||||
target.weight.ds_shape if hasattr(target.weight, "ds_shape") else target.weight.shape
|
||||
)
|
||||
else:
|
||||
in_features, out_features = target.in_features, target.out_features
|
||||
if kwargs["fan_in_fan_out"]:
|
||||
@ -185,14 +215,47 @@ class LoraModel(torch.nn.Module):
|
||||
config["inference_mode"] = True
|
||||
return config
|
||||
|
||||
def _set_adapter_layers(self, enabled=True):
|
||||
for module in self.model.modules():
|
||||
if isinstance(module, LoraLayer):
|
||||
module.disable_adapters = False if enabled else True
|
||||
|
||||
def enable_adapter_layers(self):
|
||||
self._set_adapter_layers(enabled=True)
|
||||
|
||||
def disable_adapter_layers(self):
|
||||
self._set_adapter_layers(enabled=False)
|
||||
|
||||
|
||||
# Below code is based on https://github.com/microsoft/LoRA/blob/main/loralib/layers.py
|
||||
# and modified to work with PyTorch FSDP
|
||||
|
||||
|
||||
# ------------------------------------------------------------------------------------------
|
||||
# Copyright (c) Microsoft Corporation. All rights reserved.
|
||||
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
|
||||
# ------------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
# had to adapt it for `lora_only` to work
|
||||
def mark_only_lora_as_trainable(model: nn.Module, bias: str = "none") -> None:
|
||||
for n, p in model.named_parameters():
|
||||
if "lora_" not in n:
|
||||
p.requires_grad = False
|
||||
if bias == "none":
|
||||
return
|
||||
elif bias == "all":
|
||||
for n, p in model.named_parameters():
|
||||
if "bias" in n:
|
||||
p.requires_grad = True
|
||||
elif bias == "lora_only":
|
||||
for m in model.modules():
|
||||
if isinstance(m, LoraLayer) and hasattr(m, "bias") and m.bias is not None:
|
||||
m.bias.requires_grad = True
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
class LoraLayer:
|
||||
def __init__(
|
||||
self,
|
||||
@ -211,6 +274,7 @@ class LoraLayer:
|
||||
# Mark the weight as unmerged
|
||||
self.merged = False
|
||||
self.merge_weights = merge_weights
|
||||
self.disable_adapters = False
|
||||
|
||||
|
||||
class Linear(nn.Linear, LoraLayer):
|
||||
@ -252,7 +316,14 @@ class Linear(nn.Linear, LoraLayer):
|
||||
nn.Linear.train(self, mode)
|
||||
self.lora_A.train(mode)
|
||||
self.lora_B.train(mode)
|
||||
if self.merge_weights and self.merged:
|
||||
if not mode and self.merge_weights and not self.merged:
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0:
|
||||
self.weight.data += (
|
||||
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
|
||||
)
|
||||
self.merged = True
|
||||
elif self.merge_weights and self.merged:
|
||||
# Make sure that the weights are not merged
|
||||
if self.r > 0:
|
||||
self.weight.data -= (
|
||||
@ -264,16 +335,16 @@ class Linear(nn.Linear, LoraLayer):
|
||||
nn.Linear.eval(self)
|
||||
self.lora_A.eval()
|
||||
self.lora_B.eval()
|
||||
if self.merge_weights and not self.merged:
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0:
|
||||
self.weight.data += (
|
||||
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
|
||||
)
|
||||
self.merged = True
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
if self.r > 0 and not self.merged:
|
||||
if self.disable_adapters:
|
||||
if self.r > 0 and self.merged:
|
||||
self.weight.data -= (
|
||||
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
|
||||
)
|
||||
self.merged = False
|
||||
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
|
||||
elif self.r > 0 and not self.merged:
|
||||
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
|
||||
if self.r > 0:
|
||||
result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling
|
||||
@ -340,7 +411,17 @@ class MergedLinear(nn.Linear, LoraLayer):
|
||||
nn.Linear.train(self, mode)
|
||||
self.lora_A.train(mode)
|
||||
self.lora_B.train(mode)
|
||||
if self.merge_weights and self.merged:
|
||||
if not mode and self.merge_weights and not self.merged:
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0 and any(self.enable_lora):
|
||||
delta_w = F.conv1d(
|
||||
self.lora_A.weight.data.unsqueeze(0),
|
||||
self.lora_B.weight.data.unsqueeze(-1),
|
||||
groups=sum(self.enable_lora),
|
||||
).squeeze(0)
|
||||
self.weight.data += self.zero_pad(transpose(delta_w * self.scaling, self.fan_in_fan_out))
|
||||
self.merged = True
|
||||
elif self.merge_weights and self.merged:
|
||||
# Make sure that the weights are not merged
|
||||
if self.r > 0 and any(self.enable_lora):
|
||||
delta_w = F.conv1d(
|
||||
@ -355,19 +436,19 @@ class MergedLinear(nn.Linear, LoraLayer):
|
||||
nn.Linear.eval(self)
|
||||
self.lora_A.eval()
|
||||
self.lora_B.eval()
|
||||
if self.merge_weights and not self.merged:
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0 and any(self.enable_lora):
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
if self.disable_adapters:
|
||||
if self.r > 0 and self.merged and any(self.enable_lora):
|
||||
delta_w = F.conv1d(
|
||||
self.lora_A.weight.data.unsqueeze(0),
|
||||
self.lora_B.weight.data.unsqueeze(-1),
|
||||
groups=sum(self.enable_lora),
|
||||
).squeeze(0)
|
||||
self.weight.data += self.zero_pad(transpose(delta_w * self.scaling, self.fan_in_fan_out))
|
||||
self.merged = True
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
if self.merged:
|
||||
self.weight.data -= self.zero_pad(transpose(delta_w * self.scaling, self.fan_in_fan_out))
|
||||
self.merged = False
|
||||
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
|
||||
elif self.merged:
|
||||
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
|
||||
else:
|
||||
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
|
||||
@ -378,64 +459,138 @@ class MergedLinear(nn.Linear, LoraLayer):
|
||||
return result
|
||||
|
||||
|
||||
class Linear8bitLt(bnb.nn.Linear8bitLt, LoraLayer):
|
||||
# Lora implemented in a dense layer
|
||||
def __init__(
|
||||
self,
|
||||
in_features,
|
||||
out_features,
|
||||
r: int = 0,
|
||||
lora_alpha: int = 1,
|
||||
lora_dropout: float = 0.0,
|
||||
**kwargs,
|
||||
):
|
||||
bnb.nn.Linear8bitLt.__init__(
|
||||
if is_bnb_available():
|
||||
|
||||
class Linear8bitLt(bnb.nn.Linear8bitLt, LoraLayer):
|
||||
# Lora implemented in a dense layer
|
||||
def __init__(
|
||||
self,
|
||||
in_features,
|
||||
out_features,
|
||||
bias=kwargs.get("bias", True),
|
||||
has_fp16_weights=kwargs.get("has_fp16_weights", True),
|
||||
memory_efficient_backward=kwargs.get("memory_efficient_backward", False),
|
||||
threshold=kwargs.get("threshold", 0.0),
|
||||
index=kwargs.get("index", None),
|
||||
)
|
||||
LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=False)
|
||||
# Actual trainable parameters
|
||||
if r > 0:
|
||||
self.lora_A = nn.Linear(in_features, r, bias=False)
|
||||
self.lora_B = nn.Linear(r, out_features, bias=False)
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
self.reset_parameters()
|
||||
r: int = 0,
|
||||
lora_alpha: int = 1,
|
||||
lora_dropout: float = 0.0,
|
||||
**kwargs,
|
||||
):
|
||||
bnb.nn.Linear8bitLt.__init__(
|
||||
self,
|
||||
in_features,
|
||||
out_features,
|
||||
bias=kwargs.get("bias", True),
|
||||
has_fp16_weights=kwargs.get("has_fp16_weights", True),
|
||||
memory_efficient_backward=kwargs.get("memory_efficient_backward", False),
|
||||
threshold=kwargs.get("threshold", 0.0),
|
||||
index=kwargs.get("index", None),
|
||||
)
|
||||
LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=False)
|
||||
# Actual trainable parameters
|
||||
if r > 0:
|
||||
self.lora_A = nn.Linear(in_features, r, bias=False)
|
||||
self.lora_B = nn.Linear(r, out_features, bias=False)
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
self.reset_parameters()
|
||||
|
||||
def reset_parameters(self):
|
||||
if hasattr(self, "lora_A"):
|
||||
# initialize A the same way as the default for nn.Linear and B to zero
|
||||
nn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))
|
||||
nn.init.zeros_(self.lora_B.weight)
|
||||
def reset_parameters(self):
|
||||
if hasattr(self, "lora_A"):
|
||||
# initialize A the same way as the default for nn.Linear and B to zero
|
||||
nn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))
|
||||
nn.init.zeros_(self.lora_B.weight)
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
result = super().forward(x)
|
||||
if self.r > 0:
|
||||
result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling
|
||||
return result
|
||||
def forward(self, x: torch.Tensor):
|
||||
result = super().forward(x)
|
||||
|
||||
if self.disable_adapters:
|
||||
return result
|
||||
elif self.r > 0:
|
||||
if not torch.is_autocast_enabled():
|
||||
expected_dtype = result.dtype
|
||||
|
||||
# had to adapt it for `lora_only` to work
|
||||
def mark_only_lora_as_trainable(model: nn.Module, bias: str = "none") -> None:
|
||||
for n, p in model.named_parameters():
|
||||
if "lora_" not in n:
|
||||
p.requires_grad = False
|
||||
if bias == "none":
|
||||
return
|
||||
elif bias == "all":
|
||||
for n, p in model.named_parameters():
|
||||
if "bias" in n:
|
||||
p.requires_grad = True
|
||||
elif bias == "lora_only":
|
||||
for m in model.modules():
|
||||
if isinstance(m, LoraLayer) and hasattr(m, "bias") and m.bias is not None:
|
||||
m.bias.requires_grad = True
|
||||
else:
|
||||
raise NotImplementedError
|
||||
if x.dtype != torch.float32:
|
||||
x = x.float()
|
||||
output = self.lora_B(self.lora_A(self.lora_dropout(x))).to(expected_dtype) * self.scaling
|
||||
result += output
|
||||
else:
|
||||
output = self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling
|
||||
result += output
|
||||
return result
|
||||
|
||||
class MergedLinear8bitLt(bnb.nn.Linear8bitLt, LoraLayer):
|
||||
# Lora implemented in a dense layer
|
||||
def __init__(
|
||||
self,
|
||||
in_features: int,
|
||||
out_features: int,
|
||||
r: int = 0,
|
||||
lora_alpha: int = 1,
|
||||
lora_dropout: float = 0.0,
|
||||
enable_lora: List[bool] = [False],
|
||||
**kwargs,
|
||||
):
|
||||
bnb.nn.Linear8bitLt.__init__(
|
||||
self,
|
||||
in_features,
|
||||
out_features,
|
||||
bias=kwargs.get("bias", True),
|
||||
has_fp16_weights=kwargs.get("has_fp16_weights", True),
|
||||
memory_efficient_backward=kwargs.get("memory_efficient_backward", False),
|
||||
threshold=kwargs.get("threshold", 0.0),
|
||||
index=kwargs.get("index", None),
|
||||
)
|
||||
LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=False)
|
||||
if out_features % len(enable_lora) != 0:
|
||||
raise ValueError("The length of enable_lora must divide out_features")
|
||||
self.enable_lora = enable_lora
|
||||
# Actual trainable parameters
|
||||
if r > 0 and any(enable_lora):
|
||||
self.lora_A = nn.Linear(in_features, r * sum(enable_lora), bias=False)
|
||||
self.lora_B = nn.Conv1d(
|
||||
r * sum(enable_lora),
|
||||
out_features // len(enable_lora) * sum(enable_lora),
|
||||
kernel_size=1,
|
||||
groups=2,
|
||||
bias=False,
|
||||
)
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
# Compute the indices
|
||||
self.lora_ind = self.weight.new_zeros((out_features,), dtype=torch.bool).view(len(enable_lora), -1)
|
||||
self.lora_ind[enable_lora, :] = True
|
||||
self.lora_ind = self.lora_ind.view(-1)
|
||||
self.reset_parameters()
|
||||
|
||||
def reset_parameters(self):
|
||||
if hasattr(self, "lora_A"):
|
||||
# initialize A the same way as the default for nn.Linear and B to zero
|
||||
nn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))
|
||||
nn.init.zeros_(self.lora_B.weight)
|
||||
|
||||
def zero_pad(self, x):
|
||||
result = x.new_zeros((*x.shape[:-1], self.out_features))
|
||||
result = result.view(-1, self.out_features)
|
||||
result[:, self.lora_ind] = x.reshape(
|
||||
-1, self.out_features // len(self.enable_lora) * sum(self.enable_lora)
|
||||
)
|
||||
return result.view((*x.shape[:-1], self.out_features))
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
result = super().forward(x)
|
||||
if self.disable_adapters:
|
||||
return result
|
||||
elif self.r > 0:
|
||||
if not torch.is_autocast_enabled():
|
||||
expected_dtype = result.dtype
|
||||
if x.dtype != torch.float32:
|
||||
x = x.float()
|
||||
after_A = self.lora_A(self.lora_dropout(x))
|
||||
after_B = self.lora_B(after_A.transpose(-2, -1)).transpose(-2, -1)
|
||||
output = self.zero_pad(after_B).to(expected_dtype) * self.scaling
|
||||
result += output
|
||||
else:
|
||||
after_A = self.lora_A(self.lora_dropout(x))
|
||||
after_B = self.lora_B(after_A.transpose(-2, -1)).transpose(-2, -1)
|
||||
output = self.zero_pad(after_B) * self.scaling
|
||||
result += output
|
||||
return result
|
||||
|
||||
@ -14,6 +14,7 @@
|
||||
# limitations under the License.
|
||||
|
||||
import enum
|
||||
import warnings
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Union
|
||||
|
||||
@ -131,17 +132,16 @@ class PromptEncoder(torch.nn.Module):
|
||||
)
|
||||
|
||||
elif self.encoder_type == PromptEncoderReparameterizationType.MLP:
|
||||
warnings.warn(
|
||||
f"for {self.encoder_type}, the `encoder_num_layers` is ignored. Exactly 2 MLP layers are used."
|
||||
)
|
||||
layers = [
|
||||
torch.nn.Linear(self.input_size, self.hidden_size),
|
||||
torch.nn.ReLU(),
|
||||
torch.nn.Linear(self.hidden_size, self.hidden_size),
|
||||
torch.nn.ReLU(),
|
||||
torch.nn.Linear(self.hidden_size, self.output_size),
|
||||
]
|
||||
layers.extend(
|
||||
[
|
||||
torch.nn.Linear(self.hidden_size, self.hidden_size),
|
||||
torch.nn.ReLU(),
|
||||
]
|
||||
)
|
||||
layers.append(torch.nn.Linear(self.hidden_size, self.output_size))
|
||||
self.mlp_head = torch.nn.Sequential(*layers)
|
||||
|
||||
else:
|
||||
|
||||
@ -111,6 +111,7 @@ class PromptEmbedding(torch.nn.Module):
|
||||
init_token_ids = init_token_ids[:total_virtual_tokens]
|
||||
|
||||
word_embedding_weights = word_embeddings(torch.LongTensor(init_token_ids)).detach().clone()
|
||||
word_embedding_weights = word_embedding_weights.to(torch.float32)
|
||||
self.embedding.weight = torch.nn.Parameter(word_embedding_weights)
|
||||
|
||||
def forward(self, indices):
|
||||
|
||||
@ -23,6 +23,7 @@ from .other import (
|
||||
TRANSFORMERS_MODELS_TO_PREFIX_TUNING_POSTPROCESS_MAPPING,
|
||||
_set_trainable,
|
||||
bloom_model_postprocess_past_key_value,
|
||||
prepare_model_for_int8_training,
|
||||
shift_tokens_right,
|
||||
transpose,
|
||||
)
|
||||
|
||||
@ -18,9 +18,8 @@ import os
|
||||
from dataclasses import asdict, dataclass, field
|
||||
from typing import Optional, Union
|
||||
|
||||
from transformers.utils import PushToHubMixin
|
||||
|
||||
from huggingface_hub import hf_hub_download
|
||||
from transformers.utils import PushToHubMixin
|
||||
|
||||
from .adapters_utils import CONFIG_NAME
|
||||
|
||||
@ -98,7 +97,7 @@ class PeftConfigMixin(PushToHubMixin):
|
||||
else:
|
||||
try:
|
||||
config_file = hf_hub_download(pretrained_model_name_or_path, CONFIG_NAME)
|
||||
except:
|
||||
except Exception:
|
||||
raise ValueError(f"Can't find config.json at '{pretrained_model_name_or_path}'")
|
||||
|
||||
loaded_attributes = cls.from_json_file(config_file)
|
||||
@ -161,6 +160,8 @@ class PromptLearningConfig(PeftConfig):
|
||||
token_dim: int = field(
|
||||
default=None, metadata={"help": "The hidden embedding dimension of the base transformer model"}
|
||||
)
|
||||
num_transformer_submodules: Optional[int] = field(default=1, metadata={"help": "Number of transformer submodules"})
|
||||
num_transformer_submodules: Optional[int] = field(
|
||||
default=None, metadata={"help": "Number of transformer submodules"}
|
||||
)
|
||||
num_attention_heads: Optional[int] = field(default=None, metadata={"help": "Number of attention heads"})
|
||||
num_layers: Optional[int] = field(default=None, metadata={"help": "Number of transformer layers"})
|
||||
|
||||
@ -30,6 +30,62 @@ def bloom_model_postprocess_past_key_value(past_key_values):
|
||||
return tuple(zip(keys, values))
|
||||
|
||||
|
||||
def prepare_model_for_int8_training(
|
||||
model, output_embedding_layer_name="lm_head", use_gradient_checkpointing=True, layer_norm_names=["layer_norm"]
|
||||
):
|
||||
r"""
|
||||
This method wrapps the entire protocol for preparing a model before running a training. This includes:
|
||||
1- Cast the layernorm in fp32 2- making output embedding layer require grads 3- Add the upcasting of the lm
|
||||
head to fp32
|
||||
|
||||
Args:
|
||||
model, (`transformers.PreTrainedModel`):
|
||||
The loaded model from `transformers`
|
||||
"""
|
||||
loaded_in_8bit = getattr(model, "is_loaded_in_8bit", False)
|
||||
|
||||
for name, param in model.named_parameters():
|
||||
# freeze base model's layers
|
||||
param.requires_grad = False
|
||||
|
||||
if loaded_in_8bit:
|
||||
# cast layer norm in fp32 for stability for 8bit models
|
||||
if param.ndim == 1 and any(layer_norm_name in name for layer_norm_name in layer_norm_names):
|
||||
param.data = param.data.to(torch.float32)
|
||||
|
||||
if loaded_in_8bit and use_gradient_checkpointing:
|
||||
# For backward compatibility
|
||||
if hasattr(model, "enable_input_require_grads"):
|
||||
model.enable_input_require_grads()
|
||||
else:
|
||||
|
||||
def make_inputs_require_grad(module, input, output):
|
||||
output.requires_grad_(True)
|
||||
|
||||
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
|
||||
|
||||
# enable gradient checkpointing for memory efficiency
|
||||
model.gradient_checkpointing_enable()
|
||||
|
||||
if hasattr(model, output_embedding_layer_name):
|
||||
output_embedding_layer = getattr(model, output_embedding_layer_name)
|
||||
input_dtype = output_embedding_layer.weight.dtype
|
||||
|
||||
class CastOutputToFloat(torch.nn.Sequential):
|
||||
r"""
|
||||
Manually cast to the expected dtype of the lm_head as sometimes there is a final layer norm that is casted
|
||||
in fp32
|
||||
|
||||
"""
|
||||
|
||||
def forward(self, x):
|
||||
return super().forward(x.to(input_dtype)).to(torch.float32)
|
||||
|
||||
setattr(model, output_embedding_layer_name, CastOutputToFloat(output_embedding_layer))
|
||||
|
||||
return model
|
||||
|
||||
|
||||
TRANSFORMERS_MODELS_TO_PREFIX_TUNING_POSTPROCESS_MAPPING = {
|
||||
"bloom": bloom_model_postprocess_past_key_value,
|
||||
}
|
||||
|
||||
@ -27,6 +27,7 @@ from peft import (
|
||||
PromptTuningConfig,
|
||||
get_peft_model,
|
||||
get_peft_model_state_dict,
|
||||
prepare_model_for_training,
|
||||
)
|
||||
|
||||
|
||||
@ -41,27 +42,27 @@ class PeftTestMixin:
|
||||
PromptTuningConfig,
|
||||
)
|
||||
config_kwargs = (
|
||||
dict(
|
||||
r=8,
|
||||
lora_alpha=32,
|
||||
target_modules=["q_proj", "v_proj"],
|
||||
lora_dropout=0.05,
|
||||
bias="none",
|
||||
task_type="CAUSAL_LM",
|
||||
),
|
||||
dict(
|
||||
num_virtual_tokens=10,
|
||||
task_type="CAUSAL_LM",
|
||||
),
|
||||
dict(
|
||||
num_virtual_tokens=10,
|
||||
encoder_hidden_size=32,
|
||||
task_type="CAUSAL_LM",
|
||||
),
|
||||
dict(
|
||||
num_virtual_tokens=10,
|
||||
task_type="CAUSAL_LM",
|
||||
),
|
||||
{
|
||||
"r": 8,
|
||||
"lora_alpha": 32,
|
||||
"target_modules": ["q_proj", "v_proj"],
|
||||
"lora_dropout": 0.05,
|
||||
"bias": "none",
|
||||
"task_type": "CAUSAL_LM",
|
||||
},
|
||||
{
|
||||
"num_virtual_tokens": 10,
|
||||
"task_type": "CAUSAL_LM",
|
||||
},
|
||||
{
|
||||
"num_virtual_tokens": 10,
|
||||
"encoder_hidden_size": 32,
|
||||
"task_type": "CAUSAL_LM",
|
||||
},
|
||||
{
|
||||
"num_virtual_tokens": 10,
|
||||
"task_type": "CAUSAL_LM",
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
@ -85,6 +86,42 @@ class PeftModelTester(unittest.TestCase, PeftTestMixin):
|
||||
self.assertTrue(hasattr(model, "from_pretrained"))
|
||||
self.assertTrue(hasattr(model, "push_to_hub"))
|
||||
|
||||
def test_prepare_for_training(self):
|
||||
r"""
|
||||
A test that checks if `prepare_for_training` behaves as expected
|
||||
"""
|
||||
for model_id in self.checkpoints_to_test:
|
||||
for i, config_cls in enumerate(self.config_classes):
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
config = config_cls(
|
||||
base_model_name_or_path=model_id,
|
||||
**self.config_kwargs[i],
|
||||
)
|
||||
model = get_peft_model(model, config)
|
||||
|
||||
dummy_input = torch.LongTensor([[1, 1, 1]])
|
||||
dummy_output = model.get_input_embeddings()(dummy_input)
|
||||
|
||||
self.assertTrue(not dummy_output.requires_grad)
|
||||
|
||||
# load with `prepare_model_for_training`
|
||||
model = AutoModelForCausalLM.from_pretrained(model_id)
|
||||
model = prepare_model_for_training(model)
|
||||
|
||||
for param in model.parameters():
|
||||
self.assertTrue(not param.requires_grad)
|
||||
|
||||
config = config_cls(
|
||||
base_model_name_or_path=model_id,
|
||||
**self.config_kwargs[i],
|
||||
)
|
||||
model = get_peft_model(model, config)
|
||||
|
||||
dummy_input = torch.LongTensor([[1, 1, 1]])
|
||||
dummy_output = model.get_input_embeddings()(dummy_input)
|
||||
|
||||
self.assertTrue(dummy_output.requires_grad)
|
||||
|
||||
def test_save_pretrained(self):
|
||||
r"""
|
||||
A test to check if `save_pretrained` behaves as expected. This function should only save the state dict of the
|
||||
Reference in New Issue
Block a user